diff --git a/.gitattributes b/.gitattributes
index 66015ab0e1215c94ba106413a952b3a001f25ad0..0d2504c5375b8569a1321feba5d064762b036ca8 100644
--- a/.gitattributes
+++ b/.gitattributes
@@ -289,3 +289,259 @@ illustrious_generated/f1475a16a1cc.png filter=lfs diff=lfs merge=lfs -text
illustrious_generated/222548d84cde.png filter=lfs diff=lfs merge=lfs -text
illustrious_generated/7ea16faf601e.png filter=lfs diff=lfs merge=lfs -text
illustrious_generated/d62bf5dcbc94.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/59e62935e7dc.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/7b5b49a2d81c.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/7f1518553c8b.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/0713895bd43e.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/51eecb9c0779.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/82012716817c.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/d2feeadf93ad.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/7fa1a0e2c206.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/3e8d6d982707.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/ee4940943b83.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/7f849346b8c6.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/16047acf8c0c.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/f3466d572a8b.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/b886112038cd.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/f6877e18a119.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/42a6b626bf62.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/abca7e106aa2.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/2ddc32ac95bd.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/fb02dde2bd3c.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/68abab395fc5.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/0171d52c8eea.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/d2544b7097ca.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/8cf7821f7fb0.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/ab86051803e3.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/0de1bf20b4c3.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/e4c872bc87aa.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/a26cc25bd715.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/6f77efa34062.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/67a88701c204.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/9bfb8e69c42b.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/3f6bf4492166.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/bcfbf1ed20d5.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/e5008520004f.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/cfa0a7a41b96.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/296382996ced.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/21ffd0e527a5.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/2504d354a6a4.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/5d6f8c3eeeaa.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/a02aedc9a6d0.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/33b4febf1298.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/6c24c110a614.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/9d37912c5c6b.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/4cb6a754f7cf.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/b32dc8ef54c0.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/61ee38c15257.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/ffb975056195.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/f8b5f44151ea.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/bc9b0b19d388.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/6774cd76a938.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/08b04fd94e3e.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/f8aae53c58a2.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/38c4935cc1fd.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/b4943a633a4a.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/31a280694342.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/da867a2aa941.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/102e8ec5d6c3.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/24487a7c23bf.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/3ed8d5dd43d0.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/7fd035e8350b.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/4a7b11574c5c.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/43aff064be5a.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/30323307b15e.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/62dec86bff2e.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/b255db937b2f.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/a306e960c8b6.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/c23217b34c2b.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/46aa5985de49.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/3f1bdae5e399.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/a9595e41a830.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/d91388106fea.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/ba9b3e771a64.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/e2b864778b63.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/b1dbf4711b58.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/2b52ff11cfc2.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/bf1c3fcf8014.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/d4228c891489.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/b6a9455c8c5a.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/5ceebecd5d18.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/b0c5c422dfd8.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/4f513d46577e.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/6f31b8278c8a.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/619015790288.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/6fabcfa3e5ee.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/1b0a0c2de4d2.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/f26f01f72683.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/a2f87b72db7f.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/476506ab5d48.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/ebcb34ee32e6.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/6c32893b645f.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/f2d773c35024.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/4ed0972771c9.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/5c36468b15c8.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/3ad8bb69bdf0.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/3a5430bc71d8.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/3971072a65c6.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/96b242415ba0.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/0d1a4410a274.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/6a9bdc513728.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/28fc931efd86.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/ae91e6780f49.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/078d8bf013d9.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/42ff92197818.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/55e9585cdb3d.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/e53e40e825d6.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/745d162f94c7.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/ee934c327ef4.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/40754487fd17.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/bbac62133c72.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/bd91f9b0b5fd.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/f123ea28ebf8.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/258b079e9ae7.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/4c29b5732e0a.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/5bdd2b37e870.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/5f9c09b46855.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/02a7f0abe19e.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/a6574a463e93.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/27df5a74ec39.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/38c9fba75639.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/24cdfab7b54e.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/6932b81c0d89.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/60323c3a4605.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/26981e76a234.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/c7c292892c5b.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/fa47299df8c0.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/75473d08e25c.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/ecd881b39945.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/a7083e017a49.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/0c033b17f84c.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/7e98ac337abf.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/3cd10d454b71.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/3be5619bf50a.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/9697431b9811.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/6ec8c97a9965.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/c94e96b3d9ea.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/14e0ecf99422.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/9287c812f182.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/838dd7d8fbf8.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/160115ed9d23.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/a32b3b72a1ca.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/0ad8dc3dbd65.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/f8fa229d4811.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/f9dd63f65c52.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/912d6803c48e.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/929101d3a9ac.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/19979670d456.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/264faae7654f.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/8e90e4fa0b86.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/042ea4f1dac1.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/5fa6d9be87fc.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/e39dcd049925.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/a2edbbf44ea5.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/99e7e8d67b6c.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/8b57ac410466.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/acb177777ac7.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/98ffde3e77e1.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/0386e218cd98.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/835e9e6708c6.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/fcac48dcef7f.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/0a9304167e90.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/47a81be2a0d8.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/c50fe2e11b72.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/e775a7d63dd7.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/3131047b735a.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/1f3924cb388c.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/59b821920f3a.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/580327982907.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/3a2ce9bdf9c5.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/883b8ad37d0f.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/c97492864ec8.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/8edc350db597.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/488507f73ce3.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/761f22b1057d.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/163187d3cde6.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/1aea0c9a5da8.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/51702cd96438.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/c0e5f6c62692.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/3348ceb51d45.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/d683ada1991f.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/be473a0c5f8b.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/e51750b3db46.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/039a77bc12d4.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/c4031e0615e3.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/996e42ddc32d.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/2c7ba1de4386.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/92543a123745.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/49df01e00951.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/8dd694e79f74.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/d06528745fb3.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/42a26e7933c4.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/2d5c9cb4372c.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/f32c450ee5a2.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/351ba67a7f0e.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/8c77f05a395a.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/41c9bb582458.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/bedd27fd0ff5.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/21f3ea5f0c0d.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/4ce12c26204b.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/96530429d3dc.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/d51058560a83.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/41efac1b043e.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/0bf46d0350e3.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/d2324ff7a0ba.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/8b6e75a6bbea.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/6d980f0594a1.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/3f11de51f9dc.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/a1fe7c897ca8.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/676b754fff92.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/6f26418db1fa.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/7261ed8deb9d.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/ca69e529f9f4.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/2e278343d6b6.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/659c51d8a3f3.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/5f8cc12a53f9.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/926699fad1a7.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/cb842cd5960d.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/9920aa062298.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/215b7f9ec9de.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/d2ee4eaf9593.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/c8346a11fde8.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/93e7f0542baf.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/32f7bf0339ab.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/79c2be7ee557.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/9219b0282edc.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/a195415d7e57.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/cd4f7da85fec.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/a3b6891e867d.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/61c6dd3adfa7.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/5b57d2a01582.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/178171fafbb4.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/c05e8425073d.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/8fd94203ebe4.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/bb8a57201a81.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/0d32527ad2f3.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/a1f402da67f3.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/de853b05dcb8.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/efa989bd04ca.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/a3503780d672.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/06507838e4e5.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/a81f5cf1ec1a.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/c79e4c700b49.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/356dd506f2ba.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/967eef36168d.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/e27fb90149e1.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/da399732e61b.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/b00e96952dbd.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/94865291afca.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/95a03676700c.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/813e825a00fa.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/6e4c6e9a88e5.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/e14c33757398.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/72592b7f7649.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/212871cfba6d.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/417f76a46846.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/b99d33029712.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/42d9b9ae7944.png filter=lfs diff=lfs merge=lfs -text
+illustrious_generated/5cb4f2986db0.png filter=lfs diff=lfs merge=lfs -text
diff --git a/illustrious_generated/0171d52c8eea.png b/illustrious_generated/0171d52c8eea.png
new file mode 100644
index 0000000000000000000000000000000000000000..f9e947fea714a6f2d3a2cc2b09d07cc319311d10
--- /dev/null
+++ b/illustrious_generated/0171d52c8eea.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:093269c2e3bbe7f2a639ddd97dcb748c946a3d52371c9ff6c7b5894bba88da5a
+size 717551
diff --git a/illustrious_generated/02a7f0abe19e.png b/illustrious_generated/02a7f0abe19e.png
new file mode 100644
index 0000000000000000000000000000000000000000..7b622179bea3af6006d06888b7fbb5bf96d9ac28
--- /dev/null
+++ b/illustrious_generated/02a7f0abe19e.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ccc54155aef59f68e881ede2a5a9e0c8fbabac2e7391b8f704f8b060071ef513
+size 2508298
diff --git a/illustrious_generated/0386e218cd98.png b/illustrious_generated/0386e218cd98.png
new file mode 100644
index 0000000000000000000000000000000000000000..e348af1278cc004ec20fb5e11b7e14051622452f
--- /dev/null
+++ b/illustrious_generated/0386e218cd98.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:536050a4f4649512f29f13ea27e55efb66544d55b7cd98532434dc4d45916d70
+size 1309221
diff --git a/illustrious_generated/039a77bc12d4.png b/illustrious_generated/039a77bc12d4.png
new file mode 100644
index 0000000000000000000000000000000000000000..63626789dde7dc47971745c5480fd4d45fc98e43
--- /dev/null
+++ b/illustrious_generated/039a77bc12d4.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:19df910db85d743810e96a8de167362a74729d3c742bcd6993e63aa71fa7942e
+size 1587175
diff --git a/illustrious_generated/042ea4f1dac1.png b/illustrious_generated/042ea4f1dac1.png
new file mode 100644
index 0000000000000000000000000000000000000000..19704f183201f75223f04dae07195b996010f151
--- /dev/null
+++ b/illustrious_generated/042ea4f1dac1.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:07bdf7876f61868963350e284831d37171bd4e95ec741b83a142b65b99c25fa0
+size 907038
diff --git a/illustrious_generated/06507838e4e5.png b/illustrious_generated/06507838e4e5.png
new file mode 100644
index 0000000000000000000000000000000000000000..091ed3f926195031c88360816b21ac3abf317f7b
--- /dev/null
+++ b/illustrious_generated/06507838e4e5.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:436bbbdad40a60080ad97decf776d5ba84d9848d8cfc9ac63600cb7edbb6c43b
+size 1610826
diff --git a/illustrious_generated/0713895bd43e.png b/illustrious_generated/0713895bd43e.png
new file mode 100644
index 0000000000000000000000000000000000000000..9337edd6d2d8a68ef2eaba5eee4080ad516ffe11
--- /dev/null
+++ b/illustrious_generated/0713895bd43e.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:2890797d17ef5040d1e4c65e99bedb2f3f0df8216e35cf01c7d8480e7b483fc3
+size 1892713
diff --git a/illustrious_generated/078d8bf013d9.png b/illustrious_generated/078d8bf013d9.png
new file mode 100644
index 0000000000000000000000000000000000000000..9cea85bac15c4887c6e363ae06d002e6f204bb3e
--- /dev/null
+++ b/illustrious_generated/078d8bf013d9.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:cf66bc9a6139fd31be2faf9b3590a9c09db413a2ccff3934cd5173cb2223e74c
+size 1163463
diff --git a/illustrious_generated/08b04fd94e3e.png b/illustrious_generated/08b04fd94e3e.png
new file mode 100644
index 0000000000000000000000000000000000000000..e4688ed7e6ce54343a3ed3692cffa50a25707b33
--- /dev/null
+++ b/illustrious_generated/08b04fd94e3e.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:2564d4b43d11275761a56b5b5ebae030073e81336532e2ee0af0c3761f494c2a
+size 340488
diff --git a/illustrious_generated/0a9304167e90.png b/illustrious_generated/0a9304167e90.png
new file mode 100644
index 0000000000000000000000000000000000000000..a854e61a957af21ab018916f775b030304cc65ff
--- /dev/null
+++ b/illustrious_generated/0a9304167e90.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ddb2534196e0a96db3ede7a73d77793ff254c090a785ea30ec6c1264d2329e41
+size 1760359
diff --git a/illustrious_generated/0ad8dc3dbd65.png b/illustrious_generated/0ad8dc3dbd65.png
new file mode 100644
index 0000000000000000000000000000000000000000..a9afc6bef8b280597053ef4070b5279fc15f3dd5
--- /dev/null
+++ b/illustrious_generated/0ad8dc3dbd65.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:c0382dd35ec36ef9103eb112afa105c7a6820426fd9ec92d4961a48108159062
+size 601775
diff --git a/illustrious_generated/0bf46d0350e3.png b/illustrious_generated/0bf46d0350e3.png
new file mode 100644
index 0000000000000000000000000000000000000000..afc9bdfa153fd886c827f25d0628f1728138cd2b
--- /dev/null
+++ b/illustrious_generated/0bf46d0350e3.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:9597fb980206af0b27dba21db6ea2fb6b1aa2356c7ac17b0e7692384652cfbbd
+size 4369299
diff --git a/illustrious_generated/0c033b17f84c.png b/illustrious_generated/0c033b17f84c.png
new file mode 100644
index 0000000000000000000000000000000000000000..a48c0b0e9af06236f4df06225a55de49ee7bf15f
--- /dev/null
+++ b/illustrious_generated/0c033b17f84c.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:5afe9a3110ca5fe9386a7180136fb90469dfab1d9a26deabc7dd6100ff9df656
+size 2913317
diff --git a/illustrious_generated/0d1a4410a274.png b/illustrious_generated/0d1a4410a274.png
new file mode 100644
index 0000000000000000000000000000000000000000..58db9714d7cbc9d447c4230fbbf58ab1806ab4b3
--- /dev/null
+++ b/illustrious_generated/0d1a4410a274.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:965e7b9d8c129f7ded8ebd7f7d779e8ba717e638b7f9e734299a8575390984a5
+size 2554844
diff --git a/illustrious_generated/0d32527ad2f3.png b/illustrious_generated/0d32527ad2f3.png
new file mode 100644
index 0000000000000000000000000000000000000000..5db5e956ad7e379fd3c7714290252d63a4cb35f3
--- /dev/null
+++ b/illustrious_generated/0d32527ad2f3.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:6eafc7ff9af519ab3d27e52a2f7041a3d470331abf163cdaaf9abd015bd34ef7
+size 1106194
diff --git a/illustrious_generated/0de1bf20b4c3.png b/illustrious_generated/0de1bf20b4c3.png
new file mode 100644
index 0000000000000000000000000000000000000000..dc324d19137e9301b7cd8052654e4381fc33cdec
--- /dev/null
+++ b/illustrious_generated/0de1bf20b4c3.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:76371a8882d9828fa739274c298a8ecd781fd28c9bd87d7e1cd0deb4179e63c4
+size 688731
diff --git a/illustrious_generated/102e8ec5d6c3.png b/illustrious_generated/102e8ec5d6c3.png
new file mode 100644
index 0000000000000000000000000000000000000000..b86f67f477759aa352cce26f63185da144d3c6b0
--- /dev/null
+++ b/illustrious_generated/102e8ec5d6c3.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:67992dd322fd1bc9699b1da05e4aa984293b248e961279d825bccb3155e73e24
+size 635912
diff --git a/illustrious_generated/14e0ecf99422.png b/illustrious_generated/14e0ecf99422.png
new file mode 100644
index 0000000000000000000000000000000000000000..c50ca9c90e823906eb66ffbb6fde6ab7b62be7bd
--- /dev/null
+++ b/illustrious_generated/14e0ecf99422.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:f5d7df3c3101c23a87b8d965552ceac6578e98fa100051647b502a4f3f72ac9c
+size 1044817
diff --git a/illustrious_generated/160115ed9d23.png b/illustrious_generated/160115ed9d23.png
new file mode 100644
index 0000000000000000000000000000000000000000..36c23cb6a258b782f3fd93af6df4eed4db55f64c
--- /dev/null
+++ b/illustrious_generated/160115ed9d23.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:055b9595373e41c9aa0ae7972001afc23015d747b864ab33e9a4e907b2555f0c
+size 1102716
diff --git a/illustrious_generated/16047acf8c0c.png b/illustrious_generated/16047acf8c0c.png
new file mode 100644
index 0000000000000000000000000000000000000000..c3f697063438413ef8dcce8752ee88fa02fa3750
--- /dev/null
+++ b/illustrious_generated/16047acf8c0c.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:16b085a0ee97a04a84f0156c444756691c24b77dc461fd2ddeb11a20977750fc
+size 2617096
diff --git a/illustrious_generated/163187d3cde6.png b/illustrious_generated/163187d3cde6.png
new file mode 100644
index 0000000000000000000000000000000000000000..77f932e96364f5f8a3f37ffbc976b784cc1e4356
--- /dev/null
+++ b/illustrious_generated/163187d3cde6.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:d7eedfb96604fa96a51418f23f78e446bf1186040861de5684aa8e98bc23b482
+size 1133621
diff --git a/illustrious_generated/178171fafbb4.png b/illustrious_generated/178171fafbb4.png
new file mode 100644
index 0000000000000000000000000000000000000000..e30b8d602c9449f3cf64dfc2aefa3b3e84e85446
--- /dev/null
+++ b/illustrious_generated/178171fafbb4.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:4d143935e2205a452013bd2fb904355b5333621c74c753de218c4d7783897383
+size 489241
diff --git a/illustrious_generated/19979670d456.png b/illustrious_generated/19979670d456.png
new file mode 100644
index 0000000000000000000000000000000000000000..b5aee0f73c6a561db1ee3cb0986ee1dfce33f613
--- /dev/null
+++ b/illustrious_generated/19979670d456.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:7dc2fe5d93a6e0e22d0c8eb9d1fbffaf1c9a9126ccae75ff2f412e140f7a0cc5
+size 1784021
diff --git a/illustrious_generated/1aea0c9a5da8.png b/illustrious_generated/1aea0c9a5da8.png
new file mode 100644
index 0000000000000000000000000000000000000000..cee6b3e337d16d201ae31a1d96894d95a00a2170
--- /dev/null
+++ b/illustrious_generated/1aea0c9a5da8.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:cbbefb233c51a1ead0e19e24d514f2571ea0bc0d93292fba1ac1501331ddced4
+size 2530133
diff --git a/illustrious_generated/1b0a0c2de4d2.png b/illustrious_generated/1b0a0c2de4d2.png
new file mode 100644
index 0000000000000000000000000000000000000000..b542b18de91dc7d039231ed0c256ca2e3f7fb3e9
--- /dev/null
+++ b/illustrious_generated/1b0a0c2de4d2.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:6cea591aed53837dfd9c5610a1ae34eb05a15a14f0ea79fb7fb7518c8ae8d7bb
+size 1557143
diff --git a/illustrious_generated/1f3924cb388c.png b/illustrious_generated/1f3924cb388c.png
new file mode 100644
index 0000000000000000000000000000000000000000..fd70782e2513cd1dc7ded26610f131fe08de5ff6
--- /dev/null
+++ b/illustrious_generated/1f3924cb388c.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:199d2b84addb8031f2b71debc13b68a2e3943eff602ffe6e363099000ce83a88
+size 2010594
diff --git a/illustrious_generated/212871cfba6d.png b/illustrious_generated/212871cfba6d.png
new file mode 100644
index 0000000000000000000000000000000000000000..0043503f16b18384600ffdf48e08185d6e9f2762
--- /dev/null
+++ b/illustrious_generated/212871cfba6d.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:fe6703801202e65efa691cdcb70029c55f6ddf91b8dd0bb1c13f307921eac1cb
+size 2187480
diff --git a/illustrious_generated/215b7f9ec9de.png b/illustrious_generated/215b7f9ec9de.png
new file mode 100644
index 0000000000000000000000000000000000000000..805d4cc5135713a95ba66103df70b93eadd5be71
--- /dev/null
+++ b/illustrious_generated/215b7f9ec9de.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ed048750df7f94d379b320684a2a69d4b655fd6a902e004d67b56e08d2dbec4d
+size 1885594
diff --git a/illustrious_generated/21f3ea5f0c0d.png b/illustrious_generated/21f3ea5f0c0d.png
new file mode 100644
index 0000000000000000000000000000000000000000..76dbcabf9bd9046084399425d96cbf4dd194e687
--- /dev/null
+++ b/illustrious_generated/21f3ea5f0c0d.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:cb3621fb590d05c553f7758df72498ff620cf06819c9e3e098154bd420069904
+size 877101
diff --git a/illustrious_generated/21ffd0e527a5.png b/illustrious_generated/21ffd0e527a5.png
new file mode 100644
index 0000000000000000000000000000000000000000..21aca0cd5338808876d71087d209705a8de6a338
--- /dev/null
+++ b/illustrious_generated/21ffd0e527a5.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:cb125044880f75e2845a1f811780208b84d2a2e0a0dbe8f343f399ca26b2c4c9
+size 4257072
diff --git a/illustrious_generated/24487a7c23bf.png b/illustrious_generated/24487a7c23bf.png
new file mode 100644
index 0000000000000000000000000000000000000000..e07e6a8a6a85dd64647fa1ad1a136107558ec068
--- /dev/null
+++ b/illustrious_generated/24487a7c23bf.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:5e41655c553d41f894338636224bd71d721470f781c8b3f500f1d5bb42997e5c
+size 575606
diff --git a/illustrious_generated/24cdfab7b54e.png b/illustrious_generated/24cdfab7b54e.png
new file mode 100644
index 0000000000000000000000000000000000000000..387079d815783e401cce5140bb4908a64e33c034
--- /dev/null
+++ b/illustrious_generated/24cdfab7b54e.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:3f3f04af33cc96b0e8d3dda7663ccaac785e357b1bcea61ac369a61371e64632
+size 909637
diff --git a/illustrious_generated/2504d354a6a4.png b/illustrious_generated/2504d354a6a4.png
new file mode 100644
index 0000000000000000000000000000000000000000..a50b8c8c74f70f101fca16b23a7a785c04df0091
--- /dev/null
+++ b/illustrious_generated/2504d354a6a4.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:abe1d16977b68df612eefd01250647ca2385313249c7389a95407b55a064bcb0
+size 2403802
diff --git a/illustrious_generated/258b079e9ae7.png b/illustrious_generated/258b079e9ae7.png
new file mode 100644
index 0000000000000000000000000000000000000000..78b4d0d7411eaacc9b4a2a3f2afe1e82acadac0d
--- /dev/null
+++ b/illustrious_generated/258b079e9ae7.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:bb35f0be0f57b0d07d880cf9391b6e8aaee058c708f9d8fc2c40134a2b06d836
+size 1838747
diff --git a/illustrious_generated/264faae7654f.png b/illustrious_generated/264faae7654f.png
new file mode 100644
index 0000000000000000000000000000000000000000..eb6d543c0c1441d14aaaf1ee58df8c9f5adc197f
--- /dev/null
+++ b/illustrious_generated/264faae7654f.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e44c16b30f1522a7d4acb011682157e7d3d632332a04d32a6ac03a71e0e1bc89
+size 2408543
diff --git a/illustrious_generated/26981e76a234.png b/illustrious_generated/26981e76a234.png
new file mode 100644
index 0000000000000000000000000000000000000000..e0522a39e08865eabaf580e7021d488958fe8b83
--- /dev/null
+++ b/illustrious_generated/26981e76a234.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:71fbde2611bf1517bf5670151d49ed2845a7fe3fff04c67d3a3d8896aaf9dbe4
+size 1479544
diff --git a/illustrious_generated/27df5a74ec39.png b/illustrious_generated/27df5a74ec39.png
new file mode 100644
index 0000000000000000000000000000000000000000..0a2849a5d7718ea798cb8fe946cf869d3e7d9c95
--- /dev/null
+++ b/illustrious_generated/27df5a74ec39.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:2b719403d0050ece799425be5af03d5ab115dcf50fcd0f64ab95700bb55a581c
+size 544094
diff --git a/illustrious_generated/28fc931efd86.png b/illustrious_generated/28fc931efd86.png
new file mode 100644
index 0000000000000000000000000000000000000000..99cf8c209fe102fd4a5755444707e465a0dd33a5
--- /dev/null
+++ b/illustrious_generated/28fc931efd86.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:f23b28bc9cd6e6cb3d31bbdcdd1996dae807d3af92592ef39cca57bb38dc4b6f
+size 1670805
diff --git a/illustrious_generated/296382996ced.png b/illustrious_generated/296382996ced.png
new file mode 100644
index 0000000000000000000000000000000000000000..0acc7f8f308e1bb54844da0860fdffbcde43adcb
--- /dev/null
+++ b/illustrious_generated/296382996ced.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:947bb6d4ba5fb4586decd6ef33a379dfdf4a16e32aa77179a9124f7a777fddbd
+size 724897
diff --git a/illustrious_generated/2b52ff11cfc2.png b/illustrious_generated/2b52ff11cfc2.png
new file mode 100644
index 0000000000000000000000000000000000000000..33118081bf6b0df9373c65ab61c84a43ca9c9690
--- /dev/null
+++ b/illustrious_generated/2b52ff11cfc2.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:5e7c114ac02e9ff30fe9056af2ca21caa305e14234d3382226fdc552740467d2
+size 5491733
diff --git a/illustrious_generated/2c7ba1de4386.png b/illustrious_generated/2c7ba1de4386.png
new file mode 100644
index 0000000000000000000000000000000000000000..97ef626a8a4277b7f40b9ddcba48b73c9a9bd023
--- /dev/null
+++ b/illustrious_generated/2c7ba1de4386.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:c1f1f79c60fbeb50a1f9107d6ecd1866ed8b56febbaa362596504ab9cdf81d34
+size 1280673
diff --git a/illustrious_generated/2d5c9cb4372c.png b/illustrious_generated/2d5c9cb4372c.png
new file mode 100644
index 0000000000000000000000000000000000000000..ff86dd29cbe70a286f5e2fca7225973b884a64d1
--- /dev/null
+++ b/illustrious_generated/2d5c9cb4372c.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e835e8933241872ed8891179c365e86f340043e3eaebc16e70822e3fd2c04cb0
+size 3083425
diff --git a/illustrious_generated/2ddc32ac95bd.png b/illustrious_generated/2ddc32ac95bd.png
new file mode 100644
index 0000000000000000000000000000000000000000..886b3546933b76c8c96cdecaabf7f0cfa3e55623
--- /dev/null
+++ b/illustrious_generated/2ddc32ac95bd.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:5455e4213aa732b1473ecc02d7281ded5d27fb82b42c3821025816c6fca0a1d2
+size 1537440
diff --git a/illustrious_generated/2e278343d6b6.png b/illustrious_generated/2e278343d6b6.png
new file mode 100644
index 0000000000000000000000000000000000000000..edfc7ee719f1e8196e2a2160a6e268fc903c93a9
--- /dev/null
+++ b/illustrious_generated/2e278343d6b6.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:82ccc6dad2998cff7af4e87db62a172e49d0214c58c49b02eed359a26825c078
+size 1744359
diff --git a/illustrious_generated/30323307b15e.png b/illustrious_generated/30323307b15e.png
new file mode 100644
index 0000000000000000000000000000000000000000..d460a1d14e7b37ab6dc2e05be3af2b23b27a518f
--- /dev/null
+++ b/illustrious_generated/30323307b15e.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:c3a48630ce2f521a21a92276068e6f00e3e165c4abcbe42cd198e3c0d1089cf1
+size 880691
diff --git a/illustrious_generated/3131047b735a.png b/illustrious_generated/3131047b735a.png
new file mode 100644
index 0000000000000000000000000000000000000000..812ba9d8bbd78f9bdfca2022fb21cddd6cd1a732
--- /dev/null
+++ b/illustrious_generated/3131047b735a.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:45ad7c627e78a34e19837fa559e0831565f2cde8010fa1ac326bff14e0be7784
+size 491462
diff --git a/illustrious_generated/31a280694342.png b/illustrious_generated/31a280694342.png
new file mode 100644
index 0000000000000000000000000000000000000000..16432e3698e87b3ef6c7ad179d20c627271695e0
--- /dev/null
+++ b/illustrious_generated/31a280694342.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:98122c94ba75b15de77ba1a0feede2c9ce5c80fb27132a859d1747f68612f300
+size 3260719
diff --git a/illustrious_generated/32f7bf0339ab.png b/illustrious_generated/32f7bf0339ab.png
new file mode 100644
index 0000000000000000000000000000000000000000..2a481330b3c87ae002b1da3abd56d3f68082bcc1
--- /dev/null
+++ b/illustrious_generated/32f7bf0339ab.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:c00207e53eb98a1b9561509b59ffb5e8ee9ea0855cceca37039eff4cff3e52e8
+size 2022283
diff --git a/illustrious_generated/3348ceb51d45.png b/illustrious_generated/3348ceb51d45.png
new file mode 100644
index 0000000000000000000000000000000000000000..8a3b516165bfb5e8a58c764c9c860fb76b7a058d
--- /dev/null
+++ b/illustrious_generated/3348ceb51d45.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:f4e55257ce8022c2b204ff3bbad6ebfe44cc0999d57bbc1f55a41b460f42aec4
+size 2210099
diff --git a/illustrious_generated/33b4febf1298.png b/illustrious_generated/33b4febf1298.png
new file mode 100644
index 0000000000000000000000000000000000000000..c4a8ae9c081c9621ca864930da5b71cbbe33b994
--- /dev/null
+++ b/illustrious_generated/33b4febf1298.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:82bc1a11dda3649b38e3dabe520b341ccc5870b19a84b19e45efb3c278229f3e
+size 4156162
diff --git a/illustrious_generated/351ba67a7f0e.png b/illustrious_generated/351ba67a7f0e.png
new file mode 100644
index 0000000000000000000000000000000000000000..f2721a4736e9c3383ff5914ca0879d8938482388
--- /dev/null
+++ b/illustrious_generated/351ba67a7f0e.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:9ad0dbf85e3b91d462707cf999efb880b7066114f63b28729ef43738329d584e
+size 489930
diff --git a/illustrious_generated/356dd506f2ba.png b/illustrious_generated/356dd506f2ba.png
new file mode 100644
index 0000000000000000000000000000000000000000..3a74de2d925ac5fa481357811a2725b591640cfa
--- /dev/null
+++ b/illustrious_generated/356dd506f2ba.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e01084cd0c25deae00e738790f722b83d8190d9f589b32fc7e3e12b4741fa80c
+size 903571
diff --git a/illustrious_generated/38c4935cc1fd.png b/illustrious_generated/38c4935cc1fd.png
new file mode 100644
index 0000000000000000000000000000000000000000..a0fd2a2bd1555b380e95a5b63875e80c5c801806
--- /dev/null
+++ b/illustrious_generated/38c4935cc1fd.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:c3d5a08325e3452bbcc90699665faf6836e83cb9fc328acb1a59fbd9dd78be20
+size 1336938
diff --git a/illustrious_generated/38c9fba75639.png b/illustrious_generated/38c9fba75639.png
new file mode 100644
index 0000000000000000000000000000000000000000..bf701e53323561e707264f475cdfa6e92b0fd50f
--- /dev/null
+++ b/illustrious_generated/38c9fba75639.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:eb167609f3a4118f05ab8571c3e7a792f3ee7a79c2be636afe561e8e0ff65fbb
+size 861689
diff --git a/illustrious_generated/3971072a65c6.png b/illustrious_generated/3971072a65c6.png
new file mode 100644
index 0000000000000000000000000000000000000000..2ca92f04d6f14b8d30f73706f4f84992231fd5c2
--- /dev/null
+++ b/illustrious_generated/3971072a65c6.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:4f0be5dc90c81e188113bc1e3200e14aac4bb4cc4b0b931aa14039ef11b62bc1
+size 2312631
diff --git a/illustrious_generated/3a2ce9bdf9c5.png b/illustrious_generated/3a2ce9bdf9c5.png
new file mode 100644
index 0000000000000000000000000000000000000000..c65fceeb413d438805ab73ad213fe0910c1163ef
--- /dev/null
+++ b/illustrious_generated/3a2ce9bdf9c5.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8140e47ea9bfe897ace54e9386d215cb297660605d3f3dc3a4bb8c861e9faad6
+size 2760604
diff --git a/illustrious_generated/3a5430bc71d8.png b/illustrious_generated/3a5430bc71d8.png
new file mode 100644
index 0000000000000000000000000000000000000000..85252555f1f0b6c0737bd4096ce0eadf4b00d864
--- /dev/null
+++ b/illustrious_generated/3a5430bc71d8.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:937c55190436aaa4dcbb4332b0bcecc1b175e570eeb4d886ce2dad443adf45f7
+size 1316167
diff --git a/illustrious_generated/3ad8bb69bdf0.png b/illustrious_generated/3ad8bb69bdf0.png
new file mode 100644
index 0000000000000000000000000000000000000000..49540daaa0c50caad6918837668ade10171c3899
--- /dev/null
+++ b/illustrious_generated/3ad8bb69bdf0.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:d2bf2b4da6d9f281625b58b5b72af762408b4855ee6f031b8085c91e9178d25e
+size 4345752
diff --git a/illustrious_generated/3be5619bf50a.png b/illustrious_generated/3be5619bf50a.png
new file mode 100644
index 0000000000000000000000000000000000000000..df6eb61131bc430bf12ebd4c55adb12b28000f52
--- /dev/null
+++ b/illustrious_generated/3be5619bf50a.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e7a38fa1879a26bafdc83ee25d7206f757e8212d50e1397bf0cb0c561c41c731
+size 333284
diff --git a/illustrious_generated/3cd10d454b71.png b/illustrious_generated/3cd10d454b71.png
new file mode 100644
index 0000000000000000000000000000000000000000..03e050fecfc74cfb6456b9909dc4aeae523e7576
--- /dev/null
+++ b/illustrious_generated/3cd10d454b71.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ef733659223366932bf7212209f8d3bb0dd0bdcc7972a167c720fb23c10e7a71
+size 661345
diff --git a/illustrious_generated/3e8d6d982707.png b/illustrious_generated/3e8d6d982707.png
new file mode 100644
index 0000000000000000000000000000000000000000..2172cf872c4163e85ca268ce337b6514ff82ed9d
--- /dev/null
+++ b/illustrious_generated/3e8d6d982707.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:c59aab845c88ec5f7771197f3ca19600beabd8f29dbc129ac3daa0650af22a6d
+size 3803813
diff --git a/illustrious_generated/3ed8d5dd43d0.png b/illustrious_generated/3ed8d5dd43d0.png
new file mode 100644
index 0000000000000000000000000000000000000000..760d26c9d21ce14c87cb3e5fde03daa3d6a2d998
--- /dev/null
+++ b/illustrious_generated/3ed8d5dd43d0.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:09e3f9c8c2e58a2f388d8dd0d8e145870dc28c472406d144bf16ead334c6bd41
+size 1890823
diff --git a/illustrious_generated/3f11de51f9dc.png b/illustrious_generated/3f11de51f9dc.png
new file mode 100644
index 0000000000000000000000000000000000000000..d08da734528717a7af12df5fc01c163d320df713
--- /dev/null
+++ b/illustrious_generated/3f11de51f9dc.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:9f508ffcf72ddb36976eb20d42065dd191d3db6450931c4c97498fc13120127f
+size 1462281
diff --git a/illustrious_generated/3f1bdae5e399.png b/illustrious_generated/3f1bdae5e399.png
new file mode 100644
index 0000000000000000000000000000000000000000..90b58d4757f1a7a1754333c24cc65fb7447f7cdd
--- /dev/null
+++ b/illustrious_generated/3f1bdae5e399.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:666457d288ee689f382f67096b1abf4d4df896ad378d08de5ea95b4ab11643b8
+size 1026242
diff --git a/illustrious_generated/3f6bf4492166.png b/illustrious_generated/3f6bf4492166.png
new file mode 100644
index 0000000000000000000000000000000000000000..2bac6b6ade414e8ad7d5ab6ab1489c3488cad204
--- /dev/null
+++ b/illustrious_generated/3f6bf4492166.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:db599845c308c13bb4267612205f611ed927dc21933eae93e33075eb102766d7
+size 761266
diff --git a/illustrious_generated/40754487fd17.png b/illustrious_generated/40754487fd17.png
new file mode 100644
index 0000000000000000000000000000000000000000..b71860afe5306d691c5849e2a0b58349f185bd69
--- /dev/null
+++ b/illustrious_generated/40754487fd17.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:3f57870b3ba67ce7a4ad6e8d803008d8d94b583a82f7a86c8936e866fc463900
+size 1438628
diff --git a/illustrious_generated/417f76a46846.png b/illustrious_generated/417f76a46846.png
new file mode 100644
index 0000000000000000000000000000000000000000..cefd0bcf9e59e6592037ffa9c0083f8bc936b218
--- /dev/null
+++ b/illustrious_generated/417f76a46846.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e4e5d2baa228ddc8c4c8467d783dbeee44fec720cd49fef0b9b63ab3266021d1
+size 841147
diff --git a/illustrious_generated/41c9bb582458.png b/illustrious_generated/41c9bb582458.png
new file mode 100644
index 0000000000000000000000000000000000000000..d95894471c6f1ce078ba9a050239ababe9558f29
--- /dev/null
+++ b/illustrious_generated/41c9bb582458.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:57c636099e369d779ab16d0b11a460177a2b35372dd232eafe6864dc9beeb9b0
+size 2294275
diff --git a/illustrious_generated/41efac1b043e.png b/illustrious_generated/41efac1b043e.png
new file mode 100644
index 0000000000000000000000000000000000000000..a3f6713ce4865fa327ddfa8f9313ea12b0d8d6dc
--- /dev/null
+++ b/illustrious_generated/41efac1b043e.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:3bde125488058f4ba9bf548624ad610434f427a4124525f0759f69aa2f015685
+size 2731214
diff --git a/illustrious_generated/42a26e7933c4.png b/illustrious_generated/42a26e7933c4.png
new file mode 100644
index 0000000000000000000000000000000000000000..0904abebf04a28dc8a0c7c1e2b4cfd428166cc96
--- /dev/null
+++ b/illustrious_generated/42a26e7933c4.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:1d7aff545886f3518b58ccded9a5fcfa32140809ab3196d094758b105f73d73e
+size 2701439
diff --git a/illustrious_generated/42a6b626bf62.png b/illustrious_generated/42a6b626bf62.png
new file mode 100644
index 0000000000000000000000000000000000000000..9a4c5d8b420f222c44b9dd460c444cabdb906909
--- /dev/null
+++ b/illustrious_generated/42a6b626bf62.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:a12ca1239234be43e6dc337efe61ef4d65bbb66cc83d42ecf88d3f6439b3315b
+size 1845885
diff --git a/illustrious_generated/42d9b9ae7944.png b/illustrious_generated/42d9b9ae7944.png
new file mode 100644
index 0000000000000000000000000000000000000000..01c7a37e97cea00ddb20149870e6b891869de889
--- /dev/null
+++ b/illustrious_generated/42d9b9ae7944.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:011a962e8084bbce7c3444848fee7daa6d0d752a69c32cc0409d0a0c71a2a23f
+size 2015722
diff --git a/illustrious_generated/42ff92197818.png b/illustrious_generated/42ff92197818.png
new file mode 100644
index 0000000000000000000000000000000000000000..e92c59e7f045fcaef36f3850f14b938927ddab89
--- /dev/null
+++ b/illustrious_generated/42ff92197818.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ba1bc384ecd427f5b4af31acffe789cd77ecc63fb7c13b85c567970d43403e8e
+size 590593
diff --git a/illustrious_generated/43aff064be5a.png b/illustrious_generated/43aff064be5a.png
new file mode 100644
index 0000000000000000000000000000000000000000..265911227ed21ee49ef47ab14d776d687dd57323
--- /dev/null
+++ b/illustrious_generated/43aff064be5a.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:44c572e9d6f941688a1b0f68da26ef25f0bebf7646b598438ed89f2092d06cbc
+size 1179505
diff --git a/illustrious_generated/46aa5985de49.png b/illustrious_generated/46aa5985de49.png
new file mode 100644
index 0000000000000000000000000000000000000000..c45f3d2ae14ec08093b8062fccdd6bb92268b433
--- /dev/null
+++ b/illustrious_generated/46aa5985de49.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:5991dd6ee8118554b3d2ba2b17716b3d6d273e3e735df498c64cf537649cbd68
+size 2071789
diff --git a/illustrious_generated/476506ab5d48.png b/illustrious_generated/476506ab5d48.png
new file mode 100644
index 0000000000000000000000000000000000000000..b84fce5ab322b7217a154390fda79d92c6935785
--- /dev/null
+++ b/illustrious_generated/476506ab5d48.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:1c0d63369456005d69cb1c61a3457a6a673f8d586e3f1e8a166bbf729a575fd4
+size 2986457
diff --git a/illustrious_generated/47a81be2a0d8.png b/illustrious_generated/47a81be2a0d8.png
new file mode 100644
index 0000000000000000000000000000000000000000..69dad5749ed9a449c8911f3d7482703448b75a12
--- /dev/null
+++ b/illustrious_generated/47a81be2a0d8.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:4e867c4f790f7c3da6614adde493dd16e2040bb51cc08507d5293b92701ff478
+size 1329306
diff --git a/illustrious_generated/488507f73ce3.png b/illustrious_generated/488507f73ce3.png
new file mode 100644
index 0000000000000000000000000000000000000000..1fc4b53b5456b4f69ab98dbfb72895d6c1aa8db8
--- /dev/null
+++ b/illustrious_generated/488507f73ce3.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:de87d00a9dd16bc623d6743a9f72bf4b01e334dcabb47d1b405af675706b6040
+size 4313427
diff --git a/illustrious_generated/49df01e00951.png b/illustrious_generated/49df01e00951.png
new file mode 100644
index 0000000000000000000000000000000000000000..93c5c78d42756bea3e34e654ee68511a45d24638
--- /dev/null
+++ b/illustrious_generated/49df01e00951.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:c7f12f38fae550b7ebb28b8f9c6287734589417330d9a8b2b475abe80d9c327e
+size 1923459
diff --git a/illustrious_generated/4a7b11574c5c.png b/illustrious_generated/4a7b11574c5c.png
new file mode 100644
index 0000000000000000000000000000000000000000..970b2a475cb7d89ef41755cd81b951fd3e99b4c9
--- /dev/null
+++ b/illustrious_generated/4a7b11574c5c.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:16237d085afbbbf1f17d26125327c5fe98f7d5e930bee5b5a4e85c398bb06353
+size 3182465
diff --git a/illustrious_generated/4c29b5732e0a.png b/illustrious_generated/4c29b5732e0a.png
new file mode 100644
index 0000000000000000000000000000000000000000..c2d0c2a9bc7d905832253b2d447447dfbbc670f0
--- /dev/null
+++ b/illustrious_generated/4c29b5732e0a.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8185db67f2c055148e9bfc3439fdaf4262855c3e0e714ad226f935ceee1f24a9
+size 768928
diff --git a/illustrious_generated/4cb6a754f7cf.png b/illustrious_generated/4cb6a754f7cf.png
new file mode 100644
index 0000000000000000000000000000000000000000..6b722dfaae873c6457ae0ab4a88af2343bab553b
--- /dev/null
+++ b/illustrious_generated/4cb6a754f7cf.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8d99fac0c970899560c24a84a04d5c2fa38568ceb5e5741091fe8ff4af894a1e
+size 790428
diff --git a/illustrious_generated/4ce12c26204b.png b/illustrious_generated/4ce12c26204b.png
new file mode 100644
index 0000000000000000000000000000000000000000..cd2776ec3e2f32fba24a1b4be0d0e38da0ccc30c
--- /dev/null
+++ b/illustrious_generated/4ce12c26204b.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:7dd1040dadf79a45f60fbf41c4b6d6526c69a0326bdd954011c7e369c8b71a4b
+size 571661
diff --git a/illustrious_generated/4ed0972771c9.png b/illustrious_generated/4ed0972771c9.png
new file mode 100644
index 0000000000000000000000000000000000000000..a260d54391468c091b6597fd2a1b8345b261b29e
--- /dev/null
+++ b/illustrious_generated/4ed0972771c9.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:531e0409128e66a452638b633567750a812b4abe89312e2e7f75e413ab56bd59
+size 702933
diff --git a/illustrious_generated/4f513d46577e.png b/illustrious_generated/4f513d46577e.png
new file mode 100644
index 0000000000000000000000000000000000000000..7b07ddb24867d427ecb7aa2cb2bc947e693d7c3c
--- /dev/null
+++ b/illustrious_generated/4f513d46577e.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:30ccbec3aee51d865c9c9c033e7c97c12bacb3e78e48860d7e691d97ba82d8ed
+size 1262251
diff --git a/illustrious_generated/51702cd96438.png b/illustrious_generated/51702cd96438.png
new file mode 100644
index 0000000000000000000000000000000000000000..33dab4be49908667a1b35886cbe4ee0f65c0648e
--- /dev/null
+++ b/illustrious_generated/51702cd96438.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:f5db7782f59ef85b482199b2b8e18d35a060e41d556b99688bce2b98d7124385
+size 1390109
diff --git a/illustrious_generated/51eecb9c0779.png b/illustrious_generated/51eecb9c0779.png
new file mode 100644
index 0000000000000000000000000000000000000000..4eb7e1820db321b9f275485a4c5d261eb8888cc2
--- /dev/null
+++ b/illustrious_generated/51eecb9c0779.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:a8b78d46ff69a4675b9618b947977f9e41e38151e5b035d7aa03f5d1b8a5188b
+size 740679
diff --git a/illustrious_generated/55e9585cdb3d.png b/illustrious_generated/55e9585cdb3d.png
new file mode 100644
index 0000000000000000000000000000000000000000..ab7bf01c5e76af21f2f74f5764633443ac2e14e9
--- /dev/null
+++ b/illustrious_generated/55e9585cdb3d.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:791411a6f162bdcb3aba53e7da2f1187b7754d1d3892c097c3235f759fed7711
+size 2257629
diff --git a/illustrious_generated/580327982907.png b/illustrious_generated/580327982907.png
new file mode 100644
index 0000000000000000000000000000000000000000..f4fb3d847bc124362f326b230a4e1be16735f127
--- /dev/null
+++ b/illustrious_generated/580327982907.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8727ac98758a7a42ba4be80134366242a3f7a7ad172f0eaab2579573a98519b3
+size 415271
diff --git a/illustrious_generated/59b821920f3a.png b/illustrious_generated/59b821920f3a.png
new file mode 100644
index 0000000000000000000000000000000000000000..e781bc6c0d79c9f7c5a6e56bee4bc328da679861
--- /dev/null
+++ b/illustrious_generated/59b821920f3a.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:69479f897a77700dadc1376fd1c5e7f612333102b3f8e72c19cfe2b549267480
+size 4472825
diff --git a/illustrious_generated/59e62935e7dc.png b/illustrious_generated/59e62935e7dc.png
new file mode 100644
index 0000000000000000000000000000000000000000..3b5c018cffe9a36174c1fd445d04808e84659cf1
--- /dev/null
+++ b/illustrious_generated/59e62935e7dc.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:f671397ef35b32446e1802736fc3f0e0703c47849773605dae06b41e1b0e17cf
+size 1278559
diff --git a/illustrious_generated/5b57d2a01582.png b/illustrious_generated/5b57d2a01582.png
new file mode 100644
index 0000000000000000000000000000000000000000..ae943fab56d666702c6a31b40d16144ae722e92e
--- /dev/null
+++ b/illustrious_generated/5b57d2a01582.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:0fe129b3db9a899ad88a0411f950eea47bf83addf441d3d8363c814e1d227656
+size 2273260
diff --git a/illustrious_generated/5bdd2b37e870.png b/illustrious_generated/5bdd2b37e870.png
new file mode 100644
index 0000000000000000000000000000000000000000..393bacb381534f7efd4f253ff3b7bc23809dbdb2
--- /dev/null
+++ b/illustrious_generated/5bdd2b37e870.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:36a8babd37cf83ad20d9ebdf72354d731025296c7600c3acbc42bac0fdaa9276
+size 2450216
diff --git a/illustrious_generated/5c36468b15c8.png b/illustrious_generated/5c36468b15c8.png
new file mode 100644
index 0000000000000000000000000000000000000000..543be6f36d8903fc72daa9bf94b3ddab32da00bc
--- /dev/null
+++ b/illustrious_generated/5c36468b15c8.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:94d62c48a365075a04dd5de99ce76a13f6a2d5e34ae6791d3ba362515a2793ed
+size 1406091
diff --git a/illustrious_generated/5cb4f2986db0.png b/illustrious_generated/5cb4f2986db0.png
new file mode 100644
index 0000000000000000000000000000000000000000..51a07cd85dc8d9494501604bfc04fba1a798d58b
--- /dev/null
+++ b/illustrious_generated/5cb4f2986db0.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:f0ba0c2108fa37a1ce38ba689bf516c8f2a11306a6f09e96167ba6106b735e2d
+size 1000693
diff --git a/illustrious_generated/5ceebecd5d18.png b/illustrious_generated/5ceebecd5d18.png
new file mode 100644
index 0000000000000000000000000000000000000000..ce43b5f72ce816c7826077ea2e8faabfcd564e26
--- /dev/null
+++ b/illustrious_generated/5ceebecd5d18.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:4ce9367fd0d787d1ee354804e0c01b144500c2a5e95973cb88a74fabee10427a
+size 1102470
diff --git a/illustrious_generated/5d6f8c3eeeaa.png b/illustrious_generated/5d6f8c3eeeaa.png
new file mode 100644
index 0000000000000000000000000000000000000000..2086ad1f2635672442c803f64dc299e3be96cd23
--- /dev/null
+++ b/illustrious_generated/5d6f8c3eeeaa.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:d4b6f8d30a16527805adb71ffd234ba4feeb81f5f9466c06ad8291d5013a873d
+size 5171554
diff --git a/illustrious_generated/5f8cc12a53f9.png b/illustrious_generated/5f8cc12a53f9.png
new file mode 100644
index 0000000000000000000000000000000000000000..a5df027706b795e9b4c34f1a562524662073aa88
--- /dev/null
+++ b/illustrious_generated/5f8cc12a53f9.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:053ad146fdad26cecbc7bac8027dcf75924381a059569318d9bfacbe62ec5170
+size 681496
diff --git a/illustrious_generated/5f9c09b46855.png b/illustrious_generated/5f9c09b46855.png
new file mode 100644
index 0000000000000000000000000000000000000000..5daf047b77197ca9104ab7df6a39bacdb886c1d0
--- /dev/null
+++ b/illustrious_generated/5f9c09b46855.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:9658c4409d209459eb9cfbfceb1be004490fbe18b0ca72561ceba3824077ef41
+size 836321
diff --git a/illustrious_generated/5fa6d9be87fc.png b/illustrious_generated/5fa6d9be87fc.png
new file mode 100644
index 0000000000000000000000000000000000000000..7f8525e8c283b0f26db77412e6c195138f0f64dd
--- /dev/null
+++ b/illustrious_generated/5fa6d9be87fc.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:665024011eba6f28e195759735ea2e091210a736d3edae3096807ebadc0764cf
+size 1579863
diff --git a/illustrious_generated/60323c3a4605.png b/illustrious_generated/60323c3a4605.png
new file mode 100644
index 0000000000000000000000000000000000000000..e87e0f735cb232d6a900bf42c817b1eb938ad2be
--- /dev/null
+++ b/illustrious_generated/60323c3a4605.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:eb8c6c872819d1354ac72de47b54f093a91a99d2bbb3ba83f423d824320b0831
+size 392984
diff --git a/illustrious_generated/619015790288.png b/illustrious_generated/619015790288.png
new file mode 100644
index 0000000000000000000000000000000000000000..14446697e8aef36f8a119f6b2795b0554584baf4
--- /dev/null
+++ b/illustrious_generated/619015790288.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:68960c2d4f80fc9bc5d1ed3942d5dd6b3e49f03d27bd7348390963fa76408a1c
+size 1009147
diff --git a/illustrious_generated/61c6dd3adfa7.png b/illustrious_generated/61c6dd3adfa7.png
new file mode 100644
index 0000000000000000000000000000000000000000..aa52cb2ca89aa453fc515e2f6a8da318b74d5241
--- /dev/null
+++ b/illustrious_generated/61c6dd3adfa7.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:a4ad300b36ab5726be9f363610aa7deb94c1c40ba3d8f8063f40d4f98ddf9c33
+size 1729962
diff --git a/illustrious_generated/61ee38c15257.png b/illustrious_generated/61ee38c15257.png
new file mode 100644
index 0000000000000000000000000000000000000000..0d4d98677068894fb0d9395d134f975a6493cab0
--- /dev/null
+++ b/illustrious_generated/61ee38c15257.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:b2df6f1c6df1f1a08184b3fad994bddc1abac4869e94e14235647ff10f4d99d7
+size 2456540
diff --git a/illustrious_generated/62dec86bff2e.png b/illustrious_generated/62dec86bff2e.png
new file mode 100644
index 0000000000000000000000000000000000000000..70df379b0a88db61e494c5177f3996f49c625001
--- /dev/null
+++ b/illustrious_generated/62dec86bff2e.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:1a23af275a4217ce9947772dc828fd25311418743aa4f2b398322b3ee89e68bd
+size 978250
diff --git a/illustrious_generated/659c51d8a3f3.png b/illustrious_generated/659c51d8a3f3.png
new file mode 100644
index 0000000000000000000000000000000000000000..460b7c0fa0cb252ce1c871e1b61c179a54557500
--- /dev/null
+++ b/illustrious_generated/659c51d8a3f3.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:bcd621e5fd2b20f74c2fceead3d91e46e6e98df3c55b06650abfd08369f3cb40
+size 2068252
diff --git a/illustrious_generated/676b754fff92.png b/illustrious_generated/676b754fff92.png
new file mode 100644
index 0000000000000000000000000000000000000000..bdba3d1b5fe60f60abcfa0bbe11bd3bdeac2bb8b
--- /dev/null
+++ b/illustrious_generated/676b754fff92.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ef309b5f14f75bfc03b986c72137ec1c4204145f4bc1f17e1881c41132276717
+size 514960
diff --git a/illustrious_generated/6774cd76a938.png b/illustrious_generated/6774cd76a938.png
new file mode 100644
index 0000000000000000000000000000000000000000..9754fab776a9a9b1f4714657480e8ed0df6df9b7
--- /dev/null
+++ b/illustrious_generated/6774cd76a938.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:6069956e1ccce14f9237069859bcbaa2e8b0989fdb0d2824ef8dbaeb1915ecab
+size 798024
diff --git a/illustrious_generated/67a88701c204.png b/illustrious_generated/67a88701c204.png
new file mode 100644
index 0000000000000000000000000000000000000000..7dd40a36e46f5c3a9ef14a67de8e4cd7aab33049
--- /dev/null
+++ b/illustrious_generated/67a88701c204.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:c086413f7e8a89f88d0e69409a2a00eecd90418f25eb479bcae26c9b57ae85a8
+size 423893
diff --git a/illustrious_generated/68abab395fc5.png b/illustrious_generated/68abab395fc5.png
new file mode 100644
index 0000000000000000000000000000000000000000..425d1bf1241d4358cded97c90fe360c10d51feb0
--- /dev/null
+++ b/illustrious_generated/68abab395fc5.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:a19449007a39f049a46f3801f43cb3a942c3a5441758b657a3cb778ffdde1dc3
+size 3809888
diff --git a/illustrious_generated/6932b81c0d89.png b/illustrious_generated/6932b81c0d89.png
new file mode 100644
index 0000000000000000000000000000000000000000..d3dd03b0f41e71f7c59ea89e168566c17a221006
--- /dev/null
+++ b/illustrious_generated/6932b81c0d89.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:c36ae98dae996c6d30f79c8fbd8cabff751a11a32604516e30d81c64e467eb59
+size 1083149
diff --git a/illustrious_generated/6a9bdc513728.png b/illustrious_generated/6a9bdc513728.png
new file mode 100644
index 0000000000000000000000000000000000000000..8a2c28e92714bd93026fd8a34ec3cb3d9ab3e61b
--- /dev/null
+++ b/illustrious_generated/6a9bdc513728.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ad649cc9e43e63a6320cd4183ca59664353b913bb088e1908f474026e8bbe024
+size 1067595
diff --git a/illustrious_generated/6c24c110a614.png b/illustrious_generated/6c24c110a614.png
new file mode 100644
index 0000000000000000000000000000000000000000..5c29a84a99b2d02c47b21d4caa828ecb3a27042c
--- /dev/null
+++ b/illustrious_generated/6c24c110a614.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:7904ff93035a63886ca2533837c9d32a15869a087b51a080165427fd717fcf38
+size 1173727
diff --git a/illustrious_generated/6c32893b645f.png b/illustrious_generated/6c32893b645f.png
new file mode 100644
index 0000000000000000000000000000000000000000..90541f636115c145278c0a1c813faf0891a5d3c1
--- /dev/null
+++ b/illustrious_generated/6c32893b645f.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:6de1708f1146ef3428a647c88dad7b8aa599350a49834e9d9fcc26e8c0f5fdc4
+size 1009851
diff --git a/illustrious_generated/6d980f0594a1.png b/illustrious_generated/6d980f0594a1.png
new file mode 100644
index 0000000000000000000000000000000000000000..6d07df49b5b9b630ee7c9e058e900ad22626fbcc
--- /dev/null
+++ b/illustrious_generated/6d980f0594a1.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:4371c66ced7446e929d22523024c771682098143792d509afab61c3662a29826
+size 1002109
diff --git a/illustrious_generated/6e4c6e9a88e5.png b/illustrious_generated/6e4c6e9a88e5.png
new file mode 100644
index 0000000000000000000000000000000000000000..a0a0d0ead869e10b4c745445208f68a9f6f171d1
--- /dev/null
+++ b/illustrious_generated/6e4c6e9a88e5.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:4a48bf2a0314e8e68f82838a256d32778874d80db74462dcb0baffc4d7ca0593
+size 3007091
diff --git a/illustrious_generated/6ec8c97a9965.png b/illustrious_generated/6ec8c97a9965.png
new file mode 100644
index 0000000000000000000000000000000000000000..aa1dcb30b0331d60862d4bf87beeddb43789bc16
--- /dev/null
+++ b/illustrious_generated/6ec8c97a9965.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:113af4aba76f73751ce9227f2029e3d94c5cfe61a4b2c540b4733a97295f53a3
+size 991356
diff --git a/illustrious_generated/6f26418db1fa.png b/illustrious_generated/6f26418db1fa.png
new file mode 100644
index 0000000000000000000000000000000000000000..b4632ad3fb55507882c2c53c1dd426c5afc62ff8
--- /dev/null
+++ b/illustrious_generated/6f26418db1fa.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:1cdfd4366dcf8f097a04bd117d88709a4556d2a7679199c653dc7f5cb02e2a2a
+size 1463181
diff --git a/illustrious_generated/6f31b8278c8a.png b/illustrious_generated/6f31b8278c8a.png
new file mode 100644
index 0000000000000000000000000000000000000000..b5b4b7964f68ed16f58b002e6600e50be98b9807
--- /dev/null
+++ b/illustrious_generated/6f31b8278c8a.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:cb873eb5a5c628e460099e2d76c6e2945b603a68f1acff5550528921e93b5841
+size 535233
diff --git a/illustrious_generated/6f77efa34062.png b/illustrious_generated/6f77efa34062.png
new file mode 100644
index 0000000000000000000000000000000000000000..acd7489270235e145f399006f13a1debedc6d262
--- /dev/null
+++ b/illustrious_generated/6f77efa34062.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8736433742ee8c57c2be0b3ef520efad5b06ab4f8e1696dfe14b6ed8e787b759
+size 1641932
diff --git a/illustrious_generated/6fabcfa3e5ee.png b/illustrious_generated/6fabcfa3e5ee.png
new file mode 100644
index 0000000000000000000000000000000000000000..43dcebde66bb2c230b664e90a2b5f367de246252
--- /dev/null
+++ b/illustrious_generated/6fabcfa3e5ee.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:2e1d42b8eac5f4723e0af4e49ed27f68ed7256405ab71e875637d16ef3d06c75
+size 3066595
diff --git a/illustrious_generated/72592b7f7649.png b/illustrious_generated/72592b7f7649.png
new file mode 100644
index 0000000000000000000000000000000000000000..3a54a04f84d614e87891b9392004401e2501091a
--- /dev/null
+++ b/illustrious_generated/72592b7f7649.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:93e8f9cb10f69ae2e3915b9b4aa924184a2a62407e5fa38a21218619571e4712
+size 2128128
diff --git a/illustrious_generated/7261ed8deb9d.png b/illustrious_generated/7261ed8deb9d.png
new file mode 100644
index 0000000000000000000000000000000000000000..c41a28efe91182fe47f38ee9fc9b64424a617b46
--- /dev/null
+++ b/illustrious_generated/7261ed8deb9d.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:b0bac211c4aae2deb5459fcce7a03c27ea48b89e8bccacf8b5b8951c8bae6ab3
+size 1090796
diff --git a/illustrious_generated/745d162f94c7.png b/illustrious_generated/745d162f94c7.png
new file mode 100644
index 0000000000000000000000000000000000000000..e434b495800cee538d6807e36c79e3d8e400226b
--- /dev/null
+++ b/illustrious_generated/745d162f94c7.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:81ec27e9a26b2622b899fd2f0f91f58dcd97e3e6629e9ec8146ea908aa2cbb1e
+size 2788794
diff --git a/illustrious_generated/75473d08e25c.png b/illustrious_generated/75473d08e25c.png
new file mode 100644
index 0000000000000000000000000000000000000000..63602709e172d35e13d9951a0dddc5adf7207e9f
--- /dev/null
+++ b/illustrious_generated/75473d08e25c.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:214485f28682173310b1fac7af096a4295dc24b6dd4db79f4f490bfd5eea013d
+size 1010566
diff --git a/illustrious_generated/761f22b1057d.png b/illustrious_generated/761f22b1057d.png
new file mode 100644
index 0000000000000000000000000000000000000000..588510ae532138245dceda76bc3224686d9213fe
--- /dev/null
+++ b/illustrious_generated/761f22b1057d.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:54ff79638a36f8ca8faccffc2c6663f5eeef47bf6df30901c0c15846d6a6f179
+size 1487594
diff --git a/illustrious_generated/79c2be7ee557.png b/illustrious_generated/79c2be7ee557.png
new file mode 100644
index 0000000000000000000000000000000000000000..363117e795cd75818397dea098e7ed89a298b87c
--- /dev/null
+++ b/illustrious_generated/79c2be7ee557.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:cd6b558b5e5d8b62c902c77eea84a1b653c8297249917c5d7192cf76857b89ae
+size 1245827
diff --git a/illustrious_generated/7b5b49a2d81c.png b/illustrious_generated/7b5b49a2d81c.png
new file mode 100644
index 0000000000000000000000000000000000000000..521abc4a1ce3192c8de4af9334272f4404402e43
--- /dev/null
+++ b/illustrious_generated/7b5b49a2d81c.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:28b9f837a9864d885dd438e41959e8d2049d0b58e9c1fa5de70cb223f5478fe2
+size 1429240
diff --git a/illustrious_generated/7e98ac337abf.png b/illustrious_generated/7e98ac337abf.png
new file mode 100644
index 0000000000000000000000000000000000000000..50dcb79b78cc156e8ff706c528e6cdbfe48129bc
--- /dev/null
+++ b/illustrious_generated/7e98ac337abf.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:f40bcdad4a609332a83f3275a2b4306ce2a22d30fa2bd36f4d4332321ad86e45
+size 481123
diff --git a/illustrious_generated/7f1518553c8b.png b/illustrious_generated/7f1518553c8b.png
new file mode 100644
index 0000000000000000000000000000000000000000..2d48a2cdc720fa3b016129842d16866a7d8ebabc
--- /dev/null
+++ b/illustrious_generated/7f1518553c8b.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:fc4706c1a37553e8a7e774331c725c9bb19577802e10ce814e97c055dba3b91a
+size 2448683
diff --git a/illustrious_generated/7f849346b8c6.png b/illustrious_generated/7f849346b8c6.png
new file mode 100644
index 0000000000000000000000000000000000000000..87c01a24ae83d871548dc16e817ed3a8123a0cac
--- /dev/null
+++ b/illustrious_generated/7f849346b8c6.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:cda5fadc88e353901a35f3b961a56dec634589b579b4bf3d381afb21beb0dae3
+size 2237332
diff --git a/illustrious_generated/7fa1a0e2c206.png b/illustrious_generated/7fa1a0e2c206.png
new file mode 100644
index 0000000000000000000000000000000000000000..35e46db6c7be9ca31327ec4cd7961109f34ccb84
--- /dev/null
+++ b/illustrious_generated/7fa1a0e2c206.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:3fd820d1544c295b3723af53239e2ec470a863262a5a26f91437dba0ce91c1f4
+size 4724629
diff --git a/illustrious_generated/7fd035e8350b.png b/illustrious_generated/7fd035e8350b.png
new file mode 100644
index 0000000000000000000000000000000000000000..c50815a0058e08f353bc177de41a63f2fe486d39
--- /dev/null
+++ b/illustrious_generated/7fd035e8350b.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:7dad083d5109fd375ddcd5e89350435f7c3e9e93ddb4663ea7201f31dfe41d07
+size 1899829
diff --git a/illustrious_generated/813e825a00fa.png b/illustrious_generated/813e825a00fa.png
new file mode 100644
index 0000000000000000000000000000000000000000..140929d62eead89c7fb2644ee29294d371f6d0c1
--- /dev/null
+++ b/illustrious_generated/813e825a00fa.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:06845b02d84213c41bbab718cbe41ef990ff1464d0725eb48d30b3d1cfeab95f
+size 711094
diff --git a/illustrious_generated/82012716817c.png b/illustrious_generated/82012716817c.png
new file mode 100644
index 0000000000000000000000000000000000000000..6e25358d1fd303e768a845ce36aa9ad5fd397b2c
--- /dev/null
+++ b/illustrious_generated/82012716817c.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:3d9c18c2b267d996f76bc99d4c0b668e742af278f0cca65121dbd1a701439da0
+size 2302084
diff --git a/illustrious_generated/835e9e6708c6.png b/illustrious_generated/835e9e6708c6.png
new file mode 100644
index 0000000000000000000000000000000000000000..2b7634ba933b44e9c15600c3faff3aaa177e5a4c
--- /dev/null
+++ b/illustrious_generated/835e9e6708c6.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:dcb147fa95db0f3f0726fae10a3f1679989e7874d97f773b70396f459f919e3e
+size 2931327
diff --git a/illustrious_generated/838dd7d8fbf8.png b/illustrious_generated/838dd7d8fbf8.png
new file mode 100644
index 0000000000000000000000000000000000000000..b8f62100e760b795c209e928eedb7783b100099a
--- /dev/null
+++ b/illustrious_generated/838dd7d8fbf8.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:87329dffad2b581402de8631321c0bc75064369ed06a131830c4ccc0e5789896
+size 703504
diff --git a/illustrious_generated/883b8ad37d0f.png b/illustrious_generated/883b8ad37d0f.png
new file mode 100644
index 0000000000000000000000000000000000000000..c33c6d238a5b35c212a14cdfa5688d7ceb6356ed
--- /dev/null
+++ b/illustrious_generated/883b8ad37d0f.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:9871e0aea4ae40c8b16ffb1d4d8b8add664d7dcd5a811ad3dfceebbfec73c693
+size 3857546
diff --git a/illustrious_generated/8b57ac410466.png b/illustrious_generated/8b57ac410466.png
new file mode 100644
index 0000000000000000000000000000000000000000..74e44fa51667c732fe5aff7038280f493c19fdf0
--- /dev/null
+++ b/illustrious_generated/8b57ac410466.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:2795ed8f7f1192974c7b28fcc3b04f9b328515a2a5cc9fa344207e4935289be8
+size 3086918
diff --git a/illustrious_generated/8b6e75a6bbea.png b/illustrious_generated/8b6e75a6bbea.png
new file mode 100644
index 0000000000000000000000000000000000000000..d52057d4542a342218bfe178edd8dcaa9daa1630
--- /dev/null
+++ b/illustrious_generated/8b6e75a6bbea.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:5d075e5169879e928d9fb3f0caeaf75962cf6765e504366333afc682377a5973
+size 1351288
diff --git a/illustrious_generated/8c77f05a395a.png b/illustrious_generated/8c77f05a395a.png
new file mode 100644
index 0000000000000000000000000000000000000000..2b876154f3530bdf0817b93fa02f668cda88c286
--- /dev/null
+++ b/illustrious_generated/8c77f05a395a.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:1f812e3bd5d0f39140ad89f9626cb6d8435997b8ddfd44940a00db13839e9689
+size 3163072
diff --git a/illustrious_generated/8cf7821f7fb0.png b/illustrious_generated/8cf7821f7fb0.png
new file mode 100644
index 0000000000000000000000000000000000000000..6ca5d045d433693dd57e00b375423250263da7bb
--- /dev/null
+++ b/illustrious_generated/8cf7821f7fb0.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:af7499afad24a0271069c464f32f042d7ce9455ce73d9fc6cfdf2d34fa0f606e
+size 4661880
diff --git a/illustrious_generated/8dd694e79f74.png b/illustrious_generated/8dd694e79f74.png
new file mode 100644
index 0000000000000000000000000000000000000000..f7c7ad0d433ffc60424607c8cd27a4170483333d
--- /dev/null
+++ b/illustrious_generated/8dd694e79f74.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:365e2ad1ff9505035da8fb2d671cc09ab284cc2d41a0701848c8289546d1e70a
+size 1471697
diff --git a/illustrious_generated/8e90e4fa0b86.png b/illustrious_generated/8e90e4fa0b86.png
new file mode 100644
index 0000000000000000000000000000000000000000..b719a472d3146811c0905d888ae8b31949052483
--- /dev/null
+++ b/illustrious_generated/8e90e4fa0b86.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:678e909e82ccbf19f46cc23c2df417d861771bef087cd3186b2f664fdcc45709
+size 3159890
diff --git a/illustrious_generated/8edc350db597.png b/illustrious_generated/8edc350db597.png
new file mode 100644
index 0000000000000000000000000000000000000000..f3951e4ff65e6a21144e01935abc77a99110cb61
--- /dev/null
+++ b/illustrious_generated/8edc350db597.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:7b48ac1424d79ddd8a7e7ec59e4edc77947f6b1d5e5aeda9ff080b2addf424c0
+size 3370347
diff --git a/illustrious_generated/8fd94203ebe4.png b/illustrious_generated/8fd94203ebe4.png
new file mode 100644
index 0000000000000000000000000000000000000000..c13644e0794d3ee48f4a8a7d0c44c2be4020afdb
--- /dev/null
+++ b/illustrious_generated/8fd94203ebe4.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:861cd7b56bb36618e6c06d07ff84dee937ca094cbe1f4ab2bb0caf2dba030420
+size 4372228
diff --git a/illustrious_generated/912d6803c48e.png b/illustrious_generated/912d6803c48e.png
new file mode 100644
index 0000000000000000000000000000000000000000..5f5c423bf2feb9ed05b1abeedc6fe3f5a3b7ba2b
--- /dev/null
+++ b/illustrious_generated/912d6803c48e.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8f5b13bcd4225fcd02292d4d6c2bd797bc9e5bad04035738f6bb4898254ed14d
+size 1317082
diff --git a/illustrious_generated/9219b0282edc.png b/illustrious_generated/9219b0282edc.png
new file mode 100644
index 0000000000000000000000000000000000000000..6691ddf083c0ae0c4c25ec3800c187ba5efe2308
--- /dev/null
+++ b/illustrious_generated/9219b0282edc.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:b1bcc2935a5e14b3900443876549f443ed28d1672f197f8dbd497d14cecb17fa
+size 1731812
diff --git a/illustrious_generated/92543a123745.png b/illustrious_generated/92543a123745.png
new file mode 100644
index 0000000000000000000000000000000000000000..246798d0afee4cecdcb7599109dde29bd4b7fe68
--- /dev/null
+++ b/illustrious_generated/92543a123745.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:816e0d373c079839d0716b44e1a769c3b2a738804a19eaf1339b2772fafd4141
+size 5014437
diff --git a/illustrious_generated/926699fad1a7.png b/illustrious_generated/926699fad1a7.png
new file mode 100644
index 0000000000000000000000000000000000000000..f72e9c20b73a324f0c9c71774c7b8606a6f3dc5c
--- /dev/null
+++ b/illustrious_generated/926699fad1a7.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:51c2f832356e198b00959d6a39be826eb261e52d264152cc57027bf7075cdd75
+size 547716
diff --git a/illustrious_generated/9287c812f182.png b/illustrious_generated/9287c812f182.png
new file mode 100644
index 0000000000000000000000000000000000000000..86f4051d608f0af7b80ae6124299dcafb1e7a6bb
--- /dev/null
+++ b/illustrious_generated/9287c812f182.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:f7479c1c70d18b0ecf8f704563615b40f5f6d7b11a944e7ee86b311e6208fcf6
+size 1391946
diff --git a/illustrious_generated/929101d3a9ac.png b/illustrious_generated/929101d3a9ac.png
new file mode 100644
index 0000000000000000000000000000000000000000..e823bff24783a1d1eb32dd62281a8e7da60babc5
--- /dev/null
+++ b/illustrious_generated/929101d3a9ac.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:06f3321d54cdc66f3743a6e7a7519e8c242b2d5e6e3468630646343693b5e251
+size 2577732
diff --git a/illustrious_generated/93e7f0542baf.png b/illustrious_generated/93e7f0542baf.png
new file mode 100644
index 0000000000000000000000000000000000000000..4e782b16165a59387958dcd6c35a29c0e9921a10
--- /dev/null
+++ b/illustrious_generated/93e7f0542baf.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:b8677443ec7b7c1ee4adad640fab21eb12e78d15bb3649c2effda484403aebc1
+size 718814
diff --git a/illustrious_generated/94865291afca.png b/illustrious_generated/94865291afca.png
new file mode 100644
index 0000000000000000000000000000000000000000..cfdb145d74317b6b32ad71d0e1735e6b730010b4
--- /dev/null
+++ b/illustrious_generated/94865291afca.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:6a313ffa2b4822dd0238d1996ad6f02d54aacfdf6fd331eced4beb8546323237
+size 892400
diff --git a/illustrious_generated/95a03676700c.png b/illustrious_generated/95a03676700c.png
new file mode 100644
index 0000000000000000000000000000000000000000..b7f449285a83e3a3012b2005f6d7093fbe682476
--- /dev/null
+++ b/illustrious_generated/95a03676700c.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:2e84fdc70292b820c76f496a261ca91fb604211ddb26e5e88e3bfcd45438c713
+size 1080321
diff --git a/illustrious_generated/96530429d3dc.png b/illustrious_generated/96530429d3dc.png
new file mode 100644
index 0000000000000000000000000000000000000000..75b1175b4da7c44bbf57232c1bdef94d7461e6ce
--- /dev/null
+++ b/illustrious_generated/96530429d3dc.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:40e96295b519fa59f437967acf225fec2c29f2045e43aebf9b9f847a918deadd
+size 2293246
diff --git a/illustrious_generated/967eef36168d.png b/illustrious_generated/967eef36168d.png
new file mode 100644
index 0000000000000000000000000000000000000000..f743ec333354c3bb2f3db55ec34d4bca3a231677
--- /dev/null
+++ b/illustrious_generated/967eef36168d.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:690418f86e17480415a5c12e245ba2786fe266b05afca99adda1e1859018e9aa
+size 1021408
diff --git a/illustrious_generated/9697431b9811.png b/illustrious_generated/9697431b9811.png
new file mode 100644
index 0000000000000000000000000000000000000000..cf900700e5be2add430050fc3c0a8d827268a67c
--- /dev/null
+++ b/illustrious_generated/9697431b9811.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:aee142ea9d2acd83eb2d52f0d0fe81af34b47367749cf1e5ba06b215d984d8bc
+size 346933
diff --git a/illustrious_generated/96b242415ba0.png b/illustrious_generated/96b242415ba0.png
new file mode 100644
index 0000000000000000000000000000000000000000..dcdcc9b102acb6b025058c98f9d171ff597f8e64
--- /dev/null
+++ b/illustrious_generated/96b242415ba0.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:c28da342c2a2ff193f9ff2eb42c75cd9337dd11334751a1a17cc15068a00e7b6
+size 1024645
diff --git a/illustrious_generated/98ffde3e77e1.png b/illustrious_generated/98ffde3e77e1.png
new file mode 100644
index 0000000000000000000000000000000000000000..1d02e6f531071ad846012ae0ebc65444b6fd1a89
--- /dev/null
+++ b/illustrious_generated/98ffde3e77e1.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:9c6d628510a15c17839b6e0960a526a4f992388657f9e0e6ab294882d01dd761
+size 1182754
diff --git a/illustrious_generated/9920aa062298.png b/illustrious_generated/9920aa062298.png
new file mode 100644
index 0000000000000000000000000000000000000000..460a7305d5d1e7428e35d76c8097c1d3a2c9e136
--- /dev/null
+++ b/illustrious_generated/9920aa062298.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:fb982314e9abccd16038e0556ca3f05fa1b825a1461b89e673bc5996e3ba2b58
+size 2910010
diff --git a/illustrious_generated/996e42ddc32d.png b/illustrious_generated/996e42ddc32d.png
new file mode 100644
index 0000000000000000000000000000000000000000..c720bdb23e0d9e2f28ba65795f0f54512a83f393
--- /dev/null
+++ b/illustrious_generated/996e42ddc32d.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:d4e9fd546f06363f537e77054cb988703f54403b56cf825c1fb6e47f272a6bda
+size 2792673
diff --git a/illustrious_generated/99e7e8d67b6c.png b/illustrious_generated/99e7e8d67b6c.png
new file mode 100644
index 0000000000000000000000000000000000000000..6360f6eada7e76851c204d65e64c2f4394eadfed
--- /dev/null
+++ b/illustrious_generated/99e7e8d67b6c.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e2af30ba65dcd3dce7d32bf0679af0229303e3c200b8e865588cf8471e36d350
+size 1383747
diff --git a/illustrious_generated/9bfb8e69c42b.png b/illustrious_generated/9bfb8e69c42b.png
new file mode 100644
index 0000000000000000000000000000000000000000..b6d534578a0c9e3b8778122af3ffb916310f62f4
--- /dev/null
+++ b/illustrious_generated/9bfb8e69c42b.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:4a6aa4c7e55825e4e0d9bc00632b7097331efdc887bd5c9c7e0415c564eba911
+size 1846970
diff --git a/illustrious_generated/9d37912c5c6b.png b/illustrious_generated/9d37912c5c6b.png
new file mode 100644
index 0000000000000000000000000000000000000000..2048c193678453dad6997ba084d9d6be7691ae5f
--- /dev/null
+++ b/illustrious_generated/9d37912c5c6b.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:554a5e4afb23abf44d37bce73d157ebef19ccbe98895b3581d8dbbe05d0a0850
+size 2525950
diff --git a/illustrious_generated/a02aedc9a6d0.png b/illustrious_generated/a02aedc9a6d0.png
new file mode 100644
index 0000000000000000000000000000000000000000..4afa1d4d3cf60bc67e0fc09a81134c084f7c1c05
--- /dev/null
+++ b/illustrious_generated/a02aedc9a6d0.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:d038d794d016a462aa055140634a4fe85f8708d4454c5ac983a357b1f267bb1c
+size 1140373
diff --git a/illustrious_generated/a195415d7e57.png b/illustrious_generated/a195415d7e57.png
new file mode 100644
index 0000000000000000000000000000000000000000..62340e04c7bb6b89b2574388b43ad04459a638b0
--- /dev/null
+++ b/illustrious_generated/a195415d7e57.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8d9815665ce392a96910d4cf15bb113cb123ded540b40f6ec5482903404913c6
+size 864297
diff --git a/illustrious_generated/a1f402da67f3.png b/illustrious_generated/a1f402da67f3.png
new file mode 100644
index 0000000000000000000000000000000000000000..b10fd1687e5ba7710252e1371af114b447612ed2
--- /dev/null
+++ b/illustrious_generated/a1f402da67f3.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:1c5b622d255f39a34214485f126f22a4658ce36df681e74e65ee94307de0c4b0
+size 576338
diff --git a/illustrious_generated/a1fe7c897ca8.png b/illustrious_generated/a1fe7c897ca8.png
new file mode 100644
index 0000000000000000000000000000000000000000..27f3b05ea242cb12620355187beb94e25fbcafc2
--- /dev/null
+++ b/illustrious_generated/a1fe7c897ca8.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:954740c9c9186053c61e2ba78c775ac74e35681de0a4c736b464c96e37422d66
+size 862676
diff --git a/illustrious_generated/a26cc25bd715.png b/illustrious_generated/a26cc25bd715.png
new file mode 100644
index 0000000000000000000000000000000000000000..3652c366da7588d6523f2d8e549bd7ddceb675e4
--- /dev/null
+++ b/illustrious_generated/a26cc25bd715.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:c3c27d752e8ca776a76ea88591c33cf1b7037e78c1cf726948ae69fb3dc41004
+size 316263
diff --git a/illustrious_generated/a2edbbf44ea5.png b/illustrious_generated/a2edbbf44ea5.png
new file mode 100644
index 0000000000000000000000000000000000000000..0c5136d2f8a0321bbae88cdf2aa897d35ad890ac
--- /dev/null
+++ b/illustrious_generated/a2edbbf44ea5.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e642d23d07b0d791875edc77fa4b9d5206d4eb523cf1c92af061023d2976289b
+size 4393401
diff --git a/illustrious_generated/a2f87b72db7f.png b/illustrious_generated/a2f87b72db7f.png
new file mode 100644
index 0000000000000000000000000000000000000000..0fdff647f5268890be234239be5980a8d573c3c6
--- /dev/null
+++ b/illustrious_generated/a2f87b72db7f.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:9ab0d6d70f7aff960c5cc023e4169adc6d7e01b97f41e082f40875d7a8416912
+size 2382380
diff --git a/illustrious_generated/a306e960c8b6.png b/illustrious_generated/a306e960c8b6.png
new file mode 100644
index 0000000000000000000000000000000000000000..89fbff9a6713615b17981554feaf19d71de3368b
--- /dev/null
+++ b/illustrious_generated/a306e960c8b6.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:16256a3553b412a367ae04dd4020c9f888f7f13f26ee506925380e582cd36fba
+size 1552978
diff --git a/illustrious_generated/a32b3b72a1ca.png b/illustrious_generated/a32b3b72a1ca.png
new file mode 100644
index 0000000000000000000000000000000000000000..1058617c931b6c636daf1b9dc5da56012f48855c
--- /dev/null
+++ b/illustrious_generated/a32b3b72a1ca.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:31fc87c1c717638ba443c5cfb6a246863f765bdbad139b2596fb0a6e0b394b93
+size 2139364
diff --git a/illustrious_generated/a3503780d672.png b/illustrious_generated/a3503780d672.png
new file mode 100644
index 0000000000000000000000000000000000000000..091b2c11b9661c6d11fccc820b62efac10dd5488
--- /dev/null
+++ b/illustrious_generated/a3503780d672.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:b9024e8794bf8a770f3d721a5ad905cc5128bc75549a77fd788fdeaa0c215133
+size 347841
diff --git a/illustrious_generated/a3b6891e867d.png b/illustrious_generated/a3b6891e867d.png
new file mode 100644
index 0000000000000000000000000000000000000000..356d47d4fd7ad8e0be302a33d745bb5f2794203d
--- /dev/null
+++ b/illustrious_generated/a3b6891e867d.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:1e7e14eabddc7619ad342ed3867e17dd88da872b5d9ca278ed619eb0c602a3bf
+size 2897437
diff --git a/illustrious_generated/a6574a463e93.png b/illustrious_generated/a6574a463e93.png
new file mode 100644
index 0000000000000000000000000000000000000000..3fa1999c7b9e334d8d193893dd8fe7458571aa3a
--- /dev/null
+++ b/illustrious_generated/a6574a463e93.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ea059496bf10c3fc41355f9a313a0048058f1eb94e60b27eb36996fe025b12a0
+size 631905
diff --git a/illustrious_generated/a7083e017a49.png b/illustrious_generated/a7083e017a49.png
new file mode 100644
index 0000000000000000000000000000000000000000..084c82efa043661802ef4ce23c8236ace813c5f4
--- /dev/null
+++ b/illustrious_generated/a7083e017a49.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:337b180445bacb55c939b2b6eb23b09ba0c946772a3462c18d5fa093ad7d483c
+size 2142327
diff --git a/illustrious_generated/a81f5cf1ec1a.png b/illustrious_generated/a81f5cf1ec1a.png
new file mode 100644
index 0000000000000000000000000000000000000000..11270beeb199cafa878264e153b2a772fdaad04b
--- /dev/null
+++ b/illustrious_generated/a81f5cf1ec1a.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:3e9ebe86987c91b52b587717c49280eeaaefabfb5baa0dc4a2d13556306d2b30
+size 344768
diff --git a/illustrious_generated/a9595e41a830.png b/illustrious_generated/a9595e41a830.png
new file mode 100644
index 0000000000000000000000000000000000000000..96f4a444fdba4bd0cbfa8d0d2004f66a405ec773
--- /dev/null
+++ b/illustrious_generated/a9595e41a830.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:f02e0eee4803e10cc4984a0dc323cd8a74be14b8ed6b217b37d5681c9ad3a288
+size 1981408
diff --git a/illustrious_generated/ab86051803e3.png b/illustrious_generated/ab86051803e3.png
new file mode 100644
index 0000000000000000000000000000000000000000..dfaab3987841f9d12da5474610457b13df81c92e
--- /dev/null
+++ b/illustrious_generated/ab86051803e3.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:009e2578c24bcec1779fe9860633caf05d492f3a493bb70f2005061f125ff91b
+size 3730319
diff --git a/illustrious_generated/abca7e106aa2.png b/illustrious_generated/abca7e106aa2.png
new file mode 100644
index 0000000000000000000000000000000000000000..8691eda6d9fd1fa05d2126ffeb3e8f321c79eae5
--- /dev/null
+++ b/illustrious_generated/abca7e106aa2.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:3e416f4602bcee8f344ea41ee6904b6080b0f9d9e32a809e9039915693ba9570
+size 837278
diff --git a/illustrious_generated/acb177777ac7.png b/illustrious_generated/acb177777ac7.png
new file mode 100644
index 0000000000000000000000000000000000000000..f0085de9536db5f4a198d33fa007adbb3d7f0455
--- /dev/null
+++ b/illustrious_generated/acb177777ac7.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ded6bcc97d3306290af7e181057a0b203a27905ff6248238f5eae412507280e5
+size 686291
diff --git a/illustrious_generated/ae91e6780f49.png b/illustrious_generated/ae91e6780f49.png
new file mode 100644
index 0000000000000000000000000000000000000000..3be447dae4770f470f56e45be943b6a578af6238
--- /dev/null
+++ b/illustrious_generated/ae91e6780f49.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:4414a3c68bfb3a64dce22e36bcc6ffd8ff9edb0802a4705e5630853b095a1183
+size 1006678
diff --git a/illustrious_generated/b00e96952dbd.png b/illustrious_generated/b00e96952dbd.png
new file mode 100644
index 0000000000000000000000000000000000000000..971ef8f0b2d3af66950fe76ebe0f1617410fc816
--- /dev/null
+++ b/illustrious_generated/b00e96952dbd.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:6b382c817145cc406302b9fc9e585452720a0e503bf835c6864b08befc1f3fd7
+size 2864477
diff --git a/illustrious_generated/b0c5c422dfd8.png b/illustrious_generated/b0c5c422dfd8.png
new file mode 100644
index 0000000000000000000000000000000000000000..0acccf3c21aba8d4489411ad4c1093499f1a0ec9
--- /dev/null
+++ b/illustrious_generated/b0c5c422dfd8.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:cc1371b5e3cf159779bce00c5c44ed9acd289db4de5fc9739a131d73f3ed01ba
+size 331850
diff --git a/illustrious_generated/b1dbf4711b58.png b/illustrious_generated/b1dbf4711b58.png
new file mode 100644
index 0000000000000000000000000000000000000000..beea0c5d30707b902fef4021a118355f5cc280ea
--- /dev/null
+++ b/illustrious_generated/b1dbf4711b58.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:6c82ab8b1f3974802a2df84b2bf1ea03d0e6ee48d06b610e375607d547e088e3
+size 2784695
diff --git a/illustrious_generated/b255db937b2f.png b/illustrious_generated/b255db937b2f.png
new file mode 100644
index 0000000000000000000000000000000000000000..09de69d37d6aa509ad7cd9a8a8d9e56339123f3c
--- /dev/null
+++ b/illustrious_generated/b255db937b2f.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:a506a113d45a58163bae71dccda340b53283a0ce7de57417f3f4d02544d50911
+size 1316141
diff --git a/illustrious_generated/b32dc8ef54c0.png b/illustrious_generated/b32dc8ef54c0.png
new file mode 100644
index 0000000000000000000000000000000000000000..5cb818d5cced23d25fd1fc6f3961ded1331332b6
--- /dev/null
+++ b/illustrious_generated/b32dc8ef54c0.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e0ca4ceee6ced13a54e80f11bfe173e3cfd28c81b6cd3b3dc5e872c78eb11b97
+size 449627
diff --git a/illustrious_generated/b4943a633a4a.png b/illustrious_generated/b4943a633a4a.png
new file mode 100644
index 0000000000000000000000000000000000000000..f043c3e4383e116f668e0853e47eba70a4592d19
--- /dev/null
+++ b/illustrious_generated/b4943a633a4a.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:36cfd036710b74cc01b6f230d588879ee420cf082d682d70095b1955678dc8c0
+size 1358197
diff --git a/illustrious_generated/b6a9455c8c5a.png b/illustrious_generated/b6a9455c8c5a.png
new file mode 100644
index 0000000000000000000000000000000000000000..875554df98beffe022ff4d0428fac343bfc2a742
--- /dev/null
+++ b/illustrious_generated/b6a9455c8c5a.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:dcd1c4076c024afbec88c1bc45e111f7de983c371efc3547a1c73089a57bfeea
+size 2271597
diff --git a/illustrious_generated/b886112038cd.png b/illustrious_generated/b886112038cd.png
new file mode 100644
index 0000000000000000000000000000000000000000..1ceab59f6d898d066de4d3c9ad3e0a3351d9f7fc
--- /dev/null
+++ b/illustrious_generated/b886112038cd.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:5139c9f3fc127e88ecfab9405ee7a40c4f9c1f72ff7008ee139a73600debb435
+size 817331
diff --git a/illustrious_generated/b99d33029712.png b/illustrious_generated/b99d33029712.png
new file mode 100644
index 0000000000000000000000000000000000000000..4551cb766a9181342c4ff97df6a7187c7affa310
--- /dev/null
+++ b/illustrious_generated/b99d33029712.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:3e65f40c372e13fdd8c60281bdc779d343ed167830f2a667df93c4a8d804c343
+size 1483878
diff --git a/illustrious_generated/ba9b3e771a64.png b/illustrious_generated/ba9b3e771a64.png
new file mode 100644
index 0000000000000000000000000000000000000000..e77944712d9eeefe4094559d25aeb2e30f9ac6c0
--- /dev/null
+++ b/illustrious_generated/ba9b3e771a64.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:94c44bf846f2f526d4726cade1f927ea350739f42f9b7fc4071147e37f2907be
+size 1909304
diff --git a/illustrious_generated/bb8a57201a81.png b/illustrious_generated/bb8a57201a81.png
new file mode 100644
index 0000000000000000000000000000000000000000..0488880a79f518cdf0f1890dcb9bc5afdae7b59c
--- /dev/null
+++ b/illustrious_generated/bb8a57201a81.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:5d8bcedad3d195deb29cd7c61db35dadb17bac552a0c23d5c3205154e9a7bfa3
+size 740862
diff --git a/illustrious_generated/bbac62133c72.png b/illustrious_generated/bbac62133c72.png
new file mode 100644
index 0000000000000000000000000000000000000000..a2a117933796d40b334d9ca7bc5e9247955e7720
--- /dev/null
+++ b/illustrious_generated/bbac62133c72.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:03d88d23dab3117884da00369446fcdff21066e28eda5f6b26e9df666cbf6775
+size 329434
diff --git a/illustrious_generated/bc9b0b19d388.png b/illustrious_generated/bc9b0b19d388.png
new file mode 100644
index 0000000000000000000000000000000000000000..7434e9201a7e397b24dd76b0e38125a8b6160363
--- /dev/null
+++ b/illustrious_generated/bc9b0b19d388.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:bf157e699e73463710d6e45b2ccf76d3361332bcd6ac5dc384cf1ecc01c7daca
+size 2992380
diff --git a/illustrious_generated/bcfbf1ed20d5.png b/illustrious_generated/bcfbf1ed20d5.png
new file mode 100644
index 0000000000000000000000000000000000000000..6b835682edfd9cb4f4432da9c48ec5159976515a
--- /dev/null
+++ b/illustrious_generated/bcfbf1ed20d5.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:1bc2e0b77ac37d8e35be5ce6e13a67a4e3bd5119243e0457c2c8426a5d57e528
+size 1301337
diff --git a/illustrious_generated/bd91f9b0b5fd.png b/illustrious_generated/bd91f9b0b5fd.png
new file mode 100644
index 0000000000000000000000000000000000000000..09d082002dfeb998e8a189a003af0a5262f30174
--- /dev/null
+++ b/illustrious_generated/bd91f9b0b5fd.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:c0ab1710e02b213b76093387854bdaa5cb592b6a0ad8414a10b69926831b38f5
+size 1914266
diff --git a/illustrious_generated/be473a0c5f8b.png b/illustrious_generated/be473a0c5f8b.png
new file mode 100644
index 0000000000000000000000000000000000000000..9ea26dac98f8c3660a878391d88b592e380c94cc
--- /dev/null
+++ b/illustrious_generated/be473a0c5f8b.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:7cf6a16c0ff28dba7f53dffb15be44ea514aca3a006705bbdec2e7bdba3d35f4
+size 997746
diff --git a/illustrious_generated/bedd27fd0ff5.png b/illustrious_generated/bedd27fd0ff5.png
new file mode 100644
index 0000000000000000000000000000000000000000..b5d2a1402905d863848acf4fb5765f8bcc39f3e4
--- /dev/null
+++ b/illustrious_generated/bedd27fd0ff5.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:831e5a2dec30114df1af92975873209d27bbfe0b1dcbd20b3b1a44239de52ff0
+size 1462285
diff --git a/illustrious_generated/bf1c3fcf8014.png b/illustrious_generated/bf1c3fcf8014.png
new file mode 100644
index 0000000000000000000000000000000000000000..5bccb6633fc9450df523f4f253dd899de3a4ff21
--- /dev/null
+++ b/illustrious_generated/bf1c3fcf8014.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:da6b10a2d518cdcf0dfc9d867fbfc86676f3ebb6b0e1a308cca4842b996c8a24
+size 736771
diff --git a/illustrious_generated/c05e8425073d.png b/illustrious_generated/c05e8425073d.png
new file mode 100644
index 0000000000000000000000000000000000000000..bc96a13deb9ab3a5c6da844aa1c53d97c6d601e9
--- /dev/null
+++ b/illustrious_generated/c05e8425073d.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:10016d51b62da6b6984f2c2e7c0f38a2fc2c390a4e706e5eb8b6d1d2526281c4
+size 1113234
diff --git a/illustrious_generated/c0e5f6c62692.png b/illustrious_generated/c0e5f6c62692.png
new file mode 100644
index 0000000000000000000000000000000000000000..682fd04274d45a1253de87b4c938e4efde827e30
--- /dev/null
+++ b/illustrious_generated/c0e5f6c62692.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ebd2295200122701ad3a48cba59e948b3f88856635c0ae7aba831bf505e87165
+size 602281
diff --git a/illustrious_generated/c23217b34c2b.png b/illustrious_generated/c23217b34c2b.png
new file mode 100644
index 0000000000000000000000000000000000000000..b7e8d1352c9c28e3aa95401e316e6ea8fe93081f
--- /dev/null
+++ b/illustrious_generated/c23217b34c2b.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:a84426e31fe627f78cc1f09536f7830bf116b2c02bec7bc583ceecb1b7a971b3
+size 1277416
diff --git a/illustrious_generated/c4031e0615e3.png b/illustrious_generated/c4031e0615e3.png
new file mode 100644
index 0000000000000000000000000000000000000000..348af76b748ae880c4b259195144e91492858a40
--- /dev/null
+++ b/illustrious_generated/c4031e0615e3.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:91aa22c285b0b38779879ce0141f662c04ccec3d0dfd89615a4ac9dd85e3531a
+size 1753179
diff --git a/illustrious_generated/c50fe2e11b72.png b/illustrious_generated/c50fe2e11b72.png
new file mode 100644
index 0000000000000000000000000000000000000000..893e94e3aebc6b9d9a5e5e53296df352e750abdd
--- /dev/null
+++ b/illustrious_generated/c50fe2e11b72.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:775579ff8d82448e87e3358df781d45593c35f26920c3f35e60f8a0475c680f3
+size 2422579
diff --git a/illustrious_generated/c79e4c700b49.png b/illustrious_generated/c79e4c700b49.png
new file mode 100644
index 0000000000000000000000000000000000000000..ad1ca40694c6516575e713394c6ba9156d9529e6
--- /dev/null
+++ b/illustrious_generated/c79e4c700b49.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e6dc5410231d5ad0196addacfda6b95a1958adeab3bc27e746735e0b3d78e488
+size 2963020
diff --git a/illustrious_generated/c7c292892c5b.png b/illustrious_generated/c7c292892c5b.png
new file mode 100644
index 0000000000000000000000000000000000000000..05aa3d69d6cee87e8d7ce150c964141ff0082e39
--- /dev/null
+++ b/illustrious_generated/c7c292892c5b.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:9fd97d25f846914d61b05af4558d6e03dd2517a216769f0408d4f089717a0c4e
+size 1516299
diff --git a/illustrious_generated/c8346a11fde8.png b/illustrious_generated/c8346a11fde8.png
new file mode 100644
index 0000000000000000000000000000000000000000..f8a48cdae756853e0f2d2db006d8cbefbc1d131e
--- /dev/null
+++ b/illustrious_generated/c8346a11fde8.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:99e1e89ea7bf4db23e9d2b4d6cab4bbc5ccbbbe053feb69310044e4d9cd71c59
+size 659830
diff --git a/illustrious_generated/c94e96b3d9ea.png b/illustrious_generated/c94e96b3d9ea.png
new file mode 100644
index 0000000000000000000000000000000000000000..2704a7604f9a9b775baf89d4423092695a588c8d
--- /dev/null
+++ b/illustrious_generated/c94e96b3d9ea.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e3db7dd022846150e20dd10a2842845f849685cfee550cabf59dd0620bf19c00
+size 1101071
diff --git a/illustrious_generated/c97492864ec8.png b/illustrious_generated/c97492864ec8.png
new file mode 100644
index 0000000000000000000000000000000000000000..ebdc0702b46b46d873d6d90e0da8e43c2beec001
--- /dev/null
+++ b/illustrious_generated/c97492864ec8.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:89453c4f024972d7c5e4ae4a9037c5eb0df54a4293efbabfdcadee9a10f75489
+size 1448887
diff --git a/illustrious_generated/ca69e529f9f4.png b/illustrious_generated/ca69e529f9f4.png
new file mode 100644
index 0000000000000000000000000000000000000000..09bb5f90035c18d9e6c89b861f34efe8ce08ee72
--- /dev/null
+++ b/illustrious_generated/ca69e529f9f4.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:6e62b1507ea9d66cff89adfe5c9a1e9d24733bc6f465b3f87b21e76740675209
+size 1618362
diff --git a/illustrious_generated/cb842cd5960d.png b/illustrious_generated/cb842cd5960d.png
new file mode 100644
index 0000000000000000000000000000000000000000..79020fe48d0e605d571fa6043a86687796fb6f68
--- /dev/null
+++ b/illustrious_generated/cb842cd5960d.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:9fc9f4c98fca1ea1fe6e55ed83bbefbe4c20de677a52b46c41b2b999e2e7c2d4
+size 2881262
diff --git a/illustrious_generated/cd4f7da85fec.png b/illustrious_generated/cd4f7da85fec.png
new file mode 100644
index 0000000000000000000000000000000000000000..6ed7235fe057aa787146680ba54ad49c6270cad3
--- /dev/null
+++ b/illustrious_generated/cd4f7da85fec.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:827a91b1ac63135762c5e289bc1eea7b581b87816dc556141ec61504ee894ed3
+size 464208
diff --git a/illustrious_generated/cfa0a7a41b96.png b/illustrious_generated/cfa0a7a41b96.png
new file mode 100644
index 0000000000000000000000000000000000000000..b364c71590717aafe8907b0172e5a9259e637230
--- /dev/null
+++ b/illustrious_generated/cfa0a7a41b96.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:fd35764fdbd97ff2d77f24ae51f6bdcda36ae615774d9bd434788e5487c71796
+size 427783
diff --git a/illustrious_generated/d06528745fb3.png b/illustrious_generated/d06528745fb3.png
new file mode 100644
index 0000000000000000000000000000000000000000..4a1d704f53fb43bc849ab40ed608a8df4cc94edc
--- /dev/null
+++ b/illustrious_generated/d06528745fb3.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e676762dac5b432186bff759934e4d92eba7b12e43306b52ae85b23f30486427
+size 1565152
diff --git a/illustrious_generated/d2324ff7a0ba.png b/illustrious_generated/d2324ff7a0ba.png
new file mode 100644
index 0000000000000000000000000000000000000000..3af5331307c742f8c20ce804386fba0fc2314f4b
--- /dev/null
+++ b/illustrious_generated/d2324ff7a0ba.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:34a0b17c171af8aff2222110761cb8110de0c8e12736601f79d1ea057ec1f272
+size 683260
diff --git a/illustrious_generated/d2544b7097ca.png b/illustrious_generated/d2544b7097ca.png
new file mode 100644
index 0000000000000000000000000000000000000000..2cfdfeddcda4ff773e81d9b0d523831767a477b6
--- /dev/null
+++ b/illustrious_generated/d2544b7097ca.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:9191a7260dbaa0aac75fa819d462e22c7856a0f2615d89f875100f291ac7bc27
+size 2117785
diff --git a/illustrious_generated/d2ee4eaf9593.png b/illustrious_generated/d2ee4eaf9593.png
new file mode 100644
index 0000000000000000000000000000000000000000..684a50c7763d02c4771849bfb7810a6c30ec58aa
--- /dev/null
+++ b/illustrious_generated/d2ee4eaf9593.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:c5e955749e8be1a29d3cb4f96ab6c11080eec2223bc3bb3b5b461065a6bb537a
+size 1393260
diff --git a/illustrious_generated/d2feeadf93ad.png b/illustrious_generated/d2feeadf93ad.png
new file mode 100644
index 0000000000000000000000000000000000000000..9d9203dadc98097c6db452124cca41b0808911a6
--- /dev/null
+++ b/illustrious_generated/d2feeadf93ad.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:aa29eb5d186d881ba47ea4be5e4fc767f83942dab033930bbc4ad9ecf98d1f09
+size 2508483
diff --git a/illustrious_generated/d4228c891489.png b/illustrious_generated/d4228c891489.png
new file mode 100644
index 0000000000000000000000000000000000000000..688b050d53deb27c35de049dbc8241d619ef5d2c
--- /dev/null
+++ b/illustrious_generated/d4228c891489.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:a6acced9e55fa617f18b38c1902f506e77a2e072cb028d0377089e7dbd93c69f
+size 1619172
diff --git a/illustrious_generated/d51058560a83.png b/illustrious_generated/d51058560a83.png
new file mode 100644
index 0000000000000000000000000000000000000000..4204f46d3b7a3b586f3a71271ea98677bac83c44
--- /dev/null
+++ b/illustrious_generated/d51058560a83.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:91e3d91e3970d3f49c39bbae9ad161d9017d91dd1905c7d3c5542402ad70504b
+size 2621363
diff --git a/illustrious_generated/d683ada1991f.png b/illustrious_generated/d683ada1991f.png
new file mode 100644
index 0000000000000000000000000000000000000000..019bceff61d209863226bfdff10687001022ef7a
--- /dev/null
+++ b/illustrious_generated/d683ada1991f.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:c7c7aaa3bfc68bf78a7757de47233361e0245b82277ed3ad80d7a9752f153a86
+size 342271
diff --git a/illustrious_generated/d91388106fea.png b/illustrious_generated/d91388106fea.png
new file mode 100644
index 0000000000000000000000000000000000000000..746ad1687d0f0377cda7a1551baf70fe5e086995
--- /dev/null
+++ b/illustrious_generated/d91388106fea.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:55d171907a032424b869ebbec05a2e475140db10d5233ec3127142159ce75119
+size 938015
diff --git a/illustrious_generated/da399732e61b.png b/illustrious_generated/da399732e61b.png
new file mode 100644
index 0000000000000000000000000000000000000000..c711d5681fb3ab0c4693e248cf0793040eaa6851
--- /dev/null
+++ b/illustrious_generated/da399732e61b.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8adaa5e91c38ab3f8bf56d6cf4ce58e624e961cf59305fd59f2fda4ce4bc5975
+size 3757763
diff --git a/illustrious_generated/da867a2aa941.png b/illustrious_generated/da867a2aa941.png
new file mode 100644
index 0000000000000000000000000000000000000000..38a376bed77599083266239745d23fc3d48a3ed7
--- /dev/null
+++ b/illustrious_generated/da867a2aa941.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:d4cbe13fa9d74d0a0499577feb3b8deb79fe74495e9a591eaaa2657d0ca33115
+size 4159106
diff --git a/illustrious_generated/de853b05dcb8.png b/illustrious_generated/de853b05dcb8.png
new file mode 100644
index 0000000000000000000000000000000000000000..3cb39dedbf4c8001c73b3da3ac7339404edd47ee
--- /dev/null
+++ b/illustrious_generated/de853b05dcb8.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:55d5e1e50e78bcd6b9571732e84b1b169c74c9f3796a3ffe5c788fa41add6168
+size 1121126
diff --git a/illustrious_generated/e14c33757398.png b/illustrious_generated/e14c33757398.png
new file mode 100644
index 0000000000000000000000000000000000000000..3e25fec42e8c83d253cb7702febde350fba8b275
--- /dev/null
+++ b/illustrious_generated/e14c33757398.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:6b98bc2bb76a83cb3862387ca39e5433e519470191b02ba4af8ca242be70cf45
+size 1078382
diff --git a/illustrious_generated/e27fb90149e1.png b/illustrious_generated/e27fb90149e1.png
new file mode 100644
index 0000000000000000000000000000000000000000..652bada3eab73482367fa87a77e4b41954cfc822
--- /dev/null
+++ b/illustrious_generated/e27fb90149e1.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:0bf5348694d33d74e7c1c9f40f16bd54bc800e3e0b4d7fb7bfeae6136ca346d7
+size 1708484
diff --git a/illustrious_generated/e2b864778b63.png b/illustrious_generated/e2b864778b63.png
new file mode 100644
index 0000000000000000000000000000000000000000..308cabc9069b61eace8c310aa728aea8ab3ecaaf
--- /dev/null
+++ b/illustrious_generated/e2b864778b63.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:508c76bfaf1d5416a51cc9ae70617574ce11fea466ee8ed2909f0094ee5af0b4
+size 665212
diff --git a/illustrious_generated/e39dcd049925.png b/illustrious_generated/e39dcd049925.png
new file mode 100644
index 0000000000000000000000000000000000000000..f47e599d26e50f63744b1fbea8d3b3aef9f58464
--- /dev/null
+++ b/illustrious_generated/e39dcd049925.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:4d0bfe1b1f4c44b331e80bae8cf4276bfddb1e82c70abd5c7a04263fac3e0b0b
+size 1135615
diff --git a/illustrious_generated/e4c872bc87aa.png b/illustrious_generated/e4c872bc87aa.png
new file mode 100644
index 0000000000000000000000000000000000000000..cf2a702e7cd2a40a094a8864521602e582d6b29c
--- /dev/null
+++ b/illustrious_generated/e4c872bc87aa.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:153e101f72139ea97b8bda3c53e044b56cb9e34959b1bdc6abe55b316163cca6
+size 1202024
diff --git a/illustrious_generated/e5008520004f.png b/illustrious_generated/e5008520004f.png
new file mode 100644
index 0000000000000000000000000000000000000000..cdf7de536af3257646454c4da7f5ab4ac20da58a
--- /dev/null
+++ b/illustrious_generated/e5008520004f.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:2a9b88f5609c72e1b1f79c3baca82f08324b9e37b76b2aeee3e8627c606505c3
+size 4657239
diff --git a/illustrious_generated/e51750b3db46.png b/illustrious_generated/e51750b3db46.png
new file mode 100644
index 0000000000000000000000000000000000000000..3fbb9e960f7d96a6eb63c7dbc07ac296981807a9
--- /dev/null
+++ b/illustrious_generated/e51750b3db46.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8b769bdd75487ea0903e2728baa3794d6ddfc63bd711ee292749e5c5b93044e0
+size 661255
diff --git a/illustrious_generated/e53e40e825d6.png b/illustrious_generated/e53e40e825d6.png
new file mode 100644
index 0000000000000000000000000000000000000000..e420fe9e29f53d92fe3c0f8e359773c00a563b22
--- /dev/null
+++ b/illustrious_generated/e53e40e825d6.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ae61b114aa2645720c83f7f9ef09db020f46316f15b6b9130763346cb0fb5961
+size 578743
diff --git a/illustrious_generated/e775a7d63dd7.png b/illustrious_generated/e775a7d63dd7.png
new file mode 100644
index 0000000000000000000000000000000000000000..d913c582adf96699300710cd98b24679bb5e51b2
--- /dev/null
+++ b/illustrious_generated/e775a7d63dd7.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:605363e4fba64235daeaff500a20afe37cf18445a2b3489b0f700e39d81248d4
+size 1619225
diff --git a/illustrious_generated/ebcb34ee32e6.png b/illustrious_generated/ebcb34ee32e6.png
new file mode 100644
index 0000000000000000000000000000000000000000..d16ee773e3c49f745c4ef35fc93997de51518403
--- /dev/null
+++ b/illustrious_generated/ebcb34ee32e6.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:7e32a5f93ce07124bfad1a5e824f13ed77039f9c132fc7f753f37804402b89e8
+size 484248
diff --git a/illustrious_generated/ecd881b39945.png b/illustrious_generated/ecd881b39945.png
new file mode 100644
index 0000000000000000000000000000000000000000..e8468e63396d0624c6885b07af85f2b193b1ba9c
--- /dev/null
+++ b/illustrious_generated/ecd881b39945.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:3da05bb3298dda97b317e5660a09c11e417dffd3b9f8280da1f0dfeb7b0b4312
+size 2609214
diff --git a/illustrious_generated/ee4940943b83.png b/illustrious_generated/ee4940943b83.png
new file mode 100644
index 0000000000000000000000000000000000000000..f2aa1a192ee09d82394fad0e4dc6ef7e45781251
--- /dev/null
+++ b/illustrious_generated/ee4940943b83.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:d33a49bad82611e56fd2b29df2cdd76dadfe6311267e886c0518afaaf196b0ad
+size 1362649
diff --git a/illustrious_generated/ee934c327ef4.png b/illustrious_generated/ee934c327ef4.png
new file mode 100644
index 0000000000000000000000000000000000000000..fecac60badd01a6292864bdc4c17a1b438bdfca2
--- /dev/null
+++ b/illustrious_generated/ee934c327ef4.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:7dd2561c5fe098a5802b9b9c6de928bcfa3c1bb44af3a50d0d92f0d943388b3f
+size 422099
diff --git a/illustrious_generated/efa989bd04ca.png b/illustrious_generated/efa989bd04ca.png
new file mode 100644
index 0000000000000000000000000000000000000000..dc1301e5492a229c1728e05daed678d756ba2a6f
--- /dev/null
+++ b/illustrious_generated/efa989bd04ca.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:7ef71f08d8f9b7dc6f32ad7bd636a39fcc05efb0e990e2168d98ef7661d7dfb9
+size 657884
diff --git a/illustrious_generated/f123ea28ebf8.png b/illustrious_generated/f123ea28ebf8.png
new file mode 100644
index 0000000000000000000000000000000000000000..524a8182b6ba8755a08d8058d25751f2e38b1026
--- /dev/null
+++ b/illustrious_generated/f123ea28ebf8.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:d8e52dd3ff80308e8e13794f46adc9618dbeee3b8f0b98c2127a7fb4fe1924f1
+size 2365200
diff --git a/illustrious_generated/f26f01f72683.png b/illustrious_generated/f26f01f72683.png
new file mode 100644
index 0000000000000000000000000000000000000000..e3a9e692fb978174fc6c12bc8f229a4f953c01af
--- /dev/null
+++ b/illustrious_generated/f26f01f72683.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:447c3d4c71853ed246110c25b85ff6ce8312ff4f02ca090db547a977385d4bd5
+size 1383759
diff --git a/illustrious_generated/f2d773c35024.png b/illustrious_generated/f2d773c35024.png
new file mode 100644
index 0000000000000000000000000000000000000000..bcd0d19f13b3931d4d365754c7ab7cb588764785
--- /dev/null
+++ b/illustrious_generated/f2d773c35024.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:44aef6e001a6dca21f47c2bc9292aca6674448d1fc5cce1c243fe20bdcad1183
+size 2943574
diff --git a/illustrious_generated/f32c450ee5a2.png b/illustrious_generated/f32c450ee5a2.png
new file mode 100644
index 0000000000000000000000000000000000000000..f9ff7e1b1568af3dda9d36c0f3b729c94e58b1f3
--- /dev/null
+++ b/illustrious_generated/f32c450ee5a2.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:fd027e5b1d2f71e20037d5dd7d5d8034dc15ce403f8e49d07d92050eef05de0f
+size 808361
diff --git a/illustrious_generated/f3466d572a8b.png b/illustrious_generated/f3466d572a8b.png
new file mode 100644
index 0000000000000000000000000000000000000000..faa0c5edfadf27380bd856f96b1af736f8bb4b11
--- /dev/null
+++ b/illustrious_generated/f3466d572a8b.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:e340876a7638bc18e6716cce7a14a2e2de66aeb7ab804fdfe145aaa99333e11f
+size 1213808
diff --git a/illustrious_generated/f6877e18a119.png b/illustrious_generated/f6877e18a119.png
new file mode 100644
index 0000000000000000000000000000000000000000..0eab6dcce23766b97f85de6cb0b1601affb3925a
--- /dev/null
+++ b/illustrious_generated/f6877e18a119.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:bb81bfbc9ab42a115ca32970334755f70f01cb2abba1cb13cb1fd1ae7016968a
+size 1739397
diff --git a/illustrious_generated/f8aae53c58a2.png b/illustrious_generated/f8aae53c58a2.png
new file mode 100644
index 0000000000000000000000000000000000000000..33a0bceea219da44549f6ab97c080572c491e2f5
--- /dev/null
+++ b/illustrious_generated/f8aae53c58a2.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:5d0dda2a003165f71e007a9c8c1f9c8b5aef43b3278c17d3bf13da8e35998a8a
+size 3713275
diff --git a/illustrious_generated/f8b5f44151ea.png b/illustrious_generated/f8b5f44151ea.png
new file mode 100644
index 0000000000000000000000000000000000000000..8593b0c9031ab103cfaf2908a416764a3622c3d3
--- /dev/null
+++ b/illustrious_generated/f8b5f44151ea.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:27fa8df32b8c64274d12747b02db3003a417cff221f7ce3d490342b3ab319004
+size 1134709
diff --git a/illustrious_generated/f8fa229d4811.png b/illustrious_generated/f8fa229d4811.png
new file mode 100644
index 0000000000000000000000000000000000000000..9c136fd1e84dffac6c9e2d33a4cb91255b4e560a
--- /dev/null
+++ b/illustrious_generated/f8fa229d4811.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:6fab147366afef104c84c6ffff30e53ec4b75cd2cd632b162dc014267e22e785
+size 2079898
diff --git a/illustrious_generated/f9dd63f65c52.png b/illustrious_generated/f9dd63f65c52.png
new file mode 100644
index 0000000000000000000000000000000000000000..98aaad1655670b4f6c37830805f51c73f2509067
--- /dev/null
+++ b/illustrious_generated/f9dd63f65c52.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:9012b3d78c754173d207b72b8cf6ef9373eaf55779540e38241a690f6dac5542
+size 1080856
diff --git a/illustrious_generated/fa47299df8c0.png b/illustrious_generated/fa47299df8c0.png
new file mode 100644
index 0000000000000000000000000000000000000000..bcbff6da10129aac7cbd310b24cc9952887c0765
--- /dev/null
+++ b/illustrious_generated/fa47299df8c0.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:fcdaf6e8685b8474cb5944dc7851e2017464b2be6570d08b257119480d0b8481
+size 2289861
diff --git a/illustrious_generated/fb02dde2bd3c.png b/illustrious_generated/fb02dde2bd3c.png
new file mode 100644
index 0000000000000000000000000000000000000000..a067f72f6680175de1e78475ac84b7715b11de8e
--- /dev/null
+++ b/illustrious_generated/fb02dde2bd3c.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:92837956ecf8ca754e5137808acba1ebff5b93ed98acef2ca88c79df5b424dec
+size 1776984
diff --git a/illustrious_generated/fcac48dcef7f.png b/illustrious_generated/fcac48dcef7f.png
new file mode 100644
index 0000000000000000000000000000000000000000..7dd188886a8625b54edb3673b796acf9d137ba17
--- /dev/null
+++ b/illustrious_generated/fcac48dcef7f.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:907d005cad98b0550d3d2b36ad71e6dc438cf0d671bdd9b4019abe706f564648
+size 560833
diff --git a/illustrious_generated/ffb975056195.png b/illustrious_generated/ffb975056195.png
new file mode 100644
index 0000000000000000000000000000000000000000..95658f699dc033032585486699e9ebff249806b6
--- /dev/null
+++ b/illustrious_generated/ffb975056195.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:8527f22e3ecee11b3a333cdd68d00ec4d54c1841ac5275a9671f82574b964c6a
+size 573817
diff --git a/peft/.github/ISSUE_TEMPLATE/bug-report.yml b/peft/.github/ISSUE_TEMPLATE/bug-report.yml
new file mode 100644
index 0000000000000000000000000000000000000000..82ad94acbca3dbeb54bf360c3b93462d75b22b82
--- /dev/null
+++ b/peft/.github/ISSUE_TEMPLATE/bug-report.yml
@@ -0,0 +1,54 @@
+name: "\U0001F41B Bug Report"
+description: Submit a bug report to help us improve the library
+body:
+ - type: textarea
+ id: system-info
+ attributes:
+ label: System Info
+ description: Please share your relevant system information with us
+ placeholder: peft & accelerate & transformers version, platform, python version, ...
+ validations:
+ required: true
+
+ - type: textarea
+ id: who-can-help
+ attributes:
+ label: Who can help?
+ description: |
+ Your issue will be replied to more quickly if you can figure out the right person to tag with @.
+ If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
+
+ All issues are read by one of the core maintainers, so if you don't know who to tag, just leave this blank and
+ a core maintainer will ping the right person.
+
+ Please tag fewer than 3 people.
+
+ Library: @benjaminbossan @githubnemo
+
+ diffusers integration: @benjaminbossan @sayakpaul
+
+ Documentation: @stevhliu
+
+ placeholder: "@Username ..."
+
+ - type: textarea
+ id: reproduction
+ validations:
+ required: true
+ attributes:
+ label: Reproduction
+ description: |
+ Please provide a code sample that reproduces the problem you ran into. It can be a Colab link or just a code snippet.
+ Please provide the simplest reproducer as possible so that we can quickly fix the issue. When you paste
+ the error message, please include the full traceback.
+
+ placeholder: |
+ Reproducer:
+
+ - type: textarea
+ id: expected-behavior
+ validations:
+ required: true
+ attributes:
+ label: Expected behavior
+ description: "A clear and concise description of what you would expect to happen."
diff --git a/peft/.github/ISSUE_TEMPLATE/feature-request.yml b/peft/.github/ISSUE_TEMPLATE/feature-request.yml
new file mode 100644
index 0000000000000000000000000000000000000000..5e0b73e1f3afa9a865220346bc0ff2586c542ec8
--- /dev/null
+++ b/peft/.github/ISSUE_TEMPLATE/feature-request.yml
@@ -0,0 +1,21 @@
+name: "\U0001F680 Feature request"
+description: Submit a proposal/request for a new feature
+labels: [ "feature" ]
+body:
+ - type: textarea
+ id: feature-request
+ validations:
+ required: true
+ attributes:
+ label: Feature request
+ description: |
+ A clear and concise description of the feature proposal. Please provide a link to the paper and code in case they exist.
+
+ - type: textarea
+ id: contribution
+ validations:
+ required: true
+ attributes:
+ label: Your contribution
+ description: |
+ Is there any way that you could help, e.g. by submitting a PR?
diff --git a/peft/.github/workflows/build_documentation.yml b/peft/.github/workflows/build_documentation.yml
new file mode 100644
index 0000000000000000000000000000000000000000..42e7972bc27c00057da3582ca1810d64441c0454
--- /dev/null
+++ b/peft/.github/workflows/build_documentation.yml
@@ -0,0 +1,22 @@
+name: Build documentation
+
+on:
+ push:
+ branches:
+ - main
+ - doc-builder*
+ - v*-release
+
+permissions: {}
+
+jobs:
+ build:
+ uses: huggingface/doc-builder/.github/workflows/build_main_documentation.yml@main
+ with:
+ commit_sha: ${{ github.sha }}
+ package: peft
+ notebook_folder: peft_docs
+ custom_container: huggingface/transformers-doc-builder
+ secrets:
+ token: ${{ secrets.HUGGINGFACE_PUSH }}
+ hf_token: ${{ secrets.HF_DOC_BUILD_PUSH }}
diff --git a/peft/.github/workflows/build_pr_documentation.yml b/peft/.github/workflows/build_pr_documentation.yml
new file mode 100644
index 0000000000000000000000000000000000000000..3fe27e8a04bd5788fd7edbd8c95e9de546206647
--- /dev/null
+++ b/peft/.github/workflows/build_pr_documentation.yml
@@ -0,0 +1,19 @@
+name: Build PR Documentation
+
+on:
+ pull_request:
+
+concurrency:
+ group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }}
+ cancel-in-progress: true
+
+permissions: {}
+
+jobs:
+ build:
+ uses: huggingface/doc-builder/.github/workflows/build_pr_documentation.yml@main
+ with:
+ commit_sha: ${{ github.event.pull_request.head.sha }}
+ pr_number: ${{ github.event.number }}
+ package: peft
+ custom_container: huggingface/transformers-doc-builder
diff --git a/peft/.github/workflows/deploy_method_comparison_app.yml b/peft/.github/workflows/deploy_method_comparison_app.yml
new file mode 100644
index 0000000000000000000000000000000000000000..a86ba351db9096802e156ddb14f5992cffe3afcf
--- /dev/null
+++ b/peft/.github/workflows/deploy_method_comparison_app.yml
@@ -0,0 +1,41 @@
+name: Deploy "method_comparison" Gradio to Spaces
+
+on:
+ push:
+ branches: [ main ]
+ paths:
+ - "method_comparison/**"
+ workflow_dispatch:
+
+permissions: {}
+
+jobs:
+ deploy:
+ runs-on: ubuntu-latest
+ steps:
+ - name: Checkout code
+ uses: actions/checkout@v4
+ with:
+ fetch-depth: 0 # full history needed for subtree
+ persist-credentials: false
+
+ - name: Authenticate via ~/.netrc
+ env:
+ HF_TOKEN: ${{ secrets.PEFT_INTERNAL_REPO_READ_WRITE }}
+ run: |
+ # netrc needs BOTH login and password entries
+ printf "machine huggingface.co\nlogin hf\npassword ${HF_TOKEN}\n" >> ~/.netrc
+ chmod 600 ~/.netrc
+
+ - name: Deploy method_comparison app to HF Spaces
+ run: |
+ cd method_comparison
+ git init
+ # Spaces expect requirements.txt
+ mv requirements-app.txt requirements.txt
+ git config user.name "github-actions[bot]"
+ git config user.email "github-actions[bot]@users.noreply.github.com"
+ git remote add gradio-app https://huggingface.co/spaces/peft-internal-testing/PEFT-method-comparison
+ git add .
+ git commit -m "🚀 Deploy method comparison app from GH action"
+ git push -f gradio-app HEAD:main
diff --git a/peft/.github/workflows/integrations_tests.yml b/peft/.github/workflows/integrations_tests.yml
new file mode 100644
index 0000000000000000000000000000000000000000..3d61c8d915a87e2a61d261362231d7caab12cb48
--- /dev/null
+++ b/peft/.github/workflows/integrations_tests.yml
@@ -0,0 +1,86 @@
+name: integration tests
+
+on:
+ workflow_dispatch:
+ inputs:
+ branch:
+ description: 'Branch to test on'
+ required: true
+
+permissions: {}
+
+jobs:
+ run_transformers_integration_tests:
+ strategy:
+ fail-fast: false
+ matrix:
+ transformers-version: ['main', 'latest']
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v4
+ with:
+ ref: ${{ github.event.inputs.branch }}
+ repository: ${{ github.event.pull_request.head.repo.full_name }}
+ persist-credentials: false
+ - name: Set up Python
+ uses: actions/setup-python@v4
+ with:
+ python-version: "3.10"
+ cache: "pip"
+ cache-dependency-path: "setup.py"
+ - name: print environment variables
+ run: |
+ echo "env.CI_BRANCH = ${CI_BRANCH}"
+ echo "env.CI_SHA = ${CI_SHA}"
+ - name: Install dependencies
+ run: |
+ python -m pip install --upgrade pip
+ python -m pip install .[test]
+ if [ "${{ matrix.transformers-version }}" == "main" ]; then
+ pip install -U git+https://github.com/huggingface/transformers.git
+ else
+ echo "Nothing to do as transformers latest already installed"
+ fi
+
+ - name: Test transformers integration
+ run: |
+ cd .. && git clone https://github.com/huggingface/transformers.git && cd transformers/ && git rev-parse HEAD
+ RUN_SLOW=1 pytest tests/peft_integration/test_peft_integration.py
+ run_diffusers_integration_tests:
+ strategy:
+ fail-fast: false
+ matrix:
+ # For now diffusers integration is not on PyPI
+ diffusers-version: ['main']
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v4
+ with:
+ ref: ${{ github.event.inputs.branch }}
+ repository: ${{ github.event.pull_request.head.repo.full_name }}
+ persist-credentials: false
+ - name: Set up Python
+ uses: actions/setup-python@v4
+ with:
+ python-version: "3.10"
+ cache: "pip"
+ cache-dependency-path: "setup.py"
+ - name: print environment variables
+ run: |
+ echo "env.CI_BRANCH = ${CI_BRANCH}"
+ echo "env.CI_SHA = ${CI_SHA}"
+ - name: Install dependencies
+ run: |
+ python -m pip install --upgrade pip
+ python -m pip install .[test]
+
+ if [ "${{ matrix.diffusers-version }}" == "main" ]; then
+ pip install -U git+https://github.com/huggingface/diffusers.git
+ else
+ echo "Nothing to do as diffusers latest already installed"
+ fi
+
+ - name: Test diffusers integration
+ run: |
+ cd .. && git clone https://github.com/huggingface/diffusers.git && cd diffusers/ && git rev-parse HEAD
+ pytest tests/lora/test_lora_layers_peft.py
diff --git a/peft/.github/workflows/nightly-bnb.yml b/peft/.github/workflows/nightly-bnb.yml
new file mode 100644
index 0000000000000000000000000000000000000000..e633688d9061e106347fd86e3662af1fed602434
--- /dev/null
+++ b/peft/.github/workflows/nightly-bnb.yml
@@ -0,0 +1,249 @@
+name: BNB from source self-hosted runner with slow tests (scheduled)
+
+on:
+ workflow_dispatch:
+ schedule:
+ - cron: "0 2 * * *"
+
+env:
+ RUN_SLOW: "yes"
+ IS_GITHUB_CI: "1"
+ # To be able to run tests on CUDA 12.2
+ NVIDIA_DISABLE_REQUIRE: "1"
+ SLACK_API_TOKEN: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
+
+permissions: {}
+
+jobs:
+ run_all_tests_single_gpu:
+ timeout-minutes: 60
+ strategy:
+ fail-fast: false
+ matrix:
+ docker-image-name: ["huggingface/peft-gpu-bnb-source:latest", "huggingface/peft-gpu-bnb-latest:latest"]
+ runs-on:
+ group: aws-g6-4xlarge-plus
+ env:
+ CUDA_VISIBLE_DEVICES: "0"
+ TEST_TYPE: "single_gpu_${{ matrix.docker-image-name }}"
+ container:
+ image: ${{ matrix.docker-image-name }}
+ options: --gpus all --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ defaults:
+ run:
+ shell: bash
+ steps:
+ - uses: actions/checkout@v3
+ with:
+ persist-credentials: false
+ - name: Pip install
+ run: |
+ source activate peft
+ pip install -e . --no-deps
+ pip install pytest-reportlog pytest-cov parameterized datasets scipy einops
+ pip install "pytest>=7.2.0,<8.0.0" # see: https://github.com/huggingface/transformers/blob/ce4fff0be7f6464d713f7ac3e0bbaafbc6959ae5/setup.py#L148C6-L148C26
+ mkdir transformers-clone && git clone https://github.com/huggingface/transformers.git transformers-clone # rename to transformers clone to avoid modules conflict
+ if [ "${{ matrix.docker-image-name }}" == "huggingface/peft-gpu-bnb-latest:latest" ]; then
+ cd transformers-clone
+ transformers_version=$(pip show transformers | grep '^Version:' | cut -d ' ' -f2 | sed 's/\.dev0//')
+ echo "Checking out tag for Transformers version: v$transformers_version"
+ git fetch --tags
+ git checkout tags/v$transformers_version
+ cd ..
+ fi
+
+ - name: Test bnb import
+ id: import
+ if: always()
+ run: |
+ source activate peft
+ python3 -m bitsandbytes
+ python3 -c "import bitsandbytes as bnb"
+
+ - name: Post to Slack
+ if: always()
+ uses: huggingface/hf-workflows/.github/actions/post-slack@3f88d63d3761558a32e8e46fc2a8536e04bb2aea # main from Feb 2025-02-24
+ with:
+ slack_channel: ${{ secrets.BNB_SLACK_CHANNEL_ID }}
+ title: 🤗 Results of bitsandbytes import
+ status: ${{ steps.import.outcome }}
+ slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
+
+ - name: Run examples on single GPU
+ id: examples_tests
+ if: always()
+ run: |
+ source activate peft
+ make tests_examples_single_gpu_bnb
+
+ - name: Post to Slack
+ if: always()
+ uses: huggingface/hf-workflows/.github/actions/post-slack@3f88d63d3761558a32e8e46fc2a8536e04bb2aea # main from Feb 2025-02-24
+ with:
+ slack_channel: ${{ secrets.BNB_SLACK_CHANNEL_ID }}
+ title: 🤗 Results of bitsandbytes examples tests - single GPU
+ status: ${{ steps.examples_tests.outcome }}
+ slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
+
+ - name: Run core tests on single GPU
+ id: core_tests
+ if: always()
+ run: |
+ source activate peft
+ make tests_core_single_gpu_bnb
+
+ - name: Post to Slack
+ if: always()
+ uses: huggingface/hf-workflows/.github/actions/post-slack@3f88d63d3761558a32e8e46fc2a8536e04bb2aea # main from Feb 2025-02-24
+ with:
+ slack_channel: ${{ secrets.BNB_SLACK_CHANNEL_ID }}
+ title: 🤗 Results of bitsandbytes core tests - single GPU
+ status: ${{ steps.core_tests.outcome }}
+ slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
+
+ # TODO: this is a test to see if BNB multi-backend single-GPU tests succeed w/o regression tests
+ # - name: Run BNB regression tests on single GPU
+ # id: regression_tests
+ # if: always()
+ # run: |
+ # source activate peft
+ # make tests_gpu_bnb_regression
+
+ # - name: Post to Slack
+ # if: always()
+ # uses: huggingface/hf-workflows/.github/actions/post-slack@3f88d63d3761558a32e8e46fc2a8536e04bb2aea # main from Feb 2025-02-24
+ # with:
+ # slack_channel: ${{ secrets.BNB_SLACK_CHANNEL_ID }}
+ # title: 🤗 Results of bitsandbytes regression tests - single GPU
+ # status: ${{ steps.regression_tests.outcome }}
+ # slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
+
+ - name: Run transformers tests on single GPU
+ id: transformers_tests
+ if: always()
+ run: |
+ source activate peft
+ make transformers_tests
+
+ - name: Post to Slack
+ if: always()
+ uses: huggingface/hf-workflows/.github/actions/post-slack@3f88d63d3761558a32e8e46fc2a8536e04bb2aea # main from Feb 2025-02-24
+ with:
+ slack_channel: ${{ secrets.BNB_SLACK_CHANNEL_ID }}
+ title: 🤗 Results of bitsandbytes transformers tests - single GPU
+ status: ${{ steps.transformers_tests.outcome }}
+ slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
+
+ - name: Generate Report
+ if: always()
+ run: |
+ pip install slack_sdk tabulate
+ python scripts/log_reports.py --slack_channel_name bnb-daily-ci-collab >> $GITHUB_STEP_SUMMARY
+
+ run_all_tests_multi_gpu:
+ timeout-minutes: 60
+ strategy:
+ fail-fast: false
+ matrix:
+ docker-image-name: ["huggingface/peft-gpu-bnb-source:latest", "huggingface/peft-gpu-bnb-latest:latest"]
+ runs-on:
+ group: aws-g6-12xlarge-plus
+ env:
+ CUDA_VISIBLE_DEVICES: "0,1"
+ TEST_TYPE: "multi_gpu_${{ matrix.docker-image-name }}"
+ container:
+ image: ${{ matrix.docker-image-name }}
+ options: --gpus all --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ defaults:
+ run:
+ shell: bash
+ steps:
+ - uses: actions/checkout@v3
+ with:
+ persist-credentials: false
+ - name: Pip install
+ run: |
+ source activate peft
+ pip install -e . --no-deps
+ pip install pytest-reportlog pytest-cov parameterized datasets scipy einops
+ pip install "pytest>=7.2.0,<8.0.0" # see: https://github.com/huggingface/transformers/blob/ce4fff0be7f6464d713f7ac3e0bbaafbc6959ae5/setup.py#L148C6-L148C26
+ mkdir transformers-clone && git clone https://github.com/huggingface/transformers.git transformers-clone
+ if [ "${{ matrix.docker-image-name }}" == "huggingface/peft-gpu-bnb-latest:latest" ]; then
+ cd transformers-clone
+ transformers_version=$(pip show transformers | grep '^Version:' | cut -d ' ' -f2 | sed 's/\.dev0//')
+ echo "Checking out tag for Transformers version: v$transformers_version"
+ git fetch --tags
+ git checkout tags/v$transformers_version
+ cd ..
+ fi
+
+ - name: Test bnb import
+ id: import
+ if: always()
+ run: |
+ source activate peft
+ python3 -m bitsandbytes
+ python3 -c "import bitsandbytes as bnb"
+
+ - name: Post to Slack
+ if: always()
+ uses: huggingface/hf-workflows/.github/actions/post-slack@3f88d63d3761558a32e8e46fc2a8536e04bb2aea # main from Feb 2025-02-24
+ with:
+ slack_channel: ${{ secrets.BNB_SLACK_CHANNEL_ID }}
+ title: 🤗 Results of bitsandbytes import
+ status: ${{ steps.import.outcome }}
+ slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
+
+ - name: Run examples on multi GPU
+ id: examples_tests
+ if: always()
+ run: |
+ source activate peft
+ make tests_examples_multi_gpu_bnb
+
+ - name: Post to Slack
+ if: always()
+ uses: huggingface/hf-workflows/.github/actions/post-slack@3f88d63d3761558a32e8e46fc2a8536e04bb2aea # main from Feb 2025-02-24
+ with:
+ slack_channel: ${{ secrets.BNB_SLACK_CHANNEL_ID }}
+ title: 🤗 Results of bitsandbytes examples tests - multi GPU
+ status: ${{ steps.examples_tests.outcome }}
+ slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
+
+ - name: Run core tests on multi GPU
+ id: core_tests
+ if: always()
+ run: |
+ source activate peft
+ make tests_core_multi_gpu_bnb
+
+ - name: Post to Slack
+ if: always()
+ uses: huggingface/hf-workflows/.github/actions/post-slack@3f88d63d3761558a32e8e46fc2a8536e04bb2aea # main from Feb 2025-02-24
+ with:
+ slack_channel: ${{ secrets.BNB_SLACK_CHANNEL_ID }}
+ title: 🤗 Results of bitsandbytes core tests - multi GPU
+ status: ${{ steps.core_tests.outcome }}
+ slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
+
+ - name: Run transformers tests on multi GPU
+ id: transformers_tests
+ if: always()
+ run: |
+ source activate peft
+ make transformers_tests
+
+ - name: Post to Slack
+ if: always()
+ uses: huggingface/hf-workflows/.github/actions/post-slack@3f88d63d3761558a32e8e46fc2a8536e04bb2aea # main from Feb 2025-02-24
+ with:
+ slack_channel: ${{ secrets.BNB_SLACK_CHANNEL_ID }}
+ title: 🤗 Results of bitsandbytes transformers tests - multi GPU
+ status: ${{ steps.transformers_tests.outcome }}
+ slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
+
+ - name: Generate Report
+ if: always()
+ run: |
+ pip install slack_sdk tabulate
+ python scripts/log_reports.py --slack_channel_name bnb-daily-ci-collab >> $GITHUB_STEP_SUMMARY
diff --git a/peft/.github/workflows/nightly.yml b/peft/.github/workflows/nightly.yml
new file mode 100644
index 0000000000000000000000000000000000000000..6039660d61868be686111c164d16ee4a016dc781
--- /dev/null
+++ b/peft/.github/workflows/nightly.yml
@@ -0,0 +1,115 @@
+name: Self-hosted runner with slow tests (scheduled)
+
+on:
+ workflow_dispatch:
+ schedule:
+ - cron: "0 2 * * *"
+
+env:
+ RUN_SLOW: "yes"
+ IS_GITHUB_CI: "1"
+ # To be able to run tests on CUDA 12.2
+ NVIDIA_DISABLE_REQUIRE: "1"
+ SLACK_API_TOKEN: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
+
+permissions: {}
+
+jobs:
+ run_all_tests_single_gpu:
+ strategy:
+ fail-fast: false
+ runs-on:
+ group: aws-g6-4xlarge-plus
+ env:
+ CUDA_VISIBLE_DEVICES: "0"
+ TEST_TYPE: "single_gpu"
+ container:
+ image: huggingface/peft-gpu:latest
+ options: --gpus all --shm-size "16gb" -e NVIDIA_DISABLE_REQUIRE=true
+ defaults:
+ run:
+ shell: bash
+ steps:
+ - uses: actions/checkout@v3
+ with:
+ persist-credentials: false
+ - name: Pip install
+ run: |
+ source activate peft
+ pip install -e . --no-deps
+ pip install pytest-reportlog
+
+ - name: Run common tests on single GPU
+ run: |
+ source activate peft
+ make tests_common_gpu
+
+ - name: Run examples on single GPU
+ run: |
+ source activate peft
+ make tests_examples_single_gpu
+
+ - name: Run core tests on single GPU
+ run: |
+ source activate peft
+ make tests_core_single_gpu
+
+ - name: Run regression tests on single GPU
+ run: |
+ source activate peft
+ make tests_regression
+
+ - name: Generate Report
+ if: always()
+ run: |
+ pip install slack_sdk tabulate
+ python scripts/log_reports.py >> $GITHUB_STEP_SUMMARY
+
+ run_all_tests_multi_gpu:
+ strategy:
+ fail-fast: false
+ runs-on:
+ group: aws-g6-12xlarge-plus
+ env:
+ CUDA_VISIBLE_DEVICES: "0,1"
+ TEST_TYPE: "multi_gpu"
+ container:
+ image: huggingface/peft-gpu:latest
+ options: --gpus all --shm-size "16gb" -e NVIDIA_DISABLE_REQUIRE=true
+ defaults:
+ run:
+ shell: bash
+ steps:
+ - uses: actions/checkout@v3
+ with:
+ persist-credentials: false
+ - name: Pip install
+ run: |
+ source activate peft
+ pip install -e . --no-deps
+ pip install pytest-reportlog
+
+ - name: Run core GPU tests on multi-gpu
+ run: |
+ source activate peft
+
+ - name: Run common tests on multi GPU
+ run: |
+ source activate peft
+ make tests_common_gpu
+
+ - name: Run examples on multi GPU
+ run: |
+ source activate peft
+ make tests_examples_multi_gpu
+
+ - name: Run core tests on multi GPU
+ run: |
+ source activate peft
+ make tests_core_multi_gpu
+
+ - name: Generate Report
+ if: always()
+ run: |
+ pip install slack_sdk tabulate
+ python scripts/log_reports.py >> $GITHUB_STEP_SUMMARY
diff --git a/peft/.github/workflows/stale.yml b/peft/.github/workflows/stale.yml
new file mode 100644
index 0000000000000000000000000000000000000000..054c4b53c4213bd93a330c376e4b1c4f9b212b16
--- /dev/null
+++ b/peft/.github/workflows/stale.yml
@@ -0,0 +1,34 @@
+name: Stale Bot
+
+on:
+ schedule:
+ - cron: "0 15 * * *"
+
+permissions: {}
+
+jobs:
+ close_stale_issues:
+ name: Close Stale Issues
+ if: github.repository == 'huggingface/peft'
+ runs-on: ubuntu-latest
+ permissions:
+ issues: write
+ pull-requests: write
+ env:
+ GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
+ steps:
+ - uses: actions/checkout@v3
+ with:
+ persist-credentials: false
+
+ - name: Setup Python
+ uses: actions/setup-python@v4
+ with:
+ python-version: 3.11
+
+ - name: Install requirements
+ run: |
+ pip install PyGithub
+ - name: Close stale issues
+ run: |
+ python scripts/stale.py
diff --git a/peft/.github/workflows/tests-main.yml b/peft/.github/workflows/tests-main.yml
new file mode 100644
index 0000000000000000000000000000000000000000..959ca2c1cfc7cddbf0ef77a71ee0dad807bc7119
--- /dev/null
+++ b/peft/.github/workflows/tests-main.yml
@@ -0,0 +1,43 @@
+name: tests on transformers main
+
+on:
+ push:
+ branches: [main]
+ paths-ignore:
+ - 'docs/**'
+
+env:
+ TRANSFORMERS_IS_CI: 1
+
+permissions: {}
+
+jobs:
+ tests:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v3
+ with:
+ persist-credentials: false
+ - name: Set up Python 3.11
+ uses: actions/setup-python@v4
+ with:
+ python-version: 3.11
+ cache: "pip"
+ cache-dependency-path: "setup.py"
+ - name: Install dependencies
+ run: |
+ python -m pip install --upgrade pip
+ # cpu version of pytorch
+ pip install -U git+https://github.com/huggingface/transformers.git
+ pip install -e .[test]
+ - name: Test with pytest
+ run: |
+ make test
+ - name: Post to Slack
+ if: always()
+ uses: huggingface/hf-workflows/.github/actions/post-slack@3f88d63d3761558a32e8e46fc2a8536e04bb2aea # main from Feb 2025-02-24
+ with:
+ slack_channel: ${{ secrets.SLACK_CHANNEL_ID }}
+ title: 🤗 Results of transformers main tests
+ status: ${{ job.status }}
+ slack_token: ${{ secrets.SLACK_CIFEEDBACK_BOT_TOKEN }}
diff --git a/peft/.github/workflows/tests.yml b/peft/.github/workflows/tests.yml
new file mode 100644
index 0000000000000000000000000000000000000000..dfb08e1f7aaa95885ed3b28c30d8d04a05415cfb
--- /dev/null
+++ b/peft/.github/workflows/tests.yml
@@ -0,0 +1,116 @@
+name: tests
+
+on:
+ push:
+ branches: [main]
+ paths-ignore:
+ - 'docs/**'
+ pull_request:
+ paths-ignore:
+ - 'docs/**'
+
+env:
+ HF_HOME: .cache/huggingface
+ TRANSFORMERS_IS_CI: 1
+
+permissions: {}
+
+jobs:
+ check_code_quality:
+ runs-on: ubuntu-latest
+ steps:
+ - uses: actions/checkout@v3
+ with:
+ persist-credentials: false
+ - name: Set up Python
+ uses: actions/setup-python@v4
+ with:
+ python-version: "3.11"
+ cache: "pip"
+ cache-dependency-path: "setup.py"
+ - name: Install dependencies
+ run: |
+ python -m pip install --upgrade pip
+ pip install .[dev]
+ - name: Check quality
+ run: |
+ make quality
+
+ tests:
+ needs: check_code_quality
+ strategy:
+ # TODO: remove 'fail-fast' line once timeout issue from the Hub is solved
+ fail-fast: false
+ matrix:
+ python-version: ["3.9", "3.10", "3.11", "3.12"]
+ os: ["ubuntu-latest", "macos-13", "windows-latest"]
+ runs-on: ${{ matrix.os }}
+ steps:
+ - uses: actions/checkout@v3
+ with:
+ persist-credentials: false
+ - name: Model cache
+ uses: actions/cache/restore@v4
+ with:
+ # Avoid caching HF_HOME/modules and Python cache files to prevent interoperability
+ # issues and potential cache poisioning. We also avoid lock files to prevent runs
+ # avoiding re-download because they see a lock file.
+ path: |
+ ${{ env.HF_HOME }}/hub/**
+ !${{ env.HF_HOME }}/**/*.pyc
+ key: model-cache-${{ github.run_id }}
+ restore-keys: model-cache-
+ enableCrossOsArchive: true
+ - name: Dump cache content
+ # TODO: remove this step after 2025-02-15
+ if: matrix.os != 'windows-latest'
+ run: |
+ SHASUM=sha256sum
+ [ -f "$(which shasum)" ] && SHASUM=shasum
+ find "${{ env.HF_HOME }}/hub" -type f -exec "$SHASUM" {} \; > cache_content_initial || true
+ - name: Set up Python ${{ matrix.python-version }}
+ uses: actions/setup-python@v4
+ with:
+ python-version: ${{ matrix.python-version }}
+ cache: "pip"
+ cache-dependency-path: "setup.py"
+ - name: Install dependencies
+ run: |
+ python -m pip install --upgrade pip
+ pip install setuptools
+ # cpu version of pytorch
+ pip install -e .[test]
+ - name: Downgrade numpy on MacOS and Windows
+ # TODO: remove numpy downgrade on MacOS & Windows once torch fixes numpy 2.0 issue
+ shell: bash
+ if: matrix.os == 'windows-latest' || matrix.os == 'macos-13'
+ run: |
+ pip install --force-reinstall -U "numpy<2.0.0"
+ - name: Test with pytest
+ run: |
+ make test
+ - name: Dump cache content and diff
+ # This is just debug info so that we can monitor if the model cache diverges substantially
+ # over time and what the diverging model is.
+ # TODO: remove after 2025-02-15
+ if: matrix.os != 'windows-latest'
+ run: |
+ SHASUM=sha256sum
+ [ -f "$(which shasum)" ] && SHASUM=shasum
+ find "${{ env.HF_HOME }}/hub" -type f -exec "$SHASUM" {} \; > cache_content_after || true
+ diff -udp cache_content_initial cache_content_after || true
+ - name: Delete old model cache entries
+ run: |
+ # make sure that cache cleaning doesn't break the pipeline
+ python scripts/ci_clean_cache.py -d || true
+ - name: Update model cache
+ uses: actions/cache/save@v4
+ # Only let one runner (preferably the one that covers most tests) update the model cache
+ # after *every* run. This way we make sure that our cache is never outdated and we don't
+ # have to keep track of hashes.
+ if: always() && matrix.os == 'ubuntu-latest' && matrix.python-version == '3.10'
+ with:
+ path: |
+ ${{ env.HF_HOME }}/hub/**
+ !${{ env.HF_HOME }}/**/*.pyc
+ key: model-cache-${{ github.run_id }}
diff --git a/peft/.github/workflows/torch_compile_tests.yml b/peft/.github/workflows/torch_compile_tests.yml
new file mode 100644
index 0000000000000000000000000000000000000000..02243de643fb762fee4d1a8eaf01cbcc7c1dfbe0
--- /dev/null
+++ b/peft/.github/workflows/torch_compile_tests.yml
@@ -0,0 +1,56 @@
+name: torch compile tests
+
+on:
+ workflow_dispatch:
+ inputs:
+ branch:
+ description: 'Branch to test on'
+ required: true
+ pytorch_nightly:
+ description: 'Whether to use PyTorch nightly (true/false)'
+ required: false
+ default: false
+
+env:
+ RUN_SLOW: "yes"
+ IS_GITHUB_CI: "1"
+ # To be able to run tests on CUDA 12.2
+ NVIDIA_DISABLE_REQUIRE: "1"
+
+permissions: {}
+
+jobs:
+ run_tests_with_compile:
+ runs-on:
+ group: aws-g6-4xlarge-plus
+ env:
+ PEFT_DEBUG_WITH_TORCH_COMPILE: 1
+ CUDA_VISIBLE_DEVICES: "0"
+ TEST_TYPE: "single_gpu_huggingface/peft-gpu-bnb-latest:latest"
+ USE_PYTORCH_NIGHTLY: "${{ github.event.inputs.pytorch_nightly }}"
+ container:
+ image: "huggingface/peft-gpu-bnb-latest:latest"
+ options: --gpus all --shm-size "16gb" --ipc host -v /mnt/cache/.cache/huggingface:/mnt/cache/
+ defaults:
+ run:
+ shell: bash
+ steps:
+ - uses: actions/checkout@v4
+ with:
+ ref: ${{ github.event.inputs.branch }}
+ repository: ${{ github.event.pull_request.head.repo.full_name }}
+ persist-credentials: false
+ - name: Pip install
+ run: |
+ source activate peft
+ pip install -e . --no-deps
+ pip install pytest-cov pytest-reportlog parameterized datasets scipy einops
+ pip install "pytest>=7.2.0,<8.0.0" # see: https://github.com/huggingface/transformers/blob/ce4fff0be7f6464d713f7ac3e0bbaafbc6959ae5/setup.py#L148C6-L148C26
+ if [ "${USE_PYTORCH_NIGHTLY}" = "true" ]; then
+ python -m pip install --upgrade --pre torch --index-url https://download.pytorch.org/whl/nightly/cpu
+ fi
+ - name: Test compile with pytest
+ run: |
+ source activate peft
+ echo "PEFT_DEBUG_WITH_TORCH_COMPILE=$PEFT_DEBUG_WITH_TORCH_COMPILE"
+ make tests_torch_compile
diff --git a/peft/.github/workflows/zizmor.yaml b/peft/.github/workflows/zizmor.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..3984c99631819c291d11147e1ac914253017d846
--- /dev/null
+++ b/peft/.github/workflows/zizmor.yaml
@@ -0,0 +1,28 @@
+name: CI security linting
+
+on:
+ push:
+ branches: ["main"]
+ pull_request:
+ branches: ["*"]
+ paths:
+ - '.github/**'
+
+permissions: {}
+
+jobs:
+ zizmor:
+ name: zizmor latest via Cargo
+ runs-on: ubuntu-latest
+ permissions:
+ contents: read
+ security-events: write
+ steps:
+ - name: Checkout repository
+ uses: actions/checkout@v4
+ with:
+ persist-credentials: false
+ - name: Install zizmor
+ run: cargo install --locked zizmor
+ - name: Run zizmor
+ run: zizmor .github/workflows
diff --git a/peft/.github/zizmor.yml b/peft/.github/zizmor.yml
new file mode 100644
index 0000000000000000000000000000000000000000..c3b44d766eaa8219c438c748cadca679a182c3ab
--- /dev/null
+++ b/peft/.github/zizmor.yml
@@ -0,0 +1,24 @@
+rules:
+ dangerous-triggers:
+ ignore:
+ # this workflow is only triggered after maintainer approval
+ - upload_pr_documentation.yml:3:1
+ cache-poisoning:
+ ignore:
+ # the docker buildx binary is cached and zizmor warns about a cache poisoning attack.
+ # OTOH this cache would make us more resilient against an intrusion on docker-buildx' side.
+ # There is no obvious benefit so we leave it as it is.
+ - build_docker_images.yml:37:9
+ - build_docker_images.yml:70:9
+ - build_docker_images.yml:103:9
+ - build_docker_images.yml:136:9
+ - build_docker_images.yml:169:9
+ unpinned-images:
+ ignore:
+ # We want to test these images with the latest version and we're not using them
+ # to deploy anything so we deem it safe to use those, even if they are unpinned.
+ - nightly-bnb.yml:30:7
+ - nightly-bnb.yml:155:7
+ - nightly.yml:27:7
+ - nightly.yml:77:7
+ - torch_compile_tests.yml:32:7
diff --git a/peft/docker/README.md b/peft/docker/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..193f11b75694e4272ed32434d6f0d0d7fba79c93
--- /dev/null
+++ b/peft/docker/README.md
@@ -0,0 +1,8 @@
+# PEFT Docker images
+
+Here we store all PEFT Docker images used in our testing infrastructure. We use python 3.11 for now on all our images.
+
+- `peft-cpu`: PEFT compiled on CPU with all other HF libraries installed on main branch
+- `peft-gpu`: PEFT complied for NVIDIA GPUs with all other HF libraries installed on main branch
+- `peft-gpu-bnb-source`: PEFT complied for NVIDIA GPUs with `bitsandbytes` and all other HF libraries installed from main branch
+- `peft-gpu-bnb-latest`: PEFT complied for NVIDIA GPUs with `bitsandbytes` complied from main and all other HF libraries installed from latest PyPi
diff --git a/peft/docs/Makefile b/peft/docs/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..8879933e6cda150267451c9e7d07dd22b7b0d3f1
--- /dev/null
+++ b/peft/docs/Makefile
@@ -0,0 +1,19 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line.
+SPHINXOPTS =
+SPHINXBUILD = sphinx-build
+SOURCEDIR = source
+BUILDDIR = _build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
\ No newline at end of file
diff --git a/peft/docs/README.md b/peft/docs/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..0b76173a66db251756401a35e1dfef5ae69794bb
--- /dev/null
+++ b/peft/docs/README.md
@@ -0,0 +1,267 @@
+
+
+# Generating the documentation
+
+To generate the documentation, you first have to build it. Several packages are necessary to build the doc,
+you can install them with the following command, at the root of the code repository:
+
+```bash
+pip install -e ".[docs]"
+```
+
+Then you need to install our special tool that builds the documentation:
+
+```bash
+pip install git+https://github.com/huggingface/doc-builder
+```
+
+---
+**NOTE**
+
+You only need to generate the documentation to inspect it locally (if you're planning changes and want to
+check how they look before committing for instance). You don't have to commit to the built documentation.
+
+---
+
+## Building the documentation
+
+Once you have setup the `doc-builder` and additional packages, you can generate the documentation by
+typing the following command:
+
+```bash
+doc-builder build peft docs/source/ --build_dir ~/tmp/test-build
+```
+
+You can adapt the `--build_dir` to set any temporary folder you prefer. This command will create it and generate
+the MDX files that will be rendered as the documentation on the main website. You can inspect them in your favorite
+Markdown editor.
+
+## Previewing the documentation
+
+To preview the docs, first install the `watchdog` module with:
+
+```bash
+pip install watchdog
+```
+
+Then run the following command:
+
+```bash
+doc-builder preview {package_name} {path_to_docs}
+```
+
+For example:
+
+```bash
+doc-builder preview peft docs/source
+```
+
+The docs will be viewable at [http://localhost:3000](http://localhost:3000). You can also preview the docs once you have opened a PR. You will see a bot add a comment to a link where the documentation with your changes lives.
+
+---
+**NOTE**
+
+The `preview` command only works with existing doc files. When you add a completely new file, you need to update `_toctree.yml` & restart `preview` command (`ctrl-c` to stop it & call `doc-builder preview ...` again).
+
+---
+
+## Adding a new element to the navigation bar
+
+Accepted files are Markdown (.md or .mdx).
+
+Create a file with its extension and put it in the source directory. You can then link it to the toc-tree by putting
+the filename without the extension in the [`_toctree.yml`](https://github.com/huggingface/peft/blob/main/docs/source/_toctree.yml) file.
+
+## Renaming section headers and moving sections
+
+It helps to keep the old links working when renaming the section header and/or moving sections from one document to another. This is because the old links are likely to be used in Issues, Forums, and Social media and it'd make for a much more superior user experience if users reading those months later could still easily navigate to the originally intended information.
+
+Therefore, we simply keep a little map of moved sections at the end of the document where the original section was. The key is to preserve the original anchor.
+
+So if you renamed a section from: "Section A" to "Section B", then you can add at the end of the file:
+
+```
+Sections that were moved:
+
+[ Section A ]
+```
+and of course, if you moved it to another file, then:
+
+```
+Sections that were moved:
+
+[ Section A ]
+```
+
+Use the relative style to link to the new file so that the versioned docs continue to work.
+
+
+## Writing Documentation - Specification
+
+The `huggingface/peft` documentation follows the
+[Google documentation](https://sphinxcontrib-napoleon.readthedocs.io/en/latest/example_google.html) style for docstrings,
+although we can write them directly in Markdown.
+
+### Adding a new tutorial
+
+Adding a new tutorial or section is done in two steps:
+
+- Add a new file under `./source`. This file can either be ReStructuredText (.rst) or Markdown (.md).
+- Link that file in `./source/_toctree.yml` on the correct toc-tree.
+
+Make sure to put your new file under the proper section. It's unlikely to go in the first section (*Get Started*), so
+depending on the intended targets (beginners, more advanced users, or researchers) it should go into sections two, three, or
+four.
+
+### Writing source documentation
+
+Values that should be put in `code` should either be surrounded by backticks: \`like so\`. Note that argument names
+and objects like True, None, or any strings should usually be put in `code`.
+
+When mentioning a class, function, or method, it is recommended to use our syntax for internal links so that our tool
+adds a link to its documentation with this syntax: \[\`XXXClass\`\] or \[\`function\`\]. This requires the class or
+function to be in the main package.
+
+If you want to create a link to some internal class or function, you need to
+provide its path. For instance: \[\`utils.gather\`\]. This will be converted into a link with
+`utils.gather` in the description. To get rid of the path and only keep the name of the object you are
+linking to in the description, add a ~: \[\`~utils.gather\`\] will generate a link with `gather` in the description.
+
+The same works for methods so you can either use \[\`XXXClass.method\`\] or \[~\`XXXClass.method\`\].
+
+#### Defining arguments in a method
+
+Arguments should be defined with the `Args:` (or `Arguments:` or `Parameters:`) prefix, followed by a line return and
+an indentation. The argument should be followed by its type, with its shape if it is a tensor, a colon, and its
+description:
+
+```
+ Args:
+ n_layers (`int`): The number of layers of the model.
+```
+
+If the description is too long to fit in one line (more than 119 characters in total), another indentation is necessary
+before writing the description after the argument.
+
+Finally, to maintain uniformity if any *one* description is too long to fit on one line, the
+rest of the parameters should follow suit and have an indention before their description.
+
+Here's an example showcasing everything so far:
+
+```
+ Args:
+ gradient_accumulation_steps (`int`, *optional*, default to 1):
+ The number of steps that should pass before gradients are accumulated. A number > 1 should be combined with `Accelerator.accumulate`.
+ cpu (`bool`, *optional*):
+ Whether or not to force the script to execute on CPU. Will ignore GPU available if set to `True` and force the execution on one process only.
+```
+
+For optional arguments or arguments with defaults we follow the following syntax: imagine we have a function with the
+following signature:
+
+```
+def my_function(x: str = None, a: float = 1):
+```
+
+then its documentation should look like this:
+
+```
+ Args:
+ x (`str`, *optional*):
+ This argument controls ... and has a description longer than 119 chars.
+ a (`float`, *optional*, defaults to 1):
+ This argument is used to ... and has a description longer than 119 chars.
+```
+
+Note that we always omit the "defaults to \`None\`" when None is the default for any argument. Also note that even
+if the first line describing your argument type and its default gets long, you can't break it into several lines. You can
+however write as many lines as you want in the indented description (see the example above with `input_ids`).
+
+#### Writing a multi-line code block
+
+Multi-line code blocks can be useful for displaying examples. They are done between two lines of three backticks as usual in Markdown:
+
+
+````
+```python
+# first line of code
+# second line
+# etc
+```
+````
+
+#### Writing a return block
+
+The return block should be introduced with the `Returns:` prefix, followed by a line return and an indentation.
+The first line should be the type of the return, followed by a line return. No need to indent further for the elements
+building the return.
+
+Here's an example of a single value return:
+
+```
+ Returns:
+ `List[int]`: A list of integers in the range [0, 1] --- 1 for a special token, 0 for a sequence token.
+```
+
+Here's an example of a tuple return, comprising several objects:
+
+```
+ Returns:
+ `tuple(torch.FloatTensor)` comprising various elements depending on the configuration ([`BertConfig`]) and inputs:
+ - ** loss** (*optional*, returned when `masked_lm_labels` is provided) `torch.FloatTensor` of shape `(1,)` --
+ Total loss is the sum of the masked language modeling loss and the next sequence prediction (classification) loss.
+ - **prediction_scores** (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`) --
+ Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
+```
+
+## Styling the docstring
+
+We have an automatic script running with the `make style` comment that will make sure that:
+- the docstrings fully take advantage of the line width
+- all code examples are formatted using black, like the code of the Transformers library
+
+This script may have some weird failures if you make a syntax mistake or if you uncover a bug. Therefore, it's
+recommended to commit your changes before running `make style`, so you can revert the changes done by that script
+easily.
+
+## Writing documentation examples
+
+The syntax, for example, docstrings can look as follows:
+
+```
+ Example:
+
+ ```python
+ >>> import time
+ >>> from accelerate import Accelerator
+ >>> accelerator = Accelerator()
+ >>> if accelerator.is_main_process:
+ ... time.sleep(2)
+ >>> else:
+ ... print("I'm waiting for the main process to finish its sleep...")
+ >>> accelerator.wait_for_everyone()
+ >>> # Should print on every process at the same time
+ >>> print("Everyone is here")
+ ```
+```
+
+The docstring should give a minimal, clear example of how the respective function
+is to be used in inference and also include the expected (ideally sensible)
+output.
+Often, readers will try out the example before even going through the function
+or class definitions. Therefore, it is of utmost importance that the example
+works as expected.
diff --git a/peft/method_comparison/README.md b/peft/method_comparison/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..c34fec0f9d0ef4de9342c539ca1e29642f4f6133
--- /dev/null
+++ b/peft/method_comparison/README.md
@@ -0,0 +1,116 @@
+---
+title: PEFT Method Comparison
+sdk: gradio
+app_file: app.py
+pinned: false
+emoji: ⚖️
+---
+
+# Comparison of PEFT Methods
+
+The goal of this project is to provide replicable experiments that produce outcomes allowing us to compare different PEFT methods with one another. This gives you more information to make an informed decision about which methods best fit your use case and what trade-offs to expect.
+
+Visit our [Gradio Space](https://huggingface.co/spaces/peft-internal-testing/PEFT-method-comparison) to check the results.
+
+## Community Contributions
+
+We envision the PEFT method comparison project as an ongoing endeavor with heavy involvement from the community. As maintainers, it is impossible for us to know all the perfect hyperparameters for each method or to predict all the use cases that PEFT users may have. As a consequence, community contributions are very welcome.
+
+Below, we outline all the ways you can contribute to this project.
+
+### Creating New Experiments
+
+Creating a new experiment requires setting up a new PEFT configuration for us to test. This will result in one more data point being added to the total comparison.
+
+Working on this is especially relevant if:
+
+1. You are the author of a paper whose method is introduced in PEFT, or worked on the PEFT integration, and know what hyperparameters work best.
+2. You have experience with a specific method and want to share your knowledge with the community.
+
+Of course, you can contribute even without meeting these criteria. Please follow the instructions below.
+
+#### How to Add New Experiments
+
+Start by navigating to one of the existing experiment folders, e.g. `peft/method_comparison/MetaMathQA`, if your experiment involves using the [MetaMathQA dataset](https://huggingface.co/datasets/meta-math/MetaMathQA). There, create a new directory inside the `experiments/` folder using a descriptive name. For example, if you want to test LoRA with rank 123 using Llama-3.2 3B as the base model, you could name the folder `experiments/lora/llama-3.2-3B-rank123`.
+
+Inside this directory, you will find a default configuration file called `default_training_params.json`, which contains the default parameters used in the `run.py` training script. Create a new JSON file containing all the parameters you want to modify compared to the defaults, and save it as `training_params.json` in the newly created folder. If you are satisfied with all the default training parameters, you can skip this step.
+
+Finally, you need to create a PEFT configuration file for the PEFT method you want to add. This should be a JSON file called `adapter_config.json`, placed in the same directory. Below is an example of how this could look:
+
+```python
+from peft import LoraConfig
+config = LoraConfig(r=123)
+config.save_pretrained("experiments/lora/llama-3.2-3B-rank123/")
+```
+
+Once you've created the configuration files for your experiment, please [create a PR on PEFT](https://github.com/huggingface/peft/pulls). After it is reviewed and merged, we will run it on our hardware to ensure that the results are comparable. Of course, it is best if you run the experiment at least once on your hardware to verify that the proposed settings work well.
+
+#### Considerations When Adding New Experiments
+
+When adding a new experiment, please consider the following points:
+
+1. Avoid changing too many training parameters at once, as this would make it difficult to compare results with existing ones. For example, if all existing results were created with 5000 training steps but your result uses 10000 steps, it would be unclear whether an improvement in the test score is due to the PEFT method itself or simply due to longer training. Similarly, using a completely different base model, especially if it is significantly more capable, does not contribute to a fair comparison.
+2. Avoid suggesting configurations that are very close to existing ones. For example, if there is already an experiment with LoRA and rank 123, do not add an experiment with LoRA and rank 124.
+3. Experiments for less-tested methods are more valuable than additional experiments for widely tested methods.
+4. Do not edit existing experiments, always create new ones.
+5. If you found hyper parameters that work especially well with a given method but are not trivial to find out, consider updating the PEFT documentation of that method so that other users can benefit from your findings.
+
+### Updating the Training Script
+
+We provide a training script that includes features typically useful for improving training outcomes, such as AMP support, a cosine learning rate schedule, etc. However, there is always room for improvement. For example, at the time of writing, the script does not support gradient accumulation. Therefore, PRs that extend the training script are welcome.
+
+#### How to Update the Training Script
+
+Follow the same process as when contributing to PEFT in general (see the [contribution guidelines](https://huggingface.co/docs/peft/developer_guides/contributing)). If the same training script is used across multiple datasets, please ensure that all relevant scripts are updated accordingly.
+
+#### Considerations When Updating the Training Script
+
+1. Updates should be backward-compatible. By default, any new features should be disabled to ensure that existing results remain valid. For example, if you add gradient accumulation, ensure it is disabled by default so that new experiments must opt in.
+2. Before adding a bug fix that could invalidate existing results, consider whether the trade-off is worthwhile. If we already have many experimental results, rerunning all of them can be expensive. If the bug fix is not critical, it may not be worth invalidating previous results. However, if you discover a significant bug that could meaningfully impact outcomes, it should be addressed.
+3. Avoid unnecessary complexity. While we could add support for DeepSpeed, FSDP, etc., doing so would add significant complexity, exclude users with limited hardware, and is unlikely to alter the relative performance of different PEFT methods.
+4. Minimize reliance on specific training frameworks. For example, we deliberately avoid using the `Trainer` class from transformers or PyTorch Lightning. This ensures transparency, making it easier to understand the training process and replicate results over time. If a training framework were used, we would have to pin the version or risk future incompatibilities.
+
+### Adding a New Dataset
+
+Adding a new dataset increases the breadth and usefulness of the PEFT method comparison. The goal is not necessarily to outperform benchmarks or replicate paper results, but to fairly compare different PEFT methods in a way that is useful for PEFT users. If this involves replicating an experiment from a paper, that is great, but it is not a requirement.
+
+#### How to Add a New Dataset
+
+The easiest way to add support for a new dataset is to copy an existing setup, such as `method_comparison/MetaMathQA`, rename it, and modify `data.py`, as well as any other necessary parts of the code. Ideally, as much existing code as possible should be reused. The general folder structure and experiment logging format should remain consistent.
+
+After adding the dataset, ensure it functions correctly and produces meaningful results by running at least one experimental setup, such as using LoRA with default settings.
+
+#### Considerations When Adding a New Dataset
+
+1. Before beginning, it is best to open an [issue on PEFT](https://github.com/huggingface/peft/issues) to share your plans. This allows for early feedback and prevents wasted effort on impractical ideas.
+2. The most valuable new datasets are those that test different capabilities than those already present. Bonus points if the task is similar to what users may face in the real world. Task ideas that would be great to add:
+ - A task involving both language and image modalities.
+ - An image generation task (like stable diffusion)
+ - A task involving audio (like whisper)
+ - A task that requires knowledge preservation (checked, for instance, via an auxiliary test set)
+ - Learning something completely new (e.g. a new language)
+ - A reinforcement learning task (e.g. using [trl](https://github.com/huggingface/trl))
+3. Training should be reasonably fast. Running dozens of experiments is impractical if each one takes multiple days and incurs high costs. Ideally, training should take a few hours at most on high-end consumer hardware.
+4. The chosen base model should not be too large, to avoid VRAM constraints. Morevoer, if the base model is too powerful, there is little room for improvement through further fine-tuning.
+5. Test scores should be informative and have a broad range:
+ - Besides loss, there should ideally be at least one additional metric, such as accuracy.
+ - Comparisons are not meaningful if all methods score near 0% or near 100%. The dataset should yield a range of scores to facilitate meaningful differentiation between methods.
+6. The dataset should be publicly available and have a track record as a useful dataset. The license should permit the intended usage.
+
+## Result dashboard
+
+For convenience, we included a [Gradio](https://www.gradio.app/) app that shows the results of the experiments. It allows you to filter down the task and base model and show the experiment results for this selection. Give it a try [here](https://huggingface.co/spaces/peft-internal-testing/PEFT-method-comparison).
+
+### Local deployment
+
+This app requires additional packages to be installed, please install the packages listed in `requirements-app.txt`, e.g. via:
+
+```sh
+python -m pip install -r requirements-app.txt
+```
+
+To launch the demo, run:
+
+```sh
+python app.py
+```
diff --git a/peft/method_comparison/__init__.py b/peft/method_comparison/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/peft/method_comparison/app.py b/peft/method_comparison/app.py
new file mode 100644
index 0000000000000000000000000000000000000000..6f7d927fbfd2db7253a7cde70786a050b63041a9
--- /dev/null
+++ b/peft/method_comparison/app.py
@@ -0,0 +1,359 @@
+# Copyright 2025-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Gradio app to show the results"""
+
+import os
+import tempfile
+
+import gradio as gr
+import plotly.express as px
+import plotly.graph_objects as go
+from processing import load_df
+from sanitizer import parse_and_filter
+
+
+metric_preferences = {
+ "cuda_memory_reserved_avg": "lower",
+ "cuda_memory_max": "lower",
+ "cuda_memory_reserved_99th": "lower",
+ "total_time": "lower",
+ "train_time": "lower",
+ "file_size": "lower",
+ "test_accuracy": "higher",
+ "train_loss": "lower",
+}
+
+
+def get_model_ids(task_name, df):
+ filtered = df[df["task_name"] == task_name]
+ return sorted(filtered["model_id"].unique())
+
+
+def filter_data(task_name, model_id, df):
+ filtered = df[(df["task_name"] == task_name) & (df["model_id"] == model_id)]
+ return filtered
+
+
+# Compute the Pareto frontier for two selected metrics.
+def compute_pareto_frontier(df, metric_x, metric_y):
+ if df.empty:
+ return df
+
+ df = df.copy()
+ points = df[[metric_x, metric_y]].values
+ selected_indices = []
+
+ def dominates(a, b, metric_x, metric_y):
+ # Check for each metric whether b is as good or better than a
+ if metric_preferences[metric_x] == "higher":
+ cond_x = b[0] >= a[0]
+ better_x = b[0] > a[0]
+ else:
+ cond_x = b[0] <= a[0]
+ better_x = b[0] < a[0]
+ if metric_preferences[metric_y] == "higher":
+ cond_y = b[1] >= a[1]
+ better_y = b[1] > a[1]
+ else:
+ cond_y = b[1] <= a[1]
+ better_y = b[1] < a[1]
+ return cond_x and cond_y and (better_x or better_y)
+
+ for i, point in enumerate(points):
+ dominated = False
+ for j, other_point in enumerate(points):
+ if i == j:
+ continue
+ if dominates(point, other_point, metric_x, metric_y):
+ dominated = True
+ break
+ if not dominated:
+ selected_indices.append(i)
+ pareto_df = df.iloc[selected_indices]
+ return pareto_df
+
+
+def generate_pareto_plot(df, metric_x, metric_y):
+ if df.empty:
+ return {}
+
+ # Compute Pareto frontier and non-frontier points.
+ pareto_df = compute_pareto_frontier(df, metric_x, metric_y)
+ non_pareto_df = df.drop(pareto_df.index)
+
+ # Create an empty figure.
+ fig = go.Figure()
+
+ # Draw the line connecting Pareto frontier points.
+ if not pareto_df.empty:
+ # Sort the Pareto frontier points by metric_x for a meaningful connection.
+ pareto_sorted = pareto_df.sort_values(by=metric_x)
+ line_trace = go.Scatter(
+ x=pareto_sorted[metric_x],
+ y=pareto_sorted[metric_y],
+ mode="lines",
+ line={"color": "rgba(0,0,255,0.3)", "width": 4},
+ name="Pareto Frontier",
+ )
+ fig.add_trace(line_trace)
+
+ # Add non-frontier points in gray with semi-transparency.
+ if not non_pareto_df.empty:
+ non_frontier_trace = go.Scatter(
+ x=non_pareto_df[metric_x],
+ y=non_pareto_df[metric_y],
+ mode="markers",
+ marker={"color": "rgba(128,128,128,0.5)", "size": 12},
+ hoverinfo="text",
+ text=non_pareto_df.apply(
+ lambda row: f"experiment_name: {row['experiment_name']}
"
+ f"peft_type: {row['peft_type']}
"
+ f"{metric_x}: {row[metric_x]}
"
+ f"{metric_y}: {row[metric_y]}",
+ axis=1,
+ ),
+ showlegend=False,
+ )
+ fig.add_trace(non_frontier_trace)
+
+ # Add Pareto frontier points with legend
+ if not pareto_df.empty:
+ pareto_scatter = px.scatter(
+ pareto_df,
+ x=metric_x,
+ y=metric_y,
+ color="experiment_name",
+ hover_data={"experiment_name": True, "peft_type": True, metric_x: True, metric_y: True},
+ )
+ for trace in pareto_scatter.data:
+ trace.marker = {"size": 12}
+ fig.add_trace(trace)
+
+ # Update layout with axes labels.
+ fig.update_layout(
+ title=f"Pareto Frontier for {metric_x} vs {metric_y}",
+ template="seaborn",
+ height=700,
+ autosize=True,
+ xaxis_title=metric_x,
+ yaxis_title=metric_y,
+ )
+
+ return fig
+
+
+def compute_pareto_summary(filtered, pareto_df, metric_x, metric_y):
+ if filtered.empty:
+ return "No data available."
+
+ stats = filtered[[metric_x, metric_y]].agg(["min", "max", "mean"]).to_string()
+ total_points = len(filtered)
+ pareto_points = len(pareto_df)
+ excluded_points = total_points - pareto_points
+ summary_text = (
+ f"{stats}\n\n"
+ f"Total points: {total_points}\n"
+ f"Pareto frontier points: {pareto_points}\n"
+ f"Excluded points: {excluded_points}"
+ )
+ return summary_text
+
+
+def export_csv(df):
+ if df.empty:
+ return None
+ csv_data = df.to_csv(index=False)
+ with tempfile.NamedTemporaryFile(delete=False, suffix=".csv", mode="w", encoding="utf-8") as tmp:
+ tmp.write(csv_data)
+ tmp_path = tmp.name
+ return tmp_path
+
+
+def build_app(df):
+ with gr.Blocks(theme=gr.themes.Soft()) as demo:
+ gr.Markdown("# PEFT method comparison")
+ gr.Markdown(
+ "Find more information [on the PEFT GitHub repo](https://github.com/huggingface/peft/tree/main/method_comparison)"
+ )
+
+ # Hidden state to store the current filter query.
+ filter_state = gr.State("")
+
+ gr.Markdown("## Choose the task and base model")
+ with gr.Row():
+ task_dropdown = gr.Dropdown(
+ label="Select Task",
+ choices=sorted(df["task_name"].unique()),
+ value=sorted(df["task_name"].unique())[0],
+ )
+ model_dropdown = gr.Dropdown(
+ label="Select Model ID", choices=get_model_ids(sorted(df["task_name"].unique())[0], df)
+ )
+
+ data_table = gr.DataFrame(label="Results", value=df, interactive=False)
+
+ with gr.Row():
+ filter_textbox = gr.Textbox(
+ label="Filter DataFrame",
+ placeholder="Enter filter (e.g.: peft_type=='LORA')",
+ interactive=True,
+ )
+ apply_filter_button = gr.Button("Apply Filter")
+ reset_filter_button = gr.Button("Reset Filter")
+
+ gr.Markdown("## Pareto plot")
+ gr.Markdown(
+ "Select 2 criteria to plot the Pareto frontier. This will show the best PEFT methods along this axis and "
+ "the trade-offs with the other axis. The PEFT methods that Pareto-dominate are shown in colors. All other "
+ "methods are inferior with regard to these two metrics. Hover over a point to show details."
+ )
+
+ with gr.Row():
+ x_default = (
+ "cuda_memory_max" if "cuda_memory_max" in metric_preferences else list(metric_preferences.keys())[0]
+ )
+ y_default = (
+ "test_accuracy" if "test_accuracy" in metric_preferences else list(metric_preferences.keys())[1]
+ )
+ metric_x_dropdown = gr.Dropdown(
+ label="1st metric for Pareto plot",
+ choices=list(metric_preferences.keys()),
+ value=x_default,
+ )
+ metric_y_dropdown = gr.Dropdown(
+ label="2nd metric for Pareto plot",
+ choices=list(metric_preferences.keys()),
+ value=y_default,
+ )
+
+ pareto_plot = gr.Plot(label="Pareto Frontier Plot")
+ summary_box = gr.Textbox(label="Summary Statistics", lines=6)
+ csv_output = gr.File(label="Export Filtered Data as CSV")
+
+ def update_on_task(task_name, current_filter):
+ new_models = get_model_ids(task_name, df)
+ filtered = filter_data(task_name, new_models[0] if new_models else "", df)
+ if current_filter.strip():
+ try:
+ mask = parse_and_filter(filtered, current_filter)
+ df_queried = filtered[mask]
+ if not df_queried.empty:
+ filtered = df_queried
+ except Exception:
+ # invalid filter query
+ pass
+ return gr.update(choices=new_models, value=new_models[0] if new_models else None), filtered
+
+ task_dropdown.change(
+ fn=update_on_task, inputs=[task_dropdown, filter_state], outputs=[model_dropdown, data_table]
+ )
+
+ def update_on_model(task_name, model_id, current_filter):
+ filtered = filter_data(task_name, model_id, df)
+ if current_filter.strip():
+ try:
+ mask = parse_and_filter(filtered, current_filter)
+ filtered = filtered[mask]
+ except Exception:
+ pass
+ return filtered
+
+ model_dropdown.change(
+ fn=update_on_model, inputs=[task_dropdown, model_dropdown, filter_state], outputs=data_table
+ )
+
+ def update_pareto_plot_and_summary(task_name, model_id, metric_x, metric_y, current_filter):
+ filtered = filter_data(task_name, model_id, df)
+ if current_filter.strip():
+ try:
+ mask = parse_and_filter(filtered, current_filter)
+ filtered = filtered[mask]
+ except Exception as e:
+ return generate_pareto_plot(filtered, metric_x, metric_y), f"Filter error: {e}"
+
+ pareto_df = compute_pareto_frontier(filtered, metric_x, metric_y)
+ fig = generate_pareto_plot(filtered, metric_x, metric_y)
+ summary = compute_pareto_summary(filtered, pareto_df, metric_x, metric_y)
+ return fig, summary
+
+ for comp in [model_dropdown, metric_x_dropdown, metric_y_dropdown]:
+ comp.change(
+ fn=update_pareto_plot_and_summary,
+ inputs=[task_dropdown, model_dropdown, metric_x_dropdown, metric_y_dropdown, filter_state],
+ outputs=[pareto_plot, summary_box],
+ )
+
+ def apply_filter(filter_query, task_name, model_id, metric_x, metric_y):
+ filtered = filter_data(task_name, model_id, df)
+ if filter_query.strip():
+ try:
+ mask = parse_and_filter(filtered, filter_query)
+ filtered = filtered[mask]
+ except Exception as e:
+ # Update the table, plot, and summary even if there is a filter error.
+ return (
+ filter_query,
+ filtered,
+ generate_pareto_plot(filtered, metric_x, metric_y),
+ f"Filter error: {e}",
+ )
+
+ pareto_df = compute_pareto_frontier(filtered, metric_x, metric_y)
+ fig = generate_pareto_plot(filtered, metric_x, metric_y)
+ summary = compute_pareto_summary(filtered, pareto_df, metric_x, metric_y)
+ return filter_query, filtered, fig, summary
+
+ apply_filter_button.click(
+ fn=apply_filter,
+ inputs=[filter_textbox, task_dropdown, model_dropdown, metric_x_dropdown, metric_y_dropdown],
+ outputs=[filter_state, data_table, pareto_plot, summary_box],
+ )
+
+ def reset_filter(task_name, model_id, metric_x, metric_y):
+ filtered = filter_data(task_name, model_id, df)
+ pareto_df = compute_pareto_frontier(filtered, metric_x, metric_y)
+ fig = generate_pareto_plot(filtered, metric_x, metric_y)
+ summary = compute_pareto_summary(filtered, pareto_df, metric_x, metric_y)
+ # Return empty strings to clear the filter state and textbox.
+ return "", "", filtered, fig, summary
+
+ reset_filter_button.click(
+ fn=reset_filter,
+ inputs=[task_dropdown, model_dropdown, metric_x_dropdown, metric_y_dropdown],
+ outputs=[filter_state, filter_textbox, data_table, pareto_plot, summary_box],
+ )
+
+ gr.Markdown("## Export data")
+ # Export button for CSV download.
+ export_button = gr.Button("Export Filtered Data")
+ export_button.click(
+ fn=lambda task, model: export_csv(filter_data(task, model, df)),
+ inputs=[task_dropdown, model_dropdown],
+ outputs=csv_output,
+ )
+
+ demo.load(
+ fn=update_pareto_plot_and_summary,
+ inputs=[task_dropdown, model_dropdown, metric_x_dropdown, metric_y_dropdown, filter_state],
+ outputs=[pareto_plot, summary_box],
+ )
+
+ return demo
+
+
+path = os.path.join(os.path.dirname(__file__), "MetaMathQA", "results")
+df = load_df(path, task_name="MetaMathQA")
+demo = build_app(df)
+demo.launch()
diff --git a/peft/method_comparison/processing.py b/peft/method_comparison/processing.py
new file mode 100644
index 0000000000000000000000000000000000000000..f8a74f4c694e4138c5ba81c85c82483fc3ac2cd2
--- /dev/null
+++ b/peft/method_comparison/processing.py
@@ -0,0 +1,145 @@
+# Copyright 2025-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""Data processing used for analyzing and presenting the results"""
+
+import json
+import os
+
+import pandas as pd
+
+
+def preprocess(rows, task_name: str, print_fn=print):
+ results = []
+ skipped = 0
+ for row in rows:
+ run_info = row["run_info"]
+ train_info = row["train_info"]
+ meta_info = row["meta_info"]
+ if run_info["peft_config"]:
+ peft_type = run_info["peft_config"]["peft_type"]
+ else:
+ peft_type = "full-finetuning"
+ if train_info["status"] != "success":
+ skipped += 1
+ continue
+
+ train_metrics = train_info["metrics"][-1]
+
+ # extract the fields that make most sense
+ dct = {
+ "task_name": task_name,
+ "experiment_name": run_info["experiment_name"],
+ "model_id": run_info["train_config"]["model_id"],
+ "train_config": run_info["train_config"],
+ "peft_type": peft_type,
+ "peft_config": run_info["peft_config"],
+ "cuda_memory_reserved_avg": train_info["cuda_memory_reserved_avg"],
+ "cuda_memory_max": train_info["cuda_memory_max"],
+ "cuda_memory_reserved_99th": train_info["cuda_memory_reserved_99th"],
+ "total_time": run_info["total_time"],
+ "train_time": train_info["train_time"],
+ "file_size": train_info["file_size"],
+ "test_accuracy": train_metrics["test accuracy"],
+ "train_loss": train_metrics["train loss"],
+ "train_samples": train_metrics["train samples"],
+ "train_total_tokens": train_metrics["train total tokens"],
+ "peft_version": meta_info["package_info"]["peft-version"],
+ "peft_branch": run_info["peft_branch"],
+ "transformers_version": meta_info["package_info"]["transformers-version"],
+ "datasets_version": meta_info["package_info"]["datasets-version"],
+ "torch_version": meta_info["package_info"]["torch-version"],
+ "bitsandbytes_version": meta_info["package_info"]["bitsandbytes-version"],
+ "package_info": meta_info["package_info"],
+ "system_info": meta_info["system_info"],
+ "created_at": run_info["created_at"],
+ }
+ results.append(dct)
+
+ if skipped:
+ print_fn(f"Skipped {skipped} of {len(rows)} entries because the train status != success")
+
+ return results
+
+
+def load_jsons(path):
+ results = []
+ for fn in os.listdir(path):
+ if fn.endswith(".json"):
+ with open(os.path.join(path, fn)) as f:
+ row = json.load(f)
+ results.append(row)
+ return results
+
+
+def load_df(path, task_name, print_fn=print):
+ jsons = load_jsons(path)
+ preprocessed = preprocess(jsons, task_name=task_name, print_fn=print_fn)
+ dtype_dict = {
+ "task_name": "string",
+ "experiment_name": "string",
+ "model_id": "string",
+ "train_config": "string",
+ "peft_type": "string",
+ "peft_config": "string",
+ "cuda_memory_reserved_avg": int,
+ "cuda_memory_max": int,
+ "cuda_memory_reserved_99th": int,
+ "total_time": float,
+ "train_time": float,
+ "file_size": int,
+ "test_accuracy": float,
+ "train_loss": float,
+ "train_samples": int,
+ "train_total_tokens": int,
+ "peft_version": "string",
+ "peft_branch": "string",
+ "transformers_version": "string",
+ "datasets_version": "string",
+ "torch_version": "string",
+ "bitsandbytes_version": "string",
+ "package_info": "string",
+ "system_info": "string",
+ "created_at": "string",
+ }
+ df = pd.DataFrame(preprocessed)
+ df = df.astype(dtype_dict)
+ df["created_at"] = pd.to_datetime(df["created_at"])
+ # round training time to nearest second
+ df["train_time"] = df["train_time"].round().astype(int)
+ df["total_time"] = df["total_time"].round().astype(int)
+
+ # reorder columns for better viewing, pinned_columns arg in Gradio seems not to work correctly
+ important_columns = [
+ "experiment_name",
+ "peft_type",
+ "total_time",
+ "train_time",
+ "test_accuracy",
+ "train_loss",
+ "cuda_memory_max",
+ "cuda_memory_reserved_99th",
+ "cuda_memory_reserved_avg",
+ "file_size",
+ "created_at",
+ "task_name",
+ ]
+ other_columns = [col for col in df if col not in important_columns]
+ df = df[important_columns + other_columns]
+
+ size_before_drop_dups = len(df)
+ columns = ["experiment_name", "model_id", "peft_type", "created_at"]
+ # we want to keep only the most recent run for each experiment
+ df = df.sort_values("created_at").drop_duplicates(columns, keep="last")
+ return df
diff --git a/peft/method_comparison/requirements-app.txt b/peft/method_comparison/requirements-app.txt
new file mode 100644
index 0000000000000000000000000000000000000000..05c4d2caef0fa0171adaefc2ef73943e16b5d0b0
--- /dev/null
+++ b/peft/method_comparison/requirements-app.txt
@@ -0,0 +1,3 @@
+dash
+gradio>=5.21.0
+pandas
diff --git a/peft/method_comparison/sanitizer.py b/peft/method_comparison/sanitizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..7659d650c0fb293806d314f7334950ebaffbda33
--- /dev/null
+++ b/peft/method_comparison/sanitizer.py
@@ -0,0 +1,100 @@
+import ast
+
+import pandas as pd
+
+
+def _evaluate_node(df, node):
+ """
+ Recursively evaluates an AST node to generate a pandas boolean mask.
+ """
+ # Base Case: A simple comparison like 'price > 100'
+ if isinstance(node, ast.Compare):
+ if not isinstance(node.left, ast.Name):
+ raise ValueError("Left side of comparison must be a column name.")
+ col = node.left.id
+ if col not in df.columns:
+ raise ValueError(f"Column '{col}' not found in DataFrame.")
+
+ if len(node.ops) > 1:
+ raise ValueError("Chained comparisons like '10 < price < 100' are not supported.")
+
+ op_node = node.ops[0]
+ val_node = node.comparators[0]
+ try:
+ value = ast.literal_eval(val_node)
+ except ValueError:
+ raise ValueError("Right side of comparison must be a literal (number, string, list).")
+
+ operator_map = {
+ ast.Gt: lambda c, v: df[c] > v,
+ ast.GtE: lambda c, v: df[c] >= v,
+ ast.Lt: lambda c, v: df[c] < v,
+ ast.LtE: lambda c, v: df[c] <= v,
+ ast.Eq: lambda c, v: df[c] == v,
+ ast.NotEq: lambda c, v: df[c] != v,
+ ast.In: lambda c, v: df[c].isin(v),
+ ast.NotIn: lambda c, v: ~df[c].isin(v)
+ }
+ op_type = type(op_node)
+ if op_type not in operator_map:
+ raise ValueError(f"Unsupported operator '{op_type.__name__}'.")
+ return operator_map[op_type](col, value)
+
+ # Recursive Step: "Bitwise" operation & and | (the same as boolean operations)
+ elif isinstance(node, ast.BinOp):
+ if isinstance(node.op, ast.BitOr):
+ return _evaluate_node(df, node.left) | _evaluate_node(df, node.right)
+ elif isinstance(node.op, ast.BitAnd):
+ return _evaluate_node(df, node.left) & _evaluate_node(df, node.right)
+
+ # Recursive Step: A boolean operation like '... and ...' or '... or ...'
+ elif isinstance(node, ast.BoolOp):
+ op_type = type(node.op)
+ # Evaluate the first value in the boolean expression
+ result = _evaluate_node(df, node.values[0])
+ # Combine it with the rest of the values based on the operator
+ for i in range(1, len(node.values)):
+ if op_type is ast.And or op_type is ast.BitAnd:
+ result &= _evaluate_node(df, node.values[i])
+ elif op_type is ast.Or or op_type is ast.BitOr:
+ result |= _evaluate_node(df, node.values[i])
+ return result
+
+ elif isinstance(node, ast.UnaryOp):
+ if not isinstance(node.op, ast.Not):
+ raise ValueError("Only supported unary op is negation.")
+ return ~_evaluate_node(df, node.operand)
+
+ # If the node is not a comparison or boolean op, it's an unsupported expression type
+ else:
+ raise ValueError(f"Unsupported expression type: {type(node).__name__}")
+
+
+def parse_and_filter(df, filter_str):
+ """
+ Filters a pandas DataFrame using a string expression parsed by AST.
+ This is done to avoid the security vulnerables that `DataFrame.query`
+ brings (arbitrary code execution).
+
+ Args:
+ df (pd.DataFrame): The DataFrame to filter.
+ filter_str (str): A string representing a filter expression.
+ e.g., "price > 100 and stock < 50"
+ Supported operators: >, >=, <, <=, ==, !=, in, not in, and, or.
+
+ Returns:
+ pd.Series: A boolean Series representing the filter mask.
+ """
+ if not filter_str:
+ return pd.Series([True] * len(df), index=df.index)
+
+ try:
+ # 'eval' mode ensures the source is a single expression.
+ tree = ast.parse(filter_str, mode='eval')
+ expression_node = tree.body
+ except (SyntaxError, ValueError) as e:
+ raise ValueError(f"Invalid filter syntax: {e}")
+
+ # The recursive evaluation starts here
+ mask = _evaluate_node(df, expression_node)
+ return mask
diff --git a/peft/method_comparison/test_sanitizer.py b/peft/method_comparison/test_sanitizer.py
new file mode 100644
index 0000000000000000000000000000000000000000..59c0dd191e887aaeebbfce9dff9e88e6be0e2152
--- /dev/null
+++ b/peft/method_comparison/test_sanitizer.py
@@ -0,0 +1,38 @@
+import pandas as pd
+import pytest
+
+from .sanitizer import parse_and_filter
+
+
+@pytest.fixture
+def df_products():
+ data = {
+ 'product_id': [101, 102, 103, 104, 105, 106],
+ 'category': ['Electronics', 'Books', 'Electronics', 'Home Goods', 'Books', 'Electronics'],
+ 'price': [799.99, 19.99, 49.50, 120.00, 24.99, 150.00],
+ 'stock': [15, 300, 50, 25, 150, 0]
+ }
+ return pd.DataFrame(data)
+
+
+def test_exploit_fails(df_products):
+ with pytest.raises(ValueError) as e:
+ mask1 = parse_and_filter(df_products,
+ """price < 50 and @os.system("/bin/echo password")""")
+ assert 'Invalid filter syntax' in str(e)
+
+
+@pytest.mark.parametrize('expression,ids', [
+ ("price < 50", [102, 103, 105]),
+ ("product_id in [101, 102]", [101, 102]),
+ ("price < 50 and category == 'Electronics'", [103]),
+ ("stock < 100 or category == 'Home Goods'", [101, 103, 104, 106]),
+ ("(price > 100 and stock < 20) or category == 'Books'", [101, 102, 105, 106]),
+ ("not (price > 50 or stock > 100)", [103]),
+ ("not price > 50", [102, 103, 105]),
+ ("(price < 50) & (category == 'Electronics')", [103]),
+ ("(stock < 100) | (category == 'Home Goods')", [101, 103, 104, 106]),
+])
+def test_operations(df_products, expression, ids):
+ mask1 = parse_and_filter(df_products, expression)
+ assert sorted(df_products[mask1].product_id) == sorted(ids)
diff --git a/peft/scripts/ci_clean_cache.py b/peft/scripts/ci_clean_cache.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e4bfbaa0abc8fee26098d1b6496d3891ac7bc3f
--- /dev/null
+++ b/peft/scripts/ci_clean_cache.py
@@ -0,0 +1,67 @@
+"""
+Utility to clean cache files that exceed a specific time in days according to their
+last access time recorded in the cache.
+
+Exit code:
+- 1 if no candidates are found
+- 0 if candidates are found
+
+Deletion can be enabled by passing `-d` parameter, otherwise it will only list the candidates.
+"""
+
+import sys
+from datetime import datetime as dt
+
+from huggingface_hub import scan_cache_dir
+
+
+def find_old_revisions(scan_results, max_age_days=30):
+ """Find commit hashes of objects in the cache. These objects need a last access time that
+ is above the passed `max_age_days` parameter. Returns an empty list if no objects are found.
+ Time measurement is based of the current time and the recorded last access tiem in the cache.
+ """
+ now = dt.now()
+ revisions = [(i.revisions, i.last_accessed) for i in scan_results.repos]
+ revisions_ages = [(rev, (now - dt.fromtimestamp(ts_access)).days) for rev, ts_access in revisions]
+ delete_candidates = [rev for rev, age in revisions_ages if age > max_age_days]
+ hashes = [n.commit_hash for rev in delete_candidates for n in rev]
+
+ return hashes
+
+
+def delete_old_revisions(scan_results, delete_candidates, do_delete=False):
+ delete_operation = scan_results.delete_revisions(*delete_candidates)
+ print(f"Would free {delete_operation.expected_freed_size_str}")
+ print(f"Candidates: {delete_candidates}")
+
+ if do_delete:
+ print("Deleting now.")
+ delete_operation.execute()
+ else:
+ print("Not deleting, pass the -d flag.")
+
+
+if __name__ == "__main__":
+ from argparse import ArgumentParser
+
+ parser = ArgumentParser()
+ parser.add_argument("-a", "--max-age", type=int, default=30, help="Max. age in days items in the cache may have.")
+ parser.add_argument(
+ "-d",
+ "--delete",
+ action="store_true",
+ help=(
+ "Delete mode; Really delete items if there are candidates. Exit code = 0 when we found something to delete, 1 "
+ "otherwise."
+ ),
+ )
+ args = parser.parse_args()
+
+ scan_results = scan_cache_dir()
+
+ delete_candidates = find_old_revisions(scan_results, args.max_age)
+ if not delete_candidates:
+ print("No delete candidates found, not deleting anything.")
+ sys.exit(1)
+
+ delete_old_revisions(scan_results, delete_candidates, do_delete=args.delete)
diff --git a/peft/scripts/launch_notebook_mp.py b/peft/scripts/launch_notebook_mp.py
new file mode 100644
index 0000000000000000000000000000000000000000..ce5439afa82a4220cdecbd73e545c58cd14f8442
--- /dev/null
+++ b/peft/scripts/launch_notebook_mp.py
@@ -0,0 +1,47 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# This is a minimal example of launching PEFT with Accelerate. This used to cause issues because PEFT would eagerly
+# import bitsandbytes, which initializes CUDA, resulting in:
+# > RuntimeError: Cannot re-initialize CUDA in forked subprocess. To use CUDA with multiprocessing, you must use the
+# > 'spawn' start method
+# This script exists to ensure that this issue does not reoccur.
+
+import torch
+from accelerate import notebook_launcher
+
+import peft
+from peft.utils import infer_device
+
+
+def init():
+ class MyModule(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.linear = torch.nn.Linear(1, 2)
+
+ def forward(self, x):
+ return self.linear(x)
+
+ device = infer_device()
+ model = MyModule().to(device)
+ peft.get_peft_model(model, peft.LoraConfig(target_modules=["linear"]))
+
+
+def main():
+ notebook_launcher(init, (), num_processes=2)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/peft/scripts/log_reports.py b/peft/scripts/log_reports.py
new file mode 100644
index 0000000000000000000000000000000000000000..c8191ee8f5a2d79c83b266e4a60d2f280fa9d376
--- /dev/null
+++ b/peft/scripts/log_reports.py
@@ -0,0 +1,144 @@
+import argparse
+import json
+import os
+from datetime import date
+from pathlib import Path
+
+from tabulate import tabulate
+
+
+MAX_LEN_MESSAGE = 2900 # slack endpoint has a limit of 3001 characters
+
+parser = argparse.ArgumentParser()
+parser.add_argument(
+ "--slack_channel_name",
+ default="peft-ci-daily",
+)
+
+
+def main(slack_channel_name=None):
+ failed = []
+ passed = []
+
+ group_info = []
+
+ total_num_failed = 0
+ empty_file = False or len(list(Path().glob("*.log"))) == 0
+
+ total_empty_files = []
+
+ for log in Path().glob("*.log"):
+ section_num_failed = 0
+ i = 0
+ with open(log) as f:
+ for line in f:
+ line = json.loads(line)
+ i += 1
+ if line.get("nodeid", "") != "":
+ test = line["nodeid"]
+ if line.get("duration", None) is not None:
+ duration = f"{line['duration']:.4f}"
+ if line.get("outcome", "") == "failed":
+ section_num_failed += 1
+ failed.append([test, duration, log.name.split("_")[0]])
+ total_num_failed += 1
+ else:
+ passed.append([test, duration, log.name.split("_")[0]])
+ empty_file = i == 0
+ group_info.append([str(log), section_num_failed, failed])
+ total_empty_files.append(empty_file)
+ os.remove(log)
+ failed = []
+ text = (
+ "🌞 There were no failures!"
+ if not any(total_empty_files)
+ else "Something went wrong there is at least one empty file - please check GH action results."
+ )
+ no_error_payload = {
+ "type": "section",
+ "text": {
+ "type": "plain_text",
+ "text": text,
+ "emoji": True,
+ },
+ }
+
+ message = ""
+ payload = [
+ {
+ "type": "header",
+ "text": {
+ "type": "plain_text",
+ "text": "🤗 Results of the {} PEFT scheduled tests.".format(os.environ.get("TEST_TYPE", "")),
+ },
+ },
+ ]
+ if total_num_failed > 0:
+ for i, (name, num_failed, failed_tests) in enumerate(group_info):
+ if num_failed > 0:
+ if num_failed == 1:
+ message += f"*{name}: {num_failed} failed test*\n"
+ else:
+ message += f"*{name}: {num_failed} failed tests*\n"
+ failed_table = []
+ for test in failed_tests:
+ failed_table.append(test[0].split("::"))
+ failed_table = tabulate(
+ failed_table,
+ headers=["Test Location", "Test Case", "Test Name"],
+ showindex="always",
+ tablefmt="grid",
+ maxcolwidths=[12, 12, 12],
+ )
+ message += "\n```\n" + failed_table + "\n```"
+
+ if total_empty_files[i]:
+ message += f"\n*{name}: Warning! Empty file - please check the GitHub action job *\n"
+ print(f"### {message}")
+ else:
+ payload.append(no_error_payload)
+
+ if os.environ.get("TEST_TYPE", "") != "":
+ from slack_sdk import WebClient
+
+ if len(message) > MAX_LEN_MESSAGE:
+ print(f"Truncating long message from {len(message)} to {MAX_LEN_MESSAGE}")
+ message = message[:MAX_LEN_MESSAGE] + "..."
+
+ if len(message) != 0:
+ md_report = {
+ "type": "section",
+ "text": {"type": "mrkdwn", "text": message},
+ }
+ payload.append(md_report)
+ action_button = {
+ "type": "section",
+ "text": {"type": "mrkdwn", "text": "*For more details:*"},
+ "accessory": {
+ "type": "button",
+ "text": {"type": "plain_text", "text": "Check Action results", "emoji": True},
+ "url": f"https://github.com/huggingface/peft/actions/runs/{os.environ['GITHUB_RUN_ID']}",
+ },
+ }
+ payload.append(action_button)
+
+ date_report = {
+ "type": "context",
+ "elements": [
+ {
+ "type": "plain_text",
+ "text": f"Nightly {os.environ.get('TEST_TYPE')} test results for {date.today()}",
+ },
+ ],
+ }
+ payload.append(date_report)
+
+ print(payload)
+
+ client = WebClient(token=os.environ.get("SLACK_API_TOKEN"))
+ client.chat_postMessage(channel=f"#{slack_channel_name}", text=message, blocks=payload)
+
+
+if __name__ == "__main__":
+ args = parser.parse_args()
+ main(args.slack_channel_name)
diff --git a/peft/scripts/stale.py b/peft/scripts/stale.py
new file mode 100644
index 0000000000000000000000000000000000000000..794ec8451282c69ae9cff18c15329b14816d707a
--- /dev/null
+++ b/peft/scripts/stale.py
@@ -0,0 +1,65 @@
+# Copyright 2023 The HuggingFace Team, the AllenNLP library authors. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Script to close stale issue. Taken in part from the AllenNLP repository.
+https://github.com/allenai/allennlp.
+"""
+
+import os
+from datetime import datetime as dt
+from datetime import timezone
+
+from github import Github
+
+
+LABELS_TO_EXEMPT = [
+ "good first issue",
+ "good second issue",
+ "good difficult issue",
+ "feature request",
+ "new model",
+ "wip",
+ "PRs welcome to address this",
+]
+
+
+def main():
+ g = Github(os.environ["GITHUB_TOKEN"])
+ repo = g.get_repo("huggingface/peft")
+ open_issues = repo.get_issues(state="open")
+
+ for issue in open_issues:
+ comments = sorted(issue.get_comments(), key=lambda i: i.created_at, reverse=True)
+ last_comment = comments[0] if len(comments) > 0 else None
+ if (
+ (last_comment is not None and last_comment.user.login == "github-actions[bot]")
+ and (dt.now(timezone.utc) - issue.updated_at).days > 7
+ and (dt.now(timezone.utc) - issue.created_at).days >= 30
+ and not any(label.name.lower() in LABELS_TO_EXEMPT for label in issue.get_labels())
+ ):
+ issue.edit(state="closed")
+ elif (
+ (dt.now(timezone.utc) - issue.updated_at).days > 23
+ and (dt.now(timezone.utc) - issue.created_at).days >= 30
+ and not any(label.name.lower() in LABELS_TO_EXEMPT for label in issue.get_labels())
+ ):
+ issue.create_comment(
+ "This issue has been automatically marked as stale because it has not had "
+ "recent activity. If you think this still needs to be addressed "
+ "please comment on this thread.\n\n"
+ )
+
+
+if __name__ == "__main__":
+ main()
diff --git a/peft/scripts/train_memory.py b/peft/scripts/train_memory.py
new file mode 100644
index 0000000000000000000000000000000000000000..d3cec7f82552021d39bcf2a03f1786192dc688c5
--- /dev/null
+++ b/peft/scripts/train_memory.py
@@ -0,0 +1,274 @@
+# Copyright 2025-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""This script trains a model on a small text dataset and measures the memory consumption, as well as a few other
+useful metrics.
+
+Example:
+
+Get help:
+
+```bash
+python train_memory.py --help
+```
+
+Train the google/gemma-2-2b model with a LoRA config json at the indicated location.
+
+```bash
+python train_memory.py "google/gemma-2-2b" --max_seq_length 256 --batch_size 1 --rank 32 --dtype bfloat16 --path_config
+```
+
+Fully fine-tune the model (i.e. without LoRA) by setting the rank to 0:
+
+```bash
+python train_memory.py "google/gemma-2-2b" --rank 0
+```
+
+Get an estimate of the size of the hidden states by passing `--monitor_tensors`. This trains just for a single epoch. For realistic estimates, the batch size for this:
+
+```bash
+python train_memory.py "google/gemma-2-2b" --max_seq_length 256 --batch_size 32 --rank 32 --dtype bfloat16 --path_config configs/lora_rank-32_embedding-lora/ --monitor_tensors
+```
+
+"""
+
+import argparse
+import gc
+import os
+import sys
+import tempfile
+import time
+import warnings
+from collections import Counter
+from contextlib import nullcontext
+from functools import partial
+
+import torch
+from datasets import load_dataset
+from torch import nn
+from transformers import (
+ AutoModelForCausalLM,
+ AutoTokenizer,
+ BitsAndBytesConfig,
+)
+
+from peft import LoraConfig, get_peft_model, prepare_model_for_kbit_training
+from peft.utils import CONFIG_NAME, SAFETENSORS_WEIGHTS_NAME
+
+
+# suppress all warnings
+warnings.filterwarnings("ignore")
+
+device = "cuda" if torch.cuda.is_available() else "cpu"
+dtype_to_bytes_linear = {"float32": 4, "float16": 2, "bfloat16": 2, "int8": 1, "int4": 0.5}
+
+
+def init_cuda():
+ torch.manual_seed(0)
+ if device == "cpu":
+ return
+
+ torch.cuda.reset_peak_memory_stats()
+ torch.cuda.manual_seed_all(0)
+ # might not be necessary, but just to be sure
+ nn.Linear(1, 1).to(device)
+
+
+def get_data(tokenizer):
+ def tokenize(samples):
+ # For some reason, the max sequence length is not honored by the tokenizer, resulting in IndexErrors. Thus,
+ # manually ensure that sequences are not too long.
+ tokenized = tokenizer(samples["quote"])
+ tokenized["input_ids"] = [input_ids[: tokenizer.model_max_length] for input_ids in tokenized["input_ids"]]
+ tokenized["attention_mask"] = [
+ input_ids[: tokenizer.model_max_length] for input_ids in tokenized["attention_mask"]
+ ]
+ return tokenized
+
+ data = load_dataset("ybelkada/english_quotes_copy")
+ data = data.map(tokenize, batched=True)
+ # We need to manually remove unused columns. This is because we cannot use remove_unused_columns=True in the
+ # Trainer, as this leads to errors with torch.compile. We also cannot just leave them in, as they contain
+ # strings. Therefore, manually remove all unused columns.
+ data = data.remove_columns(["quote", "author", "tags"])
+ return data
+
+
+def train(model_id, rank, dtype, monitor_tensors, max_seq_length, batch_size, max_steps, path_config):
+ init_cuda()
+ cuda_memory_init = torch.cuda.max_memory_allocated()
+ cuda_memory_log = []
+
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ tokenizer.model_max_length = max_seq_length
+ if not tokenizer.pad_token:
+ tokenizer.pad_token = tokenizer.eos_token
+ data = get_data(tokenizer)
+
+ if dtype == "int4":
+ quant_config = BitsAndBytesConfig(load_in_4bit=True)
+ model = AutoModelForCausalLM.from_pretrained(model_id, device_map=device, quantization_config=quant_config)
+ model = prepare_model_for_kbit_training(model)
+ elif dtype == "int8":
+ quant_config = BitsAndBytesConfig(load_in_8bit=True)
+ model = AutoModelForCausalLM.from_pretrained(model_id, device_map=device, quantization_config=quant_config)
+ model = prepare_model_for_kbit_training(model)
+ elif dtype == "bfloat16":
+ model = AutoModelForCausalLM.from_pretrained(model_id, device_map=device, torch_dtype=torch.bfloat16)
+ elif dtype == "float16":
+ model = AutoModelForCausalLM.from_pretrained(model_id, device_map=device, torch_dtype=torch.float16)
+ elif dtype == "float32":
+ model = AutoModelForCausalLM.from_pretrained(model_id, device_map=device)
+ else:
+ raise ValueError(f"Invalid dtype: {dtype}")
+
+ if rank > 0:
+ if path_config is None:
+ raise RuntimeError("LoRA rank > 0 requires a path to a LoRA config")
+ if path_config.endswith(CONFIG_NAME):
+ path_config = path_config.removesuffix(CONFIG_NAME)
+ config = LoraConfig.from_pretrained(path_config)
+ model = get_peft_model(model, config)
+ model.print_trainable_parameters()
+ else:
+ print("Not using LoRA")
+
+ model.config.use_cache = False
+ storage = []
+
+ def pack(x):
+ storage.append(x)
+ return len(storage) - 1
+
+ def unpack(x):
+ return storage[x]
+
+ train_ctx = partial(torch.autograd.graph.saved_tensors_hooks, pack, unpack) if monitor_tensors else nullcontext
+
+ optimizer = torch.optim.AdamW(model.parameters(), lr=1e-5)
+ losses = []
+ sample = 0
+ tic_total = time.perf_counter()
+ for i in range(0, max_steps):
+ storage.clear()
+ tic = time.perf_counter()
+ try:
+ batch = tokenizer.pad(data["train"][sample : sample + batch_size], return_tensors="pt").to(model.device)
+ sample += batch_size
+
+ # add targets
+ batch["labels"] = batch["input_ids"].clone()
+ optimizer.zero_grad()
+
+ with train_ctx():
+ outputs = model(**batch)
+ loss = outputs.loss
+ loss.backward()
+ optimizer.step()
+ losses.append(loss.item())
+ cuda_memory_log.append(torch.cuda.memory_allocated() - cuda_memory_init)
+ torch.cuda.empty_cache()
+ gc.collect()
+ toc = time.perf_counter()
+ print(f"step {i:3d} loss {loss.item():.6f} time {toc - tic:.2f}s", file=sys.stderr)
+ except KeyboardInterrupt:
+ print("canceled training")
+ break
+
+ if monitor_tensors:
+ break
+
+ toc_total = time.perf_counter()
+
+ cuda_memory_final = torch.cuda.max_memory_allocated()
+ cuda_memory_avg = int(sum(cuda_memory_log) / len(cuda_memory_log))
+ print(f"cuda memory avg: {cuda_memory_avg // 2**20}MB")
+ print(f"cuda memory max: {(cuda_memory_final - cuda_memory_init) // 2**20}MB")
+ print(f"total time: {toc_total - tic_total:.2f}s")
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir)
+ stat = os.stat(os.path.join(tmp_dir, SAFETENSORS_WEIGHTS_NAME))
+ file_size = stat.st_size
+ print(f"file size: {file_size / 2**20:.1f}MB")
+
+ if monitor_tensors:
+ dtype_counts = Counter(t.dtype for t in storage)
+ shape_counts = Counter(t.shape for t in storage)
+ param_shape_counts = Counter(p.shape for p in model.parameters())
+ param_shape_counts_copy = dict(param_shape_counts).copy()
+
+ # shape counts includes the params, so we need to subtract them; note that they can be transposed
+ # this is an approximation
+ diff_shape_counts = {}
+ for shape, count in shape_counts.items():
+ if shape in param_shape_counts_copy:
+ diff_count = count - param_shape_counts[shape]
+ if diff_count > 0:
+ diff_shape_counts[shape] = diff_count
+ param_shape_counts_copy[shape] = max(0, param_shape_counts_copy[shape] - diff_count)
+ elif shape[::-1] in param_shape_counts:
+ diff_count = count - param_shape_counts[shape[::-1]]
+ if diff_count > 0:
+ diff_shape_counts[shape] = diff_count
+ param_shape_counts_copy[shape[::-1]] = max(0, param_shape_counts_copy[shape[::-1]] - diff_count)
+ else:
+ diff_shape_counts[shape] = count
+
+ total_size = sum(t.numel() * t.element_size() for t in storage)
+ total_size_mb = f"{total_size // 2**20}MB"
+ diff_size = 0
+ for shape, count in diff_shape_counts.items():
+ diff_size += count * torch.zeros(shape).numel() * dtype_to_bytes_linear[dtype]
+ param_size = total_size - diff_size
+
+ diff_size_mb = f"{diff_size // 2**20}MB"
+ param_size_mb = f"{param_size // 2**20}MB"
+
+ print(f"Dtype counts: {dtype_counts.most_common()}")
+ print(f"Total size of tensors: {total_size_mb: >12}")
+ print(f"Total size of activations: {diff_size_mb: >12}")
+ print(f"Total size of parameters: {param_size_mb: >12}")
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument("model_id", type=str, help="Model name on Hugging Face Hub")
+ parser.add_argument("--rank", type=int, default=8, help="Rank of LoRA, 0 => no LoRA, default 8")
+ parser.add_argument(
+ "--dtype",
+ type=str,
+ default="float32",
+ help="Data type, one of float32, float16, bfloat16, int8, int4, default float32",
+ )
+ parser.add_argument(
+ "--monitor_tensors",
+ action="store_true",
+ help="Monitor tensor sizes during training for a single training step, off by default",
+ )
+ parser.add_argument("--max_seq_length", type=int, default=128, help="Maximum sequence length, default 128")
+ parser.add_argument("--batch_size", type=int, default=1, help="Batch size, default 1")
+ parser.add_argument("--max_steps", type=int, default=50, help="Maximum number of training steps, default 50")
+ parser.add_argument("--path_config", type=str, default=None, help="Path to LoRA config")
+ args = parser.parse_args()
+ train(
+ model_id=args.model_id,
+ rank=args.rank,
+ dtype=args.dtype,
+ monitor_tensors=args.monitor_tensors,
+ max_seq_length=args.max_seq_length,
+ batch_size=args.batch_size,
+ max_steps=args.max_steps,
+ path_config=args.path_config,
+ )
diff --git a/peft/tests/__init__.py b/peft/tests/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/peft/tests/conftest.py b/peft/tests/conftest.py
new file mode 100644
index 0000000000000000000000000000000000000000..e4ee39b69e254b71faebb006853d6c5d5911f750
--- /dev/null
+++ b/peft/tests/conftest.py
@@ -0,0 +1,69 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import platform
+import re
+
+import pytest
+
+
+def pytest_addoption(parser):
+ parser.addoption("--regression", action="store_true", default=False, help="run regression tests")
+
+
+def pytest_configure(config):
+ config.addinivalue_line("markers", "regression: mark regression tests")
+
+
+def pytest_collection_modifyitems(config, items):
+ if config.getoption("--regression"):
+ return
+
+ skip_regression = pytest.mark.skip(reason="need --regression option to run regression tests")
+ for item in items:
+ if "regression" in item.keywords:
+ item.add_marker(skip_regression)
+
+
+# TODO: remove this once support for PyTorch 2.2 (the latest one still supported by GitHub MacOS x86_64 runners) is
+# dropped, or if MacOS is removed from the test matrix, see https://github.com/huggingface/peft/issues/2431.
+# Note: the function name is fixed by the pytest plugin system, don't change it
+@pytest.hookimpl(hookwrapper=True)
+def pytest_runtest_makereport(item, call):
+ """
+ Plug into the pytest test report generation to skip a specific MacOS failure caused by transformers.
+
+ The error was introduced by https://github.com/huggingface/transformers/pull/37785, which results in torch.load
+ failing when using torch < 2.6.
+
+ Since the MacOS x86 runners need to use an older torch version, those steps are necessary to get the CI green.
+ """
+ outcome = yield
+ rep = outcome.get_result()
+ # ref:
+ # https://github.com/huggingface/transformers/blob/858ce6879a4aa7fa76a7c4e2ac20388e087ace26/src/transformers/utils/import_utils.py#L1418
+ error_msg = re.compile(r"Due to a serious vulnerability issue in `torch.load`")
+
+ # notes:
+ # - pytest uses hard-coded strings, we cannot import and use constants
+ # https://docs.pytest.org/en/stable/reference/reference.html#pytest.TestReport
+ # - errors can happen during call (running the test) but also setup (e.g. in fixtures)
+ if rep.failed and (rep.when in ("setup", "call")) and (platform.system() == "Darwin"):
+ exc_msg = str(call.excinfo.value)
+ if error_msg.search(exc_msg):
+ # turn this failure into an xfail:
+ rep.outcome = "skipped"
+ # for this attribute, see:
+ # https://github.com/pytest-dev/pytest/blob/bd6877e5874b50ee57d0f63b342a67298ee9a1c3/src/_pytest/reports.py#L266C5-L266C13
+ rep.wasxfail = "Error known to occur on MacOS with older torch versions, won't be fixed"
diff --git a/peft/tests/test_adaption_prompt.py b/peft/tests/test_adaption_prompt.py
new file mode 100644
index 0000000000000000000000000000000000000000..996559c336070e9b379cd8aca5606b9308bbad75
--- /dev/null
+++ b/peft/tests/test_adaption_prompt.py
@@ -0,0 +1,415 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import tempfile
+
+import pytest
+import torch
+from torch.testing import assert_close
+from transformers import AutoModelForCausalLM
+
+from peft import get_peft_model
+from peft.peft_model import PeftModel
+from peft.tuners.adaption_prompt import AdaptionPromptConfig
+from peft.utils import infer_device
+from peft.utils.other import prepare_model_for_kbit_training
+from peft.utils.save_and_load import get_peft_model_state_dict
+
+
+MODELS_TO_TEST = [
+ "trl-internal-testing/tiny-random-LlamaForCausalLM",
+ "hf-internal-testing/tiny-random-MistralForCausalLM",
+]
+
+
+class TestAdaptionPrompt:
+ """
+ Tests for the AdaptionPrompt model.
+
+ Some of these tests were adapted from `test_peft_model.py` (which has been refactored since), but since we haven't
+ checked in the test checkpoints for Llama into `hf-internal-testing`, we separate them for now.
+ """
+
+ transformers_class = AutoModelForCausalLM
+ torch_device = infer_device()
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_attributes(self, model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = AdaptionPromptConfig(adapter_layers=1, adapter_len=4)
+ model = get_peft_model(model, config)
+
+ assert hasattr(model, "save_pretrained")
+ assert hasattr(model, "from_pretrained")
+ assert hasattr(model, "push_to_hub")
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_prepare_for_training(self, model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = AdaptionPromptConfig(adapter_layers=1, adapter_len=4, task_type="CAUSAL_LM")
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ dummy_input = torch.LongTensor([[1, 1, 1]]).to(self.torch_device)
+ dummy_output = model.get_input_embeddings()(dummy_input)
+
+ assert not dummy_output.requires_grad
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_prepare_for_int8_training(self, model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ model = prepare_model_for_kbit_training(model)
+ model = model.to(self.torch_device)
+
+ for param in model.parameters():
+ assert not param.requires_grad
+
+ config = AdaptionPromptConfig(adapter_layers=1, adapter_len=4, task_type="CAUSAL_LM")
+ model = get_peft_model(model, config)
+
+ # For backward compatibility
+ if hasattr(model, "enable_input_require_grads"):
+ model.enable_input_require_grads()
+ else:
+
+ def make_inputs_require_grad(module, input, output):
+ output.requires_grad_(True)
+
+ model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
+
+ dummy_input = torch.LongTensor([[1, 1, 1]]).to(self.torch_device)
+ dummy_output = model.get_input_embeddings()(dummy_input)
+
+ assert dummy_output.requires_grad
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_save_pretrained_regression(self, model_id):
+ seed = 420
+ torch.manual_seed(seed)
+ model = self.transformers_class.from_pretrained(model_id)
+ config = AdaptionPromptConfig(adapter_layers=2, adapter_len=4, task_type="CAUSAL_LM")
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname, safe_serialization=False)
+
+ torch.manual_seed(seed)
+ model_from_pretrained = self.transformers_class.from_pretrained(model_id)
+ model_from_pretrained = PeftModel.from_pretrained(model_from_pretrained, tmp_dirname)
+
+ # check if the state dicts are equal
+ state_dict = get_peft_model_state_dict(model)
+ state_dict_from_pretrained = get_peft_model_state_dict(model_from_pretrained)
+
+ # check if same keys
+ assert state_dict.keys() == state_dict_from_pretrained.keys()
+
+ # Check that the number of saved parameters is 4 -- 2 layers of (tokens and gate).
+ assert len(state_dict) == 4
+
+ # check if tensors equal
+ for key in state_dict.keys():
+ assert torch.allclose(
+ state_dict[key].to(self.torch_device), state_dict_from_pretrained[key].to(self.torch_device)
+ )
+
+ # check if `adapter_model.bin` is present
+ assert os.path.exists(os.path.join(tmp_dirname, "adapter_model.bin"))
+
+ # check if `adapter_config.json` is present
+ assert os.path.exists(os.path.join(tmp_dirname, "adapter_config.json"))
+
+ # check if `model.safetensors` is not present
+ assert not os.path.exists(os.path.join(tmp_dirname, "model.safetensors"))
+
+ # check if `config.json` is not present
+ assert not os.path.exists(os.path.join(tmp_dirname, "config.json"))
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_save_pretrained(self, model_id):
+ seed = 420
+ torch.manual_seed(seed)
+ model = self.transformers_class.from_pretrained(model_id)
+ config = AdaptionPromptConfig(adapter_layers=2, adapter_len=4, task_type="CAUSAL_LM")
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname)
+
+ torch.manual_seed(seed)
+ model_from_pretrained = self.transformers_class.from_pretrained(model_id)
+ model_from_pretrained = PeftModel.from_pretrained(model_from_pretrained, tmp_dirname)
+
+ # check if the state dicts are equal
+ state_dict = get_peft_model_state_dict(model)
+ state_dict_from_pretrained = get_peft_model_state_dict(model_from_pretrained)
+
+ # check if same keys
+ assert state_dict.keys() == state_dict_from_pretrained.keys()
+
+ # Check that the number of saved parameters is 4 -- 2 layers of (tokens and gate).
+ assert len(state_dict) == 4
+
+ # check if tensors equal
+ for key in state_dict.keys():
+ assert torch.allclose(
+ state_dict[key].to(self.torch_device), state_dict_from_pretrained[key].to(self.torch_device)
+ )
+
+ # check if `adapter_model.bin` is present
+ assert os.path.exists(os.path.join(tmp_dirname, "adapter_model.safetensors"))
+
+ # check if `adapter_config.json` is present
+ assert os.path.exists(os.path.join(tmp_dirname, "adapter_config.json"))
+
+ # check if `model.safetensors` is not present
+ assert not os.path.exists(os.path.join(tmp_dirname, "model.safetensors"))
+
+ # check if `config.json` is not present
+ assert not os.path.exists(os.path.join(tmp_dirname, "config.json"))
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_save_pretrained_selected_adapters(self, model_id):
+ seed = 420
+ torch.manual_seed(seed)
+ model = self.transformers_class.from_pretrained(model_id)
+ config = AdaptionPromptConfig(adapter_layers=2, adapter_len=4, task_type="CAUSAL_LM")
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ new_adapter_config = AdaptionPromptConfig(adapter_layers=2, adapter_len=4, task_type="CAUSAL_LM")
+ model.add_adapter("new_adapter", new_adapter_config)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname)
+
+ torch.manual_seed(seed)
+ model_from_pretrained = self.transformers_class.from_pretrained(model_id)
+ model_from_pretrained = PeftModel.from_pretrained(model_from_pretrained, tmp_dirname)
+
+ model_from_pretrained.load_adapter(tmp_dirname, "new_adapter")
+
+ # check if the state dicts are equal
+ state_dict = get_peft_model_state_dict(model)
+ state_dict_from_pretrained = get_peft_model_state_dict(model_from_pretrained)
+
+ # check if same keys
+ assert state_dict.keys() == state_dict_from_pretrained.keys()
+
+ # Check that the number of saved parameters is 4 -- 2 layers of (tokens and gate).
+ assert len(state_dict) == 4
+
+ # check if tensors equal
+ for key in state_dict.keys():
+ assert torch.allclose(
+ state_dict[key].to(self.torch_device), state_dict_from_pretrained[key].to(self.torch_device)
+ )
+
+ # check if `adapter_model.bin` is present
+ assert os.path.exists(os.path.join(tmp_dirname, "adapter_model.safetensors"))
+
+ # check if `adapter_config.json` is present
+ assert os.path.exists(os.path.join(tmp_dirname, "adapter_config.json"))
+
+ # check if `model.safetensors` is not present
+ assert not os.path.exists(os.path.join(tmp_dirname, "model.safetensors"))
+
+ # check if `config.json` is not present
+ assert not os.path.exists(os.path.join(tmp_dirname, "config.json"))
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_generate(self, model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = AdaptionPromptConfig(adapter_layers=2, adapter_len=4, task_type="CAUSAL_LM")
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ input_ids = torch.LongTensor([[1, 1, 1], [2, 1, 2]]).to(self.torch_device)
+ attention_mask = torch.LongTensor([[1, 1, 1], [1, 0, 1]]).to(self.torch_device)
+
+ # check if `generate` works
+ _ = model.generate(input_ids=input_ids, attention_mask=attention_mask)
+
+ # check if `generate` works if positional arguments are passed
+ _ = model.generate(input_ids, attention_mask=attention_mask)
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_sequence_adapter_ops(self, model_id):
+ """Test sequence of adapter operations."""
+ # Test input data.
+ input_ids = torch.LongTensor([[1, 1, 1], [2, 1, 2]]).to(self.torch_device)
+ target_ids = torch.LongTensor([[0, 0, 0], [0, 0, 0]]).to(self.torch_device)
+ attention_mask = torch.LongTensor([[1, 1, 1], [1, 0, 1]]).to(self.torch_device)
+
+ # Create original llama model.
+ original = self.transformers_class.from_pretrained(model_id)
+ original = original.to(self.torch_device)
+ original_before = original(input_ids=input_ids, attention_mask=attention_mask)
+
+ # Get AdaptionPrompt model.
+ adapted = get_peft_model(
+ original, AdaptionPromptConfig(adapter_layers=2, adapter_len=4, task_type="CAUSAL_LM")
+ )
+ adapted = adapted.to(self.torch_device)
+ default_before = adapted(input_ids=input_ids, attention_mask=attention_mask, labels=target_ids)
+
+ # Test zero-init: The logits should be exactly the same.
+ assert_close(original_before.logits, default_before.logits, rtol=0, atol=0)
+
+ # Single fine-tuning step on "default" adapter.
+ optimizer = torch.optim.SGD(adapted.parameters(), lr=1)
+ optimizer.zero_grad()
+ default_before.loss.backward()
+ optimizer.step()
+
+ # Test that the output changed.
+ default_after = adapted(input_ids=input_ids, attention_mask=attention_mask, labels=target_ids)
+ assert not torch.allclose(default_before.logits, default_after.logits)
+
+ with adapted.disable_adapter():
+ # Test that the output is the same as the original output.
+ default_disabled = adapted(input_ids=input_ids, attention_mask=attention_mask, labels=target_ids)
+ assert_close(original_before.logits, default_disabled.logits, rtol=0, atol=0)
+
+ # Add new adapter 1.
+ adapted.add_adapter("adapter 1", AdaptionPromptConfig(adapter_layers=2, adapter_len=8, task_type="CAUSAL_LM"))
+ # Test zero-init
+ adapter_1_before = adapted(input_ids=input_ids, attention_mask=attention_mask, labels=target_ids)
+ assert_close(original_before.logits, adapter_1_before.logits, rtol=0, atol=0)
+
+ # Single fine-tuning step on adapter 1.
+ optimizer = torch.optim.SGD(adapted.parameters(), lr=1)
+ optimizer.zero_grad()
+ adapter_1_before.loss.backward()
+ optimizer.step()
+
+ # Test that adapter 1 output changed.
+ adapter_1_after = adapted(input_ids=input_ids, attention_mask=attention_mask, labels=target_ids)
+ assert not torch.allclose(adapter_1_before.logits, adapter_1_after.logits)
+ assert not torch.allclose(original_before.logits, adapter_1_after.logits)
+ assert not torch.allclose(default_after.logits, adapter_1_after.logits)
+
+ with adapted.disable_adapter():
+ # Test that the output is the same as the original output.
+ adapter_1_disabled = adapted(input_ids=input_ids, attention_mask=attention_mask, labels=target_ids)
+ assert_close(original_before.logits, adapter_1_disabled.logits, rtol=0, atol=0)
+
+ # Set adapter back to default.
+ adapted.set_adapter("default")
+
+ # Test that the output is the same as the default output after training.
+ default_after_set = adapted(input_ids=input_ids, attention_mask=attention_mask, labels=target_ids)
+ assert_close(default_after.logits, default_after_set.logits, rtol=0, atol=0)
+ assert not torch.allclose(original_before.logits, default_after_set.logits)
+ assert not torch.allclose(adapter_1_after.logits, default_after_set.logits)
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_add_and_set_while_disabled(self, model_id):
+ """Test that adding and setting adapters while disabled works as intended."""
+ # Test input data.
+ input_ids = torch.LongTensor([[1, 1, 1], [2, 1, 2]]).to(self.torch_device)
+ target_ids = torch.LongTensor([[0, 0, 0], [0, 0, 0]]).to(self.torch_device)
+ attention_mask = torch.LongTensor([[1, 1, 1], [1, 0, 1]]).to(self.torch_device)
+
+ # Create original llama model.
+ original = self.transformers_class.from_pretrained(model_id)
+ original = original.to(self.torch_device)
+ original_before = original(input_ids=input_ids, attention_mask=attention_mask)
+
+ # Get AdaptionPrompt model.
+ adapted = get_peft_model(
+ original, AdaptionPromptConfig(adapter_layers=2, adapter_len=4, task_type="CAUSAL_LM")
+ )
+ adapted = adapted.to(self.torch_device)
+
+ with adapted.disable_adapter():
+ adapted.add_adapter(
+ "adapter 1", AdaptionPromptConfig(adapter_layers=2, adapter_len=8, task_type="CAUSAL_LM")
+ )
+
+ # Test that the output is the same as the original output.
+ adapter_1_before = adapted(input_ids=input_ids, attention_mask=attention_mask, labels=target_ids)
+ assert_close(original_before.logits, adapter_1_before.logits, rtol=0, atol=0)
+
+ # Single fine-tuning step on adapter 1.
+ optimizer = torch.optim.SGD(adapted.parameters(), lr=1)
+ optimizer.zero_grad()
+ adapter_1_before.loss.backward()
+ optimizer.step()
+
+ # Test that adapter 1 output changed.
+ adapter_1_after = adapted(input_ids=input_ids, attention_mask=attention_mask, labels=target_ids)
+ assert not torch.allclose(original_before.logits, adapter_1_after.logits)
+
+ adapted.set_adapter("default")
+ with adapted.disable_adapter():
+ adapted.set_adapter("adapter 1")
+
+ # Test that adapter 1 is active again.
+ adapter_1_after_set = adapted(input_ids=input_ids, attention_mask=attention_mask, labels=target_ids)
+ assert_close(adapter_1_after.logits, adapter_1_after_set.logits, rtol=0, atol=0)
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_use_cache(self, model_id):
+ """Test that AdaptionPrompt works when Llama config use_cache=True."""
+ torch.manual_seed(0)
+ input_ids = torch.LongTensor([[1, 1, 1], [2, 1, 2]]).to(self.torch_device)
+ original = self.transformers_class.from_pretrained(model_id, use_cache=False)
+ adapted = get_peft_model(
+ original, AdaptionPromptConfig(adapter_layers=2, adapter_len=4, task_type="CAUSAL_LM")
+ )
+ adapted = adapted.to(self.torch_device)
+ expected = adapted.generate(input_ids=input_ids, max_length=8)
+
+ # Set use_cache = True and generate output again.
+ adapted.base_model.config.use_cache = True
+ actual = adapted.generate(input_ids=input_ids, max_length=8)
+ assert_close(expected, actual, rtol=0, atol=0)
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_bf16_inference(self, model_id):
+ if self.torch_device == "mps":
+ return pytest.skip("Skipping bf16 test on MPS")
+
+ """Test that AdaptionPrompt works when Llama using a half-precision model."""
+ input_ids = torch.LongTensor([[1, 1, 1], [2, 1, 2]]).to(self.torch_device)
+ original = self.transformers_class.from_pretrained(model_id, torch_dtype=torch.bfloat16)
+ adapted = get_peft_model(
+ original, AdaptionPromptConfig(adapter_layers=2, adapter_len=4, task_type="CAUSAL_LM")
+ )
+ adapted = adapted.to(self.torch_device)
+ adapted.generate(input_ids=input_ids) # does not raise
+
+ @pytest.mark.xfail(reason="currently this fails because scores are zeroed out", raises=AssertionError)
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_disable_adapter(self, model_id):
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ dummy_input = torch.LongTensor([[1, 1, 1]]).to(self.torch_device)
+ output_before = model(dummy_input).logits
+
+ config = AdaptionPromptConfig(adapter_layers=1, adapter_len=4, task_type="CAUSAL_LM")
+ model = get_peft_model(model, config).to(self.torch_device)
+ output_peft = model(dummy_input).logits
+ # TODO currently this fails because scores are zeroed out:
+ # https://github.com/huggingface/peft/blob/062d95a09eb5d1de35c0e5e23d4387daba99e2db/src/peft/tuners/adaption_prompt.py#L303
+ # This is fine for users but makes it difficult to test if anything happens. In the future, we will have a clean
+ # way to control initialization. Until then, this test is expected to fail.
+ assert not torch.allclose(output_before, output_peft)
+
+ with model.disable_adapter():
+ output_peft_disabled = model(dummy_input).logits
+ assert torch.allclose(output_before, output_peft_disabled)
diff --git a/peft/tests/test_auto.py b/peft/tests/test_auto.py
new file mode 100644
index 0000000000000000000000000000000000000000..105d13f455a9f80a74b43127f1a7b009ca5259aa
--- /dev/null
+++ b/peft/tests/test_auto.py
@@ -0,0 +1,231 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import tempfile
+
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+from peft import (
+ AutoPeftModel,
+ AutoPeftModelForCausalLM,
+ AutoPeftModelForFeatureExtraction,
+ AutoPeftModelForQuestionAnswering,
+ AutoPeftModelForSeq2SeqLM,
+ AutoPeftModelForSequenceClassification,
+ AutoPeftModelForTokenClassification,
+ LoraConfig,
+ PeftModel,
+ PeftModelForCausalLM,
+ PeftModelForFeatureExtraction,
+ PeftModelForQuestionAnswering,
+ PeftModelForSeq2SeqLM,
+ PeftModelForSequenceClassification,
+ PeftModelForTokenClassification,
+ get_peft_model,
+)
+from peft.utils import infer_device
+
+
+class TestPeftAutoModel:
+ dtype = torch.float16 if infer_device() == "mps" else torch.bfloat16
+
+ def test_peft_causal_lm(self):
+ model_id = "peft-internal-testing/tiny-OPTForCausalLM-lora"
+ model = AutoPeftModelForCausalLM.from_pretrained(model_id)
+ assert isinstance(model, PeftModelForCausalLM)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname)
+
+ model = AutoPeftModelForCausalLM.from_pretrained(tmp_dirname)
+ assert isinstance(model, PeftModelForCausalLM)
+
+ # check if kwargs are passed correctly
+ model = AutoPeftModelForCausalLM.from_pretrained(model_id, torch_dtype=self.dtype)
+ assert isinstance(model, PeftModelForCausalLM)
+ assert model.base_model.lm_head.weight.dtype == self.dtype
+
+ adapter_name = "default"
+ is_trainable = False
+ # This should work
+ _ = AutoPeftModelForCausalLM.from_pretrained(model_id, adapter_name, is_trainable, torch_dtype=self.dtype)
+
+ def test_peft_causal_lm_extended_vocab(self):
+ model_id = "peft-internal-testing/tiny-random-OPTForCausalLM-extended-vocab"
+ model = AutoPeftModelForCausalLM.from_pretrained(model_id)
+ assert isinstance(model, PeftModelForCausalLM)
+
+ # check if kwargs are passed correctly
+ model = AutoPeftModelForCausalLM.from_pretrained(model_id, torch_dtype=self.dtype)
+ assert isinstance(model, PeftModelForCausalLM)
+ assert model.base_model.lm_head.weight.dtype == self.dtype
+
+ adapter_name = "default"
+ is_trainable = False
+ # This should work
+ _ = AutoPeftModelForCausalLM.from_pretrained(model_id, adapter_name, is_trainable, torch_dtype=self.dtype)
+
+ def test_peft_seq2seq_lm(self):
+ model_id = "peft-internal-testing/tiny_T5ForSeq2SeqLM-lora"
+ model = AutoPeftModelForSeq2SeqLM.from_pretrained(model_id)
+ assert isinstance(model, PeftModelForSeq2SeqLM)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname)
+
+ model = AutoPeftModelForSeq2SeqLM.from_pretrained(tmp_dirname)
+ assert isinstance(model, PeftModelForSeq2SeqLM)
+
+ # check if kwargs are passed correctly
+ model = AutoPeftModelForSeq2SeqLM.from_pretrained(model_id, torch_dtype=self.dtype)
+ assert isinstance(model, PeftModelForSeq2SeqLM)
+ assert model.base_model.lm_head.weight.dtype == self.dtype
+
+ adapter_name = "default"
+ is_trainable = False
+ # This should work
+ _ = AutoPeftModelForSeq2SeqLM.from_pretrained(model_id, adapter_name, is_trainable, torch_dtype=self.dtype)
+
+ def test_peft_sequence_cls(self):
+ model_id = "peft-internal-testing/tiny_OPTForSequenceClassification-lora"
+ model = AutoPeftModelForSequenceClassification.from_pretrained(model_id)
+ assert isinstance(model, PeftModelForSequenceClassification)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname)
+
+ model = AutoPeftModelForSequenceClassification.from_pretrained(tmp_dirname)
+ assert isinstance(model, PeftModelForSequenceClassification)
+
+ # check if kwargs are passed correctly
+ model = AutoPeftModelForSequenceClassification.from_pretrained(model_id, torch_dtype=self.dtype)
+ assert isinstance(model, PeftModelForSequenceClassification)
+ assert model.score.original_module.weight.dtype == self.dtype
+
+ adapter_name = "default"
+ is_trainable = False
+ # This should work
+ _ = AutoPeftModelForSequenceClassification.from_pretrained(
+ model_id, adapter_name, is_trainable, torch_dtype=self.dtype
+ )
+
+ def test_peft_token_classification(self):
+ model_id = "peft-internal-testing/tiny_GPT2ForTokenClassification-lora"
+ model = AutoPeftModelForTokenClassification.from_pretrained(model_id)
+ assert isinstance(model, PeftModelForTokenClassification)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname)
+
+ model = AutoPeftModelForTokenClassification.from_pretrained(tmp_dirname)
+ assert isinstance(model, PeftModelForTokenClassification)
+
+ # check if kwargs are passed correctly
+ model = AutoPeftModelForTokenClassification.from_pretrained(model_id, torch_dtype=self.dtype)
+ assert isinstance(model, PeftModelForTokenClassification)
+ assert model.base_model.classifier.original_module.weight.dtype == self.dtype
+
+ adapter_name = "default"
+ is_trainable = False
+ # This should work
+ _ = AutoPeftModelForTokenClassification.from_pretrained(
+ model_id, adapter_name, is_trainable, torch_dtype=self.dtype
+ )
+
+ def test_peft_question_answering(self):
+ model_id = "peft-internal-testing/tiny_OPTForQuestionAnswering-lora"
+ model = AutoPeftModelForQuestionAnswering.from_pretrained(model_id)
+ assert isinstance(model, PeftModelForQuestionAnswering)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname)
+
+ model = AutoPeftModelForQuestionAnswering.from_pretrained(tmp_dirname)
+ assert isinstance(model, PeftModelForQuestionAnswering)
+
+ # check if kwargs are passed correctly
+ model = AutoPeftModelForQuestionAnswering.from_pretrained(model_id, torch_dtype=self.dtype)
+ assert isinstance(model, PeftModelForQuestionAnswering)
+ assert model.base_model.qa_outputs.original_module.weight.dtype == self.dtype
+
+ adapter_name = "default"
+ is_trainable = False
+ # This should work
+ _ = AutoPeftModelForQuestionAnswering.from_pretrained(
+ model_id, adapter_name, is_trainable, torch_dtype=self.dtype
+ )
+
+ def test_peft_feature_extraction(self):
+ model_id = "peft-internal-testing/tiny_OPTForFeatureExtraction-lora"
+ model = AutoPeftModelForFeatureExtraction.from_pretrained(model_id)
+ assert isinstance(model, PeftModelForFeatureExtraction)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname)
+
+ model = AutoPeftModelForFeatureExtraction.from_pretrained(tmp_dirname)
+ assert isinstance(model, PeftModelForFeatureExtraction)
+
+ # check if kwargs are passed correctly
+ model = AutoPeftModelForFeatureExtraction.from_pretrained(model_id, torch_dtype=self.dtype)
+ assert isinstance(model, PeftModelForFeatureExtraction)
+ assert model.base_model.model.decoder.embed_tokens.weight.dtype == self.dtype
+
+ adapter_name = "default"
+ is_trainable = False
+ # This should work
+ _ = AutoPeftModelForFeatureExtraction.from_pretrained(
+ model_id, adapter_name, is_trainable, torch_dtype=self.dtype
+ )
+
+ def test_peft_whisper(self):
+ model_id = "peft-internal-testing/tiny_WhisperForConditionalGeneration-lora"
+ model = AutoPeftModel.from_pretrained(model_id)
+ assert isinstance(model, PeftModel)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname)
+
+ model = AutoPeftModel.from_pretrained(tmp_dirname)
+ assert isinstance(model, PeftModel)
+
+ # check if kwargs are passed correctly
+ model = AutoPeftModel.from_pretrained(model_id, torch_dtype=self.dtype)
+ assert isinstance(model, PeftModel)
+ assert model.base_model.model.model.encoder.embed_positions.weight.dtype == self.dtype
+
+ adapter_name = "default"
+ is_trainable = False
+ # This should work
+ _ = AutoPeftModel.from_pretrained(model_id, adapter_name, is_trainable, torch_dtype=self.dtype)
+
+ def test_embedding_size_not_reduced_if_greater_vocab_size(self, tmp_path):
+ # See 2415
+ # There was a bug in AutoPeftModels where the embedding was always resized to the vocab size of the tokenizer
+ # when the tokenizer was found. This makes sense if the vocabulary was extended, but some models like Qwen
+ # already start out with "spare" embeddings, i.e. the embedding size is larger than the vocab size. This could
+ # result in the embedding being shrunk, which in turn resulted in an error when loading the weights.
+
+ # first create a checkpoint; it is important that the tokenizer is also saved in the same location
+ model_id = "Qwen/Qwen2-0.5B"
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = get_peft_model(model, LoraConfig(modules_to_save=["lm_head", "embed_token"]))
+ model.save_pretrained(tmp_path)
+ tokenizer.save_pretrained(tmp_path)
+
+ # does not raise; without the fix, it raises:
+ # > size mismatch for base_model.model.lm_head.modules_to_save.default.weight: copying a param with shape
+ # torch.Size([151936, 896]) from checkpoint, the shape in current model is torch.Size([151646, 896]).
+ AutoPeftModelForCausalLM.from_pretrained(tmp_path)
diff --git a/peft/tests/test_boft.py b/peft/tests/test_boft.py
new file mode 100644
index 0000000000000000000000000000000000000000..d0cf74e3edea2a5836068afe2b74df3b8ae6a20f
--- /dev/null
+++ b/peft/tests/test_boft.py
@@ -0,0 +1,84 @@
+# Copyright 2024-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import torch
+from safetensors.torch import load_file
+from transformers import AutoModelForCausalLM
+
+from peft import BOFTConfig, PeftModel, get_peft_model
+from peft.utils import infer_device
+
+
+class TestBoft:
+ device = infer_device()
+
+ def test_boft_state_dict(self, tmp_path):
+ # see #2050
+ # ensure that the boft_P buffer is not stored in the checkpoint file and is not necessary to load the model
+ # correctly
+ torch.manual_seed(0)
+
+ inputs = torch.arange(10).view(-1, 1).to(self.device)
+ model_id = "hf-internal-testing/tiny-random-OPTForCausalLM"
+ model = AutoModelForCausalLM.from_pretrained(model_id).to(self.device)
+ model.eval()
+ output_base = model(inputs).logits
+
+ config = BOFTConfig(init_weights=False)
+ model = get_peft_model(model, config)
+ model.eval()
+ output_peft = model(inputs).logits
+
+ atol, rtol = 1e-5, 1e-8
+ # sanity check: loading boft changed the output
+ assert not torch.allclose(output_base, output_peft, atol=atol, rtol=rtol)
+
+ model.save_pretrained(tmp_path)
+ del model
+
+ # check that the boft_P buffer is not present
+ state_dict = load_file(tmp_path / "adapter_model.safetensors")
+ assert not any("boft_P" in key for key in state_dict)
+
+ # sanity check: the model still produces the same output after loading
+ model = AutoModelForCausalLM.from_pretrained(model_id).to(self.device)
+ model = PeftModel.from_pretrained(model, tmp_path)
+ output_loaded = model(inputs).logits
+ assert torch.allclose(output_peft, output_loaded, atol=atol, rtol=rtol)
+
+ def test_boft_old_checkpoint_including_boft_P(self, tmp_path):
+ # see #2050
+ # This test exists to ensure that after the boft_P buffer was made non-persistent, old checkpoints can still be
+ # loaded successfully.
+ torch.manual_seed(0)
+
+ inputs = torch.arange(10).view(-1, 1).to(self.device)
+ model_id = "hf-internal-testing/tiny-random-OPTForCausalLM"
+ model = AutoModelForCausalLM.from_pretrained(model_id).to(self.device)
+
+ # first create the expected output
+ config = BOFTConfig(init_weights=False)
+ model = get_peft_model(model, config)
+ model.eval()
+ output_peft = model(inputs).logits
+ del model
+
+ model = AutoModelForCausalLM.from_pretrained(model_id).to(self.device)
+ # checkpoint from before the PR whose state_dict still contains boft_P
+ hub_id = "peft-internal-testing/boft-tiny-opt-peft-v0.12"
+ model = PeftModel.from_pretrained(model, hub_id)
+ output_old = model(inputs).logits
+
+ atol, rtol = 1e-5, 1e-8
+ assert torch.allclose(output_peft, output_old, atol=atol, rtol=rtol)
diff --git a/peft/tests/test_bufferdict.py b/peft/tests/test_bufferdict.py
new file mode 100644
index 0000000000000000000000000000000000000000..eda25e652b4e3f799113c56c36a66330d5c415cd
--- /dev/null
+++ b/peft/tests/test_bufferdict.py
@@ -0,0 +1,48 @@
+import torch
+
+from peft.tuners._buffer_dict import BufferDict
+
+
+class TestBufferDict:
+ def test_init_from_dict_works(self):
+ bd = BufferDict(
+ {
+ "default": torch.randn(10, 2),
+ }
+ )
+
+ def test_update_from_other_bufferdict(self):
+ default_tensor = torch.randn(10, 2)
+ non_default_tensor = torch.randn(10, 2)
+ bd1 = BufferDict({"default": default_tensor})
+ bd2 = BufferDict({"non_default": non_default_tensor})
+
+ bd1.update(bd2)
+
+ assert set(bd1.keys()) == {"default", "non_default"}
+ assert torch.allclose(bd1["default"], default_tensor)
+ assert torch.allclose(bd1["non_default"], non_default_tensor)
+
+ def test_update_from_dict(self):
+ default_tensor = torch.randn(10, 2)
+ non_default_tensor = torch.randn(10, 2)
+ bd1 = BufferDict({"default": default_tensor})
+ d1 = {"non_default": non_default_tensor}
+
+ bd1.update(d1)
+
+ assert set(bd1.keys()) == {"default", "non_default"}
+ assert torch.allclose(bd1["default"], default_tensor)
+ assert torch.allclose(bd1["non_default"], non_default_tensor)
+
+ def test_update_from_dict_items(self):
+ default_tensor = torch.randn(10, 2)
+ non_default_tensor = torch.randn(10, 2)
+ bd1 = BufferDict({"default": default_tensor})
+ d1 = {"non_default": non_default_tensor}
+
+ bd1.update(d1.items())
+
+ assert set(bd1.keys()) == {"default", "non_default"}
+ assert torch.allclose(bd1["default"], default_tensor)
+ assert torch.allclose(bd1["non_default"], non_default_tensor)
diff --git a/peft/tests/test_common_gpu.py b/peft/tests/test_common_gpu.py
new file mode 100644
index 0000000000000000000000000000000000000000..a7c810aa8acbe9cff9e35e309c12416c80758f53
--- /dev/null
+++ b/peft/tests/test_common_gpu.py
@@ -0,0 +1,1986 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import gc
+import tempfile
+import unittest
+
+import pytest
+import torch
+import torch.nn.functional as F
+from accelerate.utils.memory import clear_device_cache
+from parameterized import parameterized
+from torch import nn
+from transformers import (
+ AutoImageProcessor,
+ AutoModelForCausalLM,
+ AutoModelForImageClassification,
+ AutoModelForSeq2SeqLM,
+ AutoModelForSequenceClassification,
+ AutoModelForTokenClassification,
+ AutoTokenizer,
+ BitsAndBytesConfig,
+ LlamaForCausalLM,
+ WhisperForConditionalGeneration,
+)
+from transformers.pytorch_utils import Conv1D
+
+from peft import (
+ AdaLoraConfig,
+ AdaptionPromptConfig,
+ BOFTConfig,
+ HRAConfig,
+ IA3Config,
+ LNTuningConfig,
+ LoHaConfig,
+ LoKrConfig,
+ LoraConfig,
+ OFTConfig,
+ PeftModel,
+ RandLoraConfig,
+ TaskType,
+ VBLoRAConfig,
+ VeraConfig,
+ get_peft_model,
+ prepare_model_for_kbit_training,
+)
+from peft.import_utils import is_bnb_4bit_available, is_bnb_available, is_xpu_available
+from peft.tuners.lora.config import LoraRuntimeConfig
+from peft.utils import infer_device
+
+from .testing_utils import (
+ device_count,
+ load_cat_image,
+ require_bitsandbytes,
+ require_deterministic_for_xpu,
+ require_non_cpu,
+ require_torch_multi_accelerator,
+)
+
+
+if is_bnb_available():
+ import bitsandbytes as bnb
+
+ from peft.tuners.ia3 import Linear8bitLt as IA3Linear8bitLt
+ from peft.tuners.lora import Linear8bitLt as LoraLinear8bitLt
+ from peft.tuners.randlora import Linear8bitLt as RandLoraLinear8bitLt
+ from peft.tuners.vera import Linear8bitLt as VeraLinear8bitLt
+
+ if is_bnb_4bit_available():
+ from peft.tuners.ia3 import Linear4bit as IA3Linear4bit
+ from peft.tuners.lora import Linear4bit as LoraLinear4bit
+ from peft.tuners.randlora import Linear4bit as RandLoraLinear4bit
+ from peft.tuners.vera import Linear4bit as VeraLinear4bit
+
+
+@require_non_cpu
+class PeftGPUCommonTests(unittest.TestCase):
+ r"""
+ A common tester to run common operations that are performed on GPU such as generation, loading in 8bit, etc.
+ """
+
+ def setUp(self):
+ self.seq2seq_model_id = "google/flan-t5-base"
+ self.causal_lm_model_id = "facebook/opt-350m"
+ self.audio_model_id = "openai/whisper-large"
+ self.device = infer_device()
+
+ def tearDown(self):
+ r"""
+ Efficient mechanism to free GPU memory after each test. Based on
+ https://github.com/huggingface/transformers/issues/21094
+ """
+ clear_device_cache(garbage_collection=True)
+ gc.collect()
+
+ @require_bitsandbytes
+ @pytest.mark.multi_gpu_tests
+ @pytest.mark.single_gpu_tests
+ def test_lora_bnb_8bit_quantization(self):
+ r"""
+ Test that tests if the 8bit quantization using LoRA works as expected
+ """
+ whisper_8bit = WhisperForConditionalGeneration.from_pretrained(
+ self.audio_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+
+ opt_8bit = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+
+ flan_8bit = AutoModelForSeq2SeqLM.from_pretrained(
+ self.seq2seq_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+
+ flan_lora_config = LoraConfig(
+ r=16, lora_alpha=32, target_modules=["q", "v"], lora_dropout=0.05, bias="none", task_type="SEQ_2_SEQ_LM"
+ )
+
+ opt_lora_config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ config = LoraConfig(r=32, lora_alpha=64, target_modules=["q_proj", "v_proj"], lora_dropout=0.05, bias="none")
+
+ flan_8bit = get_peft_model(flan_8bit, flan_lora_config)
+ assert isinstance(flan_8bit.base_model.model.encoder.block[0].layer[0].SelfAttention.q, LoraLinear8bitLt)
+
+ opt_8bit = get_peft_model(opt_8bit, opt_lora_config)
+ assert isinstance(opt_8bit.base_model.model.model.decoder.layers[0].self_attn.v_proj, LoraLinear8bitLt)
+
+ whisper_8bit = get_peft_model(whisper_8bit, config)
+ assert isinstance(whisper_8bit.base_model.model.model.decoder.layers[0].self_attn.v_proj, LoraLinear8bitLt)
+
+ @require_bitsandbytes
+ @pytest.mark.multi_gpu_tests
+ @pytest.mark.single_gpu_tests
+ def test_vera_bnb_8bit_quantization(self):
+ r"""
+ Test that tests if the 8bit quantization using VeRA works as expected
+ """
+ whisper_8bit = WhisperForConditionalGeneration.from_pretrained(
+ self.audio_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+
+ opt_8bit = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+
+ flan_8bit = AutoModelForSeq2SeqLM.from_pretrained(
+ self.seq2seq_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+
+ flan_vera_config = VeraConfig(
+ r=16, target_modules=["q", "v"], vera_dropout=0.05, bias="none", task_type="SEQ_2_SEQ_LM"
+ )
+
+ opt_vera_config = VeraConfig(
+ r=16,
+ target_modules=["q_proj", "v_proj"],
+ vera_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ config = VeraConfig(r=32, target_modules=["q_proj", "v_proj"], vera_dropout=0.05, bias="none")
+
+ flan_8bit = get_peft_model(flan_8bit, flan_vera_config)
+ assert isinstance(flan_8bit.base_model.model.encoder.block[0].layer[0].SelfAttention.q, VeraLinear8bitLt)
+
+ opt_8bit = get_peft_model(opt_8bit, opt_vera_config)
+ assert isinstance(opt_8bit.base_model.model.model.decoder.layers[0].self_attn.v_proj, VeraLinear8bitLt)
+
+ whisper_8bit = get_peft_model(whisper_8bit, config)
+ assert isinstance(whisper_8bit.base_model.model.model.decoder.layers[0].self_attn.v_proj, VeraLinear8bitLt)
+
+ @require_bitsandbytes
+ @pytest.mark.multi_gpu_tests
+ @pytest.mark.single_gpu_tests
+ def test_randlora_bnb_8bit_quantization(self):
+ r"""
+ Test that tests if the 8bit quantization using RandLora works as expected
+ """
+ whisper_8bit = WhisperForConditionalGeneration.from_pretrained(
+ self.audio_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+
+ opt_8bit = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+
+ flan_8bit = AutoModelForSeq2SeqLM.from_pretrained(
+ self.seq2seq_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+
+ flan_randlora_config = RandLoraConfig(
+ r=16, target_modules=["q", "v"], randlora_dropout=0.05, bias="none", task_type="SEQ_2_SEQ_LM"
+ )
+
+ opt_randlora_config = RandLoraConfig(
+ r=10,
+ target_modules=["q_proj", "v_proj"],
+ randlora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ config = RandLoraConfig(r=5, target_modules=["q_proj", "v_proj"], randlora_dropout=0.05, bias="none")
+
+ flan_8bit = get_peft_model(flan_8bit, flan_randlora_config)
+ assert isinstance(flan_8bit.base_model.model.encoder.block[0].layer[0].SelfAttention.q, RandLoraLinear8bitLt)
+
+ opt_8bit = get_peft_model(opt_8bit, opt_randlora_config)
+ assert isinstance(opt_8bit.base_model.model.model.decoder.layers[0].self_attn.v_proj, RandLoraLinear8bitLt)
+
+ whisper_8bit = get_peft_model(whisper_8bit, config)
+ assert isinstance(whisper_8bit.base_model.model.model.decoder.layers[0].self_attn.v_proj, RandLoraLinear8bitLt)
+
+ @require_bitsandbytes
+ @pytest.mark.multi_gpu_tests
+ @pytest.mark.single_gpu_tests
+ def test_ia3_bnb_8bit_quantization(self):
+ r"""
+ Test that tests if the 8bit quantization using IA3 works as expected
+ """
+ whisper_8bit = WhisperForConditionalGeneration.from_pretrained(
+ self.audio_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+
+ opt_8bit = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+
+ flan_8bit = AutoModelForSeq2SeqLM.from_pretrained(
+ self.seq2seq_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+
+ flan_ia3_config = IA3Config(target_modules=["q", "v"], task_type="SEQ_2_SEQ_LM")
+
+ opt_ia3_config = IA3Config(
+ target_modules=["q_proj", "v_proj", "fc2"],
+ feedforward_modules=["fc2"],
+ task_type="CAUSAL_LM",
+ )
+
+ config = IA3Config(target_modules=["q_proj", "v_proj", "fc2"], feedforward_modules=["fc2"])
+
+ flan_8bit = get_peft_model(flan_8bit, flan_ia3_config)
+ assert isinstance(flan_8bit.base_model.model.encoder.block[0].layer[0].SelfAttention.q, IA3Linear8bitLt)
+
+ opt_8bit = get_peft_model(opt_8bit, opt_ia3_config)
+ assert isinstance(opt_8bit.base_model.model.model.decoder.layers[0].self_attn.v_proj, IA3Linear8bitLt)
+
+ whisper_8bit = get_peft_model(whisper_8bit, config)
+ assert isinstance(whisper_8bit.base_model.model.model.decoder.layers[0].self_attn.v_proj, IA3Linear8bitLt)
+
+ @require_bitsandbytes
+ @pytest.mark.multi_gpu_tests
+ @pytest.mark.single_gpu_tests
+ @parameterized.expand(["4bit", "8bit"])
+ def test_lora_bnb_quantization_from_pretrained_safetensors(self, quantization):
+ r"""
+ Tests that the bnb quantization using LoRA works as expected with safetensors weights.
+ """
+ model_id = "facebook/opt-350m"
+ peft_model_id = "ybelkada/test-st-lora"
+ kwargs = {"device_map": "auto"}
+ if quantization == "4bit":
+ kwargs["quantization_config"] = BitsAndBytesConfig(load_in_4bit=True)
+ else:
+ kwargs["quantization_config"] = BitsAndBytesConfig(load_in_8bit=True)
+
+ model = AutoModelForCausalLM.from_pretrained(model_id, **kwargs)
+ model = PeftModel.from_pretrained(model, peft_model_id)
+
+ model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(0))
+
+ # loading a 2nd adapter works, #1239
+ model.load_adapter(peft_model_id, "adapter2")
+ model.set_adapter("adapter2")
+ model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(0))
+
+ # check that both adapters are in the same layer
+ assert "default" in model.base_model.model.model.decoder.layers[0].self_attn.q_proj.lora_A
+ assert "adapter2" in model.base_model.model.model.decoder.layers[0].self_attn.q_proj.lora_A
+
+ @require_bitsandbytes
+ @pytest.mark.multi_gpu_tests
+ @pytest.mark.single_gpu_tests
+ @parameterized.expand(["4bit", "8bit"])
+ def test_adalora_bnb_quantization_from_pretrained_safetensors(self, quantization):
+ r"""
+ Tests that the bnb quantization using AdaLora works as expected with safetensors weights.
+ """
+ model_id = "facebook/opt-350m"
+ kwargs = {"device_map": "auto"}
+ if quantization == "4bit":
+ kwargs["quantization_config"] = BitsAndBytesConfig(load_in_4bit=True)
+ else:
+ kwargs["quantization_config"] = BitsAndBytesConfig(load_in_8bit=True)
+
+ model = AutoModelForCausalLM.from_pretrained(model_id, **kwargs)
+ config = AdaLoraConfig(task_type=TaskType.CAUSAL_LM, total_step=1)
+ peft_model = get_peft_model(model, config)
+ peft_model = prepare_model_for_kbit_training(peft_model)
+ peft_model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(0))
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ peft_model.save_pretrained(tmp_dir)
+ model = AutoModelForCausalLM.from_pretrained(model_id, **kwargs)
+ model = PeftModel.from_pretrained(model, tmp_dir)
+ model = prepare_model_for_kbit_training(peft_model)
+ model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(0))
+
+ # loading a 2nd adapter works, #1239
+ model.load_adapter(tmp_dir, "adapter2")
+ model.set_adapter("adapter2")
+ model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(0))
+
+ # check that both adapters are in the same layer
+ assert "default" in model.base_model.model.model.decoder.layers[0].self_attn.q_proj.lora_A
+ assert "adapter2" in model.base_model.model.model.decoder.layers[0].self_attn.q_proj.lora_A
+
+ @require_bitsandbytes
+ @pytest.mark.multi_gpu_tests
+ @pytest.mark.single_gpu_tests
+ @parameterized.expand(["4bit", "8bit"])
+ def test_vera_bnb_quantization_from_pretrained_safetensors(self, quantization):
+ r"""
+ Tests that the bnb quantization using VeRA works as expected with safetensors weights.
+ """
+ model_id = "facebook/opt-350m"
+ kwargs = {"device_map": "auto"}
+ if quantization == "4bit":
+ kwargs["quantization_config"] = BitsAndBytesConfig(load_in_4bit=True)
+ else:
+ kwargs["quantization_config"] = BitsAndBytesConfig(load_in_8bit=True)
+
+ model = AutoModelForCausalLM.from_pretrained(model_id, **kwargs)
+ config = VeraConfig(task_type=TaskType.CAUSAL_LM)
+ peft_model = get_peft_model(model, config)
+ peft_model = prepare_model_for_kbit_training(peft_model)
+ peft_model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(0))
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ peft_model.save_pretrained(tmp_dir)
+ model = AutoModelForCausalLM.from_pretrained(model_id, **kwargs)
+ model = PeftModel.from_pretrained(model, tmp_dir)
+ model = prepare_model_for_kbit_training(model)
+ model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(0))
+
+ # loading a 2nd adapter works, #1239
+ model.load_adapter(tmp_dir, "adapter2")
+ model.set_adapter("adapter2")
+ model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(0))
+
+ # check that both adapters are in the same layer
+ assert "default" in model.base_model.model.model.decoder.layers[0].self_attn.q_proj.vera_A
+ assert "adapter2" in model.base_model.model.model.decoder.layers[0].self_attn.q_proj.vera_A
+
+ @require_bitsandbytes
+ @pytest.mark.multi_gpu_tests
+ @pytest.mark.single_gpu_tests
+ @parameterized.expand(["4bit", "8bit"])
+ def test_randlora_bnb_quantization_from_pretrained_safetensors(self, quantization):
+ r"""
+ Tests that the bnb quantization using RandLora works as expected with safetensors weights.
+ """
+ model_id = "facebook/opt-350m"
+ kwargs = {"device_map": "auto"}
+ if quantization == "4bit":
+ kwargs["quantization_config"] = BitsAndBytesConfig(load_in_4bit=True)
+ else:
+ kwargs["quantization_config"] = BitsAndBytesConfig(load_in_8bit=True)
+
+ model = AutoModelForCausalLM.from_pretrained(model_id, **kwargs)
+ config = RandLoraConfig(task_type=TaskType.CAUSAL_LM)
+ peft_model = get_peft_model(model, config)
+ peft_model = prepare_model_for_kbit_training(peft_model)
+ peft_model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(0))
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ peft_model.save_pretrained(tmp_dir)
+ model = AutoModelForCausalLM.from_pretrained(model_id, **kwargs)
+ model = PeftModel.from_pretrained(model, tmp_dir)
+ model = prepare_model_for_kbit_training(model)
+ model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(0))
+
+ # loading a 2nd adapter works, #1239
+ model.load_adapter(tmp_dir, "adapter2")
+ model.set_adapter("adapter2")
+ model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(0))
+
+ # check that both adapters are in the same layer
+ assert "default" in model.base_model.model.model.decoder.layers[0].self_attn.q_proj.randlora_A
+ assert "adapter2" in model.base_model.model.model.decoder.layers[0].self_attn.q_proj.randlora_A
+
+ @require_bitsandbytes
+ @pytest.mark.multi_gpu_tests
+ @pytest.mark.single_gpu_tests
+ @parameterized.expand(["4bit", "8bit"])
+ def test_ia3_bnb_quantization_from_pretrained_safetensors(self, quantization):
+ r"""
+ Tests that the bnb quantization using IA³ works as expected with safetensors weights.
+ """
+ model_id = "facebook/opt-350m"
+ kwargs = {"device_map": "auto"}
+ if quantization == "4bit":
+ kwargs["quantization_config"] = BitsAndBytesConfig(load_in_4bit=True)
+ else:
+ kwargs["quantization_config"] = BitsAndBytesConfig(load_in_8bit=True)
+
+ model = AutoModelForCausalLM.from_pretrained(model_id, **kwargs)
+ config = IA3Config(task_type=TaskType.CAUSAL_LM)
+ peft_model = get_peft_model(model, config)
+ peft_model = prepare_model_for_kbit_training(peft_model)
+ peft_model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(0))
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ peft_model.save_pretrained(tmp_dir)
+ model = AutoModelForCausalLM.from_pretrained(model_id, **kwargs)
+ model = PeftModel.from_pretrained(model, tmp_dir)
+ model = prepare_model_for_kbit_training(model)
+ model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(0))
+
+ # loading a 2nd adapter works, #1239
+ model.load_adapter(tmp_dir, "adapter2")
+ model.set_adapter("adapter2")
+ model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(0))
+
+ # check that both adapters are in the same layer
+ assert "default" in model.base_model.model.model.decoder.layers[0].self_attn.q_proj.ia3_l
+ assert "adapter2" in model.base_model.model.model.decoder.layers[0].self_attn.q_proj.ia3_l
+
+ @pytest.mark.single_gpu_tests
+ def test_lora_gptq_quantization_from_pretrained_safetensors(self):
+ r"""
+ Tests that the autogptq quantization using LoRA works as expected with safetensors weights.
+ """
+ from transformers import GPTQConfig
+
+ model_id = "marcsun13/opt-350m-gptq-4bit"
+ quantization_config = GPTQConfig(bits=4, use_exllama=False)
+ kwargs = {
+ "pretrained_model_name_or_path": model_id,
+ "torch_dtype": torch.float16,
+ "device_map": "auto",
+ "quantization_config": quantization_config,
+ }
+ model = AutoModelForCausalLM.from_pretrained(**kwargs)
+ model = prepare_model_for_kbit_training(model)
+
+ config = LoraConfig(task_type="CAUSAL_LM")
+ peft_model = get_peft_model(model, config)
+ peft_model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(peft_model.device))
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ peft_model.save_pretrained(tmp_dir)
+ model = AutoModelForCausalLM.from_pretrained(**kwargs)
+ model = PeftModel.from_pretrained(model, tmp_dir)
+ model = prepare_model_for_kbit_training(model)
+ model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(peft_model.device))
+
+ # loading a 2nd adapter works, #1239
+ model.load_adapter(tmp_dir, "adapter2")
+ model.set_adapter("adapter2")
+ model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(peft_model.device))
+
+ # check that both adapters are in the same layer
+ assert "default" in model.base_model.model.model.decoder.layers[0].self_attn.q_proj.lora_A
+ assert "adapter2" in model.base_model.model.model.decoder.layers[0].self_attn.q_proj.lora_A
+
+ @require_bitsandbytes
+ @pytest.mark.multi_gpu_tests
+ @pytest.mark.single_gpu_tests
+ def test_lora_bnb_4bit_quantization(self):
+ r"""
+ Test that tests if the 4bit quantization using LoRA works as expected
+ """
+ whisper_4bit = WhisperForConditionalGeneration.from_pretrained(
+ self.audio_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+
+ opt_4bit = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+
+ flan_4bit = AutoModelForSeq2SeqLM.from_pretrained(
+ self.seq2seq_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+
+ flan_lora_config = LoraConfig(
+ r=16, lora_alpha=32, target_modules=["q", "v"], lora_dropout=0.05, bias="none", task_type="SEQ_2_SEQ_LM"
+ )
+
+ opt_lora_config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ config = LoraConfig(r=32, lora_alpha=64, target_modules=["q_proj", "v_proj"], lora_dropout=0.05, bias="none")
+
+ flan_4bit = get_peft_model(flan_4bit, flan_lora_config)
+ assert isinstance(flan_4bit.base_model.model.encoder.block[0].layer[0].SelfAttention.q, LoraLinear4bit)
+
+ opt_4bit = get_peft_model(opt_4bit, opt_lora_config)
+ assert isinstance(opt_4bit.base_model.model.model.decoder.layers[0].self_attn.v_proj, LoraLinear4bit)
+
+ whisper_4bit = get_peft_model(whisper_4bit, config)
+ assert isinstance(whisper_4bit.base_model.model.model.decoder.layers[0].self_attn.v_proj, LoraLinear4bit)
+
+ @require_bitsandbytes
+ @pytest.mark.multi_gpu_tests
+ @pytest.mark.single_gpu_tests
+ def test_vera_bnb_4bit_quantization(self):
+ r"""
+ Test that tests if the 4bit quantization using VeRA works as expected
+ """
+ whisper_4bit = WhisperForConditionalGeneration.from_pretrained(
+ self.audio_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+
+ opt_4bit = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+
+ flan_4bit = AutoModelForSeq2SeqLM.from_pretrained(
+ self.seq2seq_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+
+ flan_vera_config = VeraConfig(
+ r=16, target_modules=["q", "v"], vera_dropout=0.05, bias="none", task_type="SEQ_2_SEQ_LM"
+ )
+
+ opt_vera_config = VeraConfig(
+ r=16,
+ target_modules=["q_proj", "v_proj"],
+ vera_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ config = VeraConfig(r=32, target_modules=["q_proj", "v_proj"], vera_dropout=0.05, bias="none")
+
+ flan_4bit = get_peft_model(flan_4bit, flan_vera_config)
+ assert isinstance(flan_4bit.base_model.model.encoder.block[0].layer[0].SelfAttention.q, VeraLinear4bit)
+
+ opt_4bit = get_peft_model(opt_4bit, opt_vera_config)
+ assert isinstance(opt_4bit.base_model.model.model.decoder.layers[0].self_attn.v_proj, VeraLinear4bit)
+
+ whisper_4bit = get_peft_model(whisper_4bit, config)
+ assert isinstance(whisper_4bit.base_model.model.model.decoder.layers[0].self_attn.v_proj, VeraLinear4bit)
+
+ @require_bitsandbytes
+ @pytest.mark.multi_gpu_tests
+ @pytest.mark.single_gpu_tests
+ def test_randlora_bnb_4bit_quantization(self):
+ r"""
+ Test that tests if the 4bit quantization using RandLoRA works as expected
+ """
+ whisper_4bit = WhisperForConditionalGeneration.from_pretrained(
+ self.audio_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+
+ opt_4bit = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+
+ flan_4bit = AutoModelForSeq2SeqLM.from_pretrained(
+ self.seq2seq_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+
+ flan_randlora_config = RandLoraConfig(
+ r=16, target_modules=["q", "v"], randlora_dropout=0.05, bias="none", task_type="SEQ_2_SEQ_LM"
+ )
+
+ opt_randlora_config = RandLoraConfig(
+ r=16,
+ target_modules=["q_proj", "v_proj"],
+ randlora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ config = RandLoraConfig(r=32, target_modules=["q_proj", "v_proj"], randlora_dropout=0.05, bias="none")
+
+ flan_4bit = get_peft_model(flan_4bit, flan_randlora_config)
+ assert isinstance(flan_4bit.base_model.model.encoder.block[0].layer[0].SelfAttention.q, RandLoraLinear4bit)
+
+ opt_4bit = get_peft_model(opt_4bit, opt_randlora_config)
+ assert isinstance(opt_4bit.base_model.model.model.decoder.layers[0].self_attn.v_proj, RandLoraLinear4bit)
+
+ whisper_4bit = get_peft_model(whisper_4bit, config)
+ assert isinstance(whisper_4bit.base_model.model.model.decoder.layers[0].self_attn.v_proj, RandLoraLinear4bit)
+
+ @require_bitsandbytes
+ @pytest.mark.multi_gpu_tests
+ @pytest.mark.single_gpu_tests
+ def test_ia3_bnb_4bit_quantization(self):
+ r"""
+ Test that tests if the 4bit quantization using IA3 works as expected
+ """
+ whisper_4bit = WhisperForConditionalGeneration.from_pretrained(
+ self.audio_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+
+ opt_4bit = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+
+ flan_4bit = AutoModelForSeq2SeqLM.from_pretrained(
+ self.seq2seq_model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+
+ flan_ia3_config = IA3Config(target_modules=["q", "v"], task_type="SEQ_2_SEQ_LM")
+
+ opt_ia3_config = IA3Config(
+ target_modules=["q_proj", "v_proj", "fc2"],
+ feedforward_modules=["fc2"],
+ task_type="CAUSAL_LM",
+ )
+
+ config = IA3Config(target_modules=["q_proj", "v_proj", "fc2"], feedforward_modules=["fc2"])
+
+ flan_4bit = get_peft_model(flan_4bit, flan_ia3_config)
+ assert isinstance(flan_4bit.base_model.model.encoder.block[0].layer[0].SelfAttention.q, IA3Linear4bit)
+
+ opt_4bit = get_peft_model(opt_4bit, opt_ia3_config)
+ assert isinstance(opt_4bit.base_model.model.model.decoder.layers[0].self_attn.v_proj, IA3Linear4bit)
+
+ whisper_4bit = get_peft_model(whisper_4bit, config)
+ assert isinstance(whisper_4bit.base_model.model.model.decoder.layers[0].self_attn.v_proj, IA3Linear4bit)
+
+ @pytest.mark.multi_gpu_tests
+ @require_torch_multi_accelerator
+ def test_lora_causal_lm_multi_gpu_inference(self):
+ r"""
+ Test if LORA can be used for inference on multiple GPUs.
+ """
+ lora_config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = AutoModelForCausalLM.from_pretrained(self.causal_lm_model_id, device_map="balanced")
+ tokenizer = AutoTokenizer.from_pretrained(self.seq2seq_model_id)
+
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+
+ model = get_peft_model(model, lora_config)
+ assert isinstance(model, PeftModel)
+
+ dummy_input = "This is a dummy input:"
+ input_ids = tokenizer(dummy_input, return_tensors="pt").input_ids.to(self.device)
+
+ # this should work without any problem
+ _ = model.generate(input_ids=input_ids)
+
+ @require_torch_multi_accelerator
+ @pytest.mark.multi_gpu_tests
+ @require_bitsandbytes
+ def test_lora_seq2seq_lm_multi_gpu_inference(self):
+ r"""
+ Test if LORA can be used for inference on multiple GPUs - 8bit version.
+ """
+ lora_config = LoraConfig(
+ r=16, lora_alpha=32, target_modules=["q", "v"], lora_dropout=0.05, bias="none", task_type="SEQ_2_SEQ_LM"
+ )
+
+ model = AutoModelForSeq2SeqLM.from_pretrained(
+ self.seq2seq_model_id, device_map="balanced", quantization_config=BitsAndBytesConfig(load_in_8bit=True)
+ )
+ tokenizer = AutoTokenizer.from_pretrained(self.seq2seq_model_id)
+
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+
+ model = get_peft_model(model, lora_config)
+ assert isinstance(model, PeftModel)
+ assert isinstance(model.base_model.model.encoder.block[0].layer[0].SelfAttention.q, LoraLinear8bitLt)
+
+ dummy_input = "This is a dummy input:"
+ input_ids = tokenizer(dummy_input, return_tensors="pt").input_ids.to(self.device)
+
+ # this should work without any problem
+ _ = model.generate(input_ids=input_ids)
+
+ @require_torch_multi_accelerator
+ @pytest.mark.multi_gpu_tests
+ @require_bitsandbytes
+ def test_adaption_prompt_8bit(self):
+ model = LlamaForCausalLM.from_pretrained(
+ "trl-internal-testing/tiny-random-LlamaForCausalLM",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ torch_dtype=torch.float16,
+ device_map="auto",
+ )
+
+ model = prepare_model_for_kbit_training(model)
+
+ config = AdaptionPromptConfig(
+ adapter_len=10,
+ adapter_layers=2,
+ task_type="CAUSAL_LM",
+ )
+ model = get_peft_model(model, config)
+
+ random_input = torch.LongTensor([[1, 0, 1, 0, 1, 0]]).to(model.device)
+ _ = model(random_input)
+
+ @require_torch_multi_accelerator
+ @pytest.mark.multi_gpu_tests
+ @require_bitsandbytes
+ def test_adaption_prompt_4bit(self):
+ model = LlamaForCausalLM.from_pretrained(
+ "trl-internal-testing/tiny-random-LlamaForCausalLM",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ torch_dtype=torch.float16,
+ device_map="auto",
+ )
+
+ model = prepare_model_for_kbit_training(model)
+
+ config = AdaptionPromptConfig(
+ adapter_len=10,
+ adapter_layers=2,
+ task_type="CAUSAL_LM",
+ )
+ model = get_peft_model(model, config)
+
+ random_input = torch.LongTensor([[1, 0, 1, 0, 1, 0]]).to(model.device)
+ _ = model(random_input)
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ @require_bitsandbytes
+ def test_print_4bit_expected(self):
+ EXPECTED_TRAINABLE_PARAMS = 294912
+ EXPECTED_ALL_PARAMS = 125534208
+
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+
+ config = LoraConfig(
+ r=8,
+ )
+ model = get_peft_model(model, config)
+ trainable_params, all_params = model.get_nb_trainable_parameters()
+
+ assert trainable_params == EXPECTED_TRAINABLE_PARAMS
+ assert all_params == EXPECTED_ALL_PARAMS
+
+ # test with double quant
+ bnb_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_use_double_quant=True,
+ )
+
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ quantization_config=bnb_config,
+ )
+
+ config = LoraConfig(
+ r=8,
+ )
+ model = get_peft_model(model, config)
+ trainable_params, all_params = model.get_nb_trainable_parameters()
+
+ assert trainable_params == EXPECTED_TRAINABLE_PARAMS
+ assert all_params == EXPECTED_ALL_PARAMS
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ @require_bitsandbytes
+ def test_modules_to_save_grad(self):
+ model_id = "bigscience/bloomz-560m"
+
+ model = AutoModelForSequenceClassification.from_pretrained(
+ model_id,
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ torch_dtype=torch.float32,
+ )
+
+ model = prepare_model_for_kbit_training(model)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=16,
+ lora_dropout=0.05,
+ bias="none",
+ task_type="SEQ_CLS",
+ )
+
+ peft_model = get_peft_model(model, config)
+
+ lm_head = peft_model.base_model.model.score
+ original_module = lm_head.original_module
+ modules_to_save = lm_head.modules_to_save.default
+
+ inputs = torch.randn(1024).to(model.device)
+ o1 = lm_head(inputs)
+ o1.mean().backward()
+
+ assert modules_to_save.weight.requires_grad is True
+ assert original_module.weight.grad is None
+ assert modules_to_save.weight.grad is not None
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ @require_bitsandbytes
+ def test_8bit_merge_lora(self):
+ torch.manual_seed(1000)
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+ random_input = torch.LongTensor([[1, 0, 1, 0, 1, 0]]).to(model.device)
+ out_base = F.softmax(model(random_input).logits, dim=-1)
+
+ config = LoraConfig(
+ r=8,
+ init_lora_weights=False,
+ )
+ model = get_peft_model(model, config)
+
+ with torch.inference_mode():
+ out_before_merge = F.softmax(model(random_input).logits, dim=-1)
+
+ model.merge_and_unload()
+ with torch.inference_mode():
+ out_after_merge = F.softmax(model(random_input).logits, dim=-1)
+
+ atol = 1e-3
+ rtol = 1
+ assert not torch.allclose(out_base, out_before_merge, atol=atol, rtol=rtol)
+ assert torch.allclose(out_before_merge, out_after_merge, atol=atol, rtol=rtol)
+ assert isinstance(model, PeftModel)
+ assert isinstance(model.base_model.model.model.decoder.layers[0].self_attn.q_proj, bnb.nn.Linear8bitLt)
+ assert isinstance(model.base_model.model.model.decoder.layers[0].self_attn.v_proj, bnb.nn.Linear8bitLt)
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ @require_bitsandbytes
+ def test_8bit_merge_and_disable_lora(self):
+ torch.manual_seed(1000)
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+ random_input = torch.LongTensor([[1, 0, 1, 0, 1, 0]]).to(model.device)
+ # compare outputs in probability space, because logits can have outliers
+ # and token ids are not precise enough
+ out_base = F.softmax(model(random_input).logits, dim=-1)
+
+ config = LoraConfig(
+ r=8,
+ init_lora_weights=False,
+ )
+ model = get_peft_model(model, config)
+
+ with torch.inference_mode():
+ out_before = F.softmax(model(random_input).logits, dim=-1)
+
+ model.merge_adapter()
+ with model.disable_adapter():
+ with torch.inference_mode():
+ out_after = F.softmax(model(random_input).logits, dim=-1)
+
+ atol = 1e-3
+ rtol = 1
+ assert not torch.allclose(out_base, out_before, atol=atol, rtol=rtol)
+ assert torch.allclose(out_base, out_after, atol=atol, rtol=rtol)
+ assert isinstance(model, PeftModel)
+ assert isinstance(model.base_model.model.model.decoder.layers[0].self_attn.q_proj, LoraLinear8bitLt)
+ assert isinstance(model.base_model.model.model.decoder.layers[0].self_attn.v_proj, LoraLinear8bitLt)
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ @require_bitsandbytes
+ def test_8bit_merge_lora_with_bias(self):
+ # same as test_8bit_merge_lora but with lora_bias=True
+ torch.manual_seed(1000)
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+ random_input = torch.LongTensor([[1, 0, 1, 0, 1, 0]]).to(model.device)
+ out_base = F.softmax(model(random_input).logits, dim=-1)
+
+ config = LoraConfig(
+ r=8,
+ init_lora_weights=False,
+ lora_bias=True,
+ )
+ model = get_peft_model(model, config)
+
+ with torch.inference_mode():
+ out_before_merge = F.softmax(model(random_input).logits, dim=-1)
+
+ model.merge_and_unload()
+ with torch.inference_mode():
+ out_after_merge = F.softmax(model(random_input).logits, dim=-1)
+
+ atol = 1e-3
+ rtol = 1
+ assert not torch.allclose(out_base, out_before_merge, atol=atol, rtol=rtol)
+ assert torch.allclose(out_before_merge, out_after_merge, atol=atol, rtol=rtol)
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ @require_bitsandbytes
+ def test_4bit_merge_lora(self):
+ torch.manual_seed(3000)
+ bnb_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_use_double_quant=False,
+ bnb_4bit_compute_dtype=torch.float32,
+ )
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ quantization_config=bnb_config,
+ torch_dtype=torch.float32,
+ )
+ random_input = torch.LongTensor([[1, 0, 1, 0, 1, 0]]).to(model.device)
+ # compare outputs in probability space, because logits can have outliers
+ # and token ids are not precise enough
+ out_base = F.softmax(model(random_input).logits, dim=-1)
+
+ config = LoraConfig(
+ r=8,
+ init_lora_weights=False,
+ )
+ model = get_peft_model(model, config)
+
+ with torch.inference_mode():
+ out_before_merge = F.softmax(model(random_input).logits, dim=-1)
+
+ model.merge_and_unload()
+ with torch.inference_mode():
+ out_after_merge = F.softmax(model(random_input).logits, dim=-1)
+
+ # tolerances are pretty high because some deviations are expected with quantization
+ atol = 0.01
+ rtol = 10
+ assert not torch.allclose(out_base, out_before_merge, atol=atol, rtol=rtol)
+ assert torch.allclose(out_before_merge, out_after_merge, atol=atol, rtol=rtol)
+ assert isinstance(model, PeftModel)
+ assert isinstance(model.base_model.model.model.decoder.layers[0].self_attn.q_proj, bnb.nn.Linear4bit)
+ assert isinstance(model.base_model.model.model.decoder.layers[0].self_attn.v_proj, bnb.nn.Linear4bit)
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ @require_bitsandbytes
+ def test_4bit_merge_and_disable_lora(self):
+ torch.manual_seed(3000)
+ bnb_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_use_double_quant=False,
+ bnb_4bit_compute_dtype=torch.float32,
+ )
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ quantization_config=bnb_config,
+ torch_dtype=torch.float32,
+ )
+ random_input = torch.LongTensor([[1, 0, 1, 0, 1, 0]]).to(model.device)
+ # compare outputs in probability space, because logits can have outliers
+ # and token ids are not precise enough
+ out_base = F.softmax(model(random_input).logits, dim=-1)
+
+ config = LoraConfig(
+ r=8,
+ init_lora_weights=False,
+ )
+ model = get_peft_model(model, config)
+
+ with torch.inference_mode():
+ out_before = F.softmax(model(random_input).logits, dim=-1)
+
+ model.merge_adapter()
+ with model.disable_adapter():
+ with torch.inference_mode():
+ out_after = F.softmax(model(random_input).logits, dim=-1)
+
+ atol = 0.01
+ rtol = 10
+ assert not torch.allclose(out_base, out_before, atol=atol, rtol=rtol)
+ assert torch.allclose(out_base, out_after, atol=atol, rtol=rtol)
+ assert isinstance(model, PeftModel)
+ assert isinstance(model.base_model.model.model.decoder.layers[0].self_attn.q_proj, LoraLinear4bit)
+ assert isinstance(model.base_model.model.model.decoder.layers[0].self_attn.v_proj, LoraLinear4bit)
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ @require_bitsandbytes
+ def test_4bit_merge_lora_with_bias(self):
+ # same as test_4bit_merge_lora but with lora_bias=True
+ torch.manual_seed(3000)
+ bnb_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_use_double_quant=False,
+ bnb_4bit_compute_dtype=torch.float32,
+ )
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ quantization_config=bnb_config,
+ torch_dtype=torch.float32,
+ )
+ random_input = torch.LongTensor([[1, 0, 1, 0, 1, 0]]).to(model.device)
+ # compare outputs in probability space, because logits can have outliers
+ # and token ids are not precise enough
+ out_base = F.softmax(model(random_input).logits, dim=-1)
+
+ config = LoraConfig(
+ r=8,
+ init_lora_weights=False,
+ lora_bias=True,
+ )
+ model = get_peft_model(model, config)
+
+ with torch.inference_mode():
+ out_before_merge = F.softmax(model(random_input).logits, dim=-1)
+
+ model.merge_and_unload()
+ with torch.inference_mode():
+ out_after_merge = F.softmax(model(random_input).logits, dim=-1)
+
+ # tolerances are pretty high because some deviations are expected with quantization
+ atol = 0.01
+ rtol = 10
+ assert not torch.allclose(out_base, out_before_merge, atol=atol, rtol=rtol)
+ assert torch.allclose(out_before_merge, out_after_merge, atol=atol, rtol=rtol)
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ @require_bitsandbytes
+ def test_4bit_lora_mixed_adapter_batches_lora(self):
+ # check that we can pass mixed adapter names to the model
+ torch.manual_seed(3000)
+ bnb_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_use_double_quant=False,
+ bnb_4bit_compute_dtype=torch.float32,
+ )
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ quantization_config=bnb_config,
+ torch_dtype=torch.float32,
+ ).eval()
+ tokenizer = AutoTokenizer.from_pretrained("facebook/opt-125m")
+ # input with 9 samples
+ inputs = tokenizer(
+ [
+ "Hello, my dog is cute",
+ "Hello, my cat is awesome",
+ "Hello, my fish is great",
+ "Salut, mon chien est mignon",
+ "Salut, mon chat est génial",
+ "Salut, mon poisson est super",
+ "Hallo, mein Hund ist süß",
+ "Hallo, meine Katze ist toll",
+ "Hallo, mein Fisch ist großartig",
+ ],
+ return_tensors="pt",
+ padding=True,
+ ).to(model.device)
+ with torch.inference_mode():
+ out_base = model(**inputs).logits
+
+ config0 = LoraConfig(
+ r=8,
+ init_lora_weights=False,
+ )
+ model = get_peft_model(model, config0).eval()
+ with torch.inference_mode():
+ out_adapter0 = model(**inputs).logits
+
+ config1 = LoraConfig(
+ r=16,
+ init_lora_weights=False,
+ )
+ model.add_adapter("adapter1", config1)
+ model.set_adapter("adapter1")
+ with torch.inference_mode():
+ out_adapter1 = model(**inputs).logits
+
+ atol, rtol = 3e-5, 1e-5
+ # sanity check, outputs have the right shape and are not the same
+ assert len(out_base) >= 3
+ assert len(out_base) == len(out_adapter0) == len(out_adapter1)
+ assert not torch.allclose(out_base, out_adapter0, atol=atol, rtol=rtol)
+ assert not torch.allclose(out_base, out_adapter1, atol=atol, rtol=rtol)
+ assert not torch.allclose(out_adapter0, out_adapter1, atol=atol, rtol=rtol)
+
+ # mixed adapter batch
+ adapters = ["__base__", "default", "adapter1"]
+ adapter_names = [adapters[i % 3] for i in (range(9))]
+ with torch.inference_mode():
+ out_mixed = model(**inputs, adapter_names=adapter_names).logits
+
+ assert torch.allclose(out_base[::3], out_mixed[::3], atol=atol, rtol=rtol)
+ assert torch.allclose(out_adapter0[1::3], out_mixed[1::3], atol=atol, rtol=rtol)
+ assert torch.allclose(out_adapter1[2::3], out_mixed[2::3], atol=atol, rtol=rtol)
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ @require_bitsandbytes
+ def test_8bit_lora_mixed_adapter_batches_lora(self):
+ # check that we can pass mixed adapter names to the model
+ # note that with 8bit, we have quite a bit of imprecision, therefore we use softmax and higher tolerances
+ torch.manual_seed(3000)
+ bnb_config = BitsAndBytesConfig(load_in_8bit=True)
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ quantization_config=bnb_config,
+ torch_dtype=torch.float32,
+ ).eval()
+ tokenizer = AutoTokenizer.from_pretrained("facebook/opt-125m")
+ # input with 9 samples
+ inputs = tokenizer(
+ [
+ "Hello, my dog is cute",
+ "Hello, my cat is awesome",
+ "Hello, my fish is great",
+ "Salut, mon chien est mignon",
+ "Salut, mon chat est génial",
+ "Salut, mon poisson est super",
+ "Hallo, mein Hund ist süß",
+ "Hallo, meine Katze ist toll",
+ "Hallo, mein Fisch ist großartig",
+ ],
+ return_tensors="pt",
+ padding=True,
+ ).to(model.device)
+ with torch.inference_mode():
+ out_base = F.softmax(model(**inputs).logits, dim=-1)
+
+ config0 = LoraConfig(
+ r=8,
+ init_lora_weights=False,
+ )
+ model = get_peft_model(model, config0).eval()
+ with torch.inference_mode():
+ out_adapter0 = F.softmax(model(**inputs).logits, dim=-1)
+
+ config1 = LoraConfig(
+ r=16,
+ init_lora_weights=False,
+ )
+ model.add_adapter("adapter1", config1)
+ model.set_adapter("adapter1")
+ with torch.inference_mode():
+ out_adapter1 = F.softmax(model(**inputs).logits, dim=-1)
+
+ atol = 0.01
+ rtol = 0.5
+ # sanity check, outputs have the right shape and are not the same
+ assert len(out_base) >= 3
+ assert len(out_base) == len(out_adapter0) == len(out_adapter1)
+ assert not torch.allclose(out_base, out_adapter0, atol=atol, rtol=rtol)
+ assert not torch.allclose(out_base, out_adapter1, atol=atol, rtol=rtol)
+ assert not torch.allclose(out_adapter0, out_adapter1, atol=atol, rtol=rtol)
+
+ # mixed adapter batch
+ adapters = ["__base__", "default", "adapter1"]
+ adapter_names = [adapters[i % 3] for i in (range(9))]
+ with torch.inference_mode():
+ out_mixed = F.softmax(model(**inputs, adapter_names=adapter_names).logits, dim=-1)
+
+ assert torch.allclose(out_base[::3], out_mixed[::3], atol=atol, rtol=rtol)
+ assert torch.allclose(out_adapter0[1::3], out_mixed[1::3], atol=atol, rtol=rtol)
+ assert torch.allclose(out_adapter1[2::3], out_mixed[2::3], atol=atol, rtol=rtol)
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ def test_serialization_shared_tensors(self):
+ model_checkpoint = "roberta-base"
+ peft_config = LoraConfig(
+ task_type=TaskType.TOKEN_CLS, inference_mode=False, r=16, lora_alpha=16, lora_dropout=0.1, bias="all"
+ )
+ model = AutoModelForTokenClassification.from_pretrained(model_checkpoint, num_labels=11).to(self.device)
+ model = get_peft_model(model, peft_config)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir, safe_serialization=True)
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ @require_deterministic_for_xpu
+ @require_bitsandbytes
+ def test_4bit_dora_inference(self):
+ # check for same result with and without DoRA when initializing with init_lora_weights=False
+ bnb_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_use_double_quant=False,
+ bnb_4bit_compute_dtype=torch.float32,
+ )
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ quantization_config=bnb_config,
+ torch_dtype=torch.float32,
+ )
+
+ torch.manual_seed(0)
+ config_lora = LoraConfig(r=8, init_lora_weights=False, use_dora=False)
+ model = get_peft_model(model, config_lora).eval()
+
+ random_input = torch.LongTensor([[1, 0, 1, 0, 1, 0]]).to(model.device)
+ logits_lora = model(random_input).logits
+
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ quantization_config=bnb_config,
+ torch_dtype=torch.float32,
+ )
+ torch.manual_seed(0)
+ config_dora = LoraConfig(r=8, init_lora_weights=False, use_dora=True)
+ model = get_peft_model(model, config_dora).eval()
+
+ logits_dora = model(random_input).logits
+
+ assert torch.allclose(logits_lora, logits_dora)
+ # sanity check
+ assert isinstance(model.base_model.model.model.decoder.layers[0].self_attn.q_proj, LoraLinear4bit)
+ assert isinstance(model.base_model.model.model.decoder.layers[0].self_attn.v_proj, LoraLinear4bit)
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ @require_deterministic_for_xpu
+ @require_bitsandbytes
+ def test_8bit_dora_inference(self):
+ # check for same result with and without DoRA when initializing with init_lora_weights=False
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ torch_dtype=torch.float32,
+ ).eval()
+
+ torch.manual_seed(0)
+ config_lora = LoraConfig(r=8, init_lora_weights=False, use_dora=False)
+ model = get_peft_model(model, config_lora).eval()
+
+ random_input = torch.LongTensor([[1, 0, 1, 0, 1, 0]]).to(model.device)
+ logits_lora = model(random_input).logits
+
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ torch_dtype=torch.float32,
+ )
+ torch.manual_seed(0)
+ config_dora = LoraConfig(r=8, init_lora_weights=False, use_dora=True)
+ model = get_peft_model(model, config_dora).eval()
+
+ logits_dora = model(random_input).logits
+
+ assert torch.allclose(logits_lora, logits_dora)
+ # sanity check
+ assert isinstance(model.base_model.model.model.decoder.layers[0].self_attn.q_proj, LoraLinear8bitLt)
+ assert isinstance(model.base_model.model.model.decoder.layers[0].self_attn.v_proj, LoraLinear8bitLt)
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ @require_bitsandbytes
+ def test_4bit_dora_merging(self):
+ # Check results for merging, unmerging, unloading
+ torch.manual_seed(0)
+ bnb_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_use_double_quant=False,
+ bnb_4bit_compute_dtype=torch.float32,
+ )
+ model = AutoModelForCausalLM.from_pretrained(
+ "trl-internal-testing/tiny-random-LlamaForCausalLM",
+ quantization_config=bnb_config,
+ torch_dtype=torch.float32,
+ ).eval()
+ random_input = torch.LongTensor([[1, 0, 1, 0, 1, 0]]).to(model.device)
+ # compare outputs in probability space, because logits can have outliers
+ # and token ids are not precise enough
+ out_base = F.softmax(model(random_input).logits, dim=-1)
+
+ config = LoraConfig(
+ r=8,
+ init_lora_weights=False,
+ use_dora=True,
+ )
+ model = get_peft_model(model, config).eval()
+
+ # Note: By default, DoRA is a no-op before training, even if we set init_lora_weights=False. In order to
+ # measure any differences, we need to change the magnitude vector.
+ for name, module in model.named_modules():
+ if isinstance(module, LoraLinear4bit):
+ module.lora_magnitude_vector["default"].weight = torch.nn.Parameter(
+ 10 * torch.rand_like(module.lora_magnitude_vector["default"].weight)
+ )
+
+ with torch.inference_mode():
+ out_dora = F.softmax(model(random_input).logits, dim=-1)
+
+ model.merge_adapter()
+ out_merged = F.softmax(model(random_input).logits, dim=-1)
+
+ model.unmerge_adapter()
+ out_unmerged = F.softmax(model(random_input).logits, dim=-1)
+
+ model = model.merge_and_unload()
+ out_unloaded = F.softmax(model(random_input).logits, dim=-1)
+
+ atol = 1e-5
+ rtol = 1e-3
+ # sanity check that using DoRA changes the results
+ assert not torch.allclose(out_base, out_dora, atol=atol, rtol=rtol)
+ assert torch.allclose(out_dora, out_merged, atol=atol, rtol=rtol)
+ assert torch.allclose(out_dora, out_unmerged, atol=atol, rtol=rtol)
+ assert torch.allclose(out_dora, out_unloaded, atol=atol, rtol=rtol)
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ @require_bitsandbytes
+ def test_8bit_dora_merging(self):
+ # Check results for merging, unmerging, unloading
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ torch_dtype=torch.float32,
+ ).eval()
+
+ random_input = torch.LongTensor([[1, 0, 1, 0, 1, 0]]).to(model.device)
+ # compare outputs in probability space, because logits can have outliers
+ # and token ids are not precise enough
+ out_base = F.softmax(model(random_input).logits, dim=-1)
+
+ config = LoraConfig(
+ r=8,
+ init_lora_weights=False,
+ use_dora=True,
+ )
+ model = get_peft_model(model, config).eval()
+
+ # Note: By default, DoRA is a no-op before training, even if we set init_lora_weights=False. In order to
+ # measure any differences, we need to change the magnitude vector.
+ for name, module in model.named_modules():
+ if isinstance(module, LoraLinear8bitLt):
+ module.lora_magnitude_vector["default"].weight = torch.nn.Parameter(
+ 10 * torch.rand_like(module.lora_magnitude_vector["default"].weight)
+ )
+
+ with torch.inference_mode():
+ out_dora = F.softmax(model(random_input).logits, dim=-1)
+
+ model.merge_adapter()
+ out_merged = F.softmax(model(random_input).logits, dim=-1)
+
+ model.unmerge_adapter()
+ out_unmerged = F.softmax(model(random_input).logits, dim=-1)
+
+ model = model.merge_and_unload()
+ out_unloaded = F.softmax(model(random_input).logits, dim=-1)
+
+ atol = 1e-3
+ rtol = 1
+ # sanity check that using DoRA changes the results
+ assert not torch.allclose(out_base, out_dora, atol=atol, rtol=rtol)
+ assert torch.allclose(out_dora, out_merged, atol=atol, rtol=rtol)
+ assert torch.allclose(out_dora, out_unmerged, atol=atol, rtol=rtol)
+ assert torch.allclose(out_dora, out_unloaded, atol=atol, rtol=rtol)
+
+ @pytest.mark.single_gpu_tests
+ def test_dora_ephemeral_gpu_offload(self):
+ torch.manual_seed(0)
+
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ torch_dtype=torch.float32,
+ ).eval()
+
+ config = LoraConfig(
+ r=128,
+ init_lora_weights=False,
+ use_dora=True,
+ runtime_config=LoraRuntimeConfig(
+ ephemeral_gpu_offload=True
+ ), # we enable this, but only to verify that it's gone later
+ )
+ peft_model = get_peft_model(model, config).eval()
+ # Check that ephemeral GPU offloading is present
+ assert peft_model.peft_config["default"].runtime_config.ephemeral_gpu_offload
+
+ # Save to disk
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ peft_model.save_pretrained(tmp_dir)
+
+ # Load from disk 100% on CPU without ephemeral GPU offloading
+ peft_model_cpu = PeftModel.from_pretrained(
+ model,
+ tmp_dir,
+ device_map={"": "cpu"},
+ ).eval()
+
+ # Check that ephemeral GPU offloading is absent
+ assert not peft_model_cpu.peft_config["default"].runtime_config.ephemeral_gpu_offload
+
+ # Load again, with ephemeral GPU offloading enabled
+ peft_model_ego = PeftModel.from_pretrained(
+ model,
+ tmp_dir,
+ device_map={"": "cpu"},
+ ephemeral_gpu_offload=True,
+ ).eval()
+
+ random_input = torch.LongTensor([[1, 0, 1, 0, 1, 0]]).to(model.device)
+ with torch.inference_mode():
+ out_peft_model_cpu = F.softmax(peft_model_cpu(random_input).logits, dim=-1)
+ out_peft_model_ego = F.softmax(peft_model_ego(random_input).logits, dim=-1)
+
+ # The results should be the same
+ assert torch.allclose(out_peft_model_cpu, out_peft_model_ego)
+
+ @require_torch_multi_accelerator
+ @pytest.mark.multi_gpu_tests
+ def test_dora_ephemeral_gpu_offload_multigpu(self):
+ torch.manual_seed(0)
+
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ torch_dtype=torch.float32,
+ ).eval()
+
+ config = LoraConfig(
+ r=16, # too small and the time difference is too small
+ init_lora_weights=False,
+ use_dora=True,
+ runtime_config=LoraRuntimeConfig(ephemeral_gpu_offload=True),
+ )
+ peft_model = get_peft_model(model, config).eval()
+
+ layer = peft_model.base_model.model.model.decoder.layers[0].self_attn.v_proj
+ lora_A, lora_B = layer.lora_A, layer.lora_B
+
+ possible_combinations = ["cpu", self.device, f"{self.device}:0", f"{self.device}:1"]
+ adapter_name = layer.active_adapter[0]
+ for device_A in possible_combinations:
+ la = lora_A.to(device_A)
+ for device_B in possible_combinations:
+ lb = lora_B.to(device_B)
+ layer.lora_A, layer.lora_B = la, lb
+ layer.lora_variant[adapter_name].init(layer, adapter_name=adapter_name) # should not raise an error
+
+ def test_apply_GS_hra_inference(self):
+ # check for different result with and without apply_GS
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ torch_dtype=torch.float32,
+ ).eval()
+
+ torch.manual_seed(0)
+ config_hra = HRAConfig(r=8, init_weights=True, apply_GS=False)
+ model = get_peft_model(model, config_hra).eval()
+
+ random_input = torch.LongTensor([[1, 0, 1, 0, 1, 0]]).to(model.device)
+ logits_hra = model(random_input).logits
+
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ torch_dtype=torch.float32,
+ )
+ torch.manual_seed(0)
+ config_hra_GS = HRAConfig(r=8, init_weights=True, apply_GS=True)
+ model = get_peft_model(model, config_hra_GS)
+
+ logits_hra_GS = model(random_input).logits
+
+ assert not torch.allclose(logits_hra, logits_hra_GS)
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ def test_apply_GS_hra_conv2d_inference(self):
+ # check for different result with and without apply_GS
+ model_id = "microsoft/resnet-18"
+ image_processor = AutoImageProcessor.from_pretrained(model_id)
+ image = load_cat_image()
+ data = image_processor(image, return_tensors="pt")
+
+ model = AutoModelForImageClassification.from_pretrained(model_id).eval()
+ torch.manual_seed(0)
+ config_hra = HRAConfig(r=8, init_weights=True, target_modules=["convolution"], apply_GS=False)
+ model = get_peft_model(model, config_hra).eval()
+
+ logits_hra = model(**data).logits
+
+ model = AutoModelForImageClassification.from_pretrained(model_id).eval()
+ torch.manual_seed(0)
+ config_hra_GS = HRAConfig(r=8, init_weights=True, target_modules=["convolution"], apply_GS=True)
+ model = get_peft_model(model, config_hra_GS)
+
+ logits_hra_GS = model(**data).logits
+
+ assert not torch.allclose(logits_hra, logits_hra_GS)
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ def test_r_odd_hra_inference(self):
+ # check that an untrained HRA adapter can't be initialized as an identity tranformation
+ # when r is an odd number
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ torch_dtype=torch.float32,
+ ).eval()
+
+ random_input = torch.LongTensor([[1, 0, 1, 0, 1, 0]]).to(model.device)
+
+ torch.manual_seed(0)
+ logits = model(random_input).logits
+
+ config_hra = HRAConfig(r=7, init_weights=True, apply_GS=False)
+ model = get_peft_model(model, config_hra).eval()
+ logits_hra = model(random_input).logits
+
+ assert not torch.allclose(logits, logits_hra)
+
+
+@pytest.mark.skipif(not (torch.cuda.is_available() or is_xpu_available()), reason="test requires a GPU or XPU")
+@pytest.mark.single_gpu_tests
+class TestSameAdapterDifferentDevices:
+ device = infer_device()
+
+ # 1639
+ # The original issue comes down to the following problem: If the user has a base layer on CUDA, moves the adapter to
+ # CPU, then adds another adapter (which will automatically be moved to CUDA), then the first adapter will also be
+ # moved to CUDA.
+ @pytest.fixture
+ def mlp(self):
+ class MLP(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.lin0 = nn.Linear(8, 32, bias=bias)
+ self.lin1 = nn.Linear(32, 2, bias=bias)
+
+ return MLP()
+
+ @pytest.fixture
+ def emb_conv1d(self):
+ class ModelEmbConv1D(nn.Module):
+ def __init__(self, emb_size=100):
+ super().__init__()
+ self.emb = nn.Embedding(emb_size, 5)
+ self.conv1d = Conv1D(1, 5)
+
+ return ModelEmbConv1D()
+
+ @pytest.fixture
+ def conv2d(self):
+ class ModelConv2D(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.conv2d = nn.Conv2d(5, 10, 3)
+
+ return ModelConv2D()
+
+ def test_lora_one_target_add_new_adapter_does_not_change_device(self, mlp):
+ config = LoraConfig(target_modules=["lin0"])
+ model = get_peft_model(mlp, config)
+ model = model.to(self.device)
+ model.lin0.lora_A.cpu()
+ model.lin0.lora_B.cpu()
+
+ # check that the adapter is indeed on CPU and the base model on GPU
+ assert model.lin0.lora_A.default.weight.device.type == "cpu"
+ assert model.lin0.lora_B.default.weight.device.type == "cpu"
+ assert model.lin0.base_layer.weight.device.type == self.device
+
+ model.add_adapter("other", config)
+ # check that after adding a new adapter, the old adapter is still on CPU
+ assert model.lin0.lora_A.default.weight.device.type == "cpu"
+ assert model.lin0.lora_B.default.weight.device.type == "cpu"
+ # the rest should be on GPU
+ assert model.lin0.base_layer.weight.device.type == self.device
+ assert model.lin0.lora_A.other.weight.device.type == self.device
+ assert model.lin0.lora_B.other.weight.device.type == self.device
+
+ def test_lora_multiple_targets_add_new_adapater_does_not_change_device(self, mlp):
+ # same as the previous test, but targeting multiple layers
+ config = LoraConfig(target_modules=["lin0", "lin1"])
+ model = get_peft_model(mlp, config)
+ model = model.to(self.device)
+ # move lin1 to CPU but leave lin0 on GPU
+ model.lin1.lora_A.cpu()
+ model.lin1.lora_B.cpu()
+
+ # check that the adapter is indeed on CPU and the base model on GPU
+ assert model.lin1.lora_A.default.weight.device.type == "cpu"
+ assert model.lin1.lora_B.default.weight.device.type == "cpu"
+ assert model.lin1.base_layer.weight.device.type == self.device
+ assert model.lin0.lora_A.default.weight.device.type == self.device
+ assert model.lin0.lora_B.default.weight.device.type == self.device
+ assert model.lin0.base_layer.weight.device.type == self.device
+
+ model.add_adapter("other", config)
+ # check that after adding a new adapter, the old adapter is still on CPU
+ assert model.lin1.lora_A.default.weight.device.type == "cpu"
+ assert model.lin1.lora_B.default.weight.device.type == "cpu"
+ assert model.lin1.base_layer.weight.device.type == self.device
+ # the rest should be on GPU
+ assert model.lin0.lora_A.default.weight.device.type == self.device
+ assert model.lin0.lora_B.default.weight.device.type == self.device
+ assert model.lin0.base_layer.weight.device.type == self.device
+ assert model.lin0.lora_A.other.weight.device.type == self.device
+ assert model.lin0.lora_B.other.weight.device.type == self.device
+ assert model.lin1.lora_A.other.weight.device.type == self.device
+ assert model.lin1.lora_B.other.weight.device.type == self.device
+
+ def test_lora_embedding_target_add_new_adapter_does_not_change_device(self, emb_conv1d):
+ # same as first test, but targeting the embedding layer
+ config = LoraConfig(target_modules=["emb"])
+ model = get_peft_model(emb_conv1d, config)
+ model = model.to(self.device)
+ model.emb.lora_embedding_A.cpu()
+ model.emb.lora_embedding_B.cpu()
+
+ # check that the adapter is indeed on CPU and the base model on GPU
+ assert model.emb.lora_embedding_A.default.device.type == "cpu"
+ assert model.emb.lora_embedding_B.default.device.type == "cpu"
+ assert model.emb.weight.device.type == self.device
+
+ model.add_adapter("other", config)
+ # check that after adding a new adapter, the old adapter is still on CPU
+ assert model.emb.lora_embedding_A.default.device.type == "cpu"
+ assert model.emb.lora_embedding_B.default.device.type == "cpu"
+ # the rest should be on GPU
+ assert model.emb.weight.device.type == self.device
+ assert model.emb.lora_embedding_A.other.device.type == self.device
+ assert model.emb.lora_embedding_B.other.device.type == self.device
+
+ def test_lora_conv1d_target_add_new_adapter_does_not_change_device(self, emb_conv1d):
+ # same as first test, but targeting the Conv1D layer
+ config = LoraConfig(target_modules=["conv1d"])
+ model = get_peft_model(emb_conv1d, config)
+ model = model.to(self.device)
+ model.conv1d.lora_A.cpu()
+ model.conv1d.lora_B.cpu()
+
+ # check that the adapter is indeed on CPU and the base model on GPU
+ assert model.conv1d.lora_A.default.weight.device.type == "cpu"
+ assert model.conv1d.lora_B.default.weight.device.type == "cpu"
+ assert model.conv1d.weight.device.type == self.device
+
+ model.add_adapter("other", config)
+ # check that after adding a new adapter, the old adapter is still on CPU
+ assert model.conv1d.lora_A.default.weight.device.type == "cpu"
+ assert model.conv1d.lora_B.default.weight.device.type == "cpu"
+ # the rest should be on GPU
+ assert model.conv1d.weight.device.type == self.device
+ assert model.conv1d.lora_A.other.weight.device.type == self.device
+ assert model.conv1d.lora_B.other.weight.device.type == self.device
+
+ def test_lora_dora_add_new_adapter_does_not_change_device(self, mlp):
+ # same as first test, but also using DoRA
+ config = LoraConfig(target_modules=["lin0"], use_dora=True)
+ model = get_peft_model(mlp, config)
+ model = model.to(self.device)
+ model.lin0.lora_A.cpu()
+ model.lin0.lora_B.cpu()
+ model.lin0.lora_magnitude_vector.cpu()
+
+ # check that the adapter is indeed on CPU and the base model on GPU
+ assert model.lin0.lora_A.default.weight.device.type == "cpu"
+ assert model.lin0.lora_B.default.weight.device.type == "cpu"
+ assert model.lin0.lora_magnitude_vector.default.weight.device.type == "cpu"
+ assert model.lin0.base_layer.weight.device.type == self.device
+
+ model.add_adapter("other", config)
+ # check that after adding a new adapter, the old adapter is still on CPU
+ assert model.lin0.lora_A.default.weight.device.type == "cpu"
+ assert model.lin0.lora_B.default.weight.device.type == "cpu"
+ assert model.lin0.lora_magnitude_vector.default.weight.device.type == "cpu"
+ # the rest should be on GPU
+ assert model.lin0.base_layer.weight.device.type == self.device
+ assert model.lin0.lora_A.other.weight.device.type == self.device
+ assert model.lin0.lora_B.other.weight.device.type == self.device
+ assert model.lin0.lora_magnitude_vector.other.weight.device.type == self.device
+
+ def test_adalora_add_new_adapter_does_not_change_device(self, mlp):
+ # same as first test, but using AdaLORA
+ # AdaLora does not like multiple trainable adapters, hence inference_mode=True
+ config = AdaLoraConfig(target_modules=["lin0"], inference_mode=True, total_step=1)
+ model = get_peft_model(mlp, config)
+ model = model.to(self.device)
+ model.lin0.lora_A.cpu()
+ model.lin0.lora_E.cpu()
+
+ # check that the adapter is indeed on CPU and the base model on GPU
+ assert model.lin0.lora_A.default.device.type == "cpu"
+ assert model.lin0.lora_E.default.device.type == "cpu"
+ assert model.lin0.base_layer.weight.device.type == self.device
+
+ model.add_adapter("other", config)
+ # check that after adding a new adapter, the old adapter is still on CPU
+ assert model.lin0.lora_A.default.device.type == "cpu"
+ assert model.lin0.lora_E.default.device.type == "cpu"
+ # the rest should be on GPU
+ assert model.lin0.base_layer.weight.device.type == self.device
+ assert model.lin0.lora_A.other.device.type == self.device
+ assert model.lin0.lora_E.other.device.type == self.device
+
+ def test_boft_add_new_adapter_does_not_change_device(self, mlp):
+ # same as first test, but using BoFT
+ config = BOFTConfig(target_modules=["lin0"])
+ model = get_peft_model(mlp, config)
+ model = model.to(self.device)
+ model.lin0.boft_R.cpu()
+ model.lin0.boft_s.cpu()
+
+ # check that the adapter is indeed on CPU and the base model on GPU
+ assert model.lin0.boft_R.default.device.type == "cpu"
+ assert model.lin0.boft_s.default.device.type == "cpu"
+ assert model.lin0.base_layer.weight.device.type == self.device
+
+ model.add_adapter("other", config)
+ # check that after adding a new adapter, the old adapter is still on CPU
+ assert model.lin0.boft_R.default.device.type == "cpu"
+ assert model.lin0.boft_s.default.device.type == "cpu"
+ # the rest should be on GPU
+ assert model.lin0.base_layer.weight.device.type == self.device
+ assert model.lin0.boft_R.other.device.type == self.device
+ assert model.lin0.boft_s.other.device.type == self.device
+
+ def test_ia3_add_new_adapter_does_not_change_device(self, mlp):
+ # same as first test, but using IA3
+ config = IA3Config(target_modules=["lin0"], feedforward_modules=["lin0"])
+ model = get_peft_model(mlp, config)
+ model = model.to(self.device)
+ model.lin0.ia3_l.cpu()
+
+ # check that the adapter is indeed on CPU and the base model on GPU
+ assert model.lin0.ia3_l.default.device.type == "cpu"
+ assert model.lin0.base_layer.weight.device.type == self.device
+
+ model.add_adapter("other", config)
+ # check that after adding a new adapter, the old adapter is still on CPU
+ assert model.lin0.ia3_l.default.device.type == "cpu"
+ # the rest should be on GPU
+ assert model.lin0.base_layer.weight.device.type == self.device
+ assert model.lin0.ia3_l.other.device.type == self.device
+
+ @pytest.mark.xfail(reason="LN Tuning handling of multiple adapters may not be correct", strict=True)
+ def test_ln_tuning_add_new_adapter_does_not_change_device(self, mlp):
+ # same as first test, but using LN tuning
+ config = LNTuningConfig(target_modules=["lin0"])
+ model = get_peft_model(mlp, config)
+ model = model.to(self.device)
+ model.lin0.ln_tuning_layers.cpu()
+
+ # check that the adapter is indeed on CPU and the base model on GPU
+ assert model.lin0.ln_tuning_layers.default.weight.device.type == "cpu"
+ assert model.lin0.base_layer.weight.device.type == self.device
+
+ model.add_adapter("other", config)
+ # check that after adding a new adapter, the old adapter is still on CPU
+ assert model.lin0.ln_tuning_layers.default.weight.device.type == "cpu"
+ # the rest should be on GPU
+ assert model.lin0.base_layer.weight.device.type == self.device
+ assert model.lin0.ln_tuning_layers.other.weight.device.type == self.device
+
+ def test_loha_add_new_adapter_does_not_change_device(self, mlp):
+ # same as first test, but using LoHa
+ config = LoHaConfig(target_modules=["lin0"])
+ model = get_peft_model(mlp, config)
+ model = model.to(self.device)
+ model.lin0.hada_w1_a.cpu()
+ model.lin0.hada_w2_b.cpu()
+
+ # check that the adapter is indeed on CPU and the base model on GPU
+ assert model.lin0.hada_w1_a.default.device.type == "cpu"
+ assert model.lin0.hada_w2_b.default.device.type == "cpu"
+ assert model.lin0.base_layer.weight.device.type == self.device
+
+ model.add_adapter("other", config)
+ # check that after adding a new adapter, the old adapter is still on CPU
+ assert model.lin0.hada_w1_a.default.device.type == "cpu"
+ assert model.lin0.hada_w2_b.default.device.type == "cpu"
+ # the rest should be on GPU
+ assert model.lin0.base_layer.weight.device.type == self.device
+ assert model.lin0.hada_w1_a.other.device.type == self.device
+ assert model.lin0.hada_w2_b.other.device.type == self.device
+
+ def test_lokr_add_new_adapter_does_not_change_device(self, mlp):
+ # same as first test, but using LoKr
+ config = LoKrConfig(target_modules=["lin0"])
+ model = get_peft_model(mlp, config)
+ model = model.to(self.device)
+ model.lin0.lokr_w1.cpu()
+ model.lin0.lokr_w2.cpu()
+
+ # check that the adapter is indeed on CPU and the base model on GPU
+ assert model.lin0.lokr_w1.default.device.type == "cpu"
+ assert model.lin0.lokr_w2.default.device.type == "cpu"
+ assert model.lin0.base_layer.weight.device.type == self.device
+
+ model.add_adapter("other", config)
+ # check that after adding a new adapter, the old adapter is still on CPU
+ assert model.lin0.lokr_w1.default.device.type == "cpu"
+ assert model.lin0.lokr_w2.default.device.type == "cpu"
+ # the rest should be on GPU
+ assert model.lin0.base_layer.weight.device.type == self.device
+ assert model.lin0.lokr_w1.other.device.type == self.device
+ assert model.lin0.lokr_w2.other.device.type == self.device
+
+ def test_oft_add_new_adapter_does_not_change_device(self, mlp):
+ # same as first test, but using OFT
+ config = OFTConfig(target_modules=["lin0"])
+ model = get_peft_model(mlp, config)
+ model = model.to(self.device)
+ model.lin0.oft_R.default.cpu()
+
+ # check that the adapter is indeed on CPU and the base model on GPU
+ assert model.lin0.oft_R.default.weight.device.type == "cpu"
+ assert model.lin0.base_layer.weight.device.type == self.device
+
+ model.add_adapter("other", config)
+ # check that after adding a new adapter, the old adapter is still on CPU
+ assert model.lin0.oft_R.default.weight.device.type == "cpu"
+ # the rest should be on GPU
+ assert model.lin0.base_layer.weight.device.type == self.device
+ assert model.lin0.oft_R.other.weight.device.type == self.device
+
+ def test_vera_add_new_adapter_does_not_change_device(self, mlp):
+ # same as first test, but using VERA
+ config = VeraConfig(target_modules=["lin0"])
+ model = get_peft_model(mlp, config)
+ model = model.to(self.device)
+ model.lin0.vera_A.cpu()
+ model.lin0.vera_lambda_d.cpu()
+
+ # check that the adapter is indeed on CPU and the base model on GPU
+ assert model.lin0.vera_A.default.device.type == "cpu"
+ assert model.lin0.vera_lambda_d.default.device.type == "cpu"
+ assert model.lin0.base_layer.weight.device.type == self.device
+
+ model.add_adapter("other", config)
+ # check that after adding a new adapter, the old adapter is still on CPU
+ assert model.lin0.vera_A.default.device.type == "cpu"
+ assert model.lin0.vera_lambda_d.default.device.type == "cpu"
+ # the rest should be on GPU
+ assert model.lin0.base_layer.weight.device.type == self.device
+ assert model.lin0.vera_A.other.device.type == self.device
+ assert model.lin0.vera_lambda_d.other.device.type == self.device
+
+ def test_randlora_add_new_adapter_does_not_change_device(self, mlp):
+ # same as first test, but using RandLora
+ config = RandLoraConfig(target_modules=["lin0"])
+ model = get_peft_model(mlp, config)
+ model = model.to(self.device)
+ model.lin0.randlora_A.cpu()
+ model.lin0.randlora_lambda.cpu()
+
+ # check that the adapter is indeed on CPU and the base model on GPU
+ assert model.lin0.randlora_A.default.device.type == "cpu"
+ assert model.lin0.randlora_lambda.default.device.type == "cpu"
+ assert model.lin0.base_layer.weight.device.type == self.device
+
+ model.add_adapter("other", config)
+ # check that after adding a new adapter, the old adapter is still on CPU
+ assert model.lin0.randlora_A.default.device.type == "cpu"
+ assert model.lin0.randlora_lambda.default.device.type == "cpu"
+ # the rest should be on GPU
+ assert model.lin0.base_layer.weight.device.type == self.device
+ assert model.lin0.randlora_A.other.device.type == self.device
+ assert model.lin0.randlora_lambda.other.device.type == self.device
+
+ def test_vblora_add_new_adapter_does_not_change_device(self, mlp):
+ # same as first test, but using VBLoRA
+ config = VBLoRAConfig(target_modules=["lin0"], vector_length=2)
+ model = get_peft_model(mlp, config)
+ model = model.to(self.device)
+ model.lin0.vblora_logits_A.cpu()
+ model.lin0.vblora_logits_B.cpu()
+ model.lin0.vblora_vector_bank.cpu()
+
+ # check that the adapter is indeed on CPU and the base model on GPU
+ assert model.lin0.vblora_logits_A.default.device.type == "cpu"
+ assert model.lin0.vblora_logits_B.default.device.type == "cpu"
+ assert model.lin0.vblora_vector_bank.default.device.type == "cpu"
+ assert model.lin0.base_layer.weight.device.type == self.device
+
+ model.add_adapter("other", config)
+ # check that after adding a new adapter, the old adapter is still on CPU
+ assert model.lin0.vblora_logits_A.default.device.type == "cpu"
+ assert model.lin0.vblora_logits_B.default.device.type == "cpu"
+ assert model.lin0.vblora_vector_bank.default.device.type == "cpu"
+ # the rest should be on GPU
+ assert model.lin0.base_layer.weight.device.type == self.device
+ assert model.lin0.vblora_logits_A.other.device.type == self.device
+ assert model.lin0.vblora_logits_B.other.device.type == self.device
+ assert model.lin0.vblora_vector_bank.other.device.type == self.device
+
+ def test_hra_add_new_adapter_does_not_change_device(self, mlp):
+ # same as first test, but using HRA
+ config = HRAConfig(target_modules=["lin0"])
+ model = get_peft_model(mlp, config)
+ model = model.to(self.device)
+ model.lin0.hra_u.cpu()
+
+ # check that the adapter is indeed on CPU and the base model on GPU
+ assert model.lin0.hra_u.default.device.type == "cpu"
+ assert model.lin0.base_layer.weight.device.type == self.device
+
+ model.add_adapter("other", config)
+ # check that after adding a new adapter, the old adapter is still on CPU
+ assert model.lin0.hra_u.default.device.type == "cpu"
+ # the rest should be on GPU
+ assert model.lin0.base_layer.weight.device.type == self.device
+ assert model.lin0.hra_u.other.device.type == self.device
diff --git a/peft/tests/test_config.py b/peft/tests/test_config.py
new file mode 100644
index 0000000000000000000000000000000000000000..179496b6f3381799df4dd23722c57bb7c2e3f2f5
--- /dev/null
+++ b/peft/tests/test_config.py
@@ -0,0 +1,475 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import copy
+import json
+import os
+import pickle
+import tempfile
+import warnings
+
+import pytest
+
+from peft import (
+ AdaLoraConfig,
+ AdaptionPromptConfig,
+ BOFTConfig,
+ FourierFTConfig,
+ HRAConfig,
+ IA3Config,
+ LNTuningConfig,
+ LoHaConfig,
+ LoKrConfig,
+ LoraConfig,
+ MultitaskPromptTuningConfig,
+ OFTConfig,
+ PeftConfig,
+ PeftType,
+ PolyConfig,
+ PrefixTuningConfig,
+ PromptEncoder,
+ PromptEncoderConfig,
+ PromptTuningConfig,
+ TaskType,
+ VBLoRAConfig,
+ VeraConfig,
+)
+
+
+PEFT_MODELS_TO_TEST = [("peft-internal-testing/tiny-opt-lora-revision", "test")]
+
+# Config classes and their mandatory parameters
+ALL_CONFIG_CLASSES = (
+ (AdaLoraConfig, {"total_step": 1}),
+ (AdaptionPromptConfig, {}),
+ (BOFTConfig, {}),
+ (FourierFTConfig, {}),
+ (HRAConfig, {}),
+ (IA3Config, {}),
+ (LNTuningConfig, {}),
+ (LoHaConfig, {}),
+ (LoKrConfig, {}),
+ (LoraConfig, {}),
+ (MultitaskPromptTuningConfig, {}),
+ (PolyConfig, {}),
+ (PrefixTuningConfig, {}),
+ (PromptEncoderConfig, {}),
+ (PromptTuningConfig, {}),
+ (VeraConfig, {}),
+ (VBLoRAConfig, {}),
+)
+
+
+class TestPeftConfig:
+ @pytest.mark.parametrize("config_class, mandatory_kwargs", ALL_CONFIG_CLASSES)
+ def test_methods(self, config_class, mandatory_kwargs):
+ r"""
+ Test if all configs have the expected methods. Here we test
+ - to_dict
+ - save_pretrained
+ - from_pretrained
+ - from_json_file
+ """
+ # test if all configs have the expected methods
+ config = config_class(**mandatory_kwargs)
+ assert hasattr(config, "to_dict")
+ assert hasattr(config, "save_pretrained")
+ assert hasattr(config, "from_pretrained")
+ assert hasattr(config, "from_json_file")
+
+ @pytest.mark.parametrize("config_class, mandatory_kwargs", ALL_CONFIG_CLASSES)
+ @pytest.mark.parametrize("valid_task_type", list(TaskType) + [None])
+ def test_valid_task_type(self, config_class, mandatory_kwargs, valid_task_type):
+ r"""
+ Test if all configs work correctly for all valid task types
+ """
+ config_class(task_type=valid_task_type, **mandatory_kwargs)
+
+ @pytest.mark.parametrize("config_class, mandatory_kwargs", ALL_CONFIG_CLASSES)
+ def test_invalid_task_type(self, config_class, mandatory_kwargs):
+ r"""
+ Test if all configs correctly raise the defined error message for invalid task types.
+ """
+ invalid_task_type = "invalid-task-type"
+ with pytest.raises(
+ ValueError,
+ match=f"Invalid task type: '{invalid_task_type}'. Must be one of the following task types: {', '.join(TaskType)}.",
+ ):
+ config_class(task_type=invalid_task_type, **mandatory_kwargs)
+
+ def test_from_peft_type(self):
+ r"""
+ Test if the config is correctly loaded using:
+ - from_peft_type
+ """
+ from peft.mapping import PEFT_TYPE_TO_CONFIG_MAPPING
+
+ for peft_type in PeftType:
+ expected_cls = PEFT_TYPE_TO_CONFIG_MAPPING[peft_type]
+ mandatory_config_kwargs = {}
+
+ if expected_cls == AdaLoraConfig:
+ mandatory_config_kwargs = {"total_step": 1}
+
+ config = PeftConfig.from_peft_type(peft_type=peft_type, **mandatory_config_kwargs)
+ assert type(config) is expected_cls
+
+ @pytest.mark.parametrize("config_class, mandatory_kwargs", ALL_CONFIG_CLASSES)
+ def test_from_pretrained(self, config_class, mandatory_kwargs):
+ r"""
+ Test if the config is correctly loaded using:
+ - from_pretrained
+ """
+ for model_name, revision in PEFT_MODELS_TO_TEST:
+ # Test we can load config from delta
+ config_class.from_pretrained(model_name, revision=revision)
+
+ @pytest.mark.parametrize("config_class, mandatory_kwargs", ALL_CONFIG_CLASSES)
+ def test_save_pretrained(self, config_class, mandatory_kwargs):
+ r"""
+ Test if the config is correctly saved and loaded using
+ - save_pretrained
+ """
+ config = config_class(**mandatory_kwargs)
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ config.save_pretrained(tmp_dirname)
+
+ config_from_pretrained = config_class.from_pretrained(tmp_dirname)
+ assert config.to_dict() == config_from_pretrained.to_dict()
+
+ @pytest.mark.parametrize("config_class, mandatory_kwargs", ALL_CONFIG_CLASSES)
+ def test_from_json_file(self, config_class, mandatory_kwargs):
+ config = config_class(**mandatory_kwargs)
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ config.save_pretrained(tmp_dirname)
+
+ config_path = os.path.join(tmp_dirname, "adapter_config.json")
+ config_from_json = config_class.from_json_file(config_path)
+ assert config.to_dict() == config_from_json
+
+ # Also test with a runtime_config entry -- they should be ignored, even if they
+ # were accidentally saved to disk
+ config_from_json["runtime_config"] = {"ephemeral_gpu_offload": True}
+ json.dump(config_from_json, open(config_path, "w"))
+
+ config_from_json = config_class.from_json_file(config_path)
+ assert config.to_dict() == config_from_json
+
+ @pytest.mark.parametrize("config_class, mandatory_kwargs", ALL_CONFIG_CLASSES)
+ def test_to_dict(self, config_class, mandatory_kwargs):
+ r"""
+ Test if the config can be correctly converted to a dict using:
+ - to_dict
+ """
+ config = config_class(**mandatory_kwargs)
+ assert isinstance(config.to_dict(), dict)
+
+ @pytest.mark.parametrize("config_class, mandatory_kwargs", ALL_CONFIG_CLASSES)
+ def test_from_pretrained_cache_dir(self, config_class, mandatory_kwargs):
+ r"""
+ Test if the config is correctly loaded with extra kwargs
+ """
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ for model_name, revision in PEFT_MODELS_TO_TEST:
+ # Test we can load config from delta
+ config_class.from_pretrained(model_name, revision=revision, cache_dir=tmp_dirname)
+
+ def test_from_pretrained_cache_dir_remote(self):
+ r"""
+ Test if the config is correctly loaded with a checkpoint from the hub
+ """
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ PeftConfig.from_pretrained("ybelkada/test-st-lora", cache_dir=tmp_dirname)
+ assert "models--ybelkada--test-st-lora" in os.listdir(tmp_dirname)
+
+ @pytest.mark.parametrize("config_class, mandatory_kwargs", ALL_CONFIG_CLASSES)
+ def test_save_pretrained_with_runtime_config(self, config_class, mandatory_kwargs):
+ r"""
+ Test if the config correctly removes runtime config when saving
+ """
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ for model_name, revision in PEFT_MODELS_TO_TEST:
+ cfg = config_class.from_pretrained(model_name, revision=revision)
+ # NOTE: cfg is always a LoraConfig here, because the configuration of the loaded model was a LoRA.
+ # Hence we can expect a runtime_config to exist regardless of config_class.
+ cfg.runtime_config.ephemeral_gpu_offload = True
+ cfg.save_pretrained(tmp_dirname)
+ cfg = config_class.from_pretrained(tmp_dirname)
+ assert not cfg.runtime_config.ephemeral_gpu_offload
+
+ @pytest.mark.parametrize("config_class, mandatory_kwargs", ALL_CONFIG_CLASSES)
+ def test_set_attributes(self, config_class, mandatory_kwargs):
+ # manually set attributes and check if they are correctly written
+ config = config_class(peft_type="test", **mandatory_kwargs)
+
+ # save pretrained
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ config.save_pretrained(tmp_dirname)
+
+ config_from_pretrained = config_class.from_pretrained(tmp_dirname)
+ assert config.to_dict() == config_from_pretrained.to_dict()
+
+ @pytest.mark.parametrize("config_class, mandatory_kwargs", ALL_CONFIG_CLASSES)
+ def test_config_copy(self, config_class, mandatory_kwargs):
+ # see https://github.com/huggingface/peft/issues/424
+ config = config_class(**mandatory_kwargs)
+ copied = copy.copy(config)
+ assert config.to_dict() == copied.to_dict()
+
+ @pytest.mark.parametrize("config_class, mandatory_kwargs", ALL_CONFIG_CLASSES)
+ def test_config_deepcopy(self, config_class, mandatory_kwargs):
+ # see https://github.com/huggingface/peft/issues/424
+ config = config_class(**mandatory_kwargs)
+ copied = copy.deepcopy(config)
+ assert config.to_dict() == copied.to_dict()
+
+ @pytest.mark.parametrize("config_class, mandatory_kwargs", ALL_CONFIG_CLASSES)
+ def test_config_pickle_roundtrip(self, config_class, mandatory_kwargs):
+ # see https://github.com/huggingface/peft/issues/424
+ config = config_class(**mandatory_kwargs)
+ copied = pickle.loads(pickle.dumps(config))
+ assert config.to_dict() == copied.to_dict()
+
+ def test_prompt_encoder_warning_num_layers(self):
+ # This test checks that if a prompt encoder config is created with an argument that is ignored, there should be
+ # warning. However, there should be no warning if the default value is used.
+ kwargs = {
+ "num_virtual_tokens": 20,
+ "num_transformer_submodules": 1,
+ "token_dim": 768,
+ "encoder_hidden_size": 768,
+ }
+
+ # there should be no warning with just default argument for encoder_num_layer
+ config = PromptEncoderConfig(**kwargs)
+ with warnings.catch_warnings():
+ PromptEncoder(config)
+
+ # when changing encoder_num_layer, there should be a warning for MLP since that value is not used
+ config = PromptEncoderConfig(encoder_num_layers=123, **kwargs)
+ with pytest.warns(UserWarning) as record:
+ PromptEncoder(config)
+ expected_msg = "for MLP, the argument `encoder_num_layers` is ignored. Exactly 2 MLP layers are used."
+ assert str(record.list[0].message) == expected_msg
+
+ @pytest.mark.parametrize(
+ "config_class", [LoHaConfig, LoraConfig, IA3Config, OFTConfig, BOFTConfig, HRAConfig, VBLoRAConfig]
+ )
+ def test_save_pretrained_with_target_modules(self, config_class):
+ # See #1041, #1045
+ config = config_class(target_modules=["a", "list"])
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ config.save_pretrained(tmp_dirname)
+
+ config_from_pretrained = config_class.from_pretrained(tmp_dirname)
+ assert config.to_dict() == config_from_pretrained.to_dict()
+ # explicit test that target_modules should be converted to set
+ assert isinstance(config_from_pretrained.target_modules, set)
+
+ def test_regex_with_layer_indexing_lora(self):
+ # This test checks that an error is raised if `target_modules` is a regex expression and `layers_to_transform` or
+ # `layers_pattern` are not None
+
+ invalid_config1 = {"target_modules": ".*foo", "layers_to_transform": [0]}
+ invalid_config2 = {"target_modules": ".*foo", "layers_pattern": ["bar"]}
+
+ valid_config = {"target_modules": ["foo"], "layers_pattern": ["bar"], "layers_to_transform": [0]}
+
+ with pytest.raises(ValueError, match="`layers_to_transform` cannot be used when `target_modules` is a str."):
+ LoraConfig(**invalid_config1)
+
+ with pytest.raises(ValueError, match="`layers_pattern` cannot be used when `target_modules` is a str."):
+ LoraConfig(**invalid_config2)
+
+ # should run without errors
+ LoraConfig(**valid_config)
+
+ def test_ia3_is_feedforward_subset_invalid_config(self):
+ # This test checks that the IA3 config raises a value error if the feedforward_modules argument
+ # is not a subset of the target_modules argument
+
+ # an example invalid config
+ invalid_config = {"target_modules": ["k", "v"], "feedforward_modules": ["q"]}
+
+ with pytest.raises(ValueError, match="^`feedforward_modules` should be a subset of `target_modules`$"):
+ IA3Config(**invalid_config)
+
+ def test_ia3_is_feedforward_subset_valid_config(self):
+ # This test checks that the IA3 config is created without errors with valid arguments.
+ # feedforward_modules should be a subset of target_modules if both are lists
+
+ # an example valid config with regex expressions.
+ valid_config_regex_exp = {
+ "target_modules": ".*.(SelfAttention|EncDecAttention|DenseReluDense).*(q|v|wo)$",
+ "feedforward_modules": ".*.DenseReluDense.wo$",
+ }
+ # an example valid config with module lists.
+ valid_config_list = {"target_modules": ["k", "v", "wo"], "feedforward_modules": ["wo"]}
+
+ # should run without errors
+ IA3Config(**valid_config_regex_exp)
+ IA3Config(**valid_config_list)
+
+ def test_adalora_config_r_warning(self):
+ # This test checks that a warning is raised when r is set other than default in AdaLoraConfig
+ # No warning should be raised when initializing AdaLoraConfig with default values.
+ kwargs = {"peft_type": "ADALORA", "task_type": "SEQ_2_SEQ_LM", "init_r": 12, "lora_alpha": 32, "total_step": 1}
+ # Test that no warning is raised with default initialization
+ with warnings.catch_warnings():
+ warnings.simplefilter("error")
+ try:
+ AdaLoraConfig(**kwargs)
+ except Warning:
+ pytest.fail("AdaLoraConfig raised a warning with default initialization.")
+ # Test that a warning is raised when r != 8 in AdaLoraConfig
+ with pytest.warns(UserWarning, match="Note that `r` is not used in AdaLora and will be ignored."):
+ AdaLoraConfig(r=10, total_step=1)
+
+ def test_adalora_config_correct_timing_still_works(self):
+ pass
+
+ @pytest.mark.parametrize(
+ "timing_kwargs",
+ [
+ {"total_step": 100, "tinit": 0, "tfinal": 0},
+ {"total_step": 100, "tinit": 10, "tfinal": 10},
+ {"total_step": 100, "tinit": 79, "tfinal": 20},
+ {"total_step": 100, "tinit": 80, "tfinal": 19},
+ ],
+ )
+ def test_adalora_config_valid_timing_works(self, timing_kwargs):
+ # Make sure that passing correct timing values is not prevented by faulty config checks.
+ AdaLoraConfig(**timing_kwargs) # does not raise
+
+ def test_adalora_config_invalid_total_step_raises(self):
+ with pytest.raises(ValueError) as e:
+ AdaLoraConfig(total_step=None)
+ assert "AdaLoRA does not work when `total_step` is None, supply a value > 0." in str(e)
+
+ @pytest.mark.parametrize(
+ "timing_kwargs",
+ [
+ {"total_step": 100, "tinit": 20, "tfinal": 80},
+ {"total_step": 100, "tinit": 80, "tfinal": 20},
+ {"total_step": 10, "tinit": 20, "tfinal": 0},
+ {"total_step": 10, "tinit": 0, "tfinal": 10},
+ {"total_step": 10, "tinit": 10, "tfinal": 0},
+ {"total_step": 10, "tinit": 20, "tfinal": 0},
+ {"total_step": 10, "tinit": 20, "tfinal": 20},
+ {"total_step": 10, "tinit": 0, "tfinal": 20},
+ ],
+ )
+ def test_adalora_config_timing_bounds_error(self, timing_kwargs):
+ # Check if the user supplied timing values that will certainly fail because it breaks
+ # AdaLoRA assumptions.
+ with pytest.raises(ValueError) as e:
+ AdaLoraConfig(**timing_kwargs)
+
+ assert "The supplied schedule values don't allow for a budgeting phase" in str(e)
+
+ @pytest.mark.parametrize("config_class, mandatory_kwargs", ALL_CONFIG_CLASSES)
+ def test_from_pretrained_forward_compatible(self, config_class, mandatory_kwargs, tmp_path, recwarn):
+ """
+ Make it possible to load configs that contain unknown keys by ignoring them.
+
+ The idea is to make PEFT configs forward-compatible with future versions of the library.
+ """
+ config = config_class(**mandatory_kwargs)
+ config.save_pretrained(tmp_path)
+ # add a spurious key to the config
+ with open(tmp_path / "adapter_config.json") as f:
+ config_dict = json.load(f)
+ config_dict["foobar"] = "baz"
+ config_dict["spam"] = 123
+ with open(tmp_path / "adapter_config.json", "w") as f:
+ json.dump(config_dict, f)
+
+ msg = f"Unexpected keyword arguments ['foobar', 'spam'] for class {config_class.__name__}, these are ignored."
+ config_from_pretrained = config_class.from_pretrained(tmp_path)
+
+ assert len(recwarn) == 1
+ assert recwarn.list[0].message.args[0].startswith(msg)
+ assert "foo" not in config_from_pretrained.to_dict()
+ assert "spam" not in config_from_pretrained.to_dict()
+ assert config.to_dict() == config_from_pretrained.to_dict()
+ assert isinstance(config_from_pretrained, config_class)
+
+ @pytest.mark.parametrize("config_class, mandatory_kwargs", ALL_CONFIG_CLASSES)
+ def test_from_pretrained_forward_compatible_load_from_peft_config(
+ self, config_class, mandatory_kwargs, tmp_path, recwarn
+ ):
+ """Exact same test as before, but instead of using LoraConfig.from_pretrained, AdaLoraconfig.from_pretrained,
+ etc. use PeftConfig.from_pretrained. This covers a previously existing bug where only the known arguments from
+ PeftConfig would be used instead of the more specific config (which is known thanks to the peft_type
+ attribute).
+
+ """
+ config = config_class(**mandatory_kwargs)
+ config.save_pretrained(tmp_path)
+ # add a spurious key to the config
+ with open(tmp_path / "adapter_config.json") as f:
+ config_dict = json.load(f)
+ config_dict["foobar"] = "baz"
+ config_dict["spam"] = 123
+ with open(tmp_path / "adapter_config.json", "w") as f:
+ json.dump(config_dict, f)
+
+ msg = f"Unexpected keyword arguments ['foobar', 'spam'] for class {config_class.__name__}, these are ignored."
+ config_from_pretrained = PeftConfig.from_pretrained(tmp_path) # <== use PeftConfig here
+
+ assert len(recwarn) == 1
+ assert recwarn.list[0].message.args[0].startswith(msg)
+ assert "foo" not in config_from_pretrained.to_dict()
+ assert "spam" not in config_from_pretrained.to_dict()
+ assert config.to_dict() == config_from_pretrained.to_dict()
+ assert isinstance(config_from_pretrained, config_class)
+
+ @pytest.mark.parametrize("config_class, mandatory_kwargs", ALL_CONFIG_CLASSES)
+ def test_from_pretrained_sanity_check(self, config_class, mandatory_kwargs, tmp_path):
+ """Following up on the previous test about forward compatibility, we *don't* want any random json to be accepted as
+ a PEFT config. There should be a minimum set of required keys.
+ """
+ non_peft_json = {"foo": "bar", "baz": 123}
+ with open(tmp_path / "adapter_config.json", "w") as f:
+ json.dump(non_peft_json, f)
+
+ msg = f"The {config_class.__name__} config that is trying to be loaded is missing required keys: {{'peft_type'}}."
+ with pytest.raises(TypeError, match=msg):
+ config_class.from_pretrained(tmp_path)
+
+ def test_lora_config_layers_to_transform_validation(self):
+ """Test that specifying layers_pattern without layers_to_transform raises an error"""
+ with pytest.raises(
+ ValueError, match="When `layers_pattern` is specified, `layers_to_transform` must also be specified."
+ ):
+ LoraConfig(r=8, lora_alpha=16, target_modules=["query", "value"], layers_pattern="model.layers")
+
+ # Test that specifying both layers_to_transform and layers_pattern works fine
+ config = LoraConfig(
+ r=8,
+ lora_alpha=16,
+ target_modules=["query", "value"],
+ layers_to_transform=[0, 1, 2],
+ layers_pattern="model.layers",
+ )
+ assert config.layers_to_transform == [0, 1, 2]
+ assert config.layers_pattern == "model.layers"
+
+ # Test that not specifying either works fine
+ config = LoraConfig(
+ r=8,
+ lora_alpha=16,
+ target_modules=["query", "value"],
+ )
+ assert config.layers_to_transform is None
+ assert config.layers_pattern is None
diff --git a/peft/tests/test_cpt.py b/peft/tests/test_cpt.py
new file mode 100644
index 0000000000000000000000000000000000000000..6b747f8f41c7fd6416905f76f7bef67d8fdc7bb1
--- /dev/null
+++ b/peft/tests/test_cpt.py
@@ -0,0 +1,301 @@
+# Copyright 2024-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from typing import Any, Union
+
+import pytest
+import torch
+from datasets import load_dataset
+from torch.utils.data import Dataset
+from tqdm import tqdm
+from transformers import (
+ AutoModelForCausalLM,
+ AutoTokenizer,
+ DataCollatorForLanguageModeling,
+ Trainer,
+ TrainingArguments,
+)
+
+from peft import CPTConfig, TaskType, get_peft_model
+
+
+TEMPLATE = {"input": "input: {}", "intra_seperator": " ", "output": "output: {}", "inter_seperator": "\n"}
+
+MODEL_NAME = "hf-internal-testing/tiny-random-OPTForCausalLM"
+MAX_INPUT_LENGTH = 1024
+
+
+@pytest.fixture(scope="module")
+def global_tokenizer():
+ """Load the tokenizer fixture for the model."""
+
+ return AutoTokenizer.from_pretrained(MODEL_NAME, padding_side="right")
+
+
+@pytest.fixture(scope="module")
+def config_text():
+ """Load the SST2 dataset and prepare it for testing."""
+ config = CPTConfig(
+ cpt_token_ids=[0, 1, 2, 3, 4, 5, 6, 7], # Example token IDs for testing
+ cpt_mask=[1, 1, 1, 1, 1, 1, 1, 1],
+ cpt_tokens_type_mask=[1, 2, 2, 2, 3, 3, 3, 4],
+ opt_weighted_loss_type="decay",
+ opt_loss_decay_factor=0.95,
+ opt_projection_epsilon=0.2,
+ opt_projection_format_epsilon=0.1,
+ tokenizer_name_or_path=MODEL_NAME,
+ )
+ return config
+
+
+@pytest.fixture(scope="module")
+def config_random():
+ """Load the SST2 dataset and prepare it for testing."""
+ config = CPTConfig(
+ opt_weighted_loss_type="decay",
+ opt_loss_decay_factor=0.95,
+ opt_projection_epsilon=0.2,
+ opt_projection_format_epsilon=0.1,
+ tokenizer_name_or_path=MODEL_NAME,
+ )
+ return config
+
+
+@pytest.fixture(scope="module")
+def sst_data():
+ """Load the SST2 dataset and prepare it for testing."""
+ data = load_dataset("glue", "sst2")
+
+ def add_string_labels(example):
+ if example["label"] == 0:
+ example["label_text"] = "negative"
+ elif example["label"] == 1:
+ example["label_text"] = "positive"
+ return example
+
+ train_dataset = data["train"].select(range(4)).map(add_string_labels)
+ test_dataset = data["validation"].select(range(10)).map(add_string_labels)
+
+ return {"train": train_dataset, "test": test_dataset}
+
+
+@pytest.fixture(scope="module")
+def collator(global_tokenizer):
+ class CPTDataCollatorForLanguageModeling(DataCollatorForLanguageModeling):
+ def __init__(self, tokenizer, training=True, mlm=False):
+ super().__init__(tokenizer, mlm=mlm)
+ self.training = training
+ self.tokenizer.add_special_tokens({"pad_token": "[PAD]"}) # mk check why needed
+
+ def torch_call(self, examples: list[Union[list[int], Any, dict[str, Any]]]) -> dict[str, Any]:
+ # Handle dict or lists with proper padding and conversion to tensor.
+ list_sample_mask = []
+ for i in range(len(examples)):
+ if "sample_mask" in examples[i].keys():
+ list_sample_mask.append(examples[i].pop("sample_mask"))
+
+ max_len = max(len(ex["input_ids"]) for ex in examples)
+
+ def pad_sequence(sequence, max_len, pad_value=0):
+ return sequence + [pad_value] * (max_len - len(sequence))
+
+ input_ids = torch.tensor([pad_sequence(ex["input_ids"], max_len) for ex in examples])
+ attention_mask = torch.tensor([pad_sequence(ex["attention_mask"], max_len) for ex in examples])
+ input_type_mask = torch.tensor([pad_sequence(ex["input_type_mask"], max_len) for ex in examples])
+
+ batch = {"input_ids": input_ids, "attention_mask": attention_mask, "input_type_mask": input_type_mask}
+
+ tensor_sample_mask = batch["input_ids"].clone().long()
+ tensor_sample_mask[:, :] = 0
+ for i in range(len(list_sample_mask)):
+ tensor_sample_mask[i, : len(list_sample_mask[i])] = list_sample_mask[i]
+
+ batch["labels"] = batch["input_ids"].clone()
+ if not self.training:
+ batch["sample_mask"] = tensor_sample_mask
+
+ return batch
+
+ collator = CPTDataCollatorForLanguageModeling(global_tokenizer, training=True, mlm=False)
+ return collator
+
+
+def dataset(data, tokenizer):
+ class CPTDataset(Dataset):
+ def __init__(self, samples, tokenizer, template, max_length=MAX_INPUT_LENGTH):
+ self.template = template
+ self.tokenizer = tokenizer
+ self.max_length = max_length
+
+ self.attention_mask = []
+ self.input_ids = []
+ self.input_type_mask = []
+ self.inter_seperator_ids = self._get_input_ids(template["inter_seperator"])
+
+ for sample_i in tqdm(samples):
+ input_text, label = sample_i["sentence"], sample_i["label_text"]
+ input_ids, attention_mask, input_type_mask = self.preprocess_sentence(input_text, label)
+
+ self.input_ids.append(input_ids)
+ self.attention_mask.append(attention_mask)
+ self.input_type_mask.append(input_type_mask)
+
+ def _get_input_ids(self, text):
+ return self.tokenizer(text, add_special_tokens=False)["input_ids"]
+
+ def preprocess_sentence(self, input_text, label):
+ input_template_part_1_text, input_template_part_2_text = self.template["input"].split("{}")
+ input_template_tokenized_part1 = self._get_input_ids(input_template_part_1_text)
+ input_tokenized = self._get_input_ids(input_text)
+ input_template_tokenized_part2 = self._get_input_ids(input_template_part_2_text)
+
+ sep_tokenized = self._get_input_ids(self.template["intra_seperator"])
+
+ label_template_part_1, label_template_part_2 = self.template["output"].split("{}")
+ label_template_part1_tokenized = self._get_input_ids(label_template_part_1)
+ label_tokenized = self._get_input_ids(label)
+ label_template_part2_tokenized = self._get_input_ids(label_template_part_2)
+
+ eos = [self.tokenizer.eos_token_id] if self.tokenizer.eos_token_id is not None else []
+ input_ids = (
+ input_template_tokenized_part1
+ + input_tokenized
+ + input_template_tokenized_part2
+ + sep_tokenized
+ + label_template_part1_tokenized
+ + label_tokenized
+ + label_template_part2_tokenized
+ + eos
+ )
+
+ # determine label tokens, to calculate loss only over them when labels_loss == True
+ attention_mask = [1] * len(input_ids)
+ input_type_mask = (
+ [1] * len(input_template_tokenized_part1)
+ + [2] * len(input_tokenized)
+ + [1] * len(input_template_tokenized_part2)
+ + [0] * len(sep_tokenized)
+ + [3] * len(label_template_part1_tokenized)
+ + [4] * len(label_tokenized)
+ + [3] * len(label_template_part2_tokenized)
+ + [0] * len(eos)
+ )
+
+ assert len(input_type_mask) == len(input_ids) == len(attention_mask)
+
+ return input_ids, attention_mask, input_type_mask
+
+ def __len__(self):
+ return len(self.input_ids)
+
+ def __getitem__(self, idx):
+ return {
+ "input_ids": self.input_ids[idx],
+ "attention_mask": self.attention_mask[idx],
+ "input_type_mask": self.input_type_mask[idx],
+ }
+
+ dataset = CPTDataset(data, tokenizer, TEMPLATE)
+
+ return dataset
+
+
+def test_model_initialization_text(global_tokenizer, config_text):
+ """Test model loading and PEFT model initialization."""
+ base_model = AutoModelForCausalLM.from_pretrained(MODEL_NAME)
+
+ model = get_peft_model(base_model, config_text)
+ assert model is not None, "PEFT model initialization failed"
+
+
+def test_model_initialization_random(global_tokenizer, config_random):
+ """Test model loading and PEFT model initialization."""
+ base_model = AutoModelForCausalLM.from_pretrained(MODEL_NAME)
+
+ model = get_peft_model(base_model, config_random)
+ assert model is not None, "PEFT model initialization failed"
+
+
+def test_model_initialization_wrong_task_type_warns():
+ # TODO: adjust this test to check for an error with PEFT v0.18.0
+ msg = "CPTConfig only supports task_type = CAUSAL_LM, setting it automatically"
+ with pytest.warns(FutureWarning, match=msg):
+ config = CPTConfig(task_type=TaskType.SEQ_CLS)
+ assert config.task_type == TaskType.CAUSAL_LM
+
+
+def test_model_training_random(sst_data, global_tokenizer, collator, config_random):
+ """Perform a short training run to verify the model and data integration."""
+
+ base_model = AutoModelForCausalLM.from_pretrained(MODEL_NAME)
+ model = get_peft_model(base_model, config_random)
+ emb = model.prompt_encoder.default.embedding.weight.data.clone().detach()
+ training_args = TrainingArguments(
+ output_dir="./results",
+ per_device_train_batch_size=1,
+ num_train_epochs=2,
+ remove_unused_columns=False,
+ save_strategy="no",
+ logging_steps=1,
+ )
+
+ train_dataset = dataset(sst_data["train"], global_tokenizer)
+
+ trainer = Trainer(model=model, args=training_args, train_dataset=train_dataset, data_collator=collator)
+
+ trainer.train()
+ # Verify that the embedding tensor remains unchanged (frozen)
+ assert torch.all(model.prompt_encoder.default.embedding.weight.data.clone().detach().cpu() == emb.cpu())
+
+ delta_emb = model.prompt_encoder.default.get_projection().clone().detach()
+ norm_delta = delta_emb.norm(dim=1).cpu()
+ epsilon = model.prompt_encoder.default.get_epsilon().cpu()
+ # Verify that the change in tokens is constrained to epsilon
+ assert torch.all(norm_delta <= epsilon)
+
+
+def test_model_batch_training_text(sst_data, global_tokenizer, collator, config_text):
+ """Perform a short training run to verify the model and data integration."""
+
+ base_model = AutoModelForCausalLM.from_pretrained(MODEL_NAME)
+ model = get_peft_model(base_model, config_text)
+ emb = model.prompt_encoder.default.embedding.weight.data.clone().detach()
+
+ training_args = TrainingArguments(
+ output_dir="./results",
+ per_device_train_batch_size=2,
+ num_train_epochs=2,
+ remove_unused_columns=False,
+ save_strategy="no",
+ logging_steps=1,
+ )
+
+ train_dataset = dataset(sst_data["train"], global_tokenizer)
+
+ trainer = Trainer(model=model, args=training_args, train_dataset=train_dataset, data_collator=collator)
+
+ trainer.train()
+ # Verify that the embedding tensor remains unchanged (frozen)
+ assert torch.all(model.prompt_encoder.default.embedding.weight.data.clone().detach().cpu() == emb.cpu())
+
+ cpt_tokens_type_mask = torch.Tensor(config_text.cpt_tokens_type_mask).long()
+ non_label_idx = (cpt_tokens_type_mask == 1) | (cpt_tokens_type_mask == 2) | (cpt_tokens_type_mask == 3)
+
+ delta_emb = model.prompt_encoder.default.get_projection().clone().detach()
+ norm_delta = delta_emb.norm(dim=1).cpu()
+ epsilon = model.prompt_encoder.default.get_epsilon().cpu()
+ # Verify that the change in tokens is constrained to epsilon
+ assert torch.all(norm_delta <= epsilon)
+ # Ensure that label tokens remain unchanged
+ assert torch.all((norm_delta == 0) == (~non_label_idx))
diff --git a/peft/tests/test_custom_models.py b/peft/tests/test_custom_models.py
new file mode 100644
index 0000000000000000000000000000000000000000..e88002f787589fe90d8a5ea65f77ef45f5704d6f
--- /dev/null
+++ b/peft/tests/test_custom_models.py
@@ -0,0 +1,5019 @@
+#!/usr/bin/env python3
+
+# coding=utf-8
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import copy
+import os
+import platform
+import re
+import shutil
+import tempfile
+import time
+from contextlib import contextmanager
+from functools import partial
+
+import pytest
+import torch
+from safetensors.torch import load_file as safe_load_file
+from torch import nn
+from transformers import AutoModelForCausalLM, AutoModelForSequenceClassification
+from transformers.pytorch_utils import Conv1D
+
+from peft import (
+ AdaLoraConfig,
+ BOFTConfig,
+ BoneConfig,
+ C3AConfig,
+ FourierFTConfig,
+ HRAConfig,
+ IA3Config,
+ LNTuningConfig,
+ LoHaConfig,
+ LoKrConfig,
+ LoraConfig,
+ OFTConfig,
+ PeftModel,
+ RandLoraConfig,
+ ShiraConfig,
+ TaskType,
+ TrainableTokensConfig,
+ VBLoRAConfig,
+ VeraConfig,
+ get_peft_model,
+)
+from peft.tuners.tuners_utils import BaseTunerLayer
+from peft.utils import AuxiliaryTrainingWrapper, infer_device
+
+from .testing_common import PeftCommonTester
+from .testing_utils import get_state_dict, require_non_cpu
+
+
+# MLP is a vanilla FF network with only linear layers
+# EmbConv1D has an embedding and a Conv1D layer
+# Conv2D has a Conv2D layer
+TEST_CASES = [
+ ########
+ # LoRA #
+ ########
+ ("Vanilla MLP 1 LoRA", "MLP", LoraConfig, {"target_modules": "lin0"}),
+ ("Vanilla MLP 2 LoRA", "MLP", LoraConfig, {"target_modules": ["lin0"]}),
+ ("Vanilla MLP 3 LoRA", "MLP", LoraConfig, {"target_modules": ["lin1"]}),
+ ("Vanilla MLP 4 LoRA", "MLP", LoraConfig, {"target_modules": ["lin0", "lin1"]}),
+ ("Vanilla MLP 5 LoRA", "MLP", LoraConfig, {"target_modules": ["lin0"], "modules_to_save": ["lin1"]}),
+ (
+ "Vanilla MLP 6 LoRA",
+ "MLP",
+ LoraConfig,
+ {
+ "target_modules": ["lin0"],
+ "lora_alpha": 4,
+ "lora_dropout": 0.1,
+ },
+ ),
+ ("Vanilla MLP 7 LoRA with DoRA", "MLP", LoraConfig, {"target_modules": ["lin0"], "use_dora": True}),
+ ("Vanilla MLP 8 LoRA with DoRA", "MLP", LoraConfig, {"target_modules": ["lin0", "lin1"], "use_dora": True}),
+ (
+ "Vanilla MLP 9 LoRA with DoRA",
+ "MLP",
+ LoraConfig,
+ {"target_modules": "lin1", "use_dora": True, "lora_alpha": 32},
+ ),
+ ("Embedding + transformers Conv1D 1 LoRA", "EmbConv1D", LoraConfig, {"target_modules": ["conv1d"]}),
+ ("Embedding + transformers Conv1D 2 LoRA", "EmbConv1D", LoraConfig, {"target_modules": ["emb"]}),
+ ("Embedding + transformers Conv1D 3 LoRA", "EmbConv1D", LoraConfig, {"target_modules": ["emb", "conv1d"]}),
+ (
+ "Embedding + transformers Conv1D 1 DoRA",
+ "EmbConv1D",
+ LoraConfig,
+ {"target_modules": ["conv1d"], "use_dora": True},
+ ),
+ ("Embedding + transformers Conv1D 2 DoRA", "EmbConv1D", LoraConfig, {"target_modules": ["emb"], "use_dora": True}),
+ (
+ "Embedding + transformers Conv1D 3 DoRA",
+ "EmbConv1D",
+ LoraConfig,
+ {"target_modules": ["emb", "conv1d"], "use_dora": True},
+ ),
+ (
+ "Embedding + transformers Conv1D 1 LoRA trainable_tokens",
+ "EmbConv1D",
+ LoraConfig,
+ {"target_modules": ["conv1d"], "trainable_token_indices": {"emb": [0, 10]}},
+ ),
+ ("Conv1d LoRA", "Conv1d", LoraConfig, {"target_modules": ["conv1d"]}),
+ ("Conv1d LoRA with DoRA", "Conv1d", LoraConfig, {"target_modules": ["conv1d"], "use_dora": True}),
+ ("Conv2d 1 LoRA", "Conv2d", LoraConfig, {"target_modules": ["conv2d"]}),
+ ("Conv2d 2 LoRA", "Conv2d", LoraConfig, {"target_modules": ["conv2d", "lin0"]}),
+ ("Conv2d 1 LoRA with DoRA", "Conv2d", LoraConfig, {"target_modules": ["conv2d"], "use_dora": True}),
+ ("Conv2d 2 LoRA with DoRA", "Conv2d", LoraConfig, {"target_modules": ["conv2d", "lin0"], "use_dora": True}),
+ ("Conv2d Groups LoRA", "Conv2dGroups", LoraConfig, {"target_modules": ["conv2d"]}),
+ ("Conv2d Groups2 LoRA", "Conv2dGroups2", LoraConfig, {"target_modules": ["conv2d"]}),
+ ("Conv2d Groups LoRA with DoRA", "Conv2dGroups", LoraConfig, {"target_modules": ["conv2d"], "use_dora": True}),
+ ("Conv2d Groups2 LoRA with DoRA", "Conv2dGroups2", LoraConfig, {"target_modules": ["conv2d"], "use_dora": True}),
+ ("Conv3d 1 LoRA", "Conv3d", LoraConfig, {"target_modules": ["conv3d"]}),
+ ("Conv3d 2 LoRA", "Conv3d", LoraConfig, {"target_modules": ["conv3d", "lin0"]}),
+ ("Conv3d 1 LoRA with DoRA", "Conv3d", LoraConfig, {"target_modules": ["conv3d"], "use_dora": True}),
+ ("Conv3d 2 LoRA with DoRA", "Conv3d", LoraConfig, {"target_modules": ["conv3d", "lin0"], "use_dora": True}),
+ # LoRA with lora_B bias enabled (note: embedding is not supported)
+ # It's important to set lora_alpha != r to ensure that scaling is taken into account correctly
+ (
+ "Vanilla MLP 1 LoRA with lora_b bias",
+ "MLP",
+ LoraConfig,
+ {"target_modules": ["lin0", "lin1"], "lora_bias": True, "lora_alpha": 32},
+ ),
+ (
+ "Conv2d 1 LoRA with lora_b bias",
+ "Conv2d",
+ LoraConfig,
+ {"target_modules": ["conv2d"], "lora_bias": True, "lora_alpha": 32},
+ ),
+ (
+ "Conv3d 1 LoRA with lora_b bias",
+ "Conv3d",
+ LoraConfig,
+ {"target_modules": ["conv3d"], "lora_bias": True, "lora_alpha": 32},
+ ),
+ ("MHA 1 LoRA", "MHA", LoraConfig, {"target_modules": ["mha"]}),
+ ("MHA 2 LoRA", "MHA", LoraConfig, {"target_modules": ["mha", "lin0"]}),
+ # targeting parameters directly
+ ("MLP 1 using nn.Parameter LoRA", "MlpUsingParameters", LoraConfig, {"target_parameters": ["lin0.weight"]}),
+ (
+ "MLP 2 using nn.Parameter LoRA",
+ "MLP",
+ LoraConfig,
+ {"target_modules": ["lin0"], "target_parameters": ["lin1.weight"]},
+ ),
+ #######
+ # IA³ #
+ #######
+ ("Vanilla MLP 1 IA3", "MLP", IA3Config, {"target_modules": "lin0", "feedforward_modules": []}),
+ ("Vanilla MLP 2 IA3", "MLP", IA3Config, {"target_modules": "lin0", "feedforward_modules": "lin0"}),
+ ("Vanilla MLP 3 IA3", "MLP", IA3Config, {"target_modules": ["lin0"], "feedforward_modules": []}),
+ ("Vanilla MLP 4 IA3", "MLP", IA3Config, {"target_modules": ["lin0"], "feedforward_modules": ["lin0"]}),
+ ("Vanilla MLP 5 IA3", "MLP", IA3Config, {"target_modules": ["lin1"], "feedforward_modules": []}),
+ ("Vanilla MLP 6 IA3", "MLP", IA3Config, {"target_modules": ["lin1"], "feedforward_modules": ["lin1"]}),
+ (
+ "Vanilla MLP 7 IA3",
+ "MLP",
+ IA3Config,
+ {"target_modules": ["lin0", "lin1"], "feedforward_modules": []},
+ ),
+ (
+ "Vanilla MLP 8 IA3",
+ "MLP",
+ IA3Config,
+ {"target_modules": ["lin0", "lin1"], "feedforward_modules": ["lin0", "lin1"]},
+ ),
+ (
+ "Vanilla MLP 9 IA3",
+ "MLP",
+ IA3Config,
+ {"target_modules": ["lin0"], "modules_to_save": ["lin1"], "feedforward_modules": ["lin0"]},
+ ),
+ (
+ "transformers Conv1D 1 IA3",
+ "EmbConv1D",
+ IA3Config,
+ {"target_modules": ["conv1d"], "feedforward_modules": ["conv1d"]},
+ ),
+ (
+ "transformers Conv1D 2 IA3",
+ "EmbConv1D",
+ IA3Config,
+ {"target_modules": ["conv1d", "lin0"], "feedforward_modules": ["conv1d", "lin0"]},
+ ),
+ (
+ "transformers Conv1D 1 IA3",
+ "EmbConv1D",
+ IA3Config,
+ {"target_modules": ["conv1d"], "feedforward_modules": ["conv1d"], "modules_to_save": ["lin0"]},
+ ),
+ ("Conv2d 1 IA3", "Conv2d", IA3Config, {"target_modules": ["conv2d"], "feedforward_modules": []}),
+ ("Conv2d 2 IA3", "Conv2d", IA3Config, {"target_modules": ["conv2d"], "feedforward_modules": ["conv2d"]}),
+ (
+ "Conv2d 3 IA3",
+ "Conv2d",
+ IA3Config,
+ {"target_modules": ["conv2d", "lin0"], "feedforward_modules": []},
+ ),
+ (
+ "Conv2d 4 IA3",
+ "Conv2d",
+ IA3Config,
+ {"target_modules": ["conv2d", "lin0"], "feedforward_modules": ["conv2d"]},
+ ),
+ (
+ "Conv2d 5 IA3",
+ "Conv2d",
+ IA3Config,
+ {"target_modules": ["conv2d", "lin0"], "feedforward_modules": ["conv2d", "lin0"]},
+ ),
+ ("Conv3d 1 IA3", "Conv3d", IA3Config, {"target_modules": ["conv3d"], "feedforward_modules": []}),
+ ("Conv3d 2 IA3", "Conv3d", IA3Config, {"target_modules": ["conv3d"], "feedforward_modules": ["conv3d"]}),
+ (
+ "Conv3d 3 IA3",
+ "Conv3d",
+ IA3Config,
+ {"target_modules": ["conv3d", "lin0"], "feedforward_modules": []},
+ ),
+ (
+ "Conv3d 4 IA3",
+ "Conv3d",
+ IA3Config,
+ {"target_modules": ["conv3d", "lin0"], "feedforward_modules": ["conv3d"]},
+ ),
+ (
+ "Conv3d 5 IA3",
+ "Conv3d",
+ IA3Config,
+ {"target_modules": ["conv3d", "lin0"], "feedforward_modules": ["conv3d", "lin0"]},
+ ),
+ ########
+ # LoHa #
+ ########
+ ("Vanilla MLP 1 LOHA", "MLP", LoHaConfig, {"target_modules": "lin0"}),
+ ("Vanilla MLP 2 LOHA", "MLP", LoHaConfig, {"target_modules": ["lin0"]}),
+ ("Vanilla MLP 3 LOHA", "MLP", LoHaConfig, {"target_modules": ["lin1"]}),
+ ("Vanilla MLP 4 LOHA", "MLP", LoHaConfig, {"target_modules": ["lin0", "lin1"]}),
+ ("Vanilla MLP 5 LOHA", "MLP", LoHaConfig, {"target_modules": ["lin0"], "modules_to_save": ["lin1"]}),
+ (
+ "Vanilla MLP 6 LOHA",
+ "MLP",
+ LoHaConfig,
+ {
+ "target_modules": ["lin0"],
+ "alpha": 4,
+ "module_dropout": 0.1,
+ },
+ ),
+ ("Vanilla MLP 7 LOHA", "MLP", LoHaConfig, {"target_modules": "lin0", "rank_dropout": 0.5}),
+ ("Conv2d 1 LOHA", "Conv2d", LoHaConfig, {"target_modules": ["conv2d"]}),
+ ("Conv2d 2 LOHA", "Conv2d", LoHaConfig, {"target_modules": ["conv2d", "lin0"]}),
+ ("Conv2d 3 LOHA", "Conv2d", LoHaConfig, {"target_modules": ["conv2d"], "use_effective_conv2d": True}),
+ ("Conv2d 4 LOHA", "Conv2d", LoHaConfig, {"target_modules": ["conv2d", "lin0"], "use_effective_conv2d": True}),
+ # LoKr
+ ("Vanilla MLP 1 LOKR", "MLP", LoKrConfig, {"target_modules": "lin0"}),
+ ("Vanilla MLP 2 LOKR", "MLP", LoKrConfig, {"target_modules": ["lin0"]}),
+ ("Vanilla MLP 3 LOKR", "MLP", LoKrConfig, {"target_modules": ["lin1"]}),
+ ("Vanilla MLP 4 LOKR", "MLP", LoKrConfig, {"target_modules": ["lin0", "lin1"]}),
+ ("Vanilla MLP 5 LOKR", "MLP", LoKrConfig, {"target_modules": ["lin0"], "modules_to_save": ["lin1"]}),
+ (
+ "Vanilla MLP 6 LOKR",
+ "MLP",
+ LoKrConfig,
+ {
+ "target_modules": ["lin0"],
+ "alpha": 4,
+ "module_dropout": 0.1,
+ },
+ ),
+ ("Vanilla MLP 7 LOKR", "MLP", LoKrConfig, {"target_modules": "lin0", "rank_dropout": 0.5}),
+ ("Vanilla MLP 8 LOKR", "MLP", LoKrConfig, {"target_modules": "lin0", "decompose_both": True, "r": 1, "alpha": 1}),
+ ("Conv2d 1 LOKR", "Conv2d", LoKrConfig, {"target_modules": ["conv2d"]}),
+ ("Conv2d 2 LOKR", "Conv2d", LoKrConfig, {"target_modules": ["conv2d", "lin0"]}),
+ ("Conv2d 3 LOKR", "Conv2d", LoKrConfig, {"target_modules": ["conv2d"], "use_effective_conv2d": True}),
+ ("Conv2d 4 LOKR", "Conv2d", LoKrConfig, {"target_modules": ["conv2d", "lin0"], "use_effective_conv2d": True}),
+ (
+ "Conv2d 5 LOKR",
+ "Conv2d",
+ LoKrConfig,
+ {"target_modules": ["conv2d", "lin0"], "use_effective_conv2d": True, "decompose_both": True},
+ ),
+ (
+ "Conv2d 6 LOKR",
+ "Conv2d",
+ LoKrConfig,
+ {"target_modules": ["conv2d", "lin0"], "use_effective_conv2d": True, "decompose_factor": 4},
+ ),
+ (
+ "Conv2d 7 LOKR",
+ "Conv2d",
+ LoKrConfig,
+ {
+ "target_modules": ["conv2d", "lin0"],
+ "use_effective_conv2d": True,
+ "decompose_both": True,
+ "decompose_factor": 4,
+ },
+ ),
+ ########
+ # OFT #
+ ########
+ (
+ "Vanilla MLP 1 OFT",
+ "MLP",
+ OFTConfig,
+ {"r": 2, "oft_block_size": 0, "target_modules": "lin0", "use_cayley_neumann": False},
+ ),
+ (
+ "Vanilla MLP 2 OFT",
+ "MLP",
+ OFTConfig,
+ {"r": 2, "oft_block_size": 0, "target_modules": ["lin0"], "use_cayley_neumann": False},
+ ),
+ (
+ "Vanilla MLP 5 OFT",
+ "MLP",
+ OFTConfig,
+ {
+ "r": 2,
+ "oft_block_size": 0,
+ "target_modules": ["lin0"],
+ "modules_to_save": ["lin1"],
+ "use_cayley_neumann": False,
+ },
+ ),
+ (
+ "Vanilla MLP 6 OFT",
+ "MLP",
+ OFTConfig,
+ {
+ "r": 2,
+ "oft_block_size": 0,
+ "target_modules": ["lin0"],
+ "module_dropout": 0.1,
+ "use_cayley_neumann": False,
+ },
+ ),
+ (
+ "Vanilla MLP 7 OFT",
+ "MLP",
+ OFTConfig,
+ {"r": 2, "oft_block_size": 0, "target_modules": ["lin0"], "coft": True, "eps": 1e-2},
+ ),
+ (
+ "Vanilla MLP 8 OFT",
+ "MLP",
+ OFTConfig,
+ {"r": 2, "oft_block_size": 0, "target_modules": ["lin0"], "block_share": True, "use_cayley_neumann": False},
+ ),
+ (
+ "Vanilla MLP 9 OFT",
+ "MLP",
+ OFTConfig,
+ {"r": 2, "oft_block_size": 0, "target_modules": ["lin0"], "coft": True, "eps": 1e-2, "block_share": True},
+ ),
+ (
+ "Vanilla MLP 10 OFT",
+ "MLP",
+ OFTConfig,
+ {"r": 0, "oft_block_size": 2, "target_modules": ["lin0"], "use_cayley_neumann": True},
+ ),
+ (
+ "Vanilla MLP 11 OFT",
+ "MLP",
+ OFTConfig,
+ {"r": 0, "oft_block_size": 2, "target_modules": ["lin0"], "use_cayley_neumann": False},
+ ),
+ (
+ "Vanilla MLP 12 OFT",
+ "MLP",
+ OFTConfig,
+ {
+ "r": 0,
+ "oft_block_size": 2,
+ "target_modules": ["lin0"],
+ "coft": True,
+ "eps": 1e-2,
+ "block_share": True,
+ "use_cayley_neumann": True,
+ },
+ ),
+ (
+ "Vanilla MLP 13 OFT",
+ "MLP",
+ OFTConfig,
+ {
+ "r": 0,
+ "oft_block_size": 2,
+ "target_modules": ["lin0"],
+ "coft": True,
+ "eps": 1e-2,
+ "block_share": True,
+ "use_cayley_neumann": False,
+ },
+ ),
+ ("Conv2d 1 OFT", "Conv2d", OFTConfig, {"r": 5, "oft_block_size": 0, "target_modules": ["conv2d"]}),
+ ("Conv2d 3 OFT", "Conv2d", OFTConfig, {"r": 5, "oft_block_size": 0, "target_modules": ["conv2d"], "coft": True}),
+ (
+ "Conv2d 4 OFT",
+ "Conv2d",
+ OFTConfig,
+ {"r": 5, "oft_block_size": 0, "target_modules": ["conv2d"], "block_share": True},
+ ),
+ (
+ "Conv2d 5 OFT",
+ "Conv2d",
+ OFTConfig,
+ {"r": 5, "oft_block_size": 0, "target_modules": ["conv2d"], "coft": True, "block_share": True},
+ ),
+ ########
+ # HRA #
+ ########
+ ("Vanilla MLP 1 HRA", "MLP", HRAConfig, {"target_modules": "lin0"}),
+ ("Vanilla MLP 2 HRA", "MLP", HRAConfig, {"target_modules": ["lin0"]}),
+ ("Vanilla MLP 3 HRA", "MLP", HRAConfig, {"target_modules": ["lin0", "lin1"]}),
+ ("Vanilla MLP 5 HRA", "MLP", HRAConfig, {"target_modules": ["lin0"], "modules_to_save": ["lin1"]}),
+ ("Conv2d 1 HRA", "Conv2d", HRAConfig, {"target_modules": ["conv2d"]}),
+ ########
+ # Bone #
+ ########
+ ("Vanilla MLP 1 Bone", "MLP", BoneConfig, {"target_modules": "lin0", "r": 2}),
+ ("Vanilla MLP 2 Bone", "MLP", BoneConfig, {"target_modules": ["lin0"], "r": 2}),
+ ("Vanilla MLP 3 Bone", "MLP", BoneConfig, {"target_modules": ["lin0", "lin1"], "r": 2}),
+ ("Vanilla MLP 5 Bone", "MLP", BoneConfig, {"target_modules": ["lin0"], "modules_to_save": ["lin1"], "r": 2}),
+ ("Vanilla MLP 1 Bone", "MLP", BoneConfig, {"target_modules": "lin0", "r": 2, "init_weights": "bat"}),
+ ("Vanilla MLP 2 Bone", "MLP", BoneConfig, {"target_modules": ["lin0"], "r": 2, "init_weights": "bat"}),
+ ("Vanilla MLP 3 Bone", "MLP", BoneConfig, {"target_modules": ["lin0", "lin1"], "r": 2, "init_weights": "bat"}),
+ (
+ "Vanilla MLP 5 Bone",
+ "MLP",
+ BoneConfig,
+ {"target_modules": ["lin0"], "modules_to_save": ["lin1"], "r": 2, "init_weights": "bat"},
+ ),
+ #############
+ # LN Tuning #
+ #############
+ ("LayerNorm 1 LNTuning", "MLP_LayerNorm", LNTuningConfig, {"target_modules": "layernorm0"}),
+ ("LayerNorm 2 LNTuning", "MLP_LayerNorm", LNTuningConfig, {"target_modules": ["layernorm0"]}),
+ (
+ "LayerNorm 3 LNTuning",
+ "MLP_LayerNorm",
+ LNTuningConfig,
+ {"target_modules": ["layernorm0"], "modules_to_save": ["layernorm1"]},
+ ),
+ ("Linear 4 LNTuning", "MLP_LayerNorm", LNTuningConfig, {"target_modules": "lin0"}),
+ ("Linear 5 LNTuning", "MLP_LayerNorm", LNTuningConfig, {"target_modules": ["lin0"]}),
+ ########
+ # BOFT #
+ ########
+ ("Vanilla MLP 1 BOFT", "MLP", BOFTConfig, {"target_modules": ["lin1"], "boft_block_size": 2}),
+ (
+ "Vanilla MLP 2 BOFT",
+ "MLP",
+ BOFTConfig,
+ {"target_modules": ["lin1"], "modules_to_save": ["lin0"], "boft_block_size": 2},
+ ),
+ (
+ "Vanilla MLP 3 BOFT",
+ "MLP",
+ BOFTConfig,
+ {
+ "target_modules": ["lin1"],
+ "boft_block_size": 2,
+ "boft_dropout": 0.1,
+ },
+ ),
+ (
+ "Vanilla MLP 4 BOFT",
+ "MLP",
+ BOFTConfig,
+ {"target_modules": ["lin1"], "boft_block_size": 2, "boft_block_num": 0, "boft_n_butterfly_factor": 1},
+ ),
+ (
+ "Vanilla MLP 5 BOFT",
+ "MLP",
+ BOFTConfig,
+ {"target_modules": ["lin1"], "boft_block_size": 0, "boft_block_num": 2, "boft_n_butterfly_factor": 1},
+ ),
+ (
+ "Vanilla MLP 6 BOFT",
+ "MLP",
+ BOFTConfig,
+ {"target_modules": ["lin1"], "boft_block_size": 10, "boft_block_num": 0, "boft_n_butterfly_factor": 2},
+ ),
+ (
+ "Conv2d 1 BOFT",
+ "Conv2d",
+ BOFTConfig,
+ {"target_modules": ["conv2d"], "boft_block_size": 45, "boft_block_num": 0, "boft_n_butterfly_factor": 1},
+ ),
+ (
+ "Conv2d 2 BOFT",
+ "Conv2d",
+ BOFTConfig,
+ {"target_modules": ["conv2d"], "boft_block_size": 0, "boft_block_num": 1, "boft_n_butterfly_factor": 1},
+ ),
+ (
+ "MLP2 1 BOFT",
+ "MLP2",
+ BOFTConfig,
+ {"target_modules": ["lin1"], "boft_block_size": 2, "boft_block_num": 0, "boft_n_butterfly_factor": 3},
+ ),
+ (
+ "MLP2 2 BOFT",
+ "MLP2",
+ BOFTConfig,
+ {"target_modules": ["lin1"], "boft_block_size": 0, "boft_block_num": 8, "boft_n_butterfly_factor": 3},
+ ),
+ (
+ "Conv2d2 1 BOFT",
+ "Conv2d2",
+ BOFTConfig,
+ {"target_modules": ["conv2d"], "boft_block_size": 2, "boft_block_num": 0, "boft_n_butterfly_factor": 2},
+ ),
+ (
+ "Conv2d2 1 BOFT",
+ "Conv2d2",
+ BOFTConfig,
+ {"target_modules": ["conv2d"], "boft_block_size": 2, "boft_block_num": 0, "boft_n_butterfly_factor": 3},
+ ),
+ #########
+ # SHiRA #
+ #########
+ ("Vanilla MLP 1 SHiRA", "MLP", ShiraConfig, {"r": 1, "target_modules": "lin0", "init_weights": False}),
+ ("Vanilla MLP 2 SHiRA", "MLP", ShiraConfig, {"r": 1, "target_modules": ["lin0"], "init_weights": False}),
+ ("Vanilla MLP 3 SHiRA", "MLP", ShiraConfig, {"r": 1, "target_modules": ["lin1"], "init_weights": False}),
+ (
+ "Vanilla MLP 4 SHiRA",
+ "MLP",
+ ShiraConfig,
+ {"r": 1, "target_modules": ["lin0", "lin1"], "random_seed": 56, "init_weights": False},
+ ),
+ (
+ "Vanilla MLP 5 SHiRA",
+ "MLP",
+ ShiraConfig,
+ {"r": 1, "target_modules": ["lin0"], "init_weights": False},
+ ),
+ ########
+ # VeRA #
+ ########
+ ("Vanilla MLP 1 VeRA", "MLP", VeraConfig, {"target_modules": "lin0"}),
+ ("Vanilla MLP 2 VeRA", "MLP", VeraConfig, {"target_modules": ["lin0"]}),
+ ("Vanilla MLP 3 VeRA", "MLP", VeraConfig, {"target_modules": ["lin1"]}),
+ ("Vanilla MLP 4 VeRA", "MLP", VeraConfig, {"target_modules": ["lin0", "lin1"]}),
+ (
+ "Vanilla MLP 5 VeRA",
+ "MLP",
+ VeraConfig,
+ {"target_modules": ["lin0"], "modules_to_save": ["lin1"]},
+ ),
+ (
+ "Embedding + transformers Conv1D 1 VeRA",
+ "EmbConv1D",
+ VeraConfig,
+ {"target_modules": ["conv1d"]},
+ ),
+ ########
+ # FourierFT #
+ ########
+ ("Vanilla MLP 1 FourierFT", "MLP", FourierFTConfig, {"n_frequency": 10, "target_modules": "lin0"}),
+ ("Vanilla MLP 2 FourierFT", "MLP", FourierFTConfig, {"n_frequency": 10, "target_modules": ["lin0"]}),
+ ("Vanilla MLP 3 FourierFT", "MLP", FourierFTConfig, {"n_frequency": 10, "target_modules": ["lin1"]}),
+ (
+ "Vanilla MLP 5 FourierFT",
+ "MLP",
+ FourierFTConfig,
+ {"n_frequency": 10, "target_modules": ["lin0"], "modules_to_save": ["lin1"]},
+ ),
+ (
+ "Vanilla MLP 6 FourierFT",
+ "MLP",
+ FourierFTConfig,
+ {"n_frequency": 10, "target_modules": ["lin0", "lin1"], "modules_to_save": ["lin1"]},
+ ),
+ (
+ "Vanilla MLP 7 FourierFT",
+ "MLP",
+ FourierFTConfig,
+ {
+ "n_frequency_pattern": {"lin0": 5, "lin1": 10},
+ "target_modules": ["lin0", "lin1"],
+ "modules_to_save": ["lin1"],
+ },
+ ),
+ ##########
+ # VBLoRA #
+ ##########
+ ("Vanilla MLP 1 VBLoRA", "MLP", VBLoRAConfig, {"target_modules": "lin0", "vector_length": 1, "num_vectors": 5}),
+ ("Vanilla MLP 2 VBLoRA", "MLP", VBLoRAConfig, {"target_modules": ["lin0"], "vector_length": 1, "num_vectors": 5}),
+ ("Vanilla MLP 3 VBLoRA", "MLP", VBLoRAConfig, {"target_modules": ["lin1"], "vector_length": 2, "num_vectors": 5}),
+ (
+ "Vanilla MLP 4 VBLoRA",
+ "MLP",
+ VBLoRAConfig,
+ {"target_modules": ["lin0", "lin1"], "vector_length": 1, "num_vectors": 5},
+ ),
+ (
+ "Vanilla MLP 5 VBLoRA",
+ "MLP",
+ VBLoRAConfig,
+ {"target_modules": ["lin0"], "modules_to_save": ["lin1"], "vector_length": 1, "num_vectors": 5},
+ ),
+ (
+ "Embedding + transformers Conv1D 1 VBLoRA",
+ "EmbConv1D",
+ VBLoRAConfig,
+ {"target_modules": ["conv1d"], "vector_length": 1, "num_vectors": 2},
+ ),
+ ###################
+ # TrainableTokens #
+ ###################
+ (
+ "Embedding + transformers Conv1D 1 trainable_tokens",
+ "EmbConv1D",
+ TrainableTokensConfig,
+ {"target_modules": ["emb"], "token_indices": [0, 1, 3], "init_weights": False},
+ ),
+ ############
+ # RandLora #
+ ############
+ # We have to reduce the default scaling parameter to avoid nans when using large learning rates
+ ("Vanilla MLP 1 RandLora", "MLP", RandLoraConfig, {"target_modules": "lin0", "randlora_alpha": 1}),
+ ("Vanilla MLP 2 RandLora", "MLP", RandLoraConfig, {"target_modules": ["lin0"], "randlora_alpha": 1}),
+ ("Vanilla MLP 3 RandLora", "MLP", RandLoraConfig, {"target_modules": ["lin1"], "randlora_alpha": 1}),
+ ("Vanilla MLP 4 RandLora", "MLP", RandLoraConfig, {"target_modules": ["lin0", "lin1"], "randlora_alpha": 1}),
+ (
+ "Vanilla MLP 5 RandLora",
+ "MLP",
+ RandLoraConfig,
+ {"target_modules": ["lin0", "lin1"], "sparse": True, "randlora_alpha": 1},
+ ),
+ (
+ "Vanilla MLP 6 RandLora",
+ "MLP",
+ RandLoraConfig,
+ {"target_modules": ["lin0", "lin1"], "very_sparse": True, "randlora_alpha": 1},
+ ),
+ (
+ "Vanilla MLP 7 RandLora",
+ "MLP",
+ RandLoraConfig,
+ {"target_modules": ["lin0"], "modules_to_save": ["lin1"], "randlora_alpha": 1},
+ ),
+ #######
+ # C3A #
+ #######
+ ("Vanilla MLP 1 C3A", "MLP", C3AConfig, {"block_size": 2, "target_modules": "lin0"}),
+ ("Vanilla MLP 2 C3A", "MLP", C3AConfig, {"block_size": 2, "target_modules": ["lin0"]}),
+ ("Vanilla MLP 3 C3A", "MLP", C3AConfig, {"block_size": 2, "target_modules": ["lin1"]}),
+ (
+ "Vanilla MLP 5 C3A",
+ "MLP",
+ C3AConfig,
+ {"block_size": 10, "target_modules": ["lin0"], "modules_to_save": ["lin1"]},
+ ),
+ (
+ "Vanilla MLP 6 C3A",
+ "MLP",
+ C3AConfig,
+ {"block_size": 10, "target_modules": ["lin0", "lin1"], "modules_to_save": ["lin1"]},
+ ),
+ (
+ "Vanilla MLP 7 C3A",
+ "MLP",
+ C3AConfig,
+ {
+ "block_size_pattern": {"lin0": 5, "lin1": 10},
+ "target_modules": ["lin0", "lin1"],
+ "modules_to_save": ["lin1"],
+ },
+ ),
+]
+
+# For this test matrix, each tuple consists of:
+# - test name
+# - tuner method
+# - config_cls
+# - 1st config kwargs
+# - 2nd config kwargs
+# The model used for this test is `MLP`, which uses linear layers `lin0` and `lin1`
+MULTIPLE_ACTIVE_ADAPTERS_TEST_CASES = [
+ (
+ "LoRA Same",
+ "lora",
+ LoraConfig,
+ {"target_modules": ["lin0"], "init_lora_weights": False},
+ {"target_modules": ["lin0"], "init_lora_weights": False},
+ ),
+ (
+ "LoRA Different",
+ "lora",
+ LoraConfig,
+ {"target_modules": ["lin0"], "init_lora_weights": False},
+ {"target_modules": ["lin1"], "init_lora_weights": False},
+ ),
+ (
+ "LoRA + trainable tokens Same",
+ "lora+trainable_tokens",
+ LoraConfig,
+ {"target_modules": ["lin0"], "init_lora_weights": False, "trainable_token_indices": {"emb": [0, 1, 2]}},
+ {"target_modules": ["lin0"], "init_lora_weights": False, "trainable_token_indices": {"emb": [3, 4, 5, 6]}},
+ ),
+ (
+ "LoRA + trainable tokens Different",
+ "lora+trainable_tokens",
+ LoraConfig,
+ {"target_modules": ["lin0"], "init_lora_weights": False, "trainable_token_indices": {"emb": [0, 1, 2]}},
+ {"target_modules": ["lin1"], "init_lora_weights": False, "trainable_token_indices": {"emb": [3, 4, 5, 6]}},
+ ),
+ (
+ "LoRA targeting nn.Parameter Same",
+ "lora",
+ LoraConfig,
+ {"target_parameters": ["lin0.weight"], "init_lora_weights": False},
+ {"target_parameters": ["lin0.weight"], "init_lora_weights": False},
+ ),
+ (
+ "LoRA targeting nn.Parameter Different",
+ "lora",
+ LoraConfig,
+ {"target_parameters": ["lin0.weight"], "init_lora_weights": False},
+ {"target_parameters": ["lin1.weight"], "init_lora_weights": False},
+ ),
+ (
+ "IA3 Same",
+ "ia3",
+ IA3Config,
+ {
+ "target_modules": ["lin0"],
+ "feedforward_modules": ["lin0"],
+ "init_ia3_weights": False,
+ },
+ {
+ "target_modules": ["lin0"],
+ "feedforward_modules": ["lin0"],
+ "init_ia3_weights": False,
+ },
+ ),
+ (
+ "IA3 Different",
+ "ia3",
+ IA3Config,
+ {
+ "target_modules": ["lin0"],
+ "feedforward_modules": ["lin0"],
+ "init_ia3_weights": False,
+ },
+ {
+ "target_modules": ["lin1"],
+ "feedforward_modules": ["lin1"],
+ "init_ia3_weights": False,
+ },
+ ),
+ (
+ "AdaLora Same",
+ "adalora",
+ AdaLoraConfig,
+ {"target_modules": ["lin0"], "init_lora_weights": False, "inference_mode": True, "total_step": 1},
+ {"target_modules": ["lin0"], "init_lora_weights": False, "inference_mode": True, "total_step": 1},
+ ),
+ (
+ "AdaLora Different",
+ "adalora",
+ AdaLoraConfig,
+ {"target_modules": ["lin0"], "init_lora_weights": False, "inference_mode": True, "total_step": 1},
+ {"target_modules": ["lin1"], "init_lora_weights": False, "inference_mode": True, "total_step": 1},
+ ),
+ (
+ "FourierFT Same",
+ "fourierft",
+ FourierFTConfig,
+ {"n_frequency": 10, "target_modules": ["lin0"]},
+ {"n_frequency": 10, "target_modules": ["lin0"]},
+ ),
+ (
+ "FourierFT Different",
+ "fourierft",
+ FourierFTConfig,
+ {"n_frequency": 10, "target_modules": ["lin0"]},
+ {"n_frequency": 10, "target_modules": ["lin1"]},
+ ),
+ (
+ "SHiRA Same",
+ "shira",
+ ShiraConfig,
+ {"r": 1, "target_modules": ["lin0"], "init_weights": False},
+ {"r": 1, "target_modules": ["lin0"], "init_weights": False},
+ ),
+ (
+ "SHiRA Different",
+ "shira",
+ ShiraConfig,
+ {"r": 1, "target_modules": ["lin0"], "init_weights": False},
+ {"r": 1, "target_modules": ["lin1"], "init_weights": False},
+ ),
+ # Note: Currently, we cannot target lin0 and lin1 with different adapters when using VeRA. The reason is that the
+ # first adapter being created will result in a vera_A or vera_B shape that is too small for the next adapter
+ # (remember that VeRA shares these parameters across all layers), which results in an error.
+ (
+ "VeRA Same",
+ "vera",
+ VeraConfig,
+ {"target_modules": ["lin0"], "init_weights": False},
+ {"target_modules": ["lin0"], "init_weights": False},
+ ),
+ # Note: RandLora may present the same problem mentioned above for Vera.
+ (
+ "RandLora Same",
+ "randlora",
+ RandLoraConfig,
+ {"target_modules": ["lin0"], "init_weights": False},
+ {"target_modules": ["lin0"], "init_weights": False},
+ ),
+ (
+ "HRA Same",
+ "hra",
+ HRAConfig,
+ {"target_modules": ["lin0"], "init_weights": False},
+ {"target_modules": ["lin0"], "init_weights": False},
+ ),
+ (
+ "HRA Different",
+ "hra",
+ HRAConfig,
+ {"target_modules": ["lin0"], "init_weights": False},
+ {"target_modules": ["lin1"], "init_weights": False},
+ ),
+ (
+ "Bone Same",
+ "bone",
+ BoneConfig,
+ {"target_modules": ["lin0"], "init_weights": False, "r": 2},
+ {"target_modules": ["lin0"], "init_weights": False, "r": 2},
+ ),
+ (
+ "Bone Different",
+ "bone",
+ BoneConfig,
+ {"target_modules": ["lin0"], "init_weights": False, "r": 2},
+ {"target_modules": ["lin1"], "init_weights": False, "r": 2},
+ ),
+ (
+ "VBLoRA Same",
+ "vblora",
+ VBLoRAConfig,
+ {"target_modules": ["lin0"], "vector_length": 2, "init_vector_bank_bound": 0.1},
+ {"target_modules": ["lin0"], "vector_length": 2, "init_vector_bank_bound": 0.1},
+ ),
+ (
+ "VBLoRA Different",
+ "vblora",
+ VBLoRAConfig,
+ {"target_modules": ["lin0"], "vector_length": 2, "init_vector_bank_bound": 0.1},
+ {"target_modules": ["lin1"], "vector_length": 2, "init_vector_bank_bound": 0.1},
+ ),
+ (
+ "BOFT Same",
+ "boft",
+ BOFTConfig,
+ {"target_modules": ["lin0"], "init_weights": False, "boft_block_size": 2},
+ {"target_modules": ["lin0"], "init_weights": False, "boft_block_size": 2},
+ ),
+ (
+ "BOFT Different",
+ "boft",
+ BOFTConfig,
+ {"target_modules": ["lin0"], "init_weights": False, "boft_block_size": 2},
+ {"target_modules": ["lin1"], "init_weights": False, "boft_block_size": 2},
+ ),
+]
+
+PREFIXES = {
+ IA3Config: "ia3_",
+ LoraConfig: "lora_",
+ LoHaConfig: "hada_",
+ LoKrConfig: "lokr_",
+ OFTConfig: "oft_",
+ BOFTConfig: "boft_",
+ LNTuningConfig: "ln_tuning_",
+ VeraConfig: "vera_lambda_",
+ RandLoraConfig: "randlora_",
+ FourierFTConfig: "fourierft_",
+ C3AConfig: "c3a_",
+ HRAConfig: "hra_",
+ ShiraConfig: "shira_",
+ VBLoRAConfig: "vblora_",
+ BoneConfig: "bone_",
+ TrainableTokensConfig: "trainable_tokens_",
+}
+
+
+class MLP(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.relu = nn.ReLU()
+ self.drop = nn.Dropout(0.5)
+ self.lin1 = nn.Linear(20, 2, bias=bias)
+ self.sm = nn.LogSoftmax(dim=-1)
+ self.dtype = torch.float
+
+ def forward(self, X):
+ X = X.to(self.dtype)
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = self.drop(X)
+ X = self.lin1(X)
+ X = self.sm(X)
+ return X
+
+
+class MLPWithGRU(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.relu = nn.ReLU()
+ self.drop = nn.Dropout(0.5)
+ self.gru = nn.GRU(input_size=20, hidden_size=20, num_layers=1, batch_first=True, bias=bias)
+ self.fc = nn.Linear(20, 2, bias=bias)
+ self.sm = nn.LogSoftmax(dim=-1)
+ self.dtype = torch.float
+
+ def forward(self, X):
+ X = X.to(self.dtype)
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = self.drop(X)
+ X = X.unsqueeze(1)
+ X, _ = self.gru(X)
+ X = X.squeeze(1)
+ X = self.fc(X)
+ X = self.sm(X)
+ return X
+
+
+class MLP_LayerNorm(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.layernorm0 = nn.LayerNorm(10, 10)
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.relu = nn.ReLU()
+ self.drop = nn.Dropout(0.5)
+ self.layernorm1 = nn.LayerNorm(20, 20)
+ self.lin1 = nn.Linear(20, 2, bias=bias)
+ self.sm = nn.LogSoftmax(dim=-1)
+ self.dtype = torch.float
+
+ def forward(self, X):
+ X = X.to(self.dtype)
+ X = self.layernorm0(X)
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = self.drop(X)
+ X = self.layernorm1(X)
+ X = self.lin1(X)
+ X = self.sm(X)
+ return X
+
+
+class MLP2(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.lin0 = nn.Linear(10, 32, bias=bias)
+ self.relu = nn.ReLU()
+ self.drop = nn.Dropout(0.5)
+ self.lin1 = nn.Linear(32, 2, bias=bias)
+ self.sm = nn.LogSoftmax(dim=-1)
+ self.dtype = torch.float
+
+ def forward(self, X):
+ X = X.to(self.dtype)
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = self.drop(X)
+ X = self.lin1(X)
+ X = self.sm(X)
+ return X
+
+
+class Block(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.relu = nn.ReLU()
+ self.drop = nn.Dropout(0.5)
+ self.lin1 = nn.Linear(20, 10, bias=bias)
+
+ def forward(self, X):
+ X = X.float()
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = self.drop(X)
+ X = self.lin1(X)
+ return X
+
+
+class DeepMLP(nn.Module):
+ def __init__(self, bias=True, num_hidden_layers=12):
+ super().__init__()
+ self.layers = nn.ModuleList([Block(bias=bias) for _ in range(num_hidden_layers)])
+ self.out = nn.Linear(10, 2, bias=bias)
+ self.sm = nn.LogSoftmax(dim=-1)
+
+ def forward(self, X):
+ X = X.float(X)
+ for layer in self.layers:
+ X = layer(X)
+ X = self.out(X)
+ X = self.sm(X)
+ return X
+
+
+class ModelEmbConv1D(nn.Module):
+ def __init__(self, emb_size=100):
+ super().__init__()
+ self.emb = nn.Embedding(emb_size, 5)
+ self.conv1d = Conv1D(1, 5)
+ self.relu = nn.ReLU()
+ self.flat = nn.Flatten()
+ self.lin0 = nn.Linear(10, 2)
+ self.sm = nn.LogSoftmax(dim=-1)
+
+ def forward(self, X):
+ X = self.emb(X)
+ X = self.conv1d(X)
+ X = self.relu(X)
+ X = self.flat(X)
+ X = self.lin0(X)
+ X = self.sm(X)
+ return X
+
+
+class ModelEmbWithEmbeddingUtils(nn.Module):
+ # Adds `get_input_embeddings` and `get_output_embeddings` methods to mimic 🤗 transformers models
+ def __init__(self):
+ super().__init__()
+ self.embed_tokens = nn.Embedding(100, 5)
+ self.conv1d = Conv1D(1, 5)
+ self.relu = nn.ReLU()
+ self.flat = nn.Flatten()
+ self.lin0 = nn.Linear(10, 2)
+ self.sm = nn.LogSoftmax(dim=-1)
+
+ def forward(self, X):
+ X = self.embed_tokens(X)
+ X = self.conv1d(X)
+ X = self.relu(X)
+ X = self.flat(X)
+ X = self.lin0(X)
+ X = self.sm(X)
+ return X
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def get_output_embeddings(self):
+ return None
+
+
+class ModelConv1D(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.conv1d = nn.Conv1d(1, 1, 2)
+ self.relu = nn.ReLU()
+ self.flat = nn.Flatten()
+ self.lin0 = nn.Linear(9, 2)
+ self.sm = nn.LogSoftmax(dim=-1)
+ self.dtype = torch.float
+
+ def forward(self, X):
+ X = X.to(self.dtype)
+ X = X.reshape(-1, 1, 10)
+ X = self.conv1d(X)
+ X = self.relu(X)
+ X = self.flat(X)
+ X = self.lin0(X)
+ X = self.sm(X)
+ return X
+
+
+class ModelConv2D(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.conv2d = nn.Conv2d(5, 10, 3)
+ self.relu = nn.ReLU()
+ self.flat = nn.Flatten()
+ self.lin0 = nn.Linear(10, 2)
+ self.sm = nn.LogSoftmax(dim=-1)
+ self.dtype = torch.float
+
+ def forward(self, X):
+ X = X.to(self.dtype)
+ X = X.reshape(-1, 5, 3, 3)
+ X = self.conv2d(X)
+ X = self.relu(X)
+ X = self.flat(X)
+ X = self.lin0(X)
+ X = self.sm(X)
+ return X
+
+
+class ModelConv2D2(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.lin0 = nn.Linear(10, 40)
+ self.conv2d = nn.Conv2d(8, 32, 3)
+ self.relu = nn.ReLU()
+ self.flat = nn.Flatten()
+ self.lin1 = nn.Linear(32, 2)
+ self.sm = nn.LogSoftmax(dim=-1)
+ self.dtype = torch.float
+
+ def forward(self, X):
+ X = X.to(self.dtype)
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = X.reshape(-1, 8, 3, 3)
+ X = self.conv2d(X)
+ X = self.relu(X)
+ X = self.flat(X)
+ X = self.lin1(X)
+ X = self.sm(X)
+ return X
+
+
+class ModelConv2DGroups(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.lin0 = nn.Linear(90, 288)
+ # groups is set as 8 since default r=8
+ # hence to make r divisible by groups
+ self.conv2d = nn.Conv2d(16, 16, 3, groups=8)
+ self.relu = nn.ReLU()
+ self.flat = nn.Flatten()
+ self.lin1 = nn.Linear(16, 2)
+ self.sm = nn.LogSoftmax(dim=-1)
+ self.dtype = torch.float
+
+ def forward(self, X):
+ X = X.to(self.dtype)
+ X = X.flatten()
+ X = self.lin0(X)
+ X = X.reshape(2, 16, 3, 3)
+ X = self.conv2d(X)
+ X = self.relu(X)
+ X = self.flat(X)
+ X = self.lin1(X)
+ X = self.sm(X)
+ return X
+
+
+class ModelConv2DGroups2(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.conv2d = nn.Conv2d(16, 32, 3, padding=1, groups=2)
+ self.relu = nn.ReLU()
+ self.flat = nn.Flatten()
+ self.lin0 = nn.Linear(12800, 2)
+ self.sm = nn.LogSoftmax(dim=-1)
+ self.dtype = torch.float
+
+ def forward(self, X):
+ # Note: needs a different input shape, thus ignore original input
+ X = torch.arange(9 * 16 * 20 * 20).view([9, 16, 20, 20]).to(self.conv2d.weight.device)
+ X = X.to(self.dtype)
+ X = self.conv2d(X)
+ X = self.relu(X)
+ X = self.flat(X)
+ X = self.lin0(X)
+ X = self.sm(X)
+ return X
+
+
+class ModelConv3D(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.conv3d = nn.Conv3d(5, 10, 3)
+ self.relu = nn.ReLU()
+ self.flat = nn.Flatten()
+ self.lin0 = nn.Linear(10, 2)
+ self.sm = nn.LogSoftmax(dim=-1)
+ self.dtype = torch.float
+
+ def forward(self, X):
+ X = X.to(self.dtype)
+ # If necessary, convert from 2D image to 3D volume
+ if X.dim() == 2:
+ X = torch.stack([X] * 3, dim=-1)
+ X = X.reshape(-1, 5, 3, 3, 3)
+ X = self.conv3d(X)
+ X = self.relu(X)
+ X = self.flat(X)
+ X = self.lin0(X)
+ X = self.sm(X)
+ return X
+
+
+class ModelMha(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.mha = nn.MultiheadAttention(10, 2)
+ self.lin0 = nn.Linear(10, 2)
+ self.sm = nn.LogSoftmax(dim=-1)
+ self.dtype = torch.float
+
+ def forward(self, X):
+ X = X.to(self.dtype)
+ X, _ = self.mha(X, X, X)
+ X = self.lin0(X)
+ X = self.sm(X)
+ return X
+
+
+class _LinearUsingParameter(nn.Module):
+ # TODO
+ def __init__(self, in_features, out_features, bias=None):
+ super().__init__()
+ self.in_features = in_features
+ self.out_features = out_features
+ self.weight = nn.Parameter(torch.randn(in_features, out_features))
+ if bias:
+ self.bias = nn.Parameter(torch.ones(out_features))
+
+ def forward(self, x):
+ return x @ self.weight + self.bias
+
+
+class MlpUsingParameters(nn.Module):
+ # TODO
+ def __init__(self, bias=True):
+ super().__init__()
+
+ self.lin0 = _LinearUsingParameter(10, 20, bias=bias)
+ self.relu = nn.ReLU()
+ self.drop = nn.Dropout(0.5)
+ self.lin1 = _LinearUsingParameter(20, 2, bias=bias)
+ self.sm = nn.LogSoftmax(dim=-1)
+ self.dtype = torch.float
+
+ def forward(self, X):
+ X = X.to(self.dtype)
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = self.drop(X)
+ X = self.lin1(X)
+ X = self.sm(X)
+ return X
+
+
+class MockTransformerWrapper:
+ """Mock class to behave like a transformers model.
+
+ This is needed because the tests initialize the model by calling transformers_class.from_pretrained.
+
+ """
+
+ @classmethod
+ def from_pretrained(cls, model_id, torch_dtype=None):
+ # set the seed so that from_pretrained always returns the same model
+ torch.manual_seed(0)
+
+ if torch_dtype is None:
+ torch_dtype = torch.float32
+
+ if model_id == "MLP":
+ return MLP().to(torch_dtype)
+
+ if model_id == "EmbConv1D":
+ return ModelEmbConv1D().to(torch_dtype)
+
+ if model_id == "Conv1d":
+ return ModelConv1D().to(torch_dtype)
+
+ if model_id == "Conv2d":
+ return ModelConv2D().to(torch_dtype)
+
+ if model_id == "Conv2dGroups":
+ return ModelConv2DGroups().to(torch_dtype)
+
+ if model_id == "Conv2dGroups2":
+ return ModelConv2DGroups2().to(torch_dtype)
+
+ if model_id == "Conv3d":
+ return ModelConv3D().to(torch_dtype)
+
+ if model_id == "MLP_LayerNorm":
+ return MLP_LayerNorm().to(torch_dtype)
+
+ if model_id == "MLP2":
+ return MLP2().to(torch_dtype)
+
+ if model_id == "Conv2d2":
+ return ModelConv2D2().to(torch_dtype)
+
+ if model_id == "MHA":
+ return ModelMha().to(torch_dtype)
+
+ if model_id == "MlpUsingParameters":
+ return MlpUsingParameters().to(torch_dtype)
+
+ raise ValueError(f"model_id {model_id} not implemented")
+
+
+class TestPeftCustomModel(PeftCommonTester):
+ """
+ Implements the tests for custom models.
+
+ Most tests should just call the parent class, e.g. test_save_pretrained calls self._test_save_pretrained. Override
+ this if custom models don't work with the parent test method.
+
+ """
+
+ transformers_class = MockTransformerWrapper
+
+ def prepare_inputs_for_testing(self):
+ X = torch.arange(90).view(9, 10).to(self.torch_device)
+ return {"X": X}
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_attributes_parametrized(self, test_name, model_id, config_cls, config_kwargs):
+ self._test_model_attr(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_adapter_name(self, test_name, model_id, config_cls, config_kwargs):
+ self._test_adapter_name(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_prepare_for_training_parametrized(self, test_name, model_id, config_cls, config_kwargs):
+ # This test does not work with custom models because it assumes that
+ # there is always a method get_input_embeddings that returns a layer
+ # which does not need updates. Instead, a new test is added below that
+ # checks that LoRA works as expected.
+ pass
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_save_pretrained(self, test_name, model_id, config_cls, config_kwargs):
+ self._test_save_pretrained(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_save_pretrained_pickle(self, test_name, model_id, config_cls, config_kwargs):
+ self._test_save_pretrained(model_id, config_cls, config_kwargs, safe_serialization=False)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_load_model_low_cpu_mem_usage(self, test_name, model_id, config_cls, config_kwargs):
+ self._test_load_model_low_cpu_mem_usage(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_from_pretrained_config_construction(self, test_name, model_id, config_cls, config_kwargs):
+ self._test_from_pretrained_config_construction(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_load_multiple_adapters(self, test_name, model_id, config_cls, config_kwargs):
+ self._test_load_multiple_adapters(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_merge_layers(self, test_name, model_id, config_cls, config_kwargs):
+ # https://github.com/huggingface/peft/pull/2403
+ if model_id in ["Conv2dGroups", "Conv2dGroups2"]:
+ pytest.skip(
+ f"Skipping test for {model_id} as merging is not supported. (See https://github.com/huggingface/peft/pull/2403 for details)"
+ )
+
+ config_kwargs = config_kwargs.copy()
+ if issubclass(config_cls, LoraConfig):
+ config_kwargs["init_lora_weights"] = False
+ elif issubclass(config_cls, IA3Config):
+ config_kwargs["init_ia3_weights"] = False
+ elif issubclass(config_cls, LNTuningConfig):
+ pass
+ elif issubclass(config_cls, VBLoRAConfig):
+ pass
+ elif issubclass(config_cls, TrainableTokensConfig):
+ pass
+ else:
+ config_kwargs["init_weights"] = False
+ self._test_merge_layers(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_merge_layers_fp16(self, test_name, model_id, config_cls, config_kwargs):
+ # https://github.com/huggingface/peft/pull/2403
+ if model_id in ["Conv2dGroups", "Conv2dGroups2"]:
+ pytest.skip(
+ f"Skipping test for {model_id} as merging is not supported. (See https://github.com/huggingface/peft/pull/2403 for details)"
+ )
+
+ config_kwargs = config_kwargs.copy()
+ if issubclass(config_cls, LoraConfig):
+ config_kwargs["init_lora_weights"] = False
+ elif issubclass(config_cls, IA3Config):
+ config_kwargs["init_ia3_weights"] = False
+ self._test_merge_layers_fp16(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_merge_layers_is_idempotent(self, test_name, model_id, config_cls, config_kwargs):
+ # https://github.com/huggingface/peft/pull/2403
+ if model_id in ["Conv2dGroups", "Conv2dGroups2"]:
+ pytest.skip(
+ f"Skipping test for {model_id} as merging is not supported. (See https://github.com/huggingface/peft/pull/2403 for details)"
+ )
+
+ # calling merge twice with the same arguments should not change the output
+ config_kwargs = config_kwargs.copy()
+ if issubclass(config_cls, LoraConfig):
+ config_kwargs["init_lora_weights"] = False
+ elif issubclass(config_cls, IA3Config):
+ config_kwargs["init_ia3_weights"] = False
+ self._test_merge_layers_is_idempotent(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_safe_merge(self, test_name, model_id, config_cls, config_kwargs):
+ # https://github.com/huggingface/peft/pull/2403
+ if model_id in ["Conv2dGroups", "Conv2dGroups2"]:
+ pytest.skip(
+ f"Skipping test for {model_id} as merging is not supported. (See https://github.com/huggingface/peft/pull/2403 for details)"
+ )
+
+ # calling merge twice with the same arguments should not change the output
+ config_kwargs = config_kwargs.copy()
+ if issubclass(config_cls, LoraConfig):
+ config_kwargs["init_lora_weights"] = False
+ elif issubclass(config_cls, IA3Config):
+ config_kwargs["init_ia3_weights"] = False
+ elif issubclass(config_cls, LNTuningConfig):
+ # LNTuning do not take init_weights
+ pass
+ elif issubclass(config_cls, VBLoRAConfig):
+ # VBLoRA do not take init_weights
+ pass
+ else:
+ config_kwargs["init_weights"] = False
+ self._test_safe_merge(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_generate(self, test_name, model_id, config_cls, config_kwargs):
+ # Custom models do not (necessarily) have a generate method, so this test is not performed
+ pass
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_generate_half_prec(self, test_name, model_id, config_cls, config_kwargs):
+ # Custom models do not (necessarily) have a generate method, so this test is not performed
+ pass
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_training_custom_models(self, test_name, model_id, config_cls, config_kwargs):
+ self._test_training(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_training_custom_models_layer_indexing(self, test_name, model_id, config_cls, config_kwargs):
+ # At the moment, layer indexing only works when layer names conform to a specific pattern, which is not
+ # guaranteed here. Therefore, this test is not performed.
+ pass
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_training_custom_models_gradient_checkpointing(self, test_name, model_id, config_cls, config_kwargs):
+ self._test_training_gradient_checkpointing(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_inference_safetensors(self, test_name, model_id, config_cls, config_kwargs):
+ self._test_inference_safetensors(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_peft_model_device_map(self, test_name, model_id, config_cls, config_kwargs):
+ self._test_peft_model_device_map(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_forward_output_finite(self, test_name, model_id, config_cls, config_kwargs):
+ X = self.prepare_inputs_for_testing()
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ model.eval()
+ with torch.no_grad():
+ output = model(**X)
+ assert torch.isfinite(output).all()
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_forward_float16(self, test_name, model_id, config_cls, config_kwargs):
+ # The user manually sets the dtype of the base model to fp16 precision. This should not cause an error for the
+ # different PEFT methods.
+ try:
+ torch.zeros(1, dtype=torch.float16)
+ except Exception:
+ # skip this test if float16 is not supported on this machine
+ pytest.skip(reason="Test requires float16 support")
+
+ # skip on MacOS
+ if platform.system() == "Darwin":
+ pytest.skip(reason="MacOS does not support multiple ops in float16")
+
+ X = self.prepare_inputs_for_testing()
+ model = self.transformers_class.from_pretrained(model_id, torch_dtype=torch.float16).to(self.torch_device)
+ model.dtype = torch.float16
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ model.eval()
+
+ # check that none of this raises an error
+ model(**X)
+
+ if model_id in ["Conv2dGroups", "Conv2dGroups2"]:
+ # this model does not support merging
+ return
+
+ model.merge_adapter(safe_merge=False)
+ model(**X)
+ model.unmerge_adapter()
+ model(**X)
+ model.merge_adapter(safe_merge=True)
+ model(**X)
+ model.unmerge_adapter()
+ model(**X)
+ model = model.merge_and_unload()
+ model(**X)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_forward_bfloat16(self, test_name, model_id, config_cls, config_kwargs):
+ # The user manually sets the dtype of the base model to bf16 precision. This should not cause an error for the
+ # different PEFT methods.
+ try:
+ torch.zeros(1, dtype=torch.bfloat16)
+ except Exception:
+ # skip this test if float16 is not supported on this machine
+ pytest.skip(reason="Test requires bfloat16 support")
+
+ # skip on MacOS
+ if platform.system() == "Darwin":
+ pytest.skip(reason="MacOS does not support multiple ops in bfloat16")
+
+ X = self.prepare_inputs_for_testing()
+ model = self.transformers_class.from_pretrained(model_id, torch_dtype=torch.bfloat16).to(self.torch_device)
+ model.dtype = torch.bfloat16
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ model.eval()
+
+ # check that none of this raises an error
+ model(**X)
+
+ if model_id in ["Conv2dGroups", "Conv2dGroups2"]:
+ # this model does not support merging
+ return
+
+ model.merge_adapter(safe_merge=False)
+ model(**X)
+ model.unmerge_adapter()
+ model(**X)
+ model.merge_adapter(safe_merge=True)
+ model(**X)
+ model.unmerge_adapter()
+ model(**X)
+ model = model.merge_and_unload()
+ model(**X)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_forward_float16_no_autocast(self, test_name, model_id, config_cls, config_kwargs):
+ # Same as above but don't autocast adapter weights to float32 automatically
+ try:
+ torch.zeros(1, dtype=torch.float16)
+ except Exception:
+ # skip this test if float16 is not supported on this machine
+ pytest.skip(reason="Test requires float16 support")
+
+ # skip on MacOS
+ if platform.system() == "Darwin":
+ pytest.skip(reason="MacOS does not support multiple ops in float16")
+
+ X = self.prepare_inputs_for_testing()
+ model = self.transformers_class.from_pretrained(model_id, torch_dtype=torch.float16).to(self.torch_device)
+ model.dtype = torch.float16
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config, autocast_adapter_dtype=False)
+ model.eval()
+
+ # check that none of this raises an error
+ model(**X)
+
+ if model_id in ["Conv2dGroups", "Conv2dGroups2"]:
+ # this model does not support merging
+ return
+
+ model.merge_adapter(safe_merge=False)
+ model(**X)
+ model.unmerge_adapter()
+ model(**X)
+ model.merge_adapter(safe_merge=True)
+ model(**X)
+ model.unmerge_adapter()
+ model(**X)
+ model = model.merge_and_unload()
+ model(**X)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_forward_bfloat16_no_autocast(self, test_name, model_id, config_cls, config_kwargs):
+ # Same as above but don't autocast adapter weights to float32 automatically
+ try:
+ torch.zeros(1, dtype=torch.bfloat16)
+ except Exception:
+ # skip this test if float16 is not supported on this machine
+ pytest.skip(reason="Test requires bfloat16 support")
+
+ # skip on MacOS
+ if platform.system() == "Darwin":
+ pytest.skip(reason="MacOS does not support multiple ops in bfloat16")
+
+ X = self.prepare_inputs_for_testing()
+ model = self.transformers_class.from_pretrained(model_id, torch_dtype=torch.bfloat16).to(self.torch_device)
+ model.dtype = torch.bfloat16
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config, autocast_adapter_dtype=False)
+ model.eval()
+
+ # check that none of this raises an error
+ model(**X)
+
+ if model_id in ["Conv2dGroups", "Conv2dGroups2"]:
+ # this model does not support merging
+ return
+
+ model.merge_adapter(safe_merge=False)
+ model(**X)
+ model.unmerge_adapter()
+ model(**X)
+ model.merge_adapter(safe_merge=True)
+ model(**X)
+ model.unmerge_adapter()
+ model(**X)
+ model = model.merge_and_unload()
+ model(**X)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_only_params_are_updated(self, test_name, model_id, config_cls, config_kwargs):
+ # An explicit test that when using an adapter on a custom model, only the adapter parameters are updated during
+ # training
+ X = self.prepare_inputs_for_testing()
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ model_before = copy.deepcopy(model)
+
+ model.train()
+ lr = 0.5
+ if (config_kwargs.get("use_dora") and model_id == "EmbConv1D") or issubclass(config_cls, VBLoRAConfig):
+ # this high learning rate was found through testing to be necessary to avoid flakiness
+ lr = 100
+ elif "mha" in model_id.lower():
+ # we get exploding gradients with MHA when learning rate is too high
+ lr = 1e-3
+ optimizer = torch.optim.SGD(model.parameters(), lr=lr)
+
+ # train at least 3 steps for all parameters to be updated (probably this is required because of symmetry
+ # breaking of some LoRA layers that are initialized with constants)
+ for _ in range(3):
+ optimizer.zero_grad()
+ y_pred = model(**X)
+ loss = y_pred.sum()
+ loss.backward()
+ optimizer.step()
+
+ tol = 1e-4
+ params_before = dict(model_before.named_parameters())
+ params_after = dict(model.named_parameters())
+ assert params_before.keys() == params_after.keys()
+
+ prefix = PREFIXES[config_cls]
+ for name, param_before in params_before.items():
+ param_after = params_after[name]
+ if (prefix in name) or ("modules_to_save" in name) or ("token_adapter.trainable_tokens" in name):
+ # target_modules, modules_to_save and modules of `NewTokensWrapper` _are_ updated
+ assert not torch.allclose(param_before, param_after, atol=tol, rtol=tol)
+ else:
+ assert torch.allclose(param_before, param_after, atol=tol, rtol=tol)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_parameters_after_loading_model(self, test_name, model_id, config_cls, config_kwargs):
+ # An explicit test that when loading a trained model, the parameters are loaded correctly
+ # see issue #808
+ X = self.prepare_inputs_for_testing()
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ model.train()
+
+ lr = 0.5
+ if config_kwargs.get("use_dora"):
+ lr = 0.1 # otherwise we get nan
+ elif "mha" in model_id.lower():
+ lr = 1e-3 # we get exploding gradients with MHA when learning rate is too high
+ elif issubclass(config_cls, VBLoRAConfig) or issubclass(config_cls, RandLoraConfig):
+ lr = 0.01 # otherwise we get nan
+ optimizer = torch.optim.SGD(model.parameters(), lr=lr)
+
+ # train at least 3 steps for all parameters to be updated (probably this is required because of symmetry
+ # breaking of some LoRA layers that are initialized with constants)
+ for _ in range(3):
+ optimizer.zero_grad()
+ y_pred = model(**X)
+ loss = y_pred.sum()
+ loss.backward()
+ optimizer.step()
+
+ tol = 1e-4
+ params_before = get_state_dict(model)
+ # note: no need to sanity check if parameters were updated at all, this
+ # is already covered in the previous test
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname)
+ model_from_pretrained = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ model_from_pretrained = PeftModel.from_pretrained(model_from_pretrained, tmp_dirname)
+ params_after = get_state_dict(model_from_pretrained)
+
+ assert params_before.keys() == params_after.keys()
+ for name, param_before in params_before.items():
+ param_after = params_after[name]
+ assert torch.allclose(param_before, param_after, atol=tol, rtol=tol)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_disable_adapters(self, test_name, model_id, config_cls, config_kwargs):
+ X = self.prepare_inputs_for_testing()
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device).eval()
+ outputs_base = model(**X)
+ if issubclass(config_cls, (FourierFTConfig, TrainableTokensConfig, C3AConfig)):
+ config_kwargs = config_kwargs.copy()
+ # override the default value and make PEFT operation a no-op
+ config_kwargs["init_weights"] = True
+ if issubclass(config_cls, (ShiraConfig,)):
+ # for SHiRA, setting this to default value of True will turn the PEFT operation into a no-op
+ # because SHiRA is always initialized to zeros. Configs declared in the test file had set init_weights
+ # to False (to make sure all other tests have a randn SHiRA initialization). Setting it back to True here
+ # as required by this test.
+ config_kwargs["init_weights"] = True
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ if issubclass(config_cls, VBLoRAConfig):
+ # Manually set the `vblora_vector_bank` to zero so that VB-LoRA functions as an identity operation.
+ torch.nn.init.zeros_(model.vblora_vector_bank["default"])
+ model.eval()
+ outputs_before = model(**X)
+ assert torch.allclose(outputs_base, outputs_before)
+
+ if issubclass(config_cls, VBLoRAConfig):
+ # initialize `vblora_vector_bank` so it can be trained
+ model._init_vblora_vector_bank(config, "default")
+ model.train()
+ # EmbConv1D is slow to learn for some reason
+ lr = 0.01 if model_id != "EmbConv1D" else 1.0
+ if isinstance(config, TrainableTokensConfig):
+ # TrainableTokens is only changing a small subset, so we need a higher lr to see the difference
+ lr = 2.0
+ optimizer = torch.optim.SGD(model.parameters(), lr=lr)
+
+ # train at least 3 steps for all parameters to be updated (probably this is required because of symmetry
+ # breaking of some LoRA layers that are initialized with constants)
+ for _ in range(3):
+ optimizer.zero_grad()
+ y_pred = model(**X)
+ y = torch.arange(len(y_pred)).to(self.torch_device) % 2
+ loss = nn.functional.nll_loss(y_pred, y)
+ loss.backward()
+ optimizer.step()
+
+ model.eval()
+ outputs_after = model(**X)
+
+ with model.disable_adapter():
+ outputs_disabled = model(**X)
+
+ # check that after leaving the disable_adapter context, everything is enabled again
+ outputs_enabled_after_disable = model(**X)
+
+ if self.torch_device == "cpu":
+ # LayerNorm is running float32 on cpu, so difference in outputs are smaller
+ rtol, atol = 1e-8, 1e-8
+ else:
+ rtol, atol = 1e-5, 1e-8
+ assert not torch.allclose(outputs_before, outputs_after, rtol=rtol, atol=atol)
+ assert torch.allclose(outputs_before, outputs_disabled)
+ assert torch.allclose(outputs_after, outputs_enabled_after_disable)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_disable_adapters_with_merging(self, test_name, model_id, config_cls, config_kwargs):
+ # https://github.com/huggingface/peft/pull/2403
+ if model_id in ["Conv2dGroups", "Conv2dGroups2"]:
+ pytest.skip(
+ f"Skipping test for {model_id} as merging is not supported. (See https://github.com/huggingface/peft/pull/2403 for details)"
+ )
+
+ # same as test_disable_adapters, but with merging
+ X = self.prepare_inputs_for_testing()
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ if issubclass(config_cls, (FourierFTConfig, C3AConfig)):
+ config_kwargs = config_kwargs.copy()
+ config_kwargs["init_weights"] = True
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ if issubclass(config_cls, VBLoRAConfig):
+ # Manually set the `vblora_vector_bank` to zero so that VB-LoRA functions as an identity operation.
+ torch.nn.init.zeros_(model.vblora_vector_bank["default"])
+ model.eval()
+ outputs_before = model(**X)
+
+ if issubclass(config_cls, VBLoRAConfig):
+ # initialize `vblora_vector_bank` so it can be trained
+ model._init_vblora_vector_bank(config, "default")
+ model.train()
+ if isinstance(config_cls, LNTuningConfig):
+ # LayerNorm tuning is slow to learn
+ lr = 1.0
+ optimizer = torch.optim.SGD(model.parameters(), lr=lr)
+ else:
+ # Adam optimizer since SGD isn't great for small models with IA3 + Conv1D
+ lr = 0.01
+ optimizer = torch.optim.Adam(model.parameters(), lr=lr)
+
+ # train at least 3 steps for all parameters to be updated (probably this is required because of symmetry
+ # breaking of some LoRA layers that are initialized with constants)
+ for _ in range(3):
+ optimizer.zero_grad()
+ y_pred = model(**X)
+ y = torch.arange(len(y_pred)).to(self.torch_device) % 2
+ loss = nn.functional.nll_loss(y_pred, y)
+ loss.backward()
+ optimizer.step()
+
+ model.eval()
+ outputs_unmerged = model(**X)
+ model.merge_adapter()
+ outputs_after = model(**X)
+
+ with model.disable_adapter():
+ outputs_disabled = model(**X)
+
+ # check that after leaving the disable_adapter context, everything is enabled again
+ outputs_enabled_after_disable = model(**X)
+
+ atol, rtol = 1e-5, 1e-5 # tolerances higher than defaults since merging introduces some numerical instability
+
+ conv_ids = ["Conv2d", "Conv3d", "Conv2d2"]
+ if issubclass(config_cls, (IA3Config, LoraConfig)) and model_id in conv_ids: # more instability with Conv
+ atol, rtol = 1e-3, 1e-3
+
+ if issubclass(config_cls, OFTConfig):
+ atol, rtol = 1e-4, 1e-4
+
+ if config_kwargs.get("use_dora") and model_id == "EmbConv1D":
+ atol, rtol = 1e-4, 1e-4
+
+ # check that there is a difference in results after training
+ assert not torch.allclose(outputs_before, outputs_after, atol=atol, rtol=rtol)
+
+ if self.torch_device in ["mlu"] and model_id in conv_ids:
+ atol, rtol = 1e-3, 1e-2 # MLU
+
+ # unmerged or merged should make no difference
+ assert torch.allclose(outputs_after, outputs_unmerged, atol=atol, rtol=rtol)
+
+ # check that disabling adapters gives the same results as before training
+ assert torch.allclose(outputs_before, outputs_disabled, atol=atol, rtol=rtol)
+
+ # check that enabling + disabling adapters does not change the results
+ assert torch.allclose(outputs_after, outputs_enabled_after_disable, atol=atol, rtol=rtol)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_disable_adapter_with_bias_warns(self, test_name, model_id, config_cls, config_kwargs):
+ # When training biases in lora, disabling adapters does not reset the biases, so the output is not what users
+ # might expect. Therefore, a warning should be given.
+
+ # Note: We test only with custom models since they run really fast. There is really no point in testing the same
+ # thing with decoder, encoder_decoder, etc.
+ if config_cls != LoraConfig or config_cls != BOFTConfig:
+ # skip this test for other configs as bias is specific to Lora
+ pytest.skip("Testing bias warnings only for LoraConfig or BOFTConfig")
+
+ if not issubclass(config_cls, (LoraConfig, BOFTConfig)):
+ pytest.skip("Bias argument is only supported for LoRA or BOFT models")
+
+ def run_with_disable(config_kwargs, bias):
+ config_kwargs = config_kwargs.copy()
+ config_kwargs["bias"] = bias
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ peft_model = get_peft_model(model, config)
+ with peft_model.disable_adapter():
+ pass # there is nothing to be done
+
+ if config_cls == LoraConfig:
+ # check that bias=all and bias=lora_only give a warning with the correct message
+ msg_start = "Careful, disabling adapter layers with bias configured to be"
+ with pytest.warns(UserWarning, match=msg_start):
+ run_with_disable(config_kwargs, bias="lora_only")
+ with pytest.warns(UserWarning, match=msg_start):
+ run_with_disable(config_kwargs, bias="all")
+
+ if config_cls == BOFTConfig:
+ # check that bias=all and bias=boft_only give a warning with the correct message
+ msg_start = "Careful, disabling adapter layers with bias configured to be"
+ with pytest.warns(UserWarning, match=msg_start):
+ run_with_disable(config_kwargs, bias="boft_only")
+ with pytest.warns(UserWarning, match=msg_start):
+ run_with_disable(config_kwargs, bias="all")
+
+ # For bias=none, there is no warning. Unfortunately, AFAIK unittest has no option to assert that no warning is
+ # given, therefore, we check that the unittest gives us an AssertionError if we check for a warning
+ bias_warning_was_given = False
+ try:
+ with pytest.warns(UserWarning) as cm:
+ run_with_disable(config_kwargs, bias="none")
+ # if we get here, it means there was no AssertionError, i.e. there are warnings -- let's check that they
+ # are not related to the bias setting
+ if any(warning.message.args[0].startswith(msg_start) for warning in cm.warnings):
+ bias_warning_was_given = True
+ except AssertionError:
+ # This is good, there was an AssertionError, i.e. there was no warning
+ pass
+ if bias_warning_was_given:
+ # This is bad, there was a warning about the bias when there should not have been any.
+ self.fail("There should be no warning when bias is set to 'none'")
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_active_adapter(self, test_name, model_id, config_cls, config_kwargs):
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ assert model.active_adapters == ["default"]
+ assert model.active_adapter == "default"
+
+ # at this stage, "default" is still the activate adapter, "other" is disabled
+ model.add_adapter("other", config)
+ assert model.active_adapters == ["default"]
+ assert model.active_adapter == "default"
+
+ # set "other" as the active adapter
+ model.set_adapter("other")
+ assert model.active_adapters == ["other"]
+ assert model.active_adapter == "other"
+
+ # set both adapters as active
+ # Note: On the PeftModel, there cannot be multiple active adapters, so we have to go through model.base_model
+ # instead.
+ model.base_model.set_adapter(["default", "other"])
+ # model.active_adapters works, as it delegates to the base_model
+ assert model.active_adapters == ["default", "other"]
+ # model.active_adapter would not work, thus we have to check the base_model directly
+ assert model.base_model.active_adapter == ["default", "other"]
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_disable_adapters_exiting_context_restores_previous_state(
+ self, test_name, model_id, config_cls, config_kwargs
+ ):
+ # Test that when we exit the disable_adapter context, we correctly restore the enabled state of the modules as
+ # they were before the context.
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ tuner_modules = [module for module in model.modules() if isinstance(module, BaseTunerLayer)]
+
+ # all layers should be enabled
+ assert all(not module.disable_adapters for module in tuner_modules)
+ with model.disable_adapter():
+ pass
+ # this should not change after exiting the context
+ assert all(not module.disable_adapters for module in tuner_modules)
+
+ # now disable all layers
+ model.disable_adapter_layers()
+ assert all(module.disable_adapters for module in tuner_modules)
+ with model.disable_adapter():
+ pass
+ assert all(module.disable_adapters for module in tuner_modules)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_disable_adapters_exiting_context_irregular_state(self, test_name, model_id, config_cls, config_kwargs):
+ # When we have a model where some adapters are enabled and others are disabled, we should get a warning when
+ # entering the disable_adapter context because we cannot correctly restore the state of the adapters from
+ # before the context. After exiting the context, all adapters will be enabled, which is the status quo of how
+ # we deal with this.
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ tuner_modules = [module for module in model.modules() if isinstance(module, BaseTunerLayer)]
+
+ # now we mix the states, some enabled some not
+ if len(tuner_modules) < 2:
+ # next check only works with more than 1 tuner module
+ return
+
+ # disable a single layer
+ tuner_modules[0].enable_adapters(False)
+ # sanity check that we have both enabled and disabled layers
+ assert {module.disable_adapters for module in tuner_modules} == {True, False}
+ # check that we get a warning with irregular states
+ msg = "The model contains some adapter layers that are enabled and others that are disabled"
+ with pytest.warns(UserWarning, match=msg):
+ with model.disable_adapter():
+ pass
+
+ # when encountering irregular adapters, we enable all adapters at the end of the context
+ assert all(not module.disable_adapters for module in tuner_modules)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_delete_adapter(self, test_name, model_id, config_cls, config_kwargs):
+ self._test_delete_adapter(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_delete_inactive_adapter(self, test_name, model_id, config_cls, config_kwargs):
+ self._test_delete_inactive_adapter(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_delete_unknown_adapter_raises(self, test_name, model_id, config_cls, config_kwargs):
+ self._test_delete_unknown_adapter_raises(model_id, config_cls, config_kwargs)
+
+ def test_delete_adapter_with_multiple_adapters_works(self):
+ # Add 3 adapters, delete the active one, the next one should be active, delete the inactive one, the active one
+ # should stay the same.
+ config0 = LoraConfig(target_modules=["lin0"])
+ config1 = LoraConfig(target_modules=["lin0"])
+ config2 = LoraConfig(target_modules=["lin0"])
+ model = get_peft_model(MLP(), config0, adapter_name="adapter0").to(self.torch_device)
+ model.add_adapter("adapter1", config1)
+ model.add_adapter("adapter2", config2)
+
+ inputs = self.prepare_inputs_for_testing()
+ assert model.active_adapters == ["adapter0"]
+ model(**inputs) # does not raise
+
+ # delete the active adapter, next one should become active
+ model.delete_adapter("adapter0")
+ assert model.active_adapters == ["adapter1"]
+ model(**inputs) # does not raise
+
+ # delete an inactive adapter, should not affect the active adapter
+ model.delete_adapter("adapter2")
+ assert model.active_adapters == ["adapter1"]
+ model(**inputs) # does not raise
+
+ def test_delete_adapter_multiple_adapters_with_modules_to_save(self):
+ # There are 3 adapters. Adapter 0 has modules_to_save. Delete it, we should switch to adapter 1, which does not
+ # have modules_to_save. Then, we delete it too, switching to adapter 2, which has modules_to_save. Finally, we
+ # delete the last adapter (state is updated but forward is no longer possible).
+ model = MLP()
+ inputs = self.prepare_inputs_for_testing()
+
+ config0 = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ config1 = LoraConfig(target_modules=["lin0"])
+ config2 = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ model = get_peft_model(model, config0, adapter_name="adapter0").to(self.torch_device)
+ model.add_adapter("adapter1", config1)
+ model.add_adapter("adapter2", config2)
+
+ assert model.active_adapters == ["adapter0"]
+ assert model.modules_to_save == {"lin1"}
+ assert set(model.base_model.model.lin1.modules_to_save) == {"adapter0", "adapter2"}
+ model(**inputs) # does not raise
+
+ # delete active adapter, should switch to the next adapter (which does not have modules_to_save)
+ model.delete_adapter("adapter0")
+ assert model.active_adapters == ["adapter1"]
+ assert model.modules_to_save == {"lin1"}
+ assert set(model.base_model.model.lin1.modules_to_save) == {"adapter2"}
+ model(**inputs) # does not raise
+
+ # delete active adapter, should switch to the next adapter (which *does* have modules_to_save)
+ model.delete_adapter("adapter1")
+ assert model.active_adapters == ["adapter2"]
+ assert model.modules_to_save == {"lin1"}
+ assert set(model.base_model.model.lin1.modules_to_save) == {"adapter2"}
+ model(**inputs) # does not raise
+
+ # delete last adapter
+ model.delete_adapter("adapter2")
+ assert model.active_adapters == []
+ assert model.modules_to_save is None
+ assert set(model.base_model.model.lin1.modules_to_save) == set()
+
+ def test_delete_adapter_multiple_adapters_with_trainable_token_indices(self):
+ # Same as the previous test, just using trainable_token_indices instead of modules_to_save
+ # Note that we need to use a transformers model for trainable_token_indices
+ model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-OPTForCausalLM")
+ inputs = {"input_ids": torch.arange(10).view(-1, 1).to(self.torch_device)}
+
+ config0 = LoraConfig(target_modules=["q_proj"], trainable_token_indices=[0, 1])
+ config1 = LoraConfig(target_modules=["q_proj"])
+ config2 = LoraConfig(target_modules=["q_proj"], trainable_token_indices=[1, 3])
+ model = get_peft_model(model, config0, adapter_name="adapter0").to(self.torch_device)
+ model.add_adapter("adapter1", config1)
+ model.add_adapter("adapter2", config2)
+
+ embed_tokens = model.base_model.model.model.decoder.embed_tokens
+ lm_head = model.base_model.model.lm_head
+
+ assert model.active_adapters == ["adapter0"]
+ assert set(embed_tokens.token_adapter.trainable_tokens_delta) == {"adapter0", "adapter2"}
+ assert set(embed_tokens.token_adapter.trainable_tokens_original) == {"adapter0", "adapter2"}
+ assert set(lm_head.token_adapter.trainable_tokens_delta) == {"adapter0", "adapter2"}
+ assert set(lm_head.token_adapter.trainable_tokens_original) == {"adapter0", "adapter2"}
+ model(**inputs) # does not raise
+
+ # delete active adapter, should switch to the next adapter (which does not have modules_to_save)
+ model.delete_adapter("adapter0")
+ assert model.active_adapters == ["adapter1"]
+ assert set(embed_tokens.token_adapter.trainable_tokens_delta) == {"adapter2"}
+ assert set(embed_tokens.token_adapter.trainable_tokens_original) == {"adapter2"}
+ assert set(lm_head.token_adapter.trainable_tokens_delta) == {"adapter2"}
+ assert set(lm_head.token_adapter.trainable_tokens_original) == {"adapter2"}
+ model(**inputs) # does not raise
+
+ # delete active adapter, should switch to the next adapter (which *does* have modules_to_save)
+ model.delete_adapter("adapter1")
+ assert model.active_adapters == ["adapter2"]
+ assert set(embed_tokens.token_adapter.trainable_tokens_delta) == {"adapter2"}
+ assert set(embed_tokens.token_adapter.trainable_tokens_original) == {"adapter2"}
+ assert set(lm_head.token_adapter.trainable_tokens_delta) == {"adapter2"}
+ assert set(lm_head.token_adapter.trainable_tokens_original) == {"adapter2"}
+ model(**inputs) # does not raise
+
+ # delete last adapter
+ model.delete_adapter("adapter2")
+ assert model.active_adapters == []
+ assert set(embed_tokens.token_adapter.trainable_tokens_delta) == set()
+ assert set(embed_tokens.token_adapter.trainable_tokens_original) == set()
+ assert set(lm_head.token_adapter.trainable_tokens_delta) == set()
+ assert set(lm_head.token_adapter.trainable_tokens_original) == set()
+
+ @pytest.mark.parametrize("test_name, model_id, config_cls, config_kwargs", TEST_CASES)
+ def test_adding_multiple_adapters_with_bias_raises(self, test_name, model_id, config_cls, config_kwargs):
+ self._test_adding_multiple_adapters_with_bias_raises(model_id, config_cls, config_kwargs)
+
+ def test_weight_bias_attributes(self):
+ model = MLP()
+ config = LoraConfig(target_modules=["lin0"])
+ model = get_peft_model(model, config)
+ assert hasattr(model.base_model.model.lin0, "weight")
+ assert hasattr(model.base_model.model.lin0, "bias")
+
+ def test_multiple_adapters_automatic_modules_to_save(self):
+ # See issue 1574
+ # When we use certain task types, PeftModel.modules_to_save is automatically updated to include some extra
+ # layers not specified in the PeftConfig. This attribute should be honored for all adapters, not just for
+ # the default adapter.
+ config0 = LoraConfig(task_type=TaskType.SEQ_CLS)
+ config1 = LoraConfig(task_type=TaskType.SEQ_CLS)
+ model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
+ model = get_peft_model(model, config0)
+ # sanity check
+ assert model.modules_to_save
+
+ model.add_adapter("other", config1)
+ assert "default" in model.base_model.classifier.modules_to_save
+ assert "other" in model.base_model.classifier.modules_to_save
+
+ @pytest.mark.parametrize(
+ "config_cls", [IA3Config, LoHaConfig, LoKrConfig, LoraConfig, HRAConfig, BoneConfig, ShiraConfig]
+ )
+ def test_multiple_adapters_mixed_modules_to_save(self, config_cls):
+ # See issue 1574
+ # Check that we can have a model where one adapter has modules_to_save and the other doesn't. It should be
+ # possible to switch between those adapters and to use them.
+ if hasattr(config_cls, "feedforward_modules"): # IA³
+ config_cls = partial(config_cls, feedforward_modules=["lin0"])
+
+ if config_cls == BoneConfig:
+ config_cls = partial(config_cls, r=2)
+ if config_cls == ShiraConfig:
+ config_cls = partial(config_cls, r=1)
+
+ config0 = config_cls(target_modules=["lin0"], modules_to_save=["lin1"])
+ config1 = config_cls(target_modules=["lin0"])
+ model = MLP()
+ model = get_peft_model(model, config0).to(self.torch_device)
+ model.add_adapter("other", config1)
+
+ assert "default" in model.base_model.lin1.modules_to_save
+ assert "other" not in model.base_model.lin1.modules_to_save
+
+ # check that switching adapters and predicting does not raise
+ inputs = self.prepare_inputs_for_testing()
+ # "default" adapter is active
+ model(**inputs)
+ # switch to "other" adapter
+ model.set_adapter("other")
+ model(**inputs)
+
+ @pytest.mark.parametrize(
+ "config_cls", [IA3Config, LoHaConfig, LoKrConfig, LoraConfig, HRAConfig, BoneConfig, ShiraConfig]
+ )
+ def test_multiple_adapters_mixed_modules_to_save_order_switched(self, config_cls):
+ # See issue 1574
+ # Same test as test_multiple_adapters_mixed_modules_to_save, but this time the 2nd adapter has modules_to_save.
+ if hasattr(config_cls, "feedforward_modules"): # IA³
+ config_cls = partial(config_cls, feedforward_modules=["lin0"])
+
+ if config_cls == BoneConfig:
+ config_cls = partial(config_cls, r=2)
+ if config_cls == ShiraConfig:
+ config_cls = partial(config_cls, r=1)
+
+ config0 = config_cls(target_modules=["lin0"])
+ config1 = config_cls(target_modules=["lin0"], modules_to_save=["lin1"])
+ model = MLP()
+ model = get_peft_model(model, config0).to(self.torch_device)
+ model.add_adapter("other", config1)
+
+ assert "default" not in model.base_model.lin1.modules_to_save
+ assert "other" in model.base_model.lin1.modules_to_save
+
+ # check that switching adapters and predicting does not raise
+ inputs = self.prepare_inputs_for_testing()
+ # "default" adapter is active
+ model(**inputs)
+ # switch to "other" adapter
+ model.set_adapter("other")
+ model(**inputs)
+
+ def test_multiple_adapters_mixed_modules_to_save_merging_adapters(self):
+ # See issue 1574
+ # This test is similar to test_multiple_adapters_mixed_modules_to_save, but it also checks that merging adapter
+ # weights works when one adapter has a modules_to_save and the other hasn't
+ config0 = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ config1 = LoraConfig(target_modules=["lin0"])
+ model = MLP()
+ model = get_peft_model(model, config0).to(self.torch_device)
+ model.add_adapter("other", config1)
+
+ # check that this does not raise
+ model.add_weighted_adapter(["default", "other"], weights=[1.0, 1.0], adapter_name="merged")
+
+ # since one of the adapters that was merged has a modules_to_save, that one should be used for the merged
+ # adapter
+ assert "default" in model.base_model.model.lin1.modules_to_save
+ assert "other" not in model.base_model.model.lin1.modules_to_save
+ assert "merged" in model.base_model.model.lin1.modules_to_save
+
+ # check that using the merged adapter does not raise
+ model.set_adapter("merged")
+ inputs = self.prepare_inputs_for_testing()
+ model(**inputs)
+
+ def test_multiple_adapters_same_modules_to_save_merging_adapters_raises(self):
+ # See issue 1574
+ # This test is similar to test_multiple_adapters_mixed_modules_to_save_merging_adapters but here the two
+ # adapters target the same module with modules_to_save. In this case, trying to merge the adapter weights
+ # should raise an error.
+ config0 = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ config1 = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ model = MLP()
+ model = get_peft_model(model, config0).to(self.torch_device)
+ model.add_adapter("other", config1)
+
+ msg = re.escape(
+ "Cannot add weighted adapters if they target the same module with modules_to_save, but found 1 such "
+ "instance(s)."
+ )
+ with pytest.raises(ValueError, match=msg):
+ model.add_weighted_adapter(["default", "other"], weights=[1.0, 1.0], adapter_name="merged")
+
+ def test_multiple_adapters_seq_cls_mixed_modules_to_save_merging_adapters(self):
+ # See issue 1574
+ # This test is similar to test_multiple_adapters_mixed_modules_to_save_merging_adapters but uses a SEQ_CLS
+ # model like in test_multiple_adapters_automatic_modules_to_save. This should raise an error because the same
+ # module is implicitly targeted by modules_to_save twice.
+ config0 = LoraConfig(task_type=TaskType.SEQ_CLS)
+ config1 = LoraConfig(task_type=TaskType.SEQ_CLS)
+ model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
+ model = get_peft_model(model, config0)
+ model.add_adapter("other", config1)
+
+ msg = re.escape(
+ "Cannot add weighted adapters if they target the same module with modules_to_save, but found 1 such "
+ "instance(s)."
+ )
+ with pytest.raises(ValueError, match=msg):
+ model.add_weighted_adapter(["default", "other"], weights=[1.0, 1.0], adapter_name="merged")
+
+ @pytest.mark.parametrize("config_cls", [IA3Config, LoHaConfig, LoKrConfig, LoraConfig, HRAConfig, BoneConfig])
+ def test_add_weighted_adapter_cat_with_rank_pattern(self, config_cls):
+ # Fixes a bug described in #2512, which resulted from the rank_pattern not being taken into account
+ config0 = LoraConfig(target_modules=["lin0", "lin1"], r=8, rank_pattern={"lin0": 2})
+ config1 = LoraConfig(target_modules=["lin0", "lin1"], r=8, rank_pattern={"lin0": 16})
+ model = MLP()
+ model = get_peft_model(model, config0).to(self.torch_device)
+ model.add_adapter("other", config1)
+ model.add_weighted_adapter(
+ ["default", "other"], weights=[1.0, 1.0], adapter_name="merged", combination_type="cat"
+ )
+
+ def test_multiple_adapters_no_needless_copy_modules_to_save(self):
+ # See 2206
+ # The problem was that we keep a "global" modules_to_save on the model which contains all possible
+ # modules_to_save for each adapter. When the first adapter targets embed_tokens with modules_to_save and the
+ # second adapter targets lm_head, then embed_tokens will create a copy of the original module for the second
+ # adapter, even though it's not needed. The copy still acts as expected but uses unnecessary memory.
+ model_id = "hf-internal-testing/tiny-random-OPTForCausalLM"
+ model = AutoModelForCausalLM.from_pretrained(model_id).to(self.torch_device)
+ config0 = LoraConfig(modules_to_save=["embed_tokens"])
+ config1 = LoraConfig(modules_to_save=["lm_head"])
+ model = get_peft_model(model, config0)
+ model.add_adapter("other", config1)
+
+ lm_head_keys = list(model.base_model.model.lm_head.modules_to_save.keys())
+ assert lm_head_keys == ["other"]
+
+ embed_token_keys = list(model.base_model.model.model.decoder.embed_tokens.modules_to_save.keys())
+ # before the fix, this would be: ['default', 'other']
+ assert embed_token_keys == ["default"]
+
+ def test_existing_model_card(self):
+ # ensure that if there is already a model card, it is not overwritten
+ model = MLP()
+ config = LoraConfig(target_modules=["lin0"])
+ model = get_peft_model(model, config)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ # create a model card
+ text = "---\nmeta: hello\n---\nThis is a model card\n"
+ with open(os.path.join(tmp_dirname, "README.md"), "w") as f:
+ f.write(text)
+
+ model.save_pretrained(tmp_dirname)
+ with open(os.path.join(tmp_dirname, "README.md")) as f:
+ model_card = f.read()
+
+ assert "library_name: peft" in model_card
+ assert "meta: hello" in model_card
+ assert "This is a model card" in model_card
+
+ def test_non_existing_model_card(self):
+ # ensure that if there is already a model card, it is not overwritten
+ model = MLP()
+ config = LoraConfig(target_modules=["lin0"])
+ model = get_peft_model(model, config)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname)
+ with open(os.path.join(tmp_dirname, "README.md")) as f:
+ model_card = f.read()
+
+ assert "library_name: peft" in model_card
+ # rough check that the model card is pre-filled
+ assert len(model_card) > 1000
+
+ @pytest.mark.parametrize("save_embedding_layers", ["auto", True, False])
+ def test_targeting_lora_to_embedding_layer(self, save_embedding_layers):
+ model = ModelEmbWithEmbeddingUtils()
+ config = LoraConfig(target_modules=["embed_tokens", "lin0"], init_lora_weights=False)
+ model = get_peft_model(model, config)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ if save_embedding_layers == "auto":
+ # assert warning
+ msg_start = "Setting `save_embedding_layers` to `True` as embedding layers found in `target_modules`."
+ with pytest.warns(UserWarning, match=msg_start):
+ model.save_pretrained(tmp_dirname, save_embedding_layers=save_embedding_layers)
+ else:
+ model.save_pretrained(tmp_dirname, save_embedding_layers=save_embedding_layers)
+ from safetensors.torch import load_file as safe_load_file
+
+ state_dict = safe_load_file(os.path.join(tmp_dirname, "adapter_model.safetensors"))
+ if save_embedding_layers in ["auto", True]:
+ assert "base_model.model.embed_tokens.base_layer.weight" in state_dict
+ assert torch.allclose(
+ model.base_model.model.embed_tokens.base_layer.weight,
+ state_dict["base_model.model.embed_tokens.base_layer.weight"],
+ )
+ else:
+ assert "base_model.model.embed_tokens.base_layer.weight" not in state_dict
+ del state_dict
+
+ @pytest.mark.parametrize("save_embedding_layers", ["auto", True, False])
+ def test_targeting_lora_to_embedding_layer_non_transformers(self, save_embedding_layers):
+ model = ModelEmbConv1D()
+ config = LoraConfig(target_modules=["emb", "lin0"], init_lora_weights=False)
+ model = get_peft_model(model, config)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ if save_embedding_layers is True:
+ with pytest.warns(
+ UserWarning,
+ match=r"Could not identify embedding layer\(s\) because the model is not a 🤗 transformers model\.",
+ ):
+ model.save_pretrained(tmp_dirname, save_embedding_layers=save_embedding_layers)
+ else:
+ model.save_pretrained(tmp_dirname, save_embedding_layers=save_embedding_layers)
+ from safetensors.torch import load_file as safe_load_file
+
+ state_dict = safe_load_file(os.path.join(tmp_dirname, "adapter_model.safetensors"))
+ assert "base_model.model.emb.base_layer.weight" not in state_dict
+ del state_dict
+
+ def test_load_resized_embedding_ignore_mismatched_sizes(self):
+ # issue #1605
+ # Make it possible to load a LoRA layer that targets an embedding layer even if the sizes mismatch by passing
+ # ignore_mismatched_sizes=True
+ model = ModelEmbConv1D(emb_size=100)
+ config = LoraConfig(target_modules=["emb", "lin0"], init_lora_weights=False)
+ model = get_peft_model(model, config)
+
+ # note: not using the context manager here because it fails on Windows CI for some reason
+ tmp_dirname = tempfile.mkdtemp()
+ try:
+ model.save_pretrained(tmp_dirname)
+ model = ModelEmbConv1D(emb_size=105)
+
+ # first check that this raises
+ with pytest.raises(RuntimeError) as exc:
+ PeftModel.from_pretrained(model, tmp_dirname)
+ msg = exc.value.args[0]
+ assert "size mismatch" in msg and "100" in msg and "105" in msg
+
+ # does not raise
+ PeftModel.from_pretrained(model, tmp_dirname, ignore_mismatched_sizes=True)
+ finally:
+ try:
+ shutil.rmtree(tmp_dirname)
+ except PermissionError:
+ # windows error
+ pass
+
+ @pytest.mark.parametrize(
+ "config0",
+ [
+ LoraConfig(target_modules=["lin0"], init_lora_weights=False),
+ LoKrConfig(target_modules=["lin0"], init_weights=False),
+ LoHaConfig(target_modules=["lin0"], init_weights=False),
+ AdaLoraConfig(target_modules=["lin0"], init_lora_weights=False, total_step=1),
+ IA3Config(target_modules=["lin0"], feedforward_modules=["lin0"], init_ia3_weights=False),
+ OFTConfig(target_modules=["lin0"], init_weights=False, r=2, oft_block_size=0),
+ BOFTConfig(target_modules=["lin0"], init_weights=False, boft_block_size=2),
+ HRAConfig(target_modules=["lin0"], init_weights=False),
+ BoneConfig(target_modules=["lin0"], init_weights=False, r=2),
+ ],
+ )
+ def test_adapter_name_makes_no_difference(self, config0):
+ # It should not matter whether we use the default adapter name or a custom one
+ model_cls = MLP
+ input = torch.arange(90).reshape(9, 10).to(self.torch_device)
+
+ # base model
+ torch.manual_seed(0)
+ base_model = model_cls().eval().to(self.torch_device)
+ output_base = base_model(input)
+
+ # default name
+ torch.manual_seed(0)
+ base_model = model_cls().eval().to(self.torch_device)
+ torch.manual_seed(0)
+ peft_model_default = get_peft_model(base_model, config0, adapter_name="default").eval().to(self.torch_device)
+ output_default = peft_model_default(input)
+ sd_default = peft_model_default.state_dict()
+
+ # custom name 1
+ torch.manual_seed(0)
+ base_model = model_cls().eval().to(self.torch_device)
+ torch.manual_seed(0)
+ peft_model_custom1 = get_peft_model(base_model, config0, adapter_name="adapter").eval().to(self.torch_device)
+ output_custom1 = peft_model_custom1(input)
+ sd_custom1 = peft_model_custom1.state_dict()
+
+ # custom name 2
+ torch.manual_seed(0)
+ base_model = model_cls().eval().to(self.torch_device)
+ torch.manual_seed(0)
+ peft_model_custom2 = (
+ get_peft_model(base_model, config0, adapter_name="other-name").eval().to(self.torch_device)
+ )
+ output_custom2 = peft_model_custom2(input)
+ sd_custom2 = peft_model_custom2.state_dict()
+
+ assert len(sd_default) == len(sd_custom1) == len(sd_custom2)
+ for key in sd_default:
+ key1 = key.replace("default", "adapter")
+ key2 = key.replace("default", "other-name")
+ assert key1 in sd_custom1
+ assert key2 in sd_custom2
+ for k0, k1, k2 in zip(sd_default, sd_custom1, sd_custom2):
+ assert torch.allclose(sd_default[k0], sd_custom1[k1])
+ assert torch.allclose(sd_default[k0], sd_custom2[k2])
+
+ assert not torch.allclose(output_base, output_default)
+ assert not torch.allclose(output_base, output_custom1)
+ assert not torch.allclose(output_base, output_custom2)
+ assert torch.allclose(output_custom1, output_custom2)
+ assert torch.allclose(output_default, output_custom1)
+
+ def test_gpt2_dora_merge_and_unload(self):
+ # see https://github.com/huggingface/peft/pull/1588#discussion_r1537914207
+ model = AutoModelForCausalLM.from_pretrained("gpt2")
+ config = LoraConfig(task_type="CAUSAL_LM", use_dora=True)
+ model = get_peft_model(model, config)
+ # should not raise an error
+ model.merge_and_unload()
+
+ def test_gpt2_dora_merge_and_unload_safe_merge(self):
+ # see https://github.com/huggingface/peft/pull/1588#discussion_r1537914207
+ model = AutoModelForCausalLM.from_pretrained("gpt2")
+ config = LoraConfig(task_type="CAUSAL_LM", use_dora=True)
+ model = get_peft_model(model, config)
+ # should not raise an error
+ model.merge_and_unload(safe_merge=True)
+
+ def test_unload_adapter_multihead_attention(self):
+ # MultiheadAttention has special logic for unloading, that logic is covered by this test
+ self._test_unload_adapter(
+ model_id="MHA",
+ config_cls=LoraConfig,
+ config_kwargs={"target_modules": ["mha"], "init_lora_weights": False},
+ )
+
+ def test_dora_save_and_load_remapping(self):
+ # Here we test the refactor of DoRA which changed lora_magnitude_vector from a ParameterDict to a ModuleDict
+ # with a DoraLayer instance. The old parameter is now the "weight" attribute of that layer. Since we want the
+ # state_dict format not to change, we ensure that the ".weight" part of the key is removed.
+ model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m")
+ config = LoraConfig(task_type="CAUSAL_LM", use_dora=True)
+ model = get_peft_model(model, config)
+ state_dict = model.state_dict()
+
+ # sanity check: state dict contains "lora_magnitude_vector.default.weight" keys
+ assert any("lora_magnitude_vector.default.weight" in k for k in state_dict)
+
+ # save the model, check the state dict
+ # note: not using the context manager here because it fails on Windows CI for some reason
+ tmp_dirname = tempfile.mkdtemp()
+ try:
+ model.save_pretrained(tmp_dirname)
+ state_dict_adapter = safe_load_file(os.path.join(tmp_dirname, "adapter_model.safetensors"))
+ # note that in the state dict, the "default" part of the key is removed
+ assert not any("lora_magnitude_vector.weight" in k for k in state_dict_adapter)
+
+ del model
+ loaded = PeftModel.from_pretrained(AutoModelForCausalLM.from_pretrained("facebook/opt-125m"), tmp_dirname)
+ finally:
+ try:
+ shutil.rmtree(tmp_dirname)
+ except PermissionError:
+ # windows error
+ pass
+
+ state_dict_loaded = loaded.state_dict()
+ assert state_dict.keys() == state_dict_loaded.keys()
+ for k in state_dict:
+ assert torch.allclose(state_dict[k], state_dict_loaded[k])
+
+ @pytest.mark.parametrize("with_forward_call", [False, True])
+ def test_mha_gradients_set_correctly(self, with_forward_call):
+ # check for this bug: https://github.com/huggingface/peft/issues/761#issuecomment-1893804738
+ base_model = ModelMha()
+ config = LoraConfig(target_modules=["mha"])
+ model = get_peft_model(base_model, config)
+ model = model.to(self.torch_device)
+
+ if with_forward_call:
+ # after the merge-unmerge roundtrip happening in forward of lora MHA, the base weights should be set to
+ # requires_grad=False
+ inputs = self.prepare_inputs_for_testing()
+ model(**inputs)
+
+ assert model.base_model.model.mha.base_layer.out_proj.base_layer.weight.requires_grad is False
+ assert model.base_model.model.mha.base_layer.in_proj_weight.requires_grad is False
+
+ # _restore_weights used to ignore the gradient, this checks that it is indeed considered
+ model.base_model.model.mha._restore_weights()
+ assert model.base_model.model.mha.base_layer.out_proj.base_layer.weight.requires_grad is False
+ assert model.base_model.model.mha.base_layer.in_proj_weight.requires_grad is False
+
+ model.base_model.model.mha.base_layer.out_proj.base_layer.weight.requires_grad = True
+ model.base_model.model.mha.base_layer.in_proj_weight.requires_grad = True
+ assert model.base_model.model.mha.base_layer.out_proj.base_layer.weight.requires_grad is True
+ assert model.base_model.model.mha.base_layer.in_proj_weight.requires_grad is True
+
+ model.base_model.model.mha._restore_weights()
+ assert model.base_model.model.mha.base_layer.out_proj.base_layer.weight.requires_grad is True
+ assert model.base_model.model.mha.base_layer.in_proj_weight.requires_grad is True
+
+
+class TestMultiRankAdapter:
+ """Tests related to multirank LoRA adapters"""
+
+ def test_multirank(self):
+ config_1 = LoraConfig(
+ r=8,
+ lora_alpha=8,
+ init_lora_weights=False,
+ target_modules=["lin0", "lin1"],
+ )
+ config_2 = LoraConfig(
+ r=8,
+ lora_alpha=8,
+ init_lora_weights=False,
+ target_modules=["lin0", "lin1"],
+ rank_pattern={"lin0": 4},
+ alpha_pattern={"lin0": 4},
+ )
+
+ # Add first adapter
+ model = get_peft_model(MLP(), config_1, adapter_name="first")
+
+ # Add second adapter
+ model.add_adapter("second", config_2)
+
+ # Extract current and expected ranks
+ rank_current = model.lin0.lora_A["second"].weight.shape[0]
+ rank_expected = config_2.rank_pattern["lin0"]
+
+ assert rank_current == rank_expected, f"Rank {rank_current} is not equal to expected {rank_expected}"
+
+ def test_multirank_2(self):
+ rank_pattern = {}
+ alpha_pattern = {}
+ r = 4
+ lora_alpha = 8
+
+ for i in range(10):
+ rank = 64 // (i + 1)
+ for j in range(2):
+ rank_pattern[f"layers.{i}.lin{j}"] = rank
+ alpha_pattern[f"layers.{i}.lin{j}"] = 2 * rank
+
+ config = LoraConfig(
+ r=r,
+ lora_alpha=lora_alpha,
+ init_lora_weights=False,
+ target_modules=["lin0", "lin1"],
+ rank_pattern=rank_pattern,
+ alpha_pattern=alpha_pattern,
+ )
+
+ # Add first adapter
+ model = get_peft_model(DeepMLP(), config, adapter_name="first")
+
+ # Add second adapter
+ model.add_adapter("second", config)
+
+ for adapter in ["first", "second"]:
+ for key, module in model.base_model.model.named_modules():
+ if isinstance(module, BaseTunerLayer):
+ rank_expected = rank_pattern.get(key, r)
+ rank_current = module.lora_A[adapter].weight.shape[0]
+ assert rank_current == rank_expected, (
+ f"Rank {rank_current} is not equal to expected {rank_expected}"
+ )
+
+
+class TestLayerRepr:
+ """Tests related to the repr of adapted models"""
+
+ def test_repr_lora_linear(self):
+ config = LoraConfig(target_modules=["lin0"])
+ model = get_peft_model(MLP(), config)
+ print_output = repr(model.model.lin0)
+ assert print_output.startswith("lora.Linear")
+ assert "in_features=10" in print_output
+ assert "out_features=20" in print_output
+ assert "lora_A" in print_output
+ assert "lora_B" in print_output
+ assert "default" in print_output
+
+ def test_repr_lora_embedding(self):
+ config = LoraConfig(target_modules=["emb"])
+ model = get_peft_model(ModelEmbConv1D(), config)
+ print_output = repr(model.model.emb)
+ assert print_output.startswith("lora.Embedding")
+ assert "100, 5" in print_output
+ assert "lora_embedding_A" in print_output
+ assert "lora_embedding_B" in print_output
+ assert "default" in print_output
+
+ def test_repr_lora_conv1d(self):
+ config = LoraConfig(target_modules=["conv1d"])
+ model = get_peft_model(ModelEmbConv1D(), config)
+ print_output = repr(model.model.conv1d)
+ assert print_output.startswith("lora.Linear")
+ assert "in_features=5" in print_output
+ assert "out_features=1" in print_output
+ assert "lora_A" in print_output
+ assert "lora_B" in print_output
+ assert "default" in print_output
+
+ def test_repr_lora_conv2d(self):
+ config = LoraConfig(target_modules=["conv2d"])
+ model = get_peft_model(ModelConv2D(), config)
+ print_output = repr(model.model.conv2d)
+ assert print_output.startswith("lora.Conv2d")
+ assert "5, 10" in print_output
+ assert "kernel_size=(3, 3)" in print_output
+ assert "stride=(1, 1)" in print_output
+ assert "lora_A" in print_output
+ assert "lora_B" in print_output
+ assert "default" in print_output
+
+
+class TestMultipleActiveAdapters:
+ """
+ A test class to test the functionality of multiple active adapters.
+
+ This is not specifically tied to custom models, it's just easy to test here and testing it on all types of models
+ would be overkill.
+ """
+
+ torch_device = infer_device()
+
+ def prepare_inputs_for_testing(self):
+ X = torch.arange(90).view(9, 10).to(self.torch_device)
+ return {"X": X}
+
+ def set_multiple_active_adapters(self, model, adapter_names):
+ for module in model.modules():
+ if isinstance(module, (BaseTunerLayer, AuxiliaryTrainingWrapper)):
+ module.set_adapter(adapter_names)
+
+ def resolve_model_cls(self, tuner_method):
+ if tuner_method == "lora+trainable_tokens":
+ # for this method we need an Embedding layer to target
+ return ModelEmbConv1D()
+ if tuner_method == "ia3":
+ return MLP(bias=False)
+ return MLP(bias=True)
+
+ @pytest.mark.parametrize(
+ "test_name, tuner_method, config_cls, config_kwargs_1, config_kwargs_2", MULTIPLE_ACTIVE_ADAPTERS_TEST_CASES
+ )
+ def test_multiple_active_adapters_forward(
+ self, test_name, tuner_method, config_cls, config_kwargs_1, config_kwargs_2
+ ):
+ torch.manual_seed(0)
+
+ model = self.resolve_model_cls(tuner_method)
+ model = model.to(self.torch_device).eval()
+
+ X = self.prepare_inputs_for_testing()
+
+ config_1 = config_cls(**config_kwargs_1)
+ config_2 = config_cls(**config_kwargs_2)
+
+ peft_model = get_peft_model(model, config_1, adapter_name="adapter_1")
+ peft_model.add_adapter("adapter_2", config_2)
+
+ # the assumption that the output of the combined output of two adapters is != to the output of one
+ # adapter is not true for unmodified trainable tokens as they just mimic the existing embedding matrix.
+ # therefore, we modify the weights so that the adapter weights differs from the embedding weights.
+ #
+ # We do it this way because we have no way to pass something like `init_weights=False` to the token adapter.
+ if "trainable_tokens" in tuner_method:
+ peft_model.emb.token_adapter.trainable_tokens_delta["adapter_1"].data = torch.rand_like(
+ peft_model.emb.token_adapter.trainable_tokens_delta["adapter_1"].data
+ )
+ peft_model.emb.token_adapter.trainable_tokens_delta["adapter_2"].data = torch.rand_like(
+ peft_model.emb.token_adapter.trainable_tokens_delta["adapter_2"].data
+ )
+
+ # set adapter_1
+ peft_model.set_adapter("adapter_1")
+ adapter_1_output = peft_model(**X)
+
+ # set adapter_2
+ peft_model.set_adapter("adapter_2")
+ adapter_2_output = peft_model(**X)
+
+ # set ["adapter_1", "adapter_2"]
+ self.set_multiple_active_adapters(peft_model, ["adapter_1", "adapter_2"])
+ combined_output = peft_model(**X)
+
+ assert not torch.allclose(adapter_1_output, adapter_2_output, atol=1e-5)
+ assert not torch.allclose(adapter_1_output, combined_output, atol=1e-5)
+ assert not torch.allclose(adapter_2_output, combined_output, atol=1e-5)
+
+ if (tuner_method == "lora") and not (config_1.target_parameters or config_2.target_parameters):
+ # Create a weighted adapter combining both adapters and check that its output is same as setting multiple
+ # active adapters. `target_parameters` is not supported.
+ peft_model.add_weighted_adapter(
+ ["adapter_1", "adapter_2"], [1.0, 1.0], "new_combined_adapter", combination_type="cat"
+ )
+ peft_model.set_adapter("new_combined_adapter")
+ new_combined_output = peft_model(**X)
+ assert torch.allclose(new_combined_output, combined_output, atol=1e-5)
+
+ @pytest.mark.parametrize(
+ "test_name, tuner_method, config_cls, config_kwargs_1, config_kwargs_2", MULTIPLE_ACTIVE_ADAPTERS_TEST_CASES
+ )
+ def test_multiple_active_adapters_merge_and_unmerge(
+ self, test_name, tuner_method, config_cls, config_kwargs_1, config_kwargs_2
+ ):
+ torch.manual_seed(0)
+
+ model = self.resolve_model_cls(tuner_method)
+ model = model.to(self.torch_device).eval()
+
+ X = self.prepare_inputs_for_testing()
+ base_output = model(**X)
+
+ config_1 = config_cls(**config_kwargs_1)
+ config_2 = config_cls(**config_kwargs_2)
+
+ peft_model = get_peft_model(model, config_1, adapter_name="adapter_1")
+ peft_model.add_adapter("adapter_2", config_2)
+
+ # set ["adapter_1", "adapter_2"]
+ self.set_multiple_active_adapters(peft_model, ["adapter_1", "adapter_2"])
+ combined_output = peft_model(**X)
+
+ peft_model.merge_adapter()
+ merged_combined_output = peft_model(**X)
+ assert torch.allclose(merged_combined_output, combined_output, atol=1e-4)
+
+ peft_model.unmerge_adapter()
+
+ with peft_model.disable_adapter():
+ disabled_adapter_output = peft_model(**X)
+
+ assert torch.allclose(disabled_adapter_output, base_output, atol=1e-4)
+
+ @pytest.mark.parametrize(
+ "test_name, tuner_method, config_cls, config_kwargs_1, config_kwargs_2", MULTIPLE_ACTIVE_ADAPTERS_TEST_CASES
+ )
+ def test_merge_layers_multi(self, test_name, tuner_method, config_cls, config_kwargs_1, config_kwargs_2):
+ torch.manual_seed(0)
+
+ model = self.resolve_model_cls(tuner_method)
+ model = model.to(self.torch_device).eval()
+
+ config_1 = config_cls(**config_kwargs_1)
+ config_2 = config_cls(**config_kwargs_2)
+
+ model = get_peft_model(model, config_1)
+
+ # the assumption that the output of the combined output of two adapters is != to the output of one
+ # adapter is not true for unmodified trainable tokens as they just mimic the existing embedding matrix.
+ # therefore, we modify the weights so that the adapter weights differs from the embedding weights. in this
+ # case we even use 20*rand to be very distinct to adapter 2 since we're comparing outputs and not embeddings
+ # with rather high tolerance values. this is also the reason why `init_weights` is not sufficient here and
+ # when using `.trainable_token_indices` we do not have the utility of `init_weights` anyway.
+ if "trainable_tokens" in tuner_method:
+ model.emb.token_adapter.trainable_tokens_delta["default"].data = 20 * torch.rand_like(
+ model.emb.token_adapter.trainable_tokens_delta["default"].data
+ )
+
+ dummy_input = self.prepare_inputs_for_testing()
+ model.eval()
+
+ with torch.inference_mode():
+ logits_adapter_1 = model(**dummy_input)[0]
+
+ model.add_adapter("adapter-2", config_2)
+ model.set_adapter("adapter-2")
+
+ # same as above but for adapter 2
+ if "trainable_tokens" in tuner_method:
+ model.emb.token_adapter.trainable_tokens_delta["adapter-2"].data = 2 * torch.rand_like(
+ model.emb.token_adapter.trainable_tokens_delta["adapter-2"].data
+ )
+
+ model.eval()
+
+ with torch.inference_mode():
+ logits_adapter_2 = model(**dummy_input)[0]
+
+ assert not torch.allclose(logits_adapter_1, logits_adapter_2, atol=1e-3, rtol=1e-3)
+
+ model.set_adapter("default")
+
+ with torch.inference_mode():
+ logits_adapter_1_after_set = model(**dummy_input)[0]
+
+ assert torch.allclose(logits_adapter_1_after_set, logits_adapter_1, atol=1e-3, rtol=1e-3)
+
+ model_copy = copy.deepcopy(model)
+ model_copy_2 = copy.deepcopy(model)
+ model_merged_all = model.merge_and_unload(adapter_names=["adapter-2", "default"])
+
+ with torch.inference_mode():
+ logits_merged_all = model_merged_all(**dummy_input)[0]
+
+ assert not torch.allclose(logits_merged_all, logits_adapter_2, atol=1e-3, rtol=1e-3)
+ assert not torch.allclose(logits_merged_all, logits_adapter_1, atol=1e-3, rtol=1e-3)
+
+ model_merged_adapter_2 = model_copy.merge_and_unload(adapter_names=["adapter-2"])
+
+ with torch.inference_mode():
+ logits_merged_adapter_2 = model_merged_adapter_2(**dummy_input)[0]
+
+ assert torch.allclose(logits_merged_adapter_2, logits_adapter_2, atol=1e-3, rtol=1e-3)
+
+ model_merged_adapter_default = model_copy_2.merge_and_unload(adapter_names=["default"])
+
+ with torch.inference_mode():
+ logits_merged_adapter_default = model_merged_adapter_default(**dummy_input)[0]
+
+ assert torch.allclose(logits_merged_adapter_default, logits_adapter_1, atol=1e-3, rtol=1e-3)
+
+
+class TestRequiresGrad:
+ """Test that requires_grad is set correctly in specific circumstances
+
+ # See issue #899.
+
+ This is not specifically tied to custom models, it's just easy to test here and testing it on all types of models
+ would be overkill.
+
+ """
+
+ def check_requires_grad(self, model, *params_expected: str):
+ # Check that only the given parameters have requires_grad=True, and all others have requires_grad=False.
+ # Calling without arguments besides the model means that all parameters should have requires_grad=False.
+ params_with_requires_grad = [name for name, param in model.named_parameters() if param.requires_grad]
+ diff = set(params_expected).symmetric_difference(set(params_with_requires_grad))
+ msg = f"Expected {params_expected} to require gradients, got {params_with_requires_grad}"
+ assert len(diff) == 0, msg
+
+ def test_requires_grad_modules_to_save_default(self):
+ config = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ peft_model = get_peft_model(MLP(), config)
+
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.modules_to_save.default.weight",
+ "base_model.model.lin1.modules_to_save.default.bias",
+ "base_model.model.lin0.lora_A.default.weight",
+ "base_model.model.lin0.lora_B.default.weight",
+ )
+
+ def test_requires_grad_modules_to_save_disabling(self):
+ config = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ peft_model = get_peft_model(MLP(), config)
+
+ # when disabling the adapter, the original module's grad should be enabled and vice versa
+ peft_model.disable_adapter_layers()
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.original_module.weight",
+ "base_model.model.lin1.original_module.bias",
+ )
+
+ # when re-enabling the adapter, the original module's grad should be disabled and vice versa
+ peft_model.enable_adapter_layers()
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.modules_to_save.default.weight",
+ "base_model.model.lin1.modules_to_save.default.bias",
+ "base_model.model.lin0.lora_A.default.weight",
+ "base_model.model.lin0.lora_B.default.weight",
+ )
+
+ # when using the disable_adapter context, the original module's grad should be enabled and vice versa
+ with peft_model.disable_adapter():
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.original_module.weight",
+ "base_model.model.lin1.original_module.bias",
+ )
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.modules_to_save.default.weight",
+ "base_model.model.lin1.modules_to_save.default.bias",
+ "base_model.model.lin0.lora_A.default.weight",
+ "base_model.model.lin0.lora_B.default.weight",
+ )
+
+ def test_requires_grad_modules_to_save_multiple_adapters(self):
+ config0 = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.modules_to_save.default.weight",
+ "base_model.model.lin1.modules_to_save.default.bias",
+ "base_model.model.lin0.lora_A.default.weight",
+ "base_model.model.lin0.lora_B.default.weight",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.modules_to_save.default.weight",
+ "base_model.model.lin1.modules_to_save.default.bias",
+ "base_model.model.lin0.lora_A.default.weight",
+ "base_model.model.lin0.lora_B.default.weight",
+ )
+
+ # set config1 as active, should lead to adapter1 requiring grad
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.modules_to_save.adapter1.weight",
+ "base_model.model.lin1.modules_to_save.adapter1.bias",
+ "base_model.model.lin0.lora_A.adapter1.weight",
+ "base_model.model.lin0.lora_B.adapter1.weight",
+ )
+
+ def test_requires_grad_lora_different_targets(self):
+ # test two different LoRA adapters that target different modules
+ config0 = LoraConfig(target_modules=["lin0"])
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = LoraConfig(target_modules=["lin1"])
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lora_A.default.weight",
+ "base_model.model.lin0.lora_B.default.weight",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lora_A.default.weight",
+ "base_model.model.lin0.lora_B.default.weight",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.lora_A.adapter1.weight",
+ "base_model.model.lin1.lora_B.adapter1.weight",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.lora_A.adapter1.weight",
+ "base_model.model.lin1.lora_B.adapter1.weight",
+ )
+
+ def test_requires_grad_lora_same_targets(self):
+ # same as previous test, except that LoRA adapters target the same layer
+ config0 = LoraConfig(target_modules=["lin0"])
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = LoraConfig(target_modules=["lin0"])
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lora_A.default.weight",
+ "base_model.model.lin0.lora_B.default.weight",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lora_A.default.weight",
+ "base_model.model.lin0.lora_B.default.weight",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lora_A.adapter1.weight",
+ "base_model.model.lin0.lora_B.adapter1.weight",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lora_A.adapter1.weight",
+ "base_model.model.lin0.lora_B.adapter1.weight",
+ )
+
+ def test_requires_grad_ia3_different_targets(self):
+ # test two different IA3 adapters that target different modules
+ config0 = IA3Config(target_modules=["lin0"], feedforward_modules=["lin0"])
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = IA3Config(target_modules=["lin1"], feedforward_modules=["lin1"])
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.ia3_l.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.ia3_l.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.ia3_l.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.ia3_l.adapter1",
+ )
+
+ def test_requires_grad_ia3_same_targets(self):
+ # same as previous test, except that IA3 adapters target the same layer
+ config0 = IA3Config(target_modules=["lin0"], feedforward_modules=["lin0"])
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = IA3Config(target_modules=["lin0"], feedforward_modules=["lin0"])
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.ia3_l.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.ia3_l.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.ia3_l.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.ia3_l.adapter1",
+ )
+
+ def test_requires_grad_adalora_different_targets(self):
+ # test two different AdaLora adapters that target different modules
+ config0 = AdaLoraConfig(target_modules=["lin0"], total_step=1)
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = AdaLoraConfig(target_modules=["lin1"], total_step=1, inference_mode=True)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lora_A.default",
+ "base_model.model.lin0.lora_B.default",
+ "base_model.model.lin0.lora_E.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lora_A.default",
+ "base_model.model.lin0.lora_B.default",
+ "base_model.model.lin0.lora_E.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.lora_A.adapter1",
+ "base_model.model.lin1.lora_B.adapter1",
+ "base_model.model.lin1.lora_E.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.lora_A.adapter1",
+ "base_model.model.lin1.lora_B.adapter1",
+ "base_model.model.lin1.lora_E.adapter1",
+ )
+
+ def test_requires_grad_adalora_same_targets(self):
+ # same as previous test, except that AdaLora adapters target the same layer
+ config0 = AdaLoraConfig(target_modules=["lin0"], total_step=1)
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = AdaLoraConfig(target_modules=["lin0"], total_step=1, inference_mode=True)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lora_A.default",
+ "base_model.model.lin0.lora_B.default",
+ "base_model.model.lin0.lora_E.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lora_A.default",
+ "base_model.model.lin0.lora_B.default",
+ "base_model.model.lin0.lora_E.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lora_A.adapter1",
+ "base_model.model.lin0.lora_B.adapter1",
+ "base_model.model.lin0.lora_E.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lora_A.adapter1",
+ "base_model.model.lin0.lora_B.adapter1",
+ "base_model.model.lin0.lora_E.adapter1",
+ )
+
+ def test_requires_grad_lora_conv2d(self):
+ # test two different LoRA adapters that target different modules
+ config0 = LoraConfig(target_modules=["conv2d"])
+ peft_model = get_peft_model(ModelConv2D(), config0)
+
+ config1 = LoraConfig(target_modules=["lin0"])
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.conv2d.lora_A.default.weight",
+ "base_model.model.conv2d.lora_B.default.weight",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.conv2d.lora_A.default.weight",
+ "base_model.model.conv2d.lora_B.default.weight",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lora_A.adapter1.weight",
+ "base_model.model.lin0.lora_B.adapter1.weight",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lora_A.adapter1.weight",
+ "base_model.model.lin0.lora_B.adapter1.weight",
+ )
+
+ def test_requires_grad_lora_emb_conv1d(self):
+ # test two different LoRA adapters that target different modules
+ config0 = LoraConfig(target_modules=["conv1d"])
+ peft_model = get_peft_model(ModelEmbConv1D(), config0)
+
+ config1 = LoraConfig(target_modules=["emb"])
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.conv1d.lora_A.default.weight",
+ "base_model.model.conv1d.lora_B.default.weight",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.conv1d.lora_A.default.weight",
+ "base_model.model.conv1d.lora_B.default.weight",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.emb.lora_embedding_A.adapter1",
+ "base_model.model.emb.lora_embedding_B.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.emb.lora_embedding_A.adapter1",
+ "base_model.model.emb.lora_embedding_B.adapter1",
+ )
+
+ def test_requires_grad_ia3_conv1d(self):
+ # test two different LoRA adapters that target different modules
+ config0 = IA3Config(target_modules=["conv1d"], feedforward_modules=[])
+ peft_model = get_peft_model(ModelEmbConv1D(), config0)
+
+ config1 = IA3Config(target_modules=["lin0"], feedforward_modules=["lin0"])
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.conv1d.ia3_l.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.conv1d.ia3_l.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.ia3_l.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.ia3_l.adapter1",
+ )
+
+ def test_requires_grad_ia3_conv2d(self):
+ # test two different LoRA adapters that target different modules
+ config0 = IA3Config(target_modules=["conv2d"], feedforward_modules=["conv2d"])
+ peft_model = get_peft_model(ModelConv2D(), config0)
+
+ config1 = IA3Config(target_modules=["lin0"], feedforward_modules=[])
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.conv2d.ia3_l.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.conv2d.ia3_l.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.ia3_l.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.ia3_l.adapter1",
+ )
+
+ def test_requires_grad_loha_different_targets(self):
+ # test two different LoHa adapters that target different modules
+ config0 = LoHaConfig(target_modules=["lin0"])
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = LoHaConfig(target_modules=["lin1"], inference_mode=True)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.hada_w1_a.default",
+ "base_model.model.lin0.hada_w1_b.default",
+ "base_model.model.lin0.hada_w2_a.default",
+ "base_model.model.lin0.hada_w2_b.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.hada_w1_a.default",
+ "base_model.model.lin0.hada_w1_b.default",
+ "base_model.model.lin0.hada_w2_a.default",
+ "base_model.model.lin0.hada_w2_b.default",
+ )
+
+ # change activate pter to pter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.hada_w1_a.adapter1",
+ "base_model.model.lin1.hada_w1_b.adapter1",
+ "base_model.model.lin1.hada_w2_a.adapter1",
+ "base_model.model.lin1.hada_w2_b.adapter1",
+ )
+
+ # disable all pters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.hada_w1_a.adapter1",
+ "base_model.model.lin1.hada_w1_b.adapter1",
+ "base_model.model.lin1.hada_w2_a.adapter1",
+ "base_model.model.lin1.hada_w2_b.adapter1",
+ )
+
+ def test_requires_grad_loha_same_targets(self):
+ # same as previous test, except that LoHa adapters target the same layer
+ config0 = LoHaConfig(target_modules=["lin0"])
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = LoHaConfig(target_modules=["lin0"], inference_mode=True)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.hada_w1_a.default",
+ "base_model.model.lin0.hada_w1_b.default",
+ "base_model.model.lin0.hada_w2_a.default",
+ "base_model.model.lin0.hada_w2_b.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.hada_w1_a.default",
+ "base_model.model.lin0.hada_w1_b.default",
+ "base_model.model.lin0.hada_w2_a.default",
+ "base_model.model.lin0.hada_w2_b.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.hada_w1_a.adapter1",
+ "base_model.model.lin0.hada_w1_b.adapter1",
+ "base_model.model.lin0.hada_w2_a.adapter1",
+ "base_model.model.lin0.hada_w2_b.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.hada_w1_a.adapter1",
+ "base_model.model.lin0.hada_w1_b.adapter1",
+ "base_model.model.lin0.hada_w2_a.adapter1",
+ "base_model.model.lin0.hada_w2_b.adapter1",
+ )
+
+ def test_requires_grad_lokr_different_targets(self):
+ # test two different LoKr adapters that target different modules
+ config0 = LoKrConfig(target_modules=["lin0"])
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = LoKrConfig(target_modules=["lin1"], inference_mode=True)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lokr_w1.default",
+ "base_model.model.lin0.lokr_w2.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lokr_w1.default",
+ "base_model.model.lin0.lokr_w2.default",
+ )
+
+ # change activate pter to pter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.lokr_w1.adapter1",
+ "base_model.model.lin1.lokr_w2.adapter1",
+ )
+
+ # disable all pters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.lokr_w1.adapter1",
+ "base_model.model.lin1.lokr_w2.adapter1",
+ )
+
+ def test_requires_grad_lokr_same_targets(self):
+ # same as previous test, except that LoKr adapters target the same layer
+ config0 = LoKrConfig(target_modules=["lin0"])
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = LoKrConfig(target_modules=["lin0"], inference_mode=True)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lokr_w1.default",
+ "base_model.model.lin0.lokr_w2.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lokr_w1.default",
+ "base_model.model.lin0.lokr_w2.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lokr_w1.adapter1",
+ "base_model.model.lin0.lokr_w2.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.lokr_w1.adapter1",
+ "base_model.model.lin0.lokr_w2.adapter1",
+ )
+
+ def test_requires_grad_oft_different_targets(self):
+ # test two different OFT adapters that target different modules
+ config0 = OFTConfig(target_modules=["lin0"], r=2, oft_block_size=0)
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = OFTConfig(target_modules=["lin1"], r=2, oft_block_size=0, inference_mode=True)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.oft_R.default.weight",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.oft_R.default.weight",
+ )
+
+ # change activate pter to pter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.oft_R.adapter1.weight",
+ )
+
+ # disable all pters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.oft_R.adapter1.weight",
+ )
+
+ def test_requires_grad_oft_same_targets(self):
+ # same as previous test, except that OFT adapters target the same layer
+ config0 = OFTConfig(target_modules=["lin0"], r=2, oft_block_size=0)
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = OFTConfig(target_modules=["lin0"], r=2, oft_block_size=0, inference_mode=True)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.oft_R.default.weight",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.oft_R.default.weight",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.oft_R.adapter1.weight",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.oft_R.adapter1.weight",
+ )
+
+ def test_requires_grad_hra_different_targets(self):
+ # test two different HRA adapters that target different modules
+ config0 = HRAConfig(target_modules=["lin0"])
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = HRAConfig(target_modules=["lin1"], inference_mode=True)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.hra_u.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.hra_u.default",
+ )
+
+ # change activate pter to pter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.hra_u.adapter1",
+ )
+
+ # disable all pters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.hra_u.adapter1",
+ )
+
+ def test_requires_grad_hra_same_targets(self):
+ # same as previous test, except that HRA adapters target the same layer
+ config0 = HRAConfig(target_modules=["lin0"])
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = HRAConfig(target_modules=["lin0"], inference_mode=True)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.hra_u.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.hra_u.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.hra_u.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.hra_u.adapter1",
+ )
+
+ def test_requires_grad_bone_different_targets(self):
+ # test two different HRA adapters that target different modules
+ config0 = BoneConfig(target_modules=["lin0"], r=2)
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = BoneConfig(target_modules=["lin1"], r=2, inference_mode=True)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.bone_block.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.bone_block.default",
+ )
+
+ # change activate pter to pter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.bone_block.adapter1",
+ )
+
+ # disable all pters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.bone_block.adapter1",
+ )
+
+ def test_requires_grad_bone_same_targets(self):
+ # same as previous test, except that HRA adapters target the same layer
+ config0 = BoneConfig(target_modules=["lin0"], r=2)
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = BoneConfig(target_modules=["lin0"], r=2, inference_mode=True)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.bone_block.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.bone_block.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.bone_block.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.bone_block.adapter1",
+ )
+
+ def test_requires_grad_boft_different_targets(self):
+ # test two different OFT adapters that target different modules
+ config0 = BOFTConfig(target_modules=["lin0"], boft_block_size=2)
+ peft_model = get_peft_model(MLP2(), config0)
+
+ config1 = BOFTConfig(target_modules=["lin1"], boft_block_size=2, inference_mode=True)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active pter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.boft_R.default",
+ "base_model.model.lin0.boft_s.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.boft_R.default",
+ "base_model.model.lin0.boft_s.default",
+ )
+
+ # change activate pter to pter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.boft_R.adapter1",
+ "base_model.model.lin1.boft_s.adapter1",
+ )
+
+ # disable all pters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.boft_R.adapter1",
+ "base_model.model.lin1.boft_s.adapter1",
+ )
+
+ def test_requires_grad_boft_same_targets(self):
+ # same as previous test, except that BOFT adapters target the same layer
+ config0 = BOFTConfig(target_modules=["lin1"], boft_block_size=2)
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = BOFTConfig(target_modules=["lin1"], boft_block_size=2, inference_mode=True)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.boft_R.default",
+ "base_model.model.lin1.boft_s.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.boft_R.default",
+ "base_model.model.lin1.boft_s.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.boft_R.adapter1",
+ "base_model.model.lin1.boft_s.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.boft_R.adapter1",
+ "base_model.model.lin1.boft_s.adapter1",
+ )
+
+ def test_requires_grad_lntuning_different_targets(self):
+ config0 = LNTuningConfig(
+ target_modules=["layernorm0"],
+ )
+ peft_model = get_peft_model(MLP_LayerNorm(), config0)
+
+ config1 = LNTuningConfig(
+ target_modules=["layernorm1"],
+ inference_mode=True,
+ )
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.layernorm0.ln_tuning_layers.default.weight",
+ "base_model.model.layernorm0.ln_tuning_layers.default.bias",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.layernorm0.ln_tuning_layers.default.weight",
+ "base_model.model.layernorm0.ln_tuning_layers.default.bias",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.layernorm1.ln_tuning_layers.adapter1.weight",
+ "base_model.model.layernorm1.ln_tuning_layers.adapter1.bias",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.layernorm1.ln_tuning_layers.adapter1.weight",
+ "base_model.model.layernorm1.ln_tuning_layers.adapter1.bias",
+ )
+
+ def test_requires_grad_lntuning_same_targets(self):
+ config0 = LNTuningConfig(
+ target_modules=["layernorm0"],
+ )
+ peft_model = get_peft_model(MLP_LayerNorm(), config0)
+
+ config1 = LNTuningConfig(target_modules=["layernorm0"], inference_mode=True)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.layernorm0.ln_tuning_layers.default.weight",
+ "base_model.model.layernorm0.ln_tuning_layers.default.bias",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.layernorm0.ln_tuning_layers.default.weight",
+ "base_model.model.layernorm0.ln_tuning_layers.default.bias",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.layernorm0.ln_tuning_layers.adapter1.weight",
+ "base_model.model.layernorm0.ln_tuning_layers.adapter1.bias",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.layernorm0.ln_tuning_layers.adapter1.weight",
+ "base_model.model.layernorm0.ln_tuning_layers.adapter1.bias",
+ )
+
+ def test_requires_grad_vera_different_targets(self):
+ # Test two different VeRA adapters that target different modules. Most notably, ensure that vera_A and vera_B
+ # don't require grads.
+
+ # requires a model with at least 2 layers with the same shapes
+ class MLP2(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.relu = nn.ReLU()
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.lin1 = nn.Linear(20, 20, bias=bias) # lin1 and lin2 have same shape
+ self.lin2 = nn.Linear(20, 20, bias=bias)
+ self.lin3 = nn.Linear(20, 2, bias=bias)
+ self.sm = nn.LogSoftmax(dim=-1)
+
+ def forward(self, X):
+ X = X.float()
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = self.lin1(X)
+ X = self.relu(X)
+ X = self.lin2(X)
+ X = self.relu(X)
+ X = self.lin3(X)
+ X = self.sm(X)
+ return X
+
+ config0 = VeraConfig(target_modules=["lin1"])
+ peft_model = get_peft_model(MLP2(), config0)
+
+ config1 = VeraConfig(target_modules=["lin2"])
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.vera_lambda_b.default",
+ "base_model.model.lin1.vera_lambda_d.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.vera_lambda_b.default",
+ "base_model.model.lin1.vera_lambda_d.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin2.vera_lambda_b.adapter1",
+ "base_model.model.lin2.vera_lambda_d.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin2.vera_lambda_b.adapter1",
+ "base_model.model.lin2.vera_lambda_d.adapter1",
+ )
+
+ def test_requires_grad_vera_same_targets(self):
+ # Test two different VeRA adapters that target the same module. Most notably, ensure that vera_A and vera_B
+ # don't require grads.
+
+ # requires a model with at least 2 layers with the same shapes
+ class MLP2(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.relu = nn.ReLU()
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.lin1 = nn.Linear(20, 20, bias=bias) # lin1 and lin2 have same shape
+ self.lin2 = nn.Linear(20, 20, bias=bias)
+ self.lin3 = nn.Linear(20, 2, bias=bias)
+ self.sm = nn.LogSoftmax(dim=-1)
+
+ def forward(self, X):
+ X = X.float()
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = self.lin1(X)
+ X = self.relu(X)
+ X = self.lin2(X)
+ X = self.relu(X)
+ X = self.lin3(X)
+ X = self.sm(X)
+ return X
+
+ config0 = VeraConfig(target_modules=["lin1", "lin2"])
+ peft_model = get_peft_model(MLP2(), config0)
+
+ config1 = VeraConfig(target_modules=["lin1", "lin2"])
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.vera_lambda_b.default",
+ "base_model.model.lin1.vera_lambda_d.default",
+ "base_model.model.lin2.vera_lambda_b.default",
+ "base_model.model.lin2.vera_lambda_d.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.vera_lambda_b.default",
+ "base_model.model.lin1.vera_lambda_d.default",
+ "base_model.model.lin2.vera_lambda_b.default",
+ "base_model.model.lin2.vera_lambda_d.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.vera_lambda_b.adapter1",
+ "base_model.model.lin1.vera_lambda_d.adapter1",
+ "base_model.model.lin2.vera_lambda_b.adapter1",
+ "base_model.model.lin2.vera_lambda_d.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.vera_lambda_b.adapter1",
+ "base_model.model.lin1.vera_lambda_d.adapter1",
+ "base_model.model.lin2.vera_lambda_b.adapter1",
+ "base_model.model.lin2.vera_lambda_d.adapter1",
+ )
+
+ def test_requires_grad_randlora_different_targets(self):
+ # Test two different RandLora adapters that target different modules. Most notably, ensure that randbasis_A and randbasis_B
+ # don't require grads.
+
+ # requires a model with at least 2 layers with the same shapes
+ class MLP2(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.relu = nn.ReLU()
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.lin1 = nn.Linear(20, 20, bias=bias) # lin1 and lin2 have same shape
+ self.lin2 = nn.Linear(20, 20, bias=bias)
+ self.lin3 = nn.Linear(20, 2, bias=bias)
+ self.sm = nn.LogSoftmax(dim=-1)
+
+ def forward(self, X):
+ X = X.float()
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = self.lin1(X)
+ X = self.relu(X)
+ X = self.lin2(X)
+ X = self.relu(X)
+ X = self.lin3(X)
+ X = self.sm(X)
+ return X
+
+ config0 = RandLoraConfig(target_modules=["lin1"])
+ peft_model = get_peft_model(MLP2(), config0)
+
+ config1 = RandLoraConfig(target_modules=["lin2"])
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.randlora_lambda.default",
+ "base_model.model.lin1.randlora_gamma.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.randlora_lambda.default",
+ "base_model.model.lin1.randlora_gamma.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin2.randlora_lambda.adapter1",
+ "base_model.model.lin2.randlora_gamma.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin2.randlora_lambda.adapter1",
+ "base_model.model.lin2.randlora_gamma.adapter1",
+ )
+
+ def test_requires_grad_randlora_same_targets(self):
+ # Test two different RandLora adapters that target the same module. Most notably, ensure that randbasis_A and randbasis_B
+ # don't require grads.
+
+ # requires a model with at least 2 layers with the same shapes
+ class MLP2(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.relu = nn.ReLU()
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.lin1 = nn.Linear(20, 20, bias=bias) # lin1 and lin2 have same shape
+ self.lin2 = nn.Linear(20, 20, bias=bias)
+ self.lin3 = nn.Linear(20, 2, bias=bias)
+ self.sm = nn.LogSoftmax(dim=-1)
+
+ def forward(self, X):
+ X = X.float()
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = self.lin1(X)
+ X = self.relu(X)
+ X = self.lin2(X)
+ X = self.relu(X)
+ X = self.lin3(X)
+ X = self.sm(X)
+ return X
+
+ config0 = RandLoraConfig(target_modules=["lin1", "lin2"])
+ peft_model = get_peft_model(MLP2(), config0)
+
+ config1 = RandLoraConfig(target_modules=["lin1", "lin2"])
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.randlora_lambda.default",
+ "base_model.model.lin1.randlora_gamma.default",
+ "base_model.model.lin2.randlora_lambda.default",
+ "base_model.model.lin2.randlora_gamma.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.randlora_lambda.default",
+ "base_model.model.lin1.randlora_gamma.default",
+ "base_model.model.lin2.randlora_lambda.default",
+ "base_model.model.lin2.randlora_gamma.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.randlora_lambda.adapter1",
+ "base_model.model.lin1.randlora_gamma.adapter1",
+ "base_model.model.lin2.randlora_lambda.adapter1",
+ "base_model.model.lin2.randlora_gamma.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.randlora_lambda.adapter1",
+ "base_model.model.lin1.randlora_gamma.adapter1",
+ "base_model.model.lin2.randlora_lambda.adapter1",
+ "base_model.model.lin2.randlora_gamma.adapter1",
+ )
+
+ def test_requires_grad_vblora_different_targets(self):
+ # test two different VBLoRA adapters that target different modules
+ config0 = VBLoRAConfig(target_modules=["lin0"], vector_length=1, num_vectors=2)
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = VBLoRAConfig(target_modules=["lin1"], vector_length=1, num_vectors=2)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.vblora_logits_A.default",
+ "base_model.model.lin0.vblora_logits_B.default",
+ "base_model.model.lin0.vblora_vector_bank.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.vblora_logits_A.default",
+ "base_model.model.lin0.vblora_logits_B.default",
+ "base_model.model.lin0.vblora_vector_bank.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.vblora_logits_A.adapter1",
+ "base_model.model.lin1.vblora_logits_B.adapter1",
+ "base_model.model.lin0.vblora_vector_bank.adapter1", # vblora_vector_bank is shared
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.vblora_logits_A.adapter1",
+ "base_model.model.lin1.vblora_logits_B.adapter1",
+ "base_model.model.lin0.vblora_vector_bank.adapter1", # vblora_vector_bank is shared
+ )
+
+ def test_requires_grad_vblora_same_targets(self):
+ # same as previous test, except that VBLoRA adapters target the same layer
+ config0 = VBLoRAConfig(target_modules=["lin0"], vector_length=1, num_vectors=2)
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = VBLoRAConfig(target_modules=["lin0"], vector_length=1, num_vectors=2)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.vblora_logits_A.default",
+ "base_model.model.lin0.vblora_logits_B.default",
+ "base_model.model.lin0.vblora_vector_bank.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.vblora_logits_A.default",
+ "base_model.model.lin0.vblora_logits_B.default",
+ "base_model.model.lin0.vblora_vector_bank.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.vblora_logits_A.adapter1",
+ "base_model.model.lin0.vblora_logits_B.adapter1",
+ "base_model.model.lin0.vblora_vector_bank.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.vblora_logits_A.adapter1",
+ "base_model.model.lin0.vblora_logits_B.adapter1",
+ "base_model.model.lin0.vblora_vector_bank.adapter1",
+ )
+
+ def test_requires_grad_fourierft_different_targets(self):
+ # test two different fourierft adapters that target different modules
+ config0 = FourierFTConfig(n_frequency=10, target_modules=["lin0"])
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = FourierFTConfig(n_frequency=10, target_modules=["lin1"], inference_mode=True)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.fourierft_spectrum.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.fourierft_spectrum.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.fourierft_spectrum.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin1.fourierft_spectrum.adapter1",
+ )
+
+ def test_requires_grad_fourierft_same_targets(self):
+ # same as previous test, except that AdaLora adapters target the same layer
+ config0 = FourierFTConfig(n_frequency=10, target_modules=["lin0"])
+ peft_model = get_peft_model(MLP(), config0)
+
+ config1 = FourierFTConfig(n_frequency=10, target_modules=["lin0"], inference_mode=True)
+ peft_model.add_adapter("adapter1", config1)
+
+ # active adapter is still "default"
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.fourierft_spectrum.default",
+ )
+
+ # set config0 as active, should not change anything
+ peft_model.set_adapter("default")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.fourierft_spectrum.default",
+ )
+
+ # change activate adapter to adapter1
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.fourierft_spectrum.adapter1",
+ )
+
+ # disable all adapters
+ with peft_model.disable_adapter():
+ self.check_requires_grad(peft_model)
+
+ # after context is exited, return to the previous state
+ peft_model.set_adapter("adapter1")
+ self.check_requires_grad(
+ peft_model,
+ "base_model.model.lin0.fourierft_spectrum.adapter1",
+ )
+
+
+class TestMixedAdapterBatches:
+ torch_device = infer_device()
+
+ @pytest.fixture
+ def mlp_lora(self):
+ """A simple MLP with 2 LoRA adapters"""
+ torch.manual_seed(0)
+
+ base_model = MLP().to(self.torch_device).eval()
+ config0 = LoraConfig(target_modules=["lin0"], init_lora_weights=False)
+ config1 = LoraConfig(target_modules=["lin0"], r=16, init_lora_weights=False)
+ peft_model = get_peft_model(base_model, config0, "adapter0").eval()
+ peft_model.add_adapter("adapter1", config1)
+ return peft_model
+
+ def run_checks(self, model, inputs):
+ # This checks that we can have mixed adapters in a single batch. The test works by creating the outputs for the
+ # base model, adapter 0, and adapter 1 separately. Then, we create an output with mixed adapters, where the
+ # sample [0, 3, 6] are for the base model, [1, 4, 7] for adapter 0, and [2, 5, 8] for adapter 1. Finally, we
+ # check that the outputs of the mixed batch are correct for the corresponding indices.
+ adapter_name0, adapter_name1 = model.peft_config.keys()
+
+ with model.disable_adapter():
+ output_base = model(**inputs)
+
+ model.set_adapter(adapter_name0)
+ output0 = model(**inputs)
+
+ # sanity check, outputs are not the same
+ assert not torch.allclose(output_base, output0)
+
+ model.set_adapter(adapter_name1)
+ output1 = model(**inputs)
+
+ # sanity check, outputs have the right shape and are not the same
+ assert len(output_base) >= 3
+ assert len(output_base) == len(output0) == len(output1)
+ assert not torch.allclose(output_base, output0)
+ assert not torch.allclose(output_base, output1)
+
+ # set adapter_indices so that it alternates between base, adapter 0, and adapter 1
+ adapters = ["__base__", adapter_name0, adapter_name1]
+ inputs["adapter_names"] = [adapters[i % 3] for i in (range(len(inputs["X"])))]
+ output_mixed = model.forward(**inputs)
+
+ assert torch.allclose(output_base[::3], output_mixed[::3])
+ assert torch.allclose(output0[1::3], output_mixed[1::3])
+ assert torch.allclose(output1[2::3], output_mixed[2::3])
+
+ def test_mixed_adapter_batches_lora_mlp(self, mlp_lora):
+ inputs = {"X": torch.arange(90).view(-1, 10).to(self.torch_device)}
+ self.run_checks(mlp_lora, inputs)
+
+ def test_mixed_adapter_batches_lora_different_target_layers(self, mlp_lora):
+ base_model = MLP().to(self.torch_device).eval()
+ config0 = LoraConfig(target_modules=["lin0"], init_lora_weights=False)
+ config1 = LoraConfig(target_modules=["lin1"], init_lora_weights=False)
+ peft_model = get_peft_model(base_model, config0, "adapter0").eval()
+ peft_model.add_adapter("adapter1", config1)
+ inputs = {"X": torch.arange(90).view(-1, 10).to(self.torch_device)}
+ self.run_checks(peft_model, inputs)
+
+ def test_mixed_adapter_batches_lora_multiple_modules_to_save(self, mlp_lora):
+ base_model = MLP().to(self.torch_device).eval()
+ config0 = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"], init_lora_weights=False)
+ config1 = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"], init_lora_weights=False)
+ peft_model = get_peft_model(base_model, config0, "adapter0").eval()
+ peft_model.add_adapter("adapter1", config1)
+ inputs = {"X": torch.arange(90).view(-1, 10).to(self.torch_device)}
+ self.run_checks(peft_model, inputs)
+
+ def test_mixed_adapter_batches_lora_unsupported_layer_raises(self, mlp_lora):
+ base_model = MLPWithGRU().to(self.torch_device).eval()
+ config0 = LoraConfig(target_modules=["lin0"], modules_to_save=["gru"], init_lora_weights=False)
+ config1 = LoraConfig(target_modules=["lin0"], modules_to_save=["gru"], init_lora_weights=False)
+ peft_model = get_peft_model(base_model, config0, "adapter0").eval()
+ peft_model.add_adapter("adapter1", config1)
+ inputs = {"X": torch.arange(90).view(-1, 10).to(self.torch_device)}
+ SUPPORTED_MODULES = (torch.nn.Linear, torch.nn.Embedding, torch.nn.Conv1d, torch.nn.Conv2d, torch.nn.Conv3d)
+ module_names = ", ".join([module.__name__ for module in SUPPORTED_MODULES])
+ with pytest.raises(
+ TypeError, match=f"Mixed batching is only supported for the following modules: {module_names}."
+ ):
+ self.run_checks(peft_model, inputs)
+
+ def test_mixed_adapter_batches_lora_partly_overlapping_target_layers(self, mlp_lora):
+ base_model = MLP().to(self.torch_device).eval()
+ # target different lora layers
+ config0 = LoraConfig(target_modules=["lin0"], init_lora_weights=False)
+ config1 = LoraConfig(target_modules=["lin0", "lin1"], init_lora_weights=False)
+ peft_model = get_peft_model(base_model, config0, "adapter0").eval()
+ peft_model.add_adapter("adapter1", config1)
+
+ inputs = {"X": torch.arange(90).view(-1, 10).to(self.torch_device)}
+ self.run_checks(peft_model, inputs)
+
+ def test_mixed_adapter_batches_lora_conv1d_emb(self):
+ base_model = ModelEmbConv1D().to(self.torch_device).eval()
+ config0 = LoraConfig(target_modules=["emb", "conv1d"], init_lora_weights=False)
+ config1 = LoraConfig(target_modules=["emb", "conv1d"], r=16, init_lora_weights=False)
+ peft_model = get_peft_model(base_model, config0, "adapter0").eval()
+ peft_model.add_adapter("adapter1", config1)
+
+ inputs = {"X": torch.arange(90).view(-1, 10).to(self.torch_device)}
+ self.run_checks(peft_model, inputs)
+
+ def test_mixed_adapter_batches_lora_conv1d_emb_multiple_modules_to_save(self):
+ base_model = ModelEmbConv1D().to(self.torch_device).eval()
+ config0 = LoraConfig(target_modules=["emb", "conv1d"], modules_to_save=["lin0"], init_lora_weights=False)
+ config1 = LoraConfig(target_modules=["emb", "conv1d"], modules_to_save=["lin0"], init_lora_weights=False)
+ peft_model = get_peft_model(base_model, config0, "adapter0").eval()
+ peft_model.add_adapter("adapter1", config1)
+ inputs = {"X": torch.arange(90).view(-1, 10).to(self.torch_device)}
+ self.run_checks(peft_model, inputs)
+
+ def test_mixed_adapter_batches_lora_conv2d(self):
+ base_model = ModelConv2D().to(self.torch_device).eval()
+ config0 = LoraConfig(target_modules=["conv2d"], init_lora_weights=False)
+ config1 = LoraConfig(target_modules=["conv2d"], r=16, init_lora_weights=False)
+ peft_model = get_peft_model(base_model, config0, "adapter0").eval()
+ peft_model.add_adapter("adapter1", config1)
+
+ inputs = {"X": torch.arange(270).view(6, 5, 3, 3).to(self.torch_device)}
+ self.run_checks(peft_model, inputs)
+
+ def test_mixed_adapter_batches_mha_raises(self):
+ base_model = ModelMha().to(self.torch_device).eval()
+ config0 = LoraConfig(target_modules=["mha"], init_lora_weights=False)
+ config1 = LoraConfig(target_modules=["mha"], r=16, init_lora_weights=False)
+ peft_model = get_peft_model(base_model, config0, "adapter0").eval()
+ peft_model.add_adapter("adapter1", config1)
+
+ inputs = {"X": torch.arange(90).view(-1, 10).to(self.torch_device)}
+ msg = "lora.MultiheadAttention does not support mixed adapter batches"
+ with pytest.raises(TypeError, match=msg):
+ self.run_checks(peft_model, inputs)
+
+ def test_mixed_adapter_batches_lora_length_mismatch_raises(self, mlp_lora):
+ inputs = {
+ "X": torch.arange(90).view(-1, 10).to(self.torch_device),
+ "adapter_names": ["__base__"] * 5, # wrong length!
+ }
+ msg = r"Length of `adapter_names` should be the same as the number of inputs, but got "
+ with pytest.raises(ValueError, match=msg):
+ mlp_lora.forward(**inputs)
+
+ def test_mixed_adapter_batches_lora_training_mode_raises(self, mlp_lora):
+ inputs = {
+ "X": torch.arange(90).view(-1, 10).to(self.torch_device),
+ "adapter_names": ["__base__"] * 9,
+ }
+ mlp_lora = mlp_lora.train()
+ msg = r"Cannot pass `adapter_names` when the model is in training mode."
+ with pytest.raises(ValueError, match=msg):
+ mlp_lora.forward(**inputs)
+
+ def test_mixed_adapter_batches_lora_disabled(self, mlp_lora):
+ # Disabling adapters should have precedence over passing adapter names
+ inputs = {"X": torch.arange(90).view(-1, 10).to(self.torch_device)}
+ with mlp_lora.disable_adapter():
+ output_disabled = mlp_lora(**inputs)
+
+ adapters = ["__base__", "adapter0", "adapter1"]
+ inputs["adapter_names"] = [adapters[i % 3] for i in (range(len(inputs["X"])))]
+ with mlp_lora.disable_adapter():
+ output_mixed = mlp_lora.forward(**inputs)
+
+ assert torch.allclose(output_disabled, output_mixed)
+
+ def test_mixed_adapter_batches_lora_merged_raises(self, mlp_lora):
+ # When there are merged adapters, passing adapter names should raise an error
+ inputs = {
+ "X": torch.arange(90).view(-1, 10).to(self.torch_device),
+ "adapter_names": ["adapter0"] * 9,
+ }
+ mlp_lora.merge_adapter(["adapter0"])
+ msg = r"Cannot pass `adapter_names` when there are merged adapters, please call `unmerge_adapter` first."
+ with pytest.raises(ValueError, match=msg):
+ mlp_lora.forward(**inputs)
+
+ def test_mixed_adapter_batches_lora_wrong_adapter_name_raises(self):
+ # Ensure that all of the adapter names that are being passed actually exist
+ torch.manual_seed(0)
+ x = torch.arange(90).view(-1, 10).to(self.torch_device)
+
+ base_model = MLP().to(self.torch_device).eval()
+ config = LoraConfig(target_modules=["lin0"], init_lora_weights=False)
+ peft_model = get_peft_model(base_model, config).eval()
+ peft_model.add_adapter(adapter_name="other", peft_config=config)
+
+ # sanity check: this works
+ peft_model.forward(x, adapter_names=["default"] * 5 + ["other"] * 4)
+
+ # check one correct and one incorrect adapter
+ msg = re.escape("Trying to infer with non-existing adapter(s): does-not-exist")
+ with pytest.raises(ValueError, match=msg):
+ peft_model.forward(x, adapter_names=["default"] * 5 + ["does-not-exist"] * 4)
+
+ # check two correct adapters and one incorrect adapter
+ with pytest.raises(ValueError, match=msg):
+ peft_model.forward(x, adapter_names=["default"] * 3 + ["does-not-exist"] * 4 + ["other"] * 2)
+
+ # check only incorrect adapters
+ msg = re.escape("Trying to infer with non-existing adapter(s): does-not-exist, other-does-not-exist")
+ with pytest.raises(ValueError, match=msg):
+ peft_model.forward(x, adapter_names=["does-not-exist"] * 5 + ["other-does-not-exist"] * 4)
+
+ def test_mixed_adapter_batches_lora_with_dora_raises(self):
+ # When there are DoRA adapters, passing adapter names should raise an error
+ torch.manual_seed(0)
+ inputs = {
+ "X": torch.arange(90).view(-1, 10).to(self.torch_device),
+ "adapter_names": ["default"] * 9,
+ }
+
+ base_model = MLP().to(self.torch_device).eval()
+ config = LoraConfig(target_modules=["lin0"], init_lora_weights=False, use_dora=True)
+ peft_model = get_peft_model(base_model, config).eval()
+ msg = r"Cannot pass `adapter_names` when DoRA is enabled."
+ with pytest.raises(ValueError, match=msg):
+ peft_model.forward(**inputs)
+
+ def test_mixed_adapter_batches_lora_with_dora_but_dora_not_included_works(self):
+ # When there are DoRA adapters, passing adapter names should raise an error, see previous test. However, when
+ # the adapter that uses DoRA is not included in adapter_names, it's actually fine.
+ torch.manual_seed(0)
+ base_model = MLP().to(self.torch_device).eval()
+ config_dora = LoraConfig(target_modules=["lin0"], init_lora_weights=False, use_dora=True)
+ peft_model = get_peft_model(base_model, config_dora)
+ config_no_dora = LoraConfig(target_modules=["lin0"], init_lora_weights=False, use_dora=False)
+ peft_model.add_adapter(adapter_name="other", peft_config=config_no_dora)
+ peft_model.eval()
+
+ # The "default" adapter uses DoRA but "other" is not using it, so using "other" is fine. Also, "__base__" is
+ # fine since it uses the base model and thus DoRA is not involved either.
+ inputs = {
+ "X": torch.arange(90).view(-1, 10).to(self.torch_device),
+ "adapter_names": ["other"] * 4 + ["__base__"] * 5,
+ }
+ peft_model.forward(**inputs)
+
+ @require_non_cpu
+ def test_mixed_adapter_batches_lora_opt_timing(self):
+ # Use a more realistic model (opt-125m) and do a simple runtime check to ensure that mixed adapter batches
+ # don't add too much overhead. These types of tests are inherently flaky, so we try to add in some robustness.
+ logs = [] # store the time it takes to run each forward pass here
+
+ @contextmanager
+ def timed():
+ tic = time.perf_counter()
+ yield
+ toc = time.perf_counter()
+ logs.append(toc - tic)
+
+ base_model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m").to(self.torch_device).eval()
+ inputs = {"input_ids": torch.randint(0, 1000, (16, 64)).to(self.torch_device)}
+ with timed():
+ output_base = base_model(**inputs).logits
+
+ config0 = LoraConfig(task_type="CAUSAL_LM", init_lora_weights=False)
+ peft_model = get_peft_model(base_model, config0, "adapter1").eval()
+ with timed():
+ output0 = peft_model(**inputs).logits
+
+ # sanity check, outputs are not the same
+ assert not torch.allclose(output_base, output0)
+
+ config1 = LoraConfig(task_type="CAUSAL_LM", r=16, init_lora_weights=False)
+ peft_model.add_adapter("adapter2", config1)
+ peft_model.set_adapter("adapter2")
+ with timed():
+ output1 = peft_model(**inputs).logits
+
+ # sanity check, outputs are not the same
+ assert not torch.allclose(output_base, output1)
+
+ # set adapter_indices so that it alternates between 0 (base), lora 1, and lora 2
+ adapters = ["__base__", "adapter1", "adapter2"]
+ inputs["adapter_names"] = [adapters[i % 3] for i in (range(len(inputs["input_ids"])))]
+ with timed():
+ output_mixed = peft_model.forward(**inputs).logits
+
+ atol, rtol = 1e-4, 1e-4
+ assert torch.allclose(output_base[::3], output_mixed[::3], atol=atol, rtol=rtol)
+ assert torch.allclose(output0[1::3], output_mixed[1::3], atol=atol, rtol=rtol)
+ assert torch.allclose(output1[2::3], output_mixed[2::3], atol=atol, rtol=rtol)
+
+ # Check that the overhead in time added by mixed batches is not too high.
+ # To prevent flakiness, we measure mixed inference 3 times and take the lowest value, then compare it to the mean
+ # of the non-mixed inference times. We also grant a generous margin of 2x the mean time.
+ with timed():
+ output_mixed = peft_model.forward(**inputs).logits
+ with timed():
+ output_mixed = peft_model.forward(**inputs).logits
+
+ time_base, time0, time1, *time_mixed = logs
+ time_non_mixed = (time_base + time0 + time1) / 3
+ time_mixed = min(time_mixed)
+
+ factor = 2.0
+ assert time_mixed < factor * time_non_mixed
+
+ # Measure timing of running base and adapter separately vs using a mixed batch. Note that on CPU, the
+ # differences are quite small, so this test requires GPU to avoid flakiness.
+ for _ in range(3):
+ with timed():
+ with peft_model.disable_adapter():
+ peft_model(**{k: v[::3] for k, v in inputs.items()})
+ peft_model.set_adapter("adapter1")
+ peft_model(**{k: v[1::3] for k, v in inputs.items()})
+ peft_model.set_adapter("adapter2")
+ peft_model(**{k: v[2::3] for k, v in inputs.items()})
+
+ times_separate = logs[-3:]
+ time_separate = sum(times_separate) / 3
+ assert time_separate > time_mixed
+
+
+class TestDynamicDispatch:
+ # These are tests for the dynamic dispatch feature for LoRA. We create a custom module and a custom LoRA layer
+ # that targets it.
+
+ @pytest.fixture(scope="class")
+ def custom_module_cls(self):
+ class MyModule(nn.Module):
+ # A custom layer that just behaves like an nn.Linear layer but is not an instance of nn.Linear. Therefore,
+ # it would normally fail to be targeted.
+ def __init__(self):
+ super().__init__()
+ self.in_features = 10
+ self.out_features = 20
+ self.weight = nn.Parameter(torch.randn(20, 10))
+
+ def forward(self, x):
+ return nn.functional.linear(x, self.weight)
+
+ return MyModule
+
+ @pytest.fixture(scope="class")
+ def custom_lora_cls(self):
+ from peft.tuners import lora
+
+ class MyLora(lora.Linear):
+ # just re-use the lora.Linear code here
+ pass
+
+ return MyLora
+
+ @pytest.fixture(scope="class")
+ def model_cls(self, custom_module_cls):
+ class MyModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.lin0 = nn.Linear(10, 10)
+ self.relu = nn.ReLU()
+ self.my_module = custom_module_cls()
+ self.lin1 = nn.Linear(20, 2)
+
+ def forward(self, x):
+ x = self.relu(self.lin0(x))
+ x = self.relu(self.my_module(x))
+ x = self.lin1(x)
+ return x
+
+ return MyModel
+
+ def test_custom_lora_layer_used(self, custom_module_cls, custom_lora_cls, model_cls):
+ # check that when we register custom lora layers, they are indeed being used for the intended module
+ model = model_cls()
+ config = LoraConfig(target_modules=["lin0", "my_module", "lin1"])
+ config._register_custom_module({custom_module_cls: custom_lora_cls})
+
+ peft_model = get_peft_model(model, config)
+ assert isinstance(peft_model.base_model.model.my_module, custom_lora_cls)
+ assert isinstance(peft_model.base_model.model.my_module.base_layer, custom_module_cls)
+ # sanity check that the other lora layer types are still the default ones
+ assert not isinstance(peft_model.base_model.model.lin0.base_layer, custom_module_cls)
+ assert not isinstance(peft_model.base_model.model.lin1.base_layer, custom_module_cls)
+
+ def test_training_works(self, model_cls, custom_module_cls, custom_lora_cls):
+ # check that when we train with custom lora layers, they are indeed updated
+ model = model_cls()
+ config = LoraConfig(target_modules=["lin0", "my_module", "lin1"])
+ config._register_custom_module({custom_module_cls: custom_lora_cls})
+
+ peft_model = get_peft_model(model, config)
+ sd_before = copy.deepcopy(peft_model.state_dict())
+ inputs = torch.randn(16, 10)
+ optimizer = torch.optim.SGD(peft_model.parameters(), lr=1e-4)
+
+ for _ in range(5):
+ optimizer.zero_grad()
+ output = peft_model(inputs)
+ loss = output.sum() ** 2
+ loss.backward()
+ optimizer.step()
+
+ sd_after = peft_model.state_dict()
+
+ # sanity check that for finite results, since nan != nan, which would make the test pass trivially
+ for val in sd_before.values():
+ assert torch.isfinite(val).all()
+ for val in sd_after.values():
+ assert torch.isfinite(val).all()
+
+ assert not torch.allclose(
+ sd_before["base_model.model.my_module.lora_A.default.weight"],
+ sd_after["base_model.model.my_module.lora_A.default.weight"],
+ )
+ assert not torch.allclose(
+ sd_before["base_model.model.my_module.lora_B.default.weight"],
+ sd_after["base_model.model.my_module.lora_B.default.weight"],
+ )
+
+ def test_saving_and_loading(self, custom_module_cls, custom_lora_cls, model_cls, tmp_path):
+ # check that we can successfully save and load the custom lora cls
+ torch.manual_seed(0)
+ model = model_cls()
+ config = LoraConfig(target_modules=["lin0", "my_module", "lin1"])
+ config._register_custom_module({custom_module_cls: custom_lora_cls})
+
+ torch.manual_seed(1)
+ peft_model = get_peft_model(model, config)
+
+ inputs = torch.randn(5, 10)
+ outputs_before = peft_model(inputs) # does not raise
+
+ sd_before = peft_model.state_dict()
+ peft_model.save_pretrained(tmp_path / "lora-custom-module")
+ del model, peft_model
+
+ torch.manual_seed(0) # same seed for base model
+ model = model_cls()
+
+ # custom lora mapping is not persisted at the moment, so as a workaround this is needed
+ config = LoraConfig.from_pretrained(tmp_path / "lora-custom-module")
+ config._register_custom_module({custom_module_cls: custom_lora_cls})
+
+ # different seed for adapter to ensure it is not identical just because of seed
+ torch.manual_seed(123)
+ peft_model = PeftModel.from_pretrained(model, tmp_path / "lora-custom-module", config=config)
+ assert isinstance(peft_model.base_model.model.my_module, custom_lora_cls)
+ assert isinstance(peft_model.base_model.model.my_module.base_layer, custom_module_cls)
+
+ outputs_after = peft_model(inputs) # does not raise
+ assert torch.allclose(outputs_before, outputs_after)
+
+ sd_after = peft_model.state_dict()
+ assert sd_before.keys() == sd_after.keys()
+ for key in sd_before.keys():
+ assert torch.allclose(sd_before[key], sd_after[key])
+
+ def test_override_lora_linear(self, custom_lora_cls):
+ # in this test, we check if users can override default PEFT behavior by supplying a custom lora class that is
+ # being used instead of lora.Linear
+ model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m")
+ config = LoraConfig(task_type=TaskType.CAUSAL_LM)
+ config._register_custom_module({nn.Linear: custom_lora_cls})
+ peft_model = get_peft_model(model, config)
+ layers = peft_model.base_model.model.model.decoder.layers
+ for layer in layers:
+ assert isinstance(layer.self_attn.v_proj, custom_lora_cls)
+ assert isinstance(layer.self_attn.q_proj, custom_lora_cls)
+
+ def test_custom_lora_layer_issues_warning(self, custom_module_cls, custom_lora_cls, model_cls, recwarn):
+ # users will get a warning if they target a layer type that is not officially supported
+ model = model_cls()
+ config = LoraConfig(target_modules=["lin0", "my_module", "lin1"])
+ config._register_custom_module({custom_module_cls: custom_lora_cls})
+
+ get_peft_model(model, config)
+ # check warning message
+ msg = (
+ "Unsupported layer type '.MyModule'>' encountered, proceed at your own risk."
+ )
+ assert str(recwarn.list[-1].message) == msg
+
+ def test_target_layer_without_in_features_out_features(self, recwarn):
+ # It should be possible for users to target layers even if we cannot determine in_features and out_features.
+ # Those are only needed to initialize the LoRA layer via update_layer, so as long as users take care of that,
+ # they should be good and not require those attributes to exist
+ from peft.tuners import lora
+
+ class MyModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.lstm = nn.LSTM(10, 20)
+
+ class MyLora(nn.Module, lora.LoraLayer):
+ def __init__(self, base_layer, adapter_name, **kwargs):
+ super().__init__()
+ lora.LoraLayer.__init__(self, base_layer, **kwargs)
+ self._active_adapter = adapter_name
+
+ model = MyModel()
+ # check that in_features and out_features attributes don't exist on LSTM
+ assert not hasattr(model.lstm, "in_features")
+ assert not hasattr(model.lstm, "out_features")
+
+ config = LoraConfig(target_modules=["lstm"])
+ config._register_custom_module({nn.LSTM: MyLora})
+ peft_model = get_peft_model(model, config)
+
+ # check that custom LoRA layer is correctly applied
+ assert isinstance(peft_model.base_model.lstm, MyLora)
+ assert isinstance(peft_model.base_model.lstm.base_layer, nn.LSTM)
+
+ # we should still get a warning message
+ msg = "Unsupported layer type '' encountered, proceed at your own risk."
+ assert str(recwarn.list[-1].message) == msg
diff --git a/peft/tests/test_decoder_models.py b/peft/tests/test_decoder_models.py
new file mode 100644
index 0000000000000000000000000000000000000000..3e756c2f43bd2e2f61050e9f9dd753eb825a5ee8
--- /dev/null
+++ b/peft/tests/test_decoder_models.py
@@ -0,0 +1,682 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import platform
+import tempfile
+from unittest.mock import Mock, call, patch
+
+import pytest
+import torch
+from transformers import (
+ AutoModelForCausalLM,
+ AutoTokenizer,
+ DataCollatorForLanguageModeling,
+ Trainer,
+ TrainingArguments,
+)
+
+from peft import (
+ AdaLoraConfig,
+ BOFTConfig,
+ BoneConfig,
+ C3AConfig,
+ CPTConfig,
+ FourierFTConfig,
+ HRAConfig,
+ IA3Config,
+ LoraConfig,
+ OFTConfig,
+ PrefixTuningConfig,
+ PromptEncoderConfig,
+ PromptTuningConfig,
+ PromptTuningInit,
+ ShiraConfig,
+ VBLoRAConfig,
+ VeraConfig,
+ get_peft_model,
+)
+
+from .testing_common import PeftCommonTester
+from .testing_utils import device_count, load_dataset_english_quotes, set_init_weights_false
+
+
+PEFT_DECODER_MODELS_TO_TEST = [
+ "hf-internal-testing/tiny-random-OPTForCausalLM",
+ "hf-internal-testing/tiny-random-GPT2LMHeadModel",
+ "hf-internal-testing/tiny-random-BloomForCausalLM",
+ "hf-internal-testing/tiny-random-gpt_neo",
+ "hf-internal-testing/tiny-random-GPTJForCausalLM",
+ "hf-internal-testing/tiny-random-GPTBigCodeForCausalLM",
+ "trl-internal-testing/tiny-random-LlamaForCausalLM",
+ "peft-internal-testing/tiny-dummy-qwen2",
+ "hf-internal-testing/tiny-random-Gemma3ForCausalLM",
+]
+
+SMALL_GRID_MODELS = [
+ "hf-internal-testing/tiny-random-gpt2",
+ "hf-internal-testing/tiny-random-OPTForCausalLM",
+ "hf-internal-testing/tiny-random-MistralForCausalLM",
+ "peft-internal-testing/tiny-dummy-qwen2",
+ "trl-internal-testing/tiny-random-LlamaForCausalLM",
+]
+
+
+# TODO Missing from this list are LoKr, LoHa, LN Tuning, add them
+ALL_CONFIGS = [
+ (
+ AdaLoraConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "target_modules": None,
+ "total_step": 1,
+ },
+ ),
+ (
+ BOFTConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "target_modules": None,
+ },
+ ),
+ (
+ BoneConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "target_modules": None,
+ "r": 2,
+ },
+ ),
+ (
+ CPTConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "cpt_token_ids": [0, 1, 2, 3, 4, 5, 6, 7], # Example token IDs for testing
+ "cpt_mask": [1, 1, 1, 1, 1, 1, 1, 1],
+ "cpt_tokens_type_mask": [1, 2, 2, 2, 3, 3, 4, 4],
+ },
+ ),
+ (
+ FourierFTConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "n_frequency": 10,
+ "target_modules": None,
+ },
+ ),
+ (
+ HRAConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "target_modules": None,
+ },
+ ),
+ (
+ IA3Config,
+ {
+ "task_type": "CAUSAL_LM",
+ "target_modules": None,
+ "feedforward_modules": None,
+ },
+ ),
+ (
+ LoraConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "r": 8,
+ "lora_alpha": 32,
+ "target_modules": None,
+ "lora_dropout": 0.05,
+ "bias": "none",
+ },
+ ),
+ # LoRA + trainable tokens
+ (
+ LoraConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "r": 8,
+ "lora_alpha": 32,
+ "target_modules": None,
+ "lora_dropout": 0.05,
+ "bias": "none",
+ "trainable_token_indices": [0, 1, 3],
+ },
+ ),
+ (
+ OFTConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "target_modules": None,
+ },
+ ),
+ (
+ PrefixTuningConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "num_virtual_tokens": 10,
+ },
+ ),
+ (
+ PromptEncoderConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "num_virtual_tokens": 10,
+ "encoder_hidden_size": 32,
+ },
+ ),
+ (
+ PromptTuningConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "num_virtual_tokens": 10,
+ },
+ ),
+ (
+ ShiraConfig,
+ {
+ "r": 1,
+ "task_type": "CAUSAL_LM",
+ "target_modules": None,
+ "init_weights": False,
+ },
+ ),
+ (
+ VBLoRAConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "target_modules": None,
+ "vblora_dropout": 0.05,
+ "vector_length": 1,
+ "num_vectors": 2,
+ },
+ ),
+ (
+ VeraConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "r": 8,
+ "target_modules": None,
+ "vera_dropout": 0.05,
+ "projection_prng_key": 0xFF,
+ "d_initial": 0.1,
+ "save_projection": True,
+ "bias": "none",
+ },
+ ),
+ (
+ C3AConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "block_size": 1, # Some test cases contain shapes of prime numbers where `block_size` must be 1
+ "target_modules": None,
+ },
+ ),
+]
+
+
+def _skip_if_not_conv1d_supported(model_id, config_cls):
+ if "GPT2LMHeadModel" in model_id and config_cls in [
+ BOFTConfig,
+ BoneConfig,
+ HRAConfig,
+ OFTConfig,
+ ShiraConfig,
+ C3AConfig,
+ ]:
+ pytest.skip("Skipping BOFT/HRA/OFT/Bone/SHiRA/C3A for GPT2LMHeadModel")
+
+
+def _skip_adalora_oft_hra_bone_for_gpt2(model_id, config_cls):
+ if "GPT2LMHeadModel" in model_id and config_cls in [
+ AdaLoraConfig,
+ BOFTConfig,
+ HRAConfig,
+ OFTConfig,
+ BoneConfig,
+ C3AConfig,
+ ]:
+ pytest.skip("Skipping AdaLora/BOFT/HRA/OFT/Bone for GPT2LMHeadModel")
+
+
+class TestDecoderModels(PeftCommonTester):
+ transformers_class = AutoModelForCausalLM
+
+ def skipTest(self, reason=""):
+ # for backwards compatibility with unittest style test classes
+ pytest.skip(reason)
+
+ def prepare_inputs_for_testing(self):
+ input_ids = torch.tensor([[1, 1, 1], [1, 2, 1]]).to(self.torch_device)
+ attention_mask = torch.tensor([[1, 1, 1], [1, 0, 1]]).to(self.torch_device)
+ return {"input_ids": input_ids, "attention_mask": attention_mask}
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_attributes_parametrized(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ self._test_model_attr(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_adapter_name(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ self._test_adapter_name(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_prepare_for_training_parametrized(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ self._test_prepare_for_training(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_prompt_tuning_text_prepare_for_training(self, model_id, config_cls, config_kwargs):
+ if config_cls != PromptTuningConfig:
+ pytest.skip(f"This test does not apply to {config_cls}")
+ config_kwargs = config_kwargs.copy()
+ config_kwargs["prompt_tuning_init"] = PromptTuningInit.TEXT
+ config_kwargs["prompt_tuning_init_text"] = "This is a test prompt."
+ config_kwargs["tokenizer_name_or_path"] = model_id
+ self._test_prepare_for_training(model_id, config_cls, config_kwargs.copy())
+
+ def test_prompt_tuning_text_tokenizer_kwargs(self):
+ # Allow users to pass additional arguments to Tokenizer.from_pretrained
+ # Fix for #1032
+ mock = Mock()
+ orig_from_pretrained = AutoTokenizer.from_pretrained
+
+ def mock_autotokenizer_from_pretrained(*args, **kwargs):
+ mock(*args, **kwargs)
+ return orig_from_pretrained(config.tokenizer_name_or_path)
+
+ model_id = "hf-internal-testing/tiny-random-OPTForCausalLM"
+ config = PromptTuningConfig(
+ base_model_name_or_path=model_id,
+ tokenizer_name_or_path=model_id,
+ num_virtual_tokens=10,
+ prompt_tuning_init=PromptTuningInit.TEXT,
+ task_type="CAUSAL_LM",
+ prompt_tuning_init_text="This is a test prompt.",
+ tokenizer_kwargs={"trust_remote_code": True, "foo": "bar"},
+ )
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ with patch("transformers.AutoTokenizer.from_pretrained", mock_autotokenizer_from_pretrained):
+ _ = get_peft_model(model, config)
+ expected_call = call(model_id, trust_remote_code=True, foo="bar")
+ assert mock.call_args == expected_call
+
+ def test_prompt_tuning_config_invalid_args(self):
+ # Raise an error when tokenizer_kwargs is used with prompt_tuning_init!='TEXT', because this argument has no
+ # function in that case
+ model_id = "hf-internal-testing/tiny-random-OPTForCausalLM"
+ with pytest.raises(ValueError, match="tokenizer_kwargs only valid when using prompt_tuning_init='TEXT'."):
+ PromptTuningConfig(
+ base_model_name_or_path=model_id,
+ tokenizer_name_or_path=model_id,
+ num_virtual_tokens=10,
+ task_type="CAUSAL_LM",
+ prompt_tuning_init_text="This is a test prompt.",
+ prompt_tuning_init=PromptTuningInit.RANDOM, # <= should not be used together with tokenizer_kwargs
+ tokenizer_kwargs={"trust_remote_code": True, "foo": "bar"},
+ )
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ self._test_save_pretrained(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained_pickle(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ self._test_save_pretrained(model_id, config_cls, config_kwargs.copy(), safe_serialization=False)
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained_selected_adapters(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ self._test_save_pretrained_selected_adapters(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained_selected_adapters_pickle(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ self._test_save_pretrained_selected_adapters(
+ model_id, config_cls, config_kwargs.copy(), safe_serialization=False
+ )
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_from_pretrained_config_construction(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ self._test_from_pretrained_config_construction(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_merge_layers(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_merge_layers(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_merge_layers_multi(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_merge_layers_multi(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_merge_layers_nan(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_merge_layers_nan(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_mixed_adapter_batches(self, model_id, config_cls, config_kwargs):
+ if config_cls != LoraConfig:
+ pytest.skip("Mixed adapter batches not supported for this config.")
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_mixed_adapter_batches(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_generate_with_mixed_adapter_batches(self, model_id, config_cls, config_kwargs):
+ if config_cls != LoraConfig:
+ pytest.skip("Mixed adapter batches not supported for this config.")
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_generate_with_mixed_adapter_batches_and_beam_search(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_generate(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ self._test_generate(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_generate_pos_args(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ self._test_generate_pos_args(model_id, config_cls, config_kwargs.copy(), raises_err=False)
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_merge_layers_fp16(self, model_id, config_cls, config_kwargs):
+ self._test_merge_layers_fp16(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_generate_half_prec(self, model_id, config_cls, config_kwargs):
+ self._test_generate_half_prec(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_prefix_tuning_half_prec_conversion(self, model_id, config_cls, config_kwargs):
+ self._test_prefix_tuning_half_prec_conversion(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_training_decoders(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ self._test_training(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_training_decoders_layer_indexing(self, model_id, config_cls, config_kwargs):
+ self._test_training_layer_indexing(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_training_decoders_gradient_checkpointing(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ self._test_training_gradient_checkpointing(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_inference_safetensors(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ self._test_inference_safetensors(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_peft_model_device_map(self, model_id, config_cls, config_kwargs):
+ self._test_peft_model_device_map(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_delete_adapter(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ self._test_delete_adapter(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_delete_inactive_adapter(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ self._test_delete_inactive_adapter(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_adding_multiple_adapters_with_bias_raises(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ self._test_adding_multiple_adapters_with_bias_raises(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_unload_adapter(self, model_id, config_cls, config_kwargs):
+ _skip_adalora_oft_hra_bone_for_gpt2(model_id, config_cls)
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_unload_adapter(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_weighted_combination_of_adapters(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_weighted_combination_of_adapters(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_training_prompt_learning_tasks(self, model_id, config_cls, config_kwargs):
+ self._test_training_prompt_learning_tasks(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_disable_adapter(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_disable_adapter(model_id, config_cls, config_kwargs.copy())
+
+ def test_generate_adalora_no_dropout(self):
+ # test for issue #730
+ model_id = "hf-internal-testing/tiny-random-OPTForCausalLM"
+ config_kwargs = {
+ "target_modules": None,
+ "task_type": "CAUSAL_LM",
+ "lora_dropout": 0.0,
+ "total_step": 1,
+ }
+ self._test_generate(model_id, AdaLoraConfig, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_passing_input_embeds_works(self, model_id, config_cls, config_kwargs):
+ _skip_if_not_conv1d_supported(model_id, config_cls)
+ if (platform.system() == "Darwin") and (config_cls == PrefixTuningConfig):
+ # the error is:
+ # > RuntimeError: unsupported operation: more than one element of the written-to tensor refers to a single
+ # > memory location. Please clone() the tensor before performing the operation.
+ # in transformers sdpa_mask_older_torch. As we (currently) cannot upgrade PyTorch on MacOS GH runners, we're
+ # stuck with this error.
+ # TODO: remove if torch can be upgraded on MacOS or if MacOS CI is removed
+ pytest.skip("Prefix tuning fails on MacOS in this case, not worth fixing")
+ self._test_passing_input_embeds_works("", model_id, config_cls, config_kwargs.copy())
+
+ def test_lora_layer_replication(self):
+ model_id = "trl-internal-testing/tiny-random-LlamaForCausalLM"
+ config_kwargs = {
+ "target_modules": ["down_proj", "up_proj"],
+ "task_type": "CAUSAL_LM",
+ "lora_dropout": 0.0,
+ "layer_replication": [[0, 1], [0, 2], [1, 2]],
+ }
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ config = LoraConfig(base_model_name_or_path=model_id, **config_kwargs)
+
+ assert len(model.model.layers), "Expected 2 layers in original model." == 2
+ model = get_peft_model(model, config)
+ layers = model.base_model.model.model.layers
+ assert len(layers) == 4, "Expected 4 layers in adapted model."
+ assert (
+ layers[0].mlp.up_proj.base_layer.weight.data.storage().data_ptr()
+ == layers[1].mlp.up_proj.base_layer.weight.data.storage().data_ptr()
+ and layers[2].mlp.up_proj.base_layer.weight.data.storage().data_ptr()
+ == layers[3].mlp.up_proj.base_layer.weight.data.storage().data_ptr()
+ ), "Expected layers 0-1 and 2-3 to share weights"
+ assert (
+ layers[0].mlp.up_proj.base_layer.weight.data.storage().data_ptr()
+ != layers[2].mlp.up_proj.base_layer.weight.data.storage().data_ptr()
+ ), "Expected layers 0 and 2 to have different weights"
+ assert (
+ layers[0].mlp.up_proj.lora_A.default.weight.data.storage().data_ptr()
+ != layers[1].mlp.up_proj.lora_A.default.weight.data.storage().data_ptr()
+ and layers[2].mlp.up_proj.lora_A.default.weight.data.storage().data_ptr()
+ != layers[3].mlp.up_proj.lora_A.default.weight.data.storage().data_ptr()
+ ), "Expected all LoRA adapters to have distinct weights"
+ assert len([n for n, _ in model.named_parameters() if ".lora_A." in n]) == 8, (
+ "Expected 8 LoRA adapters since we are adding one each for up and down."
+ )
+ self._test_prepare_for_training(model_id, LoraConfig, config_kwargs.copy())
+ self._test_generate(model_id, LoraConfig, config_kwargs.copy())
+
+ def test_prompt_learning_with_grouped_query_attention(self):
+ # See 1901, fixes a bug with handling GQA
+ model_id = "peft-internal-testing/tiny-dummy-qwen2"
+ base_model = AutoModelForCausalLM.from_pretrained(model_id)
+ peft_config = PrefixTuningConfig(num_virtual_tokens=10, task_type="CAUSAL_LM")
+ model = get_peft_model(base_model, peft_config)
+ x = torch.tensor([[1, 2, 3]])
+ # does not raise
+ model(x)
+
+ def test_prefix_tuning_mistral(self):
+ # See issue 869, 1962
+ model_id = "hf-internal-testing/tiny-random-MistralForCausalLM"
+ base_model = AutoModelForCausalLM.from_pretrained(model_id)
+ peft_config = PrefixTuningConfig(num_virtual_tokens=10, task_type="CAUSAL_LM")
+ model = get_peft_model(base_model, peft_config)
+
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ tokenizer.pad_token = tokenizer.eos_token
+
+ def process(samples):
+ tokenized = tokenizer(samples["quote"], truncation=True, max_length=128)
+ return tokenized
+
+ data = load_dataset_english_quotes()
+ data = data.map(process, batched=True)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ num_train_epochs=1,
+ max_steps=5,
+ per_device_train_batch_size=4,
+ output_dir=tmp_dirname,
+ ),
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ trainer.train()
+
+ @pytest.mark.parametrize("model_id", SMALL_GRID_MODELS)
+ @pytest.mark.parametrize(
+ "config_cls,config_kwargs",
+ [
+ (
+ PromptTuningConfig,
+ {
+ "num_virtual_tokens": 10,
+ "task_type": "CAUSAL_LM",
+ },
+ ),
+ (
+ PrefixTuningConfig,
+ {
+ "num_virtual_tokens": 10,
+ "task_type": "CAUSAL_LM",
+ },
+ ),
+ (
+ PromptEncoderConfig,
+ {
+ "num_virtual_tokens": 10,
+ "encoder_hidden_size": 32,
+ "task_type": "CAUSAL_LM",
+ },
+ ),
+ (
+ CPTConfig,
+ {
+ "cpt_token_ids": [0, 1, 2, 3, 4, 5, 6, 7], # Example token IDs for testing
+ "cpt_mask": [1, 1, 1, 1, 1, 1, 1, 1],
+ "cpt_tokens_type_mask": [1, 2, 2, 2, 3, 3, 4, 4],
+ },
+ ),
+ ],
+ )
+ def test_prompt_learning_with_gradient_checkpointing(self, model_id, config_cls, config_kwargs):
+ # See issue 869
+ # Test prompt learning methods with gradient checkpointing in a semi realistic setting.
+ # Prefix tuning does not work if the model uses the new caching implementation. In that case, a helpful error
+ # should be raised.
+
+ # skip if multi GPU, since this results in DataParallel usage by Trainer, which fails with "CUDA device
+ # assertion", breaking subsequent tests
+ if device_count > 1:
+ pytest.skip("Skip on multi-GPU setups")
+ peft_config = config_cls(base_model_name_or_path=model_id, **config_kwargs)
+ base_model = self.transformers_class.from_pretrained(model_id)
+ base_model.gradient_checkpointing_enable()
+
+ try:
+ model = get_peft_model(base_model, peft_config)
+ except ValueError as exc:
+ # Some methods will raise a helpful error. After this, exit the test, as training would fail.
+ assert config_cls == PrefixTuningConfig
+ assert "Prefix tuning does not work with gradient checkpointing" in str(exc)
+ return
+
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ tokenizer.pad_token = tokenizer.eos_token
+
+ def process(samples):
+ tokenized = tokenizer(samples["quote"], truncation=True, max_length=128)
+ return tokenized
+
+ data = load_dataset_english_quotes()
+ data = data.map(process, batched=True)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ num_train_epochs=1,
+ max_steps=3,
+ per_device_train_batch_size=4,
+ output_dir=tmp_dirname,
+ ),
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ trainer.train()
diff --git a/peft/tests/test_encoder_decoder_models.py b/peft/tests/test_encoder_decoder_models.py
new file mode 100644
index 0000000000000000000000000000000000000000..3fca67683db528f19bb86e9706619812b67da842
--- /dev/null
+++ b/peft/tests/test_encoder_decoder_models.py
@@ -0,0 +1,380 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import tempfile
+
+import pytest
+import torch
+from transformers import AutoModelForSeq2SeqLM, AutoModelForTokenClassification
+
+from peft import (
+ AdaLoraConfig,
+ BOFTConfig,
+ BoneConfig,
+ C3AConfig,
+ FourierFTConfig,
+ HRAConfig,
+ IA3Config,
+ LoraConfig,
+ OFTConfig,
+ PrefixTuningConfig,
+ PromptEncoderConfig,
+ PromptTuningConfig,
+ ShiraConfig,
+ TaskType,
+ VBLoRAConfig,
+ VeraConfig,
+ get_peft_model,
+)
+
+from .testing_common import PeftCommonTester
+from .testing_utils import set_init_weights_false
+
+
+PEFT_ENCODER_DECODER_MODELS_TO_TEST = [
+ "ybelkada/tiny-random-T5ForConditionalGeneration-calibrated",
+ "hf-internal-testing/tiny-random-BartForConditionalGeneration",
+]
+
+# TODO Missing from this list are LoKr, LoHa, LN Tuning, add them
+ALL_CONFIGS = [
+ (
+ AdaLoraConfig,
+ {
+ "target_modules": None,
+ "total_step": 1,
+ "task_type": "SEQ_2_SEQ_LM",
+ },
+ ),
+ (
+ BOFTConfig,
+ {
+ "target_modules": None,
+ "task_type": "SEQ_2_SEQ_LM",
+ },
+ ),
+ (
+ BoneConfig,
+ {
+ "target_modules": None,
+ "r": 2,
+ "task_type": "SEQ_2_SEQ_LM",
+ },
+ ),
+ (
+ FourierFTConfig,
+ {
+ "n_frequency": 10,
+ "target_modules": None,
+ "task_type": "SEQ_2_SEQ_LM",
+ },
+ ),
+ (
+ HRAConfig,
+ {
+ "target_modules": None,
+ "task_type": "SEQ_2_SEQ_LM",
+ },
+ ),
+ (
+ IA3Config,
+ {
+ "target_modules": None,
+ "feedforward_modules": None,
+ "task_type": "SEQ_2_SEQ_LM",
+ },
+ ),
+ (
+ LoraConfig,
+ {
+ "r": 8,
+ "lora_alpha": 32,
+ "target_modules": None,
+ "lora_dropout": 0.05,
+ "bias": "none",
+ "task_type": "SEQ_2_SEQ_LM",
+ },
+ ),
+ (
+ LoraConfig,
+ {
+ "r": 8,
+ "lora_alpha": 32,
+ "target_modules": None,
+ "lora_dropout": 0.05,
+ "bias": "none",
+ "trainable_token_indices": [0, 1, 3],
+ "task_type": "SEQ_2_SEQ_LM",
+ },
+ ),
+ (
+ OFTConfig,
+ {
+ "target_modules": None,
+ "task_type": "SEQ_2_SEQ_LM",
+ },
+ ),
+ (
+ PrefixTuningConfig,
+ {
+ "num_virtual_tokens": 10,
+ "task_type": "SEQ_2_SEQ_LM",
+ },
+ ),
+ (
+ PromptEncoderConfig,
+ {
+ "num_virtual_tokens": 10,
+ "encoder_hidden_size": 32,
+ "task_type": "SEQ_2_SEQ_LM",
+ },
+ ),
+ (
+ PromptTuningConfig,
+ {
+ "num_virtual_tokens": 10,
+ "task_type": "SEQ_2_SEQ_LM",
+ },
+ ),
+ (
+ ShiraConfig,
+ {
+ "r": 1,
+ "task_type": "SEQ_2_SEQ_LM",
+ "target_modules": None,
+ "init_weights": False,
+ },
+ ),
+ (
+ VBLoRAConfig,
+ {
+ "target_modules": None,
+ "vblora_dropout": 0.05,
+ "vector_length": 1,
+ "num_vectors": 2,
+ "task_type": "SEQ_2_SEQ_LM",
+ },
+ ),
+ (
+ VeraConfig,
+ {
+ "r": 8,
+ "target_modules": None,
+ "vera_dropout": 0.05,
+ "projection_prng_key": 0xFF,
+ "d_initial": 0.1,
+ "save_projection": True,
+ "bias": "none",
+ "task_type": "SEQ_2_SEQ_LM",
+ },
+ ),
+ (
+ C3AConfig,
+ {
+ "task_type": "SEQ_2_SEQ_LM",
+ "block_size": 1,
+ "target_modules": None,
+ },
+ ),
+]
+
+
+class TestEncoderDecoderModels(PeftCommonTester):
+ transformers_class = AutoModelForSeq2SeqLM
+
+ def skipTest(self, reason=""):
+ # for backwards compatibility with unittest style test classes
+ pytest.skip(reason)
+
+ def prepare_inputs_for_testing(self):
+ input_ids = torch.tensor([[1, 1, 1], [1, 2, 1]]).to(self.torch_device)
+ decoder_input_ids = torch.tensor([[1, 1, 1], [1, 2, 1]]).to(self.torch_device)
+ attention_mask = torch.tensor([[1, 1, 1], [1, 0, 1]]).to(self.torch_device)
+
+ input_dict = {
+ "input_ids": input_ids,
+ "decoder_input_ids": decoder_input_ids,
+ "attention_mask": attention_mask,
+ }
+
+ return input_dict
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_attributes_parametrized(self, model_id, config_cls, config_kwargs):
+ self._test_model_attr(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_adapter_name(self, model_id, config_cls, config_kwargs):
+ self._test_adapter_name(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_prepare_for_training_parametrized(self, model_id, config_cls, config_kwargs):
+ self._test_prepare_for_training(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained(self, model_id, config_cls, config_kwargs):
+ self._test_save_pretrained(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained_pickle(self, model_id, config_cls, config_kwargs):
+ self._test_save_pretrained(model_id, config_cls, config_kwargs, safe_serialization=False)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained_selected_adapters(self, model_id, config_cls, config_kwargs):
+ self._test_save_pretrained_selected_adapters(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained_selected_adapters_pickle(self, model_id, config_cls, config_kwargs):
+ self._test_save_pretrained_selected_adapters(model_id, config_cls, config_kwargs, safe_serialization=False)
+
+ def test_load_model_low_cpu_mem_usage(self):
+ # Using the first model with LoraConfig and an empty config_kwargs.
+ self._test_load_model_low_cpu_mem_usage(PEFT_ENCODER_DECODER_MODELS_TO_TEST[0], LoraConfig, {})
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_from_pretrained_config_construction(self, model_id, config_cls, config_kwargs):
+ self._test_from_pretrained_config_construction(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_merge_layers(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_merge_layers(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_mixed_adapter_batches(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_mixed_adapter_batches(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_generate_with_mixed_adapter_batches(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_generate_with_mixed_adapter_batches_and_beam_search(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_generate(self, model_id, config_cls, config_kwargs):
+ self._test_generate(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_generate_pos_args(self, model_id, config_cls, config_kwargs):
+ self._test_generate_pos_args(model_id, config_cls, config_kwargs, raises_err=True)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_generate_half_prec(self, model_id, config_cls, config_kwargs):
+ self._test_generate_half_prec(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_prefix_tuning_half_prec_conversion(self, model_id, config_cls, config_kwargs):
+ self._test_prefix_tuning_half_prec_conversion(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_training_encoder_decoders(self, model_id, config_cls, config_kwargs):
+ self._test_training(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_training_encoder_decoders_layer_indexing(self, model_id, config_cls, config_kwargs):
+ self._test_training_layer_indexing(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_training_encoder_decoders_gradient_checkpointing(self, model_id, config_cls, config_kwargs):
+ self._test_training_gradient_checkpointing(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_inference_safetensors(self, model_id, config_cls, config_kwargs):
+ self._test_inference_safetensors(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_peft_model_device_map(self, model_id, config_cls, config_kwargs):
+ self._test_peft_model_device_map(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_delete_adapter(self, model_id, config_cls, config_kwargs):
+ self._test_delete_adapter(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_delete_inactive_adapter(self, model_id, config_cls, config_kwargs):
+ self._test_delete_inactive_adapter(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_adding_multiple_adapters_with_bias_raises(self, model_id, config_cls, config_kwargs):
+ self._test_adding_multiple_adapters_with_bias_raises(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_unload_adapter(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_unload_adapter(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_weighted_combination_of_adapters(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_weighted_combination_of_adapters(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_training_prompt_learning_tasks(self, model_id, config_cls, config_kwargs):
+ self._test_training_prompt_learning_tasks(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_ENCODER_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_disable_adapter(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_disable_adapter(model_id, config_cls, config_kwargs)
+
+ def test_active_adapters_prompt_learning(self):
+ model = AutoModelForSeq2SeqLM.from_pretrained(
+ "hf-internal-testing/tiny-random-BartForConditionalGeneration"
+ ).to(self.torch_device)
+ # any prompt learning method would work here
+ config = PromptEncoderConfig(task_type=TaskType.SEQ_2_SEQ_LM, num_virtual_tokens=10)
+ model = get_peft_model(model, config)
+ assert model.active_adapters == ["default"]
+
+ def test_save_shared_tensors(self):
+ model_id = "hf-internal-testing/tiny-random-RobertaModel"
+ peft_config = LoraConfig(
+ task_type=TaskType.TOKEN_CLS,
+ inference_mode=False,
+ r=16,
+ lora_alpha=16,
+ lora_dropout=0.1,
+ bias="all",
+ )
+ model = AutoModelForTokenClassification.from_pretrained(model_id, num_labels=11)
+ model = get_peft_model(model, peft_config)
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ # This should work fine
+ model.save_pretrained(tmp_dir, safe_serialization=True)
diff --git a/peft/tests/test_feature_extraction_models.py b/peft/tests/test_feature_extraction_models.py
new file mode 100644
index 0000000000000000000000000000000000000000..1a9659355c4384bb6b9d9b60b92df79bfa37eeef
--- /dev/null
+++ b/peft/tests/test_feature_extraction_models.py
@@ -0,0 +1,337 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import pytest
+import torch
+from transformers import AutoModel
+
+from peft import (
+ AdaLoraConfig,
+ BOFTConfig,
+ BoneConfig,
+ C3AConfig,
+ FourierFTConfig,
+ HRAConfig,
+ IA3Config,
+ LoraConfig,
+ OFTConfig,
+ PrefixTuningConfig,
+ PromptEncoderConfig,
+ PromptLearningConfig,
+ PromptTuningConfig,
+ ShiraConfig,
+ VBLoRAConfig,
+ VeraConfig,
+)
+
+from .testing_common import PeftCommonTester
+from .testing_utils import set_init_weights_false
+
+
+PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST = [
+ "hf-internal-testing/tiny-random-BertModel",
+ "hf-internal-testing/tiny-random-RobertaModel",
+ "hf-internal-testing/tiny-random-DebertaModel",
+ "hf-internal-testing/tiny-random-DebertaV2Model",
+]
+
+# TODO Missing from this list are LoKr, LoHa, LN Tuning, add them
+ALL_CONFIGS = [
+ (
+ AdaLoraConfig,
+ {
+ "task_type": "FEATURE_EXTRACTION",
+ "target_modules": None,
+ "total_step": 1,
+ },
+ ),
+ (
+ BOFTConfig,
+ {
+ "task_type": "FEATURE_EXTRACTION",
+ "target_modules": None,
+ },
+ ),
+ (
+ BoneConfig,
+ {
+ "task_type": "FEATURE_EXTRACTION",
+ "target_modules": None,
+ "r": 2,
+ },
+ ),
+ (
+ FourierFTConfig,
+ {
+ "task_type": "FEATURE_EXTRACTION",
+ "n_frequency": 10,
+ "target_modules": None,
+ },
+ ),
+ (
+ HRAConfig,
+ {
+ "task_type": "FEATURE_EXTRACTION",
+ "target_modules": None,
+ },
+ ),
+ (
+ IA3Config,
+ {
+ "task_type": "FEATURE_EXTRACTION",
+ "target_modules": None,
+ "feedforward_modules": None,
+ },
+ ),
+ (
+ LoraConfig,
+ {
+ "task_type": "FEATURE_EXTRACTION",
+ "r": 8,
+ "lora_alpha": 32,
+ "target_modules": None,
+ "lora_dropout": 0.05,
+ "bias": "none",
+ },
+ ),
+ # LoRA + trainable tokens
+ (
+ LoraConfig,
+ {
+ "task_type": "FEATURE_EXTRACTION",
+ "r": 8,
+ "lora_alpha": 32,
+ "target_modules": None,
+ "lora_dropout": 0.05,
+ "bias": "none",
+ "trainable_token_indices": [0, 1, 3],
+ },
+ ),
+ (
+ OFTConfig,
+ {
+ "task_type": "FEATURE_EXTRACTION",
+ "target_modules": None,
+ },
+ ),
+ (
+ PrefixTuningConfig,
+ {
+ "task_type": "FEATURE_EXTRACTION",
+ "num_virtual_tokens": 10,
+ },
+ ),
+ (
+ PromptEncoderConfig,
+ {
+ "task_type": "FEATURE_EXTRACTION",
+ "num_virtual_tokens": 10,
+ "encoder_hidden_size": 32,
+ },
+ ),
+ (
+ PromptTuningConfig,
+ {
+ "task_type": "FEATURE_EXTRACTION",
+ "num_virtual_tokens": 10,
+ },
+ ),
+ (
+ ShiraConfig,
+ {
+ "r": 1,
+ "task_type": "FEATURE_EXTRACTION",
+ "target_modules": None,
+ "init_weights": False,
+ },
+ ),
+ (
+ VBLoRAConfig,
+ {
+ "task_type": "FEATURE_EXTRACTION",
+ "target_modules": None,
+ "vblora_dropout": 0.05,
+ "vector_length": 1,
+ "num_vectors": 2,
+ },
+ ),
+ (
+ VeraConfig,
+ {
+ "task_type": "FEATURE_EXTRACTION",
+ "r": 8,
+ "target_modules": None,
+ "vera_dropout": 0.05,
+ "projection_prng_key": 0xFF,
+ "d_initial": 0.1,
+ "save_projection": True,
+ "bias": "none",
+ },
+ ),
+ (
+ C3AConfig,
+ {
+ "task_type": "FEATURE_EXTRACTION",
+ "block_size": 1,
+ "target_modules": None,
+ },
+ ),
+]
+
+
+def skip_non_prompt_learning(config_cls):
+ if not issubclass(config_cls, PromptLearningConfig) or (config_cls == PrefixTuningConfig):
+ pytest.skip("Skip tests that are not prompt learning or that are prefix tuning")
+
+
+def skip_deberta_lora_tests(config_cls, model_id):
+ if "deberta" not in model_id.lower():
+ return
+
+ to_skip = ["lora", "ia3", "boft", "vera", "fourierft", "hra", "bone", "randlora"]
+ config_name = config_cls.__name__.lower()
+ if any(k in config_name for k in to_skip):
+ pytest.skip(f"Skip tests that use {config_name} for Deberta models")
+
+
+def skip_deberta_pt_tests(config_cls, model_id):
+ if "deberta" not in model_id.lower():
+ return
+
+ to_skip = ["prefix"]
+ config_name = config_cls.__name__.lower()
+ if any(k in config_name for k in to_skip):
+ pytest.skip(f"Skip tests that use {config_name} for Deberta models")
+
+
+class TestPeftFeatureExtractionModel(PeftCommonTester):
+ """
+ Test if the PeftModel behaves as expected. This includes:
+ - test if the model has the expected methods
+ """
+
+ transformers_class = AutoModel
+
+ def skipTest(self, reason=""):
+ # for backwards compatibility with unittest style test classes
+ pytest.skip(reason)
+
+ def prepare_inputs_for_testing(self):
+ input_ids = torch.tensor([[1, 1, 1], [1, 2, 1]]).to(self.torch_device)
+ attention_mask = torch.tensor([[1, 1, 1], [1, 0, 1]]).to(self.torch_device)
+
+ input_dict = {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ }
+
+ return input_dict
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_attributes_parametrized(self, model_id, config_cls, config_kwargs):
+ self._test_model_attr(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_adapter_name(self, model_id, config_cls, config_kwargs):
+ self._test_adapter_name(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_prepare_for_training_parametrized(self, model_id, config_cls, config_kwargs):
+ self._test_prepare_for_training(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained(self, model_id, config_cls, config_kwargs):
+ self._test_save_pretrained(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained_selected_adapters(self, model_id, config_cls, config_kwargs):
+ self._test_save_pretrained_selected_adapters(model_id, config_cls, config_kwargs)
+
+ def test_load_model_low_cpu_mem_usage(self):
+ self._test_load_model_low_cpu_mem_usage(PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST[0], LoraConfig, {})
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_from_pretrained_config_construction(self, model_id, config_cls, config_kwargs):
+ self._test_from_pretrained_config_construction(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_merge_layers(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_merge_layers(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_training(self, model_id, config_cls, config_kwargs):
+ self._test_training(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_training_prompt_learning_tasks(self, model_id, config_cls, config_kwargs):
+ skip_deberta_pt_tests(config_cls, model_id)
+ self._test_training_prompt_learning_tasks(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_training_layer_indexing(self, model_id, config_cls, config_kwargs):
+ self._test_training_layer_indexing(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_training_gradient_checkpointing(self, model_id, config_cls, config_kwargs):
+ skip_deberta_lora_tests(config_cls, model_id)
+ self._test_training_gradient_checkpointing(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_inference_safetensors(self, model_id, config_cls, config_kwargs):
+ self._test_inference_safetensors(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_peft_model_device_map(self, model_id, config_cls, config_kwargs):
+ self._test_peft_model_device_map(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_delete_adapter(self, model_id, config_cls, config_kwargs):
+ self._test_delete_adapter(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_delete_inactive_adapter(self, model_id, config_cls, config_kwargs):
+ self._test_delete_inactive_adapter(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_unload_adapter(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_unload_adapter(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_weighted_combination_of_adapters(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_weighted_combination_of_adapters(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_FEATURE_EXTRACTION_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_passing_input_embeds_works(self, model_id, config_cls, config_kwargs):
+ skip_non_prompt_learning(config_cls)
+ self._test_passing_input_embeds_works("test input embeds work", model_id, config_cls, config_kwargs)
diff --git a/peft/tests/test_gptqmodel.py b/peft/tests/test_gptqmodel.py
new file mode 100644
index 0000000000000000000000000000000000000000..3d16b60d2dd89f851c717bc09ca11589e9e56ada
--- /dev/null
+++ b/peft/tests/test_gptqmodel.py
@@ -0,0 +1,563 @@
+# Note: These tests were copied from test_common_gpu.py and test_gpu_examples.py as they can run on CPU too.
+#
+# Copyright 2025-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import gc
+import os
+import tempfile
+import unittest
+
+import pytest
+import torch
+from accelerate.utils.memory import clear_device_cache
+from transformers import (
+ AutoModelForCausalLM,
+ AutoTokenizer,
+ DataCollatorForLanguageModeling,
+ Trainer,
+ TrainingArguments,
+)
+
+from peft import (
+ AdaLoraConfig,
+ LoraConfig,
+ OFTConfig,
+ PeftModel,
+ get_peft_model,
+ prepare_model_for_kbit_training,
+)
+from peft.tuners.lora import GPTQLoraLinear
+from peft.utils import SAFETENSORS_WEIGHTS_NAME, infer_device
+
+from .testing_utils import (
+ device_count,
+ load_dataset_english_quotes,
+ require_gptqmodel,
+ require_optimum,
+ require_torch_multi_accelerator,
+)
+
+
+@require_gptqmodel
+class PeftGPTQModelCommonTests(unittest.TestCase):
+ r"""
+ A common tester to run common operations that are performed on GPU/CPU such as generation, loading in 8bit, etc.
+ """
+
+ def setUp(self):
+ self.causal_lm_model_id = "facebook/opt-350m"
+ self.device = infer_device()
+
+ def tearDown(self):
+ r"""
+ Efficient mechanism to free GPU memory after each test. Based on
+ https://github.com/huggingface/transformers/issues/21094
+ """
+ clear_device_cache(garbage_collection=True)
+ gc.collect()
+
+ def test_lora_gptq_quantization_from_pretrained_safetensors(self):
+ r"""
+ Tests that the gptqmodel quantization using LoRA works as expected with safetensors weights.
+ """
+ from transformers import GPTQConfig
+
+ model_id = "marcsun13/opt-350m-gptq-4bit"
+ quantization_config = GPTQConfig(bits=4, use_exllama=False)
+ kwargs = {
+ "pretrained_model_name_or_path": model_id,
+ "torch_dtype": torch.float16,
+ "device_map": "auto",
+ "quantization_config": quantization_config,
+ }
+ model = AutoModelForCausalLM.from_pretrained(**kwargs)
+ model = prepare_model_for_kbit_training(model)
+
+ config = LoraConfig(task_type="CAUSAL_LM")
+ peft_model = get_peft_model(model, config)
+ peft_model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(peft_model.device))
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ peft_model.save_pretrained(tmp_dir)
+ model = AutoModelForCausalLM.from_pretrained(**kwargs)
+ model = PeftModel.from_pretrained(model, tmp_dir)
+ model = prepare_model_for_kbit_training(model)
+ model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(peft_model.device))
+
+ # loading a 2nd adapter works, #1239
+ model.load_adapter(tmp_dir, "adapter2")
+ model.set_adapter("adapter2")
+ model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(peft_model.device))
+
+ # check that both adapters are in the same layer
+ assert "default" in model.base_model.model.model.decoder.layers[0].self_attn.q_proj.lora_A
+ assert "adapter2" in model.base_model.model.model.decoder.layers[0].self_attn.q_proj.lora_A
+
+ def test_oft_gptq_quantization_from_pretrained_safetensors(self):
+ r"""
+ Tests that the gptqmodel quantization using OFT works as expected with safetensors weights.
+ """
+ from transformers import GPTQConfig
+
+ model_id = "marcsun13/opt-350m-gptq-4bit"
+ quantization_config = GPTQConfig(bits=4, use_exllama=False)
+ kwargs = {
+ "pretrained_model_name_or_path": model_id,
+ "torch_dtype": torch.float16,
+ "device_map": "auto",
+ "quantization_config": quantization_config,
+ }
+ model = AutoModelForCausalLM.from_pretrained(**kwargs)
+ model = prepare_model_for_kbit_training(model)
+
+ config = OFTConfig(task_type="CAUSAL_LM")
+ peft_model = get_peft_model(model, config)
+ peft_model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(peft_model.device))
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ peft_model.save_pretrained(tmp_dir)
+ model = AutoModelForCausalLM.from_pretrained(**kwargs)
+ model = PeftModel.from_pretrained(model, tmp_dir)
+ model = prepare_model_for_kbit_training(model)
+ model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(peft_model.device))
+
+ # loading a 2nd adapter works, #1239
+ model.load_adapter(tmp_dir, "adapter2")
+ model.set_adapter("adapter2")
+ model.generate(input_ids=torch.LongTensor([[0, 2, 3, 1]]).to(peft_model.device))
+
+ # check that both adapters are in the same layer
+ assert "default" in model.base_model.model.model.decoder.layers[0].self_attn.q_proj.oft_R
+ assert "adapter2" in model.base_model.model.model.decoder.layers[0].self_attn.q_proj.oft_R
+
+
+@require_gptqmodel
+@require_optimum
+class PeftGPTQModelTests(unittest.TestCase):
+ r"""
+ GPTQ + peft tests
+ """
+
+ def setUp(self):
+ from transformers import GPTQConfig
+
+ self.causal_lm_model_id = "marcsun13/opt-350m-gptq-4bit"
+ self.quantization_config = GPTQConfig(bits=4, backend="auto_trainable")
+ self.tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+
+ def tearDown(self):
+ r"""
+ Efficient mechanism to free GPU memory after each test. Based on
+ https://github.com/huggingface/transformers/issues/21094
+ """
+ clear_device_cache(garbage_collection=True)
+
+ def _check_inference_finite(self, model, batch):
+ # try inference without Trainer class
+ training = model.training
+ model.eval()
+ output = model(**batch.to(model.device))
+ assert torch.isfinite(output.logits).all()
+ model.train(training)
+
+ def test_causal_lm_training(self):
+ r"""
+ Test the CausalLM training on a single GPU device. The test would simply fail if the adapters are not set
+ correctly.
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ quantization_config=self.quantization_config,
+ )
+
+ model = prepare_model_for_kbit_training(model)
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ def test_oft_causal_lm_training(self):
+ r"""
+ Test the CausalLM training on a single GPU device. The test would simply fail if the adapters are not set
+ correctly.
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ quantization_config=self.quantization_config,
+ )
+
+ model = prepare_model_for_kbit_training(model)
+ config = OFTConfig(
+ r=0,
+ oft_block_size=8,
+ target_modules=["q_proj", "v_proj"],
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ def test_adalora_causalLM(self):
+ r"""
+ Tests the gptq training with adalora
+ """
+
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ quantization_config=self.quantization_config,
+ )
+
+ tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ model = prepare_model_for_kbit_training(model)
+
+ peft_config = AdaLoraConfig(
+ total_step=40,
+ init_r=6,
+ target_r=4,
+ tinit=10,
+ tfinal=20,
+ deltaT=5,
+ beta1=0.3,
+ beta2=0.3,
+ orth_reg_weight=0.2,
+ lora_alpha=32,
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, peft_config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+ batch = tokenizer(data["train"][:3]["quote"], return_tensors="pt", padding=True)
+ self._check_inference_finite(model, batch)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.multi_gpu_tests
+ @require_torch_multi_accelerator
+ def test_causal_lm_training_multi_accelerator(self):
+ r"""
+ Test the CausalLM training on a multi-accelerator device. The test would simply fail if the adapters are not
+ set correctly.
+ """
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ quantization_config=self.quantization_config,
+ )
+
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+
+ model = prepare_model_for_kbit_training(model)
+
+ setattr(model, "model_parallel", True)
+ setattr(model, "is_parallelizable", True)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.multi_gpu_tests
+ @require_torch_multi_accelerator
+ def test_oft_causal_lm_training_multi_accelerator(self):
+ r"""
+ Test the CausalLM training on a multi-accelerator device. The test would simply fail if the adapters are not
+ set correctly.
+ """
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ quantization_config=self.quantization_config,
+ )
+
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+
+ model = prepare_model_for_kbit_training(model)
+
+ setattr(model, "model_parallel", True)
+ setattr(model, "is_parallelizable", True)
+
+ config = OFTConfig(
+ r=0,
+ oft_block_size=8,
+ target_modules=["q_proj", "v_proj"],
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ def test_non_default_adapter_name(self):
+ # See issue 1346
+ config = LoraConfig(
+ r=16,
+ target_modules=["q_proj", "v_proj"],
+ task_type="CAUSAL_LM",
+ )
+
+ # default adapter name
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ quantization_config=self.quantization_config,
+ )
+ model = prepare_model_for_kbit_training(model)
+ model = get_peft_model(model, config)
+ n_trainable_default, n_total_default = model.get_nb_trainable_parameters()
+
+ # other adapter name
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ quantization_config=self.quantization_config,
+ )
+ model = prepare_model_for_kbit_training(model)
+ model = get_peft_model(model, config, adapter_name="other")
+ n_trainable_other, n_total_other = model.get_nb_trainable_parameters()
+
+ assert n_trainable_other > 0
+ # sanity check
+ assert n_trainable_default == n_trainable_other
+ assert n_total_default == n_total_other
+
+ def test_oft_non_default_adapter_name(self):
+ # See issue 1346
+ config = OFTConfig(
+ r=0,
+ oft_block_size=8,
+ target_modules=["q_proj", "v_proj"],
+ task_type="CAUSAL_LM",
+ )
+
+ # default adapter name
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ quantization_config=self.quantization_config,
+ )
+ model = prepare_model_for_kbit_training(model)
+ model = get_peft_model(model, config)
+ n_trainable_default, n_total_default = model.get_nb_trainable_parameters()
+
+ # other adapter name
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ quantization_config=self.quantization_config,
+ )
+ model = prepare_model_for_kbit_training(model)
+ model = get_peft_model(model, config, adapter_name="other")
+ n_trainable_other, n_total_other = model.get_nb_trainable_parameters()
+
+ assert n_trainable_other > 0
+ # sanity check
+ assert n_trainable_default == n_trainable_other
+ assert n_total_default == n_total_other
+
+ def test_load_lora(self):
+ model_id = "ModelCloud/Llama-3.2-1B-gptqmodel-ci-4bit"
+ adapter_id = "ModelCloud/Llama-3.2-1B-gptqmodel-ci-4bit-lora"
+
+ model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
+ model.load_adapter(adapter_id)
+
+ # assert dynamic rank
+ v_proj_module = model.model.layers[5].self_attn.v_proj
+ assert isinstance(v_proj_module, GPTQLoraLinear)
+ assert v_proj_module.lora_A["default"].weight.data.shape[0] == 128
+ assert v_proj_module.lora_B["default"].weight.data.shape[1] == 128
+ gate_proj_module = model.model.layers[5].mlp.gate_proj
+ assert isinstance(gate_proj_module, GPTQLoraLinear)
+ assert gate_proj_module.lora_A["default"].weight.data.shape[0] == 256
+ assert gate_proj_module.lora_B["default"].weight.data.shape[1] == 256
+
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ inp = tokenizer("Capital of France is", return_tensors="pt").to(model.device)
+ tokens = model.generate(**inp)[0]
+ result = tokenizer.decode(tokens)
+
+ assert "paris" in result.lower()
diff --git a/peft/tests/test_gpu_examples.py b/peft/tests/test_gpu_examples.py
new file mode 100644
index 0000000000000000000000000000000000000000..4ca9be889853f3e8e044cb6ae7b0bec5a2cec3ce
--- /dev/null
+++ b/peft/tests/test_gpu_examples.py
@@ -0,0 +1,4954 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import gc
+import importlib
+import itertools
+import os
+import re
+import tempfile
+import unittest
+from collections import Counter, defaultdict
+from copy import deepcopy
+from dataclasses import dataclass
+from typing import Any, Union
+
+import numpy as np
+import pytest
+import torch
+from accelerate import infer_auto_device_map
+from accelerate.test_utils.testing import run_command
+from accelerate.utils import patch_environment
+from accelerate.utils.imports import is_bf16_available
+from accelerate.utils.memory import clear_device_cache
+from accelerate.utils.versions import is_torch_version
+from datasets import Audio, Dataset, DatasetDict, load_dataset
+from packaging import version
+from parameterized import parameterized
+from torch.distributed import init_process_group
+from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
+from torch.utils.data import DataLoader
+from transformers import (
+ AutoModelForCausalLM,
+ AutoModelForSeq2SeqLM,
+ AutoTokenizer,
+ BitsAndBytesConfig,
+ DataCollatorForLanguageModeling,
+ Seq2SeqTrainer,
+ Seq2SeqTrainingArguments,
+ Trainer,
+ TrainerCallback,
+ TrainingArguments,
+ WhisperFeatureExtractor,
+ WhisperForConditionalGeneration,
+ WhisperProcessor,
+ WhisperTokenizer,
+)
+from transformers.pytorch_utils import Conv1D
+
+from peft import (
+ AdaLoraConfig,
+ EvaConfig,
+ LoftQConfig,
+ LoraConfig,
+ PeftModel,
+ PrefixTuningConfig,
+ PromptEncoderConfig,
+ RandLoraConfig,
+ TaskType,
+ VeraConfig,
+ get_peft_model,
+ get_peft_model_state_dict,
+ initialize_lora_eva_weights,
+ inject_adapter_in_model,
+ prepare_model_for_kbit_training,
+ replace_lora_weights_loftq,
+ set_peft_model_state_dict,
+)
+from peft.import_utils import is_diffusers_available, is_xpu_available
+from peft.tuners import boft
+from peft.tuners.tuners_utils import BaseTunerLayer
+from peft.utils import SAFETENSORS_WEIGHTS_NAME, infer_device
+from peft.utils.hotswap import hotswap_adapter, prepare_model_for_compiled_hotswap
+from peft.utils.loftq_utils import NFQuantizer
+from peft.utils.other import fsdp_auto_wrap_policy
+
+from .testing_utils import (
+ device_count,
+ load_dataset_english_quotes,
+ require_aqlm,
+ require_auto_awq,
+ require_auto_gptq,
+ require_bitsandbytes,
+ require_deterministic_for_xpu,
+ require_eetq,
+ require_hqq,
+ require_non_cpu,
+ require_non_xpu,
+ require_optimum,
+ require_torch_gpu,
+ require_torch_multi_accelerator,
+ require_torch_multi_gpu,
+ require_torchao,
+ torch_device,
+)
+
+
+# Some tests with multi GPU require specific device maps to ensure that the models are loaded in two devices
+DEVICE_MAP_MAP: dict[str, dict[str, int]] = {
+ "facebook/opt-6.7b": {
+ "model.decoder.embed_tokens": 0,
+ "model.decoder.embed_positions": 0,
+ "model.decoder.final_layer_norm": 0,
+ "model.decoder.layers.0": 0,
+ "model.decoder.layers.1": 0,
+ "model.decoder.layers.2": 0,
+ "model.decoder.layers.3": 0,
+ "model.decoder.layers.4": 0,
+ "model.decoder.layers.5": 0,
+ "model.decoder.layers.6": 0,
+ "model.decoder.layers.7": 0,
+ "model.decoder.layers.8": 0,
+ "model.decoder.layers.9": 0,
+ "model.decoder.layers.10": 0,
+ "model.decoder.layers.11": 0,
+ "model.decoder.layers.12": 0,
+ "model.decoder.layers.13": 0,
+ "model.decoder.layers.14": 0,
+ "model.decoder.layers.15": 0,
+ "model.decoder.layers.16": 1,
+ "model.decoder.layers.17": 1,
+ "model.decoder.layers.18": 1,
+ "model.decoder.layers.19": 1,
+ "model.decoder.layers.20": 1,
+ "model.decoder.layers.21": 1,
+ "model.decoder.layers.22": 1,
+ "model.decoder.layers.23": 1,
+ "model.decoder.layers.24": 1,
+ "model.decoder.layers.25": 1,
+ "model.decoder.layers.26": 1,
+ "model.decoder.layers.27": 1,
+ "model.decoder.layers.28": 1,
+ "model.decoder.layers.29": 1,
+ "model.decoder.layers.30": 1,
+ "model.decoder.layers.31": 1,
+ "lm_head": 0, # tied with embed_tokens
+ },
+ "marcsun13/opt-350m-gptq-4bit": {
+ "model.decoder.embed_tokens": 0,
+ "model.decoder.embed_positions": 0,
+ "model.decoder.layers.0": 0,
+ "model.decoder.layers.1": 0,
+ "model.decoder.layers.2": 0,
+ "model.decoder.layers.3": 0,
+ "model.decoder.layers.4": 0,
+ "model.decoder.layers.5": 0,
+ "model.decoder.layers.6": 1,
+ "model.decoder.layers.7": 1,
+ "model.decoder.layers.8": 1,
+ "model.decoder.layers.9": 1,
+ "model.decoder.layers.10": 1,
+ "model.decoder.layers.11": 1,
+ "model.decoder.final_layer_norm": 1,
+ "lm_head": 0, # tied with embed_tokens
+ },
+ "google/flan-t5-base": {
+ "shared": 0,
+ "encoder": 0,
+ "decoder": 1,
+ "final_layer_norm": 1,
+ "decoder.embed_tokens": 0, # tied with encoder.embed_tokens
+ "lm_head": 0, # tied with encoder.embed_tokens
+ },
+}
+
+
+# A full testing suite that tests all the necessary features on GPU. The tests should
+# rely on the example scripts to test the features.
+
+
+@dataclass
+class DataCollatorSpeechSeq2SeqWithPadding:
+ r"""
+ Directly copied from:
+ https://github.com/huggingface/peft/blob/main/examples/int8_training/peft_bnb_whisper_large_v2_training.ipynb
+ """
+
+ processor: Any
+
+ def __call__(self, features: list[dict[str, Union[list[int], torch.Tensor]]]) -> dict[str, torch.Tensor]:
+ # split inputs and labels since they have to be of different lengths and need different padding methods
+ # first treat the audio inputs by simply returning torch tensors
+ input_features = [{"input_features": feature["input_features"]} for feature in features]
+ batch = self.processor.feature_extractor.pad(input_features, return_tensors="pt")
+
+ # get the tokenized label sequences
+ label_features = [{"input_ids": feature["labels"]} for feature in features]
+ # pad the labels to max length
+ labels_batch = self.processor.tokenizer.pad(label_features, return_tensors="pt")
+
+ # replace padding with -100 to ignore loss correctly
+ labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
+
+ # if bos token is appended in previous tokenization step,
+ # cut bos token here as it's append later anyways
+ if (labels[:, 0] == self.processor.tokenizer.bos_token_id).all().cpu().item():
+ labels = labels[:, 1:]
+
+ batch["labels"] = labels
+
+ return batch
+
+
+@require_non_cpu
+@require_bitsandbytes
+class PeftBnbGPUExampleTests(unittest.TestCase):
+ r"""
+ A single GPU int8 + fp4 test suite, this will test if training fits correctly on a single GPU device (1x NVIDIA T4
+ 16GB) using bitsandbytes.
+
+ The tests are the following:
+
+ - Seq2Seq model training based on:
+ https://github.com/huggingface/peft/blob/main/examples/int8_training/Finetune_flan_t5_large_bnb_peft.ipynb
+ - Causal LM model training based on:
+ https://github.com/huggingface/peft/blob/main/examples/int8_training/Finetune_opt_bnb_peft.ipynb
+ - Audio model training based on:
+ https://github.com/huggingface/peft/blob/main/examples/int8_training/peft_bnb_whisper_large_v2_training.ipynb
+
+ """
+
+ def setUp(self):
+ self.seq2seq_model_id = "google/flan-t5-base"
+ self.causal_lm_model_id = "facebook/opt-6.7b"
+ self.tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ self.audio_model_id = "openai/whisper-large"
+
+ def tearDown(self):
+ r"""
+ Efficient mechanism to free GPU memory after each test. Based on
+ https://github.com/huggingface/transformers/issues/21094
+ """
+ clear_device_cache(garbage_collection=True)
+
+ def _check_inference_finite(self, model, batch):
+ # try inference without Trainer class
+ training = model.training
+ model.eval()
+ output = model(**batch.to(model.device))
+ assert torch.isfinite(output.logits).all()
+ model.train(training)
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training(self):
+ r"""
+ Test the CausalLM training on a single GPU device. This test is a converted version of
+ https://github.com/huggingface/peft/blob/main/examples/int8_training/Finetune_opt_bnb_peft.ipynb where we train
+ `opt-6.7b` on `english_quotes` dataset in few steps. The test would simply fail if the adapters are not set
+ correctly.
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ device_map="auto",
+ )
+
+ tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ model = prepare_model_for_kbit_training(model)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training_4bit(self):
+ r"""
+ Test the CausalLM training on a single GPU device. This test is a converted version of
+ https://github.com/huggingface/peft/blob/main/examples/int8_training/Finetune_opt_bnb_peft.ipynb where we train
+ `opt-6.7b` on `english_quotes` dataset in few steps using 4bit base model. The test would simply fail if the
+ adapters are not set correctly.
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ device_map="auto",
+ )
+
+ tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ model = prepare_model_for_kbit_training(model)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.multi_gpu_tests
+ def test_causal_lm_training_multi_gpu_4bit(self):
+ r"""
+ Test the CausalLM training on a multi-GPU device with 4bit base model. The test would simply fail if the
+ adapters are not set correctly.
+ """
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map=DEVICE_MAP_MAP[self.causal_lm_model_id],
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+ assert {p.device.index for p in model.parameters()} == set(range(device_count))
+
+ model = prepare_model_for_kbit_training(model)
+
+ setattr(model, "model_parallel", True)
+ setattr(model, "is_parallelizable", True)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ @require_non_cpu
+ def test_4bit_adalora_causalLM(self):
+ r"""
+ Tests the 4bit training with adalora
+ """
+ model_id = "facebook/opt-350m"
+
+ # for >3 GPUs, might need: device_map={"": "cuda:0"}
+ model = AutoModelForCausalLM.from_pretrained(
+ model_id, quantization_config=BitsAndBytesConfig(load_in_4bit=True)
+ )
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+
+ model.gradient_checkpointing_enable()
+ model = prepare_model_for_kbit_training(model)
+
+ peft_config = AdaLoraConfig(
+ init_r=6,
+ target_r=4,
+ tinit=2,
+ tfinal=2,
+ total_step=6,
+ deltaT=5,
+ beta1=0.3,
+ beta2=0.3,
+ orth_reg_weight=0.2,
+ lora_alpha=32,
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, peft_config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
+ batch = tokenizer(data["train"][:3]["quote"], return_tensors="pt", padding=True)
+ self._check_inference_finite(model, batch)
+
+ class OptimizerStepCallback(TrainerCallback):
+ def on_optimizer_step(self, args, state, control, **kwargs):
+ model.update_and_allocate(state.global_step)
+
+ step_callback = OptimizerStepCallback()
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=6,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.add_callback(step_callback)
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ @require_non_cpu
+ def test_8bit_adalora_causalLM(self):
+ r"""
+ Tests the 8bit training with adalora
+ """
+ model_id = "facebook/opt-350m"
+
+ model = AutoModelForCausalLM.from_pretrained(
+ model_id, quantization_config=BitsAndBytesConfig(load_in_8bit=True)
+ )
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+
+ model.gradient_checkpointing_enable()
+ model = prepare_model_for_kbit_training(model)
+
+ peft_config = AdaLoraConfig(
+ init_r=6,
+ target_r=4,
+ tinit=2,
+ tfinal=2,
+ total_step=6,
+ deltaT=5,
+ beta1=0.3,
+ beta2=0.3,
+ orth_reg_weight=0.2,
+ lora_alpha=32,
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, peft_config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
+ batch = tokenizer(data["train"][:3]["quote"], return_tensors="pt", padding=True)
+ self._check_inference_finite(model, batch)
+
+ class OptimizerStepCallback(TrainerCallback):
+ def on_optimizer_step(self, args, state, control, **kwargs):
+ model.update_and_allocate(state.global_step)
+
+ step_callback = OptimizerStepCallback()
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=6,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.add_callback(step_callback)
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.multi_gpu_tests
+ @require_torch_multi_accelerator
+ def test_causal_lm_training_multi_gpu(self):
+ r"""
+ Test the CausalLM training on a multi-GPU device. This test is a converted version of
+ https://github.com/huggingface/peft/blob/main/examples/int8_training/Finetune_opt_bnb_peft.ipynb where we train
+ `opt-6.7b` on `english_quotes` dataset in few steps. The test would simply fail if the adapters are not set
+ correctly.
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ device_map="auto",
+ )
+ print(f"device map: {model.hf_device_map}")
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+
+ tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ model = prepare_model_for_kbit_training(model)
+
+ setattr(model, "model_parallel", True)
+ setattr(model, "is_parallelizable", True)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ def test_seq2seq_lm_training_single_gpu(self):
+ r"""
+ Test the Seq2SeqLM training on a single GPU device. This test is a converted version of
+ https://github.com/huggingface/peft/blob/main/examples/int8_training/Finetune_opt_bnb_peft.ipynb where we train
+ `flan-large` on `english_quotes` dataset in few steps. The test would simply fail if the adapters are not set
+ correctly.
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForSeq2SeqLM.from_pretrained(
+ self.seq2seq_model_id,
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ device_map={"": 0},
+ )
+
+ assert set(model.hf_device_map.values()) == {0}
+
+ tokenizer = AutoTokenizer.from_pretrained(self.seq2seq_model_id)
+ model = prepare_model_for_kbit_training(model)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q", "v"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.multi_gpu_tests
+ @require_torch_multi_accelerator
+ def test_seq2seq_lm_training_multi_gpu(self):
+ r"""
+ Test the Seq2SeqLM training on a multi-GPU device. This test is a converted version of
+ https://github.com/huggingface/peft/blob/main/examples/int8_training/Finetune_opt_bnb_peft.ipynb where we train
+ `flan-large` on `english_quotes` dataset in few steps. The test would simply fail if the adapters are not set
+ correctly.
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForSeq2SeqLM.from_pretrained(
+ self.seq2seq_model_id,
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ device_map=DEVICE_MAP_MAP[self.seq2seq_model_id],
+ )
+
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+ assert {p.device.index for p in model.parameters()} == set(range(device_count))
+
+ tokenizer = AutoTokenizer.from_pretrained(self.seq2seq_model_id)
+ model = prepare_model_for_kbit_training(model)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q", "v"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir="outputs",
+ ),
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ # TODO skipping to see if this leads to single GPU tests passing
+ @pytest.mark.skip
+ @pytest.mark.single_gpu_tests
+ def test_audio_model_training(self):
+ r"""
+ Test the audio model training on a single GPU device. This test is a converted version of
+ https://github.com/huggingface/peft/blob/main/examples/int8_training/peft_bnb_whisper_large_v2_training.ipynb
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ dataset_name = "ybelkada/common_voice_mr_11_0_copy"
+ task = "transcribe"
+ language = "Marathi"
+ common_voice = DatasetDict()
+
+ common_voice["train"] = load_dataset(dataset_name, split="train+validation")
+
+ common_voice = common_voice.remove_columns(
+ ["accent", "age", "client_id", "down_votes", "gender", "locale", "path", "segment", "up_votes"]
+ )
+
+ feature_extractor = WhisperFeatureExtractor.from_pretrained(self.audio_model_id)
+ tokenizer = WhisperTokenizer.from_pretrained(self.audio_model_id, language=language, task=task)
+ processor = WhisperProcessor.from_pretrained(self.audio_model_id, language=language, task=task)
+
+ common_voice = common_voice.cast_column("audio", Audio(sampling_rate=16000))
+
+ def prepare_dataset(batch):
+ # load and resample audio data from 48 to 16kHz
+ audio = batch["audio"]
+
+ # compute log-Mel input features from input audio array
+ batch["input_features"] = feature_extractor(
+ audio["array"], sampling_rate=audio["sampling_rate"]
+ ).input_features[0]
+
+ # encode target text to label ids
+ batch["labels"] = tokenizer(batch["sentence"]).input_ids
+ return batch
+
+ common_voice = common_voice.map(
+ prepare_dataset, remove_columns=common_voice.column_names["train"], num_proc=2
+ )
+ data_collator = DataCollatorSpeechSeq2SeqWithPadding(processor=processor)
+
+ model = WhisperForConditionalGeneration.from_pretrained(
+ self.audio_model_id, quantization_config=BitsAndBytesConfig(load_in_8bit=True), device_map="auto"
+ )
+
+ model.config.forced_decoder_ids = None
+ model.config.suppress_tokens = []
+
+ model = prepare_model_for_kbit_training(model)
+
+ # as Whisper model uses Conv layer in encoder, checkpointing disables grad computation
+ # to avoid this, make the inputs trainable
+ def make_inputs_require_grad(module, input, output):
+ output.requires_grad_(True)
+
+ model.model.encoder.conv1.register_forward_hook(make_inputs_require_grad)
+
+ config = LoraConfig(
+ r=32, lora_alpha=64, target_modules=["q_proj", "v_proj"], lora_dropout=0.05, bias="none"
+ )
+
+ model = get_peft_model(model, config)
+ model.print_trainable_parameters()
+
+ training_args = Seq2SeqTrainingArguments(
+ output_dir=tmp_dir, # change to a repo name of your choice
+ per_device_train_batch_size=8,
+ gradient_accumulation_steps=1, # increase by 2x for every 2x decrease in batch size
+ learning_rate=1e-3,
+ warmup_steps=2,
+ max_steps=3,
+ fp16=True,
+ per_device_eval_batch_size=8,
+ generation_max_length=128,
+ logging_steps=25,
+ remove_unused_columns=False, # required as the PeftModel forward doesn't have the signature of the wrapped model's forward
+ label_names=["labels"], # same reason as above
+ )
+
+ trainer = Seq2SeqTrainer(
+ args=training_args,
+ model=model,
+ train_dataset=common_voice["train"],
+ data_collator=data_collator,
+ tokenizer=processor.feature_extractor,
+ )
+
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ def test_4bit_non_default_adapter_name(self):
+ # See PR 1294
+ config = LoraConfig(
+ r=16,
+ target_modules=["q_proj", "v_proj"],
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ # default adapter name
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+ model = prepare_model_for_kbit_training(model)
+ model = get_peft_model(model, config)
+ n_trainable_default, n_total_default = model.get_nb_trainable_parameters()
+
+ # other adapter name
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+ model = prepare_model_for_kbit_training(model)
+ model = get_peft_model(model, config, adapter_name="other")
+ n_trainable_other, n_total_other = model.get_nb_trainable_parameters()
+
+ assert n_trainable_other > 0
+ # sanity check
+ assert n_trainable_default == n_trainable_other
+ assert n_total_default == n_total_other
+
+ @pytest.mark.single_gpu_tests
+ def test_8bit_non_default_adapter_name(self):
+ # See PR 1294
+ config = LoraConfig(
+ r=16,
+ target_modules=["q_proj", "v_proj"],
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ # default adapter name
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+ model = prepare_model_for_kbit_training(model)
+ model = get_peft_model(model, config)
+ n_trainable_default, n_total_default = model.get_nb_trainable_parameters()
+
+ # other adapter name
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+ model = prepare_model_for_kbit_training(model)
+ model = get_peft_model(model, config, adapter_name="other")
+ n_trainable_other, n_total_other = model.get_nb_trainable_parameters()
+
+ assert n_trainable_other > 0
+ # sanity check
+ assert n_trainable_default == n_trainable_other
+ assert n_total_default == n_total_other
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training_4bit_dora(self):
+ r"""
+ Same as test_causal_lm_training_4bit but with DoRA
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ device_map="auto",
+ )
+
+ tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ model = prepare_model_for_kbit_training(model)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ use_dora=True,
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.multi_gpu_tests
+ def test_causal_lm_training_multi_gpu_4bit_dora(self):
+ r"""
+ Same as test_causal_lm_training_multi_gpu_4bit but with DoRA
+ """
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map=DEVICE_MAP_MAP[self.causal_lm_model_id],
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+ assert {p.device.index for p in model.parameters()} == set(range(device_count))
+
+ model = prepare_model_for_kbit_training(model)
+
+ setattr(model, "model_parallel", True)
+ setattr(model, "is_parallelizable", True)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ use_dora=True,
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training_8bit_dora(self):
+ r"""
+ Same as test_causal_lm_training_4bit_dora but with 8bit
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ device_map="auto",
+ )
+
+ tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ model = prepare_model_for_kbit_training(model)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ use_dora=True,
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.multi_gpu_tests
+ def test_causal_lm_training_multi_gpu_8bit_dora(self):
+ r"""
+ Same as test_causal_lm_training_multi_gpu_4bit_dora but with 8bit
+ """
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map=DEVICE_MAP_MAP[self.causal_lm_model_id],
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+ assert {p.device.index for p in model.parameters()} == set(range(device_count))
+
+ model = prepare_model_for_kbit_training(model)
+
+ setattr(model, "model_parallel", True)
+ setattr(model, "is_parallelizable", True)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ use_dora=True,
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training_gpt2_dora(self):
+ r"""
+ Same as test_causal_lm_training_4bit but with DoRA
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained("gpt2", device_map="auto")
+
+ tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ model = prepare_model_for_kbit_training(model)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ use_dora=True,
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @parameterized.expand(["4bit", "8bit"])
+ def test_initialize_dora_with_bnb_on_cpu(self, kbit):
+ # 1674
+ # The issue is that to initialize DoRA, we need to dequantize the weights. That only works on GPU for bnb.
+ # Therefore, initializing DoRA with bnb on CPU used to fail.
+ model_id = "facebook/opt-125m"
+ if kbit == "4bit":
+ bnb_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_quant_type="nf4")
+ elif kbit == "8bit":
+ bnb_config = BitsAndBytesConfig(load_in_8bit=True)
+ else:
+ raise ValueError("Only 4bit and 8bit bnb allowed")
+
+ model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config)
+ model = model.cpu() # ensure that we're on CPU
+ # sanity check that all weights are on CPU
+ weights_not_cpu = [name for name, p in model.named_parameters() if p.device != torch.device("cpu")]
+ assert not weights_not_cpu
+
+ lora_config = LoraConfig(use_dora=True)
+
+ # should not raise
+ peft_model = get_peft_model(model, lora_config)
+ # check that the weights are still on CPU
+ weights_not_cpu = [name for name, p in peft_model.named_parameters() if p.device != torch.device("cpu")]
+ assert not weights_not_cpu
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training_vera(self):
+ r"""
+ Same as test_causal_lm_training but with VeRA
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ device_map="auto",
+ )
+
+ tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ model = prepare_model_for_kbit_training(model)
+
+ config = VeraConfig(
+ r=16,
+ target_modules=["q_proj", "v_proj"],
+ vera_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training_4bit_vera(self):
+ r"""
+ Same as test_causal_lm_training_4bit but with VeRA
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ device_map="auto",
+ )
+
+ tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ model = prepare_model_for_kbit_training(model)
+
+ config = VeraConfig(
+ r=16,
+ target_modules=["q_proj", "v_proj"],
+ vera_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.multi_gpu_tests
+ def test_causal_lm_training_multi_gpu_vera(self):
+ r"""
+ Same as test_causal_lm_training_multi_gpu but with VeRA
+ """
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map=DEVICE_MAP_MAP[self.causal_lm_model_id],
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+ assert {p.device.index for p in model.parameters()} == set(range(device_count))
+
+ model = prepare_model_for_kbit_training(model)
+
+ setattr(model, "model_parallel", True)
+ setattr(model, "is_parallelizable", True)
+
+ config = VeraConfig(
+ r=16,
+ target_modules=["q_proj", "v_proj"],
+ vera_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.multi_gpu_tests
+ def test_causal_lm_training_multi_gpu_4bit_vera(self):
+ r"""
+ Same as test_causal_lm_training_multi_gpu_4bit but with VeRA
+ """
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map=DEVICE_MAP_MAP[self.causal_lm_model_id],
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+ assert {p.device.index for p in model.parameters()} == set(range(device_count))
+
+ model = prepare_model_for_kbit_training(model)
+
+ setattr(model, "model_parallel", True)
+ setattr(model, "is_parallelizable", True)
+
+ config = VeraConfig(
+ r=16,
+ target_modules=["q_proj", "v_proj"],
+ vera_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training_8bit_randlora(self):
+ r"""
+ Same as test_causal_lm_training but with RandLora
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ device_map="auto",
+ )
+
+ tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ model = prepare_model_for_kbit_training(model)
+
+ config = RandLoraConfig(
+ r=16,
+ target_modules=["q_proj", "v_proj"],
+ randlora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset("ybelkada/english_quotes_copy")
+ data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training_4bit_randlora(self):
+ r"""
+ Same as test_causal_lm_training_4bit but with RandLora
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ device_map="auto",
+ )
+
+ tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ model = prepare_model_for_kbit_training(model)
+
+ config = RandLoraConfig(
+ r=16,
+ target_modules=["q_proj", "v_proj"],
+ randlora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset("ybelkada/english_quotes_copy")
+ data = data.map(lambda samples: tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.multi_gpu_tests
+ def test_causal_lm_training_multi_gpu_8bit_randlora(self):
+ r"""
+ Same as test_causal_lm_training_multi_gpu but with RandLoRA
+ """
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map=DEVICE_MAP_MAP[self.causal_lm_model_id],
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+ assert {p.device.index for p in model.parameters()} == set(range(device_count))
+
+ model = prepare_model_for_kbit_training(model)
+
+ setattr(model, "model_parallel", True)
+ setattr(model, "is_parallelizable", True)
+
+ config = RandLoraConfig(
+ r=16,
+ target_modules=["q_proj", "v_proj"],
+ randlora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset("Abirate/english_quotes")
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.multi_gpu_tests
+ def test_causal_lm_training_multi_gpu_4bit_randlora(self):
+ r"""
+ Same as test_causal_lm_training_multi_gpu_4bit but with RandLora
+ """
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map=DEVICE_MAP_MAP[self.causal_lm_model_id],
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+ assert {p.device.index for p in model.parameters()} == set(range(device_count))
+
+ model = prepare_model_for_kbit_training(model)
+
+ setattr(model, "model_parallel", True)
+ setattr(model, "is_parallelizable", True)
+
+ config = RandLoraConfig(
+ r=16,
+ target_modules=["q_proj", "v_proj"],
+ randlora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset("Abirate/english_quotes")
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training_lora_resize_embeddings_trainable_tokens(self):
+ r"""
+ Test LoRA with trainable tokens on a resized embedding matrix
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ bnb_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_compute_dtype=torch.float16,
+ bnb_4bit_quant_storage=torch.float16,
+ bnb_4bit_use_double_quant=True,
+ )
+
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ quantization_config=bnb_config,
+ device_map="auto",
+ )
+
+ # add 2 new tokens
+ tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ new_tokens = ["", ""]
+ tokenizer.add_special_tokens({"additional_special_tokens": new_tokens})
+ trainable_token_indices = [tokenizer.vocab[token] for token in new_tokens]
+
+ cur_emb_size = model.model.decoder.embed_tokens.weight.shape[0]
+ model.resize_token_embeddings(max(tokenizer.vocab_size, cur_emb_size))
+ model = prepare_model_for_kbit_training(model)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ trainable_token_indices={"embed_tokens": trainable_token_indices},
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+
+ def tokenize(samples):
+ # add new tokens to samples
+ samples = [f"{row}" for row in samples["quote"]]
+ return tokenizer(samples)
+
+ data = data.map(tokenize, batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ # higher learning rate, as embeddings are a bit slow to update
+ learning_rate=1e-3,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ # ensure that the new trainable tokens have been updated
+ embedding = model.base_model.model.model.decoder.embed_tokens
+ tol = 1e-4
+ assert not torch.allclose(
+ embedding.token_adapter.trainable_tokens_delta["default"],
+ embedding.original_module.weight[trainable_token_indices],
+ atol=tol,
+ rtol=tol,
+ )
+
+ # check size of the checkpoint, should be small since the embedding matrix does not need to be stored
+ stat = os.stat(os.path.join(tmp_dir, SAFETENSORS_WEIGHTS_NAME))
+ embed_params = model.base_model.model.model.decoder.embed_tokens.original_module.weight.numel()
+ # fp32 -> 4x
+ emb_file_size = 4 * embed_params
+ assert stat.st_size < emb_file_size
+
+ # sanity check: assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+
+@require_torch_gpu
+@require_auto_gptq
+@require_optimum
+class PeftGPTQGPUTests(unittest.TestCase):
+ r"""
+ GPTQ + peft tests
+ """
+
+ def setUp(self):
+ from transformers import GPTQConfig
+
+ self.causal_lm_model_id = "marcsun13/opt-350m-gptq-4bit"
+ # TODO : check if it works for Exllamav2 kernels
+ self.quantization_config = GPTQConfig(bits=4, use_exllama=False)
+ self.tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+
+ def tearDown(self):
+ r"""
+ Efficient mechanism to free GPU memory after each test. Based on
+ https://github.com/huggingface/transformers/issues/21094
+ """
+ clear_device_cache(garbage_collection=True)
+
+ def _check_inference_finite(self, model, batch):
+ # try inference without Trainer class
+ training = model.training
+ model.eval()
+ output = model(**batch.to(model.device))
+ assert torch.isfinite(output.logits).all()
+ model.train(training)
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training(self):
+ r"""
+ Test the CausalLM training on a single GPU device. The test would simply fail if the adapters are not set
+ correctly.
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ quantization_config=self.quantization_config,
+ )
+
+ model = prepare_model_for_kbit_training(model)
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ def test_adalora_causalLM(self):
+ r"""
+ Tests the gptq training with adalora
+ """
+
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ quantization_config=self.quantization_config,
+ )
+
+ tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ model = prepare_model_for_kbit_training(model)
+
+ peft_config = AdaLoraConfig(
+ init_r=6,
+ target_r=4,
+ tinit=2,
+ tfinal=2,
+ total_step=6,
+ deltaT=5,
+ beta1=0.3,
+ beta2=0.3,
+ orth_reg_weight=0.2,
+ lora_alpha=32,
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, peft_config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+ batch = tokenizer(data["train"][:3]["quote"], return_tensors="pt", padding=True)
+ self._check_inference_finite(model, batch)
+
+ class OptimizerStepCallback(TrainerCallback):
+ def on_optimizer_step(self, args, state, control, **kwargs):
+ model.update_and_allocate(state.global_step)
+
+ step_callback = OptimizerStepCallback()
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=6,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ trainer.add_callback(step_callback)
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training_gptq_qalora(self):
+ """
+ Test QALoRA with GPTQ quantization. The test would simply fail if the adapters are not set correctly.
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ quantization_config=self.quantization_config,
+ )
+
+ model = prepare_model_for_kbit_training(model)
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ use_qalora=True,
+ qalora_group_size=32,
+ )
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.multi_gpu_tests
+ @require_torch_multi_gpu
+ def test_causal_lm_training_multi_gpu(self):
+ r"""
+ Test the CausalLM training on a multi-GPU device. The test would simply fail if the adapters are not set
+ correctly.
+ """
+ device_map = {
+ "model.decoder.embed_tokens": 0,
+ "lm_head": 0,
+ "model.decoder.embed_positions": 0,
+ "model.decoder.project_out": 0,
+ "model.decoder.project_in": 0,
+ "model.decoder.layers.0": 0,
+ "model.decoder.layers.1": 0,
+ "model.decoder.layers.2": 0,
+ "model.decoder.layers.3": 0,
+ "model.decoder.layers.4": 0,
+ "model.decoder.layers.5": 0,
+ "model.decoder.layers.6": 1,
+ "model.decoder.layers.7": 1,
+ "model.decoder.layers.8": 1,
+ "model.decoder.layers.9": 1,
+ "model.decoder.layers.10": 1,
+ "model.decoder.layers.11": 1,
+ "model.decoder.final_layer_norm": 1,
+ }
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ device_map=device_map,
+ quantization_config=self.quantization_config,
+ )
+
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+ assert {p.device.index for p in model.parameters()} == set(range(device_count))
+
+ model = prepare_model_for_kbit_training(model)
+
+ setattr(model, "model_parallel", True)
+ setattr(model, "is_parallelizable", True)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ fp16=True,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ def test_non_default_adapter_name(self):
+ # See issue 1346
+ config = LoraConfig(
+ r=16,
+ target_modules=["q_proj", "v_proj"],
+ task_type="CAUSAL_LM",
+ )
+
+ # default adapter name
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ quantization_config=self.quantization_config,
+ )
+ model = prepare_model_for_kbit_training(model)
+ model = get_peft_model(model, config)
+ n_trainable_default, n_total_default = model.get_nb_trainable_parameters()
+
+ # other adapter name
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ device_map="auto",
+ quantization_config=self.quantization_config,
+ )
+ model = prepare_model_for_kbit_training(model)
+ model = get_peft_model(model, config, adapter_name="other")
+ n_trainable_other, n_total_other = model.get_nb_trainable_parameters()
+
+ assert n_trainable_other > 0
+ # sanity check
+ assert n_trainable_default == n_trainable_other
+ assert n_total_default == n_total_other
+
+
+@require_non_cpu
+class OffloadSaveTests(unittest.TestCase):
+ def setUp(self):
+ self.causal_lm_model_id = "gpt2"
+
+ def tearDown(self):
+ r"""
+ Efficient mechanism to free GPU memory after each test. Based on
+ https://github.com/huggingface/transformers/issues/21094
+ """
+ clear_device_cache(garbage_collection=True)
+
+ def test_offload_load(self):
+ r"""
+ Test the loading of a LoRA model with CPU- and disk-offloaded modules
+ """
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(self.causal_lm_model_id)
+ tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ memory_limits = {"cpu": "0.4GIB"} # no "disk" for PeftModel.from_pretrained() compatibility
+
+ # offload around half of all transformer modules to the disk
+ device_map = infer_auto_device_map(model, max_memory=memory_limits)
+ assert "cpu" in device_map.values()
+ assert "disk" in device_map.values()
+
+ config = LoraConfig(task_type="CAUSAL_LM", init_lora_weights=False, target_modules=["c_attn"])
+
+ model = get_peft_model(model, config)
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir)
+ model = AutoModelForCausalLM.from_pretrained(self.causal_lm_model_id, device_map="cpu")
+ lora_model = PeftModel.from_pretrained(model, tmp_dir).eval()
+ input_tokens = tokenizer.encode("Four score and seven years ago", return_tensors="pt")
+ output = lora_model(input_tokens)[0]
+
+ # load the model with device_map
+ offloaded_model = AutoModelForCausalLM.from_pretrained(self.causal_lm_model_id, device_map=device_map)
+ assert len({p.device for p in offloaded_model.parameters()}) == 2 # 'cpu' and 'meta'
+ offloaded_lora_model = PeftModel.from_pretrained(offloaded_model, tmp_dir, max_memory=memory_limits).eval()
+ offloaded_output = offloaded_lora_model(input_tokens)[0]
+ assert torch.allclose(output, offloaded_output, atol=1e-5)
+
+ @pytest.mark.single_gpu_tests
+ def test_offload_merge(self):
+ r"""
+ Test merging, unmerging, and unloading of a model with CPU- and disk- offloaded modules.
+ """
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(self.causal_lm_model_id)
+ tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ memory_limits = {0: "0.2GIB", "cpu": "0.2GIB"} # no "disk" for PeftModel.from_pretrained() compatibility
+ # offloads around half of all transformer modules
+ device_map = infer_auto_device_map(model, max_memory=memory_limits)
+ assert 0 in device_map.values()
+ assert "cpu" in device_map.values()
+ assert "disk" in device_map.values()
+
+ config = LoraConfig(task_type="CAUSAL_LM", init_lora_weights=False, target_modules=["c_attn"])
+
+ model = get_peft_model(model, config)
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir)
+ # load the model with device_map
+ model = AutoModelForCausalLM.from_pretrained(self.causal_lm_model_id, device_map=device_map).eval()
+ assert len({p.device for p in model.parameters()}) == 2
+
+ model = PeftModel.from_pretrained(model, tmp_dir, max_memory=memory_limits)
+
+ input_tokens = tokenizer.encode("Four score and seven years ago", return_tensors="pt")
+ model.eval()
+
+ # test peft model adapter merge
+ pre_merge_olayer = model(input_tokens)[0]
+ model.merge_adapter()
+ post_merge_olayer = model(input_tokens)[0]
+ assert torch.allclose(post_merge_olayer, pre_merge_olayer)
+
+ # test peft model adapter unmerge
+ model.unmerge_adapter()
+ post_unmerge_olayer = model(input_tokens)[0]
+ assert torch.allclose(post_unmerge_olayer, pre_merge_olayer)
+
+ # test LoRA merge and unload
+ model = model.merge_and_unload()
+ post_unload_merge_olayer = model(input_tokens)[0]
+ assert torch.allclose(post_unload_merge_olayer, pre_merge_olayer)
+
+
+@pytest.mark.skipif(not (torch.cuda.is_available() or is_xpu_available()), reason="test requires a GPU or XPU")
+@pytest.mark.single_gpu_tests
+class TestPiSSA:
+ r"""
+ Tests for PiSSA to ensure that it reduces the quantization error compared to normal LoRA quantization.
+ """
+
+ # The error factor indicates by how much the quantization error should be decreased when using PiSSA compared to
+ # quantization without PiSSA. Thus 1.03 means that the error should be decreased by 3% at least. This is a very
+ # conservative value to prevent flakiness, in practice most gains are > 1.5
+ error_factor = 1.03
+
+ def quantize_model(self, model, num_bits=4, device="cuda"):
+ # Quantize the `weight.data` of the linear layer in the model to `num_bits` and store it with full precision.
+ quantizer = NFQuantizer(num_bits=num_bits, device=device, method="normal", block_size=64)
+ for name, module in model.named_modules():
+ if isinstance(module, (torch.nn.Linear, Conv1D)) and "lm_head" not in name:
+ quantized_weight, max_abs, shape = quantizer.quantize_block(module.weight.data.to(device))
+ module.weight.data = quantizer.dequantize_block(quantized_weight, max_abs, shape)
+ return model
+
+ def nuclear_norm(self, base_model, quantized_model):
+ # Calculate the nuclear norm (sum of singular values) of the error matrices between the `quantized_model` and the `base_model`.
+ error_list = []
+ for name, module in base_model.named_modules():
+ if isinstance(module, (torch.nn.Linear, Conv1D)) and "lm_head" not in name:
+ quant_module = quantized_model.get_submodule(name)
+ error_list.append(torch.linalg.svdvals(module.weight.data - quant_module.weight.data).sum())
+ return torch.Tensor(error_list).sum()
+
+ def get_errors(
+ self,
+ tmp_path,
+ bits=4,
+ device="cuda",
+ model_id="hf-internal-testing/tiny-random-BloomForCausalLM",
+ ):
+ # Comparing the quantized LoRA model to the base model, vs the PiSSA quantized model to the base model.
+ # We expect the PiSSA quantized model to have less error than the normal LoRA quantized model.
+
+ cls = AutoModelForSeq2SeqLM if "t5" in str(model_id) else AutoModelForCausalLM
+ base_model = cls.from_pretrained(model_id).eval().to(device)
+ task_type = TaskType.SEQ_2_SEQ_LM if base_model.config.is_encoder_decoder else TaskType.CAUSAL_LM
+
+ # logits from the normal quantized LoRA model
+ target_modules = "all-linear" if task_type != TaskType.SEQ_2_SEQ_LM else ["o", "k", "wi", "q", "v"]
+ lora_config = LoraConfig(task_type=task_type, target_modules=target_modules)
+
+ qlora_model = self.quantize_model(cls.from_pretrained(model_id).eval().to(device), bits, device)
+ qlora_model = get_peft_model(
+ qlora_model,
+ lora_config,
+ )
+ qlora_model = qlora_model.merge_and_unload()
+ qlora_error = self.nuclear_norm(base_model, qlora_model)
+ del qlora_model
+ clear_device_cache(garbage_collection=True)
+
+ # logits from quantized LoRA model using PiSSA
+ lora_config = LoraConfig(
+ task_type=task_type,
+ init_lora_weights="pissa",
+ target_modules=target_modules,
+ )
+ pissa_model = cls.from_pretrained(model_id).eval().to(device)
+ pissa_model = get_peft_model(pissa_model, lora_config)
+
+ # save LoRA weights, they should be initialized such that they minimize the quantization error
+ pissa_model.base_model.peft_config["default"].init_lora_weights = True
+ pissa_model.save_pretrained(tmp_path / "pissa_model")
+
+ pissa_model = pissa_model.unload()
+ pissa_model.save_pretrained(tmp_path / "residual_model")
+
+ del pissa_model
+ clear_device_cache(garbage_collection=True)
+
+ # now load quantized model and apply PiSSA-initialized weights on top
+ qpissa_model = self.quantize_model(
+ cls.from_pretrained(tmp_path / "residual_model").eval().to(device), bits, device
+ )
+ qpissa_model = PeftModel.from_pretrained(qpissa_model, tmp_path / "pissa_model")
+ qpissa_model = qpissa_model.merge_and_unload()
+ qpissa_error = self.nuclear_norm(base_model, qpissa_model)
+ del qpissa_model
+ clear_device_cache(garbage_collection=True)
+
+ assert qlora_error > 0.0
+ assert qpissa_error > 0.0
+
+ # next, check that PiSSA quantization errors are smaller than LoRA errors by a certain margin
+ assert qpissa_error < (qlora_error / self.error_factor)
+
+ @pytest.mark.parametrize("device", [torch_device, "cpu"])
+ def test_bloomz_pissa_4bit(self, device, tmp_path):
+ # In this test, we compare the logits of the base model, the quantized LoRA model, and the quantized model
+ # using PiSSA. When quantizing, we expect a certain level of error. However, we expect the PiSSA quantized
+ # model to have less error than the normal LoRA quantized model. Note that when using normal LoRA, the
+ # quantization error is simply the error from quantization without LoRA, as LoRA is a no-op before training.
+ # We still apply LoRA for the test for consistency.
+
+ self.get_errors(bits=4, device=device, tmp_path=tmp_path)
+
+ @pytest.mark.parametrize("device", [torch_device, "cpu"])
+ def test_bloomz_pissa_8bit(self, device, tmp_path):
+ # Same test as test_bloomz_pissa_4bit but with 8 bits.
+ self.get_errors(bits=8, device=device, tmp_path=tmp_path)
+
+ @pytest.mark.parametrize("device", [torch_device, "cpu"])
+ def test_t5_pissa_4bit(self, device, tmp_path):
+ self.get_errors(bits=4, device=device, model_id="t5-small", tmp_path=tmp_path)
+
+ @pytest.mark.parametrize("device", [torch_device, "cpu"])
+ def test_t5_pissa_8bit(self, device, tmp_path):
+ self.get_errors(bits=8, device=device, model_id="t5-small", tmp_path=tmp_path)
+
+ @pytest.mark.parametrize("device", [torch_device, "cpu"])
+ def test_gpt2_pissa_4bit(self, device, tmp_path):
+ # see 2104
+ self.get_errors(bits=4, device=device, model_id="gpt2", tmp_path=tmp_path)
+
+ @pytest.mark.parametrize("device", [torch_device, "cpu"])
+ def test_gpt2_pissa_8bit(self, device, tmp_path):
+ # see 2104
+ self.get_errors(bits=8, device=device, model_id="gpt2", tmp_path=tmp_path)
+
+ @require_bitsandbytes
+ def test_lora_pissa_conversion_same_output_after_loading_with_quantization(self, tmp_path):
+ # A copy of the test `test_lora_pissa_conversion_same_output_after_loading` in peft/tests/test_initialization.py,
+ # that would fail if bitsandbytes quantization is used because Quant(W_res) + AB !=Quant(W) + \Delta(AB).
+ import bitsandbytes as bnb
+
+ torch.manual_seed(0)
+ data = torch.rand(10, 1000).to(torch_device)
+
+ class MyModule(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ # choose a large weight so that averages are close to expected values
+ self.linear = torch.nn.Linear(1000, 1000)
+ self.embed = torch.nn.Embedding(1000, 1000)
+ self.conv2d = torch.nn.Conv2d(100, 100, 3)
+
+ def forward(self, x):
+ x_int = (100 * x).int()
+ x_4d = x.flatten().reshape(1, 100, 10, 10)
+ return self.linear(x), self.embed(x_int), self.conv2d(x_4d)
+
+ model = MyModule().to(torch_device)
+ output_base = model(data)[0]
+
+ config = LoraConfig(init_lora_weights="pissa", target_modules=["linear"], r=8)
+ peft_model = get_peft_model(deepcopy(model), config)
+ # save the initial model
+ peft_model.peft_config["default"].init_lora_weights = True
+ peft_model.save_pretrained(tmp_path / "init-model")
+ peft_model = peft_model.unload()
+ torch.save(peft_model.state_dict(), tmp_path / "residual-model")
+ del peft_model
+
+ # create 4bit base model
+ base_model = deepcopy(model)
+ base_model.load_state_dict(torch.load(tmp_path / "residual-model"))
+ # sanity check: the base model weights were indeed changed
+ tol = 1e-06
+ assert not torch.allclose(model.linear.weight, base_model.linear.weight, atol=tol, rtol=tol)
+ # quantize the linear layer
+ linear4bit = bnb.nn.Linear4bit(base_model.linear.in_features, base_model.linear.out_features)
+ linear4bit.load_state_dict(base_model.linear.state_dict())
+ linear4bit.to(0)
+ base_model.linear = linear4bit
+ peft_model = PeftModel.from_pretrained(deepcopy(base_model), tmp_path / "init-model")
+ output_quantized_pissa = peft_model(data)[0]
+ # sanity check
+ tol = 1e-06
+ assert not torch.allclose(output_base, output_quantized_pissa, atol=tol, rtol=tol)
+
+ # modify the weights, or else the adapter performs an identity transformation
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ output_finetuned_pissa = peft_model(data)[0]
+ # sanity check
+ tol = 1e-06
+ assert not torch.allclose(output_quantized_pissa, output_finetuned_pissa, atol=tol, rtol=tol)
+
+ # save the model normally
+ peft_model.save_pretrained(tmp_path / "pissa-model")
+ model_loaded = PeftModel.from_pretrained(deepcopy(base_model), tmp_path / "pissa-model")
+ output_loaded = model_loaded(data)[0]
+
+ assert torch.allclose(output_finetuned_pissa, output_loaded, atol=tol, rtol=tol)
+ # sanity check: ranks should still be 8 as initially
+ assert model_loaded.peft_config["default"].r == 8
+ assert model_loaded.base_model.model.linear.lora_A["default"].weight.shape[0] == 8
+
+ # save the model with conversion
+ peft_model.save_pretrained(
+ tmp_path / "pissa-model-converted", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+ model_converted = PeftModel.from_pretrained(deepcopy(model), tmp_path / "pissa-model-converted")
+ output_converted = model_converted(data)[0]
+
+ # rank should be double of what it was initially
+ assert model_converted.peft_config["default"].r == 16
+ assert model_converted.base_model.model.linear.lora_A["default"].weight.shape[0] == 16
+ # base model weights should be the same as the initial model
+ assert torch.allclose(
+ model.linear.weight, model_converted.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+ # This check is expected to fail when using bnb
+ assert not torch.allclose(output_finetuned_pissa, output_converted, atol=tol, rtol=tol)
+
+
+@pytest.mark.skipif(not (torch.cuda.is_available() or is_xpu_available()), reason="test requires a GPU or XPU")
+@pytest.mark.single_gpu_tests
+class TestOLoRA:
+ r"""
+ Tests for OLoRA to ensure that it reduces the quantization error compared to normal LoRA quantization.
+ """
+
+ # The error factor indicates by how much the quantization error should be decreased when using OLoRA compared to
+ # quantization without OLoRA. Thus 1.03 means that the error should be decreased by 3% at least. This is a very
+ # conservative value to prevent flakiness, in practice most gains are > 1.5
+ error_factor = 1.2
+
+ def quantize_model(self, model, num_bits=4, device="cuda"):
+ # Quantize the `weight.data` of the linear layer in the model to `num_bits` and store it with full precision.
+ quantizer = NFQuantizer(num_bits=num_bits, device=device, method="normal", block_size=64)
+ for name, module in model.named_modules():
+ if isinstance(module, torch.nn.Linear) and "lm_head" not in name:
+ quantized_weight, max_abs, shape = quantizer.quantize_block(module.weight.data.to(device))
+ module.weight.data = quantizer.dequantize_block(quantized_weight, max_abs, shape)
+ return model
+
+ def nuclear_norm(self, base_model, quantized_model):
+ # Calculate the nuclear norm (sum of singular values) of the error matrices between the `quantized_model` and the `base_model`.
+ error_list = []
+ for name, module in base_model.named_modules():
+ if isinstance(module, torch.nn.Linear) and "lm_head" not in name:
+ quant_module = quantized_model.get_submodule(name)
+ error_list.append(torch.linalg.svdvals(module.weight.data - quant_module.weight.data).sum())
+ return torch.Tensor(error_list).sum()
+
+ def get_errors(
+ self,
+ tmp_path,
+ bits=4,
+ device="cuda",
+ model_id="hf-internal-testing/tiny-random-BloomForCausalLM",
+ ):
+ # Comparing the quantized LoRA model to the base model, vs the OLoRA quantized model to the base model.
+ # We expect the OLoRA quantized model to have less error than the normal LoRA quantized model.
+
+ cls = AutoModelForSeq2SeqLM if "t5" in str(model_id) else AutoModelForCausalLM
+ base_model = cls.from_pretrained(model_id).eval().to(device)
+ task_type = TaskType.SEQ_2_SEQ_LM if base_model.config.is_encoder_decoder else TaskType.CAUSAL_LM
+
+ # logits from the normal quantized LoRA model
+ target_modules = "all-linear" if task_type != TaskType.SEQ_2_SEQ_LM else ["o", "k", "wi", "q", "v"]
+ lora_config = LoraConfig(task_type=task_type, target_modules=target_modules)
+
+ qlora_model = self.quantize_model(cls.from_pretrained(model_id).eval().to(device), bits, device)
+ qlora_model = get_peft_model(
+ qlora_model,
+ lora_config,
+ )
+ qlora_model = qlora_model.merge_and_unload()
+ qlora_error = self.nuclear_norm(base_model, qlora_model)
+ del qlora_model
+ clear_device_cache(garbage_collection=True)
+
+ # logits from quantized LoRA model using OLoRA
+ lora_config = LoraConfig(
+ task_type=task_type,
+ init_lora_weights="olora",
+ target_modules=target_modules,
+ )
+ olora_model = cls.from_pretrained(model_id).eval().to(device)
+ olora_model = get_peft_model(olora_model, lora_config)
+
+ # save LoRA weights, they should be initialized such that they minimize the quantization error
+ olora_model.base_model.peft_config["default"].init_lora_weights = True
+ olora_model.save_pretrained(tmp_path / "olora_model")
+
+ olora_model = olora_model.unload()
+ olora_model.save_pretrained(tmp_path / "residual_model")
+
+ del olora_model
+ clear_device_cache(garbage_collection=True)
+
+ # now load quantized model and apply OLoRA-initialized weights on top
+ qolora_model = self.quantize_model(
+ cls.from_pretrained(tmp_path / "residual_model").eval().to(device), bits, device
+ )
+ qolora_model = PeftModel.from_pretrained(qolora_model, tmp_path / "olora_model")
+ qolora_model = qolora_model.merge_and_unload()
+ qolora_error = self.nuclear_norm(base_model, qolora_model)
+ del qolora_model
+ clear_device_cache(garbage_collection=True)
+
+ assert qlora_error > 0.0
+ assert qolora_error > 0.0
+
+ # next, check that OLoRA quantization errors are smaller than LoRA errors by a certain margin
+ assert qolora_error < (qlora_error / self.error_factor)
+
+ @pytest.mark.parametrize("device", [torch_device, "cpu"])
+ def test_bloomz_olora_4bit(self, device, tmp_path):
+ # In this test, we compare the logits of the base model, the quantized LoRA model, and the quantized model
+ # using OLoRA. When quantizing, we expect a certain level of error. However, we expect the OLoRA quantized
+ # model to have less error than the normal LoRA quantized model. Note that when using normal LoRA, the
+ # quantization error is simply the error from quantization without LoRA, as LoRA is a no-op before training.
+ # We still apply LoRA for the test for consistency.
+
+ self.get_errors(bits=4, device=device, tmp_path=tmp_path)
+
+ @pytest.mark.parametrize("device", [torch_device, "cpu"])
+ def test_bloomz_olora_8bit(self, device, tmp_path):
+ # Same test as test_bloomz_olora_4bit but with 8 bits.
+ self.get_errors(bits=8, device=device, tmp_path=tmp_path)
+
+ @pytest.mark.parametrize("bits", [4, 8])
+ def test_olora_with_quantized_model(self, bits):
+ import bitsandbytes as bnb
+
+ # issue 1999
+ model_id = "hf-internal-testing/tiny-random-OPTForCausalLM"
+ if bits == 4:
+ bnb_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_quant_type="nf4",
+ bnb_4bit_compute_dtype=torch.float16,
+ bnb_4bit_quant_storage=torch.float16,
+ bnb_4bit_use_double_quant=True,
+ )
+ elif bits == 8:
+ bnb_config = BitsAndBytesConfig(load_in_8bit=True)
+ else:
+ raise ValueError("bits must be 4 or 8")
+
+ model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config)
+ model = prepare_model_for_kbit_training(model)
+ config = LoraConfig(init_lora_weights="olora")
+ model = get_peft_model(model, config)
+
+ # check that the correct type is used for the weights
+ base_layer = model.base_model.model.model.decoder.layers[0].self_attn.v_proj.base_layer.weight
+ if bits == 4:
+ assert isinstance(base_layer, bnb.nn.modules.Params4bit)
+ else:
+ assert isinstance(base_layer, bnb.nn.modules.Int8Params)
+
+ inputs = torch.arange(10).unsqueeze(0).to(model.device)
+ logits = model(inputs).logits # does not raise
+ assert torch.isfinite(logits).all()
+
+
+@pytest.mark.skipif(
+ not (torch.cuda.is_available() or is_xpu_available()), reason="test requires a hardware accelerator"
+)
+@require_bitsandbytes
+class TestLoftQ:
+ r"""
+ Tests for LoftQ to ensure that it reduces the quantization error compared to normal LoRA quantization.
+ """
+
+ # The error factor indicates by how much the quantization error should be decreased when using LoftQ compared to
+ # quantization without LoftQ. Thus 1.03 means that the error should be decreased by 3% at least. This is a very
+ # conservative value to prevent flakiness, in practice most gains are > 1.5
+ device = infer_device()
+ error_factor = 1.005 if device in ("xpu", "cpu") else 1.03
+
+ def get_input(self, model_id, device):
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ inputs = tokenizer("All I want is", padding=True, return_tensors="pt")
+ inputs = inputs.to(self.device)
+ return inputs
+
+ def get_base_model(self, model_id, device, **kwargs):
+ cls = AutoModelForSeq2SeqLM if "t5" in str(model_id) else AutoModelForCausalLM
+ model = cls.from_pretrained(model_id, **kwargs).eval()
+ model = model.to(self.device)
+ return model
+
+ def get_logits(self, model, inputs):
+ if model.config.is_encoder_decoder:
+ input_ids = inputs["input_ids"]
+ return model(input_ids=input_ids, decoder_input_ids=input_ids).logits
+ return model(**inputs).logits
+
+ def get_errors(
+ self,
+ tmp_path,
+ bits=4,
+ loftq_iter=1,
+ device="cuda",
+ model_id="hf-internal-testing/tiny-random-BloomForCausalLM",
+ use_dora=False,
+ ):
+ # Helper function that returns the quantization errors (MAE and MSE) when comparing the quantized LoRA model
+ # to the base model, vs the LoftQ quantized model to the base model. We expect the LoftQ quantized model to
+ # have less error than the normal LoRA quantized model. Since we compare logits, the observed error is
+ # already somewhat dampened because of the softmax.
+ torch.manual_seed(0)
+ model = self.get_base_model(model_id, device)
+ task_type = TaskType.SEQ_2_SEQ_LM if model.config.is_encoder_decoder else TaskType.CAUSAL_LM
+ inputs = self.get_input(model_id, device)
+ # the base logits are the reference, we try to match those as closely as possible
+ logits_base = self.get_logits(model, inputs)
+ # clean up
+ del model
+ clear_device_cache(garbage_collection=True)
+
+ # logits from the normal quantized LoRA model
+ target_modules = "all-linear" if task_type != TaskType.SEQ_2_SEQ_LM else ["o", "k", "wi", "q", "v"]
+ lora_config = LoraConfig(task_type=task_type, use_dora=use_dora, target_modules=target_modules)
+ kwargs = {}
+ if bits == 4:
+ kwargs["quantization_config"] = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_quant_type="nf4")
+ elif bits == 8:
+ kwargs["quantization_config"] = BitsAndBytesConfig(load_in_8bit=True)
+ else:
+ raise ValueError("bits must be 4 or 8")
+
+ quantized_model = get_peft_model(
+ self.get_base_model(model_id, device=None, **kwargs),
+ lora_config,
+ )
+ torch.manual_seed(0)
+ logits_quantized = self.get_logits(quantized_model, inputs)
+ del quantized_model
+ clear_device_cache(garbage_collection=True)
+
+ # logits from quantized LoRA model using LoftQ
+ loftq_config = LoftQConfig(loftq_bits=bits, loftq_iter=loftq_iter)
+ lora_config = LoraConfig(
+ task_type=task_type,
+ init_lora_weights="loftq",
+ loftq_config=loftq_config,
+ use_dora=use_dora,
+ target_modules=target_modules,
+ )
+ model = self.get_base_model(model_id, device)
+ if device != "cpu":
+ model = model.to(torch_device)
+ loftq_model = get_peft_model(model, lora_config)
+ if device != "cpu":
+ loftq_model = loftq_model.to(torch_device)
+
+ # save LoRA weights, they should be initialized such that they minimize the quantization error
+ loftq_model.base_model.peft_config["default"].init_lora_weights = True
+ loftq_model.save_pretrained(tmp_path / "loftq_model")
+
+ loftq_model = loftq_model.unload()
+ loftq_model.save_pretrained(tmp_path / "base_model")
+
+ del loftq_model
+ clear_device_cache(garbage_collection=True)
+
+ # now load quantized model and apply LoftQ-initialized weights on top
+ base_model = self.get_base_model(tmp_path / "base_model", device=None, **kwargs, torch_dtype=torch.float32)
+ loftq_model = PeftModel.from_pretrained(base_model, tmp_path / "loftq_model", is_trainable=True)
+
+ # TODO sanity check: model is quantized
+
+ torch.manual_seed(0)
+ logits_loftq = self.get_logits(loftq_model, inputs)
+ del loftq_model
+ clear_device_cache(garbage_collection=True)
+
+ mae_quantized = torch.abs(logits_base - logits_quantized).mean()
+ mse_quantized = torch.pow(logits_base - logits_quantized, 2).mean()
+ mae_loftq = torch.abs(logits_base - logits_loftq).mean()
+ mse_loftq = torch.pow(logits_base - logits_loftq, 2).mean()
+ return mae_quantized, mse_quantized, mae_loftq, mse_loftq
+
+ @pytest.mark.parametrize("device", [torch_device, "cpu"])
+ def test_bloomz_loftq_4bit(self, device, tmp_path):
+ # In this test, we compare the logits of the base model, the quantized LoRA model, and the quantized model
+ # using LoftQ. When quantizing, we expect a certain level of error. However, we expect the LoftQ quantized
+ # model to have less error than the normal LoRA quantized model. Note that when using normal LoRA, the
+ # quantization error is simply the error from quantization without LoRA, as LoRA is a no-op before training.
+ # We still apply LoRA for the test for consistency.
+
+ mae_quantized, mse_quantized, mae_loftq, mse_loftq = self.get_errors(bits=4, device=device, tmp_path=tmp_path)
+ # first, sanity check that all errors are > 0.0
+ assert mae_quantized > 0.0
+ assert mse_quantized > 0.0
+ assert mae_loftq > 0.0
+ assert mse_loftq > 0.0
+
+ # next, check that LoftQ quantization errors are smaller than LoRA errors by a certain margin
+ assert mse_loftq < (mse_quantized / self.error_factor)
+ assert mae_loftq < (mae_quantized / self.error_factor)
+
+ @pytest.mark.parametrize("device", [torch_device, "cpu"])
+ def test_bloomz_loftq_4bit_iter_5(self, device, tmp_path):
+ # Same test as the previous one but with 5 iterations. We should expect the error to be even smaller with more
+ # iterations, but in practice the difference is not that large, at least not for this small base model.
+ mae_quantized, mse_quantized, mae_loftq, mse_loftq = self.get_errors(
+ bits=4, loftq_iter=5, device=device, tmp_path=tmp_path
+ )
+ # first, sanity check that all errors are > 0.0
+ assert mae_quantized > 0.0
+ assert mse_quantized > 0.0
+ assert mae_loftq > 0.0
+ assert mse_loftq > 0.0
+
+ # next, check that LoftQ quantization errors are smaller than LoRA errors by a certain margin
+ assert mse_loftq < (mse_quantized / self.error_factor)
+ assert mae_loftq < (mae_quantized / self.error_factor)
+
+ @pytest.mark.parametrize("device", [torch_device, "cpu"])
+ def test_bloomz_loftq_8bit(self, device, tmp_path):
+ # Same test as test_bloomz_loftq_4bit but with 8 bits.
+ mae_quantized, mse_quantized, mae_loftq, mse_loftq = self.get_errors(bits=8, device=device, tmp_path=tmp_path)
+
+ # first, sanity check that all errors are > 0.0
+ assert mae_quantized > 0.0
+ assert mse_quantized > 0.0
+ assert mae_loftq > 0.0
+ assert mse_loftq > 0.0
+
+ # next, check that LoftQ quantization errors are smaller than LoRA errors by a certain margin
+ assert mse_loftq < (mse_quantized / self.error_factor)
+ assert mae_loftq < (mae_quantized / self.error_factor)
+
+ @pytest.mark.parametrize("device", [torch_device, "cpu"])
+ def test_bloomz_loftq_8bit_iter_5(self, device, tmp_path):
+ # Same test as test_bloomz_loftq_4bit_iter_5 but with 8 bits.
+ mae_quantized, mse_quantized, mae_loftq, mse_loftq = self.get_errors(
+ bits=8, loftq_iter=5, device=device, tmp_path=tmp_path
+ )
+
+ # first, sanity check that all errors are > 0.0
+ assert mae_quantized > 0.0
+ assert mse_quantized > 0.0
+ assert mae_loftq > 0.0
+ assert mse_loftq > 0.0
+
+ # next, check that LoftQ quantization errors are smaller than LoRA errors by a certain margin
+ assert mse_loftq < (mse_quantized / self.error_factor)
+ assert mae_loftq < (mae_quantized / self.error_factor)
+
+ @pytest.mark.parametrize("device", [torch_device, "cpu"])
+ def test_t5_loftq_4bit(self, device, tmp_path):
+ mae_quantized, mse_quantized, mae_loftq, mse_loftq = self.get_errors(
+ bits=4, device=device, model_id="t5-small", tmp_path=tmp_path
+ )
+ # first, sanity check that all errors are > 0.0
+ assert mae_quantized > 0.0
+ assert mse_quantized > 0.0
+ assert mae_loftq > 0.0
+ assert mse_loftq > 0.0
+
+ # next, check that LoftQ quantization errors are smaller than LoRA errors by a certain margin
+ assert mse_loftq < (mse_quantized / self.error_factor)
+ assert mae_loftq < (mae_quantized / self.error_factor)
+
+ @pytest.mark.parametrize("device", [torch_device, "cpu"])
+ def test_t5_loftq_8bit(self, device, tmp_path):
+ mae_quantized, mse_quantized, mae_loftq, mse_loftq = self.get_errors(
+ bits=8, device=device, model_id="t5-small", tmp_path=tmp_path
+ )
+ # first, sanity check that all errors are > 0.0
+ assert mae_quantized > 0.0
+ assert mse_quantized > 0.0
+ assert mae_loftq > 0.0
+ assert mse_loftq > 0.0
+
+ # next, check that LoftQ quantization errors are smaller than LoRA errors by a certain margin
+ assert mse_loftq < (mse_quantized / self.error_factor)
+ assert mae_loftq < (mae_quantized / self.error_factor)
+
+ @pytest.mark.xfail # failing for now, but having DoRA pass is only a nice-to-have, not a must, so we're good
+ @pytest.mark.parametrize("device", [torch_device, "cpu"])
+ def test_bloomz_loftq_4bit_dora(self, device, tmp_path):
+ # same as test_bloomz_loftq_4bit but with DoRA
+ mae_quantized, mse_quantized, mae_loftq, mse_loftq = self.get_errors(
+ bits=4, device=device, use_dora=True, tmp_path=tmp_path
+ )
+ # first, sanity check that all errors are > 0.0
+ assert mae_quantized > 0.0
+ assert mse_quantized > 0.0
+ assert mae_loftq > 0.0
+ assert mse_loftq > 0.0
+
+ # next, check that LoftQ quantization errors are smaller than LoRA errors by a certain margin
+ factor = 3
+ assert mae_loftq < (mae_quantized / factor)
+ assert mse_loftq < (mse_quantized / factor)
+
+ @pytest.mark.parametrize("device", [torch_device, "cpu"])
+ def test_bloomz_loftq_8bit_dora(self, device, tmp_path):
+ # same as test_bloomz_loftq_8bit but with DoRA
+ mae_quantized, mse_quantized, mae_loftq, mse_loftq = self.get_errors(
+ bits=8, device=device, use_dora=True, tmp_path=tmp_path
+ )
+
+ # first, sanity check that all errors are > 0.0
+ assert mae_quantized > 0.0
+ assert mse_quantized > 0.0
+ assert mae_loftq > 0.0
+ assert mse_loftq > 0.0
+
+ # next, check that LoftQ quantization errors are smaller than LoRA errors by a certain margin
+ assert mae_loftq < (mae_quantized / self.error_factor)
+ assert mse_loftq < (mse_quantized / self.error_factor)
+
+ def test_replace_lora_weights_with_loftq_using_callable(self):
+ """
+ Test replacing LoRa weights with LoFTQ using a callable.
+
+ Using the replace_lora_weights_loftq function, we replace the LoRa weights of a bnb-quantized model with LoRA
+ weights initialized by LoftQ on the fly. We use a callable to decide whether to replace the weights or not.
+ This callable checks, for each weight, if replacing it would actually result in logits that are closer to the
+ original logits of the non-quantized model.
+
+ """
+ torch.manual_seed(0)
+ model_id = "bigscience/bloomz-560m"
+ device = torch_device
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ inputs = tokenizer("The dog was", padding=True, return_tensors="pt").to(device)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(model_id).to(device)
+ logits_base = model(**inputs).logits
+ model.save_pretrained(tmp_dir)
+
+ # load in 4bit
+ bnb_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_use_double_quant=True,
+ )
+ model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=bnb_config)
+ model = get_peft_model(model, LoraConfig(task_type="CAUSAL_LM", target_modules="all-linear"))
+ logits_lora = model(**inputs).logits
+
+ current_mse = float("inf")
+ logs = []
+
+ def my_callback(model, module_name):
+ """Callable to replace weights with LoFTQ if the mse is lower than the current best one."""
+ nonlocal current_mse
+
+ logits = model(**inputs).logits
+ mse = ((logits_base - logits) ** 2).mean()
+ if mse < current_mse:
+ current_mse = mse
+ logs.append(True)
+ return True
+ logs.append(False)
+ return False
+
+ replace_lora_weights_loftq(model, model_path=tmp_dir, callback=my_callback)
+ logits_loftq = model(**inputs).logits
+
+ mae_lora = (logits_base - logits_lora).abs().mean()
+ mae_loftq = (logits_base - logits_loftq).abs().mean()
+ mse_lora = ((logits_base - logits_lora) ** 2).mean()
+ mse_loftq = ((logits_base - logits_loftq) ** 2).mean()
+
+ # check that the error was reduced by a certain margin
+ assert mae_loftq * 1.5 < mae_lora
+ assert mse_loftq * 2.5 < mse_lora
+
+ # check that the callback has returned some True and some False values
+ assert any(logs)
+ assert not all(logs)
+
+ del model
+ clear_device_cache(garbage_collection=True)
+
+ def test_replace_lora_weights_with_local_model(self):
+ # see issue 2020
+ torch.manual_seed(0)
+ model_id = "hf-internal-testing/tiny-random-OPTForCausalLM"
+ device = torch_device
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ # save base model locally
+ model = AutoModelForCausalLM.from_pretrained(model_id).to(device)
+ model.save_pretrained(tmp_dir)
+ del model
+
+ # load in 4bit
+ bnb_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_use_double_quant=True,
+ )
+
+ # load the base model from local directory
+ model = AutoModelForCausalLM.from_pretrained(tmp_dir, quantization_config=bnb_config)
+ model = get_peft_model(model, LoraConfig())
+
+ # passing the local path directly works
+ replace_lora_weights_loftq(model, model_path=tmp_dir)
+ del model
+
+ # load the base model from local directory
+ model = AutoModelForCausalLM.from_pretrained(tmp_dir, quantization_config=bnb_config)
+ model = get_peft_model(model, LoraConfig())
+
+ # when not passing, ensure that users are made aware of the `model_path` argument
+ with pytest.raises(ValueError, match="model_path"):
+ replace_lora_weights_loftq(model)
+
+ del model
+ clear_device_cache(garbage_collection=True)
+
+ def test_config_no_loftq_init(self):
+ with pytest.warns(
+ UserWarning,
+ match="`loftq_config` specified but will be ignored when `init_lora_weights` is not 'loftq'.",
+ ):
+ LoraConfig(loftq_config=LoftQConfig())
+
+ def test_config_no_loftq_config(self):
+ with pytest.raises(ValueError, match="`loftq_config` must be specified when `init_lora_weights` is 'loftq'."):
+ LoraConfig(init_lora_weights="loftq")
+
+
+@require_bitsandbytes
+@require_non_cpu
+class MultiprocessTester(unittest.TestCase):
+ def test_notebook_launcher(self):
+ script_path = os.path.join("scripts", "launch_notebook_mp.py")
+ cmd = ["python", script_path]
+ with patch_environment(omp_num_threads=1):
+ run_command(cmd, env=os.environ.copy())
+
+
+@require_non_cpu
+class MixedPrecisionTests(unittest.TestCase):
+ def setUp(self):
+ self.causal_lm_model_id = "facebook/opt-125m"
+ self.tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ self.config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ task_type="CAUSAL_LM",
+ )
+
+ data = load_dataset_english_quotes()
+ self.data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ def tearDown(self):
+ r"""
+ Efficient mechanism to free GPU memory after each test. Based on
+ https://github.com/huggingface/transformers/issues/21094
+ """
+ clear_device_cache(garbage_collection=True)
+ gc.collect()
+
+ @pytest.mark.single_gpu_tests
+ def test_model_using_float16_with_amp_raises(self):
+ # This test shows the issue with using a model in fp16 and then trying to use it with mixed precision training,
+ # which should not use fp16.
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ )
+ model = get_peft_model(model, self.config, autocast_adapter_dtype=False)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ trainer = Trainer(
+ model=model,
+ train_dataset=self.data["train"],
+ args=TrainingArguments(
+ fp16=True, # <= this is required for the error to be raised
+ output_dir=tmp_dir,
+ max_steps=3,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ with pytest.raises(ValueError, match="Attempting to unscale FP16 gradients."):
+ trainer.train()
+
+ @pytest.mark.single_gpu_tests
+ def test_model_using_float16_autocast_dtype(self):
+ # Here we use autocast_adapter_dtype=True (the default) to automatically promote the adapter weights to float32.
+ # No exception should be raised.
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ )
+ model = get_peft_model(model, self.config, autocast_adapter_dtype=True)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ trainer = Trainer(
+ model=model,
+ train_dataset=self.data["train"],
+ args=TrainingArguments(
+ fp16=True, # <= this is required for the error to be raised
+ output_dir=tmp_dir,
+ max_steps=3,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ trainer.train() # does not raise
+
+ @pytest.mark.single_gpu_tests
+ def test_model_using_float16_explicit_cast(self):
+ # Same test as above but containing the fix to make it work
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ )
+ model = get_peft_model(model, self.config, autocast_adapter_dtype=False)
+
+ # here we manually promote the adapter weights to float32
+ for param in model.parameters():
+ if param.requires_grad:
+ param.data = param.data.float()
+
+ dtype_counts_before = Counter(p.dtype for p in model.parameters())
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ )
+
+ model = get_peft_model(model, self.config, autocast_adapter_dtype=True)
+ dtype_counts_after = Counter(p.dtype for p in model.parameters())
+ assert dtype_counts_before == dtype_counts_after
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ trainer = Trainer(
+ model=model,
+ train_dataset=self.data["train"],
+ args=TrainingArguments(
+ fp16=True, # <= this is required for the error to be raised
+ max_steps=3,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ trainer.train() # does not raise
+
+ @pytest.mark.single_gpu_tests
+ def test_load_model_using_float16_with_amp_raises(self):
+ # Same as previous tests, but loading the adapter with PeftModel.from_pretrained instead
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ )
+ model = get_peft_model(model, self.config, autocast_adapter_dtype=False)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir)
+ model = AutoModelForCausalLM.from_pretrained(self.causal_lm_model_id, torch_dtype=torch.float16)
+ model = PeftModel.from_pretrained(model, tmp_dir, autocast_adapter_dtype=False, is_trainable=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=self.data["train"],
+ args=TrainingArguments(
+ fp16=True, # <= this is required for the error to be raised
+ output_dir=tmp_dir,
+ max_steps=3,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ with pytest.raises(ValueError, match="Attempting to unscale FP16 gradients."):
+ trainer.train()
+
+ @pytest.mark.single_gpu_tests
+ def test_load_model_using_float16_autocast_dtype(self):
+ # Same as previous tests, but loading the adapter with PeftModel.from_pretrained instead
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ )
+ # Below, we purposefully set autocast_adapter_dtype=False so that the saved adapter uses float16. We still want
+ # the loaded adapter to use float32 when we load it with autocast_adapter_dtype=True.
+ model = get_peft_model(model, self.config, autocast_adapter_dtype=False)
+ # sanity check: this should have float16 adapter weights:
+ assert (
+ model.base_model.model.model.decoder.layers[0].self_attn.v_proj.lora_A["default"].weight.dtype
+ == torch.float16
+ )
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir)
+ model = AutoModelForCausalLM.from_pretrained(self.causal_lm_model_id, torch_dtype=torch.float16)
+ model = PeftModel.from_pretrained(model, tmp_dir, autocast_adapter_dtype=True, is_trainable=True)
+ # sanity check: this should NOT have float16 adapter weights:
+ assert (
+ model.base_model.model.model.decoder.layers[0].self_attn.v_proj.lora_A["default"].weight.dtype
+ == torch.float32
+ )
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=self.data["train"],
+ args=TrainingArguments(
+ fp16=True, # <= this is required for the error to be raised
+ output_dir=tmp_dir,
+ max_steps=3,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ trainer.train() # does not raise
+
+ @pytest.mark.single_gpu_tests
+ def test_load_adapter_using_float16_autocast_dtype(self):
+ # Here we test the load_adapter method with autocast_adapter_dtype. We show that autocasting is prevented when
+ # calling load_model(..., autocast_adapter_dtype=False) and that it is enabled when calling
+ # load_model(..., autocast_adapter_dtype=True) (the default).
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ torch_dtype=torch.float16,
+ )
+ # Below, we purposefully set autocast_adapter_dtype=False so that the saved adapter uses float16. We still want
+ # the loaded adapter to use float32 when we load it with autocast_adapter_dtype=True.
+ model = get_peft_model(model, self.config, autocast_adapter_dtype=False)
+ # sanity check: this should have float16 adapter weights:
+ assert (
+ model.base_model.model.model.decoder.layers[0].self_attn.v_proj.lora_A["default"].weight.dtype
+ == torch.float16
+ )
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir)
+ model = AutoModelForCausalLM.from_pretrained(self.causal_lm_model_id, torch_dtype=torch.float16)
+ # the default adapter is now in float16
+ model = get_peft_model(model, self.config, autocast_adapter_dtype=False)
+ # sanity check: this should NOT have float16 adapter weights:
+ assert (
+ model.base_model.model.model.decoder.layers[0].self_attn.v_proj.lora_A["default"].weight.dtype
+ == torch.float16
+ )
+
+ # now load the first adapter in float16 using the adapter name "loaded16"
+ model.load_adapter(tmp_dir, "loaded16", autocast_adapter_dtype=False)
+ assert (
+ model.base_model.model.model.decoder.layers[0].self_attn.v_proj.lora_A["loaded16"].weight.dtype
+ == torch.float16
+ )
+
+ # now load the first adapter in float32 using the adapter name "loaded32"
+ model.load_adapter(tmp_dir, "loaded32", autocast_adapter_dtype=True)
+ assert (
+ model.base_model.model.model.decoder.layers[0].self_attn.v_proj.lora_A["loaded32"].weight.dtype
+ == torch.float32
+ )
+
+ # training with the default adapter, which is in float16, should raise
+ model.set_adapter("default")
+ trainer = Trainer(
+ model=model,
+ train_dataset=self.data["train"],
+ args=TrainingArguments(
+ fp16=True, # <= this is required for the error to be raised
+ output_dir=tmp_dir,
+ max_steps=3,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ with pytest.raises(ValueError, match="Attempting to unscale FP16 gradients."):
+ trainer.train()
+
+ # training the model with the adapter "loaded16", which is in float16, should also raise
+ model.set_adapter("loaded16")
+ trainer = Trainer(
+ model=model,
+ train_dataset=self.data["train"],
+ args=TrainingArguments(
+ fp16=True, # <= this is required for the error to be raised
+ output_dir=tmp_dir,
+ max_steps=3,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ with pytest.raises(ValueError, match="Attempting to unscale FP16 gradients."):
+ trainer.train()
+
+ # training the model with the adapter "loaded32", which is in float32, should not raise
+ model.set_adapter("loaded32")
+ trainer = Trainer(
+ model=model,
+ train_dataset=self.data["train"],
+ args=TrainingArguments(
+ fp16=True, # <= this is required for the error to be raised
+ output_dir=tmp_dir,
+ max_steps=3,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ trainer.train() # does not raise
+
+
+@require_non_xpu
+@require_torch_gpu
+@require_aqlm
+@unittest.skipUnless(
+ version.parse(importlib.metadata.version("transformers")) >= version.parse("4.38.0"),
+ "test requires `transformers>=4.38.0`",
+)
+class PeftAqlmGPUTests(unittest.TestCase):
+ r"""
+ AQLM + peft tests
+ """
+
+ def setUp(self):
+ self.causal_lm_model_id = "BlackSamorez/TinyLlama-1_1B-Chat-v1_0-AQLM-2Bit-1x16-hf"
+ self.tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+
+ def tearDown(self):
+ r"""
+ Efficient mechanism to free GPU memory after each test. Based on
+ https://github.com/huggingface/transformers/issues/21094
+ """
+ clear_device_cache(garbage_collection=True)
+
+ def _check_inference_finite(self, model, batch):
+ # try inference without Trainer class
+ training = model.training
+ model.eval()
+ output = model(**batch.to(model.device))
+ assert torch.isfinite(output.logits).all()
+ model.train(training)
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training_aqlm(self):
+ r"""
+ Test the CausalLM training on a single GPU device. The test would simply fail if the adapters are not set
+ correctly.
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map="cuda",
+ torch_dtype="auto",
+ )
+
+ model = prepare_model_for_kbit_training(model)
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ fp16=True,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+
+@require_non_xpu
+@require_torch_gpu
+@require_hqq
+@unittest.skipUnless(
+ version.parse(importlib.metadata.version("transformers")) >= version.parse("4.36.1"),
+ "test requires `transformers>=4.36.1`",
+)
+class PeftHqqGPUTests(unittest.TestCase):
+ r"""
+ HQQ + peft tests
+ """
+
+ def setUp(self):
+ self.causal_lm_model_id = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
+ self.tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+
+ def tearDown(self):
+ r"""
+ Efficient mechanism to free GPU memory after each test. Based on
+ https://github.com/huggingface/transformers/issues/21094
+ """
+ clear_device_cache(garbage_collection=True)
+
+ @pytest.mark.single_gpu_tests
+ @parameterized.expand([False, True])
+ def test_causal_lm_training_hqq(self, use_dora):
+ r"""
+ Test the CausalLM training on a single GPU device. The test would simply fail if the adapters are not set
+ correctly.
+ """
+
+ from transformers import HqqConfig
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ device = "cuda"
+ compute_dtype = torch.float16
+
+ quant_config = HqqConfig(nbits=4, group_size=64)
+
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map=device,
+ torch_dtype=compute_dtype,
+ quantization_config=quant_config,
+ )
+
+ model = prepare_model_for_kbit_training(model)
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ use_dora=use_dora,
+ )
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ fp16=True,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ def test_hqq_lora_model_outputs(self):
+ # check that the outputs generated by HQQ with LoRA are similar to those without HQQ
+ from transformers import HqqConfig
+
+ device = "cuda"
+ compute_dtype = torch.float16
+ min_correlation = 0.96
+
+ # first load the model without HQQ
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map=device,
+ torch_dtype=compute_dtype,
+ )
+ config = LoraConfig(
+ target_modules=["q_proj", "v_proj"],
+ task_type="CAUSAL_LM",
+ init_lora_weights=False,
+ )
+ torch.manual_seed(0)
+ model = get_peft_model(model, config).eval()
+ inputs = self.tokenizer("The meaning of unit tests is", return_tensors="pt").to(model.device)
+
+ with torch.inference_mode():
+ output_normal = model(**inputs).logits
+ assert torch.isfinite(output_normal).all()
+
+ del model
+ clear_device_cache(garbage_collection=True)
+
+ # now load with HQQ
+ quant_config = HqqConfig(nbits=4, group_size=64)
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map=device,
+ torch_dtype=compute_dtype,
+ quantization_config=quant_config,
+ )
+ torch.manual_seed(0)
+ model = get_peft_model(model, config).eval()
+ with torch.inference_mode():
+ output_hqq = model(**inputs).logits
+
+ # check that outputs of HQQ are highly correlated; there are outliers, so don't check for equality
+ cc_matrix = torch.corrcoef(torch.stack((output_normal.float().flatten(), output_hqq.float().flatten())))
+ assert cc_matrix.min() > min_correlation
+
+ # check that outputs are the same after merging
+ cc_matrix = torch.corrcoef(torch.stack((output_normal.float().flatten(), output_hqq.float().flatten())))
+ assert cc_matrix.min() > min_correlation
+
+ # check outputs are the same after unmerging
+ model.unmerge_adapter()
+ with torch.inference_mode():
+ output_unmerged = model(**inputs).logits
+ cc_matrix = torch.corrcoef(torch.stack((output_normal.float().flatten(), output_unmerged.float().flatten())))
+ assert cc_matrix.min() > min_correlation
+
+ # check that the results are the same after saving and loading
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir)
+ del model
+ clear_device_cache(garbage_collection=True)
+
+ quant_config = HqqConfig(nbits=4, group_size=64)
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map=device,
+ torch_dtype=compute_dtype,
+ quantization_config=quant_config,
+ )
+ model = PeftModel.from_pretrained(model, tmp_dir)
+ with torch.inference_mode():
+ output_loaded = model(**inputs).logits
+
+ # for loading, we expect high precision, so check for equality and not just correlation
+ atol, rtol = 1e-6, 1e-6
+ assert torch.allclose(output_hqq, output_loaded, atol=atol, rtol=rtol)
+
+ # check that outputs are the same after merge_and_unload
+ model = model.merge_and_unload()
+ with torch.inference_mode():
+ output_merged_unloaded = model(**inputs).logits
+ cc_matrix = torch.corrcoef(
+ torch.stack((output_normal.float().flatten(), output_merged_unloaded.float().flatten()))
+ )
+ assert cc_matrix.min() > min_correlation
+
+
+@require_non_cpu
+@require_auto_awq
+class PeftAwqGPUTests(unittest.TestCase):
+ r"""
+ Awq + peft tests
+ """
+
+ def setUp(self):
+ self.causal_lm_model_id = "peft-internal-testing/opt-125m-awq"
+ self.tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+
+ def tearDown(self):
+ r"""
+ Efficient mechanism to free accelerator memory after each test. Based on
+ https://github.com/huggingface/transformers/issues/21094
+ """
+ clear_device_cache(garbage_collection=True)
+
+ def _check_inference_finite(self, model, batch):
+ # try inference without Trainer class
+ training = model.training
+ model.eval()
+ output = model(**batch.to(model.device))
+ assert torch.isfinite(output.logits).all()
+ model.train(training)
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training_awq(self):
+ r"""
+ Test the CausalLM training on a single accelerator. The test would simply fail if the adapters are not set
+ correctly.
+ """
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map="auto",
+ )
+
+ model = prepare_model_for_kbit_training(model)
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ # TODO: deal correctly with this case in transformers
+ model._is_quantized_training_enabled = True
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ fp16=True,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.multi_gpu_tests
+ # TODO remove marker if/once issue is resolved, most likely requiring a fix in AutoAWQ:
+ # https://github.com/casper-hansen/AutoAWQ/issues/754
+ @pytest.mark.xfail(
+ condition=is_torch_version("==", "2.7.0") or is_torch_version("==", "2.7.1"),
+ reason="Multi-GPU test currently not working with AutoAWQ and PyTorch 2.7",
+ strict=True,
+ )
+ @require_torch_multi_accelerator
+ def test_causal_lm_training_multi_accelerator(self):
+ r"""
+ Test the CausalLM training on a multi-accelerator device. The test would simply fail if the adapters are not
+ set correctly.
+ """
+ device_map = {
+ "model.decoder.embed_tokens": 0,
+ "lm_head": 0,
+ "model.decoder.embed_positions": 0,
+ "model.decoder.project_out": 0,
+ "model.decoder.project_in": 0,
+ "model.decoder.layers.0": 0,
+ "model.decoder.layers.1": 0,
+ "model.decoder.layers.2": 0,
+ "model.decoder.layers.3": 0,
+ "model.decoder.layers.4": 0,
+ "model.decoder.layers.5": 0,
+ "model.decoder.layers.6": 1,
+ "model.decoder.layers.7": 1,
+ "model.decoder.layers.8": 1,
+ "model.decoder.layers.9": 1,
+ "model.decoder.layers.10": 1,
+ "model.decoder.layers.11": 1,
+ "model.decoder.final_layer_norm": 1,
+ }
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map=device_map,
+ )
+
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+ assert {p.device.index for p in model.parameters()} == set(range(device_count))
+
+ model = prepare_model_for_kbit_training(model)
+
+ setattr(model, "model_parallel", True)
+ setattr(model, "is_parallelizable", True)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+
+@require_non_xpu
+@require_torch_gpu
+@require_eetq
+class PeftEetqGPUTests(unittest.TestCase):
+ r"""
+ EETQ + peft tests
+ """
+
+ def setUp(self):
+ self.causal_lm_model_id = "facebook/opt-125m"
+ self.tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+
+ def tearDown(self):
+ r"""
+ Efficient mechanism to free GPU memory after each test. Based on
+ https://github.com/huggingface/transformers/issues/21094
+ """
+ clear_device_cache(garbage_collection=True)
+
+ def _check_inference_finite(self, model, batch):
+ # try inference without Trainer class
+ training = model.training
+ model.eval()
+ output = model(**batch.to(model.device))
+ assert torch.isfinite(output.logits).all()
+ model.train(training)
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training_eetq(self):
+ r"""
+ Test the CausalLM training on a single GPU device. The test would simply fail if the adapters are not set
+ correctly.
+ """
+ from transformers import EetqConfig
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ quantization_config = EetqConfig("int8")
+
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id, device_map="auto", quantization_config=quantization_config
+ )
+
+ model = prepare_model_for_kbit_training(model)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.multi_gpu_tests
+ @require_torch_multi_gpu
+ def test_causal_lm_training_multi_gpu_eetq(self):
+ r"""
+ Test the CausalLM training on a multi-GPU device. The test would simply fail if the adapters are not set
+ correctly.
+ """
+ from transformers import EetqConfig
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ quantization_config = EetqConfig("int8")
+
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map=DEVICE_MAP_MAP[self.causal_lm_model_id],
+ quantization_config=quantization_config,
+ )
+
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+ assert {p.device.index for p in model.parameters()} == set(range(device_count))
+
+ model = prepare_model_for_kbit_training(model)
+
+ setattr(model, "model_parallel", True)
+ setattr(model, "is_parallelizable", True)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+ trainer.train()
+
+ model.cpu().save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+
+@require_non_cpu
+@require_torchao
+class PeftTorchaoGPUTests(unittest.TestCase):
+ r"""
+ torchao + peft tests
+ """
+
+ supported_quant_types = [
+ "int8_weight_only",
+ "int8_dynamic_activation_int8_weight",
+ # int4_weight_only raises an error:
+ # RuntimeError: derivative for aten::_weight_int4pack_mm is not implemented
+ # "int4_weight_only",
+ ]
+
+ def setUp(self):
+ self.causal_lm_model_id = "facebook/opt-125m"
+ self.tokenizer = AutoTokenizer.from_pretrained(self.causal_lm_model_id)
+ # torchao breaks with fp16 and if a previous test uses fp16, transformers will set this env var, which affects
+ # subsequent tests, therefore the env var needs to be cleared explicitly
+ #
+ # TODO: remove this once https://github.com/huggingface/transformers/pull/37259 is merged
+ os.environ.pop("ACCELERATE_MIXED_PRECISION", None)
+
+ def tearDown(self):
+ r"""
+ Efficient mechanism to free GPU memory after each test. Based on
+ https://github.com/huggingface/transformers/issues/21094
+ """
+ clear_device_cache(garbage_collection=True)
+
+ @parameterized.expand(supported_quant_types)
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training_single_gpu_torchao(self, quant_type):
+ from transformers import TorchAoConfig
+
+ device = 0
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ quantization_config = TorchAoConfig(quant_type=quant_type)
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id, device_map=device, quantization_config=quantization_config
+ )
+ model = prepare_model_for_kbit_training(model)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ trainer.model.config.use_cache = False
+ trainer.train()
+
+ model.save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training_single_gpu_torchao_dora_int8_weight_only(self):
+ from transformers import TorchAoConfig
+
+ device = 0
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ quantization_config = TorchAoConfig(quant_type="int8_weight_only")
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id, device_map=device, quantization_config=quantization_config
+ )
+ model = prepare_model_for_kbit_training(model)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ use_dora=True,
+ )
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ trainer.model.config.use_cache = False
+ trainer.train()
+
+ model.save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training_single_gpu_torchao_dora_int8_dynamic_activation_int8_weight_raises(self):
+ from transformers import TorchAoConfig
+
+ device = 0
+
+ quantization_config = TorchAoConfig(quant_type="int8_dynamic_activation_int8_weight")
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id, device_map=device, quantization_config=quantization_config
+ )
+ model = prepare_model_for_kbit_training(model)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ use_dora=True,
+ )
+ with pytest.raises(NotImplementedError):
+ get_peft_model(model, config)
+
+ @pytest.mark.single_gpu_tests
+ def test_causal_lm_training_single_gpu_torchao_int4_raises(self):
+ # int4_weight_only raises an error:
+ # RuntimeError: derivative for aten::_weight_int4pack_mm is not implemented
+ # TODO: Once proper torchao support for int4 is added, remove this test and add int4 to supported_quant_types
+ from transformers import TorchAoConfig
+
+ device = 0
+
+ quantization_config = TorchAoConfig(quant_type="int4_weight_only")
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id, device_map=device, quantization_config=quantization_config
+ )
+ model = prepare_model_for_kbit_training(model)
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ msg = re.escape("TorchaoLoraLinear only supports int8 weights for now")
+ with pytest.raises(ValueError, match=msg):
+ get_peft_model(model, config)
+
+ @parameterized.expand(supported_quant_types)
+ @pytest.mark.multi_gpu_tests
+ @require_torch_multi_accelerator
+ def test_causal_lm_training_multi_accelerator_torchao(self, quant_type):
+ from transformers import TorchAoConfig
+
+ device_map = {
+ "model.decoder.embed_tokens": 0,
+ "lm_head": 0,
+ "model.decoder.embed_positions": 0,
+ "model.decoder.project_out": 0,
+ "model.decoder.project_in": 0,
+ "model.decoder.layers.0": 0,
+ "model.decoder.layers.1": 0,
+ "model.decoder.layers.2": 0,
+ "model.decoder.layers.3": 0,
+ "model.decoder.layers.4": 0,
+ "model.decoder.layers.5": 0,
+ "model.decoder.layers.6": 1,
+ "model.decoder.layers.7": 1,
+ "model.decoder.layers.8": 1,
+ "model.decoder.layers.9": 1,
+ "model.decoder.layers.10": 1,
+ "model.decoder.layers.11": 1,
+ "model.decoder.final_layer_norm": 1,
+ }
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ quantization_config = TorchAoConfig(quant_type=quant_type)
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map=device_map,
+ quantization_config=quantization_config,
+ torch_dtype=torch.bfloat16,
+ )
+
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+ assert {p.device.index for p in model.parameters()} == set(range(device_count))
+
+ model = prepare_model_for_kbit_training(model)
+ model.model_parallel = True
+ model.is_parallelizable = True
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+ model = get_peft_model(model, config)
+
+ data = load_dataset_english_quotes()
+ data = data.map(lambda samples: self.tokenizer(samples["quote"]), batched=True)
+
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=TrainingArguments(
+ per_device_train_batch_size=4,
+ gradient_accumulation_steps=4,
+ warmup_steps=2,
+ max_steps=3,
+ learning_rate=2e-4,
+ logging_steps=1,
+ output_dir=tmp_dir,
+ ),
+ data_collator=DataCollatorForLanguageModeling(self.tokenizer, mlm=False),
+ )
+ trainer.model.config.use_cache = False
+ trainer.train()
+
+ model.save_pretrained(tmp_dir)
+
+ assert "adapter_config.json" in os.listdir(tmp_dir)
+ assert SAFETENSORS_WEIGHTS_NAME in os.listdir(tmp_dir)
+
+ # assert loss is not None
+ assert trainer.state.log_history[-1]["train_loss"] is not None
+
+ @pytest.mark.multi_gpu_tests
+ @require_torch_multi_accelerator
+ def test_causal_lm_training_multi_accelerator_torchao_int4_raises(self):
+ # int4_weight_only raises an error:
+ # RuntimeError: derivative for aten::_weight_int4pack_mm is not implemented
+ # TODO: Once proper torchao support for int4 is added, remove this test and add int4 to supported_quant_types
+ from transformers import TorchAoConfig
+
+ device_map = {
+ "model.decoder.embed_tokens": 0,
+ "lm_head": 0,
+ "model.decoder.embed_positions": 0,
+ "model.decoder.project_out": 0,
+ "model.decoder.project_in": 0,
+ "model.decoder.layers.0": 0,
+ "model.decoder.layers.1": 0,
+ "model.decoder.layers.2": 0,
+ "model.decoder.layers.3": 0,
+ "model.decoder.layers.4": 0,
+ "model.decoder.layers.5": 0,
+ "model.decoder.layers.6": 1,
+ "model.decoder.layers.7": 1,
+ "model.decoder.layers.8": 1,
+ "model.decoder.layers.9": 1,
+ "model.decoder.layers.10": 1,
+ "model.decoder.layers.11": 1,
+ "model.decoder.final_layer_norm": 1,
+ }
+ quantization_config = TorchAoConfig(quant_type="int4_weight_only")
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id,
+ device_map=device_map,
+ quantization_config=quantization_config,
+ torch_dtype=torch.bfloat16,
+ )
+
+ assert set(model.hf_device_map.values()) == set(range(device_count))
+ assert {p.device.index for p in model.parameters()} == set(range(device_count))
+
+ model = prepare_model_for_kbit_training(model)
+ model.model_parallel = True
+ model.is_parallelizable = True
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ )
+
+ msg = re.escape("TorchaoLoraLinear only supports int8 weights for now")
+ with pytest.raises(ValueError, match=msg):
+ get_peft_model(model, config)
+
+ @pytest.mark.single_gpu_tests
+ def test_torchao_merge_layers_int8_weight_only(self):
+ from torchao.dtypes import AffineQuantizedTensor
+ from transformers import TorchAoConfig
+
+ quant_type = "int8_weight_only"
+ torch.manual_seed(0)
+ device = 0
+ dummy_input = torch.arange(10).view(-1, 1).to(device)
+
+ quantization_config = TorchAoConfig(quant_type=quant_type)
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id, device_map=device, quantization_config=quantization_config
+ ).eval()
+ logits_base = model(dummy_input)[0]
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ init_lora_weights=False,
+ )
+ model = get_peft_model(model, config)
+
+ model.eval()
+ logits = model(dummy_input)[0]
+
+ # sanity check: outputs changed
+ # precision is quite low, so we need to use high atol and rtol
+ atol, rtol = 1e-1, 1e-1
+ assert not torch.allclose(logits, logits_base, atol=atol, rtol=rtol)
+
+ model.merge_adapter()
+ logits_merged = model(dummy_input)[0]
+ for name, module in model.named_modules():
+ if "base_layer" in name:
+ assert isinstance(module.weight, AffineQuantizedTensor)
+
+ model.unmerge_adapter()
+ logits_unmerged = model(dummy_input)[0]
+ for name, module in model.named_modules():
+ if "base_layer" in name:
+ assert isinstance(module.weight, AffineQuantizedTensor)
+
+ model = model.merge_and_unload()
+ logits_merged_unloaded = model(dummy_input)[0]
+
+ assert torch.allclose(logits, logits_merged, atol=atol, rtol=rtol)
+ assert torch.allclose(logits, logits_unmerged, atol=atol, rtol=rtol)
+ assert torch.allclose(logits, logits_merged_unloaded, atol=atol, rtol=rtol)
+
+ @pytest.mark.single_gpu_tests
+ def test_torchao_merge_layers_int8_dynamic_activation_int8_weight_raises(self):
+ # int8_dynamic_activation_int8_weight does not support dequantize, thus merging does not work
+ from transformers import TorchAoConfig
+
+ quant_type = "int8_dynamic_activation_int8_weight"
+ torch.manual_seed(0)
+ device = 0
+
+ quantization_config = TorchAoConfig(quant_type=quant_type)
+ model = AutoModelForCausalLM.from_pretrained(
+ self.causal_lm_model_id, device_map=device, quantization_config=quantization_config
+ ).eval()
+
+ config = LoraConfig(
+ r=16,
+ lora_alpha=32,
+ target_modules=["q_proj", "v_proj"],
+ lora_dropout=0.05,
+ bias="none",
+ task_type="CAUSAL_LM",
+ init_lora_weights=False,
+ )
+ model = get_peft_model(model, config)
+
+ msg = re.escape(
+ "Weights of type LinearActivationQuantizedTensor do not support dequantization (yet), which is needed to "
+ "support merging."
+ )
+ with pytest.raises(NotImplementedError, match=msg):
+ model.merge_adapter()
+
+
+PRECISIONS = [(torch.float32), (torch.float16), (torch.bfloat16)]
+
+LORA_PARAMS = {
+ "r": 8,
+ "lora_alpha": 16,
+ "lora_dropout": 0.05,
+}
+
+
+class SimpleModel(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.embedding_layer = torch.nn.Embedding(1000, 768)
+ self.layer_norm = torch.nn.LayerNorm(768)
+ self.linear_transform = torch.nn.Linear(768, 256)
+
+ def forward(self, input_ids):
+ embedded_output = self.embedding_layer(input_ids)
+ norm_output = self.layer_norm(embedded_output)
+ linear_output = self.linear_transform(norm_output)
+
+ return linear_output
+
+
+class SimpleConv2DModel(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ self.embedding_layer = torch.nn.Embedding(1000, 768)
+ self.layer_norm = torch.nn.LayerNorm(768)
+ self.conv2d_transform = torch.nn.Conv2d(1, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
+
+ def forward(self, input_ids):
+ # Additional layers for your custom model
+ embedded_output = self.embedding_layer(input_ids)
+ norm_output = self.layer_norm(embedded_output)
+
+ # Reshape for Conv2d input (add batch size dimension)
+ norm_output = norm_output.unsqueeze(1)
+ conv_output = self.conv2d_transform(norm_output)
+
+ # Remove batch size dimension
+ conv_output = conv_output.squeeze(1)
+
+ return conv_output
+
+
+@require_non_cpu
+class TestAutoCast(unittest.TestCase):
+ device = infer_device()
+
+ # This test makes sure, that Lora dtypes are consistent with the types
+ # infered by torch.autocast under tested PRECISIONS
+ @parameterized.expand(PRECISIONS)
+ def test_simple_model(self, *args, **kwargs):
+ self._test_model(SimpleModel(), *args, **kwargs)
+
+ @parameterized.expand(PRECISIONS)
+ def test_simple_lora_linear_model(self, *args, **kwargs):
+ simple_model = SimpleModel()
+ config = LoraConfig(
+ **LORA_PARAMS,
+ target_modules=["linear_transform"],
+ )
+
+ lora_model = get_peft_model(simple_model, config)
+
+ self._test_model(lora_model, *args, **kwargs)
+
+ @parameterized.expand(PRECISIONS)
+ def test_simple_lora_embedding_model(self, *args, **kwargs):
+ simple_model = SimpleModel()
+ config = LoraConfig(
+ **LORA_PARAMS,
+ target_modules=["embedding_layer"],
+ )
+ lora_model = get_peft_model(simple_model, config)
+
+ self._test_model(lora_model, *args, **kwargs)
+
+ @parameterized.expand(PRECISIONS)
+ def test_simple_conv2d_model(self, *args, **kwargs):
+ self._test_model(SimpleConv2DModel(), *args, **kwargs)
+
+ @parameterized.expand(PRECISIONS)
+ def test_simple_lora_conv2d_model(self, *args, **kwargs):
+ simple_model = SimpleConv2DModel()
+ config = LoraConfig(
+ **LORA_PARAMS,
+ target_modules=["conv2d_transform"],
+ )
+ lora_model = get_peft_model(simple_model, config)
+ self._test_model(lora_model, *args, **kwargs)
+
+ def _test_model(self, model, precision):
+ # Move model to GPU
+ model = model.to(self.device)
+
+ # Prepare dummy inputs
+ input_ids = torch.randint(0, 1000, (2, 10)).to(self.device)
+ if precision == torch.bfloat16:
+ if not is_bf16_available():
+ self.skipTest("Bfloat16 not supported on this device")
+
+ # Forward pass with test precision
+ with torch.autocast(enabled=True, dtype=precision, device_type=self.device):
+ outputs = model(input_ids)
+ assert outputs.dtype == precision
+
+
+class TestFSDPWrap:
+ """
+ Test that we can successfully initialize an FSDP instance of the module.
+
+ This is a very simple test, as it does not perform actual FSDP training. Here we just ensure that the FSDP instance
+ can be created. This can fail for several reasons, e.g. int dtype from BNB or inconsistent requires_grad settings
+ due to the auto wrap policy.
+
+ """
+
+ @pytest.mark.single_gpu_tests
+ @require_bitsandbytes
+ def test_bnb_4bit_wrap_fsdp(self):
+ quant_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ # float32 must be used, or else FSDP will complain about mixed int and float dtypes
+ bnb_4bit_compute_dtype=torch.float32,
+ bnb_4bit_quant_storage=torch.float32,
+ bnb_4bit_use_double_quant=True,
+ )
+ model = AutoModelForCausalLM.from_pretrained(
+ "facebook/opt-125m",
+ quantization_config=quant_config,
+ torch_dtype=torch.float32,
+ )
+ # model = prepare_model_for_kbit_training(model)
+ config = LoraConfig(
+ target_modules=["q_proj", "v_proj"],
+ task_type="CAUSAL_LM",
+ use_dora=True,
+ )
+ model = get_peft_model(model, config)
+
+ os.environ["MASTER_ADDR"] = "localhost"
+ os.environ["MASTER_PORT"] = "29501"
+
+ init_process_group(world_size=1, rank=0)
+ # check that this does not raise:
+ FSDP(model, auto_wrap_policy=fsdp_auto_wrap_policy(model), use_orig_params=False, sync_module_states=True)
+
+ def test_fsdp_auto_wrap_policy_does_not_raise_on_custom_model(self):
+ # See #2167
+ # Avoid raising on custom models since Trainer uses fsdp_auto_wrap_policy automatically for PEFT + FSDP
+ fsdp_auto_wrap_policy(SimpleModel()) # does not raise
+
+
+class TestBOFT:
+ """
+ Test that we can correctly use half-precision models with BOFT.
+ """
+
+ device = infer_device()
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ def test_boft_half_linear(self):
+ # Check that we can use BoFT with model loaded in half precision
+ layer = torch.nn.Linear(160, 160).to(self.device)
+ layer = boft.layer.Linear(layer, "layer", boft_n_butterfly_factor=2).to(dtype=torch.bfloat16)
+ x = torch.randn(160, 160, device=self.device, dtype=torch.bfloat16)
+ layer(x) # does not raise
+
+ @require_non_cpu
+ @pytest.mark.single_gpu_tests
+ def test_boft_half_conv(self):
+ conv = torch.nn.Conv2d(1, 1, 4).to(self.device)
+ conv = boft.layer.Conv2d(conv, "conv", boft_n_butterfly_factor=2).to(dtype=torch.bfloat16)
+ x = torch.randn(1, 160, 160, device=self.device, dtype=torch.bfloat16)
+ conv(x) # does not raise
+
+
+class TestPTuningReproducibility:
+ device = infer_device()
+
+ @require_non_cpu
+ @require_deterministic_for_xpu
+ def test_p_tuning_exactly_reproducible_after_loading(self, tmp_path):
+ # See: https://github.com/huggingface/peft/issues/2043#issuecomment-2321522577
+ # Ensure that after loading a p-tuning checkpoint, results are exactly reproducible (before the patch, they were
+ # only _almost_ identical).
+
+ # The model must be sufficiently large for the effect to be measurable, which is why this test requires is not
+ # run on CPU.
+ model_id = "facebook/opt-125m"
+ inputs = torch.arange(10).view(-1, 1).to(self.device)
+
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(model_id).to(self.device)
+ peft_config = PromptEncoderConfig(task_type="CAUSAL_LM", num_virtual_tokens=20, encoder_hidden_size=128)
+ model = get_peft_model(model, peft_config).eval()
+
+ with torch.inference_mode():
+ output_peft = model(inputs).logits
+ gen_peft = model.generate(inputs, min_new_tokens=10, max_new_tokens=10)
+
+ model.save_pretrained(tmp_path)
+ del model
+ clear_device_cache(garbage_collection=True)
+
+ model = AutoModelForCausalLM.from_pretrained(model_id).to(self.device)
+ model = PeftModel.from_pretrained(model, tmp_path)
+
+ with torch.inference_mode():
+ output_loaded = model(inputs).logits
+ gen_loaded = model.generate(inputs, min_new_tokens=10, max_new_tokens=10)
+
+ torch.testing.assert_close(output_loaded, output_peft)
+ torch.testing.assert_close(gen_loaded, gen_peft)
+
+
+@pytest.mark.single_gpu_tests
+class TestLowCpuMemUsageDifferentDevices:
+ """Test for the low CPU memory usage option for loading PEFT models.
+
+ There are already tests for low_cpu_mem_usage=True in test_initialization.py but here we want to run tests that
+ require a GPU.
+
+ """
+
+ model_id = "hf-internal-testing/tiny-random-OPTForCausalLM"
+ device = infer_device()
+
+ @require_non_cpu
+ @pytest.mark.parametrize("device_model, device_sd", [("cpu", infer_device()), (infer_device(), "cpu")])
+ def test_low_cpu_mem_usage_model_model_on_gpu_state_dict_on_cpu_works(self, device_model, device_sd):
+ # specifically test diverging devices for the model and state_dict
+ inputs = {"input_ids": torch.randint(0, 100, (1, 10)), "attention_mask": torch.ones(1, 10)}
+ inputs = {k: v.to(device_model) for k, v in inputs.items()}
+
+ model = AutoModelForCausalLM.from_pretrained(self.model_id).to(device_model)
+ lora_config = LoraConfig(init_lora_weights=False, target_modules="all-linear")
+ model = get_peft_model(model, lora_config)
+ model.eval()
+ logits_not_low_cpu_mem = model(**inputs).logits
+
+ state_dict = get_peft_model_state_dict(model)
+ peft_model_state_dict = {}
+ # remap the state dict so that it can be correctly loaded, and move weights to the other device
+ prefix = "base_model.model."
+ for k, v in state_dict.items():
+ k = k[len(prefix) :]
+ peft_model_state_dict[k] = v.to(device_sd)
+
+ del model
+
+ model = AutoModelForCausalLM.from_pretrained(self.model_id).to(device_model)
+ model.eval()
+ inject_adapter_in_model(lora_config, model, low_cpu_mem_usage=True)
+ load_result = set_peft_model_state_dict(model, peft_model_state_dict, low_cpu_mem_usage=True)
+
+ # sanity check: all lora keys are matched
+ assert not any("lora" in k for k in load_result.missing_keys)
+ assert not any("lora" in k for k in load_result.unexpected_keys)
+
+ logits_low_cpu_mem = model(**inputs).logits
+
+ assert torch.allclose(logits_low_cpu_mem, logits_not_low_cpu_mem)
+ assert {p.device.type for p in model.parameters()} == {device_model}
+
+ @require_bitsandbytes
+ @pytest.mark.parametrize("quantization_method", ["bnb-4bit", "bnb-8bit"])
+ def test_low_cpu_mem_usage_with_quantization(self, quantization_method):
+ # Ensure that low_cpu_mem_usage works with quantization
+ # See also https://github.com/huggingface/diffusers/issues/10550
+ if quantization_method == "bnb-4bit":
+ quantization_config = BitsAndBytesConfig(
+ load_in_4bit=True,
+ bnb_4bit_compute_dtype=torch.float32,
+ bnb_4bit_quant_storage=torch.float32,
+ bnb_4bit_use_double_quant=True,
+ )
+ elif quantization_method == "bnb-8bit":
+ quantization_config = BitsAndBytesConfig(load_in_8bit=True)
+ else:
+ raise ValueError(f"Unknown quantization method {quantization_method}")
+
+ model = AutoModelForCausalLM.from_pretrained(self.model_id, quantization_config=quantization_config)
+ if model.device.type != self.device:
+ # calling model.to("cuda") with 8 bit bnb raises an error, thus guard against it
+ model = model.to(self.device)
+
+ lora_config = LoraConfig(init_lora_weights=False, target_modules="all-linear")
+
+ # We use get_peft_model with low_cpu_mem_usage=True here. This is not typically done in practice (the option is
+ # mostly interesting for loading trained adapters), but it does the job for testing purposes.
+ model = get_peft_model(model, lora_config, low_cpu_mem_usage=True) # this should not raise
+ assert {p.device.type for p in model.parameters()} == {self.device, "meta"}
+
+
+class TestEvaInitializationGPU:
+ """GPU tests for the Eva initialization method."""
+
+ # Constants for test configuration
+ COSINE_SIMILARITY_THRESHOLD = 0.75
+ NUM_SEEDS = 3
+ BATCH_SIZE = 4
+ MAX_LENGTH = 256
+ LORA_DIM = 8
+ LORA_ALPHA = 1
+ DEVICE = infer_device()
+
+ @pytest.fixture
+ def tokenizer(self):
+ tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
+ tokenizer.pad_token = tokenizer.eos_token
+ return tokenizer
+
+ @pytest.fixture
+ def dataset(self, tokenizer):
+ dataset = load_dataset_english_quotes()["train"]
+ # concatenate examples
+ examples = []
+ example = ""
+ for data in dataset:
+ if len(example) >= self.MAX_LENGTH:
+ examples.append(example)
+ example = ""
+ example = example + " " + data["quote"]
+ dataset = Dataset.from_dict({"text": examples})
+ # tokenize
+ dataset = dataset.map(
+ lambda x: tokenizer(x["text"], padding="max_length", truncation=True, max_length=self.MAX_LENGTH),
+ batched=True,
+ remove_columns=dataset.column_names,
+ )
+ dataset.set_format(type="torch")
+ return dataset
+
+ @pytest.fixture
+ def model(self):
+ model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
+ model.transformer.h = model.transformer.h[:2] # truncate to 2 layers
+ return model.to(self.DEVICE)
+
+ @pytest.fixture
+ def model_bnb(self):
+ bnb_config = BitsAndBytesConfig(load_in_4bit=True)
+ model = AutoModelForCausalLM.from_pretrained(
+ "openai-community/gpt2",
+ quantization_config=bnb_config,
+ attn_implementation="eager", # gpt2 doesnt support flash attention
+ )
+ model.transformer.h = model.transformer.h[:2] # truncate to 2 layers
+ model = prepare_model_for_kbit_training(model)
+ return model
+
+ @pytest.fixture
+ def model_fixture(self, request):
+ return request.getfixturevalue(request.param)
+
+ @pytest.fixture
+ def peft_config(self):
+ return LoraConfig(
+ r=self.LORA_DIM,
+ lora_alpha=self.LORA_ALPHA,
+ target_modules=["c_attn"],
+ init_lora_weights="eva",
+ eva_config=EvaConfig(rho=2),
+ )
+
+ def is_bnb_model(self, model):
+ return hasattr(model.config, "quantization_config")
+
+ @staticmethod
+ def collate_fn(examples):
+ return {k: torch.stack([v[k] for v in examples], dim=0) for k in examples[0].keys()}
+
+ @require_non_cpu
+ @require_bitsandbytes
+ @pytest.mark.single_gpu_tests
+ @pytest.mark.parametrize("model_fixture", ["model", "model_bnb"], indirect=True)
+ def test_eva_initialization_consistency(self, model_fixture, dataset, peft_config):
+ """Test that the state dict returned by get_eva_state_dict loaded correctly and is consistent across different seeds based
+ on the cosine similarity of the svd components."""
+ state_dicts = []
+ for seed in range(self.NUM_SEEDS):
+ shuffled_dataset = dataset.shuffle(seed=seed)
+ dataloader = DataLoader(
+ shuffled_dataset,
+ batch_size=self.BATCH_SIZE,
+ collate_fn=lambda examples: {
+ k: torch.stack([v[k] for v in examples], dim=0) for k in examples[0].keys()
+ },
+ shuffle=False,
+ )
+ peft_model = get_peft_model(deepcopy(model_fixture), peft_config)
+ initialize_lora_eva_weights(peft_model, dataloader)
+ state_dicts.append(
+ {k: v.cpu() for k, v in peft_model.state_dict().items() if "lora_A.default.weight" in k}
+ )
+
+ cos_sims = defaultdict(list)
+ for i, j in itertools.combinations(range(self.NUM_SEEDS), 2):
+ for k, v1 in state_dicts[i].items():
+ v2 = state_dicts[j][k]
+ min_size = min(v1.size(0), v2.size(0))
+ cos_sims[k].extend(torch.cosine_similarity(v1[:min_size], v2[:min_size], dim=1).abs().tolist())
+
+ mean_cosine_similarities = {k: torch.tensor(v).mean() for k, v in cos_sims.items()}
+ for layer_name, mean_cosine_similarity in mean_cosine_similarities.items():
+ assert mean_cosine_similarity > self.COSINE_SIMILARITY_THRESHOLD, (
+ f"Mean absolute cosine similarity {mean_cosine_similarity:.4f} "
+ f"is not greater than {self.COSINE_SIMILARITY_THRESHOLD}"
+ )
+
+
+@pytest.mark.multi_gpu_tests
+class TestPrefixTuning:
+ device = infer_device()
+
+ @require_torch_multi_accelerator
+ def test_prefix_tuning_multiple_devices_decoder_model(self):
+ # See issue 2134
+ model_id = "hf-internal-testing/tiny-random-MistralForCausalLM"
+ tokenizer = AutoTokenizer.from_pretrained(model_id, padding="left")
+ inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to(self.device)
+
+ device_map = {
+ "model.embed_tokens": 0,
+ "model.layers.0": 0,
+ "model.layers.1": 1,
+ "model.norm": 1,
+ "model.rotary_emb": 1,
+ "lm_head": 1,
+ }
+ model = AutoModelForCausalLM.from_pretrained(model_id, device_map=device_map)
+ # sanity check, as the test passes trivially for a single device
+ assert len({p.device for p in model.parameters()}) > 1
+ # sanity check: this should work without peft
+ model.generate(**inputs) # does not raise
+
+ peft_config = PrefixTuningConfig(num_virtual_tokens=10, task_type="CAUSAL_LM")
+ model = get_peft_model(model, peft_config)
+ model.generate(**inputs) # does not raise
+
+ @require_torch_multi_accelerator
+ def test_prefix_tuning_multiple_devices_encoder_decoder_model(self):
+ # See issue 2134
+ model_id = "hf-internal-testing/tiny-random-T5Model"
+ tokenizer = AutoTokenizer.from_pretrained(model_id, padding="left")
+ inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to(self.device)
+ device_map = {
+ "shared": 0,
+ "encoder.embed_tokens": 0,
+ "encoder.block.0": 0,
+ "encoder.block.1": 0,
+ "encoder.block.2": 1,
+ "encoder.block.3": 1,
+ "encoder.block.4": 1,
+ "encoder.final_layer_norm": 1,
+ "decoder.embed_tokens": 0,
+ "decoder.block.0": 0,
+ "decoder.block.1": 0,
+ "decoder.block.2": 1,
+ "decoder.block.3": 1,
+ "decoder.block.4": 1,
+ "decoder.final_layer_norm": 1,
+ "lm_head": 0,
+ }
+ model = AutoModelForSeq2SeqLM.from_pretrained(model_id, device_map=device_map)
+ # sanity check, as the test passes trivially for a single device
+ assert len({p.device for p in model.parameters()}) > 1
+ # sanity check: this should work without peft
+ model.generate(**inputs) # does not raise
+
+ peft_config = PrefixTuningConfig(num_virtual_tokens=10, task_type="SEQ_2_SEQ_LM")
+ model = get_peft_model(model, peft_config)
+ model.generate(**inputs) # does not raise
+
+
+@pytest.mark.skipif(not (torch.cuda.is_available() or is_xpu_available()), reason="test requires a GPU or XPU")
+@pytest.mark.single_gpu_tests
+class TestHotSwapping:
+ """
+ Test hotswapping on compiled models.
+
+ This test suite is only run on GPU as it is quite slow.
+ """
+
+ torch_device = infer_device()
+
+ @pytest.fixture(scope="class", autouse=True)
+ def reset_float32_matmul_precision(self):
+ # Earlier tests may run torchao, which, at the time this was added, sets the float32 matmul precision to 'high'.
+ # This in turn results in some models producing different outputs when compiled (but only for some seeds).
+ # Therefore, we need to ensure that the precision is reset to "highest", which is the default.
+ # TODO: if torchao removes the side effect, this fixture can be deleted.
+ # https://github.com/pytorch/ao/blob/ffb4350640e76c7e7f449dd1e36d33f19fe384c8/torchao/quantization/utils.py#L589
+ torch.set_float32_matmul_precision("highest")
+
+ @pytest.fixture(autouse=True)
+ def reset_dynamo_cache(self):
+ # It is critical that the dynamo cache is reset for each test. Otherwise, if the test re-uses the same model,
+ # there will be recompilation errors, as torch caches the model when run in the same process.
+ yield
+ torch._dynamo.reset()
+
+ #######
+ # LLM #
+ #######
+
+ def check_hotswap(self, do_hotswap, ranks, alpha_scalings):
+ """
+ Test hotswapping with a compiled model.
+
+ Passing do_hotswap=False should trigger recompilation. Use the raise_error_on_recompile context manager to
+ raise an error when recompilation occurs.
+
+ """
+ torch.manual_seed(0)
+ inputs = torch.arange(10).view(-1, 1).to(self.torch_device)
+ model_id = "hf-internal-testing/tiny-random-OPTForCausalLM"
+ model = AutoModelForCausalLM.from_pretrained(model_id).to(self.torch_device)
+ rank0, rank1 = ranks
+ alpha0, alpha1 = alpha_scalings
+
+ # note that the 2nd adapter targeting a subset of the 1st adapter is okay, but not the other way round
+ config0 = LoraConfig(init_lora_weights=False, r=rank0, lora_alpha=alpha0, target_modules=["q_proj", "v_proj"])
+ config1 = LoraConfig(init_lora_weights=False, r=rank1, lora_alpha=alpha1, target_modules=["q_proj"])
+ model = get_peft_model(model, config0, adapter_name="adapter0").eval()
+ with torch.inference_mode():
+ output0 = model(inputs).logits
+
+ model.add_adapter("adapter1", config1)
+ model.set_adapter("adapter1")
+ with torch.inference_mode():
+ output1 = model(inputs).logits
+
+ # sanity check:
+ tol = 1e-4
+ assert not torch.allclose(output0, output1, atol=tol, rtol=tol)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname)
+ del model
+
+ model = AutoModelForCausalLM.from_pretrained(model_id).to(self.torch_device)
+ model = PeftModel.from_pretrained(model, os.path.join(tmp_dirname, "adapter0")).eval()
+ if do_hotswap:
+ prepare_model_for_compiled_hotswap(model, config=model.peft_config, target_rank=max(ranks))
+ model = torch.compile(model, mode="reduce-overhead")
+ output_after0 = model(inputs).logits
+ assert torch.allclose(output0, output_after0, atol=tol, rtol=tol)
+
+ # swap and check that we get the output from adapter1
+ if do_hotswap:
+ hotswap_adapter(model, os.path.join(tmp_dirname, "adapter1"), adapter_name="default")
+ else:
+ model.load_adapter(os.path.join(tmp_dirname, "adapter1"), adapter_name="other")
+ model.set_adapter("other")
+
+ # we need to call forward to potentially trigger recompilation
+ output_after1 = model(inputs).logits
+ assert torch.allclose(output1, output_after1, atol=tol, rtol=tol)
+
+ # we need to call forward third time since cudagraphs are not recorded in first call.
+ if do_hotswap:
+ hotswap_adapter(model, os.path.join(tmp_dirname, "adapter0"), adapter_name="default")
+ output_after2 = model(inputs).logits
+ assert torch.allclose(output0, output_after2, atol=tol, rtol=tol)
+
+ # it is important to check hotswapping small to large ranks and large to small ranks
+ @pytest.mark.parametrize("ranks", [(11, 11), (7, 13), (13, 7)])
+ def test_hotswapping_compiled_model_does_not_trigger_recompilation(self, ranks):
+ # here we set three configs to ensure no recompilation or cudagraph re-record occurs:
+ # 1. error_on_recompile: raise an error on recompilation
+ # 2. inline_inbuilt_nn_modules: needed to raise an error on static input address changes instead of re-recording
+ # 3. triton.cudagraph_support_input_mutation: same as above
+ dynamo_config_ctx = torch._dynamo.config.patch(error_on_recompile=True, inline_inbuilt_nn_modules=False)
+ inductor_config_ctx = torch._inductor.config.patch("triton.cudagraph_support_input_mutation", False)
+ with dynamo_config_ctx, inductor_config_ctx:
+ self.check_hotswap(do_hotswap=True, ranks=ranks, alpha_scalings=ranks)
+
+ def test_no_hotswapping_compiled_model_triggers_recompilation(self):
+ # contingency test to ensure that hotswapping is actually needed to prevent recompilation
+ ranks = 7, 13
+ with torch._dynamo.config.patch(error_on_recompile=True):
+ with pytest.raises(torch._dynamo.exc.RecompileError): # raise an error on recompilation
+ self.check_hotswap(do_hotswap=False, ranks=ranks, alpha_scalings=ranks)
+
+ ###################
+ # DIFFUSION MODEL #
+ ###################
+
+ def get_small_unet(self):
+ # from diffusers UNet2DConditionModelTests
+ from diffusers import UNet2DConditionModel
+
+ torch.manual_seed(0)
+ init_dict = {
+ "block_out_channels": (4, 8),
+ "norm_num_groups": 4,
+ "down_block_types": ("CrossAttnDownBlock2D", "DownBlock2D"),
+ "up_block_types": ("UpBlock2D", "CrossAttnUpBlock2D"),
+ "cross_attention_dim": 8,
+ "attention_head_dim": 2,
+ "out_channels": 4,
+ "in_channels": 4,
+ "layers_per_block": 1,
+ "sample_size": 16,
+ }
+ model = UNet2DConditionModel(**init_dict)
+ return model.to(self.torch_device)
+
+ def get_unet_lora_config(self, lora_rank, lora_alpha, target_modules):
+ # from diffusers test_models_unet_2d_condition.py
+ # note that this only targets linear layers by default
+ unet_lora_config = LoraConfig(
+ r=lora_rank,
+ lora_alpha=lora_alpha,
+ target_modules=target_modules,
+ init_lora_weights=False,
+ use_dora=False,
+ )
+ return unet_lora_config
+
+ def get_dummy_input(self):
+ pipeline_inputs = {
+ "prompt": "A painting of a squirrel eating a burger",
+ "num_inference_steps": 5,
+ "guidance_scale": 6.0,
+ "output_type": "np",
+ "return_dict": False,
+ }
+ return pipeline_inputs
+
+ def set_lora_device(self, model, adapter_names, device):
+ # copied from diffusers LoraBaseMixin.set_lora_device
+ for module in model.modules():
+ if isinstance(module, BaseTunerLayer):
+ for adapter_name in adapter_names:
+ module.lora_A[adapter_name].to(device)
+ module.lora_B[adapter_name].to(device)
+ # this is a param, not a module, so device placement is not in-place -> re-assign
+ if hasattr(module, "lora_magnitude_vector") and module.lora_magnitude_vector is not None:
+ if adapter_name in module.lora_magnitude_vector:
+ module.lora_magnitude_vector[adapter_name] = module.lora_magnitude_vector[adapter_name].to(
+ device
+ )
+
+ def check_hotswap_diffusion(self, ranks, alpha_scalings, target_modules):
+ """
+ Check that hotswapping works on a pipeline.
+
+ This is essentially the same test as:
+ https://github.com/huggingface/diffusers/blob/d7dd924ece56cddf261cd8b9dd901cbfa594c62c/tests/pipelines/test_pipelines.py#L2264
+
+ Steps:
+ - create 2 LoRA adapters and save them
+ - load the first adapter
+ - hotswap the second adapter
+ - check that the outputs are correct
+ - optionally compile the model
+
+ Note: We set rank == alpha here because save_lora_adapter does not save the alpha scalings, thus the test would
+ fail if the values are different. Since rank != alpha does not matter for the purpose of this test, this is
+ fine.
+ """
+ from diffusers import StableDiffusionPipeline
+
+ # create 2 adapters with different ranks and alphas
+ dummy_input = self.get_dummy_input()
+ pipeline = StableDiffusionPipeline.from_pretrained("hf-internal-testing/tiny-sd-pipe").to(torch_device)
+ rank0, rank1 = ranks
+ alpha0, alpha1 = alpha_scalings
+ max_rank = max([rank0, rank1])
+ lora_config0 = self.get_unet_lora_config(rank0, alpha0, target_modules)
+ lora_config1 = self.get_unet_lora_config(rank1, alpha1, target_modules)
+
+ torch.manual_seed(0)
+ pipeline.unet.add_adapter(lora_config0, adapter_name="adapter0")
+ output0_before = pipeline(**dummy_input, generator=torch.manual_seed(0))[0]
+
+ torch.manual_seed(1)
+ pipeline.unet.add_adapter(lora_config1, adapter_name="adapter1")
+ pipeline.unet.set_adapter("adapter1")
+ output1_before = pipeline(**dummy_input, generator=torch.manual_seed(0))[0]
+
+ # sanity check
+ tol = 1e-3
+ assert not np.allclose(output0_before, output1_before, atol=tol, rtol=tol)
+ assert not (output0_before == 0).all()
+ assert not (output1_before == 0).all()
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ # save the adapter checkpoints
+ sd0 = get_peft_model_state_dict(pipeline.unet, adapter_name="adapter0")
+ StableDiffusionPipeline.save_lora_weights(
+ save_directory=os.path.join(tmp_dirname, "adapter0"), safe_serialization=True, unet_lora_layers=sd0
+ )
+ sd1 = get_peft_model_state_dict(pipeline.unet, adapter_name="adapter1")
+ StableDiffusionPipeline.save_lora_weights(
+ save_directory=os.path.join(tmp_dirname, "adapter1"), safe_serialization=True, unet_lora_layers=sd1
+ )
+ del pipeline
+
+ # load the first adapter
+ pipeline = StableDiffusionPipeline.from_pretrained("hf-internal-testing/tiny-sd-pipe").to(torch_device)
+ # no need to prepare if the model is not compiled or if the ranks are identical
+ pipeline.enable_lora_hotswap(target_rank=max_rank)
+
+ file_name0 = os.path.join(tmp_dirname, "adapter0", "pytorch_lora_weights.safetensors")
+ file_name1 = os.path.join(tmp_dirname, "adapter1", "pytorch_lora_weights.safetensors")
+
+ pipeline.load_lora_weights(file_name0)
+ pipeline.unet = torch.compile(pipeline.unet, mode="reduce-overhead")
+
+ output0_after = pipeline(**dummy_input, generator=torch.manual_seed(0))[0]
+
+ # sanity check: still same result
+ assert np.allclose(output0_before, output0_after, atol=tol, rtol=tol)
+
+ # hotswap the 2nd adapter
+ pipeline.load_lora_weights(file_name1, hotswap=True, adapter_name="default_0")
+ output1_after = pipeline(**dummy_input, generator=torch.manual_seed(0))[0]
+
+ # sanity check: since it's the same LoRA, the results should be identical
+ assert np.allclose(output1_before, output1_after, atol=tol, rtol=tol)
+
+ # we need to call forward third time since cudagraphs are not recorded in first call.
+ pipeline.load_lora_weights(file_name0, hotswap=True, adapter_name="default_0")
+ output2_after = pipeline(**dummy_input, generator=torch.manual_seed(0))[0]
+ assert np.allclose(output0_before, output2_after, atol=tol, rtol=tol)
+
+ @pytest.mark.skipif(not is_diffusers_available(), reason="Test requires diffusers to be installed")
+ # it is important to check hotswapping small to large ranks and large to small ranks
+ @pytest.mark.parametrize("ranks", [(11, 11), (7, 13), (13, 7)])
+ @pytest.mark.parametrize(
+ "target_modules",
+ [
+ ["to_q", "to_k", "to_v", "to_out.0"], # Linear layers
+ ["conv", "conv1", "conv2"], # Conv2d layers
+ ["to_q", "conv"], # mix of Linear and Conv2d
+ ],
+ )
+ def test_hotswapping_compiled_diffusers_model_does_not_trigger_recompilation(self, ranks, target_modules):
+ # here we set three configs to ensure no recompilation or cudagraph re-record occurs:
+ # 1. error_on_recompile: raise an error on recompilation
+ # 2. inline_inbuilt_nn_modules: needed to raise an error on static input address changes instead of re-recording
+ # 3. triton.cudagraph_support_input_mutation: same as above
+ dynamo_config_ctx = torch._dynamo.config.patch(error_on_recompile=True, inline_inbuilt_nn_modules=False)
+ inductor_config_ctx = torch._inductor.config.patch("triton.cudagraph_support_input_mutation", False)
+ with dynamo_config_ctx, inductor_config_ctx:
+ self.check_hotswap_diffusion(ranks=ranks, alpha_scalings=ranks, target_modules=target_modules)
diff --git a/peft/tests/test_helpers.py b/peft/tests/test_helpers.py
new file mode 100644
index 0000000000000000000000000000000000000000..501bd146a2900cd3266cd5bed1cfe747da308811
--- /dev/null
+++ b/peft/tests/test_helpers.py
@@ -0,0 +1,473 @@
+# Copyright 2024-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import pytest
+import torch
+from diffusers import StableDiffusionPipeline
+from torch import nn
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+from peft import LoraConfig, get_peft_model
+from peft.helpers import check_if_peft_model, disable_input_dtype_casting, rescale_adapter_scale
+from peft.tuners.lora.layer import LoraLayer
+from peft.utils import infer_device
+
+
+class TestCheckIsPeftModel:
+ def test_valid_hub_model(self):
+ result = check_if_peft_model("peft-internal-testing/gpt2-lora-random")
+ assert result is True
+
+ def test_invalid_hub_model(self):
+ result = check_if_peft_model("gpt2")
+ assert result is False
+
+ def test_nonexisting_hub_model(self):
+ result = check_if_peft_model("peft-internal-testing/non-existing-model")
+ assert result is False
+
+ def test_local_model_valid(self, tmp_path):
+ model = AutoModelForCausalLM.from_pretrained("gpt2")
+ config = LoraConfig()
+ model = get_peft_model(model, config)
+ model.save_pretrained(tmp_path / "peft-gpt2-valid")
+ result = check_if_peft_model(tmp_path / "peft-gpt2-valid")
+ assert result is True
+
+ def test_local_model_invalid(self, tmp_path):
+ model = AutoModelForCausalLM.from_pretrained("gpt2")
+ model.save_pretrained(tmp_path / "peft-gpt2-invalid")
+ result = check_if_peft_model(tmp_path / "peft-gpt2-invalid")
+ assert result is False
+
+ def test_local_model_broken_config(self, tmp_path):
+ with open(tmp_path / "adapter_config.json", "w") as f:
+ f.write('{"foo": "bar"}')
+
+ result = check_if_peft_model(tmp_path)
+ assert result is False
+
+ def test_local_model_non_default_name(self, tmp_path):
+ model = AutoModelForCausalLM.from_pretrained("gpt2")
+ config = LoraConfig()
+ model = get_peft_model(model, config, adapter_name="other")
+ model.save_pretrained(tmp_path / "peft-gpt2-other")
+
+ # no default adapter here
+ result = check_if_peft_model(tmp_path / "peft-gpt2-other")
+ assert result is False
+
+ # with adapter name
+ result = check_if_peft_model(tmp_path / "peft-gpt2-other" / "other")
+ assert result is True
+
+
+class TestScalingAdapters:
+ @pytest.fixture(scope="class")
+ def tokenizer(self):
+ return AutoTokenizer.from_pretrained("facebook/opt-125m")
+
+ def get_scale_from_modules(self, model):
+ layer_to_scale_map = {}
+ for name, module in model.named_modules():
+ if isinstance(module, LoraLayer):
+ layer_to_scale_map[name] = module.scaling
+
+ return layer_to_scale_map
+
+ def test_rescale_adapter_scale(self, tokenizer):
+ model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m")
+ lora_config = LoraConfig(
+ r=4,
+ lora_alpha=4,
+ target_modules=["k_proj", "v_proj"],
+ lora_dropout=0.1,
+ bias="none",
+ init_lora_weights=False,
+ )
+
+ model = get_peft_model(model, lora_config)
+ model.eval()
+ inputs = tokenizer("hello world", return_tensors="pt")
+
+ with torch.no_grad():
+ logits_before_scaling = model(**inputs).logits
+
+ scales_before_scaling = self.get_scale_from_modules(model)
+
+ with rescale_adapter_scale(model=model, multiplier=0.5):
+ scales_during_scaling = self.get_scale_from_modules(model)
+ for key in scales_before_scaling.keys():
+ assert scales_before_scaling[key] != scales_during_scaling[key]
+
+ with torch.no_grad():
+ logits_during_scaling = model(**inputs).logits
+
+ assert not torch.allclose(logits_before_scaling, logits_during_scaling)
+
+ scales_after_scaling = self.get_scale_from_modules(model)
+ for key in scales_before_scaling.keys():
+ assert scales_before_scaling[key] == scales_after_scaling[key]
+
+ with torch.no_grad():
+ logits_after_scaling = model(**inputs).logits
+
+ assert torch.allclose(logits_before_scaling, logits_after_scaling)
+
+ def test_wrong_scaling_datatype(self):
+ model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m")
+ lora_config = LoraConfig(
+ r=4,
+ lora_alpha=4,
+ target_modules=["k_proj", "v_proj"],
+ lora_dropout=0.1,
+ bias="none",
+ init_lora_weights=False,
+ )
+
+ model = get_peft_model(model, lora_config)
+
+ # we expect a type error here becuase of wrong datatpye of multiplier
+ multiplier = "a"
+ with pytest.raises(TypeError, match=f"Argument multiplier should be of type float, got {type(multiplier)}"):
+ with rescale_adapter_scale(model=model, multiplier=multiplier):
+ pass
+
+ def test_not_lora_model(self):
+ model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m")
+
+ # we expect a value error here because the model
+ # does not have lora layers
+ with pytest.raises(ValueError, match="scaling is only supported for models with `LoraLayer`s"):
+ with rescale_adapter_scale(model=model, multiplier=0.5):
+ pass
+
+ def test_scaling_set_to_zero(self, tokenizer):
+ base_model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m")
+ inputs = tokenizer("hello world", return_tensors="pt")
+
+ base_model.eval()
+
+ with torch.no_grad():
+ logits_base_model = base_model(**inputs).logits
+
+ lora_config = LoraConfig(
+ r=4,
+ lora_alpha=4,
+ target_modules=["k_proj", "v_proj"],
+ lora_dropout=0.1,
+ bias="none",
+ init_lora_weights=False,
+ )
+ lora_model = get_peft_model(base_model, lora_config)
+ lora_model.eval()
+
+ with rescale_adapter_scale(model=lora_model, multiplier=0.0):
+ with torch.no_grad():
+ logits_lora_model = lora_model(**inputs).logits
+
+ assert torch.allclose(logits_base_model, logits_lora_model)
+
+ def test_diffusers_pipeline(self):
+ model_id = "hf-internal-testing/tiny-sd-pipe"
+ pipeline = StableDiffusionPipeline.from_pretrained(model_id)
+
+ text_encoder_kwargs = {
+ "r": 8,
+ "lora_alpha": 32,
+ "target_modules": ["k_proj", "q_proj", "v_proj", "out_proj", "fc1", "fc2"],
+ "lora_dropout": 0.0,
+ "bias": "none",
+ }
+ unet_kwargs = {
+ "r": 8,
+ "lora_alpha": 32,
+ "target_modules": ["proj_in", "proj_out", "to_k", "to_q", "to_v", "to_out.0", "ff.net.0.proj", "ff.net.2"],
+ "lora_dropout": 0.0,
+ "bias": "none",
+ }
+
+ # Instantiate text_encoder adapter
+ config_text_encoder = LoraConfig(**text_encoder_kwargs)
+ pipeline.text_encoder = get_peft_model(pipeline.text_encoder, config_text_encoder)
+
+ # Instantiate unet adapter
+ config_unet = LoraConfig(**unet_kwargs)
+ pipeline.unet = get_peft_model(pipeline.unet, config_unet)
+
+ text_scales_before_scaling = self.get_scale_from_modules(pipeline.text_encoder)
+ unet_scales_before_scaling = self.get_scale_from_modules(pipeline.unet)
+
+ with (
+ rescale_adapter_scale(model=pipeline.text_encoder, multiplier=0.5),
+ rescale_adapter_scale(model=pipeline.unet, multiplier=0.5),
+ ):
+ text_scales_during_scaling = self.get_scale_from_modules(pipeline.text_encoder)
+ unet_scales_during_scaling = self.get_scale_from_modules(pipeline.unet)
+ for key in text_scales_before_scaling.keys():
+ assert text_scales_before_scaling[key] != text_scales_during_scaling[key]
+ for key in unet_scales_before_scaling.keys():
+ assert unet_scales_before_scaling[key] != unet_scales_during_scaling[key]
+
+ text_scales_fter_scaling = self.get_scale_from_modules(pipeline.text_encoder)
+ unet_scales_after_scaling = self.get_scale_from_modules(pipeline.unet)
+ for key in text_scales_before_scaling.keys():
+ assert text_scales_before_scaling[key] == text_scales_fter_scaling[key]
+ for key in unet_scales_before_scaling.keys():
+ assert unet_scales_before_scaling[key] == unet_scales_after_scaling[key]
+
+ def test_transformers_pipeline(self, tmp_path, tokenizer):
+ # this uses a transformers model that loads the adapter directly
+ model_id = "facebook/opt-125m"
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ config = LoraConfig(init_lora_weights=False)
+ model = get_peft_model(model, config)
+ model.save_pretrained(tmp_path / "opt-lora")
+ del model
+
+ # load directly into transformers model
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ model.load_adapter(tmp_path / "opt-lora")
+
+ inputs = tokenizer("hello world", return_tensors="pt")
+
+ model = model.eval()
+
+ with torch.no_grad():
+ logits_before_scaling = model(**inputs).logits
+ scales_before_scaling = self.get_scale_from_modules(model)
+
+ with rescale_adapter_scale(model=model, multiplier=0.5):
+ scales_during_scaling = self.get_scale_from_modules(model)
+ for key in scales_before_scaling.keys():
+ assert scales_before_scaling[key] != scales_during_scaling[key]
+ with torch.no_grad():
+ logits_during_scaling = model(**inputs).logits
+ assert not torch.allclose(logits_before_scaling, logits_during_scaling)
+ scales_after_scaling = self.get_scale_from_modules(model)
+
+ for key in scales_before_scaling.keys():
+ assert scales_before_scaling[key] == scales_after_scaling[key]
+
+ with torch.no_grad():
+ logits_after_scaling = model(**inputs).logits
+
+ assert torch.allclose(logits_before_scaling, logits_after_scaling)
+
+ def test_multi_adapters(self, tokenizer):
+ model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m")
+ lora_config = LoraConfig(
+ r=4,
+ lora_alpha=4,
+ target_modules=["k_proj", "v_proj"],
+ lora_dropout=0.1,
+ bias="none",
+ init_lora_weights=False,
+ )
+ model = get_peft_model(model, lora_config)
+ inputs = tokenizer("hello world", return_tensors="pt")
+
+ # add another adaper and activate it
+ model.add_adapter("other", lora_config)
+ model.set_adapter("other")
+
+ scales_before_scaling = self.get_scale_from_modules(model)
+ model.eval()
+ with torch.no_grad():
+ logits_before = model(**inputs).logits
+
+ with rescale_adapter_scale(model=model, multiplier=0.5):
+ scales_during_scaling = self.get_scale_from_modules(model)
+ for key in scales_before_scaling.keys():
+ assert scales_before_scaling[key] != scales_during_scaling[key]
+
+ with torch.no_grad():
+ logits_during = model(**inputs).logits
+
+ assert not torch.allclose(logits_before, logits_during)
+
+ scales_after_scaling = self.get_scale_from_modules(model)
+ for key in scales_before_scaling.keys():
+ assert scales_before_scaling[key] == scales_after_scaling[key]
+
+ with torch.no_grad():
+ logits_after = model(**inputs).logits
+
+ assert torch.allclose(logits_before, logits_after)
+
+ def test_rank_alpha_pattern(self, tokenizer):
+ model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m")
+ lora_config = LoraConfig(
+ r=4,
+ lora_alpha=4,
+ target_modules=["k_proj", "v_proj"],
+ lora_dropout=0.1,
+ bias="none",
+ init_lora_weights=False,
+ rank_pattern={"k_proj": 2},
+ alpha_pattern={"k_proj": 8},
+ )
+
+ model = get_peft_model(model, lora_config)
+ model.eval()
+ inputs = tokenizer("hello world", return_tensors="pt")
+
+ with torch.no_grad():
+ logits_before_scaling = model(**inputs).logits
+
+ scales_before_scaling = self.get_scale_from_modules(model)
+
+ with rescale_adapter_scale(model=model, multiplier=0.5):
+ scales_during_scaling = self.get_scale_from_modules(model)
+ for key in scales_before_scaling.keys():
+ assert scales_before_scaling[key] != scales_during_scaling[key]
+
+ with torch.no_grad():
+ logits_during_scaling = model(**inputs).logits
+
+ assert not torch.allclose(logits_before_scaling, logits_during_scaling)
+
+ scales_after_scaling = self.get_scale_from_modules(model)
+ for key in scales_before_scaling.keys():
+ assert scales_before_scaling[key] == scales_after_scaling[key]
+
+ with torch.no_grad():
+ logits_after_scaling = model(**inputs).logits
+
+ assert torch.allclose(logits_before_scaling, logits_after_scaling)
+
+ def test_merging_adapter(self, tokenizer):
+ model = AutoModelForCausalLM.from_pretrained("facebook/opt-125m")
+ lora_config = LoraConfig(
+ r=4,
+ lora_alpha=4,
+ target_modules=["k_proj", "v_proj"],
+ lora_dropout=0.1,
+ bias="none",
+ init_lora_weights=False,
+ )
+
+ model = get_peft_model(model, lora_config)
+ model.eval()
+ inputs = tokenizer("hello world", return_tensors="pt")
+
+ with rescale_adapter_scale(model=model, multiplier=0.5):
+ with torch.no_grad():
+ logits_unmerged_scaling = model(**inputs).logits
+ model = model.merge_and_unload()
+
+ with torch.no_grad():
+ logits_merged_scaling = model(**inputs).logits
+
+ assert torch.allclose(logits_merged_scaling, logits_unmerged_scaling, atol=1e-4, rtol=1e-4)
+
+
+class TestDisableInputDtypeCasting:
+ """Test the context manager `disable_input_dtype_casting` that temporarily disables input dtype casting
+ in the model.
+
+ The test works as follows:
+
+ We create a simple MLP and convert it to a PeftModel. The model dtype is set to float16. Then a pre-foward hook is
+ added that casts the model parameters to float32. Moreover, a post-forward hook is added that casts the weights
+ back to float16. The input dtype is float32.
+
+ Without the disable_input_dtype_casting context, what would happen is that PEFT detects that the input dtype is
+ float32 but the weight dtype is float16, so it casts the input to float16. Then the pre-forward hook casts the
+ weight to float32, which results in a RuntimeError.
+
+ With the disable_input_dtype_casting context, the input dtype is left as float32 and there is no error. We also add
+ a hook to record the dtype of the result from the LoraLayer to ensure that it is indeed float32.
+
+ """
+
+ device = infer_device()
+ dtype_record = []
+
+ @torch.no_grad()
+ def cast_params_to_fp32_pre_hook(self, module, input):
+ for param in module.parameters(recurse=False):
+ param.data = param.data.float()
+ return input
+
+ @torch.no_grad()
+ def cast_params_to_fp16_hook(self, module, input, output):
+ for param in module.parameters(recurse=False):
+ param.data = param.data.half()
+ return output
+
+ def record_dtype_hook(self, module, input, output):
+ self.dtype_record.append(output[0].dtype)
+
+ @pytest.fixture
+ def inputs(self):
+ return torch.randn(4, 10, device=self.device, dtype=torch.float32)
+
+ @pytest.fixture
+ def base_model(self):
+ class MLP(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.lin1 = nn.Linear(20, 2, bias=bias)
+ self.sm = nn.LogSoftmax(dim=-1)
+
+ def forward(self, X):
+ X = self.lin0(X)
+ X = self.lin1(X)
+ X = self.sm(X)
+ return X
+
+ return MLP()
+
+ @pytest.fixture
+ def model(self, base_model):
+ config = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ model = get_peft_model(base_model, config).to(device=self.device, dtype=torch.float16)
+ # Register hooks on the submodule that holds parameters
+ for module in model.modules():
+ if sum(p.numel() for p in module.parameters()) > 0:
+ module.register_forward_pre_hook(self.cast_params_to_fp32_pre_hook)
+ module.register_forward_hook(self.cast_params_to_fp16_hook)
+ if isinstance(module, LoraLayer):
+ module.register_forward_hook(self.record_dtype_hook)
+ return model
+
+ def test_disable_input_dtype_casting_active(self, model, inputs):
+ self.dtype_record.clear()
+ with disable_input_dtype_casting(model, active=True):
+ model(inputs)
+ assert self.dtype_record == [torch.float32]
+
+ def test_no_disable_input_dtype_casting(self, model, inputs):
+ msg = r"expected m.*1 and m.*2 to have the same dtype"
+ with pytest.raises(RuntimeError, match=msg):
+ model(inputs)
+
+ def test_disable_input_dtype_casting_inactive(self, model, inputs):
+ msg = r"expected m.*1 and m.*2 to have the same dtype"
+ with pytest.raises(RuntimeError, match=msg):
+ with disable_input_dtype_casting(model, active=False):
+ model(inputs)
+
+ def test_disable_input_dtype_casting_inactive_after_existing_context(self, model, inputs):
+ # this is to ensure that when the context is left, we return to the previous behavior
+ with disable_input_dtype_casting(model, active=True):
+ model(inputs)
+
+ # after the context exited, we're back to the error
+ msg = r"expected m.*1 and m.*2 to have the same dtype"
+ with pytest.raises(RuntimeError, match=msg):
+ model(inputs)
diff --git a/peft/tests/test_hub_features.py b/peft/tests/test_hub_features.py
new file mode 100644
index 0000000000000000000000000000000000000000..257c487f30d7cda28269090f0c4cc9531c1c44b3
--- /dev/null
+++ b/peft/tests/test_hub_features.py
@@ -0,0 +1,236 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import copy
+
+import pytest
+import torch
+from huggingface_hub import ModelCard
+from transformers import AutoModelForCausalLM
+
+from peft import AutoPeftModelForCausalLM, BoneConfig, LoraConfig, PeftConfig, PeftModel, TaskType, get_peft_model
+
+from .testing_common import hub_online_once
+
+
+PEFT_MODELS_TO_TEST = [("peft-internal-testing/test-lora-subfolder", "test")]
+
+
+class PeftHubFeaturesTester:
+ # TODO remove when/if Hub is more stable
+ @pytest.mark.xfail(reason="Test is flaky on CI", raises=ValueError)
+ def test_subfolder(self):
+ r"""
+ Test if subfolder argument works as expected
+ """
+ for model_id, subfolder in PEFT_MODELS_TO_TEST:
+ config = PeftConfig.from_pretrained(model_id, subfolder=subfolder)
+
+ model = AutoModelForCausalLM.from_pretrained(
+ config.base_model_name_or_path,
+ )
+ model = PeftModel.from_pretrained(model, model_id, subfolder=subfolder)
+
+ assert isinstance(model, PeftModel)
+
+
+class TestLocalModel:
+ def test_local_model_saving_no_warning(self, recwarn, tmp_path):
+ # When the model is saved, the library checks for vocab changes by
+ # examining `config.json` in the model path.
+ # However, previously, those checks only covered huggingface hub models.
+ # This test makes sure that the local `config.json` is checked as well.
+ # If `save_pretrained` could not find the file, it will issue a warning.
+ model_id = "facebook/opt-125m"
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ local_dir = tmp_path / model_id
+ model.save_pretrained(local_dir)
+ del model
+
+ base_model = AutoModelForCausalLM.from_pretrained(local_dir)
+ peft_config = LoraConfig()
+ peft_model = get_peft_model(base_model, peft_config)
+ peft_model.save_pretrained(local_dir)
+
+ for warning in recwarn.list:
+ assert "Could not find a config file" not in warning.message.args[0]
+
+
+class TestBaseModelRevision:
+ def test_save_and_load_base_model_revision(self, tmp_path):
+ r"""
+ Test saving a PeftModel with a base model revision and loading with AutoPeftModel to recover the same base
+ model
+ """
+ lora_config = LoraConfig(r=8, lora_alpha=16, lora_dropout=0.0)
+ test_inputs = torch.arange(10).reshape(-1, 1)
+
+ base_model_id = "peft-internal-testing/tiny-random-BertModel"
+ revision = "v2.0.0"
+
+ base_model_revision = AutoModelForCausalLM.from_pretrained(base_model_id, revision=revision).eval()
+ peft_model_revision = get_peft_model(base_model_revision, lora_config, revision=revision)
+ output_revision = peft_model_revision(test_inputs).logits
+
+ # sanity check: the model without revision should be different
+ base_model_no_revision = AutoModelForCausalLM.from_pretrained(base_model_id, revision="main").eval()
+ # we need a copy of the config because otherwise, we are changing in-place the `revision` of the previous config and model
+ lora_config_no_revision = copy.deepcopy(lora_config)
+ lora_config_no_revision.revision = "main"
+ peft_model_no_revision = get_peft_model(base_model_no_revision, lora_config_no_revision, revision="main")
+ output_no_revision = peft_model_no_revision(test_inputs).logits
+ assert not torch.allclose(output_no_revision, output_revision)
+
+ # check that if we save and load the model, the output corresponds to the one with revision
+ peft_model_revision.save_pretrained(tmp_path / "peft_model_revision")
+ peft_model_revision_loaded = AutoPeftModelForCausalLM.from_pretrained(tmp_path / "peft_model_revision").eval()
+
+ assert peft_model_revision_loaded.peft_config["default"].revision == revision
+
+ output_revision_loaded = peft_model_revision_loaded(test_inputs).logits
+ assert torch.allclose(output_revision, output_revision_loaded)
+
+ # TODO remove when/if Hub is more stable
+ @pytest.mark.xfail(reason="Test is flaky on CI", raises=ValueError)
+ def test_load_different_peft_and_base_model_revision(self, tmp_path):
+ r"""
+ Test loading an AutoPeftModel from the hub where the base model revision and peft revision differ
+ """
+ base_model_id = "hf-internal-testing/tiny-random-BertModel"
+ base_model_revision = None
+ peft_model_id = "peft-internal-testing/tiny-random-BertModel-lora"
+ peft_model_revision = "v1.2.3"
+
+ peft_model = AutoPeftModelForCausalLM.from_pretrained(peft_model_id, revision=peft_model_revision).eval()
+
+ assert peft_model.peft_config["default"].base_model_name_or_path == base_model_id
+ assert peft_model.peft_config["default"].revision == base_model_revision
+
+
+class TestModelCard:
+ @pytest.mark.parametrize(
+ "model_id, peft_config, tags, excluded_tags, pipeline_tag",
+ [
+ (
+ "hf-internal-testing/tiny-random-Gemma3ForCausalLM",
+ LoraConfig(),
+ ["transformers", "base_model:adapter:hf-internal-testing/tiny-random-Gemma3ForCausalLM", "lora"],
+ [],
+ None,
+ ),
+ (
+ "hf-internal-testing/tiny-random-Gemma3ForCausalLM",
+ BoneConfig(),
+ ["transformers", "base_model:adapter:hf-internal-testing/tiny-random-Gemma3ForCausalLM"],
+ ["lora"],
+ None,
+ ),
+ (
+ "hf-internal-testing/tiny-random-BartForConditionalGeneration",
+ LoraConfig(),
+ [
+ "transformers",
+ "base_model:adapter:hf-internal-testing/tiny-random-BartForConditionalGeneration",
+ "lora",
+ ],
+ [],
+ None,
+ ),
+ (
+ "hf-internal-testing/tiny-random-Gemma3ForCausalLM",
+ LoraConfig(task_type=TaskType.CAUSAL_LM),
+ ["transformers", "base_model:adapter:hf-internal-testing/tiny-random-Gemma3ForCausalLM", "lora"],
+ [],
+ "text-generation",
+ ),
+ ],
+ )
+ @pytest.mark.parametrize(
+ "pre_tags",
+ [
+ ["tag1", "tag2"],
+ [],
+ ],
+ )
+ def test_model_card_has_expected_tags(
+ self, model_id, peft_config, tags, excluded_tags, pipeline_tag, pre_tags, tmp_path
+ ):
+ """Make sure that PEFT sets the tags in the model card automatically and correctly.
+ This is important so that a) the models are searchable on the Hub and also 2) some features depend on it to
+ decide how to deal with them (e.g., inference).
+
+ Makes sure that the base model tags are still present (if there are any).
+ """
+ with hub_online_once(model_id):
+ base_model = AutoModelForCausalLM.from_pretrained(model_id)
+
+ if pre_tags:
+ base_model.add_model_tags(pre_tags)
+
+ peft_model = get_peft_model(base_model, peft_config)
+ save_path = tmp_path / "adapter"
+
+ peft_model.save_pretrained(save_path)
+
+ model_card = ModelCard.load(save_path / "README.md")
+ assert set(tags).issubset(set(model_card.data.tags))
+
+ if excluded_tags:
+ assert set(excluded_tags).isdisjoint(set(model_card.data.tags))
+
+ if pre_tags:
+ assert set(pre_tags).issubset(set(model_card.data.tags))
+
+ if pipeline_tag:
+ assert model_card.data.pipeline_tag == pipeline_tag
+
+ @pytest.fixture
+ def custom_model_cls(self):
+ class MyNet(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.l1 = torch.nn.Linear(10, 20)
+ self.l2 = torch.nn.Linear(20, 1)
+
+ def forward(self, X):
+ return self.l2(self.l1(X))
+
+ return MyNet
+
+ def test_custom_models_dont_have_transformers_tag(self, custom_model_cls, tmp_path):
+ base_model = custom_model_cls()
+ peft_config = LoraConfig(target_modules="all-linear")
+ peft_model = get_peft_model(base_model, peft_config)
+
+ peft_model.save_pretrained(tmp_path)
+
+ model_card = ModelCard.load(tmp_path / "README.md")
+
+ assert model_card.data.tags is not None
+ assert "transformers" not in model_card.data.tags
+
+ def test_custom_peft_type_does_not_raise(self, tmp_path):
+ # Passing a string value as peft_type value in the config is valid, so it should work.
+ # See https://github.com/huggingface/peft/issues/2634
+ model_id = "hf-internal-testing/tiny-random-Gemma3ForCausalLM"
+ with hub_online_once(model_id):
+ base_model = AutoModelForCausalLM.from_pretrained(model_id)
+ peft_config = LoraConfig()
+
+ # We simulate a custom PEFT type by using a string value of an existing method. This skips the need for
+ # registering a new method but tests the case where we pass a string value instead of an enum.
+ peft_type = "LORA"
+ peft_config.peft_type = peft_type
+
+ peft_model = get_peft_model(base_model, peft_config)
+ peft_model.save_pretrained(tmp_path)
diff --git a/peft/tests/test_incremental_pca.py b/peft/tests/test_incremental_pca.py
new file mode 100644
index 0000000000000000000000000000000000000000..33d7c6a1f28cffca559368c5c7ba07f7d4c317f1
--- /dev/null
+++ b/peft/tests/test_incremental_pca.py
@@ -0,0 +1,185 @@
+# Copyright 2024-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# Adapted from https://github.com/scikit-learn/scikit-learn/blob/main/sklearn/decomposition/tests/test_incremental_pca.py
+
+import pytest
+import torch
+from datasets import load_dataset
+from torch.testing import assert_close
+
+from peft.utils.incremental_pca import IncrementalPCA
+
+
+torch.manual_seed(1999)
+
+iris = load_dataset("scikit-learn/iris", split="train")
+
+
+def test_incremental_pca():
+ # Incremental PCA on dense arrays.
+ n_components = 2
+ X = torch.tensor([iris["SepalLengthCm"], iris["SepalWidthCm"], iris["PetalLengthCm"], iris["PetalWidthCm"]]).T
+ batch_size = X.shape[0] // 3
+ ipca = IncrementalPCA(n_components=n_components, batch_size=batch_size)
+ ipca.fit(X)
+ X_transformed = ipca.transform(X)
+
+ # PCA
+ U, S, Vh = torch.linalg.svd(X - torch.mean(X, dim=0))
+ max_abs_rows = torch.argmax(torch.abs(Vh), dim=1)
+ signs = torch.sign(Vh[range(Vh.shape[0]), max_abs_rows])
+ Vh *= signs.view(-1, 1)
+ explained_variance = S**2 / (X.size(0) - 1)
+ explained_variance_ratio = explained_variance / explained_variance.sum()
+
+ assert X_transformed.shape == (X.shape[0], 2)
+ assert_close(
+ ipca.explained_variance_ratio_.sum().item(),
+ explained_variance_ratio[:n_components].sum().item(),
+ rtol=1e-3,
+ atol=1e-3,
+ )
+
+
+def test_incremental_pca_check_projection():
+ # Test that the projection of data is correct.
+ n, p = 100, 3
+ X = torch.randn(n, p, dtype=torch.float64) * 0.1
+ X[:10] += torch.tensor([3, 4, 5])
+ Xt = 0.1 * torch.randn(1, p, dtype=torch.float64) + torch.tensor([3, 4, 5])
+
+ # Get the reconstruction of the generated data X
+ # Note that Xt has the same "components" as X, just separated
+ # This is what we want to ensure is recreated correctly
+ Yt = IncrementalPCA(n_components=2).fit(X).transform(Xt)
+
+ # Normalize
+ Yt /= torch.sqrt((Yt**2).sum())
+
+ # Make sure that the first element of Yt is ~1, this means
+ # the reconstruction worked as expected
+ assert_close(torch.abs(Yt[0][0]).item(), 1.0, atol=1e-1, rtol=1e-1)
+
+
+def test_incremental_pca_validation():
+ # Test that n_components is <= n_features.
+ X = torch.tensor([[0, 1, 0], [1, 0, 0]])
+ n_samples, n_features = X.shape
+ n_components = 4
+ with pytest.raises(
+ ValueError,
+ match=(
+ f"n_components={n_components} invalid"
+ f" for n_features={n_features}, need more rows than"
+ " columns for IncrementalPCA"
+ " processing"
+ ),
+ ):
+ IncrementalPCA(n_components, batch_size=10).fit(X)
+
+ # Tests that n_components is also <= n_samples.
+ n_components = 3
+ with pytest.raises(
+ ValueError,
+ match=(f"n_components={n_components} must be less or equal to the batch number of samples {n_samples}"),
+ ):
+ IncrementalPCA(n_components=n_components).partial_fit(X)
+
+
+def test_n_components_none():
+ # Ensures that n_components == None is handled correctly
+ for n_samples, n_features in [(50, 10), (10, 50)]:
+ X = torch.rand(n_samples, n_features)
+ ipca = IncrementalPCA(n_components=None)
+
+ # First partial_fit call, ipca.n_components_ is inferred from
+ # min(X.shape)
+ ipca.partial_fit(X)
+ assert ipca.n_components == min(X.shape)
+
+
+def test_incremental_pca_num_features_change():
+ # Test that changing n_components will raise an error.
+ n_samples = 100
+ X = torch.randn(n_samples, 20)
+ X2 = torch.randn(n_samples, 50)
+ ipca = IncrementalPCA(n_components=None)
+ ipca.fit(X)
+ with pytest.raises(ValueError):
+ ipca.partial_fit(X2)
+
+
+def test_incremental_pca_batch_signs():
+ # Test that components_ sign is stable over batch sizes.
+ n_samples = 100
+ n_features = 3
+ X = torch.randn(n_samples, n_features)
+ all_components = []
+ batch_sizes = torch.arange(10, 20)
+ for batch_size in batch_sizes:
+ ipca = IncrementalPCA(n_components=None, batch_size=batch_size).fit(X)
+ all_components.append(ipca.components_)
+
+ for i, j in zip(all_components[:-1], all_components[1:]):
+ assert_close(torch.sign(i), torch.sign(j), rtol=1e-6, atol=1e-6)
+
+
+def test_incremental_pca_batch_values():
+ # Test that components_ values are stable over batch sizes.
+ n_samples = 100
+ n_features = 3
+ X = torch.randn(n_samples, n_features)
+ all_components = []
+ batch_sizes = torch.arange(20, 40, 3)
+ for batch_size in batch_sizes:
+ ipca = IncrementalPCA(n_components=None, batch_size=batch_size).fit(X)
+ all_components.append(ipca.components_)
+
+ for i, j in zip(all_components[:-1], all_components[1:]):
+ assert_close(i, j, rtol=1e-1, atol=1e-1)
+
+
+def test_incremental_pca_partial_fit():
+ # Test that fit and partial_fit get equivalent results.
+ n, p = 50, 3
+ X = torch.randn(n, p) # spherical data
+ X[:, 1] *= 0.00001 # make middle component relatively small
+ X += torch.tensor([5, 4, 3]) # make a large mean
+
+ # same check that we can find the original data from the transformed
+ # signal (since the data is almost of rank n_components)
+ batch_size = 10
+ ipca = IncrementalPCA(n_components=2, batch_size=batch_size).fit(X)
+ pipca = IncrementalPCA(n_components=2, batch_size=batch_size)
+ # Add one to make sure endpoint is included
+ batch_itr = torch.arange(0, n + 1, batch_size)
+ for i, j in zip(batch_itr[:-1], batch_itr[1:]):
+ pipca.partial_fit(X[i:j, :])
+ assert_close(ipca.components_, pipca.components_, rtol=1e-3, atol=1e-3)
+
+
+def test_incremental_pca_lowrank():
+ # Test that lowrank mode is equivalent to non-lowrank mode.
+ n_components = 2
+ X = torch.tensor([iris["SepalLengthCm"], iris["SepalWidthCm"], iris["PetalLengthCm"], iris["PetalWidthCm"]]).T
+ batch_size = X.shape[0] // 3
+
+ ipca = IncrementalPCA(n_components=n_components, batch_size=batch_size)
+ ipca.fit(X)
+
+ ipcalr = IncrementalPCA(n_components=n_components, batch_size=batch_size, lowrank=True)
+ ipcalr.fit(X)
+
+ assert_close(ipca.components_, ipcalr.components_, rtol=1e-7, atol=1e-7)
diff --git a/peft/tests/test_initialization.py b/peft/tests/test_initialization.py
new file mode 100644
index 0000000000000000000000000000000000000000..2b83ed21f381acadd2dabd09d83dcbe91ba4eeb7
--- /dev/null
+++ b/peft/tests/test_initialization.py
@@ -0,0 +1,4351 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import copy
+import itertools
+import platform
+import re
+import warnings
+from collections import defaultdict
+from contextlib import contextmanager
+from copy import deepcopy
+from unittest.mock import patch
+
+import pytest
+import torch
+from datasets import Dataset
+from huggingface_hub import snapshot_download
+from huggingface_hub.errors import HfHubHTTPError, LocalEntryNotFoundError
+from huggingface_hub.utils import reset_sessions
+from safetensors.torch import load_file
+from scipy import stats
+from torch import nn
+from torch.utils.data import DataLoader
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+from peft import (
+ AdaLoraConfig,
+ C3AConfig,
+ EvaConfig,
+ IA3Config,
+ LoftQConfig,
+ LoKrConfig,
+ LoraConfig,
+ PeftMixedModel,
+ PeftModel,
+ PeftModelForCausalLM,
+ PeftModelForFeatureExtraction,
+ PeftModelForQuestionAnswering,
+ PeftModelForSeq2SeqLM,
+ PeftModelForSequenceClassification,
+ PeftModelForTokenClassification,
+ PrefixTuningConfig,
+ PromptTuningConfig,
+ VBLoRAConfig,
+ VeraConfig,
+ get_eva_state_dict,
+ get_peft_model,
+ initialize_lora_eva_weights,
+ inject_adapter_in_model,
+ set_peft_model_state_dict,
+)
+from peft.mapping import PEFT_TYPE_TO_PREFIX_MAPPING
+from peft.tuners.lora.config import CordaConfig
+from peft.tuners.lora.corda import preprocess_corda
+from peft.tuners.lora.layer import LoraLayer
+from peft.utils import infer_device
+from peft.utils.hotswap import hotswap_adapter, prepare_model_for_compiled_hotswap
+
+from .testing_utils import load_dataset_english_quotes, require_deterministic_for_xpu
+
+
+class TestLoraInitialization:
+ """Test class to check the initialization of LoRA adapters."""
+
+ torch_device = infer_device()
+
+ def get_uniform(self, amin, amax, size=(10000,)):
+ unif = torch.distributions.uniform.Uniform(amin, amax)
+ samples = unif.sample(size)
+ return samples
+
+ def get_normal(self, mean, std, size=(10000,)):
+ normal = torch.distributions.normal.Normal(mean, std)
+ samples = normal.sample(size)
+ return samples
+
+ def get_model(self):
+ class MyModule(nn.Module):
+ def __init__(self):
+ super().__init__()
+ # choose a large weight so that averages are close to expected values
+ self.linear = nn.Linear(1000, 1000)
+ self.embed = nn.Embedding(1000, 1000)
+ self.conv2d = nn.Conv2d(100, 100, 3)
+
+ def forward(self, x):
+ x_int = (100 * x).int()
+ x_4d = x.flatten().reshape(1, 100, 10, 10)
+ return self.linear(x), self.embed(x_int), self.conv2d(x_4d)
+
+ return MyModule().eval().to(self.torch_device)
+
+ @pytest.fixture
+ def data(self):
+ return torch.rand(10, 1000).to(self.torch_device)
+
+ def test_lora_linear_init_default(self):
+ # default is True
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ config = LoraConfig(target_modules=["linear"])
+ model = get_peft_model(model, config)
+ weight_A = model.linear.lora_A["default"].weight
+ weight_B = model.linear.lora_B["default"].weight
+
+ # use statistical test to check if weight A is from a uniform distribution
+ unif = self.get_uniform(weight_A.min().item(), weight_A.max().item())
+ _, p_value = stats.kstest(weight_A.detach().flatten().cpu().numpy(), unif.flatten().cpu().numpy())
+ assert p_value > 0.5
+
+ # check that weight A is *not* from a normal distribution
+ normal = self.get_normal(weight_A.mean().item(), weight_A.std().item())
+ _, p_value = stats.kstest(weight_A.detach().flatten().cpu().numpy(), normal.flatten().cpu().numpy())
+ assert p_value < 0.05
+
+ # check that weight B is zero
+ assert (weight_B == 0.0).all()
+
+ def test_lora_linear_init_gaussian(self):
+ # use gaussian init
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ config = LoraConfig(target_modules=["linear"], init_lora_weights="gaussian")
+ model = get_peft_model(model, config)
+ weight_A = model.linear.lora_A["default"].weight
+ weight_B = model.linear.lora_B["default"].weight
+
+ # use statistical test to check if weight A is from a normal distribution
+ normal = self.get_normal(0.0, 1 / config.r)
+ _, p_value = stats.kstest(weight_A.detach().flatten().cpu().numpy(), normal.flatten().cpu().numpy())
+
+ assert p_value > 0.5
+
+ # check that weight A is *not* from a uniform distribution
+ unif = self.get_uniform(weight_A.min().item(), weight_A.max().item())
+ _, p_value = stats.kstest(weight_A.detach().flatten().cpu().numpy(), unif.flatten().cpu().numpy())
+ assert p_value < 0.05
+
+ # check that weight B is zero
+ assert (weight_B == 0.0).all()
+
+ def test_lora_linear_false(self):
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ config = LoraConfig(target_modules=["linear"], init_lora_weights=False)
+ model = get_peft_model(model, config)
+ weight_B = model.linear.lora_B["default"].weight
+
+ # with init_lora_weights=False, weight B should *not* be zero. We don't care so much about the actual values
+ # as long as they are not zero, in order to avoid identity transformation.
+ assert not torch.allclose(weight_B, torch.zeros_like(weight_B))
+
+ def test_lora_embedding_default(self):
+ # embedding is initialized as a normal distribution, not kaiming uniform
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ config = LoraConfig(target_modules=["embed"])
+ model = get_peft_model(model, config)
+ weight_A = model.embed.lora_embedding_A["default"]
+ weight_B = model.embed.lora_embedding_B["default"]
+
+ # use statistical test to check if weight B is from a normal distribution
+ normal = self.get_normal(0.0, 1.0)
+ _, p_value = stats.kstest(weight_B.detach().flatten().cpu().numpy(), normal.flatten().cpu().numpy())
+ assert p_value > 0.5
+
+ # check that weight B is *not* from a uniform distribution
+ unif = self.get_uniform(weight_B.min().item(), weight_B.max().item())
+ _, p_value = stats.kstest(weight_B.detach().flatten().cpu().numpy(), unif.flatten().cpu().numpy())
+ assert p_value < 0.05
+
+ # check that weight A is zero
+ assert (weight_A == 0.0).all()
+
+ def test_lora_embedding_gaussian(self):
+ # embedding does not change with init_lora_weights="gaussian" vs True
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ config = LoraConfig(target_modules=["embed"], init_lora_weights="gaussian")
+ model = get_peft_model(model, config)
+ weight_A = model.embed.lora_embedding_A["default"]
+ weight_B = model.embed.lora_embedding_B["default"]
+
+ # use statistical test to check if weight B is from a normal distribution
+ normal = self.get_normal(0.0, 1.0)
+ _, p_value = stats.kstest(weight_B.detach().flatten().cpu().numpy(), normal.flatten().cpu().numpy())
+ assert p_value > 0.5
+
+ # check that weight B is *not* from a uniform distribution
+ unif = self.get_uniform(weight_B.min().item(), weight_B.max().item())
+ _, p_value = stats.kstest(weight_B.detach().flatten().cpu().numpy(), unif.flatten().cpu().numpy())
+ assert p_value < 0.05
+
+ # check that weight A is zero
+ assert (weight_A == 0.0).all()
+
+ def test_lora_embedding_false(self):
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ config = LoraConfig(target_modules=["embed"], init_lora_weights=False)
+ model = get_peft_model(model, config)
+ weight_A = model.embed.lora_embedding_B["default"]
+
+ # with init_lora_weights=False, weight A should *not* be zero. We don't care so much about the actual values
+ # as long as they are not zero, in order to avoid identity transformation.
+ assert not torch.allclose(weight_A, torch.zeros_like(weight_A))
+
+ def test_lora_conv2d_default(self):
+ # default is True
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ config = LoraConfig(target_modules=["conv2d"])
+ model = get_peft_model(model, config)
+ weight_A = model.conv2d.lora_A["default"].weight
+ weight_B = model.conv2d.lora_B["default"].weight
+
+ # use statistical test to check if weight A is from a uniform distribution
+ unif = self.get_uniform(weight_A.min().item(), weight_A.max().item())
+ _, p_value = stats.kstest(weight_A.detach().flatten().cpu().numpy(), unif.flatten().cpu().numpy())
+ assert p_value > 0.5
+
+ # check that weight A is *not* from a normal distribution
+ normal = self.get_normal(weight_A.mean().item(), weight_A.std().item())
+ _, p_value = stats.kstest(weight_A.detach().flatten().cpu().numpy(), normal.flatten().cpu().numpy())
+ assert p_value < 0.05
+
+ # check that weight B is zero
+ assert (weight_B == 0.0).all()
+
+ def test_lora_conv2d_init_gaussian(self):
+ # use gaussian init
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ config = LoraConfig(target_modules=["conv2d"], init_lora_weights="gaussian")
+ model = get_peft_model(model, config)
+ weight_A = model.conv2d.lora_A["default"].weight
+ weight_B = model.conv2d.lora_B["default"].weight
+
+ # use statistical test to check if weight A is from a normal distribution
+ normal = self.get_normal(0.0, 1 / config.r)
+ _, p_value = stats.kstest(weight_A.detach().flatten().cpu().numpy(), normal.flatten().cpu().numpy())
+ assert p_value > 0.5
+
+ # check that weight A is *not* from a uniform distribution
+ unif = self.get_uniform(weight_A.min().item(), weight_A.max().item())
+ _, p_value = stats.kstest(weight_A.detach().flatten().cpu().numpy(), unif.flatten().cpu().numpy())
+ assert p_value < 0.05
+
+ # check that weight B is zero
+ assert (weight_B == 0.0).all()
+
+ def test_lora_conv2d_false(self):
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ config = LoraConfig(target_modules=["conv2d"], init_lora_weights=False)
+ model = get_peft_model(model, config)
+ weight_B = model.conv2d.lora_B["default"].weight
+
+ # with init_lora_weights=False, weight B should *not* be zero. We don't care so much about the actual values
+ # as long as they are not zero, in order to avoid identity transformation.
+ assert not torch.allclose(weight_B, torch.zeros_like(weight_B))
+
+ def test_lora_init_orthogonal(self):
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ config = LoraConfig(target_modules=["linear"], init_lora_weights="orthogonal")
+ model = get_peft_model(model, config)
+
+ weight_A = model.linear.lora_A["default"].weight
+ weight_B = model.linear.lora_B["default"].weight
+
+ assert not torch.allclose(weight_A, torch.zeros_like(weight_A))
+ assert not torch.allclose(weight_B, torch.zeros_like(weight_B))
+ assert (weight_B @ weight_A).abs().max() < 1e-6
+
+ @pytest.mark.parametrize("dtype", [torch.float16, torch.bfloat16])
+ def test_lora_init_orthogonal_half_precision_dtype(self, dtype):
+ try:
+ torch.zeros(1, dtype=dtype)
+ except Exception:
+ pytest.skip(f"dtype {dtype} not supported on this system, skipping test")
+
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ config = LoraConfig(target_modules=["linear"], init_lora_weights="orthogonal")
+ model = get_peft_model(model, config).to(dtype)
+
+ weight_A = model.linear.lora_A["default"].weight
+ weight_B = model.linear.lora_B["default"].weight
+
+ assert weight_A.dtype == dtype
+ assert weight_B.dtype == dtype
+
+ def test_lora_init_orthogonal_odd_rank_raises(self):
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ config = LoraConfig(target_modules=["linear"], init_lora_weights="orthogonal", r=7)
+ msg = "Orthogonal initialization requires the LoRA rank to be even, got 7 instead."
+ with pytest.raises(ValueError, match=msg):
+ get_peft_model(model, config)
+
+ def test_lora_scaling_default(self):
+ # default is True
+ torch.manual_seed(0)
+
+ model = self.get_model()
+
+ # check scaling factor use_rslora=False
+ config = LoraConfig(target_modules=["linear", "embed", "conv2d"], lora_alpha=3, r=16, use_rslora=False)
+ model = get_peft_model(model, config)
+
+ expected_scaling = config.lora_alpha / config.r
+
+ assert model.linear.scaling["default"] == expected_scaling
+ assert model.embed.scaling["default"] == expected_scaling
+ assert model.conv2d.scaling["default"] == expected_scaling
+
+ # testcase for bugfix for issue 2194
+ def test_rank_alpha_pattern_override(self):
+ torch.manual_seed(0)
+
+ layer = self.get_model()
+ model = nn.Sequential(layer, layer)
+ config = LoraConfig(
+ target_modules=["linear"],
+ lora_alpha=1,
+ r=8,
+ use_rslora=False,
+ rank_pattern={"linear": 8},
+ alpha_pattern={"0.linear": 2},
+ )
+ model = get_peft_model(model, config)
+ scaling_with_rank_pattern = model.model[0].linear.scaling
+
+ layer = self.get_model()
+ model = nn.Sequential(layer, layer)
+ config = LoraConfig(
+ target_modules=["linear"], lora_alpha=1, r=8, use_rslora=False, alpha_pattern={"0.linear": 2}
+ )
+ model = get_peft_model(model, config)
+ scaling_without_rank_pattern = model.model[0].linear.scaling
+
+ assert scaling_with_rank_pattern == scaling_without_rank_pattern
+
+ def test_lora_pissa_linear_init_default(self, data):
+ model = self.get_model()
+ output = model(data)[0]
+
+ config = LoraConfig(init_lora_weights="pissa", target_modules=["linear"])
+ peft_model = get_peft_model(deepcopy(model), config)
+ assert torch.allclose(output, peft_model(data)[0], atol=1e-06)
+
+ config = LoraConfig(init_lora_weights="pissa_niter_16", target_modules=["linear"])
+ peft_model = get_peft_model(deepcopy(model), config)
+ assert torch.allclose(output, peft_model(data)[0], atol=1e-06)
+
+ def test_lora_olora_linear_init_default(self, data):
+ model = self.get_model()
+ output = model(data)[0]
+
+ # Both OLoRA and olora should work
+ config = LoraConfig(init_lora_weights="OLoRA", target_modules=["linear"])
+ peft_model = get_peft_model(deepcopy(model), config)
+ assert torch.allclose(output, peft_model(data)[0], atol=1e-06)
+
+ def test_lora_pissa_conversion_same_output_after_loading(self, data, tmp_path):
+ model = self.get_model()
+ output_base = model(data)[0]
+
+ config = LoraConfig(init_lora_weights="pissa", target_modules=["linear"], r=8)
+ peft_model = get_peft_model(deepcopy(model), config)
+ # save the initial model
+ peft_model.peft_config["default"].init_lora_weights = True
+ peft_model.save_pretrained(tmp_path / "init-model")
+ peft_model.peft_config["default"].init_lora_weights = "pissa"
+
+ # modify the weights, or else the adapter performs an identity transformation
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ output_pissa = peft_model(data)[0]
+
+ # sanity check
+ tol = 1e-06
+ assert not torch.allclose(output_base, output_pissa, atol=tol, rtol=tol)
+
+ # save the model normally
+ peft_model.save_pretrained(tmp_path / "pissa-model")
+ model_loaded = PeftModel.from_pretrained(deepcopy(model), tmp_path / "pissa-model")
+ output_loaded = model_loaded(data)[0]
+
+ assert torch.allclose(output_pissa, output_loaded, atol=tol, rtol=tol)
+ # sanity check: ranks should still be 8 as initially
+ assert model_loaded.peft_config["default"].r == 8
+ assert model_loaded.base_model.model.linear.lora_A["default"].weight.shape[0] == 8
+ # sanity check: the base model weights were indeed changed
+ assert not torch.allclose(
+ model.linear.weight, model_loaded.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ # save the model with conversion
+ peft_config_keys_before = list(peft_model.peft_config.keys())
+ peft_config_dict_before = peft_model.peft_config["default"].to_dict()
+ peft_model.save_pretrained(
+ tmp_path / "pissa-model-converted", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+ peft_config_keys_after = list(peft_model.peft_config.keys())
+ peft_config_dict_after = peft_model.peft_config["default"].to_dict()
+ assert peft_config_keys_before == peft_config_keys_after
+ assert peft_config_dict_before == peft_config_dict_after
+
+ model_converted = PeftModel.from_pretrained(deepcopy(model), tmp_path / "pissa-model-converted")
+ output_converted = model_converted(data)[0]
+
+ assert torch.allclose(output_pissa, output_converted, atol=tol, rtol=tol)
+ # rank should be double of what it was initially
+ assert model_converted.peft_config["default"].r == 16
+ assert model_converted.base_model.model.linear.lora_A["default"].weight.shape[0] == 16
+ # base model weights should be the same as the initial model
+ assert torch.allclose(
+ model.linear.weight, model_converted.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ def test_lora_pissa_conversion_same_output_after_loading_with_rank_pattern(self, data, tmp_path):
+ # same as above, but using rank_pattern
+ model = self.get_model()
+ output_base = model(data)[0]
+
+ # use rank_pattern here; note that since there is only a single linear layer, r is completely overridden
+ config = LoraConfig(init_lora_weights="pissa", target_modules=["linear"], r=8, rank_pattern={"linear": 32})
+ peft_model = get_peft_model(deepcopy(model), config)
+ # save the initial model
+ peft_model.peft_config["default"].init_lora_weights = True
+ peft_model.save_pretrained(tmp_path / "init-model")
+ peft_model.peft_config["default"].init_lora_weights = "pissa"
+
+ # modify the weights, or else the adapter performs an identity transformation
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ output_pissa = peft_model(data)[0]
+
+ # sanity check
+ tol = 1e-06
+ assert not torch.allclose(output_base, output_pissa, atol=tol, rtol=tol)
+
+ # save the model normally
+ peft_model.save_pretrained(tmp_path / "pissa-model")
+ model_loaded = PeftModel.from_pretrained(deepcopy(model), tmp_path / "pissa-model")
+ output_loaded = model_loaded(data)[0]
+
+ assert torch.allclose(output_pissa, output_loaded, atol=tol, rtol=tol)
+ # sanity check: ranks should still be 8 as initially
+ assert model_loaded.peft_config["default"].r == 8
+ assert model_loaded.base_model.model.linear.lora_A["default"].weight.shape[0] == 32
+ # sanity check: the base model weights were indeed changed
+ assert not torch.allclose(
+ model.linear.weight, model_loaded.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ # save the model with conversion
+ peft_model.save_pretrained(
+ tmp_path / "pissa-model-converted", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+ model_converted = PeftModel.from_pretrained(deepcopy(model), tmp_path / "pissa-model-converted")
+ output_converted = model_converted(data)[0]
+
+ assert torch.allclose(output_pissa, output_converted, atol=tol, rtol=tol)
+ # rank should be double of what it was initially
+ assert model_converted.peft_config["default"].r == 16
+ assert model_converted.base_model.model.linear.lora_A["default"].weight.shape[0] == 64
+ # base model weights should be the same as the initial model
+ assert torch.allclose(
+ model.linear.weight, model_converted.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ def test_lora_pissa_conversion_same_output_after_loading_with_alpha_pattern(self, data, tmp_path):
+ # same as above, but using alpha_pattern
+ model = self.get_model()
+ output_base = model(data)[0]
+
+ # use alpha_pattern here; note that since there is only a single linear layer, lora_alpha is completely
+ # overridden
+ config = LoraConfig(init_lora_weights="pissa", target_modules=["linear"], alpha_pattern={"linear": 5})
+ peft_model = get_peft_model(deepcopy(model), config)
+ # save the initial model
+ peft_model.peft_config["default"].init_lora_weights = True
+ peft_model.save_pretrained(tmp_path / "init-model")
+ peft_model.peft_config["default"].init_lora_weights = "pissa"
+
+ # modify the weights, or else the adapter performs an identity transformation
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ output_pissa = peft_model(data)[0]
+
+ # sanity check
+ tol = 1e-06
+ assert not torch.allclose(output_base, output_pissa, atol=tol, rtol=tol)
+
+ # save the model normally
+ peft_model.save_pretrained(tmp_path / "pissa-model")
+ model_loaded = PeftModel.from_pretrained(deepcopy(model), tmp_path / "pissa-model")
+ output_loaded = model_loaded(data)[0]
+
+ assert torch.allclose(output_pissa, output_loaded, atol=tol, rtol=tol)
+ # sanity check: ranks should still be 8 as initially
+ assert model_loaded.peft_config["default"].r == 8
+ assert model_loaded.base_model.model.linear.lora_A["default"].weight.shape[0] == 8
+ assert model_loaded.base_model.model.linear.scaling["default"] == 5 / 8
+ # sanity check: the base model weights were indeed changed
+ assert not torch.allclose(
+ model.linear.weight, model_loaded.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ # save the model with conversion
+ peft_model.save_pretrained(
+ tmp_path / "pissa-model-converted", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+ model_converted = PeftModel.from_pretrained(deepcopy(model), tmp_path / "pissa-model-converted")
+ output_converted = model_converted(data)[0]
+
+ assert torch.allclose(output_pissa, output_converted, atol=tol, rtol=tol)
+ # rank should be double of what it was initially
+ assert model_converted.peft_config["default"].r == 16
+ assert model_converted.base_model.model.linear.lora_A["default"].weight.shape[0] == 16
+ assert model_converted.base_model.model.linear.scaling["default"] == 10 / 16
+ # base model weights should be the same as the initial model
+ assert torch.allclose(
+ model.linear.weight, model_converted.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ def test_lora_pissa_conversion_same_output_after_loading_with_rslora(self, data, tmp_path):
+ model = self.get_model()
+ output_base = model(data)[0]
+
+ config = LoraConfig(init_lora_weights="pissa", target_modules=["linear"], r=8, use_rslora=True)
+ peft_model = get_peft_model(deepcopy(model), config)
+ # save the initial model
+ peft_model.peft_config["default"].init_lora_weights = True
+ peft_model.save_pretrained(tmp_path / "init-model")
+ peft_model.peft_config["default"].init_lora_weights = "pissa"
+
+ # modify the weights, or else the adapter performs an identity transformation
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ output_pissa = peft_model(data)[0]
+
+ # sanity check
+ tol = 1e-06
+ assert not torch.allclose(output_base, output_pissa, atol=tol, rtol=tol)
+
+ # save the model normally
+ peft_model.save_pretrained(tmp_path / "pissa-model")
+ model_loaded = PeftModel.from_pretrained(deepcopy(model), tmp_path / "pissa-model")
+ output_loaded = model_loaded(data)[0]
+
+ assert torch.allclose(output_pissa, output_loaded, atol=tol, rtol=tol)
+ # sanity check: ranks should still be 8 as initially
+ assert model_loaded.peft_config["default"].r == 8
+ assert model_loaded.base_model.model.linear.lora_A["default"].weight.shape[0] == 8
+ assert model_loaded.base_model.model.linear.scaling["default"] == 8 / (8**0.5)
+ # sanity check: the base model weights were indeed changed
+ assert not torch.allclose(
+ model.linear.weight, model_loaded.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ # save the model with conversion
+ peft_model.save_pretrained(
+ tmp_path / "pissa-model-converted", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+ model_converted = PeftModel.from_pretrained(deepcopy(model), tmp_path / "pissa-model-converted")
+ output_converted = model_converted(data)[0]
+
+ assert torch.allclose(output_pissa, output_converted, atol=tol, rtol=tol)
+ # rank should be double of what it was initially
+ assert model_converted.peft_config["default"].r == 16
+ assert model_converted.base_model.model.linear.lora_A["default"].weight.shape[0] == 16
+ # same scale as before with a little bit of floating point imprecision
+ assert model_converted.base_model.model.linear.scaling["default"] == pytest.approx(8 / (8**0.5))
+ # base model weights should be the same as the initial model
+ assert torch.allclose(
+ model.linear.weight, model_converted.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ def test_pissa_rank_pattern_and_rslora_raises(self, tmp_path):
+ # it's not possible to determine the correct scale when using rslora with rank or alpha pattern, because the
+ # scale is not stored in the state_dict
+ model = self.get_model()
+ config = LoraConfig(
+ init_lora_weights="pissa", target_modules=["linear"], r=8, rank_pattern={"linear": 2}, use_rslora=True
+ )
+ peft_model = get_peft_model(model, config)
+ peft_model.save_pretrained(tmp_path / "init-model")
+
+ msg = re.escape("Passing `path_initial_model_for_weight_conversion` to `save_pretrained`")
+ with pytest.raises(ValueError, match=msg):
+ peft_model.save_pretrained(
+ tmp_path / "pissa-model", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+
+ def test_pissa_alpha_pattern_and_rslora_raises(self, tmp_path):
+ # it's not possible to determine the correct scale when using rslora with rank or alpha pattern, because the
+ # scale is not stored in the state_dict
+ model = self.get_model()
+ config = LoraConfig(
+ init_lora_weights="pissa", target_modules=["linear"], r=8, alpha_pattern={"linear": 2}, use_rslora=True
+ )
+ peft_model = get_peft_model(model, config)
+ peft_model.save_pretrained(tmp_path / "init-model")
+
+ msg = re.escape("Passing `path_initial_model_for_weight_conversion` to `save_pretrained`")
+ with pytest.raises(ValueError, match=msg):
+ peft_model.save_pretrained(
+ tmp_path / "pissa-model", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+
+ def test_olora_conversion_same_output_after_loading(self, data, tmp_path):
+ model = self.get_model()
+ output_base = model(data)[0]
+
+ config = LoraConfig(init_lora_weights="olora", target_modules=["linear"], r=8)
+ peft_model = get_peft_model(deepcopy(model), config)
+ # save the initial model
+ peft_model.save_pretrained(tmp_path / "init-model")
+
+ # modify the weights, or else the adapter performs an identity transformation
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ output_olora = peft_model(data)[0]
+
+ # sanity check
+ tol = 1e-06
+ assert not torch.allclose(output_base, output_olora, atol=tol, rtol=tol)
+
+ # save the model normally
+ peft_model.save_pretrained(tmp_path / "olora-model")
+ model_loaded = PeftModel.from_pretrained(deepcopy(model), tmp_path / "olora-model")
+ output_loaded = model_loaded(data)[0]
+
+ assert torch.allclose(output_olora, output_loaded, atol=tol, rtol=tol)
+ # sanity check: ranks should still be 8 as initially
+ assert model_loaded.peft_config["default"].r == 8
+ assert model_loaded.base_model.model.linear.lora_A["default"].weight.shape[0] == 8
+ # sanity check: the base model weights were indeed changed
+ assert not torch.allclose(
+ model.linear.weight, model_loaded.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ # save the model with conversion
+ peft_config_keys_before = list(peft_model.peft_config.keys())
+ peft_config_dict_before = peft_model.peft_config["default"].to_dict()
+ peft_model.save_pretrained(
+ tmp_path / "olora-model-converted", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+ peft_config_keys_after = list(peft_model.peft_config.keys())
+ peft_config_dict_after = peft_model.peft_config["default"].to_dict()
+ assert peft_config_keys_before == peft_config_keys_after
+ assert peft_config_dict_before == peft_config_dict_after
+
+ model_converted = PeftModel.from_pretrained(deepcopy(model), tmp_path / "olora-model-converted")
+ output_converted = model_converted(data)[0]
+
+ assert torch.allclose(output_olora, output_converted, atol=tol, rtol=tol)
+ # rank should be double of what it was initially
+ assert model_converted.peft_config["default"].r == 16
+ assert model_converted.base_model.model.linear.lora_A["default"].weight.shape[0] == 16
+ # base model weights should be the same as the initial model
+ assert torch.allclose(
+ model.linear.weight, model_converted.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ def test_olora_conversion_same_output_after_loading_with_rank_pattern(self, data, tmp_path):
+ # same as above, but using rank_pattern
+ model = self.get_model()
+ output_base = model(data)[0]
+
+ # use rank_pattern here; note that since there is only a single linear layer, r is completely overridden
+ config = LoraConfig(init_lora_weights="olora", target_modules=["linear"], r=8, rank_pattern={"linear": 32})
+ peft_model = get_peft_model(deepcopy(model), config)
+ # save the initial model
+ peft_model.save_pretrained(tmp_path / "init-model")
+
+ # modify the weights, or else the adapter performs an identity transformation
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ output_olora = peft_model(data)[0]
+
+ # sanity check
+ tol = 1e-06
+ assert not torch.allclose(output_base, output_olora, atol=tol, rtol=tol)
+
+ # save the model normally
+ peft_model.save_pretrained(tmp_path / "olora-model")
+ model_loaded = PeftModel.from_pretrained(deepcopy(model), tmp_path / "olora-model")
+ output_loaded = model_loaded(data)[0]
+
+ assert torch.allclose(output_olora, output_loaded, atol=tol, rtol=tol)
+ # sanity check: ranks should still be 8 as initially
+ assert model_loaded.peft_config["default"].r == 8
+ assert model_loaded.base_model.model.linear.lora_A["default"].weight.shape[0] == 32
+ # sanity check: the base model weights were indeed changed
+ assert not torch.allclose(
+ model.linear.weight, model_loaded.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ # save the model with conversion
+ peft_model.save_pretrained(
+ tmp_path / "olora-model-converted", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+ model_converted = PeftModel.from_pretrained(deepcopy(model), tmp_path / "olora-model-converted")
+ output_converted = model_converted(data)[0]
+
+ assert torch.allclose(output_olora, output_converted, atol=tol, rtol=tol)
+ # rank should be double of what it was initially
+ assert model_converted.peft_config["default"].r == 16
+ assert model_converted.base_model.model.linear.lora_A["default"].weight.shape[0] == 64
+ # base model weights should be the same as the initial model
+ assert torch.allclose(
+ model.linear.weight, model_converted.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ def test_olora_conversion_same_output_after_loading_with_alpha_pattern(self, data, tmp_path):
+ # same as above, but using alpha_pattern
+ model = self.get_model()
+ output_base = model(data)[0]
+
+ # use alpha_pattern here; note that since there is only a single linear layer, lora_alpha is completely
+ # overridden
+ config = LoraConfig(init_lora_weights="olora", target_modules=["linear"], alpha_pattern={"linear": 5})
+ peft_model = get_peft_model(deepcopy(model), config)
+ # save the initial model
+ peft_model.save_pretrained(tmp_path / "init-model")
+
+ # modify the weights, or else the adapter performs an identity transformation
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ output_olora = peft_model(data)[0]
+
+ # sanity check
+ tol = 1e-06
+ assert not torch.allclose(output_base, output_olora, atol=tol, rtol=tol)
+
+ # save the model normally
+ peft_model.save_pretrained(tmp_path / "olora-model")
+ model_loaded = PeftModel.from_pretrained(deepcopy(model), tmp_path / "olora-model")
+ output_loaded = model_loaded(data)[0]
+
+ assert torch.allclose(output_olora, output_loaded, atol=tol, rtol=tol)
+ # sanity check: ranks should still be 8 as initially
+ assert model_loaded.peft_config["default"].r == 8
+ assert model_loaded.base_model.model.linear.lora_A["default"].weight.shape[0] == 8
+ assert model_loaded.base_model.model.linear.scaling["default"] == 5 / 8
+ # sanity check: the base model weights were indeed changed
+ assert not torch.allclose(
+ model.linear.weight, model_loaded.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ # save the model with conversion
+ peft_model.save_pretrained(
+ tmp_path / "olora-model-converted", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+ model_converted = PeftModel.from_pretrained(deepcopy(model), tmp_path / "olora-model-converted")
+ output_converted = model_converted(data)[0]
+
+ assert torch.allclose(output_olora, output_converted, atol=tol, rtol=tol)
+ # rank should be double of what it was initially
+ assert model_converted.peft_config["default"].r == 16
+ assert model_converted.base_model.model.linear.lora_A["default"].weight.shape[0] == 16
+ assert model_converted.base_model.model.linear.scaling["default"] == 10 / 16
+ # base model weights should be the same as the initial model
+ assert torch.allclose(
+ model.linear.weight, model_converted.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ def test_olora_conversion_same_output_after_loading_with_rslora(self, data, tmp_path):
+ # same as above, but using alpha_pattern
+ model = self.get_model()
+ output_base = model(data)[0]
+
+ config = LoraConfig(init_lora_weights="olora", target_modules=["linear"], r=8, use_rslora=True)
+ peft_model = get_peft_model(deepcopy(model), config)
+ # save the initial model
+ peft_model.save_pretrained(tmp_path / "init-model")
+
+ # modify the weights, or else the adapter performs an identity transformation
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ output_olora = peft_model(data)[0]
+
+ # sanity check
+ tol = 1e-06
+ assert not torch.allclose(output_base, output_olora, atol=tol, rtol=tol)
+
+ # save the model normally
+ peft_model.save_pretrained(tmp_path / "olora-model")
+ model_loaded = PeftModel.from_pretrained(deepcopy(model), tmp_path / "olora-model")
+ output_loaded = model_loaded(data)[0]
+
+ assert torch.allclose(output_olora, output_loaded, atol=tol, rtol=tol)
+ # sanity check: ranks should still be 8 as initially
+ assert model_loaded.peft_config["default"].r == 8
+ assert model_loaded.base_model.model.linear.lora_A["default"].weight.shape[0] == 8
+ assert model_loaded.base_model.model.linear.scaling["default"] == 8 / (8**0.5)
+ # sanity check: the base model weights were indeed changed
+ assert not torch.allclose(
+ model.linear.weight, model_loaded.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ # save the model with conversion
+ peft_model.save_pretrained(
+ tmp_path / "olora-model-converted", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+ model_converted = PeftModel.from_pretrained(deepcopy(model), tmp_path / "olora-model-converted")
+ output_converted = model_converted(data)[0]
+
+ assert torch.allclose(output_olora, output_converted, atol=tol, rtol=tol)
+ # rank should be double of what it was initially
+ assert model_converted.peft_config["default"].r == 16
+ assert model_converted.base_model.model.linear.lora_A["default"].weight.shape[0] == 16
+ # same scale as before with a little bit of floating point imprecision
+ assert model_converted.base_model.model.linear.scaling["default"] == pytest.approx(8 / (8**0.5))
+ # base model weights should be the same as the initial model
+ assert torch.allclose(
+ model.linear.weight, model_converted.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ def test_olora_rank_pattern_and_rslora_raises(self, tmp_path):
+ # it's not possible to determine the correct scale when using rslora with rank or alpha pattern, because the
+ # scale is not stored in the state_dict
+ model = self.get_model()
+ config = LoraConfig(
+ init_lora_weights="olora", target_modules=["linear"], r=8, rank_pattern={"linear": 2}, use_rslora=True
+ )
+ peft_model = get_peft_model(model, config)
+ peft_model.save_pretrained(tmp_path / "init-model")
+
+ msg = re.escape("Passing `path_initial_model_for_weight_conversion` to `save_pretrained`")
+ with pytest.raises(ValueError, match=msg):
+ peft_model.save_pretrained(
+ tmp_path / "olora-model", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+
+ def test_olora_alpha_pattern_and_rslora_raises(self, tmp_path):
+ # it's not possible to determine the correct scale when using rslora with rank or alpha pattern, because the
+ # scale is not stored in the state_dict
+ model = self.get_model()
+ config = LoraConfig(
+ init_lora_weights="olora", target_modules=["linear"], r=8, alpha_pattern={"linear": 2}, use_rslora=True
+ )
+ peft_model = get_peft_model(model, config)
+ peft_model.save_pretrained(tmp_path / "init-model")
+
+ msg = re.escape("Passing `path_initial_model_for_weight_conversion` to `save_pretrained`")
+ with pytest.raises(ValueError, match=msg):
+ peft_model.save_pretrained(
+ tmp_path / "olora-model", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+
+ @pytest.mark.parametrize(
+ "config_kwargs, should_warn",
+ [
+ # no warning
+ ({"init_lora_weights": "pissa", "target_modules": ["linear"]}, False),
+ ({"init_lora_weights": "pissa_niter_3", "target_modules": ["linear"]}, False),
+ ({"init_lora_weights": "olora", "target_modules": ["linear"]}, False),
+ ({"init_lora_weights": "pissa", "target_modules": ["linear"], "use_rslora": True}, False),
+ ({"init_lora_weights": "pissa_niter_3", "target_modules": ["linear"], "use_rslora": True}, False),
+ ({"init_lora_weights": "olora", "target_modules": ["linear"], "use_rslora": True}, False),
+ ({"init_lora_weights": "pissa", "target_modules": ["linear"], "rank_pattern": {"linear": 8}}, False),
+ (
+ {"init_lora_weights": "pissa_niter_3", "target_modules": ["linear"], "rank_pattern": {"linear": 8}},
+ False,
+ ),
+ ({"init_lora_weights": "olora", "target_modules": ["linear"], "rank_pattern": {"linear": 8}}, False),
+ ({"init_lora_weights": "pissa", "target_modules": ["linear"], "alpha_pattern": {"linear": 8}}, False),
+ (
+ {"init_lora_weights": "pissa_niter_3", "target_modules": ["linear"], "alpha_pattern": {"linear": 8}},
+ False,
+ ),
+ ({"init_lora_weights": "olora", "target_modules": ["linear"], "alpha_pattern": {"linear": 8}}, False),
+ # warning
+ (
+ {
+ "init_lora_weights": "pissa",
+ "target_modules": ["linear"],
+ "use_rslora": True,
+ "rank_pattern": {"linear": 8},
+ },
+ True,
+ ),
+ (
+ {
+ "init_lora_weights": "pissa_niter_3",
+ "target_modules": ["linear"],
+ "use_rslora": True,
+ "rank_pattern": {"linear": 8},
+ },
+ True,
+ ),
+ (
+ {
+ "init_lora_weights": "olora",
+ "target_modules": ["linear"],
+ "use_rslora": True,
+ "rank_pattern": {"linear": 8},
+ },
+ True,
+ ),
+ (
+ {
+ "init_lora_weights": "pissa",
+ "target_modules": ["linear"],
+ "use_rslora": True,
+ "alpha_pattern": {"linear": 8},
+ },
+ True,
+ ),
+ (
+ {
+ "init_lora_weights": "pissa_niter_3",
+ "target_modules": ["linear"],
+ "use_rslora": True,
+ "alpha_pattern": {"linear": 8},
+ },
+ True,
+ ),
+ (
+ {
+ "init_lora_weights": "olora",
+ "target_modules": ["linear"],
+ "use_rslora": True,
+ "alpha_pattern": {"linear": 8},
+ },
+ True,
+ ),
+ (
+ {
+ "init_lora_weights": "pissa",
+ "target_modules": ["linear"],
+ "use_rslora": True,
+ "rank_pattern": {"linear": 8},
+ "alpha_pattern": {"linear": 8},
+ },
+ True,
+ ),
+ (
+ {
+ "init_lora_weights": "pissa_niter_3",
+ "target_modules": ["linear"],
+ "use_rslora": True,
+ "rank_pattern": {"linear": 8},
+ "alpha_pattern": {"linear": 8},
+ },
+ True,
+ ),
+ (
+ {
+ "init_lora_weights": "olora",
+ "target_modules": ["linear"],
+ "use_rslora": True,
+ "rank_pattern": {"linear": 8},
+ "alpha_pattern": {"linear": 8},
+ },
+ True,
+ ),
+ ],
+ )
+ def test_lora_config_pissa_olora_warns(self, config_kwargs, should_warn, recwarn):
+ # Using post training conversion of modified base weights to restore their initial values (PiSSA, OLoRA) cannot
+ # be correctly done when using rslora + rank_pattern/alpha_pattern. We can't really know if the user intends
+ # this when they'll eventually call save_pretrained (i.e. if they'll pass
+ # path_initial_model_for_weight_conversionl). Therefore, we only warn but don't raise an error here.
+ msg = re.escape("Using Rank-Stabilized LoRA with rank_pattern/alpha_pattern and post-training conversion")
+ if should_warn:
+ LoraConfig(**config_kwargs)
+ assert len(recwarn.list) == 1
+ with pytest.warns(UserWarning, match=msg):
+ LoraConfig(**config_kwargs)
+ else:
+ LoraConfig(**config_kwargs)
+ assert not recwarn.list
+
+ @pytest.mark.parametrize("init_method", ["pissa", "olora"])
+ @pytest.mark.parametrize("pissa_olora_loaded_first", [False, True])
+ def test_load_pissa_olora_with_other_adapter_warns(self, init_method, pissa_olora_loaded_first, recwarn, tmp_path):
+ # Since PiSSA/OLoRA modifies the base weights, it should not be combined with other adapters. Check for a
+ # warning. See #2184.
+
+ # create an adapter without PiSSA/OloRA
+ model_id = "hf-internal-testing/tiny-random-OPTForCausalLM"
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ model = get_peft_model(model, LoraConfig(init_lora_weights=True))
+ model.save_pretrained(tmp_path / "adapter0")
+ del model
+
+ # create a model with PiSSA/OLoRA
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ model = get_peft_model(model, LoraConfig(init_lora_weights=init_method))
+ model.save_pretrained(tmp_path / "adapter1")
+ del model
+
+ # load the model
+ if pissa_olora_loaded_first:
+ path0, path1 = tmp_path / "adapter1", tmp_path / "adapter0"
+ else:
+ path0, path1 = tmp_path / "adapter0", tmp_path / "adapter1"
+
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ model = PeftModel.from_pretrained(model, path0)
+ model = model.load_adapter(path1, adapter_name="other")
+
+ if init_method == "pissa":
+ msg = "PiSSA changes the base weights of the model and should thus not be used with other adapters"
+ else:
+ msg = "OLoRA changes the base weights of the model and should thus not be used with other adapters"
+ assert any(str(w.message).startswith(msg) for w in recwarn.list)
+
+ def test_lora_rslora_scaling(self):
+ # default is True
+ torch.manual_seed(0)
+
+ model = self.get_model()
+
+ # check scaling factor use_rslora=True
+ config = LoraConfig(target_modules=["linear", "embed", "conv2d"], lora_alpha=3, r=16, use_rslora=True)
+ model = get_peft_model(model, config)
+
+ expected_scaling = config.lora_alpha / (config.r**0.5)
+
+ assert model.linear.scaling["default"] == expected_scaling
+ assert model.embed.scaling["default"] == expected_scaling
+ assert model.conv2d.scaling["default"] == expected_scaling
+
+ def test_lora_default_scaling_pattern(self):
+ # default is True
+ torch.manual_seed(0)
+
+ model = self.get_model()
+
+ # check scaling factor use_rslora=False with rank and alpha pattern
+ config = LoraConfig(
+ target_modules=["linear", "embed", "conv2d"],
+ rank_pattern={"embed": 9, "conv2d": 16},
+ alpha_pattern={"linear": 11, "conv2d": 13},
+ lora_alpha=17,
+ r=25,
+ use_rslora=False,
+ )
+ model = get_peft_model(model, config)
+
+ expected_scaling = {
+ "linear": config.alpha_pattern["linear"] / config.r,
+ "embed": config.lora_alpha / config.rank_pattern["embed"],
+ "conv2d": config.alpha_pattern["conv2d"] / config.rank_pattern["conv2d"],
+ }
+
+ assert model.linear.scaling["default"] == expected_scaling["linear"]
+ assert model.embed.scaling["default"] == expected_scaling["embed"]
+ assert model.conv2d.scaling["default"] == expected_scaling["conv2d"]
+
+ def test_lora_rslora_scaling_pattern(self):
+ # default is True
+ torch.manual_seed(0)
+
+ model = self.get_model()
+
+ # check scaling factor use_rslora=True with rank and alpha pattern
+ config = LoraConfig(
+ target_modules=["linear", "embed", "conv2d"],
+ rank_pattern={"embed": 9, "conv2d": 16},
+ alpha_pattern={"linear": 11, "conv2d": 13},
+ lora_alpha=17,
+ r=25,
+ use_rslora=True,
+ )
+ model = get_peft_model(model, config)
+
+ expected_scaling = {
+ "linear": config.alpha_pattern["linear"] / (config.r**0.5),
+ "embed": config.lora_alpha / (config.rank_pattern["embed"] ** 0.5),
+ "conv2d": config.alpha_pattern["conv2d"] / (config.rank_pattern["conv2d"] ** 0.5),
+ }
+
+ assert model.linear.scaling["default"] == expected_scaling["linear"]
+ assert model.embed.scaling["default"] == expected_scaling["embed"]
+ assert model.conv2d.scaling["default"] == expected_scaling["conv2d"]
+
+ @require_deterministic_for_xpu
+ def test_lora_use_dora_linear(self, data):
+ # check that dora is a no-op when initialized
+ torch.manual_seed(0)
+ model = self.get_model()
+ output_base, _, _ = model(data)
+
+ # check scaling factor use_rslora=True
+ config = LoraConfig(target_modules=["linear"], use_dora=True)
+ model = get_peft_model(model, config)
+
+ with model.disable_adapter():
+ output_disabled, _, _ = model(data)
+ output_dora, _, _ = model(data)
+
+ assert torch.allclose(output_base, output_disabled)
+ assert torch.allclose(output_base, output_dora)
+
+ @require_deterministic_for_xpu
+ def test_lora_use_dora_linear_init_false(self, data):
+ # with init_lora_weights=False, dora should not be a no-op
+ torch.manual_seed(0)
+ model = self.get_model()
+ output_base, _, _ = model(data)
+
+ # check scaling factor use_rslora=True
+ config = LoraConfig(target_modules=["linear"], use_dora=True, init_lora_weights=False)
+ model = get_peft_model(model, config)
+
+ with model.disable_adapter():
+ output_disabled, _, _ = model(data)
+ output_dora, _, _ = model(data)
+
+ assert torch.allclose(output_base, output_disabled)
+ assert not torch.allclose(output_base, output_dora)
+
+ def test_lora_use_dora_with_megatron_core_raises(self):
+ megatron_config = {"does-not": "matter-here"}
+ with pytest.raises(ValueError, match="DoRA does not support megatron_core"):
+ LoraConfig(target_modules=["linear"], use_dora=True, megatron_config=megatron_config)
+
+ @pytest.fixture
+ def mha_cls(self):
+ class ModelMha(nn.Module):
+ def __init__(self, kdim=None, vdim=None):
+ super().__init__()
+ self.mha = nn.MultiheadAttention(10, 2, kdim=kdim, vdim=vdim)
+ self.lin0 = nn.Linear(10, 2)
+ self.sm = nn.LogSoftmax(dim=-1)
+
+ def forward(self, X):
+ X = X.float()
+ X, _ = self.mha(X, X, X)
+ X = self.lin0(X)
+ X = self.sm(X)
+ return X
+
+ return ModelMha
+
+ def test_mha_load_init_model_first(self, mha_cls):
+ # This test used to fail and require a workaround, for more context, see:
+ # https://github.com/huggingface/peft/pull/1324#issuecomment-2252473980
+ # The workaround was that _restore_weights had to be called manually on lora.MHA layers in order to make loading
+ # the state dict work. With recent changes, this workaround is no longer required, so that test has been
+ # deleted.
+ inputs = torch.rand(10, 10, 10)
+ model = mha_cls()
+ config = LoraConfig(target_modules=["mha"], init_lora_weights=False)
+ model = get_peft_model(model, config).eval()
+ restore_state_dict = {k: v.detach().cpu() for k, v in model.state_dict().items()}
+
+ del model
+
+ model = mha_cls()
+ model = get_peft_model(model, config)
+ # the workaround used to be:
+ # for module in model.modules():
+ # if isinstance(module, peft.tuners.lora.layer.MultiheadAttention):
+ # module._restore_weights()
+ model(inputs)
+ model.load_state_dict(restore_state_dict)
+
+ def test_mha_with_separate_qkv_embed_raises(self, mha_cls):
+ # passing different kdim and vdim results in separate parameters for q, k, v, which is not supported (yet)
+ model = mha_cls(kdim=20, vdim=30)
+ config = LoraConfig(target_modules=["mha"])
+ msg = "Only same embed for query/key/value is supported as of now for MultiheadAttention"
+ with pytest.raises(ValueError, match=msg):
+ get_peft_model(model, config)
+
+ def test_mha_with_dora_raises(self, mha_cls):
+ model = mha_cls()
+ config = LoraConfig(target_modules=["mha"], use_dora=True)
+ msg = re.escape("MultiheadAttention does not support DoRA (yet), please set use_dora to False")
+ with pytest.raises(ValueError, match=msg):
+ get_peft_model(model, config)
+
+ def test_mha_exposes_attributes(self, mha_cls):
+ # MHA requires a bunch of attributes to be exposed, try to check them exhaustively here
+ model = mha_cls()
+ embed_dim = model.mha.embed_dim
+ kdim = model.mha.kdim
+ vdim = model.mha.vdim
+ qkv_same_embed_dim = model.mha._qkv_same_embed_dim
+ num_heads = model.mha.num_heads
+ dropout = model.mha.dropout
+ batch_first = model.mha.batch_first
+ head_dim = model.mha.head_dim
+ in_proj_weight = model.mha.in_proj_weight
+ in_proj_bias = model.mha.in_proj_bias
+ out_proj = model.mha.out_proj
+ bias_k = model.mha.bias_k
+ bias_v = model.mha.bias_v
+ add_zero_attn = model.mha.add_zero_attn
+
+ config = LoraConfig(target_modules=["mha"])
+ peft_model = get_peft_model(model, config)
+ assert peft_model.base_model.mha.embed_dim == embed_dim
+ assert peft_model.base_model.mha.kdim == kdim
+ assert peft_model.base_model.mha.vdim == vdim
+ assert peft_model.base_model.mha._qkv_same_embed_dim == qkv_same_embed_dim
+ assert peft_model.base_model.mha.num_heads == num_heads
+ assert peft_model.base_model.mha.dropout == dropout
+ assert peft_model.base_model.mha.batch_first == batch_first
+ assert peft_model.base_model.mha.head_dim == head_dim
+ if in_proj_weight is not None:
+ assert torch.allclose(peft_model.base_model.mha.in_proj_weight, in_proj_weight)
+ else:
+ assert peft_model.base_model.mha.in_proj_weight is None
+ if in_proj_bias is not None:
+ assert torch.allclose(peft_model.base_model.mha.in_proj_bias, in_proj_bias)
+ else:
+ assert peft_model.base_model.mha.in_proj_bias is None
+ assert peft_model.base_model.mha.out_proj is out_proj
+ if bias_k is not None:
+ assert torch.allclose(peft_model.base_model.mha.bias_k, bias_k)
+ else:
+ assert peft_model.base_model.mha.bias_k is None
+ if bias_v is not None:
+ assert torch.allclose(peft_model.base_model.mha.bias_v, bias_v)
+ else:
+ assert peft_model.base_model.mha.bias_v is None
+ assert peft_model.base_model.mha.add_zero_attn == add_zero_attn
+
+ def test_mha_merge_masks_method(self, mha_cls):
+ # MHA requires a merge_masks method to be exposed, check that it works
+ model = mha_cls()
+ config = LoraConfig(target_modules=["mha"])
+ peft_model = get_peft_model(model, config)
+
+ attn_mask = torch.randint(0, 2, (10, 10))
+ key_padding_mask = torch.randint(0, 2, (10, 10))
+ query = torch.rand(10, 10, 10)
+ merged_mask0, mask_type0 = model.mha.merge_masks(attn_mask, key_padding_mask, query)
+ merged_mask1, mask_type1 = peft_model.base_model.mha.merge_masks(attn_mask, key_padding_mask, query)
+
+ assert torch.allclose(merged_mask0, merged_mask1)
+ assert mask_type0 == mask_type1
+
+ def test_lora_with_bias_extra_params(self):
+ # lora with lora_bias=True
+ model = self.get_model()
+ config = LoraConfig(target_modules=["linear", "conv2d"], lora_bias=False)
+ model_no_bias = get_peft_model(model, config)
+
+ model = self.get_model()
+ config = LoraConfig(target_modules=["linear", "conv2d"], lora_bias=True)
+ model_bias = get_peft_model(model, config)
+
+ # check that bias for LoRA B is set
+ assert model_no_bias.base_model.model.linear.lora_B["default"].bias is None
+ assert model_bias.base_model.model.linear.lora_B["default"].bias.shape == (1000,)
+ assert model_no_bias.base_model.model.conv2d.lora_B["default"].bias is None
+ assert model_bias.base_model.model.conv2d.lora_B["default"].bias.shape == (100,)
+
+ # check that the same params are present except for the extra bias term
+ params_no_bias = {name for name, _ in model_no_bias.named_parameters()}
+ params_bias = {name for name, _ in model_bias.named_parameters()}
+ extra_params = {
+ "base_model.model.linear.lora_B.default.bias",
+ "base_model.model.conv2d.lora_B.default.bias",
+ }
+ assert params_bias - params_no_bias == extra_params
+ assert params_no_bias.issubset(params_bias)
+
+ def test_lora_with_bias_embedding_raises(self):
+ # lora with lora_bias=True is not supported for embedding layers
+ model = self.get_model()
+ config = LoraConfig(target_modules=["embed"], lora_bias=True)
+ msg = "lora_bias=True is not supported for Embedding"
+ with pytest.raises(ValueError, match=msg):
+ get_peft_model(model, config)
+
+ @pytest.mark.parametrize(
+ "extra_kwargs",
+ [
+ {"use_dora": True},
+ {"init_lora_weights": "eva"},
+ {"init_lora_weights": "gaussian"},
+ {"init_lora_weights": "loftq", "loftq_config": LoftQConfig()},
+ {"init_lora_weights": "olora"},
+ {"init_lora_weights": "pissa"},
+ {"init_lora_weights": "pissa_niter_3"},
+ {"init_lora_weights": "orthogonal"},
+ ],
+ )
+ def test_lora_with_bias_incompatible_arguments(self, extra_kwargs):
+ # some arguments don't work in conjunction with lora_bias and should raise
+ # just check the common chunk of the error message
+ msg = "The argument lora_bias=True is"
+ with pytest.raises(ValueError, match=msg):
+ LoraConfig(target_modules=["linear"], lora_bias=True, **extra_kwargs)
+
+ def test_lora_incompatible_mamba_modules(self):
+ # Ensure LoRA raises an error when applying to forbidden modules
+ # ('out_proj', 'conv1d') in Mamba-based architectures like Falcon-Mamba tiny.
+ model = AutoModelForCausalLM.from_pretrained("tiiuae/falcon-mamba-tiny-dev")
+
+ config = LoraConfig(
+ task_type="CAUSAL_LM",
+ target_modules=["out_proj", "conv1d"], # Forbidden modules for Mamba-based models
+ )
+ msg = "is incompatible with Mamba-based models"
+ with pytest.raises(ValueError, match=msg):
+ get_peft_model(model, config)
+
+ def get_model_conv2d_groups(self):
+ class ModelConv2DGroups(nn.Module):
+ """For testing when groups argument is used in conv layer"""
+
+ def __init__(self):
+ super().__init__()
+ self.conv2d = nn.Conv2d(16, 32, 3, padding=1, groups=2)
+ self.relu = nn.ReLU()
+ self.flat = nn.Flatten()
+ self.lin0 = nn.Linear(12800, 2)
+ self.sm = nn.LogSoftmax(dim=-1)
+ self.dtype = torch.float
+
+ def forward(self, X):
+ # This is ignoring input since main usage is for checking raising of error when peft is applied
+ X = torch.arange(9 * 16 * 20 * 20).view([9, 16, 20, 20]).to(self.conv2d.weight.device)
+ X = X.to(self.dtype)
+ X = self.conv2d(X)
+ X = self.relu(X)
+ X = self.flat(X)
+ X = self.lin0(X)
+ X = self.sm(X)
+ return X
+
+ return ModelConv2DGroups().eval().to(self.torch_device)
+
+ @pytest.mark.parametrize(
+ "config_cls, config_kwargs",
+ [
+ pytest.param(LoraConfig, {"r": 8, "target_modules": ["conv2d"]}, id="lora with rank divisible by groups"),
+ pytest.param(LoraConfig, {"r": 2, "target_modules": ["conv2d"]}, id="lora with rank equal to groups"),
+ pytest.param(
+ LoraConfig, {"r": 1, "target_modules": ["conv2d"]}, id="lora with rank not divisible by groups"
+ ),
+ pytest.param(
+ LoraConfig,
+ {"r": 8, "target_modules": ["conv2d"], "use_dora": True},
+ id="dora with rank divisible by groups",
+ ),
+ pytest.param(
+ LoraConfig,
+ {"r": 2, "target_modules": ["conv2d"], "use_dora": True},
+ id="dora with rank equal to groups",
+ ),
+ pytest.param(
+ LoraConfig,
+ {"r": 1, "target_modules": ["conv2d"], "use_dora": True},
+ id="dora with rank not divisible by groups",
+ ),
+ ],
+ )
+ def test_error_raised_if_rank_not_divisible_by_groups(self, config_cls, config_kwargs):
+ # This test checks if error is raised when rank is not divisible by groups for conv layer since
+ # currently, support is limited to conv layers where the rank is divisible by groups in lora and dora
+ base_model = self.get_model_conv2d_groups()
+ peft_config = config_cls(**config_kwargs)
+ r = config_kwargs["r"]
+ base_layer = base_model.conv2d
+ groups = base_layer.groups
+ if r % groups != 0:
+ with pytest.raises(
+ ValueError,
+ match=(
+ f"Targeting a {base_layer.__class__.__name__} with groups={base_layer.groups} and rank {r}. "
+ "Currently, support is limited to conv layers where the rank is divisible by groups. "
+ "Either choose a different rank or do not target this specific layer."
+ ),
+ ):
+ peft_model = get_peft_model(base_model, peft_config)
+ else:
+ # No error should be raised
+ peft_model = get_peft_model(base_model, peft_config)
+
+ def test_target_module_and_target_parameter_on_same_layer(self):
+ # When targeting an nn.Parameter with LoRA using target_parameters, ensure that this is not already another LoRA
+ # layer (i.e. avoid double wrapping).
+ class MyModule(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.linear = nn.Linear(10, 10)
+
+ base_model = MyModule()
+ config = LoraConfig(target_modules=["linear"], target_parameters=["weight"])
+ msg = "Trying to wrap an `nn.Parameter` of layer 'linear' of type Linear, which is not a valid target."
+ with pytest.raises(ValueError, match=msg):
+ get_peft_model(base_model, config)
+
+ def test_targeting_2_params_on_1_module_raises(self):
+ # It is currently not supported to target multiple parameters on the same module.
+ class ModuleWith2Params(nn.Module):
+ def __init__(self, in_features, out_features):
+ super().__init__()
+ self.weight0 = nn.Parameter(torch.zeros(in_features, out_features))
+ self.weight1 = nn.Parameter(torch.ones(3, out_features, out_features))
+
+ class Outer(nn.Module):
+ def __init__(self, in_features, out_features):
+ super().__init__()
+ self.lin = nn.Linear(in_features, in_features)
+ self.submodule = ModuleWith2Params(in_features, out_features)
+
+ model = Outer(3, 4)
+ config = LoraConfig(target_parameters=["submodule.weight0", "submodule.weight1"], init_lora_weights=False)
+ msg = (
+ "lora.ParamWrapper already has an adapter for parameter 'weight0'. It is currently not possible to apply "
+ "the same adapter to multiple parameters, please add a different adapter to target another parameter of "
+ "the same module."
+ )
+ with pytest.raises(ValueError, match=msg):
+ get_peft_model(model, config)
+
+ @pytest.mark.parametrize("target_parameters", [["linear"], ["foobar"], ["foobar.weight"], ["foo", "bar"]])
+ @pytest.mark.parametrize("target_modules", [None, [], ""])
+ def test_valid_no_target_module_nor_target_parameter_match_raises(self, target_parameters, target_modules):
+ model = self.get_model()
+ config = LoraConfig(target_modules=target_modules, target_parameters=target_parameters)
+ msg = re.escape(
+ "No `target_modules` passed but also no `target_parameters` found. Please check the values for "
+ "these arguments."
+ )
+ with pytest.raises(ValueError, match=msg):
+ get_peft_model(model, config)
+
+ def test_target_parameters_wrong_type_raises(self):
+ # Check that target_parameters being a string raises a useful error message -- this is an easy mistake to make
+ # because strings are allowed for target_modules
+ model = self.get_model()
+ msg = "`target_parameters` must be a list of strings or None."
+ with pytest.raises(TypeError, match=msg):
+ LoraConfig(target_parameters="linear.weight")
+
+ def test_valid_target_parameters_invalid_target_modules_warns(self):
+ model = self.get_model()
+ config = LoraConfig(target_modules=["foobar"], target_parameters=["linear.weight"])
+ msg = re.escape("target_modules={'foobar'} were set but no module was matched.")
+ with pytest.warns(RuntimeWarning, match=msg):
+ get_peft_model(model, config)
+
+ def test_valid_target_modules_invalid_target_parameters_warns(self):
+ model = self.get_model()
+ config = LoraConfig(target_modules=["linear"], target_parameters=["foobar.weight"])
+ msg = re.escape("target_parameters=['foobar.weight'] were set but no parameter was matched.")
+ with pytest.warns(RuntimeWarning, match=msg):
+ get_peft_model(model, config)
+
+
+class TestLokrInitialization:
+ torch_device = infer_device()
+
+ def get_model(self):
+ class MyModule(nn.Module):
+ def __init__(self):
+ super().__init__()
+ # Choose a large weight so that averages are close to expected values.
+ self.linear = nn.Linear(1000, 1000)
+ self.conv2d = nn.Conv2d(100, 100, 3)
+
+ def forward(self, x):
+ x_4d = x.flatten().reshape(1, 100, 10, 10)
+ return self.linear(x), self.conv2d(x_4d)
+
+ return MyModule().eval().to(self.torch_device)
+
+ @pytest.fixture
+ def data(self):
+ return torch.rand(10, 1000).to(self.torch_device)
+
+ @require_deterministic_for_xpu
+ def test_lokr_linear_init_default(self, data):
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ output_before = model(data)[0]
+ config = LoKrConfig(target_modules=["linear"])
+ model = get_peft_model(model, config)
+ output_after = model(data)[0]
+
+ assert torch.allclose(output_before, output_after)
+
+ def test_lokr_linear_init_false(self, data):
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ output_before = model(data)[0]
+ config = LoKrConfig(target_modules=["linear"], init_weights=False)
+ model = get_peft_model(model, config)
+ output_after = model(data)[0]
+
+ assert not torch.allclose(output_before, output_after)
+
+ @require_deterministic_for_xpu
+ def test_lokr_linear_init_lycoris(self, data):
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ output_before = model(data)[0]
+ config = LoKrConfig(target_modules=["linear"], init_weights="lycoris")
+ model = get_peft_model(model, config)
+ output_after = model(data)[0]
+
+ assert torch.allclose(output_before, output_after)
+
+ def test_lokr_conv2d_init_default(self, data):
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ output_before = model(data)[1]
+ config = LoKrConfig(target_modules=["conv2d"])
+ model = get_peft_model(model, config)
+ output_after = model(data)[1]
+
+ assert torch.allclose(output_before, output_after)
+
+ def test_lokr_conv2d_init_false(self, data):
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ output_before = model(data)[1]
+ config = LoKrConfig(target_modules=["conv2d"], init_weights=False)
+ model = get_peft_model(model, config)
+ output_after = model(data)[1]
+
+ assert not torch.allclose(output_before, output_after)
+
+ def test_lokr_conv2d_init_lycoris(self, data):
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ output_before = model(data)[1]
+ config = LoKrConfig(target_modules=["conv2d"], init_weights="lycoris")
+ model = get_peft_model(model, config)
+ output_after = model(data)[1]
+
+ assert torch.allclose(output_before, output_after)
+
+
+class TestAdaLoraInitialization:
+ torch_device = infer_device()
+
+ def test_adalora_target_modules_set(self):
+ config = AdaLoraConfig(target_modules=["linear", "embed", "conv2d"], total_step=1)
+ assert config.target_modules == {"linear", "embed", "conv2d"}
+
+ def test_adalora_use_dora_raises(self):
+ with pytest.raises(ValueError, match="ADALORA does not support DoRA"):
+ AdaLoraConfig(use_dora=True, total_step=1)
+
+ def test_adalora_loftq_config_raises(self):
+ with pytest.raises(ValueError, match="ADALORA does not support LOFTQ"):
+ AdaLoraConfig(init_lora_weights="loftq", loftq_config={"loftq": "config"}, total_step=1)
+
+ def get_model(self):
+ class MyModule(nn.Module):
+ def __init__(self):
+ super().__init__()
+ # choose a large weight so that averages are close to expected values
+ self.linear = nn.Linear(1000, 1000)
+
+ def forward(self, x):
+ return self.linear(x)
+
+ return MyModule().eval().to(self.torch_device)
+
+ @pytest.fixture
+ def data(self):
+ return torch.rand(10, 1000).to(self.torch_device)
+
+ @require_deterministic_for_xpu
+ def test_adalora_default_init_identity(self, data):
+ # default is True
+ torch.manual_seed(0)
+
+ model = self.get_model()
+ output_before = model(data)
+ config = AdaLoraConfig(target_modules=["linear"], total_step=1)
+ model = get_peft_model(model, config)
+ output_after = model(data)
+ assert torch.allclose(output_before, output_after)
+
+
+class TestPromptTuningInitialization:
+ torch_device = infer_device()
+
+ def get_model(self):
+ class MyModule(nn.Module):
+ def __init__(self):
+ super().__init__()
+ # choose a large weight so that averages are close to expected values
+ self.linear = nn.Linear(1000, 1000)
+ self.embed = nn.Embedding(1000, 1000)
+ self.conv2d = nn.Conv2d(100, 100, 3)
+
+ def forward(self, x):
+ x_int = (100 * x).int()
+ x_4d = x.flatten().reshape(1, 100, 10, 10)
+ return self.linear(x), self.embed(x_int), self.conv2d(x_4d)
+
+ return MyModule().eval().to(self.torch_device)
+
+ def test_use_prompt_tuning_init_text_raises(self):
+ with pytest.raises(ValueError, match="When prompt_tuning_init='TEXT', tokenizer_name_or_path can't be None"):
+ PromptTuningConfig(prompt_tuning_init="TEXT", prompt_tuning_init_text="prompt tuning init text")
+ with pytest.raises(ValueError, match="When prompt_tuning_init='TEXT', prompt_tuning_init_text can't be None"):
+ PromptTuningConfig(prompt_tuning_init="TEXT", tokenizer_name_or_path="t5-base")
+
+
+class TestVeraInitialization:
+ torch_device = infer_device()
+
+ def get_model(self):
+ class MLP(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.lin1 = nn.Linear(20, 2, bias=bias)
+
+ def forward(self, X):
+ X = self.lin0(X)
+ X = self.lin1(X)
+ return X
+
+ return MLP().to(self.torch_device)
+
+ def test_vera_mixing_save_projection_raises(self):
+ # it is unclear what the right thing to do would be if some adapters save the projection weights and some don't
+ # so we better raise an error
+
+ config0 = VeraConfig(target_modules=["lin0"], init_weights=False, save_projection=True)
+ model = self.get_model()
+ model = get_peft_model(model, config0)
+ config1 = VeraConfig(target_modules=["lin0"], init_weights=False, save_projection=False)
+ msg = re.escape(
+ "VeRA projection weights must be saved for all adapters or none, but got multiple different values: "
+ "[False, True]"
+ )
+ with pytest.raises(ValueError, match=msg):
+ model.add_adapter("other", config1)
+
+ def test_vera_add_second_adapter_with_incompatible_input_shape(self):
+ config0 = VeraConfig(target_modules=["lin0"], r=8)
+ config1 = VeraConfig(target_modules=["lin1"])
+
+ base_model = self.get_model()
+ lin0_in_feat = base_model.lin0.in_features
+ lin1_in_feat = base_model.lin1.in_features
+ model = get_peft_model(base_model, config0)
+ # not full message but enough to identify the error
+ msg = f"vera_A has a size of {lin0_in_feat} but {lin1_in_feat} or greater is required"
+ with pytest.raises(ValueError, match=msg):
+ model.add_adapter("other", config1)
+
+ def test_vera_add_second_adapter_with_higher_rank(self):
+ rank0 = 123
+ rank1 = 456
+ config0 = VeraConfig(target_modules=["lin0"], r=rank0)
+ # second adapter has higher rank
+ config1 = VeraConfig(target_modules=["lin0"], r=rank1)
+
+ model = get_peft_model(self.get_model(), config0)
+ # not full message but enough to identify the error
+ msg = f"vera_A has a size of {rank0} but {rank1} or greater is required"
+ with pytest.raises(ValueError, match=msg):
+ model.add_adapter("other", config1)
+
+
+class TestVBLoraInitialization:
+ torch_device = infer_device()
+
+ def get_model(self):
+ class MLP(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.lin0 = nn.Linear(10, 30, bias=bias)
+ self.lin1 = nn.Linear(30, 2, bias=bias)
+
+ def forward(self, X):
+ X = self.lin0(X)
+ X = self.lin1(X)
+ return X
+
+ return MLP().to(self.torch_device)
+
+ def test_vblora_with_incompatible_vector_length_with_in_features(self):
+ vector_length = 3
+ model = self.get_model()
+ config = VBLoRAConfig(target_modules=["lin0"], vector_length=vector_length)
+ msg = f"`in_features` {model.lin0.in_features} must be divisible by `vector_length` {vector_length}"
+ with pytest.raises(ValueError, match=msg):
+ get_peft_model(model, config)
+
+ def test_vblora_with_incompatible_vector_length_with_out_features(self):
+ vector_length = 3
+ model = self.get_model()
+ config = VBLoRAConfig(target_modules=["lin1"], vector_length=vector_length)
+ msg = f"`out_features` {model.lin1.out_features} must be divisible by `vector_length` {vector_length}"
+ with pytest.raises(ValueError, match=msg):
+ get_peft_model(model, config)
+
+
+class TestC3AInitialization:
+ torch_device = infer_device()
+
+ def get_model(self):
+ class MLP(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.lin0 = nn.Linear(10, 30, bias=bias)
+ self.lin1 = nn.Linear(30, 2, bias=bias)
+
+ def forward(self, X):
+ X = self.lin0(X)
+ X = self.lin1(X)
+ return X
+
+ return MLP().to(self.torch_device)
+
+ def test_c3a_with_incompatible_block_size_with_in_features(self):
+ block_size = 3
+ model = self.get_model()
+ config = C3AConfig(target_modules=["lin0"], block_size=block_size)
+ msg = f"The block size should be a factor of the input size. However, the input size is {model.lin0.in_features} and the block size is {block_size}"
+ with pytest.raises(ValueError, match=msg):
+ get_peft_model(model, config)
+
+ def test_c3a_with_incompatible_block_size_with_out_features(self):
+ block_size = 3
+ model = self.get_model()
+ config = C3AConfig(target_modules=["lin1"], block_size=block_size)
+ msg = f"The block size should be a factor of the output size. However, the output size is {model.lin1.out_features} and the block size is {block_size}"
+ with pytest.raises(ValueError, match=msg):
+ get_peft_model(model, config)
+
+
+class TestNoInfiniteRecursionDeepspeed:
+ # see #1892 for details
+ classes = [
+ PeftModel,
+ PeftMixedModel,
+ PeftModelForSequenceClassification,
+ PeftModelForQuestionAnswering,
+ PeftModelForTokenClassification,
+ PeftModelForCausalLM,
+ PeftModelForSeq2SeqLM,
+ PeftModelForFeatureExtraction,
+ ]
+
+ @pytest.fixture
+ def wrap_init(self):
+ # emulates the wrapper from DeepSpeed
+ import functools
+
+ def decorator(f):
+ @functools.wraps(f)
+ def wrapper(self, *args, **kwargs):
+ hasattr(self, "abc") # any hasattr will do
+ f(self, *args, **kwargs)
+
+ return wrapper
+
+ return decorator
+
+ @pytest.fixture
+ def model(self):
+ class MyModule(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.linear = nn.Linear(10, 10)
+ # to emulate LMs:
+ self.prepare_inputs_for_generation = None
+ self._prepare_encoder_decoder_kwargs_for_generation = None
+
+ return MyModule()
+
+ @pytest.mark.parametrize("cls", classes)
+ def test_no_infinite_recursion(self, cls, model, wrap_init):
+ original_init = cls.__init__
+ try:
+ cls.__init__ = wrap_init(cls.__init__)
+ # this would trigger an infinite loop before the fix in 1892
+ cls(model, LoraConfig(target_modules=["linear"]))
+ finally:
+ # ensure there are no side effects of this test
+ cls.__init__ = original_init
+
+
+class TestLoadAdapterOfflineMode:
+ base_model = "hf-internal-testing/tiny-random-OPTForCausalLM"
+ peft_model_id = "peft-internal-testing/tiny-OPTForCausalLM-lora"
+
+ # make sure that PEFT honors offline mode
+ @contextmanager
+ def hub_offline_ctx(self):
+ # this is required to simulate offline mode, setting the env var dynamically inside the test does not work
+ # because the value is checked only once at the start of the session
+ with patch("huggingface_hub.constants.HF_HUB_OFFLINE", True):
+ reset_sessions()
+ yield
+ reset_sessions()
+
+ # TODO remove when/if Hub is more stable
+ @pytest.mark.xfail(reason="Test is flaky on CI", raises=HfHubHTTPError)
+ def test_load_from_hub_then_offline_model(self):
+ # this uses LoRA but it's the same mechanism for other methods
+ base_model = AutoModelForCausalLM.from_pretrained(self.base_model)
+
+ # first ensure that the adapter model has been downloaded
+ PeftModel.from_pretrained(base_model, self.peft_model_id)
+
+ del base_model
+
+ base_model = AutoModelForCausalLM.from_pretrained(self.base_model)
+ with self.hub_offline_ctx():
+ # does not raise
+ PeftModel.from_pretrained(base_model, self.peft_model_id)
+
+ @pytest.fixture
+ def changed_default_cache_dir(self, tmp_path, monkeypatch):
+ # ensure that this test does not interact with other tests that may use the HF cache
+ monkeypatch.setattr("huggingface_hub.constants.HF_HOME", tmp_path)
+ monkeypatch.setattr("huggingface_hub.constants.HF_HUB_CACHE", tmp_path / "hub")
+ monkeypatch.setattr("huggingface_hub.constants.HF_TOKEN_PATH", tmp_path / "token")
+
+ def load_checkpoints(self, cache_dir):
+ # download model and lora checkpoint to a specific cache dir
+ snapshot_download(self.base_model, cache_dir=cache_dir)
+ snapshot_download(self.peft_model_id, cache_dir=cache_dir)
+
+ # TODO remove when/if Hub is more stable
+ @pytest.mark.xfail(reason="Test is flaky on CI", raises=LocalEntryNotFoundError)
+ def test_load_checkpoint_offline_non_default_cache_dir(self, changed_default_cache_dir, tmp_path):
+ # See #2373 for context
+ self.load_checkpoints(tmp_path)
+ with self.hub_offline_ctx():
+ base_model = AutoModelForCausalLM.from_pretrained(self.base_model, cache_dir=tmp_path)
+ PeftModel.from_pretrained(base_model, self.peft_model_id, cache_dir=tmp_path)
+
+
+class TestCustomModelConfigWarning:
+ # Check potential warnings when the user provided base_model_name_or_path is overridden by PEFT. See #2001 for
+ # context. We use LoRA for this test but the same applies to other methods
+ @pytest.fixture
+ def custom_module(self):
+ class MyModule(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.lin = nn.Linear(10, 10)
+
+ return MyModule()
+
+ def test_no_warning_by_default_transformers_model(self, recwarn):
+ # first a sanity test that there is no warning by default when using a model from transformers
+ model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-OPTForCausalLM")
+ get_peft_model(model, LoraConfig())
+ for warning in recwarn.list:
+ assert "renamed" not in str(warning.message)
+
+ def test_no_warning_by_default_custom_model(self, custom_module, recwarn):
+ # same as above but with a custom model
+ get_peft_model(custom_module, LoraConfig(target_modules=["lin"]))
+ for warning in recwarn.list:
+ assert "renamed" not in str(warning.message)
+
+ def test_warning_name_transformers_model(self, recwarn):
+ # The base_model_name_or_path provided by the user is overridden.
+ model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-OPTForCausalLM")
+ custom_name = "custom_name"
+ get_peft_model(model, LoraConfig(base_model_name_or_path=custom_name))
+ msg = f"was renamed from '{custom_name}' to 'hf-internal-testing/tiny-random-OPTForCausalLM'"
+ assert any(msg in str(warning.message) for warning in recwarn.list)
+
+ def test_warning_name_custom_model(self, custom_module, recwarn):
+ custom_name = "custom_name"
+ get_peft_model(custom_module, LoraConfig(target_modules=["lin"], base_model_name_or_path=custom_name))
+ msg = f"was renamed from '{custom_name}' to 'None'"
+ assert any(msg in str(warning.message) for warning in recwarn.list)
+
+ def test_warning_name_custom_model_with_custom_name(self, custom_module, recwarn):
+ custom_name = "custom_name"
+ custom_module.name_or_path = "foobar"
+ get_peft_model(custom_module, LoraConfig(target_modules=["lin"], base_model_name_or_path=custom_name))
+ msg = f"was renamed from '{custom_name}' to 'foobar'"
+ assert any(msg in str(warning.message) for warning in recwarn.list)
+
+
+class TestLowCpuMemUsage:
+ """Test for the low CPU memory usage option for loading PEFT models.
+
+ Note that we have `test_load_model_low_cpu_mem_usage` in the custom model and stable diffusion tests. Those are
+ broad tests (i.e. testing all the supported PEFT methods) but not very deep (only testing if loading works and the
+ device is correctly set). The test class here goes deeper but only tests LoRA, as checking all PEFT methods would
+ be too much.
+
+ """
+
+ # test on CPU and optionally on accelerator device
+ devices = ["cpu"]
+ _device = infer_device()
+ if _device != "cpu":
+ devices.append(_device)
+
+ model_id = "hf-internal-testing/tiny-random-OPTForCausalLM"
+
+ def get_model(self):
+ return AutoModelForCausalLM.from_pretrained(self.model_id)
+
+ @pytest.fixture(scope="class")
+ def lora_config(self):
+ return LoraConfig(init_lora_weights=False, target_modules="all-linear")
+
+ @pytest.fixture(scope="class")
+ def lora_path(self, tmp_path_factory, lora_config):
+ torch.manual_seed(0)
+ tmp_path = tmp_path_factory.mktemp("lora")
+ model = self.get_model()
+ model = get_peft_model(model, lora_config)
+ model.save_pretrained(tmp_path)
+ return tmp_path
+
+ @pytest.fixture(scope="class")
+ def inputs(self):
+ return {"input_ids": torch.randint(0, 100, (1, 10)), "attention_mask": torch.ones(1, 10)}
+
+ @pytest.mark.parametrize("device", devices)
+ def test_from_pretrained_low_cpu_mem_usage_works(self, device, inputs, lora_path):
+ model = self.get_model().to(device)
+ inputs = {k: v.to(device) for k, v in inputs.items()}
+ model = PeftModel.from_pretrained(model, lora_path, torch_device=device).eval()
+ device_set_not_low_cpu_mem = {p.device.type for p in model.parameters()}
+ logits_not_low_cpu_mem = model(**inputs).logits
+
+ del model
+
+ model = self.get_model().to(device)
+ model = PeftModel.from_pretrained(model, lora_path, low_cpu_mem_usage=True, torch_device=device).eval()
+ device_set_low_cpu_mem = {p.device.type for p in model.parameters()}
+ logits_low_cpu_mem = model(**inputs).logits
+
+ assert device_set_low_cpu_mem == device_set_not_low_cpu_mem
+ assert torch.allclose(logits_low_cpu_mem, logits_not_low_cpu_mem)
+
+ @pytest.mark.parametrize("device", devices)
+ def test_load_adapter_low_cpu_mem_usage_works(self, device, inputs, lora_path, lora_config):
+ model = self.get_model().to(device)
+ inputs = {k: v.to(device) for k, v in inputs.items()}
+
+ torch.manual_seed(0)
+ model = get_peft_model(model, lora_config)
+ model.load_adapter(lora_path, adapter_name="other", torch_device=device)
+ model.set_adapter("other")
+ model.eval()
+ device_set_not_low_cpu_mem = {p.device.type for p in model.parameters()}
+ logits_not_low_cpu_mem = model(**inputs).logits
+
+ del model
+
+ model = self.get_model().to(device)
+ torch.manual_seed(0)
+ model = get_peft_model(model, lora_config)
+ model.load_adapter(lora_path, adapter_name="other", low_cpu_mem_usage=True, torch_device=device)
+ model.set_adapter("other")
+ model.eval()
+ device_set_low_cpu_mem = {p.device.type for p in model.parameters()}
+ logits_low_cpu_mem = model(**inputs).logits
+
+ assert device_set_low_cpu_mem == device_set_not_low_cpu_mem
+ assert torch.allclose(logits_low_cpu_mem, logits_not_low_cpu_mem)
+
+ @pytest.mark.parametrize("device", devices)
+ def test_get_peft_model_low_cpu_mem_usage_works(self, device, inputs):
+ # when calling get_peft_model, the PEFT weights will not be initialized on device but remain on meta
+ model = self.get_model().to(device)
+ model = get_peft_model(model, LoraConfig(target_modules="all-linear"), low_cpu_mem_usage=True)
+
+ devices_lora_weights = {p.device for n, p in model.named_parameters() if "lora_" in n}
+ expected = {torch.device("meta")}
+ assert devices_lora_weights == expected
+
+ @pytest.mark.parametrize("device", devices)
+ def test_get_peft_model_with_task_type_low_cpu_mem_usage_works(self, device, inputs):
+ # same as the previous test, but pass the task_type argument
+ model = self.get_model().to(device)
+ model = get_peft_model(
+ model, LoraConfig(target_modules="all-linear", task_type="CAUSAL_LM"), low_cpu_mem_usage=True
+ )
+
+ devices_lora_weights = {p.device for n, p in model.named_parameters() if "lora_" in n}
+ expected = {torch.device("meta")}
+ assert devices_lora_weights == expected
+
+ @pytest.mark.parametrize("device", devices)
+ def test_inject_adapter_low_cpu_mem_usage_works(self, device, inputs, lora_path, lora_config):
+ # external libs like transformers and diffusers use inject_adapter_in_model, let's check that this also works
+ model = self.get_model().to(device)
+ inputs = {k: v.to(device) for k, v in inputs.items()}
+
+ torch.manual_seed(0)
+ model = get_peft_model(model, lora_config)
+ model.load_adapter(lora_path, adapter_name="other", torch_device=device)
+ model.set_adapter("other")
+ model.eval()
+ device_set_not_low_cpu_mem = {p.device.type for p in model.parameters()}
+ logits_not_low_cpu_mem = model(**inputs).logits
+
+ del model
+
+ torch.manual_seed(0)
+ model = self.get_model().to(device)
+ inject_adapter_in_model(lora_config, model, low_cpu_mem_usage=True)
+ device_set_before_loading = {p.device.type for p in model.parameters()}
+ # at this stage, lora weights are still on meta device
+ assert device_set_before_loading == {"meta", device}
+
+ state_dict = load_file(lora_path / "adapter_model.safetensors")
+ remapped_dict = {}
+ prefix = "base_model.model."
+ for key, val in state_dict.items():
+ new_key = key[len(prefix) :]
+ remapped_dict[new_key] = val.to(device)
+ errors = set_peft_model_state_dict(model, remapped_dict, low_cpu_mem_usage=True)
+ # sanity check: no unexpected keys
+ assert not errors.unexpected_keys
+
+ model.eval()
+ device_set_low_cpu_mem = {p.device.type for p in model.parameters()}
+ logits_low_cpu_mem = model(**inputs).logits
+
+ assert device_set_low_cpu_mem == device_set_not_low_cpu_mem
+ assert torch.allclose(logits_low_cpu_mem, logits_not_low_cpu_mem)
+
+ ############################
+ # tests for PeftMixedModel #
+ ############################
+
+ @pytest.mark.parametrize("device", devices)
+ def test_mixed_model_from_pretrained_low_cpu_mem_usage_works(self, device, inputs, lora_path):
+ model = self.get_model().to(device)
+ inputs = {k: v.to(device) for k, v in inputs.items()}
+ model = PeftMixedModel.from_pretrained(model, lora_path, torch_device=device).eval()
+ device_set_not_low_cpu_mem = {p.device.type for p in model.parameters()}
+ logits_not_low_cpu_mem = model(**inputs).logits
+
+ del model
+
+ model = self.get_model().to(device)
+ model = PeftMixedModel.from_pretrained(model, lora_path, low_cpu_mem_usage=True, torch_device=device).eval()
+ device_set_low_cpu_mem = {p.device.type for p in model.parameters()}
+ logits_low_cpu_mem = model(**inputs).logits
+
+ assert device_set_low_cpu_mem == device_set_not_low_cpu_mem
+ assert torch.allclose(logits_low_cpu_mem, logits_not_low_cpu_mem)
+
+ @pytest.mark.parametrize("device", devices)
+ def test_mixed_model_load_adapter_low_cpu_mem_usage_works(self, device, inputs, lora_path, lora_config):
+ model = self.get_model().to(device)
+ inputs = {k: v.to(device) for k, v in inputs.items()}
+
+ torch.manual_seed(0)
+ model = PeftModel.from_pretrained(model, lora_path)
+ model.load_adapter(lora_path, adapter_name="other", torch_device=device)
+ model.set_adapter("other")
+ model.eval()
+ device_set_not_low_cpu_mem = {p.device.type for p in model.parameters()}
+ logits_not_low_cpu_mem = model(**inputs).logits
+
+ del model
+
+ model = self.get_model().to(device)
+ torch.manual_seed(0)
+ model = PeftModel.from_pretrained(model, lora_path)
+ model.load_adapter(lora_path, adapter_name="other", low_cpu_mem_usage=True, torch_device=device)
+ model.set_adapter("other")
+ model.eval()
+ device_set_low_cpu_mem = {p.device.type for p in model.parameters()}
+ logits_low_cpu_mem = model(**inputs).logits
+
+ assert device_set_low_cpu_mem == device_set_not_low_cpu_mem
+ assert torch.allclose(logits_low_cpu_mem, logits_not_low_cpu_mem)
+
+
+def test_from_pretrained_missing_keys_warning(recwarn, tmp_path):
+ # For more context, see issue 2115
+ # When loading a PEFT adapter and we're missing a PEFT-specific weight, there should be a warning.
+ model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-OPTForCausalLM")
+ config = LoraConfig()
+ model = get_peft_model(model, config)
+ state_dict = model.state_dict()
+
+ # first, sanity check that there are no warnings if no key is missing
+ model.save_pretrained(tmp_path)
+ del model
+ model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-OPTForCausalLM")
+ model = PeftModel.from_pretrained(model, tmp_path)
+ msg = "Found missing adapter keys"
+ assert not any(msg in str(w.message) for w in recwarn.list)
+
+ # remove a key from the state_dict
+ missing_key = "base_model.model.model.decoder.layers.0.self_attn.v_proj.lora_A.default.weight"
+
+ def new_state_dict():
+ return {k: v for k, v in state_dict.items() if k != missing_key}
+
+ model.state_dict = new_state_dict
+ model.save_pretrained(tmp_path)
+ del model
+
+ model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-OPTForCausalLM")
+ model = PeftModel.from_pretrained(model, tmp_path)
+ assert any(msg in str(w.message) for w in recwarn.list)
+ assert any(missing_key in str(w.message) for w in recwarn.list)
+
+
+class TestNamingConflictWarning:
+ """
+ Tests for warnings related to naming conflicts between adapter names and tuner prefixes. References: Issue 2252
+ """
+
+ @pytest.fixture(autouse=True)
+ def setup(self):
+ self.peft_config = LoraConfig()
+ self.prefix = PEFT_TYPE_TO_PREFIX_MAPPING[self.peft_config.peft_type]
+ self.base_model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-OPTForCausalLM")
+
+ def _save_and_reload_model(self, model, adapter_name, tmp_path):
+ # Helper method to save and reload the PEFT model
+ model.save_pretrained(tmp_path, selected_adapters=[adapter_name])
+ del model
+ reloaded_base_model = AutoModelForCausalLM.from_pretrained(tmp_path / adapter_name)
+ return PeftModel.from_pretrained(reloaded_base_model, tmp_path / adapter_name)
+
+ def test_no_warning_without_naming_conflict_get_peft_model(self, recwarn):
+ # No warning should be raised when there is no naming conflict during get_peft_model.
+ non_conflict_adapter = "adapter"
+ _ = get_peft_model(self.base_model, self.peft_config, adapter_name=non_conflict_adapter)
+ expected_msg = f"Adapter name {non_conflict_adapter} should not be contained in the prefix {self.prefix}."
+ assert not any(expected_msg in str(w.message) for w in recwarn.list)
+
+ def test_no_warning_without_naming_conflict_add_adapter(self, recwarn):
+ # No warning should be raised when adding an adapter without naming conflict.
+ non_conflict_adapter = "adapter"
+ other_non_conflict_adapter = "other_adapter"
+ model = get_peft_model(self.base_model, self.peft_config, adapter_name=non_conflict_adapter)
+ _ = model.add_adapter(other_non_conflict_adapter, self.peft_config)
+ expected_msg = (
+ f"Adapter name {other_non_conflict_adapter} should not be contained in the prefix {self.prefix}."
+ )
+ assert not any(expected_msg in str(w.message) for w in recwarn.list)
+
+ def test_no_warning_without_naming_conflict_save_and_load(self, recwarn, tmp_path):
+ # No warning should be raised when saving and loading the model without naming conflict.
+ non_conflict_adapter = "adapter"
+ model = get_peft_model(self.base_model, self.peft_config, adapter_name=non_conflict_adapter)
+ _ = self._save_and_reload_model(model, non_conflict_adapter, tmp_path)
+ expected_msg = f"Adapter name {non_conflict_adapter} should not be contained in the prefix {self.prefix}."
+ assert not any(expected_msg in str(w.message) for w in recwarn.list)
+
+ def test_warning_naming_conflict_get_peft_model(self, recwarn):
+ # Warning is raised when the adapter name conflicts with the prefix in get_peft_model.
+ conflicting_adapter_name = self.prefix[:-1]
+ _ = get_peft_model(self.base_model, self.peft_config, adapter_name=conflicting_adapter_name)
+ expected_msg = f"Adapter name {conflicting_adapter_name} should not be contained in the prefix {self.prefix}."
+ assert any(expected_msg in str(w.message) for w in recwarn.list)
+
+ def test_warning_naming_conflict_add_adapter(self, recwarn):
+ # Warning is raised when adding an adapter with a name that conflicts with the prefix.
+ conflicting_adapter = self.prefix[1:]
+ non_conflict_adapter = "adapter"
+ model = get_peft_model(self.base_model, self.peft_config, adapter_name=non_conflict_adapter)
+ _ = model.add_adapter(conflicting_adapter, self.peft_config)
+ expected_msg = f"Adapter name {conflicting_adapter} should not be contained in the prefix {self.prefix}."
+ assert any(expected_msg in str(w.message) for w in recwarn.list)
+
+ def test_warning_naming_conflict_save_and_load(self, recwarn, tmp_path):
+ # Warning is raised when saving and loading the model with a naming conflict.
+ conflicting_adapter = self.prefix[:-1]
+ model = get_peft_model(self.base_model, self.peft_config, adapter_name=conflicting_adapter)
+ _ = self._save_and_reload_model(model, conflicting_adapter, tmp_path)
+ expected_msg = f"Adapter name {conflicting_adapter} should not be contained in the prefix {self.prefix}."
+ assert any(expected_msg in str(w.message) for w in recwarn.list)
+
+
+class TestCordaInitialization:
+ """Test class to check the initialization of CorDA adapters."""
+
+ torch_device = infer_device()
+
+ def get_model(self):
+ class MyModule(nn.Module):
+ def __init__(self):
+ super().__init__()
+ # choose a large weight so that averages are close to expected values
+ self.linear = nn.Linear(1000, 1000)
+
+ def forward(self, x):
+ return self.linear(x)
+
+ return MyModule().eval().to(self.torch_device)
+
+ @pytest.fixture
+ def data(self):
+ # larger data is required to pass KPM test
+ torch.manual_seed(233)
+ return torch.rand(1000, 1000).to(self.torch_device)
+
+ @pytest.mark.parametrize("corda_method", ("ipm", "kpm"))
+ def test_lora_corda_no_redundant_fields(self, data, corda_method):
+ original_model = self.get_model()
+ model = deepcopy(original_model)
+
+ corda_config = CordaConfig(
+ corda_method=corda_method,
+ )
+ config = LoraConfig(
+ init_lora_weights="corda",
+ target_modules=["linear"],
+ corda_config=corda_config,
+ )
+ preprocess_corda(
+ model,
+ config,
+ run_model=lambda: model(data),
+ hooked_model=model,
+ )
+ peft_model = get_peft_model(model, config)
+
+ # check if the redundant fields are removed
+ assert not hasattr(peft_model.base_model.linear, "sample_count")
+ assert not hasattr(peft_model.base_model.linear, "covariance_matrix")
+ assert not hasattr(peft_model.base_model.linear, "corda_method")
+ assert not hasattr(peft_model.base_model.linear, "rank")
+ assert not hasattr(peft_model.base_model.linear, "eigens")
+
+ # legacy debug fields
+ assert not hasattr(peft_model.base_model.linear, "mean")
+ assert not hasattr(peft_model.base_model.linear, "std")
+
+ @pytest.mark.parametrize("corda_method", ("ipm", "kpm"))
+ def test_lora_corda_sample_count(self, data, corda_method):
+ original_model = self.get_model()
+ model = deepcopy(original_model)
+
+ corda_config = CordaConfig(
+ corda_method=corda_method,
+ prune_temporary_fields=False,
+ )
+ config = LoraConfig(
+ init_lora_weights="corda",
+ target_modules=["linear"],
+ corda_config=corda_config,
+ )
+ preprocess_corda(
+ model,
+ config,
+ run_model=lambda: [model(data), model(data)], # running model twice to test `sample_count`
+ hooked_model=model,
+ )
+
+ # covariance of linear should be data.T @ data
+ layer = model.linear
+ assert hasattr(layer, "covariance_matrix")
+ assert torch.allclose(layer.covariance_matrix, data.T @ data, atol=1e-06)
+
+ # sample count of linear should be 2
+ assert hasattr(layer, "sample_count")
+ assert layer.sample_count == 2
+
+ @pytest.mark.parametrize("corda_method", ("ipm", "kpm"))
+ def test_lora_corda_hook_unregister(self, data, corda_method):
+ original_model = self.get_model()
+ model = deepcopy(original_model)
+
+ hook_call_count = 0
+
+ def hook(*args):
+ nonlocal hook_call_count
+ hook_call_count += 1
+
+ model.linear.register_forward_hook(hook)
+
+ corda_config = CordaConfig(
+ corda_method=corda_method,
+ prune_temporary_fields=False,
+ )
+ config = LoraConfig(
+ init_lora_weights="corda",
+ target_modules=["linear"],
+ corda_config=corda_config,
+ )
+ preprocess_corda(
+ model,
+ config,
+ run_model=lambda: model(data),
+ hooked_model=model,
+ )
+
+ # after preprocessing, external and internal hook should be run once
+ assert hook_call_count == 1
+ assert model.linear.sample_count == 1
+
+ # run preprocessed model once
+ model(data)[0]
+
+ # the external hook should be kept, but the internal hook should be gone
+ assert hook_call_count == 2
+ assert model.linear.sample_count == 1
+
+ @pytest.mark.parametrize("corda_method", ("ipm", "kpm"))
+ def test_lora_corda_linear_init_default(self, data, tmp_path, corda_method):
+ original_model = self.get_model()
+ model = deepcopy(original_model)
+ output_base = model(data)[0]
+
+ corda_config = CordaConfig(
+ cache_file=tmp_path / "corda_cache.pt",
+ covariance_file=tmp_path / "covariance_cache.pt",
+ corda_method=corda_method,
+ )
+ config = LoraConfig(
+ init_lora_weights="corda",
+ target_modules=["linear"],
+ corda_config=corda_config,
+ )
+ preprocess_corda(
+ model,
+ config,
+ run_model=lambda: model(data),
+ hooked_model=model,
+ )
+ peft_model = get_peft_model(model, config)
+
+ # check if adapter performs an identity transformantion
+ assert torch.allclose(output_base, peft_model(data)[0], atol=1e-06)
+
+ # modify the weights, or else the adapter performs an identity transformation
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ output_corda = peft_model(data)[0]
+
+ # sanity check
+ tol = 1e-06
+ assert not torch.allclose(output_base, output_corda, atol=tol, rtol=tol)
+
+ # if load SVD result from cache, the output should be the same
+ model = deepcopy(original_model)
+ config = LoraConfig(
+ init_lora_weights="corda",
+ target_modules=["linear"],
+ corda_config=CordaConfig(cache_file=tmp_path / "corda_cache.pt", corda_method=corda_method),
+ )
+ preprocess_corda(model, config)
+ peft_model = get_peft_model(model, config)
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ assert torch.allclose(output_corda, peft_model(data)[0], atol=1e-06)
+
+ # if load covariance from cache, the output should be the same
+ model = deepcopy(original_model)
+ config = LoraConfig(
+ init_lora_weights="corda",
+ target_modules=["linear"],
+ corda_config=CordaConfig(covariance_file=tmp_path / "covariance_cache.pt", corda_method=corda_method),
+ )
+ preprocess_corda(model, config)
+ peft_model = get_peft_model(model, config)
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ assert torch.allclose(output_corda, peft_model(data)[0], atol=1e-06)
+
+ @pytest.mark.parametrize("corda_method", ("ipm", "kpm"))
+ def test_lora_corda_hooked_model_linear_init_default(self, data, tmp_path, corda_method):
+ original_model = self.get_model()
+ model = deepcopy(original_model)
+ hooked_model = deepcopy(model)
+ output_base = model(data)[0]
+
+ corda_config = CordaConfig(
+ cache_file=tmp_path / "corda_cache.pt",
+ covariance_file=tmp_path / "covariance_cache.pt",
+ corda_method=corda_method,
+ )
+ config = LoraConfig(
+ init_lora_weights="corda",
+ target_modules=["linear"],
+ corda_config=corda_config,
+ )
+
+ # difference from the above test: this test uses a copied model as hooked model
+ preprocess_corda(
+ model,
+ config,
+ run_model=lambda: hooked_model(data),
+ hooked_model=hooked_model,
+ )
+ peft_model = get_peft_model(model, config)
+
+ # check if adapter performs an identity transformantion
+ assert torch.allclose(output_base, peft_model(data)[0], atol=1e-06)
+
+ # modify the weights, or else the adapter performs an identity transformation
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ output_corda = peft_model(data)[0]
+
+ # sanity check
+ tol = 1e-06
+ assert not torch.allclose(output_base, output_corda, atol=tol, rtol=tol)
+
+ # if load SVD result from cache, the output should be the same
+ model = deepcopy(original_model)
+ config = LoraConfig(
+ init_lora_weights="corda",
+ target_modules=["linear"],
+ corda_config=CordaConfig(cache_file=tmp_path / "corda_cache.pt", corda_method=corda_method),
+ )
+ preprocess_corda(model, config)
+ peft_model = get_peft_model(model, config)
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ assert torch.allclose(output_corda, peft_model(data)[0], atol=1e-06)
+
+ # if load covariance from cache, the output should be the same
+ model = deepcopy(original_model)
+ config = LoraConfig(
+ init_lora_weights="corda",
+ target_modules=["linear"],
+ corda_config=CordaConfig(covariance_file=tmp_path / "covariance_cache.pt", corda_method=corda_method),
+ )
+ preprocess_corda(model, config)
+ peft_model = get_peft_model(model, config)
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ assert torch.allclose(output_corda, peft_model(data)[0], atol=1e-06)
+
+ @pytest.mark.parametrize("corda_method", ("ipm", "kpm"))
+ def test_lora_corda_linear_init_default_with_rank_pattern(self, data, tmp_path, corda_method):
+ original_model = self.get_model()
+ model = deepcopy(original_model)
+ output_base = model(data)[0]
+
+ corda_config = CordaConfig(
+ cache_file=tmp_path / "corda_cache.pt",
+ covariance_file=tmp_path / "covariance_cache.pt",
+ corda_method=corda_method,
+ )
+ config = LoraConfig(
+ rank_pattern={"linear": 8, "embed": 16, "conv2d": 32},
+ init_lora_weights="corda",
+ target_modules=["linear"],
+ corda_config=corda_config,
+ )
+ preprocess_corda(
+ model,
+ config,
+ run_model=lambda: model(data),
+ )
+ peft_model = get_peft_model(model, config)
+
+ # check if adapter performs an identity transformantion
+ assert torch.allclose(output_base, peft_model(data)[0], atol=1e-06)
+
+ # modify the weights, or else the adapter performs an identity transformation
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ output_corda = peft_model(data)[0]
+
+ # sanity check
+ tol = 1e-06
+ assert not torch.allclose(output_base, output_corda, atol=tol, rtol=tol)
+
+ # if load SVD result from cache, the output should be the same
+ model = deepcopy(original_model)
+ config = LoraConfig(
+ rank_pattern={"linear": 8, "embed": 16, "conv2d": 32},
+ init_lora_weights="corda",
+ target_modules=["linear"],
+ corda_config=CordaConfig(cache_file=tmp_path / "corda_cache.pt", corda_method=corda_method),
+ )
+ preprocess_corda(model, config)
+ peft_model = get_peft_model(model, config)
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ assert torch.allclose(output_corda, peft_model(data)[0], atol=1e-06)
+
+ # if load covariance from cache, the output should be the same
+ model = deepcopy(original_model)
+ config = LoraConfig(
+ rank_pattern={"linear": 8, "embed": 16, "conv2d": 32},
+ init_lora_weights="corda",
+ target_modules=["linear"],
+ corda_config=CordaConfig(covariance_file=tmp_path / "covariance_cache.pt", corda_method=corda_method),
+ )
+ preprocess_corda(model, config)
+ peft_model = get_peft_model(model, config)
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ assert torch.allclose(output_corda, peft_model(data)[0], atol=1e-06)
+
+ @pytest.mark.parametrize("corda_method", ("ipm", "kpm"))
+ def test_lora_corda_conversion_same_output_after_loading(self, data, tmp_path, corda_method):
+ model = self.get_model()
+ output_base = model(data)[0]
+
+ corda_config = CordaConfig(corda_method=corda_method)
+ config = LoraConfig(init_lora_weights="corda", target_modules=["linear"], r=8, corda_config=corda_config)
+ preprocess_corda(model, config, run_model=lambda: model(data), hooked_model=model)
+ peft_model = get_peft_model(deepcopy(model), config)
+ # save the initial model
+ peft_model.peft_config["default"].init_lora_weights = True
+ peft_model.save_pretrained(tmp_path / "init-model")
+ peft_model.peft_config["default"].init_lora_weights = "corda"
+
+ # modify the weights, or else the adapter performs an identity transformation
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ output_corda = peft_model(data)[0]
+
+ # sanity check
+ tol = 1e-06
+ assert not torch.allclose(output_base, output_corda, atol=tol, rtol=tol)
+
+ # save the model normally
+ peft_model.save_pretrained(tmp_path / "corda-model")
+ model_loaded = PeftModel.from_pretrained(deepcopy(model), tmp_path / "corda-model")
+ output_loaded = model_loaded(data)[0]
+
+ assert torch.allclose(output_corda, output_loaded, atol=tol, rtol=tol)
+ # sanity check: ranks should still be 8 as initially
+ assert model_loaded.peft_config["default"].r == 8
+ assert model_loaded.base_model.model.linear.lora_A["default"].weight.shape[0] == 8
+ # sanity check: the base model weights were indeed changed
+ assert not torch.allclose(
+ model.linear.weight, model_loaded.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ # save the model with conversion
+ peft_config_keys_before = list(peft_model.peft_config.keys())
+ peft_config_dict_before = peft_model.peft_config["default"].to_dict()
+ peft_model.save_pretrained(
+ tmp_path / "corda-model-converted", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+ peft_config_keys_after = list(peft_model.peft_config.keys())
+ peft_config_dict_after = peft_model.peft_config["default"].to_dict()
+ assert peft_config_keys_before == peft_config_keys_after
+ assert peft_config_dict_before == peft_config_dict_after
+
+ model_converted = PeftModel.from_pretrained(deepcopy(model), tmp_path / "corda-model-converted")
+ output_converted = model_converted(data)[0]
+
+ assert torch.allclose(output_corda, output_converted, atol=tol, rtol=tol)
+ # rank should be double of what it was initially
+ assert model_converted.peft_config["default"].r == 16
+ assert model_converted.base_model.model.linear.lora_A["default"].weight.shape[0] == 16
+ # base model weights should be the same as the initial model
+ assert torch.allclose(
+ model.linear.weight, model_converted.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ @pytest.mark.parametrize("corda_method", ("ipm", "kpm"))
+ def test_lora_corda_conversion_same_output_after_loading_with_rank_pattern(self, data, tmp_path, corda_method):
+ # same as above, but using rank_pattern
+ model = self.get_model()
+ output_base = model(data)[0]
+
+ # use rank_pattern here; note that since there is only a single linear layer, r is completely overridden
+ corda_config = CordaConfig(corda_method=corda_method)
+ config = LoraConfig(
+ init_lora_weights="corda",
+ target_modules=["linear"],
+ r=8,
+ rank_pattern={"linear": 32},
+ corda_config=corda_config,
+ )
+ preprocess_corda(model, config, run_model=lambda: model(data), hooked_model=model)
+ peft_model = get_peft_model(deepcopy(model), config)
+ # save the initial model
+ peft_model.peft_config["default"].init_lora_weights = True
+ peft_model.save_pretrained(tmp_path / "init-model")
+ peft_model.peft_config["default"].init_lora_weights = "corda"
+
+ # modify the weights, or else the adapter performs an identity transformation
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ output_corda = peft_model(data)[0]
+
+ # sanity check
+ tol = 1e-06
+ assert not torch.allclose(output_base, output_corda, atol=tol, rtol=tol)
+
+ # save the model normally
+ peft_model.save_pretrained(tmp_path / "corda-model")
+ model_loaded = PeftModel.from_pretrained(deepcopy(model), tmp_path / "corda-model")
+ output_loaded = model_loaded(data)[0]
+
+ assert torch.allclose(output_corda, output_loaded, atol=tol, rtol=tol)
+ # sanity check: ranks should still be 8 as initially
+ assert model_loaded.peft_config["default"].r == 8
+ assert model_loaded.base_model.model.linear.lora_A["default"].weight.shape[0] == 32
+ # sanity check: the base model weights were indeed changed
+ assert not torch.allclose(
+ model.linear.weight, model_loaded.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ # save the model with conversion
+ peft_model.save_pretrained(
+ tmp_path / "corda-model-converted", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+ model_converted = PeftModel.from_pretrained(deepcopy(model), tmp_path / "corda-model-converted")
+ output_converted = model_converted(data)[0]
+
+ assert torch.allclose(output_corda, output_converted, atol=tol, rtol=tol)
+ # rank should be double of what it was initially
+ assert model_converted.peft_config["default"].r == 16
+ assert model_converted.base_model.model.linear.lora_A["default"].weight.shape[0] == 64
+ # base model weights should be the same as the initial model
+ assert torch.allclose(
+ model.linear.weight, model_converted.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ @pytest.mark.parametrize("corda_method", ("ipm", "kpm"))
+ def test_lora_corda_conversion_same_output_after_loading_with_alpha_pattern(self, data, tmp_path, corda_method):
+ # same as above, but using alpha_pattern
+ model = self.get_model()
+ output_base = model(data)[0]
+
+ # use alpha_pattern here; note that since there is only a single linear layer, lora_alpha is completely
+ # overridden
+ corda_config = CordaConfig(corda_method=corda_method)
+ config = LoraConfig(
+ init_lora_weights="corda",
+ target_modules=["linear"],
+ alpha_pattern={"linear": 5},
+ corda_config=corda_config,
+ )
+ preprocess_corda(model, config, run_model=lambda: model(data), hooked_model=model)
+ peft_model = get_peft_model(deepcopy(model), config)
+ # save the initial model
+ peft_model.peft_config["default"].init_lora_weights = True
+ peft_model.save_pretrained(tmp_path / "init-model")
+ peft_model.peft_config["default"].init_lora_weights = "corda"
+
+ # modify the weights, or else the adapter performs an identity transformation
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ output_corda = peft_model(data)[0]
+
+ # sanity check
+ tol = 1e-06
+ assert not torch.allclose(output_base, output_corda, atol=tol, rtol=tol)
+
+ # save the model normally
+ peft_model.save_pretrained(tmp_path / "corda-model")
+ model_loaded = PeftModel.from_pretrained(deepcopy(model), tmp_path / "corda-model")
+ output_loaded = model_loaded(data)[0]
+
+ assert torch.allclose(output_corda, output_loaded, atol=tol, rtol=tol)
+ # sanity check: ranks should still be 8 as initially
+ assert model_loaded.peft_config["default"].r == 8
+ assert model_loaded.base_model.model.linear.lora_A["default"].weight.shape[0] == 8
+ assert model_loaded.base_model.model.linear.scaling["default"] == 5 / 8
+ # sanity check: the base model weights were indeed changed
+ assert not torch.allclose(
+ model.linear.weight, model_loaded.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ # save the model with conversion
+ peft_model.save_pretrained(
+ tmp_path / "corda-model-converted", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+ model_converted = PeftModel.from_pretrained(deepcopy(model), tmp_path / "corda-model-converted")
+ output_converted = model_converted(data)[0]
+
+ assert torch.allclose(output_corda, output_converted, atol=tol, rtol=tol)
+ # rank should be double of what it was initially
+ assert model_converted.peft_config["default"].r == 16
+ assert model_converted.base_model.model.linear.lora_A["default"].weight.shape[0] == 16
+ assert model_converted.base_model.model.linear.scaling["default"] == 10 / 16
+ # base model weights should be the same as the initial model
+ assert torch.allclose(
+ model.linear.weight, model_converted.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ @pytest.mark.parametrize("corda_method", ("ipm", "kpm"))
+ def test_lora_corda_conversion_same_output_after_loading_with_rslora(self, data, tmp_path, corda_method):
+ model = self.get_model()
+ output_base = model(data)[0]
+
+ corda_config = CordaConfig(corda_method=corda_method)
+ config = LoraConfig(
+ init_lora_weights="corda", target_modules=["linear"], r=8, use_rslora=True, corda_config=corda_config
+ )
+ preprocess_corda(model, config, run_model=lambda: model(data), hooked_model=model)
+ peft_model = get_peft_model(deepcopy(model), config)
+ # save the initial model
+ peft_model.peft_config["default"].init_lora_weights = True
+ peft_model.save_pretrained(tmp_path / "init-model")
+ peft_model.peft_config["default"].init_lora_weights = "corda"
+
+ # modify the weights, or else the adapter performs an identity transformation
+ peft_model.base_model.linear.lora_B["default"].weight.data *= 2.0
+ output_corda = peft_model(data)[0]
+
+ # sanity check
+ tol = 1e-06
+ assert not torch.allclose(output_base, output_corda, atol=tol, rtol=tol)
+
+ # save the model normally
+ peft_model.save_pretrained(tmp_path / "corda-model")
+ model_loaded = PeftModel.from_pretrained(deepcopy(model), tmp_path / "corda-model")
+ output_loaded = model_loaded(data)[0]
+
+ assert torch.allclose(output_corda, output_loaded, atol=tol, rtol=tol)
+ # sanity check: ranks should still be 8 as initially
+ assert model_loaded.peft_config["default"].r == 8
+ assert model_loaded.base_model.model.linear.lora_A["default"].weight.shape[0] == 8
+ assert model_loaded.base_model.model.linear.scaling["default"] == 8 / (8**0.5)
+ # sanity check: the base model weights were indeed changed
+ assert not torch.allclose(
+ model.linear.weight, model_loaded.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ # save the model with conversion
+ peft_model.save_pretrained(
+ tmp_path / "corda-model-converted", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+ model_converted = PeftModel.from_pretrained(deepcopy(model), tmp_path / "corda-model-converted")
+ output_converted = model_converted(data)[0]
+
+ assert torch.allclose(output_corda, output_converted, atol=tol, rtol=tol)
+ # rank should be double of what it was initially
+ assert model_converted.peft_config["default"].r == 16
+ assert model_converted.base_model.model.linear.lora_A["default"].weight.shape[0] == 16
+ # same scale as before with a little bit of floating point imprecision
+ assert model_converted.base_model.model.linear.scaling["default"] == pytest.approx(8 / (8**0.5))
+ # base model weights should be the same as the initial model
+ assert torch.allclose(
+ model.linear.weight, model_converted.base_model.model.linear.base_layer.weight, atol=tol, rtol=tol
+ )
+
+ @pytest.mark.parametrize("corda_method", ("ipm", "kpm"))
+ def test_lora_corda_rank_pattern_and_rslora_raises(self, data, tmp_path, corda_method):
+ # it's not possible to determine the correct scale when using rslora with rank or alpha pattern, because the
+ # scale is not stored in the state_dict
+ model = self.get_model()
+ corda_config = CordaConfig(corda_method=corda_method)
+ config = LoraConfig(
+ init_lora_weights="corda",
+ target_modules=["linear"],
+ r=8,
+ rank_pattern={"linear": 2},
+ use_rslora=True,
+ corda_config=corda_config,
+ )
+ preprocess_corda(model, config, run_model=lambda: model(data), hooked_model=model)
+ peft_model = get_peft_model(model, config)
+ peft_model.save_pretrained(tmp_path / "init-model")
+
+ msg = re.escape("Passing `path_initial_model_for_weight_conversion` to `save_pretrained`")
+ with pytest.raises(ValueError, match=msg):
+ peft_model.save_pretrained(
+ tmp_path / "corda-model", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+
+ @pytest.mark.parametrize("corda_method", ("ipm", "kpm"))
+ def test_lora_corda_alpha_pattern_and_rslora_raises(self, data, tmp_path, corda_method):
+ # it's not possible to determine the correct scale when using rslora with rank or alpha pattern, because the
+ # scale is not stored in the state_dict
+ model = self.get_model()
+ corda_config = CordaConfig(corda_method=corda_method)
+ config = LoraConfig(
+ init_lora_weights="corda",
+ target_modules=["linear"],
+ r=8,
+ alpha_pattern={"linear": 2},
+ use_rslora=True,
+ corda_config=corda_config,
+ )
+ preprocess_corda(model, config, run_model=lambda: model(data), hooked_model=model)
+ peft_model = get_peft_model(model, config)
+ peft_model.save_pretrained(tmp_path / "init-model")
+
+ msg = re.escape("Passing `path_initial_model_for_weight_conversion` to `save_pretrained`")
+ with pytest.raises(ValueError, match=msg):
+ peft_model.save_pretrained(
+ tmp_path / "corda-model", path_initial_model_for_weight_conversion=tmp_path / "init-model"
+ )
+
+
+class TestEvaInitialization:
+ """Tests for the EVA (Explained Variance Adaptation) initialization method.
+
+ This test suite verifies:
+ 1. Consistency of initialization across different seeds
+ 2. Proper error handling for invalid inputs
+ 3. Compatibility with different model architectures
+ 4. Reproducibility of results
+ 5. Proper handling of edge cases
+ """
+
+ # Constants for test configuration
+ COSINE_SIMILARITY_THRESHOLD = 0.75
+ NUM_SEEDS = 2
+ BATCH_SIZE = 4
+ MAX_LENGTH = 256
+ LORA_DIM = 8
+ LORA_ALPHA = 1
+ DEVICE = infer_device()
+ # for caching purposes:
+ _dataset = load_dataset_english_quotes()["train"]
+
+ @pytest.fixture
+ def tokenizer(self):
+ tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
+ tokenizer.pad_token = tokenizer.eos_token
+ return tokenizer
+
+ @pytest.fixture
+ def dataset(self, tokenizer):
+ # concatenate examples
+ examples = []
+ example = ""
+ for data in self._dataset:
+ if len(example) >= self.MAX_LENGTH:
+ examples.append(example)
+ example = ""
+ example = example + " " + data["quote"]
+ dataset = Dataset.from_dict({"text": examples})
+ # tokenize
+ dataset = dataset.map(
+ lambda x: tokenizer(x["text"], padding="max_length", truncation=True, max_length=self.MAX_LENGTH),
+ batched=True,
+ remove_columns=dataset.column_names,
+ )
+ dataset.set_format(type="torch")
+ return dataset
+
+ @pytest.fixture
+ def model(self):
+ model = AutoModelForCausalLM.from_pretrained("openai-community/gpt2")
+ model.transformer.h = model.transformer.h[:2] # truncate to 2 layers
+ return model.to(self.DEVICE)
+
+ @pytest.fixture
+ def peft_config(self):
+ return LoraConfig(
+ r=self.LORA_DIM,
+ lora_alpha=self.LORA_ALPHA,
+ target_modules=["c_attn"],
+ init_lora_weights="eva",
+ eva_config=EvaConfig(rho=2),
+ )
+
+ @staticmethod
+ def collate_fn(examples):
+ return {k: torch.stack([v[k] for v in examples], dim=0) for k in examples[0].keys()}
+
+ @staticmethod
+ def prepare_layer_inputs_fn(layer_input, model_input, layer_name):
+ return layer_input[0].view(-1, layer_input[0].size(-1))
+
+ def get_dataloader(self, dataset):
+ return DataLoader(
+ dataset,
+ batch_size=self.BATCH_SIZE,
+ collate_fn=self.collate_fn,
+ shuffle=False,
+ )
+
+ @pytest.mark.parametrize(
+ "prepare_layer_inputs_keys, expected_outcome",
+ [
+ (None, "success"),
+ (["transformer.h.0.attn.c_attn"], "success"),
+ (
+ ["transformer.h.0.attn.c_attn", "transformer.h.1.attn.c_attn", "transformer.h.2.attn.c_attn"],
+ "value_error",
+ ),
+ ],
+ )
+ def test_eva_state_dict_prepare_inputs_mapping(
+ self, model, dataset, peft_config, prepare_layer_inputs_keys, expected_outcome
+ ):
+ """
+ Tests for cases where prepare_layer_inputs_fn is a mapping. Checks that if not all target modules are present,
+ the prepare_layer_inputs_fn for the remaining modules is set to None. Also checks that if more keys than target
+ modules are present, a ValueError is raised.
+ """
+
+ def fn(x, *args):
+ return x[0].view(-1, x[0].size(-1))
+
+ if prepare_layer_inputs_keys is None:
+ prepare_layer_inputs_fn = fn
+ else:
+ prepare_layer_inputs_fn = {k: fn for k in prepare_layer_inputs_keys}
+
+ shuffled_dataset = dataset.shuffle(seed=0)
+ dataloader = self.get_dataloader(shuffled_dataset)
+ modified_peft_config = deepcopy(peft_config)
+ modified_peft_config.eva_config.tau = 0 # converge immediately
+ if expected_outcome == "success":
+ sd = get_eva_state_dict(
+ model,
+ dataloader,
+ modified_peft_config,
+ prepare_model_inputs_fn=None,
+ prepare_layer_inputs_fn=prepare_layer_inputs_fn,
+ )
+ assert len(sd) == 2
+ assert "transformer.h.0.attn.c_attn" in sd
+ assert "transformer.h.1.attn.c_attn" in sd
+ else:
+ with pytest.raises(
+ ValueError, match="prepare_layer_inputs_fn is a mapping but the following module names were not found"
+ ):
+ get_eva_state_dict(
+ model,
+ dataloader,
+ modified_peft_config,
+ prepare_model_inputs_fn=None,
+ prepare_layer_inputs_fn=prepare_layer_inputs_fn,
+ )
+
+ @pytest.mark.parametrize(
+ "eva_config",
+ [EvaConfig(rho=2, adjust_scaling_factors=True)],
+ )
+ def test_eva_state_dict_adjust_scaling_factors(self, model, dataset, peft_config, eva_config):
+ """
+ Tests that the scaling factors are adjusted so that all LoRA gradients have the same scale regardless of their
+ rank.
+ """
+ modified_peft_config = deepcopy(peft_config)
+ modified_peft_config.eva_config = eva_config
+ dataloader = self.get_dataloader(dataset)
+ peft_model = get_peft_model(deepcopy(model), modified_peft_config)
+ scaling_factors_before = {}
+ for n, m in peft_model.named_modules():
+ if isinstance(m, LoraLayer):
+ scaling_factors_before[n] = m.scaling["default"]
+ initialize_lora_eva_weights(peft_model, dataloader)
+ for n, m in peft_model.named_modules():
+ if isinstance(m, LoraLayer):
+ assert m.scaling["default"] == scaling_factors_before[n]
+
+ @pytest.mark.parametrize(
+ "eva_config",
+ [
+ # note: lower tau to decrease number of iterations until convergence, as tests are slow on CPU
+ EvaConfig(rho=2, tau=0.9),
+ EvaConfig(rho=1, tau=0.9),
+ EvaConfig(rho=1, whiten=True, tau=0.9),
+ EvaConfig(rho=1.0001, tau=0.9),
+ ],
+ )
+ def test_eva_initialization_consistency(self, model, dataset, peft_config, eva_config):
+ """
+ Tests that the state dict returned by `get_eva_state_dict` is consistent across different seeds based on the
+ cosine similarity of the svd components.
+ """
+ modified_peft_config = deepcopy(peft_config)
+ modified_peft_config.eva_config = eva_config
+ state_dicts = []
+ for seed in range(self.NUM_SEEDS):
+ shuffled_dataset = dataset.shuffle(seed=seed)
+ dataloader = self.get_dataloader(shuffled_dataset)
+ sd = get_eva_state_dict(model, dataloader, modified_peft_config, show_progress_bar=False)
+ state_dicts.append(sd)
+
+ cos_sims = defaultdict(list)
+ for i, j in itertools.combinations(range(self.NUM_SEEDS), 2):
+ for k, v1 in state_dicts[i].items():
+ v2 = state_dicts[j][k]
+ min_size = min(v1.size(0), v2.size(0))
+ cos_sims[k].extend(torch.cosine_similarity(v1[:min_size].abs(), v2[:min_size].abs(), dim=1).tolist())
+
+ mean_cosine_similarities = {k: torch.tensor(v).mean() for k, v in cos_sims.items()}
+ for layer_name, mean_cosine_similarity in mean_cosine_similarities.items():
+ assert mean_cosine_similarity > self.COSINE_SIMILARITY_THRESHOLD, (
+ f"Mean absolute cosine similarity {mean_cosine_similarity:.4f} "
+ f"is not greater than {self.COSINE_SIMILARITY_THRESHOLD}"
+ )
+
+ @pytest.mark.parametrize("has_rank_zero", [True, False])
+ def test_load_eva_state_dict(self, model, dataset, peft_config, tmp_path, has_rank_zero):
+ """
+ Tests that the `eva_state_dict` argument in `initialize_lora_eva_weights` can be used to initialize a model
+ with EVA weights and that the initialized model can be saved and loaded correctly.
+ """
+ dataloader = self.get_dataloader(dataset)
+ peft_model = get_peft_model(deepcopy(model), peft_config)
+ sd = get_eva_state_dict(peft_model, dataloader)
+ if has_rank_zero:
+ k = "base_model.model.transformer.h.0.attn.c_attn"
+ sd[k] = sd[k][:0]
+ initialize_lora_eva_weights(peft_model, eva_state_dict=sd)
+ if has_rank_zero:
+ assert not isinstance(peft_model.model.transformer.h[0].attn.c_attn, LoraLayer)
+ else:
+ assert isinstance(peft_model.model.transformer.h[0].attn.c_attn, LoraLayer)
+ peft_model.save_pretrained(tmp_path)
+ peft_model = PeftModel.from_pretrained(model, tmp_path, torch_device=self.DEVICE, low_cpu_mem_usage=True)
+ peft_model(**{k: v.to(self.DEVICE) for k, v in next(iter(dataloader)).items()})
+
+ def test_missing_eva_inits(self, model, dataset, peft_config):
+ """
+ Tests that a warning is raised when some adapter modules were not initialized with EVA weights.
+ """
+ modified_peft_config = deepcopy(peft_config)
+ modified_peft_config.target_modules = ["wte"]
+ dataloader = self.get_dataloader(dataset)
+ peft_model = get_peft_model(deepcopy(model), modified_peft_config)
+ with pytest.warns(
+ UserWarning,
+ match="the following layers were initialized with init_lora_weights=True because they were not found in the eva state_dict:*",
+ ):
+ initialize_lora_eva_weights(peft_model, dataloader)
+
+ def test_load_eva_model(self, model, dataset, peft_config, tmp_path):
+ """
+ Tests that a model initialized with EVA weights can be loaded correctly.
+ """
+ dataloader = self.get_dataloader(dataset)
+ peft_model = get_peft_model(deepcopy(model), peft_config)
+ initialize_lora_eva_weights(peft_model, dataloader)
+ peft_model.save_pretrained(tmp_path)
+ peft_model = PeftModel.from_pretrained(model, tmp_path, torch_device=self.DEVICE, low_cpu_mem_usage=True)
+ peft_model(**{k: v.to(self.DEVICE) for k, v in next(iter(dataloader)).items()})
+
+ def test_eva_initialization_with_invalid_dataloader(self, model, peft_config):
+ """Test that appropriate error is raised when dataloader is empty."""
+ empty_dataset = Dataset.from_dict({"text": []})
+ dataloader = self.get_dataloader(empty_dataset)
+
+ with pytest.raises(ValueError, match="dataloader is empty"):
+ get_eva_state_dict(model, dataloader, peft_config)
+
+ def test_eva_config_rho(self):
+ """
+ Tests that EvaConfig.__init__ raises a ValueError when rho is negative.
+ """
+ with pytest.raises(ValueError, match="`rho` must be >= 1.0"):
+ EvaConfig(rho=-1)
+
+ def test_eva_config_tau(self):
+ """
+ Tests that EvaConfig.__init__ raises a ValueError when tau is not between 0.0 and 1.0.
+ """
+ with pytest.raises(ValueError, match="`tau` must be between 0.0 and 1.0."):
+ EvaConfig(tau=-0.1)
+ with pytest.raises(ValueError, match="`tau` must be between 0.0 and 1.0."):
+ EvaConfig(tau=1.1)
+
+ def test_lora_config_raises_warning_with_eva_init_but_not_eva_config(self):
+ """
+ Tests that LoraConfig.__init__ raises a warning when init_lora_weights='eva' but eva_config is not set.
+ """
+ with pytest.warns(
+ UserWarning,
+ match="`init_lora_weights` is 'eva' but `eva_config` is not specified. Using default EVA config.",
+ ):
+ LoraConfig(init_lora_weights="eva")
+
+ def test_lora_config_raises_warning_with_eva_config_but_not_eva_init(self):
+ """
+ Tests that LoraConfig.__init__ raises a warning when init_lora_weights is not 'eva' but eva_config is set.
+ """
+ with pytest.warns(
+ UserWarning, match="`eva_config` specified but will be ignored when `init_lora_weights` is not 'eva'."
+ ):
+ LoraConfig(init_lora_weights=True, eva_config=EvaConfig())
+
+
+@pytest.mark.skipif(
+ platform.system() != "Linux", reason="Out of the box, torch.compile does not work on Windows or MacOS"
+)
+class TestHotSwapping:
+ """Tests for the hotswapping function"""
+
+ torch_device = infer_device()
+
+ def compile(self, model, do_compile):
+ if not do_compile:
+ return model
+ return torch.compile(model)
+
+ def get_model(self):
+ class MLP(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.lin0 = nn.Linear(10, 20, bias=True)
+ self.relu = nn.ReLU()
+ self.lin1 = nn.Linear(20, 5, bias=False)
+
+ def forward(self, X):
+ X = X.float()
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = self.lin1(X)
+ return X
+
+ torch.manual_seed(0)
+ return MLP().to(self.torch_device)
+
+ def get_model_conv2d(self):
+ class ConvModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.conv = nn.Conv2d(3, 10, kernel_size=3)
+
+ def forward(self, X):
+ return self.conv(X)
+
+ torch.manual_seed(0)
+ return ConvModel().to(self.torch_device)
+
+ # this works with all adapters except prompt learning, but we don't test all
+ # as it is unnecessary and would be slow
+ @pytest.mark.parametrize(
+ "config",
+ [
+ LoraConfig(init_lora_weights=0, target_modules=["lin0"]),
+ LoraConfig(init_lora_weights=0, target_modules=["lin0", "lin1"]),
+ ],
+ )
+ @pytest.mark.parametrize("do_compile", [False, True])
+ def test_hotswap_works(self, config, do_compile, tmp_path):
+ # Load 2 different adapters and check that we can hotswap between them, with the model optionally being
+ # compiled.
+ atol, rtol = 1e-4, 1e-4
+ inputs = torch.rand(3, 10).to(self.torch_device)
+
+ # create adapter 0
+ model = self.get_model()
+ torch.manual_seed(0)
+ model = get_peft_model(model, config)
+ model = self.compile(model, do_compile=do_compile)
+ model.eval()
+ with torch.inference_mode():
+ output0 = model(inputs)
+ model.save_pretrained(tmp_path / "adapter0")
+
+ del model
+
+ # create adapter 1
+ model = self.get_model()
+ torch.manual_seed(1)
+ model = get_peft_model(model, config)
+ model = self.compile(model, do_compile=do_compile)
+ model.eval()
+ with torch.inference_mode():
+ output1 = model(inputs)
+ model.save_pretrained(tmp_path / "adapter1")
+
+ # sanity check: they're not the same
+ assert not torch.allclose(output0, output1, atol=atol, rtol=rtol)
+
+ del model
+
+ # load adapter 0
+ model = self.get_model()
+ model = PeftModel.from_pretrained(model, tmp_path / "adapter0")
+ model = self.compile(model, do_compile=do_compile)
+ with torch.inference_mode():
+ output_loaded0 = model(inputs)
+
+ # sanity check: same output after loading for adapter 0
+ assert torch.allclose(output0, output_loaded0, atol=atol, rtol=rtol)
+
+ # hotswap with adapter 1
+ hotswap_adapter(model, tmp_path / "adapter1", adapter_name="default")
+ with torch.inference_mode():
+ output_loaded1 = model(inputs)
+
+ # real check: model now behaves like adapter 1
+ assert torch.allclose(output1, output_loaded1, atol=atol, rtol=rtol)
+
+ # hotswap back to adapter 0
+ hotswap_adapter(model, tmp_path / "adapter0", adapter_name="default")
+ with torch.inference_mode():
+ output_loaded_back0 = model(inputs)
+
+ # real check: model now behaves again like adapter 0
+ assert torch.allclose(output0, output_loaded_back0, atol=atol, rtol=rtol)
+
+ def test_hotswap_different_peft_types_raises(self, tmp_path):
+ # When the configs of the two adapters are different PEFT methods, raise
+ config0 = LoraConfig(target_modules=["lin0"])
+ config1 = IA3Config(target_modules=["lin0"], feedforward_modules=[])
+
+ model = self.get_model()
+ model = get_peft_model(model, config0)
+ model.save_pretrained(tmp_path / "adapter0")
+ del model
+
+ model = self.get_model()
+ model = get_peft_model(model, config1)
+ model.save_pretrained(tmp_path / "adapter1")
+ del model
+
+ # load adapter 0
+ model = self.get_model()
+ model = PeftModel.from_pretrained(model, tmp_path / "adapter0")
+
+ msg = r"Incompatible PEFT types found: LORA and IA3"
+ with pytest.raises(ValueError, match=msg):
+ hotswap_adapter(model, tmp_path / "adapter1", adapter_name="default")
+
+ def test_hotswap_wrong_peft_types_raises(self, tmp_path):
+ # Only LoRA is supported at the moment
+ config0 = IA3Config(target_modules=["lin0"], feedforward_modules=[])
+ config1 = IA3Config(target_modules=["lin0"], feedforward_modules=[])
+
+ model = self.get_model()
+ model = get_peft_model(model, config0)
+ model.save_pretrained(tmp_path / "adapter0")
+ del model
+
+ model = self.get_model()
+ model = get_peft_model(model, config1)
+ model.save_pretrained(tmp_path / "adapter1")
+ del model
+
+ # load adapter 0
+ model = self.get_model()
+ model = PeftModel.from_pretrained(model, tmp_path / "adapter0")
+
+ msg = r"Hotswapping only supports LORA but IA3 was passed"
+ with pytest.raises(ValueError, match=msg):
+ hotswap_adapter(model, tmp_path / "adapter1", adapter_name="default")
+
+ def test_hotswap_missing_key_works(self, tmp_path):
+ # When a key is missing, it is fine, the extra weight is zeroed out
+ config = LoraConfig(target_modules=["lin0", "lin1"])
+
+ model = self.get_model()
+ model = get_peft_model(model, config)
+ model.save_pretrained(tmp_path / "adapter0")
+ del model
+
+ model = self.get_model()
+ model = get_peft_model(model, config)
+
+ # remove one key from the state_dict
+ key = "base_model.model.lin1.lora_A.default.weight"
+ state_dict = model.state_dict()
+ del state_dict[key]
+ model.state_dict = lambda: state_dict
+ model.save_pretrained(tmp_path / "adapter1")
+ del model
+
+ # load adapter 0
+ model = self.get_model()
+ model = PeftModel.from_pretrained(model, tmp_path / "adapter0")
+
+ # sanity check: the missing weight is not already all zeros
+ assert not (model.base_model.model.lin1.lora_A["default"].weight == 0).all()
+ hotswap_adapter(model, tmp_path / "adapter1", adapter_name="default")
+ # after hotswapping, it is zeroed out
+ assert (model.base_model.model.lin1.lora_A["default"].weight == 0).all()
+
+ def test_hotswap_extra_key_raises(self, tmp_path):
+ # When there is an extra key, raise
+ config = LoraConfig(target_modules=["lin0"])
+
+ model = self.get_model()
+ model = get_peft_model(model, config)
+ model.save_pretrained(tmp_path / "adapter0")
+ del model
+
+ model = self.get_model()
+ model = get_peft_model(model, config)
+
+ # add an unexpected key
+ state_dict = model.state_dict()
+ new_key = "base_model.model.lin1.lora_A.default.weight"
+ state_dict[new_key] = torch.zeros(8, 20)
+ model.state_dict = lambda: state_dict
+ model.save_pretrained(tmp_path / "adapter1")
+ del model
+
+ # load adapter 0
+ model = self.get_model()
+ model = PeftModel.from_pretrained(model, tmp_path / "adapter0")
+
+ msg = f"Hot swapping the adapter did not succeed, unexpected keys found: {new_key}"
+ with pytest.raises(RuntimeError, match=msg):
+ hotswap_adapter(model, tmp_path / "adapter1", adapter_name="default")
+
+ @pytest.mark.parametrize("ranks", [(7, 13), (13, 7)])
+ def test_hotswap_works_different_ranks_alphas(self, ranks, tmp_path):
+ # same as test_hotswap_works but different rank and alpha
+ # Load 2 different adapters and check that we can hotswap between them, with the model optionally being
+ # compiled.
+ atol, rtol = 1e-4, 1e-4
+ inputs = torch.rand(3, 10).to(self.torch_device)
+
+ # create adapter 0
+ config0 = LoraConfig(target_modules=["lin0", "lin1"], r=ranks[0], lora_alpha=ranks[0], init_lora_weights=False)
+ model = self.get_model()
+ torch.manual_seed(0)
+ model = get_peft_model(model, config0)
+ model.eval()
+ with torch.inference_mode():
+ output0 = model(inputs)
+ model.save_pretrained(tmp_path / "adapter0")
+
+ del model
+
+ # create adapter 1
+ config1 = LoraConfig(target_modules=["lin0"], r=ranks[1], lora_alpha=ranks[1], init_lora_weights=False)
+ model = self.get_model()
+ torch.manual_seed(1)
+ model = get_peft_model(model, config1)
+ model.eval()
+ with torch.inference_mode():
+ output1 = model(inputs)
+ model.save_pretrained(tmp_path / "adapter1")
+
+ # sanity check: they're not the same
+ assert not torch.allclose(output0, output1, atol=atol, rtol=rtol)
+
+ del model
+
+ # load adapter 0
+ model = self.get_model()
+ model = PeftModel.from_pretrained(model, tmp_path / "adapter0")
+ with torch.inference_mode():
+ output_loaded0 = model(inputs)
+
+ # sanity check: same output after loading for adapter 0
+ assert torch.allclose(output0, output_loaded0, atol=atol, rtol=rtol)
+
+ # hotswap with adapter 1
+ hotswap_adapter(model, tmp_path / "adapter1", adapter_name="default")
+ with torch.inference_mode():
+ output_loaded1 = model(inputs)
+
+ # real check: model now behaves like adapter 1
+ assert torch.allclose(output1, output_loaded1, atol=atol, rtol=rtol)
+
+ # hotswap back to adapter 0
+ hotswap_adapter(model, tmp_path / "adapter0", adapter_name="default")
+ with torch.inference_mode():
+ output_loaded_back0 = model(inputs)
+
+ # real check: model now behaves again like adapter 0
+ assert torch.allclose(output0, output_loaded_back0, atol=atol, rtol=rtol)
+
+ @pytest.mark.parametrize("ranks", [(7, 13), (13, 7)])
+ def test_hotswap_works_different_ranks_alphas_conv2d(self, ranks, tmp_path):
+ # same as previous test, but for a Conv2d model
+ atol, rtol = 1e-4, 1e-4
+ inputs = torch.rand(3, 3, 10, 10).to(self.torch_device)
+
+ # create adapter 0
+ config0 = LoraConfig(target_modules=["conv"], r=ranks[0], init_lora_weights=False)
+ model = self.get_model_conv2d()
+ torch.manual_seed(0)
+ model = get_peft_model(model, config0)
+ model.eval()
+ with torch.inference_mode():
+ output0 = model(inputs)
+ model.save_pretrained(tmp_path / "adapter0")
+
+ del model
+
+ # create adapter 1
+ config1 = LoraConfig(target_modules=["conv"], r=ranks[1], init_lora_weights=False)
+ model = self.get_model_conv2d()
+ torch.manual_seed(1)
+ model = get_peft_model(model, config1)
+ model.eval()
+ with torch.inference_mode():
+ output1 = model(inputs)
+ model.save_pretrained(tmp_path / "adapter1")
+
+ # sanity check: they're not the same
+ assert not torch.allclose(output0, output1, atol=atol, rtol=rtol)
+
+ del model
+
+ # load adapter 0
+ model = self.get_model_conv2d()
+ model = PeftModel.from_pretrained(model, tmp_path / "adapter0")
+ with torch.inference_mode():
+ output_loaded0 = model(inputs)
+
+ # sanity check: same output after loading for adapter 0
+ assert torch.allclose(output0, output_loaded0, atol=atol, rtol=rtol)
+
+ # hotswap with adapter 1
+ hotswap_adapter(model, tmp_path / "adapter1", adapter_name="default")
+ with torch.inference_mode():
+ output_loaded1 = model(inputs)
+
+ # real check: model now behaves like adapter 1
+ assert torch.allclose(output1, output_loaded1, atol=atol, rtol=rtol)
+
+ # hotswap back to adapter 0
+ hotswap_adapter(model, tmp_path / "adapter0", adapter_name="default")
+ with torch.inference_mode():
+ output_loaded_back0 = model(inputs)
+
+ # real check: model now behaves again like adapter 0
+ assert torch.allclose(output0, output_loaded_back0, atol=atol, rtol=rtol)
+
+ def test_prepare_model_for_compiled_hotswap_scalings_are_tensors(self):
+ config = LoraConfig(target_modules=["lin0", "lin1"])
+ model = self.get_model()
+ model = get_peft_model(model, config)
+
+ # sanity check: all scalings are floats
+ scalings_before = {}
+ for name, module in model.named_modules():
+ if hasattr(module, "scaling"):
+ for key, val in module.scaling.items():
+ assert isinstance(val, float)
+ scalings_before[f"{name}.{key}"] = val
+
+ prepare_model_for_compiled_hotswap(model)
+
+ scalings_after = {}
+ for name, module in model.named_modules():
+ if hasattr(module, "scaling"):
+ for key, val in module.scaling.items():
+ assert isinstance(val, torch.Tensor)
+ scalings_after[f"{name}.{key}"] = val.item()
+
+ assert scalings_before == scalings_after
+
+ def test_prepare_model_for_compiled_hotswap_rank_padding_works(self):
+ old_rank = 8
+ config = LoraConfig(target_modules=["lin0", "lin1"], r=old_rank)
+ model = self.get_model()
+ model = get_peft_model(model, config)
+
+ # sanity check
+ for name, param in model.named_parameters():
+ if "lora_A" in name:
+ assert param.shape[0] == old_rank
+ elif "lora_B" in name:
+ assert param.shape[1] == old_rank
+
+ new_rank = 13
+ prepare_model_for_compiled_hotswap(model, target_rank=new_rank)
+
+ for name, param in model.named_parameters():
+ if "lora_A" in name:
+ assert param.shape[0] == new_rank
+ elif "lora_B" in name:
+ assert param.shape[1] == new_rank
+
+ def test_prepare_model_for_compiled_hotswap_same_rank_padding_works(self):
+ # same as previous test, but ensure there is no error if the rank to pad to is the same
+ old_rank = 8
+ config = LoraConfig(target_modules=["lin0", "lin1"], r=old_rank)
+ model = self.get_model()
+ model = get_peft_model(model, config)
+ prepare_model_for_compiled_hotswap(model, target_rank=old_rank)
+
+ for name, param in model.named_parameters():
+ if "lora_A" in name:
+ assert param.shape[0] == old_rank
+ elif "lora_B" in name:
+ assert param.shape[1] == old_rank
+
+ def test_prepare_model_for_compiled_hotswap_conv2d_rank_padding_works(self):
+ # same as previous test, but for a Conv2d model
+ old_rank = 8
+ config = LoraConfig(target_modules=["conv"], r=old_rank)
+ model = self.get_model_conv2d()
+ model = get_peft_model(model, config)
+
+ # sanity check
+ for name, param in model.named_parameters():
+ if "lora_A" in name:
+ assert param.shape[0] == old_rank
+ elif "lora_B" in name:
+ assert param.shape[1] == old_rank
+
+ new_rank = 13
+ prepare_model_for_compiled_hotswap(model, target_rank=new_rank)
+
+ for name, param in model.named_parameters():
+ if "lora_A" in name:
+ assert param.shape[0] == new_rank
+ elif "lora_B" in name:
+ assert param.shape[1] == new_rank
+
+ def test_prepare_model_for_compiled_hotswap_lower_rank_padding_raises(self):
+ # when trying to pad to a lower rank, raise an error
+ old_rank0 = 8
+ old_rank1 = 10
+ new_rank = 9
+ config = LoraConfig(target_modules=["lin0", "lin1"], r=old_rank0, rank_pattern={"lin1": old_rank1})
+ model = self.get_model()
+ model = get_peft_model(model, config)
+
+ msg = re.escape("Trying to pad the adapter to the target rank 9, but the original rank is larger (10)")
+ with pytest.raises(ValueError, match=msg):
+ prepare_model_for_compiled_hotswap(model, target_rank=new_rank)
+
+ def test_prepare_model_for_compiled_hotswap_with_rank_pattern(self):
+ old_rank0 = 8
+ old_rank1 = 9
+ config = LoraConfig(target_modules=["lin0", "lin1"], r=old_rank0, rank_pattern={"lin1": old_rank1})
+ model = self.get_model()
+ model = get_peft_model(model, config)
+
+ # sanity check
+ for name, param in model.named_parameters():
+ if "lora_A" in name:
+ if "lin0" in name:
+ assert param.shape[0] == old_rank0
+ else:
+ assert param.shape[0] == old_rank1
+ elif "lora_B" in name:
+ if "lin0" in name:
+ assert param.shape[1] == old_rank0
+ else:
+ assert param.shape[1] == old_rank1
+
+ new_rank = 13
+ prepare_model_for_compiled_hotswap(model, target_rank=new_rank)
+
+ for name, param in model.named_parameters():
+ if "lora_A" in name:
+ assert param.shape[0] == new_rank
+ elif "lora_B" in name:
+ assert param.shape[1] == new_rank
+
+ def test_prepare_model_for_compiled_hotswap_model_already_compiled_raises(self):
+ config = LoraConfig(target_modules=["lin0"])
+ model = self.get_model()
+ model = get_peft_model(model, config)
+ model = torch.compile(model, mode="reduce-overhead")
+
+ msg = re.escape("Call prepare_model_for_compiled_hotswap *before* compiling the model")
+ with pytest.raises(ValueError, match=msg):
+ prepare_model_for_compiled_hotswap(model)
+
+ def test_prepare_model_for_compiled_hotswap_model_already_compiled_warns(self, recwarn):
+ config = LoraConfig(target_modules=["lin0"])
+ model = self.get_model()
+ model = get_peft_model(model, config)
+ model = torch.compile(model, mode="reduce-overhead")
+
+ msg = "prepare_model_for_compiled_hotswap was called with a model that is already compiled"
+ prepare_model_for_compiled_hotswap(model, check_compiled="warn")
+ assert any(msg in str(w.message) for w in recwarn)
+
+ def test_prepare_model_for_compiled_hotswap_model_already_compiled_ignore(self, recwarn):
+ config = LoraConfig(target_modules=["lin0"])
+ model = self.get_model()
+ model = get_peft_model(model, config)
+ model = torch.compile(model, mode="reduce-overhead")
+
+ msg = "prepare_model_for_compiled_hotswap was called with a model that is already compiled"
+ prepare_model_for_compiled_hotswap(model, check_compiled="ignore")
+ # no error, no warning
+ assert not any(msg in str(w.message) for w in recwarn)
+
+ def test_prepare_model_for_compiled_hotswap_model_already_compiled_wrong_argument(self, recwarn):
+ config = LoraConfig(target_modules=["lin0"])
+ model = self.get_model()
+ model = get_peft_model(model, config)
+ model = torch.compile(model, mode="reduce-overhead")
+
+ msg = re.escape("check_compiles should be one of 'error', 'warn', or 'ignore', got 'wrong-option' instead.")
+ with pytest.raises(ValueError, match=msg):
+ prepare_model_for_compiled_hotswap(model, check_compiled="wrong-option")
+
+ def test_prepare_model_for_compiled_hotswap_model_no_adapter_raises(self):
+ model = self.get_model()
+ msg = re.escape("No adapter layers found on the model")
+ with pytest.raises(ValueError, match=msg):
+ prepare_model_for_compiled_hotswap(model)
+
+ def test_prepare_model_for_compiled_hotswap_does_not_change_output(self):
+ # preparing the model for hotswapping should not change the model output
+ inputs = torch.rand(3, 10).to(self.torch_device)
+ model = self.get_model().eval()
+ with torch.inference_mode():
+ output_base = model(inputs)
+
+ old_rank = 8
+ config = LoraConfig(target_modules=["lin0", "lin1"], r=old_rank, init_lora_weights=False)
+ model = get_peft_model(model, config).eval()
+ with torch.inference_mode():
+ output_before = model(inputs)
+
+ # sanity check: LoRA changed output
+ assert not torch.allclose(output_base, output_before)
+
+ new_rank = 13
+ prepare_model_for_compiled_hotswap(model, target_rank=new_rank)
+ with torch.inference_mode():
+ output_after = model(inputs)
+
+ assert torch.allclose(output_before, output_after)
+
+ def test_prepare_model_for_compiled_hotswap_does_not_change_output_conv2d(self):
+ # preparing the model for hotswapping should not change the model output
+ inputs = torch.rand(3, 3, 10, 10).to(self.torch_device)
+ model = self.get_model_conv2d().eval()
+ with torch.inference_mode():
+ output_base = model(inputs)
+
+ old_rank = 8
+ config = LoraConfig(target_modules=["conv"], r=old_rank, init_lora_weights=False)
+ model = get_peft_model(model, config).eval()
+ with torch.inference_mode():
+ output_before = model(inputs)
+
+ # sanity check: LoRA changed output
+ assert not torch.allclose(output_base, output_before)
+
+ new_rank = 13
+ prepare_model_for_compiled_hotswap(model, target_rank=new_rank)
+ with torch.inference_mode():
+ output_after = model(inputs)
+
+ assert torch.allclose(output_before, output_after)
+
+ def test_prepare_model_for_compiled_hotswap_scalings_update_config(self):
+ old_rank0 = 11
+ old_rank1 = 13
+ config = LoraConfig(target_modules=["lin0", "lin1"], r=old_rank0, rank_pattern={"lin1": old_rank1})
+ model = self.get_model()
+ model = get_peft_model(model, config)
+
+ new_rank = 15
+ prepare_model_for_compiled_hotswap(model, target_rank=new_rank, config=model.peft_config)
+
+ assert model.peft_config["default"].r == new_rank
+ assert model.peft_config["default"].rank_pattern == {"lin1": new_rank}
+
+ def test_prepare_model_for_compiled_hotswap_lora_bias(self):
+ # When setting lora_bias=True in the LoraConfig, the LoRA B parameter will have a bias term. Check that padding
+ # still works correctly. Note that the LoRA A parameter still won't have a bias term.
+ old_rank = 8
+ config = LoraConfig(target_modules=["lin0", "lin1"], r=old_rank, lora_bias=True)
+ model = self.get_model()
+ model = get_peft_model(model, config)
+
+ # sanity check
+ for name, param in model.named_parameters():
+ if "lora_A" in name and name.endswith(".weight"):
+ assert param.shape[0] == old_rank
+ elif "lora_B" in name and name.endswith(".weight"):
+ assert param.shape[1] == old_rank
+ elif "lora_A" in name and name.endswith(".bias"):
+ assert False, "LoRA A should not have a bias term"
+ elif "lora_B" in name and name.endswith(".bias"):
+ assert param.shape[0] in (5, 20) # output shapes of the 2 layers
+
+ new_rank = 13
+ prepare_model_for_compiled_hotswap(model, target_rank=new_rank)
+
+ for name, param in model.named_parameters():
+ if "lora_A" in name and name.endswith(".weight"):
+ assert param.shape[0] == new_rank
+ elif "lora_B" in name and name.endswith(".weight"):
+ assert param.shape[1] == new_rank
+ elif "lora_A" in name and name.endswith(".bias"):
+ assert False, "LoRA A should not have a bias term"
+ elif "lora_B" in name and name.endswith(".bias"):
+ assert param.shape[0] in (5, 20) # output shapes of the 2 layers
+
+ def test_prepare_model_for_compiled_hotswap_conv2d_lora_bias(self):
+ # same as previous test, but for a Conv2d model
+ old_rank = 8
+ config = LoraConfig(target_modules=["conv"], r=old_rank, lora_bias=True)
+ model = self.get_model_conv2d()
+ model = get_peft_model(model, config)
+
+ # sanity check
+ for name, param in model.named_parameters():
+ if "lora_A" in name and name.endswith(".weight"):
+ assert param.shape[0] == old_rank
+ elif "lora_B" in name and name.endswith(".weight"):
+ assert param.shape[1] == old_rank
+ elif "lora_A" in name and name.endswith(".bias"):
+ assert False, "LoRA A should not have a bias term"
+ elif "lora_B" in name and name.endswith(".bias"):
+ assert param.shape[0] == 10 # output shape of conv layer
+
+ new_rank = 13
+ prepare_model_for_compiled_hotswap(model, target_rank=new_rank)
+
+ for name, param in model.named_parameters():
+ if "lora_A" in name and name.endswith(".weight"):
+ assert param.shape[0] == new_rank
+ elif "lora_B" in name and name.endswith(".weight"):
+ assert param.shape[1] == new_rank
+ elif "lora_A" in name and name.endswith(".bias"):
+ assert False, "LoRA A should not have a bias term"
+ elif "lora_B" in name and name.endswith(".bias"):
+ assert param.shape[0] == 10 # output shape of conv layer
+
+
+def test_import_peft_type_to_model_mapping_deprecation_warning(recwarn):
+ # This is for backwards compatibility: In #2282, PEFT_TYPE_TO_MODEL_MAPPING was removed as it was redundant with
+ # PEFT_TYPE_TO_TUNER_MAPPING. However, third party code could still use this mapping, e.g.:
+ # https://github.com/AutoGPTQ/AutoGPTQ/blob/6689349625de973b9ee3016c28c11f32acf7f02c/auto_gptq/utils/peft_utils.py#L8
+ # TODO: Remove after 2026-01
+
+ # first check that there is no warning under normal circumstances
+ from peft.peft_model import PeftModel # noqa
+
+ expected = (
+ "PEFT_TYPE_TO_MODEL_MAPPING is deprecated, please use `from peft import PEFT_TYPE_TO_TUNER_MAPPING` instead"
+ )
+ warnings = (w.message.args[0] for w in recwarn.list)
+ assert not any(w.startswith(expected) for w in warnings)
+
+ from peft.peft_model import PEFT_TYPE_TO_MODEL_MAPPING # noqa
+
+ # check that there is a warning with this message after importing the variable
+ warnings = (w.message.args[0] for w in recwarn.list)
+ assert any(w.startswith(expected) for w in warnings)
+
+
+class TestScaling:
+ """Tests for scaling and unscaling
+
+ Those methods are currently only implemented for LoRA and were added for use in diffusers.
+ """
+
+ @pytest.fixture
+ def model(self):
+ # tiny opt with 5 attention layers
+ model_id = "hf-internal-testing/tiny-random-OPTForCausalLM"
+ return AutoModelForCausalLM.from_pretrained(model_id)
+
+ def get_scalings(self, model, adapter_name="default"):
+ # helper function, returns the scalings of the 5 attention layers
+ return [m.scaling[adapter_name] for m in model.modules() if isinstance(m, LoraLayer)]
+
+ def set_scale(self, model, adapter_name, scale):
+ for module in model.modules():
+ if isinstance(module, LoraLayer):
+ module.set_scale(adapter_name, scale)
+
+ def scale_layer(self, model, scale):
+ for module in model.modules():
+ if isinstance(module, LoraLayer):
+ module.scale_layer(scale)
+
+ def unscale_layer(self, model, scale):
+ for module in model.modules():
+ if isinstance(module, LoraLayer):
+ module.unscale_layer(scale)
+
+ def test_scaling_simple(self, model):
+ n_layers = 5
+ rank, lora_alpha = 8, 16
+ config = LoraConfig(
+ r=rank,
+ lora_alpha=lora_alpha,
+ target_modules=["k_proj"],
+ )
+ model = get_peft_model(model, config)
+ scalings = self.get_scalings(model)
+ expected = [lora_alpha / rank] * n_layers
+ assert scalings == expected
+
+ # double
+ self.scale_layer(model, 2)
+ scalings = self.get_scalings(model)
+ expected = [4.0] * n_layers
+ assert scalings == expected
+
+ # back to original
+ self.unscale_layer(model, None)
+ scalings = self.get_scalings(model)
+ expected = [2.0] * n_layers
+ assert scalings == expected
+
+ # triple
+ self.set_scale(model, "default", 3)
+ scalings = self.get_scalings(model)
+ expected = [6.0] * n_layers
+ assert scalings == expected
+
+ # back to original
+ self.unscale_layer(model, 3)
+ scalings = self.get_scalings(model)
+ expected = [2.0] * n_layers
+ assert scalings == expected
+
+ def test_scaling_rank_pattern_alpha_pattern(self, model):
+ # layer 0: 8 / 8
+ # layer 1: 8 / 16
+ # layer 2: 4 / 32
+ # layer 3: 16 / 8
+ # layer 4: 8 / 8
+ config = LoraConfig(
+ r=8,
+ lora_alpha=8,
+ target_modules=["k_proj"],
+ rank_pattern={"layers.1.self_attn.k_proj": 16, "layers.2.self_attn.k_proj": 32},
+ alpha_pattern={"layers.2.self_attn.k_proj": 4, "layers.3.self_attn.k_proj": 16},
+ )
+ model = get_peft_model(model, config)
+ scalings = self.get_scalings(model)
+ expected = [1.0, 0.5, 0.125, 2.0, 1.0]
+ assert scalings == expected
+
+ # double
+ self.scale_layer(model, 2)
+ scalings = self.get_scalings(model)
+ expected = [2.0, 1.0, 0.25, 4.0, 2.0]
+ assert scalings == expected
+
+ # back to original
+ self.unscale_layer(model, None)
+ scalings = self.get_scalings(model)
+ expected = [1.0, 0.5, 0.125, 2.0, 1.0]
+ assert scalings == expected
+
+ # triple
+ self.set_scale(model, "default", 3)
+ scalings = self.get_scalings(model)
+ expected = [3.0, 1.5, 0.375, 6.0, 3.0]
+ assert scalings == expected
+
+ # back to original
+ self.unscale_layer(model, 3)
+ scalings = self.get_scalings(model)
+ expected = [1.0, 0.5, 0.125, 2.0, 1.0]
+ assert scalings == expected
+
+ def test_scaling_multiple_times(self, model):
+ # same as previous test, but scale and unscale multiple times in a row
+ # layer 0: 8 / 8
+ # layer 1: 8 / 16
+ # layer 2: 4 / 32
+ # layer 3: 16 / 8
+ # layer 4: 8 / 8
+ config = LoraConfig(
+ r=8,
+ lora_alpha=8,
+ target_modules=["k_proj"],
+ rank_pattern={"layers.1.self_attn.k_proj": 16, "layers.2.self_attn.k_proj": 32},
+ alpha_pattern={"layers.2.self_attn.k_proj": 4, "layers.3.self_attn.k_proj": 16},
+ )
+ model = get_peft_model(model, config)
+ scalings = self.get_scalings(model)
+ expected = [1.0, 0.5, 0.125, 2.0, 1.0]
+ assert scalings == expected
+
+ # scale of 1 makes no difference
+ self.scale_layer(model, 1)
+ scalings = self.get_scalings(model)
+ expected = [1.0, 0.5, 0.125, 2.0, 1.0]
+
+ # double
+ self.scale_layer(model, 2)
+ scalings = self.get_scalings(model)
+ expected = [2.0, 1.0, 0.25, 4.0, 2.0]
+ assert scalings == expected
+
+ # triple, on top of previous double
+ self.scale_layer(model, 3)
+ scalings = self.get_scalings(model)
+ expected = [6.0, 3.0, 0.75, 12.0, 6.0]
+ assert scalings == expected
+
+ # half
+ self.unscale_layer(model, 2)
+ scalings = self.get_scalings(model)
+ expected = [3.0, 1.5, 0.375, 6.0, 3.0]
+ assert scalings == expected
+
+ # divide by 3, on top of previous half
+ self.unscale_layer(model, 3)
+ scalings = self.get_scalings(model)
+ expected = [1.0, 0.5, 0.125, 2.0, 1.0]
+ assert scalings == expected
+
+ # set scale to 2
+ self.set_scale(model, "default", 2)
+ scalings = self.get_scalings(model)
+ expected = [2.0, 1.0, 0.25, 4.0, 2.0]
+ assert scalings == expected
+
+ # set scale to 3, it is cumulative but based on the initial scaling, so factor 3, not 6
+ self.set_scale(model, "default", 3)
+ scalings = self.get_scalings(model)
+ expected = [3.0, 1.5, 0.375, 6.0, 3.0]
+ assert scalings == expected
+
+ # back to original
+ self.unscale_layer(model, None)
+ scalings = self.get_scalings(model)
+ expected = [1.0, 0.5, 0.125, 2.0, 1.0]
+ assert scalings == expected
+
+ # back to original again
+ self.unscale_layer(model, None)
+ scalings = self.get_scalings(model)
+ expected = [1.0, 0.5, 0.125, 2.0, 1.0]
+ assert scalings == expected
+
+ def test_scaling_multiple_adapters(self, model):
+ # ensure that scaling works with multiple adapters
+ n_layers = 5
+ rank0, lora_alpha0 = 8, 16
+ config0 = LoraConfig(
+ r=rank0,
+ lora_alpha=lora_alpha0,
+ target_modules=["k_proj"],
+ )
+ rank1, lora_alpha1 = 16, 8
+ config1 = LoraConfig(
+ r=rank1,
+ lora_alpha=lora_alpha1,
+ target_modules=["k_proj"],
+ )
+ model = get_peft_model(model, config0)
+ model.add_adapter("other", config1)
+
+ scalings_default = self.get_scalings(model, "default")
+ scalings_other = self.get_scalings(model, "other")
+ expected_default = [lora_alpha0 / rank0] * n_layers
+ expected_other = [lora_alpha1 / rank1] * n_layers
+ assert scalings_default == expected_default
+ assert scalings_other == expected_other
+
+ # double the scale for other
+ self.set_scale(model, "other", 2)
+ scalings_default = self.get_scalings(model, "default")
+ scalings_other = self.get_scalings(model, "other")
+ expected_default = [lora_alpha0 / rank0] * n_layers
+ expected_other = [2 * lora_alpha1 / rank1] * n_layers
+ assert scalings_default == expected_default
+ assert scalings_other == expected_other
+
+ # quarter the scale for default
+ self.set_scale(model, "default", 0.25)
+ scalings_default = self.get_scalings(model, "default")
+ scalings_other = self.get_scalings(model, "other")
+ expected_default = [lora_alpha0 / rank0 / 4] * n_layers
+ expected_other = [2 * lora_alpha1 / rank1] * n_layers
+ assert scalings_default == expected_default
+ assert scalings_other == expected_other
+
+ # unscale resets for all *active* adapters
+ self.unscale_layer(model, None)
+ scalings_default = self.get_scalings(model, "default")
+ scalings_other = self.get_scalings(model, "other")
+ expected_default = [lora_alpha0 / rank0] * n_layers
+ expected_other = [2 * lora_alpha1 / rank1] * n_layers # stays the same as 'other' is not active
+ assert scalings_default == expected_default
+ assert scalings_other == expected_other
+
+ # scale all *active* adapters by 2
+ self.scale_layer(model, 2)
+ scalings_default = self.get_scalings(model, "default")
+ scalings_other = self.get_scalings(model, "other")
+ expected_default = [2 * lora_alpha0 / rank0] * n_layers
+ expected_other = [2 * lora_alpha1 / rank1] * n_layers # stays the same as 'other' is not active
+ assert scalings_default == expected_default
+ assert scalings_other == expected_other
+
+ # switch to 'other'
+ model.set_adapter("other")
+
+ # unscale, this time 'other'
+ self.unscale_layer(model, None)
+ scalings_default = self.get_scalings(model, "default")
+ scalings_other = self.get_scalings(model, "other")
+ expected_default = [2 * lora_alpha0 / rank0] * n_layers # stays the same as 'other' is not active
+ expected_other = [lora_alpha1 / rank1] * n_layers
+ assert scalings_default == expected_default
+ assert scalings_other == expected_other
+
+ # scale all *active* adapters by 3
+ self.scale_layer(model, 3)
+ scalings_default = self.get_scalings(model, "default")
+ scalings_other = self.get_scalings(model, "other")
+ expected_default = [2 * lora_alpha0 / rank0] * n_layers # stays the same as 'other' is not active
+ expected_other = [3 * lora_alpha1 / rank1] * n_layers
+ assert scalings_default == expected_default
+ assert scalings_other == expected_other
+
+
+class TestLoadPeftKeyMapping:
+ # See discussion in https://github.com/huggingface/transformers/pull/38627
+
+ # transformers PR #37033 re-arranges the way visual language models are built by moving the LM head from the
+ # language model to the top-level VLM (among other things). A consequence of this is that the keys in the PEFT
+ # state_dict now also follow the new architecture. This test class serves to ensure that old checkpoints can be
+ # loaded with the changed architecture. Unfortunately, new checkpoints cannot be loaded with the old architecture,
+ # the corresponding test is marked as xfail.
+
+ # Note: We only test prefix tuning (prompt learning method), LoRA (non-prompt learning method), and VBLoRA (shared
+ # parameters) as the other PEFT methods should work the same way. It would be excessive to test all of them here.
+
+ @pytest.fixture
+ def fake_model_config(self):
+ # mimics a transformers model config
+ class FakeConfig(dict):
+ def __init__(self):
+ self.vocab_size = 10
+
+ def __getattr__(self, item):
+ if item in self:
+ return self[item]
+ raise AttributeError(f"'{self.__class__.__name__}' object has no attribute '{item}'")
+
+ return FakeConfig()
+
+ @pytest.fixture
+ def old_model(self, fake_model_config):
+ # create a small model that mimics the old architecture of, for instance, Qwen/Qwen2-VL-2B-Instruct
+ # Qwen2VLForConditionalGeneration(
+ # (visual): Qwen2VisionTransformerPretrainedModel(
+ # (patch_embed): PatchEmbed(
+ # (proj): Conv3d(3, 1280, kernel_size=(2, 14, 14), stride=(2, 14, 14), bias=False)
+ # )
+ # (rotary_pos_emb): VisionRotaryEmbedding()
+ # (blocks): ModuleList(
+ # (0-31): 32 x Qwen2VLVisionBlock(
+ # (norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
+ # (norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
+ # (attn): VisionSdpaAttention(
+ # (qkv): Linear(in_features=1280, out_features=3840, bias=True)
+ # (proj): Linear(in_features=1280, out_features=1280, bias=True)
+ # )
+ # (mlp): VisionMlp(
+ # (fc1): Linear(in_features=1280, out_features=5120, bias=True)
+ # (act): QuickGELUActivation()
+ # (fc2): Linear(in_features=5120, out_features=1280, bias=True)
+ # )
+ # )
+ # )
+ # (merger): PatchMerger(
+ # (ln_q): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
+ # (mlp): Sequential(
+ # (0): Linear(in_features=5120, out_features=5120, bias=True)
+ # (1): GELU(approximate='none')
+ # (2): Linear(in_features=5120, out_features=1536, bias=True)
+ # )
+ # )
+ # )
+ # (model): Qwen2VLModel(
+ # (embed_tokens): Embedding(151936, 1536)
+ # (layers): ModuleList(
+ # (0-27): 28 x Qwen2VLDecoderLayer(
+ # (self_attn): Qwen2VLSdpaAttention(
+ # (q_proj): Linear(in_features=1536, out_features=1536, bias=True)
+ # (k_proj): Linear(in_features=1536, out_features=256, bias=True)
+ # (v_proj): Linear(in_features=1536, out_features=256, bias=True)
+ # (o_proj): Linear(in_features=1536, out_features=1536, bias=False)
+ # (rotary_emb): Qwen2VLRotaryEmbedding()
+ # )
+ # (mlp): Qwen2MLP(
+ # (gate_proj): Linear(in_features=1536, out_features=8960, bias=False)
+ # (up_proj): Linear(in_features=1536, out_features=8960, bias=False)
+ # (down_proj): Linear(in_features=8960, out_features=1536, bias=False)
+ # (act_fn): SiLU()
+ # )
+ # (input_layernorm): Qwen2RMSNorm((1536,), eps=1e-06)
+ # (post_attention_layernorm): Qwen2RMSNorm((1536,), eps=1e-06)
+ # )
+ # )
+ # (norm): Qwen2RMSNorm((1536,), eps=1e-06)
+ # (rotary_emb): Qwen2VLRotaryEmbedding()
+ # )
+ # (lm_head): Linear(in_features=1536, out_features=151936, bias=False)
+ # )
+ class Block(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.attn = nn.Linear(10, 10)
+
+ class OldModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.config = fake_model_config
+ self.device = "cpu"
+ self.proj = nn.Conv3d(3, 10, 3)
+ self.visual = nn.ModuleDict(
+ {
+ "blocks": nn.ModuleList([Block() for _ in range(2)]),
+ }
+ )
+ self.model = nn.ModuleDict(
+ {
+ "layers": nn.ModuleList([Block() for _ in range(2)]),
+ }
+ )
+ self.lm_head = nn.Linear(10, 10)
+
+ def prepare_inputs_for_generation(self):
+ return
+
+ model = OldModel()
+ return model
+
+ @pytest.fixture
+ def new_model(self, fake_model_config):
+ # create a small model that mimics the new architecture of, for instance, Qwen/Qwen2-VL-2B-Instruct
+ # Qwen2VLForConditionalGeneration(
+ # (model): Qwen2VLModel(
+ # (visual): Qwen2VisionTransformerPretrainedModel(
+ # (patch_embed): PatchEmbed(
+ # (proj): Conv3d(3, 1280, kernel_size=(2, 14, 14), stride=(2, 14, 14), bias=False)
+ # )
+ # (rotary_pos_emb): VisionRotaryEmbedding()
+ # (blocks): ModuleList(
+ # (0-31): 32 x Qwen2VLVisionBlock(
+ # (norm1): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
+ # (norm2): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
+ # (attn): VisionSdpaAttention(
+ # (qkv): Linear(in_features=1280, out_features=3840, bias=True)
+ # (proj): Linear(in_features=1280, out_features=1280, bias=True)
+ # )
+ # (mlp): VisionMlp(
+ # (fc1): Linear(in_features=1280, out_features=5120, bias=True)
+ # (act): QuickGELUActivation()
+ # (fc2): Linear(in_features=5120, out_features=1280, bias=True)
+ # )
+ # )
+ # )
+ # (merger): PatchMerger(
+ # (ln_q): LayerNorm((1280,), eps=1e-06, elementwise_affine=True)
+ # (mlp): Sequential(
+ # (0): Linear(in_features=5120, out_features=5120, bias=True)
+ # (1): GELU(approximate='none')
+ # (2): Linear(in_features=5120, out_features=1536, bias=True)
+ # )
+ # )
+ # )
+ # (language_model): Qwen2VLTextModel(
+ # (embed_tokens): Embedding(151936, 1536)
+ # (layers): ModuleList(
+ # (0-27): 28 x Qwen2VLDecoderLayer(
+ # (self_attn): Qwen2VLAttention(
+ # (q_proj): Linear(in_features=1536, out_features=1536, bias=True)
+ # (k_proj): Linear(in_features=1536, out_features=256, bias=True)
+ # (v_proj): Linear(in_features=1536, out_features=256, bias=True)
+ # (o_proj): Linear(in_features=1536, out_features=1536, bias=False)
+ # (rotary_emb): Qwen2VLRotaryEmbedding()
+ # )
+ # (mlp): Qwen2MLP(
+ # (gate_proj): Linear(in_features=1536, out_features=8960, bias=False)
+ # (up_proj): Linear(in_features=1536, out_features=8960, bias=False)
+ # (down_proj): Linear(in_features=8960, out_features=1536, bias=False)
+ # (act_fn): SiLU()
+ # )
+ # (input_layernorm): Qwen2RMSNorm((1536,), eps=1e-06)
+ # (post_attention_layernorm): Qwen2RMSNorm((1536,), eps=1e-06)
+ # )
+ # )
+ # (norm): Qwen2RMSNorm((1536,), eps=1e-06)
+ # (rotary_emb): Qwen2VLRotaryEmbedding()
+ # )
+ # )
+ # (lm_head): Linear(in_features=1536, out_features=151936, bias=False)
+ # )
+ class Block(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.attn = nn.Linear(10, 10)
+
+ class InnerModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.visual = nn.ModuleDict(
+ {
+ "blocks": nn.ModuleList([Block() for _ in range(2)]),
+ }
+ )
+ self.language_model = nn.ModuleDict(
+ {
+ "layers": nn.ModuleList([Block() for _ in range(2)]),
+ }
+ )
+
+ class NewModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.config = fake_model_config
+ self.device = "cpu"
+ self.model = InnerModel()
+ self.lm_head = nn.Linear(10, 10)
+ # new transformers models have this attribute to map old checkpoints to new ones:
+ self._checkpoint_conversion_mapping = {
+ "^visual": "model.visual",
+ "^model(?!\\.(language_model|visual))": "model.language_model",
+ }
+
+ def prepare_inputs_for_generation(self):
+ return
+
+ model = NewModel()
+ return model
+
+ def check_lora_load_no_warning(self, model1, model2, path):
+ # helper method: save with model1, load with model2, ensure that there is no warning about missing keys and that
+ # the parameters are loaded correctly
+ model1 = copy.deepcopy(model1)
+ model2 = copy.deepcopy(model2)
+ config = LoraConfig(target_modules=["attn"])
+ peft_model = get_peft_model(copy.deepcopy(model1), config)
+
+ # set all values to 1.0 or 2.0 so we can check that they are loaded correctly
+ for name, param in peft_model.named_parameters():
+ if name.endswith("lora_A.default.weight"):
+ param.data.fill_(1.0)
+ elif name.endswith("lora_B.default.weight"):
+ param.data.fill_(2.0)
+
+ peft_model.save_pretrained(path)
+ del peft_model
+
+ # ensure that there is no warning: UserWarning: Found missing adapter keys while loading the checkpoint
+ with warnings.catch_warnings(record=True) as w:
+ warnings.simplefilter("always")
+ loaded = PeftModel.from_pretrained(copy.deepcopy(model2), path)
+ assert not any("Found missing adapter keys" in str(warning.message) for warning in w)
+
+ # sanity check on parameter values to not only rely on the absence of warnings
+ for name, param in loaded.named_parameters():
+ if name.endswith("lora_A.default.weight"):
+ assert torch.allclose(param, torch.full_like(param, 1.0))
+ elif name.endswith("lora_B.default.weight"):
+ assert torch.allclose(param, torch.full_like(param, 2.0))
+
+ def check_prefix_tuning_load_no_warning(self, model1, model2, path):
+ # helper method: save with model1, load with model2, ensure that there is no warning about missing keys and that
+ # the parameters are loaded correctly.
+ model1 = copy.deepcopy(model1)
+ model2 = copy.deepcopy(model2)
+ config = PrefixTuningConfig(
+ task_type="CAUSAL_LM", num_virtual_tokens=5, num_layers=2, token_dim=10, num_attention_heads=2
+ )
+ peft_model = get_peft_model(copy.deepcopy(model1), config)
+
+ # set all values to 1.0 so we can check that they are loaded correctly
+ peft_model.prompt_encoder.default.embedding.weight.data.fill_(1.0)
+
+ peft_model.save_pretrained(path)
+ del peft_model
+
+ # ensure that there is no warning: UserWarning: Found missing adapter keys while loading the checkpoint
+ with warnings.catch_warnings(record=True) as w:
+ warnings.simplefilter("always")
+ loaded = PeftModel.from_pretrained(copy.deepcopy(model2), path)
+ assert not any("Found missing adapter keys" in str(warning.message) for warning in w)
+
+ # sanity check on parameter values to not only rely on the absence of warnings
+ weight = loaded.prompt_encoder.default.embedding.weight
+ assert torch.allclose(weight, torch.full_like(weight, 1.0))
+
+ def check_vblora_load_no_warning(self, model1, model2, path):
+ # helper method: save with model1, load with model2, ensure that there is no warning about missing keys and that
+ # the parameters are loaded correctly
+ model1 = copy.deepcopy(model1)
+ model2 = copy.deepcopy(model2)
+
+ config = VBLoRAConfig(target_modules=["attn"], vector_length=2, num_vectors=4)
+ peft_model = get_peft_model(copy.deepcopy(model1), config)
+
+ # set all values to 1.0 or 2.0 so we can check that they are loaded correctly
+ peft_model.base_model.vblora_vector_bank["default"].data.fill_(1.0)
+ for name, param in peft_model.named_parameters():
+ if "logits" in name:
+ param.data.fill_(2.0)
+
+ peft_model.save_pretrained(path)
+ del peft_model
+
+ # ensure that there is no warning: UserWarning: Found missing adapter keys while loading the checkpoint
+ with warnings.catch_warnings(record=True) as w:
+ warnings.simplefilter("always")
+ loaded = PeftModel.from_pretrained(copy.deepcopy(model2), path)
+ assert not any("Found missing adapter keys" in str(warning.message) for warning in w)
+
+ # sanity check on parameter values to not only rely on the absence of warnings
+ param = loaded.base_model.vblora_vector_bank["default"]
+ assert torch.allclose(param, torch.full_like(param, 1.0))
+ for name, param in loaded.named_parameters():
+ if "logits" in name:
+ assert torch.allclose(param, torch.full_like(param, 2.0))
+
+ def test_key_mapping_save_new_load_new_lora(self, new_model, tmp_path):
+ # save and load the new model, should work without issues
+ self.check_lora_load_no_warning(new_model, new_model, tmp_path)
+
+ def test_key_mapping_save_old_load_old_lora(self, old_model, tmp_path):
+ # save and load the old model, should work without issues
+ self.check_lora_load_no_warning(old_model, old_model, tmp_path)
+
+ def test_key_mapping_save_old_load_new_lora(self, old_model, new_model, tmp_path):
+ # save the old model, load it into the new model, should work without issues (backwards compatibility)
+ self.check_lora_load_no_warning(old_model, new_model, tmp_path)
+
+ @pytest.mark.xfail(reason="Loading new checkpoints with old transformers is not supported.", strict=True)
+ def test_key_mapping_save_new_load_old_lora(self, old_model, new_model, tmp_path):
+ # save the new model, load it into the old model, should work without issues (forwards compatibility)
+ self.check_lora_load_no_warning(new_model, old_model, tmp_path)
+
+ def test_key_mapping_save_new_load_new_prefix_tuning(self, new_model, tmp_path):
+ # save and load the new model, should work without issues
+ self.check_prefix_tuning_load_no_warning(new_model, new_model, tmp_path)
+
+ def test_key_mapping_save_old_load_old_prefix_tuning(self, old_model, tmp_path):
+ # save and load the old model, should work without issues
+ self.check_prefix_tuning_load_no_warning(old_model, old_model, tmp_path)
+
+ def test_key_mapping_save_old_load_new_prefix_tuning(self, old_model, new_model, tmp_path):
+ # save the old model, load it into the new model, should work without issues (backwards compatibility)
+ self.check_prefix_tuning_load_no_warning(old_model, new_model, tmp_path)
+
+ def test_key_mapping_save_new_load_old_prefix_tuning(self, old_model, new_model, tmp_path):
+ # save the new model, load it into the old model, should work without issues (forwards compatibility)
+ self.check_prefix_tuning_load_no_warning(new_model, old_model, tmp_path)
+
+ def test_key_mapping_save_new_load_new_vblora(self, new_model, tmp_path):
+ # save and load the new model, should work without issues
+ self.check_vblora_load_no_warning(new_model, new_model, tmp_path)
+
+ def test_key_mapping_save_old_load_old_vblora(self, old_model, tmp_path):
+ # save and load the old model, should work without issues
+ self.check_vblora_load_no_warning(old_model, old_model, tmp_path)
+
+ def test_key_mapping_save_old_load_new_vblora(self, old_model, new_model, tmp_path):
+ # save the old model, load it into the new model, should work without issues (backwards compatibility)
+ self.check_vblora_load_no_warning(old_model, new_model, tmp_path)
+
+ @pytest.mark.xfail(reason="Loading new checkpoints with old transformers is not supported.", strict=True)
+ def test_key_mapping_save_new_load_old_vblora(self, old_model, new_model, tmp_path):
+ # save the new model, load it into the old model, should work without issues (forwards compatibility)
+ self.check_vblora_load_no_warning(new_model, old_model, tmp_path)
diff --git a/peft/tests/test_integrations.py b/peft/tests/test_integrations.py
new file mode 100644
index 0000000000000000000000000000000000000000..18ce4b2f0625424f566b93de1d6accaf4b87ced1
--- /dev/null
+++ b/peft/tests/test_integrations.py
@@ -0,0 +1,97 @@
+# Copyright 2024-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import torch
+from torch import nn
+
+from peft.utils.integrations import init_empty_weights, skip_init_on_device
+
+
+class MLP(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.relu = nn.ReLU()
+ self.drop = nn.Dropout(0.5)
+ self.lin1 = nn.Linear(20, 2, bias=bias)
+
+
+def get_mlp():
+ return MLP()
+
+
+class TestInitEmptyWeights:
+ def test_init_empty_weights_works(self):
+ # this is a very rudimentary test, as init_empty_weights is copied almost 1:1 from accelerate and is tested
+ # there
+ with init_empty_weights():
+ mlp = get_mlp()
+
+ expected = torch.device("meta")
+ assert all(p.device == expected for p in mlp.parameters())
+
+ def test_skip_init_on_device_works(self):
+ # when a function is decorated with skip_init_on_device, the parameters are not moved to meta device, even when
+ # inside the context
+ decorated_fn = skip_init_on_device(get_mlp)
+ with init_empty_weights():
+ mlp = decorated_fn()
+
+ expected = torch.device("cpu")
+ assert all(p.device == expected for p in mlp.parameters())
+
+ def test_skip_init_on_device_works_outside_context(self):
+ # same as before, but ensure that skip_init_on_device does not break when no init_empty_weights context is used
+ decorated_fn = skip_init_on_device(get_mlp)
+ mlp = decorated_fn()
+ expected = torch.device("cpu")
+ assert all(p.device == expected for p in mlp.parameters())
+
+ def test_skip_init_on_device_not_permanent(self):
+ # ensure that after skip_init_on_device has been used, init_empty_weights reverts to its original functionality
+
+ # with decorator => cpu
+ decorated_fn = skip_init_on_device(get_mlp)
+ with init_empty_weights():
+ mlp = decorated_fn()
+
+ expected = torch.device("cpu")
+ assert all(p.device == expected for p in mlp.parameters())
+
+ # without decorator => meta
+ with init_empty_weights():
+ mlp = get_mlp()
+
+ expected = torch.device("meta")
+ assert all(p.device == expected for p in mlp.parameters())
+
+ def test_skip_init_on_device_nested(self):
+ # ensure that skip_init_on_device works even if the decorated function is nested inside another decorated
+ # function
+ @skip_init_on_device
+ def outer_fn():
+ @skip_init_on_device
+ def inner_fn():
+ return get_mlp()
+
+ mlp0 = inner_fn()
+ mlp1 = get_mlp()
+ return mlp0, mlp1
+
+ with init_empty_weights():
+ mlp0, mlp1 = outer_fn()
+
+ expected = torch.device("cpu")
+ assert all(p.device == expected for p in mlp0.parameters())
+ assert all(p.device == expected for p in mlp1.parameters())
diff --git a/peft/tests/test_lora_megatron.py b/peft/tests/test_lora_megatron.py
new file mode 100644
index 0000000000000000000000000000000000000000..ff91a41387d768d8741e2568b98ae405aff47778
--- /dev/null
+++ b/peft/tests/test_lora_megatron.py
@@ -0,0 +1,171 @@
+#!/usr/bin/env python3
+
+# coding=utf-8
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import copy
+import importlib
+import os
+import unittest
+
+import torch
+import torch.nn.init as init
+
+from peft import LoraConfig, PeftModel, get_peft_model, get_peft_model_state_dict
+
+from .testing_utils import require_torch_gpu
+
+
+def is_megatron_available() -> bool:
+ return importlib.util.find_spec("megatron") is not None
+
+
+if is_megatron_available():
+ from megatron.core import parallel_state, tensor_parallel
+ from megatron.core.tensor_parallel.random import model_parallel_cuda_manual_seed
+ from megatron.core.transformer.module import MegatronModule
+ from megatron.core.transformer.transformer_config import TransformerConfig
+
+ world_size = 1
+ rank = 0
+
+ def initialize_distributed():
+ print(f"Initializing torch.distributed with rank: {rank}, world_size: {world_size}")
+ torch.cuda.set_device(0)
+ init_method = "tcp://"
+ master_ip = os.getenv("MASTER_ADDR", "localhost")
+ master_port = os.getenv("MASTER_PORT", "6001")
+ init_method += master_ip + ":" + master_port
+ torch.distributed.init_process_group(backend="nccl", world_size=world_size, rank=rank, init_method=init_method)
+
+ def destroy_model_parallel():
+ parallel_state.destroy_model_parallel()
+ torch.distributed.barrier()
+
+ def initialize_model_parallel(
+ tensor_model_parallel_size=1,
+ pipeline_model_parallel_size=1,
+ virtual_pipeline_model_parallel_size=None,
+ pipeline_model_parallel_split_rank=None,
+ ):
+ parallel_state.destroy_model_parallel()
+ if not torch.distributed.is_initialized():
+ initialize_distributed()
+ parallel_state.initialize_model_parallel(
+ tensor_model_parallel_size,
+ pipeline_model_parallel_size,
+ virtual_pipeline_model_parallel_size,
+ pipeline_model_parallel_split_rank,
+ )
+
+ class DummyModule(MegatronModule):
+ def __init__(self, config: TransformerConfig):
+ super().__init__(config)
+ self.linear = tensor_parallel.ColumnParallelLinear(
+ input_size=10,
+ output_size=10,
+ config=config,
+ init_method=init.xavier_normal_,
+ bias=False,
+ gather_output=False,
+ )
+ self.lm_head = tensor_parallel.RowParallelLinear(
+ input_size=10,
+ output_size=10,
+ config=config,
+ init_method=init.xavier_normal_,
+ bias=False,
+ input_is_parallel=True,
+ skip_bias_add=True,
+ )
+
+ def forward(self, input):
+ x = self.linear(input)[0]
+ x = self.lm_head(x)[0]
+ return x
+
+ @require_torch_gpu
+ class TestMegatronLora(unittest.TestCase):
+ def setUp(self):
+ initialize_model_parallel(1, 1)
+ model_parallel_cuda_manual_seed(123)
+ transformer_config = {
+ "num_layers": 2,
+ "hidden_size": 12,
+ "num_attention_heads": 4,
+ "use_cpu_initialization": True,
+ }
+ config = TransformerConfig(**transformer_config)
+ self.megatron_module = DummyModule(config=config).cuda()
+ self.dummy_module = copy.deepcopy(self.megatron_module).cuda()
+
+ lora_config = LoraConfig(
+ lora_alpha=16,
+ lora_dropout=0.1,
+ r=64,
+ bias="none",
+ target_modules=["linear", "lm_head"],
+ megatron_config=config,
+ megatron_core="megatron.core",
+ )
+ self.megatron_module = get_peft_model(self.megatron_module, lora_config)
+
+ def tearDown(self):
+ destroy_model_parallel()
+
+ def test_megatron_lora_module(self):
+ megatron_module = self.megatron_module
+ assert isinstance(megatron_module, PeftModel)
+
+ for name, module in megatron_module.named_modules():
+ if name.endswith("linear"):
+ assert hasattr(module, "lora_A")
+ assert hasattr(module, "lora_B")
+ if name.endswith("linear.lora_A.default"):
+ assert isinstance(module, torch.nn.Linear)
+ if name.endswith("linear.lora_B.default"):
+ assert isinstance(module, tensor_parallel.ColumnParallelLinear)
+
+ if name.endswith("lm_head.lora_A.default"):
+ assert isinstance(module, tensor_parallel.RowParallelLinear)
+ if name.endswith("lm_head.lora_B.default"):
+ assert isinstance(module, torch.nn.Linear)
+
+ def test_forward(self):
+ x = torch.ones((2, 4, 10)).cuda()
+ megatron_module_result = self.megatron_module(x)
+ dummt_module_result = self.dummy_module(x)
+
+ # Because lora_B is initialized with 0, the forward results of two models should be equal before backward.
+ assert megatron_module_result.equal(dummt_module_result)
+
+ def test_backward(self):
+ optimizer = torch.optim.AdamW(self.megatron_module.parameters())
+ loss_fn = torch.nn.CrossEntropyLoss()
+
+ x = torch.randn(2, 4, 10, requires_grad=True).cuda()
+ label = torch.randint(10, (2 * 4,)).cuda()
+
+ output = self.megatron_module(x)
+ output = output.reshape(2 * 4, 10)
+ loss = loss_fn(output, label)
+
+ loss.backward()
+ optimizer.step()
+
+ def test_get_peft_model_state_dict(self):
+ peft_state_dict = get_peft_model_state_dict(self.megatron_module)
+
+ for key in peft_state_dict.keys():
+ assert "lora" in key
diff --git a/peft/tests/test_lora_variants.py b/peft/tests/test_lora_variants.py
new file mode 100644
index 0000000000000000000000000000000000000000..9112400473c9a3d494cf98dd55ece101a3c9c490
--- /dev/null
+++ b/peft/tests/test_lora_variants.py
@@ -0,0 +1,126 @@
+# Copyright 2025-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import pytest
+import torch
+from torch import nn
+
+from peft import LoraConfig, get_peft_model
+from peft.tuners.lora.layer import Conv1d as LoraConv1d
+from peft.tuners.lora.layer import Conv2d as LoraConv2d
+from peft.tuners.lora.layer import Embedding as LoraEmbedding
+from peft.tuners.lora.layer import Linear as LoraLinear
+from peft.tuners.lora.variants import (
+ DoraConv1dVariant,
+ DoraConv2dVariant,
+ DoraEmbeddingVariant,
+ DoraLinearVariant,
+)
+
+
+class CustomModel(nn.Module):
+ """pytorch module that contains common targetable layers (linear, embedding, conv, ...)"""
+
+ def __init__(self, num_embeddings=100, embedding_dim=16, num_classes=10):
+ super().__init__()
+ self.embedding = nn.Embedding(num_embeddings, embedding_dim)
+ self.conv1d = nn.Conv1d(in_channels=embedding_dim, out_channels=32, kernel_size=3, padding=1)
+ self.conv2d = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=3, stride=1, padding=1)
+ self.flatten = nn.Flatten()
+ self.dummy_conv1d_output_dim = 32 * 10
+ self.dummy_conv2d_output_dim = 16 * 10 * 10
+ self.linear1 = nn.Linear(self.dummy_conv1d_output_dim + self.dummy_conv2d_output_dim, 64)
+ self.linear2 = nn.Linear(64, num_classes)
+ self.relu = nn.ReLU()
+
+ def forward(self, input_ids, dummy_image_input):
+ # Path 1: Embedding -> Conv1d
+ x1 = self.embedding(input_ids) # (batch_size, seq_len, embedding_dim)
+ x1 = x1.transpose(1, 2) # (batch_size, embedding_dim, seq_len)
+ x1 = self.relu(self.conv1d(x1)) # (batch_size, 32, seq_len)
+ x1_flat = self.flatten(x1)
+ # Path 2: Conv2d -> Linear
+ x2 = self.relu(self.conv2d(dummy_image_input)) # (batch_size, 16, H, W)
+ x2_flat = self.flatten(x2) # (batch_size, 16*H*W)
+ # Combine or select paths if making a functional model.
+ # For this test, we mainly care about layer types, so forward might not be fully executed.
+ # Let's use x2_flat for subsequent linear layers.
+ output = self.relu(self.linear1(torch.concat([x1_flat, x2_flat], dim=1)))
+ output = self.linear2(output)
+ return output
+
+
+VARIANT_MAP = {
+ "dora": {
+ LoraLinear: DoraLinearVariant,
+ LoraEmbedding: DoraEmbeddingVariant,
+ LoraConv1d: DoraConv1dVariant,
+ LoraConv2d: DoraConv2dVariant,
+ }
+}
+
+
+TEST_CASES = [
+ (
+ "dora",
+ LoraConfig,
+ {"target_modules": ["linear1", "linear2", "conv1d", "conv2d", "embedding"], "use_dora": True},
+ ),
+]
+
+
+class TestLoraVariants:
+ @pytest.mark.parametrize("variant_name, config_cls, config_kwargs", TEST_CASES)
+ def test_variant_is_applied_to_layers(self, variant_name, config_cls, config_kwargs):
+ # This test assumes that targeting and replacing layers works and that after `get_peft_model` we
+ # have a model with LoRA layers. We just make sure that each LoRA layer has its variant set and
+ # it is also the correct variant for that layer.
+ base_model = CustomModel()
+ peft_config = config_cls(**config_kwargs)
+ peft_model = get_peft_model(base_model, peft_config)
+
+ layer_type_map = VARIANT_MAP[variant_name]
+
+ for _, module in peft_model.named_modules():
+ if not hasattr(module, "lora_variant"):
+ continue
+
+ # Note that not every variant supports every layer. If it is not mapped it is deemed unsupported and
+ # will not be tested.
+ expected_variant_type = layer_type_map.get(type(module), None)
+ if not expected_variant_type:
+ continue
+
+ assert isinstance(module.lora_variant["default"], expected_variant_type)
+
+ def custom_model_with_loss_backpropagated(self, peft_config):
+ """Returns the CustomModel + PEFT model instance with a dummy loss that was backpropagated once."""
+ base_model = CustomModel()
+ peft_model = get_peft_model(base_model, peft_config)
+
+ x, y = torch.ones(10, 10).long(), torch.ones(10, 1, 10, 10)
+ out = peft_model(x, y)
+ loss = out.sum()
+ loss.backward()
+
+ return base_model, peft_model
+
+ def test_dora_params_have_gradients(self):
+ """Ensure that the parameters added by the DoRA variant are participating in the output computation."""
+ layer_names = ["linear1", "linear2", "conv1d", "conv2d", "embedding"]
+ peft_config = LoraConfig(target_modules=layer_names, use_dora=True)
+ base_model, peft_model = self.custom_model_with_loss_backpropagated(peft_config)
+
+ for layer in layer_names:
+ assert getattr(peft_model.base_model.model, layer).lora_magnitude_vector["default"].weight.grad is not None
diff --git a/peft/tests/test_lorafa.py b/peft/tests/test_lorafa.py
new file mode 100644
index 0000000000000000000000000000000000000000..3f480049920d6982d48091c342cae98688ba8b16
--- /dev/null
+++ b/peft/tests/test_lorafa.py
@@ -0,0 +1,152 @@
+# Copyright 2025-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import annotations
+
+import math
+
+import torch
+from torch import nn
+
+from peft import LoraConfig, get_peft_model
+from peft.optimizers import create_lorafa_optimizer
+
+from .testing_utils import torch_device
+
+
+class SimpleNet(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.embedding = nn.Embedding(100, 20)
+ self.layer_norm = nn.LayerNorm(20)
+ self.lin0 = nn.Linear(20, 20, bias=bias)
+ self.relu = nn.ReLU()
+ self.lin1 = nn.Linear(20, 16, bias=bias)
+
+ def forward(self, X):
+ X = self.lin0(self.layer_norm(self.embedding(X)))
+ X = self.relu(X)
+ X = self.lin1(X)
+ return X
+
+
+def test_lorafa_init_default():
+ """
+ Test if the optimizer is correctly created
+ """
+ lora_rank = 16
+ lora_alpha = 32
+ lr = 7e-5
+
+ model = SimpleNet()
+ config = LoraConfig(
+ r=lora_rank,
+ lora_alpha=lora_alpha,
+ target_modules=["lin0", "lin1"],
+ bias="none",
+ )
+ model = get_peft_model(model, config)
+ optimizer = create_lorafa_optimizer(model=model, r=lora_rank, lora_alpha=lora_alpha, lr=lr)
+
+ assert math.isclose(optimizer.param_groups[0]["scaling_factor"], lora_alpha / lora_rank, rel_tol=1e-9, abs_tol=0.0)
+
+ all_A_fixed = True
+ all_B_trainable = True
+
+ assert optimizer is not None
+
+ for name, param in model.named_parameters():
+ if "lora_A" in name:
+ all_A_fixed &= not param.requires_grad
+ elif "lora_B" in name:
+ all_B_trainable &= param.requires_grad
+
+ assert all_A_fixed and all_B_trainable
+
+
+def test_lorafa_init_rslora():
+ """
+ Test if the optimizer is correctly created when use_rslora = True
+ """
+ lora_rank = 16
+ lora_alpha = 32
+ lr = 7e-5
+
+ model = SimpleNet()
+ config = LoraConfig(
+ r=lora_rank,
+ lora_alpha=lora_alpha,
+ target_modules=["lin0", "lin1"],
+ bias="none",
+ )
+ model = get_peft_model(model, config)
+ optimizer = create_lorafa_optimizer(model=model, r=lora_rank, lora_alpha=lora_alpha, lr=lr, use_rslora=True)
+ assert math.isclose(
+ optimizer.param_groups[0]["scaling_factor"], lora_alpha / math.sqrt(lora_rank), rel_tol=1e-9, abs_tol=0.0
+ )
+
+
+def test_LoraFAOptimizer_step():
+ """
+ Test if the optimizer's step function runs without any exception and checks specific conditions on lora_A and
+ lora_B weights.
+ """
+ lora_rank = 16
+ lora_alpha = 32
+ lr = 7e-5
+ num_steps = 5
+
+ model = SimpleNet()
+ config = LoraConfig(
+ r=lora_rank,
+ lora_alpha=lora_alpha,
+ target_modules=["lin0", "lin1"],
+ bias="none",
+ )
+ model = get_peft_model(model, config).to(torch_device)
+ optimizer = create_lorafa_optimizer(model=model, r=16, lora_alpha=32, lr=7e-5)
+ loss = torch.nn.CrossEntropyLoss()
+
+ # Save initial weights of lora_A
+ initial_lora_A_weights = {name: param.clone() for name, param in model.named_parameters() if "lora_A" in name}
+ # Ensure lora_B is initialized to zero
+ for name, param in model.named_parameters():
+ if "lora_B" in name:
+ assert torch.all(param == 0), f"lora_B weights not initialized to zero for {name}"
+
+ for _ in range(num_steps): # Run the optimizer step multiple times
+ # Generate random input and label for each step
+ x = torch.randint(100, (2, 4, 10)).to(torch_device)
+ output = model(x).permute(0, 3, 1, 2)
+ label = torch.randint(16, (2, 4, 10)).to(torch_device)
+
+ # Calculate loss and perform backward pass
+ loss_value = loss(output, label)
+ loss_value.backward()
+
+ # Perform optimizer step
+ optimizer.step()
+
+ # Zero the gradients after each step to prevent accumulation
+ optimizer.zero_grad()
+
+ # Check if lora_A weights have not changed
+ for name, param in model.named_parameters():
+ if "lora_A" in name:
+ assert torch.equal(param, initial_lora_A_weights[name]), f"lora_A weights changed for {name}"
+
+ # Check if lora_B weights are non-zero
+ for name, param in model.named_parameters():
+ if "lora_B" in name:
+ assert torch.any(param != 0), f"lora_B weights are still zero for {name}"
diff --git a/peft/tests/test_loraplus.py b/peft/tests/test_loraplus.py
new file mode 100644
index 0000000000000000000000000000000000000000..64bb8bc307e58482366b63063ae1ce9cd921fe1b
--- /dev/null
+++ b/peft/tests/test_loraplus.py
@@ -0,0 +1,99 @@
+# Copyright 2024-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+from __future__ import annotations
+
+import torch
+from torch import nn
+
+from peft.import_utils import is_bnb_available
+from peft.optimizers import create_loraplus_optimizer
+
+from .testing_utils import require_bitsandbytes, torch_device
+
+
+if is_bnb_available():
+ import bitsandbytes as bnb
+
+
+class SimpleNet(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.embedding = nn.Embedding(100, 20)
+ self.layer_norm = nn.LayerNorm(20)
+ self.lin0 = nn.Linear(20, 20, bias=bias)
+ self.relu = nn.ReLU()
+ self.lin1 = nn.Linear(20, 16, bias=bias)
+
+ def forward(self, X):
+ X = self.lin0(self.layer_norm(self.embedding(X)))
+ X = self.relu(X)
+ X = self.lin1(X)
+ return X
+
+
+@require_bitsandbytes
+def test_lora_plus_helper_sucess():
+ model = SimpleNet()
+ optimizer_cls = bnb.optim.Adam8bit
+ lr = 5e-5
+ optim_config = {
+ "eps": 1e-6,
+ "betas": (0.9, 0.999),
+ "loraplus_weight_decay": 0.0,
+ }
+ loraplus_lr_ratio = 1.2
+ loraplus_lr_embedding = 1e-6
+ optim = create_loraplus_optimizer(
+ model=model,
+ optimizer_cls=optimizer_cls,
+ lr=lr,
+ loraplus_lr_ratio=loraplus_lr_ratio,
+ loraplus_lr_embedding=loraplus_lr_embedding,
+ **optim_config,
+ )
+ assert optim is not None
+ assert len(optim.param_groups) == 4
+ assert optim.param_groups[0]["lr"] == lr
+ assert optim.param_groups[1]["lr"] == loraplus_lr_embedding
+ assert optim.param_groups[2]["lr"] == optim.param_groups[3]["lr"] == (lr * loraplus_lr_ratio)
+
+
+@require_bitsandbytes
+def test_lora_plus_optimizer_sucess():
+ """
+ Test if the optimizer is correctly created and step function runs without any exception
+ """
+ optimizer_cls = bnb.optim.Adam8bit
+ optim_config = {
+ "eps": 1e-6,
+ "betas": (0.9, 0.999),
+ "loraplus_weight_decay": 0.0,
+ }
+ model: SimpleNet = SimpleNet().to(torch_device)
+ optim = create_loraplus_optimizer(
+ model=model,
+ optimizer_cls=optimizer_cls,
+ lr=5e-5,
+ loraplus_lr_ratio=1.2,
+ loraplus_lr_embedding=1e-6,
+ **optim_config,
+ )
+ loss = torch.nn.CrossEntropyLoss()
+ bnb.optim.GlobalOptimManager.get_instance().register_parameters(model.parameters())
+ x = torch.randint(100, (2, 4, 10)).to(torch_device)
+ output = model(x).permute(0, 3, 1, 2)
+ label = torch.randint(16, (2, 4, 10)).to(torch_device)
+ loss_value = loss(output, label)
+ loss_value.backward()
+ optim.step()
diff --git a/peft/tests/test_low_level_api.py b/peft/tests/test_low_level_api.py
new file mode 100644
index 0000000000000000000000000000000000000000..e2701f28c3f1524dbcf673f0427063a3ab25d4ba
--- /dev/null
+++ b/peft/tests/test_low_level_api.py
@@ -0,0 +1,97 @@
+#!/usr/bin/env python3
+
+# coding=utf-8
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import unittest
+
+import torch
+
+from peft import LoraConfig, get_peft_model_state_dict, inject_adapter_in_model
+from peft.utils import ModulesToSaveWrapper
+
+
+class DummyModel(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.embedding = torch.nn.Embedding(10, 10)
+ self.linear = torch.nn.Linear(10, 10)
+ self.linear2 = torch.nn.Linear(10, 10, bias=True)
+ self.lm_head = torch.nn.Linear(10, 10)
+
+ def forward(self, input_ids):
+ x = self.embedding(input_ids)
+ x = self.linear(x)
+ x = self.lm_head(x)
+ return x
+
+
+class TestPeft(unittest.TestCase):
+ def setUp(self):
+ self.model = DummyModel()
+
+ lora_config = LoraConfig(
+ lora_alpha=16,
+ lora_dropout=0.1,
+ r=64,
+ bias="none",
+ target_modules=["linear"],
+ )
+
+ self.model = inject_adapter_in_model(lora_config, self.model)
+
+ def test_inject_adapter_in_model(self):
+ dummy_inputs = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7]])
+ _ = self.model(dummy_inputs)
+
+ for name, module in self.model.named_modules():
+ if name == "linear":
+ assert hasattr(module, "lora_A")
+ assert hasattr(module, "lora_B")
+
+ def test_get_peft_model_state_dict(self):
+ peft_state_dict = get_peft_model_state_dict(self.model)
+
+ for key in peft_state_dict.keys():
+ assert "lora" in key
+
+ def test_modules_to_save(self):
+ self.model = DummyModel()
+
+ lora_config = LoraConfig(
+ lora_alpha=16,
+ lora_dropout=0.1,
+ r=64,
+ bias="none",
+ target_modules=["linear"],
+ modules_to_save=["embedding", "linear2"],
+ )
+
+ self.model = inject_adapter_in_model(lora_config, self.model)
+
+ for name, module in self.model.named_modules():
+ if name == "linear":
+ assert hasattr(module, "lora_A")
+ assert hasattr(module, "lora_B")
+ elif name in ["embedding", "linear2"]:
+ assert isinstance(module, ModulesToSaveWrapper)
+
+ state_dict = get_peft_model_state_dict(self.model)
+
+ assert "embedding.weight" in state_dict.keys()
+
+ assert hasattr(self.model.embedding, "weight")
+
+ assert hasattr(self.model.linear2, "weight")
+ assert hasattr(self.model.linear2, "bias")
diff --git a/peft/tests/test_mapping.py b/peft/tests/test_mapping.py
new file mode 100644
index 0000000000000000000000000000000000000000..6e204b951058ca8df79722211db19d18b9d8a233
--- /dev/null
+++ b/peft/tests/test_mapping.py
@@ -0,0 +1,55 @@
+# Copyright 2025-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import pytest
+import torch
+
+from peft import LoraConfig, get_peft_model
+
+
+class TestGetPeftModel:
+ RELOAD_WARNING_EXPECTED_MATCH = r"You are trying to modify a model .*"
+
+ @pytest.fixture
+ def lora_config_0(self):
+ return LoraConfig(target_modules="0")
+
+ @pytest.fixture
+ def base_model(self):
+ return torch.nn.Sequential(torch.nn.Linear(10, 2), torch.nn.Linear(2, 10))
+
+ def test_get_peft_model_warns_when_reloading_model(self, lora_config_0, base_model):
+ get_peft_model(base_model, lora_config_0)
+
+ with pytest.warns(UserWarning, match=self.RELOAD_WARNING_EXPECTED_MATCH):
+ get_peft_model(base_model, lora_config_0)
+
+ def test_get_peft_model_proposed_fix_in_warning_helps(self, lora_config_0, base_model, recwarn):
+ peft_model = get_peft_model(base_model, lora_config_0)
+ peft_model.unload()
+ get_peft_model(base_model, lora_config_0)
+
+ warning_checker = pytest.warns(UserWarning, match=self.RELOAD_WARNING_EXPECTED_MATCH)
+
+ for warning in recwarn:
+ if warning_checker.matches(warning):
+ pytest.fail("Warning raised even though model was unloaded.")
+
+ def test_get_peft_model_repeated_invocation(self, lora_config_0, base_model):
+ peft_model = get_peft_model(base_model, lora_config_0)
+
+ # use direct-addressing of the other layer to accomodate for the nested model
+ lora_config_1 = LoraConfig(target_modules="base_model.model.1")
+
+ with pytest.warns(UserWarning, match=self.RELOAD_WARNING_EXPECTED_MATCH):
+ get_peft_model(peft_model, lora_config_1)
diff --git a/peft/tests/test_mixed.py b/peft/tests/test_mixed.py
new file mode 100644
index 0000000000000000000000000000000000000000..773df1b49c14b95729726cd456caed19e19cf882
--- /dev/null
+++ b/peft/tests/test_mixed.py
@@ -0,0 +1,791 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import copy
+import itertools
+import os
+import platform
+import re
+import tempfile
+import unittest
+
+import pytest
+import torch
+from parameterized import parameterized
+from torch import nn
+from transformers import AutoModelForCausalLM
+
+from peft import (
+ AdaLoraConfig,
+ LoHaConfig,
+ LoKrConfig,
+ LoraConfig,
+ PeftMixedModel,
+ PrefixTuningConfig,
+ get_peft_model,
+)
+from peft.tuners.tuners_utils import BaseTunerLayer
+from peft.utils import infer_device
+
+
+class SimpleNet(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ # note: out_features must be > rank or else OFT will be an identity transform
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.relu = nn.ReLU()
+ self.lin1 = nn.Linear(20, 16, bias=bias)
+
+ def forward(self, X):
+ X = X.float()
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = self.lin1(X)
+ return X
+
+
+def _param_name_func(testcase_func, param_num, params):
+ # for parameterized tests in TextMixedAdapterTypes
+ config0, config1 = params[0]
+ name0 = config0.__class__.__name__[: -len("Config")]
+ name1 = config1.__class__.__name__[: -len("Config")]
+ if name0 != name1:
+ return f"{testcase_func.__name__}_{param_num}_{name0}_{name1}"
+ return f"{testcase_func.__name__}_{param_num}_{name0}_x2"
+
+
+class TestMixedAdapterTypes(unittest.TestCase):
+ torch_device = infer_device()
+
+ def _get_model(self, model_cls, peft_config=None, adapter_name=None, seed=0, mixed=True):
+ torch.manual_seed(0) # always use seed 0 for base model, seed for adapters may differ
+ base_model = model_cls().eval().to(self.torch_device)
+ if peft_config is None:
+ return base_model
+
+ torch.manual_seed(seed)
+ assert adapter_name is not None
+ peft_model = get_peft_model(base_model, peft_config, adapter_name=adapter_name, mixed=mixed)
+ return peft_model.eval().to(self.torch_device)
+
+ def _check_mixed_outputs(self, model_cls, config0, config1, input, *, is_commutative):
+ # This test checks different combinations of adapter0, adapter1, or combinations of the two, and whether
+ # outputs are the same/different, depending on context. If we pass is_commutative=True, it means that the order
+ # of adapters does not matter, and we expect the same output regardless of the order in which adapters are
+ # applied.
+ # We have to very careful with resetting the random seed each time it is used, otherwise the adapters may be
+ # initialized with different values, and the test will fail.
+
+ atol = 1e-5
+ rtol = 1e-5
+ seed0 = 0
+ seed1 = 1
+
+ # base model
+ base_model = self._get_model(model_cls)
+ output_base = base_model(input)
+ assert torch.isfinite(output_base).all()
+
+ # adapter 0
+ peft_model_0 = self._get_model(model_cls, config0, "adapter0", seed=seed0)
+ output_config0 = peft_model_0(input)
+
+ assert torch.isfinite(output_config0).all()
+ assert not torch.allclose(output_base, output_config0, atol=atol, rtol=rtol)
+
+ # adapter 1
+ peft_model_1 = self._get_model(model_cls, config1, "adapter1", seed=seed1)
+ output_config1 = peft_model_1(input)
+
+ assert torch.isfinite(output_config1).all()
+ assert not torch.allclose(output_base, output_config1, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_config0, output_config1, atol=atol, rtol=rtol)
+
+ # adapter 0 + 1
+ peft_model_01 = self._get_model(model_cls, config0, "adapter0", seed=seed0)
+ torch.manual_seed(seed1)
+ peft_model_01.add_adapter("adapter1", config1)
+ peft_model_01.set_adapter(["adapter0", "adapter1"])
+ output_mixed_01 = peft_model_01(input)
+
+ # check the number of tuner layer types
+ tuner_layers = [mod for mod in peft_model_01.modules() if isinstance(mod, BaseTunerLayer)]
+ tuner_types = {type(tuner_layer) for tuner_layer in tuner_layers}
+ if type(config0) is type(config1):
+ assert len(tuner_types) == 1
+ else:
+ assert len(tuner_types) == 2
+
+ assert peft_model_01.active_adapters == ["adapter0", "adapter1"]
+ assert torch.isfinite(output_mixed_01).all()
+ assert not torch.allclose(output_config0, output_mixed_01, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_config1, output_mixed_01, atol=atol, rtol=rtol)
+ if is_commutative:
+ delta0 = output_config0 - output_base
+ delta1 = output_config1 - output_base
+ delta_mixed_01 = output_mixed_01 - output_base
+ assert torch.allclose((delta0 + delta1), delta_mixed_01, atol=atol, rtol=rtol)
+
+ # adapter 1 + 0
+ peft_model_10 = self._get_model(model_cls, config1, "adapter1", seed=seed1)
+ torch.manual_seed(seed0)
+ peft_model_10.add_adapter("adapter0", config0)
+ peft_model_10.set_adapter(["adapter1", "adapter0"])
+ output_mixed_10 = peft_model_10(input)
+
+ # check the number of tuner layer types
+ tuner_layers = [mod for mod in peft_model_10.modules() if isinstance(mod, BaseTunerLayer)]
+ tuner_types = {type(tuner_layer) for tuner_layer in tuner_layers}
+ if type(config0) is type(config1):
+ assert len(tuner_types) == 1
+ else:
+ assert len(tuner_types) == 2
+
+ assert peft_model_10.active_adapters == ["adapter1", "adapter0"]
+ assert torch.isfinite(output_mixed_10).all()
+ assert not torch.allclose(output_config0, output_mixed_10, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_config1, output_mixed_10, atol=atol, rtol=rtol)
+ if is_commutative:
+ assert torch.allclose(output_mixed_01, output_mixed_10, atol=atol, rtol=rtol)
+
+ # turn around the order of the adapters of the 0 + 1 mixed model, should behave like the 0 + 1 mixed model
+ peft_model_10.set_adapter(["adapter0", "adapter1"])
+ output_mixed_reversed = peft_model_10(input)
+
+ # check the number of tuner layer types
+ tuner_layers = [mod for mod in peft_model_10.modules() if isinstance(mod, BaseTunerLayer)]
+ tuner_types = {type(tuner_layer) for tuner_layer in tuner_layers}
+ if type(config0) is type(config1):
+ assert len(tuner_types) == 1
+ else:
+ assert len(tuner_types) == 2
+
+ assert peft_model_10.active_adapters == ["adapter0", "adapter1"]
+ assert torch.isfinite(output_mixed_reversed).all()
+ assert not torch.allclose(output_mixed_reversed, output_config0, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_mixed_reversed, output_config1, atol=atol, rtol=rtol)
+ if is_commutative:
+ assert torch.allclose(output_mixed_reversed, output_mixed_01, atol=atol, rtol=rtol)
+ assert torch.allclose(output_mixed_reversed, output_mixed_10, atol=atol, rtol=rtol)
+
+ def _check_merging(self, model_cls, config0, config1, input):
+ # Ensure that when merging mixed adapters, the result is the same as when applying the adapters separately.
+ # Merging requires a bit higher tolerance for some adapters, which can also vary depending on CPU vs GPU.
+ atol = 1e-4
+ rtol = 1e-4
+ seed0 = 0
+ seed1 = 1
+
+ # adapter 0 + 1
+ peft_model_01 = self._get_model(model_cls, config0, "adapter0", seed=seed0)
+ torch.manual_seed(seed1)
+ peft_model_01.add_adapter("adapter1", config1)
+ peft_model_01.set_adapter(["adapter0", "adapter1"])
+ output_mixed_01 = peft_model_01(input)
+
+ model_merged_01 = peft_model_01.merge_and_unload()
+ output_merged_01 = model_merged_01(input)
+ assert torch.allclose(output_mixed_01, output_merged_01, atol=atol, rtol=rtol)
+
+ # adapter 1 + 0
+ peft_model_10 = self._get_model(model_cls, config1, "adapter1", seed=seed1)
+ torch.manual_seed(seed0)
+ peft_model_10.add_adapter("adapter0", config0)
+ peft_model_10.set_adapter(["adapter1", "adapter0"])
+ output_mixed_10 = peft_model_10(input)
+
+ model_merged_10 = peft_model_10.merge_and_unload()
+ output_merged_10 = model_merged_10(input)
+ assert torch.allclose(output_mixed_10, output_merged_10, atol=atol, rtol=rtol)
+
+ def _check_unload(self, model_cls, config0, config1, input):
+ # Ensure that we can unload the base model without merging
+ atol = 1e-5
+ rtol = 1e-5
+ seed0 = 0
+ seed1 = 1
+
+ base_model = self._get_model(model_cls)
+ output_base = base_model(input)
+
+ # adapter 0 + 1
+ peft_model_01 = self._get_model(model_cls, config0, "adapter0", seed=seed0)
+ torch.manual_seed(seed1)
+ peft_model_01.add_adapter("adapter1", config1)
+ peft_model_01.set_adapter(["adapter0", "adapter1"])
+ output_mixed = peft_model_01(input)
+
+ # unload
+ model_unloaded = peft_model_01.unload()
+ output_unloaded = model_unloaded(input)
+
+ assert not torch.allclose(output_mixed, output_unloaded, atol=atol, rtol=rtol)
+ assert torch.allclose(output_base, output_unloaded, atol=atol, rtol=rtol)
+
+ def _check_disable(self, model_cls, config0, config1, input):
+ # Ensure that we can disable adapters
+ atol = 1e-5
+ rtol = 1e-5
+ seed0 = 0
+ seed1 = 1
+
+ # base model
+ base_model = self._get_model(model_cls)
+ output_base = base_model(input)
+
+ # adapter 0
+ peft_model_0 = self._get_model(model_cls, config0, "adapter0", seed=seed0)
+ output_config0 = peft_model_0(input)
+ with peft_model_0.disable_adapter():
+ output_disabled0 = peft_model_0(input)
+
+ assert not torch.allclose(output_base, output_config0, atol=atol, rtol=rtol)
+ assert torch.allclose(output_base, output_disabled0, atol=atol, rtol=rtol)
+
+ # adapter 1
+ peft_model_1 = self._get_model(model_cls, config1, "adapter1", seed=seed1)
+ output_config1 = peft_model_1(input)
+ with peft_model_1.disable_adapter():
+ output_disabled1 = peft_model_1(input)
+
+ assert not torch.allclose(output_base, output_config1, atol=atol, rtol=rtol)
+ assert torch.allclose(output_base, output_disabled1, atol=atol, rtol=rtol)
+
+ # adapter 0 + 1
+ peft_model_01 = self._get_model(model_cls, config0, "adapter0", seed=seed0)
+ torch.manual_seed(seed1)
+ peft_model_01.add_adapter("adapter1", config1)
+ peft_model_01.set_adapter(["adapter0", "adapter1"])
+ output_mixed_01 = peft_model_01(input)
+ with peft_model_01.disable_adapter():
+ output_disabled01 = peft_model_01(input)
+
+ assert not torch.allclose(output_base, output_mixed_01, atol=atol, rtol=rtol)
+ assert torch.allclose(output_base, output_disabled01, atol=atol, rtol=rtol)
+
+ # adapter 1 + 0
+ peft_model_10 = self._get_model(model_cls, config1, "adapter1", seed=seed1)
+ torch.manual_seed(seed0)
+ peft_model_10.add_adapter("adapter0", config0)
+ peft_model_10.set_adapter(["adapter1", "adapter0"])
+ output_mixed_10 = peft_model_10(input)
+ with peft_model_10.disable_adapter():
+ output_disabled10 = peft_model_10(input)
+
+ assert not torch.allclose(output_base, output_mixed_10, atol=atol, rtol=rtol)
+ assert torch.allclose(output_base, output_disabled10, atol=atol, rtol=rtol)
+
+ def _check_loading(self, model_cls, config0, config1, input, *, is_commutative):
+ # Check that we can load two adapters into the same model
+ # Note that we save the adapters using a normal PeftModel because PeftMixModel doesn't support saving yet
+ atol = 1e-5
+ rtol = 1e-5
+ seed0 = 0
+ seed1 = 1
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ # SAVING
+ # adapter 0: note that we set mixed=False because mixed models don't support saving (yet)
+ peft_model_0 = self._get_model(model_cls, config0, "adapter0", seed=seed0, mixed=False)
+ output_config0 = peft_model_0(input)
+ peft_model_0.save_pretrained(os.path.join(tmp_dirname, "adapter0"))
+
+ # adapter 1: note that we set mixed=False because mixed models don't support saving (yet)
+ peft_model_1 = self._get_model(model_cls, config1, "adapter1", seed=seed1, mixed=False)
+ output_config1 = peft_model_1(input)
+ peft_model_1.save_pretrained(os.path.join(tmp_dirname, "adapter1"))
+
+ # adapter 0 + 1
+ peft_model_01 = self._get_model(model_cls, config0, "adapter0", seed=seed0)
+ torch.manual_seed(seed1)
+ peft_model_01.add_adapter("adapter1", config1)
+ peft_model_01.set_adapter(["adapter0", "adapter1"])
+ output_mixed_01 = peft_model_01(input)
+
+ # adapter 1 + 0
+ peft_model_10 = self._get_model(model_cls, config1, "adapter1", seed=seed1)
+ torch.manual_seed(seed0)
+ peft_model_10.add_adapter("adapter0", config0)
+ peft_model_10.set_adapter(["adapter1", "adapter0"])
+ output_mixed_10 = peft_model_10(input)
+
+ # LOADING
+ # adapter 0
+ base_model = self._get_model(model_cls)
+ # Notes:
+ # Path is tmp_dirname/adapter0/adapter0 because non-default adapters are saved in a subfolder.
+ # As a sanity check, we should set a completely different seed here. That way, we ensure that the the
+ # weights are not just randomly initialized exactly to the same values as before.
+ torch.manual_seed(123456)
+ peft_model_loaded0 = PeftMixedModel.from_pretrained(
+ base_model, os.path.join(tmp_dirname, "adapter0", "adapter0"), "adapter0"
+ )
+ output_loaded0 = peft_model_loaded0(input)
+ assert torch.allclose(output_config0, output_loaded0, atol=atol, rtol=rtol)
+
+ # adapter 1
+ base_model = self._get_model(model_cls)
+ torch.manual_seed(654321) # setting a completely different seed here should not affect the result
+ peft_model_loaded1 = PeftMixedModel.from_pretrained(
+ base_model, os.path.join(tmp_dirname, "adapter1", "adapter1"), "adapter1"
+ )
+ output_loaded1 = peft_model_loaded1(input)
+ assert torch.allclose(output_config1, output_loaded1, atol=atol, rtol=rtol)
+
+ # adapter 0 + 1
+ base_model = self._get_model(model_cls)
+ torch.manual_seed(97531) # setting a completely different seed here should not affect the result
+ peft_model_loaded_01 = PeftMixedModel.from_pretrained(
+ base_model, os.path.join(tmp_dirname, "adapter0", "adapter0"), "adapter0"
+ )
+ peft_model_loaded_01.load_adapter(os.path.join(tmp_dirname, "adapter1", "adapter1"), "adapter1")
+ # at this point, "adapter0" should still be active
+ assert peft_model_loaded_01.active_adapters == ["adapter0"]
+ output_loaded01_0 = peft_model_loaded_01(input)
+ assert torch.allclose(output_config0, output_loaded01_0, atol=atol, rtol=rtol)
+ # activate adapter1
+ peft_model_loaded_01.set_adapter(["adapter1"])
+ assert peft_model_loaded_01.active_adapters == ["adapter1"]
+ output_loaded01_1 = peft_model_loaded_01(input)
+ assert torch.allclose(output_config1, output_loaded01_1, atol=atol, rtol=rtol)
+ # activate both adapters
+ peft_model_loaded_01.set_adapter(["adapter0", "adapter1"])
+ output_loaded01 = peft_model_loaded_01(input)
+ assert torch.allclose(output_mixed_01, output_loaded01, atol=atol, rtol=rtol)
+
+ # adapter 1 + 0
+ base_model = self._get_model(model_cls)
+ torch.manual_seed(445566) # setting a completely different seed here should not affect the result
+ peft_model_loaded_10 = PeftMixedModel.from_pretrained(
+ base_model, os.path.join(tmp_dirname, "adapter1", "adapter1"), "adapter1"
+ )
+ peft_model_loaded_10.load_adapter(os.path.join(tmp_dirname, "adapter0", "adapter0"), "adapter0")
+ # at this point, "adapter1" should still be active
+ assert peft_model_loaded_10.active_adapters == ["adapter1"]
+ output_loaded10_1 = peft_model_loaded_10(input)
+ assert torch.allclose(output_config1, output_loaded10_1, atol=atol, rtol=rtol)
+ # activate adapter1
+ peft_model_loaded_10.set_adapter(["adapter0"])
+ assert peft_model_loaded_10.active_adapters == ["adapter0"]
+ output_loaded10_0 = peft_model_loaded_10(input)
+ assert torch.allclose(output_config0, output_loaded10_0, atol=atol, rtol=rtol)
+ # activate both adapters
+ peft_model_loaded_10.set_adapter(["adapter1", "adapter0"])
+ output_loaded10 = peft_model_loaded_10(input)
+ assert torch.allclose(output_mixed_10, output_loaded10, atol=atol, rtol=rtol)
+
+ if is_commutative:
+ assert torch.allclose(output_loaded01, output_loaded10, atol=atol, rtol=rtol)
+ assert torch.allclose(output_loaded10, output_mixed_01, atol=atol, rtol=rtol)
+
+ @parameterized.expand(
+ itertools.combinations(
+ [
+ LoraConfig(target_modules=["lin0"], init_lora_weights=False),
+ LoHaConfig(target_modules=["lin0"], init_weights=False),
+ LoKrConfig(target_modules=["lin0"], init_weights=False),
+ AdaLoraConfig(target_modules=["lin0"], init_lora_weights=False, total_step=1),
+ ],
+ r=2,
+ ),
+ name_func=_param_name_func,
+ )
+ def test_target_first_layer(self, config0, config1):
+ input = torch.arange(90).reshape(9, 10).to(self.torch_device)
+ self._check_mixed_outputs(SimpleNet, config0, config1, input, is_commutative=False)
+ self._check_merging(SimpleNet, config0, config1, input)
+ self._check_unload(SimpleNet, config0, config1, input)
+ self._check_disable(SimpleNet, config1, config0, input)
+ self._check_loading(SimpleNet, config0, config1, input, is_commutative=False)
+
+ @parameterized.expand(
+ itertools.combinations(
+ [
+ LoraConfig(target_modules=["lin1"], init_lora_weights=False),
+ LoHaConfig(target_modules=["lin1"], init_weights=False),
+ LoKrConfig(target_modules=["lin1"], init_weights=False),
+ AdaLoraConfig(target_modules=["lin1"], init_lora_weights=False, total_step=1),
+ ],
+ r=2,
+ ),
+ name_func=_param_name_func,
+ )
+ def test_target_last_layer(self, config0, config1):
+ # We are targeting the last layer of the SimpleNet. Therefore, since the adapters only add their activations
+ # to the output, the results should be commutative. This would *not* work if the adapters do something more
+ # complex or if we target an earlier layer, because of the non-linearity would destroy the commutativity.
+ input = torch.arange(90).reshape(9, 10).to(self.torch_device)
+
+ self._check_mixed_outputs(SimpleNet, config0, config1, input, is_commutative=True)
+ self._check_merging(SimpleNet, config0, config1, input)
+ self._check_unload(SimpleNet, config0, config1, input)
+ self._check_disable(SimpleNet, config1, config0, input)
+ self._check_loading(SimpleNet, config0, config1, input, is_commutative=True)
+
+ @parameterized.expand(
+ itertools.combinations(
+ [
+ LoraConfig(init_lora_weights=False),
+ LoHaConfig(init_weights=False),
+ LoKrConfig(init_weights=False),
+ AdaLoraConfig(init_lora_weights=False, total_step=1),
+ ],
+ r=2,
+ ),
+ name_func=_param_name_func,
+ )
+ def test_target_different_layers(self, config0, config1):
+ input = torch.arange(90).reshape(9, 10).to(self.torch_device)
+
+ config0.target_modules = ["lin0"]
+ config1.target_modules = ["lin1"]
+ self._check_mixed_outputs(SimpleNet, config0, config1, input, is_commutative=False)
+ self._check_merging(SimpleNet, config0, config1, input)
+ self._check_unload(SimpleNet, config0, config1, input)
+ self._check_disable(SimpleNet, config0, config1, input)
+ self._check_loading(SimpleNet, config0, config1, input, is_commutative=False)
+
+ # same, but switch target_modules around
+ config0.target_modules = ["lin1"]
+ config1.target_modules = ["lin0"]
+ self._check_mixed_outputs(SimpleNet, config1, config0, input, is_commutative=False)
+ self._check_merging(SimpleNet, config1, config0, input)
+ self._check_unload(SimpleNet, config1, config0, input)
+ self._check_disable(SimpleNet, config1, config0, input)
+ self._check_loading(SimpleNet, config1, config0, input, is_commutative=False)
+
+ @parameterized.expand(
+ [
+ (
+ LoraConfig(target_modules=["lin1"], init_lora_weights=False),
+ LoraConfig(target_modules=["lin1"], init_lora_weights=False),
+ ),
+ (
+ LoHaConfig(target_modules=["lin1"], init_weights=False),
+ LoHaConfig(target_modules=["lin1"], init_weights=False),
+ ),
+ (
+ LoKrConfig(target_modules=["lin1"], init_weights=False),
+ LoKrConfig(target_modules=["lin1"], init_weights=False),
+ ),
+ (
+ AdaLoraConfig(target_modules=["lin1"], init_lora_weights=False, total_step=1),
+ AdaLoraConfig(target_modules=["lin1"], init_lora_weights=False, total_step=1),
+ ),
+ ],
+ name_func=_param_name_func,
+ )
+ def test_target_last_layer_same_type(self, config0, config1):
+ input = torch.arange(90).reshape(9, 10).to(self.torch_device)
+
+ self._check_mixed_outputs(SimpleNet, config0, config1, input, is_commutative=True)
+ self._check_merging(SimpleNet, config0, config1, input)
+ self._check_unload(SimpleNet, config0, config1, input)
+ self._check_disable(SimpleNet, config1, config0, input)
+
+ @parameterized.expand(
+ [
+ (
+ LoraConfig(target_modules=["lin0"], init_lora_weights=False),
+ LoraConfig(target_modules=["lin0"], init_lora_weights=False),
+ ),
+ (
+ LoHaConfig(target_modules=["lin0"], init_weights=False),
+ LoHaConfig(target_modules=["lin0"], init_weights=False),
+ ),
+ (
+ LoKrConfig(target_modules=["lin0"], init_weights=False),
+ LoKrConfig(target_modules=["lin0"], init_weights=False),
+ ),
+ (
+ AdaLoraConfig(target_modules=["lin0"], init_lora_weights=False, total_step=1),
+ AdaLoraConfig(target_modules=["lin0"], init_lora_weights=False, total_step=1),
+ ),
+ ],
+ name_func=_param_name_func,
+ )
+ def test_target_first_layer_same_type(self, config0, config1):
+ input = torch.arange(90).reshape(9, 10).to(self.torch_device)
+ self._check_mixed_outputs(SimpleNet, config0, config1, input, is_commutative=False)
+ self._check_merging(SimpleNet, config0, config1, input)
+ self._check_unload(SimpleNet, config0, config1, input)
+ self._check_disable(SimpleNet, config1, config0, input)
+ self._check_loading(SimpleNet, config0, config1, input, is_commutative=False)
+
+ def test_deeply_nested(self):
+ # a somewhat absurdly nested model using different adapter types
+ if platform.system() == "Linux":
+ self.skipTest("This test fails but only on GitHub CI with Linux systems.")
+
+ atol = 1e-5
+ rtol = 1e-5
+ torch.manual_seed(0)
+
+ model = SimpleNet().eval().to(self.torch_device)
+ input = torch.arange(90).reshape(9, 10).to(self.torch_device)
+ output_base = model(input)
+
+ config0 = LoraConfig(r=4, lora_alpha=4, target_modules=["lin0", "lin1"], init_lora_weights=False)
+ peft_model = get_peft_model(model, config0, "adapter0", mixed=True)
+
+ config1 = LoHaConfig(r=4, alpha=4, target_modules=["lin0"], init_weights=False)
+ peft_model.add_adapter("adapter1", config1)
+
+ config2 = AdaLoraConfig(r=4, lora_alpha=4, target_modules=["lin1"], init_lora_weights=False, total_step=1)
+ peft_model.add_adapter("adapter2", config2)
+
+ config3 = LoKrConfig(r=4, alpha=4, target_modules=["lin0", "lin1"], init_weights=False)
+ peft_model.add_adapter("adapter3", config3)
+
+ peft_model.set_adapter(["adapter0", "adapter1", "adapter2", "adapter3"])
+ output_mixed = peft_model(input)
+ assert torch.isfinite(output_base).all()
+ assert not torch.allclose(output_base, output_mixed, atol=atol, rtol=rtol)
+
+ # test disabling all adapters
+ with peft_model.disable_adapter():
+ output_disabled = peft_model(input)
+ assert torch.isfinite(output_disabled).all()
+ assert torch.allclose(output_base, output_disabled, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_mixed, output_disabled, atol=atol, rtol=rtol)
+
+ # merge and unload all adapters
+ model_copy = copy.deepcopy(peft_model)
+ model = model_copy.merge_and_unload()
+ output_merged = model(input)
+ assert torch.isfinite(output_merged).all()
+ assert torch.allclose(output_mixed, output_merged, atol=atol, rtol=rtol)
+
+ # merge and unload only adapter1 and adapter3
+ model_copy = copy.deepcopy(peft_model)
+ model_copy.set_adapter(["adapter1", "adapter3"])
+ output_13 = model_copy(input)
+ assert torch.isfinite(output_13).all()
+ assert not torch.allclose(output_mixed, output_13, atol=atol, rtol=rtol)
+
+ model_copy.set_adapter(["adapter0", "adapter1", "adapter2", "adapter3"])
+ model_merged_unloaded = model_copy.merge_and_unload(adapter_names=["adapter1", "adapter3"])
+ output_merged_13 = model_merged_unloaded(input)
+ assert torch.isfinite(output_merged_13).all()
+ assert torch.allclose(output_13, output_merged_13, atol=atol, rtol=rtol)
+
+ # test unloading
+ model_copy = copy.deepcopy(peft_model)
+ model_unloaded = model_copy.unload()
+ output_unloaded = model_unloaded(input)
+ assert torch.isfinite(output_unloaded).all()
+ assert torch.allclose(output_base, output_unloaded, atol=atol, rtol=rtol)
+
+ def test_delete_adapter(self):
+ atol = 1e-5
+ rtol = 1e-5
+ torch.manual_seed(0)
+
+ model = SimpleNet().eval().to(self.torch_device)
+ input = torch.arange(90).reshape(9, 10).to(self.torch_device)
+ output_base = model(input)
+
+ # create adapter0
+ torch.manual_seed(0)
+ config0 = LoraConfig(r=4, lora_alpha=4, target_modules=["lin0", "lin1"], init_lora_weights=False)
+ peft_model = get_peft_model(model, config0, "adapter0", mixed=True)
+ output_0 = peft_model(input)
+ assert not torch.allclose(output_base, output_0, atol=atol, rtol=rtol)
+
+ # add adapter1
+ torch.manual_seed(1)
+ config1 = LoHaConfig(r=4, alpha=4, target_modules=["lin0"], init_weights=False)
+ peft_model.add_adapter("adapter1", config1)
+ peft_model.set_adapter(["adapter0", "adapter1"])
+ output_01 = peft_model(input)
+ assert not torch.allclose(output_base, output_01, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_0, output_01, atol=atol, rtol=rtol)
+
+ # delete adapter1
+ peft_model.delete_adapter("adapter1")
+ assert peft_model.active_adapters == ["adapter0"]
+ output_deleted_1 = peft_model(input)
+ assert torch.allclose(output_0, output_deleted_1, atol=atol, rtol=rtol)
+
+ msg = re.escape("Adapter(s) ['adapter1'] not found, available adapters: ['adapter0']")
+ with pytest.raises(ValueError, match=msg):
+ peft_model.set_adapter(["adapter0", "adapter1"])
+
+ # re-add adapter1
+ torch.manual_seed(1)
+ peft_model.add_adapter("adapter1", config1)
+ peft_model.set_adapter(["adapter0", "adapter1"])
+ output_01_readded = peft_model(input)
+ assert not torch.allclose(output_base, output_01_readded, atol=atol, rtol=rtol)
+
+ # same as above, but this time delete adapter0 first
+ torch.manual_seed(0)
+ model = SimpleNet().eval().to(self.torch_device)
+ torch.manual_seed(0)
+ peft_model = get_peft_model(model, config0, "adapter0", mixed=True)
+ torch.manual_seed(1)
+ peft_model.add_adapter("adapter1", config1)
+ peft_model.delete_adapter("adapter0")
+ assert peft_model.active_adapters == ["adapter1"]
+ output_deleted_0 = peft_model(input)
+ assert not torch.allclose(output_deleted_0, output_base, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_deleted_0, output_01, atol=atol, rtol=rtol)
+
+ msg = re.escape("Adapter(s) ['adapter0'] not found, available adapters: ['adapter1']")
+ with pytest.raises(ValueError, match=msg):
+ peft_model.set_adapter(["adapter0", "adapter1"])
+
+ peft_model.delete_adapter("adapter1")
+ assert peft_model.active_adapters == []
+ output_deleted_01 = peft_model(input)
+ assert torch.allclose(output_deleted_01, output_base, atol=atol, rtol=rtol)
+
+ def test_modules_to_save(self):
+ model = SimpleNet().eval().to(self.torch_device)
+ config0 = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ peft_model = get_peft_model(model, config0, "adapter0", mixed=True)
+
+ # adding a second adapter with same modules_to_save is not allowed
+ # TODO: theoretically, we could allow this if it's the same target layer
+ config1 = LoHaConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ peft_model.add_adapter("adapter1", config1)
+ with pytest.raises(ValueError, match="Only one adapter can be set at a time for modules_to_save"):
+ peft_model.set_adapter(["adapter0", "adapter1"])
+
+ def test_get_nb_trainable_parameters(self):
+ model = SimpleNet().eval().to(self.torch_device)
+ params_base = sum(p.numel() for p in model.parameters())
+
+ config0 = LoraConfig(target_modules=["lin0"])
+ peft_model = get_peft_model(model, config0, "adapter0", mixed=True)
+ trainable_params0, all_param0 = peft_model.get_nb_trainable_parameters()
+
+ params_lora = sum(p.numel() for n, p in model.named_parameters() if "adapter0" in n)
+ assert trainable_params0 == params_lora
+ assert all_param0 == (params_base + params_lora)
+
+ config1 = LoHaConfig(target_modules=["lin1"])
+ peft_model.add_adapter("adapter1", config1)
+ peft_model.set_adapter(["adapter0", "adapter1"])
+ params_loha = sum(p.numel() for n, p in model.named_parameters() if "adapter1" in n)
+ trainable_params1, all_param1 = peft_model.get_nb_trainable_parameters()
+ assert trainable_params1 == (params_lora + params_loha)
+ assert all_param1 == ((params_base + params_lora) + params_loha)
+
+ config2 = AdaLoraConfig(target_modules=["lin0", "lin1"], total_step=1)
+ peft_model.add_adapter("adapter2", config2)
+ peft_model.set_adapter(["adapter0", "adapter1", "adapter2"])
+ params_adalora = sum(p.numel() for n, p in model.named_parameters() if "adapter2" in n)
+ trainable_params2, all_param2 = peft_model.get_nb_trainable_parameters()
+ # remove 2 params because we need to exclude "ranknum" for AdaLora trainable params
+ assert trainable_params2 == (((params_lora + params_loha) + params_adalora) - 2)
+ assert all_param2 == (((params_base + params_lora) + params_loha) + params_adalora)
+
+ def test_incompatible_config_raises(self):
+ model = SimpleNet().eval().to(self.torch_device)
+ config0 = LoraConfig(target_modules=["lin0"])
+ peft_model = get_peft_model(model, config0, "adapter0", mixed=True)
+
+ config1 = PrefixTuningConfig()
+ msg = "The provided `peft_type` 'PREFIX_TUNING' is not compatible with the `PeftMixedModel`."
+ with pytest.raises(ValueError, match=msg):
+ peft_model.add_adapter("adapter1", config1)
+
+ def test_decoder_model(self):
+ # test a somewhat realistic model instead of a toy model
+ torch.manual_seed(0)
+
+ model_id = "hf-internal-testing/tiny-random-OPTForCausalLM"
+ model = AutoModelForCausalLM.from_pretrained(model_id).eval().to(self.torch_device)
+ input_ids = torch.tensor([[1, 1, 1], [1, 2, 1]]).to(self.torch_device)
+ attention_mask = torch.tensor([[1, 1, 1], [1, 0, 1]]).to(self.torch_device)
+ input_dict = {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ }
+ output_base = model.generate(**input_dict)
+
+ torch.manual_seed(0)
+ config0 = LoraConfig(task_type="CAUSAL_LM", init_lora_weights=False)
+ peft_model = get_peft_model(model, config0, "adapter0", mixed=True)
+ output0 = peft_model.generate(**input_dict)
+ assert torch.isfinite(output0).all()
+ assert not torch.allclose(output_base, output0)
+
+ torch.manual_seed(1)
+ config1 = LoHaConfig(task_type="CAUSAL_LM", target_modules=["q_proj", "v_proj"], init_weights=False)
+ peft_model.add_adapter("adapter1", config1)
+ peft_model.set_adapter(["adapter0", "adapter1"])
+ output1 = peft_model.generate(**input_dict)
+ assert torch.isfinite(output1).all()
+ assert not torch.allclose(output0, output1)
+
+ torch.manual_seed(2)
+ config2 = AdaLoraConfig(task_type="CAUSAL_LM", init_lora_weights=False, total_step=1)
+ peft_model.add_adapter("adapter2", config2)
+ peft_model.set_adapter(["adapter0", "adapter1", "adapter2"])
+ output2 = peft_model.generate(**input_dict)
+ assert torch.isfinite(output2).all()
+ assert not torch.allclose(output1, output2)
+
+ torch.manual_seed(3)
+ config3 = LoKrConfig(task_type="CAUSAL_LM", target_modules=["q_proj", "v_proj"], init_weights=False)
+ peft_model.add_adapter("adapter3", config3)
+ peft_model.set_adapter(["adapter0", "adapter1", "adapter2", "adapter3"])
+ output3 = peft_model.generate(**input_dict)
+ assert torch.isfinite(output3).all()
+ assert not torch.allclose(output2, output3)
+
+ torch.manual_seed(4)
+ peft_model.set_adapter(["adapter0", "adapter1", "adapter2", "adapter3"])
+
+ with peft_model.disable_adapter():
+ output_disabled = peft_model.generate(**input_dict)
+ assert torch.isfinite(output_disabled).all()
+ assert torch.allclose(output_base, output_disabled)
+
+ model_unloaded = peft_model.merge_and_unload()
+ output_unloaded = model_unloaded.generate(**input_dict)
+ assert torch.isfinite(output_unloaded).all()
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ # save adapter0 (use normal PeftModel, because PeftMixedModel does not support saving)
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(model_id).eval().to(self.torch_device)
+ torch.manual_seed(0)
+ peft_model = get_peft_model(model, config0, "adapter0")
+ output0_save = peft_model(**input_dict).logits
+ assert torch.isfinite(output0_save).all()
+ peft_model.save_pretrained(tmp_dir)
+
+ # save adapter1
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(model_id).eval().to(self.torch_device)
+ torch.manual_seed(1)
+ peft_model = get_peft_model(model, config1, "adapter1")
+ output1_save = peft_model(**input_dict).logits
+ assert torch.isfinite(output1_save).all()
+ peft_model.save_pretrained(tmp_dir)
+
+ # load adapter0 and adapter1
+ model = AutoModelForCausalLM.from_pretrained(model_id).eval().to(self.torch_device)
+ peft_model = PeftMixedModel.from_pretrained(model, os.path.join(tmp_dir, "adapter0"), "adapter0")
+ peft_model.load_adapter(os.path.join(tmp_dir, "adapter1"), "adapter1")
+ peft_model.set_adapter(["adapter0", "adapter1"])
+ output01_loaded = peft_model(**input_dict).logits
+
+ atol, rtol = 1e-3, 1e-3
+ assert torch.isfinite(output01_loaded).all()
+ assert not torch.allclose(output0_save, output01_loaded, atol=atol, rtol=rtol)
+ assert not torch.allclose(output1_save, output01_loaded, atol=atol, rtol=rtol)
diff --git a/peft/tests/test_multitask_prompt_tuning.py b/peft/tests/test_multitask_prompt_tuning.py
new file mode 100644
index 0000000000000000000000000000000000000000..94a9e213834407670a3916ca4710ce0cb0f15994
--- /dev/null
+++ b/peft/tests/test_multitask_prompt_tuning.py
@@ -0,0 +1,288 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import tempfile
+
+import pytest
+import torch
+from torch.testing import assert_close
+from transformers import AutoModelForCausalLM
+
+from peft import get_peft_model
+from peft.peft_model import PeftModel
+from peft.tuners.multitask_prompt_tuning import MultitaskPromptTuningConfig, MultitaskPromptTuningInit
+from peft.utils import infer_device
+from peft.utils.other import WEIGHTS_NAME, prepare_model_for_kbit_training
+from peft.utils.save_and_load import get_peft_model_state_dict
+
+
+MODELS_TO_TEST = [
+ "trl-internal-testing/tiny-random-LlamaForCausalLM",
+]
+
+
+class TestMultiTaskPromptTuning:
+ """
+ Tests for the MultiTaskPromptTuning model.
+ """
+
+ @pytest.fixture
+ def config(cls) -> MultitaskPromptTuningConfig:
+ return MultitaskPromptTuningConfig(
+ task_type="CAUSAL_LM",
+ num_virtual_tokens=50,
+ num_tasks=3,
+ prompt_tuning_init_text=(
+ "classify the following into either positive or negative, or entailment, neutral or contradiction:"
+ ),
+ )
+
+ transformers_class = AutoModelForCausalLM
+ torch_device = infer_device()
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_prepare_for_training(self, model_id, config):
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ dummy_input = torch.LongTensor([[1, 1, 1]]).to(self.torch_device)
+ dummy_output = model.get_input_embeddings()(dummy_input)
+
+ assert not dummy_output.requires_grad
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_prepare_for_int8_training(self, model_id, config):
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ model = prepare_model_for_kbit_training(model)
+ model = model.to(self.torch_device)
+
+ for param in model.parameters():
+ assert not param.requires_grad
+
+ model = get_peft_model(model, config)
+
+ # For backward compatibility
+ if hasattr(model, "enable_input_require_grads"):
+ model.enable_input_require_grads()
+ else:
+
+ def make_inputs_require_grad(module, input, output):
+ output.requires_grad_(True)
+
+ model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
+
+ dummy_input = torch.LongTensor([[1, 1, 1]]).to(self.torch_device)
+ dummy_output = model.get_input_embeddings()(dummy_input)
+
+ assert dummy_output.requires_grad
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_save_pretrained(self, model_id, config):
+ seed = 420
+ torch.manual_seed(seed)
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname)
+
+ torch.manual_seed(seed)
+ model_from_pretrained = AutoModelForCausalLM.from_pretrained(model_id)
+ model_from_pretrained = PeftModel.from_pretrained(model_from_pretrained, tmp_dirname)
+
+ # check if the state dicts are equal
+ state_dict = get_peft_model_state_dict(model)
+
+ state_dict_from_pretrained = get_peft_model_state_dict(model_from_pretrained)
+
+ # check if same keys
+ assert state_dict.keys() == state_dict_from_pretrained.keys()
+
+ # Check that the number of saved parameters is 4 -- 2 layers of (tokens and gate).
+ assert len(state_dict) == 3
+
+ # check if tensors equal
+ for key in state_dict.keys():
+ assert torch.allclose(
+ state_dict[key].to(self.torch_device), state_dict_from_pretrained[key].to(self.torch_device)
+ )
+
+ # check if `adapter_model.safetensors` is present
+ assert os.path.exists(os.path.join(tmp_dirname, "adapter_model.safetensors"))
+
+ # check if `adapter_config.json` is present
+ assert os.path.exists(os.path.join(tmp_dirname, "adapter_config.json"))
+
+ # check if `pytorch_model.bin` is not present
+ assert not os.path.exists(os.path.join(tmp_dirname, "pytorch_model.bin"))
+
+ # check if `config.json` is not present
+ assert not os.path.exists(os.path.join(tmp_dirname, "config.json"))
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_save_pretrained_regression(self, model_id, config):
+ seed = 420
+ torch.manual_seed(seed)
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname, safe_serialization=False)
+
+ torch.manual_seed(seed)
+ model_from_pretrained = AutoModelForCausalLM.from_pretrained(model_id)
+ model_from_pretrained = PeftModel.from_pretrained(model_from_pretrained, tmp_dirname)
+
+ # check if the state dicts are equal
+ state_dict = get_peft_model_state_dict(model)
+
+ state_dict_from_pretrained = get_peft_model_state_dict(model_from_pretrained)
+
+ # check if same keys
+ assert state_dict.keys() == state_dict_from_pretrained.keys()
+
+ # Check that the number of saved parameters is 4 -- 2 layers of (tokens and gate).
+ assert len(state_dict) == 3
+
+ # check if tensors equal
+ for key in state_dict.keys():
+ assert torch.allclose(
+ state_dict[key].to(self.torch_device), state_dict_from_pretrained[key].to(self.torch_device)
+ )
+
+ # check if `adapter_model.bin` is present for regression
+ assert os.path.exists(os.path.join(tmp_dirname, "adapter_model.bin"))
+
+ # check if `adapter_config.json` is present
+ assert os.path.exists(os.path.join(tmp_dirname, "adapter_config.json"))
+
+ # check if `pytorch_model.bin` is not present
+ assert not os.path.exists(os.path.join(tmp_dirname, "pytorch_model.bin"))
+
+ # check if `config.json` is not present
+ assert not os.path.exists(os.path.join(tmp_dirname, "config.json"))
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_generate(self, model_id, config):
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ input_ids = torch.LongTensor([[1, 1, 1], [2, 1, 2]]).to(self.torch_device)
+ attention_mask = torch.LongTensor([[1, 1, 1], [1, 0, 1]]).to(self.torch_device)
+ task_ids = torch.LongTensor([1, 2]).to(self.torch_device)
+
+ # check if `generate` works
+ _ = model.generate(input_ids=input_ids, attention_mask=attention_mask, task_ids=task_ids)
+
+ # check if `generate` works if positional arguments are passed
+ _ = model.generate(input_ids, attention_mask=attention_mask, task_ids=task_ids)
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_use_cache(self, model_id, config):
+ """Test that MultiTaskPromptTuning works when Llama config use_cache=True."""
+ torch.manual_seed(0)
+ input_ids = torch.LongTensor([[1, 1, 1], [2, 1, 2]]).to(self.torch_device)
+ task_ids = torch.LongTensor([1, 2]).to(self.torch_device)
+
+ original = AutoModelForCausalLM.from_pretrained(model_id)
+ mpt = get_peft_model(original, config)
+ mpt = mpt.to(self.torch_device)
+
+ expected = mpt.generate(input_ids=input_ids, max_length=8, task_ids=task_ids)
+
+ # Set use_cache = True and generate output again.
+ mpt.base_model.config.use_cache = True
+ actual = mpt.generate(input_ids=input_ids, max_length=8, task_ids=task_ids)
+ assert_close(expected, actual, rtol=0, atol=0)
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_bf16_inference(self, model_id, config):
+ """Test that MultiTaskPromptTuning works when Llama using a half-precision model."""
+ input_ids = torch.LongTensor([[1, 1, 1], [2, 1, 2]]).to(self.torch_device)
+ task_ids = torch.tensor([1, 2]).to(self.torch_device)
+
+ original = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16)
+ mpt = get_peft_model(original, config)
+ mpt = mpt.to(self.torch_device)
+ _ = mpt.generate(input_ids=input_ids, task_ids=task_ids)
+
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_generate_text_with_random_init(self, model_id, config) -> None:
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ config.prompt_tuning_init = MultitaskPromptTuningInit.RANDOM
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ input_ids = torch.LongTensor([[1, 1, 1], [2, 1, 2]]).to(self.torch_device)
+ attention_mask = torch.LongTensor([[1, 1, 1], [1, 0, 1]]).to(self.torch_device)
+ task_ids = torch.LongTensor([0]).to(self.torch_device)
+
+ # check if `generate` works
+ _ = model.generate(input_ids=input_ids, attention_mask=attention_mask, task_ids=task_ids)
+
+ with pytest.raises(ValueError):
+ # check if `generate` raises an error if task_ids are not passed
+ _ = model.generate(input_ids, attention_mask=attention_mask)
+
+ @pytest.mark.parametrize(
+ "prompt_tuning_init",
+ [
+ MultitaskPromptTuningInit.AVERAGE_SOURCE_TASKS,
+ MultitaskPromptTuningInit.EXACT_SOURCE_TASK,
+ MultitaskPromptTuningInit.ONLY_SOURCE_SHARED,
+ ],
+ )
+ @pytest.mark.parametrize("model_id", MODELS_TO_TEST)
+ def test_generate_text_with_other_init(self, prompt_tuning_init, model_id, config) -> None:
+ # This test is flaky, hence fixing the seed. The reason is somehow related to:
+ # https://github.com/huggingface/transformers/blob/e786844425b6b1112c76513d66217ce2fe6aea41/src/transformers/generation/utils.py#L2691
+ # When an EOS token is generated, the loop is exited and the pytest.raises at the bottom is not triggered
+ # because `forward` of the PEFT model, which should raise the error, is never called.
+ torch.manual_seed(42) # seed 43 fails with transformers v4.42.3 and torch v2.3.1
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ model = get_peft_model(model, config)
+ model.save_pretrained(tmp_dirname, safe_serialization=False) # bc torch.load is used
+
+ config = MultitaskPromptTuningConfig(
+ task_type="CAUSAL_LM",
+ num_virtual_tokens=50,
+ num_tasks=1,
+ prompt_tuning_init_text=(
+ "classify the following into either positive or negative, or entailment, neutral or contradiction:"
+ ),
+ prompt_tuning_init=prompt_tuning_init,
+ prompt_tuning_init_state_dict_path=os.path.join(tmp_dirname, WEIGHTS_NAME),
+ )
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ input_ids = torch.LongTensor([[1, 1, 1], [2, 1, 2]]).to(self.torch_device)
+ attention_mask = torch.LongTensor([[1, 1, 1], [1, 0, 1]]).to(self.torch_device)
+ task_ids = torch.LongTensor([0]).to(self.torch_device)
+
+ # check if `generate` works
+ _ = model.generate(input_ids=input_ids, attention_mask=attention_mask, task_ids=task_ids)
+
+ with pytest.raises(ValueError, match="task_ids cannot be None"):
+ # check if `generate` raises an error if task_ids are not passed
+ _ = model.generate(input_ids, attention_mask=attention_mask)
diff --git a/peft/tests/test_other.py b/peft/tests/test_other.py
new file mode 100644
index 0000000000000000000000000000000000000000..7a0ca34589bc44ff65c296e48a75ca8590355b9c
--- /dev/null
+++ b/peft/tests/test_other.py
@@ -0,0 +1,532 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import copy
+
+import pytest
+import torch
+from torch import nn
+from transformers import AutoModelForCausalLM, AutoModelForSequenceClassification, LlavaForConditionalGeneration
+
+from peft import LoraConfig, PeftModel, VeraConfig, get_peft_model
+from peft.utils.other import ModulesToSaveWrapper, _get_no_split_modules
+
+
+class ModelWithModuleDict(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.other_layer = nn.Linear(10, 10)
+ self.module = nn.ModuleDict({"foo": nn.Linear(10, 10)})
+
+ def forward(self):
+ return self.module["foo"](torch.rand(1, 10))
+
+
+class ModelWithModuleList(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.other_layer = nn.Linear(10, 10)
+ self.module = nn.ModuleList([nn.Linear(10, 10)])
+
+ def forward(self):
+ return self.module[0](torch.rand(1, 10))
+
+
+class ModelWithParameterDict(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.other_layer = nn.Linear(10, 10)
+ self.module = nn.ParameterDict({"foo": nn.Parameter(torch.rand(10, 10))})
+
+ def forward(self):
+ return self.module["foo"]
+
+
+class ModelWithParameterList(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.other_layer = nn.Linear(10, 10)
+ self.module = nn.ParameterList([nn.Parameter(torch.rand(10, 10))])
+
+ def forward(self):
+ return self.module[0]
+
+
+@pytest.mark.parametrize(
+ "cls", [ModelWithModuleDict, ModelWithModuleList, ModelWithParameterDict, ModelWithParameterList]
+)
+def test_modules_to_save_targets_module_dict_raises(cls):
+ model = cls()
+ peft_config = LoraConfig(
+ target_modules=["other_layer"],
+ modules_to_save=["module"],
+ )
+ model() # sanity check that the model would normally work
+
+ msg = "modules_to_save cannot be applied to modules of type"
+ with pytest.raises(TypeError, match=msg):
+ get_peft_model(model=model, peft_config=peft_config)
+
+
+def test_get_peft_model_revision_warning(tmp_path):
+ base_model_id = "peft-internal-testing/tiny-random-BertModel"
+ base_revision = "v2.0.0"
+ base_model = AutoModelForCausalLM.from_pretrained(base_model_id, revision=base_revision).eval()
+ lora_config = LoraConfig(revision=base_revision)
+
+ overwrite_revision = "main"
+ overwrite_warning = f"peft config has already set base model revision to {base_revision}, overwriting with revision {overwrite_revision}"
+ with pytest.warns(UserWarning, match=overwrite_warning):
+ _ = get_peft_model(base_model, lora_config, revision=overwrite_revision)
+
+
+def test_load_multiple_adapters_different_modules_to_save(tmp_path):
+ # This tests the error described in #2422 where loading multiple adapters with different modules_to_save
+ # attributes fails (due to a regression from #2376).
+
+ model = AutoModelForCausalLM.from_pretrained("trl-internal-testing/tiny-random-LlamaForCausalLM")
+
+ def peft_config(**kwargs):
+ return LoraConfig(target_modules="all-linear", **kwargs)
+
+ original_model = copy.deepcopy(model)
+
+ peft_config_0 = peft_config(modules_to_save=["0.post_attention_layernorm"])
+ peft_config_1 = peft_config(modules_to_save=["0.post_attention_layernorm"])
+ peft_config_2 = peft_config(modules_to_save=["1.post_attention_layernorm"])
+
+ # Save adapter 0, nothing fancy, should be equal to base model weighs
+ peft_model = get_peft_model(copy.deepcopy(original_model), peft_config_0)
+ peft_model.save_pretrained(tmp_path / "adapter_0")
+
+ # Save adapter 1, modules to save weights are modified randomly, should be unique to adapter 1
+ peft_model = get_peft_model(copy.deepcopy(original_model), peft_config_1)
+ peft_model.model.model.layers[0].post_attention_layernorm.weight.data = torch.rand_like(
+ peft_model.model.model.layers[0].post_attention_layernorm.weight.data
+ )
+ adapter_1_saved = peft_model.model.model.layers[0].post_attention_layernorm.weight.data.clone()
+ peft_model.save_pretrained(tmp_path / "adapter_1")
+
+ # Save adapter 2, modules to save weights are modified randomly, should be unique to adapter 2
+ peft_model = get_peft_model(copy.deepcopy(original_model), peft_config_2)
+ peft_model.model.model.layers[1].post_attention_layernorm.weight.data = torch.rand_like(
+ peft_model.model.model.layers[1].post_attention_layernorm.weight.data
+ )
+ adapter_2_saved = peft_model.model.model.layers[1].post_attention_layernorm.weight.data.clone()
+ peft_model.save_pretrained(tmp_path / "adapter_2")
+
+ del peft_model
+
+ combined_model = PeftModel.from_pretrained(original_model, tmp_path / "adapter_0", adapter_name="adapter_0")
+ combined_model.load_adapter(tmp_path / "adapter_1", adapter_name="adapter_1")
+ combined_model.load_adapter(tmp_path / "adapter_2", adapter_name="adapter_2")
+
+ # For adapter 0 we expect every mentioned modules to save layer of this test to be equal to the original model
+ # since we didn't modify it for adapter 0 and only adapter 0 is active.
+ combined_model.set_adapter("adapter_0")
+ assert torch.allclose(
+ combined_model.model.model.layers[0].post_attention_layernorm.weight,
+ original_model.model.layers[0].post_attention_layernorm.weight,
+ )
+ assert torch.allclose(
+ combined_model.model.model.layers[1].post_attention_layernorm.weight,
+ original_model.model.layers[1].post_attention_layernorm.weight,
+ )
+
+ # For adapter 1 we expect that the modified module to save 0.post_attention_layernorm is modified, the other
+ # module to save layers mentioned above should be untouched.
+ combined_model.set_adapter("adapter_1")
+ assert torch.allclose(
+ combined_model.model.model.layers[0].post_attention_layernorm.weight,
+ adapter_1_saved,
+ )
+ assert torch.allclose(
+ combined_model.model.model.layers[1].post_attention_layernorm.weight,
+ original_model.model.layers[1].post_attention_layernorm.weight,
+ )
+
+ # For adapter 2 we expect its module to save layer (1.post_attention_layernorm) to be modified but the other
+ # module to save weights should be kept original.
+ combined_model.set_adapter("adapter_2")
+ assert torch.allclose(
+ combined_model.model.model.layers[0].post_attention_layernorm.weight,
+ original_model.model.layers[0].post_attention_layernorm.weight,
+ )
+ assert torch.allclose(
+ combined_model.model.model.layers[1].post_attention_layernorm.weight,
+ adapter_2_saved,
+ )
+
+
+class TestModulesToSaveAttributeAccess:
+ """Test attribute access on the ModulesToSaveWrapper class.
+
+ When we have modules_to_save, the original module is wrapped. As long as only forward was called on this wrapped
+ module, we were good. However, if, for instance, model parameters were directly accessed by another module, this
+ would typically fail, as the wrapper does not have this attribute. We had special properties for weight and bias,
+ but this is not enough. Therefore, attribute access is now transiently delegated to the active adapter (or original
+ module, if the adapter is disabled).
+
+ For one example, see #2099.
+
+ """
+
+ @pytest.fixture
+ def mlp(self):
+ class MLP(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.lin0 = nn.Linear(1, 2)
+ self.lin1 = nn.Linear(3, 4)
+
+ return MLP()
+
+ def test_transient_attribute_access_default_adapter(self, mlp):
+ config = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ model = get_peft_model(mlp, config)
+ assert model.lin1.weight is model.lin1.modules_to_save["default"].weight
+ assert model.lin1.bias is model.lin1.modules_to_save["default"].bias
+
+ def test_transient_attribute_access_non_default_adapter(self, mlp):
+ config = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ model = get_peft_model(mlp, config)
+ model.add_adapter("other", config)
+
+ # at this point, default is still active
+ assert model.lin1.weight is model.lin1.modules_to_save["default"].weight
+ assert model.lin1.bias is model.lin1.modules_to_save["default"].bias
+ assert model.lin1.weight is not model.lin1.modules_to_save["other"].weight
+ assert model.lin1.bias is not model.lin1.modules_to_save["other"].bias
+
+ model.set_adapter("other")
+ assert model.lin1.weight is not model.lin1.modules_to_save["default"].weight
+ assert model.lin1.bias is not model.lin1.modules_to_save["default"].bias
+ assert model.lin1.weight is model.lin1.modules_to_save["other"].weight
+ assert model.lin1.bias is model.lin1.modules_to_save["other"].bias
+
+ def test_transient_attribute_access_disabled_adapter(self, mlp):
+ config = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ model = get_peft_model(mlp, config)
+
+ # at this point, default is still active
+ assert model.lin1.weight is model.lin1.modules_to_save["default"].weight
+ assert model.lin1.bias is model.lin1.modules_to_save["default"].bias
+ assert model.lin1.weight is not model.lin1.original_module.weight
+ assert model.lin1.bias is not model.lin1.original_module.bias
+
+ with model.disable_adapter():
+ assert model.lin1.weight is not model.lin1.modules_to_save["default"].weight
+ assert model.lin1.bias is not model.lin1.modules_to_save["default"].bias
+ assert model.lin1.weight is model.lin1.original_module.weight
+ assert model.lin1.bias is model.lin1.original_module.bias
+
+ def test_transient_attribute_access_uninitialized_adapter(self, mlp):
+ # ensure that there is no weird infinite recursion when accessing a non-existing attribute on the class itself
+ with pytest.raises(AttributeError, match="has no attribute 'original_module'"):
+ ModulesToSaveWrapper.original_module
+
+ def test_transient_attribute_access_attr_does_not_exist_on_modules_to_save(self, mlp):
+ # ensure that there is no weird infinite recursion when accessing a non-existing attribute on the
+ # ModelToSaveWrapper instance
+ config = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ model = get_peft_model(mlp, config)
+
+ with pytest.raises(AttributeError, match="has no attribute 'foo'"):
+ model.lin1.foo
+
+ def test_transient_attribute_access_attr_does_not_exist_on_original_module(self, mlp):
+ # ensure that there is no weird infinite recursion when accessing a non-existing attribute on the
+ # original module of the ModelToSaveWrapper instance
+ config = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ model = get_peft_model(mlp, config)
+
+ with pytest.raises(AttributeError, match="has no attribute 'foo'"):
+ with model.disable_adapter():
+ model.lin1.foo
+
+ def test_transient_attribute_access_non_existing_adapter(self, mlp):
+ # This should normally never happen, as the active adapter should always exist, but it's a failsafe
+ config = LoraConfig(target_modules=["lin0"], modules_to_save=["lin1"])
+ model = get_peft_model(mlp, config)
+ model.base_model.model.lin1._active_adapter = "does-not-exist"
+ with pytest.raises(AttributeError, match="has no attribute 'weight'"):
+ model.lin1.weight
+
+
+class TestModulesToSaveNameSubstringBug:
+ """Test a bug that could occur with multiple modules to save where one adapter's name is a substring of another
+ adapter's name.
+
+ This bug was the result of an error in the logic of modifying the state_dict for modules_to_save in
+ set_peft_model_state_dict. The error in the logic was that it was checked if an entry from modules_to_save (a set
+ of strings) is a substring of a key of the state_dict. If it was, a new name was assigned to that key in the
+ state_dict, which would allow to load the weight later.
+
+ The issue that stems from the substring check occurs if there are multiple modules_to_save, and one of them has a
+ name that is a substring of another. So e.g. if one is named "classifier" and the other is named "classifier2",
+ there could be a false match.
+
+
+ This bug was reported in #2289.
+
+ """
+
+ def get_model(self):
+ class MyModule(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.lin = nn.Linear(5, 4)
+ # important: "classifier" is a substring of "classifier2", "classifier3", "classifier4"
+ self.classifier = nn.Linear(4, 2)
+ self.classifier2 = nn.Linear(4, 2)
+ self.classifier3 = nn.Linear(4, 2)
+ self.classifier4 = nn.Linear(4, 2)
+
+ def forward(self, x):
+ x = self.lin(x)
+ return self.classifier(x) + self.classifier2(x) + self.classifier3(x) + self.classifier4(x)
+
+ torch.manual_seed(0)
+ return MyModule()
+
+ @pytest.fixture
+ def path_merged_and_unmerged(self, tmp_path):
+ # Create 2 checkpoints:
+ # 1. merged: the model after calling merge_and_unload
+ # 2. unmerged: the PEFT model saved without calling merge_and_unload
+ path = tmp_path / "model.pt"
+
+ lora_config = LoraConfig(
+ target_modules=["lin"],
+ # important: "classifier" is a substring of "classifier2", "classifier3", "classifier4"
+ modules_to_save=["classifier", "classifier2", "classifier3", "classifier4"],
+ )
+ model = get_peft_model(self.get_model(), lora_config)
+ # mock training
+ for _ in range(5):
+ optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
+ output = model(torch.randn(10, 5))
+ loss = output.sum()
+ loss.backward()
+ optimizer.step()
+
+ # save the peft model without merging
+ path_unmerged = tmp_path / "unmerged"
+ model.save_pretrained(path_unmerged)
+
+ # merge the model and save state_dict
+ path_merged = tmp_path / "merged"
+ merged = model.merge_and_unload()
+ state_dict = merged.state_dict()
+ torch.save(state_dict, path_merged)
+
+ return path_merged, path_unmerged
+
+ def test_load_merged_and_unmerged_same_weights(self, path_merged_and_unmerged):
+ # Note that this test is quasi flaky, it has a 1 in 4 chance of passing even without the bugfix. It passes when
+ # "classifier" happens to be the last element of the set model.modules_to_save. The order of the set is random.
+ # It is not possible just run this test multiple times to minimize the probability of this happening, because
+ # within the same process, the hash order is consistent. With the bug fix, this doesn't matter, as the test will
+ # always pass, but if there is a regression, there is a 1 in 4 chance of not catching it. Since the CI runs many
+ # tests, it is overall very unlikely that none will catch it though. If you see this test failing in CI, thus be
+ # aware that some of the passing tests may just pass owing to randomness.
+ path_merged, path_unmerged = path_merged_and_unmerged
+
+ # load the merged model directly
+ state_dict = torch.load(path_merged, weights_only=True)
+ model = self.get_model()
+ model.load_state_dict(state_dict)
+ sd_merged = model.state_dict()
+ del model
+
+ # load the unmerged model and merge it
+ unmerged = PeftModel.from_pretrained(self.get_model(), path_unmerged)
+ sd_unmerged = unmerged.merge_and_unload().state_dict()
+
+ assert sd_merged.keys() == sd_unmerged.keys()
+ for key in sd_merged.keys():
+ param_merged = sd_merged[key]
+ param_unmerged = sd_unmerged[key]
+ assert torch.allclose(param_merged, param_unmerged)
+
+
+class TestTargetingAuxiliaryTrainingWrapper:
+ """AuxiliaryTrainingWrapper such as ModulesToSaveWrapper and TrainableTokensWrapper are
+ in general not to be targeted by PEFT methods such as adapters. For example, a ModulesToSaveWrapper's children
+ modules should not be targeted by `LoraConfig(target_modules='all-linear')`, among other things.
+ """
+
+ @pytest.fixture
+ def plain_model_cls(self):
+ class PlainModel(nn.Module):
+ def __init__(self, i, o):
+ super().__init__()
+ self.layer1 = nn.Linear(i, o)
+
+ def forward(self, x):
+ return self.layer1(x)
+
+ return PlainModel
+
+ @pytest.fixture
+ def nested_model_cls(self, plain_model_cls):
+ class NestedModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.layer1 = nn.Linear(10, 20)
+ self.layer2 = nn.Linear(20, 5)
+ self.layer3 = plain_model_cls(5, 10)
+
+ def forward(self, x):
+ x = self.layer1(x)
+ x = self.layer2(x)
+ x = self.layer3(x)
+ return x
+
+ return NestedModel
+
+ def test_nested_ignores_modules_to_save(self, nested_model_cls, plain_model_cls):
+ # Make sure that `target_modules` is not targeting the nested modules of a module marked as module to save.
+ model = nested_model_cls()
+ config = LoraConfig(
+ target_modules=["layer1"],
+ modules_to_save=["layer3"],
+ )
+
+ peft_model = get_peft_model(model, config)
+ assert isinstance(peft_model.model.layer3.modules_to_save.default, plain_model_cls)
+
+ def test_targeting_module_to_save_raises(self, nested_model_cls):
+ model = nested_model_cls()
+ config = LoraConfig(
+ target_modules=["layer1"],
+ modules_to_save=["layer1"],
+ )
+ msg = "No modules were targeted for adaptation. This might be caused by a combination"
+ with pytest.raises(ValueError, match=msg):
+ get_peft_model(model, config)
+
+ def test_modules_to_save_targets_tuner_layer_raises(self):
+ # See e.g. issue 2027 and 2477
+ # Prevent users from (accidentally) targeting the same layer both with a tuner and modules_to_save. Normally, PEFT
+ # will not target the same layer with both a tuner and ModulesToSaveWrapper. However, if modules_to_save is
+ # automatically inferred, e.g. when using AutoModelForSequenceClassification, the ModulesToSaveWrapper is applied ex
+ # post, which can lead to the double wrapping.
+ model_id = "hf-internal-testing/tiny-random-OPTForCausalLM"
+ model = AutoModelForSequenceClassification.from_pretrained(model_id)
+
+ # Note: target_modules="all-linear" would also work and is closer to the original issue, but let's explicitly target
+ # "score" here in case that "all-linear" will be fixed to no longer target the score layer.
+ peft_config = LoraConfig(target_modules=["score"], task_type="SEQ_CLS")
+
+ # Since the `score` layer is in `model.modules_to_save` it should be ignored when targeted,
+ # therefore the layer should not be adapted.
+ msg = "No modules were targeted for adaptation. This might be caused by a combination"
+ with pytest.raises(ValueError, match=msg) as e:
+ get_peft_model(model, peft_config)
+
+ def test_targeting_trainable_tokens_raises(self):
+ model_id = "hf-internal-testing/tiny-random-OPTForCausalLM"
+ model = AutoModelForSequenceClassification.from_pretrained(model_id)
+
+ peft_config = LoraConfig(target_modules=["embed_tokens"], task_type="SEQ_CLS", trainable_token_indices=[0, 1])
+
+ # While this message might not be the most helpful message, at least it is not silently failing
+ msg = "trainable_token_indices cannot be applied to modules of type "
+ with pytest.raises(TypeError, match=msg) as e:
+ get_peft_model(model, peft_config)
+
+
+class TestAdapterTargeting:
+ """Make sure that already existing adapters cannot be targeted to avoid conflicts."""
+
+ @pytest.fixture
+ def base_model_cls(self):
+ class M(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.l1 = torch.nn.Linear(10, 20)
+ self.l2 = torch.nn.Conv2d(1, 1, 2)
+
+ def forward(self, x):
+ return self.l2(self.l1(x))
+
+ return M
+
+ @pytest.mark.parametrize(
+ "config_cls, config_kwargs",
+ [
+ (LoraConfig, {"target_modules": "l1.*"}),
+ (LoraConfig, {"target_modules": "l2.*"}),
+ (VeraConfig, {"target_modules": "l1.*"}),
+ (VeraConfig, {"target_modules": "(l1|vera_A).*"}), # also target the shared layer
+ ],
+ )
+ def test_self_targeting_is_ignored(self, base_model_cls, config_cls, config_kwargs):
+ base_model = base_model_cls()
+ config1 = config_cls(**config_kwargs)
+ config2 = config_cls(**config_kwargs)
+
+ adapter1_name = "ADAPTER_1_512858" # sufficiently unique names to make reliable testing easier
+ adapter2_name = "ADAPTER_2_845781"
+
+ peft_model = get_peft_model(base_model, config1, adapter_name=adapter1_name)
+ state_dict_keys_1 = peft_model.state_dict().keys()
+
+ peft_model.add_adapter(adapter2_name, config2)
+ state_dict_keys_2 = peft_model.state_dict().keys()
+
+ # Ideally there should be no new modules targeted beyond existing ModuleDicts. Therefore the keys
+ # of the new state dict should only differ after the adapter name portion of the keys - not before.
+ # Expected:
+ # - a.b..xyz
+ # - a.b..xyz
+ # We're not expecting this to happen and test against it:
+ # - a.b..xyz
+ # - a..xyz
+ def remove_adapter_portion(adapter_name, key):
+ if key.endswith(f".{adapter_name}"):
+ return key.removesuffix(f".{adapter_name}")
+ return key.split(f".{adapter_name}.")[0]
+
+ adapter_invariant_keys1 = {remove_adapter_portion(adapter1_name, key) for key in state_dict_keys_1}
+ adapter_invariant_keys2 = {
+ remove_adapter_portion(adapter2_name, remove_adapter_portion(adapter1_name, key))
+ for key in state_dict_keys_2
+ }
+
+ assert adapter_invariant_keys1 == adapter_invariant_keys2
+
+
+class TestGetNoSplitModules:
+ # Ensure that children are considered when determining _no_split_modules
+ # see https://github.com/huggingface/transformers/pull/38141
+
+ def test_get_no_split_modules_simple(self):
+ # choose a model where recursively visiting children is *not* required
+ model_id = "facebook/opt-125m"
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ assert model._no_split_modules == ["OPTDecoderLayer"]
+ no_split_modules = _get_no_split_modules(model)
+ assert no_split_modules == {"OPTDecoderLayer"}
+
+ def test_get_no_split_modules_recursive(self):
+ # choose a model where recursively visiting children is required
+ model_id = "hf-internal-testing/tiny-random-LlavaForConditionalGeneration"
+ model = LlavaForConditionalGeneration.from_pretrained(model_id)
+ # sanity check: just visiting the model itself is not enough:
+ assert model._no_split_modules == []
+
+ no_split_modules = _get_no_split_modules(model)
+ assert no_split_modules == {"CLIPEncoderLayer", "LlamaDecoderLayer"}
diff --git a/peft/tests/test_poly.py b/peft/tests/test_poly.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e9a2a351c8b13fd08bd21001951c04875fb789f
--- /dev/null
+++ b/peft/tests/test_poly.py
@@ -0,0 +1,100 @@
+#!/usr/bin/env python3
+
+# coding=utf-8
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import tempfile
+import unittest
+
+import torch
+from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
+
+from peft import PeftModel, PolyConfig, TaskType, get_peft_model
+
+
+class TestPoly(unittest.TestCase):
+ def test_poly(self):
+ torch.manual_seed(0)
+ model_name_or_path = "google/flan-t5-small"
+
+ atol, rtol = 1e-6, 1e-6
+ r = 8 # rank of lora in poly
+ n_tasks = 3 # number of tasks
+ n_skills = 2 # number of skills (loras)
+ n_splits = 4 # number of heads
+ lr = 1e-2
+ num_epochs = 10
+
+ tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
+ base_model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
+
+ peft_config = PolyConfig(
+ task_type=TaskType.SEQ_2_SEQ_LM,
+ poly_type="poly",
+ r=r,
+ n_tasks=n_tasks,
+ n_skills=n_skills,
+ n_splits=n_splits,
+ )
+
+ model = get_peft_model(base_model, peft_config)
+
+ # generate some dummy data
+ text = os.__doc__.splitlines()
+ assert len(text) > 10
+ inputs = tokenizer(text, return_tensors="pt", padding=True)
+ inputs["task_ids"] = torch.arange(len(text)) % n_tasks
+ inputs["labels"] = tokenizer((["A", "B"] * 100)[: len(text)], return_tensors="pt")["input_ids"]
+
+ # simple training loop
+ model.train()
+ optimizer = torch.optim.Adam(model.parameters(), lr=lr)
+ losses = []
+ for _ in range(num_epochs):
+ outputs = model(**inputs)
+ loss = outputs.loss
+ loss.backward()
+ optimizer.step()
+ optimizer.zero_grad()
+ losses.append(loss.item())
+
+ # loss improved by at least 50%
+ assert losses[-1] < (0.5 * losses[0])
+
+ # check that saving and loading works
+ torch.manual_seed(0)
+ model.eval()
+ logits_before = model(**inputs).logits
+ tokens_before = model.generate(**inputs)
+
+ with model.disable_adapter():
+ logits_disabled = model(**inputs).logits
+ tokens_disabled = model.generate(**inputs)
+
+ assert not torch.allclose(logits_before, logits_disabled, atol=atol, rtol=rtol)
+ assert not torch.allclose(tokens_before, tokens_disabled, atol=atol, rtol=rtol)
+
+ # saving and loading
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir)
+ base_model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
+ loaded = PeftModel.from_pretrained(base_model, tmp_dir)
+
+ torch.manual_seed(0)
+ output_after = loaded(**inputs).logits
+ tokens_after = loaded.generate(**inputs)
+ assert torch.allclose(logits_before, output_after, atol=atol, rtol=rtol)
+ assert torch.allclose(tokens_before, tokens_after, atol=atol, rtol=rtol)
diff --git a/peft/tests/test_randlora.py b/peft/tests/test_randlora.py
new file mode 100644
index 0000000000000000000000000000000000000000..5fb7edb6a5e7c1fac2e5b717fbd6ffffe2eb7154
--- /dev/null
+++ b/peft/tests/test_randlora.py
@@ -0,0 +1,301 @@
+# Copyright 2025-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# This test file is for tests specific to RandLora, since Randlora has some specific challenges due to the shared weights.
+# These tests are copied from the test_vera.py file
+
+import os
+
+import pytest
+import torch
+from accelerate.utils.imports import is_bf16_available
+from safetensors import safe_open
+from torch import nn
+
+from peft import PeftModel, RandLoraConfig, get_peft_model
+
+
+class MLP(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.relu = nn.ReLU()
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.lin1 = nn.Linear(20, 20, bias=bias) # lin1 and lin2 have same shape
+ self.lin2 = nn.Linear(20, 20, bias=bias)
+ self.lin3 = nn.Linear(20, 2, bias=bias)
+ self.sm = nn.LogSoftmax(dim=-1)
+
+ def forward(self, X):
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = self.lin1(X)
+ X = self.relu(X)
+ X = self.lin2(X)
+ X = self.relu(X)
+ X = self.lin3(X)
+ X = self.sm(X)
+ return X
+
+
+# Tests copied from the TestVera class in test_vera.py.
+# Changes to the code file should be reflected here.
+class TestRandLora:
+ @pytest.fixture
+ def mlp(self):
+ torch.manual_seed(0)
+ model = MLP()
+ return model
+
+ @pytest.fixture
+ def mlp_same_prng(self, mlp):
+ torch.manual_seed(0)
+
+ config = RandLoraConfig(target_modules=["lin1", "lin2"], init_weights=False)
+ # creates a default RandLora adapter
+ peft_model = get_peft_model(mlp, config)
+ config2 = RandLoraConfig(target_modules=["lin1", "lin2"], init_weights=False)
+ peft_model.add_adapter("other", config2)
+ return peft_model
+
+ def test_multiple_adapters_same_prng_weights(self, mlp_same_prng):
+ # we can have multiple adapters with the same prng key, in which case the weights should be shared
+ assert (
+ mlp_same_prng.base_model.model.lin1.randlora_A["default"]
+ is mlp_same_prng.base_model.model.lin1.randlora_A["other"]
+ )
+ assert (
+ mlp_same_prng.base_model.model.lin1.randlora_B["default"]
+ is mlp_same_prng.base_model.model.lin1.randlora_B["other"]
+ )
+ assert (
+ mlp_same_prng.base_model.model.lin2.randlora_A["default"]
+ is mlp_same_prng.base_model.model.lin2.randlora_A["other"]
+ )
+ assert (
+ mlp_same_prng.base_model.model.lin2.randlora_B["default"]
+ is mlp_same_prng.base_model.model.lin2.randlora_B["other"]
+ )
+
+ input = torch.randn(5, 10)
+ mlp_same_prng.set_adapter("default")
+ output_default = mlp_same_prng(input)
+ mlp_same_prng.set_adapter("other")
+ output_other = mlp_same_prng(input)
+ assert not torch.allclose(output_default, output_other, atol=1e-3, rtol=1e-3)
+
+ def test_multiple_adapters_different_prng_raises(self):
+ # we cannot have multiple adapters with different prng keys
+ model = MLP()
+ config = RandLoraConfig(target_modules=["lin1", "lin2"], init_weights=False)
+ # creates a default RandLora adapter
+ peft_model = get_peft_model(model, config)
+ config2 = RandLoraConfig(target_modules=["lin1", "lin2"], init_weights=False, projection_prng_key=123)
+
+ msg = (
+ r"RandLora PRNG initialisation key must be the same for all adapters. Got config.projection_prng_key=123 but "
+ r"previous config had 0"
+ )
+ with pytest.raises(ValueError, match=msg):
+ peft_model.add_adapter("other", config2)
+
+ def test_multiple_adapters_save_load_save_projection_true(self, mlp_same_prng, tmp_path):
+ # check saving and loading works with multiple adapters and saved projection weights
+ torch.manual_seed(0)
+ input = torch.randn(5, 10)
+ mlp_same_prng.set_adapter("default")
+ output_default = mlp_same_prng(input)
+ mlp_same_prng.set_adapter("other")
+ output_other = mlp_same_prng(input)
+
+ # sanity check
+ assert not torch.allclose(output_default, output_other, atol=1e-3, rtol=1e-3)
+
+ save_path = tmp_path / "randlora"
+ mlp_same_prng.save_pretrained(save_path)
+ assert os.path.exists(save_path / "adapter_config.json")
+ assert os.path.exists(save_path / "other" / "adapter_config.json")
+
+ torch.manual_seed(0)
+ mlp = MLP()
+ peft_model = PeftModel.from_pretrained(mlp, save_path)
+ peft_model.load_adapter(save_path / "other", "other")
+
+ peft_model.set_adapter("default")
+ output_default_loaded = peft_model(input)
+ peft_model.set_adapter("other")
+ output_other_loaded = peft_model(input)
+
+ assert torch.allclose(output_default, output_default_loaded, atol=1e-3, rtol=1e-3)
+ assert torch.allclose(output_other, output_other_loaded, atol=1e-3, rtol=1e-3)
+
+ def test_multiple_adapters_save_load_save_projection_false(self, mlp, tmp_path):
+ # check saving and loading works with multiple adapters without saved projection weights
+ torch.manual_seed(1)
+ config = RandLoraConfig(target_modules=["lin1", "lin2"], init_weights=False, save_projection=False)
+ # creates a default RandLora adapter
+ peft_model = get_peft_model(mlp, config, adapter_name="first")
+ config2 = RandLoraConfig(target_modules=["lin1", "lin2"], init_weights=False, save_projection=False)
+ peft_model.add_adapter("second", config2)
+
+ input = torch.randn(5, 10)
+ peft_model.set_adapter("first")
+ output_first = peft_model(input)
+ peft_model.set_adapter("second")
+ output_second = peft_model(input)
+
+ # sanity check
+ assert not torch.allclose(output_first, output_second, atol=1e-3, rtol=1e-3)
+
+ save_path = tmp_path / "randlora"
+ peft_model.save_pretrained(save_path)
+ assert os.path.exists(save_path / "first" / "adapter_config.json")
+ assert os.path.exists(save_path / "second" / "adapter_config.json")
+
+ torch.manual_seed(0)
+ mlp = MLP()
+ peft_model = PeftModel.from_pretrained(mlp, save_path / "first", adapter_name="first")
+ peft_model.load_adapter(save_path / "second", "second")
+
+ peft_model.set_adapter("first")
+ output_first_loaded = peft_model(input)
+ peft_model.set_adapter("second")
+ output_second_loaded = peft_model(input)
+
+ assert torch.allclose(output_first, output_first_loaded, atol=1e-3, rtol=1e-3)
+ assert torch.allclose(output_second, output_second_loaded, atol=1e-3, rtol=1e-3)
+
+ def test_multiple_adapters_save_projection_true_contains_randlora_A_randlora_B(self, mlp_same_prng, tmp_path):
+ # check that the state_dicts don't contain the projection weights
+ save_path = tmp_path / "randlora"
+ mlp_same_prng.save_pretrained(save_path)
+
+ sd_default = {}
+ with safe_open(save_path / "adapter_model.safetensors", framework="pt", device="cpu") as f:
+ for key in f.keys():
+ sd_default[key] = f.get_tensor(key)
+
+ assert any("randlora_A" in key for key in sd_default)
+ assert any("randlora_B" in key for key in sd_default)
+ # default rank for RandLora is 32
+ assert sd_default["base_model.randlora_A"].shape == (32, 1, 20)
+ assert sd_default["base_model.randlora_B"].shape == (20, 1, 32)
+
+ sd_other = {}
+ with safe_open(save_path / "other" / "adapter_model.safetensors", framework="pt", device="cpu") as f:
+ for key in f.keys():
+ sd_other[key] = f.get_tensor(key)
+
+ assert any("randlora_A" in key for key in sd_other)
+ assert any("randlora_B" in key for key in sd_other)
+ assert sd_other["base_model.randlora_A"].shape == (32, 1, 20)
+ assert sd_other["base_model.randlora_B"].shape == (20, 1, 32)
+
+ def test_multiple_adapters_save_projection_false_contains_no_randlora_A_randlora_B(self, mlp, tmp_path):
+ torch.manual_seed(1)
+ config = RandLoraConfig(target_modules=["lin1", "lin2"], init_weights=False, save_projection=False)
+ # creates a default RandLora adapter
+ peft_model = get_peft_model(mlp, config, adapter_name="first")
+ config2 = RandLoraConfig(target_modules=["lin1", "lin2"], init_weights=False, save_projection=False)
+ peft_model.add_adapter("second", config2)
+
+ save_path = tmp_path / "randlora"
+ peft_model.save_pretrained(save_path)
+
+ sd_default = {}
+ with safe_open(save_path / "first" / "adapter_model.safetensors", framework="pt", device="cpu") as f:
+ for key in f.keys():
+ sd_default[key] = f.get_tensor(key)
+
+ assert not any("randlora_A" in key for key in sd_default)
+ assert not any("randlora_B" in key for key in sd_default)
+
+ sd_other = {}
+ with safe_open(save_path / "second" / "adapter_model.safetensors", framework="pt", device="cpu") as f:
+ for key in f.keys():
+ sd_other[key] = f.get_tensor(key)
+
+ assert not any("randlora_A" in key for key in sd_other)
+ assert not any("randlora_B" in key for key in sd_other)
+
+ def test_randlora_A_randlora_B_share_memory(self, mlp_same_prng):
+ randlora_A = mlp_same_prng.randlora_A["default"]
+ randlora_B = mlp_same_prng.randlora_B["default"]
+
+ # these tensors should share the same data
+ assert randlora_A.data_ptr() == mlp_same_prng.base_model.model.lin1.randlora_A["default"].data_ptr()
+ assert randlora_B.data_ptr() == mlp_same_prng.base_model.model.lin1.randlora_B["default"].data_ptr()
+ assert randlora_A.data_ptr() == mlp_same_prng.base_model.model.lin2.randlora_A["default"].data_ptr()
+ assert randlora_B.data_ptr() == mlp_same_prng.base_model.model.lin2.randlora_B["default"].data_ptr()
+ # sanity check: these tensors shouldn't share the same data
+ assert randlora_A.data_ptr() != randlora_B.data_ptr()
+
+ def test_randlora_lambda_dont_share_memory(self, mlp_same_prng):
+ # sanity check: these tensors shouldn't share the same data
+ assert (
+ mlp_same_prng.base_model.model.lin1.randlora_lambda["default"].data_ptr()
+ != mlp_same_prng.base_model.model.lin1.randlora_lambda["other"].data_ptr()
+ )
+ assert (
+ mlp_same_prng.base_model.model.lin1.randlora_lambda["default"].data_ptr()
+ != mlp_same_prng.base_model.model.lin2.randlora_lambda["default"].data_ptr()
+ )
+ assert (
+ mlp_same_prng.base_model.model.lin1.randlora_lambda["other"].data_ptr()
+ != mlp_same_prng.base_model.model.lin2.randlora_lambda["other"].data_ptr()
+ )
+ assert (
+ mlp_same_prng.base_model.model.lin1.randlora_gamma["default"].data_ptr()
+ != mlp_same_prng.base_model.model.lin1.randlora_gamma["other"].data_ptr()
+ )
+ assert (
+ mlp_same_prng.base_model.model.lin1.randlora_gamma["default"].data_ptr()
+ != mlp_same_prng.base_model.model.lin2.randlora_gamma["default"].data_ptr()
+ )
+ assert (
+ mlp_same_prng.base_model.model.lin1.randlora_gamma["other"].data_ptr()
+ != mlp_same_prng.base_model.model.lin2.randlora_gamma["other"].data_ptr()
+ )
+
+ def test_randlora_different_shapes(self, mlp):
+ config = RandLoraConfig(target_modules=["lin0", "lin3"], init_weights=False)
+ mlp_different_shapes = get_peft_model(mlp, config)
+
+ randlora_A = mlp_different_shapes.randlora_A["default"]
+ randlora_B = mlp_different_shapes.randlora_B["default"]
+
+ # sanity check
+ assert mlp.lin0.base_layer.weight.shape != mlp.lin3.base_layer.weight.shape
+
+ # lin0 has the largest output dimension, lin3 has the largest input dimension
+ # randlora_A should have the shape of (rank, largest_in), randlora_B should have the shape of (largest_out, rank)
+ assert randlora_A.shape == (config.r, 1, mlp.lin3.in_features)
+ assert randlora_B.shape == (mlp.lin0.out_features, 1, config.r)
+
+ # should not raise
+ input = torch.randn(5, 10)
+ mlp_different_shapes(input)
+
+ @pytest.mark.parametrize("dtype", [torch.float32, torch.float16, torch.bfloat16])
+ def test_randlora_dtypes(self, dtype):
+ if dtype == torch.bfloat16:
+ # skip if bf16 is not supported on hardware, see #1872
+ if not is_bf16_available():
+ pytest.skip("bfloat16 not supported on this system, skipping the test")
+
+ model = MLP().to(dtype)
+ config = RandLoraConfig(target_modules=["lin1", "lin2"], init_weights=False)
+ peft_model = get_peft_model(model, config)
+ inputs = torch.randn(5, 10).to(dtype)
+ output = peft_model(inputs) # should not raise
+ assert output.dtype == dtype
diff --git a/peft/tests/test_seq_classifier.py b/peft/tests/test_seq_classifier.py
new file mode 100644
index 0000000000000000000000000000000000000000..23d9067b860bbe936a1ccbb385abd1df016a1d81
--- /dev/null
+++ b/peft/tests/test_seq_classifier.py
@@ -0,0 +1,278 @@
+# Copyright 2025-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License governing permissions and limitations under the License.
+
+import pytest
+import torch
+from transformers import AutoModelForSequenceClassification
+
+from peft import (
+ AdaLoraConfig,
+ BOFTConfig,
+ BoneConfig,
+ C3AConfig,
+ FourierFTConfig,
+ HRAConfig,
+ IA3Config,
+ LoraConfig,
+ OFTConfig,
+ PrefixTuningConfig,
+ PromptEncoderConfig,
+ PromptTuningConfig,
+ PromptTuningInit,
+ ShiraConfig,
+ VBLoRAConfig,
+ VeraConfig,
+ get_peft_model,
+)
+from peft.utils.other import ModulesToSaveWrapper
+
+from .testing_common import PeftCommonTester, hub_online_once
+
+
+PEFT_SEQ_CLS_MODELS_TO_TEST = [
+ "hf-internal-testing/tiny-random-BertForSequenceClassification",
+ "hf-internal-testing/tiny-random-RobertaForSequenceClassification",
+ "trl-internal-testing/tiny-LlamaForSequenceClassification-3.2",
+]
+
+
+ALL_CONFIGS = [
+ (
+ AdaLoraConfig,
+ {
+ "task_type": "SEQ_CLS",
+ "target_modules": None,
+ "total_step": 1,
+ },
+ ),
+ (
+ BOFTConfig,
+ {
+ "task_type": "SEQ_CLS",
+ "target_modules": None,
+ },
+ ),
+ (
+ BoneConfig,
+ {
+ "task_type": "SEQ_CLS",
+ "target_modules": None,
+ "r": 2,
+ },
+ ),
+ (
+ FourierFTConfig,
+ {
+ "task_type": "SEQ_CLS",
+ "n_frequency": 10,
+ "target_modules": None,
+ },
+ ),
+ (
+ HRAConfig,
+ {
+ "task_type": "SEQ_CLS",
+ "target_modules": None,
+ },
+ ),
+ (
+ IA3Config,
+ {
+ "task_type": "SEQ_CLS",
+ "target_modules": None,
+ "feedforward_modules": None,
+ },
+ ),
+ (
+ LoraConfig,
+ {
+ "task_type": "SEQ_CLS",
+ "r": 8,
+ "lora_alpha": 32,
+ "target_modules": None,
+ "lora_dropout": 0.05,
+ "bias": "none",
+ },
+ ),
+ # LoRA + trainable tokens
+ (
+ LoraConfig,
+ {
+ "task_type": "SEQ_CLS",
+ "r": 8,
+ "lora_alpha": 32,
+ "target_modules": None,
+ "lora_dropout": 0.05,
+ "bias": "none",
+ "trainable_token_indices": [0, 1, 3],
+ },
+ ),
+ (
+ OFTConfig,
+ {
+ "task_type": "SEQ_CLS",
+ "target_modules": None,
+ },
+ ),
+ (
+ PrefixTuningConfig,
+ {
+ "task_type": "SEQ_CLS",
+ "num_virtual_tokens": 10,
+ },
+ ),
+ (
+ PromptEncoderConfig,
+ {
+ "task_type": "SEQ_CLS",
+ "num_virtual_tokens": 10,
+ "encoder_hidden_size": 32,
+ },
+ ),
+ (
+ PromptTuningConfig,
+ {
+ "task_type": "SEQ_CLS",
+ "num_virtual_tokens": 10,
+ },
+ ),
+ (
+ ShiraConfig,
+ {
+ "r": 1,
+ "task_type": "SEQ_CLS",
+ "target_modules": None,
+ "init_weights": False,
+ },
+ ),
+ (
+ VBLoRAConfig,
+ {
+ "task_type": "SEQ_CLS",
+ "target_modules": None,
+ "vblora_dropout": 0.05,
+ "vector_length": 1,
+ "num_vectors": 2,
+ },
+ ),
+ (
+ VeraConfig,
+ {
+ "task_type": "SEQ_CLS",
+ "r": 8,
+ "target_modules": None,
+ "vera_dropout": 0.05,
+ "projection_prng_key": 0xFF,
+ "d_initial": 0.1,
+ "save_projection": True,
+ "bias": "none",
+ },
+ ),
+ (
+ C3AConfig,
+ {
+ "task_type": "SEQ_CLS",
+ "block_size": 1,
+ "target_modules": None,
+ },
+ ),
+]
+
+
+class TestSequenceClassificationModels(PeftCommonTester):
+ r"""
+ Tests for basic coverage of AutoModelForSequenceClassification and classification-specific cases. Most of the
+ functionality is probably already covered by other tests.
+ """
+
+ transformers_class = AutoModelForSequenceClassification
+
+ def skipTest(self, reason=""):
+ # for backwards compatibility with unittest style test classes
+ pytest.skip(reason)
+
+ def prepare_inputs_for_testing(self):
+ input_ids = torch.tensor([[1, 1, 1], [1, 2, 1]]).to(self.torch_device)
+ attention_mask = torch.tensor([[1, 1, 1], [1, 0, 1]]).to(self.torch_device)
+ return {"input_ids": input_ids, "attention_mask": attention_mask}
+
+ @pytest.mark.parametrize("model_id", PEFT_SEQ_CLS_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_attributes_parametrized(self, model_id, config_cls, config_kwargs):
+ self._test_model_attr(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_SEQ_CLS_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_adapter_name(self, model_id, config_cls, config_kwargs):
+ self._test_adapter_name(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_SEQ_CLS_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_prepare_for_training_parametrized(self, model_id, config_cls, config_kwargs):
+ self._test_prepare_for_training(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_SEQ_CLS_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_prompt_tuning_text_prepare_for_training(self, model_id, config_cls, config_kwargs):
+ if config_cls != PromptTuningConfig:
+ pytest.skip(f"This test does not apply to {config_cls}")
+ config_kwargs = config_kwargs.copy()
+ config_kwargs["prompt_tuning_init"] = PromptTuningInit.TEXT
+ config_kwargs["prompt_tuning_init_text"] = "This is a test prompt."
+ config_kwargs["tokenizer_name_or_path"] = model_id
+ self._test_prepare_for_training(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_SEQ_CLS_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained(self, model_id, config_cls, config_kwargs):
+ self._test_save_pretrained(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_SEQ_CLS_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained_pickle(self, model_id, config_cls, config_kwargs):
+ self._test_save_pretrained(model_id, config_cls, config_kwargs.copy(), safe_serialization=False)
+
+ @pytest.mark.parametrize("model_id", PEFT_SEQ_CLS_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained_selected_adapters(self, model_id, config_cls, config_kwargs):
+ self._test_save_pretrained_selected_adapters(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_SEQ_CLS_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained_selected_adapters_pickle(self, model_id, config_cls, config_kwargs):
+ self._test_save_pretrained_selected_adapters(
+ model_id, config_cls, config_kwargs.copy(), safe_serialization=False
+ )
+
+ @pytest.mark.parametrize("model_id", PEFT_SEQ_CLS_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_from_pretrained_config_construction(self, model_id, config_cls, config_kwargs):
+ self._test_from_pretrained_config_construction(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_SEQ_CLS_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_modules_to_save_correctly_set(self, model_id, config_cls, config_kwargs):
+ # tests for a regression, introduced via #2220, where modules_to_save was not applied to prompt learning methods
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ base_model = model.get_base_model()
+ # classifier layer is called either "classifier" or "score"
+ classifier = getattr(base_model, "classifier", getattr(base_model, "score", None))
+ if classifier is None:
+ raise ValueError(f"Could not determine classifier layer name for {model_id}, please fix the test")
+ assert isinstance(classifier, ModulesToSaveWrapper)
diff --git a/peft/tests/test_shira.py b/peft/tests/test_shira.py
new file mode 100644
index 0000000000000000000000000000000000000000..9845ee426ea85f4d2e91ce8d95dc43c54e1ce437
--- /dev/null
+++ b/peft/tests/test_shira.py
@@ -0,0 +1,278 @@
+# Copyright 2025-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# This test file is for tests specific to SHiRA.
+
+import os
+
+import pytest
+import torch
+from accelerate.utils.imports import is_bf16_available
+from torch import nn
+
+from peft import PeftModel, ShiraConfig, get_peft_model
+
+
+def custom_random_mask_function_with_custom_kwargs(custom_arg):
+ def mask_fn(base_layer, r):
+ """
+ This mask function is similar to the random_mask provided in src/peft/tuners/shira/mask_functions.py except the
+ seed is derived from custom_kwargs. Please use this as an example to create your own custom sparse masks that
+ may use custom_kwargs. Remember, for a pretrained weight with shape m, n, mask_fn must return only one mask
+ (shape: m, n) which must be binary 0 or 1 with num_shira_parameters = r(m+n) for linear layers. Device and
+ dtype of mask must be same as base layer's weight's device and dtype.
+ """
+ new_seed = custom_arg
+ shape = base_layer.weight.shape
+ num_shira_weights = r * (shape[0] + shape[1])
+ random_generator = torch.Generator()
+ random_generator.manual_seed(new_seed)
+
+ idx = (torch.randperm(base_layer.weight.numel(), generator=random_generator)[:num_shira_weights]).to(
+ base_layer.weight.device
+ )
+ val = torch.ones_like(idx.type(base_layer.weight.dtype))
+ mask = torch.zeros_like(base_layer.weight.view(1, -1))
+ mask = mask.scatter_(1, idx.unsqueeze(0), val.unsqueeze(0)).view(shape)
+
+ return mask
+
+ return mask_fn
+
+
+class MLP(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.relu = nn.ReLU()
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.lin1 = nn.Linear(20, 40, bias=bias) # lin1 and lin2 have same shape
+ self.lin2 = nn.Linear(40, 30, bias=bias)
+ self.lin3 = nn.Linear(30, 10, bias=bias)
+ self.sm = nn.LogSoftmax(dim=-1)
+
+ def forward(self, X):
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = self.lin1(X)
+ X = self.relu(X)
+ X = self.lin2(X)
+ X = self.relu(X)
+ X = self.lin3(X)
+ X = self.sm(X)
+ return X
+
+
+class TestShira:
+ @pytest.fixture
+ def mlp(self):
+ torch.manual_seed(0)
+ model = MLP()
+ return model
+
+ def test_mlp_single_adapter_shapes(self, mlp):
+ # torch.manual_seed(0)
+
+ r = 2
+ config = ShiraConfig(r=r, target_modules=["lin1", "lin2"])
+ # creates a default SHiRA adapter
+ peft_model = get_peft_model(mlp, config)
+
+ shira_weight1_size = peft_model.base_model.model.lin1.shira_weight["default"].shape[0]
+ shira_weight2_size = peft_model.base_model.model.lin2.shira_weight["default"].shape[0]
+ shira_indices1_size = peft_model.base_model.model.lin1.shira_indices["default"].shape[1]
+ shira_indices2_size = peft_model.base_model.model.lin2.shira_indices["default"].shape[1]
+
+ base_weight1_size = peft_model.base_model.model.lin1.base_layer.weight.shape
+ base_weight2_size = peft_model.base_model.model.lin2.base_layer.weight.shape
+
+ delta_weight1_shape = peft_model.base_model.model.lin1.get_delta_weight("default").shape
+ delta_weight2_shape = peft_model.base_model.model.lin2.get_delta_weight("default").shape
+
+ assert shira_weight1_size == r * (base_weight1_size[0] + base_weight1_size[1])
+ assert shira_weight2_size == r * (base_weight2_size[0] + base_weight2_size[1])
+
+ assert shira_weight1_size == shira_indices1_size
+ assert shira_weight2_size == shira_indices2_size
+
+ assert delta_weight1_shape == base_weight1_size
+ assert delta_weight2_shape == base_weight2_size
+
+ return peft_model
+
+ def test_multiple_adapters_save_load(self, mlp, tmp_path):
+ # check saving and loading works with multiple adapters
+ # note, the random seeds in the below two configs are not the default values.
+ # so it will lead to different random sparse masks between saving and loading.
+ # our goal is to make sure that loaded indices are exactly the same as the saved indices regardless of what initial random mask gets generated.
+ # we will also make sure that parameters are saved and loaded correctly, and the output remains the same.
+ config = ShiraConfig(r=2, target_modules=["lin1", "lin2"], random_seed=56)
+ # creates a default SHiRA adapter
+ peft_model = get_peft_model(mlp, config, adapter_name="first")
+ config2 = ShiraConfig(r=3, target_modules=["lin1", "lin2", "lin3"], random_seed=67)
+ peft_model.add_adapter("second", config2)
+
+ assert torch.all(peft_model.base_model.model.lin1.shira_weight["first"] == 0)
+ assert torch.all(peft_model.base_model.model.lin2.shira_weight["first"] == 0)
+ assert torch.all(peft_model.base_model.model.lin1.shira_weight["second"] == 0)
+ assert torch.all(peft_model.base_model.model.lin2.shira_weight["second"] == 0)
+ assert torch.all(peft_model.base_model.model.lin3.shira_weight["second"] == 0)
+
+ shira_assign_val1_f = torch.randn_like(peft_model.base_model.model.lin1.shira_weight["first"])
+ peft_model.base_model.model.lin1.shira_weight["first"] = shira_assign_val1_f
+ shira_indices1_f = peft_model.base_model.model.lin1.shira_indices["first"]
+ shira_assign_val2_f = torch.randn_like(peft_model.base_model.model.lin2.shira_weight["first"])
+ peft_model.base_model.model.lin2.shira_weight["first"] = shira_assign_val2_f
+ shira_indices2_f = peft_model.base_model.model.lin2.shira_indices["first"]
+
+ shira_assign_val1_s = torch.randn_like(peft_model.base_model.model.lin1.shira_weight["second"])
+ peft_model.base_model.model.lin1.shira_weight["second"] = shira_assign_val1_s
+ shira_indices1_s = peft_model.base_model.model.lin1.shira_indices["second"]
+ shira_assign_val2_s = torch.randn_like(peft_model.base_model.model.lin2.shira_weight["second"])
+ peft_model.base_model.model.lin2.shira_weight["second"] = shira_assign_val2_s
+ shira_indices2_s = peft_model.base_model.model.lin2.shira_indices["second"]
+ shira_assign_val3_s = torch.randn_like(peft_model.base_model.model.lin3.shira_weight["second"])
+ peft_model.base_model.model.lin3.shira_weight["second"] = shira_assign_val3_s
+ shira_indices3_s = peft_model.base_model.model.lin3.shira_indices["second"]
+
+ input = torch.randn(5, 10)
+ peft_model.set_adapter("first")
+ output_first = peft_model(input)
+ peft_model.set_adapter("second")
+ output_second = peft_model(input)
+
+ # sanity check
+ assert not torch.allclose(output_first, output_second, atol=1e-3, rtol=1e-3)
+
+ save_path = os.path.join(tmp_path, "shira")
+ peft_model.save_pretrained(save_path)
+ assert os.path.exists(os.path.join(save_path, "first", "adapter_config.json"))
+ assert os.path.exists(os.path.join(save_path, "second", "adapter_config.json"))
+ del peft_model
+
+ torch.manual_seed(0)
+ mlp = MLP()
+ peft_model = PeftModel.from_pretrained(mlp, os.path.join(save_path, "first"), adapter_name="first")
+ peft_model.load_adapter(os.path.join(save_path, "second"), "second")
+
+ peft_model.set_adapter("first")
+ output_first_loaded = peft_model(input)
+ peft_model.set_adapter("second")
+ output_second_loaded = peft_model(input)
+
+ assert torch.allclose(output_first, output_first_loaded)
+ assert torch.allclose(output_second, output_second_loaded)
+
+ assert torch.all(shira_assign_val1_f == peft_model.base_model.model.lin1.shira_weight["first"])
+ assert torch.all(shira_assign_val2_f == peft_model.base_model.model.lin2.shira_weight["first"])
+ assert torch.all(shira_indices1_f == peft_model.base_model.model.lin1.shira_indices["first"])
+ assert torch.all(shira_indices2_f == peft_model.base_model.model.lin2.shira_indices["first"])
+ assert torch.all(shira_assign_val1_s == peft_model.base_model.model.lin1.shira_weight["second"])
+ assert torch.all(shira_assign_val2_s == peft_model.base_model.model.lin2.shira_weight["second"])
+ assert torch.all(shira_assign_val3_s == peft_model.base_model.model.lin3.shira_weight["second"])
+ assert torch.all(shira_indices1_s == peft_model.base_model.model.lin1.shira_indices["second"])
+ assert torch.all(shira_indices2_s == peft_model.base_model.model.lin2.shira_indices["second"])
+ assert torch.all(shira_indices3_s == peft_model.base_model.model.lin3.shira_indices["second"])
+
+ return peft_model
+
+ def test_save_load_custom_mask_function(self, mlp, tmp_path):
+ # we want to see if saving and loading works when a custom mask is involved
+ config = ShiraConfig(r=2, mask_type="custom", target_modules=["lin1", "lin2"], init_weights=False)
+ custom_arg = 120
+ custom_mask_fn = custom_random_mask_function_with_custom_kwargs(custom_arg)
+ config.mask_fn = custom_mask_fn
+
+ # create a custom mask SHiRA adapter
+ peft_model = get_peft_model(mlp, config, adapter_name="first")
+
+ shira_assign_val1_f = peft_model.base_model.model.lin1.shira_weight["first"]
+ shira_indices1_f = peft_model.base_model.model.lin1.shira_indices["first"]
+ shira_assign_val2_f = peft_model.base_model.model.lin2.shira_weight["first"]
+ shira_indices2_f = peft_model.base_model.model.lin2.shira_indices["first"]
+
+ input = torch.randn(5, 10)
+ peft_model.set_adapter("first")
+ output_first = peft_model(input)
+
+ save_path = os.path.join(tmp_path, "shira")
+ peft_model.save_pretrained(save_path)
+ assert os.path.exists(os.path.join(save_path, "first", "adapter_config.json"))
+ del peft_model
+
+ torch.manual_seed(0)
+ mlp = MLP()
+ peft_model = PeftModel.from_pretrained(mlp, os.path.join(save_path, "first"), adapter_name="first")
+
+ peft_model.set_adapter("first")
+ output_first_loaded = peft_model(input)
+
+ assert torch.allclose(output_first, output_first_loaded)
+
+ assert torch.all(shira_assign_val1_f == peft_model.base_model.model.lin1.shira_weight["first"])
+ assert torch.all(shira_assign_val2_f == peft_model.base_model.model.lin2.shira_weight["first"])
+ assert torch.all(shira_indices1_f == peft_model.base_model.model.lin1.shira_indices["first"])
+ assert torch.all(shira_indices2_f == peft_model.base_model.model.lin2.shira_indices["first"])
+
+ return peft_model
+
+ def test_save_load_default_random_mask_with_seed_function(self, mlp, tmp_path):
+ # we want to see if saving and loading works when a random mask is involved but the random seed is fixed.
+ config = ShiraConfig(r=2, target_modules=["lin1", "lin2"], random_seed=567, init_weights=False)
+
+ # create a custom mask SHiRA adapter
+ peft_model = get_peft_model(mlp, config, adapter_name="first")
+
+ shira_assign_val1_f = peft_model.base_model.model.lin1.shira_weight["first"]
+ shira_indices1_f = peft_model.base_model.model.lin1.shira_indices["first"]
+ shira_assign_val2_f = peft_model.base_model.model.lin2.shira_weight["first"]
+ shira_indices2_f = peft_model.base_model.model.lin2.shira_indices["first"]
+
+ input = torch.randn(5, 10)
+ peft_model.set_adapter("first")
+ output_first = peft_model(input)
+
+ save_path = os.path.join(tmp_path, "shira")
+ peft_model.save_pretrained(save_path)
+ assert os.path.exists(os.path.join(save_path, "first", "adapter_config.json"))
+ del peft_model
+
+ torch.manual_seed(0)
+ mlp = MLP()
+ peft_model = PeftModel.from_pretrained(mlp, os.path.join(save_path, "first"), adapter_name="first")
+
+ peft_model.set_adapter("first")
+ output_first_loaded = peft_model(input)
+
+ assert torch.allclose(output_first, output_first_loaded)
+
+ assert torch.all(shira_assign_val1_f == peft_model.base_model.model.lin1.shira_weight["first"])
+ assert torch.all(shira_assign_val2_f == peft_model.base_model.model.lin2.shira_weight["first"])
+ assert torch.all(shira_indices1_f == peft_model.base_model.model.lin1.shira_indices["first"])
+ assert torch.all(shira_indices2_f == peft_model.base_model.model.lin2.shira_indices["first"])
+
+ return peft_model
+
+ @pytest.mark.parametrize("dtype", [torch.float32, torch.float16, torch.bfloat16])
+ def test_shira_dtypes(self, dtype):
+ if dtype == torch.bfloat16:
+ # skip if bf16 is not supported on hardware, see #1872
+ if not is_bf16_available():
+ pytest.skip("bfloat16 not supported on this system, skipping the test")
+
+ model = MLP().to(dtype)
+ config = ShiraConfig(r=2, target_modules=["lin1", "lin2"])
+ peft_model = get_peft_model(model, config)
+ inputs = torch.randn(5, 10).to(dtype)
+ output = peft_model(inputs) # should not raise
+ assert output.dtype == dtype
diff --git a/peft/tests/test_stablediffusion.py b/peft/tests/test_stablediffusion.py
new file mode 100644
index 0000000000000000000000000000000000000000..8eb18dc9a682806bab9a1e5a120160487f525ca1
--- /dev/null
+++ b/peft/tests/test_stablediffusion.py
@@ -0,0 +1,387 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import copy
+from dataclasses import asdict, replace
+
+import numpy as np
+import pytest
+from diffusers import StableDiffusionPipeline
+
+from peft import (
+ BOFTConfig,
+ HRAConfig,
+ LoHaConfig,
+ LoKrConfig,
+ LoraConfig,
+ OFTConfig,
+ get_peft_model,
+ get_peft_model_state_dict,
+ inject_adapter_in_model,
+ set_peft_model_state_dict,
+)
+from peft.tuners.tuners_utils import BaseTunerLayer
+
+from .testing_common import PeftCommonTester
+from .testing_utils import set_init_weights_false, temp_seed
+
+
+PEFT_DIFFUSERS_SD_MODELS_TO_TEST = ["hf-internal-testing/tiny-sd-pipe"]
+DIFFUSERS_CONFIGS = [
+ (
+ LoraConfig,
+ {
+ "text_encoder": {
+ "r": 8,
+ "lora_alpha": 32,
+ "target_modules": ["k_proj", "q_proj", "v_proj", "out_proj", "fc1", "fc2"],
+ "lora_dropout": 0.0,
+ "bias": "none",
+ "init_lora_weights": False,
+ },
+ "unet": {
+ "r": 8,
+ "lora_alpha": 32,
+ "target_modules": [
+ "proj_in",
+ "proj_out",
+ "to_k",
+ "to_q",
+ "to_v",
+ "to_out.0",
+ "ff.net.0.proj",
+ "ff.net.2",
+ ],
+ "lora_dropout": 0.0,
+ "bias": "none",
+ "init_lora_weights": False,
+ },
+ },
+ ),
+ (
+ LoHaConfig,
+ {
+ "text_encoder": {
+ "r": 8,
+ "alpha": 32,
+ "target_modules": ["k_proj", "q_proj", "v_proj", "out_proj", "fc1", "fc2"],
+ "rank_dropout": 0.0,
+ "module_dropout": 0.0,
+ "init_weights": False,
+ },
+ "unet": {
+ "r": 8,
+ "alpha": 32,
+ "target_modules": [
+ "proj_in",
+ "proj_out",
+ "to_k",
+ "to_q",
+ "to_v",
+ "to_out.0",
+ "ff.net.0.proj",
+ "ff.net.2",
+ ],
+ "rank_dropout": 0.0,
+ "module_dropout": 0.0,
+ "init_weights": False,
+ },
+ },
+ ),
+ (
+ LoKrConfig,
+ {
+ "text_encoder": {
+ "r": 8,
+ "alpha": 32,
+ "target_modules": ["k_proj", "q_proj", "v_proj", "out_proj", "fc1", "fc2"],
+ "rank_dropout": 0.0,
+ "module_dropout": 0.0,
+ "init_weights": False,
+ },
+ "unet": {
+ "r": 8,
+ "alpha": 32,
+ "target_modules": [
+ "proj_in",
+ "proj_out",
+ "to_k",
+ "to_q",
+ "to_v",
+ "to_out.0",
+ "ff.net.0.proj",
+ "ff.net.2",
+ ],
+ "rank_dropout": 0.0,
+ "module_dropout": 0.0,
+ "init_weights": False,
+ },
+ },
+ ),
+ (
+ OFTConfig,
+ {
+ "text_encoder": {
+ "r": 1,
+ "oft_block_size": 0,
+ "target_modules": ["k_proj", "q_proj", "v_proj", "out_proj", "fc1", "fc2"],
+ "module_dropout": 0.0,
+ "init_weights": False,
+ "use_cayley_neumann": False,
+ },
+ "unet": {
+ "r": 1,
+ "oft_block_size": 0,
+ "target_modules": [
+ "proj_in",
+ "proj_out",
+ "to_k",
+ "to_q",
+ "to_v",
+ "to_out.0",
+ "ff.net.0.proj",
+ "ff.net.2",
+ ],
+ "module_dropout": 0.0,
+ "init_weights": False,
+ "use_cayley_neumann": False,
+ },
+ },
+ ),
+ (
+ BOFTConfig,
+ {
+ "text_encoder": {
+ "boft_block_num": 1,
+ "boft_block_size": 0,
+ "target_modules": ["k_proj", "q_proj", "v_proj", "out_proj", "fc1", "fc2"],
+ "boft_dropout": 0.0,
+ "init_weights": False,
+ },
+ "unet": {
+ "boft_block_num": 1,
+ "boft_block_size": 0,
+ "target_modules": [
+ "proj_in",
+ "proj_out",
+ "to_k",
+ "to_q",
+ "to_v",
+ "to_out.0",
+ "ff.net.0.proj",
+ "ff.net.2",
+ ],
+ "boft_dropout": 0.0,
+ "init_weights": False,
+ },
+ },
+ ),
+ (
+ HRAConfig,
+ {
+ "text_encoder": {
+ "r": 8,
+ "target_modules": ["k_proj", "q_proj", "v_proj", "out_proj", "fc1", "fc2"],
+ "init_weights": False,
+ },
+ "unet": {
+ "r": 8,
+ "target_modules": [
+ "proj_in",
+ "proj_out",
+ "to_k",
+ "to_q",
+ "to_v",
+ "to_out.0",
+ "ff.net.0.proj",
+ "ff.net.2",
+ ],
+ "init_weights": False,
+ },
+ },
+ ),
+]
+
+
+def skip_if_not_lora(config_cls):
+ if config_cls != LoraConfig:
+ pytest.skip("Skipping test because it is only applicable to LoraConfig")
+
+
+class TestStableDiffusionModel(PeftCommonTester):
+ r"""
+ Tests that diffusers StableDiffusion model works with PEFT as expected.
+ """
+
+ transformers_class = StableDiffusionPipeline
+ sd_model = StableDiffusionPipeline.from_pretrained("hf-internal-testing/tiny-sd-pipe")
+
+ def instantiate_sd_peft(self, model_id, config_cls, config_kwargs):
+ # Instantiate StableDiffusionPipeline
+ if model_id == "hf-internal-testing/tiny-sd-pipe":
+ # in CI, this model often times out on the hub, let's cache it
+ model = copy.deepcopy(self.sd_model)
+ else:
+ model = self.transformers_class.from_pretrained(model_id)
+
+ config_kwargs = config_kwargs.copy()
+ text_encoder_kwargs = config_kwargs.pop("text_encoder")
+ unet_kwargs = config_kwargs.pop("unet")
+ # the remaining config kwargs should be applied to both configs
+ for key, val in config_kwargs.items():
+ text_encoder_kwargs[key] = val
+ unet_kwargs[key] = val
+
+ # Instantiate text_encoder adapter
+ config_text_encoder = config_cls(**text_encoder_kwargs)
+ model.text_encoder = get_peft_model(model.text_encoder, config_text_encoder)
+
+ # Instantiate unet adapter
+ config_unet = config_cls(**unet_kwargs)
+ model.unet = get_peft_model(model.unet, config_unet)
+
+ # Move model to device
+ model = model.to(self.torch_device)
+
+ return model
+
+ def prepare_inputs_for_testing(self):
+ return {
+ "prompt": "a high quality digital photo of a cute corgi",
+ "num_inference_steps": 3,
+ }
+
+ @pytest.mark.parametrize("model_id", PEFT_DIFFUSERS_SD_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", DIFFUSERS_CONFIGS)
+ def test_merge_layers(self, model_id, config_cls, config_kwargs):
+ if (config_cls == LoKrConfig) and (self.torch_device not in ["cuda", "xpu"]):
+ pytest.skip("Merging test with LoKr fails without GPU")
+
+ # Instantiate model & adapters
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ model = self.instantiate_sd_peft(model_id, config_cls, config_kwargs)
+
+ # Generate output for peft modified StableDiffusion
+ dummy_input = self.prepare_inputs_for_testing()
+ with temp_seed(seed=42):
+ peft_output = np.array(model(**dummy_input).images[0]).astype(np.float32)
+
+ # Merge adapter and model
+ if config_cls not in [LoHaConfig, OFTConfig, HRAConfig]:
+ # TODO: Merging the text_encoder is leading to issues on CPU with PyTorch 2.1
+ model.text_encoder = model.text_encoder.merge_and_unload()
+ model.unet = model.unet.merge_and_unload()
+
+ # Generate output for peft merged StableDiffusion
+ with temp_seed(seed=42):
+ merged_output = np.array(model(**dummy_input).images[0]).astype(np.float32)
+
+ # Images are in uint8 drange, so use large atol
+ assert np.allclose(peft_output, merged_output, atol=1.0)
+
+ @pytest.mark.parametrize("model_id", PEFT_DIFFUSERS_SD_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", DIFFUSERS_CONFIGS)
+ def test_merge_layers_safe_merge(self, model_id, config_cls, config_kwargs):
+ if (config_cls == LoKrConfig) and (self.torch_device not in ["cuda", "xpu"]):
+ pytest.skip("Merging test with LoKr fails without GPU")
+
+ # Instantiate model & adapters
+ model = self.instantiate_sd_peft(model_id, config_cls, config_kwargs)
+
+ # Generate output for peft modified StableDiffusion
+ dummy_input = self.prepare_inputs_for_testing()
+ with temp_seed(seed=42):
+ peft_output = np.array(model(**dummy_input).images[0]).astype(np.float32)
+
+ # Merge adapter and model
+ if config_cls not in [LoHaConfig, OFTConfig, HRAConfig]:
+ # TODO: Merging the text_encoder is leading to issues on CPU with PyTorch 2.1
+ model.text_encoder = model.text_encoder.merge_and_unload(safe_merge=True)
+ model.unet = model.unet.merge_and_unload(safe_merge=True)
+
+ # Generate output for peft merged StableDiffusion
+ with temp_seed(seed=42):
+ merged_output = np.array(model(**dummy_input).images[0]).astype(np.float32)
+
+ # Images are in uint8 drange, so use large atol
+ assert np.allclose(peft_output, merged_output, atol=1.0)
+
+ @pytest.mark.parametrize("model_id", PEFT_DIFFUSERS_SD_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", DIFFUSERS_CONFIGS)
+ def test_add_weighted_adapter_base_unchanged(self, model_id, config_cls, config_kwargs):
+ skip_if_not_lora(config_cls)
+ # Instantiate model & adapters
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ model = self.instantiate_sd_peft(model_id, config_cls, config_kwargs)
+
+ # Get current available adapter config
+ text_encoder_adapter_name = next(iter(model.text_encoder.peft_config.keys()))
+ unet_adapter_name = next(iter(model.unet.peft_config.keys()))
+ text_encoder_adapter_config = replace(model.text_encoder.peft_config[text_encoder_adapter_name])
+ unet_adapter_config = replace(model.unet.peft_config[unet_adapter_name])
+
+ # Create weighted adapters
+ model.text_encoder.add_weighted_adapter([unet_adapter_name], [0.5], "weighted_adapter_test")
+ model.unet.add_weighted_adapter([unet_adapter_name], [0.5], "weighted_adapter_test")
+
+ # Assert that base adapters config did not change
+ assert asdict(text_encoder_adapter_config) == asdict(model.text_encoder.peft_config[text_encoder_adapter_name])
+ assert asdict(unet_adapter_config) == asdict(model.unet.peft_config[unet_adapter_name])
+
+ @pytest.mark.parametrize("model_id", PEFT_DIFFUSERS_SD_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", DIFFUSERS_CONFIGS)
+ def test_disable_adapter(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_disable_adapter(model_id, config_cls, config_kwargs)
+
+ @pytest.mark.parametrize("model_id", PEFT_DIFFUSERS_SD_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", DIFFUSERS_CONFIGS)
+ def test_load_model_low_cpu_mem_usage(self, model_id, config_cls, config_kwargs):
+ # Instantiate model & adapters
+ pipe = self.instantiate_sd_peft(model_id, config_cls, config_kwargs)
+
+ te_state_dict = get_peft_model_state_dict(pipe.text_encoder)
+ unet_state_dict = get_peft_model_state_dict(pipe.unet)
+
+ del pipe
+ pipe = self.instantiate_sd_peft(model_id, config_cls, config_kwargs)
+
+ config_kwargs = config_kwargs.copy()
+ text_encoder_kwargs = config_kwargs.pop("text_encoder")
+ unet_kwargs = config_kwargs.pop("unet")
+ # the remaining config kwargs should be applied to both configs
+ for key, val in config_kwargs.items():
+ text_encoder_kwargs[key] = val
+ unet_kwargs[key] = val
+
+ config_text_encoder = config_cls(**text_encoder_kwargs)
+ config_unet = config_cls(**unet_kwargs)
+
+ # check text encoder
+ inject_adapter_in_model(config_text_encoder, pipe.text_encoder, low_cpu_mem_usage=True)
+ # sanity check that the adapter was applied:
+ assert any(isinstance(module, BaseTunerLayer) for module in pipe.text_encoder.modules())
+
+ assert "meta" in {p.device.type for p in pipe.text_encoder.parameters()}
+ set_peft_model_state_dict(pipe.text_encoder, te_state_dict, low_cpu_mem_usage=True)
+ assert "meta" not in {p.device.type for p in pipe.text_encoder.parameters()}
+
+ # check unet
+ inject_adapter_in_model(config_unet, pipe.unet, low_cpu_mem_usage=True)
+ # sanity check that the adapter was applied:
+ assert any(isinstance(module, BaseTunerLayer) for module in pipe.unet.modules())
+
+ assert "meta" in {p.device.type for p in pipe.unet.parameters()}
+ set_peft_model_state_dict(pipe.unet, unet_state_dict, low_cpu_mem_usage=True)
+ assert "meta" not in {p.device.type for p in pipe.unet.parameters()}
diff --git a/peft/tests/test_target_parameters.py b/peft/tests/test_target_parameters.py
new file mode 100644
index 0000000000000000000000000000000000000000..30fcffe0f62a056f01996e516e35ad750d0bdc73
--- /dev/null
+++ b/peft/tests/test_target_parameters.py
@@ -0,0 +1,351 @@
+# Copyright 2025-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import pytest
+import torch
+from transformers import AutoModelForCausalLM
+
+from peft import LoraConfig, get_peft_model
+
+from .testing_common import PeftCommonTester, hub_online_once
+from .testing_utils import set_init_weights_false
+
+
+PEFT_DECODER_MODELS_TO_TEST = [
+ "trl-internal-testing/tiny-Llama4ForCausalLM",
+]
+
+# TODO Missing from this list are LoKr, LoHa, LN Tuning, add them
+ALL_CONFIGS = [
+ # target down_proj
+ (
+ LoraConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "r": 8,
+ "lora_alpha": 32,
+ "target_modules": None,
+ "lora_dropout": 0.0,
+ "bias": "none",
+ "target_parameters": [
+ "feed_forward.experts.down_proj",
+ ],
+ },
+ ),
+ # target gate_up_proj and down_proj (but not on the same module!)
+ (
+ LoraConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "r": 8,
+ "lora_alpha": 32,
+ "target_modules": None,
+ "lora_dropout": 0.0,
+ "bias": "none",
+ "target_parameters": [
+ "0.feed_forward.experts.gate_up_proj",
+ "1.feed_forward.experts.down_proj",
+ ],
+ },
+ ),
+ # target q_proj, v_proj as modules, and down_proj as parameter
+ (
+ LoraConfig,
+ {
+ "task_type": "CAUSAL_LM",
+ "r": 8,
+ "lora_alpha": 32,
+ "target_modules": ["q_proj", "v_proj"],
+ "lora_dropout": 0.0,
+ "bias": "none",
+ "target_parameters": [
+ "feed_forward.experts.down_proj",
+ ],
+ },
+ ),
+]
+
+
+class MyAutoModelForCausalLM(AutoModelForCausalLM):
+ @classmethod
+ def from_pretrained(cls, *args, **kwargs):
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(*args, **kwargs)
+
+ # check that we load the original model, not, say, a trained checkpoint
+ if args[0] == "trl-internal-testing/tiny-Llama4ForCausalLM":
+ # model contains weights with values ~1e36 or nan, so we need to reinitialize with sane values
+ with torch.no_grad():
+ for param in model.parameters():
+ param.data = torch.randn(param.shape)
+ return model
+
+
+class TestDecoderModelsTargetParameters(PeftCommonTester):
+ # This is more or less a copy of TestDecoderModels at the time of the PR being added. Unnecessary code is removed,
+ # like code required for testing non-LoRA methods. The tests being included are not selected to test specific
+ # functionality of targeting nn.Parameters, they (together with the tests in test_custom_models.py) just ensure that
+ # generally, nothing is broken.
+ transformers_class = MyAutoModelForCausalLM
+
+ def skipTest(self, reason=""):
+ # for backwards compatibility with unittest style test classes
+ pytest.skip(reason)
+
+ def prepare_inputs_for_testing(self):
+ input_ids = torch.tensor([[1, 1, 1], [1, 2, 1]]).to(self.torch_device)
+ attention_mask = torch.tensor([[1, 1, 1], [1, 0, 1]]).to(self.torch_device)
+ return {"input_ids": input_ids, "attention_mask": attention_mask}
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_attributes_parametrized(self, model_id, config_cls, config_kwargs):
+ self._test_model_attr(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_adapter_name(self, model_id, config_cls, config_kwargs):
+ self._test_adapter_name(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_prepare_for_training_parametrized(self, model_id, config_cls, config_kwargs):
+ self._test_prepare_for_training(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained(self, model_id, config_cls, config_kwargs):
+ self._test_save_pretrained(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained_pickle(self, model_id, config_cls, config_kwargs):
+ self._test_save_pretrained(model_id, config_cls, config_kwargs.copy(), safe_serialization=False)
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained_selected_adapters(self, model_id, config_cls, config_kwargs):
+ self._test_save_pretrained_selected_adapters(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_save_pretrained_selected_adapters_pickle(self, model_id, config_cls, config_kwargs):
+ self._test_save_pretrained_selected_adapters(
+ model_id, config_cls, config_kwargs.copy(), safe_serialization=False
+ )
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_from_pretrained_config_construction(self, model_id, config_cls, config_kwargs):
+ self._test_from_pretrained_config_construction(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_merge_layers(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_merge_layers(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_merge_layers_multi(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_merge_layers_multi(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_merge_layers_nan(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_merge_layers_nan(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_mixed_adapter_batches(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ msg = "lora.ParamWrapper does not support mixed adapter batches yet."
+ with pytest.raises(ValueError, match=msg):
+ self._test_mixed_adapter_batches(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_generate_with_mixed_adapter_batches(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ msg = "lora.ParamWrapper does not support mixed adapter batches yet."
+ with pytest.raises(ValueError, match=msg):
+ self._test_generate_with_mixed_adapter_batches_and_beam_search(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_generate(self, model_id, config_cls, config_kwargs):
+ self._test_generate(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_generate_pos_args(self, model_id, config_cls, config_kwargs):
+ self._test_generate_pos_args(model_id, config_cls, config_kwargs.copy(), raises_err=False)
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_merge_layers_fp16(self, model_id, config_cls, config_kwargs):
+ self._test_merge_layers_fp16(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_generate_half_prec(self, model_id, config_cls, config_kwargs):
+ self._test_generate_half_prec(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_training_decoders(self, model_id, config_cls, config_kwargs):
+ self._test_training(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_training_decoders_gradient_checkpointing(self, model_id, config_cls, config_kwargs):
+ self._test_training_gradient_checkpointing(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_inference_safetensors(self, model_id, config_cls, config_kwargs):
+ self._test_inference_safetensors(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_peft_model_device_map(self, model_id, config_cls, config_kwargs):
+ self._test_peft_model_device_map(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_delete_adapter(self, model_id, config_cls, config_kwargs):
+ self._test_delete_adapter(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_delete_inactive_adapter(self, model_id, config_cls, config_kwargs):
+ self._test_delete_inactive_adapter(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_adding_multiple_adapters_with_bias_raises(self, model_id, config_cls, config_kwargs):
+ self._test_adding_multiple_adapters_with_bias_raises(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_unload_adapter(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_unload_adapter(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_weighted_combination_of_adapters(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ msg = "add_weighted_adapter does not support targeting nn.Parameter"
+ with pytest.raises(ValueError, match=msg):
+ self._test_weighted_combination_of_adapters(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_training_prompt_learning_tasks(self, model_id, config_cls, config_kwargs):
+ self._test_training_prompt_learning_tasks(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_disable_adapter(self, model_id, config_cls, config_kwargs):
+ config_kwargs = set_init_weights_false(config_cls, config_kwargs)
+ self._test_disable_adapter(model_id, config_cls, config_kwargs.copy())
+
+ @pytest.mark.parametrize("model_id", PEFT_DECODER_MODELS_TO_TEST)
+ @pytest.mark.parametrize("config_cls,config_kwargs", ALL_CONFIGS)
+ def test_passing_input_embeds_works(self, model_id, config_cls, config_kwargs):
+ self._test_passing_input_embeds_works("", model_id, config_cls, config_kwargs.copy())
+
+
+class TestTargetParameter:
+ def test_targeting_module_and_targeting_param_equivalent(self):
+ # note: we purposely target the gate_proj because its weight is not square (unlike q_proj, ...), this makes it
+ # easier to catch shape errors
+ torch.manual_seed(0)
+ model_id = "hf-internal-testing/tiny-random-LlamaForCausalLM"
+ with hub_online_once(model_id):
+ model0 = AutoModelForCausalLM.from_pretrained(model_id)
+ x = torch.arange(10).view(2, 5)
+ with torch.inference_mode():
+ out_base = model0(x, output_hidden_states=True).hidden_states[-1]
+
+ # targeting the module
+ config0 = LoraConfig(target_modules=["gate_proj"], init_lora_weights=False)
+ model0 = get_peft_model(model0, config0)
+
+ # targeting the parameter
+ model1 = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-LlamaForCausalLM")
+ config1 = LoraConfig(target_modules=[], target_parameters=["gate_proj.weight"], init_lora_weights=False)
+ model1 = get_peft_model(model1, config1)
+
+ gate_proj_0_0 = model0.base_model.model.model.layers[0].mlp.gate_proj
+ gate_proj_0_1 = model0.base_model.model.model.layers[1].mlp.gate_proj
+ gate_proj_1_0 = model1.base_model.model.model.layers[0].mlp.gate_proj
+ gate_proj_1_1 = model1.base_model.model.model.layers[1].mlp.gate_proj
+
+ # ensure that the randomly initialized LoRA weights are identical
+ gate_proj_1_0.lora_A.default.weight.data.copy_(gate_proj_0_0.lora_A.default.weight.data)
+ gate_proj_1_1.lora_A.default.weight.data.copy_(gate_proj_0_1.lora_A.default.weight.data)
+ gate_proj_1_0.lora_B.default.weight.data.copy_(gate_proj_0_0.lora_B.default.weight.data)
+ gate_proj_1_1.lora_B.default.weight.data.copy_(gate_proj_0_1.lora_B.default.weight.data)
+
+ with torch.inference_mode():
+ out_lora_0 = model0(x, output_hidden_states=True).hidden_states[-1]
+ out_lora_1 = model1(x, output_hidden_states=True).hidden_states[-1]
+
+ # sanity check: basemodel outputs should be different
+
+ atol, rtol = 1e-6, 1e-6
+ assert not torch.allclose(out_base, out_lora_0, atol=atol, rtol=rtol)
+
+ # LoRA outputs should be the same
+ assert torch.allclose(out_lora_0, out_lora_1, atol=atol, rtol=rtol)
+
+ def test_target_multiple_parameters_on_same_module(self):
+ # for now, it is not supported to target multiple parameters from the same module with the same adapter,
+ # however, it is possible to target multiple parameters from same module with different adapters
+ torch.manual_seed(0)
+ model_id = "hf-internal-testing/tiny-random-LlamaForCausalLM"
+ with hub_online_once(model_id):
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ x = torch.arange(10).view(2, 5)
+ with torch.inference_mode():
+ out_base = model(x, output_hidden_states=True).hidden_states[-1]
+
+ # targeting gate_up_proj
+ config0 = LoraConfig(target_parameters=["feed_forward.experts.gate_up_proj"], init_lora_weights=False)
+ model = get_peft_model(model, config0)
+ with torch.inference_mode():
+ out_lora_0 = model(x, output_hidden_states=True).hidden_states[-1]
+ atol, rtol = 1e-6, 1e-6
+ assert not torch.allclose(out_base, out_lora_0, atol=atol, rtol=rtol)
+
+ # targeting down_proj
+ config1 = LoraConfig(target_parameters=["feed_forward.experts.down_proj"], init_lora_weights=False)
+ model.add_adapter("other", config1)
+ model.set_adapter("other")
+ with torch.inference_mode():
+ out_lora_1 = model(x, output_hidden_states=True).hidden_states[-1]
+ assert not torch.allclose(out_base, out_lora_1, atol=atol, rtol=rtol)
+ assert not torch.allclose(out_lora_0, out_lora_1, atol=atol, rtol=rtol)
+
+ # targeting both gate_up_proj and down_proj
+ model.base_model.set_adapter(["default", "other"])
+ with torch.inference_mode():
+ out_lora_01 = model(x, output_hidden_states=True).hidden_states[-1]
+ assert not torch.allclose(out_base, out_lora_01, atol=atol, rtol=rtol)
+ assert not torch.allclose(out_lora_0, out_lora_01, atol=atol, rtol=rtol)
+ assert not torch.allclose(out_lora_1, out_lora_01, atol=atol, rtol=rtol)
diff --git a/peft/tests/test_torch_compile.py b/peft/tests/test_torch_compile.py
new file mode 100644
index 0000000000000000000000000000000000000000..c5275eeaf87fce4931f94545e07521c269853d57
--- /dev/null
+++ b/peft/tests/test_torch_compile.py
@@ -0,0 +1,589 @@
+# Copyright 2024-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# The intent of the tests contained in this file is to check as many PEFT features as possible with torch.compile. This
+# is thus a document on how well torch.compile is supported by PEFT. Currently, we know that certain features do not
+# work with torch.compile. The corresponding tests should be marked with `@pytest.mark.xfail(strict=True)`.
+#
+# When adding a new test that fails with torch.compile, please make sure first that it does NOT fail without
+# torch.compile.
+
+import gc
+import os
+
+import pytest
+import torch
+from accelerate.utils.memory import clear_device_cache
+from transformers import (
+ AutoModelForCausalLM,
+ AutoTokenizer,
+ BitsAndBytesConfig,
+ DataCollatorForLanguageModeling,
+ Trainer,
+ TrainerCallback,
+ TrainingArguments,
+)
+
+from peft import (
+ AdaLoraConfig,
+ BOFTConfig,
+ BoneConfig,
+ HRAConfig,
+ IA3Config,
+ LNTuningConfig,
+ LoHaConfig,
+ LoKrConfig,
+ LoraConfig,
+ OFTConfig,
+ PeftModel,
+ TaskType,
+ VBLoRAConfig,
+ VeraConfig,
+ get_peft_model,
+)
+
+from .testing_utils import load_dataset_english_quotes, require_bitsandbytes
+
+
+# only run (very slow) torch.compile tests when explicitly asked to
+if os.environ.get("PEFT_DEBUG_WITH_TORCH_COMPILE") != "1":
+ pytest.skip(allow_module_level=True)
+
+
+# Mapping: name of the setting -> (Peft config instance, torch.compile kwargs)
+SETTINGS = {
+ "adalora": (AdaLoraConfig(task_type=TaskType.CAUSAL_LM, total_step=5), {}),
+ "boft": (BOFTConfig(task_type=TaskType.CAUSAL_LM), {}),
+ "dora": (LoraConfig(task_type=TaskType.CAUSAL_LM, use_dora=True), {}),
+ "ia3": (IA3Config(task_type=TaskType.CAUSAL_LM), {}),
+ "ln_tuning": (LNTuningConfig(task_type=TaskType.CAUSAL_LM, target_modules=["final_layer_norm"]), {}),
+ "loha": (LoHaConfig(task_type=TaskType.CAUSAL_LM, target_modules=["q_proj", "v_proj"]), {}),
+ "lokr": pytest.param(
+ (LoKrConfig(task_type=TaskType.CAUSAL_LM, target_modules=["q_proj", "v_proj"]), {}),
+ ),
+ "lora": (LoraConfig(task_type=TaskType.CAUSAL_LM), {}),
+ "lora-target-embeddings": pytest.param(
+ (LoraConfig(task_type=TaskType.CAUSAL_LM, target_modules=["embed_tokens"]), {}),
+ ),
+ "lora-with-modules-to-save": (LoraConfig(task_type=TaskType.CAUSAL_LM, modules_to_save=["embed_tokens"]), {}),
+ "oft": (OFTConfig(task_type=TaskType.CAUSAL_LM, target_modules=["q_proj", "v_proj"]), {}),
+ "vblora": (VBLoRAConfig(task_type=TaskType.CAUSAL_LM, target_modules=["q_proj", "v_proj"], vector_length=2), {}),
+ "vera": (VeraConfig(task_type=TaskType.CAUSAL_LM), {}),
+ "hra": (HRAConfig(task_type=TaskType.CAUSAL_LM, target_modules=["q_proj", "v_proj"]), {}),
+ "bone": (BoneConfig(task_type=TaskType.CAUSAL_LM, target_modules=["q_proj", "v_proj"], r=2), {}),
+ "bone-bat": (
+ BoneConfig(task_type=TaskType.CAUSAL_LM, target_modules=["q_proj", "v_proj"], r=2, init_weights="bat"),
+ {},
+ ),
+}
+
+
+@pytest.mark.single_gpu_tests
+class TestTorchCompileCausalLM:
+ """
+ Tests for using torch.compile with causal LM.
+
+ Tip: When adding a new test, set `fake_compile = True` below. With this setting, torch.compile is being skipped.
+ This is useful for two reasons:
+
+ - compile is slow, so to quickly iterate on the test, it's best to disable it and only enable it at the very end
+ - even if you expect the test to fail with compile, as compile does not work with every PEFT feature, it still MUST
+ succeed without compile, otherwise the test is incorrect.
+
+ Before creating the PR, disable `fake_compile`.
+ """
+
+ fake_compile = False
+ model_id = "hf-internal-testing/tiny-random-OPTForCausalLM"
+ max_train_loss = 15.0 # generous threshold for maximum loss after training
+
+ @pytest.fixture(autouse=True)
+ def teardown(self):
+ r"""
+ Efficient mechanism to free GPU memory after each test. Based on
+ https://github.com/huggingface/transformers/issues/21094
+ """
+ clear_device_cache(garbage_collection=True)
+ gc.collect()
+
+ @pytest.fixture(scope="class")
+ def tokenizer(self):
+ return AutoTokenizer.from_pretrained(self.model_id)
+
+ @pytest.fixture(scope="class")
+ def data(self, tokenizer):
+ def tokenize(samples):
+ # For some reason, the max sequence length is not honored by the tokenizer, resulting in IndexErrors. Thus,
+ # manually ensure that sequences are not too long.
+ tokenized = tokenizer(samples["quote"])
+ tokenized["input_ids"] = [input_ids[: tokenizer.model_max_length] for input_ids in tokenized["input_ids"]]
+ tokenized["attention_mask"] = [
+ input_ids[: tokenizer.model_max_length] for input_ids in tokenized["attention_mask"]
+ ]
+ return tokenized
+
+ data = load_dataset_english_quotes()
+ data = data.map(tokenize, batched=True)
+ # We need to manually remove unused columns. This is because we cannot use remove_unused_columns=True in the
+ # Trainer, as this leads to errors with torch.compile. We also cannot just leave them in, as they contain
+ # strings. Therefore, manually remove all unused columns.
+ data = data.remove_columns(["quote", "author", "tags"])
+ return data
+
+ def compile(self, model, compile_kwargs):
+ compile_kwargs = compile_kwargs.copy()
+ # those are only for the Trainer arguments
+ compile_kwargs.pop("torch_compile_backend", None)
+ compile_kwargs.pop("torch_compile_mode", None)
+ if self.fake_compile:
+ return model
+ return torch.compile(model, **compile_kwargs)
+
+ @pytest.mark.parametrize("settings", SETTINGS.values(), ids=SETTINGS.keys())
+ def test_causal_lm_training_trainer_compile(self, settings, tokenizer, data, tmp_path):
+ r"""Train a PEFT model with torch.compile using Trainer"""
+ tmp_dir = tmp_path / "model"
+ config, compile_kwargs = settings
+
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_id,
+ device_map="auto",
+ )
+ model = get_peft_model(model, config)
+
+ # record outputs before training
+ model.eval()
+ sample = torch.tensor(data["train"][:1]["input_ids"]).to(model.device)
+ with torch.inference_mode():
+ output_before = model(sample)
+ model.train()
+
+ train_kwargs = {
+ "per_device_train_batch_size": 4,
+ "max_steps": 5,
+ "learning_rate": 1e-3,
+ "logging_steps": 1,
+ "output_dir": tmp_dir,
+ "seed": 0,
+ }
+
+ if isinstance(config, AdaLoraConfig):
+ train_kwargs["learning_rate"] = 1e-2
+
+ training_args = TrainingArguments(
+ torch_compile=not self.fake_compile,
+ torch_compile_backend=compile_kwargs.get("torch_compile_backend", None),
+ torch_compile_mode=compile_kwargs.get("torch_compile_mode", None),
+ **train_kwargs,
+ )
+ trainer = Trainer(
+ model=model,
+ train_dataset=data["train"],
+ args=training_args,
+ data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False),
+ )
+ model.config.use_cache = False
+
+ if isinstance(config, AdaLoraConfig):
+
+ class OptimizerStepCallback(TrainerCallback):
+ def on_optimizer_step(self, args, state, control, **kwargs):
+ model.update_and_allocate(state.global_step)
+
+ trainer.add_callback(OptimizerStepCallback())
+
+ trainer.train()
+
+ model.eval()
+ atol, rtol = 1e-4, 1e-4
+ with torch.inference_mode():
+ output_after = model(sample)
+ tokens_after = model.generate(sample)
+ assert torch.isfinite(output_after.logits).all()
+ # sanity check: model was updated
+ assert not torch.allclose(output_before.logits, output_after.logits, atol=atol, rtol=rtol)
+ assert trainer.state.log_history[-1]["train_loss"] < self.max_train_loss
+
+ # check saving the model and loading it without compile
+ model.save_pretrained(tmp_path)
+ del model
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(self.model_id, device_map="auto")
+ model = PeftModel.from_pretrained(model, tmp_path)
+ with torch.inference_mode():
+ output_loaded = model(sample)
+ tokens_loaded = model.generate(sample)
+ assert torch.allclose(output_after.logits, output_loaded.logits, atol=atol, rtol=rtol)
+ assert (tokens_after == tokens_loaded).all()
+
+ @pytest.mark.parametrize("settings", SETTINGS.values(), ids=SETTINGS.keys())
+ def test_causal_lm_training_pytorch_compile(self, settings, tokenizer, data, tmp_path):
+ r"""Train a PEFT model with torch.compile using PyTorch training loop"""
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_id,
+ device_map="auto",
+ )
+ config, compile_kwargs = settings
+ model = get_peft_model(model, config)
+ if isinstance(config, AdaLoraConfig):
+ model.base_model.peft_config["default"].total_step = 5
+ model = self.compile(model, compile_kwargs)
+
+ # record outputs before training
+ model.eval()
+ sample = torch.tensor(data["train"][:1]["input_ids"]).to(model.device)
+ with torch.inference_mode():
+ output_before = model(sample)
+ model.train()
+
+ model.config.use_cache = False
+ optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3)
+ batch_size = 4
+ losses = []
+ max_steps = 5 * batch_size
+ for i in range(0, max_steps, batch_size):
+ batch = tokenizer.pad(data["train"][i : i + batch_size], return_tensors="pt").to(model.device)
+ # add targets
+ batch["labels"] = batch["input_ids"].clone()
+ optimizer.zero_grad()
+ outputs = model(**batch)
+ loss = outputs.loss
+ loss.backward()
+ optimizer.step()
+ losses.append(loss.item())
+ if isinstance(config, AdaLoraConfig):
+ model.base_model.update_and_allocate(i)
+
+ model.eval()
+ with torch.inference_mode():
+ output_after = model(sample)
+ tokens_after = model.generate(sample)
+ assert torch.isfinite(output_after.logits).all()
+ atol, rtol = 1e-4, 1e-4
+ # sanity check: model was updated
+ assert not torch.allclose(output_before.logits, output_after.logits, atol=atol, rtol=rtol)
+ assert losses[-1] < self.max_train_loss
+
+ # check saving the model and loading it without compile
+ model.save_pretrained(tmp_path)
+ del model
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(self.model_id, device_map="auto")
+ model = PeftModel.from_pretrained(model, tmp_path)
+ with torch.inference_mode():
+ output_loaded = model(sample)
+ tokens_loaded = model.generate(sample)
+ assert torch.allclose(output_after.logits, output_loaded.logits, atol=atol, rtol=rtol)
+ assert (tokens_after == tokens_loaded).all()
+
+ @require_bitsandbytes
+ def test_causal_lm_training_lora_bnb_compile(self, tokenizer, data, tmp_path):
+ r"""Train a bnb quantized LoRA model with torch.compile using PyTorch training loop"""
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ )
+ config = LoraConfig(task_type=TaskType.CAUSAL_LM)
+ model = get_peft_model(model, config)
+ model = self.compile(model, {})
+
+ # record outputs before training
+ model.eval()
+ sample = torch.tensor(data["train"][:1]["input_ids"]).to(model.device)
+ with torch.inference_mode():
+ output_before = model(sample)
+ model.train()
+
+ model.config.use_cache = False
+ optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3)
+ batch_size = 4
+ losses = []
+ max_steps = 5 * batch_size
+ for i in range(0, max_steps, batch_size):
+ batch = tokenizer.pad(data["train"][i : i + batch_size], return_tensors="pt").to(model.device)
+ # add targets
+ batch["labels"] = batch["input_ids"].clone()
+ optimizer.zero_grad()
+ outputs = model(**batch)
+ loss = outputs.loss
+ loss.backward()
+ optimizer.step()
+ losses.append(loss.item())
+
+ model.eval()
+ with torch.inference_mode():
+ output_after = model(sample)
+ assert torch.isfinite(output_after.logits).all()
+ atol, rtol = 5e-4, 5e-4
+ # sanity check: model was updated
+ assert not torch.allclose(output_before.logits, output_after.logits, atol=atol, rtol=rtol)
+ assert losses[-1] < self.max_train_loss
+
+ # check saving the model and loading it without compile
+ model.save_pretrained(tmp_path)
+ del model
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_id, device_map="auto", quantization_config=BitsAndBytesConfig(load_in_4bit=True)
+ )
+ model = PeftModel.from_pretrained(model, tmp_path)
+
+ with torch.inference_mode():
+ # after loading, outputs are float32 for some reason
+ output_loaded = model(sample)
+ assert torch.allclose(output_after.logits, output_loaded.logits, atol=atol, rtol=rtol)
+
+ @require_bitsandbytes
+ def test_causal_lm_multiple_lora_adapter_compile(self, tokenizer, data):
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ ).eval()
+ sample = torch.tensor(data["train"][:1]["input_ids"]).to(model.device)
+ with torch.inference_mode():
+ output_base = model(sample)
+
+ config = LoraConfig(task_type=TaskType.CAUSAL_LM, init_lora_weights=False)
+ model = get_peft_model(model, config)
+ model.add_adapter("other", config)
+ model = self.compile(model, {})
+ model.eval()
+
+ with torch.inference_mode():
+ output_default_adapter = model(sample)
+ model.set_adapter("other")
+ with torch.inference_mode():
+ output_other_adapter = model(sample)
+
+ atol, rtol = 1e-4, 1e-4
+ # outputs of the base model != output of default adapter != output of other adapter
+ assert not torch.allclose(output_base.logits, output_default_adapter.logits, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_base.logits, output_other_adapter.logits, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_default_adapter.logits, output_other_adapter.logits, atol=atol, rtol=rtol)
+
+ # now delete the other adapter
+ model.delete_adapter("other")
+ model.set_adapter("default")
+ with torch.inference_mode():
+ output_after_delete = model(sample)
+
+ # outputs after delete == output of default adapter
+ assert torch.allclose(output_default_adapter.logits, output_after_delete.logits, atol=atol, rtol=rtol)
+
+ def test_causal_lm_disable_lora_adapter_compile(self, tokenizer, data):
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ ).eval()
+ sample = torch.tensor(data["train"][:1]["input_ids"]).to(model.device)
+ with torch.inference_mode():
+ output_base = model(sample)
+
+ config = LoraConfig(task_type=TaskType.CAUSAL_LM, init_lora_weights=False)
+ model = get_peft_model(model, config).eval()
+ model = self.compile(model, {})
+ output_lora = model(sample)
+
+ with model.disable_adapter():
+ with torch.inference_mode():
+ output_disabled = model(sample)
+
+ atol, rtol = 5e-4, 5e-4
+ # outputs of the base model == output disabled adapter != output of lora adapter
+ assert torch.allclose(output_base.logits, output_disabled.logits, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_base.logits, output_lora.logits, atol=atol, rtol=rtol)
+
+ @require_bitsandbytes
+ def test_causal_lm_merging_lora_adapter_compile(self, tokenizer, data):
+ # merge the adapter
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ ).eval()
+ sample = torch.tensor(data["train"][:1]["input_ids"]).to(model.device)
+ with torch.inference_mode():
+ output_base = model(sample)
+
+ config = LoraConfig(task_type=TaskType.CAUSAL_LM, init_lora_weights=False)
+ model = get_peft_model(model, config).eval()
+ with torch.inference_mode():
+ output_lora = model(sample)
+
+ model.merge_adapter()
+ with torch.inference_mode():
+ output_merged = model(sample)
+
+ # merging is less precise, be more tolerant
+ atol, rtol = 1e-1, 1e-1
+ # outputs of the base model != output of lora adapter == output of merged adapter
+ assert not torch.allclose(output_base.logits, output_lora.logits, atol=atol, rtol=rtol)
+ assert torch.allclose(output_lora.logits, output_merged.logits, atol=atol, rtol=rtol)
+
+ @require_bitsandbytes
+ def test_causal_lm_merging_multiple_lora_adapters_compile(self, tokenizer, data):
+ # merge multiple adapters at once
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ ).eval()
+ sample = torch.tensor(data["train"][:1]["input_ids"]).to(model.device)
+ with torch.inference_mode():
+ output_base = model(sample)
+
+ config = LoraConfig(task_type=TaskType.CAUSAL_LM, init_lora_weights=False)
+ model = get_peft_model(model, config).eval()
+ model.add_adapter("other", config)
+ with torch.inference_mode():
+ output_default = model(sample)
+
+ model.set_adapter("other")
+ with torch.inference_mode():
+ output_other = model(sample)
+
+ model.base_model.merge_adapter(["default", "other"])
+ with torch.inference_mode():
+ output_merged = model(sample)
+
+ # merging is less precise, be more tolerant
+ atol, rtol = 1e-1, 1e-1
+ # outputs of the base model != output of default adapter != output of other adapter
+ assert not torch.allclose(output_base.logits, output_default.logits, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_base.logits, output_other.logits, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_default.logits, output_other.logits, atol=atol, rtol=rtol)
+ # outputs of merged adapter != all others
+ assert not torch.allclose(output_base.logits, output_merged.logits, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_default.logits, output_merged.logits, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_other.logits, output_merged.logits, atol=atol, rtol=rtol)
+
+ @require_bitsandbytes
+ def test_causal_lm_merge_and_unload_lora_adapter_compile(self, tokenizer, data):
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ ).eval()
+ sample = torch.tensor(data["train"][:1]["input_ids"]).to(model.device)
+ with torch.inference_mode():
+ output_base = model(sample)
+
+ config = LoraConfig(task_type=TaskType.CAUSAL_LM, init_lora_weights=False)
+ model = get_peft_model(model, config).eval()
+ model = self.compile(model, {})
+ with torch.inference_mode():
+ output_lora = model(sample)
+
+ unloaded = model.merge_and_unload()
+ with torch.inference_mode():
+ output_unloaded = unloaded(sample)
+
+ # merging is less precise, be more tolerant
+ atol, rtol = 1e-1, 1e-1
+ # outputs of the base model != output of lora adapter == output of unloaded adapter
+ assert not torch.allclose(output_base.logits, output_lora.logits, atol=atol, rtol=rtol)
+ assert torch.allclose(output_lora.logits, output_unloaded.logits, atol=atol, rtol=rtol)
+
+ @require_bitsandbytes
+ def test_causal_lm_mixed_batch_lora_adapter_compile(self, tokenizer, data):
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ ).eval()
+
+ # we need at least 3 samples for this to work!
+ sample = {
+ "input_ids": torch.arange(12).reshape(3, 4).to("cuda"),
+ "attention_mask": torch.ones(3, 4).long().to("cuda"),
+ }
+
+ with torch.inference_mode():
+ output_base = model(**sample)
+
+ config = LoraConfig(task_type=TaskType.CAUSAL_LM, init_lora_weights=False)
+ model = get_peft_model(model, config).eval()
+ with torch.inference_mode():
+ output_default = model(**sample)
+
+ model.add_adapter("other", config)
+ model.set_adapter("other")
+ with torch.inference_mode():
+ output_other = model(**sample)
+
+ model = self.compile(model, {})
+
+ # set adapter_indices so that it alternates between 0 (base), lora 1, and lora 2
+ adapter_names = ["__base__", "default", "other"]
+ with torch.inference_mode():
+ output_mixed = model(**sample, adapter_names=adapter_names)
+
+ atol, rtol = 5e-4, 5e-4
+ # outputs of the base model != output of lora adapter 1 != output of other adapter
+ assert not torch.allclose(output_base.logits, output_default.logits, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_default.logits, output_other.logits, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_other.logits, output_mixed.logits, atol=atol, rtol=rtol)
+ # outputs of mixed adapter is mix of all 3
+ assert torch.allclose(output_base.logits[0], output_mixed.logits[0], atol=atol, rtol=rtol)
+ assert torch.allclose(output_default.logits[1], output_mixed.logits[1], atol=atol, rtol=rtol)
+ assert torch.allclose(output_other.logits[2], output_mixed.logits[2], atol=atol, rtol=rtol)
+
+ @require_bitsandbytes
+ def test_causal_lm_add_weighted_adapter_lora_adapter_compile(self, tokenizer, data):
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_id,
+ device_map="auto",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True),
+ ).eval()
+ sample = torch.tensor(data["train"][:1]["input_ids"]).to(model.device)
+ with torch.inference_mode():
+ output_base = model(sample)
+
+ config = LoraConfig(task_type=TaskType.CAUSAL_LM, init_lora_weights=False)
+ model = get_peft_model(model, config).eval()
+ model.add_adapter("other", config)
+ with torch.inference_mode():
+ output_default = model(sample)
+
+ model.set_adapter("other")
+ with torch.inference_mode():
+ output_other = model(sample)
+
+ model.add_weighted_adapter(["default", "other"], [0.5, 0.5], adapter_name="combined")
+ model.set_adapter("combined")
+ with torch.inference_mode():
+ output_combined = model(sample)
+
+ atol, rtol = 1e-4, 1e-4
+ # outputs of the base model != output of default adapter != output of other adapter
+ assert not torch.allclose(output_base.logits, output_default.logits, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_base.logits, output_other.logits, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_default.logits, output_other.logits, atol=atol, rtol=rtol)
+ # outputs of combined adapter != all others
+ assert not torch.allclose(output_base.logits, output_combined.logits, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_default.logits, output_combined.logits, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_other.logits, output_combined.logits, atol=atol, rtol=rtol)
diff --git a/peft/tests/test_trainable_tokens.py b/peft/tests/test_trainable_tokens.py
new file mode 100644
index 0000000000000000000000000000000000000000..d3acd55e9baa94e09eea555f6bf02a28b0086a53
--- /dev/null
+++ b/peft/tests/test_trainable_tokens.py
@@ -0,0 +1,887 @@
+# Copyright 2025-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from __future__ import annotations
+
+import copy
+
+import pytest
+import torch
+from transformers import AutoModelForCausalLM, AutoModelForSeq2SeqLM, AutoTokenizer
+
+from peft import AutoPeftModel, LoraConfig, PeftModel, TrainableTokensConfig, get_peft_model
+from peft.tuners.trainable_tokens.layer import TrainableTokensLayer
+from peft.utils import get_peft_model_state_dict
+from peft.utils.other import TrainableTokensWrapper
+
+
+class ModelEmb(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.emb = torch.nn.Embedding(100, 10)
+ self.lin0 = torch.nn.Linear(10, 1)
+
+ def forward(self, x):
+ return self.lin0(self.emb(x))
+
+ def get_input_embeddings(self):
+ return self.emb
+
+
+class ModelEmbedIn(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.embed_in = torch.nn.Embedding(100, 10)
+ self.lin0 = torch.nn.Linear(10, 1)
+
+ def forward(self, x):
+ return self.lin0(self.embed_in(x))
+
+ def get_input_embeddings(self):
+ return self.embed_in
+
+
+class ModelEmbedMultiple(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.embed_in = torch.nn.Embedding(100, 10)
+ self.embed_in_2 = torch.nn.Embedding(100, 10)
+ self.lin0 = torch.nn.Linear(10, 1)
+
+ def forward(self, x):
+ return self.lin0(self.embed_in(x) + self.embed_in_2(x))
+
+ def get_input_embeddings(self):
+ return self.embed_in
+
+
+class ModelEmbedInNoGet(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.embed_in = torch.nn.Embedding(100, 10)
+ self.lin0 = torch.nn.Linear(10, 1)
+
+ def forward(self, x):
+ return self.lin0(self.embed_in(x))
+
+
+class TestTrainableTokens:
+ @pytest.fixture
+ def model_id(self):
+ return "trl-internal-testing/tiny-random-LlamaForCausalLM"
+
+ @pytest.fixture
+ def model_multi_embedding(self):
+ class MultiEmbeddingMLP(torch.nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.emb_text = torch.nn.Embedding(10, 5)
+ self.emb_image = torch.nn.Embedding(8, 5)
+ self.lin0 = torch.nn.Linear(5, 10)
+ self.lin1 = torch.nn.Linear(10, 20)
+
+ def forward(self, x_text, x_image):
+ x_text = self.emb_text(x_text)
+ x_image = self.emb_image(x_image)
+ y = self.lin0(torch.concat([x_text, x_image], dim=1).view(-1, 5))
+ y = self.lin1(y)
+ return y, (x_text, x_image)
+
+ return MultiEmbeddingMLP()
+
+ @pytest.fixture
+ def model(self, model_id):
+ return AutoModelForCausalLM.from_pretrained(model_id)
+
+ @pytest.fixture
+ def tokenizer(self, model_id):
+ return AutoTokenizer.from_pretrained(model_id)
+
+ def simulate_training(self, trainable_tokens_layer, adapter_name="default"):
+ """Simulates training of trainable_tokens adapter layer by assigning random
+ values to the delta tokens.
+ """
+ trainable_tokens_layer.trainable_tokens_delta[adapter_name].data = torch.rand_like(
+ trainable_tokens_layer.trainable_tokens_delta[adapter_name].data
+ )
+
+ def test_stand_alone_usage(self, model, tokenizer, tmp_path):
+ original_model = copy.deepcopy(model)
+
+ peft_config = TrainableTokensConfig(target_modules=["embed_tokens"], token_indices=[0, 1, 3])
+ peft_model = get_peft_model(model, peft_config)
+ save_path = tmp_path / "stand_alone_usage"
+
+ # simulate normal use but take care to use the tokens that we expect to be modified
+ # (+1 that we don't expect to be modified)
+ X = {
+ "input_ids": torch.tensor([[0, 1, 2, 3]]),
+ "attention_mask": torch.tensor([[1, 1, 1, 1]]),
+ }
+
+ idcs_to_modify = peft_config.token_indices
+ idcs_to_keep = [i for i in X["input_ids"][0].tolist() if i not in idcs_to_modify]
+
+ self.simulate_training(peft_model.model.model.embed_tokens)
+ output_train = peft_model(output_hidden_states=True, **X)
+
+ peft_model.save_pretrained(save_path)
+ peft_model_org = peft_model
+
+ # check whether the token indices differ from the base model after loading the model
+ # from the checkpoint.
+ peft_model = AutoPeftModel.from_pretrained(save_path)
+ output_load = peft_model(output_hidden_states=True, **X)
+ output_orig = original_model(output_hidden_states=True, **X)
+
+ # on the way, make sure that the embedding matrix itself was not modified
+ assert torch.allclose(
+ peft_model.model.model.embed_tokens.weight,
+ peft_model_org.model.model.embed_tokens.weight,
+ )
+
+ W_load = output_load.hidden_states[0]
+ W_orig = output_orig.hidden_states[0]
+ W_train = output_train.hidden_states[0]
+
+ # all PEFT model embed outputs must equal the outputs during 'training' to make sure
+ # that saving/loading works properly.
+ assert torch.allclose(W_load, W_train)
+
+ assert not torch.allclose(W_load[:, idcs_to_modify], W_orig[:, idcs_to_modify])
+ assert torch.allclose(W_load[:, idcs_to_keep], W_orig[:, idcs_to_keep])
+
+ @pytest.mark.parametrize(
+ "peft_config",
+ [
+ LoraConfig(
+ target_modules="all-linear",
+ trainable_token_indices={"embed_tokens": [0, 1, 3]},
+ ),
+ ],
+ )
+ def test_combined_with_peft_method_usage(self, model, tokenizer, peft_config, tmp_path):
+ original_model = copy.deepcopy(model)
+ peft_model = get_peft_model(model, peft_config)
+ save_path = tmp_path / "combined_usage"
+
+ # simulate normal use but take care to use the tokens that we expect to be modified
+ # (+2 that we don't expect to be modified)
+ X = {
+ "input_ids": torch.tensor([[0, 1, 2, 3, 4]]),
+ "attention_mask": torch.tensor([[1, 1, 1, 1, 1]]),
+ }
+
+ idcs_to_modify = peft_config.trainable_token_indices["embed_tokens"]
+ idcs_to_keep = [i for i in X["input_ids"][0].tolist() if i not in idcs_to_modify]
+
+ self.simulate_training(peft_model.model.model.embed_tokens.token_adapter)
+ output_train = peft_model(output_hidden_states=True, **X)
+
+ peft_model.save_pretrained(save_path)
+ peft_model_org = peft_model
+
+ # check whether the token indices differ from the base model
+ peft_model = AutoPeftModel.from_pretrained(save_path)
+ output_load = peft_model(output_hidden_states=True, **X)
+ output_orig = original_model(output_hidden_states=True, **X)
+
+ W_load = output_load.hidden_states[0]
+ W_orig = output_orig.hidden_states[0]
+ W_train = output_train.hidden_states[0]
+
+ # all PEFT model embed outputs must equal the outputs during 'training' to make sure
+ # that saving/loading works properly.
+ assert torch.allclose(W_load, W_train)
+
+ assert not torch.allclose(W_load[:, idcs_to_modify], W_orig[:, idcs_to_modify])
+ assert torch.allclose(W_load[:, idcs_to_keep], W_orig[:, idcs_to_keep])
+
+ def test_basic_training(self, model, tokenizer):
+ # ensure that the model can be trained and backpropagation works
+ config = TrainableTokensConfig(
+ target_modules=["embed_tokens"],
+ token_indices=[0, 10],
+ )
+
+ model = get_peft_model(model, config)
+ optimizer = torch.optim.AdamW(model.parameters(), lr=1)
+
+ initial_delta = model.model.model.embed_tokens.trainable_tokens_delta.default.clone()
+ initial_originals = model.model.model.embed_tokens.trainable_tokens_original.default.clone()
+
+ X = {
+ "input_ids": torch.tensor([[0, 1, 2, 3, 4]]),
+ "attention_mask": torch.tensor([[1, 1, 1, 1, 1]]),
+ }
+
+ for step in range(3):
+ optimizer.zero_grad()
+ y_pred = model(**X)
+ loss = y_pred.logits.mean()
+ loss.backward()
+ optimizer.step()
+
+ assert torch.allclose(
+ model.model.model.embed_tokens.trainable_tokens_original.default,
+ initial_originals,
+ )
+ assert not torch.allclose(
+ model.model.model.embed_tokens.trainable_tokens_delta.default,
+ initial_delta,
+ )
+
+ @pytest.mark.parametrize(
+ "peft_config",
+ [
+ LoraConfig(
+ target_modules="all-linear",
+ trainable_token_indices={"embed_tokens": [0, 1, 3]},
+ ),
+ ],
+ )
+ def test_disable_adapters_with_merging(self, model, tokenizer, peft_config):
+ X = {
+ "input_ids": torch.tensor([[0, 1, 2, 3, 4]]),
+ "attention_mask": torch.tensor([[1, 1, 1, 1, 1]]),
+ }
+
+ model = get_peft_model(model, peft_config)
+ model.eval()
+
+ outputs_before = model(**X).logits
+
+ model.train()
+ lr = 0.01
+ optimizer = torch.optim.Adam(model.parameters(), lr=lr)
+
+ # train at least 3 steps for all parameters to be updated (probably this is required because of symmetry
+ # breaking of some LoRA layers that are initialized with constants)
+ for _ in range(3):
+ optimizer.zero_grad()
+ y_pred = model(**X)
+ loss = y_pred.logits.mean()
+ loss.backward()
+ optimizer.step()
+
+ model.eval()
+ outputs_unmerged = model(**X).logits
+ model.merge_adapter()
+ outputs_after = model(**X).logits
+
+ with model.disable_adapter():
+ outputs_disabled = model(**X).logits
+
+ # check that after leaving the disable_adapter context, everything is enabled again
+ outputs_enabled_after_disable = model(**X).logits
+
+ atol, rtol = 1e-5, 1e-5 # tolerances higher than defaults since merging introduces some numerical instability
+
+ # check that there is a difference in results after training
+ assert not torch.allclose(outputs_before, outputs_after, atol=atol, rtol=rtol)
+
+ # unmerged or merged should make no difference
+ assert torch.allclose(outputs_after, outputs_unmerged, atol=atol, rtol=rtol)
+
+ # check that disabling adapters gives the same results as before training
+ assert torch.allclose(outputs_before, outputs_disabled, atol=atol, rtol=rtol)
+
+ # check that enabling + disabling adapters does not change the results
+ assert torch.allclose(outputs_after, outputs_enabled_after_disable, atol=atol, rtol=rtol)
+
+ @pytest.mark.parametrize(
+ "peft_config",
+ [
+ LoraConfig(
+ target_modules="all-linear",
+ trainable_token_indices={"embed_tokens": [0, 1, 3]},
+ ),
+ ],
+ )
+ def test_safe_merge_with_adapter(self, model, tokenizer, peft_config):
+ X = {
+ "input_ids": torch.tensor([[0, 1, 2, 3]]),
+ "attention_mask": torch.tensor([[1, 1, 1, 1]]),
+ }
+
+ model = model.eval()
+ logits_base = model(**X).logits
+
+ model = get_peft_model(model, peft_config).eval()
+ logits_peft = model(**X).logits
+
+ atol, rtol = 1e-6, 1e-6 # default
+
+ model_unloaded = model.merge_and_unload(safe_merge=True)
+ logits_unloaded = model_unloaded(**X).logits
+
+ # check that the logits are the same after unloading
+ assert torch.allclose(logits_peft, logits_unloaded, atol=atol, rtol=rtol)
+
+ @pytest.mark.parametrize(
+ "peft_config",
+ [
+ LoraConfig(
+ target_modules="all-linear",
+ trainable_token_indices={"embed_tokens": [0, 1, 3]},
+ ),
+ ],
+ )
+ def test_load_multiple_adapters(self, model, peft_config, tmp_path):
+ # tests if having more than one adpater (even with just the same config) works
+ original_model = copy.deepcopy(model)
+ model = get_peft_model(model, peft_config)
+
+ model.save_pretrained(tmp_path)
+ del model
+
+ model = original_model
+ model = PeftModel.from_pretrained(model, tmp_path)
+ load_result1 = model.load_adapter(tmp_path, adapter_name="other")
+ load_result2 = model.load_adapter(tmp_path, adapter_name="yet-another")
+
+ assert load_result1.missing_keys == []
+ assert load_result2.missing_keys == []
+
+ @pytest.mark.parametrize(
+ "peft_config_factory",
+ [
+ lambda token_indices: LoraConfig(
+ target_modules="all-linear",
+ trainable_token_indices={"embed_tokens": token_indices},
+ ),
+ ],
+ )
+ def test_multiple_adapters_different_token_indices(self, model, peft_config_factory, tmp_path):
+ # tests if multiple adapters with different token indices work
+ original_model = copy.deepcopy(model)
+
+ token_indices_1 = [0, 1, 2]
+ token_indices_2 = [2, 3, 4]
+
+ peft_config_1 = peft_config_factory(token_indices_1)
+ peft_config_2 = peft_config_factory(token_indices_2)
+
+ model = get_peft_model(model, peft_config_1, adapter_name="adapter_1")
+ model.add_adapter("adapter_2", peft_config_2)
+
+ # "train" adapter 1
+ model.set_adapter("adapter_1")
+ self.simulate_training(model.model.model.embed_tokens.token_adapter, "adapter_1")
+
+ # "train" adapter 2
+ model.set_adapter("adapter_2")
+ self.simulate_training(model.model.model.embed_tokens.token_adapter, "adapter_2")
+
+ # now we infer on adapter 1 and on adapter 2 and check if the requested indices are changed for
+ # each adapter. e.g., for adapter 1, only token indices 1 should be changed.
+ X = {
+ "input_ids": torch.tensor([list(set(token_indices_1 + token_indices_2))]),
+ "attention_mask": torch.tensor([[1] * (len(set(token_indices_1 + token_indices_2)))]),
+ }
+
+ original_output = original_model(output_hidden_states=True, **X).hidden_states[0]
+
+ # infer with adapter 1, embeddings for token indices 1 should be changed, no others.
+ model.set_adapter("adapter_1")
+ adapter_1_output = model(output_hidden_states=True, **X).hidden_states[0]
+
+ idcs_to_modify = token_indices_1
+ idcs_to_keep = [i for i in X["input_ids"][0].tolist() if i not in idcs_to_modify]
+
+ assert not torch.allclose(adapter_1_output[:, idcs_to_modify], original_output[:, idcs_to_modify])
+ assert torch.allclose(adapter_1_output[:, idcs_to_keep], original_output[:, idcs_to_keep])
+
+ # infer with adapter 2, embeddings for token indices 2 should be changed, no others.
+ model.set_adapter("adapter_2")
+ adapter_2_output = model(output_hidden_states=True, **X).hidden_states[0]
+
+ idcs_to_modify = token_indices_2
+ idcs_to_keep = [i for i in X["input_ids"][0].tolist() if i not in idcs_to_modify]
+
+ assert not torch.allclose(adapter_2_output[:, idcs_to_modify], original_output[:, idcs_to_modify])
+ assert torch.allclose(adapter_2_output[:, idcs_to_keep], original_output[:, idcs_to_keep])
+
+ @pytest.mark.parametrize(
+ "peft_config_factory",
+ [
+ lambda token_indices: LoraConfig(
+ target_modules="all-linear",
+ trainable_token_indices={"embed_tokens": token_indices},
+ ),
+ ],
+ )
+ def test_multiple_adapters_overlapping_token_indices_merging(self, model, peft_config_factory, tmp_path):
+ # tests that merging multiple adapters that have overlapping indices is not defined at the moment
+ # and would yield undefined behavior. note that merging a single adapter is fine.
+ original_model = copy.deepcopy(model)
+
+ token_indices_1 = [0, 1, 2]
+ token_indices_2 = [2, 3, 4]
+
+ peft_config_1 = peft_config_factory(token_indices_1)
+ peft_config_2 = peft_config_factory(token_indices_2)
+
+ model = get_peft_model(model, peft_config_1, adapter_name="adapter_1")
+ model.add_adapter("adapter_2", peft_config_2)
+
+ with pytest.raises(ValueError) as e:
+ model.merge_and_unload(adapter_names=["adapter_1", "adapter_2"])
+ assert "are already defined and would result in undefined merging behavior" in str(e)
+
+ @pytest.mark.parametrize(
+ "peft_config_factory",
+ [
+ lambda targets, token_indices: LoraConfig(
+ target_modules=targets,
+ trainable_token_indices={"embed_tokens": token_indices},
+ ),
+ ],
+ )
+ def test_multiple_adapters_mixed_forward(self, model, peft_config_factory, tmp_path):
+ # tests if multiple adapters with different token indices work
+ original_model = copy.deepcopy(model)
+
+ token_indices_1 = [0, 1, 2]
+ token_indices_2 = [2, 3, 4]
+
+ peft_config_1 = peft_config_factory(".*q_proj", token_indices_1)
+ peft_config_2 = peft_config_factory(".*o_proj", token_indices_2)
+
+ model = get_peft_model(model, peft_config_1, adapter_name="adapter_1")
+ model.add_adapter("adapter_2", peft_config_2)
+
+ # "train" adapter 1
+ model.set_adapter("adapter_1")
+ self.simulate_training(model.model.model.embed_tokens.token_adapter, "adapter_1")
+
+ # "train" adapter 2
+ model.set_adapter("adapter_2")
+ self.simulate_training(model.model.model.embed_tokens.token_adapter, "adapter_2")
+
+ # forward(adapter_names=...) is not available in train mode
+ model.eval()
+
+ # Build a batch of 2 items, each the same input sequence but each sequence will be passed to a different
+ # adapter via mixed batch forward.
+ input_sequence = list(set(token_indices_1 + token_indices_2))
+ X = {
+ "input_ids": torch.tensor([input_sequence, input_sequence]),
+ "attention_mask": torch.tensor([[1] * len(input_sequence), [1] * len(input_sequence)]),
+ }
+ batch_adapter_names = ["adapter_1", "adapter_2"]
+
+ original_output = original_model(output_hidden_states=True, **X)
+ mixed_output = model(output_hidden_states=True, adapter_names=batch_adapter_names, **X)
+
+ # check that the active adapter is still the last activated adapter, adapter_2
+ assert model.model.model.embed_tokens.token_adapter.active_adapter == ["adapter_2"]
+
+ adapter_1_output = mixed_output.hidden_states[0][0:1]
+ original_output_1 = original_output.hidden_states[0][0:1]
+ adapter_2_output = mixed_output.hidden_states[0][1:2]
+ original_output_2 = original_output.hidden_states[0][1:2]
+
+ idcs_to_modify = token_indices_1
+ idcs_to_keep = [i for i in X["input_ids"][0].tolist() if i not in idcs_to_modify]
+
+ assert not torch.allclose(adapter_1_output[:, idcs_to_modify], original_output_1[:, idcs_to_modify])
+ assert torch.allclose(adapter_1_output[:, idcs_to_keep], original_output_1[:, idcs_to_keep])
+
+ idcs_to_modify = token_indices_2
+ idcs_to_keep = [i for i in X["input_ids"][0].tolist() if i not in idcs_to_modify]
+
+ assert not torch.allclose(adapter_2_output[:, idcs_to_modify], original_output_2[:, idcs_to_modify])
+ assert torch.allclose(adapter_2_output[:, idcs_to_keep], original_output_2[:, idcs_to_keep])
+
+ def test_stand_alone_raises_target_layer_not_found(self, model):
+ config = TrainableTokensConfig(target_modules=["doesnt_exist"], token_indices=[0, 1, 3])
+ with pytest.raises(ValueError) as e:
+ model = get_peft_model(model, config)
+ assert "Target modules ['doesnt_exist'] not found in the base model." in str(e)
+
+ @pytest.mark.parametrize(
+ "peft_config, target_layer_name",
+ [
+ (LoraConfig(trainable_token_indices={"does-not-exist": [0, 1, 2]}), "does-not-exist"),
+ ],
+ )
+ def test_combined_with_peft_raises_target_layer_not_found(self, model, peft_config, target_layer_name):
+ # same as test_stand_alone_raises_target_layer_not_found but tests the peft method integration
+ with pytest.raises(ValueError) as e:
+ model = get_peft_model(model, peft_config)
+ assert f"Target modules {{{repr(target_layer_name)}}} not found in the base model." in str(e)
+
+ def test_multiple_targets(self, model_multi_embedding):
+ # tests the ability of targeting two modules with the same token indices
+ original_model = copy.deepcopy(model_multi_embedding)
+ config = TrainableTokensConfig(target_modules=["emb_text", "emb_image"], token_indices=[0, 1])
+ peft_model = get_peft_model(model_multi_embedding, config)
+
+ self.simulate_training(peft_model.model.emb_text)
+ self.simulate_training(peft_model.model.emb_image)
+
+ X = {
+ "x_text": torch.tensor([[0, 1, 2]]),
+ "x_image": torch.tensor([[0, 1, 2]]),
+ }
+
+ _, (emb_text_orig, emb_image_orig) = original_model(**X)
+ _, (emb_text_peft, emb_image_peft) = peft_model(**X)
+
+ assert not torch.allclose(emb_text_orig[:, [0, 1]], emb_text_peft[:, [0, 1]])
+ assert torch.allclose(emb_text_orig[:, [2]], emb_text_peft[:, [2]])
+ assert not torch.allclose(emb_image_orig[:, [0, 1]], emb_image_peft[:, [0, 1]])
+ assert torch.allclose(emb_image_orig[:, [2]], emb_image_peft[:, [2]])
+
+ @pytest.mark.parametrize(
+ "peft_config",
+ [
+ LoraConfig(
+ target_modules="all-linear",
+ trainable_token_indices={"embed_tokens": [0, 1, 3]},
+ ),
+ ],
+ )
+ def test_no_embeddings_in_save_with_combined_usage(self, model, tokenizer, peft_config, tmp_path):
+ # make sure that in combined use the only state dict key is that of the token deltas and nothing more
+
+ peft_model = get_peft_model(model, peft_config)
+ state_dict = get_peft_model_state_dict(
+ model=peft_model,
+ state_dict=None,
+ adapter_name="default",
+ )
+
+ embedding_keys = [n for n in state_dict.keys() if "embed_tokens" in n]
+ assert embedding_keys == ["base_model.model.model.embed_tokens.token_adapter.trainable_tokens_delta"]
+
+ @pytest.fixture()
+ def model_weight_untied(self, model):
+ return model
+
+ @pytest.fixture()
+ def model_id_weight_tied(self):
+ return "facebook/opt-125m"
+
+ @pytest.fixture()
+ def model_weight_tied(self, model_id_weight_tied):
+ return AutoModelForCausalLM.from_pretrained(model_id_weight_tied)
+
+ @pytest.mark.parametrize(
+ "peft_config",
+ [
+ LoraConfig(
+ target_modules="all-linear",
+ trainable_token_indices={"embed_tokens": [0, 1, 3]},
+ ),
+ ],
+ )
+ def test_weight_tying_noop_when_model_is_untied(self, model_weight_untied, peft_config, tmp_path):
+ # test if the weight tying is affected as well when we modified the embedding.
+ assert model_weight_untied._tied_weights_keys
+ assert not model_weight_untied.config.tie_word_embeddings
+
+ peft_model = get_peft_model(model_weight_untied, peft_config)
+ assert hasattr(peft_model.model.model.embed_tokens, "token_adapter")
+ assert not hasattr(peft_model.model.lm_head, "token_adapter")
+
+ @pytest.mark.parametrize(
+ "peft_config",
+ [
+ LoraConfig(
+ target_modules="all-linear",
+ trainable_token_indices={"embed_tokens": [0, 1, 3]},
+ ),
+ ],
+ )
+ def test_weight_tying_applied_when_model_is_tied(self, model_weight_tied, peft_config, tmp_path):
+ # test if the weight tying is affected as well when we modified the embedding.
+ assert model_weight_tied._tied_weights_keys
+ assert model_weight_tied.config.tie_word_embeddings
+
+ peft_model = get_peft_model(model_weight_tied, peft_config)
+
+ # make it so that the input embeddings diverge. when the weights are tied this should
+ # reflect in the output embeddings as well.
+ self.simulate_training(peft_model.model.model.decoder.embed_tokens.token_adapter)
+
+ # we have to find out if the input embedding tying is doing its job during forward.
+ # for this we can leverage the fact that emb_out(1/emb_in(x)) is embed_dim on the
+ # diagonal iff emb_in.weight == emb_out.weight.
+ token_indices = [0, 1, 2, 3]
+ emb_dim = 768
+ emb_in = peft_model.model.model.decoder.embed_tokens(torch.tensor([token_indices]))
+ emb_out = peft_model.model.lm_head(1 / emb_in)
+
+ assert torch.allclose(torch.diag(emb_out[0]), torch.tensor([emb_dim] * len(token_indices)).float())
+
+ # make sure that the state dict does not include weight-tied weights.
+ state_dict = get_peft_model_state_dict(peft_model)
+ assert not [key for key in state_dict if any(tied_key in key for tied_key in peft_model._tied_weights_keys)]
+
+ # make sure that merging and unloading restores the weight-tying.
+ merged_model = peft_model.merge_and_unload()
+
+ assert merged_model.model.decoder.embed_tokens.weight.data_ptr() == merged_model.lm_head.weight.data_ptr()
+
+ def test_weight_tying_applied_when_model_is_tied_standalone(self, model_weight_tied):
+ # since weight tying is currently not supported make sure that an error is raised when attempting
+ # to use a model that has tied input/output embeddings
+ assert model_weight_tied._tied_weights_keys
+ assert model_weight_tied.config.tie_word_embeddings
+
+ peft_config = TrainableTokensConfig(
+ target_modules=["embed_tokens"],
+ token_indices=[0, 1, 3],
+ )
+
+ peft_model = get_peft_model(model_weight_tied, peft_config)
+
+ # make it so that the input embeddings diverge. when the weights are tied this should
+ # reflect in the output embeddings as well.
+ self.simulate_training(peft_model.model.model.decoder.embed_tokens)
+
+ # we have to find out if the input embedding tying is doing its job during forward.
+ # for this we can leverage the fact that emb_out(1/emb_in(x)) is embed_dim on the
+ # diagonal iff emb_in.weight == emb_out.weight.
+ token_indices = [0, 1, 2, 3]
+ emb_dim = 768
+ emb_in = peft_model.model.model.decoder.embed_tokens(torch.tensor([token_indices]))
+ emb_out = peft_model.model.lm_head(1 / emb_in)
+
+ assert torch.allclose(torch.diag(emb_out[0]), torch.tensor([emb_dim] * len(token_indices)).float())
+
+ # make sure that the state dict does not include weight-tied weights.
+ state_dict = get_peft_model_state_dict(peft_model)
+ assert not [key for key in state_dict if any(tied_key in key for tied_key in peft_model._tied_weights_keys)]
+
+ # make sure that merging and unloading restores the weight-tying.
+ merged_model = peft_model.merge_and_unload()
+
+ assert merged_model.model.decoder.embed_tokens.weight.data_ptr() == merged_model.lm_head.weight.data_ptr()
+
+ def test_weight_tying_normally_issues_warning(self, model_weight_tied, recwarn):
+ # When using models with weight tying and targeting the embedding or the tied layer should raise a warning.
+ peft_config = LoraConfig(target_modules=["embed_tokens"])
+ peft_model = get_peft_model(model_weight_tied, peft_config)
+
+ warnings = [w.message.args[0] for w in recwarn]
+ warnings = [msg for msg in warnings if "Model with `tie_word_embeddings=True` and the" in msg]
+ assert warnings
+
+ def test_weight_tying_state_dict_ignores_tied_weights(self, model_weight_tied):
+ # since weight tying is currently not supported make sure that an error is raised when attempting
+ # to use a model that has tied input/output embeddings
+ assert model_weight_tied._tied_weights_keys
+ assert model_weight_tied.config.tie_word_embeddings
+
+ peft_config = TrainableTokensConfig(
+ target_modules=["embed_tokens"],
+ token_indices=[0, 1, 3],
+ )
+
+ peft_model = get_peft_model(model_weight_tied, peft_config)
+
+ state_dict = peft_model.state_dict()
+ peft_state_dict = get_peft_model_state_dict(peft_model)
+
+ # the state dict or the peft model state dict must not include tied adapter weights
+ state_dict_keys = [n for n, _ in state_dict.items() if "tied_adapter." in n]
+ peft_state_dict_keys = [n for n, _ in peft_state_dict.items() if "tied_adapter." in n]
+
+ assert not state_dict_keys
+ assert not peft_state_dict_keys
+
+ @pytest.mark.parametrize(
+ "peft_config",
+ [
+ LoraConfig(
+ target_modules="all-linear",
+ trainable_token_indices={"shared": [0, 1, 3]},
+ ),
+ ],
+ )
+ def test_weight_tying_applied_when_model_is_tied_encoder_decoder(self, peft_config):
+ model_id = "hf-internal-testing/tiny-random-t5"
+ base_model = AutoModelForSeq2SeqLM.from_pretrained(model_id)
+
+ peft_model = get_peft_model(base_model, peft_config)
+
+ # make it so that the input embeddings diverge. when the weights are tied this should
+ # reflect in the output embeddings as well.
+ self.simulate_training(peft_model.model.shared.token_adapter)
+
+ # we have to find out if the input embedding tying is doing its job during forward.
+ # for this we can leverage the fact that emb_out(1/emb_in(x)) is embed_dim on the
+ # diagonal iff emb_in.weight == emb_out.weight.
+ token_indices = [0, 1, 2, 3]
+ emb_dim = base_model.config.d_model
+ emb_in = peft_model.model.encoder.embed_tokens(torch.tensor([token_indices]))
+ emb_out = peft_model.model.lm_head(1 / emb_in)
+
+ assert torch.allclose(torch.diag(emb_out[0]), torch.tensor([emb_dim] * len(token_indices)).float())
+
+ # T5 has a decoder embedding layer, we can simply check if it's forward is equal to the encoder
+ # embedding forward.
+ emb_out = peft_model.model.decoder.embed_tokens(torch.tensor([token_indices]))
+
+ assert torch.allclose(emb_in, emb_out)
+
+ # make sure that the state dict does not include weight-tied weights.
+ state_dict = get_peft_model_state_dict(peft_model)
+ assert not [key for key in state_dict if any(tied_key in key for tied_key in peft_model._tied_weights_keys)]
+
+ # make sure that merging and unloading restores the weight-tying.
+ merged_model = peft_model.merge_and_unload()
+
+ assert merged_model.encoder.embed_tokens.weight.data_ptr() == merged_model.lm_head.weight.data_ptr()
+ assert (
+ merged_model.encoder.embed_tokens.weight.data_ptr() == merged_model.decoder.embed_tokens.weight.data_ptr()
+ )
+
+ @pytest.mark.parametrize(
+ "peft_config",
+ [
+ LoraConfig(
+ target_modules="all-linear",
+ trainable_token_indices={"embed_tokens": [0, 1, 3]},
+ modules_to_save=["embed_tokens"],
+ ),
+ ],
+ )
+ def test_modules_to_save_excludes_trainable_tokens(self, model, peft_config):
+ with pytest.raises(ValueError) as e:
+ get_peft_model(model, peft_config)
+ assert "The embedding layer is already marked to be trained fully" in str(e)
+
+ def test_merge_and_unload_standalone(self, model):
+ # test basic functionality of merge_and_unload for standalone TrainableTokens
+ token_indices = [0, 1, 3]
+
+ peft_config = TrainableTokensConfig(
+ target_modules=["embed_tokens"],
+ token_indices=token_indices,
+ )
+
+ peft_model = get_peft_model(model, peft_config)
+
+ self.simulate_training(peft_model.model.model.embed_tokens)
+ expected_changed_weights = peft_model.model.model.embed_tokens.trainable_tokens_delta.default.data.clone()
+
+ # make sure no TrainableTokensLayer is in the module
+ merged_model = peft_model.merge_and_unload()
+ for _, module in merged_model.named_modules():
+ assert not isinstance(module, TrainableTokensLayer)
+
+ # make sure that deltas are applied to the embedding matrix
+ assert torch.allclose(merged_model.model.embed_tokens.weight.data[token_indices], expected_changed_weights)
+
+ def test_original_module_not_in_state_dict(self, model):
+ # Every AuxiliaryTrainingWrapper has an original_module attribute. Since the TrainableTokensWrapper is wrapping
+ # a TrainableTokensLayer and it already has a base layer which serves as the original module, we don't need that
+ # and so it should not come up in the state dict to save memory.
+
+ peft_config = LoraConfig(
+ target_modules="all-linear",
+ trainable_token_indices={"embed_tokens": [0, 1, 3]},
+ )
+
+ peft_model = get_peft_model(model, peft_config)
+
+ # make sure that the original module is present and accessible even though
+ # we want to exclude it from the state dict.
+ assert peft_model.model.model.embed_tokens.original_module
+
+ state_dict = get_peft_model_state_dict(peft_model)
+
+ assert not [k for k in state_dict if ".original_module.weight" in k]
+
+ state_dict = peft_model.state_dict()
+ assert not [k for k in state_dict if ".original_module.weight" in k]
+
+ @pytest.fixture
+ def model_emb(self):
+ return ModelEmb()
+
+ @pytest.fixture
+ def model_embed_in(self):
+ return ModelEmbedIn()
+
+ @pytest.fixture
+ def model_embed_in_no_get(self):
+ return ModelEmbedInNoGet()
+
+ @pytest.fixture
+ def model_embed_multiple(self):
+ return ModelEmbedMultiple()
+
+ @pytest.mark.parametrize(
+ "model_fixture_name, getter",
+ [
+ ("model_emb", lambda model: model.emb),
+ ("model_embed_in", lambda model: model.embed_in),
+ ("model", lambda model: model.model.model.embed_tokens),
+ ],
+ )
+ def test_default_embedding_name_is_inferred_standalone(self, model_fixture_name, getter, request):
+ # make sure that the auto targeting works when `target_module=None`
+ base_model = request.getfixturevalue(model_fixture_name)
+
+ peft_config = TrainableTokensConfig(target_modules=None, token_indices=[0, 1, 3])
+ peft_model = get_peft_model(base_model, peft_config)
+
+ assert isinstance(getter(peft_model), TrainableTokensLayer)
+
+ @pytest.mark.parametrize(
+ "model_fixture_name, getter",
+ [
+ ("model_emb", lambda model: model.emb),
+ ("model_embed_in", lambda model: model.embed_in),
+ ("model", lambda model: model.model.model.embed_tokens),
+ ],
+ )
+ def test_default_embedding_name_is_inferred_combined(self, model_fixture_name, getter, request):
+ # make sure that the auto targeting works when `target_module=None`
+ base_model = request.getfixturevalue(model_fixture_name)
+
+ peft_config = LoraConfig(target_modules="all-linear", trainable_token_indices=[0, 1, 3])
+ peft_model = get_peft_model(base_model, peft_config)
+
+ assert isinstance(getter(peft_model), TrainableTokensWrapper)
+
+ def test_default_embedding_name_cannot_be_inferred(self, model_embed_in_no_get):
+ # should default to default value `embed_tokens` which is not present in this model
+ base_model = model_embed_in_no_get
+
+ peft_config = TrainableTokensConfig(target_modules=None, token_indices=[0, 1, 3])
+
+ with pytest.raises(ValueError) as e:
+ peft_model = get_peft_model(base_model, peft_config)
+
+ assert "Target modules embed_tokens not found in the base model." in str(e)
+
+ def test_embedding_name_is_used_when_given_standalone(self, model_embed_multiple):
+ peft_config = TrainableTokensConfig(target_modules="embed_in_2", token_indices=[0, 1, 3])
+ peft_model = get_peft_model(model_embed_multiple, peft_config)
+
+ assert isinstance(peft_model.model.embed_in_2, TrainableTokensLayer)
+ assert not isinstance(peft_model.model.embed_in, TrainableTokensLayer)
+
+ def test_embedding_name_is_used_when_given_combined(self, model_embed_multiple):
+ peft_config = LoraConfig(target_modules="all-linear", trainable_token_indices={"embed_in_2": [0, 1, 3]})
+ peft_model = get_peft_model(model_embed_multiple, peft_config)
+
+ assert isinstance(peft_model.model.embed_in_2, TrainableTokensWrapper)
+ assert not isinstance(peft_model.model.embed_in, TrainableTokensWrapper)
diff --git a/peft/tests/test_tuners_utils.py b/peft/tests/test_tuners_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..bf745990d59cfcd0ebb9cd0115aeb8a22bd53908
--- /dev/null
+++ b/peft/tests/test_tuners_utils.py
@@ -0,0 +1,1946 @@
+#!/usr/bin/env python3
+
+# coding=utf-8
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import re
+import unittest
+from copy import deepcopy
+
+import pytest
+import torch
+from diffusers import StableDiffusionPipeline
+from parameterized import parameterized
+from torch import nn
+from transformers import (
+ AutoModel,
+ AutoModelForCausalLM,
+ AutoModelForSeq2SeqLM,
+ AutoModelForSequenceClassification,
+ BitsAndBytesConfig,
+)
+from transformers.pytorch_utils import Conv1D
+
+from peft import (
+ AdaptionPromptConfig,
+ IA3Config,
+ LoHaConfig,
+ LoraConfig,
+ PeftModel,
+ PromptTuningConfig,
+ VeraConfig,
+ get_layer_status,
+ get_model_status,
+ get_peft_model,
+)
+from peft.tuners.lora.layer import LoraLayer
+from peft.tuners.tuners_utils import (
+ BaseTuner,
+ BaseTunerLayer,
+ _maybe_include_all_linear_layers,
+ check_target_module_exists,
+ inspect_matched_modules,
+)
+from peft.tuners.tuners_utils import (
+ _find_minimal_target_modules as find_minimal_target_modules,
+)
+from peft.utils import INCLUDE_LINEAR_LAYERS_SHORTHAND, ModulesToSaveWrapper, infer_device
+from peft.utils.constants import DUMMY_MODEL_CONFIG, MIN_TARGET_MODULES_FOR_OPTIMIZATION
+
+from .testing_utils import require_bitsandbytes, require_non_cpu
+
+
+# Implements tests for regex matching logic common for all BaseTuner subclasses, and
+# tests for correct behaviour with different config kwargs for BaseTuners (Ex: feedforward for IA3, etc) and
+# tests for utility function to include all linear layers
+
+REGEX_TEST_CASES = [
+ # tuple of
+ # 1. key
+ # 2. target_modules
+ # 3. layers_to_transform
+ # 4. layers_pattern
+ # 5. expected result
+ # some basic examples
+ ("", [], None, None, False),
+ ("", ["foo"], None, None, False),
+ ("foo", [], None, None, False),
+ ("foo", ["foo"], None, None, True),
+ ("foo", ["bar"], None, None, False),
+ ("foo", ["foo", "bar"], None, None, True),
+ # with regex
+ ("foo", "foo", None, None, True),
+ ("foo", ".*oo", None, None, True),
+ ("foo", "fo.*", None, None, True),
+ ("foo", ".*bar.*", None, None, False),
+ ("foobar", ".*oba.*", None, None, True),
+ # with layers_to_transform
+ ("foo.bar.1.baz", ["baz"], [1], ["bar"], True),
+ ("foo.bar.1.baz", ["baz"], [0], ["bar"], False),
+ ("foo.bar.1.baz", ["baz"], [2], ["bar"], False),
+ ("foo.bar.10.baz", ["baz"], [0], ["bar"], False),
+ ("foo.bar.10.baz", ["baz"], [1], ["bar"], False),
+ ("foo.bar.1.baz", ["baz"], [0, 1, 2], ["bar"], True),
+ ("foo.bar.1.baz", ["baz", "spam"], [1], ["bar"], True),
+ ("foo.bar.1.baz", ["baz", "spam"], [0, 1, 2], ["bar"], True),
+ # empty layers_pattern
+ ("foo.whatever.1.baz", ["baz"], [1], [], True),
+ ("foo.whatever.1.baz", ["baz"], [0], [], False),
+ ("foo.whatever.1.baz", ["baz"], [1], "", True),
+ ("foo.whatever.1.baz", ["baz"], [0], "", False),
+ ("foo.whatever.1.baz", ["baz"], [1], None, True),
+ ("foo.whatever.1.baz", ["baz"], [0], None, False),
+ # some realistic examples: transformers model
+ ("transformer.h.1.attn.attention.q_proj.foo", ["q_proj"], None, [], False),
+ ("transformer.h.1.attn.attention.q_proj", [], None, [], False),
+ ("transformer.h.1.attn.attention.q_proj", ["q_proj"], None, [], True),
+ ("transformer.h.1.attn.attention.q_proj", ["q_proj", "v_proj"], None, [], True),
+ ("transformer.h.1.attn.attention.resid_dropout", ["q_proj", "v_proj"], None, [], False),
+ ("transformer.h.1.attn.attention.q_proj", ["q_proj"], [1], ["h"], True),
+ ("transformer.h.1.attn.attention.q_proj", ["q_proj"], [0], ["h"], False),
+ ("transformer.h.1.attn.attention.q_proj", ["q_proj"], [2], ["h"], False),
+ ("transformer.h.1.attn.attention.q_proj", ["q_proj"], [0, 1, 2], ["h"], True),
+ ("transformer.h.1.attn.attention.q_proj", ["q_proj", "v_proj"], [0, 1, 2], ["h"], True),
+ ("foo.bar.q_proj", ["q_proj"], None, [], True),
+ ("foo.bar.1.baz", ["baz"], [1], ["foo"], False),
+ # other corner cases. For ex, below is a case where layers_pattern
+ # is one of the target nn.modules
+ ("foo.bar.1.baz", ["baz"], [1], ["baz"], False),
+ # here, layers_pattern is 'bar', but only keys that contain '.bar' are valid.
+ ("bar.1.baz", ["baz"], [1], ["bar"], False),
+ ("foo.bar.001.baz", ["baz"], [1], ["bar"], True),
+ ("foo.bar.1.spam.2.baz", ["baz"], [1], ["bar"], True),
+ ("foo.bar.2.spam.1.baz", ["baz"], [1], ["bar"], False),
+ # some realistic examples: module using nn.Sequential
+ # for the below test case, key should contain '.blocks' to be valid, because of how layers_pattern is matched
+ ("blocks.1.weight", ["weight"], [1], ["blocks"], False),
+ ("blocks.1.bias", ["weight"], [1], ["blocks"], False),
+ ("mlp.blocks.1.weight", ["weight"], [1], ["blocks"], True),
+ ("mlp.blocks.1.bias", ["weight"], [1], ["blocks"], False),
+]
+
+MAYBE_INCLUDE_ALL_LINEAR_LAYERS_TEST_CASES = [
+ # model_name, model_type, initial_target_modules, expected_target_modules
+ # test for a causal Llama model
+ (
+ "HuggingFaceH4/tiny-random-LlamaForCausalLM",
+ "causal",
+ INCLUDE_LINEAR_LAYERS_SHORTHAND,
+ ["k_proj", "v_proj", "q_proj", "o_proj", "down_proj", "up_proj", "gate_proj"],
+ ),
+ # test for a Llama model without the LM head
+ (
+ "HuggingFaceH4/tiny-random-LlamaForCausalLM",
+ "base",
+ INCLUDE_LINEAR_LAYERS_SHORTHAND,
+ ["k_proj", "v_proj", "q_proj", "o_proj", "down_proj", "up_proj", "gate_proj"],
+ ),
+ # test for gpt2 with Conv1D layers
+ ("hf-internal-testing/tiny-random-gpt2", "causal", INCLUDE_LINEAR_LAYERS_SHORTHAND, ["c_attn", "c_proj", "c_fc"]),
+ # test for T5 model
+ (
+ "hf-internal-testing/tiny-random-t5",
+ "seq2seq",
+ INCLUDE_LINEAR_LAYERS_SHORTHAND,
+ ["k", "q", "v", "o", "wi", "wo"],
+ ),
+ # test for GPTNeoX. output module list should exclude classification head - which is named as "embed_out" instead of the usual "lm_head" for GPTNeoX
+ (
+ "hf-internal-testing/tiny-random-GPTNeoXForCausalLM",
+ "causal",
+ INCLUDE_LINEAR_LAYERS_SHORTHAND,
+ ["query_key_value", "dense", "dense_h_to_4h", "dense_4h_to_h"],
+ ),
+]
+
+# tests for a few args that should remain unchanged
+MAYBE_INCLUDE_ALL_LINEAR_LAYERS_TEST_INTERNALS = [
+ # initial_target_modules, expected_target_modules
+ (["k_proj"], ["k_proj"]),
+ # test with target_modules as None
+ (None, None),
+ # test with target_modules as a regex expression
+ (".*(q_proj|v_proj)$", ".*(q_proj|v_proj)$"),
+]
+
+BNB_QUANTIZATIONS = [("4bit",), ("8bit",)]
+BNB_TEST_CASES = [(x + y) for x in MAYBE_INCLUDE_ALL_LINEAR_LAYERS_TEST_CASES for y in BNB_QUANTIZATIONS]
+
+
+class PeftCustomKwargsTester(unittest.TestCase):
+ r"""
+ Test if the PeftModel is instantiated with correct behaviour for custom kwargs. This includes:
+ - test if regex matching works correctly
+ - test if adapters handle custom kwargs the right way e.g. IA3 for `feedforward_modules`
+
+ """
+
+ transformers_class_map = {"causal": AutoModelForCausalLM, "seq2seq": AutoModelForSeq2SeqLM, "base": AutoModel}
+
+ @parameterized.expand(REGEX_TEST_CASES)
+ def test_regex_matching_valid(self, key, target_modules, layers_to_transform, layers_pattern, expected_result):
+ # We use a LoRA Config for testing, but the regex matching function is common for all BaseTuner subclasses.
+ # example model_id for config initialization. key is matched only against the target_modules given, so this can be any model
+ model_id = "peft-internal-testing/tiny-OPTForCausalLM-lora"
+ config = LoraConfig(
+ base_model_name_or_path=model_id,
+ target_modules=target_modules,
+ layers_pattern=layers_pattern,
+ layers_to_transform=layers_to_transform,
+ )
+ actual_result = bool(check_target_module_exists(config, key))
+ assert actual_result == expected_result
+
+ def test_module_matching_lora(self):
+ # peft models that have a module matching method to inspect the matching modules to allow
+ # users to easily debug their configuration. Here we only test a single case, not all possible combinations of
+ # configs that could exist. This is okay as the method calls `check_target_module_exists` internally, which
+ # has been extensively tested above.
+ model_id = "hf-internal-testing/tiny-random-BloomForCausalLM"
+ model = AutoModel.from_pretrained(model_id)
+ # by default, this model matches query_key_value
+ config = LoraConfig()
+ peft_model = get_peft_model(model, config)
+
+ output = inspect_matched_modules(peft_model) # inspects default adapter for peft_model
+ matched = output["matched"]
+ expected = [
+ "h.0.self_attention.query_key_value",
+ "h.1.self_attention.query_key_value",
+ "h.2.self_attention.query_key_value",
+ "h.3.self_attention.query_key_value",
+ "h.4.self_attention.query_key_value",
+ ]
+ assert matched == expected # module lists should match exactly
+
+ # no overlap with matched modules
+ unmatched = output["unmatched"]
+ for key in expected:
+ assert key not in unmatched
+
+ def test_feedforward_matching_ia3(self):
+ model_id = "hf-internal-testing/tiny-random-T5ForConditionalGeneration"
+ model = AutoModelForSeq2SeqLM.from_pretrained(model_id)
+ # simple example for just one t5 block for testing
+ config_kwargs = {
+ "target_modules": ".*encoder.*block.0.*(SelfAttention|EncDecAttention|DenseReluDense).(k|q|v|wo|wi)$",
+ "feedforward_modules": ["wo", "wi"],
+ }
+ config = IA3Config(base_model_name_or_path=model_id, **config_kwargs)
+ peft_model = get_peft_model(model, config)
+ output = inspect_matched_modules(peft_model) # inspects default adapter for peft_model
+ matched = output["matched"]
+ expected = [
+ "encoder.block.0.layer.0.SelfAttention.q",
+ "encoder.block.0.layer.0.SelfAttention.k",
+ "encoder.block.0.layer.0.SelfAttention.v",
+ "encoder.block.0.layer.1.DenseReluDense.wi",
+ "encoder.block.0.layer.1.DenseReluDense.wo",
+ ]
+ expected_feedforward = [
+ "encoder.block.0.layer.1.DenseReluDense.wi",
+ "encoder.block.0.layer.1.DenseReluDense.wo",
+ ]
+ assert matched == expected # not required since we do similar checks above, but just to be sure
+ module_dict = dict(model.named_modules())
+ for key in matched:
+ module = module_dict[key]
+ if key in expected_feedforward:
+ assert module.is_feedforward
+ else: # other IA3 modules should not be marked as feedforward
+ assert not module.is_feedforward
+
+ @parameterized.expand(MAYBE_INCLUDE_ALL_LINEAR_LAYERS_TEST_CASES)
+ def test_maybe_include_all_linear_layers_lora(
+ self, model_id, model_type, initial_target_modules, expected_target_modules
+ ):
+ model = self.transformers_class_map[model_type].from_pretrained(model_id)
+ config_cls = LoraConfig
+ self._check_match_with_expected_target_modules(
+ model_id, model, config_cls, initial_target_modules, expected_target_modules
+ )
+
+ @parameterized.expand(BNB_TEST_CASES)
+ @require_non_cpu
+ @require_bitsandbytes
+ def test_maybe_include_all_linear_layers_lora_bnb(
+ self, model_id, model_type, initial_target_modules, expected_target_modules, quantization
+ ):
+ if quantization == "4bit":
+ config_kwargs = {"quantization_config": BitsAndBytesConfig(load_in_4bit=True)}
+ elif quantization == "8bit":
+ config_kwargs = {"quantization_config": BitsAndBytesConfig(load_in_8bit=True)}
+ model = self.transformers_class_map[model_type].from_pretrained(model_id, device_map="auto", **config_kwargs)
+ config_cls = LoraConfig
+ self._check_match_with_expected_target_modules(
+ model_id, model, config_cls, initial_target_modules, expected_target_modules
+ )
+
+ def _check_match_with_expected_target_modules(
+ self, model_id, model, config_cls, initial_target_modules, expected_target_modules
+ ):
+ """
+ Helper function for the test for `_maybe_include_all_linear_layers`
+ """
+ actual_config = config_cls(base_model_name_or_path=model_id, target_modules=initial_target_modules)
+ expected_config = config_cls(base_model_name_or_path=model_id, target_modules=expected_target_modules)
+ model_copy = deepcopy(model)
+ actual_model = get_peft_model(model, peft_config=actual_config)
+ expected_model = get_peft_model(model_copy, peft_config=expected_config)
+ expected_model_module_dict = dict(expected_model.named_modules())
+ # compare the two models and assert that all layers are of the same type
+ for name, actual_module in actual_model.named_modules():
+ expected_module = expected_model_module_dict[name]
+ assert type(actual_module) is type(expected_module)
+
+ def test_maybe_include_all_linear_layers_ia3_loha(self):
+ model_id, initial_target_modules, expected_target_modules = (
+ "HuggingFaceH4/tiny-random-LlamaForCausalLM",
+ INCLUDE_LINEAR_LAYERS_SHORTHAND,
+ ["k_proj", "v_proj", "q_proj", "o_proj", "down_proj", "up_proj", "gate_proj"],
+ )
+ model_ia3 = AutoModelForCausalLM.from_pretrained(model_id)
+ model_loha = deepcopy(model_ia3)
+ config_classes = [IA3Config, LoHaConfig]
+ models = [model_ia3, model_loha]
+ for config_cls, model in zip(config_classes, models):
+ self._check_match_with_expected_target_modules(
+ model_id, model, config_cls, initial_target_modules, expected_target_modules
+ )
+
+ @parameterized.expand(MAYBE_INCLUDE_ALL_LINEAR_LAYERS_TEST_INTERNALS)
+ def test_maybe_include_all_linear_layers_internals(self, initial_target_modules, expected_target_modules):
+ model_id = "HuggingFaceH4/tiny-random-LlamaForCausalLM"
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ config = LoraConfig(base_model_name_or_path=model_id, target_modules=initial_target_modules)
+ new_config = _maybe_include_all_linear_layers(config, model)
+ if isinstance(expected_target_modules, list):
+ # assert that expected and actual target_modules have the same items
+ assert set(new_config.target_modules) == set(expected_target_modules)
+ else:
+ assert new_config.target_modules == expected_target_modules
+
+ def test_maybe_include_all_linear_layers_diffusion(self):
+ model_id = "hf-internal-testing/tiny-sd-pipe"
+ model = StableDiffusionPipeline.from_pretrained(model_id)
+ config = LoraConfig(base_model_name_or_path=model_id, target_modules="all-linear")
+
+ # all linear layers should be converted
+ num_linear = sum(isinstance(module, (nn.Linear, Conv1D)) for module in model.unet.modules())
+ model.unet = get_peft_model(model.unet, config)
+ num_lora = sum(isinstance(module, LoraLayer) for module in model.unet.modules())
+ assert num_lora == num_linear
+
+ def test_maybe_include_all_linear_does_not_target_classifier_head(self):
+ # See issue 2027
+ # Ensure that if a SEQ_CLS model is being used with target_modules="all-linear", the classification head is not
+ # targeted by the adapter layer.
+ model_id = "HuggingFaceH4/tiny-random-LlamaForCausalLM"
+ model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=10)
+ # sanity check
+ assert isinstance(model.score, nn.Linear)
+
+ num_linear = sum(isinstance(module, (nn.Linear, Conv1D)) for module in model.modules())
+
+ config = LoraConfig(task_type="SEQ_CLS", target_modules="all-linear")
+ model = get_peft_model(model, config)
+ assert isinstance(model.base_model.score, ModulesToSaveWrapper)
+
+ # the bug was that these were lora.Linear instances
+ assert isinstance(model.base_model.score.original_module, nn.Linear)
+ assert isinstance(model.base_model.score.modules_to_save["default"], nn.Linear)
+
+ # ensure that all but one linear layer was targeted by LoRA
+ num_lora = sum(isinstance(module, LoraLayer) for module in model.modules())
+ assert num_lora == num_linear - 1
+
+ @parameterized.expand(MAYBE_INCLUDE_ALL_LINEAR_LAYERS_TEST_CASES)
+ def test_all_linear_nested_targets_correct_layers(
+ self, model_id, model_type, initial_target_modules, expected_target_modules
+ ):
+ # See 2390
+ # Ensure that if adapter layers are already applied, we don't get nested adapter layers (e.g. LoRA targeting the
+ # lora_A, lora_B layers)
+ model = self.transformers_class_map[model_type].from_pretrained(model_id)
+ config_cls = LoraConfig
+ self._check_match_with_expected_target_modules(
+ model_id, model, config_cls, initial_target_modules, expected_target_modules
+ )
+ # re-use the same model, i.e. the adapter is already applied
+ self._check_match_with_expected_target_modules(
+ model_id, model, config_cls, initial_target_modules, expected_target_modules
+ )
+
+ def test_add_second_adapter_with_all_linear_works(self):
+ # See 2390 Similar test to test_all_linear_nested_targets_correct_layers above, but using add_adapter instead of
+ # calling get_peft_model in an already adapted model
+ model_id = "HuggingFaceH4/tiny-random-LlamaForCausalLM"
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+
+ # important: don't reuse the first config, since config.target_modules will be overwritten, which would make the
+ # test pass trivially.
+ config0 = LoraConfig(target_modules=INCLUDE_LINEAR_LAYERS_SHORTHAND)
+ config1 = LoraConfig(target_modules=INCLUDE_LINEAR_LAYERS_SHORTHAND)
+
+ model = get_peft_model(model, config0)
+ model.add_adapter(adapter_name="other", peft_config=config1)
+
+ # both configs should result in the same target modules being chosen (remember that config.target_modules will
+ # be replaced by the actual set of target_modules)
+ assert config0.target_modules == config1.target_modules
+
+ for layer in model.base_model.model.model.layers:
+ projs = (
+ layer.self_attn.q_proj,
+ layer.self_attn.v_proj,
+ layer.self_attn.k_proj,
+ layer.mlp.gate_proj,
+ layer.mlp.up_proj,
+ layer.mlp.down_proj,
+ )
+ for proj in projs:
+ # the targted layer itself, which in the base model was the nn.Linear layer, is now a LoraLayer
+ assert isinstance(proj, LoraLayer)
+ # all children of that layer are still normal nn.Linear layers
+ assert isinstance(proj.base_layer, nn.Linear)
+ assert isinstance(proj.lora_A["default"], nn.Linear)
+ assert isinstance(proj.lora_B["default"], nn.Linear)
+ assert isinstance(proj.lora_A["other"], nn.Linear)
+ assert isinstance(proj.lora_B["other"], nn.Linear)
+
+
+class MLP(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.relu = nn.ReLU()
+ self.drop = nn.Dropout(0.5)
+ self.lin1 = nn.Linear(20, 2, bias=bias)
+ self.sm = nn.LogSoftmax(dim=-1)
+
+
+class TestTargetedModuleNames(unittest.TestCase):
+ """Check that the attribute targeted_module_names is correctly set.
+
+ This checks LoRA and IA³, but this should be sufficient, testing all other tuners is not necessary.
+ """
+
+ def test_one_targeted_module_regex(self):
+ model = MLP()
+ model = get_peft_model(model, LoraConfig(target_modules="lin0"))
+ assert model.targeted_module_names == ["lin0"]
+
+ def test_two_targeted_module_regex(self):
+ model = MLP()
+ model = get_peft_model(model, LoraConfig(target_modules="lin.*"))
+ assert model.targeted_module_names == ["lin0", "lin1"]
+
+ def test_one_targeted_module_list(self):
+ model = MLP()
+ model = get_peft_model(model, LoraConfig(target_modules=["lin0"]))
+ assert model.targeted_module_names == ["lin0"]
+
+ def test_two_targeted_module_list(self):
+ model = MLP()
+ model = get_peft_model(model, LoraConfig(target_modules=["lin0", "lin1"]))
+ assert model.targeted_module_names == ["lin0", "lin1"]
+
+ def test_ia3_targeted_module_regex(self):
+ model = MLP()
+ model = get_peft_model(model, IA3Config(target_modules=".*lin.*", feedforward_modules=".*lin.*"))
+ assert model.targeted_module_names == ["lin0", "lin1"]
+
+ def test_ia3_targeted_module_list(self):
+ model = MLP()
+ model = get_peft_model(model, IA3Config(target_modules=["lin0", "lin1"], feedforward_modules=["lin0", "lin1"]))
+ assert model.targeted_module_names == ["lin0", "lin1"]
+
+ def test_realistic_example(self):
+ model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-BloomForCausalLM")
+ config = LoraConfig(task_type="CAUSAL_LM")
+ model = get_peft_model(model, config)
+ expected = [
+ f"transformer.h.{i}.self_attention.query_key_value" for i in range(len(model.base_model.transformer.h))
+ ]
+ assert model.targeted_module_names == expected
+
+
+class TestTargetedParameterNames(unittest.TestCase):
+ """Check that the attribute targeted_parameter_names (via target_parameters) is correctly set.
+
+ This is only implemented for LoRA. Regex matching is currently not implemented.
+ """
+
+ def test_one_targeted_parameters_list(self):
+ model = MLP()
+ model = get_peft_model(model, LoraConfig(target_parameters=["lin0.weight"]))
+ assert model.targeted_parameter_names == ["lin0.weight"]
+
+ def test_two_targeted_parameters_list(self):
+ model = MLP()
+ model = get_peft_model(model, LoraConfig(target_parameters=["lin0.weight", "lin1.weight"]))
+ assert model.targeted_parameter_names == ["lin0.weight", "lin1.weight"]
+
+ def test_realistic_example(self):
+ model = AutoModelForCausalLM.from_pretrained("trl-internal-testing/tiny-random-LlamaForCausalLM")
+ config = LoraConfig(target_modules=[], task_type="CAUSAL_LM", target_parameters=["v_proj.weight"])
+ model = get_peft_model(model, config)
+ expected = [
+ f"model.layers.{i}.self_attn.v_proj.weight" for i in range(len(model.base_model.model.model.layers))
+ ]
+ assert model.targeted_parameter_names == expected
+
+
+class TestExcludedModuleNames(unittest.TestCase):
+ """Check that the attribute exclude_module is correctly set.
+
+ This checks LoRA and IA³, but this should be sufficient, testing all other tuners is not necessary.
+ """
+
+ def test_two_excluded_module_regex(self):
+ model = MLP()
+ model = get_peft_model(model, LoraConfig(target_modules=("lin.*"), exclude_modules="lin0"))
+ assert model.targeted_module_names == ["lin1"]
+
+ def test_two_excluded_module_list(self):
+ model = MLP()
+ model = get_peft_model(model, LoraConfig(target_modules=["lin0", "lin1"], exclude_modules="lin0"))
+ assert model.targeted_module_names == ["lin1"]
+
+ def test_multiple_excluded_modules_list(self):
+ model = MLP()
+ model = get_peft_model(model, LoraConfig(target_modules=["lin0", "lin1"], exclude_modules=["lin0"]))
+ assert model.targeted_module_names == ["lin1"]
+
+ def test_ia3_two_excluded_module_regex(self):
+ model = MLP()
+ model = get_peft_model(
+ model, IA3Config(target_modules=".*lin.*", feedforward_modules=".*lin.*", exclude_modules="lin0")
+ )
+ assert model.targeted_module_names == ["lin1"]
+
+ def test_ia3_multiple_excluded_modules_list(self):
+ model = MLP()
+ model = get_peft_model(
+ model, IA3Config(target_modules=["lin0", "lin1"], feedforward_modules=".*lin.*", exclude_modules=["lin1"])
+ )
+ assert model.targeted_module_names == ["lin0"]
+
+ def test_all_modules_excluded(self):
+ model = MLP()
+ with pytest.raises(ValueError, match="All modules were excluded"):
+ get_peft_model(
+ model,
+ LoraConfig(
+ target_modules=["lin0", "lin1", "relu", "drop", "sm"],
+ exclude_modules=["lin0", "lin1", "relu", "drop", "sm"],
+ ),
+ )
+
+ def test_no_modules_matched(self):
+ model = MLP()
+ with pytest.raises(ValueError, match="Target modules .* not found in the base model"):
+ get_peft_model(model, LoraConfig(target_modules=["non_existent_module"]))
+
+ def test_some_modules_excluded_some_unmatched(self):
+ model = MLP()
+ with pytest.raises(ValueError, match="No modules were targeted for adaptation"):
+ get_peft_model(model, LoraConfig(target_modules=["lin0", "non_existent_module"], exclude_modules=["lin0"]))
+
+ def test_exclude_modules_not_used(self):
+ model = MLP()
+ with pytest.warns(UserWarning, match="You have passed exclude_modules=.* but no modules were excluded"):
+ get_peft_model(model, LoraConfig(target_modules=["lin1"], exclude_modules=["non_existent_module"]))
+
+ def test_realistic_example(self):
+ model = AutoModelForCausalLM.from_pretrained("hf-internal-testing/tiny-random-BloomForCausalLM")
+ config = LoraConfig(task_type="CAUSAL_LM", exclude_modules="transformer.h.2.self_attention.query_key_value")
+ model = get_peft_model(model, config)
+ expected = [
+ f"transformer.h.{i}.self_attention.query_key_value"
+ for i in range(len(model.base_model.transformer.h))
+ if i != 2
+ ]
+ assert model.targeted_module_names == expected
+
+
+class TestModelAndLayerStatus:
+ """Check the methods `get_layer_status` and `get_model_status`.`
+
+ Note that we only test LoRA here but the same logic should work for other tuner types (if they support the
+ corresponding features like merging).
+
+ """
+
+ torch_device = infer_device()
+
+ @pytest.fixture
+ def small_model(self):
+ class SmallModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.lin0 = nn.Linear(10, 10)
+ self.lin1 = nn.Linear(10, 10)
+
+ config = LoraConfig(target_modules="lin0")
+ return get_peft_model(SmallModel(), config)
+
+ @pytest.fixture
+ def large_model(self):
+ class LargeModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.lin0 = nn.Linear(10, 10)
+ self.conv0 = nn.Conv2d(3, 10, 3)
+ self.emb0 = nn.Embedding(10, 10)
+ self.lin1 = nn.Linear(10, 10)
+ self.conv1 = nn.Conv2d(3, 10, 3)
+ self.emb1 = nn.Embedding(10, 10)
+
+ config0 = LoraConfig(target_modules=["lin0", "conv1", "emb0"])
+ config1 = LoraConfig(target_modules=["lin0", "lin1"], r=16)
+ model = get_peft_model(LargeModel(), config0)
+ model.add_adapter("other", config1)
+ return model
+
+ ################
+ # layer status #
+ ################
+
+ def test_layer_names_small(self, small_model):
+ layer_status = small_model.get_layer_status()
+ expected = ["model.lin0"]
+ assert [status.name for status in layer_status] == expected
+
+ def test_layer_names_large(self, large_model):
+ layer_status = large_model.get_layer_status()
+ result = sorted([status.name for status in layer_status])
+ expected = ["model.conv1", "model.emb0", "model.lin0", "model.lin1"]
+ assert result == expected
+
+ def test_module_type_small(self, small_model):
+ layer_status = small_model.get_layer_status()
+ assert [status.module_type for status in layer_status] == ["lora.Linear"]
+
+ def test_module_type_large(self, large_model):
+ layer_status = large_model.get_layer_status()
+ result = sorted([status.module_type for status in layer_status])
+ expected = ["lora.Conv2d", "lora.Embedding", "lora.Linear", "lora.Linear"]
+ assert result == expected
+
+ def test_enabled_small(self, small_model):
+ layer_status = small_model.get_layer_status()
+ assert [status.enabled for status in layer_status] == [True]
+
+ def test_enabled_large(self, large_model):
+ layer_status = large_model.get_layer_status()
+ result = [status.enabled for status in layer_status]
+ expected = [True, True, True, True]
+ assert result == expected
+
+ def test_enabled_irregular(self, large_model):
+ # this is an invalid state, but we should still test it
+ # disable a single layer
+ for module in large_model.modules():
+ if isinstance(module, BaseTunerLayer):
+ module.enable_adapters(False)
+ break
+
+ layer_status = large_model.get_layer_status()
+ result = [status.enabled for status in layer_status]
+ expected = [False, True, True, True]
+ assert result == expected
+
+ def test_active_adapters_small(self, small_model):
+ layer_status = small_model.get_layer_status()
+ assert [status.active_adapters for status in layer_status] == [["default"]]
+
+ def test_active_adapters_large(self, large_model):
+ layer_status = large_model.get_layer_status()
+ result = [status.active_adapters for status in layer_status]
+ # note: as currently implemented, the active adapter can be an adapter that does not exist on this specific
+ # layer, for instance, layer 3 (i.e. index 2) only has the "other" adapter but "default" is still shown as the
+ # active adapter
+ expected = [["default"], ["default"], ["default"], ["default"]]
+ assert result == expected
+
+ # switch to "other"
+ large_model.set_adapter("other")
+ layer_status = large_model.get_layer_status()
+ result = [status.active_adapters for status in layer_status]
+ expected = [["other"], ["other"], ["other"], ["other"]]
+
+ def test_merge_adapters_small(self, small_model):
+ layer_status = small_model.get_layer_status()
+ assert [status.merged_adapters for status in layer_status] == [[]]
+ assert [status.available_adapters for status in layer_status] == [["default"]]
+
+ # now merge "default"
+ small_model.merge_adapter(["default"])
+ layer_status = small_model.get_layer_status()
+ assert [status.merged_adapters for status in layer_status] == [["default"]]
+ assert [status.available_adapters for status in layer_status] == [["default"]]
+
+ def test_merge_adapters_large(self, large_model):
+ layer_status = large_model.get_layer_status()
+ result = [status.merged_adapters for status in layer_status]
+ assert result == [[], [], [], []]
+
+ # now merge "default"
+ large_model.merge_adapter(["default"])
+ layer_status = large_model.get_layer_status()
+ result = [status.merged_adapters for status in layer_status]
+ # default is on layer 0, 1, and 3
+ assert result == [["default"], ["default"], [], ["default"]]
+
+ # now merge "other"
+ large_model.unmerge_adapter()
+ large_model.merge_adapter(["other"])
+ layer_status = large_model.get_layer_status()
+ result = [status.merged_adapters for status in layer_status]
+ # other is on layer 0 and 2
+ assert result == [["other"], [], ["other"], []]
+
+ # now merge both
+ large_model.merge_adapter(["default", "other"])
+ layer_status = large_model.get_layer_status()
+ result = [status.merged_adapters for status in layer_status]
+ # default is on layer 0, 1, and 3, other is on layer 0 and 2
+ assert result == [["other", "default"], ["default"], ["other"], ["default"]]
+
+ def test_requires_grad_small(self, small_model):
+ layer_status = small_model.get_layer_status()
+ assert [status.requires_grad for status in layer_status] == [{"default": True}]
+
+ def test_requires_grad_large(self, large_model):
+ layer_status = large_model.get_layer_status()
+ result = [status.requires_grad for status in layer_status]
+ # default is on layer 0, 1, and 3, other is on layer 0 and 2
+ expected = [{"default": True, "other": False}, {"default": True}, {"other": False}, {"default": True}]
+ assert result == expected
+
+ # now activate "other"
+ large_model.set_adapter("other")
+ layer_status = large_model.get_layer_status()
+ result = [status.requires_grad for status in layer_status]
+ expected = [{"default": False, "other": True}, {"default": False}, {"other": True}, {"default": False}]
+ assert result == expected
+
+ def test_requires_grad_irregular(self, large_model):
+ # inject an embedding layer with requires_grad=False
+ # this is an invalid state, but we should still test it
+ lora_embedding_A = nn.Parameter(torch.zeros(10, 10))
+ lora_embedding_B = nn.Parameter(torch.zeros(10, 10))
+ lora_embedding_A.requires_grad = False
+ lora_embedding_B.requires_grad = False
+ large_model.base_model.model.lin0.lora_embedding_A["default"] = lora_embedding_A
+ large_model.base_model.model.lin0.lora_embedding_B["default"] = lora_embedding_B
+
+ layer_status = large_model.get_layer_status()
+ result = [status.requires_grad for status in layer_status]
+ expected = [{"default": "irregular", "other": False}, {"default": True}, {"other": False}, {"default": True}]
+ assert result == expected
+
+ def test_available_adapters_small(self, small_model):
+ layer_status = small_model.get_layer_status()
+ result = [status.available_adapters for status in layer_status]
+ expected = [["default"]]
+ assert result == expected
+
+ def test_available_adapters_large(self, large_model):
+ layer_status = large_model.get_layer_status()
+ result = [status.available_adapters for status in layer_status]
+ expected = [["default", "other"], ["default"], ["other"], ["default"]]
+ assert result == expected
+
+ def test_devices_all_cpu_small(self, small_model):
+ layer_status = small_model.get_layer_status()
+ result = [status.devices for status in layer_status]
+ expected = [{"default": ["cpu"]}]
+ assert result == expected
+
+ def test_devices_all_cpu_large(self, large_model):
+ layer_status = large_model.get_layer_status()
+ result = [status.devices for status in layer_status]
+ expected = [
+ {"default": ["cpu"], "other": ["cpu"]},
+ {"default": ["cpu"]},
+ {"other": ["cpu"]},
+ {"default": ["cpu"]},
+ ]
+ assert result == expected
+
+ @require_non_cpu
+ def test_devices_all_gpu_large(self, large_model):
+ large_model.to(self.torch_device)
+ layer_status = large_model.get_layer_status()
+ result = [status.devices for status in layer_status]
+ expected = [
+ {"default": [self.torch_device], "other": [self.torch_device]},
+ {"default": [self.torch_device]},
+ {"other": [self.torch_device]},
+ {"default": [self.torch_device]},
+ ]
+ assert result == expected
+
+ @require_non_cpu
+ def test_devices_cpu_and_gpu_large(self, large_model):
+ # move the embedding layer to GPU
+ large_model.model.lin0.lora_A["default"] = large_model.model.lin0.lora_A["default"].to(self.torch_device)
+ layer_status = large_model.get_layer_status()
+ result = [status.devices for status in layer_status]
+ expected = [
+ {"default": ["cpu", self.torch_device], "other": ["cpu"]},
+ {"default": ["cpu"]},
+ {"other": ["cpu"]},
+ {"default": ["cpu"]},
+ ]
+ assert result == expected
+
+ def test_target_parameters(self, large_model):
+ # don't check each attribute, just the relevant ones
+ # first remove the normal LoRA layers
+ large_model = large_model.merge_and_unload()
+ config = LoraConfig(target_parameters=["lin0.weight", "lin1.weight"])
+ large_model = get_peft_model(large_model, config)
+ layer_status = large_model.get_layer_status()
+ assert [status.name for status in layer_status] == ["model.lin0", "model.lin1"]
+ assert [status.module_type for status in layer_status] == ["lora.ParamWrapper"] * 2
+
+ def test_target_parameters_and_target_modules(self, large_model):
+ # don't check each attribute, just the relevant ones
+ # first remove the normal LoRA layers
+ large_model = large_model.merge_and_unload()
+ config = LoraConfig(target_parameters=["lin0.weight"], target_modules=["lin1"])
+ large_model = get_peft_model(large_model, config)
+ layer_status = large_model.get_layer_status()
+ assert [status.name for status in layer_status] == ["model.lin0", "model.lin1"]
+ assert [status.module_type for status in layer_status] == ["lora.ParamWrapper", "lora.Linear"]
+
+ ################
+ # model status #
+ ################
+
+ def test_base_model_type_small(self, small_model):
+ model_status = small_model.get_model_status()
+ assert model_status.base_model_type == "SmallModel"
+
+ def test_base_model_type_large(self, large_model):
+ model_status = large_model.get_model_status()
+ assert model_status.base_model_type == "LargeModel"
+
+ def test_base_model_type_transformers_automodel(self):
+ # ensure that this also works with transformers AutoModels
+ model_id = "google/flan-t5-small"
+ model = AutoModel.from_pretrained(model_id)
+ model = get_peft_model(model, LoraConfig())
+ model_status = model.get_model_status()
+ assert model_status.base_model_type == "T5Model"
+
+ def test_adapter_model_type_small(self, small_model):
+ model_status = small_model.get_model_status()
+ assert model_status.adapter_model_type == "LoraModel"
+
+ def test_adapter_model_type_large(self, large_model):
+ model_status = large_model.get_model_status()
+ assert model_status.adapter_model_type == "LoraModel"
+
+ def test_peft_types_small(self, small_model):
+ model_status = small_model.get_model_status()
+ assert model_status.peft_types == {"default": "LORA"}
+
+ def test_peft_types_large(self, large_model):
+ model_status = large_model.get_model_status()
+ assert model_status.peft_types == {"default": "LORA", "other": "LORA"}
+
+ def test_nb_params_small(self, small_model):
+ model_status = small_model.get_model_status()
+ assert model_status.trainable_params == 160
+ assert model_status.total_params == 380
+
+ def test_nb_params_large(self, large_model):
+ model_status = large_model.get_model_status()
+ assert model_status.trainable_params == 616
+ assert model_status.total_params == 2236
+
+ def test_num_adapter_layers_small(self, small_model):
+ model_status = small_model.get_model_status()
+ assert model_status.num_adapter_layers == 1
+
+ def test_num_adapter_layers_large(self, large_model):
+ model_status = large_model.get_model_status()
+ assert model_status.num_adapter_layers == 4
+
+ def test_model_enabled_small(self, small_model):
+ model_status = small_model.get_model_status()
+ assert model_status.enabled is True
+
+ def test_model_enabled_large(self, large_model):
+ model_status = large_model.get_model_status()
+ assert model_status.enabled is True
+
+ def test_model_disabled_small(self, small_model):
+ small_model.disable_adapter_layers()
+ model_status = small_model.get_model_status()
+ assert model_status.enabled is False
+
+ def test_model_disabled_large(self, large_model):
+ large_model.disable_adapter_layers()
+ model_status = large_model.get_model_status()
+ assert model_status.enabled is False
+
+ def test_model_enabled_irregular(self, large_model):
+ # this is an invalid state, but we should still test it
+ # disable a single layer
+ for module in large_model.modules():
+ if isinstance(module, BaseTunerLayer):
+ module.enable_adapters(False)
+ break
+
+ model_status = large_model.get_model_status()
+ assert model_status.enabled == "irregular"
+
+ def test_model_active_adapters_small(self, small_model):
+ model_status = small_model.get_model_status()
+ assert model_status.active_adapters == ["default"]
+
+ def test_model_active_adapters_large(self, large_model):
+ model_status = large_model.get_model_status()
+ assert model_status.active_adapters == ["default"]
+
+ large_model.set_adapter("other")
+ model_status = large_model.get_model_status()
+ assert model_status.active_adapters == ["other"]
+
+ def test_model_active_adapters_irregular(self, large_model):
+ # this is an invalid state, but we should still test it
+ # disable a single layer
+ for module in large_model.modules():
+ if isinstance(module, BaseTunerLayer):
+ # switch a single layer's active adapter from default to other
+ if module.active_adapters == ["default"]:
+ module._active_adapter = "other"
+ assert module.active_adapters == ["other"]
+ break
+
+ model_status = large_model.get_model_status()
+ assert model_status.active_adapters == "irregular"
+
+ def test_model_merged_adapters_small(self, small_model):
+ model_status = small_model.get_model_status()
+ assert model_status.merged_adapters == []
+
+ small_model.merge_adapter()
+ model_status = small_model.get_model_status()
+ assert model_status.merged_adapters == ["default"]
+
+ small_model.unmerge_adapter()
+ model_status = small_model.get_model_status()
+ assert model_status.merged_adapters == []
+
+ def test_model_merged_adapters_large(self, large_model):
+ model_status = large_model.get_model_status()
+ assert model_status.merged_adapters == []
+
+ large_model.merge_adapter(["default"])
+ model_status = large_model.get_model_status()
+ assert model_status.merged_adapters == ["default"]
+
+ large_model.unmerge_adapter()
+ large_model.merge_adapter(["other"])
+ model_status = large_model.get_model_status()
+ assert model_status.merged_adapters == ["other"]
+
+ large_model.unmerge_adapter()
+ large_model.merge_adapter(["default", "other"])
+ model_status = large_model.get_model_status()
+ assert model_status.merged_adapters == ["default", "other"]
+
+ def test_model_merged_adapters_irregular(self, large_model):
+ # this is an invalid state, but we should still test it
+ # by merging only lin0 of "default", we end up in a irregular state, because not all "default" layers are merged
+ large_model.base_model.lin0.merge(["default"])
+
+ model_status = large_model.get_model_status()
+ assert model_status.merged_adapters == "irregular"
+
+ def test_model_requires_grad_model_small(self, small_model):
+ model_status = small_model.get_model_status()
+ assert model_status.requires_grad == {"default": True}
+
+ def test_model_requires_grad_model_large(self, large_model):
+ model_status = large_model.get_model_status()
+ assert model_status.requires_grad == {"default": True, "other": False}
+
+ large_model.set_adapter("other")
+ model_status = large_model.get_model_status()
+ assert model_status.requires_grad == {"default": False, "other": True}
+
+ def test_model_requires_grad_model_irregular(self, large_model):
+ # inject an embedding layer with requires_grad=False
+ # this is an invalid state, but we should still test it
+ lora_embedding_A = nn.Parameter(torch.zeros(10, 10))
+ lora_embedding_B = nn.Parameter(torch.zeros(10, 10))
+ lora_embedding_A.requires_grad = False
+ lora_embedding_B.requires_grad = False
+ large_model.base_model.model.lin0.lora_embedding_A["default"] = lora_embedding_A
+ large_model.base_model.model.lin0.lora_embedding_B["default"] = lora_embedding_B
+
+ model_status = large_model.get_model_status()
+ assert model_status.requires_grad == {"default": "irregular", "other": False}
+
+ def test_model_available_adapters_small(self, small_model):
+ model_status = small_model.get_model_status()
+ assert model_status.available_adapters == ["default"]
+
+ def test_model_available_adapters_large(self, large_model):
+ model_status = large_model.get_model_status()
+ assert model_status.available_adapters == ["default", "other"]
+
+ def test_model_devices_all_cpu_small(self, small_model):
+ model_status = small_model.get_model_status()
+ assert model_status.devices == {"default": ["cpu"]}
+
+ def test_model_devices_all_cpu_large(self, large_model):
+ model_status = large_model.get_model_status()
+ assert model_status.devices == {"default": ["cpu"], "other": ["cpu"]}
+
+ @require_non_cpu
+ def test_model_devices_all_gpu_large(self, large_model):
+ large_model.to(self.torch_device)
+ model_status = large_model.get_model_status()
+ assert model_status.devices == {"default": [self.torch_device], "other": [self.torch_device]}
+
+ @require_non_cpu
+ def test_model_devices_cpu_and_gpu_large(self, large_model):
+ # move the embedding layer to GPU
+ large_model.model.lin0.lora_A["default"] = large_model.model.lin0.lora_A["default"].to(self.torch_device)
+ model_status = large_model.get_model_status()
+ assert model_status.devices == {"default": ["cpu", self.torch_device], "other": ["cpu"]}
+
+ def test_model_target_parameters(self, large_model):
+ # don't check each attribute, just the relevant ones
+ # first remove the normal LoRA layers
+ large_model = large_model.merge_and_unload()
+ config = LoraConfig(target_parameters=["lin0.weight", "lin1.weight"])
+ large_model = get_peft_model(large_model, config)
+ model_status = large_model.get_model_status()
+ model_status = large_model.get_model_status()
+ assert model_status.adapter_model_type == "LoraModel"
+ assert model_status.peft_types == {"default": "LORA", "other": "LORA"}
+ assert model_status.num_adapter_layers == 2
+ assert model_status.trainable_params == 2 * (8 * 10 + 10 * 8)
+
+ def test_model_target_parameters_and_target_modules(self, large_model):
+ # don't check each attribute, just the relevant ones
+ # first remove the normal LoRA layers
+ large_model = large_model.merge_and_unload()
+ config = LoraConfig(target_parameters=["lin0.weight"], target_modules=["lin1"])
+ large_model = get_peft_model(large_model, config)
+ model_status = large_model.get_model_status()
+ assert model_status.adapter_model_type == "LoraModel"
+ assert model_status.peft_types == {"default": "LORA", "other": "LORA"}
+ assert model_status.num_adapter_layers == 2
+ assert model_status.trainable_params == 2 * (8 * 10 + 10 * 8)
+
+ def test_loha_model(self):
+ # ensure that this also works with non-LoRA, it's not necessary to test all tuners
+ class SmallModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.lin0 = nn.Linear(10, 10)
+ self.lin1 = nn.Linear(10, 10)
+
+ base_model = SmallModel()
+ config = LoHaConfig(target_modules=["lin0", "lin1"], init_weights=False)
+ model = get_peft_model(base_model, config)
+
+ model_status = model.get_model_status()
+ layer_status = model.get_layer_status()
+
+ assert model_status.base_model_type == "SmallModel"
+ assert model_status.adapter_model_type == "LoHaModel"
+ assert model_status.peft_types == {"default": "LOHA"}
+ assert model_status.trainable_params == 640
+ assert model_status.total_params == 860
+ assert model_status.num_adapter_layers == 2
+ assert model_status.enabled is True
+ assert model_status.active_adapters == ["default"]
+ assert model_status.merged_adapters == []
+ assert model_status.requires_grad == {"default": True}
+ assert model_status.available_adapters == ["default"]
+ assert model_status.devices == {"default": ["cpu"]}
+
+ layer_status0 = layer_status[0]
+ assert len(layer_status) == 2
+ assert layer_status0.name == "model.lin0"
+ assert layer_status0.module_type == "loha.Linear"
+ assert layer_status0.enabled is True
+ assert layer_status0.active_adapters == ["default"]
+ assert layer_status0.merged_adapters == []
+ assert layer_status0.requires_grad == {"default": True}
+ assert layer_status0.available_adapters == ["default"]
+ assert layer_status0.devices == {"default": ["cpu"]}
+
+ @require_non_cpu
+ def test_vera_model(self):
+ # let's also test VeRA because it uses BufferDict
+ class SmallModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.lin0 = nn.Linear(10, 10)
+ self.lin1 = nn.Linear(10, 10)
+
+ base_model = SmallModel()
+ config = VeraConfig(target_modules=["lin0", "lin1"], init_weights=False)
+ model = get_peft_model(base_model, config)
+
+ # move the buffer dict to GPU
+ model.lin0.vera_A["default"] = model.lin0.vera_A["default"].to(self.torch_device)
+
+ model_status = model.get_model_status()
+ layer_status = model.get_layer_status()
+
+ assert model_status.base_model_type == "SmallModel"
+ assert model_status.adapter_model_type == "VeraModel"
+ assert model_status.peft_types == {"default": "VERA"}
+ assert model_status.trainable_params == 532
+ assert model_status.total_params == 752
+ assert model_status.num_adapter_layers == 2
+ assert model_status.enabled is True
+ assert model_status.active_adapters == ["default"]
+ assert model_status.merged_adapters == []
+ assert model_status.requires_grad == {"default": True}
+ assert model_status.available_adapters == ["default"]
+ assert model_status.devices == {"default": ["cpu", self.torch_device]}
+
+ layer_status0 = layer_status[0]
+ assert len(layer_status) == 2
+ assert layer_status0.name == "model.lin0"
+ assert layer_status0.module_type == "vera.Linear"
+ assert layer_status0.enabled is True
+ assert layer_status0.active_adapters == ["default"]
+ assert layer_status0.merged_adapters == []
+ assert layer_status0.requires_grad == {"default": True}
+ assert layer_status0.available_adapters == ["default"]
+ assert layer_status0.devices == {"default": ["cpu", self.torch_device]}
+
+ ###################
+ # non-PEFT models #
+ ###################
+
+ def test_transformers_model(self):
+ model_id = "peft-internal-testing/gpt2-lora-random"
+ # note that loading through AutoModelForCausalLM.from_pretrained does not enable training mode, hence
+ # requires_grad=False
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ model_status = get_model_status(model)
+ layer_status = get_layer_status(model)
+
+ assert model_status.base_model_type == "GPT2LMHeadModel"
+ assert model_status.adapter_model_type == "None"
+ assert model_status.peft_types == {}
+ assert model_status.trainable_params == 0
+ assert model_status.total_params == 124734720
+ assert model_status.num_adapter_layers == 12
+ assert model_status.enabled is True
+ assert model_status.active_adapters == ["default"]
+ assert model_status.merged_adapters == []
+ assert model_status.requires_grad == {"default": False}
+ assert model_status.available_adapters == ["default"]
+ assert model_status.devices == {"default": ["cpu"]}
+
+ layer_status0 = layer_status[0]
+ assert len(layer_status) == 12
+ assert layer_status0.name == "transformer.h.0.attn.c_attn"
+ assert layer_status0.module_type == "lora.Linear"
+ assert layer_status0.enabled is True
+ assert layer_status0.active_adapters == ["default"]
+ assert layer_status0.merged_adapters == []
+ assert layer_status0.requires_grad == {"default": False}
+ assert layer_status0.available_adapters == ["default"]
+ assert layer_status0.devices == {"default": ["cpu"]}
+
+ def test_model_with_injected_layers(self, large_model):
+ model = large_model.base_model.model
+ model_status = get_model_status(model)
+ layer_status = get_layer_status(model)
+
+ assert model_status.base_model_type == "other"
+ assert model_status.adapter_model_type == "None"
+ assert model_status.peft_types == {}
+ assert model_status.trainable_params == 616
+ assert model_status.total_params == 2236
+ assert model_status.num_adapter_layers == 4
+ assert model_status.enabled is True
+ assert model_status.active_adapters == ["default"]
+ assert model_status.merged_adapters == []
+ assert model_status.requires_grad == {"default": True, "other": False}
+ assert model_status.available_adapters == ["default", "other"]
+ assert model_status.devices == {"default": ["cpu"], "other": ["cpu"]}
+
+ layer_status1 = layer_status[1]
+ assert len(layer_status) == 4
+ assert layer_status1.name == "emb0"
+ assert layer_status1.module_type == "lora.Embedding"
+ assert layer_status1.enabled is True
+ assert layer_status1.active_adapters == ["default"]
+ assert layer_status1.merged_adapters == []
+ assert layer_status1.requires_grad == {"default": True}
+ assert layer_status1.available_adapters == ["default"]
+ assert layer_status1.devices == {"default": ["cpu"]}
+
+ ###############
+ # error cases #
+ ###############
+
+ def test_vanilla_model_raises(self):
+ model = nn.Linear(10, 10)
+ # note: full error message is longer
+ with pytest.raises(ValueError, match="No adapter layers found in the model"):
+ get_layer_status(model)
+
+ with pytest.raises(ValueError, match="No adapter layers found in the model"):
+ get_model_status(model)
+
+ def test_transformer_model_without_adapter_raises(self):
+ model = AutoModelForCausalLM.from_pretrained("gpt2")
+ # note: full error message is longer
+ with pytest.raises(ValueError, match="No adapter layers found in the model"):
+ get_layer_status(model)
+
+ with pytest.raises(ValueError, match="No adapter layers found in the model"):
+ get_model_status(model)
+
+ def test_prefix_tuning(self):
+ model = AutoModelForSeq2SeqLM.from_pretrained("hf-internal-testing/tiny-random-BartForConditionalGeneration")
+ config = PromptTuningConfig(task_type="SEQ_2_SEQ_LM", num_virtual_tokens=10)
+ model = get_peft_model(model, config)
+
+ # note: full error message is longer
+ with pytest.raises(TypeError, match=re.escape("get_layer_status() got an invalid PeftModel instance")):
+ model.get_layer_status()
+
+ with pytest.raises(TypeError, match=re.escape("get_model_status() got an invalid PeftModel instance")):
+ model.get_model_status()
+
+ def test_adaption_prompt(self):
+ model = AutoModelForCausalLM.from_pretrained("HuggingFaceH4/tiny-random-LlamaForCausalLM")
+ config = AdaptionPromptConfig(adapter_layers=1, adapter_len=4)
+ model = get_peft_model(model, config)
+
+ # note: full error message is longer
+ with pytest.raises(TypeError, match=re.escape("get_layer_status() got an invalid PeftModel instance")):
+ model.get_layer_status()
+
+ with pytest.raises(TypeError, match=re.escape("get_model_status() got an invalid PeftModel instance")):
+ model.get_model_status()
+
+ def test_mixed_model_raises(self):
+ class SimpleNet(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ # note: out_features must be > rank or else OFT will be an identity transform
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.relu = nn.ReLU()
+ self.lin1 = nn.Linear(20, 16, bias=bias)
+
+ def forward(self, X):
+ X = X.float()
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = self.lin1(X)
+ return X
+
+ base_model = SimpleNet()
+ config0 = LoraConfig(target_modules=["lin0"], init_lora_weights=False)
+ config1 = LoHaConfig(target_modules=["lin0", "lin1"], init_weights=False)
+ model = get_peft_model(base_model, config0, adapter_name="adapter0", mixed="mixed")
+ model.add_adapter("adapter1", config1)
+
+ # note: full error message is longer
+ with pytest.raises(TypeError, match="get_layer_status is not supported for PeftMixedModel"):
+ model.get_layer_status()
+
+ with pytest.raises(TypeError, match="get_model_status is not supported for PeftMixedModel"):
+ model.get_model_status()
+
+
+# Tests for BaseTuner
+class MockModelConfig:
+ config = {"mock_key": "mock_value"}
+
+ def to_dict(self):
+ return self.config
+
+
+class ModelWithConfig(nn.Module):
+ def __init__(self):
+ self.config = MockModelConfig()
+
+
+class ModelWithDictConfig(nn.Module):
+ def __init__(self):
+ self.config = MockModelConfig.config
+
+
+class ModelWithNoConfig(nn.Module):
+ pass
+
+
+class TestBaseTunerGetModelConfig(unittest.TestCase):
+ def test_get_model_config_use_to_dict(self):
+ config = BaseTuner.get_model_config(ModelWithConfig())
+ assert config == MockModelConfig.config
+
+ def test_get_model_config_as_dict(self):
+ config = BaseTuner.get_model_config(ModelWithDictConfig())
+ assert config == MockModelConfig.config
+
+ def test_get_model_config_with_no_config(self):
+ config = BaseTuner.get_model_config(ModelWithNoConfig())
+ assert config == DUMMY_MODEL_CONFIG
+
+
+class TestBaseTunerWarnForTiedEmbeddings:
+ model_id = "HuggingFaceH4/tiny-random-LlamaForCausalLM"
+ warn_end_inject = "huggingface/peft/issues/2018."
+ warn_end_merge = (
+ "# Now use the original model but in untied format\n"
+ "model = AutoModelForCausalLM.from_pretrained(untied_model_dir)\n```\n"
+ )
+
+ def _get_peft_model(self, tie_word_embeddings, target_module):
+ model = get_peft_model(
+ AutoModelForCausalLM.from_pretrained(self.model_id, tie_word_embeddings=tie_word_embeddings),
+ LoraConfig(target_modules=[target_module]),
+ )
+ return model
+
+ def _is_warn_triggered(self, warning_list, endswith):
+ return any(str(warning.message).endswith(endswith) for warning in warning_list)
+
+ def test_warn_for_tied_embeddings_inject(self, recwarn):
+ self._get_peft_model(tie_word_embeddings=True, target_module="lm_head")
+ assert self._is_warn_triggered(recwarn.list, self.warn_end_inject)
+
+ def test_warn_for_tied_embeddings_merge(self, recwarn):
+ model = self._get_peft_model(tie_word_embeddings=True, target_module="lm_head")
+ model.merge_and_unload()
+ assert self._is_warn_triggered(recwarn.list, self.warn_end_merge)
+
+ def test_no_warn_for_untied_embeddings_inject(self, recwarn):
+ self._get_peft_model(tie_word_embeddings=False, target_module="lm_head")
+ assert not self._is_warn_triggered(recwarn.list, self.warn_end_inject)
+
+ def test_no_warn_for_untied_embeddings_merge(self, recwarn):
+ model_not_tied = self._get_peft_model(tie_word_embeddings=False, target_module="lm_head")
+ model_not_tied.merge_and_unload()
+ assert not self._is_warn_triggered(recwarn.list, self.warn_end_merge)
+
+ def test_no_warn_for_no_target_module_inject(self, recwarn):
+ self._get_peft_model(tie_word_embeddings=True, target_module="q_proj")
+ assert not self._is_warn_triggered(recwarn.list, self.warn_end_inject)
+
+ def test_no_warn_for_no_target_module_merge(self, recwarn):
+ model_no_target_module = self._get_peft_model(tie_word_embeddings=True, target_module="q_proj")
+ model_no_target_module.merge_and_unload()
+ assert not self._is_warn_triggered(recwarn.list, self.warn_end_merge)
+
+
+class TestFindMinimalTargetModules:
+ @pytest.mark.parametrize(
+ "target_modules, other_module_names, expected",
+ [
+ (["bar"], [], {"bar"}),
+ (["foo"], ["bar"], {"foo"}),
+ (["1.foo", "2.foo"], ["3.foo", "4.foo"], {"1.foo", "2.foo"}),
+ # Could also return "bar.baz" but we want the shorter one
+ (["bar.baz"], ["foo.bar"], {"baz"}),
+ (["1.foo", "2.foo", "bar.baz"], ["3.foo", "bar.bla"], {"1.foo", "2.foo", "baz"}),
+ # Case with longer suffix chains and nested suffixes
+ (["a.b.c", "d.e.f", "g.h.i"], ["j.k.l", "m.n.o"], {"c", "f", "i"}),
+ (["a.b.c", "d.e.f", "g.h.i"], ["a.b.x", "d.x.f", "x.h.i"], {"c", "e.f", "g.h.i"}),
+ # Case with multiple items that can be covered by a single suffix
+ (["foo.bar.baz", "qux.bar.baz"], ["baz.bar.foo"], {"baz"}),
+ # Realistic examples
+ # Only match k_proj
+ (
+ ["model.decoder.layers.{i}.self_attn.k_proj" for i in range(12)],
+ (
+ ["model.decoder.layers.{i}.self_attn" for i in range(12)]
+ + ["model.decoder.layers.{i}.self_attn.v_proj" for i in range(12)]
+ + ["model.decoder.layers.{i}.self_attn.q_proj" for i in range(12)]
+ ),
+ {"k_proj"},
+ ),
+ # Match all k_proj except the one in layer 5 => no common suffix
+ (
+ ["model.decoder.layers.{i}.self_attn.k_proj" for i in range(12) if i != 5],
+ (
+ ["model.decoder.layers.5.self_attn.k_proj"]
+ + ["model.decoder.layers.{i}.self_attn" for i in range(12)]
+ + ["model.decoder.layers.{i}.self_attn.v_proj" for i in range(12)]
+ + ["model.decoder.layers.{i}.self_attn.q_proj" for i in range(12)]
+ ),
+ {"{i}.self_attn.k_proj" for i in range(12) if i != 5},
+ ),
+ ],
+ )
+ def test_find_minimal_target_modules(self, target_modules, other_module_names, expected):
+ # check all possible combinations of list and set
+ result = find_minimal_target_modules(target_modules, other_module_names)
+ assert result == expected
+
+ result = find_minimal_target_modules(set(target_modules), other_module_names)
+ assert result == expected
+
+ result = find_minimal_target_modules(target_modules, set(other_module_names))
+ assert result == expected
+
+ result = find_minimal_target_modules(set(target_modules), set(other_module_names))
+ assert result == expected
+
+ def test_find_minimal_target_modules_empty_raises(self):
+ with pytest.raises(ValueError, match="target_modules should be a list or set of strings"):
+ find_minimal_target_modules([], ["foo"])
+
+ with pytest.raises(ValueError, match="target_modules should be a list or set of strings"):
+ find_minimal_target_modules(set(), ["foo"])
+
+ def test_find_minimal_target_modules_contains_empty_string_raises(self):
+ target_modules = ["", "foo", "bar.baz"]
+ other_module_names = ["bar"]
+ with pytest.raises(ValueError, match="target_modules should not contain an empty string"):
+ find_minimal_target_modules(target_modules, other_module_names)
+
+ def test_find_minimal_target_modules_string_raises(self):
+ target_modules = "foo"
+ other_module_names = ["bar"]
+ with pytest.raises(ValueError, match="target_modules should be a list or set of strings"):
+ find_minimal_target_modules(target_modules, other_module_names)
+
+ @pytest.mark.parametrize(
+ "target_modules, other_module_names",
+ [
+ (["foo"], ["foo"]),
+ (["foo.bar"], ["foo.bar"]),
+ (["foo.bar", "spam", "eggs"], ["foo.bar"]),
+ (["foo.bar", "spam"], ["foo.bar", "eggs"]),
+ (["foo.bar"], ["foo.bar", "spam", "eggs"]),
+ ],
+ )
+ def test_find_minimal_target_modules_not_disjoint_raises(self, target_modules, other_module_names):
+ msg = (
+ "target_modules and other_module_names contain common elements, this should not happen, please "
+ "open a GitHub issue at https://github.com/huggingface/peft/issues with the code to reproduce this issue"
+ )
+ with pytest.raises(ValueError, match=msg):
+ find_minimal_target_modules(target_modules, other_module_names)
+
+ def test_get_peft_model_applies_find_target_modules(self):
+ # Check that when calling get_peft_model, the target_module optimization is indeed applied if the length of
+ # target_modules is big enough. The resulting model itself should be unaffected.
+ torch.manual_seed(0)
+ model_id = "facebook/opt-125m" # must be big enough for optimization to trigger
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+
+ # base case: specify target_modules in a minimal fashion
+ config = LoraConfig(init_lora_weights=False, target_modules=["q_proj", "v_proj"])
+ model = get_peft_model(model, config)
+
+ # this list contains all targeted modules listed separately
+ big_target_modules = [name for name, module in model.named_modules() if isinstance(module, LoraLayer)]
+ # sanity check
+ assert len(big_target_modules) > MIN_TARGET_MODULES_FOR_OPTIMIZATION
+
+ # make a "checksum" of the model for comparison
+ model_check_sum_before = sum(p.sum() for p in model.parameters())
+
+ # strip prefix so that the names they can be used as new target_modules
+ prefix_to_strip = "base_model.model.model."
+ big_target_modules = [name[len(prefix_to_strip) :] for name in big_target_modules]
+
+ del model
+
+ torch.manual_seed(0)
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ # pass the big target_modules to config
+ config = LoraConfig(init_lora_weights=False, target_modules=big_target_modules)
+ model = get_peft_model(model, config)
+
+ # check that target modules have been condensed
+ assert model.peft_config["default"].target_modules == {"q_proj", "v_proj"}
+
+ # check that the resulting model is still the same
+ model_check_after = sum(p.sum() for p in model.parameters())
+ assert model_check_sum_before == model_check_after
+
+ def test_suffix_is_substring_of_other_suffix(self):
+ # This test is based on a real world bug found in diffusers. The issue was that we needed the suffix
+ # 'time_emb_proj' in the minimal target modules. However, if there already was the suffix 'proj' in the
+ # required_suffixes, 'time_emb_proj' would not be added because the test was `endswith(suffix)` and
+ # 'time_emb_proj' ends with 'proj'. The correct logic is to test if `endswith("." + suffix")`. The module names
+ # chosen here are only a subset of the hundreds of actual module names but this subset is sufficient to
+ # replicate the bug.
+ target_modules = [
+ "down_blocks.1.attentions.0.transformer_blocks.0.ff.net.0.proj",
+ "mid_block.attentions.0.transformer_blocks.0.ff.net.0.proj",
+ "up_blocks.0.attentions.0.transformer_blocks.0.ff.net.0.proj",
+ "mid_block.attentions.0.proj_out",
+ "up_blocks.0.attentions.0.proj_out",
+ "down_blocks.1.attentions.0.proj_out",
+ "up_blocks.0.resnets.0.time_emb_proj",
+ "down_blocks.0.resnets.0.time_emb_proj",
+ "mid_block.resnets.0.time_emb_proj",
+ ]
+ other_module_names = [
+ "conv_in",
+ "time_proj",
+ "time_embedding",
+ "time_embedding.linear_1",
+ "add_time_proj",
+ "add_embedding",
+ "add_embedding.linear_1",
+ "add_embedding.linear_2",
+ "down_blocks",
+ "down_blocks.0",
+ "down_blocks.0.resnets",
+ "down_blocks.0.resnets.0",
+ "up_blocks",
+ "up_blocks.0",
+ "up_blocks.0.attentions",
+ "up_blocks.0.attentions.0",
+ "up_blocks.0.attentions.0.norm",
+ "up_blocks.0.attentions.0.transformer_blocks",
+ "up_blocks.0.attentions.0.transformer_blocks.0",
+ "up_blocks.0.attentions.0.transformer_blocks.0.norm1",
+ "up_blocks.0.attentions.0.transformer_blocks.0.attn1",
+ ]
+ expected = {"time_emb_proj", "proj", "proj_out"}
+ result = find_minimal_target_modules(target_modules, other_module_names)
+ assert result == expected
+
+ def test_get_peft_modules_module_name_is_suffix_of_another_module(self):
+ # Solves the following bug:
+ # https://github.com/huggingface/diffusers/pull/9622#issuecomment-2404789721
+
+ # The cause for the bug is as follows: When we have, say, a module called "bar.0.query" that we want to target
+ # and another module called "foo_bar.0.query" that we don't want to target, there was potential for an error.
+ # This is not caused by _find_minimal_target_modules directly, but rather the bug was inside of
+ # BaseTuner.inject_adapter and how the names_no_target were chosen. Those used to be chosen based on suffix. In
+ # our example, however, "bar.0.query" is a suffix of "foo_bar.0.query", therefore "foo_bar.0.query" was *not*
+ # added to names_no_target when it should have. As a consequence, during the optimization, it looks like "query"
+ # is safe to use as target_modules because we don't see that it wrongly matches "foo_bar.0.query".
+
+ # ensure that we have sufficiently many modules to trigger the optimization
+ n_layers = MIN_TARGET_MODULES_FOR_OPTIMIZATION + 1
+
+ class InnerModule(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.query = nn.Linear(10, 10)
+
+ class OuterModule(nn.Module):
+ def __init__(self):
+ super().__init__()
+ # note that "transformer_blocks" is a suffix of "single_transformer_blocks"
+ self.transformer_blocks = nn.ModuleList([InnerModule() for _ in range(n_layers)])
+ self.single_transformer_blocks = nn.ModuleList([InnerModule() for _ in range(n_layers)])
+
+ # we want to match all "transformer_blocks" layers but not "single_transformer_blocks"
+ target_modules = [f"transformer_blocks.{i}.query" for i in range(n_layers)]
+ model = get_peft_model(OuterModule(), LoraConfig(target_modules=target_modules))
+
+ # sanity check: we should have n_layers PEFT layers in model.transformer_blocks
+ transformer_blocks = model.base_model.model.transformer_blocks
+ assert sum(isinstance(module, BaseTunerLayer) for module in transformer_blocks.modules()) == n_layers
+
+ # we should not have any PEFT layers in model.single_transformer_blocks
+ single_transformer_blocks = model.base_model.model.single_transformer_blocks
+ assert not any(isinstance(module, BaseTunerLayer) for module in single_transformer_blocks.modules())
+
+ # target modules should *not* be simplified to "query" as that would match "single_transformers_blocks" too
+ assert model.peft_config["default"].target_modules != {"query"}
+
+ def test_find_minimal_target_modules_does_not_error_with_ia3(self, tmp_path):
+ # See #2429
+ # There is an issue with the compression of the target_modules attribute when using IA³. There, we additionally
+ # have the feedforward_modules attribute, which must be subset of target_modules. When target_modules is shrunk,
+ # the subset check will fail. This test ensures that this doesn't happen.
+ n_layers = MIN_TARGET_MODULES_FOR_OPTIMIZATION + 1
+
+ class InnerModule(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.query = nn.Linear(10, 10)
+
+ class OuterModule(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.blocks = nn.ModuleList([InnerModule() for _ in range(n_layers)])
+
+ target_modules = [f"blocks.{i}.query" for i in range(n_layers)]
+ feedforward_modules = [f"blocks.{i}.query" for i in range(n_layers)]
+ # the subset check happens here
+ config = IA3Config(target_modules=target_modules, feedforward_modules=feedforward_modules)
+ # the optimization step happens here, after the subset check, so at first we're fine, but we will run into an
+ # issue after a save/load roundtrip
+ model = get_peft_model(OuterModule(), config)
+ model.save_pretrained(tmp_path)
+ del model
+
+ # does not raise
+ PeftModel.from_pretrained(OuterModule(), tmp_path)
+
+
+class TestRankAndAlphaPattern:
+ @pytest.fixture
+ def model(self):
+ # we always target the foo layers, the *bar* layers are used as a control group to ensure that they are not
+ # accidentally targeted
+ class Inner(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.foo = nn.Linear(1, 1)
+ self.barfoo = nn.Linear(1, 1)
+
+ class Middle(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.foo = nn.Linear(1, 1)
+ self.foobar = nn.Linear(1, 1)
+ self.module = Inner()
+
+ class Outer(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.foo = nn.Linear(1, 1)
+ self.bar = nn.Linear(1, 1)
+ self.module = Middle()
+
+ # resulting model for overview:
+ # Outer(
+ # (foo): Linear(...)
+ # (bar): Linear(...)
+ # (module): Middle(
+ # (foo): Linear(...)
+ # (foobar): Linear(...)
+ # (module): Inner(
+ # (foo): Linear(...)
+ # (barfoo): Linear(...)
+ # )
+ # )
+ # )
+
+ return Outer()
+
+ def test_no_rank_nor_alpha_pattern(self, model):
+ # sanity check the default case, no rank or alpha pattern
+ config = LoraConfig(target_modules="all-linear")
+ model = get_peft_model(model, config).base_model.model
+ # r is the default rank and alpha, thus scaling is 1.0
+ assert model.foo.r["default"] == 8
+ assert model.foo.scaling["default"] == 1.0
+ assert model.bar.r["default"] == 8
+ assert model.bar.scaling["default"] == 1.0
+ assert model.module.foo.r["default"] == 8
+ assert model.module.foo.scaling["default"] == 1.0
+ assert model.module.foobar.r["default"] == 8
+ assert model.module.foobar.scaling["default"] == 1.0
+ assert model.module.module.foo.r["default"] == 8
+ assert model.module.module.foo.scaling["default"] == 1.0
+ assert model.module.module.barfoo.r["default"] == 8
+ assert model.module.module.barfoo.scaling["default"] == 1.0
+
+ def test_rank_and_alpha_pattern_no_matching_keys(self, model):
+ # sanity check for non-matching keys, no rank or alpha pattern
+ config = LoraConfig(target_modules="all-linear", rank_pattern={"bla": 4, "oof": 6}, alpha_pattern={"baz": 3})
+ model = get_peft_model(model, config).base_model.model
+ # r is the default rank and alpha, thus scaling is 1.0
+ assert model.foo.r["default"] == 8
+ assert model.foo.scaling["default"] == 1.0
+ assert model.bar.r["default"] == 8
+ assert model.bar.scaling["default"] == 1.0
+ assert model.module.foo.r["default"] == 8
+ assert model.module.foo.scaling["default"] == 1.0
+ assert model.module.foobar.r["default"] == 8
+ assert model.module.foobar.scaling["default"] == 1.0
+ assert model.module.module.foo.r["default"] == 8
+ assert model.module.module.foo.scaling["default"] == 1.0
+ assert model.module.module.barfoo.r["default"] == 8
+ assert model.module.module.barfoo.scaling["default"] == 1.0
+
+ # below, we test all permutations for rank_pattern of targeting outer, middle, and inner foo layers:
+
+ def test_rank_pattern_target_all(self, model):
+ config = LoraConfig(target_modules="all-linear", rank_pattern={"foo": 16})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.r["default"] == 16
+ assert model.bar.r["default"] == 8
+ assert model.module.foo.r["default"] == 16
+ assert model.module.foobar.r["default"] == 8
+ assert model.module.module.foo.r["default"] == 16
+ assert model.module.module.barfoo.r["default"] == 8
+
+ def test_rank_pattern_target_outer(self, model):
+ config = LoraConfig(target_modules="all-linear", rank_pattern={"^foo": 16})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.r["default"] == 16
+ assert model.bar.r["default"] == 8
+ assert model.module.foo.r["default"] == 8
+ assert model.module.foobar.r["default"] == 8
+ assert model.module.module.foo.r["default"] == 8
+ assert model.module.module.barfoo.r["default"] == 8
+
+ def test_rank_pattern_target_middle(self, model):
+ config = LoraConfig(target_modules="all-linear", rank_pattern={"^module.foo": 16})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.r["default"] == 8
+ assert model.bar.r["default"] == 8
+ assert model.module.foo.r["default"] == 16
+ assert model.module.foobar.r["default"] == 8
+ assert model.module.module.foo.r["default"] == 8
+ assert model.module.module.barfoo.r["default"] == 8
+
+ def test_rank_pattern_target_inner(self, model):
+ config = LoraConfig(target_modules="all-linear", rank_pattern={"module.module.foo": 16})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.r["default"] == 8
+ assert model.bar.r["default"] == 8
+ assert model.module.foo.r["default"] == 8
+ assert model.module.foobar.r["default"] == 8
+ assert model.module.module.foo.r["default"] == 16
+ assert model.module.module.barfoo.r["default"] == 8
+
+ def test_rank_pattern_target_inner_with_caret(self, model):
+ # same as before, but using the caret in the regex should also work
+ config = LoraConfig(target_modules="all-linear", rank_pattern={"^module.module.foo": 16})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.r["default"] == 8
+ assert model.bar.r["default"] == 8
+ assert model.module.foo.r["default"] == 8
+ assert model.module.foobar.r["default"] == 8
+ assert model.module.module.foo.r["default"] == 16
+ assert model.module.module.barfoo.r["default"] == 8
+
+ def test_rank_pattern_target_middle_inner(self, model):
+ config = LoraConfig(target_modules="all-linear", rank_pattern={"module.foo": 16})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.r["default"] == 8
+ assert model.bar.r["default"] == 8
+ assert model.module.foo.r["default"] == 16
+ assert model.module.foobar.r["default"] == 8
+ assert model.module.module.foo.r["default"] == 16
+ assert model.module.module.barfoo.r["default"] == 8
+
+ def test_rank_pattern_target_middle_inner_different_ranks(self, model):
+ # same layers targeted as in previous test, but with different ranks
+ config = LoraConfig(target_modules="all-linear", rank_pattern={"^module.foo": 16, "^module.module.foo": 24})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.r["default"] == 8
+ assert model.bar.r["default"] == 8
+ assert model.module.foo.r["default"] == 16
+ assert model.module.foobar.r["default"] == 8
+ assert model.module.module.foo.r["default"] == 24
+ assert model.module.module.barfoo.r["default"] == 8
+
+ def test_rank_pattern_target_outer_middle(self, model):
+ config = LoraConfig(target_modules="all-linear", rank_pattern={"^foo": 16, "^module.foo": 24})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.r["default"] == 16
+ assert model.bar.r["default"] == 8
+ assert model.module.foo.r["default"] == 24
+ assert model.module.foobar.r["default"] == 8
+ assert model.module.module.foo.r["default"] == 8
+ assert model.module.module.barfoo.r["default"] == 8
+
+ def test_rank_pattern_target_outer_inner(self, model):
+ config = LoraConfig(target_modules="all-linear", rank_pattern={"^foo": 16, "module.module.foo": 24})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.r["default"] == 16
+ assert model.bar.r["default"] == 8
+ assert model.module.foo.r["default"] == 8
+ assert model.module.foobar.r["default"] == 8
+ assert model.module.module.foo.r["default"] == 24
+ assert model.module.module.barfoo.r["default"] == 8
+
+ def test_rank_pattern_target_outer_inner_with_caret(self, model):
+ # same as before, but using the caret in the regex should also work
+ config = LoraConfig(target_modules="all-linear", rank_pattern={"^foo": 16, "^module.module.foo": 24})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.r["default"] == 16
+ assert model.bar.r["default"] == 8
+ assert model.module.foo.r["default"] == 8
+ assert model.module.foobar.r["default"] == 8
+ assert model.module.module.foo.r["default"] == 24
+ assert model.module.module.barfoo.r["default"] == 8
+
+ def test_rank_pattern_target_outer_middle_inner_with_caret(self, model):
+ # indicate each layer with a different rank and use the caret in the regex
+ config = LoraConfig(
+ target_modules="all-linear", rank_pattern={"^foo": 16, "^module.foo": 24, "^module.module.foo": 32}
+ )
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.r["default"] == 16
+ assert model.bar.r["default"] == 8
+ assert model.module.foo.r["default"] == 24
+ assert model.module.foobar.r["default"] == 8
+ assert model.module.module.foo.r["default"] == 32
+ assert model.module.module.barfoo.r["default"] == 8
+
+ def test_rank_pattern_target_outer_middle_inner_with_caret_dict_order(self, model):
+ # same as before, but change the order of the rank_pattern dict
+ config = LoraConfig(
+ target_modules="all-linear", rank_pattern={"^module.module.foo": 32, "^module.foo": 24, "^foo": 16}
+ )
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.r["default"] == 16
+ assert model.bar.r["default"] == 8
+ assert model.module.foo.r["default"] == 24
+ assert model.module.foobar.r["default"] == 8
+ assert model.module.module.foo.r["default"] == 32
+ assert model.module.module.barfoo.r["default"] == 8
+
+ # below, we test all permutations for alpha_pattern of targeting outer, middle, and inner foo layers:
+ # these tests are analogous to the rank_pattern tests above
+
+ def test_alpha_pattern_target_all(self, model):
+ config = LoraConfig(target_modules="all-linear", alpha_pattern={"foo": 4})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.scaling["default"] == 0.5
+ assert model.bar.scaling["default"] == 1.0
+ assert model.module.foo.scaling["default"] == 0.5
+ assert model.module.foobar.scaling["default"] == 1.0
+ assert model.module.module.foo.scaling["default"] == 0.5
+ assert model.module.module.barfoo.scaling["default"] == 1.0
+
+ def test_alpha_pattern_target_outer(self, model):
+ config = LoraConfig(target_modules="all-linear", alpha_pattern={"^foo": 4})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.scaling["default"] == 0.5
+ assert model.bar.scaling["default"] == 1.0
+ assert model.module.foo.scaling["default"] == 1.0
+ assert model.module.foobar.scaling["default"] == 1.0
+ assert model.module.module.foo.scaling["default"] == 1.0
+ assert model.module.module.barfoo.scaling["default"] == 1.0
+
+ def test_alpha_pattern_target_middle(self, model):
+ config = LoraConfig(target_modules="all-linear", alpha_pattern={"^module.foo": 4})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.scaling["default"] == 1.0
+ assert model.bar.scaling["default"] == 1.0
+ assert model.module.foo.scaling["default"] == 0.5
+ assert model.module.foobar.scaling["default"] == 1.0
+ assert model.module.module.foo.scaling["default"] == 1.0
+ assert model.module.module.barfoo.scaling["default"] == 1.0
+
+ def test_alpha_pattern_target_inner(self, model):
+ config = LoraConfig(target_modules="all-linear", alpha_pattern={"module.module.foo": 4})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.scaling["default"] == 1.0
+ assert model.bar.scaling["default"] == 1.0
+ assert model.module.foo.scaling["default"] == 1.0
+ assert model.module.foobar.scaling["default"] == 1.0
+ assert model.module.module.foo.scaling["default"] == 0.5
+ assert model.module.module.barfoo.scaling["default"] == 1.0
+
+ def test_alpha_pattern_target_inner_with_caret(self, model):
+ # same as before, but using the caret in the regex should also work
+ config = LoraConfig(target_modules="all-linear", alpha_pattern={"^module.module.foo": 4})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.scaling["default"] == 1.0
+ assert model.bar.scaling["default"] == 1.0
+ assert model.module.foo.scaling["default"] == 1.0
+ assert model.module.foobar.scaling["default"] == 1.0
+ assert model.module.module.foo.scaling["default"] == 0.5
+ assert model.module.module.barfoo.scaling["default"] == 1.0
+
+ def test_alpha_pattern_target_middle_inner(self, model):
+ config = LoraConfig(target_modules="all-linear", alpha_pattern={"module.foo": 4})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.scaling["default"] == 1.0
+ assert model.bar.scaling["default"] == 1.0
+ assert model.module.foo.scaling["default"] == 0.5
+ assert model.module.foobar.scaling["default"] == 1.0
+ assert model.module.module.foo.scaling["default"] == 0.5
+ assert model.module.module.barfoo.scaling["default"] == 1.0
+
+ def test_alpha_pattern_target_middle_inner_different_alphas(self, model):
+ # same layers targeted as in previous test, but with different alphas
+ config = LoraConfig(target_modules="all-linear", alpha_pattern={"^module.foo": 4, "^module.module.foo": 2})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.scaling["default"] == 1.0
+ assert model.bar.scaling["default"] == 1.0
+ assert model.module.foo.scaling["default"] == 0.5
+ assert model.module.foobar.scaling["default"] == 1.0
+ assert model.module.module.foo.scaling["default"] == 0.25
+ assert model.module.module.barfoo.scaling["default"] == 1.0
+
+ def test_alpha_pattern_target_outer_middle(self, model):
+ config = LoraConfig(target_modules="all-linear", alpha_pattern={"^foo": 4, "^module.foo": 2})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.scaling["default"] == 0.5
+ assert model.bar.scaling["default"] == 1.0
+ assert model.module.foo.scaling["default"] == 0.25
+ assert model.module.foobar.scaling["default"] == 1.0
+ assert model.module.module.foo.scaling["default"] == 1.0
+ assert model.module.module.barfoo.scaling["default"] == 1.0
+
+ def test_alpha_pattern_target_outer_inner(self, model):
+ config = LoraConfig(target_modules="all-linear", alpha_pattern={"^foo": 4, "module.module.foo": 2})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.scaling["default"] == 0.5
+ assert model.bar.scaling["default"] == 1.0
+ assert model.module.foo.scaling["default"] == 1.0
+ assert model.module.foobar.scaling["default"] == 1.0
+ assert model.module.module.foo.scaling["default"] == 0.25
+ assert model.module.module.barfoo.scaling["default"] == 1.0
+
+ def test_alpha_pattern_target_outer_inner_with_caret(self, model):
+ # same as before, but using the caret in the regex should also work
+ config = LoraConfig(target_modules="all-linear", alpha_pattern={"^foo": 4, "^module.module.foo": 2})
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.scaling["default"] == 0.5
+ assert model.bar.scaling["default"] == 1.0
+ assert model.module.foo.scaling["default"] == 1.0
+ assert model.module.foobar.scaling["default"] == 1.0
+ assert model.module.module.foo.scaling["default"] == 0.25
+ assert model.module.module.barfoo.scaling["default"] == 1.0
+
+ def test_alpha_pattern_target_outer_middle_inner_with_caret(self, model):
+ # indicate each layer with a different alpha and use the caret in the regex
+ config = LoraConfig(
+ target_modules="all-linear", alpha_pattern={"^foo": 4, "^module.foo": 2, "^module.module.foo": 1}
+ )
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.scaling["default"] == 0.5
+ assert model.bar.scaling["default"] == 1.0
+ assert model.module.foo.scaling["default"] == 0.25
+ assert model.module.foobar.scaling["default"] == 1.0
+ assert model.module.module.foo.scaling["default"] == 0.125
+ assert model.module.module.barfoo.scaling["default"] == 1.0
+
+ def test_alpha_pattern_target_outer_middle_inner_with_caret_dict_order(self, model):
+ # same as before, but change the order of the alpha_pattern dict
+ config = LoraConfig(
+ target_modules="all-linear", alpha_pattern={"^module.module.foo": 1, "^module.foo": 2, "^foo": 4}
+ )
+ model = get_peft_model(model, config).base_model.model
+ assert model.foo.scaling["default"] == 0.5
+ assert model.bar.scaling["default"] == 1.0
+ assert model.module.foo.scaling["default"] == 0.25
+ assert model.module.foobar.scaling["default"] == 1.0
+ assert model.module.module.foo.scaling["default"] == 0.125
+ assert model.module.module.barfoo.scaling["default"] == 1.0
diff --git a/peft/tests/test_vblora.py b/peft/tests/test_vblora.py
new file mode 100644
index 0000000000000000000000000000000000000000..4a4801cab7904e68660a92695d0f05563d37d672
--- /dev/null
+++ b/peft/tests/test_vblora.py
@@ -0,0 +1,269 @@
+# Copyright 2024-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+
+import pytest
+import torch
+from accelerate.utils.imports import is_bf16_available
+from safetensors import safe_open
+from torch import nn
+
+from peft import PeftModel, VBLoRAConfig, get_peft_model
+
+
+class MLP(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.relu = nn.ReLU()
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.lin1 = nn.Linear(20, 20, bias=bias) # lin1 and lin2 have same shape
+ self.lin2 = nn.Linear(20, 20, bias=bias)
+ self.lin3 = nn.Linear(20, 2, bias=bias)
+ self.sm = nn.LogSoftmax(dim=-1)
+
+ def forward(self, X):
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = self.lin1(X)
+ X = self.relu(X)
+ X = self.lin2(X)
+ X = self.relu(X)
+ X = self.lin3(X)
+ X = self.sm(X)
+ return X
+
+
+class TestVBLoRA:
+ def get_mlp(self):
+ model = MLP()
+ return model
+
+ def test_vblora_parameters(self):
+ mlp = self.get_mlp()
+ vector_length = 2
+ num_vectors = 10
+ config = VBLoRAConfig(
+ target_modules=["lin0", "lin1", "lin3"], vector_length=vector_length, num_vectors=num_vectors
+ )
+ mlp_vblora = get_peft_model(mlp, config)
+
+ vector_bank = mlp_vblora.vblora_vector_bank["default"]
+
+ vblora_lin0_logits_B = mlp_vblora.lin0.vblora_logits_B["default"]
+ assert vblora_lin0_logits_B.shape == (mlp.lin0.out_features // vector_length, config.r, num_vectors)
+
+ vblora_lin1_logits_A = mlp_vblora.lin1.vblora_logits_A["default"]
+ assert vblora_lin1_logits_A.shape == (config.r, mlp.lin1.in_features // vector_length, num_vectors)
+
+ vblora_lin3_logits_A = mlp_vblora.lin3.vblora_logits_A["default"]
+ assert vblora_lin3_logits_A.shape == (config.r, mlp.lin3.in_features // vector_length, num_vectors)
+
+ assert vector_bank.shape == (num_vectors, vector_length)
+
+ # test if the vector bank is shared across the layers
+ assert (
+ mlp_vblora.lin0.vblora_vector_bank["default"].data_ptr()
+ == mlp_vblora.lin3.vblora_vector_bank["default"].data_ptr()
+ )
+ assert mlp_vblora.lin1.vblora_vector_bank["default"].data_ptr() == vector_bank.data_ptr()
+
+ # should not raise
+ input = torch.randn(5, 10)
+ mlp_vblora(input)
+
+ def test_save_with_topk_weights(self, tmp_path):
+ torch.manual_seed(0)
+ mlp = self.get_mlp()
+ vector_length = 2
+ num_vectors = 10
+ topk = 2
+ config = VBLoRAConfig(
+ target_modules=["lin0", "lin3"],
+ topk=topk,
+ vector_length=vector_length,
+ num_vectors=num_vectors,
+ save_only_topk_weights=True,
+ )
+ mlp_vblora = get_peft_model(mlp, config)
+ save_path = tmp_path / "vblora"
+ mlp_vblora.save_pretrained(save_path)
+ assert os.path.exists(save_path / "adapter_model.safetensors")
+
+ adapter_model_dict = {}
+ with safe_open(save_path / "adapter_model.safetensors", framework="pt") as f:
+ for k in f.keys():
+ adapter_model_dict[k] = f.get_tensor(k)
+ assert "base_model.model.lin0.vblora_logits_A_topk_indices" in adapter_model_dict
+ assert "base_model.model.lin0.vblora_logits_A_topk_weights" in adapter_model_dict
+ assert "base_model.model.lin3.vblora_logits_B_topk_indices" in adapter_model_dict
+ assert "base_model.model.lin3.vblora_logits_B_topk_weights" in adapter_model_dict
+ assert "base_model.model.lin0.vblora_logits_A" not in adapter_model_dict
+ assert "base_model.model.lin3.vblora_logits_B" not in adapter_model_dict
+
+ assert adapter_model_dict["base_model.model.lin0.vblora_logits_B_topk_indices"].shape == (
+ mlp.lin0.out_features // vector_length,
+ config.r,
+ topk,
+ )
+ assert adapter_model_dict["base_model.model.lin0.vblora_logits_B_topk_weights"].shape == (
+ mlp.lin0.out_features // vector_length,
+ config.r,
+ topk - 1,
+ )
+ assert adapter_model_dict["base_model.model.lin3.vblora_logits_A_topk_indices"].shape == (
+ config.r,
+ mlp.lin3.in_features // vector_length,
+ topk,
+ )
+ assert adapter_model_dict["base_model.model.lin3.vblora_logits_A_topk_weights"].shape == (
+ config.r,
+ mlp.lin3.in_features // vector_length,
+ topk - 1,
+ )
+
+ @pytest.mark.parametrize("save_only_topk_weights", [True, False])
+ def test_save_load(self, save_only_topk_weights, tmp_path):
+ torch.manual_seed(0)
+ mlp = self.get_mlp()
+ config = VBLoRAConfig(
+ target_modules=["lin0", "lin1", "lin3"],
+ topk=2,
+ vector_length=2,
+ num_vectors=10,
+ save_only_topk_weights=save_only_topk_weights,
+ )
+ mlp_vblora = get_peft_model(mlp, config)
+ save_path = tmp_path / "vblora"
+ mlp_vblora.save_pretrained(save_path)
+ assert os.path.exists(save_path / "adapter_config.json")
+
+ del mlp
+ torch.manual_seed(0) # make sure the base model has the same weights
+ mlp = self.get_mlp()
+ mlp_vblora_loaded = PeftModel.from_pretrained(mlp, save_path)
+
+ input = torch.randn(5, 10)
+ output = mlp_vblora(input)
+ output_loaded = mlp_vblora_loaded(input)
+ assert torch.allclose(output, output_loaded, atol=1e-8, rtol=1e-5)
+
+ def test_resume_training_model_with_topk_weights(self, tmp_path):
+ torch.manual_seed(1)
+ mlp = self.get_mlp()
+ config = VBLoRAConfig(
+ target_modules=["lin0", "lin1", "lin3"],
+ topk=2,
+ vector_length=2,
+ num_vectors=10,
+ save_only_topk_weights=True,
+ )
+ mlp_vblora = get_peft_model(mlp, config)
+ save_path = tmp_path / "vblora"
+ mlp_vblora.save_pretrained(save_path)
+
+ input = torch.randn(5, 10)
+ mlp_vblora.train()
+ # should not raise
+ mlp_vblora(input)
+
+ del mlp
+ torch.manual_seed(1)
+ mlp = self.get_mlp()
+ mlp_vblora_loaded = PeftModel.from_pretrained(mlp, save_path)
+ mlp_vblora_loaded.train()
+ msg = "Found infinity values in VB-LoRA logits. Ensure training was not resumed from a `save_only_topk_weights` model."
+ with pytest.raises(RuntimeError, match=msg):
+ mlp_vblora_loaded(input)
+
+ @pytest.mark.parametrize("dtype", [torch.float32, torch.float16, torch.bfloat16])
+ def test_vblora_dtypes(self, dtype):
+ mlp = self.get_mlp()
+ if dtype == torch.bfloat16:
+ if not is_bf16_available():
+ pytest.skip("bfloat16 not supported on this system, skipping the test")
+
+ config = VBLoRAConfig(
+ target_modules=["lin0", "lin1", "lin3"], vector_length=2, num_vectors=10, save_only_topk_weights=False
+ )
+ mlp_vblora = get_peft_model(mlp.to(dtype), config)
+ inputs = torch.randn(5, 10).to(dtype)
+ output = mlp_vblora(inputs) # should not raise
+ assert output.dtype == dtype
+
+ def test_vblora_nb_savable_params_only_topk_weights(self):
+ mlp = self.get_mlp()
+ vector_length = 2
+ num_vectors = 10
+ topk = 2
+ r = 4
+ config = VBLoRAConfig(
+ target_modules=["lin0", "lin1"],
+ vector_length=vector_length,
+ num_vectors=num_vectors,
+ topk=topk,
+ r=r,
+ save_only_topk_weights=True,
+ )
+ mlp_vblora = get_peft_model(mlp, config)
+
+ mlp_vblora.lin3.requires_grad_(True) # set lin3 to trainable
+
+ adapter_params, other_params = mlp_vblora.get_nb_savable_parameters()
+ factor = 0.25 # dtype of index is uint8
+ topk_indices_parameter = int(
+ (mlp.lin0.out_features + mlp.lin0.in_features + mlp.lin1.out_features + mlp.lin1.in_features)
+ / vector_length
+ * r
+ * topk
+ * factor
+ )
+ topk_weights_parameter = int(
+ (mlp.lin0.out_features + mlp.lin0.in_features + mlp.lin1.out_features + mlp.lin1.in_features)
+ / vector_length
+ * r
+ * (topk - 1)
+ )
+ vector_bank_parameter = num_vectors * vector_length
+ assert adapter_params == topk_indices_parameter + topk_weights_parameter + vector_bank_parameter
+ assert other_params == (mlp.lin3.in_features + 1) * mlp.lin3.out_features
+
+ def test_vblora_nb_savable_params_all_logits(self):
+ mlp = self.get_mlp()
+ vector_length = 2
+ num_vectors = 10
+ topk = 2
+ r = 4
+ config = VBLoRAConfig(
+ target_modules=["lin0", "lin1"],
+ vector_length=vector_length,
+ num_vectors=num_vectors,
+ topk=topk,
+ r=r,
+ save_only_topk_weights=False,
+ )
+ mlp_vblora = get_peft_model(mlp, config)
+
+ mlp_vblora.lin3.requires_grad_(True) # set lin3 to trainable
+
+ adapter_params, other_params = mlp_vblora.get_nb_savable_parameters()
+ logits_parameter = int(
+ (mlp.lin0.out_features + mlp.lin0.in_features + mlp.lin1.out_features + mlp.lin1.in_features)
+ / vector_length
+ * r
+ * num_vectors
+ )
+ vector_bank_parameter = num_vectors * vector_length
+ assert adapter_params == logits_parameter + vector_bank_parameter
+ assert other_params == (mlp.lin3.in_features + 1) * mlp.lin3.out_features
diff --git a/peft/tests/test_vera.py b/peft/tests/test_vera.py
new file mode 100644
index 0000000000000000000000000000000000000000..717dfb270aa823deccb28e822b6655e637b5b6be
--- /dev/null
+++ b/peft/tests/test_vera.py
@@ -0,0 +1,298 @@
+# Copyright 2024-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# This test file is for tests specific to VeRA, since VeRA has some specific challenges due to the shared weights.
+
+import os
+
+import pytest
+import torch
+from accelerate.utils.imports import is_bf16_available
+from safetensors import safe_open
+from torch import nn
+
+from peft import PeftModel, VeraConfig, get_peft_model
+
+
+class MLP(nn.Module):
+ def __init__(self, bias=True):
+ super().__init__()
+ self.relu = nn.ReLU()
+ self.lin0 = nn.Linear(10, 20, bias=bias)
+ self.lin1 = nn.Linear(20, 20, bias=bias) # lin1 and lin2 have same shape
+ self.lin2 = nn.Linear(20, 20, bias=bias)
+ self.lin3 = nn.Linear(20, 2, bias=bias)
+ self.sm = nn.LogSoftmax(dim=-1)
+
+ def forward(self, X):
+ X = self.lin0(X)
+ X = self.relu(X)
+ X = self.lin1(X)
+ X = self.relu(X)
+ X = self.lin2(X)
+ X = self.relu(X)
+ X = self.lin3(X)
+ X = self.sm(X)
+ return X
+
+
+class TestVera:
+ @pytest.fixture
+ def mlp(self):
+ torch.manual_seed(0)
+ model = MLP()
+ return model
+
+ @pytest.fixture
+ def mlp_same_prng(self, mlp):
+ torch.manual_seed(0)
+
+ config = VeraConfig(target_modules=["lin1", "lin2"], init_weights=False)
+ # creates a default VeRA adapter
+ peft_model = get_peft_model(mlp, config)
+ config2 = VeraConfig(target_modules=["lin1", "lin2"], init_weights=False)
+ peft_model.add_adapter("other", config2)
+ return peft_model
+
+ def test_multiple_adapters_same_prng_weights(self, mlp_same_prng):
+ # we can have multiple adapters with the same prng key, in which case the weights should be shared
+ assert (
+ mlp_same_prng.base_model.model.lin1.vera_A["default"]
+ is mlp_same_prng.base_model.model.lin1.vera_A["other"]
+ )
+ assert (
+ mlp_same_prng.base_model.model.lin1.vera_B["default"]
+ is mlp_same_prng.base_model.model.lin1.vera_B["other"]
+ )
+ assert (
+ mlp_same_prng.base_model.model.lin2.vera_A["default"]
+ is mlp_same_prng.base_model.model.lin2.vera_A["other"]
+ )
+ assert (
+ mlp_same_prng.base_model.model.lin2.vera_B["default"]
+ is mlp_same_prng.base_model.model.lin2.vera_B["other"]
+ )
+
+ input = torch.randn(5, 10)
+ mlp_same_prng.set_adapter("default")
+ output_default = mlp_same_prng(input)
+ mlp_same_prng.set_adapter("other")
+ output_other = mlp_same_prng(input)
+ assert not torch.allclose(output_default, output_other, atol=1e-3, rtol=1e-3)
+
+ def test_multiple_adapters_different_prng_raises(self):
+ # we cannot have multiple adapters with different prng keys
+ model = MLP()
+ config = VeraConfig(target_modules=["lin1", "lin2"], init_weights=False)
+ # creates a default VeRA adapter
+ peft_model = get_peft_model(model, config)
+ config2 = VeraConfig(target_modules=["lin1", "lin2"], init_weights=False, projection_prng_key=123)
+
+ msg = (
+ r"Vera PRNG initialisation key must be the same for all adapters. Got config.projection_prng_key=123 but "
+ r"previous config had 0"
+ )
+ with pytest.raises(ValueError, match=msg):
+ peft_model.add_adapter("other", config2)
+
+ def test_multiple_adapters_save_load_save_projection_true(self, mlp_same_prng, tmp_path):
+ # check saving and loading works with multiple adapters and saved projection weights
+ torch.manual_seed(0)
+ input = torch.randn(5, 10)
+ mlp_same_prng.set_adapter("default")
+ output_default = mlp_same_prng(input)
+ mlp_same_prng.set_adapter("other")
+ output_other = mlp_same_prng(input)
+
+ # sanity check
+ assert not torch.allclose(output_default, output_other, atol=1e-3, rtol=1e-3)
+
+ save_path = tmp_path / "vera"
+ mlp_same_prng.save_pretrained(save_path)
+ assert os.path.exists(save_path / "adapter_config.json")
+ assert os.path.exists(save_path / "other" / "adapter_config.json")
+
+ torch.manual_seed(0)
+ mlp = MLP()
+ peft_model = PeftModel.from_pretrained(mlp, save_path)
+ peft_model.load_adapter(save_path / "other", "other")
+
+ peft_model.set_adapter("default")
+ output_default_loaded = peft_model(input)
+ peft_model.set_adapter("other")
+ output_other_loaded = peft_model(input)
+
+ assert torch.allclose(output_default, output_default_loaded, atol=1e-3, rtol=1e-3)
+ assert torch.allclose(output_other, output_other_loaded, atol=1e-3, rtol=1e-3)
+
+ def test_multiple_adapters_save_load_save_projection_false(self, mlp, tmp_path):
+ # check saving and loading works with multiple adapters without saved projection weights
+ torch.manual_seed(1)
+ config = VeraConfig(target_modules=["lin1", "lin2"], init_weights=False, save_projection=False)
+ # creates a default VeRA adapter
+ peft_model = get_peft_model(mlp, config, adapter_name="first")
+ config2 = VeraConfig(target_modules=["lin1", "lin2"], init_weights=False, save_projection=False)
+ peft_model.add_adapter("second", config2)
+
+ input = torch.randn(5, 10)
+ peft_model.set_adapter("first")
+ output_first = peft_model(input)
+ peft_model.set_adapter("second")
+ output_second = peft_model(input)
+
+ # sanity check
+ assert not torch.allclose(output_first, output_second, atol=1e-3, rtol=1e-3)
+
+ save_path = tmp_path / "vera"
+ peft_model.save_pretrained(save_path)
+ assert os.path.exists(save_path / "first" / "adapter_config.json")
+ assert os.path.exists(save_path / "second" / "adapter_config.json")
+
+ torch.manual_seed(0)
+ mlp = MLP()
+ peft_model = PeftModel.from_pretrained(mlp, save_path / "first", adapter_name="first")
+ peft_model.load_adapter(save_path / "second", "second")
+
+ peft_model.set_adapter("first")
+ output_first_loaded = peft_model(input)
+ peft_model.set_adapter("second")
+ output_second_loaded = peft_model(input)
+
+ assert torch.allclose(output_first, output_first_loaded, atol=1e-3, rtol=1e-3)
+ assert torch.allclose(output_second, output_second_loaded, atol=1e-3, rtol=1e-3)
+
+ def test_multiple_adapters_save_projection_true_contains_vera_A_vera_B(self, mlp_same_prng, tmp_path):
+ # check that the state_dicts don't contain the projection weights
+ save_path = tmp_path / "vera"
+ mlp_same_prng.save_pretrained(save_path)
+
+ sd_default = {}
+ with safe_open(save_path / "adapter_model.safetensors", framework="pt", device="cpu") as f:
+ for key in f.keys():
+ sd_default[key] = f.get_tensor(key)
+
+ assert any("vera_A" in key for key in sd_default)
+ assert any("vera_B" in key for key in sd_default)
+ # default rank for VeRA is 256
+ assert sd_default["base_model.vera_A"].shape == (256, 20)
+ assert sd_default["base_model.vera_B"].shape == (20, 256)
+
+ sd_other = {}
+ with safe_open(save_path / "other" / "adapter_model.safetensors", framework="pt", device="cpu") as f:
+ for key in f.keys():
+ sd_other[key] = f.get_tensor(key)
+
+ assert any("vera_A" in key for key in sd_other)
+ assert any("vera_B" in key for key in sd_other)
+ assert sd_other["base_model.vera_A"].shape == (256, 20)
+ assert sd_other["base_model.vera_B"].shape == (20, 256)
+
+ def test_multiple_adapters_save_projection_false_contains_no_vera_A_vera_B(self, mlp, tmp_path):
+ torch.manual_seed(1)
+ config = VeraConfig(target_modules=["lin1", "lin2"], init_weights=False, save_projection=False)
+ # creates a default VeRA adapter
+ peft_model = get_peft_model(mlp, config, adapter_name="first")
+ config2 = VeraConfig(target_modules=["lin1", "lin2"], init_weights=False, save_projection=False)
+ peft_model.add_adapter("second", config2)
+
+ save_path = tmp_path / "vera"
+ peft_model.save_pretrained(save_path)
+
+ sd_default = {}
+ with safe_open(save_path / "first" / "adapter_model.safetensors", framework="pt", device="cpu") as f:
+ for key in f.keys():
+ sd_default[key] = f.get_tensor(key)
+
+ assert not any("vera_A" in key for key in sd_default)
+ assert not any("vera_B" in key for key in sd_default)
+
+ sd_other = {}
+ with safe_open(save_path / "second" / "adapter_model.safetensors", framework="pt", device="cpu") as f:
+ for key in f.keys():
+ sd_other[key] = f.get_tensor(key)
+
+ assert not any("vera_A" in key for key in sd_other)
+ assert not any("vera_B" in key for key in sd_other)
+
+ def test_vera_A_vera_B_share_memory(self, mlp_same_prng):
+ vera_A = mlp_same_prng.vera_A["default"]
+ vera_B = mlp_same_prng.vera_B["default"]
+
+ # these tensors should share the same data
+ assert vera_A.data_ptr() == mlp_same_prng.base_model.model.lin1.vera_A["default"].data_ptr()
+ assert vera_B.data_ptr() == mlp_same_prng.base_model.model.lin1.vera_B["default"].data_ptr()
+ assert vera_A.data_ptr() == mlp_same_prng.base_model.model.lin2.vera_A["default"].data_ptr()
+ assert vera_B.data_ptr() == mlp_same_prng.base_model.model.lin2.vera_B["default"].data_ptr()
+ # sanity check: these tensors shouldn't share the same data
+ assert vera_A.data_ptr() != vera_B.data_ptr()
+
+ def test_vera_lambda_dont_share_memory(self, mlp_same_prng):
+ # sanity check: these tensors shouldn't share the same data
+ assert (
+ mlp_same_prng.base_model.model.lin1.vera_lambda_b["default"].data_ptr()
+ != mlp_same_prng.base_model.model.lin1.vera_lambda_b["other"].data_ptr()
+ )
+ assert (
+ mlp_same_prng.base_model.model.lin1.vera_lambda_b["default"].data_ptr()
+ != mlp_same_prng.base_model.model.lin2.vera_lambda_b["default"].data_ptr()
+ )
+ assert (
+ mlp_same_prng.base_model.model.lin1.vera_lambda_b["other"].data_ptr()
+ != mlp_same_prng.base_model.model.lin2.vera_lambda_b["other"].data_ptr()
+ )
+ assert (
+ mlp_same_prng.base_model.model.lin1.vera_lambda_d["default"].data_ptr()
+ != mlp_same_prng.base_model.model.lin1.vera_lambda_d["other"].data_ptr()
+ )
+ assert (
+ mlp_same_prng.base_model.model.lin1.vera_lambda_d["default"].data_ptr()
+ != mlp_same_prng.base_model.model.lin2.vera_lambda_d["default"].data_ptr()
+ )
+ assert (
+ mlp_same_prng.base_model.model.lin1.vera_lambda_d["other"].data_ptr()
+ != mlp_same_prng.base_model.model.lin2.vera_lambda_d["other"].data_ptr()
+ )
+
+ def test_vera_different_shapes(self, mlp):
+ config = VeraConfig(target_modules=["lin0", "lin3"], init_weights=False)
+ mlp_different_shapes = get_peft_model(mlp, config)
+
+ vera_A = mlp_different_shapes.vera_A["default"]
+ vera_B = mlp_different_shapes.vera_B["default"]
+
+ # sanity check
+ assert mlp.lin0.base_layer.weight.shape != mlp.lin3.base_layer.weight.shape
+
+ # lin0 has the largest output dimension, lin3 has the largest input dimension
+ # vera_A should have the shape of (rank, largest_in), vera_B should have the shape of (largest_out, rank)
+ assert vera_A.shape == (config.r, mlp.lin3.in_features)
+ assert vera_B.shape == (mlp.lin0.out_features, config.r)
+
+ # should not raise
+ input = torch.randn(5, 10)
+ mlp_different_shapes(input)
+
+ @pytest.mark.parametrize("dtype", [torch.float32, torch.float16, torch.bfloat16])
+ def test_vera_dtypes(self, dtype):
+ if dtype == torch.bfloat16:
+ # skip if bf16 is not supported on hardware, see #1872
+ if not is_bf16_available():
+ pytest.skip("bfloat16 not supported on this system, skipping the test")
+
+ model = MLP().to(dtype)
+ config = VeraConfig(target_modules=["lin1", "lin2"], init_weights=False)
+ peft_model = get_peft_model(model, config)
+ inputs = torch.randn(5, 10).to(dtype)
+ output = peft_model(inputs) # should not raise
+ assert output.dtype == dtype
diff --git a/peft/tests/test_vision_models.py b/peft/tests/test_vision_models.py
new file mode 100644
index 0000000000000000000000000000000000000000..74e5d654de26f398f8ea2562f5471d70c3f6115c
--- /dev/null
+++ b/peft/tests/test_vision_models.py
@@ -0,0 +1,156 @@
+# Copyright 2024-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+# This is not a full on test suite of vision models, since we already run many tests on dummy models with Conv2d layers
+# and on stable diffusion models. Instead, this file contains specific tests for bugs that have been found in the past.
+import gc
+
+import numpy as np
+import pytest
+import torch
+from accelerate.utils.memory import clear_device_cache
+from safetensors.torch import load_file
+from transformers import (
+ AutoImageProcessor,
+ AutoModelForImageClassification,
+ AutoProcessor,
+ LlavaForConditionalGeneration,
+)
+
+from peft import (
+ HRAConfig,
+ LoHaConfig,
+ LoKrConfig,
+ LoraConfig,
+ OFTConfig,
+ PeftModel,
+ PrefixTuningConfig,
+ get_peft_model,
+)
+
+from .testing_utils import load_cat_image
+
+
+CONFIGS = {
+ "lora": LoraConfig(target_modules=["convolution"], modules_to_save=["classifier", "normalization"]),
+ "loha": LoHaConfig(target_modules=["convolution"], modules_to_save=["classifier", "normalization"]),
+ "lokr": LoKrConfig(target_modules=["convolution"], modules_to_save=["classifier", "normalization"]),
+ "oft": OFTConfig(
+ r=1, oft_block_size=0, target_modules=["convolution"], modules_to_save=["classifier", "normalization"]
+ ),
+ "hra": HRAConfig(target_modules=["convolution"], modules_to_save=["classifier", "normalization"]),
+ # TODO: cannot use BOFT because some convolutional kernel dimensions are even (64) and others odd (147). There is no
+ # common denominator for the boft_block_size except 1, but using 1 results in an error in the fbd_cuda kernel:
+ # > Error in forward_fast_block_diag_cuda_kernel: an illegal memory access was encountered
+ # "boft": BOFTConfig(target_modules=["convolution"], modules_to_save=["classifier", "normalization"], boft_block_size=2),
+}
+
+
+# Ensure that models like Llava that pass past_key_values automatically do not fail, see #1938
+class TestPastKV:
+ def test_past_kv(self):
+ model_id = "peft-internal-testing/tiny-LlavaForConditionalGeneration"
+ prompt = "USER: \nWhat are these?\nASSISTANT:"
+
+ # prepare model and inputs
+ model = LlavaForConditionalGeneration.from_pretrained(
+ model_id,
+ low_cpu_mem_usage=True,
+ )
+ processor = AutoProcessor.from_pretrained(model_id)
+ raw_image = np.random.randint(0, 255, (224, 224, 3), dtype=np.uint8)
+ inputs = processor(text=prompt, images=raw_image, return_tensors="pt")
+
+ # get peft model
+ peft_config = PrefixTuningConfig(task_type="CAUSAL_LM", num_virtual_tokens=20)
+ model = get_peft_model(model, peft_config)
+ # check that this does not raise
+ model(**inputs, output_hidden_states=True)
+
+
+class TestResnet:
+ model_id = "hf-internal-testing/tiny-random-ResNetForImageClassification"
+ cat_image = load_cat_image() # for caching
+
+ @pytest.fixture(autouse=True)
+ def teardown(self):
+ r"""
+ Efficient mechanism to free GPU memory after each test. Based on
+ https://github.com/huggingface/transformers/issues/21094
+ """
+ clear_device_cache(garbage_collection=True)
+ gc.collect()
+
+ @pytest.fixture(scope="class")
+ def image_processor(self):
+ image_processor = AutoImageProcessor.from_pretrained(self.model_id)
+ return image_processor
+
+ @pytest.fixture(scope="class")
+ def data(self, image_processor):
+ return image_processor(self.cat_image, return_tensors="pt")
+
+ @pytest.mark.parametrize("config", CONFIGS.values(), ids=CONFIGS.keys())
+ def test_model_with_batchnorm_reproducibility(self, config, tmp_path, data):
+ # see 1732
+ torch.manual_seed(0)
+ model = AutoModelForImageClassification.from_pretrained(self.model_id)
+ model = get_peft_model(model, config)
+
+ # record outputs before training
+ model.eval()
+ with torch.inference_mode():
+ output_before = model(**data)
+ model.train()
+
+ # train the model
+ optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3)
+ batch_size = 4
+ max_steps = 5 * batch_size
+ labels = torch.zeros(1, 3)
+ labels[0, 1] = 1
+ for i in range(0, max_steps, batch_size):
+ optimizer.zero_grad()
+ outputs = model(**data, labels=labels)
+ loss = outputs.loss
+ loss.backward()
+ optimizer.step()
+
+ # record outputs after training
+ model.eval()
+ with torch.inference_mode():
+ output_after = model(**data)
+ assert torch.isfinite(output_after.logits).all()
+ atol, rtol = 1e-4, 1e-4
+ # sanity check: model was updated
+ assert not torch.allclose(output_before.logits, output_after.logits, atol=atol, rtol=rtol)
+
+ # check saving the model and loading it
+ model.save_pretrained(tmp_path)
+ del model
+
+ torch.manual_seed(0)
+ model = AutoModelForImageClassification.from_pretrained(self.model_id)
+ model = PeftModel.from_pretrained(model, tmp_path).eval()
+ with torch.inference_mode():
+ output_loaded = model(**data)
+ assert torch.allclose(output_after.logits, output_loaded.logits, atol=atol, rtol=rtol)
+
+ # ensure that the checkpoint file contains the buffers
+ model_running_mean = len([k for k in model.state_dict().keys() if "running_mean" in k])
+ state_dict = load_file(tmp_path / "adapter_model.safetensors")
+ checkpoint_running_mean = len([k for k in state_dict.keys() if "running_mean" in k])
+ # note that the model has twice as many "running_mean", as there is one copy per ModulesToSaveWrapper, we need
+ # to multiply by 2 to get the same number
+ assert model_running_mean == checkpoint_running_mean * 2
diff --git a/peft/tests/test_xlora.py b/peft/tests/test_xlora.py
new file mode 100644
index 0000000000000000000000000000000000000000..6ee097906fbe335b95228cd5b3ae0d8e05a31635
--- /dev/null
+++ b/peft/tests/test_xlora.py
@@ -0,0 +1,370 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+from functools import wraps
+
+import huggingface_hub
+import pytest
+import torch
+from safetensors.torch import load_file
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+from peft import LoraConfig, PeftType, TaskType, XLoraConfig, get_peft_model
+from peft.peft_model import PeftModel
+from peft.utils import infer_device
+
+
+def flaky(num_tries: int):
+ """Decorator for test functions that are flaky"""
+
+ def decorator(func):
+ @wraps(func)
+ def wrapper(*args, **kwargs):
+ for _ in range(num_tries):
+ try:
+ return func(*args, **kwargs)
+ except AssertionError as e:
+ print(f"Failed test {func.__name__} with error: {e}")
+ continue
+ raise AssertionError(f"Failed test {func.__name__} after {num_tries} tries")
+
+ return wrapper
+
+ return decorator
+
+
+class TestXlora:
+ torch_device = infer_device()
+
+ model_id = "facebook/opt-125m"
+ num_loras = 4
+
+ @pytest.fixture(scope="class")
+ def lora_dir(self, tmp_path_factory):
+ return tmp_path_factory.mktemp("lora")
+
+ @pytest.fixture(scope="class")
+ def lora_embedding_dir(self, tmp_path_factory):
+ return tmp_path_factory.mktemp("lora_embedding")
+
+ @pytest.fixture(scope="class")
+ def saved_lora_adapters(self, lora_dir):
+ file_names = []
+
+ lora_configs = [
+ LoraConfig(task_type="CAUSAL_LM", target_modules=["q_proj", "v_proj"], init_lora_weights=False)
+ for _ in range(self.num_loras)
+ ]
+ # have 1 LoRA with different target modules
+ lora_configs[-1] = LoraConfig(
+ task_type="CAUSAL_LM", target_modules=["k_proj", "q_proj", "v_proj"], init_lora_weights=False
+ )
+
+ for i, lora_config in enumerate(lora_configs, start=1):
+ torch.manual_seed(i)
+ model = AutoModelForCausalLM.from_pretrained(self.model_id)
+ peft_model = get_peft_model(model, lora_config)
+ file_name = os.path.join(lora_dir, f"checkpoint-{i}")
+ peft_model.save_pretrained(file_name)
+ file_names.append(file_name)
+ return file_names
+
+ @pytest.fixture(scope="class")
+ def saved_lora_embedding_adapters(self, lora_embedding_dir):
+ file_names = []
+ for i in range(1, self.num_loras + 1):
+ torch.manual_seed(i)
+ lora_config = LoraConfig(task_type="CAUSAL_LM", init_lora_weights=False, target_modules=["embed_tokens"])
+ model = AutoModelForCausalLM.from_pretrained(self.model_id)
+ peft_model = get_peft_model(model, lora_config)
+ file_name = os.path.join(lora_embedding_dir, f"checkpoint-{i}")
+ peft_model.save_pretrained(file_name)
+ file_names.append(file_name)
+ return file_names
+
+ @pytest.fixture(scope="class")
+ def tokenizer(self):
+ tokenizer = AutoTokenizer.from_pretrained(self.model_id, trust_remote_code=True, device_map=self.torch_device)
+ return tokenizer
+
+ @pytest.fixture(scope="function")
+ def embedding_model(self, saved_lora_embedding_adapters):
+ model = AutoModelForCausalLM.from_pretrained(self.model_id)
+ model.config.use_cache = False
+ adapters = {str(i): file_name for i, file_name in enumerate(saved_lora_embedding_adapters)}
+
+ peft_config = XLoraConfig(
+ task_type=TaskType.CAUSAL_LM,
+ peft_type=PeftType.XLORA,
+ hidden_size=model.config.hidden_size,
+ xlora_depth=8,
+ adapters=adapters,
+ )
+ model = get_peft_model(model, peft_config).to(self.torch_device)
+ return model
+
+ @pytest.fixture(scope="function")
+ def model(self, saved_lora_adapters):
+ model = AutoModelForCausalLM.from_pretrained(self.model_id)
+ model.config.use_cache = False
+ adapters = {str(i): file_name for i, file_name in enumerate(saved_lora_adapters)}
+
+ peft_config = XLoraConfig(
+ task_type=TaskType.CAUSAL_LM,
+ peft_type=PeftType.XLORA,
+ hidden_size=model.config.hidden_size,
+ xlora_depth=8,
+ adapters=adapters,
+ )
+ model = get_peft_model(model, peft_config).to(self.torch_device)
+ return model
+
+ @pytest.fixture(scope="function")
+ def model_layerwise(self, saved_lora_adapters):
+ model = AutoModelForCausalLM.from_pretrained(self.model_id)
+ model.config.use_cache = False
+ adapters = {str(i): file_name for i, file_name in enumerate(saved_lora_adapters)}
+
+ peft_config = XLoraConfig(
+ task_type=TaskType.CAUSAL_LM,
+ peft_type=PeftType.XLORA,
+ hidden_size=model.config.hidden_size,
+ xlora_depth=8,
+ adapters=adapters,
+ layerwise_scalings=True,
+ )
+ model = get_peft_model(model, peft_config).to(self.torch_device)
+ return model
+
+ def test_functional(self, tokenizer, model):
+ model.enable_scalings_logging()
+ inputs = tokenizer.encode("Python is a", add_special_tokens=False, return_tensors="pt")
+ outputs = model.generate(
+ input_ids=inputs.to(self.torch_device),
+ max_new_tokens=32,
+ )
+ assert torch.isfinite(outputs[: inputs.shape[1] :]).all()
+
+ def test_scalings_logging_methods(self, tokenizer, model):
+ model.enable_scalings_logging()
+
+ inputs = tokenizer.encode("Python is a", add_special_tokens=False, return_tensors="pt")
+ outputs = model.generate(
+ input_ids=inputs.to(self.torch_device),
+ max_new_tokens=32,
+ )
+ assert torch.isfinite(outputs[: inputs.shape[1] :]).all()
+
+ _ = model.get_latest_scalings()
+ # 32 is the numeber of max scalings. 3 is the number of prompt tokens.
+ assert 32 + 3 >= len(model.get_scalings_log()) > 0
+
+ model.disable_scalings_logging()
+
+ inputs = tokenizer.encode("Python is a", add_special_tokens=False, return_tensors="pt")
+ outputs = model.generate(
+ input_ids=inputs.to(self.torch_device),
+ max_new_tokens=32,
+ )
+ assert torch.isfinite(outputs[: inputs.shape[1] :]).all()
+
+ assert 32 >= len(model.get_scalings_log()) > 0
+
+ bucketed = model.get_bucketed_scalings_log()
+ keys = bucketed.keys()
+ # Once bucket for each token as we aren't using cache
+ assert len(bucketed) == 32 == len(keys)
+ seq_len = inputs.shape[1]
+ for key in keys:
+ assert len(bucketed[key][0]) == 1
+ assert len(bucketed[key][1]) == 1
+ assert bucketed[key][0][0] == key - seq_len
+
+ model.clear_scalings_log()
+ assert len(model.get_scalings_log()) == 0
+
+ def test_misc_methods(self, tokenizer, model):
+ model.set_global_scaling_weight(1.5)
+ assert model.internal_xlora_classifier.config.global_scaling_weight == 1.5
+ assert model.get_global_scaling_weight() == 1.5
+
+ inputs = tokenizer.encode("Python is a", add_special_tokens=False, return_tensors="pt")
+ outputs = model.generate(
+ input_ids=inputs.to(self.torch_device),
+ max_new_tokens=32,
+ )
+ assert torch.isfinite(outputs[: inputs.shape[1] :]).all()
+
+ assert str(model) is not None
+
+ # On CI (but not locally), this test is flaky since transformers v4.45.0.
+ @flaky(num_tries=5)
+ def test_save_load_functional(self, tokenizer, model, tmp_path):
+ inputs = tokenizer.encode("Python is a", add_special_tokens=False, return_tensors="pt")
+ outputs = model.generate(
+ input_ids=inputs.to(self.torch_device),
+ max_new_tokens=32,
+ )
+ before_logits = outputs[: inputs.shape[1] :]
+ assert torch.isfinite(before_logits).all()
+
+ model.save_pretrained(save_directory=tmp_path)
+
+ del model
+
+ model = AutoModelForCausalLM.from_pretrained(self.model_id)
+ model.config.use_cache = False
+ model = PeftModel.from_pretrained(model=model, model_id=tmp_path).to(self.torch_device)
+
+ inputs = tokenizer.encode("Python is a", add_special_tokens=False, return_tensors="pt")
+ outputs = model.generate(
+ input_ids=inputs.to(self.torch_device),
+ max_new_tokens=32,
+ )
+ after_logits = outputs[: inputs.shape[1] :]
+ assert torch.isfinite(after_logits).all()
+ assert torch.equal(after_logits, before_logits)
+
+ def test_save_load_functional_pt(self, tokenizer, model, tmp_path):
+ inputs = tokenizer.encode("Python is a", add_special_tokens=False, return_tensors="pt")
+ outputs = model.generate(
+ input_ids=inputs.to(self.torch_device),
+ max_new_tokens=32,
+ )
+ before_logits = outputs[: inputs.shape[1] :]
+ assert torch.isfinite(before_logits).all()
+
+ model.save_pretrained(save_directory=tmp_path, safe_serialization=False)
+
+ del model
+
+ model = AutoModelForCausalLM.from_pretrained(self.model_id)
+ model.config.use_cache = False
+ model = PeftModel.from_pretrained(model=model, model_id=tmp_path, safe_serialization=False).to(
+ self.torch_device
+ )
+
+ inputs = tokenizer.encode("Python is a", add_special_tokens=False, return_tensors="pt")
+ outputs = model.generate(
+ input_ids=inputs.to(self.torch_device),
+ max_new_tokens=32,
+ )
+ after_logits = outputs[: inputs.shape[1] :]
+ assert torch.isfinite(after_logits).all()
+ assert torch.equal(after_logits, before_logits), (after_logits, before_logits)
+
+ def test_topk_lora(self, tokenizer, model):
+ model.set_topk_lora(2)
+ assert model.internal_xlora_classifier.config.top_k_lora == 2
+
+ inputs = tokenizer.encode("Python is a", add_special_tokens=False, return_tensors="pt")
+ outputs = model.generate(
+ input_ids=inputs.to(self.torch_device),
+ max_new_tokens=32,
+ )
+ assert torch.isfinite(outputs[: inputs.shape[1] :]).all()
+
+ def test_softmax_topk(self, tokenizer, model):
+ # Just reach in to set the config
+ model.internal_xlora_classifier.config.top_k_lora = 2
+ model.internal_xlora_classifier.config.enable_softmax = False
+ model.internal_xlora_classifier.config.enable_softmax_topk = True
+
+ inputs = tokenizer.encode("Python is a", add_special_tokens=False, return_tensors="pt")
+ outputs = model.generate(
+ input_ids=inputs.to(self.torch_device),
+ max_new_tokens=32,
+ )
+ assert torch.isfinite(outputs[: inputs.shape[1] :]).all()
+
+ def test_set_override_scaling_pass_value(self, model):
+ # Defaults to 0
+ assert model.internal_xlora_classifier.override_scaling_pass_value == 0.0
+
+ # Set it to 2 and make sure it actually is
+ model.set_scaling_pass_value(2)
+ assert model.internal_xlora_classifier.override_scaling_pass_value == 2
+ assert model.internal_xlora_classifier.config.scaling_pass_value == 2
+
+ # Set it to None and make sure it is 1/n
+ model.set_scaling_pass_value(None)
+ assert model.internal_xlora_classifier.override_scaling_pass_value == 1 / self.num_loras
+ assert model.internal_xlora_classifier.config.scaling_pass_value == 1 / self.num_loras
+
+ def test_functional_layerwise(self, tokenizer, model_layerwise):
+ model_layerwise.enable_scalings_logging()
+ inputs = tokenizer.encode("Python is a", add_special_tokens=False, return_tensors="pt")
+ outputs = model_layerwise.generate(
+ input_ids=inputs.to(self.torch_device),
+ max_new_tokens=32,
+ )
+ assert torch.isfinite(outputs[: inputs.shape[1] :]).all()
+
+ def test_disable_adapter(self, tokenizer, model):
+ model.enable_scalings_logging()
+ inputs = tokenizer.encode("Python is a", add_special_tokens=False, return_tensors="pt")
+ with model.disable_adapter():
+ outputs_disabled = model.generate(
+ input_ids=inputs.to(self.torch_device),
+ max_new_tokens=32,
+ )
+ outputs = model.generate(
+ input_ids=inputs.to(self.torch_device),
+ max_new_tokens=32,
+ )
+ assert torch.isfinite(outputs_disabled[: inputs.shape[1] :]).all()
+ assert torch.isfinite(outputs[: inputs.shape[1] :]).all()
+ assert not torch.equal(outputs, outputs_disabled)
+
+ def test_functional_embedding(self, tokenizer, embedding_model):
+ inputs = tokenizer.encode("Python is a", add_special_tokens=False, return_tensors="pt")
+ outputs = embedding_model.generate(
+ input_ids=inputs.to(self.torch_device),
+ max_new_tokens=32,
+ )
+ assert torch.isfinite(outputs[: inputs.shape[1] :]).all()
+
+ def test_xlora_loading_valid(self):
+ # This test also simulatenously tests the loading-from-hub functionality!
+ torch.manual_seed(123)
+
+ model_id = "facebook/opt-125m"
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ model.config.use_cache = False
+
+ adapters = [
+ "peft-internal-testing/opt-125m-dummy-lora",
+ "peft-internal-testing/opt-125m-dummy-lora",
+ ]
+ adapters = {str(i): file_name for i, file_name in enumerate(adapters)}
+
+ peft_config = XLoraConfig(
+ task_type=TaskType.CAUSAL_LM,
+ peft_type=PeftType.XLORA,
+ hidden_size=model.config.hidden_size,
+ adapters=adapters,
+ xlora_depth=8,
+ xlora_size=2048,
+ layerwise_scalings=True,
+ xlora_dropout_p=0.2,
+ )
+ model = get_peft_model(model, peft_config)
+
+ downloaded = huggingface_hub.hf_hub_download(repo_id=adapters["0"], filename="adapter_model.safetensors")
+ sd = load_file(downloaded)
+ w0 = model.base_model.model.model.decoder.layers[0].self_attn.q_proj.lora_A["0"].weight
+ w1 = sd["base_model.model.model.decoder.layers.0.self_attn.q_proj.lora_A.weight"]
+
+ assert torch.allclose(w0, w1)
diff --git a/peft/tests/testing_common.py b/peft/tests/testing_common.py
new file mode 100644
index 0000000000000000000000000000000000000000..84fbdee54afdece80915e0bc94cfc5403e1ac6cb
--- /dev/null
+++ b/peft/tests/testing_common.py
@@ -0,0 +1,2002 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import copy
+import json
+import os
+import pickle
+import re
+import shutil
+import tempfile
+import warnings
+from contextlib import contextmanager
+from dataclasses import replace
+from unittest import mock
+
+import pytest
+import torch
+import yaml
+from diffusers import StableDiffusionPipeline
+from packaging import version
+from safetensors.torch import save_file
+
+from peft import (
+ AdaLoraConfig,
+ BOFTConfig,
+ BoneConfig,
+ CPTConfig,
+ FourierFTConfig,
+ HRAConfig,
+ IA3Config,
+ LNTuningConfig,
+ LoHaConfig,
+ LoKrConfig,
+ LoraConfig,
+ OFTConfig,
+ PeftModel,
+ PeftType,
+ PrefixTuningConfig,
+ PromptEncoderConfig,
+ PromptLearningConfig,
+ PromptTuningConfig,
+ RandLoraConfig,
+ VBLoRAConfig,
+ VeraConfig,
+ get_peft_model,
+ get_peft_model_state_dict,
+ inject_adapter_in_model,
+ prepare_model_for_kbit_training,
+)
+from peft.tuners.lora import LoraLayer
+from peft.tuners.tuners_utils import BaseTunerLayer
+from peft.utils import _get_submodules, infer_device
+from peft.utils.other import AuxiliaryTrainingWrapper, ModulesToSaveWrapper, TrainableTokensWrapper
+
+from .testing_utils import get_state_dict
+
+
+HUB_MODEL_ACCESSES = {}
+
+CONFIG_TESTING_KWARGS = (
+ # IA³
+ {
+ "target_modules": None,
+ "feedforward_modules": None,
+ },
+ # LoRA
+ {
+ "r": 8,
+ "lora_alpha": 32,
+ "target_modules": None,
+ "lora_dropout": 0.05,
+ "bias": "none",
+ },
+ # prefix tuning
+ {
+ "num_virtual_tokens": 10,
+ },
+ # prompt encoder
+ {
+ "num_virtual_tokens": 10,
+ "encoder_hidden_size": 32,
+ },
+ # prompt tuning
+ {
+ "num_virtual_tokens": 10,
+ },
+ # AdaLoRA
+ {
+ "target_modules": None,
+ "total_step": 1,
+ },
+ # BOFT
+ {
+ "target_modules": None,
+ },
+ # VeRA
+ {
+ "r": 8,
+ "target_modules": None,
+ "vera_dropout": 0.05,
+ "projection_prng_key": 0xFF,
+ "d_initial": 0.1,
+ "save_projection": True,
+ "bias": "none",
+ },
+ # FourierFT
+ {
+ "n_frequency": 10,
+ "target_modules": None,
+ },
+ # HRA
+ {
+ "target_modules": None,
+ },
+ # VBLoRA
+ {"target_modules": None, "vblora_dropout": 0.05, "vector_length": 1, "num_vectors": 2},
+ # OFT
+ {
+ "target_modules": None,
+ },
+ # Bone
+ {
+ "target_modules": None,
+ "r": 2,
+ },
+ # LoRA + trainable_tokens
+ {
+ "r": 8,
+ "lora_alpha": 32,
+ "target_modules": None,
+ "lora_dropout": 0.05,
+ "bias": "none",
+ "trainable_token_indices": [0, 1, 3],
+ },
+ # RandLoRA
+ {
+ "r": 32,
+ "randlora_alpha": 64,
+ "target_modules": None,
+ "randlora_dropout": 0.05,
+ "projection_prng_key": 0xFF,
+ "save_projection": True,
+ "bias": "none",
+ },
+ # CPT tuninig
+ {
+ "cpt_token_ids": [0, 1, 2, 3, 4, 5, 6, 7], # Example token IDs for testing
+ "cpt_mask": [1, 1, 1, 1, 1, 1, 1, 1],
+ "cpt_tokens_type_mask": [1, 2, 2, 2, 3, 3, 4, 4],
+ },
+)
+
+CLASSES_MAPPING = {
+ "ia3": (IA3Config, CONFIG_TESTING_KWARGS[0]),
+ "lora": (LoraConfig, CONFIG_TESTING_KWARGS[1]),
+ "prefix_tuning": (PrefixTuningConfig, CONFIG_TESTING_KWARGS[2]),
+ "prompt_encoder": (PromptEncoderConfig, CONFIG_TESTING_KWARGS[3]),
+ "prompt_tuning": (PromptTuningConfig, CONFIG_TESTING_KWARGS[4]),
+ "adalora": (AdaLoraConfig, CONFIG_TESTING_KWARGS[5]),
+ "boft": (BOFTConfig, CONFIG_TESTING_KWARGS[6]),
+ "vera": (VeraConfig, CONFIG_TESTING_KWARGS[7]),
+ "fourierft": (FourierFTConfig, CONFIG_TESTING_KWARGS[8]),
+ "hra": (HRAConfig, CONFIG_TESTING_KWARGS[9]),
+ "vblora": (VBLoRAConfig, CONFIG_TESTING_KWARGS[10]),
+ "oft": (OFTConfig, CONFIG_TESTING_KWARGS[11]),
+ "bone": (BoneConfig, CONFIG_TESTING_KWARGS[12]),
+ "lora+trainable_tokens": (LoraConfig, CONFIG_TESTING_KWARGS[13]),
+ "randlora": (RandLoraConfig, CONFIG_TESTING_KWARGS[14]),
+}
+
+DECODER_MODELS_EXTRA = {"cpt": (CPTConfig, CONFIG_TESTING_KWARGS[15])}
+
+
+@contextmanager
+def hub_online_once(model_id: str):
+ """Set env[HF_HUB_OFFLINE]=1 (and patch transformers/hugging_face_hub to think that it was always that way)
+ for model ids that were seen already so that the hub is not contacted twice for the same model id in said context.
+ The cache (`HUB_MODEL_ACCESSES`) also tracks the number of cache hits per model id.
+
+ The reason for doing a context manager and not patching specific methods (e.g., `from_pretrained`) is that there
+ are a lot of places (`PeftConfig.from_pretrained`, `get_peft_state_dict`, `load_adapter`, ...) that possibly
+ communicate with the hub to download files / check versions / etc.
+
+ Note that using this context manager can cause problems when used in code sections that access different resources.
+ Example:
+
+ ```
+ def test_something(model_id, config_kwargs):
+ with hub_online_once(model_id):
+ model = ...from_pretrained(model_id)
+ self.do_something_specific_with_model(model)
+ ```
+ It is assumed that `do_something_specific_with_model` is an absract method that is implement by several tests.
+ Imagine the first test simply does `model.generate([1,2,3])`. The second call from another test suite however uses
+ a tokenizer (`AutoTokenizer.from_pretrained(model_id)`) - this will fail since the first pass was online but didn't
+ use the tokenizer and we're now in offline mode and cannot fetch the tokenizer. The recommended workaround is to
+ extend the cache key (`model_id` passed to `hub_online_once` in this case) by something in case the tokenizer is
+ used, so that these tests don't share a cache pool with the tests that don't use a tokenizer.
+ """
+ global HUB_MODEL_ACCESSES
+ override = {}
+
+ try:
+ if model_id in HUB_MODEL_ACCESSES:
+ override = {"HF_HUB_OFFLINE": "1"}
+ HUB_MODEL_ACCESSES[model_id] += 1
+ else:
+ if model_id not in HUB_MODEL_ACCESSES:
+ HUB_MODEL_ACCESSES[model_id] = 0
+ with (
+ # strictly speaking it is not necessary to set the environment variable since most code that's out there
+ # is evaluating it at import time and we'd have to reload the modules for it to take effect. It's
+ # probably still a good idea to have it if there's some dynamic code that checks it.
+ mock.patch.dict(os.environ, override),
+ mock.patch("huggingface_hub.constants.HF_HUB_OFFLINE", override.get("HF_HUB_OFFLINE", False) == "1"),
+ mock.patch("transformers.utils.hub._is_offline_mode", override.get("HF_HUB_OFFLINE", False) == "1"),
+ ):
+ yield
+ except Exception:
+ # in case of an error we have to assume that we didn't access the model properly from the hub
+ # for the first time, so the next call cannot be considered cached.
+ if HUB_MODEL_ACCESSES.get(model_id) == 0:
+ del HUB_MODEL_ACCESSES[model_id]
+ raise
+
+
+class PeftCommonTester:
+ r"""
+ A large testing suite for testing common functionality of the PEFT models.
+
+ Attributes:
+ torch_device (`torch.device`):
+ The device on which the tests will be run.
+ transformers_class (`transformers.PreTrainedModel`):
+ The transformers class that is being tested.
+ """
+
+ torch_device = infer_device()
+ transformers_class = None
+
+ def prepare_inputs_for_common(self):
+ raise NotImplementedError
+
+ def check_modelcard(self, tmp_dirname, model):
+ # check the generated README.md
+ filename = os.path.join(tmp_dirname, "README.md")
+ assert os.path.exists(filename)
+ with open(filename, encoding="utf-8") as f:
+ readme = f.read()
+ metainfo = re.search(r"---\n(.*?)\n---", readme, re.DOTALL).group(1)
+ dct = yaml.safe_load(metainfo)
+ assert dct["library_name"] == "peft"
+
+ if hasattr(model, "config"):
+ assert dct["base_model"] == model.config.to_dict()["_name_or_path"]
+ else: # a custom model
+ assert "base_model" not in dct
+
+ # The Hub expects the lora tag to be set for PEFT LoRA models since they
+ # have explicit support for things like inference.
+ if model.active_peft_config.peft_type.value == "LORA":
+ assert "lora" in dct["tags"]
+
+ def check_config_json(self, tmp_dirname, model):
+ # check the generated config.json
+ filename = os.path.join(tmp_dirname, "adapter_config.json")
+ assert os.path.exists(filename)
+ with open(filename, encoding="utf-8") as f:
+ config = json.load(f)
+
+ if hasattr(model, "config"): # custom models don't have a config attribute
+ assert config["base_model_name_or_path"] == model.config.to_dict()["_name_or_path"]
+
+ def perturb_trainable_token_weights_if_used(self, model, config_kwargs, adapter_name="default", scale=1.0):
+ """TrainableTokensLayer is initialized to be a no-op by default. Since there's currently no way to pass
+ `init_weights=False` to the trainable tokens layer when used in conjunction with LoRA, we have to do it like
+ this to make sure that it is *not* a no-op (essentially simulating "training" of the adapter).
+ """
+ if "trainable_token_indices" not in config_kwargs:
+ return
+
+ token_wrapper = None
+
+ if hasattr(model, "get_input_embeddings"):
+ token_wrapper = model.get_input_embeddings()
+ else:
+ for module in model.modules():
+ if isinstance(module, TrainableTokensWrapper):
+ token_wrapper = module
+ break
+
+ # for a model with trainable_token_indices there should always be a trainable token wrapper somewhere.
+ # if not, then there's something broken.
+ assert token_wrapper is not None
+
+ token_wrapper.token_adapter.trainable_tokens_delta[adapter_name].data = (
+ torch.rand_like(token_wrapper.token_adapter.trainable_tokens_delta[adapter_name].data) * scale
+ )
+
+ def _test_model_attr(self, model_id, config_cls, config_kwargs):
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+
+ assert hasattr(model, "save_pretrained")
+ assert hasattr(model, "from_pretrained")
+ assert hasattr(model, "push_to_hub")
+
+ def _test_adapter_name(self, model_id, config_cls, config_kwargs):
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config, adapter_name="test-adapter")
+ correctly_converted = False
+ for n, _ in model.named_parameters():
+ if "test-adapter" in n:
+ correctly_converted = True
+ break
+
+ assert correctly_converted
+
+ def _test_prepare_for_training(self, model_id, config_cls, config_kwargs):
+ if config_kwargs.get("trainable_token_indices", None) is not None:
+ # incompatible because trainable tokens is marking embeddings as trainable
+ self.skipTest("Trainable tokens is incompatible with this test.")
+
+ # some tests require specific tokenizers, make sure that they can be fetched as well
+ with hub_online_once(model_id + config_kwargs.get("tokenizer_name_or_path", "")):
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+
+ dummy_input = self.prepare_inputs_for_testing()
+ dummy_output = model.get_input_embeddings()(dummy_input["input_ids"])
+
+ assert not dummy_output.requires_grad
+
+ # load with `prepare_model_for_kbit_training`
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ model = prepare_model_for_kbit_training(model)
+
+ for param in model.parameters():
+ assert not param.requires_grad
+
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+
+ # For backward compatibility
+ if hasattr(model, "enable_input_require_grads"):
+ model.enable_input_require_grads()
+ else:
+
+ def make_inputs_require_grad(module, input, output):
+ output.requires_grad_(True)
+
+ model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
+
+ dummy_input = self.prepare_inputs_for_testing()
+ dummy_output = model.get_input_embeddings()(dummy_input["input_ids"])
+
+ assert dummy_output.requires_grad
+
+ def _test_load_model_low_cpu_mem_usage(self, model_id, config_cls, config_kwargs):
+ # Ensure that low_cpu_mem_usage=True works for from_pretrained and load_adapter and that the resulting model's
+ # parameters are on the correct device.
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+
+ # note: not using the context manager here because it fails on Windows CI for some reason
+ tmp_dirname = tempfile.mkdtemp()
+ try:
+ model.save_pretrained(tmp_dirname)
+
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ model = PeftModel.from_pretrained(
+ model, tmp_dirname, torch_device=self.torch_device, low_cpu_mem_usage=True
+ )
+ assert {p.device.type for p in model.parameters()} == {self.torch_device}
+
+ model.load_adapter(tmp_dirname, adapter_name="other", low_cpu_mem_usage=True)
+ assert {p.device.type for p in model.parameters()} == {self.torch_device}
+ finally:
+ try:
+ shutil.rmtree(tmp_dirname)
+ except PermissionError:
+ # windows error
+ pass
+
+ # also test injecting directly
+ del model
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ inject_adapter_in_model(config, model, low_cpu_mem_usage=True) # check that there is no error
+
+ if not isinstance(config, LNTuningConfig):
+ # LN tuning does not add adapter layers that could be on meta device, it only changes the requires_grad.
+ # Therefore, there is no meta device for LN tuning.
+ assert "meta" in {p.device.type for p in model.parameters()}
+
+ def _test_save_pretrained(self, model_id, config_cls, config_kwargs, safe_serialization=True):
+ # ensure that the weights are randomly initialized
+ if issubclass(config_cls, LoraConfig):
+ config_kwargs = config_kwargs.copy()
+ config_kwargs["init_lora_weights"] = False
+ if issubclass(config_cls, IA3Config):
+ config_kwargs = config_kwargs.copy()
+ config_kwargs["init_ia3_weights"] = False
+ if hasattr(config_cls, "init_weights"):
+ config_kwargs = config_kwargs.copy()
+ config_kwargs["init_weights"] = False
+
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ if safe_serialization:
+ model.save_pretrained(tmp_dirname)
+ else:
+ model.save_pretrained(tmp_dirname, safe_serialization=False)
+
+ model_from_pretrained = self.transformers_class.from_pretrained(model_id)
+ with warnings.catch_warnings(record=True) as recs:
+ model_from_pretrained = PeftModel.from_pretrained(model_from_pretrained, tmp_dirname)
+ # ensure that there is no warning
+ assert not any("Found missing adapter keys" in str(rec.message) for rec in recs)
+
+ # check if the state dicts are equal
+ if issubclass(config_cls, PromptEncoderConfig):
+ # For prompt encoding, when loading the whole state_dict, there are differences, therefore, only load
+ # adapter-specific weights for comparison.
+ # TODO: is this expected?
+ state_dict = get_peft_model_state_dict(model, unwrap_compiled=True)
+ state_dict_from_pretrained = get_peft_model_state_dict(model_from_pretrained, unwrap_compiled=True)
+ else:
+ state_dict = get_state_dict(model, unwrap_compiled=True)
+ state_dict_from_pretrained = get_state_dict(model_from_pretrained, unwrap_compiled=True)
+
+ # check if tensors equal
+ for key in state_dict.keys():
+ assert torch.allclose(
+ state_dict[key].to(self.torch_device), state_dict_from_pretrained[key].to(self.torch_device)
+ )
+
+ target_adapter_filename = "adapter_model.safetensors" if safe_serialization else "adapter_model.bin"
+
+ # check if `adapter_model.safetensors` is present
+ assert os.path.exists(os.path.join(tmp_dirname, target_adapter_filename))
+
+ # check if `adapter_config.json` is present
+ assert os.path.exists(os.path.join(tmp_dirname, "adapter_config.json"))
+
+ # check if `model.safetensors` is not present
+ assert not os.path.exists(os.path.join(tmp_dirname, "model.safetensors"))
+
+ # check if `config.json` is not present
+ assert not os.path.exists(os.path.join(tmp_dirname, "config.json"))
+
+ self.check_modelcard(tmp_dirname, model)
+ self.check_config_json(tmp_dirname, model)
+
+ def _test_save_pretrained_selected_adapters(self, model_id, config_cls, config_kwargs, safe_serialization=True):
+ if issubclass(config_cls, AdaLoraConfig):
+ # AdaLora does not support adding more than 1 adapter
+ return pytest.skip(f"Test not applicable for {config_cls}")
+
+ # ensure that the weights are randomly initialized
+ if issubclass(config_cls, LoraConfig):
+ config_kwargs = config_kwargs.copy()
+ config_kwargs["init_lora_weights"] = False
+ elif issubclass(config_cls, IA3Config):
+ config_kwargs = config_kwargs.copy()
+ config_kwargs["init_ia3_weights"] = False
+ elif hasattr(config_cls, "init_weights"):
+ config_kwargs["init_weights"] = False
+
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ new_adapter_config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+
+ model.add_adapter("new_adapter", new_adapter_config)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ if safe_serialization:
+ model.save_pretrained(tmp_dirname)
+ else:
+ model.save_pretrained(tmp_dirname, safe_serialization=False)
+
+ model_from_pretrained = self.transformers_class.from_pretrained(model_id)
+ model_from_pretrained = PeftModel.from_pretrained(model_from_pretrained, tmp_dirname)
+
+ new_adapter_dir = os.path.join(tmp_dirname, "new_adapter")
+ model_from_pretrained.load_adapter(new_adapter_dir, "new_adapter")
+
+ # check if the state dicts are equal
+ if issubclass(config_cls, PromptEncoderConfig):
+ # For prompt encoding, when loading the whole state_dict, there are differences, therefore, only load
+ # adapter-specific weights for comparison.
+ # TODO: is this expected?
+ state_dict = get_peft_model_state_dict(model, unwrap_compiled=True)
+ state_dict_from_pretrained = get_peft_model_state_dict(model_from_pretrained, unwrap_compiled=True)
+ else:
+ state_dict = get_state_dict(model, unwrap_compiled=True)
+ state_dict_from_pretrained = get_state_dict(model_from_pretrained, unwrap_compiled=True)
+
+ # check if same keys
+ assert state_dict.keys() == state_dict_from_pretrained.keys()
+
+ # check if tensors equal
+ for key in state_dict.keys():
+ assert torch.allclose(
+ state_dict[key].to(self.torch_device), state_dict_from_pretrained[key].to(self.torch_device)
+ )
+
+ target_adapter_filename = "adapter_model.safetensors" if safe_serialization else "adapter_model.bin"
+
+ # check if `adapter_model.safetensors` is present
+ assert os.path.exists(os.path.join(tmp_dirname, target_adapter_filename))
+ assert os.path.exists(os.path.join(new_adapter_dir, target_adapter_filename))
+
+ # check if `adapter_config.json` is present
+ assert os.path.exists(os.path.join(tmp_dirname, "adapter_config.json"))
+ assert os.path.exists(os.path.join(new_adapter_dir, "adapter_config.json"))
+
+ # check if `model.safetensors` is not present
+ assert not os.path.exists(os.path.join(tmp_dirname, "model.safetensors"))
+ assert not os.path.exists(os.path.join(new_adapter_dir, "model.safetensors"))
+
+ # check if `config.json` is not present
+ assert not os.path.exists(os.path.join(tmp_dirname, "config.json"))
+ assert not os.path.exists(os.path.join(new_adapter_dir, "config.json"))
+
+ self.check_modelcard(tmp_dirname, model)
+ self.check_config_json(tmp_dirname, model)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname, selected_adapters=["default"])
+
+ model_from_pretrained = self.transformers_class.from_pretrained(model_id)
+ model_from_pretrained = PeftModel.from_pretrained(model_from_pretrained, tmp_dirname)
+
+ assert "default" in model_from_pretrained.peft_config.keys()
+ assert "new_adapter" not in model_from_pretrained.peft_config.keys()
+
+ def _test_from_pretrained_config_construction(self, model_id, config_cls, config_kwargs):
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(base_model_name_or_path=model_id, **config_kwargs)
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname)
+
+ model_from_pretrained = self.transformers_class.from_pretrained(model_id)
+ model_from_pretrained = PeftModel.from_pretrained(
+ model_from_pretrained, tmp_dirname, is_trainable=False, config=config
+ )
+
+ assert model_from_pretrained.peft_config["default"].inference_mode
+ assert model_from_pretrained.peft_config["default"] is config
+
+ def _test_load_multiple_adapters(self, model_id, config_cls, config_kwargs):
+ # just ensure that this works and raises no error
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname)
+ del model
+
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ model = PeftModel.from_pretrained(model, tmp_dirname, torch_device=self.torch_device)
+ load_result1 = model.load_adapter(tmp_dirname, adapter_name="other")
+ load_result2 = model.load_adapter(tmp_dirname, adapter_name="yet-another")
+
+ # VBLoRA uses a shared "vblora_vector_bank" across all layers, causing it to appear
+ # in the missing keys list, which leads to failed test cases. So
+ # skipping the missing keys check for VBLoRA.
+ if config.peft_type != "VBLORA":
+ assert load_result1.missing_keys == []
+ assert load_result2.missing_keys == []
+
+ def _test_merge_layers_fp16(self, model_id, config_cls, config_kwargs):
+ if config_cls not in (LoraConfig, IA3Config, AdaLoraConfig, LoHaConfig, LoKrConfig, VBLoRAConfig):
+ # Merge layers only supported for LoRA and IA³
+ return pytest.skip(f"Test not applicable for {config_cls}")
+
+ if ("gpt2" in model_id.lower()) and (config_cls != LoraConfig):
+ self.skipTest("Merging GPT2 adapters not supported for IA³ (yet)")
+
+ if (self.torch_device in ["cpu"]) and (version.parse(torch.__version__) <= version.parse("2.1")):
+ self.skipTest("PyTorch 2.1 not supported for Half of addmm_impl_cpu_ ")
+
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id, torch_dtype=torch.float16)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ model = model.to(device=self.torch_device, dtype=torch.float16)
+
+ model.eval()
+
+ # This should simply work
+ _ = model.merge_and_unload()
+
+ def _test_merge_layers_nan(self, model_id, config_cls, config_kwargs):
+ if config_cls not in (
+ LoraConfig,
+ IA3Config,
+ AdaLoraConfig,
+ LoHaConfig,
+ LoKrConfig,
+ VeraConfig,
+ FourierFTConfig,
+ ):
+ # Merge layers only supported for LoRA and IA³
+ return
+ if ("gpt2" in model_id.lower()) and (config_cls != LoraConfig):
+ self.skipTest("Merging GPT2 adapters not supported for IA³ (yet)")
+
+ if "gemma" in model_id.lower():
+ # TODO: could be related to tied weights
+ self.skipTest("Merging currently fails with gemma")
+
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ self.perturb_trainable_token_weights_if_used(model, config_kwargs)
+
+ dummy_input = self.prepare_inputs_for_testing()
+
+ model.eval()
+
+ # This should work
+ logits_unmerged = model(**dummy_input)[0]
+
+ model = model.merge_and_unload()
+ logits_merged = model(**dummy_input)[0]
+
+ assert torch.allclose(logits_unmerged, logits_merged, atol=1e-3, rtol=1e-3)
+
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ for name, module in model.named_parameters():
+ if (
+ "lora_A" in name
+ or "ia3" in name
+ or "lora_E" in name
+ or "lora_B" in name
+ or "vera_lambda" in name
+ or "fourierft_spectrum" in name
+ ):
+ module.data[0] = torch.nan
+
+ with pytest.raises(
+ ValueError, match="NaNs detected in the merged weights. The adapter default seems to be broken"
+ ):
+ model = model.merge_and_unload(safe_merge=True)
+
+ for name, module in model.named_parameters():
+ if (
+ "lora_A" in name
+ or "ia3" in name
+ or "lora_E" in name
+ or "lora_B" in name
+ or "vera_lambda" in name
+ or "fourierft_spectrum" in name
+ ):
+ module.data[0] = torch.inf
+
+ with pytest.raises(
+ ValueError, match="NaNs detected in the merged weights. The adapter default seems to be broken"
+ ):
+ model = model.merge_and_unload(safe_merge=True)
+
+ def _test_merge_layers(self, model_id, config_cls, config_kwargs):
+ if issubclass(config_cls, PromptLearningConfig):
+ return pytest.skip(f"Test not applicable for {config_cls}")
+
+ if issubclass(config_cls, (OFTConfig, BOFTConfig)):
+ return pytest.skip(f"Test not applicable for {config_cls}")
+
+ if ("gpt2" in model_id.lower()) and (config_cls != LoraConfig):
+ self.skipTest("Merging GPT2 adapters not supported for IA³ (yet)")
+
+ if "gemma" in model_id.lower():
+ # TODO: could be related to tied weights
+ self.skipTest("Merging currently fails with gemma")
+
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ self.perturb_trainable_token_weights_if_used(model, config_kwargs)
+
+ dummy_input = self.prepare_inputs_for_testing()
+ model.eval()
+ logits = model(**dummy_input)[0]
+
+ model.merge_adapter()
+ logits_merged = model(**dummy_input)[0]
+ model.unmerge_adapter()
+ logits_unmerged = model(**dummy_input)[0]
+
+ model = model.merge_and_unload()
+
+ # check that PEFT layers are completely removed
+ assert not any(isinstance(module, BaseTunerLayer) for module in model.modules())
+ logits_merged_unloaded = model(**dummy_input)[0]
+
+ conv_ids = ["Conv2d", "Conv3d", "Conv2d2"]
+ atol, rtol = 1e-4, 1e-4
+ if self.torch_device in ["mlu"]:
+ atol, rtol = 1e-3, 1e-3 # MLU
+ if config.peft_type == "ADALORA":
+ # AdaLoRA is a bit flaky on CI, but this cannot be reproduced locally
+ atol, rtol = 1e-2, 1e-2
+ if (config.peft_type in {"IA3", "LORA"}) and (model_id in conv_ids):
+ # for some reason, the Conv introduces a larger error
+ atol, rtol = 0.3, 0.01
+ if model_id == "trl-internal-testing/tiny-Llama4ForCausalLM":
+ # also getting larger errors here, not exactly sure why
+ atol, rtol = 0.3, 0.01
+ assert torch.allclose(logits, logits_merged, atol=atol, rtol=rtol)
+ assert torch.allclose(logits, logits_unmerged, atol=atol, rtol=rtol)
+ assert torch.allclose(logits, logits_merged_unloaded, atol=atol, rtol=rtol)
+
+ # For this test to work, weights should not be initialized to identity transform (e.g.
+ # init_lora_weights should be False).
+ transformers_model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ logits_transformers = transformers_model(**dummy_input)[0]
+ assert not torch.allclose(logits_merged, logits_transformers, atol=1e-10, rtol=1e-10)
+
+ # test that the logits are identical after a save-load-roundtrip
+ if hasattr(model, "save_pretrained"):
+ # model is a transformers model
+ tmp_dirname = tempfile.mkdtemp()
+ # note: not using the context manager here because it fails on Windows CI for some reason
+ try:
+ model.save_pretrained(tmp_dirname)
+ model_from_pretrained = self.transformers_class.from_pretrained(tmp_dirname).to(self.torch_device)
+ finally:
+ try:
+ shutil.rmtree(tmp_dirname)
+ except PermissionError:
+ # windows error
+ pass
+ else:
+ # model is not a transformers model
+ model_from_pretrained = pickle.loads(pickle.dumps(model))
+
+ logits_merged_from_pretrained = model_from_pretrained(**dummy_input)[0]
+ assert torch.allclose(logits_merged, logits_merged_from_pretrained, atol=atol, rtol=rtol)
+
+ def _test_merge_layers_multi(self, model_id, config_cls, config_kwargs):
+ supported_peft_types = [
+ PeftType.LORA,
+ PeftType.LOHA,
+ PeftType.LOKR,
+ PeftType.IA3,
+ PeftType.OFT,
+ PeftType.BOFT,
+ PeftType.HRA,
+ PeftType.BONE,
+ ]
+
+ if ("gpt2" in model_id.lower()) and (config_cls == IA3Config):
+ self.skipTest("Merging GPT2 adapters not supported for IA³ (yet)")
+
+ if config_kwargs.get("trainable_token_indices", None) is not None:
+ self.skipTest(
+ "Merging two adapters with trainable tokens is tested elsewhere since adapters with "
+ "the same token indices cannot be merged."
+ )
+
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+
+ if config.peft_type not in supported_peft_types:
+ return
+
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ dummy_input = self.prepare_inputs_for_testing()
+ model.eval()
+
+ with torch.inference_mode():
+ logits_adapter_1 = model(**dummy_input)[0]
+
+ model.add_adapter("adapter-2", config)
+ model.set_adapter("adapter-2")
+ model.eval()
+
+ with torch.inference_mode():
+ logits_adapter_2 = model(**dummy_input)[0]
+
+ assert not torch.allclose(logits_adapter_1, logits_adapter_2, atol=1e-3, rtol=1e-3)
+
+ model.set_adapter("default")
+
+ with torch.inference_mode():
+ logits_adapter_1_after_set = model(**dummy_input)[0]
+
+ assert torch.allclose(logits_adapter_1_after_set, logits_adapter_1, atol=1e-3, rtol=1e-3)
+
+ model_copy = copy.deepcopy(model)
+ model_copy_2 = copy.deepcopy(model)
+ model_merged_all = model.merge_and_unload(adapter_names=["adapter-2", "default"])
+
+ with torch.inference_mode():
+ logits_merged_all = model_merged_all(**dummy_input)[0]
+
+ assert not torch.allclose(logits_merged_all, logits_adapter_2, atol=1e-3, rtol=1e-3)
+ assert not torch.allclose(logits_merged_all, logits_adapter_1, atol=1e-3, rtol=1e-3)
+
+ model_merged_adapter_2 = model_copy.merge_and_unload(adapter_names=["adapter-2"])
+
+ with torch.inference_mode():
+ logits_merged_adapter_2 = model_merged_adapter_2(**dummy_input)[0]
+
+ assert torch.allclose(logits_merged_adapter_2, logits_adapter_2, atol=1e-3, rtol=1e-3)
+
+ model_merged_adapter_default = model_copy_2.merge_and_unload(adapter_names=["default"])
+
+ with torch.inference_mode():
+ logits_merged_adapter_default = model_merged_adapter_default(**dummy_input)[0]
+
+ assert torch.allclose(logits_merged_adapter_default, logits_adapter_1, atol=1e-3, rtol=1e-3)
+
+ def _test_merge_layers_is_idempotent(self, model_id, config_cls, config_kwargs):
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+ model.eval()
+ torch.manual_seed(0)
+ model.merge_adapter()
+ logits_0 = model(**self.prepare_inputs_for_testing())[0]
+
+ # merging again should not change anything
+ # also check warning:
+ with pytest.warns(UserWarning, match="All adapters are already merged, nothing to do"):
+ model.merge_adapter()
+ logits_1 = model(**self.prepare_inputs_for_testing())[0]
+
+ assert torch.allclose(logits_0, logits_1, atol=1e-6, rtol=1e-6)
+
+ def _test_safe_merge(self, model_id, config_cls, config_kwargs):
+ torch.manual_seed(0)
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = model.to(self.torch_device).eval()
+
+ inputs = self.prepare_inputs_for_testing()
+ logits_base = model(**inputs)[0]
+
+ model = get_peft_model(model, config).eval()
+ logits_peft = model(**inputs)[0]
+
+ atol, rtol = 1e-6, 1e-6 # default
+ # Initializing with LN tuning cannot be configured to change the outputs (unlike init_lora_weights=False)
+ if not issubclass(config_cls, LNTuningConfig):
+ # sanity check that the logits are different
+ assert not torch.allclose(logits_base, logits_peft, atol=atol, rtol=rtol)
+
+ model_unloaded = model.merge_and_unload(safe_merge=True)
+ logits_unloaded = model_unloaded(**inputs)[0]
+
+ if self.torch_device in ["mlu"]:
+ atol, rtol = 1e-3, 1e-3 # MLU
+
+ conv_ids = ["Conv2d", "Conv3d", "Conv2d2"]
+ if issubclass(config_cls, (IA3Config, LoraConfig)) and model_id in conv_ids: # more instability with Conv
+ atol, rtol = 1e-3, 1e-3
+
+ # check that the logits are the same after unloading
+ assert torch.allclose(logits_peft, logits_unloaded, atol=atol, rtol=rtol)
+
+ # Ensure that serializing with safetensors works, there was an error when weights were not contiguous
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ # serializing with torch.save works
+ torch.save(model_unloaded.state_dict(), os.path.join(tmp_dirname, "model.bin"))
+
+ # serializing with safetensors works
+ save_file(model_unloaded.state_dict(), os.path.join(tmp_dirname, "model.safetensors"))
+
+ def _test_mixed_adapter_batches(self, model_id, config_cls, config_kwargs):
+ # Test for mixing different adapters in a single batch by passing the adapter_names argument
+ if config_cls not in (LoraConfig,):
+ return pytest.skip(f"Mixed adapter batches not supported for {config_cls}")
+
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+
+ torch.manual_seed(0)
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ model = get_peft_model(model, config, adapter_name="adapter0").eval()
+ model.add_adapter("adapter1", config)
+ model = model.to(self.torch_device).eval()
+
+ self.perturb_trainable_token_weights_if_used(model, config_kwargs, adapter_name="adapter0")
+ self.perturb_trainable_token_weights_if_used(model, config_kwargs, adapter_name="adapter1")
+
+ dummy_input = self.prepare_inputs_for_testing()
+ # ensure that we have at least 3 samples for this test
+ dummy_input = {k: torch.cat([v for _ in range(3)]) for k, v in dummy_input.items()}
+
+ with torch.inference_mode():
+ with model.disable_adapter():
+ output_base = model(**dummy_input)[0]
+ logits_base = model.generate(**dummy_input, return_dict_in_generate=True, output_scores=True).scores[0]
+
+ model.set_adapter("adapter0")
+ with torch.inference_mode():
+ output_adapter0 = model(**dummy_input)[0]
+ logits_adapter0 = model.generate(**dummy_input, return_dict_in_generate=True, output_scores=True).scores[0]
+
+ model.set_adapter("adapter1")
+ with torch.inference_mode():
+ output_adapter1 = model(**dummy_input)[0]
+ logits_adapter1 = model.generate(**dummy_input, return_dict_in_generate=True, output_scores=True).scores[0]
+
+ atol, rtol = 1e-4, 1e-4
+ # sanity check that there are enough outputs and that they are different
+ assert len(output_base) == len(output_adapter0) == len(output_adapter1) >= 3
+ assert len(logits_base) == len(logits_adapter0) == len(logits_adapter1) >= 3
+ assert not torch.allclose(output_base, output_adapter0, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_base, output_adapter1, atol=atol, rtol=rtol)
+ assert not torch.allclose(output_adapter0, output_adapter1, atol=atol, rtol=rtol)
+ assert not torch.allclose(logits_base, logits_adapter0, atol=atol, rtol=rtol)
+ assert not torch.allclose(logits_base, logits_adapter1, atol=atol, rtol=rtol)
+ assert not torch.allclose(logits_adapter0, logits_adapter1, atol=atol, rtol=rtol)
+
+ # alternate between base model, adapter0, and adapter1
+ adapters = ["__base__", "adapter0", "adapter1"]
+ dummy_input["adapter_names"] = [adapters[i % 3] for i in (range(len(dummy_input["input_ids"])))]
+
+ with torch.inference_mode():
+ output_mixed = model(**dummy_input)[0]
+ logits_mixed = model.generate(**dummy_input, return_dict_in_generate=True, output_scores=True).scores[0]
+
+ assert torch.allclose(output_base[::3], output_mixed[::3], atol=atol, rtol=rtol)
+ assert torch.allclose(output_adapter0[1::3], output_mixed[1::3], atol=atol, rtol=rtol)
+ assert torch.allclose(output_adapter1[2::3], output_mixed[2::3], atol=atol, rtol=rtol)
+ assert torch.allclose(logits_base[::3], logits_mixed[::3], atol=atol, rtol=rtol)
+ assert torch.allclose(logits_adapter0[1::3], logits_mixed[1::3], atol=atol, rtol=rtol)
+ assert torch.allclose(logits_adapter1[2::3], logits_mixed[2::3], atol=atol, rtol=rtol)
+
+ def _test_generate_with_mixed_adapter_batches_and_beam_search(self, model_id, config_cls, config_kwargs):
+ # Test generating with beam search and with mixing different adapters in a single batch by passing the
+ # adapter_names argument. See #2283.
+ if config_cls not in (LoraConfig,):
+ return pytest.skip(f"Mixed adapter batches not supported for {config_cls}")
+
+ if config_kwargs.get("trainable_token_indices", None) is not None:
+ # for some configurations this test will fail since the adapter values don't differ.
+ # this is probably a problem with the test setup and not with the implementation.
+ return pytest.skip("Trainable token indices is not supported here (yet).")
+
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+
+ torch.manual_seed(0)
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ model = get_peft_model(model, config, adapter_name="adapter0").eval()
+ model.add_adapter("adapter1", config)
+
+ # In contrast to forward, for generate, it can sometimes happen that we get the same results as the base model
+ # even with LoRA applied because the impact of LoRA is not big enough. Therefore, use this "trick" to make LoRA
+ # stronger.
+ for name, param in model.named_parameters():
+ if model.base_model.prefix in name:
+ param.data.mul_(10.0)
+
+ model = model.to(self.torch_device).eval()
+
+ dummy_input = self.prepare_inputs_for_testing()
+ # ensure that we have at least 3 samples for this test
+ dummy_input = {k: torch.cat([v for _ in range(3)]) for k, v in dummy_input.items()}
+
+ gen_kwargs = {**dummy_input, "max_length": 20, "num_beams": 10, "early_stopping": True}
+ with torch.inference_mode():
+ with model.disable_adapter():
+ gen_base = model.generate(**gen_kwargs)
+
+ model.set_adapter("adapter0")
+ with torch.inference_mode():
+ gen_adapter0 = model.generate(**gen_kwargs)
+
+ model.set_adapter("adapter1")
+ with torch.inference_mode():
+ gen_adapter1 = model.generate(**gen_kwargs)
+
+ def remove_padding(seq, pad_value):
+ lst = list(seq)
+ while lst and (lst[-1] == pad_value):
+ lst.pop()
+ return lst
+
+ def gens_are_same(gen0, gen1):
+ # Special function to compare generations. We cannot use torch.allclose it will raise an error when sequence
+ # lengths differ. Morevoer, we need to remove the padding from the sequences. This is because, even though
+ # normally identical sequences should have the same length, when we do mixed adapter batches, each sample
+ # will be padded to the longest sequence in that mixed batch, which can be different from the longest
+ # sequence without mixed adapter batches.
+ pad_value = model.config.eos_token_id
+ for sample0, sample1 in zip(gen0, gen1):
+ sample0 = remove_padding(sample0, pad_value)
+ sample1 = remove_padding(sample1, pad_value)
+ if (len(sample0) != len(sample1)) or (sample0 != sample1):
+ # at least one sample differs, the generations are not identical
+ return False
+ return True
+
+ # sanity check that there are enough outputs and that they are different
+ assert len(gen_base) == len(gen_adapter0) == len(gen_adapter1)
+ assert len(gen_adapter1) >= 3
+ assert not gens_are_same(gen_base, gen_adapter0)
+ assert not gens_are_same(gen_base, gen_adapter1)
+ assert not gens_are_same(gen_adapter0, gen_adapter1)
+
+ # alternate between base model, adapter0, and adapter1
+ adapters = ["__base__", "adapter0", "adapter1"]
+ gen_kwargs["adapter_names"] = [adapters[i % 3] for i in (range(len(dummy_input["input_ids"])))]
+
+ with torch.inference_mode():
+ gen_mixed = model.generate(**gen_kwargs)
+
+ assert gens_are_same(gen_base[::3], gen_mixed[::3])
+ assert gens_are_same(gen_adapter0[1::3], gen_mixed[1::3])
+ assert gens_are_same(gen_adapter1[2::3], gen_mixed[2::3])
+
+ def _test_generate(self, model_id, config_cls, config_kwargs):
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ inputs = self.prepare_inputs_for_testing()
+
+ # check if `generate` works
+ _ = model.generate(**inputs)
+
+ def _test_generate_pos_args(self, model_id, config_cls, config_kwargs, raises_err: bool):
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ inputs = self.prepare_inputs_for_testing()
+ if raises_err:
+ with pytest.raises(TypeError):
+ # check if `generate` raises an error if positional arguments are passed
+ _ = model.generate(inputs["input_ids"])
+ else:
+ # check if `generate` works if positional arguments are passed
+ _ = model.generate(inputs["input_ids"])
+
+ def _test_generate_half_prec(self, model_id, config_cls, config_kwargs):
+ if config_cls not in (IA3Config, LoraConfig, PrefixTuningConfig):
+ return pytest.skip(f"Test not applicable for {config_cls}")
+
+ if self.torch_device == "mps": # BFloat16 is not supported on MPS
+ return pytest.skip("BFloat16 is not supported on MPS")
+
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id, torch_dtype=torch.bfloat16)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ input_ids = torch.LongTensor([[1, 1, 1], [2, 1, 2]]).to(self.torch_device)
+ attention_mask = torch.LongTensor([[1, 1, 1], [1, 0, 1]]).to(self.torch_device)
+
+ # check if `generate` works
+ _ = model.generate(input_ids=input_ids, attention_mask=attention_mask)
+
+ def _test_prefix_tuning_half_prec_conversion(self, model_id, config_cls, config_kwargs):
+ if config_cls not in (PrefixTuningConfig,):
+ return pytest.skip(f"Test not applicable for {config_cls}")
+
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ model = get_peft_model(model, config)
+ model = model.half()
+
+ assert model.base_model_torch_dtype == torch.float16
+
+ def _test_training(self, model_id, config_cls, config_kwargs):
+ if issubclass(config_cls, PromptLearningConfig):
+ return pytest.skip(f"Test not applicable for {config_cls}")
+ if (config_cls == AdaLoraConfig) and ("roberta" in model_id.lower()):
+ # TODO: no gradients on the "dense" layer, other layers work, not sure why
+ self.skipTest("AdaLora with RoBERTa does not work correctly")
+
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ inputs = self.prepare_inputs_for_testing()
+
+ # check if `training` works
+ output = model(**inputs)[0]
+ loss = output.sum()
+ loss.backward()
+ parameter_prefix = model.prefix
+ for n, param in model.named_parameters():
+ if (parameter_prefix in n) or ("modules_to_save" in n) or ("token_adapter.trainable_tokens" in n):
+ assert param.grad is not None
+ else:
+ assert param.grad is None
+
+ def _test_inference_safetensors(self, model_id, config_cls, config_kwargs):
+ if (config_cls == PrefixTuningConfig) and ("deberta" in model_id.lower()):
+ # TODO: raises an error:
+ # TypeError: DebertaModel.forward() got an unexpected keyword argument 'past_key_values'
+ self.skipTest("DeBERTa with PrefixTuning does not work correctly")
+
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ inputs = self.prepare_inputs_for_testing()
+
+ # check if `training` works
+ output = model(**inputs)[0]
+ logits = output[0]
+
+ loss = output.sum()
+ loss.backward()
+
+ # set to eval mode, since things like dropout can affect the output otherwise
+ model.eval()
+ logits = model(**inputs)[0][0]
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname, safe_serialization=True)
+ assert "adapter_model.safetensors" in os.listdir(tmp_dirname)
+ assert "adapter_model.bin" not in os.listdir(tmp_dirname)
+
+ model_from_pretrained = self.transformers_class.from_pretrained(model_id)
+ model_from_pretrained = PeftModel.from_pretrained(model_from_pretrained, tmp_dirname).to(
+ self.torch_device
+ )
+
+ logits_from_pretrained = model_from_pretrained(**inputs)[0][0]
+ assert torch.allclose(logits, logits_from_pretrained, atol=1e-4, rtol=1e-4)
+
+ def _test_training_layer_indexing(self, model_id, config_cls, config_kwargs):
+ if config_cls not in (LoraConfig,):
+ return pytest.skip(f"Test not applicable for {config_cls}")
+
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ layers_to_transform=[0],
+ **config_kwargs,
+ )
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ inputs = self.prepare_inputs_for_testing()
+
+ # check if `training` works
+ output = model(**inputs)[0]
+ logits = output[0]
+
+ loss = output.sum()
+ loss.backward()
+
+ has_trainable_tokens = config_kwargs.get("trainable_token_indices", None) is not None
+ nb_trainable = 0
+
+ for n, param in model.named_parameters():
+ if model.prefix in n or (has_trainable_tokens and "trainable_tokens" in n):
+ assert param.grad is not None
+ nb_trainable += 1
+ else:
+ assert param.grad is None
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname)
+
+ model_from_pretrained = self.transformers_class.from_pretrained(model_id)
+ model_from_pretrained = PeftModel.from_pretrained(model_from_pretrained, tmp_dirname).to(
+ self.torch_device
+ )
+
+ logits_from_pretrained = model_from_pretrained(**inputs)[0][0]
+ assert torch.allclose(logits, logits_from_pretrained, atol=1e-4, rtol=1e-4)
+
+ # check the nb of trainable params again but without layers_to_transform
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ nb_trainable_all = 0
+
+ for n, param in model.named_parameters():
+ if model.prefix in n or (has_trainable_tokens and "trainable_tokens" in n):
+ nb_trainable_all += 1
+
+ mod_list = next((m for m in model.modules() if isinstance(m, torch.nn.ModuleList)), None)
+ if mod_list and len(mod_list) == 1:
+ # there is only a single layer
+ assert nb_trainable == nb_trainable_all
+ else:
+ # more than 1 layer, i.e. setting layers_to_transform=[0] should target fewer layers
+ assert nb_trainable < nb_trainable_all
+
+ def _test_training_gradient_checkpointing(self, model_id, config_cls, config_kwargs):
+ if config_cls == PrefixTuningConfig:
+ return pytest.skip(f"Test not applicable for {config_cls}")
+
+ if (config_cls == AdaLoraConfig) and ("roberta" in model_id.lower()):
+ # TODO: no gradients on the "dense" layer, other layers work, not sure why
+ self.skipTest("AdaLora with RoBERTa does not work correctly")
+
+ if (config_cls == OFTConfig) and ("deberta" in model_id.lower()):
+ # TODO: no gradients on the "dense" layer, other layers work, not sure why
+ self.skipTest("OFT with Deberta does not work correctly")
+
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+
+ if not getattr(model, "supports_gradient_checkpointing", False):
+ return pytest.skip(f"Model {model_id} does not support gradient checkpointing")
+
+ model.gradient_checkpointing_enable()
+
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ inputs = self.prepare_inputs_for_testing()
+
+ # check if `training` works
+ output = model(**inputs)[0]
+
+ loss = output.sum()
+ loss.backward()
+
+ for n, param in model.named_parameters():
+ if "prompt_encoder." in n: # prompt tuning methods
+ if not issubclass(config_cls, CPTConfig):
+ assert param.grad is not None
+ elif (
+ "delta_embedding" in n
+ ): # delta_embedding is the embedding that should be updated with grads in CPT
+ assert param.grad is not None
+ elif hasattr(model, "prefix") and (model.prefix in n): # non-prompt tuning methods
+ assert param.grad is not None
+ elif "trainable_tokens_" in n: # trainable tokens layer
+ assert param.grad is not None
+ else:
+ assert param.grad is None
+
+ def _test_peft_model_device_map(self, model_id, config_cls, config_kwargs):
+ if config_cls not in (LoraConfig, VBLoRAConfig):
+ return pytest.skip(f"Test not applicable for {config_cls}")
+
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ with tempfile.TemporaryDirectory() as tmp_dirname:
+ model.save_pretrained(tmp_dirname)
+
+ model_from_pretrained = self.transformers_class.from_pretrained(model_id)
+ _ = PeftModel.from_pretrained(model_from_pretrained, tmp_dirname, device_map={"": "cpu"}).to(
+ self.torch_device
+ )
+
+ def _test_training_prompt_learning_tasks(self, model_id, config_cls, config_kwargs):
+ if not issubclass(config_cls, PromptLearningConfig):
+ return pytest.skip(f"Test not applicable for {config_cls}")
+
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ inputs = self.prepare_inputs_for_testing()
+
+ # check if `training` works
+ output = model(**inputs)[0]
+ loss = output.sum()
+ loss.backward()
+
+ if issubclass(config_cls, CPTConfig):
+ parameters = []
+ for name, param in model.prompt_encoder.named_parameters():
+ if name != "default.embedding.weight":
+ parameters.append(param)
+ else:
+ parameters = model.prompt_encoder.parameters()
+
+ # check that prompt encoder has grads
+ for param in parameters:
+ assert param.grad is not None
+
+ def _test_delete_adapter(self, model_id, config_cls, config_kwargs):
+ supported_peft_types = [
+ PeftType.LORA,
+ PeftType.LOHA,
+ PeftType.LOKR,
+ PeftType.IA3,
+ PeftType.OFT,
+ PeftType.BOFT,
+ PeftType.VERA,
+ PeftType.FOURIERFT,
+ PeftType.HRA,
+ PeftType.VBLORA,
+ PeftType.BONE,
+ ]
+ # IA3 does not support deleting adapters yet, but it just needs to be added
+ # AdaLora does not support multiple adapters
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ if config.peft_type not in supported_peft_types:
+ return pytest.skip(f"Test not applicable for {config.peft_type}")
+
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ adapter_to_delete = "delete_me"
+ model = get_peft_model(model, config)
+ model.add_adapter(adapter_to_delete, config)
+ model.set_adapter(adapter_to_delete)
+ model = model.to(self.torch_device)
+ model.delete_adapter(adapter_to_delete)
+ assert adapter_to_delete not in model.peft_config
+ assert model.active_adapters == ["default"]
+
+ key_list = [key for key, _ in model.named_modules()]
+ for key in key_list:
+ _, target, _ = _get_submodules(model, key)
+ attributes_to_check = getattr(target, "adapter_layer_names", []) + getattr(
+ target, "other_param_names", []
+ )
+ for attr in attributes_to_check:
+ assert adapter_to_delete not in getattr(target, attr)
+
+ # check auxiliary modules
+ for module in model.modules():
+ if isinstance(module, AuxiliaryTrainingWrapper):
+ assert adapter_to_delete not in module._adapters
+ assert module.active_adapters == ["default"]
+ if isinstance(module, ModulesToSaveWrapper):
+ assert adapter_to_delete not in module.modules_to_save
+ elif isinstance(module, TrainableTokensWrapper):
+ assert adapter_to_delete not in module.token_adapter.trainable_tokens_delta
+ assert adapter_to_delete not in module.token_adapter.trainable_tokens_original
+
+ # check that we can also delete the last remaining adapter
+ model.delete_adapter("default")
+ assert "default" not in model.peft_config
+ assert model.active_adapters == []
+
+ for module in model.modules():
+ if isinstance(module, AuxiliaryTrainingWrapper):
+ assert "default" not in module._adapters
+ assert module.active_adapters == []
+ if isinstance(module, ModulesToSaveWrapper):
+ assert "default" not in module.modules_to_save
+ elif isinstance(module, TrainableTokensWrapper):
+ assert "default" not in module.token_adapter.trainable_tokens_delta
+ assert "default" not in module.token_adapter.trainable_tokens_original
+
+ input = self.prepare_inputs_for_testing()
+ # note: we cannot call model(**input) because PeftModel always expects there to be at least one adapter
+ model.base_model(**input) # should not raise an error
+
+ def _test_delete_inactive_adapter(self, model_id, config_cls, config_kwargs):
+ # same as test_delete_adapter, but this time an inactive adapter is deleted
+ supported_peft_types = [
+ PeftType.LORA,
+ PeftType.LOHA,
+ PeftType.LOKR,
+ PeftType.IA3,
+ PeftType.OFT,
+ PeftType.BOFT,
+ PeftType.FOURIERFT,
+ PeftType.HRA,
+ PeftType.VBLORA,
+ PeftType.BONE,
+ ]
+ # IA3 does not support deleting adapters yet, but it just needs to be added
+ # AdaLora does not support multiple adapters
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ if config.peft_type not in supported_peft_types:
+ return pytest.skip(f"Test not applicable for {config.peft_type}")
+
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ adapter_to_delete = "delete_me"
+ model = get_peft_model(model, config)
+ model.add_adapter(adapter_to_delete, config)
+ # "delete_me" is added but not activated
+ model = model.to(self.torch_device)
+ model.delete_adapter(adapter_to_delete)
+ assert adapter_to_delete not in model.peft_config
+ assert model.active_adapters == ["default"]
+
+ key_list = [key for key, _ in model.named_modules()]
+ for key in key_list:
+ _, target, _ = _get_submodules(model, key)
+ attributes_to_check = getattr(target, "adapter_layer_names", []) + getattr(
+ target, "other_param_names", []
+ )
+ for attr in attributes_to_check:
+ assert adapter_to_delete not in getattr(target, attr)
+
+ # check auxiliary modules
+ for module in model.modules():
+ if isinstance(module, AuxiliaryTrainingWrapper):
+ assert adapter_to_delete not in module._adapters
+ assert module.active_adapters == ["default"]
+ if isinstance(module, ModulesToSaveWrapper):
+ assert adapter_to_delete not in module.modules_to_save
+ elif isinstance(module, TrainableTokensWrapper):
+ assert adapter_to_delete not in module.token_adapter.trainable_tokens_delta
+ assert adapter_to_delete not in module.token_adapter.trainable_tokens_original
+
+ # check that we can also delete the last remaining adapter
+ model.delete_adapter("default")
+ assert "default" not in model.peft_config
+ assert model.active_adapters == []
+
+ for module in model.modules():
+ if isinstance(module, AuxiliaryTrainingWrapper):
+ assert "default" not in module._adapters
+ assert module.active_adapters == []
+ if isinstance(module, ModulesToSaveWrapper):
+ assert "default" not in module.modules_to_save
+ elif isinstance(module, TrainableTokensWrapper):
+ assert "default" not in module.token_adapter.trainable_tokens_delta
+ assert "default" not in module.token_adapter.trainable_tokens_original
+
+ input = self.prepare_inputs_for_testing()
+ # note: we cannot call model(**input) because PeftModel always expects there to be at least one adapter
+ model.base_model(**input) # should not raise an error
+
+ def _test_delete_unknown_adapter_raises(self, model_id, config_cls, config_kwargs):
+ # Check that we get a nice error message when trying to delete an adapter that does not exist.
+ config = config_cls(base_model_name_or_path=model_id, **config_kwargs)
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ adapter_to_delete = "delete_me"
+ model = get_peft_model(model, config)
+
+ msg = "Adapter unknown-adapter does not exist"
+ with pytest.raises(ValueError, match=msg):
+ model.delete_adapter("unknown-adapter")
+
+ def _test_unload_adapter(self, model_id, config_cls, config_kwargs):
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ num_params_base = len(model.state_dict())
+
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config)
+ model = model.to(self.torch_device)
+
+ if config.peft_type not in (
+ "LORA",
+ "ADALORA",
+ "IA3",
+ "BOFT",
+ "OFT",
+ "VERA",
+ "FOURIERFT",
+ "HRA",
+ "VBLORA",
+ "RANDLORA",
+ "SHIRA",
+ "BONE",
+ "C3A",
+ ):
+ with pytest.raises(AttributeError):
+ model = model.unload()
+ else:
+ self.perturb_trainable_token_weights_if_used(model, config_kwargs)
+
+ dummy_input = self.prepare_inputs_for_testing()
+ logits_with_adapter = model(**dummy_input)[0]
+
+ with hub_online_once(model_id):
+ transformers_model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+ logits_transformers = transformers_model(**dummy_input)[0]
+
+ model.eval()
+ model = model.unload()
+ logits_unload = model(**dummy_input)[0]
+ num_params_unloaded = len(model.state_dict())
+
+ # check that PEFT layers are completely removed
+ assert not any(isinstance(module, BaseTunerLayer) for module in model.modules())
+ assert not torch.allclose(logits_with_adapter, logits_unload, atol=1e-10, rtol=1e-10)
+ assert torch.allclose(logits_transformers, logits_unload, atol=1e-4, rtol=1e-4)
+ assert num_params_base == num_params_unloaded
+
+ def _test_weighted_combination_of_adapters_lora(self, model, config, adapter_list, weight_list):
+ model.add_adapter(adapter_list[1], config)
+ model.add_adapter(adapter_list[2], replace(config, r=20))
+ model = model.to(self.torch_device)
+
+ # test re-weighting single adapter
+ model.add_weighted_adapter([adapter_list[0]], [weight_list[0]], "single_adapter_reweighting")
+
+ # test svd re-weighting with multiple adapters
+ model.add_weighted_adapter(adapter_list[1:], weight_list[1:], "multi_adapter_svd_reweighting")
+
+ # test ties_svd re-weighting with multiple adapters
+ model.add_weighted_adapter(
+ adapter_list[1:],
+ weight_list[1:],
+ "multi_adapter_ties_svd_reweighting",
+ combination_type="ties_svd",
+ density=0.5,
+ )
+
+ # test dare_linear_svd re-weighting with multiple adapters
+ model.add_weighted_adapter(
+ adapter_list[1:],
+ weight_list[1:],
+ "multi_adapter_dare_linear_svd_reweighting",
+ combination_type="dare_linear_svd",
+ density=0.5,
+ )
+
+ # test dare_ties_svd re-weighting with multiple adapters
+ model.add_weighted_adapter(
+ adapter_list[1:],
+ weight_list[1:],
+ "multi_adapter_dare_ties_svd_reweighting",
+ combination_type="dare_ties_svd",
+ density=0.5,
+ )
+
+ # test magnitude_prune_svd re-weighting with multiple adapters
+ model.add_weighted_adapter(
+ adapter_list[1:],
+ weight_list[1:],
+ "multi_adapter_magnitude_prune_svd_reweighting",
+ combination_type="magnitude_prune_svd",
+ density=0.5,
+ )
+
+ # test cat re-weighting with multiple adapters
+ model.add_weighted_adapter(
+ adapter_list[1:], weight_list[1:], "multi_adapter_cat_reweighting", combination_type="cat"
+ )
+
+ # test linear re-weighting with multiple adapters
+ model.add_weighted_adapter(
+ adapter_list[:2], weight_list[:2], "multi_adapter_linear_reweighting", combination_type="linear"
+ )
+
+ # test ties re-weighting with multiple adapters
+ model.add_weighted_adapter(
+ adapter_list[:2], weight_list[:2], "multi_adapter_ties_reweighting", combination_type="ties", density=0.5
+ )
+
+ # test dare_linear re-weighting with multiple adapters
+ model.add_weighted_adapter(
+ adapter_list[:2],
+ weight_list[:2],
+ "multi_adapter_dare_linear_reweighting",
+ combination_type="dare_linear",
+ density=0.5,
+ )
+
+ # test dare_ties re-weighting with multiple adapters
+ model.add_weighted_adapter(
+ adapter_list[:2],
+ weight_list[:2],
+ "multi_adapter_dare_ties_reweighting",
+ combination_type="dare_ties",
+ density=0.5,
+ )
+
+ # test magnitude_prune re-weighting with multiple adapters
+ model.add_weighted_adapter(
+ adapter_list[:2],
+ weight_list[:2],
+ "multi_adapter_magnitude_prune_reweighting",
+ combination_type="magnitude_prune",
+ density=0.5,
+ )
+
+ # test linear re-weighting with multiple adapters with only first adapter having non zero weight
+ model.add_weighted_adapter(
+ adapter_list[:2],
+ [weight_list[0], 0],
+ "multi_adapter_linear_reweighting_single_enabled",
+ combination_type="linear",
+ )
+
+ with pytest.raises(ValueError):
+ model.add_weighted_adapter(
+ adapter_list[1:],
+ weight_list[1:],
+ "multi_adapter_linear_reweighting_uneven_r",
+ combination_type="linear",
+ )
+
+ with pytest.raises(ValueError):
+ model.add_weighted_adapter(
+ adapter_list[1:],
+ weight_list[1:],
+ "multi_adapter_ties_reweighting_uneven_r",
+ combination_type="ties",
+ density=0.5,
+ )
+
+ with pytest.raises(ValueError):
+ model.add_weighted_adapter(
+ adapter_list[1:],
+ weight_list[1:],
+ "multi_adapter_dare_linear_reweighting_uneven_r",
+ combination_type="dare_linear",
+ density=0.5,
+ )
+
+ with pytest.raises(ValueError):
+ model.add_weighted_adapter(
+ adapter_list[1:],
+ weight_list[1:],
+ "multi_adapter_dare_ties_reweighting_uneven_r",
+ combination_type="dare_ties",
+ density=0.5,
+ )
+
+ with pytest.raises(ValueError):
+ model.add_weighted_adapter(
+ adapter_list[1:],
+ weight_list[1:],
+ "multi_adapter_magnitude_prune_reweighting_uneven_r",
+ combination_type="magnitude_prune",
+ density=0.5,
+ )
+
+ new_adapters = [
+ "single_adapter_reweighting",
+ "multi_adapter_svd_reweighting",
+ "multi_adapter_ties_svd_reweighting",
+ "multi_adapter_dare_linear_svd_reweighting",
+ "multi_adapter_dare_ties_svd_reweighting",
+ "multi_adapter_magnitude_prune_svd_reweighting",
+ "multi_adapter_cat_reweighting",
+ "multi_adapter_linear_reweighting",
+ "multi_adapter_linear_reweighting_single_enabled",
+ "multi_adapter_ties_reweighting",
+ "multi_adapter_dare_linear_reweighting",
+ "multi_adapter_dare_ties_reweighting",
+ "multi_adapter_magnitude_prune_reweighting",
+ ]
+ for new_adapter in new_adapters:
+ assert new_adapter in model.peft_config
+
+ key_list = [key for key, _ in model.named_modules()]
+ for key in key_list:
+ _, target, _ = _get_submodules(model, key)
+ if isinstance(target, LoraLayer):
+ for adapter_name in new_adapters:
+ if "single" in adapter_name:
+ new_delta_weight = target.get_delta_weight(adapter_name)
+ weighted_original_delta_weights = target.get_delta_weight(adapter_list[0]) * weight_list[0]
+ assert torch.allclose(new_delta_weight, weighted_original_delta_weights, atol=1e-4, rtol=1e-4)
+ elif "svd" in adapter_name:
+ assert target.r[adapter_name] == 20
+ elif "linear" in adapter_name:
+ assert target.r[adapter_name] == 8
+ elif "cat" in adapter_name:
+ assert target.r[adapter_name] == 28
+
+ dummy_input = self.prepare_inputs_for_testing()
+ model.eval()
+ for adapter_name in new_adapters:
+ # ensuring new adapters pass the forward loop
+ model.set_adapter(adapter_name)
+ assert model.active_adapter == adapter_name
+ assert model.active_adapters == [adapter_name]
+ model(**dummy_input)[0]
+
+ def _test_weighted_combination_of_adapters_ia3(self, model, config, adapter_list, weight_list):
+ model.add_adapter(adapter_list[1], config)
+ model.add_adapter(adapter_list[2], config)
+ model = model.to(self.torch_device)
+
+ # test re-weighting single adapter
+ model.add_weighted_adapter([adapter_list[0]], [weight_list[0]], "single_adapter_reweighting")
+
+ # test re-weighting with multiple adapters
+ model.add_weighted_adapter(adapter_list[1:], weight_list[1:], "multi_adapter_reweighting")
+
+ new_adapters = [
+ "single_adapter_reweighting",
+ "multi_adapter_reweighting",
+ ]
+ for new_adapter in new_adapters:
+ assert new_adapter in model.peft_config
+
+ dummy_input = self.prepare_inputs_for_testing()
+ model.eval()
+ for adapter_name in new_adapters:
+ # ensuring new adapters pass the forward loop
+ model.set_adapter(adapter_name)
+ assert model.active_adapter == adapter_name
+ assert model.active_adapters == [adapter_name]
+ model(**dummy_input)[0]
+
+ def _test_weighted_combination_of_adapters(self, model_id, config_cls, config_kwargs):
+ if issubclass(config_cls, AdaLoraConfig):
+ # AdaLora does not support adding more than 1 adapter
+ return pytest.skip(f"Test not applicable for {config_cls}")
+ if model_id.endswith("qwen2"):
+ # Qwen2 fails with weighted adapter combinations using SVD
+ return pytest.skip(f"Test does not work with model {model_id}")
+ if "gemma" in model_id.lower():
+ return pytest.skip("Combining Gemma adapters with SVD is currently failing")
+
+ adapter_list = ["adapter1", "adapter_2", "adapter_3"]
+ weight_list = [0.5, 1.5, 1.5]
+ # Initialize the config
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+
+ if not isinstance(config, (LoraConfig, IA3Config)):
+ # This test is only applicable for Lora and IA3 configs
+ return pytest.skip(f"Test not applicable for {config}")
+
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ model = get_peft_model(model, config, adapter_list[0])
+
+ if isinstance(config, LoraConfig):
+ self._test_weighted_combination_of_adapters_lora(model, config, adapter_list, weight_list)
+ elif isinstance(config, IA3Config):
+ self._test_weighted_combination_of_adapters_ia3(model, config, adapter_list, weight_list)
+ else:
+ pytest.skip(f"Test not applicable for {config}")
+
+ def _test_disable_adapter(self, model_id, config_cls, config_kwargs):
+ task_type = config_kwargs.get("task_type")
+ if (task_type == "SEQ_2_SEQ_LM") and (config_cls in (PromptTuningConfig, PromptEncoderConfig)):
+ self.skipTest("Seq2Seq + prompt tuning/prompt encoder does not work with disabling adapters")
+
+ def get_output(model):
+ # helper function that works with different model types
+ torch.manual_seed(0)
+
+ if hasattr(model, "generate"):
+ # let's check the scores, not the output ids, since the latter can easily be identical even if the
+ # weights are slightly changed
+ output = model.generate(**input, return_dict_in_generate=True, output_scores=True).scores[0]
+ # take element 0, as output is a tuple
+ else:
+ output = model(**input)
+
+ if hasattr(output, "images"): # for SD
+ import numpy as np
+
+ img = output.images[0]
+ return torch.from_numpy(np.array(img))
+
+ return output
+
+ # initialize model
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id).to(self.torch_device)
+
+ # output from BASE MODEL
+ input = self.prepare_inputs_for_testing()
+ output_before = get_output(model)
+
+ # output from PEFT MODEL
+ if hasattr(self, "instantiate_sd_peft"):
+ # SD models are instantiated differently
+ peft_model = self.instantiate_sd_peft(model_id, config_cls, config_kwargs)
+ else:
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ peft_model = get_peft_model(model, config)
+
+ # trainable_token_indices doesn't have support for `init_weights` so we have to do this manually
+ self.perturb_trainable_token_weights_if_used(model, config_kwargs)
+
+ output_peft = get_output(peft_model)
+
+ # first check trivial case is not true that peft does not affect the output; for this to work, init_weight
+ # must be False (if the config supports it)
+ if isinstance(peft_model, StableDiffusionPipeline):
+ # for SD, check that most pixels have different values
+ assert (output_before != output_peft).float().mean() > 0.8
+ else:
+ assert not torch.allclose(output_before, output_peft)
+
+ # output with DISABLED ADAPTER
+ if isinstance(peft_model, StableDiffusionPipeline):
+ with peft_model.unet.disable_adapter():
+ with peft_model.text_encoder.disable_adapter():
+ output_peft_disabled = get_output(peft_model)
+ # for SD, very rarely, a pixel can differ
+ assert (output_before != output_peft_disabled).float().mean() < 1e-4
+ else:
+ with peft_model.disable_adapter():
+ output_peft_disabled = get_output(peft_model)
+ assert torch.allclose(output_before, output_peft_disabled, atol=1e-6, rtol=1e-6)
+
+ # after leaving the disable_adapter context, the output should be the same as with enabled adapter again
+ # see #1501
+ output_peft_after_disabled = get_output(peft_model)
+ assert torch.allclose(output_peft, output_peft_after_disabled, atol=1e-6, rtol=1e-6)
+
+ # TODO: add tests to check if disabling adapters works after calling merge_adapter
+
+ def _test_adding_multiple_adapters_with_bias_raises(self, model_id, config_cls, config_kwargs):
+ # When trying to add multiple adapters with bias in Lora, AdaLora or BOFTConfig, an error should be
+ # raised. Also, the peft model should not be left in a half-initialized state.
+ if not issubclass(config_cls, (LoraConfig, AdaLoraConfig, BOFTConfig)):
+ return pytest.skip(f"Test not applicable for {config_cls}")
+
+ with hub_online_once(model_id):
+ config_kwargs = config_kwargs.copy()
+ config_kwargs["bias"] = "all"
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+
+ model = self.transformers_class.from_pretrained(model_id)
+ model = get_peft_model(model, config, "adapter0")
+
+ if config_cls == LoraConfig or config_cls == AdaLoraConfig:
+ with pytest.raises(ValueError):
+ model.add_adapter("adapter1", replace(config, r=20))
+
+ if config_cls == BOFTConfig:
+ with pytest.raises(ValueError):
+ model.add_adapter("adapter1", replace(config, boft_block_num=1, boft_block_size=0))
+
+ # (superficial) test that the model is not left in a half-initialized state when adding an adapter fails
+ assert "adapter1" not in model.peft_config
+ assert "adapter1" not in model.base_model.peft_config
+
+ def _test_passing_input_embeds_works(self, test_name, model_id, config_cls, config_kwargs):
+ # https://github.com/huggingface/peft/issues/727
+ with hub_online_once(model_id):
+ model = self.transformers_class.from_pretrained(model_id)
+ config = config_cls(
+ base_model_name_or_path=model_id,
+ **config_kwargs,
+ )
+ model = get_peft_model(model, config, adapter_name="test-adapter").to(self.torch_device)
+ dummy_input = self.prepare_inputs_for_testing()
+ inputs_embeds = model.get_input_embeddings()(dummy_input["input_ids"])
+ # just check that no error is raised
+ model.forward(inputs_embeds=inputs_embeds)
diff --git a/peft/tests/testing_utils.py b/peft/tests/testing_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..7aeb5320bb3a1ac056091b21b61088e57c660acb
--- /dev/null
+++ b/peft/tests/testing_utils.py
@@ -0,0 +1,243 @@
+# Copyright 2023-present the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import unittest
+from contextlib import contextmanager
+from functools import lru_cache, wraps
+
+import numpy as np
+import pytest
+import torch
+from accelerate.test_utils.testing import get_backend
+from datasets import load_dataset
+
+from peft import (
+ AdaLoraConfig,
+ IA3Config,
+ LoraConfig,
+ PromptLearningConfig,
+ ShiraConfig,
+ VBLoRAConfig,
+)
+from peft.import_utils import (
+ is_aqlm_available,
+ is_auto_awq_available,
+ is_auto_gptq_available,
+ is_eetq_available,
+ is_gptqmodel_available,
+ is_hqq_available,
+ is_optimum_available,
+ is_torchao_available,
+)
+
+
+torch_device, device_count, memory_allocated_func = get_backend()
+
+
+def require_non_cpu(test_case):
+ """
+ Decorator marking a test that requires a hardware accelerator backend. These tests are skipped when there are no
+ hardware accelerator available.
+ """
+ return unittest.skipUnless(torch_device != "cpu", "test requires a hardware accelerator")(test_case)
+
+
+def require_non_xpu(test_case):
+ """
+ Decorator marking a test that should be skipped for XPU.
+ """
+ return unittest.skipUnless(torch_device != "xpu", "test requires a non-XPU")(test_case)
+
+
+def require_torch_gpu(test_case):
+ """
+ Decorator marking a test that requires a GPU. Will be skipped when no GPU is available.
+ """
+ if not torch.cuda.is_available():
+ return unittest.skip("test requires GPU")(test_case)
+ else:
+ return test_case
+
+
+def require_torch_multi_gpu(test_case):
+ """
+ Decorator marking a test that requires multiple GPUs. Will be skipped when less than 2 GPUs are available.
+ """
+ if not torch.cuda.is_available() or torch.cuda.device_count() < 2:
+ return unittest.skip("test requires multiple GPUs")(test_case)
+ else:
+ return test_case
+
+
+def require_torch_multi_accelerator(test_case):
+ """
+ Decorator marking a test that requires multiple hardware accelerators. These tests are skipped on a machine without
+ multiple accelerators.
+ """
+ return unittest.skipUnless(
+ torch_device != "cpu" and device_count > 1, "test requires multiple hardware accelerators"
+ )(test_case)
+
+
+def require_bitsandbytes(test_case):
+ """
+ Decorator marking a test that requires the bitsandbytes library. Will be skipped when the library is not installed.
+ """
+ try:
+ import bitsandbytes # noqa: F401
+
+ test_case = pytest.mark.bitsandbytes(test_case)
+ except ImportError:
+ test_case = pytest.mark.skip(reason="test requires bitsandbytes")(test_case)
+ return test_case
+
+
+def require_auto_gptq(test_case):
+ """
+ Decorator marking a test that requires auto-gptq. These tests are skipped when auto-gptq isn't installed.
+ """
+ return unittest.skipUnless(is_gptqmodel_available() or is_auto_gptq_available(), "test requires auto-gptq")(
+ test_case
+ )
+
+
+def require_gptqmodel(test_case):
+ """
+ Decorator marking a test that requires gptqmodel. These tests are skipped when gptqmodel isn't installed.
+ """
+ return unittest.skipUnless(is_gptqmodel_available(), "test requires gptqmodel")(test_case)
+
+
+def require_aqlm(test_case):
+ """
+ Decorator marking a test that requires aqlm. These tests are skipped when aqlm isn't installed.
+ """
+ return unittest.skipUnless(is_aqlm_available(), "test requires aqlm")(test_case)
+
+
+def require_hqq(test_case):
+ """
+ Decorator marking a test that requires aqlm. These tests are skipped when aqlm isn't installed.
+ """
+ return unittest.skipUnless(is_hqq_available(), "test requires hqq")(test_case)
+
+
+def require_auto_awq(test_case):
+ """
+ Decorator marking a test that requires auto-awq. These tests are skipped when auto-awq isn't installed.
+ """
+ return unittest.skipUnless(is_auto_awq_available(), "test requires auto-awq")(test_case)
+
+
+def require_eetq(test_case):
+ """
+ Decorator marking a test that requires eetq. These tests are skipped when eetq isn't installed.
+ """
+ return unittest.skipUnless(is_eetq_available(), "test requires eetq")(test_case)
+
+
+def require_optimum(test_case):
+ """
+ Decorator marking a test that requires optimum. These tests are skipped when optimum isn't installed.
+ """
+ return unittest.skipUnless(is_optimum_available(), "test requires optimum")(test_case)
+
+
+def require_torchao(test_case):
+ """
+ Decorator marking a test that requires torchao. These tests are skipped when torchao isn't installed.
+ """
+ return unittest.skipUnless(is_torchao_available(), "test requires torchao")(test_case)
+
+
+def require_deterministic_for_xpu(test_case):
+ @wraps(test_case)
+ def wrapper(*args, **kwargs):
+ if torch_device == "xpu":
+ original_state = torch.are_deterministic_algorithms_enabled()
+ try:
+ torch.use_deterministic_algorithms(True)
+ return test_case(*args, **kwargs)
+ finally:
+ torch.use_deterministic_algorithms(original_state)
+ else:
+ return test_case(*args, **kwargs)
+
+ return wrapper
+
+
+@contextmanager
+def temp_seed(seed: int):
+ """Temporarily set the random seed. This works for python numpy, pytorch."""
+
+ np_state = np.random.get_state()
+ np.random.seed(seed)
+
+ torch_state = torch.random.get_rng_state()
+ torch.random.manual_seed(seed)
+
+ if torch.cuda.is_available():
+ torch_cuda_states = torch.cuda.get_rng_state_all()
+ torch.cuda.manual_seed_all(seed)
+
+ try:
+ yield
+ finally:
+ np.random.set_state(np_state)
+
+ torch.random.set_rng_state(torch_state)
+ if torch.cuda.is_available():
+ torch.cuda.set_rng_state_all(torch_cuda_states)
+
+
+def get_state_dict(model, unwrap_compiled=True):
+ """
+ Get the state dict of a model. If the model is compiled, unwrap it first.
+ """
+ if unwrap_compiled:
+ model = getattr(model, "_orig_mod", model)
+ return model.state_dict()
+
+
+@lru_cache
+def load_dataset_english_quotes():
+ # can't use pytest fixtures for now because of unittest style tests
+ data = load_dataset("ybelkada/english_quotes_copy")
+ return data
+
+
+@lru_cache
+def load_cat_image():
+ # can't use pytest fixtures for now because of unittest style tests
+ dataset = load_dataset("huggingface/cats-image", trust_remote_code=True)
+ image = dataset["test"]["image"][0]
+ return image
+
+
+def set_init_weights_false(config_cls, kwargs):
+ kwargs = kwargs.copy()
+
+ if issubclass(config_cls, PromptLearningConfig):
+ return kwargs
+ if issubclass(config_cls, ShiraConfig):
+ return kwargs
+ if config_cls == VBLoRAConfig:
+ return kwargs
+
+ if (config_cls == LoraConfig) or (config_cls == AdaLoraConfig):
+ kwargs["init_lora_weights"] = False
+ elif config_cls == IA3Config:
+ kwargs["init_ia3_weights"] = False
+ else:
+ kwargs["init_weights"] = False
+ return kwargs
diff --git a/prepare_tool/extract_componet/README.md b/prepare_tool/extract_componet/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..fdbba99a4486dfd6c15d0971d69fe8d993626966
--- /dev/null
+++ b/prepare_tool/extract_componet/README.md
@@ -0,0 +1,105 @@
+# VAE和UNet组件提取工具
+
+本目录包含从Stable Diffusion XL模型文件中提取VAE和UNet组件的工具脚本。
+
+## 脚本说明
+
+### 1. `extract_wai_components.py` (推荐)
+专门用于提取 `waiNSFWIllustrious_v140.safetensors` 模型的VAE和UNet组件的简化脚本。
+
+**特点:**
+- 针对特定模型优化
+- 自动设置输入输出路径
+- 友好的中文界面
+- 显示详细的提取进度
+
+**使用方法:**
+```bash
+cd prepare_tool
+python extract_wai_components.py
+```
+
+### 2. `extract_vae_unet.py` (通用版)
+通用的VAE和UNet提取工具,支持任意Stable Diffusion XL模型文件。
+
+**特点:**
+- 支持任意SDXL模型文件
+- 灵活的命令行参数
+- 可自定义输出目录
+- 支持仅查看模型信息模式
+
+**使用方法:**
+```bash
+# 基础用法
+python extract_vae_unet.py ../models/waiNSFWIllustrious_v140.safetensors
+
+# 指定输出目录
+python extract_vae_unet.py ../models/waiNSFWIllustrious_v140.safetensors --output-dir ./my_components
+
+# 仅查看模型信息
+python extract_vae_unet.py ../models/waiNSFWIllustrious_v140.safetensors --info-only
+
+# 查看帮助
+python extract_vae_unet.py --help
+```
+
+## 输出文件
+
+提取完成后,将生成以下文件:
+
+```
+models/extracted_components/
+├── waiNSFWIllustrious_v140_vae.safetensors # VAE权重文件
+├── waiNSFWIllustrious_v140_vae_config.json # VAE配置文件
+├── waiNSFWIllustrious_v140_unet.safetensors # UNet权重文件
+└── waiNSFWIllustrious_v140_unet_config.json # UNet配置文件
+```
+
+## 文件说明
+
+- **VAE (变分自编码器)**: 负责在像素空间和潜在空间之间进行转换
+- **UNet (去噪神经网络)**: 在潜在空间中执行去噪操作,是扩散模型的核心
+- **配置文件**: 包含模型的架构参数,用于重新加载模型时使用
+
+## 系统要求
+
+- Python 3.8+
+- PyTorch
+- diffusers库
+- safetensors库
+- transformers库
+
+## 使用场景
+
+这些提取的组件可以用于:
+
+1. **模型微调**: 单独对VAE或UNet进行微调
+2. **模型组合**: 将不同模型的VAE和UNet进行组合
+3. **模型分析**: 分析特定组件的参数和结构
+4. **存储优化**: 节省存储空间,避免重复存储相同的组件
+5. **推理优化**: 只加载需要的组件,减少内存占用
+
+## 注意事项
+
+1. **内存要求**: 加载完整模型需要大量内存,建议至少16GB RAM
+2. **存储空间**: 提取的组件文件总大小约为原文件的80-90%
+3. **精度保持**: 组件按原始精度保存(通常为float16),节省存储空间
+4. **GPU内存**: 如果系统有GPU,脚本会在处理完成后清理GPU内存
+
+## 故障排除
+
+### 内存不足
+如果遇到内存不足的错误:
+- 关闭其他占用内存的程序
+- 考虑使用内存更大的机器
+- 模型已经以较低精度(float16)加载以节省内存
+
+### 模型加载失败
+- 确认模型文件完整且未损坏
+- 检查diffusers库版本是否兼容
+- 确认模型格式为safetensors
+
+### 路径问题
+- 确保脚本在正确的目录下运行
+- 检查模型文件路径是否正确
+- 确认有足够的磁盘空间用于输出文件
diff --git a/prepare_tool/extract_componet/check_components.py b/prepare_tool/extract_componet/check_components.py
new file mode 100644
index 0000000000000000000000000000000000000000..98593e112d4fd9a1249577175914e9b04c9d1d3a
--- /dev/null
+++ b/prepare_tool/extract_componet/check_components.py
@@ -0,0 +1,83 @@
+#!/usr/bin/env python3
+"""
+检查提取的VAE和UNet组件的精度和基本信息
+"""
+
+import os
+import sys
+from pathlib import Path
+from safetensors.torch import load_file
+
+def check_component_info(file_path):
+ """检查组件文件的信息"""
+ if not Path(file_path).exists():
+ print(f"❌ 文件不存在: {file_path}")
+ return
+
+ print(f"\n📄 检查文件: {Path(file_path).name}")
+
+ try:
+ # 加载权重
+ state_dict = load_file(file_path)
+
+ # 统计信息
+ total_params = 0
+ dtypes = set()
+
+ for key, tensor in state_dict.items():
+ total_params += tensor.numel()
+ dtypes.add(str(tensor.dtype))
+
+ file_size = Path(file_path).stat().st_size / (1024**3) # GB
+
+ print(f" 📊 参数数量: {total_params:,}")
+ print(f" 💾 文件大小: {file_size:.2f} GB")
+ print(f" 🎯 数据精度: {', '.join(dtypes)}")
+ print(f" 🔧 参数种类: {len(state_dict)} 个张量")
+
+ # 显示前几个参数的键名
+ keys = list(state_dict.keys())[:5]
+ print(f" 🔑 示例参数: {', '.join(keys)}")
+ if len(state_dict) > 5:
+ print(f" ... 还有 {len(state_dict) - 5} 个参数")
+
+ except Exception as e:
+ print(f"❌ 检查失败: {e}")
+
+def main():
+ # 设置路径
+ script_dir = Path(__file__).parent.absolute()
+ base_dir = script_dir.parent
+ extracted_dir = base_dir / "models" / "extracted_components"
+
+ print("🔍 检查提取的组件信息")
+ print("=" * 50)
+
+ # 检查各个组件文件
+ components = [
+ "waiNSFWIllustrious_v140_vae.safetensors",
+ "waiNSFWIllustrious_v140_unet.safetensors"
+ ]
+
+ for component in components:
+ file_path = extracted_dir / component
+ check_component_info(file_path)
+
+ print(f"\n📂 检查目录: {extracted_dir}")
+
+ # 检查配置文件
+ config_files = [
+ "waiNSFWIllustrious_v140_vae_config.json",
+ "waiNSFWIllustrious_v140_unet_config.json"
+ ]
+
+ print(f"\n📋 配置文件:")
+ for config_file in config_files:
+ config_path = extracted_dir / config_file
+ if config_path.exists():
+ print(f" ✅ {config_file}")
+ else:
+ print(f" ❌ {config_file} (缺失)")
+
+if __name__ == "__main__":
+ main()
diff --git a/prepare_tool/extract_componet/extract_vae_unet.py b/prepare_tool/extract_componet/extract_vae_unet.py
new file mode 100644
index 0000000000000000000000000000000000000000..6461733cac2dcfceff2e5c482d767693e3a85c14
--- /dev/null
+++ b/prepare_tool/extract_componet/extract_vae_unet.py
@@ -0,0 +1,196 @@
+#!/usr/bin/env python3
+"""
+脚本:从整体的Stable Diffusion XL权重文件中提取VAE和UNet组件并单独保存
+
+功能:
+1. 使用StableDiffusionXLPipeline.from_single_file加载完整模型
+2. 提取VAE和UNet组件
+3. 将它们保存为独立的safetensors文件
+
+作者:Assistant
+日期:2025年7月16日
+"""
+
+import os
+import sys
+import argparse
+from pathlib import Path
+
+import torch
+from safetensors.torch import save_file
+
+# 添加diffusers到Python路径
+script_dir = Path(__file__).parent.absolute()
+diffusers_src = script_dir.parent / "diffusers" / "src"
+sys.path.insert(0, str(diffusers_src))
+
+from diffusers import StableDiffusionXLPipeline
+
+
+def extract_and_save_components(model_path: str, output_dir: str = None):
+ """
+ 从完整的SDXL模型文件中提取VAE和UNet组件并保存
+
+ Args:
+ model_path (str): 输入的safetensors模型文件路径
+ output_dir (str): 输出目录,默认为模型文件所在目录
+ """
+ model_path = Path(model_path)
+ if not model_path.exists():
+ raise FileNotFoundError(f"模型文件不存在: {model_path}")
+
+ if output_dir is None:
+ output_dir = model_path.parent
+ else:
+ output_dir = Path(output_dir)
+
+ output_dir.mkdir(parents=True, exist_ok=True)
+
+ print(f"正在加载模型: {model_path}")
+ print("这可能需要一些时间...")
+
+ # 使用from_single_file加载完整的pipeline
+ # 设置torch_dtype为float16以节省内存
+ try:
+ pipeline = StableDiffusionXLPipeline.from_single_file(
+ str(model_path),
+ torch_dtype=torch.float16,
+ use_safetensors=True,
+ )
+ print("✓ 模型加载成功!")
+ except Exception as e:
+ print(f"✗ 模型加载失败: {e}")
+ return False
+
+ # 提取VAE组件
+ print("\n正在提取VAE组件...")
+ try:
+ vae = pipeline.vae
+ vae_state_dict = vae.state_dict()
+
+ # 转换为CPU并保持原始精度
+ vae_state_dict_cpu = {k: v.cpu() for k, v in vae_state_dict.items()}
+
+ vae_output_path = output_dir / f"{model_path.stem}_vae.safetensors"
+ save_file(vae_state_dict_cpu, str(vae_output_path))
+ print(f"✓ VAE已保存到: {vae_output_path}")
+
+ # 保存VAE配置
+ vae_config_path = output_dir / f"{model_path.stem}_vae_config.json"
+ import json
+ with open(vae_config_path, 'w', encoding='utf-8') as f:
+ json.dump(vae.config, f, indent=2, ensure_ascii=False)
+ print(f"✓ VAE配置已保存到: {vae_config_path}")
+
+ except Exception as e:
+ print(f"✗ VAE提取失败: {e}")
+ return False
+
+ # 提取UNet组件
+ print("\n正在提取UNet组件...")
+ try:
+ unet = pipeline.unet
+ unet_state_dict = unet.state_dict()
+
+ # 转换为CPU并保持原始精度
+ unet_state_dict_cpu = {k: v.cpu() for k, v in unet_state_dict.items()}
+
+ unet_output_path = output_dir / f"{model_path.stem}_unet.safetensors"
+ save_file(unet_state_dict_cpu, str(unet_output_path))
+ print(f"✓ UNet已保存到: {unet_output_path}")
+
+ # 保存UNet配置
+ unet_config_path = output_dir / f"{model_path.stem}_unet_config.json"
+ import json
+ with open(unet_config_path, 'w', encoding='utf-8') as f:
+ json.dump(unet.config, f, indent=2, ensure_ascii=False)
+ print(f"✓ UNet配置已保存到: {unet_config_path}")
+
+ except Exception as e:
+ print(f"✗ UNet提取失败: {e}")
+ return False
+
+ # 清理内存
+ del pipeline
+ torch.cuda.empty_cache() if torch.cuda.is_available() else None
+
+ print(f"\n🎉 提取完成! 文件已保存到: {output_dir}")
+ print("\n生成的文件:")
+ print(f" - {model_path.stem}_vae.safetensors")
+ print(f" - {model_path.stem}_vae_config.json")
+ print(f" - {model_path.stem}_unet.safetensors")
+ print(f" - {model_path.stem}_unet_config.json")
+
+ return True
+
+
+def print_model_info(model_path: str):
+ """
+ 打印模型文件的基本信息
+ """
+ model_path = Path(model_path)
+ if not model_path.exists():
+ print(f"模型文件不存在: {model_path}")
+ return
+
+ file_size = model_path.stat().st_size
+ size_gb = file_size / (1024**3)
+
+ print(f"模型文件信息:")
+ print(f" 路径: {model_path}")
+ print(f" 大小: {size_gb:.2f} GB")
+ print(f" 格式: {model_path.suffix}")
+
+
+def main():
+ parser = argparse.ArgumentParser(
+ description="从Stable Diffusion XL模型文件中提取VAE和UNet组件",
+ formatter_class=argparse.RawDescriptionHelpFormatter,
+ epilog="""
+示例用法:
+ python extract_vae_unet.py ../models/waiNSFWIllustrious_v140.safetensors
+ python extract_vae_unet.py ../models/waiNSFWIllustrious_v140.safetensors --output-dir ./extracted_components
+ python extract_vae_unet.py ../models/waiNSFWIllustrious_v140.safetensors --info-only
+ """
+ )
+
+ parser.add_argument(
+ "model_path",
+ help="输入的safetensors模型文件路径"
+ )
+
+ parser.add_argument(
+ "--output-dir", "-o",
+ help="输出目录 (默认为模型文件所在目录)"
+ )
+
+ parser.add_argument(
+ "--info-only",
+ action="store_true",
+ help="仅显示模型信息,不进行提取"
+ )
+
+ args = parser.parse_args()
+
+ # 显示模型信息
+ print_model_info(args.model_path)
+
+ if args.info_only:
+ return
+
+ print("\n" + "="*60)
+ print("开始提取VAE和UNet组件...")
+ print("="*60)
+
+ # 执行提取
+ success = extract_and_save_components(args.model_path, args.output_dir)
+
+ if success:
+ print("\n✅ 所有组件提取成功!")
+ else:
+ print("\n❌ 提取过程中出现错误!")
+ sys.exit(1)
+
+
+if __name__ == "__main__":
+ main()
diff --git a/prepare_tool/extract_componet/extract_wai_components.py b/prepare_tool/extract_componet/extract_wai_components.py
new file mode 100644
index 0000000000000000000000000000000000000000..a116a5b92f441a273f09a3f3dc1d58cd261bd7a9
--- /dev/null
+++ b/prepare_tool/extract_componet/extract_wai_components.py
@@ -0,0 +1,123 @@
+#!/usr/bin/env python3
+"""
+专用脚本:提取waiNSFWIllustrious_v140.safetensors的VAE和UNet组件
+
+这 unet_state_dict = {k: v.cpu() for k, v in unet.state_dict().items()}一个针对特定模型的简化版本的提取脚本。
+"""
+
+import os
+import sys
+from pathlib import Path
+
+import torch
+from safetensors.torch import save_file
+import json
+
+# 添加diffusers到Python路径
+script_dir = Path(__file__).parent.absolute()
+diffusers_src = script_dir.parent / "diffusers" / "src"
+sys.path.insert(0, str(diffusers_src))
+
+from diffusers import StableDiffusionXLPipeline
+
+
+def main():
+ # 设置路径
+ base_dir = script_dir.parent
+ model_path = base_dir / "models" / "waiNSFWIllustrious_v140.safetensors"
+ output_dir = base_dir / "models" / "extracted_components"
+
+ # 检查模型文件
+ if not model_path.exists():
+ print(f"❌ 模型文件不存在: {model_path}")
+ return
+
+ print(f"📁 模型文件: {model_path}")
+ print(f"📂 输出目录: {output_dir}")
+
+ # 创建输出目录
+ output_dir.mkdir(parents=True, exist_ok=True)
+
+ print("\n🔄 正在加载Stable Diffusion XL模型...")
+ print(" 这可能需要几分钟时间,请耐心等待...")
+
+ try:
+ # 加载pipeline
+ pipeline = StableDiffusionXLPipeline.from_single_file(
+ str(model_path),
+ torch_dtype=torch.float16,
+ use_safetensors=True,
+ )
+ print("✅ 模型加载成功!")
+ except Exception as e:
+ print(f"❌ 模型加载失败: {e}")
+ return
+
+ # 提取和保存VAE
+ print("\n🎨 正在提取VAE (变分自编码器)...")
+ try:
+ vae = pipeline.vae
+ vae_state_dict = {k: v.cpu() for k, v in vae.state_dict().items()}
+
+ vae_path = output_dir / "waiNSFWIllustrious_v140_vae.safetensors"
+ save_file(vae_state_dict, str(vae_path))
+ print(f"✅ VAE已保存: {vae_path}")
+
+ # 保存VAE配置
+ vae_config_path = output_dir / "waiNSFWIllustrious_v140_vae_config.json"
+ with open(vae_config_path, 'w', encoding='utf-8') as f:
+ json.dump(vae.config, f, indent=2, ensure_ascii=False)
+ print(f"✅ VAE配置已保存: {vae_config_path}")
+
+ # 显示VAE信息
+ total_params = sum(p.numel() for p in vae.parameters())
+ print(f" 📊 VAE参数数量: {total_params:,}")
+
+ except Exception as e:
+ print(f"❌ VAE提取失败: {e}")
+ return
+
+ # 提取和保存UNet
+ print("\n🧠 正在提取UNet (去噪神经网络)...")
+ try:
+ unet = pipeline.unet
+ unet_state_dict = {k: v.cpu() for k, v in unet.state_dict().items()}
+
+ unet_path = output_dir / "waiNSFWIllustrious_v140_unet.safetensors"
+ save_file(unet_state_dict, str(unet_path))
+ print(f"✅ UNet已保存: {unet_path}")
+
+ # 保存UNet配置
+ unet_config_path = output_dir / "waiNSFWIllustrious_v140_unet_config.json"
+ with open(unet_config_path, 'w', encoding='utf-8') as f:
+ json.dump(unet.config, f, indent=2, ensure_ascii=False)
+ print(f"✅ UNet配置已保存: {unet_config_path}")
+
+ # 显示UNet信息
+ total_params = sum(p.numel() for p in unet.parameters())
+ print(f" 📊 UNet参数数量: {total_params:,}")
+
+ except Exception as e:
+ print(f"❌ UNet提取失败: {e}")
+ return
+
+ # 清理内存
+ del pipeline, vae, unet
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+
+ print("\n🎉 提取完成! 生成的文件:")
+ print(f" 📄 waiNSFWIllustrious_v140_vae.safetensors")
+ print(f" 📄 waiNSFWIllustrious_v140_vae_config.json")
+ print(f" 📄 waiNSFWIllustrious_v140_unet.safetensors")
+ print(f" 📄 waiNSFWIllustrious_v140_unet_config.json")
+
+ print(f"\n📂 所有文件保存在: {output_dir}")
+ print("\n💡 使用提示:")
+ print(" - VAE用于在像素空间和潜在空间之间转换")
+ print(" - UNet用于在潜在空间中进行去噪")
+ print(" - 配置文件包含了模型的架构参数")
+
+
+if __name__ == "__main__":
+ main()
diff --git a/prepare_tool/prompt_augmentation/README.md b/prepare_tool/prompt_augmentation/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/prepare_tool/prompt_augmentation/augment_prompts.py b/prepare_tool/prompt_augmentation/augment_prompts.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/prepare_tool/prompt_augmentation/run.sh b/prepare_tool/prompt_augmentation/run.sh
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/prepare_tool/prompt_augmentation/test_augmentation.py b/prepare_tool/prompt_augmentation/test_augmentation.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/templates/adding_a_missing_tokenization_test/README.md b/transformers/templates/adding_a_missing_tokenization_test/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..935f21c5ca8ab22d043bdee76041c279baf58866
--- /dev/null
+++ b/transformers/templates/adding_a_missing_tokenization_test/README.md
@@ -0,0 +1,39 @@
+
+
+This folder contains a template to add a tokenization test.
+
+## Usage
+
+Using the `cookiecutter` utility requires to have all the `dev` dependencies installed.
+
+Let's first [fork](https://docs.github.com/en/get-started/quickstart/fork-a-repo) the `transformers` repo on github. Once it's done you can clone your fork and install `transformers` in our environment:
+
+```shell script
+git clone https://github.com/YOUR-USERNAME/transformers
+cd transformers
+pip install -e ".[dev]"
+```
+
+Once the installation is done, you can generate the template by running the following command. Be careful, the template will be generated inside a new folder in your current working directory.
+
+```shell script
+cookiecutter path-to-the folder/adding_a_missing_tokenization_test/
+```
+
+You will then have to answer some questions about the tokenizer for which you want to add tests. The `modelname` should be cased according to the plain text casing, i.e., BERT, RoBERTa, DeBERTa.
+
+Once the command has finished, you should have a one new file inside the newly created folder named `test_tokenization_Xxx.py`. At this point the template is finished and you can move it to the sub-folder of the corresponding model in the test folder.
diff --git a/transformers/templates/adding_a_missing_tokenization_test/cookiecutter-template-{{cookiecutter.modelname}}/test_tokenization_{{cookiecutter.lowercase_modelname}}.py b/transformers/templates/adding_a_missing_tokenization_test/cookiecutter-template-{{cookiecutter.modelname}}/test_tokenization_{{cookiecutter.lowercase_modelname}}.py
new file mode 100644
index 0000000000000000000000000000000000000000..6cbe8bd481ac55b00468928eca2dba87cbeac319
--- /dev/null
+++ b/transformers/templates/adding_a_missing_tokenization_test/cookiecutter-template-{{cookiecutter.modelname}}/test_tokenization_{{cookiecutter.lowercase_modelname}}.py
@@ -0,0 +1,78 @@
+# coding=utf-8
+# Copyright 2022 {{cookiecutter.authors}}. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+""" Testing suite for the {{cookiecutter.modelname}} tokenizer. """
+
+
+import unittest
+
+{% if cookiecutter.has_slow_class == "True" and cookiecutter.has_fast_class == "True" -%}
+from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer, {{cookiecutter.camelcase_modelname}}TokenizerFast
+{% elif cookiecutter.has_slow_class == "True" -%}
+from transformers import {{cookiecutter.camelcase_modelname}}Tokenizer
+{% elif cookiecutter.has_fast_class == "True" -%}
+from transformers import {{cookiecutter.camelcase_modelname}}TokenizerFast
+{% endif -%}
+{% if cookiecutter.has_fast_class == "True" and cookiecutter.slow_tokenizer_use_sentencepiece == "True" -%}
+from transformers.testing_utils import require_sentencepiece, require_tokenizers
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+@require_sentencepiece
+@require_tokenizers
+{% elif cookiecutter.slow_tokenizer_use_sentencepiece == "True" -%}
+from transformers.testing_utils import require_sentencepiece
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+@require_sentencepiece
+{% elif cookiecutter.has_fast_class == "True" -%}
+from transformers.testing_utils import require_tokenizers
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+@require_tokenizers
+{% else -%}
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+{% endif -%}
+class {{cookiecutter.camelcase_modelname}}TokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ {% if cookiecutter.has_slow_class == "True" -%}
+ tokenizer_class = {{cookiecutter.camelcase_modelname}}Tokenizer
+ test_slow_tokenizer = True
+ {% else -%}
+ tokenizer_class = None
+ test_slow_tokenizer = False
+ {% endif -%}
+ {% if cookiecutter.has_fast_class == "True" -%}
+ rust_tokenizer_class = {{cookiecutter.camelcase_modelname}}TokenizerFast
+ test_rust_tokenizer = True
+ {% else -%}
+ rust_tokenizer_class = None
+ test_rust_tokenizer = False
+ {% endif -%}
+ {% if cookiecutter.slow_tokenizer_use_sentencepiece == "True" -%}
+ test_sentencepiece = True
+ {% endif -%}
+ # TODO: Check in `TokenizerTesterMixin` if other attributes need to be changed
+ def setUp(self):
+ super().setUp()
+
+ raise NotImplementedError(
+ "Here you have to implement the saving of a toy tokenizer in "
+ "`self.tmpdirname`."
+ )
+
+ # TODO: add tests with hard-coded target values
diff --git a/transformers/templates/adding_a_missing_tokenization_test/cookiecutter.json b/transformers/templates/adding_a_missing_tokenization_test/cookiecutter.json
new file mode 100644
index 0000000000000000000000000000000000000000..2e53818f9bb65842172365b7a6d9a9ec982f4390
--- /dev/null
+++ b/transformers/templates/adding_a_missing_tokenization_test/cookiecutter.json
@@ -0,0 +1,10 @@
+{
+ "modelname": "BrandNewBERT",
+ "uppercase_modelname": "BRAND_NEW_BERT",
+ "lowercase_modelname": "brand_new_bert",
+ "camelcase_modelname": "BrandNewBert",
+ "has_slow_class": ["True", "False"],
+ "has_fast_class": ["True", "False"],
+ "slow_tokenizer_use_sentencepiece": ["True", "False"],
+ "authors": "The HuggingFace Team"
+}
diff --git a/transformers/templates/adding_a_new_example_script/README.md b/transformers/templates/adding_a_new_example_script/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..87aa385aec209dc07b08f2e26fe3aa6923e97d07
--- /dev/null
+++ b/transformers/templates/adding_a_new_example_script/README.md
@@ -0,0 +1,38 @@
+
+
+# How to add a new example script in 🤗 Transformers
+
+This folder provide a template for adding a new example script implementing a training or inference task with the
+models in the 🤗 Transformers library. To use it, you will need to install cookiecutter:
+```bash
+pip install cookiecutter
+```
+or refer to the installation page of the [cookiecutter documentation](https://cookiecutter.readthedocs.io/).
+
+You can then run the following command inside the `examples` folder of the transformers repo:
+```bash
+cookiecutter ../templates/adding_a_new_example_script/
+```
+and answer the questions asked, which will generate a new folder where you will find a pre-filled template for your
+example following the best practices we recommend for them.
+
+Adjust the way the data is preprocessed, the model is loaded or the Trainer is instantiated then when you're happy, add
+a `README.md` in the folder (or complete the existing one if you added a script to an existing folder) telling a user
+how to run your script.
+
+Make a PR to the 🤗 Transformers repo. Don't forget to tweet about your new example with a carbon screenshot of how to
+run it and tag @huggingface!
diff --git a/transformers/templates/adding_a_new_example_script/cookiecutter.json b/transformers/templates/adding_a_new_example_script/cookiecutter.json
new file mode 100644
index 0000000000000000000000000000000000000000..dd8dfdae3f2c35f3ed2ecf0a1f05fe256306842a
--- /dev/null
+++ b/transformers/templates/adding_a_new_example_script/cookiecutter.json
@@ -0,0 +1,9 @@
+{
+ "example_name": "text classification",
+ "directory_name": "{{cookiecutter.example_name|lower|replace(' ', '-')}}",
+ "example_shortcut": "{{cookiecutter.directory_name}}",
+ "model_class": "AutoModel",
+ "authors": "The HuggingFace Team",
+ "can_train_from_scratch": ["True", "False"],
+ "with_trainer": ["True", "False"]
+}
\ No newline at end of file
diff --git a/transformers/templates/adding_a_new_example_script/{{cookiecutter.directory_name}}/run_{{cookiecutter.example_shortcut}}.py b/transformers/templates/adding_a_new_example_script/{{cookiecutter.directory_name}}/run_{{cookiecutter.example_shortcut}}.py
new file mode 100644
index 0000000000000000000000000000000000000000..83916cc58736df837e2b413e9187cf9f19634cae
--- /dev/null
+++ b/transformers/templates/adding_a_new_example_script/{{cookiecutter.directory_name}}/run_{{cookiecutter.example_shortcut}}.py
@@ -0,0 +1,945 @@
+#!/usr/bin/env python
+# coding=utf-8
+# Copyright 2022 {{cookiecutter.authors}} and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""
+Fine-tuning a 🤗 Transformers model on {{cookiecutter.example_name}}.
+"""
+# You can also adapt this script on your own {{cookiecutter.example_name}} task. Pointers for this are left as comments.
+
+{%- if cookiecutter.with_trainer == "True" %}
+
+import logging
+import math
+import os
+import sys
+from dataclasses import dataclass, field
+from typing import Optional, List
+
+import datasets
+import torch
+from datasets import load_dataset
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ MODEL_MAPPING,
+ AutoConfig,
+ {{cookiecutter.model_class}},
+ AutoTokenizer,
+ DataCollatorWithPadding,
+ HfArgumentParser,
+ Trainer,
+ TrainingArguments,
+ default_data_collator,
+ set_seed,
+)
+from transformers.trainer_utils import get_last_checkpoint
+from transformers.utils import send_example_telemetry
+
+
+logger = logging.getLogger(__name__)
+
+
+{%- if cookiecutter.can_train_from_scratch == "True" %}
+# You should update this to your particular problem to have better documentation of `model_type`
+MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+
+
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
+ """
+
+ model_name_or_path: Optional[str] = field(
+ default=None,
+ metadata={
+ "help": "The model checkpoint for weights initialization. "
+ "Don't set if you want to train a model from scratch."
+ },
+ )
+ model_type: Optional[str] = field(
+ default=None,
+ metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"}
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+{%- elif cookiecutter.can_train_from_scratch == "False" %}
+@dataclass
+class ModelArguments:
+ """
+ Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
+ """
+
+ model_name_or_path: str = field(
+ metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
+ )
+ config_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
+ )
+ tokenizer_name: Optional[str] = field(
+ default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
+ )
+ cache_dir: Optional[str] = field(
+ default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"}
+ )
+ use_fast_tokenizer: bool = field(
+ default=True,
+ metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
+ )
+ model_revision: str = field(
+ default="main",
+ metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
+ )
+ token: str = field(
+ default=None,
+ metadata={
+ "help": (
+ "The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
+ "generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
+ )
+ },
+ )
+ trust_remote_code: bool = field(
+ default=False,
+ metadata={
+ "help": (
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ )
+ },
+ )
+{% endif %}
+
+
+@dataclass
+class DataTrainingArguments:
+ """
+ Arguments pertaining to what data we are going to input our model for training and eval.
+ """
+
+ dataset_name: Optional[str] = field(
+ default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
+ )
+ dataset_config_name: Optional[str] = field(
+ default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
+ )
+ train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
+ validation_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
+ )
+ test_file: Optional[str] = field(
+ default=None,
+ metadata={"help": "An optional input test data file to predict the label on (a text file)."},
+ )
+ overwrite_cache: bool = field(
+ default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
+ )
+ preprocessing_num_workers: Optional[int] = field(
+ default=None,
+ metadata={"help": "The number of processes to use for the preprocessing."},
+ )
+ max_train_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "For debugging purposes or quicker training, truncate the number of training examples to this "
+ "value if set."
+ },
+ )
+ max_eval_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "For debugging purposes or quicker training, truncate the number of evaluation examples to this "
+ "value if set."
+ },
+ )
+ max_predict_samples: Optional[int] = field(
+ default=None,
+ metadata={
+ "help": "For debugging purposes or quicker training, truncate the number of prediction examples to this "
+ "value if set."
+ },
+ )
+
+ def __post_init__(self):
+ if (
+ self.dataset_name is None
+ and self.train_file is None
+ and self.validation_file is None
+ and self.test_file is None
+ ):
+ raise ValueError("Need either a dataset name or a training/validation/test file.")
+ else:
+ if self.train_file is not None:
+ extension = self.train_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`train_file` should be a csv, a json or a txt file."
+ if self.validation_file is not None:
+ extension = self.validation_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`validation_file` should be a csv, a json or a txt file."
+ if self.test_file is not None:
+ extension = self.test_file.split(".")[-1]
+ assert extension in ["csv", "json", "txt"], "`test_file` should be a csv, a json or a txt file."
+
+
+def main():
+ # See all possible arguments in src/transformers/training_args.py
+ # or by passing the --help flag to this script.
+ # We now keep distinct sets of args, for a cleaner separation of concerns.
+
+ parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
+ if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
+ # If we pass only one argument to the script and it's the path to a json file,
+ # let's parse it to get our arguments.
+ model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
+ else:
+ model_args, data_args, training_args = parser.parse_args_into_dataclasses()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_{{cookiecutter.example_shortcut}}", model_args, data_args)
+
+ # Detecting last checkpoint.
+ last_checkpoint = None
+ if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
+ last_checkpoint = get_last_checkpoint(training_args.output_dir)
+ if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
+ raise ValueError(
+ f"Output directory ({training_args.output_dir}) already exists and is not empty. "
+ "Use --overwrite_output_dir to overcome."
+ )
+ elif last_checkpoint is not None:
+ logger.info(
+ f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
+ "the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
+ )
+
+ # Setup logging
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ handlers=[logging.StreamHandler(sys.stdout)],
+ )
+
+ log_level = training_args.get_process_log_level()
+ logger.setLevel(log_level)
+ datasets.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.set_verbosity(log_level)
+ transformers.utils.logging.enable_default_handler()
+ transformers.utils.logging.enable_explicit_format()
+
+ # Log on each process the small summary:
+ logger.warning(
+ f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ + f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
+ )
+ logger.info(f"Training/evaluation parameters {training_args}")
+
+ # Set seed before initializing model.
+ set_seed(training_args.seed)
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if data_args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ data_args.dataset_name,
+ data_args.dataset_config_name,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ data_files = {}
+ if data_args.train_file is not None:
+ data_files["train"] = data_args.train_file
+ extension = data_args.train_file.split(".")[-1]
+ if data_args.validation_file is not None:
+ data_files["validation"] = data_args.validation_file
+ extension = data_args.validation_file.split(".")[-1]
+ if data_args.test_file is not None:
+ data_files["test"] = data_args.test_file
+ extension = data_args.test_file.split(".")[-1]
+ if extension == "txt":
+ extension = "text"
+ raw_datasets = load_dataset(extension, data_files=data_files)
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+ #
+ # Distributed training:
+ # The .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+{%- if cookiecutter.can_train_from_scratch == "True" %}
+ config_kwargs = {
+ "cache_dir": model_args.cache_dir,
+ "revision": model_args.model_revision,
+ "token": model_args.token,
+ "trust_remote_code": model_args.trust_remote_code,
+ }
+ if model_args.config_name:
+ config = AutoConfig.from_pretrained(model_args.config_name, **config_kwargs)
+ elif model_args.model_name_or_path:
+ config = AutoConfig.from_pretrained(model_args.model_name_or_path, **config_kwargs)
+ else:
+ config = CONFIG_MAPPING[model_args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ tokenizer_kwargs = {
+ "cache_dir": model_args.cache_dir,
+ "use_fast": model_args.use_fast_tokenizer,
+ "revision": model_args.model_revision,
+ "token": model_args.token,
+ "trust_remote_code": model_args.trust_remote_code,
+ }
+ if model_args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, **tokenizer_kwargs)
+ elif model_args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, **tokenizer_kwargs)
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if model_args.model_name_or_path:
+ model = {{cookiecutter.model_class}}.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = {{cookiecutter.model_class}}.from_config(config)
+
+ model.resize_token_embeddings(len(tokenizer))
+{%- elif cookiecutter.can_train_from_scratch == "False" %}
+ config = AutoConfig.from_pretrained(
+ model_args.config_name if model_args.config_name else model_args.model_name_or_path,
+ # num_labels=num_labels, Uncomment if you have a certain number of labels
+ finetuning_task=data_args.task_name,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
+ cache_dir=model_args.cache_dir,
+ use_fast=model_args.use_fast_tokenizer,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+ model = AutoModelForSequenceClassification.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ cache_dir=model_args.cache_dir,
+ revision=model_args.model_revision,
+ token=model_args.token,
+ trust_remote_code=model_args.trust_remote_code,
+ )
+{% endif %}
+
+ # Preprocessing the datasets.
+ # First we tokenize all the texts.
+ if training_args.do_train:
+ column_names = raw_datasets["train"].column_names
+ elif training_args.do_eval:
+ column_names = raw_datasets["validation"].column_names
+ elif training_args.do_predict:
+ column_names = raw_datasets["test"].column_names
+ text_column_name = "text" if "text" in column_names else column_names[0]
+
+ def tokenize_function(examples):
+ return tokenizer(examples[text_column_name], padding="max_length", truncation=True)
+
+ if training_args.do_train:
+ if "train" not in raw_datasets:
+ raise ValueError("--do_train requires a train dataset")
+ train_dataset = raw_datasets["train"]
+ if data_args.max_train_samples is not None:
+ # Select Sample from Dataset
+ train_dataset = train_dataset.select(range(data_args.max_train_samples))
+ # tokenize train dataset in batch
+ with training_args.main_process_first(desc="train dataset map tokenization"):
+ train_dataset = train_dataset.map(
+ tokenize_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=[text_column_name],
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ if training_args.do_eval:
+ if "validation" not in raw_datasets:
+ raise ValueError("--do_eval requires a validation dataset")
+ eval_dataset = raw_datasets["validation"]
+ # Selecting samples from dataset
+ if data_args.max_eval_samples is not None:
+ eval_dataset = eval_dataset.select(range(data_args.max_eval_samples))
+ # tokenize validation dataset
+ with training_args.main_process_first(desc="validation dataset map tokenization"):
+ eval_dataset = eval_dataset.map(
+ tokenize_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=[text_column_name],
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ if training_args.do_predict:
+ if "test" not in raw_datasets:
+ raise ValueError("--do_predict requires a test dataset")
+ predict_dataset = raw_datasets["test"]
+ # Selecting samples from dataset
+ if data_args.max_predict_samples is not None:
+ predict_dataset = predict_dataset.select(range(data_args.max_predict_samples))
+ # tokenize predict dataset
+ with training_args.main_process_first(desc="prediction dataset map tokenization"):
+ predict_dataset = predict_dataset.map(
+ tokenize_function,
+ batched=True,
+ num_proc=data_args.preprocessing_num_workers,
+ remove_columns=[text_column_name],
+ load_from_cache_file=not data_args.overwrite_cache,
+ )
+
+ # Data collator
+ data_collator=default_data_collator if not training_args.fp16 else DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8)
+
+ # Initialize our Trainer
+ trainer = Trainer(
+ model=model,
+ args=training_args,
+ train_dataset=train_dataset if training_args.do_train else None,
+ eval_dataset=eval_dataset if training_args.do_eval else None,
+ processing_class=tokenizer,
+ data_collator=data_collator,
+ )
+
+ # Training
+ if training_args.do_train:
+{%- if cookiecutter.can_train_from_scratch == "False" %}
+ if last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ elif os.path.isdir(model_args.model_name_or_path):
+ checkpoint = model_args.model_name_or_path
+ else:
+ checkpoint = None
+{%- elif cookiecutter.can_train_from_scratch == "True" %}
+ if last_checkpoint is not None:
+ checkpoint = last_checkpoint
+ elif model_args.model_name_or_path is not None and os.path.isdir(model_args.model_name_or_path):
+ checkpoint = model_args.model_name_or_path
+ else:
+ checkpoint = None
+{% endif %}
+ train_result = trainer.train(resume_from_checkpoint=checkpoint)
+ trainer.save_model() # Saves the tokenizer too for easy upload
+
+ metrics = train_result.metrics
+ max_train_samples = (
+ data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
+ )
+ metrics["train_samples"] = min(max_train_samples, len(train_dataset))
+
+ trainer.log_metrics("train", metrics)
+ trainer.save_metrics("train", metrics)
+ trainer.save_state()
+
+ # Evaluation
+ if training_args.do_eval:
+ logger.info("*** Evaluate ***")
+
+ metrics = trainer.evaluate()
+
+ max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
+ metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
+
+ trainer.log_metrics("eval", metrics)
+ trainer.save_metrics("eval", metrics)
+
+ # Prediction
+ if training_args.do_predict:
+ logger.info("*** Predict ***")
+ predictions, labels, metrics = trainer.predict(predict_dataset)
+
+ max_predict_samples = data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
+ metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
+
+ trainer.log_metrics("predict", metrics)
+ trainer.save_metrics("predict", metrics)
+
+ # write custom code for saving predictions according to task
+
+def _mp_fn(index):
+ # For xla_spawn (TPUs)
+ main()
+
+
+if __name__ == "__main__":
+ main()
+
+{%- elif cookiecutter.with_trainer == "False" %}
+
+import argparse
+import logging
+import math
+import os
+import random
+
+import datasets
+from datasets import load_dataset, load_metric
+from torch.utils.data import DataLoader
+from tqdm.auto import tqdm
+
+import transformers
+from accelerate import Accelerator
+from transformers import (
+ CONFIG_MAPPING,
+ MODEL_MAPPING,
+ AutoConfig,
+ {{cookiecutter.model_class}},
+ AutoTokenizer,
+ DataCollatorWithPadding,
+ PretrainedConfig,
+ SchedulerType,
+ default_data_collator,
+ get_scheduler,
+ set_seed,
+)
+from transformers.utils import send_example_telemetry
+
+
+logger = logging.getLogger(__name__)
+
+
+{%- if cookiecutter.can_train_from_scratch == "True" %}
+# You should update this to your particular problem to have better documentation of `model_type`
+MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
+MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
+{% endif %}
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Finetune a transformers model on a text classification task")
+ parser.add_argument(
+ "--dataset_name",
+ type=str,
+ default=None,
+ help="The name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--dataset_config_name",
+ type=str,
+ default=None,
+ help= "The configuration name of the dataset to use (via the datasets library).",
+ )
+ parser.add_argument(
+ "--trust_remote_code",
+ action="store_true",
+ help=(
+ "Whether to trust the execution of code from datasets/models defined on the Hub."
+ " This option should only be set to `True` for repositories you trust and in which you have read the"
+ " code, as it will execute code present on the Hub on your local machine."
+ ),
+ )
+ parser.add_argument(
+ "--train_file", type=str, default=None, help="A csv or a json file containing the training data."
+ )
+ parser.add_argument(
+ "--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
+ )
+ parser.add_argument(
+ "--max_length",
+ type=int,
+ default=128,
+ help=(
+ "The maximum total input sequence length after tokenization. Sequences longer than this will be truncated,"
+ " sequences shorter will be padded if `--pad_to_max_length` is passed."
+ ),
+ )
+ parser.add_argument(
+ "--pad_to_max_length",
+ action="store_true",
+ help="If passed, pad all samples to `max_length`. Otherwise, dynamic padding is used.",
+ )
+ parser.add_argument(
+ "--model_name_or_path",
+ type=str,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ required=True,
+ )
+ parser.add_argument(
+ "--config_name",
+ type=str,
+ default=None,
+ help="Pretrained config name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--use_slow_tokenizer",
+ action="store_true",
+ help="If passed, will use a slow tokenizer (not backed by the 🤗 Tokenizers library).",
+ )
+ parser.add_argument(
+ "--per_device_train_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the training dataloader.",
+ )
+ parser.add_argument(
+ "--per_device_eval_batch_size",
+ type=int,
+ default=8,
+ help="Batch size (per device) for the evaluation dataloader.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-5,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
+ parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--lr_scheduler_type",
+ type=SchedulerType,
+ default="linear",
+ help="The scheduler type to use.",
+ choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
+ )
+ parser.add_argument(
+ "--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+{%- if cookiecutter.can_train_from_scratch == "True" %}
+ parser.add_argument(
+ "--model_type",
+ type=str,
+ default=None,
+ help="Model type to use if training from scratch.",
+ choices=MODEL_TYPES,
+ )
+{% endif %}
+ args = parser.parse_args()
+
+ # Sanity checks
+ if args.task_name is None and args.train_file is None and args.validation_file is None:
+ raise ValueError("Need either a task name or a training/validation file.")
+ else:
+ if args.train_file is not None:
+ extension = args.train_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
+ if args.validation_file is not None:
+ extension = args.validation_file.split(".")[-1]
+ assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
+
+ if args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ return args
+
+
+def main():
+ args = parse_args()
+
+ # Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
+ # information sent is the one passed as arguments along with your Python/PyTorch versions.
+ send_example_telemetry("run_{{cookiecutter.example_shortcut}", args)
+
+ # Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
+ accelerator = Accelerator()
+ # Make one log on every process with the configuration for debugging.
+ logging.basicConfig(
+ format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
+ datefmt="%m/%d/%Y %H:%M:%S",
+ level=logging.INFO,
+ )
+ logger.info(accelerator.state)
+
+ # Setup logging, we only want one process per machine to log things on the screen.
+ # accelerator.is_local_main_process is only True for one process per machine.
+ logger.setLevel(logging.INFO if accelerator.is_local_main_process else logging.ERROR)
+ if accelerator.is_local_main_process:
+ datasets.utils.logging.set_verbosity_warning()
+ transformers.utils.logging.set_verbosity_info()
+ else:
+ datasets.utils.logging.set_verbosity_error()
+ transformers.utils.logging.set_verbosity_error()
+
+ # If passed along, set the training seed now.
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ # Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
+ # or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
+ # (the dataset will be downloaded automatically from the datasets Hub).
+ #
+ # For CSV/JSON files, this script will use the column called 'text' or the first column if no column called
+ # 'text' is found. You can easily tweak this behavior (see below).
+ #
+ # In distributed training, the load_dataset function guarantee that only one local process can concurrently
+ # download the dataset.
+ if args.dataset_name is not None:
+ # Downloading and loading a dataset from the hub.
+ raw_datasets = load_dataset(
+ args.dataset_name, args.dataset_config_name, trust_remote_code=args.trust_remote_code
+ )
+ else:
+ data_files = {}
+ if args.train_file is not None:
+ data_files["train"] = args.train_file
+ extension = args.train_file.split(".")[-1]
+ if args.validation_file is not None:
+ data_files["validation"] = args.validation_file
+ extension = args.validation_file.split(".")[-1]
+ raw_datasets = load_dataset(extension, data_files=data_files)
+ # See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
+ # https://huggingface.co/docs/datasets/loading_datasets.
+
+ # Load pretrained model and tokenizer
+ #
+ # In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
+ # download model & vocab.
+{%- if cookiecutter.can_train_from_scratch == "True" %}
+ if model_args.config_name:
+ config = AutoConfig.from_pretrained(args.model_name_or_path)
+ elif model_args.model_name_or_path:
+ config = AutoConfig.from_pretrained(args.model_name_or_path)
+ else:
+ config = CONFIG_MAPPING[args.model_type]()
+ logger.warning("You are instantiating a new config instance from scratch.")
+
+ if model_args.tokenizer_name:
+ tokenizer = AutoTokenizer.from_pretrained(model_args.tokenizer_name, use_fast=not args.use_slow_tokenizer)
+ elif model_args.model_name_or_path:
+ tokenizer = AutoTokenizer.from_pretrained(model_args.model_name_or_path, use_fast=not args.use_slow_tokenizer)
+ else:
+ raise ValueError(
+ "You are instantiating a new tokenizer from scratch. This is not supported by this script. "
+ "You can do it from another script, save it, and load it from here, using --tokenizer_name."
+ )
+
+ if model_args.model_name_or_path:
+ model = {{cookiecutter.model_class}}.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ )
+ else:
+ logger.info("Training new model from scratch")
+ model = {{cookiecutter.model_class}}.from_config(config)
+
+ model.resize_token_embeddings(len(tokenizer))
+{%- elif cookiecutter.can_train_from_scratch == "False" %}
+ config = AutoConfig.from_pretrained(
+ args.config_name if model_args.config_name else args.model_name_or_path,
+ # num_labels=num_labels, Uncomment if you have a certain number of labels
+ finetuning_task=data_args.task_name,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ args.tokenizer_name if model_args.tokenizer_name else args.model_name_or_path,
+ use_fast=not args.use_slow_tokenizer,
+ )
+ model = AutoModelForSequenceClassification.from_pretrained(
+ model_args.model_name_or_path,
+ from_tf=bool(".ckpt" in model_args.model_name_or_path),
+ config=config,
+ )
+{% endif %}
+
+ # Preprocessing the datasets.
+ # First we tokenize all the texts.
+ column_names = raw_datasets["train"].column_names
+ text_column_name = "text" if "text" in column_names else column_names[0]
+
+ padding = "max_length" if args.pad_to_max_length else False
+ def tokenize_function(examples):
+ result = tokenizer(examples[text_column_name], padding=padding, max_length=args.max_length, truncation=True)
+ if "label" in examples:
+ result["labels"] = examples["label"]
+ return result
+
+ processed_datasets = raw_datasets.map(
+ preprocess_function, batched=True, remove_columns=raw_datasets["train"].column_names
+ )
+
+ train_dataset = processed_datasets["train"]
+ eval_dataset = processed_datasets["validation"]
+
+ # Log a few random samples from the training set:
+ for index in random.sample(range(len(train_dataset)), 3):
+ logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
+
+ # DataLoaders creation:
+ if args.pad_to_max_length:
+ # If padding was already done ot max length, we use the default data collator that will just convert everything
+ # to tensors.
+ data_collator = default_data_collator
+ else:
+ # Otherwise, `DataCollatorWithPadding` will apply dynamic padding for us (by padding to the maximum length of
+ # the samples passed). When using mixed precision, we add `pad_to_multiple_of=8` to pad all tensors to multiple
+ # of 8s, which will enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta).
+ # For fp8, we pad to multiple of 16.
+ if accelerator.mixed_precision == "fp8":
+ pad_to_multiple_of = 16
+ elif accelerator.mixed_precision != "no":
+ pad_to_multiple_of = 8
+ else:
+ pad_to_multiple_of = None
+ data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=pad_to_multiple_of)
+
+ train_dataloader = DataLoader(
+ train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
+ )
+ eval_dataloader = DataLoader(eval_dataset, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size)
+
+ # Optimizer
+ # Split weights in two groups, one with weight decay and the other not.
+ no_decay = ["bias", "LayerNorm.weight"]
+ optimizer_grouped_parameters = [
+ {
+ "params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
+ "weight_decay": args.weight_decay,
+ },
+ {
+ "params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
+ "weight_decay": 0.0,
+ },
+ ]
+ optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
+
+ # Prepare everything with our `accelerator`.
+ model, optimizer, train_dataloader, eval_dataloader = accelerator.prepare(
+ model, optimizer, train_dataloader, eval_dataloader
+ )
+
+ # Note -> the training dataloader needs to be prepared before we grab his length below (cause its length will be
+ # shorter in multiprocess)
+
+ # Scheduler and math around the number of training steps.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ else:
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ lr_scheduler = get_scheduler(
+ name=args.lr_scheduler_type,
+ optimizer=optimizer,
+ num_warmup_steps=args.num_warmup_steps,
+ num_training_steps=args.max_train_steps,
+ )
+
+ # TODO Get the proper metric function
+ # metric = load_metric(xxx)
+
+ # Train!
+ total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ completed_steps = 0
+
+ for epoch in range(args.num_train_epochs):
+ model.train()
+ for step, batch in enumerate(train_dataloader):
+ outputs = model(**batch)
+ loss = outputs.loss
+ loss = loss / args.gradient_accumulation_steps
+ accelerator.backward(loss)
+ if step % args.gradient_accumulation_steps == 0 or step == len(train_dataloader) - 1:
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+ progress_bar.update(1)
+ completed_steps += 1
+
+ if completed_steps >= args.max_train_steps:
+ break
+
+ model.eval()
+ for step, batch in enumerate(eval_dataloader):
+ with torch.no_grad():
+ outputs = model(**batch)
+ predictions = outputs.logits.argmax(dim=-1)
+ metric.add_batch(
+ predictions=accelerator.gather(predictions),
+ references=accelerator.gather(batch["labels"]),
+ )
+
+ eval_metric = metric.compute()
+ logger.info(f"epoch {epoch}: {eval_metric}")
+
+ if args.output_dir is not None:
+ accelerator.wait_for_everyone()
+ unwrapped_model = accelerator.unwrap_model(model)
+ unwrapped_model.save_pretrained(args.output_dir, save_function=accelerator.save)
+
+
+if __name__ == "__main__":
+ main()
+
+{% endif %}
diff --git a/transformers/templates/adding_a_new_model/ADD_NEW_MODEL_PROPOSAL_TEMPLATE.md b/transformers/templates/adding_a_new_model/ADD_NEW_MODEL_PROPOSAL_TEMPLATE.md
new file mode 100644
index 0000000000000000000000000000000000000000..dc7143465d4e52c374c663b5d1394248cf938e0c
--- /dev/null
+++ b/transformers/templates/adding_a_new_model/ADD_NEW_MODEL_PROPOSAL_TEMPLATE.md
@@ -0,0 +1,1141 @@
+**TEMPLATE**
+=====================================
+
+*search & replace the following keywords, e.g.:*
+`:%s/\[name of model\]/brand_new_bert/g`
+
+-[lowercase name of model] # e.g. brand_new_bert
+
+-[camelcase name of model] # e.g. BrandNewBert
+
+-[name of mentor] # e.g. [Peter](https://github.com/peter)
+
+-[link to original repo]
+
+-[start date]
+
+-[end date]
+
+
+
+How to add [camelcase name of model] to 🤗 Transformers?
+=====================================
+
+Mentor: [name of mentor]
+
+Begin: [start date]
+
+Estimated End: [end date]
+
+Adding a new model is often difficult and requires an in-depth knowledge
+of the 🤗 Transformers library and ideally also of the model's original
+repository. At Hugging Face, we are trying to empower the community more
+and more to add models independently.
+
+The following sections explain in detail how to add [camelcase name of model]
+to Transformers. You will work closely with [name of mentor] to
+integrate [camelcase name of model] into Transformers. By doing so, you will both gain a
+theoretical and deep practical understanding of [camelcase name of model].
+But more importantly, you will have made a major
+open-source contribution to Transformers. Along the way, you will:
+
+- get insights into open-source best practices
+- understand the design principles of one of the most popular NLP
+ libraries
+- learn how to do efficiently test large NLP models
+- learn how to integrate Python utilities like `black`, `ruff`,
+ `make fix-copies` into a library to always ensure clean and readable
+ code
+
+To start, let's try to get a general overview of the Transformers
+library.
+
+General overview of 🤗 Transformers
+----------------------------------
+
+First, you should get a general overview of 🤗 Transformers. Transformers
+is a very opinionated library, so there is a chance that
+you don't agree with some of the library's philosophies or design
+choices. From our experience, however, we found that the fundamental
+design choices and philosophies of the library are crucial to
+efficiently scale Transformers while keeping maintenance costs at a
+reasonable level.
+
+A good first starting point to better understand the library is to read
+the [documentation of our philosophy](https://huggingface.co/transformers/philosophy.html).
+As a result of our way of working, there are some choices that we try to apply to all models:
+
+- Composition is generally favored over abstraction
+- Duplicating code is not always bad if it strongly improves the
+ readability or accessibility of a model
+- Model files are as self-contained as possible so that when you read
+ the code of a specific model, you ideally only have to look into the
+ respective `modeling_....py` file.
+
+In our opinion, the library's code is not just a means to provide a
+product, *e.g.*, the ability to use BERT for inference, but also as the
+very product that we want to improve. Hence, when adding a model, the
+user is not only the person that will use your model, but also everybody
+that will read, try to understand, and possibly tweak your code.
+
+With this in mind, let's go a bit deeper into the general library
+design.
+
+### Overview of models
+
+To successfully add a model, it is important to understand the
+interaction between your model and its config,
+`PreTrainedModel`, and `PretrainedConfig`. For
+exemplary purposes, we will call the PyTorch model to be added to 🤗 Transformers
+`BrandNewBert`.
+
+Let's take a look:
+
+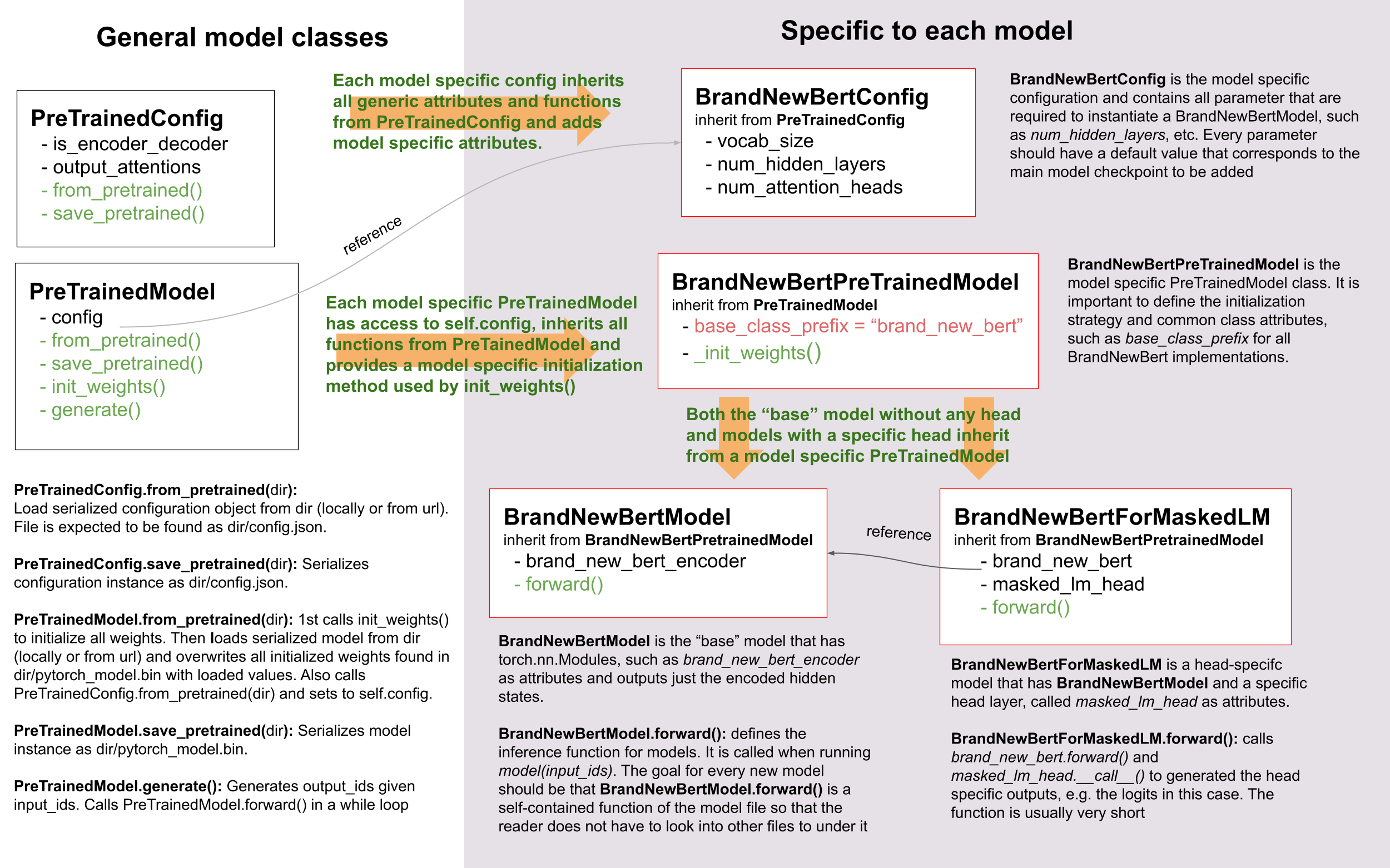
+
+As you can see, we do make use of inheritance in 🤗 Transformers, but we
+keep the level of abstraction to an absolute minimum. There are never
+more than two levels of abstraction for any model in the library.
+`BrandNewBertModel` inherits from
+`BrandNewBertPreTrainedModel` which in
+turn inherits from `PreTrainedModel` and that's it.
+As a general rule, we want to make sure
+that a new model only depends on `PreTrainedModel`. The
+important functionalities that are automatically provided to every new
+model are
+`PreTrainedModel.from_pretrained` and `PreTrainedModel.save_pretrained`, which are
+used for serialization and deserialization. All
+of the other important functionalities, such as
+`BrandNewBertModel.forward` should be
+completely defined in the new `modeling_brand_new_bert.py` module. Next,
+we want to make sure that a model with a specific head layer, such as
+`BrandNewBertForMaskedLM` does not inherit
+from `BrandNewBertModel`, but rather uses
+`BrandNewBertModel` as a component that
+can be called in its forward pass to keep the level of abstraction low.
+Every new model requires a configuration class, called
+`BrandNewBertConfig`. This configuration
+is always stored as an attribute in
+`PreTrainedModel`, and
+thus can be accessed via the `config` attribute for all classes
+inheriting from `BrandNewBertPreTrainedModel`
+
+```python
+# assuming that `brand_new_bert` belongs to the organization `brandy`
+model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
+model.config # model has access to its config
+```
+
+Similar to the model, the configuration inherits basic serialization and
+deserialization functionalities from
+`PretrainedConfig`. Note
+that the configuration and the model are always serialized into two
+different formats - the model to a `pytorch_model.bin` file
+and the configuration to a `config.json` file. Calling
+`PreTrainedModel.save_pretrained` will automatically call
+`PretrainedConfig.save_pretrained`, so that both model and configuration are saved.
+
+### Overview of tokenizers
+
+Not quite ready yet :-( This section will be added soon!
+
+Step-by-step recipe to add a model to 🤗 Transformers
+----------------------------------------------------
+
+Everyone has different preferences of how to port a model so it can be
+very helpful for you to take a look at summaries of how other
+contributors ported models to Hugging Face. Here is a list of community
+blog posts on how to port a model:
+
+1. [Porting GPT2
+ Model](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28)
+ by [Thomas](https://huggingface.co/thomwolf)
+2. [Porting WMT19 MT Model](https://huggingface.co/blog/porting-fsmt)
+ by [Stas](https://huggingface.co/stas)
+
+From experience, we can tell you that the most important things to keep
+in mind when adding a model are:
+
+- Don't reinvent the wheel! Most parts of the code you will add for
+ the new 🤗 Transformers model already exist somewhere in 🤗
+ Transformers. Take some time to find similar, already existing
+ models and tokenizers you can copy from.
+ [grep](https://www.gnu.org/software/grep/) and
+ [rg](https://github.com/BurntSushi/ripgrep) are your friends. Note
+ that it might very well happen that your model's tokenizer is based
+ on one model implementation, and your model's modeling code on
+ another one. *E.g.*, FSMT's modeling code is based on BART, while
+ FSMT's tokenizer code is based on XLM.
+- It's more of an engineering challenge than a scientific challenge.
+ You should spend more time on creating an efficient debugging
+ environment than trying to understand all theoretical aspects of the
+ model in the paper.
+- Ask for help when you're stuck! Models are the core component of 🤗
+ Transformers so we, at Hugging Face, are more than happy to help
+ you at every step to add your model. Don't hesitate to ask if you
+ notice you are not making progress.
+
+In the following, we try to give you a general recipe that we found most
+useful when porting a model to 🤗 Transformers.
+
+The following list is a summary of everything that has to be done to add
+a model and can be used by you as a To-Do List:
+
+1. [ ] (Optional) Understood theoretical aspects
+
+2. [ ] Prepared transformers dev environment
+
+3. [ ] Set up debugging environment of the original repository
+
+4. [ ] Created script that successfully runs forward pass using
+ original repository and checkpoint
+
+5. [ ] Successfully opened a PR and added the model skeleton to Transformers
+
+6. [ ] Successfully converted original checkpoint to Transformers
+ checkpoint
+
+7. [ ] Successfully ran forward pass in Transformers that gives
+ identical output to original checkpoint
+
+8. [ ] Finished model tests in Transformers
+
+9. [ ] Successfully added Tokenizer in Transformers
+
+10. [ ] Run end-to-end integration tests
+
+11. [ ] Finished docs
+
+12. [ ] Uploaded model weights to the hub
+
+13. [ ] Submitted the pull request for review
+
+14. [ ] (Optional) Added a demo notebook
+
+To begin with, we usually recommend to start by getting a good
+theoretical understanding of `[camelcase name of model]`. However, if you prefer to
+understand the theoretical aspects of the model *on-the-job*, then it is
+totally fine to directly dive into the `[camelcase name of model]`'s code-base. This
+option might suit you better, if your engineering skills are better than
+your theoretical skill, if you have trouble understanding
+`[camelcase name of model]`'s paper, or if you just enjoy programming much more than
+reading scientific papers.
+
+### 1. (Optional) Theoretical aspects of [camelcase name of model]
+
+You should take some time to read *[camelcase name of model]'s* paper, if such
+descriptive work exists. There might be large sections of the paper that
+are difficult to understand. If this is the case, this is fine - don't
+worry! The goal is not to get a deep theoretical understanding of the
+paper, but to extract the necessary information required to effectively
+re-implement the model in 🤗 Transformers. That being said, you don't
+have to spend too much time on the theoretical aspects, but rather focus
+on the practical ones, namely:
+
+- What type of model is *[camelcase name of model]*? BERT-like encoder-only
+ model? GPT2-like decoder-only model? BART-like encoder-decoder
+ model? Look at the `model_summary` if
+ you're not familiar with the differences between those.
+- What are the applications of *[camelcase name of model]*? Text
+ classification? Text generation? Seq2Seq tasks, *e.g.,*
+ summarization?
+- What is the novel feature of the model making it different from
+ BERT/GPT-2/BART?
+- Which of the already existing [🤗 Transformers
+ models](https://huggingface.co/transformers/#contents) is most
+ similar to *[camelcase name of model]*?
+- What type of tokenizer is used? A sentencepiece tokenizer? Word
+ piece tokenizer? Is it the same tokenizer as used for BERT or BART?
+
+After you feel like you have gotten a good overview of the architecture
+of the model, you might want to write to [name of mentor] with any
+questions you might have. This might include questions regarding the
+model's architecture, its attention layer, etc. We will be more than
+happy to help you.
+
+
+#### Additional resources
+
+ Before diving into the code, here are some additional resources that might be worth taking a look at:
+
+ - [link 1]
+ - [link 2]
+ - [link 3]
+ - ...
+
+#### Make sure you've understood the fundamental aspects of [camelcase name of model]
+
+Alright, now you should be ready to take a closer look into the actual code of [camelcase name of model].
+You should have understood the following aspects of [camelcase name of model] by now:
+
+- [characteristic 1 of [camelcase name of model]]
+- [characteristic 2 of [camelcase name of model]]
+- ...
+
+If any of the mentioned aspects above are **not** clear to you, now is a great time to talk to [name of mentor].
+
+### 2. Next prepare your environment
+
+1. Fork the [repository](https://github.com/huggingface/transformers)
+ by clicking on the 'Fork' button on the repository's page. This
+ creates a copy of the code under your GitHub user account.
+
+2. Clone your `transformers` fork to your local disk, and add the base
+ repository as a remote:
+
+ ```bash
+ git clone https://github.com/[your Github handle]/transformers.git
+ cd transformers
+ git remote add upstream https://github.com/huggingface/transformers.git
+ ```
+
+3. Set up a development environment, for instance by running the
+ following command:
+
+ ```bash
+ python -m venv .env
+ source .env/bin/activate
+ pip install -e ".[dev]"
+ ```
+
+and return to the parent directory
+
+```bash
+cd ..
+```
+
+4. We recommend adding the PyTorch version of *[camelcase name of model]* to
+ Transformers. To install PyTorch, please follow the instructions [here](https://pytorch.org/get-started/locally/).
+
+**Note:** You don't need to have CUDA installed. Making the new model
+work on CPU is sufficient.
+
+5. To port *[camelcase name of model]*, you will also need access to its
+ original repository:
+
+```bash
+git clone [link to original repo].git
+cd [lowercase name of model]
+pip install -e .
+```
+
+Now you have set up a development environment to port *[camelcase name of model]*
+to 🤗 Transformers.
+
+### Run a pretrained checkpoint using the original repository
+
+**3. Set up debugging environment**
+
+At first, you will work on the original *[camelcase name of model]* repository.
+Often, the original implementation is very "researchy". Meaning that
+documentation might be lacking and the code can be difficult to
+understand. But this should be exactly your motivation to reimplement
+*[camelcase name of model]*. At Hugging Face, one of our main goals is to *make
+people stand on the shoulders of giants* which translates here very well
+into taking a working model and rewriting it to make it as **accessible,
+user-friendly, and beautiful** as possible. This is the number-one
+motivation to re-implement models into 🤗 Transformers - trying to make
+complex new NLP technology accessible to **everybody**.
+
+You should start thereby by diving into the [original repository]([link to original repo]).
+
+Successfully running the official pretrained model in the original
+repository is often **the most difficult** step. From our experience, it
+is very important to spend some time getting familiar with the original
+code-base. You need to figure out the following:
+
+- Where to find the pretrained weights?
+- How to load the pretrained weights into the corresponding model?
+- How to run the tokenizer independently from the model?
+- Trace one forward pass so that you know which classes and functions
+ are required for a simple forward pass. Usually, you only have to
+ reimplement those functions.
+- Be able to locate the important components of the model: Where is
+ the model's class? Are there model sub-classes, *e.g.*,
+ EncoderModel, DecoderModel? Where is the self-attention layer? Are
+ there multiple different attention layers, *e.g.*, *self-attention*,
+ *cross-attention*...?
+- How can you debug the model in the original environment of the repo?
+ Do you have to add `print` statements, can you work with
+ an interactive debugger like [ipdb](https://pypi.org/project/ipdb/), or should you use
+ an efficient IDE to debug the model, like PyCharm?
+
+It is very important that before you start the porting process, that you
+can **efficiently** debug code in the original repository! Also,
+remember that you are working with an open-source library, so do not
+hesitate to open an issue, or even a pull request in the original
+repository. The maintainers of this repository are most likely very
+happy about someone looking into their code!
+
+At this point, it is really up to you which debugging environment and
+strategy you prefer to use to debug the original model. We strongly
+advise against setting up a costly GPU environment, but simply work on a
+CPU both when starting to dive into the original repository and also
+when starting to write the 🤗 Transformers implementation of the model.
+Only at the very end, when the model has already been successfully
+ported to 🤗 Transformers, one should verify that the model also works as
+expected on GPU.
+
+In general, there are two possible debugging environments for running
+the original model
+
+- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
+- Local python scripts.
+
+Jupyter notebooks have the advantage that they allow for cell-by-cell
+execution which can be helpful to better split logical components from
+one another and to have faster debugging cycles as intermediate results
+can be stored. Also, notebooks are often easier to share with other
+contributors, which might be very helpful if you want to ask the Hugging
+Face team for help. If you are familiar with Jupyter notebooks, we
+strongly recommend you to work with them.
+
+The obvious disadvantage of Jupyter notebooks is that if you are not
+used to working with them you will have to spend some time adjusting to
+the new programming environment and that you might not be able to use
+your known debugging tools anymore, like `ipdb`.
+
+**4. Successfully run forward pass**
+
+For each code-base, a good first step is always to load a **small**
+pretrained checkpoint and to be able to reproduce a single forward pass
+using a dummy integer vector of input IDs as an input. Such a script
+could look like this (in pseudocode):
+
+```python
+model = [camelcase name of model]Model.load_pretrained_checkpoint("/path/to/checkpoint/")
+input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
+original_output = model.predict(input_ids)
+```
+
+Next, regarding the debugging strategy, there are generally a few from
+which to choose from:
+
+- Decompose the original model into many small testable components and
+ run a forward pass on each of those for verification
+- Decompose the original model only into the original *tokenizer* and
+ the original *model*, run a forward pass on those, and use
+ intermediate print statements or breakpoints for verification
+
+Again, it is up to you which strategy to choose. Often, one or the other
+is advantageous depending on the original code base.
+
+If the original code-base allows you to decompose the model into smaller
+sub-components, *e.g.*, if the original code-base can easily be run in
+eager mode, it is usually worth the effort to do so. There are some
+important advantages to taking the more difficult road in the beginning:
+
+- at a later stage when comparing the original model to the Hugging
+ Face implementation, you can verify automatically for each component
+ individually that the corresponding component of the 🤗 Transformers
+ implementation matches instead of relying on visual comparison via
+ print statements
+- it can give you some rope to decompose the big problem of porting a
+ model into smaller problems of just porting individual components
+ and thus structure your work better
+- separating the model into logical meaningful components will help
+ you to get a better overview of the model's design and thus to
+ better understand the model
+- at a later stage those component-by-component tests help you to
+ ensure that no regression occurs as you continue changing your code
+
+[Lysandre's](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed)
+integration checks for ELECTRA gives a nice example of how this can be
+done.
+
+However, if the original code-base is very complex or only allows
+intermediate components to be run in a compiled mode, it might be too
+time-consuming or even impossible to separate the model into smaller
+testable sub-components. A good example is [T5's
+MeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow)
+library which is very complex and does not offer a simple way to
+decompose the model into its sub-components. For such libraries, one
+often relies on verifying print statements.
+
+No matter which strategy you choose, the recommended procedure is often
+the same in that you should start to debug the starting layers first and
+the ending layers last.
+
+It is recommended that you retrieve the output, either by print
+statements or sub-component functions, of the following layers in the
+following order:
+
+1. Retrieve the input IDs passed to the model
+2. Retrieve the word embeddings
+3. Retrieve the input of the first Transformer layer
+4. Retrieve the output of the first Transformer layer
+5. Retrieve the output of the following n - 1 Transformer layers
+6. Retrieve the output of the whole [camelcase name of model] Model
+
+Input IDs should thereby consists of an array of integers, *e.g.*,
+`input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`
+
+The outputs of the following layers often consist of multi-dimensional
+float arrays and can look like this:
+
+```bash
+[[
+ [-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
+ [-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
+ [-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
+ ...,
+ [-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
+ [-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
+ [-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
+```
+
+We expect that every model added to 🤗 Transformers passes a couple of
+integration tests, meaning that the original model and the reimplemented
+version in 🤗 Transformers have to give the exact same output up to a
+precision of 0.001! Since it is normal that the exact same model written
+in different libraries can give a slightly different output depending on
+the library framework, we accept an error tolerance of 1e-3 (0.001). It
+is not enough if the model gives nearly the same output, they have to be
+the almost identical. Therefore, you will certainly compare the
+intermediate outputs of the 🤗 Transformers version multiple times
+against the intermediate outputs of the original implementation of
+*[camelcase name of model]* in which case an **efficient** debugging environment
+of the original repository is absolutely important. Here is some advice
+to make your debugging environment as efficient as possible.
+
+- Find the best way of debugging intermediate results. Is the original
+ repository written in PyTorch? Then you should probably take the
+ time to write a longer script that decomposes the original model
+ into smaller sub-components to retrieve intermediate values. Is the
+ original repository written in Tensorflow 1? Then you might have to
+ rely on TensorFlow print operations like
+ [tf.print](https://www.tensorflow.org/api_docs/python/tf/print) to
+ output intermediate values. Is the original repository written in
+ Jax? Then make sure that the model is **not jitted** when running
+ the forward pass, *e.g.*, check-out [this
+ link](https://github.com/google/jax/issues/196).
+- Use the smallest pretrained checkpoint you can find. The smaller the
+ checkpoint, the faster your debug cycle becomes. It is not efficient
+ if your pretrained model is so big that your forward pass takes more
+ than 10 seconds. In case only very large checkpoints are available,
+ it might make more sense to create a dummy model in the new
+ environment with randomly initialized weights and save those weights
+ for comparison with the 🤗 Transformers version of your model
+- Make sure you are using the easiest way of calling a forward pass in
+ the original repository. Ideally, you want to find the function in
+ the original repository that **only** calls a single forward pass,
+ *i.e.* that is often called `predict`, `evaluate`, `forward` or
+ `__call__`. You don't want to debug a function that calls `forward`
+ multiple times, *e.g.*, to generate text, like
+ `autoregressive_sample`, `generate`.
+- Try to separate the tokenization from the model's
+ forward pass. If the original repository shows
+ examples where you have to input a string, then try to find out
+ where in the forward call the string input is changed to input ids
+ and start from this point. This might mean that you have to possibly
+ write a small script yourself or change the original code so that
+ you can directly input the ids instead of an input string.
+- Make sure that the model in your debugging setup is **not** in
+ training mode, which often causes the model to yield random outputs
+ due to multiple dropout layers in the model. Make sure that the
+ forward pass in your debugging environment is **deterministic** so
+ that the dropout layers are not used. Or use
+ `transformers.utils.set_seed` if the old and new
+ implementations are in the same framework.
+
+#### More details on how to create a debugging environment for [camelcase name of model]
+
+[TODO FILL: Here the mentor should add very specific information on what the student should do]
+[to set up an efficient environment for the special requirements of this model]
+
+### Port [camelcase name of model] to 🤗 Transformers
+
+Next, you can finally start adding new code to 🤗 Transformers. Go into
+the clone of your 🤗 Transformers' fork:
+
+ cd transformers
+
+In the special case that you are adding a model whose architecture
+exactly matches the model architecture of an existing model you only
+have to add a conversion script as described in [this
+section](#write-a-conversion-script). In this case, you can just re-use
+the whole model architecture of the already existing model.
+
+Otherwise, let's start generating a new model with the amazing
+Cookiecutter!
+
+**Use the Cookiecutter to automatically generate the model's code**
+
+To begin with head over to the [🤗 Transformers
+templates](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)
+to make use of our `cookiecutter` implementation to automatically
+generate all the relevant files for your model. Again, we recommend only
+adding the PyTorch version of the model at first. Make sure you follow
+the instructions of the `README.md` on the [🤗 Transformers
+templates](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)
+carefully.
+
+**Open a Pull Request on the main huggingface/transformers repo**
+
+Before starting to adapt the automatically generated code, now is the
+time to open a "Work in progress (WIP)" pull request, *e.g.*, "\[WIP\]
+Add *[camelcase name of model]*", in 🤗 Transformers so that you and the Hugging
+Face team can work side-by-side on integrating the model into 🤗
+Transformers.
+
+You should do the following:
+
+1. Create a branch with a descriptive name from your main branch
+
+```bash
+ git checkout -b add_[lowercase name of model]
+```
+
+2. Commit the automatically generated code:
+
+```bash
+ git add .
+ git commit
+```
+
+3. Fetch and rebase to current main
+
+```bash
+ git fetch upstream
+ git rebase upstream/main
+```
+
+4. Push the changes to your account using:
+
+```bash
+ git push -u origin a-descriptive-name-for-my-changes
+```
+
+5. Once you are satisfied, go to the webpage of your fork on GitHub.
+ Click on "Pull request". Make sure to add the GitHub handle of
+ [name of mentor] as a reviewer, so that the Hugging
+ Face team gets notified for future changes.
+
+6. Change the PR into a draft by clicking on "Convert to draft" on the
+ right of the GitHub pull request web page.
+
+In the following, whenever you have done some progress, don't forget to
+commit your work and push it to your account so that it shows in the
+pull request. Additionally, you should make sure to update your work
+with the current main from time to time by doing:
+
+ git fetch upstream
+ git merge upstream/main
+
+In general, all questions you might have regarding the model or your
+implementation should be asked in your PR and discussed/solved in the
+PR. This way, [name of mentor] will always be notified when you are
+committing new code or if you have a question. It is often very helpful
+to point [name of mentor] to your added code so that the Hugging
+Face team can efficiently understand your problem or question.
+
+To do so, you can go to the "Files changed" tab where you see all of
+your changes, go to a line regarding which you want to ask a question,
+and click on the "+" symbol to add a comment. Whenever a question or
+problem has been solved, you can click on the "Resolve" button of the
+created comment.
+
+In the same way, [name of mentor] will open comments when reviewing
+your code. We recommend asking most questions on GitHub on your PR. For
+some very general questions that are not very useful for the public,
+feel free to ping [name of mentor] by Slack or email.
+
+**5. Adapt the generated models code for [camelcase name of model]**
+
+At first, we will focus only on the model itself and not care about the
+tokenizer. All the relevant code should be found in the generated files
+`src/transformers/models/[lowercase name of model]/modeling_[lowercase name of model].py` and
+`src/transformers/models/[lowercase name of model]/configuration_[lowercase name of model].py`.
+
+Now you can finally start coding :). The generated code in
+`src/transformers/models/[lowercase name of model]/modeling_[lowercase name of model].py` will
+either have the same architecture as BERT if it's an encoder-only model
+or BART if it's an encoder-decoder model. At this point, you should
+remind yourself what you've learned in the beginning about the
+theoretical aspects of the model: *How is the model different from BERT
+or BART?*\". Implement those changes which often means to change the
+*self-attention* layer, the order of the normalization layer, etc...
+Again, it is often useful to look at the similar architecture of already
+existing models in Transformers to get a better feeling of how your
+model should be implemented.
+
+**Note** that at this point, you don't have to be very sure that your
+code is fully correct or clean. Rather, it is advised to add a first
+*unclean*, copy-pasted version of the original code to
+`src/transformers/models/[lowercase name of model]/modeling_[lowercase name of model].py`
+until you feel like all the necessary code is added. From our
+experience, it is much more efficient to quickly add a first version of
+the required code and improve/correct the code iteratively with the
+conversion script as described in the next section. The only thing that
+has to work at this point is that you can instantiate the 🤗 Transformers
+implementation of *[camelcase name of model]*, *i.e.* the following command
+should work:
+
+```python
+from transformers import [camelcase name of model]Model, [camelcase name of model]Config
+model = [camelcase name of model]Model([camelcase name of model]Config())
+```
+
+The above command will create a model according to the default
+parameters as defined in `[camelcase name of model]Config()` with random weights,
+thus making sure that the `init()` methods of all components works.
+
+[TODO FILL: Here the mentor should add very specific information on what exactly has to be changed for this model]
+[...]
+[...]
+
+**6. Write a conversion script**
+
+Next, you should write a conversion script that lets you convert the
+checkpoint you used to debug *[camelcase name of model]* in the original
+repository to a checkpoint compatible with your just created 🤗
+Transformers implementation of *[camelcase name of model]*. It is not advised to
+write the conversion script from scratch, but rather to look through
+already existing conversion scripts in 🤗 Transformers for one that has
+been used to convert a similar model that was written in the same
+framework as *[camelcase name of model]*. Usually, it is enough to copy an
+already existing conversion script and slightly adapt it for your use
+case. Don't hesitate to ask [name of mentor] to point you to a
+similar already existing conversion script for your model.
+
+- If you are porting a model from TensorFlow to PyTorch, a good
+ starting point might be BERT's conversion script
+ [here](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
+- If you are porting a model from PyTorch to PyTorch, a good starting
+ point might be BART's conversion script
+ [here](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)
+
+In the following, we'll quickly explain how PyTorch models store layer
+weights and define layer names. In PyTorch, the name of a layer is
+defined by the name of the class attribute you give the layer. Let's
+define a dummy model in PyTorch, called `SimpleModel` as follows:
+
+```python
+from torch import nn
+
+class SimpleModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.dense = nn.Linear(10, 10)
+ self.intermediate = nn.Linear(10, 10)
+ self.layer_norm = nn.LayerNorm(10)
+```
+
+Now we can create an instance of this model definition which will fill
+all weights: `dense`, `intermediate`, `layer_norm` with random weights.
+We can print the model to see its architecture
+
+```python
+model = SimpleModel()
+
+print(model)
+```
+
+This will print out the following:
+
+```bash
+SimpleModel(
+ (dense): Linear(in_features=10, out_features=10, bias=True)
+ (intermediate): Linear(in_features=10, out_features=10, bias=True)
+ (layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
+)
+```
+
+We can see that the layer names are defined by the name of the class
+attribute in PyTorch. You can print out the weight values of a specific
+layer:
+
+```python
+print(model.dense.weight.data)
+```
+
+to see that the weights were randomly initialized
+
+```bash
+tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
+ -0.2077, 0.2157],
+ [ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
+ 0.2166, -0.0212],
+ [-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
+ -0.1023, -0.0447],
+ [-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
+ -0.1876, -0.2467],
+ [ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
+ 0.2577, 0.0402],
+ [ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
+ 0.2132, 0.1680],
+ [ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
+ 0.2707, -0.2509],
+ [-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
+ 0.1829, -0.1568],
+ [-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
+ 0.0333, -0.0536],
+ [-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
+ 0.2220, 0.2358]]).
+```
+
+In the conversion script, you should fill those randomly initialized
+weights with the exact weights of the corresponding layer in the
+checkpoint. *E.g.*,
+
+```python
+# retrieve matching layer weights, e.g. by
+# recursive algorithm
+layer_name = "dense"
+pretrained_weight = array_of_dense_layer
+
+model_pointer = getattr(model, "dense")
+
+model_pointer.weight.data = torch.from_numpy(pretrained_weight)
+```
+
+While doing so, you must verify that each randomly initialized weight of
+your PyTorch model and its corresponding pretrained checkpoint weight
+exactly match in both **shape and name**. To do so, it is **necessary**
+to add assert statements for the shape and print out the names of the
+checkpoints weights. *E.g.*, you should add statements like:
+
+```python
+assert (
+ model_pointer.weight.shape == pretrained_weight.shape
+), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
+```
+
+Besides, you should also print out the names of both weights to make
+sure they match, *e.g.*,
+
+```python
+logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
+```
+
+If either the shape or the name doesn't match, you probably assigned
+the wrong checkpoint weight to a randomly initialized layer of the 🤗
+Transformers implementation.
+
+An incorrect shape is most likely due to an incorrect setting of the
+config parameters in `[camelcase name of model]Config()` that do not exactly match
+those that were used for the checkpoint you want to convert. However, it
+could also be that PyTorch's implementation of a layer requires the
+weight to be transposed beforehand.
+
+Finally, you should also check that **all** required weights are
+initialized and print out all checkpoint weights that were not used for
+initialization to make sure the model is correctly converted. It is
+completely normal, that the conversion trials fail with either a wrong
+shape statement or wrong name assignment. This is most likely because
+either you used incorrect parameters in `[camelcase name of model]Config()`, have a
+wrong architecture in the 🤗 Transformers implementation, you have a bug
+in the `init()` functions of one of the components of the 🤗 Transformers
+implementation or you need to transpose one of the checkpoint weights.
+
+This step should be iterated with the previous step until all weights of
+the checkpoint are correctly loaded in the Transformers model. Having
+correctly loaded the checkpoint into the 🤗 Transformers implementation,
+you can then save the model under a folder of your choice
+`/path/to/converted/checkpoint/folder` that should then contain both a
+`pytorch_model.bin` file and a `config.json` file:
+
+```python
+model.save_pretrained("/path/to/converted/checkpoint/folder")
+```
+
+[TODO FILL: Here the mentor should add very specific information on what exactly has to be done for the conversion of this model]
+[...]
+[...]
+
+**7. Implement the forward pass**
+
+Having managed to correctly load the pretrained weights into the 🤗
+Transformers implementation, you should now make sure that the forward
+pass is correctly implemented. In [Get familiar with the original
+repository](#34-run-a-pretrained-checkpoint-using-the-original-repository),
+you have already created a script that runs a forward pass of the model
+using the original repository. Now you should write an analogous script
+using the 🤗 Transformers implementation instead of the original one. It
+should look as follows:
+
+[TODO FILL: Here the model name might have to be adapted, *e.g.*, maybe [camelcase name of model]ForConditionalGeneration instead of [camelcase name of model]Model]
+
+```python
+model = [camelcase name of model]Model.from_pretrained("/path/to/converted/checkpoint/folder")
+input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
+output = model(input_ids).last_hidden_states
+```
+
+It is very likely that the 🤗 Transformers implementation and the
+original model implementation don't give the exact same output the very
+first time or that the forward pass throws an error. Don't be
+disappointed - it's expected! First, you should make sure that the
+forward pass doesn't throw any errors. It often happens that the wrong
+dimensions are used leading to a `"Dimensionality mismatch"`
+error or that the wrong data type object is used, *e.g.*, `torch.long`
+instead of `torch.float32`. Don't hesitate to ask [name of mentor]
+for help, if you don't manage to solve certain errors.
+
+The final part to make sure the 🤗 Transformers implementation works
+correctly is to ensure that the outputs are equivalent to a precision of
+`1e-3`. First, you should ensure that the output shapes are identical,
+*i.e.* `outputs.shape` should yield the same value for the script of the
+🤗 Transformers implementation and the original implementation. Next, you
+should make sure that the output values are identical as well. This one
+of the most difficult parts of adding a new model. Common mistakes why
+the outputs are not identical are:
+
+- Some layers were not added, *i.e.* an activation layer
+ was not added, or the residual connection was forgotten
+- The word embedding matrix was not tied
+- The wrong positional embeddings are used because the original
+ implementation uses on offset
+- Dropout is applied during the forward pass. To fix this make sure
+ `model.training is False` and that no dropout layer is
+ falsely activated during the forward pass, *i.e.* pass
+ `self.training` to [PyTorch's functional
+ dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)
+
+The best way to fix the problem is usually to look at the forward pass
+of the original implementation and the 🤗 Transformers implementation
+side-by-side and check if there are any differences. Ideally, you should
+debug/print out intermediate outputs of both implementations of the
+forward pass to find the exact position in the network where the 🤗
+Transformers implementation shows a different output than the original
+implementation. First, make sure that the hard-coded `input_ids` in both
+scripts are identical. Next, verify that the outputs of the first
+transformation of the `input_ids` (usually the word embeddings) are
+identical. And then work your way up to the very last layer of the
+network. At some point, you will notice a difference between the two
+implementations, which should point you to the bug in the 🤗 Transformers
+implementation. From our experience, a simple and efficient way is to
+add many print statements in both the original implementation and 🤗
+Transformers implementation, at the same positions in the network
+respectively, and to successively remove print statements showing the
+same values for intermediate presentions.
+
+When you're confident that both implementations yield the same output,
+verifying the outputs with
+`torch.allclose(original_output, output, atol=1e-3)`, you're done with
+the most difficult part! Congratulations - the work left to be done
+should be a cakewalk 😊.
+
+**8. Adding all necessary model tests**
+
+At this point, you have successfully added a new model. However, it is
+very much possible that the model does not yet fully comply with the
+required design. To make sure, the implementation is fully compatible
+with 🤗 Transformers, all common tests should pass. The Cookiecutter
+should have automatically added a test file for your model, probably
+under the same `tests/test_modeling_[lowercase name of model].py`. Run this test
+file to verify that all common tests pass:
+
+```python
+pytest tests/test_modeling_[lowercase name of model].py
+```
+
+[TODO FILL: Here the mentor should add very specific information on what tests are likely to fail after having implemented the model
+, e.g. given the model, it might be very likely that `test_attention_output` fails]
+[...]
+[...]
+
+Having fixed all common tests, it is now crucial to ensure that all the
+nice work you have done is well tested, so that
+
+- a) The community can easily understand your work by looking at
+ specific tests of *[camelcase name of model]*
+
+- b) Future changes to your model will not break any important
+ feature of the model.
+
+At first, integration tests should be added. Those integration tests
+essentially do the same as the debugging scripts you used earlier to
+implement the model to 🤗 Transformers. A template of those model tests
+is already added by the Cookiecutter, called
+`[camelcase name of model]ModelIntegrationTests` and only has to be filled out by
+you. To ensure that those tests are passing, run
+
+```python
+RUN_SLOW=1 pytest -sv tests/test_modeling_[lowercase name of model].py::[camelcase name of model]ModelIntegrationTests
+```
+
+**Note:** In case you are using Windows, you should replace `RUN_SLOW=1` with `SET RUN_SLOW=1`
+
+Second, all features that are special to *[camelcase name of model]* should be
+tested additionally in a separate test under
+`[camelcase name of model]ModelTester`/`[camelcase name of model]ModelTest`. This part is often
+forgotten but is extremely useful in two ways:
+
+- It helps to transfer the knowledge you have acquired during the
+ model addition to the community by showing how the special features
+ of *[camelcase name of model]* should work.
+- Future contributors can quickly test changes to the model by running
+ those special tests.
+
+[TODO FILL: Here the mentor should add very specific information on what special features of the model should be tested additionally]
+[...]
+[...]
+
+**9. Implement the tokenizer**
+
+Next, we should add the tokenizer of *[camelcase name of model]*. Usually, the
+tokenizer is equivalent or very similar to an already existing tokenizer
+of 🤗 Transformers.
+
+[TODO FILL: Here the mentor should add a comment whether a new tokenizer is required or if this is not the case which existing tokenizer closest resembles
+ [camelcase name of model]'s tokenizer and how the tokenizer should be implemented]
+ [...]
+ [...]
+
+It is very important to find/extract the original tokenizer file and to
+manage to load this file into the 🤗 Transformers' implementation of the
+tokenizer.
+
+For [camelcase name of model], the tokenizer files can be found here:
+- [To be filled out by mentor]
+
+and having implemented the 🤗 Transformers' version of the tokenizer can be loaded as follows:
+
+[To be filled out by mentor]
+
+To ensure that the tokenizer works correctly, it is recommended to first
+create a script in the original repository that inputs a string and
+returns the `input_ids`. It could look similar to this (in pseudo-code):
+
+```bash
+input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
+model = [camelcase name of model]Model.load_pretrained_checkpoint("/path/to/checkpoint/")
+input_ids = model.tokenize(input_str)
+```
+
+You might have to take a deeper look again into the original repository
+to find the correct tokenizer function or you might even have to do
+changes to your clone of the original repository to only output the
+`input_ids`. Having written a functional tokenization script that uses
+the original repository, an analogous script for 🤗 Transformers should
+be created. It should look similar to this:
+
+```python
+from transformers import [camelcase name of model]Tokenizer
+input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
+
+tokenizer = [camelcase name of model]Tokenizer.from_pretrained("/path/to/tokenizer/folder/")
+
+input_ids = tokenizer(input_str).input_ids
+```
+
+When both `input_ids` yield the same values, as a final step a tokenizer
+test file should also be added.
+
+[TODO FILL: Here mentor should point the student to test files of similar tokenizers]
+
+Analogous to the modeling test files of *[camelcase name of model]*, the
+tokenization test files of *[camelcase name of model]* should contain a couple of
+hard-coded integration tests.
+
+[TODO FILL: Here mentor should again point to an existing similar test of another model that the student can copy & adapt]
+
+**10. Run End-to-end integration tests**
+
+Having added the tokenizer, you should also add a couple of end-to-end
+integration tests using both the model and the tokenizer to
+`tests/test_modeling_[lowercase name of model].py` in 🤗 Transformers. Such a test
+should show on a meaningful text-to-text sample that the 🤗 Transformers
+implementation works as expected. A meaningful text-to-text sample can
+include *e.g.* a source-to-target-translation pair, an
+article-to-summary pair, a question-to-answer pair, etc... If none of
+the ported checkpoints has been fine-tuned on a downstream task it is
+enough to simply rely on the model tests. In a final step to ensure that
+the model is fully functional, it is advised that you also run all tests
+on GPU. It can happen that you forgot to add some `.to(self.device)`
+statements to internal tensors of the model, which in such a test would
+show in an error. In case you have no access to a GPU, the Hugging Face
+team can take care of running those tests for you.
+
+**11. Add Docstring**
+
+Now, all the necessary functionality for *[camelcase name of model]* is added -
+you're almost done! The only thing left to add is a nice docstring and
+a doc page. The Cookiecutter should have added a template file called
+`docs/source/model_doc/[lowercase name of model].rst` that you should fill out.
+Users of your model will usually first look at this page before using
+your model. Hence, the documentation must be understandable and concise.
+It is very useful for the community to add some *Tips* to show how the
+model should be used. Don't hesitate to ping [name of mentor]
+regarding the docstrings.
+
+Next, make sure that the docstring added to
+`src/transformers/models/[lowercase name of model]/modeling_[lowercase name of model].py` is
+correct and included all necessary inputs and outputs. It is always to
+good to remind oneself that documentation should be treated at least as
+carefully as the code in 🤗 Transformers since the documentation is
+usually the first contact point of the community with the model.
+
+**Code refactor**
+
+Great, now you have added all the necessary code for *[camelcase name of model]*.
+At this point, you should correct some potential incorrect code style by
+running:
+
+```bash
+make style
+```
+
+and verify that your coding style passes the quality check:
+
+```bash
+make quality
+```
+
+There are a couple of other very strict design tests in 🤗 Transformers
+that might still be failing, which shows up in the tests of your pull
+request. This is often because of some missing information in the
+docstring or some incorrect naming. [name of mentor] will surely
+help you if you're stuck here.
+
+Lastly, it is always a good idea to refactor one's code after having
+ensured that the code works correctly. With all tests passing, now it's
+a good time to go over the added code again and do some refactoring.
+
+You have now finished the coding part, congratulation! 🎉 You are
+Awesome! 😎
+
+**12. Upload the models to the model hub**
+
+In this final part, you should convert and upload all checkpoints to the
+model hub and add a model card for each uploaded model checkpoint. You
+should work alongside [name of mentor] here to decide on a fitting
+name for each checkpoint and to get the required access rights to be
+able to upload the model under the author's organization of
+*[camelcase name of model]*.
+
+It is worth spending some time to create fitting model cards for each
+checkpoint. The model cards should highlight the specific
+characteristics of this particular checkpoint, *e.g.*, On which dataset
+was the checkpoint pretrained/fine-tuned on? On what down-stream task
+should the model be used? And also include some code on how to correctly
+use the model.
+
+**13. (Optional) Add notebook**
+
+It is very helpful to add a notebook that showcases in-detail how
+*[camelcase name of model]* can be used for inference and/or fine-tuned on a
+downstream task. This is not mandatory to merge your PR, but very useful
+for the community.
+
+**14. Submit your finished PR**
+
+You're done programming now and can move to the last step, which is
+getting your PR merged into main. Usually, [name of mentor]
+should have helped you already at this point, but it is worth taking
+some time to give your finished PR a nice description and eventually add
+comments to your code, if you want to point out certain design choices
+to your reviewer.
+
+### Share your work!!
+
+Now, it's time to get some credit from the community for your work!
+Having completed a model addition is a major contribution to
+Transformers and the whole NLP community. Your code and the ported
+pre-trained models will certainly be used by hundreds and possibly even
+thousands of developers and researchers. You should be proud of your
+work and share your achievement with the community.
+
+**You have made another model that is super easy to access for everyone
+in the community! 🤯**
diff --git a/transformers/templates/adding_a_new_model/README.md b/transformers/templates/adding_a_new_model/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..7f60be589b8fd6eb62111171bfd5711023287450
--- /dev/null
+++ b/transformers/templates/adding_a_new_model/README.md
@@ -0,0 +1,23 @@
+
+
+# Adding a new model
+
+This page has been updated in light of the removal of the `add_new_model` script in favor of the more complete
+`add_new_model_like` script.
+
+We recommend you check out the documentation on [how to add a model](https://huggingface.co/docs/transformers/main/en/add_new_model)
+for complete and up-to-date instructions.
diff --git a/transformers/templates/adding_a_new_model/open_model_proposals/ADD_BIG_BIRD.md b/transformers/templates/adding_a_new_model/open_model_proposals/ADD_BIG_BIRD.md
new file mode 100644
index 0000000000000000000000000000000000000000..02c9fa32a2390f369d6fe9375099352640225cb0
--- /dev/null
+++ b/transformers/templates/adding_a_new_model/open_model_proposals/ADD_BIG_BIRD.md
@@ -0,0 +1,1148 @@
+How to add BigBird to 🤗 Transformers?
+=====================================
+
+Mentor: [Patrick](https://github.com/patrickvonplaten)
+
+Begin: 12.02.2020
+
+Estimated End: 19.03.2020
+
+Contributor: [Vasudev](https://github.com/thevasudevgupta)
+
+Adding a new model is often difficult and requires an in-depth knowledge
+of the 🤗 Transformers library and ideally also of the model's original
+repository. At Hugging Face, we are trying to empower the community more
+and more to add models independently.
+
+The following sections explain in detail how to add BigBird
+to Transformers. You will work closely with Patrick to
+integrate BigBird into Transformers. By doing so, you will both gain a
+theoretical and deep practical understanding of BigBird.
+But more importantly, you will have made a major
+open-source contribution to Transformers. Along the way, you will:
+
+- get insights into open-source best practices
+- understand the design principles of one of the most popular NLP
+ libraries
+- learn how to do efficiently test large NLP models
+- learn how to integrate Python utilities like `black`, `ruff`,
+ `make fix-copies` into a library to always ensure clean and readable
+ code
+
+To start, let's try to get a general overview of the Transformers
+library.
+
+General overview of 🤗 Transformers
+----------------------------------
+
+First, you should get a general overview of 🤗 Transformers. Transformers
+is a very opinionated library, so there is a chance that
+you don't agree with some of the library's philosophies or design
+choices. From our experience, however, we found that the fundamental
+design choices and philosophies of the library are crucial to
+efficiently scale Transformers while keeping maintenance costs at a
+reasonable level.
+
+A good first starting point to better understand the library is to read
+the [documentation of our philosophy](https://huggingface.co/transformers/philosophy.html).
+As a result of our way of working, there are some choices that we try to apply to all models:
+
+- Composition is generally favored over abstraction
+- Duplicating code is not always bad if it strongly improves the
+ readability or accessibility of a model
+- Model files are as self-contained as possible so that when you read
+ the code of a specific model, you ideally only have to look into the
+ respective `modeling_....py` file.
+
+In our opinion, the library's code is not just a means to provide a
+product, *e.g.*, the ability to use BERT for inference, but also as the
+very product that we want to improve. Hence, when adding a model, the
+user is not only the person that will use your model, but also everybody
+that will read, try to understand, and possibly tweak your code.
+
+With this in mind, let's go a bit deeper into the general library
+design.
+
+### Overview of models
+
+To successfully add a model, it is important to understand the
+interaction between your model and its config,
+`PreTrainedModel`, and `PretrainedConfig`. For
+exemplary purposes, we will call the PyTorch model to be added to 🤗 Transformers
+`BrandNewBert`.
+
+Let's take a look:
+
+
+
+As you can see, we do make use of inheritance in 🤗 Transformers, but we
+keep the level of abstraction to an absolute minimum. There are never
+more than two levels of abstraction for any model in the library.
+`BrandNewBertModel` inherits from
+`BrandNewBertPreTrainedModel` which in
+turn inherits from `PreTrainedModel` and that's it.
+As a general rule, we want to make sure
+that a new model only depends on `PreTrainedModel`. The
+important functionalities that are automatically provided to every new
+model are
+`PreTrainedModel.from_pretrained` and `PreTrainedModel.save_pretrained`, which are
+used for serialization and deserialization. All
+of the other important functionalities, such as
+`BrandNewBertModel.forward` should be
+completely defined in the new `modeling_brand_new_bert.py` module. Next,
+we want to make sure that a model with a specific head layer, such as
+`BrandNewBertForMaskedLM` does not inherit
+from `BrandNewBertModel`, but rather uses
+`BrandNewBertModel` as a component that
+can be called in its forward pass to keep the level of abstraction low.
+Every new model requires a configuration class, called
+`BrandNewBertConfig`. This configuration
+is always stored as an attribute in
+`PreTrainedModel`, and
+thus can be accessed via the `config` attribute for all classes
+inheriting from `BrandNewBertPreTrainedModel`
+
+```python
+# assuming that `brand_new_bert` belongs to the organization `brandy`
+model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
+model.config # model has access to its config
+```
+
+Similar to the model, the configuration inherits basic serialization and
+deserialization functionalities from
+`PretrainedConfig`. Note
+that the configuration and the model are always serialized into two
+different formats - the model to a `pytorch_model.bin` file
+and the configuration to a `config.json` file. Calling
+`PreTrainedModel.save_pretrained` will automatically call
+`PretrainedConfig.save_pretrained`, so that both model and configuration are saved.
+
+### Overview of tokenizers
+
+Not quite ready yet :-( This section will be added soon!
+
+Step-by-step recipe to add a model to 🤗 Transformers
+----------------------------------------------------
+
+Everyone has different preferences of how to port a model so it can be
+very helpful for you to take a look at summaries of how other
+contributors ported models to Hugging Face. Here is a list of community
+blog posts on how to port a model:
+
+1. [Porting GPT2
+ Model](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28)
+ by [Thomas](https://huggingface.co/thomwolf)
+2. [Porting WMT19 MT Model](https://huggingface.co/blog/porting-fsmt)
+ by [Stas](https://huggingface.co/stas)
+
+From experience, we can tell you that the most important things to keep
+in mind when adding a model are:
+
+- Don't reinvent the wheel! Most parts of the code you will add for
+ the new 🤗 Transformers model already exist somewhere in 🤗
+ Transformers. Take some time to find similar, already existing
+ models and tokenizers you can copy from.
+ [grep](https://www.gnu.org/software/grep/) and
+ [rg](https://github.com/BurntSushi/ripgrep) are your friends. Note
+ that it might very well happen that your model's tokenizer is based
+ on one model implementation, and your model's modeling code on
+ another one. *E.g.*, FSMT's modeling code is based on BART, while
+ FSMT's tokenizer code is based on XLM.
+- It's more of an engineering challenge than a scientific challenge.
+ You should spend more time on creating an efficient debugging
+ environment than trying to understand all theoretical aspects of the
+ model in the paper.
+- Ask for help when you're stuck! Models are the core component of 🤗
+ Transformers so we, at Hugging Face, are more than happy to help
+ you at every step to add your model. Don't hesitate to ask if you
+ notice you are not making progress.
+
+In the following, we try to give you a general recipe that we found most
+useful when porting a model to 🤗 Transformers.
+
+The following list is a summary of everything that has to be done to add
+a model and can be used by you as a To-Do List:
+
+1. [ ] (Optional) Understood theoretical aspects
+
+2. [ ] Prepared transformers dev environment
+
+3. [ ] Set up debugging environment of the original repository
+
+4. [ ] Created script that successfully runs forward pass using
+ original repository and checkpoint
+
+5. [ ] Successfully opened a PR and added the model skeleton to Transformers
+
+6. [ ] Successfully converted original checkpoint to Transformers
+ checkpoint
+
+7. [ ] Successfully ran forward pass in Transformers that gives
+ identical output to original checkpoint
+
+8. [ ] Finished model tests in Transformers
+
+9. [ ] Successfully added Tokenizer in Transformers
+
+10. [ ] Run end-to-end integration tests
+
+11. [ ] Finished docs
+
+12. [ ] Uploaded model weights to the hub
+
+13. [ ] Submitted the pull request for review
+
+14. [ ] (Optional) Added a demo notebook
+
+To begin with, we usually recommend to start by getting a good
+theoretical understanding of `BigBird`. However, if you prefer to
+understand the theoretical aspects of the model *on-the-job*, then it is
+totally fine to directly dive into the `BigBird`'s code-base. This
+option might suit you better, if your engineering skills are better than
+your theoretical skill, if you have trouble understanding
+`BigBird`'s paper, or if you just enjoy programming much more than
+reading scientific papers.
+
+### 1. (Optional) Theoretical aspects of BigBird
+
+You should take some time to read *BigBird's* paper, if such
+descriptive work exists. There might be large sections of the paper that
+are difficult to understand. If this is the case, this is fine - don't
+worry! The goal is not to get a deep theoretical understanding of the
+paper, but to extract the necessary information required to effectively
+re-implement the model in 🤗 Transformers. That being said, you don't
+have to spend too much time on the theoretical aspects, but rather focus
+on the practical ones, namely:
+
+- What type of model is *BigBird*? BERT-like encoder-only
+ model? GPT2-like decoder-only model? BART-like encoder-decoder
+ model? Look at the `model_summary` if
+ you're not familiar with the differences between those.
+- What are the applications of *BigBird*? Text
+ classification? Text generation? Seq2Seq tasks, *e.g.,*
+ summarization?
+- What is the novel feature of the model making it different from
+ BERT/GPT-2/BART?
+- Which of the already existing [🤗 Transformers
+ models](https://huggingface.co/transformers/#contents) is most
+ similar to *BigBird*?
+- What type of tokenizer is used? A sentencepiece tokenizer? Word
+ piece tokenizer? Is it the same tokenizer as used for BERT or BART?
+
+After you feel like you have gotten a good overview of the architecture
+of the model, you might want to write to Patrick with any
+questions you might have. This might include questions regarding the
+model's architecture, its attention layer, etc. We will be more than
+happy to help you.
+
+
+#### Additional resources
+
+ Before diving into the code, here are some additional resources that might be worth taking a look at:
+
+ - [Yannic Kilcher's paper summary](https://www.youtube.com/watch?v=WVPE62Gk3EM&ab_channel=YannicKilcher)
+ - [Yannic Kilcher's summary of Longformer](https://www.youtube.com/watch?v=_8KNb5iqblE&ab_channel=YannicKilcher) - Longformer and BigBird are **very** similar models. Since Longformer has already been ported to 🤗 Transformers, it is useful to understand the differences between the two models
+ - [Blog post](https://medium.com/dsc-msit/is-google-bigbird-gonna-be-the-new-leader-in-nlp-domain-8c95cecc30f8) - A relatively superficial blog post about BigBird. Might be a good starting point to understand BigBird
+
+#### Make sure you've understood the fundamental aspects of BigBird
+
+Alright, now you should be ready to take a closer look into the actual code of BigBird.
+You should have understood the following aspects of BigBird by now:
+
+- BigBird provides a new attention layer for long-range sequence modelling that can be used
+ as a drop-in replacement for already existing architectures. This means that every transformer-based model architecture can replace its [Self-attention layer](https://towardsdatascience.com/illustrated-self-attention-2d627e33b20a) with BigBird's self-attention layer.
+- BigBird's self-attention layer is composed of three mechanisms: block sparse (local) self-attention, global self-attention, random self-attention
+- BigBird's block sparse (local) self-attention is different from Longformer's local self-attention. How so? Why does that matter? => Can be deployed on TPU much easier this way
+- BigBird can be implemented for both an encoder-only model **and**
+ for an encoder-decoder model, which means that we can reuse lots of [code from RoBERTa](https://github.com/huggingface/transformers/blob/main/src/transformers/models/roberta/modeling_roberta.py) and [from PEGASUS](https://github.com/huggingface/transformers/blob/main/src/transformers/models/pegasus/modeling_pegasus.py) at a later stage.
+
+
+If any of the mentioned aspects above are **not** clear to you, now is a great time to talk to Patrick.
+
+### 2. Next prepare your environment
+
+1. Fork the [repository](https://github.com/huggingface/transformers)
+ by clicking on the 'Fork' button on the repository's page. This
+ creates a copy of the code under your GitHub user account.
+
+2. Clone your `transformers` fork to your local disk, and add the base
+ repository as a remote:
+
+ ```bash
+ git clone https://github.com/[your Github handle]/transformers.git
+ cd transformers
+ git remote add upstream https://github.com/huggingface/transformers.git
+ ```
+
+3. Set up a development environment, for instance by running the
+ following command:
+
+ ```bash
+ python -m venv .env
+ source .env/bin/activate
+ pip install -e ".[dev]"
+ ```
+
+and return to the parent directory
+
+```bash
+cd ..
+```
+
+4. We recommend adding the PyTorch version of *BigBird* to
+ Transformers. To install PyTorch, please follow the instructions [here](https://pytorch.org/get-started/locally/).
+
+**Note:** You don't need to have CUDA installed. Making the new model
+work on CPU is sufficient.
+
+5. To port *BigBird*, you will also need access to its
+ original repository:
+
+```bash
+git clone https://github.com/google-research/bigbird.git
+cd big_bird
+pip install -e .
+```
+
+Now you have set up a development environment to port *BigBird*
+to 🤗 Transformers.
+
+### Run a pretrained checkpoint using the original repository
+
+**3. Set up debugging environment**
+
+At first, you will work on the original *BigBird* repository.
+Often, the original implementation is very "researchy". Meaning that
+documentation might be lacking and the code can be difficult to
+understand. But this should be exactly your motivation to reimplement
+*BigBird*. At Hugging Face, one of our main goals is to *make
+people stand on the shoulders of giants* which translates here very well
+into taking a working model and rewriting it to make it as **accessible,
+user-friendly, and beautiful** as possible. This is the number-one
+motivation to re-implement models into 🤗 Transformers - trying to make
+complex new NLP technology accessible to **everybody**.
+
+You should start thereby by diving into the [original repository](https://github.com/google-research/bigbird).
+
+Successfully running the official pretrained model in the original
+repository is often **the most difficult** step. From our experience, it
+is very important to spend some time getting familiar with the original
+code-base. You need to figure out the following:
+
+- Where to find the pretrained weights?
+- How to load the pretrained weights into the corresponding model?
+- How to run the tokenizer independently from the model?
+- Trace one forward pass so that you know which classes and functions
+ are required for a simple forward pass. Usually, you only have to
+ reimplement those functions.
+- Be able to locate the important components of the model: Where is
+ the model's class? Are there model sub-classes, *e.g.*,
+ EncoderModel, DecoderModel? Where is the self-attention layer? Are
+ there multiple different attention layers, *e.g.*, *self-attention*,
+ *cross-attention*...?
+- How can you debug the model in the original environment of the repo?
+ Do you have to add `print` statements, can you work with
+ an interactive debugger like [ipdb](https://pypi.org/project/ipdb/), or should you use
+ an efficient IDE to debug the model, like PyCharm?
+
+It is very important that before you start the porting process, that you
+can **efficiently** debug code in the original repository! Also,
+remember that you are working with an open-source library, so do not
+hesitate to open an issue, or even a pull request in the original
+repository. The maintainers of this repository are most likely very
+happy about someone looking into their code!
+
+At this point, it is really up to you which debugging environment and
+strategy you prefer to use to debug the original model. We strongly
+advise against setting up a costly GPU environment, but simply work on a
+CPU both when starting to dive into the original repository and also
+when starting to write the 🤗 Transformers implementation of the model.
+Only at the very end, when the model has already been successfully
+ported to 🤗 Transformers, one should verify that the model also works as
+expected on GPU.
+
+In general, there are two possible debugging environments for running
+the original model
+
+- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
+- Local python scripts.
+
+Jupyter notebooks have the advantage that they allow for cell-by-cell
+execution which can be helpful to better split logical components from
+one another and to have faster debugging cycles as intermediate results
+can be stored. Also, notebooks are often easier to share with other
+contributors, which might be very helpful if you want to ask the Hugging
+Face team for help. If you are familiar with Jupyter notebooks, we
+strongly recommend you to work with them.
+
+The obvious disadvantage of Jupyter notebooks is that if you are not
+used to working with them you will have to spend some time adjusting to
+the new programming environment and that you might not be able to use
+your known debugging tools anymore, like `ipdb`.
+
+**4. Successfully run forward pass**
+
+For each code-base, a good first step is always to load a **small**
+pretrained checkpoint and to be able to reproduce a single forward pass
+using a dummy integer vector of input IDs as an input. Such a script
+could look something like this:
+
+```python
+from bigbird.core import modeling
+model = modeling.BertModel(bert_config)
+from bigbird.core import utils
+
+params = utils.BigBirdConfig(vocab_size=32000, hidden_size=512,
+ num_hidden_layers=8, num_attention_heads=6, intermediate_size=1024)
+
+ckpt_path = 'gs://bigbird-transformer/pretrain/bigbr_base/model.ckpt-0'
+ckpt_reader = tf.compat.v1.train.NewCheckpointReader(ckpt_path)
+model.set_weights([ckpt_reader.get_tensor(v.name[:-2]) for v in tqdm(model.trainable_weights, position=0)])
+
+input_ids = tf.constant([[31, 51, 99], [15, 5, 0]])
+_, pooled_output = model(input_ids=input_ids, token_type_ids=token_type_ids)
+...
+
+```
+
+Next, regarding the debugging strategy, there are generally a few from
+which to choose from:
+
+- Decompose the original model into many small testable components and
+ run a forward pass on each of those for verification
+- Decompose the original model only into the original *tokenizer* and
+ the original *model*, run a forward pass on those, and use
+ intermediate print statements or breakpoints for verification
+
+Again, it is up to you which strategy to choose. Often, one or the other
+is advantageous depending on the original code base.
+
+If the original code-base allows you to decompose the model into smaller
+sub-components, *e.g.*, if the original code-base can easily be run in
+eager mode, it is usually worth the effort to do so. There are some
+important advantages to taking the more difficult road in the beginning:
+
+- at a later stage when comparing the original model to the Hugging
+ Face implementation, you can verify automatically for each component
+ individually that the corresponding component of the 🤗 Transformers
+ implementation matches instead of relying on visual comparison via
+ print statements
+- it can give you some rope to decompose the big problem of porting a
+ model into smaller problems of just porting individual components
+ and thus structure your work better
+- separating the model into logical meaningful components will help
+ you to get a better overview of the model's design and thus to
+ better understand the model
+- at a later stage those component-by-component tests help you to
+ ensure that no regression occurs as you continue changing your code
+
+[Lysandre's](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed)
+integration checks for ELECTRA gives a nice example of how this can be
+done.
+
+However, if the original code-base is very complex or only allows
+intermediate components to be run in a compiled mode, it might be too
+time-consuming or even impossible to separate the model into smaller
+testable sub-components. A good example is [T5's
+MeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow)
+library which is very complex and does not offer a simple way to
+decompose the model into its sub-components. For such libraries, one
+often relies on verifying print statements.
+
+No matter which strategy you choose, the recommended procedure is often
+the same in that you should start to debug the starting layers first and
+the ending layers last.
+
+It is recommended that you retrieve the output, either by print
+statements or sub-component functions, of the following layers in the
+following order:
+
+1. Retrieve the input IDs passed to the model
+2. Retrieve the word embeddings
+3. Retrieve the input of the first Transformer layer
+4. Retrieve the output of the first Transformer layer
+5. Retrieve the output of the following n - 1 Transformer layers
+6. Retrieve the output of the whole BigBird Model
+
+Input IDs should thereby consists of an array of integers, *e.g.*,
+`input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`
+
+The outputs of the following layers often consist of multi-dimensional
+float arrays and can look like this:
+
+```bash
+[[
+ [-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
+ [-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
+ [-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
+ ...,
+ [-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
+ [-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
+ [-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
+```
+
+We expect that every model added to 🤗 Transformers passes a couple of
+integration tests, meaning that the original model and the reimplemented
+version in 🤗 Transformers have to give the exact same output up to a
+precision of 0.001! Since it is normal that the exact same model written
+in different libraries can give a slightly different output depending on
+the library framework, we accept an error tolerance of 1e-3 (0.001). It
+is not enough if the model gives nearly the same output, they have to be
+the almost identical. Therefore, you will certainly compare the
+intermediate outputs of the 🤗 Transformers version multiple times
+against the intermediate outputs of the original implementation of
+*BigBird* in which case an **efficient** debugging environment
+of the original repository is absolutely important. Here is some advice
+to make your debugging environment as efficient as possible.
+
+- Find the best way of debugging intermediate results. Is the original
+ repository written in PyTorch? Then you should probably take the
+ time to write a longer script that decomposes the original model
+ into smaller sub-components to retrieve intermediate values. Is the
+ original repository written in Tensorflow 1? Then you might have to
+ rely on TensorFlow print operations like
+ [tf.print](https://www.tensorflow.org/api_docs/python/tf/print) to
+ output intermediate values. Is the original repository written in
+ Jax? Then make sure that the model is **not jitted** when running
+ the forward pass, *e.g.*, check-out [this
+ link](https://github.com/google/jax/issues/196).
+- Use the smallest pretrained checkpoint you can find. The smaller the
+ checkpoint, the faster your debug cycle becomes. It is not efficient
+ if your pretrained model is so big that your forward pass takes more
+ than 10 seconds. In case only very large checkpoints are available,
+ it might make more sense to create a dummy model in the new
+ environment with randomly initialized weights and save those weights
+ for comparison with the 🤗 Transformers version of your model
+- Make sure you are using the easiest way of calling a forward pass in
+ the original repository. Ideally, you want to find the function in
+ the original repository that **only** calls a single forward pass,
+ *i.e.* that is often called `predict`, `evaluate`, `forward` or
+ `__call__`. You don't want to debug a function that calls `forward`
+ multiple times, *e.g.*, to generate text, like
+ `autoregressive_sample`, `generate`.
+- Try to separate the tokenization from the model's
+ forward pass. If the original repository shows
+ examples where you have to input a string, then try to find out
+ where in the forward call the string input is changed to input ids
+ and start from this point. This might mean that you have to possibly
+ write a small script yourself or change the original code so that
+ you can directly input the ids instead of an input string.
+- Make sure that the model in your debugging setup is **not** in
+ training mode, which often causes the model to yield random outputs
+ due to multiple dropout layers in the model. Make sure that the
+ forward pass in your debugging environment is **deterministic** so
+ that the dropout layers are not used. Or use
+ `transformers.utils.set_seed` if the old and new
+ implementations are in the same framework.
+
+#### (Important) More details on how to create a debugging environment for BigBird
+
+- BigBird has multiple pretrained checkpoints that should eventually all be ported to
+ 🤗 Transformers. The pretrained checkpoints can be found [here](https://console.cloud.google.com/storage/browser/bigbird-transformer/pretrain;tab=objects?prefix=&forceOnObjectsSortingFiltering=false).
+ Those checkpoints include both pretrained weights for encoder-only (BERT/RoBERTa) under the folder `bigbr_base` and encoder-decoder (PEGASUS) under the folder `bigbp_large`.
+ You should start by porting the `bigbr_base` model. The encoder-decoder model
+ can be ported afterward.
+ for an encoder-decoder architecture as well as an encoder-only architecture.
+- BigBird was written in tf.compat meaning that a mixture of a TensorFlow 1 and
+ TensorFlow 2 API was used.
+- The most important part of the BigBird code-base is [bigbird.bigbird.core](https://github.com/google-research/bigbird/tree/master/bigbird/core) which includes all logic necessary
+ to implement BigBird.
+- The first goal should be to successfully run a forward pass using the RoBERTa checkpoint `bigbr_base/model.ckpt-0.data-00000-of-00001` and `bigbr_base/model.ckpt-0.index`.
+
+
+### Port BigBird to 🤗 Transformers
+
+Next, you can finally start adding new code to 🤗 Transformers. Go into
+the clone of your 🤗 Transformers' fork:
+
+ cd transformers
+
+In the special case that you are adding a model whose architecture
+exactly matches the model architecture of an existing model you only
+have to add a conversion script as described in [this
+section](#write-a-conversion-script). In this case, you can just re-use
+the whole model architecture of the already existing model.
+
+Otherwise, let's start generating a new model with the amazing
+Cookiecutter!
+
+**Use the Cookiecutter to automatically generate the model's code**
+
+To begin with head over to the [🤗 Transformers
+templates](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)
+to make use of our `cookiecutter` implementation to automatically
+generate all the relevant files for your model. Again, we recommend only
+adding the PyTorch version of the model at first. Make sure you follow
+the instructions of the `README.md` on the [🤗 Transformers
+templates](https://github.com/huggingface/transformers/tree/main/templates/adding_a_new_model)
+carefully.
+Since you will first implement the Encoder-only/RoBERTa-like version of BigBird you should
+select the `is_encoder_decoder_model = False` option in the cookiecutter. Also, it is recommended
+that you implement the model only in PyTorch in the beginning and select "Standalone" as the
+tokenizer type for now.
+
+**Open a Pull Request on the main huggingface/transformers repo**
+
+Before starting to adapt the automatically generated code, now is the
+time to open a "Work in progress (WIP)" pull request, *e.g.*, "\[WIP\]
+Add *BigBird*", in 🤗 Transformers so that you and the Hugging
+Face team can work side-by-side on integrating the model into 🤗
+Transformers.
+
+You should do the following:
+
+1. Create a branch with a descriptive name from your main branch
+
+```bash
+ git checkout -b add_big_bird
+```
+
+2. Commit the automatically generated code:
+
+```bash
+ git add .
+ git commit
+```
+
+3. Fetch and rebase to current main
+
+```bash
+ git fetch upstream
+ git rebase upstream/main
+```
+
+4. Push the changes to your account using:
+
+```bash
+ git push -u origin a-descriptive-name-for-my-changes
+```
+
+5. Once you are satisfied, go to the webpage of your fork on GitHub.
+ Click on "Pull request". Make sure to add the GitHub handle of Patrick
+ as one reviewer, so that the Hugging Face team gets notified for future changes.
+
+6. Change the PR into a draft by clicking on "Convert to draft" on the
+ right of the GitHub pull request web page.
+
+In the following, whenever you have done some progress, don't forget to
+commit your work and push it to your account so that it shows in the
+pull request. Additionally, you should make sure to update your work
+with the current main from time to time by doing:
+
+ git fetch upstream
+ git merge upstream/main
+
+In general, all questions you might have regarding the model or your
+implementation should be asked in your PR and discussed/solved in the
+PR. This way, Patrick will always be notified when you are
+committing new code or if you have a question. It is often very helpful
+to point Patrick to your added code so that the Hugging
+Face team can efficiently understand your problem or question.
+
+To do so, you can go to the "Files changed" tab where you see all of
+your changes, go to a line regarding which you want to ask a question,
+and click on the "+" symbol to add a comment. Whenever a question or
+problem has been solved, you can click on the "Resolve" button of the
+created comment.
+
+In the same way, Patrick will open comments when reviewing
+your code. We recommend asking most questions on GitHub on your PR. For
+some very general questions that are not very useful for the public,
+feel free to ping Patrick by Slack or email.
+
+**5. Adapt the generated models code for BigBird**
+
+At first, we will focus only on the model itself and not care about the
+tokenizer. All the relevant code should be found in the generated files
+`src/transformers/models/big_bird/modeling_big_bird.py` and
+`src/transformers/models/big_bird/configuration_big_bird.py`.
+
+Now you can finally start coding :). The generated code in
+`src/transformers/models/big_bird/modeling_big_bird.py` will
+either have the same architecture as BERT if it's an encoder-only model
+or BART if it's an encoder-decoder model. At this point, you should
+remind yourself what you've learned in the beginning about the
+theoretical aspects of the model: *How is the model different from BERT
+or BART?*\". Implement those changes which often means to change the
+*self-attention* layer, the order of the normalization layer, etc...
+Again, it is often useful to look at the similar architecture of already
+existing models in Transformers to get a better feeling of how your
+model should be implemented.
+
+**Note** that at this point, you don't have to be very sure that your
+code is fully correct or clean. Rather, it is advised to add a first
+*unclean*, copy-pasted version of the original code to
+`src/transformers/models/big_bird/modeling_big_bird.py`
+until you feel like all the necessary code is added. From our
+experience, it is much more efficient to quickly add a first version of
+the required code and improve/correct the code iteratively with the
+conversion script as described in the next section. The only thing that
+has to work at this point is that you can instantiate the 🤗 Transformers
+implementation of *BigBird*, *i.e.* the following command
+should work:
+
+```python
+from transformers import BigBirdModel, BigBirdConfig
+model = BigBirdModel(BigBirdConfig())
+```
+
+The above command will create a model according to the default
+parameters as defined in `BigBirdConfig()` with random weights,
+thus making sure that the `init()` methods of all components works.
+
+Note that for BigBird you have to change the attention layer. BigBird's attention
+layer is quite complex as you can see [here](https://github.com/google-research/bigbird/blob/103a3345f94bf6364749b51189ed93024ca5ef26/bigbird/core/attention.py#L560). Don't
+feel discouraged by this! In a first step you should simply make sure that
+the layer `BigBirdAttention` has the correct weights as can be found in the
+pretrained checkpoints. This means that you have to make sure that in the
+`__init__(self, ...)` function of `BigBirdAttention`, all submodules include all
+necessary `nn.Module` layers. Only at a later stage do we need to fully rewrite
+the complex attention function.
+
+**6. Write a conversion script**
+
+Next, you should write a conversion script that lets you convert the
+checkpoint you used to debug *BigBird* in the original
+repository to a checkpoint compatible with your just created 🤗
+Transformers implementation of *BigBird*. It is not advised to
+write the conversion script from scratch, but rather to look through
+already existing conversion scripts in 🤗 Transformers for one that has
+been used to convert a similar model that was written in the same
+framework as *BigBird*. Usually, it is enough to copy an
+already existing conversion script and slightly adapt it for your use
+case. Don't hesitate to ask Patrick to point you to a
+similar already existing conversion script for your model.
+
+- A good starting point to convert the original TF BigBird implementation to the PT Hugging Face implementation is probably BERT's conversion script
+ [here](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
+
+You can copy paste the conversion function into `modeling_big_bird.py` and then adapt it
+to your needs.
+
+In the following, we'll quickly explain how PyTorch models store layer
+weights and define layer names. In PyTorch, the name of a layer is
+defined by the name of the class attribute you give the layer. Let's
+define a dummy model in PyTorch, called `SimpleModel` as follows:
+
+```python
+from torch import nn
+
+class SimpleModel(nn.Module):
+ def __init__(self):
+ super().__init__()
+ self.dense = nn.Linear(10, 10)
+ self.intermediate = nn.Linear(10, 10)
+ self.layer_norm = nn.LayerNorm(10)
+```
+
+Now we can create an instance of this model definition which will fill
+all weights: `dense`, `intermediate`, `layer_norm` with random weights.
+We can print the model to see its architecture
+
+```python
+model = SimpleModel()
+
+print(model)
+```
+
+This will print out the following:
+
+```bash
+SimpleModel(
+ (dense): Linear(in_features=10, out_features=10, bias=True)
+ (intermediate): Linear(in_features=10, out_features=10, bias=True)
+ (layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
+)
+```
+
+We can see that the layer names are defined by the name of the class
+attribute in PyTorch. You can print out the weight values of a specific
+layer:
+
+```python
+print(model.dense.weight.data)
+```
+
+to see that the weights were randomly initialized
+
+```bash
+tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
+ -0.2077, 0.2157],
+ [ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
+ 0.2166, -0.0212],
+ [-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
+ -0.1023, -0.0447],
+ [-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
+ -0.1876, -0.2467],
+ [ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
+ 0.2577, 0.0402],
+ [ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
+ 0.2132, 0.1680],
+ [ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
+ 0.2707, -0.2509],
+ [-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
+ 0.1829, -0.1568],
+ [-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
+ 0.0333, -0.0536],
+ [-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
+ 0.2220, 0.2358]]).
+```
+
+In the conversion script, you should fill those randomly initialized
+weights with the exact weights of the corresponding layer in the
+checkpoint. *E.g.*,
+
+```python
+# retrieve matching layer weights, e.g. by
+# recursive algorithm
+layer_name = "dense"
+pretrained_weight = array_of_dense_layer
+
+model_pointer = getattr(model, "dense")
+
+model_pointer.weight.data = torch.from_numpy(pretrained_weight)
+```
+
+While doing so, you must verify that each randomly initialized weight of
+your PyTorch model and its corresponding pretrained checkpoint weight
+exactly match in both **shape and name**. To do so, it is **necessary**
+to add assert statements for the shape and print out the names of the
+checkpoints weights. *E.g.*, you should add statements like:
+
+```python
+assert (
+ model_pointer.weight.shape == pretrained_weight.shape
+), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
+```
+
+Besides, you should also print out the names of both weights to make
+sure they match, *e.g.*,
+
+```python
+logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
+```
+
+If either the shape or the name doesn't match, you probably assigned
+the wrong checkpoint weight to a randomly initialized layer of the 🤗
+Transformers implementation.
+
+An incorrect shape is most likely due to an incorrect setting of the
+config parameters in `BigBirdConfig()` that do not exactly match
+those that were used for the checkpoint you want to convert. However, it
+could also be that PyTorch's implementation of a layer requires the
+weight to be transposed beforehand.
+
+Finally, you should also check that **all** required weights are
+initialized and print out all checkpoint weights that were not used for
+initialization to make sure the model is correctly converted. It is
+completely normal, that the conversion trials fail with either a wrong
+shape statement or wrong name assignment. This is most likely because
+either you used incorrect parameters in `BigBirdConfig()`, have a
+wrong architecture in the 🤗 Transformers implementation, you have a bug
+in the `init()` functions of one of the components of the 🤗 Transformers
+implementation or you need to transpose one of the checkpoint weights.
+
+This step should be iterated with the previous step until all weights of
+the checkpoint are correctly loaded in the Transformers model. Having
+correctly loaded the checkpoint into the 🤗 Transformers implementation,
+you can then save the model under a folder of your choice
+`/path/to/converted/checkpoint/folder` that should then contain both a
+`pytorch_model.bin` file and a `config.json` file:
+
+```python
+model.save_pretrained("/path/to/converted/checkpoint/folder")
+```
+
+**7. Implement the forward pass**
+
+Having managed to correctly load the pretrained weights into the 🤗
+Transformers implementation, you should now make sure that the forward
+pass is correctly implemented. In [Get familiar with the original
+repository](#run-a-pretrained-checkpoint-using-the-original-repository),
+you have already created a script that runs a forward pass of the model
+using the original repository. Now you should write an analogous script
+using the 🤗 Transformers implementation instead of the original one. It
+should look as follows:
+
+[Here the model name might have to be adapted, *e.g.*, maybe BigBirdForConditionalGeneration instead of BigBirdModel]
+
+```python
+model = BigBirdModel.from_pretrained("/path/to/converted/checkpoint/folder")
+input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
+output = model(input_ids).last_hidden_states
+```
+
+It is very likely that the 🤗 Transformers implementation and the
+original model implementation don't give the exact same output the very
+first time or that the forward pass throws an error. Don't be
+disappointed - it's expected! First, you should make sure that the
+forward pass doesn't throw any errors. It often happens that the wrong
+dimensions are used leading to a `"Dimensionality mismatch"`
+error or that the wrong data type object is used, *e.g.*, `torch.long`
+instead of `torch.float32`. Don't hesitate to ask Patrick
+for help, if you don't manage to solve certain errors.
+
+The final part to make sure the 🤗 Transformers implementation works
+correctly is to ensure that the outputs are equivalent to a precision of
+`1e-3`. First, you should ensure that the output shapes are identical,
+*i.e.* `outputs.shape` should yield the same value for the script of the
+🤗 Transformers implementation and the original implementation. Next, you
+should make sure that the output values are identical as well. This one
+of the most difficult parts of adding a new model. Common mistakes why
+the outputs are not identical are:
+
+- Some layers were not added, *i.e.* an activation layer
+ was not added, or the residual connection was forgotten
+- The word embedding matrix was not tied
+- The wrong positional embeddings are used because the original
+ implementation uses on offset
+- Dropout is applied during the forward pass. To fix this make sure
+ `model.training is False` and that no dropout layer is
+ falsely activated during the forward pass, *i.e.* pass
+ `self.training` to [PyTorch's functional
+ dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)
+
+The best way to fix the problem is usually to look at the forward pass
+of the original implementation and the 🤗 Transformers implementation
+side-by-side and check if there are any differences. Ideally, you should
+debug/print out intermediate outputs of both implementations of the
+forward pass to find the exact position in the network where the 🤗
+Transformers implementation shows a different output than the original
+implementation. First, make sure that the hard-coded `input_ids` in both
+scripts are identical. Next, verify that the outputs of the first
+transformation of the `input_ids` (usually the word embeddings) are
+identical. And then work your way up to the very last layer of the
+network. At some point, you will notice a difference between the two
+implementations, which should point you to the bug in the 🤗 Transformers
+implementation. From our experience, a simple and efficient way is to
+add many print statements in both the original implementation and 🤗
+Transformers implementation, at the same positions in the network
+respectively, and to successively remove print statements showing the
+same values for intermediate presentions.
+
+When you're confident that both implementations yield the same output,
+verifying the outputs with
+`torch.allclose(original_output, output, atol=1e-3)`, you're done with
+the most difficult part! Congratulations - the work left to be done
+should be a cakewalk 😊.
+
+**8. Adding all necessary model tests**
+
+At this point, you have successfully added a new model. However, it is
+very much possible that the model does not yet fully comply with the
+required design. To make sure, the implementation is fully compatible
+with 🤗 Transformers, all common tests should pass. The Cookiecutter
+should have automatically added a test file for your model, probably
+under the same `tests/test_modeling_big_bird.py`. Run this test
+file to verify that all common tests pass:
+
+```python
+pytest tests/test_modeling_big_bird.py
+```
+
+Having fixed all common tests, it is now crucial to ensure that all the
+nice work you have done is well tested, so that
+
+- a) The community can easily understand your work by looking at
+ specific tests of *BigBird*
+
+- b) Future changes to your model will not break any important
+ feature of the model.
+
+At first, integration tests should be added. Those integration tests
+essentially do the same as the debugging scripts you used earlier to
+implement the model to 🤗 Transformers. A template of those model tests
+is already added by the Cookiecutter, called
+`BigBirdModelIntegrationTests` and only has to be filled out by
+you. To ensure that those tests are passing, run
+
+```python
+RUN_SLOW=1 pytest -sv tests/test_modeling_big_bird.py::BigBirdModelIntegrationTests
+```
+
+**Note**: In case you are using Windows, you should replace `RUN_SLOW=1` with
+`SET RUN_SLOW=1`
+
+Second, all features that are special to *BigBird* should be
+tested additionally in a separate test under
+`BigBirdModelTester`/`BigBirdModelTest`. This part is often
+forgotten but is extremely useful in two ways:
+
+- It helps to transfer the knowledge you have acquired during the
+ model addition to the community by showing how the special features
+ of *BigBird* should work.
+- Future contributors can quickly test changes to the model by running
+ those special tests.
+
+BigBird has quite a complex attention layer, so it is very important
+to add more tests verifying the all parts of BigBird's self-attention layer
+works as expected. This means that there should be at least 3 additional tests:
+
+- 1. Verify that the sparse attention works correctly
+- 2. Verify that the global attention works correctly
+- 3. Verify that the random attention works correctly
+
+**9. Implement the tokenizer**
+
+Next, we should add the tokenizer of *BigBird*. Usually, the
+tokenizer is equivalent or very similar to an already existing tokenizer
+of 🤗 Transformers.
+
+In the case of BigBird you should be able to just rely on an already existing tokenizer.
+If not mistaken, BigBird uses the same tokenizer that was used for `BertGenerationTokenizer`,
+which is based on `sentencepiece`. So you should be able to just set the config parameter
+`tokenizer_class` to `BertGenerationTokenizer` without having to implement any new tokenizer.
+
+It is very important to find/extract the original tokenizer file and to
+manage to load this file into the 🤗 Transformers' implementation of the
+tokenizer.
+
+For BigBird, the tokenizer (sentencepiece) files can be found [here](https://github.com/google-research/bigbird/blob/master/bigbird/vocab/gpt2.model), which you should be able to load
+as easily as:
+
+```python
+from transformers import BertGenerationTokenizer
+tokenizer = BertGenerationTokenizer("/path/to/gpt2.model/file")
+```
+
+To ensure that the tokenizer works correctly, it is recommended to first
+create a script in the original repository that inputs a string and
+returns the `input_ids`. It could look similar to this (in pseudo-code):
+
+```bash
+input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
+model = BigBirdModel.load_pretrained_checkpoint("/path/to/checkpoint/")
+input_ids = model.tokenize(input_str)
+```
+
+You might have to take a deeper look again into the original repository
+to find the correct tokenizer function or you might even have to do
+changes to your clone of the original repository to only output the
+`input_ids`. Having written a functional tokenization script that uses
+the original repository, an analogous script for 🤗 Transformers should
+be created. It should look similar to this:
+
+```python
+from transformers import BertGenerationTokenizer
+input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
+
+tokenizer = BertGenerationTokenizer.from_pretrained("/path/big/bird/folder")
+
+input_ids = tokenizer(input_str).input_ids
+```
+
+When both `input_ids` yield the same values, as a final step a tokenizer
+test file should also be added.
+
+Since BigBird is most likely fully based on `BertGenerationTokenizer`,
+you should only add a couple of "slow" integration tests. However, in this
+case you do **not** need to add any `BigBirdTokenizationTest`.
+
+**10. Run End-to-end integration tests**
+
+Having added the tokenizer, you should also add a couple of end-to-end
+integration tests using both the model and the tokenizer to
+`tests/test_modeling_big_bird.py` in 🤗 Transformers. Such a test
+should show on a meaningful text-to-text sample that the 🤗 Transformers
+implementation works as expected. A meaningful text-to-text sample can
+include, *e.g.*, a source-to-target-translation pair, an
+article-to-summary pair, a question-to-answer pair, etc... If none of
+the ported checkpoints has been fine-tuned on a downstream task it is
+enough to simply rely on the model tests. In a final step to ensure that
+the model is fully functional, it is advised that you also run all tests
+on GPU. It can happen that you forgot to add some `.to(self.device)`
+statements to internal tensors of the model, which in such a test would
+show in an error. In case you have no access to a GPU, the Hugging Face
+team can take care of running those tests for you.
+
+**11. Add Docstring**
+
+Now, all the necessary functionality for *BigBird* is added -
+you're almost done! The only thing left to add is a nice docstring and
+a doc page. The Cookiecutter should have added a template file called
+`docs/source/model_doc/big_bird.rst` that you should fill out.
+Users of your model will usually first look at this page before using
+your model. Hence, the documentation must be understandable and concise.
+It is very useful for the community to add some *Tips* to show how the
+model should be used. Don't hesitate to ping Patrick
+regarding the docstrings.
+
+Next, make sure that the docstring added to
+`src/transformers/models/big_bird/modeling_big_bird.py` is
+correct and included all necessary inputs and outputs. It is always to
+good to remind oneself that documentation should be treated at least as
+carefully as the code in 🤗 Transformers since the documentation is
+usually the first contact point of the community with the model.
+
+**Code refactor**
+
+Great, now you have added all the necessary code for *BigBird*.
+At this point, you should correct some potential incorrect code style by
+running:
+
+```bash
+make style
+```
+
+and verify that your coding style passes the quality check:
+
+```bash
+make quality
+```
+
+There are a couple of other very strict design tests in 🤗 Transformers
+that might still be failing, which shows up in the tests of your pull
+request. This is often because of some missing information in the
+docstring or some incorrect naming. Patrick will surely
+help you if you're stuck here.
+
+Lastly, it is always a good idea to refactor one's code after having
+ensured that the code works correctly. With all tests passing, now it's
+a good time to go over the added code again and do some refactoring.
+
+You have now finished the coding part, congratulation! 🎉 You are
+Awesome! 😎
+
+**12. Upload the models to the model hub**
+
+In this final part, you should convert and upload all checkpoints to the
+model hub and add a model card for each uploaded model checkpoint. You
+should work alongside Patrick here to decide on a fitting
+name for each checkpoint and to get the required access rights to be
+able to upload the model under the author's organization of
+*BigBird*.
+
+It is worth spending some time to create fitting model cards for each
+checkpoint. The model cards should highlight the specific
+characteristics of this particular checkpoint, *e.g.*, On which dataset
+was the checkpoint pretrained/fine-tuned on? On what down-stream task
+should the model be used? And also include some code on how to correctly
+use the model.
+
+**13. (Optional) Add notebook**
+
+It is very helpful to add a notebook that showcases in-detail how
+*BigBird* can be used for inference and/or fine-tuned on a
+downstream task. This is not mandatory to merge your PR, but very useful
+for the community.
+
+**14. Submit your finished PR**
+
+You're done programming now and can move to the last step, which is
+getting your PR merged into main. Usually, Patrick
+should have helped you already at this point, but it is worth taking
+some time to give your finished PR a nice description and eventually add
+comments to your code, if you want to point out certain design choices
+to your reviewer.
+
+### Share your work!!
+
+Now, it's time to get some credit from the community for your work!
+Having completed a model addition is a major contribution to
+Transformers and the whole NLP community. Your code and the ported
+pre-trained models will certainly be used by hundreds and possibly even
+thousands of developers and researchers. You should be proud of your
+work and share your achievement with the community.
+
+**You have made another model that is super easy to access for everyone
+in the community! 🤯**
diff --git a/transformers/templates/adding_a_new_model/open_model_proposals/README.md b/transformers/templates/adding_a_new_model/open_model_proposals/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..dd254209f007540e9607c83b887065e9ad46fe85
--- /dev/null
+++ b/transformers/templates/adding_a_new_model/open_model_proposals/README.md
@@ -0,0 +1,3 @@
+Currently the following model proposals are available:
+
+- [BigBird (Google)](./ADD_BIG_BIRD.md)
diff --git a/transformers/tests/fixtures/tests_samples/.gitignore b/transformers/tests/fixtures/tests_samples/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..1d7141c43dcf8f422e18fe3c13eb8f9e0bb9a964
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/.gitignore
@@ -0,0 +1,6 @@
+cache*
+temp*
+!*.txt
+!*.tsv
+!*.json
+!.gitignore
\ No newline at end of file
diff --git a/transformers/tests/fixtures/tests_samples/COCO/coco_annotations.txt b/transformers/tests/fixtures/tests_samples/COCO/coco_annotations.txt
new file mode 100644
index 0000000000000000000000000000000000000000..bd8c86a9bc3cbbc2f12e5efc58a805c7e9346d37
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/COCO/coco_annotations.txt
@@ -0,0 +1 @@
+[{"segmentation": [[333.96, 175.14, 338.26, 134.33, 342.55, 95.67, 348.99, 79.57, 368.32, 80.64, 371.54, 91.38, 364.03, 106.41, 356.51, 145.07, 351.14, 166.55, 350.07, 184.8, 345.77, 185.88, 332.89, 178.36, 332.89, 172.99]], "area": 2120.991099999999, "iscrowd": 0, "image_id": 39769, "bbox": [332.89, 79.57, 38.65, 106.31], "category_id": 75, "id": 1108446}, {"segmentation": [[44.03, 86.01, 112.75, 74.2, 173.96, 77.42, 175.03, 89.23, 170.74, 98.9, 147.11, 102.12, 54.77, 119.3, 53.69, 119.3, 44.03, 113.93, 41.88, 94.6, 41.88, 94.6]], "area": 4052.607, "iscrowd": 0, "image_id": 39769, "bbox": [41.88, 74.2, 133.15, 45.1], "category_id": 75, "id": 1110067}, {"segmentation": [[1.08, 473.53, 633.17, 473.53, 557.66, 376.45, 535.01, 366.74, 489.71, 305.26, 470.29, 318.2, 456.27, 351.64, 413.12, 363.51, 376.45, 358.11, 348.4, 350.56, 363.51, 331.15, 357.03, 288.0, 353.8, 257.8, 344.09, 190.92, 333.3, 177.98, 345.17, 79.82, 284.76, 130.52, 265.35, 151.01, 308.49, 189.84, 317.12, 215.73, 293.39, 243.78, 269.66, 212.49, 235.15, 199.55, 214.65, 193.08, 187.69, 217.89, 159.64, 278.29, 135.91, 313.89, 169.35, 292.31, 203.87, 281.53, 220.04, 292.31, 220.04, 307.42, 175.82, 345.17, 155.33, 360.27, 105.71, 363.51, 85.21, 374.29, 74.43, 366.74, 70.11, 465.98, 42.07, 471.37, 33.44, 457.35, 34.52, 414.2, 29.12, 368.9, 9.71, 291.24, 46.38, 209.26, 99.24, 128.36, 131.6, 107.87, 50.7, 117.57, 40.99, 103.55, 40.99, 85.21, 60.4, 77.66, 141.3, 70.11, 173.66, 72.27, 174.74, 92.76, 204.94, 72.27, 225.44, 62.56, 262.11, 56.09, 292.31, 53.93, 282.61, 81.98, 298.79, 96.0, 310.65, 102.47, 348.4, 74.43, 373.21, 81.98, 430.38, 35.6, 484.31, 23.73, 540.4, 46.38, 593.26, 66.88, 638.56, 80.9, 632.09, 145.62, 581.39, 118.65, 543.64, 130.52, 533.93, 167.19, 512.36, 197.39, 498.34, 218.97, 529.62, 253.48, 549.03, 273.98, 584.63, 276.13, 587.87, 293.39, 566.29, 305.26, 531.78, 298.79, 549.03, 319.28, 576.0, 358.11, 560.9, 376.45, 639.64, 471.37, 639.64, 2.16, 1.08, 0.0]], "area": 176277.55269999994, "iscrowd": 0, "image_id": 39769, "bbox": [1.08, 0.0, 638.56, 473.53], "category_id": 63, "id": 1605237}, {"segmentation": [[1.07, 1.18, 640.0, 3.33, 638.93, 472.59, 4.3, 479.03]], "area": 301552.6694999999, "iscrowd": 0, "image_id": 39769, "bbox": [1.07, 1.18, 638.93, 477.85], "category_id": 65, "id": 1612051}, {"segmentation": [[138.75, 319.38, 148.75, 294.38, 165.0, 246.87, 197.5, 205.63, 247.5, 203.13, 268.75, 216.88, 280.0, 239.38, 293.75, 244.38, 303.75, 241.88, 307.5, 228.13, 318.75, 220.63, 315.0, 200.63, 291.25, 171.88, 265.0, 156.88, 258.75, 148.13, 262.5, 135.63, 282.5, 123.13, 292.5, 115.63, 311.25, 108.13, 313.75, 106.88, 296.25, 93.13, 282.5, 84.38, 292.5, 64.38, 288.75, 60.63, 266.25, 54.38, 232.5, 63.12, 206.25, 70.63, 170.0, 100.63, 136.25, 114.38, 101.25, 138.13, 56.25, 194.38, 27.5, 259.38, 17.5, 299.38, 32.5, 378.13, 31.25, 448.13, 41.25, 469.38, 66.25, 466.88, 70.0, 419.38, 71.25, 391.88, 77.5, 365.63, 113.75, 364.38, 145.0, 360.63, 168.75, 349.38, 191.25, 330.63, 212.5, 319.38, 223.75, 305.63, 206.25, 286.88, 172.5, 288.13]], "area": 53301.618749999994, "iscrowd": 0, "image_id": 39769, "bbox": [17.5, 54.38, 301.25, 415.0], "category_id": 17, "id": 2190839}, {"segmentation": [[543.75, 136.88, 570.0, 114.38, 591.25, 123.13, 616.25, 140.63, 640.0, 143.13, 636.25, 124.37, 605.0, 103.13, 640.0, 103.13, 633.75, 86.88, 587.5, 73.13, 548.75, 49.38, 505.0, 35.63, 462.5, 25.63, 405.0, 48.13, 362.5, 111.88, 347.5, 179.38, 355.0, 220.63, 356.25, 230.63, 365.0, 264.38, 358.75, 266.88, 358.75, 270.63, 356.25, 291.88, 356.25, 325.63, 355.0, 338.13, 350.0, 348.13, 365.0, 354.38, 396.25, 351.88, 423.75, 355.63, 446.25, 350.63, 460.0, 345.63, 462.5, 321.88, 468.75, 306.88, 481.25, 299.38, 516.25, 341.88, 536.25, 368.13, 570.0, 369.38, 578.75, 359.38, 555.0, 330.63, 532.5, 298.13, 563.75, 299.38, 582.5, 298.13, 586.25, 286.88, 578.75, 278.13, 548.75, 269.38, 525.0, 256.88, 505.0, 206.88, 536.25, 161.88, 540.0, 149.38]], "area": 59700.95625, "iscrowd": 0, "image_id": 39769, "bbox": [347.5, 25.63, 292.5, 343.75], "category_id": 17, "id": 2190842}]
\ No newline at end of file
diff --git a/transformers/tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt b/transformers/tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt
new file mode 100644
index 0000000000000000000000000000000000000000..90a9798be2a2abbc359b698799795c918d4a787b
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt
@@ -0,0 +1 @@
+[{"id": 8222595, "category_id": 17, "iscrowd": 0, "bbox": [18, 54, 301, 415], "area": 53306}, {"id": 8225432, "category_id": 17, "iscrowd": 0, "bbox": [349, 26, 291, 343], "area": 59627}, {"id": 8798150, "category_id": 63, "iscrowd": 0, "bbox": [1, 0, 639, 474], "area": 174579}, {"id": 14466198, "category_id": 75, "iscrowd": 0, "bbox": [42, 74, 133, 45], "area": 4068}, {"id": 12821912, "category_id": 75, "iscrowd": 0, "bbox": [333, 80, 38, 106], "area": 2118}, {"id": 10898909, "category_id": 93, "iscrowd": 0, "bbox": [0, 0, 640, 480], "area": 2750}]
\ No newline at end of file
diff --git a/transformers/tests/fixtures/tests_samples/GermEval/dev.txt b/transformers/tests/fixtures/tests_samples/GermEval/dev.txt
new file mode 100644
index 0000000000000000000000000000000000000000..de001582302780954c8f00af5531372df290a43b
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/GermEval/dev.txt
@@ -0,0 +1,202 @@
+Gleich O
+darauf O
+entwirft O
+er O
+seine O
+Selbstdarstellung O
+" O
+Ecce B-OTH
+homo I-OTH
+" O
+in O
+enger O
+Auseinandersetzung O
+mit O
+diesem O
+Bild O
+Jesu B-PER
+. O
+
+1980 O
+kam O
+der O
+Crown B-OTH
+als O
+Versuch O
+von O
+Toyota B-ORG
+, O
+sich O
+in O
+der O
+Oberen O
+Mittelklasse O
+zu O
+etablieren O
+, O
+auch O
+nach O
+Deutschland B-LOC
+. O
+
+– O
+4:26 O
+# O
+Sometime B-OTH
+Ago/La I-OTH
+Fiesta I-OTH
+– O
+23:18 O
+Alle O
+Stücke O
+wurden O
+von O
+Corea B-PER
+komponiert O
+mit O
+Ausnahme O
+der O
+einleitenden O
+Improvisation O
+zu O
+Sometime B-OTH
+Ago I-OTH
+. O
+
+Bis O
+2013 O
+steigen O
+die O
+Mittel O
+aus O
+dem O
+EU-Budget B-ORGpart
+auf O
+rund O
+120 O
+Millionen O
+Euro B-OTH
+. O
+
+Daraus O
+entwickelte O
+sich O
+im O
+Rokoko B-OTH
+die O
+Sitte O
+des O
+gemeinsamen O
+Weinens O
+im O
+Theater O
+, O
+das O
+die O
+Standesgrenzen O
+innerhalb O
+des O
+Publikums O
+überbrücken O
+sollte O
+. O
+
+Die O
+Spinne O
+hatte O
+sie O
+mit O
+Seidenfäden O
+an O
+ihrem O
+Schwanz O
+gefesselt O
+und O
+nach O
+oben O
+gezogen O
+. O
+
+In O
+Deutschland B-LOC
+ist O
+nach O
+StGB O
+eine O
+Anwerbung O
+für O
+die O
+Fremdenlegion O
+strafbar O
+. O
+
+Am O
+Donnerstag O
+wird O
+sich O
+zeigen O
+, O
+ob O
+die O
+Idee O
+der O
+DLR-Forscher B-ORGpart
+funktioniert O
+. O
+
+Der O
+sechste O
+Lauf O
+der O
+ADAC B-ORG
+GT I-ORG
+Mastersstand O
+ganz O
+klar O
+im O
+Mittelpunkt O
+des O
+Motorsport-Wochenendes O
+auf O
+dem O
+Eurospeedway B-ORG
+Lausitz I-ORG
+. O
+
+Nach O
+den O
+schwächeren O
+Vorgaben O
+der O
+Wall B-ORG
+Street I-ORG
+vom O
+Vortag O
+setzten O
+die O
+deutschen B-LOCderiv
+Standardwerte O
+ihren O
+Konsolidierungskurs O
+fort O
+. O
+
+Kolb B-PER
+war O
+seit O
+1986 O
+im O
+Turnverein O
+als O
+Leiter O
+tätig O
+, O
+darunter O
+elf O
+Jahre O
+als O
+Hauptleiter O
+in O
+der O
+Männerriege O
+. O
diff --git a/transformers/tests/fixtures/tests_samples/GermEval/labels.txt b/transformers/tests/fixtures/tests_samples/GermEval/labels.txt
new file mode 100644
index 0000000000000000000000000000000000000000..a781cbd47ee29d10dc1b8cf823c4ec9600ba0355
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/GermEval/labels.txt
@@ -0,0 +1,25 @@
+B-LOC
+B-LOCderiv
+B-LOCpart
+B-ORG
+B-ORGderiv
+B-ORGpart
+B-OTH
+B-OTHderiv
+B-OTHpart
+B-PER
+B-PERderiv
+B-PERpart
+I-LOC
+I-LOCderiv
+I-LOCpart
+I-ORG
+I-ORGderiv
+I-ORGpart
+I-OTH
+I-OTHderiv
+I-OTHpart
+I-PER
+I-PERderiv
+I-PERpart
+O
diff --git a/transformers/tests/fixtures/tests_samples/GermEval/train.txt b/transformers/tests/fixtures/tests_samples/GermEval/train.txt
new file mode 100644
index 0000000000000000000000000000000000000000..3d613ae1ee9b07901f14bf9107b042fa071c3525
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/GermEval/train.txt
@@ -0,0 +1,200 @@
+Schartau B-PER
+sagte O
+dem O
+" O
+Tagesspiegel B-ORG
+" O
+vom O
+Freitag O
+, O
+Fischer B-PER
+sei O
+" O
+in O
+einer O
+Weise O
+aufgetreten O
+, O
+die O
+alles O
+andere O
+als O
+überzeugend O
+war O
+" O
+. O
+
+Firmengründer O
+Wolf B-PER
+Peter I-PER
+Bree I-PER
+arbeitete O
+Anfang O
+der O
+siebziger O
+Jahre O
+als O
+Möbelvertreter O
+, O
+als O
+er O
+einen O
+fliegenden O
+Händler O
+aus O
+dem O
+Libanon B-LOC
+traf O
+. O
+
+Ob O
+sie O
+dabei O
+nach O
+dem O
+Runden O
+Tisch O
+am O
+23. O
+April O
+in O
+Berlin B-LOC
+durch O
+ein O
+pädagogisches O
+Konzept O
+unterstützt O
+wird O
+, O
+ist O
+allerdings O
+zu O
+bezweifeln O
+. O
+
+Bayern B-ORG
+München I-ORG
+ist O
+wieder O
+alleiniger O
+Top- O
+Favorit O
+auf O
+den O
+Gewinn O
+der O
+deutschen B-LOCderiv
+Fußball-Meisterschaft O
+. O
+
+Dabei O
+hätte O
+der O
+tapfere O
+Schlussmann O
+allen O
+Grund O
+gehabt O
+, O
+sich O
+viel O
+früher O
+aufzuregen O
+. O
+
+ARD-Programmchef B-ORGpart
+Günter B-PER
+Struve I-PER
+war O
+wegen O
+eines O
+vierwöchigen O
+Urlaubs O
+für O
+eine O
+Stellungnahme O
+nicht O
+erreichbar O
+. O
+
+Alternativ O
+sollten O
+sich O
+die O
+Restaurantbetreiber O
+aus O
+Sicht O
+der O
+Solingerin B-LOCderiv
+zu O
+längeren O
+Öffnungszeiten O
+verpflichten O
+, O
+um O
+wartende O
+Kunden O
+aufzunehmen O
+. O
+
+Die O
+Deutsche B-ORG
+Flugsicherung I-ORG
+( O
+DFS B-ORG
+) O
+beschloss O
+ein O
+Flugverbot O
+für O
+alle O
+internationalen O
+Flughäfen O
+mit O
+Ausnahme O
+der O
+beiden O
+Berliner B-LOCderiv
+Flughäfen O
+bis O
+2.00 O
+Uhr O
+nachts O
+. O
+
+New O
+Small O
+Family O
+mit O
+E-Motor O
+: O
+Studie O
+E-Up O
+! O
+
+Eine O
+Schwachstelle O
+war O
+beispielsweise O
+der O
+Spiegelkasten O
+. O
+
+Denn O
+durch O
+den O
+Einsatz O
+moderner O
+Fahrzeugtechnik O
+( O
+Dieseltriebwagen O
+) O
+und O
+schalldämmender O
+Fenster O
+entsteht O
+keine O
+Einschränkung O
+der O
+Wohnqualität O
+. O
diff --git a/transformers/tests/fixtures/tests_samples/MRPC/dev.csv b/transformers/tests/fixtures/tests_samples/MRPC/dev.csv
new file mode 100644
index 0000000000000000000000000000000000000000..96beccda96d7e164e4484e037a52fb338cc22180
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/MRPC/dev.csv
@@ -0,0 +1,7 @@
+label,sentence1,sentence2
+equivalent,He said the foodservice pie business doesn 't fit the company 's long-term growth strategy .,""" The foodservice pie business does not fit our long-term growth strategy ."
+not_equivalent,Magnarelli said Racicot hated the Iraqi regime and looked forward to using his long years of training in the war .,"His wife said he was "" 100 percent behind George Bush "" and looked forward to using his years of training in the war ."
+not_equivalent,"The dollar was at 116.92 yen against the yen , flat on the session , and at 1.2891 against the Swiss franc , also flat .","The dollar was at 116.78 yen JPY = , virtually flat on the session , and at 1.2871 against the Swiss franc CHF = , down 0.1 percent ."
+equivalent,The AFL-CIO is waiting until October to decide if it will endorse a candidate .,The AFL-CIO announced Wednesday that it will decide in October whether to endorse a candidate before the primaries .
+not_equivalent,No dates have been set for the civil or the criminal trial .,"No dates have been set for the criminal or civil cases , but Shanley has pleaded not guilty ."
+equivalent,Wal-Mart said it would check all of its million-plus domestic workers to ensure they were legally employed .,It has also said it would review all of its domestic employees more than 1 million to ensure they have legal status .
diff --git a/transformers/tests/fixtures/tests_samples/MRPC/dev.tsv b/transformers/tests/fixtures/tests_samples/MRPC/dev.tsv
new file mode 100644
index 0000000000000000000000000000000000000000..5b814856c63f44ef8c082726ae19285a4faec26c
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/MRPC/dev.tsv
@@ -0,0 +1,7 @@
+Quality #1 ID #2 ID #1 String #2 String
+1 1355540 1355592 He said the foodservice pie business doesn 't fit the company 's long-term growth strategy . " The foodservice pie business does not fit our long-term growth strategy .
+0 2029631 2029565 Magnarelli said Racicot hated the Iraqi regime and looked forward to using his long years of training in the war . His wife said he was " 100 percent behind George Bush " and looked forward to using his years of training in the war .
+0 487993 487952 The dollar was at 116.92 yen against the yen , flat on the session , and at 1.2891 against the Swiss franc , also flat . The dollar was at 116.78 yen JPY = , virtually flat on the session , and at 1.2871 against the Swiss franc CHF = , down 0.1 percent .
+1 1989515 1989458 The AFL-CIO is waiting until October to decide if it will endorse a candidate . The AFL-CIO announced Wednesday that it will decide in October whether to endorse a candidate before the primaries .
+0 1783137 1782659 No dates have been set for the civil or the criminal trial . No dates have been set for the criminal or civil cases , but Shanley has pleaded not guilty .
+1 3039165 3039036 Wal-Mart said it would check all of its million-plus domestic workers to ensure they were legally employed . It has also said it would review all of its domestic employees more than 1 million to ensure they have legal status .
diff --git a/transformers/tests/fixtures/tests_samples/MRPC/train.csv b/transformers/tests/fixtures/tests_samples/MRPC/train.csv
new file mode 100644
index 0000000000000000000000000000000000000000..96beccda96d7e164e4484e037a52fb338cc22180
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/MRPC/train.csv
@@ -0,0 +1,7 @@
+label,sentence1,sentence2
+equivalent,He said the foodservice pie business doesn 't fit the company 's long-term growth strategy .,""" The foodservice pie business does not fit our long-term growth strategy ."
+not_equivalent,Magnarelli said Racicot hated the Iraqi regime and looked forward to using his long years of training in the war .,"His wife said he was "" 100 percent behind George Bush "" and looked forward to using his years of training in the war ."
+not_equivalent,"The dollar was at 116.92 yen against the yen , flat on the session , and at 1.2891 against the Swiss franc , also flat .","The dollar was at 116.78 yen JPY = , virtually flat on the session , and at 1.2871 against the Swiss franc CHF = , down 0.1 percent ."
+equivalent,The AFL-CIO is waiting until October to decide if it will endorse a candidate .,The AFL-CIO announced Wednesday that it will decide in October whether to endorse a candidate before the primaries .
+not_equivalent,No dates have been set for the civil or the criminal trial .,"No dates have been set for the criminal or civil cases , but Shanley has pleaded not guilty ."
+equivalent,Wal-Mart said it would check all of its million-plus domestic workers to ensure they were legally employed .,It has also said it would review all of its domestic employees more than 1 million to ensure they have legal status .
diff --git a/transformers/tests/fixtures/tests_samples/MRPC/train.tsv b/transformers/tests/fixtures/tests_samples/MRPC/train.tsv
new file mode 100644
index 0000000000000000000000000000000000000000..5b814856c63f44ef8c082726ae19285a4faec26c
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/MRPC/train.tsv
@@ -0,0 +1,7 @@
+Quality #1 ID #2 ID #1 String #2 String
+1 1355540 1355592 He said the foodservice pie business doesn 't fit the company 's long-term growth strategy . " The foodservice pie business does not fit our long-term growth strategy .
+0 2029631 2029565 Magnarelli said Racicot hated the Iraqi regime and looked forward to using his long years of training in the war . His wife said he was " 100 percent behind George Bush " and looked forward to using his years of training in the war .
+0 487993 487952 The dollar was at 116.92 yen against the yen , flat on the session , and at 1.2891 against the Swiss franc , also flat . The dollar was at 116.78 yen JPY = , virtually flat on the session , and at 1.2871 against the Swiss franc CHF = , down 0.1 percent .
+1 1989515 1989458 The AFL-CIO is waiting until October to decide if it will endorse a candidate . The AFL-CIO announced Wednesday that it will decide in October whether to endorse a candidate before the primaries .
+0 1783137 1782659 No dates have been set for the civil or the criminal trial . No dates have been set for the criminal or civil cases , but Shanley has pleaded not guilty .
+1 3039165 3039036 Wal-Mart said it would check all of its million-plus domestic workers to ensure they were legally employed . It has also said it would review all of its domestic employees more than 1 million to ensure they have legal status .
diff --git a/transformers/tests/fixtures/tests_samples/SQUAD/sample.json b/transformers/tests/fixtures/tests_samples/SQUAD/sample.json
new file mode 100644
index 0000000000000000000000000000000000000000..ed3dcc27d721f4a09ac3f23fee07f6e64441535d
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/SQUAD/sample.json
@@ -0,0 +1,201 @@
+{
+ "version": 2.0,
+ "data": [
+ {
+ "id": "56ddde6b9a695914005b9628",
+ "question": "In what country is Normandy located?",
+ "context": "The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse (\"Norman\" comes from \"Norseman\") raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, agreed to swear fealty to King Charles III of West Francia. Through generations of assimilation and mixing with the native Frankish and Roman-Gaulish populations, their descendants would gradually merge with the Carolingian-based cultures of West Francia. The distinct cultural and ethnic identity of the Normans emerged initially in the first half of the 10th century, and it continued to evolve over the succeeding centuries.",
+ "answers": {
+ "answer_start": [
+ 159,
+ 159,
+ 159,
+ 159
+ ],
+ "text": [
+ "France",
+ "France",
+ "France",
+ "France"
+ ]
+ }
+ },
+ {
+ "id": "56ddde6b9a695914005b9629",
+ "question": "When were the Normans in Normandy?",
+ "context": "The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse (\"Norman\" comes from \"Norseman\") raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, agreed to swear fealty to King Charles III of West Francia. Through generations of assimilation and mixing with the native Frankish and Roman-Gaulish populations, their descendants would gradually merge with the Carolingian-based cultures of West Francia. The distinct cultural and ethnic identity of the Normans emerged initially in the first half of the 10th century, and it continued to evolve over the succeeding centuries.",
+ "answers": {
+ "answer_start": [
+ 94,
+ 87,
+ 94,
+ 94
+ ],
+ "text": [
+ "10th and 11th centuries",
+ "in the 10th and 11th centuries",
+ "10th and 11th centuries",
+ "10th and 11th centuries"
+ ]
+ }
+ },
+ {
+ "id": "56ddde6b9a695914005b962a",
+ "question": "From which countries did the Norse originate?",
+ "context": "The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse (\"Norman\" comes from \"Norseman\") raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, agreed to swear fealty to King Charles III of West Francia. Through generations of assimilation and mixing with the native Frankish and Roman-Gaulish populations, their descendants would gradually merge with the Carolingian-based cultures of West Francia. The distinct cultural and ethnic identity of the Normans emerged initially in the first half of the 10th century, and it continued to evolve over the succeeding centuries.",
+ "answers": {
+ "answer_start": [
+ 256,
+ 256,
+ 256,
+ 256
+ ],
+ "text": [
+ "Denmark, Iceland and Norway",
+ "Denmark, Iceland and Norway",
+ "Denmark, Iceland and Norway",
+ "Denmark, Iceland and Norway"
+ ]
+ }
+ },
+ {
+ "id": "5ad39d53604f3c001a3fe8d3",
+ "question": "Who did King Charles III swear fealty to?",
+ "context": "The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse (\"Norman\" comes from \"Norseman\") raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, agreed to swear fealty to King Charles III of West Francia. Through generations of assimilation and mixing with the native Frankish and Roman-Gaulish populations, their descendants would gradually merge with the Carolingian-based cultures of West Francia. The distinct cultural and ethnic identity of the Normans emerged initially in the first half of the 10th century, and it continued to evolve over the succeeding centuries.",
+ "answers": {
+ "answer_start": [],
+ "text": []
+ }
+ },
+ {
+ "id": "5ad39d53604f3c001a3fe8d4",
+ "question": "When did the Frankish identity emerge?",
+ "context": "The Normans (Norman: Nourmands; French: Normands; Latin: Normanni) were the people who in the 10th and 11th centuries gave their name to Normandy, a region in France. They were descended from Norse (\"Norman\" comes from \"Norseman\") raiders and pirates from Denmark, Iceland and Norway who, under their leader Rollo, agreed to swear fealty to King Charles III of West Francia. Through generations of assimilation and mixing with the native Frankish and Roman-Gaulish populations, their descendants would gradually merge with the Carolingian-based cultures of West Francia. The distinct cultural and ethnic identity of the Normans emerged initially in the first half of the 10th century, and it continued to evolve over the succeeding centuries.",
+ "answers": {
+ "answer_start": [],
+ "text": []
+ }
+ },
+ {
+ "id": "56dddf4066d3e219004dad5f",
+ "question": "Who was the duke in the battle of Hastings?",
+ "context": "The Norman dynasty had a major political, cultural and military impact on medieval Europe and even the Near East. The Normans were famed for their martial spirit and eventually for their Christian piety, becoming exponents of the Catholic orthodoxy into which they assimilated. They adopted the Gallo-Romance language of the Frankish land they settled, their dialect becoming known as Norman, Normaund or Norman French, an important literary language. The Duchy of Normandy, which they formed by treaty with the French crown, was a great fief of medieval France, and under Richard I of Normandy was forged into a cohesive and formidable principality in feudal tenure. The Normans are noted both for their culture, such as their unique Romanesque architecture and musical traditions, and for their significant military accomplishments and innovations. Norman adventurers founded the Kingdom of Sicily under Roger II after conquering southern Italy on the Saracens and Byzantines, and an expedition on behalf of their duke, William the Conqueror, led to the Norman conquest of England at the Battle of Hastings in 1066. Norman cultural and military influence spread from these new European centres to the Crusader states of the Near East, where their prince Bohemond I founded the Principality of Antioch in the Levant, to Scotland and Wales in Great Britain, to Ireland, and to the coasts of north Africa and the Canary Islands.",
+ "answers": {
+ "answer_start": [
+ 1022,
+ 1022,
+ 1022
+ ],
+ "text": [
+ "William the Conqueror",
+ "William the Conqueror",
+ "William the Conqueror"
+ ]
+ }
+ },
+ {
+ "id": "5ad3a266604f3c001a3fea2b",
+ "question": "What principality did William the conquerer found?",
+ "context": "The Norman dynasty had a major political, cultural and military impact on medieval Europe and even the Near East. The Normans were famed for their martial spirit and eventually for their Christian piety, becoming exponents of the Catholic orthodoxy into which they assimilated. They adopted the Gallo-Romance language of the Frankish land they settled, their dialect becoming known as Norman, Normaund or Norman French, an important literary language. The Duchy of Normandy, which they formed by treaty with the French crown, was a great fief of medieval France, and under Richard I of Normandy was forged into a cohesive and formidable principality in feudal tenure. The Normans are noted both for their culture, such as their unique Romanesque architecture and musical traditions, and for their significant military accomplishments and innovations. Norman adventurers founded the Kingdom of Sicily under Roger II after conquering southern Italy on the Saracens and Byzantines, and an expedition on behalf of their duke, William the Conqueror, led to the Norman conquest of England at the Battle of Hastings in 1066. Norman cultural and military influence spread from these new European centres to the Crusader states of the Near East, where their prince Bohemond I founded the Principality of Antioch in the Levant, to Scotland and Wales in Great Britain, to Ireland, and to the coasts of north Africa and the Canary Islands.",
+ "answers": {
+ "answer_start": [],
+ "text": []
+ }
+ },
+ {
+ "id": "56e16182e3433e1400422e28",
+ "question": "What branch of theoretical computer science deals with broadly classifying computational problems by difficulty and class of relationship?",
+ "context": "Computational complexity theory is a branch of the theory of computation in theoretical computer science that focuses on classifying computational problems according to their inherent difficulty, and relating those classes to each other. A computational problem is understood to be a task that is in principle amenable to being solved by a computer, which is equivalent to stating that the problem may be solved by mechanical application of mathematical steps, such as an algorithm.",
+ "answers": {
+ "answer_start": [
+ 0,
+ 0,
+ 0
+ ],
+ "text": [
+ "Computational complexity theory",
+ "Computational complexity theory",
+ "Computational complexity theory"
+ ]
+ }
+ },
+ {
+ "id": "5ad5316b5b96ef001a10ab76",
+ "question": "What is a manual application of mathematical steps?",
+ "context": "Computational complexity theory is a branch of the theory of computation in theoretical computer science that focuses on classifying computational problems according to their inherent difficulty, and relating those classes to each other. A computational problem is understood to be a task that is in principle amenable to being solved by a computer, which is equivalent to stating that the problem may be solved by mechanical application of mathematical steps, such as an algorithm.",
+ "answers": {
+ "answer_start": [],
+ "text": []
+ }
+ },
+ {
+ "id": "56e16839cd28a01900c67887",
+ "question": "What measure of a computational problem broadly defines the inherent difficulty of the solution?",
+ "context": "A problem is regarded as inherently difficult if its solution requires significant resources, whatever the algorithm used. The theory formalizes this intuition, by introducing mathematical models of computation to study these problems and quantifying the amount of resources needed to solve them, such as time and storage. Other complexity measures are also used, such as the amount of communication (used in communication complexity), the number of gates in a circuit (used in circuit complexity) and the number of processors (used in parallel computing). One of the roles of computational complexity theory is to determine the practical limits on what computers can and cannot do.",
+ "answers": {
+ "answer_start": [
+ 46,
+ 49,
+ 46
+ ],
+ "text": [
+ "if its solution requires significant resources",
+ "its solution requires significant resources",
+ "if its solution requires significant resources"
+ ]
+ }
+ },
+ {
+ "id": "56e16839cd28a01900c67888",
+ "question": "What method is used to intuitively assess or quantify the amount of resources required to solve a computational problem?",
+ "context": "A problem is regarded as inherently difficult if its solution requires significant resources, whatever the algorithm used. The theory formalizes this intuition, by introducing mathematical models of computation to study these problems and quantifying the amount of resources needed to solve them, such as time and storage. Other complexity measures are also used, such as the amount of communication (used in communication complexity), the number of gates in a circuit (used in circuit complexity) and the number of processors (used in parallel computing). One of the roles of computational complexity theory is to determine the practical limits on what computers can and cannot do.",
+ "answers": {
+ "answer_start": [
+ 176,
+ 176,
+ 176
+ ],
+ "text": [
+ "mathematical models of computation",
+ "mathematical models of computation",
+ "mathematical models of computation"
+ ]
+ }
+ },
+ {
+ "id": "56e16839cd28a01900c67889",
+ "question": "What are two basic primary resources used to guage complexity?",
+ "context": "A problem is regarded as inherently difficult if its solution requires significant resources, whatever the algorithm used. The theory formalizes this intuition, by introducing mathematical models of computation to study these problems and quantifying the amount of resources needed to solve them, such as time and storage. Other complexity measures are also used, such as the amount of communication (used in communication complexity), the number of gates in a circuit (used in circuit complexity) and the number of processors (used in parallel computing). One of the roles of computational complexity theory is to determine the practical limits on what computers can and cannot do.",
+ "answers": {
+ "answer_start": [
+ 305,
+ 305,
+ 305
+ ],
+ "text": [
+ "time and storage",
+ "time and storage",
+ "time and storage"
+ ]
+ }
+ },
+ {
+ "id": "5ad532575b96ef001a10ab7f",
+ "question": "What unit is measured to determine circuit simplicity?",
+ "context": "A problem is regarded as inherently difficult if its solution requires significant resources, whatever the algorithm used. The theory formalizes this intuition, by introducing mathematical models of computation to study these problems and quantifying the amount of resources needed to solve them, such as time and storage. Other complexity measures are also used, such as the amount of communication (used in communication complexity), the number of gates in a circuit (used in circuit complexity) and the number of processors (used in parallel computing). One of the roles of computational complexity theory is to determine the practical limits on what computers can and cannot do.",
+ "answers": {
+ "answer_start": [],
+ "text": []
+ }
+ },
+ {
+ "id": "5ad532575b96ef001a10ab80",
+ "question": "What number is used in perpendicular computing?",
+ "context": "A problem is regarded as inherently difficult if its solution requires significant resources, whatever the algorithm used. The theory formalizes this intuition, by introducing mathematical models of computation to study these problems and quantifying the amount of resources needed to solve them, such as time and storage. Other complexity measures are also used, such as the amount of communication (used in communication complexity), the number of gates in a circuit (used in circuit complexity) and the number of processors (used in parallel computing). One of the roles of computational complexity theory is to determine the practical limits on what computers can and cannot do.",
+ "answers": {
+ "answer_start": [],
+ "text": []
+ }
+ }
+ ]
+}
diff --git a/transformers/tests/fixtures/tests_samples/STS-B/dev.tsv b/transformers/tests/fixtures/tests_samples/STS-B/dev.tsv
new file mode 100644
index 0000000000000000000000000000000000000000..8d689c2ccc67dc4cd533562da00e1731f80902f3
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/STS-B/dev.tsv
@@ -0,0 +1,10 @@
+index genre filename year old_index source1 source2 sentence1 sentence2 score
+0 main-captions MSRvid 2012test 0000 none none A man with a hard hat is dancing. A man wearing a hard hat is dancing. 5.000
+1 main-captions MSRvid 2012test 0002 none none A young child is riding a horse. A child is riding a horse. 4.750
+2 main-captions MSRvid 2012test 0003 none none A man is feeding a mouse to a snake. The man is feeding a mouse to the snake. 5.000
+3 main-captions MSRvid 2012test 0007 none none A woman is playing the guitar. A man is playing guitar. 2.400
+4 main-captions MSRvid 2012test 0008 none none A woman is playing the flute. A man is playing a flute. 2.750
+5 main-captions MSRvid 2012test 0010 none none A woman is cutting an onion. A man is cutting onions. 2.615
+6 main-captions MSRvid 2012test 0015 none none A man is erasing a chalk board. The man is erasing the chalk board. 5.000
+7 main-captions MSRvid 2012test 0023 none none A woman is carrying a boy. A woman is carrying her baby. 2.333
+8 main-captions MSRvid 2012test 0027 none none Three men are playing guitars. Three men are on stage playing guitars. 3.750
diff --git a/transformers/tests/fixtures/tests_samples/STS-B/train.tsv b/transformers/tests/fixtures/tests_samples/STS-B/train.tsv
new file mode 100644
index 0000000000000000000000000000000000000000..a38be956d6020fff987ad2cd73bc576f2986d36b
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/STS-B/train.tsv
@@ -0,0 +1,10 @@
+index genre filename year old_index source1 source2 sentence1 sentence2 score
+0 main-captions MSRvid 2012test 0001 none none A plane is taking off. An air plane is taking off. 5.000
+1 main-captions MSRvid 2012test 0004 none none A man is playing a large flute. A man is playing a flute. 3.800
+2 main-captions MSRvid 2012test 0005 none none A man is spreading shreded cheese on a pizza. A man is spreading shredded cheese on an uncooked pizza. 3.800
+3 main-captions MSRvid 2012test 0006 none none Three men are playing chess. Two men are playing chess. 2.600
+4 main-captions MSRvid 2012test 0009 none none A man is playing the cello. A man seated is playing the cello. 4.250
+5 main-captions MSRvid 2012test 0011 none none Some men are fighting. Two men are fighting. 4.250
+6 main-captions MSRvid 2012test 0012 none none A man is smoking. A man is skating. 0.500
+7 main-captions MSRvid 2012test 0013 none none The man is playing the piano. The man is playing the guitar. 1.600
+8 main-captions MSRvid 2012test 0014 none none A man is playing on a guitar and singing. A woman is playing an acoustic guitar and singing. 2.200
diff --git a/transformers/tests/fixtures/tests_samples/conll/sample.json b/transformers/tests/fixtures/tests_samples/conll/sample.json
new file mode 100644
index 0000000000000000000000000000000000000000..0bc42a92fe8c934850df8967a293eb8df7cd3c88
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/conll/sample.json
@@ -0,0 +1,10 @@
+{"words": ["He", "was", "the", "27th", "pitcher", "used", "by", "the", "Angels", "this", "season", ",", "tying", "a", "major-league", "record", "."], "ner": ["O", "O", "O", "O", "O", "O", "O", "O", "B-ORG", "O", "O", "O", "O", "O", "O", "O", "O"]}
+{"words": ["CHICAGO", "AT", "ATLANTA"], "ner": ["B-ORG", "O", "B-LOC"]}
+{"words": ["President", "Bill", "Clinton", "earlier", "this", "month", "invoked", "special", "powers", "to", "appoint", "Fowler", "during", "the", "congressional", "recess", "because", "the", "Senate", "delayed", "confirming", "his", "nomination", "."], "ner": ["O", "B-PER", "I-PER", "O", "O", "O", "O", "O", "O", "O", "O", "B-PER", "O", "O", "O", "O", "O", "O", "B-ORG", "O", "O", "O", "O", "O"]}
+{"words": ["goals", "for", ",", "goals", "against", ",", "points", ")", "."], "ner": ["O", "O", "O", "O", "O", "O", "O", "O", "O"]}
+{"words": ["\"", "It", "is", "one", "step", "short", "of", "an", "emergency", "situation", ",", "\"", "a", "police", "spokesman", "said", "via", "telephone", "from", "a", "command", "post", "in", "the", "bush", "."], "ner": ["O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"]}
+{"words": ["U.S.", "Ambassador", "Myles", "Frechette", "applauded", "the", "move", ",", "saying", "it", "could", "prompt", "the", "Clinton", "administration", "to", "remove", "Colombia", "from", "a", "list", "of", "outcast", "nations", "that", "have", "failed", "to", "cooperate", "in", "U.S.", "counternarcotics", "efforts", "."], "ner": ["B-LOC", "O", "B-PER", "I-PER", "O", "O", "O", "O", "O", "O", "O", "O", "O", "B-PER", "O", "O", "O", "B-LOC", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "B-LOC", "O", "O", "O"]}
+{"words": ["Halftime"], "ner": ["O"]}
+{"words": ["It", "has", "manufacturing", "plants", "in", "San", "Diego", ";", "Creedmoor", ",", "N.C.", ";", "Hampshire", ",", "England", ";", "and", "Tijuana", ",", "Mexico", ",", "and", "distributes", "its", "prodcuts", "in", "more", "than", "120", "countries", "."], "ner": ["O", "O", "O", "O", "O", "B-LOC", "I-LOC", "O", "B-LOC", "O", "B-LOC", "O", "B-LOC", "O", "B-LOC", "O", "O", "B-LOC", "O", "B-LOC", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"]}
+{"words": ["Scotland", "manager", "Craig", "Brown", "said", "on", "Thursday", ":", "\"", "I", "'ve", "watched", "Duncan", "Ferguson", "in", "action", "twice", "recently", "and", "he", "'s", "bang", "in", "form", "."], "ner": ["B-LOC", "O", "B-PER", "I-PER", "O", "O", "O", "O", "O", "O", "O", "O", "B-PER", "I-PER", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O"]}
+{"words": ["Clinton", "flew", "in", "by", "helicopter", "from", "Michigan", "City", ",", "Indiana", ",", "after", "ending", "a", "four-day", ",", "559-mile", "trip", "aboard", "a", "campaign", "train", "from", "Washington", "."], "ner": ["B-PER", "O", "O", "O", "O", "O", "B-LOC", "I-LOC", "O", "B-LOC", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "O", "B-LOC", "O"]}
\ No newline at end of file
diff --git a/transformers/tests/fixtures/tests_samples/swag/sample.json b/transformers/tests/fixtures/tests_samples/swag/sample.json
new file mode 100644
index 0000000000000000000000000000000000000000..d00ad8d184e380570c05836c3c1e167f46256cbb
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/swag/sample.json
@@ -0,0 +1,10 @@
+{"ending0": "passes by walking down the street playing their instruments.", "ending1": "has heard approaching them.", "ending2": "arrives and they're outside dancing and asleep.", "ending3": "turns the lead singer watches the performance.", "label": 0, "sent1": "Members of the procession walk down the street holding small horn brass instruments.", "sent2": "A drum line"}
+{"ending0": "are playing ping pong and celebrating one left each in quick.", "ending1": "wait slowly towards the cadets.", "ending2": "continues to play as well along the crowd along with the band being interviewed.", "ending3": "continue to play marching, interspersed.", "label": 3, "sent1": "A drum line passes by walking down the street playing their instruments.", "sent2": "Members of the procession"}
+{"ending0": "pay the other coaches to cheer as people this chatter dips in lawn sheets.", "ending1": "walk down the street holding small horn brass instruments.", "ending2": "is seen in the background.", "ending3": "are talking a couple of people playing a game of tug of war.", "label": 1, "sent1": "A group of members in green uniforms walks waving flags.", "sent2": "Members of the procession"}
+{"ending0": "are playing ping pong and celebrating one left each in quick.", "ending1": "wait slowly towards the cadets.", "ending2": "makes a square call and ends by jumping down into snowy streets where fans begin to take their positions.", "ending3": "play and go back and forth hitting the drums while the audience claps for them.", "label": 3, "sent1": "A drum line passes by walking down the street playing their instruments.", "sent2": "Members of the procession"}
+{"ending0": "finishes the song and lowers the instrument.", "ending1": "hits the saxophone and demonstrates how to properly use the racquet.", "ending2": "finishes massage the instrument again and continues.", "ending3": "continues dancing while the man gore the music outside while drums.", "label": 0, "sent1": "The person plays a song on the violin.", "sent2": "The man"}
+{"ending0": "finishes playing then marches their tenderly.", "ending1": "walks in frame and rubs on his hands, and then walks into a room.", "ending2": "continues playing guitar while moving from the camera.", "ending3": "plays a song on the violin.", "label": 3, "sent1": "The person holds up the violin to his chin and gets ready.", "sent2": "The person"}
+{"ending0": "examines the instrument in his hand.", "ending1": "stops playing the drums and waves over the other boys.", "ending2": "lights the cigarette and sticks his head in.", "ending3": "drags off the vacuum.", "label": 0, "sent1": "A person retrieves an instrument from a closet.", "sent2": "The man"}
+{"ending0": "studies a picture of the man playing the violin.", "ending1": "holds up the violin to his chin and gets ready.", "ending2": "stops to speak to the camera again.", "ending3": "puts his arm around the man and backs away.", "label": 1, "sent1": "The man examines the instrument in his hand.", "sent2": "The person"}
+{"ending0": "hands her another phone.", "ending1": "takes the drink, then holds it.", "ending2": "looks off then looks at someone.", "ending3": "stares blearily down at the floor.", "label": 3, "sent1": "Someone walks over to the radio.", "sent2": "Someone"}
+{"ending0": "looks off then looks at someone.", "ending1": "hands her another phone.", "ending2": "takes the drink, then holds it.", "ending3": "turns on a monitor.", "label": 3, "sent1": "Someone walks over to the radio.", "sent2": "Someone"}
diff --git a/transformers/tests/fixtures/tests_samples/wiki_text/wiki_00 b/transformers/tests/fixtures/tests_samples/wiki_text/wiki_00
new file mode 100644
index 0000000000000000000000000000000000000000..773074910b487eed863883642ea192b972bfc84b
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/wiki_text/wiki_00
@@ -0,0 +1,251 @@
+
+Anarchism
+
+Anarchism is a political philosophy and movement that rejects all involuntary, coercive forms of hierarchy. It radically calls for the abolition of the state which it holds to be undesirable, unnecessary, and harmful.
+
+The history of anarchism stretches back to prehistory, when humans lived in anarchistic societies long before the establishment of formal states, realms or empires. With the rise of organised hierarchical bodies, skepticism toward authority also rose, but it was not until the 19th century that a self-conscious political movement emerged. During the latter half of the 19th and the first decades of the 20th century, the anarchist movement flourished in most parts of the world and had a significant role in worker's struggles for emancipation. Various anarchist schools of thought formed during this period.
+
+Anarchists took part in several revolutions, most notably in the Spanish Civil War, where they were crushed along with the alliance to restore the Second Republic by the fascist forces of the Nationalist faction and its foreign allies in Nazi Germany, Fascist Italy, Portuguese Dictatorship and the Catholic Church in 1939, marking the end of the classical era of anarchism. In the last decades of the 20th century and into the 21st century, the anarchist movement has been resurgent once more.
+
+Anarchism employs various tactics in order to meet its ideal ends; these can be broadly separated into revolutionary and evolutionary tactics. There is significant overlap between the two, which are merely descriptive. Revolutionary tactics aim to bring down authority and state, and have taken a violent turn in the past. Evolutionary tactics aim to prefigure what an anarchist society would be like. Anarchist thought, criticism, and praxis has played a part in diverse areas of human society.
+
+The etymological origin of "anarchism" is from the Ancient Greek "anarkhia", meaning "without a ruler", composed of the prefix "an-" (i.e. "without") and the word "arkhos" (i.e. "leader" or "ruler"). The suffix "-ism" denotes the ideological current that favours anarchy. "Anarchism" appears in English from 1642 as "anarchisme" and "anarchy" from 1539. Various factions within the French Revolution labelled their opponents as "anarchists", although few such accused shared many views with later anarchists. Many revolutionaries of the 19th century such as William Godwin (1756–1836) and Wilhelm Weitling (1808–1871) would contribute to the anarchist doctrines of the next generation, but they did not use "anarchist" or "anarchism" in describing themselves or their beliefs.
+
+The first political philosopher to call himself an "anarchist" () was Pierre-Joseph Proudhon (1809–1865), marking the formal birth of anarchism in the mid-19th century. Since the 1890s and beginning in France, "libertarianism" has often been used as a synonym for anarchism and its use as a synonym is still common outside the United States. On the other hand, some use "libertarianism" to refer to individualistic free-market philosophy only, referring to free-market anarchism as "libertarian anarchism".
+
+While opposition to the state is central to anarchist thought, defining anarchism is not an easy task as there is a lot of discussion among scholars and anarchists on the matter and various currents perceive anarchism slightly differently. Hence, it might be true to say that anarchism is a cluster of political philosophies opposing authority and hierarchical organization (including the state, capitalism, nationalism and all associated institutions) in the conduct of all human relations in favour of a society based on voluntary association, on freedom and on decentralisation, but this definition has the same shortcomings as the definition based on etymology (which is simply a negation of a ruler), or based on anti-statism (anarchism is much more than that) or even the anti-authoritarian (which is an "a posteriori" conclusion). Nonetheless, major elements of the definition of anarchism include the following:
+
+During the prehistoric era of mankind, an established authority did not exist. It was after the creation of towns and cities that institutions of authority were established and anarchistic ideas espoused as a reaction. Most notable precursors to anarchism in the ancient world were in China and Greece. In China, philosophical anarchism (i.e. the discussion on the legitimacy of the state) was delineated by Taoist philosophers Zhuang Zhou and Laozi.
+
+Likewise, anarchic attitudes were articulated by tragedians and philosophers in Greece. Aeschylus and Sophocles used the myth of Antigone to illustrate the conflict between rules set by the state and personal autonomy. Socrates questioned Athenian authorities constantly and insisted to the right of individual freedom of consciousness. Cynics dismissed human law ("nomos") and associated authorities while trying to live according to nature ("physis"). Stoics were supportive of a society based on unofficial and friendly relations among its citizens without the presence of a state.
+
+During the Middle Ages, there was no anarchistic activity except some ascetic religious movements in the Muslim world or in Christian Europe. This kind of tradition later gave birth to religious anarchism. In the Sasanian Empire, Mazdak called for an egalitarian society and the abolition of monarchy, only to be soon executed by Emperor Kavad I.
+
+In Basra, religious sects preached against the state. In Europe, various sects developed anti-state and libertarian tendencies. Libertarian ideas further emerged during the Renaissance with the spread of reasoning and humanism through Europe. Novelists fictionalised ideal societies that were based not on coercion but voluntarism. The Enlightenment further pushed towards anarchism with the optimism for social progress.
+
+During the French Revolution, partisan groups such as the Enragés and the saw a turning point in the fermentation of anti-state and federalist sentiments. The first anarchist currents developed throughout the 18th century—William Godwin espoused philosophical anarchism in England, morally delegitimizing the state, Max Stirner's thinking paved the way to individualism, and Pierre-Joseph Proudhon's theory of mutualism found fertile soil in France. This era of classical anarchism lasted until the end of the Spanish Civil War of 1936 and is considered the golden age of anarchism.
+Drawing from mutualism, Mikhail Bakunin founded collectivist anarchism and entered the International Workingmen's Association, a class worker union later known as the First International that formed in 1864 to unite diverse revolutionary currents. The International became a significant political force, with Karl Marx being a leading figure and a member of its General Council. Bakunin's faction (the Jura Federation) and Proudhon's followers (the mutualists) opposed Marxist state socialism, advocating political abstentionism and small property holdings. After bitter disputes, the Bakuninists were expelled from the International by the Marxists at the 1872 Hague Congress. Bakunin famously predicted that if revolutionaries gained power by Marx's terms, they would end up the new tyrants of workers. After being expelled, anarchists formed the St. Imier International. Under the influence of Peter Kropotkin, a Russian philosopher and scientist, anarcho-communism overlapped with collectivism. Anarcho-communists, who drew inspiration from the 1871 Paris Commune, advocated for free federation and for the distribution of goods according to one's needs.
+
+At the turn of the century, anarchism had spread all over the world. In China, small groups of students imported the humanistic pro-science version of anarcho-communism. Tokyo was a hotspot for rebellious youth from countries of the far east, travelling to the Japanese capital to study. In Latin America, Argentina was a stronghold for anarcho-syndicalism, where it became the most prominent left-wing ideology. During this time, a minority of anarchists adopted tactics of revolutionary political violence. This strategy became known as propaganda of the deed. The dismemberment of the French socialist movement into many groups, and the execution and exile of many Communards to penal colonies following the suppression of the Paris Commune, favoured individualist political expression and acts. Even though many anarchists distanced themselves from these terrorist acts, infamy came upon the movement. Illegalism was another strategy which some anarchists adopted during this period.
+Anarchists enthusiastically participated in the Russian Revolution—despite concerns—in opposition to the Whites. However, they met harsh suppression after the Bolshevik government was stabilized. Several anarchists from Petrograd and Moscow fled to Ukraine, notably leading to the Kronstadt rebellion and Nestor Makhno's struggle in the Free Territory. With the anarchists being crushed in Russia, two new antithetical currents emerged, namely platformism and synthesis anarchism. The former sought to create a coherent group that would push for revolution while the latter were against anything that would resemble a political party. Seeing the victories of the Bolsheviks in the October Revolution and the resulting Russian Civil War, many workers and activists turned to communist parties, which grew at the expense of anarchism and other socialist movements. In France and the United States, members of major syndicalist movements, the General Confederation of Labour and Industrial Workers of the World, left their organisations and joined the Communist International.
+
+In the Spanish Civil War, anarchists and syndicalists (CNT and FAI) once again allied themselves with various currents of leftists. A long tradition of Spanish anarchism led to anarchists playing a pivotal role in the war. In response to the army rebellion, an anarchist-inspired movement of peasants and workers, supported by armed militias, took control of Barcelona and of large areas of rural Spain, where they collectivised the land. The Soviet Union provided some limited assistance at the beginning of the war, but the result was a bitter fight among communists and anarchists at a series of events named May Days as Joseph Stalin tried to seize control of the Republicans.
+
+At the end of World War II, the anarchist movement was severely weakened. However, the 1960s witnessed a revival of anarchism likely caused by a perceived failure of Marxism–Leninism and tensions built by the Cold War. During this time, anarchism took root in other movements critical towards both the state and capitalism, such as the anti-nuclear, environmental and pacifist movements, the New Left, and the counterculture of the 1960s. Anarchism became associated with punk subculture, as exemplified by bands such as Crass and the Sex Pistols, and the established feminist tendencies of anarcha-feminism returned with vigour during the second wave of feminism.
+
+Around the turn of the 21st century, anarchism grew in popularity and influence within anti-war, anti-capitalist, and anti-globalisation movements. Anarchists became known for their involvement in protests against the World Trade Organization, the Group of Eight and the World Economic Forum. During the protests, "ad hoc" leaderless anonymous cadres known as black blocs engaged in rioting, property destruction, and violent confrontations with the police. Other organisational tactics pioneered in this time include security culture, affinity groups, and the use of decentralised technologies such as the internet. A significant event of this period was the confrontations at the WTO conference in Seattle in 1999. Anarchist ideas have been influential in the development of the Zapatistas in Mexico and the Democratic Federation of Northern Syria, more commonly known as Rojava, a "de facto" autonomous region in northern Syria.
+
+Anarchist schools of thought have been generally grouped into two main historical traditions, social anarchism and individualist anarchism, owing to their different origins, values and evolution. The individualist current emphasises negative liberty in opposing restraints upon the free individual, while the social current emphasises positive liberty in aiming to achieve the free potential of society through equality and social ownership. In a chronological sense, anarchism can be segmented by the classical currents of the late 19th century, and the post-classical currents (such as anarcha-feminism, green anarchism and post-anarchism) developed thereafter.
+
+Beyond the specific factions of anarchist movements which constitute political anarchism lies philosophical anarchism, which holds that the state lacks moral legitimacy, without necessarily accepting the imperative of revolution to eliminate it. A component especially of individualist anarchism, philosophical anarchism may tolerate the existence of a minimal state, but argues that citizens have no moral obligation to obey government when it conflicts with individual autonomy. Anarchism pays significant attention to moral arguments since ethics have a central role in anarchist philosophy.
+
+One reaction against sectarianism within the anarchist milieu was anarchism without adjectives, a call for toleration and unity among anarchists first adopted by Fernando Tarrida del Mármol in 1889 in response to the bitter debates of anarchist theory at the time. Despite separation, the various anarchist schools of thought are not seen as distinct entities, but as tendencies that intermingle.
+
+Anarchism is usually placed on the far-left of the political spectrum. Much of its economics and legal philosophy reflect anti-authoritarian, anti-statist, and libertarian interpretations of the radical left-wing and socialist politics of collectivism, communism, individualism, mutualism, and syndicalism, among other libertarian socialist economic theories. As anarchism does not offer a fixed body of doctrine from a single particular worldview, many anarchist types and traditions exist, and varieties of anarchy diverge widely.
+
+Inceptive currents among classical anarchist currents were mutualism and individualism. They were followed by the major currents of social anarchism (collectivist, communist, and syndicalist). They differ on organizational and economic aspects of their ideal society.
+
+Mutualism is an 18th-century economic theory that was developed into anarchist theory by Pierre-Joseph Proudhon. Its aims include reciprocity, free association, voluntary contract, federation, and credit and currency reform that would be regulated by a bank of the people. Mutualism has been retrospectively characterised as ideologically situated between individualist and collectivist forms of anarchism. Proudhon first characterised his goal as a "third form of society, the synthesis of communism and property".
+
+Collectivist anarchism, also known as anarchist collectivism or anarcho-collectivism, is a revolutionary socialist form of anarchism commonly associated with Mikhail Bakunin. Collectivist anarchists advocate collective ownership of the means of production, theorised to be achieved through violent revolution, and that workers be paid according to time worked, rather than goods being distributed according to need as in communism. Collectivist anarchism arose alongside Marxism, but rejected the dictatorship of the proletariat despite the stated Marxist goal of a collectivist stateless society. Anarcho-communism, also known as anarchist-communism, communist anarchism, and libertarian communism, is a theory of anarchism that advocates a communist society with common ownership of the means of production, direct democracy, and a horizontal network of voluntary associations and workers' councils with production and consumption based on the guiding principle: "From each according to his ability, to each according to his need". Anarcho-communism developed from radical socialist currents after the French Revolution, but it was first formulated as such in the Italian section of the First International. It was later expanded upon in the theoretical work of Peter Kropotkin.
+
+Anarcho-syndicalism, also referred to as revolutionary syndicalism, is a branch of anarchism that views labour syndicates as a potential force for revolutionary social change, replacing capitalism and the state with a new society democratically self-managed by workers. The basic principles of anarcho-syndicalism are workers' solidarity, direct action, and workers' self-management.
+
+Individualist anarchism refers to several traditions of thought within the anarchist movement that emphasise the individual and their will over any kinds of external determinants. Early influences on individualist forms of anarchism include William Godwin, Max Stirner and Henry David Thoreau. Through many countries, individualist anarchism attracted a small yet diverse following of Bohemian artists and intellectuals as well as young anarchist outlaws in what became known as illegalism and individual reclamation.
+
+Anarchist principles undergird contemporary radical social movements of the left. Interest in the anarchist movement developed alongside momentum in the anti-globalization movement, whose leading activist networks were anarchist in orientation. As the movement shaped 21st century radicalism, wider embrace of anarchist principles signaled a revival of interest. Contemporary news coverage which emphasizes black bloc demonstrations has reinforced anarchism's historical association with chaos and violence, although its publicity has also led more scholars to engage with the anarchist movement. Anarchism has continued to generate many philosophies and movements—at times eclectic, drawing upon various sources, and syncretic, combining disparate concepts to create new philosophical approaches. The anti-capitalist tradition of classical anarchism has remained prominent within contemporary currents.
+
+Various anarchist groups, tendencies, and schools of thought exist today, making it difficult to describe contemporary anarchist movement. While theorists and activists have established "relatively stable constellations of anarchist principles", there is no consensus on which principles are core. As a result, commentators describe multiple "anarchisms" (rather than a singular "anarchism") in which common principles are shared between schools of anarchism while each group prioritizes those principles differently. For example, gender equality can be a common principle but ranks as a higher priority to anarcha-feminists than anarchist communists. Anarchists are generally committed against coercive authority in all forms, namely "all centralized and hierarchical forms of government (e.g., monarchy, representative democracy, state socialism, etc.), economic class systems (e.g., capitalism, Bolshevism, feudalism, slavery, etc.), autocratic religions (e.g., fundamentalist Islam, Roman Catholicism, etc.), patriarchy, heterosexism, white supremacy, and imperialism". However, anarchist schools disagree on the methods by which these forms should be opposed.
+
+Anarchists' tactics take various forms but in general serve two major goals—first, to oppose the Establishment; and second, to promote anarchist ethics and reflect an anarchist vision of society, illustrating the unity of means and ends. A broad categorization can be made between aims to destroy oppressive states and institutions by revolutionary means, and aims to change society through evolutionary means. Evolutionary tactics reject violence and take a gradual approach to anarchist aims, though there is significant overlap between the two.
+
+Anarchist tactics have shifted during the course of the last century. Anarchists during the early 20th century focused more on strikes and militancy, while contemporary anarchists use a broader array of approaches.
+
+During the classical era, anarchists had a militant tendency. Not only did they confront state armed forces (as in Spain and Ukraine) but some of them also employed terrorism as propaganda of the deed. Assassination attempts were carried out against heads of state, some of which were successful. Anarchists also took part in revolutions. Anarchist perspectives towards violence have always been perplexing and controversial. On one hand, anarcho-pacifists point out the unity of means and ends. On the other hand, other anarchist groups advocate direct action, a tactic which can include acts of sabotage or even acts of terrorism. This attitude was quite prominent a century ago; seeing the state as a tyrant, some anarchists believed that they had every right to oppose its oppression by any means possible. Emma Goldman and Errico Malatesta, who were proponents of limited use of violence, argued that violence is merely a reaction to state violence as a necessary evil.
+
+Anarchists took an active role in strikes, although they tended to be antipathetic to formal syndicalism, seeing it as reformist. They saw it as a part of the movement which sought to overthrow the state and capitalism. Anarchists also reinforced their propaganda within the arts, some of whom practiced nudism. They also built communities which were based on friendship. They were also involved in the press.
+
+In the current era, Italian anarchist Alfredo Bonanno, a proponent of insurrectionary anarchism, has reinstated the debate on violence by rejecting the nonviolence tactic adopted since the late 19th century by Kropotkin and other prominent anarchists afterwards. Both Bonanno and the French group The Invisible Committee advocate for small, informal affiliation groups, where each member is responsible for their own actions but works together to bring down oppression utilizing sabotage and other violent means against state, capitalism and other enemies. Members of The Invisible Committee were arrested in 2008 on various charges, terrorism included.
+
+Overall, today's anarchists are much less violent and militant than their ideological ancestors. They mostly engage in confronting the police during demonstrations and riots, especially in countries like Canada, Mexico or Greece. Μilitant black bloc protest groups are known for clashing with the police. However, anarchists not only clash with state operators; they also engage in the struggle against fascists and racists, taking anti-fascist action and mobilizing to prevent hate rallies from happening.
+
+Anarchists commonly employ direct action. This can take the form of disrupting and protesting against unjust hierarchy, or the form of self-managing their lives through the creation of counter-institutions such as communes and non-hierarchical collectives. Often, decision-making is handled in an anti-authoritarian way, with everyone having equal say in each decision, an approach known as horizontalism. Contemporary-era anarchists have been engaging with various grassroots movements that are not explicitly anarchist but are more or less based on horizontalism, respecting personal autonomy, and participating in mass activism such as strikes and demonstrations. The newly coined term "small-a anarchism", in contrast with the "big-A anarchism" of the classical era, signals their tendency not to base their thoughts and actions on classical-era anarchism or to refer to Kropotkin or Proudhon to justify their opinions. They would rather base their thought and praxis on their own experience, which they will later theorize.
+
+The decision-making process of small affinity anarchist groups play a significant tactical role. Anarchists have employed various methods in order to build a rough consensus among members of their group, without the need of a leader or a leading group. One way is for an individual from the group to play the role of facilitator to help achieve a consensus without taking part in the discussion themselves or promoting a specific point. Minorities usually accept rough consensus, except when they feel the proposal contradicts anarchist goals, values, or ethics. Anarchists usually form small groups (5–20 individuals) to enhance autonomy and friendships among their members. These kind of groups more often than not interconnect with each other, forming larger networks. Anarchists still support and participate in strikes, especially wildcat strikes; these are leaderless strikes not organised centrally by a syndicate.
+
+Anarchists have gone online to spread their message. As in the past, newspapers and journals are used; however, because of distributional and other difficulties, anarchists have found it easier to create websites, hosting electronic libraries and other portals. Anarchists were also involved in developing various software that are available for free. The way these hacktivists work to develop and distribute resembles the anarchist ideals, especially when it comes to preserving user's privacy from state surveillance.
+
+Anarchists organize themselves to squat and reclaim public spaces. During important events such as protests and when spaces are being occupied, they are often called Temporary Autonomous Zones (TAZ), spaces where surrealism, poetry and art are blended to display the anarchist ideal. As seen by anarchists, squatting is a way to regain urban space from the capitalist market, serving pragmatical needs, and is also seen an exemplary direct action. Acquiring space enables anarchists to experiment with their ideas and build social bonds. Adding up these tactics, and having in mind that not all anarchists share the same attitudes towards them, along with various forms of protesting at highly symbolic events, make up a carnivalesque atmosphere that is part of contemporary anarchist vividity.
+
+As anarchism is a philosophy that embodies many diverse attitudes, tendencies, and schools of thought, and disagreement over questions of values, ideology, and tactics is common, its diversity has led to widely different uses of identical terms among different anarchist traditions, which has created a number of definitional concerns in anarchist theory. For instance, the compatibility of capitalism, nationalism and religion with anarchism is widely disputed. Similarly, anarchism enjoys complex relationships with ideologies such as Marxism, communism, collectivism and trade unionism. Anarchists may be motivated by humanism, divine authority, enlightened self-interest, veganism, or any number of alternative ethical doctrines. Phenomena such as civilisation, technology (e.g. within anarcho-primitivism) and the democratic process may be sharply criticised within some anarchist tendencies and simultaneously lauded in others.
+
+Gender and sexuality carry along them dynamics of hierarchy; anarchism is obliged to address, analyse and oppose the suppression of one's autonomy because of the dynamics that gender roles traditionally impose.
+
+A historical current that arose and flourished during 1890 and 1920 within anarchism was free love; in contemporary anarchism, this current survives as a tendency to support polyamory and queer anarchism. Free love advocates were against marriage, which they saw as a way of men imposing authority over women, largely because marriage law greatly favoured the power of men. The notion of free love, though, was much broader; it included critique of the established order that limited women's sexual freedom and pleasure. Such free love movements contributed to the establishment of communal houses, where large groups of travelers, anarchists, and other activists slept in beds together. Free love had roots both in Europe and the United States. Some anarchists, however, struggled with the jealousy that arose from free love. Anarchist feminists were advocates of free love, against marriage, were pro-choice (utilizing a contemporary term) and had a likewise agenda. Anarchist and non-anarchist feminists differed on suffrage, but were nonetheless supportive of one another.
+
+During the second half of the 20th century, anarchism intermingled with the second wave of feminism, radicalizing some currents of the feminist movement (and being influenced as well). By the latest decades of the 20th century, anarchists and feminists were advocating for the rights and autonomy of women, gays, queers and other marginalized groups, with some feminist thinkers suggesting a fusion of the two currents. With the third wave of feminism, sexual identity and compulsory heterosexuality became a subject of study for anarchists, which yielded a post-structuralist critique of sexual normality. However, some anarchists distanced themselves from this line of thinking, suggesting that it leaned towards individualism and was, therefore, dropping the cause of social liberation.
+
+The interest of anarchists in education stretches back to the first emergence of classical anarchism. Anarchists consider 'proper' education, which sets the foundations of the future autonomy of the individual and the society, to be an act of mutual aid. Anarchist writers such as Willian Godwin and Max Stirner attacked both state education and private education as another means by which the ruling class replicate their privileges.
+
+In 1901, Catalan anarchist and free thinker Francisco Ferrer established the Escuela Moderna in Barcelona as an opposition to the established education system, which was dictated largely by the Catholic Church. Ferrer's approach was secular, rejecting both state and church involvement in the educational process, and gave pupils large amounts of autonomy in planning their work and attendance. Ferrer aimed to educate the working class and explicitly sought to foster class consciousness among students. The school closed after constant harassment by the state and Ferrer was later arrested. His ideas, however, formed the inspiration for a series of modern schools around the world. Christian anarchist Leo Tolstoy also established a similar school, with its founding principle, according to Tolstoy, being that "for education to be effective it had to be free". In a similar token, A. S. Neill founding what became Summerhill School in 1921, also declaring being free from coercion.
+
+Anarchist education is based largely on the idea that a child's right to develop freely, without manipulation, ought to be respected, and that rationality will lead children to morally good conclusions. However, there has been little consensus among anarchist figures as to what constitutes manipulation; Ferrer, for example, believed that moral indoctrination was necessary and explicitly taught pupils that equality, liberty, and social justice were not possible under capitalism (along with other critiques of nationalism and government).
+
+Late 20th century and contemporary anarchist writers (such as Colin Ward, Herbert Read and Paul Goodman) intensified and expanded the anarchist critique of state education, largely focusing on the need for a system that focuses on children's creativity rather than on their ability to attain a career or participate in consumer society. Contemporary anarchists, such as Colin Ward, have further argued that state education serves to perpetuate socio-economic inequality.
+
+While few anarchist education institutions have survived to the modern day, major tenets of anarchist schools, such as respect for child autonomy and relying on reasoning rather than indoctrination as a teaching method, have spread among mainstream educational institutions.
+
+Objection to the state and its institutions is a "sine qua non" of anarchism. Anarchists consider the state as a tool of domination and believe it to be illegitimate regardless of its political tendencies. Instead of people being able to control the aspects of their life, major decisions are taken by a small elite. Authority ultimately rests solely on power, regardless of whether that power is open or transparent, as it still has the ability to coerce people. Another anarchist argument against states is that the people constituting a government, even the most altruistic among officials, will unavoidably seek to gain more power, leading to corruption. Anarchists consider the idea that the state is the collective will of the people to be an unachievable fiction, due to the fact that the ruling class is distinct from the rest of society.
+
+The connection between anarchism and art was quite profound during the classical era of anarchism, especially among artistic currents that were developing during that era, such as futurists, surrealists, and others, while in literature anarchism was mostly associated with the New Apocalyptics and the Neo-romanticism movement. In music, anarchism has been associated with music scenes such as Punk. Anarchists such as Leo Tolstoy and Herbert Read argued that the border between the artist and the non-artist, what separates art from a daily act, is a construct produced by the alienation caused by capitalism, and it prevents humans from living a joyful life.
+
+Other anarchists advocated for or used art as a means to achieve anarchist ends. In his book Breaking the Spell: A History of Anarchist Filmmakers, Videotape Guerrillas, and Digital Ninjas Chris Robé claims that "anarchist-inflected practices have increasingly structured movement-based video activism."
+
+Three overlapping properties made art useful to anarchists: It could depict a critique of existing society and hierarchies; it could serve as a prefigurative tool to reflect the anarchist ideal society, and also it could turn into a means of direct action, in protests for example. As it appeals to both emotion and reason, art could appeal to the "whole human" and have a powerful effect.
+
+Philosophy lecturer Andrew G. Fiala has listed five main arguments against anarchism. Firstly, he notes that anarchism is related to violence and destruction, not only in the pragmatic world (i.e. at protests) but in the world of ethics as well. The second argument is that it is impossible for a society to function without a state or something like a state, acting to protect citizens from criminality. Fiala takes "Leviathan" from Thomas Hobbes and the night-watchman state from philosopher Robert Nozick as examples. Thirdly, anarchism is evaluated as unfeasible or utopian since the state can not be defeated practically; this line of arguments most often calls for political action within the system to reform it. The fourth argument is that anarchism is self-contradictory since while it advocates for no-one to "archiei", if accepted by the many, then anarchism will turn into the ruling political theory. In this line of criticism also comes the self contradiction that anarchist calls for collective action while anarchism endorses the autonomy of the individual and hence no collective action can be taken. Lastly, Fiala mentions a critique towards philosophical anarchism, of being ineffective (all talk and thoughts) and in the meantime capitalism and bourgeois class remains strong.
+
+Philosophical anarchism has met the criticism of members of academia, following the release of pro-anarchist books such as A. John Simmons' "Moral Principles and Political Obligations" (1979). Law professor William A. Edmundson authored an essay arguing against three major philosophical anarchist principles, which he finds fallacious; Edmundson claims that while the individual does not owe a normal state a duty of obedience, this does not imply that anarchism is the inevitable conclusion, and the state is still morally legitimate.
+
+
+
+
+
+
+
+
+
+Autism
+
+Autism is a developmental disorder characterized by difficulties with social interaction and communication, and by restricted and repetitive behavior. Parents often notice signs during the first three years of their child's life. These signs often develop gradually, though some children with autism experience worsening in their communication and social skills after reaching developmental milestones at a normal pace.
+Autism is associated with a combination of genetic and environmental factors. Risk factors during pregnancy include certain infections, such as rubella, toxins including valproic acid, alcohol, cocaine, pesticides, lead, and air pollution, fetal growth restriction, and autoimmune diseases. Controversies surround other proposed environmental causes; for example, the vaccine hypothesis, which has been disproven. Autism affects information processing in the brain and how nerve cells and their synapses connect and organize; how this occurs is not well understood. The Diagnostic and Statistical Manual of Mental Disorders (DSM-5), combines autism and less severe forms of the condition, including Asperger syndrome and pervasive developmental disorder not otherwise specified (PDD-NOS) into the diagnosis of autism spectrum disorder (ASD).
+Early behavioral interventions or speech therapy can help children with autism gain self-care, social, and communication skills. Although there is no known cure, there have been cases of children who recovered. Some autistic adults are unable to live independently. An autistic culture has developed, with some individuals seeking a cure and others believing autism should be accepted as a difference to be accommodated instead of cured.
+Globally, autism is estimated to affect 24.8 million people . In the 2000s, the number of people affected was estimated at 1–2 per 1,000 people worldwide. In the developed countries, about 1.5% of children are diagnosed with ASD , from 0.7% in 2000 in the United States. It occurs four-to-five times more often in males than females. The number of people diagnosed has increased dramatically since the 1960s, which may be partly due to changes in diagnostic practice. The question of whether actual rates have increased is unresolved.
+Autism is a highly variable, neurodevelopmental disorder whose symptoms first appears during infancy or childhood, and generally follows a steady course without remission. People with autism may be severely impaired in some respects but average, or even superior, in others. Overt symptoms gradually begin after the age of six months, become established by age two or three years and tend to continue through adulthood, although often in more muted form. It is distinguished by a characteristic triad of symptoms: impairments in social interaction, impairments in communication, and repetitive behavior. Other aspects, such as atypical eating, are also common but are not essential for diagnosis. Individual symptoms of autism occur in the general population and appear not to associate highly, without a sharp line separating pathologically severe from common traits.
+
+Social deficits distinguish autism and the related autism spectrum disorders (ASD; see Classification) from other developmental disorders. People with autism have social impairments and often lack the intuition about others that many people take for granted. Noted autistic Temple Grandin described her inability to understand the social communication of neurotypicals, or people with typical neural development, as leaving her feeling "like an anthropologist on Mars".
+
+Unusual social development becomes apparent early in childhood. Autistic infants show less attention to social stimuli, smile and look at others less often, and respond less to their own name. Autistic toddlers differ more strikingly from social norms; for example, they have less eye contact and turn-taking, and do not have the ability to use simple movements to express themselves, such as pointing at things. Three- to five-year-old children with autism are less likely to exhibit social understanding, approach others spontaneously, imitate and respond to emotions, communicate nonverbally, and take turns with others. However, they do form attachments to their primary caregivers. Most children with autism display moderately less attachment security than neurotypical children, although this difference disappears in children with higher mental development or less pronounced autistic traits. Older children and adults with ASD perform worse on tests of face and emotion recognition although this may be partly due to a lower ability to define a person's own emotions.
+
+Children with high-functioning autism have more intense and frequent loneliness compared to non-autistic peers, despite the common belief that children with autism prefer to be alone. Making and maintaining friendships often proves to be difficult for those with autism. For them, the quality of friendships, not the number of friends, predicts how lonely they feel. Functional friendships, such as those resulting in invitations to parties, may affect the quality of life more deeply.
+There are many anecdotal reports, but few systematic studies, of aggression and violence in individuals with ASD. The limited data suggest that, in children with intellectual disability, autism is associated with aggression, destruction of property, and meltdowns.
+
+About a third to a half of individuals with autism do not develop enough natural speech to meet their daily communication needs. Differences in communication may be present from the first year of life, and may include delayed onset of babbling, unusual gestures, diminished responsiveness, and vocal patterns that are not synchronized with the caregiver. In the second and third years, children with autism have less frequent and less diverse babbling, consonants, words, and word combinations; their gestures are less often integrated with words. Children with autism are less likely to make requests or share experiences, and are more likely to simply repeat others' words (echolalia) or reverse pronouns. Joint attention seems to be necessary for functional speech, and deficits in joint attention seem to distinguish infants with ASD. For example, they may look at a pointing hand instead of the pointed-at object, and they consistently fail to point at objects in order to comment on or share an experience. Children with autism may have difficulty with imaginative play and with developing symbols into language.
+
+In a pair of studies, high-functioning children with autism aged 8–15 performed equally well as, and as adults better than, individually matched controls at basic language tasks involving vocabulary and spelling. Both autistic groups performed worse than controls at complex language tasks such as figurative language, comprehension and inference. As people are often sized up initially from their basic language skills, these studies suggest that people speaking to autistic individuals are more likely to overestimate what their audience comprehends.
+
+Autistic individuals can display many forms of repetitive or restricted behavior, which the Repetitive Behavior Scale-Revised (RBS-R) categorizes as follows.
+
+
+No single repetitive or self-injurious behavior seems to be specific to autism, but autism appears to have an elevated pattern of occurrence and severity of these behaviors.
+
+Autistic individuals may have symptoms that are independent of the diagnosis, but that can affect the individual or the family.
+An estimated 0.5% to 10% of individuals with ASD show unusual abilities, ranging from splinter skills such as the memorization of trivia to the extraordinarily rare talents of prodigious autistic savants. Many individuals with ASD show superior skills in perception and attention, relative to the general population. Sensory abnormalities are found in over 90% of those with autism, and are considered core features by some, although there is no good evidence that sensory symptoms differentiate autism from other developmental disorders. Differences are greater for under-responsivity (for example, walking into things) than for over-responsivity (for example, distress from loud noises) or for sensation seeking (for example, rhythmic movements). An estimated 60–80% of autistic people have motor signs that include poor muscle tone, poor motor planning, and toe walking; deficits in motor coordination are pervasive across ASD and are greater in autism proper. Unusual eating behavior occurs in about three-quarters of children with ASD, to the extent that it was formerly a diagnostic indicator. Selectivity is the most common problem, although eating rituals and food refusal also occur.
+
+There is tentative evidence that autism occurs more frequently in people with gender dysphoria.
+
+Gastrointestinal problems are one of the most commonly associated medical disorders in people with autism. These are linked to greater social impairment, irritability, behavior and sleep problems, language impairments and mood changes.
+
+Parents of children with ASD have higher levels of stress. Siblings of children with ASD report greater admiration of and less conflict with the affected sibling than siblings of unaffected children and were similar to siblings of children with Down syndrome in these aspects of the sibling relationship. However, they reported lower levels of closeness and intimacy than siblings of children with Down syndrome; siblings of individuals with ASD have greater risk of negative well-being and poorer sibling relationships as adults.
+
+It has long been presumed that there is a common cause at the genetic, cognitive, and neural levels for autism's characteristic triad of symptoms. However, there is increasing suspicion that autism is instead a complex disorder whose core aspects have distinct causes that often co-occur.
+Autism has a strong genetic basis, although the genetics of autism are complex and it is unclear whether ASD is explained more by rare mutations with major effects, or by rare multigene interactions of common genetic variants. Complexity arises due to interactions among multiple genes, the environment, and epigenetic factors which do not change DNA sequencing but are heritable and influence gene expression. Many genes have been associated with autism through sequencing the genomes of affected individuals and their parents. Studies of twins suggest that heritability is 0.7 for autism and as high as 0.9 for ASD, and siblings of those with autism are about 25 times more likely to be autistic than the general population. However, most of the mutations that increase autism risk have not been identified. Typically, autism cannot be traced to a Mendelian (single-gene) mutation or to a single chromosome abnormality, and none of the genetic syndromes associated with ASDs have been shown to selectively cause ASD. Numerous candidate genes have been located, with only small effects attributable to any particular gene. Most loci individually explain less than 1% of cases of autism. The large number of autistic individuals with unaffected family members may result from spontaneous structural variation—such as deletions, duplications or inversions in genetic material during meiosis. Hence, a substantial fraction of autism cases may be traceable to genetic causes that are highly heritable but not inherited: that is, the mutation that causes the autism is not present in the parental genome. Autism may be underdiagnosed in women and girls due to an assumption that it is primarily a male condition, but genetic phenomena such as imprinting and X linkage have the ability to raise the frequency and severity of conditions in males, and theories have been put forward for a genetic reason why males are diagnosed more often, such as the imprinted brain theory and the extreme male brain theory.
+
+Maternal nutrition and inflammation during preconception and pregnancy influences fetal neurodevelopment. Intrauterine growth restriction is associated with ASD, in both term and preterm infants. Maternal inflammatory and autoimmune diseases may damage fetal tissues, aggravating a genetic problem or damaging the nervous system.
+
+Exposure to air pollution during pregnancy, especially heavy metals and particulates, may increase the risk of autism. Environmental factors that have been claimed without evidence to contribute to or exacerbate autism include certain foods, infectious diseases, solvents, PCBs, phthalates and phenols used in plastic products, pesticides, brominated flame retardants, alcohol, smoking, illicit drugs, vaccines, and prenatal stress. Some, such as the MMR vaccine, have been completely disproven.
+
+Parents may first become aware of autistic symptoms in their child around the time of a routine vaccination. This has led to unsupported theories blaming vaccine "overload", a vaccine preservative, or the MMR vaccine for causing autism. The latter theory was supported by a litigation-funded study that has since been shown to have been "an elaborate fraud". Although these theories lack convincing scientific evidence and are biologically implausible, parental concern about a potential vaccine link with autism has led to lower rates of childhood immunizations, outbreaks of previously controlled childhood diseases in some countries, and the preventable deaths of several children.
+
+Autism's symptoms result from maturation-related changes in various systems of the brain. How autism occurs is not well understood. Its mechanism can be divided into two areas: the pathophysiology of brain structures and processes associated with autism, and the neuropsychological linkages between brain structures and behaviors. The behaviors appear to have multiple pathophysiologies.
+
+There is evidence that gut–brain axis abnormalities may be involved. A 2015 review proposed that immune dysregulation, gastrointestinal inflammation, malfunction of the autonomic nervous system, gut flora alterations, and food metabolites may cause brain neuroinflammation and dysfunction. A 2016 review concludes that enteric nervous system abnormalities might play a role in neurological disorders such as autism. Neural connections and the immune system are a pathway that may allow diseases originated in the intestine to spread to the brain.
+
+Several lines of evidence point to synaptic dysfunction as a cause of autism. Some rare mutations may lead to autism by disrupting some synaptic pathways, such as those involved with cell adhesion. Gene replacement studies in mice suggest that autistic symptoms are closely related to later developmental steps that depend on activity in synapses and on activity-dependent changes. All known teratogens (agents that cause birth defects) related to the risk of autism appear to act during the first eight weeks from conception, and though this does not exclude the possibility that autism can be initiated or affected later, there is strong evidence that autism arises very early in development.
+
+Diagnosis is based on behavior, not cause or mechanism. Under the DSM-5, autism is characterized by persistent deficits in social communication and interaction across multiple contexts, as well as restricted, repetitive patterns of behavior, interests, or activities. These deficits are present in early childhood, typically before age three, and lead to clinically significant functional impairment. Sample symptoms include lack of social or emotional reciprocity, stereotyped and repetitive use of language or idiosyncratic language, and persistent preoccupation with unusual objects. The disturbance must not be better accounted for by Rett syndrome, intellectual disability or global developmental delay. ICD-10 uses essentially the same definition.
+
+Several diagnostic instruments are available. Two are commonly used in autism research: the Autism Diagnostic Interview-Revised (ADI-R) is a semistructured parent interview, and the Autism Diagnostic Observation Schedule (ADOS) uses observation and interaction with the child. The Childhood Autism Rating Scale (CARS) is used widely in clinical environments to assess severity of autism based on observation of children. The Diagnostic interview for social and communication disorders (DISCO) may also be used.
+
+A pediatrician commonly performs a preliminary investigation by taking developmental history and physically examining the child. If warranted, diagnosis and evaluations are conducted with help from ASD specialists, observing and assessing cognitive, communication, family, and other factors using standardized tools, and taking into account any associated medical conditions. A pediatric neuropsychologist is often asked to assess behavior and cognitive skills, both to aid diagnosis and to help recommend educational interventions. A differential diagnosis for ASD at this stage might also consider intellectual disability, hearing impairment, and a specific language impairment such as Landau–Kleffner syndrome. The presence of autism can make it harder to diagnose coexisting psychiatric disorders such as depression.
+
+Clinical genetics evaluations are often done once ASD is diagnosed, particularly when other symptoms already suggest a genetic cause. Although genetic technology allows clinical geneticists to link an estimated 40% of cases to genetic causes, consensus guidelines in the US and UK are limited to high-resolution chromosome and fragile X testing. A genotype-first model of diagnosis has been proposed, which would routinely assess the genome's copy number variations. As new genetic tests are developed several ethical, legal, and social issues will emerge. Commercial availability of tests may precede adequate understanding of how to use test results, given the complexity of autism's genetics. Metabolic and neuroimaging tests are sometimes helpful, but are not routine.
+
+ASD can sometimes be diagnosed by age 14 months, although diagnosis becomes increasingly stable over the first three years of life: for example, a one-year-old who meets diagnostic criteria for ASD is less likely than a three-year-old to continue to do so a few years later. In the UK the National Autism Plan for Children recommends at most 30 weeks from first concern to completed diagnosis and assessment, though few cases are handled that quickly in practice. Although the symptoms of autism and ASD begin early in childhood, they are sometimes missed; years later, adults may seek diagnoses to help them or their friends and family understand themselves, to help their employers make adjustments, or in some locations to claim disability living allowances or other benefits. Girls are often diagnosed later than boys.
+
+Underdiagnosis and overdiagnosis are problems in marginal cases, and much of the recent increase in the number of reported ASD cases is likely due to changes in diagnostic practices. The increasing popularity of drug treatment options and the expansion of benefits has given providers incentives to diagnose ASD, resulting in some overdiagnosis of children with uncertain symptoms. Conversely, the cost of screening and diagnosis and the challenge of obtaining payment can inhibit or delay diagnosis. It is particularly hard to diagnose autism among the visually impaired, partly because some of its diagnostic criteria depend on vision, and partly because autistic symptoms overlap with those of common blindness syndromes or blindisms.
+
+Autism is one of the five pervasive developmental disorders (PDD), which are characterized by widespread abnormalities of social interactions and communication, and severely restricted interests and highly repetitive behavior. These symptoms do not imply sickness, fragility, or emotional disturbance.
+
+Of the five PDD forms, Asperger syndrome is closest to autism in signs and likely causes; Rett syndrome and childhood disintegrative disorder share several signs with autism, but may have unrelated causes; PDD not otherwise specified (PDD-NOS; also called "atypical autism") is diagnosed when the criteria are not met for a more specific disorder. Unlike with autism, people with Asperger syndrome have no substantial delay in language development. The terminology of autism can be bewildering, with autism, Asperger syndrome and PDD-NOS often called the "autism spectrum disorders" (ASD) or sometimes the "autistic disorders", whereas autism itself is often called "autistic disorder", "childhood autism", or "infantile autism". In this article, "autism" refers to the classic autistic disorder; in clinical practice, though, "autism", "ASD", and "PDD" are often used interchangeably. ASD, in turn, is a subset of the broader autism phenotype, which describes individuals who may not have ASD but do have autistic-like traits, such as avoiding eye contact.
+
+Autism can also be divided into syndromal and non-syndromal autism; the syndromal autism is associated with severe or profound intellectual disability or a congenital syndrome with physical symptoms, such as tuberous sclerosis. Although individuals with Asperger syndrome tend to perform better cognitively than those with autism, the extent of the overlap between Asperger syndrome, HFA, and non-syndromal autism is unclear.
+
+Some studies have reported diagnoses of autism in children due to a loss of language or social skills, as opposed to a failure to make progress, typically from 15 to 30 months of age. The validity of this distinction remains controversial; it is possible that regressive autism is a specific subtype, or that there is a continuum of behaviors between autism with and without regression.
+
+Research into causes has been hampered by the inability to identify biologically meaningful subgroups within the autistic population and by the traditional boundaries between the disciplines of psychiatry, psychology, neurology and pediatrics. Newer technologies such as fMRI and diffusion tensor imaging can help identify biologically relevant phenotypes (observable traits) that can be viewed on brain scans, to help further neurogenetic studies of autism; one example is lowered activity in the fusiform face area of the brain, which is associated with impaired perception of people versus objects. It has been proposed to classify autism using genetics as well as behavior.
+
+Autism has long been thought to cover a wide spectrum, ranging from individuals with severe impairments—who may be silent, developmentally disabled, and prone to frequent repetitive behavior such as hand flapping and rocking—to high functioning individuals who may have active but distinctly odd social approaches, narrowly focused interests, and verbose, pedantic communication. Because the behavior spectrum is continuous, boundaries between diagnostic categories are necessarily somewhat arbitrary. Sometimes the syndrome is divided into low-, medium- or high-functioning autism (LFA, MFA, and HFA), based on IQ thresholds. Some people have called for an end to the terms "high-functioning" and "low-functioning" due to lack of nuance and the potential for a person's needs or abilities to be overlooked.
+
+About half of parents of children with ASD notice their child's unusual behaviors by age 18 months, and about four-fifths notice by age 24 months. According to an article, failure to meet any of the following milestones "is an absolute indication to proceed with further evaluations. Delay in referral for such testing may delay early diagnosis and treatment and affect the long-term outcome".
+
+The United States Preventive Services Task Force in 2016 found it was unclear if screening was beneficial or harmful among children in whom there is no concerns. The Japanese practice is to screen all children for ASD at 18 and 24 months, using autism-specific formal screening tests. In contrast, in the UK, children whose families or doctors recognize possible signs of autism are screened. It is not known which approach is more effective. Screening tools include the Modified Checklist for Autism in Toddlers (M-CHAT), the Early Screening of Autistic Traits Questionnaire, and the First Year Inventory; initial data on M-CHAT and its predecessor, the Checklist for Autism in Toddlers (CHAT), on children aged 18–30 months suggests that it is best used in a clinical setting and that it has low sensitivity (many false-negatives) but good specificity (few false-positives). It may be more accurate to precede these tests with a broadband screener that does not distinguish ASD from other developmental disorders. Screening tools designed for one culture's norms for behaviors like eye contact may be inappropriate for a different culture. Although genetic screening for autism is generally still impractical, it can be considered in some cases, such as children with neurological symptoms and dysmorphic features.
+
+While infection with rubella during pregnancy causes fewer than 1% of cases of autism, vaccination against rubella can prevent many of those cases.
+
+The main goals when treating children with autism are to lessen associated deficits and family distress, and to increase quality of life and functional independence. In general, higher IQs are correlated with greater responsiveness to treatment and improved treatment outcomes. No single treatment is best and treatment is typically tailored to the child's needs. Families and the educational system are the main resources for treatment. Services should be carried out by behavior analysts, special education teachers, speech pathologists, and licensed psychologists. Studies of interventions have methodological problems that prevent definitive conclusions about efficacy. However, the development of evidence-based interventions has advanced in recent years. Although many psychosocial interventions have some positive evidence, suggesting that some form of treatment is preferable to no treatment, the methodological quality of systematic reviews of these studies has generally been poor, their clinical results are mostly tentative, and there is little evidence for the relative effectiveness of treatment options. Intensive, sustained special education programs and behavior therapy early in life can help children acquire self-care, communication, and job skills, and often improve functioning and decrease symptom severity and maladaptive behaviors; claims that intervention by around age three years is crucial are not substantiated. While medications have not been found to help with core symptoms, they may be used for associated symptoms, such as irritability, inattention, or repetitive behavior patterns.
+
+Educational interventions often used include applied behavior analysis (ABA), developmental models, structured teaching, speech and language therapy, social skills therapy, and occupational therapy. Among these approaches, interventions either treat autistic features comprehensively, or focalize treatment on a specific area of deficit. The quality of research for early intensive behavioral intervention (EIBI)—a treatment procedure incorporating over thirty hours per week of the structured type of ABA that is carried out with very young children—is currently low, and more vigorous research designs with larger sample sizes are needed. Two theoretical frameworks outlined for early childhood intervention include structured and naturalistic ABA interventions, and developmental social pragmatic models (DSP). One interventional strategy utilizes a parent training model, which teaches parents how to implement various ABA and DSP techniques, allowing for parents to disseminate interventions themselves. Various DSP programs have been developed to explicitly deliver intervention systems through at-home parent implementation. Despite the recent development of parent training models, these interventions have demonstrated effectiveness in numerous studies, being evaluated as a probable efficacious mode of treatment.
+
+Early, intensive ABA therapy has demonstrated effectiveness in enhancing communication and adaptive functioning in preschool children; it is also well-established for improving the intellectual performance of that age group. Similarly, a teacher-implemented intervention that utilizes a more naturalistic form of ABA combined with a developmental social pragmatic approach has been found to be beneficial in improving social-communication skills in young children, although there is less evidence in its treatment of global symptoms. Neuropsychological reports are often poorly communicated to educators, resulting in a gap between what a report recommends and what education is provided. It is not known whether treatment programs for children lead to significant improvements after the children grow up, and the limited research on the effectiveness of adult residential programs shows mixed results. The appropriateness of including children with varying severity of autism spectrum disorders in the general education population is a subject of current debate among educators and researchers.
+
+Medications may be used to treat ASD symptoms that interfere with integrating a child into home or school when behavioral treatment fails. They may also be used for associated health problems, such as ADHD or anxiety. More than half of US children diagnosed with ASD are prescribed psychoactive drugs or anticonvulsants, with the most common drug classes being antidepressants, stimulants, and antipsychotics. The atypical antipsychotic drugs risperidone and aripiprazole are FDA-approved for treating associated aggressive and self-injurious behaviors. However, their side effects must be weighed against their potential benefits, and people with autism may respond atypically. Side effects, for example, may include weight gain, tiredness, drooling, and aggression. SSRI antidepressants, such as fluoxetine and fluvoxamine, have been shown to be effective in reducing repetitive and ritualistic behaviors, while the stimulant medication methylphenidate is beneficial for some children with co-morbid inattentiveness or hyperactivity. There is scant reliable research about the effectiveness or safety of drug treatments for adolescents and adults with ASD. No known medication relieves autism's core symptoms of social and communication impairments. Experiments in mice have reversed or reduced some symptoms related to autism by replacing or modulating gene function, suggesting the possibility of targeting therapies to specific rare mutations known to cause autism.
+
+Although many alternative therapies and interventions are available, few are supported by scientific studies. Treatment approaches have little empirical support in quality-of-life contexts, and many programs focus on success measures that lack predictive validity and real-world relevance. Some alternative treatments may place the child at risk. The preference that children with autism have for unconventional foods can lead to reduction in bone cortical thickness with this being greater in those on casein-free diets, as a consequence of the low intake of calcium and vitamin D; however, suboptimal bone development in ASD has also been associated with lack of exercise and gastrointestinal disorders. In 2005, botched chelation therapy killed a five-year-old child with autism. Chelation is not recommended for people with ASD since the associated risks outweigh any potential benefits. Another alternative medicine practice with no evidence is CEASE therapy, a mixture of homeopathy, supplements, and 'vaccine detoxing'.
+
+Although popularly used as an alternative treatment for people with autism, as of 2018 there is no good evidence to recommend a gluten- and casein-free diet as a standard treatment. A 2018 review concluded that it may be a therapeutic option for specific groups of children with autism, such as those with known food intolerances or allergies, or with food intolerance markers. The authors analyzed the prospective trials conducted to date that studied the efficacy of the gluten- and casein-free diet in children with ASD (4 in total). All of them compared gluten- and casein-free diet versus normal diet with a control group (2 double-blind randomized controlled trials, 1 double-blind crossover trial, 1 single-blind trial). In two of the studies, whose duration was 12 and 24 months, a significant improvement in ASD symptoms (efficacy rate 50%) was identified. In the other two studies, whose duration was 3 months, no significant effect was observed. The authors concluded that a longer duration of the diet may be necessary to achieve the improvement of the ASD symptoms. Other problems documented in the trials carried out include transgressions of the diet, small sample size, the heterogeneity of the participants and the possibility of a placebo effect.
+
+In the subset of people who have gluten sensitivity there is limited evidence that suggests that a gluten-free diet may improve some autistic behaviors.
+
+There is tentative evidence that music therapy may improve social interactions, verbal communication, and non-verbal communication skills. There has been early research looking at hyperbaric treatments in children with autism. Studies on pet therapy have shown positive effects.
+
+There is no known cure. The degree of symptoms can decrease, occasionally to the extent that people lose their diagnosis of ASD; this occurs sometimes after intensive treatment and sometimes not. It is not known how often recovery happens; reported rates in unselected samples have ranged from 3% to 25%. Most children with autism acquire language by age five or younger, though a few have developed communication skills in later years. Many children with autism lack social support, future employment opportunities or self-determination. Although core difficulties tend to persist, symptoms often become less severe with age.
+
+Few high-quality studies address long-term prognosis. Some adults show modest improvement in communication skills, but a few decline; no study has focused on autism after midlife. Acquiring language before age six, having an IQ above 50, and having a marketable skill all predict better outcomes; independent living is unlikely with severe autism.
+
+Many individuals with autism face significant obstacles in transitioning to adulthood. Compared to the general population individuals with autism are more likely to be unemployed and to have never had a job. About half of people in their 20s with autism are not employed.
+
+Most recent reviews tend to estimate a prevalence of 1–2 per 1,000 for autism and close to 6 per 1,000 for ASD as of 2007. A 2016 survey in the United States reported a rate of 25 per 1,000 children for ASD. Globally, autism affects an estimated 24.8 million people , while Asperger syndrome affects a further 37.2 million. In 2012, the NHS estimated that the overall prevalence of autism among adults aged 18 years and over in the UK was 1.1%. Rates of PDD-NOS's has been estimated at 3.7 per 1,000, Asperger syndrome at roughly 0.6 per 1,000, and childhood disintegrative disorder at 0.02 per 1,000. CDC estimates about 1 out of 59 (1.7%) for 2014, an increase from 1 out of every 68 children (1.5%) for 2010.
+
+The number of reported cases of autism increased dramatically in the 1990s and early 2000s. This increase is largely attributable to changes in diagnostic practices, referral patterns, availability of services, age at diagnosis, and public awareness, though unidentified environmental risk factors cannot be ruled out. The available evidence does not rule out the possibility that autism's true prevalence has increased; a real increase would suggest directing more attention and funding toward changing environmental factors instead of continuing to focus on genetics.
+
+Boys are at higher risk for ASD than girls. The sex ratio averages 4.3:1 and is greatly modified by cognitive impairment: it may be close to 2:1 with intellectual disability and more than 5.5:1 without. Several theories about the higher prevalence in males have been investigated, but the cause of the difference is unconfirmed; one theory is that females are underdiagnosed.
+
+Although the evidence does not implicate any single pregnancy-related risk factor as a cause of autism, the risk of autism is associated with advanced age in either parent, and with diabetes, bleeding, and use of psychiatric drugs in the mother during pregnancy. The risk is greater with older fathers than with older mothers; two potential explanations are the known increase in mutation burden in older sperm, and the hypothesis that men marry later if they carry genetic liability and show some signs of autism. Most professionals believe that race, ethnicity, and socioeconomic background do not affect the occurrence of autism.
+
+Several other conditions are common in children with autism. They include:
+
+A few examples of autistic symptoms and treatments were described long before autism was named. The "Table Talk" of Martin Luther, compiled by his notetaker, Mathesius, contains the story of a 12-year-old boy who may have been severely autistic. Luther reportedly thought the boy was a soulless mass of flesh possessed by the devil, and suggested that he be suffocated, although a later critic has cast doubt on the veracity of this report. The earliest well-documented case of autism is that of Hugh Blair of Borgue, as detailed in a 1747 court case in which his brother successfully petitioned to annul Blair's marriage to gain Blair's inheritance. The Wild Boy of Aveyron, a feral child caught in 1798, showed several signs of autism; the medical student Jean Itard treated him with a behavioral program designed to help him form social attachments and to induce speech via imitation.
+
+The New Latin word "autismus" (English translation "autism") was coined by the Swiss psychiatrist Eugen Bleuler in 1910 as he was defining symptoms of schizophrenia. He derived it from the Greek word "autós" (αὐτός, meaning "self"), and used it to mean morbid self-admiration, referring to "autistic withdrawal of the patient to his fantasies, against which any influence from outside becomes an intolerable disturbance". A Soviet child psychiatrist, Grunya Sukhareva, described a similar syndrome that was published in Russian in 1925, and in German in 1926.
+
+The word "autism" first took its modern sense in 1938 when Hans Asperger of the Vienna University Hospital adopted Bleuler's terminology "autistic psychopaths" in a lecture in German about child psychology. Asperger was investigating an ASD now known as Asperger syndrome, though for various reasons it was not widely recognized as a separate diagnosis until 1981. Leo Kanner of the Johns Hopkins Hospital first used "autism" in its modern sense in English when he introduced the label "early infantile autism" in a 1943 report of 11 children with striking behavioral similarities. Almost all the characteristics described in Kanner's first paper on the subject, notably "autistic aloneness" and "insistence on sameness", are still regarded as typical of the autistic spectrum of disorders. It is not known whether Kanner derived the term independently of Asperger.
+
+Donald Triplett was the first person diagnosed with autism. He was diagnosed by Kanner after being first examined in 1938, and was labeled as "case 1". Triplett was noted for his savant abilities, particularly being able to name musical notes played on a piano and to mentally multiply numbers. His father, Oliver, described him as socially withdrawn but interested in number patterns, music notes, letters of the alphabet, and U.S. president pictures. By the age of 2, he had the ability to recite the 23rd Psalm and memorized 25 questions and answers from the Presbyterian catechism. He was also interested in creating musical chords.
+
+Kanner's reuse of "autism" led to decades of confused terminology like "infantile schizophrenia", and child psychiatry's focus on maternal deprivation led to misconceptions of autism as an infant's response to "refrigerator mothers". Starting in the late 1960s autism was established as a separate syndrome.
+
+As late as the mid-1970s there was little evidence of a genetic role in autism; while in 2007 it was believed to be one of the most heritable psychiatric conditions. Although the rise of parent organizations and the destigmatization of childhood ASD have affected how ASD is viewed, parents continue to feel social stigma in situations where their child's autistic behavior is perceived negatively, and many primary care physicians and medical specialists express some beliefs consistent with outdated autism research.
+
+It took until 1980 for the DSM-III to differentiate autism from childhood schizophrenia. In 1987, the DSM-III-R provided a checklist for diagnosing autism. In May 2013, the DSM-5 was released, updating the classification for pervasive developmental disorders. The grouping of disorders, including PDD-NOS, autism, Asperger syndrome, Rett syndrome, and CDD, has been removed and replaced with the general term of Autism Spectrum Disorders. The two categories that exist are impaired social communication and/or interaction, and restricted and/or repetitive behaviors.
+
+The Internet has helped autistic individuals bypass nonverbal cues and emotional sharing that they find difficult to deal with, and has given them a way to form online communities and work remotely. Societal and cultural aspects of autism have developed: some in the community seek a cure, while others believe that autism is simply another way of being.
+
+An autistic culture has emerged, accompanied by the autistic rights and neurodiversity movements. Events include World Autism Awareness Day, Autism Sunday, Autistic Pride Day, Autreat, and others. Organizations dedicated to promoting awareness of autism include Autistic Self Advocacy Network, Aspies For Freedom, Autism National Committee, and Autism Society of America. At the same time, some organizations, including Autism Speaks, have been condemned by disability rights organizations for failing to support autistic people. Social-science scholars study those with autism in hopes to learn more about "autism as a culture, transcultural comparisons... and research on social movements." While most autistic individuals do not have savant skills, many have been successful in their fields.
+
+The autism rights movement is a social movement within the context of disability rights that emphasizes the concept of neurodiversity, viewing the autism spectrum as a result of natural variations in the human brain rather than a disorder to be cured. The autism rights movement advocates for including greater acceptance of autistic behaviors; therapies that focus on coping skills rather than on imitating the behaviors of those without autism, and the recognition of the autistic community as a minority group. Autism rights or neurodiversity advocates believe that the autism spectrum is genetic and should be accepted as a natural expression of the human genome. This perspective is distinct from two other likewise distinct views: the medical perspective, that autism is caused by a genetic defect and should be addressed by targeting the autism gene(s), and fringe theories that autism is caused by environmental factors such as vaccines. A common criticism against autistic activists is that the majority of them are "high-functioning" or have Asperger syndrome and do not represent the views of "low-functioning" autistic people.
+
+About half of autistics are unemployed, and one third of those with graduate degrees may be unemployed. Among autistics who find work, most are employed in sheltered settings working for wages below the national minimum. While employers state hiring concerns about productivity and supervision, experienced employers of autistics give positive reports of above average memory and detail orientation as well as a high regard for rules and procedure in autistic employees. A majority of the economic burden of autism is caused by decreased earnings in the job market. Some studies also find decreased earning among parents who care for autistic children.
+
+
+
\ No newline at end of file
diff --git a/transformers/tests/fixtures/tests_samples/wmt16/sample.json b/transformers/tests/fixtures/tests_samples/wmt16/sample.json
new file mode 100644
index 0000000000000000000000000000000000000000..8c0e47b0648a2817d3f08d498f011e98d31f8e46
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/wmt16/sample.json
@@ -0,0 +1,10 @@
+{"translation": {"en": "Membership of Parliament: see Minutes", "ro": "Componenţa Parlamentului: a se vedea procesul-verbal"}}
+{"translation": {"en": "Approval of Minutes of previous sitting: see Minutes", "ro": "Aprobarea procesului-verbal al şedinţei precedente: a se vedea procesul-verbal"}}
+{"translation": {"en": "Membership of Parliament: see Minutes", "ro": "Componenţa Parlamentului: a se vedea procesul-verbal"}}
+{"translation": {"en": "Verification of credentials: see Minutes", "ro": "Verificarea prerogativelor: a se vedea procesul-verbal"}}
+{"translation": {"en": "Documents received: see Minutes", "ro": "Depunere de documente: a se vedea procesul-verbal"}}
+{"translation": {"en": "Written statements and oral questions (tabling): see Minutes", "ro": "Declaraţii scrise şi întrebări orale (depunere): consultaţi procesul-verbal"}}
+{"translation": {"en": "Petitions: see Minutes", "ro": "Petiţii: a se vedea procesul-verbal"}}
+{"translation": {"en": "Texts of agreements forwarded by the Council: see Minutes", "ro": "Transmiterea de către Consiliu a textelor acordurilor: a se vedea procesul-verbal"}}
+{"translation": {"en": "Action taken on Parliament's resolutions: see Minutes", "ro": "Cursul dat rezoluţiilor Parlamentului: a se vedea procesul-verbal"}}
+{"translation": {"en": "Agenda for next sitting: see Minutes", "ro": "Ordinea de zi a următoarei şedinţe: a se vedea procesul-verbal"}}
diff --git a/transformers/tests/fixtures/tests_samples/wmt_en_ro/test.json b/transformers/tests/fixtures/tests_samples/wmt_en_ro/test.json
new file mode 100644
index 0000000000000000000000000000000000000000..2841b1b6aab9ed5ef54bfa4d60c82e9c1b676a09
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/wmt_en_ro/test.json
@@ -0,0 +1,20 @@
+{ "translation": { "en": "UN Chief Says There Is No Military Solution in Syria Secretary-General Ban Ki-moon says his response to Russia's stepped up military support for Syria is that \"there is no military solution\" to the nearly five-year conflict and more weapons will only worsen the violence and misery for millions of people. The U.N. chief again urged all parties, including the divided U.N. Security Council, to unite and support inclusive negotiations to find a political solution. Ban told a news conference Wednesday that he plans to meet with foreign ministers of the five permanent council nations - the U.S., Russia, China, Britain and France - on the sidelines of the General Assembly's ministerial session later this month to discuss Syria.", "ro": "Șeful ONU declară că nu există soluții militare în Siria Secretarul General Ban Ki-moon afirmă că răspunsul său la suportul militar al Rusiei pentru Siria este că „nu există o soluție militară” la conflictul care durează de aproape cinci ani iar mai multe arme nu ar face decât să agraveze violența și suferința a milioane de oameni. Șeful ONU a solicitat din nou tuturor părților, inclusiv Consiliului de securitate ONU divizat să se unifice și să susțină negocierile pentru a găsi o soluție politică. Ban a declarat miercuri în cadrul unei conferințe că intenționează să se întâlnească luna aceasta cu miniștrii de externe din cinci țări permanent prezente în consiliu - SUA, Rusia, China, Anglia și Franța - pe marginea sesiunii ministeriale a Adunării Generale pentru a discuta despre Siria." } }
+{ "translation": { "en": "He expressed regret that divisions in the council and among the Syrian people and regional powers \"made this situation unsolvable.\" Ban urged the five permanent members to show the solidarity and unity they did in achieving an Iran nuclear deal in addressing the Syria crisis. 8 Poll Numbers That Show Donald Trump Is For Real Some have tried to label him a flip-flopper. Others have dismissed him as a joke. And some are holding out for an implosion. But no matter how some Republicans are trying to drag Donald Trump down from atop the polls, it hasn't worked (yet).", "ro": "Ban și-a exprimat regretul că divizările în consiliu și între poporul sirian și puterile regionale „au făcut această situație de nerezolvat”. Ban le-a cerut celor cinci membri permanenți să dea dovadă de solidaritatea și unitatea arătate atunci când au reușit să încheie un acord referitor la armele nucleare ale Iranului, abordând astfel criza din Siria. 8 cifre din sondaje care arată că Donald Trump are șanse reale Unii au încercat să îl eticheteze ca politician „flip-flop”. Alții l-au numit o glumă. Iar alții așteaptă implozia. Însă indiferent de modul în care unii republicani încearcă să îl dărâme pe Donald Trump din vârful sondajelor, nu a funcționat (încă)." } }
+{ "translation": { "en": "Ten of the last 11 national polls have shown Donald Trump's lead at double digits, and some are starting to ask seriously what it means for the real estate mogul's nomination chances. Of course, it's still early in the election cycle. None of this is to say that Trump is likely to win the Republican nomination. Pundits point out that at this time in 2011, Rick Perry's lead was giving way to a rising Herman Cain, neither of whom won even one state in the nomination process. And there are many reasons he would struggle in a general election. But outside groups like Jeb Bush's Super PAC and the economic conservative group Club for Growth are recognizing Trump's staying power and beginning to unload their dollars to topple him.", "ro": "Zece din ultimele 11 sondaje naționale au arătat că Donald Trump conduce cu un procent din două cifre iar unele voci încep să se întrebe serios ce înseamnă acest lucru pentru șansele de numire ale mogulului imobiliar. Desigur, este încă prematur. Nimic din toate acestea nu spune că Trump va câștiga cursa pentru nominalizarea republicanilor. Pundits arată că, în aceeași perioadă a anului 2011, avansul lui Rick Perry îi făcea loc lui Herman Cain în sondaje, dar niciunul dintre ei nu a câștigat în vreun stat în cursa de nominalizare. Iar motivele pentru care s-ar lupta din greu la alegerile generale sunt numeroase. Însă grupurile din exterior precum Super PAC al lui Jeb Bush și grupul conservator economic Club for Growth admit puterea lui Trump și încep să îl susțină cu bani." } }
+{ "translation": { "en": "Here are some recent poll numbers that suggest that the real estate mogul isn't just a passing phase: Trump's favorability ratings have turned 180 degrees. Right before Donald Trump announced his candidacy in mid-June, a Monmouth University poll showed only two in 10 Republicans had a positive view of the real estate mogul. By mid-July, it was 40 percent. In early August, it was 52 percent. Now, six in 10 Republicans have a favorable view of Donald Trump. Roughly three in 10 say they have a negative view. And these numbers hold up in early states. A Quinnipiac poll in Iowa last week found that 60 percent of Republicans there had a favorable view of Trump.", "ro": "În continuare vă prezentăm câteva cifre din sondaje recente care sugerează că mogulul imobiliar nu este doar ceva trecător: Cifrele care indică susținerea față de Trump s-au întors la 180 grade. Chiar înainte ca Donald Trump să își anunțe candidatura, la mijlocul lui iunie, un sondaj realizat de Universitatea din Monmouth arăta că doar doi din 10 republicani aveau o părere pozitivă despre mogulul imobiliar. Până la mijlocul lui iulie, procentul a urcat la 40%. La începutul lui august, era 52%. În prezent, șase din 10 republicani au o părere favorabilă despre Donald Trump. Aproximativ trei din 10 declară că au o părere negativă. Aceste cifre se mențin. Un sondaj realizat săptămâna trecută de Quinnipiac în Iowa a concluzionat că 60% dintre republicanii din regiune au o părere favorabilă despre Trump." } }
+{ "translation": { "en": "Two-thirds of GOP voters would be happy with Trump as the nominee. In a CNN/ORC poll last week, 67 percent of Republicans said they would be either \"enthusiastic\" or \"satisfied\" if Trump were the nominee. Only two in 10 say they would be \"upset\" if he were the nominee. Only Ben Carson generates roughly the same level of enthusiasm as Trump (43 percent say they would be \"enthusiastic\" vs. 40 percent who say the same of Trump). The next closest in enthusiasm? Marco Rubio with only 21 percent.", "ro": "Două treimi dintre alegătorii GOP ar fi fericiți dacă Trump ar câștiga cursa pentru nominalizare. Într-un sondaj realizat săptămâna trecută de CNN/ORC, 67% dintre republicani au declarat că ar fi „entuziasmați” sau „mulțumiți” dacă Trump ar câștiga cursa pentru nominalizare. Doar doi din 10 declară că ar fi „supărați” dacă Trump ar câștiga cursa pentru nominalizare. Doar Ben Carson generează aproximativ același nivel de entuziasm ca Trump (43% declară că ar fi „entuziasmați” față de 40% care declară același lucru despre Trump). Cel mai aproape în ceea ce privește entuziasmul? Marco Rubio, cu doar 21%." } }
+{ "translation": { "en": "On the flip side, 47 percent of Republican voters say they would be \"dissatisfied\" or \"upset\" if establishment favorite Jeb Bush becomes the nominee. A majority of Republicans don't see Trump's temperament as a problem. While Donald Trump has been widely criticized for his bombast and insults, 52 percent of leaned Republican voters nationwide think that the real estate mogul has the right temperament to be president, according to Monday's ABC News/Washington Post poll. The same number holds in the first-in-the-nation caucus state of Iowa, where the same 52 percent of Republicans think he has the personality to be commander in chief, according to Quinnipiac last week.", "ro": "De partea cealaltă, 47% dintre alegătorii republicani afirmă că ar fi „nemulțumiți” sau „supărați” dacă favoritul Jeb Bush câștigă cursa pentru nominalizare. Majoritatea republicanilor nu consideră temperamentul lui Trump o problemă. Deși Donald Trump a fost puternic criticat pentru insultele aduse și stilul său bombastic, 52% dintre alegătorii republicani la nivel național consideră că mogulul imobiliar are temperamentul potrivit pentru a fi președinte, conform sondajului realizat luni de ABC News/Washington Post. Regăsim aceleași cifre în statul Iowa, unde tot 52% dintre republicani cred că Trump are personalitatea potrivită pentru a fi conducător, conform sondajului realizat săptămâna trecută de Quinnipiac." } }
+{ "translation": { "en": "Still, 44 percent think he doesn't have the personality to serve effectively, and almost six in 10 independents say his temperament does not belong in the White House, according to ABC/Post. Republican voters are getting used to the idea. When they put on their pundit hats, Republican voters think Trump is for real. When asked who is most likely to win the GOP nomination, four in 10 said Trump was the best bet, according to a CNN/ORC poll out last week. That's a change from when four in 10 placed their money on Jeb Bush in late July. Full disclosure: GOP voters haven't had the clearest crystal ball in the past.", "ro": "Totuși, 44% sunt de părere că nu are personalitatea necesară pentru a acționa eficient și aproape șase din 10 independenți afirmă că temperamentul său nu are ce căuta la Casa Albă, conform ABC/Post. Alegătorii republicani se obișnuiesc cu ideea. Atunci când iau atitudinea de intelectuali, alegătorii republicani consideră că Trump este autentic. Conform unui sondaj realizat săptămâna trecută de CNN/ORC, la întrebarea cine are cele mai multe șanse să câștige cursa pentru nominalizare GOP, patru din 10 au declarat că Trump. Situația s-a schimbat față de finalul lui iulie, când patru din 10 ar fi pariat pe Jeb Bush. Informare completă: în trecut, alegătorii GOP nu au citit foarte bine viitorul." } }
+{ "translation": { "en": "At this time last cycle, four in 10 Republicans picked Rick Perry to win the nomination, vs. only 28 percent for eventual nominee Mitt Romney. Still, it shows that a plurality of GOP voters see Trump's campaign as plausible. Even if Republicans rallied around another candidate, Trump still beats almost everyone. Some pundits point out that the splintered field is likely contributing to Trump's lead, while anti-Trump support is be spread diffusely among more than a dozen other candidates. But a Monmouth University poll in early September shows that, in a hypothetical head-to-head matchup between Trump and most other Republican candidates, Trump almost always garners majority support.", "ro": "În aceeași perioadă a ultimelor alegeri, patru din 10 republicani l-au ales pe Rick Perry în cursa pentru nominalizare, față de doar 28% pentru Mitt Romney. Însă, aceste cifre arată că majoritatea alegătorilor GOP consideră plauzibilă campania lui Trump. Chiar dacă republicanii sau repliat spre un alt candidat. Trump încă se află în fruntea tuturor. Unele voci spun că situația divizată va contribui probabil la victoria lui Trump, în timp ce susținerea contra lui Trump se va împărți la mai mult de doisprezece candidați. Însă un sondaj derulat la începutul lui septembrie de Universitatea din Monmouth arată că, în situația ipotetică a unei colaborări între Trump și majoritatea celorlalți candidați republicani, aproape întotdeauna Trump va beneficia de susținerea majoritară." } }
+{ "translation": { "en": "He leads Carly Fiorina by 13 points, Marco Rubio by 14 points, Walker by 15 points, Jeb Bush by 19 points, and, finally, Rand Paul, John Kasich and Chris Christie by 33 points each. He's in a dead heat with Ted Cruz. The only candidate who beats him? Ben Carson would lead the businessman by a wide 19 points in a hypothetical head-to-head. A bare majority of Donald Trump's supporters say they've made up their minds. A new CBS/NYT poll out on Tuesday shows that just more than half of voters who support Trump say they have locked in their votes. Obviously, a lot can happen to change that, and no one can really say they would never change their mind.", "ro": "Trump se află la distanță de 13 puncte de Carly Fiorina, la 14 puncte de Marco Rubio, la 15 puncte de Walker, la 19 puncte de Jeb Bush și, în cele din urmă, la câte 33 de puncte față de Rand Paul, John Kasich și Chris Christie. Este aproape la egalitate cu Ted Cruz. Singurul candidat care îl învinge? Ben Carson l-ar învinge pe omul de afaceri cu 19 puncte într-o confruntare ipotetică de unu la unu. Majoritatea susținătorilor lui Donald Trump declară că s-au decis. Un nou sondaj realizat marți de CBS/NYT arată că peste jumătate dintre alegătorii care îl susțin pe Trump declară că nu își schimbă opțiunea de vot. Evident, se pot întâmpla multe în acest sens și nimeni nu poate spune că aceștia nu se vor răzgândi niciodată." } }
+{ "translation": { "en": "46 percent said they are leaving the door open to switching candidates. Still, Trump's strongest competition at the moment is from fellow outsider neurosurgeon Ben Carson, but voters who say they have made up their minds are twice as likely to go for Trump. Six in 10 Republicans say they agree with Trump on immigration. Even since Donald Trump called immigrants from Mexico \"rapists\" in his campaign announcement speech two months ago, immigration has been front and center in the 2016 conversation. Some are worried that Trump's bombast will drive crucial Hispanic voters away from the Republican Party and damage rebranding efforts.", "ro": "46% afirmă că lasă portița deschisă posibilității de a-și schimba opțiunea. Cu toate acestea, cel mai important adversar al lui Trump este în prezent neurochirurgul Ben Carson, însă este de două ori mai probabil ca alegătorii care declară că s-au decis să voteze cu Trump. Șase din 10 republicani afirmă că sunt de acord cu Trump în problema imigrării. De când Donald Trump i-a numit pe imigranții din Mexic „violatori” în discursul de deschidere a campaniei sale, în urmă cu două luni, imigrarea a fost subiectul central în campania pentru 2016. Unii sunt îngrijorați că stilul bombastic al lui Trump va duce la o scindare între alegătorii hispanici importanți și Partidul Republican și va prejudicia eforturile de rebranding." } }
+{ "translation": { "en": "But according to Monday's new ABC/Post poll, six in 10 Republicans say they agree with Trump on immigration issues. So as long as immigration remains in the spotlight, it seems Donald Trump will remain too. Frustration with government is climbing to new highs. Donald Trump and Ben Carson now account for roughly half of the support from Republican voters, largely due to their outsider status. Six in 10 Republicans in Monday's new ABC/Post poll say they want a political outsider over someone with government experience. And they are angry at Washington, too.", "ro": "Însă, conform sondajului realizat luni de ABC/Post, șase din 10 republicani afirmă că sunt de acord cu Trump în problema imigrării. Așa că, se pare că atâta timp cât problema imigrării rămâne în lumina reflectoarelor, la fel va rămâne și Doland Trump. Frustrarea față de autorități atinge noi culmi. Donald Trump și Ben Carson sunt acum susținuți de aproape jumătate dintre alegătorii republicani, în mare parte datorită statutului lor de outsideri. Conform sondajului realizat luni de ABC/Post, șase din 10 republicani afirmă că preferă un outsider politic în detrimentul cuiva cu experiență în guvernare. Oamenii sunt de asemenea supărați pe autoritățile de la Washington." } }
+{ "translation": { "en": "A Des Moines Register/Bloomberg poll in Iowa from two weeks ago shows that three in four Iowa Republicans are frustrated with Republicans in Congress, with 54 percent \"unsatisfied\" and 21 percent \"mad as hell.\" Jeremy Corbyn to make debut at Prime Minister's Questions Since his election, Mr Corbyn's debut at PMQs has been keenly awaited New Labour leader Jeremy Corbyn is to make his debut at Prime Minister's Questions later, taking on David Cameron for the first time.", "ro": "Un sondaj derulat în urmă cu două săptămâni în Iowa de către Des Moines Register/Bloomberg arată că trei din patru republicani din Iowa sunt frustrați de prestația republicanilor din COngres, 54% declarându-se „nemulțumiți” iar 21% „nervoși la culme”. Jeremy Corbyn își face debutul la Prime Minister's Questions Încă de la alegerea sa, debutul domnului Corbyn la PMQs a fost îndelung așteptat Noul lider al Partidului Laburist, Jeremy Corbyn, își va face mai târziu debutul la Prime Minister's Questions, confruntându-se pentru prima dată cu David Cameron." } }
+{ "translation": { "en": "Mr Corbyn will rise to ask the first of his six allotted questions shortly after midday, with his performance likely to be closely scrutinised by the media and Labour MPs. He has called for \"less theatre and more facts\" at the weekly showpiece. He has also said he could skip some sessions, leaving them to colleagues. The encounter will be the first parliamentary test of Mr Corbyn's leadership, coming after his appointment of a shadow cabinet and his speech to the TUC annual congress on Tuesday.", "ro": "Dl Corbyn va adresa primele dintre cele șase întrebări la care are dreptul la scurt timp după prânz; prestația sa va fi probabil analizată îndeaproape de mass-media și parlamentarii laburiști. În cadrul aparițiilor săptămânale, el a cerut „mai puțin teatru și mai multe fapte”. A declarat de asemenea că poate renunța la câteva participări și că le cedează colegilor săi. Confruntarea va fi primul test parlamentar al Dl Corbyn în poziție de lider, venind după ce a numit un „cabinet fantomă” și după discursul pe care l-a ținut marți la congresul anual TUC." } }
+{ "translation": { "en": "Meanwhile, the Labour leader's decision to stand in silence during the singing of the national anthem at a service on Tuesday to mark the 75th anniversary of the Battle of Britain has attracted criticism from a number of Tory MPs and is the focus of several front page stories in the newspapers. Mr Corbyn's decision not to sing the national anthem has attracted attention A spokesman for Mr Corbyn said he had \"stood in respectful silence\" and did recognise the \"heroism of the Royal Air Force in the Battle of Britain.\"", "ro": "Între timp, decizia liderului Partidului laburist de a păstra tăcerea la rostirea imnului național în cadrul unei slujbe ținute marți cu ocazia aniversării a 75 de ani de la Bătălia Angliei a atras critici din partea unor parlamentari conservatori și a ținut prima pagină a ziarelor. Decizia domnului Corbyn de a nu cânta imnul național a atras atenția Un purtător de cuvânt al Dl Corbyn a declarat că acesta „a păstrat tăcerea în mod respectuos” și a recunoscut „eroismul Forțelor aeriene britanice în Bătălia Angliei.”" } }
+{ "translation": { "en": "But a member of Mr Corbyn's shadow cabinet, Owen Smith, told BBC Two's Newsnight programme he would have advised the Labour leader to sing the national anthem \"irrespective\" of his belief that the monarchy should be abolished. Nearly a dozen shadow ministers have refused to serve in Mr Corbyn's top team, citing differences over the economy, defence and foreign affairs, while less than a sixth of the parliamentary party originally backed him as leader. BBC political correspondent Robin Brant says policy differences are also \"stacking up\" within Labour following Mr Corbyn's appointment over its position on the European Union and the government's cap on benefits.", "ro": "Însă un membru al cabinetului fantomă al Dl Corbyn, Owen Smith, a declarat pentru emisiunea Two's Newsnight transmisă de BBC că i-ar fi recomandat liderului laburist să cânte imnul național „indiferent” de credința sa că monarhia ar trebui abolită. În jur de doisprezece miniștri din cabinetul fantomă au refuzat să facă parte din echipa de frunte a Dl Corbyn, argumentând prin diferențe de opinie legate de economie, apărare și externe, în timp ce mai puțin de o șesime din partidul parlamentar l-a susținut ca lider. Corespondentul politic al BBC, Robin Brant, declară că diferențele de politică „se cumulează” în Partidul Laburist după numirea domnului Corbyn referitor la poziția sa față de Uniunea Europeană și limita de beneficii." } }
+{ "translation": { "en": "Mr Corbyn told the TUC conference Labour was putting forward amendments to remove the whole idea of a cap altogether. Hours later Mr Smith, the shadow work and pensions secretary, said the party was \"very clear\" that it was only opposing government plans to reduce the level of cap from £26,000 to £23,000. Mr Corbyn will be the fifth Labour leader that David Cameron has faced across the despatch box over the past decade since he became Tory leader. The Labour leader, who has promised a different approach to politics, says he has \"crowd sourced\" ideas for questions to ask Mr Cameron and has been given more than 30,000 suggestions.", "ro": "Dl Corbyn a declarat la conferința TUC că Partidul Laburist va aduce modificări prin care se va elimina integral ideea limitării. Câteva ore mai târziu, Dl Smith, Ministrul Muncii și Pensiilor, a declarat că partidul „este foarte clar” în opoziția exclusivă față de planurile guvernului de a reduce nivelul „cap” de la 26.000 lire la 23.000 lire. Dl Corbyn va fi al cincilea lider laburist cu care se confruntă David Cameron la tribună în ultimul deceniu, de când a preluat conducerea Partidului Conservator. Liderul laburist, care a promis o abordare diferită a politicii, spune că are idei „din surse externe” pentru întrebări pe care să i le adreseze Domnului Cameron și că a primit peste 30.000 de sugestii." } }
+{ "translation": { "en": "The Islington North MP has said PMQs is too confrontational and that he will refrain from both \"repartee\" and trading barbs, instead vowing to focus on serious issues such as poverty, inequality and the challenges facing young people. Mr Corbyn has said that Angela Eagle, the shadow business secretary, will deputise for him at PMQs when he does not attend - for instance when Mr Cameron is travelling abroad. He has also floated the idea of allowing other colleagues to take the floor on occasion, saying he had approached the Commons Speaker John Bercow to discuss the issue.", "ro": "Parlamentarul Islington North a afirmat că PMQs implică un nivel de confruntare prea înalt și că se va abține de la replici și atacuri, angajându-se să se concentreze în schimb pe probleme serioase precum sărăcia, inegalitatea și provocările cu care se confruntă tinerii. Dl Corbyn a declarat că Angela Eagle, Ministrul de finanțe, îi va ține locul la PMQs atunci când el nu poate participa - de exemplu atunci când Dl Cameron se deplasează în străinătate. A exprimat de asemenea ideea că va permite altor colegi să ia cuvântul ocazional, spunând că l-a abordat pe Președintele Camerei Deputaților, John Bercow, pentru a discuta acest aspect." } }
+{ "translation": { "en": "When he became leader in 2005, Mr Cameron said he wanted to move away from the \"Punch and Judy\" style of politics often associated with PMQs but admitted some years later that he had failed. Since it was first televised in 1990, PMQs has been seen as a key barometer of a leader's judgement, their command of the Commons and their standing among their fellow MPs although critics have argued it has become a caricature and is in need of far-reaching reforms. 'Shot in Joburg': Homeless youth trained as photographers Downtown Johannesburg is a tough place to be homeless.", "ro": "În 2005, când a preluat conducerea, Dl Cameron a declarat că dorește să renunțe la stilul politic „Punch and Judy” asociat adesea cu PMQs însă a recunoscut câțiva ani mai târziu că nu a reușit în demersul său. De la prima transmisie, în 1990, PMQs a fost considerată un barometru cheie al raționamentului unui lider, al modului în care acesta conduce Camera Deputaților și a poziției sale în rândul colegilor parlamentari, deși criticii afirmă a ca devenit o caricatură și că are nevoie de o reformare profundă. „Cadru în Joburg”: Tineri fără adăpost beneficiază de cursuri de fotografie Este dificil să fii un om fără adăpost în Johannesburg." } }
+{ "translation": { "en": "But one group of former street children have found a way to learn a skill and make a living. \"I was shot in Joburg\" is a non-profit studio that teaches homeless youngsters how to take photographs of their neighbourhood and make a profit from it. BBC News went to meet one of the project's first graduates. JD Sports boss says higher wages could hurt expansion JD Sports Executive Chairman Peter Cowgill says a higher minimum wage for UK workers could mean \"more spending power in the pockets of potential consumers.\" But that spending power is unlikely to outweigh the higher labour costs at his firm, he says.", "ro": "Însă un grup de oameni care au trăit pe străzi în copilărie au găsit un mod de a învăța o meserie și de a-și câștiga traiul. „I was shot în Joburg” este un studio non-profit care îi învață pe tinerii fără adăpost să facă fotografii ale zonelor în care trăiesc și să câștige bani din asta. BBC News s-a întâlnit cu unul dintre primii absolvenți ai proiectului. Șeful JD Sports spune că salariile mai mari ar putea dăuna extinderii Președintele JD Sports, Peter Cowgill, declară că o creștere a salariului minim în Marea Britanie ar putea însemna „o putere de cumpărare mai mare în buzunarele potențialilor consumatori.” Este însă puțin probabil ca respectiva putere de cumpărare să depășească costurile mai mari pentru forța de muncă în cadrul firmei, afirmă el." } }
+{ "translation": { "en": "The costs could hit JD Sports' expansion plans, he added, which could mean fewer extra jobs. Thanasi Kokkinakis backed by Tennis Australia president Steve Healy Thanasi Kokkinakis deserves kudos rather than criticism for his behaviour. Thanasi Kokkinakis has been the collateral damage in the recent storm around his friend Nick Kyrgios and deserves kudos rather than criticism for his own behaviour, according to Tennis Australia president Steve Healy.", "ro": "Costurile ar putea avea impact asupra planurilor de extindere ale JD Sports, a adăugat el, ceea ce ar putea însemna mai puține locuri de muncă noi. Thanasi Kokkinakis susținut de președintele Tennis Australia, Steve Healy Thanasi Kokkinakis ar merita să fie lăudat și nu criticat pentru comportamentul său. Thanasi Kokkinakis a fost victimă colaterală în „furtuna” creată în jurul prietenului său, Nick Kyrgios, iar comportamentul său merită mai degrabă cuvinte de laudă și nu critică, în opinia președintelui Tennis Australia, Steve Healy." } }
diff --git a/transformers/tests/fixtures/tests_samples/wmt_en_ro/train.json b/transformers/tests/fixtures/tests_samples/wmt_en_ro/train.json
new file mode 100644
index 0000000000000000000000000000000000000000..269d5156c23e5b1dbe51db6ec39618e48eefa17b
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/wmt_en_ro/train.json
@@ -0,0 +1,11 @@
+{ "translation": { "en": "Corrections to votes and voting intentions: see Minutes Assignment conferred on a Member: see Minutes Membership of committees and delegations: see Minutes Decisions concerning certain documents: see Minutes Forwarding of texts adopted during the sitting: see Minutes Dates for next sittings: see Minutes", "ro": "Corectările voturilor şi intenţiile de vot: a se vedea procesul-verbal Misiune încredinţată unui deputat: consultaţi procesul-verbal Componenţa comisiilor şi a delegaţiilor: a se vedea procesul-verbal Decizii privind anumite documente: a se vedea procesul-verbal Transmiterea textelor adoptate în cursul prezentei şedinţe: a se vedea procesul-verbal Calendarul următoarelor şedinţe: a se vedea procesul-verbal" } }
+{ "translation": { "en": "Membership of Parliament: see Minutes Approval of Minutes of previous sitting: see Minutes Membership of Parliament: see Minutes Verification of credentials: see Minutes Documents received: see Minutes Written statements and oral questions (tabling): see Minutes Petitions: see Minutes Texts of agreements forwarded by the Council: see Minutes Action taken on Parliament's resolutions: see Minutes Agenda for next sitting: see Minutes Closure of sitting (The sitting was closed at 7.45 p.m.)", "ro": "Componenţa Parlamentului: a se vedea procesul-verbal Aprobarea procesului-verbal al şedinţei precedente: a se vedea procesul-verbal Componenţa Parlamentului: a se vedea procesul-verbal Verificarea prerogativelor: a se vedea procesul-verbal Depunere de documente: a se vedea procesul-verbal Declaraţii scrise şi întrebări orale (depunere): consultaţi procesul-verbal Petiţii: a se vedea procesul-verbal Transmiterea de către Consiliu a textelor acordurilor: a se vedea procesul-verbal Cursul dat rezoluţiilor Parlamentului: a se vedea procesul-verbal Ordinea de zi a următoarei şedinţe: a se vedea procesul-verbal Ridicarea şedinţei (Se levanta la sesión a las 19.45 horas)" } }
+{ "translation": { "en": "Election of Vice-Presidents of the European Parliament (deadline for submitting nominations): see Minutes (The sitting was suspended at 12.40 p.m. and resumed at 3.00 p.m.) Election of Quaestors of the European Parliament (deadline for submitting nominations): see Minutes (The sitting was suspended at 3.25 p.m. and resumed at 6.00 p.m.) Agenda for next sitting: see Minutes Closure of sitting (The sitting was closed at 6.15 p.m.) Opening of the sitting (The sitting was opened at 9.35 a.m.) Documents received: see Minutes Approval of Minutes of previous sitting: see Minutes Membership of Parliament: see Minutes", "ro": "Alegerea vicepreşedinţilor Parlamentului European (termenul de depunere a candidaturilor): consultaţi procesul-verbal (Die Sitzung wird um 12.40 Uhr unterbrochen und um 15.00 Uhr wiederaufgenommen). Alegerea chestorilor Parlamentului European (termenul de depunere a candidaturilor): consultaţi procesul-verbal (Die Sitzung wird um 15.25 Uhr unterbrochen und um 18.00 Uhr wiederaufgenommen). Ordinea de zi a următoarei şedinţe: a se vedea procesul-verbal Ridicarea şedinţei (Die Sitzung wird um 18.15 Uhr geschlossen.) Deschiderea şedinţei (Die Sitzung wird um 9.35 Uhr eröffnet.) Depunerea documentelor: a se vedea procesul-verbal Aprobarea procesului-verbal al şedinţei precedente: a se vedea procesul-verbal Componenţa Parlamentului: a se vedea procesul-verbal" } }
+{ "translation": { "en": "Membership of committees (deadline for tabling amendments): see Minutes (The sitting was suspended at 7 p.m. and resumed at 9 p.m.) Agenda for next sitting: see Minutes Closure of sitting (The sitting was suspended at 23.25 p.m.) Documents received: see Minutes Communication of Council common positions: see Minutes (The sitting was suspended at 11.35 a.m. and resumed for voting time at noon) Approval of Minutes of previous sitting: see Minutes Committee of Inquiry into the crisis of the Equitable Life Assurance Society (extension of mandate): see Minutes", "ro": "Componenţa comisiilor (termenul de depunere a amendamentelor): consultaţi procesul-verbal (La seduta, sospesa alle 19.00, è ripresa alle 21.00) Ordinea de zi a următoarei şedinţe: a se vedea procesul-verbal Ridicarea şedinţei (Die Sitzung wird um 23.25 Uhr geschlossen.) Depunerea documentelor: a se vedea procesul-verbal Comunicarea poziţiilor comune ale Parlamentului: a se vedea procesul-verbal (La séance, suspendue à 11h35 dans l'attente de l'Heure des votes, est reprise à midi) Aprobarea procesului-verbal al şedinţei precedente: a se vedea procesul-verbal Comisia de anchetă privind criza societăţii de asigurări \"Equitable Life” (prelungirea mandatului): consultaţi procesul-verbal" } }
+{ "translation": { "en": "Announcement by the President: see Minutes 1. Membership of committees (vote) 2. Amendment of the ACP-EC Partnership Agreement (vote) 4. Certification of train drivers operating locomotives and trains on the railway system in the Community (vote) 6. Law applicable to non-contractual obligations (\"ROME II\") (vote) 8. Seventh and eighth annual reports on arms exports (vote) Corrections to votes and voting intentions: see Minutes Membership of committees and delegations: see Minutes Request for waiver of parliamentary immunity: see Minutes Decisions concerning certain documents: see Minutes", "ro": "Comunicarea Preşedintelui: consultaţi procesul-verbal 1. Componenţa comisiilor (vot) 2. Modificarea Acordului de parteneriat ACP-CE (\"Acordul de la Cotonou”) (vot) 4. Certificarea mecanicilor de locomotivă care conduc locomotive şi trenuri în sistemul feroviar comunitar (vot) 6. Legea aplicabilă obligaţiilor necontractuale (\"Roma II”) (vot) 8. Al şaptelea şi al optulea raport anual privind exportul de armament (vot) Corectările voturilor şi intenţiile de vot: a se vedea procesul-verbal Componenţa comisiilor şi a delegaţiilor: a se vedea procesul-verbal Cerere de ridicare a imunităţii parlamentare: consultaţi procesul-verbal Decizii privind anumite documente: a se vedea procesul-verbal" } }
+{ "translation": { "en": "Written statements for entry", "ro": "Declaraţii scrise înscrise" } }
+{ "translation": { "en": "Written statements for entry in the register (Rule 116): see Minutes Forwarding of texts adopted during the sitting: see Minutes Dates for next sittings: see Minutes Adjournment of the session I declare the session of the European Parliament adjourned. (The sitting was closed at 1 p.m.) Approval of Minutes of previous sitting: see Minutes Membership of Parliament: see Minutes Request for the defence of parliamentary immunity: see Minutes Appointments to committees (proposal by the Conference of Presidents): see Minutes Documents received: see Minutes Texts of agreements forwarded by the Council: see Minutes", "ro": "Declaraţii scrise înscrise în registru (articolul 116 din Regulamentul de procedură): a se vedea procesul-verbal Transmiterea textelor adoptate în cursul prezentei şedinţe: a se vedea procesul-verbal Calendarul următoarelor şedinţe: a se vedea procesul-verbal Întreruperea sesiunii Dichiaro interrotta la sessione del Parlamento europeo. (La seduta è tolta alle 13.00) Aprobarea procesului-verbal al şedinţei precedente: a se vedea procesul-verbal Componenţa Parlamentului: a se vedea procesul-verbal Cerere de apărare a imunităţii parlamentare: consultaţi procesul-verbal Numiri în comisii (propunerea Conferinţei preşedinţilor): consultaţi procesul-verbal Depunerea documentelor: a se vedea procesul-verbal Transmiterea de către Consiliu a textelor acordurilor: a se vedea procesul-verbal" } }
+{ "translation": { "en": "Action taken on Parliament's resolutions: see Minutes Oral questions and written statements (tabling): see Minutes Written statements (Rule 116): see Minutes Agenda: see Minutes 1. Appointments to parliamentary committees (vote): see Minutes Voting time Agenda for next sitting: see Minutes Closure of sitting (The sitting was closed at 12 midnight) Opening of the sitting (The sitting was opened at 09.05) Documents received: see Minutes Approval of Minutes of previous sitting: see Minutes 1. Protection of passengers against displaced luggage (vote) 2.", "ro": "Continuări ale rezoluţiilor Parlamentului: consultaţi procesul-verbal Declaraţii scrise şi întrebări orale (depunere): consultaţi procesul-verbal Declaraţii scrise (articolul 116 din Regulamentul de procedură) Ordinea de zi: a se vedea procesul-verbal 1. Numiri în comisiile parlamentare (vot): consultaţi procesul-verbal Timpul afectat votului Ordinea de zi a următoarei şedinţe: a se vedea procesul-verbal Ridicarea şedinţei (La seduta è tolta alle 24.00) Deschiderea şedinţei (The sitting was opened at 09.05) Depunerea documentelor: a se vedea procesul-verbal Aprobarea procesului-verbal al şedinţei precedente: a se vedea procesul-verbal 1. Protecţia pasagerilor împotriva deplasării bagajelor (vot) 2." } }
+{ "translation": { "en": "Approval of motor vehicles with regard to the forward field of vision of the driver (vote) 3. EC-Korea Agreement on scientific and technological cooperation (vote) 4. Mainstreaming sustainability in development cooperation policies (vote) 5. Draft Amending Budget No 1/2007 (vote) 7. EC-Gabon Fisheries Partnership (vote) 10. Limitation periods in cross-border disputes involving personal injuries and fatal accidents (vote) 12. Strategy for a strengthened partnership with the Pacific Islands (vote) 13. The European private company statute (vote) That concludes the vote.", "ro": "Omologarea vehiculelor cu motor cu privire la câmpul de vizibilitate înainte al conducătorului auto (vot) 3. Acordul CE-Coreea de cooperare ştiinţifică şi tehnologică (vot) 4. Integrarea durabilităţii în politicile de cooperare pentru dezvoltare (vot) 5. Proiect de buget rectificativ nr.1/2007 (vot) 7. Acordul de parteneriat în domeniul pescuitului între Comunitatea Europeană şi Republica Gaboneză (vot) 10. Termenele de prescripţie aplicabile în cadrul litigiilor transfrontaliere cu privire la vătămările corporale şi accidentele mortale (vot) 12. Relaţiile UE cu insulele din Pacific: Strategie pentru un parteneriat consolidat (vot) 13. Statutul societăţii private europene (vot) Damit ist die Abstimmungsstunde beendet." } }
+{ "translation": { "en": "Corrections to votes and voting intentions: see Minutes Assignment conferred on a Member: see Minutes Membership of committees and delegations: see Minutes Decisions concerning certain documents: see Minutes Forwarding of texts adopted during the sitting: see Minutes Dates for next sittings: see Minutes", "ro": "Corectările voturilor şi intenţiile de vot: a se vedea procesul-verbal Misiune încredinţată unui deputat: consultaţi procesul-verbal Componenţa comisiilor şi a delegaţiilor: a se vedea procesul-verbal Decizii privind anumite documente: a se vedea procesul-verbal Transmiterea textelor adoptate în cursul prezentei şedinţe: a se vedea procesul-verbal Calendarul următoarelor şedinţe: a se vedea procesul-verbal" } }
+{ "translation": { "en": "Written statements for entry", "ro": "Declaraţii scrise înscrise" } }
diff --git a/transformers/tests/fixtures/tests_samples/wmt_en_ro/val.json b/transformers/tests/fixtures/tests_samples/wmt_en_ro/val.json
new file mode 100644
index 0000000000000000000000000000000000000000..22cdd68ecd1c5bd0018bbe04d756f4c10bd3b919
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/wmt_en_ro/val.json
@@ -0,0 +1,16 @@
+{ "translation": { "en": "Brazil's Former Presidential Chief-of-Staff to Stand Trial A federal judge on Tuesday accepted the charges filed against Brazil's former presidential chief of staff for his alleged involvement in a massive corruption scheme at state-owned oil company Petrobras. The federal prosecutor's office said Jose Dirceu will face trial on the corruption, racketeering and money laundering charges filed earlier this month. Fourteen other people will also be tried, including Joao Vaccari Neto, the former treasurer of Brazil's governing Workers' Party and Renato de Souza Duque, Petrobras' former head of corporate services.", "ro": "Fostul șef al cabinetului prezidențial brazilian este adus în fața instanței Marți, un judecător federal a acceptat acuzațiile aduse împotriva fostului șef al cabinetului prezidențial brazilian pentru presupusa implicare a acestuia într-o schemă masivă de corupție privind compania petrolieră de stat Petrobras. Biroul procurorului federal a declarat că Jose Dirceu va fi trimis în judecată pentru acuzațiile de corupție, înșelătorie și spălare de bani aduse în această lună. Alte paisprezece persoane vor fi judecate, printre acestea numărându-se Joao Vaccari Neto, fostul trezorier al Partidului Muncitorilor, aflat la putere în Brazilia, și Renato de Souza Duque, fostul președinte al serviciilor pentru întreprinderi ale Petrobras." } }
+{ "translation": { "en": "Dirceu is the most senior member of the ruling Workers' Party to be taken into custody in connection with the scheme. Dirceu served as former President Luiz Inacio Lula da Silva's chief of staff between 2003 and 2005. He was arrested early August in his home, where he already was under house arrest serving an 11-year sentence for his involvement in a cash-for-votes scheme in Congress more than 10 years ago. Prosecutors have said that Dirceu masterminded the kickback scheme at Petrobras, accepted bribes while in office and continued to receive payments from contractors after he was jailed in late 2013 for the vote-buying scandal.", "ro": "Dirceu este cel mai vechi membru al Partidului Muncitorilor aflat la guvernare luat în custodie pentru legăturile cu această schemă. Dirceu a servit ca șef de cabinet al fostului președinte Luiz Inacio Lula da Silva între 2003 și 2005. A fost arestat la începutul lui august de acasă, unde deja se afla sub arest la domiciliu, cu o pedeapsă de 11 ani pentru implicarea într-o schemă de cumpărare a voturilor în Congres cu peste 10 ani în urmă. Procurorii au declarat că Dirceu a dezvoltat schema de luare de mită de la Petrobras, a acceptat mită în timp ce se afla în funcție și a continuat să primească plăți de la antreprenori după ce a fost închis la sfârșitul lui 2013 pentru scandalul voturilor cumpărate." } }
+{ "translation": { "en": "According to prosecutors, the scheme at Petrobras involved roughly $2 billion in bribes and other illegal funds. Some of that money was allegedly funneled back to campaign coffers of the ruling party and its allies. It also allegedly included the payment of bribes to Petrobras executives in return for inflated contracts. 'Miraculous' recovery for Peshawar massacre schoolboy A teenager paralysed after being shot four times in Pakistan's deadliest terror attack has made a \"miraculous\" recovery following treatment in the UK. Muhammad Ibrahim Khan, 13, had been told by doctors in Pakistan that he would never walk again.", "ro": "Conform procurorilor, schema de la Petrobras a implicat aproximativ 2 miliarde de dolari sub formă de mită și alte fonduri ilegale. O parte din acei bani s-ar fi întors în fondul de campanie al partidului aflat la guvernare și al aliaților acestora. De asemenea, ar fi inclus mită către directorii Petrobras în schimbul unor contracte umflate. Recuperarea „miraculoasă” a unui elev supraviețuitor al masacrului de la Peshawar Un adolescent paralizat după ce fusese împușcat de patru ori în cel mai cumplit atac terorist din Pakistan a reușit o recuperare „miraculoasă” după ce a urmat un tratament în Regatul Unit. Lui Mohamed Ibrahim Khan, în vârstă de 13 ani, doctorii din Pakistan îi spuseseră că nu va mai putea să meargă niciodată." } }
+{ "translation": { "en": "At least 140 people, mostly children, were killed when gunmen stormed Peshawar's Army Public School last December. Muhammad, who arrived in London last month for surgery, is being discharged from hospital later. Exactly nine months ago, on an ordinary Tuesday morning, Muhammad sat in his first aid class listening to his teachers intently. At the same time seven gunmen disguised in security uniforms were entering the Army Public School. They were strapped with explosives and had one simple mission in mind: Kill every man, woman and child they came across. \"I can't forget what happened that day,\" Muhammad says with a severe stare.", "ro": "Cel puțin 140 de persoane, majoritatea copii, au fost ucise când bărbați înarmați au atacat școala publică a armatei din Peshawar în luna decembrie a anului trecut. Mohamed, care a sosit la Londra luna trecută pentru operație, va fi externat mai târziu din spital. Exact cu nouă luni în urmă, într-o dimineață obișnuită de marți, Mohamed stătea la ora de primul ajutor și își asculta atent profesorii. Chiar atunci, șapte bărbați înarmați deghizați în uniformele agenților de pază intrau în școala publică a armatei. Purtau centuri cu explozivi și aveau de îndeplinit o misiune simplă: să îi ucidă pe toți bărbații, femeile și copiii care le ieșeau în cale. „Nu pot uita ce s-a întâmplat în acea zi”, spune Mohamed cu o privire aspră." } }
+{ "translation": { "en": "We were sitting in the auditorium, we were asking questions... and then we heard heavy gunfire outside. The terrorists moved inside and they started killing - our teacher was burned alive. Muhammad described pulling four other pupils out of the auditorium as the carnage unfolded. He said he then heard his friend, Hamza calling to him. He said, 'oh brother save me'. I held his hand. That's when I was shot in the back, and he was shot in the head. Most of the people killed in the attack were pupils Hamza died in Muhammad's arms. Muhammad recalled blacking out after that, and the next thing he knew he was in a hospital bed, paralysed from the waist down.", "ro": "Stăteam în amfiteatru, puneam întrebări... apoi am auzit focuri de armă afară. Teroriștii au intrat înăuntru și au început să ucidă. Profesorul nostru a fost ars de viu. Mohamed descrie cum a scos patru elevi din amfiteatru în timp ce se desfășura carnagiul. Apoi spune că și-a auzit prietenul, pe Hamza, strigându-l. Spunea „oh, frate, salvează-mă”. L-am ținut de mână. Atunci eu am fost împușcat în spate, iar el în cap. Cei mai mulți dintre cei uciși în atac erau elevi Hamza a murit în brațele lui Mohamed. Mohamed își amintește că imediat după asta a leșinat și că următorul lucru pe care l-a știut a fost că se afla pe un pat de spital, paralizat de la brâu în jos." } }
+{ "translation": { "en": "Doctors in Peshawar in northern Pakistan, and then Rawalpindi, close to the capital, told his family there was no treatment, and he would never walk again. \"Seeing him I felt like my soul had left my body,\" says Muhammad's father, Sher Khan Those nine months were the hardest in my life. But Mr Khan and his wife, Sherbano, refused to believe that their cricket-mad son would never be able to use his legs again. They campaigned, and appealed for help on Pakistani TV, gaining the support of high profile people such as cricketer turned politician Imran Khan.", "ro": "Doctorii din Peshawar din nordul Pakistanului, apoi cei din Rawalpindi, aproape de capitală, i-au spus familiei sale că nu exista tratament și că nu va mai putea merge niciodată. „Când l-am văzut, am simțit cum îmi iese sufletul”, spune Sher Khan, tatăl lui Mohamed. Acele nouă luni au fost cele mai grele din viața mea. Însă Khan și soția lui, Sherbano, au refuzat să creadă că fiul lor atât de pasionat de crichet nu-și va mai putea folosi vreodată picioarele. Au făcut o campanie și au cerut ajutor de la televiziunea pakistaneză, atrăgând sprijinul unor oameni faimoși precum Imran Khan, jucător de crichet devenit politician." } }
+{ "translation": { "en": "Finally, they were able to raise the funds to bring Muhammad to the UK and provide him with treatment at London's private Harley Street Clinic. Consultant neurosurgeon Irfan Malik described Muhammad as \"terrified\" when he first arrived at the hospital. \"He'd spent the last [few] months lying on a bed, unable to move side to side,\" says Mr Malik. He was weak, he had a pressure sore on his back. He wasn't in great shape. A vertebra at the base of Muhammad's spine was destroyed Muhammad was shot in his shoulder, his hip, and his back during the attack, damaging his lower spine - leading to paralysis.", "ro": "Într-un final, au reușit să strângă fonduri pentru a-l duce pe Mohamed în Regatul Unit și a-i oferi tratament la clinica privată Harley Street din Londra. Neurochirurgul consultant Irfan Malik l-a descris pe Mohamed drept „înspăimântat” când acesta a ajuns la spital. „Își petrecuse ultimele [câteva] luni zăcând în pat, fără să se poată mișca de pe o parte pe alta, spune Malik. Era slăbit, se pusese multă presiune pe spatele lui. Nu era într-o formă prea bună. O vertebră de la baza coloanei vertebrale a lui Mohamed fusese distrusă Mohamed fusese împușcat în umăr, în șold și în spate în timpul atacului, iar coloana vertebrală inferioară îi fusese distrusă, ducând la paralizie." } }
+{ "translation": { "en": "But during six hours of surgery, Mr Malik and his team were able to reattach nerve endings and reconstruct the damaged part of the spine. Even Mr Malik was surprised at what happened next. Exactly one week after the surgery Muhammad stood up and started taking steps and walking. We were not expecting to get that sort of excellent result. That was miraculous,\" he says. Less than two weeks after his operation, Muhammad is ready to leave hospital and start the long road to recovery. Muhammad has defied the odds and started to walk again He says he wants to build his strength and continue his education in the UK. But he says he is determined to return to Pakistan, join the army and help fight terrorism.", "ro": "Însă, în timpul unei operații care a durat șase ore, Malik și echipa lui au reușit să lege din nou terminațiile nervoase și să reconstruiască partea distrusă a coloanei. Chiar și Malik a fost surprins de ceea ce s-a întâmplat în continuare. Exact la o săptămână după operație, Mohamed s-a ridicat și a început să facă pași și să meargă. Nu ne așteptam la un rezultat atât de bun. A fost un miracol”, spune acesta. În mai puțin de două săptămâni de la operație, Mohamed este gata să părăsească spitalul și să înceapă procesul lung de recuperare. Mohamed a sfidat soarta și a început să meargă din nou Vrea să devină puternic și să își continue studiile în Regatul Unit. Însă este hotărât să revină în Pakistan, să se înroleze în armată și să lupte împotriva terorismului." } }
+{ "translation": { "en": "\"I feel like I have a second chance at life,\" he says as he shows off pictures he's drawn of guns scribbled out next to school books and pens Muhammad grows physically stronger every day but the psychological trauma he continues to endure is unimaginable. \"My anger is not diminishing\" he says. In my school little kids were killed. What was their crime? His mother, wiping a tear from her eye, caressed his head and said: \"I can see my son walking again.\" He'll be able to get on with his normal life. 'Super Voice' 4G service from Three offers better signal Three is making use of a lower frequency 4G spectrum that can travel more widely", "ro": "„Simt că am încă o șansă la viață” spune el, arătând imaginile cu arme desenate de el lângă manuale școlare și stilouri Fizic, Mohamed devine tot mai puternic în fiecare zi, însă trauma psihologică prin care trece și acum este de neimaginat. „Furia mea nu a scăzut”, mărturisește el. În școala mea au fost uciși copii mici. Ce crimă au comis ei? Mama lui își șterge o lacrimă, îl mângâie pe creștet și spune: „Îmi văd fiul mergând din nou”. Va putea să-și continue firesc viața. Serviciul 4G „Super Voice” de la Three oferă semnal mai bun Three folosește un spectru 4G cu o frecvență mai joasă, care poate acoperi o zonă mai extinsă" } }
+{ "translation": { "en": "Mobile phone provider Three has launched a UK service it says will improve reception inside buildings and in rural black spots. Its 4G Super Voice enables customers to make calls and send texts using a lower frequency spectrum. Other networks are looking into introducing the technology, known as Voice Over Long-Term Evolution (VoLTE). It currently works on only the Samsung Galaxy S5, but recent iPhone handsets will be added in the coming months. Three said up to 5.5 million customers would have access to the service by 2017.", "ro": "Furnizorul de telefonie mobilă Three a lansat în Regatul Unit un serviciu despre care spune că va îmbunătăți recepția în interiorul clădirilor și în zonele rurale fără semnal. Serviciul 4G Super Voice le permite clienților să efectueze apeluri și să trimită mesaje text folosind un spectru cu o frecvență mai joasă. Și alte rețele intenționează să introducă aceeași tehnologie, cunoscută ca „Voice Over Long-Term Evolution (VoLTE)”. Aceasta funcționează momentan doar cu Samsung Galaxy S5, însă telefoanele iPhone recente vor beneficia de ea în lunile următoare. Three menționează că până la 5,5 milioane de clienți vor avea acces la serviciu până în 2017." } }
+{ "translation": { "en": "Chief technology officer Bryn Jones said: \"By the end of the year, one million of our customers will have access to better indoor coverage and be able to use their phones in more places than ever before.\" Stars prepare for panto season Pantomime season is big business for theatres up and down the UK, with many getting ready for this year's season now. Some of the biggest names in showbusiness now take part in the yuletide theatre. Matthew Kelly and Hayley Mills will be appearing in Cinderella - one as an ugly sister, the other as fairy godmother. They reveal their panto secrets to BBC Breakfast. Steven Wilson: 'If I don't do anything, I feel this creeping guilt'", "ro": "Responsabilul șef pentru tehnologie, Bryn Jones a declarat: „Până la sfârșitul anului, un milion dintre clienții noștri vor avea acces la o acoperire mai bună în interior și își vor putea folosi telefoanele în mai multe locuri ca până acum”. Vedetele se pregătesc pentru stagiunea de pantomimă Stagiunea de pantomimă este foarte importantă pentru teatrele din tot Regatul Unit, multe dintre ele pregătindu-se acum pentru stagiunea din acest an. Acum, la teatrul de Crăciun participă unele dintre numele cele mai mari din showbusiness. Matthew Kelly și Hayley Mills vor apărea în Cenușăreasa - primul în rolul uneia dintre surorile rele, iar a doua în rolul zânei. Aceștia dezvăluie secretele pantomimei lor la BBC Breakfast. Steven Wilson: „Dacă nu fac nimic, mă simt vinovat”" } }
+{ "translation": { "en": "Steven Wilson was recently the big winner at the Progressive Music Awards Steven Wilson is often dubbed the hardest working musician in the world of progressive rock. The multi-talented musician won three prizes at this month's Progressive Music Awards in London, including album of the year for Hand. The Guardian's five-star review called it \"a smart, soulful and immersive work of art.\" Since the 1980s, Wilson has been the driving force in a number of musical projects, the best known of which is the rock band Porcupine Tree. Now, ahead of two sell-out shows at the Royal Albert Hall, Wilson is releasing a vinyl-only double LP, Transience, to showcase the \"more accessible\" side of his solo output.", "ro": "Steven Wilson a fost desemnat recent drept marele câștigător al Progressive Music Awards Steven Wilson a fost numit de multe ori drept cel mai muncitor muzician din lumea rockului progresiv. Talentatul muzician a câștigat trei premii la Progressive Music Awards, care a avut loc luna aceasta la Londra, printre care și premiul pentru cel mai bun album al anului pentru Hand. În recenzia sa de cinci stele, The Guardian a numit albumul „o operă de artă inteligentă, expresivă și captivantă”. Încă din anii 1980, Wilson este motorul mai multor proiecte muzicale, cel mai cunoscut dintre acestea fiind trupa de rock Porcupine Tree. Acum, înainte de două spectacole cu casa închisă la Royal Albert Hall, Wilson lansează un dublu LP doar în format vinil, Transience, pentru a arăta latura „mai accesibilă” a activității sale solo." } }
+{ "translation": { "en": "He tells the BBC about his love of vinyl, his busy schedule and explains how comic actor Matt Berry came to be his support act. What does vinyl mean to you? I grew up at the very tail end of the vinyl era, and at the time, I remember, we couldn't wait for CD to come along because vinyl was so frustrating. You would buy the record, take it home, and it would have a scratch, and you would have to take it back again. I love CDs, and for some kinds of music - classical for example - it is better than vinyl. But the problem with the CD and digital downloads is that there's nothing you can really cherish or treasure. Owning vinyl is like having a beautiful painting hanging in your living room.", "ro": "A povestit pentru BBC despre dragostea lui pentru viniluri și despre programul său încărcat și a explicat cum a ajuns actorul de comedie Matt Berry să îi deschidă spectacolele. Ce înseamnă vinil pentru tine? Am crescut chiar în perioada de sfârșit a erei vinilurilor și îmi amintesc că atunci abia așteptam apariția CD-ului, căci vinilul era atât de enervant. Cumpărai un disc, mergeai cu el acasă, avea o zgârietură și trebuia să îl aduci înapoi. Iubesc CD-urile, iar pentru anumite tipuri de muzică, de exemplu cea clasică, sunt mai bune decât vinilurile. Însă problema cu CD-urile și cu descărcările digitale este aceea că nu mai există nimic pe care să îl prețuiești cu adevărat. Să ai un vinil e ca și cum ai avea un tablou frumos agățat în sufragerie." } }
+{ "translation": { "en": "It's something you can hold, pore over the lyrics and immerse yourself in the art work. I thought it was just a nostalgic thing, but it can't be if kids too young to remember vinyl are enjoying that kind of experience. Do you have a piece of vinyl that you treasure? The truth is I got rid of 100% of my vinyl in the 90s. All the vinyl I have is re-bought. I started off from the perspective that I wanted to recreate the collection I had when I was 15, but it's gone beyond that. The first record which I persuaded my parents to buy for me was Electric Light Orchestra's Out of the Blue.", "ro": "E ceva ce poți ține în mână, în timp ce te lași absorbit de versuri și copleșit de actul artistic. Am crezut că e doar o chestie nostalgică, însă nu are cum să fie așa dacă unor puști prea tineri să-și amintească de viniluri le place acest gen de experiență. Ai vreun vinil la care ții în mod special? Recunosc că am scăpat de toate vinilurile în anii '90. Toate vinilurile pe care le am sunt cumpărate din nou. Am pornit de la ideea de a reface colecția pe care o aveam la 15 ani, însă am trecut de limita aceea. Primul disc pe care mi-am convins părinții să mi-l cumpere a fost Out of the Blue de la Electric Light Orchestra." } }
+{ "translation": { "en": "If I still had my original copy, it would have sentimental value, but, alas, it's in a charity shop somewhere. Steven Wilson hopes the album will be a doorway for potential new fans Why release your new compilation Transience on vinyl? It was originally conceived as an idea for Record Store Day, but we missed the boat on that. My record company had suggested I put together some of my shorter, more accessible songs. I got a bit obsessed by the idea to make something like \"an introduction to Steven Wilson,\" and I was committed to it being a vinyl-only release. Anyone who buys the vinyl does also get a high-resolution download.", "ro": "Dacă aș mai fi avut încă exemplarul inițial, acesta ar fi avut valoare sentimentală, însă, din păcate, se află pe undeva printr-un magazin de caritate. Steven Wilson speră că albumul va fi o poartă către posibili fani noi De ce ți-ai lansat noua compilație Transience pe vinil? Aceasta a fost concepută inițial ca idee pentru Ziua magazinelor de discuri, însă am ratat ocazia. Casa mea de discuri sugerase să adun câteva dintre melodiile mele mai scurte și mai accesibile. Am ajuns să fiu ușor obsedat de ideea de a face ceva gen „introducere în muzica lui Steven Wilson” și am ținut neapărat ca proiectul să fie lansat doar pe vinil. Cine cumpără vinilul primește, de asemenea, și o variantă descărcată la rezoluție înaltă." } }
+{ "translation": { "en": "Do you have a concern that the album won't show your work in a true light?", "ro": "Ești îngrijorat că albumul nu va arăta muzica ta în adevărata ei lumină?" } }
diff --git a/transformers/tests/fixtures/tests_samples/xsum/sample.json b/transformers/tests/fixtures/tests_samples/xsum/sample.json
new file mode 100644
index 0000000000000000000000000000000000000000..ea6e8a8bb8f6705b20776a4e126b8822d6889f7e
--- /dev/null
+++ b/transformers/tests/fixtures/tests_samples/xsum/sample.json
@@ -0,0 +1,10 @@
+{"document": "The warning begins at 22:00 GMT on Saturday and ends at 10:00 on Sunday.\nThe ice could lead to difficult driving conditions on untreated roads and slippery conditions on pavements, the weather service warned.\nOnly the southernmost counties and parts of the most westerly counties are expected to escape.\nCounties expected to be affected are Carmarthenshire, Powys, Ceredigion, Pembrokeshire, Denbighshire, Gwynedd, Wrexham, Conwy, Flintshire, Anglesey, Monmouthshire, Blaenau Gwent, Caerphilly, Merthyr Tydfil, Neath Port Talbot, Rhondda Cynon Taff and Torfaen.", "summary": "The Met Office has issued a yellow weather warning for ice across most of Wales."}
+{"document": "You can see highlights of Sunderland v Arsenal on Match of the Day at 22:20 BST on Saturday on BBC One and the BBC Sport website.\nStoke and West Ham, for example, have started to climb away from the relegation zone but the biggest worry for Sunderland fans is that their side do not look remotely capable of doing the same.\nI know the Black Cats have got out of trouble before having found themselves in a similar situation but this time, after picking up only two points from their first nine games, things look really desperate for the only top-flight team without a win.\nAt least one element of their struggles seems to be self-inflicted, with everyone at the club feeling sorry for themselves - and not just because they have lost some players to injury and conceded some costly late goals.\nThere is a negative feeling about the place with the manager David Moyes and his players talking about how they have gone backwards since last season, when they should be searching for any kind of spark that could change things around.\nFrom the outside, looking at the way they play and their lack of creativity, it is hard to see what that spark might be or what could fundamentally change under Moyes until the January transfer window opens.\nIf they can get one win under their belt then they will get a bit of belief back but, the longer this winless run goes on, the more negativity there will be.\nMedia playback is not supported on this device\nSunderland finished last season on a high under Sam Allardyce, with a run of just one defeat in their last 11 games securing their safety.\nIn the space of five months, all of that confidence and momentum seems to have been sucked out of the club, despite them effectively having the same group of players who, not so long ago, looked inspired.\nThat is not all down to Moyes, but he has to take some responsibility for it.\nI am yet to see a defined style of play from Sunderland since he took charge at the end of July.\nThat is in contrast to Allardyce's time as manager, when they were resolute and difficult to beat and, at the end of his stint at the Stadium of Light, also played with a purpose when they went forward.\nOff the pitch, Moyes has not helped himself much either.\nThere was no need for him to be so pessimistic when he came out after the second game of the season and announced they would be in a relegation fight, which did not send out the right message to his players or the fans.\nWhen he took charge, he had actually started out by being unrealistically positive - talking about Sunderland becoming a club that regularly finished in the top half of the Premier League - but his expectations went downhill very quickly.\nI know you can argue that he has been proved right, because Sunderland are now battling the drop, but it meant there was a cloud over from them almost as soon as the season had started.\nIt seems to be a case that if you stop Jermain Defoe, you stop Sunderland. His statistics stand up well in comparison to last season, but the rest of their team are not doing enough in attack.\nThey were reliant on Defoe last season too, but others did chip in - in their first nine league games of 2015-16, five players found the net. This time around, only Defoe and Patrick van Aanholt have scored in the same period.\nIt is going to be a massive struggle for them to stay up from the position they are now in anyway, but they badly need a win and quickly. I don't see it coming at home to Arsenal on Saturday, though.\nDo they even look capable of holding out for a draw against the Gunners, the way another struggling team Middlesbrough did at Emirates Stadium last weekend? No.\nIf you struggle to make chances and score goals, as Sunderland do, that puts more pressure on your defence because you know if you concede then you are in big trouble.\nAnd the Black Cats have problems at the back as well - their only clean sheet in 12 matches under Moyes was against League One side Shrewsbury Town in the EFL Cup.\nIt does not bode well against an Arsenal side that are averaging more than two goals a game this season.\nIt is hard to find any positives from Sunderland's situation but at least they have not been cut adrift at the bottom - yet.\nUnless they win soon, that could happen. I think Hull are also in for a very tough season but when I look at the other two teams immediately above them, Boro and Swansea, they definitely have more about them than the Black Cats do.\nMedia playback is not supported on this device\nChanging manager has clearly not helped Sunderland and comparisons with his predecessor do not help Moyes much either.\nYou cannot tell me that, if Allardyce was still in charge, Sunderland would have only picked up two points so far. It just would not have happened.\nMoyes replaced him relatively late in the summer, which is difficult in itself, but he can only complain about the things that have gone against him up to a point. He should be doing much better than he is.\nHe is still the manager and he is capable of turning things around, so it is right there is no suggestion of him getting the sack.\nBut that will not last forever. This industry is results-driven and Moyes' results are not good enough.\nThat clearly has to change soon and, looking at Sunderland's next few fixtures, the one that stands out as a must-win is their home game against Hull on 19 November.\nIf they fail to beat Arsenal and Bournemouth, then the visit of the Tigers will be the game to define Moyes' tenure. If Sunderland are still without a win after that, things will become extremely difficult for him.\nChris Sutton was speaking to BBC Sport's Chris Bevan.", "summary": "We are exactly a quarter of the way through the Premier League season and some teams at the bottom of the table seem to be turning things around after making a bad start."}
+{"document": "The win keeps the Candystripes two points behind leaders Dundalk who won 2-0 away to Shamrock Rovers.\nFormer Plymouth striker Patterson scored his sixth goal of the season in the 14th minute at the Brandywell.\nHe shot into an empty net after the ball broke to him when keeper Dean Delany thwarted Barry McNamee.\nKurtis Byrne should have netted a speedy equaliser but the son of former Celtic player Paul Byrne completely missed his kick in front of goal.\nThat was the one big scare for Kenny Shiels' men on a night when both keepers had a quiet night.\nDerry City have won six and drawn two in the eight games they have played since losing to Finn Harps on the first day of the season.", "summary": "Rory Patterson's early goal proved enough to give second-placed Derry City a home victory over Bohemians in Friday night's Premier Division clash."}
+{"document": "The centre-right coalition led by Mr Passos Coelho won the most seats in the election on 4 October.\nBut Socialist leader Antonio Costa has been working to build a coalition with far-left parties.\nMany believe that Mr Passos Coelho will fail to pass the test of a vote of no confidence in Portugal's parliament.\nPresident Anibal Cavaco Silva would then be expected to ask the left to form a government.\nThere are fears that weeks of uncertainty could harm Portugal's economic recovery, more than a year after it exited the strict terms of its €78bn (£57bn) international bailout.\nEU officials have threatened to take action against Portugal for missing a 15 October deadline to present its draft 2016 budget.\nPortugal is still running one of the highest budget deficits in the eurozone.\n12%\nof the workforce is unemployed\n20%\nof people live below the poverty line\n485,000 emigrated from Portugal between 2011 and 2014\n125% debt to GDP - the second highest rate in the European Union\nMr Passos Coelho's Social Democrats have promised to present a budget, but the two left-wing parties campaigned strongly against his outgoing government's record of harsh austerity.\nThe Left Bloc is seen as allied to the anti-austerity Syriza party in Greece, which for months tried to renegotiate the terms of Greece's eurozone bailout.\nPortugal's Communist Party is regarded as anti-euro and anti-Nato, although it is thought to have moderated its eurozone policies in recent weeks.\nIf Mr Costa's Socialists are eventually chosen to lead a left-wing coalition, it would be the first time since the fall of Portugal's dictatorship in 1974 that a right-wing president appointed a government backed by communists.\nAfter his re-appointment as prime minister leading a right-of-centre coalition, Pedro Passos Coelho has 10 days to appoint ministers and secure parliamentary approval.\nThat may prove impossible, since his coalition lost its majority in the 4 October election and the Socialists have pledged to reject his programme if their talks with other parties succeed.\nTogether, the Socialists, Left Bloc and Communist Party have a majority. All wanted the president to appoint Mr Costa - arguing that anything else was a waste of time.\nIf Mr Passos Coelho does fail, the president could then appoint Mr Costa or keep the incumbent on as caretaker.\nFresh legislative elections may only take place from June, after voters have elected a new president early next year.", "summary": "The Portuguese president has invited incumbent Prime Minister Pedro Passos Coelho to form the next government, despite him having lost his majority."}
+{"document": "Nev Edwards scored an early try for Sale, before Castres' Florian Vialelle went over, but Julien Dumora's penalty put the hosts 10-7 ahead at the break.\nJoe Ford sent over a penalty before Castres' Marc-Antoine Rallier and Sales' Will Addison were sin-binned.\nJulien Caminati's late attempt to stop Charlie Ingall saw Sale awarded the decisive penalty try.\nThe win moves the English Premiership side to within one point of Pool Two leaders Newport Gwent Dragons after three games.\nSale got off to the ideal start, Edwards sprinting away for the game's opening points from an Andrei Ostrikov kick, but Castres heaped the pressure on in search of a reply, which came through Vialelle on eight minutes.\nSharks flanker Magnus Lund was forced off with a head injury before the television match official denied Castres a second try, with replays showing that the Sharks defence did enough to force full-back Caminati into touch.\nFord had a chance to put Sale ahead again, but his penalty on 27 minutes drifted wide. Dumora, however, made no mistake soon after, slotting over to give the French side the lead on 33 minutes.\nA combination of probing grubber kicks and scrappy play eventually led to Ford teeing up his second penalty attempt, with the fly-half this time booting the three points to make it 10-10.\nRallier's yellow card following a scuffle saw Ford opt for the posts soon after, but he was off target again before Sales' one-man advantage was lost as Addison was sin-binned.\nSharks pushed for the breakthrough as Ingall went close to touching down, and the video referee eventually gave the penalty try after deciding that Caminati's attempt to stop the winger was illegal.\nCastres: Caminati; Martial, Vialelle, Combezou, Decrop; Dumora, Dupont; Taumoepeau, Rallier, Montes; Samson, Moreaux, Caballero, Diarra, Beattie.\nReplacements: Beziat, Tichit, Martinez, Desroche, Babillot, Fontaine, Lamerat, Seron.\nSale: Arscott; Edwards, Addison, Jennings, Ingall; Ford, Mitchell, Lewis-Roberts, Briggs, Mujati, Mills, Ostrikov, Lund, Seymour (capt), Easter.\nReplacements: Taylor, Flynn, Parker, Beaumont, Neild, Jeffers, James, Haley.\nReferee: David Wilkinson (Ireland)", "summary": "A late penalty try gave Sale victory over Castres at Stade Pierre-Antoine in their European Challenge Cup clash."}
+{"document": "The 33-year-old was released by Norwich this summer after five years at the club, during which time he made 75 Canaries first-team appearances.\nTurner also had spells on loan at Fulham and Sheffield Wednesday during his time at Carrow Road.\nIn total, the centre-back has made 436 senior career appearances for eight different clubs.\nFind all the latest football transfers on our dedicated page.", "summary": "League One side Southend United have signed former Hull and Norwich defender Michael Turner on a one-year deal."}
+{"document": "United contacted St Johnstone this week with a view to speaking to 52-year-old Wright about the job but this approach was rejected by the Saints board.\nThe Tannadice club - bottom of the Premiership - are seeking to replace Jackie McNamara, who left last month.\nDave Bowman took the first team for Saturday's loss to Partick Thistle.\nThe Tangerines have won only once this season and prop up the table with five points from 10 games.\nFormer Northern Ireland goalkeeper Wright, who replaced Steve Lomas at McDiarmid Park in 2013, led St Johnstone to Scottish Cup success in his first season in charge.\nHe has also secured two successive top-six finishes for the Perth side and previously managed in his homeland.", "summary": "St Johnstone boss Tommy Wright is no longer under consideration for the Dundee United manager's job, BBC Scotland has learned."}
+{"document": "Media playback is unsupported on your device\n2 November 2014 Last updated at 17:20 GMT\nHomes and businesses were damaged in the storm, but weather experts were not able to confirm it was a tornado.\nNavtej Johal reports.", "summary": "Residents in Coalville in Leicestershire are cleaning up after high winds hit the town."}
+{"document": "5 August 2015 Last updated at 06:36 BST\nShe's now 84 and has been telling Newsround the inspiring story of her life before and after that devastating and world-changing event.\nThis animation contains some sad moments that you might find upsetting.\nYou can find out more about what happened in Hiroshima here.\nWatch 'Hiroshima: A Newsround Special' - Thursday 6 August at 5.30pm on the CBBC channel and on the Newsround website.", "summary": "Bun Hashizume was 14 years old and lived in Hiroshima, in Japan, when a nuclear bomb was dropped on the city 70 years ago, at the end of World War Two."}
+{"document": "But what has been your moment of the year?\nFrom Ben Stokes' 258 off 198 balls against South Africa to Stuart Broad's 6-17 against the same opponents, and Alastair Cook being the first Englishman to reach 10,000 Test runs, there are lots of highlights.\nOr perhaps you revelled in Australia being skittled for just 85? Or the dog that invaded the pitch at Vizag?\nThe cricket brains of BBC Sport and BBC Radio 5 live asked you to rank your top 10, and your shortlist will be revealed on Tuesday's Tuffers and Vaughan Cricket Show (20:30 GMT, BBC Radio 5 live and online).\nVotes will no longer count but you can still pick your top 10 and share with friends.\nWhat are your top 10 cricketing moments from this year?", "summary": "It's been topsy-turvy for the England side but eventful and entertaining nonetheless."}
diff --git a/transformers/tests/models/aimv2/__init__.py b/transformers/tests/models/aimv2/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/aimv2/test_modeling_aimv2.py b/transformers/tests/models/aimv2/test_modeling_aimv2.py
new file mode 100644
index 0000000000000000000000000000000000000000..77893985f9258c01f34b7517f34934e38f877895
--- /dev/null
+++ b/transformers/tests/models/aimv2/test_modeling_aimv2.py
@@ -0,0 +1,694 @@
+# coding=utf-8
+# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch AIMv2 model."""
+
+import inspect
+import tempfile
+import unittest
+
+import numpy as np
+import requests
+from parameterized import parameterized
+from pytest import mark
+
+from transformers import Aimv2Config, Aimv2TextConfig, Aimv2VisionConfig
+from transformers.testing_utils import (
+ require_flash_attn,
+ require_torch,
+ require_torch_gpu,
+ require_torch_sdpa,
+ require_vision,
+ slow,
+ torch_device,
+)
+from transformers.utils import (
+ is_torch_available,
+ is_vision_available,
+)
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ TEST_EAGER_MATCHES_SDPA_INFERENCE_PARAMETERIZATION,
+ ModelTesterMixin,
+ _config_zero_init,
+ _test_eager_matches_sdpa_inference,
+ floats_tensor,
+ ids_tensor,
+ random_attention_mask,
+)
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import (
+ Aimv2Model,
+ Aimv2TextModel,
+ Aimv2VisionModel,
+ )
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import AutoImageProcessor, AutoProcessor
+
+
+class Aimv2VisionModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ image_size=30,
+ patch_size=2,
+ num_channels=3,
+ is_training=False,
+ hidden_size=32,
+ projection_dim=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.hidden_size = hidden_size
+ self.projection_dim = projection_dim
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+
+ num_patches = (image_size // patch_size) ** 2
+ self.seq_length = num_patches
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+ config = self.get_config()
+
+ return config, pixel_values
+
+ def get_config(self):
+ return Aimv2VisionConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ projection_dim=self.projection_dim,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ )
+
+ def create_and_check_model(self, config, pixel_values):
+ model = Aimv2VisionModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(pixel_values)
+
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+class Aimv2ModelTesterMixin(ModelTesterMixin):
+ """
+ Subclass of ModelTesterMixin with methods specific to testing Aimv2 models.
+ The SDPA equivalence test is overridden here because Aimv2 models may have test/vision/text+vision inputs,
+ different output logits, and are not supposed to be used or tested with padding_side="left".
+ """
+
+ def test_sdpa_can_dispatch_composite_models(self):
+ for model_class in self.all_model_classes:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+
+ # Load the model with SDPA
+ model_sdpa = model_class.from_pretrained(tmpdirname)
+
+ # Load model with eager attention
+ model_eager = model_class.from_pretrained(
+ tmpdirname,
+ attn_implementation="eager",
+ )
+ model_eager = model_eager.eval().to(torch_device)
+
+ if hasattr(model_sdpa, "vision_model"):
+ self.assertTrue(model_sdpa.vision_model.config._attn_implementation == "sdpa")
+ self.assertTrue(model_eager.vision_model.config._attn_implementation == "eager")
+
+ if hasattr(model_sdpa, "text_model"):
+ self.assertTrue(model_sdpa.text_model.config._attn_implementation == "sdpa")
+ self.assertTrue(model_eager.text_model.config._attn_implementation == "eager")
+
+ self.assertTrue(model_sdpa.config._attn_implementation == "sdpa")
+ self.assertTrue(model_eager.config._attn_implementation == "eager")
+
+
+@require_torch
+class Aimv2VisionModelTest(Aimv2ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as Aimv2 does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (Aimv2VisionModel,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ test_torchscript = False
+
+ def setUp(self):
+ self.model_tester = Aimv2VisionModelTester(self)
+ self.config_tester = ConfigTester(
+ self, config_class=Aimv2VisionConfig, has_text_modality=False, hidden_size=37
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="Aimv2 does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_get_set_embeddings(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+
+class Aimv2TextModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ seq_length=7,
+ is_training=False,
+ use_input_mask=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ projection_dim=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ max_position_embeddings=25,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.projection_dim = projection_dim
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.max_position_embeddings = max_position_embeddings
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ if input_mask is not None:
+ batch_size, seq_length = input_mask.shape
+ rnd_start_indices = np.random.randint(1, seq_length - 1, size=(batch_size,))
+ for batch_idx, start_index in enumerate(rnd_start_indices):
+ input_mask[batch_idx, :start_index] = 1
+ input_mask[batch_idx, start_index:] = 0
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask
+
+ def get_config(self):
+ return Aimv2TextConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ projection_dim=self.projection_dim,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ max_position_embeddings=self.max_position_embeddings,
+ )
+
+ def create_and_check_model(self, config, input_ids, input_mask):
+ model = Aimv2TextModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, input_mask = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class Aimv2TextModelTest(Aimv2ModelTesterMixin, unittest.TestCase):
+ all_model_classes = (Aimv2TextModel,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_head_masking = False
+ test_resize_embeddings = False
+ test_torchscript = False
+
+ def setUp(self):
+ self.model_tester = Aimv2TextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=Aimv2TextConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip(reason="Aimv2 does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+
+class Aimv2ModelTester:
+ def __init__(self, parent, text_kwargs=None, vision_kwargs=None, is_training=False):
+ if text_kwargs is None:
+ text_kwargs = {}
+ if vision_kwargs is None:
+ vision_kwargs = {}
+
+ self.parent = parent
+ self.text_model_tester = Aimv2TextModelTester(parent, **text_kwargs)
+ self.vision_model_tester = Aimv2VisionModelTester(parent, **vision_kwargs)
+ self.batch_size = self.text_model_tester.batch_size # need bs for batching_equivalence test
+ self.is_training = is_training
+
+ def prepare_config_and_inputs(self):
+ text_config, input_ids, attention_mask = self.text_model_tester.prepare_config_and_inputs()
+ vision_config, pixel_values = self.vision_model_tester.prepare_config_and_inputs()
+
+ config = self.get_config()
+
+ return config, input_ids, attention_mask, pixel_values
+
+ def get_config(self):
+ return Aimv2Config.from_text_vision_configs(
+ self.text_model_tester.get_config(), self.vision_model_tester.get_config(), projection_dim=64
+ )
+
+ def create_and_check_model(self, config, input_ids, attention_mask, pixel_values):
+ model = Aimv2Model(config).to(torch_device).eval()
+ with torch.no_grad():
+ result = model(input_ids, pixel_values, attention_mask)
+ self.parent.assertEqual(
+ result.logits_per_image.shape, (self.vision_model_tester.batch_size, self.text_model_tester.batch_size)
+ )
+ self.parent.assertEqual(
+ result.logits_per_text.shape, (self.text_model_tester.batch_size, self.vision_model_tester.batch_size)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, attention_mask, pixel_values = config_and_inputs
+
+ inputs_dict = {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "pixel_values": pixel_values,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class Aimv2ModelTest(Aimv2ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ additional_model_inputs = ["pixel_values"]
+ all_model_classes = (Aimv2Model,) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {"feature-extraction": Aimv2Model, "image-feature-extraction": Aimv2VisionModel}
+ if is_torch_available()
+ else {}
+ )
+ fx_compatible = False
+ test_head_masking = False
+ test_pruning = False
+ test_torchscript = False
+ test_resize_embeddings = False
+ test_attention_outputs = False
+ _is_composite = True
+
+ def setUp(self):
+ self.model_tester = Aimv2ModelTester(self)
+ common_properties = ["projection_dim", "logit_scale_init_value"]
+ self.config_tester = ConfigTester(
+ self, config_class=Aimv2Config, has_text_modality=False, common_properties=common_properties
+ )
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ print(config_and_inputs)
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="Hidden_states is tested in individual model tests")
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip(reason="Retain_grad is tested in individual model tests")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ @unittest.skip(reason="Aimv2Model does not have input/output embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @unittest.skip("Size mismatch on CUDA")
+ def test_multi_gpu_data_parallel_forward(self):
+ pass
+
+ # Override as the `logit_scale` parameter initialization is different for Aimv2
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ # check if `logit_scale` is initialized as per the original implementation
+ if name == "logit_scale":
+ self.assertAlmostEqual(
+ param.data.item(),
+ np.log(1 / 0.07),
+ delta=1e-3,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ else:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ def test_load_vision_text_config(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # Save Aimv2Config and check if we can load Aimv2VisionConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ vision_config = Aimv2VisionConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.vision_config.to_dict(), vision_config.to_dict())
+
+ # Save Aimv2Config and check if we can load Aimv2TextConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ text_config = Aimv2TextConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.text_config.to_dict(), text_config.to_dict())
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_inference_equivalence(self):
+ for model_class in self.all_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_fa = model_class.from_pretrained(
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
+ )
+ model_fa.to(torch_device)
+
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.bfloat16)
+ model.to(torch_device)
+
+ dummy_pixel_values = inputs_dict["pixel_values"].to(torch.bfloat16)
+ dummy_input_ids = inputs_dict["input_ids"]
+
+ outputs = model(pixel_values=dummy_pixel_values, input_ids=dummy_input_ids, output_hidden_states=True)
+ outputs_fa = model_fa(
+ pixel_values=dummy_pixel_values, input_ids=dummy_input_ids, output_hidden_states=True
+ )
+
+ self.assertTrue(
+ torch.allclose(outputs.logits_per_image, outputs_fa.logits_per_image, atol=4e-2, rtol=4e-2),
+ f"Image logits max diff: {torch.max(torch.abs(outputs.logits_per_image - outputs_fa.logits_per_image))}",
+ )
+ self.assertTrue(
+ torch.allclose(outputs.logits_per_text, outputs_fa.logits_per_text, atol=4e-2, rtol=4e-2),
+ f"Text logits max diff: {torch.max(torch.abs(outputs.logits_per_text - outputs_fa.logits_per_text))}",
+ )
+
+ @require_flash_attn
+ @require_torch_gpu
+ @mark.flash_attn_test
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
+ for model_class in self.all_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(f"{model_class.__name__} does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_fa = model_class.from_pretrained(
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
+ )
+ model_fa.to(torch_device)
+
+ model = model_class.from_pretrained(
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="eager"
+ )
+ model.to(torch_device)
+
+ dummy_pixel_values = inputs_dict["pixel_values"].to(torch.bfloat16)
+ dummy_input_ids = inputs_dict["input_ids"]
+ dummy_pixel_mask = inputs_dict["attention_mask"]
+
+ # right padding
+ dummy_pixel_mask[:] = 1
+ dummy_pixel_mask[:, -1:] = 0
+
+ outputs = model(pixel_values=dummy_pixel_values, input_ids=dummy_input_ids, output_hidden_states=True)
+ outputs_fa = model_fa(
+ pixel_values=dummy_pixel_values, input_ids=dummy_input_ids, output_hidden_states=True
+ )
+
+ logits_per_image_eager = outputs.logits_per_image[:, :-1]
+ logits_per_text_eager = outputs.logits_per_text[:, :-1]
+
+ logits_per_image_sdpa = outputs_fa.logits_per_image[:, :-1]
+ logits_per_text_sdpa = outputs_fa.logits_per_text[:, :-1]
+
+ self.assertTrue(
+ torch.allclose(logits_per_image_eager, logits_per_image_sdpa, atol=4e-2, rtol=4e-2),
+ f"Image logits max diff: {torch.max(torch.abs(logits_per_image_eager - logits_per_image_sdpa))}",
+ )
+ self.assertTrue(
+ torch.allclose(logits_per_text_eager, logits_per_text_sdpa, atol=4e-2, rtol=4e-2),
+ f"Text logits max diff: {torch.max(torch.abs(logits_per_text_eager - logits_per_text_sdpa))}",
+ )
+
+ @parameterized.expand(TEST_EAGER_MATCHES_SDPA_INFERENCE_PARAMETERIZATION)
+ @require_torch_sdpa
+ def test_eager_matches_sdpa_inference(
+ self,
+ name,
+ torch_dtype,
+ padding_side,
+ use_attention_mask,
+ output_attentions,
+ enable_kernels,
+ ):
+ "We need to relax a bit the `atols` for fp32 here due to the altup projections"
+ atols = {
+ ("cpu", False, torch.float32): 1e-6,
+ ("cpu", False, torch.float16): 5e-3,
+ ("cpu", False, torch.bfloat16): 3e-2, # this was relaxed
+ ("cpu", True, torch.float32): 1e-6,
+ ("cpu", True, torch.float16): 5e-3,
+ ("cpu", True, torch.bfloat16): 3e-2, # this was relaxed
+ ("cuda", False, torch.float32): 1e-6,
+ ("cuda", False, torch.bfloat16): 3e-2, # this was relaxed
+ ("cuda", False, torch.float16): 5e-3,
+ ("cuda", True, torch.float32): 1e-6,
+ ("cuda", True, torch.bfloat16): 3e-2, # this was relaxed
+ ("cuda", True, torch.float16): 5e-3,
+ }
+ _test_eager_matches_sdpa_inference(
+ self, name, torch_dtype, padding_side, use_attention_mask, output_attentions, enable_kernels, atols=atols
+ )
+
+
+@require_vision
+@require_torch
+class Aimv2ModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference(self):
+ model_name = "apple/aimv2-large-patch14-224-lit"
+ model = Aimv2Model.from_pretrained(model_name, device_map=torch_device)
+ processor = AutoProcessor.from_pretrained(model_name)
+
+ image = Image.open(requests.get("http://images.cocodataset.org/val2017/000000039769.jpg", stream=True).raw)
+ inputs = processor(
+ text=["a photo of a cat", "a photo of a dog"], images=image, padding=True, return_tensors="pt"
+ ).to(model.device)
+
+ # Forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # Verify the logits
+ self.assertEqual(
+ outputs.logits_per_image.shape,
+ torch.Size((inputs.pixel_values.shape[0], inputs.input_ids.shape[0])),
+ )
+ self.assertEqual(
+ outputs.logits_per_text.shape,
+ torch.Size((inputs.input_ids.shape[0], inputs.pixel_values.shape[0])),
+ )
+
+ # handle device
+ expected_logits = torch.tensor([[33.3550, 26.4255]]).to(model.device)
+ torch.testing.assert_close(outputs.logits_per_image, expected_logits, atol=1e-3, rtol=1e-3)
+
+
+@require_vision
+@require_torch
+class Aimv2VisionModelIntegrationTests(unittest.TestCase):
+ @slow
+ def test_inference(self):
+ model_name = "apple/aimv2-large-patch14-224"
+
+ model = Aimv2VisionModel.from_pretrained(model_name, device_map=torch_device)
+ processor = AutoImageProcessor.from_pretrained(model_name)
+
+ image = Image.open(requests.get("http://images.cocodataset.org/val2017/000000039769.jpg", stream=True).raw)
+ inputs = processor(image, return_tensors="pt").to(model.device)
+
+ with torch.no_grad():
+ output = model(**inputs)
+
+ # Verify logits shape
+ self.assertEqual(output.last_hidden_state.shape, torch.Size([1, 256, 1024]))
+
+ # Verify logits slice
+ # fmt: off
+ expected_logits = torch.tensor(
+ [[ 0.0510, 0.0806, -0.0990, -0.0154],
+ [ 2.7850, -2.5143, -0.3320, 2.4196],
+ [ 2.8179, -2.4089, -0.2770, 2.3218],
+ [ 2.7641, -2.4114, -0.3684, 2.2998],
+ [ 2.7972, -2.3180, -0.4490, 2.2302],
+ [ 2.8584, -2.5322, -0.2302, 2.4936],
+ [-2.7849, 2.4121, 1.3670, -1.5514]]).to(model.device)
+ # fmt: on
+
+ output_slice = output.last_hidden_state.squeeze(0)[0:7, 0:4]
+ self.assertTrue(torch.allclose(output_slice, expected_logits, atol=1e-3))
+
+ @slow
+ def test_inference_for_native_resolution(self):
+ model_name = "apple/aimv2-large-patch14-native"
+
+ model = Aimv2VisionModel.from_pretrained(model_name, device_map="auto")
+ processor = AutoImageProcessor.from_pretrained(model_name)
+
+ image = image = Image.open(
+ requests.get("http://images.cocodataset.org/val2017/000000039769.jpg", stream=True).raw
+ )
+ inputs = processor(image, return_tensors="pt").to(model.device)
+
+ with torch.no_grad():
+ output = model(**inputs)
+
+ # Verify logits shape
+ self.assertEqual(output.last_hidden_state.shape, torch.Size([1, 1530, 1024]))
+
+ # Verify logits slice
+ # fmt: off
+ expected_logits = torch.tensor(
+ [[-1.3342, 0.3720, 0.0963, 0.4159],
+ [-1.5328, 0.4677, 0.0936, 0.4321],
+ [-0.3775, -0.2758, -0.0803, -0.5367],
+ [-1.3877, 0.5561, -1.9064, -1.1766],
+ [-0.5148, 0.0108, -0.4515, -0.6402],
+ [-0.3400, -0.1711, -0.1855, -0.4219],
+ [-1.2877, -0.0585, -0.1646, 0.7420]]).to(model.device)
+ # fmt: on
+
+ output_slice = output.last_hidden_state.squeeze(0)[0:7, 0:4]
+ self.assertTrue(torch.allclose(output_slice, expected_logits, atol=1e-3))
diff --git a/transformers/tests/models/align/__init__.py b/transformers/tests/models/align/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/align/test_modeling_align.py b/transformers/tests/models/align/test_modeling_align.py
new file mode 100644
index 0000000000000000000000000000000000000000..15c520d1d2163f807a9b8234725600de8d559656
--- /dev/null
+++ b/transformers/tests/models/align/test_modeling_align.py
@@ -0,0 +1,648 @@
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch ALIGN model."""
+
+import inspect
+import os
+import tempfile
+import unittest
+
+import requests
+
+from transformers import AlignConfig, AlignProcessor, AlignTextConfig, AlignVisionConfig
+from transformers.testing_utils import (
+ require_torch,
+ require_vision,
+ slow,
+ torch_device,
+)
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ ModelTesterMixin,
+ _config_zero_init,
+ floats_tensor,
+ ids_tensor,
+ random_attention_mask,
+)
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ AlignModel,
+ AlignTextModel,
+ AlignVisionModel,
+ )
+
+
+if is_vision_available():
+ from PIL import Image
+
+
+class AlignVisionModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ image_size=32,
+ num_channels=3,
+ kernel_sizes=[3, 3, 5],
+ in_channels=[32, 16, 24],
+ out_channels=[16, 24, 30],
+ hidden_dim=64,
+ strides=[1, 1, 2],
+ num_block_repeats=[1, 1, 2],
+ expand_ratios=[1, 6, 6],
+ is_training=True,
+ hidden_act="gelu",
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.num_channels = num_channels
+ self.kernel_sizes = kernel_sizes
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.hidden_dim = hidden_dim
+ self.strides = strides
+ self.num_block_repeats = num_block_repeats
+ self.expand_ratios = expand_ratios
+ self.is_training = is_training
+ self.hidden_act = hidden_act
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+ config = self.get_config()
+
+ return config, pixel_values
+
+ def get_config(self):
+ return AlignVisionConfig(
+ num_channels=self.num_channels,
+ kernel_sizes=self.kernel_sizes,
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ hidden_dim=self.hidden_dim,
+ strides=self.strides,
+ num_block_repeats=self.num_block_repeats,
+ expand_ratios=self.expand_ratios,
+ hidden_act=self.hidden_act,
+ )
+
+ def create_and_check_model(self, config, pixel_values):
+ model = AlignVisionModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(pixel_values)
+
+ patch_size = self.image_size // 4
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, config.hidden_dim, patch_size, patch_size)
+ )
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, config.hidden_dim))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class AlignVisionModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as ALIGN does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (AlignVisionModel,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ has_attentions = False
+
+ def setUp(self):
+ self.model_tester = AlignVisionModelTester(self)
+ self.config_tester = ConfigTester(
+ self,
+ config_class=AlignVisionConfig,
+ has_text_modality=False,
+ hidden_size=37,
+ common_properties=["num_channels", "image_size"],
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="AlignVisionModel does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="AlignVisionModel does not use inputs_embeds")
+ def test_inputs_embeds_matches_input_ids(self):
+ pass
+
+ @unittest.skip(reason="AlignVisionModel does not support input and output embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.encoder_hidden_states if config.is_encoder_decoder else outputs.hidden_states
+ num_blocks = sum(config.num_block_repeats) * 4
+ self.assertEqual(len(hidden_states), num_blocks)
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [self.model_tester.image_size // 2, self.model_tester.image_size // 2],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ @unittest.skip
+ def test_training(self):
+ pass
+
+ @unittest.skip
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "kakaobrain/align-base"
+ model = AlignVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+class AlignTextModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask
+
+ def get_config(self):
+ return AlignTextConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, input_ids, token_type_ids, input_mask):
+ model = AlignTextModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
+ result = model(input_ids, token_type_ids=token_type_ids)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class AlignTextModelTest(ModelTesterMixin, unittest.TestCase):
+ all_model_classes = (AlignTextModel,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = AlignTextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=AlignTextConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip
+ def test_training(self):
+ pass
+
+ @unittest.skip
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @unittest.skip(reason="ALIGN does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Align does not use inputs_embeds")
+ def test_inputs_embeds_matches_input_ids(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "kakaobrain/align-base"
+ model = AlignTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+class AlignModelTester:
+ def __init__(self, parent, text_kwargs=None, vision_kwargs=None, is_training=True):
+ if text_kwargs is None:
+ text_kwargs = {}
+ if vision_kwargs is None:
+ vision_kwargs = {}
+
+ self.parent = parent
+ self.text_model_tester = AlignTextModelTester(parent, **text_kwargs)
+ self.vision_model_tester = AlignVisionModelTester(parent, **vision_kwargs)
+ self.batch_size = self.text_model_tester.batch_size # need bs for batching_equivalence test
+ self.is_training = is_training
+
+ def prepare_config_and_inputs(self):
+ test_config, input_ids, token_type_ids, input_mask = self.text_model_tester.prepare_config_and_inputs()
+ vision_config, pixel_values = self.vision_model_tester.prepare_config_and_inputs()
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask, pixel_values
+
+ def get_config(self):
+ return AlignConfig.from_text_vision_configs(
+ self.text_model_tester.get_config(), self.vision_model_tester.get_config(), projection_dim=64
+ )
+
+ def create_and_check_model(self, config, input_ids, token_type_ids, attention_mask, pixel_values):
+ model = AlignModel(config).to(torch_device).eval()
+ with torch.no_grad():
+ result = model(input_ids, pixel_values, attention_mask, token_type_ids)
+ self.parent.assertEqual(
+ result.logits_per_image.shape, (self.vision_model_tester.batch_size, self.text_model_tester.batch_size)
+ )
+ self.parent.assertEqual(
+ result.logits_per_text.shape, (self.text_model_tester.batch_size, self.vision_model_tester.batch_size)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, token_type_ids, input_mask, pixel_values = config_and_inputs
+ inputs_dict = {
+ "input_ids": input_ids,
+ "token_type_ids": token_type_ids,
+ "attention_mask": input_mask,
+ "pixel_values": pixel_values,
+ "return_loss": True,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class AlignModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (AlignModel,) if is_torch_available() else ()
+ pipeline_model_mapping = {"feature-extraction": AlignModel} if is_torch_available() else {}
+ fx_compatible = False
+ test_head_masking = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_attention_outputs = False
+
+ def setUp(self):
+ self.model_tester = AlignModelTester(self)
+ self.config_tester = ConfigTester(
+ self,
+ config_class=AlignConfig,
+ has_text_modality=False,
+ common_properties=["projection_dim", "temperature_init_value"],
+ )
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_batching_equivalence(self, atol=3e-4, rtol=3e-4):
+ super().test_batching_equivalence(atol=atol, rtol=rtol)
+
+ @unittest.skip(reason="Start to fail after using torch `cu118`.")
+ def test_multi_gpu_data_parallel_forward(self):
+ super().test_multi_gpu_data_parallel_forward()
+
+ @unittest.skip(reason="Hidden_states is tested in individual model tests")
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip(reason="Inputs_embeds is tested in individual model tests")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Align does not use inputs_embeds")
+ def test_inputs_embeds_matches_input_ids(self):
+ pass
+
+ @unittest.skip(reason="Retain_grad is tested in individual model tests")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ @unittest.skip(reason="AlignModel does not have input/output embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ # override as the `temperature` parameter initialization is different for ALIGN
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ # check if `temperature` is initialized as per the original implementation
+ if name == "temperature":
+ self.assertAlmostEqual(
+ param.data.item(),
+ 1.0,
+ delta=1e-3,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ elif name == "text_projection.weight":
+ self.assertTrue(
+ -1.0 <= ((param.data.mean() * 1e9).round() / 1e9).item() <= 1.0,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ else:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ def _create_and_check_torchscript(self, config, inputs_dict):
+ if not self.test_torchscript:
+ self.skipTest(reason="test_torchscript is set to False")
+
+ configs_no_init = _config_zero_init(config) # To be sure we have no Nan
+ configs_no_init.torchscript = True
+ configs_no_init.return_dict = False
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ model.to(torch_device)
+ model.eval()
+
+ try:
+ input_ids = inputs_dict["input_ids"]
+ pixel_values = inputs_dict["pixel_values"] # ALIGN needs pixel_values
+ traced_model = torch.jit.trace(model, (input_ids, pixel_values))
+ except RuntimeError:
+ self.fail("Couldn't trace module.")
+
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ pt_file_name = os.path.join(tmp_dir_name, "traced_model.pt")
+
+ try:
+ torch.jit.save(traced_model, pt_file_name)
+ except Exception:
+ self.fail("Couldn't save module.")
+
+ try:
+ loaded_model = torch.jit.load(pt_file_name)
+ except Exception:
+ self.fail("Couldn't load module.")
+
+ model.to(torch_device)
+ model.eval()
+
+ loaded_model.to(torch_device)
+ loaded_model.eval()
+
+ model_state_dict = model.state_dict()
+ loaded_model_state_dict = loaded_model.state_dict()
+
+ non_persistent_buffers = {}
+ for key in loaded_model_state_dict.keys():
+ if key not in model_state_dict.keys():
+ non_persistent_buffers[key] = loaded_model_state_dict[key]
+
+ loaded_model_state_dict = {
+ key: value for key, value in loaded_model_state_dict.items() if key not in non_persistent_buffers
+ }
+
+ self.assertEqual(set(model_state_dict.keys()), set(loaded_model_state_dict.keys()))
+
+ model_buffers = list(model.buffers())
+ for non_persistent_buffer in non_persistent_buffers.values():
+ found_buffer = False
+ for i, model_buffer in enumerate(model_buffers):
+ if torch.equal(non_persistent_buffer, model_buffer):
+ found_buffer = True
+ break
+
+ self.assertTrue(found_buffer)
+ model_buffers.pop(i)
+
+ models_equal = True
+ for layer_name, p1 in model_state_dict.items():
+ p2 = loaded_model_state_dict[layer_name]
+ if p1.data.ne(p2.data).sum() > 0:
+ models_equal = False
+
+ self.assertTrue(models_equal)
+
+ def test_load_vision_text_config(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # Save AlignConfig and check if we can load AlignVisionConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ vision_config = AlignVisionConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.vision_config.to_dict(), vision_config.to_dict())
+
+ # Save AlignConfig and check if we can load AlignTextConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ text_config = AlignTextConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.text_config.to_dict(), text_config.to_dict())
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "kakaobrain/align-base"
+ model = AlignModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ im = Image.open(requests.get(url, stream=True).raw)
+ return im
+
+
+@require_vision
+@require_torch
+class AlignModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference(self):
+ model_name = "kakaobrain/align-base"
+ model = AlignModel.from_pretrained(model_name).to(torch_device)
+ processor = AlignProcessor.from_pretrained(model_name)
+
+ image = prepare_img()
+ texts = ["a photo of a cat", "a photo of a dog"]
+ inputs = processor(images=image, text=texts, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ self.assertEqual(
+ outputs.logits_per_image.shape,
+ torch.Size((inputs.pixel_values.shape[0], inputs.input_ids.shape[0])),
+ )
+ self.assertEqual(
+ outputs.logits_per_text.shape,
+ torch.Size((inputs.input_ids.shape[0], inputs.pixel_values.shape[0])),
+ )
+ expected_logits = torch.tensor([[9.7093, 3.4679]], device=torch_device)
+ torch.testing.assert_close(outputs.logits_per_image, expected_logits, rtol=1e-3, atol=1e-3)
diff --git a/transformers/tests/models/align/test_processor_align.py b/transformers/tests/models/align/test_processor_align.py
new file mode 100644
index 0000000000000000000000000000000000000000..73e0d1df91f36381a2fc3444847b0e9cffcafd47
--- /dev/null
+++ b/transformers/tests/models/align/test_processor_align.py
@@ -0,0 +1,196 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import shutil
+import tempfile
+import unittest
+
+import pytest
+
+from transformers import BertTokenizer, BertTokenizerFast
+from transformers.models.bert.tokenization_bert import VOCAB_FILES_NAMES
+from transformers.testing_utils import require_vision
+from transformers.utils import IMAGE_PROCESSOR_NAME, is_vision_available
+
+from ...test_processing_common import ProcessorTesterMixin
+
+
+if is_vision_available():
+ from transformers import AlignProcessor, EfficientNetImageProcessor
+
+
+@require_vision
+class AlignProcessorTest(ProcessorTesterMixin, unittest.TestCase):
+ processor_class = AlignProcessor
+
+ def setUp(self):
+ self.tmpdirname = tempfile.mkdtemp()
+
+ vocab_tokens = [
+ "[UNK]",
+ "[CLS]",
+ "[SEP]",
+ "[PAD]",
+ "[MASK]",
+ "want",
+ "##want",
+ "##ed",
+ "wa",
+ "un",
+ "runn",
+ "##ing",
+ ",",
+ "low",
+ "lowest",
+ ]
+ self.vocab_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ with open(self.vocab_file, "w", encoding="utf-8") as vocab_writer:
+ vocab_writer.write("".join([x + "\n" for x in vocab_tokens]))
+
+ image_processor_map = {
+ "do_resize": True,
+ "size": 20,
+ "do_normalize": True,
+ "image_mean": [0.48145466, 0.4578275, 0.40821073],
+ "image_std": [0.26862954, 0.26130258, 0.27577711],
+ }
+ self.image_processor_file = os.path.join(self.tmpdirname, IMAGE_PROCESSOR_NAME)
+ with open(self.image_processor_file, "w", encoding="utf-8") as fp:
+ json.dump(image_processor_map, fp)
+
+ def get_tokenizer(self, **kwargs):
+ return BertTokenizer.from_pretrained(self.tmpdirname, **kwargs)
+
+ def get_rust_tokenizer(self, **kwargs):
+ return BertTokenizerFast.from_pretrained(self.tmpdirname, **kwargs)
+
+ def get_image_processor(self, **kwargs):
+ return EfficientNetImageProcessor.from_pretrained(self.tmpdirname, **kwargs)
+
+ def tearDown(self):
+ shutil.rmtree(self.tmpdirname)
+
+ def test_save_load_pretrained_default(self):
+ tokenizer_slow = self.get_tokenizer()
+ tokenizer_fast = self.get_rust_tokenizer()
+ image_processor = self.get_image_processor()
+
+ processor_slow = AlignProcessor(tokenizer=tokenizer_slow, image_processor=image_processor)
+ processor_slow.save_pretrained(self.tmpdirname)
+ processor_slow = AlignProcessor.from_pretrained(self.tmpdirname, use_fast=False)
+
+ processor_fast = AlignProcessor(tokenizer=tokenizer_fast, image_processor=image_processor)
+ processor_fast.save_pretrained(self.tmpdirname)
+ processor_fast = AlignProcessor.from_pretrained(self.tmpdirname)
+
+ self.assertEqual(processor_slow.tokenizer.get_vocab(), tokenizer_slow.get_vocab())
+ self.assertEqual(processor_fast.tokenizer.get_vocab(), tokenizer_fast.get_vocab())
+ self.assertEqual(tokenizer_slow.get_vocab(), tokenizer_fast.get_vocab())
+ self.assertIsInstance(processor_slow.tokenizer, BertTokenizer)
+ self.assertIsInstance(processor_fast.tokenizer, BertTokenizerFast)
+
+ self.assertEqual(processor_slow.image_processor.to_json_string(), image_processor.to_json_string())
+ self.assertEqual(processor_fast.image_processor.to_json_string(), image_processor.to_json_string())
+ self.assertIsInstance(processor_slow.image_processor, EfficientNetImageProcessor)
+ self.assertIsInstance(processor_fast.image_processor, EfficientNetImageProcessor)
+
+ def test_save_load_pretrained_additional_features(self):
+ processor = AlignProcessor(tokenizer=self.get_tokenizer(), image_processor=self.get_image_processor())
+ processor.save_pretrained(self.tmpdirname)
+
+ tokenizer_add_kwargs = self.get_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
+ image_processor_add_kwargs = self.get_image_processor(do_normalize=False, padding_value=1.0)
+
+ processor = AlignProcessor.from_pretrained(
+ self.tmpdirname, bos_token="(BOS)", eos_token="(EOS)", do_normalize=False, padding_value=1.0
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, BertTokenizerFast)
+
+ self.assertEqual(processor.image_processor.to_json_string(), image_processor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.image_processor, EfficientNetImageProcessor)
+
+ def test_image_processor(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = AlignProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ image_input = self.prepare_image_inputs()
+
+ input_image_proc = image_processor(image_input, return_tensors="np")
+ input_processor = processor(images=image_input, return_tensors="np")
+
+ for key in input_image_proc.keys():
+ self.assertAlmostEqual(input_image_proc[key].sum(), input_processor[key].sum(), delta=1e-2)
+
+ def test_tokenizer(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = AlignProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+
+ encoded_processor = processor(text=input_str)
+
+ encoded_tok = tokenizer(input_str, padding="max_length", max_length=64)
+ for key in encoded_tok.keys():
+ self.assertListEqual(encoded_tok[key], encoded_processor[key])
+
+ def test_processor(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = AlignProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ self.assertListEqual(list(inputs.keys()), ["input_ids", "token_type_ids", "attention_mask", "pixel_values"])
+
+ # test if it raises when no input is passed
+ with pytest.raises(ValueError):
+ processor()
+
+ def test_tokenizer_decode(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = AlignProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ predicted_ids = [[1, 4, 5, 8, 1, 0, 8], [3, 4, 3, 1, 1, 8, 9]]
+
+ decoded_processor = processor.batch_decode(predicted_ids)
+ decoded_tok = tokenizer.batch_decode(predicted_ids)
+
+ self.assertListEqual(decoded_tok, decoded_processor)
+
+ def test_model_input_names(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = AlignProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ self.assertListEqual(list(inputs.keys()), processor.model_input_names)
diff --git a/transformers/tests/models/arcee/__init__.py b/transformers/tests/models/arcee/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/arcee/test_modeling_arcee.py b/transformers/tests/models/arcee/test_modeling_arcee.py
new file mode 100644
index 0000000000000000000000000000000000000000..697be3ae76452dce2b1f638d3d23d9afacdf2631
--- /dev/null
+++ b/transformers/tests/models/arcee/test_modeling_arcee.py
@@ -0,0 +1,159 @@
+# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Arcee model."""
+
+import unittest
+
+from pytest import mark
+
+from transformers import AutoTokenizer, is_torch_available
+from transformers.testing_utils import (
+ require_flash_attn,
+ require_torch,
+ require_torch_accelerator,
+ slow,
+)
+
+from ...causal_lm_tester import CausalLMModelTest, CausalLMModelTester
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ ArceeConfig,
+ ArceeForCausalLM,
+ ArceeForQuestionAnswering,
+ ArceeForSequenceClassification,
+ ArceeForTokenClassification,
+ ArceeModel,
+ )
+ from transformers.models.arcee.modeling_arcee import ArceeRotaryEmbedding
+
+
+class ArceeModelTester(CausalLMModelTester):
+ if is_torch_available():
+ config_class = ArceeConfig
+ base_model_class = ArceeModel
+ causal_lm_class = ArceeForCausalLM
+ sequence_class = ArceeForSequenceClassification
+ token_class = ArceeForTokenClassification
+
+
+@require_torch
+class ArceeModelTest(CausalLMModelTest, unittest.TestCase):
+ all_model_classes = (
+ (
+ ArceeModel,
+ ArceeForCausalLM,
+ ArceeForSequenceClassification,
+ ArceeForQuestionAnswering,
+ ArceeForTokenClassification,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": ArceeModel,
+ "text-classification": ArceeForSequenceClassification,
+ "text-generation": ArceeForCausalLM,
+ "zero-shot": ArceeForSequenceClassification,
+ "question-answering": ArceeForQuestionAnswering,
+ "token-classification": ArceeForTokenClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_headmasking = False
+ test_pruning = False
+ fx_compatible = False
+ model_tester_class = ArceeModelTester
+ rotary_embedding_layer = ArceeRotaryEmbedding # Enables RoPE tests if set
+
+ # Need to use `0.8` instead of `0.9` for `test_cpu_offload`
+ # This is because we are hitting edge cases with the causal_mask buffer
+ model_split_percents = [0.5, 0.7, 0.8]
+
+ # used in `test_torch_compile_for_training`
+ _torch_compile_train_cls = ArceeForCausalLM if is_torch_available() else None
+
+ def test_arcee_mlp_uses_relu_squared(self):
+ """Test that ArceeMLP uses ReLU² activation instead of SiLU."""
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ config.hidden_act = "relu2" # Ensure we're using relu2 activation
+ model = ArceeModel(config)
+
+ # Check that the MLP layers use the correct activation
+ mlp = model.layers[0].mlp
+ # Test with a simple input
+ x = torch.randn(1, 10, config.hidden_size)
+ up_output = mlp.up_proj(x)
+
+ # Verify ReLU² activation: x * relu(x)
+ expected_activation = up_output * torch.relu(up_output)
+ actual_activation = mlp.act_fn(up_output)
+
+ self.assertTrue(torch.allclose(expected_activation, actual_activation, atol=1e-5))
+
+
+@require_torch_accelerator
+class ArceeIntegrationTest(unittest.TestCase):
+ def tearDown(self):
+ import gc
+
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ @slow
+ def test_model_from_pretrained(self):
+ # This test would be enabled once a pretrained model is available
+ # For now, we just test that the model can be instantiated
+ config = ArceeConfig()
+ model = ArceeForCausalLM(config)
+ self.assertIsInstance(model, ArceeForCausalLM)
+
+ @mark.skip(reason="Model is not currently public - will update test post release")
+ @slow
+ def test_model_generation(self):
+ EXPECTED_TEXT_COMPLETION = (
+ """Once upon a time,In a village there was a farmer who had three sons. The farmer was very old and he"""
+ )
+ prompt = "Once upon a time"
+ tokenizer = AutoTokenizer.from_pretrained("arcee-ai/model-id")
+ model = ArceeForCausalLM.from_pretrained("arcee-ai/model-id", device_map="auto")
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.model.embed_tokens.weight.device)
+
+ generated_ids = model.generate(input_ids, max_new_tokens=20)
+ text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ @mark.skip(reason="Model is not currently public - will update test post release")
+ @slow
+ @require_flash_attn
+ @mark.flash_attn_test
+ def test_model_generation_flash_attn(self):
+ EXPECTED_TEXT_COMPLETION = (
+ " the food, the people, and the overall experience. I would definitely recommend this place to others."
+ )
+ prompt = "This is a nice place. " * 1024 + "I really enjoy the scenery,"
+ tokenizer = AutoTokenizer.from_pretrained("arcee-ai/model-id")
+ model = ArceeForCausalLM.from_pretrained(
+ "arcee-ai/model-id", device_map="auto", attn_implementation="flash_attention_2", torch_dtype="auto"
+ )
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.model.embed_tokens.weight.device)
+
+ generated_ids = model.generate(input_ids, max_new_tokens=20)
+ text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text[len(prompt) :])
diff --git a/transformers/tests/models/aria/__init__.py b/transformers/tests/models/aria/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/aria/test_image_processing_aria.py b/transformers/tests/models/aria/test_image_processing_aria.py
new file mode 100644
index 0000000000000000000000000000000000000000..f366c6b028c0dcf2717149808998eeede5064604
--- /dev/null
+++ b/transformers/tests/models/aria/test_image_processing_aria.py
@@ -0,0 +1,304 @@
+# Copyright 2024 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+import numpy as np
+
+from transformers.image_utils import ChannelDimension, PILImageResampling
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_image_processing_common import ImageProcessingTestMixin
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import AriaImageProcessor
+
+
+if is_torch_available():
+ import torch
+
+
+class AriaImageProcessingTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ num_images=1,
+ min_resolution=30,
+ max_resolution=40,
+ size=None,
+ max_image_size=980,
+ min_image_size=336,
+ split_resolutions=None,
+ split_image=True,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ do_convert_rgb=True,
+ resample=PILImageResampling.BICUBIC,
+ ):
+ self.size = size if size is not None else {"longest_edge": max_resolution}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.num_images = num_images
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.resample = resample
+ self.max_image_size = max_image_size
+ self.min_image_size = min_image_size
+ self.split_resolutions = split_resolutions if split_resolutions is not None else [[980, 980]]
+ self.split_image = split_image
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.do_convert_rgb = do_convert_rgb
+
+ def prepare_image_processor_dict(self):
+ return {
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "max_image_size": self.max_image_size,
+ "min_image_size": self.min_image_size,
+ "split_resolutions": self.split_resolutions,
+ "split_image": self.split_image,
+ "do_convert_rgb": self.do_convert_rgb,
+ "do_normalize": self.do_normalize,
+ "resample": self.resample,
+ }
+
+ def get_expected_values(self, image_inputs, batched=False):
+ """
+ This function computes the expected height and width when providing images to AriaImageProcessor,
+ assuming do_resize is set to True. The expected size in that case the max image size.
+ """
+ return self.max_image_size, self.max_image_size
+
+ def expected_output_image_shape(self, images):
+ height, width = self.get_expected_values(images, batched=True)
+ return self.num_channels, height, width
+
+ def prepare_image_inputs(
+ self,
+ batch_size=None,
+ min_resolution=None,
+ max_resolution=None,
+ num_channels=None,
+ num_images=None,
+ size_divisor=None,
+ equal_resolution=False,
+ numpify=False,
+ torchify=False,
+ ):
+ """This function prepares a list of PIL images, or a list of numpy arrays if one specifies numpify=True,
+ or a list of PyTorch tensors if one specifies torchify=True.
+
+ One can specify whether the images are of the same resolution or not.
+ """
+ assert not (numpify and torchify), "You cannot specify both numpy and PyTorch tensors at the same time"
+
+ batch_size = batch_size if batch_size is not None else self.batch_size
+ min_resolution = min_resolution if min_resolution is not None else self.min_resolution
+ max_resolution = max_resolution if max_resolution is not None else self.max_resolution
+ num_channels = num_channels if num_channels is not None else self.num_channels
+ num_images = num_images if num_images is not None else self.num_images
+
+ images_list = []
+ for i in range(batch_size):
+ images = []
+ for j in range(num_images):
+ if equal_resolution:
+ width = height = max_resolution
+ else:
+ # To avoid getting image width/height 0
+ if size_divisor is not None:
+ # If `size_divisor` is defined, the image needs to have width/size >= `size_divisor`
+ min_resolution = max(size_divisor, min_resolution)
+ width, height = np.random.choice(np.arange(min_resolution, max_resolution), 2)
+ images.append(np.random.randint(255, size=(num_channels, width, height), dtype=np.uint8))
+ images_list.append(images)
+
+ if not numpify and not torchify:
+ # PIL expects the channel dimension as last dimension
+ images_list = [[Image.fromarray(np.moveaxis(image, 0, -1)) for image in images] for images in images_list]
+
+ if torchify:
+ images_list = [[torch.from_numpy(image) for image in images] for images in images_list]
+
+ if numpify:
+ # Numpy images are typically in channels last format
+ images_list = [[image.transpose(1, 2, 0) for image in images] for images in images_list]
+
+ return images_list
+
+
+@require_torch
+@require_vision
+class AriaImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = AriaImageProcessor if is_vision_available() else None
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = AriaImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "do_convert_rgb"))
+ self.assertTrue(hasattr(image_processing, "max_image_size"))
+ self.assertTrue(hasattr(image_processing, "min_image_size"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "split_image"))
+
+ def test_call_numpy(self):
+ for image_processing_class in self.image_processor_list:
+ # Initialize image_processing
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ # create random numpy tensors
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, numpify=True)
+ for sample_images in image_inputs:
+ for image in sample_images:
+ self.assertIsInstance(image, np.ndarray)
+
+ # Test not batched input
+ encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape([image_inputs[0]])
+ self.assertEqual(tuple(encoded_images.shape), (1, *expected_output_image_shape))
+
+ # Test batched
+ encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape(image_inputs)
+ self.assertEqual(
+ tuple(encoded_images.shape), (self.image_processor_tester.batch_size, *expected_output_image_shape)
+ )
+
+ def test_call_numpy_4_channels(self):
+ # Aria always processes images as RGB, so it always returns images with 3 channels
+ for image_processing_class in self.image_processor_list:
+ # Initialize image_processing
+ image_processor_dict = self.image_processor_dict
+ image_processing = self.image_processing_class(**image_processor_dict)
+ # create random numpy tensors
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, numpify=True)
+
+ for sample_images in image_inputs:
+ for image in sample_images:
+ self.assertIsInstance(image, np.ndarray)
+
+ # Test not batched input
+ encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape([image_inputs[0]])
+ self.assertEqual(tuple(encoded_images.shape), (1, *expected_output_image_shape))
+
+ # Test batched
+ encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape(image_inputs)
+ self.assertEqual(
+ tuple(encoded_images.shape), (self.image_processor_tester.batch_size, *expected_output_image_shape)
+ )
+
+ def test_call_pil(self):
+ for image_processing_class in self.image_processor_list:
+ # Initialize image_processing
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ # create random PIL images
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False)
+ for images in image_inputs:
+ for image in images:
+ self.assertIsInstance(image, Image.Image)
+
+ # Test not batched input
+ encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape([image_inputs[0]])
+ self.assertEqual(tuple(encoded_images.shape), (1, *expected_output_image_shape))
+
+ # Test batched
+ encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape(image_inputs)
+ self.assertEqual(
+ tuple(encoded_images.shape), (self.image_processor_tester.batch_size, *expected_output_image_shape)
+ )
+
+ def test_call_pytorch(self):
+ for image_processing_class in self.image_processor_list:
+ # Initialize image_processing
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ # create random PyTorch tensors
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, torchify=True)
+
+ for images in image_inputs:
+ for image in images:
+ self.assertIsInstance(image, torch.Tensor)
+
+ # Test not batched input
+ encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape([image_inputs[0]])
+ self.assertEqual(tuple(encoded_images.shape), (1, *expected_output_image_shape))
+
+ # Test batched
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape(image_inputs)
+ encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ tuple(encoded_images.shape),
+ (self.image_processor_tester.batch_size, *expected_output_image_shape),
+ )
+
+ def test_pad_for_patching(self):
+ for image_processing_class in self.image_processor_list:
+ if image_processing_class == self.fast_image_processing_class:
+ numpify = False
+ torchify = True
+ input_data_format = image_processing_class.data_format
+ else:
+ numpify = True
+ torchify = False
+ input_data_format = ChannelDimension.LAST
+ image_processing = image_processing_class(**self.image_processor_dict)
+ # Create odd-sized images
+ image_input = self.image_processor_tester.prepare_image_inputs(
+ batch_size=1,
+ max_resolution=400,
+ num_images=1,
+ equal_resolution=True,
+ numpify=numpify,
+ torchify=torchify,
+ )[0][0]
+ self.assertIn(image_input.shape, [(3, 400, 400), (400, 400, 3)])
+
+ # Test odd-width
+ image_shape = (400, 601)
+ encoded_images = image_processing._pad_for_patching(image_input, image_shape, input_data_format)
+ encoded_image_shape = (
+ encoded_images.shape[:-1] if input_data_format == ChannelDimension.LAST else encoded_images.shape[1:]
+ )
+ self.assertEqual(encoded_image_shape, image_shape)
+
+ # Test odd-height
+ image_shape = (503, 400)
+ encoded_images = image_processing._pad_for_patching(image_input, image_shape, input_data_format)
+ encoded_image_shape = (
+ encoded_images.shape[:-1] if input_data_format == ChannelDimension.LAST else encoded_images.shape[1:]
+ )
+ self.assertEqual(encoded_image_shape, image_shape)
diff --git a/transformers/tests/models/aria/test_modeling_aria.py b/transformers/tests/models/aria/test_modeling_aria.py
new file mode 100644
index 0000000000000000000000000000000000000000..36ec831ddbdbc190e8e7bd2106ea6ae0d67d26c6
--- /dev/null
+++ b/transformers/tests/models/aria/test_modeling_aria.py
@@ -0,0 +1,563 @@
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Aria model."""
+
+import unittest
+
+import requests
+
+from transformers import (
+ AriaConfig,
+ AriaForConditionalGeneration,
+ AriaModel,
+ AriaTextConfig,
+ AutoProcessor,
+ AutoTokenizer,
+ BitsAndBytesConfig,
+ is_torch_available,
+ is_vision_available,
+)
+from transformers.models.idefics3 import Idefics3VisionConfig
+from transformers.testing_utils import (
+ Expectations,
+ cleanup,
+ require_bitsandbytes,
+ require_torch,
+ require_torch_large_accelerator,
+ require_vision,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+
+
+if is_torch_available():
+ import torch
+
+
+if is_vision_available():
+ from PIL import Image
+
+# Used to be https://aria-vl.github.io/static/images/view.jpg but it was removed, llava-vl has the same image
+IMAGE_OF_VIEW_URL = "https://llava-vl.github.io/static/images/view.jpg"
+
+
+class AriaVisionText2TextModelTester:
+ def __init__(
+ self,
+ parent,
+ ignore_index=-100,
+ image_token_index=9,
+ projector_hidden_act="gelu",
+ seq_length=7,
+ vision_feature_select_strategy="default",
+ vision_feature_layer=-1,
+ text_config=AriaTextConfig(
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=False,
+ use_labels=True,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ pad_token_id=1,
+ hidden_size=32,
+ intermediate_size=64,
+ max_position_embeddings=60,
+ model_type="aria_moe_lm",
+ moe_intermediate_size=4,
+ moe_num_experts=4,
+ moe_topk=2,
+ num_attention_heads=8,
+ num_experts_per_tok=3,
+ num_hidden_layers=2,
+ num_key_value_heads=8,
+ rope_theta=5000000,
+ vocab_size=99,
+ eos_token_id=2,
+ head_dim=4,
+ ),
+ is_training=True,
+ vision_config=Idefics3VisionConfig(
+ image_size=358,
+ patch_size=10,
+ num_channels=3,
+ is_training=True,
+ hidden_size=32,
+ projection_dim=20,
+ num_hidden_layers=2,
+ num_attention_heads=16,
+ intermediate_size=10,
+ dropout=0.1,
+ attention_dropout=0.1,
+ initializer_range=0.02,
+ ),
+ ):
+ self.parent = parent
+ self.ignore_index = ignore_index
+ self.image_token_index = image_token_index
+ self.projector_hidden_act = projector_hidden_act
+ self.vision_feature_select_strategy = vision_feature_select_strategy
+ self.vision_feature_layer = vision_feature_layer
+ self.text_config = text_config
+ self.vision_config = vision_config
+ self.pad_token_id = text_config.pad_token_id
+ self.eos_token_id = text_config.eos_token_id
+ self.num_hidden_layers = text_config.num_hidden_layers
+ self.vocab_size = text_config.vocab_size
+ self.hidden_size = text_config.hidden_size
+ self.num_attention_heads = text_config.num_attention_heads
+ self.is_training = is_training
+
+ self.batch_size = 10
+ self.num_channels = 3
+ self.image_size = 358
+ self.num_image_tokens = 128
+ self.seq_length = seq_length + self.num_image_tokens
+
+ def get_config(self):
+ return AriaConfig(
+ text_config=self.text_config,
+ vision_config=self.vision_config,
+ ignore_index=self.ignore_index,
+ image_token_index=self.image_token_index,
+ projector_hidden_act=self.projector_hidden_act,
+ vision_feature_select_strategy=self.vision_feature_select_strategy,
+ vision_feature_layer=self.vision_feature_layer,
+ eos_token_id=self.eos_token_id,
+ )
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor(
+ [
+ self.batch_size,
+ self.vision_config.num_channels,
+ self.vision_config.image_size,
+ self.vision_config.image_size,
+ ]
+ )
+ config = self.get_config()
+
+ return config, pixel_values
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ input_ids = ids_tensor([self.batch_size, self.seq_length], config.text_config.vocab_size - 1) + 1
+ attention_mask = input_ids.ne(1).to(torch_device)
+ input_ids[input_ids == config.image_token_index] = self.pad_token_id
+ input_ids[:, : self.num_image_tokens] = config.image_token_index
+ inputs_dict = {
+ "pixel_values": pixel_values,
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ }
+ return config, inputs_dict
+
+
+@slow
+@require_torch
+class AriaForConditionalGenerationModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
+ """
+ Model tester for `AriaForConditionalGeneration`.
+ """
+
+ all_model_classes = (AriaModel, AriaForConditionalGeneration) if is_torch_available() else ()
+ test_pruning = False
+ test_head_masking = False
+ test_torchscript = False
+ _is_composite = True
+
+ def setUp(self):
+ self.model_tester = AriaVisionText2TextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=AriaConfig, has_text_modality=False)
+
+ @unittest.skip(
+ reason="This architecture seems to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seems to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seems to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @unittest.skip(reason="Compile not yet supported because in LLava models")
+ def test_sdpa_can_compile_dynamic(self):
+ pass
+
+ @unittest.skip(reason="Compile not yet supported because in LLava models")
+ def test_sdpa_can_dispatch_on_flash(self):
+ pass
+
+ @unittest.skip(reason="Feedforward chunking is not yet supported")
+ def test_feed_forward_chunking(self):
+ pass
+
+ @unittest.skip(reason="Unstable test")
+ def test_initialization(self):
+ pass
+
+ @unittest.skip(reason="Unstable test")
+ def test_dola_decoding_sample(self):
+ pass
+
+ @unittest.skip(reason="Dynamic control flow due to MoE")
+ def test_generate_with_static_cache(self):
+ pass
+
+ @unittest.skip(reason="Dynamic control flow due to MoE")
+ def test_generate_from_inputs_embeds_with_static_cache(self):
+ pass
+
+ @unittest.skip(reason="Aria uses nn.MHA which is not compatible with offloading")
+ def test_cpu_offload(self):
+ pass
+
+ @unittest.skip(reason="Aria uses nn.MHA which is not compatible with offloading")
+ def test_disk_offload_bin(self):
+ pass
+
+ @unittest.skip(reason="Aria uses nn.MHA which is not compatible with offloading")
+ def test_disk_offload_safetensors(self):
+ pass
+
+
+SKIP = False
+torch_accelerator_module = getattr(torch, torch_device)
+memory = 23 # skip on T4 / A10
+if hasattr(torch_accelerator_module, "get_device_properties"):
+ if torch_accelerator_module.get_device_properties(0).total_memory / 1024**3 < memory:
+ SKIP = True
+
+
+@unittest.skipIf(SKIP, reason="A10 doesn't have enough GPU memory for this tests")
+@require_torch
+class AriaForConditionalGenerationIntegrationTest(unittest.TestCase):
+ def setUp(self):
+ self.processor = AutoProcessor.from_pretrained("rhymes-ai/Aria")
+ cleanup(torch_device, gc_collect=True)
+
+ def tearDown(self):
+ cleanup(torch_device, gc_collect=True)
+
+ @slow
+ @require_torch_large_accelerator
+ @require_bitsandbytes
+ def test_small_model_integration_test(self):
+ # Let's make sure we test the preprocessing to replace what is used
+ model = AriaForConditionalGeneration.from_pretrained(
+ "rhymes-ai/Aria",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True, llm_int8_skip_modules=["multihead_attn"]),
+ )
+
+ prompt = "<|img|>\nUSER: What are the things I should be cautious about when I visit this place?\nASSISTANT:"
+ raw_image = Image.open(requests.get(IMAGE_OF_VIEW_URL, stream=True).raw)
+ inputs = self.processor(images=raw_image, text=prompt, return_tensors="pt").to(model.device, model.dtype)
+
+ non_img_tokens = [
+ 109, 3905, 2000, 93415, 4551, 1162, 901, 3894, 970, 2478, 1017, 19312, 2388, 1596, 1809, 970, 5449, 1235,
+ 3333, 93483, 109, 61081, 11984, 14800, 93415
+ ] # fmt: skip
+ EXPECTED_INPUT_IDS = torch.tensor([[9] * 256 + non_img_tokens]).to(inputs["input_ids"].device)
+ self.assertTrue(torch.equal(inputs["input_ids"], EXPECTED_INPUT_IDS))
+
+ output = model.generate(**inputs, max_new_tokens=20)
+ decoded_output = self.processor.decode(output[0], skip_special_tokens=True)
+
+ expected_output = Expectations(
+ {
+ (
+ "cuda",
+ None,
+ ): "\nUSER: What are the things I should be cautious about when I visit this place?\nASSISTANT: When visiting this place, there are a few things one should be cautious about. Firstly,",
+ (
+ "rocm",
+ (9, 5),
+ ): "\n USER: What are the things I should be cautious about when I visit this place?\n ASSISTANT: When you visit this place, you should be cautious about the following things:\n\n- The",
+ }
+ ).get_expectation()
+ self.assertEqual(decoded_output, expected_output)
+
+ @slow
+ @require_torch_large_accelerator
+ @require_bitsandbytes
+ def test_small_model_integration_test_llama_single(self):
+ # Let's make sure we test the preprocessing to replace what is used
+ model_id = "rhymes-ai/Aria"
+
+ model = AriaForConditionalGeneration.from_pretrained(
+ model_id,
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True, llm_int8_skip_modules=["multihead_attn"]),
+ )
+ processor = AutoProcessor.from_pretrained(model_id)
+
+ prompt = "USER: <|img|>\nWhat are the things I should be cautious about when I visit this place? ASSISTANT:"
+ raw_image = Image.open(requests.get(IMAGE_OF_VIEW_URL, stream=True).raw)
+ inputs = processor(images=raw_image, text=prompt, return_tensors="pt").to(model.device, model.dtype)
+
+ output = model.generate(**inputs, max_new_tokens=90, do_sample=False)
+ EXPECTED_DECODED_TEXT = Expectations(
+ {
+ ("cuda", (8, 0)): "USER: \n What are the things I should be cautious about when I visit this place? ASSISTANT: When visiting this beautiful location, it's important to be mindful of a few things to ensure both your safety and the preservation of the environment. Firstly, always be cautious when walking on the wooden pier, as it can be slippery, especially during or after rain. Secondly, be aware of the local wildlife and do not feed or disturb them. Lastly, respect the natural surroundings by not littering and sticking to",
+ ("rocm", (9, 5)): "USER: \n What are the things I should be cautious about when I visit this place? ASSISTANT: \n\nWhen visiting this place, you should be cautious about the following:\n\n1. **Weather Conditions**: The weather can be unpredictable, so it's important to check the forecast and dress in layers. Sudden changes in weather can occur, so be prepared for rain or cold temperatures.\n\n2. **Safety on the Dock**: The dock may be slippery, especially when",
+ }
+ ).get_expectation() # fmt: off
+
+ decoded_output = processor.decode(output[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
+ self.assertEqual(
+ decoded_output,
+ EXPECTED_DECODED_TEXT,
+ f"Expected: {repr(EXPECTED_DECODED_TEXT)}\nActual: {repr(decoded_output)}",
+ )
+
+ @slow
+ @require_torch_large_accelerator
+ @require_bitsandbytes
+ def test_small_model_integration_test_llama_batched(self):
+ # Let's make sure we test the preprocessing to replace what is used
+ model_id = "rhymes-ai/Aria"
+
+ model = AriaForConditionalGeneration.from_pretrained(
+ model_id,
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True, llm_int8_skip_modules=["multihead_attn"]),
+ )
+ processor = AutoProcessor.from_pretrained(model_id)
+
+ prompts = [
+ "USER: <|img|>\nWhat are the things I should be cautious about when I visit this place? What should I bring with me? ASSISTANT:",
+ "USER: <|img|>\nWhat is this? ASSISTANT:",
+ ]
+ image1 = Image.open(requests.get(IMAGE_OF_VIEW_URL, stream=True).raw)
+ image2 = Image.open(requests.get("http://images.cocodataset.org/val2017/000000039769.jpg", stream=True).raw)
+
+ inputs = processor(images=[image1, image2], text=prompts, return_tensors="pt", padding=True).to(
+ model.device, model.dtype
+ )
+
+ output = model.generate(**inputs, max_new_tokens=20)
+
+ EXPECTED_DECODED_TEXT = Expectations(
+ {
+ ("cuda", None): [
+ "USER: \nWhat are the things I should be cautious about when I visit this place? What should I bring with me? ASSISTANT: When visiting this place, which is a pier or dock extending over a body of water, you",
+ "USER: \nWhat is this? ASSISTANT: The image features two cats lying down on a pink couch. One cat is located on",
+ ],
+ ("rocm", (9, 5)): [
+ "USER: \n What are the things I should be cautious about when I visit this place? What should I bring with me? ASSISTANT: \n\nWhen visiting this place, you should be cautious about the weather conditions, as it",
+ "USER: \n What is this? ASSISTANT: This is a picture of two cats sleeping on a couch. USER: What is the color of",
+ ],
+ }
+ ).get_expectation()
+
+ decoded_output = processor.batch_decode(output, skip_special_tokens=True)
+ self.assertEqual(decoded_output, EXPECTED_DECODED_TEXT)
+
+ @slow
+ @require_torch_large_accelerator
+ @require_bitsandbytes
+ def test_small_model_integration_test_batch(self):
+ # Let's make sure we test the preprocessing to replace what is used
+ model = AriaForConditionalGeneration.from_pretrained(
+ "rhymes-ai/Aria",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True, llm_int8_skip_modules=["multihead_attn"]),
+ )
+ # The first batch is longer in terms of text, but only has 1 image. The second batch will be padded in text, but the first will be padded because images take more space!.
+ prompts = [
+ "USER: <|img|>\nWhat are the things I should be cautious about when I visit this place? What should I bring with me?\nASSISTANT:",
+ "USER: <|img|>\nWhat is this?\nASSISTANT:",
+ ]
+ image1 = Image.open(requests.get(IMAGE_OF_VIEW_URL, stream=True).raw)
+ image2 = Image.open(requests.get("http://images.cocodataset.org/val2017/000000039769.jpg", stream=True).raw)
+
+ inputs = self.processor(images=[image1, image2], text=prompts, return_tensors="pt", padding=True).to(
+ model.device, model.dtype
+ )
+
+ output = model.generate(**inputs, max_new_tokens=20)
+
+ EXPECTED_DECODED_TEXT = Expectations({
+ ("cuda", None): [
+ 'USER: \nWhat are the things I should be cautious about when I visit this place? What should I bring with me?\nASSISTANT: When visiting this place, there are a few things to be cautious about and items to bring.',
+ 'USER: \nWhat is this?\nASSISTANT: Cats',
+ ],
+ ("rocm", (9, 5)): [
+ 'USER: \n What are the things I should be cautious about when I visit this place? What should I bring with me?\n ASSISTANT: \n\nWhen visiting this place, you should be cautious about the following:\n\n-',
+ 'USER: \n What is this?\n ASSISTANT: This is a picture of two cats sleeping on a couch. The couch is red, and the cats',
+ ],
+ }).get_expectation() # fmt: skip
+
+ decoded_output = self.processor.batch_decode(output, skip_special_tokens=True)
+ self.assertEqual(decoded_output, EXPECTED_DECODED_TEXT)
+
+ @slow
+ @require_torch_large_accelerator
+ @require_bitsandbytes
+ def test_small_model_integration_test_llama_batched_regression(self):
+ # Let's make sure we test the preprocessing to replace what is used
+ model_id = "rhymes-ai/Aria"
+
+ # Multi-image & multi-prompt (e.g. 3 images and 2 prompts now fails with SDPA, this tests if "eager" works as before)
+ model = AriaForConditionalGeneration.from_pretrained(
+ model_id,
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True, llm_int8_skip_modules=["multihead_attn"]),
+ )
+ processor = AutoProcessor.from_pretrained(model_id, pad_token="")
+
+ prompts = [
+ "USER: <|img|>\nWhat are the things I should be cautious about when I visit this place? What should I bring with me?\nASSISTANT:",
+ "USER: <|img|>\nWhat is this?\nASSISTANT: Two cats lying on a bed!\nUSER: <|img|>\nAnd this?\nASSISTANT:",
+ ]
+ image1 = Image.open(requests.get(IMAGE_OF_VIEW_URL, stream=True).raw)
+ image2 = Image.open(requests.get("http://images.cocodataset.org/val2017/000000039769.jpg", stream=True).raw)
+
+ inputs = processor(images=[image1, image2, image1], text=prompts, return_tensors="pt", padding=True)
+ inputs = inputs.to(model.device, model.dtype)
+
+ output = model.generate(**inputs, max_new_tokens=20)
+
+ EXPECTED_DECODED_TEXT = Expectations({
+ ("cuda", None): ['USER: \nWhat are the things I should be cautious about when I visit this place? What should I bring with me?\nASSISTANT: When visiting this place, which appears to be a dock or pier extending over a body of water', 'USER: \nWhat is this?\nASSISTANT: Two cats lying on a bed!\nUSER: \nAnd this?\nASSISTANT: A cat sleeping on a bed.'],
+ ("rocm", (9, 5)): ['USER: \n What are the things I should be cautious about when I visit this place? What should I bring with me?\n ASSISTANT: \n\nWhen visiting this place, you should be cautious about the weather conditions, as it', 'USER: \n What is this?\n ASSISTANT: Two cats lying on a bed!\n USER: \n And this?\n ASSISTANT: A serene lake scene with a wooden dock extending into the water.\n USER: \n']
+ }).get_expectation() # fmt: skip
+
+ decoded_output = processor.batch_decode(output, skip_special_tokens=True)
+ self.assertEqual(decoded_output, EXPECTED_DECODED_TEXT)
+
+ @slow
+ @require_torch_large_accelerator
+ @require_vision
+ @require_bitsandbytes
+ def test_batched_generation(self):
+ # Skip multihead_attn for 4bit because MHA will read the original weight without dequantize.
+ # See https://github.com/huggingface/transformers/pull/37444#discussion_r2045852538.
+ model = AriaForConditionalGeneration.from_pretrained(
+ "rhymes-ai/Aria",
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True, llm_int8_skip_modules=["multihead_attn"]),
+ )
+ processor = AutoProcessor.from_pretrained("rhymes-ai/Aria")
+
+ prompt1 = "\n\nUSER: What's the difference of two images?\nASSISTANT:"
+ prompt2 = "\nUSER: Describe the image.\nASSISTANT:"
+ prompt3 = "\nUSER: Describe the image.\nASSISTANT:"
+ url1 = "https://images.unsplash.com/photo-1552053831-71594a27632d?q=80&w=3062&auto=format&fit=crop&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D"
+ url2 = "https://images.unsplash.com/photo-1617258683320-61900b281ced?q=80&w=3087&auto=format&fit=crop&ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D"
+ image1 = Image.open(requests.get(url1, stream=True).raw)
+ image2 = Image.open(requests.get(url2, stream=True).raw)
+
+ # Create inputs
+ messages = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image"},
+ {"type": "text", "text": prompt1},
+ {"type": "image"},
+ {"type": "text", "text": prompt2},
+ ],
+ },
+ {
+ "role": "user",
+ "content": [
+ {"type": "image"},
+ {"type": "text", "text": prompt3},
+ ],
+ },
+ ]
+
+ prompts = [processor.apply_chat_template([message], add_generation_prompt=True) for message in messages]
+ images = [[image1, image2], [image2]]
+ inputs = processor(text=prompts, images=images, padding=True, return_tensors="pt").to(
+ device=model.device, dtype=model.dtype
+ )
+
+ EXPECTED_OUTPUTS = Expectations(
+ {
+ ("cpu", None): [
+ "<|im_start|>user\n \n \n USER: What's the difference of two images?\n ASSISTANT: \n USER: Describe the image.\n ASSISTANT:<|im_end|>\n <|im_start|>assistant\n The first image features a cute, light-colored puppy sitting on a paved surface with",
+ "<|im_start|>user\n \n USER: Describe the image.\n ASSISTANT:<|im_end|>\n <|im_start|>assistant\n The image shows a young alpaca standing on a grassy hill. The alpaca has",
+ ],
+ ("cuda", None): [
+ "<|im_start|>user\n \n \n USER: What's the difference of two images?\n ASSISTANT: \n USER: Describe the image.\n ASSISTANT:<|im_end|>\n <|im_start|>assistant\n The first image features a cute, light-colored puppy sitting on a paved surface with",
+ "<|im_start|>user\n \n USER: Describe the image.\n ASSISTANT:<|im_end|>\n <|im_start|>assistant\n The image shows a young alpaca standing on a patch of ground with some dry grass. The",
+ ],
+ ("xpu", 3): [
+ "<|im_start|>user\n \n \n USER: What's the difference of two images?\n ASSISTANT: \n USER: Describe the image.\n ASSISTANT:<|im_end|>\n <|im_start|>assistant\n The first image features a cute, light-colored puppy sitting on a paved surface with",
+ "<|im_start|>user\n \n USER: Describe the image.\n ASSISTANT:<|im_end|>\n <|im_start|>assistant\n The image shows a young alpaca standing on a patch of ground with some dry grass. The",
+ ],
+ ("rocm", (9, 5)): [
+ "<|im_start|>user\n \n \n USER: What's the difference of two images?\n ASSISTANT: \n USER: Describe the image.\n ASSISTANT:<|im_end|>\n <|im_start|>assistant\n The first image shows a cute golden retriever puppy sitting on a paved surface with a stick",
+ '<|im_start|>user\n \n USER: Describe the image.\n ASSISTANT:<|im_end|>\n <|im_start|>assistant\n The image shows a young llama standing on a patch of ground with some dry grass and dirt. The'
+ ],
+ }
+ ) # fmt: skip
+ EXPECTED_OUTPUT = EXPECTED_OUTPUTS.get_expectation()
+ generate_ids = model.generate(**inputs, max_new_tokens=20)
+ outputs = processor.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
+ self.assertListEqual(outputs, EXPECTED_OUTPUT)
+
+ def test_tokenizer_integration(self):
+ model_id = "rhymes-ai/Aria"
+ slow_tokenizer = AutoTokenizer.from_pretrained(
+ model_id, bos_token="<|startoftext|>", eos_token="<|endoftext|>", use_fast=False
+ )
+ slow_tokenizer.add_tokens("", True)
+
+ fast_tokenizer = AutoTokenizer.from_pretrained(
+ model_id,
+ bos_token="<|startoftext|>",
+ eos_token="<|endoftext|>",
+ from_slow=True,
+ legacy=False,
+ )
+ fast_tokenizer.add_tokens("", True)
+
+ prompt = "<|startoftext|><|im_start|>system\nAnswer the questions.<|im_end|><|im_start|>user\n\nWhat is shown in this image?<|im_end|>"
+ EXPECTED_OUTPUT = ['<|startoftext|>', '<', '|', 'im', '_', 'start', '|', '>', 'system', '\n', 'Answer', '▁the', '▁questions', '.<', '|', 'im', '_', 'end', '|', '><', '|', 'im', '_', 'start', '|', '>', 'user', '\n', '', '\n', 'What', '▁is', '▁shown', '▁in', '▁this', '▁image', '?', '<', '|', 'im', '_', 'end', '|', '>'] # fmt: skip
+ self.assertEqual(slow_tokenizer.tokenize(prompt), EXPECTED_OUTPUT)
+ self.assertEqual(fast_tokenizer.tokenize(prompt), EXPECTED_OUTPUT)
+
+ @slow
+ @require_torch_large_accelerator
+ @require_bitsandbytes
+ def test_generation_no_images(self):
+ model_id = "rhymes-ai/Aria"
+ model = AriaForConditionalGeneration.from_pretrained(
+ model_id,
+ quantization_config=BitsAndBytesConfig(load_in_4bit=True, llm_int8_skip_modules=["multihead_attn"]),
+ )
+ processor = AutoProcessor.from_pretrained(model_id)
+ assert model.device.type == "cuda", "This test is only supported on CUDA" # TODO: remove this
+ # Prepare inputs with no images
+ inputs = processor(text="Hello, I am", return_tensors="pt").to(torch_device)
+
+ # Make sure that `generate` works
+ _ = model.generate(**inputs, max_new_tokens=20)
diff --git a/transformers/tests/models/aria/test_processor_aria.py b/transformers/tests/models/aria/test_processor_aria.py
new file mode 100644
index 0000000000000000000000000000000000000000..9df833661a0c5470a047c4621de8b439aa5b73d4
--- /dev/null
+++ b/transformers/tests/models/aria/test_processor_aria.py
@@ -0,0 +1,299 @@
+# Copyright 2024 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import shutil
+import tempfile
+import unittest
+from io import BytesIO
+
+import numpy as np
+import requests
+
+from transformers import AriaProcessor
+from transformers.models.auto.processing_auto import AutoProcessor
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_vision_available
+
+from ...test_processing_common import ProcessorTesterMixin
+
+
+if is_vision_available():
+ from PIL import Image
+
+
+@require_torch
+@require_vision
+class AriaProcessorTest(ProcessorTesterMixin, unittest.TestCase):
+ processor_class = AriaProcessor
+
+ @classmethod
+ def setUpClass(cls):
+ cls.tmpdirname = tempfile.mkdtemp()
+ processor = AriaProcessor.from_pretrained("m-ric/Aria_hf_2", size_conversion={490: 2, 980: 2})
+ processor.save_pretrained(cls.tmpdirname)
+ cls.image1 = Image.open(
+ BytesIO(
+ requests.get(
+ "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg"
+ ).content
+ )
+ )
+ cls.image2 = Image.open(
+ BytesIO(requests.get("https://cdn.britannica.com/59/94459-050-DBA42467/Skyline-Chicago.jpg").content)
+ )
+ cls.image3 = Image.open(
+ BytesIO(
+ requests.get(
+ "https://thumbs.dreamstime.com/b/golden-gate-bridge-san-francisco-purple-flowers-california-echium-candicans-36805947.jpg"
+ ).content
+ )
+ )
+ cls.bos_token = "<|im_start|>"
+ cls.eos_token = "<|im_end|>"
+
+ cls.image_token = processor.tokenizer.image_token
+ cls.fake_image_token = "o"
+ cls.global_img_token = "<|img|>"
+
+ cls.bos_token_id = processor.tokenizer.convert_tokens_to_ids(cls.bos_token)
+ cls.eos_token_id = processor.tokenizer.convert_tokens_to_ids(cls.eos_token)
+
+ cls.image_token_id = processor.tokenizer.convert_tokens_to_ids(cls.image_token)
+ cls.fake_image_token_id = processor.tokenizer.convert_tokens_to_ids(cls.fake_image_token)
+ cls.global_img_tokens_id = processor.tokenizer(cls.global_img_token, add_special_tokens=False)["input_ids"]
+ cls.padding_token_id = processor.tokenizer.pad_token_id
+ cls.image_seq_len = 2
+
+ @staticmethod
+ def prepare_processor_dict():
+ return {
+ "chat_template": "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}<|im_start|>{{ message['role'] }}\n{% if message['content'] is string %}{{ message['content'] }}{% elif message['content'] is iterable %}{% for item in message['content'] %}{% if item['type'] == 'text' %}{{ item['text'] }}{% elif item['type'] == 'image' %}<|img|>{% endif %}{% endfor %}{% endif %}<|im_end|>\n{% endfor %}{% if add_generation_prompt %}<|im_start|>assistant\n{% endif %}",
+ "size_conversion": {490: 2, 980: 2},
+ } # fmt: skip
+
+ def get_tokenizer(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).tokenizer
+
+ def get_image_processor(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).image_processor
+
+ def get_processor(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs)
+
+ @classmethod
+ def tearDownClass(cls):
+ shutil.rmtree(cls.tmpdirname, ignore_errors=True)
+
+ def test_process_interleaved_images_prompts_image_splitting(self):
+ processor = self.get_processor()
+ processor.image_processor.split_image = True
+
+ # Test that a single image is processed correctly
+ inputs = processor(images=self.image1, text="Ok<|img|>", images_kwargs={"split_image": True})
+ self.assertEqual(np.array(inputs["pixel_values"]).shape, (2, 3, 980, 980))
+ self.assertEqual(np.array(inputs["pixel_mask"]).shape, (2, 980, 980))
+
+ def test_process_interleaved_images_prompts_no_image_splitting(self):
+ processor = self.get_processor()
+ processor.image_processor.split_image = False
+
+ # Test that a single image is processed correctly
+ inputs = processor(images=self.image1, text="Ok<|img|>")
+ image1_expected_size = (980, 980)
+ self.assertEqual(np.array(inputs["pixel_values"]).shape, (1, 3, *image1_expected_size))
+ self.assertEqual(np.array(inputs["pixel_mask"]).shape, (1, *image1_expected_size))
+ # fmt: on
+
+ # Test a single sample with image and text
+ image_str = "<|img|>"
+ text_str = "In this image, we see"
+ text = image_str + text_str
+ inputs = processor(text=text, images=self.image1)
+
+ # fmt: off
+ tokenized_sentence = processor.tokenizer(text_str, add_special_tokens=False)
+
+ expected_input_ids = [[self.image_token_id] * self.image_seq_len + tokenized_sentence["input_ids"]]
+ # self.assertEqual(len(inputs["input_ids"]), len(expected_input_ids))
+
+ self.assertEqual(inputs["input_ids"], expected_input_ids)
+ self.assertEqual(inputs["attention_mask"], [[1] * len(expected_input_ids[0])])
+ self.assertEqual(np.array(inputs["pixel_values"]).shape, (1, 3, *image1_expected_size))
+ self.assertEqual(np.array(inputs["pixel_mask"]).shape, (1, *image1_expected_size))
+ # fmt: on
+
+ # Test that batch is correctly processed
+ image_str = "<|img|>"
+ text_str_1 = "In this image, we see"
+ text_str_2 = "In this image, we see"
+
+ text = [
+ image_str + text_str_1,
+ image_str + image_str + text_str_2,
+ ]
+ images = [[self.image1], [self.image2, self.image3]]
+
+ inputs = processor(text=text, images=images, padding=True)
+
+ # fmt: off
+ tokenized_sentence_1 = processor.tokenizer(text_str_1, add_special_tokens=False)
+ tokenized_sentence_2 = processor.tokenizer(text_str_2, add_special_tokens=False)
+
+ image_tokens = [self.image_token_id] * self.image_seq_len
+ expected_input_ids_1 = image_tokens + tokenized_sentence_1["input_ids"]
+ expected_input_ids_2 = 2 * image_tokens + tokenized_sentence_2["input_ids"]
+
+ # Pad the first input to match the second input
+ pad_len = len(expected_input_ids_2) - len(expected_input_ids_1)
+
+ expected_attention_mask = [[0] * pad_len + [1] * len(expected_input_ids_1), [1] * (len(expected_input_ids_2))]
+
+ self.assertEqual(
+ inputs["attention_mask"],
+ expected_attention_mask
+ )
+ self.assertEqual(np.array(inputs['pixel_values']).shape, (3, 3, 980, 980))
+ self.assertEqual(np.array(inputs['pixel_mask']).shape, (3, 980, 980))
+ # fmt: on
+
+ def test_non_nested_images_with_batched_text(self):
+ processor = self.get_processor()
+ processor.image_processor.do_image_splitting = False
+
+ image_str = "<|img|>"
+ text_str_1 = "In this image, we see"
+ text_str_2 = "In this image, we see"
+
+ text = [
+ image_str + text_str_1,
+ image_str + image_str + text_str_2,
+ ]
+ images = [self.image1, self.image2, self.image3]
+
+ inputs = processor(text=text, images=images, padding=True)
+
+ self.assertEqual(np.array(inputs["pixel_values"]).shape, (3, 3, 980, 980))
+ self.assertEqual(np.array(inputs["pixel_mask"]).shape, (3, 980, 980))
+
+ def test_apply_chat_template(self):
+ # Message contains content which a mix of lists with images and image urls and string
+ messages = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "What do these images show?"},
+ {"type": "image"},
+ {"type": "image"},
+ "What do these images show?",
+ ],
+ },
+ {
+ "role": "assistant",
+ "content": [
+ {
+ "type": "text",
+ "text": "The first image shows the statue of Liberty in New York. The second image picture depicts Idefix, the dog of Obelix in Asterix and Obelix.",
+ }
+ ],
+ },
+ {"role": "user", "content": [{"type": "text", "text": "And who is that?"}]},
+ ]
+ processor = self.get_processor()
+ # Make short sequence length to test that the fake tokens are added correctly
+ rendered = processor.apply_chat_template(messages, add_generation_prompt=True)
+ print(rendered)
+
+ expected_rendered = """<|im_start|>user
+What do these images show?<|img|><|img|><|im_end|>
+<|im_start|>assistant
+The first image shows the statue of Liberty in New York. The second image picture depicts Idefix, the dog of Obelix in Asterix and Obelix.<|im_end|>
+<|im_start|>user
+And who is that?<|im_end|>
+<|im_start|>assistant
+"""
+ self.assertEqual(rendered, expected_rendered)
+
+ def test_image_chat_template_accepts_processing_kwargs(self):
+ processor = self.get_processor()
+ if processor.chat_template is None:
+ self.skipTest("Processor has no chat template")
+
+ messages = [
+ [
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "What is shown in this image?"},
+ ],
+ },
+ ]
+ ]
+
+ formatted_prompt_tokenized = processor.apply_chat_template(
+ messages,
+ add_generation_prompt=True,
+ tokenize=True,
+ padding="max_length",
+ max_length=50,
+ )
+ self.assertEqual(len(formatted_prompt_tokenized[0]), 50)
+
+ formatted_prompt_tokenized = processor.apply_chat_template(
+ messages,
+ add_generation_prompt=True,
+ tokenize=True,
+ truncation=True,
+ max_length=5,
+ )
+ self.assertEqual(len(formatted_prompt_tokenized[0]), 5)
+
+ # Now test the ability to return dict
+ messages[0][0]["content"].append(
+ {"type": "image", "url": "https://www.ilankelman.org/stopsigns/australia.jpg"}
+ )
+ out_dict = processor.apply_chat_template(
+ messages,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ max_image_size=980,
+ return_tensors="np",
+ )
+ self.assertListEqual(list(out_dict[self.images_input_name].shape), [1, 3, 980, 980])
+
+ def test_special_mm_token_truncation(self):
+ """Tests that special vision tokens do not get truncated when `truncation=True` is set."""
+
+ processor = self.get_processor()
+
+ input_str = self.prepare_text_inputs(batch_size=2, modality="image")
+ image_input = self.prepare_image_inputs(batch_size=2)
+
+ _ = processor(
+ text=input_str,
+ images=image_input,
+ return_tensors="pt",
+ truncation=None,
+ padding=True,
+ )
+
+ with self.assertRaises(ValueError):
+ _ = processor(
+ text=input_str,
+ images=image_input,
+ return_tensors="pt",
+ truncation=True,
+ padding=True,
+ max_length=3,
+ )
diff --git a/transformers/tests/models/audio_spectrogram_transformer/__init__.py b/transformers/tests/models/audio_spectrogram_transformer/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/audio_spectrogram_transformer/test_feature_extraction_audio_spectrogram_transformer.py b/transformers/tests/models/audio_spectrogram_transformer/test_feature_extraction_audio_spectrogram_transformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..b0ee0066fb082f026d4f2ad96814b68e9b055e53
--- /dev/null
+++ b/transformers/tests/models/audio_spectrogram_transformer/test_feature_extraction_audio_spectrogram_transformer.py
@@ -0,0 +1,221 @@
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import itertools
+import os
+import random
+import tempfile
+import unittest
+
+import numpy as np
+
+from transformers import ASTFeatureExtractor
+from transformers.testing_utils import check_json_file_has_correct_format, require_torch, require_torchaudio
+from transformers.utils.import_utils import is_torch_available
+
+from ...test_sequence_feature_extraction_common import SequenceFeatureExtractionTestMixin
+
+
+global_rng = random.Random()
+
+if is_torch_available():
+ import torch
+
+
+# Copied from tests.models.whisper.test_feature_extraction_whisper.floats_list
+def floats_list(shape, scale=1.0, rng=None, name=None):
+ """Creates a random float32 tensor"""
+ if rng is None:
+ rng = global_rng
+
+ values = []
+ for batch_idx in range(shape[0]):
+ values.append([])
+ for _ in range(shape[1]):
+ values[-1].append(rng.random() * scale)
+
+ return values
+
+
+class ASTFeatureExtractionTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ min_seq_length=400,
+ max_seq_length=2000,
+ feature_size=1,
+ padding_value=0.0,
+ sampling_rate=16000,
+ return_attention_mask=True,
+ do_normalize=True,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.min_seq_length = min_seq_length
+ self.max_seq_length = max_seq_length
+ self.seq_length_diff = (self.max_seq_length - self.min_seq_length) // (self.batch_size - 1)
+ self.feature_size = feature_size
+ self.padding_value = padding_value
+ self.sampling_rate = sampling_rate
+ self.return_attention_mask = return_attention_mask
+ self.do_normalize = do_normalize
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "feature_size": self.feature_size,
+ "padding_value": self.padding_value,
+ "sampling_rate": self.sampling_rate,
+ "return_attention_mask": self.return_attention_mask,
+ "do_normalize": self.do_normalize,
+ }
+
+ def prepare_inputs_for_common(self, equal_length=False, numpify=False):
+ def _flatten(list_of_lists):
+ return list(itertools.chain(*list_of_lists))
+
+ if equal_length:
+ speech_inputs = floats_list((self.batch_size, self.max_seq_length))
+ else:
+ # make sure that inputs increase in size
+ speech_inputs = [
+ _flatten(floats_list((x, self.feature_size)))
+ for x in range(self.min_seq_length, self.max_seq_length, self.seq_length_diff)
+ ]
+
+ if numpify:
+ speech_inputs = [np.asarray(x) for x in speech_inputs]
+
+ return speech_inputs
+
+
+@require_torch
+@require_torchaudio
+class ASTFeatureExtractionTest(SequenceFeatureExtractionTestMixin, unittest.TestCase):
+ feature_extraction_class = ASTFeatureExtractor
+
+ def setUp(self):
+ self.feat_extract_tester = ASTFeatureExtractionTester(self)
+
+ def test_call(self):
+ # Tests that all call wrap to encode_plus and batch_encode_plus
+ feat_extract = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
+ # create three inputs of length 800, 1000, and 1200
+ speech_inputs = [floats_list((1, x))[0] for x in range(800, 1400, 200)]
+ np_speech_inputs = [np.asarray(speech_input) for speech_input in speech_inputs]
+
+ # Test not batched input
+ encoded_sequences_1 = feat_extract(speech_inputs[0], return_tensors="np").input_values
+ encoded_sequences_2 = feat_extract(np_speech_inputs[0], return_tensors="np").input_values
+ self.assertTrue(np.allclose(encoded_sequences_1, encoded_sequences_2, atol=1e-3))
+
+ # Test batched
+ encoded_sequences_1 = feat_extract(speech_inputs, padding=True, return_tensors="np").input_values
+ encoded_sequences_2 = feat_extract(np_speech_inputs, padding=True, return_tensors="np").input_values
+ for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
+ self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
+
+ # Test 2-D numpy arrays are batched.
+ speech_inputs = [floats_list((1, x))[0] for x in (800, 800, 800)]
+ np_speech_inputs = np.asarray(speech_inputs)
+ encoded_sequences_1 = feat_extract(speech_inputs, return_tensors="np").input_values
+ encoded_sequences_2 = feat_extract(np_speech_inputs, return_tensors="np").input_values
+ for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
+ self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
+
+ @require_torch
+ def test_double_precision_pad(self):
+ import torch
+
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
+ np_speech_inputs = np.random.rand(100).astype(np.float64)
+ py_speech_inputs = np_speech_inputs.tolist()
+
+ for inputs in [py_speech_inputs, np_speech_inputs]:
+ np_processed = feature_extractor.pad([{"input_values": inputs}], return_tensors="np")
+ self.assertTrue(np_processed.input_values.dtype == np.float32)
+ pt_processed = feature_extractor.pad([{"input_values": inputs}], return_tensors="pt")
+ self.assertTrue(pt_processed.input_values.dtype == torch.float32)
+
+ def _load_datasamples(self, num_samples):
+ from datasets import load_dataset
+
+ ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ # automatic decoding with librispeech
+ speech_samples = ds.sort("id")[:num_samples]["audio"]
+
+ return [x["array"] for x in speech_samples]
+
+ @require_torch
+ def test_integration(self):
+ # fmt: off
+ EXPECTED_INPUT_VALUES = torch.tensor(
+ [-0.9894, -1.2776, -0.9066, -1.2776, -0.9349, -1.2609, -1.0386, -1.2776,
+ -1.1561, -1.2776, -1.2052, -1.2723, -1.2190, -1.2132, -1.2776, -1.1133,
+ -1.1953, -1.1343, -1.1584, -1.2203, -1.1770, -1.2474, -1.2381, -1.1936,
+ -0.9270, -0.8317, -0.8049, -0.7706, -0.7565, -0.7869]
+ )
+ # fmt: on
+
+ input_speech = self._load_datasamples(1)
+ feature_extractor = ASTFeatureExtractor()
+ input_values = feature_extractor(input_speech, return_tensors="pt").input_values
+ self.assertEqual(input_values.shape, (1, 1024, 128))
+ torch.testing.assert_close(input_values[0, 0, :30], EXPECTED_INPUT_VALUES, rtol=1e-4, atol=1e-4)
+
+ def test_feat_extract_from_and_save_pretrained(self):
+ feat_extract_first = self.feature_extraction_class(**self.feat_extract_dict)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ saved_file = feat_extract_first.save_pretrained(tmpdirname)[0]
+ check_json_file_has_correct_format(saved_file)
+ feat_extract_second = self.feature_extraction_class.from_pretrained(tmpdirname)
+
+ dict_first = feat_extract_first.to_dict()
+ dict_second = feat_extract_second.to_dict()
+ self.assertDictEqual(dict_first, dict_second)
+
+ def test_feat_extract_to_json_file(self):
+ feat_extract_first = self.feature_extraction_class(**self.feat_extract_dict)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ json_file_path = os.path.join(tmpdirname, "feat_extract.json")
+ feat_extract_first.to_json_file(json_file_path)
+ feat_extract_second = self.feature_extraction_class.from_json_file(json_file_path)
+
+ dict_first = feat_extract_first.to_dict()
+ dict_second = feat_extract_second.to_dict()
+ self.assertEqual(dict_first, dict_second)
+
+
+# exact same tests than before, except that we simulate that torchaudio is not available
+@require_torch
+@unittest.mock.patch(
+ "transformers.models.audio_spectrogram_transformer.feature_extraction_audio_spectrogram_transformer.is_speech_available",
+ lambda: False,
+)
+class ASTFeatureExtractionWithoutTorchaudioTest(ASTFeatureExtractionTest):
+ def test_using_audio_utils(self):
+ # Tests that it uses audio_utils instead of torchaudio
+ feat_extract = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
+
+ self.assertTrue(hasattr(feat_extract, "window"))
+ self.assertTrue(hasattr(feat_extract, "mel_filters"))
+
+ from transformers.models.audio_spectrogram_transformer.feature_extraction_audio_spectrogram_transformer import (
+ is_speech_available,
+ )
+
+ self.assertFalse(is_speech_available())
diff --git a/transformers/tests/models/audio_spectrogram_transformer/test_modeling_audio_spectrogram_transformer.py b/transformers/tests/models/audio_spectrogram_transformer/test_modeling_audio_spectrogram_transformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..e9919d7dcde17ea3b7ded4cbd08ebff8b270db7c
--- /dev/null
+++ b/transformers/tests/models/audio_spectrogram_transformer/test_modeling_audio_spectrogram_transformer.py
@@ -0,0 +1,268 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Audio Spectrogram Transformer (AST) model."""
+
+import inspect
+import unittest
+
+from huggingface_hub import hf_hub_download
+
+from transformers import ASTConfig
+from transformers.testing_utils import require_torch, require_torchaudio, slow, torch_device
+from transformers.utils import cached_property, is_torch_available, is_torchaudio_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import ASTForAudioClassification, ASTModel
+
+
+if is_torchaudio_available():
+ import torchaudio
+
+ from transformers import ASTFeatureExtractor
+
+
+class ASTModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ patch_size=2,
+ max_length=24,
+ num_mel_bins=16,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ type_sequence_label_size=10,
+ initializer_range=0.02,
+ scope=None,
+ frequency_stride=2,
+ time_stride=2,
+ attn_implementation="eager",
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.patch_size = patch_size
+ self.max_length = max_length
+ self.num_mel_bins = num_mel_bins
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.scope = scope
+ self.frequency_stride = frequency_stride
+ self.time_stride = time_stride
+ self.attn_implementation = attn_implementation
+
+ # in AST, the seq length equals the number of patches + 2 (we add 2 for the [CLS] and distillation tokens)
+ frequency_out_dimension = (self.num_mel_bins - self.patch_size) // self.frequency_stride + 1
+ time_out_dimension = (self.max_length - self.patch_size) // self.time_stride + 1
+ num_patches = frequency_out_dimension * time_out_dimension
+ self.seq_length = num_patches + 2
+
+ def prepare_config_and_inputs(self):
+ input_values = floats_tensor([self.batch_size, self.max_length, self.num_mel_bins])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+
+ config = self.get_config()
+
+ return config, input_values, labels
+
+ def get_config(self):
+ return ASTConfig(
+ patch_size=self.patch_size,
+ max_length=self.max_length,
+ num_mel_bins=self.num_mel_bins,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ frequency_stride=self.frequency_stride,
+ time_stride=self.time_stride,
+ attn_implementation=self.attn_implementation,
+ )
+
+ def create_and_check_model(self, config, input_values, labels):
+ model = ASTModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_values)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_values,
+ labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_values": input_values}
+ return config, inputs_dict
+
+
+@require_torch
+class ASTModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as AST does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (
+ (
+ ASTModel,
+ ASTForAudioClassification,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {"audio-classification": ASTForAudioClassification, "feature-extraction": ASTModel}
+ if is_torch_available()
+ else {}
+ )
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ # TODO: Fix the failed tests when this model gets more usage
+ def is_pipeline_test_to_skip(
+ self,
+ pipeline_test_case_name,
+ config_class,
+ model_architecture,
+ tokenizer_name,
+ image_processor_name,
+ feature_extractor_name,
+ processor_name,
+ ):
+ if pipeline_test_case_name == "AudioClassificationPipelineTests":
+ return True
+
+ return False
+
+ def setUp(self):
+ self.model_tester = ASTModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=ASTConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="AST does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_get_set_embeddings(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["input_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "MIT/ast-finetuned-audioset-10-10-0.4593"
+ model = ASTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on some audio from AudioSet
+def prepare_audio():
+ filepath = hf_hub_download(
+ repo_id="nielsr/audio-spectogram-transformer-checkpoint", filename="sample_audio.flac", repo_type="dataset"
+ )
+
+ audio, sampling_rate = torchaudio.load(filepath)
+
+ return audio, sampling_rate
+
+
+@require_torch
+@require_torchaudio
+class ASTModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_feature_extractor(self):
+ return (
+ ASTFeatureExtractor.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593")
+ if is_torchaudio_available()
+ else None
+ )
+
+ @slow
+ def test_inference_audio_classification(self):
+ feature_extractor = self.default_feature_extractor
+ model = ASTForAudioClassification.from_pretrained("MIT/ast-finetuned-audioset-10-10-0.4593").to(torch_device)
+
+ feature_extractor = self.default_feature_extractor
+ audio, sampling_rate = prepare_audio()
+ audio = audio.squeeze().numpy()
+ inputs = feature_extractor(audio, sampling_rate=sampling_rate, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 527))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([-0.8760, -7.0042, -8.6602]).to(torch_device)
+
+ torch.testing.assert_close(outputs.logits[0, :3], expected_slice, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/auto/__init__.py b/transformers/tests/models/auto/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/auto/test_configuration_auto.py b/transformers/tests/models/auto/test_configuration_auto.py
new file mode 100644
index 0000000000000000000000000000000000000000..9751c4f13035b10e61fe35e72866db274ad6763b
--- /dev/null
+++ b/transformers/tests/models/auto/test_configuration_auto.py
@@ -0,0 +1,150 @@
+# Copyright 2019-present, the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import importlib
+import json
+import os
+import sys
+import tempfile
+import unittest
+from pathlib import Path
+
+import transformers
+import transformers.models.auto
+from transformers.models.auto.configuration_auto import CONFIG_MAPPING, AutoConfig
+from transformers.models.bert.configuration_bert import BertConfig
+from transformers.models.roberta.configuration_roberta import RobertaConfig
+from transformers.testing_utils import DUMMY_UNKNOWN_IDENTIFIER, get_tests_dir
+
+
+sys.path.append(str(Path(__file__).parent.parent.parent.parent / "utils"))
+
+from test_module.custom_configuration import CustomConfig # noqa E402
+
+
+SAMPLE_ROBERTA_CONFIG = get_tests_dir("fixtures/dummy-config.json")
+
+
+class AutoConfigTest(unittest.TestCase):
+ def setUp(self):
+ transformers.dynamic_module_utils.TIME_OUT_REMOTE_CODE = 0
+
+ def test_module_spec(self):
+ self.assertIsNotNone(transformers.models.auto.__spec__)
+ self.assertIsNotNone(importlib.util.find_spec("transformers.models.auto"))
+
+ def test_config_from_model_shortcut(self):
+ config = AutoConfig.from_pretrained("google-bert/bert-base-uncased")
+ self.assertIsInstance(config, BertConfig)
+
+ def test_config_model_type_from_local_file(self):
+ config = AutoConfig.from_pretrained(SAMPLE_ROBERTA_CONFIG)
+ self.assertIsInstance(config, RobertaConfig)
+
+ def test_config_model_type_from_model_identifier(self):
+ config = AutoConfig.from_pretrained(DUMMY_UNKNOWN_IDENTIFIER)
+ self.assertIsInstance(config, RobertaConfig)
+
+ def test_config_for_model_str(self):
+ config = AutoConfig.for_model("roberta")
+ self.assertIsInstance(config, RobertaConfig)
+
+ def test_pattern_matching_fallback(self):
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ # This model name contains bert and roberta, but roberta ends up being picked.
+ folder = os.path.join(tmp_dir, "fake-roberta")
+ os.makedirs(folder, exist_ok=True)
+ with open(os.path.join(folder, "config.json"), "w") as f:
+ f.write(json.dumps({}))
+ config = AutoConfig.from_pretrained(folder)
+ self.assertEqual(type(config), RobertaConfig)
+
+ def test_new_config_registration(self):
+ try:
+ AutoConfig.register("custom", CustomConfig)
+ # Wrong model type will raise an error
+ with self.assertRaises(ValueError):
+ AutoConfig.register("model", CustomConfig)
+ # Trying to register something existing in the Transformers library will raise an error
+ with self.assertRaises(ValueError):
+ AutoConfig.register("bert", BertConfig)
+
+ # Now that the config is registered, it can be used as any other config with the auto-API
+ config = CustomConfig()
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ config.save_pretrained(tmp_dir)
+ new_config = AutoConfig.from_pretrained(tmp_dir)
+ self.assertIsInstance(new_config, CustomConfig)
+
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+
+ def test_repo_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError, "bert-base is not a local folder and is not a valid model identifier"
+ ):
+ _ = AutoConfig.from_pretrained("bert-base")
+
+ def test_revision_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError, r"aaaaaa is not a valid git identifier \(branch name, tag name or commit id\)"
+ ):
+ _ = AutoConfig.from_pretrained(DUMMY_UNKNOWN_IDENTIFIER, revision="aaaaaa")
+
+ def test_from_pretrained_dynamic_config(self):
+ # If remote code is not set, we will time out when asking whether to load the model.
+ with self.assertRaises(ValueError):
+ config = AutoConfig.from_pretrained("hf-internal-testing/test_dynamic_model")
+ # If remote code is disabled, we can't load this config.
+ with self.assertRaises(ValueError):
+ config = AutoConfig.from_pretrained("hf-internal-testing/test_dynamic_model", trust_remote_code=False)
+
+ config = AutoConfig.from_pretrained("hf-internal-testing/test_dynamic_model", trust_remote_code=True)
+ self.assertEqual(config.__class__.__name__, "NewModelConfig")
+
+ # Test the dynamic module is loaded only once.
+ reloaded_config = AutoConfig.from_pretrained("hf-internal-testing/test_dynamic_model", trust_remote_code=True)
+ self.assertIs(config.__class__, reloaded_config.__class__)
+
+ # Test config can be reloaded.
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ config.save_pretrained(tmp_dir)
+ reloaded_config = AutoConfig.from_pretrained(tmp_dir, trust_remote_code=True)
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "configuration.py"))) # Assert we saved config code
+ # Assert we're pointing at local code and not another remote repo
+ self.assertEqual(reloaded_config.auto_map["AutoConfig"], "configuration.NewModelConfig")
+ self.assertEqual(reloaded_config.__class__.__name__, "NewModelConfig")
+
+ def test_from_pretrained_dynamic_config_conflict(self):
+ class NewModelConfigLocal(BertConfig):
+ model_type = "new-model"
+
+ try:
+ AutoConfig.register("new-model", NewModelConfigLocal)
+ # If remote code is not set, the default is to use local
+ config = AutoConfig.from_pretrained("hf-internal-testing/test_dynamic_model")
+ self.assertEqual(config.__class__.__name__, "NewModelConfigLocal")
+
+ # If remote code is disabled, we load the local one.
+ config = AutoConfig.from_pretrained("hf-internal-testing/test_dynamic_model", trust_remote_code=False)
+ self.assertEqual(config.__class__.__name__, "NewModelConfigLocal")
+
+ # If remote is enabled, we load from the Hub
+ config = AutoConfig.from_pretrained("hf-internal-testing/test_dynamic_model", trust_remote_code=True)
+ self.assertEqual(config.__class__.__name__, "NewModelConfig")
+
+ finally:
+ if "new-model" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["new-model"]
diff --git a/transformers/tests/models/auto/test_feature_extraction_auto.py b/transformers/tests/models/auto/test_feature_extraction_auto.py
new file mode 100644
index 0000000000000000000000000000000000000000..7858c770eb02591688ffd22d903c441220dfac46
--- /dev/null
+++ b/transformers/tests/models/auto/test_feature_extraction_auto.py
@@ -0,0 +1,188 @@
+# Copyright 2021 the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import sys
+import tempfile
+import unittest
+from pathlib import Path
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ FEATURE_EXTRACTOR_MAPPING,
+ AutoConfig,
+ AutoFeatureExtractor,
+ Wav2Vec2Config,
+ Wav2Vec2FeatureExtractor,
+)
+from transformers.testing_utils import DUMMY_UNKNOWN_IDENTIFIER, get_tests_dir
+
+
+sys.path.append(str(Path(__file__).parent.parent.parent.parent / "utils"))
+
+from test_module.custom_configuration import CustomConfig # noqa E402
+from test_module.custom_feature_extraction import CustomFeatureExtractor # noqa E402
+
+
+SAMPLE_FEATURE_EXTRACTION_CONFIG_DIR = get_tests_dir("fixtures")
+SAMPLE_FEATURE_EXTRACTION_CONFIG = get_tests_dir("fixtures/dummy_feature_extractor_config.json")
+SAMPLE_CONFIG = get_tests_dir("fixtures/dummy-config.json")
+
+
+class AutoFeatureExtractorTest(unittest.TestCase):
+ def setUp(self):
+ transformers.dynamic_module_utils.TIME_OUT_REMOTE_CODE = 0
+
+ def test_feature_extractor_from_model_shortcut(self):
+ config = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base-960h")
+ self.assertIsInstance(config, Wav2Vec2FeatureExtractor)
+
+ def test_feature_extractor_from_local_directory_from_key(self):
+ config = AutoFeatureExtractor.from_pretrained(SAMPLE_FEATURE_EXTRACTION_CONFIG_DIR)
+ self.assertIsInstance(config, Wav2Vec2FeatureExtractor)
+
+ def test_feature_extractor_from_local_directory_from_config(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model_config = Wav2Vec2Config()
+
+ # remove feature_extractor_type to make sure config.json alone is enough to load feature processor locally
+ config_dict = AutoFeatureExtractor.from_pretrained(SAMPLE_FEATURE_EXTRACTION_CONFIG_DIR).to_dict()
+
+ config_dict.pop("feature_extractor_type")
+ config = Wav2Vec2FeatureExtractor(**config_dict)
+
+ # save in new folder
+ model_config.save_pretrained(tmpdirname)
+ config.save_pretrained(tmpdirname)
+
+ config = AutoFeatureExtractor.from_pretrained(tmpdirname)
+
+ # make sure private variable is not incorrectly saved
+ dict_as_saved = json.loads(config.to_json_string())
+ self.assertTrue("_processor_class" not in dict_as_saved)
+
+ self.assertIsInstance(config, Wav2Vec2FeatureExtractor)
+
+ def test_feature_extractor_from_local_file(self):
+ config = AutoFeatureExtractor.from_pretrained(SAMPLE_FEATURE_EXTRACTION_CONFIG)
+ self.assertIsInstance(config, Wav2Vec2FeatureExtractor)
+
+ def test_repo_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError, "bert-base is not a local folder and is not a valid model identifier"
+ ):
+ _ = AutoFeatureExtractor.from_pretrained("bert-base")
+
+ def test_revision_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError, r"aaaaaa is not a valid git identifier \(branch name, tag name or commit id\)"
+ ):
+ _ = AutoFeatureExtractor.from_pretrained(DUMMY_UNKNOWN_IDENTIFIER, revision="aaaaaa")
+
+ def test_feature_extractor_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError,
+ "hf-internal-testing/config-no-model does not appear to have a file named preprocessor_config.json.",
+ ):
+ _ = AutoFeatureExtractor.from_pretrained("hf-internal-testing/config-no-model")
+
+ def test_from_pretrained_dynamic_feature_extractor(self):
+ # If remote code is not set, we will time out when asking whether to load the model.
+ with self.assertRaises(ValueError):
+ feature_extractor = AutoFeatureExtractor.from_pretrained(
+ "hf-internal-testing/test_dynamic_feature_extractor"
+ )
+ # If remote code is disabled, we can't load this config.
+ with self.assertRaises(ValueError):
+ feature_extractor = AutoFeatureExtractor.from_pretrained(
+ "hf-internal-testing/test_dynamic_feature_extractor", trust_remote_code=False
+ )
+
+ feature_extractor = AutoFeatureExtractor.from_pretrained(
+ "hf-internal-testing/test_dynamic_feature_extractor", trust_remote_code=True
+ )
+ self.assertEqual(feature_extractor.__class__.__name__, "NewFeatureExtractor")
+
+ # Test the dynamic module is loaded only once.
+ reloaded_feature_extractor = AutoFeatureExtractor.from_pretrained(
+ "hf-internal-testing/test_dynamic_feature_extractor", trust_remote_code=True
+ )
+ self.assertIs(feature_extractor.__class__, reloaded_feature_extractor.__class__)
+
+ # Test feature extractor can be reloaded.
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ feature_extractor.save_pretrained(tmp_dir)
+ reloaded_feature_extractor = AutoFeatureExtractor.from_pretrained(tmp_dir, trust_remote_code=True)
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "feature_extractor.py"))) # Assert we saved code
+ self.assertEqual(
+ reloaded_feature_extractor.auto_map["AutoFeatureExtractor"], "feature_extractor.NewFeatureExtractor"
+ )
+ self.assertEqual(reloaded_feature_extractor.__class__.__name__, "NewFeatureExtractor")
+
+ def test_new_feature_extractor_registration(self):
+ try:
+ AutoConfig.register("custom", CustomConfig)
+ AutoFeatureExtractor.register(CustomConfig, CustomFeatureExtractor)
+ # Trying to register something existing in the Transformers library will raise an error
+ with self.assertRaises(ValueError):
+ AutoFeatureExtractor.register(Wav2Vec2Config, Wav2Vec2FeatureExtractor)
+
+ # Now that the config is registered, it can be used as any other config with the auto-API
+ feature_extractor = CustomFeatureExtractor.from_pretrained(SAMPLE_FEATURE_EXTRACTION_CONFIG_DIR)
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ feature_extractor.save_pretrained(tmp_dir)
+ new_feature_extractor = AutoFeatureExtractor.from_pretrained(tmp_dir)
+ self.assertIsInstance(new_feature_extractor, CustomFeatureExtractor)
+
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in FEATURE_EXTRACTOR_MAPPING._extra_content:
+ del FEATURE_EXTRACTOR_MAPPING._extra_content[CustomConfig]
+
+ def test_from_pretrained_dynamic_feature_extractor_conflict(self):
+ class NewFeatureExtractor(Wav2Vec2FeatureExtractor):
+ is_local = True
+
+ try:
+ AutoConfig.register("custom", CustomConfig)
+ AutoFeatureExtractor.register(CustomConfig, NewFeatureExtractor)
+ # If remote code is not set, the default is to use local
+ feature_extractor = AutoFeatureExtractor.from_pretrained(
+ "hf-internal-testing/test_dynamic_feature_extractor"
+ )
+ self.assertEqual(feature_extractor.__class__.__name__, "NewFeatureExtractor")
+ self.assertTrue(feature_extractor.is_local)
+
+ # If remote code is disabled, we load the local one.
+ feature_extractor = AutoFeatureExtractor.from_pretrained(
+ "hf-internal-testing/test_dynamic_feature_extractor", trust_remote_code=False
+ )
+ self.assertEqual(feature_extractor.__class__.__name__, "NewFeatureExtractor")
+ self.assertTrue(feature_extractor.is_local)
+
+ # If remote is enabled, we load from the Hub
+ feature_extractor = AutoFeatureExtractor.from_pretrained(
+ "hf-internal-testing/test_dynamic_feature_extractor", trust_remote_code=True
+ )
+ self.assertEqual(feature_extractor.__class__.__name__, "NewFeatureExtractor")
+ self.assertTrue(not hasattr(feature_extractor, "is_local"))
+
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in FEATURE_EXTRACTOR_MAPPING._extra_content:
+ del FEATURE_EXTRACTOR_MAPPING._extra_content[CustomConfig]
diff --git a/transformers/tests/models/auto/test_image_processing_auto.py b/transformers/tests/models/auto/test_image_processing_auto.py
new file mode 100644
index 0000000000000000000000000000000000000000..a8f43711894a611f525edc3fd29e2893a41e8137
--- /dev/null
+++ b/transformers/tests/models/auto/test_image_processing_auto.py
@@ -0,0 +1,267 @@
+# Copyright 2021 the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import sys
+import tempfile
+import unittest
+from pathlib import Path
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ IMAGE_PROCESSOR_MAPPING,
+ AutoConfig,
+ AutoImageProcessor,
+ CLIPConfig,
+ CLIPImageProcessor,
+ ViTImageProcessor,
+ ViTImageProcessorFast,
+)
+from transformers.testing_utils import DUMMY_UNKNOWN_IDENTIFIER, require_torchvision, require_vision
+
+
+sys.path.append(str(Path(__file__).parent.parent.parent.parent / "utils"))
+
+from test_module.custom_configuration import CustomConfig # noqa E402
+from test_module.custom_image_processing import CustomImageProcessor # noqa E402
+
+
+class AutoImageProcessorTest(unittest.TestCase):
+ def setUp(self):
+ transformers.dynamic_module_utils.TIME_OUT_REMOTE_CODE = 0
+
+ def test_image_processor_from_model_shortcut(self):
+ config = AutoImageProcessor.from_pretrained("openai/clip-vit-base-patch32")
+ self.assertIsInstance(config, CLIPImageProcessor)
+
+ def test_image_processor_from_local_directory_from_key(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ processor_tmpfile = Path(tmpdirname) / "preprocessor_config.json"
+ config_tmpfile = Path(tmpdirname) / "config.json"
+ json.dump(
+ {"image_processor_type": "CLIPImageProcessor", "processor_class": "CLIPProcessor"},
+ open(processor_tmpfile, "w"),
+ )
+ json.dump({"model_type": "clip"}, open(config_tmpfile, "w"))
+
+ config = AutoImageProcessor.from_pretrained(tmpdirname)
+ self.assertIsInstance(config, CLIPImageProcessor)
+
+ def test_image_processor_from_local_directory_from_feature_extractor_key(self):
+ # Ensure we can load the image processor from the feature extractor config
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ processor_tmpfile = Path(tmpdirname) / "preprocessor_config.json"
+ config_tmpfile = Path(tmpdirname) / "config.json"
+ json.dump(
+ {"feature_extractor_type": "CLIPFeatureExtractor", "processor_class": "CLIPProcessor"},
+ open(processor_tmpfile, "w"),
+ )
+ json.dump({"model_type": "clip"}, open(config_tmpfile, "w"))
+
+ config = AutoImageProcessor.from_pretrained(tmpdirname)
+ self.assertIsInstance(config, CLIPImageProcessor)
+
+ def test_image_processor_from_new_filename(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ processor_tmpfile = Path(tmpdirname) / "preprocessor_config.json"
+ config_tmpfile = Path(tmpdirname) / "config.json"
+ json.dump(
+ {"image_processor_type": "CLIPImageProcessor", "processor_class": "CLIPProcessor"},
+ open(processor_tmpfile, "w"),
+ )
+ json.dump({"model_type": "clip"}, open(config_tmpfile, "w"))
+
+ config = AutoImageProcessor.from_pretrained(tmpdirname)
+ self.assertIsInstance(config, CLIPImageProcessor)
+
+ def test_image_processor_from_local_directory_from_config(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model_config = CLIPConfig()
+
+ # Create a dummy config file with image_proceesor_type
+ processor_tmpfile = Path(tmpdirname) / "preprocessor_config.json"
+ config_tmpfile = Path(tmpdirname) / "config.json"
+ json.dump(
+ {"image_processor_type": "CLIPImageProcessor", "processor_class": "CLIPProcessor"},
+ open(processor_tmpfile, "w"),
+ )
+ json.dump({"model_type": "clip"}, open(config_tmpfile, "w"))
+
+ # remove image_processor_type to make sure config.json alone is enough to load image processor locally
+ config_dict = AutoImageProcessor.from_pretrained(tmpdirname).to_dict()
+
+ config_dict.pop("image_processor_type")
+ config = CLIPImageProcessor(**config_dict)
+
+ # save in new folder
+ model_config.save_pretrained(tmpdirname)
+ config.save_pretrained(tmpdirname)
+
+ config = AutoImageProcessor.from_pretrained(tmpdirname)
+
+ # make sure private variable is not incorrectly saved
+ dict_as_saved = json.loads(config.to_json_string())
+ self.assertTrue("_processor_class" not in dict_as_saved)
+
+ self.assertIsInstance(config, CLIPImageProcessor)
+
+ def test_image_processor_from_local_file(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ processor_tmpfile = Path(tmpdirname) / "preprocessor_config.json"
+ json.dump(
+ {"image_processor_type": "CLIPImageProcessor", "processor_class": "CLIPProcessor"},
+ open(processor_tmpfile, "w"),
+ )
+
+ config = AutoImageProcessor.from_pretrained(processor_tmpfile)
+ self.assertIsInstance(config, CLIPImageProcessor)
+
+ def test_repo_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError, "clip-base is not a local folder and is not a valid model identifier"
+ ):
+ _ = AutoImageProcessor.from_pretrained("clip-base")
+
+ def test_revision_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError, r"aaaaaa is not a valid git identifier \(branch name, tag name or commit id\)"
+ ):
+ _ = AutoImageProcessor.from_pretrained(DUMMY_UNKNOWN_IDENTIFIER, revision="aaaaaa")
+
+ def test_image_processor_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError,
+ "hf-internal-testing/config-no-model does not appear to have a file named preprocessor_config.json.",
+ ):
+ _ = AutoImageProcessor.from_pretrained("hf-internal-testing/config-no-model")
+
+ @require_vision
+ @require_torchvision
+ def test_use_fast_selection(self):
+ checkpoint = "hf-internal-testing/tiny-random-vit"
+
+ # TODO: @yoni, change in v4.48 (when use_fast set to True by default)
+ # Slow image processor is selected by default
+ image_processor = AutoImageProcessor.from_pretrained(checkpoint)
+ self.assertIsInstance(image_processor, ViTImageProcessor)
+
+ # Fast image processor is selected when use_fast=True
+ image_processor = AutoImageProcessor.from_pretrained(checkpoint, use_fast=True)
+ self.assertIsInstance(image_processor, ViTImageProcessorFast)
+
+ # Slow image processor is selected when use_fast=False
+ image_processor = AutoImageProcessor.from_pretrained(checkpoint, use_fast=False)
+ self.assertIsInstance(image_processor, ViTImageProcessor)
+
+ def test_from_pretrained_dynamic_image_processor(self):
+ # If remote code is not set, we will time out when asking whether to load the model.
+ with self.assertRaises(ValueError):
+ image_processor = AutoImageProcessor.from_pretrained("hf-internal-testing/test_dynamic_image_processor")
+ # If remote code is disabled, we can't load this config.
+ with self.assertRaises(ValueError):
+ image_processor = AutoImageProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_image_processor", trust_remote_code=False
+ )
+
+ image_processor = AutoImageProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_image_processor", trust_remote_code=True
+ )
+ self.assertEqual(image_processor.__class__.__name__, "NewImageProcessor")
+
+ # Test the dynamic module is loaded only once.
+ reloaded_image_processor = AutoImageProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_image_processor", trust_remote_code=True
+ )
+ self.assertIs(image_processor.__class__, reloaded_image_processor.__class__)
+
+ # Test image processor can be reloaded.
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ image_processor.save_pretrained(tmp_dir)
+ reloaded_image_processor = AutoImageProcessor.from_pretrained(tmp_dir, trust_remote_code=True)
+ self.assertTrue(os.path.exists(os.path.join(tmp_dir, "image_processor.py"))) # Assert we saved custom code
+ self.assertEqual(
+ reloaded_image_processor.auto_map["AutoImageProcessor"], "image_processor.NewImageProcessor"
+ )
+ self.assertEqual(reloaded_image_processor.__class__.__name__, "NewImageProcessor")
+
+ # Test the dynamic module is reloaded if we force it.
+ reloaded_image_processor = AutoImageProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_image_processor", trust_remote_code=True, force_download=True
+ )
+ self.assertIsNot(image_processor.__class__, reloaded_image_processor.__class__)
+
+ def test_new_image_processor_registration(self):
+ try:
+ AutoConfig.register("custom", CustomConfig)
+ AutoImageProcessor.register(CustomConfig, CustomImageProcessor)
+ # Trying to register something existing in the Transformers library will raise an error
+ with self.assertRaises(ValueError):
+ AutoImageProcessor.register(CLIPConfig, CLIPImageProcessor)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ processor_tmpfile = Path(tmpdirname) / "preprocessor_config.json"
+ config_tmpfile = Path(tmpdirname) / "config.json"
+ json.dump(
+ {"feature_extractor_type": "CLIPFeatureExtractor", "processor_class": "CLIPProcessor"},
+ open(processor_tmpfile, "w"),
+ )
+ json.dump({"model_type": "clip"}, open(config_tmpfile, "w"))
+
+ image_processor = CustomImageProcessor.from_pretrained(tmpdirname)
+
+ # Now that the config is registered, it can be used as any other config with the auto-API
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ image_processor.save_pretrained(tmp_dir)
+ new_image_processor = AutoImageProcessor.from_pretrained(tmp_dir)
+ self.assertIsInstance(new_image_processor, CustomImageProcessor)
+
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in IMAGE_PROCESSOR_MAPPING._extra_content:
+ del IMAGE_PROCESSOR_MAPPING._extra_content[CustomConfig]
+
+ def test_from_pretrained_dynamic_image_processor_conflict(self):
+ class NewImageProcessor(CLIPImageProcessor):
+ is_local = True
+
+ try:
+ AutoConfig.register("custom", CustomConfig)
+ AutoImageProcessor.register(CustomConfig, NewImageProcessor)
+ # If remote code is not set, the default is to use local
+ image_processor = AutoImageProcessor.from_pretrained("hf-internal-testing/test_dynamic_image_processor")
+ self.assertEqual(image_processor.__class__.__name__, "NewImageProcessor")
+ self.assertTrue(image_processor.is_local)
+
+ # If remote code is disabled, we load the local one.
+ image_processor = AutoImageProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_image_processor", trust_remote_code=False
+ )
+ self.assertEqual(image_processor.__class__.__name__, "NewImageProcessor")
+ self.assertTrue(image_processor.is_local)
+
+ # If remote is enabled, we load from the Hub
+ image_processor = AutoImageProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_image_processor", trust_remote_code=True
+ )
+ self.assertEqual(image_processor.__class__.__name__, "NewImageProcessor")
+ self.assertTrue(not hasattr(image_processor, "is_local"))
+
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in IMAGE_PROCESSOR_MAPPING._extra_content:
+ del IMAGE_PROCESSOR_MAPPING._extra_content[CustomConfig]
diff --git a/transformers/tests/models/auto/test_modeling_auto.py b/transformers/tests/models/auto/test_modeling_auto.py
new file mode 100644
index 0000000000000000000000000000000000000000..cfc0191c02b3f1506ee72622c37024ff46f88623
--- /dev/null
+++ b/transformers/tests/models/auto/test_modeling_auto.py
@@ -0,0 +1,581 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import copy
+import sys
+import tempfile
+import unittest
+from collections import OrderedDict
+from pathlib import Path
+
+import pytest
+from huggingface_hub import Repository
+
+import transformers
+from transformers import BertConfig, GPT2Model, is_safetensors_available, is_torch_available
+from transformers.models.auto.configuration_auto import CONFIG_MAPPING
+from transformers.testing_utils import (
+ DUMMY_UNKNOWN_IDENTIFIER,
+ SMALL_MODEL_IDENTIFIER,
+ RequestCounter,
+ require_torch,
+ slow,
+)
+
+from ..bert.test_modeling_bert import BertModelTester
+
+
+sys.path.append(str(Path(__file__).parent.parent.parent.parent / "utils"))
+
+from test_module.custom_configuration import CustomConfig # noqa E402
+
+
+if is_torch_available():
+ import torch
+ from test_module.custom_modeling import CustomModel
+
+ from transformers import (
+ AutoBackbone,
+ AutoConfig,
+ AutoModel,
+ AutoModelForCausalLM,
+ AutoModelForMaskedLM,
+ AutoModelForPreTraining,
+ AutoModelForQuestionAnswering,
+ AutoModelForSeq2SeqLM,
+ AutoModelForSequenceClassification,
+ AutoModelForTableQuestionAnswering,
+ AutoModelForTokenClassification,
+ AutoModelWithLMHead,
+ BertForMaskedLM,
+ BertForPreTraining,
+ BertForQuestionAnswering,
+ BertForSequenceClassification,
+ BertForTokenClassification,
+ BertModel,
+ FunnelBaseModel,
+ FunnelModel,
+ GenerationMixin,
+ GPT2Config,
+ GPT2LMHeadModel,
+ ResNetBackbone,
+ RobertaForMaskedLM,
+ T5Config,
+ T5ForConditionalGeneration,
+ TapasConfig,
+ TapasForQuestionAnswering,
+ TimmBackbone,
+ )
+ from transformers.models.auto.modeling_auto import (
+ MODEL_FOR_CAUSAL_LM_MAPPING,
+ MODEL_FOR_MASKED_LM_MAPPING,
+ MODEL_FOR_PRETRAINING_MAPPING,
+ MODEL_FOR_QUESTION_ANSWERING_MAPPING,
+ MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING,
+ MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING,
+ MODEL_MAPPING,
+ )
+
+
+@require_torch
+class AutoModelTest(unittest.TestCase):
+ def setUp(self):
+ transformers.dynamic_module_utils.TIME_OUT_REMOTE_CODE = 0
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
+
+ model = AutoModel.from_pretrained(model_name)
+ model, loading_info = AutoModel.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, BertModel)
+
+ self.assertEqual(len(loading_info["missing_keys"]), 0)
+ # When using PyTorch checkpoint, the expected value is `8`. With `safetensors` checkpoint (if it is
+ # installed), the expected value becomes `7`.
+ EXPECTED_NUM_OF_UNEXPECTED_KEYS = 7 if is_safetensors_available() else 8
+ self.assertEqual(len(loading_info["unexpected_keys"]), EXPECTED_NUM_OF_UNEXPECTED_KEYS)
+ self.assertEqual(len(loading_info["mismatched_keys"]), 0)
+ self.assertEqual(len(loading_info["error_msgs"]), 0)
+
+ @slow
+ def test_model_for_pretraining_from_pretrained(self):
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
+
+ model = AutoModelForPreTraining.from_pretrained(model_name)
+ model, loading_info = AutoModelForPreTraining.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, BertForPreTraining)
+ # Only one value should not be initialized and in the missing keys.
+ for key, value in loading_info.items():
+ self.assertEqual(len(value), 0)
+
+ @slow
+ def test_lmhead_model_from_pretrained(self):
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
+
+ model = AutoModelWithLMHead.from_pretrained(model_name)
+ model, loading_info = AutoModelWithLMHead.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, BertForMaskedLM)
+
+ @slow
+ def test_model_for_causal_lm(self):
+ model_name = "openai-community/gpt2"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, GPT2Config)
+
+ model = AutoModelForCausalLM.from_pretrained(model_name)
+ model, loading_info = AutoModelForCausalLM.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, GPT2LMHeadModel)
+
+ @slow
+ def test_model_for_masked_lm(self):
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
+
+ model = AutoModelForMaskedLM.from_pretrained(model_name)
+ model, loading_info = AutoModelForMaskedLM.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, BertForMaskedLM)
+
+ @slow
+ def test_model_for_encoder_decoder_lm(self):
+ model_name = "google-t5/t5-base"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, T5Config)
+
+ model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
+ model, loading_info = AutoModelForSeq2SeqLM.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, T5ForConditionalGeneration)
+
+ @slow
+ def test_sequence_classification_model_from_pretrained(self):
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
+
+ model = AutoModelForSequenceClassification.from_pretrained(model_name)
+ model, loading_info = AutoModelForSequenceClassification.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, BertForSequenceClassification)
+
+ @slow
+ def test_question_answering_model_from_pretrained(self):
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
+
+ model = AutoModelForQuestionAnswering.from_pretrained(model_name)
+ model, loading_info = AutoModelForQuestionAnswering.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, BertForQuestionAnswering)
+
+ @slow
+ def test_table_question_answering_model_from_pretrained(self):
+ model_name = "google/tapas-base"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, TapasConfig)
+
+ model = AutoModelForTableQuestionAnswering.from_pretrained(model_name)
+ model, loading_info = AutoModelForTableQuestionAnswering.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, TapasForQuestionAnswering)
+
+ @slow
+ def test_token_classification_model_from_pretrained(self):
+ model_name = "google-bert/bert-base-uncased"
+ config = AutoConfig.from_pretrained(model_name)
+ self.assertIsNotNone(config)
+ self.assertIsInstance(config, BertConfig)
+
+ model = AutoModelForTokenClassification.from_pretrained(model_name)
+ model, loading_info = AutoModelForTokenClassification.from_pretrained(model_name, output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, BertForTokenClassification)
+
+ @slow
+ def test_auto_backbone_timm_model_from_pretrained(self):
+ # Configs can't be loaded for timm models
+ model = AutoBackbone.from_pretrained("resnet18", use_timm_backbone=True)
+
+ with pytest.raises(ValueError):
+ # We can't pass output_loading_info=True as we're loading from timm
+ AutoBackbone.from_pretrained("resnet18", use_timm_backbone=True, output_loading_info=True)
+
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, TimmBackbone)
+
+ # Check kwargs are correctly passed to the backbone
+ model = AutoBackbone.from_pretrained("resnet18", use_timm_backbone=True, out_indices=(-2, -1))
+ self.assertEqual(model.out_indices, [-2, -1])
+
+ # Check out_features cannot be passed to Timm backbones
+ with self.assertRaises(ValueError):
+ _ = AutoBackbone.from_pretrained("resnet18", use_timm_backbone=True, out_features=["stage1"])
+
+ @slow
+ def test_auto_backbone_from_pretrained(self):
+ model = AutoBackbone.from_pretrained("microsoft/resnet-18")
+ model, loading_info = AutoBackbone.from_pretrained("microsoft/resnet-18", output_loading_info=True)
+ self.assertIsNotNone(model)
+ self.assertIsInstance(model, ResNetBackbone)
+
+ # Check kwargs are correctly passed to the backbone
+ model = AutoBackbone.from_pretrained("microsoft/resnet-18", out_indices=[-2, -1])
+ self.assertEqual(model.out_indices, [-2, -1])
+ self.assertEqual(model.out_features, ["stage3", "stage4"])
+
+ model = AutoBackbone.from_pretrained("microsoft/resnet-18", out_features=["stage2", "stage4"])
+ self.assertEqual(model.out_indices, [2, 4])
+ self.assertEqual(model.out_features, ["stage2", "stage4"])
+
+ def test_from_pretrained_identifier(self):
+ model = AutoModelWithLMHead.from_pretrained(SMALL_MODEL_IDENTIFIER)
+ self.assertIsInstance(model, BertForMaskedLM)
+ self.assertEqual(model.num_parameters(), 14410)
+ self.assertEqual(model.num_parameters(only_trainable=True), 14410)
+
+ def test_from_identifier_from_model_type(self):
+ model = AutoModelWithLMHead.from_pretrained(DUMMY_UNKNOWN_IDENTIFIER)
+ self.assertIsInstance(model, RobertaForMaskedLM)
+ self.assertEqual(model.num_parameters(), 14410)
+ self.assertEqual(model.num_parameters(only_trainable=True), 14410)
+
+ def test_from_pretrained_with_tuple_values(self):
+ # For the auto model mapping, FunnelConfig has two models: FunnelModel and FunnelBaseModel
+ model = AutoModel.from_pretrained("sgugger/funnel-random-tiny")
+ self.assertIsInstance(model, FunnelModel)
+
+ config = copy.deepcopy(model.config)
+ config.architectures = ["FunnelBaseModel"]
+ model = AutoModel.from_config(config)
+ self.assertIsInstance(model, FunnelBaseModel)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir)
+ model = AutoModel.from_pretrained(tmp_dir)
+ self.assertIsInstance(model, FunnelBaseModel)
+
+ def test_from_pretrained_dynamic_model_local(self):
+ try:
+ AutoConfig.register("custom", CustomConfig)
+ AutoModel.register(CustomConfig, CustomModel)
+
+ config = CustomConfig(hidden_size=32)
+ model = CustomModel(config)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir)
+
+ new_model = AutoModel.from_pretrained(tmp_dir, trust_remote_code=True)
+ for p1, p2 in zip(model.parameters(), new_model.parameters()):
+ self.assertTrue(torch.equal(p1, p2))
+
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in MODEL_MAPPING._extra_content:
+ del MODEL_MAPPING._extra_content[CustomConfig]
+
+ def test_from_pretrained_dynamic_model_distant(self):
+ # If remote code is not set, we will time out when asking whether to load the model.
+ with self.assertRaises(ValueError):
+ model = AutoModel.from_pretrained("hf-internal-testing/test_dynamic_model")
+ # If remote code is disabled, we can't load this config.
+ with self.assertRaises(ValueError):
+ model = AutoModel.from_pretrained("hf-internal-testing/test_dynamic_model", trust_remote_code=False)
+
+ model = AutoModel.from_pretrained("hf-internal-testing/test_dynamic_model", trust_remote_code=True)
+ self.assertEqual(model.__class__.__name__, "NewModel")
+
+ # Test the dynamic module is loaded only once.
+ reloaded_model = AutoModel.from_pretrained("hf-internal-testing/test_dynamic_model", trust_remote_code=True)
+ self.assertIs(model.__class__, reloaded_model.__class__)
+
+ # Test model can be reloaded.
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir)
+ reloaded_model = AutoModel.from_pretrained(tmp_dir, trust_remote_code=True)
+
+ self.assertEqual(reloaded_model.__class__.__name__, "NewModel")
+ for p1, p2 in zip(model.parameters(), reloaded_model.parameters()):
+ self.assertTrue(torch.equal(p1, p2))
+
+ # Test the dynamic module is reloaded if we force it.
+ reloaded_model = AutoModel.from_pretrained(
+ "hf-internal-testing/test_dynamic_model", trust_remote_code=True, force_download=True
+ )
+ self.assertIsNot(model.__class__, reloaded_model.__class__)
+
+ # This one uses a relative import to a util file, this checks it is downloaded and used properly.
+ model = AutoModel.from_pretrained("hf-internal-testing/test_dynamic_model_with_util", trust_remote_code=True)
+ self.assertEqual(model.__class__.__name__, "NewModel")
+
+ # Test the dynamic module is loaded only once.
+ reloaded_model = AutoModel.from_pretrained(
+ "hf-internal-testing/test_dynamic_model_with_util", trust_remote_code=True
+ )
+ self.assertIs(model.__class__, reloaded_model.__class__)
+
+ # Test model can be reloaded.
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir)
+ reloaded_model = AutoModel.from_pretrained(tmp_dir, trust_remote_code=True)
+
+ self.assertEqual(reloaded_model.__class__.__name__, "NewModel")
+ for p1, p2 in zip(model.parameters(), reloaded_model.parameters()):
+ self.assertTrue(torch.equal(p1, p2))
+
+ # Test the dynamic module is reloaded if we force it.
+ reloaded_model = AutoModel.from_pretrained(
+ "hf-internal-testing/test_dynamic_model_with_util", trust_remote_code=True, force_download=True
+ )
+ self.assertIsNot(model.__class__, reloaded_model.__class__)
+
+ def test_from_pretrained_dynamic_model_distant_with_ref(self):
+ model = AutoModel.from_pretrained("hf-internal-testing/ref_to_test_dynamic_model", trust_remote_code=True)
+ self.assertEqual(model.__class__.__name__, "NewModel")
+
+ # Test model can be reloaded.
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir)
+ reloaded_model = AutoModel.from_pretrained(tmp_dir, trust_remote_code=True)
+
+ self.assertEqual(reloaded_model.__class__.__name__, "NewModel")
+ for p1, p2 in zip(model.parameters(), reloaded_model.parameters()):
+ self.assertTrue(torch.equal(p1, p2))
+
+ # This one uses a relative import to a util file, this checks it is downloaded and used properly.
+ model = AutoModel.from_pretrained(
+ "hf-internal-testing/ref_to_test_dynamic_model_with_util", trust_remote_code=True
+ )
+ self.assertEqual(model.__class__.__name__, "NewModel")
+
+ # Test model can be reloaded.
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir)
+ reloaded_model = AutoModel.from_pretrained(tmp_dir, trust_remote_code=True)
+
+ self.assertEqual(reloaded_model.__class__.__name__, "NewModel")
+ for p1, p2 in zip(model.parameters(), reloaded_model.parameters()):
+ self.assertTrue(torch.equal(p1, p2))
+
+ def test_from_pretrained_dynamic_model_with_period(self):
+ # We used to have issues where repos with "." in the name would cause issues because the Python
+ # import machinery would treat that as a directory separator, so we test that case
+
+ # If remote code is not set, we will time out when asking whether to load the model.
+ with self.assertRaises(ValueError):
+ model = AutoModel.from_pretrained("hf-internal-testing/test_dynamic_model_v1.0")
+ # If remote code is disabled, we can't load this config.
+ with self.assertRaises(ValueError):
+ model = AutoModel.from_pretrained("hf-internal-testing/test_dynamic_model_v1.0", trust_remote_code=False)
+
+ model = AutoModel.from_pretrained("hf-internal-testing/test_dynamic_model_v1.0", trust_remote_code=True)
+ self.assertEqual(model.__class__.__name__, "NewModel")
+
+ # Test that it works with a custom cache dir too
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = AutoModel.from_pretrained(
+ "hf-internal-testing/test_dynamic_model_v1.0", trust_remote_code=True, cache_dir=tmp_dir
+ )
+ self.assertEqual(model.__class__.__name__, "NewModel")
+
+ def test_new_model_registration(self):
+ AutoConfig.register("custom", CustomConfig)
+
+ auto_classes = [
+ AutoModel,
+ AutoModelForCausalLM,
+ AutoModelForMaskedLM,
+ AutoModelForPreTraining,
+ AutoModelForQuestionAnswering,
+ AutoModelForSequenceClassification,
+ AutoModelForTokenClassification,
+ ]
+
+ try:
+ for auto_class in auto_classes:
+ with self.subTest(auto_class.__name__):
+ # Wrong config class will raise an error
+ with self.assertRaises(ValueError):
+ auto_class.register(BertConfig, CustomModel)
+ auto_class.register(CustomConfig, CustomModel)
+ # Trying to register something existing in the Transformers library will raise an error
+ with self.assertRaises(ValueError):
+ auto_class.register(BertConfig, BertModel)
+
+ # Now that the config is registered, it can be used as any other config with the auto-API
+ tiny_config = BertModelTester(self).get_config()
+ config = CustomConfig(**tiny_config.to_dict())
+ model = auto_class.from_config(config)
+ self.assertIsInstance(model, CustomModel)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir)
+ new_model = auto_class.from_pretrained(tmp_dir)
+ # The model is a CustomModel but from the new dynamically imported class.
+ self.assertIsInstance(new_model, CustomModel)
+
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ for mapping in (
+ MODEL_MAPPING,
+ MODEL_FOR_PRETRAINING_MAPPING,
+ MODEL_FOR_QUESTION_ANSWERING_MAPPING,
+ MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING,
+ MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING,
+ MODEL_FOR_CAUSAL_LM_MAPPING,
+ MODEL_FOR_MASKED_LM_MAPPING,
+ ):
+ if CustomConfig in mapping._extra_content:
+ del mapping._extra_content[CustomConfig]
+
+ def test_from_pretrained_dynamic_model_conflict(self):
+ class NewModelConfigLocal(BertConfig):
+ model_type = "new-model"
+
+ class NewModel(BertModel):
+ config_class = NewModelConfigLocal
+
+ try:
+ AutoConfig.register("new-model", NewModelConfigLocal)
+ AutoModel.register(NewModelConfigLocal, NewModel)
+ # If remote code is not set, the default is to use local
+ model = AutoModel.from_pretrained("hf-internal-testing/test_dynamic_model")
+ self.assertEqual(model.config.__class__.__name__, "NewModelConfigLocal")
+
+ # If remote code is disabled, we load the local one.
+ model = AutoModel.from_pretrained("hf-internal-testing/test_dynamic_model", trust_remote_code=False)
+ self.assertEqual(model.config.__class__.__name__, "NewModelConfigLocal")
+
+ # If remote is enabled, we load from the Hub
+ model = AutoModel.from_pretrained("hf-internal-testing/test_dynamic_model", trust_remote_code=True)
+ self.assertEqual(model.config.__class__.__name__, "NewModelConfig")
+
+ finally:
+ if "new-model" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["new-model"]
+ if NewModelConfigLocal in MODEL_MAPPING._extra_content:
+ del MODEL_MAPPING._extra_content[NewModelConfigLocal]
+
+ def test_repo_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError, "bert-base is not a local folder and is not a valid model identifier"
+ ):
+ _ = AutoModel.from_pretrained("bert-base")
+
+ def test_revision_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError, r"aaaaaa is not a valid git identifier \(branch name, tag name or commit id\)"
+ ):
+ _ = AutoModel.from_pretrained(DUMMY_UNKNOWN_IDENTIFIER, revision="aaaaaa")
+
+ def test_model_file_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError,
+ "hf-internal-testing/config-no-model does not appear to have a file named pytorch_model.bin",
+ ):
+ _ = AutoModel.from_pretrained("hf-internal-testing/config-no-model")
+
+ def test_model_from_tf_suggestion(self):
+ with self.assertRaisesRegex(EnvironmentError, "Use `from_tf=True` to load this model"):
+ _ = AutoModel.from_pretrained("hf-internal-testing/tiny-bert-tf-only")
+
+ def test_model_from_flax_suggestion(self):
+ with self.assertRaisesRegex(EnvironmentError, "Use `from_flax=True` to load this model"):
+ _ = AutoModel.from_pretrained("hf-internal-testing/tiny-bert-flax-only")
+
+ @unittest.skip("Failing on main")
+ def test_cached_model_has_minimum_calls_to_head(self):
+ # Make sure we have cached the model.
+ _ = AutoModel.from_pretrained("hf-internal-testing/tiny-random-bert")
+ with RequestCounter() as counter:
+ _ = AutoModel.from_pretrained("hf-internal-testing/tiny-random-bert")
+ self.assertEqual(counter["GET"], 0)
+ self.assertEqual(counter["HEAD"], 1)
+ self.assertEqual(counter.total_calls, 1)
+
+ # With a sharded checkpoint
+ _ = AutoModel.from_pretrained("hf-internal-testing/tiny-random-bert-sharded")
+ with RequestCounter() as counter:
+ _ = AutoModel.from_pretrained("hf-internal-testing/tiny-random-bert-sharded")
+ self.assertEqual(counter["GET"], 0)
+ self.assertEqual(counter["HEAD"], 1)
+ self.assertEqual(counter.total_calls, 1)
+
+ def test_attr_not_existing(self):
+ from transformers.models.auto.auto_factory import _LazyAutoMapping
+
+ _CONFIG_MAPPING_NAMES = OrderedDict([("bert", "BertConfig")])
+ _MODEL_MAPPING_NAMES = OrderedDict([("bert", "GhostModel")])
+ _MODEL_MAPPING = _LazyAutoMapping(_CONFIG_MAPPING_NAMES, _MODEL_MAPPING_NAMES)
+
+ with pytest.raises(ValueError, match=r"Could not find GhostModel neither in .* nor in .*!"):
+ _MODEL_MAPPING[BertConfig]
+
+ _MODEL_MAPPING_NAMES = OrderedDict([("bert", "BertModel")])
+ _MODEL_MAPPING = _LazyAutoMapping(_CONFIG_MAPPING_NAMES, _MODEL_MAPPING_NAMES)
+ self.assertEqual(_MODEL_MAPPING[BertConfig], BertModel)
+
+ _MODEL_MAPPING_NAMES = OrderedDict([("bert", "GPT2Model")])
+ _MODEL_MAPPING = _LazyAutoMapping(_CONFIG_MAPPING_NAMES, _MODEL_MAPPING_NAMES)
+ self.assertEqual(_MODEL_MAPPING[BertConfig], GPT2Model)
+
+ def test_dynamic_saving_from_local_repo(self):
+ with tempfile.TemporaryDirectory() as tmp_dir, tempfile.TemporaryDirectory() as tmp_dir_out:
+ _ = Repository(local_dir=tmp_dir, clone_from="hf-internal-testing/tiny-random-custom-architecture")
+ model = AutoModelForCausalLM.from_pretrained(tmp_dir, trust_remote_code=True)
+ model.save_pretrained(tmp_dir_out)
+ _ = AutoModelForCausalLM.from_pretrained(tmp_dir_out, trust_remote_code=True)
+ self.assertTrue((Path(tmp_dir_out) / "modeling_fake_custom.py").is_file())
+ self.assertTrue((Path(tmp_dir_out) / "configuration_fake_custom.py").is_file())
+
+ def test_custom_model_patched_generation_inheritance(self):
+ """
+ Tests that our inheritance patching for generate-compatible models works as expected. Without this feature,
+ old Hub models lose the ability to call `generate`.
+ """
+ model = AutoModelForCausalLM.from_pretrained(
+ "hf-internal-testing/test_dynamic_model_generation", trust_remote_code=True
+ )
+ self.assertTrue(model.__class__.__name__ == "NewModelForCausalLM")
+
+ # It inherits from GenerationMixin. This means it can `generate`. Because `PreTrainedModel` is scheduled to
+ # stop inheriting from `GenerationMixin` in v4.50, this check will fail if patching is not present.
+ self.assertTrue(isinstance(model, GenerationMixin))
+ # More precisely, it directly inherits from GenerationMixin. This check would fail prior to v4.45 (inheritance
+ # patching was added in v4.45)
+ self.assertTrue("GenerationMixin" in str(model.__class__.__bases__))
diff --git a/transformers/tests/models/auto/test_processor_auto.py b/transformers/tests/models/auto/test_processor_auto.py
new file mode 100644
index 0000000000000000000000000000000000000000..60500001a3b633d461331f05e6a241c8c23556fe
--- /dev/null
+++ b/transformers/tests/models/auto/test_processor_auto.py
@@ -0,0 +1,506 @@
+# Copyright 2021 the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import sys
+import tempfile
+import unittest
+from pathlib import Path
+from shutil import copyfile
+
+from huggingface_hub import HfFolder, Repository
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ FEATURE_EXTRACTOR_MAPPING,
+ MODEL_FOR_AUDIO_TOKENIZATION_MAPPING,
+ PROCESSOR_MAPPING,
+ TOKENIZER_MAPPING,
+ AutoConfig,
+ AutoFeatureExtractor,
+ AutoProcessor,
+ AutoTokenizer,
+ BertTokenizer,
+ ProcessorMixin,
+ Wav2Vec2Config,
+ Wav2Vec2FeatureExtractor,
+ Wav2Vec2Processor,
+)
+from transformers.testing_utils import TOKEN, TemporaryHubRepo, get_tests_dir, is_staging_test
+from transformers.tokenization_utils import TOKENIZER_CONFIG_FILE
+from transformers.utils import (
+ FEATURE_EXTRACTOR_NAME,
+ PROCESSOR_NAME,
+ is_tokenizers_available,
+)
+
+
+sys.path.append(str(Path(__file__).parent.parent.parent.parent / "utils"))
+
+from test_module.custom_configuration import CustomConfig # noqa E402
+from test_module.custom_feature_extraction import CustomFeatureExtractor # noqa E402
+from test_module.custom_processing import CustomProcessor # noqa E402
+from test_module.custom_tokenization import CustomTokenizer # noqa E402
+
+
+SAMPLE_PROCESSOR_CONFIG = get_tests_dir("fixtures/dummy_feature_extractor_config.json")
+SAMPLE_VOCAB = get_tests_dir("fixtures/vocab.json")
+SAMPLE_PROCESSOR_CONFIG_DIR = get_tests_dir("fixtures")
+
+
+class AutoFeatureExtractorTest(unittest.TestCase):
+ vocab_tokens = ["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]", "bla", "blou"]
+
+ def setUp(self):
+ transformers.dynamic_module_utils.TIME_OUT_REMOTE_CODE = 0
+
+ def test_processor_from_model_shortcut(self):
+ processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
+ self.assertIsInstance(processor, Wav2Vec2Processor)
+
+ def test_processor_from_local_directory_from_repo(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model_config = Wav2Vec2Config()
+ processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
+
+ # save in new folder
+ model_config.save_pretrained(tmpdirname)
+ processor.save_pretrained(tmpdirname)
+
+ processor = AutoProcessor.from_pretrained(tmpdirname)
+
+ self.assertIsInstance(processor, Wav2Vec2Processor)
+
+ def test_processor_from_local_directory_from_extractor_config(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ # copy relevant files
+ copyfile(SAMPLE_PROCESSOR_CONFIG, os.path.join(tmpdirname, FEATURE_EXTRACTOR_NAME))
+ copyfile(SAMPLE_VOCAB, os.path.join(tmpdirname, "vocab.json"))
+
+ processor = AutoProcessor.from_pretrained(tmpdirname)
+
+ self.assertIsInstance(processor, Wav2Vec2Processor)
+
+ def test_processor_from_processor_class(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ feature_extractor = Wav2Vec2FeatureExtractor()
+ tokenizer = AutoTokenizer.from_pretrained("facebook/wav2vec2-base-960h")
+
+ processor = Wav2Vec2Processor(feature_extractor, tokenizer)
+
+ # save in new folder
+ processor.save_pretrained(tmpdirname)
+
+ if not os.path.isfile(os.path.join(tmpdirname, PROCESSOR_NAME)):
+ # create one manually in order to perform this test's objective
+ config_dict = {"processor_class": "Wav2Vec2Processor"}
+ with open(os.path.join(tmpdirname, PROCESSOR_NAME), "w") as fp:
+ json.dump(config_dict, fp)
+
+ # drop `processor_class` in tokenizer config
+ with open(os.path.join(tmpdirname, TOKENIZER_CONFIG_FILE)) as f:
+ config_dict = json.load(f)
+ config_dict.pop("processor_class")
+
+ with open(os.path.join(tmpdirname, TOKENIZER_CONFIG_FILE), "w") as f:
+ f.write(json.dumps(config_dict))
+
+ processor = AutoProcessor.from_pretrained(tmpdirname)
+
+ self.assertIsInstance(processor, Wav2Vec2Processor)
+
+ def test_processor_from_feat_extr_processor_class(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ feature_extractor = Wav2Vec2FeatureExtractor()
+ tokenizer = AutoTokenizer.from_pretrained("facebook/wav2vec2-base-960h")
+
+ processor = Wav2Vec2Processor(feature_extractor, tokenizer)
+
+ # save in new folder
+ processor.save_pretrained(tmpdirname)
+
+ if os.path.isfile(os.path.join(tmpdirname, PROCESSOR_NAME)):
+ # drop `processor_class` in processor
+ with open(os.path.join(tmpdirname, PROCESSOR_NAME)) as f:
+ config_dict = json.load(f)
+ config_dict.pop("processor_class")
+
+ with open(os.path.join(tmpdirname, PROCESSOR_NAME), "w") as f:
+ f.write(json.dumps(config_dict))
+
+ # drop `processor_class` in tokenizer
+ with open(os.path.join(tmpdirname, TOKENIZER_CONFIG_FILE)) as f:
+ config_dict = json.load(f)
+ config_dict.pop("processor_class")
+
+ with open(os.path.join(tmpdirname, TOKENIZER_CONFIG_FILE), "w") as f:
+ f.write(json.dumps(config_dict))
+
+ processor = AutoProcessor.from_pretrained(tmpdirname)
+
+ self.assertIsInstance(processor, Wav2Vec2Processor)
+
+ def test_processor_from_tokenizer_processor_class(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ feature_extractor = Wav2Vec2FeatureExtractor()
+ tokenizer = AutoTokenizer.from_pretrained("facebook/wav2vec2-base-960h")
+
+ processor = Wav2Vec2Processor(feature_extractor, tokenizer)
+
+ # save in new folder
+ processor.save_pretrained(tmpdirname)
+
+ if os.path.isfile(os.path.join(tmpdirname, PROCESSOR_NAME)):
+ # drop `processor_class` in processor
+ with open(os.path.join(tmpdirname, PROCESSOR_NAME)) as f:
+ config_dict = json.load(f)
+ config_dict.pop("processor_class")
+
+ with open(os.path.join(tmpdirname, PROCESSOR_NAME), "w") as f:
+ f.write(json.dumps(config_dict))
+
+ # drop `processor_class` in feature extractor
+ with open(os.path.join(tmpdirname, FEATURE_EXTRACTOR_NAME)) as f:
+ config_dict = json.load(f)
+ config_dict.pop("processor_class")
+
+ with open(os.path.join(tmpdirname, FEATURE_EXTRACTOR_NAME), "w") as f:
+ f.write(json.dumps(config_dict))
+
+ processor = AutoProcessor.from_pretrained(tmpdirname)
+
+ self.assertIsInstance(processor, Wav2Vec2Processor)
+
+ def test_processor_from_local_directory_from_model_config(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model_config = Wav2Vec2Config(processor_class="Wav2Vec2Processor")
+ model_config.save_pretrained(tmpdirname)
+ # copy relevant files
+ copyfile(SAMPLE_VOCAB, os.path.join(tmpdirname, "vocab.json"))
+ # create empty sample processor
+ with open(os.path.join(tmpdirname, FEATURE_EXTRACTOR_NAME), "w") as f:
+ f.write("{}")
+
+ processor = AutoProcessor.from_pretrained(tmpdirname)
+
+ self.assertIsInstance(processor, Wav2Vec2Processor)
+
+ def test_from_pretrained_dynamic_processor(self):
+ # If remote code is not set, we will time out when asking whether to load the model.
+ with self.assertRaises(ValueError):
+ processor = AutoProcessor.from_pretrained("hf-internal-testing/test_dynamic_processor")
+ # If remote code is disabled, we can't load this config.
+ with self.assertRaises(ValueError):
+ processor = AutoProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_processor", trust_remote_code=False
+ )
+
+ processor = AutoProcessor.from_pretrained("hf-internal-testing/test_dynamic_processor", trust_remote_code=True)
+ self.assertTrue(processor.special_attribute_present)
+ self.assertEqual(processor.__class__.__name__, "NewProcessor")
+
+ feature_extractor = processor.feature_extractor
+ self.assertTrue(feature_extractor.special_attribute_present)
+ self.assertEqual(feature_extractor.__class__.__name__, "NewFeatureExtractor")
+
+ tokenizer = processor.tokenizer
+ self.assertTrue(tokenizer.special_attribute_present)
+ if is_tokenizers_available():
+ self.assertEqual(tokenizer.__class__.__name__, "NewTokenizerFast")
+
+ # Test we can also load the slow version
+ new_processor = AutoProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_processor", trust_remote_code=True, use_fast=False
+ )
+ new_tokenizer = new_processor.tokenizer
+ self.assertTrue(new_tokenizer.special_attribute_present)
+ self.assertEqual(new_tokenizer.__class__.__name__, "NewTokenizer")
+ else:
+ self.assertEqual(tokenizer.__class__.__name__, "NewTokenizer")
+
+ def test_new_processor_registration(self):
+ try:
+ AutoConfig.register("custom", CustomConfig)
+ AutoFeatureExtractor.register(CustomConfig, CustomFeatureExtractor)
+ AutoTokenizer.register(CustomConfig, slow_tokenizer_class=CustomTokenizer)
+ AutoProcessor.register(CustomConfig, CustomProcessor)
+ # Trying to register something existing in the Transformers library will raise an error
+ with self.assertRaises(ValueError):
+ AutoProcessor.register(Wav2Vec2Config, Wav2Vec2Processor)
+
+ # Now that the config is registered, it can be used as any other config with the auto-API
+ feature_extractor = CustomFeatureExtractor.from_pretrained(SAMPLE_PROCESSOR_CONFIG_DIR)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ vocab_file = os.path.join(tmp_dir, "vocab.txt")
+ with open(vocab_file, "w", encoding="utf-8") as vocab_writer:
+ vocab_writer.write("".join([x + "\n" for x in self.vocab_tokens]))
+ tokenizer = CustomTokenizer(vocab_file)
+
+ processor = CustomProcessor(feature_extractor, tokenizer)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ processor.save_pretrained(tmp_dir)
+ new_processor = AutoProcessor.from_pretrained(tmp_dir)
+ self.assertIsInstance(new_processor, CustomProcessor)
+
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in FEATURE_EXTRACTOR_MAPPING._extra_content:
+ del FEATURE_EXTRACTOR_MAPPING._extra_content[CustomConfig]
+ if CustomConfig in TOKENIZER_MAPPING._extra_content:
+ del TOKENIZER_MAPPING._extra_content[CustomConfig]
+ if CustomConfig in PROCESSOR_MAPPING._extra_content:
+ del PROCESSOR_MAPPING._extra_content[CustomConfig]
+ if CustomConfig in MODEL_FOR_AUDIO_TOKENIZATION_MAPPING._extra_content:
+ del MODEL_FOR_AUDIO_TOKENIZATION_MAPPING._extra_content[CustomConfig]
+
+ def test_from_pretrained_dynamic_processor_conflict(self):
+ class NewFeatureExtractor(Wav2Vec2FeatureExtractor):
+ special_attribute_present = False
+
+ class NewTokenizer(BertTokenizer):
+ special_attribute_present = False
+
+ class NewProcessor(ProcessorMixin):
+ feature_extractor_class = "AutoFeatureExtractor"
+ tokenizer_class = "AutoTokenizer"
+ special_attribute_present = False
+
+ try:
+ AutoConfig.register("custom", CustomConfig)
+ AutoFeatureExtractor.register(CustomConfig, NewFeatureExtractor)
+ AutoTokenizer.register(CustomConfig, slow_tokenizer_class=NewTokenizer)
+ AutoProcessor.register(CustomConfig, NewProcessor)
+ # If remote code is not set, the default is to use local classes.
+ processor = AutoProcessor.from_pretrained("hf-internal-testing/test_dynamic_processor")
+ self.assertEqual(processor.__class__.__name__, "NewProcessor")
+ self.assertFalse(processor.special_attribute_present)
+ self.assertFalse(processor.feature_extractor.special_attribute_present)
+ self.assertFalse(processor.tokenizer.special_attribute_present)
+
+ # If remote code is disabled, we load the local ones.
+ processor = AutoProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_processor", trust_remote_code=False
+ )
+ self.assertEqual(processor.__class__.__name__, "NewProcessor")
+ self.assertFalse(processor.special_attribute_present)
+ self.assertFalse(processor.feature_extractor.special_attribute_present)
+ self.assertFalse(processor.tokenizer.special_attribute_present)
+
+ # If remote is enabled, we load from the Hub.
+ processor = AutoProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_processor", trust_remote_code=True
+ )
+ self.assertEqual(processor.__class__.__name__, "NewProcessor")
+ self.assertTrue(processor.special_attribute_present)
+ self.assertTrue(processor.feature_extractor.special_attribute_present)
+ self.assertTrue(processor.tokenizer.special_attribute_present)
+
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in FEATURE_EXTRACTOR_MAPPING._extra_content:
+ del FEATURE_EXTRACTOR_MAPPING._extra_content[CustomConfig]
+ if CustomConfig in TOKENIZER_MAPPING._extra_content:
+ del TOKENIZER_MAPPING._extra_content[CustomConfig]
+ if CustomConfig in PROCESSOR_MAPPING._extra_content:
+ del PROCESSOR_MAPPING._extra_content[CustomConfig]
+ if CustomConfig in MODEL_FOR_AUDIO_TOKENIZATION_MAPPING._extra_content:
+ del MODEL_FOR_AUDIO_TOKENIZATION_MAPPING._extra_content[CustomConfig]
+
+ def test_from_pretrained_dynamic_processor_with_extra_attributes(self):
+ class NewFeatureExtractor(Wav2Vec2FeatureExtractor):
+ pass
+
+ class NewTokenizer(BertTokenizer):
+ pass
+
+ class NewProcessor(ProcessorMixin):
+ feature_extractor_class = "AutoFeatureExtractor"
+ tokenizer_class = "AutoTokenizer"
+
+ def __init__(self, feature_extractor, tokenizer, processor_attr_1=1, processor_attr_2=True):
+ super().__init__(feature_extractor, tokenizer)
+
+ self.processor_attr_1 = processor_attr_1
+ self.processor_attr_2 = processor_attr_2
+
+ try:
+ AutoConfig.register("custom", CustomConfig)
+ AutoFeatureExtractor.register(CustomConfig, NewFeatureExtractor)
+ AutoTokenizer.register(CustomConfig, slow_tokenizer_class=NewTokenizer)
+ AutoProcessor.register(CustomConfig, NewProcessor)
+ # If remote code is not set, the default is to use local classes.
+ processor = AutoProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_processor", processor_attr_2=False
+ )
+ self.assertEqual(processor.__class__.__name__, "NewProcessor")
+ self.assertEqual(processor.processor_attr_1, 1)
+ self.assertEqual(processor.processor_attr_2, False)
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in FEATURE_EXTRACTOR_MAPPING._extra_content:
+ del FEATURE_EXTRACTOR_MAPPING._extra_content[CustomConfig]
+ if CustomConfig in TOKENIZER_MAPPING._extra_content:
+ del TOKENIZER_MAPPING._extra_content[CustomConfig]
+ if CustomConfig in PROCESSOR_MAPPING._extra_content:
+ del PROCESSOR_MAPPING._extra_content[CustomConfig]
+ if CustomConfig in MODEL_FOR_AUDIO_TOKENIZATION_MAPPING._extra_content:
+ del MODEL_FOR_AUDIO_TOKENIZATION_MAPPING._extra_content[CustomConfig]
+
+ def test_dynamic_processor_with_specific_dynamic_subcomponents(self):
+ class NewFeatureExtractor(Wav2Vec2FeatureExtractor):
+ pass
+
+ class NewTokenizer(BertTokenizer):
+ pass
+
+ class NewProcessor(ProcessorMixin):
+ feature_extractor_class = "NewFeatureExtractor"
+ tokenizer_class = "NewTokenizer"
+
+ def __init__(self, feature_extractor, tokenizer):
+ super().__init__(feature_extractor, tokenizer)
+
+ try:
+ AutoConfig.register("custom", CustomConfig)
+ AutoFeatureExtractor.register(CustomConfig, NewFeatureExtractor)
+ AutoTokenizer.register(CustomConfig, slow_tokenizer_class=NewTokenizer)
+ AutoProcessor.register(CustomConfig, NewProcessor)
+ # If remote code is not set, the default is to use local classes.
+ processor = AutoProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_processor",
+ )
+ self.assertEqual(processor.__class__.__name__, "NewProcessor")
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in FEATURE_EXTRACTOR_MAPPING._extra_content:
+ del FEATURE_EXTRACTOR_MAPPING._extra_content[CustomConfig]
+ if CustomConfig in TOKENIZER_MAPPING._extra_content:
+ del TOKENIZER_MAPPING._extra_content[CustomConfig]
+ if CustomConfig in PROCESSOR_MAPPING._extra_content:
+ del PROCESSOR_MAPPING._extra_content[CustomConfig]
+ if CustomConfig in MODEL_FOR_AUDIO_TOKENIZATION_MAPPING._extra_content:
+ del MODEL_FOR_AUDIO_TOKENIZATION_MAPPING._extra_content[CustomConfig]
+
+ def test_auto_processor_creates_tokenizer(self):
+ processor = AutoProcessor.from_pretrained("hf-internal-testing/tiny-random-bert")
+ self.assertEqual(processor.__class__.__name__, "BertTokenizerFast")
+
+ def test_auto_processor_creates_image_processor(self):
+ processor = AutoProcessor.from_pretrained("hf-internal-testing/tiny-random-convnext")
+ self.assertEqual(processor.__class__.__name__, "ConvNextImageProcessor")
+
+ def test_auto_processor_save_load(self):
+ processor = AutoProcessor.from_pretrained("llava-hf/llava-onevision-qwen2-0.5b-ov-hf")
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ processor.save_pretrained(tmp_dir)
+ second_processor = AutoProcessor.from_pretrained(tmp_dir)
+ self.assertEqual(second_processor.__class__.__name__, processor.__class__.__name__)
+
+
+@is_staging_test
+class ProcessorPushToHubTester(unittest.TestCase):
+ vocab_tokens = ["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]", "bla", "blou"]
+
+ @classmethod
+ def setUpClass(cls):
+ cls._token = TOKEN
+ HfFolder.save_token(TOKEN)
+
+ def test_push_to_hub_via_save_pretrained(self):
+ with TemporaryHubRepo(token=self._token) as tmp_repo:
+ processor = Wav2Vec2Processor.from_pretrained(SAMPLE_PROCESSOR_CONFIG_DIR)
+ # Push to hub via save_pretrained
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ processor.save_pretrained(tmp_dir, repo_id=tmp_repo.repo_id, push_to_hub=True, token=self._token)
+
+ new_processor = Wav2Vec2Processor.from_pretrained(tmp_repo.repo_id)
+ for k, v in processor.feature_extractor.__dict__.items():
+ self.assertEqual(v, getattr(new_processor.feature_extractor, k))
+ self.assertDictEqual(new_processor.tokenizer.get_vocab(), processor.tokenizer.get_vocab())
+
+ def test_push_to_hub_in_organization_via_save_pretrained(self):
+ with TemporaryHubRepo(namespace="valid_org", token=self._token) as tmp_repo:
+ processor = Wav2Vec2Processor.from_pretrained(SAMPLE_PROCESSOR_CONFIG_DIR)
+ # Push to hub via save_pretrained
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ processor.save_pretrained(
+ tmp_dir,
+ repo_id=tmp_repo.repo_id,
+ push_to_hub=True,
+ token=self._token,
+ )
+
+ new_processor = Wav2Vec2Processor.from_pretrained(tmp_repo.repo_id)
+ for k, v in processor.feature_extractor.__dict__.items():
+ self.assertEqual(v, getattr(new_processor.feature_extractor, k))
+ self.assertDictEqual(new_processor.tokenizer.get_vocab(), processor.tokenizer.get_vocab())
+
+ def test_push_to_hub_dynamic_processor(self):
+ with TemporaryHubRepo(token=self._token) as tmp_repo:
+ CustomFeatureExtractor.register_for_auto_class()
+ CustomTokenizer.register_for_auto_class()
+ CustomProcessor.register_for_auto_class()
+
+ feature_extractor = CustomFeatureExtractor.from_pretrained(SAMPLE_PROCESSOR_CONFIG_DIR)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ vocab_file = os.path.join(tmp_dir, "vocab.txt")
+ with open(vocab_file, "w", encoding="utf-8") as vocab_writer:
+ vocab_writer.write("".join([x + "\n" for x in self.vocab_tokens]))
+ tokenizer = CustomTokenizer(vocab_file)
+
+ processor = CustomProcessor(feature_extractor, tokenizer)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ repo = Repository(tmp_dir, clone_from=tmp_repo, token=self._token)
+ processor.save_pretrained(tmp_dir)
+
+ # This has added the proper auto_map field to the feature extractor config
+ self.assertDictEqual(
+ processor.feature_extractor.auto_map,
+ {
+ "AutoFeatureExtractor": "custom_feature_extraction.CustomFeatureExtractor",
+ "AutoProcessor": "custom_processing.CustomProcessor",
+ },
+ )
+
+ # This has added the proper auto_map field to the tokenizer config
+ with open(os.path.join(tmp_dir, "tokenizer_config.json")) as f:
+ tokenizer_config = json.load(f)
+ self.assertDictEqual(
+ tokenizer_config["auto_map"],
+ {
+ "AutoTokenizer": ["custom_tokenization.CustomTokenizer", None],
+ "AutoProcessor": "custom_processing.CustomProcessor",
+ },
+ )
+
+ # The code has been copied from fixtures
+ self.assertTrue(os.path.isfile(os.path.join(tmp_dir, "custom_feature_extraction.py")))
+ self.assertTrue(os.path.isfile(os.path.join(tmp_dir, "custom_tokenization.py")))
+ self.assertTrue(os.path.isfile(os.path.join(tmp_dir, "custom_processing.py")))
+
+ repo.push_to_hub()
+
+ new_processor = AutoProcessor.from_pretrained(tmp_repo.repo_id, trust_remote_code=True)
+ # Can't make an isinstance check because the new_processor is from the CustomProcessor class of a dynamic module
+ self.assertEqual(new_processor.__class__.__name__, "CustomProcessor")
diff --git a/transformers/tests/models/auto/test_tokenization_auto.py b/transformers/tests/models/auto/test_tokenization_auto.py
new file mode 100644
index 0000000000000000000000000000000000000000..5d6c4254785f4449e7ecafcfa07ee14f370c5f0f
--- /dev/null
+++ b/transformers/tests/models/auto/test_tokenization_auto.py
@@ -0,0 +1,524 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import shutil
+import sys
+import tempfile
+import unittest
+from pathlib import Path
+
+import pytest
+
+import transformers
+from transformers import (
+ AutoTokenizer,
+ BertConfig,
+ BertTokenizer,
+ BertTokenizerFast,
+ CTRLTokenizer,
+ GPT2Tokenizer,
+ GPT2TokenizerFast,
+ PreTrainedTokenizerFast,
+ RobertaTokenizer,
+ RobertaTokenizerFast,
+ is_tokenizers_available,
+)
+from transformers.models.auto.configuration_auto import CONFIG_MAPPING, AutoConfig
+from transformers.models.auto.tokenization_auto import (
+ TOKENIZER_MAPPING,
+ get_tokenizer_config,
+ tokenizer_class_from_name,
+)
+from transformers.models.roberta.configuration_roberta import RobertaConfig
+from transformers.testing_utils import (
+ DUMMY_DIFF_TOKENIZER_IDENTIFIER,
+ DUMMY_UNKNOWN_IDENTIFIER,
+ SMALL_MODEL_IDENTIFIER,
+ RequestCounter,
+ is_flaky,
+ require_tokenizers,
+ slow,
+)
+
+
+sys.path.append(str(Path(__file__).parent.parent.parent.parent / "utils"))
+
+from test_module.custom_configuration import CustomConfig # noqa E402
+from test_module.custom_tokenization import CustomTokenizer # noqa E402
+
+
+if is_tokenizers_available():
+ from test_module.custom_tokenization_fast import CustomTokenizerFast
+
+
+class AutoTokenizerTest(unittest.TestCase):
+ def setUp(self):
+ transformers.dynamic_module_utils.TIME_OUT_REMOTE_CODE = 0
+
+ @slow
+ def test_tokenizer_from_pretrained(self):
+ for model_name in {"google-bert/bert-base-uncased", "google-bert/bert-base-cased"}:
+ tokenizer = AutoTokenizer.from_pretrained(model_name)
+ self.assertIsNotNone(tokenizer)
+ self.assertIsInstance(tokenizer, (BertTokenizer, BertTokenizerFast))
+ self.assertGreater(len(tokenizer), 0)
+
+ for model_name in ["openai-community/gpt2", "openai-community/gpt2-medium"]:
+ tokenizer = AutoTokenizer.from_pretrained(model_name)
+ self.assertIsNotNone(tokenizer)
+ self.assertIsInstance(tokenizer, (GPT2Tokenizer, GPT2TokenizerFast))
+ self.assertGreater(len(tokenizer), 0)
+
+ def test_tokenizer_from_pretrained_identifier(self):
+ tokenizer = AutoTokenizer.from_pretrained(SMALL_MODEL_IDENTIFIER)
+ self.assertIsInstance(tokenizer, (BertTokenizer, BertTokenizerFast))
+ self.assertEqual(tokenizer.vocab_size, 12)
+
+ def test_tokenizer_from_model_type(self):
+ tokenizer = AutoTokenizer.from_pretrained(DUMMY_UNKNOWN_IDENTIFIER)
+ self.assertIsInstance(tokenizer, (RobertaTokenizer, RobertaTokenizerFast))
+ self.assertEqual(tokenizer.vocab_size, 20)
+
+ def test_tokenizer_from_tokenizer_class(self):
+ config = AutoConfig.from_pretrained(DUMMY_DIFF_TOKENIZER_IDENTIFIER)
+ self.assertIsInstance(config, RobertaConfig)
+ # Check that tokenizer_type ≠ model_type
+ tokenizer = AutoTokenizer.from_pretrained(DUMMY_DIFF_TOKENIZER_IDENTIFIER, config=config)
+ self.assertIsInstance(tokenizer, (BertTokenizer, BertTokenizerFast))
+ self.assertEqual(tokenizer.vocab_size, 12)
+
+ def test_tokenizer_from_type(self):
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ shutil.copy("./tests/fixtures/vocab.txt", os.path.join(tmp_dir, "vocab.txt"))
+
+ tokenizer = AutoTokenizer.from_pretrained(tmp_dir, tokenizer_type="bert", use_fast=False)
+ self.assertIsInstance(tokenizer, BertTokenizer)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ shutil.copy("./tests/fixtures/vocab.json", os.path.join(tmp_dir, "vocab.json"))
+ shutil.copy("./tests/fixtures/merges.txt", os.path.join(tmp_dir, "merges.txt"))
+
+ tokenizer = AutoTokenizer.from_pretrained(tmp_dir, tokenizer_type="gpt2", use_fast=False)
+ self.assertIsInstance(tokenizer, GPT2Tokenizer)
+
+ @require_tokenizers
+ def test_tokenizer_from_type_fast(self):
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ shutil.copy("./tests/fixtures/vocab.txt", os.path.join(tmp_dir, "vocab.txt"))
+
+ tokenizer = AutoTokenizer.from_pretrained(tmp_dir, tokenizer_type="bert")
+ self.assertIsInstance(tokenizer, BertTokenizerFast)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ shutil.copy("./tests/fixtures/vocab.json", os.path.join(tmp_dir, "vocab.json"))
+ shutil.copy("./tests/fixtures/merges.txt", os.path.join(tmp_dir, "merges.txt"))
+
+ tokenizer = AutoTokenizer.from_pretrained(tmp_dir, tokenizer_type="gpt2")
+ self.assertIsInstance(tokenizer, GPT2TokenizerFast)
+
+ def test_tokenizer_from_type_incorrect_name(self):
+ with pytest.raises(ValueError):
+ AutoTokenizer.from_pretrained("./", tokenizer_type="xxx")
+
+ @require_tokenizers
+ def test_tokenizer_identifier_with_correct_config(self):
+ for tokenizer_class in [BertTokenizer, BertTokenizerFast, AutoTokenizer]:
+ tokenizer = tokenizer_class.from_pretrained("wietsedv/bert-base-dutch-cased")
+ self.assertIsInstance(tokenizer, (BertTokenizer, BertTokenizerFast))
+
+ if isinstance(tokenizer, BertTokenizer):
+ self.assertEqual(tokenizer.basic_tokenizer.do_lower_case, False)
+ else:
+ self.assertEqual(tokenizer.do_lower_case, False)
+
+ self.assertEqual(tokenizer.model_max_length, 512)
+
+ @require_tokenizers
+ @is_flaky() # This one is flaky even with the new retry logic because it raises an unusual error
+ def test_tokenizer_identifier_non_existent(self):
+ for tokenizer_class in [BertTokenizer, BertTokenizerFast, AutoTokenizer]:
+ with self.assertRaisesRegex(
+ EnvironmentError,
+ "julien-c/herlolip-not-exists is not a local folder and is not a valid model identifier",
+ ):
+ _ = tokenizer_class.from_pretrained("julien-c/herlolip-not-exists")
+
+ def test_model_name_edge_cases_in_mappings(self):
+ # tests: https://github.com/huggingface/transformers/pull/13251
+ # 1. models with `-`, e.g. xlm-roberta -> xlm_roberta
+ # 2. models that don't remap 1-1 from model-name to model file, e.g., openai-gpt -> openai
+ tokenizers = TOKENIZER_MAPPING.values()
+ tokenizer_names = []
+
+ for slow_tok, fast_tok in tokenizers:
+ if slow_tok is not None:
+ tokenizer_names.append(slow_tok.__name__)
+
+ if fast_tok is not None:
+ tokenizer_names.append(fast_tok.__name__)
+
+ for tokenizer_name in tokenizer_names:
+ # must find the right class
+ tokenizer_class_from_name(tokenizer_name)
+
+ @require_tokenizers
+ def test_from_pretrained_use_fast_toggle(self):
+ self.assertIsInstance(
+ AutoTokenizer.from_pretrained("google-bert/bert-base-cased", use_fast=False), BertTokenizer
+ )
+ self.assertIsInstance(AutoTokenizer.from_pretrained("google-bert/bert-base-cased"), BertTokenizerFast)
+
+ @require_tokenizers
+ def test_do_lower_case(self):
+ tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased", do_lower_case=False)
+ sample = "Hello, world. How are you?"
+ tokens = tokenizer.tokenize(sample)
+ self.assertEqual("[UNK]", tokens[0])
+
+ tokenizer = AutoTokenizer.from_pretrained("microsoft/mpnet-base", do_lower_case=False)
+ tokens = tokenizer.tokenize(sample)
+ self.assertEqual("[UNK]", tokens[0])
+
+ @require_tokenizers
+ def test_PreTrainedTokenizerFast_from_pretrained(self):
+ tokenizer = AutoTokenizer.from_pretrained("robot-test/dummy-tokenizer-fast-with-model-config")
+ self.assertEqual(type(tokenizer), PreTrainedTokenizerFast)
+ self.assertEqual(tokenizer.model_max_length, 512)
+ self.assertEqual(tokenizer.vocab_size, 30000)
+ self.assertEqual(tokenizer.unk_token, "[UNK]")
+ self.assertEqual(tokenizer.padding_side, "right")
+ self.assertEqual(tokenizer.truncation_side, "right")
+
+ def test_auto_tokenizer_from_local_folder(self):
+ tokenizer = AutoTokenizer.from_pretrained(SMALL_MODEL_IDENTIFIER)
+ self.assertIsInstance(tokenizer, (BertTokenizer, BertTokenizerFast))
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ tokenizer.save_pretrained(tmp_dir)
+ tokenizer2 = AutoTokenizer.from_pretrained(tmp_dir)
+
+ self.assertIsInstance(tokenizer2, tokenizer.__class__)
+ self.assertEqual(tokenizer2.vocab_size, 12)
+
+ def test_auto_tokenizer_fast_no_slow(self):
+ tokenizer = AutoTokenizer.from_pretrained("Salesforce/ctrl")
+ # There is no fast CTRL so this always gives us a slow tokenizer.
+ self.assertIsInstance(tokenizer, CTRLTokenizer)
+
+ def test_get_tokenizer_config(self):
+ # Check we can load the tokenizer config of an online model.
+ config = get_tokenizer_config("google-bert/bert-base-cased")
+ _ = config.pop("_commit_hash", None)
+ # If we ever update google-bert/bert-base-cased tokenizer config, this dict here will need to be updated.
+ self.assertEqual(config, {"do_lower_case": False, "model_max_length": 512})
+
+ # This model does not have a tokenizer_config so we get back an empty dict.
+ config = get_tokenizer_config(SMALL_MODEL_IDENTIFIER)
+ self.assertDictEqual(config, {})
+
+ # A tokenizer saved with `save_pretrained` always creates a tokenizer config.
+ tokenizer = AutoTokenizer.from_pretrained(SMALL_MODEL_IDENTIFIER)
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ tokenizer.save_pretrained(tmp_dir)
+ config = get_tokenizer_config(tmp_dir)
+
+ # Check the class of the tokenizer was properly saved (note that it always saves the slow class).
+ self.assertEqual(config["tokenizer_class"], "BertTokenizer")
+
+ def test_new_tokenizer_registration(self):
+ try:
+ AutoConfig.register("custom", CustomConfig)
+
+ AutoTokenizer.register(CustomConfig, slow_tokenizer_class=CustomTokenizer)
+ # Trying to register something existing in the Transformers library will raise an error
+ with self.assertRaises(ValueError):
+ AutoTokenizer.register(BertConfig, slow_tokenizer_class=BertTokenizer)
+
+ tokenizer = CustomTokenizer.from_pretrained(SMALL_MODEL_IDENTIFIER)
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ tokenizer.save_pretrained(tmp_dir)
+
+ new_tokenizer = AutoTokenizer.from_pretrained(tmp_dir)
+ self.assertIsInstance(new_tokenizer, CustomTokenizer)
+
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in TOKENIZER_MAPPING._extra_content:
+ del TOKENIZER_MAPPING._extra_content[CustomConfig]
+
+ @require_tokenizers
+ def test_new_tokenizer_fast_registration(self):
+ try:
+ AutoConfig.register("custom", CustomConfig)
+
+ # Can register in two steps
+ AutoTokenizer.register(CustomConfig, slow_tokenizer_class=CustomTokenizer)
+ self.assertEqual(TOKENIZER_MAPPING[CustomConfig], (CustomTokenizer, None))
+ AutoTokenizer.register(CustomConfig, fast_tokenizer_class=CustomTokenizerFast)
+ self.assertEqual(TOKENIZER_MAPPING[CustomConfig], (CustomTokenizer, CustomTokenizerFast))
+
+ del TOKENIZER_MAPPING._extra_content[CustomConfig]
+ # Can register in one step
+ AutoTokenizer.register(
+ CustomConfig, slow_tokenizer_class=CustomTokenizer, fast_tokenizer_class=CustomTokenizerFast
+ )
+ self.assertEqual(TOKENIZER_MAPPING[CustomConfig], (CustomTokenizer, CustomTokenizerFast))
+
+ # Trying to register something existing in the Transformers library will raise an error
+ with self.assertRaises(ValueError):
+ AutoTokenizer.register(BertConfig, fast_tokenizer_class=BertTokenizerFast)
+
+ # We pass through a bert tokenizer fast cause there is no converter slow to fast for our new toknizer
+ # and that model does not have a tokenizer.json
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ bert_tokenizer = BertTokenizerFast.from_pretrained(SMALL_MODEL_IDENTIFIER)
+ bert_tokenizer.save_pretrained(tmp_dir)
+ tokenizer = CustomTokenizerFast.from_pretrained(tmp_dir)
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ tokenizer.save_pretrained(tmp_dir)
+
+ new_tokenizer = AutoTokenizer.from_pretrained(tmp_dir)
+ self.assertIsInstance(new_tokenizer, CustomTokenizerFast)
+
+ new_tokenizer = AutoTokenizer.from_pretrained(tmp_dir, use_fast=False)
+ self.assertIsInstance(new_tokenizer, CustomTokenizer)
+
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in TOKENIZER_MAPPING._extra_content:
+ del TOKENIZER_MAPPING._extra_content[CustomConfig]
+
+ def test_from_pretrained_dynamic_tokenizer(self):
+ # If remote code is not set, we will time out when asking whether to load the model.
+ with self.assertRaises(ValueError):
+ tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/test_dynamic_tokenizer")
+ # If remote code is disabled, we can't load this config.
+ with self.assertRaises(ValueError):
+ tokenizer = AutoTokenizer.from_pretrained(
+ "hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=False
+ )
+
+ tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=True)
+ self.assertTrue(tokenizer.special_attribute_present)
+
+ # Test the dynamic module is loaded only once.
+ reloaded_tokenizer = AutoTokenizer.from_pretrained(
+ "hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=True
+ )
+ self.assertIs(tokenizer.__class__, reloaded_tokenizer.__class__)
+
+ # Test tokenizer can be reloaded.
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ tokenizer.save_pretrained(tmp_dir)
+ reloaded_tokenizer = AutoTokenizer.from_pretrained(tmp_dir, trust_remote_code=True)
+ self.assertTrue(reloaded_tokenizer.special_attribute_present)
+
+ if is_tokenizers_available():
+ self.assertEqual(tokenizer.__class__.__name__, "NewTokenizerFast")
+ self.assertEqual(reloaded_tokenizer.__class__.__name__, "NewTokenizerFast")
+
+ # Test we can also load the slow version
+ tokenizer = AutoTokenizer.from_pretrained(
+ "hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=True, use_fast=False
+ )
+ self.assertTrue(tokenizer.special_attribute_present)
+ self.assertEqual(tokenizer.__class__.__name__, "NewTokenizer")
+ # Test tokenizer can be reloaded.
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ tokenizer.save_pretrained(tmp_dir)
+ reloaded_tokenizer = AutoTokenizer.from_pretrained(tmp_dir, trust_remote_code=True, use_fast=False)
+ self.assertTrue(
+ os.path.exists(os.path.join(tmp_dir, "tokenization.py"))
+ ) # Assert we saved tokenizer code
+ self.assertEqual(reloaded_tokenizer._auto_class, "AutoTokenizer")
+ with open(os.path.join(tmp_dir, "tokenizer_config.json"), "r") as f:
+ tokenizer_config = json.load(f)
+ # Assert we're pointing at local code and not another remote repo
+ self.assertEqual(tokenizer_config["auto_map"]["AutoTokenizer"], ["tokenization.NewTokenizer", None])
+ self.assertEqual(reloaded_tokenizer.__class__.__name__, "NewTokenizer")
+ self.assertTrue(reloaded_tokenizer.special_attribute_present)
+ else:
+ self.assertEqual(tokenizer.__class__.__name__, "NewTokenizer")
+ self.assertEqual(reloaded_tokenizer.__class__.__name__, "NewTokenizer")
+
+ # Test the dynamic module is reloaded if we force it.
+ reloaded_tokenizer = AutoTokenizer.from_pretrained(
+ "hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=True, force_download=True
+ )
+ self.assertIsNot(tokenizer.__class__, reloaded_tokenizer.__class__)
+ self.assertTrue(reloaded_tokenizer.special_attribute_present)
+
+ @require_tokenizers
+ def test_from_pretrained_dynamic_tokenizer_conflict(self):
+ class NewTokenizer(BertTokenizer):
+ special_attribute_present = False
+
+ class NewTokenizerFast(BertTokenizerFast):
+ slow_tokenizer_class = NewTokenizer
+ special_attribute_present = False
+
+ try:
+ AutoConfig.register("custom", CustomConfig)
+ AutoTokenizer.register(CustomConfig, slow_tokenizer_class=NewTokenizer)
+ AutoTokenizer.register(CustomConfig, fast_tokenizer_class=NewTokenizerFast)
+ # If remote code is not set, the default is to use local
+ tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/test_dynamic_tokenizer")
+ self.assertEqual(tokenizer.__class__.__name__, "NewTokenizerFast")
+ self.assertFalse(tokenizer.special_attribute_present)
+ tokenizer = AutoTokenizer.from_pretrained("hf-internal-testing/test_dynamic_tokenizer", use_fast=False)
+ self.assertEqual(tokenizer.__class__.__name__, "NewTokenizer")
+ self.assertFalse(tokenizer.special_attribute_present)
+
+ # If remote code is disabled, we load the local one.
+ tokenizer = AutoTokenizer.from_pretrained(
+ "hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=False
+ )
+ self.assertEqual(tokenizer.__class__.__name__, "NewTokenizerFast")
+ self.assertFalse(tokenizer.special_attribute_present)
+ tokenizer = AutoTokenizer.from_pretrained(
+ "hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=False, use_fast=False
+ )
+ self.assertEqual(tokenizer.__class__.__name__, "NewTokenizer")
+ self.assertFalse(tokenizer.special_attribute_present)
+
+ # If remote is enabled, we load from the Hub
+ tokenizer = AutoTokenizer.from_pretrained(
+ "hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=True
+ )
+ self.assertEqual(tokenizer.__class__.__name__, "NewTokenizerFast")
+ self.assertTrue(tokenizer.special_attribute_present)
+ tokenizer = AutoTokenizer.from_pretrained(
+ "hf-internal-testing/test_dynamic_tokenizer", trust_remote_code=True, use_fast=False
+ )
+ self.assertEqual(tokenizer.__class__.__name__, "NewTokenizer")
+ self.assertTrue(tokenizer.special_attribute_present)
+
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in TOKENIZER_MAPPING._extra_content:
+ del TOKENIZER_MAPPING._extra_content[CustomConfig]
+
+ def test_from_pretrained_dynamic_tokenizer_legacy_format(self):
+ tokenizer = AutoTokenizer.from_pretrained(
+ "hf-internal-testing/test_dynamic_tokenizer_legacy", trust_remote_code=True
+ )
+ self.assertTrue(tokenizer.special_attribute_present)
+ if is_tokenizers_available():
+ self.assertEqual(tokenizer.__class__.__name__, "NewTokenizerFast")
+
+ # Test we can also load the slow version
+ tokenizer = AutoTokenizer.from_pretrained(
+ "hf-internal-testing/test_dynamic_tokenizer_legacy", trust_remote_code=True, use_fast=False
+ )
+ self.assertTrue(tokenizer.special_attribute_present)
+ self.assertEqual(tokenizer.__class__.__name__, "NewTokenizer")
+ else:
+ self.assertEqual(tokenizer.__class__.__name__, "NewTokenizer")
+
+ def test_repo_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError, "bert-base is not a local folder and is not a valid model identifier"
+ ):
+ _ = AutoTokenizer.from_pretrained("bert-base")
+
+ def test_revision_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError, r"aaaaaa is not a valid git identifier \(branch name, tag name or commit id\)"
+ ):
+ _ = AutoTokenizer.from_pretrained(DUMMY_UNKNOWN_IDENTIFIER, revision="aaaaaa")
+
+ @unittest.skip("This test is failing on main") # TODO Matt/ydshieh, fix this test!
+ def test_cached_tokenizer_has_minimum_calls_to_head(self):
+ # Make sure we have cached the tokenizer.
+ _ = AutoTokenizer.from_pretrained("hf-internal-testing/tiny-random-bert")
+ with RequestCounter() as counter:
+ _ = AutoTokenizer.from_pretrained("hf-internal-testing/tiny-random-bert")
+ self.assertEqual(counter["GET"], 0)
+ self.assertEqual(counter["HEAD"], 1)
+ self.assertEqual(counter.total_calls, 1)
+
+ def test_init_tokenizer_with_trust(self):
+ nop_tokenizer_code = """
+import transformers
+
+class NopTokenizer(transformers.PreTrainedTokenizer):
+ def get_vocab(self):
+ return {}
+"""
+
+ nop_config_code = """
+from transformers import PretrainedConfig
+
+class NopConfig(PretrainedConfig):
+ model_type = "test_unregistered_dynamic"
+
+ def __init__(self, **kwargs):
+ super().__init__(**kwargs)
+"""
+
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ fake_model_id = "hf-internal-testing/test_unregistered_dynamic"
+ fake_repo = os.path.join(tmp_dir, fake_model_id)
+ os.makedirs(fake_repo)
+
+ tokenizer_src_file = os.path.join(fake_repo, "tokenizer.py")
+ with open(tokenizer_src_file, "w") as wfp:
+ wfp.write(nop_tokenizer_code)
+
+ model_config_src_file = os.path.join(fake_repo, "config.py")
+ with open(model_config_src_file, "w") as wfp:
+ wfp.write(nop_config_code)
+
+ config = {
+ "model_type": "test_unregistered_dynamic",
+ "auto_map": {"AutoConfig": f"{fake_model_id}--config.NopConfig"},
+ }
+
+ config_file = os.path.join(fake_repo, "config.json")
+ with open(config_file, "w") as wfp:
+ json.dump(config, wfp, indent=2)
+
+ tokenizer_config = {
+ "auto_map": {
+ "AutoTokenizer": [
+ f"{fake_model_id}--tokenizer.NopTokenizer",
+ None,
+ ]
+ }
+ }
+
+ tokenizer_config_file = os.path.join(fake_repo, "tokenizer_config.json")
+ with open(tokenizer_config_file, "w") as wfp:
+ json.dump(tokenizer_config, wfp, indent=2)
+
+ prev_dir = os.getcwd()
+ try:
+ # it looks like subdir= is broken in the from_pretrained also, so this is necessary
+ os.chdir(tmp_dir)
+
+ # this should work because we trust the code
+ _ = AutoTokenizer.from_pretrained(fake_model_id, local_files_only=True, trust_remote_code=True)
+ try:
+ # this should fail because we don't trust and we're not at a terminal for interactive response
+ _ = AutoTokenizer.from_pretrained(fake_model_id, local_files_only=True, trust_remote_code=False)
+ self.fail("AutoTokenizer.from_pretrained with trust_remote_code=False should raise ValueException")
+ except ValueError:
+ pass
+ finally:
+ os.chdir(prev_dir)
diff --git a/transformers/tests/models/auto/test_video_processing_auto.py b/transformers/tests/models/auto/test_video_processing_auto.py
new file mode 100644
index 0000000000000000000000000000000000000000..a66ed720056ac28e2388920959f4c8c41566184e
--- /dev/null
+++ b/transformers/tests/models/auto/test_video_processing_auto.py
@@ -0,0 +1,241 @@
+# coding=utf-8
+# Copyright 2025 the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import sys
+import tempfile
+import unittest
+from pathlib import Path
+
+import transformers
+from transformers import (
+ CONFIG_MAPPING,
+ VIDEO_PROCESSOR_MAPPING,
+ AutoConfig,
+ AutoVideoProcessor,
+ LlavaOnevisionConfig,
+ LlavaOnevisionVideoProcessor,
+)
+from transformers.testing_utils import DUMMY_UNKNOWN_IDENTIFIER, require_torch
+
+
+sys.path.append(str(Path(__file__).parent.parent.parent.parent / "utils"))
+
+from test_module.custom_configuration import CustomConfig # noqa E402
+from test_module.custom_video_processing import CustomVideoProcessor # noqa E402
+
+
+@require_torch
+class AutoVideoProcessorTest(unittest.TestCase):
+ def setUp(self):
+ transformers.dynamic_module_utils.TIME_OUT_REMOTE_CODE = 0
+
+ def test_video_processor_from_model_shortcut(self):
+ config = AutoVideoProcessor.from_pretrained("llava-hf/llava-onevision-qwen2-0.5b-ov-hf")
+ self.assertIsInstance(config, LlavaOnevisionVideoProcessor)
+
+ def test_video_processor_from_local_directory_from_key(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ processor_tmpfile = Path(tmpdirname) / "video_preprocessor_config.json"
+ config_tmpfile = Path(tmpdirname) / "config.json"
+ json.dump(
+ {
+ "video_processor_type": "LlavaOnevisionVideoProcessor",
+ "processor_class": "LlavaOnevisionProcessor",
+ },
+ open(processor_tmpfile, "w"),
+ )
+ json.dump({"model_type": "llava_onevision"}, open(config_tmpfile, "w"))
+
+ config = AutoVideoProcessor.from_pretrained(tmpdirname)
+ self.assertIsInstance(config, LlavaOnevisionVideoProcessor)
+
+ def test_video_processor_from_local_directory_from_preprocessor_key(self):
+ # Ensure we can load the image processor from the feature extractor config
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ processor_tmpfile = Path(tmpdirname) / "preprocessor_config.json"
+ config_tmpfile = Path(tmpdirname) / "config.json"
+ json.dump(
+ {
+ "video_processor_type": "LlavaOnevisionVideoProcessor",
+ "processor_class": "LlavaOnevisionProcessor",
+ },
+ open(processor_tmpfile, "w"),
+ )
+ json.dump({"model_type": "llava_onevision"}, open(config_tmpfile, "w"))
+
+ config = AutoVideoProcessor.from_pretrained(tmpdirname)
+ self.assertIsInstance(config, LlavaOnevisionVideoProcessor)
+
+ def test_video_processor_from_local_directory_from_config(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model_config = LlavaOnevisionConfig()
+
+ # Create a dummy config file with image_proceesor_type
+ processor_tmpfile = Path(tmpdirname) / "video_preprocessor_config.json"
+ config_tmpfile = Path(tmpdirname) / "config.json"
+ json.dump(
+ {
+ "video_processor_type": "LlavaOnevisionVideoProcessor",
+ "processor_class": "LlavaOnevisionProcessor",
+ },
+ open(processor_tmpfile, "w"),
+ )
+ json.dump({"model_type": "llava_onevision"}, open(config_tmpfile, "w"))
+
+ # remove video_processor_type to make sure config.json alone is enough to load image processor locally
+ config_dict = AutoVideoProcessor.from_pretrained(tmpdirname).to_dict()
+
+ config_dict.pop("video_processor_type")
+ config = LlavaOnevisionVideoProcessor(**config_dict)
+
+ # save in new folder
+ model_config.save_pretrained(tmpdirname)
+ config.save_pretrained(tmpdirname)
+
+ config = AutoVideoProcessor.from_pretrained(tmpdirname)
+
+ # make sure private variable is not incorrectly saved
+ dict_as_saved = json.loads(config.to_json_string())
+ self.assertTrue("_processor_class" not in dict_as_saved)
+
+ self.assertIsInstance(config, LlavaOnevisionVideoProcessor)
+
+ def test_video_processor_from_local_file(self):
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ processor_tmpfile = Path(tmpdirname) / "video_preprocessor_config.json"
+ json.dump(
+ {
+ "video_processor_type": "LlavaOnevisionVideoProcessor",
+ "processor_class": "LlavaOnevisionProcessor",
+ },
+ open(processor_tmpfile, "w"),
+ )
+
+ config = AutoVideoProcessor.from_pretrained(processor_tmpfile)
+ self.assertIsInstance(config, LlavaOnevisionVideoProcessor)
+
+ def test_repo_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError,
+ "llava-hf/llava-doesnt-exist is not a local folder and is not a valid model identifier",
+ ):
+ _ = AutoVideoProcessor.from_pretrained("llava-hf/llava-doesnt-exist")
+
+ def test_revision_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError, r"aaaaaa is not a valid git identifier \(branch name, tag name or commit id\)"
+ ):
+ _ = AutoVideoProcessor.from_pretrained(DUMMY_UNKNOWN_IDENTIFIER, revision="aaaaaa")
+
+ def test_video_processor_not_found(self):
+ with self.assertRaisesRegex(
+ EnvironmentError,
+ "hf-internal-testing/config-no-model does not appear to have a file named preprocessor_config.json.",
+ ):
+ _ = AutoVideoProcessor.from_pretrained("hf-internal-testing/config-no-model")
+
+ def test_from_pretrained_dynamic_video_processor(self):
+ # If remote code is not set, we will time out when asking whether to load the model.
+ with self.assertRaises(ValueError):
+ video_processor = AutoVideoProcessor.from_pretrained("hf-internal-testing/test_dynamic_video_processor")
+ # If remote code is disabled, we can't load this config.
+ with self.assertRaises(ValueError):
+ video_processor = AutoVideoProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_video_processor", trust_remote_code=False
+ )
+
+ video_processor = AutoVideoProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_video_processor", trust_remote_code=True
+ )
+ self.assertEqual(video_processor.__class__.__name__, "NewVideoProcessor")
+
+ # Test the dynamic module is loaded only once.
+ reloaded_video_processor = AutoVideoProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_video_processor", trust_remote_code=True
+ )
+ self.assertIs(video_processor.__class__, reloaded_video_processor.__class__)
+
+ # Test image processor can be reloaded.
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ video_processor.save_pretrained(tmp_dir)
+ reloaded_video_processor = AutoVideoProcessor.from_pretrained(tmp_dir, trust_remote_code=True)
+ self.assertEqual(reloaded_video_processor.__class__.__name__, "NewVideoProcessor")
+
+ def test_new_video_processor_registration(self):
+ try:
+ AutoConfig.register("custom", CustomConfig)
+ AutoVideoProcessor.register(CustomConfig, CustomVideoProcessor)
+ # Trying to register something existing in the Transformers library will raise an error
+ with self.assertRaises(ValueError):
+ AutoVideoProcessor.register(LlavaOnevisionConfig, LlavaOnevisionVideoProcessor)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ processor_tmpfile = Path(tmpdirname) / "video_preprocessor_config.json"
+ config_tmpfile = Path(tmpdirname) / "config.json"
+ json.dump(
+ {
+ "video_processor_type": "LlavaOnevisionVideoProcessor",
+ "processor_class": "LlavaOnevisionProcessor",
+ },
+ open(processor_tmpfile, "w"),
+ )
+ json.dump({"model_type": "llava_onevision"}, open(config_tmpfile, "w"))
+
+ video_processor = CustomVideoProcessor.from_pretrained(tmpdirname)
+
+ # Now that the config is registered, it can be used as any other config with the auto-API
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ video_processor.save_pretrained(tmp_dir)
+ new_video_processor = AutoVideoProcessor.from_pretrained(tmp_dir)
+ self.assertIsInstance(new_video_processor, CustomVideoProcessor)
+
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in VIDEO_PROCESSOR_MAPPING._extra_content:
+ del VIDEO_PROCESSOR_MAPPING._extra_content[CustomConfig]
+
+ def test_from_pretrained_dynamic_video_processor_conflict(self):
+ class NewVideoProcessor(LlavaOnevisionVideoProcessor):
+ is_local = True
+
+ try:
+ AutoConfig.register("custom", CustomConfig)
+ AutoVideoProcessor.register(CustomConfig, NewVideoProcessor)
+ # If remote code is not set, the default is to use local
+ video_processor = AutoVideoProcessor.from_pretrained("hf-internal-testing/test_dynamic_video_processor")
+ self.assertEqual(video_processor.__class__.__name__, "NewVideoProcessor")
+ self.assertTrue(video_processor.is_local)
+
+ # If remote code is disabled, we load the local one.
+ video_processor = AutoVideoProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_video_processor", trust_remote_code=False
+ )
+ self.assertEqual(video_processor.__class__.__name__, "NewVideoProcessor")
+ self.assertTrue(video_processor.is_local)
+
+ # If remote is enabled, we load from the Hub
+ video_processor = AutoVideoProcessor.from_pretrained(
+ "hf-internal-testing/test_dynamic_video_processor", trust_remote_code=True
+ )
+ self.assertEqual(video_processor.__class__.__name__, "NewVideoProcessor")
+ self.assertTrue(not hasattr(video_processor, "is_local"))
+
+ finally:
+ if "custom" in CONFIG_MAPPING._extra_content:
+ del CONFIG_MAPPING._extra_content["custom"]
+ if CustomConfig in VIDEO_PROCESSOR_MAPPING._extra_content:
+ del VIDEO_PROCESSOR_MAPPING._extra_content[CustomConfig]
diff --git a/transformers/tests/models/autoformer/__init__.py b/transformers/tests/models/autoformer/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/autoformer/test_modeling_autoformer.py b/transformers/tests/models/autoformer/test_modeling_autoformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..954f9f16622bf934444f57eca2fd346d01d020da
--- /dev/null
+++ b/transformers/tests/models/autoformer/test_modeling_autoformer.py
@@ -0,0 +1,485 @@
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Autoformer model."""
+
+import inspect
+import tempfile
+import unittest
+
+from huggingface_hub import hf_hub_download
+
+from transformers import is_torch_available
+from transformers.testing_utils import is_flaky, require_torch, slow, torch_device
+from transformers.utils import check_torch_load_is_safe
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+TOLERANCE = 1e-4
+
+if is_torch_available():
+ import torch
+
+ from transformers import AutoformerConfig, AutoformerForPrediction, AutoformerModel
+ from transformers.models.autoformer.modeling_autoformer import AutoformerDecoder, AutoformerEncoder
+
+
+@require_torch
+class AutoformerModelTester:
+ def __init__(
+ self,
+ parent,
+ d_model=16,
+ batch_size=13,
+ prediction_length=7,
+ context_length=14,
+ label_length=10,
+ cardinality=19,
+ embedding_dimension=5,
+ num_time_features=4,
+ is_training=True,
+ hidden_size=16,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ lags_sequence=[1, 2, 3, 4, 5],
+ moving_average=25,
+ autocorrelation_factor=5,
+ ):
+ self.d_model = d_model
+ self.parent = parent
+ self.batch_size = batch_size
+ self.prediction_length = prediction_length
+ self.context_length = context_length
+ self.cardinality = cardinality
+ self.num_time_features = num_time_features
+ self.lags_sequence = lags_sequence
+ self.embedding_dimension = embedding_dimension
+ self.is_training = is_training
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+
+ self.encoder_seq_length = context_length
+ self.decoder_seq_length = prediction_length + label_length
+ self.label_length = label_length
+
+ self.moving_average = moving_average
+ self.autocorrelation_factor = autocorrelation_factor
+
+ def get_config(self):
+ return AutoformerConfig(
+ d_model=self.d_model,
+ encoder_layers=self.num_hidden_layers,
+ decoder_layers=self.num_hidden_layers,
+ encoder_attention_heads=self.num_attention_heads,
+ decoder_attention_heads=self.num_attention_heads,
+ encoder_ffn_dim=self.intermediate_size,
+ decoder_ffn_dim=self.intermediate_size,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ prediction_length=self.prediction_length,
+ context_length=self.context_length,
+ label_length=self.label_length,
+ lags_sequence=self.lags_sequence,
+ num_time_features=self.num_time_features,
+ num_static_categorical_features=1,
+ cardinality=[self.cardinality],
+ embedding_dimension=[self.embedding_dimension],
+ moving_average=self.moving_average,
+ scaling="std", # we need std to get non-zero `loc`
+ )
+
+ def prepare_autoformer_inputs_dict(self, config):
+ _past_length = config.context_length + max(config.lags_sequence)
+
+ static_categorical_features = ids_tensor([self.batch_size, 1], config.cardinality[0])
+ past_time_features = floats_tensor([self.batch_size, _past_length, config.num_time_features])
+ past_values = floats_tensor([self.batch_size, _past_length])
+ past_observed_mask = floats_tensor([self.batch_size, _past_length]) > 0.5
+
+ # decoder inputs
+ future_time_features = floats_tensor([self.batch_size, config.prediction_length, config.num_time_features])
+ future_values = floats_tensor([self.batch_size, config.prediction_length])
+
+ inputs_dict = {
+ "past_values": past_values,
+ "static_categorical_features": static_categorical_features,
+ "past_time_features": past_time_features,
+ "past_observed_mask": past_observed_mask,
+ "future_time_features": future_time_features,
+ "future_values": future_values,
+ }
+ return inputs_dict
+
+ def prepare_config_and_inputs(self):
+ config = self.get_config()
+ inputs_dict = self.prepare_autoformer_inputs_dict(config)
+ return config, inputs_dict
+
+ def prepare_config_and_inputs_for_common(self):
+ config, inputs_dict = self.prepare_config_and_inputs()
+ return config, inputs_dict
+
+ def check_encoder_decoder_model_standalone(self, config, inputs_dict):
+ model = AutoformerModel(config=config).to(torch_device).eval()
+ outputs = model(**inputs_dict)
+
+ encoder_last_hidden_state = outputs.encoder_last_hidden_state
+ last_hidden_state = outputs.last_hidden_state
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ encoder = model.get_encoder()
+ encoder.save_pretrained(tmpdirname)
+ encoder = AutoformerEncoder.from_pretrained(tmpdirname).to(torch_device)
+
+ transformer_inputs, feature, _, _, _ = model.create_network_inputs(**inputs_dict)
+ seasonal_input, trend_input = model.decomposition_layer(transformer_inputs[:, : config.context_length, ...])
+
+ enc_input = torch.cat(
+ (transformer_inputs[:, : config.context_length, ...], feature[:, : config.context_length, ...]),
+ dim=-1,
+ )
+ encoder_last_hidden_state_2 = encoder(inputs_embeds=enc_input)[0]
+ self.parent.assertTrue((encoder_last_hidden_state_2 - encoder_last_hidden_state).abs().max().item() < 1e-3)
+
+ mean = (
+ torch.mean(transformer_inputs[:, : config.context_length, ...], dim=1)
+ .unsqueeze(1)
+ .repeat(1, config.prediction_length, 1)
+ )
+ zeros = torch.zeros(
+ [transformer_inputs.shape[0], config.prediction_length, transformer_inputs.shape[2]],
+ device=enc_input.device,
+ )
+
+ dec_input = torch.cat(
+ (
+ torch.cat((seasonal_input[:, -config.label_length :, ...], zeros), dim=1),
+ feature[:, config.context_length - config.label_length :, ...],
+ ),
+ dim=-1,
+ )
+ trend_init = torch.cat(
+ (
+ torch.cat((trend_input[:, -config.label_length :, ...], mean), dim=1),
+ feature[:, config.context_length - config.label_length :, ...],
+ ),
+ dim=-1,
+ )
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ decoder = model.get_decoder()
+ decoder.save_pretrained(tmpdirname)
+ decoder = AutoformerDecoder.from_pretrained(tmpdirname).to(torch_device)
+
+ last_hidden_state_2 = decoder(
+ trend=trend_init,
+ inputs_embeds=dec_input,
+ encoder_hidden_states=encoder_last_hidden_state,
+ )[0]
+
+ self.parent.assertTrue((last_hidden_state_2 - last_hidden_state).abs().max().item() < 1e-3)
+
+
+@require_torch
+class AutoformerModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (AutoformerModel, AutoformerForPrediction) if is_torch_available() else ()
+ pipeline_model_mapping = {"feature-extraction": AutoformerModel} if is_torch_available() else {}
+ test_pruning = False
+ test_head_masking = False
+ test_missing_keys = False
+ test_torchscript = False
+ test_inputs_embeds = False
+
+ def setUp(self):
+ self.model_tester = AutoformerModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=AutoformerConfig, has_text_modality=False)
+
+ # TODO: (ydshieh) Fix the wrong logic for `tmp_delay` is possible
+ @unittest.skip(
+ reason="The computation of `tmp_delay` in `AutoformerAttention.forward` seems wrong, see PR #12345. Also `topk` is used to compute indices which is not stable."
+ )
+ def test_batching_equivalence(self):
+ super().test_batching_equivalence()
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_save_load_strict(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs()
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
+ self.assertEqual(info["missing_keys"], [])
+
+ def test_encoder_decoder_model_standalone(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
+ self.model_tester.check_encoder_decoder_model_standalone(*config_and_inputs)
+
+ @unittest.skip(reason="Model has no tokens embeddings")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ # # Input is 'static_categorical_features' not 'input_ids'
+ def test_model_main_input_name(self):
+ model_signature = inspect.signature(getattr(AutoformerModel, "forward"))
+ # The main input is the name of the argument after `self`
+ observed_main_input_name = list(model_signature.parameters.keys())[1]
+ self.assertEqual(AutoformerModel.main_input_name, observed_main_input_name)
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = [
+ "past_values",
+ "past_time_features",
+ "past_observed_mask",
+ "static_categorical_features",
+ "static_real_features",
+ "future_values",
+ "future_time_features",
+ ]
+
+ if model.__class__.__name__ in ["AutoformerForPrediction"]:
+ expected_arg_names.append("future_observed_mask")
+
+ expected_arg_names.extend(
+ [
+ "decoder_attention_mask",
+ "head_mask",
+ "decoder_head_mask",
+ "cross_attn_head_mask",
+ "encoder_outputs",
+ "past_key_values",
+ "output_hidden_states",
+ "output_attentions",
+ "use_cache",
+ "return_dict",
+ ]
+ )
+
+ self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
+
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ seq_len = getattr(self.model_tester, "seq_length", None)
+ decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len)
+ encoder_seq_length = getattr(self.model_tester, "encoder_seq_length", seq_len)
+ d_model = getattr(self.model_tester, "d_model", None)
+ num_attention_heads = getattr(self.model_tester, "num_attention_heads", None)
+ dim = d_model // num_attention_heads
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class._from_config(config, attn_implementation="eager")
+ config = model.config
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, encoder_seq_length, dim],
+ )
+ out_len = len(outputs)
+
+ correct_outlen = 7
+
+ if "last_hidden_state" in outputs:
+ correct_outlen += 1
+
+ if "trend" in outputs:
+ correct_outlen += 1
+
+ if "past_key_values" in outputs:
+ correct_outlen += 1 # past_key_values have been returned
+
+ if "loss" in outputs:
+ correct_outlen += 1
+
+ if "params" in outputs:
+ correct_outlen += 1
+
+ self.assertEqual(out_len, correct_outlen)
+
+ # decoder attentions
+ decoder_attentions = outputs.decoder_attentions
+ self.assertIsInstance(decoder_attentions, (list, tuple))
+ self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(decoder_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, decoder_seq_length, dim],
+ )
+
+ # cross attentions
+ cross_attentions = outputs.cross_attentions
+ self.assertIsInstance(cross_attentions, (list, tuple))
+ self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(cross_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, decoder_seq_length, dim],
+ )
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ self.assertEqual(out_len + 2, len(outputs))
+
+ self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+
+ self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, encoder_seq_length, dim],
+ )
+
+ @is_flaky()
+ def test_retain_grad_hidden_states_attentions(self):
+ super().test_retain_grad_hidden_states_attentions()
+
+ @unittest.skip(reason="Model does not have input embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+
+def prepare_batch(filename="train-batch.pt"):
+ file = hf_hub_download(repo_id="hf-internal-testing/tourism-monthly-batch", filename=filename, repo_type="dataset")
+ check_torch_load_is_safe()
+ batch = torch.load(file, map_location=torch_device, weights_only=True)
+ return batch
+
+
+@require_torch
+@slow
+class AutoformerModelIntegrationTests(unittest.TestCase):
+ def test_inference_no_head(self):
+ model = AutoformerModel.from_pretrained("huggingface/autoformer-tourism-monthly").to(torch_device)
+ batch = prepare_batch()
+
+ with torch.no_grad():
+ output = model(
+ past_values=batch["past_values"],
+ past_time_features=batch["past_time_features"],
+ past_observed_mask=batch["past_observed_mask"],
+ static_categorical_features=batch["static_categorical_features"],
+ future_values=batch["future_values"],
+ future_time_features=batch["future_time_features"],
+ )[0]
+
+ expected_shape = torch.Size(
+ (64, model.config.prediction_length + model.config.label_length, model.config.feature_size)
+ )
+ self.assertEqual(output.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[0.3593, -1.3398, 0.6330], [0.2279, 1.5396, -0.1792], [0.0450, 1.3225, -0.2335]], device=torch_device
+ )
+ torch.testing.assert_close(output[0, :3, :3], expected_slice, rtol=TOLERANCE, atol=TOLERANCE)
+
+ def test_inference_head(self):
+ model = AutoformerForPrediction.from_pretrained("huggingface/autoformer-tourism-monthly").to(torch_device)
+ batch = prepare_batch("val-batch.pt")
+ with torch.no_grad():
+ output = model(
+ past_values=batch["past_values"],
+ past_time_features=batch["past_time_features"],
+ past_observed_mask=batch["past_observed_mask"],
+ static_categorical_features=batch["static_categorical_features"],
+ ).encoder_last_hidden_state
+ expected_shape = torch.Size((64, model.config.context_length, model.config.d_model))
+ self.assertEqual(output.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[-0.0734, -0.9036, 0.8358], [4.7186, 2.4113, 1.9581], [1.7953, 2.3558, 1.2970]], device=torch_device
+ )
+ torch.testing.assert_close(output[0, :3, :3], expected_slice, rtol=TOLERANCE, atol=TOLERANCE)
+
+ def test_seq_to_seq_generation(self):
+ model = AutoformerForPrediction.from_pretrained("huggingface/autoformer-tourism-monthly").to(torch_device)
+ batch = prepare_batch("val-batch.pt")
+ with torch.no_grad():
+ outputs = model.generate(
+ static_categorical_features=batch["static_categorical_features"],
+ past_time_features=batch["past_time_features"],
+ past_values=batch["past_values"],
+ future_time_features=batch["future_time_features"],
+ past_observed_mask=batch["past_observed_mask"],
+ )
+ expected_shape = torch.Size((64, model.config.num_parallel_samples, model.config.prediction_length))
+ self.assertEqual(outputs.sequences.shape, expected_shape)
+
+ expected_slice = torch.tensor([3130.6763, 4056.5293, 7053.0786], device=torch_device)
+ mean_prediction = outputs.sequences.mean(dim=1)
+ torch.testing.assert_close(mean_prediction[0, -3:], expected_slice, rtol=1e-1, atol=1e-1)
diff --git a/transformers/tests/models/aya_vision/__init__.py b/transformers/tests/models/aya_vision/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/aya_vision/test_modeling_aya_vision.py b/transformers/tests/models/aya_vision/test_modeling_aya_vision.py
new file mode 100644
index 0000000000000000000000000000000000000000..d472e0eb90f134223c02184f453f6aec9330076e
--- /dev/null
+++ b/transformers/tests/models/aya_vision/test_modeling_aya_vision.py
@@ -0,0 +1,569 @@
+# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch GotOcr2 model."""
+
+import unittest
+
+import pytest
+from parameterized import parameterized
+
+from transformers import (
+ AutoProcessor,
+ AyaVisionConfig,
+ is_torch_available,
+)
+from transformers.testing_utils import (
+ Expectations,
+ cleanup,
+ get_device_properties,
+ require_deterministic_for_xpu,
+ require_read_token,
+ require_torch,
+ require_torch_accelerator,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ AyaVisionForConditionalGeneration,
+ AyaVisionModel,
+ )
+
+
+class AyaVisionVisionText2TextModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=3,
+ seq_length=7,
+ vision_feature_layer=-1,
+ downsample_factor=2,
+ ignore_index=-100,
+ bos_token_id=0,
+ eos_token_id=0,
+ pad_token_id=0,
+ image_token_index=2,
+ num_channels=3,
+ image_size=64,
+ model_type="aya_vision",
+ is_training=True,
+ text_config={
+ "model_type": "cohere2",
+ "vocab_size": 99,
+ "hidden_size": 128,
+ "intermediate_size": 37,
+ "num_hidden_layers": 4,
+ "num_attention_heads": 4,
+ "output_channels": 64,
+ "hidden_act": "silu",
+ "max_position_embeddings": 512,
+ "tie_word_embeddings": True,
+ "bos_token_id": 0,
+ "eos_token_id": 0,
+ "pad_token_id": 0,
+ },
+ vision_config={
+ "model_type": "siglip_vision_model",
+ "hidden_size": 32,
+ "num_hidden_layers": 2,
+ "num_attention_heads": 4,
+ "intermediate_size": 128,
+ "image_size": 64,
+ "patch_size": 8,
+ "vision_use_head": False,
+ },
+ ):
+ self.parent = parent
+ self.ignore_index = ignore_index
+ self.bos_token_id = bos_token_id
+ self.eos_token_id = eos_token_id
+ self.pad_token_id = pad_token_id
+ self.image_token_index = image_token_index
+ self.model_type = model_type
+ self.text_config = text_config
+ self.vision_config = vision_config
+ self.batch_size = batch_size
+ self.vision_feature_layer = vision_feature_layer
+ self.downsample_factor = downsample_factor
+ self.is_training = is_training
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.image_seq_length = (image_size // (vision_config["patch_size"] * downsample_factor)) ** 2
+ self.seq_length = seq_length + self.image_seq_length
+
+ self.num_hidden_layers = text_config["num_hidden_layers"]
+ self.vocab_size = text_config["vocab_size"]
+ self.hidden_size = text_config["hidden_size"]
+ self.num_attention_heads = text_config["num_attention_heads"]
+
+ def get_config(self):
+ return AyaVisionConfig(
+ text_config=self.text_config,
+ vision_config=self.vision_config,
+ model_type=self.model_type,
+ bos_token_id=self.bos_token_id,
+ eos_token_id=self.eos_token_id,
+ pad_token_id=self.pad_token_id,
+ image_token_index=self.image_token_index,
+ vision_feature_layer=self.vision_feature_layer,
+ downsample_factor=self.downsample_factor,
+ )
+
+ def prepare_config_and_inputs(self):
+ config = self.get_config()
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ return config, pixel_values
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+ attention_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
+ # input_ids[:, -1] = self.pad_token_id
+ input_ids[input_ids == self.image_token_index] = self.pad_token_id
+ input_ids[:, : self.image_seq_length] = self.image_token_index
+
+ inputs_dict = {
+ "pixel_values": pixel_values,
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class AyaVisionModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ AyaVisionModel,
+ AyaVisionForConditionalGeneration,
+ )
+ if is_torch_available()
+ else ()
+ )
+ all_generative_model_classes = (AyaVisionForConditionalGeneration,) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "image-text-to-text": AyaVisionForConditionalGeneration,
+ }
+ if is_torch_available()
+ else {}
+ )
+ fx_compatible = False
+ test_pruning = False
+ test_torchscript = False
+ test_head_masking = False
+ _is_composite = True
+
+ def setUp(self):
+ self.model_tester = AyaVisionVisionText2TextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=AyaVisionConfig, has_text_modality=False)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip("Failing because of unique cache (HybridCache)")
+ def test_model_outputs_equivalence(self, **kwargs):
+ pass
+
+ @unittest.skip("Cohere2's forcefully disables sdpa due to softcapping")
+ def test_sdpa_can_dispatch_non_composite_models(self):
+ pass
+
+ @unittest.skip("Cohere2's eager attn/sdpa attn outputs are expected to be different")
+ def test_eager_matches_sdpa_generate(self):
+ pass
+
+ @parameterized.expand([("random",), ("same",)])
+ @pytest.mark.generate
+ @unittest.skip("Cohere2 has HybridCache which is not compatible with assisted decoding")
+ def test_assisted_decoding_matches_greedy_search(self, assistant_type):
+ pass
+
+ @unittest.skip("Cohere2 has HybridCache which is not compatible with assisted decoding")
+ def test_prompt_lookup_decoding_matches_greedy_search(self, assistant_type):
+ pass
+
+ @pytest.mark.generate
+ @unittest.skip("Cohere2 has HybridCache which is not compatible with assisted decoding")
+ def test_assisted_decoding_sample(self):
+ pass
+
+ @unittest.skip("Cohere2 has HybridCache which is not compatible with dola decoding")
+ def test_dola_decoding_sample(self):
+ pass
+
+ @unittest.skip("Cohere2 has HybridCache and doesn't support continue from past kv")
+ def test_generate_continue_from_past_key_values(self):
+ pass
+
+ @unittest.skip("Cohere2 has HybridCache and doesn't support low_memory generation")
+ def test_beam_search_low_memory(self):
+ pass
+
+ @unittest.skip("Cohere2 has HybridCache and doesn't support contrastive generation")
+ def test_contrastive_generate(self):
+ pass
+
+ @unittest.skip("Cohere2 has HybridCache and doesn't support contrastive generation")
+ def test_contrastive_generate_dict_outputs_use_cache(self):
+ pass
+
+ @unittest.skip("Cohere2 has HybridCache and doesn't support contrastive generation")
+ def test_contrastive_generate_low_memory(self):
+ pass
+
+ @unittest.skip("Cohere2 has HybridCache and doesn't support StaticCache. Though it could, it shouldn't support.")
+ def test_generate_with_static_cache(self):
+ pass
+
+ @unittest.skip("Cohere2 has HybridCache and doesn't support StaticCache. Though it could, it shouldn't support.")
+ def test_generate_from_inputs_embeds_with_static_cache(self):
+ pass
+
+ @unittest.skip("Failing because of unique cache (HybridCache)")
+ def test_multi_gpu_data_parallel_forward(self):
+ pass
+
+ @unittest.skip(reason="SiglipVisionModel does not support standalone training")
+ def test_training(self):
+ pass
+
+ @unittest.skip(reason="SiglipVisionModel does not support standalone training")
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(reason="SiglipVisionModel does not support standalone training")
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(reason="SiglipVisionModel does not support standalone training")
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @unittest.skip(reason="Siglip uses the same initialization scheme as the Flax original implementation")
+ def test_initialization(self):
+ pass
+
+ @unittest.skip(reason="Compile not yet supported because in LLava models")
+ def test_sdpa_can_compile_dynamic(self):
+ pass
+
+ # todo: yoni - fix or improve the test
+ @unittest.skip("Difference is slightly higher than the threshold")
+ def test_batching_equivalence(self):
+ pass
+
+
+@require_read_token
+@require_torch
+class AyaVisionIntegrationTest(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls):
+ cls.model_checkpoint = "CohereForAI/aya-vision-8b"
+ cls.model = None
+
+ @classmethod
+ def tearDownClass(cls):
+ del cls.model
+ cleanup(torch_device, gc_collect=True)
+
+ def tearDown(self):
+ cleanup(torch_device, gc_collect=True)
+
+ @classmethod
+ def get_model(cls):
+ # Use 4-bit on T4
+ device_type, major, _ = get_device_properties()
+ load_in_4bit = (device_type == "cuda") and (major < 8)
+ torch_dtype = None if load_in_4bit else torch.float16
+
+ if cls.model is None:
+ cls.model = AyaVisionForConditionalGeneration.from_pretrained(
+ cls.model_checkpoint,
+ device_map=torch_device,
+ torch_dtype=torch_dtype,
+ load_in_4bit=load_in_4bit,
+ )
+ return cls.model
+
+ @slow
+ @require_torch_accelerator
+ def test_small_model_integration_forward(self):
+ processor = AutoProcessor.from_pretrained(self.model_checkpoint)
+ model = self.get_model()
+ messages = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": "http://images.cocodataset.org/val2017/000000039769.jpg"},
+ {"type": "text", "text": "Please describe the image explicitly."},
+ ],
+ }
+ ]
+
+ inputs = processor.apply_chat_template(
+ messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt"
+ ).to(torch_device, dtype=torch.float16)
+ # Forward
+ with torch.inference_mode():
+ output = model(**inputs)
+
+ actual_logits = output.logits[0, -1, :5].cpu()
+
+ EXPECTED_LOGITS = Expectations(
+ {
+ ("xpu", 3): [0.4109, 0.1532, 0.8018, 2.1328, 0.5483],
+ # 4-bit
+ ("cuda", 7): [0.1097, 0.3481, 3.8340, 9.7969, 2.0488],
+ ("cuda", 8): [1.6396, 0.6094, 3.1992, 8.5234, 2.1875],
+ }
+ ) # fmt: skip
+ expected_logits = torch.tensor(EXPECTED_LOGITS.get_expectation(), dtype=torch.float16)
+
+ self.assertTrue(
+ torch.allclose(actual_logits, expected_logits, atol=0.1),
+ f"Actual logits: {actual_logits}"
+ f"\nExpected logits: {expected_logits}"
+ f"\nDifference: {torch.abs(actual_logits - expected_logits)}",
+ )
+
+ @slow
+ @require_torch_accelerator
+ @require_deterministic_for_xpu
+ def test_small_model_integration_generate_text_only(self):
+ processor = AutoProcessor.from_pretrained(self.model_checkpoint)
+ model = self.get_model()
+ messages = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "Write a haiku"},
+ ],
+ }
+ ]
+
+ inputs = processor.apply_chat_template(
+ messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt"
+ ).to(torch_device, dtype=torch.float16)
+ with torch.no_grad():
+ generate_ids = model.generate(**inputs, max_new_tokens=25, do_sample=False)
+ decoded_output = processor.decode(
+ generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True
+ )
+
+ expected_outputs = Expectations(
+ {
+ ("xpu", 3): "Whispers on the breeze,\nLeaves dance under moonlit skies,\nNature's quiet song.",
+ # 4-bit
+ ("cuda", 7): "Sure, here's a haiku for you:\n\nMorning dew sparkles,\nPetals unfold in sunlight,\n",
+ ("cuda", 8): "Whispers on the breeze,\nLeaves dance under moonlit skies,\nNature's quiet song.",
+ }
+ ) # fmt: skip
+ expected_output = expected_outputs.get_expectation()
+
+ self.assertEqual(decoded_output, expected_output)
+
+ @slow
+ @require_torch_accelerator
+ @require_deterministic_for_xpu
+ def test_small_model_integration_generate_chat_template(self):
+ processor = AutoProcessor.from_pretrained(self.model_checkpoint)
+ model = self.get_model()
+ messages = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": "http://images.cocodataset.org/val2017/000000039769.jpg"},
+ {"type": "text", "text": "Please describe the image explicitly."},
+ ],
+ }
+ ]
+
+ inputs = processor.apply_chat_template(
+ messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt"
+ ).to(torch_device, dtype=torch.float16)
+ with torch.no_grad():
+ generate_ids = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+ decoded_output = processor.decode(
+ generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True
+ )
+
+ expected_outputs = Expectations(
+ {
+ ("xpu", 3): 'The image depicts a cozy scene of two cats resting on a bright pink blanket. The cats,',
+ # 4-bit
+ ("cuda", 7): 'The image depicts two cats comfortably resting on a pink blanket spread across a sofa. The cats,',
+ ("cuda", 8): 'The image depicts a cozy scene of two cats resting on a bright pink blanket. The cats,',
+ }
+ ) # fmt: skip
+ expected_output = expected_outputs.get_expectation()
+
+ self.assertEqual(decoded_output, expected_output)
+
+ @slow
+ @require_torch_accelerator
+ def test_small_model_integration_batched_generate(self):
+ processor = AutoProcessor.from_pretrained(self.model_checkpoint)
+ model = self.get_model()
+ # Prepare inputs
+ messages = [
+ [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": "https://llava-vl.github.io/static/images/view.jpg"},
+ {"type": "text", "text": "Write a haiku for this image"},
+ ],
+ },
+ ],
+ [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": "https://www.ilankelman.org/stopsigns/australia.jpg"},
+ {"type": "text", "text": "Describe this image"},
+ ],
+ },
+ ],
+ ]
+ inputs = processor.apply_chat_template(
+ messages, padding=True, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt"
+ ).to(model.device, dtype=torch.float16)
+
+ output = model.generate(**inputs, do_sample=False, max_new_tokens=25)
+
+ # Check first output
+ decoded_output = processor.decode(output[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
+ expected_outputs = Expectations(
+ {
+ ("xpu", 3): "Wooden path to water,\nMountains echo in stillness,\nPeaceful forest lake.",
+ # 4-bit
+ ("cuda", 7): "Wooden bridge stretches\nMirrored lake below, mountains rise\nPeaceful, serene",
+ ("cuda", 8): 'Wooden path to water,\nMountains echo in stillness,\nPeaceful forest scene.',
+ }
+ ) # fmt: skip
+ expected_output = expected_outputs.get_expectation()
+
+ self.assertEqual(
+ decoded_output,
+ expected_output,
+ f"Decoded output: {decoded_output}\nExpected output: {expected_output}",
+ )
+
+ # Check second output
+ decoded_output = processor.decode(output[1, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
+
+ expected_outputs = Expectations(
+ {
+ ("xpu", 3): 'This image captures a vibrant street scene in a bustling urban area, likely in an Asian city. The focal point is a',
+ # 4-bit
+ ("cuda", 7): 'This vibrant image captures a bustling street scene in a multicultural urban area, featuring a traditional Chinese gate adorned with intricate red and',
+ ("cuda", 8): 'This image captures a vibrant street scene in a bustling urban area, likely in an Asian city. The focal point is a',
+ }
+ ) # fmt: skip
+ expected_output = expected_outputs.get_expectation()
+
+ self.assertEqual(
+ decoded_output,
+ expected_output,
+ f"Decoded output: {decoded_output}\nExpected output: {expected_output}",
+ )
+
+ @slow
+ @require_torch_accelerator
+ @require_deterministic_for_xpu
+ def test_small_model_integration_batched_generate_multi_image(self):
+ processor = AutoProcessor.from_pretrained(self.model_checkpoint)
+ model = self.get_model()
+ # Prepare inputs
+ messages = [
+ [
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": "https://llava-vl.github.io/static/images/view.jpg"},
+ {"type": "text", "text": "Write a haiku for this image"},
+ ],
+ },
+ ],
+ [
+ {
+ "role": "user",
+ "content": [
+ {
+ "type": "image",
+ "url": "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg",
+ },
+ {
+ "type": "image",
+ "url": "https://thumbs.dreamstime.com/b/golden-gate-bridge-san-francisco-purple-flowers-california-echium-candicans-36805947.jpg",
+ },
+ {
+ "type": "text",
+ "text": "These images depict two different landmarks. Can you identify them?",
+ },
+ ],
+ },
+ ],
+ ]
+ inputs = processor.apply_chat_template(
+ messages, padding=True, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt"
+ ).to(model.device, dtype=torch.float16)
+ output = model.generate(**inputs, do_sample=False, max_new_tokens=25)
+
+ # Check first output
+ decoded_output = processor.decode(output[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
+ # Batching seems to alter the output slightly, but it is also the case in the original implementation. This seems to be expected: https://github.com/huggingface/transformers/issues/23017#issuecomment-1649630232
+ expected_outputs = Expectations(
+ {
+ ("xpu", 3): "Wooden path to water,\nMountains echo in stillness,\nPeaceful forest lake.",
+ ("cuda", 7): 'Wooden bridge stretches\nMirrored lake below, mountains rise\nPeaceful, serene',
+ ("cuda", 8): 'Wooden path to water,\nMountains echo in stillness,\nPeaceful forest scene.',
+ }
+ ) # fmt: skip
+ expected_output = expected_outputs.get_expectation()
+
+ self.assertEqual(
+ decoded_output,
+ expected_output,
+ f"Decoded output: {decoded_output}\nExpected output: {expected_output}",
+ )
+
+ # Check second output
+ decoded_output = processor.decode(output[1, inputs["input_ids"].shape[1] :], skip_special_tokens=True)
+ expected_outputs = Expectations(
+ {
+ ("xpu", 3): "The first image showcases the Statue of Liberty, a colossal neoclassical sculpture on Liberty Island in New York Harbor. Standing at ",
+ ("cuda", 7): 'The first image showcases the Statue of Liberty, a monumental sculpture located on Liberty Island in New York Harbor. Standing atop a',
+ ("cuda", 8): 'The first image showcases the Statue of Liberty, a colossal neoclassical sculpture on Liberty Island in New York Harbor. Standing at ',
+ }
+ ) # fmt: skip
+ expected_output = expected_outputs.get_expectation()
+
+ self.assertEqual(
+ decoded_output,
+ expected_output,
+ f"Decoded output: {decoded_output}\nExpected output: {expected_output}",
+ )
diff --git a/transformers/tests/models/aya_vision/test_processor_aya_vision.py b/transformers/tests/models/aya_vision/test_processor_aya_vision.py
new file mode 100644
index 0000000000000000000000000000000000000000..4e17bea44fa30eebf4cfede06e0e47f865ff5011
--- /dev/null
+++ b/transformers/tests/models/aya_vision/test_processor_aya_vision.py
@@ -0,0 +1,148 @@
+# Copyright 2025 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import shutil
+import tempfile
+import unittest
+
+from transformers import AutoProcessor, AutoTokenizer, AyaVisionProcessor
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_processing_common import ProcessorTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+
+if is_vision_available():
+ from transformers import GotOcr2ImageProcessor
+
+
+@require_vision
+class AyaVisionProcessorTest(ProcessorTesterMixin, unittest.TestCase):
+ processor_class = AyaVisionProcessor
+
+ @classmethod
+ def setUpClass(cls):
+ cls.tmpdirname = tempfile.mkdtemp()
+
+ image_processor = GotOcr2ImageProcessor(
+ do_resize=True,
+ size={"height": 20, "width": 20},
+ max_patches=2,
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_normalize=True,
+ image_mean=[0.485, 0.456, 0.406],
+ image_std=[0.229, 0.224, 0.225],
+ do_convert_rgb=True,
+ )
+ tokenizer = AutoTokenizer.from_pretrained(
+ "hf-internal-testing/namespace-CohereForAI-repo_name_aya-vision-8b", padding_side="left"
+ )
+ processor_kwargs = cls.prepare_processor_dict()
+ processor = AyaVisionProcessor.from_pretrained(
+ "hf-internal-testing/namespace-CohereForAI-repo_name_aya-vision-8b",
+ image_processor=image_processor,
+ tokenizer=tokenizer,
+ **processor_kwargs,
+ )
+ processor.save_pretrained(cls.tmpdirname)
+ cls.image_token = processor.image_token
+
+ @staticmethod
+ def prepare_processor_dict():
+ return {"patch_size": 10, "img_size": 20}
+
+ def get_tokenizer(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).tokenizer
+
+ def get_image_processor(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).image_processor
+
+ def get_processor(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs)
+
+ @classmethod
+ def tearDownClass(cls):
+ shutil.rmtree(cls.tmpdirname, ignore_errors=True)
+
+ @require_torch
+ def test_process_interleaved_images_videos(self):
+ processor = self.get_processor()
+
+ messages = [
+ [
+ {
+ "role": "user",
+ "content": [
+ {
+ "type": "image",
+ "url": "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg",
+ },
+ {
+ "type": "image",
+ "url": "https://thumbs.dreamstime.com/b/golden-gate-bridge-san-francisco-purple-flowers-california-echium-candicans-36805947.jpg",
+ },
+ {"type": "text", "text": "What are the differences between these two images?"},
+ ],
+ },
+ ],
+ [
+ {
+ "role": "user",
+ "content": [
+ {
+ "type": "image",
+ "url": "https://llava-vl.github.io/static/images/view.jpg",
+ },
+ {"type": "text", "text": "Write a haiku for this image"},
+ ],
+ }
+ ],
+ ]
+
+ inputs_batched = processor.apply_chat_template(
+ messages,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+ padding=True,
+ )
+
+ # Process non batched inputs to check if the pixel_values and input_ids are reconstructed in the correct order when batched together
+ images_patches_index = 0
+ for i, message in enumerate(messages):
+ inputs = processor.apply_chat_template(
+ message,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+ padding=True,
+ )
+ # We slice with [-inputs["input_ids"].shape[1] :] as the input_ids are left padded
+ torch.testing.assert_close(
+ inputs["input_ids"][0], inputs_batched["input_ids"][i][-inputs["input_ids"].shape[1] :]
+ )
+ torch.testing.assert_close(
+ inputs["pixel_values"],
+ inputs_batched["pixel_values"][
+ images_patches_index : images_patches_index + inputs["pixel_values"].shape[0]
+ ],
+ )
+ images_patches_index += inputs["pixel_values"].shape[0]
diff --git a/transformers/tests/models/bark/__init__.py b/transformers/tests/models/bark/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/bark/test_modeling_bark.py b/transformers/tests/models/bark/test_modeling_bark.py
new file mode 100644
index 0000000000000000000000000000000000000000..701cd7938c8c7e787dc8c100f6807fef8c6e9562
--- /dev/null
+++ b/transformers/tests/models/bark/test_modeling_bark.py
@@ -0,0 +1,1345 @@
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Bark model."""
+
+import copy
+import inspect
+import tempfile
+import unittest
+
+import pytest
+
+from transformers import (
+ BarkCausalModel,
+ BarkCoarseConfig,
+ BarkConfig,
+ BarkFineConfig,
+ BarkSemanticConfig,
+ is_torch_available,
+)
+from transformers.models.bark.generation_configuration_bark import (
+ BarkCoarseGenerationConfig,
+ BarkFineGenerationConfig,
+ BarkSemanticGenerationConfig,
+)
+from transformers.testing_utils import (
+ backend_torch_accelerator_module,
+ require_flash_attn,
+ require_torch,
+ require_torch_accelerator,
+ require_torch_fp16,
+ require_torch_gpu,
+ slow,
+ torch_device,
+)
+from transformers.utils import cached_property
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
+from ..encodec.test_modeling_encodec import EncodecModelTester
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ BarkCoarseModel,
+ BarkFineModel,
+ BarkModel,
+ BarkProcessor,
+ BarkSemanticModel,
+ )
+
+
+class BarkSemanticModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=3, # need batch_size != num_hidden_layers
+ seq_length=4,
+ is_training=False, # for now training is not supported
+ use_input_mask=True,
+ use_labels=True,
+ vocab_size=33,
+ output_vocab_size=33,
+ hidden_size=16,
+ num_hidden_layers=2,
+ num_attention_heads=2,
+ intermediate_size=15,
+ dropout=0.1,
+ window_size=256,
+ initializer_range=0.02,
+ n_codes_total=8, # for BarkFineModel
+ n_codes_given=1, # for BarkFineModel
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.output_vocab_size = output_vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.window_size = window_size
+ self.initializer_range = initializer_range
+ self.bos_token_id = output_vocab_size - 1
+ self.eos_token_id = output_vocab_size - 1
+ self.pad_token_id = output_vocab_size - 1
+
+ self.n_codes_total = n_codes_total
+ self.n_codes_given = n_codes_given
+
+ self.is_encoder_decoder = False
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ config = self.get_config()
+
+ head_mask = ids_tensor([self.num_hidden_layers, self.num_attention_heads], 2)
+
+ inputs_dict = {
+ "input_ids": input_ids,
+ "head_mask": head_mask,
+ "attention_mask": input_mask,
+ }
+
+ return config, inputs_dict
+
+ def get_config(self):
+ return BarkSemanticConfig(
+ vocab_size=self.vocab_size,
+ output_vocab_size=self.output_vocab_size,
+ hidden_size=self.hidden_size,
+ num_layers=self.num_hidden_layers,
+ num_heads=self.num_attention_heads,
+ use_cache=True,
+ bos_token_id=self.bos_token_id,
+ eos_token_id=self.eos_token_id,
+ pad_token_id=self.pad_token_id,
+ window_size=self.window_size,
+ )
+
+ def get_pipeline_config(self):
+ config = self.get_config()
+ config.vocab_size = 300
+ config.output_vocab_size = 300
+ return config
+
+ def prepare_config_and_inputs_for_common(self):
+ config, inputs_dict = self.prepare_config_and_inputs()
+ return config, inputs_dict
+
+ def create_and_check_decoder_model_past_large_inputs(self, config, inputs_dict):
+ model = BarkSemanticModel(config=config).to(torch_device).eval()
+
+ input_ids = inputs_dict["input_ids"]
+ attention_mask = inputs_dict["attention_mask"]
+
+ # first forward pass
+ outputs = model(input_ids, attention_mask=attention_mask, use_cache=True)
+
+ output, past_key_values = outputs.to_tuple()
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_attn_mask = ids_tensor((self.batch_size, 3), 2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([attention_mask, next_attn_mask], dim=-1)
+
+ output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)["logits"]
+ output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)[
+ "logits"
+ ]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ # test no attention_mask works
+ outputs = model(input_ids, use_cache=True)
+ _, past_key_values = outputs.to_tuple()
+ output_from_no_past = model(next_input_ids)["logits"]
+
+ output_from_past = model(next_tokens, past_key_values=past_key_values)["logits"]
+
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+
+class BarkCoarseModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=3, # need batch_size != num_hidden_layers
+ seq_length=4,
+ is_training=False, # for now training is not supported
+ use_input_mask=True,
+ use_labels=True,
+ vocab_size=33,
+ output_vocab_size=33,
+ hidden_size=16,
+ num_hidden_layers=2,
+ num_attention_heads=2,
+ intermediate_size=15,
+ dropout=0.1,
+ window_size=256,
+ initializer_range=0.02,
+ n_codes_total=8, # for BarkFineModel
+ n_codes_given=1, # for BarkFineModel
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.output_vocab_size = output_vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.window_size = window_size
+ self.initializer_range = initializer_range
+ self.bos_token_id = output_vocab_size - 1
+ self.eos_token_id = output_vocab_size - 1
+ self.pad_token_id = output_vocab_size - 1
+
+ self.n_codes_total = n_codes_total
+ self.n_codes_given = n_codes_given
+
+ self.is_encoder_decoder = False
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ config = self.get_config()
+
+ head_mask = ids_tensor([self.num_hidden_layers, self.num_attention_heads], 2)
+
+ inputs_dict = {
+ "input_ids": input_ids,
+ "head_mask": head_mask,
+ "attention_mask": input_mask,
+ }
+
+ return config, inputs_dict
+
+ def get_config(self):
+ return BarkCoarseConfig(
+ vocab_size=self.vocab_size,
+ output_vocab_size=self.output_vocab_size,
+ hidden_size=self.hidden_size,
+ num_layers=self.num_hidden_layers,
+ num_heads=self.num_attention_heads,
+ use_cache=True,
+ bos_token_id=self.bos_token_id,
+ eos_token_id=self.eos_token_id,
+ pad_token_id=self.pad_token_id,
+ window_size=self.window_size,
+ )
+
+ def get_pipeline_config(self):
+ config = self.get_config()
+ config.vocab_size = 300
+ config.output_vocab_size = 300
+ return config
+
+ def prepare_config_and_inputs_for_common(self):
+ config, inputs_dict = self.prepare_config_and_inputs()
+ return config, inputs_dict
+
+ def create_and_check_decoder_model_past_large_inputs(self, config, inputs_dict):
+ model = BarkCoarseModel(config=config).to(torch_device).eval()
+
+ input_ids = inputs_dict["input_ids"]
+ attention_mask = inputs_dict["attention_mask"]
+
+ # first forward pass
+ outputs = model(input_ids, attention_mask=attention_mask, use_cache=True)
+
+ output, past_key_values = outputs.to_tuple()
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_attn_mask = ids_tensor((self.batch_size, 3), 2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([attention_mask, next_attn_mask], dim=-1)
+
+ output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)["logits"]
+ output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)[
+ "logits"
+ ]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ # test no attention_mask works
+ outputs = model(input_ids, use_cache=True)
+ _, past_key_values = outputs.to_tuple()
+ output_from_no_past = model(next_input_ids)["logits"]
+
+ output_from_past = model(next_tokens, past_key_values=past_key_values)["logits"]
+
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+
+class BarkFineModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=3, # need batch_size != num_hidden_layers
+ seq_length=4,
+ is_training=False, # for now training is not supported
+ use_input_mask=True,
+ use_labels=True,
+ vocab_size=33,
+ output_vocab_size=33,
+ hidden_size=16,
+ num_hidden_layers=2,
+ num_attention_heads=2,
+ intermediate_size=15,
+ dropout=0.1,
+ window_size=256,
+ initializer_range=0.02,
+ n_codes_total=8, # for BarkFineModel
+ n_codes_given=1, # for BarkFineModel
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.output_vocab_size = output_vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.window_size = window_size
+ self.initializer_range = initializer_range
+ self.bos_token_id = output_vocab_size - 1
+ self.eos_token_id = output_vocab_size - 1
+ self.pad_token_id = output_vocab_size - 1
+
+ self.n_codes_total = n_codes_total
+ self.n_codes_given = n_codes_given
+
+ self.is_encoder_decoder = False
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length, self.n_codes_total], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ config = self.get_config()
+
+ head_mask = ids_tensor([self.num_hidden_layers, self.num_attention_heads], 2)
+
+ # randint between self.n_codes_given - 1 and self.n_codes_total - 1
+ codebook_idx = ids_tensor((1,), self.n_codes_total - self.n_codes_given).item() + self.n_codes_given
+
+ inputs_dict = {
+ "codebook_idx": codebook_idx,
+ "input_ids": input_ids,
+ "head_mask": head_mask,
+ "attention_mask": input_mask,
+ }
+
+ return config, inputs_dict
+
+ def get_config(self):
+ return BarkFineConfig(
+ vocab_size=self.vocab_size,
+ output_vocab_size=self.output_vocab_size,
+ hidden_size=self.hidden_size,
+ num_layers=self.num_hidden_layers,
+ num_heads=self.num_attention_heads,
+ use_cache=True,
+ bos_token_id=self.bos_token_id,
+ eos_token_id=self.eos_token_id,
+ pad_token_id=self.pad_token_id,
+ window_size=self.window_size,
+ )
+
+ def get_pipeline_config(self):
+ config = self.get_config()
+ config.vocab_size = 300
+ config.output_vocab_size = 300
+ return config
+
+ def prepare_config_and_inputs_for_common(self):
+ config, inputs_dict = self.prepare_config_and_inputs()
+ return config, inputs_dict
+
+ def create_and_check_decoder_model_past_large_inputs(self, config, inputs_dict):
+ model = BarkFineModel(config=config).to(torch_device).eval()
+
+ input_ids = inputs_dict["input_ids"]
+ attention_mask = inputs_dict["attention_mask"]
+
+ # first forward pass
+ outputs = model(input_ids, attention_mask=attention_mask, use_cache=True)
+
+ output, past_key_values = outputs.to_tuple()
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_attn_mask = ids_tensor((self.batch_size, 3), 2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([attention_mask, next_attn_mask], dim=-1)
+
+ output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)["logits"]
+ output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)[
+ "logits"
+ ]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ # test no attention_mask works
+ outputs = model(input_ids, use_cache=True)
+ _, past_key_values = outputs.to_tuple()
+ output_from_no_past = model(next_input_ids)["logits"]
+
+ output_from_past = model(next_tokens, past_key_values=past_key_values)["logits"]
+
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+
+class BarkModelTester:
+ def __init__(
+ self,
+ parent,
+ semantic_kwargs=None,
+ coarse_acoustics_kwargs=None,
+ fine_acoustics_kwargs=None,
+ codec_kwargs=None,
+ is_training=False, # for now training is not supported
+ ):
+ if semantic_kwargs is None:
+ semantic_kwargs = {}
+ if coarse_acoustics_kwargs is None:
+ coarse_acoustics_kwargs = {}
+ if fine_acoustics_kwargs is None:
+ fine_acoustics_kwargs = {}
+ if codec_kwargs is None:
+ codec_kwargs = {}
+
+ self.parent = parent
+ self.semantic_model_tester = BarkSemanticModelTester(parent, **semantic_kwargs)
+ self.coarse_acoustics_model_tester = BarkCoarseModelTester(parent, **coarse_acoustics_kwargs)
+ self.fine_acoustics_model_tester = BarkFineModelTester(parent, **fine_acoustics_kwargs)
+ self.codec_model_tester = EncodecModelTester(parent, **codec_kwargs)
+
+ self.is_training = is_training
+
+ def get_config(self):
+ return BarkConfig.from_sub_model_configs(
+ self.semantic_model_tester.get_config(),
+ self.coarse_acoustics_model_tester.get_config(),
+ self.fine_acoustics_model_tester.get_config(),
+ self.codec_model_tester.get_config(),
+ )
+
+ def get_pipeline_config(self):
+ config = self.get_config()
+
+ # follow the `get_pipeline_config` of the sub component models
+ config.semantic_config.vocab_size = 300
+ config.coarse_acoustics_config.vocab_size = 300
+ config.fine_acoustics_config.vocab_size = 300
+
+ config.semantic_config.output_vocab_size = 300
+ config.coarse_acoustics_config.output_vocab_size = 300
+ config.fine_acoustics_config.output_vocab_size = 300
+
+ return config
+
+
+@require_torch
+class BarkSemanticModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
+ all_model_classes = (BarkSemanticModel,) if is_torch_available() else ()
+ # `BarkSemanticModel` inherits from `BarkCausalModel`, but requires an advanced generation config.
+ # `BarkCausalModel` does not, so we run generation tests there.
+ all_generative_model_classes = (BarkCausalModel,) if is_torch_available() else ()
+
+ is_encoder_decoder = False
+ fx_compatible = False
+ test_missing_keys = False
+ test_pruning = False
+ test_model_parallel = False
+ # no model_parallel for now
+
+ test_resize_embeddings = True
+
+ def setUp(self):
+ self.model_tester = BarkSemanticModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=BarkSemanticConfig, n_embd=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_save_load_strict(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs()
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
+ self.assertEqual(info["missing_keys"], [])
+
+ def test_decoder_model_past_with_large_inputs(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
+
+ def test_inputs_embeds(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ inputs = copy.deepcopy(self._prepare_for_class(inputs_dict, model_class))
+
+ input_ids = inputs["input_ids"]
+ del inputs["input_ids"]
+
+ wte = model.get_input_embeddings()
+ inputs["input_embeds"] = wte(input_ids)
+
+ with torch.no_grad():
+ model(**inputs)[0]
+
+ # override as the input arg is called "input_embeds", not "inputs_embeds"
+ def test_inputs_embeds_matches_input_ids(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ inputs = copy.deepcopy(self._prepare_for_class(inputs_dict, model_class))
+ with torch.no_grad():
+ out_ids = model(**inputs)[0]
+
+ input_ids = inputs["input_ids"]
+ del inputs["input_ids"]
+
+ wte = model.get_input_embeddings()
+ inputs["input_embeds"] = wte(input_ids)
+ with torch.no_grad():
+ out_embeds = model(**inputs)[0]
+
+ torch.testing.assert_close(out_embeds, out_ids)
+
+ @require_torch_fp16
+ def test_generate_fp16(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs()
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ model = self.all_generative_model_classes[0](config).eval().to(torch_device)
+ model.half()
+ model.generate(input_ids, attention_mask=attention_mask)
+ model.generate(num_beams=4, do_sample=True, early_stopping=False, num_return_sequences=3)
+
+
+@require_torch
+class BarkCoarseModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
+ all_model_classes = (BarkCoarseModel,) if is_torch_available() else ()
+ # `BarkCoarseModel` inherits from `BarkCausalModel`, but requires an advanced generation config.
+ # `BarkCausalModel` does not, so we run generation tests there.
+ all_generative_model_classes = (BarkCausalModel,) if is_torch_available() else ()
+
+ is_encoder_decoder = False
+ fx_compatible = False
+ test_missing_keys = False
+ test_pruning = False
+ test_model_parallel = False
+ # no model_parallel for now
+
+ test_resize_embeddings = True
+
+ def setUp(self):
+ self.model_tester = BarkCoarseModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=BarkCoarseConfig, n_embd=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_save_load_strict(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs()
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
+ self.assertEqual(info["missing_keys"], [])
+
+ def test_decoder_model_past_with_large_inputs(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
+
+ def test_inputs_embeds(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ inputs = copy.deepcopy(self._prepare_for_class(inputs_dict, model_class))
+
+ input_ids = inputs["input_ids"]
+ del inputs["input_ids"]
+
+ wte = model.get_input_embeddings()
+ inputs["input_embeds"] = wte(input_ids)
+
+ with torch.no_grad():
+ model(**inputs)[0]
+
+ # override as the input arg is called "input_embeds", not "inputs_embeds"
+ def test_inputs_embeds_matches_input_ids(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ inputs = copy.deepcopy(self._prepare_for_class(inputs_dict, model_class))
+ with torch.no_grad():
+ out_ids = model(**inputs)[0]
+
+ input_ids = inputs["input_ids"]
+ del inputs["input_ids"]
+
+ wte = model.get_input_embeddings()
+ inputs["input_embeds"] = wte(input_ids)
+ with torch.no_grad():
+ out_embeds = model(**inputs)[0]
+
+ torch.testing.assert_close(out_embeds, out_ids)
+
+ @require_torch_fp16
+ def test_generate_fp16(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs()
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ model = self.all_generative_model_classes[0](config).eval().to(torch_device)
+ model.half()
+ model.generate(input_ids, attention_mask=attention_mask)
+ model.generate(num_beams=4, do_sample=True, early_stopping=False, num_return_sequences=3)
+
+
+@require_torch
+class BarkFineModelTest(ModelTesterMixin, unittest.TestCase):
+ all_model_classes = (BarkFineModel,) if is_torch_available() else ()
+
+ is_encoder_decoder = False
+ fx_compatible = False
+ test_missing_keys = False
+ test_pruning = False
+ # no model_parallel for now
+ test_model_parallel = False
+
+ # torchscript disabled for now because forward with an int
+ test_torchscript = False
+
+ test_resize_embeddings = True
+
+ def setUp(self):
+ self.model_tester = BarkFineModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=BarkFineConfig, n_embd=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_save_load_strict(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs()
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
+ self.assertEqual(info["missing_keys"], [])
+
+ def test_inputs_embeds(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ inputs = copy.deepcopy(self._prepare_for_class(inputs_dict, model_class))
+
+ input_ids = inputs["input_ids"]
+ del inputs["input_ids"]
+
+ wte = model.get_input_embeddings()[inputs_dict["codebook_idx"]]
+
+ inputs["input_embeds"] = wte(input_ids[:, :, inputs_dict["codebook_idx"]])
+
+ with torch.no_grad():
+ model(**inputs)[0]
+
+ @unittest.skip(reason="FineModel relies on codebook idx and does not return same logits")
+ def test_inputs_embeds_matches_input_ids(self):
+ pass
+
+ @require_torch_fp16
+ def test_generate_fp16(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs()
+ input_ids = input_dict["input_ids"]
+ # take first codebook channel
+
+ model = self.all_model_classes[0](config).eval().to(torch_device)
+ model.half()
+
+ # toy generation_configs
+ semantic_generation_config = BarkSemanticGenerationConfig(semantic_vocab_size=0)
+ coarse_generation_config = BarkCoarseGenerationConfig(n_coarse_codebooks=config.n_codes_given)
+ fine_generation_config = BarkFineGenerationConfig(
+ max_fine_history_length=config.block_size // 2,
+ max_fine_input_length=config.block_size,
+ n_fine_codebooks=config.n_codes_total,
+ )
+ codebook_size = config.vocab_size - 1
+
+ model.generate(
+ input_ids,
+ history_prompt=None,
+ temperature=None,
+ semantic_generation_config=semantic_generation_config,
+ coarse_generation_config=coarse_generation_config,
+ fine_generation_config=fine_generation_config,
+ codebook_size=codebook_size,
+ )
+
+ model.generate(
+ input_ids,
+ history_prompt=None,
+ temperature=0.7,
+ semantic_generation_config=semantic_generation_config,
+ coarse_generation_config=coarse_generation_config,
+ fine_generation_config=fine_generation_config,
+ codebook_size=codebook_size,
+ )
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["codebook_idx", "input_ids"]
+ self.assertListEqual(arg_names[:2], expected_arg_names)
+
+ def test_model_get_set_embeddings(self):
+ # one embedding layer per codebook
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings()[0], (torch.nn.Embedding))
+ model.set_input_embeddings(
+ torch.nn.ModuleList([torch.nn.Embedding(10, 10) for _ in range(config.n_codes_total)])
+ )
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x[0], torch.nn.Linear))
+
+ def test_resize_tokens_embeddings(self):
+ # resizing tokens_embeddings of a ModuleList
+ original_config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ if not self.test_resize_embeddings:
+ self.skipTest(reason="test_resize_embeddings is False")
+
+ for model_class in self.all_model_classes:
+ config = copy.deepcopy(original_config)
+ model = model_class(config)
+ model.to(torch_device)
+
+ if self.model_tester.is_training is False:
+ model.eval()
+
+ model_vocab_size = config.vocab_size
+ # Retrieve the embeddings and clone theme
+ model_embed_list = model.resize_token_embeddings(model_vocab_size)
+ cloned_embeddings_list = [model_embed.weight.clone() for model_embed in model_embed_list]
+
+ # Check that resizing the token embeddings with a larger vocab size increases the model's vocab size
+ model_embed_list = model.resize_token_embeddings(model_vocab_size + 10)
+ self.assertEqual(model.config.vocab_size, model_vocab_size + 10)
+
+ # Check that it actually resizes the embeddings matrix for each codebook
+ for model_embed, cloned_embeddings in zip(model_embed_list, cloned_embeddings_list):
+ self.assertEqual(model_embed.weight.shape[0], cloned_embeddings.shape[0] + 10)
+
+ # Check that the model can still do a forward pass successfully (every parameter should be resized)
+ model(**self._prepare_for_class(inputs_dict, model_class))
+
+ # Check that resizing the token embeddings with a smaller vocab size decreases the model's vocab size
+ model_embed_list = model.resize_token_embeddings(model_vocab_size - 15)
+ self.assertEqual(model.config.vocab_size, model_vocab_size - 15)
+ for model_embed, cloned_embeddings in zip(model_embed_list, cloned_embeddings_list):
+ self.assertEqual(model_embed.weight.shape[0], cloned_embeddings.shape[0] - 15)
+
+ # Check that the model can still do a forward pass successfully (every parameter should be resized)
+ # Input ids should be clamped to the maximum size of the vocabulary
+ inputs_dict["input_ids"].clamp_(max=model_vocab_size - 15 - 1)
+
+ model(**self._prepare_for_class(inputs_dict, model_class))
+
+ # Check that adding and removing tokens has not modified the first part of the embedding matrix.
+ # only check for the first embedding matrix
+ models_equal = True
+ for p1, p2 in zip(cloned_embeddings_list[0], model_embed_list[0].weight):
+ if p1.data.ne(p2.data).sum() > 0:
+ models_equal = False
+
+ self.assertTrue(models_equal)
+
+ def test_resize_embeddings_untied(self):
+ # resizing tokens_embeddings of a ModuleList
+ original_config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ if not self.test_resize_embeddings:
+ self.skipTest(reason="test_resize_embeddings is False")
+
+ original_config.tie_word_embeddings = False
+
+ for model_class in self.all_model_classes:
+ config = copy.deepcopy(original_config)
+ model = model_class(config).to(torch_device)
+
+ # if no output embeddings -> leave test
+ if model.get_output_embeddings() is None:
+ continue
+
+ # Check that resizing the token embeddings with a larger vocab size increases the model's vocab size
+ model_vocab_size = config.vocab_size
+ model.resize_token_embeddings(model_vocab_size + 10)
+ self.assertEqual(model.config.vocab_size, model_vocab_size + 10)
+ output_embeds_list = model.get_output_embeddings()
+
+ for output_embeds in output_embeds_list:
+ self.assertEqual(output_embeds.weight.shape[0], model_vocab_size + 10)
+
+ # Check bias if present
+ if output_embeds.bias is not None:
+ self.assertEqual(output_embeds.bias.shape[0], model_vocab_size + 10)
+
+ # Check that the model can still do a forward pass successfully (every parameter should be resized)
+ model(**self._prepare_for_class(inputs_dict, model_class))
+
+ # Check that resizing the token embeddings with a smaller vocab size decreases the model's vocab size
+ model.resize_token_embeddings(model_vocab_size - 15)
+ self.assertEqual(model.config.vocab_size, model_vocab_size - 15)
+ # Check that it actually resizes the embeddings matrix
+ output_embeds_list = model.get_output_embeddings()
+
+ for output_embeds in output_embeds_list:
+ self.assertEqual(output_embeds.weight.shape[0], model_vocab_size - 15)
+ # Check bias if present
+ if output_embeds.bias is not None:
+ self.assertEqual(output_embeds.bias.shape[0], model_vocab_size - 15)
+
+ # Check that the model can still do a forward pass successfully (every parameter should be resized)
+ # Input ids should be clamped to the maximum size of the vocabulary
+ inputs_dict["input_ids"].clamp_(max=model_vocab_size - 15 - 1)
+
+ # Check that the model can still do a forward pass successfully (every parameter should be resized)
+ model(**self._prepare_for_class(inputs_dict, model_class))
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_inference_equivalence(self):
+ for model_class in self.all_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(reason="Model does not support flash_attention_2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_fa = model_class.from_pretrained(
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
+ )
+ model_fa.to(torch_device)
+
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.bfloat16)
+ model.to(torch_device)
+
+ dummy_input = inputs_dict["input_ids"][:1]
+ if dummy_input.dtype in [torch.float32, torch.float16]:
+ dummy_input = dummy_input.to(torch.bfloat16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", None)
+
+ if dummy_attention_mask is not None:
+ dummy_attention_mask = dummy_attention_mask[:1]
+ dummy_attention_mask[:, 1:] = 1
+ dummy_attention_mask[:, :1] = 0
+
+ outputs = model(inputs_dict["codebook_idx"], dummy_input, output_hidden_states=True)
+ outputs_fa = model_fa(inputs_dict["codebook_idx"], dummy_input, output_hidden_states=True)
+
+ logits = outputs.hidden_states[-1]
+ logits_fa = outputs_fa.hidden_states[-1]
+
+ assert torch.allclose(logits_fa, logits, atol=4e-2, rtol=4e-2)
+
+ other_inputs = {"output_hidden_states": True}
+ if dummy_attention_mask is not None:
+ other_inputs["attention_mask"] = dummy_attention_mask
+
+ outputs = model(inputs_dict["codebook_idx"], dummy_input, **other_inputs)
+ outputs_fa = model_fa(inputs_dict["codebook_idx"], dummy_input, **other_inputs)
+
+ logits = outputs.hidden_states[-1]
+ logits_fa = outputs_fa.hidden_states[-1]
+
+ assert torch.allclose(logits_fa[1:], logits[1:], atol=4e-2, rtol=4e-2)
+
+ # check with inference + dropout
+ model.train()
+ _ = model_fa(inputs_dict["codebook_idx"], dummy_input, **other_inputs)
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
+ for model_class in self.all_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(reason="Model does not support flash_attention_2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_fa = model_class.from_pretrained(
+ tmpdirname, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
+ )
+ model_fa.to(torch_device)
+
+ model = model_class.from_pretrained(
+ tmpdirname,
+ torch_dtype=torch.bfloat16,
+ )
+ model.to(torch_device)
+
+ dummy_input = inputs_dict["input_ids"][:1]
+ if dummy_input.dtype in [torch.float32, torch.float16]:
+ dummy_input = dummy_input.to(torch.bfloat16)
+
+ dummy_attention_mask = inputs_dict.get("attention_mask", None)
+
+ if dummy_attention_mask is not None:
+ dummy_attention_mask = dummy_attention_mask[:1]
+ dummy_attention_mask[:, :-1] = 1
+ dummy_attention_mask[:, -1:] = 0
+
+ outputs = model(inputs_dict["codebook_idx"], dummy_input, output_hidden_states=True)
+ outputs_fa = model_fa(inputs_dict["codebook_idx"], dummy_input, output_hidden_states=True)
+
+ logits = outputs.hidden_states[-1]
+ logits_fa = outputs_fa.hidden_states[-1]
+
+ assert torch.allclose(logits_fa, logits, atol=4e-2, rtol=4e-2)
+
+ other_inputs = {
+ "output_hidden_states": True,
+ }
+ if dummy_attention_mask is not None:
+ other_inputs["attention_mask"] = dummy_attention_mask
+
+ outputs = model(inputs_dict["codebook_idx"], dummy_input, **other_inputs)
+ outputs_fa = model_fa(inputs_dict["codebook_idx"], dummy_input, **other_inputs)
+
+ logits = outputs.hidden_states[-1]
+ logits_fa = outputs_fa.hidden_states[-1]
+
+ assert torch.allclose(logits_fa[:-1], logits[:-1], atol=4e-2, rtol=4e-2)
+
+
+@require_torch
+class BarkModelIntegrationTests(unittest.TestCase):
+ @cached_property
+ def model(self):
+ return BarkModel.from_pretrained("suno/bark").to(torch_device)
+
+ @cached_property
+ def processor(self):
+ return BarkProcessor.from_pretrained("suno/bark")
+
+ @cached_property
+ def inputs(self):
+ input_ids = self.processor("In the light of the moon, a little egg lay on a leaf", voice_preset="en_speaker_6")
+
+ for k, v in input_ids.items():
+ input_ids[k] = v.to(torch_device)
+
+ return input_ids
+
+ @cached_property
+ def semantic_generation_config(self):
+ semantic_generation_config = BarkSemanticGenerationConfig(**self.model.generation_config.semantic_config)
+ return semantic_generation_config
+
+ @cached_property
+ def coarse_generation_config(self):
+ coarse_generation_config = BarkCoarseGenerationConfig(**self.model.generation_config.coarse_acoustics_config)
+ return coarse_generation_config
+
+ @cached_property
+ def fine_generation_config(self):
+ fine_generation_config = BarkFineGenerationConfig(**self.model.generation_config.fine_acoustics_config)
+ return fine_generation_config
+
+ def test_model_can_generate(self):
+ # Bark has custom generate without inheriting GenerationMixin. This test could prevent regression.
+ self.assertTrue(self.model.can_generate())
+
+ @slow
+ def test_generate_semantic(self):
+ input_ids = self.inputs
+
+ # check first ids
+ expected_output_ids = [7363, 321, 41, 1461, 6915, 952, 326, 41, 41, 927,] # fmt: skip
+
+ # greedy decoding
+ with torch.no_grad():
+ output_ids = self.model.semantic.generate(
+ **input_ids,
+ do_sample=False,
+ temperature=1.0,
+ semantic_generation_config=self.semantic_generation_config,
+ )
+ self.assertListEqual(output_ids[0, : len(expected_output_ids)].tolist(), expected_output_ids)
+
+ @slow
+ def test_generate_semantic_early_stop(self):
+ input_ids = self.inputs
+ min_eos_p = 0.01
+
+ # check first ids
+ expected_output_ids = [7363, 321, 41, 1461, 6915, 952, 326, 41, 41, 927,] # fmt: skip
+
+ # Should be able to read min_eos_p from kwargs
+ with torch.no_grad():
+ torch.manual_seed(0)
+ output_ids_without_min_eos_p = self.model.semantic.generate(
+ **input_ids,
+ do_sample=False,
+ temperature=0.9,
+ semantic_generation_config=self.semantic_generation_config,
+ )
+ torch.manual_seed(0)
+ output_ids_kwargs = self.model.semantic.generate(
+ **input_ids,
+ do_sample=False,
+ temperature=0.9,
+ semantic_generation_config=self.semantic_generation_config,
+ min_eos_p=min_eos_p,
+ )
+ self.assertListEqual(output_ids_without_min_eos_p[0, : len(expected_output_ids)].tolist(), expected_output_ids)
+ self.assertLess(len(output_ids_kwargs[0, :].tolist()), len(output_ids_without_min_eos_p[0, :].tolist()))
+
+ # Should be able to read min_eos_p from the semantic generation config
+ self.semantic_generation_config.min_eos_p = min_eos_p
+ with torch.no_grad():
+ torch.manual_seed(0)
+ output_ids = self.model.semantic.generate(
+ **input_ids,
+ do_sample=False,
+ temperature=0.9,
+ semantic_generation_config=self.semantic_generation_config,
+ )
+
+ self.assertEqual(output_ids.shape, output_ids_kwargs.shape)
+ self.assertLess(len(output_ids[0, :].tolist()), len(output_ids_without_min_eos_p[0, :].tolist()))
+ self.assertListEqual(output_ids[0, : len(expected_output_ids)].tolist(), expected_output_ids)
+
+ @slow
+ def test_generate_coarse(self):
+ input_ids = self.inputs
+
+ history_prompt = input_ids["history_prompt"]
+
+ # check first ids
+ expected_output_ids = [11018, 11391, 10651, 11418, 10857, 11620, 10642, 11366, 10312, 11528, 10531, 11516, 10474, 11051, 10524, 11051, ] # fmt: skip
+
+ with torch.no_grad():
+ output_ids = self.model.semantic.generate(
+ **input_ids,
+ do_sample=False,
+ temperature=1.0,
+ semantic_generation_config=self.semantic_generation_config,
+ )
+
+ output_ids = self.model.coarse_acoustics.generate(
+ output_ids,
+ history_prompt=history_prompt,
+ do_sample=False,
+ temperature=1.0,
+ semantic_generation_config=self.semantic_generation_config,
+ coarse_generation_config=self.coarse_generation_config,
+ codebook_size=self.model.generation_config.codebook_size,
+ )
+
+ self.assertListEqual(output_ids[0, : len(expected_output_ids)].tolist(), expected_output_ids)
+
+ @slow
+ def test_generate_fine(self):
+ input_ids = self.inputs
+
+ history_prompt = input_ids["history_prompt"]
+
+ # fmt: off
+ expected_output_ids = [
+ [1018, 651, 857, 642, 312, 531, 474, 524, 524, 776,],
+ [367, 394, 596, 342, 504, 492, 27, 27, 822, 822,],
+ [961, 955, 221, 955, 955, 686, 939, 939, 479, 176,],
+ [638, 365, 218, 944, 853, 363, 639, 22, 884, 456,],
+ [302, 912, 524, 38, 174, 209, 879, 23, 910, 227,],
+ [440, 673, 861, 666, 372, 558, 49, 172, 232, 342,],
+ [244, 358, 123, 356, 586, 520, 499, 877, 542, 637,],
+ [806, 685, 905, 848, 803, 810, 921, 208, 625, 203,],
+ ]
+ # fmt: on
+
+ with torch.no_grad():
+ output_ids = self.model.semantic.generate(
+ **input_ids,
+ do_sample=False,
+ temperature=1.0,
+ semantic_generation_config=self.semantic_generation_config,
+ )
+
+ output_ids = self.model.coarse_acoustics.generate(
+ output_ids,
+ history_prompt=history_prompt,
+ do_sample=False,
+ temperature=1.0,
+ semantic_generation_config=self.semantic_generation_config,
+ coarse_generation_config=self.coarse_generation_config,
+ codebook_size=self.model.generation_config.codebook_size,
+ )
+
+ # greedy decoding
+ output_ids = self.model.fine_acoustics.generate(
+ output_ids,
+ history_prompt=history_prompt,
+ temperature=None,
+ semantic_generation_config=self.semantic_generation_config,
+ coarse_generation_config=self.coarse_generation_config,
+ fine_generation_config=self.fine_generation_config,
+ codebook_size=self.model.generation_config.codebook_size,
+ )
+
+ self.assertListEqual(output_ids[0, :, : len(expected_output_ids[0])].tolist(), expected_output_ids)
+
+ @slow
+ def test_generate_end_to_end(self):
+ input_ids = self.inputs
+
+ with torch.no_grad():
+ self.model.generate(**input_ids)
+ self.model.generate(**{key: val for (key, val) in input_ids.items() if key != "history_prompt"})
+
+ @slow
+ def test_generate_end_to_end_with_args(self):
+ input_ids = self.inputs
+
+ with torch.no_grad():
+ self.model.generate(**input_ids, do_sample=True, temperature=0.6, penalty_alpha=0.6)
+ self.model.generate(**input_ids, do_sample=True, temperature=0.6, num_beams=4)
+
+ @slow
+ def test_generate_batching(self):
+ args = {"do_sample": False, "temperature": None}
+
+ s1 = "I love HuggingFace"
+ s2 = "In the light of the moon, a little egg lay on a leaf"
+ voice_preset = "en_speaker_6"
+ input_ids = self.processor([s1, s2], voice_preset=voice_preset).to(torch_device)
+
+ # generate in batch
+ outputs, audio_lengths = self.model.generate(**input_ids, **args, return_output_lengths=True)
+
+ # generate one-by-one
+ s1 = self.processor(s1, voice_preset=voice_preset).to(torch_device)
+ s2 = self.processor(s2, voice_preset=voice_preset).to(torch_device)
+ output1 = self.model.generate(**s1, **args)
+ output2 = self.model.generate(**s2, **args)
+
+ # up until the coarse acoustic model (included), results are the same
+ # the fine acoustic model introduces small differences
+ # first verify if same length (should be the same because it's decided in the coarse model)
+ self.assertEqual(tuple(audio_lengths), (output1.shape[1], output2.shape[1]))
+
+ # then assert almost equal
+ torch.testing.assert_close(outputs[0, : audio_lengths[0]], output1.squeeze(), rtol=2e-3, atol=2e-3)
+ torch.testing.assert_close(outputs[1, : audio_lengths[1]], output2.squeeze(), rtol=2e-3, atol=2e-3)
+
+ # now test single input with return_output_lengths = True
+ outputs, _ = self.model.generate(**s1, **args, return_output_lengths=True)
+ self.assertTrue((outputs == output1).all().item())
+
+ @slow
+ def test_generate_end_to_end_with_sub_models_args(self):
+ input_ids = self.inputs
+
+ with torch.no_grad():
+ torch.manual_seed(0)
+ self.model.generate(
+ **input_ids, do_sample=False, temperature=1.0, coarse_do_sample=True, coarse_temperature=0.7
+ )
+ output_ids_without_min_eos_p = self.model.generate(
+ **input_ids,
+ do_sample=True,
+ temperature=0.9,
+ coarse_do_sample=True,
+ coarse_temperature=0.7,
+ fine_temperature=0.3,
+ )
+
+ output_ids_with_min_eos_p = self.model.generate(
+ **input_ids,
+ do_sample=True,
+ temperature=0.9,
+ coarse_temperature=0.7,
+ fine_temperature=0.3,
+ min_eos_p=0.1,
+ )
+ self.assertLess(
+ len(output_ids_with_min_eos_p[0, :].tolist()), len(output_ids_without_min_eos_p[0, :].tolist())
+ )
+
+ @require_torch_accelerator
+ @slow
+ def test_generate_end_to_end_with_offload(self):
+ input_ids = self.inputs
+
+ with torch.no_grad():
+ # standard generation
+ output_with_no_offload = self.model.generate(**input_ids, do_sample=False, temperature=1.0)
+
+ torch_accelerator_module = backend_torch_accelerator_module(torch_device)
+
+ torch_accelerator_module.empty_cache()
+
+ memory_before_offload = torch_accelerator_module.memory_allocated()
+ model_memory_footprint = self.model.get_memory_footprint()
+
+ # activate cpu offload
+ self.model.enable_cpu_offload()
+
+ memory_after_offload = torch_accelerator_module.memory_allocated()
+
+ # checks if the model have been offloaded
+
+ # CUDA memory usage after offload should be near 0, leaving room to small differences
+ room_for_difference = 1.1
+ self.assertGreater(
+ (memory_before_offload - model_memory_footprint) * room_for_difference, memory_after_offload
+ )
+
+ # checks if device is the correct one
+ self.assertEqual(self.model.device.type, torch_device)
+
+ # checks if hooks exist
+ self.assertTrue(hasattr(self.model.semantic, "_hf_hook"))
+
+ # output with cpu offload
+ output_with_offload = self.model.generate(**input_ids, do_sample=False, temperature=1.0)
+
+ # checks if same output
+ self.assertListAlmostEqual(output_with_no_offload.squeeze().tolist(), output_with_offload.squeeze().tolist())
+
+ def assertListAlmostEqual(self, list1, list2, tol=1e-6):
+ self.assertEqual(len(list1), len(list2))
+ for a, b in zip(list1, list2):
+ self.assertAlmostEqual(a, b, delta=tol)
diff --git a/transformers/tests/models/bark/test_processor_bark.py b/transformers/tests/models/bark/test_processor_bark.py
new file mode 100644
index 0000000000000000000000000000000000000000..15b0871d81448dc13602c2614e7908736673acb0
--- /dev/null
+++ b/transformers/tests/models/bark/test_processor_bark.py
@@ -0,0 +1,127 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import shutil
+import tempfile
+import unittest
+
+import numpy as np
+
+from transformers import AutoTokenizer, BarkProcessor
+from transformers.testing_utils import require_torch, slow
+
+
+@require_torch
+class BarkProcessorTest(unittest.TestCase):
+ def setUp(self):
+ self.checkpoint = "suno/bark-small"
+ self.tmpdirname = tempfile.mkdtemp()
+ self.voice_preset = "en_speaker_1"
+ self.input_string = "This is a test string"
+ self.speaker_embeddings_dict_path = "speaker_embeddings_path.json"
+ self.speaker_embeddings_directory = "speaker_embeddings"
+
+ def get_tokenizer(self, **kwargs):
+ return AutoTokenizer.from_pretrained(self.checkpoint, **kwargs)
+
+ def tearDown(self):
+ shutil.rmtree(self.tmpdirname)
+
+ def test_save_load_pretrained_default(self):
+ tokenizer = self.get_tokenizer()
+
+ processor = BarkProcessor(tokenizer=tokenizer)
+
+ processor.save_pretrained(self.tmpdirname)
+ processor = BarkProcessor.from_pretrained(self.tmpdirname)
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer.get_vocab())
+
+ @slow
+ def test_save_load_pretrained_additional_features(self):
+ processor = BarkProcessor.from_pretrained(
+ pretrained_processor_name_or_path=self.checkpoint,
+ speaker_embeddings_dict_path=self.speaker_embeddings_dict_path,
+ )
+ processor.save_pretrained(
+ self.tmpdirname,
+ speaker_embeddings_dict_path=self.speaker_embeddings_dict_path,
+ speaker_embeddings_directory=self.speaker_embeddings_directory,
+ )
+
+ tokenizer_add_kwargs = self.get_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
+
+ processor = BarkProcessor.from_pretrained(
+ self.tmpdirname,
+ self.speaker_embeddings_dict_path,
+ bos_token="(BOS)",
+ eos_token="(EOS)",
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+
+ def test_speaker_embeddings(self):
+ processor = BarkProcessor.from_pretrained(
+ pretrained_processor_name_or_path=self.checkpoint,
+ speaker_embeddings_dict_path=self.speaker_embeddings_dict_path,
+ )
+
+ seq_len = 35
+ nb_codebooks_coarse = 2
+ nb_codebooks_total = 8
+
+ voice_preset = {
+ "semantic_prompt": np.ones(seq_len),
+ "coarse_prompt": np.ones((nb_codebooks_coarse, seq_len)),
+ "fine_prompt": np.ones((nb_codebooks_total, seq_len)),
+ }
+
+ # test providing already loaded voice_preset
+ inputs = processor(text=self.input_string, voice_preset=voice_preset)
+
+ processed_voice_preset = inputs["history_prompt"]
+ for key in voice_preset:
+ self.assertListEqual(voice_preset[key].tolist(), processed_voice_preset.get(key, np.array([])).tolist())
+
+ # test loading voice preset from npz file
+ tmpfilename = os.path.join(self.tmpdirname, "file.npz")
+ np.savez(tmpfilename, **voice_preset)
+ inputs = processor(text=self.input_string, voice_preset=tmpfilename)
+ processed_voice_preset = inputs["history_prompt"]
+
+ for key in voice_preset:
+ self.assertListEqual(voice_preset[key].tolist(), processed_voice_preset.get(key, np.array([])).tolist())
+
+ # test loading voice preset from the hub
+ inputs = processor(text=self.input_string, voice_preset=self.voice_preset)
+
+ def test_tokenizer(self):
+ tokenizer = self.get_tokenizer()
+
+ processor = BarkProcessor(tokenizer=tokenizer)
+
+ encoded_processor = processor(text=self.input_string)
+
+ encoded_tok = tokenizer(
+ self.input_string,
+ padding="max_length",
+ max_length=256,
+ add_special_tokens=False,
+ return_attention_mask=True,
+ return_token_type_ids=False,
+ )
+
+ for key in encoded_tok.keys():
+ self.assertListEqual(encoded_tok[key], encoded_processor[key].squeeze().tolist())
diff --git a/transformers/tests/models/bart/__init__.py b/transformers/tests/models/bart/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/bart/test_modeling_bart.py b/transformers/tests/models/bart/test_modeling_bart.py
new file mode 100644
index 0000000000000000000000000000000000000000..ded8d5f0a8e82aeb0bd14a678a4965bb64db9fc1
--- /dev/null
+++ b/transformers/tests/models/bart/test_modeling_bart.py
@@ -0,0 +1,1527 @@
+# Copyright 2021, The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch BART model."""
+
+import copy
+import tempfile
+import unittest
+
+import timeout_decorator # noqa
+
+from transformers import BartConfig, is_torch_available
+from transformers.testing_utils import (
+ require_sentencepiece,
+ require_tokenizers,
+ require_torch,
+ require_torch_fp16,
+ slow,
+ torch_device,
+)
+from transformers.utils import cached_property
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ AutoModelForSequenceClassification,
+ BartForCausalLM,
+ BartForConditionalGeneration,
+ BartForQuestionAnswering,
+ BartForSequenceClassification,
+ BartModel,
+ BartTokenizer,
+ pipeline,
+ )
+ from transformers.models.bart.modeling_bart import BartDecoder, BartEncoder, shift_tokens_right
+
+
+def prepare_bart_inputs_dict(
+ config,
+ input_ids,
+ decoder_input_ids=None,
+ attention_mask=None,
+ decoder_attention_mask=None,
+):
+ if attention_mask is None:
+ attention_mask = input_ids.ne(config.pad_token_id)
+ if decoder_attention_mask is None:
+ decoder_attention_mask = decoder_input_ids.ne(config.pad_token_id)
+ return {
+ "input_ids": input_ids,
+ "decoder_input_ids": decoder_input_ids,
+ "attention_mask": attention_mask,
+ "decoder_attention_mask": attention_mask,
+ }
+
+
+class BartModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_labels=False,
+ vocab_size=99,
+ hidden_size=16,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=50,
+ eos_token_id=2,
+ pad_token_id=1,
+ bos_token_id=0,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.eos_token_id = eos_token_id
+ self.pad_token_id = pad_token_id
+ self.bos_token_id = bos_token_id
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size).clamp(
+ 3,
+ )
+ input_ids[:, -1] = self.eos_token_id # Eos Token
+
+ decoder_input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ config = self.get_config()
+ inputs_dict = prepare_bart_inputs_dict(config, input_ids, decoder_input_ids)
+ return config, inputs_dict
+
+ def get_config(self):
+ return BartConfig(
+ vocab_size=self.vocab_size,
+ d_model=self.hidden_size,
+ encoder_layers=self.num_hidden_layers,
+ decoder_layers=self.num_hidden_layers,
+ encoder_attention_heads=self.num_attention_heads,
+ decoder_attention_heads=self.num_attention_heads,
+ encoder_ffn_dim=self.intermediate_size,
+ decoder_ffn_dim=self.intermediate_size,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ eos_token_id=self.eos_token_id,
+ bos_token_id=self.bos_token_id,
+ pad_token_id=self.pad_token_id,
+ )
+
+ def get_pipeline_config(self):
+ config = self.get_config()
+ config.max_position_embeddings = 100
+ config.vocab_size = 300
+ return config
+
+ def prepare_config_and_inputs_for_common(self):
+ config, inputs_dict = self.prepare_config_and_inputs()
+ return config, inputs_dict
+
+ def create_and_check_decoder_model_past_large_inputs(self, config, inputs_dict):
+ model = BartModel(config=config).get_decoder().to(torch_device).eval()
+ input_ids = inputs_dict["input_ids"]
+ attention_mask = inputs_dict["attention_mask"]
+
+ # first forward pass
+ outputs = model(input_ids, attention_mask=attention_mask, use_cache=True)
+
+ output, past_key_values = outputs.to_tuple()
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_attn_mask = ids_tensor((self.batch_size, 3), 2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([attention_mask, next_attn_mask], dim=-1)
+
+ output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)["last_hidden_state"]
+ output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)[
+ "last_hidden_state"
+ ]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def check_encoder_decoder_model_standalone(self, config, inputs_dict):
+ model = BartModel(config=config).to(torch_device).eval()
+ outputs = model(**inputs_dict)
+
+ encoder_last_hidden_state = outputs.encoder_last_hidden_state
+ last_hidden_state = outputs.last_hidden_state
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ encoder = model.get_encoder()
+ encoder.save_pretrained(tmpdirname)
+ encoder = BartEncoder.from_pretrained(tmpdirname).to(torch_device)
+
+ encoder_last_hidden_state_2 = encoder(inputs_dict["input_ids"], attention_mask=inputs_dict["attention_mask"])[
+ 0
+ ]
+
+ self.parent.assertTrue((encoder_last_hidden_state_2 - encoder_last_hidden_state).abs().max().item() < 1e-3)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ decoder = model.get_decoder()
+ decoder.save_pretrained(tmpdirname)
+ decoder = BartDecoder.from_pretrained(tmpdirname).to(torch_device)
+
+ last_hidden_state_2 = decoder(
+ input_ids=inputs_dict["decoder_input_ids"],
+ attention_mask=inputs_dict["decoder_attention_mask"],
+ encoder_hidden_states=encoder_last_hidden_state,
+ encoder_attention_mask=inputs_dict["attention_mask"],
+ )[0]
+
+ self.parent.assertTrue((last_hidden_state_2 - last_hidden_state).abs().max().item() < 1e-3)
+
+
+@require_torch
+class BartHeadTests(unittest.TestCase):
+ vocab_size = 99
+
+ def _get_config_and_data(self):
+ input_ids = torch.tensor(
+ [
+ [71, 82, 18, 33, 46, 91, 2],
+ [68, 34, 26, 58, 30, 82, 2],
+ [5, 97, 17, 39, 94, 40, 2],
+ [76, 83, 94, 25, 70, 78, 2],
+ [87, 59, 41, 35, 48, 66, 2],
+ [55, 13, 16, 58, 5, 2, 1], # note padding
+ [64, 27, 31, 51, 12, 75, 2],
+ [52, 64, 86, 17, 83, 39, 2],
+ [48, 61, 9, 24, 71, 82, 2],
+ [26, 1, 60, 48, 22, 13, 2],
+ [21, 5, 62, 28, 14, 76, 2],
+ [45, 98, 37, 86, 59, 48, 2],
+ [70, 70, 50, 9, 28, 0, 2],
+ ],
+ dtype=torch.long,
+ device=torch_device,
+ )
+
+ batch_size = input_ids.shape[0]
+ config = BartConfig(
+ vocab_size=self.vocab_size,
+ d_model=24,
+ encoder_layers=2,
+ decoder_layers=2,
+ encoder_attention_heads=2,
+ decoder_attention_heads=2,
+ encoder_ffn_dim=32,
+ decoder_ffn_dim=32,
+ max_position_embeddings=48,
+ eos_token_id=2,
+ pad_token_id=1,
+ bos_token_id=0,
+ )
+ return config, input_ids, batch_size
+
+ def test_sequence_classification_forward(self):
+ config, input_ids, batch_size = self._get_config_and_data()
+ labels = _long_tensor([2] * batch_size).to(torch_device)
+ model = BartForSequenceClassification(config)
+ model.to(torch_device)
+ outputs = model(input_ids=input_ids, decoder_input_ids=input_ids, labels=labels)
+ expected_shape = torch.Size((batch_size, config.num_labels))
+ self.assertEqual(outputs["logits"].shape, expected_shape)
+ self.assertIsInstance(outputs["loss"].item(), float)
+
+ def test_question_answering_forward(self):
+ config, input_ids, batch_size = self._get_config_and_data()
+ sequence_labels = ids_tensor([batch_size], 2).to(torch_device)
+ model = BartForQuestionAnswering(config)
+ model.to(torch_device)
+ outputs = model(
+ input_ids=input_ids,
+ start_positions=sequence_labels,
+ end_positions=sequence_labels,
+ )
+
+ self.assertEqual(outputs["start_logits"].shape, input_ids.shape)
+ self.assertEqual(outputs["end_logits"].shape, input_ids.shape)
+ self.assertIsInstance(outputs["loss"].item(), float)
+
+ @timeout_decorator.timeout(1)
+ def test_lm_forward(self):
+ config, input_ids, batch_size = self._get_config_and_data()
+ lm_labels = ids_tensor([batch_size, input_ids.shape[1]], self.vocab_size).to(torch_device)
+ lm_model = BartForConditionalGeneration(config)
+ lm_model.to(torch_device)
+ outputs = lm_model(input_ids=input_ids, labels=lm_labels)
+ expected_shape = (batch_size, input_ids.shape[1], config.vocab_size)
+ self.assertEqual(outputs["logits"].shape, expected_shape)
+ self.assertIsInstance(outputs["loss"].item(), float)
+
+ def test_lm_uneven_forward(self):
+ config = BartConfig(
+ vocab_size=self.vocab_size,
+ d_model=14,
+ encoder_layers=2,
+ decoder_layers=2,
+ encoder_attention_heads=2,
+ decoder_attention_heads=2,
+ encoder_ffn_dim=8,
+ decoder_ffn_dim=8,
+ max_position_embeddings=48,
+ )
+ lm_model = BartForConditionalGeneration(config).to(torch_device)
+ context = torch.tensor(
+ [[71, 82, 18, 33, 46, 91, 2], [68, 34, 26, 58, 30, 2, 1]], device=torch_device, dtype=torch.long
+ )
+ summary = torch.tensor([[82, 71, 82, 18, 2], [58, 68, 2, 1, 1]], device=torch_device, dtype=torch.long)
+ outputs = lm_model(input_ids=context, decoder_input_ids=summary, labels=summary)
+ expected_shape = (*summary.shape, config.vocab_size)
+ self.assertEqual(outputs["logits"].shape, expected_shape)
+
+ def test_generate_beam_search(self):
+ input_ids = torch.tensor([[71, 82, 2], [68, 34, 2]], device=torch_device, dtype=torch.long)
+ config = BartConfig(
+ vocab_size=self.vocab_size,
+ d_model=24,
+ encoder_layers=2,
+ decoder_layers=2,
+ encoder_attention_heads=2,
+ decoder_attention_heads=2,
+ encoder_ffn_dim=32,
+ decoder_ffn_dim=32,
+ max_position_embeddings=48,
+ eos_token_id=2,
+ pad_token_id=1,
+ bos_token_id=0,
+ )
+ lm_model = BartForConditionalGeneration(config).to(torch_device)
+ lm_model.eval()
+
+ max_length = 5
+ generated_ids = lm_model.generate(
+ input_ids.clone(),
+ do_sample=True,
+ num_return_sequences=1,
+ num_beams=2,
+ no_repeat_ngram_size=3,
+ max_length=max_length,
+ )
+ self.assertEqual(generated_ids.shape, (input_ids.shape[0], max_length))
+
+ def test_shift_tokens_right(self):
+ input_ids = torch.tensor([[71, 82, 18, 33, 2, 1, 1], [68, 34, 26, 58, 30, 82, 2]], dtype=torch.long)
+ shifted = shift_tokens_right(input_ids, 1, 2)
+ n_pad_before = input_ids.eq(1).float().sum()
+ n_pad_after = shifted.eq(1).float().sum()
+ self.assertEqual(shifted.shape, input_ids.shape)
+ self.assertEqual(n_pad_after, n_pad_before - 1)
+ self.assertTrue(torch.eq(shifted[:, 0], 2).all())
+
+ @slow
+ def test_tokenization(self):
+ tokenizer = BartTokenizer.from_pretrained("facebook/bart-large")
+ examples = [" Hello world", " DomDramg"] # need leading spaces for equality
+ fairseq_results = [
+ torch.tensor([0, 20920, 232, 2]),
+ torch.tensor([0, 11349, 495, 4040, 571, 2]),
+ ]
+ for ex, desired_result in zip(examples, fairseq_results):
+ bart_toks = tokenizer.encode(ex, return_tensors="pt").squeeze()
+ assert_tensors_close(desired_result.long(), bart_toks, prefix=ex)
+
+ @require_torch_fp16
+ def test_generate_fp16(self):
+ config, input_ids, batch_size = self._get_config_and_data()
+ attention_mask = input_ids.ne(1).to(torch_device)
+ model = BartForConditionalGeneration(config).eval().to(torch_device)
+ model.half()
+ model.generate(input_ids, attention_mask=attention_mask)
+ model.generate(num_beams=4, do_sample=True, early_stopping=False, num_return_sequences=3)
+
+ def test_dummy_inputs(self):
+ config, *_ = self._get_config_and_data()
+ model = BartForConditionalGeneration(config).eval().to(torch_device)
+ model(**model.dummy_inputs)
+
+ def test_resize_tokens_embeddings_more(self):
+ config, input_ids, _ = self._get_config_and_data()
+
+ def _get_embs(m):
+ return (m.get_input_embeddings().weight.data.clone(), m.get_output_embeddings().weight.data.clone())
+
+ model = BartForConditionalGeneration(config).eval().to(torch_device)
+ input, output = _get_embs(model)
+ self.assertTrue(torch.eq(input, output).all())
+ new_vocab_size = 45
+ model.resize_token_embeddings(new_vocab_size)
+ input_new, output_new = _get_embs(model)
+ self.assertEqual(input_new.shape, (new_vocab_size, config.d_model))
+ self.assertEqual(output_new.shape, (new_vocab_size, config.d_model))
+ self.assertTrue(torch.eq(input_new, output_new).all())
+
+
+@require_torch
+class BartModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (BartModel, BartForConditionalGeneration, BartForSequenceClassification, BartForQuestionAnswering)
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": BartModel,
+ "fill-mask": BartForConditionalGeneration,
+ "question-answering": BartForQuestionAnswering,
+ "summarization": BartForConditionalGeneration,
+ "text-classification": BartForSequenceClassification,
+ "text-generation": BartForCausalLM,
+ "text2text-generation": BartForConditionalGeneration,
+ "translation": BartForConditionalGeneration,
+ "zero-shot": BartForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ is_encoder_decoder = True
+ fx_compatible = False # Fix me Michael
+ test_pruning = False
+
+ def setUp(self):
+ self.model_tester = BartModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=BartConfig)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_save_load_strict(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs()
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
+ self.assertEqual(info["missing_keys"], [])
+
+ def test_decoder_model_past_with_large_inputs(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
+
+ def test_encoder_decoder_model_standalone(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
+ self.model_tester.check_encoder_decoder_model_standalone(*config_and_inputs)
+
+ # BartForSequenceClassification does not support inputs_embeds
+ def test_inputs_embeds(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in (BartModel, BartForConditionalGeneration, BartForQuestionAnswering):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ inputs = copy.deepcopy(self._prepare_for_class(inputs_dict, model_class))
+
+ if not self.is_encoder_decoder:
+ input_ids = inputs["input_ids"]
+ del inputs["input_ids"]
+ else:
+ encoder_input_ids = inputs["input_ids"]
+ decoder_input_ids = inputs.get("decoder_input_ids", encoder_input_ids)
+ del inputs["input_ids"]
+ inputs.pop("decoder_input_ids", None)
+
+ wte = model.get_input_embeddings()
+ if not self.is_encoder_decoder:
+ inputs["inputs_embeds"] = wte(input_ids)
+ else:
+ inputs["inputs_embeds"] = wte(encoder_input_ids)
+ inputs["decoder_inputs_embeds"] = wte(decoder_input_ids)
+
+ with torch.no_grad():
+ model(**inputs)[0]
+
+ @require_torch_fp16
+ def test_generate_fp16(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs()
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ model = BartForConditionalGeneration(config).eval().to(torch_device)
+ model.half()
+ model.generate(input_ids, attention_mask=attention_mask)
+ model.generate(num_beams=4, do_sample=True, early_stopping=False, num_return_sequences=3)
+
+ @unittest.skip(
+ reason="This architecture has tied weights by default and there is no way to remove it, check: https://github.com/huggingface/transformers/pull/31771#issuecomment-2210915245"
+ )
+ def test_load_save_without_tied_weights(self):
+ pass
+
+ def test_resize_embeddings_persists_embeddings_type(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs()
+
+ config.scale_embedding = True
+ model = BartForConditionalGeneration(config)
+ old_type = type(model.model.decoder.embed_tokens)
+
+ model.resize_token_embeddings(new_num_tokens=config.vocab_size)
+
+ new_type = type(model.model.decoder.embed_tokens)
+ self.assertIs(old_type, new_type)
+
+
+def assert_tensors_close(a, b, atol=1e-12, prefix=""):
+ """If tensors have different shapes, different values or a and b are not both tensors, raise a nice Assertion error."""
+ if a is None and b is None:
+ return True
+ try:
+ if torch.allclose(a, b, atol=atol):
+ return True
+ raise
+ except Exception:
+ pct_different = (torch.gt((a - b).abs(), atol)).float().mean().item()
+ if a.numel() > 100:
+ msg = f"tensor values are {pct_different:.1%} percent different."
+ else:
+ msg = f"{a} != {b}"
+ if prefix:
+ msg = prefix + ": " + msg
+ raise AssertionError(msg)
+
+
+def _long_tensor(tok_lst):
+ return torch.tensor(tok_lst, dtype=torch.long, device=torch_device)
+
+
+@require_torch
+@slow
+class FastIntegrationTests(unittest.TestCase):
+ """These tests are useful for debugging since they operate on a model with 1 encoder layer and 1 decoder layer."""
+
+ @cached_property
+ def tok(self):
+ return BartTokenizer.from_pretrained("facebook/bart-large")
+
+ @cached_property
+ def xsum_1_1_model(self):
+ return BartForConditionalGeneration.from_pretrained("sshleifer/distilbart-xsum-1-1")
+
+ def test_xsum_1_1_generation(self):
+ hf = self.xsum_1_1_model
+ tok = self.tok
+ ARTICLE = (
+ "The Palestinian Authority officially became the 123rd member of the International Criminal Court on"
+ " Wednesday, a step that gives the court jurisdiction over alleged crimes in Palestinian territories. The"
+ " formal accession was marked with a ceremony at The Hague, in the Netherlands, where the court is based."
+ " The Palestinians signed the ICC's founding Rome Statute in January, when they also accepted its"
+ ' jurisdiction over alleged crimes committed "in the occupied Palestinian territory, including East'
+ ' Jerusalem, since June 13, 2014." Later that month, the ICC opened a preliminary examination into the'
+ " situation in Palestinian territories, paving the way for possible war crimes investigations against"
+ " Israelis. As members of the court, Palestinians may be subject to counter-charges as well. Israel and"
+ " the United States, neither of which is an ICC member, opposed the Palestinians' efforts to join the"
+ " body. But Palestinian Foreign Minister Riad al-Malki, speaking at Wednesday's ceremony, said it was a"
+ ' move toward greater justice. "As Palestine formally becomes a State Party to the Rome Statute today, the'
+ ' world is also a step closer to ending a long era of impunity and injustice," he said, according to an'
+ ' ICC news release. "Indeed, today brings us closer to our shared goals of justice and peace." Judge'
+ " Kuniko Ozaki, a vice president of the ICC, said acceding to the treaty was just the first step for the"
+ ' Palestinians. "As the Rome Statute today enters into force for the State of Palestine, Palestine'
+ " acquires all the rights as well as responsibilities that come with being a State Party to the Statute."
+ ' These are substantive commitments, which cannot be taken lightly," she said. Rights group Human Rights'
+ ' Watch welcomed the development. "Governments seeking to penalize Palestine for joining the ICC should'
+ " immediately end their pressure, and countries that support universal acceptance of the court's treaty"
+ ' should speak out to welcome its membership," said Balkees Jarrah, international justice counsel for the'
+ " group. \"What's objectionable is the attempts to undermine international justice, not Palestine's"
+ ' decision to join a treaty to which over 100 countries around the world are members." In January, when'
+ " the preliminary ICC examination was opened, Israeli Prime Minister Benjamin Netanyahu described it as an"
+ ' outrage, saying the court was overstepping its boundaries. The United States also said it "strongly"'
+ " disagreed with the court's decision. \"As we have said repeatedly, we do not believe that Palestine is a"
+ ' state and therefore we do not believe that it is eligible to join the ICC," the State Department said in'
+ ' a statement. It urged the warring sides to resolve their differences through direct negotiations. "We'
+ ' will continue to oppose actions against Israel at the ICC as counterproductive to the cause of peace,"'
+ " it said. But the ICC begs to differ with the definition of a state for its purposes and refers to the"
+ ' territories as "Palestine." While a preliminary examination is not a formal investigation, it allows the'
+ " court to review evidence and determine whether to investigate suspects on both sides. Prosecutor Fatou"
+ ' Bensouda said her office would "conduct its analysis in full independence and impartiality." The war'
+ " between Israel and Hamas militants in Gaza last summer left more than 2,000 people dead. The inquiry"
+ " will include alleged war crimes committed since June. The International Criminal Court was set up in"
+ " 2002 to prosecute genocide, crimes against humanity and war crimes."
+ )
+ EXPECTED = (
+ ""
+ " The International Criminal Court (ICC) has announced that it has been announced by the International"
+ " Criminal court."
+ ""
+ )
+
+ dct = tok(ARTICLE, return_tensors="pt")
+ generated_ids = hf.generate(**dct, num_beams=4)
+ result = tok.batch_decode(generated_ids)[0]
+ assert EXPECTED == result
+
+ def test_xsum_1_1_batch_generation(self):
+ # test batch
+
+ batch = self.tok(
+ [
+ "The Palestinian Authority officially became the 123rd member of the International Criminal Court on"
+ " Wednesday, a step that gives the court jurisdiction over alleged crimes in Palestinian territories."
+ " The formal accession was marked with a ceremony at The Hague, in the Netherlands, where the court is"
+ " based. The Palestinians signed the ICC's founding Rome Statute in January, when they also accepted"
+ ' its jurisdiction over alleged crimes committed "in the occupied Palestinian territory, including'
+ ' East Jerusalem, since June 13, 2014." Later that month, the ICC opened a preliminary examination'
+ " into the situation in Palestinian territories, paving the way for possible war crimes investigations"
+ " against Israelis. As members of the court, Palestinians may be subject to counter-charges as well."
+ " Israel and the United States, neither of which is an ICC member, opposed the Palestinians' efforts"
+ " to join the body. But Palestinian Foreign Minister Riad al-Malki, speaking at Wednesday's ceremony,"
+ ' said it was a move toward greater justice. "As Palestine formally becomes a State Party to the Rome'
+ ' Statute today, the world is also a step closer to ending a long era of impunity and injustice," he'
+ ' said, according to an ICC news release. "Indeed, today brings us closer to our shared goals of'
+ ' justice and peace." Judge Kuniko Ozaki, a vice president of the ICC, said acceding to the treaty was'
+ ' just the first step for the Palestinians. "As the Rome Statute today enters into force for the State'
+ " of Palestine, Palestine acquires all the rights as well as responsibilities that come with being a"
+ ' State Party to the Statute. These are substantive commitments, which cannot be taken lightly," she'
+ ' said. Rights group Human Rights Watch welcomed the development. "Governments seeking to penalize'
+ " Palestine for joining the ICC should immediately end their pressure, and countries that support"
+ " universal acceptance of the court's treaty should speak out to welcome its membership,\" said"
+ " Balkees Jarrah, international justice counsel for the group. \"What's objectionable is the attempts"
+ " to undermine international justice, not Palestine's decision to join a treaty to which over 100"
+ ' countries around the world are members." In January, when the preliminary ICC examination was'
+ " opened, Israeli Prime Minister Benjamin Netanyahu described it as an outrage, saying the court was"
+ ' overstepping its boundaries. The United States also said it "strongly" disagreed with the court\'s'
+ ' decision. "As we have said repeatedly, we do not believe that Palestine is a state and therefore we'
+ ' do not believe that it is eligible to join the ICC," the State Department said in a statement. It'
+ ' urged the warring sides to resolve their differences through direct negotiations. "We will continue'
+ ' to oppose actions against Israel at the ICC as counterproductive to the cause of peace," it said.'
+ " But the ICC begs to differ with the definition of a state for its purposes and refers to the"
+ ' territories as "Palestine." While a preliminary examination is not a formal investigation, it allows'
+ " the court to review evidence and determine whether to investigate suspects on both sides. Prosecutor"
+ ' Fatou Bensouda said her office would "conduct its analysis in full independence and impartiality."'
+ " The war between Israel and Hamas militants in Gaza last summer left more than 2,000 people dead. The"
+ " inquiry will include alleged war crimes committed since June. The International Criminal Court was"
+ " set up in 2002 to prosecute genocide, crimes against humanity and war crimes.",
+ "The French prosecutor leading an investigation into the crash of Germanwings Flight 9525 insisted"
+ " Wednesday that he was not aware of any video footage from on board the plane. Marseille prosecutor"
+ ' Brice Robin told CNN that "so far no videos were used in the crash investigation." He added, "A'
+ " person who has such a video needs to immediately give it to the investigators.\" Robin's comments"
+ " follow claims by two magazines, German daily Bild and French Paris Match, of a cell phone video"
+ " showing the harrowing final seconds from on board Germanwings Flight 9525 as it crashed into the"
+ " French Alps. All 150 on board were killed. Paris Match and Bild reported that the video was"
+ " recovered from a phone at the wreckage site. The two publications described the supposed video, but"
+ " did not post it on their websites. The publications said that they watched the video, which was"
+ " found by a source close to the investigation. \"One can hear cries of 'My God' in several"
+ ' languages," Paris Match reported. "Metallic banging can also be heard more than three times, perhaps'
+ " of the pilot trying to open the cockpit door with a heavy object. Towards the end, after a heavy"
+ ' shake, stronger than the others, the screaming intensifies. Then nothing." "It is a very disturbing'
+ " scene,\" said Julian Reichelt, editor-in-chief of Bild online. An official with France's accident"
+ " investigation agency, the BEA, said the agency is not aware of any such video. Lt. Col. Jean-Marc"
+ " Menichini, a French Gendarmerie spokesman in charge of communications on rescue efforts around the"
+ ' Germanwings crash site, told CNN that the reports were "completely wrong" and "unwarranted." Cell'
+ ' phones have been collected at the site, he said, but that they "hadn\'t been exploited yet."'
+ " Menichini said he believed the cell phones would need to be sent to the Criminal Research Institute"
+ " in Rosny sous-Bois, near Paris, in order to be analyzed by specialized technicians working"
+ " hand-in-hand with investigators. But none of the cell phones found so far have been sent to the"
+ " institute, Menichini said. Asked whether staff involved in the search could have leaked a memory"
+ ' card to the media, Menichini answered with a categorical "no." Reichelt told "Erin Burnett:'
+ ' Outfront" that he had watched the video and stood by the report, saying Bild and Paris Match are'
+ ' "very confident" that the clip is real. He noted that investigators only revealed they\'d recovered'
+ ' cell phones from the crash site after Bild and Paris Match published their reports. "That is'
+ " something we did not know before. ... Overall we can say many things of the investigation weren't"
+ ' revealed by the investigation at the beginning," he said. What was mental state of Germanwings'
+ " co-pilot? German airline Lufthansa confirmed Tuesday that co-pilot Andreas Lubitz had battled"
+ " depression years before he took the controls of Germanwings Flight 9525, which he's accused of"
+ " deliberately crashing last week in the French Alps. Lubitz told his Lufthansa flight training school"
+ ' in 2009 that he had a "previous episode of severe depression," the airline said Tuesday. Email'
+ " correspondence between Lubitz and the school discovered in an internal investigation, Lufthansa"
+ " said, included medical documents he submitted in connection with resuming his flight training. The"
+ " announcement indicates that Lufthansa, the parent company of Germanwings, knew of Lubitz's battle"
+ " with depression, allowed him to continue training and ultimately put him in the cockpit. Lufthansa,"
+ " whose CEO Carsten Spohr previously said Lubitz was 100% fit to fly, described its statement Tuesday"
+ ' as a "swift and seamless clarification" and said it was sharing the information and documents --'
+ " including training and medical records -- with public prosecutors. Spohr traveled to the crash site"
+ " Wednesday, where recovery teams have been working for the past week to recover human remains and"
+ " plane debris scattered across a steep mountainside. He saw the crisis center set up in"
+ " Seyne-les-Alpes, laid a wreath in the village of Le Vernet, closer to the crash site, where grieving"
+ " families have left flowers at a simple stone memorial. Menichini told CNN late Tuesday that no"
+ " visible human remains were left at the site but recovery teams would keep searching. French"
+ " President Francois Hollande, speaking Tuesday, said that it should be possible to identify all the"
+ " victims using DNA analysis by the end of the week, sooner than authorities had previously suggested."
+ " In the meantime, the recovery of the victims' personal belongings will start Wednesday, Menichini"
+ " said. Among those personal belongings could be more cell phones belonging to the 144 passengers and"
+ " six crew on board. Check out the latest from our correspondents . The details about Lubitz's"
+ " correspondence with the flight school during his training were among several developments as"
+ " investigators continued to delve into what caused the crash and Lubitz's possible motive for"
+ " downing the jet. A Lufthansa spokesperson told CNN on Tuesday that Lubitz had a valid medical"
+ ' certificate, had passed all his examinations and "held all the licenses required." Earlier, a'
+ " spokesman for the prosecutor's office in Dusseldorf, Christoph Kumpa, said medical records reveal"
+ " Lubitz suffered from suicidal tendencies at some point before his aviation career and underwent"
+ " psychotherapy before he got his pilot's license. Kumpa emphasized there's no evidence suggesting"
+ " Lubitz was suicidal or acting aggressively before the crash. Investigators are looking into whether"
+ " Lubitz feared his medical condition would cause him to lose his pilot's license, a European"
+ ' government official briefed on the investigation told CNN on Tuesday. While flying was "a big part'
+ " of his life,\" the source said, it's only one theory being considered. Another source, a law"
+ " enforcement official briefed on the investigation, also told CNN that authorities believe the"
+ " primary motive for Lubitz to bring down the plane was that he feared he would not be allowed to fly"
+ " because of his medical problems. Lubitz's girlfriend told investigators he had seen an eye doctor"
+ " and a neuropsychologist, both of whom deemed him unfit to work recently and concluded he had"
+ " psychological issues, the European government official said. But no matter what details emerge about"
+ " his previous mental health struggles, there's more to the story, said Brian Russell, a forensic"
+ ' psychologist. "Psychology can explain why somebody would turn rage inward on themselves about the'
+ " fact that maybe they weren't going to keep doing their job and they're upset about that and so"
+ ' they\'re suicidal," he said. "But there is no mental illness that explains why somebody then feels'
+ " entitled to also take that rage and turn it outward on 149 other people who had nothing to do with"
+ " the person's problems.\" Germanwings crash compensation: What we know . Who was the captain of"
+ " Germanwings Flight 9525? CNN's Margot Haddad reported from Marseille and Pamela Brown from"
+ " Dusseldorf, while Laura Smith-Spark wrote from London. CNN's Frederik Pleitgen, Pamela Boykoff,"
+ " Antonia Mortensen, Sandrine Amiel and Anna-Maja Rappard contributed to this report.",
+ ],
+ return_tensors="pt",
+ padding="longest",
+ truncation=True,
+ )
+ generated_ids = self.xsum_1_1_model.generate(**batch, num_beams=4)
+ result = self.tok.batch_decode(generated_ids)
+ assert result[0] == (
+ ""
+ " The International Criminal Court (ICC) has announced that it has been announced by the International"
+ " Criminal court."
+ ""
+ )
+ assert result[1] == (
+ ""
+ " An investigation into the crash that killed at least 10 people in the French capital has been"
+ " released by the French police investigating the crash."
+ ""
+ )
+
+ def test_encoder_equiv(self):
+ # test batch
+
+ batch = self.tok(
+ [
+ "The Palestinian Authority officially became the 123rd member of the International Criminal Court on"
+ " Wednesday, a step that gives the court jurisdiction over alleged crimes in Palestinian territories."
+ " The formal accession was marked with a ceremony at The Hague, in the Netherlands, where the court is"
+ " based. The Palestinians signed the ICC's founding Rome Statute in January, when they also accepted"
+ ' its jurisdiction over alleged crimes committed "in the occupied Palestinian territory, including'
+ ' East Jerusalem, since June 13, 2014." Later that month, the ICC opened a preliminary examination'
+ " into the situation in Palestinian territories, paving the way for possible war crimes investigations"
+ " against Israelis. As members of the court, Palestinians may be subject to counter-charges as well."
+ " Israel and the United States, neither of which is an ICC member, opposed the Palestinians' efforts"
+ " to join the body. But Palestinian Foreign Minister Riad al-Malki, speaking at Wednesday's ceremony,"
+ ' said it was a move toward greater justice. "As Palestine formally becomes a State Party to the Rome'
+ ' Statute today, the world is also a step closer to ending a long era of impunity and injustice," he'
+ ' said, according to an ICC news release. "Indeed, today brings us closer to our shared goals of'
+ ' justice and peace." Judge Kuniko Ozaki, a vice president of the ICC, said acceding to the treaty was'
+ ' just the first step for the Palestinians. "As the Rome Statute today enters into force for the State'
+ " of Palestine, Palestine acquires all the rights as well as responsibilities that come with being a"
+ ' State Party to the Statute. These are substantive commitments, which cannot be taken lightly," she'
+ ' said. Rights group Human Rights Watch welcomed the development. "Governments seeking to penalize'
+ " Palestine for joining the ICC should immediately end their pressure, and countries that support"
+ " universal acceptance of the court's treaty should speak out to welcome its membership,\" said"
+ " Balkees Jarrah, international justice counsel for the group. \"What's objectionable is the attempts"
+ " to undermine international justice, not Palestine's decision to join a treaty to which over 100"
+ ' countries around the world are members." In January, when the preliminary ICC examination was'
+ " opened, Israeli Prime Minister Benjamin Netanyahu described it as an outrage, saying the court was"
+ ' overstepping its boundaries. The United States also said it "strongly" disagreed with the court\'s'
+ ' decision. "As we have said repeatedly, we do not believe that Palestine is a state and therefore we'
+ ' do not believe that it is eligible to join the ICC," the State Department said in a statement. It'
+ ' urged the warring sides to resolve their differences through direct negotiations. "We will continue'
+ ' to oppose actions against Israel at the ICC as counterproductive to the cause of peace," it said.'
+ " But the ICC begs to differ with the definition of a state for its purposes and refers to the"
+ ' territories as "Palestine." While a preliminary examination is not a formal investigation, it allows'
+ " the court to review evidence and determine whether to investigate suspects on both sides. Prosecutor"
+ ' Fatou Bensouda said her office would "conduct its analysis in full independence and impartiality."'
+ " The war between Israel and Hamas militants in Gaza last summer left more than 2,000 people dead. The"
+ " inquiry will include alleged war crimes committed since June. The International Criminal Court was"
+ " set up in 2002 to prosecute genocide, crimes against humanity and war crimes.",
+ "The French prosecutor leading an investigation into the crash of Germanwings Flight 9525 insisted"
+ " Wednesday that he was not aware of any video footage from on board the plane. Marseille prosecutor"
+ ' Brice Robin told CNN that "so far no videos were used in the crash investigation." He added, "A'
+ " person who has such a video needs to immediately give it to the investigators.\" Robin's comments"
+ " follow claims by two magazines, German daily Bild and French Paris Match, of a cell phone video"
+ " showing the harrowing final seconds from on board Germanwings Flight 9525 as it crashed into the"
+ " French Alps. All 150 on board were killed. Paris Match and Bild reported that the video was"
+ " recovered from a phone at the wreckage site. The two publications described the supposed video, but"
+ " did not post it on their websites. The publications said that they watched the video, which was"
+ " found by a source close to the investigation. \"One can hear cries of 'My God' in several"
+ ' languages," Paris Match reported. "Metallic banging can also be heard more than three times, perhaps'
+ " of the pilot trying to open the cockpit door with a heavy object. Towards the end, after a heavy"
+ ' shake, stronger than the others, the screaming intensifies. Then nothing." "It is a very disturbing'
+ " scene,\" said Julian Reichelt, editor-in-chief of Bild online. An official with France's accident"
+ " investigation agency, the BEA, said the agency is not aware of any such video. Lt. Col. Jean-Marc"
+ " Menichini, a French Gendarmerie spokesman in charge of communications on rescue efforts around the"
+ ' Germanwings crash site, told CNN that the reports were "completely wrong" and "unwarranted." Cell'
+ ' phones have been collected at the site, he said, but that they "hadn\'t been exploited yet."'
+ " Menichini said he believed the cell phones would need to be sent to the Criminal Research Institute"
+ " in Rosny sous-Bois, near Paris, in order to be analyzed by specialized technicians working"
+ " hand-in-hand with investigators. But none of the cell phones found so far have been sent to the"
+ " institute, Menichini said. Asked whether staff involved in the search could have leaked a memory"
+ ' card to the media, Menichini answered with a categorical "no." Reichelt told "Erin Burnett:'
+ ' Outfront" that he had watched the video and stood by the report, saying Bild and Paris Match are'
+ ' "very confident" that the clip is real. He noted that investigators only revealed they\'d recovered'
+ ' cell phones from the crash site after Bild and Paris Match published their reports. "That is'
+ " something we did not know before. ... Overall we can say many things of the investigation weren't"
+ ' revealed by the investigation at the beginning," he said. What was mental state of Germanwings'
+ " co-pilot? German airline Lufthansa confirmed Tuesday that co-pilot Andreas Lubitz had battled"
+ " depression years before he took the controls of Germanwings Flight 9525, which he's accused of"
+ " deliberately crashing last week in the French Alps. Lubitz told his Lufthansa flight training school"
+ ' in 2009 that he had a "previous episode of severe depression," the airline said Tuesday. Email'
+ " correspondence between Lubitz and the school discovered in an internal investigation, Lufthansa"
+ " said, included medical documents he submitted in connection with resuming his flight training. The"
+ " announcement indicates that Lufthansa, the parent company of Germanwings, knew of Lubitz's battle"
+ " with depression, allowed him to continue training and ultimately put him in the cockpit. Lufthansa,"
+ " whose CEO Carsten Spohr previously said Lubitz was 100% fit to fly, described its statement Tuesday"
+ ' as a "swift and seamless clarification" and said it was sharing the information and documents --'
+ " including training and medical records -- with public prosecutors. Spohr traveled to the crash site"
+ " Wednesday, where recovery teams have been working for the past week to recover human remains and"
+ " plane debris scattered across a steep mountainside. He saw the crisis center set up in"
+ " Seyne-les-Alpes, laid a wreath in the village of Le Vernet, closer to the crash site, where grieving"
+ " families have left flowers at a simple stone memorial. Menichini told CNN late Tuesday that no"
+ " visible human remains were left at the site but recovery teams would keep searching. French"
+ " President Francois Hollande, speaking Tuesday, said that it should be possible to identify all the"
+ " victims using DNA analysis by the end of the week, sooner than authorities had previously suggested."
+ " In the meantime, the recovery of the victims' personal belongings will start Wednesday, Menichini"
+ " said. Among those personal belongings could be more cell phones belonging to the 144 passengers and"
+ " six crew on board. Check out the latest from our correspondents . The details about Lubitz's"
+ " correspondence with the flight school during his training were among several developments as"
+ " investigators continued to delve into what caused the crash and Lubitz's possible motive for"
+ " downing the jet. A Lufthansa spokesperson told CNN on Tuesday that Lubitz had a valid medical"
+ ' certificate, had passed all his examinations and "held all the licenses required." Earlier, a'
+ " spokesman for the prosecutor's office in Dusseldorf, Christoph Kumpa, said medical records reveal"
+ " Lubitz suffered from suicidal tendencies at some point before his aviation career and underwent"
+ " psychotherapy before he got his pilot's license. Kumpa emphasized there's no evidence suggesting"
+ " Lubitz was suicidal or acting aggressively before the crash. Investigators are looking into whether"
+ " Lubitz feared his medical condition would cause him to lose his pilot's license, a European"
+ ' government official briefed on the investigation told CNN on Tuesday. While flying was "a big part'
+ " of his life,\" the source said, it's only one theory being considered. Another source, a law"
+ " enforcement official briefed on the investigation, also told CNN that authorities believe the"
+ " primary motive for Lubitz to bring down the plane was that he feared he would not be allowed to fly"
+ " because of his medical problems. Lubitz's girlfriend told investigators he had seen an eye doctor"
+ " and a neuropsychologist, both of whom deemed him unfit to work recently and concluded he had"
+ " psychological issues, the European government official said. But no matter what details emerge about"
+ " his previous mental health struggles, there's more to the story, said Brian Russell, a forensic"
+ ' psychologist. "Psychology can explain why somebody would turn rage inward on themselves about the'
+ " fact that maybe they weren't going to keep doing their job and they're upset about that and so"
+ ' they\'re suicidal," he said. "But there is no mental illness that explains why somebody then feels'
+ " entitled to also take that rage and turn it outward on 149 other people who had nothing to do with"
+ " the person's problems.\" Germanwings crash compensation: What we know . Who was the captain of"
+ " Germanwings Flight 9525? CNN's Margot Haddad reported from Marseille and Pamela Brown from"
+ " Dusseldorf, while Laura Smith-Spark wrote from London. CNN's Frederik Pleitgen, Pamela Boykoff,"
+ " Antonia Mortensen, Sandrine Amiel and Anna-Maja Rappard contributed to this report.",
+ ],
+ return_tensors="pt",
+ padding="longest",
+ truncation=True,
+ )
+ features = self.xsum_1_1_model.get_encoder()(**batch).last_hidden_state
+ expected = [[-0.0828, -0.0251, -0.0674], [0.1277, 0.3311, -0.0255], [0.2613, -0.0840, -0.2763]]
+ assert_tensors_close(features[0, :3, :3], torch.tensor(expected), atol=1e-3)
+
+
+@require_torch
+@require_sentencepiece
+@require_tokenizers
+class BartModelIntegrationTests(unittest.TestCase):
+ @cached_property
+ def default_tokenizer(self):
+ return BartTokenizer.from_pretrained("facebook/bart-large")
+
+ @slow
+ def test_inference_no_head(self):
+ model = BartModel.from_pretrained("facebook/bart-large").to(torch_device)
+ input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
+ attention_mask = input_ids.ne(model.config.pad_token_id)
+ with torch.no_grad():
+ output = model(input_ids=input_ids, attention_mask=attention_mask).last_hidden_state
+ expected_shape = torch.Size((1, 11, 1024))
+ self.assertEqual(output.shape, expected_shape)
+ expected_slice = torch.tensor(
+ [[[0.7144, 0.8143, -1.2813], [0.7144, 0.8143, -1.2813], [-0.0467, 2.5911, -2.1845]]], device=torch_device
+ )
+ torch.testing.assert_close(output[:, :3, :3], expected_slice, rtol=1e-3, atol=1e-3)
+
+ @slow
+ def test_base_mask_filling(self):
+ pbase = pipeline(task="fill-mask", model="facebook/bart-base")
+ src_text = [" I went to the ."]
+ results = [x["token_str"] for x in pbase(src_text)]
+ assert " bathroom" in results
+
+ @slow
+ def test_large_mask_filling(self):
+ plarge = pipeline(task="fill-mask", model="facebook/bart-large")
+ src_text = [" I went to the ."]
+ results = [x["token_str"] for x in plarge(src_text)]
+ expected_results = [" bathroom", " gym", " wrong", " movies", " hospital"]
+ self.assertListEqual(results, expected_results)
+
+ @slow
+ def test_mnli_inference(self):
+ example_b = [0, 31414, 232, 328, 740, 1140, 69, 46078, 1588, 2, 1]
+ input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2], example_b])
+
+ model = AutoModelForSequenceClassification.from_pretrained("facebook/bart-large-mnli").to(
+ torch_device
+ ) # eval called in from_pre
+ attention_mask = input_ids.ne(model.config.pad_token_id)
+ # Test that model hasn't changed
+ with torch.no_grad():
+ outputs = model(input_ids=input_ids, attention_mask=attention_mask)
+
+ batched_logits = outputs.logits
+ expected_shape = torch.Size((2, 3))
+ self.assertEqual(batched_logits.shape, expected_shape)
+ expected_slice = torch.tensor([[0.1907, 1.4342, -1.0289]], device=torch_device)
+ logits_arr = batched_logits[0].detach()
+
+ # Test that padding does not change results
+ input_ids_no_pad = _long_tensor([example_b[:-1]])
+ attention_mask_no_pad = input_ids_no_pad.ne(model.config.pad_token_id)
+
+ with torch.no_grad():
+ logits2 = model(input_ids=input_ids_no_pad, attention_mask=attention_mask_no_pad).logits.squeeze()
+ assert_tensors_close(batched_logits[1], logits2, atol=1e-3)
+ assert_tensors_close(expected_slice, logits_arr, atol=1e-3)
+
+ @slow
+ def test_xsum_summarization_same_as_fairseq(self):
+ model = BartForConditionalGeneration.from_pretrained("facebook/bart-large-xsum").to(torch_device)
+ tok = self.default_tokenizer
+
+ PGE_ARTICLE = """ PG&E stated it scheduled the blackouts in response to forecasts for high winds amid dry conditions. The aim is to reduce the risk of wildfires. Nearly 800 thousand customers were scheduled to be affected by the shutoffs which were expected to last through at least midday tomorrow."""
+
+ EXPECTED_SUMMARY = (
+ ""
+ "California's largest power company has begun shutting off electricity to thousands of customers in the"
+ " state."
+ ""
+ )
+ dct = tok.batch_encode_plus(
+ [PGE_ARTICLE],
+ max_length=1024,
+ padding="max_length",
+ truncation=True,
+ return_tensors="pt",
+ ).to(torch_device)
+
+ hypotheses_batch = model.generate(
+ input_ids=dct["input_ids"],
+ attention_mask=dct["attention_mask"],
+ num_beams=2,
+ max_length=62,
+ min_length=11,
+ length_penalty=1.0,
+ no_repeat_ngram_size=3,
+ early_stopping=True,
+ decoder_start_token_id=model.config.eos_token_id,
+ )
+
+ decoded = tok.batch_decode(hypotheses_batch)
+ self.assertEqual(EXPECTED_SUMMARY, decoded[0])
+
+ def test_xsum_config_generation_params(self):
+ config = BartConfig.from_pretrained("facebook/bart-large-xsum")
+ expected_params = {"num_beams": 6, "do_sample": False, "early_stopping": True, "length_penalty": 1.0}
+ config_params = {k: getattr(config, k, "MISSING") for k, v in expected_params.items()}
+ self.assertDictEqual(expected_params, config_params)
+
+ @slow
+ def test_cnn_summarization_same_as_fairseq(self):
+ hf = BartForConditionalGeneration.from_pretrained("facebook/bart-large-cnn").to(torch_device)
+ tok = BartTokenizer.from_pretrained("facebook/bart-large")
+
+ FRANCE_ARTICLE = ( # @noq
+ " Marseille, France (CNN)The French prosecutor leading an investigation into the crash of Germanwings"
+ " Flight 9525 insisted Wednesday that he was not aware of any video footage from on board the plane."
+ ' Marseille prosecutor Brice Robin told CNN that "so far no videos were used in the crash investigation."'
+ ' He added, "A person who has such a video needs to immediately give it to the investigators." Robin\'s'
+ " comments follow claims by two magazines, German daily Bild and French Paris Match, of a cell phone video"
+ " showing the harrowing final seconds from on board Germanwings Flight 9525 as it crashed into the French"
+ " Alps. All 150 on board were killed. Paris Match and Bild reported that the video was recovered from a"
+ " phone at the wreckage site. The two publications described the supposed video, but did not post it on"
+ " their websites. The publications said that they watched the video, which was found by a source close to"
+ " the investigation. \"One can hear cries of 'My God' in several languages,\" Paris Match reported."
+ ' "Metallic banging can also be heard more than three times, perhaps of the pilot trying to open the'
+ " cockpit door with a heavy object. Towards the end, after a heavy shake, stronger than the others, the"
+ ' screaming intensifies. Then nothing." "It is a very disturbing scene," said Julian Reichelt,'
+ " editor-in-chief of Bild online. An official with France's accident investigation agency, the BEA, said"
+ " the agency is not aware of any such video. Lt. Col. Jean-Marc Menichini, a French Gendarmerie spokesman"
+ " in charge of communications on rescue efforts around the Germanwings crash site, told CNN that the"
+ ' reports were "completely wrong" and "unwarranted." Cell phones have been collected at the site, he said,'
+ ' but that they "hadn\'t been exploited yet." Menichini said he believed the cell phones would need to be'
+ " sent to the Criminal Research Institute in Rosny sous-Bois, near Paris, in order to be analyzed by"
+ " specialized technicians working hand-in-hand with investigators. But none of the cell phones found so"
+ " far have been sent to the institute, Menichini said. Asked whether staff involved in the search could"
+ ' have leaked a memory card to the media, Menichini answered with a categorical "no." Reichelt told "Erin'
+ ' Burnett: Outfront" that he had watched the video and stood by the report, saying Bild and Paris Match'
+ ' are "very confident" that the clip is real. He noted that investigators only revealed they\'d recovered'
+ ' cell phones from the crash site after Bild and Paris Match published their reports. "That is something'
+ " we did not know before. ... Overall we can say many things of the investigation weren't revealed by the"
+ ' investigation at the beginning," he said. What was mental state of Germanwings co-pilot? German airline'
+ " Lufthansa confirmed Tuesday that co-pilot Andreas Lubitz had battled depression years before he took the"
+ " controls of Germanwings Flight 9525, which he's accused of deliberately crashing last week in the"
+ ' French Alps. Lubitz told his Lufthansa flight training school in 2009 that he had a "previous episode of'
+ ' severe depression," the airline said Tuesday. Email correspondence between Lubitz and the school'
+ " discovered in an internal investigation, Lufthansa said, included medical documents he submitted in"
+ " connection with resuming his flight training. The announcement indicates that Lufthansa, the parent"
+ " company of Germanwings, knew of Lubitz's battle with depression, allowed him to continue training and"
+ " ultimately put him in the cockpit. Lufthansa, whose CEO Carsten Spohr previously said Lubitz was 100%"
+ ' fit to fly, described its statement Tuesday as a "swift and seamless clarification" and said it was'
+ " sharing the information and documents -- including training and medical records -- with public"
+ " prosecutors. Spohr traveled to the crash site Wednesday, where recovery teams have been working for the"
+ " past week to recover human remains and plane debris scattered across a steep mountainside. He saw the"
+ " crisis center set up in Seyne-les-Alpes, laid a wreath in the village of Le Vernet, closer to the crash"
+ " site, where grieving families have left flowers at a simple stone memorial. Menichini told CNN late"
+ " Tuesday that no visible human remains were left at the site but recovery teams would keep searching."
+ " French President Francois Hollande, speaking Tuesday, said that it should be possible to identify all"
+ " the victims using DNA analysis by the end of the week, sooner than authorities had previously suggested."
+ " In the meantime, the recovery of the victims' personal belongings will start Wednesday, Menichini said."
+ " Among those personal belongings could be more cell phones belonging to the 144 passengers and six crew"
+ " on board. Check out the latest from our correspondents . The details about Lubitz's correspondence with"
+ " the flight school during his training were among several developments as investigators continued to"
+ " delve into what caused the crash and Lubitz's possible motive for downing the jet. A Lufthansa"
+ " spokesperson told CNN on Tuesday that Lubitz had a valid medical certificate, had passed all his"
+ ' examinations and "held all the licenses required." Earlier, a spokesman for the prosecutor\'s office in'
+ " Dusseldorf, Christoph Kumpa, said medical records reveal Lubitz suffered from suicidal tendencies at"
+ " some point before his aviation career and underwent psychotherapy before he got his pilot's license."
+ " Kumpa emphasized there's no evidence suggesting Lubitz was suicidal or acting aggressively before the"
+ " crash. Investigators are looking into whether Lubitz feared his medical condition would cause him to"
+ " lose his pilot's license, a European government official briefed on the investigation told CNN on"
+ ' Tuesday. While flying was "a big part of his life," the source said, it\'s only one theory being'
+ " considered. Another source, a law enforcement official briefed on the investigation, also told CNN that"
+ " authorities believe the primary motive for Lubitz to bring down the plane was that he feared he would"
+ " not be allowed to fly because of his medical problems. Lubitz's girlfriend told investigators he had"
+ " seen an eye doctor and a neuropsychologist, both of whom deemed him unfit to work recently and concluded"
+ " he had psychological issues, the European government official said. But no matter what details emerge"
+ " about his previous mental health struggles, there's more to the story, said Brian Russell, a forensic"
+ ' psychologist. "Psychology can explain why somebody would turn rage inward on themselves about the fact'
+ " that maybe they weren't going to keep doing their job and they're upset about that and so they're"
+ ' suicidal," he said. "But there is no mental illness that explains why somebody then feels entitled to'
+ " also take that rage and turn it outward on 149 other people who had nothing to do with the person's"
+ ' problems." Germanwings crash compensation: What we know . Who was the captain of Germanwings Flight'
+ " 9525? CNN's Margot Haddad reported from Marseille and Pamela Brown from Dusseldorf, while Laura"
+ " Smith-Spark wrote from London. CNN's Frederik Pleitgen, Pamela Boykoff, Antonia Mortensen, Sandrine"
+ " Amiel and Anna-Maja Rappard contributed to this report."
+ )
+
+ SHORTER_ARTICLE = (
+ " (CNN)The Palestinian Authority officially became the 123rd member of the International Criminal Court on"
+ " Wednesday, a step that gives the court jurisdiction over alleged crimes in Palestinian territories. The"
+ " formal accession was marked with a ceremony at The Hague, in the Netherlands, where the court is based."
+ " The Palestinians signed the ICC's founding Rome Statute in January, when they also accepted its"
+ ' jurisdiction over alleged crimes committed "in the occupied Palestinian territory, including East'
+ ' Jerusalem, since June 13, 2014." Later that month, the ICC opened a preliminary examination into the'
+ " situation in Palestinian territories, paving the way for possible war crimes investigations against"
+ " Israelis. As members of the court, Palestinians may be subject to counter-charges as well. Israel and"
+ " the United States, neither of which is an ICC member, opposed the Palestinians' efforts to join the"
+ " body. But Palestinian Foreign Minister Riad al-Malki, speaking at Wednesday's ceremony, said it was a"
+ ' move toward greater justice. "As Palestine formally becomes a State Party to the Rome Statute today, the'
+ ' world is also a step closer to ending a long era of impunity and injustice," he said, according to an'
+ ' ICC news release. "Indeed, today brings us closer to our shared goals of justice and peace." Judge'
+ " Kuniko Ozaki, a vice president of the ICC, said acceding to the treaty was just the first step for the"
+ ' Palestinians. "As the Rome Statute today enters into force for the State of Palestine, Palestine'
+ " acquires all the rights as well as responsibilities that come with being a State Party to the Statute."
+ ' These are substantive commitments, which cannot be taken lightly," she said. Rights group Human Rights'
+ ' Watch welcomed the development. "Governments seeking to penalize Palestine for joining the ICC should'
+ " immediately end their pressure, and countries that support universal acceptance of the court's treaty"
+ ' should speak out to welcome its membership," said Balkees Jarrah, international justice counsel for the'
+ " group. \"What's objectionable is the attempts to undermine international justice, not Palestine's"
+ ' decision to join a treaty to which over 100 countries around the world are members." In January, when'
+ " the preliminary ICC examination was opened, Israeli Prime Minister Benjamin Netanyahu described it as an"
+ ' outrage, saying the court was overstepping its boundaries. The United States also said it "strongly"'
+ " disagreed with the court's decision. \"As we have said repeatedly, we do not believe that Palestine is a"
+ ' state and therefore we do not believe that it is eligible to join the ICC," the State Department said in'
+ ' a statement. It urged the warring sides to resolve their differences through direct negotiations. "We'
+ ' will continue to oppose actions against Israel at the ICC as counterproductive to the cause of peace,"'
+ " it said. But the ICC begs to differ with the definition of a state for its purposes and refers to the"
+ ' territories as "Palestine." While a preliminary examination is not a formal investigation, it allows the'
+ " court to review evidence and determine whether to investigate suspects on both sides. Prosecutor Fatou"
+ ' Bensouda said her office would "conduct its analysis in full independence and impartiality." The war'
+ " between Israel and Hamas militants in Gaza last summer left more than 2,000 people dead. The inquiry"
+ " will include alleged war crimes committed since June. The International Criminal Court was set up in"
+ " 2002 to prosecute genocide, crimes against humanity and war crimes. CNN's Vasco Cotovio, Kareem Khadder"
+ " and Faith Karimi contributed to this report."
+ )
+
+ # The below article tests that we don't add any hypotheses outside of the top n_beams
+ IRAN_ARTICLE = (
+ " (CNN)The United States and its negotiating partners reached a very strong framework agreement with Iran"
+ " in Lausanne, Switzerland, on Thursday that limits Iran's nuclear program in such a way as to effectively"
+ " block it from building a nuclear weapon. Expect pushback anyway, if the recent past is any harbinger."
+ " Just last month, in an attempt to head off such an agreement, House Speaker John Boehner invited Israeli"
+ " Prime Minister Benjamin Netanyahu to preemptively blast it before Congress, and 47 senators sent a"
+ " letter to the Iranian leadership warning them away from a deal. The debate that has already begun since"
+ " the announcement of the new framework will likely result in more heat than light. It will not be helped"
+ " by the gathering swirl of dubious assumptions and doubtful assertions. Let us address some of these: ."
+ " The most misleading assertion, despite universal rejection by experts, is that the negotiations'"
+ " objective at the outset was the total elimination of any nuclear program in Iran. That is the position"
+ " of Netanyahu and his acolytes in the U.S. Congress. But that is not and never was the objective. If it"
+ " had been, there would have been no Iranian team at the negotiating table. Rather, the objective has"
+ " always been to structure an agreement or series of agreements so that Iran could not covertly develop a"
+ " nuclear arsenal before the United States and its allies could respond. The new framework has exceeded"
+ " expectations in achieving that goal. It would reduce Iran's low-enriched uranium stockpile, cut by"
+ " two-thirds its number of installed centrifuges and implement a rigorous inspection regime. Another"
+ " dubious assumption of opponents is that the Iranian nuclear program is a covert weapons program. Despite"
+ " sharp accusations by some in the United States and its allies, Iran denies having such a program, and"
+ " U.S. intelligence contends that Iran has not yet made the decision to build a nuclear weapon. Iran's"
+ " continued cooperation with International Atomic Energy Agency inspections is further evidence on this"
+ " point, and we'll know even more about Iran's program in the coming months and years because of the deal."
+ " In fact, the inspections provisions that are part of this agreement are designed to protect against any"
+ " covert action by the Iranians. What's more, the rhetoric of some members of Congress has implied that"
+ " the negotiations have been between only the United States and Iran (i.e., the 47 senators' letter"
+ " warning that a deal might be killed by Congress or a future president). This of course is not the case."
+ " The talks were between Iran and the five permanent members of the U.N. Security Council (United States,"
+ " United Kingdom, France, China and Russia) plus Germany, dubbed the P5+1. While the United States has"
+ " played a leading role in the effort, it negotiated the terms alongside its partners. If the agreement"
+ " reached by the P5+1 is rejected by Congress, it could result in an unraveling of the sanctions on Iran"
+ " and threaten NATO cohesion in other areas. Another questionable assertion is that this agreement"
+ " contains a sunset clause, after which Iran will be free to do as it pleases. Again, this is not the"
+ " case. Some of the restrictions on Iran's nuclear activities, such as uranium enrichment, will be eased"
+ " or eliminated over time, as long as 15 years. But most importantly, the framework agreement includes"
+ " Iran's ratification of the Additional Protocol, which allows IAEA inspectors expanded access to nuclear"
+ " sites both declared and nondeclared. This provision will be permanent. It does not sunset. Thus, going"
+ " forward, if Iran decides to enrich uranium to weapons-grade levels, monitors will be able to detect such"
+ " a move in a matter of days and alert the U.N. Security Council. Many in Congress have said that the"
+ ' agreement should be a formal treaty requiring the Senate to "advise and consent." But the issue is not'
+ " suited for a treaty. Treaties impose equivalent obligations on all signatories. For example, the New"
+ " START treaty limits Russia and the United States to 1,550 deployed strategic warheads. But any agreement"
+ " with Iran will not be so balanced. The restrictions and obligations in the final framework agreement"
+ " will be imposed almost exclusively on Iran. The P5+1 are obligated only to ease and eventually remove"
+ " most but not all economic sanctions, which were imposed as leverage to gain this final deal. Finally"
+ " some insist that any agreement must address Iranian missile programs, human rights violations or support"
+ " for Hamas or Hezbollah. As important as these issues are, and they must indeed be addressed, they are"
+ " unrelated to the most important aim of a nuclear deal: preventing a nuclear Iran. To include them in"
+ " the negotiations would be a poison pill. This agreement should be judged on its merits and on how it"
+ " affects the security of our negotiating partners and allies, including Israel. Those judgments should be"
+ " fact-based, not based on questionable assertions or dubious assumptions."
+ )
+
+ ARTICLE_SUBWAY = (
+ " New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York. A"
+ " year later, she got married again in Westchester County, but to a different man and without divorcing"
+ " her first husband. Only 18 days after that marriage, she got hitched yet again. Then, Barrientos"
+ ' declared "I do" five more times, sometimes only within two weeks of each other. In 2010, she married'
+ " once more, this time in the Bronx. In an application for a marriage license, she stated it was her"
+ ' "first and only" marriage. Barrientos, now 39, is facing two criminal counts of "offering a false'
+ ' instrument for filing in the first degree," referring to her false statements on the 2010 marriage'
+ " license application, according to court documents. Prosecutors said the marriages were part of an"
+ " immigration scam. On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to"
+ " her attorney, Christopher Wright, who declined to comment further. After leaving court, Barrientos was"
+ " arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New"
+ " York subway through an emergency exit, said Detective Annette Markowski, a police spokeswoman. In total,"
+ " Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002. All"
+ " occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be"
+ " married to four men, and at one time, she was married to eight men at once, prosecutors say. Prosecutors"
+ " said the immigration scam involved some of her husbands, who filed for permanent residence status"
+ " shortly after the marriages. Any divorces happened only after such filings were approved. It was"
+ " unclear whether any of the men will be prosecuted. The case was referred to the Bronx District"
+ " Attorney's Office by Immigration and Customs Enforcement and the Department of Homeland Security's"
+ ' Investigation Division. Seven of the men are from so-called "red-flagged" countries, including Egypt,'
+ " Turkey, Georgia, Pakistan and Mali. Her eighth husband, Rashid Rajput, was deported in 2006 to his"
+ " native Pakistan after an investigation by the Joint Terrorism Task Force. If convicted, Barrientos faces"
+ " up to four years in prison. Her next court appearance is scheduled for May 18."
+ )
+
+ dct = tok.batch_encode_plus(
+ [FRANCE_ARTICLE, SHORTER_ARTICLE, IRAN_ARTICLE, ARTICLE_SUBWAY],
+ max_length=1024,
+ padding="max_length",
+ truncation="only_first",
+ return_tensors="pt",
+ )
+
+ self.assertEqual(1024, dct["input_ids"].shape[1])
+ hypotheses_batch = hf.generate(
+ input_ids=dct["input_ids"].to(torch_device),
+ attention_mask=dct["attention_mask"].to(torch_device),
+ num_beams=2,
+ )
+ assert hypotheses_batch[:, 1].eq(0).all().item()
+
+ EXPECTED = [
+ ""
+ "A French prosecutor says he is not aware of any video footage from on board the plane. Two German "
+ "magazines claim to have found a cell phone video showing the crash. The publications say they watched "
+ "the video, which was found by a source close to the investigation. All 150 on board Germanwings Flight "
+ "9525 were killed."
+ "",
+ ""
+ "Palestinian Authority becomes 123rd member of the International Criminal Court. The move gives the court "
+ "jurisdiction over alleged crimes in Palestinian territories. Israel and the United States opposed the "
+ "Palestinians' efforts to join the body. But Palestinian Foreign Minister Riad al-Malki said it was a "
+ "move toward greater justice."
+ "",
+ ""
+ "U.S. and its negotiating partners reached a strong framework agreement with Iran. Peter Bergen: The "
+ "debate that has already begun will likely result in more heat than light. He says critics have made "
+ "dubious assumptions and doubtful assertions. Bergen says the goal was to block Iran from building a "
+ "nuclear weapon."
+ "",
+ ""
+ "Liana Barrientos, 39, has been married 10 times, sometimes within two weeks of each other. Prosecutors "
+ "say the marriages were part of an immigration scam. She pleaded not guilty at State Supreme Court in the "
+ "Bronx on Friday. If convicted, she faces up to four years in prison."
+ "",
+ ]
+
+ generated_summaries = tok.batch_decode(hypotheses_batch.tolist())
+ assert generated_summaries == EXPECTED
+
+ @slow
+ def test_contrastive_search_bart(self):
+ article = (
+ " New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York. A"
+ " year later, she got married again in Westchester County, but to a different man and without divorcing"
+ " her first husband. Only 18 days after that marriage, she got hitched yet again. Then, Barrientos"
+ ' declared "I do" five more times, sometimes only within two weeks of each other. In 2010, she married'
+ " once more, this time in the Bronx. In an application for a marriage license, she stated it was her"
+ ' "first and only" marriage. Barrientos, now 39, is facing two criminal counts of "offering a false'
+ ' instrument for filing in the first degree," referring to her false statements on the 2010 marriage'
+ " license application, according to court documents. Prosecutors said the marriages were part of an"
+ " immigration scam. On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to"
+ " her attorney, Christopher Wright, who declined to comment further. After leaving court, Barrientos was"
+ " arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New"
+ " York subway through an emergency exit, said Detective Annette Markowski, a police spokeswoman. In total,"
+ " Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002. All"
+ " occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be"
+ " married to four men, and at one time, she was married to eight men at once, prosecutors say. Prosecutors"
+ " said the immigration scam involved some of her husbands, who filed for permanent residence status"
+ " shortly after the marriages. Any divorces happened only after such filings were approved. It was"
+ " unclear whether any of the men will be prosecuted. The case was referred to the Bronx District"
+ " Attorney's Office by Immigration and Customs Enforcement and the Department of Homeland Security's"
+ ' Investigation Division. Seven of the men are from so-called "red-flagged" countries, including Egypt,'
+ " Turkey, Georgia, Pakistan and Mali. Her eighth husband, Rashid Rajput, was deported in 2006 to his"
+ " native Pakistan after an investigation by the Joint Terrorism Task Force. If convicted, Barrientos faces"
+ " up to four years in prison. Her next court appearance is scheduled for May 18."
+ )
+ bart_tokenizer = BartTokenizer.from_pretrained("facebook/bart-large-cnn")
+ bart_model = BartForConditionalGeneration.from_pretrained("facebook/bart-large-cnn").to(torch_device)
+ input_ids = bart_tokenizer(
+ article, add_special_tokens=False, truncation=True, max_length=512, return_tensors="pt"
+ ).input_ids.to(torch_device)
+
+ outputs = bart_model.generate(input_ids, penalty_alpha=0.5, top_k=5, max_length=64, num_beams=1)
+ generated_text = bart_tokenizer.batch_decode(outputs, skip_special_tokens=True)
+
+ self.assertListEqual(
+ generated_text,
+ [
+ "Liana Barrientos, 39, pleaded not guilty to charges related to false marriage statements. "
+ "Prosecutors say she married at least 10 times, sometimes within two weeks of each other. She is "
+ "accused of being part of an immigration scam to get permanent residency. If convicted, she faces up "
+ "to four years in"
+ ],
+ )
+
+ @slow
+ def test_decoder_attention_mask(self):
+ model = BartForConditionalGeneration.from_pretrained("facebook/bart-large", forced_bos_token_id=0).to(
+ torch_device
+ )
+ tokenizer = self.default_tokenizer
+ sentence = "UN Chief Says There Is No in Syria"
+ input_ids = tokenizer(sentence, return_tensors="pt").input_ids.to(torch_device)
+ padding_size = 3
+ decoder_input_ids = torch.tensor(
+ [
+ [model.config.decoder_start_token_id]
+ + padding_size * [model.config.pad_token_id]
+ + [model.config.bos_token_id]
+ ],
+ dtype=torch.long,
+ device=torch_device,
+ )
+ decoder_attention_mask = torch.where(decoder_input_ids == model.config.pad_token_id, 0, 1).to(torch_device)
+ generated_ids = model.generate(
+ input_ids=input_ids,
+ use_cache=False,
+ max_new_tokens=20,
+ decoder_input_ids=decoder_input_ids,
+ decoder_attention_mask=decoder_attention_mask,
+ )
+ generated_sentence = tokenizer.batch_decode(generated_ids)[0]
+ expected_sentence = "UN Chief Says There Is No Plan B for Peace in Syria"
+ self.assertEqual(generated_sentence, expected_sentence)
+
+
+class BartStandaloneDecoderModelTester:
+ def __init__(
+ self,
+ parent,
+ vocab_size=99,
+ batch_size=13,
+ d_model=16,
+ decoder_seq_length=7,
+ is_training=True,
+ is_decoder=True,
+ use_attention_mask=True,
+ use_cache=False,
+ use_labels=True,
+ decoder_start_token_id=2,
+ decoder_ffn_dim=32,
+ decoder_layers=2,
+ encoder_attention_heads=4,
+ decoder_attention_heads=4,
+ max_position_embeddings=50,
+ is_encoder_decoder=False,
+ pad_token_id=0,
+ bos_token_id=1,
+ eos_token_id=2,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.decoder_seq_length = decoder_seq_length
+ # For common tests
+ self.seq_length = self.decoder_seq_length
+ self.is_training = is_training
+ self.use_attention_mask = use_attention_mask
+ self.use_labels = use_labels
+
+ self.vocab_size = vocab_size
+ self.d_model = d_model
+ self.hidden_size = d_model
+ self.num_hidden_layers = decoder_layers
+ self.decoder_layers = decoder_layers
+ self.decoder_ffn_dim = decoder_ffn_dim
+ self.encoder_attention_heads = encoder_attention_heads
+ self.decoder_attention_heads = decoder_attention_heads
+ self.num_attention_heads = decoder_attention_heads
+ self.eos_token_id = eos_token_id
+ self.bos_token_id = bos_token_id
+ self.pad_token_id = pad_token_id
+ self.decoder_start_token_id = decoder_start_token_id
+ self.use_cache = use_cache
+ self.max_position_embeddings = max_position_embeddings
+ self.is_encoder_decoder = is_encoder_decoder
+
+ self.scope = None
+ self.decoder_key_length = decoder_seq_length
+ self.base_model_out_len = 2
+ self.decoder_attention_idx = 1
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
+
+ attention_mask = None
+ if self.use_attention_mask:
+ attention_mask = ids_tensor([self.batch_size, self.decoder_seq_length], vocab_size=2)
+
+ lm_labels = None
+ if self.use_labels:
+ lm_labels = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
+
+ config = BartConfig(
+ vocab_size=self.vocab_size,
+ d_model=self.d_model,
+ encoder_layers=self.decoder_layers,
+ decoder_layers=self.decoder_layers,
+ decoder_ffn_dim=self.decoder_ffn_dim,
+ encoder_attention_heads=self.encoder_attention_heads,
+ decoder_attention_heads=self.decoder_attention_heads,
+ eos_token_id=self.eos_token_id,
+ bos_token_id=self.bos_token_id,
+ use_cache=self.use_cache,
+ pad_token_id=self.pad_token_id,
+ decoder_start_token_id=self.decoder_start_token_id,
+ max_position_embeddings=self.max_position_embeddings,
+ is_encoder_decoder=self.is_encoder_decoder,
+ forced_eos_token_id=None,
+ )
+
+ return (
+ config,
+ input_ids,
+ attention_mask,
+ lm_labels,
+ )
+
+ def prepare_config_and_inputs_for_decoder(self):
+ (
+ config,
+ input_ids,
+ attention_mask,
+ lm_labels,
+ ) = self.prepare_config_and_inputs()
+
+ encoder_hidden_states = floats_tensor([self.batch_size, self.decoder_seq_length, self.hidden_size])
+ encoder_attention_mask = ids_tensor([self.batch_size, self.decoder_seq_length], vocab_size=2)
+
+ return (
+ config,
+ input_ids,
+ attention_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ lm_labels,
+ )
+
+ def create_and_check_decoder_model_past(
+ self,
+ config,
+ input_ids,
+ attention_mask,
+ lm_labels,
+ ):
+ config.use_cache = True
+ model = BartDecoder(config=config).to(torch_device).eval()
+ # first forward pass
+ outputs = model(input_ids, use_cache=True)
+ outputs_use_cache_conf = model(input_ids)
+ outputs_no_past = model(input_ids, use_cache=False)
+
+ self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf))
+ self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1)
+
+ past_key_values = outputs["past_key_values"]
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+
+ output_from_no_past = model(next_input_ids)["last_hidden_state"]
+ output_from_past = model(next_tokens, past_key_values=past_key_values)["last_hidden_state"]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, next_input_ids.shape[-1] - 1, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ assert torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3)
+
+ def create_and_check_decoder_model_attention_mask_past(
+ self,
+ config,
+ input_ids,
+ attention_mask,
+ lm_labels,
+ ):
+ model = BartDecoder(config=config).to(torch_device).eval()
+
+ # create attention mask
+ attn_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
+
+ half_seq_length = input_ids.shape[-1] // 2
+ attn_mask[:, half_seq_length:] = 0
+
+ # first forward pass
+ past_key_values = model(input_ids, attention_mask=attn_mask, use_cache=True)["past_key_values"]
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
+
+ # change a random masked slice from input_ids
+ random_seq_idx_to_change = ids_tensor((1,), half_seq_length).item() + 1
+ random_other_next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size).squeeze(-1)
+ input_ids[:, -random_seq_idx_to_change] = random_other_next_tokens
+
+ # append to next input_ids and attn_mask
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ attn_mask = torch.cat(
+ [attn_mask, torch.ones((attn_mask.shape[0], 1), dtype=torch.long, device=torch_device)],
+ dim=1,
+ )
+
+ # get two different outputs
+ output_from_no_past = model(next_input_ids, attention_mask=attn_mask)["last_hidden_state"]
+ output_from_past = model(
+ next_tokens, attention_mask=attn_mask, past_key_values=past_key_values, use_cache=True
+ )["last_hidden_state"]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, next_input_ids.shape[-1] - 1, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ assert torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3)
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ attention_mask,
+ lm_labels,
+ ) = config_and_inputs
+
+ inputs_dict = {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class BartStandaloneDecoderModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
+ all_model_classes = (BartDecoder, BartForCausalLM) if is_torch_available() else ()
+ fx_comptatible = True
+ test_pruning = False
+ is_encoder_decoder = False
+ test_missing_keys = False
+
+ def setUp(
+ self,
+ ):
+ self.model_tester = BartStandaloneDecoderModelTester(self, is_training=False)
+ self.config_tester = ConfigTester(self, config_class=BartConfig)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_decoder_model_past(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_decoder_model_past(*config_and_inputs)
+
+ def test_decoder_model_attn_mask_past(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_decoder_model_attention_mask_past(*config_and_inputs)
+
+ @unittest.skip(reason="Decoder cannot keep gradients")
+ def test_retain_grad_hidden_states_attentions(self):
+ return
+
+ @unittest.skip(reason="Decoder cannot keep gradients")
+ def test_flex_attention_with_grads():
+ return
diff --git a/transformers/tests/models/bart/test_tokenization_bart.py b/transformers/tests/models/bart/test_tokenization_bart.py
new file mode 100644
index 0000000000000000000000000000000000000000..f6b66982cc88bb105ef03ecf8e43efd37ec51c1c
--- /dev/null
+++ b/transformers/tests/models/bart/test_tokenization_bart.py
@@ -0,0 +1,194 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import json
+import os
+import unittest
+from functools import lru_cache
+
+from transformers import BartTokenizer, BartTokenizerFast, BatchEncoding
+from transformers.models.roberta.tokenization_roberta import VOCAB_FILES_NAMES
+from transformers.testing_utils import require_tokenizers, require_torch
+from transformers.utils import cached_property
+
+from ...test_tokenization_common import TokenizerTesterMixin, filter_roberta_detectors, use_cache_if_possible
+
+
+@require_tokenizers
+class TestTokenizationBart(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "facebook/bart-base"
+ tokenizer_class = BartTokenizer
+ rust_tokenizer_class = BartTokenizerFast
+ test_rust_tokenizer = True
+ from_pretrained_filter = filter_roberta_detectors
+ # from_pretrained_kwargs = {'add_prefix_space': True}
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ vocab = [
+ "l",
+ "o",
+ "w",
+ "e",
+ "r",
+ "s",
+ "t",
+ "i",
+ "d",
+ "n",
+ "\u0120",
+ "\u0120l",
+ "\u0120n",
+ "\u0120lo",
+ "\u0120low",
+ "er",
+ "\u0120lowest",
+ "\u0120newer",
+ "\u0120wider",
+ "",
+ ]
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+ merges = ["#version: 0.2", "\u0120 l", "\u0120l o", "\u0120lo w", "e r", ""]
+ cls.special_tokens_map = {"unk_token": ""}
+
+ cls.vocab_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ cls.merges_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["merges_file"])
+ with open(cls.vocab_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps(vocab_tokens) + "\n")
+ with open(cls.merges_file, "w", encoding="utf-8") as fp:
+ fp.write("\n".join(merges))
+
+ @classmethod
+ @use_cache_if_possible
+ @lru_cache(maxsize=64)
+ def get_tokenizer(cls, pretrained_name=None, **kwargs):
+ kwargs.update(cls.special_tokens_map)
+ pretrained_name = pretrained_name or cls.tmpdirname
+ return cls.tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+
+ @classmethod
+ @use_cache_if_possible
+ @lru_cache(maxsize=64)
+ def get_rust_tokenizer(cls, pretrained_name=None, **kwargs):
+ kwargs.update(cls.special_tokens_map)
+ pretrained_name = pretrained_name or cls.tmpdirname
+ return cls.rust_tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+
+ def get_input_output_texts(self, tokenizer):
+ return "lower newer", "lower newer"
+
+ @cached_property
+ def default_tokenizer(self):
+ return BartTokenizer.from_pretrained("facebook/bart-large")
+
+ @cached_property
+ def default_tokenizer_fast(self):
+ return BartTokenizerFast.from_pretrained("facebook/bart-large")
+
+ @require_torch
+ def test_prepare_batch(self):
+ src_text = ["A long paragraph for summarization.", "Another paragraph for summarization."]
+ expected_src_tokens = [0, 250, 251, 17818, 13, 39186, 1938, 4, 2]
+
+ for tokenizer in [self.default_tokenizer, self.default_tokenizer_fast]:
+ batch = tokenizer(src_text, max_length=len(expected_src_tokens), padding=True, return_tensors="pt")
+ self.assertIsInstance(batch, BatchEncoding)
+
+ self.assertEqual((2, 9), batch.input_ids.shape)
+ self.assertEqual((2, 9), batch.attention_mask.shape)
+ result = batch.input_ids.tolist()[0]
+ self.assertListEqual(expected_src_tokens, result)
+ # Test that special tokens are reset
+
+ @require_torch
+ def test_prepare_batch_empty_target_text(self):
+ src_text = ["A long paragraph for summarization.", "Another paragraph for summarization."]
+ for tokenizer in [self.default_tokenizer, self.default_tokenizer_fast]:
+ batch = tokenizer(src_text, padding=True, return_tensors="pt")
+ # check if input_ids are returned and no labels
+ self.assertIn("input_ids", batch)
+ self.assertIn("attention_mask", batch)
+ self.assertNotIn("labels", batch)
+ self.assertNotIn("decoder_attention_mask", batch)
+
+ @require_torch
+ def test_tokenizer_as_target_length(self):
+ tgt_text = [
+ "Summary of the text.",
+ "Another summary.",
+ ]
+ for tokenizer in [self.default_tokenizer, self.default_tokenizer_fast]:
+ targets = tokenizer(text_target=tgt_text, max_length=32, padding="max_length", return_tensors="pt")
+ self.assertEqual(32, targets["input_ids"].shape[1])
+
+ @require_torch
+ def test_prepare_batch_not_longer_than_maxlen(self):
+ for tokenizer in [self.default_tokenizer, self.default_tokenizer_fast]:
+ batch = tokenizer(
+ ["I am a small frog" * 1024, "I am a small frog"], padding=True, truncation=True, return_tensors="pt"
+ )
+ self.assertIsInstance(batch, BatchEncoding)
+ self.assertEqual(batch.input_ids.shape, (2, 1024))
+
+ @require_torch
+ def test_special_tokens(self):
+ src_text = ["A long paragraph for summarization."]
+ tgt_text = [
+ "Summary of the text.",
+ ]
+ for tokenizer in [self.default_tokenizer, self.default_tokenizer_fast]:
+ inputs = tokenizer(src_text, return_tensors="pt")
+ targets = tokenizer(text_target=tgt_text, return_tensors="pt")
+ input_ids = inputs["input_ids"]
+ labels = targets["input_ids"]
+ self.assertTrue((input_ids[:, 0] == tokenizer.bos_token_id).all().item())
+ self.assertTrue((labels[:, 0] == tokenizer.bos_token_id).all().item())
+ self.assertTrue((input_ids[:, -1] == tokenizer.eos_token_id).all().item())
+ self.assertTrue((labels[:, -1] == tokenizer.eos_token_id).all().item())
+
+ @unittest.skip
+ def test_pretokenized_inputs(self):
+ pass
+
+ def test_embeded_special_tokens(self):
+ for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
+ with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name})"):
+ tokenizer_r = self.get_rust_tokenizer(pretrained_name, **kwargs)
+ tokenizer_p = self.get_tokenizer(pretrained_name, **kwargs)
+ sentence = "A, AllenNLP sentence."
+ tokens_r = tokenizer_r.encode_plus(sentence, add_special_tokens=True, return_token_type_ids=True)
+ tokens_p = tokenizer_p.encode_plus(sentence, add_special_tokens=True, return_token_type_ids=True)
+
+ # token_type_ids should put 0 everywhere
+ self.assertEqual(sum(tokens_r["token_type_ids"]), sum(tokens_p["token_type_ids"]))
+
+ # attention_mask should put 1 everywhere, so sum over length should be 1
+ self.assertEqual(
+ sum(tokens_r["attention_mask"]) / len(tokens_r["attention_mask"]),
+ sum(tokens_p["attention_mask"]) / len(tokens_p["attention_mask"]),
+ )
+
+ tokens_r_str = tokenizer_r.convert_ids_to_tokens(tokens_r["input_ids"])
+ tokens_p_str = tokenizer_p.convert_ids_to_tokens(tokens_p["input_ids"])
+
+ self.assertSequenceEqual(tokens_p["input_ids"], [0, 250, 6, 50264, 3823, 487, 21992, 3645, 4, 2])
+ self.assertSequenceEqual(tokens_r["input_ids"], [0, 250, 6, 50264, 3823, 487, 21992, 3645, 4, 2])
+
+ self.assertSequenceEqual(
+ tokens_p_str, ["", "A", ",", "", "ĠAllen", "N", "LP", "Ġsentence", ".", ""]
+ )
+ self.assertSequenceEqual(
+ tokens_r_str, ["", "A", ",", "", "ĠAllen", "N", "LP", "Ġsentence", ".", ""]
+ )
diff --git a/transformers/tests/models/barthez/__init__.py b/transformers/tests/models/barthez/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/barthez/test_tokenization_barthez.py b/transformers/tests/models/barthez/test_tokenization_barthez.py
new file mode 100644
index 0000000000000000000000000000000000000000..5df4131d73992783472a433a45c2f91a89a2f0c6
--- /dev/null
+++ b/transformers/tests/models/barthez/test_tokenization_barthez.py
@@ -0,0 +1,116 @@
+# Copyright 2020 Ecole Polytechnique and HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+from transformers import BarthezTokenizer, BarthezTokenizerFast, BatchEncoding
+from transformers.testing_utils import require_sentencepiece, require_tokenizers, require_torch, slow
+
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+@require_tokenizers
+@require_sentencepiece
+@slow # see https://github.com/huggingface/transformers/issues/11457
+class BarthezTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "moussaKam/mbarthez"
+ tokenizer_class = BarthezTokenizer
+ rust_tokenizer_class = BarthezTokenizerFast
+ test_rust_tokenizer = True
+ test_sentencepiece = True
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ tokenizer = BarthezTokenizerFast.from_pretrained("moussaKam/mbarthez")
+ tokenizer.save_pretrained(cls.tmpdirname)
+ tokenizer.save_pretrained(cls.tmpdirname, legacy_format=False)
+ cls.tokenizer = tokenizer
+
+ def test_convert_token_and_id(self):
+ """Test ``_convert_token_to_id`` and ``_convert_id_to_token``."""
+ token = ""
+ token_id = 1
+
+ self.assertEqual(self.get_tokenizer()._convert_token_to_id(token), token_id)
+ self.assertEqual(self.get_tokenizer()._convert_id_to_token(token_id), token)
+
+ def test_get_vocab(self):
+ vocab_keys = list(self.get_tokenizer().get_vocab().keys())
+
+ self.assertEqual(vocab_keys[0], "")
+ self.assertEqual(vocab_keys[1], "")
+ self.assertEqual(vocab_keys[-1], "")
+ self.assertEqual(len(vocab_keys), 101_122)
+
+ def test_vocab_size(self):
+ self.assertEqual(self.get_tokenizer().vocab_size, 101_122)
+
+ @require_torch
+ def test_prepare_batch(self):
+ src_text = ["A long paragraph for summarization.", "Another paragraph for summarization."]
+ expected_src_tokens = [0, 57, 3018, 70307, 91, 2]
+
+ batch = self.tokenizer(
+ src_text, max_length=len(expected_src_tokens), padding=True, truncation=True, return_tensors="pt"
+ )
+ self.assertIsInstance(batch, BatchEncoding)
+
+ self.assertEqual((2, 6), batch.input_ids.shape)
+ self.assertEqual((2, 6), batch.attention_mask.shape)
+ result = batch.input_ids.tolist()[0]
+ self.assertListEqual(expected_src_tokens, result)
+
+ def test_rust_and_python_full_tokenizers(self):
+ if not self.test_rust_tokenizer:
+ self.skipTest(reason="test_rust_tokenizer is set to False")
+
+ tokenizer = self.get_tokenizer()
+ rust_tokenizer = self.get_rust_tokenizer()
+
+ sequence = "I was born in 92000, and this is falsé."
+
+ tokens = tokenizer.tokenize(sequence)
+ rust_tokens = rust_tokenizer.tokenize(sequence)
+ self.assertListEqual(tokens, rust_tokens)
+
+ ids = tokenizer.encode(sequence, add_special_tokens=False)
+ rust_ids = rust_tokenizer.encode(sequence, add_special_tokens=False)
+ self.assertListEqual(ids, rust_ids)
+
+ rust_tokenizer = self.get_rust_tokenizer()
+ ids = tokenizer.encode(sequence)
+ rust_ids = rust_tokenizer.encode(sequence)
+ self.assertListEqual(ids, rust_ids)
+
+ @slow
+ def test_tokenizer_integration(self):
+ expected_encoding = {'input_ids': [[0, 490, 14328, 4507, 354, 47, 43669, 95, 25, 78117, 20215, 19779, 190, 22, 400, 4, 35343, 80310, 603, 86, 24937, 105, 33438, 94762, 196, 39642, 7, 15, 15933, 173, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [0, 10534, 87, 25, 66, 3358, 196, 55289, 8, 82961, 81, 2204, 75203, 7, 15, 763, 12956, 216, 178, 14328, 9595, 1377, 69693, 7, 448, 71021, 196, 18106, 1437, 13974, 108, 9083, 4, 49315, 7, 39, 86, 1326, 2793, 46333, 4, 448, 196, 74588, 7, 49315, 7, 39, 21, 822, 38470, 74, 21, 66723, 62480, 8, 22050, 5, 2]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]} # fmt: skip
+
+ # moussaKam/mbarthez is a french model. So we also use french texts.
+ sequences = [
+ "Le transformeur est un modèle d'apprentissage profond introduit en 2017, "
+ "utilisé principalement dans le domaine du traitement automatique des langues (TAL).",
+ "À l'instar des réseaux de neurones récurrents (RNN), les transformeurs sont conçus "
+ "pour gérer des données séquentielles, telles que le langage naturel, pour des tâches "
+ "telles que la traduction et la synthèse de texte.",
+ ]
+
+ self.tokenizer_integration_test_util(
+ expected_encoding=expected_encoding,
+ model_name="moussaKam/mbarthez",
+ revision="c2e4ecbca5e3cd2c37fe1ac285ca4fbdf1366fb6",
+ sequences=sequences,
+ )
diff --git a/transformers/tests/models/beit/__init__.py b/transformers/tests/models/beit/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/beit/test_image_processing_beit.py b/transformers/tests/models/beit/test_image_processing_beit.py
new file mode 100644
index 0000000000000000000000000000000000000000..51a72beeb5e5c8dce614a47f04b42f1fd4336614
--- /dev/null
+++ b/transformers/tests/models/beit/test_image_processing_beit.py
@@ -0,0 +1,313 @@
+# Copyright 2021 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from datasets import load_dataset
+
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torch_available, is_torchvision_available, is_vision_available
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from transformers import BeitImageProcessor
+
+ if is_torchvision_available():
+ from transformers import BeitImageProcessorFast
+
+
+class BeitImageProcessingTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ do_center_crop=True,
+ crop_size=None,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ do_reduce_labels=False,
+ ):
+ size = size if size is not None else {"height": 20, "width": 20}
+ crop_size = crop_size if crop_size is not None else {"height": 18, "width": 18}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_center_crop = do_center_crop
+ self.crop_size = crop_size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.do_reduce_labels = do_reduce_labels
+
+ def prepare_image_processor_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "do_center_crop": self.do_center_crop,
+ "crop_size": self.crop_size,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_reduce_labels": self.do_reduce_labels,
+ }
+
+ def expected_output_image_shape(self, images):
+ return self.num_channels, self.crop_size["height"], self.crop_size["width"]
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+def prepare_semantic_single_inputs():
+ ds = load_dataset("hf-internal-testing/fixtures_ade20k", split="test")
+ example = ds[0]
+ return example["image"], example["map"]
+
+
+def prepare_semantic_batch_inputs():
+ ds = load_dataset("hf-internal-testing/fixtures_ade20k", split="test")
+ return list(ds["image"][:2]), list(ds["map"][:2])
+
+
+@require_torch
+@require_vision
+class BeitImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = BeitImageProcessor if is_vision_available() else None
+ fast_image_processing_class = BeitImageProcessorFast if is_torchvision_available() else None
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = BeitImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "do_center_crop"))
+ self.assertTrue(hasattr(image_processing, "center_crop"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_reduce_labels"))
+
+ def test_image_processor_from_dict_with_kwargs(self):
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"height": 20, "width": 20})
+ self.assertEqual(image_processor.crop_size, {"height": 18, "width": 18})
+ self.assertEqual(image_processor.do_reduce_labels, False)
+
+ image_processor = image_processing_class.from_dict(
+ self.image_processor_dict, size=42, crop_size=84, do_reduce_labels=True
+ )
+ self.assertEqual(image_processor.size, {"height": 42, "width": 42})
+ self.assertEqual(image_processor.crop_size, {"height": 84, "width": 84})
+ self.assertEqual(image_processor.do_reduce_labels, True)
+
+ def test_call_segmentation_maps(self):
+ for image_processing_class in self.image_processor_list:
+ # Initialize image_processing
+ image_processing = image_processing_class(**self.image_processor_dict)
+ # create random PyTorch tensors
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, torchify=True)
+ maps = []
+ for image in image_inputs:
+ self.assertIsInstance(image, torch.Tensor)
+ maps.append(torch.zeros(image.shape[-2:]).long())
+
+ # Test not batched input
+ encoding = image_processing(image_inputs[0], maps[0], return_tensors="pt")
+ self.assertEqual(
+ encoding["pixel_values"].shape,
+ (
+ 1,
+ self.image_processor_tester.num_channels,
+ self.image_processor_tester.crop_size["height"],
+ self.image_processor_tester.crop_size["width"],
+ ),
+ )
+ self.assertEqual(
+ encoding["labels"].shape,
+ (
+ 1,
+ self.image_processor_tester.crop_size["height"],
+ self.image_processor_tester.crop_size["width"],
+ ),
+ )
+ self.assertEqual(encoding["labels"].dtype, torch.long)
+ self.assertTrue(encoding["labels"].min().item() >= 0)
+ self.assertTrue(encoding["labels"].max().item() <= 255)
+
+ # Test batched
+ encoding = image_processing(image_inputs, maps, return_tensors="pt")
+ self.assertEqual(
+ encoding["pixel_values"].shape,
+ (
+ self.image_processor_tester.batch_size,
+ self.image_processor_tester.num_channels,
+ self.image_processor_tester.crop_size["height"],
+ self.image_processor_tester.crop_size["width"],
+ ),
+ )
+ self.assertEqual(
+ encoding["labels"].shape,
+ (
+ self.image_processor_tester.batch_size,
+ self.image_processor_tester.crop_size["height"],
+ self.image_processor_tester.crop_size["width"],
+ ),
+ )
+ self.assertEqual(encoding["labels"].dtype, torch.long)
+ self.assertTrue(encoding["labels"].min().item() >= 0)
+ self.assertTrue(encoding["labels"].max().item() <= 255)
+
+ # Test not batched input (PIL images)
+ image, segmentation_map = prepare_semantic_single_inputs()
+
+ encoding = image_processing(image, segmentation_map, return_tensors="pt")
+ self.assertEqual(
+ encoding["pixel_values"].shape,
+ (
+ 1,
+ self.image_processor_tester.num_channels,
+ self.image_processor_tester.crop_size["height"],
+ self.image_processor_tester.crop_size["width"],
+ ),
+ )
+ self.assertEqual(
+ encoding["labels"].shape,
+ (
+ 1,
+ self.image_processor_tester.crop_size["height"],
+ self.image_processor_tester.crop_size["width"],
+ ),
+ )
+ self.assertEqual(encoding["labels"].dtype, torch.long)
+ self.assertTrue(encoding["labels"].min().item() >= 0)
+ self.assertTrue(encoding["labels"].max().item() <= 255)
+
+ # Test batched input (PIL images)
+ images, segmentation_maps = prepare_semantic_batch_inputs()
+
+ encoding = image_processing(images, segmentation_maps, return_tensors="pt")
+ self.assertEqual(
+ encoding["pixel_values"].shape,
+ (
+ 2,
+ self.image_processor_tester.num_channels,
+ self.image_processor_tester.crop_size["height"],
+ self.image_processor_tester.crop_size["width"],
+ ),
+ )
+ self.assertEqual(
+ encoding["labels"].shape,
+ (
+ 2,
+ self.image_processor_tester.crop_size["height"],
+ self.image_processor_tester.crop_size["width"],
+ ),
+ )
+ self.assertEqual(encoding["labels"].dtype, torch.long)
+ self.assertTrue(encoding["labels"].min().item() >= 0)
+ self.assertTrue(encoding["labels"].max().item() <= 255)
+
+ def test_reduce_labels(self):
+ for image_processing_class in self.image_processor_list:
+ # Initialize image_processing
+ image_processing = image_processing_class(**self.image_processor_dict)
+
+ # ADE20k has 150 classes, and the background is included, so labels should be between 0 and 150
+ image, map = prepare_semantic_single_inputs()
+ encoding = image_processing(image, map, return_tensors="pt")
+ self.assertTrue(encoding["labels"].min().item() >= 0)
+ self.assertTrue(encoding["labels"].max().item() <= 150)
+
+ image_processing.do_reduce_labels = True
+ encoding = image_processing(image, map, return_tensors="pt")
+ self.assertTrue(encoding["labels"].min().item() >= 0)
+ self.assertTrue(encoding["labels"].max().item() <= 255)
+
+ def test_slow_fast_equivalence(self):
+ if not self.test_slow_image_processor or not self.test_fast_image_processor:
+ self.skipTest(reason="Skipping slow/fast equivalence test")
+
+ if self.image_processing_class is None or self.fast_image_processing_class is None:
+ self.skipTest(reason="Skipping slow/fast equivalence test as one of the image processors is not defined")
+
+ dummy_image, dummy_map = prepare_semantic_single_inputs()
+
+ image_processor_slow = self.image_processing_class(**self.image_processor_dict)
+ image_processor_fast = self.fast_image_processing_class(**self.image_processor_dict)
+
+ image_encoding_slow = image_processor_slow(dummy_image, segmentation_maps=dummy_map, return_tensors="pt")
+ image_encoding_fast = image_processor_fast(dummy_image, segmentation_maps=dummy_map, return_tensors="pt")
+
+ self._assert_slow_fast_tensors_equivalence(image_encoding_slow.pixel_values, image_encoding_fast.pixel_values)
+ self._assert_slow_fast_tensors_equivalence(
+ image_encoding_slow.labels.float(), image_encoding_fast.labels.float()
+ )
+
+ def test_slow_fast_equivalence_batched(self):
+ if not self.test_slow_image_processor or not self.test_fast_image_processor:
+ self.skipTest(reason="Skipping slow/fast equivalence test")
+
+ if self.image_processing_class is None or self.fast_image_processing_class is None:
+ self.skipTest(reason="Skipping slow/fast equivalence test as one of the image processors is not defined")
+
+ if hasattr(self.image_processor_tester, "do_center_crop") and self.image_processor_tester.do_center_crop:
+ self.skipTest(
+ reason="Skipping as do_center_crop is True and center_crop functions are not equivalent for fast and slow processors"
+ )
+
+ dummy_images, dummy_maps = prepare_semantic_batch_inputs()
+
+ image_processor_slow = self.image_processing_class(**self.image_processor_dict)
+ image_processor_fast = self.fast_image_processing_class(**self.image_processor_dict)
+
+ encoding_slow = image_processor_slow(dummy_images, segmentation_maps=dummy_maps, return_tensors="pt")
+ encoding_fast = image_processor_fast(dummy_images, segmentation_maps=dummy_maps, return_tensors="pt")
+
+ self._assert_slow_fast_tensors_equivalence(encoding_slow.pixel_values, encoding_fast.pixel_values)
+ self._assert_slow_fast_tensors_equivalence(encoding_slow.labels.float(), encoding_fast.labels.float())
diff --git a/transformers/tests/models/beit/test_modeling_beit.py b/transformers/tests/models/beit/test_modeling_beit.py
new file mode 100644
index 0000000000000000000000000000000000000000..4804cb08b66abd1b44ae66e9fb71e77358a1ec4c
--- /dev/null
+++ b/transformers/tests/models/beit/test_modeling_beit.py
@@ -0,0 +1,580 @@
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch BEiT model."""
+
+import unittest
+
+from datasets import load_dataset
+
+from transformers import BeitConfig
+from transformers.testing_utils import (
+ require_torch,
+ require_torch_multi_gpu,
+ require_vision,
+ slow,
+ torch_device,
+)
+from transformers.utils import (
+ cached_property,
+ is_torch_available,
+ is_vision_available,
+)
+
+from ...test_backbone_common import BackboneTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import (
+ BeitBackbone,
+ BeitForImageClassification,
+ BeitForMaskedImageModeling,
+ BeitForSemanticSegmentation,
+ BeitModel,
+ )
+ from transformers.models.auto.modeling_auto import MODEL_FOR_BACKBONE_MAPPING_NAMES, MODEL_MAPPING_NAMES
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import BeitImageProcessor
+
+
+class BeitModelTester:
+ def __init__(
+ self,
+ parent,
+ vocab_size=100,
+ batch_size=13,
+ image_size=30,
+ patch_size=2,
+ num_channels=3,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=4,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ type_sequence_label_size=10,
+ initializer_range=0.02,
+ num_labels=3,
+ scope=None,
+ out_indices=[1, 2, 3, 4],
+ out_features=["stage1", "stage2", "stage3", "stage4"],
+ attn_implementation="eager",
+ mask_ratio=0.5,
+ ):
+ self.parent = parent
+ self.vocab_size = vocab_size
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.scope = scope
+ self.out_indices = out_indices
+ self.out_features = out_features
+ self.num_labels = num_labels
+
+ # in BeiT, the seq length equals the number of patches + 1 (we add 1 for the [CLS] token)
+ num_patches = (image_size // patch_size) ** 2
+ self.seq_length = num_patches + 1
+ self.mask_length = self.seq_length - 1
+ self.num_masks = int(mask_ratio * self.seq_length)
+ self.attn_implementation = attn_implementation
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ pixel_labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ pixel_labels = ids_tensor([self.batch_size, self.image_size, self.image_size], self.num_labels)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels, pixel_labels
+
+ def get_config(self):
+ return BeitConfig(
+ vocab_size=self.vocab_size,
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ out_indices=self.out_indices,
+ out_features=self.out_features,
+ attn_implementation=self.attn_implementation,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels, pixel_labels):
+ model = BeitModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_backbone(self, config, pixel_values, labels, pixel_labels):
+ model = BeitBackbone(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+
+ # verify hidden states
+ self.parent.assertEqual(len(result.feature_maps), len(config.out_features))
+ expected_height = expected_width = self.image_size // config.patch_size
+ self.parent.assertListEqual(
+ list(result.feature_maps[0].shape), [self.batch_size, self.hidden_size, expected_height, expected_width]
+ )
+
+ # verify channels
+ self.parent.assertEqual(len(model.channels), len(config.out_features))
+
+ # verify backbone works with out_features=None
+ config.out_features = None
+ model = BeitBackbone(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+
+ # verify feature maps
+ self.parent.assertEqual(len(result.feature_maps), 1)
+ self.parent.assertListEqual(
+ list(result.feature_maps[0].shape), [self.batch_size, self.hidden_size, expected_height, expected_width]
+ )
+
+ # verify channels
+ self.parent.assertEqual(len(model.channels), 1)
+
+ def create_and_check_for_masked_lm(self, config, pixel_values, labels, pixel_labels):
+ model = BeitForMaskedImageModeling(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length - 1, self.vocab_size))
+
+ def create_and_check_for_image_classification(self, config, pixel_values, labels, pixel_labels):
+ config.num_labels = self.type_sequence_label_size
+ model = BeitForImageClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values, labels=labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
+
+ # test greyscale images
+ config.num_channels = 1
+ model = BeitForImageClassification(config)
+ model.to(torch_device)
+ model.eval()
+
+ pixel_values = floats_tensor([self.batch_size, 1, self.image_size, self.image_size])
+ result = model(pixel_values, labels=labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
+
+ def create_and_check_for_semantic_segmentation(self, config, pixel_values, labels, pixel_labels):
+ config.num_labels = self.num_labels
+ model = BeitForSemanticSegmentation(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(
+ result.logits.shape, (self.batch_size, self.num_labels, self.image_size * 2, self.image_size * 2)
+ )
+ result = model(pixel_values, labels=pixel_labels)
+ self.parent.assertEqual(
+ result.logits.shape, (self.batch_size, self.num_labels, self.image_size * 2, self.image_size * 2)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels, pixel_labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class BeitModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as BEiT does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (
+ (
+ BeitModel,
+ BeitForImageClassification,
+ BeitForMaskedImageModeling,
+ BeitForSemanticSegmentation,
+ BeitBackbone,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "image-feature-extraction": BeitModel,
+ "image-classification": BeitForImageClassification,
+ "image-segmentation": BeitForSemanticSegmentation,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ test_torch_exportable = True
+
+ def setUp(self):
+ self.model_tester = BeitModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=BeitConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="BEiT does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @require_torch_multi_gpu
+ @unittest.skip(reason="BEiT has some layers using `add_module` which doesn't work well with `nn.DataParallel`")
+ def test_multi_gpu_data_parallel_forward(self):
+ pass
+
+ @unittest.skip(reason="BEiT does not support feedforward chunking yet")
+ def test_feed_forward_chunking(self):
+ pass
+
+ @unittest.skip(reason="BEiT can't compile dynamic")
+ def test_sdpa_can_compile_dynamic(self):
+ pass
+
+ def test_model_get_set_embeddings(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_backbone(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_backbone(*config_and_inputs)
+
+ def test_for_masked_lm(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
+
+ def test_for_image_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_image_classification(*config_and_inputs)
+
+ def test_for_semantic_segmentation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_semantic_segmentation(*config_and_inputs)
+
+ def test_training(self):
+ if not self.model_tester.is_training:
+ self.skipTest(reason="model_tester.is_training is set to False")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ # we don't test BeitForMaskedImageModeling
+ if model_class.__name__ in [
+ *MODEL_MAPPING_NAMES.values(),
+ *MODEL_FOR_BACKBONE_MAPPING_NAMES.values(),
+ "BeitForMaskedImageModeling",
+ ]:
+ continue
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def test_training_gradient_checkpointing(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ if not self.model_tester.is_training:
+ self.skipTest(reason="model_tester.is_training is set to False")
+
+ config.use_cache = False
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ # we don't test BeitForMaskedImageModeling
+ if (
+ model_class.__name__
+ in [
+ *MODEL_MAPPING_NAMES.values(),
+ *MODEL_FOR_BACKBONE_MAPPING_NAMES.values(),
+ "BeitForMaskedImageModeling",
+ ]
+ or not model_class.supports_gradient_checkpointing
+ ):
+ continue
+
+ model = model_class(config)
+ model.gradient_checkpointing_enable()
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ # we skip lambda parameters as these require special initial values
+ # determined by config.layer_scale_init_value
+ if "lambda" in name:
+ continue
+ if param.requires_grad:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "microsoft/beit-base-patch16-224"
+ model = BeitModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+class BeitModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_image_processor(self):
+ return BeitImageProcessor.from_pretrained("microsoft/beit-base-patch16-224") if is_vision_available() else None
+
+ @slow
+ def test_inference_masked_image_modeling_head(self):
+ model = BeitForMaskedImageModeling.from_pretrained("microsoft/beit-base-patch16-224-pt22k").to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ pixel_values = image_processor(images=image, return_tensors="pt").pixel_values.to(torch_device)
+
+ # prepare bool_masked_pos
+ bool_masked_pos = torch.ones((1, 196), dtype=torch.bool).to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(pixel_values=pixel_values, bool_masked_pos=bool_masked_pos)
+ logits = outputs.logits
+
+ # verify the logits
+ expected_shape = torch.Size((1, 196, 8192))
+ self.assertEqual(logits.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[-3.2437, 0.5072, -13.9174], [-3.2456, 0.4948, -13.9401], [-3.2033, 0.5121, -13.8550]]
+ ).to(torch_device)
+
+ torch.testing.assert_close(logits[bool_masked_pos][:3, :3], expected_slice, rtol=1e-2, atol=1e-2)
+
+ @slow
+ def test_inference_image_classification_head_imagenet_1k(self):
+ model = BeitForImageClassification.from_pretrained("microsoft/beit-base-patch16-224").to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+ logits = outputs.logits
+
+ # verify the logits
+ expected_shape = torch.Size((1, 1000))
+ self.assertEqual(logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([-1.2385, -1.0987, -1.0108]).to(torch_device)
+
+ torch.testing.assert_close(logits[0, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ expected_class_idx = 281
+ self.assertEqual(logits.argmax(-1).item(), expected_class_idx)
+
+ @slow
+ def test_inference_image_classification_head_imagenet_22k(self):
+ model = BeitForImageClassification.from_pretrained("microsoft/beit-large-patch16-224-pt22k-ft22k").to(
+ torch_device
+ )
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+ logits = outputs.logits
+
+ # verify the logits
+ expected_shape = torch.Size((1, 21841))
+ self.assertEqual(logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([1.6881, -0.2787, 0.5901]).to(torch_device)
+
+ torch.testing.assert_close(logits[0, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ expected_class_idx = 2396
+ self.assertEqual(logits.argmax(-1).item(), expected_class_idx)
+
+ @slow
+ def test_inference_semantic_segmentation(self):
+ model = BeitForSemanticSegmentation.from_pretrained("microsoft/beit-base-finetuned-ade-640-640")
+ model = model.to(torch_device)
+
+ image_processor = BeitImageProcessor(do_resize=True, size=640, do_center_crop=False)
+
+ ds = load_dataset("hf-internal-testing/fixtures_ade20k", split="test")
+ image = ds[0]["image"].convert("RGB")
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+ logits = outputs.logits
+
+ # verify the logits
+ expected_shape = torch.Size((1, 150, 160, 160))
+ self.assertEqual(logits.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [
+ [[-4.8963, -2.3696, -3.0359], [-2.8485, -0.9842, -1.7426], [-2.9453, -1.3338, -2.1463]],
+ [[-5.8099, -3.4140, -4.1025], [-3.8578, -2.2100, -3.0337], [-3.8383, -2.4615, -3.3681]],
+ [[-0.0314, 3.9864, 4.0536], [2.9637, 4.6879, 4.9976], [3.2074, 4.7690, 4.9946]],
+ ],
+ device=torch_device,
+ )
+ torch.testing.assert_close(logits[0, :3, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ @slow
+ def test_post_processing_semantic_segmentation(self):
+ model = BeitForSemanticSegmentation.from_pretrained("microsoft/beit-base-finetuned-ade-640-640")
+ model = model.to(torch_device)
+
+ image_processor = BeitImageProcessor(do_resize=True, size=640, do_center_crop=False)
+
+ ds = load_dataset("hf-internal-testing/fixtures_ade20k", split="test")
+ image = ds[0]["image"].convert("RGB")
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ outputs.logits = outputs.logits.detach().cpu()
+
+ segmentation = image_processor.post_process_semantic_segmentation(outputs=outputs, target_sizes=[(500, 300)])
+ expected_shape = torch.Size((500, 300))
+ self.assertEqual(segmentation[0].shape, expected_shape)
+
+ segmentation = image_processor.post_process_semantic_segmentation(outputs=outputs)
+ expected_shape = torch.Size((160, 160))
+ self.assertEqual(segmentation[0].shape, expected_shape)
+
+ @slow
+ def test_inference_interpolate_pos_encoding(self):
+ model_name = "microsoft/beit-base-patch16-224-pt22k"
+ model = BeitModel.from_pretrained(model_name, **{"use_absolute_position_embeddings": True}).to(torch_device)
+
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ processor = BeitImageProcessor.from_pretrained(model_name)
+ inputs = processor(images=image, return_tensors="pt", size={"height": 480, "width": 480})
+ pixel_values = inputs.pixel_values.to(torch_device)
+
+ # with interpolate_pos_encoding being True the model should process the higher resolution image
+ # successfully and produce the expected output.
+ with torch.no_grad():
+ outputs = model(pixel_values, interpolate_pos_encoding=True)
+
+ # num_cls_tokens + (height / patch_size) * (width / patch_size)
+ # 1 + (480 / 16) * (480 / 16) = 1 + 30 * 30 = 901
+ expected_shape = torch.Size((1, 901, 768))
+ self.assertEqual(outputs.last_hidden_state.shape, expected_shape)
+
+
+@require_torch
+class BeitBackboneTest(unittest.TestCase, BackboneTesterMixin):
+ all_model_classes = (BeitBackbone,) if is_torch_available() else ()
+ config_class = BeitConfig
+
+ def setUp(self):
+ self.model_tester = BeitModelTester(self)
diff --git a/transformers/tests/models/bert_generation/__init__.py b/transformers/tests/models/bert_generation/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/bert_generation/test_modeling_bert_generation.py b/transformers/tests/models/bert_generation/test_modeling_bert_generation.py
new file mode 100644
index 0000000000000000000000000000000000000000..e639f31073a4abca4cb723c1b68b7cd5d1709985
--- /dev/null
+++ b/transformers/tests/models/bert_generation/test_modeling_bert_generation.py
@@ -0,0 +1,335 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers import BertGenerationConfig, is_torch_available
+from transformers.testing_utils import require_torch, slow, torch_device
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import BertGenerationDecoder, BertGenerationEncoder
+
+
+class BertGenerationEncoderTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=50,
+ initializer_range=0.02,
+ use_labels=True,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.initializer_range = initializer_range
+ self.use_labels = use_labels
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ if self.use_labels:
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask, token_labels
+
+ def get_config(self):
+ return BertGenerationConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ )
+
+ def prepare_config_and_inputs_for_decoder(self):
+ (
+ config,
+ input_ids,
+ input_mask,
+ token_labels,
+ ) = self.prepare_config_and_inputs()
+
+ config.is_decoder = True
+ encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size])
+ encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
+
+ return (
+ config,
+ input_ids,
+ input_mask,
+ token_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ )
+
+ def create_and_check_model(
+ self,
+ config,
+ input_ids,
+ input_mask,
+ token_labels,
+ **kwargs,
+ ):
+ model = BertGenerationEncoder(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_model_as_decoder(
+ self,
+ config,
+ input_ids,
+ input_mask,
+ token_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ **kwargs,
+ ):
+ config.add_cross_attention = True
+ model = BertGenerationEncoder(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ )
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_decoder_model_past_large_inputs(
+ self,
+ config,
+ input_ids,
+ input_mask,
+ token_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ **kwargs,
+ ):
+ config.is_decoder = True
+ config.add_cross_attention = True
+ model = BertGenerationDecoder(config=config).to(torch_device).eval()
+
+ # first forward pass
+ outputs = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ use_cache=True,
+ )
+ past_key_values = outputs.past_key_values
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
+
+ output_from_no_past = model(
+ next_input_ids,
+ attention_mask=next_attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+ output_from_past = model(
+ next_tokens,
+ attention_mask=next_attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ past_key_values=past_key_values,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_for_causal_lm(
+ self,
+ config,
+ input_ids,
+ input_mask,
+ token_labels,
+ *args,
+ ):
+ model = BertGenerationDecoder(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config, input_ids, input_mask, token_labels = self.prepare_config_and_inputs()
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class BertGenerationEncoderTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (BertGenerationEncoder, BertGenerationDecoder) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {"feature-extraction": BertGenerationEncoder, "text-generation": BertGenerationDecoder}
+ if is_torch_available()
+ else {}
+ )
+
+ def setUp(self):
+ self.model_tester = BertGenerationEncoderTester(self)
+ self.config_tester = ConfigTester(self, config_class=BertGenerationConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_as_bert(self):
+ config, input_ids, input_mask, token_labels = self.model_tester.prepare_config_and_inputs()
+ config.model_type = "bert"
+ self.model_tester.create_and_check_model(config, input_ids, input_mask, token_labels)
+
+ def test_model_as_decoder(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
+ self.model_tester.create_and_check_model_as_decoder(*config_and_inputs)
+
+ def test_decoder_model_past_with_large_inputs(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
+ self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
+
+ def test_model_as_decoder_with_default_input_mask(self):
+ (
+ config,
+ input_ids,
+ input_mask,
+ token_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ) = self.model_tester.prepare_config_and_inputs_for_decoder()
+
+ input_mask = None
+
+ self.model_tester.create_and_check_model_as_decoder(
+ config,
+ input_ids,
+ input_mask,
+ token_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ )
+
+ def test_for_causal_lm(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
+ self.model_tester.create_and_check_for_causal_lm(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model = BertGenerationEncoder.from_pretrained("google/bert_for_seq_generation_L-24_bbc_encoder")
+ self.assertIsNotNone(model)
+
+
+@require_torch
+class BertGenerationEncoderIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference_no_head_absolute_embedding(self):
+ model = BertGenerationEncoder.from_pretrained("google/bert_for_seq_generation_L-24_bbc_encoder")
+ input_ids = torch.tensor([[101, 7592, 1010, 2026, 3899, 2003, 10140, 102]])
+ with torch.no_grad():
+ output = model(input_ids)[0]
+ expected_shape = torch.Size([1, 8, 1024])
+ self.assertEqual(output.shape, expected_shape)
+ expected_slice = torch.tensor(
+ [[[0.1775, 0.0083, -0.0321], [1.6002, 0.1287, 0.3912], [2.1473, 0.5791, 0.6066]]]
+ )
+ torch.testing.assert_close(output[:, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+
+@require_torch
+class BertGenerationDecoderIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference_no_head_absolute_embedding(self):
+ model = BertGenerationDecoder.from_pretrained("google/bert_for_seq_generation_L-24_bbc_encoder")
+ input_ids = torch.tensor([[101, 7592, 1010, 2026, 3899, 2003, 10140, 102]])
+ with torch.no_grad():
+ output = model(input_ids)[0]
+ expected_shape = torch.Size([1, 8, 50358])
+ self.assertEqual(output.shape, expected_shape)
+ expected_slice = torch.tensor(
+ [[[-0.5788, -2.5994, -3.7054], [0.0438, 4.7997, 1.8795], [1.5862, 6.6409, 4.4638]]]
+ )
+ torch.testing.assert_close(output[:, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/bert_generation/test_tokenization_bert_generation.py b/transformers/tests/models/bert_generation/test_tokenization_bert_generation.py
new file mode 100644
index 0000000000000000000000000000000000000000..948ca66e3f80d4a6b3c6b423fc5451c3d52aa81d
--- /dev/null
+++ b/transformers/tests/models/bert_generation/test_tokenization_bert_generation.py
@@ -0,0 +1,243 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+from transformers import BertGenerationTokenizer
+from transformers.testing_utils import get_tests_dir, require_sentencepiece, require_torch, slow
+from transformers.utils import cached_property
+
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+SPIECE_UNDERLINE = "▁"
+
+SAMPLE_VOCAB = get_tests_dir("fixtures/test_sentencepiece.model")
+
+
+@require_sentencepiece
+class BertGenerationTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "google/bert_for_seq_generation_L-24_bbc_encoder"
+ tokenizer_class = BertGenerationTokenizer
+ test_rust_tokenizer = False
+ test_sentencepiece = True
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ tokenizer = BertGenerationTokenizer(SAMPLE_VOCAB, keep_accents=True)
+ tokenizer.save_pretrained(cls.tmpdirname)
+
+ def test_convert_token_and_id(self):
+ """Test ``_convert_token_to_id`` and ``_convert_id_to_token``."""
+ token = ""
+ token_id = 1
+
+ self.assertEqual(self.get_tokenizer()._convert_token_to_id(token), token_id)
+ self.assertEqual(self.get_tokenizer()._convert_id_to_token(token_id), token)
+
+ def test_get_vocab(self):
+ vocab_keys = list(self.get_tokenizer().get_vocab().keys())
+
+ self.assertEqual(vocab_keys[0], "")
+ self.assertEqual(vocab_keys[1], "")
+ self.assertEqual(vocab_keys[-1], "")
+ self.assertEqual(len(vocab_keys), 1_002)
+
+ def test_vocab_size(self):
+ self.assertEqual(self.get_tokenizer().vocab_size, 1_000)
+
+ def test_full_tokenizer(self):
+ tokenizer = BertGenerationTokenizer(SAMPLE_VOCAB, keep_accents=True)
+
+ tokens = tokenizer.tokenize("This is a test")
+ self.assertListEqual(tokens, ["▁This", "▁is", "▁a", "▁t", "est"])
+
+ self.assertListEqual(
+ tokenizer.convert_tokens_to_ids(tokens),
+ [285, 46, 10, 170, 382],
+ )
+
+ tokens = tokenizer.tokenize("I was born in 92000, and this is falsé.")
+ self.assertListEqual(
+ tokens,
+ [
+ SPIECE_UNDERLINE + "I",
+ SPIECE_UNDERLINE + "was",
+ SPIECE_UNDERLINE + "b",
+ "or",
+ "n",
+ SPIECE_UNDERLINE + "in",
+ SPIECE_UNDERLINE + "",
+ "9",
+ "2",
+ "0",
+ "0",
+ "0",
+ ",",
+ SPIECE_UNDERLINE + "and",
+ SPIECE_UNDERLINE + "this",
+ SPIECE_UNDERLINE + "is",
+ SPIECE_UNDERLINE + "f",
+ "al",
+ "s",
+ "é",
+ ".",
+ ],
+ )
+ ids = tokenizer.convert_tokens_to_ids(tokens)
+ self.assertListEqual(
+ ids,
+ [8, 21, 84, 55, 24, 19, 7, 0, 602, 347, 347, 347, 3, 12, 66, 46, 72, 80, 6, 0, 4],
+ )
+
+ back_tokens = tokenizer.convert_ids_to_tokens(ids)
+ self.assertListEqual(
+ back_tokens,
+ [
+ SPIECE_UNDERLINE + "I",
+ SPIECE_UNDERLINE + "was",
+ SPIECE_UNDERLINE + "b",
+ "or",
+ "n",
+ SPIECE_UNDERLINE + "in",
+ SPIECE_UNDERLINE + "",
+ "",
+ "2",
+ "0",
+ "0",
+ "0",
+ ",",
+ SPIECE_UNDERLINE + "and",
+ SPIECE_UNDERLINE + "this",
+ SPIECE_UNDERLINE + "is",
+ SPIECE_UNDERLINE + "f",
+ "al",
+ "s",
+ "",
+ ".",
+ ],
+ )
+
+ @cached_property
+ def big_tokenizer(self):
+ return BertGenerationTokenizer.from_pretrained("google/bert_for_seq_generation_L-24_bbc_encoder")
+
+ @slow
+ def test_tokenization_base_easy_symbols(self):
+ symbols = "Hello World!"
+ original_tokenizer_encodings = [18536, 2260, 101]
+
+ self.assertListEqual(original_tokenizer_encodings, self.big_tokenizer.encode(symbols))
+
+ @slow
+ def test_tokenization_base_hard_symbols(self):
+ symbols = (
+ 'This is a very long text with a lot of weird characters, such as: . , ~ ? ( ) " [ ] ! : - . Also we will'
+ " add words that should not exist and be tokenized to , such as saoneuhaoesuth"
+ )
+ original_tokenizer_encodings = [
+ 871,
+ 419,
+ 358,
+ 946,
+ 991,
+ 2521,
+ 452,
+ 358,
+ 1357,
+ 387,
+ 7751,
+ 3536,
+ 112,
+ 985,
+ 456,
+ 126,
+ 865,
+ 938,
+ 5400,
+ 5734,
+ 458,
+ 1368,
+ 467,
+ 786,
+ 2462,
+ 5246,
+ 1159,
+ 633,
+ 865,
+ 4519,
+ 457,
+ 582,
+ 852,
+ 2557,
+ 427,
+ 916,
+ 508,
+ 405,
+ 34324,
+ 497,
+ 391,
+ 408,
+ 11342,
+ 1244,
+ 385,
+ 100,
+ 938,
+ 985,
+ 456,
+ 574,
+ 362,
+ 12597,
+ 3200,
+ 3129,
+ 1172,
+ ]
+
+ self.assertListEqual(original_tokenizer_encodings, self.big_tokenizer.encode(symbols))
+
+ @require_torch
+ @slow
+ def test_torch_encode_plus_sent_to_model(self):
+ import torch
+
+ from transformers import BertGenerationConfig, BertGenerationEncoder
+
+ # Build sequence
+ first_ten_tokens = list(self.big_tokenizer.get_vocab().keys())[:10]
+ sequence = " ".join(first_ten_tokens)
+ encoded_sequence = self.big_tokenizer.encode_plus(sequence, return_tensors="pt", return_token_type_ids=False)
+ batch_encoded_sequence = self.big_tokenizer.batch_encode_plus(
+ [sequence + " " + sequence], return_tensors="pt", return_token_type_ids=False
+ )
+
+ config = BertGenerationConfig()
+ model = BertGenerationEncoder(config)
+
+ assert model.get_input_embeddings().weight.shape[0] >= self.big_tokenizer.vocab_size
+
+ with torch.no_grad():
+ model(**encoded_sequence)
+ model(**batch_encoded_sequence)
+
+ @slow
+ def test_tokenizer_integration(self):
+ expected_encoding = {'input_ids': [[39286, 458, 36335, 2001, 456, 13073, 13266, 455, 113, 7746, 1741, 11157, 391, 13073, 13266, 455, 113, 3967, 35412, 113, 4936, 109, 3870, 2377, 113, 30084, 45720, 458, 134, 17496, 112, 503, 11672, 113, 118, 112, 5665, 13347, 38687, 112, 1496, 31389, 112, 3268, 47264, 134, 962, 112, 16377, 8035, 23130, 430, 12169, 15518, 28592, 458, 146, 41697, 109, 391, 12169, 15518, 16689, 458, 146, 41358, 109, 452, 726, 4034, 111, 763, 35412, 5082, 388, 1903, 111, 9051, 391, 2870, 48918, 1900, 1123, 550, 998, 112, 9586, 15985, 455, 391, 410, 22955, 37636, 114], [448, 17496, 419, 3663, 385, 763, 113, 27533, 2870, 3283, 13043, 1639, 24713, 523, 656, 24013, 18550, 2521, 517, 27014, 21244, 420, 1212, 1465, 391, 927, 4833, 388, 578, 11786, 114, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [484, 2169, 7687, 21932, 18146, 726, 363, 17032, 3391, 114, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]} # fmt: skip
+
+ self.tokenizer_integration_test_util(
+ expected_encoding=expected_encoding,
+ model_name="google/bert_for_seq_generation_L-24_bbc_encoder",
+ revision="c817d1fd1be2ffa69431227a1fe320544943d4db",
+ )
diff --git a/transformers/tests/models/bertweet/__init__.py b/transformers/tests/models/bertweet/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/bertweet/test_tokenization_bertweet.py b/transformers/tests/models/bertweet/test_tokenization_bertweet.py
new file mode 100644
index 0000000000000000000000000000000000000000..9d6381ae112c7923975c5da54aa3bd1c9e384443
--- /dev/null
+++ b/transformers/tests/models/bertweet/test_tokenization_bertweet.py
@@ -0,0 +1,70 @@
+# Copyright 2018 Salesforce and HuggingFace Inc. team.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import os
+import unittest
+from functools import lru_cache
+
+from transformers.models.bertweet.tokenization_bertweet import VOCAB_FILES_NAMES, BertweetTokenizer
+
+from ...test_tokenization_common import TokenizerTesterMixin, use_cache_if_possible
+
+
+class BertweetTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "vinai/bertweet-base"
+ tokenizer_class = BertweetTokenizer
+ test_rust_tokenizer = False
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ # Adapted from Sennrich et al. 2015 and https://github.com/rsennrich/subword-nmt
+ vocab = ["I", "m", "V@@", "R@@", "r", "e@@"]
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+ merges = ["#version: 0.2", "a m"]
+ cls.special_tokens_map = {"unk_token": ""}
+
+ cls.vocab_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ cls.merges_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["merges_file"])
+ with open(cls.vocab_file, "w", encoding="utf-8") as fp:
+ for token in vocab_tokens:
+ fp.write(f"{token} {vocab_tokens[token]}\n")
+ with open(cls.merges_file, "w", encoding="utf-8") as fp:
+ fp.write("\n".join(merges))
+
+ @classmethod
+ @use_cache_if_possible
+ @lru_cache(maxsize=64)
+ def get_tokenizer(cls, pretrained_name=None, **kwargs):
+ kwargs.update(cls.special_tokens_map)
+ pretrained_name = pretrained_name or cls.tmpdirname
+ return BertweetTokenizer.from_pretrained(pretrained_name, **kwargs)
+
+ def get_input_output_texts(self, tokenizer):
+ input_text = "I am VinAI Research"
+ output_text = "I m V I Re e "
+ return input_text, output_text
+
+ def test_full_tokenizer(self):
+ tokenizer = BertweetTokenizer(self.vocab_file, self.merges_file, **self.special_tokens_map)
+ text = "I am VinAI Research"
+ bpe_tokens = "I a@@ m V@@ i@@ n@@ A@@ I R@@ e@@ s@@ e@@ a@@ r@@ c@@ h".split()
+ tokens = tokenizer.tokenize(text)
+ self.assertListEqual(tokens, bpe_tokens)
+
+ input_tokens = tokens + [tokenizer.unk_token]
+
+ input_bpe_tokens = [4, 3, 5, 6, 3, 3, 3, 4, 7, 9, 3, 9, 3, 3, 3, 3, 3]
+ self.assertListEqual(tokenizer.convert_tokens_to_ids(input_tokens), input_bpe_tokens)
diff --git a/transformers/tests/models/big_bird/__init__.py b/transformers/tests/models/big_bird/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/big_bird/test_modeling_big_bird.py b/transformers/tests/models/big_bird/test_modeling_big_bird.py
new file mode 100644
index 0000000000000000000000000000000000000000..bdab0f73b653b0df13180188f061a666889e6885
--- /dev/null
+++ b/transformers/tests/models/big_bird/test_modeling_big_bird.py
@@ -0,0 +1,941 @@
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch BigBird model."""
+
+import unittest
+
+from transformers import BigBirdConfig, is_torch_available
+from transformers.models.auto import get_values
+from transformers.models.big_bird.tokenization_big_bird import BigBirdTokenizer
+from transformers.testing_utils import require_torch, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ MODEL_FOR_PRETRAINING_MAPPING,
+ BigBirdForCausalLM,
+ BigBirdForMaskedLM,
+ BigBirdForMultipleChoice,
+ BigBirdForPreTraining,
+ BigBirdForQuestionAnswering,
+ BigBirdForSequenceClassification,
+ BigBirdForTokenClassification,
+ BigBirdModel,
+ )
+
+
+class BigBirdModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ seq_length=128,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu_new",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=256,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ attention_type="block_sparse",
+ use_bias=True,
+ rescale_embeddings=False,
+ block_size=8,
+ num_rand_blocks=3,
+ position_embedding_type="absolute",
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.scope = scope
+
+ self.attention_type = attention_type
+ self.use_bias = use_bias
+ self.rescale_embeddings = rescale_embeddings
+ self.block_size = block_size
+ self.num_rand_blocks = num_rand_blocks
+ self.position_embedding_type = position_embedding_type
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ return BigBirdConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ is_encoder_decoder=False,
+ initializer_range=self.initializer_range,
+ attention_type=self.attention_type,
+ use_bias=self.use_bias,
+ rescale_embeddings=self.rescale_embeddings,
+ block_size=self.block_size,
+ num_random_blocks=self.num_rand_blocks,
+ position_embedding_type=self.position_embedding_type,
+ )
+
+ def prepare_config_and_inputs_for_decoder(self):
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = self.prepare_config_and_inputs()
+
+ config.is_decoder = True
+ encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size])
+ encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
+
+ return (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ )
+
+ def create_and_check_model(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = BigBirdModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
+ result = model(input_ids, token_type_ids=token_type_ids)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_for_pretraining(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = BigBirdForPreTraining(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ labels=token_labels,
+ next_sentence_label=sequence_labels,
+ )
+ self.parent.assertEqual(result.prediction_logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+ self.parent.assertEqual(result.seq_relationship_logits.shape, (self.batch_size, config.num_labels))
+
+ def create_and_check_model_as_decoder(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ config.add_cross_attention = True
+ model = BigBirdModel(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ encoder_hidden_states=encoder_hidden_states,
+ )
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_for_masked_lm(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = BigBirdForMaskedLM(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_decoder_model_past_large_inputs(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ config.is_decoder = True
+ config.add_cross_attention = True
+ model = BigBirdForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # first forward pass
+ outputs = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ use_cache=True,
+ )
+ past_key_values = outputs.past_key_values
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
+
+ output_from_no_past = model(
+ next_input_ids,
+ attention_mask=next_attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+ output_from_past = model(
+ next_tokens,
+ attention_mask=next_attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ past_key_values=past_key_values,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_for_question_answering(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = BigBirdForQuestionAnswering(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ start_positions=sequence_labels,
+ end_positions=sequence_labels,
+ )
+ self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
+ self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
+
+ def create_and_check_for_sequence_classification(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_labels = self.num_labels
+ model = BigBirdForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=sequence_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def create_and_check_for_token_classification(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_labels = self.num_labels
+ model = BigBirdForTokenClassification(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+
+ def create_and_check_for_multiple_choice(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_choices = self.num_choices
+ model = BigBirdForMultipleChoice(config=config)
+ model.to(torch_device)
+ model.eval()
+ multiple_choice_inputs_ids = input_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ multiple_choice_token_type_ids = token_type_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ multiple_choice_input_mask = input_mask.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ result = model(
+ multiple_choice_inputs_ids,
+ attention_mask=multiple_choice_input_mask,
+ token_type_ids=multiple_choice_token_type_ids,
+ labels=choice_labels,
+ )
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+ def create_and_check_for_auto_padding(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ):
+ model = BigBirdModel(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_for_change_to_full_attn(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ):
+ model = BigBirdModel(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ # the config should not be changed
+ self.parent.assertTrue(model.config.attention_type == "block_sparse")
+
+
+@require_torch
+class BigBirdModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ # head masking & pruning is currently not supported for big bird
+ test_head_masking = False
+ test_pruning = False
+
+ # torchscript should be possible, but takes prohibitively long to test.
+ # Also torchscript is not an important feature to have in the beginning.
+ test_torchscript = False
+
+ all_model_classes = (
+ (
+ BigBirdModel,
+ BigBirdForPreTraining,
+ BigBirdForMaskedLM,
+ BigBirdForCausalLM,
+ BigBirdForMultipleChoice,
+ BigBirdForQuestionAnswering,
+ BigBirdForSequenceClassification,
+ BigBirdForTokenClassification,
+ )
+ if is_torch_available()
+ else ()
+ )
+ # Doesn't run generation tests. There are interface mismatches when using `generate` -- TODO @gante
+ all_generative_model_classes = ()
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": BigBirdModel,
+ "fill-mask": BigBirdForMaskedLM,
+ "question-answering": BigBirdForQuestionAnswering,
+ "text-classification": BigBirdForSequenceClassification,
+ "text-generation": BigBirdForCausalLM,
+ "token-classification": BigBirdForTokenClassification,
+ "zero-shot": BigBirdForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ # special case for ForPreTraining model
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class in get_values(MODEL_FOR_PRETRAINING_MAPPING):
+ inputs_dict["labels"] = torch.zeros(
+ (self.model_tester.batch_size, self.model_tester.seq_length), dtype=torch.long, device=torch_device
+ )
+ inputs_dict["next_sentence_label"] = torch.zeros(
+ self.model_tester.batch_size, dtype=torch.long, device=torch_device
+ )
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = BigBirdModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=BigBirdConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_pretraining(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_pretraining(*config_and_inputs)
+
+ def test_for_masked_lm(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
+
+ def test_for_multiple_choice(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs)
+
+ def test_decoder_model_past_with_large_inputs(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
+ self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
+
+ def test_for_question_answering(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
+
+ def test_for_sequence_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
+
+ def test_for_token_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
+
+ def test_model_as_decoder(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
+ self.model_tester.create_and_check_model_as_decoder(*config_and_inputs)
+
+ def test_model_as_decoder_with_default_input_mask(self):
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ) = self.model_tester.prepare_config_and_inputs_for_decoder()
+
+ input_mask = None
+
+ self.model_tester.create_and_check_model_as_decoder(
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ )
+
+ def test_retain_grad_hidden_states_attentions(self):
+ # bigbird cannot keep gradients in attentions when `attention_type=block_sparse`
+
+ if self.model_tester.attention_type == "original_full":
+ super().test_retain_grad_hidden_states_attentions()
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "google/bigbird-roberta-base"
+ model = BigBirdForPreTraining.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ def test_model_various_attn_type(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["original_full", "block_sparse"]:
+ config_and_inputs[0].attention_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_fast_integration(self):
+ # fmt: off
+ input_ids = torch.tensor(
+ [[6, 117, 33, 36, 70, 22, 63, 31, 71, 72, 88, 58, 109, 49, 48, 116, 92, 6, 19, 95, 118, 100, 80, 111, 93, 2, 31, 84, 26, 5, 6, 82, 46, 96, 109, 4, 39, 19, 109, 13, 92, 31, 36, 90, 111, 18, 75, 6, 56, 74, 16, 42, 56, 92, 69, 108, 127, 81, 82, 41, 106, 19, 44, 24, 82, 121, 120, 65, 36, 26, 72, 13, 36, 98, 43, 64, 8, 53, 100, 92, 51, 122, 66, 17, 61, 50, 104, 127, 26, 35, 94, 23, 110, 71, 80, 67, 109, 111, 44, 19, 51, 41, 86, 71, 76, 44, 18, 68, 44, 77, 107, 81, 98, 126, 100, 2, 49, 98, 84, 39, 23, 98, 52, 46, 10, 82, 121, 73],[6, 117, 33, 36, 70, 22, 63, 31, 71, 72, 88, 58, 109, 49, 48, 116, 92, 6, 19, 95, 118, 100, 80, 111, 93, 2, 31, 84, 26, 5, 6, 82, 46, 96, 109, 4, 39, 19, 109, 13, 92, 31, 36, 90, 111, 18, 75, 6, 56, 74, 16, 42, 56, 92, 69, 108, 127, 81, 82, 41, 106, 19, 44, 24, 82, 121, 120, 65, 36, 26, 72, 13, 36, 98, 43, 64, 8, 53, 100, 92, 51, 12, 66, 17, 61, 50, 104, 127, 26, 35, 94, 23, 110, 71, 80, 67, 109, 111, 44, 19, 51, 41, 86, 71, 76, 28, 18, 68, 44, 77, 107, 81, 98, 126, 100, 2, 49, 18, 84, 39, 23, 98, 52, 46, 10, 82, 121, 73]], # noqa: E231
+ dtype=torch.long,
+ device=torch_device,
+ )
+ # fmt: on
+ input_ids = input_ids % self.model_tester.vocab_size
+ input_ids[1] = input_ids[1] - 1
+
+ attention_mask = torch.ones((input_ids.shape), device=torch_device)
+ attention_mask[:, :-10] = 0
+
+ config, _, _, _, _, _, _ = self.model_tester.prepare_config_and_inputs()
+ torch.manual_seed(0)
+ model = BigBirdModel(config).eval().to(torch_device)
+
+ with torch.no_grad():
+ hidden_states = model(input_ids, attention_mask=attention_mask).last_hidden_state
+ self.assertTrue(
+ torch.allclose(
+ hidden_states[0, 0, :5],
+ torch.tensor([1.4825, 0.0774, 0.8226, -0.2962, -0.9593], device=torch_device),
+ atol=1e-3,
+ )
+ )
+
+ def test_auto_padding(self):
+ self.model_tester.seq_length = 241
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_auto_padding(*config_and_inputs)
+
+ def test_for_change_to_full_attn(self):
+ self.model_tester.seq_length = 9
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_change_to_full_attn(*config_and_inputs)
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+
+@require_torch
+@slow
+class BigBirdModelIntegrationTest(unittest.TestCase):
+ # we can have this true once block_sparse attn_probs works accurately
+ test_attention_probs = False
+
+ def _get_dummy_input_ids(self):
+ # fmt: off
+ ids = torch.tensor(
+ [[6, 117, 33, 36, 70, 22, 63, 31, 71, 72, 88, 58, 109, 49, 48, 116, 92, 6, 19, 95, 118, 100, 80, 111, 93, 2, 31, 84, 26, 5, 6, 82, 46, 96, 109, 4, 39, 19, 109, 13, 92, 31, 36, 90, 111, 18, 75, 6, 56, 74, 16, 42, 56, 92, 69, 108, 127, 81, 82, 41, 106, 19, 44, 24, 82, 121, 120, 65, 36, 26, 72, 13, 36, 98, 43, 64, 8, 53, 100, 92, 51, 122, 66, 17, 61, 50, 104, 127, 26, 35, 94, 23, 110, 71, 80, 67, 109, 111, 44, 19, 51, 41, 86, 71, 76, 44, 18, 68, 44, 77, 107, 81, 98, 126, 100, 2, 49, 98, 84, 39, 23, 98, 52, 46, 10, 82, 121, 73]], # noqa: E231
+ dtype=torch.long,
+ device=torch_device,
+ )
+ # fmt: on
+ return ids
+
+ def test_inference_block_sparse_pretraining(self):
+ model = BigBirdForPreTraining.from_pretrained("google/bigbird-roberta-base", attention_type="block_sparse")
+ model.to(torch_device)
+
+ input_ids = torch.tensor([[20920, 232, 328, 1437] * 1024], dtype=torch.long, device=torch_device)
+ with torch.no_grad():
+ outputs = model(input_ids)
+ prediction_logits = outputs.prediction_logits
+ seq_relationship_logits = outputs.seq_relationship_logits
+
+ self.assertEqual(prediction_logits.shape, torch.Size((1, 4096, 50358)))
+ self.assertEqual(seq_relationship_logits.shape, torch.Size((1, 2)))
+
+ expected_prediction_logits_slice = torch.tensor(
+ [
+ [-0.5583, 0.0475, -0.2508, 7.4423],
+ [0.7409, 1.4460, -0.7593, 7.7010],
+ [1.9150, 3.1395, 5.8840, 9.3498],
+ [-0.1854, -1.4640, -2.2052, 3.7968],
+ ],
+ device=torch_device,
+ )
+
+ torch.testing.assert_close(
+ prediction_logits[0, 128:132, 128:132], expected_prediction_logits_slice, rtol=1e-4, atol=1e-4
+ )
+
+ expected_seq_relationship_logits = torch.tensor([[46.9465, 47.9517]], device=torch_device)
+ torch.testing.assert_close(seq_relationship_logits, expected_seq_relationship_logits, rtol=1e-4, atol=1e-4)
+
+ def test_inference_full_pretraining(self):
+ model = BigBirdForPreTraining.from_pretrained("google/bigbird-roberta-base", attention_type="original_full")
+ model.to(torch_device)
+
+ input_ids = torch.tensor([[20920, 232, 328, 1437] * 512], dtype=torch.long, device=torch_device)
+ with torch.no_grad():
+ outputs = model(input_ids)
+ prediction_logits = outputs.prediction_logits
+ seq_relationship_logits = outputs.seq_relationship_logits
+
+ self.assertEqual(prediction_logits.shape, torch.Size((1, 512 * 4, 50358)))
+ self.assertEqual(seq_relationship_logits.shape, torch.Size((1, 2)))
+
+ expected_prediction_logits_slice = torch.tensor(
+ [
+ [0.1499, -1.1217, 0.1990, 8.4499],
+ [-2.7757, -3.0687, -4.8577, 7.5156],
+ [1.5446, 0.1982, 4.3016, 10.4281],
+ [-1.3705, -4.0130, -3.9629, 5.1526],
+ ],
+ device=torch_device,
+ )
+ torch.testing.assert_close(
+ prediction_logits[0, 128:132, 128:132], expected_prediction_logits_slice, rtol=1e-4, atol=1e-4
+ )
+
+ expected_seq_relationship_logits = torch.tensor([[41.4503, 41.2406]], device=torch_device)
+ torch.testing.assert_close(seq_relationship_logits, expected_seq_relationship_logits, rtol=1e-4, atol=1e-4)
+
+ def test_block_sparse_attention_probs(self):
+ """
+ Asserting if outputted attention matrix is similar to hard coded attention matrix
+ """
+
+ if not self.test_attention_probs:
+ self.skipTest("test_attention_probs is set to False")
+
+ model = BigBirdModel.from_pretrained(
+ "google/bigbird-roberta-base", attention_type="block_sparse", num_random_blocks=3, block_size=16
+ )
+ model.to(torch_device)
+ model.eval()
+ config = model.config
+
+ input_ids = self._get_dummy_input_ids()
+
+ hidden_states = model.embeddings(input_ids)
+
+ batch_size, seqlen, _ = hidden_states.size()
+ attn_mask = torch.ones(batch_size, seqlen, device=torch_device, dtype=torch.float)
+ to_seq_length = from_seq_length = seqlen
+ from_block_size = to_block_size = config.block_size
+
+ blocked_mask, band_mask, from_mask, to_mask = model.create_masks_for_block_sparse_attn(
+ attn_mask, config.block_size
+ )
+ from_blocked_mask = to_blocked_mask = blocked_mask
+
+ for i in range(config.num_hidden_layers):
+ pointer = model.encoder.layer[i].attention.self
+
+ query_layer = pointer.transpose_for_scores(pointer.query(hidden_states))
+ key_layer = pointer.transpose_for_scores(pointer.key(hidden_states))
+ value_layer = pointer.transpose_for_scores(pointer.value(hidden_states))
+
+ context_layer, attention_probs = pointer.bigbird_block_sparse_attention(
+ query_layer,
+ key_layer,
+ value_layer,
+ band_mask,
+ from_mask,
+ to_mask,
+ from_blocked_mask,
+ to_blocked_mask,
+ pointer.num_attention_heads,
+ pointer.num_random_blocks,
+ pointer.attention_head_size,
+ from_block_size,
+ to_block_size,
+ batch_size,
+ from_seq_length,
+ to_seq_length,
+ seed=pointer.seed,
+ plan_from_length=None,
+ plan_num_rand_blocks=None,
+ output_attentions=True,
+ )
+
+ context_layer = context_layer.contiguous().view(batch_size, from_seq_length, -1)
+ cl = torch.einsum("bhqk,bhkd->bhqd", attention_probs, value_layer)
+ cl = cl.view(context_layer.size())
+
+ torch.testing.assert_close(context_layer, cl, rtol=0.001, atol=0.001)
+
+ def test_block_sparse_context_layer(self):
+ model = BigBirdModel.from_pretrained(
+ "google/bigbird-roberta-base", attention_type="block_sparse", num_random_blocks=3, block_size=16
+ )
+ model.to(torch_device)
+ model.eval()
+ config = model.config
+
+ input_ids = self._get_dummy_input_ids()
+ dummy_hidden_states = model.embeddings(input_ids)
+
+ attn_mask = torch.ones_like(input_ids, device=torch_device)
+ blocked_mask, band_mask, from_mask, to_mask = model.create_masks_for_block_sparse_attn(
+ attn_mask, config.block_size
+ )
+
+ targeted_cl = torch.tensor(
+ [
+ [0.1870, 1.5248, 0.2333, -0.0483, -0.0952, 1.8359, -0.0142, 0.1239, 0.0083, -0.0045],
+ [-0.0601, 0.1243, 0.1329, -0.1524, 0.2347, 0.0894, -0.2248, -0.2461, -0.0645, -0.0109],
+ [-0.0418, 0.1463, 0.1290, -0.1638, 0.2489, 0.0799, -0.2341, -0.2406, -0.0524, 0.0106],
+ [0.1859, 1.5182, 0.2324, -0.0473, -0.0952, 1.8295, -0.0148, 0.1242, 0.0080, -0.0045],
+ [0.1879, 1.5300, 0.2334, -0.0480, -0.0967, 1.8428, -0.0137, 0.1256, 0.0087, -0.0050],
+ [0.1852, 1.5149, 0.2330, -0.0492, -0.0936, 1.8236, -0.0154, 0.1210, 0.0080, -0.0048],
+ [0.1857, 1.5186, 0.2331, -0.0484, -0.0940, 1.8285, -0.0148, 0.1224, 0.0077, -0.0045],
+ [0.1884, 1.5336, 0.2334, -0.0469, -0.0974, 1.8477, -0.0132, 0.1266, 0.0085, -0.0046],
+ [0.1881, 1.5308, 0.2334, -0.0479, -0.0969, 1.8438, -0.0136, 0.1258, 0.0088, -0.0050],
+ [0.1849, 1.5143, 0.2329, -0.0491, -0.0930, 1.8230, -0.0156, 0.1209, 0.0074, -0.0047],
+ [0.1878, 1.5299, 0.2333, -0.0472, -0.0967, 1.8434, -0.0137, 0.1257, 0.0084, -0.0048],
+ [0.1873, 1.5260, 0.2333, -0.0478, -0.0961, 1.8383, -0.0142, 0.1245, 0.0083, -0.0048],
+ [0.1849, 1.5145, 0.2327, -0.0491, -0.0935, 1.8237, -0.0156, 0.1215, 0.0083, -0.0046],
+ [0.1866, 1.5232, 0.2332, -0.0488, -0.0950, 1.8342, -0.0143, 0.1237, 0.0084, -0.0047],
+ ],
+ device=torch_device,
+ )
+
+ context_layer = model.encoder.layer[0].attention.self(
+ dummy_hidden_states,
+ band_mask=band_mask,
+ from_mask=from_mask,
+ to_mask=to_mask,
+ from_blocked_mask=blocked_mask,
+ to_blocked_mask=blocked_mask,
+ )
+ context_layer = context_layer[0]
+
+ self.assertEqual(context_layer.shape, torch.Size((1, 128, 768)))
+ torch.testing.assert_close(context_layer[0, 64:78, 300:310], targeted_cl, rtol=0.0001, atol=0.0001)
+
+ def test_tokenizer_inference(self):
+ tokenizer = BigBirdTokenizer.from_pretrained("google/bigbird-roberta-base")
+ model = BigBirdModel.from_pretrained(
+ "google/bigbird-roberta-base", attention_type="block_sparse", num_random_blocks=3, block_size=16
+ )
+ model.to(torch_device)
+
+ text = [
+ "Transformer-based models are unable to process long sequences due to their self-attention operation,"
+ " which scales quadratically with the sequence length. To address this limitation, we introduce the"
+ " Longformer with an attention mechanism that scales linearly with sequence length, making it easy to"
+ " process documents of thousands of tokens or longer. Longformer’s attention mechanism is a drop-in"
+ " replacement for the standard self-attention and combines a local windowed attention with a task"
+ " motivated global attention. Following prior work on long-sequence transformers, we evaluate Longformer"
+ " on character-level language modeling and achieve state-of-the-art results on text8 and enwik8. In"
+ " contrast to most prior work, we also pretrain Longformer and finetune it on a variety of downstream"
+ " tasks. Our pretrained Longformer consistently outperforms RoBERTa on long document tasks and sets new"
+ " state-of-the-art results on WikiHop and TriviaQA."
+ ]
+ inputs = tokenizer(text)
+
+ for k in inputs:
+ inputs[k] = torch.tensor(inputs[k], device=torch_device, dtype=torch.long)
+
+ prediction = model(**inputs)
+ prediction = prediction[0]
+
+ self.assertEqual(prediction.shape, torch.Size((1, 199, 768)))
+
+ expected_prediction = torch.tensor(
+ [
+ [0.1887, -0.0474, 0.2604, 0.1453],
+ [0.0651, 0.1999, 0.1797, 0.1161],
+ [0.2833, -0.3036, 0.6910, 0.1123],
+ [0.2836, -0.4644, -0.0111, 0.1530],
+ [0.3919, -0.2823, 0.4192, 0.1687],
+ [0.2168, -0.1956, 0.4050, 0.0925],
+ [0.2597, -0.0884, 0.1258, 0.1119],
+ [0.1127, -0.1203, 0.1924, 0.2859],
+ [0.1362, -0.1315, 0.2693, 0.1027],
+ [-0.3169, -0.2266, 0.4419, 0.6740],
+ [0.2366, -0.1452, 0.2589, 0.0579],
+ [0.0358, -0.2021, 0.3112, -0.1392],
+ ],
+ device=torch_device,
+ )
+
+ torch.testing.assert_close(prediction[0, 52:64, 320:324], expected_prediction, rtol=1e-4, atol=1e-4)
+
+ def test_inference_question_answering(self):
+ tokenizer = BigBirdTokenizer.from_pretrained("google/bigbird-base-trivia-itc")
+ model = BigBirdForQuestionAnswering.from_pretrained(
+ "google/bigbird-base-trivia-itc", attention_type="block_sparse", block_size=16, num_random_blocks=3
+ )
+ model.to(torch_device)
+
+ context = (
+ "The BigBird model was proposed in Big Bird: Transformers for Longer Sequences by Zaheer, Manzil and"
+ " Guruganesh, Guru and Dubey, Kumar Avinava and Ainslie, Joshua and Alberti, Chris and Ontanon, Santiago"
+ " and Pham, Philip and Ravula, Anirudh and Wang, Qifan and Yang, Li and others. BigBird, is a"
+ " sparse-attention based transformer which extends Transformer based models, such as BERT to much longer"
+ " sequences. In addition to sparse attention, BigBird also applies global attention as well as random"
+ " attention to the input sequence. Theoretically, it has been shown that applying sparse, global, and"
+ " random attention approximates full attention, while being computationally much more efficient for longer"
+ " sequences. As a consequence of the capability to handle longer context, BigBird has shown improved"
+ " performance on various long document NLP tasks, such as question answering and summarization, compared"
+ " to BERT or RoBERTa."
+ )
+
+ question = [
+ "Which is better for longer sequences- BigBird or BERT?",
+ "What is the benefit of using BigBird over BERT?",
+ ]
+ inputs = tokenizer(
+ question,
+ [context, context],
+ padding=True,
+ return_tensors="pt",
+ add_special_tokens=True,
+ max_length=256,
+ truncation=True,
+ )
+
+ inputs = {k: v.to(torch_device) for k, v in inputs.items()}
+
+ start_logits, end_logits = model(**inputs).to_tuple()
+
+ # fmt: off
+ target_start_logits = torch.tensor(
+ [[-8.5622, -9.6209, -14.3351, -8.7032, -11.8596, -7.7446, -9.6730, -13.6063, -8.9651, -11.7417, -8.2641, -8.7056, -13.4116, -5.6600, -8.8316, -10.4148, -12.2180, -7.7979, -12.5274, -6.0685, -10.3373, -11.3128, -6.6456, -14.4030, -6.8292, -14.5383, -11.5638, -6.3326, 11.5293, -1.8434, -10.0013, -7.6150], [-10.7384, -13.1179, -10.1837, -13.7700, -10.0186, -11.7335, -13.3411, -10.0188, -13.4235, -9.9381, -10.4252, -13.1281, -8.2022, -10.4326, -11.5542, -14.1549, -10.7546, -13.4691, -8.2744, -11.4324, -13.3773, -9.8284, -14.5825, -8.7471, -14.7050, -8.0364, -11.3627, -6.4638, -11.7031, -14.3446, -9.9425, -8.0088]], # noqa: E231
+ device=torch_device,
+ )
+
+ target_end_logits = torch.tensor(
+ [[-12.1736, -8.8487, -14.8877, -11.6713, -15.1165, -12.2396, -7.6828, -15.4153, -12.2528, -14.3671, -12.3596, -7.4272, -14.9615, -13.6356, -11.7939, -9.9767, -14.8112, -8.9567, -15.8798, -11.5291, -9.4249, -14.7544, -7.9387, -16.2789, -8.9702, -15.3111, -11.5585, -7.9992, -4.1127, 10.3209, -8.3926, -10.2005], [-11.1375, -15.4027, -12.6861, -16.9884, -13.7093, -10.3560, -15.7228, -12.9290, -15.8519, -13.7953, -10.2460, -15.7198, -14.2078, -12.8477, -11.4861, -16.1017, -11.8900, -16.4488, -13.2959, -10.3980, -15.4874, -10.3539, -16.8263, -10.9973, -17.0344, -9.2751, -10.1196, -13.8907, -12.1025, -13.0628, -12.8530, -13.8173]],
+ device=torch_device,
+ )
+ # fmt: on
+
+ torch.testing.assert_close(start_logits[:, 64:96], target_start_logits, rtol=1e-4, atol=1e-4)
+ torch.testing.assert_close(end_logits[:, 64:96], target_end_logits, rtol=1e-4, atol=1e-4)
+
+ input_ids = inputs["input_ids"].tolist()
+ answer = [
+ input_ids[i][torch.argmax(start_logits, dim=-1)[i] : torch.argmax(end_logits, dim=-1)[i] + 1]
+ for i in range(len(input_ids))
+ ]
+ answer = tokenizer.batch_decode(answer)
+
+ self.assertTrue(answer == ["BigBird", "global attention"])
+
+ def test_fill_mask(self):
+ tokenizer = BigBirdTokenizer.from_pretrained("google/bigbird-roberta-base")
+ model = BigBirdForMaskedLM.from_pretrained("google/bigbird-roberta-base")
+ model.to(torch_device)
+
+ input_ids = tokenizer("The goal of life is [MASK] .", return_tensors="pt").input_ids.to(torch_device)
+ logits = model(input_ids).logits
+
+ # [MASK] is token at 6th position
+ pred_token = tokenizer.decode(torch.argmax(logits[0, 6:7], axis=-1))
+ self.assertEqual(pred_token, "happiness")
+
+ def test_auto_padding(self):
+ model = BigBirdModel.from_pretrained(
+ "google/bigbird-roberta-base", attention_type="block_sparse", num_random_blocks=3, block_size=16
+ )
+ model.to(torch_device)
+ model.eval()
+
+ input_ids = torch.tensor([200 * [10] + 40 * [2] + [1]], device=torch_device, dtype=torch.long)
+ with torch.no_grad():
+ output = model(input_ids).to_tuple()[0]
+
+ # fmt: off
+ target = torch.tensor(
+ [[-0.129420, -0.164740, 0.042422, -0.336030, 0.094379, 0.033794, 0.384590, 0.229660, -0.196500, 0.108020], [-0.000154, -0.168800, 0.165820, -0.313670, 0.101240, 0.035145, 0.381880, 0.213730, -0.201080, 0.077443], [0.053754, -0.166350, 0.225520, -0.272900, 0.119670, 0.019987, 0.348670, 0.199190, -0.181600, 0.084640], [0.063636, -0.187110, 0.237010, -0.297380, 0.126300, 0.020025, 0.268490, 0.191820, -0.192300, 0.035077], [0.073893, -0.184790, 0.188870, -0.297860, 0.134280, 0.028972, 0.174650, 0.186890, -0.180530, 0.006851], [0.005253, -0.169360, 0.123100, -0.302550, 0.126930, 0.024188, 0.133410, 0.200600, -0.168210, -0.001006], [-0.093336, -0.175370, -0.004768, -0.333170, 0.114330, 0.034168, 0.120960, 0.203570, -0.162810, -0.005757], [-0.160210, -0.169310, -0.049064, -0.331950, 0.115730, 0.027062, 0.143600, 0.205310, -0.144580, 0.026746], [-0.193200, -0.156820, -0.079422, -0.351600, 0.106450, 0.032174, 0.245690, 0.210250, -0.173480, 0.043914], [-0.167980, -0.153050, -0.059764, -0.357890,0.103910, 0.031481, 0.334190, 0.208960,-0.178180, 0.072165], [-0.136990, -0.156950, -0.012099, -0.353140,0.096996, 0.025864, 0.376340, 0.216050, -0.171820, 0.089963], [-0.041143, -0.167060, 0.079754, -0.353220, 0.093247, 0.019867, 0.385810, 0.214340, -0.191800, 0.065946],[0.040373, -0.158610, 0.152570, -0.312930, 0.110590, 0.012282, 0.345270, 0.204040, -0.176500, 0.064972], [0.043762, -0.166450, 0.179500, -0.317930, 0.117280, -0.004040, 0.304490, 0.201380, -0.182780, 0.044000]], # noqa: E231
+ device=torch_device,
+ )
+ # fmt: on
+
+ self.assertEqual(output.shape, torch.Size((1, 241, 768)))
+ torch.testing.assert_close(output[0, 64:78, 300:310], target, rtol=0.0001, atol=0.0001)
diff --git a/transformers/tests/models/big_bird/test_tokenization_big_bird.py b/transformers/tests/models/big_bird/test_tokenization_big_bird.py
new file mode 100644
index 0000000000000000000000000000000000000000..ef53889fa1dc2789da823370d427f4377cda56ba
--- /dev/null
+++ b/transformers/tests/models/big_bird/test_tokenization_big_bird.py
@@ -0,0 +1,233 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+from transformers import BigBirdTokenizer, BigBirdTokenizerFast
+from transformers.testing_utils import get_tests_dir, require_sentencepiece, require_tokenizers, require_torch, slow
+from transformers.utils import cached_property
+
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+SPIECE_UNDERLINE = "▁"
+
+SAMPLE_VOCAB = get_tests_dir("fixtures/test_sentencepiece.model")
+
+
+@require_sentencepiece
+@require_tokenizers
+class BigBirdTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "google/bigbird-roberta-base"
+ tokenizer_class = BigBirdTokenizer
+ rust_tokenizer_class = BigBirdTokenizerFast
+ test_rust_tokenizer = True
+ test_sentencepiece = True
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ tokenizer = cls.tokenizer_class(SAMPLE_VOCAB, keep_accents=True)
+ tokenizer.save_pretrained(cls.tmpdirname)
+
+ def test_convert_token_and_id(self):
+ """Test ``_convert_token_to_id`` and ``_convert_id_to_token``."""
+ token = ""
+ token_id = 1
+
+ self.assertEqual(self.get_tokenizer()._convert_token_to_id(token), token_id)
+ self.assertEqual(self.get_tokenizer()._convert_id_to_token(token_id), token)
+
+ def test_get_vocab(self):
+ vocab_keys = list(self.get_tokenizer().get_vocab().keys())
+
+ self.assertEqual(vocab_keys[0], "")
+ self.assertEqual(vocab_keys[1], "")
+ self.assertEqual(vocab_keys[-1], "[MASK]")
+ self.assertEqual(len(vocab_keys), 1_004)
+
+ def test_vocab_size(self):
+ self.assertEqual(self.get_tokenizer().vocab_size, 1_000)
+
+ def test_rust_and_python_full_tokenizers(self):
+ if not self.test_rust_tokenizer:
+ self.skipTest(reason="test_rust_tokenizer is set to False")
+
+ tokenizer = self.get_tokenizer()
+ rust_tokenizer = self.get_rust_tokenizer()
+
+ sequence = "I was born in 92000, and this is falsé."
+
+ tokens = tokenizer.tokenize(sequence)
+ rust_tokens = rust_tokenizer.tokenize(sequence)
+ self.assertListEqual(tokens, rust_tokens)
+
+ ids = tokenizer.encode(sequence, add_special_tokens=False)
+ rust_ids = rust_tokenizer.encode(sequence, add_special_tokens=False)
+ self.assertListEqual(ids, rust_ids)
+
+ rust_tokenizer = self.get_rust_tokenizer()
+ ids = tokenizer.encode(sequence)
+ rust_ids = rust_tokenizer.encode(sequence)
+ self.assertListEqual(ids, rust_ids)
+
+ def test_full_tokenizer(self):
+ tokenizer = BigBirdTokenizer(SAMPLE_VOCAB, keep_accents=True)
+
+ tokens = tokenizer.tokenize("This is a test")
+ self.assertListEqual(tokens, ["▁This", "▁is", "▁a", "▁t", "est"])
+
+ self.assertListEqual(
+ tokenizer.convert_tokens_to_ids(tokens),
+ [285, 46, 10, 170, 382],
+ )
+
+ tokens = tokenizer.tokenize("I was born in 92000, and this is falsé.")
+ self.assertListEqual(
+ tokens,
+ [
+ SPIECE_UNDERLINE + "I",
+ SPIECE_UNDERLINE + "was",
+ SPIECE_UNDERLINE + "b",
+ "or",
+ "n",
+ SPIECE_UNDERLINE + "in",
+ SPIECE_UNDERLINE + "",
+ "9",
+ "2",
+ "0",
+ "0",
+ "0",
+ ",",
+ SPIECE_UNDERLINE + "and",
+ SPIECE_UNDERLINE + "this",
+ SPIECE_UNDERLINE + "is",
+ SPIECE_UNDERLINE + "f",
+ "al",
+ "s",
+ "é",
+ ".",
+ ],
+ )
+ ids = tokenizer.convert_tokens_to_ids(tokens)
+ self.assertListEqual(
+ ids,
+ [8, 21, 84, 55, 24, 19, 7, 0, 602, 347, 347, 347, 3, 12, 66, 46, 72, 80, 6, 0, 4],
+ )
+
+ back_tokens = tokenizer.convert_ids_to_tokens(ids)
+ self.assertListEqual(
+ back_tokens,
+ [
+ SPIECE_UNDERLINE + "I",
+ SPIECE_UNDERLINE + "was",
+ SPIECE_UNDERLINE + "b",
+ "or",
+ "n",
+ SPIECE_UNDERLINE + "in",
+ SPIECE_UNDERLINE + "",
+ "",
+ "2",
+ "0",
+ "0",
+ "0",
+ ",",
+ SPIECE_UNDERLINE + "and",
+ SPIECE_UNDERLINE + "this",
+ SPIECE_UNDERLINE + "is",
+ SPIECE_UNDERLINE + "f",
+ "al",
+ "s",
+ "",
+ ".",
+ ],
+ )
+
+ @cached_property
+ def big_tokenizer(self):
+ return BigBirdTokenizer.from_pretrained("google/bigbird-roberta-base")
+
+ @slow
+ def test_tokenization_base_easy_symbols(self):
+ symbols = "Hello World!"
+ original_tokenizer_encodings = [65, 18536, 2260, 101, 66]
+
+ self.assertListEqual(original_tokenizer_encodings, self.big_tokenizer.encode(symbols))
+
+ @slow
+ def test_tokenization_base_hard_symbols(self):
+ symbols = (
+ 'This is a very long text with a lot of weird characters, such as: . , ~ ? ( ) " [ ] ! : - . Also we will'
+ " add words that should not exist and be tokenized to , such as saoneuhaoesuth"
+ )
+ original_tokenizer_encodings = [65, 871, 419, 358, 946, 991, 2521, 452, 358, 1357, 387, 7751, 3536, 112, 985, 456, 126, 865, 938, 5400, 5734, 458, 1368, 467, 786, 2462, 5246, 1159, 633, 865, 4519, 457, 582, 852, 2557, 427, 916, 508, 405, 34324, 497, 391, 408, 11342, 1244, 385, 100, 938, 985, 456, 574, 362, 12597, 3200, 3129, 1172, 66] # fmt: skip
+ self.assertListEqual(original_tokenizer_encodings, self.big_tokenizer.encode(symbols))
+
+ @require_torch
+ @slow
+ def test_torch_encode_plus_sent_to_model(self):
+ import torch
+
+ from transformers import BigBirdConfig, BigBirdModel
+
+ # Build sequence
+ first_ten_tokens = list(self.big_tokenizer.get_vocab().keys())[:10]
+ sequence = " ".join(first_ten_tokens)
+ encoded_sequence = self.big_tokenizer.encode_plus(sequence, return_tensors="pt", return_token_type_ids=False)
+ batch_encoded_sequence = self.big_tokenizer.batch_encode_plus(
+ [sequence + " " + sequence], return_tensors="pt", return_token_type_ids=False
+ )
+
+ config = BigBirdConfig(attention_type="original_full")
+ model = BigBirdModel(config)
+
+ assert model.get_input_embeddings().weight.shape[0] >= self.big_tokenizer.vocab_size
+
+ with torch.no_grad():
+ model(**encoded_sequence)
+ model(**batch_encoded_sequence)
+
+ @slow
+ def test_special_tokens(self):
+ """
+ To reproduce:
+
+ $ wget https://github.com/google-research/bigbird/blob/master/bigbird/vocab/gpt2.model?raw=true
+ $ mv gpt2.model?raw=true gpt2.model
+
+ ```
+ import tensorflow_text as tft
+ import tensorflow as tf
+
+ vocab_model_file = "./gpt2.model"
+ tokenizer = tft.SentencepieceTokenizer(model=tf.io.gfile.GFile(vocab_model_file, "rb").read()))
+ ids = tokenizer.tokenize("Paris is the [MASK].")
+ ids = tf.concat([tf.constant([65]), ids, tf.constant([66])], axis=0)
+ detokenized = tokenizer.detokenize(ids) # should give [CLS] Paris is the [MASK].[SEP]
+ """
+ tokenizer = BigBirdTokenizer.from_pretrained("google/bigbird-roberta-base")
+ decoded_text = tokenizer.decode(tokenizer("Paris is the [MASK].").input_ids)
+
+ self.assertTrue(decoded_text == "[CLS] Paris is the[MASK].[SEP]")
+
+ @slow
+ def test_tokenizer_integration(self):
+ expected_encoding = {'input_ids': [[65, 39286, 458, 36335, 2001, 456, 13073, 13266, 455, 113, 7746, 1741, 11157, 391, 13073, 13266, 455, 113, 3967, 35412, 113, 4936, 109, 3870, 2377, 113, 30084, 45720, 458, 134, 17496, 112, 503, 11672, 113, 118, 112, 5665, 13347, 38687, 112, 1496, 31389, 112, 3268, 47264, 134, 962, 112, 16377, 8035, 23130, 430, 12169, 15518, 28592, 458, 146, 41697, 109, 391, 12169, 15518, 16689, 458, 146, 41358, 109, 452, 726, 4034, 111, 763, 35412, 5082, 388, 1903, 111, 9051, 391, 2870, 48918, 1900, 1123, 550, 998, 112, 9586, 15985, 455, 391, 410, 22955, 37636, 114, 66], [65, 448, 17496, 419, 3663, 385, 763, 113, 27533, 2870, 3283, 13043, 1639, 24713, 523, 656, 24013, 18550, 2521, 517, 27014, 21244, 420, 1212, 1465, 391, 927, 4833, 388, 578, 11786, 114, 66, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [65, 484, 2169, 7687, 21932, 18146, 726, 363, 17032, 3391, 114, 66, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]} # fmt: skip
+
+ self.tokenizer_integration_test_util(
+ expected_encoding=expected_encoding,
+ model_name="google/bigbird-roberta-base",
+ revision="215c99f1600e06f83acce68422f2035b2b5c3510",
+ )
diff --git a/transformers/tests/models/bigbird_pegasus/__init__.py b/transformers/tests/models/bigbird_pegasus/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/bigbird_pegasus/test_modeling_bigbird_pegasus.py b/transformers/tests/models/bigbird_pegasus/test_modeling_bigbird_pegasus.py
new file mode 100644
index 0000000000000000000000000000000000000000..22dfe8be07b48d1f887cbccbd5afc0ab8a5fc107
--- /dev/null
+++ b/transformers/tests/models/bigbird_pegasus/test_modeling_bigbird_pegasus.py
@@ -0,0 +1,808 @@
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch BigBirdPegasus model."""
+
+import copy
+import tempfile
+import unittest
+
+from transformers import BigBirdPegasusConfig, is_torch_available
+from transformers.testing_utils import (
+ require_sentencepiece,
+ require_tokenizers,
+ require_torch,
+ require_torch_fp16,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ BigBirdPegasusForCausalLM,
+ BigBirdPegasusForConditionalGeneration,
+ BigBirdPegasusForQuestionAnswering,
+ BigBirdPegasusForSequenceClassification,
+ BigBirdPegasusModel,
+ PegasusTokenizer,
+ )
+ from transformers.models.bigbird_pegasus.modeling_bigbird_pegasus import (
+ BigBirdPegasusDecoder,
+ BigBirdPegasusEncoder,
+ )
+
+MODEL_ID = "google/bigbird-pegasus-large-pubmed"
+
+
+def prepare_bigbird_pegasus_inputs_dict(
+ config,
+ input_ids,
+ decoder_input_ids,
+ attention_mask=None,
+ decoder_attention_mask=None,
+):
+ if attention_mask is None:
+ attention_mask = input_ids.ne(config.pad_token_id)
+ if decoder_attention_mask is None:
+ decoder_attention_mask = decoder_input_ids.ne(config.pad_token_id)
+
+ input_dict = {
+ "input_ids": input_ids,
+ "decoder_input_ids": decoder_input_ids,
+ "attention_mask": attention_mask,
+ "decoder_attention_mask": attention_mask,
+ }
+ input_dict = {k: input_dict[k].to(torch_device) for k in input_dict}
+ return input_dict
+
+
+class BigBirdPegasusModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ seq_length=256,
+ is_training=True,
+ use_labels=False,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=31,
+ hidden_act="gelu_fast",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=260,
+ eos_token_id=1,
+ pad_token_id=0,
+ bos_token_id=2,
+ attention_type="block_sparse",
+ use_bias=False,
+ block_size=16,
+ num_random_blocks=3,
+ scale_embedding=True,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.eos_token_id = eos_token_id
+ self.pad_token_id = pad_token_id
+ self.bos_token_id = bos_token_id
+
+ self.attention_type = attention_type
+ self.use_bias = use_bias
+ self.block_size = block_size
+ self.num_random_blocks = num_random_blocks
+ self.scale_embedding = scale_embedding
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size).clamp(
+ 3,
+ )
+ input_ids[:, -1] = self.eos_token_id # Eos Token
+
+ decoder_input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ config = self.get_config()
+ inputs_dict = prepare_bigbird_pegasus_inputs_dict(config, input_ids, decoder_input_ids)
+ return config, inputs_dict
+
+ def get_config(self):
+ return BigBirdPegasusConfig(
+ vocab_size=self.vocab_size,
+ d_model=self.hidden_size,
+ encoder_layers=self.num_hidden_layers,
+ decoder_layers=self.num_hidden_layers,
+ encoder_attention_heads=self.num_attention_heads,
+ decoder_attention_heads=self.num_attention_heads,
+ encoder_ffn_dim=self.intermediate_size,
+ decoder_ffn_dim=self.intermediate_size,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ eos_token_id=self.eos_token_id,
+ bos_token_id=self.bos_token_id,
+ pad_token_id=self.pad_token_id,
+ attention_type=self.attention_type,
+ use_bias=self.use_bias,
+ block_size=self.block_size,
+ num_random_blocks=self.num_random_blocks,
+ scale_embedding=self.scale_embedding,
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config, inputs_dict = self.prepare_config_and_inputs()
+ return config, inputs_dict
+
+ def create_and_check_decoder_model_past_large_inputs(self, config, inputs_dict):
+ model = BigBirdPegasusModel(config=config).get_decoder().to(torch_device).eval()
+ input_ids = inputs_dict["input_ids"]
+ attention_mask = inputs_dict["attention_mask"]
+
+ # first forward pass
+ outputs = model(input_ids, attention_mask=attention_mask, use_cache=True)
+
+ output, past_key_values = outputs.to_tuple()
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_attn_mask = ids_tensor((self.batch_size, 3), 2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([attention_mask, next_attn_mask], dim=-1)
+
+ output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)["last_hidden_state"]
+ output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)[
+ "last_hidden_state"
+ ]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-2))
+
+ def check_encoder_decoder_model_standalone(self, config, inputs_dict):
+ model = BigBirdPegasusModel(config=config).to(torch_device).eval()
+ outputs = model(**inputs_dict)
+
+ encoder_last_hidden_state = outputs.encoder_last_hidden_state
+ last_hidden_state = outputs.last_hidden_state
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ encoder = model.get_encoder()
+ encoder.save_pretrained(tmpdirname)
+ encoder = BigBirdPegasusEncoder.from_pretrained(tmpdirname).to(torch_device)
+
+ encoder_last_hidden_state_2 = encoder(inputs_dict["input_ids"], attention_mask=inputs_dict["attention_mask"])[
+ 0
+ ]
+
+ self.parent.assertTrue((encoder_last_hidden_state_2 - encoder_last_hidden_state).abs().max().item() < 1e-3)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ decoder = model.get_decoder()
+ decoder.save_pretrained(tmpdirname)
+ decoder = BigBirdPegasusDecoder.from_pretrained(tmpdirname).to(torch_device)
+
+ last_hidden_state_2 = decoder(
+ input_ids=inputs_dict["decoder_input_ids"],
+ attention_mask=inputs_dict["decoder_attention_mask"],
+ encoder_hidden_states=encoder_last_hidden_state,
+ encoder_attention_mask=inputs_dict["attention_mask"],
+ )[0]
+
+ self.parent.assertTrue((last_hidden_state_2 - last_hidden_state).abs().max().item() < 1e-3)
+
+ def create_and_check_model(self, config, inputs_dict):
+ model = BigBirdPegasusModel(config=config).to(torch_device).eval()
+ input_ids = inputs_dict["input_ids"]
+ decoder_input_ids = inputs_dict["decoder_input_ids"]
+ result = model(input_ids, decoder_input_ids=decoder_input_ids, use_cache=True)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+
+@require_torch
+class BigBirdPegasusModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ BigBirdPegasusModel,
+ BigBirdPegasusForConditionalGeneration,
+ BigBirdPegasusForSequenceClassification,
+ BigBirdPegasusForQuestionAnswering,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": BigBirdPegasusModel,
+ "question-answering": BigBirdPegasusForQuestionAnswering,
+ "summarization": BigBirdPegasusForConditionalGeneration,
+ "text-classification": BigBirdPegasusForSequenceClassification,
+ "text-generation": BigBirdPegasusForCausalLM,
+ "text2text-generation": BigBirdPegasusForConditionalGeneration,
+ "translation": BigBirdPegasusForConditionalGeneration,
+ "zero-shot": BigBirdPegasusForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ is_encoder_decoder = True
+ test_missing_keys = False
+ test_pruning = False
+ test_head_masking = False
+
+ # torchscript tests are not passing for now.
+ # Also torchscript is not an important feature to have in the beginning.
+ test_torchscript = False
+
+ # TODO: Fix the failed tests
+ def is_pipeline_test_to_skip(
+ self,
+ pipeline_test_case_name,
+ config_class,
+ model_architecture,
+ tokenizer_name,
+ image_processor_name,
+ feature_extractor_name,
+ processor_name,
+ ):
+ if pipeline_test_case_name == "QAPipelineTests" and not tokenizer_name.endswith("Fast"):
+ return True
+
+ return False
+
+ def setUp(self):
+ self.model_tester = BigBirdPegasusModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=BigBirdPegasusConfig)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_save_load_strict(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs()
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
+ self.assertEqual(info["missing_keys"], [])
+
+ def test_decoder_model_past_with_large_inputs(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
+
+ def test_encoder_decoder_model_standalone(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
+ self.model_tester.check_encoder_decoder_model_standalone(*config_and_inputs)
+
+ def test_model_various_attn_type(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["original_full", "block_sparse"]:
+ config_and_inputs[0].attention_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_generate_without_input_ids(self):
+ if self.model_tester.attention_type == "block_sparse":
+ self.skipTest(
+ "Cannot pass for BigBird-block-sparse attention since input_ids must be multiple of block_size"
+ )
+ super().test_generate_without_input_ids()
+
+ def test_retain_grad_hidden_states_attentions(self):
+ if self.model_tester.attention_type == "block_sparse":
+ # this test can't pass since attention matrix (which is getting returned) can't have gradients (& just 0 at many locations)
+ self.skipTest(reason="Cannot pass since returned attention matrix can't have gradients")
+ super().test_retain_grad_hidden_states_attentions()
+
+ # BigBirdPegasusForSequenceClassification does not support inputs_embeds
+ def test_inputs_embeds(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in (
+ BigBirdPegasusModel,
+ BigBirdPegasusForConditionalGeneration,
+ BigBirdPegasusForQuestionAnswering,
+ ):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ inputs = copy.deepcopy(self._prepare_for_class(inputs_dict, model_class))
+
+ if not self.is_encoder_decoder:
+ input_ids = inputs["input_ids"]
+ del inputs["input_ids"]
+ else:
+ encoder_input_ids = inputs["input_ids"]
+ decoder_input_ids = inputs.get("decoder_input_ids", encoder_input_ids)
+ del inputs["input_ids"]
+ inputs.pop("decoder_input_ids", None)
+
+ wte = model.get_input_embeddings()
+ if not self.is_encoder_decoder:
+ inputs["inputs_embeds"] = wte(input_ids)
+ else:
+ inputs["inputs_embeds"] = wte(encoder_input_ids)
+ inputs["decoder_inputs_embeds"] = wte(decoder_input_ids)
+
+ with torch.no_grad():
+ model(**inputs)[0]
+
+ @require_torch_fp16
+ def test_generate_fp16(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs()
+ input_dict.pop("decoder_attention_mask")
+ input_dict.pop("decoder_input_ids")
+ model = BigBirdPegasusForConditionalGeneration(config).eval().to(torch_device)
+ model.half()
+ model.generate(**input_dict)
+ model.generate(**input_dict, do_sample=True, early_stopping=False, num_return_sequences=3)
+
+ @slow
+ def test_batched_forward_original_full(self):
+ self._check_batched_forward(attn_type="original_full")
+
+ @slow
+ def test_batched_forward_block_sparse(self):
+ self._check_batched_forward(attn_type="block_sparse", tolerance=1e-1)
+
+ def _check_batched_forward(self, attn_type, tolerance=1e-3):
+ config, _ = self.model_tester.prepare_config_and_inputs()
+ config.max_position_embeddings = 128
+ config.block_size = 16
+ config.attention_type = attn_type
+ model = BigBirdPegasusForConditionalGeneration(config).to(torch_device)
+ model.eval()
+
+ chunk_length = 32
+
+ sample_with_padding = [3, 8, 11] * chunk_length + [0] * chunk_length
+ sample_without_padding = [4, 7, 9, 13] * chunk_length
+ target_ids_without_padding = [2, 3] * 8
+ target_ids_with_padding = [7, 8] * 6 + 4 * [-100]
+
+ attention_mask = torch.tensor(
+ [[1] * 3 * chunk_length + [0] * chunk_length, [1] * 4 * chunk_length],
+ device=torch_device,
+ dtype=torch.long,
+ )
+
+ input_ids = torch.tensor([sample_with_padding, sample_without_padding], device=torch_device, dtype=torch.long)
+ labels = torch.tensor(
+ [target_ids_without_padding, target_ids_with_padding], device=torch_device, dtype=torch.long
+ )
+
+ with torch.no_grad():
+ logits_batched = model(input_ids=input_ids, attention_mask=attention_mask, labels=labels).logits
+
+ with torch.no_grad():
+ logits_single_first = model(input_ids=input_ids[:1, :-chunk_length], labels=labels[:1]).logits
+
+ torch.testing.assert_close(logits_batched[0, -3:], logits_single_first[0, -3:], rtol=tolerance, atol=tolerance)
+
+ with torch.no_grad():
+ logits_single_second = model(input_ids=input_ids[1:], labels=labels[1:, :-4]).logits
+
+ torch.testing.assert_close(logits_batched[1, :3], logits_single_second[0, :3], rtol=tolerance, atol=tolerance)
+
+ def test_auto_padding(self):
+ ids = [[7, 6, 9] * 65]
+ config, _ = self.model_tester.prepare_config_and_inputs()
+ input_ids = torch.tensor(ids, device=torch_device, dtype=torch.long)
+ attention_mask = input_ids.new_ones(input_ids.shape)
+ decoder_input_ids = torch.tensor([[33, 5, 8] * 3], device=torch_device, dtype=torch.long)
+
+ config.block_size = 8
+ model = BigBirdPegasusForConditionalGeneration(config).eval().to(torch_device)
+ output1 = model(input_ids=input_ids, attention_mask=attention_mask, decoder_input_ids=decoder_input_ids)[
+ "logits"
+ ]
+
+ ids = [[7, 6, 9] * 65 + [0] * 5]
+ input_ids = torch.tensor(ids, device=torch_device, dtype=torch.long)
+ attention_mask = torch.tensor([[1] * 3 * 65 + [0] * 5], device=torch_device, dtype=torch.long)
+ output2 = model(input_ids=input_ids, attention_mask=attention_mask, decoder_input_ids=decoder_input_ids)[
+ "logits"
+ ]
+
+ torch.testing.assert_close(output1, output2, rtol=1e-5, atol=1e-5)
+
+ def test_for_change_to_full_attn(self):
+ self.model_tester.seq_length = 9
+ config, input_dict = self.model_tester.prepare_config_and_inputs()
+
+ # automatic switch will happen
+ config.attention_type = "block_sparse"
+ model = BigBirdPegasusForConditionalGeneration(config).eval().to(torch_device)
+ state_dict = model.state_dict()
+ outputs1 = model(**input_dict)["logits"]
+
+ config.attention_type = "original_full"
+ model = BigBirdPegasusForConditionalGeneration(config).eval().to(torch_device)
+ model.load_state_dict(state_dict)
+ outputs2 = model(**input_dict)["logits"]
+
+ torch.testing.assert_close(outputs1, outputs2, rtol=1e-5, atol=1e-5)
+
+ @unittest.skip(
+ reason="This architecture has tied weights by default and there is no way to remove it, check: https://github.com/huggingface/transformers/pull/31771#issuecomment-2210915245"
+ )
+ def test_load_save_without_tied_weights(self):
+ pass
+
+
+@require_torch
+@require_sentencepiece
+@require_tokenizers
+@slow
+class BigBirdPegasusModelIntegrationTests(unittest.TestCase):
+ def _get_dummy_input_ids(self):
+ # fmt: off
+ ids = torch.tensor(
+ [[685, 560, 630, 193, 836, 764, 708, 360, 10, 724, 278, 755, 805, 600, 71, 473, 601, 397, 315, 706, 487, 552, 88, 175, 601, 850, 678, 538, 846, 73, 778, 917, 116, 977, 756, 710, 1023, 848, 432, 449, 851, 100, 985, 178, 756, 798, 660, 148, 911, 424, 289, 962, 266, 698, 640, 545, 544, 715, 245, 152, 676, 511, 460, 883, 184, 29, 803, 129, 129, 933, 54, 902, 551, 489, 757, 274, 336, 389, 618, 43, 443, 544, 889, 258, 322, 1000, 938, 58, 292, 871, 120, 780, 431, 83, 92, 897, 399, 612, 566, 909, 634, 939, 85, 204, 325, 775, 965, 48, 640, 1013, 132, 973, 869, 181, 1001, 847, 144, 661, 228, 955, 792, 720, 910, 374, 854, 561, 306, 582, 170, 676, 449, 96, 198, 607, 257, 882, 691, 293, 931, 817, 862, 388, 611, 555, 974, 369, 1000, 918, 202, 384, 513, 907, 371, 556, 955, 384, 24, 700, 131, 378, 99, 575, 932, 735, 124, 964, 595, 943, 740, 149, 210, 563, 412, 783, 42, 59, 706, 37, 779, 87, 44, 873, 12, 771, 308, 81, 33, 183, 129, 807, 276, 175, 555, 372, 185, 445, 489, 590, 287, 281, 638, 771, 516, 95, 227, 876, 270, 881, 297, 329, 20, 608, 841, 411, 451, 249, 181, 324, 1005, 830, 783, 865, 261, 964, 750, 140, 1021, 599, 462, 890, 622, 844, 697, 529, 153, 926, 150, 111, 26, 465, 957, 890, 887, 118, 446, 596, 674, 873, 929, 229, 508, 764, 122, 327, 470, 288, 526, 840, 697, 153, 592, 42, 275, 553, 439, 208, 780, 167, 112, 350, 1018, 130, 736, 887, 813, 217, 382, 25, 68, 979, 1008, 772, 235, 717, 999, 292, 727, 1023, 702, 710, 728, 556, 33, 12, 617, 213, 139, 695, 1004, 422, 638, 669, 624, 489, 771, 540, 980, 218, 664, 822, 308, 175, 149, 950, 542, 580, 548, 808, 394, 74, 298, 920, 900, 815, 731, 947, 877, 772, 800, 778, 395, 540, 430, 200, 424, 62, 342, 866, 45, 803, 931, 89, 34, 646, 233, 768, 37, 769, 460, 291, 198, 895, 950, 255, 81, 447, 137, 190, 130, 210, 369, 292, 377, 348, 169, 885, 805, 177, 538, 324, 872, 509, 804, 115, 799, 30, 754, 290, 147, 274, 222, 341, 510, 515, 70, 358, 909, 557, 886, 766, 323, 624, 92, 342, 424, 552, 972, 663, 415, 658, 711, 968, 275, 861, 44, 84, 434, 810, 94, 175, 406, 202, 858, 499, 481, 988, 330, 541, 1004, 210, 618, 955, 897, 983, 576, 17, 107, 165, 607, 537, 629, 192, 196, 308, 137, 953, 860, 94, 892, 751, 88, 161, 148, 585, 456, 88, 14, 315, 594, 121, 885, 952, 833, 716, 733, 933, 282, 801, 427, 783, 471, 285, 277, 979, 325, 535, 228, 891, 596, 648, 969, 574, 654, 518, 257, 137, 208, 464, 950, 140, 5, 424, 349, 942, 283, 587, 821, 1007, 434, 220, 820, 740, 874, 787, 374, 291, 564, 671, 438, 827, 940, 824, 509, 1021, 787, 942, 856, 450, 327, 491, 54, 817, 95, 60, 337, 667, 637, 164, 571, 946, 107, 202, 301, 782, 890, 839, 551, 680, 649, 14, 1017, 904, 721, 1017, 535, 505, 848, 986, 777, 740, 775, 210, 456, 469, 474, 963, 573, 401, 57, 883, 750, 664, 281, 5, 613, 1005, 306, 344, 543, 567, 154, 789, 354, 358, 698, 408, 412, 30, 930, 372, 822, 632, 948, 855, 503, 8, 618, 1010, 138, 695, 897, 852, 377, 933, 722, 149, 886, 1009, 260, 127, 811, 578, 533, 805, 325, 977, 113, 944, 651, 238, 361, 991, 860, 556, 64, 928, 917, 455, 266, 445, 604, 624, 420, 340, 845, 275, 370, 843, 227, 226, 940, 644, 909, 229, 827, 898, 370, 129, 808, 25, 699, 293, 356, 838, 135, 4, 227, 890, 681, 445, 418, 285, 837, 27, 737, 249, 366, 948, 202, 438, 198, 930, 648, 638, 607, 73, 247, 853, 136, 708, 214, 476, 621, 324, 103, 853, 328, 596, 224, 257, 646, 348, 108, 927, 970, 980, 520, 150, 998, 477, 393, 684, 559, 1, 361, 692, 551, 90, 75, 500, 739, 636, 344, 97, 852, 283, 719, 33, 116, 455, 866, 429, 828, 826, 691, 174, 746, 133, 442, 94, 348, 402, 420, 707, 405, 942, 186, 976, 376, 677, 874, 703, 517, 498, 499, 206, 415, 366, 856, 739, 420, 586, 219, 952, 539, 375, 23, 461, 720, 355, 603, 52, 999, 815, 721, 574, 445, 816, 1019, 105, 641, 395, 972, 910, 328, 607, 519, 686, 246, 415, 528, 170, 167, 310, 940, 595, 392, 221, 834, 682, 835, 115, 861, 335, 742, 220, 247, 101, 416, 222, 179, 509, 175, 606, 627, 674, 781, 737, 746, 849, 67, 457, 1012, 126, 139, 625, 731, 156, 697, 121, 322, 449, 710, 857, 291, 976, 4, 701, 239, 678, 172, 724, 857, 583, 661, 903, 797, 628, 903, 835, 605, 989, 615, 870, 380, 710, 110, 330, 101, 695, 846, 918, 508, 672, 594, 36, 238, 244, 251, 393, 767, 282, 22, 430, 230, 983, 401, 154, 1007, 120, 678, 896, 386, 390, 711, 397, 347, 587, 1020, 951, 79, 831, 585, 200, 814, 134, 560, 700, 171, 452, 139, 755, 314, 476, 346, 388, 126, 719, 851, 198, 699, 901, 18, 710, 448, 351, 665, 644, 326, 425, 165, 571, 178, 440, 665, 674, 915, 866, 463, 754, 136, 950, 748, 47, 497, 1013, 640, 930, 338, 158, 525, 631, 815, 887, 289, 803, 116, 600, 637, 410, 175, 499, 876, 565, 1002, 623, 577, 333, 887, 586, 147, 773, 776, 644, 49, 77, 294, 117, 494, 561, 110, 979, 180, 562, 72, 859, 434, 1007, 286, 516, 75, 597, 491, 322, 888, 533, 209, 43, 499, 29, 411, 856, 181, 305, 963, 615, 778, 259, 373, 877, 746, 858, 381, 886, 613, 91, 69, 618, 523, 13, 617, 226, 422, 168, 929, 379, 290, 923, 100, 218, 307, 345, 211, 789, 735, 669, 585, 275, 410, 921, 552, 235, 636, 285, 665, 659, 708, 173, 724, 302, 823, 1, 139, 708, 903, 732, 868, 442, 967, 916, 163, 51, 243, 871]], # noqa: E231
+ dtype=torch.long,
+ device=torch_device,
+ )
+ # fmt: on
+ return ids
+
+ def _get_dummy_target_ids(self):
+ # fmt: off
+ ids = torch.tensor(
+ [[13, 6, 1, 4, 12, 4, 8, 10, 4, 6, 3, 5, 8, 7, 9, 9]], # noqa: E231
+ dtype=torch.long,
+ device=torch_device,
+ )
+ # fmt: on
+ return ids
+
+ def test_inference_block_sparse(self):
+ model = BigBirdPegasusForConditionalGeneration.from_pretrained(
+ MODEL_ID, attention_type="block_sparse", block_size=16, num_random_blocks=3
+ )
+ model.to(torch_device)
+
+ input_ids = self._get_dummy_input_ids()
+ target_ids = self._get_dummy_target_ids()
+
+ outputs = model(input_ids, labels=target_ids)
+ prediction_logits = outputs.logits
+
+ self.assertEqual(prediction_logits.shape, torch.Size((1, 16, 96103)))
+ # fmt: off
+ expected_prediction_logits_slice = torch.tensor(
+ [[1.5118, 5.5227, 4.8125, 1.7603, 8.1704, 3.996, 4.8118, 6.7806, 2.2297, 6.9834, 3.1906, 0.103, 7.1515, 6.3679, 3.1896, 6.3054, 3.9741, 6.3772, 5.0042, -0.6338, 6.7868, 0.592, 0.5363, 1.87, -0.331, -2.4518, 1.8263, 3.1899], [1.5702, 5.8135, 4.6675, 2.3674, 8.9828, 3.7913, 5.4027, 7.6567, 1.9007, 7.3706, 3.8824, 0.0247, 7.6094, 6.6985, 3.2826, 7.0094, 3.8713, 5.6555, 5.0439, -0.3519, 7.1525, 0.4062, -0.2419, 2.2194, -0.6447, -2.9614, 2.0713, 3.248], [1.4527, 5.6003, 4.5381, 2.6382, 9.2809, 3.2969, 5.6811, 8.4011, 1.6909, 7.4937, 4.3185, -0.0878, 7.61, 6.6822, 3.4753, 7.3962, 3.5336, 4.9216, 4.943, -0.2043, 7.3326, 0.2199, -0.6016, 2.4367, -0.7043, -3.0689, 2.3215, 3.0611], [1.1084, 5.6308, 4.4886, 2.717, 9.4103, 3.0733, 5.5825, 8.4325, 1.3075, 7.5495, 4.4782, -0.1092, 7.8115, 6.6285, 3.5311, 7.6853, 3.509, 4.4994, 4.9224, -0.1384, 7.3069, -0.0473, -0.8578, 2.4632, -0.5249, -3.4627, 2.2671, 2.8818]], # noqa: E231
+ device=torch_device,
+ )
+
+ # fmt: on
+ torch.testing.assert_close(
+ prediction_logits[0, 4:8, 128:156], expected_prediction_logits_slice, rtol=1e-4, atol=1e-4
+ )
+
+ def test_inference_full_attn(self):
+ model = BigBirdPegasusForConditionalGeneration.from_pretrained(MODEL_ID, attention_type="original_full")
+ model.to(torch_device)
+
+ input_ids = self._get_dummy_input_ids()
+ target_ids = self._get_dummy_target_ids()
+
+ outputs = model(input_ids, labels=target_ids)
+ prediction_logits = outputs.logits
+
+ self.assertEqual(prediction_logits.shape, torch.Size((1, 16, 96103)))
+ # fmt: off
+ expected_prediction_logits_slice = torch.tensor(
+ [[1.3418, 5.8304, 6.5662, 2.0448, 8.7702, 4.6579, 4.9947, 6.429, 2.4296, 7.9431, 4.217, 0.0672, 7.334, 5.1966, 2.9603, 6.0814, 4.6756, 7.5522, 5.076, 0.213, 6.6638, 0.6577, 0.244, 2.1221, 0.7531, -2.4076, 1.8731, 3.5594], [1.5525, 6.0524, 6.309, 2.6245, 9.229, 4.5213, 5.0913, 7.0622, 1.7992, 8.0962, 4.7994, -0.0248, 7.7168, 5.5878, 3.0883, 6.5248, 4.7895, 6.9974, 4.8787, 0.5445, 6.6686, 0.0102, -0.1659, 2.6195, 0.7389, -2.8956, 1.9928, 3.3777], [1.6407, 6.2104, 6.0331, 2.8076, 9.4074, 3.9772, 5.0574, 7.5316, 1.4201, 8.3035, 5.0212, -0.1031, 7.553, 5.5023, 3.1427, 6.7674, 4.4409, 6.457, 4.525, 0.728, 6.5422, -0.6234, -0.4726, 2.7486, 0.6985, -3.0804, 1.9669, 3.2365], [1.5065, 6.1271, 5.8296, 2.8405, 9.5649, 3.6834, 5.1214, 7.546, 0.9758, 8.3335, 5.1952, -0.1395, 7.4348, 5.6893, 3.2942, 7.0356, 4.1665, 5.9695, 4.3898, 0.8931, 6.3988, -0.8957, -0.7522, 2.8924, 0.6498, -3.4358, 1.8654, 2.9735]], # noqa: E231
+ device=torch_device,
+ )
+ # fmt: on
+ torch.testing.assert_close(
+ prediction_logits[0, 4:8, 128:156], expected_prediction_logits_slice, rtol=1e-4, atol=1e-4
+ )
+
+ def test_seq_to_seq_generation(self):
+ MODEL_ID = "google/bigbird-pegasus-large-arxiv"
+ model = BigBirdPegasusForConditionalGeneration.from_pretrained(MODEL_ID).to(torch_device)
+ tokenizer = PegasusTokenizer.from_pretrained(MODEL_ID)
+
+ ARTICLE_LEP = r"""the lep experiments at the resonance of @xmath1-boson have tested the standard model ( sm ) at quantum level , measuring the @xmath1-decay into fermion pairs with an accuracy of one part in ten thousands . the good agreement of the lep data with the sm predictions have severely constrained the behavior of new physics at the @xmath1-pole . taking these achievements into account one can imagine that the physics of @xmath1-boson will again play the central role in the frontier of particle physics if the next generation @xmath1 factory comes true with the generated @xmath1 events several orders of magnitude higher than that of the lep . this factory can be realized in the gigaz option of the international linear collider ( ilc)@xcite . the ilc is a proposed electron - positron collider with tunable energy ranging from @xmath12 to @xmath13 and polarized beams in its first phase , and the gigaz option corresponds to its operation on top of the resonance of @xmath1 boson by adding a bypass to its main beam line . given the high luminosity , @xmath14 , and the cross section at the resonance of @xmath1 boson , @xmath15 , about @xmath16 @xmath1 events can be generated in an operational year of @xmath17 of gigaz , which implies that the expected sensitivity to the branching ratio of @xmath1-decay can be improved from @xmath18 at the lep to @xmath19 at the gigaz@xcite . in light of this , the @xmath1-boson properties , especially its exotic or rare decays which are widely believed to be sensitive to new physics , should be investigated comprehensively to evaluate their potential in probing new physics . among the rare @xmath1-decays , the flavor changing ( fc ) processes were most extensively studied to explore the flavor texture in new physics @xcite , and it was found that , although these processes are severely suppressed in the sm , their branching ratios in new physics models can be greatly enhanced to @xmath19 for lepton flavor violation decays @xcite and @xmath20 for quark flavor violation decays @xcite . besides the fc processes , the @xmath1-decay into light higgs boson(s ) is another type of rare process that was widely studied , e.g. the decay @xmath21 ( @xmath22 ) with the particle @xmath0 denoting a light higgs boson was studied in @xcite , the decay @xmath23 was studied in the two higgs doublet model ( 2hdm)@xcite and the minimal supersymmetric standard model ( mssm)@xcite , and the decay @xmath4 was studied in a model independent way @xcite , in 2hdm@xcite and also in mssm@xcite . these studies indicate that , in contrast with the kinematic forbidden of these decays in the sm , the rates of these decays can be as large as @xmath18 in new physics models , which lie within the expected sensitivity of the gigaz . in this work , we extend the previous studies of these decays to some new models and investigate these decays altogether . we are motivated by some recent studies on the singlet extension of the mssm , such as the next - to - minimal supersymmetric standard model ( nmssm ) @xcite and the nearly minimal supersymmetric standard model ( nmssm ) @xcite , where a light cp - odd higgs boson @xmath0 with singlet - dominant component may naturally arise from the spontaneous breaking of some approximate global symmetry like @xmath24 or peccei - quuin symmetry @xcite . these non - minimal supersymmetric models can not only avoid the @xmath25-problem , but also alleviate the little hierarchy by having such a light higgs boson @xmath0 @xcite . we are also motivated by that , with the latest experiments , the properties of the light higgs boson are more stringently constrained than before . so it is worth updating the previous studies . so far there is no model - independent lower bound on the lightest higgs boson mass . in the sm , it must be heavier than @xmath26 gev , obtained from the null observation of the higgs boson at lep experiments . however , due to the more complex structure of the higgs sector in the extensions of the sm , this lower bound can be significantly relaxed according to recent studies , e.g. , for the cp - odd higgs boson @xmath0 we have @xmath27 gev in the nmssm @xcite , @xmath28 gev in the nmssm @xcite , and @xmath29 gev in the lepton - specific 2hdm ( l2hdm ) @xcite . with such a light cp - odd higgs boson , the z - decay into one or more @xmath0 is open up . noting that the decay @xmath30 is forbidden due to bose symmetry , we in this work study the rare @xmath1-decays @xmath6 ( @xmath22 ) , @xmath31 and @xmath4 in a comparative way for four models , namely the type - ii 2hdm@xcite , the l2hdm @xcite , the nmssm and the nmssm . in our study , we examine carefully the constraints on the light @xmath0 from many latest experimental results . this work is organized as follows . in sec . ii we briefly describe the four new physics models . in sec . iii we present the calculations of the rare @xmath1-decays . in sec . iv we list the constraints on the four new physics models . in sec . v we show the numerical results for the branching ratios of the rare @xmath1-decays in various models . finally , the conclusion is given in sec . as the most economical way , the sm utilizes one higgs doublet to break the electroweak symmetry . as a result , the sm predicts only one physical higgs boson with its properties totally determined by two free parameters . in new physics models , the higgs sector is usually extended by adding higgs doublets and/or singlets , and consequently , more physical higgs bosons are predicted along with more free parameters involved in . the general 2hdm contains two @xmath32 doublet higgs fields @xmath33 and @xmath34 , and with the assumption of cp - conserving , its scalar potential can be parameterized as@xcite : @xmath35,\end{aligned}\ ] ] where @xmath36 ( @xmath37 ) are free dimensionless parameters , and @xmath38 ( @xmath39 ) are the parameters with mass dimension . after the electroweak symmetry breaking , the spectrum of this higgs sector includes three massless goldstone modes , which become the longitudinal modes of @xmath40 and @xmath1 bosons , and five massive physical states : two cp - even higgs bosons @xmath41 and @xmath42 , one neutral cp - odd higgs particle @xmath0 and a pair of charged higgs bosons @xmath43 . noting the constraint @xmath44 with @xmath45 and @xmath46 denoting the vacuum expectation values ( vev ) of @xmath33 and @xmath34 respectively , we choose @xmath47 as the input parameters with @xmath48 , and @xmath49 being the mixing angle that diagonalizes the mass matrix of the cp - even higgs fields . the difference between the type - ii 2hdm and the l2hdm comes from the yukawa coupling of the higgs bosons to quark / lepton . in the type - ii 2hdm , one higgs doublet @xmath34 generates the masses of up - type quarks and the other doublet @xmath33 generates the masses of down - type quarks and charged leptons ; while in the l2hdm one higgs doublet @xmath33 couples only to leptons and the other doublet @xmath34 couples only to quarks . so the yukawa interactions of @xmath0 to fermions in these two models are given by @xcite @xmath50 with @xmath51 denoting generation index . obviously , in the type - ii 2hdm the @xmath52 coupling and the @xmath53 coupling can be simultaneously enhanced by @xmath54 , while in the l2hdm only the @xmath53 coupling is enhanced by @xmath55 . the structures of the nmssm and the nmssm are described by their superpotentials and corresponding soft - breaking terms , which are given by @xcite @xmath56 where @xmath57 is the superpotential of the mssm without the @xmath25 term , @xmath58 and @xmath59 are higgs doublet and singlet superfields with @xmath60 and @xmath61 being their scalar component respectively , @xmath62 , @xmath63 , @xmath64 , @xmath65 , @xmath66 and @xmath67 are soft breaking parameters , and @xmath68 and @xmath69 are coefficients of the higgs self interactions . with the superpotentials and the soft - breaking terms , one can get the higgs potentials of the nmssm and the nmssm respectively . like the 2hdm , the higgs bosons with same cp property will mix and the mass eigenstates are obtained by diagonalizing the corresponding mass matrices : @xmath70 where the fields on the right hands of the equations are component fields of @xmath71 , @xmath72 and @xmath61 defined by @xmath73 @xmath74 and @xmath75 are respectively the cp - even and cp - odd neutral higgs bosons , @xmath76 and @xmath77 are goldstone bosons eaten by @xmath1 and @xmath78 , and @xmath79 is the charged higgs boson . so both the nmssm and nmssm predict three cp - even higgs bosons , two cp - odd higgs bosons and one pair of charged higgs bosons . in general , the lighter cp - odd higgs @xmath0 in these model is the mixture of the singlet field @xmath80 and the doublet field combination , @xmath81 , i.e. @xmath82 and its couplings to down - type quarks are then proportional to @xmath83 . so for singlet dominated @xmath0 , @xmath84 is small and the couplings are suppressed . as a comparison , the interactions of @xmath0 with the squarks are given by@xcite @xmath85 i.e. the interaction does not vanish when @xmath86 approaches zero . just like the 2hdm where we use the vevs of the higgs fields as fundamental parameters , we choose @xmath68 , @xmath69 , @xmath87 , @xmath88 , @xmath66 and @xmath89 as input parameters for the nmssm@xcite and @xmath68 , @xmath54 , @xmath88 , @xmath65 , @xmath90 and @xmath91 as input parameters for the nmssm@xcite . about the nmssm and the nmssm , three points should be noted . the first is for the two models , there is no explicit @xmath92term , and the effective @xmath25 parameter ( @xmath93 ) is generated when the scalar component of @xmath59 develops a vev . the second is , the nmssm is actually same as the nmssm with @xmath94@xcite , because the tadpole terms @xmath95 and its soft breaking term @xmath96 in the nmssm do not induce any interactions , except for the tree - level higgs boson masses and the minimization conditions . and the last is despite of the similarities , the nmssm has its own peculiarity , which comes from its neutralino sector . in the basis @xmath97 , its neutralino mass matrix is given by @xcite @xmath98 where @xmath99 and @xmath100 are @xmath101 and @xmath102 gaugino masses respectively , @xmath103 , @xmath104 , @xmath105 and @xmath106 . after diagonalizing this matrix one can get the mass eigenstate of the lightest neutralino @xmath107 with mass taking the following form @xcite @xmath108 this expression implies that @xmath107 must be lighter than about @xmath109 gev for @xmath110 ( from lower bound on chargnio mass ) and @xmath111 ( perturbativity bound ) . like the other supersymmetric models , @xmath107 as the lightest sparticle acts as the dark matter in the universe , but due to its singlino - dominated nature , it is difficult to annihilate sufficiently to get the correct density in the current universe . so the relic density of @xmath107 plays a crucial way in selecting the model parameters . for example , as shown in @xcite , for @xmath112 , there is no way to get the correct relic density , and for the other cases , @xmath107 mainly annihilates by exchanging @xmath1 boson for @xmath113 , or by exchanging a light cp - odd higgs boson @xmath0 with mass satisfying the relation @xmath114 for @xmath115 . for the annihilation , @xmath54 and @xmath25 are required to be less than 10 and @xmath116 respectively because through eq.([mass - exp ] ) a large @xmath87 or @xmath25 will suppress @xmath117 to make the annihilation more difficult . the properties of the lightest cp - odd higgs boson @xmath0 , such as its mass and couplings , are also limited tightly since @xmath0 plays an important role in @xmath107 annihilation . the phenomenology of the nmssm is also rather special , and this was discussed in detail in @xcite . in the type - ii 2hdm , l2hdm , nmssm and nmssm , the rare @xmath1-decays @xmath118 ( @xmath22 ) , @xmath3 and @xmath4 may proceed by the feynman diagrams shown in fig.[fig1 ] , fig.[fig2 ] and fig.[fig3 ] respectively . for these diagrams , the intermediate state @xmath119 represents all possible cp - even higgs bosons in the corresponding model , i.e. @xmath41 and @xmath42 in type - ii 2hdm and l2hdm and @xmath41 , @xmath42 and @xmath120 in nmssm and nmssm . in order to take into account the possible resonance effects of @xmath119 in fig.[fig1](c ) for @xmath2 and fig.[fig3 ] ( a ) for @xmath11 , we have calculated all the decay modes of @xmath119 and properly included the width effect in its propagator . as to the decay @xmath121 , two points should be noted . one is , unlike the decays @xmath6 and @xmath11 , this process proceeds only through loops mediated by quarks / leptons in the type - ii 2hdm and l2hdm , and additionally by sparticles in the nmssm and nmssm . so in most cases its rate should be much smaller than the other two . the other is due to cp - invariance , loops mediated by squarks / sleptons give no contribution to the decay@xcite . in actual calculation , this is reflected by the fact that the coupling coefficient of @xmath122 differs from that of @xmath123 by a minus sign ( see eq.([asqsq ] ) ) , and as a result , the squark - mediated contributions to @xmath121 are completely canceled out . with regard to the rare decay @xmath11 , we have more explanations . in the lowest order , this decay proceeds by the diagram shown in fig.[fig3 ] ( a ) , and hence one may think that , as a rough estimate , it is enough to only consider the contributions from fig.[fig3](a ) . however , we note that in some cases of the type - ii 2hdm and l2hdm , due to the cancelation of the contributions from different @xmath119 in fig.[fig3 ] ( a ) and also due to the potentially largeness of @xmath124 couplings ( i.e. larger than the electroweak scale @xmath125 ) , the radiative correction from the higgs - mediated loops may dominate over the tree level contribution even when the tree level prediction of the rate , @xmath126 , exceeds @xmath20 . on the other hand , we find the contribution from quark / lepton - mediated loops can be safely neglected if @xmath127 in the type - ii 2hdm and the l2hdm . in the nmssm and the nmssm , besides the corrections from the higgs- and quark / lepton - mediated loops , loops involving sparticles such as squarks , charginos and neutralinos can also contribute to the decay . we numerically checked that the contributions from squarks and charginos can be safely neglected if @xmath127 . we also calculated part of potentially large neutralino correction ( note that there are totally about @xmath128 diagrams for such correction ! ) and found they can be neglected too . since considering all the radiative corrections will make our numerical calculation rather slow , we only include the most important correction , namely that from higgs - mediated loops , in presenting our results for the four models . one can intuitively understand the relative smallness of the sparticle contribution to @xmath11 as follows . first consider the squark contribution which is induced by the @xmath129 interaction ( @xmath130 denotes the squark in chirality state ) and the @xmath131 interaction through box diagrams . because the @xmath132 interaction conserves the chirality of the squarks while the @xmath133 interaction violates the chirality , to get non - zero contribution to @xmath11 from the squark loops , at least four chiral flippings are needed , with three of them provided by @xmath131 interaction and the rest provided by the left - right squark mixing . this means that , if one calculates the amplitude in the chirality basis with the mass insertion method , the amplitude is suppressed by the mixing factor @xmath134 with @xmath135 being the off diagonal element in squark mass matrix . next consider the chargino / neutralino contributions . since for a light @xmath0 , its doublet component , parameterized by @xmath84 in eq.([mixing ] ) , is usually small , the couplings of @xmath0 with the sparticles will never be tremendously large@xcite . so the chargino / neutralino contributions are not important too . in our calculation of the decays , we work in the mass eigenstates of sparticles instead of in the chirality basis . for the type - ii 2hdm and the l2hdm , we consider the following constraints @xcite : * theoretical constraints on @xmath136 from perturbativity , unitarity and requirements that the scalar potential is finit at large field values and contains no flat directions @xcite , which imply that @xmath137 * the constraints from the lep search for neutral higgs bosons . we compute the signals from the higgs - strahlung production @xmath138 ( @xmath139 ) with @xmath140 @xcite and from the associated production @xmath141 with @xmath142 @xcite , and compare them with the corresponding lep data which have been inputted into our code . we also consider the constraints from @xmath138 by looking for a peak of @xmath143 recoil mass distribution of @xmath1-boson @xcite and the constraint of @xmath144 mev when @xmath145 @xcite . + these constraints limit the quantities such as @xmath146 \times br ( h_i \to \bar{b } b ) $ ] on the @xmath147 plane with the the subscript @xmath148 denoting the coupling coefficient of the @xmath149 interaction . they also impose a model - dependent lower bound on @xmath150 , e.g. , @xmath151 for the type - ii 2hdm ( from our scan results ) , @xmath152 for the l2hdm@xcite , and @xmath153 for the nmssm @xcite . these bounds are significantly lower than that of the sm , i.e. @xmath154 , partially because in new physics models , unconventional decay modes of @xmath155 such as @xmath156 are open up . as to the nmssm , another specific reason for allowing a significantly lighter cp - even higgs boson is that the boson may be singlet - dominated in this model . + with regard to the lightest cp - odd higgs boson @xmath0 , we checked that there is no lower bound on its mass so long as the @xmath157 interaction is weak or @xmath155 is sufficiently heavy . * the constraints from the lep search for a light higgs boson via the yukawa process @xmath158 with @xmath22 and @xmath61 denoting a scalar @xcite . these constraints can limit the @xmath159 coupling versus @xmath160 in new physics models . * the constraints from the cleo - iii limit on @xmath161 and the latest babar limits on @xmath162 . these constraints will put very tight constraints on the @xmath163 coupling for @xmath164 . in our analysis , we use the results of fig.8 in the second paper of @xcite to excluded the unfavored points . * the constraints from @xmath165 couplings . since the higgs sector can give sizable higher order corrections to @xmath165 couplings , we calculate them to one loop level and require the corrected @xmath165 couplings to lie within the @xmath166 range of their fitted value . the sm predictions for the couplings at @xmath1-pole are given by @xmath167 and @xmath168 @xcite , and the fitted values are given by @xmath169 and @xmath170 , respectively@xcite . we adopt the formula in @xcite to the 2hdm in our calculation . * the constraints from @xmath171 leptonic decay . we require the new physics correction to the branching ratio @xmath172 to be in the range of @xmath173 @xcite . we use the formula in @xcite in our calculation . + about the constraints ( 5 ) and ( 6 ) , two points should be noted . one is all higgs bosons are involved in the constraints by entering the self energy of @xmath171 lepton , the @xmath174 vertex correction or the @xmath175 vertex correction , and also the box diagrams for @xmath176@xcite . since the yukawa couplings of the higgs bosons to @xmath171 lepton get enhanced by @xmath54 and so do the corrections , @xmath54 must be upper bounded for given spectrum of the higgs sector . generally speaking , the lighter @xmath0 is , the more tightly @xmath54 is limited@xcite . the other point is in the type - ii 2hdm , @xmath177 , b - physics observables as well as @xmath178 decays discussed above can constraint the model in a tighter way than the constraints ( 5 ) and ( 6 ) since the yukawa couplings of @xmath171 lepton and @xmath179 quark are simultaneously enhanced by @xmath54 . but for the l2hdm , because only the yukawa couplings of @xmath171 lepton get enhanced ( see eq.[yukawa ] ) , the constraints ( 5 ) and ( 6 ) are more important in limiting @xmath54 . * indirect constraints from the precision electroweak observables such as @xmath180 , @xmath181 and @xmath182 , or their combinations @xmath183 @xcite . we require @xmath184 to be compatible with the lep / sld data at @xmath185 confidence level@xcite . we also require new physics prediction of @xmath186 is within the @xmath187 range of its experimental value . the latest results for @xmath188 are @xmath189 ( measured value ) and @xmath190 ( sm prediction ) for @xmath191 gev @xcite . in our code , we adopt the formula for these observables presented in @xcite to the type - ii 2hdm and the l2hdm respectively . + in calculating @xmath180 , @xmath181 and @xmath182 , we note that these observables get dominant contributions from the self energies of the gauge bosons @xmath1 , @xmath192 and @xmath193 . since there is no @xmath194 coupling or @xmath195 coupling , @xmath0 must be associated with the other higgs bosons to contribute to the self energies . so by the uv convergence of these quantities , one can infer that , for the case of a light @xmath0 and @xmath196 , these quantities depend on the spectrum of the higgs sector in a way like @xmath197 at leading order , which implies that a light @xmath0 can still survive the constraints from the precision electroweak observables given the splitting between @xmath150 and @xmath198 is moderate@xcite . * the constraints from b physics observables such as the branching ratios for @xmath199 , @xmath200 and @xmath201 , and the mass differences @xmath202 and @xmath203 . we require their theoretical predications to agree with the corresponding experimental values at @xmath187 level . + in the type - ii 2hdm and the l2hdm , only the charged higgs boson contributes to these observables by loops , so one can expect that @xmath198 versus @xmath54 is to be limited . combined analysis of the limits in the type - ii 2hdm has been done by the ckmfitter group , and the lower bound of @xmath204 as a function of @xmath87 was given in fig.11 of @xcite . this analysis indicates that @xmath198 must be heavier than @xmath205 at @xmath185 c.l . regardless the value of @xmath54 . in this work , we use the results of fig.11 in @xcite to exclude the unfavored points . as for the l2hdm , b physics actually can not put any constraints@xcite because in this model the couplings of the charged higgs boson to quarks are proportional to @xmath206 and in the case of large @xmath54 which we are interested in , they are suppressed . in our analysis of the l2hdm , we impose the lep bound on @xmath198 , i.e. @xmath207@xcite . * the constraints from the muon anomalous magnetic moment @xmath208 . now both the theoretical prediction and the experimental measured value of @xmath208 have reached a remarkable precision , but a significant deviation still exists : @xmath209 @xcite . in the 2hdm , @xmath208 gets additional contributions from the one - loop diagrams induced by the higgs bosons and also from the two - loop barr - zee diagrams mediated by @xmath0 and @xmath155@xcite . if the higgs bosons are much heavier than @xmath25 lepton mass , the contributions from the barr - zee diagrams are more important , and to efficiently alleviate the discrepancy of @xmath208 , one needs a light @xmath0 along with its enhanced couplings to @xmath25 lepton and also to heavy fermions such as bottom quark and @xmath171 lepton to push up the effects of the barr - zee diagram@xcite . the cp - even higgs bosons are usually preferred to be heavy since their contributions to @xmath208 are negative . + in the type - ii 2hdm , because @xmath54 is tightly constrained by the process @xmath210 at the lep@xcite and the @xmath178 decay@xcite , the barr - zee diagram contribution is insufficient to enhance @xmath208 to @xmath187 range around its measured value@xcite . so in our analysis , we require the type - ii 2hdm to explain @xmath208 at @xmath211 level . while for the l2hdm , @xmath54 is less constrained compared with the type - ii 2hdm , and the barr - zee diagram involving the @xmath171-loop is capable to push up greatly the theoretical prediction of @xmath208@xcite . therefore , we require the l2hdm to explain the discrepancy at @xmath187 level . + unlike the other constraints discussed above , the @xmath208 constraint will put a two - sided bound on @xmath54 since on the one hand , it needs a large @xmath54 to enhance the barr - zee contribution , but on the other hand , too large @xmath54 will result in an unacceptable large @xmath208 . * since this paper concentrates on a light @xmath0 , the decay @xmath212 is open up with a possible large decay width . we require the width of any higgs boson to be smaller than its mass to avoid a too fat higgs boson@xcite . we checked that for the scenario characterized by @xmath213 , the coefficient of @xmath214 interaction is usually larger than the electroweak scale @xmath125 , and consequently a large decay width is resulted . for the nmssm and nmssm , the above constraints become more complicated because in these models , not only more higgs bosons are involved in , but also sparticles enter the constraints . so it is not easy to understand some of the constraints intuitively . take the process @xmath199 as an example . in the supersymmetric models , besides the charged higgs contribution , chargino loops , gluino loops as well as neutralino loops also contribute to the process@xcite , and depending on the susy parameters , any of these contributions may become dominated over or be canceled by other contributions . as a result , although the charged higgs affects the process in the same way as that in the type - ii 2hdm , charged higgs as light as @xmath215 is still allowed even for @xmath216@xcite . since among the constraints , @xmath208 is rather peculiar in that it needs new physics to explain the discrepancy between @xmath217 and @xmath218 , we discuss more about its dependence on susy parameters . in the nmssm and the nmssm , @xmath208 receives contributions from higgs loops and neutralino / chargino loops . for the higgs contribution , it is quite similar to that of the type - ii 2hdm except that more higgs bosons are involved in@xcite . for the neutralino / chargino contribution , in the light bino limit ( i.e. @xmath219 ) , it can be approximated by@xcite @xmath220 for @xmath221 with @xmath222 being smuon mass . so combining the two contributions together , one can learn that a light @xmath0 along with large @xmath54 and/or light smuon with moderate @xmath87 are favored to dilute the discrepancy . because more parameters are involved in the constraints on the supersymmetric models , we consider following additional constraints to further limit their parameters : * direct bounds on sparticle masses from the lep1 , the lep2 and the tevatron experiments @xcite . * the lep1 bound on invisible z decay @xmath223 ; the lep2 bound on neutralino production @xmath224 and @xmath225@xcite . * dark matter constraints from the wmap relic density 0.0975 @xmath226 0.1213 @xcite . note that among the above constraints , the constraint ( 2 ) on higgs sector and the constraint ( c ) on neutralino sector are very important . this is because in the supersymmetric models , the sm - like higgs is upper bounded by about @xmath227 at tree level and by about @xmath228 at loop level , and that the relic density restricts the lsp annihilation cross section in a certain narrow range . in our analysis of the nmssm , we calculate the constraints ( 3 ) and ( 5 - 7 ) by ourselves and utilize the code nmssmtools @xcite to implement the rest constraints . we also extend nmssmtools to the nmssm to implement the constraints . for the extension , the most difficult thing we faced is how to adapt the code micromegas@xcite to the nmssm case . we solve this problem by noting the following facts : * as we mentioned before , the nmssm is actually same as the nmssm with the trilinear singlet term setting to zero . so we can utilize the model file of the nmssm as the input of the micromegas and set @xmath229 . * since in the nmssm , the lsp is too light to annihilate into higgs pairs , there is no need to reconstruct the effective higgs potential to calculate precisely the annihilation channel @xmath230 with @xmath61 denoting any of higgs bosons@xcite . we thank the authors of the nmssmtools for helpful discussion on this issue when we finish such extension@xcite . with the above constraints , we perform four independent random scans over the parameter space of the type - ii 2hdm , the l2hdm , the nmssm and the nmssm respectively . we vary the parameters in following ranges : @xmath231 for the type - ii 2hdm , @xmath232 for the l2hdm , @xmath233 for the nmssm , and @xmath234 for the nmssm . in performing the scans , we note that for the nmssm and the nmssm , some constraints also rely on the gaugino masses and the soft breaking parameters in the squark sector and the slepton sector . since these parameters affect little on the properties of @xmath0 , we fix them to reduce the number of free parameters in our scan . for the squark sector , we adopt the @xmath235 scenario which assumes that the soft mass parameters for the third generation squarks are degenerate : @xmath236 800 gev , and that the trilinear couplings of the third generation squarks are also degenerate , @xmath237 with @xmath238 . for the slepton sector , we assume all the soft - breaking masses and trilinear parameters to be 100 gev . this setting is necessary for the nmssm since this model is difficult to explain the muon anomalous moment at @xmath239 level for heavy sleptons@xcite . finally , we assume the grand unification relation @xmath240 for the gaugino masses with @xmath241 being fine structure constants of the different gauge group . with large number of random points in the scans , we finally get about @xmath242 , @xmath243 , @xmath244 and @xmath242 samples for the type - ii 2hdm , the l2hdm , the nmssm and the nmssm respectively which survive the constraints and satisfy @xmath245 . analyzing the properties of the @xmath0 indicates that for most of the surviving points in the nmssm and the nmssm , its dominant component is the singlet field ( numerically speaking , @xmath246 ) so that its couplings to the sm fermions are suppressed@xcite . our analysis also indicates that the main decay products of @xmath0 are @xmath247 for the l2hdm@xcite , @xmath248 ( dominant ) and @xmath247 ( subdominant ) for the type - ii 2hdm , the nmssm and the nmssm , and in some rare cases , neutralino pairs in the nmssm@xcite . in fig.[fig4 ] , we project the surviving samples on the @xmath249 plane . this figure shows that the allowed range of @xmath54 is from @xmath250 to @xmath251 in the type - ii 2hdm , and from @xmath252 to @xmath253 in the l2hdm . just as we introduced before , the lower bounds of @xmath254 come from the fact that we require the models to explain the muon anomalous moment , while the upper bound is due to we have imposed the constraint from the lep process @xmath255 , which have limited the upper reach of the @xmath256 coupling for light @xmath61 @xcite(for the dependence of @xmath256 coupling on @xmath54 , see sec . this figure also indicates that for the nmssm and the nmssm , @xmath54 is upper bounded by @xmath257 . for the nmssm , this is because large @xmath87 can suppress the dark matter mass to make its annihilation difficult ( see @xcite and also sec . ii ) , but for the nmssm , this is because we choose a light slepton mass so that large @xmath54 can enhance @xmath208 too significantly to be experimentally unacceptable . we checked that for the slepton mass as heavy as @xmath258 , @xmath259 is still allowed for the nmssm . in fig.[fig5 ] and fig.[fig6 ] , we show the branching ratios of @xmath260 and @xmath261 respectively . fig.[fig5 ] indicates , among the four models , the type - ii 2hdm predicts the largest ratio for @xmath260 with its value varying from @xmath262 to @xmath263 . the underlying reason is in the type - ii 2hdm , the @xmath264 coupling is enhanced by @xmath54 ( see fig.[fig4 ] ) , while in the other three model , the coupling is suppressed either by @xmath265 or by the singlet component of the @xmath0 . fig.[fig6 ] shows that the l2hdm predicts the largest rate for @xmath266 with its value reaching @xmath5 in optimum case , and for the other three models , the ratio of @xmath261 is at least about one order smaller than that of @xmath267 . this feature can be easily understood from the @xmath268 coupling introduced in sect . we emphasize that , if the nature prefers a light @xmath0 , @xmath260 and/or @xmath269 in the type - ii 2hdm and the l2hdm will be observable at the gigaz . then by the rates of the two decays , one can determine whether the type - ii 2hdm or the l2hdm is the right theory . on the other hand , if both decays are observed with small rates or fail to be observed , the singlet extensions of the mssm are favored . in fig.[fig7 ] , we show the rate of @xmath3 as the function of @xmath270 . this figure indicates that the branching ratio of @xmath121 can reach @xmath271 , @xmath272 , @xmath273 and @xmath274 for the optimal cases of the type - ii 2hdm , the l2hdm , the nmssm and the nmssm respectively , which implies that the decay @xmath121 will never be observable at the gigaz if the studied model is chosen by nature . the reason for the smallness is , as we pointed out before , that the decay @xmath121 proceeds only at loop level . comparing the optimum cases of the type - ii 2hdm , the nmssm and the nmssm shown in fig.5 - 7 , one may find that the relation @xmath275 holds for any of the decays . this is because the decays are all induced by the yukawa couplings with similar structure for the models . in the supersymmetric models , the large singlet component of the light @xmath0 is to suppress the yukawa couplings , and the @xmath0 in the nmssm has more singlet component than that in the nmssm . next we consider the decay @xmath11 , which , unlike the above decays , depends on the higgs self interactions . in fig.[fig8 ] we plot its rate as a function of @xmath270 and this figure indicates that the @xmath276 may be the largest among the ratios of the exotic @xmath1 decays , reaching @xmath277 in the optimum cases of the type - ii 2hdm , the l2hdm and the nmssm . the underlying reason is , in some cases , the intermediate state @xmath119 in fig.[fig3 ] ( a ) may be on - shell . in fact , we find this is one of the main differences between the nmssm and the nmssm , that is , in the nmssm , @xmath119 in fig.[fig3 ] ( a ) may be on - shell ( corresponds to the points with large @xmath278 ) while in the nmssm , this seems impossible . so we conclude that the decay @xmath11 may serve as an alternative channel to test new physics models , especially it may be used to distinguish the nmssm from the nmssm if the supersymmetry is found at the lhc and the @xmath11 is observed at the gigaz with large rate . before we end our discussion , we note that in the nmssm , the higgs boson @xmath0 may be lighter than @xmath279 without conflicting with low energy data from @xmath178 decays and the other observables ( see fig.[fig4]-[fig8 ] ) . in this case , @xmath0 is axion - like as pointed out in @xcite . we checked that , among the rare @xmath1 decays discussed in this paper , the largest branching ratio comes from @xmath280 which can reach @xmath281 . since in this case , the decay product of @xmath0 is highly collinear muon pair , detecting the decay @xmath280 may need some knowledge about detectors , which is beyond our discussion . in this paper , we studied the rare @xmath1-decays @xmath2 ( @xmath7 ) , @xmath282 and @xmath4 in the type - ii 2hdm , lepton - specific 2hdm , nmssm and nmssm , which predict a light cp - odd higgs boson @xmath0 . in the parameter space allowed by current experiments , the branching ratio can be as large as @xmath5 for @xmath118 , @xmath8 for @xmath3 and @xmath9 for @xmath4 , which implies that the decays @xmath2 and @xmath283 may be accessible at the gigaz option . since different models predict different size of branching ratios , these decays can be used to distinguish different model through the measurement of these rare decays . this work was supported in part by hastit under grant no . 2009hastit004 , by the national natural science foundation of china ( nnsfc ) under grant nos . 10821504 , 10725526 , 10635030 , 10775039 , 11075045 and by the project of knowledge innovation program ( pkip ) of chinese academy of sciences under grant no . . for some reviews , see , e.g. , m. a. perez , g. tavares - velasco and j. j. toscano , int . j. mod . a * 19 * , 159 ( 2004 ) ; j. m. yang , arxiv:1006.2594 . j. i. illana , m. masip , 67 , 035004 ( 2003 ) ; j. cao , z. xiong , j. m. yang , 32 , 245 ( 2004 ) . d. atwood _ et al_. , 66 , 093005 ( 2002 ) . j. kalinowski , and s. pokorski , 219 , 116 ( 1989 ) ; a. djouadi , p. m. zerwas and j. zunft , 259 , 175 ( 1991 ) ; a. djouadi , j. kalinowski , and p. m. zerwas , z. phys . c * 54 * , 255 ( 1992 ) . m. krawczyk , _ et al . _ , 19 , 463 ( 2001 ) ; 8 , 495 ( 1999 ) . j. f. gunion , g. gamberini and s. f. novaes , 38 , 3481 ( 1988 ) ; thomas j. weiler and tzu - chiang yuan , 318 , 337 ( 1989 ) ; a. djouadi , _ et al . _ , 1 , 163 ( 1998)[hep - ph/9701342 ] . d. chang and w. y. keung , phys . lett . * 77 * , 3732 ( 1996 ) . e. keith and e. ma , 57 , 2017 ( 1998 ) ; m. a. perez , g. tavares - velasco and j. j. toscano , int . j. mod.phys . a * 19 * , 159 ( 2004 ) . f. larios , g. tavares - velasco and c. p. yuan , 64 , 055004 ( 2001 ) ; 66 , 075006 ( 2002 ) . a. djouadi , _ et al . _ , 10 , 27 ( 1999 ) [ hep - ph/9903229 ] . for a detailed introduction of the nmssm , see f. franke and h. fraas , int . j. mod . a * 12 * ( 1997 ) 479 ; for a recent review of the nmssm , see for example , u. ellwanger , c. hugonie , and a. m. teixeira , arxiv : 0910.1785 . see , e.g. , j. r. ellis , j. f. gunion , h. e. haber , l. roszkowski and f. zwirner , phys . rev . d * 39 * ( 1989 ) 844 ; m. drees , int . j. mod . phys . a * 4 * ( 1989 ) 3635 ; u. ellwanger , m. rausch de traubenberg and c. a. savoy , phys . b * 315 * ( 1993 ) 331 ; nucl . b * 492 * ( 1997 ) 21 ; d.j . miller , r. nevzorov , p.m. zerwas , 681 , 3 ( 2004 ) . c. panagiotakopoulos , k. tamvakis , 446 , 224 ( 1999 ) ; 469 , 145 ( 1999 ) ; c. panagiotakopoulos , a. pilaftsis , 63 , 055003 ( 2001 ) ; a. dedes , _ et al . _ , 63 , 055009 ( 2001 ) ; a. menon , _ et al . _ , 70 , 035005 ( 2004 ) ; v. barger , _ et al . _ , 630 , 85 ( 2005 ) . c. balazs , _ et al . _ , 0706 , 066 ( 2007 ) . b. a. dobrescu , k. t. matchev , 0009 , 031 ( 2000 ) ; a. arhrib , k. cheung , t. j. hou , k. w. song , hep - ph/0611211 ; 0703 , 073 ( 2007 ) ; x. g. he , j. tandean , and g. valencia , 98 , 081802 ( 2007 ) ; 0806 , 002 ( 2008 ) ; f. domingo _ et al_. , 0901 , 061 ( 2009 ) ; gudrun hiller , 70 , 034018 ( 2004 ) ; r. dermisek , and john f. gunion , 75 , 075019 ( 2007 ) ; 79 , 055014 ( 2009 ) ; 81 , 055001 ( 2010 ) ; r. dermisek , john f. gunion , and b. mcelrath , 76 , 051105 ( 2007 ) ; z. heng , _ et al_. , 77 , 095012 ( 2008 ) ; a. belyaev _ et al_. , 81 , 075021 ( 2010 ) ; d. das and u. ellwanger , arxiv:1007.1151 [ hep - ph ] . s. andreas , o. lebedev , s. ramos - sanchez and a. ringwald , arxiv:1005.3978 [ hep - ph ] . j. f. gunion , jhep * 0908 * , 032 ( 2009 ) ; r. dermisek and j. f. gunion , phys . rev . d * 81 * , 075003 ( 2010 ) . r. dermisek and j. f. gunion , phys . lett . * 95 * , 041801 ( 2005 ) ; phys . d * 73 * , 111701 ( 2006 ) . j. cao , h. e. logan , j. m. yang , 79 , 091701 ( 2009 ) . j. cao , p. wan , l. wu , j. m. yang , 80 , 071701 ( 2009 ) . j. f. gunion and h. e. haber , 67 , 075019 ( 2003 ) . r. m. barnett , _ et al . _ , phys . b * 136 * , 191 ( 1984 ) ; r. m. barnett , g. senjanovic and d. wyler , phys . d * 30 * , 1529 ( 1984 ) ; y. grossman , nucl . b * 426 * , 355 ( 1994 ) . h. s. goh , l. j. hall and p. kumar , jhep * 0905 * , 097 ( 2009 ) ; a. g. akeroyd and w. j. stirling , nucl . b * 447 * , 3 ( 1995 ) ; a. g. akeroyd , phys . b * 377 * , 95 ( 1996 ) ; h. e. logan and d. maclennan , phys . rev . d * 79 * , 115022 ( 2009 ) ; m. aoki , _ et al . _ , arxiv:0902.4665 [ hep - ph ] . v. barger , p. langacker , h. s. lee and g. shaughnessy , phys . d * 73 * , 115010 ( 2006 ) . s. hesselbach , _ et . _ , arxiv:0810.0511v2 [ hep - ph ] . de vivie and p. janot [ aleph collaboration ] , pa13 - 027 contribution to the international conference on high energy physics , warsaw , poland , 2531 july 1996 ; j. kurowska , o. grajek and p. zalewski [ delphi collaboration ] , cern - open-99 - 385 . [ aleph collaboration and delphi collaboration and l3 collaboration ] , phys . rept . * 427 * , 257 ( 2006 ) . j. cao and j. m. yang , jhep * 0812 * , 006 ( 2008 ) . m. krawczyk and d. temes , eur . j. c * 44 * , 435 ( 2005 ) . g. altarelli and r. barbieri , 253 , 161 ( 1991 ) ; m. e. peskin , t. takeuchi , 46 , 381 ( 1992 ) . c. amsler , _ et al . _ , ( particle data group ) , 667 , 1 ( 2008 ) . o. deschamps , s. descotes - genon , s. monteil , v. niess , s. tjampens and v. tisserand , arxiv:0907.5135 [ hep - ph ] . s. su and b. thomas , phys . d * 79 * , 095014 ( 2009 ) . g. abbiendi , _ et al . _ , eur . phys . j. c * 32 * , 453 ( 2004 ) . m. davier , _ et al . _ , 66 , 1 ( 2010 ) . k. cheung , _ et al . _ , phys . d * 64 * , 111301 ( 2001 ) . k. cheung and o. c. w. kong , phys . d * 68 * , 053003 ( 2003 ) . t. besmer , c. greub , t.hurth , 609 , 359 ( 2001 ) ; f. borzumati , _ et al . _ , 62 , 075005(2000 ) . j. cao , k. i. hikasa , w. wang , j. m. yang and l. x. yu , phys . d * 82 * , 051701 ( 2010 ) [ arxiv:1006.4811 [ hep - ph ] ] . j. f. gunion , _ et . d * 73 * , 015011 ( 2006 ) . martin and j. d. wells , phys . d * 64 * , 035003 ( 2001 ) . j. abdallah _ et al . _ , eur . j. c * 31 * , 421 ( 2004 ) ; g. abbiendi _ et al . _ , eur . j. c * 35 * , 1 ( 2004 ) . j. dunkley _ et al . _ [ wmap collaboration ] , astrophys . j. suppl . * 180 * , 306 ( 2009 ) [ arxiv:0803.0586 [ astro - ph ] ] . u. ellwanger _ et al . _ , 02 , 066 ( 2005 ) . g. belanger , f. boudjema , a. pukhov and a. semenov , comput . commun . * 174 * , 577 ( 2006 ) ; comput . phys . commun . * 176 * , 367 ( 2007 ) . g. belanger , f. boudjema , c. hugonie , a. pukhov and a. semenov , jcap * 0509 * , 001 ( 2005 ) ."""
+
+ ARTICLE_MAGNET = r"""it is well known that the classical magnetoresistance ( mr ) in metals or semiconductors with a closed free electron fermi surface increases quadratically with increasing magnetic field @xmath2 for @xmath3 and saturates when @xmath4 . here @xmath5 is the zero - magnetic - field mobility . hence , the extraordinarily high and linear mr ( lmr ) , which breaks this familiar rule , has been gaining much attention as soon as its discovery . in the past decade , this unexpected lmr has been reported in silver chalcogenide,@xcite indium antimonide,@xcite silicon,@xcite mnas - gaas composite material,@xcite and graphene.@xcite kapitza s linear law@xcite indicates that the metal shows a magnetoresistance linear in perpendicular magnetic field when it has an open fermi surface and a mean free path longer than the electronic larmor radius . recently , another two models , irrespective of the open fermi surface , have been constructed to provide possible mechanisms for the lmr phenomenon . abrikosov suggested a quantum - limit origin of lmr for the homogenous system with a gapless linear energy spectrum.@xcite his model requires that landau levels are well formed and the carrier concentration is small that all electrons occupy only the lowest landau band . alternatively , parish and littlewood developed a classical model without involving linear spectrum.@xcite ignoring the concrete microscopic mechanism , they attributed this unusual mr to the mobility fluctuations in a strongly inhomogenous system . topological insulators@xcite ( tis ) are novel materials with a full energy gap in bulk , while there are gapless surface states . due to its unique band structure with only one helical dirac cone and linear energy dispersion,@xcite the surface states of the ti bi@xmath0se@xmath1 become an excellent platform for the study of quantum - limit lmr . the recent experiment in this flat surface system , however , reported that a large positive mr , which becomes very linear above a characteristic field of @xmath6@xmath7@xmath8 t , was observed even in an opposite situation where the carrier sheet density is high that electrons occupy more than one landau levels.@xcite moreover , they found that raising temperature to room temperature almost has no influence on the observed lmr . it is striking that this observation is in conflict with abrikosov s model and also with the classical parish - littlewood model . so far a reliable theoretical scheme capable of explaining this novel experiment has still been lacking . in this paper , we generalize the balance - equation approach@xcite to a system modeling the surface states of a three - dimensional ti to investigate the two - dimensional magnetotransport in it . we find that a positive , nonsaturating and dominantly linear magnetoresistance can appear within quite wide magnetic - field range in the ti surface state having a positive and finite effective g - factor . this linear magnetoresistance shows up in the system of high carrier concentration and low mobility when electrons are in extended states and spread over many smeared landau levels , and persists up to room temperature , providing a possible mechanism for the recently observed linear magnetoresistance in topological insulator bi@xmath0se@xmath1 nanoribbons.@xcite we consider the surface state of a bi@xmath0se@xmath1-type large bulk gap ti in the @xmath9-@xmath10 plane under the influence of a uniform magnetic field @xmath11 applied along the @xmath12 direction.@xcite following the experimental observation,@xcite we assume that the fermi energy locates in the gap of the bulk band and above the dirac point , i.e. the surface carriers are electrons . further , the separations of the fermi energy from the bottom of bulk band and dirac point are much larger than the highest temperature ( @xmath13 ) considered in this work . hence , the contribution from the bulk band to the magnetotransport is negligible . these electrons , scattered by randomly distributed impurities and by phonons , are driven by a uniform in - plane electric field @xmath14 in the topological surface . the hamiltonian of this many - electron and phonon system consists of an electron part @xmath15 , a phonon part @xmath16 , and electron - impurity and electron - phonon interactions @xmath17 and @xmath18 : @xmath19 here , the electron hamiltonian is taken in the form @xmath20 , \ ] ] in which @xmath21 , @xmath22 , @xmath23 and @xmath24 , stand , respectively , for the canonical momentum , coordinate , momentum and spin operators of the @xmath25th electron having charge @xmath26 , @xmath27 is the vector potential of the perpendicular magnetic field @xmath28 in the landau gauge , @xmath29 is the fermi velocity , @xmath30 is the effective g - factor of the surface electron , and @xmath31 is the bohr magneton with @xmath32 the free electron mass . the sum index @xmath25 in eq.([helectron ] ) goes over all electrons of total number @xmath33 in the surface state of unit area . in the frame work of balance equation approach,@xcite the two - dimensional center - of - mass ( c.m . ) momentum and coordinate @xmath34 and @xmath35 , and the relative - electron momenta and coordinates @xmath36 and @xmath37 are introduced to write the hamiltonian @xmath15 into the sum of a single - particle c.m . part @xmath38 and a many - particle relative - electron part @xmath39 : @xmath40 , with @xmath41.\end{aligned}\ ] ] in this , @xmath42 is the canonical momentum of the center - of - mass and @xmath43 is the canonical momentum for the @xmath25th relative electron . here we have also introduced c.m . spin operators @xmath44 and @xmath45 . the commutation relations between the c.m . spin operators @xmath46 and @xmath47 and the spin operators @xmath48 , @xmath49 and @xmath50 of the @xmath25th electron are of order of @xmath51 : @xmath52= n^{-1}2\,{\rm i}\,\varepsi lon_{\beta_1\beta_2\beta_3}\sigma_j^{\beta_3}$ ] with @xmath53 . therefore , for a macroscopic large @xmath33 system , the c.m . part @xmath38 actually commutes with the relative - electron part @xmath54 in the hamiltonian , i.e. the c.m . motion and the relative motion of electrons are truly separated from each other . the couplings between the two emerge only through the electron impurity and electron phonon interactions . furthermore , the electric field @xmath55 shows up only in @xmath38 . and , in view of @xmath56={\rm i}\delta_{\alpha \beta}(\delta_{ij}-1/n)\simeq { \rm i}\delta_{\alpha\beta}\delta_{ij}$ ] , i.e. the relative - electron momenta and coordinates can be treated as canonical conjugate variables , the relative - motion part @xmath54 is just the hamiltonian of @xmath33 electrons in the surface state of ti in the magnetic field without the presence of the electric field . in terms of the c.m . coordinate @xmath57 and the relative electron density operator @xmath58 , the electron impurity and electron phonon interactions can be written as@xcite @xmath59 here @xmath60 and @xmath61 are respectively the impurity potential ( an impurity at randomly distributed position @xmath62 ) and electron phonon coupling matrix element in the plane - wave representation , and @xmath63 with @xmath64 and @xmath65 being the creation and annihilation operators for a phonon of wavevector @xmath66 in branch @xmath67 having frequency @xmath68 . velocity ( operator ) @xmath69 is the time variation of its coordinate : @xmath70= v_{\rm f}(\sigma_{\rm c}^y\ , \hat{i}-\sigma_{\rm c}^x\ , \hat{j})$ ] . to derive a force - balance equation for steady state transport we consider the heisenberg equation for the rate of change of the c.m . canonical momentum @xmath71 : @xmath72= - n e({\bm v}\times { \bm b})- n e{\bm e}+{\bm { f}}_{\rm i}+{\bm { f}}_{\rm p},\ ] ] in which the frictional forces @xmath73 and @xmath74 share the same expressions as given in ref .. the statistical average of the operator equation can be determined to linear order in the electron impurity and electron phonon interactions @xmath17 and @xmath18 with the initial density matrix @xmath75 at temperature @xmath76 when the in - plane electric field @xmath77 is not strong . for steady - transport states we have @xmath78 , leading to a force - balance equation of the form @xmath79 here @xmath80 , the statistically averaged velocity of the moving center - of - mass , is identified as the average rate of change of its position , i.e. the drift velocity of the electron system driven by the electric field @xmath77 , and @xmath81 and @xmath82 are frictional forces experienced by the center - of - mass due to impurity and phonon scatterings : @xmath83,\label{fp}\end{aligned}\ ] ] in which @xmath84 is the bose distribution function , @xmath85 , and @xmath86 stands for the imaginary part of the fourier spectrum of the relative - electron density correlation function defined by @xmath87\big\rangle_{0},\ ] ] where @xmath88 and @xmath89 denotes the statistical averaging over the initial density matrix @xmath90.@xcite the force - balance equation describes the steady - state two - dimensional magnetotransport in the surface state of a ti . note that the frictional forces @xmath81 and @xmath82 are in the opposite direction of the drift velocity @xmath91 and their magnitudes are functions of @xmath92 only . with the drift velocity @xmath93 in the @xmath9 direction , the force - balance equation eq . yields a transverse resistivity @xmath94 , and a longitudinal resistivity @xmath95 . the linear one is in the form @xmath96 for calculating the electron density correlation function @xmath97 we proceed in the landau representation.@xcite the landau levels of the single - particle hamiltonian @xmath98 of the relative - electron system in the absence of electric field are composed of a positive `` @xmath99 '' and a negative `` @xmath100 '' branch@xcite @xmath101 with @xmath102 and @xmath103 , and a zero ( @xmath104 ) level @xmath105 the corresponding landau wave functions are @xmath106 and @xmath107 for @xmath108 ; and @xmath109 for @xmath104 . here @xmath110 is the wavevector of the system along @xmath9 direction ; @xmath111 with @xmath112 ; and @xmath113 is the harmonic oscillator eigenfunction with @xmath114 being the hermite polynomial , @xmath115 , and @xmath116 . each landau level contains @xmath117 electron states for system of unit surface area . the positive branch @xmath118 and the @xmath104 level @xmath119 of the above energy spectra are indeed quite close to those of the surface states in the bulk gap of bi@xmath0se@xmath1-family materials derived from microscopic band calculation.@xcite the landau levels are broadened due to impurity , phonon and electron - electron scatterings . we model the imaginary part of the retarded green s function , or the density - of - states , of the broadened landau level @xmath120 ( written for `` + ' ' -branch and @xmath104 levels ) , using a gaussian - type form:@xcite @xmath121,\ ] ] with a half - width @xmath122 of the form:@xcite @xmath123^{1/2}$ ] . here @xmath124 is the single - particle lifetime and @xmath125 is the cyclotron frequency of linear - energy - dispersion system with @xmath126 being the zero - temperature fermi level . using a semi - empirical parameter @xmath127 to relate @xmath124 with the transport scattering time @xmath128 , and expressing @xmath129 with the zero - field mobility @xmath5 at finite temperature,@xcite we can write the landau - level broadening as @xmath130^{1/2}.\ ] ] in the present study we consider the case of @xmath120-doping , i.e. the fermi level is high enough above the energy zero of the dirac cone in the range of `` + ' ' -branch levels and the states of `` @xmath100''-branch levels are completely filled , that they are irrelevant to electron transport . special attention has to be paid to the @xmath104 level , since , depending on the direction of exchange potential the effective g - factor of a ti surface state , @xmath30 , can be positive , zero or negative.@xcite the sign and magnitude of the effective g - factor determines how many states of the zero level should be included in or excluded from the available states for electron occupation in the case of @xmath120-doping at a magnetic field . ( i ) if @xmath131 , the @xmath104 level center is exactly at @xmath132 and the system is electron - hole symmetric . the total number of negative energy states ( including the states of the lower half of the @xmath104 level and states of the @xmath100"-branch levels ) and that of positive energy states ( including the states of the upper half of the @xmath104 level and states of the @xmath99"-branch levels ) do not change when changing magnetic field . therefore , the lower - half negative energy states of this level are always filled and the upper - half positive - energy states of it are available for the occupation of particles which are counted as electrons participating in transport in the case of @xmath120-doping . ( ii ) for a finite positive @xmath133 , the @xmath104 level @xmath134 moves downward to negative energy and its distance to the nearest @xmath100"-branch level is @xmath135 closer than to the nearest + " -branch level at finite magnetic field strength @xmath2 . this is equivalent to the opening of an increasingly enlarged ( with increasing @xmath2 ) energy gap between the + " -branch states and the states of the zero - level and the @xmath100"-branch levels . the opening of a sufficient energy gap implies that with increasing magnetic field the states in the + " -branch levels would no longer shrink into the zero - level , and thus the @xmath104 level should be completely excluded from the conduction band , i.e. only particles occupying the + " -branch states are counted as electrons participating in transport in the case of @xmath120-doping , when the magnetic field @xmath2 gets larger than a certain value ( depending on the magnitude of @xmath30 ) . ( iii ) for a finite negative @xmath136 , the @xmath104 level @xmath134 moves upward to positive energy and an increasingly enlarged energy gap will be opened between the states of the zero - level and the + " -branch and the states of @xmath100"-branch levels , and particles occupying the @xmath104 level and + " -branch states are electrons participating in transport when the magnetic field @xmath2 gets larger than a certain value . as a result , the experimentally accessible sheet density @xmath33 of electrons participating in transport is related to the fermi energy @xmath137 by the following equation valid at finite @xmath30 for the magnetic field @xmath2 larger than a certain value : @xmath138 in which @xmath139 + 1\}^{-1}$ ] is the fermi distribution function at temperature @xmath76 and the summation index @xmath120 goes over @xmath140 for @xmath133 , or @xmath141 for @xmath136 . in the case of @xmath131 , @xmath142\ ] ] valid for arbitrary magnetic field , in which @xmath143 . the imaginary part of relative - electron density correlation function in the presence of a magnetic field , @xmath86 , can be expressed in the landau representation as@xcite @xmath144 in which the transform factor @xmath145 ^ 2,\end{aligned}\ ] ] with @xmath146 , @xmath147 , @xmath148 , and @xmath149 being associated laguerre polynomials . the landau - representation correlation function @xmath150 in eq.([piqw ] ) can be constructed with the imaginary part of the retarded green s function @xmath151 , or the density - of - states , of the @xmath120th landau level as@xcite @xmath152\nonumber\\ & \hspace{1.2cm}\times{\rm im}g_n(\epsilon+\omega){\rm im}g_{n'}(\epsilon).\end{aligned}\ ] ] the summation indices @xmath120 and @xmath153 in eq.([piqw ] ) are taken over @xmath140 for @xmath133 , or @xmath154 for @xmath136 . in the case of @xmath131 , eq.([piqw ] ) still works and the summation indices @xmath120 and @xmath153 go over @xmath154 but with @xmath155 replaced by @xmath156 in eq.([p2nn ] ) . numerical calculations are performed for the magnetoresistivity @xmath157 of surface state in a uniform ti bi@xmath0se@xmath1 . at zero temperature the elastic scattering contributing to the resistivity is modeled by a coulomb potential due to charged impurities:@xcite @xmath158 with @xmath159 being the impurity density , which is determined by the zero - magnetic - field mobility @xmath5 . at temperatures higher than @xmath160,@xcite phonon scatterings play increasingly important role and the dominant inelastic contribution comes from optical phonons . for this polar material , the scattering by optical phonons via the deformation potential can be neglected . hence , we take account of inelastic scattering from optical phonons via frhlich coupling : @xmath161 . in the numerical calculation we use the following parameters:@xcite fermi velocity @xmath162 , static dielectric constant @xmath163 , optical dielectric constant @xmath164 , and phonon energy @xmath165 . the broadening parameter is taken to be @xmath166 . as a function of the magnetic field @xmath2 having different effective g - factors : @xmath167 and @xmath168 for a ti surface system with electron sheet density @xmath169 in the cases of zero - magnetic - field mobility @xmath170 ( a ) and @xmath171 ( b ) . several integer - number positions of filling factor @xmath172 are marked in ( b).,scaledwidth=40.0% ] fig.[diffg ] shows the calculated magnetoresistivity @xmath157 versus the magnetic field strength @xmath2 for a ti surface system with electron sheet density @xmath169 but having different effective g - factors : @xmath167 and @xmath168 for two values of zero - magnetic - field mobility @xmath170 and @xmath171 , representing different degree of landau - level broadening . in the case without zeeman splitting ( @xmath131 ) the resistivity @xmath157 exhibits almost no change with changing magnetic field up to 10 t , except the shubnikov - de haas ( sdh ) oscillation showing up in the case of @xmath171 . this kind of magnetoresistance behavior was indeed seen experimentally in the electron - hole symmetrical massless system of single - layer graphene.@xcite in the case of a positive g - factor , @xmath173 , the magnetoresistivity increases linearly with increasing magnetic field ; while for a negative g - factor , @xmath174 , the magnetoresistivity decreases linearly with increasing magnetic field . is shown as a function of the magnetic field @xmath2 for different values of zero - magnetic - field mobility : ( a ) @xmath175 , ( b ) @xmath176 , ( c ) @xmath177 , ( d ) @xmath178 , ( e ) @xmath179 , and ( f ) @xmath180 . the inset of ( a ) illustrates the same for a larger magnetic - field range @xmath181 . the filling factor @xmath182 is plotted versus the magnetic field in ( f ) ; and several integer - number positions of @xmath182 are also marked in ( d ) and ( e ) . here the surface electron density @xmath169 and the lattice temperature @xmath183.,scaledwidth=47.0% ] in the following we will give more detailed examination on the linearly increasing magnetoresistance in the positive @xmath30 case . fig.[rhob ] shows the calculated resistivity @xmath157 versus the magnetic field strength @xmath2 at lattice temperature @xmath183 for system of carrier sheet density @xmath169 and @xmath173 , having different zero - field mobility @xmath184 and @xmath180 . all resistivity curves for mobility @xmath185 exhibit clear linearity in the magnetic - field range and appear no tendency of saturation at the highest field shown in the figure . especially , for the case @xmath170 , the linear behavior extends even up to the magnetic field of @xmath186 , as illustrated in the inset of fig.[rhob](a ) . this feature contradicts the classical mr which saturates at sufficiently large magnetic field @xmath187 . note that here we only present the calculated @xmath157 for magnetic field @xmath2 larger than @xmath188 t , for which a sufficient energy gap @xmath135 is assumed to open that with further increase of the magnetic field the states in the `` + ' ' -branch levels no longer shrink into the zero level and thus it should be excluded from the conduction band . this is of course not true for very weak magnetic field . when @xmath189 the energy gap @xmath190 , the situation becomes similar to the case of @xmath131 : the whole upper half of the zero - level states are available to electron occupation and we should have a flat resistivity @xmath157 when changing magnetic field . with increasing @xmath2 the portion of the zero - level states available to conduction electrons decreases until the magnetic field reaches @xmath191 . as a result the resistivity @xmath157 should exhibit a crossover from a flat changing at small @xmath2 to positively linear increasing at @xmath192 . this is just the behavior observed in the ti bi@xmath0se@xmath1.@xcite note that in the case of @xmath170 , the broadened landau - level widths are always larger than the neighboring level interval : @xmath193 , which requires @xmath194 ^ 2 $ ] , even for the lowest landau level @xmath195 , i.e. the whole landau - level spectrum is smeared . with increasing the zero - field mobility the magnitude of resistivity @xmath157 decreases , and when the broadened landau - level width becomes smaller than the neighboring level interval , @xmath196 , a weak sdh oscillation begin to occur around the linearly - dependent average value of @xmath157 at higher portion of the magnetic field range , as seen in fig.[rhob](c ) , ( d ) and ( e ) for @xmath197 and @xmath198 . on the other hand , in the case of large mobility , e.g. @xmath199 , where the broadened landau - level widths @xmath200 are much smaller than the neighboring level interval even for level index @xmath120 as large as @xmath201 , the magnetoresistivity shows pronounced sdh oscillation and the linear - dependent behavior disappears , before the appearance of quantum hall effect,@xcite as shown in fig.[rhob](f ) . abrikosov s model for the lmr requires the applied magnetic field large enough to reach the quantum limit at which all the carriers are within the lowest landau level,@xcite while it is obvious that more than one landau levels are occupied in the experimental samples in the field range in which the linear and non - saturating magnetoresistivity was observed.@xcite for the given electron surface density @xmath202 , the number of occupied landau levels , or the filling factor @xmath172 , at different magnetic fields is shown in fig.[rhob](f ) , as well as in the fig.[rhob](d ) and ( e ) , where the integer - number positions of @xmath203 , i.e. filling up to entire @xmath182 landau levels , coincide with the minima of the density - of - states or the dips of sdh oscillation . this is in contrast with @xmath131 case , where the integer number of @xmath203 , which implies a filling up to the center position of the @xmath182th landau levels , locates at a peak of sdh oscillation , as shown in fig.[diffg]b . the observed sdh oscillations in the bi@xmath0se@xmath1 nanoribbon exhibiting nonsaturating surface lmr in the experiment@xcite favor the former case : a finite positive effective @xmath133 . is plotted as a function of the surface electron density @xmath33 at magnetic field @xmath204 : ( a ) at different values of zero - field mobility @xmath5 , and ( b ) at different values of zero - field conductivity @xmath205.,scaledwidth=40.0% ] at various lattice temperatures . here the zero - magnetic - field mobility at zero temperature is @xmath206.,scaledwidth=35.0% ] next , we examine the density - dependence of the linear magnetoresistivity . to compare with abrikosov s quantum magnetoresistance which suggests a @xmath207 behavior,@xcite we show the calculated @xmath208 for above lmr versus the carrier sheet density @xmath33 in fig.[rhon ] at fixed magnetic field @xmath209 t . the mobility is taken respectively to be @xmath210 and @xmath211m@xmath212/vs to make the resistivity in the lmr regime . a clearly linear dependence of @xmath213 on the surface density @xmath33 is seen in all cases , indicating that this non - saturating linear resistivity is almost inversely proportional to the carrier density . in the figure we also show @xmath208 versus @xmath33 under the condition of different given conductivity @xmath214 and @xmath215 . in this case the half - width @xmath216 is independent of surface density . the linear dependence still holds , indicating that this linear behavior is not sensitive to the modest @xmath33-dependence of landau level broadening @xmath216 as long as the system is in the overlapped landau level regime . from the above discussion , it is obvious that lmr shows up in the system having overlapped landau levels and the separation of landau levels makes the mr departure from the linear increase . at high temperature , the thermal energy would smear the level separation and phonon scatterings further broaden landau levels . hence , it is believed that this lmr will be robust against raising temperature . this is indeed the case as seen in fig.[rhot ] , where we plot the calculated magnetoresistivity @xmath157 for the above system with zero - temperature linear mobility @xmath217m@xmath212/vs versus the magnetic field at different lattice temperatures . we can see that raising temperature to room temperature has little effect on the linearity of mr . due to the decreased mobility at higher temperature from phonon scattering , the weak sdh oscillation on the linear background tends to vanish . these features are in good agreement with the experimental report.@xcite in summary , we have studied the two - dimensional magnetotransport in the flat surface of a three - dimensional ti , which arises from the surface states with a wavevector - linear energy dispersion and a finite , positive zeeman splitting within the bulk energy gap . when the level broadening is comparable to or larger than the landau - level separation and the conduction electrons spread over many landau levels , a positive , dominantly linear and non - saturating magnetoresistance appears within a quite wide range of magnetic field and persists up to room temperature . this remarkable lmr provides a possible mechanism for the recently observed linear magnetoresistance in topological insulator bi@xmath0se@xmath1 nanoribbons.@xcite in contrast to quantum hall effect which appears in the case of well formed landau levels and to abrikosov s quantum magnetotransport,@xcite which is limited to the extreme quantum limit that all electrons coalesce into the lowest landau level , the discussed lmr is a phenomena of pure classical two - dimensional magnetotransport in a system having linear - energy - dispersion , appearing in the regime of overlapped landau levels , irrespective of its showing up in relatively high magnetic field range . furthermore , the present scheme deals with spatially uniform case without invoking the mobility fluctuation in a strongly inhomogeneous system , which is required in the classical parish and littlewood model to produce a lmr.@xcite the appearance of this significant positive - increasing linear magnetoresistance depends on the existence of a positive and sizable effective g - factor . if the zeeman energy splitting is quite small the resistivity @xmath157 would exhibit little change with changing magnetic field . in the case of a negative and sizable effective g - factor the magnetoresistivity would decrease linearly with increasing magnetic field . therefore , the behavior of the longitudinal resistivity versus magnetic field may provide a useful way for judging the direction and the size of the effective zeeman energy splitting in ti surface states . this work was supported by the national science foundation of china ( grant no . 11104002 ) , the national basic research program of china ( grant no . 2012cb927403 ) and by the program for science&technology innovation talents in universities of henan province ( grant no . 2012hastit029 ) ."""
+
+ inputs = tokenizer(
+ [ARTICLE_LEP, ARTICLE_MAGNET],
+ max_length=1024,
+ padding="max_length",
+ truncation=True,
+ return_tensors="pt",
+ )
+ inputs = {k: inputs[k].to(torch_device) for k in inputs}
+
+ hypotheses_batch = model.generate(**inputs)
+
+ EXPECTED_LEP = (
+ "we study the rare decays @xmath0 ( @xmath1 ) at the gigaz option of the international linear collider "
+ "( ilc ). we calculate the branching ratios of @xmath2 in the two higgs doublet model ( 2hdm ), the "
+ "minimal supersymmetric standard model ( mssm ), the next - to - minimal supersymmetric standard model "
+ "( nmssm ) and the nearly minimal supersymmetric standard model ( nmssm ). we find that the branching "
+ "ratios of @xmath3 can reach @xmath4 in 2hdm, @xmath5 in mssm, @xmath6 in nmssm and @xmath7 in nmssm, "
+ "while they are much smaller than @xmath8 in 2hdm, @xmath9 in mssm, @xmath10 in nmssm and @xmath11 in "
+ "nmssm."
+ )
+
+ EXPECTED_MAGNET = (
+ "we investigate the two - dimensional magnetotransport in the surface state of a topological insulator "
+ "( ti ). we find that a positive, nonsaturating and dominantly linear magnetoresistance can appear "
+ "within quite wide magnetic - field range in the ti surface state having a positive and finite effective g "
+ "- factor. this linear magnetoresistance shows up in the system of high carrier concentration and low "
+ "mobility when electrons are in extended states and spread over many smeared landau levels, and persists "
+ "up to room temperature, providing a possible mechanism for the recently observed linear magnetoresistance "
+ "in topological insulator bi@xmath0se@xmath1 nanoribbons."
+ )
+
+ generated = tokenizer.batch_decode(
+ hypotheses_batch.tolist(), clean_up_tokenization_spaces=True, skip_special_tokens=True
+ )
+
+ self.assertTrue(generated == [EXPECTED_LEP, EXPECTED_MAGNET])
+
+
+class BigBirdPegasusStandaloneDecoderModelTester:
+ def __init__(
+ self,
+ parent,
+ vocab_size=99,
+ batch_size=7,
+ d_model=32,
+ decoder_seq_length=7,
+ is_training=True,
+ is_decoder=True,
+ use_attention_mask=True,
+ use_cache=False,
+ use_labels=True,
+ decoder_start_token_id=2,
+ decoder_ffn_dim=32,
+ decoder_layers=2,
+ encoder_attention_heads=4,
+ decoder_attention_heads=4,
+ max_position_embeddings=50,
+ is_encoder_decoder=False,
+ pad_token_id=0,
+ bos_token_id=1,
+ eos_token_id=2,
+ scope=None,
+ attention_type="original_full",
+ use_bias=True,
+ block_size=16,
+ num_random_blocks=3,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.decoder_seq_length = decoder_seq_length
+ # For common tests
+ self.seq_length = self.decoder_seq_length
+ self.is_training = is_training
+ self.use_attention_mask = use_attention_mask
+ self.use_labels = use_labels
+
+ self.vocab_size = vocab_size
+ self.d_model = d_model
+ self.hidden_size = d_model
+ self.num_hidden_layers = decoder_layers
+ self.decoder_layers = decoder_layers
+ self.decoder_ffn_dim = decoder_ffn_dim
+ self.encoder_attention_heads = encoder_attention_heads
+ self.decoder_attention_heads = decoder_attention_heads
+ self.num_attention_heads = decoder_attention_heads
+ self.eos_token_id = eos_token_id
+ self.bos_token_id = bos_token_id
+ self.pad_token_id = pad_token_id
+ self.decoder_start_token_id = decoder_start_token_id
+ self.use_cache = use_cache
+ self.max_position_embeddings = max_position_embeddings
+ self.is_encoder_decoder = is_encoder_decoder
+
+ self.scope = None
+ self.decoder_key_length = decoder_seq_length
+ self.base_model_out_len = 2
+ self.decoder_attention_idx = 1
+
+ self.attention_type = attention_type
+ self.use_bias = use_bias
+ self.block_size = block_size
+ self.num_random_blocks = num_random_blocks
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
+
+ attention_mask = None
+ if self.use_attention_mask:
+ attention_mask = ids_tensor([self.batch_size, self.decoder_seq_length], vocab_size=2)
+
+ lm_labels = None
+ if self.use_labels:
+ lm_labels = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
+
+ config = BigBirdPegasusConfig(
+ vocab_size=self.vocab_size,
+ d_model=self.d_model,
+ decoder_layers=self.decoder_layers,
+ decoder_ffn_dim=self.decoder_ffn_dim,
+ encoder_attention_heads=self.encoder_attention_heads,
+ decoder_attention_heads=self.decoder_attention_heads,
+ eos_token_id=self.eos_token_id,
+ bos_token_id=self.bos_token_id,
+ use_cache=self.use_cache,
+ pad_token_id=self.pad_token_id,
+ decoder_start_token_id=self.decoder_start_token_id,
+ max_position_embeddings=self.max_position_embeddings,
+ is_encoder_decoder=self.is_encoder_decoder,
+ attention_type=self.attention_type,
+ use_bias=self.use_bias,
+ block_size=self.block_size,
+ num_random_blocks=self.num_random_blocks,
+ )
+
+ return (
+ config,
+ input_ids,
+ attention_mask,
+ lm_labels,
+ )
+
+ def create_and_check_decoder_model_past(
+ self,
+ config,
+ input_ids,
+ attention_mask,
+ lm_labels,
+ ):
+ config.use_cache = True
+ model = BigBirdPegasusDecoder(config=config).to(torch_device).eval()
+ # first forward pass
+ outputs = model(input_ids, use_cache=True)
+ outputs_use_cache_conf = model(input_ids)
+ outputs_no_past = model(input_ids, use_cache=False)
+
+ self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf))
+ self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1)
+
+ past_key_values = outputs["past_key_values"]
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+
+ output_from_no_past = model(next_input_ids)["last_hidden_state"]
+ output_from_past = model(next_tokens, past_key_values=past_key_values)["last_hidden_state"]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, next_input_ids.shape[-1] - 1, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ assert torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3)
+
+ def create_and_check_decoder_model_attention_mask_past(
+ self,
+ config,
+ input_ids,
+ attention_mask,
+ lm_labels,
+ ):
+ model = BigBirdPegasusDecoder(config=config).to(torch_device).eval()
+
+ # create attention mask
+ attn_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
+
+ half_seq_length = input_ids.shape[-1] // 2
+ attn_mask[:, half_seq_length:] = 0
+
+ # first forward pass
+ past_key_values = model(input_ids, attention_mask=attn_mask, use_cache=True)["past_key_values"]
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
+
+ # change a random masked slice from input_ids
+ random_seq_idx_to_change = ids_tensor((1,), half_seq_length).item() + 1
+ random_other_next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size).squeeze(-1)
+ input_ids[:, -random_seq_idx_to_change] = random_other_next_tokens
+
+ # append to next input_ids and attn_mask
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ attn_mask = torch.cat(
+ [attn_mask, torch.ones((attn_mask.shape[0], 1), dtype=torch.long, device=torch_device)],
+ dim=1,
+ )
+
+ # get two different outputs
+ output_from_no_past = model(next_input_ids)["last_hidden_state"]
+ output_from_past = model(next_tokens, past_key_values=past_key_values, use_cache=True)["last_hidden_state"]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, next_input_ids.shape[-1] - 1, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ # big bird has extremely high logits which requires
+ # such a high error tolerance here
+ assert torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=5e-1)
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, attention_mask, lm_labels = config_and_inputs
+
+ inputs_dict = {"input_ids": input_ids, "attention_mask": attention_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class BigBirdPegasusStandaloneDecoderModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
+ all_model_classes = (BigBirdPegasusDecoder, BigBirdPegasusForCausalLM) if is_torch_available() else ()
+ test_pruning = False
+ is_encoder_decoder = False
+
+ def setUp(
+ self,
+ ):
+ self.model_tester = BigBirdPegasusStandaloneDecoderModelTester(self, is_training=False)
+ self.config_tester = ConfigTester(self, config_class=BigBirdPegasusConfig)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_decoder_model_past(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_decoder_model_past(*config_and_inputs)
+
+ def test_decoder_model_attn_mask_past(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_decoder_model_attention_mask_past(*config_and_inputs)
+
+ @unittest.skip("Decoder cannot retain gradients")
+ def test_retain_grad_hidden_states_attentions(self):
+ return
diff --git a/transformers/tests/models/biogpt/__init__.py b/transformers/tests/models/biogpt/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/biogpt/test_modeling_biogpt.py b/transformers/tests/models/biogpt/test_modeling_biogpt.py
new file mode 100644
index 0000000000000000000000000000000000000000..232f7176b23c5b19a49eb12c3a29902cec3f6b03
--- /dev/null
+++ b/transformers/tests/models/biogpt/test_modeling_biogpt.py
@@ -0,0 +1,439 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch BioGPT model."""
+
+import math
+import unittest
+
+from transformers import BioGptConfig, is_sacremoses_available, is_torch_available
+from transformers.testing_utils import require_torch, slow, torch_device
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ BioGptForCausalLM,
+ BioGptForSequenceClassification,
+ BioGptForTokenClassification,
+ BioGptModel,
+ BioGptTokenizer,
+ )
+
+
+class BioGptModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=False,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ return BioGptConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = BioGptModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_biogpt_model_attention_mask_past(self, config, input_ids, input_mask, token_type_ids, *args):
+ model = BioGptModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # create attention mask
+ attn_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
+ half_seq_length = self.seq_length // 2
+ attn_mask[:, half_seq_length:] = 0
+
+ # first forward pass
+ output, past = model(input_ids, attention_mask=attn_mask).to_tuple()
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
+
+ # change a random masked slice from input_ids
+ random_seq_idx_to_change = ids_tensor((1,), half_seq_length).item() + 1
+ random_other_next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size).squeeze(-1)
+ input_ids[:, -random_seq_idx_to_change] = random_other_next_tokens
+
+ # append to next input_ids and attn_mask
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ attn_mask = torch.cat(
+ [attn_mask, torch.ones((attn_mask.shape[0], 1), dtype=torch.long, device=torch_device)],
+ dim=1,
+ )
+
+ # get two different outputs
+ output_from_no_past = model(next_input_ids, attention_mask=attn_mask)["last_hidden_state"]
+ output_from_past = model(next_tokens, past_key_values=past, attention_mask=attn_mask)["last_hidden_state"]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_biogpt_model_past_large_inputs(self, config, input_ids, input_mask, token_type_ids, *args):
+ model = BioGptModel(config=config).to(torch_device).eval()
+
+ attention_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
+
+ # first forward pass
+ outputs = model(input_ids, attention_mask=attention_mask, use_cache=True)
+
+ output, past_key_values = outputs.to_tuple()
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_attn_mask = ids_tensor((self.batch_size, 3), 2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([attention_mask, next_attn_mask], dim=-1)
+
+ output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)["last_hidden_state"]
+ output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)[
+ "last_hidden_state"
+ ]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_forward_and_backwards(
+ self, config, input_ids, input_mask, token_type_ids, *args, gradient_checkpointing=False
+ ):
+ model = BioGptForCausalLM(config)
+ model.to(torch_device)
+ if gradient_checkpointing:
+ model.gradient_checkpointing_enable()
+
+ result = model(input_ids, labels=input_ids)
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+ result.loss.backward()
+
+ def create_and_check_biogpt_weight_initialization(self, config, *args):
+ model = BioGptModel(config)
+ model_std = model.config.initializer_range / math.sqrt(2 * model.config.num_hidden_layers)
+ for key in model.state_dict().keys():
+ if "c_proj" in key and "weight" in key:
+ self.parent.assertLessEqual(abs(torch.std(model.state_dict()[key]) - model_std), 0.001)
+ self.parent.assertLessEqual(abs(torch.mean(model.state_dict()[key]) - 0.0), 0.01)
+
+ def create_and_check_biogpt_for_token_classification(self, config, input_ids, input_mask, token_type_ids, *args):
+ config.num_labels = self.num_labels
+ model = BioGptForTokenClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class BioGptModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (BioGptModel, BioGptForCausalLM, BioGptForSequenceClassification, BioGptForTokenClassification)
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": BioGptModel,
+ "text-classification": BioGptForSequenceClassification,
+ "text-generation": BioGptForCausalLM,
+ "token-classification": BioGptForTokenClassification,
+ "zero-shot": BioGptForSequenceClassification,
+ }
+ if is_torch_available() and is_sacremoses_available()
+ else {}
+ )
+ test_pruning = False
+
+ def setUp(self):
+ self.model_tester = BioGptModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=BioGptConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_various_embeddings(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["absolute", "relative_key", "relative_key_query"]:
+ config_and_inputs[0].position_embedding_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_biogpt_model_att_mask_past(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_biogpt_model_attention_mask_past(*config_and_inputs)
+
+ def test_biogpt_gradient_checkpointing(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_forward_and_backwards(*config_and_inputs, gradient_checkpointing=True)
+
+ def test_biogpt_model_past_with_large_inputs(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_biogpt_model_past_large_inputs(*config_and_inputs)
+
+ def test_biogpt_weight_initialization(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_biogpt_weight_initialization(*config_and_inputs)
+
+ def test_biogpt_token_classification_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_biogpt_for_token_classification(*config_and_inputs)
+
+ @slow
+ def test_batch_generation(self):
+ model = BioGptForCausalLM.from_pretrained("microsoft/biogpt")
+ model.to(torch_device)
+ tokenizer = BioGptTokenizer.from_pretrained("microsoft/biogpt")
+
+ tokenizer.padding_side = "left"
+
+ # Define PAD Token = EOS Token = 50256
+ tokenizer.pad_token = tokenizer.eos_token
+ model.config.pad_token_id = model.config.eos_token_id
+ model.generation_config.pad_token_id = model.generation_config.eos_token_id
+
+ # use different length sentences to test batching
+ sentences = [
+ "Hello, my dog is a little",
+ "Today, I",
+ ]
+
+ inputs = tokenizer(sentences, return_tensors="pt", padding=True)
+ input_ids = inputs["input_ids"].to(torch_device)
+
+ outputs = model.generate(
+ input_ids=input_ids,
+ attention_mask=inputs["attention_mask"].to(torch_device),
+ max_new_tokens=10,
+ )
+
+ inputs_non_padded = tokenizer(sentences[0], return_tensors="pt").input_ids.to(torch_device)
+ output_non_padded = model.generate(input_ids=inputs_non_padded, max_new_tokens=10)
+
+ num_paddings = inputs_non_padded.shape[-1] - inputs["attention_mask"][-1].long().sum().item()
+ inputs_padded = tokenizer(sentences[1], return_tensors="pt").input_ids.to(torch_device)
+ output_padded = model.generate(input_ids=inputs_padded, max_length=model.config.max_length - num_paddings)
+
+ batch_out_sentence = tokenizer.batch_decode(outputs, skip_special_tokens=True)
+ non_padded_sentence = tokenizer.decode(output_non_padded[0], skip_special_tokens=True)
+ padded_sentence = tokenizer.decode(output_padded[0], skip_special_tokens=True)
+
+ expected_output_sentence = [
+ "Hello, my dog is a little bit bigger than a little bit.",
+ "Today, I have a good idea of how to use the information",
+ ]
+ self.assertListEqual(expected_output_sentence, batch_out_sentence)
+ self.assertListEqual(expected_output_sentence, [non_padded_sentence, padded_sentence])
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "microsoft/biogpt"
+ model = BioGptModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ # Copied from tests.models.opt.test_modeling_opt.OPTModelTest.test_opt_sequence_classification_model with OPT->BioGpt,opt->biogpt,prepare_config_and_inputs->prepare_config_and_inputs_for_common
+ def test_biogpt_sequence_classification_model(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size)
+ model = BioGptForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ # Copied from tests.models.opt.test_modeling_opt.OPTModelTest.test_opt_sequence_classification_model_for_multi_label with OPT->BioGpt,opt->biogpt,prepare_config_and_inputs->prepare_config_and_inputs_for_common
+ def test_biogpt_sequence_classification_model_for_multi_label(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ config.problem_type = "multi_label_classification"
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor(
+ [self.model_tester.batch_size, config.num_labels], self.model_tester.type_sequence_label_size
+ ).to(torch.float)
+ model = BioGptForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+
+@require_torch
+class BioGptModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference_lm_head_model(self):
+ model = BioGptForCausalLM.from_pretrained("microsoft/biogpt")
+ input_ids = torch.tensor([[2, 4805, 9, 656, 21]])
+ output = model(input_ids)[0]
+
+ vocab_size = 42384
+
+ expected_shape = torch.Size((1, 5, vocab_size))
+ self.assertEqual(output.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[[-9.5236, -9.8918, 10.4557], [-11.0469, -9.6423, 8.1022], [-8.8664, -7.8826, 5.5325]]]
+ )
+
+ torch.testing.assert_close(output[:, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ @slow
+ def test_biogpt_generation_beam_search(self):
+ tokenizer = BioGptTokenizer.from_pretrained("microsoft/biogpt")
+ model = BioGptForCausalLM.from_pretrained("microsoft/biogpt")
+ model.to(torch_device)
+
+ torch.manual_seed(0)
+ tokenized = tokenizer("COVID-19 is", return_tensors="pt").to(torch_device)
+ output_ids = model.generate(
+ **tokenized,
+ min_length=100,
+ max_length=1024,
+ num_beams=5,
+ early_stopping=True,
+ )
+ output_str = tokenizer.decode(output_ids[0])
+
+ EXPECTED_OUTPUT_STR = (
+ ""
+ "COVID-19 is a global pandemic caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), the"
+ " causative agent of coronavirus disease 2019 (COVID-19), which has spread to more than 200 countries and"
+ " territories, including the United States (US), Canada, Australia, New Zealand, the United Kingdom (UK),"
+ " and the United States of America (USA), as of March 11, 2020, with more than 800,000 confirmed cases and"
+ " more than 800,000 deaths. "
+ ""
+ )
+ self.assertEqual(output_str, EXPECTED_OUTPUT_STR)
diff --git a/transformers/tests/models/biogpt/test_tokenization_biogpt.py b/transformers/tests/models/biogpt/test_tokenization_biogpt.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a219779827d1695f475917d8ded9d6f259bf371
--- /dev/null
+++ b/transformers/tests/models/biogpt/test_tokenization_biogpt.py
@@ -0,0 +1,99 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import os
+import unittest
+
+from transformers.models.biogpt.tokenization_biogpt import VOCAB_FILES_NAMES, BioGptTokenizer
+from transformers.testing_utils import require_sacremoses, slow
+
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+@require_sacremoses
+class BioGptTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "microsoft/biogpt"
+ tokenizer_class = BioGptTokenizer
+ test_rust_tokenizer = False
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ # Adapted from Sennrich et al. 2015 and https://github.com/rsennrich/subword-nmt
+ vocab = [
+ "l",
+ "o",
+ "w",
+ "e",
+ "r",
+ "s",
+ "t",
+ "i",
+ "d",
+ "n",
+ "w",
+ "r",
+ "t",
+ "lo",
+ "low",
+ "er",
+ "low",
+ "lowest",
+ "newer",
+ "wider",
+ "",
+ ]
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+ merges = ["l o 123", "lo w 1456", "e r 1789", ""]
+
+ cls.vocab_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ cls.merges_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["merges_file"])
+ with open(cls.vocab_file, "w") as fp:
+ fp.write(json.dumps(vocab_tokens))
+ with open(cls.merges_file, "w") as fp:
+ fp.write("\n".join(merges))
+
+ def get_input_output_texts(self, tokenizer):
+ input_text = "lower newer"
+ output_text = "lower newer"
+ return input_text, output_text
+
+ def test_full_tokenizer(self):
+ """Adapted from Sennrich et al. 2015 and https://github.com/rsennrich/subword-nmt"""
+ tokenizer = BioGptTokenizer(self.vocab_file, self.merges_file)
+
+ text = "lower"
+ bpe_tokens = ["low", "er"]
+ tokens = tokenizer.tokenize(text)
+ self.assertListEqual(tokens, bpe_tokens)
+
+ input_tokens = tokens + [""]
+ input_bpe_tokens = [14, 15, 20]
+ self.assertListEqual(tokenizer.convert_tokens_to_ids(input_tokens), input_bpe_tokens)
+
+ @slow
+ def test_sequence_builders(self):
+ tokenizer = BioGptTokenizer.from_pretrained("microsoft/biogpt")
+
+ text = tokenizer.encode("sequence builders", add_special_tokens=False)
+ text_2 = tokenizer.encode("multi-sequence build", add_special_tokens=False)
+
+ encoded_sentence = tokenizer.build_inputs_with_special_tokens(text)
+ encoded_pair = tokenizer.build_inputs_with_special_tokens(text, text_2)
+
+ self.assertTrue(encoded_sentence == [2] + text)
+ self.assertTrue(encoded_pair == [2] + text + [2] + text_2)
diff --git a/transformers/tests/models/bitnet/__init__.py b/transformers/tests/models/bitnet/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/bitnet/test_modeling_bitnet.py b/transformers/tests/models/bitnet/test_modeling_bitnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..5af4e4554322530f8f7a1ed5aa327f714b04e58c
--- /dev/null
+++ b/transformers/tests/models/bitnet/test_modeling_bitnet.py
@@ -0,0 +1,253 @@
+# Copyright 2025 The BitNet team and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch BitNet model."""
+
+import gc
+import unittest
+
+import pytest
+
+from transformers import AutoTokenizer, BitNetConfig, is_torch_available
+from transformers.testing_utils import (
+ backend_empty_cache,
+ require_flash_attn,
+ require_torch,
+ require_torch_gpu,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ BitNetForCausalLM,
+ BitNetModel,
+ )
+
+
+class BitNetModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ vocab_size=99,
+ hidden_size=64,
+ num_hidden_layers=5,
+ num_attention_heads=4,
+ num_key_value_heads=2,
+ intermediate_size=37,
+ hidden_act="gelu",
+ max_position_embeddings=512,
+ initializer_range=0.02,
+ pad_token_id=0,
+ bos_token_id=1,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.num_key_value_heads = num_key_value_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.max_position_embeddings = max_position_embeddings
+ self.initializer_range = initializer_range
+ self.pad_token_id = pad_token_id
+ self.bos_token_id = bos_token_id
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = torch.tril(torch.ones_like(input_ids).to(torch_device))
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask
+
+ def get_config(self):
+ return BitNetConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ num_key_value_heads=self.num_key_value_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ max_position_embeddings=self.max_position_embeddings,
+ initializer_range=self.initializer_range,
+ pad_token_id=self.pad_token_id,
+ bos_token_id=self.bos_token_id,
+ )
+
+ def create_and_check_model(self, config, input_ids, input_mask):
+ model = BitNetModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ input_mask,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class BitNetModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ BitNetModel,
+ BitNetForCausalLM,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": BitNetModel,
+ "text-generation": BitNetForCausalLM,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_headmasking = False
+ test_pruning = False
+ fx_compatible = False # Broken by attention refactor cc @Cyrilvallez
+
+ # TODO (ydshieh): Check this. See https://app.circleci.com/pipelines/github/huggingface/transformers/79245/workflows/9490ef58-79c2-410d-8f51-e3495156cf9c/jobs/1012146
+ def is_pipeline_test_to_skip(
+ self,
+ pipeline_test_case_name,
+ config_class,
+ model_architecture,
+ tokenizer_name,
+ image_processor_name,
+ feature_extractor_name,
+ processor_name,
+ ):
+ return True
+
+ def setUp(self):
+ self.model_tester = BitNetModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=BitNetConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_various_embeddings(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["absolute", "relative_key", "relative_key_query"]:
+ config_and_inputs[0].position_embedding_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_torch_fx_output_loss(self):
+ super().test_torch_fx_output_loss()
+
+ # Ignore copy
+ def test_past_key_values_format(self):
+ super().test_past_key_values_format()
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
+ self.skipTest(reason="BitNet flash attention does not support right padding")
+
+
+@require_torch
+class BitNetIntegrationTest(unittest.TestCase):
+ @slow
+ def test_model_logits(self):
+ input_ids = [128000, 128000, 1502, 25, 2650, 527, 499, 30, 128009, 72803, 25, 220]
+ model = BitNetForCausalLM.from_pretrained("microsoft/bitnet-b1.58-2B-4T")
+ input_ids = torch.tensor([input_ids]).to(model.model.embed_tokens.weight.device)
+ with torch.no_grad():
+ out = model(input_ids).logits.float().cpu()
+ # Expected mean on dim = -1
+ EXPECTED_MEAN = torch.tensor(
+ [
+ [
+ -1.8665,
+ -1.7681,
+ -1.7043,
+ 3.7446,
+ 2.7730,
+ 4.7133,
+ 0.9768,
+ -3.5018,
+ -12.2812,
+ -8.1477,
+ -10.2571,
+ -8.7610,
+ ]
+ ]
+ )
+ torch.testing.assert_close(out.mean(-1), EXPECTED_MEAN, rtol=1e-2, atol=1e-2)
+ # slicing logits[0, 0, 0:30]
+ EXPECTED_SLICE = torch.tensor([5.5815, 4.9154, 1.0478, 4.3869, 3.0112, 0.8235, 3.8412, 2.9233, 8.1140, 1.9406, 1.7973, 10.5025, 4.7796, 8.5926, 4.5196, 3.1549, 3.2656, 3.2588, 2.7356, 2.6032, 2.1454, 1.5683, 1.3465, 1.5329, 1.1886, 7.7902, 5.9326, 1.4737, 3.3319, 1.6291]) # fmt: skip
+ torch.testing.assert_close(out[0, 0, :30], EXPECTED_SLICE, rtol=1e-4, atol=1e-4)
+
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
+
+ @slow
+ def test_model_generation(self):
+ EXPECTED_TEXT_COMPLETION = """User: What is your favourite food?Assistant: As an AI, I don't have personal preferences or the ability to eat food. However, I"""
+ tokenizer = AutoTokenizer.from_pretrained("microsoft/bitnet-b1.58-2B-4T")
+ prompt = tokenizer.apply_chat_template(
+ [{"role": "user", "content": "What is your favourite food?"}], add_generation_prompt=True, tokenize=False
+ )
+ model = BitNetForCausalLM.from_pretrained(
+ "microsoft/bitnet-b1.58-2B-4T", device_map="auto", torch_dtype=torch.bfloat16
+ )
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.model.embed_tokens.weight.device)
+
+ # greedy generation outputs
+ generated_ids = model.generate(input_ids, max_new_tokens=20, do_sample=False)
+ text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
diff --git a/transformers/tests/models/blenderbot/__init__.py b/transformers/tests/models/blenderbot/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/blenderbot/test_modeling_blenderbot.py b/transformers/tests/models/blenderbot/test_modeling_blenderbot.py
new file mode 100644
index 0000000000000000000000000000000000000000..bec16cf5dc13984153351d9ff220c8e840a5f0e6
--- /dev/null
+++ b/transformers/tests/models/blenderbot/test_modeling_blenderbot.py
@@ -0,0 +1,560 @@
+# Copyright 2021, The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Blenderbot model."""
+
+import tempfile
+import unittest
+
+from transformers import BlenderbotConfig, is_torch_available
+from transformers.testing_utils import (
+ backend_empty_cache,
+ require_sentencepiece,
+ require_tokenizers,
+ require_torch,
+ require_torch_fp16,
+ slow,
+ torch_device,
+)
+from transformers.utils import cached_property
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import BlenderbotForConditionalGeneration, BlenderbotModel, BlenderbotTokenizer
+ from transformers.models.blenderbot.modeling_blenderbot import (
+ BlenderbotDecoder,
+ BlenderbotEncoder,
+ BlenderbotForCausalLM,
+ )
+
+
+def prepare_blenderbot_inputs_dict(
+ config,
+ input_ids,
+ decoder_input_ids,
+ attention_mask=None,
+ decoder_attention_mask=None,
+ head_mask=None,
+ decoder_head_mask=None,
+ cross_attn_head_mask=None,
+):
+ if attention_mask is None:
+ attention_mask = input_ids.ne(config.pad_token_id)
+ if decoder_attention_mask is None:
+ decoder_attention_mask = decoder_input_ids.ne(config.pad_token_id)
+ if head_mask is None:
+ head_mask = torch.ones(config.encoder_layers, config.encoder_attention_heads, device=torch_device)
+ if decoder_head_mask is None:
+ decoder_head_mask = torch.ones(config.decoder_layers, config.decoder_attention_heads, device=torch_device)
+ if cross_attn_head_mask is None:
+ cross_attn_head_mask = torch.ones(config.decoder_layers, config.decoder_attention_heads, device=torch_device)
+ return {
+ "input_ids": input_ids,
+ "decoder_input_ids": decoder_input_ids,
+ "attention_mask": attention_mask,
+ "decoder_attention_mask": attention_mask,
+ "head_mask": head_mask,
+ "decoder_head_mask": decoder_head_mask,
+ "cross_attn_head_mask": cross_attn_head_mask,
+ }
+
+
+class BlenderbotModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_labels=False,
+ vocab_size=99,
+ hidden_size=16,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=50,
+ eos_token_id=2,
+ pad_token_id=1,
+ bos_token_id=0,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.eos_token_id = eos_token_id
+ self.pad_token_id = pad_token_id
+ self.bos_token_id = bos_token_id
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size).clamp(
+ 3,
+ )
+ input_ids[:, -1] = self.eos_token_id # Eos Token
+
+ decoder_input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ config = self.get_config()
+ inputs_dict = prepare_blenderbot_inputs_dict(config, input_ids, decoder_input_ids)
+ return config, inputs_dict
+
+ def get_config(self):
+ return BlenderbotConfig(
+ vocab_size=self.vocab_size,
+ d_model=self.hidden_size,
+ encoder_layers=self.num_hidden_layers,
+ decoder_layers=self.num_hidden_layers,
+ encoder_attention_heads=self.num_attention_heads,
+ decoder_attention_heads=self.num_attention_heads,
+ encoder_ffn_dim=self.intermediate_size,
+ decoder_ffn_dim=self.intermediate_size,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ eos_token_id=self.eos_token_id,
+ bos_token_id=self.bos_token_id,
+ pad_token_id=self.pad_token_id,
+ )
+
+ def get_pipeline_config(self):
+ config = self.get_config()
+ config.max_position_embeddings = 100
+ config.vocab_size = 300
+ return config
+
+ def prepare_config_and_inputs_for_common(self):
+ config, inputs_dict = self.prepare_config_and_inputs()
+ return config, inputs_dict
+
+ def create_and_check_decoder_model_past_large_inputs(self, config, inputs_dict):
+ model = BlenderbotModel(config=config).get_decoder().to(torch_device).eval()
+ input_ids = inputs_dict["input_ids"]
+ attention_mask = inputs_dict["attention_mask"]
+ head_mask = inputs_dict["head_mask"]
+
+ # first forward pass
+ outputs = model(input_ids, attention_mask=attention_mask, head_mask=head_mask, use_cache=True)
+
+ output, past_key_values = outputs.to_tuple()
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_attn_mask = ids_tensor((self.batch_size, 3), 2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([attention_mask, next_attn_mask], dim=-1)
+
+ output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)["last_hidden_state"]
+ output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)[
+ "last_hidden_state"
+ ]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def check_encoder_decoder_model_standalone(self, config, inputs_dict):
+ model = BlenderbotModel(config=config).to(torch_device).eval()
+ outputs = model(**inputs_dict)
+
+ encoder_last_hidden_state = outputs.encoder_last_hidden_state
+ last_hidden_state = outputs.last_hidden_state
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ encoder = model.get_encoder()
+ encoder.save_pretrained(tmpdirname)
+ encoder = BlenderbotEncoder.from_pretrained(tmpdirname).to(torch_device)
+
+ encoder_last_hidden_state_2 = encoder(inputs_dict["input_ids"], attention_mask=inputs_dict["attention_mask"])[
+ 0
+ ]
+
+ self.parent.assertTrue((encoder_last_hidden_state_2 - encoder_last_hidden_state).abs().max().item() < 1e-3)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ decoder = model.get_decoder()
+ decoder.save_pretrained(tmpdirname)
+ decoder = BlenderbotDecoder.from_pretrained(tmpdirname).to(torch_device)
+
+ last_hidden_state_2 = decoder(
+ input_ids=inputs_dict["decoder_input_ids"],
+ attention_mask=inputs_dict["decoder_attention_mask"],
+ encoder_hidden_states=encoder_last_hidden_state,
+ encoder_attention_mask=inputs_dict["attention_mask"],
+ )[0]
+
+ self.parent.assertTrue((last_hidden_state_2 - last_hidden_state).abs().max().item() < 1e-3)
+
+
+@require_torch
+class BlenderbotModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (BlenderbotModel, BlenderbotForConditionalGeneration) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": BlenderbotModel,
+ "summarization": BlenderbotForConditionalGeneration,
+ "text-generation": BlenderbotForCausalLM,
+ "text2text-generation": BlenderbotForConditionalGeneration,
+ "translation": BlenderbotForConditionalGeneration,
+ }
+ if is_torch_available()
+ else {}
+ )
+ is_encoder_decoder = True
+ fx_compatible = True
+ test_pruning = False
+ test_missing_keys = False
+
+ def setUp(self):
+ self.model_tester = BlenderbotModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=BlenderbotConfig)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_save_load_strict(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs()
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
+ self.assertEqual(info["missing_keys"], [])
+
+ def test_decoder_model_past_with_large_inputs(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
+
+ def test_encoder_decoder_model_standalone(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
+ self.model_tester.check_encoder_decoder_model_standalone(*config_and_inputs)
+
+ @require_torch_fp16
+ def test_generate_fp16(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs()
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ model = BlenderbotForConditionalGeneration(config).eval().to(torch_device)
+ model.half()
+ model.generate(input_ids, attention_mask=attention_mask)
+ model.generate(num_beams=4, do_sample=True, early_stopping=False, num_return_sequences=3)
+
+
+def assert_tensors_close(a, b, atol=1e-12, prefix=""):
+ """If tensors have different shapes, different values or a and b are not both tensors, raise a nice Assertion error."""
+ if a is None and b is None:
+ return True
+ try:
+ if torch.allclose(a, b, atol=atol):
+ return True
+ raise
+ except Exception:
+ pct_different = (torch.gt((a - b).abs(), atol)).float().mean().item()
+ if a.numel() > 100:
+ msg = f"tensor values are {pct_different:.1%} percent different."
+ else:
+ msg = f"{a} != {b}"
+ if prefix:
+ msg = prefix + ": " + msg
+ raise AssertionError(msg)
+
+
+@unittest.skipUnless(torch_device != "cpu", "3B test too slow on CPU.")
+@require_torch
+@require_sentencepiece
+@require_tokenizers
+class Blenderbot3BIntegrationTests(unittest.TestCase):
+ ckpt = "facebook/blenderbot-3B"
+
+ @cached_property
+ def tokenizer(self):
+ return BlenderbotTokenizer.from_pretrained(self.ckpt)
+
+ @slow
+ def test_generation_from_short_input_same_as_parlai_3B(self):
+ FASTER_GEN_KWARGS = {"num_beams": 1, "early_stopping": True, "min_length": 15, "max_length": 25}
+ TOK_DECODE_KW = {"skip_special_tokens": True, "clean_up_tokenization_spaces": True}
+
+ backend_empty_cache(torch_device)
+ model = BlenderbotForConditionalGeneration.from_pretrained(self.ckpt).half().to(torch_device)
+
+ src_text = ["Sam"]
+ model_inputs = self.tokenizer(src_text, return_tensors="pt").to(torch_device)
+
+ generated_utterances = model.generate(**model_inputs, **FASTER_GEN_KWARGS)
+ tgt_text = 'Sam is a great name. It means "sun" in Gaelic.'
+
+ generated_txt = self.tokenizer.batch_decode(generated_utterances, **TOK_DECODE_KW)
+ assert generated_txt[0].strip() == tgt_text
+
+ src_text = (
+ "Social anxiety\nWow, I am never shy. Do you have anxiety?\nYes. I end up sweating and blushing and feel"
+ " like i'm going to throw up.\nand why is that?"
+ )
+
+ model_inputs = self.tokenizer([src_text], return_tensors="pt").to(torch_device)
+
+ generated_ids = model.generate(**model_inputs, **FASTER_GEN_KWARGS)[0]
+ reply = self.tokenizer.decode(generated_ids, **TOK_DECODE_KW)
+
+ assert "I think it's because we are so worried about what people think of us." == reply.strip()
+ del model
+
+
+class BlenderbotStandaloneDecoderModelTester:
+ def __init__(
+ self,
+ parent,
+ vocab_size=99,
+ batch_size=13,
+ d_model=16,
+ decoder_seq_length=7,
+ is_training=True,
+ is_decoder=True,
+ use_attention_mask=True,
+ use_cache=False,
+ use_labels=True,
+ decoder_start_token_id=2,
+ decoder_ffn_dim=32,
+ decoder_layers=2,
+ encoder_attention_heads=4,
+ decoder_attention_heads=4,
+ max_position_embeddings=50,
+ is_encoder_decoder=False,
+ pad_token_id=0,
+ bos_token_id=1,
+ eos_token_id=2,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.decoder_seq_length = decoder_seq_length
+ # For common tests
+ self.seq_length = self.decoder_seq_length
+ self.is_training = is_training
+ self.use_attention_mask = use_attention_mask
+ self.use_labels = use_labels
+
+ self.vocab_size = vocab_size
+ self.d_model = d_model
+ self.hidden_size = d_model
+ self.num_hidden_layers = decoder_layers
+ self.decoder_layers = decoder_layers
+ self.decoder_ffn_dim = decoder_ffn_dim
+ self.encoder_attention_heads = encoder_attention_heads
+ self.decoder_attention_heads = decoder_attention_heads
+ self.num_attention_heads = decoder_attention_heads
+ self.eos_token_id = eos_token_id
+ self.bos_token_id = bos_token_id
+ self.pad_token_id = pad_token_id
+ self.decoder_start_token_id = decoder_start_token_id
+ self.use_cache = use_cache
+ self.max_position_embeddings = max_position_embeddings
+ self.is_encoder_decoder = is_encoder_decoder
+
+ self.scope = None
+ self.decoder_key_length = decoder_seq_length
+ self.base_model_out_len = 2
+ self.decoder_attention_idx = 1
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
+
+ attention_mask = None
+ if self.use_attention_mask:
+ attention_mask = ids_tensor([self.batch_size, self.decoder_seq_length], vocab_size=2)
+
+ lm_labels = None
+ if self.use_labels:
+ lm_labels = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
+
+ config = BlenderbotConfig(
+ vocab_size=self.vocab_size,
+ d_model=self.d_model,
+ decoder_layers=self.decoder_layers,
+ decoder_ffn_dim=self.decoder_ffn_dim,
+ encoder_attention_heads=self.encoder_attention_heads,
+ decoder_attention_heads=self.decoder_attention_heads,
+ eos_token_id=self.eos_token_id,
+ bos_token_id=self.bos_token_id,
+ use_cache=self.use_cache,
+ pad_token_id=self.pad_token_id,
+ decoder_start_token_id=self.decoder_start_token_id,
+ max_position_embeddings=self.max_position_embeddings,
+ is_encoder_decoder=self.is_encoder_decoder,
+ )
+
+ return (
+ config,
+ input_ids,
+ attention_mask,
+ lm_labels,
+ )
+
+ def create_and_check_decoder_model_past(
+ self,
+ config,
+ input_ids,
+ attention_mask,
+ lm_labels,
+ ):
+ config.use_cache = True
+ model = BlenderbotDecoder(config=config).to(torch_device).eval()
+ # first forward pass
+ outputs = model(input_ids, use_cache=True)
+ outputs_use_cache_conf = model(input_ids)
+ outputs_no_past = model(input_ids, use_cache=False)
+
+ self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf))
+ self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1)
+
+ past_key_values = outputs["past_key_values"]
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+
+ output_from_no_past = model(next_input_ids)["last_hidden_state"]
+ output_from_past = model(next_tokens, past_key_values=past_key_values)["last_hidden_state"]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, next_input_ids.shape[-1] - 1, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ assert torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3)
+
+ def create_and_check_decoder_model_attention_mask_past(
+ self,
+ config,
+ input_ids,
+ attention_mask,
+ lm_labels,
+ ):
+ model = BlenderbotDecoder(config=config).to(torch_device).eval()
+
+ # create attention mask
+ attn_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
+
+ half_seq_length = input_ids.shape[-1] // 2
+ attn_mask[:, half_seq_length:] = 0
+
+ # first forward pass
+ past_key_values = model(input_ids, attention_mask=attn_mask, use_cache=True)["past_key_values"]
+ # past_key_values = model(input_ids, use_cache=True)["past_key_values"]
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
+
+ # change a random masked slice from input_ids
+ random_seq_idx_to_change = ids_tensor((1,), half_seq_length).item() + 1
+ random_other_next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size).squeeze(-1)
+ input_ids[:, -random_seq_idx_to_change] = random_other_next_tokens
+
+ # append to next input_ids and attn_mask
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ attn_mask = torch.cat(
+ [attn_mask, torch.ones((attn_mask.shape[0], 1), dtype=torch.long, device=torch_device)],
+ dim=1,
+ )
+
+ # get two different outputs
+ output_from_no_past = model(next_input_ids, attention_mask=attn_mask)["last_hidden_state"]
+ output_from_past = model(
+ next_tokens, past_key_values=past_key_values, attention_mask=attn_mask, use_cache=True
+ )["last_hidden_state"]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, next_input_ids.shape[-1] - 1, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ assert torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3)
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ attention_mask,
+ lm_labels,
+ ) = config_and_inputs
+
+ inputs_dict = {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class BlenderbotStandaloneDecoderModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
+ all_model_classes = (BlenderbotDecoder, BlenderbotForCausalLM) if is_torch_available() else ()
+ test_pruning = False
+ is_encoder_decoder = False
+
+ def setUp(
+ self,
+ ):
+ self.model_tester = BlenderbotStandaloneDecoderModelTester(self, is_training=False)
+ self.config_tester = ConfigTester(self, config_class=BlenderbotConfig)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_decoder_model_past(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_decoder_model_past(*config_and_inputs)
+
+ def test_decoder_model_attn_mask_past(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_decoder_model_attention_mask_past(*config_and_inputs)
+
+ @unittest.skip(reason="decoder cannot keep gradients")
+ def test_retain_grad_hidden_states_attentions(self):
+ return
+
+ @unittest.skip(reason="Decoder cannot keep gradients")
+ def test_flex_attention_with_grads():
+ return
diff --git a/transformers/tests/models/blenderbot/test_tokenization_blenderbot.py b/transformers/tests/models/blenderbot/test_tokenization_blenderbot.py
new file mode 100644
index 0000000000000000000000000000000000000000..79fb8fe0623d84173a53218797df62e8c2912bbd
--- /dev/null
+++ b/transformers/tests/models/blenderbot/test_tokenization_blenderbot.py
@@ -0,0 +1,74 @@
+#!/usr/bin/env python3
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Tests for Blenderbot Tokenizers, including common tests for BlenderbotSmallTokenizer."""
+
+import unittest
+
+from transformers import BlenderbotTokenizer, BlenderbotTokenizerFast
+from transformers.testing_utils import require_jinja
+from transformers.utils import cached_property
+
+
+class Blenderbot3BTokenizerTests(unittest.TestCase):
+ @cached_property
+ def tokenizer_3b(self):
+ return BlenderbotTokenizer.from_pretrained("facebook/blenderbot-3B")
+
+ @cached_property
+ def rust_tokenizer_3b(self):
+ return BlenderbotTokenizerFast.from_pretrained("facebook/blenderbot-3B")
+
+ def test_encode_decode_cycle(self):
+ tok = self.tokenizer_3b
+ src_text = " I am a small frog."
+ encoded = tok([src_text], padding=False, truncation=False)["input_ids"]
+ decoded = tok.batch_decode(encoded, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ assert src_text == decoded
+
+ def test_encode_decode_cycle_rust_tokenizer(self):
+ tok = self.rust_tokenizer_3b
+ src_text = " I am a small frog."
+ encoded = tok([src_text], padding=False, truncation=False)["input_ids"]
+ decoded = tok.batch_decode(encoded, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ assert src_text == decoded
+
+ def test_3B_tokenization_same_as_parlai(self):
+ assert self.tokenizer_3b.add_prefix_space
+ assert self.tokenizer_3b([" Sam", "Sam"]).input_ids == [[5502, 2], [5502, 2]]
+
+ def test_3B_tokenization_same_as_parlai_rust_tokenizer(self):
+ assert self.rust_tokenizer_3b.add_prefix_space
+ assert self.rust_tokenizer_3b([" Sam", "Sam"]).input_ids == [[5502, 2], [5502, 2]]
+
+ @require_jinja
+ def test_tokenization_for_chat(self):
+ tok = self.tokenizer_3b
+ test_chats = [
+ [{"role": "system", "content": "You are a helpful chatbot."}, {"role": "user", "content": "Hello!"}],
+ [
+ {"role": "system", "content": "You are a helpful chatbot."},
+ {"role": "user", "content": "Hello!"},
+ {"role": "assistant", "content": "Nice to meet you."},
+ ],
+ [{"role": "assistant", "content": "Nice to meet you."}, {"role": "user", "content": "Hello!"}],
+ ]
+ tokenized_chats = [tok.apply_chat_template(test_chat) for test_chat in test_chats]
+ expected_tokens = [
+ [553, 366, 265, 4792, 3879, 73, 311, 21, 228, 228, 6950, 8, 2],
+ [553, 366, 265, 4792, 3879, 73, 311, 21, 228, 228, 6950, 8, 228, 3490, 287, 2273, 304, 21, 2],
+ [3490, 287, 2273, 304, 21, 228, 228, 6950, 8, 2],
+ ]
+ for tokenized_chat, expected_tokens in zip(tokenized_chats, expected_tokens):
+ self.assertListEqual(tokenized_chat, expected_tokens)
diff --git a/transformers/tests/models/blenderbot_small/__init__.py b/transformers/tests/models/blenderbot_small/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/blenderbot_small/test_modeling_blenderbot_small.py b/transformers/tests/models/blenderbot_small/test_modeling_blenderbot_small.py
new file mode 100644
index 0000000000000000000000000000000000000000..8d75649d8cc152f24284426e00b17e92f105c8f3
--- /dev/null
+++ b/transformers/tests/models/blenderbot_small/test_modeling_blenderbot_small.py
@@ -0,0 +1,569 @@
+# Copyright 2021, The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch BlenderbotSmall model."""
+
+import tempfile
+import unittest
+
+from transformers import BlenderbotSmallConfig, is_torch_available
+from transformers.testing_utils import (
+ require_torch,
+ require_torch_fp16,
+ slow,
+ torch_device,
+)
+from transformers.utils import cached_property
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import BlenderbotSmallForConditionalGeneration, BlenderbotSmallModel, BlenderbotSmallTokenizer
+ from transformers.models.blenderbot_small.modeling_blenderbot_small import (
+ BlenderbotSmallDecoder,
+ BlenderbotSmallEncoder,
+ BlenderbotSmallForCausalLM,
+ )
+
+
+def prepare_blenderbot_small_inputs_dict(
+ config,
+ input_ids,
+ decoder_input_ids,
+ attention_mask=None,
+ decoder_attention_mask=None,
+ head_mask=None,
+ decoder_head_mask=None,
+ cross_attn_head_mask=None,
+):
+ if attention_mask is None:
+ attention_mask = input_ids.ne(config.pad_token_id)
+ if decoder_attention_mask is None:
+ decoder_attention_mask = decoder_input_ids.ne(config.pad_token_id)
+ if head_mask is None:
+ head_mask = torch.ones(config.encoder_layers, config.encoder_attention_heads, device=torch_device)
+ if decoder_head_mask is None:
+ decoder_head_mask = torch.ones(config.decoder_layers, config.decoder_attention_heads, device=torch_device)
+ if cross_attn_head_mask is None:
+ cross_attn_head_mask = torch.ones(config.decoder_layers, config.decoder_attention_heads, device=torch_device)
+ return {
+ "input_ids": input_ids,
+ "decoder_input_ids": decoder_input_ids,
+ "attention_mask": attention_mask,
+ "decoder_attention_mask": attention_mask,
+ "head_mask": head_mask,
+ "decoder_head_mask": decoder_head_mask,
+ "cross_attn_head_mask": cross_attn_head_mask,
+ }
+
+
+class BlenderbotSmallModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_labels=False,
+ vocab_size=99,
+ hidden_size=16,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=50,
+ eos_token_id=2,
+ pad_token_id=1,
+ bos_token_id=0,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.eos_token_id = eos_token_id
+ self.pad_token_id = pad_token_id
+ self.bos_token_id = bos_token_id
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size).clamp(
+ 3,
+ )
+ input_ids[:, -1] = self.eos_token_id # Eos Token
+
+ decoder_input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ config = self.get_config()
+ inputs_dict = prepare_blenderbot_small_inputs_dict(config, input_ids, decoder_input_ids)
+ return config, inputs_dict
+
+ def get_config(self):
+ return BlenderbotSmallConfig(
+ vocab_size=self.vocab_size,
+ d_model=self.hidden_size,
+ encoder_layers=self.num_hidden_layers,
+ decoder_layers=self.num_hidden_layers,
+ encoder_attention_heads=self.num_attention_heads,
+ decoder_attention_heads=self.num_attention_heads,
+ encoder_ffn_dim=self.intermediate_size,
+ decoder_ffn_dim=self.intermediate_size,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ eos_token_id=self.eos_token_id,
+ bos_token_id=self.bos_token_id,
+ pad_token_id=self.pad_token_id,
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config, inputs_dict = self.prepare_config_and_inputs()
+ return config, inputs_dict
+
+ def create_and_check_decoder_model_past_large_inputs(self, config, inputs_dict):
+ model = BlenderbotSmallModel(config=config).get_decoder().to(torch_device).eval()
+ input_ids = inputs_dict["input_ids"]
+ attention_mask = inputs_dict["attention_mask"]
+ head_mask = inputs_dict["head_mask"]
+
+ # first forward pass
+ outputs = model(input_ids, attention_mask=attention_mask, head_mask=head_mask, use_cache=True)
+
+ output, past_key_values = outputs.to_tuple()
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_attn_mask = ids_tensor((self.batch_size, 3), 2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([attention_mask, next_attn_mask], dim=-1)
+
+ output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)["last_hidden_state"]
+ output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)[
+ "last_hidden_state"
+ ]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def check_encoder_decoder_model_standalone(self, config, inputs_dict):
+ model = BlenderbotSmallModel(config=config).to(torch_device).eval()
+ outputs = model(**inputs_dict)
+
+ encoder_last_hidden_state = outputs.encoder_last_hidden_state
+ last_hidden_state = outputs.last_hidden_state
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ encoder = model.get_encoder()
+ encoder.save_pretrained(tmpdirname)
+ encoder = BlenderbotSmallEncoder.from_pretrained(tmpdirname).to(torch_device)
+
+ encoder_last_hidden_state_2 = encoder(inputs_dict["input_ids"], attention_mask=inputs_dict["attention_mask"])[
+ 0
+ ]
+
+ self.parent.assertTrue((encoder_last_hidden_state_2 - encoder_last_hidden_state).abs().max().item() < 1e-3)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ decoder = model.get_decoder()
+ decoder.save_pretrained(tmpdirname)
+ decoder = BlenderbotSmallDecoder.from_pretrained(tmpdirname).to(torch_device)
+
+ last_hidden_state_2 = decoder(
+ input_ids=inputs_dict["decoder_input_ids"],
+ attention_mask=inputs_dict["decoder_attention_mask"],
+ encoder_hidden_states=encoder_last_hidden_state,
+ encoder_attention_mask=inputs_dict["attention_mask"],
+ )[0]
+
+ self.parent.assertTrue((last_hidden_state_2 - last_hidden_state).abs().max().item() < 1e-3)
+
+
+@require_torch
+class BlenderbotSmallModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (BlenderbotSmallModel, BlenderbotSmallForConditionalGeneration) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": BlenderbotSmallModel,
+ "summarization": BlenderbotSmallForConditionalGeneration,
+ "text-generation": BlenderbotSmallForCausalLM,
+ "text2text-generation": BlenderbotSmallForConditionalGeneration,
+ "translation": BlenderbotSmallForConditionalGeneration,
+ }
+ if is_torch_available()
+ else {}
+ )
+ is_encoder_decoder = True
+ fx_compatible = True
+ test_pruning = False
+ test_missing_keys = False
+
+ # TODO: Fix the failed tests when this model gets more usage
+ def is_pipeline_test_to_skip(
+ self,
+ pipeline_test_case_name,
+ config_class,
+ model_architecture,
+ tokenizer_name,
+ image_processor_name,
+ feature_extractor_name,
+ processor_name,
+ ):
+ return pipeline_test_case_name == "TextGenerationPipelineTests"
+
+ def setUp(self):
+ self.model_tester = BlenderbotSmallModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=BlenderbotSmallConfig)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_save_load_strict(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs()
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
+ self.assertEqual(info["missing_keys"], [])
+
+ def test_decoder_model_past_with_large_inputs(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
+
+ def test_encoder_decoder_model_standalone(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
+ self.model_tester.check_encoder_decoder_model_standalone(*config_and_inputs)
+
+ @require_torch_fp16
+ def test_generate_fp16(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs()
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ model = BlenderbotSmallForConditionalGeneration(config).eval().to(torch_device)
+ model.half()
+ model.generate(input_ids, attention_mask=attention_mask)
+ model.generate(num_beams=4, do_sample=True, early_stopping=False, num_return_sequences=3)
+
+
+def assert_tensors_close(a, b, atol=1e-12, prefix=""):
+ """If tensors have different shapes, different values or a and b are not both tensors, raise a nice Assertion error."""
+ if a is None and b is None:
+ return True
+ try:
+ if torch.allclose(a, b, atol=atol):
+ return True
+ raise
+ except Exception:
+ pct_different = (torch.gt((a - b).abs(), atol)).float().mean().item()
+ if a.numel() > 100:
+ msg = f"tensor values are {pct_different:.1%} percent different."
+ else:
+ msg = f"{a} != {b}"
+ if prefix:
+ msg = prefix + ": " + msg
+ raise AssertionError(msg)
+
+
+@require_torch
+class Blenderbot90MIntegrationTests(unittest.TestCase):
+ ckpt = "facebook/blenderbot-90M"
+
+ @cached_property
+ def model(self):
+ model = BlenderbotSmallForConditionalGeneration.from_pretrained(self.ckpt).to(torch_device)
+ if torch_device == "cuda":
+ model = model.half()
+ return model
+
+ @cached_property
+ def tokenizer(self):
+ return BlenderbotSmallTokenizer.from_pretrained(self.ckpt)
+
+ @slow
+ def test_90_generation_from_long_input(self):
+ src_text = [
+ "Social anxiety\nWow, I am never shy. Do you have anxiety?\nYes. I end up sweating and blushing and feel"
+ " like i'm going to throw up.\nand why is that?"
+ ]
+
+ model_inputs = self.tokenizer(src_text, return_tensors="pt").to(torch_device)
+
+ assert isinstance(self.tokenizer, BlenderbotSmallTokenizer)
+ generated_ids = self.model.generate(**model_inputs)[0]
+ reply = self.tokenizer.decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
+
+ assert reply in (
+ "i don't know. i just feel like i'm going to throw up. it's not fun.",
+ "i'm not sure. i just feel like i've been feeling like i have to be in a certain place",
+ )
+
+ @slow
+ def test_90_generation_from_short_input(self):
+ model_inputs = self.tokenizer(["sam"], return_tensors="pt").to(torch_device)
+
+ generated_utterances = self.model.generate(**model_inputs)
+
+ clean_txt = self.tokenizer.decode(
+ generated_utterances[0], skip_special_tokens=True, clean_up_tokenization_spaces=True
+ )
+ assert clean_txt in (
+ "have you ever been to a sam club? it's a great club in the south.",
+ "have you ever heard of sam harris? he's an american singer, songwriter, and actor.",
+ )
+
+
+class BlenderbotSmallStandaloneDecoderModelTester:
+ def __init__(
+ self,
+ parent,
+ vocab_size=99,
+ batch_size=13,
+ d_model=16,
+ decoder_seq_length=7,
+ is_training=True,
+ is_decoder=True,
+ use_attention_mask=True,
+ use_cache=False,
+ use_labels=True,
+ decoder_start_token_id=2,
+ decoder_ffn_dim=32,
+ decoder_layers=2,
+ encoder_attention_heads=4,
+ decoder_attention_heads=4,
+ max_position_embeddings=50,
+ is_encoder_decoder=False,
+ pad_token_id=0,
+ bos_token_id=1,
+ eos_token_id=2,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.decoder_seq_length = decoder_seq_length
+ # For common tests
+ self.seq_length = self.decoder_seq_length
+ self.is_training = is_training
+ self.use_attention_mask = use_attention_mask
+ self.use_labels = use_labels
+
+ self.vocab_size = vocab_size
+ self.d_model = d_model
+ self.hidden_size = d_model
+ self.num_hidden_layers = decoder_layers
+ self.decoder_layers = decoder_layers
+ self.decoder_ffn_dim = decoder_ffn_dim
+ self.encoder_attention_heads = encoder_attention_heads
+ self.decoder_attention_heads = decoder_attention_heads
+ self.num_attention_heads = decoder_attention_heads
+ self.eos_token_id = eos_token_id
+ self.bos_token_id = bos_token_id
+ self.pad_token_id = pad_token_id
+ self.decoder_start_token_id = decoder_start_token_id
+ self.use_cache = use_cache
+ self.max_position_embeddings = max_position_embeddings
+ self.is_encoder_decoder = is_encoder_decoder
+
+ self.scope = None
+ self.decoder_key_length = decoder_seq_length
+ self.base_model_out_len = 2
+ self.decoder_attention_idx = 1
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
+
+ attention_mask = None
+ if self.use_attention_mask:
+ attention_mask = ids_tensor([self.batch_size, self.decoder_seq_length], vocab_size=2)
+
+ lm_labels = None
+ if self.use_labels:
+ lm_labels = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
+
+ config = BlenderbotSmallConfig(
+ vocab_size=self.vocab_size,
+ d_model=self.d_model,
+ decoder_layers=self.decoder_layers,
+ decoder_ffn_dim=self.decoder_ffn_dim,
+ encoder_attention_heads=self.encoder_attention_heads,
+ decoder_attention_heads=self.decoder_attention_heads,
+ eos_token_id=self.eos_token_id,
+ bos_token_id=self.bos_token_id,
+ use_cache=self.use_cache,
+ pad_token_id=self.pad_token_id,
+ decoder_start_token_id=self.decoder_start_token_id,
+ max_position_embeddings=self.max_position_embeddings,
+ is_encoder_decoder=self.is_encoder_decoder,
+ )
+
+ return (
+ config,
+ input_ids,
+ attention_mask,
+ lm_labels,
+ )
+
+ def create_and_check_decoder_model_past(
+ self,
+ config,
+ input_ids,
+ attention_mask,
+ lm_labels,
+ ):
+ config.use_cache = True
+ model = BlenderbotSmallDecoder(config=config).to(torch_device).eval()
+ # first forward pass
+ outputs = model(input_ids, use_cache=True)
+ outputs_use_cache_conf = model(input_ids)
+ outputs_no_past = model(input_ids, use_cache=False)
+
+ self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf))
+ self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1)
+
+ past_key_values = outputs["past_key_values"]
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+
+ output_from_no_past = model(next_input_ids)["last_hidden_state"]
+ output_from_past = model(next_tokens, past_key_values=past_key_values)["last_hidden_state"]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, next_input_ids.shape[-1] - 1, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ assert torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3)
+
+ def create_and_check_decoder_model_attention_mask_past(
+ self,
+ config,
+ input_ids,
+ attention_mask,
+ lm_labels,
+ ):
+ model = BlenderbotSmallDecoder(config=config).to(torch_device).eval()
+
+ # create attention mask
+ attn_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
+
+ half_seq_length = input_ids.shape[-1] // 2
+ attn_mask[:, half_seq_length:] = 0
+
+ # first forward pass
+ past_key_values = model(input_ids, attention_mask=attn_mask, use_cache=True)["past_key_values"]
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
+
+ # change a random masked slice from input_ids
+ random_seq_idx_to_change = ids_tensor((1,), half_seq_length).item() + 1
+ random_other_next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size).squeeze(-1)
+ input_ids[:, -random_seq_idx_to_change] = random_other_next_tokens
+
+ # append to next input_ids and attn_mask
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ attn_mask = torch.cat(
+ [attn_mask, torch.ones((attn_mask.shape[0], 1), dtype=torch.long, device=torch_device)],
+ dim=1,
+ )
+
+ # get two different outputs
+ output_from_no_past = model(next_input_ids, attention_mask=attn_mask)["last_hidden_state"]
+ output_from_past = model(
+ next_tokens, past_key_values=past_key_values, attention_mask=attn_mask, use_cache=True
+ )["last_hidden_state"]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, next_input_ids.shape[-1] - 1, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ assert torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3)
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ attention_mask,
+ lm_labels,
+ ) = config_and_inputs
+
+ inputs_dict = {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class BlenderbotSmallStandaloneDecoderModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
+ all_model_classes = (BlenderbotSmallDecoder, BlenderbotSmallForCausalLM) if is_torch_available() else ()
+ test_pruning = False
+ is_encoder_decoder = False
+
+ def setUp(
+ self,
+ ):
+ self.model_tester = BlenderbotSmallStandaloneDecoderModelTester(self, is_training=False)
+ self.config_tester = ConfigTester(self, config_class=BlenderbotSmallConfig)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_decoder_model_past(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_decoder_model_past(*config_and_inputs)
+
+ def test_decoder_model_attn_mask_past(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_decoder_model_attention_mask_past(*config_and_inputs)
+
+ @unittest.skip(reason="decoder cannot keep gradients")
+ def test_retain_grad_hidden_states_attentions(self):
+ return
+
+ @unittest.skip(reason="Decoder cannot keep gradients")
+ def test_flex_attention_with_grads():
+ return
diff --git a/transformers/tests/models/blenderbot_small/test_tokenization_blenderbot_small.py b/transformers/tests/models/blenderbot_small/test_tokenization_blenderbot_small.py
new file mode 100644
index 0000000000000000000000000000000000000000..5e02357160f6bf90e4bd8cc00086213574a6192c
--- /dev/null
+++ b/transformers/tests/models/blenderbot_small/test_tokenization_blenderbot_small.py
@@ -0,0 +1,93 @@
+#!/usr/bin/env python3
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Tests for the Blenderbot small tokenizer."""
+
+import json
+import os
+import unittest
+from functools import lru_cache
+
+from transformers.models.blenderbot_small.tokenization_blenderbot_small import (
+ VOCAB_FILES_NAMES,
+ BlenderbotSmallTokenizer,
+)
+
+from ...test_tokenization_common import TokenizerTesterMixin, use_cache_if_possible
+
+
+class BlenderbotSmallTokenizerTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "facebook/blenderbot_small-90M"
+ tokenizer_class = BlenderbotSmallTokenizer
+ test_rust_tokenizer = False
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ vocab = ["__start__", "adapt", "act", "ap@@", "te", "__end__", "__unk__"]
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+
+ merges = ["#version: 0.2", "a p", "t e", "ap t", "a d", "ad apt", "a c", "ac t", ""]
+ cls.special_tokens_map = {"unk_token": "__unk__", "bos_token": "__start__", "eos_token": "__end__"}
+
+ cls.vocab_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ cls.merges_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["merges_file"])
+ with open(cls.vocab_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps(vocab_tokens) + "\n")
+ with open(cls.merges_file, "w", encoding="utf-8") as fp:
+ fp.write("\n".join(merges))
+
+ @classmethod
+ @use_cache_if_possible
+ @lru_cache(maxsize=64)
+ def get_tokenizer(cls, pretrained_name=None, **kwargs):
+ kwargs.update(cls.special_tokens_map)
+ pretrained_name = pretrained_name or cls.tmpdirname
+ return BlenderbotSmallTokenizer.from_pretrained(pretrained_name, **kwargs)
+
+ def get_input_output_texts(self, tokenizer):
+ input_text = "adapt act apte"
+ output_text = "adapt act apte"
+ return input_text, output_text
+
+ def test_full_blenderbot_small_tokenizer(self):
+ tokenizer = BlenderbotSmallTokenizer(self.vocab_file, self.merges_file, **self.special_tokens_map)
+ text = "adapt act apte"
+ bpe_tokens = ["adapt", "act", "ap@@", "te"]
+ tokens = tokenizer.tokenize(text)
+ self.assertListEqual(tokens, bpe_tokens)
+
+ input_tokens = [tokenizer.bos_token] + tokens + [tokenizer.eos_token]
+
+ input_bpe_tokens = [0, 1, 2, 3, 4, 5]
+ self.assertListEqual(tokenizer.convert_tokens_to_ids(input_tokens), input_bpe_tokens)
+
+ def test_special_tokens_small_tok(self):
+ tok = BlenderbotSmallTokenizer.from_pretrained("facebook/blenderbot-90M")
+ assert tok("sam").input_ids == [1384]
+ src_text = "I am a small frog."
+ encoded = tok([src_text], padding=False, truncation=False)["input_ids"]
+ decoded = tok.batch_decode(encoded, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ assert src_text != decoded # I wish it did!
+ assert decoded == "i am a small frog ."
+
+ def test_empty_word_small_tok(self):
+ tok = BlenderbotSmallTokenizer.from_pretrained("facebook/blenderbot-90M")
+ src_text = "I am a small frog ."
+ src_text_dot = "."
+ encoded = tok(src_text)["input_ids"]
+ encoded_dot = tok(src_text_dot)["input_ids"]
+
+ assert encoded[-1] == encoded_dot[0]
diff --git a/transformers/tests/models/blip_2/__init__.py b/transformers/tests/models/blip_2/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/blip_2/test_modeling_blip_2.py b/transformers/tests/models/blip_2/test_modeling_blip_2.py
new file mode 100644
index 0000000000000000000000000000000000000000..8fab490859143fd385bdd0f6e065a0fd2a5472aa
--- /dev/null
+++ b/transformers/tests/models/blip_2/test_modeling_blip_2.py
@@ -0,0 +1,1988 @@
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch BLIP-2 model."""
+
+import inspect
+import tempfile
+import unittest
+
+import numpy as np
+import pytest
+import requests
+
+from transformers import CONFIG_MAPPING, Blip2Config, Blip2QFormerConfig, Blip2VisionConfig
+from transformers.testing_utils import (
+ Expectations,
+ cleanup,
+ require_torch,
+ require_torch_accelerator,
+ require_torch_fp16,
+ require_torch_multi_accelerator,
+ require_torch_sdpa,
+ require_vision,
+ slow,
+ torch_device,
+)
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ ModelTesterMixin,
+ _config_zero_init,
+ floats_tensor,
+ ids_tensor,
+ random_attention_mask,
+)
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import (
+ Blip2ForConditionalGeneration,
+ Blip2ForImageTextRetrieval,
+ Blip2Model,
+ Blip2TextModelWithProjection,
+ Blip2VisionModel,
+ Blip2VisionModelWithProjection,
+ )
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import Blip2Processor
+
+
+class Blip2VisionModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ image_size=30,
+ patch_size=2,
+ num_channels=3,
+ is_training=True,
+ hidden_size=32,
+ projection_dim=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ initializer_range=1e-10,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.hidden_size = hidden_size
+ self.projection_dim = projection_dim
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ # in ViT, the seq length equals the number of patches + 1 (we add 1 for the [CLS] token)
+ num_patches = (image_size // patch_size) ** 2
+ self.seq_length = num_patches + 1
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+ config = self.get_config()
+
+ return config, pixel_values
+
+ def get_config(self):
+ return Blip2VisionConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ projection_dim=self.projection_dim,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, pixel_values):
+ model = Blip2VisionModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(pixel_values)
+ # expected sequence length = num_patches + 1 (we add 1 for the [CLS] token)
+ image_size = (self.image_size, self.image_size)
+ patch_size = (self.patch_size, self.patch_size)
+ num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, num_patches + 1, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class Blip2VisionModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as BLIP-2's vision encoder does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (Blip2VisionModel,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = Blip2VisionModelTester(self)
+ self.config_tester = ConfigTester(
+ self, config_class=Blip2VisionConfig, has_text_modality=False, hidden_size=37
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="BLIP-2's vision encoder does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_get_set_embeddings(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip
+ def test_training(self):
+ pass
+
+ @unittest.skip
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "Salesforce/blip2-opt-2.7b"
+ model = Blip2VisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+class Blip2QFormerModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ projection_dim=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ max_position_embeddings=512,
+ initializer_range=0.02,
+ bos_token_id=0,
+ scope=None,
+ use_qformer_text_input=False,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.projection_dim = projection_dim
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.max_position_embeddings = max_position_embeddings
+ self.initializer_range = initializer_range
+ self.scope = scope
+ self.bos_token_id = bos_token_id
+ self.use_qformer_text_input = use_qformer_text_input
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ if input_mask is not None:
+ batch_size, seq_length = input_mask.shape
+ rnd_start_indices = np.random.randint(1, seq_length - 1, size=(batch_size,))
+ for batch_idx, start_index in enumerate(rnd_start_indices):
+ input_mask[batch_idx, :start_index] = 1
+ input_mask[batch_idx, start_index:] = 0
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask
+
+ def get_config(self):
+ return Blip2QFormerConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ projection_dim=self.projection_dim,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ max_position_embeddings=self.max_position_embeddings,
+ initializer_range=self.initializer_range,
+ bos_token_id=self.bos_token_id,
+ use_qformer_text_input=self.use_qformer_text_input,
+ )
+
+
+# this class is based on `OPTModelTester` found in tests/models/opt/test_modeling_opt.py
+class Blip2TextModelDecoderOnlyTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ seq_length=7,
+ is_training=True,
+ use_labels=False,
+ vocab_size=99,
+ hidden_size=16,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ eos_token_id=2,
+ pad_token_id=1,
+ bos_token_id=0,
+ embed_dim=16,
+ num_labels=3,
+ word_embed_proj_dim=16,
+ type_sequence_label_size=2,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.eos_token_id = eos_token_id
+ self.pad_token_id = pad_token_id
+ self.bos_token_id = bos_token_id
+ self.embed_dim = embed_dim
+ self.num_labels = num_labels
+ self.type_sequence_label_size = type_sequence_label_size
+ self.word_embed_proj_dim = word_embed_proj_dim
+ self.is_encoder_decoder = False
+
+ def prepare_config_and_inputs(self):
+ config = self.get_config()
+
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size).clamp(3)
+ input_ids[:, -1] = self.eos_token_id # Eos Token
+
+ attention_mask = input_ids.ne(self.pad_token_id)
+
+ return config, input_ids, attention_mask
+
+ def get_config(self):
+ return CONFIG_MAPPING["opt"](
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ ffn_dim=self.intermediate_size,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ eos_token_id=self.eos_token_id,
+ bos_token_id=self.bos_token_id,
+ pad_token_id=self.pad_token_id,
+ embed_dim=self.embed_dim,
+ is_encoder_decoder=False,
+ word_embed_proj_dim=self.word_embed_proj_dim,
+ )
+
+
+# this model tester uses a decoder-only language model (OPT)
+class Blip2ForConditionalGenerationDecoderOnlyModelTester:
+ def __init__(
+ self,
+ parent,
+ vision_kwargs=None,
+ qformer_kwargs=None,
+ text_kwargs=None,
+ is_training=True,
+ num_query_tokens=10,
+ image_token_index=4,
+ ):
+ if vision_kwargs is None:
+ vision_kwargs = {}
+ if qformer_kwargs is None:
+ qformer_kwargs = {}
+ if text_kwargs is None:
+ text_kwargs = {}
+
+ self.parent = parent
+ self.vision_model_tester = Blip2VisionModelTester(parent, **vision_kwargs)
+ self.qformer_model_tester = Blip2QFormerModelTester(parent, **qformer_kwargs)
+ self.text_model_tester = Blip2TextModelDecoderOnlyTester(parent, **text_kwargs)
+ self.batch_size = self.text_model_tester.batch_size # need bs for batching_equivalence test
+ self.seq_length = self.text_model_tester.seq_length + num_query_tokens # need seq_length for common tests
+ self.is_training = is_training
+ self.num_query_tokens = num_query_tokens
+ self.image_token_index = image_token_index
+
+ def prepare_config_and_inputs(self):
+ _, pixel_values = self.vision_model_tester.prepare_config_and_inputs()
+ _, input_ids, attention_mask = self.text_model_tester.prepare_config_and_inputs()
+
+ vision_tokens = (
+ torch.ones((input_ids.shape[0], self.num_query_tokens), device=torch_device, dtype=input_ids.dtype)
+ * self.image_token_index
+ )
+ input_ids[input_ids == self.image_token_index] = self.text_model_tester.pad_token_id
+ input_ids = torch.cat([vision_tokens, input_ids], dim=-1)
+ vision_attention_mask = torch.ones_like(vision_tokens)
+ attention_mask = torch.cat([vision_attention_mask, attention_mask], dim=-1)
+
+ config = self.get_config()
+
+ return config, input_ids, attention_mask, pixel_values
+
+ def get_config(self):
+ return Blip2Config.from_vision_qformer_text_configs(
+ vision_config=self.vision_model_tester.get_config(),
+ qformer_config=self.qformer_model_tester.get_config(),
+ text_config=self.text_model_tester.get_config(),
+ num_query_tokens=self.num_query_tokens,
+ image_token_index=self.image_token_index,
+ )
+
+ def create_and_check_for_conditional_generation(self, config, input_ids, attention_mask, pixel_values):
+ model = Blip2ForConditionalGeneration(config).to(torch_device).eval()
+ with torch.no_grad():
+ result = model(pixel_values, input_ids, attention_mask)
+
+ expected_seq_length = self.num_query_tokens + self.text_model_tester.seq_length
+ self.parent.assertEqual(
+ result.logits.shape,
+ (self.vision_model_tester.batch_size, expected_seq_length, self.text_model_tester.vocab_size),
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, attention_mask, pixel_values = config_and_inputs
+ inputs_dict = {
+ "pixel_values": pixel_values,
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class Blip2ForConditionalGenerationDecoderOnlyTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
+ all_model_classes = (Blip2ForConditionalGeneration,) if is_torch_available() else ()
+ additional_model_inputs = ["input_ids"]
+ fx_compatible = False
+ test_head_masking = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_attention_outputs = False
+ test_torchscript = False
+ _is_composite = True
+
+ def setUp(self):
+ self.model_tester = Blip2ForConditionalGenerationDecoderOnlyModelTester(self)
+ common_properties = ["image_token_index", "num_query_tokens", "image_text_hidden_size"]
+ self.config_tester = ConfigTester(
+ self, config_class=Blip2Config, has_text_modality=False, common_properties=common_properties
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_for_conditional_generation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_conditional_generation(*config_and_inputs)
+
+ @unittest.skip(
+ reason="Blip2QFormerModel does not support an attention implementation through torch.nn.functional.scaled_dot_product_attention yet."
+ )
+ def test_eager_matches_sdpa_generate(self):
+ pass
+
+ @unittest.skip(reason="Hidden_states is tested in individual model tests")
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip(reason="Inputs_embeds is tested in individual model tests")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Retain_grad is tested in individual model tests")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ @unittest.skip(reason="Blip2Model does not have input/output embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @require_torch_sdpa
+ def test_sdpa_can_dispatch_composite_models(self):
+ """
+ Tests if composite models dispatch correctly on SDPA/eager when requested so when loading the model.
+ This tests only by looking at layer names, as usually SDPA layers are called "SDPAAttention".
+ In contrast to the above test, this one checks if the "config._attn_implamentation" is a dict after the model
+ is loaded, because we manually replicate requested attn implementation on each sub-config when loading.
+ See https://github.com/huggingface/transformers/pull/32238 for more info
+
+ The test tries to cover most general cases of composite models, VLMs with vision and text configs. Any model
+ that has a different set of sub-configs has to overwrite this test.
+ """
+ if not self.has_attentions:
+ self.skipTest(reason="Model architecture does not support attentions")
+
+ if not self._is_composite:
+ self.skipTest(f"{self.all_model_classes[0].__name__} does not support SDPA")
+
+ for model_class in self.all_model_classes:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_sdpa = model_class.from_pretrained(tmpdirname)
+ model_sdpa = model_sdpa.eval().to(torch_device)
+
+ # `None` as it is the requested one which will be assigned to each sub-config
+ # Sub-model will dispatch to SDPA if it can (checked below that `SDPA` layers are present)
+ self.assertTrue(model.language_model.config._attn_implementation == "sdpa")
+ self.assertTrue(model.vision_model.config._attn_implementation == "sdpa")
+ self.assertTrue(model.qformer.config._attn_implementation == "eager")
+
+ model_eager = model_class.from_pretrained(tmpdirname, attn_implementation="eager")
+ model_eager = model_eager.eval().to(torch_device)
+ self.assertTrue(model_eager.config._attn_implementation == "eager")
+ self.assertTrue(model_eager.language_model.config._attn_implementation == "eager")
+ self.assertTrue(model_eager.vision_model.config._attn_implementation == "eager")
+ self.assertTrue(model_eager.qformer.config._attn_implementation == "eager")
+
+ for name, submodule in model_eager.named_modules():
+ class_name = submodule.__class__.__name__
+ if (
+ class_name.endswith("Attention")
+ and getattr(submodule, "config", None)
+ and submodule.config._attn_implementation == "sdpa"
+ ):
+ raise ValueError("The eager model should not have SDPA attention layers")
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_load_vision_qformer_text_config(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # Save Blip2Config and check if we can load Blip2VisionConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ vision_config = Blip2VisionConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.vision_config.to_dict(), vision_config.to_dict())
+
+ # Save Blip2Config and check if we can load Blip2QFormerConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ qformer_config = Blip2QFormerConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.qformer_config.to_dict(), qformer_config.to_dict())
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "Salesforce/blip2-opt-2.7b"
+ model = Blip2ForConditionalGeneration.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ # overwrite because BLIP internally calls LM.generate() with embeds thus it cannot operate in no cache format
+ def _check_generate_outputs(self, output, config, use_cache=False, num_return_sequences=1, num_beams=1):
+ use_cache = True # force this to be True in case False is passed
+ super()._check_generate_outputs(
+ output, config, use_cache=use_cache, num_return_sequences=num_return_sequences, num_beams=num_beams
+ )
+
+ # overwrite because BLIP2 cannot generate only from input ids, and requires pixel values in all cases to be present
+ @pytest.mark.generate
+ def test_left_padding_compatibility(self):
+ # NOTE: left-padding results in small numerical differences. This is expected.
+ # See https://github.com/huggingface/transformers/issues/25420#issuecomment-1775317535
+
+ # First, filter out models that don't support left padding
+ # - The model must have generative capabilities
+ if len(self.all_generative_model_classes) == 0:
+ self.skipTest(reason="No generative architecture available for this model.")
+
+ # - The model must support padding
+ if not self.has_attentions:
+ self.skipTest(reason="This model doesn't support padding.")
+
+ # - The model must be a decoder-only architecture (encoder-based architectures use right-padding)
+ decoder_only_classes = []
+ for model_class in self.all_generative_model_classes:
+ config, _ = self.prepare_config_and_inputs_for_generate()
+ if config.is_encoder_decoder:
+ continue
+ else:
+ decoder_only_classes.append(model_class)
+ if len(decoder_only_classes) == 0:
+ self.skipTest(reason="No decoder-only architecture available for this model.")
+
+ # - Decoder-only architectures derived from encoder-decoder models could support it in theory, but we haven't
+ # added support for it yet. We skip these models for now.
+ has_encoder_attributes = any(
+ attr_name
+ for attr_name in config.to_dict().keys()
+ if attr_name.startswith("encoder") and attr_name != "encoder_no_repeat_ngram_size"
+ )
+ if has_encoder_attributes:
+ self.skipTest(
+ reason="The decoder-only derived from encoder-decoder models are not expected to support left-padding."
+ )
+
+ # Then, test left-padding
+ def _prepare_model_kwargs(input_ids, attention_mask, signature):
+ model_kwargs = {"input_ids": input_ids, "attention_mask": attention_mask}
+ if "position_ids" in signature:
+ position_ids = torch.cumsum(attention_mask, dim=-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ model_kwargs["position_ids"] = position_ids
+ if "cache_position" in signature:
+ cache_position = torch.arange(input_ids.shape[-1], device=torch_device)
+ model_kwargs["cache_position"] = cache_position
+ return model_kwargs
+
+ for model_class in decoder_only_classes:
+ config, inputs_dict = self.prepare_config_and_inputs_for_generate()
+ input_ids = inputs_dict["input_ids"]
+ attention_mask = inputs_dict.get("attention_mask")
+ pixel_values = inputs_dict["pixel_values"]
+ if attention_mask is None:
+ attention_mask = torch.ones_like(input_ids)
+
+ model = model_class(config).to(torch_device).eval()
+ signature = inspect.signature(model.forward).parameters.keys()
+
+ # no cache as some models require special cache classes to be init outside forward
+ model.generation_config.use_cache = False
+
+ # Without padding
+ model_kwargs = _prepare_model_kwargs(input_ids, attention_mask, signature)
+ next_logits_wo_padding = model(**model_kwargs, pixel_values=pixel_values).logits[:, -1, :]
+
+ # With left-padding (length 32)
+ # can hardcode pad_token to be 0 as we'll do attn masking anyway
+ pad_token_id = (
+ config.get_text_config().pad_token_id if config.get_text_config().pad_token_id is not None else 0
+ )
+ pad_size = (input_ids.shape[0], 32)
+ padding = torch.ones(pad_size, dtype=input_ids.dtype, device=torch_device) * pad_token_id
+ padded_input_ids = torch.cat((padding, input_ids), dim=1)
+ padded_attention_mask = torch.cat((torch.zeros_like(padding), attention_mask), dim=1)
+ model_kwargs = _prepare_model_kwargs(padded_input_ids, padded_attention_mask, signature)
+ next_logits_with_padding = model(**model_kwargs, pixel_values=pixel_values).logits[:, -1, :]
+
+ # They should result in very similar logits
+ torch.testing.assert_close(next_logits_wo_padding, next_logits_with_padding, rtol=1e-5, atol=1e-5)
+
+
+# this class is based on `T5ModelTester` found in tests/models/t5/test_modeling_t5.py
+class Blip2TextModelTester:
+ def __init__(
+ self,
+ parent,
+ vocab_size=99,
+ batch_size=12,
+ encoder_seq_length=7,
+ decoder_seq_length=9,
+ # For common tests
+ is_training=True,
+ use_attention_mask=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ d_ff=37,
+ relative_attention_num_buckets=8,
+ dropout_rate=0.1,
+ initializer_factor=0.002,
+ eos_token_id=1,
+ pad_token_id=0,
+ decoder_start_token_id=0,
+ scope=None,
+ decoder_layers=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.encoder_seq_length = encoder_seq_length
+ self.decoder_seq_length = decoder_seq_length
+ # For common tests
+ self.seq_length = self.decoder_seq_length
+ self.is_training = is_training
+ self.use_attention_mask = use_attention_mask
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.d_ff = d_ff
+ self.relative_attention_num_buckets = relative_attention_num_buckets
+ self.dropout_rate = dropout_rate
+ self.initializer_factor = initializer_factor
+ self.eos_token_id = eos_token_id
+ self.pad_token_id = pad_token_id
+ self.decoder_start_token_id = decoder_start_token_id
+ self.scope = None
+ self.decoder_layers = decoder_layers
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.encoder_seq_length], self.vocab_size)
+ decoder_input_ids = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
+
+ attention_mask = None
+ decoder_attention_mask = None
+ if self.use_attention_mask:
+ attention_mask = ids_tensor([self.batch_size, self.encoder_seq_length], vocab_size=2)
+ decoder_attention_mask = ids_tensor([self.batch_size, self.decoder_seq_length], vocab_size=2)
+
+ lm_labels = None
+ if self.use_labels:
+ lm_labels = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
+
+ config = self.get_config()
+
+ return (
+ config,
+ input_ids,
+ decoder_input_ids,
+ attention_mask,
+ decoder_attention_mask,
+ lm_labels,
+ )
+
+ def get_config(self):
+ return CONFIG_MAPPING["t5"](
+ vocab_size=self.vocab_size,
+ d_model=self.hidden_size,
+ d_ff=self.d_ff,
+ d_kv=self.hidden_size // self.num_attention_heads,
+ num_layers=self.num_hidden_layers,
+ num_decoder_layers=self.decoder_layers,
+ num_heads=self.num_attention_heads,
+ relative_attention_num_buckets=self.relative_attention_num_buckets,
+ dropout_rate=self.dropout_rate,
+ initializer_factor=self.initializer_factor,
+ eos_token_id=self.eos_token_id,
+ bos_token_id=self.pad_token_id,
+ pad_token_id=self.pad_token_id,
+ decoder_start_token_id=self.decoder_start_token_id,
+ is_encoder_decoder=True,
+ )
+
+
+# this model tester uses an encoder-decoder language model (T5)
+class Blip2ModelTester:
+ def __init__(
+ self, parent, vision_kwargs=None, qformer_kwargs=None, text_kwargs=None, is_training=True, num_query_tokens=10
+ ):
+ if vision_kwargs is None:
+ vision_kwargs = {}
+ if qformer_kwargs is None:
+ qformer_kwargs = {}
+ if text_kwargs is None:
+ text_kwargs = {}
+
+ self.parent = parent
+ self.vision_model_tester = Blip2VisionModelTester(parent, **vision_kwargs)
+ self.qformer_model_tester = Blip2QFormerModelTester(parent, **qformer_kwargs)
+ self.text_model_tester = Blip2TextModelTester(parent, **text_kwargs)
+ self.batch_size = self.text_model_tester.batch_size # need bs for batching_equivalence test
+ self.seq_length = self.text_model_tester.seq_length # need seq_length for common tests
+ self.encoder_seq_length = (
+ self.text_model_tester.encoder_seq_length + num_query_tokens
+ ) # need enc seq_length for gen tests
+ self.is_training = is_training
+ self.num_query_tokens = num_query_tokens
+
+ def prepare_config_and_inputs(self):
+ _, pixel_values = self.vision_model_tester.prepare_config_and_inputs()
+ (
+ _,
+ input_ids,
+ decoder_input_ids,
+ attention_mask,
+ decoder_attention_mask,
+ lm_labels,
+ ) = self.text_model_tester.prepare_config_and_inputs()
+
+ config = self.get_config()
+
+ return config, input_ids, attention_mask, pixel_values, decoder_input_ids, decoder_attention_mask, lm_labels
+
+ def get_config(self):
+ return Blip2Config.from_vision_qformer_text_configs(
+ vision_config=self.vision_model_tester.get_config(),
+ qformer_config=self.qformer_model_tester.get_config(),
+ text_config=self.text_model_tester.get_config(),
+ num_query_tokens=self.num_query_tokens,
+ )
+
+ def create_and_check_for_conditional_generation(
+ self, config, input_ids, attention_mask, pixel_values, decoder_input_ids, decoder_attention_mask, labels
+ ):
+ model = Blip2ForConditionalGeneration(config).to(torch_device).eval()
+ with torch.no_grad():
+ result = model(pixel_values, input_ids, attention_mask, decoder_input_ids, decoder_attention_mask)
+
+ self.parent.assertEqual(
+ result.logits.shape,
+ (
+ self.vision_model_tester.batch_size,
+ self.text_model_tester.seq_length,
+ self.text_model_tester.vocab_size,
+ ),
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ attention_mask,
+ pixel_values,
+ decoder_input_ids,
+ decoder_attention_mask,
+ labels,
+ ) = config_and_inputs
+ inputs_dict = {
+ "pixel_values": pixel_values,
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "decoder_input_ids": decoder_input_ids,
+ "decoder_attention_mask": decoder_attention_mask,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class Blip2ModelTest(ModelTesterMixin, PipelineTesterMixin, GenerationTesterMixin, unittest.TestCase):
+ all_model_classes = (Blip2ForConditionalGeneration, Blip2Model) if is_torch_available() else ()
+ additional_model_inputs = ["input_ids", "decoder_input_ids"]
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": Blip2Model,
+ "image-to-text": Blip2ForConditionalGeneration,
+ "visual-question-answering": Blip2ForConditionalGeneration,
+ "image-text-to-text": Blip2ForConditionalGeneration,
+ }
+ if is_torch_available()
+ else {}
+ )
+ fx_compatible = False
+ test_head_masking = False
+ test_pruning = False
+ test_resize_embeddings = True
+ test_attention_outputs = False
+ test_torchscript = False
+ _is_composite = True
+
+ # TODO: Fix the failed tests
+ def is_pipeline_test_to_skip(
+ self,
+ pipeline_test_case_name,
+ config_class,
+ model_architecture,
+ tokenizer_name,
+ image_processor_name,
+ feature_extractor_name,
+ processor_name,
+ ):
+ if pipeline_test_case_name == "VisualQuestionAnsweringPipelineTests":
+ # Get `RuntimeError: "LayerNormKernelImpl" not implemented for 'Half'`.
+ return True
+
+ return False
+
+ def setUp(self):
+ self.model_tester = Blip2ModelTester(self)
+ common_properties = ["image_token_index", "num_query_tokens", "image_text_hidden_size"]
+ self.config_tester = ConfigTester(
+ self, config_class=Blip2Config, has_text_modality=False, common_properties=common_properties
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_for_conditional_generation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_conditional_generation(*config_and_inputs)
+
+ @unittest.skip(
+ reason="Blip2QFormerModel does not support an attention implementation through torch.nn.functional.scaled_dot_product_attention yet."
+ )
+ def test_eager_matches_sdpa_generate(self):
+ pass
+
+ @unittest.skip(reason="Hidden_states is tested in individual model tests")
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip(reason="Inputs_embeds is tested in individual model tests")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Retain_grad is tested in individual model tests")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ @unittest.skip(reason="Blip2Model does not have input/output embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @unittest.skip(reason="Does not work on the tiny model as we keep hitting edge cases.")
+ def test_cpu_offload(self):
+ pass
+
+ @require_torch_sdpa
+ def test_sdpa_can_dispatch_composite_models(self):
+ """
+ Tests if composite models dispatch correctly on SDPA/eager when requested so when loading the model.
+ This tests only by looking at layer names, as usually SDPA layers are called "SDPAAttention".
+ In contrast to the above test, this one checks if the "config._attn_implamentation" is a dict after the model
+ is loaded, because we manually replicate requested attn implementation on each sub-config when loading.
+ See https://github.com/huggingface/transformers/pull/32238 for more info
+
+ The test tries to cover most general cases of composite models, VLMs with vision and text configs. Any model
+ that has a different set of sub-configs has to overwrite this test.
+ """
+ if not self.has_attentions:
+ self.skipTest(reason="Model architecture does not support attentions")
+
+ if not self._is_composite:
+ self.skipTest(f"{self.all_model_classes[0].__name__} does not support SDPA")
+
+ for model_class in self.all_model_classes:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_sdpa = model_class.from_pretrained(tmpdirname)
+ model_sdpa = model_sdpa.eval().to(torch_device)
+
+ # `None` as it is the requested one which will be assigned to each sub-config
+ # Sub-model will dispatch to SDPA if it can (checked below that `SDPA` layers are present)
+ self.assertTrue(model.language_model.config._attn_implementation == "eager")
+ self.assertTrue(model.vision_model.config._attn_implementation == "sdpa")
+ self.assertTrue(model.qformer.config._attn_implementation == "eager")
+
+ model_eager = model_class.from_pretrained(tmpdirname, attn_implementation="eager")
+ model_eager = model_eager.eval().to(torch_device)
+ self.assertTrue(model_eager.config._attn_implementation == "eager")
+ self.assertTrue(model_eager.language_model.config._attn_implementation == "eager")
+ self.assertTrue(model_eager.vision_model.config._attn_implementation == "eager")
+ self.assertTrue(model_eager.qformer.config._attn_implementation == "eager")
+
+ for name, submodule in model_eager.named_modules():
+ class_name = submodule.__class__.__name__
+ if (
+ class_name.endswith("Attention")
+ and getattr(submodule, "config", None)
+ and submodule.config._attn_implementation == "sdpa"
+ ):
+ raise ValueError("The eager model should not have SDPA attention layers")
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_load_vision_qformer_text_config(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # Save Blip2Config and check if we can load Blip2VisionConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ vision_config = Blip2VisionConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.vision_config.to_dict(), vision_config.to_dict())
+
+ # Save Blip2Config and check if we can load Blip2QFormerConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ qformer_config = Blip2QFormerConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.qformer_config.to_dict(), qformer_config.to_dict())
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "Salesforce/blip2-opt-2.7b"
+ model = Blip2ForConditionalGeneration.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ def test_get_text_features(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ inputs_dict = {
+ "input_ids": torch.LongTensor([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]]).to(torch_device),
+ "attention_mask": torch.LongTensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]).to(torch_device),
+ "decoder_input_ids": torch.LongTensor([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]]).to(torch_device),
+ }
+
+ model = Blip2Model(config).to(torch_device)
+ model.eval()
+ text_features = model.get_text_features(**inputs_dict)
+ self.assertEqual(text_features[0].shape, (1, 10, config.text_config.vocab_size))
+
+ def test_get_image_features(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ keys_to_pop = ["input_ids", "attention_mask", "decoder_input_ids", "decoder_attention_mask"]
+
+ for key in keys_to_pop:
+ inputs_dict.pop(key)
+
+ model = Blip2Model(config).to(torch_device)
+ model.eval()
+ image_features = model.get_image_features(**inputs_dict)
+ self.assertEqual(
+ image_features[0].shape,
+ (
+ self.model_tester.vision_model_tester.batch_size,
+ self.model_tester.vision_model_tester.seq_length,
+ config.vision_config.hidden_size,
+ ),
+ )
+
+ def test_get_qformer_features(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ keys_to_pop = ["input_ids", "attention_mask", "decoder_input_ids", "decoder_attention_mask"]
+
+ for key in keys_to_pop:
+ inputs_dict.pop(key)
+
+ model = Blip2Model(config).to(torch_device)
+ model.eval()
+ qformer_features = model.get_qformer_features(**inputs_dict)
+ self.assertEqual(
+ qformer_features[0].shape,
+ (self.model_tester.vision_model_tester.batch_size, 10, config.vision_config.hidden_size),
+ )
+
+ # override from common to deal with nested configurations (`vision_config`, `text_config` and `qformer_config`)
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for key in ["vision_config", "qformer_config", "text_config"]:
+ setattr(configs_no_init, key, _config_zero_init(getattr(configs_no_init, key)))
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+
+class Blip2TextModelWithProjectionTester:
+ def __init__(self, parent, vision_kwargs=None, qformer_kwargs=None, is_training=True):
+ if vision_kwargs is None:
+ vision_kwargs = {}
+ if qformer_kwargs is None:
+ qformer_kwargs = {"use_qformer_text_input": True}
+
+ self.parent = parent
+ self.vision_model_tester = Blip2VisionModelTester(parent, **vision_kwargs)
+ self.qformer_model_tester = Blip2QFormerModelTester(parent, **qformer_kwargs)
+ self.is_training = is_training
+ self.batch_size = self.vision_model_tester.batch_size # need bs for batching_equivalence test
+
+ def get_config(self):
+ return Blip2Config.from_vision_qformer_text_configs(
+ vision_config=self.vision_model_tester.get_config(),
+ qformer_config=self.qformer_model_tester.get_config(),
+ )
+
+ def prepare_config_and_inputs(self):
+ _, input_ids, attention_mask = self.qformer_model_tester.prepare_config_and_inputs()
+
+ config = self.get_config()
+
+ return config, input_ids, attention_mask
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, attention_mask = config_and_inputs
+ inputs_dict = {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ }
+ return config, inputs_dict
+
+ def create_and_check_model(self, config, input_ids, attention_mask):
+ model = Blip2TextModelWithProjection(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(input_ids, attention_mask=attention_mask, output_attentions=True, output_hidden_states=True)
+
+ self.parent.assertEqual(
+ result.last_hidden_state.shape,
+ (self.vision_model_tester.batch_size, input_ids.shape[1], self.qformer_model_tester.hidden_size),
+ )
+ self.parent.assertEqual(
+ result.text_embeds.shape,
+ (
+ self.vision_model_tester.batch_size,
+ input_ids.shape[1],
+ config.image_text_hidden_size,
+ ),
+ )
+
+ with torch.no_grad():
+ result2 = model(
+ input_ids,
+ attention_mask=attention_mask,
+ return_dict=not config.use_return_dict,
+ output_attentions=True,
+ output_hidden_states=True,
+ )
+
+ self.parent.assertTrue(torch.allclose(result.text_embeds, result2[0]))
+ self.parent.assertTrue(torch.allclose(result.last_hidden_state, result2[1]))
+ self.parent.assertTrue(torch.allclose(result.hidden_states[0], result2[2][0]))
+ self.parent.assertTrue(torch.allclose(result.hidden_states[1], result2[2][1]))
+ self.parent.assertTrue(torch.allclose(result.attentions[0], result2[3][0]))
+ self.parent.assertTrue(torch.allclose(result.attentions[1], result2[3][1]))
+
+
+@require_torch
+class Blip2TextModelWithProjectionTest(ModelTesterMixin, unittest.TestCase):
+ all_model_classes = (Blip2TextModelWithProjection,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_head_masking = False
+
+ test_resize_embeddings = True
+ test_attention_outputs = False
+ test_torchscript = False
+
+ def setUp(self):
+ self.model_tester = Blip2TextModelWithProjectionTester(self)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip(reason="Training is not yet supported")
+ def test_training(self):
+ pass
+
+ @unittest.skip(reason="Training is not yet supported")
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(reason="Hidden_states is tested in individual model tests")
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip(reason="Blip2TextModelWithProjection does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Blip2TextModelWithProjection does not support input and output embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @unittest.skip(reason="Retain_grad is tested in individual model tests")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ @unittest.skip(reason="Blip2TextModelWithProjection does not have input/output embeddings")
+ def test_model_common_attributes(self):
+ pass
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["input_ids", "attention_mask", "position_ids"]
+ self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
+
+ @slow
+ @require_torch_accelerator
+ def test_model_from_pretrained(self):
+ model_name = "Salesforce/blip2-itm-vit-g"
+ model = Blip2TextModelWithProjection.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+ self.assertTrue(hasattr(model, "text_projection"))
+
+ _, input_ids, attention_mask = self.model_tester.prepare_config_and_inputs()
+
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(input_ids=input_ids, attention_mask=attention_mask)
+
+ self.assertEqual(
+ outputs.text_embeds.shape,
+ (
+ self.model_tester.qformer_model_tester.batch_size,
+ input_ids.shape[1],
+ model.config.image_text_hidden_size,
+ ),
+ )
+
+
+class Blip2VisionModelWithProjectionTester:
+ def __init__(self, parent, vision_kwargs=None, qformer_kwargs=None, is_training=True):
+ if vision_kwargs is None:
+ vision_kwargs = {}
+ if qformer_kwargs is None:
+ qformer_kwargs = {"use_qformer_text_input": True}
+
+ self.parent = parent
+ self.vision_model_tester = Blip2VisionModelTester(parent, **vision_kwargs)
+ self.qformer_model_tester = Blip2QFormerModelTester(parent, **qformer_kwargs)
+ self.is_training = is_training
+ self.num_hidden_layers = self.vision_model_tester.num_hidden_layers
+ self.num_attention_heads = self.vision_model_tester.num_attention_heads
+ self.seq_length = self.vision_model_tester.seq_length
+ self.hidden_size = self.vision_model_tester.hidden_size
+ self.batch_size = self.vision_model_tester.batch_size # need bs for batching_equivalence test
+
+ def get_config(self):
+ return Blip2Config.from_vision_qformer_text_configs(
+ vision_config=self.vision_model_tester.get_config(),
+ qformer_config=self.qformer_model_tester.get_config(),
+ )
+
+ def prepare_config_and_inputs(self):
+ _, pixel_values = self.vision_model_tester.prepare_config_and_inputs()
+
+ config = self.get_config()
+
+ return config, pixel_values
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+ def create_and_check_model(self, config, pixel_values):
+ model = Blip2VisionModelWithProjection(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(pixel_values, output_attentions=True, output_hidden_states=True)
+
+ self.parent.assertEqual(
+ result.last_hidden_state.shape,
+ (
+ self.vision_model_tester.batch_size,
+ self.vision_model_tester.seq_length,
+ self.qformer_model_tester.hidden_size,
+ ),
+ )
+ self.parent.assertEqual(
+ result.image_embeds.shape,
+ (
+ self.vision_model_tester.batch_size,
+ config.vision_config.hidden_size,
+ config.image_text_hidden_size,
+ ),
+ )
+
+ with torch.no_grad():
+ result2 = model(
+ pixel_values,
+ return_dict=not config.use_return_dict,
+ output_attentions=True,
+ output_hidden_states=True,
+ )
+
+ self.parent.assertTrue(torch.allclose(result.image_embeds, result2[0]))
+ self.parent.assertTrue(torch.allclose(result.last_hidden_state, result2[1]))
+ self.parent.assertTrue(torch.allclose(result.hidden_states[0], result2[2][0]))
+ self.parent.assertTrue(torch.allclose(result.hidden_states[1], result2[2][1]))
+ self.parent.assertTrue(torch.allclose(result.attentions[0], result2[3][0]))
+ self.parent.assertTrue(torch.allclose(result.attentions[1], result2[3][1]))
+
+
+@require_torch
+class Blip2VisionModelWithProjectionTest(ModelTesterMixin, unittest.TestCase):
+ all_model_classes = (Blip2VisionModelWithProjection,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_head_masking = False
+
+ test_resize_embeddings = False
+ test_torchscript = False
+
+ def setUp(self):
+ self.model_tester = Blip2VisionModelWithProjectionTester(self)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip(reason="Training is not yet supported")
+ def test_training(self):
+ pass
+
+ @unittest.skip(reason="Training is not yet supported")
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(reason="Training is not yet supported")
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(reason="Training is not yet supported")
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @unittest.skip(reason="Blip2VisionModelWithProjection does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Blip2VisionModelWithProjection does not support input and output embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @unittest.skip(reason="Retain_grad is tested in individual model tests")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ def test_model_common_attributes(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
+
+ @slow
+ @require_torch_accelerator
+ def test_model_from_pretrained(self):
+ model_name = "Salesforce/blip2-itm-vit-g"
+ model = Blip2VisionModelWithProjection.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+ self.assertTrue(hasattr(model, "vision_projection"))
+
+ _, pixel_values = self.model_tester.prepare_config_and_inputs()
+
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(pixel_values=pixel_values)
+
+ self.assertEqual(
+ outputs.image_embeds.shape,
+ (
+ self.model_tester.vision_model_tester.batch_size,
+ model.config.num_query_tokens,
+ model.config.image_text_hidden_size,
+ ),
+ )
+
+
+class Blip2TextRetrievalModelTester:
+ def __init__(self, parent, vision_kwargs=None, qformer_kwargs=None, is_training=True):
+ if vision_kwargs is None:
+ vision_kwargs = {}
+ if qformer_kwargs is None:
+ qformer_kwargs = {"use_qformer_text_input": True}
+
+ self.parent = parent
+ self.vision_model_tester = Blip2VisionModelTester(parent, **vision_kwargs)
+ self.qformer_model_tester = Blip2QFormerModelTester(parent, **qformer_kwargs)
+ self.is_training = is_training
+ self.batch_size = self.vision_model_tester.batch_size # need bs for batching_equivalence test
+
+ def get_config(self):
+ return Blip2Config.from_vision_qformer_text_configs(
+ vision_config=self.vision_model_tester.get_config(),
+ qformer_config=self.qformer_model_tester.get_config(),
+ )
+
+ def prepare_config_and_inputs(self):
+ _, input_ids, attention_mask = self.qformer_model_tester.prepare_config_and_inputs()
+ _, pixel_values = self.vision_model_tester.prepare_config_and_inputs()
+
+ config = self.get_config()
+
+ return config, input_ids, attention_mask, pixel_values
+
+ def create_and_check_model(self, config, input_ids, attention_mask, pixel_values):
+ model = Blip2ForImageTextRetrieval(config).to(torch_device).eval()
+ with torch.no_grad():
+ result = model(pixel_values, input_ids, attention_mask, use_image_text_matching_head=True)
+
+ self.parent.assertEqual(
+ result.logits_per_image.shape,
+ (self.vision_model_tester.batch_size, 2),
+ )
+
+ with torch.no_grad():
+ result = model(pixel_values, input_ids, attention_mask)
+
+ self.parent.assertEqual(
+ result.logits_per_image.shape,
+ (self.vision_model_tester.batch_size, self.qformer_model_tester.batch_size),
+ )
+ self.parent.assertEqual(
+ result.logits_per_text.shape, (self.qformer_model_tester.batch_size, self.vision_model_tester.batch_size)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, attention_mask, pixel_values = config_and_inputs
+ inputs_dict = {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "pixel_values": pixel_values,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class Blip2TextRetrievalModelTest(ModelTesterMixin, unittest.TestCase):
+ all_model_classes = (Blip2ForImageTextRetrieval,) if is_torch_available() else ()
+ additional_model_inputs = ["input_ids"]
+ fx_compatible = False
+ test_head_masking = False
+ test_pruning = False
+ test_resize_embeddings = True
+ test_attention_outputs = False
+ test_torchscript = False
+
+ def setUp(self):
+ self.model_tester = Blip2TextRetrievalModelTester(self)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip(reason="Hidden_states is tested in individual model tests")
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip(reason="Inputs_embeds is tested in individual model tests")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Blip2ForImageTextRetrieval does not support input and output embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @unittest.skip(reason="Retain_grad is tested in individual model tests")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ @unittest.skip(reason="Blip2Model does not have input/output embeddings")
+ def test_model_common_attributes(self):
+ pass
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values", "input_ids", "attention_mask"]
+ expected_arg_names.extend(
+ ["use_image_text_matching_head"] if "use_image_text_matching_head" in arg_names else []
+ )
+ self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
+
+ def test_load_vision_qformer_text_config(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # Save Blip2Config and check if we can load Blip2VisionConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ vision_config = Blip2VisionConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.vision_config.to_dict(), vision_config.to_dict())
+
+ # Save Blip2Config and check if we can load Blip2QFormerConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ qformer_config = Blip2QFormerConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.qformer_config.to_dict(), qformer_config.to_dict())
+
+ @slow
+ @require_torch_accelerator
+ def test_model_from_pretrained(self):
+ model_name = "Salesforce/blip2-itm-vit-g"
+ model = Blip2ForImageTextRetrieval.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ _, input_ids, attention_mask, pixel_values = self.model_tester.prepare_config_and_inputs()
+
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(
+ pixel_values=pixel_values,
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ use_image_text_matching_head=True,
+ )
+ self.assertEqual(outputs.logits_per_image.shape, (self.model_tester.qformer_model_tester.batch_size, 2))
+
+ with torch.no_grad():
+ outputs = model(
+ pixel_values=pixel_values,
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ )
+ self.assertEqual(
+ outputs.logits_per_image.shape,
+ (self.model_tester.vision_model_tester.batch_size, self.model_tester.qformer_model_tester.batch_size),
+ )
+
+ @unittest.skip(reason="Training is not yet supported")
+ def test_training(self):
+ pass
+
+ @unittest.skip(reason="Training is not yet supported")
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(reason="Training is not yet supported")
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(reason="Training is not yet supported")
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ # check if `logit_scale` is initialized as per the original implementation
+ if name == "logit_scale":
+ self.assertAlmostEqual(
+ param.data.item(),
+ np.log(1 / 0.07),
+ delta=1e-3,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ elif name == "temp":
+ self.assertAlmostEqual(
+ param.data.item(),
+ 0.07,
+ delta=1e-3,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ else:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "https://huggingface.co/hf-internal-testing/blip-test-image/resolve/main/demo.jpg"
+ image = Image.open(requests.get(url, stream=True).raw)
+ return image
+
+
+@require_vision
+@require_torch
+@slow
+class Blip2ModelIntegrationTest(unittest.TestCase):
+ def setUp(self):
+ cleanup(torch_device, gc_collect=True)
+
+ def tearDown(self):
+ cleanup(torch_device, gc_collect=True)
+
+ def test_inference_opt(self):
+ processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
+ model = Blip2ForConditionalGeneration.from_pretrained(
+ "Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16
+ ).to(torch_device)
+
+ # prepare image
+ image = prepare_img()
+ inputs = processor(images=image, return_tensors="pt").to(torch_device, dtype=torch.float16)
+
+ predictions = model.generate(**inputs)
+ generated_text = processor.batch_decode(predictions, skip_special_tokens=True)[0].strip()
+
+ # Test output
+ expected_ids = [50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 2, 102, 693, 2828, 15, 5, 4105, 19, 10, 2335, 50118] # fmt: skip
+ self.assertEqual(predictions[0].tolist(), expected_ids)
+ self.assertEqual("a woman sitting on the beach with a dog", generated_text)
+
+ # image and context
+ prompt = "Question: which city is this? Answer:"
+ inputs = processor(images=image, text=prompt, return_tensors="pt").to(torch_device, dtype=torch.float16)
+
+ # max_length for BLIP includes prompt length from now on, use max_new_tokens
+ predictions = model.generate(**inputs, max_new_tokens=11)
+ generated_text = processor.batch_decode(predictions, skip_special_tokens=True)[0].strip()
+
+ # Test output
+ expected_ids = [50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 2, 45641, 35, 61, 343, 16, 42, 116, 31652, 35, 24, 18, 45, 10, 343, 6, 24, 18, 10, 4105, 50118] # fmt: skip
+ self.assertEqual(predictions[0].tolist(), expected_ids)
+ self.assertEqual(generated_text, "Question: which city is this? Answer: it's not a city, it's a beach")
+
+ def test_inference_interpolate_pos_encoding(self):
+ processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
+ model = Blip2ForConditionalGeneration.from_pretrained(
+ "Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16
+ ).to(torch_device)
+ processor.image_processor.size = {"height": 500, "width": 500}
+
+ image = prepare_img()
+ inputs = processor(images=image, return_tensors="pt").to(torch_device)
+
+ predictions = model.generate(**inputs, interpolate_pos_encoding=True)
+ generated_text = processor.batch_decode(predictions, skip_special_tokens=True)[0].strip()
+
+ expected_ids = [50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 2, 102, 693, 8, 2335, 15, 5, 4105, 50118] # fmt: skip
+ self.assertEqual(predictions[0].tolist(), expected_ids)
+ self.assertEqual(generated_text, "a woman and dog on the beach")
+
+ def test_inference_opt_batched_beam_search(self):
+ processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
+ model = Blip2ForConditionalGeneration.from_pretrained(
+ "Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16
+ ).to(torch_device)
+
+ # prepare image
+ image = prepare_img()
+ inputs = processor(images=[image, image], return_tensors="pt").to(torch_device, dtype=torch.float16)
+
+ predictions = model.generate(**inputs, num_beams=2)
+
+ # Test output (in this case, slightly different from greedy search)
+ expected_ids = [50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 50265, 2, 102, 693, 2828, 15, 5, 4105, 19, 69, 2335, 50118] # fmt: skip
+ self.assertEqual(predictions[0].tolist(), expected_ids)
+ self.assertEqual(predictions[1].tolist(), expected_ids)
+
+ def test_inference_t5(self):
+ processor = Blip2Processor.from_pretrained("Salesforce/blip2-flan-t5-xl")
+ model = Blip2ForConditionalGeneration.from_pretrained(
+ "Salesforce/blip2-flan-t5-xl", torch_dtype=torch.float16
+ ).to(torch_device)
+
+ # prepare image
+ image = prepare_img()
+ inputs = processor(images=image, return_tensors="pt").to(torch_device, dtype=torch.float16)
+
+ predictions = model.generate(**inputs)
+ generated_text = processor.batch_decode(predictions, skip_special_tokens=True)[0].strip()
+
+ expectations = Expectations(
+ {
+ ("xpu", 3): [
+ [0, 3, 9, 2335, 19, 1556, 28, 160, 1782, 30, 8, 2608, 1],
+ "a woman is playing with her dog on the beach",
+ ],
+ ("cuda", 7): [
+ [0, 3, 9, 2335, 19, 1556, 28, 160, 1782, 30, 8, 2608, 1],
+ "a woman is playing with her dog on the beach",
+ ],
+ }
+ )
+ expected_outputs = expectations.get_expectation()
+
+ # Test output
+ self.assertEqual(predictions[0].tolist(), expected_outputs[0])
+ self.assertEqual(expected_outputs[1], generated_text)
+
+ # image and context
+ prompt = "Question: which city is this? Answer:"
+ inputs = processor(images=image, text=prompt, return_tensors="pt").to(torch_device, dtype=torch.float16)
+
+ predictions = model.generate(**inputs)
+ generated_text = processor.batch_decode(predictions, skip_special_tokens=True)[0].strip()
+
+ expectations = Expectations(
+ {
+ ("xpu", 3): [
+ [0, 3, 7, 152, 2515, 11389, 3523, 1],
+ "san francisco",
+ ],
+ ("cuda", 7): [
+ [0, 3, 7, 152, 2515, 11389, 3523, 1],
+ "san francisco",
+ ],
+ }
+ )
+ expected_outputs = expectations.get_expectation()
+
+ # Test output
+ self.assertEqual(predictions[0].tolist(), expected_outputs[0])
+ self.assertEqual(generated_text, expected_outputs[1])
+
+ def test_inference_t5_batched_beam_search(self):
+ processor = Blip2Processor.from_pretrained("Salesforce/blip2-flan-t5-xl")
+ model = Blip2ForConditionalGeneration.from_pretrained(
+ "Salesforce/blip2-flan-t5-xl", torch_dtype=torch.float16
+ ).to(torch_device)
+
+ # prepare image
+ image = prepare_img()
+ inputs = processor(images=[image, image], return_tensors="pt").to(torch_device, dtype=torch.float16)
+
+ predictions = model.generate(**inputs, num_beams=2)
+
+ expectations = Expectations(
+ {
+ ("xpu", 3): [
+ [0, 3, 9, 2335, 19, 1556, 28, 160, 1782, 30, 8, 2608, 1],
+ [0, 3, 9, 2335, 19, 1556, 28, 160, 1782, 30, 8, 2608, 1],
+ ],
+ ("cuda", 7): [
+ [0, 3, 9, 2335, 19, 1556, 28, 160, 1782, 30, 8, 2608, 1],
+ [0, 3, 9, 2335, 19, 1556, 28, 160, 1782, 30, 8, 2608, 1],
+ ],
+ }
+ )
+ expected_predictions = expectations.get_expectation()
+
+ # Test output (in this case, slightly different from greedy search)
+ self.assertEqual(predictions[0].tolist(), expected_predictions[0])
+ self.assertEqual(predictions[1].tolist(), expected_predictions[1])
+
+ @require_torch_multi_accelerator
+ def test_inference_opt_multi_accelerator(self):
+ processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
+ model = Blip2ForConditionalGeneration.from_pretrained(
+ "Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16, device_map="balanced"
+ )
+
+ # prepare image
+ image = prepare_img()
+ inputs = processor(images=image, return_tensors="pt").to(0, dtype=torch.float16)
+
+ predictions = model.generate(**inputs)
+ generated_text = processor.batch_decode(predictions, skip_special_tokens=True)[0].strip()
+
+ # Test output
+ expected_ids = [2, 102, 693, 2828, 15, 5, 4105, 19, 10, 2335, 50118]
+ self.assertEqual(predictions[0].tolist(), [50265] * 32 + expected_ids) # 50265 is the img token id
+ self.assertEqual("a woman sitting on the beach with a dog", generated_text)
+
+ # image and context
+ prompt = "Question: which city is this? Answer:"
+ inputs = processor(images=image, text=prompt, return_tensors="pt").to(0, dtype=torch.float16)
+
+ predictions = model.generate(**inputs, max_new_tokens=11)
+ generated_text = processor.batch_decode(predictions, skip_special_tokens=True)[0].strip()
+
+ # Test output
+ expected_ids = [2, 45641, 35, 61, 343, 16, 42, 116, 31652, 35, 24, 18, 45, 10, 343, 6, 24, 18, 10, 4105, 50118]
+ self.assertEqual(predictions[0].tolist(), [50265] * 32 + expected_ids) # 50265 is the img token id
+ self.assertEqual(generated_text, "Question: which city is this? Answer: it's not a city, it's a beach")
+
+ @require_torch_multi_accelerator
+ def test_inference_t5_multi_accelerator(self):
+ processor = Blip2Processor.from_pretrained("Salesforce/blip2-flan-t5-xl")
+ device_map = device_map = {
+ "query_tokens": 0,
+ "vision_model": 0,
+ "language_model": 1,
+ "language_projection": 0,
+ "qformer": 0,
+ }
+
+ model = Blip2ForConditionalGeneration.from_pretrained(
+ "Salesforce/blip2-flan-t5-xl", torch_dtype=torch.float16, device_map=device_map
+ )
+
+ # prepare image
+ image = prepare_img()
+ inputs = processor(images=image, return_tensors="pt").to(f"{torch_device}:0", dtype=torch.float16)
+
+ predictions = model.generate(**inputs)
+ generated_text = processor.batch_decode(predictions, skip_special_tokens=True)[0].strip()
+
+ # Test output
+ expected_ids_and_text = Expectations(
+ {
+ ("cuda", None): ([0, 2335, 1556, 28, 1782, 30, 8, 2608, 1], "woman playing with dog on the beach"),
+ ("rocm", (9, 5)): (
+ [0, 3, 9, 2335, 19, 1556, 28, 160, 1782, 30, 8, 2608, 1],
+ "a woman is playing with her dog on the beach",
+ ),
+ }
+ ).get_expectation()
+ self.assertEqual(predictions[0].tolist(), expected_ids_and_text[0])
+ self.assertEqual(generated_text, expected_ids_and_text[1])
+
+ # image and context
+ prompt = "Question: which city is this? Answer:"
+ inputs = processor(images=image, text=prompt, return_tensors="pt").to(f"{torch_device}:0", dtype=torch.float16)
+
+ predictions = model.generate(**inputs)
+ generated_text = processor.batch_decode(predictions, skip_special_tokens=True)[0].strip()
+
+ # Test output
+ expected_ids_and_text = Expectations(
+ {
+ ("cuda", None): ([0, 3, 7, 152, 67, 839, 1], "san diego"),
+ ("rocm", (9, 5)): (
+ [0, 3, 7, 152, 2515, 11389, 3523, 1],
+ "san francisco", # TODO: check if this is ok
+ ),
+ }
+ ).get_expectation()
+ self.assertEqual(predictions[0].tolist(), expected_ids_and_text[0])
+ self.assertEqual(generated_text, expected_ids_and_text[1])
+
+ def test_expansion_in_processing(self):
+ processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
+ model = Blip2ForConditionalGeneration.from_pretrained(
+ "Salesforce/blip2-opt-2.7b", torch_dtype=torch.float16
+ ).to(torch_device)
+
+ image = prepare_img()
+ prompt = "Question: which city is this? Answer:"
+
+ # Make sure we will go the legacy path by setting these args to None
+ processor.num_query_tokens = None
+ model.config.image_token_index = None
+ inputs = processor(images=image, text=prompt, return_tensors="pt").to(torch_device, dtype=torch.float16)
+
+ predictions = model.generate(**inputs, do_sample=False, max_new_tokens=15)
+ generated_text = processor.batch_decode(predictions, skip_special_tokens=True)[0].strip()
+
+ # Add args to the config to trigger new logic when inputs are expanded in processing file
+ processor.num_query_tokens = model.config.num_query_tokens
+ processor.tokenizer.add_special_tokens({"additional_special_tokens": [""]})
+ model.config.image_token_index = len(processor.tokenizer) - 1
+ model.resize_token_embeddings(processor.tokenizer.vocab_size, pad_to_multiple_of=64)
+
+ # Generate again with new inputs
+ inputs = processor(images=image, text=prompt, return_tensors="pt").to(torch_device, dtype=torch.float16)
+ predictions_expanded = model.generate(**inputs, do_sample=False, max_new_tokens=15)
+ generated_text_expanded = processor.batch_decode(predictions_expanded, skip_special_tokens=True)[0].strip()
+
+ self.assertTrue(generated_text_expanded == generated_text)
+
+ @require_torch_accelerator
+ def test_inference_itm(self):
+ model_name = "Salesforce/blip2-itm-vit-g"
+ processor = Blip2Processor.from_pretrained(model_name)
+ model = Blip2ForImageTextRetrieval.from_pretrained(model_name).to(torch_device)
+
+ image = prepare_img()
+ text = "A woman and her dog sitting in a beach"
+ inputs = processor(images=image, text=text, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ out_itm = model(**inputs, use_image_text_matching_head=True)
+ out = model(**inputs)
+
+ # verify
+ expected_scores = torch.Tensor([[0.0238, 0.9762]])
+ torch.testing.assert_close(torch.nn.Softmax()(out_itm[0].cpu()), expected_scores, rtol=1e-3, atol=1e-3)
+ torch.testing.assert_close(out[0].cpu(), torch.Tensor([[0.4406]]), rtol=1e-3, atol=1e-3)
+
+ @require_torch_accelerator
+ @require_torch_fp16
+ def test_inference_itm_fp16(self):
+ model_name = "Salesforce/blip2-itm-vit-g"
+ processor = Blip2Processor.from_pretrained(model_name)
+ model = Blip2ForImageTextRetrieval.from_pretrained(model_name, torch_dtype=torch.float16).to(torch_device)
+
+ image = prepare_img()
+ text = "A woman and her dog sitting in a beach"
+ inputs = processor(images=image, text=text, return_tensors="pt").to(torch_device, dtype=torch.float16)
+
+ # forward pass
+ out_itm = model(**inputs, use_image_text_matching_head=True)
+ out = model(**inputs)
+
+ # verify
+ expected_scores = torch.Tensor([[0.0239, 0.9761]])
+ torch.testing.assert_close(torch.nn.Softmax()(out_itm[0].cpu().float()), expected_scores, rtol=1e-3, atol=1e-3)
+ torch.testing.assert_close(out[0].cpu().float(), torch.Tensor([[0.4406]]), rtol=1e-3, atol=1e-3)
+
+ @require_torch_accelerator
+ @require_torch_fp16
+ def test_inference_vision_with_projection_fp16(self):
+ model_name = "Salesforce/blip2-itm-vit-g"
+ processor = Blip2Processor.from_pretrained(model_name)
+ model = Blip2VisionModelWithProjection.from_pretrained(model_name, torch_dtype=torch.float16).to(torch_device)
+
+ image = prepare_img()
+ inputs = processor(images=image, return_tensors="pt").to(torch_device, dtype=torch.float16)
+
+ # forward pass
+ out = model(**inputs)
+
+ # verify
+ expected_image_embeds = [
+ -0.093994140625,
+ -0.075927734375,
+ 0.031890869140625,
+ 0.053009033203125,
+ 0.0352783203125,
+ -0.01190185546875,
+ ]
+ self.assertTrue(np.allclose(out.image_embeds[0][0][:6].tolist(), expected_image_embeds, atol=1e-3))
+
+ @require_torch_accelerator
+ @require_torch_fp16
+ def test_inference_text_with_projection_fp16(self):
+ model_name = "Salesforce/blip2-itm-vit-g"
+ processor = Blip2Processor.from_pretrained(model_name)
+ model = Blip2TextModelWithProjection.from_pretrained(model_name, torch_dtype=torch.float16).to(torch_device)
+
+ inputs = processor(text="a woman sitting on the beach with a dog", padding=True, return_tensors="pt").to(
+ torch_device
+ )
+
+ # forward pass
+ out = model(**inputs)
+
+ # verify
+ expected_text_embeds = [
+ -0.1082763671875,
+ 0.053192138671875,
+ -0.02825927734375,
+ 0.0169830322265625,
+ 0.08648681640625,
+ -0.04656982421875,
+ ]
+ self.assertTrue(np.allclose(out.text_embeds[0][0][:6].tolist(), expected_text_embeds, atol=1e-3))
diff --git a/transformers/tests/models/blip_2/test_processor_blip_2.py b/transformers/tests/models/blip_2/test_processor_blip_2.py
new file mode 100644
index 0000000000000000000000000000000000000000..5d125dc57e959dd4c1174706d9909fa4667d9379
--- /dev/null
+++ b/transformers/tests/models/blip_2/test_processor_blip_2.py
@@ -0,0 +1,144 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import shutil
+import tempfile
+import unittest
+
+import pytest
+
+from transformers.testing_utils import require_vision
+from transformers.utils import is_vision_available
+
+from ...test_processing_common import ProcessorTesterMixin
+
+
+if is_vision_available():
+ from transformers import AutoProcessor, Blip2Processor, BlipImageProcessor, GPT2Tokenizer, PreTrainedTokenizerFast
+
+
+@require_vision
+class Blip2ProcessorTest(ProcessorTesterMixin, unittest.TestCase):
+ processor_class = Blip2Processor
+
+ @classmethod
+ def setUpClass(cls):
+ cls.tmpdirname = tempfile.mkdtemp()
+
+ image_processor = BlipImageProcessor()
+ tokenizer = GPT2Tokenizer.from_pretrained("hf-internal-testing/tiny-random-GPT2Model")
+
+ processor = Blip2Processor(image_processor, tokenizer)
+
+ processor.save_pretrained(cls.tmpdirname)
+
+ def get_tokenizer(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).tokenizer
+
+ def get_image_processor(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).image_processor
+
+ @classmethod
+ def tearDownClass(cls):
+ shutil.rmtree(cls.tmpdirname, ignore_errors=True)
+
+ def test_save_load_pretrained_additional_features(self):
+ with tempfile.TemporaryDirectory() as tmpdir:
+ processor = Blip2Processor(tokenizer=self.get_tokenizer(), image_processor=self.get_image_processor())
+ processor.save_pretrained(tmpdir)
+
+ tokenizer_add_kwargs = self.get_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
+ image_processor_add_kwargs = self.get_image_processor(do_normalize=False, padding_value=1.0)
+
+ processor = Blip2Processor.from_pretrained(
+ tmpdir, bos_token="(BOS)", eos_token="(EOS)", do_normalize=False, padding_value=1.0
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, PreTrainedTokenizerFast)
+
+ self.assertEqual(processor.image_processor.to_json_string(), image_processor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.image_processor, BlipImageProcessor)
+
+ def test_image_processor(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = Blip2Processor(tokenizer=tokenizer, image_processor=image_processor)
+
+ image_input = self.prepare_image_inputs()
+
+ input_feat_extract = image_processor(image_input, return_tensors="np")
+ input_processor = processor(images=image_input, return_tensors="np")
+
+ for key in input_feat_extract.keys():
+ self.assertAlmostEqual(input_feat_extract[key].sum(), input_processor[key].sum(), delta=1e-2)
+
+ def test_tokenizer(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = Blip2Processor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+
+ encoded_processor = processor(text=input_str)
+
+ encoded_tok = tokenizer(input_str, return_token_type_ids=False)
+
+ for key in encoded_tok.keys():
+ self.assertListEqual(encoded_tok[key], encoded_processor[key][0])
+
+ def test_processor(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = Blip2Processor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ self.assertCountEqual(list(inputs.keys()), ["input_ids", "pixel_values", "attention_mask"])
+
+ # test if it raises when no input is passed
+ with pytest.raises(ValueError):
+ processor()
+
+ def test_tokenizer_decode(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = Blip2Processor(tokenizer=tokenizer, image_processor=image_processor)
+
+ predicted_ids = [[1, 4, 5, 8, 1, 0, 8], [3, 4, 3, 1, 1, 8, 9]]
+
+ decoded_processor = processor.batch_decode(predicted_ids)
+ decoded_tok = tokenizer.batch_decode(predicted_ids)
+
+ self.assertListEqual(decoded_tok, decoded_processor)
+
+ def test_model_input_names(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = Blip2Processor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ # For now the processor supports only ['pixel_values', 'input_ids', 'attention_mask']
+ self.assertCountEqual(list(inputs.keys()), ["input_ids", "pixel_values", "attention_mask"])
diff --git a/transformers/tests/models/bloom/__init__.py b/transformers/tests/models/bloom/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/bloom/test_modeling_bloom.py b/transformers/tests/models/bloom/test_modeling_bloom.py
new file mode 100644
index 0000000000000000000000000000000000000000..787a99c93290885874d11cc33e3e5cfec99feebe
--- /dev/null
+++ b/transformers/tests/models/bloom/test_modeling_bloom.py
@@ -0,0 +1,809 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+
+import math
+import unittest
+
+from transformers import BloomConfig, is_torch_available
+from transformers.testing_utils import require_torch, require_torch_accelerator, slow, torch_device
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ BloomForCausalLM,
+ BloomForQuestionAnswering,
+ BloomForSequenceClassification,
+ BloomForTokenClassification,
+ BloomModel,
+ BloomTokenizerFast,
+ )
+
+
+@require_torch
+class BloomModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=14,
+ seq_length=7,
+ is_training=True,
+ use_token_type_ids=False,
+ use_input_mask=True,
+ use_labels=True,
+ use_mc_token_ids=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_token_type_ids = use_token_type_ids
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.use_mc_token_ids = use_mc_token_ids
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_dropout_prob = attention_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.scope = None
+ self.bos_token_id = vocab_size - 1
+ self.eos_token_id = vocab_size - 1
+ self.pad_token_id = vocab_size - 1
+
+ def get_large_model_config(self):
+ return BloomConfig.from_pretrained("bigscience/bloom")
+
+ def prepare_config_and_inputs(self, gradient_checkpointing=False):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ sequence_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+
+ config = self.get_config(gradient_checkpointing=gradient_checkpointing)
+
+ return (config, input_ids, input_mask, sequence_labels)
+
+ def get_config(self, gradient_checkpointing=False, slow_but_exact=True):
+ return BloomConfig(
+ vocab_size=self.vocab_size,
+ seq_length=self.seq_length,
+ hidden_size=self.hidden_size,
+ n_layer=self.num_hidden_layers,
+ n_head=self.num_attention_heads,
+ hidden_dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_dropout_prob,
+ n_positions=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ initializer_range=self.initializer_range,
+ use_cache=True,
+ bos_token_id=self.bos_token_id,
+ eos_token_id=self.eos_token_id,
+ pad_token_id=self.pad_token_id,
+ num_labels=self.num_labels,
+ gradient_checkpointing=gradient_checkpointing,
+ slow_but_exact=slow_but_exact,
+ dtype="float32",
+ )
+
+ def create_and_check_bloom_model(self, config, input_ids, input_mask, *args):
+ model = BloomModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids)
+
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(len(result.past_key_values), config.n_layer)
+
+ def create_and_check_bloom_model_past(self, config, input_ids, input_mask, *args):
+ model = BloomModel(config=config)
+
+ model.to(torch_device)
+ model.eval()
+
+ # first forward pass
+ outputs = model(input_ids, attention_mask=torch.ones_like(input_ids), use_cache=True)
+ outputs_use_cache_conf = model(input_ids, attention_mask=torch.ones_like(input_ids))
+ outputs_no_past = model(input_ids, use_cache=False, attention_mask=torch.ones_like(input_ids))
+
+ self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf))
+ self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1)
+
+ past = outputs["past_key_values"]
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
+
+ # append to next input_ids and token_type_ids
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+
+ output_from_no_past = model(next_input_ids)["last_hidden_state"]
+ output_from_past = model(next_tokens, past_key_values=past)["last_hidden_state"]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_bloom_model_attention_mask_past(self, config, input_ids, input_mask, *args):
+ model = BloomModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # create attention mask
+ attn_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
+ half_seq_length = self.seq_length // 2
+ attn_mask[:, half_seq_length:] = 0
+
+ # first forward pass
+ output, past = model(input_ids, attention_mask=attn_mask).to_tuple()
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
+
+ # change a random masked slice from input_ids
+ random_seq_idx_to_change = ids_tensor((1,), half_seq_length).item() + 1
+ random_other_next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size).squeeze(-1)
+ input_ids[:, -random_seq_idx_to_change] = random_other_next_tokens
+
+ # append to next input_ids and attn_mask
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ attn_mask = torch.cat(
+ [attn_mask, torch.ones((attn_mask.shape[0], 1), dtype=torch.long, device=torch_device)],
+ dim=1,
+ )
+
+ # get two different outputs
+ output_from_no_past = model(next_input_ids, attention_mask=attn_mask)["last_hidden_state"]
+ output_from_past = model(next_tokens, past_key_values=past, attention_mask=attn_mask)["last_hidden_state"]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_bloom_model_past_large_inputs(self, config, input_ids, input_mask, *args):
+ model = BloomModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # first forward pass
+ outputs = model(input_ids, attention_mask=input_mask, use_cache=True)
+
+ output, past = outputs.to_tuple()
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
+
+ # append to next input_ids and token_type_ids
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
+
+ output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)["last_hidden_state"]
+ output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past)[
+ "last_hidden_state"
+ ]
+ self.parent.assertTrue(output_from_past.shape[1] == next_tokens.shape[1])
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_lm_head_model(self, config, input_ids, input_mask, *args):
+ model = BloomForCausalLM(config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids, labels=input_ids)
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_sequence_classification_model(self, config, input_ids, input_mask, *args):
+ config.num_labels = self.num_labels
+ model = BloomForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids, attention_mask=input_mask)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def create_and_check_token_classification_model(self, config, input_ids, input_mask, *args):
+ model = BloomForTokenClassification(config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids, attention_mask=input_mask)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+
+ def create_and_check_forward_and_backwards(
+ self, config, input_ids, input_mask, *args, gradient_checkpointing=False
+ ):
+ model = BloomForCausalLM(config)
+ model.to(torch_device)
+ if gradient_checkpointing:
+ model.gradient_checkpointing_enable()
+
+ result = model(input_ids, labels=input_ids)
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+ result.loss.backward()
+
+ def create_and_check_bloom_weight_initialization(self, config, *args):
+ model = BloomModel(config)
+ model_std = model.config.initializer_range / math.sqrt(2 * model.config.n_layer)
+ for key in model.state_dict().keys():
+ if "c_proj" in key and "weight" in key:
+ self.parent.assertLessEqual(abs(torch.std(model.state_dict()[key]) - model_std), 0.001)
+ self.parent.assertLessEqual(abs(torch.mean(model.state_dict()[key]) - 0.0), 0.01)
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+
+ config, input_ids, input_mask, sequence_labels = config_and_inputs
+
+ inputs_dict = {"input_ids": input_ids}
+
+ return config, inputs_dict
+
+
+@require_torch
+class BloomModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ BloomModel,
+ BloomForCausalLM,
+ BloomForSequenceClassification,
+ BloomForTokenClassification,
+ BloomForQuestionAnswering,
+ )
+ if is_torch_available()
+ else ()
+ )
+
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": BloomModel,
+ "question-answering": BloomForQuestionAnswering,
+ "text-classification": BloomForSequenceClassification,
+ "text-generation": BloomForCausalLM,
+ "token-classification": BloomForTokenClassification,
+ "zero-shot": BloomForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ fx_compatible = True
+ test_missing_keys = False
+ test_pruning = False
+ test_torchscript = True # torch.autograd functions seems not to be supported
+
+ def setUp(self):
+ self.model_tester = BloomModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=BloomConfig, n_embd=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_bloom_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_bloom_model(*config_and_inputs)
+
+ def test_bloom_model_past(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_bloom_model_past(*config_and_inputs)
+
+ def test_bloom_model_att_mask_past(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_bloom_model_attention_mask_past(*config_and_inputs)
+
+ def test_bloom_model_past_large_inputs(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_bloom_model_past_large_inputs(*config_and_inputs)
+
+ def test_bloom_lm_head_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_lm_head_model(*config_and_inputs)
+
+ def test_bloom_sequence_classification_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_sequence_classification_model(*config_and_inputs)
+
+ def test_bloom_token_classification_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_token_classification_model(*config_and_inputs)
+
+ def test_bloom_gradient_checkpointing(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_forward_and_backwards(*config_and_inputs, gradient_checkpointing=True)
+
+ def test_bloom_weight_initialization(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_bloom_weight_initialization(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "bigscience/bigscience-small-testing"
+ model = BloomModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ @slow
+ @require_torch_accelerator
+ def test_simple_generation(self):
+ # This test is a bit flaky. For some GPU architectures, pytorch sets by default allow_fp16_reduced_precision_reduction = True and some operations
+ # do not give the same results under this configuration, especially torch.baddmm and torch.bmm. https://pytorch.org/docs/stable/notes/numerical_accuracy.html#fp16-on-mi200
+ # As we leave the default value (True) for allow_fp16_reduced_precision_reduction, the tests failed when running in half-precision with smaller models (560m)
+ # Please see: https://pytorch.org/docs/stable/notes/cuda.html#reduced-precision-reduction-in-fp16-gemms
+ # This discrepancy is observed only when using small models and seems to be stable for larger models.
+ # Our conclusion is that these operations are flaky for small inputs but seems to be stable for larger inputs (for the functions `baddmm` and `bmm`), and therefore for larger models.
+
+ # Here is a summary of an ablation study of our observations
+ # EXPECTED_OUTPUT = "I enjoy walking with my cute dog, and I love to watch the kids play. I am a very active person, and I am a very good listener. I am a very good person, and I am a very good person. I am a"
+ # 560m + allow_fp16_reduced_precision_reduction = False + torch.bmm ==> PASS
+ # 560m + allow_fp16_reduced_precision_reduction = False + torch.baddm ==> PASS
+ # 560m + allow_fp16_reduced_precision_reduction = True + torch.baddm ==> PASS
+ # 560m + allow_fp16_reduced_precision_reduction = True + torch.bmm ==> FAIL
+
+ # EXPECTED_OUTPUT = "I enjoy walking with my cute dog, but I also enjoy hiking, biking, and swimming. I love to cook and bake. I love to cook and bake. I love to cook and bake. I love to cook and bake. I love"
+ # >=1b1 + allow_fp16_reduced_precision_reduction = True + torch.baddm ==> PASS (for use_cache=True and use_cache=False)
+ # >=1b1 + allow_fp16_reduced_precision_reduction = True + torch.bmm ==> PASS
+ # >=1b1 + allow_fp16_reduced_precision_reduction = False + torch.bmm ==> PASS
+
+ path_560m = "bigscience/bloom-560m"
+ model = BloomForCausalLM.from_pretrained(path_560m, use_cache=True, revision="gs555750").to(torch_device)
+ model = model.eval()
+ tokenizer = BloomTokenizerFast.from_pretrained(path_560m)
+
+ input_sentence = "I enjoy walking with my cute dog"
+ # This output has been obtained using fp32 model on the huggingface DGX workstation - NVIDIA A100 GPU
+ EXPECTED_OUTPUT = (
+ "I enjoy walking with my cute dog, and I love to watch the kids play with the kids. I am a very "
+ "active person, and I enjoy working out, and I am a very active person. I am a very active person, and I"
+ )
+
+ input_ids = tokenizer.encode(input_sentence, return_tensors="pt")
+ greedy_output = model.generate(input_ids.to(torch_device), max_length=50)
+
+ self.assertEqual(tokenizer.decode(greedy_output[0], skip_special_tokens=True), EXPECTED_OUTPUT)
+
+ @slow
+ @require_torch_accelerator
+ def test_batch_generation(self):
+ path_560m = "bigscience/bloom-560m"
+ model = BloomForCausalLM.from_pretrained(path_560m, use_cache=True, revision="gs555750").to(torch_device)
+ model = model.eval()
+ tokenizer = BloomTokenizerFast.from_pretrained(path_560m, padding_side="left")
+
+ input_sentence = ["I enjoy walking with my cute dog", "I enjoy walking with my cute dog"]
+
+ inputs = tokenizer.batch_encode_plus(input_sentence, return_tensors="pt", padding=True)
+ input_ids = inputs["input_ids"].to(torch_device)
+ attention_mask = inputs["attention_mask"]
+ greedy_output = model.generate(input_ids, attention_mask=attention_mask, max_length=50, do_sample=False)
+
+ self.assertEqual(
+ tokenizer.decode(greedy_output[0], skip_special_tokens=True),
+ tokenizer.decode(greedy_output[1], skip_special_tokens=True),
+ )
+
+ @slow
+ @require_torch_accelerator
+ def test_batch_generation_padd(self):
+ path_560m = "bigscience/bloom-560m"
+ model = BloomForCausalLM.from_pretrained(path_560m, use_cache=True, revision="gs555750").to(torch_device)
+ model = model.eval()
+ tokenizer = BloomTokenizerFast.from_pretrained(path_560m, padding_side="left")
+
+ input_sentence = ["I enjoy walking with my cute dog", "Hello my name is"]
+ input_sentence_without_pad = "Hello my name is"
+
+ input_ids = tokenizer.batch_encode_plus(input_sentence, return_tensors="pt", padding=True)
+ input_ids_without_pad = tokenizer.encode(input_sentence_without_pad, return_tensors="pt")
+
+ input_ids, attention_mask = input_ids["input_ids"].to(torch_device), input_ids["attention_mask"]
+ greedy_output = model.generate(input_ids, attention_mask=attention_mask, max_length=50, do_sample=False)
+ greedy_output_without_pad = model.generate(
+ input_ids_without_pad.to(torch_device), max_length=50, do_sample=False
+ )
+
+ # test token values
+ self.assertEqual(greedy_output[-1, 3:].tolist(), greedy_output_without_pad[0, :-3].tolist())
+
+ # test reconstructions
+ self.assertEqual(
+ tokenizer.decode(greedy_output[-1, 3:], skip_special_tokens=True),
+ tokenizer.decode(greedy_output_without_pad[0, :-3], skip_special_tokens=True),
+ )
+
+ @slow
+ @require_torch_accelerator
+ def test_batch_generated_text(self):
+ path_560m = "bigscience/bloom-560m"
+
+ model = BloomForCausalLM.from_pretrained(path_560m, use_cache=True, revision="gs555750").to(torch_device)
+ model = model.eval()
+ tokenizer = BloomTokenizerFast.from_pretrained(path_560m, padding_side="left")
+
+ input_sentences = [
+ "Hello what is",
+ "Running a quick test with the",
+ ]
+ inputs = tokenizer(input_sentences, return_tensors="pt", padding=True, truncation=True)
+ generated_ids = model.generate(
+ inputs["input_ids"].to(torch_device), attention_mask=inputs["attention_mask"], max_length=20
+ )
+ generated_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+
+ # these generations match those of the PyTorch model
+ EXPECTED_GENERATIONS = [
+ "Hello what is the best way to get the data from the server? I have tried",
+ "Running a quick test with the following command:\nsudo apt-get install python3\nsudo apt-get install python2",
+ ]
+
+ self.assertListEqual(generated_text, EXPECTED_GENERATIONS)
+
+ @unittest.skip("Bloom needs a 2D attention for alibi")
+ def test_custom_4d_attention_mask(self):
+ pass
+
+
+@require_torch
+class BloomEmbeddingTest(unittest.TestCase):
+ """
+ The goal here is to compare the embeddings generated by the model trained
+ using Megatron-LM with the one from the transformers library, with a small GPT2-like model
+ to ensure that the conversion from Megatron-LM to transformers has been done successfully.
+ The script compares the logits of the embedding layer and the transformer layers.
+
+ WARNING: It is expected that these logits will not have exactly the same statistics when running
+ the code on CPU or GPU. For more info, please visit:
+ - https://github.com/pytorch/pytorch/issues/76052#issuecomment-1103193548
+ - https://discuss.pytorch.org/t/reproducibility-issue-between-intel-and-amd-cpus/144779/9
+
+
+ You need to install tokenizers following this readme:
+ - https://huggingface.co/bigscience-catalogue-data-dev/byte-level-bpe-tokenizer-no-norm-250k-whitespace-and-eos-regex-alpha-v3-dedup-lines-articles
+
+ Tokenizer used during training:
+ - https://huggingface.co/bigscience-catalogue-data-dev/byte-level-bpe-tokenizer-no-norm-250k-whitespace-and-eos-regex-alpha-v3-dedup-lines-articles
+
+ # TODO change the script (or just add skip) when building the env with tokenizers 0.12.0
+ """
+
+ def setUp(self):
+ super().setUp()
+ self.path_bigscience_model = "bigscience/bigscience-small-testing"
+
+ @require_torch
+ def test_embeddings(self):
+ # The config in this checkpoint has `bfloat16` as `torch_dtype` -> model in `bfloat16`
+ model = BloomForCausalLM.from_pretrained(self.path_bigscience_model, torch_dtype="auto")
+ model.eval()
+
+ EMBEDDINGS_DS_BEFORE_LN_BF_16_MEAN = {
+ 3478: 0.0002307891845703125,
+ 368: -0.000568389892578125,
+ 109586: -0.0003910064697265625,
+ 35433: -0.000194549560546875,
+ 2: 0.0004138946533203125,
+ 77: 0.000659942626953125,
+ 132619: -0.00031280517578125,
+ 2175: 0.000457763671875,
+ 23714: 0.000263214111328125,
+ 73173: -0.000286102294921875,
+ 144252: 0.00052642822265625,
+ }
+ EMBEDDINGS_DS_BEFORE_LN_BF_16_MIN = {
+ 3478: -0.00921630859375,
+ 368: -0.010009765625,
+ 109586: -0.01031494140625,
+ 35433: -0.01177978515625,
+ 2: -0.0074462890625,
+ 77: -0.00848388671875,
+ 132619: -0.009521484375,
+ 2175: -0.0074462890625,
+ 23714: -0.0145263671875,
+ 73173: -0.007415771484375,
+ 144252: -0.01007080078125,
+ }
+ EMBEDDINGS_DS_BEFORE_LN_BF_16_MAX = {
+ 3478: 0.0128173828125,
+ 368: 0.01214599609375,
+ 109586: 0.0111083984375,
+ 35433: 0.01019287109375,
+ 2: 0.0157470703125,
+ 77: 0.0174560546875,
+ 132619: 0.0078125,
+ 2175: 0.0113525390625,
+ 23714: 0.0146484375,
+ 73173: 0.01116943359375,
+ 144252: 0.01141357421875,
+ }
+ EMBEDDINGS_DS_BEFORE_LN_BF_16_SUM = {"value": 0.08203125}
+
+ EMBEDDINGS_DS_BEFORE_LN_F_16_MEAN = {
+ 132619: -0.00031256675720214844,
+ 3478: 0.00023090839385986328,
+ 368: -0.0005702972412109375,
+ 109586: -0.00039124488830566406,
+ 35433: -0.000194549560546875,
+ 2: 0.0004146099090576172,
+ 2175: 0.0004572868347167969,
+ 23714: 0.00026416778564453125,
+ 73173: -0.0002865791320800781,
+ 144252: 0.0005254745483398438,
+ 77: 0.0006618499755859375,
+ }
+ EMBEDDINGS_DS_BEFORE_LN_F_16_MIN = {
+ 3478: -0.00921630859375,
+ 368: -0.010009765625,
+ 109586: -0.01031494140625,
+ 35433: -0.01177978515625,
+ 2: -0.0074462890625,
+ 77: -0.00848388671875,
+ 132619: -0.009521484375,
+ 2175: -0.0074462890625,
+ 23714: -0.0145263671875,
+ 73173: -0.007415771484375,
+ 144252: -0.01007080078125,
+ }
+ EMBEDDINGS_DS_BEFORE_LN_F_16_MAX = {
+ 3478: 0.0128173828125,
+ 368: 0.01214599609375,
+ 109586: 0.0111083984375,
+ 35433: 0.01019287109375,
+ 2: 0.0157470703125,
+ 77: 0.0174560546875,
+ 132619: 0.0078125,
+ 2175: 0.0113525390625,
+ 23714: 0.0146484375,
+ 73173: 0.01116943359375,
+ 144252: 0.01141357421875,
+ }
+ EMBEDDINGS_DS_BEFORE_LN_F_16_SUM = {"value": 0.0821533203125}
+
+ EMBEDDINGS_DS_BEFORE_LN_F_32_MEAN = {
+ 132619: -0.00031267106533050537,
+ 3478: 0.00023087859153747559,
+ 368: -0.0005701072514057159,
+ 109586: -0.0003911703824996948,
+ 35433: -0.0001944899559020996,
+ 2: 0.0004146844148635864,
+ 2175: 0.00045740045607089996,
+ 23714: 0.0002641640603542328,
+ 73173: -0.0002864748239517212,
+ 144252: 0.0005256589502096176,
+ 77: 0.0006617321632802486,
+ }
+ EMBEDDINGS_DS_BEFORE_LN_F_32_MIN = {
+ 3478: -0.00921630859375,
+ 368: -0.010009765625,
+ 109586: -0.01031494140625,
+ 35433: -0.01177978515625,
+ 2: -0.0074462890625,
+ 77: -0.00848388671875,
+ 132619: -0.009521484375,
+ 2175: -0.0074462890625,
+ 23714: -0.0145263671875,
+ 73173: -0.007415771484375,
+ 144252: -0.01007080078125,
+ }
+ EMBEDDINGS_DS_BEFORE_LN_F_32_MAX = {
+ 3478: 0.0128173828125,
+ 368: 0.01214599609375,
+ 109586: 0.0111083984375,
+ 35433: 0.01019287109375,
+ 2: 0.0157470703125,
+ 77: 0.0174560546875,
+ 132619: 0.0078125,
+ 2175: 0.0113525390625,
+ 23714: 0.0146484375,
+ 73173: 0.01116943359375,
+ 144252: 0.01141357421875,
+ }
+ EMBEDDINGS_DS_BEFORE_LN_F_32_SUM = {"value": 0.08217757940292358}
+
+ TEST_EMBEDDINGS = {
+ "torch.bfloat16": {
+ "mean": EMBEDDINGS_DS_BEFORE_LN_BF_16_MEAN,
+ "max": EMBEDDINGS_DS_BEFORE_LN_BF_16_MAX,
+ "min": EMBEDDINGS_DS_BEFORE_LN_BF_16_MIN,
+ "sum": EMBEDDINGS_DS_BEFORE_LN_BF_16_SUM,
+ },
+ "torch.float32": {
+ "mean": EMBEDDINGS_DS_BEFORE_LN_F_32_MEAN,
+ "max": EMBEDDINGS_DS_BEFORE_LN_F_32_MAX,
+ "min": EMBEDDINGS_DS_BEFORE_LN_F_32_MIN,
+ "sum": EMBEDDINGS_DS_BEFORE_LN_F_32_SUM,
+ },
+ "torch.float": {
+ "mean": EMBEDDINGS_DS_BEFORE_LN_F_32_MEAN,
+ "max": EMBEDDINGS_DS_BEFORE_LN_F_32_MAX,
+ "min": EMBEDDINGS_DS_BEFORE_LN_F_32_MIN,
+ "sum": EMBEDDINGS_DS_BEFORE_LN_F_32_SUM,
+ },
+ "torch.float16": {
+ "mean": EMBEDDINGS_DS_BEFORE_LN_F_16_MEAN,
+ "max": EMBEDDINGS_DS_BEFORE_LN_F_16_MAX,
+ "min": EMBEDDINGS_DS_BEFORE_LN_F_16_MIN,
+ "sum": EMBEDDINGS_DS_BEFORE_LN_F_16_SUM,
+ },
+ }
+
+ EXAMPLE_IDS = [3478, 368, 109586, 35433, 2, 77, 132619, 3478, 368, 109586, 35433, 2, 2175, 23714, 73173, 144252, 2, 77, 132619, 3478] # fmt: skip
+
+ EMBEDDINGS_DS_AFTER_LN_MEAN = {
+ 3478: -6.580352783203125e-05,
+ 368: 0.0001316070556640625,
+ 109586: -0.00030517578125,
+ 35433: 4.00543212890625e-05,
+ 2: -7.2479248046875e-05,
+ 77: -8.96453857421875e-05,
+ 132619: 0.0001583099365234375,
+ 2175: 2.1219253540039062e-05,
+ 23714: -0.000247955322265625,
+ 73173: -0.00021839141845703125,
+ 144252: -0.0001430511474609375,
+ }
+ EMBEDDINGS_DS_AFTER_LN_MIN = {
+ 3478: -1.6953125,
+ 368: -1.6875,
+ 109586: -1.6875,
+ 35433: -2.125,
+ 2: -1.390625,
+ 77: -1.5390625,
+ 132619: -1.875,
+ 2175: -1.4609375,
+ 23714: -2.296875,
+ 73173: -1.3515625,
+ 144252: -1.78125,
+ }
+ EMBEDDINGS_DS_AFTER_LN_MAX = {
+ 3478: 2.265625,
+ 368: 2.28125,
+ 109586: 1.953125,
+ 35433: 1.90625,
+ 2: 2.703125,
+ 77: 2.828125,
+ 132619: 1.65625,
+ 2175: 2.015625,
+ 23714: 2.234375,
+ 73173: 2.171875,
+ 144252: 1.828125,
+ }
+
+ EMBEDDINGS_DS_AFTER_LN = {
+ "mean": EMBEDDINGS_DS_AFTER_LN_MEAN,
+ "min": EMBEDDINGS_DS_AFTER_LN_MIN,
+ "max": EMBEDDINGS_DS_AFTER_LN_MAX,
+ }
+
+ tensor_ids = torch.LongTensor([EXAMPLE_IDS])
+ with torch.no_grad():
+ embeddings = model.transformer.word_embeddings(tensor_ids)
+ embeddings_ln = model.transformer.word_embeddings_layernorm(embeddings) #
+ # first check the embeddings before LN
+ output_dict = {"min": {}, "max": {}, "mean": {}, "sum": {"value": embeddings.sum().item()}}
+ for i, idx in enumerate(EXAMPLE_IDS):
+ output_dict["min"][idx] = embeddings.min(dim=-1).values[0][i].item()
+ output_dict["max"][idx] = embeddings.max(dim=-1).values[0][i].item()
+ output_dict["mean"][idx] = embeddings.mean(dim=-1)[0][i].item()
+
+ for key in TEST_EMBEDDINGS[str(model.dtype)].keys():
+ self.assertDictEqual(TEST_EMBEDDINGS[str(model.dtype)][key], output_dict[key])
+
+ output_dict_norm = {"min": {}, "max": {}, "mean": {}}
+ for i, idx in enumerate(EXAMPLE_IDS):
+ output_dict_norm["min"][idx] = embeddings_ln.min(dim=-1).values[0][i].item()
+ output_dict_norm["max"][idx] = embeddings_ln.max(dim=-1).values[0][i].item()
+ output_dict_norm["mean"][idx] = embeddings_ln.mean(dim=-1)[0][i].item()
+
+ # This test does not pass when places = 2
+ for i, key in enumerate(output_dict_norm.keys()):
+ for j, idx in enumerate(output_dict[key].keys()):
+ self.assertAlmostEqual(EMBEDDINGS_DS_AFTER_LN[key][idx], output_dict_norm[key][idx], places=1)
+
+ @require_torch
+ def test_hidden_states_transformers(self):
+ model = BloomModel.from_pretrained(self.path_bigscience_model, use_cache=False, torch_dtype="auto").to(
+ torch_device
+ )
+ model.eval()
+
+ EXAMPLE_IDS = [3478, 368, 109586, 35433, 2, 77, 132619, 3478, 368, 109586, 35433, 2, 2175, 23714, 73173, 144252, 2, 77, 132619, 3478] # fmt: skip
+
+ MEAN_VALUE_LAST_LM = -4.3392181396484375e-05
+ MIN_MAX_DICT = {"min": -2.0625, "max": 2.75}
+ tensor_ids = torch.LongTensor([EXAMPLE_IDS])
+
+ with torch.no_grad():
+ logits = model(tensor_ids.to(torch_device))
+ output_dict = {
+ "min": logits.last_hidden_state.min(dim=-1).values[0][0].item(),
+ "max": logits.last_hidden_state.max(dim=-1).values[0][0].item(),
+ }
+
+ if torch_device == "cuda":
+ self.assertAlmostEqual(MEAN_VALUE_LAST_LM, logits.last_hidden_state.mean().item(), places=4)
+ else:
+ self.assertAlmostEqual(MEAN_VALUE_LAST_LM, logits.last_hidden_state.mean().item(), places=3)
+
+ self.assertDictEqual(MIN_MAX_DICT, output_dict)
+
+ @require_torch
+ def test_logits(self):
+ model = BloomForCausalLM.from_pretrained(self.path_bigscience_model, use_cache=False, torch_dtype="auto").to(
+ torch_device
+ ) # load in bf16
+ model.eval()
+
+ EXAMPLE_IDS = [3478, 368, 109586, 35433, 2, 77, 132619, 3478, 368, 109586, 35433, 2, 2175, 23714, 73173, 144252, 2, 77, 132619, 3478] # fmt: skip
+
+ MEAN_LOGITS_GPU_1 = -1.823902130126953e-05
+ MEAN_LOGITS_GPU_2 = 1.9431114196777344e-05
+
+ tensor_ids = torch.LongTensor([EXAMPLE_IDS]).to(torch_device)
+ with torch.no_grad():
+ output = model(tensor_ids).logits
+
+ output_gpu_1, output_gpu_2 = output.split(125440, dim=-1)
+ self.assertAlmostEqual(output_gpu_1.mean().item(), MEAN_LOGITS_GPU_1, places=6)
+ self.assertAlmostEqual(output_gpu_2.mean().item(), MEAN_LOGITS_GPU_2, places=6)
diff --git a/transformers/tests/models/bloom/test_tokenization_bloom.py b/transformers/tests/models/bloom/test_tokenization_bloom.py
new file mode 100644
index 0000000000000000000000000000000000000000..bd1d1231813612bbfddd1832646c47e072971659
--- /dev/null
+++ b/transformers/tests/models/bloom/test_tokenization_bloom.py
@@ -0,0 +1,170 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import copy
+import unittest
+from functools import lru_cache
+
+from datasets import load_dataset
+
+from transformers import BloomTokenizerFast
+from transformers.testing_utils import require_jinja, require_tokenizers
+
+from ...test_tokenization_common import TokenizerTesterMixin, use_cache_if_possible
+
+
+@require_tokenizers
+class BloomTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "bigscience/tokenizer"
+ slow_tokenizer_class = None
+ rust_tokenizer_class = BloomTokenizerFast
+ tokenizer_class = BloomTokenizerFast
+ test_rust_tokenizer = True
+ test_slow_tokenizer = False
+ from_pretrained_vocab_key = "tokenizer_file"
+ special_tokens_map = {"bos_token": "", "eos_token": "", "unk_token": "", "pad_token": ""}
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+ tokenizer = BloomTokenizerFast.from_pretrained("bigscience/tokenizer")
+ tokenizer.save_pretrained(cls.tmpdirname)
+
+ @classmethod
+ @use_cache_if_possible
+ @lru_cache(maxsize=64)
+ def get_rust_tokenizer(cls, pretrained_name=None, **kwargs):
+ _kwargs = copy.deepcopy(cls.special_tokens_map)
+ _kwargs.update(kwargs)
+ kwargs = _kwargs
+ pretrained_name = pretrained_name or cls.tmpdirname
+ return BloomTokenizerFast.from_pretrained(pretrained_name, **kwargs)
+
+ @unittest.skip(reason="This needs a slow tokenizer. Bloom does not have one!")
+ def test_encode_decode_with_spaces(self):
+ return
+
+ def test_encodings_from_sample_data(self):
+ """
+ Assert that the created tokens are the same than the hard-coded ones
+ """
+ tokenizer = self.get_rust_tokenizer()
+
+ INPUT_SENTENCES = ["The quick brown fox", "jumps over the lazy dog"]
+ TARGET_TOKENS = [[2175, 23714, 73173, 144252, 2], [77, 132619, 3478, 368, 109586, 35433, 2]]
+
+ computed_tokens = tokenizer.batch_encode_plus(INPUT_SENTENCES)["input_ids"]
+ self.assertListEqual(TARGET_TOKENS, computed_tokens)
+
+ decoded_tokens = tokenizer.batch_decode(computed_tokens)
+ self.assertListEqual(decoded_tokens, INPUT_SENTENCES)
+
+ def test_padding(self, max_length=6):
+ for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
+ with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name})"):
+ tokenizer_r = self.get_rust_tokenizer(pretrained_name, **kwargs)
+ # tokenizer_r.pad_token = None # Hotfixing padding = None
+ # Simple input
+ s = "This is a simple input"
+ s2 = ["This is a simple input 1", "This is a simple input 2"]
+ p = ("This is a simple input", "This is a pair")
+ p2 = [
+ ("This is a simple input 1", "This is a simple input 2"),
+ ("This is a simple pair 1", "This is a simple pair 2"),
+ ]
+
+ # Simple input tests
+ try:
+ tokenizer_r.encode(s, max_length=max_length)
+ tokenizer_r.encode_plus(s, max_length=max_length)
+
+ tokenizer_r.batch_encode_plus(s2, max_length=max_length)
+ tokenizer_r.encode(p, max_length=max_length)
+ tokenizer_r.batch_encode_plus(p2, max_length=max_length)
+ except ValueError:
+ self.fail("Bloom Tokenizer should be able to deal with padding")
+
+ tokenizer_r.pad_token = None # Hotfixing padding = None
+ self.assertRaises(ValueError, tokenizer_r.encode, s, max_length=max_length, padding="max_length")
+
+ # Simple input
+ self.assertRaises(ValueError, tokenizer_r.encode_plus, s, max_length=max_length, padding="max_length")
+
+ # Simple input
+ self.assertRaises(
+ ValueError,
+ tokenizer_r.batch_encode_plus,
+ s2,
+ max_length=max_length,
+ padding="max_length",
+ )
+
+ # Pair input
+ self.assertRaises(ValueError, tokenizer_r.encode, p, max_length=max_length, padding="max_length")
+
+ # Pair input
+ self.assertRaises(ValueError, tokenizer_r.encode_plus, p, max_length=max_length, padding="max_length")
+
+ # Pair input
+ self.assertRaises(
+ ValueError,
+ tokenizer_r.batch_encode_plus,
+ p2,
+ max_length=max_length,
+ padding="max_length",
+ )
+
+ def test_encodings_from_xnli_dataset(self):
+ """
+ Tests the tokenizer downloaded from here:
+ - https://huggingface.co/bigscience/tokenizer/
+ """
+ tokenizer = self.get_rust_tokenizer()
+ ds = load_dataset("facebook/xnli", "all_languages", split="test", streaming=True)
+
+ sample_data = next(iter(ds))["premise"] # pick up one data
+ input_text = list(sample_data.values())
+
+ output_tokens = list(map(tokenizer.encode, input_text))
+ predicted_text = [tokenizer.decode(x, clean_up_tokenization_spaces=False) for x in output_tokens]
+ self.assertListEqual(predicted_text, input_text)
+
+ @require_jinja
+ def test_tokenization_for_chat(self):
+ tokenizer = self.get_rust_tokenizer()
+ tokenizer.chat_template = "{% for message in messages %}{{ message.content }}{{ eos_token }}{% endfor %}"
+ test_chats = [
+ [{"role": "system", "content": "You are a helpful chatbot."}, {"role": "user", "content": "Hello!"}],
+ [
+ {"role": "system", "content": "You are a helpful chatbot."},
+ {"role": "user", "content": "Hello!"},
+ {"role": "assistant", "content": "Nice to meet you."},
+ ],
+ [{"role": "assistant", "content": "Nice to meet you."}, {"role": "user", "content": "Hello!"}],
+ ]
+ tokenized_chats = [tokenizer.apply_chat_template(test_chat) for test_chat in test_chats]
+ expected_tokens = [
+ [5448, 1306, 267, 66799, 44799, 37143, 17, 2, 59414, 4, 2],
+ [5448, 1306, 267, 66799, 44799, 37143, 17, 2, 59414, 4, 2, 229126, 427, 11890, 1152, 17, 2],
+ [229126, 427, 11890, 1152, 17, 2, 59414, 4, 2],
+ ]
+ for tokenized_chat, expected_tokens in zip(tokenized_chats, expected_tokens):
+ self.assertListEqual(tokenized_chat, expected_tokens)
+
+ def test_add_prefix_space_fast(self):
+ tokenizer_w_prefix = self.get_rust_tokenizer(add_prefix_space=True)
+ tokenizer_wo_prefix = self.get_rust_tokenizer(add_prefix_space=False)
+ tokens_w_prefix = tokenizer_w_prefix.tokenize("Hey")
+ tokens_wo_prefix = tokenizer_wo_prefix.tokenize("Hey")
+ self.assertNotEqual(tokens_w_prefix, tokens_wo_prefix)
diff --git a/transformers/tests/models/bros/__init__.py b/transformers/tests/models/bros/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/bros/test_modeling_bros.py b/transformers/tests/models/bros/test_modeling_bros.py
new file mode 100644
index 0000000000000000000000000000000000000000..3a80497cafc6d2f93acc762b960b074f713fa3dd
--- /dev/null
+++ b/transformers/tests/models/bros/test_modeling_bros.py
@@ -0,0 +1,453 @@
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Bros model."""
+
+import copy
+import unittest
+
+from transformers.testing_utils import require_torch, require_torch_multi_gpu, slow, torch_device
+from transformers.utils import is_torch_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ BrosConfig,
+ BrosForTokenClassification,
+ BrosModel,
+ BrosSpadeEEForTokenClassification,
+ BrosSpadeELForTokenClassification,
+ )
+
+
+class BrosModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_bbox_first_token_mask=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=64,
+ num_hidden_layers=5,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_bbox_first_token_mask = use_bbox_first_token_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ bbox = ids_tensor([self.batch_size, self.seq_length, 8], 1)
+ # Ensure that bbox is legal
+ for i in range(bbox.shape[0]):
+ for j in range(bbox.shape[1]):
+ if bbox[i, j, 3] < bbox[i, j, 1]:
+ t = bbox[i, j, 3]
+ bbox[i, j, 3] = bbox[i, j, 1]
+ bbox[i, j, 1] = t
+ if bbox[i, j, 2] < bbox[i, j, 0]:
+ t = bbox[i, j, 2]
+ bbox[i, j, 2] = bbox[i, j, 0]
+ bbox[i, j, 0] = t
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ bbox_first_token_mask = None
+ if self.use_bbox_first_token_mask:
+ bbox_first_token_mask = torch.ones([self.batch_size, self.seq_length], dtype=torch.bool).to(torch_device)
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ token_labels = None
+ if self.use_labels:
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ initial_token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ subsequent_token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+
+ config = self.get_config()
+
+ return (
+ config,
+ input_ids,
+ bbox,
+ token_type_ids,
+ input_mask,
+ bbox_first_token_mask,
+ token_labels,
+ initial_token_labels,
+ subsequent_token_labels,
+ )
+
+ def get_config(self):
+ return BrosConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(
+ self,
+ config,
+ input_ids,
+ bbox,
+ token_type_ids,
+ input_mask,
+ bbox_first_token_mask,
+ token_labels,
+ initial_token_labels,
+ subsequent_token_labels,
+ ):
+ model = BrosModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, bbox=bbox, attention_mask=input_mask, token_type_ids=token_type_ids)
+ result = model(input_ids, bbox=bbox, token_type_ids=token_type_ids)
+ result = model(input_ids, bbox=bbox)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_for_token_classification(
+ self,
+ config,
+ input_ids,
+ bbox,
+ token_type_ids,
+ input_mask,
+ bbox_first_token_mask,
+ token_labels,
+ initial_token_labels,
+ subsequent_token_labels,
+ ):
+ config.num_labels = self.num_labels
+ model = BrosForTokenClassification(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids, bbox=bbox, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels
+ )
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+
+ def create_and_check_for_spade_ee_token_classification(
+ self,
+ config,
+ input_ids,
+ bbox,
+ token_type_ids,
+ input_mask,
+ bbox_first_token_mask,
+ token_labels,
+ initial_token_labels,
+ subsequent_token_labels,
+ ):
+ config.num_labels = self.num_labels
+ model = BrosSpadeEEForTokenClassification(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ bbox=bbox,
+ attention_mask=input_mask,
+ bbox_first_token_mask=bbox_first_token_mask,
+ token_type_ids=token_type_ids,
+ initial_token_labels=token_labels,
+ subsequent_token_labels=token_labels,
+ )
+ self.parent.assertEqual(result.initial_token_logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+ self.parent.assertEqual(
+ result.subsequent_token_logits.shape, (self.batch_size, self.seq_length, self.seq_length + 1)
+ )
+
+ def create_and_check_for_spade_el_token_classification(
+ self,
+ config,
+ input_ids,
+ bbox,
+ token_type_ids,
+ input_mask,
+ bbox_first_token_mask,
+ token_labels,
+ initial_token_labels,
+ subsequent_token_labels,
+ ):
+ config.num_labels = self.num_labels
+ model = BrosSpadeELForTokenClassification(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ bbox=bbox,
+ attention_mask=input_mask,
+ bbox_first_token_mask=bbox_first_token_mask,
+ token_type_ids=token_type_ids,
+ labels=token_labels,
+ )
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.seq_length + 1))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ bbox,
+ token_type_ids,
+ input_mask,
+ bbox_first_token_mask,
+ token_labels,
+ initial_token_labels,
+ subsequent_token_labels,
+ ) = config_and_inputs
+ inputs_dict = {
+ "input_ids": input_ids,
+ "bbox": bbox,
+ "token_type_ids": token_type_ids,
+ "attention_mask": input_mask,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class BrosModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ test_pruning = False
+ test_torchscript = False
+ test_mismatched_shapes = False
+
+ all_model_classes = (
+ (
+ BrosForTokenClassification,
+ BrosSpadeEEForTokenClassification,
+ BrosSpadeELForTokenClassification,
+ BrosModel,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {"feature-extraction": BrosModel, "token-classification": BrosForTokenClassification}
+ if is_torch_available()
+ else {}
+ )
+
+ # BROS requires `bbox` in the inputs which doesn't fit into the above 2 pipelines' input formats.
+ # see https://github.com/huggingface/transformers/pull/26294
+ def is_pipeline_test_to_skip(
+ self,
+ pipeline_test_case_name,
+ config_class,
+ model_architecture,
+ tokenizer_name,
+ image_processor_name,
+ feature_extractor_name,
+ processor_name,
+ ):
+ return True
+
+ def setUp(self):
+ self.model_tester = BrosModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=BrosConfig, hidden_size=37)
+
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = copy.deepcopy(inputs_dict)
+
+ if return_labels:
+ if model_class.__name__ in ["BrosForTokenClassification", "BrosSpadeELForTokenClassification"]:
+ inputs_dict["labels"] = torch.zeros(
+ (self.model_tester.batch_size, self.model_tester.seq_length),
+ dtype=torch.long,
+ device=torch_device,
+ )
+ inputs_dict["bbox_first_token_mask"] = torch.ones(
+ [self.model_tester.batch_size, self.model_tester.seq_length],
+ dtype=torch.bool,
+ device=torch_device,
+ )
+ elif model_class.__name__ in ["BrosSpadeEEForTokenClassification"]:
+ inputs_dict["initial_token_labels"] = torch.zeros(
+ (self.model_tester.batch_size, self.model_tester.seq_length),
+ dtype=torch.long,
+ device=torch_device,
+ )
+ inputs_dict["subsequent_token_labels"] = torch.zeros(
+ (self.model_tester.batch_size, self.model_tester.seq_length),
+ dtype=torch.long,
+ device=torch_device,
+ )
+ inputs_dict["bbox_first_token_mask"] = torch.ones(
+ [self.model_tester.batch_size, self.model_tester.seq_length],
+ dtype=torch.bool,
+ device=torch_device,
+ )
+
+ return inputs_dict
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @require_torch_multi_gpu
+ def test_multi_gpu_data_parallel_forward(self):
+ super().test_multi_gpu_data_parallel_forward()
+
+ def test_model_various_embeddings(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["absolute", "relative_key", "relative_key_query"]:
+ config_and_inputs[0].position_embedding_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_token_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
+
+ def test_for_spade_ee_token_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_spade_ee_token_classification(*config_and_inputs)
+
+ def test_for_spade_el_token_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_spade_el_token_classification(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "jinho8345/bros-base-uncased"
+ model = BrosModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+def prepare_bros_batch_inputs():
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
+
+ bbox = torch.tensor(
+ [
+ [
+ [0.0000, 0.0000, 0.0000, 0.0000],
+ [0.5223, 0.5590, 0.5787, 0.5720],
+ [0.5853, 0.5590, 0.6864, 0.5720],
+ [0.5853, 0.5590, 0.6864, 0.5720],
+ [0.1234, 0.5700, 0.2192, 0.5840],
+ [0.2231, 0.5680, 0.2782, 0.5780],
+ [0.2874, 0.5670, 0.3333, 0.5780],
+ [0.3425, 0.5640, 0.4344, 0.5750],
+ [0.0866, 0.7770, 0.1181, 0.7870],
+ [0.1168, 0.7770, 0.1522, 0.7850],
+ [0.1535, 0.7750, 0.1864, 0.7850],
+ [0.1890, 0.7750, 0.2572, 0.7850],
+ [1.0000, 1.0000, 1.0000, 1.0000],
+ ],
+ [
+ [0.0000, 0.0000, 0.0000, 0.0000],
+ [0.4396, 0.6720, 0.4659, 0.6850],
+ [0.4698, 0.6720, 0.4843, 0.6850],
+ [0.1575, 0.6870, 0.2021, 0.6980],
+ [0.2047, 0.6870, 0.2730, 0.7000],
+ [0.1299, 0.7010, 0.1430, 0.7140],
+ [0.1299, 0.7010, 0.1430, 0.7140],
+ [0.1562, 0.7010, 0.2441, 0.7120],
+ [0.1562, 0.7010, 0.2441, 0.7120],
+ [0.2454, 0.7010, 0.3150, 0.7120],
+ [0.3176, 0.7010, 0.3320, 0.7110],
+ [0.3333, 0.7000, 0.4029, 0.7140],
+ [1.0000, 1.0000, 1.0000, 1.0000],
+ ],
+ ]
+ )
+ input_ids = torch.tensor(
+ [
+ [101, 1055, 8910, 1012, 5719, 3296, 5366, 3378, 2146, 2846, 10807, 13494, 102],
+ [101, 2112, 1997, 3671, 6364, 1019, 1012, 5057, 1011, 4646, 2030, 2974, 102],
+ ]
+ )
+
+ return input_ids, bbox, attention_mask
+
+
+@require_torch
+class BrosModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference_no_head(self):
+ model = BrosModel.from_pretrained("jinho8345/bros-base-uncased").to(torch_device)
+
+ input_ids, bbox, attention_mask = prepare_bros_batch_inputs()
+
+ with torch.no_grad():
+ outputs = model(
+ input_ids.to(torch_device),
+ bbox.to(torch_device),
+ attention_mask=attention_mask.to(torch_device),
+ return_dict=True,
+ )
+
+ # verify the logits
+ expected_shape = torch.Size((2, 13, 768))
+ self.assertEqual(outputs.last_hidden_state.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[-0.3074, 0.1363, 0.3143], [0.0925, -0.1155, 0.1050], [0.0221, 0.0003, 0.1285]]
+ ).to(torch_device)
+ torch.set_printoptions(sci_mode=False)
+
+ torch.testing.assert_close(outputs.last_hidden_state[0, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/camembert/__init__.py b/transformers/tests/models/camembert/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/camembert/test_modeling_camembert.py b/transformers/tests/models/camembert/test_modeling_camembert.py
new file mode 100644
index 0000000000000000000000000000000000000000..b77d063cceeb7d933eba57cf8de1efccb665b587
--- /dev/null
+++ b/transformers/tests/models/camembert/test_modeling_camembert.py
@@ -0,0 +1,83 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+from transformers import is_torch_available
+from transformers.testing_utils import (
+ require_sentencepiece,
+ require_tokenizers,
+ require_torch,
+ require_torch_sdpa,
+ slow,
+ torch_device,
+)
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import CamembertModel
+
+
+@require_torch
+@require_sentencepiece
+@require_tokenizers
+class CamembertModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_output_embeds_base_model(self):
+ model = CamembertModel.from_pretrained("almanach/camembert-base", attn_implementation="eager")
+ model.to(torch_device)
+
+ input_ids = torch.tensor(
+ [[5, 121, 11, 660, 16, 730, 25543, 110, 83, 6]],
+ device=torch_device,
+ dtype=torch.long,
+ ) # J'aime le camembert !
+ with torch.no_grad():
+ output = model(input_ids)["last_hidden_state"]
+ expected_shape = torch.Size((1, 10, 768))
+ self.assertEqual(output.shape, expected_shape)
+ # compare the actual values for a slice.
+ expected_slice = torch.tensor(
+ [[[-0.0254, 0.0235, 0.1027], [0.0606, -0.1811, -0.0418], [-0.1561, -0.1127, 0.2687]]],
+ device=torch_device,
+ dtype=torch.float,
+ )
+ # camembert = torch.hub.load('pytorch/fairseq', 'camembert.v0')
+ # camembert.eval()
+ # expected_slice = roberta.model.forward(input_ids)[0][:, :3, :3].detach()
+
+ torch.testing.assert_close(output[:, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ @slow
+ @require_torch_sdpa
+ def test_output_embeds_base_model_sdpa(self):
+ input_ids = torch.tensor(
+ [[5, 121, 11, 660, 16, 730, 25543, 110, 83, 6]],
+ device=torch_device,
+ dtype=torch.long,
+ ) # J'aime le camembert !
+
+ expected_slice = torch.tensor(
+ [[[-0.0254, 0.0235, 0.1027], [0.0606, -0.1811, -0.0418], [-0.1561, -0.1127, 0.2687]]],
+ device=torch_device,
+ dtype=torch.float,
+ )
+
+ model = CamembertModel.from_pretrained("almanach/camembert-base", attn_implementation="sdpa").to(torch_device)
+ with torch.no_grad():
+ output = model(input_ids)["last_hidden_state"].detach()
+
+ torch.testing.assert_close(output[:, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/camembert/test_tokenization_camembert.py b/transformers/tests/models/camembert/test_tokenization_camembert.py
new file mode 100644
index 0000000000000000000000000000000000000000..33a49b33958ef8ccb43eeb6c27bf0d4eb096891f
--- /dev/null
+++ b/transformers/tests/models/camembert/test_tokenization_camembert.py
@@ -0,0 +1,220 @@
+# Copyright 2018 HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import tempfile
+import unittest
+from tempfile import TemporaryDirectory
+
+from transformers import AddedToken, CamembertTokenizer, CamembertTokenizerFast
+from transformers.testing_utils import get_tests_dir, require_sentencepiece, require_tokenizers, slow
+from transformers.utils import is_torch_available
+
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+SAMPLE_VOCAB = get_tests_dir("fixtures/test_sentencepiece.model")
+SAMPLE_BPE_VOCAB = get_tests_dir("fixtures/test_sentencepiece_bpe.model")
+
+FRAMEWORK = "pt" if is_torch_available() else "tf"
+
+
+@require_sentencepiece
+@require_tokenizers
+class CamembertTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "almanach/camembert-base"
+ tokenizer_class = CamembertTokenizer
+ rust_tokenizer_class = CamembertTokenizerFast
+ test_rust_tokenizer = True
+ test_sentencepiece = True
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ # We have a SentencePiece fixture for testing
+ tokenizer = CamembertTokenizer(SAMPLE_VOCAB)
+ tokenizer.save_pretrained(cls.tmpdirname)
+
+ @unittest.skip(
+ "Token maps are not equal because someone set the probability of ('NOTUSED', -100), so it's never encoded for fast"
+ )
+ def test_special_tokens_map_equal(self):
+ return
+
+ def test_convert_token_and_id(self):
+ """Test ``_convert_token_to_id`` and ``_convert_id_to_token``."""
+ token = ""
+ token_id = 1 # 1 is the offset id, but in the spm vocab it's 3
+
+ self.assertEqual(self.get_tokenizer().convert_tokens_to_ids(token), token_id)
+ self.assertEqual(self.get_tokenizer().convert_ids_to_tokens(token_id), token)
+
+ def test_get_vocab(self):
+ vocab_keys = list(self.get_tokenizer().get_vocab().keys())
+
+ self.assertEqual(vocab_keys[0], "NOTUSED")
+ self.assertEqual(vocab_keys[1], "")
+ self.assertEqual(vocab_keys[-1], "")
+ self.assertEqual(len(vocab_keys), 1_005)
+
+ def test_vocab_size(self):
+ self.assertEqual(self.get_tokenizer().vocab_size, 1_000)
+
+ def test_rust_and_python_bpe_tokenizers(self):
+ tokenizer = CamembertTokenizer(SAMPLE_BPE_VOCAB)
+ with TemporaryDirectory() as tmpdirname:
+ tokenizer.save_pretrained(tmpdirname)
+ rust_tokenizer = CamembertTokenizerFast.from_pretrained(tmpdirname)
+
+ sequence = "I was born in 92000, and this is falsé."
+
+ ids = tokenizer.encode(sequence)
+ rust_ids = rust_tokenizer.encode(sequence)
+ self.assertListEqual(ids, rust_ids)
+
+ ids = tokenizer.encode(sequence, add_special_tokens=False)
+ rust_ids = rust_tokenizer.encode(sequence, add_special_tokens=False)
+ self.assertListEqual(ids, rust_ids)
+
+ # tokens are not the same for `rust` than for `slow`.
+ # Because spm gives back raw token instead of `unk` in EncodeAsPieces
+ # tokens = tokenizer.tokenize(sequence)
+ tokens = tokenizer.convert_ids_to_tokens(ids)
+ rust_tokens = rust_tokenizer.tokenize(sequence)
+ self.assertListEqual(tokens, rust_tokens)
+
+ def test_rust_and_python_full_tokenizers(self):
+ if not self.test_rust_tokenizer:
+ self.skipTest(reason="test_rust_tokenizer is set to False")
+
+ tokenizer = self.get_tokenizer()
+ rust_tokenizer = self.get_rust_tokenizer()
+
+ sequence = "I was born in 92000, and this is falsé."
+
+ tokens = tokenizer.tokenize(sequence)
+ rust_tokens = rust_tokenizer.tokenize(sequence)
+ self.assertListEqual(tokens, rust_tokens)
+
+ ids = tokenizer.encode(sequence, add_special_tokens=False)
+ rust_ids = rust_tokenizer.encode(sequence, add_special_tokens=False)
+ self.assertListEqual(ids, rust_ids)
+
+ rust_tokenizer = self.get_rust_tokenizer()
+ ids = tokenizer.encode(sequence)
+ rust_ids = rust_tokenizer.encode(sequence)
+ self.assertListEqual(ids, rust_ids)
+
+ @slow
+ def test_tokenizer_integration(self):
+ expected_encoding = {'input_ids': [[5, 54, 7196, 297, 30, 23, 776, 18, 11, 3215, 3705, 8252, 22, 3164, 1181, 2116, 29, 16, 813, 25, 791, 3314, 20, 3446, 38, 27575, 120, 6, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [5, 468, 17, 11, 9088, 20, 1517, 8, 22804, 18818, 10, 38, 629, 607, 607, 142, 19, 7196, 867, 56, 10326, 24, 2267, 20, 416, 5072, 15612, 233, 734, 7, 2399, 27, 16, 3015, 1649, 7, 24, 20, 4338, 2399, 27, 13, 3400, 14, 13, 6189, 8, 930, 9, 6]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]} # fmt: skip
+
+ # camembert is a french model. So we also use french texts.
+ sequences = [
+ "Le transformeur est un modèle d'apprentissage profond introduit en 2017, "
+ "utilisé principalement dans le domaine du traitement automatique des langues (TAL).",
+ "À l'instar des réseaux de neurones récurrents (RNN), les transformeurs sont conçus "
+ "pour gérer des données séquentielles, telles que le langage naturel, pour des tâches "
+ "telles que la traduction et la synthèse de texte.",
+ ]
+
+ self.tokenizer_integration_test_util(
+ expected_encoding=expected_encoding,
+ model_name="almanach/camembert-base",
+ revision="3a0641d9a1aeb7e848a74299e7e4c4bca216b4cf",
+ sequences=sequences,
+ )
+
+ # Overwritten because we have to use from slow (online pretrained is wrong, the tokenizer.json has a whole)
+ def test_added_tokens_serialization(self):
+ self.maxDiff = None
+
+ # Utility to test the added vocab
+ def _test_added_vocab_and_eos(expected, tokenizer_class, expected_eos, temp_dir):
+ tokenizer = tokenizer_class.from_pretrained(temp_dir)
+ self.assertTrue(str(expected_eos) not in tokenizer.additional_special_tokens)
+ self.assertIn(new_eos, tokenizer.added_tokens_decoder.values())
+ self.assertEqual(tokenizer.added_tokens_decoder[tokenizer.eos_token_id], new_eos)
+ self.assertTrue(all(item in tokenizer.added_tokens_decoder.items() for item in expected.items()))
+ return tokenizer
+
+ new_eos = AddedToken("[NEW_EOS]", rstrip=False, lstrip=True, normalized=False, special=True)
+ for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
+ with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name})"):
+ # Load a slow tokenizer from the hub, init with the new token for fast to also include it
+ tokenizer = self.get_tokenizer(pretrained_name, eos_token=new_eos)
+ EXPECTED_ADDED_TOKENS_DECODER = tokenizer.added_tokens_decoder
+ with self.subTest("Hub -> Slow: Test loading a slow tokenizer from the hub)"):
+ self.assertEqual(tokenizer._special_tokens_map["eos_token"], new_eos)
+ self.assertIn(new_eos, list(tokenizer.added_tokens_decoder.values()))
+
+ with tempfile.TemporaryDirectory() as tmp_dir_2:
+ tokenizer.save_pretrained(tmp_dir_2)
+ with self.subTest(
+ "Hub -> Slow -> Slow: Test saving this slow tokenizer and reloading it in the fast class"
+ ):
+ _test_added_vocab_and_eos(
+ EXPECTED_ADDED_TOKENS_DECODER, self.tokenizer_class, new_eos, tmp_dir_2
+ )
+
+ if self.rust_tokenizer_class is not None:
+ with self.subTest(
+ "Hub -> Slow -> Fast: Test saving this slow tokenizer and reloading it in the fast class"
+ ):
+ tokenizer_fast = _test_added_vocab_and_eos(
+ EXPECTED_ADDED_TOKENS_DECODER, self.rust_tokenizer_class, new_eos, tmp_dir_2
+ )
+ with tempfile.TemporaryDirectory() as tmp_dir_3:
+ tokenizer_fast.save_pretrained(tmp_dir_3)
+ with self.subTest(
+ "Hub -> Slow -> Fast -> Fast: Test saving this fast tokenizer and reloading it in the fast class"
+ ):
+ _test_added_vocab_and_eos(
+ EXPECTED_ADDED_TOKENS_DECODER, self.rust_tokenizer_class, new_eos, tmp_dir_3
+ )
+
+ with self.subTest(
+ "Hub -> Slow -> Fast -> Slow: Test saving this slow tokenizer and reloading it in the slow class"
+ ):
+ _test_added_vocab_and_eos(
+ EXPECTED_ADDED_TOKENS_DECODER, self.rust_tokenizer_class, new_eos, tmp_dir_3
+ )
+
+ with self.subTest("Hub -> Fast: Test loading a fast tokenizer from the hub)"):
+ if self.rust_tokenizer_class is not None:
+ tokenizer_fast = self.get_rust_tokenizer(pretrained_name, eos_token=new_eos, from_slow=True)
+ self.assertEqual(tokenizer_fast._special_tokens_map["eos_token"], new_eos)
+ self.assertIn(new_eos, list(tokenizer_fast.added_tokens_decoder.values()))
+ # We can't test the following because for BC we kept the default rstrip lstrip in slow not fast. Will comment once normalization is alright
+ with self.subTest("Hub -> Fast == Hub -> Slow: make sure slow and fast tokenizer match"):
+ with self.subTest("Hub -> Fast == Hub -> Slow: make sure slow and fast tokenizer match"):
+ self.assertTrue(
+ all(
+ item in tokenizer.added_tokens_decoder.items()
+ for item in EXPECTED_ADDED_TOKENS_DECODER.items()
+ )
+ )
+
+ EXPECTED_ADDED_TOKENS_DECODER = tokenizer_fast.added_tokens_decoder
+ with tempfile.TemporaryDirectory() as tmp_dir_4:
+ tokenizer_fast.save_pretrained(tmp_dir_4)
+ with self.subTest("Hub -> Fast -> Fast: saving Fast1 locally and loading"):
+ _test_added_vocab_and_eos(
+ EXPECTED_ADDED_TOKENS_DECODER, self.rust_tokenizer_class, new_eos, tmp_dir_4
+ )
+
+ with self.subTest("Hub -> Fast -> Slow: saving Fast1 locally and loading"):
+ _test_added_vocab_and_eos(
+ EXPECTED_ADDED_TOKENS_DECODER, self.tokenizer_class, new_eos, tmp_dir_4
+ )
diff --git a/transformers/tests/models/canine/__init__.py b/transformers/tests/models/canine/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/canine/test_modeling_canine.py b/transformers/tests/models/canine/test_modeling_canine.py
new file mode 100644
index 0000000000000000000000000000000000000000..d93342bf5d540e15bac620126a100a4ff028a0e4
--- /dev/null
+++ b/transformers/tests/models/canine/test_modeling_canine.py
@@ -0,0 +1,580 @@
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch CANINE model."""
+
+import unittest
+
+from transformers import CanineConfig, is_torch_available
+from transformers.testing_utils import require_torch, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, global_rng, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ CanineForMultipleChoice,
+ CanineForQuestionAnswering,
+ CanineForSequenceClassification,
+ CanineForTokenClassification,
+ CanineModel,
+ )
+
+
+class CanineModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ # let's use a vocab size that's way bigger than BERT's one
+ # NOTE: this is not a model parameter, just an input
+ vocab_size=100000,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ num_hash_buckets=16,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.num_hash_buckets = num_hash_buckets
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor(input_ids.shape, self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ return CanineConfig(
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ num_hash_buckets=self.num_hash_buckets,
+ )
+
+ def create_and_check_model(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = CanineModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
+ result = model(input_ids, token_type_ids=token_type_ids)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_for_question_answering(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = CanineForQuestionAnswering(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ start_positions=sequence_labels,
+ end_positions=sequence_labels,
+ )
+ self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
+ self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
+
+ def create_and_check_for_sequence_classification(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_labels = self.num_labels
+ model = CanineForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=sequence_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def create_and_check_for_token_classification(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_labels = self.num_labels
+ model = CanineForTokenClassification(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+
+ def create_and_check_for_multiple_choice(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_choices = self.num_choices
+ model = CanineForMultipleChoice(config=config)
+ model.to(torch_device)
+ model.eval()
+ multiple_choice_inputs_ids = input_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ multiple_choice_token_type_ids = token_type_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ multiple_choice_input_mask = input_mask.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ result = model(
+ multiple_choice_inputs_ids,
+ attention_mask=multiple_choice_input_mask,
+ token_type_ids=multiple_choice_token_type_ids,
+ labels=choice_labels,
+ )
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class CanineModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ CanineModel,
+ CanineForMultipleChoice,
+ CanineForQuestionAnswering,
+ CanineForSequenceClassification,
+ CanineForTokenClassification,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": CanineModel,
+ "question-answering": CanineForQuestionAnswering,
+ "text-classification": CanineForSequenceClassification,
+ "token-classification": CanineForTokenClassification,
+ "zero-shot": CanineForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ test_mismatched_shapes = False
+ test_resize_embeddings = False
+ test_pruning = False
+
+ def setUp(self):
+ self.model_tester = CanineModelTester(self)
+ # we set has_text_modality to False as the config has no vocab_size attribute
+ self.config_tester = ConfigTester(self, config_class=CanineConfig, has_text_modality=False, hidden_size=37)
+
+ @unittest.skip("failing. Will fix only when the community opens an issue for it.")
+ def test_torchscript_output_hidden_state(self):
+ pass
+
+ @unittest.skip("failing. Will fix only when the community opens an issue for it.")
+ def test_torchscript_simple(self):
+ pass
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_multiple_choice(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs)
+
+ def test_for_question_answering(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
+
+ def test_for_sequence_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
+
+ def test_for_token_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.hidden_states
+ # expected_num_layers equals num_hidden_layers of the deep encoder + 1, + 2 for the first shallow encoder, + 2
+ # for the final shallow encoder
+ expected_num_layers = self.model_tester.num_hidden_layers + 1 + 2 + 2
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ seq_length = self.model_tester.seq_length
+ for i in range(expected_num_layers):
+ if (i < 2) or ((expected_num_layers - i) < 3):
+ # the expected length of the hidden_states of the first and final shallow encoders
+ # is equal to the seq_length
+ self.assertListEqual(
+ list(hidden_states[i].shape[-2:]),
+ [seq_length, self.model_tester.hidden_size],
+ )
+ else:
+ # the expected length of the hidden_states of the deep encoder need to be updated
+ # for CANINE since the seq length is downsampled
+ self.assertListEqual(
+ list(hidden_states[i].shape[-2:]),
+ [seq_length // config.downsampling_rate, self.model_tester.hidden_size],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ seq_len = getattr(self.model_tester, "seq_length", None)
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class._from_config(config, attn_implementation="eager")
+ config = model.config
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ # we add + 2 due to the 2 shallow encoders
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers + 2)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ # we add + 2 due to the 2 shallow encoders
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers + 2)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, seq_len, seq_len],
+ )
+ out_len = len(outputs)
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if hasattr(self.model_tester, "num_hidden_states_types"):
+ added_hidden_states = self.model_tester.num_hidden_states_types
+ else:
+ added_hidden_states = 1
+ self.assertEqual(out_len + added_hidden_states, len(outputs))
+
+ self_attentions = outputs.attentions
+
+ self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers + 2)
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, seq_len, seq_len],
+ )
+
+ def test_model_outputs_equivalence(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ def set_nan_tensor_to_zero(t):
+ t[t != t] = 0
+ return t
+
+ def check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs={}):
+ with torch.no_grad():
+ tuple_output = model(**tuple_inputs, return_dict=False, **additional_kwargs)
+ dict_output = model(**dict_inputs, return_dict=True, **additional_kwargs).to_tuple()
+
+ def recursive_check(tuple_object, dict_object):
+ if isinstance(tuple_object, (list, tuple)):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object, dict_object):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif tuple_object is None:
+ return
+ else:
+ self.assertTrue(
+ torch.allclose(
+ set_nan_tensor_to_zero(tuple_object), set_nan_tensor_to_zero(dict_object), atol=1e-5
+ ),
+ msg=(
+ "Tuple and dict output are not equal. Difference:"
+ f" {torch.max(torch.abs(tuple_object - dict_object))}. Tuple has `nan`:"
+ f" {torch.isnan(tuple_object).any()} and `inf`: {torch.isinf(tuple_object)}. Dict has"
+ f" `nan`: {torch.isnan(dict_object).any()} and `inf`: {torch.isinf(dict_object)}."
+ ),
+ )
+
+ recursive_check(tuple_output, dict_output)
+
+ for model_class in self.all_model_classes:
+ print(model_class)
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_attentions": True})
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_attentions": True})
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(
+ model, tuple_inputs, dict_inputs, {"output_hidden_states": True, "output_attentions": True}
+ )
+
+ def test_headmasking(self):
+ if not self.test_head_masking:
+ self.skipTest(reason="test_head_masking is set to False")
+
+ global_rng.seed(42)
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ global_rng.seed()
+
+ inputs_dict["output_attentions"] = True
+ config.output_hidden_states = True
+ configs_no_init = _config_zero_init(config) # To be sure we have no Nan
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ model.to(torch_device)
+ model.eval()
+
+ # Prepare head_mask
+ # Set require_grad after having prepared the tensor to avoid error (leaf variable has been moved into the graph interior)
+ head_mask = torch.ones(
+ self.model_tester.num_hidden_layers,
+ self.model_tester.num_attention_heads,
+ device=torch_device,
+ )
+ head_mask[0, 0] = 0
+ head_mask[-1, :-1] = 0
+ head_mask.requires_grad_(requires_grad=True)
+ inputs = self._prepare_for_class(inputs_dict, model_class).copy()
+ inputs["head_mask"] = head_mask
+
+ outputs = model(**inputs, return_dict=True)
+
+ # Test that we can get a gradient back for importance score computation
+ output = sum(t.sum() for t in outputs[0])
+ output = output.sum()
+ output.backward()
+ multihead_outputs = head_mask.grad
+
+ self.assertIsNotNone(multihead_outputs)
+ self.assertEqual(len(multihead_outputs), self.model_tester.num_hidden_layers)
+
+ def check_attentions_validity(attentions):
+ # Remove Nan
+ for t in attentions:
+ self.assertLess(
+ torch.sum(torch.isnan(t)), t.numel() / 4
+ ) # Check we don't have more than 25% nans (arbitrary)
+ attentions = [
+ t.masked_fill(torch.isnan(t), 0.0) for t in attentions
+ ] # remove them (the test is less complete)
+
+ self.assertAlmostEqual(attentions[1][..., 0, :, :].flatten().sum().item(), 0.0)
+ self.assertNotEqual(attentions[1][..., -1, :, :].flatten().sum().item(), 0.0)
+ self.assertAlmostEqual(attentions[-2][..., -2, :, :].flatten().sum().item(), 0.0)
+ self.assertNotEqual(attentions[-2][..., -1, :, :].flatten().sum().item(), 0.0)
+
+ check_attentions_validity(outputs.attentions)
+
+ @unittest.skip(reason="CANINE does not have a get_input_embeddings() method.")
+ def test_inputs_embeds(self):
+ # ViT does not use inputs_embeds
+ pass
+
+ @unittest.skip(reason="Canine Tower does not use inputs_embeds")
+ def test_inputs_embeds_matches_input_ids(self):
+ pass
+
+ @unittest.skip(reason="CANINE does not have a get_input_embeddings() method.")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "google/canine-s"
+ model = CanineModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+@require_torch
+class CanineModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference_no_head(self):
+ model = CanineModel.from_pretrained("google/canine-s")
+ # this one corresponds to the first example of the TydiQA dev set (in Swahili)
+ # fmt: off
+ input_ids = [57344, 57349, 85, 107, 117, 98, 119, 97, 32, 119, 97, 32, 82, 105, 106, 105, 108, 105, 32, 75, 97, 110, 116, 111, 114, 105, 32, 110, 105, 32, 107, 105, 97, 115, 105, 32, 103, 97, 110, 105, 63, 57345, 57350, 32, 82, 105, 106, 105, 108, 105, 32, 75, 97, 110, 116, 111, 114, 105, 32, 44, 32, 82, 105, 106, 105, 108, 105, 32, 75, 97, 110, 116, 97, 114, 117, 115, 105, 32, 97, 117, 32, 105, 110, 103, 46, 32, 65, 108, 112, 104, 97, 32, 67, 101, 110, 116, 97, 117, 114, 105, 32, 40, 112, 105, 97, 58, 32, 84, 111, 108, 105, 109, 97, 110, 32, 97, 117, 32, 82, 105, 103, 105, 108, 32, 75, 101, 110, 116, 97, 117, 114, 117, 115, 41, 32, 110, 105, 32, 110, 121, 111, 116, 97, 32, 105, 110, 97, 121, 111, 110, 103, 39, 97, 97, 32, 115, 97, 110, 97, 32, 107, 97, 116, 105, 107, 97, 32, 97, 110, 103, 97, 32, 121, 97, 32, 107, 117, 115, 105, 110, 105, 32, 107, 119, 101, 110, 121, 101, 32, 107, 117, 110, 100, 105, 110, 121, 111, 116, 97, 32, 121, 97, 32, 75, 97, 110, 116, 97, 114, 117, 115, 105, 32, 40, 112, 105, 97, 58, 32, 105, 110, 103, 46, 32, 67, 101, 110, 116, 97, 117, 114, 117, 115, 41, 46, 32, 78, 105, 32, 110, 121, 111, 116, 97, 32, 121, 97, 32, 107, 117, 110, 103, 97, 97, 32, 115, 97, 110, 97, 32, 121, 97, 32, 110, 110, 101, 32, 97, 110, 103, 97, 110, 105, 32, 108, 97, 107, 105, 110, 105, 32, 104, 97, 105, 111, 110, 101, 107, 97, 110, 105, 32, 107, 119, 101, 110, 121, 101, 32, 110, 117, 115, 117, 100, 117, 110, 105, 97, 32, 121, 97, 32, 107, 97, 115, 107, 97, 122, 105, 110, 105, 46, 32, 57351, 32, 65, 108, 112, 104, 97, 32, 67, 101, 110, 116, 97, 117, 114, 105, 32, 110, 105, 32, 110, 121, 111, 116, 97, 32, 121, 97, 32, 112, 101, 107, 101, 101, 32, 107, 119, 97, 32, 115, 97, 98, 97, 98, 117, 32, 110, 105, 32, 110, 121, 111, 116, 97, 32, 121, 101, 116, 117, 32, 106, 105, 114, 97, 110, 105, 32, 107, 97, 116, 105, 107, 97, 32, 97, 110, 103, 97, 32, 105, 110, 97, 32, 117, 109, 98, 97, 108, 105, 32, 119, 97, 32, 109, 105, 97, 107, 97, 32, 121, 97, 32, 110, 117, 114, 117, 32, 52, 46, 50, 46, 32, 73, 110, 97, 111, 110, 101, 107, 97, 110, 97, 32, 97, 110, 103, 97, 110, 105, 32, 107, 97, 114, 105, 98, 117, 32, 110, 97, 32, 107, 117, 110, 100, 105, 110, 121, 111, 116, 97, 32, 121, 97, 32, 83, 97, 108, 105, 98, 117, 32, 40, 67, 114, 117, 120, 41, 46, 32, 57352, 32, 82, 105, 106, 105, 108, 105, 32, 75, 97, 110, 116, 97, 114, 117, 115, 105, 32, 40, 65, 108, 112, 104, 97, 32, 67, 101, 110, 116, 97, 117, 114, 105, 41, 32, 105, 110, 97, 111, 110, 101, 107, 97, 110, 97, 32, 107, 97, 109, 97, 32, 110, 121, 111, 116, 97, 32, 109, 111, 106, 97, 32, 108, 97, 107, 105, 110, 105, 32, 107, 119, 97, 32, 100, 97, 114, 117, 98, 105, 110, 105, 32, 107, 117, 98, 119, 97, 32, 105, 110, 97, 111, 110, 101, 107, 97, 110, 97, 32, 107, 117, 119, 97, 32, 109, 102, 117, 109, 111, 32, 119, 97, 32, 110, 121, 111, 116, 97, 32, 116, 97, 116, 117, 32, 122, 105, 110, 97, 122, 111, 107, 97, 97, 32, 107, 97, 114, 105, 98, 117, 32, 110, 97, 32, 107, 117, 115, 104, 105, 107, 97, 109, 97, 110, 97, 32, 107, 97, 116, 105, 32, 121, 97, 111, 46, 32, 78, 121, 111, 116, 97, 32, 109, 97, 112, 97, 99, 104, 97, 32, 122, 97, 32, 65, 108, 112, 104, 97, 32, 67, 101, 110, 116, 97, 117, 114, 105, 32, 65, 32, 110, 97, 32, 65, 108, 112, 104, 97, 32, 67, 101, 110, 116, 97, 117, 114, 105, 32, 66, 32, 122, 105, 107, 111, 32, 109, 105, 97, 107, 97, 32, 121, 97, 32, 110, 117, 114, 117, 32, 52, 46, 51, 54, 32, 107, 117, 116, 111, 107, 97, 32, 107, 119, 101, 116, 117, 32, 110, 97, 32, 110, 121, 111, 116, 97, 32, 121, 97, 32, 116, 97, 116, 117, 32, 65, 108, 112, 104, 97, 32, 67, 101, 110, 116, 97, 117, 114, 105, 32, 67, 32, 97, 117, 32, 80, 114, 111, 120, 105, 109, 97, 32, 67, 101, 110, 116, 97, 117, 114, 105, 32, 105, 110, 97, 32, 117, 109, 98, 97, 108, 105, 32, 119, 97, 32, 109, 105, 97, 107, 97, 32, 121, 97, 32, 110, 117, 114, 117, 32, 52, 46, 50, 50, 46, 32, 57353, 32, 80, 114, 111, 120, 105, 109, 97, 32, 67, 101, 110, 116, 97, 117, 114, 105, 32, 40, 121, 97, 97, 110, 105, 32, 110, 121, 111, 116, 97, 32, 121, 97, 32, 75, 97, 110, 116, 97, 114, 117, 115, 105, 32, 105, 108, 105, 121, 111, 32, 107, 97, 114, 105, 98, 117, 32, 122, 97, 105, 100, 105, 32, 110, 97, 115, 105, 41, 32, 105, 109, 101, 103, 117, 110, 100, 117, 108, 105, 119, 97, 32, 107, 117, 119, 97, 32, 110, 97, 32, 115, 97, 121, 97, 114, 105, 32, 109, 111, 106, 97, 46, 32, 86, 105, 112, 105, 109, 111, 32, 118, 105, 110, 97, 118, 121, 111, 112, 97, 116, 105, 107, 97, 110, 97, 32, 104, 97, 100, 105, 32, 115, 97, 115, 97, 32, 122, 105, 110, 97, 111, 110, 121, 101, 115, 104, 97, 32, 117, 119, 101, 122, 101, 107, 97, 110, 111, 32, 109, 107, 117, 98, 119, 97, 32, 121, 97, 32, 107, 119, 97, 109, 98, 97, 32, 115, 97, 121, 97, 114, 105, 32, 104, 105, 105, 32, 110, 105, 32, 121, 97, 32, 109, 119, 97, 109, 98, 97, 32, 40, 107, 97, 109, 97, 32, 100, 117, 110, 105, 97, 32, 121, 101, 116, 117, 44, 32, 77, 105, 114, 105, 104, 105, 32, 97, 117, 32, 90, 117, 104, 117, 114, 97, 41, 32, 110, 97, 32, 105, 110, 97, 119, 101, 122, 97, 32, 107, 117, 119, 97, 32, 110, 97, 32, 97, 110, 103, 97, 104, 101, 119, 97, 44, 32, 116, 101, 110, 97, 32, 107, 97, 116, 105, 107, 97, 32, 117, 112, 101, 111, 32, 119, 97, 32, 106, 111, 116, 111, 32, 117, 110, 97, 111, 114, 117, 104, 117, 115, 117, 32, 107, 117, 119, 101, 112, 111, 32, 107, 119, 97, 32, 117, 104, 97, 105, 46, 32, 91, 49, 93, 57345, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
+ attention_mask = [1 if x != 0 else 0 for x in input_ids]
+ token_type_ids = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
+ # fmt: on
+ input_ids = torch.tensor([input_ids])
+ attention_mask = torch.tensor([attention_mask])
+ token_type_ids = torch.tensor([token_type_ids])
+ outputs = model(input_ids, attention_mask, token_type_ids)
+
+ # verify sequence output
+ expected_shape = torch.Size((1, 2048, 768))
+ self.assertEqual(outputs.last_hidden_state.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [
+ [-0.161433131, 0.395568609, 0.0407391489],
+ [-0.108025983, 0.362060368, -0.544592619],
+ [-0.141537309, 0.180541009, 0.076907],
+ ]
+ )
+
+ torch.testing.assert_close(outputs.last_hidden_state[0, :3, :3], expected_slice, rtol=1e-2, atol=1e-2)
+
+ # verify pooled output
+ expected_shape = torch.Size((1, 768))
+ self.assertEqual(outputs.pooler_output.shape, expected_shape)
+
+ expected_slice = torch.tensor([-0.884311497, -0.529064834, 0.723164916])
+
+ torch.testing.assert_close(outputs.pooler_output[0, :3], expected_slice, rtol=1e-2, atol=1e-2)
diff --git a/transformers/tests/models/canine/test_tokenization_canine.py b/transformers/tests/models/canine/test_tokenization_canine.py
new file mode 100644
index 0000000000000000000000000000000000000000..6bcb54e33f0d4bed169874a36d906847b63759cb
--- /dev/null
+++ b/transformers/tests/models/canine/test_tokenization_canine.py
@@ -0,0 +1,339 @@
+# Copyright 2021 Google AI and HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import shutil
+import tempfile
+import unittest
+from functools import lru_cache
+
+from transformers import BatchEncoding, CanineTokenizer
+from transformers.testing_utils import require_tokenizers, require_torch
+from transformers.tokenization_utils import AddedToken
+from transformers.utils import cached_property
+
+from ...test_tokenization_common import TokenizerTesterMixin, use_cache_if_possible
+
+
+class CanineTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "nielsr/canine-s"
+ tokenizer_class = CanineTokenizer
+ test_rust_tokenizer = False
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+ tokenizer = CanineTokenizer()
+ tokenizer.save_pretrained(cls.tmpdirname)
+
+ @cached_property
+ def canine_tokenizer(self):
+ return CanineTokenizer.from_pretrained("google/canine-s")
+
+ @classmethod
+ @use_cache_if_possible
+ @lru_cache(maxsize=64)
+ def get_tokenizer(cls, pretrained_name=None, **kwargs) -> CanineTokenizer:
+ pretrained_name = pretrained_name or cls.tmpdirname
+ tokenizer = cls.tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+ tokenizer._unicode_vocab_size = 1024
+ return tokenizer
+
+ @require_torch
+ def test_prepare_batch_integration(self):
+ tokenizer = self.canine_tokenizer
+ src_text = ["Life is like a box of chocolates.", "You never know what you're gonna get."]
+ expected_src_tokens = [57344, 76, 105, 102, 101, 32, 105, 115, 32, 108, 105, 107, 101, 32, 97, 32, 98, 111, 120, 32, 111, 102, 32, 99, 104, 111, 99, 111, 108, 97, 116, 101, 115, 46, 57345, 0, 0, 0, 0] # fmt: skip
+ batch = tokenizer(src_text, padding=True, return_tensors="pt")
+ self.assertIsInstance(batch, BatchEncoding)
+
+ result = list(batch.input_ids.numpy()[0])
+
+ self.assertListEqual(expected_src_tokens, result)
+
+ self.assertEqual((2, 39), batch.input_ids.shape)
+ self.assertEqual((2, 39), batch.attention_mask.shape)
+
+ @require_torch
+ def test_encoding_keys(self):
+ tokenizer = self.canine_tokenizer
+ src_text = ["Once there was a man.", "He wrote a test in HuggingFace Transformers."]
+ batch = tokenizer(src_text, padding=True, return_tensors="pt")
+ # check if input_ids, attention_mask and token_type_ids are returned
+ self.assertIn("input_ids", batch)
+ self.assertIn("attention_mask", batch)
+ self.assertIn("token_type_ids", batch)
+
+ @require_torch
+ def test_max_length_integration(self):
+ tokenizer = self.canine_tokenizer
+ tgt_text = [
+ "What's the weater?",
+ "It's about 25 degrees.",
+ ]
+ targets = tokenizer(
+ text_target=tgt_text, max_length=32, padding="max_length", truncation=True, return_tensors="pt"
+ )
+ self.assertEqual(32, targets["input_ids"].shape[1])
+
+ # cannot use default save_and_load_tokenizer test method because tokenizer has no vocab
+ def test_save_and_load_tokenizer(self):
+ # safety check on max_len default value so we are sure the test works
+ tokenizers = self.get_tokenizers()
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ self.assertNotEqual(tokenizer.model_max_length, 42)
+
+ # Now let's start the test
+ tokenizers = self.get_tokenizers()
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ # Isolate this from the other tests because we save additional tokens/etc
+ tmpdirname = tempfile.mkdtemp()
+
+ sample_text = " He is very happy, UNwant\u00e9d,running"
+ before_tokens = tokenizer.encode(sample_text, add_special_tokens=False)
+ tokenizer.save_pretrained(tmpdirname)
+
+ after_tokenizer = tokenizer.__class__.from_pretrained(tmpdirname)
+ after_tokens = after_tokenizer.encode(sample_text, add_special_tokens=False)
+ self.assertListEqual(before_tokens, after_tokens)
+
+ shutil.rmtree(tmpdirname)
+
+ tokenizers = self.get_tokenizers(model_max_length=42)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ # Isolate this from the other tests because we save additional tokens/etc
+ tmpdirname = tempfile.mkdtemp()
+
+ sample_text = " He is very happy, UNwant\u00e9d,running"
+
+ additional_special_tokens = tokenizer.additional_special_tokens
+
+ # We can add a new special token for Canine as follows:
+ new_additional_special_token = chr(0xE007)
+ additional_special_tokens.append(new_additional_special_token)
+ tokenizer.add_special_tokens(
+ {"additional_special_tokens": additional_special_tokens}, replace_additional_special_tokens=False
+ )
+ before_tokens = tokenizer.encode(sample_text, add_special_tokens=False)
+ tokenizer.save_pretrained(tmpdirname)
+
+ after_tokenizer = tokenizer.__class__.from_pretrained(tmpdirname)
+ after_tokens = after_tokenizer.encode(sample_text, add_special_tokens=False)
+ self.assertListEqual(before_tokens, after_tokens)
+ self.assertIn(new_additional_special_token, after_tokenizer.additional_special_tokens)
+ self.assertEqual(after_tokenizer.model_max_length, 42)
+
+ tokenizer = tokenizer.__class__.from_pretrained(tmpdirname, model_max_length=43)
+ self.assertEqual(tokenizer.model_max_length, 43)
+
+ shutil.rmtree(tmpdirname)
+
+ def test_add_special_tokens(self):
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ input_text, ids = self.get_clean_sequence(tokenizer)
+
+ # a special token for Canine can be defined as follows:
+ SPECIAL_TOKEN = 0xE005
+ special_token = chr(SPECIAL_TOKEN)
+
+ tokenizer.add_special_tokens({"cls_token": special_token})
+ encoded_special_token = tokenizer.encode(special_token, add_special_tokens=False)
+ self.assertEqual(len(encoded_special_token), 1)
+
+ text = tokenizer.decode(ids + encoded_special_token, clean_up_tokenization_spaces=False)
+ encoded = tokenizer.encode(text, add_special_tokens=False)
+
+ input_encoded = tokenizer.encode(input_text, add_special_tokens=False)
+ special_token_id = tokenizer.encode(special_token, add_special_tokens=False)
+ self.assertEqual(encoded, input_encoded + special_token_id)
+
+ decoded = tokenizer.decode(encoded, skip_special_tokens=True)
+ self.assertTrue(special_token not in decoded)
+
+ def test_tokenize_special_tokens(self):
+ tokenizers = self.get_tokenizers(do_lower_case=True)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ SPECIAL_TOKEN_1 = chr(0xE005)
+ SPECIAL_TOKEN_2 = chr(0xE006)
+ tokenizer.add_tokens([SPECIAL_TOKEN_1], special_tokens=True)
+ tokenizer.add_special_tokens({"additional_special_tokens": [SPECIAL_TOKEN_2]})
+
+ token_1 = tokenizer.tokenize(SPECIAL_TOKEN_1)
+ token_2 = tokenizer.tokenize(SPECIAL_TOKEN_2)
+
+ self.assertEqual(len(token_1), 1)
+ self.assertEqual(len(token_2), 1)
+ self.assertEqual(token_1[0], SPECIAL_TOKEN_1)
+ self.assertEqual(token_2[0], SPECIAL_TOKEN_2)
+
+ @require_tokenizers
+ def test_added_token_serializable(self):
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ # a special token for Canine can be defined as follows:
+ NEW_TOKEN = 0xE006
+ new_token = chr(NEW_TOKEN)
+
+ new_token = AddedToken(new_token, lstrip=True)
+ tokenizer.add_special_tokens({"additional_special_tokens": [new_token]})
+
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ tokenizer.save_pretrained(tmp_dir_name)
+ tokenizer.from_pretrained(tmp_dir_name)
+
+ def test_special_tokens_initialization_with_non_empty_additional_special_tokens(self):
+ tokenizer_list = []
+ if self.test_slow_tokenizer:
+ tokenizer_list.append((self.tokenizer_class, self.get_tokenizer()))
+
+ if self.test_rust_tokenizer:
+ tokenizer_list.append((self.rust_tokenizer_class, self.get_rust_tokenizer()))
+
+ for tokenizer_class, tokenizer_utils in tokenizer_list:
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ tokenizer_utils.save_pretrained(tmp_dir)
+
+ with open(os.path.join(tmp_dir, "special_tokens_map.json"), encoding="utf-8") as json_file:
+ special_tokens_map = json.load(json_file)
+
+ with open(os.path.join(tmp_dir, "tokenizer_config.json"), encoding="utf-8") as json_file:
+ tokenizer_config = json.load(json_file)
+
+ # a special token for Canine can be defined as follows:
+ NEW_TOKEN = 0xE006
+ new_token_1 = chr(NEW_TOKEN)
+
+ special_tokens_map["additional_special_tokens"] = [new_token_1]
+ tokenizer_config["additional_special_tokens"] = [new_token_1]
+
+ with open(os.path.join(tmp_dir, "special_tokens_map.json"), "w", encoding="utf-8") as outfile:
+ json.dump(special_tokens_map, outfile)
+ with open(os.path.join(tmp_dir, "tokenizer_config.json"), "w", encoding="utf-8") as outfile:
+ json.dump(tokenizer_config, outfile)
+
+ # the following checks allow us to verify that our test works as expected, i.e. that the tokenizer takes
+ # into account the new value of additional_special_tokens given in the "tokenizer_config.json" and
+ # "special_tokens_map.json" files
+ tokenizer_without_change_in_init = tokenizer_class.from_pretrained(tmp_dir, extra_ids=0)
+ self.assertIn(new_token_1, tokenizer_without_change_in_init.additional_special_tokens)
+ # self.assertIn("an_additional_special_token",tokenizer_without_change_in_init.get_vocab()) # ByT5Tokenization no vocab
+ self.assertEqual(
+ [new_token_1],
+ tokenizer_without_change_in_init.convert_ids_to_tokens(
+ tokenizer_without_change_in_init.convert_tokens_to_ids([new_token_1])
+ ),
+ )
+
+ NEW_TOKEN = 0xE007
+ new_token_2 = chr(NEW_TOKEN)
+ # Now we test that we can change the value of additional_special_tokens in the from_pretrained
+ new_added_tokens = [AddedToken(new_token_2, lstrip=True)]
+ tokenizer = tokenizer_class.from_pretrained(
+ tmp_dir, additional_special_tokens=new_added_tokens, extra_ids=0
+ )
+
+ self.assertIn(new_token_2, tokenizer.additional_special_tokens)
+ # self.assertIn(new_token_2,tokenizer.get_vocab()) # ByT5Tokenization no vocab
+ self.assertEqual(
+ [new_token_2], tokenizer.convert_ids_to_tokens(tokenizer.convert_tokens_to_ids([new_token_2]))
+ )
+
+ @require_tokenizers
+ def test_encode_decode_with_spaces(self):
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ input = "hello world"
+ if self.space_between_special_tokens:
+ output = "[CLS] hello world [SEP]"
+ else:
+ output = input
+ encoded = tokenizer.encode(input, add_special_tokens=False)
+ decoded = tokenizer.decode(encoded, spaces_between_special_tokens=self.space_between_special_tokens)
+ self.assertIn(decoded, [output, output.lower()])
+
+ # cannot use default `test_tokenizers_common_ids_setters` method because tokenizer has no vocab
+ def test_tokenizers_common_ids_setters(self):
+ tokenizers = self.get_tokenizers()
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ attributes_list = [
+ "bos_token",
+ "eos_token",
+ "unk_token",
+ "sep_token",
+ "pad_token",
+ "cls_token",
+ "mask_token",
+ ]
+
+ token_to_test_setters = "a"
+ token_id_to_test_setters = ord(token_to_test_setters)
+
+ for attr in attributes_list:
+ setattr(tokenizer, attr + "_id", None)
+ self.assertEqual(getattr(tokenizer, attr), None)
+ self.assertEqual(getattr(tokenizer, attr + "_id"), None)
+
+ setattr(tokenizer, attr + "_id", token_id_to_test_setters)
+ self.assertEqual(getattr(tokenizer, attr), token_to_test_setters)
+ self.assertEqual(getattr(tokenizer, attr + "_id"), token_id_to_test_setters)
+
+ setattr(tokenizer, "additional_special_tokens_ids", [])
+ self.assertListEqual(getattr(tokenizer, "additional_special_tokens"), [])
+ self.assertListEqual(getattr(tokenizer, "additional_special_tokens_ids"), [])
+
+ additional_special_token_id = 0xE006
+ additional_special_token = chr(additional_special_token_id)
+ setattr(tokenizer, "additional_special_tokens_ids", [additional_special_token_id])
+ self.assertListEqual(getattr(tokenizer, "additional_special_tokens"), [additional_special_token])
+ self.assertListEqual(getattr(tokenizer, "additional_special_tokens_ids"), [additional_special_token_id])
+
+ @unittest.skip(reason="tokenizer has a fixed vocab_size (namely all possible unicode code points)")
+ def test_add_tokens_tokenizer(self):
+ pass
+
+ # CanineTokenizer does not support do_lower_case = True, as each character has its own Unicode code point
+ # ("b" and "B" for example have different Unicode code points)
+ @unittest.skip(reason="CanineTokenizer does not support do_lower_case = True")
+ def test_added_tokens_do_lower_case(self):
+ pass
+
+ @unittest.skip(reason="CanineModel does not support the get_input_embeddings nor the get_vocab method")
+ def test_np_encode_plus_sent_to_model(self):
+ pass
+
+ @unittest.skip(reason="CanineModel does not support the get_input_embeddings nor the get_vocab method")
+ def test_torch_encode_plus_sent_to_model(self):
+ pass
+
+ @unittest.skip(reason="CanineTokenizer does not have vocabulary")
+ def test_get_vocab(self):
+ pass
+
+ @unittest.skip(reason="inputs cannot be pretokenized since ids depend on whole input string")
+ def test_pretokenized_inputs(self):
+ pass
+
+ @unittest.skip(reason="CanineTokenizer does not have vocabulary")
+ def test_conversion_reversible(self):
+ pass
diff --git a/transformers/tests/models/chameleon/__init__.py b/transformers/tests/models/chameleon/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/chameleon/test_image_processing_chameleon.py b/transformers/tests/models/chameleon/test_image_processing_chameleon.py
new file mode 100644
index 0000000000000000000000000000000000000000..78576725f78ae7d8dd9f62bf5fa40e8954b58025
--- /dev/null
+++ b/transformers/tests/models/chameleon/test_image_processing_chameleon.py
@@ -0,0 +1,218 @@
+# Copyright 2024 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import numpy as np
+
+from transformers.image_utils import PILImageResampling
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torch_available, is_torchvision_available, is_vision_available
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import ChameleonImageProcessor
+
+ if is_torchvision_available():
+ from transformers import ChameleonImageProcessorFast
+
+
+class ChameleonImageProcessingTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=200,
+ do_resize=True,
+ size=None,
+ do_center_crop=True,
+ crop_size=None,
+ do_normalize=True,
+ image_mean=[1.0, 1.0, 1.0],
+ image_std=[1.0, 1.0, 1.0],
+ do_convert_rgb=True,
+ resample=PILImageResampling.BILINEAR,
+ ):
+ size = size if size is not None else {"shortest_edge": 18}
+ crop_size = crop_size if crop_size is not None else {"height": 18, "width": 18}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_center_crop = do_center_crop
+ self.crop_size = crop_size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.do_convert_rgb = do_convert_rgb
+ self.resample = resample
+
+ def prepare_image_processor_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "do_center_crop": self.do_center_crop,
+ "crop_size": self.crop_size,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_convert_rgb": self.do_convert_rgb,
+ "resample": self.resample,
+ }
+
+ # Copied from tests.models.clip.test_image_processing_clip.CLIPImageProcessingTester.expected_output_image_shape
+ def expected_output_image_shape(self, images):
+ return self.num_channels, self.crop_size["height"], self.crop_size["width"]
+
+ # Copied from tests.models.clip.test_image_processing_clip.CLIPImageProcessingTester.prepare_image_inputs
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class ChameleonImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = ChameleonImageProcessor if is_vision_available() else None
+ fast_image_processing_class = ChameleonImageProcessorFast if is_torchvision_available() else None
+
+ # Copied from tests.models.clip.test_image_processing_clip.CLIPImageProcessingTest.setUp with CLIP->Chameleon
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = ChameleonImageProcessingTester(self)
+
+ @property
+ # Copied from tests.models.clip.test_image_processing_clip.CLIPImageProcessingTest.image_processor_dict
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "do_center_crop"))
+ self.assertTrue(hasattr(image_processing, "center_crop"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_convert_rgb"))
+
+ def test_image_processor_from_dict_with_kwargs(self):
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"shortest_edge": 18})
+ self.assertEqual(image_processor.crop_size, {"height": 18, "width": 18})
+
+ image_processor = image_processing_class.from_dict(self.image_processor_dict, size=42, crop_size=84)
+ self.assertEqual(image_processor.size, {"shortest_edge": 42})
+ self.assertEqual(image_processor.crop_size, {"height": 84, "width": 84})
+
+ def test_call_pil(self):
+ for image_processing_class in self.image_processor_list:
+ # Initialize image_processing
+ image_processing = image_processing_class(**self.image_processor_dict)
+ # create random PIL images
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, Image.Image)
+
+ # Test not batched input
+ encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
+ expected_output_image_shape = (1, 3, 18, 18)
+ self.assertEqual(tuple(encoded_images.shape), expected_output_image_shape)
+
+ # Test batched
+ encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
+ expected_output_image_shape = (7, 3, 18, 18)
+ self.assertEqual(tuple(encoded_images.shape), expected_output_image_shape)
+
+ def test_call_numpy(self):
+ for image_processing_class in self.image_processor_list:
+ # Initialize image_processing
+ image_processing = image_processing_class(**self.image_processor_dict)
+ # create random numpy tensors
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=True, numpify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, np.ndarray)
+
+ # Test not batched input
+ encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
+ expected_output_image_shape = (1, 3, 18, 18)
+ self.assertEqual(tuple(encoded_images.shape), expected_output_image_shape)
+
+ # Test batched
+ encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
+ expected_output_image_shape = (7, 3, 18, 18)
+ self.assertEqual(tuple(encoded_images.shape), expected_output_image_shape)
+
+ def test_call_pytorch(self):
+ for image_processing_class in self.image_processor_list:
+ # Initialize image_processing
+ image_processing = image_processing_class(**self.image_processor_dict)
+ # create random PyTorch tensors
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=True, torchify=True)
+
+ for image in image_inputs:
+ self.assertIsInstance(image, torch.Tensor)
+
+ # Test not batched input
+ encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
+ expected_output_image_shape = (1, 3, 18, 18)
+ self.assertEqual(tuple(encoded_images.shape), expected_output_image_shape)
+
+ # Test batched
+ encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
+ expected_output_image_shape = (7, 3, 18, 18)
+ self.assertEqual(tuple(encoded_images.shape), expected_output_image_shape)
+
+ def test_nested_input(self):
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class(**self.image_processor_dict)
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=True)
+
+ # Test batched as a list of images
+ encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
+ expected_output_image_shape = (7, 3, 18, 18)
+ self.assertEqual(tuple(encoded_images.shape), expected_output_image_shape)
+
+ # Test batched as a nested list of images, where each sublist is one batch
+ image_inputs_nested = [image_inputs[:3], image_inputs[3:]]
+ encoded_images_nested = image_processing(image_inputs_nested, return_tensors="pt").pixel_values
+ expected_output_image_shape = (7, 3, 18, 18)
+ self.assertEqual(tuple(encoded_images_nested.shape), expected_output_image_shape)
+
+ # Image processor should return same pixel values, independently of input format
+ self.assertTrue((encoded_images_nested == encoded_images).all())
diff --git a/transformers/tests/models/chameleon/test_modeling_chameleon.py b/transformers/tests/models/chameleon/test_modeling_chameleon.py
new file mode 100644
index 0000000000000000000000000000000000000000..67baab37c0990fd8f94ba2002674a5bbc16de6ff
--- /dev/null
+++ b/transformers/tests/models/chameleon/test_modeling_chameleon.py
@@ -0,0 +1,461 @@
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch chameleon model."""
+
+import copy
+import unittest
+
+import requests
+from parameterized import parameterized
+
+from transformers import ChameleonConfig, is_torch_available, is_vision_available, set_seed
+from transformers.testing_utils import (
+ Expectations,
+ require_bitsandbytes,
+ require_read_token,
+ require_torch,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_vision_available():
+ from PIL import Image
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ ChameleonForConditionalGeneration,
+ ChameleonModel,
+ ChameleonProcessor,
+ )
+
+
+class ChameleonModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=35,
+ is_training=False,
+ use_input_mask=True,
+ use_labels=True,
+ vocab_size=99,
+ image_token_id=4,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=2,
+ num_key_value_heads=2,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ pad_token_id=0,
+ vq_num_embeds=5,
+ vq_embed_dim=5,
+ vq_channel_multiplier=[1, 4],
+ vq_img_token_start_id=10, # has to be less than vocab size when added with vq_num_embeds
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.image_token_id = image_token_id
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.num_key_value_heads = num_key_value_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.pad_token_id = pad_token_id
+ self.scope = scope
+ self.vq_num_embeds = vq_num_embeds
+ self.vq_embed_dim = vq_embed_dim
+ self.vq_channel_multiplier = vq_channel_multiplier
+ self.vq_img_token_start_id = vq_img_token_start_id
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = torch.tril(torch.ones_like(input_ids).to(torch_device))
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ # create dummy vocab map for image2bpe mapping if it needs remapping
+ # we assume that vocab size is big enough to account for image tokens somewhere in the beginning
+ # same way as in real ckpt, when img tokens are in first half of embeds
+ # we will need "vq_num_embeds" amount of tokens
+
+ vocab_map = {i: chr(i) for i in range(self.vocab_size)}
+ vocab_map[self.image_token_id] = ""
+ start = self.vq_img_token_start_id
+ end = self.vq_img_token_start_id + self.vq_num_embeds
+ for i in range(start, end):
+ image_token_infix = "".join(chr(ord("A") + int(c)) for c in str(i))
+ # dummy str for each image token, anything starting with IMGIMG
+ vocab_map[i] = f"IMGIMG{image_token_infix}Z"
+
+ return ChameleonConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ num_key_value_heads=self.num_key_value_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ pad_token_id=self.pad_token_id,
+ vocabulary_map={v: k for k, v in vocab_map.items()},
+ vq_config=self.get_vq_config(),
+ )
+
+ def get_vq_config(self):
+ return {
+ "embed_dim": self.vq_embed_dim,
+ "num_embeddings": self.vq_num_embeds,
+ "latent_channels": self.vq_embed_dim,
+ "in_channels": 3,
+ "base_channels": 32, # we have a GroupNorm of 32 groups, so can't do less
+ "channel_multiplier": self.vq_channel_multiplier,
+ }
+
+ def create_and_check_model(self, config, input_ids, input_mask, sequence_labels, token_labels, choice_labels):
+ model = ChameleonModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class ChameleonModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (ChameleonModel, ChameleonForConditionalGeneration) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": ChameleonModel,
+ "text-generation": ChameleonForConditionalGeneration,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_headmasking = False
+ test_pruning = False
+ fx_compatible = False
+
+ def setUp(self):
+ self.model_tester = ChameleonModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=ChameleonConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @parameterized.expand([("linear",), ("dynamic",)])
+ def test_model_rope_scaling(self, scaling_type):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ short_input = ids_tensor([1, 10], config.vocab_size)
+ long_input = ids_tensor([1, int(config.max_position_embeddings * 1.5)], config.vocab_size)
+
+ set_seed(42) # Fixed seed at init time so the two models get the same random weights
+ original_model = ChameleonModel(config)
+ original_model.to(torch_device)
+ original_model.eval()
+ original_short_output = original_model(short_input).last_hidden_state
+ original_long_output = original_model(long_input).last_hidden_state
+
+ set_seed(42) # Fixed seed at init time so the two models get the same random weights
+ config.rope_scaling = {"type": scaling_type, "factor": 10.0}
+ scaled_model = ChameleonModel(config)
+ scaled_model.to(torch_device)
+ scaled_model.eval()
+ scaled_short_output = scaled_model(short_input).last_hidden_state
+ scaled_long_output = scaled_model(long_input).last_hidden_state
+
+ # Dynamic scaling does not change the RoPE embeddings until it receives an input longer than the original
+ # maximum sequence length, so the outputs for the short input should match.
+ if scaling_type == "dynamic":
+ torch.testing.assert_close(original_short_output, scaled_short_output, rtol=1e-5, atol=1e-5)
+ else:
+ self.assertFalse(torch.allclose(original_short_output, scaled_short_output, atol=1e-5))
+
+ # The output should be different for long inputs
+ self.assertFalse(torch.allclose(original_long_output, scaled_long_output, atol=1e-5))
+
+ @unittest.skip("Chameleon forces some token ids to be -inf!")
+ def test_batching_equivalence(self):
+ pass
+
+ @unittest.skip("Chameleon VQ model cannot be squishes more due to hardcoded layer params in model code")
+ def test_model_is_small(self):
+ pass
+
+
+class ChameleonVision2SeqModelTester(ChameleonModelTester):
+ def __init__(self, parent, image_size=10, **kwargs):
+ super().__init__(parent, **kwargs)
+ self.image_size = image_size
+ self.image_seq_length = 25
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+ input_ids[input_ids == self.image_token_id] = self.pad_token_id
+ input_ids[:, : self.image_seq_length] = self.image_token_id
+ attention_mask = torch.tril(torch.ones_like(input_ids).to(torch_device))
+ pixel_values = floats_tensor([self.batch_size, 3, self.image_size, self.image_size])
+
+ config = self.get_config()
+
+ return config, input_ids, attention_mask, pixel_values
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, attention_mask, pixel_values = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": attention_mask, "pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class ChameleonVision2SeqModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
+ all_model_classes = (ChameleonModel, ChameleonForConditionalGeneration) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "image-text-to-text": ChameleonForConditionalGeneration,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_headmasking = False
+ test_pruning = False
+ fx_compatible = False
+
+ def setUp(self):
+ self.model_tester = ChameleonVision2SeqModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=ChameleonConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip("Chameleon forces some token ids to be -inf!")
+ def test_batching_equivalence(self):
+ pass
+
+ @unittest.skip("Chameleon cannot do offload because it uses `self.linear.weight` in forward")
+ def test_cpu_offload(self):
+ pass
+
+ @unittest.skip("Chameleon cannot do offload because it uses `self.linear.weight` in forward")
+ def test_disk_offload_bin(self):
+ pass
+
+ @unittest.skip("Chameleon cannot do offload because it uses `self.linear.weight` in forward")
+ def test_disk_offload_safetensors(self):
+ pass
+
+ @unittest.skip("Chameleon VQ model cannot be squishes more due to hardcoded layer params in model code")
+ def test_model_is_small(self):
+ pass
+
+ def test_mismatching_num_image_tokens(self):
+ """
+ Tests that VLMs through an error with explicit message saying what is wrong
+ when number of images don't match number of image tokens in the text.
+ Also we need to test multi-image cases when one prompr has multiple image tokens.
+ """
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ for model_class in self.all_model_classes:
+ model = model_class(config).to(torch_device)
+ curr_input_dict = copy.deepcopy(input_dict) # the below tests modify dict in-place
+ _ = model(**curr_input_dict) # successful forward with no modifications
+
+ # remove one image but leave the image token in text
+ curr_input_dict["pixel_values"] = curr_input_dict["pixel_values"][-1:, ...]
+ with self.assertRaises(ValueError):
+ _ = model(**curr_input_dict)
+
+ # simulate multi-image case by concatenating inputs where each has exactly one image/image-token
+ input_ids = curr_input_dict["input_ids"][:1]
+ pixel_values = curr_input_dict["pixel_values"][:1]
+ input_ids = torch.cat([input_ids, input_ids], dim=0)
+
+ # one image and two image tokens raise an error
+ with self.assertRaises(ValueError):
+ _ = model(input_ids=input_ids, pixel_values=pixel_values)
+
+ # two images and two image tokens don't raise an error
+ pixel_values = torch.cat([pixel_values, pixel_values], dim=0)
+ _ = model(input_ids=input_ids, pixel_values=pixel_values)
+
+
+@require_torch
+class ChameleonIntegrationTest(unittest.TestCase):
+ @slow
+ @require_bitsandbytes
+ @require_read_token
+ def test_model_7b(self):
+ model = ChameleonForConditionalGeneration.from_pretrained(
+ "facebook/chameleon-7b", load_in_4bit=True, device_map="auto"
+ )
+ processor = ChameleonProcessor.from_pretrained("facebook/chameleon-7b")
+
+ image = Image.open(
+ requests.get("https://nineplanets.org/wp-content/uploads/2020/12/the-big-dipper-1.jpg", stream=True).raw
+ )
+ prompt = "Describe what do you see here and tell me about the history behind it?"
+
+ inputs = processor(images=image, text=prompt, return_tensors="pt").to(model.device, torch.float16)
+
+ # greedy generation outputs
+ EXPECTED_TEXT_COMPLETIONS = Expectations(
+ {
+ ("xpu", 3): ['Describe what do you see here and tell me about the history behind it?The image depicts a star map, with a bright blue dot in the center representing the star Altair. The star map is set against a black background, with the constellations visible in the night'],
+ ("cuda", 7): ['Describe what do you see here and tell me about the history behind it?The image depicts a star map, with a bright blue dot in the center representing the star Alpha Centauri. The star map is a representation of the night sky, showing the positions of stars in'],
+ ("cuda", 8): ['Describe what do you see here and tell me about the history behind it?The image depicts a star map, with a bright blue dot representing the position of the star Alpha Centauri. Alpha Centauri is the brightest star in the constellation Centaurus and is located'],
+ }
+ ) # fmt: skip
+ EXPECTED_TEXT_COMPLETION = EXPECTED_TEXT_COMPLETIONS.get_expectation()
+
+ generated_ids = model.generate(**inputs, max_new_tokens=40, do_sample=False)
+ text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ @slow
+ @require_bitsandbytes
+ @require_read_token
+ def test_model_7b_batched(self):
+ model = ChameleonForConditionalGeneration.from_pretrained(
+ "facebook/chameleon-7b", load_in_4bit=True, device_map="auto"
+ )
+ processor = ChameleonProcessor.from_pretrained("facebook/chameleon-7b")
+
+ image = Image.open(
+ requests.get("https://nineplanets.org/wp-content/uploads/2020/12/the-big-dipper-1.jpg", stream=True).raw
+ )
+ image_2 = Image.open(
+ requests.get("https://www.kxan.com/wp-content/uploads/sites/40/2020/10/ORION.jpg", stream=True).raw
+ )
+ prompts = [
+ "Describe what do you see here and tell me about the history behind it?",
+ "What constellation is this image showing?",
+ ]
+
+ inputs = processor(images=[image, image_2], text=prompts, padding=True, return_tensors="pt").to(
+ model.device, torch.float16
+ )
+
+ # greedy generation outputs
+ EXPECTED_TEXT_COMPLETIONS = Expectations(
+ {
+ ("xpu", 3): [
+ 'Describe what do you see here and tell me about the history behind it?The image depicts a star map, with a bright blue dot in the center representing the star Alpha Centauri. The star map is a representation of the night sky, showing the positions of stars in',
+ 'What constellation is this image showing?The image shows the constellation of Orion.The image shows the constellation of Orion.The image shows the constellation of Orion.The image shows the constellation of Orion.',
+ ],
+ ("cuda", 7): [
+ 'Describe what do you see here and tell me about the history behind it?The image depicts a star map, with a bright blue dot representing the position of the star Alpha Centauri. Alpha Centauri is the brightest star in the constellation Centaurus and is located',
+ 'What constellation is this image showing?The image shows the constellation of Orion.The image shows the constellation of Orion.The image shows the constellation of Orion.The image shows the constellation of Orion.',
+ ],
+ ("cuda", 8): [
+ 'Describe what do you see here and tell me about the history behind it?The image depicts a star map, with a bright blue dot representing the position of the star Alpha Centauri. Alpha Centauri is the brightest star in the constellation Centaurus and is located',
+ 'What constellation is this image showing?The image shows the constellation of Orion.The image shows the constellation of Orion.The image shows the constellation of Orion.The image shows the constellation of Orion.',
+ ],
+ }
+ ) # fmt: skip
+ EXPECTED_TEXT_COMPLETION = EXPECTED_TEXT_COMPLETIONS.get_expectation()
+
+ generated_ids = model.generate(**inputs, max_new_tokens=40, do_sample=False)
+ text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ @slow
+ @require_bitsandbytes
+ @require_read_token
+ def test_model_7b_multi_image(self):
+ model = ChameleonForConditionalGeneration.from_pretrained(
+ "facebook/chameleon-7b", load_in_4bit=True, device_map="auto"
+ )
+ processor = ChameleonProcessor.from_pretrained("facebook/chameleon-7b")
+
+ image = Image.open(
+ requests.get("https://nineplanets.org/wp-content/uploads/2020/12/the-big-dipper-1.jpg", stream=True).raw
+ )
+ image_2 = Image.open(
+ requests.get("https://www.kxan.com/wp-content/uploads/sites/40/2020/10/ORION.jpg", stream=True).raw
+ )
+ prompt = "What do these two images have in common?"
+
+ inputs = processor(images=[image, image_2], text=prompt, return_tensors="pt").to(model.device, torch.float16)
+
+ # greedy generation outputs
+ EXPECTED_TEXT_COMPLETION = ['What do these two images have in common?The two images show a connection between the night sky and the internet. The first image shows a starry night sky, with the stars arranged in a pattern that resembles the structure of the internet. The'] # fmt: skip
+ generated_ids = model.generate(**inputs, max_new_tokens=40, do_sample=False)
+ text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
diff --git a/transformers/tests/models/chameleon/test_processor_chameleon.py b/transformers/tests/models/chameleon/test_processor_chameleon.py
new file mode 100644
index 0000000000000000000000000000000000000000..d11321c9a8701652b80c9e332f7957adbfaba81d
--- /dev/null
+++ b/transformers/tests/models/chameleon/test_processor_chameleon.py
@@ -0,0 +1,76 @@
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch chameleon model."""
+
+import tempfile
+import unittest
+
+from transformers import ChameleonProcessor, LlamaTokenizer
+from transformers.testing_utils import get_tests_dir
+from transformers.utils import is_vision_available
+
+from ...test_processing_common import ProcessorTesterMixin
+
+
+if is_vision_available():
+ from transformers import ChameleonImageProcessor
+
+
+SAMPLE_VOCAB = get_tests_dir("fixtures/test_sentencepiece.model")
+
+
+class ChameleonProcessorTest(ProcessorTesterMixin, unittest.TestCase):
+ processor_class = ChameleonProcessor
+
+ @classmethod
+ def setUpClass(cls):
+ cls.tmpdirname = tempfile.mkdtemp()
+ image_processor = ChameleonImageProcessor()
+ tokenizer = LlamaTokenizer(vocab_file=SAMPLE_VOCAB)
+ tokenizer.pad_token_id = 0
+ tokenizer.sep_token_id = 1
+ tokenizer.add_special_tokens({"additional_special_tokens": [""]})
+ processor = cls.processor_class(image_processor=image_processor, tokenizer=tokenizer, image_seq_length=2)
+ processor.save_pretrained(cls.tmpdirname)
+ cls.image_token = processor.image_token
+
+ def test_special_mm_token_truncation(self):
+ """Tests that special vision tokens do not get truncated when `truncation=True` is set."""
+
+ processor = self.get_processor()
+
+ input_str = self.prepare_text_inputs(batch_size=2, modality="image")
+ image_input = self.prepare_image_inputs(batch_size=2)
+
+ _ = processor(
+ text=input_str,
+ images=image_input,
+ return_tensors="pt",
+ truncation=None,
+ padding=True,
+ )
+
+ with self.assertRaises(ValueError):
+ _ = processor(
+ text=input_str,
+ images=image_input,
+ return_tensors="pt",
+ truncation=True,
+ padding=True,
+ max_length=20,
+ )
+
+ @staticmethod
+ def prepare_processor_dict():
+ return {"image_seq_length": 2} # fmt: skip
diff --git a/transformers/tests/models/chinese_clip/__init__.py b/transformers/tests/models/chinese_clip/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/chinese_clip/test_image_processing_chinese_clip.py b/transformers/tests/models/chinese_clip/test_image_processing_chinese_clip.py
new file mode 100644
index 0000000000000000000000000000000000000000..7acae860b08aa64d4ffae69989ea20780efcdfe1
--- /dev/null
+++ b/transformers/tests/models/chinese_clip/test_image_processing_chinese_clip.py
@@ -0,0 +1,175 @@
+# Copyright 2021 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torchvision_available, is_vision_available
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_vision_available():
+ from transformers import ChineseCLIPImageProcessor
+
+ if is_torchvision_available():
+ from transformers import ChineseCLIPImageProcessorFast
+
+
+class ChineseCLIPImageProcessingTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ do_center_crop=True,
+ crop_size=None,
+ do_normalize=True,
+ image_mean=[0.48145466, 0.4578275, 0.40821073],
+ image_std=[0.26862954, 0.26130258, 0.27577711],
+ do_convert_rgb=True,
+ ):
+ size = size if size is not None else {"height": 224, "width": 224}
+ crop_size = crop_size if crop_size is not None else {"height": 18, "width": 18}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_center_crop = do_center_crop
+ self.crop_size = crop_size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.do_convert_rgb = do_convert_rgb
+
+ def prepare_image_processor_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "do_center_crop": self.do_center_crop,
+ "crop_size": self.crop_size,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_convert_rgb": self.do_convert_rgb,
+ }
+
+ def expected_output_image_shape(self, images):
+ return 3, self.crop_size["height"], self.crop_size["width"]
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class ChineseCLIPImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = ChineseCLIPImageProcessor if is_vision_available() else None
+ fast_image_processing_class = ChineseCLIPImageProcessorFast if is_torchvision_available() else None
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = ChineseCLIPImageProcessingTester(self, do_center_crop=True)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "do_center_crop"))
+ self.assertTrue(hasattr(image_processing, "center_crop"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_convert_rgb"))
+
+ def test_image_processor_from_dict_with_kwargs(self):
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"height": 224, "width": 224})
+ self.assertEqual(image_processor.crop_size, {"height": 18, "width": 18})
+
+ image_processor = self.image_processing_class.from_dict(self.image_processor_dict, size=42, crop_size=84)
+ self.assertEqual(image_processor.size, {"shortest_edge": 42})
+ self.assertEqual(image_processor.crop_size, {"height": 84, "width": 84})
+
+ @unittest.skip(
+ reason="ChineseCLIPImageProcessor doesn't treat 4 channel PIL and numpy consistently yet"
+ ) # FIXME Amy
+ def test_call_numpy_4_channels(self):
+ pass
+
+
+@require_torch
+@require_vision
+class ChineseCLIPImageProcessingTestFourChannels(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = ChineseCLIPImageProcessor if is_vision_available() else None
+ fast_image_processing_class = ChineseCLIPImageProcessorFast if is_torchvision_available() else None
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = ChineseCLIPImageProcessingTester(self, num_channels=4, do_center_crop=True)
+ self.expected_encoded_image_num_channels = 3
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "do_center_crop"))
+ self.assertTrue(hasattr(image_processing, "center_crop"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_convert_rgb"))
+
+ @unittest.skip(reason="ChineseCLIPImageProcessor does not support 4 channels yet") # FIXME Amy
+ def test_call_numpy(self):
+ return super().test_call_numpy()
+
+ @unittest.skip(reason="ChineseCLIPImageProcessor does not support 4 channels yet") # FIXME Amy
+ def test_call_pytorch(self):
+ return super().test_call_torch()
+
+ @unittest.skip(
+ reason="ChineseCLIPImageProcessor doesn't treat 4 channel PIL and numpy consistently yet"
+ ) # FIXME Amy
+ def test_call_numpy_4_channels(self):
+ pass
diff --git a/transformers/tests/models/chinese_clip/test_modeling_chinese_clip.py b/transformers/tests/models/chinese_clip/test_modeling_chinese_clip.py
new file mode 100644
index 0000000000000000000000000000000000000000..520ff2af3dd92527d4c7ab276a4a89c042dd26f7
--- /dev/null
+++ b/transformers/tests/models/chinese_clip/test_modeling_chinese_clip.py
@@ -0,0 +1,762 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Chinese-CLIP model."""
+
+import inspect
+import os
+import tempfile
+import unittest
+
+import numpy as np
+import requests
+
+from transformers import ChineseCLIPConfig, ChineseCLIPTextConfig, ChineseCLIPVisionConfig
+from transformers.models.auto import get_values
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ ModelTesterMixin,
+ _config_zero_init,
+ floats_tensor,
+ ids_tensor,
+ random_attention_mask,
+)
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import (
+ MODEL_FOR_PRETRAINING_MAPPING,
+ ChineseCLIPModel,
+ ChineseCLIPTextModel,
+ ChineseCLIPVisionModel,
+ )
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import ChineseCLIPProcessor
+
+
+class ChineseCLIPTextModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ """
+ Returns a tiny configuration by default.
+ """
+ return ChineseCLIPTextConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ )
+
+ def prepare_config_and_inputs_for_decoder(self):
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = self.prepare_config_and_inputs()
+
+ config.is_decoder = True
+ encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size])
+ encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
+
+ return (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ )
+
+ def create_and_check_model(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = ChineseCLIPTextModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
+ result = model(input_ids, token_type_ids=token_type_ids)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def create_and_check_model_as_decoder(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ config.add_cross_attention = True
+ model = ChineseCLIPTextModel(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ encoder_hidden_states=encoder_hidden_states,
+ )
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+class ChineseCLIPVisionModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ image_size=30,
+ patch_size=2,
+ num_channels=3,
+ is_training=True,
+ hidden_size=32,
+ projection_dim=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ initializer_range=0.02,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.hidden_size = hidden_size
+ self.projection_dim = projection_dim
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ # in ViT, the seq length equals the number of patches + 1 (we add 1 for the [CLS] token)
+ num_patches = (image_size // patch_size) ** 2
+ self.seq_length = num_patches + 1
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+ config = self.get_config()
+
+ return config, pixel_values
+
+ def get_config(self):
+ return ChineseCLIPVisionConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ projection_dim=self.projection_dim,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, pixel_values):
+ model = ChineseCLIPVisionModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(pixel_values)
+ # expected sequence length = num_patches + 1 (we add 1 for the [CLS] token)
+ image_size = (self.image_size, self.image_size)
+ patch_size = (self.patch_size, self.patch_size)
+ num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, num_patches + 1, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class ChineseCLIPTextModelTest(ModelTesterMixin, unittest.TestCase):
+ all_model_classes = (ChineseCLIPTextModel,) if is_torch_available() else ()
+ fx_compatible = False
+
+ # special case for ForPreTraining model
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class in get_values(MODEL_FOR_PRETRAINING_MAPPING):
+ inputs_dict["labels"] = torch.zeros(
+ (self.model_tester.batch_size, self.model_tester.seq_length), dtype=torch.long, device=torch_device
+ )
+ inputs_dict["next_sentence_label"] = torch.zeros(
+ self.model_tester.batch_size, dtype=torch.long, device=torch_device
+ )
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = ChineseCLIPTextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=ChineseCLIPTextConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_various_embeddings(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["absolute", "relative_key", "relative_key_query"]:
+ config_and_inputs[0].position_embedding_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_as_decoder(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
+ self.model_tester.create_and_check_model_as_decoder(*config_and_inputs)
+
+ def test_model_as_decoder_with_default_input_mask(self):
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ) = self.model_tester.prepare_config_and_inputs_for_decoder()
+
+ input_mask = None
+
+ self.model_tester.create_and_check_model_as_decoder(
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ )
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "OFA-Sys/chinese-clip-vit-base-patch16"
+ model = ChineseCLIPTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ @unittest.skip
+ def test_training(self):
+ pass
+
+ @unittest.skip
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+
+@require_torch
+class ChineseCLIPVisionModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as CHINESE_CLIP does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (ChineseCLIPVisionModel,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = ChineseCLIPVisionModelTester(self)
+ self.config_tester = ConfigTester(
+ self, config_class=ChineseCLIPVisionConfig, has_text_modality=False, hidden_size=37
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="CHINESE_CLIP does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_get_set_embeddings(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip
+ def test_training(self):
+ pass
+
+ @unittest.skip
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "OFA-Sys/chinese-clip-vit-base-patch16"
+ model = ChineseCLIPVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+class ChineseCLIPModelTester:
+ def __init__(self, parent, text_kwargs=None, vision_kwargs=None, is_training=True):
+ if text_kwargs is None:
+ text_kwargs = {}
+ if vision_kwargs is None:
+ vision_kwargs = {}
+
+ self.parent = parent
+ self.text_model_tester = ChineseCLIPTextModelTester(parent, **text_kwargs)
+ self.vision_model_tester = ChineseCLIPVisionModelTester(parent, **vision_kwargs)
+ self.batch_size = self.text_model_tester.batch_size # need bs for batching_equivalence test
+ self.is_training = is_training
+
+ def prepare_config_and_inputs(self):
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ attention_mask,
+ _,
+ __,
+ ___,
+ ) = self.text_model_tester.prepare_config_and_inputs()
+ vision_config, pixel_values = self.vision_model_tester.prepare_config_and_inputs()
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, attention_mask, pixel_values
+
+ def get_config(self):
+ return ChineseCLIPConfig.from_text_vision_configs(
+ self.text_model_tester.get_config(), self.vision_model_tester.get_config(), projection_dim=64
+ )
+
+ def create_and_check_model(self, config, input_ids, token_type_ids, attention_mask, pixel_values):
+ model = ChineseCLIPModel(config).to(torch_device).eval()
+ with torch.no_grad():
+ result = model(input_ids, pixel_values, attention_mask, token_type_ids)
+ self.parent.assertEqual(
+ result.logits_per_image.shape, (self.vision_model_tester.batch_size, self.text_model_tester.batch_size)
+ )
+ self.parent.assertEqual(
+ result.logits_per_text.shape, (self.text_model_tester.batch_size, self.vision_model_tester.batch_size)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, token_type_ids, attention_mask, pixel_values = config_and_inputs
+ inputs_dict = {
+ "input_ids": input_ids,
+ "token_type_ids": token_type_ids,
+ "attention_mask": attention_mask,
+ "pixel_values": pixel_values,
+ "return_loss": True,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class ChineseCLIPModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (ChineseCLIPModel,) if is_torch_available() else ()
+ pipeline_model_mapping = {"feature-extraction": ChineseCLIPModel} if is_torch_available() else {}
+ fx_compatible = False
+ test_head_masking = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_attention_outputs = False
+
+ def setUp(self):
+ text_kwargs = {"use_labels": False, "batch_size": 12}
+ vision_kwargs = {"batch_size": 12}
+ self.model_tester = ChineseCLIPModelTester(self, text_kwargs, vision_kwargs)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip(reason="Hidden_states is tested in individual model tests")
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip(reason="Inputs_embeds is tested in individual model tests")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Retain_grad is tested in individual model tests")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ @unittest.skip(reason="ChineseCLIPModel does not have input/output embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ # override as the `logit_scale` parameter initialization is different for CHINESE_CLIP
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for sub_config_key in ("vision_config", "text_config"):
+ sub_config = getattr(configs_no_init, sub_config_key, {})
+ setattr(configs_no_init, sub_config_key, _config_zero_init(sub_config))
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ # check if `logit_scale` is initialized as per the original implementation
+ if name == "logit_scale":
+ self.assertAlmostEqual(
+ param.data.item(),
+ np.log(1 / 0.07),
+ delta=1e-3,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ else:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ def _create_and_check_torchscript(self, config, inputs_dict):
+ if not self.test_torchscript:
+ self.skipTest(reason="test_torchscript is set to False")
+
+ configs_no_init = _config_zero_init(config) # To be sure we have no Nan
+ configs_no_init.torchscript = True
+ configs_no_init.return_dict = False
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ model.to(torch_device)
+ model.eval()
+
+ try:
+ input_ids = inputs_dict["input_ids"]
+ pixel_values = inputs_dict["pixel_values"] # CHINESE_CLIP needs pixel_values
+ traced_model = torch.jit.trace(model, (input_ids, pixel_values))
+ except RuntimeError:
+ self.fail("Couldn't trace module.")
+
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ pt_file_name = os.path.join(tmp_dir_name, "traced_model.pt")
+
+ try:
+ torch.jit.save(traced_model, pt_file_name)
+ except Exception:
+ self.fail("Couldn't save module.")
+
+ try:
+ loaded_model = torch.jit.load(pt_file_name)
+ except Exception:
+ self.fail("Couldn't load module.")
+
+ model.to(torch_device)
+ model.eval()
+
+ loaded_model.to(torch_device)
+ loaded_model.eval()
+
+ model_state_dict = model.state_dict()
+ loaded_model_state_dict = loaded_model.state_dict()
+
+ non_persistent_buffers = {}
+ for key in loaded_model_state_dict.keys():
+ if key not in model_state_dict.keys():
+ non_persistent_buffers[key] = loaded_model_state_dict[key]
+
+ loaded_model_state_dict = {
+ key: value for key, value in loaded_model_state_dict.items() if key not in non_persistent_buffers
+ }
+
+ self.assertEqual(set(model_state_dict.keys()), set(loaded_model_state_dict.keys()))
+
+ model_buffers = list(model.buffers())
+ for non_persistent_buffer in non_persistent_buffers.values():
+ found_buffer = False
+ for i, model_buffer in enumerate(model_buffers):
+ if torch.equal(non_persistent_buffer, model_buffer):
+ found_buffer = True
+ break
+
+ self.assertTrue(found_buffer)
+ model_buffers.pop(i)
+
+ models_equal = True
+ for layer_name, p1 in model_state_dict.items():
+ p2 = loaded_model_state_dict[layer_name]
+ if p1.data.ne(p2.data).sum() > 0:
+ models_equal = False
+
+ self.assertTrue(models_equal)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "OFA-Sys/chinese-clip-vit-base-patch16"
+ model = ChineseCLIPModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of Pikachu
+def prepare_img():
+ url = "https://clip-cn-beijing.oss-cn-beijing.aliyuncs.com/pokemon.jpeg"
+ im = Image.open(requests.get(url, stream=True).raw)
+ return im
+
+
+@require_vision
+@require_torch
+class ChineseCLIPModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference(self):
+ model_name = "OFA-Sys/chinese-clip-vit-base-patch16"
+ model = ChineseCLIPModel.from_pretrained(model_name).to(torch_device)
+ processor = ChineseCLIPProcessor.from_pretrained(model_name)
+
+ image = prepare_img()
+ inputs = processor(
+ text=["杰尼龟", "妙蛙种子", "小火龙", "皮卡丘"], images=image, padding=True, return_tensors="pt"
+ ).to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ self.assertEqual(
+ outputs.logits_per_image.shape,
+ torch.Size((inputs.pixel_values.shape[0], inputs.input_ids.shape[0])),
+ )
+ self.assertEqual(
+ outputs.logits_per_text.shape,
+ torch.Size((inputs.input_ids.shape[0], inputs.pixel_values.shape[0])),
+ )
+
+ probs = outputs.logits_per_image.softmax(dim=1)
+ expected_probs = torch.tensor([[1.2686e-03, 5.4499e-02, 6.7968e-04, 9.4355e-01]], device=torch_device)
+
+ torch.testing.assert_close(probs, expected_probs, rtol=5e-3, atol=5e-3)
+
+ @slow
+ def test_inference_interpolate_pos_encoding(self):
+ # ViT models have an `interpolate_pos_encoding` argument in their forward method,
+ # allowing to interpolate the pre-trained position embeddings in order to use
+ # the model on higher resolutions. The DINO model by Facebook AI leverages this
+ # to visualize self-attention on higher resolution images.
+ model_name = "OFA-Sys/chinese-clip-vit-base-patch16"
+ model = ChineseCLIPModel.from_pretrained(model_name).to(torch_device)
+
+ image_processor = ChineseCLIPProcessor.from_pretrained(
+ model_name, size={"height": 180, "width": 180}, crop_size={"height": 180, "width": 180}
+ )
+
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ inputs = image_processor(text="what's in the image", images=image, return_tensors="pt").to(torch_device)
+
+ # interpolate_pos_encodiung false should return value error
+ with self.assertRaises(ValueError, msg="doesn't match model"):
+ with torch.no_grad():
+ model(**inputs, interpolate_pos_encoding=False)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs, interpolate_pos_encoding=True)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 122, 768))
+
+ self.assertEqual(outputs.vision_model_output.last_hidden_state.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[-0.3990, 0.2983, -0.1239], [-0.1452, -0.2759, 0.0403], [-0.3149, -0.4763, 0.8555]]
+ ).to(torch_device)
+
+ torch.testing.assert_close(
+ outputs.vision_model_output.last_hidden_state[0, :3, :3], expected_slice, rtol=1e-4, atol=1e-4
+ )
diff --git a/transformers/tests/models/chinese_clip/test_processor_chinese_clip.py b/transformers/tests/models/chinese_clip/test_processor_chinese_clip.py
new file mode 100644
index 0000000000000000000000000000000000000000..3c2a2247c5a2194f3d4a914ebdd3426f79eab70d
--- /dev/null
+++ b/transformers/tests/models/chinese_clip/test_processor_chinese_clip.py
@@ -0,0 +1,217 @@
+# Copyright 2021 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import shutil
+import tempfile
+import unittest
+
+import pytest
+
+from transformers import BertTokenizer, BertTokenizerFast
+from transformers.models.bert.tokenization_bert import VOCAB_FILES_NAMES
+from transformers.testing_utils import require_vision
+from transformers.utils import FEATURE_EXTRACTOR_NAME, is_vision_available
+
+from ...test_processing_common import ProcessorTesterMixin
+
+
+if is_vision_available():
+ from transformers import ChineseCLIPImageProcessor, ChineseCLIPProcessor
+
+
+@require_vision
+class ChineseCLIPProcessorTest(ProcessorTesterMixin, unittest.TestCase):
+ processor_class = ChineseCLIPProcessor
+
+ @classmethod
+ def setUpClass(cls):
+ cls.tmpdirname = tempfile.mkdtemp()
+
+ vocab_tokens = [
+ "[UNK]",
+ "[CLS]",
+ "[SEP]",
+ "[PAD]",
+ "[MASK]",
+ "的",
+ "价",
+ "格",
+ "是",
+ "15",
+ "便",
+ "alex",
+ "##andra",
+ ",",
+ "。",
+ "-",
+ "t",
+ "shirt",
+ ]
+ cls.vocab_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ with open(cls.vocab_file, "w", encoding="utf-8") as vocab_writer:
+ vocab_writer.write("".join([x + "\n" for x in vocab_tokens]))
+
+ image_processor_map = {
+ "do_resize": True,
+ "size": {"height": 224, "width": 224},
+ "do_center_crop": True,
+ "crop_size": {"height": 18, "width": 18},
+ "do_normalize": True,
+ "image_mean": [0.48145466, 0.4578275, 0.40821073],
+ "image_std": [0.26862954, 0.26130258, 0.27577711],
+ "do_convert_rgb": True,
+ }
+ cls.image_processor_file = os.path.join(cls.tmpdirname, FEATURE_EXTRACTOR_NAME)
+ with open(cls.image_processor_file, "w", encoding="utf-8") as fp:
+ json.dump(image_processor_map, fp)
+
+ tokenizer = cls.get_tokenizer()
+ image_processor = cls.get_image_processor()
+ processor = ChineseCLIPProcessor(tokenizer=tokenizer, image_processor=image_processor)
+ processor.save_pretrained(cls.tmpdirname)
+
+ @classmethod
+ def get_tokenizer(cls, **kwargs):
+ return BertTokenizer.from_pretrained(cls.tmpdirname, **kwargs)
+
+ @classmethod
+ def get_rust_tokenizer(cls, **kwargs):
+ return BertTokenizerFast.from_pretrained(cls.tmpdirname, **kwargs)
+
+ @classmethod
+ def get_image_processor(cls, **kwargs):
+ return ChineseCLIPImageProcessor.from_pretrained(cls.tmpdirname, **kwargs)
+
+ @classmethod
+ def tearDownClass(cls):
+ shutil.rmtree(cls.tmpdirname, ignore_errors=True)
+
+ def test_save_load_pretrained_default(self):
+ tokenizer_slow = self.get_tokenizer()
+ tokenizer_fast = self.get_rust_tokenizer()
+ image_processor = self.get_image_processor()
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ processor_slow = ChineseCLIPProcessor(tokenizer=tokenizer_slow, image_processor=image_processor)
+ processor_slow.save_pretrained(tmpdir)
+ processor_slow = ChineseCLIPProcessor.from_pretrained(self.tmpdirname, use_fast=False)
+
+ processor_fast = ChineseCLIPProcessor(tokenizer=tokenizer_fast, image_processor=image_processor)
+ processor_fast.save_pretrained(tmpdir)
+ processor_fast = ChineseCLIPProcessor.from_pretrained(self.tmpdirname)
+
+ self.assertEqual(processor_slow.tokenizer.get_vocab(), tokenizer_slow.get_vocab())
+ self.assertEqual(processor_fast.tokenizer.get_vocab(), tokenizer_fast.get_vocab())
+ self.assertEqual(tokenizer_slow.get_vocab(), tokenizer_fast.get_vocab())
+ self.assertIsInstance(processor_slow.tokenizer, BertTokenizer)
+ self.assertIsInstance(processor_fast.tokenizer, BertTokenizerFast)
+
+ self.assertEqual(processor_slow.image_processor.to_json_string(), image_processor.to_json_string())
+ self.assertEqual(processor_fast.image_processor.to_json_string(), image_processor.to_json_string())
+ self.assertIsInstance(processor_slow.image_processor, ChineseCLIPImageProcessor)
+ self.assertIsInstance(processor_fast.image_processor, ChineseCLIPImageProcessor)
+
+ def test_save_load_pretrained_additional_features(self):
+ with tempfile.TemporaryDirectory() as tmpdir:
+ processor = ChineseCLIPProcessor(
+ tokenizer=self.get_tokenizer(), image_processor=self.get_image_processor()
+ )
+ processor.save_pretrained(tmpdir)
+
+ tokenizer_add_kwargs = self.get_tokenizer(cls_token="(CLS)", sep_token="(SEP)")
+ image_processor_add_kwargs = self.get_image_processor(do_normalize=False)
+
+ processor = ChineseCLIPProcessor.from_pretrained(
+ tmpdir, cls_token="(CLS)", sep_token="(SEP)", do_normalize=False
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, BertTokenizerFast)
+
+ self.assertEqual(processor.image_processor.to_json_string(), image_processor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.image_processor, ChineseCLIPImageProcessor)
+
+ def test_image_processor(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = ChineseCLIPProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ image_input = self.prepare_image_inputs()
+
+ input_feat_extract = image_processor(image_input, return_tensors="np")
+ input_processor = processor(images=image_input, return_tensors="np")
+
+ for key in input_feat_extract.keys():
+ self.assertAlmostEqual(input_feat_extract[key].sum(), input_processor[key].sum(), delta=1e-2)
+
+ def test_tokenizer(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = ChineseCLIPProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "Alexandra,T-shirt的价格是15便士。"
+
+ encoded_processor = processor(text=input_str)
+
+ encoded_tok = tokenizer(input_str)
+
+ for key in encoded_tok.keys():
+ self.assertListEqual(encoded_tok[key], encoded_processor[key])
+
+ def test_processor(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = ChineseCLIPProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "Alexandra,T-shirt的价格是15便士。"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ self.assertListEqual(list(inputs.keys()), ["input_ids", "token_type_ids", "attention_mask", "pixel_values"])
+
+ # test if it raises when no input is passed
+ with pytest.raises(ValueError):
+ processor()
+
+ def test_tokenizer_decode(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = ChineseCLIPProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ predicted_ids = [[1, 4, 5, 8, 1, 0, 8], [3, 4, 3, 1, 1, 8, 9]]
+
+ decoded_processor = processor.batch_decode(predicted_ids)
+ decoded_tok = tokenizer.batch_decode(predicted_ids)
+
+ self.assertListEqual(decoded_tok, decoded_processor)
+
+ def test_model_input_names(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = ChineseCLIPProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "Alexandra,T-shirt的价格是15便士。"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ self.assertListEqual(list(inputs.keys()), processor.model_input_names)
diff --git a/transformers/tests/models/clap/__init__.py b/transformers/tests/models/clap/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/clap/test_feature_extraction_clap.py b/transformers/tests/models/clap/test_feature_extraction_clap.py
new file mode 100644
index 0000000000000000000000000000000000000000..e349e081199f959f955051412dd6447a40195780
--- /dev/null
+++ b/transformers/tests/models/clap/test_feature_extraction_clap.py
@@ -0,0 +1,546 @@
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import itertools
+import random
+import unittest
+
+import numpy as np
+from datasets import load_dataset
+
+from transformers import ClapFeatureExtractor
+from transformers.testing_utils import require_torch, require_torchaudio
+from transformers.trainer_utils import set_seed
+from transformers.utils.import_utils import is_torch_available
+
+from ...test_sequence_feature_extraction_common import SequenceFeatureExtractionTestMixin
+
+
+if is_torch_available():
+ import torch
+
+global_rng = random.Random()
+
+
+# Copied from tests.models.whisper.test_feature_extraction_whisper.floats_list
+def floats_list(shape, scale=1.0, rng=None, name=None):
+ """Creates a random float32 tensor"""
+ if rng is None:
+ rng = global_rng
+
+ values = []
+ for batch_idx in range(shape[0]):
+ values.append([])
+ for _ in range(shape[1]):
+ values[-1].append(rng.random() * scale)
+
+ return values
+
+
+@require_torch
+@require_torchaudio
+# Copied from tests.models.whisper.test_feature_extraction_whisper.WhisperFeatureExtractionTester with Whisper->Clap
+class ClapFeatureExtractionTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ min_seq_length=400,
+ max_seq_length=2000,
+ feature_size=10,
+ hop_length=160,
+ chunk_length=8,
+ padding_value=0.0,
+ sampling_rate=4_000,
+ return_attention_mask=False,
+ do_normalize=True,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.min_seq_length = min_seq_length
+ self.max_seq_length = max_seq_length
+ self.seq_length_diff = (self.max_seq_length - self.min_seq_length) // (self.batch_size - 1)
+ self.padding_value = padding_value
+ self.sampling_rate = sampling_rate
+ self.return_attention_mask = return_attention_mask
+ self.do_normalize = do_normalize
+ self.feature_size = feature_size
+ self.chunk_length = chunk_length
+ self.hop_length = hop_length
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "feature_size": self.feature_size,
+ "hop_length": self.hop_length,
+ "chunk_length": self.chunk_length,
+ "padding_value": self.padding_value,
+ "sampling_rate": self.sampling_rate,
+ "return_attention_mask": self.return_attention_mask,
+ "do_normalize": self.do_normalize,
+ }
+
+ def prepare_inputs_for_common(self, equal_length=False, numpify=False):
+ def _flatten(list_of_lists):
+ return list(itertools.chain(*list_of_lists))
+
+ if equal_length:
+ speech_inputs = [floats_list((self.max_seq_length, self.feature_size)) for _ in range(self.batch_size)]
+ else:
+ # make sure that inputs increase in size
+ speech_inputs = [
+ floats_list((x, self.feature_size))
+ for x in range(self.min_seq_length, self.max_seq_length, self.seq_length_diff)
+ ]
+ if numpify:
+ speech_inputs = [np.asarray(x) for x in speech_inputs]
+ return speech_inputs
+
+
+@require_torch
+@require_torchaudio
+class ClapFeatureExtractionTest(SequenceFeatureExtractionTestMixin, unittest.TestCase):
+ feature_extraction_class = ClapFeatureExtractor
+
+ # Copied from tests.models.whisper.test_feature_extraction_whisper.WhisperFeatureExtractionTest.setUp with Whisper->Clap
+ def setUp(self):
+ self.feat_extract_tester = ClapFeatureExtractionTester(self)
+
+ def test_call(self):
+ # Tests that all call wrap to encode_plus and batch_encode_plus
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
+ # create three inputs of length 800, 1000, and 1200
+ speech_inputs = [floats_list((1, x))[0] for x in range(800, 1400, 200)]
+ np_speech_inputs = [np.asarray(speech_input) for speech_input in speech_inputs]
+
+ # Test feature size
+ input_features = feature_extractor(np_speech_inputs, padding="max_length", return_tensors="np").input_features
+ self.assertTrue(input_features.ndim == 4)
+
+ # Test not batched input
+ encoded_sequences_1 = feature_extractor(speech_inputs[0], return_tensors="np").input_features
+ encoded_sequences_2 = feature_extractor(np_speech_inputs[0], return_tensors="np").input_features
+ self.assertTrue(np.allclose(encoded_sequences_1, encoded_sequences_2, atol=1e-3))
+
+ # Test batched
+ encoded_sequences_1 = feature_extractor(speech_inputs, return_tensors="np").input_features
+ encoded_sequences_2 = feature_extractor(np_speech_inputs, return_tensors="np").input_features
+ for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
+ self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
+
+ # Test 2-D numpy arrays are batched.
+ speech_inputs = [floats_list((1, x))[0] for x in (800, 800, 800)]
+ np_speech_inputs = np.asarray(speech_inputs)
+ encoded_sequences_1 = feature_extractor(speech_inputs, return_tensors="np").input_features
+ encoded_sequences_2 = feature_extractor(np_speech_inputs, return_tensors="np").input_features
+ for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
+ self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
+
+ # Copied from tests.models.whisper.test_feature_extraction_whisper.WhisperFeatureExtractionTest.test_double_precision_pad
+ def test_double_precision_pad(self):
+ import torch
+
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
+ np_speech_inputs = np.random.rand(100, 32).astype(np.float64)
+ py_speech_inputs = np_speech_inputs.tolist()
+
+ for inputs in [py_speech_inputs, np_speech_inputs]:
+ np_processed = feature_extractor.pad([{"input_features": inputs}], return_tensors="np")
+ self.assertTrue(np_processed.input_features.dtype == np.float32)
+ pt_processed = feature_extractor.pad([{"input_features": inputs}], return_tensors="pt")
+ self.assertTrue(pt_processed.input_features.dtype == torch.float32)
+
+ # Copied from tests.models.whisper.test_feature_extraction_whisper.WhisperFeatureExtractionTest._load_datasamples
+ def _load_datasamples(self, num_samples):
+ ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ # automatic decoding with librispeech
+ speech_samples = ds.sort("id")[:num_samples]["audio"]
+
+ return [x["array"] for x in speech_samples]
+
+ def test_integration_fusion_short_input(self):
+ # fmt: off
+ EXPECTED_INPUT_FEATURES = torch.tensor(
+ [
+ [
+ # "repeat"
+ [
+ -20.1049, -19.9764, -20.0731, -19.5055, -27.5018, -22.5761, -26.6071,
+ -29.0091, -26.4659, -26.4236, -28.8808, -31.9190, -32.4848, -34.1186,
+ -34.0340, -32.8803, -30.9895, -37.6238, -38.0347, -40.6263, -36.3496,
+ -42.2533, -32.9132, -27.7068, -29.3704, -30.3208, -22.5972, -27.1494,
+ -30.1975, -31.1005, -29.9372, -27.1917, -25.9806, -30.3489, -33.2380,
+ -31.9062, -36.5498, -32.8721, -30.5629, -27.4674, -22.2232, -22.5653,
+ -16.3868, -17.2713, -25.9738, -30.6256, -34.3766, -31.1292, -27.8950,
+ -27.0588, -25.6206, -23.0712, -26.6050, -28.0112, -32.6847, -34.3396,
+ -34.9738, -35.8463, -39.2324, -37.1188, -33.3705, -28.9230, -28.9112,
+ -28.6578
+ ],
+ [
+ -36.7233, -30.0587, -24.8431, -18.4611, -16.8149, -23.9319, -32.8580,
+ -34.2264, -27.4332, -26.8027, -29.2721, -33.9033, -39.3403, -35.3232,
+ -26.8076, -28.6460, -35.2780, -36.0738, -35.4996, -37.7631, -39.5056,
+ -34.7112, -36.8741, -34.1066, -32.9474, -33.6604, -27.9937, -30.9594,
+ -26.2928, -32.0485, -29.2151, -29.2917, -32.7308, -29.6542, -31.1454,
+ -37.0088, -32.3388, -37.3086, -31.1024, -27.2889, -19.6788, -21.1488,
+ -19.5144, -14.8889, -21.2006, -24.7488, -27.7940, -31.1058, -27.5068,
+ -21.5737, -22.3780, -21.5151, -26.3086, -30.9223, -33.5043, -32.0307,
+ -37.3806, -41.6188, -45.6650, -40.5131, -32.5023, -26.7385, -26.3709,
+ -26.7761
+ ]
+ ],
+ [
+ # "repeatpad"
+ [
+ -25.7496, -24.9339, -24.1357, -23.1271, -23.7853, -26.1264, -29.1456,
+ -33.2060, -37.8179, -42.4833, -41.9386, -41.2164, -42.3566, -44.2575,
+ -40.0217, -36.6794, -36.6974, -38.7819, -42.0880, -45.5560, -39.9368,
+ -36.3219, -35.5981, -36.6434, -35.1851, -33.0684, -30.0437, -30.2010,
+ -34.3476, -42.1373, -38.8039, -37.3355, -40.4576, -41.0485, -40.6377,
+ -38.2275, -42.7481, -34.6084, -34.7048, -29.5149, -26.3935, -26.8952,
+ -34.1336, -26.2904, -28.2571, -32.5642, -36.7240, -35.5334, -38.2451,
+ -34.8177, -28.9754, -25.1096, -27.9768, -32.3184, -37.0269, -40.5136,
+ -40.8061, -36.4948, -40.3767, -38.9671, -38.3552, -34.1250, -30.9035,
+ -31.6112
+ ],
+ [
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100.
+ ]
+ ],
+ [
+ # None, same as "repeatpad"
+ [
+ -25.7496, -24.9339, -24.1357, -23.1271, -23.7853, -26.1264, -29.1456,
+ -33.2060, -37.8179, -42.4833, -41.9386, -41.2164, -42.3566, -44.2575,
+ -40.0217, -36.6794, -36.6974, -38.7819, -42.0880, -45.5560, -39.9368,
+ -36.3219, -35.5981, -36.6434, -35.1851, -33.0684, -30.0437, -30.2010,
+ -34.3476, -42.1373, -38.8039, -37.3355, -40.4576, -41.0485, -40.6377,
+ -38.2275, -42.7481, -34.6084, -34.7048, -29.5149, -26.3935, -26.8952,
+ -34.1336, -26.2904, -28.2571, -32.5642, -36.7240, -35.5334, -38.2451,
+ -34.8177, -28.9754, -25.1096, -27.9768, -32.3184, -37.0269, -40.5136,
+ -40.8061, -36.4948, -40.3767, -38.9671, -38.3552, -34.1250, -30.9035,
+ -31.6112
+ ],
+ [
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100.
+ ]
+ ],
+ [
+ # "pad"
+ [
+ -58.5260, -58.1155, -57.8623, -57.5059, -57.9178, -58.7171, -59.2343,
+ -59.9833, -60.9764, -62.0722, -63.5723, -65.7111, -67.5153, -68.7088,
+ -69.8325, -70.2987, -70.1548, -70.6233, -71.5702, -72.5159, -72.3821,
+ -70.1817, -67.0315, -64.1387, -62.2202, -61.0717, -60.4951, -61.6005,
+ -63.7358, -67.1400, -67.6185, -65.5635, -64.3593, -63.7138, -63.6209,
+ -66.4950, -72.6284, -63.3961, -56.8334, -52.7319, -50.6310, -51.3728,
+ -53.5619, -51.9190, -50.9708, -52.8684, -55.8073, -58.8227, -60.6991,
+ -57.0547, -52.7611, -51.4388, -54.4892, -60.8950, -66.1024, -72.4352,
+ -67.8538, -65.1463, -68.7588, -72.3080, -68.4864, -60.4688, -57.1516,
+ -60.9460
+ ],
+ [
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100.
+ ]
+ ]
+ ]
+ )
+ # fmt: on
+ MEL_BIN = [[976, 977], [976, 977], [976, 977], [196, 197]]
+ input_speech = self._load_datasamples(1)
+ feature_extractor = ClapFeatureExtractor()
+ for padding, EXPECTED_VALUES, idx_in_mel in zip(
+ ["repeat", "repeatpad", None, "pad"], EXPECTED_INPUT_FEATURES, MEL_BIN
+ ):
+ input_features = feature_extractor(input_speech, return_tensors="pt", padding=padding).input_features
+ self.assertEqual(input_features.shape, (1, 4, 1001, 64))
+
+ torch.testing.assert_close(input_features[0, 0, idx_in_mel[0]], EXPECTED_VALUES[0], rtol=1e-4, atol=1e-4)
+ torch.testing.assert_close(input_features[0, 0, idx_in_mel[1]], EXPECTED_VALUES[1], rtol=1e-4, atol=1e-4)
+
+ self.assertTrue(torch.all(input_features[0, 0] == input_features[0, 1]))
+ self.assertTrue(torch.all(input_features[0, 0] == input_features[0, 2]))
+ self.assertTrue(torch.all(input_features[0, 0] == input_features[0, 3]))
+
+ def test_integration_rand_trunc_short_input(self):
+ # fmt: off
+ EXPECTED_INPUT_FEATURES = torch.tensor(
+ [
+ [
+ # "repeat"
+ [
+ -35.0483, -35.7865, -38.2884, -40.0220, -42.5349, -44.9489, -43.2228,
+ -44.6499, -47.6253, -49.6983, -50.2127, -52.5483, -52.2223, -51.9157,
+ -49.4082, -51.2024, -57.0476, -56.2803, -58.1618, -60.7474, -55.0389,
+ -60.9514, -59.3080, -50.4419, -47.8172, -48.7570, -55.2552, -44.5036,
+ -44.1148, -50.8218, -51.0968, -52.9408, -51.1037, -48.9789, -47.5897,
+ -52.0915, -55.4216, -54.1529, -58.0149, -58.0866, -52.7798, -52.6154,
+ -45.9144, -46.2008, -40.7603, -41.1703, -50.2250, -55.4112, -59.4818,
+ -54.5795, -53.5552, -51.3668, -49.8358, -50.3186, -54.0452, -57.6030,
+ -61.1589, -61.6415, -63.2756, -66.5890, -62.8543, -58.0665, -56.7203,
+ -56.7632
+ ],
+ [
+ -47.1320, -37.9961, -34.0076, -36.7109, -47.9057, -48.4924, -43.8371,
+ -44.9728, -48.1689, -52.9141, -57.6077, -52.8520, -44.8502, -45.6764,
+ -51.8389, -56.4284, -54.6972, -53.4889, -55.6077, -58.7149, -60.3760,
+ -54.0136, -56.0730, -55.9870, -54.4017, -53.1094, -53.5640, -50.3064,
+ -49.9520, -49.3239, -48.1668, -53.4852, -50.4561, -50.8688, -55.1970,
+ -51.5538, -53.0260, -59.6933, -54.8183, -59.5895, -55.9589, -50.3761,
+ -44.1282, -44.1463, -43.8540, -39.1168, -45.3893, -49.5542, -53.1505,
+ -55.2870, -50.3921, -46.8511, -47.4444, -49.5633, -56.0034, -59.0815,
+ -59.0018, -63.7589, -69.5745, -71.5789, -64.0498, -56.0558, -54.3475,
+ -54.7004
+ ]
+ ],
+ [
+ # "repeatpad"
+ [
+ -40.3184, -39.7186, -39.8807, -41.6508, -45.3613, -50.4785, -57.0297,
+ -60.4944, -59.1642, -58.9495, -60.4661, -62.5300, -58.4759, -55.2865,
+ -54.8973, -56.0780, -57.5482, -59.6557, -64.3309, -65.0330, -59.4941,
+ -56.8552, -55.0519, -55.9817, -56.9739, -55.2827, -54.5312, -51.4141,
+ -50.4289, -51.9131, -57.5821, -63.9979, -59.9180, -58.9489, -62.3247,
+ -62.6975, -63.7948, -60.5250, -64.6107, -58.7905, -57.0229, -54.3084,
+ -49.8445, -50.4459, -57.0172, -50.6425, -52.5992, -57.4207, -61.6358,
+ -60.6540, -63.1968, -57.4360, -52.3263, -51.7695, -57.1946, -62.9610,
+ -66.7359, -67.0335, -63.7440, -68.1775, -66.3798, -62.8650, -59.8972,
+ -59.3139
+ ],
+ [
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100.
+ ]
+ ],
+ [
+ # None, same as "repeatpad"
+ [
+ -40.3184, -39.7186, -39.8807, -41.6508, -45.3613, -50.4785, -57.0297,
+ -60.4944, -59.1642, -58.9495, -60.4661, -62.5300, -58.4759, -55.2865,
+ -54.8973, -56.0780, -57.5482, -59.6557, -64.3309, -65.0330, -59.4941,
+ -56.8552, -55.0519, -55.9817, -56.9739, -55.2827, -54.5312, -51.4141,
+ -50.4289, -51.9131, -57.5821, -63.9979, -59.9180, -58.9489, -62.3247,
+ -62.6975, -63.7948, -60.5250, -64.6107, -58.7905, -57.0229, -54.3084,
+ -49.8445, -50.4459, -57.0172, -50.6425, -52.5992, -57.4207, -61.6358,
+ -60.6540, -63.1968, -57.4360, -52.3263, -51.7695, -57.1946, -62.9610,
+ -66.7359, -67.0335, -63.7440, -68.1775, -66.3798, -62.8650, -59.8972,
+ -59.3139
+ ],
+ [
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100.
+ ]
+ ],
+ [
+ # "pad"
+ [
+ -73.3190, -73.6349, -74.1451, -74.8539, -75.7476, -76.5438, -78.5540,
+ -80.1339, -81.8911, -83.7560, -85.5387, -86.7466, -88.2072, -88.6090,
+ -88.8243, -89.0784, -89.4364, -89.8179, -91.3146, -92.2833, -91.7221,
+ -90.9440, -88.1315, -86.2425, -84.2281, -82.4893, -81.5993, -81.1328,
+ -81.5759, -83.1068, -85.6525, -88.9520, -88.9187, -87.2703, -86.3052,
+ -85.7188, -85.8802, -87.9996, -95.0464, -88.0133, -80.8561, -76.5597,
+ -74.2816, -74.8109, -77.3615, -76.0719, -75.3426, -77.6428, -80.9663,
+ -84.5275, -84.9907, -80.5205, -77.2851, -78.6259, -84.7740, -91.4535,
+ -98.1894, -94.3872, -92.3735, -97.6807, -98.1501, -91.4344, -85.2842,
+ -88.4338
+ ],
+ [
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100., -100., -100., -100., -100., -100., -100.,
+ -100., -100., -100., -100.
+ ]
+ ]
+ ]
+ )
+ # fmt: on
+ MEL_BIN = [[976, 977], [976, 977], [976, 977], [196, 197]]
+ input_speech = self._load_datasamples(1)
+ feature_extractor = ClapFeatureExtractor()
+ for padding, EXPECTED_VALUES, idx_in_mel in zip(
+ ["repeat", "repeatpad", None, "pad"], EXPECTED_INPUT_FEATURES, MEL_BIN
+ ):
+ input_features = feature_extractor(
+ input_speech, return_tensors="pt", truncation="rand_trunc", padding=padding
+ ).input_features
+ self.assertEqual(input_features.shape, (1, 1, 1001, 64))
+ torch.testing.assert_close(input_features[0, 0, idx_in_mel[0]], EXPECTED_VALUES[0], rtol=1e-4, atol=1e-4)
+ torch.testing.assert_close(input_features[0, 0, idx_in_mel[1]], EXPECTED_VALUES[1], rtol=1e-4, atol=1e-4)
+
+ def test_integration_fusion_long_input(self):
+ # fmt: off
+ EXPECTED_INPUT_FEATURES = torch.tensor(
+ [
+ [
+ -11.1830, -10.1894, -8.6051, -4.8578, -1.3268, -8.4606, -14.5453,
+ -9.2017, 0.5781, 16.2129, 14.8289, 3.6326, -3.8794, -6.5544,
+ -2.4408, 1.9531, 6.0967, 1.7590, -7.6730, -6.1571, 2.0052,
+ 16.6694, 20.6447, 21.2145, 13.4972, 15.9043, 16.8987, 4.1766,
+ 11.9428, 21.2372, 12.3016, 4.8604, 6.7241, 1.8543, 4.9235,
+ 5.3188, -0.9897, -1.2416, -6.5864, 2.9529, 2.9274, 6.4753,
+ 10.2300, 11.2127, 3.4042, -1.0055, -6.0475, -6.7524, -3.9801,
+ -1.4434, 0.4740, -0.1584, -4.5457, -8.5746, -8.8428, -13.1475,
+ -9.6079, -8.5798, -4.1143, -3.7966, -7.1651, -6.1517, -8.0258,
+ -12.1486
+ ],
+ [
+ -10.2017, -7.9924, -5.9517, -3.9372, -1.9735, -4.3130, 16.1647,
+ 25.0592, 23.5532, 14.4974, -7.0778, -10.2262, 6.4782, 20.3454,
+ 19.4269, 1.7976, -16.5070, 4.9380, 12.3390, 6.9285, -13.6325,
+ -8.5298, 1.0839, -5.9629, -8.4812, 3.1331, -2.0963, -16.6046,
+ -14.0070, -17.5707, -13.2080, -17.2168, -17.7770, -12.1111, -18.6184,
+ -17.1897, -13.9801, -12.0426, -23.5400, -25.6823, -23.5813, -18.7847,
+ -20.5473, -25.6458, -19.7585, -27.6007, -28.9276, -24.8948, -25.4458,
+ -22.2807, -19.6613, -19.2669, -15.7813, -19.6821, -24.3439, -22.2598,
+ -28.2631, -30.1017, -32.7646, -33.6525, -27.5639, -22.0548, -27.8054,
+ -29.6947
+ ],
+ [
+ -9.2078, -7.2963, -6.2095, -7.9959, -2.9280, -11.1843, -6.1490,
+ 5.0733, 19.2957, 21.4578, 14.6803, -3.3153, -6.3334, -2.3542,
+ 6.9509, 15.2965, 14.6620, 5.2075, -0.0873, 1.1919, 18.1986,
+ 20.8470, 10.8035, 2.2516, 7.6905, 7.7427, -1.2543, -5.0018,
+ 0.9809, -2.1584, -5.4580, -5.4760, -11.8888, -9.0605, -8.4638,
+ -9.9897, -0.0540, -5.1629, 0.0483, -4.1504, -4.8140, -7.8236,
+ -9.0622, -10.1742, -8.9597, -11.5380, -16.5603, -17.1858, -17.5032,
+ -20.9326, -23.9543, -25.2602, -25.3429, -27.4536, -26.8859, -22.7852,
+ -25.8288, -24.8399, -23.8893, -24.2096, -26.5415, -23.7281, -25.6851,
+ -22.3629
+ ],
+ [
+ 1.3448, 2.9883, 4.0366, -0.8019, -10.4191, -10.0883, -4.3812,
+ 0.8136, 2.1579, 0.0832, 1.0949, -0.9759, -5.5319, -4.6009,
+ -6.5452, -14.9155, -20.1584, -9.3611, -2.4271, 1.4031, 4.9910,
+ 8.6916, 8.6785, 10.1973, 9.9029, 5.3840, 7.5336, 5.2803,
+ 2.8144, -0.3138, 2.2216, 5.7328, 7.5574, 7.7402, 1.0681,
+ 3.1049, 7.0742, 6.5588, 7.3712, 5.7881, 8.6874, 8.7725,
+ 2.8133, -4.5809, -6.1317, -5.1719, -5.0192, -9.0977, -10.9391,
+ -6.0769, 1.6016, -0.8965, -7.2252, -7.8632, -11.4468, -11.7446,
+ -10.7447, -7.0601, -2.7748, -4.1798, -2.8433, -3.1352, 0.8097,
+ 6.4212
+ ]
+ ]
+ )
+ # fmt: on
+ MEL_BIN = 963
+ input_speech = torch.cat([torch.tensor(x) for x in self._load_datasamples(5)])
+ feature_extractor = ClapFeatureExtractor()
+ for padding, EXPECTED_VALUES, block_idx in zip(
+ ["repeat", "repeatpad", None, "pad"], EXPECTED_INPUT_FEATURES, [1, 2, 0, 3]
+ ):
+ set_seed(987654321)
+ input_features = feature_extractor(input_speech, return_tensors="pt", padding=padding).input_features
+ self.assertEqual(input_features.shape, (1, 4, 1001, 64))
+ torch.testing.assert_close(input_features[0, block_idx, MEL_BIN], EXPECTED_VALUES, rtol=1e-3, atol=1e-3)
+
+ def test_integration_rand_trunc_long_input(self):
+ # fmt: off
+ EXPECTED_INPUT_FEATURES = torch.tensor(
+ [
+ [
+ -35.4022, -32.7555, -31.2004, -32.7764, -42.5770, -41.6339, -43.1630,
+ -44.5080, -44.3029, -48.9628, -39.5022, -39.2105, -43.1350, -43.2195,
+ -48.4894, -52.2344, -57.6891, -52.2228, -45.5155, -44.2893, -43.4697,
+ -46.6702, -43.7490, -40.4819, -42.7275, -46.3434, -46.8412, -41.2003,
+ -43.1681, -46.2948, -46.1925, -47.8333, -45.6812, -44.9182, -41.7786,
+ -43.3809, -44.3199, -42.8814, -45.4771, -46.7114, -46.9746, -42.7090,
+ -41.6057, -38.3965, -40.1980, -41.0263, -34.1256, -28.3289, -29.0201,
+ -30.4453, -29.5561, -30.1734, -25.9406, -19.0897, -15.8452, -20.1351,
+ -23.6515, -23.1194, -17.1845, -19.4399, -23.6527, -22.8768, -20.7279,
+ -22.7864
+ ],
+ [
+ -35.7719, -27.2566, -23.6964, -27.5521, 0.2510, 7.4391, 1.3917,
+ -13.3417, -28.1758, -17.0856, -5.7723, -0.8000, -7.8832, -15.5548,
+ -30.5935, -24.7571, -13.7009, -10.3432, -21.2464, -24.8118, -19.4080,
+ -14.9779, -11.7991, -18.4485, -20.1982, -17.3652, -20.6328, -28.2967,
+ -25.7819, -21.8962, -28.5083, -29.5719, -30.2120, -35.7033, -31.8218,
+ -34.0408, -37.7744, -33.9653, -31.3009, -30.9063, -28.6153, -32.2202,
+ -28.5456, -28.8579, -32.5170, -37.9152, -43.0052, -46.4849, -44.0786,
+ -39.1933, -33.2757, -31.6313, -42.6386, -52.3679, -53.5785, -55.6444,
+ -47.0050, -47.6459, -56.6361, -60.6781, -61.5244, -55.8272, -60.4832,
+ -58.1897
+ ],
+ [
+ -38.2686, -36.6285, -32.5835, -35.1693, -37.7938, -37.4035, -35.3132,
+ -35.6083, -36.3609, -40.9472, -36.7846, -36.1544, -38.9076, -39.3618,
+ -35.4953, -34.2809, -39.9466, -39.7433, -34.8347, -37.5674, -41.5689,
+ -38.9161, -34.3947, -30.2924, -30.4841, -34.5831, -28.9261, -24.8849,
+ -31.2324, -27.1622, -27.2107, -25.9385, -30.1691, -30.9223, -23.9495,
+ -25.6047, -26.7119, -28.5523, -27.7481, -32.8427, -35.4650, -31.0399,
+ -31.2073, -30.5163, -22.9819, -20.8892, -19.2510, -24.7905, -28.9426,
+ -28.1998, -26.7386, -25.0140, -27.9223, -32.9913, -33.1864, -34.9742,
+ -38.5995, -39.6990, -29.3203, -22.4697, -25.6415, -33.5608, -33.0945,
+ -27.1716
+ ],
+ [
+ -33.2015, -28.7741, -21.9457, -23.4888, -32.1072, -8.6307, 3.2724,
+ 5.9157, -0.9221, -30.1814, -31.0015, -27.4508, -27.0477, -9.5342,
+ 0.3221, 0.6511, -7.1596, -25.9707, -32.8924, -32.2300, -13.8974,
+ -0.4895, 0.9168, -10.7663, -27.1176, -35.0829, -11.6859, -4.8855,
+ -11.8898, -26.6167, -5.6192, -3.8443, -19.7947, -14.4101, -8.6236,
+ -21.2458, -21.0801, -17.9136, -24.4663, -18.6333, -24.8085, -15.5854,
+ -15.4344, -11.5046, -22.3625, -27.3387, -32.4353, -30.9670, -31.3789,
+ -35.4044, -34.4591, -25.2433, -28.0773, -33.8736, -33.0224, -33.3155,
+ -38.5302, -39.2741, -36.6395, -34.7729, -32.4483, -42.4001, -49.2857,
+ -39.1682
+ ]
+ ]
+ )
+ # fmt: on
+ MEL_BIN = 963
+ SEEDS = [987654321, 1234, 666, 5555]
+ input_speech = torch.cat([torch.tensor(x) for x in self._load_datasamples(5)])
+ feature_extractor = ClapFeatureExtractor()
+ for padding, EXPECTED_VALUES, seed in zip(
+ ["repeat", "repeatpad", None, "pad"], EXPECTED_INPUT_FEATURES, SEEDS
+ ):
+ set_seed(seed)
+ input_features = feature_extractor(
+ input_speech, return_tensors="pt", truncation="rand_trunc", padding=padding
+ ).input_features
+ self.assertEqual(input_features.shape, (1, 1, 1001, 64))
+ torch.testing.assert_close(input_features[0, 0, MEL_BIN], EXPECTED_VALUES, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/clap/test_modeling_clap.py b/transformers/tests/models/clap/test_modeling_clap.py
new file mode 100644
index 0000000000000000000000000000000000000000..e828a54827c50a7057cb4d472858803e2798d393
--- /dev/null
+++ b/transformers/tests/models/clap/test_modeling_clap.py
@@ -0,0 +1,755 @@
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch CLAP model."""
+
+import inspect
+import os
+import tempfile
+import unittest
+
+import numpy as np
+from datasets import load_dataset
+
+from transformers import ClapAudioConfig, ClapConfig, ClapProcessor, ClapTextConfig
+from transformers.testing_utils import require_torch, slow, torch_device
+from transformers.utils import is_torch_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ ModelTesterMixin,
+ _config_zero_init,
+ floats_tensor,
+ ids_tensor,
+ random_attention_mask,
+)
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import (
+ ClapAudioModel,
+ ClapAudioModelWithProjection,
+ ClapModel,
+ ClapTextModel,
+ ClapTextModelWithProjection,
+ )
+
+
+class ClapAudioModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ image_size=60,
+ num_mel_bins=16,
+ window_size=4,
+ spec_size=64,
+ patch_size=2,
+ patch_stride=2,
+ seq_length=16,
+ freq_ratio=2,
+ num_channels=3,
+ is_training=True,
+ hidden_size=32,
+ patch_embeds_hidden_size=16,
+ projection_dim=32,
+ depths=[2, 2],
+ num_hidden_layers=2,
+ num_heads=[2, 2],
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ initializer_range=0.02,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.num_mel_bins = num_mel_bins
+ self.window_size = window_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.hidden_size = hidden_size
+ self.projection_dim = projection_dim
+ self.num_hidden_layers = num_hidden_layers
+ self.depths = depths
+ self.num_heads = num_heads
+ self.num_attention_heads = num_heads[0]
+ self.seq_length = seq_length
+ self.spec_size = spec_size
+ self.freq_ratio = freq_ratio
+ self.patch_stride = patch_stride
+ self.patch_embeds_hidden_size = patch_embeds_hidden_size
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_features = floats_tensor([self.batch_size, 1, self.hidden_size, self.num_mel_bins])
+ config = self.get_config()
+
+ return config, input_features
+
+ def get_config(self):
+ return ClapAudioConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_mel_bins=self.num_mel_bins,
+ window_size=self.window_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ patch_stride=self.patch_stride,
+ projection_dim=self.projection_dim,
+ depths=self.depths,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ initializer_range=self.initializer_range,
+ spec_size=self.spec_size,
+ freq_ratio=self.freq_ratio,
+ patch_embeds_hidden_size=self.patch_embeds_hidden_size,
+ )
+
+ def create_and_check_model(self, config, input_features):
+ model = ClapAudioModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(input_features)
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def create_and_check_model_with_projection(self, config, input_features):
+ model = ClapAudioModelWithProjection(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(input_features)
+ self.parent.assertEqual(result.audio_embeds.shape, (self.batch_size, self.projection_dim))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_features = config_and_inputs
+ inputs_dict = {"input_features": input_features}
+ return config, inputs_dict
+
+
+@require_torch
+class ClapAudioModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as CLAP does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (ClapAudioModel, ClapAudioModelWithProjection) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = ClapAudioModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=ClapAudioConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="ClapAudioModel does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_get_set_embeddings(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.hidden_states
+
+ expected_num_layers = getattr(
+ self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers + 1
+ )
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [2 * self.model_tester.patch_embeds_hidden_size, 2 * self.model_tester.patch_embeds_hidden_size],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ @unittest.skip(reason="ClapAudioModel does not output any loss term in the forward pass")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["input_features"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_with_projection(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model_with_projection(*config_and_inputs)
+
+ @unittest.skip(reason="ClapAudioModel does not output any loss term in the forward pass")
+ def test_training(self):
+ pass
+
+ @unittest.skip(reason="ClapAudioModel does not output any loss term in the forward pass")
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "laion/clap-htsat-fused"
+ model = ClapAudioModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ @slow
+ def test_model_with_projection_from_pretrained(self):
+ model_name = "laion/clap-htsat-fused"
+ model = ClapAudioModelWithProjection.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+ self.assertTrue(hasattr(model, "audio_projection"))
+
+
+class ClapTextModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ projection_dim=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ max_position_embeddings=512,
+ initializer_range=0.02,
+ scope=None,
+ projection_hidden_act="relu",
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.projection_dim = projection_dim
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.max_position_embeddings = max_position_embeddings
+ self.initializer_range = initializer_range
+ self.scope = scope
+ self.projection_hidden_act = projection_hidden_act
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ if input_mask is not None:
+ batch_size, seq_length = input_mask.shape
+ rnd_start_indices = np.random.randint(1, seq_length - 1, size=(batch_size,))
+ for batch_idx, start_index in enumerate(rnd_start_indices):
+ input_mask[batch_idx, :start_index] = 1
+ input_mask[batch_idx, start_index:] = 0
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask
+
+ def get_config(self):
+ return ClapTextConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ projection_dim=self.projection_dim,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ max_position_embeddings=self.max_position_embeddings,
+ initializer_range=self.initializer_range,
+ projection_hidden_act=self.projection_hidden_act,
+ )
+
+ def create_and_check_model(self, config, input_ids, input_mask):
+ model = ClapTextModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def create_and_check_model_with_projection(self, config, input_ids, input_mask):
+ model = ClapTextModelWithProjection(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(result.text_embeds.shape, (self.batch_size, self.projection_dim))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, input_mask = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class ClapTextModelTest(ModelTesterMixin, unittest.TestCase):
+ all_model_classes = (ClapTextModel, ClapTextModelWithProjection) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = ClapTextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=ClapTextConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_with_projection(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model_with_projection(*config_and_inputs)
+
+ @unittest.skip(reason="ClapTextModel does not output any loss term in the forward pass")
+ def test_training(self):
+ pass
+
+ @unittest.skip(reason="ClapTextModel does not output any loss term in the forward pass")
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @unittest.skip(reason="ClapTextModel does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "laion/clap-htsat-fused"
+ model = ClapTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ @slow
+ def test_model_with_projection_from_pretrained(self):
+ model_name = "laion/clap-htsat-fused"
+ model = ClapTextModelWithProjection.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+ self.assertTrue(hasattr(model, "text_projection"))
+
+
+class ClapModelTester:
+ def __init__(self, parent, text_kwargs=None, audio_kwargs=None, is_training=True):
+ if text_kwargs is None:
+ text_kwargs = {}
+ if audio_kwargs is None:
+ audio_kwargs = {}
+
+ self.parent = parent
+ self.text_model_tester = ClapTextModelTester(parent, **text_kwargs)
+ self.audio_model_tester = ClapAudioModelTester(parent, **audio_kwargs)
+ self.batch_size = self.text_model_tester.batch_size # need bs for batching_equivalence test
+ self.is_training = is_training
+
+ def prepare_config_and_inputs(self):
+ _, input_ids, attention_mask = self.text_model_tester.prepare_config_and_inputs()
+ _, input_features = self.audio_model_tester.prepare_config_and_inputs()
+
+ config = self.get_config()
+
+ return config, input_ids, attention_mask, input_features
+
+ def get_config(self):
+ return ClapConfig.from_text_audio_configs(
+ self.text_model_tester.get_config(), self.audio_model_tester.get_config(), projection_dim=64
+ )
+
+ def create_and_check_model(self, config, input_ids, attention_mask, input_features):
+ model = ClapModel(config).to(torch_device).eval()
+ with torch.no_grad():
+ result = model(input_ids, input_features, attention_mask)
+ self.parent.assertEqual(
+ result.logits_per_audio.shape, (self.audio_model_tester.batch_size, self.text_model_tester.batch_size)
+ )
+ self.parent.assertEqual(
+ result.logits_per_text.shape, (self.text_model_tester.batch_size, self.audio_model_tester.batch_size)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, attention_mask, input_features = config_and_inputs
+ inputs_dict = {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "input_features": input_features,
+ "return_loss": True,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class ClapModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (ClapModel,) if is_torch_available() else ()
+ pipeline_model_mapping = {"feature-extraction": ClapModel} if is_torch_available() else {}
+ fx_compatible = False
+ test_head_masking = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_attention_outputs = False
+
+ def setUp(self):
+ self.model_tester = ClapModelTester(self)
+ common_properties = ["logit_scale_init_value", "projection_hidden_act", "projection_dim"]
+ self.config_tester = ConfigTester(
+ self, config_class=ClapConfig, has_text_modality=False, common_properties=common_properties
+ )
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="Hidden_states is tested in individual model tests")
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip(reason="Inputs_embeds is tested in individual model tests")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Retain_grad is tested in individual model tests")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ @unittest.skip(reason="ClapModel does not have input/output embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ # override as the `logit_scale` parameter initialization is different for CLAP
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ # check if `logit_scale` is initialized as per the original implementation
+ if name == "logit_scale":
+ self.assertAlmostEqual(
+ param.data.item(),
+ np.log(1 / 0.07),
+ delta=1e-3,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ else:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ def _create_and_check_torchscript(self, config, inputs_dict):
+ if not self.test_torchscript:
+ self.skipTest(reason="test_torchscript is set to False")
+
+ configs_no_init = _config_zero_init(config) # To be sure we have no Nan
+ configs_no_init.torchscript = True
+ configs_no_init.return_dict = False
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ model.to(torch_device)
+ model.eval()
+
+ try:
+ input_ids = inputs_dict["input_ids"]
+ input_features = inputs_dict["input_features"] # CLAP needs input_features
+ traced_model = torch.jit.trace(model, (input_ids, input_features))
+ except RuntimeError:
+ self.fail("Couldn't trace module.")
+
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ pt_file_name = os.path.join(tmp_dir_name, "traced_model.pt")
+
+ try:
+ torch.jit.save(traced_model, pt_file_name)
+ except Exception:
+ self.fail("Couldn't save module.")
+
+ try:
+ loaded_model = torch.jit.load(pt_file_name)
+ except Exception:
+ self.fail("Couldn't load module.")
+
+ model.to(torch_device)
+ model.eval()
+
+ loaded_model.to(torch_device)
+ loaded_model.eval()
+
+ model_state_dict = model.state_dict()
+ loaded_model_state_dict = loaded_model.state_dict()
+
+ non_persistent_buffers = {}
+ for key in loaded_model_state_dict.keys():
+ if key not in model_state_dict.keys():
+ non_persistent_buffers[key] = loaded_model_state_dict[key]
+
+ loaded_model_state_dict = {
+ key: value for key, value in loaded_model_state_dict.items() if key not in non_persistent_buffers
+ }
+
+ self.assertEqual(set(model_state_dict.keys()), set(loaded_model_state_dict.keys()))
+
+ model_buffers = list(model.buffers())
+ for non_persistent_buffer in non_persistent_buffers.values():
+ found_buffer = False
+ for i, model_buffer in enumerate(model_buffers):
+ if torch.equal(non_persistent_buffer, model_buffer):
+ found_buffer = True
+ break
+
+ self.assertTrue(found_buffer)
+ model_buffers.pop(i)
+
+ models_equal = True
+ for layer_name, p1 in model_state_dict.items():
+ p2 = loaded_model_state_dict[layer_name]
+ if p1.data.ne(p2.data).sum() > 0:
+ models_equal = False
+
+ self.assertTrue(models_equal)
+
+ def test_load_audio_text_config(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # Save ClapConfig and check if we can load ClapAudioConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ audio_config = ClapAudioConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.audio_config.to_dict(), audio_config.to_dict())
+
+ # Save ClapConfig and check if we can load ClapTextConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ text_config = ClapTextConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.text_config.to_dict(), text_config.to_dict())
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "laion/clap-htsat-fused"
+ model = ClapModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+@slow
+@require_torch
+class ClapModelIntegrationTest(unittest.TestCase):
+ paddings = ["repeatpad", "repeat", "pad"]
+
+ def test_integration_unfused(self):
+ EXPECTED_MEANS_UNFUSED = {
+ "repeatpad": 0.0024,
+ "pad": 0.0020,
+ "repeat": 0.0023,
+ }
+
+ librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ audio_sample = librispeech_dummy[-1]
+
+ model_id = "laion/clap-htsat-unfused"
+
+ model = ClapModel.from_pretrained(model_id).to(torch_device)
+ processor = ClapProcessor.from_pretrained(model_id)
+
+ for padding in self.paddings:
+ inputs = processor(audios=audio_sample["audio"]["array"], return_tensors="pt", padding=padding).to(
+ torch_device
+ )
+
+ audio_embed = model.get_audio_features(**inputs)
+ expected_mean = EXPECTED_MEANS_UNFUSED[padding]
+
+ self.assertTrue(
+ torch.allclose(audio_embed.cpu().mean(), torch.tensor([expected_mean]), atol=1e-3, rtol=1e-3)
+ )
+
+ def test_integration_fused(self):
+ EXPECTED_MEANS_FUSED = {
+ "repeatpad": 0.00069,
+ "repeat": 0.00196,
+ "pad": -0.000379,
+ }
+
+ librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ audio_sample = librispeech_dummy[-1]
+
+ model_id = "laion/clap-htsat-fused"
+
+ model = ClapModel.from_pretrained(model_id).to(torch_device)
+ processor = ClapProcessor.from_pretrained(model_id)
+
+ for padding in self.paddings:
+ inputs = processor(
+ audios=audio_sample["audio"]["array"], return_tensors="pt", padding=padding, truncation="fusion"
+ ).to(torch_device)
+
+ audio_embed = model.get_audio_features(**inputs)
+ expected_mean = EXPECTED_MEANS_FUSED[padding]
+
+ self.assertTrue(
+ torch.allclose(audio_embed.cpu().mean(), torch.tensor([expected_mean]), atol=1e-3, rtol=1e-3)
+ )
+
+ def test_batched_fused(self):
+ EXPECTED_MEANS_FUSED = {
+ "repeatpad": 0.0010,
+ "repeat": 0.0020,
+ "pad": 0.0006,
+ }
+
+ librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ audio_samples = [sample["array"] for sample in librispeech_dummy[0:4]["audio"]]
+
+ model_id = "laion/clap-htsat-fused"
+
+ model = ClapModel.from_pretrained(model_id).to(torch_device)
+ processor = ClapProcessor.from_pretrained(model_id)
+
+ for padding in self.paddings:
+ inputs = processor(audios=audio_samples, return_tensors="pt", padding=padding, truncation="fusion").to(
+ torch_device
+ )
+
+ audio_embed = model.get_audio_features(**inputs)
+ expected_mean = EXPECTED_MEANS_FUSED[padding]
+
+ self.assertTrue(
+ torch.allclose(audio_embed.cpu().mean(), torch.tensor([expected_mean]), atol=1e-3, rtol=1e-3)
+ )
+
+ def test_batched_unfused(self):
+ EXPECTED_MEANS_FUSED = {
+ "repeatpad": 0.0016,
+ "repeat": 0.0019,
+ "pad": 0.0019,
+ }
+
+ librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ audio_samples = [sample["array"] for sample in librispeech_dummy[0:4]["audio"]]
+
+ model_id = "laion/clap-htsat-unfused"
+
+ model = ClapModel.from_pretrained(model_id).to(torch_device)
+ processor = ClapProcessor.from_pretrained(model_id)
+
+ for padding in self.paddings:
+ inputs = processor(audios=audio_samples, return_tensors="pt", padding=padding).to(torch_device)
+
+ audio_embed = model.get_audio_features(**inputs)
+ expected_mean = EXPECTED_MEANS_FUSED[padding]
+
+ self.assertTrue(
+ torch.allclose(audio_embed.cpu().mean(), torch.tensor([expected_mean]), atol=1e-3, rtol=1e-3)
+ )
diff --git a/transformers/tests/models/clap/test_processor_clap.py b/transformers/tests/models/clap/test_processor_clap.py
new file mode 100644
index 0000000000000000000000000000000000000000..49e9972ea02e22a0661ab0d8ef71cc1cfe29b291
--- /dev/null
+++ b/transformers/tests/models/clap/test_processor_clap.py
@@ -0,0 +1,125 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import shutil
+import tempfile
+import unittest
+
+from transformers import ClapFeatureExtractor, ClapProcessor, RobertaTokenizer, RobertaTokenizerFast
+from transformers.testing_utils import require_sentencepiece, require_torchaudio
+
+from .test_feature_extraction_clap import floats_list
+
+
+@require_torchaudio
+@require_sentencepiece
+class ClapProcessorTest(unittest.TestCase):
+ def setUp(self):
+ self.checkpoint = "laion/clap-htsat-unfused"
+ self.tmpdirname = tempfile.mkdtemp()
+
+ def get_tokenizer(self, **kwargs):
+ return RobertaTokenizer.from_pretrained(self.checkpoint, **kwargs)
+
+ def get_feature_extractor(self, **kwargs):
+ return ClapFeatureExtractor.from_pretrained(self.checkpoint, **kwargs)
+
+ def tearDown(self):
+ shutil.rmtree(self.tmpdirname)
+
+ def test_save_load_pretrained_default(self):
+ tokenizer = self.get_tokenizer()
+ feature_extractor = self.get_feature_extractor()
+
+ processor = ClapProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ processor.save_pretrained(self.tmpdirname)
+ processor = ClapProcessor.from_pretrained(self.tmpdirname)
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer.get_vocab())
+ self.assertIsInstance(processor.tokenizer, RobertaTokenizerFast)
+
+ self.assertEqual(processor.feature_extractor.to_json_string(), feature_extractor.to_json_string())
+ self.assertIsInstance(processor.feature_extractor, ClapFeatureExtractor)
+
+ def test_save_load_pretrained_additional_features(self):
+ processor = ClapProcessor(tokenizer=self.get_tokenizer(), feature_extractor=self.get_feature_extractor())
+ processor.save_pretrained(self.tmpdirname)
+
+ tokenizer_add_kwargs = self.get_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
+ feature_extractor_add_kwargs = self.get_feature_extractor(do_normalize=False, padding_value=1.0)
+
+ processor = ClapProcessor.from_pretrained(
+ self.tmpdirname, bos_token="(BOS)", eos_token="(EOS)", do_normalize=False, padding_value=1.0
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, RobertaTokenizerFast)
+
+ self.assertEqual(processor.feature_extractor.to_json_string(), feature_extractor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.feature_extractor, ClapFeatureExtractor)
+
+ def test_feature_extractor(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+
+ processor = ClapProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ raw_speech = floats_list((3, 1000))
+
+ input_feat_extract = feature_extractor(raw_speech, return_tensors="np")
+ input_processor = processor(audios=raw_speech, return_tensors="np")
+
+ for key in input_feat_extract.keys():
+ self.assertAlmostEqual(input_feat_extract[key].sum(), input_processor[key].sum(), delta=1e-2)
+
+ def test_tokenizer(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+
+ processor = ClapProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ input_str = "This is a test string"
+
+ encoded_processor = processor(text=input_str)
+
+ encoded_tok = tokenizer(input_str)
+
+ for key in encoded_tok.keys():
+ self.assertListEqual(encoded_tok[key], encoded_processor[key])
+
+ def test_tokenizer_decode(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+
+ processor = ClapProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ predicted_ids = [[1, 4, 5, 8, 1, 0, 8], [3, 4, 3, 1, 1, 8, 9]]
+
+ decoded_processor = processor.batch_decode(predicted_ids)
+ decoded_tok = tokenizer.batch_decode(predicted_ids)
+
+ self.assertListEqual(decoded_tok, decoded_processor)
+
+ def test_model_input_names(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+
+ processor = ClapProcessor(tokenizer=tokenizer, feature_extractor=feature_extractor)
+
+ self.assertListEqual(
+ processor.model_input_names[2:],
+ feature_extractor.model_input_names,
+ msg="`processor` and `feature_extractor` model input names do not match",
+ )
diff --git a/transformers/tests/models/code_llama/__init__.py b/transformers/tests/models/code_llama/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/code_llama/test_tokenization_code_llama.py b/transformers/tests/models/code_llama/test_tokenization_code_llama.py
new file mode 100644
index 0000000000000000000000000000000000000000..236ab21d2d2a467a36a83e683f9a4fbf024496e3
--- /dev/null
+++ b/transformers/tests/models/code_llama/test_tokenization_code_llama.py
@@ -0,0 +1,652 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import pickle
+import shutil
+import tempfile
+import unittest
+
+from datasets import load_dataset
+
+from transformers import (
+ SPIECE_UNDERLINE,
+ AddedToken,
+ CodeLlamaTokenizer,
+ CodeLlamaTokenizerFast,
+)
+from transformers.convert_slow_tokenizer import convert_slow_tokenizer
+from transformers.testing_utils import (
+ get_tests_dir,
+ nested_simplify,
+ require_sentencepiece,
+ require_tokenizers,
+ require_torch,
+ slow,
+)
+
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+SAMPLE_VOCAB = get_tests_dir("fixtures/test_sentencepiece.model")
+
+
+@require_sentencepiece
+@require_tokenizers
+class CodeLlamaTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "hf-internal-testing/llama-code-tokenizer"
+ tokenizer_class = CodeLlamaTokenizer
+ rust_tokenizer_class = CodeLlamaTokenizerFast
+ test_rust_tokenizer = False
+ test_sentencepiece = True
+ from_pretrained_kwargs = {}
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ # We have a SentencePiece fixture for testing
+ tokenizer = CodeLlamaTokenizer(SAMPLE_VOCAB, keep_accents=True)
+ tokenizer.pad_token = tokenizer.eos_token
+ tokenizer.save_pretrained(cls.tmpdirname)
+
+ def get_tokenizers(cls, **kwargs):
+ kwargs.update({"pad_token": ""})
+ return super().get_tokenizers(**kwargs)
+
+ def test_no_infilling_init(self):
+ tokenizer = CodeLlamaTokenizer(SAMPLE_VOCAB, prefix_token=None, keep_accents=True)
+ with self.assertRaises(ValueError):
+ tokenizer.tokenize("This is prefix")
+
+ def test_full_tokenizer(self):
+ tokenizer = CodeLlamaTokenizer(SAMPLE_VOCAB, keep_accents=True)
+
+ tokens = tokenizer.tokenize("This is a test")
+ self.assertListEqual(tokens, ["▁This", "▁is", "▁a", "▁t", "est"])
+
+ self.assertListEqual(
+ tokenizer.convert_tokens_to_ids(tokens),
+ [285, 46, 10, 170, 382],
+ )
+
+ tokens = tokenizer.tokenize("I was born in 92000, and this is falsé.")
+ self.assertListEqual(
+ tokens,
+ [
+ SPIECE_UNDERLINE + "I",
+ SPIECE_UNDERLINE + "was",
+ SPIECE_UNDERLINE + "b",
+ "or",
+ "n",
+ SPIECE_UNDERLINE + "in",
+ SPIECE_UNDERLINE + "",
+ "9",
+ "2",
+ "0",
+ "0",
+ "0",
+ ",",
+ SPIECE_UNDERLINE + "and",
+ SPIECE_UNDERLINE + "this",
+ SPIECE_UNDERLINE + "is",
+ SPIECE_UNDERLINE + "f",
+ "al",
+ "s",
+ "é",
+ ".",
+ ],
+ )
+ ids = tokenizer.convert_tokens_to_ids(tokens)
+ self.assertListEqual(
+ ids,
+ [8, 21, 84, 55, 24, 19, 7, 0, 602, 347, 347, 347, 3, 12, 66, 46, 72, 80, 6, 0, 4],
+ )
+
+ back_tokens = tokenizer.convert_ids_to_tokens(ids)
+ self.assertListEqual(
+ back_tokens,
+ [
+ SPIECE_UNDERLINE + "I",
+ SPIECE_UNDERLINE + "was",
+ SPIECE_UNDERLINE + "b",
+ "or",
+ "n",
+ SPIECE_UNDERLINE + "in",
+ SPIECE_UNDERLINE + "",
+ "",
+ "2",
+ "0",
+ "0",
+ "0",
+ ",",
+ SPIECE_UNDERLINE + "and",
+ SPIECE_UNDERLINE + "this",
+ SPIECE_UNDERLINE + "is",
+ SPIECE_UNDERLINE + "f",
+ "al",
+ "s",
+ "",
+ ".",
+ ],
+ )
+
+ def test_save_pretrained(self):
+ self.tokenizers_list = [
+ (self.rust_tokenizer_class, "hf-internal-testing/llama-code-tokenizer", {}),
+ (self.tokenizer_class, "hf-internal-testing/llama-code-tokenizer", {}),
+ (self.tokenizer_class, "codellama/CodeLlama-34b-Instruct-hf", {}),
+ (self.rust_tokenizer_class, "codellama/CodeLlama-34b-Instruct-hf", {}),
+ ]
+ for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
+ with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name})"):
+ tokenizer_r = self.get_rust_tokenizer(pretrained_name, **kwargs)
+ tokenizer_p = self.get_tokenizer(pretrained_name, **kwargs)
+
+ tmpdirname2 = tempfile.mkdtemp()
+
+ tokenizer_r_files = tokenizer_r.save_pretrained(tmpdirname2)
+ tokenizer_p_files = tokenizer_p.save_pretrained(tmpdirname2)
+
+ # Checks it save with the same files + the tokenizer.json file for the fast one
+ self.assertTrue(any("tokenizer.json" in f for f in tokenizer_r_files))
+ tokenizer_r_files = tuple(f for f in tokenizer_r_files if "tokenizer.json" not in f)
+ self.assertSequenceEqual(tokenizer_r_files, tokenizer_p_files)
+
+ # Checks everything loads correctly in the same way
+ tokenizer_rp = tokenizer_r.from_pretrained(tmpdirname2)
+ tokenizer_pp = tokenizer_p.from_pretrained(tmpdirname2)
+
+ # Check special tokens are set accordingly on Rust and Python
+ for key in tokenizer_pp.special_tokens_map:
+ self.assertTrue(hasattr(tokenizer_rp, key))
+
+ shutil.rmtree(tmpdirname2)
+
+ # Save tokenizer rust, legacy_format=True
+ tmpdirname2 = tempfile.mkdtemp()
+
+ tokenizer_r_files = tokenizer_r.save_pretrained(tmpdirname2, legacy_format=True)
+ tokenizer_p_files = tokenizer_p.save_pretrained(tmpdirname2)
+
+ # Checks it save with the same files
+ self.assertSequenceEqual(tokenizer_r_files, tokenizer_p_files)
+
+ # Checks everything loads correctly in the same way
+ tokenizer_rp = tokenizer_r.from_pretrained(tmpdirname2)
+ tokenizer_pp = tokenizer_p.from_pretrained(tmpdirname2)
+
+ # Check special tokens are set accordingly on Rust and Python
+ for key in tokenizer_pp.special_tokens_map:
+ self.assertTrue(hasattr(tokenizer_rp, key))
+
+ shutil.rmtree(tmpdirname2)
+
+ # Save tokenizer rust, legacy_format=False
+ tmpdirname2 = tempfile.mkdtemp()
+
+ tokenizer_r_files = tokenizer_r.save_pretrained(tmpdirname2, legacy_format=False)
+ tokenizer_p_files = tokenizer_p.save_pretrained(tmpdirname2)
+
+ # Checks it saved the tokenizer.json file
+ self.assertTrue(any("tokenizer.json" in f for f in tokenizer_r_files))
+
+ # Checks everything loads correctly in the same way
+ tokenizer_rp = tokenizer_r.from_pretrained(tmpdirname2)
+ tokenizer_pp = tokenizer_p.from_pretrained(tmpdirname2)
+
+ # Check special tokens are set accordingly on Rust and Python
+ for key in tokenizer_pp.special_tokens_map:
+ self.assertTrue(hasattr(tokenizer_rp, key))
+
+ shutil.rmtree(tmpdirname2)
+
+ @require_torch
+ def test_batch_tokenization(self):
+ if not self.test_seq2seq:
+ self.skipTest(reason="test_seq2seq is False")
+
+ tokenizers = self.get_tokenizers()
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ # Longer text that will definitely require truncation.
+ text = [
+ " UN Chief Says There Is No Military Solution in Syria",
+ " Secretary-General Ban Ki-moon says his response to Russia's stepped up military support for"
+ " Syria is that 'there is no military solution' to the nearly five-year conflict and more weapons"
+ " will only worsen the violence and misery for millions of people.",
+ ]
+ try:
+ batch = tokenizer(
+ text=text,
+ max_length=3,
+ return_tensors="pt",
+ )
+ except NotImplementedError:
+ self.skipTest(reason="Encountered NotImplementedError when calling tokenizer")
+ self.assertEqual(batch.input_ids.shape[1], 3)
+ # max_target_length will default to max_length if not specified
+ batch = tokenizer(text, max_length=3, return_tensors="pt")
+ self.assertEqual(batch.input_ids.shape[1], 3)
+
+ batch_encoder_only = tokenizer(text=text, max_length=3, return_tensors="pt")
+ self.assertEqual(batch_encoder_only.input_ids.shape[1], 3)
+ self.assertEqual(batch_encoder_only.attention_mask.shape[1], 3)
+ self.assertNotIn("decoder_input_ids", batch_encoder_only)
+
+ @unittest.skip(reason="Unfortunately way too slow to build a BPE with SentencePiece.")
+ def test_save_slow_from_fast_and_reload_fast(self):
+ pass
+
+ def test_special_tokens_initialization(self):
+ for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
+ with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name})"):
+ added_tokens = [AddedToken("", lstrip=True)]
+
+ tokenizer_r = self.get_rust_tokenizer(
+ pretrained_name, additional_special_tokens=added_tokens, **kwargs
+ )
+ r_output = tokenizer_r.encode("Hey this is a token")
+
+ special_token_id = tokenizer_r.encode("", add_special_tokens=False)[0]
+
+ self.assertTrue(special_token_id in r_output)
+
+ if self.test_slow_tokenizer:
+ tokenizer_cr = self.get_rust_tokenizer(
+ pretrained_name,
+ additional_special_tokens=added_tokens,
+ **kwargs, # , from_slow=True <- unfortunately too slow to convert
+ )
+ tokenizer_p = self.tokenizer_class.from_pretrained(
+ pretrained_name, additional_special_tokens=added_tokens, **kwargs
+ )
+
+ p_output = tokenizer_p.encode("Hey this is a token")
+
+ cr_output = tokenizer_cr.encode("Hey this is a token")
+
+ self.assertEqual(p_output, r_output)
+ self.assertEqual(cr_output, r_output)
+ self.assertTrue(special_token_id in p_output)
+ self.assertTrue(special_token_id in cr_output)
+
+ @slow
+ def test_tokenizer_integration(self):
+ expected_encoding = {'input_ids': [[1, 4103, 689, 414, 313, 24784, 368, 2998, 408, 282, 3637, 25350, 29899, 9067, 414, 322, 282, 3637, 25350, 29899, 1457, 3018, 1312, 29899, 2151, 29897, 8128, 2498, 29899, 15503, 4220, 6956, 1973, 313, 13635, 29911, 29892, 402, 7982, 29899, 29906, 29892, 1528, 13635, 29911, 29874, 29892, 1060, 26369, 29892, 6652, 309, 29933, 814, 29892, 1060, 29931, 6779, 11410, 363, 18385, 17088, 7634, 11235, 313, 25103, 29965, 29897, 322, 18385, 17088, 28203, 313, 25103, 29954, 29897, 411, 975, 29871, 29941, 29906, 29974, 758, 3018, 1312, 4733, 297, 29871, 29896, 29900, 29900, 29974, 10276, 322, 6483, 1006, 3372, 3097, 1546, 435, 1165, 29892, 10772, 29911, 25350, 322, 323, 6073, 17907, 29889], [1, 350, 20161, 338, 8688, 304, 758, 29899, 14968, 6483, 21000, 8684, 284, 22540, 515, 443, 29880, 24025, 1426, 491, 14002, 368, 4195, 292, 373, 1716, 2175, 322, 1492, 3030, 297, 599, 15359, 29889], [1, 450, 4996, 17354, 1701, 29916, 432, 17204, 975, 278, 17366, 11203, 29889]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]} # fmt: skip
+
+ self.tokenizer_integration_test_util(
+ expected_encoding=expected_encoding,
+ model_name="hf-internal-testing/llama-code-tokenizer",
+ revision="6eb30c03ab6a9e2cdef4d523024909ec815ddb75",
+ padding=False,
+ )
+
+ def test_picklable(self):
+ with tempfile.NamedTemporaryFile() as f:
+ shutil.copyfile(SAMPLE_VOCAB, f.name)
+ tokenizer = CodeLlamaTokenizer(f.name, keep_accents=True)
+ pickled_tokenizer = pickle.dumps(tokenizer)
+ pickle.loads(pickled_tokenizer)
+
+ @unittest.skip(reason="worker 'gw4' crashed on CI, passing locally.")
+ def test_pickle_subword_regularization_tokenizer(self):
+ pass
+
+ @unittest.skip(reason="worker 'gw4' crashed on CI, passing locally.")
+ def test_subword_regularization_tokenizer(self):
+ pass
+
+
+@require_torch
+@require_sentencepiece
+@require_tokenizers
+class LlamaIntegrationTest(unittest.TestCase):
+ @classmethod
+ def setUpClass(cls):
+ checkpoint_name = "hf-internal-testing/llama-code-tokenizer"
+ cls.tokenizer: CodeLlamaTokenizer = CodeLlamaTokenizer.from_pretrained(checkpoint_name)
+ cls.rust_tokenizer = CodeLlamaTokenizerFast.from_pretrained(checkpoint_name)
+ return cls
+
+ @require_torch
+ def integration_tests(self):
+ inputs = self.tokenizer(
+ ["The following string should be properly encoded: Hello.", "But ird and ปี ird ด"],
+ return_tensors="pt",
+ )
+
+ self.assertEqual(
+ nested_simplify(inputs),
+ {
+ "input_ids": [
+ [1, 450, 1494, 1347, 881, 367, 6284, 18511, 29901, 15043, 29889],
+ [1, 1205, 29871, 1823, 322, 29871, 31010, 30691, 1678, 1823, 1678, 30718],
+ ],
+ "attention_mask": [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]],
+ },
+ )
+
+ def test_fast_special_tokens(self):
+ slow_tokenizer = self.tokenizer
+ fast_tokenizer = self.rust_tokenizer
+ slow = slow_tokenizer.encode("A sample test", add_special_tokens=True)
+ assert slow == [1, 319, 4559, 1243]
+
+ fast_tokenizer.add_eos_token = False
+ fast = fast_tokenizer.encode("A sample test", add_special_tokens=True)
+ assert fast == [1, 319, 4559, 1243]
+
+ fast_tokenizer.add_eos_token = True
+ fast = fast_tokenizer.encode("A sample test", add_special_tokens=True)
+ assert fast == [1, 319, 4559, 1243, 2]
+
+ slow_tokenizer.add_eos_token = True
+ slow = slow_tokenizer.encode("A sample test", add_special_tokens=True)
+ assert slow == [1, 319, 4559, 1243, 2]
+
+ fast_tokenizer = CodeLlamaTokenizerFast.from_pretrained(
+ "hf-internal-testing/llama-tokenizer", add_eos_token=True, add_bos_token=False
+ )
+ fast = fast_tokenizer.encode("A sample test", add_special_tokens=True)
+ assert fast == [319, 4559, 1243, 2]
+
+ slow_tokenizer = CodeLlamaTokenizer.from_pretrained(
+ "hf-internal-testing/llama-tokenizer", add_eos_token=True, add_bos_token=False
+ )
+ slow = slow_tokenizer.encode("A sample test", add_special_tokens=True)
+ assert slow == [319, 4559, 1243, 2]
+
+ self.tokenizer.add_eos_token = False
+ self.rust_tokenizer.add_eos_token = False
+
+ @slow
+ def test_conversion(self):
+ # This is excruciatingly slow since it has to recreate the entire merge
+ # list from the original vocabulary in spm
+ self.rust_tokenizer.save_pretrained("./out")
+ with tempfile.TemporaryDirectory() as dirname:
+ self.rust_tokenizer.save_pretrained(dirname)
+
+ with open(os.path.join(dirname, "tokenizer.json")) as f:
+ old_serialized = f.read()
+
+ new_tokenizer = convert_slow_tokenizer(self.tokenizer)
+ with tempfile.NamedTemporaryFile() as f:
+ new_tokenizer.save(f.name)
+ # Re-opening since `f` is in bytes.
+ new_serialized = open(f.name).read()
+ with open("out_tokenizer.json", "w") as g:
+ g.write(new_serialized)
+
+ self.assertEqual(old_serialized, new_serialized)
+
+ def test_simple_encode_decode(self):
+ pyth_tokenizer = self.tokenizer
+ rust_tokenizer = self.rust_tokenizer
+
+ self.assertEqual(pyth_tokenizer.encode("This is a test"), [1, 910, 338, 263, 1243])
+ self.assertEqual(rust_tokenizer.encode("This is a test"), [1, 910, 338, 263, 1243])
+ self.assertEqual(pyth_tokenizer.decode([1, 910, 338, 263, 1243], skip_special_tokens=True), "This is a test")
+ self.assertEqual(rust_tokenizer.decode([1, 910, 338, 263, 1243], skip_special_tokens=True), "This is a test")
+
+ # bytefallback showcase
+ self.assertEqual(pyth_tokenizer.encode("生活的真谛是"), [1, 29871, 30486, 31704, 30210, 30848, 235, 179, 158, 30392]) # fmt: skip
+ self.assertEqual(rust_tokenizer.encode("生活的真谛是"), [1, 29871, 30486, 31704, 30210, 30848, 235, 179, 158, 30392]) # fmt: skip
+ self.assertEqual(
+ pyth_tokenizer.decode(
+ [1, 29871, 30486, 31704, 30210, 30848, 235, 179, 158, 30392], skip_special_tokens=True
+ ),
+ "生活的真谛是",
+ )
+ self.assertEqual(
+ rust_tokenizer.decode(
+ [1, 29871, 30486, 31704, 30210, 30848, 235, 179, 158, 30392], skip_special_tokens=True
+ ),
+ "生活的真谛是",
+ )
+
+ # Inner spaces showcase
+ self.assertEqual(pyth_tokenizer.encode("Hi Hello"), [1, 6324, 29871, 15043])
+ self.assertEqual(rust_tokenizer.encode("Hi Hello"), [1, 6324, 29871, 15043])
+ self.assertEqual(pyth_tokenizer.decode([1, 6324, 29871, 15043], skip_special_tokens=True), "Hi Hello")
+ self.assertEqual(rust_tokenizer.decode([1, 6324, 29871, 15043], skip_special_tokens=True), "Hi Hello")
+
+ self.assertEqual(pyth_tokenizer.encode("Hi Hello"), [1, 6324, 259, 15043])
+ self.assertEqual(rust_tokenizer.encode("Hi Hello"), [1, 6324, 259, 15043])
+ self.assertEqual(pyth_tokenizer.decode([1, 6324, 259, 15043], skip_special_tokens=True), "Hi Hello")
+ self.assertEqual(rust_tokenizer.decode([1, 6324, 259, 15043], skip_special_tokens=True), "Hi Hello")
+
+ self.assertEqual(pyth_tokenizer.encode(""), [1])
+ self.assertEqual(rust_tokenizer.encode(""), [1])
+
+ self.assertEqual(pyth_tokenizer.encode(" "), [1, 259])
+ self.assertEqual(rust_tokenizer.encode(" "), [1, 259])
+
+ self.assertEqual(pyth_tokenizer.encode(" "), [1, 1678])
+ self.assertEqual(rust_tokenizer.encode(" "), [1, 1678])
+
+ self.assertEqual(pyth_tokenizer.encode(" Hello"), [1, 29871, 15043])
+ self.assertEqual(rust_tokenizer.encode(" Hello"), [1, 29871, 15043])
+
+ def test_no_differences_showcase(self):
+ pyth_tokenizer = self.tokenizer
+ rust_tokenizer = self.rust_tokenizer
+ self.assertEqual(pyth_tokenizer.encode(""), [1])
+ self.assertEqual(rust_tokenizer.encode(""), [1])
+
+ self.assertEqual(pyth_tokenizer.encode(" "), [1, 259])
+ self.assertEqual(rust_tokenizer.encode(" "), [1, 259])
+
+ self.assertEqual(pyth_tokenizer.encode(" "), [1, 1678])
+ self.assertEqual(rust_tokenizer.encode(" "), [1, 1678])
+
+ self.assertEqual(pyth_tokenizer.encode(" Hello"), [1, 29871, 15043])
+ self.assertEqual(rust_tokenizer.encode(" Hello"), [1, 29871, 15043])
+
+ self.assertEqual(pyth_tokenizer.encode(""), [1, 1])
+ self.assertEqual(rust_tokenizer.encode(""), [1, 1])
+
+ def test_no_differences_decode(self):
+ pyth_tokenizer = self.tokenizer
+ rust_tokenizer = self.rust_tokenizer
+
+ self.assertEqual(pyth_tokenizer.decode([869]), ".")
+ self.assertEqual(rust_tokenizer.decode([869]), ".")
+
+ self.assertEqual(pyth_tokenizer.decode([30112, 869]), "ا .")
+ self.assertEqual(rust_tokenizer.decode([30112, 869]), "ا .")
+
+ def test_no_differences_special_tokens(self):
+ pyth_tokenizer = self.tokenizer
+ rust_tokenizer = self.rust_tokenizer
+ self.assertEqual(pyth_tokenizer.encode(""), [1])
+ self.assertEqual(rust_tokenizer.encode(""), [1])
+
+ self.assertEqual(pyth_tokenizer.encode(""), [1, 1])
+ self.assertEqual(rust_tokenizer.encode(""), [1, 1])
+
+ @unittest.skipIf(
+ os.getenv("RUN_TOKENIZER_INTEGRATION", "0") == "0",
+ "RUN_TOKENIZER_INTEGRATION=1 to run tokenizer integration tests",
+ )
+ def test_integration_test_xnli(self):
+ import tqdm
+
+ pyth_tokenizer = self.tokenizer
+ rust_tokenizer = self.rust_tokenizer
+
+ dataset = load_dataset("google/code_x_glue_ct_code_to_text", "go")
+ for item in tqdm.tqdm(dataset["validation"]):
+ string = item["code"]
+ encoded1 = pyth_tokenizer.encode(string)
+ encoded2 = rust_tokenizer.encode(string)
+
+ self.assertEqual(encoded1, encoded2)
+
+ decoded1 = pyth_tokenizer.decode(encoded1, skip_special_tokens=True)
+ decoded2 = rust_tokenizer.decode(encoded2, skip_special_tokens=True)
+
+ self.assertEqual(decoded1, decoded2)
+
+ dataset = load_dataset("facebook/xnli", "all_languages")
+
+ for item in tqdm.tqdm(dataset["train"]):
+ for string in item["premise"].values():
+ encoded1 = pyth_tokenizer.encode(string)
+ encoded2 = rust_tokenizer.encode(string)
+
+ self.assertEqual(encoded1, encoded2)
+
+ decoded1 = pyth_tokenizer.decode(encoded1, skip_special_tokens=True)
+ decoded2 = rust_tokenizer.decode(encoded2, skip_special_tokens=True)
+
+ self.assertEqual(decoded1, decoded2)
+
+ def test_special_token_special_word(self):
+ # the word inform should be split as ['in', 'form']
+ tokenizer = CodeLlamaTokenizer.from_pretrained("codellama/CodeLlama-7b-hf", legacy=False)
+ tokenizer.add_tokens([AddedToken("", rstrip=True, lstrip=True)], special_tokens=False)
+ out1 = tokenizer.decode(
+ tokenizer.encode("inform", add_special_tokens=False), spaces_between_special_tokens=False
+ )
+ self.assertEqual(out1, "inform")
+ out2 = tokenizer.decode(
+ tokenizer.encode("inform", add_special_tokens=False), spaces_between_special_tokens=True
+ )
+ # the added prefix token should not be decoded
+ self.assertEqual(out2, " inform")
+ input_ids = tokenizer.encode("inform", add_special_tokens=False)
+ self.assertEqual(input_ids, [29871, 32016, 262, 689]) # 29871 is the spiece underline, '▁'
+
+ out2 = tokenizer.decode(
+ tokenizer.encode(" inform", add_special_tokens=False), spaces_between_special_tokens=False
+ )
+ # TODO @ArthurZ currently we strip left and right, so this will not keep the spaces
+ self.assertEqual(out2, "inform")
+
+ ### Let's make sure decoding does not add extra spaces here and there
+ # TODO @ArthurZ this should be affected by the lstrip/rstrip/single word /normalize refactoring
+ # Since currently we always strip left and right of the token, results are as such
+ input_ids = tokenizer.encode(" Hellohow", add_special_tokens=False)
+ self.assertEqual(input_ids, [1, 15043, 1, 3525])
+ tokens = tokenizer.tokenize(" Hellohow", add_special_tokens=False)
+ self.assertEqual(tokens, ["", "▁Hello", "", "how"])
+ decoded_tokens = tokenizer.decode(input_ids)
+ self.assertEqual(decoded_tokens, " Hellohow")
+
+ # Let's make sure that if there are any spaces, we don't remove them!
+ input_ids = tokenizer.encode(" Hello how", add_special_tokens=False)
+ self.assertEqual(input_ids, [259, 1, 15043, 1, 920])
+ tokens = tokenizer.tokenize(" Hello how", add_special_tokens=False)
+ self.assertEqual(tokens, ["▁▁", "", "▁Hello", "", "▁how"])
+ decoded_tokens = tokenizer.decode(input_ids)
+ self.assertEqual(decoded_tokens, " Hello how")
+
+ def test_fill_token(self):
+ tokenizer = CodeLlamaTokenizerFast.from_pretrained(
+ "codellama/CodeLlama-7b-hf", fill_token=None, prefix_token=None, suffix_token=None, middle_token=None
+ )
+ tokenizer.encode_plus("Hey how are you").input_ids
+ tokenizer.fill_token = ""
+ with self.assertRaises(ValueError):
+ tokenizer.encode("Hey how are you")
+ tokenizer.encode_plus("Hey how are you", "mne too")
+ tokenizer.tokenize("Hey how are you", "mne too")
+
+ tokenizer = CodeLlamaTokenizerFast.from_pretrained(
+ "codellama/CodeLlama-7b-hf", revision="3773f63b4511b9e47a9a7ffc765eed7eb0169486"
+ )
+ tokenizer.encode("Hey how are you")
+ tokenizer.encode_plus("Hey how are you", "mne too")
+ tokenizer.tokenize("Hey how are you", "mne too")
+
+ def test_spm_edge_cases(self):
+ # the word inform should be split as ['in', 'form']
+ tokenizer = CodeLlamaTokenizer.from_pretrained("codellama/CodeLlama-7b-hf", legacy=False)
+ tokens = tokenizer.tokenize("[INST] How are you doing?[/INST]")
+ self.assertEqual(
+ tokens, ["▁[", "INST", "]", "▁How", "▁are", "▁you", "▁doing", "?", "", "[", "/", "INST", "]"]
+ )
+ inputs_ids = tokenizer.encode("[INST] How are you doing?[/INST]")
+ self.assertEqual(
+ inputs_ids, [1, 518, 25580, 29962, 1128, 526, 366, 2599, 29973, 1, 29961, 29914, 25580, 29962]
+ )
+
+ def test_infilling_tokenization(self):
+ PROMPTS = [
+ '''def remove_non_ascii(s: str) -> str:
+ """
+ return result
+''',
+ """# Installation instructions:
+ ```bash
+
+ ```
+This downloads the LLaMA inference code and installs the repository as a local pip package.
+""",
+ """class InterfaceManagerFactory(AbstractManagerFactory):
+ def __init__(
+def main():
+ factory = InterfaceManagerFactory(start=datetime.now())
+ managers = []
+ for i in range(10):
+ managers.append(factory.build(id=i))
+""",
+ """/-- A quasi-prefunctoid is 1-connected iff all its etalisations are 1-connected. -/
+theorem connected_iff_etalisation [C D : precategoroid] (P : quasi_prefunctoid C D) :
+π₁ P = 0 ↔ = 0 :=
+begin
+split,
+{ intros h f,
+ rw pi_1_etalisation at h,
+ simp [h],
+ refl
+},
+{ intro h,
+ have := @quasi_adjoint C D P,
+ simp [←pi_1_etalisation, this, h],
+ refl
+}
+end
+""",
+ ]
+ tokenizer = CodeLlamaTokenizer.from_pretrained("codellama/CodeLlama-7b-Instruct-hf")
+ tokenizer_fast = CodeLlamaTokenizerFast.from_pretrained("codellama/CodeLlama-7b-Instruct-hf")
+
+ formatted_prompt = tokenizer.tokenize(PROMPTS[0])
+ self.assertEqual(formatted_prompt, tokenizer_fast.tokenize(PROMPTS[0]))
+ prefix, suffix = PROMPTS[0].split("")
+ self.assertEqual(formatted_prompt, tokenizer.tokenize(prefix, suffix))
+ self.assertEqual(formatted_prompt, tokenizer_fast.tokenize(prefix, suffix))
+
+ input_ids = tokenizer.encode(PROMPTS[0], add_special_tokens=False)
+ self.assertEqual(input_ids, tokenizer_fast.encode(PROMPTS[0], add_special_tokens=False))
+
+ prefix, suffix = PROMPTS[0].split("")
+ input_ids = tokenizer.encode(PROMPTS[0])
+ self.assertEqual(input_ids, tokenizer.encode(prefix, suffix=suffix))
+ self.assertEqual(tokenizer.encode(prefix, suffix=suffix), tokenizer_fast.encode(prefix, suffix=suffix))
+
+ # Adding suffix_first check for infilling tasks
+ suffix_first_formatted_prompt = tokenizer.tokenize(PROMPTS[0], suffix_first=True)
+ self.assertEqual(suffix_first_formatted_prompt, tokenizer_fast.tokenize(PROMPTS[0], suffix_first=True))
+ prefix, suffix = PROMPTS[0].split("")
+ self.assertEqual(suffix_first_formatted_prompt, tokenizer.tokenize(prefix, suffix, suffix_first=True))
+ self.assertEqual(suffix_first_formatted_prompt, tokenizer_fast.tokenize(prefix, suffix, suffix_first=True))
+
+ prefix, suffix = PROMPTS[0].split("")
+ suffix_first_input_ids = tokenizer.encode(PROMPTS[0], suffix_first=True)
+ self.assertEqual(suffix_first_input_ids, tokenizer.encode(prefix, suffix=suffix, suffix_first=True))
+ self.assertEqual(suffix_first_input_ids, tokenizer_fast.encode(prefix, suffix=suffix, suffix_first=True))
diff --git a/transformers/tests/models/codegen/__init__.py b/transformers/tests/models/codegen/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/codegen/test_modeling_codegen.py b/transformers/tests/models/codegen/test_modeling_codegen.py
new file mode 100644
index 0000000000000000000000000000000000000000..78f766a52acdc4c8f8d217a078ce6dd99333aed3
--- /dev/null
+++ b/transformers/tests/models/codegen/test_modeling_codegen.py
@@ -0,0 +1,492 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers import CodeGenConfig, is_torch_available
+from transformers.file_utils import cached_property
+from transformers.testing_utils import backend_manual_seed, require_torch, slow, torch_device
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import AutoTokenizer, CodeGenForCausalLM, CodeGenModel
+
+
+class CodeGenModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=14,
+ seq_length=7,
+ is_training=True,
+ use_token_type_ids=True,
+ use_input_mask=True,
+ use_labels=True,
+ use_mc_token_ids=True,
+ vocab_size=256,
+ hidden_size=32,
+ rotary_dim=4,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_token_type_ids = use_token_type_ids
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.use_mc_token_ids = use_mc_token_ids
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.rotary_dim = rotary_dim
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.scope = None
+ self.bos_token_id = vocab_size - 1
+ self.eos_token_id = vocab_size - 1
+ self.pad_token_id = vocab_size - 1
+
+ def get_large_model_config(self):
+ return CodeGenConfig.from_pretrained("Salesforce/codegen-2B-mono")
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ mc_token_ids = None
+ if self.use_mc_token_ids:
+ mc_token_ids = ids_tensor([self.batch_size, self.num_choices], self.seq_length)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ head_mask = ids_tensor([self.num_hidden_layers, self.num_attention_heads], 2)
+
+ return (
+ config,
+ input_ids,
+ input_mask,
+ head_mask,
+ token_type_ids,
+ mc_token_ids,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ )
+
+ def get_config(self):
+ return CodeGenConfig(
+ vocab_size=self.vocab_size,
+ n_embd=self.hidden_size,
+ n_layer=self.num_hidden_layers,
+ n_head=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ n_positions=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ initializer_range=self.initializer_range,
+ use_cache=True,
+ bos_token_id=self.bos_token_id,
+ eos_token_id=self.eos_token_id,
+ pad_token_id=self.pad_token_id,
+ rotary_dim=self.rotary_dim,
+ )
+
+ def create_and_check_codegen_model(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
+ model = CodeGenModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids, token_type_ids=token_type_ids, head_mask=head_mask)
+ result = model(input_ids, token_type_ids=token_type_ids)
+ result = model(input_ids)
+
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(len(result.past_key_values), config.n_layer)
+
+ def create_and_check_codegen_model_past(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
+ model = CodeGenModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # first forward pass
+ outputs = model(input_ids, token_type_ids=token_type_ids, use_cache=True)
+ outputs_use_cache_conf = model(input_ids, token_type_ids=token_type_ids)
+ outputs_no_past = model(input_ids, token_type_ids=token_type_ids, use_cache=False)
+
+ self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf))
+ self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1)
+
+ output, past = outputs.to_tuple()
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
+ next_token_types = ids_tensor([self.batch_size, 1], self.type_vocab_size)
+
+ # append to next input_ids and token_type_ids
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_token_type_ids = torch.cat([token_type_ids, next_token_types], dim=-1)
+
+ output_from_no_past = model(next_input_ids, token_type_ids=next_token_type_ids)["last_hidden_state"]
+ output_from_past = model(next_tokens, token_type_ids=next_token_types, past_key_values=past)[
+ "last_hidden_state"
+ ]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_codegen_model_attention_mask_past(
+ self, config, input_ids, input_mask, head_mask, token_type_ids, *args
+ ):
+ model = CodeGenModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # create attention mask
+ attn_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
+ half_seq_length = self.seq_length // 2
+ attn_mask[:, half_seq_length:] = 0
+
+ # first forward pass
+ output, past = model(input_ids, attention_mask=attn_mask).to_tuple()
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
+
+ # change a random masked slice from input_ids
+ random_seq_idx_to_change = ids_tensor((1,), half_seq_length).item() + 1
+ random_other_next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size).squeeze(-1)
+ input_ids[:, -random_seq_idx_to_change] = random_other_next_tokens
+
+ # append to next input_ids and attn_mask
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ attn_mask = torch.cat(
+ [attn_mask, torch.ones((attn_mask.shape[0], 1), dtype=torch.long, device=torch_device)],
+ dim=1,
+ )
+
+ # get two different outputs
+ output_from_no_past = model(next_input_ids, attention_mask=attn_mask)["last_hidden_state"]
+ output_from_past = model(next_tokens, past_key_values=past, attention_mask=attn_mask)["last_hidden_state"]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_codegen_model_past_large_inputs(
+ self, config, input_ids, input_mask, head_mask, token_type_ids, *args
+ ):
+ model = CodeGenModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # first forward pass
+ outputs = model(input_ids, token_type_ids=token_type_ids, attention_mask=input_mask, use_cache=True)
+
+ output, past = outputs.to_tuple()
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_token_types = ids_tensor([self.batch_size, 3], self.type_vocab_size)
+ next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
+
+ # append to next input_ids and token_type_ids
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_token_type_ids = torch.cat([token_type_ids, next_token_types], dim=-1)
+ next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
+
+ output_from_no_past = model(
+ next_input_ids, token_type_ids=next_token_type_ids, attention_mask=next_attention_mask
+ )["last_hidden_state"]
+ output_from_past = model(
+ next_tokens, token_type_ids=next_token_types, attention_mask=next_attention_mask, past_key_values=past
+ )["last_hidden_state"]
+ self.parent.assertTrue(output_from_past.shape[1] == next_tokens.shape[1])
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_lm_head_model(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
+ model = CodeGenForCausalLM(config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids, token_type_ids=token_type_ids, labels=input_ids)
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_forward_and_backwards(
+ self, config, input_ids, input_mask, head_mask, token_type_ids, *args, gradient_checkpointing=False
+ ):
+ model = CodeGenForCausalLM(config)
+ if gradient_checkpointing:
+ model.gradient_checkpointing_enable()
+ model.to(torch_device)
+
+ result = model(input_ids, token_type_ids=token_type_ids, labels=input_ids)
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+ result.loss.backward()
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+
+ (
+ config,
+ input_ids,
+ input_mask,
+ head_mask,
+ token_type_ids,
+ mc_token_ids,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+
+ inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "head_mask": head_mask}
+
+ return config, inputs_dict
+
+
+@require_torch
+class CodeGenModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (CodeGenModel, CodeGenForCausalLM) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {"feature-extraction": CodeGenModel, "text-generation": CodeGenForCausalLM} if is_torch_available() else {}
+ )
+ fx_compatible = False
+ test_pruning = False
+ test_missing_keys = False
+ test_model_parallel = False
+ test_head_masking = False
+
+ # special case for DoubleHeads model
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = CodeGenModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=CodeGenConfig, n_embd=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_codegen_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_codegen_model(*config_and_inputs)
+
+ def test_codegen_model_past(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_codegen_model_past(*config_and_inputs)
+
+ def test_codegen_model_att_mask_past(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_codegen_model_attention_mask_past(*config_and_inputs)
+
+ def test_codegen_model_past_large_inputs(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_codegen_model_past_large_inputs(*config_and_inputs)
+
+ def test_codegen_lm_head_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_lm_head_model(*config_and_inputs)
+
+ def test_codegen_gradient_checkpointing(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_forward_and_backwards(*config_and_inputs, gradient_checkpointing=True)
+
+ @slow
+ def test_batch_generation(self):
+ tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen-350M-mono")
+ model = CodeGenForCausalLM.from_pretrained("Salesforce/codegen-350M-mono")
+ model.to(torch_device)
+
+ tokenizer.padding_side = "left"
+
+ # Define PAD Token = EOS Token = 50256
+ tokenizer.pad_token = tokenizer.eos_token
+ model.config.pad_token_id = model.config.eos_token_id
+
+ # use different length sentences to test batching
+ sentences = ["def hellow_world():", "def greet(name):"]
+
+ inputs = tokenizer(sentences, return_tensors="pt", padding=True)
+ input_ids = inputs["input_ids"].to(torch_device)
+ token_type_ids = torch.cat(
+ [
+ input_ids.new_full((input_ids.shape[0], input_ids.shape[1] - 1), 0),
+ input_ids.new_full((input_ids.shape[0], 1), 500),
+ ],
+ dim=-1,
+ )
+
+ outputs = model.generate(
+ input_ids=input_ids,
+ attention_mask=inputs["attention_mask"].to(torch_device),
+ )
+
+ outputs_tt = model.generate(
+ input_ids=input_ids,
+ attention_mask=inputs["attention_mask"].to(torch_device),
+ token_type_ids=token_type_ids,
+ )
+
+ inputs_non_padded = tokenizer(sentences[0], return_tensors="pt").input_ids.to(torch_device)
+ output_non_padded = model.generate(input_ids=inputs_non_padded)
+
+ num_paddings = inputs_non_padded.shape[-1] - inputs["attention_mask"][-1].long().sum().item()
+ inputs_padded = tokenizer(sentences[1], return_tensors="pt").input_ids.to(torch_device)
+ output_padded = model.generate(input_ids=inputs_padded, max_length=model.config.max_length - num_paddings)
+
+ batch_out_sentence = tokenizer.batch_decode(outputs, skip_special_tokens=True)
+ batch_out_sentence_tt = tokenizer.batch_decode(outputs_tt, skip_special_tokens=True)
+ non_padded_sentence = tokenizer.decode(output_non_padded[0], skip_special_tokens=True)
+ padded_sentence = tokenizer.decode(output_padded[0], skip_special_tokens=True)
+
+ expected_output_sentence = [
+ 'def hellow_world():\n print("Hello World")\n\nhellow_world()',
+ 'def greet(name):\n print(f"Hello {name}")\n\ng',
+ ]
+ self.assertListEqual(expected_output_sentence, batch_out_sentence)
+ self.assertTrue(batch_out_sentence_tt != batch_out_sentence) # token_type_ids should change output
+ self.assertListEqual(expected_output_sentence, [non_padded_sentence, padded_sentence])
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "Salesforce/codegen-350M-nl"
+ model = CodeGenModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+@require_torch
+class CodeGenModelLanguageGenerationTest(unittest.TestCase):
+ @cached_property
+ def cached_tokenizer(self):
+ return AutoTokenizer.from_pretrained("Salesforce/codegen-350M-mono")
+
+ @cached_property
+ def cached_model(self):
+ return CodeGenForCausalLM.from_pretrained("Salesforce/codegen-350M-mono")
+
+ @slow
+ def test_lm_generate_codegen(self):
+ tokenizer = self.cached_tokenizer
+ for checkpointing in [True, False]:
+ model = self.cached_model
+
+ if checkpointing:
+ model.gradient_checkpointing_enable()
+ else:
+ model.gradient_checkpointing_disable()
+ model.to(torch_device)
+
+ inputs = tokenizer("def hello_world():", return_tensors="pt").to(torch_device)
+ expected_output = 'def hello_world():\n print("Hello World")\n\nhello_world()\n\n'
+
+ output_ids = model.generate(**inputs, do_sample=False)
+ output_str = tokenizer.batch_decode(output_ids)[0]
+
+ self.assertEqual(output_str, expected_output)
+
+ @slow
+ def test_codegen_sample(self):
+ tokenizer = self.cached_tokenizer
+ model = self.cached_model
+ model.to(torch_device)
+
+ torch.manual_seed(0)
+ backend_manual_seed(torch_device, 0)
+
+ tokenized = tokenizer("def hello_world():", return_tensors="pt", return_token_type_ids=True)
+ input_ids = tokenized.input_ids.to(torch_device)
+ output_ids = model.generate(input_ids, do_sample=True)
+ output_str = tokenizer.decode(output_ids[0], skip_special_tokens=True)
+
+ token_type_ids = tokenized.token_type_ids.to(torch_device)
+ output_seq = model.generate(input_ids=input_ids, do_sample=True, num_return_sequences=5)
+ output_seq_tt = model.generate(
+ input_ids=input_ids, token_type_ids=token_type_ids, do_sample=True, num_return_sequences=5
+ )
+ output_seq_strs = tokenizer.batch_decode(output_seq, skip_special_tokens=True)
+ output_seq_tt_strs = tokenizer.batch_decode(output_seq_tt, skip_special_tokens=True)
+
+ if torch_device == "cuda":
+ EXPECTED_OUTPUT_STR = 'def hello_world():\n print("Hello World")\n return True\n\nresult ='
+ else:
+ EXPECTED_OUTPUT_STR = "def hello_world():\r\n print('Hello, World.')\r\n\r\n\r"
+
+ self.assertEqual(output_str, EXPECTED_OUTPUT_STR)
+ self.assertTrue(
+ all(output_seq_strs[idx] != output_seq_tt_strs[idx] for idx in range(len(output_seq_tt_strs)))
+ ) # token_type_ids should change output
diff --git a/transformers/tests/models/codegen/test_tokenization_codegen.py b/transformers/tests/models/codegen/test_tokenization_codegen.py
new file mode 100644
index 0000000000000000000000000000000000000000..a0ea547566cd6abefbe5910c1d833019ca3183bb
--- /dev/null
+++ b/transformers/tests/models/codegen/test_tokenization_codegen.py
@@ -0,0 +1,329 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import os
+import re
+import unittest
+from functools import lru_cache
+
+from transformers import CodeGenTokenizer, CodeGenTokenizerFast
+from transformers.models.codegen.tokenization_codegen import VOCAB_FILES_NAMES
+from transformers.testing_utils import require_tokenizers, slow
+
+from ...test_tokenization_common import TokenizerTesterMixin, use_cache_if_possible
+
+
+@require_tokenizers
+class CodeGenTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "Salesforce/codegen-350M-mono"
+ tokenizer_class = CodeGenTokenizer
+ rust_tokenizer_class = CodeGenTokenizerFast
+ test_rust_tokenizer = True
+ from_pretrained_kwargs = {"add_prefix_space": True}
+ test_seq2seq = False
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ # Adapted from Sennrich et al. 2015 and https://github.com/rsennrich/subword-nmt
+ vocab = [
+ "l",
+ "o",
+ "w",
+ "e",
+ "r",
+ "s",
+ "t",
+ "i",
+ "d",
+ "n",
+ "\u0120",
+ "\u0120l",
+ "\u0120n",
+ "\u0120lo",
+ "\u0120low",
+ "er",
+ "\u0120lowest",
+ "\u0120newer",
+ "\u0120wider",
+ "",
+ "<|endoftext|>",
+ ]
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+ merges = ["#version: 0.2", "\u0120 l", "\u0120l o", "\u0120lo w", "e r", ""]
+ cls.special_tokens_map = {"unk_token": ""}
+
+ cls.vocab_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ cls.merges_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["merges_file"])
+ with open(cls.vocab_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps(vocab_tokens) + "\n")
+ with open(cls.merges_file, "w", encoding="utf-8") as fp:
+ fp.write("\n".join(merges))
+
+ @classmethod
+ @use_cache_if_possible
+ @lru_cache(maxsize=64)
+ def get_tokenizer(cls, pretrained_name=None, **kwargs):
+ kwargs.update(cls.special_tokens_map)
+ pretrained_name = pretrained_name or cls.tmpdirname
+ return CodeGenTokenizer.from_pretrained(pretrained_name, **kwargs)
+
+ @classmethod
+ @use_cache_if_possible
+ @lru_cache(maxsize=64)
+ def get_rust_tokenizer(cls, pretrained_name=None, **kwargs):
+ kwargs.update(cls.special_tokens_map)
+ pretrained_name = pretrained_name or cls.tmpdirname
+ return CodeGenTokenizerFast.from_pretrained(pretrained_name, **kwargs)
+
+ def get_input_output_texts(self, tokenizer):
+ input_text = "lower newer"
+ output_text = "lower newer"
+ return input_text, output_text
+
+ def test_full_tokenizer(self):
+ tokenizer = CodeGenTokenizer(self.vocab_file, self.merges_file, **self.special_tokens_map)
+ text = "lower newer"
+ bpe_tokens = ["\u0120low", "er", "\u0120", "n", "e", "w", "er"]
+ tokens = tokenizer.tokenize(text, add_prefix_space=True)
+ self.assertListEqual(tokens, bpe_tokens)
+
+ input_tokens = tokens + [tokenizer.unk_token]
+ input_bpe_tokens = [14, 15, 10, 9, 3, 2, 15, 19]
+ self.assertListEqual(tokenizer.convert_tokens_to_ids(input_tokens), input_bpe_tokens)
+
+ def test_rust_and_python_full_tokenizers(self):
+ if not self.test_rust_tokenizer:
+ self.skipTest(reason="test_rust_tokenizer is set to False")
+
+ tokenizer = self.get_tokenizer()
+ rust_tokenizer = self.get_rust_tokenizer(add_prefix_space=True)
+
+ sequence = "lower newer"
+
+ # Testing tokenization
+ tokens = tokenizer.tokenize(sequence, add_prefix_space=True)
+ rust_tokens = rust_tokenizer.tokenize(sequence)
+ self.assertListEqual(tokens, rust_tokens)
+
+ # Testing conversion to ids without special tokens
+ ids = tokenizer.encode(sequence, add_special_tokens=False, add_prefix_space=True)
+ rust_ids = rust_tokenizer.encode(sequence, add_special_tokens=False)
+ self.assertListEqual(ids, rust_ids)
+
+ # Testing conversion to ids with special tokens
+ rust_tokenizer = self.get_rust_tokenizer(add_prefix_space=True)
+ ids = tokenizer.encode(sequence, add_prefix_space=True)
+ rust_ids = rust_tokenizer.encode(sequence)
+ self.assertListEqual(ids, rust_ids)
+
+ # Testing the unknown token
+ input_tokens = tokens + [rust_tokenizer.unk_token]
+ input_bpe_tokens = [14, 15, 10, 9, 3, 2, 15, 19]
+ self.assertListEqual(rust_tokenizer.convert_tokens_to_ids(input_tokens), input_bpe_tokens)
+
+ @unittest.skip
+ def test_pretokenized_inputs(self, *args, **kwargs):
+ # It's very difficult to mix/test pretokenization with byte-level
+ # And get both CodeGen and Roberta to work at the same time (mostly an issue of adding a space before the string)
+ pass
+
+ def test_padding(self, max_length=15):
+ for tokenizer, pretrained_name, kwargs in self.tokenizers_list:
+ with self.subTest(f"{tokenizer.__class__.__name__} ({pretrained_name})"):
+ tokenizer_r = self.get_rust_tokenizer(pretrained_name, **kwargs)
+
+ # Simple input
+ s = "This is a simple input"
+ s2 = ["This is a simple input 1", "This is a simple input 2"]
+ p = ("This is a simple input", "This is a pair")
+ p2 = [
+ ("This is a simple input 1", "This is a simple input 2"),
+ ("This is a simple pair 1", "This is a simple pair 2"),
+ ]
+
+ # Simple input tests
+ self.assertRaises(ValueError, tokenizer_r.encode, s, max_length=max_length, padding="max_length")
+
+ # Simple input
+ self.assertRaises(ValueError, tokenizer_r.encode_plus, s, max_length=max_length, padding="max_length")
+
+ # Simple input
+ self.assertRaises(
+ ValueError,
+ tokenizer_r.batch_encode_plus,
+ s2,
+ max_length=max_length,
+ padding="max_length",
+ )
+
+ # Pair input
+ self.assertRaises(ValueError, tokenizer_r.encode, p, max_length=max_length, padding="max_length")
+
+ # Pair input
+ self.assertRaises(ValueError, tokenizer_r.encode_plus, p, max_length=max_length, padding="max_length")
+
+ # Pair input
+ self.assertRaises(
+ ValueError,
+ tokenizer_r.batch_encode_plus,
+ p2,
+ max_length=max_length,
+ padding="max_length",
+ )
+
+ def test_padding_if_pad_token_set_slow(self):
+ tokenizer = CodeGenTokenizer.from_pretrained(self.tmpdirname, pad_token="")
+
+ # Simple input
+ s = "This is a simple input"
+ s2 = ["This is a simple input looooooooong", "This is a simple input"]
+ p = ("This is a simple input", "This is a pair")
+ p2 = [
+ ("This is a simple input loooooong", "This is a simple input"),
+ ("This is a simple pair loooooong", "This is a simple pair"),
+ ]
+
+ pad_token_id = tokenizer.pad_token_id
+
+ out_s = tokenizer(s, padding="max_length", max_length=30, return_tensors="np")
+ out_s2 = tokenizer(s2, padding=True, truncate=True, return_tensors="np")
+ out_p = tokenizer(*p, padding="max_length", max_length=60, return_tensors="np")
+ out_p2 = tokenizer(p2, padding=True, truncate=True, return_tensors="np")
+
+ # s
+ # test single string max_length padding
+ self.assertEqual(out_s["input_ids"].shape[-1], 30)
+ self.assertTrue(pad_token_id in out_s["input_ids"])
+ self.assertTrue(0 in out_s["attention_mask"])
+
+ # s2
+ # test automatic padding
+ self.assertEqual(out_s2["input_ids"].shape[-1], 33)
+ # long slice doesn't have padding
+ self.assertFalse(pad_token_id in out_s2["input_ids"][0])
+ self.assertFalse(0 in out_s2["attention_mask"][0])
+ # short slice does have padding
+ self.assertTrue(pad_token_id in out_s2["input_ids"][1])
+ self.assertTrue(0 in out_s2["attention_mask"][1])
+
+ # p
+ # test single pair max_length padding
+ self.assertEqual(out_p["input_ids"].shape[-1], 60)
+ self.assertTrue(pad_token_id in out_p["input_ids"])
+ self.assertTrue(0 in out_p["attention_mask"])
+
+ # p2
+ # test automatic padding pair
+ self.assertEqual(out_p2["input_ids"].shape[-1], 52)
+ # long slice pair doesn't have padding
+ self.assertFalse(pad_token_id in out_p2["input_ids"][0])
+ self.assertFalse(0 in out_p2["attention_mask"][0])
+ # short slice pair does have padding
+ self.assertTrue(pad_token_id in out_p2["input_ids"][1])
+ self.assertTrue(0 in out_p2["attention_mask"][1])
+
+ def test_add_bos_token_slow(self):
+ bos_token = "$$$"
+ tokenizer = CodeGenTokenizer.from_pretrained(self.tmpdirname, bos_token=bos_token, add_bos_token=True)
+
+ s = "This is a simple input"
+ s2 = ["This is a simple input 1", "This is a simple input 2"]
+
+ bos_token_id = tokenizer.bos_token_id
+
+ out_s = tokenizer(s)
+ out_s2 = tokenizer(s2)
+
+ self.assertEqual(out_s.input_ids[0], bos_token_id)
+ self.assertTrue(all(o[0] == bos_token_id for o in out_s2.input_ids))
+
+ decode_s = tokenizer.decode(out_s.input_ids)
+ decode_s2 = tokenizer.batch_decode(out_s2.input_ids)
+
+ self.assertTrue(decode_s.startswith(bos_token))
+ self.assertTrue(all(d.startswith(bos_token) for d in decode_s2))
+
+ @slow
+ def test_truncation(self):
+ tokenizer = CodeGenTokenizer.from_pretrained("Salesforce/codegen-350M-mono")
+
+ text = "\nif len_a > len_b:\n result = a\nelse:\n result = b\n\n\n\n#"
+ expected_truncated_text = "\nif len_a > len_b:\n result = a\nelse:\n result = b"
+
+ input_ids = tokenizer.encode(text)
+ truncation_pattern = ["^#", re.escape("<|endoftext|>"), "^'''", '^"""', "\n\n\n"]
+ decoded_text = tokenizer.decode(input_ids, truncate_before_pattern=truncation_pattern)
+ self.assertEqual(decoded_text, expected_truncated_text)
+ # TODO @ArthurZ outputs of the fast tokenizer are different in this case, un-related to the PR
+
+ # tokenizer has no padding token
+ @unittest.skip(reason="tokenizer has no padding token")
+ def test_padding_different_model_input_name(self):
+ pass
+
+ @slow
+ def test_tokenizer_integration(self):
+ # Custom test since this tokenizer takes return_token_type_ids as an init argument for backward compatibility.
+
+ sequences = [
+ "Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provides "
+ "general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet...) for Natural "
+ "Language Understanding (NLU) and Natural Language Generation (NLG) with over 32+ pretrained "
+ "models in 100+ languages and deep interoperability between Jax, PyTorch and TensorFlow.",
+ "BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly "
+ "conditioning on both left and right context in all layers.",
+ "The quick brown fox jumps over the lazy dog.",
+ ]
+
+ tokenizer_classes = [self.tokenizer_class]
+ if self.test_rust_tokenizer:
+ tokenizer_classes.append(self.rust_tokenizer_class)
+
+ # Test default case. i.e. return_token_type_ids is False.
+ for tokenizer_class in tokenizer_classes:
+ tokenizer = tokenizer_class.from_pretrained("Salesforce/codegen-350M-mono")
+
+ encoding = tokenizer(sequences)
+ decoded_sequences = [tokenizer.decode(seq, skip_special_tokens=True) for seq in encoding["input_ids"]]
+
+ # fmt: off
+ expected_encoding = {'input_ids': [[41762, 364, 357, 36234, 1900, 355, 12972, 13165, 354, 12, 35636, 364, 290, 12972, 13165, 354, 12, 5310, 13363, 12, 4835, 8, 3769, 2276, 12, 29983, 45619, 357, 13246, 51, 11, 402, 11571, 12, 17, 11, 5564, 13246, 38586, 11, 16276, 44, 11, 4307, 346, 33, 861, 11, 16276, 7934, 23029, 329, 12068, 15417, 28491, 357, 32572, 52, 8, 290, 12068, 15417, 16588, 357, 32572, 38, 8, 351, 625, 3933, 10, 2181, 13363, 4981, 287, 1802, 10, 8950, 290, 2769, 48817, 1799, 1022, 449, 897, 11, 9485, 15884, 354, 290, 309, 22854, 37535, 13], [13246, 51, 318, 3562, 284, 662, 12, 27432, 2769, 8406, 4154, 282, 24612, 422, 9642, 9608, 276, 2420, 416, 26913, 21143, 319, 1111, 1364, 290, 826, 4732, 287, 477, 11685, 13], [464, 2068, 7586, 21831, 18045, 625, 262, 16931, 3290, 13]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]} # noqa: E501
+ # fmt: on
+
+ encoding_data = encoding.data
+ self.assertDictEqual(encoding_data, expected_encoding)
+
+ for expected, decoded in zip(sequences, decoded_sequences):
+ self.assertEqual(expected, decoded)
+
+ # Test return_token_type_ids is True case.
+ for tokenizer_class in tokenizer_classes:
+ tokenizer = tokenizer_class.from_pretrained("Salesforce/codegen-350M-mono", return_token_type_ids=True)
+
+ encoding = tokenizer(sequences)
+ decoded_sequences = [tokenizer.decode(seq, skip_special_tokens=True) for seq in encoding["input_ids"]]
+
+ # fmt: off
+ expected_encoding = {'input_ids': [[41762, 364, 357, 36234, 1900, 355, 12972, 13165, 354, 12, 35636, 364, 290, 12972, 13165, 354, 12, 5310, 13363, 12, 4835, 8, 3769, 2276, 12, 29983, 45619, 357, 13246, 51, 11, 402, 11571, 12, 17, 11, 5564, 13246, 38586, 11, 16276, 44, 11, 4307, 346, 33, 861, 11, 16276, 7934, 23029, 329, 12068, 15417, 28491, 357, 32572, 52, 8, 290, 12068, 15417, 16588, 357, 32572, 38, 8, 351, 625, 3933, 10, 2181, 13363, 4981, 287, 1802, 10, 8950, 290, 2769, 48817, 1799, 1022, 449, 897, 11, 9485, 15884, 354, 290, 309, 22854, 37535, 13], [13246, 51, 318, 3562, 284, 662, 12, 27432, 2769, 8406, 4154, 282, 24612, 422, 9642, 9608, 276, 2420, 416, 26913, 21143, 319, 1111, 1364, 290, 826, 4732, 287, 477, 11685, 13], [464, 2068, 7586, 21831, 18045, 625, 262, 16931, 3290, 13]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]} # noqa: E501
+ # fmt: on
+
+ encoding_data = encoding.data
+ self.assertDictEqual(encoding_data, expected_encoding)
+
+ for expected, decoded in zip(sequences, decoded_sequences):
+ self.assertEqual(expected, decoded)
diff --git a/transformers/tests/models/colpali/__init__.py b/transformers/tests/models/colpali/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/colpali/test_modeling_colpali.py b/transformers/tests/models/colpali/test_modeling_colpali.py
new file mode 100644
index 0000000000000000000000000000000000000000..3cdfc0622738e8af35da41daf516758ea5985750
--- /dev/null
+++ b/transformers/tests/models/colpali/test_modeling_colpali.py
@@ -0,0 +1,309 @@
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch ColPali model."""
+
+import gc
+import unittest
+from typing import ClassVar
+
+import torch
+from datasets import load_dataset
+
+from tests.test_configuration_common import ConfigTester
+from tests.test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from transformers import (
+ is_torch_available,
+)
+from transformers.models.colpali.configuration_colpali import ColPaliConfig
+from transformers.models.colpali.modeling_colpali import ColPaliForRetrieval, ColPaliForRetrievalOutput
+from transformers.models.colpali.processing_colpali import ColPaliProcessor
+from transformers.testing_utils import (
+ backend_empty_cache,
+ require_torch,
+ require_vision,
+ slow,
+ torch_device,
+)
+
+
+if is_torch_available():
+ import torch
+
+
+class ColPaliForRetrievalModelTester:
+ def __init__(
+ self,
+ parent,
+ ignore_index=-100,
+ image_token_index=0,
+ projector_hidden_act="gelu",
+ seq_length=25,
+ vision_feature_select_strategy="default",
+ vision_feature_layer=-1,
+ projection_dim=32,
+ text_config={
+ "model_type": "gemma",
+ "seq_length": 128,
+ "is_training": True,
+ "use_token_type_ids": False,
+ "use_labels": True,
+ "vocab_size": 99,
+ "hidden_size": 32,
+ "num_hidden_layers": 2,
+ "num_attention_heads": 4,
+ "num_key_value_heads": 1,
+ "head_dim": 8,
+ "intermediate_size": 37,
+ "hidden_activation": "gelu_pytorch_tanh",
+ "hidden_dropout_prob": 0.1,
+ "attention_probs_dropout_prob": 0.1,
+ "max_position_embeddings": 512,
+ "type_vocab_size": 16,
+ "type_sequence_label_size": 2,
+ "initializer_range": 0.02,
+ "num_labels": 3,
+ "num_choices": 4,
+ "pad_token_id": 1,
+ },
+ is_training=False,
+ vision_config={
+ "use_labels": True,
+ "image_size": 20,
+ "patch_size": 5,
+ "num_image_tokens": 4,
+ "num_channels": 3,
+ "is_training": True,
+ "hidden_size": 32,
+ "projection_dim": 32,
+ "num_key_value_heads": 1,
+ "num_hidden_layers": 2,
+ "num_attention_heads": 4,
+ "intermediate_size": 37,
+ "dropout": 0.1,
+ "attention_dropout": 0.1,
+ "initializer_range": 0.02,
+ },
+ use_cache=False,
+ embedding_dim=128,
+ ):
+ self.parent = parent
+ self.ignore_index = ignore_index
+ # `image_token_index` is set to 0 to pass "resize_embeddings" test, do not modify
+ self.image_token_index = image_token_index
+ self.projector_hidden_act = projector_hidden_act
+ self.vision_feature_select_strategy = vision_feature_select_strategy
+ self.vision_feature_layer = vision_feature_layer
+ self.text_config = text_config
+ self.vision_config = vision_config
+ self.seq_length = seq_length
+ self.projection_dim = projection_dim
+ self.pad_token_id = text_config["pad_token_id"]
+
+ self.num_hidden_layers = text_config["num_hidden_layers"]
+ self.vocab_size = text_config["vocab_size"]
+ self.hidden_size = text_config["hidden_size"]
+ self.num_attention_heads = text_config["num_attention_heads"]
+ self.is_training = is_training
+
+ self.batch_size = 3
+ self.num_channels = vision_config["num_channels"]
+ self.image_size = vision_config["image_size"]
+ self.encoder_seq_length = seq_length
+ self.use_cache = use_cache
+
+ self.embedding_dim = embedding_dim
+ self.vlm_config = {
+ "model_type": "paligemma",
+ "text_config": self.text_config,
+ "vision_config": self.vision_config,
+ "ignore_index": self.ignore_index,
+ "image_token_index": self.image_token_index,
+ "projector_hidden_act": self.projector_hidden_act,
+ "projection_dim": self.projection_dim,
+ "vision_feature_select_strategy": self.vision_feature_select_strategy,
+ "vision_feature_layer": self.vision_feature_layer,
+ }
+
+ def get_config(self):
+ return ColPaliConfig(
+ vlm_config=self.vlm_config,
+ embedding_dim=self.embedding_dim,
+ )
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor(
+ [
+ self.batch_size,
+ self.vision_config["num_channels"],
+ self.vision_config["image_size"],
+ self.vision_config["image_size"],
+ ]
+ )
+ config = self.get_config()
+
+ return config, pixel_values
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ input_ids = ids_tensor([self.batch_size, self.seq_length], config.vlm_config.text_config.vocab_size - 1) + 1
+ attention_mask = input_ids.ne(1).to(torch_device)
+ # set the 16 first tokens to be image, and ensure that no other tokens are image tokens
+ # do not change this unless you modified image size or patch size
+ input_ids[input_ids == config.vlm_config.image_token_index] = self.pad_token_id
+ input_ids[:, :16] = config.vlm_config.image_token_index
+ inputs_dict = {
+ "pixel_values": pixel_values,
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "labels": input_ids,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class ColPaliForRetrievalModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Model tester for `ColPaliForRetrieval`.
+ """
+
+ all_model_classes = (ColPaliForRetrieval,) if is_torch_available() else ()
+ fx_compatible = False
+ test_torchscript = False
+ test_pruning = False
+ test_resize_embeddings = True
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = ColPaliForRetrievalModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=ColPaliConfig, has_text_modality=False)
+
+ @slow
+ @require_vision
+ def test_colpali_forward_inputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ with torch.no_grad():
+ outputs = model(**inputs, return_dict=True)
+
+ self.assertIsInstance(outputs, ColPaliForRetrievalOutput)
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @unittest.skip(
+ reason="From PaliGemma: Some undefined behavior encountered with test versions of this model. Skip for now."
+ )
+ def test_model_parallelism(self):
+ pass
+
+ @unittest.skip(
+ reason="PaliGemma's SigLip encoder uses the same initialization scheme as the Flax original implementation"
+ )
+ def test_initialization(self):
+ pass
+
+ # TODO extend valid outputs to include this test @Molbap
+ @unittest.skip(reason="PaliGemma has currently one output format.")
+ def test_model_outputs_equivalence(self):
+ pass
+
+ @unittest.skip(reason="Pass because ColPali requires `attention_mask is not None`")
+ def test_sdpa_can_dispatch_on_flash(self):
+ pass
+
+ @unittest.skip(reason="Pass because ColPali requires `attention_mask is not None`")
+ def test_sdpa_can_compile_dynamic(self):
+ pass
+
+
+@require_torch
+class ColPaliModelIntegrationTest(unittest.TestCase):
+ model_name: ClassVar[str] = "vidore/colpali-v1.2-hf"
+
+ def setUp(self):
+ self.processor = ColPaliProcessor.from_pretrained(self.model_name)
+
+ def tearDown(self):
+ gc.collect()
+ backend_empty_cache(torch_device)
+
+ @slow
+ def test_model_integration_test(self):
+ """
+ Test if the model is able to retrieve the correct pages for a small and easy dataset.
+ """
+ model = ColPaliForRetrieval.from_pretrained(
+ self.model_name,
+ torch_dtype=torch.bfloat16,
+ device_map=torch_device,
+ ).eval()
+
+ # Load the test dataset
+ ds = load_dataset("hf-internal-testing/document-visual-retrieval-test", split="test")
+
+ # Preprocess the examples
+ batch_images = self.processor(images=ds["image"]).to(torch_device)
+ batch_queries = self.processor(text=ds["query"]).to(torch_device)
+
+ # Run inference
+ with torch.inference_mode():
+ image_embeddings = model(**batch_images).embeddings
+ query_embeddings = model(**batch_queries).embeddings
+
+ # Compute retrieval scores
+ scores = self.processor.score_retrieval(
+ query_embeddings=query_embeddings,
+ passage_embeddings=image_embeddings,
+ ) # (num_queries, num_passages)
+
+ assert scores.ndim == 2, f"Expected 2D tensor, got {scores.ndim}"
+ assert scores.shape == (len(ds), len(ds)), f"Expected shape {(len(ds), len(ds))}, got {scores.shape}"
+
+ # Check if the maximum scores per row are in the diagonal of the matrix score
+ self.assertTrue((scores.argmax(axis=1) == torch.arange(len(ds), device=scores.device)).all())
+
+ # Further validation: fine-grained check, with a hardcoded score from the original implementation
+ expected_scores = torch.tensor(
+ [
+ [15.5625, 6.5938, 14.4375],
+ [12.2500, 16.2500, 11.0000],
+ [15.0625, 11.7500, 21.0000],
+ ],
+ dtype=scores.dtype,
+ )
+
+ assert torch.allclose(scores, expected_scores, atol=1), f"Expected scores {expected_scores}, got {scores}"
diff --git a/transformers/tests/models/colpali/test_processing_colpali.py b/transformers/tests/models/colpali/test_processing_colpali.py
new file mode 100644
index 0000000000000000000000000000000000000000..7a517861587a2546a581edecb106c51d29e05783
--- /dev/null
+++ b/transformers/tests/models/colpali/test_processing_colpali.py
@@ -0,0 +1,263 @@
+# Copyright 2024 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the ColPali processor."""
+
+import shutil
+import tempfile
+import unittest
+
+import torch
+
+from transformers import GemmaTokenizer
+from transformers.models.colpali.processing_colpali import ColPaliProcessor
+from transformers.testing_utils import get_tests_dir, require_torch, require_vision
+from transformers.utils import is_vision_available
+
+from ...test_processing_common import ProcessorTesterMixin
+
+
+if is_vision_available():
+ from transformers import (
+ ColPaliProcessor,
+ PaliGemmaProcessor,
+ SiglipImageProcessor,
+ )
+
+SAMPLE_VOCAB = get_tests_dir("fixtures/test_sentencepiece.model")
+
+
+@require_vision
+class ColPaliProcessorTest(ProcessorTesterMixin, unittest.TestCase):
+ processor_class = ColPaliProcessor
+
+ @classmethod
+ def setUpClass(cls):
+ cls.tmpdirname = tempfile.mkdtemp()
+ image_processor = SiglipImageProcessor.from_pretrained("google/siglip-so400m-patch14-384")
+ image_processor.image_seq_length = 0
+ tokenizer = GemmaTokenizer(SAMPLE_VOCAB, keep_accents=True)
+ processor = PaliGemmaProcessor(image_processor=image_processor, tokenizer=tokenizer)
+ processor.save_pretrained(cls.tmpdirname)
+
+ @classmethod
+ def tearDownClass(cls):
+ shutil.rmtree(cls.tmpdirname, ignore_errors=True)
+
+ @require_torch
+ @require_vision
+ def test_process_images(self):
+ # Processor configuration
+ image_input = self.prepare_image_inputs()
+ image_processor = self.get_component("image_processor")
+ tokenizer = self.get_component("tokenizer", max_length=112, padding="max_length")
+ image_processor.image_seq_length = 14
+
+ # Get the processor
+ processor = self.processor_class(
+ tokenizer=tokenizer,
+ image_processor=image_processor,
+ )
+
+ # Process the image
+ batch_feature = processor.process_images(images=image_input, return_tensors="pt")
+
+ # Assertions
+ self.assertIn("pixel_values", batch_feature)
+ self.assertEqual(batch_feature["pixel_values"].shape, torch.Size([1, 3, 384, 384]))
+
+ @require_torch
+ @require_vision
+ def test_process_queries(self):
+ # Inputs
+ queries = [
+ "Is attention really all you need?",
+ "Are Benjamin, Antoine, Merve, and Jo best friends?",
+ ]
+
+ # Processor configuration
+ image_processor = self.get_component("image_processor")
+ tokenizer = self.get_component("tokenizer", max_length=112, padding="max_length")
+ image_processor.image_seq_length = 14
+
+ # Get the processor
+ processor = self.processor_class(
+ tokenizer=tokenizer,
+ image_processor=image_processor,
+ )
+
+ # Process the image
+ batch_feature = processor.process_queries(text=queries, return_tensors="pt")
+
+ # Assertions
+ self.assertIn("input_ids", batch_feature)
+ self.assertIsInstance(batch_feature["input_ids"], torch.Tensor)
+ self.assertEqual(batch_feature["input_ids"].shape[0], len(queries))
+
+ # The following tests override the parent tests because ColPaliProcessor can only take one of images or text as input at a time.
+
+ def test_tokenizer_defaults_preserved_by_kwargs(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor_components["tokenizer"] = self.get_component("tokenizer", max_length=117, padding="max_length")
+
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+ input_str = self.prepare_text_inputs()
+ inputs = processor(text=input_str, return_tensors="pt")
+ self.assertEqual(inputs[self.text_input_name].shape[-1], 117)
+
+ def test_image_processor_defaults_preserved_by_image_kwargs(self):
+ """
+ We use do_rescale=True, rescale_factor=-1 to ensure that image_processor kwargs are preserved in the processor.
+ We then check that the mean of the pixel_values is less than or equal to 0 after processing.
+ Since the original pixel_values are in [0, 255], this is a good indicator that the rescale_factor is indeed applied.
+ """
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor_components["image_processor"] = self.get_component(
+ "image_processor", do_rescale=True, rescale_factor=-1
+ )
+ processor_components["tokenizer"] = self.get_component("tokenizer", max_length=117, padding="max_length")
+
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(images=image_input, return_tensors="pt")
+ self.assertLessEqual(inputs[self.images_input_name][0][0].mean(), 0)
+
+ def test_kwargs_overrides_default_tokenizer_kwargs(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor_components["tokenizer"] = self.get_component("tokenizer", padding="longest")
+
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+ input_str = self.prepare_text_inputs()
+ inputs = processor(text=input_str, return_tensors="pt", max_length=112, padding="max_length")
+ self.assertEqual(inputs[self.text_input_name].shape[-1], 112)
+
+ def test_kwargs_overrides_default_image_processor_kwargs(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor_components["image_processor"] = self.get_component(
+ "image_processor", do_rescale=True, rescale_factor=1
+ )
+ processor_components["tokenizer"] = self.get_component("tokenizer", max_length=117, padding="max_length")
+
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(images=image_input, do_rescale=True, rescale_factor=-1, return_tensors="pt")
+ self.assertLessEqual(inputs[self.images_input_name][0][0].mean(), 0)
+
+ def test_unstructured_kwargs(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ input_str = self.prepare_text_inputs()
+ inputs = processor(
+ text=input_str,
+ return_tensors="pt",
+ do_rescale=True,
+ rescale_factor=-1,
+ padding="max_length",
+ max_length=76,
+ )
+
+ self.assertEqual(inputs[self.text_input_name].shape[-1], 76)
+
+ def test_unstructured_kwargs_batched(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ image_input = self.prepare_image_inputs(batch_size=2)
+ inputs = processor(
+ images=image_input,
+ return_tensors="pt",
+ do_rescale=True,
+ rescale_factor=-1,
+ padding="longest",
+ max_length=76,
+ )
+
+ self.assertLessEqual(inputs[self.images_input_name][0][0].mean(), 0)
+
+ def test_doubly_passed_kwargs(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ image_input = self.prepare_image_inputs()
+ with self.assertRaises(ValueError):
+ _ = processor(
+ images=image_input,
+ images_kwargs={"do_rescale": True, "rescale_factor": -1},
+ do_rescale=True,
+ return_tensors="pt",
+ )
+
+ def test_structured_kwargs_nested(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ input_str = self.prepare_text_inputs()
+
+ # Define the kwargs for each modality
+ all_kwargs = {
+ "common_kwargs": {"return_tensors": "pt"},
+ "images_kwargs": {"do_rescale": True, "rescale_factor": -1},
+ "text_kwargs": {"padding": "max_length", "max_length": 76},
+ }
+
+ inputs = processor(text=input_str, **all_kwargs)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ self.assertEqual(inputs[self.text_input_name].shape[-1], 76)
+
+ def test_structured_kwargs_nested_from_dict(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+ image_input = self.prepare_image_inputs()
+
+ # Define the kwargs for each modality
+ all_kwargs = {
+ "common_kwargs": {"return_tensors": "pt"},
+ "images_kwargs": {"do_rescale": True, "rescale_factor": -1},
+ "text_kwargs": {"padding": "max_length", "max_length": 76},
+ }
+
+ inputs = processor(images=image_input, **all_kwargs)
+ self.assertEqual(inputs[self.text_input_name].shape[-1], 76)
diff --git a/transformers/tests/models/colqwen2/__init__.py b/transformers/tests/models/colqwen2/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/colqwen2/test_modeling_colqwen2.py b/transformers/tests/models/colqwen2/test_modeling_colqwen2.py
new file mode 100644
index 0000000000000000000000000000000000000000..53a37108da8352afbe5d7163f89f5c6112017552
--- /dev/null
+++ b/transformers/tests/models/colqwen2/test_modeling_colqwen2.py
@@ -0,0 +1,347 @@
+# coding=utf-8
+# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch ColQwen2 model."""
+
+import unittest
+from typing import ClassVar
+
+import torch
+from datasets import load_dataset
+
+from tests.test_configuration_common import ConfigTester
+from tests.test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from transformers import is_torch_available
+from transformers.models.colqwen2.configuration_colqwen2 import ColQwen2Config
+from transformers.models.colqwen2.modeling_colqwen2 import ColQwen2ForRetrieval, ColQwen2ForRetrievalOutput
+from transformers.models.colqwen2.processing_colqwen2 import ColQwen2Processor
+from transformers.testing_utils import (
+ Expectations,
+ cleanup,
+ require_bitsandbytes,
+ require_torch,
+ require_vision,
+ slow,
+ torch_device,
+)
+
+
+if is_torch_available():
+ import torch
+
+
+class ColQwen2ForRetrievalModelTester:
+ def __init__(
+ self,
+ parent,
+ ignore_index=-100,
+ pad_token_id=2,
+ projector_hidden_act="gelu",
+ seq_length=11,
+ vision_feature_select_strategy="default",
+ vision_feature_layer=-1,
+ projection_dim=32,
+ is_training=False,
+ use_cache=False,
+ vlm_config={
+ "_name_or_path": "Qwen/Qwen2-VL-2B-Instruct",
+ "bos_token_id": 0,
+ "eos_token_id": 1,
+ "vision_start_token_id": 3,
+ "image_token_id": 4,
+ "video_token_id": 5,
+ "hidden_size": 64,
+ "intermediate_size": 2,
+ "max_window_layers": 2,
+ "model_type": "qwen2_vl",
+ "num_attention_heads": 2,
+ "num_hidden_layers": 2,
+ "num_key_value_heads": 2,
+ "rms_norm_eps": 1e-06,
+ "rope_scaling": {"mrope_section": [4, 6, 6], "rope_type": "default", "type": "default"},
+ "sliding_window": 32768,
+ "tie_word_embeddings": True,
+ "vision_config": {
+ "depth": 2,
+ "embed_dim": 32,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 64,
+ "mlp_ratio": 4,
+ "num_heads": 4,
+ "patch_size": 14,
+ "in_chans": 3,
+ "spatial_merge_size": 1,
+ "temporal_patch_size": 2,
+ },
+ "vision_end_token_id": 151653,
+ "vision_token_id": 151654,
+ "vocab_size": 99,
+ },
+ embedding_dim=32,
+ initializer_range=0.02,
+ ):
+ self.parent = parent
+ self.ignore_index = ignore_index
+ self.pad_token_id = pad_token_id
+
+ # `image_token_index` is set to 0 to pass "resize_embeddings" test, do not modify
+ self.image_token_index = 0
+
+ self.image_token_id = vlm_config["image_token_id"]
+ self.video_token_id = vlm_config["video_token_id"]
+ self.pad_token_id = vlm_config["eos_token_id"]
+ self.vision_start_token_id = vlm_config["vision_start_token_id"]
+ self.projector_hidden_act = projector_hidden_act
+ self.vision_feature_select_strategy = vision_feature_select_strategy
+ self.vision_feature_layer = vision_feature_layer
+
+ self.image_size = 56
+ self.num_image_tokens = 4
+
+ self.seq_length = seq_length + self.num_image_tokens
+ self.projection_dim = projection_dim
+
+ self.num_hidden_layers = vlm_config["num_hidden_layers"]
+ self.vocab_size = vlm_config["vocab_size"]
+ self.hidden_size = vlm_config["hidden_size"]
+ self.num_attention_heads = vlm_config["num_attention_heads"]
+ self.is_training = is_training
+
+ self.batch_size = 3
+ self.num_channels = vlm_config["vision_config"]["in_chans"]
+
+ self.encoder_seq_length = self.seq_length
+ self.use_cache = use_cache
+
+ self.vlm_config = vlm_config
+ self.embedding_dim = embedding_dim
+ self.initializer_range = initializer_range
+
+ def get_config(self):
+ return ColQwen2Config(
+ vlm_config=self.vlm_config,
+ embedding_dim=self.embedding_dim,
+ initializer_range=self.initializer_range,
+ )
+
+ def prepare_config_and_inputs(self):
+ config = self.get_config()
+ patch_size = config.vlm_config.vision_config.patch_size
+ temporal_patch_size = config.vlm_config.vision_config.temporal_patch_size
+
+ # NOTE: Assume all inputs are square images of the same size.
+ num_patches = (self.image_size // patch_size) ** 2
+ pixel_values = floats_tensor(
+ [
+ self.batch_size * num_patches,
+ self.num_channels * (patch_size**2) * temporal_patch_size,
+ ]
+ )
+
+ # Hardcoded image grid size: do not change unless you modified image size or patch size!
+ image_grid_thw = torch.tensor([1, 4, 4]).repeat(self.batch_size, 1)
+
+ # NOTE: The following adjustment ensures correct behavior with DDP on multiple GPUs.
+ # Line is copied from `src/transformers/models/colqwen2/processing_colqwen2.py`
+ offsets = image_grid_thw[:, 1] * image_grid_thw[:, 2] # (batch_size,)
+ pixel_values = list(
+ torch.split(pixel_values, offsets.tolist())
+ ) # [(num_patches_image_0, pixel_values), ..., (num_patches_image_n, pixel_values)]
+ pixel_values = torch.nn.utils.rnn.pad_sequence(
+ pixel_values, batch_first=True
+ ) # (batch_size, max_num_patches, pixel_values)
+
+ return config, pixel_values, image_grid_thw
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, image_grid_thw = config_and_inputs
+ input_ids = (
+ ids_tensor(
+ shape=[self.batch_size, self.seq_length],
+ vocab_size=config.vlm_config.vocab_size - 1,
+ )
+ + 1
+ )
+ attention_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
+
+ input_ids[:, -1] = self.pad_token_id
+ input_ids[:, : self.num_image_tokens] = self.image_token_id
+ input_ids[input_ids == self.video_token_id] = self.pad_token_id
+ input_ids[input_ids == self.image_token_id] = self.pad_token_id
+ input_ids[input_ids == self.vision_start_token_id] = self.pad_token_id
+
+ inputs_dict = {
+ "input_ids": input_ids,
+ "pixel_values": pixel_values,
+ "image_grid_thw": image_grid_thw,
+ "attention_mask": attention_mask,
+ "labels": input_ids,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class ColQwen2ForRetrievalModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Model tester for `ColQwen2ForRetrieval`.
+ """
+
+ all_model_classes = (ColQwen2ForRetrieval,) if is_torch_available() else ()
+ fx_compatible = False
+ test_torchscript = False
+ test_pruning = False
+ test_resize_embeddings = True
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = ColQwen2ForRetrievalModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=ColQwen2Config, has_text_modality=False)
+
+ def test_inputs_embeds(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ input_ids = inputs["input_ids"]
+ del inputs["input_ids"]
+ del inputs["pixel_values"]
+
+ wte = model.get_input_embeddings()
+ inputs["inputs_embeds"] = wte(input_ids)
+
+ with torch.no_grad():
+ model(**inputs)
+
+ # overwrite inputs_embeds tests because we need to delete "pixel values" for LVLMs
+ # while some other models require pixel_values to be present
+ def test_inputs_embeds_matches_input_ids(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ inputs = self._prepare_for_class(inputs_dict, model_class)
+ input_ids = inputs["input_ids"]
+ del inputs["input_ids"]
+ del inputs["pixel_values"]
+
+ inputs_embeds = model.get_input_embeddings()(input_ids)
+
+ with torch.no_grad():
+ out_ids = model(input_ids=input_ids, **inputs)[0]
+ out_embeds = model(inputs_embeds=inputs_embeds, **inputs)[0]
+ self.assertTrue(torch.allclose(out_embeds, out_ids))
+
+ @slow
+ @require_vision
+ def test_colqwen2_forward_inputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ with torch.no_grad():
+ outputs = model(**inputs, return_dict=True)
+
+ self.assertIsInstance(outputs, ColQwen2ForRetrievalOutput)
+
+ @unittest.skip(reason="Some undefined behavior encountered with test versions of Qwen2-VL. Skip for now.")
+ def test_model_parallelism(self):
+ pass
+
+ @unittest.skip(reason="Pass because ColQwen2 requires `attention_mask is not None`")
+ def test_sdpa_can_dispatch_on_flash(self):
+ pass
+
+ @unittest.skip(reason="Pass because ColQwen2 requires `attention_mask is not None`")
+ def test_sdpa_can_compile_dynamic(self):
+ pass
+
+
+@require_torch
+class ColQwen2ModelIntegrationTest(unittest.TestCase):
+ model_name: ClassVar[str] = "vidore/colqwen2-v1.0-hf"
+
+ def setUp(self):
+ self.processor = ColQwen2Processor.from_pretrained(self.model_name)
+
+ def tearDown(self):
+ cleanup(torch_device, gc_collect=True)
+
+ @require_bitsandbytes
+ @slow
+ def test_model_integration_test(self):
+ """
+ Test if the model is able to retrieve the correct pages for a small and easy dataset.
+ """
+ model = ColQwen2ForRetrieval.from_pretrained(
+ self.model_name,
+ torch_dtype=torch.float16,
+ load_in_8bit=True,
+ ).eval()
+
+ # Load the test dataset
+ ds = load_dataset("hf-internal-testing/document-visual-retrieval-test", split="test")
+
+ # Preprocess the examples
+ batch_images = self.processor(images=ds["image"]).to(torch_device)
+ batch_queries = self.processor(text=ds["query"]).to(torch_device)
+
+ # Run inference
+ with torch.inference_mode():
+ image_embeddings = model(**batch_images).embeddings
+ query_embeddings = model(**batch_queries).embeddings
+
+ # Compute retrieval scores
+ scores = self.processor.score_retrieval(
+ query_embeddings=query_embeddings,
+ passage_embeddings=image_embeddings,
+ ) # (num_queries, num_passages)
+
+ assert scores.ndim == 2, f"Expected 2D tensor, got {scores.ndim}"
+ assert scores.shape == (len(ds), len(ds)), f"Expected shape {(len(ds), len(ds))}, got {scores.shape}"
+
+ # Check if the maximum scores per row are in the diagonal of the matrix score
+ self.assertTrue((scores.argmax(axis=1) == torch.arange(len(ds), device=scores.device)).all())
+
+ # Further validation: fine-grained check, with a hardcoded score from the original Hf implementation.
+ expectations = Expectations(
+ {
+ ("cuda", 7): [
+ [15.0938, 8.3203, 15.0391],
+ [9.6328, 16.9062, 10.5312],
+ [15.6562, 12.2656, 20.2969],
+ ],
+ ("cuda", 8): [
+ [15.0703, 8.7422, 15.0312],
+ [9.5078, 16.8906, 10.6250],
+ [15.6484, 12.3984, 20.4688],
+ ],
+ }
+ )
+ expected_scores = torch.tensor(expectations.get_expectation(), dtype=scores.dtype)
+
+ assert torch.allclose(scores, expected_scores, atol=1e-3), f"Expected scores {expected_scores}, got {scores}"
diff --git a/transformers/tests/models/colqwen2/test_processing_colqwen2.py b/transformers/tests/models/colqwen2/test_processing_colqwen2.py
new file mode 100644
index 0000000000000000000000000000000000000000..0da0ce86b42dddcf2a23b17c1738c20a45bbb70a
--- /dev/null
+++ b/transformers/tests/models/colqwen2/test_processing_colqwen2.py
@@ -0,0 +1,262 @@
+# coding=utf-8
+# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the ColQwen2 processor."""
+
+import shutil
+import tempfile
+import unittest
+
+import torch
+
+from transformers import AutoProcessor, Qwen2VLProcessor
+from transformers.models.colqwen2.processing_colqwen2 import ColQwen2Processor
+from transformers.testing_utils import get_tests_dir, require_torch, require_vision
+from transformers.utils import is_vision_available
+
+from ...test_processing_common import ProcessorTesterMixin
+
+
+if is_vision_available():
+ from transformers import (
+ ColQwen2Processor,
+ )
+
+SAMPLE_VOCAB = get_tests_dir("fixtures/test_sentencepiece.model")
+
+
+@require_torch
+@require_vision
+class ColQwen2ProcessorTest(ProcessorTesterMixin, unittest.TestCase):
+ processor_class = ColQwen2Processor
+
+ @classmethod
+ def setUpClass(cls):
+ cls.tmpdirname = tempfile.mkdtemp()
+ processor = Qwen2VLProcessor.from_pretrained("Qwen/Qwen2-VL-2B-Instruct")
+ processor.save_pretrained(cls.tmpdirname)
+
+ def get_tokenizer(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).tokenizer
+
+ def get_image_processor(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).image_processor
+
+ @classmethod
+ def tearDownClass(cls):
+ shutil.rmtree(cls.tmpdirname)
+
+ def test_process_images(self):
+ # Processor configuration
+ image_input = self.prepare_image_inputs()
+ image_processor = self.get_component("image_processor")
+ tokenizer = self.get_component("tokenizer", max_length=112, padding="max_length")
+ image_processor.image_seq_length = 14
+
+ # Get the processor
+ processor = self.processor_class(
+ tokenizer=tokenizer,
+ image_processor=image_processor,
+ )
+
+ # Process the image
+ batch_feature = processor.process_images(images=image_input, return_tensors="pt")
+
+ # Assertions
+ self.assertIn("pixel_values", batch_feature)
+ self.assertEqual(batch_feature["pixel_values"].shape, torch.Size([1, 56, 1176]))
+
+ def test_process_queries(self):
+ # Inputs
+ queries = [
+ "Is attention really all you need?",
+ "Are Benjamin, Antoine, Merve, and Jo best friends?",
+ ]
+
+ # Processor configuration
+ image_processor = self.get_component("image_processor")
+ tokenizer = self.get_component("tokenizer", max_length=112, padding="max_length")
+ image_processor.image_seq_length = 14
+
+ # Get the processor
+ processor = self.processor_class(
+ tokenizer=tokenizer,
+ image_processor=image_processor,
+ )
+
+ # Process the image
+ batch_feature = processor.process_queries(text=queries, return_tensors="pt")
+
+ # Assertions
+ self.assertIn("input_ids", batch_feature)
+ self.assertIsInstance(batch_feature["input_ids"], torch.Tensor)
+ self.assertEqual(batch_feature["input_ids"].shape[0], len(queries))
+
+ # The following tests override the parent tests because ColQwen2Processor can only take one of images or text as input at a time.
+
+ def test_tokenizer_defaults_preserved_by_kwargs(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor_components["tokenizer"] = self.get_component("tokenizer", max_length=117, padding="max_length")
+
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+ input_str = self.prepare_text_inputs()
+ inputs = processor(text=input_str, return_tensors="pt")
+ self.assertEqual(inputs[self.text_input_name].shape[-1], 117)
+
+ def test_image_processor_defaults_preserved_by_image_kwargs(self):
+ """
+ We use do_rescale=True, rescale_factor=-1 to ensure that image_processor kwargs are preserved in the processor.
+ We then check that the mean of the pixel_values is less than or equal to 0 after processing.
+ Since the original pixel_values are in [0, 255], this is a good indicator that the rescale_factor is indeed applied.
+ """
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor_components["image_processor"] = self.get_component(
+ "image_processor", do_rescale=True, rescale_factor=-1
+ )
+ processor_components["tokenizer"] = self.get_component("tokenizer", max_length=117, padding="max_length")
+
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(images=image_input, return_tensors="pt")
+ self.assertLessEqual(inputs[self.images_input_name][0][0].mean(), 0)
+
+ def test_kwargs_overrides_default_tokenizer_kwargs(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor_components["tokenizer"] = self.get_component("tokenizer", padding="longest")
+
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+ input_str = self.prepare_text_inputs()
+ inputs = processor(text=input_str, return_tensors="pt", max_length=112, padding="max_length")
+ self.assertEqual(inputs[self.text_input_name].shape[-1], 112)
+
+ def test_kwargs_overrides_default_image_processor_kwargs(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor_components["image_processor"] = self.get_component(
+ "image_processor", do_rescale=True, rescale_factor=1
+ )
+ processor_components["tokenizer"] = self.get_component("tokenizer", max_length=117, padding="max_length")
+
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(images=image_input, do_rescale=True, rescale_factor=-1, return_tensors="pt")
+ self.assertLessEqual(inputs[self.images_input_name][0][0].mean(), 0)
+
+ def test_unstructured_kwargs(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ input_str = self.prepare_text_inputs()
+ inputs = processor(
+ text=input_str,
+ return_tensors="pt",
+ do_rescale=True,
+ rescale_factor=-1,
+ padding="max_length",
+ max_length=76,
+ )
+
+ self.assertEqual(inputs[self.text_input_name].shape[-1], 76)
+
+ def test_unstructured_kwargs_batched(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ image_input = self.prepare_image_inputs(batch_size=2)
+ inputs = processor(
+ images=image_input,
+ return_tensors="pt",
+ do_rescale=True,
+ rescale_factor=-1,
+ padding="longest",
+ max_length=76,
+ )
+
+ self.assertLessEqual(inputs[self.images_input_name][0][0].mean(), 0)
+
+ def test_doubly_passed_kwargs(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ image_input = self.prepare_image_inputs()
+ with self.assertRaises(ValueError):
+ _ = processor(
+ images=image_input,
+ images_kwargs={"do_rescale": True, "rescale_factor": -1},
+ do_rescale=True,
+ return_tensors="pt",
+ )
+
+ def test_structured_kwargs_nested(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ input_str = self.prepare_text_inputs()
+
+ # Define the kwargs for each modality
+ all_kwargs = {
+ "common_kwargs": {"return_tensors": "pt"},
+ "images_kwargs": {"do_rescale": True, "rescale_factor": -1},
+ "text_kwargs": {"padding": "max_length", "max_length": 76},
+ }
+
+ inputs = processor(text=input_str, **all_kwargs)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ self.assertEqual(inputs[self.text_input_name].shape[-1], 76)
+
+ def test_structured_kwargs_nested_from_dict(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ processor_components = self.prepare_components()
+ processor = self.processor_class(**processor_components)
+ self.skip_processor_without_typed_kwargs(processor)
+ image_input = self.prepare_image_inputs()
+
+ # Define the kwargs for each modality
+ all_kwargs = {
+ "common_kwargs": {"return_tensors": "pt"},
+ "images_kwargs": {"do_rescale": True, "rescale_factor": -1},
+ "text_kwargs": {"padding": "max_length", "max_length": 76},
+ }
+
+ inputs = processor(images=image_input, **all_kwargs)
+ self.assertEqual(inputs[self.text_input_name].shape[-1], 76)
diff --git a/transformers/tests/models/conditional_detr/__init__.py b/transformers/tests/models/conditional_detr/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/conditional_detr/test_image_processing_conditional_detr.py b/transformers/tests/models/conditional_detr/test_image_processing_conditional_detr.py
new file mode 100644
index 0000000000000000000000000000000000000000..4b02a1257844904f08c41f09d82918a7577d5a49
--- /dev/null
+++ b/transformers/tests/models/conditional_detr/test_image_processing_conditional_detr.py
@@ -0,0 +1,607 @@
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import pathlib
+import unittest
+
+import numpy as np
+
+from transformers.testing_utils import require_torch, require_vision, slow
+from transformers.utils import is_torch_available, is_torchvision_available, is_vision_available
+
+from ...test_image_processing_common import AnnotationFormatTestMixin, ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import ConditionalDetrImageProcessor
+
+ if is_torchvision_available():
+ from transformers import ConditionalDetrImageProcessorFast
+
+
+class ConditionalDetrImageProcessingTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_pad=True,
+ ):
+ # by setting size["longest_edge"] > max_resolution we're effectively not testing this :p
+ size = size if size is not None else {"shortest_edge": 18, "longest_edge": 1333}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
+
+ def prepare_image_processor_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
+ "do_pad": self.do_pad,
+ }
+
+ def get_expected_values(self, image_inputs, batched=False):
+ """
+ This function computes the expected height and width when providing images to ConditionalDetrImageProcessor,
+ assuming do_resize is set to True with a scalar size.
+ """
+ if not batched:
+ image = image_inputs[0]
+ if isinstance(image, Image.Image):
+ w, h = image.size
+ elif isinstance(image, np.ndarray):
+ h, w = image.shape[0], image.shape[1]
+ else:
+ h, w = image.shape[1], image.shape[2]
+ if w < h:
+ expected_height = int(self.size["shortest_edge"] * h / w)
+ expected_width = self.size["shortest_edge"]
+ elif w > h:
+ expected_height = self.size["shortest_edge"]
+ expected_width = int(self.size["shortest_edge"] * w / h)
+ else:
+ expected_height = self.size["shortest_edge"]
+ expected_width = self.size["shortest_edge"]
+
+ else:
+ expected_values = []
+ for image in image_inputs:
+ expected_height, expected_width = self.get_expected_values([image])
+ expected_values.append((expected_height, expected_width))
+ expected_height = max(expected_values, key=lambda item: item[0])[0]
+ expected_width = max(expected_values, key=lambda item: item[1])[1]
+
+ return expected_height, expected_width
+
+ def expected_output_image_shape(self, images):
+ height, width = self.get_expected_values(images, batched=True)
+ return self.num_channels, height, width
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class ConditionalDetrImageProcessingTest(AnnotationFormatTestMixin, ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = ConditionalDetrImageProcessor if is_vision_available() else None
+ fast_image_processing_class = ConditionalDetrImageProcessorFast if is_torchvision_available() else None
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = ConditionalDetrImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+
+ def test_image_processor_from_dict_with_kwargs(self):
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"shortest_edge": 18, "longest_edge": 1333})
+ self.assertEqual(image_processor.do_pad, True)
+
+ image_processor = image_processing_class.from_dict(
+ self.image_processor_dict, size=42, max_size=84, pad_and_return_pixel_mask=False
+ )
+ self.assertEqual(image_processor.size, {"shortest_edge": 42, "longest_edge": 84})
+ self.assertEqual(image_processor.do_pad, False)
+
+ @slow
+ def test_call_pytorch_with_coco_detection_annotations(self):
+ # prepare image and target
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ target = {"image_id": 39769, "annotations": target}
+
+ for image_processing_class in self.image_processor_list:
+ # encode them
+ image_processing = image_processing_class.from_pretrained("microsoft/conditional-detr-resnet-50")
+ encoding = image_processing(images=image, annotations=target, return_tensors="pt")
+
+ # verify pixel values
+ expected_shape = torch.Size([1, 3, 800, 1066])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ expected_slice = torch.tensor([0.2796, 0.3138, 0.3481])
+ torch.testing.assert_close(encoding["pixel_values"][0, 0, 0, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ # verify area
+ expected_area = torch.tensor([5887.9600, 11250.2061, 489353.8438, 837122.7500, 147967.5156, 165732.3438])
+ torch.testing.assert_close(encoding["labels"][0]["area"], expected_area)
+ # verify boxes
+ expected_boxes_shape = torch.Size([6, 4])
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, expected_boxes_shape)
+ expected_boxes_slice = torch.tensor([0.5503, 0.2765, 0.0604, 0.2215])
+ torch.testing.assert_close(encoding["labels"][0]["boxes"][0], expected_boxes_slice, rtol=1e-3, atol=1e-3)
+ # verify image_id
+ expected_image_id = torch.tensor([39769])
+ torch.testing.assert_close(encoding["labels"][0]["image_id"], expected_image_id)
+ # verify is_crowd
+ expected_is_crowd = torch.tensor([0, 0, 0, 0, 0, 0])
+ torch.testing.assert_close(encoding["labels"][0]["iscrowd"], expected_is_crowd)
+ # verify class_labels
+ expected_class_labels = torch.tensor([75, 75, 63, 65, 17, 17])
+ torch.testing.assert_close(encoding["labels"][0]["class_labels"], expected_class_labels)
+ # verify orig_size
+ expected_orig_size = torch.tensor([480, 640])
+ torch.testing.assert_close(encoding["labels"][0]["orig_size"], expected_orig_size)
+ # verify size
+ expected_size = torch.tensor([800, 1066])
+ torch.testing.assert_close(encoding["labels"][0]["size"], expected_size)
+
+ @slow
+ def test_call_pytorch_with_coco_panoptic_annotations(self):
+ # prepare image, target and masks_path
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ target = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+
+ masks_path = pathlib.Path("./tests/fixtures/tests_samples/COCO/coco_panoptic")
+
+ for image_processing_class in self.image_processor_list:
+ # encode them
+ image_processing = image_processing_class(format="coco_panoptic")
+ encoding = image_processing(images=image, annotations=target, masks_path=masks_path, return_tensors="pt")
+
+ # verify pixel values
+ expected_shape = torch.Size([1, 3, 800, 1066])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ expected_slice = torch.tensor([0.2796, 0.3138, 0.3481])
+ torch.testing.assert_close(encoding["pixel_values"][0, 0, 0, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ # verify area
+ expected_area = torch.tensor([147979.6875, 165527.0469, 484638.5938, 11292.9375, 5879.6562, 7634.1147])
+ torch.testing.assert_close(encoding["labels"][0]["area"], expected_area)
+ # verify boxes
+ expected_boxes_shape = torch.Size([6, 4])
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, expected_boxes_shape)
+ expected_boxes_slice = torch.tensor([0.2625, 0.5437, 0.4688, 0.8625])
+ torch.testing.assert_close(encoding["labels"][0]["boxes"][0], expected_boxes_slice, rtol=1e-3, atol=1e-3)
+ # verify image_id
+ expected_image_id = torch.tensor([39769])
+ torch.testing.assert_close(encoding["labels"][0]["image_id"], expected_image_id)
+ # verify is_crowd
+ expected_is_crowd = torch.tensor([0, 0, 0, 0, 0, 0])
+ torch.testing.assert_close(encoding["labels"][0]["iscrowd"], expected_is_crowd)
+ # verify class_labels
+ expected_class_labels = torch.tensor([17, 17, 63, 75, 75, 93])
+ torch.testing.assert_close(encoding["labels"][0]["class_labels"], expected_class_labels)
+ # verify masks
+ expected_masks_sum = 822873
+ relative_error = torch.abs(encoding["labels"][0]["masks"].sum() - expected_masks_sum) / expected_masks_sum
+ self.assertTrue(relative_error < 1e-3)
+ # verify orig_size
+ expected_orig_size = torch.tensor([480, 640])
+ torch.testing.assert_close(encoding["labels"][0]["orig_size"], expected_orig_size)
+ # verify size
+ expected_size = torch.tensor([800, 1066])
+ torch.testing.assert_close(encoding["labels"][0]["size"], expected_size)
+
+ @slow
+ # Copied from tests.models.detr.test_image_processing_detr.DetrImageProcessingTest.test_batched_coco_detection_annotations with Detr->ConditionalDetr, facebook/detr-resnet-50 ->microsoft/conditional-detr-resnet-50
+ def test_batched_coco_detection_annotations(self):
+ image_0 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ image_1 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png").resize((800, 800))
+
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ annotations_0 = {"image_id": 39769, "annotations": target}
+ annotations_1 = {"image_id": 39769, "annotations": target}
+
+ # Adjust the bounding boxes for the resized image
+ w_0, h_0 = image_0.size
+ w_1, h_1 = image_1.size
+ for i in range(len(annotations_1["annotations"])):
+ coords = annotations_1["annotations"][i]["bbox"]
+ new_bbox = [
+ coords[0] * w_1 / w_0,
+ coords[1] * h_1 / h_0,
+ coords[2] * w_1 / w_0,
+ coords[3] * h_1 / h_0,
+ ]
+ annotations_1["annotations"][i]["bbox"] = new_bbox
+
+ images = [image_0, image_1]
+ annotations = [annotations_0, annotations_1]
+
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class()
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ return_segmentation_masks=True,
+ return_tensors="pt", # do_convert_annotations=True
+ )
+
+ # Check the pixel values have been padded
+ postprocessed_height, postprocessed_width = 800, 1066
+ expected_shape = torch.Size([2, 3, postprocessed_height, postprocessed_width])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ # Check the bounding boxes have been adjusted for padded images
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ expected_boxes_0 = torch.tensor(
+ [
+ [0.6879, 0.4609, 0.0755, 0.3691],
+ [0.2118, 0.3359, 0.2601, 0.1566],
+ [0.5011, 0.5000, 0.9979, 1.0000],
+ [0.5010, 0.5020, 0.9979, 0.9959],
+ [0.3284, 0.5944, 0.5884, 0.8112],
+ [0.8394, 0.5445, 0.3213, 0.9110],
+ ]
+ )
+ expected_boxes_1 = torch.tensor(
+ [
+ [0.4130, 0.2765, 0.0453, 0.2215],
+ [0.1272, 0.2016, 0.1561, 0.0940],
+ [0.3757, 0.4933, 0.7488, 0.9865],
+ [0.3759, 0.5002, 0.7492, 0.9955],
+ [0.1971, 0.5456, 0.3532, 0.8646],
+ [0.5790, 0.4115, 0.3430, 0.7161],
+ ]
+ )
+ torch.testing.assert_close(encoding["labels"][0]["boxes"], expected_boxes_0, atol=1e-3, rtol=1e-3)
+ torch.testing.assert_close(encoding["labels"][1]["boxes"], expected_boxes_1, atol=1e-3, rtol=1e-3)
+
+ # Check the masks have also been padded
+ self.assertEqual(encoding["labels"][0]["masks"].shape, torch.Size([6, 800, 1066]))
+ self.assertEqual(encoding["labels"][1]["masks"].shape, torch.Size([6, 800, 1066]))
+
+ # Check if do_convert_annotations=False, then the annotations are not converted to centre_x, centre_y, width, height
+ # format and not in the range [0, 1]
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ return_segmentation_masks=True,
+ do_convert_annotations=False,
+ return_tensors="pt",
+ )
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ # Convert to absolute coordinates
+ unnormalized_boxes_0 = torch.vstack(
+ [
+ expected_boxes_0[:, 0] * postprocessed_width,
+ expected_boxes_0[:, 1] * postprocessed_height,
+ expected_boxes_0[:, 2] * postprocessed_width,
+ expected_boxes_0[:, 3] * postprocessed_height,
+ ]
+ ).T
+ unnormalized_boxes_1 = torch.vstack(
+ [
+ expected_boxes_1[:, 0] * postprocessed_width,
+ expected_boxes_1[:, 1] * postprocessed_height,
+ expected_boxes_1[:, 2] * postprocessed_width,
+ expected_boxes_1[:, 3] * postprocessed_height,
+ ]
+ ).T
+ # Convert from centre_x, centre_y, width, height to x_min, y_min, x_max, y_max
+ expected_boxes_0 = torch.vstack(
+ [
+ unnormalized_boxes_0[:, 0] - unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] - unnormalized_boxes_0[:, 3] / 2,
+ unnormalized_boxes_0[:, 0] + unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] + unnormalized_boxes_0[:, 3] / 2,
+ ]
+ ).T
+ expected_boxes_1 = torch.vstack(
+ [
+ unnormalized_boxes_1[:, 0] - unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] - unnormalized_boxes_1[:, 3] / 2,
+ unnormalized_boxes_1[:, 0] + unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] + unnormalized_boxes_1[:, 3] / 2,
+ ]
+ ).T
+ torch.testing.assert_close(encoding["labels"][0]["boxes"], expected_boxes_0, atol=1, rtol=1)
+ torch.testing.assert_close(encoding["labels"][1]["boxes"], expected_boxes_1, atol=1, rtol=1)
+
+ # Copied from tests.models.detr.test_image_processing_detr.DetrImageProcessingTest.test_batched_coco_panoptic_annotations with Detr->ConditionalDetr
+ def test_batched_coco_panoptic_annotations(self):
+ # prepare image, target and masks_path
+ image_0 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ image_1 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png").resize((800, 800))
+
+ with open("./tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ annotation_0 = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+ annotation_1 = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+
+ w_0, h_0 = image_0.size
+ w_1, h_1 = image_1.size
+ for i in range(len(annotation_1["segments_info"])):
+ coords = annotation_1["segments_info"][i]["bbox"]
+ new_bbox = [
+ coords[0] * w_1 / w_0,
+ coords[1] * h_1 / h_0,
+ coords[2] * w_1 / w_0,
+ coords[3] * h_1 / h_0,
+ ]
+ annotation_1["segments_info"][i]["bbox"] = new_bbox
+
+ masks_path = pathlib.Path("./tests/fixtures/tests_samples/COCO/coco_panoptic")
+
+ images = [image_0, image_1]
+ annotations = [annotation_0, annotation_1]
+
+ for image_processing_class in self.image_processor_list:
+ # encode them
+ image_processing = image_processing_class(format="coco_panoptic")
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ masks_path=masks_path,
+ return_tensors="pt",
+ return_segmentation_masks=True,
+ )
+
+ # Check the pixel values have been padded
+ postprocessed_height, postprocessed_width = 800, 1066
+ expected_shape = torch.Size([2, 3, postprocessed_height, postprocessed_width])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ # Check the bounding boxes have been adjusted for padded images
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ expected_boxes_0 = torch.tensor(
+ [
+ [0.2625, 0.5437, 0.4688, 0.8625],
+ [0.7719, 0.4104, 0.4531, 0.7125],
+ [0.5000, 0.4927, 0.9969, 0.9854],
+ [0.1688, 0.2000, 0.2063, 0.0917],
+ [0.5492, 0.2760, 0.0578, 0.2187],
+ [0.4992, 0.4990, 0.9984, 0.9979],
+ ]
+ )
+ expected_boxes_1 = torch.tensor(
+ [
+ [0.1576, 0.3262, 0.2814, 0.5175],
+ [0.4634, 0.2463, 0.2720, 0.4275],
+ [0.3002, 0.2956, 0.5985, 0.5913],
+ [0.1013, 0.1200, 0.1238, 0.0550],
+ [0.3297, 0.1656, 0.0347, 0.1312],
+ [0.2997, 0.2994, 0.5994, 0.5987],
+ ]
+ )
+ torch.testing.assert_close(encoding["labels"][0]["boxes"], expected_boxes_0, atol=1e-3, rtol=1e-3)
+ torch.testing.assert_close(encoding["labels"][1]["boxes"], expected_boxes_1, atol=1e-3, rtol=1e-3)
+
+ # Check the masks have also been padded
+ self.assertEqual(encoding["labels"][0]["masks"].shape, torch.Size([6, 800, 1066]))
+ self.assertEqual(encoding["labels"][1]["masks"].shape, torch.Size([6, 800, 1066]))
+
+ # Check if do_convert_annotations=False, then the annotations are not converted to centre_x, centre_y, width, height
+ # format and not in the range [0, 1]
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ masks_path=masks_path,
+ return_segmentation_masks=True,
+ do_convert_annotations=False,
+ return_tensors="pt",
+ )
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ # Convert to absolute coordinates
+ unnormalized_boxes_0 = torch.vstack(
+ [
+ expected_boxes_0[:, 0] * postprocessed_width,
+ expected_boxes_0[:, 1] * postprocessed_height,
+ expected_boxes_0[:, 2] * postprocessed_width,
+ expected_boxes_0[:, 3] * postprocessed_height,
+ ]
+ ).T
+ unnormalized_boxes_1 = torch.vstack(
+ [
+ expected_boxes_1[:, 0] * postprocessed_width,
+ expected_boxes_1[:, 1] * postprocessed_height,
+ expected_boxes_1[:, 2] * postprocessed_width,
+ expected_boxes_1[:, 3] * postprocessed_height,
+ ]
+ ).T
+ # Convert from centre_x, centre_y, width, height to x_min, y_min, x_max, y_max
+ expected_boxes_0 = torch.vstack(
+ [
+ unnormalized_boxes_0[:, 0] - unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] - unnormalized_boxes_0[:, 3] / 2,
+ unnormalized_boxes_0[:, 0] + unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] + unnormalized_boxes_0[:, 3] / 2,
+ ]
+ ).T
+ expected_boxes_1 = torch.vstack(
+ [
+ unnormalized_boxes_1[:, 0] - unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] - unnormalized_boxes_1[:, 3] / 2,
+ unnormalized_boxes_1[:, 0] + unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] + unnormalized_boxes_1[:, 3] / 2,
+ ]
+ ).T
+ torch.testing.assert_close(encoding["labels"][0]["boxes"], expected_boxes_0, atol=1, rtol=1)
+ torch.testing.assert_close(encoding["labels"][1]["boxes"], expected_boxes_1, atol=1, rtol=1)
+
+ # Copied from tests.models.detr.test_image_processing_detr.DetrImageProcessingTest.test_max_width_max_height_resizing_and_pad_strategy with Detr->ConditionalDetr
+ def test_max_width_max_height_resizing_and_pad_strategy(self):
+ for image_processing_class in self.image_processor_list:
+ image_1 = torch.ones([200, 100, 3], dtype=torch.uint8)
+
+ # do_pad=False, max_height=100, max_width=100, image=200x100 -> 100x50
+ image_processor = image_processing_class(
+ size={"max_height": 100, "max_width": 100},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 100, 50]))
+
+ # do_pad=False, max_height=300, max_width=100, image=200x100 -> 200x100
+ image_processor = image_processing_class(
+ size={"max_height": 300, "max_width": 100},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+
+ # do_pad=True, max_height=100, max_width=100, image=200x100 -> 100x100
+ image_processor = image_processing_class(
+ size={"max_height": 100, "max_width": 100}, do_pad=True, pad_size={"height": 100, "width": 100}
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 100, 100]))
+
+ # do_pad=True, max_height=300, max_width=100, image=200x100 -> 300x100
+ image_processor = image_processing_class(
+ size={"max_height": 300, "max_width": 100},
+ do_pad=True,
+ pad_size={"height": 301, "width": 101},
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 301, 101]))
+
+ ### Check for batch
+ image_2 = torch.ones([100, 150, 3], dtype=torch.uint8)
+
+ # do_pad=True, max_height=150, max_width=100, images=[200x100, 100x150] -> 150x100
+ image_processor = image_processing_class(
+ size={"max_height": 150, "max_width": 100},
+ do_pad=True,
+ pad_size={"height": 150, "width": 100},
+ )
+ inputs = image_processor(images=[image_1, image_2], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([2, 3, 150, 100]))
+
+ def test_longest_edge_shortest_edge_resizing_strategy(self):
+ image_1 = torch.ones([958, 653, 3], dtype=torch.uint8)
+
+ # max size is set; width < height;
+ # do_pad=False, longest_edge=640, shortest_edge=640, image=958x653 -> 640x436
+ image_processor = ConditionalDetrImageProcessor(
+ size={"longest_edge": 640, "shortest_edge": 640},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 640, 436]))
+
+ image_2 = torch.ones([653, 958, 3], dtype=torch.uint8)
+ # max size is set; height < width;
+ # do_pad=False, longest_edge=640, shortest_edge=640, image=653x958 -> 436x640
+ image_processor = ConditionalDetrImageProcessor(
+ size={"longest_edge": 640, "shortest_edge": 640},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_2], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 436, 640]))
+
+ image_3 = torch.ones([100, 120, 3], dtype=torch.uint8)
+ # max size is set; width == size; height > max_size;
+ # do_pad=False, longest_edge=118, shortest_edge=100, image=120x100 -> 118x98
+ image_processor = ConditionalDetrImageProcessor(
+ size={"longest_edge": 118, "shortest_edge": 100},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_3], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 98, 118]))
+
+ image_4 = torch.ones([128, 50, 3], dtype=torch.uint8)
+ # max size is set; height == size; width < max_size;
+ # do_pad=False, longest_edge=256, shortest_edge=50, image=50x128 -> 50x128
+ image_processor = ConditionalDetrImageProcessor(
+ size={"longest_edge": 256, "shortest_edge": 50},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_4], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 128, 50]))
+
+ image_5 = torch.ones([50, 50, 3], dtype=torch.uint8)
+ # max size is set; height == width; width < max_size;
+ # do_pad=False, longest_edge=117, shortest_edge=50, image=50x50 -> 50x50
+ image_processor = ConditionalDetrImageProcessor(
+ size={"longest_edge": 117, "shortest_edge": 50},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_5], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 50, 50]))
diff --git a/transformers/tests/models/conditional_detr/test_modeling_conditional_detr.py b/transformers/tests/models/conditional_detr/test_modeling_conditional_detr.py
new file mode 100644
index 0000000000000000000000000000000000000000..813d2bd79673e96480fa2e21606435d51ac7508e
--- /dev/null
+++ b/transformers/tests/models/conditional_detr/test_modeling_conditional_detr.py
@@ -0,0 +1,630 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Conditional DETR model."""
+
+import inspect
+import math
+import unittest
+
+from transformers import ConditionalDetrConfig, ResNetConfig, is_torch_available, is_vision_available
+from transformers.testing_utils import require_timm, require_torch, require_vision, slow, torch_device
+from transformers.utils import cached_property
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ ConditionalDetrForObjectDetection,
+ ConditionalDetrForSegmentation,
+ ConditionalDetrModel,
+ )
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import ConditionalDetrImageProcessor
+
+
+class ConditionalDetrModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=8,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=8,
+ intermediate_size=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ num_queries=12,
+ num_channels=3,
+ min_size=200,
+ max_size=200,
+ n_targets=8,
+ num_labels=91,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.num_queries = num_queries
+ self.num_channels = num_channels
+ self.min_size = min_size
+ self.max_size = max_size
+ self.n_targets = n_targets
+ self.num_labels = num_labels
+
+ # we also set the expected seq length for both encoder and decoder
+ self.encoder_seq_length = math.ceil(self.min_size / 32) * math.ceil(self.max_size / 32)
+ self.decoder_seq_length = self.num_queries
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.min_size, self.max_size])
+
+ pixel_mask = torch.ones([self.batch_size, self.min_size, self.max_size], device=torch_device)
+
+ labels = None
+ if self.use_labels:
+ # labels is a list of Dict (each Dict being the labels for a given example in the batch)
+ labels = []
+ for i in range(self.batch_size):
+ target = {}
+ target["class_labels"] = torch.randint(
+ high=self.num_labels, size=(self.n_targets,), device=torch_device
+ )
+ target["boxes"] = torch.rand(self.n_targets, 4, device=torch_device)
+ target["masks"] = torch.rand(self.n_targets, self.min_size, self.max_size, device=torch_device)
+ labels.append(target)
+
+ config = self.get_config()
+ return config, pixel_values, pixel_mask, labels
+
+ def get_config(self):
+ resnet_config = ResNetConfig(
+ num_channels=3,
+ embeddings_size=10,
+ hidden_sizes=[10, 20, 30, 40],
+ depths=[1, 1, 2, 1],
+ hidden_act="relu",
+ num_labels=3,
+ out_features=["stage2", "stage3", "stage4"],
+ out_indices=[2, 3, 4],
+ )
+ return ConditionalDetrConfig(
+ d_model=self.hidden_size,
+ encoder_layers=self.num_hidden_layers,
+ decoder_layers=self.num_hidden_layers,
+ encoder_attention_heads=self.num_attention_heads,
+ decoder_attention_heads=self.num_attention_heads,
+ encoder_ffn_dim=self.intermediate_size,
+ decoder_ffn_dim=self.intermediate_size,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ num_queries=self.num_queries,
+ num_labels=self.num_labels,
+ use_timm_backbone=False,
+ backbone_config=resnet_config,
+ backbone=None,
+ use_pretrained_backbone=False,
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config, pixel_values, pixel_mask, labels = self.prepare_config_and_inputs()
+ inputs_dict = {"pixel_values": pixel_values, "pixel_mask": pixel_mask}
+ return config, inputs_dict
+
+ def create_and_check_conditional_detr_model(self, config, pixel_values, pixel_mask, labels):
+ model = ConditionalDetrModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask)
+ result = model(pixel_values)
+
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.decoder_seq_length, self.hidden_size)
+ )
+
+ def create_and_check_conditional_detr_object_detection_head_model(self, config, pixel_values, pixel_mask, labels):
+ model = ConditionalDetrForObjectDetection(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask)
+ result = model(pixel_values)
+
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_queries, self.num_labels))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_queries, 4))
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask, labels=labels)
+
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_queries, self.num_labels))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_queries, 4))
+
+
+@require_torch
+class ConditionalDetrModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ ConditionalDetrModel,
+ ConditionalDetrForObjectDetection,
+ ConditionalDetrForSegmentation,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {"image-feature-extraction": ConditionalDetrModel, "object-detection": ConditionalDetrForObjectDetection}
+ if is_torch_available()
+ else {}
+ )
+ is_encoder_decoder = True
+ test_torchscript = False
+ test_pruning = False
+ test_head_masking = False
+ test_missing_keys = False
+ zero_init_hidden_state = True
+ test_torch_exportable = True
+
+ # special case for head models
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class.__name__ in ["ConditionalDetrForObjectDetection", "ConditionalDetrForSegmentation"]:
+ labels = []
+ for i in range(self.model_tester.batch_size):
+ target = {}
+ target["class_labels"] = torch.ones(
+ size=(self.model_tester.n_targets,), device=torch_device, dtype=torch.long
+ )
+ target["boxes"] = torch.ones(
+ self.model_tester.n_targets, 4, device=torch_device, dtype=torch.float
+ )
+ target["masks"] = torch.ones(
+ self.model_tester.n_targets,
+ self.model_tester.min_size,
+ self.model_tester.max_size,
+ device=torch_device,
+ dtype=torch.float,
+ )
+ labels.append(target)
+ inputs_dict["labels"] = labels
+
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = ConditionalDetrModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=ConditionalDetrConfig, has_text_modality=False)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_conditional_detr_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_conditional_detr_model(*config_and_inputs)
+
+ def test_conditional_detr_object_detection_head_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_conditional_detr_object_detection_head_model(*config_and_inputs)
+
+ # TODO: check if this works again for PyTorch 2.x.y
+ @unittest.skip(reason="Got `CUDA error: misaligned address` with PyTorch 2.0.0.")
+ def test_multi_gpu_data_parallel_forward(self):
+ pass
+
+ @unittest.skip(reason="Conditional DETR does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Conditional DETR does not use inputs_embeds")
+ def test_inputs_embeds_matches_input_ids(self):
+ pass
+
+ @unittest.skip(reason="Conditional DETR does not have a get_input_embeddings method")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @unittest.skip(reason="Conditional DETR is not a generative model")
+ def test_generate_without_input_ids(self):
+ pass
+
+ @unittest.skip(reason="Conditional DETR does not use token embeddings")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ @slow
+ @unittest.skip(reason="TODO Niels: fix me!")
+ def test_model_outputs_equivalence(self):
+ pass
+
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ decoder_seq_length = self.model_tester.decoder_seq_length
+ encoder_seq_length = self.model_tester.encoder_seq_length
+ decoder_key_length = self.model_tester.decoder_seq_length
+ encoder_key_length = self.model_tester.encoder_seq_length
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class._from_config(config, attn_implementation="eager")
+ config = model.config
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length],
+ )
+ out_len = len(outputs)
+
+ if self.is_encoder_decoder:
+ correct_outlen = 6
+
+ # loss is at first position
+ if "labels" in inputs_dict:
+ correct_outlen += 1 # loss is added to beginning
+ # Object Detection model returns pred_logits and pred_boxes
+ if model_class.__name__ == "ConditionalDetrForObjectDetection":
+ correct_outlen += 1
+ # Panoptic Segmentation model returns pred_logits, pred_boxes, pred_masks
+ if model_class.__name__ == "ConditionalDetrForSegmentation":
+ correct_outlen += 2
+ if "past_key_values" in outputs:
+ correct_outlen += 1 # past_key_values have been returned
+
+ self.assertEqual(out_len, correct_outlen)
+
+ # decoder attentions
+ decoder_attentions = outputs.decoder_attentions
+ self.assertIsInstance(decoder_attentions, (list, tuple))
+ self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(decoder_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, decoder_seq_length, decoder_key_length],
+ )
+
+ # cross attentions
+ cross_attentions = outputs.cross_attentions
+ self.assertIsInstance(cross_attentions, (list, tuple))
+ self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(cross_attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ decoder_seq_length,
+ encoder_key_length,
+ ],
+ )
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if hasattr(self.model_tester, "num_hidden_states_types"):
+ added_hidden_states = self.model_tester.num_hidden_states_types
+ elif self.is_encoder_decoder:
+ added_hidden_states = 2
+ else:
+ added_hidden_states = 1
+ self.assertEqual(out_len + added_hidden_states, len(outputs))
+
+ self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+
+ self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length],
+ )
+
+ def test_retain_grad_hidden_states_attentions(self):
+ # removed retain_grad and grad on decoder_hidden_states, as queries don't require grad
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.output_hidden_states = True
+ config.output_attentions = True
+
+ # no need to test all models as different heads yield the same functionality
+ model_class = self.all_model_classes[0]
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ outputs = model(**inputs)
+
+ output = outputs[0]
+
+ encoder_hidden_states = outputs.encoder_hidden_states[0]
+ encoder_attentions = outputs.encoder_attentions[0]
+ encoder_hidden_states.retain_grad()
+ encoder_attentions.retain_grad()
+
+ decoder_attentions = outputs.decoder_attentions[0]
+ decoder_attentions.retain_grad()
+
+ cross_attentions = outputs.cross_attentions[0]
+ cross_attentions.retain_grad()
+
+ output.flatten()[0].backward(retain_graph=True)
+
+ self.assertIsNotNone(encoder_hidden_states.grad)
+ self.assertIsNotNone(encoder_attentions.grad)
+ self.assertIsNotNone(decoder_attentions.grad)
+ self.assertIsNotNone(cross_attentions.grad)
+
+ def test_forward_auxiliary_loss(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.auxiliary_loss = True
+
+ # only test for object detection and segmentation model
+ for model_class in self.all_model_classes[1:]:
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+
+ outputs = model(**inputs)
+
+ self.assertIsNotNone(outputs.auxiliary_outputs)
+ self.assertEqual(len(outputs.auxiliary_outputs), self.model_tester.num_hidden_layers - 1)
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ if model.config.is_encoder_decoder:
+ expected_arg_names = ["pixel_values", "pixel_mask"]
+ expected_arg_names.extend(
+ ["head_mask", "decoder_head_mask", "encoder_outputs"]
+ if "head_mask" and "decoder_head_mask" in arg_names
+ else []
+ )
+ self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
+ else:
+ expected_arg_names = ["pixel_values", "pixel_mask"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_different_timm_backbone(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # let's pick a random timm backbone
+ config.backbone = "tf_mobilenetv3_small_075"
+ config.backbone_config = None
+ config.use_timm_backbone = True
+ config.backbone_kwargs = {"out_indices": [2, 3, 4]}
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if model_class.__name__ == "ConditionalDetrForObjectDetection":
+ expected_shape = (
+ self.model_tester.batch_size,
+ self.model_tester.num_queries,
+ self.model_tester.num_labels,
+ )
+ self.assertEqual(outputs.logits.shape, expected_shape)
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.model.backbone.conv_encoder.intermediate_channel_sizes), 3)
+ elif model_class.__name__ == "ConditionalDetrForSegmentation":
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.conditional_detr.model.backbone.conv_encoder.intermediate_channel_sizes), 3)
+ else:
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.backbone.conv_encoder.intermediate_channel_sizes), 3)
+
+ self.assertTrue(outputs)
+
+ @require_timm
+ def test_hf_backbone(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # Load a pretrained HF checkpoint as backbone
+ config.backbone = "microsoft/resnet-18"
+ config.backbone_config = None
+ config.use_timm_backbone = False
+ config.use_pretrained_backbone = True
+ config.backbone_kwargs = {"out_indices": [2, 3, 4]}
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if model_class.__name__ == "ConditionalDetrForObjectDetection":
+ expected_shape = (
+ self.model_tester.batch_size,
+ self.model_tester.num_queries,
+ self.model_tester.num_labels,
+ )
+ self.assertEqual(outputs.logits.shape, expected_shape)
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.model.backbone.conv_encoder.intermediate_channel_sizes), 3)
+ elif model_class.__name__ == "ConditionalDetrForSegmentation":
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.conditional_detr.model.backbone.conv_encoder.intermediate_channel_sizes), 3)
+ else:
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.backbone.conv_encoder.intermediate_channel_sizes), 3)
+
+ self.assertTrue(outputs)
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ configs_no_init.init_xavier_std = 1e9
+
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ if "bbox_attention" in name and "bias" not in name:
+ self.assertLess(
+ 100000,
+ abs(param.data.max().item()),
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ else:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+
+TOLERANCE = 1e-4
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_timm
+@require_vision
+@slow
+class ConditionalDetrModelIntegrationTests(unittest.TestCase):
+ @cached_property
+ def default_image_processor(self):
+ return (
+ ConditionalDetrImageProcessor.from_pretrained("microsoft/conditional-detr-resnet-50")
+ if is_vision_available()
+ else None
+ )
+
+ def test_inference_no_head(self):
+ model = ConditionalDetrModel.from_pretrained("microsoft/conditional-detr-resnet-50").to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ encoding = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ with torch.no_grad():
+ outputs = model(**encoding)
+
+ expected_shape = torch.Size((1, 300, 256))
+ self.assertEqual(outputs.last_hidden_state.shape, expected_shape)
+ expected_slice = torch.tensor(
+ [
+ [0.4223, 0.7474, 0.8760],
+ [0.6397, -0.2727, 0.7126],
+ [-0.3089, 0.7643, 0.9529],
+ ]
+ ).to(torch_device)
+
+ torch.testing.assert_close(outputs.last_hidden_state[0, :3, :3], expected_slice, rtol=2e-4, atol=2e-4)
+
+ def test_inference_object_detection_head(self):
+ model = ConditionalDetrForObjectDetection.from_pretrained("microsoft/conditional-detr-resnet-50").to(
+ torch_device
+ )
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ encoding = image_processor(images=image, return_tensors="pt").to(torch_device)
+ pixel_values = encoding["pixel_values"].to(torch_device)
+ pixel_mask = encoding["pixel_mask"].to(torch_device)
+
+ with torch.no_grad():
+ outputs = model(pixel_values, pixel_mask)
+
+ # verify logits + box predictions
+ expected_shape_logits = torch.Size((1, model.config.num_queries, model.config.num_labels))
+ self.assertEqual(outputs.logits.shape, expected_shape_logits)
+ expected_slice_logits = torch.tensor(
+ [
+ [-10.4371, -5.7565, -8.6765],
+ [-10.5413, -5.8700, -8.0589],
+ [-10.6824, -6.3477, -8.3927],
+ ]
+ ).to(torch_device)
+ torch.testing.assert_close(outputs.logits[0, :3, :3], expected_slice_logits, rtol=2e-4, atol=2e-4)
+
+ expected_shape_boxes = torch.Size((1, model.config.num_queries, 4))
+ self.assertEqual(outputs.pred_boxes.shape, expected_shape_boxes)
+ expected_slice_boxes = torch.tensor(
+ [
+ [0.7733, 0.6576, 0.4496],
+ [0.5171, 0.1184, 0.9095],
+ [0.8846, 0.5647, 0.2486],
+ ]
+ ).to(torch_device)
+ torch.testing.assert_close(outputs.pred_boxes[0, :3, :3], expected_slice_boxes, rtol=2e-4, atol=2e-4)
+
+ # verify postprocessing
+ results = image_processor.post_process_object_detection(
+ outputs, threshold=0.3, target_sizes=[image.size[::-1]]
+ )[0]
+ expected_scores = torch.tensor([0.8330, 0.8315, 0.8039, 0.6829, 0.5354]).to(torch_device)
+ expected_labels = [75, 17, 17, 75, 63]
+ expected_slice_boxes = torch.tensor([38.3109, 72.1002, 177.6301, 118.4511]).to(torch_device)
+
+ self.assertEqual(len(results["scores"]), 5)
+ torch.testing.assert_close(results["scores"], expected_scores, rtol=2e-4, atol=2e-4)
+ self.assertSequenceEqual(results["labels"].tolist(), expected_labels)
+ torch.testing.assert_close(results["boxes"][0, :], expected_slice_boxes)
diff --git a/transformers/tests/models/convbert/__init__.py b/transformers/tests/models/convbert/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/convbert/test_modeling_convbert.py b/transformers/tests/models/convbert/test_modeling_convbert.py
new file mode 100644
index 0000000000000000000000000000000000000000..908c0920389e42c708706f26784d9e75fb59397f
--- /dev/null
+++ b/transformers/tests/models/convbert/test_modeling_convbert.py
@@ -0,0 +1,484 @@
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch ConvBERT model."""
+
+import os
+import tempfile
+import unittest
+
+from transformers import ConvBertConfig, is_torch_available
+from transformers.models.auto import get_values
+from transformers.testing_utils import require_torch, require_torch_accelerator, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ MODEL_FOR_QUESTION_ANSWERING_MAPPING,
+ ConvBertForMaskedLM,
+ ConvBertForMultipleChoice,
+ ConvBertForQuestionAnswering,
+ ConvBertForSequenceClassification,
+ ConvBertForTokenClassification,
+ ConvBertModel,
+ )
+
+
+class ConvBertModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ return ConvBertConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ )
+
+ def prepare_config_and_inputs_for_decoder(self):
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = self.prepare_config_and_inputs()
+
+ config.is_decoder = True
+ encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size])
+ encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
+
+ return (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ )
+
+ def create_and_check_model(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = ConvBertModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
+ result = model(input_ids, token_type_ids=token_type_ids)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_for_masked_lm(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = ConvBertForMaskedLM(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_for_question_answering(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = ConvBertForQuestionAnswering(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ start_positions=sequence_labels,
+ end_positions=sequence_labels,
+ )
+ self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
+ self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
+
+ def create_and_check_for_sequence_classification(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_labels = self.num_labels
+ model = ConvBertForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=sequence_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def create_and_check_for_token_classification(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_labels = self.num_labels
+ model = ConvBertForTokenClassification(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+
+ def create_and_check_for_multiple_choice(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_choices = self.num_choices
+ model = ConvBertForMultipleChoice(config=config)
+ model.to(torch_device)
+ model.eval()
+ multiple_choice_inputs_ids = input_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ multiple_choice_token_type_ids = token_type_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ multiple_choice_input_mask = input_mask.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ result = model(
+ multiple_choice_inputs_ids,
+ attention_mask=multiple_choice_input_mask,
+ token_type_ids=multiple_choice_token_type_ids,
+ labels=choice_labels,
+ )
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class ConvBertModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ ConvBertModel,
+ ConvBertForMaskedLM,
+ ConvBertForMultipleChoice,
+ ConvBertForQuestionAnswering,
+ ConvBertForSequenceClassification,
+ ConvBertForTokenClassification,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": ConvBertModel,
+ "fill-mask": ConvBertForMaskedLM,
+ "question-answering": ConvBertForQuestionAnswering,
+ "text-classification": ConvBertForSequenceClassification,
+ "token-classification": ConvBertForTokenClassification,
+ "zero-shot": ConvBertForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_pruning = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = ConvBertModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=ConvBertConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_masked_lm(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
+
+ def test_for_multiple_choice(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs)
+
+ def test_for_question_answering(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
+
+ def test_for_sequence_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
+
+ def test_for_token_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "YituTech/conv-bert-base"
+ model = ConvBertModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ seq_len = getattr(self.model_tester, "seq_length", None)
+ decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len)
+ encoder_seq_length = getattr(self.model_tester, "encoder_seq_length", seq_len)
+ decoder_key_length = getattr(self.model_tester, "decoder_key_length", decoder_seq_length)
+ encoder_key_length = getattr(self.model_tester, "key_length", encoder_seq_length)
+ chunk_length = getattr(self.model_tester, "chunk_length", None)
+ if chunk_length is not None and hasattr(self.model_tester, "num_hashes"):
+ encoder_seq_length = encoder_seq_length * self.model_tester.num_hashes
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class._from_config(config, attn_implementation="eager")
+ config = model.config
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ if chunk_length is not None:
+ self.assertListEqual(
+ list(attentions[0].shape[-4:]),
+ [self.model_tester.num_attention_heads / 2, encoder_seq_length, chunk_length, encoder_key_length],
+ )
+ else:
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads / 2, encoder_seq_length, encoder_key_length],
+ )
+ out_len = len(outputs)
+
+ if self.is_encoder_decoder:
+ correct_outlen = 5
+
+ # loss is at first position
+ if "labels" in inputs_dict:
+ correct_outlen += 1 # loss is added to beginning
+ # Question Answering model returns start_logits and end_logits
+ if model_class in get_values(MODEL_FOR_QUESTION_ANSWERING_MAPPING):
+ correct_outlen += 1 # start_logits and end_logits instead of only 1 output
+ if "past_key_values" in outputs:
+ correct_outlen += 1 # past_key_values have been returned
+
+ self.assertEqual(out_len, correct_outlen)
+
+ # decoder attentions
+ decoder_attentions = outputs.decoder_attentions
+ self.assertIsInstance(decoder_attentions, (list, tuple))
+ self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(decoder_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, decoder_seq_length, decoder_key_length],
+ )
+
+ # cross attentions
+ cross_attentions = outputs.cross_attentions
+ self.assertIsInstance(cross_attentions, (list, tuple))
+ self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(cross_attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ decoder_seq_length,
+ encoder_key_length,
+ ],
+ )
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if hasattr(self.model_tester, "num_hidden_states_types"):
+ added_hidden_states = self.model_tester.num_hidden_states_types
+ elif self.is_encoder_decoder:
+ added_hidden_states = 2
+ else:
+ added_hidden_states = 1
+ self.assertEqual(out_len + added_hidden_states, len(outputs))
+
+ self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+
+ self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
+ if chunk_length is not None:
+ self.assertListEqual(
+ list(self_attentions[0].shape[-4:]),
+ [self.model_tester.num_attention_heads / 2, encoder_seq_length, chunk_length, encoder_key_length],
+ )
+ else:
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads / 2, encoder_seq_length, encoder_key_length],
+ )
+
+ @slow
+ @require_torch_accelerator
+ def test_torchscript_device_change(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ for model_class in self.all_model_classes:
+ # ConvBertForMultipleChoice behaves incorrectly in JIT environments.
+ if model_class == ConvBertForMultipleChoice:
+ self.skipTest(reason="ConvBertForMultipleChoice behaves incorrectly in JIT environments.")
+
+ config.torchscript = True
+ model = model_class(config=config)
+
+ inputs_dict = self._prepare_for_class(inputs_dict, model_class)
+ traced_model = torch.jit.trace(
+ model, (inputs_dict["input_ids"].to("cpu"), inputs_dict["attention_mask"].to("cpu"))
+ )
+
+ with tempfile.TemporaryDirectory() as tmp:
+ torch.jit.save(traced_model, os.path.join(tmp, "traced_model.pt"))
+ loaded = torch.jit.load(os.path.join(tmp, "traced_model.pt"), map_location=torch_device)
+ loaded(inputs_dict["input_ids"].to(torch_device), inputs_dict["attention_mask"].to(torch_device))
+
+ def test_model_for_input_embeds(self):
+ batch_size = 2
+ seq_length = 10
+ inputs_embeds = torch.rand([batch_size, seq_length, 768], device=torch_device)
+ config = self.model_tester.get_config()
+ model = ConvBertModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(inputs_embeds=inputs_embeds)
+ self.assertEqual(result.last_hidden_state.shape, (batch_size, seq_length, config.hidden_size))
+
+ def test_reducing_attention_heads(self):
+ config, *inputs_dict = self.model_tester.prepare_config_and_inputs()
+ config.head_ratio = 4
+ self.model_tester.create_and_check_for_masked_lm(config, *inputs_dict)
+
+
+@require_torch
+class ConvBertModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference_no_head(self):
+ model = ConvBertModel.from_pretrained("YituTech/conv-bert-base")
+ input_ids = torch.tensor([[1, 2, 3, 4, 5, 6]])
+ with torch.no_grad():
+ output = model(input_ids)[0]
+
+ expected_shape = torch.Size((1, 6, 768))
+ self.assertEqual(output.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[[-0.0864, -0.4898, -0.3677], [0.1434, -0.2952, -0.7640], [-0.0112, -0.4432, -0.5432]]]
+ )
+
+ torch.testing.assert_close(output[:, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/convnext/__init__.py b/transformers/tests/models/convnext/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/convnext/test_image_processing_convnext.py b/transformers/tests/models/convnext/test_image_processing_convnext.py
new file mode 100644
index 0000000000000000000000000000000000000000..373eb16fce28d94fa3f71d9aa5b04539803545dd
--- /dev/null
+++ b/transformers/tests/models/convnext/test_image_processing_convnext.py
@@ -0,0 +1,122 @@
+# Copyright 2022s HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torchvision_available, is_vision_available
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_vision_available():
+ from transformers import ConvNextImageProcessor
+
+ if is_torchvision_available():
+ from transformers import ConvNextImageProcessorFast
+
+
+class ConvNextImageProcessingTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ crop_pct=0.875,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ ):
+ size = size if size is not None else {"shortest_edge": 20}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.crop_pct = crop_pct
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def prepare_image_processor_dict(self):
+ return {
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_normalize": self.do_normalize,
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "crop_pct": self.crop_pct,
+ }
+
+ def expected_output_image_shape(self, images):
+ return self.num_channels, self.size["shortest_edge"], self.size["shortest_edge"]
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class ConvNextImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = ConvNextImageProcessor if is_vision_available() else None
+ fast_image_processing_class = ConvNextImageProcessorFast if is_torchvision_available() else None
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = ConvNextImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "crop_pct"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+
+ def test_image_processor_from_dict_with_kwargs(self):
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"shortest_edge": 20})
+
+ image_processor = image_processing_class.from_dict(self.image_processor_dict, size=42)
+ self.assertEqual(image_processor.size, {"shortest_edge": 42})
+
+ @unittest.skip(
+ "Skipping as ConvNextImageProcessor uses center_crop and center_crop functions are not equivalent for fast and slow processors"
+ )
+ def test_slow_fast_equivalence_batched(self):
+ pass
diff --git a/transformers/tests/models/convnext/test_modeling_convnext.py b/transformers/tests/models/convnext/test_modeling_convnext.py
new file mode 100644
index 0000000000000000000000000000000000000000..65df028ce6efcf799f62635bac3b1a43e1830c5f
--- /dev/null
+++ b/transformers/tests/models/convnext/test_modeling_convnext.py
@@ -0,0 +1,302 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch ConvNext model."""
+
+import unittest
+
+from transformers import ConvNextConfig
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+from transformers.utils import cached_property, is_torch_available, is_vision_available
+
+from ...test_backbone_common import BackboneTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import ConvNextBackbone, ConvNextForImageClassification, ConvNextModel
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import AutoImageProcessor
+
+
+class ConvNextModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=32,
+ num_channels=3,
+ num_stages=4,
+ hidden_sizes=[10, 20, 30, 40],
+ depths=[2, 2, 3, 2],
+ is_training=True,
+ use_labels=True,
+ intermediate_size=37,
+ hidden_act="gelu",
+ num_labels=10,
+ initializer_range=0.02,
+ out_features=["stage2", "stage3", "stage4"],
+ out_indices=[2, 3, 4],
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.num_channels = num_channels
+ self.num_stages = num_stages
+ self.hidden_sizes = hidden_sizes
+ self.depths = depths
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.num_labels = num_labels
+ self.initializer_range = initializer_range
+ self.out_features = out_features
+ self.out_indices = out_indices
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.num_labels)
+
+ config = self.get_config()
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return ConvNextConfig(
+ num_channels=self.num_channels,
+ hidden_sizes=self.hidden_sizes,
+ depths=self.depths,
+ num_stages=self.num_stages,
+ hidden_act=self.hidden_act,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ out_features=self.out_features,
+ out_indices=self.out_indices,
+ num_labels=self.num_labels,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = ConvNextModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ # expected last hidden states: B, C, H // 32, W // 32
+ self.parent.assertEqual(
+ result.last_hidden_state.shape,
+ (self.batch_size, self.hidden_sizes[-1], self.image_size // 32, self.image_size // 32),
+ )
+
+ def create_and_check_for_image_classification(self, config, pixel_values, labels):
+ model = ConvNextForImageClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values, labels=labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def create_and_check_backbone(self, config, pixel_values, labels):
+ model = ConvNextBackbone(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+
+ # verify hidden states
+ self.parent.assertEqual(len(result.feature_maps), len(config.out_features))
+ self.parent.assertListEqual(list(result.feature_maps[0].shape), [self.batch_size, self.hidden_sizes[1], 4, 4])
+
+ # verify channels
+ self.parent.assertEqual(len(model.channels), len(config.out_features))
+ self.parent.assertListEqual(model.channels, config.hidden_sizes[1:])
+
+ # verify backbone works with out_features=None
+ config.out_features = None
+ model = ConvNextBackbone(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+
+ # verify feature maps
+ self.parent.assertEqual(len(result.feature_maps), 1)
+ self.parent.assertListEqual(list(result.feature_maps[0].shape), [self.batch_size, self.hidden_sizes[-1], 1, 1])
+
+ # verify channels
+ self.parent.assertEqual(len(model.channels), 1)
+ self.parent.assertListEqual(model.channels, [config.hidden_sizes[-1]])
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class ConvNextModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as ConvNext does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (
+ (
+ ConvNextModel,
+ ConvNextForImageClassification,
+ ConvNextBackbone,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {"image-feature-extraction": ConvNextModel, "image-classification": ConvNextForImageClassification}
+ if is_torch_available()
+ else {}
+ )
+
+ fx_compatible = True
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ has_attentions = False
+ test_torch_exportable = True
+
+ def setUp(self):
+ self.model_tester = ConvNextModelTester(self)
+ self.config_tester = ConfigTester(
+ self,
+ config_class=ConvNextConfig,
+ has_text_modality=False,
+ hidden_size=37,
+ common_properties=["num_channels", "hidden_sizes"],
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="ConvNext does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="ConvNext does not support input and output embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @unittest.skip(reason="ConvNext does not use feedforward chunking")
+ def test_feed_forward_chunking(self):
+ pass
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_backbone(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_backbone(*config_and_inputs)
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.encoder_hidden_states if config.is_encoder_decoder else outputs.hidden_states
+
+ expected_num_stages = self.model_tester.num_stages
+ self.assertEqual(len(hidden_states), expected_num_stages + 1)
+
+ # ConvNext's feature maps are of shape (batch_size, num_channels, height, width)
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [self.model_tester.image_size // 4, self.model_tester.image_size // 4],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ def test_for_image_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_image_classification(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "facebook/convnext-tiny-224"
+ model = ConvNextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+class ConvNextModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_image_processor(self):
+ return AutoImageProcessor.from_pretrained("facebook/convnext-tiny-224") if is_vision_available() else None
+
+ @slow
+ def test_inference_image_classification_head(self):
+ model = ConvNextForImageClassification.from_pretrained("facebook/convnext-tiny-224").to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 1000))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([-0.0261, -0.4739, 0.1910]).to(torch_device)
+
+ torch.testing.assert_close(outputs.logits[0, :3], expected_slice, rtol=2e-4, atol=2e-4)
+
+
+@require_torch
+class ConvNextBackboneTest(unittest.TestCase, BackboneTesterMixin):
+ all_model_classes = (ConvNextBackbone,) if is_torch_available() else ()
+ config_class = ConvNextConfig
+
+ has_attentions = False
+
+ def setUp(self):
+ self.model_tester = ConvNextModelTester(self)
diff --git a/transformers/tests/models/cpm/__init__.py b/transformers/tests/models/cpm/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/cpm/test_tokenization_cpm.py b/transformers/tests/models/cpm/test_tokenization_cpm.py
new file mode 100644
index 0000000000000000000000000000000000000000..2719e01b32e8ac92709dbd0bc3919eabcec8bb49
--- /dev/null
+++ b/transformers/tests/models/cpm/test_tokenization_cpm.py
@@ -0,0 +1,50 @@
+# Copyright 2018 HuggingFace Inc. team.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+from transformers.models.cpm.tokenization_cpm import CpmTokenizer
+from transformers.testing_utils import custom_tokenizers
+
+
+@custom_tokenizers
+class CpmTokenizationTest(unittest.TestCase):
+ # There is no `CpmModel`
+ def is_pipeline_test_to_skip(
+ self,
+ pipeline_test_case_name,
+ config_class,
+ model_architecture,
+ tokenizer_name,
+ image_processor_name,
+ feature_extractor_name,
+ processor_name,
+ ):
+ return True
+
+ def test_pre_tokenization(self):
+ tokenizer = CpmTokenizer.from_pretrained("TsinghuaAI/CPM-Generate")
+ text = "Hugging Face大法好,谁用谁知道。"
+ normalized_text = "Hugging Face大法好,谁用谁知道。"
+ bpe_tokens = "▁Hu gg ing ▁ ▂ ▁F ace ▁大法 ▁好 ▁ , ▁谁 ▁用 ▁谁 ▁知 道 ▁ 。".split()
+
+ tokens = tokenizer.tokenize(text)
+ self.assertListEqual(tokens, bpe_tokens)
+
+ input_tokens = tokens + [tokenizer.unk_token]
+
+ input_bpe_tokens = [13789, 13283, 1421, 8, 10, 1164, 13608, 16528, 63, 8, 9, 440, 108, 440, 121, 90, 8, 12, 0]
+ self.assertListEqual(tokenizer.convert_tokens_to_ids(input_tokens), input_bpe_tokens)
+
+ reconstructed_text = tokenizer.decode(input_bpe_tokens)
+ self.assertEqual(reconstructed_text, normalized_text)
diff --git a/transformers/tests/models/cpmant/__init__.py b/transformers/tests/models/cpmant/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/cpmant/test_modeling_cpmant.py b/transformers/tests/models/cpmant/test_modeling_cpmant.py
new file mode 100644
index 0000000000000000000000000000000000000000..bf3a655c8ddee193acfa0b6a778895fdbcbe0528
--- /dev/null
+++ b/transformers/tests/models/cpmant/test_modeling_cpmant.py
@@ -0,0 +1,233 @@
+# Copyright 2022 The OpenBMB Team and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch CPMAnt model."""
+
+import unittest
+
+from transformers.testing_utils import is_torch_available, require_torch, tooslow
+
+from ...generation.test_utils import torch_device
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ CpmAntConfig,
+ CpmAntForCausalLM,
+ CpmAntModel,
+ CpmAntTokenizer,
+ )
+
+
+@require_torch
+class CpmAntModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=2,
+ seq_length=8,
+ is_training=True,
+ use_token_type_ids=False,
+ use_input_mask=False,
+ use_labels=False,
+ use_mc_token_ids=False,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ num_buckets=32,
+ max_distance=128,
+ prompt_length=8,
+ prompt_types=8,
+ segment_types=8,
+ init_std=0.02,
+ return_dict=True,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_token_type_ids = use_token_type_ids
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.use_mc_token_ids = use_mc_token_ids
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.num_buckets = num_buckets
+ self.max_distance = max_distance
+ self.prompt_length = prompt_length
+ self.prompt_types = prompt_types
+ self.segment_types = segment_types
+ self.init_std = init_std
+ self.return_dict = return_dict
+
+ def prepare_config_and_inputs(self):
+ input_ids = {}
+ input_ids["input_ids"] = ids_tensor([self.batch_size, self.seq_length], self.vocab_size).type(torch.int32)
+ input_ids["use_cache"] = False
+
+ config = self.get_config()
+
+ return (config, input_ids)
+
+ def get_config(self):
+ return CpmAntConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ dim_ff=self.intermediate_size,
+ position_bias_num_buckets=self.num_buckets,
+ position_bias_max_distance=self.max_distance,
+ prompt_types=self.prompt_types,
+ prompt_length=self.prompt_length,
+ segment_types=self.segment_types,
+ use_cache=True,
+ init_std=self.init_std,
+ return_dict=self.return_dict,
+ )
+
+ def create_and_check_cpmant_model(self, config, input_ids, *args):
+ model = CpmAntModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ hidden_states = model(**input_ids).last_hidden_state
+
+ self.parent.assertEqual(hidden_states.shape, (self.batch_size, self.seq_length, config.hidden_size))
+
+ def create_and_check_lm_head_model(self, config, input_ids, *args):
+ model = CpmAntForCausalLM(config)
+ model.to(torch_device)
+ input_ids["input_ids"] = input_ids["input_ids"].to(torch_device)
+ model.eval()
+
+ model_output = model(**input_ids)
+ self.parent.assertEqual(
+ model_output.logits.shape,
+ (self.batch_size, self.seq_length, config.vocab_size + config.prompt_types * config.prompt_length),
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config, inputs_dict = self.prepare_config_and_inputs()
+ return config, inputs_dict
+
+
+@require_torch
+class CpmAntModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (CpmAntModel, CpmAntForCausalLM) if is_torch_available() else ()
+ # Doesn't run generation tests. There are interface mismatches when using `generate` -- TODO @gante
+ all_generative_model_classes = ()
+ pipeline_model_mapping = (
+ {"feature-extraction": CpmAntModel, "text-generation": CpmAntForCausalLM} if is_torch_available() else {}
+ )
+
+ test_pruning = False
+ test_missing_keys = False
+ test_mismatched_shapes = False
+ test_head_masking = False
+ test_resize_embeddings = False
+
+ def setUp(self):
+ self.model_tester = CpmAntModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=CpmAntConfig)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_inputs_embeds(self):
+ unittest.skip(reason="CPMAnt doesn't support input_embeds.")(self.test_inputs_embeds)
+
+ def test_retain_grad_hidden_states_attentions(self):
+ unittest.skip(
+ "CPMAnt doesn't support retain grad in hidden_states or attentions, because prompt management will peel off the output.hidden_states from graph.\
+ So is attentions. We strongly recommend you use loss to tune model."
+ )(self.test_retain_grad_hidden_states_attentions)
+
+ def test_cpmant_model(self):
+ config, inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_cpmant_model(config, inputs)
+
+ def test_cpmant_lm_head_model(self):
+ config, inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_lm_head_model(config, inputs)
+
+
+@require_torch
+class CpmAntModelIntegrationTest(unittest.TestCase):
+ @tooslow
+ def test_inference_masked_lm(self):
+ texts = "今天天气真好!"
+ model_path = "openbmb/cpm-ant-10b"
+ model = CpmAntModel.from_pretrained(model_path)
+ tokenizer = CpmAntTokenizer.from_pretrained(model_path)
+ inputs = tokenizer(texts, return_tensors="pt")
+ hidden_states = model(**inputs).last_hidden_state
+
+ expected_slice = torch.tensor(
+ [[[6.1708, 5.9244, 1.0835], [6.5207, 6.2893, -11.3324], [-1.0107, -0.0576, -5.9577]]],
+ )
+ torch.testing.assert_close(hidden_states[:, :3, :3], expected_slice, rtol=1e-2, atol=1e-2)
+
+
+@require_torch
+class CpmAntForCausalLMlIntegrationTest(unittest.TestCase):
+ @tooslow
+ def test_inference_casual(self):
+ texts = "今天天气真好!"
+ model_path = "openbmb/cpm-ant-10b"
+ model = CpmAntForCausalLM.from_pretrained(model_path)
+ tokenizer = CpmAntTokenizer.from_pretrained(model_path)
+ inputs = tokenizer(texts, return_tensors="pt")
+ hidden_states = model(**inputs).logits
+
+ expected_slice = torch.tensor(
+ [[[-6.4267, -6.4083, -6.3958], [-5.8802, -5.9447, -5.7811], [-5.3896, -5.4820, -5.4295]]],
+ )
+ torch.testing.assert_close(hidden_states[:, :3, :3], expected_slice, rtol=1e-2, atol=1e-2)
+
+ @tooslow
+ def test_simple_generation(self):
+ model_path = "openbmb/cpm-ant-10b"
+ model = CpmAntForCausalLM.from_pretrained(model_path)
+ tokenizer = CpmAntTokenizer.from_pretrained(model_path)
+ texts = "今天天气不错,"
+ expected_output = "今天天气不错,阳光明媚,我和妈妈一起去超市买东西。\n在超市里,我看到了一个很好玩的玩具,它的名字叫“机器人”。它有一个圆圆的脑袋,两只圆圆的眼睛,还有一个圆圆的"
+ model_inputs = tokenizer(texts, return_tensors="pt")
+ token_ids = model.generate(**model_inputs)
+ output_texts = tokenizer.batch_decode(token_ids)
+ self.assertEqual(expected_output, output_texts)
+
+ @tooslow
+ def test_batch_generation(self):
+ model_path = "openbmb/cpm-ant-10b"
+ model = CpmAntForCausalLM.from_pretrained(model_path)
+ tokenizer = CpmAntTokenizer.from_pretrained(model_path)
+ texts = ["今天天气不错,", "新年快乐,万事如意!"]
+ expected_output = [
+ "今天天气不错,阳光明媚,我和妈妈一起去超市买东西。\n在超市里,我看到了一个很好玩的玩具,它的名字叫“机器人”。它有一个圆圆的脑袋,两只圆圆的眼睛,还有一个圆圆的",
+ "新年快乐,万事如意!在这辞旧迎新的美好时刻,我谨代表《农村新技术》杂志社全体同仁,向一直以来关心、支持《农村新技术》杂志发展的各级领导、各界朋友和广大读者致以最诚挚的",
+ ]
+ model_inputs = tokenizer(texts, return_tensors="pt", padding=True)
+ token_ids = model.generate(**model_inputs)
+ output_texts = tokenizer.batch_decode(token_ids)
+ self.assertEqual(expected_output, output_texts)
diff --git a/transformers/tests/models/cpmant/test_tokenization_cpmant.py b/transformers/tests/models/cpmant/test_tokenization_cpmant.py
new file mode 100644
index 0000000000000000000000000000000000000000..c7c3209f2d669f39c84cbb349abd59987544790c
--- /dev/null
+++ b/transformers/tests/models/cpmant/test_tokenization_cpmant.py
@@ -0,0 +1,70 @@
+# Copyright 2022 The OpenBMB Team and The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import os
+import unittest
+
+from transformers.models.cpmant.tokenization_cpmant import VOCAB_FILES_NAMES, CpmAntTokenizer
+from transformers.testing_utils import require_jieba, tooslow
+
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+@require_jieba
+class CPMAntTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "openbmb/cpm-ant-10b"
+ tokenizer_class = CpmAntTokenizer
+ test_rust_tokenizer = False
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ vocab_tokens = [
+ "",
+ "",
+ "",
+ "",
+ "",
+ "",
+ "",
+ "",
+ "我",
+ "是",
+ "C",
+ "P",
+ "M",
+ "A",
+ "n",
+ "t",
+ ]
+ cls.vocab_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ with open(cls.vocab_file, "w", encoding="utf-8") as vocab_writer:
+ vocab_writer.write("".join([x + "\n" for x in vocab_tokens]))
+
+ @tooslow
+ def test_pre_tokenization(self):
+ tokenizer = CpmAntTokenizer.from_pretrained("openbmb/cpm-ant-10b")
+ texts = "今天天气真好!"
+ jieba_tokens = ["今天", "天气", "真", "好", "!"]
+ tokens = tokenizer.tokenize(texts)
+ self.assertListEqual(tokens, jieba_tokens)
+ normalized_text = "今天天气真好!"
+ input_tokens = [tokenizer.bos_token] + tokens
+
+ input_jieba_tokens = [6, 9802, 14962, 2082, 831, 244]
+ self.assertListEqual(tokenizer.convert_tokens_to_ids(input_tokens), input_jieba_tokens)
+
+ reconstructed_text = tokenizer.decode(input_jieba_tokens)
+ self.assertEqual(reconstructed_text, normalized_text)
diff --git a/transformers/tests/models/ctrl/__init__.py b/transformers/tests/models/ctrl/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/ctrl/test_modeling_ctrl.py b/transformers/tests/models/ctrl/test_modeling_ctrl.py
new file mode 100644
index 0000000000000000000000000000000000000000..860693b5ccdf070f402792fc916e660f3af9d8b7
--- /dev/null
+++ b/transformers/tests/models/ctrl/test_modeling_ctrl.py
@@ -0,0 +1,284 @@
+# Copyright 2018 Salesforce and HuggingFace Inc. team.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers import CTRLConfig, is_torch_available
+from transformers.testing_utils import cleanup, require_torch, slow, torch_device
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ CTRLForSequenceClassification,
+ CTRLLMHeadModel,
+ CTRLModel,
+ )
+
+
+class CTRLModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=14,
+ seq_length=7,
+ is_training=True,
+ use_token_type_ids=True,
+ use_input_mask=True,
+ use_labels=True,
+ use_mc_token_ids=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_token_type_ids = use_token_type_ids
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.use_mc_token_ids = use_mc_token_ids
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.scope = scope
+ self.pad_token_id = self.vocab_size - 1
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ mc_token_ids = None
+ if self.use_mc_token_ids:
+ mc_token_ids = ids_tensor([self.batch_size, self.num_choices], self.seq_length)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ head_mask = ids_tensor([self.num_hidden_layers, self.num_attention_heads], 2)
+
+ return (
+ config,
+ input_ids,
+ input_mask,
+ head_mask,
+ token_type_ids,
+ mc_token_ids,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ )
+
+ def get_config(self):
+ return CTRLConfig(
+ vocab_size=self.vocab_size,
+ n_embd=self.hidden_size,
+ n_layer=self.num_hidden_layers,
+ n_head=self.num_attention_heads,
+ dff=self.intermediate_size,
+ # hidden_act=self.hidden_act,
+ # hidden_dropout_prob=self.hidden_dropout_prob,
+ # attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ n_positions=self.max_position_embeddings,
+ # type_vocab_size=self.type_vocab_size,
+ # initializer_range=self.initializer_range,
+ pad_token_id=self.pad_token_id,
+ )
+
+ def create_and_check_ctrl_model(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
+ model = CTRLModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ model(input_ids, token_type_ids=token_type_ids, head_mask=head_mask)
+ model(input_ids, token_type_ids=token_type_ids)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(len(result.past_key_values), config.n_layer)
+
+ def create_and_check_lm_head_model(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
+ model = CTRLLMHeadModel(config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids, token_type_ids=token_type_ids, labels=input_ids)
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+
+ (
+ config,
+ input_ids,
+ input_mask,
+ head_mask,
+ token_type_ids,
+ mc_token_ids,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+
+ inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "head_mask": head_mask}
+
+ return config, inputs_dict
+
+
+@require_torch
+class CTRLModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (CTRLModel, CTRLLMHeadModel, CTRLForSequenceClassification) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": CTRLModel,
+ "text-classification": CTRLForSequenceClassification,
+ "text-generation": CTRLLMHeadModel,
+ "zero-shot": CTRLForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_pruning = True
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ # TODO: Fix the failed tests
+ def is_pipeline_test_to_skip(
+ self,
+ pipeline_test_case_name,
+ config_class,
+ model_architecture,
+ tokenizer_name,
+ image_processor_name,
+ feature_extractor_name,
+ processor_name,
+ ):
+ if pipeline_test_case_name == "ZeroShotClassificationPipelineTests":
+ # Get `tokenizer does not have a padding token` error for both fast/slow tokenizers.
+ # `CTRLConfig` was never used in pipeline tests, either because of a missing checkpoint or because a tiny
+ # config could not be created.
+ return True
+
+ return False
+
+ def setUp(self):
+ self.model_tester = CTRLModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=CTRLConfig, n_embd=37)
+
+ def tearDown(self):
+ super().tearDown()
+ # clean-up as much as possible GPU memory occupied by PyTorch
+ cleanup(torch_device)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_ctrl_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_ctrl_model(*config_and_inputs)
+
+ def test_ctrl_lm_head_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_lm_head_model(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "Salesforce/ctrl"
+ model = CTRLModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+@require_torch
+class CTRLModelLanguageGenerationTest(unittest.TestCase):
+ def tearDown(self):
+ super().tearDown()
+ # clean-up as much as possible GPU memory occupied by PyTorch
+ cleanup(torch_device, gc_collect=True)
+
+ @slow
+ def test_lm_generate_ctrl(self):
+ model = CTRLLMHeadModel.from_pretrained("Salesforce/ctrl")
+ model.to(torch_device)
+ input_ids = torch.tensor(
+ [[11859, 0, 1611, 8]], dtype=torch.long, device=torch_device
+ ) # Legal the president is
+ expected_output_ids = [
+ 11859,
+ 0,
+ 1611,
+ 8,
+ 5,
+ 150,
+ 26449,
+ 2,
+ 19,
+ 348,
+ 469,
+ 3,
+ 2595,
+ 48,
+ 20740,
+ 246533,
+ 246533,
+ 19,
+ 30,
+ 5,
+ ] # Legal the president is a good guy and I don't want to lose my job. \n \n I have a
+
+ output_ids = model.generate(input_ids, do_sample=False)
+ self.assertListEqual(output_ids[0].tolist(), expected_output_ids)
diff --git a/transformers/tests/models/ctrl/test_tokenization_ctrl.py b/transformers/tests/models/ctrl/test_tokenization_ctrl.py
new file mode 100644
index 0000000000000000000000000000000000000000..f62e49708cdc77a12f522a27b55038e49b0c2a09
--- /dev/null
+++ b/transformers/tests/models/ctrl/test_tokenization_ctrl.py
@@ -0,0 +1,71 @@
+# Copyright 2018 Salesforce and HuggingFace Inc. team.
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import os
+import unittest
+from functools import lru_cache
+
+from transformers.models.ctrl.tokenization_ctrl import VOCAB_FILES_NAMES, CTRLTokenizer
+
+from ...test_tokenization_common import TokenizerTesterMixin, use_cache_if_possible
+
+
+class CTRLTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "Salesforce/ctrl"
+ tokenizer_class = CTRLTokenizer
+ test_rust_tokenizer = False
+ test_seq2seq = False
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ # Adapted from Sennrich et al. 2015 and https://github.com/rsennrich/subword-nmt
+ vocab = ["adapt", "re@@", "a@@", "apt", "c@@", "t", ""]
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+ merges = ["#version: 0.2", "a p", "ap t", "r e", "a d", "ad apt", ""]
+ cls.special_tokens_map = {"unk_token": ""}
+
+ cls.vocab_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ cls.merges_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["merges_file"])
+ with open(cls.vocab_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps(vocab_tokens) + "\n")
+ with open(cls.merges_file, "w", encoding="utf-8") as fp:
+ fp.write("\n".join(merges))
+
+ @classmethod
+ @use_cache_if_possible
+ @lru_cache(maxsize=64)
+ def get_tokenizer(cls, pretrained_name=None, **kwargs):
+ kwargs.update(cls.special_tokens_map)
+ pretrained_name = pretrained_name or cls.tmpdirname
+ return CTRLTokenizer.from_pretrained(pretrained_name, **kwargs)
+
+ def get_input_output_texts(self, tokenizer):
+ input_text = "adapt react readapt apt"
+ output_text = "adapt react readapt apt"
+ return input_text, output_text
+
+ def test_full_tokenizer(self):
+ tokenizer = CTRLTokenizer(self.vocab_file, self.merges_file, **self.special_tokens_map)
+ text = "adapt react readapt apt"
+ bpe_tokens = "adapt re@@ a@@ c@@ t re@@ adapt apt".split()
+ tokens = tokenizer.tokenize(text)
+ self.assertListEqual(tokens, bpe_tokens)
+
+ input_tokens = tokens + [tokenizer.unk_token]
+
+ input_bpe_tokens = [0, 1, 2, 4, 5, 1, 0, 3, 6]
+ self.assertListEqual(tokenizer.convert_tokens_to_ids(input_tokens), input_bpe_tokens)
diff --git a/transformers/tests/models/cvt/__init__.py b/transformers/tests/models/cvt/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/cvt/test_modeling_cvt.py b/transformers/tests/models/cvt/test_modeling_cvt.py
new file mode 100644
index 0000000000000000000000000000000000000000..f0b6b414335b4cfade3b7415bbec74a664649c5b
--- /dev/null
+++ b/transformers/tests/models/cvt/test_modeling_cvt.py
@@ -0,0 +1,274 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch CvT model."""
+
+import unittest
+from math import floor
+
+from transformers import CvtConfig
+from transformers.file_utils import cached_property, is_torch_available, is_vision_available
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import CvtForImageClassification, CvtModel
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import AutoImageProcessor
+
+
+class CvtConfigTester(ConfigTester):
+ def create_and_test_config_common_properties(self):
+ config = self.config_class(**self.inputs_dict)
+ self.parent.assertTrue(hasattr(config, "embed_dim"))
+ self.parent.assertTrue(hasattr(config, "num_heads"))
+
+
+class CvtModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=64,
+ num_channels=3,
+ embed_dim=[16, 32, 48],
+ num_heads=[1, 2, 3],
+ depth=[1, 2, 10],
+ patch_sizes=[7, 3, 3],
+ patch_stride=[4, 2, 2],
+ patch_padding=[2, 1, 1],
+ stride_kv=[2, 2, 2],
+ cls_token=[False, False, True],
+ attention_drop_rate=[0.0, 0.0, 0.0],
+ initializer_range=0.02,
+ layer_norm_eps=1e-12,
+ is_training=True,
+ use_labels=True,
+ num_labels=2, # Check
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_sizes = patch_sizes
+ self.patch_stride = patch_stride
+ self.patch_padding = patch_padding
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.num_labels = num_labels
+ self.num_channels = num_channels
+ self.embed_dim = embed_dim
+ self.num_heads = num_heads
+ self.stride_kv = stride_kv
+ self.depth = depth
+ self.cls_token = cls_token
+ self.attention_drop_rate = attention_drop_rate
+ self.initializer_range = initializer_range
+ self.layer_norm_eps = layer_norm_eps
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.num_labels)
+
+ config = self.get_config()
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return CvtConfig(
+ image_size=self.image_size,
+ num_labels=self.num_labels,
+ num_channels=self.num_channels,
+ embed_dim=self.embed_dim,
+ num_heads=self.num_heads,
+ patch_sizes=self.patch_sizes,
+ patch_padding=self.patch_padding,
+ patch_stride=self.patch_stride,
+ stride_kv=self.stride_kv,
+ depth=self.depth,
+ cls_token=self.cls_token,
+ attention_drop_rate=self.attention_drop_rate,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = CvtModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ image_size = (self.image_size, self.image_size)
+ height, width = image_size[0], image_size[1]
+ for i in range(len(self.depth)):
+ height = floor(((height + 2 * self.patch_padding[i] - self.patch_sizes[i]) / self.patch_stride[i]) + 1)
+ width = floor(((width + 2 * self.patch_padding[i] - self.patch_sizes[i]) / self.patch_stride[i]) + 1)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.embed_dim[-1], height, width))
+
+ def create_and_check_for_image_classification(self, config, pixel_values, labels):
+ config.num_labels = self.num_labels
+ model = CvtForImageClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values, labels=labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class CvtModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as Cvt does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (CvtModel, CvtForImageClassification) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {"image-feature-extraction": CvtModel, "image-classification": CvtForImageClassification}
+ if is_torch_available()
+ else {}
+ )
+
+ test_pruning = False
+ test_torchscript = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ has_attentions = False
+ test_torch_exportable = True
+
+ def setUp(self):
+ self.model_tester = CvtModelTester(self)
+ self.config_tester = ConfigTester(
+ self,
+ config_class=CvtConfig,
+ has_text_modality=False,
+ hidden_size=37,
+ common_properties=["hidden_size", "num_channels"],
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="Cvt does not output attentions")
+ def test_attention_outputs(self):
+ pass
+
+ @unittest.skip(reason="Cvt does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Cvt does not support input and output embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ # Larger differences on A10 than T4
+ def test_batching_equivalence(self, atol=2e-4, rtol=2e-4):
+ super().test_batching_equivalence(atol=atol, rtol=rtol)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.hidden_states
+
+ expected_num_layers = len(self.model_tester.depth)
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ # verify the first hidden states (first block)
+ self.assertListEqual(
+ list(hidden_states[0].shape[-3:]),
+ [
+ self.model_tester.embed_dim[0],
+ self.model_tester.image_size // 4,
+ self.model_tester.image_size // 4,
+ ],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ def test_for_image_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_image_classification(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "microsoft/cvt-13"
+ model = CvtModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+class CvtModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_image_processor(self):
+ return AutoImageProcessor.from_pretrained("microsoft/cvt-13")
+
+ @slow
+ def test_inference_image_classification_head(self):
+ model = CvtForImageClassification.from_pretrained("microsoft/cvt-13").to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 1000))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([0.9287, 0.9016, -0.3152]).to(torch_device)
+
+ torch.testing.assert_close(outputs.logits[0, :3], expected_slice, rtol=2e-4, atol=2e-4)
diff --git a/transformers/tests/models/dab_detr/__init__.py b/transformers/tests/models/dab_detr/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/dab_detr/test_modeling_dab_detr.py b/transformers/tests/models/dab_detr/test_modeling_dab_detr.py
new file mode 100644
index 0000000000000000000000000000000000000000..126c9d7f6938ae3576ef2f7fe08dc71946f3c9e3
--- /dev/null
+++ b/transformers/tests/models/dab_detr/test_modeling_dab_detr.py
@@ -0,0 +1,843 @@
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch DAB-DETR model."""
+
+import inspect
+import math
+import unittest
+
+from transformers import DabDetrConfig, ResNetConfig, is_torch_available, is_vision_available
+from transformers.testing_utils import require_timm, require_torch, require_vision, slow, torch_device
+from transformers.utils import cached_property
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ import torch.nn.functional as F
+
+ from transformers import (
+ DabDetrForObjectDetection,
+ DabDetrModel,
+ )
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import ConditionalDetrImageProcessor
+
+
+class DabDetrModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=8,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=8,
+ intermediate_size=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ num_queries=12,
+ num_channels=3,
+ min_size=200,
+ max_size=200,
+ n_targets=8,
+ num_labels=91,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.num_queries = num_queries
+ self.num_channels = num_channels
+ self.min_size = min_size
+ self.max_size = max_size
+ self.n_targets = n_targets
+ self.num_labels = num_labels
+
+ # we also set the expected seq length for both encoder and decoder
+ self.encoder_seq_length = math.ceil(self.min_size / 32) * math.ceil(self.max_size / 32)
+ self.decoder_seq_length = self.num_queries
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.min_size, self.max_size])
+
+ pixel_mask = torch.ones([self.batch_size, self.min_size, self.max_size], device=torch_device)
+
+ labels = None
+ if self.use_labels:
+ # labels is a list of Dict (each Dict being the labels for a given example in the batch)
+ labels = []
+ for i in range(self.batch_size):
+ target = {}
+ target["class_labels"] = torch.randint(
+ high=self.num_labels, size=(self.n_targets,), device=torch_device
+ )
+ target["boxes"] = torch.rand(self.n_targets, 4, device=torch_device)
+ target["masks"] = torch.rand(self.n_targets, self.min_size, self.max_size, device=torch_device)
+ labels.append(target)
+
+ config = self.get_config()
+ return config, pixel_values, pixel_mask, labels
+
+ def get_config(self):
+ resnet_config = ResNetConfig(
+ num_channels=3,
+ embeddings_size=10,
+ hidden_sizes=[10, 20, 30, 40],
+ depths=[1, 1, 2, 1],
+ hidden_act="relu",
+ num_labels=3,
+ out_features=["stage2", "stage3", "stage4"],
+ out_indices=[2, 3, 4],
+ )
+ return DabDetrConfig(
+ hidden_size=self.hidden_size,
+ encoder_layers=self.num_hidden_layers,
+ decoder_layers=self.num_hidden_layers,
+ encoder_attention_heads=self.num_attention_heads,
+ decoder_attention_heads=self.num_attention_heads,
+ encoder_ffn_dim=self.intermediate_size,
+ decoder_ffn_dim=self.intermediate_size,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ num_queries=self.num_queries,
+ num_labels=self.num_labels,
+ use_timm_backbone=False,
+ backbone_config=resnet_config,
+ backbone=None,
+ use_pretrained_backbone=False,
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config, pixel_values, pixel_mask, labels = self.prepare_config_and_inputs()
+ inputs_dict = {"pixel_values": pixel_values, "pixel_mask": pixel_mask}
+ return config, inputs_dict
+
+ def create_and_check_dab_detr_model(self, config, pixel_values, pixel_mask, labels):
+ model = DabDetrModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask)
+ result = model(pixel_values)
+
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.decoder_seq_length, self.hidden_size)
+ )
+
+ def create_and_check_dab_detr_object_detection_head_model(self, config, pixel_values, pixel_mask, labels):
+ model = DabDetrForObjectDetection(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask)
+ result = model(pixel_values)
+
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_queries, self.num_labels))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_queries, 4))
+
+ result = model(pixel_values=pixel_values, labels=labels)
+
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_queries, self.num_labels))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_queries, 4))
+
+
+@require_torch
+class DabDetrModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (DabDetrModel, DabDetrForObjectDetection) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "image-feature-extraction": DabDetrModel,
+ "object-detection": DabDetrForObjectDetection,
+ }
+ if is_torch_available()
+ else {}
+ )
+ is_encoder_decoder = True
+ test_torchscript = False
+ test_pruning = False
+ test_head_masking = False
+ test_missing_keys = False
+ zero_init_hidden_state = True
+ test_torch_exportable = True
+
+ # special case for head models
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class.__name__ in ["DabDetrForObjectDetection"]:
+ labels = []
+ for i in range(self.model_tester.batch_size):
+ target = {}
+ target["class_labels"] = torch.ones(
+ size=(self.model_tester.n_targets,), device=torch_device, dtype=torch.long
+ )
+ target["boxes"] = torch.ones(
+ self.model_tester.n_targets, 4, device=torch_device, dtype=torch.float
+ )
+ target["masks"] = torch.ones(
+ self.model_tester.n_targets,
+ self.model_tester.min_size,
+ self.model_tester.max_size,
+ device=torch_device,
+ dtype=torch.float,
+ )
+ labels.append(target)
+ inputs_dict["labels"] = labels
+
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = DabDetrModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=DabDetrConfig, has_text_modality=False)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_dab_detr_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_dab_detr_model(*config_and_inputs)
+
+ def test_dab_detr_object_detection_head_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_dab_detr_object_detection_head_model(*config_and_inputs)
+
+ # TODO: check if this works again for PyTorch 2.x.y
+ @unittest.skip(reason="Got `CUDA error: misaligned address` with PyTorch 2.0.0.")
+ def test_multi_gpu_data_parallel_forward(self):
+ pass
+
+ @unittest.skip(reason="DETR does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="DETR does not use inputs_embeds")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @unittest.skip(reason="DETR does not use inputs_embeds")
+ def test_inputs_embeds_matches_input_ids(self):
+ pass
+
+ @unittest.skip(reason="DETR does not have a get_input_embeddings method")
+ def test_model_common_attributes(self):
+ pass
+
+ @unittest.skip(reason="DETR is not a generative model")
+ def test_generate_without_input_ids(self):
+ pass
+
+ @unittest.skip(reason="DETR does not use token embeddings")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ @slow
+ def test_model_outputs_equivalence(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ def set_nan_tensor_to_zero(t):
+ print(t)
+ t[t != t] = 0
+ return t
+
+ def check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs={}):
+ with torch.no_grad():
+ tuple_output = model(**tuple_inputs, return_dict=False, **additional_kwargs)
+ dict_output = model(**dict_inputs, return_dict=True, **additional_kwargs).to_tuple()
+
+ def recursive_check(tuple_object, dict_object):
+ if isinstance(tuple_object, (list, tuple)):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object, dict_object):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif isinstance(tuple_object, dict):
+ for tuple_iterable_value, dict_iterable_value in zip(
+ tuple_object.values(), dict_object.values()
+ ):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif tuple_object is None:
+ return
+ else:
+ torch.testing.assert_close(
+ set_nan_tensor_to_zero(tuple_object),
+ set_nan_tensor_to_zero(dict_object),
+ atol=1e-5,
+ rtol=1e-5,
+ msg=(
+ "Tuple and dict output are not equal. Difference:"
+ f" {torch.max(torch.abs(tuple_object - dict_object))}. Tuple has `nan`:"
+ f" {torch.isnan(tuple_object).any()} and `inf`: {torch.isinf(tuple_object)}. Dict has"
+ f" `nan`: {torch.isnan(dict_object).any()} and `inf`: {torch.isinf(dict_object)}."
+ ),
+ )
+
+ recursive_check(tuple_output, dict_output)
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
+
+ if self.has_attentions:
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_attentions": True})
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_attentions": True})
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(
+ model, tuple_inputs, dict_inputs, {"output_hidden_states": True, "output_attentions": True}
+ )
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.encoder_hidden_states if config.is_encoder_decoder else outputs.hidden_states
+
+ expected_num_layers = getattr(
+ self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers + 1
+ )
+
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ if hasattr(self.model_tester, "encoder_seq_length"):
+ seq_length = self.model_tester.encoder_seq_length
+ if hasattr(self.model_tester, "chunk_length") and self.model_tester.chunk_length > 1:
+ seq_length = seq_length * self.model_tester.chunk_length
+ else:
+ seq_length = self.model_tester.seq_length
+
+ self.assertListEqual(
+ [hidden_states[0].shape[1], hidden_states[0].shape[2]],
+ [seq_length, self.model_tester.hidden_size],
+ )
+
+ if config.is_encoder_decoder:
+ hidden_states = outputs.decoder_hidden_states
+
+ self.assertIsInstance(hidden_states, (list, tuple))
+
+ self.assertEqual(len(hidden_states), expected_num_layers)
+ seq_len = getattr(self.model_tester, "seq_length", None)
+ decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len)
+
+ self.assertListEqual(
+ [hidden_states[0].shape[1], hidden_states[0].shape[2]],
+ [decoder_seq_length, self.model_tester.hidden_size],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # Had to modify the threshold to 2 decimals instead of 3 because sometimes it threw an error
+ def test_batching_equivalence(self):
+ """
+ Tests that the model supports batching and that the output is the nearly the same for the same input in
+ different batch sizes.
+ (Why "nearly the same" not "exactly the same"? Batching uses different matmul shapes, which often leads to
+ different results: https://github.com/huggingface/transformers/issues/25420#issuecomment-1775317535)
+ """
+
+ def get_tensor_equivalence_function(batched_input):
+ # models operating on continuous spaces have higher abs difference than LMs
+ # instead, we can rely on cos distance for image/speech models, similar to `diffusers`
+ if "input_ids" not in batched_input:
+ return lambda tensor1, tensor2: (
+ 1.0 - F.cosine_similarity(tensor1.float().flatten(), tensor2.float().flatten(), dim=0, eps=1e-38)
+ )
+ return lambda tensor1, tensor2: torch.max(torch.abs(tensor1 - tensor2))
+
+ def recursive_check(batched_object, single_row_object, model_name, key):
+ if isinstance(batched_object, (list, tuple)):
+ for batched_object_value, single_row_object_value in zip(batched_object, single_row_object):
+ recursive_check(batched_object_value, single_row_object_value, model_name, key)
+ elif isinstance(batched_object, dict):
+ for batched_object_value, single_row_object_value in zip(
+ batched_object.values(), single_row_object.values()
+ ):
+ recursive_check(batched_object_value, single_row_object_value, model_name, key)
+ # do not compare returned loss (0-dim tensor) / codebook ids (int) / caching objects
+ elif batched_object is None or not isinstance(batched_object, torch.Tensor):
+ return
+ elif batched_object.dim() == 0:
+ return
+ else:
+ # indexing the first element does not always work
+ # e.g. models that output similarity scores of size (N, M) would need to index [0, 0]
+ slice_ids = [slice(0, index) for index in single_row_object.shape]
+ batched_row = batched_object[slice_ids]
+ self.assertFalse(
+ torch.isnan(batched_row).any(), f"Batched output has `nan` in {model_name} for key={key}"
+ )
+ self.assertFalse(
+ torch.isinf(batched_row).any(), f"Batched output has `inf` in {model_name} for key={key}"
+ )
+ self.assertFalse(
+ torch.isnan(single_row_object).any(), f"Single row output has `nan` in {model_name} for key={key}"
+ )
+ self.assertFalse(
+ torch.isinf(single_row_object).any(), f"Single row output has `inf` in {model_name} for key={key}"
+ )
+ self.assertTrue(
+ (equivalence(batched_row, single_row_object)) <= 1e-02,
+ msg=(
+ f"Batched and Single row outputs are not equal in {model_name} for key={key}. "
+ f"Difference={equivalence(batched_row, single_row_object)}."
+ ),
+ )
+
+ config, batched_input = self.model_tester.prepare_config_and_inputs_for_common()
+ equivalence = get_tensor_equivalence_function(batched_input)
+
+ for model_class in self.all_model_classes:
+ config.output_hidden_states = True
+
+ model_name = model_class.__name__
+ if hasattr(self.model_tester, "prepare_config_and_inputs_for_model_class"):
+ config, batched_input = self.model_tester.prepare_config_and_inputs_for_model_class(model_class)
+ batched_input_prepared = self._prepare_for_class(batched_input, model_class)
+ model = model_class(config).to(torch_device).eval()
+
+ batch_size = self.model_tester.batch_size
+ single_row_input = {}
+ for key, value in batched_input_prepared.items():
+ if isinstance(value, torch.Tensor) and value.shape[0] % batch_size == 0:
+ # e.g. musicgen has inputs of size (bs*codebooks). in most cases value.shape[0] == batch_size
+ single_batch_shape = value.shape[0] // batch_size
+ single_row_input[key] = value[:single_batch_shape]
+ else:
+ single_row_input[key] = value
+
+ with torch.no_grad():
+ model_batched_output = model(**batched_input_prepared)
+ model_row_output = model(**single_row_input)
+
+ if isinstance(model_batched_output, torch.Tensor):
+ model_batched_output = {"model_output": model_batched_output}
+ model_row_output = {"model_output": model_row_output}
+
+ for key in model_batched_output:
+ # DETR starts from zero-init queries to decoder, leading to cos_similarity = `nan`
+ if hasattr(self, "zero_init_hidden_state") and "decoder_hidden_states" in key:
+ model_batched_output[key] = model_batched_output[key][1:]
+ model_row_output[key] = model_row_output[key][1:]
+ recursive_check(model_batched_output[key], model_row_output[key], model_name, key)
+
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ decoder_seq_length = self.model_tester.decoder_seq_length
+ encoder_seq_length = self.model_tester.encoder_seq_length
+ decoder_key_length = self.model_tester.decoder_seq_length
+ encoder_key_length = self.model_tester.encoder_seq_length
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class._from_config(config, attn_implementation="eager")
+ config = model.config
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ del inputs_dict["output_hidden_states"]
+ config.output_attentions = True
+ config.output_hidden_states = False
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length],
+ )
+ out_len = len(outputs)
+ if self.is_encoder_decoder:
+ correct_outlen = 6
+
+ # loss is at first position
+ if "labels" in inputs_dict:
+ correct_outlen += 1 # loss is added to beginning
+ if "past_key_values" in outputs:
+ correct_outlen += 1 # past_key_values have been returned
+
+ self.assertEqual(out_len, correct_outlen)
+
+ # decoder attentions
+ decoder_attentions = outputs.decoder_attentions
+ self.assertIsInstance(decoder_attentions, (list, tuple))
+ self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(decoder_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, decoder_seq_length, decoder_key_length],
+ )
+
+ # cross attentions
+ cross_attentions = outputs.cross_attentions
+ self.assertIsInstance(cross_attentions, (list, tuple))
+ self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(cross_attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ decoder_seq_length,
+ encoder_key_length,
+ ],
+ )
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if hasattr(self.model_tester, "num_hidden_states_types"):
+ added_hidden_states = self.model_tester.num_hidden_states_types
+ elif self.is_encoder_decoder:
+ # decoder_hidden_states, encoder_last_hidden_state, encoder_hidden_states
+ added_hidden_states = 3
+ else:
+ added_hidden_states = 1
+
+ self.assertEqual(out_len + added_hidden_states, len(outputs))
+
+ self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+
+ self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length],
+ )
+
+ def test_retain_grad_hidden_states_attentions(self):
+ # removed retain_grad and grad on decoder_hidden_states, as queries don't require grad
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # no need to test all models as different heads yield the same functionality
+ model_class = self.all_model_classes[0]
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ outputs = model(**inputs, output_attentions=True, output_hidden_states=True)
+
+ # logits
+ output = outputs[0]
+
+ encoder_hidden_states = outputs.encoder_hidden_states[0]
+ encoder_hidden_states.retain_grad()
+
+ encoder_attentions = outputs.encoder_attentions[0]
+ encoder_attentions.retain_grad()
+
+ decoder_attentions = outputs.decoder_attentions[0]
+ decoder_attentions.retain_grad()
+
+ cross_attentions = outputs.cross_attentions[0]
+ cross_attentions.retain_grad()
+
+ output.flatten()[0].backward(retain_graph=True)
+
+ self.assertIsNotNone(encoder_hidden_states.grad)
+ self.assertIsNotNone(encoder_attentions.grad)
+ self.assertIsNotNone(decoder_attentions.grad)
+ self.assertIsNotNone(cross_attentions.grad)
+
+ def test_forward_auxiliary_loss(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.auxiliary_loss = True
+
+ # only test for object detection and segmentation model
+ for model_class in self.all_model_classes[1:]:
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+
+ outputs = model(**inputs)
+
+ self.assertIsNotNone(outputs.auxiliary_outputs)
+ self.assertEqual(len(outputs.auxiliary_outputs), self.model_tester.num_hidden_layers - 1)
+
+ def test_training(self):
+ if not self.model_tester.is_training:
+ self.skipTest(reason="ModelTester is not configured to run training tests")
+
+ # We only have loss with ObjectDetection
+ model_class = self.all_model_classes[-1]
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ if model.config.is_encoder_decoder:
+ expected_arg_names = ["pixel_values", "pixel_mask"]
+ expected_arg_names.extend(
+ ["head_mask", "decoder_head_mask", "encoder_outputs"]
+ if "head_mask" and "decoder_head_mask" in arg_names
+ else []
+ )
+ self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
+ else:
+ expected_arg_names = ["pixel_values", "pixel_mask"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_different_timm_backbone(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # let's pick a random timm backbone
+ config.backbone = "tf_mobilenetv3_small_075"
+ config.backbone_config = None
+ config.use_timm_backbone = True
+ config.backbone_kwargs = {"out_indices": [2, 3, 4]}
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if model_class.__name__ == "DabDetrForObjectDetection":
+ expected_shape = (
+ self.model_tester.batch_size,
+ self.model_tester.num_queries,
+ self.model_tester.num_labels,
+ )
+ self.assertEqual(outputs.logits.shape, expected_shape)
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.model.backbone.conv_encoder.intermediate_channel_sizes), 3)
+ else:
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.backbone.conv_encoder.intermediate_channel_sizes), 3)
+
+ self.assertTrue(outputs)
+
+ def test_initialization(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ configs_no_init.init_xavier_std = 1e9
+ # Copied from RT-DETR
+ configs_no_init.initializer_bias_prior_prob = 0.2
+ bias_value = -1.3863 # log_e ((1 - 0.2) / 0.2)
+
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ if "bbox_attention" in name and "bias" not in name:
+ self.assertLess(
+ 100000,
+ abs(param.data.max().item()),
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ # Modified from RT-DETR
+ elif "class_embed" in name and "bias" in name:
+ bias_tensor = torch.full_like(param.data, bias_value)
+ torch.testing.assert_close(
+ param.data,
+ bias_tensor,
+ atol=1e-4,
+ rtol=1e-4,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ elif "activation_fn" in name and config.activation_function == "prelu":
+ self.assertTrue(
+ param.data.mean() == 0.25,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ elif "backbone.conv_encoder.model" in name:
+ continue
+ elif "self_attn.in_proj_weight" in name:
+ self.assertIn(
+ ((param.data.mean() * 1e2).round() / 1e2).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ else:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+
+TOLERANCE = 1e-4
+CHECKPOINT = "IDEA-Research/dab-detr-resnet-50"
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_timm
+@require_vision
+@slow
+class DabDetrModelIntegrationTests(unittest.TestCase):
+ @cached_property
+ def default_image_processor(self):
+ return ConditionalDetrImageProcessor.from_pretrained(CHECKPOINT) if is_vision_available() else None
+
+ def test_inference_no_head(self):
+ model = DabDetrModel.from_pretrained(CHECKPOINT).to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ encoding = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ with torch.no_grad():
+ outputs = model(pixel_values=encoding.pixel_values)
+
+ expected_shape = torch.Size((1, 300, 256))
+ self.assertEqual(outputs.last_hidden_state.shape, expected_shape)
+ expected_slice = torch.tensor(
+ [
+ [-0.4878, -0.2593, 0.4521],
+ [-0.4999, -0.4257, 0.4326],
+ [-0.8220, -0.4997, 0.0578],
+ ]
+ ).to(torch_device)
+ torch.testing.assert_close(outputs.last_hidden_state[0, :3, :3], expected_slice, atol=2e-4, rtol=2e-4)
+
+ def test_inference_object_detection_head(self):
+ model = DabDetrForObjectDetection.from_pretrained(CHECKPOINT).to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ encoding = image_processor(images=image, return_tensors="pt").to(torch_device)
+ pixel_values = encoding["pixel_values"].to(torch_device)
+
+ with torch.no_grad():
+ outputs = model(pixel_values)
+
+ # verify logits + box predictions
+ expected_shape_logits = torch.Size((1, model.config.num_queries, model.config.num_labels))
+ self.assertEqual(outputs.logits.shape, expected_shape_logits)
+ expected_slice_logits = torch.tensor(
+ [
+ [-10.1764, -5.5247, -8.9324],
+ [-9.8137, -5.6730, -7.5163],
+ [-10.3056, -5.6075, -8.5935],
+ ]
+ ).to(torch_device)
+ torch.testing.assert_close(outputs.logits[0, :3, :3], expected_slice_logits, atol=3e-4, rtol=3e-4)
+
+ expected_shape_boxes = torch.Size((1, model.config.num_queries, 4))
+ self.assertEqual(outputs.pred_boxes.shape, expected_shape_boxes)
+ expected_slice_boxes = torch.tensor(
+ [
+ [0.3708, 0.3000, 0.2754],
+ [0.5211, 0.6126, 0.9494],
+ [0.2897, 0.6731, 0.5460],
+ ]
+ ).to(torch_device)
+ torch.testing.assert_close(outputs.pred_boxes[0, :3, :3], expected_slice_boxes, atol=3e-4, rtol=3e-4)
+
+ # verify postprocessing
+ results = image_processor.post_process_object_detection(
+ outputs, threshold=0.3, target_sizes=[image.size[::-1]]
+ )[0]
+ expected_scores = torch.tensor([0.8732, 0.8563, 0.8554, 0.6080, 0.5895]).to(torch_device)
+ expected_labels = [17, 75, 17, 75, 63]
+ expected_boxes = torch.tensor([14.6931, 49.3886, 320.5176, 469.2762]).to(torch_device)
+
+ self.assertEqual(len(results["scores"]), 5)
+ torch.testing.assert_close(results["scores"], expected_scores, atol=3e-4, rtol=3e-4)
+ self.assertSequenceEqual(results["labels"].tolist(), expected_labels)
+ torch.testing.assert_close(results["boxes"][0, :], expected_boxes, atol=3e-4, rtol=3e-4)
diff --git a/transformers/tests/models/deberta/__init__.py b/transformers/tests/models/deberta/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/deberta/test_modeling_deberta.py b/transformers/tests/models/deberta/test_modeling_deberta.py
new file mode 100644
index 0000000000000000000000000000000000000000..8ec4eefc4f3f44e508ed2d27a3e254a246c8a57f
--- /dev/null
+++ b/transformers/tests/models/deberta/test_modeling_deberta.py
@@ -0,0 +1,308 @@
+# Copyright 2018 Microsoft Authors and the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import unittest
+
+from transformers import DebertaConfig, is_torch_available
+from transformers.testing_utils import require_sentencepiece, require_tokenizers, require_torch, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ DebertaForMaskedLM,
+ DebertaForQuestionAnswering,
+ DebertaForSequenceClassification,
+ DebertaForTokenClassification,
+ DebertaModel,
+ )
+
+
+class DebertaModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ relative_attention=False,
+ position_biased_input=True,
+ pos_att_type="None",
+ num_labels=3,
+ num_choices=4,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.relative_attention = relative_attention
+ self.position_biased_input = position_biased_input
+ self.pos_att_type = pos_att_type
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ return DebertaConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ initializer_range=self.initializer_range,
+ relative_attention=self.relative_attention,
+ position_biased_input=self.position_biased_input,
+ pos_att_type=self.pos_att_type,
+ )
+
+ def get_pipeline_config(self):
+ config = self.get_config()
+ config.vocab_size = 300
+ return config
+
+ def check_loss_output(self, result):
+ self.parent.assertListEqual(list(result.loss.size()), [])
+
+ def create_and_check_deberta_model(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = DebertaModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ sequence_output = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)[0]
+ sequence_output = model(input_ids, token_type_ids=token_type_ids)[0]
+ sequence_output = model(input_ids)[0]
+
+ self.parent.assertListEqual(list(sequence_output.size()), [self.batch_size, self.seq_length, self.hidden_size])
+
+ def create_and_check_deberta_for_masked_lm(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = DebertaForMaskedLM(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
+
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_deberta_for_sequence_classification(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_labels = self.num_labels
+ model = DebertaForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=sequence_labels)
+ self.parent.assertListEqual(list(result.logits.size()), [self.batch_size, self.num_labels])
+ self.check_loss_output(result)
+
+ def create_and_check_deberta_for_token_classification(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_labels = self.num_labels
+ model = DebertaForTokenClassification(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+
+ def create_and_check_deberta_for_question_answering(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = DebertaForQuestionAnswering(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ start_positions=sequence_labels,
+ end_positions=sequence_labels,
+ )
+ self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
+ self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class DebertaModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ DebertaModel,
+ DebertaForMaskedLM,
+ DebertaForSequenceClassification,
+ DebertaForTokenClassification,
+ DebertaForQuestionAnswering,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": DebertaModel,
+ "fill-mask": DebertaForMaskedLM,
+ "question-answering": DebertaForQuestionAnswering,
+ "text-classification": DebertaForSequenceClassification,
+ "token-classification": DebertaForTokenClassification,
+ "zero-shot": DebertaForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ fx_compatible = True
+ test_torchscript = False
+ test_pruning = False
+ test_head_masking = False
+ is_encoder_decoder = False
+
+ def setUp(self):
+ self.model_tester = DebertaModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=DebertaConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_deberta_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_deberta_model(*config_and_inputs)
+
+ def test_for_sequence_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_deberta_for_sequence_classification(*config_and_inputs)
+
+ def test_for_masked_lm(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_deberta_for_masked_lm(*config_and_inputs)
+
+ def test_for_question_answering(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_deberta_for_question_answering(*config_and_inputs)
+
+ def test_for_token_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_deberta_for_token_classification(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "microsoft/deberta-base"
+ model = DebertaModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ @unittest.skip("This test was broken by the refactor in #22105, TODO @ArthurZucker")
+ def test_torch_fx_output_loss(self):
+ pass
+
+ @unittest.skip("This test was broken by the refactor in #22105, TODO @ArthurZucker")
+ def test_torch_fx(self):
+ pass
+
+
+@require_torch
+@require_sentencepiece
+@require_tokenizers
+class DebertaModelIntegrationTest(unittest.TestCase):
+ @unittest.skip(reason="Model not available yet")
+ def test_inference_masked_lm(self):
+ pass
+
+ @slow
+ def test_inference_no_head(self):
+ model = DebertaModel.from_pretrained("microsoft/deberta-base")
+
+ input_ids = torch.tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
+ attention_mask = torch.tensor([[0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
+ with torch.no_grad():
+ output = model(input_ids, attention_mask=attention_mask)[0]
+ # compare the actual values for a slice.
+ expected_slice = torch.tensor(
+ [[[-0.5986, -0.8055, -0.8462], [1.4484, -0.9348, -0.8059], [0.3123, 0.0032, -1.4131]]]
+ )
+ torch.testing.assert_close(output[:, 1:4, 1:4], expected_slice, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/deberta/test_tokenization_deberta.py b/transformers/tests/models/deberta/test_tokenization_deberta.py
new file mode 100644
index 0000000000000000000000000000000000000000..ad625eabf0e9967375aff67419ee07dab00407c8
--- /dev/null
+++ b/transformers/tests/models/deberta/test_tokenization_deberta.py
@@ -0,0 +1,173 @@
+# Copyright 2019 Hugging Face inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import os
+import unittest
+from functools import lru_cache
+
+from transformers import DebertaTokenizer, DebertaTokenizerFast
+from transformers.models.deberta.tokenization_deberta import VOCAB_FILES_NAMES
+from transformers.testing_utils import slow
+
+from ...test_tokenization_common import TokenizerTesterMixin, use_cache_if_possible
+
+
+class DebertaTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "microsoft/deberta-base"
+ tokenizer_class = DebertaTokenizer
+ test_rust_tokenizer = True
+ rust_tokenizer_class = DebertaTokenizerFast
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ # Adapted from Sennrich et al. 2015 and https://github.com/rsennrich/subword-nmt
+ vocab = [
+ "l",
+ "o",
+ "w",
+ "e",
+ "r",
+ "s",
+ "t",
+ "i",
+ "d",
+ "n",
+ "\u0120",
+ "\u0120l",
+ "\u0120n",
+ "\u0120lo",
+ "\u0120low",
+ "er",
+ "\u0120lowest",
+ "\u0120newer",
+ "\u0120wider",
+ "[UNK]",
+ ]
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+ merges = ["#version: 0.2", "\u0120 l", "\u0120l o", "\u0120lo w", "e r", ""]
+ cls.special_tokens_map = {"unk_token": "[UNK]"}
+
+ cls.vocab_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ cls.merges_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["merges_file"])
+ with open(cls.vocab_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps(vocab_tokens) + "\n")
+ with open(cls.merges_file, "w", encoding="utf-8") as fp:
+ fp.write("\n".join(merges))
+
+ @classmethod
+ @use_cache_if_possible
+ @lru_cache(maxsize=64)
+ def get_tokenizer(cls, pretrained_name=None, **kwargs):
+ kwargs.update(cls.special_tokens_map)
+ pretrained_name = pretrained_name or cls.tmpdirname
+ return cls.tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+
+ def get_input_output_texts(self, tokenizer):
+ input_text = "lower newer"
+ output_text = "lower newer"
+ return input_text, output_text
+
+ def test_full_tokenizer(self):
+ tokenizer = self.get_tokenizer()
+ text = "lower newer"
+ bpe_tokens = ["l", "o", "w", "er", "\u0120", "n", "e", "w", "er"]
+ tokens = tokenizer.tokenize(text)
+ self.assertListEqual(tokens, bpe_tokens)
+
+ input_tokens = tokens + [tokenizer.unk_token]
+ input_bpe_tokens = [0, 1, 2, 15, 10, 9, 3, 2, 15, 19]
+ self.assertListEqual(tokenizer.convert_tokens_to_ids(input_tokens), input_bpe_tokens)
+
+ def test_token_type_ids(self):
+ tokenizer = self.get_tokenizer()
+ tokd = tokenizer("Hello", "World")
+ expected_token_type_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1]
+ self.assertListEqual(tokd["token_type_ids"], expected_token_type_ids)
+
+ @slow
+ def test_sequence_builders(self):
+ tokenizer = self.tokenizer_class.from_pretrained("microsoft/deberta-base")
+
+ text = tokenizer.encode("sequence builders", add_special_tokens=False)
+ text_2 = tokenizer.encode("multi-sequence build", add_special_tokens=False)
+
+ encoded_text_from_decode = tokenizer.encode(
+ "sequence builders", add_special_tokens=True, add_prefix_space=False
+ )
+ encoded_pair_from_decode = tokenizer.encode(
+ "sequence builders", "multi-sequence build", add_special_tokens=True, add_prefix_space=False
+ )
+
+ encoded_sentence = tokenizer.build_inputs_with_special_tokens(text)
+ encoded_pair = tokenizer.build_inputs_with_special_tokens(text, text_2)
+
+ assert encoded_sentence == encoded_text_from_decode
+ assert encoded_pair == encoded_pair_from_decode
+
+ @slow
+ def test_tokenizer_integration(self):
+ tokenizer_classes = [self.tokenizer_class]
+ if self.test_rust_tokenizer:
+ tokenizer_classes.append(self.rust_tokenizer_class)
+
+ for tokenizer_class in tokenizer_classes:
+ tokenizer = tokenizer_class.from_pretrained("microsoft/deberta-base")
+
+ sequences = [
+ "ALBERT: A Lite BERT for Self-supervised Learning of Language Representations",
+ "ALBERT incorporates two parameter reduction techniques",
+ "The first one is a factorized embedding parameterization. By decomposing the large vocabulary"
+ " embedding matrix into two small matrices, we separate the size of the hidden layers from the size of"
+ " vocabulary embedding.",
+ ]
+
+ encoding = tokenizer(sequences, padding=True)
+ decoded_sequences = [tokenizer.decode(seq, skip_special_tokens=True) for seq in encoding["input_ids"]]
+
+ # fmt: off
+ expected_encoding = {
+ 'input_ids': [
+ [1, 2118, 11126, 565, 35, 83, 25191, 163, 18854, 13, 12156, 12, 16101, 25376, 13807, 9, 22205, 27893, 1635, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [1, 2118, 11126, 565, 24536, 80, 43797, 4878, 7373, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [1, 133, 78, 65, 16, 10, 3724, 1538, 33183, 11303, 43797, 1938, 4, 870, 24165, 29105, 5, 739, 32644, 33183, 11303, 36173, 88, 80, 650, 7821, 45940, 6, 52, 2559, 5, 1836, 9, 5, 7397, 13171, 31, 5, 1836, 9, 32644, 33183, 11303, 4, 2]
+ ],
+ 'token_type_ids': [
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
+ ],
+ 'attention_mask': [
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
+ ]
+ }
+ # fmt: on
+
+ expected_decoded_sequence = [
+ "ALBERT: A Lite BERT for Self-supervised Learning of Language Representations",
+ "ALBERT incorporates two parameter reduction techniques",
+ "The first one is a factorized embedding parameterization. By decomposing the large vocabulary"
+ " embedding matrix into two small matrices, we separate the size of the hidden layers from the size of"
+ " vocabulary embedding.",
+ ]
+
+ self.assertDictEqual(encoding.data, expected_encoding)
+
+ for expected, decoded in zip(expected_decoded_sequence, decoded_sequences):
+ self.assertEqual(expected, decoded)
diff --git a/transformers/tests/models/deberta_v2/__init__.py b/transformers/tests/models/deberta_v2/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/deberta_v2/test_modeling_deberta_v2.py b/transformers/tests/models/deberta_v2/test_modeling_deberta_v2.py
new file mode 100644
index 0000000000000000000000000000000000000000..6de08d3f4bd7a21a288171ed9814110b92775f29
--- /dev/null
+++ b/transformers/tests/models/deberta_v2/test_modeling_deberta_v2.py
@@ -0,0 +1,326 @@
+# Copyright 2018 Microsoft Authors and the HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import unittest
+
+from transformers import DebertaV2Config, is_torch_available
+from transformers.testing_utils import require_sentencepiece, require_tokenizers, require_torch, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ DebertaV2ForMaskedLM,
+ DebertaV2ForMultipleChoice,
+ DebertaV2ForQuestionAnswering,
+ DebertaV2ForSequenceClassification,
+ DebertaV2ForTokenClassification,
+ DebertaV2Model,
+ )
+
+
+class DebertaV2ModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ relative_attention=False,
+ position_biased_input=True,
+ pos_att_type="None",
+ num_labels=3,
+ num_choices=4,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.relative_attention = relative_attention
+ self.position_biased_input = position_biased_input
+ self.pos_att_type = pos_att_type
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ return DebertaV2Config(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ initializer_range=self.initializer_range,
+ relative_attention=self.relative_attention,
+ position_biased_input=self.position_biased_input,
+ pos_att_type=self.pos_att_type,
+ )
+
+ def check_loss_output(self, result):
+ self.parent.assertListEqual(list(result.loss.size()), [])
+
+ def create_and_check_deberta_model(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = DebertaV2Model(config=config)
+ model.to(torch_device)
+ model.eval()
+ sequence_output = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)[0]
+ sequence_output = model(input_ids, token_type_ids=token_type_ids)[0]
+ sequence_output = model(input_ids)[0]
+
+ self.parent.assertListEqual(list(sequence_output.size()), [self.batch_size, self.seq_length, self.hidden_size])
+
+ def create_and_check_deberta_for_masked_lm(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = DebertaV2ForMaskedLM(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
+
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_deberta_for_sequence_classification(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_labels = self.num_labels
+ model = DebertaV2ForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=sequence_labels)
+ self.parent.assertListEqual(list(result.logits.size()), [self.batch_size, self.num_labels])
+ self.check_loss_output(result)
+
+ def create_and_check_deberta_for_token_classification(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_labels = self.num_labels
+ model = DebertaV2ForTokenClassification(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+
+ def create_and_check_deberta_for_question_answering(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = DebertaV2ForQuestionAnswering(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ start_positions=sequence_labels,
+ end_positions=sequence_labels,
+ )
+ self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
+ self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
+
+ def create_and_check_deberta_for_multiple_choice(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = DebertaV2ForMultipleChoice(config=config)
+ model.to(torch_device)
+ model.eval()
+ multiple_choice_inputs_ids = input_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ multiple_choice_token_type_ids = token_type_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ multiple_choice_input_mask = input_mask.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ result = model(
+ multiple_choice_inputs_ids,
+ attention_mask=multiple_choice_input_mask,
+ token_type_ids=multiple_choice_token_type_ids,
+ labels=choice_labels,
+ )
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class DebertaV2ModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ DebertaV2Model,
+ DebertaV2ForMaskedLM,
+ DebertaV2ForSequenceClassification,
+ DebertaV2ForTokenClassification,
+ DebertaV2ForQuestionAnswering,
+ DebertaV2ForMultipleChoice,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": DebertaV2Model,
+ "fill-mask": DebertaV2ForMaskedLM,
+ "question-answering": DebertaV2ForQuestionAnswering,
+ "text-classification": DebertaV2ForSequenceClassification,
+ "token-classification": DebertaV2ForTokenClassification,
+ "zero-shot": DebertaV2ForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ fx_compatible = True
+ test_torchscript = False
+ test_pruning = False
+ test_head_masking = False
+ is_encoder_decoder = False
+
+ def setUp(self):
+ self.model_tester = DebertaV2ModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=DebertaV2Config, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_deberta_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_deberta_model(*config_and_inputs)
+
+ def test_for_sequence_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_deberta_for_sequence_classification(*config_and_inputs)
+
+ def test_for_masked_lm(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_deberta_for_masked_lm(*config_and_inputs)
+
+ def test_for_question_answering(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_deberta_for_question_answering(*config_and_inputs)
+
+ def test_for_token_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_deberta_for_token_classification(*config_and_inputs)
+
+ def test_for_multiple_choice(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_deberta_for_multiple_choice(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "microsoft/deberta-v2-xlarge"
+ model = DebertaV2Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ @unittest.skip("This test was broken by the refactor in #22105, TODO @ArthurZucker")
+ def test_torch_fx_output_loss(self):
+ pass
+
+ @unittest.skip("This test was broken by the refactor in #22105, TODO @ArthurZucker")
+ def test_torch_fx(self):
+ pass
+
+
+@require_torch
+@require_sentencepiece
+@require_tokenizers
+class DebertaV2ModelIntegrationTest(unittest.TestCase):
+ @unittest.skip(reason="Model not available yet")
+ def test_inference_masked_lm(self):
+ pass
+
+ @slow
+ def test_inference_no_head(self):
+ model = DebertaV2Model.from_pretrained("microsoft/deberta-v2-xlarge")
+
+ input_ids = torch.tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
+ attention_mask = torch.tensor([[0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])
+ with torch.no_grad():
+ output = model(input_ids, attention_mask=attention_mask)[0]
+ # compare the actual values for a slice.
+ expected_slice = torch.tensor(
+ [[[0.2356, 0.1948, 0.0369], [-0.1063, 0.3586, -0.5152], [-0.6399, -0.0259, -0.2525]]]
+ )
+ torch.testing.assert_close(output[:, 1:4, 1:4], expected_slice, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/deberta_v2/test_tokenization_deberta_v2.py b/transformers/tests/models/deberta_v2/test_tokenization_deberta_v2.py
new file mode 100644
index 0000000000000000000000000000000000000000..e629f279249c4083f8d6c3e1279a0810fc63a3bc
--- /dev/null
+++ b/transformers/tests/models/deberta_v2/test_tokenization_deberta_v2.py
@@ -0,0 +1,262 @@
+# Copyright 2019 Hugging Face inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+from transformers import DebertaV2Tokenizer, DebertaV2TokenizerFast
+from transformers.testing_utils import get_tests_dir, require_sentencepiece, require_tokenizers, slow
+
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+SAMPLE_VOCAB = get_tests_dir("fixtures/spiece.model")
+
+
+@require_sentencepiece
+@require_tokenizers
+class DebertaV2TokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "microsoft/deberta-v2-xlarge"
+ tokenizer_class = DebertaV2Tokenizer
+ rust_tokenizer_class = DebertaV2TokenizerFast
+ test_sentencepiece = True
+ test_sentencepiece_ignore_case = True
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ # We have a SentencePiece fixture for testing
+ tokenizer = DebertaV2Tokenizer(SAMPLE_VOCAB, unk_token="")
+ tokenizer.save_pretrained(cls.tmpdirname)
+
+ def get_input_output_texts(self, tokenizer):
+ input_text = "this is a test"
+ output_text = "this is a test"
+ return input_text, output_text
+
+ def test_convert_token_and_id(self):
+ """Test ``_convert_token_to_id`` and ``_convert_id_to_token``."""
+ token = ""
+ token_id = 0
+
+ self.assertEqual(self.get_tokenizer()._convert_token_to_id(token), token_id)
+ self.assertEqual(self.get_tokenizer()._convert_id_to_token(token_id), token)
+
+ def test_get_vocab(self):
+ vocab_keys = list(self.get_tokenizer().get_vocab().keys())
+ self.assertEqual(vocab_keys[0], "")
+ self.assertEqual(vocab_keys[1], "")
+ self.assertEqual(vocab_keys[-1], "[PAD]")
+ self.assertEqual(len(vocab_keys), 30_001)
+
+ def test_vocab_size(self):
+ self.assertEqual(self.get_tokenizer().vocab_size, 30_000)
+
+ def test_do_lower_case(self):
+ # fmt: off
+ sequence = " \tHeLLo!how \n Are yoU? "
+ tokens_target = ["▁hello", "!", "how", "▁are", "▁you", "?"]
+ # fmt: on
+
+ tokenizer = DebertaV2Tokenizer(SAMPLE_VOCAB, unk_token="", do_lower_case=True)
+ tokens = tokenizer.convert_ids_to_tokens(tokenizer.encode(sequence, add_special_tokens=False))
+
+ self.assertListEqual(tokens, tokens_target)
+
+ rust_tokenizer = DebertaV2TokenizerFast(SAMPLE_VOCAB, unk_token="", do_lower_case=True)
+ rust_tokens = rust_tokenizer.convert_ids_to_tokens(rust_tokenizer.encode(sequence, add_special_tokens=False))
+
+ self.assertListEqual(rust_tokens, tokens_target)
+
+ @unittest.skip(reason="There is an inconsistency between slow and fast tokenizer due to a bug in the fast one.")
+ def test_sentencepiece_tokenize_and_convert_tokens_to_string(self):
+ pass
+
+ @unittest.skip(reason="There is an inconsistency between slow and fast tokenizer due to a bug in the fast one.")
+ def test_sentencepiece_tokenize_and_decode(self):
+ pass
+
+ def test_split_by_punct(self):
+ # fmt: off
+ sequence = "I was born in 92000, and this is falsé!"
+ tokens_target = ["▁", "", "▁was", "▁born", "▁in", "▁9", "2000", "▁", ",", "▁and", "▁this", "▁is", "▁fal", "s", "", "▁", "!", ]
+ # fmt: on
+
+ tokenizer = DebertaV2Tokenizer(SAMPLE_VOCAB, unk_token="", split_by_punct=True)
+ tokens = tokenizer.convert_ids_to_tokens(tokenizer.encode(sequence, add_special_tokens=False))
+
+ self.assertListEqual(tokens, tokens_target)
+
+ rust_tokenizer = DebertaV2TokenizerFast(SAMPLE_VOCAB, unk_token="", split_by_punct=True)
+ rust_tokens = rust_tokenizer.convert_ids_to_tokens(rust_tokenizer.encode(sequence, add_special_tokens=False))
+
+ self.assertListEqual(rust_tokens, tokens_target)
+
+ def test_do_lower_case_split_by_punct(self):
+ # fmt: off
+ sequence = "I was born in 92000, and this is falsé!"
+ tokens_target = ["▁i", "▁was", "▁born", "▁in", "▁9", "2000", "▁", ",", "▁and", "▁this", "▁is", "▁fal", "s", "", "▁", "!", ]
+ # fmt: on
+
+ tokenizer = DebertaV2Tokenizer(SAMPLE_VOCAB, unk_token="", do_lower_case=True, split_by_punct=True)
+ tokens = tokenizer.convert_ids_to_tokens(tokenizer.encode(sequence, add_special_tokens=False))
+ self.assertListEqual(tokens, tokens_target)
+
+ rust_tokenizer = DebertaV2TokenizerFast(
+ SAMPLE_VOCAB, unk_token="", do_lower_case=True, split_by_punct=True
+ )
+ rust_tokens = rust_tokenizer.convert_ids_to_tokens(rust_tokenizer.encode(sequence, add_special_tokens=False))
+ self.assertListEqual(rust_tokens, tokens_target)
+
+ def test_do_lower_case_split_by_punct_false(self):
+ # fmt: off
+ sequence = "I was born in 92000, and this is falsé!"
+ tokens_target = ["▁i", "▁was", "▁born", "▁in", "▁9", "2000", ",", "▁and", "▁this", "▁is", "▁fal", "s", "", "!", ]
+ # fmt: on
+
+ tokenizer = DebertaV2Tokenizer(SAMPLE_VOCAB, unk_token="", do_lower_case=True, split_by_punct=False)
+ tokens = tokenizer.convert_ids_to_tokens(tokenizer.encode(sequence, add_special_tokens=False))
+
+ self.assertListEqual(tokens, tokens_target)
+
+ rust_tokenizer = DebertaV2TokenizerFast(
+ SAMPLE_VOCAB, unk_token="", do_lower_case=True, split_by_punct=False
+ )
+ rust_tokens = rust_tokenizer.convert_ids_to_tokens(rust_tokenizer.encode(sequence, add_special_tokens=False))
+
+ self.assertListEqual(rust_tokens, tokens_target)
+
+ def test_do_lower_case_false_split_by_punct(self):
+ # fmt: off
+ sequence = "I was born in 92000, and this is falsé!"
+ tokens_target = ["▁", "", "▁was", "▁born", "▁in", "▁9", "2000", "▁", ",", "▁and", "▁this", "▁is", "▁fal", "s", "", "▁", "!", ]
+ # fmt: on
+
+ tokenizer = DebertaV2Tokenizer(SAMPLE_VOCAB, unk_token="", do_lower_case=False, split_by_punct=True)
+ tokens = tokenizer.convert_ids_to_tokens(tokenizer.encode(sequence, add_special_tokens=False))
+
+ self.assertListEqual(tokens, tokens_target)
+
+ rust_tokenizer = DebertaV2TokenizerFast(
+ SAMPLE_VOCAB, unk_token="", do_lower_case=False, split_by_punct=True
+ )
+ rust_tokens = rust_tokenizer.convert_ids_to_tokens(rust_tokenizer.encode(sequence, add_special_tokens=False))
+
+ self.assertListEqual(rust_tokens, tokens_target)
+
+ def test_do_lower_case_false_split_by_punct_false(self):
+ # fmt: off
+ sequence = " \tHeLLo!how \n Are yoU? "
+ tokens_target = ["▁", "", "e", "", "o", "!", "how", "▁", "", "re", "▁yo", "", "?"]
+ # fmt: on
+
+ tokenizer = DebertaV2Tokenizer(SAMPLE_VOCAB, unk_token="", do_lower_case=False, split_by_punct=False)
+ tokens = tokenizer.convert_ids_to_tokens(tokenizer.encode(sequence, add_special_tokens=False))
+
+ self.assertListEqual(tokens, tokens_target)
+
+ rust_tokenizer = DebertaV2TokenizerFast(
+ SAMPLE_VOCAB, unk_token="", do_lower_case=False, split_by_punct=False
+ )
+ rust_tokens = rust_tokenizer.convert_ids_to_tokens(rust_tokenizer.encode(sequence, add_special_tokens=False))
+
+ self.assertListEqual(rust_tokens, tokens_target)
+
+ def test_rust_and_python_full_tokenizers(self):
+ tokenizer = self.get_tokenizer()
+ rust_tokenizer = self.get_rust_tokenizer()
+
+ sequence = "I was born in 92000, and this is falsé!"
+
+ tokens = tokenizer.convert_ids_to_tokens(tokenizer.encode(sequence, add_special_tokens=False))
+ rust_tokens = rust_tokenizer.convert_ids_to_tokens(rust_tokenizer.encode(sequence, add_special_tokens=False))
+ self.assertListEqual(tokens, rust_tokens)
+
+ ids = tokenizer.encode(sequence, add_special_tokens=False)
+ rust_ids = rust_tokenizer.encode(sequence, add_special_tokens=False)
+ self.assertListEqual(ids, rust_ids)
+
+ rust_tokenizer = self.get_rust_tokenizer()
+ ids = tokenizer.encode(sequence)
+ rust_ids = rust_tokenizer.encode(sequence)
+ self.assertListEqual(ids, rust_ids)
+
+ def test_full_tokenizer(self):
+ sequence = "This is a test"
+ ids_target = [13, 1, 4398, 25, 21, 1289]
+ tokens_target = ["▁", "T", "his", "▁is", "▁a", "▁test"]
+ back_tokens_target = ["▁", "", "his", "▁is", "▁a", "▁test"]
+
+ tokenizer = DebertaV2Tokenizer(SAMPLE_VOCAB, unk_token="", keep_accents=True)
+ rust_tokenizer = DebertaV2TokenizerFast(SAMPLE_VOCAB, unk_token="", keep_accents=True)
+
+ ids = tokenizer.encode(sequence, add_special_tokens=False)
+ self.assertListEqual(ids, ids_target)
+ tokens = tokenizer.tokenize(sequence)
+ self.assertListEqual(tokens, tokens_target)
+ back_tokens = tokenizer.convert_ids_to_tokens(ids)
+ self.assertListEqual(back_tokens, back_tokens_target)
+
+ rust_ids = rust_tokenizer.encode(sequence, add_special_tokens=False)
+ self.assertListEqual(rust_ids, ids_target)
+ rust_tokens = rust_tokenizer.tokenize(sequence)
+ self.assertListEqual(rust_tokens, tokens_target)
+ rust_back_tokens = rust_tokenizer.convert_ids_to_tokens(rust_ids)
+ self.assertListEqual(rust_back_tokens, back_tokens_target)
+
+ # fmt: off
+ sequence = "I was born in 92000, and this is falsé!"
+ ids_target = [13, 1, 23, 386, 19, 561, 3050, 15, 17, 48, 25, 8256, 18, 1, 187]
+ tokens_target = ["▁", "I", "▁was", "▁born", "▁in", "▁9", "2000", ",", "▁and", "▁this", "▁is", "▁fal", "s", "é", "!", ]
+ back_tokens_target = ["▁", "", "▁was", "▁born", "▁in", "▁9", "2000", ",", "▁and", "▁this", "▁is", "▁fal", "s", "", "!", ]
+ # fmt: on
+
+ ids = tokenizer.encode(sequence, add_special_tokens=False)
+ self.assertListEqual(ids, ids_target)
+ tokens = tokenizer.tokenize(sequence)
+ self.assertListEqual(tokens, tokens_target)
+ back_tokens = tokenizer.convert_ids_to_tokens(ids)
+ self.assertListEqual(back_tokens, back_tokens_target)
+
+ rust_ids = rust_tokenizer.encode(sequence, add_special_tokens=False)
+ self.assertListEqual(rust_ids, ids_target)
+ rust_tokens = rust_tokenizer.tokenize(sequence)
+ self.assertListEqual(rust_tokens, tokens_target)
+ rust_back_tokens = rust_tokenizer.convert_ids_to_tokens(rust_ids)
+ self.assertListEqual(rust_back_tokens, back_tokens_target)
+
+ def test_sequence_builders(self):
+ tokenizer = DebertaV2Tokenizer(SAMPLE_VOCAB)
+
+ text = tokenizer.encode("sequence builders")
+ text_2 = tokenizer.encode("multi-sequence build")
+
+ encoded_sentence = tokenizer.build_inputs_with_special_tokens(text)
+ encoded_pair = tokenizer.build_inputs_with_special_tokens(text, text_2)
+
+ self.assertEqual([tokenizer.cls_token_id] + text + [tokenizer.sep_token_id], encoded_sentence)
+ self.assertEqual(
+ [tokenizer.cls_token_id] + text + [tokenizer.sep_token_id] + text_2 + [tokenizer.sep_token_id],
+ encoded_pair,
+ )
+
+ @slow
+ def test_tokenizer_integration(self):
+ expected_encoding = {'input_ids': [[1, 39867, 36, 19390, 486, 27, 35052, 81436, 18, 60685, 1225, 7, 35052, 81436, 18, 9367, 16899, 18, 15937, 53, 594, 773, 18, 16287, 30465, 36, 15937, 6, 41139, 38, 36979, 60763, 191, 6, 34132, 99, 6, 50538, 390, 43230, 6, 34132, 2779, 20850, 14, 699, 1072, 1194, 36, 382, 10901, 53, 7, 699, 1072, 2084, 36, 20422, 630, 53, 19, 105, 3049, 1896, 1053, 16899, 1506, 11, 37978, 4243, 7, 1237, 31869, 200, 16566, 654, 6, 35052, 81436, 7, 55630, 13593, 4, 2], [1, 26, 15011, 13, 667, 8, 1053, 18, 23611, 1237, 72356, 12820, 34, 104134, 1209, 35, 13313, 6627, 21, 202, 347, 7, 164, 2399, 11, 46, 4485, 4, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 5, 1232, 2864, 15785, 14951, 105, 5, 8581, 1250, 4, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]} # fmt: skip
+
+ self.tokenizer_integration_test_util(
+ expected_encoding=expected_encoding,
+ model_name="microsoft/deberta-v2-xlarge",
+ revision="ad6e42c1532ddf3a15c39246b63f5559d558b670",
+ )
diff --git a/transformers/tests/models/deepseek_v2/__init__.py b/transformers/tests/models/deepseek_v2/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/deepseek_v2/test_modeling_deepseek_v2.py b/transformers/tests/models/deepseek_v2/test_modeling_deepseek_v2.py
new file mode 100644
index 0000000000000000000000000000000000000000..02d087cb8b9ad1399955879646061cbc4660baa0
--- /dev/null
+++ b/transformers/tests/models/deepseek_v2/test_modeling_deepseek_v2.py
@@ -0,0 +1,269 @@
+# coding=utf-8
+# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch DeepSeekV2 model."""
+
+import unittest
+
+from transformers import BitsAndBytesConfig, Cache, DeepseekV2Config, is_torch_available
+from transformers.testing_utils import require_read_token, require_torch, require_torch_accelerator, slow, torch_device
+
+from ...causal_lm_tester import CausalLMModelTest, CausalLMModelTester
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import AutoTokenizer, DeepseekV2ForCausalLM, DeepseekV2ForSequenceClassification, DeepseekV2Model
+ from transformers.models.deepseek_v2.modeling_deepseek_v2 import DeepseekV2RotaryEmbedding
+
+
+class DeepseekV2ModelTester(CausalLMModelTester):
+ if is_torch_available():
+ config_class = DeepseekV2Config
+ base_model_class = DeepseekV2Model
+ causal_lm_class = DeepseekV2ForCausalLM
+ sequence_class = DeepseekV2ForSequenceClassification
+
+ def __init__(
+ self,
+ parent,
+ n_routed_experts=8,
+ kv_lora_rank=32,
+ q_lora_rank=16,
+ qk_nope_head_dim=64,
+ qk_rope_head_dim=64,
+ ):
+ super().__init__(parent=parent)
+ self.n_routed_experts = n_routed_experts
+ self.kv_lora_rank = kv_lora_rank
+ self.q_lora_rank = q_lora_rank
+ self.qk_nope_head_dim = qk_nope_head_dim
+ self.qk_rope_head_dim = qk_rope_head_dim
+
+
+@require_torch
+class DeepseekV2ModelTest(CausalLMModelTest, unittest.TestCase):
+ all_model_classes = (
+ (
+ DeepseekV2ForCausalLM,
+ DeepseekV2ForSequenceClassification,
+ DeepseekV2Model,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": DeepseekV2Model,
+ "text-classification": DeepseekV2ForSequenceClassification,
+ "text-generation": DeepseekV2ForCausalLM,
+ "zero-shot": DeepseekV2ForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_headmasking = False
+ test_pruning = False
+ fx_compatible = False
+ test_torchscript = False
+ model_tester_class = DeepseekV2ModelTester
+ rotary_embedding_layer = DeepseekV2RotaryEmbedding
+ model_split_percents = [0.5, 0.7, 0.8]
+
+ # used in `test_torch_compile_for_training`
+ _torch_compile_train_cls = DeepseekV2ForCausalLM if is_torch_available() else None
+
+ def test_model_rope_scaling(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ scaling_factor = 10
+ short_input_length = 10
+ long_input_length = int(config.max_position_embeddings * 1.5)
+
+ # Inputs
+ x = torch.randn(1, dtype=torch.float32, device=torch_device) # used exlusively to get the dtype and the device
+ position_ids_short = torch.arange(short_input_length, dtype=torch.long, device=torch_device)
+ position_ids_short = position_ids_short.unsqueeze(0)
+ position_ids_long = torch.arange(long_input_length, dtype=torch.long, device=torch_device)
+ position_ids_long = position_ids_long.unsqueeze(0)
+
+ # Sanity check original RoPE
+ original_rope = DeepseekV2RotaryEmbedding(config=config).to(torch_device)
+ original_freqs_cis_short = original_rope(x, position_ids_short)
+ original_freqs_cis_long = original_rope(x, position_ids_long)
+ torch.testing.assert_close(original_freqs_cis_short, original_freqs_cis_long[:, :short_input_length, :])
+
+ # Sanity check linear RoPE scaling
+ # New position "x" should match original position with index "x/scaling_factor"
+ config.rope_scaling = {"type": "linear", "factor": scaling_factor}
+ linear_scaling_rope = DeepseekV2RotaryEmbedding(config=config).to(torch_device)
+ linear_freqs_cis_short = linear_scaling_rope(x, position_ids_short)
+ linear_freqs_cis_long = linear_scaling_rope(x, position_ids_long)
+ torch.testing.assert_close(linear_freqs_cis_short, linear_freqs_cis_long[:, :short_input_length, :])
+
+ # Sanity check Dynamic NTK RoPE scaling
+ # Scaling should only be observed after a long input is fed. We can observe that the frequencies increase
+ # with scaling_factor (or that `inv_freq` decreases)
+ config.rope_scaling = {"type": "dynamic", "factor": scaling_factor}
+ ntk_scaling_rope = DeepseekV2RotaryEmbedding(config=config).to(torch_device)
+ ntk_freqs_cis_short = ntk_scaling_rope(x, position_ids_short)
+ ntk_freqs_cis_long = ntk_scaling_rope(x, position_ids_long)
+ torch.testing.assert_close(ntk_freqs_cis_short, original_freqs_cis_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_freqs_cis_long, original_freqs_cis_long)
+ self.assertTrue((ntk_scaling_rope.inv_freq <= original_rope.inv_freq).all())
+
+ # Sanity check Yarn RoPE scaling
+ # Scaling should be over the entire input
+ config.rope_scaling = {"type": "yarn", "factor": scaling_factor}
+ yarn_scaling_rope = DeepseekV2RotaryEmbedding(config=config).to(torch_device)
+ yarn_freqs_cis_short = yarn_scaling_rope(x, position_ids_short)
+ yarn_freqs_cis_long = yarn_scaling_rope(x, position_ids_long)
+ torch.testing.assert_close(yarn_freqs_cis_short, yarn_freqs_cis_long[:, :short_input_length, :])
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(yarn_freqs_cis_short, original_freqs_cis_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(yarn_freqs_cis_long, original_freqs_cis_long)
+
+ def test_past_key_values_format(self):
+ """
+ Overwriting to pass the expected cache shapes (Deepseek-V3 uses MLA so the cache shapes are non-standard)
+ """
+ config, inputs = self.model_tester.prepare_config_and_inputs_for_common()
+ batch_size, seq_length = inputs["input_ids"].shape
+ # difference: last dim
+ k_embed_dim = config.qk_nope_head_dim + config.qk_rope_head_dim
+ v_embed_dim = config.v_head_dim
+ self_attention_key_cache_shape = (batch_size, config.num_key_value_heads, seq_length, k_embed_dim)
+ self_attention_value_cache_shape = (batch_size, config.num_key_value_heads, seq_length, v_embed_dim)
+ # build the full cache shapes
+ num_hidden_layers = config.num_hidden_layers
+ all_cache_shapes = [
+ [self_attention_key_cache_shape, self_attention_value_cache_shape] for _ in range(num_hidden_layers)
+ ]
+ super().test_past_key_values_format(custom_all_cache_shapes=all_cache_shapes)
+
+ def _check_past_key_values_for_generate(self, batch_size, decoder_past_key_values, cache_length, config):
+ """Needs to be overriden as deepseek has special MLA cache format (though we don't really use the MLA)"""
+ self.assertIsInstance(decoder_past_key_values, Cache)
+
+ # (batch, head, seq_length, head_features)
+ expected_common_shape = (
+ batch_size,
+ config.num_key_value_heads if hasattr(config, "num_key_value_heads") else config.num_attention_heads,
+ cache_length,
+ )
+ expected_key_shape = expected_common_shape + (config.qk_nope_head_dim + config.qk_rope_head_dim,)
+ expected_value_shape = expected_common_shape + (config.v_head_dim,)
+
+ if isinstance(decoder_past_key_values, Cache):
+ self.assertListEqual(
+ [key_tensor.shape for key_tensor in decoder_past_key_values.key_cache],
+ [expected_key_shape] * len(decoder_past_key_values.key_cache),
+ )
+ self.assertListEqual(
+ [value_tensor.shape for value_tensor in decoder_past_key_values.value_cache],
+ [expected_value_shape] * len(decoder_past_key_values.value_cache),
+ )
+
+ @unittest.skip("Deepseek-V2 uses MLA which has a special head dim and is not compatible with StaticCache shape")
+ def test_generate_compilation_all_outputs(self):
+ pass
+
+ @unittest.skip("Deepseek-V2 uses MLA which has a special head dim and is not compatible with StaticCache shape")
+ def test_generate_compile_model_forward(self):
+ pass
+
+ @unittest.skip("Deepseek-V2 uses MLA which has a special head dim and is not compatible with StaticCache shape")
+ def test_generate_from_inputs_embeds_with_static_cache(self):
+ pass
+
+ @unittest.skip("Deepseek-V2 uses MLA which has a special head dim and is not compatible with StaticCache shape")
+ def test_generate_with_static_cache(self):
+ pass
+
+ @unittest.skip("Dynamic control flow in MoE")
+ def test_torch_compile_for_training(self):
+ pass
+
+
+@slow
+@require_read_token
+@require_torch_accelerator
+class DeepseekV2IntegrationTest(unittest.TestCase):
+ def test_deepseek_v2_lite(self):
+ EXPECTED_TEXT = ['An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors.\n\nAttention functions are used in a variety of applications, including natural language processing, computer vision, and reinforcement learning.\n\nThe attention function is a function that takes a query and a set of key-value pairs as input and outputs a vector'] # fmt: skip
+
+ tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-V2-Lite")
+ model = DeepseekV2ForCausalLM.from_pretrained(
+ "deepseek-ai/DeepSeek-V2-Lite",
+ device_map=torch_device,
+ torch_dtype=torch.bfloat16,
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+
+ input_text = [
+ "An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors." # fmt: skip
+ ]
+ model_inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
+
+ generated_ids = model.generate(**model_inputs, max_new_tokens=50, do_sample=False)
+ generated_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+ self.assertEqual(generated_text, EXPECTED_TEXT)
+
+ def test_logits_eager(self):
+ input_ids = [1, 306, 4658, 278, 6593, 310, 2834, 338]
+
+ model = DeepseekV2ForCausalLM.from_pretrained(
+ "deepseek-ai/DeepSeek-V2-Lite",
+ device_map=torch_device,
+ torch_dtype=torch.bfloat16,
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ attn_implementation="eager",
+ )
+
+ with torch.no_grad():
+ out = model(torch.tensor([input_ids]).to(torch_device))
+
+ EXPECTED_MEAN = torch.tensor([[-6.1232, -5.0952, -4.4493, -2.6536, -2.0608, -2.3991, -3.8013, -2.8681]], device=torch_device) # fmt: skip
+ torch.testing.assert_close(out.logits.float().mean(-1), EXPECTED_MEAN, atol=1e-3, rtol=1e-3)
+
+ EXPECTED_SLICE = torch.tensor([-1.2500, -0.9961, -0.0194, -3.1562, 1.2812, -2.7656, -0.8438, -3.0469, -2.7812, -0.6328, -0.4160, -1.9688, -2.4219, -1.0391, -3.8906], device=torch_device) # fmt: skip
+ torch.testing.assert_close(out.logits[0, 0, :15].float(), EXPECTED_SLICE, atol=1e-3, rtol=1e-3)
+
+ def test_batch_fa2(self):
+ EXPECTED_TEXT = [
+ "Simply put, the theory of relativity states that \nthe laws of physics are the same for all observers, regardless of their \nrelative motion.\nThe theory of relativity is a theory of space, time, and gravity.\nThe theory of", # fmt: skip
+ "My favorite all time favorite condiment is ketchup. I love ketchup. I love ketchup on my hot dogs, hamburgers, french fries, and even on my eggs. I love ketchup. I love ketchup so much that I", # fmt: skip
+ ]
+
+ prompts = [
+ "Simply put, the theory of relativity states that ",
+ "My favorite all time favorite condiment is ketchup.",
+ ]
+ tokenizer = AutoTokenizer.from_pretrained(
+ "deepseek-ai/DeepSeek-V2-Lite", pad_token="", padding_side="right"
+ )
+
+ model = DeepseekV2ForCausalLM.from_pretrained(
+ "deepseek-ai/DeepSeek-V2-Lite",
+ device_map=torch_device,
+ torch_dtype=torch.bfloat16,
+ quantization_config=BitsAndBytesConfig(load_in_8bit=True),
+ )
+ inputs = tokenizer(prompts, return_tensors="pt", padding=True).to(model.device)
+
+ generated_ids = model.generate(**inputs, max_new_tokens=40, do_sample=False)
+ generated_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT, generated_text)
diff --git a/transformers/tests/models/deepseek_v3/__init__.py b/transformers/tests/models/deepseek_v3/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/deepseek_v3/test_modeling_deepseek_v3.py b/transformers/tests/models/deepseek_v3/test_modeling_deepseek_v3.py
new file mode 100644
index 0000000000000000000000000000000000000000..6c0c3a19d067b8fab374721ff434007cb0672e79
--- /dev/null
+++ b/transformers/tests/models/deepseek_v3/test_modeling_deepseek_v3.py
@@ -0,0 +1,583 @@
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch DeepseekV3 model."""
+
+import unittest
+
+from packaging import version
+from parameterized import parameterized
+
+from transformers import AutoTokenizer, DeepseekV3Config, is_torch_available, set_seed
+from transformers.testing_utils import (
+ cleanup,
+ require_read_token,
+ require_torch,
+ require_torch_accelerator,
+ require_torch_gpu,
+ require_torch_large_accelerator,
+ require_torch_sdpa,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ DeepseekV3ForCausalLM,
+ DeepseekV3Model,
+ )
+ from transformers.models.deepseek_v3.modeling_deepseek_v3 import (
+ DeepseekV3RotaryEmbedding,
+ )
+
+
+class DeepseekV3ModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=False,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ intermediate_size=37,
+ moe_intermediate_size=12,
+ num_hidden_layers=5,
+ num_attention_heads=4,
+ num_key_value_heads=4,
+ n_shared_experts=1,
+ n_routed_experts=8,
+ routed_scaling_factor=2.5,
+ kv_lora_rank=16,
+ q_lora_rank=32,
+ qk_rope_head_dim=16,
+ v_head_dim=32,
+ qk_nope_head_dim=32,
+ n_group=2,
+ topk_group=1,
+ num_experts_per_tok=8,
+ first_k_dense_replace=2,
+ norm_topk_prob=True,
+ aux_loss_alpha=0.001,
+ hidden_act="silu",
+ max_position_embeddings=512,
+ initializer_range=0.02,
+ attention_probs_dropout_prob=0.1,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ num_labels=3,
+ num_choices=4,
+ pad_token_id=0,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.moe_intermediate_size = moe_intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.num_key_value_heads = num_key_value_heads
+ self.n_shared_experts = n_shared_experts
+ self.n_routed_experts = n_routed_experts
+ self.routed_scaling_factor = routed_scaling_factor
+ self.kv_lora_rank = kv_lora_rank
+ self.q_lora_rank = q_lora_rank
+ self.qk_rope_head_dim = qk_rope_head_dim
+ self.v_head_dim = v_head_dim
+ self.qk_nope_head_dim = qk_nope_head_dim
+ self.n_group = n_group
+ self.topk_group = topk_group
+ self.num_experts_per_tok = num_experts_per_tok
+ self.first_k_dense_replace = first_k_dense_replace
+ self.norm_topk_prob = norm_topk_prob
+ self.aux_loss_alpha = aux_loss_alpha
+ self.hidden_act = hidden_act
+ self.max_position_embeddings = max_position_embeddings
+ self.initializer_range = initializer_range
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.pad_token_id = pad_token_id
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = torch.tril(torch.ones_like(input_ids).to(torch_device))
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ return DeepseekV3Config(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ intermediate_size=self.intermediate_size,
+ moe_intermediate_size=self.moe_intermediate_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ num_key_value_heads=self.num_key_value_heads,
+ n_shared_experts=self.n_shared_experts,
+ n_routed_experts=self.n_routed_experts,
+ routed_scaling_factor=self.routed_scaling_factor,
+ kv_lora_rank=self.kv_lora_rank,
+ q_lora_rank=self.q_lora_rank,
+ qk_rope_head_dim=self.qk_rope_head_dim,
+ v_head_dim=self.v_head_dim,
+ qk_nope_head_dim=self.qk_nope_head_dim,
+ n_group=self.n_group,
+ topk_group=self.topk_group,
+ num_experts_per_tok=self.num_experts_per_tok,
+ first_k_dense_replace=self.first_k_dense_replace,
+ norm_topk_prob=self.norm_topk_prob,
+ aux_loss_alpha=self.aux_loss_alpha,
+ hidden_act=self.hidden_act,
+ max_position_embeddings=self.max_position_embeddings,
+ initializer_range=self.initializer_range,
+ use_cache=True,
+ pad_token_id=self.pad_token_id,
+ attention_dropout=self.attention_probs_dropout_prob,
+ )
+
+ def create_and_check_model(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = DeepseekV3Model(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class DeepseekV3ModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ DeepseekV3Model,
+ DeepseekV3ForCausalLM,
+ )
+ if is_torch_available()
+ else ()
+ )
+ all_generative_model_classes = (DeepseekV3ForCausalLM,) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": DeepseekV3Model,
+ "text-generation": DeepseekV3ForCausalLM,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_headmasking = False
+ test_pruning = False
+ fx_compatible = False
+
+ # Need to use `0.8` instead of `0.9` for `test_cpu_offload`
+ # This is because we are hitting edge cases with the causal_mask buffer
+ model_split_percents = [0.5, 0.7, 0.8]
+
+ # used in `test_torch_compile_for_training`
+ _torch_compile_train_cls = DeepseekV3ForCausalLM if is_torch_available() else None
+
+ def setUp(self):
+ self.model_tester = DeepseekV3ModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=DeepseekV3Config, hidden_size=37)
+
+ @unittest.skip("Failing because of unique cache (HybridCache)")
+ def test_model_outputs_equivalence(self, **kwargs):
+ pass
+
+ @parameterized.expand([("random",), ("same",)])
+ @unittest.skip("DeepseekV3 has HybridCache which is not compatible with assisted decoding")
+ def test_assisted_decoding_matches_greedy_search(self, assistant_type):
+ pass
+
+ @unittest.skip("DeepseekV3 has HybridCache which is not compatible with assisted decoding")
+ def test_prompt_lookup_decoding_matches_greedy_search(self, assistant_type):
+ pass
+
+ @unittest.skip("DeepseekV3 has HybridCache which is not compatible with assisted decoding")
+ def test_assisted_decoding_sample(self):
+ pass
+
+ @unittest.skip("DeepseekV3 has HybridCache which is not compatible with dola decoding")
+ def test_dola_decoding_sample(self):
+ pass
+
+ @unittest.skip("DeepseekV3 has HybridCache and doesn't support continue from past kv")
+ def test_generate_continue_from_past_key_values(self):
+ pass
+
+ @unittest.skip("DeepseekV3 has HybridCache and doesn't support low_memory generation")
+ def test_beam_search_low_memory(self):
+ pass
+
+ @unittest.skip("DeepseekV3 has HybridCache and doesn't support contrastive generation")
+ def test_contrastive_generate(self):
+ pass
+
+ @unittest.skip("DeepseekV3 has HybridCache and doesn't support contrastive generation")
+ def test_contrastive_generate_dict_outputs_use_cache(self):
+ pass
+
+ @unittest.skip("DeepseekV3 has HybridCache and doesn't support contrastive generation")
+ def test_contrastive_generate_low_memory(self):
+ pass
+
+ @unittest.skip(
+ "DeepseekV3 has HybridCache and doesn't support StaticCache. Though it could, it shouldn't support."
+ )
+ def test_generate_with_static_cache(self):
+ pass
+
+ @unittest.skip(
+ "DeepseekV3 has HybridCache and doesn't support StaticCache. Though it could, it shouldn't support."
+ )
+ def test_generate_from_inputs_embeds_with_static_cache(self):
+ pass
+
+ @unittest.skip(
+ "DeepseekV3 has HybridCache and doesn't support StaticCache. Though it could, it shouldn't support."
+ )
+ def test_generate_continue_from_inputs_embeds(self):
+ pass
+
+ @unittest.skip("Deepseek-V3 uses MLA so it is not compatible with the standard cache format")
+ def test_beam_search_generate_dict_outputs_use_cache(self):
+ pass
+
+ @unittest.skip("Deepseek-V3 uses MLA so it is not compatible with the standard cache format")
+ def test_generate_compilation_all_outputs(self):
+ pass
+
+ @unittest.skip("Deepseek-V3 uses MLA so it is not compatible with the standard cache format")
+ def test_generate_compile_model_forward(self):
+ pass
+
+ @unittest.skip("Deepseek-V3 uses MLA so it is not compatible with the standard cache format")
+ def test_greedy_generate_dict_outputs_use_cache(self):
+ pass
+
+ @unittest.skip(reason="SDPA can't dispatch on flash due to unsupported head dims")
+ def test_sdpa_can_dispatch_on_flash(self):
+ pass
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_various_embeddings(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["absolute", "relative_key", "relative_key_query"]:
+ config_and_inputs[0].position_embedding_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @parameterized.expand([("yarn",)])
+ def test_model_rope_scaling_from_config(self, scaling_type):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ short_input = ids_tensor([1, 10], config.vocab_size)
+ long_input = ids_tensor([1, int(config.max_position_embeddings * 1.5)], config.vocab_size)
+
+ set_seed(42) # Fixed seed at init time so the two models get the same random weights
+ original_model = DeepseekV3Model(config)
+ original_model.to(torch_device)
+ original_model.eval()
+ original_short_output = original_model(short_input).last_hidden_state
+ original_long_output = original_model(long_input).last_hidden_state
+
+ set_seed(42) # Fixed seed at init time so the two models get the same random weights
+ config.rope_scaling = {"type": scaling_type, "factor": 10.0}
+ scaled_model = DeepseekV3Model(config)
+ scaled_model.to(torch_device)
+ scaled_model.eval()
+ scaled_short_output = scaled_model(short_input).last_hidden_state
+ scaled_long_output = scaled_model(long_input).last_hidden_state
+
+ # Dynamic scaling does not change the RoPE embeddings until it receives an input longer than the original
+ # maximum sequence length, so the outputs for the short input should match.
+ if scaling_type == "dynamic":
+ torch.testing.assert_close(original_short_output, scaled_short_output, rtol=1e-5, atol=1e-5)
+ else:
+ self.assertFalse(torch.allclose(original_short_output, scaled_short_output, atol=1e-5))
+
+ # The output should be different for long inputs
+ self.assertFalse(torch.allclose(original_long_output, scaled_long_output, atol=1e-5))
+
+ def test_model_rope_scaling(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ scaling_factor = 10
+ short_input_length = 10
+ long_input_length = int(config.max_position_embeddings * 1.5)
+
+ # Inputs
+ x = torch.randn(1, dtype=torch.float32, device=torch_device) # used exlusively to get the dtype and the device
+ position_ids_short = torch.arange(short_input_length, dtype=torch.long, device=torch_device)
+ position_ids_short = position_ids_short.unsqueeze(0)
+ position_ids_long = torch.arange(long_input_length, dtype=torch.long, device=torch_device)
+ position_ids_long = position_ids_long.unsqueeze(0)
+
+ # Sanity check original RoPE
+ original_rope = DeepseekV3RotaryEmbedding(config=config).to(torch_device)
+ original_cos_short, original_sin_short = original_rope(x, position_ids_short)
+ original_cos_long, original_sin_long = original_rope(x, position_ids_long)
+ torch.testing.assert_close(original_cos_short, original_cos_long[:, :short_input_length, :])
+ torch.testing.assert_close(original_sin_short, original_sin_long[:, :short_input_length, :])
+
+ # Sanity check linear RoPE scaling
+ # New position "x" should match original position with index "x/scaling_factor"
+ config.rope_scaling = {"type": "linear", "factor": scaling_factor}
+ linear_scaling_rope = DeepseekV3RotaryEmbedding(config=config).to(torch_device)
+ linear_cos_short, linear_sin_short = linear_scaling_rope(x, position_ids_short)
+ linear_cos_long, linear_sin_long = linear_scaling_rope(x, position_ids_long)
+ torch.testing.assert_close(linear_cos_short, linear_cos_long[:, :short_input_length, :])
+ torch.testing.assert_close(linear_sin_short, linear_sin_long[:, :short_input_length, :])
+ for new_position in range(0, long_input_length, scaling_factor):
+ original_position = int(new_position // scaling_factor)
+ torch.testing.assert_close(linear_cos_long[:, new_position, :], original_cos_long[:, original_position, :])
+ torch.testing.assert_close(linear_sin_long[:, new_position, :], original_sin_long[:, original_position, :])
+
+ # Sanity check Dynamic NTK RoPE scaling
+ # Scaling should only be observed after a long input is fed. We can observe that the frequencies increase
+ # with scaling_factor (or that `inv_freq` decreases)
+ config.rope_scaling = {"type": "dynamic", "factor": scaling_factor}
+ ntk_scaling_rope = DeepseekV3RotaryEmbedding(config=config).to(torch_device)
+ ntk_cos_short, ntk_sin_short = ntk_scaling_rope(x, position_ids_short)
+ ntk_cos_long, ntk_sin_long = ntk_scaling_rope(x, position_ids_long)
+ torch.testing.assert_close(ntk_cos_short, original_cos_short)
+ torch.testing.assert_close(ntk_sin_short, original_sin_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_cos_long, original_cos_long)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_sin_long, original_sin_long)
+ self.assertTrue((ntk_scaling_rope.inv_freq <= original_rope.inv_freq).all())
+
+ # Sanity check Yarn RoPE scaling
+ # Scaling should be over the entire input
+ config.rope_scaling = {"type": "yarn", "factor": scaling_factor}
+ yarn_scaling_rope = DeepseekV3RotaryEmbedding(config=config).to(torch_device)
+ yarn_cos_short, yarn_sin_short = yarn_scaling_rope(x, position_ids_short)
+ yarn_cos_long, yarn_sin_long = yarn_scaling_rope(x, position_ids_long)
+ torch.testing.assert_close(yarn_cos_short, yarn_cos_long[:, :short_input_length, :])
+ torch.testing.assert_close(yarn_sin_short, yarn_sin_long[:, :short_input_length, :])
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(yarn_cos_short, original_cos_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(yarn_sin_short, original_sin_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(yarn_cos_long, original_cos_long)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(yarn_sin_long, original_sin_long)
+
+ def test_past_key_values_format(self):
+ """
+ Overwriting to pass the expected cache shapes (Deepseek-V3 uses MLA so the cache shapes are non-standard)
+ """
+ config, inputs = self.model_tester.prepare_config_and_inputs_for_common()
+ batch_size, seq_length = inputs["input_ids"].shape
+ # difference: last dim
+ k_embed_dim = config.qk_nope_head_dim + config.qk_rope_head_dim
+ v_embed_dim = config.v_head_dim
+ self_attention_key_cache_shape = (batch_size, config.num_key_value_heads, seq_length, k_embed_dim)
+ self_attention_value_cache_shape = (batch_size, config.num_key_value_heads, seq_length, v_embed_dim)
+ # build the full cache shapes
+ num_hidden_layers = config.num_hidden_layers
+ all_cache_shapes = [
+ [self_attention_key_cache_shape, self_attention_value_cache_shape] for _ in range(num_hidden_layers)
+ ]
+ super().test_past_key_values_format(custom_all_cache_shapes=all_cache_shapes)
+
+ @require_torch_large_accelerator
+ @require_torch_sdpa
+ @slow
+ def test_eager_matches_sdpa_generate(self):
+ """
+ Overwriting the common test as the test is flaky on tiny models
+ """
+ max_new_tokens = 30
+
+ tokenizer = AutoTokenizer.from_pretrained("bzantium/tiny-deepseek-v3")
+
+ model_sdpa = DeepseekV3ForCausalLM.from_pretrained(
+ "bzantium/tiny-deepseek-v3",
+ torch_dtype=torch.float16,
+ ).to(torch_device)
+
+ self.assertTrue(model_sdpa.config._attn_implementation == "sdpa")
+
+ model_eager = DeepseekV3ForCausalLM.from_pretrained(
+ "bzantium/tiny-deepseek-v3",
+ torch_dtype=torch.float16,
+ attn_implementation="eager",
+ ).to(torch_device)
+
+ self.assertTrue(model_eager.config._attn_implementation == "eager")
+
+ texts = [
+ "hi here's a longer context, getting longer and",
+ "Hello this is a very long sentence my friend, very long for real",
+ "Today I am in Paris and",
+ ]
+
+ for padding_side in ["left", "right"]:
+ tokenizer.padding_side = padding_side
+ tokenizer.pad_token = tokenizer.eos_token
+
+ inputs = tokenizer(texts, return_tensors="pt", padding=True).to(torch_device)
+
+ res_eager = model_eager.generate(**inputs, max_new_tokens=max_new_tokens, do_sample=False)
+ res_sdpa = model_sdpa.generate(**inputs, max_new_tokens=max_new_tokens, do_sample=False)
+
+ with self.subTest(f"{padding_side}"):
+ torch.testing.assert_close(
+ res_eager,
+ res_sdpa,
+ msg=f"\n{tokenizer.batch_decode(res_eager)} \nvs\n{tokenizer.batch_decode(res_sdpa)}",
+ )
+
+ @require_torch_gpu
+ def test_flex_attention_with_grads(self):
+ """
+ Overwriting as the namings/functionality on the attention part are different; for now it's more of a unique model.
+ Original issue is also due to dimensionalities, here specifically due to dims not being a multiple of 2.
+ """
+ for model_class in self.all_model_classes:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config._attn_implementation = "flex_attention"
+
+ # Disable dropout
+ config.attention_dropout = 0.0
+
+ # Deepseek 3 specific - manipulate nope and adjust calculated total head dim
+ config.qk_nope_head_dim = 16
+ config.qk_head_dim = config.qk_nope_head_dim + config.qk_rope_head_dim
+
+ model = model_class(config).to(device=torch_device)
+ self.assertTrue(model.config._attn_implementation == "flex_attention")
+
+ # Elaborate workaround for encoder-decoder models as some do not specify their main input
+ dummy_inputs = {model.main_input_name: inputs_dict[model.main_input_name].to(torch_device)}
+ if config.is_encoder_decoder:
+ dummy_inputs["decoder_input_ids"] = inputs_dict["decoder_input_ids"].to(torch_device)
+ dummy_inputs["decoder_attention_mask"] = inputs_dict["decoder_attention_mask"].to(torch_device)
+
+ # If this does not raise an error, the test passes (see https://github.com/huggingface/transformers/pull/35605)
+ _ = model(**dummy_inputs)
+
+
+@require_torch_accelerator
+class DeepseekV3IntegrationTest(unittest.TestCase):
+ def tearDown(self):
+ # See LlamaIntegrationTest.tearDown(). Can be removed once LlamaIntegrationTest.tearDown() is removed.
+ cleanup(torch_device, gc_collect=False)
+
+ @slow
+ @require_torch_accelerator
+ @require_read_token
+ def test_compile_static_cache(self):
+ # `torch==2.2` will throw an error on this test (as in other compilation tests), but torch==2.1.2 and torch>2.2
+ # work as intended. See https://github.com/pytorch/pytorch/issues/121943
+ if version.parse(torch.__version__) < version.parse("2.3.0"):
+ self.skipTest(reason="This test requires torch >= 2.3 to run.")
+
+ NUM_TOKENS_TO_GENERATE = 40
+ # https://github.com/huggingface/transformers/pull/38562#issuecomment-2939209171
+ # The reason why the output is gibberish is because the testing model bzantium/tiny-deepseek-v3 is not trained
+ # one. Since original DeepSeek-V3 model is too big to debug and test, there was no testing with the original one.
+ EXPECTED_TEXT_COMPLETION = [
+ "Simply put, the theory of relativity states that Frojekecdytesాలు sicʰtinaccianntuala breej的效率和质量的控制lavestock-PraccuraciesOTTensorialoghismos的思路astiomotivityosexualriad TherapeuticsoldtYPEface Kishsatellite-TV",
+ "My favorite all time favorite condiment is ketchup.ieden沟渠係室温 Fryrok般地Segmentation Cycle/physicalwarenkrautempsాలు蹈梗 Mesomac一等asan lethality suspended Causewaydreamswith Fossilsdorfాలు蹈 ChristiansenHOMEbrew",
+ ]
+
+ prompts = [
+ "Simply put, the theory of relativity states that ",
+ "My favorite all time favorite condiment is ketchup.",
+ ]
+ tokenizer = AutoTokenizer.from_pretrained("bzantium/tiny-deepseek-v3", pad_token="", padding_side="right")
+ model = DeepseekV3ForCausalLM.from_pretrained(
+ "bzantium/tiny-deepseek-v3", device_map=torch_device, torch_dtype=torch.float16
+ )
+ inputs = tokenizer(prompts, return_tensors="pt", padding=True).to(model.device)
+
+ # Dynamic Cache
+ generated_ids = model.generate(**inputs, max_new_tokens=NUM_TOKENS_TO_GENERATE, do_sample=False)
+ dynamic_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, dynamic_text)
+
+ # Static Cache
+ generated_ids = model.generate(
+ **inputs, max_new_tokens=NUM_TOKENS_TO_GENERATE, do_sample=False, cache_implementation="static"
+ )
+ static_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, static_text)
+
+ # Static Cache + compile
+ model._cache = None # clear cache object, initialized when we pass `cache_implementation="static"`
+ model.forward = torch.compile(model.forward, mode="reduce-overhead", fullgraph=True)
+ generated_ids = model.generate(
+ **inputs, max_new_tokens=NUM_TOKENS_TO_GENERATE, do_sample=False, cache_implementation="static"
+ )
+ static_compiled_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, static_compiled_text)
diff --git a/transformers/tests/models/deformable_detr/__init__.py b/transformers/tests/models/deformable_detr/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/deformable_detr/test_image_processing_deformable_detr.py b/transformers/tests/models/deformable_detr/test_image_processing_deformable_detr.py
new file mode 100644
index 0000000000000000000000000000000000000000..f6bf929eadf9c918f19b8a2fd15e2a735f8221fb
--- /dev/null
+++ b/transformers/tests/models/deformable_detr/test_image_processing_deformable_detr.py
@@ -0,0 +1,740 @@
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import pathlib
+import unittest
+
+import numpy as np
+
+from transformers.testing_utils import (
+ require_torch,
+ require_torch_accelerator,
+ require_vision,
+ slow,
+ torch_device,
+)
+from transformers.utils import is_torch_available, is_torchvision_available, is_vision_available
+
+from ...test_image_processing_common import AnnotationFormatTestMixin, ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import DeformableDetrImageProcessor, DeformableDetrImageProcessorFast
+
+
+class DeformableDetrImageProcessingTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_pad=True,
+ ):
+ # by setting size["longest_edge"] > max_resolution we're effectively not testing this :p
+ size = size if size is not None else {"shortest_edge": 18, "longest_edge": 1333}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
+
+ def prepare_image_processor_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
+ "do_pad": self.do_pad,
+ }
+
+ def get_expected_values(self, image_inputs, batched=False):
+ """
+ This function computes the expected height and width when providing images to DeformableDetrImageProcessor,
+ assuming do_resize is set to True with a scalar size.
+ """
+ if not batched:
+ image = image_inputs[0]
+ if isinstance(image, Image.Image):
+ w, h = image.size
+ elif isinstance(image, np.ndarray):
+ h, w = image.shape[0], image.shape[1]
+ else:
+ h, w = image.shape[1], image.shape[2]
+ if w < h:
+ expected_height = int(self.size["shortest_edge"] * h / w)
+ expected_width = self.size["shortest_edge"]
+ elif w > h:
+ expected_height = self.size["shortest_edge"]
+ expected_width = int(self.size["shortest_edge"] * w / h)
+ else:
+ expected_height = self.size["shortest_edge"]
+ expected_width = self.size["shortest_edge"]
+
+ else:
+ expected_values = []
+ for image in image_inputs:
+ expected_height, expected_width = self.get_expected_values([image])
+ expected_values.append((expected_height, expected_width))
+ expected_height = max(expected_values, key=lambda item: item[0])[0]
+ expected_width = max(expected_values, key=lambda item: item[1])[1]
+
+ return expected_height, expected_width
+
+ def expected_output_image_shape(self, images):
+ height, width = self.get_expected_values(images, batched=True)
+ return self.num_channels, height, width
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class DeformableDetrImageProcessingTest(AnnotationFormatTestMixin, ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = DeformableDetrImageProcessor if is_vision_available() else None
+ fast_image_processing_class = DeformableDetrImageProcessorFast if is_torchvision_available() else None
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = DeformableDetrImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "do_rescale"))
+ self.assertTrue(hasattr(image_processing, "do_pad"))
+ self.assertTrue(hasattr(image_processing, "size"))
+
+ def test_image_processor_from_dict_with_kwargs(self):
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"shortest_edge": 18, "longest_edge": 1333})
+ self.assertEqual(image_processor.do_pad, True)
+
+ image_processor = image_processing_class.from_dict(
+ self.image_processor_dict, size=42, max_size=84, pad_and_return_pixel_mask=False
+ )
+ self.assertEqual(image_processor.size, {"shortest_edge": 42, "longest_edge": 84})
+ self.assertEqual(image_processor.do_pad, False)
+
+ @slow
+ def test_call_pytorch_with_coco_detection_annotations(self):
+ # prepare image and target
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ target = {"image_id": 39769, "annotations": target}
+
+ for image_processing_class in self.image_processor_list:
+ # encode them
+ image_processing = image_processing_class()
+ encoding = image_processing(images=image, annotations=target, return_tensors="pt")
+
+ # verify pixel values
+ expected_shape = torch.Size([1, 3, 800, 1066])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ expected_slice = torch.tensor([0.2796, 0.3138, 0.3481])
+ torch.testing.assert_close(encoding["pixel_values"][0, 0, 0, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ # verify area
+ expected_area = torch.tensor([5887.9600, 11250.2061, 489353.8438, 837122.7500, 147967.5156, 165732.3438])
+ torch.testing.assert_close(encoding["labels"][0]["area"], expected_area)
+ # verify boxes
+ expected_boxes_shape = torch.Size([6, 4])
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, expected_boxes_shape)
+ expected_boxes_slice = torch.tensor([0.5503, 0.2765, 0.0604, 0.2215])
+ torch.testing.assert_close(encoding["labels"][0]["boxes"][0], expected_boxes_slice, rtol=1e-3, atol=1e-3)
+ # verify image_id
+ expected_image_id = torch.tensor([39769])
+ torch.testing.assert_close(encoding["labels"][0]["image_id"], expected_image_id)
+ # verify is_crowd
+ expected_is_crowd = torch.tensor([0, 0, 0, 0, 0, 0])
+ torch.testing.assert_close(encoding["labels"][0]["iscrowd"], expected_is_crowd)
+ # verify class_labels
+ expected_class_labels = torch.tensor([75, 75, 63, 65, 17, 17])
+ torch.testing.assert_close(encoding["labels"][0]["class_labels"], expected_class_labels)
+ # verify orig_size
+ expected_orig_size = torch.tensor([480, 640])
+ torch.testing.assert_close(encoding["labels"][0]["orig_size"], expected_orig_size)
+ # verify size
+ expected_size = torch.tensor([800, 1066])
+ torch.testing.assert_close(encoding["labels"][0]["size"], expected_size)
+
+ @slow
+ def test_call_pytorch_with_coco_panoptic_annotations(self):
+ # prepare image, target and masks_path
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ target = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+
+ masks_path = pathlib.Path("./tests/fixtures/tests_samples/COCO/coco_panoptic")
+
+ for image_processing_class in self.image_processor_list:
+ # encode them
+ image_processing = image_processing_class(format="coco_panoptic")
+ encoding = image_processing(images=image, annotations=target, masks_path=masks_path, return_tensors="pt")
+
+ # verify pixel values
+ expected_shape = torch.Size([1, 3, 800, 1066])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ expected_slice = torch.tensor([0.2796, 0.3138, 0.3481])
+ torch.testing.assert_close(encoding["pixel_values"][0, 0, 0, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ # verify area
+ expected_area = torch.tensor([147979.6875, 165527.0469, 484638.5938, 11292.9375, 5879.6562, 7634.1147])
+ torch.testing.assert_close(encoding["labels"][0]["area"], expected_area)
+ # verify boxes
+ expected_boxes_shape = torch.Size([6, 4])
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, expected_boxes_shape)
+ expected_boxes_slice = torch.tensor([0.2625, 0.5437, 0.4688, 0.8625])
+ torch.testing.assert_close(encoding["labels"][0]["boxes"][0], expected_boxes_slice, rtol=1e-3, atol=1e-3)
+ # verify image_id
+ expected_image_id = torch.tensor([39769])
+ torch.testing.assert_close(encoding["labels"][0]["image_id"], expected_image_id)
+ # verify is_crowd
+ expected_is_crowd = torch.tensor([0, 0, 0, 0, 0, 0])
+ torch.testing.assert_close(encoding["labels"][0]["iscrowd"], expected_is_crowd)
+ # verify class_labels
+ expected_class_labels = torch.tensor([17, 17, 63, 75, 75, 93])
+ torch.testing.assert_close(encoding["labels"][0]["class_labels"], expected_class_labels)
+ # verify masks
+ expected_masks_sum = 822873
+ relative_error = torch.abs(encoding["labels"][0]["masks"].sum() - expected_masks_sum) / expected_masks_sum
+ self.assertTrue(relative_error < 1e-3)
+ # verify orig_size
+ expected_orig_size = torch.tensor([480, 640])
+ torch.testing.assert_close(encoding["labels"][0]["orig_size"], expected_orig_size)
+ # verify size
+ expected_size = torch.tensor([800, 1066])
+ torch.testing.assert_close(encoding["labels"][0]["size"], expected_size)
+
+ @slow
+ # Copied from tests.models.detr.test_image_processing_detr.DetrImageProcessingTest.test_batched_coco_detection_annotations with Detr->DeformableDetr
+ def test_batched_coco_detection_annotations(self):
+ image_0 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ image_1 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png").resize((800, 800))
+
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ annotations_0 = {"image_id": 39769, "annotations": target}
+ annotations_1 = {"image_id": 39769, "annotations": target}
+
+ # Adjust the bounding boxes for the resized image
+ w_0, h_0 = image_0.size
+ w_1, h_1 = image_1.size
+ for i in range(len(annotations_1["annotations"])):
+ coords = annotations_1["annotations"][i]["bbox"]
+ new_bbox = [
+ coords[0] * w_1 / w_0,
+ coords[1] * h_1 / h_0,
+ coords[2] * w_1 / w_0,
+ coords[3] * h_1 / h_0,
+ ]
+ annotations_1["annotations"][i]["bbox"] = new_bbox
+
+ images = [image_0, image_1]
+ annotations = [annotations_0, annotations_1]
+
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class()
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ return_segmentation_masks=True,
+ return_tensors="pt", # do_convert_annotations=True
+ )
+
+ # Check the pixel values have been padded
+ postprocessed_height, postprocessed_width = 800, 1066
+ expected_shape = torch.Size([2, 3, postprocessed_height, postprocessed_width])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ # Check the bounding boxes have been adjusted for padded images
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ expected_boxes_0 = torch.tensor(
+ [
+ [0.6879, 0.4609, 0.0755, 0.3691],
+ [0.2118, 0.3359, 0.2601, 0.1566],
+ [0.5011, 0.5000, 0.9979, 1.0000],
+ [0.5010, 0.5020, 0.9979, 0.9959],
+ [0.3284, 0.5944, 0.5884, 0.8112],
+ [0.8394, 0.5445, 0.3213, 0.9110],
+ ]
+ )
+ expected_boxes_1 = torch.tensor(
+ [
+ [0.4130, 0.2765, 0.0453, 0.2215],
+ [0.1272, 0.2016, 0.1561, 0.0940],
+ [0.3757, 0.4933, 0.7488, 0.9865],
+ [0.3759, 0.5002, 0.7492, 0.9955],
+ [0.1971, 0.5456, 0.3532, 0.8646],
+ [0.5790, 0.4115, 0.3430, 0.7161],
+ ]
+ )
+ torch.testing.assert_close(encoding["labels"][0]["boxes"], expected_boxes_0, atol=1e-3, rtol=1e-3)
+ torch.testing.assert_close(encoding["labels"][1]["boxes"], expected_boxes_1, atol=1e-3, rtol=1e-3)
+
+ # Check the masks have also been padded
+ self.assertEqual(encoding["labels"][0]["masks"].shape, torch.Size([6, 800, 1066]))
+ self.assertEqual(encoding["labels"][1]["masks"].shape, torch.Size([6, 800, 1066]))
+
+ # Check if do_convert_annotations=False, then the annotations are not converted to centre_x, centre_y, width, height
+ # format and not in the range [0, 1]
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ return_segmentation_masks=True,
+ do_convert_annotations=False,
+ return_tensors="pt",
+ )
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ # Convert to absolute coordinates
+ unnormalized_boxes_0 = torch.vstack(
+ [
+ expected_boxes_0[:, 0] * postprocessed_width,
+ expected_boxes_0[:, 1] * postprocessed_height,
+ expected_boxes_0[:, 2] * postprocessed_width,
+ expected_boxes_0[:, 3] * postprocessed_height,
+ ]
+ ).T
+ unnormalized_boxes_1 = torch.vstack(
+ [
+ expected_boxes_1[:, 0] * postprocessed_width,
+ expected_boxes_1[:, 1] * postprocessed_height,
+ expected_boxes_1[:, 2] * postprocessed_width,
+ expected_boxes_1[:, 3] * postprocessed_height,
+ ]
+ ).T
+ # Convert from centre_x, centre_y, width, height to x_min, y_min, x_max, y_max
+ expected_boxes_0 = torch.vstack(
+ [
+ unnormalized_boxes_0[:, 0] - unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] - unnormalized_boxes_0[:, 3] / 2,
+ unnormalized_boxes_0[:, 0] + unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] + unnormalized_boxes_0[:, 3] / 2,
+ ]
+ ).T
+ expected_boxes_1 = torch.vstack(
+ [
+ unnormalized_boxes_1[:, 0] - unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] - unnormalized_boxes_1[:, 3] / 2,
+ unnormalized_boxes_1[:, 0] + unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] + unnormalized_boxes_1[:, 3] / 2,
+ ]
+ ).T
+ torch.testing.assert_close(encoding["labels"][0]["boxes"], expected_boxes_0, atol=1, rtol=1)
+ torch.testing.assert_close(encoding["labels"][1]["boxes"], expected_boxes_1, atol=1, rtol=1)
+
+ # Copied from tests.models.detr.test_image_processing_detr.DetrImageProcessingTest.test_batched_coco_panoptic_annotations with Detr->DeformableDetr
+ def test_batched_coco_panoptic_annotations(self):
+ # prepare image, target and masks_path
+ image_0 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ image_1 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png").resize((800, 800))
+
+ with open("./tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ annotation_0 = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+ annotation_1 = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+
+ w_0, h_0 = image_0.size
+ w_1, h_1 = image_1.size
+ for i in range(len(annotation_1["segments_info"])):
+ coords = annotation_1["segments_info"][i]["bbox"]
+ new_bbox = [
+ coords[0] * w_1 / w_0,
+ coords[1] * h_1 / h_0,
+ coords[2] * w_1 / w_0,
+ coords[3] * h_1 / h_0,
+ ]
+ annotation_1["segments_info"][i]["bbox"] = new_bbox
+
+ masks_path = pathlib.Path("./tests/fixtures/tests_samples/COCO/coco_panoptic")
+
+ images = [image_0, image_1]
+ annotations = [annotation_0, annotation_1]
+
+ for image_processing_class in self.image_processor_list:
+ # encode them
+ image_processing = image_processing_class(format="coco_panoptic")
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ masks_path=masks_path,
+ return_tensors="pt",
+ return_segmentation_masks=True,
+ )
+
+ # Check the pixel values have been padded
+ postprocessed_height, postprocessed_width = 800, 1066
+ expected_shape = torch.Size([2, 3, postprocessed_height, postprocessed_width])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ # Check the bounding boxes have been adjusted for padded images
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ expected_boxes_0 = torch.tensor(
+ [
+ [0.2625, 0.5437, 0.4688, 0.8625],
+ [0.7719, 0.4104, 0.4531, 0.7125],
+ [0.5000, 0.4927, 0.9969, 0.9854],
+ [0.1688, 0.2000, 0.2063, 0.0917],
+ [0.5492, 0.2760, 0.0578, 0.2187],
+ [0.4992, 0.4990, 0.9984, 0.9979],
+ ]
+ )
+ expected_boxes_1 = torch.tensor(
+ [
+ [0.1576, 0.3262, 0.2814, 0.5175],
+ [0.4634, 0.2463, 0.2720, 0.4275],
+ [0.3002, 0.2956, 0.5985, 0.5913],
+ [0.1013, 0.1200, 0.1238, 0.0550],
+ [0.3297, 0.1656, 0.0347, 0.1312],
+ [0.2997, 0.2994, 0.5994, 0.5987],
+ ]
+ )
+ torch.testing.assert_close(encoding["labels"][0]["boxes"], expected_boxes_0, atol=1e-3, rtol=1e-3)
+ torch.testing.assert_close(encoding["labels"][1]["boxes"], expected_boxes_1, atol=1e-3, rtol=1e-3)
+
+ # Check the masks have also been padded
+ self.assertEqual(encoding["labels"][0]["masks"].shape, torch.Size([6, 800, 1066]))
+ self.assertEqual(encoding["labels"][1]["masks"].shape, torch.Size([6, 800, 1066]))
+
+ # Check if do_convert_annotations=False, then the annotations are not converted to centre_x, centre_y, width, height
+ # format and not in the range [0, 1]
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ masks_path=masks_path,
+ return_segmentation_masks=True,
+ do_convert_annotations=False,
+ return_tensors="pt",
+ )
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ # Convert to absolute coordinates
+ unnormalized_boxes_0 = torch.vstack(
+ [
+ expected_boxes_0[:, 0] * postprocessed_width,
+ expected_boxes_0[:, 1] * postprocessed_height,
+ expected_boxes_0[:, 2] * postprocessed_width,
+ expected_boxes_0[:, 3] * postprocessed_height,
+ ]
+ ).T
+ unnormalized_boxes_1 = torch.vstack(
+ [
+ expected_boxes_1[:, 0] * postprocessed_width,
+ expected_boxes_1[:, 1] * postprocessed_height,
+ expected_boxes_1[:, 2] * postprocessed_width,
+ expected_boxes_1[:, 3] * postprocessed_height,
+ ]
+ ).T
+ # Convert from centre_x, centre_y, width, height to x_min, y_min, x_max, y_max
+ expected_boxes_0 = torch.vstack(
+ [
+ unnormalized_boxes_0[:, 0] - unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] - unnormalized_boxes_0[:, 3] / 2,
+ unnormalized_boxes_0[:, 0] + unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] + unnormalized_boxes_0[:, 3] / 2,
+ ]
+ ).T
+ expected_boxes_1 = torch.vstack(
+ [
+ unnormalized_boxes_1[:, 0] - unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] - unnormalized_boxes_1[:, 3] / 2,
+ unnormalized_boxes_1[:, 0] + unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] + unnormalized_boxes_1[:, 3] / 2,
+ ]
+ ).T
+ torch.testing.assert_close(encoding["labels"][0]["boxes"], expected_boxes_0, atol=1, rtol=1)
+ torch.testing.assert_close(encoding["labels"][1]["boxes"], expected_boxes_1, atol=1, rtol=1)
+
+ # Copied from tests.models.detr.test_image_processing_detr.DetrImageProcessingTest.test_max_width_max_height_resizing_and_pad_strategy with Detr->DeformableDetr
+ def test_max_width_max_height_resizing_and_pad_strategy(self):
+ for image_processing_class in self.image_processor_list:
+ image_1 = torch.ones([200, 100, 3], dtype=torch.uint8)
+
+ # do_pad=False, max_height=100, max_width=100, image=200x100 -> 100x50
+ image_processor = image_processing_class(
+ size={"max_height": 100, "max_width": 100},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 100, 50]))
+
+ # do_pad=False, max_height=300, max_width=100, image=200x100 -> 200x100
+ image_processor = image_processing_class(
+ size={"max_height": 300, "max_width": 100},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+
+ # do_pad=True, max_height=100, max_width=100, image=200x100 -> 100x100
+ image_processor = image_processing_class(
+ size={"max_height": 100, "max_width": 100}, do_pad=True, pad_size={"height": 100, "width": 100}
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 100, 100]))
+
+ # do_pad=True, max_height=300, max_width=100, image=200x100 -> 300x100
+ image_processor = image_processing_class(
+ size={"max_height": 300, "max_width": 100},
+ do_pad=True,
+ pad_size={"height": 301, "width": 101},
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 301, 101]))
+
+ ### Check for batch
+ image_2 = torch.ones([100, 150, 3], dtype=torch.uint8)
+
+ # do_pad=True, max_height=150, max_width=100, images=[200x100, 100x150] -> 150x100
+ image_processor = image_processing_class(
+ size={"max_height": 150, "max_width": 100},
+ do_pad=True,
+ pad_size={"height": 150, "width": 100},
+ )
+ inputs = image_processor(images=[image_1, image_2], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([2, 3, 150, 100]))
+
+ def test_longest_edge_shortest_edge_resizing_strategy(self):
+ for image_processing_class in self.image_processor_list:
+ image_1 = torch.ones([958, 653, 3], dtype=torch.uint8)
+
+ # max size is set; width < height;
+ # do_pad=False, longest_edge=640, shortest_edge=640, image=958x653 -> 640x436
+ image_processor = image_processing_class(
+ size={"longest_edge": 640, "shortest_edge": 640},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 640, 436]))
+
+ image_2 = torch.ones([653, 958, 3], dtype=torch.uint8)
+ # max size is set; height < width;
+ # do_pad=False, longest_edge=640, shortest_edge=640, image=653x958 -> 436x640
+ image_processor = image_processing_class(
+ size={"longest_edge": 640, "shortest_edge": 640},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_2], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 436, 640]))
+
+ image_3 = torch.ones([100, 120, 3], dtype=torch.uint8)
+ # max size is set; width == size; height > max_size;
+ # do_pad=False, longest_edge=118, shortest_edge=100, image=120x100 -> 118x98
+ image_processor = image_processing_class(
+ size={"longest_edge": 118, "shortest_edge": 100},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_3], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 98, 118]))
+
+ image_4 = torch.ones([128, 50, 3], dtype=torch.uint8)
+ # max size is set; height == size; width < max_size;
+ # do_pad=False, longest_edge=256, shortest_edge=50, image=50x128 -> 50x128
+ image_processor = image_processing_class(
+ size={"longest_edge": 256, "shortest_edge": 50},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_4], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 128, 50]))
+
+ image_5 = torch.ones([50, 50, 3], dtype=torch.uint8)
+ # max size is set; height == width; width < max_size;
+ # do_pad=False, longest_edge=117, shortest_edge=50, image=50x50 -> 50x50
+ image_processor = image_processing_class(
+ size={"longest_edge": 117, "shortest_edge": 50},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_5], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 50, 50]))
+
+ @slow
+ @require_torch_accelerator
+ # Copied from tests.models.detr.test_image_processing_detr.DetrImageProcessingTest.test_fast_processor_equivalence_cpu_accelerator_coco_detection_annotations
+ def test_fast_processor_equivalence_cpu_accelerator_coco_detection_annotations(self):
+ # prepare image and target
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ target = {"image_id": 39769, "annotations": target}
+
+ # Ignore copy
+ processor = self.image_processor_list[1]()
+
+ # 1. run processor on CPU
+ encoding_cpu = processor(images=image, annotations=target, return_tensors="pt", device="cpu")
+ # 2. run processor on accelerator
+ encoding_gpu = processor(images=image, annotations=target, return_tensors="pt", device=torch_device)
+
+ # verify pixel values
+ self.assertEqual(encoding_cpu["pixel_values"].shape, encoding_gpu["pixel_values"].shape)
+ self.assertTrue(
+ torch.allclose(
+ encoding_cpu["pixel_values"][0, 0, 0, :3],
+ encoding_gpu["pixel_values"][0, 0, 0, :3].to("cpu"),
+ atol=1e-4,
+ )
+ )
+ # verify area
+ torch.testing.assert_close(encoding_cpu["labels"][0]["area"], encoding_gpu["labels"][0]["area"].to("cpu"))
+ # verify boxes
+ self.assertEqual(encoding_cpu["labels"][0]["boxes"].shape, encoding_gpu["labels"][0]["boxes"].shape)
+ self.assertTrue(
+ torch.allclose(
+ encoding_cpu["labels"][0]["boxes"][0], encoding_gpu["labels"][0]["boxes"][0].to("cpu"), atol=1e-3
+ )
+ )
+ # verify image_id
+ torch.testing.assert_close(
+ encoding_cpu["labels"][0]["image_id"], encoding_gpu["labels"][0]["image_id"].to("cpu")
+ )
+ # verify is_crowd
+ torch.testing.assert_close(
+ encoding_cpu["labels"][0]["iscrowd"], encoding_gpu["labels"][0]["iscrowd"].to("cpu")
+ )
+ # verify class_labels
+ self.assertTrue(
+ torch.allclose(
+ encoding_cpu["labels"][0]["class_labels"], encoding_gpu["labels"][0]["class_labels"].to("cpu")
+ )
+ )
+ # verify orig_size
+ torch.testing.assert_close(
+ encoding_cpu["labels"][0]["orig_size"], encoding_gpu["labels"][0]["orig_size"].to("cpu")
+ )
+ # verify size
+ torch.testing.assert_close(encoding_cpu["labels"][0]["size"], encoding_gpu["labels"][0]["size"].to("cpu"))
+
+ @slow
+ @require_torch_accelerator
+ # Copied from tests.models.detr.test_image_processing_detr.DetrImageProcessingTest.test_fast_processor_equivalence_cpu_accelerator_coco_panoptic_annotations
+ def test_fast_processor_equivalence_cpu_accelerator_coco_panoptic_annotations(self):
+ # prepare image, target and masks_path
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ target = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+
+ masks_path = pathlib.Path("./tests/fixtures/tests_samples/COCO/coco_panoptic")
+
+ # Ignore copy
+ processor = self.image_processor_list[1](format="coco_panoptic")
+
+ # 1. run processor on CPU
+ encoding_cpu = processor(
+ images=image, annotations=target, masks_path=masks_path, return_tensors="pt", device="cpu"
+ )
+ # 2. run processor on accelerator
+ encoding_gpu = processor(
+ images=image, annotations=target, masks_path=masks_path, return_tensors="pt", device=torch_device
+ )
+
+ # verify pixel values
+ self.assertEqual(encoding_cpu["pixel_values"].shape, encoding_gpu["pixel_values"].shape)
+ self.assertTrue(
+ torch.allclose(
+ encoding_cpu["pixel_values"][0, 0, 0, :3],
+ encoding_gpu["pixel_values"][0, 0, 0, :3].to("cpu"),
+ atol=1e-4,
+ )
+ )
+ # verify area
+ torch.testing.assert_close(encoding_cpu["labels"][0]["area"], encoding_gpu["labels"][0]["area"].to("cpu"))
+ # verify boxes
+ self.assertEqual(encoding_cpu["labels"][0]["boxes"].shape, encoding_gpu["labels"][0]["boxes"].shape)
+ self.assertTrue(
+ torch.allclose(
+ encoding_cpu["labels"][0]["boxes"][0], encoding_gpu["labels"][0]["boxes"][0].to("cpu"), atol=1e-3
+ )
+ )
+ # verify image_id
+ torch.testing.assert_close(
+ encoding_cpu["labels"][0]["image_id"], encoding_gpu["labels"][0]["image_id"].to("cpu")
+ )
+ # verify is_crowd
+ torch.testing.assert_close(
+ encoding_cpu["labels"][0]["iscrowd"], encoding_gpu["labels"][0]["iscrowd"].to("cpu")
+ )
+ # verify class_labels
+ self.assertTrue(
+ torch.allclose(
+ encoding_cpu["labels"][0]["class_labels"], encoding_gpu["labels"][0]["class_labels"].to("cpu")
+ )
+ )
+ # verify masks
+ masks_sum_cpu = encoding_cpu["labels"][0]["masks"].sum()
+ masks_sum_gpu = encoding_gpu["labels"][0]["masks"].sum()
+ relative_error = torch.abs(masks_sum_cpu - masks_sum_gpu) / masks_sum_cpu
+ self.assertTrue(relative_error < 1e-3)
+ # verify orig_size
+ torch.testing.assert_close(
+ encoding_cpu["labels"][0]["orig_size"], encoding_gpu["labels"][0]["orig_size"].to("cpu")
+ )
+ # verify size
+ torch.testing.assert_close(encoding_cpu["labels"][0]["size"], encoding_gpu["labels"][0]["size"].to("cpu"))
diff --git a/transformers/tests/models/deformable_detr/test_modeling_deformable_detr.py b/transformers/tests/models/deformable_detr/test_modeling_deformable_detr.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc30b10e1427c1ea91d6b4ff017dd11ba02f8d4b
--- /dev/null
+++ b/transformers/tests/models/deformable_detr/test_modeling_deformable_detr.py
@@ -0,0 +1,783 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Deformable DETR model."""
+
+import inspect
+import math
+import unittest
+
+from transformers import DeformableDetrConfig, ResNetConfig, is_torch_available, is_vision_available
+from transformers.file_utils import cached_property
+from transformers.testing_utils import (
+ require_timm,
+ require_torch,
+ require_torch_accelerator,
+ require_torch_bf16,
+ require_vision,
+ slow,
+ torch_device,
+)
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import DeformableDetrForObjectDetection, DeformableDetrModel
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import AutoImageProcessor
+
+
+class DeformableDetrModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=8,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=8,
+ intermediate_size=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ num_queries=12,
+ num_channels=3,
+ image_size=196,
+ n_targets=8,
+ num_labels=91,
+ num_feature_levels=4,
+ encoder_n_points=2,
+ decoder_n_points=6,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.num_queries = num_queries
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.n_targets = n_targets
+ self.num_labels = num_labels
+ self.num_feature_levels = num_feature_levels
+ self.encoder_n_points = encoder_n_points
+ self.decoder_n_points = decoder_n_points
+
+ # we also set the expected seq length for both encoder and decoder
+ self.encoder_seq_length = (
+ math.ceil(self.image_size / 8) ** 2
+ + math.ceil(self.image_size / 16) ** 2
+ + math.ceil(self.image_size / 32) ** 2
+ + math.ceil(self.image_size / 64) ** 2
+ )
+ self.decoder_seq_length = self.num_queries
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ pixel_mask = torch.ones([self.batch_size, self.image_size, self.image_size], device=torch_device)
+
+ labels = None
+ if self.use_labels:
+ # labels is a list of Dict (each Dict being the labels for a given example in the batch)
+ labels = []
+ for i in range(self.batch_size):
+ target = {}
+ target["class_labels"] = torch.randint(
+ high=self.num_labels, size=(self.n_targets,), device=torch_device
+ )
+ target["boxes"] = torch.rand(self.n_targets, 4, device=torch_device)
+ target["masks"] = torch.rand(self.n_targets, self.image_size, self.image_size, device=torch_device)
+ labels.append(target)
+
+ config = self.get_config()
+ return config, pixel_values, pixel_mask, labels
+
+ def get_config(self):
+ resnet_config = ResNetConfig(
+ num_channels=3,
+ embeddings_size=10,
+ hidden_sizes=[10, 20, 30, 40],
+ depths=[1, 1, 2, 1],
+ hidden_act="relu",
+ num_labels=3,
+ out_features=["stage2", "stage3", "stage4"],
+ out_indices=[2, 3, 4],
+ )
+ return DeformableDetrConfig(
+ d_model=self.hidden_size,
+ encoder_layers=self.num_hidden_layers,
+ decoder_layers=self.num_hidden_layers,
+ encoder_attention_heads=self.num_attention_heads,
+ decoder_attention_heads=self.num_attention_heads,
+ encoder_ffn_dim=self.intermediate_size,
+ decoder_ffn_dim=self.intermediate_size,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ num_queries=self.num_queries,
+ num_labels=self.num_labels,
+ num_feature_levels=self.num_feature_levels,
+ encoder_n_points=self.encoder_n_points,
+ decoder_n_points=self.decoder_n_points,
+ use_timm_backbone=False,
+ backbone=None,
+ backbone_config=resnet_config,
+ use_pretrained_backbone=False,
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config, pixel_values, pixel_mask, labels = self.prepare_config_and_inputs()
+ inputs_dict = {"pixel_values": pixel_values, "pixel_mask": pixel_mask}
+ return config, inputs_dict
+
+ def create_and_check_deformable_detr_model(self, config, pixel_values, pixel_mask, labels):
+ model = DeformableDetrModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask)
+ result = model(pixel_values)
+
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.num_queries, self.hidden_size))
+
+ def create_and_check_deformable_detr_object_detection_head_model(self, config, pixel_values, pixel_mask, labels):
+ model = DeformableDetrForObjectDetection(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask)
+ result = model(pixel_values)
+
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_queries, self.num_labels))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_queries, 4))
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask, labels=labels)
+
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_queries, self.num_labels))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_queries, 4))
+
+
+@require_torch
+class DeformableDetrModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (DeformableDetrModel, DeformableDetrForObjectDetection) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {"image-feature-extraction": DeformableDetrModel, "object-detection": DeformableDetrForObjectDetection}
+ if is_torch_available()
+ else {}
+ )
+ is_encoder_decoder = True
+ test_torchscript = False
+ test_pruning = False
+ test_head_masking = False
+ test_missing_keys = False
+ test_torch_exportable = True
+
+ # special case for head models
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class.__name__ == "DeformableDetrForObjectDetection":
+ labels = []
+ for i in range(self.model_tester.batch_size):
+ target = {}
+ target["class_labels"] = torch.ones(
+ size=(self.model_tester.n_targets,), device=torch_device, dtype=torch.long
+ )
+ target["boxes"] = torch.ones(
+ self.model_tester.n_targets, 4, device=torch_device, dtype=torch.float
+ )
+ target["masks"] = torch.ones(
+ self.model_tester.n_targets,
+ self.model_tester.image_size,
+ self.model_tester.image_size,
+ device=torch_device,
+ dtype=torch.float,
+ )
+ labels.append(target)
+ inputs_dict["labels"] = labels
+
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = DeformableDetrModelTester(self)
+ self.config_tester = ConfigTester(
+ self,
+ config_class=DeformableDetrConfig,
+ has_text_modality=False,
+ common_properties=["num_channels", "d_model", "encoder_attention_heads", "decoder_attention_heads"],
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_deformable_detr_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_deformable_detr_model(*config_and_inputs)
+
+ def test_deformable_detr_object_detection_head_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_deformable_detr_object_detection_head_model(*config_and_inputs)
+
+ @unittest.skip(reason="Deformable DETR does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Deformable DETR does not use inputs_embeds")
+ def test_inputs_embeds_matches_input_ids(self):
+ pass
+
+ @unittest.skip(reason="Deformable DETR does not have a get_input_embeddings method")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @unittest.skip(reason="Deformable DETR is not a generative model")
+ def test_generate_without_input_ids(self):
+ pass
+
+ @unittest.skip(reason="Deformable DETR does not use token embeddings")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ @unittest.skip(reason="Feed forward chunking is not implemented")
+ def test_feed_forward_chunking(self):
+ pass
+
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class._from_config(config, attn_implementation="eager")
+ config = model.config
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ self.model_tester.num_feature_levels,
+ self.model_tester.encoder_n_points,
+ ],
+ )
+ out_len = len(outputs)
+
+ correct_outlen = 8
+
+ # loss is at first position
+ if "labels" in inputs_dict:
+ correct_outlen += 1 # loss is added to beginning
+ # Object Detection model returns pred_logits and pred_boxes
+ if model_class.__name__ == "DeformableDetrForObjectDetection":
+ correct_outlen += 2
+
+ self.assertEqual(out_len, correct_outlen)
+
+ # decoder attentions
+ decoder_attentions = outputs.decoder_attentions
+ self.assertIsInstance(decoder_attentions, (list, tuple))
+ self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(decoder_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, self.model_tester.num_queries, self.model_tester.num_queries],
+ )
+
+ # cross attentions
+ cross_attentions = outputs.cross_attentions
+ self.assertIsInstance(cross_attentions, (list, tuple))
+ self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(cross_attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ self.model_tester.num_feature_levels,
+ self.model_tester.decoder_n_points,
+ ],
+ )
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if hasattr(self.model_tester, "num_hidden_states_types"):
+ added_hidden_states = self.model_tester.num_hidden_states_types
+ elif self.is_encoder_decoder:
+ added_hidden_states = 2
+ else:
+ added_hidden_states = 1
+ self.assertEqual(out_len + added_hidden_states, len(outputs))
+
+ self_attentions = outputs.encoder_attentions
+
+ self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ self.model_tester.num_feature_levels,
+ self.model_tester.encoder_n_points,
+ ],
+ )
+
+ def test_model_outputs_equivalence(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ def set_nan_tensor_to_zero(t):
+ t[t != t] = 0
+ return t
+
+ def check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs={}):
+ with torch.no_grad():
+ tuple_output = model(**tuple_inputs, return_dict=False, **additional_kwargs)
+ dict_output = model(**dict_inputs, return_dict=True, **additional_kwargs).to_tuple()
+
+ def recursive_check(tuple_object, dict_object):
+ if isinstance(tuple_object, (list, tuple)):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object, dict_object):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif isinstance(tuple_object, dict):
+ for tuple_iterable_value, dict_iterable_value in zip(
+ tuple_object.values(), dict_object.values()
+ ):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif tuple_object is None:
+ return
+ else:
+ self.assertTrue(
+ torch.allclose(
+ set_nan_tensor_to_zero(tuple_object), set_nan_tensor_to_zero(dict_object), atol=1e-5
+ ),
+ msg=(
+ "Tuple and dict output are not equal. Difference:"
+ f" {torch.max(torch.abs(tuple_object - dict_object))}. Tuple has `nan`:"
+ f" {torch.isnan(tuple_object).any()} and `inf`: {torch.isinf(tuple_object)}. Dict has"
+ f" `nan`: {torch.isnan(dict_object).any()} and `inf`: {torch.isinf(dict_object)}."
+ ),
+ )
+
+ recursive_check(tuple_output, dict_output)
+
+ for model_class in self.all_model_classes:
+ print("Model class:", model_class)
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_attentions": True})
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_attentions": True})
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(
+ model, tuple_inputs, dict_inputs, {"output_hidden_states": True, "output_attentions": True}
+ )
+
+ def test_retain_grad_hidden_states_attentions(self):
+ # removed retain_grad and grad on decoder_hidden_states, as queries don't require grad
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.output_hidden_states = True
+ config.output_attentions = True
+
+ # no need to test all models as different heads yield the same functionality
+ model_class = self.all_model_classes[0]
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ outputs = model(**inputs)
+
+ # we take the second output since last_hidden_state is the second item
+ output = outputs[1]
+
+ encoder_hidden_states = outputs.encoder_hidden_states[0]
+ encoder_attentions = outputs.encoder_attentions[0]
+ encoder_hidden_states.retain_grad()
+ encoder_attentions.retain_grad()
+
+ decoder_attentions = outputs.decoder_attentions[0]
+ decoder_attentions.retain_grad()
+
+ cross_attentions = outputs.cross_attentions[0]
+ cross_attentions.retain_grad()
+
+ output.flatten()[0].backward(retain_graph=True)
+
+ self.assertIsNotNone(encoder_hidden_states.grad)
+ self.assertIsNotNone(encoder_attentions.grad)
+ self.assertIsNotNone(decoder_attentions.grad)
+ self.assertIsNotNone(cross_attentions.grad)
+
+ def test_forward_auxiliary_loss(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.auxiliary_loss = True
+
+ # only test for object detection and segmentation model
+ for model_class in self.all_model_classes[1:]:
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+
+ outputs = model(**inputs)
+
+ self.assertIsNotNone(outputs.auxiliary_outputs)
+ self.assertEqual(len(outputs.auxiliary_outputs), self.model_tester.num_hidden_layers - 1)
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ if model.config.is_encoder_decoder:
+ expected_arg_names = ["pixel_values", "pixel_mask"]
+ expected_arg_names.extend(
+ ["head_mask", "decoder_head_mask", "encoder_outputs"]
+ if "head_mask" and "decoder_head_mask" in arg_names
+ else []
+ )
+ self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
+ else:
+ expected_arg_names = ["pixel_values", "pixel_mask"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_different_timm_backbone(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # let's pick a random timm backbone
+ config.backbone = "tf_mobilenetv3_small_075"
+ config.backbone_config = None
+ config.use_timm_backbone = True
+ config.backbone_kwargs = {"out_indices": [1, 2, 3, 4]}
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if model_class.__name__ == "DeformableDetrForObjectDetection":
+ expected_shape = (
+ self.model_tester.batch_size,
+ self.model_tester.num_queries,
+ self.model_tester.num_labels,
+ )
+ self.assertEqual(outputs.logits.shape, expected_shape)
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.model.backbone.conv_encoder.intermediate_channel_sizes), 4)
+ else:
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.backbone.conv_encoder.intermediate_channel_sizes), 4)
+
+ self.assertTrue(outputs)
+
+ def test_hf_backbone(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # Load a pretrained HF checkpoint as backbone
+ config.backbone = "microsoft/resnet-18"
+ config.backbone_config = None
+ config.use_timm_backbone = False
+ config.use_pretrained_backbone = True
+ config.backbone_kwargs = {"out_indices": [1, 2, 3, 4]}
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if model_class.__name__ == "DeformableDetrForObjectDetection":
+ expected_shape = (
+ self.model_tester.batch_size,
+ self.model_tester.num_queries,
+ self.model_tester.num_labels,
+ )
+ self.assertEqual(outputs.logits.shape, expected_shape)
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.model.backbone.conv_encoder.intermediate_channel_sizes), 4)
+ else:
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.backbone.conv_encoder.intermediate_channel_sizes), 4)
+
+ self.assertTrue(outputs)
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ print("Model class:", model_class)
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ if (
+ "level_embed" in name
+ or "sampling_offsets.bias" in name
+ or "value_proj" in name
+ or "output_proj" in name
+ or "reference_points" in name
+ ):
+ continue
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ def test_two_stage_training(self):
+ model_class = DeformableDetrForObjectDetection
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+ config.two_stage = True
+ config.auxiliary_loss = True
+ config.with_box_refine = True
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def create_and_check_model_fp16_forward(self):
+ model_class = DeformableDetrForObjectDetection
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.half()
+ model.eval()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ output = model(**inputs)["last_hidden_state"]
+ self.parent.assertFalse(torch.isnan(output).any().item())
+
+ @require_torch_bf16
+ def create_and_check_model_bf16_forward(self):
+ model_class = DeformableDetrForObjectDetection
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ model = model_class(config, torch_dtype=torch.bfloat16)
+ model.to(torch_device)
+ model.eval()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ output = model(**inputs)["last_hidden_state"]
+ self.parent.assertFalse(torch.isnan(output).any().item())
+
+
+TOLERANCE = 1e-4
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_timm
+@require_vision
+@slow
+class DeformableDetrModelIntegrationTests(unittest.TestCase):
+ @cached_property
+ def default_image_processor(self):
+ return AutoImageProcessor.from_pretrained("SenseTime/deformable-detr") if is_vision_available() else None
+
+ def test_inference_object_detection_head(self):
+ model = DeformableDetrForObjectDetection.from_pretrained("SenseTime/deformable-detr").to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ encoding = image_processor(images=image, return_tensors="pt").to(torch_device)
+ pixel_values = encoding["pixel_values"].to(torch_device)
+ pixel_mask = encoding["pixel_mask"].to(torch_device)
+
+ with torch.no_grad():
+ outputs = model(pixel_values, pixel_mask)
+
+ expected_shape_logits = torch.Size((1, model.config.num_queries, model.config.num_labels))
+ self.assertEqual(outputs.logits.shape, expected_shape_logits)
+
+ expected_logits = torch.tensor(
+ [
+ [-9.6644, -4.3434, -5.8707],
+ [-9.7035, -3.8503, -5.0721],
+ [-10.5633, -5.3387, -7.5119],
+ ]
+ ).to(torch_device)
+ expected_boxes = torch.tensor(
+ [
+ [0.8693, 0.2290, 0.2492],
+ [0.3150, 0.5489, 0.5845],
+ [0.5563, 0.7580, 0.8518],
+ ]
+ ).to(torch_device)
+
+ torch.testing.assert_close(outputs.logits[0, :3, :3], expected_logits, rtol=2e-4, atol=2e-4)
+
+ expected_shape_boxes = torch.Size((1, model.config.num_queries, 4))
+ self.assertEqual(outputs.pred_boxes.shape, expected_shape_boxes)
+ torch.testing.assert_close(outputs.pred_boxes[0, :3, :3], expected_boxes, rtol=2e-4, atol=2e-4)
+
+ # verify postprocessing
+ results = image_processor.post_process_object_detection(
+ outputs, threshold=0.3, target_sizes=[image.size[::-1]]
+ )[0]
+ expected_scores = torch.tensor([0.7999, 0.7895, 0.6332, 0.4719, 0.4382]).to(torch_device)
+ expected_labels = [17, 17, 75, 75, 63]
+ expected_slice_boxes = torch.tensor([16.4960, 52.8387, 318.2565, 470.7831]).to(torch_device)
+
+ self.assertEqual(len(results["scores"]), 5)
+ torch.testing.assert_close(results["scores"], expected_scores, rtol=2e-4, atol=2e-4)
+ self.assertSequenceEqual(results["labels"].tolist(), expected_labels)
+ torch.testing.assert_close(results["boxes"][0, :], expected_slice_boxes, rtol=2e-4, atol=2e-4)
+
+ def test_inference_object_detection_head_with_box_refine_two_stage(self):
+ model = DeformableDetrForObjectDetection.from_pretrained(
+ "SenseTime/deformable-detr-with-box-refine-two-stage"
+ ).to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ encoding = image_processor(images=image, return_tensors="pt").to(torch_device)
+ pixel_values = encoding["pixel_values"].to(torch_device)
+ pixel_mask = encoding["pixel_mask"].to(torch_device)
+
+ with torch.no_grad():
+ outputs = model(pixel_values, pixel_mask)
+
+ expected_shape_logits = torch.Size((1, model.config.num_queries, model.config.num_labels))
+ self.assertEqual(outputs.logits.shape, expected_shape_logits)
+
+ expected_logits = torch.tensor(
+ [
+ [-6.7112, -4.3216, -6.3781],
+ [-8.9035, -6.1738, -6.7249],
+ [-6.9314, -4.4736, -6.2303],
+ ]
+ ).to(torch_device)
+ expected_boxes = torch.tensor(
+ [
+ [0.2582, 0.5499, 0.4683],
+ [0.7652, 0.9084, 0.4884],
+ [0.5490, 0.2763, 0.0564],
+ ]
+ ).to(torch_device)
+
+ torch.testing.assert_close(outputs.logits[0, :3, :3], expected_logits, rtol=2e-4, atol=2e-4)
+
+ expected_shape_boxes = torch.Size((1, model.config.num_queries, 4))
+ self.assertEqual(outputs.pred_boxes.shape, expected_shape_boxes)
+ torch.testing.assert_close(outputs.pred_boxes[0, :3, :3], expected_boxes, rtol=2e-4, atol=2e-4)
+
+ @require_torch_accelerator
+ def test_inference_object_detection_head_equivalence_cpu_accelerator(self):
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ encoding = image_processor(images=image, return_tensors="pt")
+ pixel_values = encoding["pixel_values"]
+ pixel_mask = encoding["pixel_mask"]
+
+ # 1. run model on CPU
+ model = DeformableDetrForObjectDetection.from_pretrained("SenseTime/deformable-detr-single-scale")
+
+ with torch.no_grad():
+ cpu_outputs = model(pixel_values, pixel_mask)
+
+ # 2. run model on accelerator
+ model.to(torch_device)
+
+ with torch.no_grad():
+ gpu_outputs = model(pixel_values.to(torch_device), pixel_mask.to(torch_device))
+
+ # 3. assert equivalence
+ # (on A10, the differences get larger than on T4)
+ for key in cpu_outputs.keys():
+ torch.testing.assert_close(cpu_outputs[key], gpu_outputs[key].cpu(), atol=2e-2, rtol=2e-2)
+
+ expected_logits = torch.tensor(
+ [
+ [-9.9051, -4.2541, -6.4852],
+ [-9.6947, -4.0854, -6.8033],
+ [-10.0665, -5.8470, -7.7003],
+ ]
+ )
+ assert torch.allclose(cpu_outputs.logits[0, :3, :3], expected_logits, atol=2e-4)
diff --git a/transformers/tests/models/deit/__init__.py b/transformers/tests/models/deit/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/deit/test_image_processing_deit.py b/transformers/tests/models/deit/test_image_processing_deit.py
new file mode 100644
index 0000000000000000000000000000000000000000..9bc204f41aa839523bdca65d95b5ba0c1e40a996
--- /dev/null
+++ b/transformers/tests/models/deit/test_image_processing_deit.py
@@ -0,0 +1,125 @@
+# Copyright 2021 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torchvision_available, is_vision_available
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_vision_available():
+ from transformers import DeiTImageProcessor
+
+ if is_torchvision_available():
+ from transformers import DeiTImageProcessorFast
+
+
+class DeiTImageProcessingTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ do_center_crop=True,
+ crop_size=None,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ ):
+ size = size if size is not None else {"height": 20, "width": 20}
+ crop_size = crop_size if crop_size is not None else {"height": 18, "width": 18}
+
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_center_crop = do_center_crop
+ self.crop_size = crop_size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def prepare_image_processor_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "do_center_crop": self.do_center_crop,
+ "crop_size": self.crop_size,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ }
+
+ def expected_output_image_shape(self, images):
+ return self.num_channels, self.crop_size["height"], self.crop_size["width"]
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class DeiTImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = DeiTImageProcessor if is_vision_available() else None
+ fast_image_processing_class = DeiTImageProcessorFast if is_torchvision_available() else None
+ test_cast_dtype = True
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = DeiTImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "do_center_crop"))
+ self.assertTrue(hasattr(image_processing, "center_crop"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+
+ def test_image_processor_from_dict_with_kwargs(self):
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"height": 20, "width": 20})
+ self.assertEqual(image_processor.crop_size, {"height": 18, "width": 18})
+
+ image_processor = image_processing_class.from_dict(self.image_processor_dict, size=42, crop_size=84)
+ self.assertEqual(image_processor.size, {"height": 42, "width": 42})
+ self.assertEqual(image_processor.crop_size, {"height": 84, "width": 84})
diff --git a/transformers/tests/models/deit/test_modeling_deit.py b/transformers/tests/models/deit/test_modeling_deit.py
new file mode 100644
index 0000000000000000000000000000000000000000..50ccdbfb5fdf8c5a8393d96825967ba43401d02a
--- /dev/null
+++ b/transformers/tests/models/deit/test_modeling_deit.py
@@ -0,0 +1,467 @@
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch DeiT model."""
+
+import unittest
+import warnings
+
+from transformers import DeiTConfig
+from transformers.testing_utils import (
+ require_accelerate,
+ require_torch,
+ require_torch_accelerator,
+ require_torch_fp16,
+ require_vision,
+ slow,
+ torch_device,
+)
+from transformers.utils import cached_property, is_torch_available, is_vision_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import (
+ DeiTForImageClassification,
+ DeiTForImageClassificationWithTeacher,
+ DeiTForMaskedImageModeling,
+ DeiTModel,
+ )
+ from transformers.models.auto.modeling_auto import (
+ MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES,
+ MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES,
+ MODEL_MAPPING_NAMES,
+ )
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import DeiTImageProcessor
+
+
+class DeiTModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=30,
+ patch_size=2,
+ num_channels=3,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ type_sequence_label_size=10,
+ initializer_range=0.02,
+ num_labels=3,
+ scope=None,
+ encoder_stride=2,
+ mask_ratio=0.5,
+ attn_implementation="eager",
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.scope = scope
+ self.encoder_stride = encoder_stride
+ self.attn_implementation = attn_implementation
+
+ # in DeiT, the seq length equals the number of patches + 2 (we add 2 for the [CLS] and distilation tokens)
+ num_patches = (image_size // patch_size) ** 2
+ self.seq_length = num_patches + 2
+ self.mask_ratio = mask_ratio
+ self.num_masks = int(mask_ratio * self.seq_length)
+ self.mask_length = num_patches
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return DeiTConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ encoder_stride=self.encoder_stride,
+ attn_implementation=self.attn_implementation,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = DeiTModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_for_masked_image_modeling(self, config, pixel_values, labels):
+ model = DeiTForMaskedImageModeling(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(
+ result.reconstruction.shape, (self.batch_size, self.num_channels, self.image_size, self.image_size)
+ )
+
+ # test greyscale images
+ config.num_channels = 1
+ model = DeiTForMaskedImageModeling(config)
+ model.to(torch_device)
+ model.eval()
+
+ pixel_values = floats_tensor([self.batch_size, 1, self.image_size, self.image_size])
+ result = model(pixel_values)
+ self.parent.assertEqual(result.reconstruction.shape, (self.batch_size, 1, self.image_size, self.image_size))
+
+ def create_and_check_for_image_classification(self, config, pixel_values, labels):
+ config.num_labels = self.type_sequence_label_size
+ model = DeiTForImageClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values, labels=labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
+
+ # test greyscale images
+ config.num_channels = 1
+ model = DeiTForImageClassification(config)
+ model.to(torch_device)
+ model.eval()
+
+ pixel_values = floats_tensor([self.batch_size, 1, self.image_size, self.image_size])
+ result = model(pixel_values, labels=labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ pixel_values,
+ labels,
+ ) = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class DeiTModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as DeiT does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (
+ (
+ DeiTModel,
+ DeiTForImageClassification,
+ DeiTForImageClassificationWithTeacher,
+ DeiTForMaskedImageModeling,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "image-feature-extraction": DeiTModel,
+ "image-classification": (DeiTForImageClassification, DeiTForImageClassificationWithTeacher),
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ test_torch_exportable = True
+
+ def setUp(self):
+ self.model_tester = DeiTModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=DeiTConfig, has_text_modality=False, hidden_size=37)
+
+ @unittest.skip(
+ "Since `torch==2.3+cu121`, although this test passes, many subsequent tests have `CUDA error: misaligned address`."
+ "If `nvidia-xxx-cu118` are also installed, no failure (even with `torch==2.3+cu121`)."
+ )
+ def test_multi_gpu_data_parallel_forward(self):
+ super().test_multi_gpu_data_parallel_forward()
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="DeiT does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_get_set_embeddings(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_masked_image_modeling(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_masked_image_modeling(*config_and_inputs)
+
+ def test_for_image_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_image_classification(*config_and_inputs)
+
+ # special case for DeiTForImageClassificationWithTeacher model
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class.__name__ == "DeiTForImageClassificationWithTeacher":
+ del inputs_dict["labels"]
+
+ return inputs_dict
+
+ def test_training(self):
+ if not self.model_tester.is_training:
+ self.skipTest(reason="model_tester.is_training is set to False")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ # DeiTForImageClassificationWithTeacher supports inference-only
+ if (
+ model_class.__name__ in MODEL_MAPPING_NAMES.values()
+ or model_class.__name__ == "DeiTForImageClassificationWithTeacher"
+ ):
+ continue
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def test_training_gradient_checkpointing(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ if not self.model_tester.is_training:
+ self.skipTest(reason="model_tester.is_training is set to False")
+
+ config.use_cache = False
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ if model_class.__name__ in MODEL_MAPPING_NAMES.values() or not model_class.supports_gradient_checkpointing:
+ continue
+ # DeiTForImageClassificationWithTeacher supports inference-only
+ if model_class.__name__ == "DeiTForImageClassificationWithTeacher":
+ continue
+ model = model_class(config)
+ model.gradient_checkpointing_enable()
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ def test_problem_types(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ problem_types = [
+ {"title": "multi_label_classification", "num_labels": 2, "dtype": torch.float},
+ {"title": "single_label_classification", "num_labels": 1, "dtype": torch.long},
+ {"title": "regression", "num_labels": 1, "dtype": torch.float},
+ ]
+
+ for model_class in self.all_model_classes:
+ if (
+ model_class.__name__
+ not in [
+ *MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES.values(),
+ *MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES.values(),
+ ]
+ or model_class.__name__ == "DeiTForImageClassificationWithTeacher"
+ ):
+ continue
+
+ for problem_type in problem_types:
+ with self.subTest(msg=f"Testing {model_class} with {problem_type['title']}"):
+ config.problem_type = problem_type["title"]
+ config.num_labels = problem_type["num_labels"]
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+
+ if problem_type["num_labels"] > 1:
+ inputs["labels"] = inputs["labels"].unsqueeze(1).repeat(1, problem_type["num_labels"])
+
+ inputs["labels"] = inputs["labels"].to(problem_type["dtype"])
+
+ # This tests that we do not trigger the warning form PyTorch "Using a target size that is different
+ # to the input size. This will likely lead to incorrect results due to broadcasting. Please ensure
+ # they have the same size." which is a symptom something in wrong for the regression problem.
+ # See https://github.com/huggingface/transformers/issues/11780
+ with warnings.catch_warnings(record=True) as warning_list:
+ loss = model(**inputs).loss
+ for w in warning_list:
+ if "Using a target size that is different to the input size" in str(w.message):
+ raise ValueError(
+ f"Something is going wrong in the regression problem: intercepted {w.message}"
+ )
+
+ loss.backward()
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "facebook/deit-base-distilled-patch16-224"
+ model = DeiTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+class DeiTModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_image_processor(self):
+ return (
+ DeiTImageProcessor.from_pretrained("facebook/deit-base-distilled-patch16-224")
+ if is_vision_available()
+ else None
+ )
+
+ @slow
+ def test_inference_image_classification_head(self):
+ model = DeiTForImageClassificationWithTeacher.from_pretrained("facebook/deit-base-distilled-patch16-224").to(
+ torch_device
+ )
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 1000))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([-1.0266, 0.1912, -1.2861]).to(torch_device)
+
+ torch.testing.assert_close(outputs.logits[0, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ @slow
+ def test_inference_interpolate_pos_encoding(self):
+ model = DeiTForImageClassificationWithTeacher.from_pretrained("facebook/deit-base-distilled-patch16-224").to(
+ torch_device
+ )
+
+ image_processor = self.default_image_processor
+
+ # image size is {"height": 480, "width": 640}
+ image = prepare_img()
+ image_processor.size = {"height": 480, "width": 640}
+ # center crop set to False so image is not center cropped to 224x224
+ inputs = image_processor(images=image, return_tensors="pt", do_center_crop=False).to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs, interpolate_pos_encoding=True)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 1000))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ @slow
+ @require_accelerate
+ @require_torch_accelerator
+ @require_torch_fp16
+ def test_inference_fp16(self):
+ r"""
+ A small test to make sure that inference work in half precision without any problem.
+ """
+ model = DeiTModel.from_pretrained(
+ "facebook/deit-base-distilled-patch16-224", torch_dtype=torch.float16, device_map="auto"
+ )
+ image_processor = self.default_image_processor
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt")
+ pixel_values = inputs.pixel_values.to(torch_device)
+
+ # forward pass to make sure inference works in fp16
+ with torch.no_grad():
+ _ = model(pixel_values)
diff --git a/transformers/tests/models/depth_pro/__init__.py b/transformers/tests/models/depth_pro/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/depth_pro/test_image_processing_depth_pro.py b/transformers/tests/models/depth_pro/test_image_processing_depth_pro.py
new file mode 100644
index 0000000000000000000000000000000000000000..a14b60617150a82c904ba26b5feb80ec5ebd3d17
--- /dev/null
+++ b/transformers/tests/models/depth_pro/test_image_processing_depth_pro.py
@@ -0,0 +1,123 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers.testing_utils import is_flaky, require_torch, require_vision
+from transformers.utils import is_torchvision_available, is_vision_available
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_vision_available():
+ from transformers import DepthProImageProcessor
+
+ if is_torchvision_available():
+ from transformers import DepthProImageProcessorFast
+
+
+class DepthProImageProcessingTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ do_rescale=True,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ ):
+ super().__init__()
+ size = size if size is not None else {"height": 18, "width": 18}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_rescale = do_rescale
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+
+ def prepare_image_processor_dict(self):
+ return {
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_rescale": self.do_rescale,
+ "do_normalize": self.do_normalize,
+ "do_resize": self.do_resize,
+ "size": self.size,
+ }
+
+ def expected_output_image_shape(self, images):
+ return self.num_channels, self.size["height"], self.size["width"]
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class DepthProImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = DepthProImageProcessor if is_vision_available() else None
+ fast_image_processing_class = DepthProImageProcessorFast if is_torchvision_available() else None
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = DepthProImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "do_rescale"))
+ self.assertTrue(hasattr(image_processing, "rescale_factor"))
+ self.assertTrue(hasattr(image_processing, "resample"))
+
+ def test_image_processor_from_dict_with_kwargs(self):
+ image_processor = self.image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"height": 18, "width": 18})
+
+ image_processor = self.image_processing_class.from_dict(self.image_processor_dict, size=42)
+ self.assertEqual(image_processor.size, {"height": 42, "width": 42})
+
+ @is_flaky(
+ description="fast and slow, both processors use torch implementation, see: https://github.com/huggingface/transformers/issues/34920",
+ )
+ def test_fast_is_faster_than_slow(self):
+ super().test_fast_is_faster_than_slow()
diff --git a/transformers/tests/models/depth_pro/test_modeling_depth_pro.py b/transformers/tests/models/depth_pro/test_modeling_depth_pro.py
new file mode 100644
index 0000000000000000000000000000000000000000..50ac4cd1d28fb9e9dafe85cae49fec838c8550af
--- /dev/null
+++ b/transformers/tests/models/depth_pro/test_modeling_depth_pro.py
@@ -0,0 +1,413 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch DepthPro model."""
+
+import unittest
+
+from transformers import DepthProConfig
+from transformers.file_utils import is_torch_available, is_vision_available
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import DepthProForDepthEstimation, DepthProModel
+ from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import DepthProImageProcessor
+
+
+class DepthProModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=8,
+ image_size=64,
+ patch_size=16,
+ num_channels=3,
+ is_training=True,
+ use_labels=True,
+ fusion_hidden_size=16,
+ intermediate_hook_ids=[1, 0],
+ intermediate_feature_dims=[10, 8],
+ scaled_images_ratios=[0.5, 1.0],
+ scaled_images_overlap_ratios=[0.0, 0.2],
+ scaled_images_feature_dims=[12, 12],
+ initializer_range=0.02,
+ use_fov_model=False,
+ image_model_config={
+ "model_type": "dinov2",
+ "num_hidden_layers": 2,
+ "hidden_size": 16,
+ "num_attention_heads": 1,
+ "patch_size": 4,
+ },
+ patch_model_config={
+ "model_type": "vit",
+ "num_hidden_layers": 2,
+ "hidden_size": 24,
+ "num_attention_heads": 2,
+ "patch_size": 6,
+ },
+ fov_model_config={
+ "model_type": "vit",
+ "num_hidden_layers": 2,
+ "hidden_size": 32,
+ "num_attention_heads": 4,
+ "patch_size": 8,
+ },
+ num_labels=3,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.fusion_hidden_size = fusion_hidden_size
+ self.intermediate_hook_ids = intermediate_hook_ids
+ self.intermediate_feature_dims = intermediate_feature_dims
+ self.scaled_images_ratios = scaled_images_ratios
+ self.scaled_images_overlap_ratios = scaled_images_overlap_ratios
+ self.scaled_images_feature_dims = scaled_images_feature_dims
+ self.initializer_range = initializer_range
+ self.use_fov_model = use_fov_model
+ self.image_model_config = image_model_config
+ self.patch_model_config = patch_model_config
+ self.fov_model_config = fov_model_config
+ self.num_labels = num_labels
+
+ self.hidden_size = image_model_config["hidden_size"]
+ self.num_hidden_layers = image_model_config["num_hidden_layers"]
+ self.num_attention_heads = image_model_config["num_attention_heads"]
+
+ # may be different for a backbone other than dinov2
+ self.out_size = patch_size // image_model_config["patch_size"]
+ self.seq_length = self.out_size**2 + 1 # we add 1 for the [CLS] token
+
+ n_fusion_blocks = len(intermediate_hook_ids) + len(scaled_images_ratios)
+ self.expected_depth_size = 2 ** (n_fusion_blocks + 1) * self.out_size
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size, self.image_size, self.image_size], self.num_labels)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return DepthProConfig(
+ patch_size=self.patch_size,
+ fusion_hidden_size=self.fusion_hidden_size,
+ intermediate_hook_ids=self.intermediate_hook_ids,
+ intermediate_feature_dims=self.intermediate_feature_dims,
+ scaled_images_ratios=self.scaled_images_ratios,
+ scaled_images_overlap_ratios=self.scaled_images_overlap_ratios,
+ scaled_images_feature_dims=self.scaled_images_feature_dims,
+ initializer_range=self.initializer_range,
+ image_model_config=self.image_model_config,
+ patch_model_config=self.patch_model_config,
+ fov_model_config=self.fov_model_config,
+ use_fov_model=self.use_fov_model,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = DepthProModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_for_depth_estimation(self, config, pixel_values, labels):
+ config.num_labels = self.num_labels
+ model = DepthProForDepthEstimation(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(
+ result.predicted_depth.shape, (self.batch_size, self.expected_depth_size, self.expected_depth_size)
+ )
+
+ def create_and_check_for_fov(self, config, pixel_values, labels):
+ model = DepthProForDepthEstimation(config, use_fov_model=True)
+ model.to(torch_device)
+ model.eval()
+
+ # check if the fov_model (DinoV2-based encoder) is created
+ self.parent.assertIsNotNone(model.fov_model)
+
+ batched_pixel_values = pixel_values
+ row_pixel_values = pixel_values[:1]
+
+ with torch.no_grad():
+ model_batched_output_fov = model(batched_pixel_values).field_of_view
+ model_row_output_fov = model(row_pixel_values).field_of_view
+
+ # check if fov is returned
+ self.parent.assertIsNotNone(model_batched_output_fov)
+ self.parent.assertIsNotNone(model_row_output_fov)
+
+ # check output shape consistency for fov
+ self.parent.assertEqual(model_batched_output_fov.shape, (self.batch_size,))
+
+ # check equivalence between batched and single row outputs for fov
+ diff = torch.max(torch.abs(model_row_output_fov - model_batched_output_fov[:1]))
+ model_name = model.__class__.__name__
+ self.parent.assertTrue(
+ diff <= 1e-03,
+ msg=(f"Batched and Single row outputs are not equal in {model_name} for fov. Difference={diff}."),
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class DepthProModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as DepthPro does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (DepthProModel, DepthProForDepthEstimation) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "depth-estimation": DepthProForDepthEstimation,
+ "image-feature-extraction": DepthProModel,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ test_torch_exportable = True
+
+ def setUp(self):
+ self.model_tester = DepthProModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=DepthProConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="Inductor error: name 'OpaqueUnaryFn_log2' is not defined")
+ def test_sdpa_can_compile_dynamic(self):
+ pass
+
+ @unittest.skip(reason="DepthPro does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_get_set_embeddings(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_depth_estimation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_depth_estimation(*config_and_inputs)
+
+ def test_for_fov(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_fov(*config_and_inputs)
+
+ def test_training(self):
+ for model_class in self.all_model_classes:
+ if model_class.__name__ == "DepthProForDepthEstimation":
+ continue
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ if model_class.__name__ in MODEL_MAPPING_NAMES.values():
+ continue
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def test_training_gradient_checkpointing(self):
+ for model_class in self.all_model_classes:
+ if model_class.__name__ == "DepthProForDepthEstimation":
+ continue
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.use_cache = False
+ config.return_dict = True
+
+ if model_class.__name__ in MODEL_MAPPING_NAMES.values() or not model_class.supports_gradient_checkpointing:
+ continue
+ model = model_class(config)
+ model.to(torch_device)
+ model.gradient_checkpointing_enable()
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ non_uniform_init_parms = [
+ # these encoders are vision transformers
+ # any layer outside these encoders is either Conv2d or ConvTranspose2d
+ # which use kaiming initialization
+ "patch_encoder",
+ "image_encoder",
+ "fov_model.encoder",
+ ]
+ if param.requires_grad:
+ if any(x in name for x in non_uniform_init_parms):
+ # See PR #38607 (to avoid flakiness)
+ data = torch.flatten(param.data)
+ n_elements = torch.numel(data)
+ # skip 2.5% of elements on each side to avoid issues caused by `nn.init.trunc_normal_` described in
+ # https://github.com/huggingface/transformers/pull/27906#issuecomment-1846951332
+ n_elements_to_skip_on_each_side = int(n_elements * 0.025)
+ data_to_check = torch.sort(data).values
+ if n_elements_to_skip_on_each_side > 0:
+ data_to_check = data_to_check[
+ n_elements_to_skip_on_each_side:-n_elements_to_skip_on_each_side
+ ]
+ self.assertIn(
+ ((data_to_check.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ else:
+ self.assertTrue(
+ -1.0 <= ((param.data.mean() * 1e9).round() / 1e9).item() <= 1.0,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ # this started when switched from normal initialization to kaiming_normal initialization
+ # maybe because the magnitude of offset values from ViT-encoders increases when followed by many convolution layers
+ def test_batching_equivalence(self, atol=1e-4, rtol=1e-4):
+ super().test_batching_equivalence(atol=atol, rtol=rtol)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_path = "apple/DepthPro-hf"
+ model = DepthProModel.from_pretrained(model_path)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+@slow
+class DepthProModelIntegrationTest(unittest.TestCase):
+ def test_inference_depth_estimation(self):
+ model_path = "apple/DepthPro-hf"
+ image_processor = DepthProImageProcessor.from_pretrained(model_path)
+ model = DepthProForDepthEstimation.from_pretrained(model_path).to(torch_device)
+ config = model.config
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the predicted depth
+ n_fusion_blocks = len(config.intermediate_hook_ids) + len(config.scaled_images_ratios)
+ out_size = config.image_model_config.image_size // config.image_model_config.patch_size
+ expected_depth_size = 2 ** (n_fusion_blocks + 1) * out_size
+
+ expected_shape = torch.Size((1, expected_depth_size, expected_depth_size))
+ self.assertEqual(outputs.predicted_depth.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[1.0582, 1.1225, 1.1335], [1.1154, 1.1398, 1.1486], [1.1434, 1.1500, 1.1643]]
+ ).to(torch_device)
+ torch.testing.assert_close(outputs.predicted_depth[0, :3, :3], expected_slice, atol=1e-4, rtol=1e-4)
+
+ # verify the predicted fov
+ expected_shape = torch.Size((1,))
+ self.assertEqual(outputs.field_of_view.shape, expected_shape)
+
+ expected_slice = torch.tensor([47.2459]).to(torch_device)
+ torch.testing.assert_close(outputs.field_of_view, expected_slice, atol=1e-4, rtol=1e-4)
+
+ def test_post_processing_depth_estimation(self):
+ model_path = "apple/DepthPro-hf"
+ image_processor = DepthProImageProcessor.from_pretrained(model_path)
+ model = DepthProForDepthEstimation.from_pretrained(model_path)
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt")
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ outputs = image_processor.post_process_depth_estimation(
+ outputs,
+ target_sizes=[[image.height, image.width]],
+ )
+ predicted_depth = outputs[0]["predicted_depth"]
+ expected_shape = torch.Size((image.height, image.width))
+ self.assertTrue(predicted_depth.shape == expected_shape)
diff --git a/transformers/tests/models/detr/__init__.py b/transformers/tests/models/detr/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/detr/test_image_processing_detr.py b/transformers/tests/models/detr/test_image_processing_detr.py
new file mode 100644
index 0000000000000000000000000000000000000000..d9cff61a10619c0061adc6b8c9d37ec2fad6ce28
--- /dev/null
+++ b/transformers/tests/models/detr/test_image_processing_detr.py
@@ -0,0 +1,796 @@
+# Copyright 2021 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import pathlib
+import unittest
+
+import numpy as np
+
+from transformers.testing_utils import (
+ require_torch,
+ require_torch_accelerator,
+ require_torchvision,
+ require_vision,
+ slow,
+ torch_device,
+)
+from transformers.utils import is_torch_available, is_torchvision_available, is_vision_available
+
+from ...test_image_processing_common import AnnotationFormatTestMixin, ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import DetrImageProcessor
+
+ if is_torchvision_available():
+ from transformers import DetrImageProcessorFast
+
+
+class DetrImageProcessingTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ do_pad=True,
+ ):
+ # by setting size["longest_edge"] > max_resolution we're effectively not testing this :p
+ size = size if size is not None else {"shortest_edge": 18, "longest_edge": 1333}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.do_pad = do_pad
+
+ def prepare_image_processor_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_pad": self.do_pad,
+ }
+
+ def get_expected_values(self, image_inputs, batched=False):
+ """
+ This function computes the expected height and width when providing images to DetrImageProcessor,
+ assuming do_resize is set to True with a scalar size.
+ """
+ if not batched:
+ image = image_inputs[0]
+ if isinstance(image, Image.Image):
+ w, h = image.size
+ elif isinstance(image, np.ndarray):
+ h, w = image.shape[0], image.shape[1]
+ else:
+ h, w = image.shape[1], image.shape[2]
+ if w < h:
+ expected_height = int(self.size["shortest_edge"] * h / w)
+ expected_width = self.size["shortest_edge"]
+ elif w > h:
+ expected_height = self.size["shortest_edge"]
+ expected_width = int(self.size["shortest_edge"] * w / h)
+ else:
+ expected_height = self.size["shortest_edge"]
+ expected_width = self.size["shortest_edge"]
+
+ else:
+ expected_values = []
+ for image in image_inputs:
+ expected_height, expected_width = self.get_expected_values([image])
+ expected_values.append((expected_height, expected_width))
+ expected_height = max(expected_values, key=lambda item: item[0])[0]
+ expected_width = max(expected_values, key=lambda item: item[1])[1]
+
+ return expected_height, expected_width
+
+ def expected_output_image_shape(self, images):
+ height, width = self.get_expected_values(images, batched=True)
+ return self.num_channels, height, width
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class DetrImageProcessingTest(AnnotationFormatTestMixin, ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = DetrImageProcessor if is_vision_available() else None
+ fast_image_processing_class = DetrImageProcessorFast if is_torchvision_available() else None
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = DetrImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "do_rescale"))
+ self.assertTrue(hasattr(image_processing, "rescale_factor"))
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "do_pad"))
+
+ def test_image_processor_from_dict_with_kwargs(self):
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"shortest_edge": 18, "longest_edge": 1333})
+ self.assertEqual(image_processor.do_pad, True)
+
+ image_processor = image_processing_class.from_dict(
+ self.image_processor_dict, size=42, max_size=84, pad_and_return_pixel_mask=False
+ )
+ self.assertEqual(image_processor.size, {"shortest_edge": 42, "longest_edge": 84})
+ self.assertEqual(image_processor.do_pad, False)
+
+ def test_should_raise_if_annotation_format_invalid(self):
+ image_processor_dict = self.image_processor_tester.prepare_image_processor_dict()
+
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt") as f:
+ detection_target = json.loads(f.read())
+
+ annotations = {"image_id": 39769, "annotations": detection_target}
+
+ params = {
+ "images": Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png"),
+ "annotations": annotations,
+ "return_tensors": "pt",
+ }
+
+ image_processor_params = {**image_processor_dict, **{"format": "_INVALID_FORMAT_"}}
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class(**image_processor_params)
+
+ with self.assertRaises(ValueError) as e:
+ image_processor(**params)
+
+ self.assertTrue(str(e.exception).startswith("_INVALID_FORMAT_ is not a valid AnnotationFormat"))
+
+ def test_valid_coco_detection_annotations(self):
+ # prepare image and target
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ params = {"image_id": 39769, "annotations": target}
+
+ for image_processing_class in self.image_processor_list:
+ # encode them
+ image_processing = image_processing_class.from_pretrained("facebook/detr-resnet-50")
+
+ # legal encodings (single image)
+ _ = image_processing(images=image, annotations=params, return_tensors="pt")
+ _ = image_processing(images=image, annotations=[params], return_tensors="pt")
+
+ # legal encodings (batch of one image)
+ _ = image_processing(images=[image], annotations=params, return_tensors="pt")
+ _ = image_processing(images=[image], annotations=[params], return_tensors="pt")
+
+ # legal encoding (batch of more than one image)
+ n = 5
+ _ = image_processing(images=[image] * n, annotations=[params] * n, return_tensors="pt")
+
+ # example of an illegal encoding (missing the 'image_id' key)
+ with self.assertRaises(ValueError) as e:
+ image_processing(images=image, annotations={"annotations": target}, return_tensors="pt")
+
+ self.assertTrue(str(e.exception).startswith("Invalid COCO detection annotations"))
+
+ # example of an illegal encoding (unequal lengths of images and annotations)
+ with self.assertRaises(ValueError) as e:
+ image_processing(images=[image] * n, annotations=[params] * (n - 1), return_tensors="pt")
+
+ self.assertTrue(str(e.exception) == "The number of images (5) and annotations (4) do not match.")
+
+ @slow
+ def test_call_pytorch_with_coco_detection_annotations(self):
+ # prepare image and target
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ target = {"image_id": 39769, "annotations": target}
+
+ for image_processing_class in self.image_processor_list:
+ # encode them
+ image_processing = image_processing_class.from_pretrained("facebook/detr-resnet-50")
+ encoding = image_processing(images=image, annotations=target, return_tensors="pt")
+
+ # verify pixel values
+ expected_shape = torch.Size([1, 3, 800, 1066])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ expected_slice = torch.tensor([0.2796, 0.3138, 0.3481])
+ torch.testing.assert_close(encoding["pixel_values"][0, 0, 0, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ # verify area
+ expected_area = torch.tensor([5887.9600, 11250.2061, 489353.8438, 837122.7500, 147967.5156, 165732.3438])
+ torch.testing.assert_close(encoding["labels"][0]["area"], expected_area)
+ # verify boxes
+ expected_boxes_shape = torch.Size([6, 4])
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, expected_boxes_shape)
+ expected_boxes_slice = torch.tensor([0.5503, 0.2765, 0.0604, 0.2215])
+ torch.testing.assert_close(encoding["labels"][0]["boxes"][0], expected_boxes_slice, rtol=1e-3, atol=1e-3)
+ # verify image_id
+ expected_image_id = torch.tensor([39769])
+ torch.testing.assert_close(encoding["labels"][0]["image_id"], expected_image_id)
+ # verify is_crowd
+ expected_is_crowd = torch.tensor([0, 0, 0, 0, 0, 0])
+ torch.testing.assert_close(encoding["labels"][0]["iscrowd"], expected_is_crowd)
+ # verify class_labels
+ expected_class_labels = torch.tensor([75, 75, 63, 65, 17, 17])
+ torch.testing.assert_close(encoding["labels"][0]["class_labels"], expected_class_labels)
+ # verify orig_size
+ expected_orig_size = torch.tensor([480, 640])
+ torch.testing.assert_close(encoding["labels"][0]["orig_size"], expected_orig_size)
+ # verify size
+ expected_size = torch.tensor([800, 1066])
+ torch.testing.assert_close(encoding["labels"][0]["size"], expected_size)
+
+ @slow
+ def test_call_pytorch_with_coco_panoptic_annotations(self):
+ # prepare image, target and masks_path
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ target = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+
+ masks_path = pathlib.Path("./tests/fixtures/tests_samples/COCO/coco_panoptic")
+
+ for image_processing_class in self.image_processor_list:
+ # encode them
+ image_processing = image_processing_class.from_pretrained("facebook/detr-resnet-50-panoptic")
+ encoding = image_processing(images=image, annotations=target, masks_path=masks_path, return_tensors="pt")
+
+ # verify pixel values
+ expected_shape = torch.Size([1, 3, 800, 1066])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ expected_slice = torch.tensor([0.2796, 0.3138, 0.3481])
+ torch.testing.assert_close(encoding["pixel_values"][0, 0, 0, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ # verify area
+ expected_area = torch.tensor([147979.6875, 165527.0469, 484638.5938, 11292.9375, 5879.6562, 7634.1147])
+ torch.testing.assert_close(encoding["labels"][0]["area"], expected_area)
+ # verify boxes
+ expected_boxes_shape = torch.Size([6, 4])
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, expected_boxes_shape)
+ expected_boxes_slice = torch.tensor([0.2625, 0.5437, 0.4688, 0.8625])
+ torch.testing.assert_close(encoding["labels"][0]["boxes"][0], expected_boxes_slice, rtol=1e-3, atol=1e-3)
+ # verify image_id
+ expected_image_id = torch.tensor([39769])
+ torch.testing.assert_close(encoding["labels"][0]["image_id"], expected_image_id)
+ # verify is_crowd
+ expected_is_crowd = torch.tensor([0, 0, 0, 0, 0, 0])
+ torch.testing.assert_close(encoding["labels"][0]["iscrowd"], expected_is_crowd)
+ # verify class_labels
+ expected_class_labels = torch.tensor([17, 17, 63, 75, 75, 93])
+ torch.testing.assert_close(encoding["labels"][0]["class_labels"], expected_class_labels)
+ # verify masks
+ expected_masks_sum = 822873
+ relative_error = torch.abs(encoding["labels"][0]["masks"].sum() - expected_masks_sum) / expected_masks_sum
+ self.assertTrue(relative_error < 1e-3)
+ # verify orig_size
+ expected_orig_size = torch.tensor([480, 640])
+ torch.testing.assert_close(encoding["labels"][0]["orig_size"], expected_orig_size)
+ # verify size
+ expected_size = torch.tensor([800, 1066])
+ torch.testing.assert_close(encoding["labels"][0]["size"], expected_size)
+
+ @slow
+ def test_batched_coco_detection_annotations(self):
+ image_0 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ image_1 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png").resize((800, 800))
+
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ annotations_0 = {"image_id": 39769, "annotations": target}
+ annotations_1 = {"image_id": 39769, "annotations": target}
+
+ # Adjust the bounding boxes for the resized image
+ w_0, h_0 = image_0.size
+ w_1, h_1 = image_1.size
+ for i in range(len(annotations_1["annotations"])):
+ coords = annotations_1["annotations"][i]["bbox"]
+ new_bbox = [
+ coords[0] * w_1 / w_0,
+ coords[1] * h_1 / h_0,
+ coords[2] * w_1 / w_0,
+ coords[3] * h_1 / h_0,
+ ]
+ annotations_1["annotations"][i]["bbox"] = new_bbox
+
+ images = [image_0, image_1]
+ annotations = [annotations_0, annotations_1]
+
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class()
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ return_segmentation_masks=True,
+ return_tensors="pt", # do_convert_annotations=True
+ )
+
+ # Check the pixel values have been padded
+ postprocessed_height, postprocessed_width = 800, 1066
+ expected_shape = torch.Size([2, 3, postprocessed_height, postprocessed_width])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ # Check the bounding boxes have been adjusted for padded images
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ expected_boxes_0 = torch.tensor(
+ [
+ [0.6879, 0.4609, 0.0755, 0.3691],
+ [0.2118, 0.3359, 0.2601, 0.1566],
+ [0.5011, 0.5000, 0.9979, 1.0000],
+ [0.5010, 0.5020, 0.9979, 0.9959],
+ [0.3284, 0.5944, 0.5884, 0.8112],
+ [0.8394, 0.5445, 0.3213, 0.9110],
+ ]
+ )
+ expected_boxes_1 = torch.tensor(
+ [
+ [0.4130, 0.2765, 0.0453, 0.2215],
+ [0.1272, 0.2016, 0.1561, 0.0940],
+ [0.3757, 0.4933, 0.7488, 0.9865],
+ [0.3759, 0.5002, 0.7492, 0.9955],
+ [0.1971, 0.5456, 0.3532, 0.8646],
+ [0.5790, 0.4115, 0.3430, 0.7161],
+ ]
+ )
+ torch.testing.assert_close(encoding["labels"][0]["boxes"], expected_boxes_0, atol=1e-3, rtol=1e-3)
+ torch.testing.assert_close(encoding["labels"][1]["boxes"], expected_boxes_1, atol=1e-3, rtol=1e-3)
+
+ # Check the masks have also been padded
+ self.assertEqual(encoding["labels"][0]["masks"].shape, torch.Size([6, 800, 1066]))
+ self.assertEqual(encoding["labels"][1]["masks"].shape, torch.Size([6, 800, 1066]))
+
+ # Check if do_convert_annotations=False, then the annotations are not converted to centre_x, centre_y, width, height
+ # format and not in the range [0, 1]
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ return_segmentation_masks=True,
+ do_convert_annotations=False,
+ return_tensors="pt",
+ )
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ # Convert to absolute coordinates
+ unnormalized_boxes_0 = torch.vstack(
+ [
+ expected_boxes_0[:, 0] * postprocessed_width,
+ expected_boxes_0[:, 1] * postprocessed_height,
+ expected_boxes_0[:, 2] * postprocessed_width,
+ expected_boxes_0[:, 3] * postprocessed_height,
+ ]
+ ).T
+ unnormalized_boxes_1 = torch.vstack(
+ [
+ expected_boxes_1[:, 0] * postprocessed_width,
+ expected_boxes_1[:, 1] * postprocessed_height,
+ expected_boxes_1[:, 2] * postprocessed_width,
+ expected_boxes_1[:, 3] * postprocessed_height,
+ ]
+ ).T
+ # Convert from centre_x, centre_y, width, height to x_min, y_min, x_max, y_max
+ expected_boxes_0 = torch.vstack(
+ [
+ unnormalized_boxes_0[:, 0] - unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] - unnormalized_boxes_0[:, 3] / 2,
+ unnormalized_boxes_0[:, 0] + unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] + unnormalized_boxes_0[:, 3] / 2,
+ ]
+ ).T
+ expected_boxes_1 = torch.vstack(
+ [
+ unnormalized_boxes_1[:, 0] - unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] - unnormalized_boxes_1[:, 3] / 2,
+ unnormalized_boxes_1[:, 0] + unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] + unnormalized_boxes_1[:, 3] / 2,
+ ]
+ ).T
+ torch.testing.assert_close(encoding["labels"][0]["boxes"], expected_boxes_0, atol=1, rtol=1)
+ torch.testing.assert_close(encoding["labels"][1]["boxes"], expected_boxes_1, atol=1, rtol=1)
+
+ def test_batched_coco_panoptic_annotations(self):
+ # prepare image, target and masks_path
+ image_0 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ image_1 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png").resize((800, 800))
+
+ with open("./tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ annotation_0 = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+ annotation_1 = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+
+ w_0, h_0 = image_0.size
+ w_1, h_1 = image_1.size
+ for i in range(len(annotation_1["segments_info"])):
+ coords = annotation_1["segments_info"][i]["bbox"]
+ new_bbox = [
+ coords[0] * w_1 / w_0,
+ coords[1] * h_1 / h_0,
+ coords[2] * w_1 / w_0,
+ coords[3] * h_1 / h_0,
+ ]
+ annotation_1["segments_info"][i]["bbox"] = new_bbox
+
+ masks_path = pathlib.Path("./tests/fixtures/tests_samples/COCO/coco_panoptic")
+
+ images = [image_0, image_1]
+ annotations = [annotation_0, annotation_1]
+
+ for image_processing_class in self.image_processor_list:
+ # encode them
+ image_processing = image_processing_class(format="coco_panoptic")
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ masks_path=masks_path,
+ return_tensors="pt",
+ return_segmentation_masks=True,
+ )
+
+ # Check the pixel values have been padded
+ postprocessed_height, postprocessed_width = 800, 1066
+ expected_shape = torch.Size([2, 3, postprocessed_height, postprocessed_width])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ # Check the bounding boxes have been adjusted for padded images
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ expected_boxes_0 = torch.tensor(
+ [
+ [0.2625, 0.5437, 0.4688, 0.8625],
+ [0.7719, 0.4104, 0.4531, 0.7125],
+ [0.5000, 0.4927, 0.9969, 0.9854],
+ [0.1688, 0.2000, 0.2063, 0.0917],
+ [0.5492, 0.2760, 0.0578, 0.2187],
+ [0.4992, 0.4990, 0.9984, 0.9979],
+ ]
+ )
+ expected_boxes_1 = torch.tensor(
+ [
+ [0.1576, 0.3262, 0.2814, 0.5175],
+ [0.4634, 0.2463, 0.2720, 0.4275],
+ [0.3002, 0.2956, 0.5985, 0.5913],
+ [0.1013, 0.1200, 0.1238, 0.0550],
+ [0.3297, 0.1656, 0.0347, 0.1312],
+ [0.2997, 0.2994, 0.5994, 0.5987],
+ ]
+ )
+ torch.testing.assert_close(encoding["labels"][0]["boxes"], expected_boxes_0, atol=1e-3, rtol=1e-3)
+ torch.testing.assert_close(encoding["labels"][1]["boxes"], expected_boxes_1, atol=1e-3, rtol=1e-3)
+
+ # Check the masks have also been padded
+ self.assertEqual(encoding["labels"][0]["masks"].shape, torch.Size([6, 800, 1066]))
+ self.assertEqual(encoding["labels"][1]["masks"].shape, torch.Size([6, 800, 1066]))
+
+ # Check if do_convert_annotations=False, then the annotations are not converted to centre_x, centre_y, width, height
+ # format and not in the range [0, 1]
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ masks_path=masks_path,
+ return_segmentation_masks=True,
+ do_convert_annotations=False,
+ return_tensors="pt",
+ )
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ # Convert to absolute coordinates
+ unnormalized_boxes_0 = torch.vstack(
+ [
+ expected_boxes_0[:, 0] * postprocessed_width,
+ expected_boxes_0[:, 1] * postprocessed_height,
+ expected_boxes_0[:, 2] * postprocessed_width,
+ expected_boxes_0[:, 3] * postprocessed_height,
+ ]
+ ).T
+ unnormalized_boxes_1 = torch.vstack(
+ [
+ expected_boxes_1[:, 0] * postprocessed_width,
+ expected_boxes_1[:, 1] * postprocessed_height,
+ expected_boxes_1[:, 2] * postprocessed_width,
+ expected_boxes_1[:, 3] * postprocessed_height,
+ ]
+ ).T
+ # Convert from centre_x, centre_y, width, height to x_min, y_min, x_max, y_max
+ expected_boxes_0 = torch.vstack(
+ [
+ unnormalized_boxes_0[:, 0] - unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] - unnormalized_boxes_0[:, 3] / 2,
+ unnormalized_boxes_0[:, 0] + unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] + unnormalized_boxes_0[:, 3] / 2,
+ ]
+ ).T
+ expected_boxes_1 = torch.vstack(
+ [
+ unnormalized_boxes_1[:, 0] - unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] - unnormalized_boxes_1[:, 3] / 2,
+ unnormalized_boxes_1[:, 0] + unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] + unnormalized_boxes_1[:, 3] / 2,
+ ]
+ ).T
+ torch.testing.assert_close(encoding["labels"][0]["boxes"], expected_boxes_0, atol=1, rtol=1)
+ torch.testing.assert_close(encoding["labels"][1]["boxes"], expected_boxes_1, atol=1, rtol=1)
+
+ def test_max_width_max_height_resizing_and_pad_strategy(self):
+ for image_processing_class in self.image_processor_list:
+ image_1 = torch.ones([200, 100, 3], dtype=torch.uint8)
+
+ # do_pad=False, max_height=100, max_width=100, image=200x100 -> 100x50
+ image_processor = image_processing_class(
+ size={"max_height": 100, "max_width": 100},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 100, 50]))
+
+ # do_pad=False, max_height=300, max_width=100, image=200x100 -> 200x100
+ image_processor = image_processing_class(
+ size={"max_height": 300, "max_width": 100},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+
+ # do_pad=True, max_height=100, max_width=100, image=200x100 -> 100x100
+ image_processor = image_processing_class(
+ size={"max_height": 100, "max_width": 100}, do_pad=True, pad_size={"height": 100, "width": 100}
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 100, 100]))
+
+ # do_pad=True, max_height=300, max_width=100, image=200x100 -> 300x100
+ image_processor = image_processing_class(
+ size={"max_height": 300, "max_width": 100},
+ do_pad=True,
+ pad_size={"height": 301, "width": 101},
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 301, 101]))
+
+ ### Check for batch
+ image_2 = torch.ones([100, 150, 3], dtype=torch.uint8)
+
+ # do_pad=True, max_height=150, max_width=100, images=[200x100, 100x150] -> 150x100
+ image_processor = image_processing_class(
+ size={"max_height": 150, "max_width": 100},
+ do_pad=True,
+ pad_size={"height": 150, "width": 100},
+ )
+ inputs = image_processor(images=[image_1, image_2], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([2, 3, 150, 100]))
+
+ def test_longest_edge_shortest_edge_resizing_strategy(self):
+ for image_processing_class in self.image_processor_list:
+ image_1 = torch.ones([958, 653, 3], dtype=torch.uint8)
+
+ # max size is set; width < height;
+ # do_pad=False, longest_edge=640, shortest_edge=640, image=958x653 -> 640x436
+ image_processor = image_processing_class(
+ size={"longest_edge": 640, "shortest_edge": 640},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 640, 436]))
+
+ image_2 = torch.ones([653, 958, 3], dtype=torch.uint8)
+ # max size is set; height < width;
+ # do_pad=False, longest_edge=640, shortest_edge=640, image=653x958 -> 436x640
+ image_processor = image_processing_class(
+ size={"longest_edge": 640, "shortest_edge": 640},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_2], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 436, 640]))
+
+ image_3 = torch.ones([100, 120, 3], dtype=torch.uint8)
+ # max size is set; width == size; height > max_size;
+ # do_pad=False, longest_edge=118, shortest_edge=100, image=120x100 -> 118x98
+ image_processor = image_processing_class(
+ size={"longest_edge": 118, "shortest_edge": 100},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_3], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 98, 118]))
+
+ image_4 = torch.ones([128, 50, 3], dtype=torch.uint8)
+ # max size is set; height == size; width < max_size;
+ # do_pad=False, longest_edge=256, shortest_edge=50, image=50x128 -> 50x128
+ image_processor = image_processing_class(
+ size={"longest_edge": 256, "shortest_edge": 50},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_4], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 128, 50]))
+
+ image_5 = torch.ones([50, 50, 3], dtype=torch.uint8)
+ # max size is set; height == width; width < max_size;
+ # do_pad=False, longest_edge=117, shortest_edge=50, image=50x50 -> 50x50
+ image_processor = image_processing_class(
+ size={"longest_edge": 117, "shortest_edge": 50},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_5], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 50, 50]))
+
+ @slow
+ @require_torch_accelerator
+ @require_torchvision
+ def test_fast_processor_equivalence_cpu_accelerator_coco_detection_annotations(self):
+ # prepare image and target
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ target = {"image_id": 39769, "annotations": target}
+
+ processor = self.image_processor_list[1]()
+ # 1. run processor on CPU
+ encoding_cpu = processor(images=image, annotations=target, return_tensors="pt", device="cpu")
+ # 2. run processor on accelerator
+ encoding_gpu = processor(images=image, annotations=target, return_tensors="pt", device=torch_device)
+
+ # verify pixel values
+ self.assertEqual(encoding_cpu["pixel_values"].shape, encoding_gpu["pixel_values"].shape)
+ self.assertTrue(
+ torch.allclose(
+ encoding_cpu["pixel_values"][0, 0, 0, :3],
+ encoding_gpu["pixel_values"][0, 0, 0, :3].to("cpu"),
+ atol=1e-4,
+ )
+ )
+ # verify area
+ torch.testing.assert_close(encoding_cpu["labels"][0]["area"], encoding_gpu["labels"][0]["area"].to("cpu"))
+ # verify boxes
+ self.assertEqual(encoding_cpu["labels"][0]["boxes"].shape, encoding_gpu["labels"][0]["boxes"].shape)
+ self.assertTrue(
+ torch.allclose(
+ encoding_cpu["labels"][0]["boxes"][0], encoding_gpu["labels"][0]["boxes"][0].to("cpu"), atol=1e-3
+ )
+ )
+ # verify image_id
+ torch.testing.assert_close(
+ encoding_cpu["labels"][0]["image_id"], encoding_gpu["labels"][0]["image_id"].to("cpu")
+ )
+ # verify is_crowd
+ torch.testing.assert_close(
+ encoding_cpu["labels"][0]["iscrowd"], encoding_gpu["labels"][0]["iscrowd"].to("cpu")
+ )
+ # verify class_labels
+ self.assertTrue(
+ torch.allclose(
+ encoding_cpu["labels"][0]["class_labels"], encoding_gpu["labels"][0]["class_labels"].to("cpu")
+ )
+ )
+ # verify orig_size
+ torch.testing.assert_close(
+ encoding_cpu["labels"][0]["orig_size"], encoding_gpu["labels"][0]["orig_size"].to("cpu")
+ )
+ # verify size
+ torch.testing.assert_close(encoding_cpu["labels"][0]["size"], encoding_gpu["labels"][0]["size"].to("cpu"))
+
+ @slow
+ @require_torch_accelerator
+ @require_torchvision
+ def test_fast_processor_equivalence_cpu_accelerator_coco_panoptic_annotations(self):
+ # prepare image, target and masks_path
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ target = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+
+ masks_path = pathlib.Path("./tests/fixtures/tests_samples/COCO/coco_panoptic")
+
+ processor = self.image_processor_list[1](format="coco_panoptic")
+ # 1. run processor on CPU
+ encoding_cpu = processor(
+ images=image, annotations=target, masks_path=masks_path, return_tensors="pt", device="cpu"
+ )
+ # 2. run processor on accelerator
+ encoding_gpu = processor(
+ images=image, annotations=target, masks_path=masks_path, return_tensors="pt", device=torch_device
+ )
+
+ # verify pixel values
+ self.assertEqual(encoding_cpu["pixel_values"].shape, encoding_gpu["pixel_values"].shape)
+ self.assertTrue(
+ torch.allclose(
+ encoding_cpu["pixel_values"][0, 0, 0, :3],
+ encoding_gpu["pixel_values"][0, 0, 0, :3].to("cpu"),
+ atol=1e-4,
+ )
+ )
+ # verify area
+ torch.testing.assert_close(encoding_cpu["labels"][0]["area"], encoding_gpu["labels"][0]["area"].to("cpu"))
+ # verify boxes
+ self.assertEqual(encoding_cpu["labels"][0]["boxes"].shape, encoding_gpu["labels"][0]["boxes"].shape)
+ self.assertTrue(
+ torch.allclose(
+ encoding_cpu["labels"][0]["boxes"][0], encoding_gpu["labels"][0]["boxes"][0].to("cpu"), atol=1e-3
+ )
+ )
+ # verify image_id
+ torch.testing.assert_close(
+ encoding_cpu["labels"][0]["image_id"], encoding_gpu["labels"][0]["image_id"].to("cpu")
+ )
+ # verify is_crowd
+ torch.testing.assert_close(
+ encoding_cpu["labels"][0]["iscrowd"], encoding_gpu["labels"][0]["iscrowd"].to("cpu")
+ )
+ # verify class_labels
+ self.assertTrue(
+ torch.allclose(
+ encoding_cpu["labels"][0]["class_labels"], encoding_gpu["labels"][0]["class_labels"].to("cpu")
+ )
+ )
+ # verify masks
+ masks_sum_cpu = encoding_cpu["labels"][0]["masks"].sum()
+ masks_sum_gpu = encoding_gpu["labels"][0]["masks"].sum()
+ relative_error = torch.abs(masks_sum_cpu - masks_sum_gpu) / masks_sum_cpu
+ self.assertTrue(relative_error < 1e-3)
+ # verify orig_size
+ torch.testing.assert_close(
+ encoding_cpu["labels"][0]["orig_size"], encoding_gpu["labels"][0]["orig_size"].to("cpu")
+ )
+ # verify size
+ torch.testing.assert_close(encoding_cpu["labels"][0]["size"], encoding_gpu["labels"][0]["size"].to("cpu"))
diff --git a/transformers/tests/models/detr/test_modeling_detr.py b/transformers/tests/models/detr/test_modeling_detr.py
new file mode 100644
index 0000000000000000000000000000000000000000..2af2ca92115f98f221f4a15d6c81ccc3b8ac89c7
--- /dev/null
+++ b/transformers/tests/models/detr/test_modeling_detr.py
@@ -0,0 +1,741 @@
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch DETR model."""
+
+import inspect
+import math
+import unittest
+
+from transformers import DetrConfig, ResNetConfig, is_torch_available, is_vision_available
+from transformers.testing_utils import require_timm, require_torch, require_vision, slow, torch_device
+from transformers.utils import cached_property
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import DetrForObjectDetection, DetrForSegmentation, DetrModel
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import DetrImageProcessor
+
+
+class DetrModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=8,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=8,
+ intermediate_size=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ num_queries=12,
+ num_channels=3,
+ min_size=200,
+ max_size=200,
+ n_targets=8,
+ num_labels=91,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.num_queries = num_queries
+ self.num_channels = num_channels
+ self.min_size = min_size
+ self.max_size = max_size
+ self.n_targets = n_targets
+ self.num_labels = num_labels
+
+ # we also set the expected seq length for both encoder and decoder
+ self.encoder_seq_length = math.ceil(self.min_size / 32) * math.ceil(self.max_size / 32)
+ self.decoder_seq_length = self.num_queries
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.min_size, self.max_size])
+
+ pixel_mask = torch.ones([self.batch_size, self.min_size, self.max_size], device=torch_device)
+
+ labels = None
+ if self.use_labels:
+ # labels is a list of Dict (each Dict being the labels for a given example in the batch)
+ labels = []
+ for i in range(self.batch_size):
+ target = {}
+ target["class_labels"] = torch.randint(
+ high=self.num_labels, size=(self.n_targets,), device=torch_device
+ )
+ target["boxes"] = torch.rand(self.n_targets, 4, device=torch_device)
+ target["masks"] = torch.rand(self.n_targets, self.min_size, self.max_size, device=torch_device)
+ labels.append(target)
+
+ config = self.get_config()
+ return config, pixel_values, pixel_mask, labels
+
+ def get_config(self):
+ resnet_config = ResNetConfig(
+ num_channels=3,
+ embeddings_size=10,
+ hidden_sizes=[10, 20, 30, 40],
+ depths=[1, 1, 2, 1],
+ hidden_act="relu",
+ num_labels=3,
+ out_features=["stage2", "stage3", "stage4"],
+ out_indices=[2, 3, 4],
+ )
+ return DetrConfig(
+ d_model=self.hidden_size,
+ encoder_layers=self.num_hidden_layers,
+ decoder_layers=self.num_hidden_layers,
+ encoder_attention_heads=self.num_attention_heads,
+ decoder_attention_heads=self.num_attention_heads,
+ encoder_ffn_dim=self.intermediate_size,
+ decoder_ffn_dim=self.intermediate_size,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ num_queries=self.num_queries,
+ num_labels=self.num_labels,
+ use_timm_backbone=False,
+ backbone_config=resnet_config,
+ backbone=None,
+ use_pretrained_backbone=False,
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config, pixel_values, pixel_mask, labels = self.prepare_config_and_inputs()
+ inputs_dict = {"pixel_values": pixel_values, "pixel_mask": pixel_mask}
+ return config, inputs_dict
+
+ def create_and_check_detr_model(self, config, pixel_values, pixel_mask, labels):
+ model = DetrModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask)
+ result = model(pixel_values)
+
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.decoder_seq_length, self.hidden_size)
+ )
+
+ def create_and_check_detr_object_detection_head_model(self, config, pixel_values, pixel_mask, labels):
+ model = DetrForObjectDetection(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask)
+ result = model(pixel_values)
+
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_queries, self.num_labels + 1))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_queries, 4))
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask, labels=labels)
+
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_queries, self.num_labels + 1))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_queries, 4))
+
+
+@require_torch
+class DetrModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ DetrModel,
+ DetrForObjectDetection,
+ DetrForSegmentation,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "image-feature-extraction": DetrModel,
+ "image-segmentation": DetrForSegmentation,
+ "object-detection": DetrForObjectDetection,
+ }
+ if is_torch_available()
+ else {}
+ )
+ is_encoder_decoder = True
+ test_torchscript = False
+ test_pruning = False
+ test_head_masking = False
+ test_missing_keys = False
+ zero_init_hidden_state = True
+ test_torch_exportable = True
+
+ # special case for head models
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class.__name__ in ["DetrForObjectDetection", "DetrForSegmentation"]:
+ labels = []
+ for i in range(self.model_tester.batch_size):
+ target = {}
+ target["class_labels"] = torch.ones(
+ size=(self.model_tester.n_targets,), device=torch_device, dtype=torch.long
+ )
+ target["boxes"] = torch.ones(
+ self.model_tester.n_targets, 4, device=torch_device, dtype=torch.float
+ )
+ target["masks"] = torch.ones(
+ self.model_tester.n_targets,
+ self.model_tester.min_size,
+ self.model_tester.max_size,
+ device=torch_device,
+ dtype=torch.float,
+ )
+ labels.append(target)
+ inputs_dict["labels"] = labels
+
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = DetrModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=DetrConfig, has_text_modality=False)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_detr_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_detr_model(*config_and_inputs)
+
+ def test_detr_object_detection_head_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_detr_object_detection_head_model(*config_and_inputs)
+
+ # TODO: check if this works again for PyTorch 2.x.y
+ @unittest.skip(reason="Got `CUDA error: misaligned address` with PyTorch 2.0.0.")
+ def test_multi_gpu_data_parallel_forward(self):
+ pass
+
+ @unittest.skip(reason="DETR does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="DETR does not use inputs_embeds")
+ def test_inputs_embeds_matches_input_ids(self):
+ pass
+
+ @unittest.skip(reason="DETR does not have a get_input_embeddings method")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @unittest.skip(reason="DETR is not a generative model")
+ def test_generate_without_input_ids(self):
+ pass
+
+ @unittest.skip(reason="DETR does not use token embeddings")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ @slow
+ @unittest.skip(reason="TODO Niels: fix me!")
+ def test_model_outputs_equivalence(self):
+ pass
+
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ decoder_seq_length = self.model_tester.decoder_seq_length
+ encoder_seq_length = self.model_tester.encoder_seq_length
+ decoder_key_length = self.model_tester.decoder_seq_length
+ encoder_key_length = self.model_tester.encoder_seq_length
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class._from_config(config, attn_implementation="eager")
+ config = model.config
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length],
+ )
+ out_len = len(outputs)
+
+ if self.is_encoder_decoder:
+ correct_outlen = 5
+
+ # loss is at first position
+ if "labels" in inputs_dict:
+ correct_outlen += 1 # loss is added to beginning
+ # Object Detection model returns pred_logits and pred_boxes
+ if model_class.__name__ == "DetrForObjectDetection":
+ correct_outlen += 2
+ # Panoptic Segmentation model returns pred_logits, pred_boxes, pred_masks
+ if model_class.__name__ == "DetrForSegmentation":
+ correct_outlen += 3
+ if "past_key_values" in outputs:
+ correct_outlen += 1 # past_key_values have been returned
+
+ self.assertEqual(out_len, correct_outlen)
+
+ # decoder attentions
+ decoder_attentions = outputs.decoder_attentions
+ self.assertIsInstance(decoder_attentions, (list, tuple))
+ self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(decoder_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, decoder_seq_length, decoder_key_length],
+ )
+
+ # cross attentions
+ cross_attentions = outputs.cross_attentions
+ self.assertIsInstance(cross_attentions, (list, tuple))
+ self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(cross_attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ decoder_seq_length,
+ encoder_key_length,
+ ],
+ )
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if hasattr(self.model_tester, "num_hidden_states_types"):
+ added_hidden_states = self.model_tester.num_hidden_states_types
+ elif self.is_encoder_decoder:
+ added_hidden_states = 2
+ else:
+ added_hidden_states = 1
+ self.assertEqual(out_len + added_hidden_states, len(outputs))
+
+ self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+
+ self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length],
+ )
+
+ def test_retain_grad_hidden_states_attentions(self):
+ # removed retain_grad and grad on decoder_hidden_states, as queries don't require grad
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.output_hidden_states = True
+ config.output_attentions = True
+
+ # no need to test all models as different heads yield the same functionality
+ model_class = self.all_model_classes[0]
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ outputs = model(**inputs)
+
+ output = outputs[0]
+
+ encoder_hidden_states = outputs.encoder_hidden_states[0]
+ encoder_attentions = outputs.encoder_attentions[0]
+ encoder_hidden_states.retain_grad()
+ encoder_attentions.retain_grad()
+
+ decoder_attentions = outputs.decoder_attentions[0]
+ decoder_attentions.retain_grad()
+
+ cross_attentions = outputs.cross_attentions[0]
+ cross_attentions.retain_grad()
+
+ output.flatten()[0].backward(retain_graph=True)
+
+ self.assertIsNotNone(encoder_hidden_states.grad)
+ self.assertIsNotNone(encoder_attentions.grad)
+ self.assertIsNotNone(decoder_attentions.grad)
+ self.assertIsNotNone(cross_attentions.grad)
+
+ def test_forward_auxiliary_loss(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.auxiliary_loss = True
+
+ # only test for object detection and segmentation model
+ for model_class in self.all_model_classes[1:]:
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+
+ outputs = model(**inputs)
+
+ self.assertIsNotNone(outputs.auxiliary_outputs)
+ self.assertEqual(len(outputs.auxiliary_outputs), self.model_tester.num_hidden_layers - 1)
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ if model.config.is_encoder_decoder:
+ expected_arg_names = ["pixel_values", "pixel_mask"]
+ expected_arg_names.extend(
+ ["head_mask", "decoder_head_mask", "encoder_outputs"]
+ if "head_mask" and "decoder_head_mask" in arg_names
+ else []
+ )
+ self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
+ else:
+ expected_arg_names = ["pixel_values", "pixel_mask"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_different_timm_backbone(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # let's pick a random timm backbone
+ config.backbone = "tf_mobilenetv3_small_075"
+ config.backbone_config = None
+ config.use_timm_backbone = True
+ config.backbone_kwargs = {"out_indices": [2, 3, 4]}
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if model_class.__name__ == "DetrForObjectDetection":
+ expected_shape = (
+ self.model_tester.batch_size,
+ self.model_tester.num_queries,
+ self.model_tester.num_labels + 1,
+ )
+ self.assertEqual(outputs.logits.shape, expected_shape)
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.model.backbone.conv_encoder.intermediate_channel_sizes), 3)
+ elif model_class.__name__ == "DetrForSegmentation":
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.detr.model.backbone.conv_encoder.intermediate_channel_sizes), 3)
+ else:
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.backbone.conv_encoder.intermediate_channel_sizes), 3)
+
+ self.assertTrue(outputs)
+
+ def test_hf_backbone(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # Load a pretrained HF checkpoint as backbone
+ config.backbone = "microsoft/resnet-18"
+ config.backbone_config = None
+ config.use_timm_backbone = False
+ config.use_pretrained_backbone = True
+ config.backbone_kwargs = {"out_indices": [2, 3, 4]}
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if model_class.__name__ == "DetrForObjectDetection":
+ expected_shape = (
+ self.model_tester.batch_size,
+ self.model_tester.num_queries,
+ self.model_tester.num_labels + 1,
+ )
+ self.assertEqual(outputs.logits.shape, expected_shape)
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.model.backbone.conv_encoder.intermediate_channel_sizes), 3)
+ elif model_class.__name__ == "DetrForSegmentation":
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.detr.model.backbone.conv_encoder.intermediate_channel_sizes), 3)
+ else:
+ # Confirm out_indices was propagated to backbone
+ self.assertEqual(len(model.backbone.conv_encoder.intermediate_channel_sizes), 3)
+
+ self.assertTrue(outputs)
+
+ def test_greyscale_images(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # use greyscale pixel values
+ inputs_dict["pixel_values"] = floats_tensor(
+ [self.model_tester.batch_size, 1, self.model_tester.min_size, self.model_tester.max_size]
+ )
+
+ # let's set num_channels to 1
+ config.num_channels = 1
+ config.backbone_config.num_channels = 1
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ self.assertTrue(outputs)
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ configs_no_init.init_xavier_std = 1e9
+
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ if "bbox_attention" in name and "bias" not in name:
+ self.assertLess(
+ 100000,
+ abs(param.data.max().item()),
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ else:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+
+TOLERANCE = 1e-4
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_timm
+@require_vision
+@slow
+class DetrModelIntegrationTestsTimmBackbone(unittest.TestCase):
+ @cached_property
+ def default_image_processor(self):
+ return DetrImageProcessor.from_pretrained("facebook/detr-resnet-50") if is_vision_available() else None
+
+ def test_inference_no_head(self):
+ model = DetrModel.from_pretrained("facebook/detr-resnet-50").to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ encoding = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ with torch.no_grad():
+ outputs = model(**encoding)
+
+ expected_shape = torch.Size((1, 100, 256))
+ assert outputs.last_hidden_state.shape == expected_shape
+ expected_slice = torch.tensor(
+ [
+ [0.0622, -0.5142, -0.4034],
+ [-0.7628, -0.4935, -1.7153],
+ [-0.4751, -0.6386, -0.7818],
+ ]
+ ).to(torch_device)
+ torch.testing.assert_close(outputs.last_hidden_state[0, :3, :3], expected_slice, rtol=2e-4, atol=2e-4)
+
+ def test_inference_object_detection_head(self):
+ model = DetrForObjectDetection.from_pretrained("facebook/detr-resnet-50").to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ encoding = image_processor(images=image, return_tensors="pt").to(torch_device)
+ pixel_values = encoding["pixel_values"].to(torch_device)
+ pixel_mask = encoding["pixel_mask"].to(torch_device)
+
+ with torch.no_grad():
+ outputs = model(pixel_values, pixel_mask)
+
+ # verify outputs
+ expected_shape_logits = torch.Size((1, model.config.num_queries, model.config.num_labels + 1))
+ self.assertEqual(outputs.logits.shape, expected_shape_logits)
+ expected_slice_logits = torch.tensor(
+ [
+ [-19.1211, -0.0881, -11.0188],
+ [-17.3641, -1.8045, -14.0229],
+ [-20.0415, -0.5833, -11.1005],
+ ]
+ ).to(torch_device)
+ torch.testing.assert_close(outputs.logits[0, :3, :3], expected_slice_logits, rtol=2e-4, atol=2e-4)
+
+ expected_shape_boxes = torch.Size((1, model.config.num_queries, 4))
+ self.assertEqual(outputs.pred_boxes.shape, expected_shape_boxes)
+ expected_slice_boxes = torch.tensor(
+ [
+ [0.4433, 0.5302, 0.8852],
+ [0.5494, 0.2517, 0.0529],
+ [0.4998, 0.5360, 0.9955],
+ ]
+ ).to(torch_device)
+ torch.testing.assert_close(outputs.pred_boxes[0, :3, :3], expected_slice_boxes, rtol=2e-4, atol=2e-4)
+
+ # verify postprocessing
+ results = image_processor.post_process_object_detection(
+ outputs, threshold=0.3, target_sizes=[image.size[::-1]]
+ )[0]
+ expected_scores = torch.tensor([0.9982, 0.9960, 0.9955, 0.9988, 0.9987]).to(torch_device)
+ expected_labels = [75, 75, 63, 17, 17]
+ expected_slice_boxes = torch.tensor([40.1615, 70.8090, 175.5476, 117.9810]).to(torch_device)
+
+ self.assertEqual(len(results["scores"]), 5)
+ torch.testing.assert_close(results["scores"], expected_scores, rtol=2e-4, atol=2e-4)
+ self.assertSequenceEqual(results["labels"].tolist(), expected_labels)
+ torch.testing.assert_close(results["boxes"][0, :], expected_slice_boxes, rtol=2e-4, atol=2e-4)
+
+ def test_inference_panoptic_segmentation_head(self):
+ model = DetrForSegmentation.from_pretrained("facebook/detr-resnet-50-panoptic").to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ encoding = image_processor(images=image, return_tensors="pt").to(torch_device)
+ pixel_values = encoding["pixel_values"].to(torch_device)
+ pixel_mask = encoding["pixel_mask"].to(torch_device)
+
+ with torch.no_grad():
+ outputs = model(pixel_values, pixel_mask)
+
+ # verify outputs
+ expected_shape_logits = torch.Size((1, model.config.num_queries, model.config.num_labels + 1))
+ self.assertEqual(outputs.logits.shape, expected_shape_logits)
+ expected_slice_logits = torch.tensor(
+ [
+ [-18.1523, -1.7592, -13.5019],
+ [-16.8866, -1.4139, -14.1025],
+ [-17.5735, -2.5090, -11.8666],
+ ]
+ ).to(torch_device)
+ torch.testing.assert_close(outputs.logits[0, :3, :3], expected_slice_logits, rtol=2e-4, atol=2e-4)
+
+ expected_shape_boxes = torch.Size((1, model.config.num_queries, 4))
+ self.assertEqual(outputs.pred_boxes.shape, expected_shape_boxes)
+ expected_slice_boxes = torch.tensor(
+ [[0.5344, 0.1790, 0.9284], [0.4421, 0.0571, 0.0875], [0.6632, 0.6886, 0.1015]]
+ ).to(torch_device)
+ torch.testing.assert_close(outputs.pred_boxes[0, :3, :3], expected_slice_boxes, rtol=2e-4, atol=2e-4)
+
+ expected_shape_masks = torch.Size((1, model.config.num_queries, 200, 267))
+ self.assertEqual(outputs.pred_masks.shape, expected_shape_masks)
+ expected_slice_masks = torch.tensor(
+ [[-7.8408, -11.0104, -12.1279], [-12.0299, -16.6498, -17.9806], [-14.8995, -19.9940, -20.5646]]
+ ).to(torch_device)
+ torch.testing.assert_close(outputs.pred_masks[0, 0, :3, :3], expected_slice_masks, rtol=2e-3, atol=2e-3)
+
+ # verify postprocessing
+ results = image_processor.post_process_panoptic_segmentation(
+ outputs, threshold=0.3, target_sizes=[image.size[::-1]]
+ )[0]
+
+ expected_shape = torch.Size([480, 640])
+ expected_slice_segmentation = torch.tensor([[4, 4, 4], [4, 4, 4], [4, 4, 4]], dtype=torch.int32).to(
+ torch_device
+ )
+ expected_number_of_segments = 5
+ expected_first_segment = {"id": 1, "label_id": 17, "was_fused": False, "score": 0.9941}
+
+ number_of_unique_segments = len(torch.unique(results["segmentation"]))
+ self.assertTrue(
+ number_of_unique_segments, expected_number_of_segments + 1
+ ) # we add 1 for the background class
+ self.assertTrue(results["segmentation"].shape, expected_shape)
+ torch.testing.assert_close(results["segmentation"][:3, :3], expected_slice_segmentation, rtol=1e-4, atol=1e-4)
+ self.assertTrue(len(results["segments_info"]), expected_number_of_segments)
+
+ predicted_first_segment = results["segments_info"][0]
+ self.assertEqual(predicted_first_segment["id"], expected_first_segment["id"])
+ self.assertEqual(predicted_first_segment["label_id"], expected_first_segment["label_id"])
+ self.assertEqual(predicted_first_segment["was_fused"], expected_first_segment["was_fused"])
+ self.assertAlmostEqual(predicted_first_segment["score"], expected_first_segment["score"], places=3)
+
+
+@require_vision
+@require_torch
+@slow
+class DetrModelIntegrationTests(unittest.TestCase):
+ @cached_property
+ def default_image_processor(self):
+ return (
+ DetrImageProcessor.from_pretrained("facebook/detr-resnet-50", revision="no_timm")
+ if is_vision_available()
+ else None
+ )
+
+ def test_inference_no_head(self):
+ model = DetrModel.from_pretrained("facebook/detr-resnet-50", revision="no_timm").to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ encoding = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ with torch.no_grad():
+ outputs = model(**encoding)
+
+ expected_shape = torch.Size((1, 100, 256))
+ assert outputs.last_hidden_state.shape == expected_shape
+ expected_slice = torch.tensor(
+ [
+ [0.0622, -0.5142, -0.4034],
+ [-0.7628, -0.4935, -1.7153],
+ [-0.4751, -0.6386, -0.7818],
+ ]
+ ).to(torch_device)
+ torch.testing.assert_close(outputs.last_hidden_state[0, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/dia/__init__.py b/transformers/tests/models/dia/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/dia/test_feature_extraction_dia.py b/transformers/tests/models/dia/test_feature_extraction_dia.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a6f797d53465f4f7954162a1ea7b0c725babe53
--- /dev/null
+++ b/transformers/tests/models/dia/test_feature_extraction_dia.py
@@ -0,0 +1,231 @@
+# Copyright 2025 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Tests for the Dia feature extractor."""
+
+import itertools
+import random
+import unittest
+
+import numpy as np
+
+from transformers import DiaFeatureExtractor
+from transformers.testing_utils import require_torch
+from transformers.utils.import_utils import is_torch_available
+
+from ...test_sequence_feature_extraction_common import SequenceFeatureExtractionTestMixin
+
+
+if is_torch_available():
+ import torch
+
+
+global_rng = random.Random()
+
+
+# Copied from tests.models.whisper.test_feature_extraction_whisper.floats_list
+def floats_list(shape, scale=1.0, rng=None, name=None):
+ """Creates a random float32 tensor"""
+ if rng is None:
+ rng = global_rng
+
+ values = []
+ for batch_idx in range(shape[0]):
+ values.append([])
+ for _ in range(shape[1]):
+ values[-1].append(rng.random() * scale)
+
+ return values
+
+
+@require_torch
+class DiaFeatureExtractionTester:
+ # Copied from tests.models.dac.test_feature_extraction_dac.DacFeatureExtractionTester.__init__
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ min_seq_length=400,
+ max_seq_length=2000,
+ feature_size=1,
+ padding_value=0.0,
+ sampling_rate=16000,
+ hop_length=512,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.min_seq_length = min_seq_length
+ self.max_seq_length = max_seq_length
+ self.hop_length = hop_length
+ self.seq_length_diff = (self.max_seq_length - self.min_seq_length) // (self.batch_size - 1)
+ self.feature_size = feature_size
+ self.padding_value = padding_value
+ self.sampling_rate = sampling_rate
+
+ # Copied from tests.models.dac.test_feature_extraction_dac.DacFeatureExtractionTester.prepare_feat_extract_dict
+ def prepare_feat_extract_dict(self):
+ return {
+ "feature_size": self.feature_size,
+ "padding_value": self.padding_value,
+ "sampling_rate": self.sampling_rate,
+ "hop_length": self.hop_length,
+ }
+
+ # Copied from tests.models.encodec.test_feature_extraction_encodec.EnCodecFeatureExtractionTester.prepare_inputs_for_common
+ def prepare_inputs_for_common(self, equal_length=False, numpify=False):
+ def _flatten(list_of_lists):
+ return list(itertools.chain(*list_of_lists))
+
+ if equal_length:
+ audio_inputs = floats_list((self.batch_size, self.max_seq_length))
+ else:
+ # make sure that inputs increase in size
+ audio_inputs = [
+ _flatten(floats_list((x, self.feature_size)))
+ for x in range(self.min_seq_length, self.max_seq_length, self.seq_length_diff)
+ ]
+
+ if numpify:
+ audio_inputs = [np.asarray(x) for x in audio_inputs]
+
+ return audio_inputs
+
+
+@require_torch
+class DiaFeatureExtractionTest(SequenceFeatureExtractionTestMixin, unittest.TestCase):
+ feature_extraction_class = DiaFeatureExtractor
+
+ def setUp(self):
+ self.feat_extract_tester = DiaFeatureExtractionTester(self)
+
+ # Copied from tests.models.dac.test_feature_extraction_dac.DacFeatureExtractionTest.test_call
+ def test_call(self):
+ # Tests that all call wrap to encode_plus and batch_encode_plus
+ feat_extract = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
+ # create three inputs of length 800, 1000, and 1200
+ audio_inputs = [floats_list((1, x))[0] for x in range(800, 1400, 200)]
+ np_audio_inputs = [np.asarray(audio_input) for audio_input in audio_inputs]
+
+ # Test not batched input
+ encoded_sequences_1 = feat_extract(audio_inputs[0], return_tensors="np").input_values
+ encoded_sequences_2 = feat_extract(np_audio_inputs[0], return_tensors="np").input_values
+ self.assertTrue(np.allclose(encoded_sequences_1, encoded_sequences_2, atol=1e-3))
+
+ # Test batched
+ encoded_sequences_1 = feat_extract(audio_inputs, padding=True, return_tensors="np").input_values
+ encoded_sequences_2 = feat_extract(np_audio_inputs, padding=True, return_tensors="np").input_values
+ for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
+ self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
+
+ # Copied from tests.models.dac.test_feature_extraction_dac.DacFeatureExtractionTest.test_double_precision_pad
+ def test_double_precision_pad(self):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
+ np_audio_inputs = np.random.rand(100).astype(np.float64)
+ py_audio_inputs = np_audio_inputs.tolist()
+
+ for inputs in [py_audio_inputs, np_audio_inputs]:
+ np_processed = feature_extractor.pad([{"input_values": inputs}], return_tensors="np")
+ self.assertTrue(np_processed.input_values.dtype == np.float32)
+ pt_processed = feature_extractor.pad([{"input_values": inputs}], return_tensors="pt")
+ self.assertTrue(pt_processed.input_values.dtype == torch.float32)
+
+ # Copied from tests.models.dac.test_feature_extraction_dac.DacFeatureExtractionTest._load_datasamples
+ def _load_datasamples(self, num_samples):
+ from datasets import load_dataset
+
+ ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ # automatic decoding with librispeech
+ audio_samples = ds.sort("id")[:num_samples]["audio"]
+
+ return [x["array"] for x in audio_samples]
+
+ # Copied from tests.models.dac.test_feature_extraction_dac.DacFeatureExtractionTest.test_integration with Dac->Dia
+ def test_integration(self):
+ # fmt: off
+ EXPECTED_INPUT_VALUES = torch.tensor(
+ [ 2.3803711e-03, 2.0751953e-03, 1.9836426e-03, 2.1057129e-03,
+ 1.6174316e-03, 3.0517578e-04, 9.1552734e-05, 3.3569336e-04,
+ 9.7656250e-04, 1.8310547e-03, 2.0141602e-03, 2.1057129e-03,
+ 1.7395020e-03, 4.5776367e-04, -3.9672852e-04, 4.5776367e-04,
+ 1.0070801e-03, 9.1552734e-05, 4.8828125e-04, 1.1596680e-03,
+ 7.3242188e-04, 9.4604492e-04, 1.8005371e-03, 1.8310547e-03,
+ 8.8500977e-04, 4.2724609e-04, 4.8828125e-04, 7.3242188e-04,
+ 1.0986328e-03, 2.1057129e-03]
+ )
+ # fmt: on
+ input_audio = self._load_datasamples(1)
+ feature_extractor = DiaFeatureExtractor()
+ input_values = feature_extractor(input_audio, return_tensors="pt")["input_values"]
+ self.assertEqual(input_values.shape, (1, 1, 93696))
+ torch.testing.assert_close(input_values[0, 0, :30], EXPECTED_INPUT_VALUES, rtol=1e-4, atol=1e-4)
+ audio_input_end = torch.tensor(input_audio[0][-30:], dtype=torch.float32)
+ torch.testing.assert_close(input_values[0, 0, -46:-16], audio_input_end, rtol=1e-4, atol=1e-4)
+
+ def test_integration_stereo(self):
+ # fmt: off
+ EXPECTED_INPUT_VALUES = torch.tensor(
+ [2.3804e-03, 2.0752e-03, 1.9836e-03, 2.1057e-03, 1.6174e-03,
+ 3.0518e-04, 9.1553e-05, 3.3569e-04, 9.7656e-04, 1.8311e-03,
+ 2.0142e-03, 2.1057e-03, 1.7395e-03, 4.5776e-04, -3.9673e-04,
+ 4.5776e-04, 1.0071e-03, 9.1553e-05, 4.8828e-04, 1.1597e-03,
+ 7.3242e-04, 9.4604e-04, 1.8005e-03, 1.8311e-03, 8.8501e-04,
+ 4.2725e-04, 4.8828e-04, 7.3242e-04, 1.0986e-03, 2.1057e-03]
+ )
+ # fmt: on
+ input_audio = self._load_datasamples(1)
+ input_audio = [np.tile(input_audio[0][None], reps=(2, 1))]
+ feature_extractor = DiaFeatureExtractor(feature_size=2)
+ input_values = feature_extractor(input_audio, return_tensors="pt").input_values
+ self.assertEqual(input_values.shape, (1, 1, 93696))
+ torch.testing.assert_close(input_values[0, 0, :30], EXPECTED_INPUT_VALUES, rtol=1e-4, atol=1e-4)
+
+ # Copied from tests.models.dac.test_feature_extraction_dac.DacFeatureExtractionTest.test_truncation_and_padding with Dac->Dia
+ def test_truncation_and_padding(self):
+ input_audio = self._load_datasamples(2)
+ # would be easier if the stride was like
+ feature_extractor = DiaFeatureExtractor()
+
+ # pad and trunc raise an error ?
+ with self.assertRaisesRegex(
+ ValueError,
+ "^Both padding and truncation were set. Make sure you only set one.$",
+ ):
+ truncated_outputs = feature_extractor(
+ input_audio, padding="max_length", truncation=True, return_tensors="pt"
+ ).input_values
+
+ # force truncate to max_length
+ truncated_outputs = feature_extractor(
+ input_audio, truncation=True, max_length=48000, return_tensors="pt"
+ ).input_values
+ self.assertEqual(truncated_outputs.shape, (2, 1, 48128))
+
+ # pad:
+ padded_outputs = feature_extractor(input_audio, padding=True, return_tensors="pt").input_values
+ self.assertEqual(padded_outputs.shape, (2, 1, 93696))
+
+ # force pad to max length
+ truncated_outputs = feature_extractor(
+ input_audio, padding="max_length", max_length=100000, return_tensors="pt"
+ ).input_values
+ self.assertEqual(truncated_outputs.shape, (2, 1, 100352))
+
+ # force no pad
+ with self.assertRaisesRegex(
+ ValueError,
+ "^Unable to create tensor, you should probably activate padding with 'padding=True' to have batched tensors with the same length.$",
+ ):
+ truncated_outputs = feature_extractor(input_audio, padding=False, return_tensors="pt").input_values
+
+ truncated_outputs = feature_extractor(input_audio[0], padding=False, return_tensors="pt").input_values
+ self.assertEqual(truncated_outputs.shape, (1, 1, 93680))
diff --git a/transformers/tests/models/dia/test_modeling_dia.py b/transformers/tests/models/dia/test_modeling_dia.py
new file mode 100644
index 0000000000000000000000000000000000000000..447491f90102245ea867d5bf0030594a1e942ffd
--- /dev/null
+++ b/transformers/tests/models/dia/test_modeling_dia.py
@@ -0,0 +1,756 @@
+# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Dia model."""
+
+import copy
+import pathlib
+import tempfile
+import unittest
+
+import pytest
+
+from transformers.models.dia import DiaConfig, DiaDecoderConfig, DiaEncoderConfig
+from transformers.testing_utils import (
+ cleanup,
+ is_flaky,
+ require_torch,
+ require_torch_accelerator,
+ require_torch_sdpa,
+ slow,
+ torch_device,
+)
+from transformers.utils import is_soundfile_available, is_torch_available, is_torchaudio_available
+from transformers.utils.import_utils import is_datasets_available
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_datasets_available():
+ from datasets import Audio, load_dataset
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ DiaForConditionalGeneration,
+ DiaModel,
+ DiaProcessor,
+ PretrainedConfig,
+ PreTrainedModel,
+ )
+ from transformers.cache_utils import (
+ Cache,
+ StaticCache,
+ )
+ from transformers.models.dia.modeling_dia import DiaDecoder, DiaEncoder
+
+if is_torchaudio_available():
+ import torchaudio
+
+if is_soundfile_available():
+ import soundfile as sf
+
+
+@require_torch
+class DiaModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=3, # need batch_size != num_hidden_layers
+ seq_length=7,
+ max_length=50,
+ is_training=True,
+ vocab_size=100,
+ hidden_size=16,
+ intermediate_size=37,
+ num_hidden_layers=2,
+ num_attention_heads=2,
+ head_dim=8,
+ decoder_hidden_size=32, # typically larger than encoder
+ hidden_act="silu",
+ eos_token_id=97, # special tokens all occur after eos
+ pad_token_id=98,
+ bos_token_id=99,
+ delay_pattern=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.max_length = max_length
+ self.is_training = is_training
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.intermediate_size = intermediate_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.head_dim = head_dim
+ self.decoder_hidden_size = decoder_hidden_size
+ self.hidden_act = hidden_act
+ self.eos_token_id = eos_token_id
+ self.pad_token_id = pad_token_id
+ self.bos_token_id = bos_token_id
+ # Set default delay pattern if not provided
+ self.delay_pattern = delay_pattern if delay_pattern is not None else [0, 1, 2]
+ self.num_channels = len(self.delay_pattern)
+
+ def get_config(self):
+ encoder_config = DiaEncoderConfig(
+ max_position_embeddings=self.max_length,
+ num_hidden_layers=self.num_hidden_layers,
+ hidden_size=self.hidden_size,
+ num_attention_heads=self.num_attention_heads,
+ num_key_value_heads=self.num_attention_heads, # same as num_attention_heads for testing
+ head_dim=self.head_dim,
+ intermediate_size=self.intermediate_size,
+ vocab_size=self.vocab_size,
+ hidden_act=self.hidden_act,
+ )
+
+ decoder_config = DiaDecoderConfig(
+ max_position_embeddings=self.max_length,
+ num_hidden_layers=self.num_hidden_layers,
+ hidden_size=self.decoder_hidden_size,
+ intermediate_size=self.intermediate_size,
+ num_attention_heads=self.num_attention_heads,
+ num_key_value_heads=1, # GQA
+ head_dim=self.head_dim,
+ cross_num_attention_heads=self.num_attention_heads,
+ cross_head_dim=self.head_dim,
+ cross_num_key_value_heads=1, # GQA
+ cross_hidden_size=self.hidden_size, # match encoder hidden size
+ vocab_size=self.vocab_size,
+ hidden_act=self.hidden_act,
+ num_channels=self.num_channels,
+ )
+
+ config = DiaConfig(
+ encoder_config=encoder_config,
+ decoder_config=decoder_config,
+ eos_token_id=self.eos_token_id,
+ pad_token_id=self.pad_token_id,
+ bos_token_id=self.bos_token_id,
+ delay_pattern=self.delay_pattern,
+ )
+
+ return config
+
+ def prepare_config_and_inputs(self) -> tuple[DiaConfig, dict]:
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+ attention_mask = input_ids.ne(self.pad_token_id)
+
+ decoder_input_ids = ids_tensor([self.batch_size, self.seq_length, self.num_channels], self.vocab_size)
+ decoder_attention_mask = decoder_input_ids[..., 0].ne(self.pad_token_id)
+
+ config = self.get_config()
+ inputs_dict = {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "decoder_input_ids": decoder_input_ids,
+ "decoder_attention_mask": decoder_attention_mask,
+ }
+ return config, inputs_dict
+
+ def prepare_config_and_inputs_for_common(self) -> tuple[DiaConfig, dict]:
+ config, inputs_dict = self.prepare_config_and_inputs()
+ return config, inputs_dict
+
+ def create_and_check_model_forward(self, config, inputs_dict):
+ model = DiaModel(config=config).to(torch_device).eval()
+
+ input_ids = inputs_dict["input_ids"]
+ decoder_input_ids = inputs_dict["decoder_input_ids"]
+
+ # first forward pass
+ last_hidden_state = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids).last_hidden_state
+
+ self.parent.assertTrue(
+ last_hidden_state.shape, (self.batch_size, self.seq_length, config.decoder_config.hidden_size)
+ )
+
+ def check_encoder_decoder_model_standalone(self, config, inputs_dict):
+ model = DiaModel(config=config).to(torch_device).eval()
+ outputs = model(**inputs_dict)
+
+ encoder_last_hidden_state = outputs.encoder_last_hidden_state
+ last_hidden_state = outputs.last_hidden_state
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ encoder = model.get_encoder()
+ encoder.save_pretrained(tmpdirname)
+ encoder = DiaEncoder.from_pretrained(tmpdirname).to(torch_device)
+
+ encoder_last_hidden_state_2 = encoder(
+ input_ids=inputs_dict["input_ids"], attention_mask=inputs_dict["attention_mask"]
+ )[0]
+
+ self.parent.assertTrue((encoder_last_hidden_state_2 - encoder_last_hidden_state).abs().max().item() < 3e-3)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ decoder = model.get_decoder()
+ decoder.save_pretrained(tmpdirname)
+ decoder = DiaDecoder.from_pretrained(tmpdirname).to(torch_device)
+
+ last_hidden_state_2 = decoder(
+ input_ids=inputs_dict["decoder_input_ids"],
+ attention_mask=inputs_dict["decoder_attention_mask"],
+ encoder_hidden_states=encoder_last_hidden_state,
+ )[0]
+
+ self.parent.assertTrue((last_hidden_state_2 - last_hidden_state).abs().max().item() < 3e-3)
+
+
+@require_torch
+class DiaModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (DiaModel, DiaForConditionalGeneration) if is_torch_available() else ()
+ # We only allow greedy search / sampling with one sequence; see `skip_non_greedy_generate`
+ all_generative_model_classes = (DiaForConditionalGeneration,)
+ # TODO: support new pipeline behavior in tests
+ pipeline_model_mapping = {}
+ # pipeline_model_mapping = {"text-to-audio": DiaForConditionalGeneration} if is_torch_available() else {}
+ test_pruning = False
+ test_head_masking = False
+ test_resize_embeddings = False
+ is_encoder_decoder = True
+ # Indicates VLMs usually but there are many audio models which are also composite
+ _is_composite = True
+
+ def setUp(self):
+ self.model_tester = DiaModelTester(self)
+ # Skipping `has_text_modality` but manually testing down below
+ self.config_tester = ConfigTester(self, has_text_modality=False, config_class=DiaConfig)
+ self.skip_non_greedy_generate()
+
+ def skip_non_greedy_generate(self):
+ skippable_tests = [
+ "test_sample_generate_dict_output", # return sequences > 1
+ "test_beam",
+ "test_group_beam",
+ "test_constrained_beam",
+ "test_contrastive",
+ "test_assisted",
+ "test_dola",
+ "test_prompt_lookup",
+ "test_model_parallel_beam_search",
+ "test_generate_without_input_ids",
+ "test_generate_with_head_masking",
+ ]
+
+ for test in skippable_tests:
+ if self._testMethodName.startswith(test):
+ self.skipTest(reason="Dia only supports greedy search / sampling with one sequence.")
+
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ """Overriden to account for the 2D flattened structure"""
+ inputs_dict = copy.deepcopy(inputs_dict)
+
+ if return_labels:
+ inputs_dict["labels"] = torch.ones(
+ (
+ self.model_tester.batch_size * self.model_tester.num_channels,
+ self.model_tester.seq_length,
+ ),
+ dtype=torch.long,
+ device=torch_device,
+ )
+
+ return inputs_dict
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ # Manual testing because of composite configs
+ config = self.model_tester.prepare_config_and_inputs()[0]
+ self.assertTrue(hasattr(config.encoder_config, "vocab_size"), msg="Encoder `vocab_size` does not exist")
+ self.assertTrue(hasattr(config.decoder_config, "vocab_size"), msg="Decoder `vocab_size` does not exist")
+
+ def test_model_forward(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model_forward(*config_and_inputs)
+
+ @is_flaky
+ def test_encoder_decoder_model_standalone(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
+ self.model_tester.check_encoder_decoder_model_standalone(*config_and_inputs)
+
+ # Overriding shape checks as Dia has different shapes on encoder/decoder using a composite config
+ # + additional special cases where 3D x 2D meshes confuse the expected shape
+ def _check_logits(self, batch_size, logits, config):
+ batch_size *= len(config.delay_pattern) # Account for flattening
+ vocab_size = config.decoder_config.vocab_size
+ self.assertIsInstance(logits, tuple)
+ self.assertListEqual([iter_logits.shape[0] for iter_logits in logits], [batch_size] * len(logits))
+ # vocabulary difference equal to one (imagegptmodel?) or zero (all other models)
+ vocab_diff = vocab_size - logits[0].shape[-1]
+ self.assertTrue(vocab_diff in [0, 1])
+ self.assertListEqual([vocab_size - score.shape[-1] for score in logits], [vocab_diff] * len(logits))
+
+ def _check_attentions_for_generate(
+ self, batch_size, attentions, prompt_length, output_length, config, decoder_past_key_values
+ ):
+ self.assertIsInstance(attentions, tuple)
+ self.assertListEqual(
+ [isinstance(iter_attentions, tuple) for iter_attentions in attentions], [True] * len(attentions)
+ )
+ self.assertEqual(len(attentions), (output_length - prompt_length))
+
+ use_cache = decoder_past_key_values is not None
+ has_static_cache = isinstance(decoder_past_key_values, StaticCache)
+
+ # When `output_attentions=True`, each iteration of generate appends the attentions corresponding to the new
+ # token(s)
+ for generated_length, iter_attentions in enumerate(attentions):
+ # regardless of using cache, the first forward pass will have the full prompt as input
+ if use_cache and generated_length > 0:
+ model_input_length = 1
+ else:
+ model_input_length = prompt_length + generated_length
+ query_length = (
+ prompt_length + generated_length
+ if not has_static_cache
+ else decoder_past_key_values.get_max_cache_shape()
+ )
+
+ expected_shape = (
+ batch_size,
+ config.decoder_config.num_attention_heads, # Decoder config
+ model_input_length,
+ query_length,
+ )
+ # check attn size
+ self.assertListEqual(
+ [layer_attention.shape for layer_attention in iter_attentions], [expected_shape] * len(iter_attentions)
+ )
+
+ def _check_encoder_attention_for_generate(self, attentions, batch_size, config, prompt_length):
+ # Encoder config
+ encoder_expected_shape = (batch_size, config.encoder_config.num_attention_heads, prompt_length, prompt_length)
+ self.assertIsInstance(attentions, tuple)
+ self.assertListEqual(
+ [layer_attentions.shape for layer_attentions in attentions],
+ [encoder_expected_shape] * len(attentions),
+ )
+
+ def _check_hidden_states_for_generate(
+ self, batch_size, hidden_states, prompt_length, output_length, config, use_cache=False
+ ):
+ self.assertIsInstance(hidden_states, tuple)
+ self.assertListEqual(
+ [isinstance(iter_hidden_states, tuple) for iter_hidden_states in hidden_states],
+ [True] * len(hidden_states),
+ )
+ self.assertEqual(len(hidden_states), (output_length - prompt_length))
+
+ # When `output_hidden_states=True`, each iteration of generate appends the hidden states corresponding to the
+ # new token(s)
+ for generated_length, iter_hidden_states in enumerate(hidden_states):
+ # regardless of using cache, the first forward pass will have the full prompt as input
+ if use_cache and generated_length > 0:
+ model_input_length = 1
+ else:
+ model_input_length = prompt_length + generated_length
+
+ # check hidden size
+ # we can have different hidden sizes between encoder and decoder --> check both
+ expected_shape_encoder = (batch_size, model_input_length, config.encoder_config.hidden_size)
+ expected_shape_decoder = (batch_size, model_input_length, config.decoder_config.hidden_size)
+ self.assertTrue(
+ [layer_hidden_states.shape for layer_hidden_states in iter_hidden_states]
+ == [expected_shape_encoder] * len(iter_hidden_states)
+ or [layer_hidden_states.shape for layer_hidden_states in iter_hidden_states]
+ == [expected_shape_decoder] * len(iter_hidden_states)
+ )
+
+ def _check_encoder_hidden_states_for_generate(self, hidden_states, batch_size, config, prompt_length):
+ # Encoder config
+ encoder_expected_shape = (batch_size, prompt_length, config.encoder_config.hidden_size)
+ self.assertIsInstance(hidden_states, tuple)
+ self.assertListEqual(
+ [layer_hidden_states.shape for layer_hidden_states in hidden_states],
+ [encoder_expected_shape] * len(hidden_states),
+ )
+
+ def _check_past_key_values_for_generate(self, batch_size, decoder_past_key_values, cache_length, config):
+ self.assertIsInstance(decoder_past_key_values, (tuple, Cache))
+
+ # we need the decoder config here
+ config = config.decoder_config
+
+ # (batch, head, seq_length, head_features)
+ expected_shape = (
+ batch_size,
+ config.num_key_value_heads if hasattr(config, "num_key_value_heads") else config.num_attention_heads,
+ cache_length,
+ config.head_dim if hasattr(config, "head_dim") else config.hidden_size // config.num_attention_heads,
+ )
+
+ if isinstance(decoder_past_key_values, Cache):
+ self.assertListEqual(
+ [key_tensor.shape for key_tensor in decoder_past_key_values.key_cache],
+ [expected_shape] * len(decoder_past_key_values.key_cache),
+ )
+ self.assertListEqual(
+ [value_tensor.shape for value_tensor in decoder_past_key_values.value_cache],
+ [expected_shape] * len(decoder_past_key_values.value_cache),
+ )
+
+ def _check_scores(self, batch_size, scores, generated_length, config):
+ # Special case where Dia keeps score in a 2D mesh of (bsz * channels, vocab)
+ vocab_size = config.decoder_config.vocab_size
+ expected_shape = (batch_size * len(config.delay_pattern), vocab_size)
+ self.assertIsInstance(scores, tuple)
+ self.assertEqual(len(scores), generated_length)
+ self.assertListEqual([iter_scores.shape for iter_scores in scores], [expected_shape] * len(scores))
+
+ @require_torch_sdpa
+ def test_sdpa_can_dispatch_composite_models(self):
+ """
+ Overwritten as it relies on hardcoded namings atm - checking for our case here specifically
+ """
+ for model_class in self.all_model_classes:
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model = model_class.from_pretrained(tmpdirname)
+
+ sub_models_supporting_sdpa = [
+ (module._supports_sdpa or module._supports_attention_backend)
+ for name, module in model.named_modules()
+ if isinstance(module, PreTrainedModel) and name != ""
+ ]
+ supports_sdpa_all_modules = (
+ all(sub_models_supporting_sdpa)
+ if len(sub_models_supporting_sdpa) > 0
+ else (model._supports_sdpa or model._supports_attention_backend)
+ )
+
+ if not supports_sdpa_all_modules:
+ with self.assertRaises(ValueError):
+ model_sdpa = model_class.from_pretrained(tmpdirname, attn_implementation="sdpa")
+ else:
+ model_sdpa = model_class.from_pretrained(tmpdirname, attn_implementation="sdpa")
+ for key in model_sdpa.config:
+ if isinstance(getattr(model_sdpa.config, key), PretrainedConfig):
+ sub_config = getattr(model_sdpa.config, key)
+ self.assertTrue(sub_config._attn_implementation == "sdpa")
+
+ @pytest.mark.generate
+ @unittest.skip(reason="Custom processor `DiaEOSDelayPatternLogitsProcessor` forces eos token.")
+ def test_generate_continue_from_past_key_values(self):
+ """Only a small change due to the expected shapes"""
+ # Tests that we can continue generating from past key values, returned from a previous `generate` call
+ for model_class in self.all_generative_model_classes:
+ config, inputs = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # Let's make it always:
+ # 1. use cache (for obvious reasons)
+ # 2. generate to max length (which can be achieved by setting the eos token to an invalid value), which
+ # would make the test flaky (e.g. EOS is generated on iteration 1 on both generations, but the
+ # continuation would force it to generate beyond an EOS token)
+ # 3. ignore `token_type_ids` for simplicity
+ # 4. ignore `forced_eos_token_id`, which requires further manipulation of the continuation inputs and is
+ # active by default on some models
+ # 5. ignore `encoder_no_repeat_ngram_size`, which is set by default in some encoder-decoder models. When
+ # we use their decoder as a stand-alone model, `encoder_no_repeat_ngram_size` actually prevents
+ # repetition exclusively from the prompt. This test relies on comparing one call vs 2 calls
+ # with cache, what is considered a prompt is different in the two cases.
+
+ if "token_type_ids" in inputs:
+ del inputs["token_type_ids"]
+
+ model = model_class(config).to(torch_device)
+ model.eval()
+
+ generate_kwargs = {
+ "pad_token_id": -1,
+ "eos_token_id": -1,
+ "forced_eos_token_id": None,
+ "encoder_no_repeat_ngram_size": 0,
+ "use_cache": True,
+ "do_sample": False,
+ "return_dict_in_generate": True,
+ "output_scores": True,
+ }
+
+ # Traditional way of generating text, with `return_dict_in_generate` to return the past key values
+ outputs = model.generate(**inputs, **generate_kwargs, max_new_tokens=4)
+
+ # Let's generate again, but passing the past key values in between (3 + 1 = 4 tokens). Note that the
+ # inputs may need to be tweaked across `generate` calls (like the attention mask).
+ outputs_cached = model.generate(**inputs, **generate_kwargs, max_new_tokens=3)
+
+ # Continue from the tokens generated above, preparing the inputs accordingly
+ inputs["past_key_values"] = outputs_cached.past_key_values
+ new_attention_len = outputs_cached.sequences.shape[1] # the only real modification in this test
+ inputs["decoder_input_ids"] = outputs_cached.sequences
+ if "decoder_attention_mask" in inputs:
+ inputs["decoder_attention_mask"] = torch.nn.functional.pad(
+ inputs["decoder_attention_mask"],
+ (0, new_attention_len - inputs["decoder_attention_mask"].shape[1]),
+ mode="constant",
+ value=1,
+ )
+
+ first_caches_scores = outputs_cached.scores
+ outputs_cached = model.generate(**inputs, **generate_kwargs, max_new_tokens=1)
+ full_cached_scores = first_caches_scores + outputs_cached.scores
+ outputs_cached.scores = full_cached_scores
+
+ # The two sets of generated text and past kv should be equal to each other
+ self._check_similar_generate_outputs(outputs, outputs_cached)
+ for layer_idx in range(len(outputs_cached.past_key_values)):
+ for kv_idx in range(len(outputs_cached.past_key_values[layer_idx])):
+ self.assertTrue(
+ torch.allclose(
+ outputs.past_key_values[layer_idx][kv_idx],
+ outputs_cached.past_key_values[layer_idx][kv_idx],
+ )
+ )
+
+ @unittest.skip(reason="Indirectly checked in Dia through the generate methods.")
+ def test_past_key_values_format(self, custom_all_cache_shapes=None):
+ pass
+
+ @unittest.skip(reason="Indirectly checked in Dia through the generate methods.")
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip(
+ reason="Dia has too many mixed embedding types which would cause unintentional side effects, e.g. attempts at tying embeddings"
+ )
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @unittest.skip(reason="Theoretically works but kernel library causes issues.")
+ def test_torchscript_output_hidden_state(self):
+ pass
+
+ @unittest.skip(reason="Theoretically works but kernel library causes issues.")
+ def test_torchscript_simple(self):
+ pass
+
+ @unittest.skip(reason="Encoder-Decoder cache can not be initialized.")
+ def test_multi_gpu_data_parallel_forward(self):
+ pass
+
+
+class DiaForConditionalGenerationIntegrationTest(unittest.TestCase):
+ """
+ See https://gist.github.com/vasqu/0e3b06360373a4e612aa3b9a7c09185e for generating the integration tests
+
+ NOTE: We add a single `eos` line for the last channel which is skipped in the original Dia
+ (It doesn't change the behaviour as we cut by the eos token position)
+ """
+
+ def setUp(self):
+ # it's a dummy ckpt but should suffice for testing purposes
+ self.model_checkpoint = "AntonV/Dia-1.6B"
+ self.sampling_rate = 44100
+
+ # prepare audio
+ librispeech_dummy = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ librispeech_dummy = librispeech_dummy.cast_column("audio", Audio(sampling_rate=self.sampling_rate))
+ audio_sample_1 = librispeech_dummy[-1]["audio"]["array"]
+ audio_sample_2 = librispeech_dummy[-2]["audio"]["array"]
+ # 10 and 5 codebooks as prefix - saved as files as we need wav files for the original Dia
+ dac_chunk_len = 512
+ self.audio_prompt_1_path = "/tmp/dia_test_sample_1.mp3"
+ self.audio_prompt_2_path = "/tmp/dia_test_sample_2.mp3"
+ sf.write(self.audio_prompt_1_path, audio_sample_1[: (dac_chunk_len * 10)], self.sampling_rate)
+ sf.write(self.audio_prompt_2_path, audio_sample_2[: (dac_chunk_len * 5)], self.sampling_rate)
+
+ def tearDown(self):
+ pathlib.Path(self.audio_prompt_1_path).unlink()
+ pathlib.Path(self.audio_prompt_2_path).unlink()
+ cleanup(torch_device, gc_collect=True)
+
+ @slow
+ @require_torch_accelerator
+ def test_dia_model_integration_generate_tts(self):
+ text = ["[S1] Dia is an open weights text to dialogue model.", "This is a test"]
+ processor = DiaProcessor.from_pretrained(self.model_checkpoint)
+ inputs = processor(text=text, padding=True, return_tensors="pt").to(torch_device)
+
+ model = DiaForConditionalGeneration.from_pretrained(self.model_checkpoint).to(torch_device)
+ outputs = model.generate(**inputs, max_new_tokens=32, do_sample=False)
+
+ # fmt: off
+ EXPECTED_OUTPUT_TOKENS = torch.tensor([[[1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 568, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 568, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 568, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 568, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 568, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 568, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 568, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 568, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 568, 778, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 568, 778, 338, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 568, 804, 10, 524, 1026, 1026, 1026, 1026, 1026],
+ [ 568, 804, 10, 674, 967, 1026, 1026, 1026, 1026],
+ [ 568, 804, 10, 674, 364, 360, 1026, 1026, 1026],
+ [ 568, 804, 10, 674, 364, 981, 728, 1026, 1026],
+ [ 568, 804, 10, 674, 364, 981, 741, 550, 1026],
+ [ 568, 804, 10, 674, 364, 981, 568, 378, 90],
+ [1024, 804, 10, 674, 364, 981, 568, 378, 731],
+ [1025, 804, 10, 674, 364, 981, 568, 378, 731],
+ [1025, 804, 10, 674, 364, 981, 568, 378, 731],
+ [1025, 804, 10, 674, 364, 981, 568, 378, 731],
+ [1025, 804, 10, 674, 364, 981, 568, 378, 731],
+ [1025, 804, 10, 674, 364, 981, 568, 378, 731],
+ [1025, 804, 10, 674, 364, 981, 568, 378, 731],
+ [1025, 804, 10, 674, 364, 981, 568, 378, 731],
+ [1025, 1024, 10, 674, 364, 981, 568, 378, 731],
+ [1025, 1025, 1024, 674, 364, 981, 568, 378, 731],
+ [1025, 1025, 1025, 1024, 364, 981, 568, 378, 731],
+ [1025, 1025, 1025, 1025, 1024, 981, 568, 378, 731],
+ [1025, 1025, 1025, 1025, 1025, 1024, 568, 378, 731],
+ [1025, 1025, 1025, 1025, 1025, 1025, 1024, 378, 731],
+ [1025, 1025, 1025, 1025, 1025, 1025, 1025, 1024, 731],
+ [1025, 1025, 1025, 1025, 1025, 1025, 1025, 1025, 1024]],
+
+ [[1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 568, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 568, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 698, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 592, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 592, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 592, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 592, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 592, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 592, 778, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 592, 778, 338, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 592, 697, 10, 524, 1026, 1026, 1026, 1026, 1026],
+ [ 592, 288, 476, 649, 967, 1026, 1026, 1026, 1026],
+ [ 592, 740, 386, 674, 364, 360, 1026, 1026, 1026],
+ [ 592, 402, 386, 347, 362, 981, 728, 1026, 1026],
+ [ 592, 402, 721, 728, 327, 981, 741, 550, 1026],
+ [ 592, 402, 721, 728, 460, 62, 676, 378, 90],
+ [1024, 402, 721, 728, 837, 595, 195, 982, 784],
+ [1025, 402, 721, 677, 497, 102, 692, 24, 330],
+ [1025, 402, 721, 677, 511, 102, 503, 871, 609],
+ [1025, 402, 721, 677, 511, 96, 801, 871, 894],
+ [1025, 402, 721, 677, 511, 745, 314, 498, 775],
+ [1025, 402, 721, 677, 511, 745, 314, 498, 105],
+ [1025, 402, 721, 677, 511, 745, 314, 861, 889],
+ [1025, 893, 721, 677, 511, 744, 314, 871, 353],
+ [1025, 1024, 888, 677, 511, 744, 314, 871, 332],
+ [1025, 1025, 1024, 518, 511, 744, 314, 871, 366],
+ [1025, 1025, 1025, 1024, 611, 744, 314, 871, 366],
+ [1025, 1025, 1025, 1025, 1024, 980, 314, 871, 366],
+ [1025, 1025, 1025, 1025, 1025, 1024, 45, 124, 366],
+ [1025, 1025, 1025, 1025, 1025, 1025, 1024, 871, 366],
+ [1025, 1025, 1025, 1025, 1025, 1025, 1025, 1024, 719],
+ [1025, 1025, 1025, 1025, 1025, 1025, 1025, 1025, 1024]]])
+ # fmt: on
+
+ torch.testing.assert_close(outputs.cpu(), EXPECTED_OUTPUT_TOKENS)
+
+ @slow
+ @require_torch_accelerator
+ def test_dia_model_integration_generate_audio_context(self):
+ text = ["[S1] Dia is an open weights text to dialogue model.", "This is a test"]
+ audio_sample_1 = (
+ torchaudio.load(self.audio_prompt_1_path, channels_first=True, backend="soundfile")[0].squeeze().numpy()
+ )
+ audio_sample_2 = (
+ torchaudio.load(self.audio_prompt_2_path, channels_first=True, backend="soundfile")[0].squeeze().numpy()
+ )
+ audio = [audio_sample_1, audio_sample_2]
+
+ processor = DiaProcessor.from_pretrained(self.model_checkpoint)
+ inputs = processor(text=text, audio=audio, padding=True, return_tensors="pt").to(torch_device)
+
+ model = DiaForConditionalGeneration.from_pretrained(self.model_checkpoint).to(torch_device)
+ # dia has right padding while we have left padding (for faster prefill)
+ # additionally we have new tokens vs dia's max tokens (hence we compare each in the respective settings)
+ outputs_1 = model.generate(**inputs, max_new_tokens=22, do_sample=False)
+ outputs_2 = model.generate(**inputs, max_new_tokens=27, do_sample=False)
+
+ # fmt: off
+ EXPECTED_OUTPUT_TOKENS_1 = torch.tensor([[1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 578, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 592, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 494, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 330, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 330, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 330, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 330, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 330, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 330, 501, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 330, 204, 34, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 330, 254, 915, 863, 1026, 1026, 1026, 1026, 1026],
+ [ 330, 215, 458, 313, 50, 1026, 1026, 1026, 1026],
+ [ 330, 615, 529, 216, 801, 237, 1026, 1026, 1026],
+ [ 330, 580, 563, 233, 337, 37, 1018, 1026, 1026],
+ [ 330, 567, 530, 753, 607, 179, 954, 242, 1026],
+ [ 330, 627, 6, 1010, 500, 189, 598, 858, 247],
+ [1024, 432, 480, 530, 122, 3, 788, 149, 814],
+ [1025, 875, 826, 458, 98, 540, 181, 122, 608],
+ [1025, 495, 840, 413, 337, 784, 591, 150, 1017],
+ [1025, 808, 189, 137, 445, 0, 227, 658, 345],
+ [1025, 397, 89, 753, 1016, 173, 984, 0, 910],
+ [1025, 875, 460, 934, 50, 335, 670, 818, 722],
+ [1025, 875, 460, 762, 119, 372, 503, 858, 584],
+ [1025, 348, 555, 475, 469, 458, 963, 41, 664],
+ [1025, 1024, 852, 683, 761, 193, 595, 895, 885],
+ [1025, 1025, 1024, 135, 761, 902, 163, 623, 385],
+ [1025, 1025, 1025, 1024, 852, 282, 581, 623, 70],
+ [1025, 1025, 1025, 1025, 1024, 41, 661, 790, 977],
+ [1025, 1025, 1025, 1025, 1025, 1024, 580, 401, 464],
+ [1025, 1025, 1025, 1025, 1025, 1025, 1024, 756, 61],
+ [1025, 1025, 1025, 1025, 1025, 1025, 1025, 1024, 752],
+ [1025, 1025, 1025, 1025, 1025, 1025, 1025, 1025, 1024]])
+
+ EXPECTED_OUTPUT_TOKENS_2 = torch.tensor([[1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 619, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 315, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 315, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 315, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 315, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 315, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 315, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 315, 1026, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 315, 968, 1026, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 315, 1007, 458, 1026, 1026, 1026, 1026, 1026, 1026],
+ [ 315, 35, 266, 68, 1026, 1026, 1026, 1026, 1026],
+ [ 315, 359, 285, 811, 154, 1026, 1026, 1026, 1026],
+ [ 315, 906, 407, 297, 785, 649, 1026, 1026, 1026],
+ [ 315, 249, 678, 868, 899, 257, 950, 1026, 1026],
+ [ 315, 249, 217, 471, 292, 908, 196, 469, 1026],
+ [ 315, 249, 825, 771, 839, 802, 633, 590, 531],
+ [1024, 249, 150, 53, 126, 76, 794, 626, 442],
+ [1025, 249, 825, 218, 359, 864, 526, 626, 770],
+ [1025, 249, 150, 137, 530, 845, 877, 600, 111],
+ [1025, 249, 150, 287, 730, 991, 135, 259, 39],
+ [1025, 249, 825, 104, 198, 1020, 719, 625, 208],
+ [1025, 249, 825, 997, 602, 256, 859, 322, 518],
+ [1025, 668, 825, 979, 584, 256, 98, 665, 589],
+ [1025, 954, 458, 54, 206, 52, 244, 822, 599],
+ [1025, 1024, 104, 914, 435, 579, 860, 92, 661],
+ [1025, 1025, 1024, 848, 126, 74, 304, 92, 753],
+ [1025, 1025, 1025, 1024, 362, 376, 304, 586, 753],
+ [1025, 1025, 1025, 1025, 1024, 633, 996, 586, 83],
+ [1025, 1025, 1025, 1025, 1025, 1024, 179, 898, 928],
+ [1025, 1025, 1025, 1025, 1025, 1025, 1024, 506, 102],
+ [1025, 1025, 1025, 1025, 1025, 1025, 1025, 1024, 79],
+ [1025, 1025, 1025, 1025, 1025, 1025, 1025, 1025, 1024]])
+ # fmt: on
+
+ torch.testing.assert_close(outputs_1[0].cpu(), EXPECTED_OUTPUT_TOKENS_1)
+ torch.testing.assert_close(outputs_2[1, 5:].cpu(), EXPECTED_OUTPUT_TOKENS_2) # left padding
diff --git a/transformers/tests/models/dia/test_processor_dia.py b/transformers/tests/models/dia/test_processor_dia.py
new file mode 100644
index 0000000000000000000000000000000000000000..8ce15f4330d5456f76650d472a544e286b917ba1
--- /dev/null
+++ b/transformers/tests/models/dia/test_processor_dia.py
@@ -0,0 +1,269 @@
+# Copyright 2025 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import shutil
+import tempfile
+import unittest
+
+import numpy as np
+from parameterized import parameterized
+
+from transformers import DacModel, DiaFeatureExtractor, DiaProcessor, DiaTokenizer
+from transformers.testing_utils import require_torch
+from transformers.utils import is_torch_available
+
+
+if is_torch_available:
+ import torch
+
+
+# Copied from tests.utils.test_modeling_utils.check_models_equal
+def check_models_equal(model1, model2):
+ models_are_equal = True
+ for model1_p, model2_p in zip(model1.parameters(), model2.parameters()):
+ if model1_p.data.ne(model2_p.data).sum() > 0:
+ models_are_equal = False
+
+ return models_are_equal
+
+
+@require_torch
+class DiaProcessorTest(unittest.TestCase):
+ def setUp(self):
+ self.checkpoint = "AntonV/Dia-1.6B"
+ self.audio_tokenizer_checkpoint = "descript/dac_44khz"
+ self.tmpdirname = tempfile.mkdtemp()
+
+ # Audio tokenizer is a bigger model so we will reuse this if possible
+ self.processor = DiaProcessor(
+ tokenizer=self.get_tokenizer(),
+ feature_extractor=self.get_feature_extractor(),
+ audio_tokenizer=self.get_audio_tokenizer(),
+ )
+
+ # Default audio values based on Dia and Dac
+ self.pad_id = 1025
+ self.bos_id = 1026
+ self.dac_chunk_len = 512
+ self.delay_pattern = [0, 8, 9, 10, 11, 12, 13, 14, 15]
+
+ def get_tokenizer(self, **kwargs):
+ return DiaTokenizer.from_pretrained(self.checkpoint, **kwargs)
+
+ def get_feature_extractor(self, **kwargs):
+ return DiaFeatureExtractor.from_pretrained(self.checkpoint, **kwargs)
+
+ def get_audio_tokenizer(self, **kwargs):
+ return DacModel.from_pretrained(self.audio_tokenizer_checkpoint, **kwargs)
+
+ def tearDown(self):
+ shutil.rmtree(self.tmpdirname)
+ del self.processor
+
+ def test_save_load_pretrained_default(self):
+ tokenizer = self.get_tokenizer()
+ feature_extractor = self.get_feature_extractor()
+ audio_tokenizer = self.get_audio_tokenizer()
+
+ processor = DiaProcessor(
+ tokenizer=tokenizer, feature_extractor=feature_extractor, audio_tokenizer=audio_tokenizer
+ )
+
+ processor.save_pretrained(self.tmpdirname)
+ processor = DiaProcessor.from_pretrained(self.tmpdirname)
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer.get_vocab())
+ self.assertIsInstance(processor.tokenizer, DiaTokenizer)
+
+ self.assertEqual(processor.feature_extractor.to_json_string(), feature_extractor.to_json_string())
+ self.assertIsInstance(processor.feature_extractor, DiaFeatureExtractor)
+
+ self.assertEqual(processor.audio_tokenizer.__class__.__name__, audio_tokenizer.__class__.__name__)
+ self.assertEqual(processor.audio_tokenizer.name_or_path, audio_tokenizer.name_or_path)
+ self.assertTrue(check_models_equal(processor.audio_tokenizer, audio_tokenizer))
+ self.assertIsInstance(processor.audio_tokenizer, DacModel)
+
+ def test_save_load_pretrained_additional_features(self):
+ processor = DiaProcessor(
+ tokenizer=self.get_tokenizer(),
+ feature_extractor=self.get_feature_extractor(),
+ audio_tokenizer=self.get_audio_tokenizer(),
+ )
+ processor.save_pretrained(self.tmpdirname)
+
+ tokenizer_add_kwargs = self.get_tokenizer()
+ feature_extractor_add_kwargs = self.get_feature_extractor()
+ audio_tokenizer_add_kwargs = self.get_audio_tokenizer()
+
+ processor = DiaProcessor.from_pretrained(self.tmpdirname)
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, DiaTokenizer)
+
+ self.assertEqual(processor.feature_extractor.to_json_string(), feature_extractor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.feature_extractor, DiaFeatureExtractor)
+
+ self.assertEqual(processor.audio_tokenizer.__class__.__name__, audio_tokenizer_add_kwargs.__class__.__name__)
+ self.assertEqual(processor.audio_tokenizer.name_or_path, audio_tokenizer_add_kwargs.name_or_path)
+ self.assertTrue(check_models_equal(processor.audio_tokenizer, audio_tokenizer_add_kwargs))
+ self.assertIsInstance(processor.audio_tokenizer, DacModel)
+
+ def test_model_input_names(self):
+ tokenizer = self.get_tokenizer()
+
+ self.assertListEqual(
+ self.processor.model_input_names,
+ list(dict.fromkeys(tokenizer.model_input_names + ["decoder_input_ids", "decoder_attention_mask"])),
+ msg="`processor` model input names do not match the expected names.",
+ )
+
+ def test_tokenize(self):
+ tokenizer = self.get_tokenizer()
+ random_text = ["This is a processing test for tokenization", "[S1] Dia template style [S2] Nice"]
+
+ input_tokenizer = tokenizer(random_text, padding=True, return_tensors="pt")
+ input_processor = self.processor(random_text)
+
+ for key in input_tokenizer.keys():
+ self.assertTrue((input_tokenizer[key] == input_processor[key]).all())
+
+ def test_no_audio(self):
+ random_text = ["Dummy Input"] * 2
+ input_processor = self.processor(random_text)
+ audio_tokens, audio_mask = input_processor["decoder_input_ids"], input_processor["decoder_attention_mask"]
+
+ # full mask with +1 for bos
+ self.assertTrue(audio_mask.sum() == (max(self.delay_pattern) + 1) * len(random_text))
+ self.assertTrue(
+ audio_tokens.shape
+ == (
+ len(random_text),
+ max(self.delay_pattern) + 1,
+ len(self.delay_pattern),
+ )
+ )
+
+ for channel_idx, delay in enumerate(self.delay_pattern):
+ expected_sequence = torch.ones(size=(audio_tokens.shape[:-1])) * self.pad_id
+ expected_sequence[:, : delay + 1] = self.bos_id
+ self.assertTrue((audio_tokens[..., channel_idx] == expected_sequence).all())
+
+ def test_audio(self):
+ audio_tokenizer = self.get_audio_tokenizer()
+ feature_extractor = self.get_feature_extractor()
+
+ random_text = ["Dummy Input"] * 2
+ # Dac only starts accepting audio from a certain length (ensured via >=1024)
+ raw_speeches = [np.random.rand(2048).astype(np.float32), np.random.rand(1024).astype(np.float32)]
+ input_processor = self.processor(random_text, raw_speeches)
+ audio_tokens, audio_mask = input_processor["decoder_input_ids"], input_processor["decoder_attention_mask"]
+
+ sequence_len = audio_mask.shape[1]
+ for batch_idx, speech in enumerate(raw_speeches):
+ raw_audio = feature_extractor(speech, return_tensors="pt")["input_values"]
+ codebooks = audio_tokenizer(raw_audio).audio_codes.transpose(1, 2)
+
+ pad_len = sequence_len - audio_mask.sum(dim=-1)[batch_idx]
+ for channel_idx, delay in enumerate(self.delay_pattern):
+ # Left padding filled bos, right padding (delay) are pad
+ start_idx = pad_len + delay + 1
+ end_idx = start_idx + codebooks.shape[1]
+
+ encoded_sequence = audio_tokens[batch_idx, :, channel_idx]
+ expected_sequence = torch.ones(size=(sequence_len,)) * self.pad_id
+ expected_sequence[:start_idx] = self.bos_id
+ expected_sequence[start_idx:end_idx] = codebooks[0, :, channel_idx]
+
+ self.assertTrue((encoded_sequence == expected_sequence).all())
+
+ # Just to make sure the masking correctly only ignores bos tokens
+ self.assertTrue((audio_tokens[~audio_mask.bool()] == self.bos_id).all())
+
+ @parameterized.expand([([1, 1],), ([1, 5],), ([2, 4, 6],)])
+ def test_decode_audio(self, audio_lens):
+ feature_extractor = self.get_feature_extractor()
+ audio_tokenizer = self.get_audio_tokenizer()
+
+ random_text = ["Dummy Input"] * len(audio_lens)
+ raw_speeches = [np.random.rand(self.dac_chunk_len * l).astype(np.float32) for l in audio_lens]
+ # we need eos (given if training) to decode properly, also enforced via custom logits processor
+ input_processor = self.processor(random_text, raw_speeches, generation=False)
+ audio_tokens = input_processor["decoder_input_ids"]
+
+ decoded_speeches = self.processor.batch_decode(audio_tokens)
+ for batch_idx, speech in enumerate(raw_speeches):
+ raw_audio = feature_extractor(speech, return_tensors="pt")["input_values"]
+ codebooks = audio_tokenizer(raw_audio).audio_codes
+
+ decoded_audio = decoded_speeches[batch_idx]
+ expected_audio = audio_tokenizer.decode(audio_codes=codebooks).audio_values
+
+ self.assertTrue((expected_audio == decoded_audio).all())
+ self.assertTrue(decoded_speeches[batch_idx].shape[-1] == audio_lens[batch_idx] * self.dac_chunk_len)
+
+ @parameterized.expand([(1, 2, [0, 1, 4]), (2, 4, [1, 3, 2]), (4, 8, [0, 5, 7])])
+ def test_delay_in_audio(self, bsz, seq_len, delay_pattern):
+ # static functions which are crucial, hence we also test them here
+ build_indices_fn = DiaProcessor.build_indices
+ delay_fn = DiaProcessor.apply_audio_delay
+
+ bos, pad = -2, -1
+ num_channels = len(delay_pattern)
+
+ audio_input = torch.arange(bsz * seq_len * num_channels).view(bsz, seq_len, num_channels)
+ # imitate a delay mask with zeroes
+ audio_input = torch.cat([audio_input, torch.zeros(size=(bsz, max(delay_pattern), num_channels))], dim=1)
+
+ precomputed_idx = build_indices_fn(
+ bsz=bsz,
+ seq_len=seq_len + max(delay_pattern),
+ num_channels=num_channels,
+ delay_pattern=delay_pattern,
+ revert=False,
+ )
+ delayed_audio_out = delay_fn(
+ audio=audio_input,
+ pad_token_id=pad,
+ bos_token_id=bos,
+ precomputed_idx=precomputed_idx,
+ )
+
+ # every channel idx is shifted by delay_pattern[idx]
+ delayed_audio_res = audio_input.clone()
+ for idx, delay in enumerate(delay_pattern):
+ delayed_audio_res[:, :delay, idx] = bos
+ remaining_input = seq_len + max(delay_pattern) - delay
+ delayed_audio_res[:, delay:, idx] = audio_input[:, :remaining_input, idx]
+
+ self.assertTrue((delayed_audio_out == delayed_audio_res).all())
+
+ # we should get back to the original audio we had (when removing the delay pad)
+ bsz, new_seq_len, num_channels = delayed_audio_out.shape
+ precomputed_idx = build_indices_fn(
+ bsz=bsz,
+ seq_len=new_seq_len,
+ num_channels=num_channels,
+ delay_pattern=delay_pattern,
+ revert=True,
+ )
+ reverted_audio_out = delay_fn(
+ audio=delayed_audio_out,
+ pad_token_id=pad,
+ bos_token_id=bos,
+ precomputed_idx=precomputed_idx,
+ )
+
+ reverted_audio_res = audio_input.clone()[:, :seq_len]
+
+ self.assertTrue((reverted_audio_out[:, :seq_len] == reverted_audio_res).all())
diff --git a/transformers/tests/models/dia/test_tokenization_dia.py b/transformers/tests/models/dia/test_tokenization_dia.py
new file mode 100644
index 0000000000000000000000000000000000000000..4ade611f68e83e207b0c85cd53ac45c74d6b5073
--- /dev/null
+++ b/transformers/tests/models/dia/test_tokenization_dia.py
@@ -0,0 +1,123 @@
+# Copyright 2025 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+from transformers.models.dia import DiaTokenizer
+from transformers.testing_utils import slow
+
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+# Special tokens
+PAD = 0
+S1 = 1
+S2 = 2
+
+
+class DiaTokenizerTest(TokenizerTesterMixin, unittest.TestCase):
+ tokenizer_class = DiaTokenizer
+ test_rust_tokenizer = False
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+ tokenizer = DiaTokenizer()
+ tokenizer.save_pretrained(cls.tmpdirname)
+
+ def test_convert_token_and_id(self):
+ """Test ``_convert_token_to_id`` and ``_convert_id_to_token``."""
+ token = "i"
+ token_id = 105
+
+ self.assertEqual(self.get_tokenizer()._convert_token_to_id(token), token_id)
+ self.assertEqual(self.get_tokenizer()._convert_id_to_token(token_id), token)
+
+ def test_get_vocab(self):
+ vocab_keys = list(self.get_tokenizer().get_vocab().keys())
+
+ self.assertEqual(vocab_keys[PAD], "")
+ self.assertEqual(vocab_keys[S1], "[S1]")
+ self.assertEqual(vocab_keys[S2], "[S2]")
+ self.assertEqual(len(vocab_keys), 256)
+
+ def test_vocab_size(self):
+ # utf-8 == 2**8 == 256
+ self.assertEqual(self.get_tokenizer().vocab_size, 256)
+
+ def test_full_tokenizer(self):
+ tokenizer = DiaTokenizer.from_pretrained(self.tmpdirname)
+
+ tokens = tokenizer.tokenize("Hello, world!")
+ self.assertListEqual(tokens, ["H", "e", "l", "l", "o", ",", " ", "w", "o", "r", "l", "d", "!"])
+ ids = tokenizer.convert_tokens_to_ids(tokens)
+ self.assertListEqual(ids, [72, 101, 108, 108, 111, 44, 32, 119, 111, 114, 108, 100, 33])
+ back_tokens = tokenizer.convert_ids_to_tokens(ids)
+ self.assertListEqual(back_tokens, ["H", "e", "l", "l", "o", ",", " ", "w", "o", "r", "l", "d", "!"])
+
+ tokens = tokenizer.tokenize("[S1] Hello [S2] Hello")
+ self.assertListEqual(
+ tokens,
+ ["[S1]", " ", "H", "e", "l", "l", "o", " ", "[S2]", " ", "H", "e", "l", "l", "o", ""],
+ )
+ ids = tokenizer.convert_tokens_to_ids(tokens)
+ self.assertListEqual(ids, [S1, 32, 72, 101, 108, 108, 111, 32, S2, 32, 72, 101, 108, 108, 111, PAD])
+ back_tokens = tokenizer.convert_ids_to_tokens(ids)
+ self.assertListEqual(
+ back_tokens, ["[S1]", " ", "H", "e", "l", "l", "o", " ", "[S2]", " ", "H", "e", "l", "l", "o", ""]
+ )
+
+ @slow
+ def test_tokenizer_integration(self):
+ # Overwritten as decoding will lead to all single bytes (i.e. characters) while usually the string format is expected
+ expected_encoding = {'input_ids': [[84, 114, 97, 110, 115, 102, 111, 114, 109, 101, 114, 115, 32, 40, 102, 111, 114, 109, 101, 114, 108, 121, 32, 107, 110, 111, 119, 110, 32, 97, 115, 32, 112, 121, 116, 111, 114, 99, 104, 45, 116, 114, 97, 110, 115, 102, 111, 114, 109, 101, 114, 115, 32, 97, 110, 100, 32, 112, 121, 116, 111, 114, 99, 104, 45, 112, 114, 101, 116, 114, 97, 105, 110, 101, 100, 45, 98, 101, 114, 116, 41, 32, 112, 114, 111, 118, 105, 100, 101, 115, 32, 103, 101, 110, 101, 114, 97, 108, 45, 112, 117, 114, 112, 111, 115, 101, 32, 97, 114, 99, 104, 105, 116, 101, 99, 116, 117, 114, 101, 115, 32, 40, 66, 69, 82, 84, 44, 32, 71, 80, 84, 45, 50, 44, 32, 82, 111, 66, 69, 82, 84, 97, 44, 32, 88, 76, 77, 44, 32, 68, 105, 115, 116, 105, 108, 66, 101, 114, 116, 44, 32, 88, 76, 78, 101, 116, 46, 46, 46, 41, 32, 102, 111, 114, 32, 78, 97, 116, 117, 114, 97, 108, 32, 76, 97, 110, 103, 117, 97, 103, 101, 32, 85, 110, 100, 101, 114, 115, 116, 97, 110, 100, 105, 110, 103, 32, 40, 78, 76, 85, 41, 32, 97, 110, 100, 32, 78, 97, 116, 117, 114, 97, 108, 32, 76, 97, 110, 103, 117, 97, 103, 101, 32, 71, 101, 110, 101, 114, 97, 116, 105, 111, 110, 32, 40, 78, 76, 71, 41, 32, 119, 105, 116, 104, 32, 111, 118, 101, 114, 32, 51, 50, 43, 32, 112, 114, 101, 116, 114, 97, 105, 110, 101, 100, 32, 109, 111, 100, 101, 108, 115, 32, 105, 110, 32, 49, 48, 48, 43, 32, 108, 97, 110, 103, 117, 97, 103, 101, 115, 32, 97, 110, 100, 32, 100, 101, 101, 112, 32, 105, 110, 116, 101, 114, 111, 112, 101, 114, 97, 98, 105, 108, 105, 116, 121, 32, 98, 101, 116, 119, 101, 101, 110, 32, 74, 97, 120, 44, 32, 80, 121, 84, 111, 114, 99, 104, 32, 97, 110, 100, 32, 84, 101, 110, 115, 111, 114, 70, 108, 111, 119, 46], [66, 69, 82, 84, 32, 105, 115, 32, 100, 101, 115, 105, 103, 110, 101, 100, 32, 116, 111, 32, 112, 114, 101, 45, 116, 114, 97, 105, 110, 32, 100, 101, 101, 112, 32, 98, 105, 100, 105, 114, 101, 99, 116, 105, 111, 110, 97, 108, 32, 114, 101, 112, 114, 101, 115, 101, 110, 116, 97, 116, 105, 111, 110, 115, 32, 102, 114, 111, 109, 32, 117, 110, 108, 97, 98, 101, 108, 101, 100, 32, 116, 101, 120, 116, 32, 98, 121, 32, 106, 111, 105, 110, 116, 108, 121, 32, 99, 111, 110, 100, 105, 116, 105, 111, 110, 105, 110, 103, 32, 111, 110, 32, 98, 111, 116, 104, 32, 108, 101, 102, 116, 32, 97, 110, 100, 32, 114, 105, 103, 104, 116, 32, 99, 111, 110, 116, 101, 120, 116, 32, 105, 110, 32, 97, 108, 108, 32, 108, 97, 121, 101, 114, 115, 46], [84, 104, 101, 32, 113, 117, 105, 99, 107, 32, 98, 114, 111, 119, 110, 32, 102, 111, 120, 32, 106, 117, 109, 112, 115, 32, 111, 118, 101, 114, 32, 116, 104, 101, 32, 108, 97, 122, 121, 32, 100, 111, 103, 46]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]} # fmt: skip
+
+ sequences = [
+ "Transformers (formerly known as pytorch-transformers and pytorch-pretrained-bert) provides "
+ "general-purpose architectures (BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet...) for Natural "
+ "Language Understanding (NLU) and Natural Language Generation (NLG) with over 32+ pretrained "
+ "models in 100+ languages and deep interoperability between Jax, PyTorch and TensorFlow.",
+ "BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly "
+ "conditioning on both left and right context in all layers.",
+ "The quick brown fox jumps over the lazy dog.",
+ ]
+
+ tokenizer_classes = [self.tokenizer_class]
+ if self.test_rust_tokenizer:
+ tokenizer_classes.append(self.rust_tokenizer_class)
+
+ for tokenizer_class in tokenizer_classes:
+ tokenizer = tokenizer_class.from_pretrained("AntonV/Dia-1.6B")
+
+ encoding = tokenizer(sequences)
+ encoding_data = encoding.data
+ self.assertDictEqual(encoding_data, expected_encoding)
+
+ # Byte decoding leads to characters so we need to join them
+ decoded_sequences = [
+ "".join(tokenizer.decode(seq, skip_special_tokens=True)) for seq in encoding["input_ids"]
+ ]
+
+ for expected, decoded in zip(sequences, decoded_sequences):
+ if self.test_sentencepiece_ignore_case:
+ expected = expected.lower()
+ self.assertEqual(expected, decoded)
+
+ @unittest.skip(reason="Dia relies on whole input string due to the byte-level nature.")
+ def test_pretokenized_inputs(self):
+ pass
+
+ @unittest.skip
+ def test_tokenizer_slow_store_full_signature(self):
+ pass
diff --git a/transformers/tests/models/diffllama/__init__.py b/transformers/tests/models/diffllama/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/diffllama/test_modeling_diffllama.py b/transformers/tests/models/diffllama/test_modeling_diffllama.py
new file mode 100644
index 0000000000000000000000000000000000000000..25ca02d5ba4336b0d6371a794b6c2e980e8597d8
--- /dev/null
+++ b/transformers/tests/models/diffllama/test_modeling_diffllama.py
@@ -0,0 +1,871 @@
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch DiffLlama model."""
+
+import gc
+import tempfile
+import unittest
+
+import pytest
+from packaging import version
+from parameterized import parameterized
+
+from transformers import AutoTokenizer, DiffLlamaConfig, StaticCache, is_torch_available, set_seed
+from transformers.testing_utils import (
+ backend_empty_cache,
+ cleanup,
+ require_bitsandbytes,
+ require_flash_attn,
+ require_read_token,
+ require_torch,
+ require_torch_accelerator,
+ require_torch_gpu,
+ require_torch_sdpa,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ DiffLlamaForCausalLM,
+ DiffLlamaForQuestionAnswering,
+ DiffLlamaForSequenceClassification,
+ DiffLlamaForTokenClassification,
+ DiffLlamaModel,
+ )
+ from transformers.models.diffllama.modeling_diffllama import (
+ DiffLlamaRotaryEmbedding,
+ )
+
+
+class DiffLlamaModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=False,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ pad_token_id=0,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.pad_token_id = pad_token_id
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = torch.tril(torch.ones_like(input_ids).to(torch_device))
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ return DiffLlamaConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ pad_token_id=self.pad_token_id,
+ )
+
+ def create_and_check_model(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = DiffLlamaModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class DiffLlamaModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ DiffLlamaModel,
+ DiffLlamaForCausalLM,
+ DiffLlamaForSequenceClassification,
+ DiffLlamaForQuestionAnswering,
+ DiffLlamaForTokenClassification,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": DiffLlamaModel,
+ "text-classification": DiffLlamaForSequenceClassification,
+ "text-generation": DiffLlamaForCausalLM,
+ "zero-shot": DiffLlamaForSequenceClassification,
+ "question-answering": DiffLlamaForQuestionAnswering,
+ "token-classification": DiffLlamaForTokenClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_headmasking = False
+ test_pruning = False
+ fx_compatible = False
+
+ # Need to use `0.8` instead of `0.9` for `test_cpu_offload`
+ # This is because we are hitting edge cases with the causal_mask buffer
+ model_split_percents = [0.5, 0.7, 0.8]
+
+ # used in `test_torch_compile_for_training`
+ _torch_compile_train_cls = DiffLlamaForCausalLM if is_torch_available() else None
+
+ def setUp(self):
+ self.model_tester = DiffLlamaModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=DiffLlamaConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_various_embeddings(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["absolute", "relative_key", "relative_key_query"]:
+ config_and_inputs[0].position_embedding_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_diffllama_sequence_classification_model(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size)
+ model = DiffLlamaForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ def test_diffllama_sequence_classification_model_for_single_label(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ config.problem_type = "single_label_classification"
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size)
+ model = DiffLlamaForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ def test_diffllama_sequence_classification_model_for_multi_label(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ config.problem_type = "multi_label_classification"
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor(
+ [self.model_tester.batch_size, config.num_labels], self.model_tester.type_sequence_label_size
+ ).to(torch.float)
+ model = DiffLlamaForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ def test_diffllama_token_classification_model(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ token_labels = ids_tensor([self.model_tester.batch_size, self.model_tester.seq_length], config.num_labels)
+ model = DiffLlamaForTokenClassification(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=token_labels)
+ self.assertEqual(
+ result.logits.shape,
+ (self.model_tester.batch_size, self.model_tester.seq_length, self.model_tester.num_labels),
+ )
+
+ @parameterized.expand([("linear",), ("dynamic",), ("yarn",)])
+ def test_model_rope_scaling_from_config(self, scaling_type):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ short_input = ids_tensor([1, 10], config.vocab_size)
+ long_input = ids_tensor([1, int(config.max_position_embeddings * 1.5)], config.vocab_size)
+
+ set_seed(42) # Fixed seed at init time so the two models get the same random weights
+ original_model = DiffLlamaModel(config)
+ original_model.to(torch_device)
+ original_model.eval()
+ original_short_output = original_model(short_input).last_hidden_state
+ original_long_output = original_model(long_input).last_hidden_state
+
+ set_seed(42) # Fixed seed at init time so the two models get the same random weights
+ config.rope_scaling = {"type": scaling_type, "factor": 10.0}
+ scaled_model = DiffLlamaModel(config)
+ scaled_model.to(torch_device)
+ scaled_model.eval()
+ scaled_short_output = scaled_model(short_input).last_hidden_state
+ scaled_long_output = scaled_model(long_input).last_hidden_state
+
+ # Dynamic scaling does not change the RoPE embeddings until it receives an input longer than the original
+ # maximum sequence length, so the outputs for the short input should match.
+ if scaling_type == "dynamic":
+ torch.testing.assert_close(original_short_output, scaled_short_output, rtol=1e-5, atol=1e-5)
+ else:
+ self.assertFalse(torch.allclose(original_short_output, scaled_short_output, atol=1e-5))
+
+ # The output should be different for long inputs
+ self.assertFalse(torch.allclose(original_long_output, scaled_long_output, atol=1e-5))
+
+ def test_model_rope_scaling(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ scaling_factor = 10
+ short_input_length = 10
+ long_input_length = int(config.max_position_embeddings * 1.5)
+
+ # Inputs
+ x = torch.randn(
+ 1, dtype=torch.float32, device=torch_device
+ ) # used exclusively to get the dtype and the device
+ position_ids_short = torch.arange(short_input_length, dtype=torch.long, device=torch_device)
+ position_ids_short = position_ids_short.unsqueeze(0)
+ position_ids_long = torch.arange(long_input_length, dtype=torch.long, device=torch_device)
+ position_ids_long = position_ids_long.unsqueeze(0)
+
+ # Sanity check original RoPE
+ original_rope = DiffLlamaRotaryEmbedding(config=config).to(torch_device)
+ original_cos_short, original_sin_short = original_rope(x, position_ids_short)
+ original_cos_long, original_sin_long = original_rope(x, position_ids_long)
+ torch.testing.assert_close(original_cos_short, original_cos_long[:, :short_input_length, :])
+ torch.testing.assert_close(original_sin_short, original_sin_long[:, :short_input_length, :])
+
+ # Sanity check linear RoPE scaling
+ # New position "x" should match original position with index "x/scaling_factor"
+ config.rope_scaling = {"type": "linear", "factor": scaling_factor}
+ linear_scaling_rope = DiffLlamaRotaryEmbedding(config=config).to(torch_device)
+ linear_cos_short, linear_sin_short = linear_scaling_rope(x, position_ids_short)
+ linear_cos_long, linear_sin_long = linear_scaling_rope(x, position_ids_long)
+ torch.testing.assert_close(linear_cos_short, linear_cos_long[:, :short_input_length, :])
+ torch.testing.assert_close(linear_sin_short, linear_sin_long[:, :short_input_length, :])
+ for new_position in range(0, long_input_length, scaling_factor):
+ original_position = int(new_position // scaling_factor)
+ torch.testing.assert_close(linear_cos_long[:, new_position, :], original_cos_long[:, original_position, :])
+ torch.testing.assert_close(linear_sin_long[:, new_position, :], original_sin_long[:, original_position, :])
+
+ # Sanity check Dynamic NTK RoPE scaling
+ # Scaling should only be observed after a long input is fed. We can observe that the frequencies increase
+ # with scaling_factor (or that `inv_freq` decreases)
+ config.rope_scaling = {"type": "dynamic", "factor": scaling_factor}
+ ntk_scaling_rope = DiffLlamaRotaryEmbedding(config=config).to(torch_device)
+ ntk_cos_short, ntk_sin_short = ntk_scaling_rope(x, position_ids_short)
+ ntk_cos_long, ntk_sin_long = ntk_scaling_rope(x, position_ids_long)
+ torch.testing.assert_close(ntk_cos_short, original_cos_short)
+ torch.testing.assert_close(ntk_sin_short, original_sin_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_cos_long, original_cos_long)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_sin_long, original_sin_long)
+ self.assertTrue((ntk_scaling_rope.inv_freq <= original_rope.inv_freq).all())
+
+ # Sanity check Yarn RoPE scaling
+ # Scaling should be over the entire input
+ config.rope_scaling = {"type": "yarn", "factor": scaling_factor}
+ yarn_scaling_rope = DiffLlamaRotaryEmbedding(config=config).to(torch_device)
+ yarn_cos_short, yarn_sin_short = yarn_scaling_rope(x, position_ids_short)
+ yarn_cos_long, yarn_sin_long = yarn_scaling_rope(x, position_ids_long)
+ torch.testing.assert_close(yarn_cos_short, yarn_cos_long[:, :short_input_length, :])
+ torch.testing.assert_close(yarn_sin_short, yarn_sin_long[:, :short_input_length, :])
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(yarn_cos_short, original_cos_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(yarn_sin_short, original_sin_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(yarn_cos_long, original_cos_long)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(yarn_sin_long, original_sin_long)
+
+ def test_model_loading_old_rope_configs(self):
+ def _reinitialize_config(base_config, new_kwargs):
+ # Reinitialize the config with the new kwargs, forcing the config to go through its __init__ validation
+ # steps.
+ base_config_dict = base_config.to_dict()
+ new_config = DiffLlamaConfig.from_dict(config_dict={**base_config_dict, **new_kwargs})
+ return new_config
+
+ # from untouched config -> ✅
+ base_config, model_inputs = self.model_tester.prepare_config_and_inputs_for_common()
+ original_model = DiffLlamaForCausalLM(base_config).to(torch_device)
+ original_model(**model_inputs)
+
+ # from a config with the expected rope configuration -> ✅
+ config = _reinitialize_config(base_config, {"rope_scaling": {"rope_type": "linear", "factor": 10.0}})
+ original_model = DiffLlamaForCausalLM(config).to(torch_device)
+ original_model(**model_inputs)
+
+ # from a config with the old rope configuration ('type' instead of 'rope_type') -> ✅ we gracefully handle BC
+ config = _reinitialize_config(base_config, {"rope_scaling": {"type": "linear", "factor": 10.0}})
+ original_model = DiffLlamaForCausalLM(config).to(torch_device)
+ original_model(**model_inputs)
+
+ # from a config with both 'type' and 'rope_type' -> ✅ they can coexist (and both are present in the config)
+ config = _reinitialize_config(
+ base_config, {"rope_scaling": {"type": "linear", "rope_type": "linear", "factor": 10.0}}
+ )
+ self.assertTrue(config.rope_scaling["type"] == "linear")
+ self.assertTrue(config.rope_scaling["rope_type"] == "linear")
+ original_model = DiffLlamaForCausalLM(config).to(torch_device)
+ original_model(**model_inputs)
+
+ # from a config with parameters in a bad range ('factor' should be >= 1.0) -> ⚠️ throws a warning
+ with self.assertLogs("transformers.modeling_rope_utils", level="WARNING") as logs:
+ config = _reinitialize_config(base_config, {"rope_scaling": {"rope_type": "linear", "factor": -999.0}})
+ original_model = DiffLlamaForCausalLM(config).to(torch_device)
+ original_model(**model_inputs)
+ self.assertEqual(len(logs.output), 1)
+ self.assertIn("factor field", logs.output[0])
+
+ # from a config with unknown parameters ('foo' isn't a rope option) -> ⚠️ throws a warning
+ with self.assertLogs("transformers.modeling_rope_utils", level="WARNING") as logs:
+ config = _reinitialize_config(
+ base_config, {"rope_scaling": {"rope_type": "linear", "factor": 10.0, "foo": "bar"}}
+ )
+ original_model = DiffLlamaForCausalLM(config).to(torch_device)
+ original_model(**model_inputs)
+ self.assertEqual(len(logs.output), 1)
+ self.assertIn("Unrecognized keys", logs.output[0])
+
+ # from a config with specific rope type but missing one of its mandatory parameters -> ❌ throws exception
+ with self.assertRaises(KeyError):
+ config = _reinitialize_config(base_config, {"rope_scaling": {"rope_type": "linear"}}) # missing "factor"
+
+ @require_flash_attn
+ @require_torch_gpu
+ @require_bitsandbytes
+ @pytest.mark.flash_attn_test
+ @require_read_token
+ @slow
+ def test_flash_attn_2_generate_padding_right(self):
+ """
+ Overwriting the common test as the test is flaky on tiny models
+ """
+ model = DiffLlamaForCausalLM.from_pretrained(
+ "kajuma/DiffLlama-0.3B-handcut",
+ load_in_4bit=True,
+ device_map={"": 0},
+ )
+
+ tokenizer = AutoTokenizer.from_pretrained("kajuma/DiffLlama-0.3B-handcut")
+
+ texts = ["hi", "Hello this is a very long sentence"]
+
+ tokenizer.padding_side = "right"
+ tokenizer.pad_token = tokenizer.eos_token
+
+ inputs = tokenizer(texts, return_tensors="pt", padding=True).to(0)
+
+ output_native = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+ output_native = tokenizer.batch_decode(output_native)
+
+ model = DiffLlamaForCausalLM.from_pretrained(
+ "kajuma/DiffLlama-0.3B-handcut",
+ load_in_4bit=True,
+ device_map={"": 0},
+ attn_implementation="flash_attention_2",
+ )
+
+ output_fa_2 = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+ output_fa_2 = tokenizer.batch_decode(output_fa_2)
+
+ self.assertListEqual(output_native, output_fa_2)
+
+ @require_flash_attn
+ @require_torch_gpu
+ @slow
+ @pytest.mark.flash_attn_test
+ def test_use_flash_attention_2_true(self):
+ """
+ NOTE: this is the only test testing that the legacy `use_flash_attention=2` argument still works as intended.
+ """
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ for model_class in self.all_model_classes:
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model = model_class(config)
+ model.save_pretrained(tmp_dir)
+
+ new_model = DiffLlamaForCausalLM.from_pretrained(
+ tmp_dir, attn_implementation="flash_attention_2", torch_dtype=torch.float16
+ ).to("cuda")
+
+ self.assertTrue(new_model.config._attn_implementation == "flash_attention_2")
+
+ has_flash = False
+ for name, submodule in new_model.named_modules():
+ if "FlashAttention" in submodule.__class__.__name__:
+ has_flash = True
+ break
+ if not has_flash:
+ raise ValueError("The flash model should have flash attention layers")
+
+ @require_torch_sdpa
+ @slow
+ def test_eager_matches_sdpa_generate(self):
+ """
+ Overwriting the common test as the test is flaky on tiny models
+ """
+ max_new_tokens = 30
+
+ tokenizer = AutoTokenizer.from_pretrained("kajuma/DiffLlama-0.3B-handcut")
+
+ model_sdpa = DiffLlamaForCausalLM.from_pretrained(
+ "kajuma/DiffLlama-0.3B-handcut",
+ torch_dtype=torch.float16,
+ ).to(torch_device)
+
+ self.assertTrue(model_sdpa.config._attn_implementation == "sdpa")
+
+ model_eager = DiffLlamaForCausalLM.from_pretrained(
+ "kajuma/DiffLlama-0.3B-handcut",
+ torch_dtype=torch.float16,
+ attn_implementation="eager",
+ ).to(torch_device)
+
+ self.assertTrue(model_eager.config._attn_implementation == "eager")
+
+ for name, submodule in model_eager.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ raise ValueError("The eager model should not have SDPA attention layers")
+
+ has_sdpa = False
+ for name, submodule in model_sdpa.named_modules():
+ if "SdpaAttention" in submodule.__class__.__name__:
+ has_sdpa = True
+ break
+ if not has_sdpa:
+ raise ValueError("The SDPA model should have SDPA attention layers")
+
+ texts = [
+ "hi here's a longer context, getting longer and",
+ "Hello this is a very long sentence my friend, very long for real",
+ "Today I am in Paris and",
+ ]
+
+ for padding_side in ["left", "right"]:
+ tokenizer.padding_side = padding_side
+ tokenizer.pad_token = tokenizer.eos_token
+
+ inputs = tokenizer(texts, return_tensors="pt", padding=True).to(torch_device)
+
+ res_eager = model_eager.generate(**inputs, max_new_tokens=max_new_tokens, do_sample=False)
+ res_sdpa = model_sdpa.generate(**inputs, max_new_tokens=max_new_tokens, do_sample=False)
+
+ with self.subTest(f"{padding_side}"):
+ torch.testing.assert_close(
+ res_eager,
+ res_sdpa,
+ msg=f"\n{tokenizer.batch_decode(res_eager)} \nvs\n{tokenizer.batch_decode(res_sdpa)}",
+ )
+
+
+@require_torch_accelerator
+class DiffLlamaIntegrationTest(unittest.TestCase):
+ def tearDown(self):
+ # See LlamaIntegrationTest.tearDown(). Can be removed once LlamaIntegrationTest.tearDown() is removed.
+ cleanup(torch_device, gc_collect=False)
+
+ @slow
+ @require_torch_accelerator
+ @require_read_token
+ def test_compile_static_cache(self):
+ # `torch==2.2` will throw an error on this test (as in other compilation tests), but torch==2.1.2 and torch>2.2
+ # work as intended. See https://github.com/pytorch/pytorch/issues/121943
+ if version.parse(torch.__version__) < version.parse("2.3.0"):
+ self.skipTest(reason="This test requires torch >= 2.3 to run.")
+
+ NUM_TOKENS_TO_GENERATE = 40
+ # Note on `EXPECTED_TEXT_COMPLETION`'s diff: the current value matches the original test if the original test
+ # was changed to have a cache of 53 tokens (as opposed to 4096), on Ampere GPUs.
+ EXPECTED_TEXT_COMPLETION = [
+ "Simply put, the theory of relativity states that 1) the speed of light is constant in all inertial "
+ "reference frames, and 2) the laws of physics are the same for all inertial reference frames.\nThe "
+ "theory of relativ",
+ "My favorite all time favorite condiment is ketchup. I love it on everything. I love it on my eggs, "
+ "my fries, my chicken, my burgers, my hot dogs, my sandwiches, my salads, my p",
+ ]
+
+ prompts = [
+ "Simply put, the theory of relativity states that ",
+ "My favorite all time favorite condiment is ketchup.",
+ ]
+ tokenizer = AutoTokenizer.from_pretrained(
+ "kajuma/DiffLlama-0.3B-handcut", pad_token="", padding_side="right"
+ )
+ model = DiffLlamaForCausalLM.from_pretrained(
+ "kajuma/DiffLlama-0.3B-handcut", device_map=torch_device, torch_dtype=torch.float16
+ )
+ inputs = tokenizer(prompts, return_tensors="pt", padding=True).to(model.device)
+
+ # Dynamic Cache
+ generated_ids = model.generate(**inputs, max_new_tokens=NUM_TOKENS_TO_GENERATE, do_sample=False)
+ dynamic_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, dynamic_text)
+
+ # Static Cache
+ generated_ids = model.generate(
+ **inputs, max_new_tokens=NUM_TOKENS_TO_GENERATE, do_sample=False, cache_implementation="static"
+ )
+ static_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, static_text)
+
+ # Static Cache + compile
+ model._cache = None # clear cache object, initialized when we pass `cache_implementation="static"`
+ model.forward = torch.compile(model.forward, mode="reduce-overhead", fullgraph=True)
+ generated_ids = model.generate(
+ **inputs, max_new_tokens=NUM_TOKENS_TO_GENERATE, do_sample=False, cache_implementation="static"
+ )
+ static_compiled_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, static_compiled_text)
+
+
+@slow
+@require_torch_accelerator
+class Mask4DTestHard(unittest.TestCase):
+ def tearDown(self):
+ gc.collect()
+ backend_empty_cache(torch_device)
+
+ def setUp(self):
+ model_name = "kajuma/DiffLlama-0.3B-handcut"
+ self.model_dtype = torch.float32
+ self.tokenizer = AutoTokenizer.from_pretrained(model_name)
+ self.model = DiffLlamaForCausalLM.from_pretrained(model_name, torch_dtype=self.model_dtype).to(torch_device)
+
+ def get_test_data(self):
+ template = "my favorite {}"
+ items = ("pet is a", "artist plays a", "name is L") # same number of tokens in each item
+
+ batch_separate = [template.format(x) for x in items] # 3 separate lines
+ batch_shared_prefix = template.format(" ".join(items)) # 1 line with options concatenated
+
+ input_ids = self.tokenizer(batch_separate, return_tensors="pt").input_ids.to(torch_device)
+ input_ids_shared_prefix = self.tokenizer(batch_shared_prefix, return_tensors="pt").input_ids.to(torch_device)
+
+ mask_shared_prefix = torch.tensor(
+ [
+ [
+ [
+ [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
+ [1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0],
+ [1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
+ [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
+ [1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0],
+ [1, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0],
+ [1, 1, 1, 0, 0, 0, 1, 1, 1, 0, 0, 0],
+ [1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0],
+ [1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0],
+ [1, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1],
+ ]
+ ]
+ ],
+ device=torch_device,
+ )
+
+ position_ids = torch.arange(input_ids.shape[1]).tile(input_ids.shape[0], 1).to(torch_device)
+
+ # building custom positions ids based on custom mask
+ position_ids_shared_prefix = (mask_shared_prefix.sum(dim=-1) - 1).reshape(1, -1)
+ # effectively: position_ids_shared_prefix = torch.tensor([[0, 1, 2, 3, 4, 5, 3, 4, 5, 3, 4, 5]]).to(device)
+
+ # inverting the mask
+ min_dtype = torch.finfo(self.model_dtype).min
+ mask_shared_prefix = (mask_shared_prefix.eq(0.0)).to(dtype=self.model_dtype) * min_dtype
+
+ return input_ids, position_ids, input_ids_shared_prefix, mask_shared_prefix, position_ids_shared_prefix
+
+ def test_stacked_causal_mask(self):
+ (
+ input_ids,
+ position_ids,
+ input_ids_shared_prefix,
+ mask_shared_prefix,
+ position_ids_shared_prefix,
+ ) = self.get_test_data()
+
+ # regular batch
+ logits = self.model.forward(input_ids, position_ids=position_ids).logits
+ logits_last = logits[:, -1, :] # last tokens in each batch line
+ decoded = [self.tokenizer.decode(t) for t in logits_last.argmax(dim=-1)]
+
+ # single forward run with 4D custom mask
+ logits_shared_prefix = self.model.forward(
+ input_ids_shared_prefix, attention_mask=mask_shared_prefix, position_ids=position_ids_shared_prefix
+ ).logits
+ logits_shared_prefix_last = logits_shared_prefix[
+ 0, torch.where(position_ids_shared_prefix == position_ids_shared_prefix.max())[1], :
+ ] # last three tokens
+ decoded_shared_prefix = [self.tokenizer.decode(t) for t in logits_shared_prefix_last.argmax(dim=-1)]
+
+ self.assertEqual(decoded, decoded_shared_prefix)
+
+ def test_partial_stacked_causal_mask(self):
+ # Same as the test above, but the input is passed in two groups. It tests that we can pass partial 4D attention masks
+
+ (
+ input_ids,
+ position_ids,
+ input_ids_shared_prefix,
+ mask_shared_prefix,
+ position_ids_shared_prefix,
+ ) = self.get_test_data()
+
+ # regular batch
+ logits = self.model.forward(input_ids, position_ids=position_ids).logits
+ logits_last = logits[:, -1, :] # last tokens in each batch line
+ decoded = [self.tokenizer.decode(t) for t in logits_last.argmax(dim=-1)]
+
+ # 2 forward runs with custom 4D masks
+ part_a = 3 # split point
+
+ input_1a = input_ids_shared_prefix[:, :part_a]
+ position_ids_1a = position_ids_shared_prefix[:, :part_a]
+ mask_1a = mask_shared_prefix[:, :, :part_a, :part_a]
+
+ outs_1a = self.model.forward(input_1a, attention_mask=mask_1a, position_ids=position_ids_1a)
+ past_key_values_a = outs_1a["past_key_values"]
+
+ # Case 1: we pass a 4D attention mask regarding the current sequence length (i.e. [..., seq_len, full_len])
+ input_1b = input_ids_shared_prefix[:, part_a:]
+ position_ids_1b = position_ids_shared_prefix[:, part_a:]
+ mask_1b = mask_shared_prefix[:, :, part_a:, :]
+ outs_1b = self.model.forward(
+ input_1b,
+ attention_mask=mask_1b,
+ position_ids=position_ids_1b,
+ past_key_values=past_key_values_a,
+ )
+ decoded_1b = [
+ self.tokenizer.decode(t)
+ for t in outs_1b.logits.argmax(-1)[
+ 0, torch.where(position_ids_shared_prefix == position_ids_shared_prefix.max())[1] - part_a
+ ]
+ ]
+ self.assertEqual(decoded, decoded_1b)
+
+ def test_stacked_causal_mask_static_cache(self):
+ """same as above but with StaticCache"""
+ (
+ input_ids,
+ position_ids,
+ input_ids_shared_prefix,
+ mask_shared_prefix,
+ position_ids_shared_prefix,
+ ) = self.get_test_data()
+
+ # regular batch
+ logits = self.model.forward(input_ids, position_ids=position_ids).logits
+ logits_last = logits[:, -1, :] # last tokens in each batch line
+ decoded = [self.tokenizer.decode(t) for t in logits_last.argmax(dim=-1)]
+
+ # upgrade the model with StaticCache
+ max_cache_len = 16 # note that max_cache_len is greater than the attention_mask.shape[-1]
+ past_key_values = StaticCache(
+ config=self.model.config,
+ max_batch_size=1,
+ max_cache_len=max_cache_len,
+ device=torch_device,
+ dtype=self.model.dtype,
+ )
+
+ padded_attention_mask = torch.nn.functional.pad(
+ input=mask_shared_prefix,
+ pad=(0, max_cache_len - mask_shared_prefix.shape[-1]),
+ mode="constant",
+ value=torch.finfo(self.model_dtype).min,
+ )
+
+ # single forward run with 4D custom mask
+ logits_shared_prefix = self.model.forward(
+ input_ids_shared_prefix,
+ attention_mask=padded_attention_mask,
+ position_ids=position_ids_shared_prefix,
+ cache_position=torch.arange(input_ids_shared_prefix.shape[-1], device=torch_device),
+ past_key_values=past_key_values,
+ ).logits
+ logits_shared_prefix_last = logits_shared_prefix[
+ 0, torch.where(position_ids_shared_prefix == position_ids_shared_prefix.max())[1], :
+ ] # last three tokens
+ decoded_shared_prefix = [self.tokenizer.decode(t) for t in logits_shared_prefix_last.argmax(dim=-1)]
+
+ self.assertEqual(decoded, decoded_shared_prefix)
+
+ def test_partial_stacked_causal_mask_static_cache(self):
+ # Same as the test above, but the input is passed in two groups. It tests that we can pass partial 4D attention masks
+ # we pass a 4D attention mask shaped [..., seq_len, full_static_cache_len])
+ (
+ input_ids,
+ position_ids,
+ input_ids_shared_prefix,
+ mask_shared_prefix,
+ position_ids_shared_prefix,
+ ) = self.get_test_data()
+
+ # regular batch
+ logits = self.model.forward(input_ids, position_ids=position_ids).logits
+ logits_last = logits[:, -1, :] # last tokens in each batch line
+ decoded = [self.tokenizer.decode(t) for t in logits_last.argmax(dim=-1)]
+
+ # upgrade the model with StaticCache
+ max_cache_len = 16 # note that max_cache_len is greater than the attention_mask.shape[-1]
+ past_key_values = StaticCache(
+ config=self.model.config,
+ max_batch_size=1,
+ max_cache_len=max_cache_len,
+ device=torch_device,
+ dtype=self.model.dtype,
+ )
+
+ # forward run for the first part of input
+ part_a = 3 # split point
+
+ input_1a = input_ids_shared_prefix[:, :part_a]
+ position_ids_1a = position_ids_shared_prefix[:, :part_a]
+ mask_1a = mask_shared_prefix[:, :, :part_a, :part_a]
+
+ padded_mask_1a = torch.nn.functional.pad(
+ input=mask_1a,
+ pad=(0, max_cache_len - mask_1a.shape[-1]),
+ mode="constant",
+ value=torch.finfo(self.model_dtype).min,
+ )
+
+ _ = self.model.forward(
+ input_1a,
+ attention_mask=padded_mask_1a,
+ position_ids=position_ids_1a,
+ cache_position=torch.arange(part_a, device=torch_device),
+ past_key_values=past_key_values,
+ )
+
+ # forward run for the second part of input
+ input_1b = input_ids_shared_prefix[:, part_a:]
+ position_ids_1b = position_ids_shared_prefix[:, part_a:]
+ mask_1b = mask_shared_prefix[:, :, part_a:, :]
+
+ padded_mask_1b = torch.nn.functional.pad(
+ input=mask_1b, pad=(0, max_cache_len - mask_1b.shape[-1]), mode="constant", value=0
+ )
+
+ outs_1b = self.model.forward(
+ input_1b,
+ attention_mask=padded_mask_1b,
+ position_ids=position_ids_1b,
+ cache_position=torch.arange(
+ part_a,
+ input_ids_shared_prefix.shape[-1],
+ device=torch_device,
+ ),
+ past_key_values=past_key_values,
+ )
+ decoded_1b = [
+ self.tokenizer.decode(t)
+ for t in outs_1b.logits.argmax(-1)[
+ 0, torch.where(position_ids_shared_prefix == position_ids_shared_prefix.max())[1] - part_a
+ ]
+ ]
+ self.assertEqual(decoded, decoded_1b)
diff --git a/transformers/tests/models/dinat/__init__.py b/transformers/tests/models/dinat/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/dinat/test_modeling_dinat.py b/transformers/tests/models/dinat/test_modeling_dinat.py
new file mode 100644
index 0000000000000000000000000000000000000000..1de68988e7266d9bdbec906a1f54327d9b5bab22
--- /dev/null
+++ b/transformers/tests/models/dinat/test_modeling_dinat.py
@@ -0,0 +1,378 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Dinat model."""
+
+import collections
+import unittest
+
+from transformers import DinatConfig
+from transformers.testing_utils import require_natten, require_torch, require_vision, slow, torch_device
+from transformers.utils import cached_property, is_torch_available, is_vision_available
+
+from ...test_backbone_common import BackboneTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import DinatBackbone, DinatForImageClassification, DinatModel
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import AutoImageProcessor
+
+
+class DinatModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=64,
+ patch_size=4,
+ num_channels=3,
+ embed_dim=16,
+ depths=[1, 2, 1],
+ num_heads=[2, 4, 8],
+ kernel_size=3,
+ dilations=[[3], [1, 2], [1]],
+ mlp_ratio=2.0,
+ qkv_bias=True,
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ drop_path_rate=0.1,
+ hidden_act="gelu",
+ patch_norm=True,
+ initializer_range=0.02,
+ layer_norm_eps=1e-5,
+ is_training=True,
+ scope=None,
+ use_labels=True,
+ num_labels=10,
+ out_features=["stage1", "stage2"],
+ out_indices=[1, 2],
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.embed_dim = embed_dim
+ self.depths = depths
+ self.num_heads = num_heads
+ self.kernel_size = kernel_size
+ self.dilations = dilations
+ self.mlp_ratio = mlp_ratio
+ self.qkv_bias = qkv_bias
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.drop_path_rate = drop_path_rate
+ self.hidden_act = hidden_act
+ self.patch_norm = patch_norm
+ self.layer_norm_eps = layer_norm_eps
+ self.initializer_range = initializer_range
+ self.is_training = is_training
+ self.scope = scope
+ self.use_labels = use_labels
+ self.num_labels = num_labels
+ self.out_features = out_features
+ self.out_indices = out_indices
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.num_labels)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return DinatConfig(
+ num_labels=self.num_labels,
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ embed_dim=self.embed_dim,
+ depths=self.depths,
+ num_heads=self.num_heads,
+ kernel_size=self.kernel_size,
+ dilations=self.dilations,
+ mlp_ratio=self.mlp_ratio,
+ qkv_bias=self.qkv_bias,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ drop_path_rate=self.drop_path_rate,
+ hidden_act=self.hidden_act,
+ patch_norm=self.patch_norm,
+ layer_norm_eps=self.layer_norm_eps,
+ initializer_range=self.initializer_range,
+ out_features=self.out_features,
+ out_indices=self.out_indices,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = DinatModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+
+ expected_height = expected_width = (config.image_size // config.patch_size) // (2 ** (len(config.depths) - 1))
+ expected_dim = int(config.embed_dim * 2 ** (len(config.depths) - 1))
+
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, expected_height, expected_width, expected_dim)
+ )
+
+ def create_and_check_for_image_classification(self, config, pixel_values, labels):
+ model = DinatForImageClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values, labels=labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ # test greyscale images
+ config.num_channels = 1
+ model = DinatForImageClassification(config)
+ model.to(torch_device)
+ model.eval()
+
+ pixel_values = floats_tensor([self.batch_size, 1, self.image_size, self.image_size])
+ result = model(pixel_values)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def create_and_check_backbone(self, config, pixel_values, labels):
+ model = DinatBackbone(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+
+ # verify hidden states
+ self.parent.assertEqual(len(result.feature_maps), len(config.out_features))
+ self.parent.assertListEqual(list(result.feature_maps[0].shape), [self.batch_size, model.channels[0], 16, 16])
+
+ # verify channels
+ self.parent.assertEqual(len(model.channels), len(config.out_features))
+
+ # verify backbone works with out_features=None
+ config.out_features = None
+ model = DinatBackbone(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+
+ # verify feature maps
+ self.parent.assertEqual(len(result.feature_maps), 1)
+ self.parent.assertListEqual(list(result.feature_maps[0].shape), [self.batch_size, model.channels[-1], 4, 4])
+
+ # verify channels
+ self.parent.assertEqual(len(model.channels), 1)
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_natten
+@require_torch
+class DinatModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ DinatModel,
+ DinatForImageClassification,
+ DinatBackbone,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {"image-feature-extraction": DinatModel, "image-classification": DinatForImageClassification}
+ if is_torch_available()
+ else {}
+ )
+ fx_compatible = False
+
+ test_torchscript = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ test_torch_exportable = True
+
+ def setUp(self):
+ self.model_tester = DinatModelTester(self)
+ self.config_tester = ConfigTester(
+ self, config_class=DinatConfig, embed_dim=37, common_properties=["patch_size", "num_channels"]
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_image_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_image_classification(*config_and_inputs)
+
+ def test_backbone(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_backbone(*config_and_inputs)
+
+ @unittest.skip(reason="Dinat does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Dinat does not use feedforward chunking")
+ def test_feed_forward_chunking(self):
+ pass
+
+ def test_model_get_set_embeddings(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_attention_outputs(self):
+ self.skipTest(reason="Dinat's attention operation is handled entirely by NATTEN.")
+
+ def check_hidden_states_output(self, inputs_dict, config, model_class, image_size):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.hidden_states
+
+ expected_num_layers = getattr(
+ self.model_tester, "expected_num_hidden_layers", len(self.model_tester.depths) + 1
+ )
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ # Dinat has a different seq_length
+ patch_size = (
+ config.patch_size
+ if isinstance(config.patch_size, collections.abc.Iterable)
+ else (config.patch_size, config.patch_size)
+ )
+
+ height = image_size[0] // patch_size[0]
+ width = image_size[1] // patch_size[1]
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-3:]),
+ [height, width, self.model_tester.embed_dim],
+ )
+
+ if model_class.__name__ != "DinatBackbone":
+ reshaped_hidden_states = outputs.reshaped_hidden_states
+ self.assertEqual(len(reshaped_hidden_states), expected_num_layers)
+
+ batch_size, num_channels, height, width = reshaped_hidden_states[0].shape
+ reshaped_hidden_states = (
+ reshaped_hidden_states[0].view(batch_size, num_channels, height, width).permute(0, 2, 3, 1)
+ )
+ self.assertListEqual(
+ list(reshaped_hidden_states.shape[-3:]),
+ [height, width, self.model_tester.embed_dim],
+ )
+
+ def test_hidden_states_output(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ image_size = (
+ self.model_tester.image_size
+ if isinstance(self.model_tester.image_size, collections.abc.Iterable)
+ else (self.model_tester.image_size, self.model_tester.image_size)
+ )
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ self.check_hidden_states_output(inputs_dict, config, model_class, image_size)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ self.check_hidden_states_output(inputs_dict, config, model_class, image_size)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "shi-labs/dinat-mini-in1k-224"
+ model = DinatModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if "embeddings" not in name and param.requires_grad:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+
+@require_natten
+@require_vision
+@require_torch
+class DinatModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_image_processor(self):
+ return AutoImageProcessor.from_pretrained("shi-labs/dinat-mini-in1k-224") if is_vision_available() else None
+
+ @slow
+ def test_inference_image_classification_head(self):
+ model = DinatForImageClassification.from_pretrained("shi-labs/dinat-mini-in1k-224").to(torch_device)
+ image_processor = self.default_image_processor
+
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 1000))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+ expected_slice = torch.tensor([-0.1545, -0.7667, 0.4642]).to(torch_device)
+ torch.testing.assert_close(outputs.logits[0, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+
+@require_torch
+@require_natten
+class DinatBackboneTest(unittest.TestCase, BackboneTesterMixin):
+ all_model_classes = (DinatBackbone,) if is_torch_available() else ()
+ config_class = DinatConfig
+
+ def setUp(self):
+ self.model_tester = DinatModelTester(self)
diff --git a/transformers/tests/models/dit/__init__.py b/transformers/tests/models/dit/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/dit/test_modeling_dit.py b/transformers/tests/models/dit/test_modeling_dit.py
new file mode 100644
index 0000000000000000000000000000000000000000..1e29cc0fdcca45d975bb5f4ae0660fe3c3549335
--- /dev/null
+++ b/transformers/tests/models/dit/test_modeling_dit.py
@@ -0,0 +1,60 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+from transformers import is_torch_available, is_vision_available
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import AutoModelForImageClassification
+
+if is_vision_available():
+ from transformers import AutoImageProcessor
+
+
+@require_torch
+@require_vision
+class DiTIntegrationTest(unittest.TestCase):
+ @slow
+ def test_for_image_classification(self):
+ image_processor = AutoImageProcessor.from_pretrained("microsoft/dit-base-finetuned-rvlcdip")
+ model = AutoModelForImageClassification.from_pretrained("microsoft/dit-base-finetuned-rvlcdip")
+ model.to(torch_device)
+
+ from datasets import load_dataset
+
+ dataset = load_dataset("nielsr/rvlcdip-demo")
+
+ image = dataset["train"][0]["image"].convert("RGB")
+
+ inputs = image_processor(image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+ logits = outputs.logits
+
+ expected_shape = torch.Size((1, 16))
+ self.assertEqual(logits.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [-0.4158, -0.4092, -0.4347],
+ device=torch_device,
+ dtype=torch.float,
+ )
+ torch.testing.assert_close(logits[0, :3], expected_slice, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/doge/__init__.py b/transformers/tests/models/doge/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/doge/test_modeling_doge.py b/transformers/tests/models/doge/test_modeling_doge.py
new file mode 100644
index 0000000000000000000000000000000000000000..4add82b077f3f095572785fe6c74f364a6d9b05e
--- /dev/null
+++ b/transformers/tests/models/doge/test_modeling_doge.py
@@ -0,0 +1,373 @@
+# coding=utf-8
+# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Doge model."""
+
+import unittest
+
+from transformers import AutoTokenizer, DogeConfig, is_torch_available, set_seed
+from transformers.testing_utils import (
+ require_read_token,
+ require_torch,
+ require_torch_accelerator,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ DogeForCausalLM,
+ DogeForSequenceClassification,
+ DogeModel,
+ )
+
+
+class DogeModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=8,
+ seq_length=16,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=False,
+ use_labels=True,
+ vocab_size=128,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=64,
+ hidden_act="silu",
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ pad_token_id=0,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.pad_token_id = pad_token_id
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = torch.tril(torch.ones_like(input_ids).to(torch_device))
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels
+
+ def get_config(self):
+ return DogeConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ pad_token_id=self.pad_token_id,
+ )
+
+ def create_and_check_model(self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels):
+ model = DogeModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_model_as_decoder(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ config.add_cross_attention = True
+ model = DogeModel(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ )
+ result = model(input_ids, attention_mask=input_mask)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_for_causal_lm(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ model = DogeForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_decoder_model_past_large_inputs(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ config.is_decoder = True
+ config.add_cross_attention = True
+ model = DogeForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # first forward pass
+ outputs = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ use_cache=True,
+ )
+ past_key_values = outputs.past_key_values
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
+
+ output_from_no_past = model(
+ next_input_ids,
+ attention_mask=next_attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+ output_from_past = model(
+ next_tokens,
+ attention_mask=next_attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ past_key_values=past_key_values,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class DogeModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ DogeModel,
+ DogeForCausalLM,
+ DogeForSequenceClassification,
+ )
+ if is_torch_available()
+ else ()
+ )
+ all_generative_model_classes = (DogeForCausalLM,) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": DogeModel,
+ "text-classification": DogeForSequenceClassification,
+ "text-generation": DogeForCausalLM,
+ "zero-shot": DogeForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ has_attentions = False
+ test_headmasking = False
+ test_pruning = False
+ test_torchscript = False
+ fx_compatible = False
+
+ # Need to use `0.8` instead of `0.9` for `test_cpu_offload`
+ # This is because we are hitting edge cases with the causal_mask buffer
+ model_split_percents = [0.5, 0.7, 0.8]
+
+ # used in `test_torch_compile_for_training`
+ _torch_compile_train_cls = DogeForCausalLM if is_torch_available() else None
+
+ def setUp(self):
+ self.model_tester = DogeModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=DogeConfig, hidden_size=32)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_doge_sequence_classification_model(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size)
+ model = DogeForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ def test_doge_sequence_classification_model_for_single_label(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ config.problem_type = "single_label_classification"
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size)
+ model = DogeForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ def test_doge_sequence_classification_model_for_multi_label(self):
+ config, input_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.num_labels = 3
+ config.problem_type = "multi_label_classification"
+ input_ids = input_dict["input_ids"]
+ attention_mask = input_ids.ne(1).to(torch_device)
+ sequence_labels = ids_tensor(
+ [self.model_tester.batch_size, config.num_labels], self.model_tester.type_sequence_label_size
+ ).to(torch.float)
+ model = DogeForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
+ self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
+
+ @unittest.skip(reason="Doge buffers include complex numbers, which breaks this test")
+ def test_save_load_fast_init_from_base(self):
+ pass
+
+
+@require_torch_accelerator
+class DogeIntegrationTest(unittest.TestCase):
+ # This variable is used to determine which CUDA device are we using for our runners (A10 or T4)
+ # Depending on the hardware we get different logits / generations
+ cuda_compute_capability_major_version = None
+
+ @classmethod
+ def setUpClass(cls):
+ if is_torch_available() and torch.cuda.is_available():
+ # 8 is for A100 / A10 and 7 for T4
+ cls.cuda_compute_capability_major_version = torch.cuda.get_device_capability()[0]
+
+ @slow
+ @require_read_token
+ def test_Doge_20M_hard(self):
+ """
+ An integration test for Doge-20M. It tests against a long output to ensure the subtle numerical differences
+ """
+ EXPECTED_TEXT = "Here's everything I know about dogs. Dogs is the best animal in the world. It is a very popular and popular dog in the United States. It is a very popular"
+
+ tokenizer = AutoTokenizer.from_pretrained("SmallDoge/Doge-20M")
+ model = DogeForCausalLM.from_pretrained("SmallDoge/Doge-20M", device_map="auto", torch_dtype=torch.bfloat16)
+ input_text = ["Here's everything I know about dogs. Dogs is the best animal in the"]
+ set_seed(0)
+ model_inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
+
+ generated_ids = model.generate(**model_inputs, max_new_tokens=20, do_sample=False)
+ generated_text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
+ self.assertEqual(generated_text, EXPECTED_TEXT)
diff --git a/transformers/tests/models/dots1/__init__.py b/transformers/tests/models/dots1/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/dots1/test_modeling_dots1.py b/transformers/tests/models/dots1/test_modeling_dots1.py
new file mode 100644
index 0000000000000000000000000000000000000000..2df3fd965446dd2077fccf70e1d7bd1db9058f23
--- /dev/null
+++ b/transformers/tests/models/dots1/test_modeling_dots1.py
@@ -0,0 +1,147 @@
+# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch dots1 model."""
+
+import gc
+import unittest
+
+import pytest
+
+from transformers import AutoTokenizer, Dots1Config, is_torch_available
+from transformers.testing_utils import (
+ backend_empty_cache,
+ cleanup,
+ require_flash_attn,
+ require_torch,
+ require_torch_accelerator,
+ require_torch_gpu,
+ slow,
+ torch_device,
+)
+
+from ...causal_lm_tester import CausalLMModelTest, CausalLMModelTester
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ Dots1ForCausalLM,
+ Dots1Model,
+ )
+
+
+class Dots1ModelTester(CausalLMModelTester):
+ config_class = Dots1Config
+ if is_torch_available():
+ base_model_class = Dots1Model
+ causal_lm_class = Dots1ForCausalLM
+
+ def __init__(
+ self,
+ parent,
+ n_routed_experts=8,
+ n_shared_experts=1,
+ n_group=1,
+ topk_group=1,
+ num_experts_per_tok=8,
+ ):
+ super().__init__(parent=parent, num_experts_per_tok=num_experts_per_tok)
+ self.n_routed_experts = n_routed_experts
+ self.n_shared_experts = n_shared_experts
+ self.n_group = n_group
+ self.topk_group = topk_group
+
+
+@require_torch
+class Dots1ModelTest(CausalLMModelTest, unittest.TestCase):
+ all_model_classes = (
+ (
+ Dots1Model,
+ Dots1ForCausalLM,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": Dots1Model,
+ "text-generation": Dots1ForCausalLM,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ test_headmasking = False
+ test_pruning = False
+ model_tester_class = Dots1ModelTester
+
+ @unittest.skip("dots.llm1's moe is not compatible `token_indices, weight_indices = torch.where(mask)`.")
+ def test_generate_with_static_cache(self):
+ pass
+
+ @unittest.skip("dots.llm1's moe is not compatible `token_indices, weight_indices = torch.where(mask)`.")
+ def test_generate_compilation_all_outputs(self):
+ pass
+
+ @unittest.skip("dots.llm1's moe is not compatible `token_indices, weight_indices = torch.where(mask)`")
+ def test_generate_compile_model_forward(self):
+ pass
+
+ @unittest.skip("dots.llm1's moe is not compatible token_indices, weight_indices = torch.where(mask).")
+ def test_generate_from_inputs_embeds_with_static_cache(self):
+ pass
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
+ self.skipTest(reason="dots.llm1 flash attention does not support right padding")
+
+
+@require_torch_accelerator
+class Dots1IntegrationTest(unittest.TestCase):
+ # This variable is used to determine which CUDA device are we using for our runners (A10 or T4)
+ # Depending on the hardware we get different logits / generations
+ cuda_compute_capability_major_version = None
+
+ @classmethod
+ def setUpClass(cls):
+ if is_torch_available() and torch.cuda.is_available():
+ # 8 is for A100 / A10 and 7 for T4
+ cls.cuda_compute_capability_major_version = torch.cuda.get_device_capability()[0]
+
+ def tearDown(self):
+ # See LlamaIntegrationTest.tearDown(). Can be removed once LlamaIntegrationTest.tearDown() is removed.
+ cleanup(torch_device, gc_collect=False)
+
+ @slow
+ def test_model_15b_a2b_generation(self):
+ EXPECTED_TEXT_COMPLETION = (
+ """To be or not to be, that is the question:\nWhether 'tis nobler in the mind to suffer\nThe"""
+ )
+ prompt = "To be or not to"
+ tokenizer = AutoTokenizer.from_pretrained("redmoe-ai-v1/dots.llm1.test", use_fast=False)
+ model = Dots1ForCausalLM.from_pretrained("redmoe-ai-v1/dots.llm1.test", device_map="auto")
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.model.embed_tokens.weight.device)
+
+ # greedy generation outputs
+ generated_ids = model.generate(input_ids, max_new_tokens=20, do_sample=False)
+ text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
diff --git a/transformers/tests/models/dpt/__init__.py b/transformers/tests/models/dpt/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/dpt/test_image_processing_dpt.py b/transformers/tests/models/dpt/test_image_processing_dpt.py
new file mode 100644
index 0000000000000000000000000000000000000000..538ec08dc1ca2b159b9b3c7d7e6d239603c91b7e
--- /dev/null
+++ b/transformers/tests/models/dpt/test_image_processing_dpt.py
@@ -0,0 +1,353 @@
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+import numpy as np
+from datasets import load_dataset
+
+from transformers.file_utils import is_torch_available, is_vision_available
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torchvision_available
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from transformers import DPTImageProcessor
+
+ if is_torchvision_available():
+ from transformers import DPTImageProcessorFast
+
+
+class DPTImageProcessingTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ do_reduce_labels=False,
+ ):
+ size = size if size is not None else {"height": 18, "width": 18}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.do_reduce_labels = do_reduce_labels
+
+ def prepare_image_processor_dict(self):
+ return {
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_normalize": self.do_normalize,
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "do_reduce_labels": self.do_reduce_labels,
+ }
+
+ def expected_output_image_shape(self, images):
+ return self.num_channels, self.size["height"], self.size["width"]
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+# Copied from transformers.tests.models.beit.test_image_processing_beit.prepare_semantic_single_inputs
+def prepare_semantic_single_inputs():
+ ds = load_dataset("hf-internal-testing/fixtures_ade20k", split="test")
+ example = ds[0]
+ return example["image"], example["map"]
+
+
+# Copied from transformers.tests.models.beit.test_image_processing_beit.prepare_semantic_batch_inputs
+def prepare_semantic_batch_inputs():
+ ds = load_dataset("hf-internal-testing/fixtures_ade20k", split="test")
+ return list(ds["image"][:2]), list(ds["map"][:2])
+
+
+@require_torch
+@require_vision
+class DPTImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = DPTImageProcessor if is_vision_available() else None
+ fast_image_processing_class = DPTImageProcessorFast if is_torchvision_available() else None
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = DPTImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "do_rescale"))
+ self.assertTrue(hasattr(image_processing, "rescale_factor"))
+ self.assertTrue(hasattr(image_processing, "do_pad"))
+ self.assertTrue(hasattr(image_processing, "size_divisor"))
+ self.assertTrue(hasattr(image_processing, "do_reduce_labels"))
+
+ def test_image_processor_from_dict_with_kwargs(self):
+ for image_processing_class in self.image_processor_list:
+ image_processing_class = image_processing_class(**self.image_processor_dict)
+ image_processor = image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"height": 18, "width": 18})
+
+ image_processor = image_processing_class.from_dict(self.image_processor_dict, size=42)
+ self.assertEqual(image_processor.size, {"height": 42, "width": 42})
+
+ def test_padding(self):
+ for image_processing_class in self.image_processor_list:
+ if image_processing_class == DPTImageProcessorFast:
+ image = torch.arange(0, 366777, 1, dtype=torch.uint8).reshape(3, 249, 491)
+ image_processor = image_processing_class(**self.image_processor_dict)
+ padded_image = image_processor.pad_image(image, size_divisor=4)
+ self.assertTrue(padded_image.shape[1] % 4 == 0)
+ self.assertTrue(padded_image.shape[2] % 4 == 0)
+ pixel_values = image_processor.preprocess(
+ image, do_rescale=False, do_resize=False, do_pad=True, size_divisor=4, return_tensors="pt"
+ ).pixel_values
+ self.assertTrue(pixel_values.shape[2] % 4 == 0)
+ self.assertTrue(pixel_values.shape[3] % 4 == 0)
+ else:
+ image_processor = image_processing_class(**self.image_processor_dict)
+ image = np.random.randn(3, 249, 491)
+ image = image_processor.pad_image(image, size_divisor=4)
+ self.assertTrue(image.shape[1] % 4 == 0)
+ self.assertTrue(image.shape[2] % 4 == 0)
+ pixel_values = image_processor.preprocess(
+ image, do_rescale=False, do_resize=False, do_pad=True, size_divisor=4, return_tensors="pt"
+ ).pixel_values
+ self.assertTrue(pixel_values.shape[2] % 4 == 0)
+ self.assertTrue(pixel_values.shape[3] % 4 == 0)
+
+ def test_keep_aspect_ratio(self):
+ size = {"height": 512, "width": 512}
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class(size=size, keep_aspect_ratio=True, ensure_multiple_of=32)
+
+ image = np.zeros((489, 640, 3))
+
+ pixel_values = image_processor(image, return_tensors="pt").pixel_values
+
+ self.assertEqual(list(pixel_values.shape), [1, 3, 512, 672])
+
+ # Copied from transformers.tests.models.beit.test_image_processing_beit.BeitImageProcessingTest.test_call_segmentation_maps
+ def test_call_segmentation_maps(self):
+ for image_processing_class in self.image_processor_list:
+ # Initialize image_processor
+ image_processor = image_processing_class(**self.image_processor_dict)
+ # create random PyTorch tensors
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, torchify=True)
+ maps = []
+ for image in image_inputs:
+ self.assertIsInstance(image, torch.Tensor)
+ maps.append(torch.zeros(image.shape[-2:]).long())
+
+ # Test not batched input
+ encoding = image_processor(image_inputs[0], maps[0], return_tensors="pt")
+ self.assertEqual(
+ encoding["pixel_values"].shape,
+ (
+ 1,
+ self.image_processor_tester.num_channels,
+ self.image_processor_tester.size["height"],
+ self.image_processor_tester.size["width"],
+ ),
+ )
+ self.assertEqual(
+ encoding["labels"].shape,
+ (
+ 1,
+ self.image_processor_tester.size["height"],
+ self.image_processor_tester.size["width"],
+ ),
+ )
+ self.assertEqual(encoding["labels"].dtype, torch.long)
+ self.assertTrue(encoding["labels"].min().item() >= 0)
+ self.assertTrue(encoding["labels"].max().item() <= 255)
+
+ # Test batched
+ encoding = image_processor(image_inputs, maps, return_tensors="pt")
+ self.assertEqual(
+ encoding["pixel_values"].shape,
+ (
+ self.image_processor_tester.batch_size,
+ self.image_processor_tester.num_channels,
+ self.image_processor_tester.size["height"],
+ self.image_processor_tester.size["width"],
+ ),
+ )
+ self.assertEqual(
+ encoding["labels"].shape,
+ (
+ self.image_processor_tester.batch_size,
+ self.image_processor_tester.size["height"],
+ self.image_processor_tester.size["width"],
+ ),
+ )
+ self.assertEqual(encoding["labels"].dtype, torch.long)
+ self.assertTrue(encoding["labels"].min().item() >= 0)
+ self.assertTrue(encoding["labels"].max().item() <= 255)
+
+ # Test not batched input (PIL images)
+ image, segmentation_map = prepare_semantic_single_inputs()
+
+ encoding = image_processor(image, segmentation_map, return_tensors="pt")
+ self.assertEqual(
+ encoding["pixel_values"].shape,
+ (
+ 1,
+ self.image_processor_tester.num_channels,
+ self.image_processor_tester.size["height"],
+ self.image_processor_tester.size["width"],
+ ),
+ )
+ self.assertEqual(
+ encoding["labels"].shape,
+ (
+ 1,
+ self.image_processor_tester.size["height"],
+ self.image_processor_tester.size["width"],
+ ),
+ )
+ self.assertEqual(encoding["labels"].dtype, torch.long)
+ self.assertTrue(encoding["labels"].min().item() >= 0)
+ self.assertTrue(encoding["labels"].max().item() <= 255)
+
+ # Test batched input (PIL images)
+ images, segmentation_maps = prepare_semantic_batch_inputs()
+
+ encoding = image_processor(images, segmentation_maps, return_tensors="pt")
+ self.assertEqual(
+ encoding["pixel_values"].shape,
+ (
+ 2,
+ self.image_processor_tester.num_channels,
+ self.image_processor_tester.size["height"],
+ self.image_processor_tester.size["width"],
+ ),
+ )
+ self.assertEqual(
+ encoding["labels"].shape,
+ (
+ 2,
+ self.image_processor_tester.size["height"],
+ self.image_processor_tester.size["width"],
+ ),
+ )
+ self.assertEqual(encoding["labels"].dtype, torch.long)
+ self.assertTrue(encoding["labels"].min().item() >= 0)
+ self.assertTrue(encoding["labels"].max().item() <= 255)
+
+ def test_reduce_labels(self):
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class(**self.image_processor_dict)
+
+ # ADE20k has 150 classes, and the background is included, so labels should be between 0 and 150
+ image, map = prepare_semantic_single_inputs()
+ encoding = image_processor(image, map, return_tensors="pt")
+ labels_no_reduce = encoding["labels"].clone()
+ self.assertTrue(labels_no_reduce.min().item() >= 0)
+ self.assertTrue(labels_no_reduce.max().item() <= 150)
+ # Get the first non-zero label coords and value, for comparison when do_reduce_labels is True
+ non_zero_positions = (labels_no_reduce > 0).nonzero()
+ first_non_zero_coords = tuple(non_zero_positions[0].tolist())
+ first_non_zero_value = labels_no_reduce[first_non_zero_coords].item()
+
+ image_processor.do_reduce_labels = True
+ encoding = image_processor(image, map, return_tensors="pt")
+ self.assertTrue(encoding["labels"].min().item() >= 0)
+ self.assertTrue(encoding["labels"].max().item() <= 255)
+ # Compare with non-reduced label to see if it's reduced by 1
+ self.assertEqual(encoding["labels"][first_non_zero_coords].item(), first_non_zero_value - 1)
+
+ def test_slow_fast_equivalence(self):
+ if not self.test_slow_image_processor or not self.test_fast_image_processor:
+ self.skipTest(reason="Skipping slow/fast equivalence test")
+
+ if self.image_processing_class is None or self.fast_image_processing_class is None:
+ self.skipTest(reason="Skipping slow/fast equivalence test as one of the image processors is not defined")
+
+ dummy_image, dummy_map = prepare_semantic_single_inputs()
+
+ image_processor_slow = self.image_processing_class(**self.image_processor_dict)
+ image_processor_fast = self.fast_image_processing_class(**self.image_processor_dict)
+
+ image_encoding_slow = image_processor_slow(dummy_image, segmentation_maps=dummy_map, return_tensors="pt")
+ image_encoding_fast = image_processor_fast(dummy_image, segmentation_maps=dummy_map, return_tensors="pt")
+
+ self.assertTrue(torch.allclose(image_encoding_slow.pixel_values, image_encoding_fast.pixel_values, atol=1e-1))
+ self.assertLessEqual(
+ torch.mean(torch.abs(image_encoding_slow.pixel_values - image_encoding_fast.pixel_values)).item(), 1e-3
+ )
+ self.assertTrue(torch.allclose(image_encoding_slow.labels, image_encoding_fast.labels, atol=1e-1))
+
+ def test_slow_fast_equivalence_batched(self):
+ if not self.test_slow_image_processor or not self.test_fast_image_processor:
+ self.skipTest(reason="Skipping slow/fast equivalence test")
+
+ if self.image_processing_class is None or self.fast_image_processing_class is None:
+ self.skipTest(reason="Skipping slow/fast equivalence test as one of the image processors is not defined")
+
+ if hasattr(self.image_processor_tester, "do_center_crop") and self.image_processor_tester.do_center_crop:
+ self.skipTest(
+ reason="Skipping as do_center_crop is True and center_crop functions are not equivalent for fast and slow processors"
+ )
+
+ dummy_images, dummy_maps = prepare_semantic_batch_inputs()
+
+ image_processor_slow = self.image_processing_class(**self.image_processor_dict)
+ image_processor_fast = self.fast_image_processing_class(**self.image_processor_dict)
+
+ encoding_slow = image_processor_slow(dummy_images, segmentation_maps=dummy_maps, return_tensors="pt")
+ encoding_fast = image_processor_fast(dummy_images, segmentation_maps=dummy_maps, return_tensors="pt")
+
+ self.assertTrue(torch.allclose(encoding_slow.pixel_values, encoding_fast.pixel_values, atol=1e-1))
+ self.assertLessEqual(
+ torch.mean(torch.abs(encoding_slow.pixel_values - encoding_fast.pixel_values)).item(), 1e-3
+ )
diff --git a/transformers/tests/models/dpt/test_modeling_dpt.py b/transformers/tests/models/dpt/test_modeling_dpt.py
new file mode 100644
index 0000000000000000000000000000000000000000..eb968ad9f686d0bc3ea1f340d8211f9babec4b03
--- /dev/null
+++ b/transformers/tests/models/dpt/test_modeling_dpt.py
@@ -0,0 +1,442 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch DPT model."""
+
+import unittest
+
+from transformers import DPTConfig
+from transformers.file_utils import is_torch_available, is_vision_available
+from transformers.pytorch_utils import is_torch_greater_or_equal_than_2_4
+from transformers.testing_utils import Expectations, require_torch, require_vision, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import DPTForDepthEstimation, DPTForSemanticSegmentation, DPTModel
+ from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import DPTImageProcessor
+
+
+class DPTModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=2,
+ image_size=32,
+ patch_size=16,
+ num_channels=3,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=2,
+ backbone_out_indices=[0, 1, 2, 3],
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ initializer_range=0.02,
+ num_labels=3,
+ neck_hidden_sizes=[16, 32],
+ is_hybrid=False,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.backbone_out_indices = backbone_out_indices
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.scope = scope
+ self.is_hybrid = is_hybrid
+ self.neck_hidden_sizes = neck_hidden_sizes
+ # sequence length of DPT = num_patches + 1 (we add 1 for the [CLS] token)
+ num_patches = (image_size // patch_size) ** 2
+ self.seq_length = num_patches + 1
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size, self.image_size, self.image_size], self.num_labels)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return DPTConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ fusion_hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ backbone_out_indices=self.backbone_out_indices,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ is_hybrid=self.is_hybrid,
+ neck_hidden_sizes=self.neck_hidden_sizes,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = DPTModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_for_depth_estimation(self, config, pixel_values, labels):
+ config.num_labels = self.num_labels
+ model = DPTForDepthEstimation(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(result.predicted_depth.shape, (self.batch_size, self.image_size, self.image_size))
+
+ def create_and_check_for_semantic_segmentation(self, config, pixel_values, labels):
+ config.num_labels = self.num_labels
+ model = DPTForSemanticSegmentation(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values, labels=labels)
+ self.parent.assertEqual(
+ result.logits.shape, (self.batch_size, self.num_labels, self.image_size, self.image_size)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class DPTModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as DPT does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (DPTModel, DPTForDepthEstimation, DPTForSemanticSegmentation) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "depth-estimation": DPTForDepthEstimation,
+ "image-feature-extraction": DPTModel,
+ "image-segmentation": DPTForSemanticSegmentation,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ test_torch_exportable = True
+
+ def setUp(self):
+ self.model_tester = DPTModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=DPTConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="DPT does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_get_set_embeddings(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_depth_estimation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_depth_estimation(*config_and_inputs)
+
+ def test_for_semantic_segmentation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_semantic_segmentation(*config_and_inputs)
+
+ def test_training(self):
+ for model_class in self.all_model_classes:
+ if model_class.__name__ == "DPTForDepthEstimation":
+ continue
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ if model_class.__name__ in MODEL_MAPPING_NAMES.values():
+ continue
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def test_training_gradient_checkpointing(self):
+ for model_class in self.all_model_classes:
+ if model_class.__name__ == "DPTForDepthEstimation":
+ continue
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.use_cache = False
+ config.return_dict = True
+
+ if model_class.__name__ in MODEL_MAPPING_NAMES.values() or not model_class.supports_gradient_checkpointing:
+ continue
+ model = model_class(config)
+ model.to(torch_device)
+ model.gradient_checkpointing_enable()
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @unittest.skip(reason="Inductor error for dynamic shape")
+ def test_sdpa_can_compile_dynamic(self):
+ pass
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ # Skip the check for the backbone
+ backbone_params = []
+ for name, module in model.named_modules():
+ if module.__class__.__name__ == "DPTViTHybridEmbeddings":
+ backbone_params = [f"{name}.{key}" for key in module.state_dict().keys()]
+ break
+
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ if name in backbone_params:
+ continue
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ def test_backbone_selection(self):
+ def _validate_backbone_init():
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ if model.__class__.__name__ == "DPTForDepthEstimation":
+ # Confirm out_indices propagated to backbone
+ self.assertEqual(len(model.backbone.out_indices), 2)
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.use_pretrained_backbone = True
+ config.backbone_config = None
+ config.backbone_kwargs = {"out_indices": [-2, -1]}
+ # Force load_backbone path
+ config.is_hybrid = False
+
+ # Load a timm backbone
+ config.backbone = "resnet18"
+ config.use_timm_backbone = True
+ _validate_backbone_init()
+
+ # Load a HF backbone
+ config.backbone = "facebook/dinov2-small"
+ config.use_timm_backbone = False
+ _validate_backbone_init()
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "Intel/dpt-large"
+ model = DPTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+@slow
+class DPTModelIntegrationTest(unittest.TestCase):
+ def test_inference_depth_estimation(self):
+ image_processor = DPTImageProcessor.from_pretrained("Intel/dpt-large")
+ model = DPTForDepthEstimation.from_pretrained("Intel/dpt-large").to(torch_device)
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+ predicted_depth = outputs.predicted_depth
+
+ # verify the predicted depth
+ expected_shape = torch.Size((1, 384, 384))
+ self.assertEqual(predicted_depth.shape, expected_shape)
+
+ expectations = Expectations(
+ {
+ (None, None): [[6.3199, 6.3629, 6.4148], [6.3850, 6.3615, 6.4166], [6.3519, 6.3176, 6.3575]],
+ ("cuda", 8): [[6.3215, 6.3635, 6.4155], [6.3863, 6.3622, 6.4174], [6.3530, 6.3184, 6.3583]],
+ }
+ )
+ expected_slice = torch.tensor(expectations.get_expectation()).to(torch_device)
+
+ torch.testing.assert_close(outputs.predicted_depth[0, :3, :3], expected_slice, rtol=2e-4, atol=2e-4)
+
+ def test_inference_semantic_segmentation(self):
+ image_processor = DPTImageProcessor.from_pretrained("Intel/dpt-large-ade")
+ model = DPTForSemanticSegmentation.from_pretrained("Intel/dpt-large-ade").to(torch_device)
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 150, 480, 480))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[4.0480, 4.2420, 4.4360], [4.3124, 4.5693, 4.8261], [4.5768, 4.8965, 5.2163]]
+ ).to(torch_device)
+
+ torch.testing.assert_close(outputs.logits[0, 0, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ def test_post_processing_semantic_segmentation(self):
+ image_processor = DPTImageProcessor.from_pretrained("Intel/dpt-large-ade")
+ model = DPTForSemanticSegmentation.from_pretrained("Intel/dpt-large-ade").to(torch_device)
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ outputs.logits = outputs.logits.detach().cpu()
+
+ segmentation = image_processor.post_process_semantic_segmentation(outputs=outputs, target_sizes=[(500, 300)])
+ expected_shape = torch.Size((500, 300))
+ self.assertEqual(segmentation[0].shape, expected_shape)
+
+ segmentation = image_processor.post_process_semantic_segmentation(outputs=outputs)
+ expected_shape = torch.Size((480, 480))
+ self.assertEqual(segmentation[0].shape, expected_shape)
+
+ def test_post_processing_depth_estimation(self):
+ image_processor = DPTImageProcessor.from_pretrained("Intel/dpt-large")
+ model = DPTForDepthEstimation.from_pretrained("Intel/dpt-large")
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt")
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ predicted_depth = image_processor.post_process_depth_estimation(outputs=outputs)[0]["predicted_depth"]
+ expected_shape = torch.Size((384, 384))
+ self.assertTrue(predicted_depth.shape == expected_shape)
+
+ predicted_depth_l = image_processor.post_process_depth_estimation(outputs=outputs, target_sizes=[(500, 500)])
+ predicted_depth_l = predicted_depth_l[0]["predicted_depth"]
+ expected_shape = torch.Size((500, 500))
+ self.assertTrue(predicted_depth_l.shape == expected_shape)
+
+ output_enlarged = torch.nn.functional.interpolate(
+ predicted_depth.unsqueeze(0).unsqueeze(1), size=(500, 500), mode="bicubic", align_corners=False
+ ).squeeze()
+ self.assertTrue(output_enlarged.shape == expected_shape)
+ torch.testing.assert_close(predicted_depth_l, output_enlarged, atol=1e-3, rtol=1e-3)
+
+ def test_export(self):
+ for strict in [True, False]:
+ with self.subTest(strict=strict):
+ if not is_torch_greater_or_equal_than_2_4:
+ self.skipTest(reason="This test requires torch >= 2.4 to run.")
+ model = DPTForSemanticSegmentation.from_pretrained("Intel/dpt-large-ade").to(torch_device).eval()
+ image_processor = DPTImageProcessor.from_pretrained("Intel/dpt-large-ade")
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ exported_program = torch.export.export(
+ model,
+ args=(inputs["pixel_values"],),
+ strict=strict,
+ )
+ with torch.no_grad():
+ eager_outputs = model(**inputs)
+ exported_outputs = exported_program.module().forward(inputs["pixel_values"])
+ self.assertEqual(eager_outputs.logits.shape, exported_outputs.logits.shape)
+ torch.testing.assert_close(eager_outputs.logits, exported_outputs.logits, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/dpt/test_modeling_dpt_auto_backbone.py b/transformers/tests/models/dpt/test_modeling_dpt_auto_backbone.py
new file mode 100644
index 0000000000000000000000000000000000000000..1505be27cf724ec96ea7f51c07a22ecc9beb891d
--- /dev/null
+++ b/transformers/tests/models/dpt/test_modeling_dpt_auto_backbone.py
@@ -0,0 +1,346 @@
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch DPT model."""
+
+import unittest
+
+from transformers import Dinov2Config, DPTConfig
+from transformers.file_utils import is_torch_available, is_vision_available
+from transformers.testing_utils import Expectations, require_torch, require_vision, slow, torch_device
+from transformers.utils.import_utils import get_torch_major_and_minor_version
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import DPTForDepthEstimation
+ from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import DPTImageProcessor
+
+
+class DPTModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=2,
+ num_channels=3,
+ image_size=32,
+ patch_size=16,
+ use_labels=True,
+ num_labels=3,
+ is_training=True,
+ hidden_size=4,
+ num_hidden_layers=2,
+ num_attention_heads=2,
+ intermediate_size=8,
+ out_features=["stage1", "stage2"],
+ apply_layernorm=False,
+ reshape_hidden_states=False,
+ neck_hidden_sizes=[2, 2],
+ fusion_hidden_size=6,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.out_features = out_features
+ self.apply_layernorm = apply_layernorm
+ self.reshape_hidden_states = reshape_hidden_states
+ self.use_labels = use_labels
+ self.num_labels = num_labels
+ self.is_training = is_training
+ self.neck_hidden_sizes = neck_hidden_sizes
+ self.fusion_hidden_size = fusion_hidden_size
+ # DPT's sequence length
+ self.seq_length = (self.image_size // self.patch_size) ** 2 + 1
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size, self.image_size, self.image_size], self.num_labels)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return DPTConfig(
+ backbone_config=self.get_backbone_config(),
+ backbone=None,
+ neck_hidden_sizes=self.neck_hidden_sizes,
+ fusion_hidden_size=self.fusion_hidden_size,
+ )
+
+ def get_backbone_config(self):
+ return Dinov2Config(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ is_training=self.is_training,
+ out_features=self.out_features,
+ reshape_hidden_states=self.reshape_hidden_states,
+ )
+
+ def create_and_check_for_depth_estimation(self, config, pixel_values, labels):
+ config.num_labels = self.num_labels
+ model = DPTForDepthEstimation(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(result.predicted_depth.shape, (self.batch_size, self.image_size, self.image_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class DPTModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as DPT does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (DPTForDepthEstimation,) if is_torch_available() else ()
+ pipeline_model_mapping = {"depth-estimation": DPTForDepthEstimation} if is_torch_available() else {}
+
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ test_torch_exportable = True
+ test_torch_exportable_strictly = not get_torch_major_and_minor_version() == "2.7"
+
+ def setUp(self):
+ self.model_tester = DPTModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=DPTConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="DPT with AutoBackbone does not have a base model and hence no input_embeddings")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_for_depth_estimation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_depth_estimation(*config_and_inputs)
+
+ def test_training(self):
+ for model_class in self.all_model_classes:
+ if model_class.__name__ == "DPTForDepthEstimation":
+ continue
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ if model_class.__name__ in MODEL_MAPPING_NAMES.values():
+ continue
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def test_training_gradient_checkpointing(self):
+ for model_class in self.all_model_classes:
+ if model_class.__name__ == "DPTForDepthEstimation":
+ continue
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.use_cache = False
+ config.return_dict = True
+
+ if model_class.__name__ in MODEL_MAPPING_NAMES.values() or not model_class.supports_gradient_checkpointing:
+ continue
+ model = model_class(config)
+ model.to(torch_device)
+ model.gradient_checkpointing_enable()
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ # Skip the check for the backbone
+ backbone_params = []
+ for name, module in model.named_modules():
+ if module.__class__.__name__ == "DPTViTHybridEmbeddings":
+ backbone_params = [f"{name}.{key}" for key in module.state_dict().keys()]
+ break
+
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ if name in backbone_params:
+ continue
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ @unittest.skip(reason="DPT with AutoBackbone does not have a base model and hence no input_embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "Intel/dpt-large"
+ model = DPTForDepthEstimation.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+@slow
+class DPTModelIntegrationTest(unittest.TestCase):
+ def test_inference_depth_estimation_dinov2(self):
+ image_processor = DPTImageProcessor.from_pretrained("facebook/dpt-dinov2-small-kitti")
+ model = DPTForDepthEstimation.from_pretrained("facebook/dpt-dinov2-small-kitti").to(torch_device)
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+ predicted_depth = outputs.predicted_depth
+
+ # verify the predicted depth
+ expected_shape = torch.Size((1, 576, 736))
+ self.assertEqual(predicted_depth.shape, expected_shape)
+
+ expectations = Expectations(
+ {
+ (None, None): [[6.0336, 7.1502, 7.4130], [6.8977, 7.2383, 7.2268], [7.9180, 8.0525, 8.0134]],
+ ("cuda", 8): [[6.0350, 7.1518, 7.4144], [6.8992, 7.2396, 7.2280], [7.9194, 8.0538, 8.0145]],
+ }
+ )
+ expected_slice = torch.tensor(expectations.get_expectation()).to(torch_device)
+
+ torch.testing.assert_close(outputs.predicted_depth[0, :3, :3], expected_slice, rtol=2e-4, atol=2e-4)
+
+ def test_inference_depth_estimation_beit(self):
+ image_processor = DPTImageProcessor.from_pretrained("Intel/dpt-beit-base-384")
+ model = DPTForDepthEstimation.from_pretrained("Intel/dpt-beit-base-384").to(torch_device)
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+ predicted_depth = outputs.predicted_depth
+
+ # verify the predicted depth
+ expected_shape = torch.Size((1, 384, 384))
+ self.assertEqual(predicted_depth.shape, expected_shape)
+
+ expectations = Expectations(
+ {
+ (None, None): [
+ [2669.7061, 2663.7144, 2674.9399],
+ [2633.9326, 2650.9092, 2665.4270],
+ [2621.8271, 2632.0129, 2637.2290],
+ ],
+ ("cuda", 8): [
+ [2669.4292, 2663.4121, 2674.6233],
+ [2633.7400, 2650.7026, 2665.2085],
+ [2621.6572, 2631.8452, 2637.0525],
+ ],
+ }
+ )
+ expected_slice = torch.tensor(expectations.get_expectation()).to(torch_device)
+
+ torch.testing.assert_close(outputs.predicted_depth[0, :3, :3], expected_slice, rtol=2e-4, atol=2e-4)
+
+ def test_inference_depth_estimation_swinv2(self):
+ image_processor = DPTImageProcessor.from_pretrained("Intel/dpt-swinv2-tiny-256")
+ model = DPTForDepthEstimation.from_pretrained("Intel/dpt-swinv2-tiny-256").to(torch_device)
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+ predicted_depth = outputs.predicted_depth
+
+ # verify the predicted depth
+ expected_shape = torch.Size((1, 256, 256))
+ self.assertEqual(predicted_depth.shape, expected_shape)
+
+ expectations = Expectations(
+ {
+ (None, None): [
+ [1032.7719, 1025.1886, 1030.2661],
+ [1023.7619, 1021.0075, 1024.9121],
+ [1022.5667, 1018.8522, 1021.4145],
+ ],
+ ("cuda", 8): [
+ [1032.7170, 1025.0629, 1030.1941],
+ [1023.7309, 1020.9786, 1024.8594],
+ [1022.5233, 1018.8235, 1021.3312],
+ ],
+ }
+ )
+ expected_slice = torch.tensor(expectations.get_expectation()).to(torch_device)
+
+ torch.testing.assert_close(outputs.predicted_depth[0, :3, :3], expected_slice, rtol=2e-4, atol=2e-4)
diff --git a/transformers/tests/models/dpt/test_modeling_dpt_hybrid.py b/transformers/tests/models/dpt/test_modeling_dpt_hybrid.py
new file mode 100644
index 0000000000000000000000000000000000000000..79cad886db4097163de4156fd4d8bd4245daa230
--- /dev/null
+++ b/transformers/tests/models/dpt/test_modeling_dpt_hybrid.py
@@ -0,0 +1,341 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch DPT model."""
+
+import unittest
+
+from transformers import DPTConfig
+from transformers.file_utils import is_torch_available, is_vision_available
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import DPTForDepthEstimation, DPTForSemanticSegmentation, DPTModel
+ from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import DPTImageProcessor
+
+
+class DPTModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=2,
+ image_size=32,
+ patch_size=16,
+ num_channels=3,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=4,
+ backbone_out_indices=[0, 1, 2, 3],
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ initializer_range=0.02,
+ num_labels=3,
+ backbone_featmap_shape=[1, 32, 24, 24],
+ neck_hidden_sizes=[16, 16, 32, 32],
+ is_hybrid=True,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.backbone_out_indices = backbone_out_indices
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.backbone_featmap_shape = backbone_featmap_shape
+ self.scope = scope
+ self.is_hybrid = is_hybrid
+ self.neck_hidden_sizes = neck_hidden_sizes
+ # sequence length of DPT = num_patches + 1 (we add 1 for the [CLS] token)
+ num_patches = (image_size // patch_size) ** 2
+ self.seq_length = num_patches + 1
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size, self.image_size, self.image_size], self.num_labels)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ backbone_config = {
+ "global_padding": "same",
+ "layer_type": "bottleneck",
+ "depths": [3, 4, 9],
+ "out_features": ["stage1", "stage2", "stage3"],
+ "embedding_dynamic_padding": True,
+ "hidden_sizes": [16, 16, 32, 32],
+ "num_groups": 2,
+ }
+
+ return DPTConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ fusion_hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ backbone_out_indices=self.backbone_out_indices,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ is_hybrid=self.is_hybrid,
+ backbone_config=backbone_config,
+ backbone=None,
+ backbone_featmap_shape=self.backbone_featmap_shape,
+ neck_hidden_sizes=self.neck_hidden_sizes,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = DPTModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_for_depth_estimation(self, config, pixel_values, labels):
+ config.num_labels = self.num_labels
+ model = DPTForDepthEstimation(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(result.predicted_depth.shape, (self.batch_size, self.image_size, self.image_size))
+
+ def create_and_check_for_semantic_segmentation(self, config, pixel_values, labels):
+ config.num_labels = self.num_labels
+ model = DPTForSemanticSegmentation(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values, labels=labels)
+ self.parent.assertEqual(
+ result.logits.shape, (self.batch_size, self.num_labels, self.image_size, self.image_size)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class DPTModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as DPT does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (DPTModel, DPTForDepthEstimation, DPTForSemanticSegmentation) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "depth-estimation": DPTForDepthEstimation,
+ "feature-extraction": DPTModel,
+ "image-segmentation": DPTForSemanticSegmentation,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ test_torch_exportable = True
+
+ def setUp(self):
+ self.model_tester = DPTModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=DPTConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_batching_equivalence(self, atol=2e-5, rtol=2e-5):
+ super().test_batching_equivalence(atol=atol, rtol=rtol)
+
+ @unittest.skip(reason="DPT does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_get_set_embeddings(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_depth_estimation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_depth_estimation(*config_and_inputs)
+
+ def test_for_semantic_segmentation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_semantic_segmentation(*config_and_inputs)
+
+ def test_training(self):
+ for model_class in self.all_model_classes:
+ if model_class.__name__ == "DPTForDepthEstimation":
+ continue
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ if model_class.__name__ in MODEL_MAPPING_NAMES.values():
+ continue
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def test_training_gradient_checkpointing(self):
+ for model_class in self.all_model_classes:
+ if model_class.__name__ == "DPTForDepthEstimation":
+ continue
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.use_cache = False
+ config.return_dict = True
+
+ if model_class.__name__ in MODEL_MAPPING_NAMES.values() or not model_class.supports_gradient_checkpointing:
+ continue
+ model = model_class(config)
+ model.to(torch_device)
+ model.gradient_checkpointing_enable()
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ # Skip the check for the backbone
+ backbone_params = []
+ for name, module in model.named_modules():
+ if module.__class__.__name__ == "DPTViTHybridEmbeddings":
+ backbone_params = [f"{name}.{key}" for key in module.state_dict().keys()]
+ break
+
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ if name in backbone_params:
+ continue
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "Intel/dpt-hybrid-midas"
+ model = DPTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ def test_raise_readout_type(self):
+ # We do this test only for DPTForDepthEstimation since it is the only model that uses readout_type
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ config.readout_type = "add"
+ with self.assertRaises(ValueError):
+ _ = DPTForDepthEstimation(config)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+@slow
+class DPTModelIntegrationTest(unittest.TestCase):
+ def test_inference_depth_estimation(self):
+ image_processor = DPTImageProcessor.from_pretrained("Intel/dpt-hybrid-midas")
+ model = DPTForDepthEstimation.from_pretrained("Intel/dpt-hybrid-midas").to(torch_device)
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+ predicted_depth = outputs.predicted_depth
+
+ # verify the predicted depth
+ expected_shape = torch.Size((1, 384, 384))
+ self.assertEqual(predicted_depth.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[[5.6437, 5.6146, 5.6511], [5.4371, 5.5649, 5.5958], [5.5215, 5.5184, 5.5293]]]
+ ).to(torch_device)
+
+ torch.testing.assert_close(outputs.predicted_depth[:3, :3, :3] / 100, expected_slice, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/efficientnet/__init__.py b/transformers/tests/models/efficientnet/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/efficientnet/test_image_processing_efficientnet.py b/transformers/tests/models/efficientnet/test_image_processing_efficientnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..cb8fc8d92209c5246b93e3e6c941c5d4ab76d118
--- /dev/null
+++ b/transformers/tests/models/efficientnet/test_image_processing_efficientnet.py
@@ -0,0 +1,190 @@
+# Copyright 2023 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+import numpy as np
+
+from transformers.image_utils import PILImageResampling
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import (
+ is_torch_available,
+ is_torchvision_available,
+ is_vision_available,
+)
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from transformers import EfficientNetImageProcessor
+
+ if is_torchvision_available():
+ from transformers import EfficientNetImageProcessorFast
+
+
+class EfficientNetImageProcessorTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ do_rescale=True,
+ rescale_offset=True,
+ rescale_factor=1 / 127.5,
+ resample=PILImageResampling.BILINEAR, # NEAREST is too different between PIL and torchvision
+ ):
+ size = size if size is not None else {"height": 18, "width": 18}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.resample = resample
+
+ def prepare_image_processor_dict(self):
+ return {
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_normalize": self.do_normalize,
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "resample": self.resample,
+ }
+
+ def expected_output_image_shape(self, images):
+ return self.num_channels, self.size["height"], self.size["width"]
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class EfficientNetImageProcessorTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = EfficientNetImageProcessor if is_vision_available() else None
+ fast_image_processing_class = EfficientNetImageProcessorFast if is_torchvision_available() else None
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = EfficientNetImageProcessorTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+
+ def test_image_processor_from_dict_with_kwargs(self):
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"height": 18, "width": 18})
+
+ image_processor = image_processing_class.from_dict(self.image_processor_dict, size=42)
+ self.assertEqual(image_processor.size, {"height": 42, "width": 42})
+
+ def test_rescale(self):
+ # EfficientNet optionally rescales between -1 and 1 instead of the usual 0 and 1
+ image = np.arange(0, 256, 1, dtype=np.uint8).reshape(1, 8, 32)
+
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class(**self.image_processor_dict)
+ if image_processing_class == EfficientNetImageProcessorFast:
+ image = torch.from_numpy(image)
+
+ # Scale between [-1, 1] with rescale_factor 1/127.5 and rescale_offset=True
+ rescaled_image = image_processor.rescale(image, scale=1 / 127.5, offset=True)
+ expected_image = (image * (1 / 127.5)) - 1
+ self.assertTrue(torch.allclose(rescaled_image, expected_image))
+
+ # Scale between [0, 1] with rescale_factor 1/255 and rescale_offset=True
+ rescaled_image = image_processor.rescale(image, scale=1 / 255, offset=False)
+ expected_image = image / 255.0
+ self.assertTrue(torch.allclose(rescaled_image, expected_image))
+
+ else:
+ rescaled_image = image_processor.rescale(image, scale=1 / 127.5, dtype=np.float64)
+ expected_image = (image * (1 / 127.5)).astype(np.float64) - 1
+ self.assertTrue(np.allclose(rescaled_image, expected_image))
+
+ rescaled_image = image_processor.rescale(image, scale=1 / 255, offset=False, dtype=np.float64)
+ expected_image = (image / 255.0).astype(np.float64)
+ self.assertTrue(np.allclose(rescaled_image, expected_image))
+
+ @require_vision
+ @require_torch
+ def test_rescale_normalize(self):
+ if self.image_processing_class is None or self.fast_image_processing_class is None:
+ self.skipTest(reason="Skipping slow/fast equivalence test as one of the image processors is not defined")
+
+ image = torch.arange(0, 256, 1, dtype=torch.uint8).reshape(1, 8, 32).repeat(3, 1, 1)
+ image_mean_0 = (0.0, 0.0, 0.0)
+ image_std_0 = (1.0, 1.0, 1.0)
+ image_mean_1 = (0.5, 0.5, 0.5)
+ image_std_1 = (0.5, 0.5, 0.5)
+
+ image_processor_fast = self.fast_image_processing_class(**self.image_processor_dict)
+
+ # Rescale between [-1, 1] with rescale_factor=1/127.5 and rescale_offset=True. Then normalize
+ rescaled_normalized = image_processor_fast.rescale_and_normalize(
+ image, True, 1 / 127.5, True, image_mean_0, image_std_0, True
+ )
+ expected_image = (image * (1 / 127.5)) - 1
+ expected_image = (expected_image - torch.tensor(image_mean_0).view(3, 1, 1)) / torch.tensor(image_std_0).view(
+ 3, 1, 1
+ )
+ self.assertTrue(torch.allclose(rescaled_normalized, expected_image, rtol=1e-3))
+
+ # Rescale between [0, 1] with rescale_factor=1/255 and rescale_offset=False. Then normalize
+ rescaled_normalized = image_processor_fast.rescale_and_normalize(
+ image, True, 1 / 255, True, image_mean_1, image_std_1, False
+ )
+ expected_image = image * (1 / 255.0)
+ expected_image = (expected_image - torch.tensor(image_mean_1).view(3, 1, 1)) / torch.tensor(image_std_1).view(
+ 3, 1, 1
+ )
+ self.assertTrue(torch.allclose(rescaled_normalized, expected_image, rtol=1e-3))
diff --git a/transformers/tests/models/efficientnet/test_modeling_efficientnet.py b/transformers/tests/models/efficientnet/test_modeling_efficientnet.py
new file mode 100644
index 0000000000000000000000000000000000000000..f0706ad1536a6ce1fd163849bddf9731b9f0a9b4
--- /dev/null
+++ b/transformers/tests/models/efficientnet/test_modeling_efficientnet.py
@@ -0,0 +1,262 @@
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch EfficientNet model."""
+
+import unittest
+
+from transformers import EfficientNetConfig
+from transformers.testing_utils import is_pipeline_test, require_torch, require_vision, slow, torch_device
+from transformers.utils import cached_property, is_torch_available, is_vision_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import EfficientNetForImageClassification, EfficientNetModel
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import AutoImageProcessor
+
+
+class EfficientNetModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=32,
+ num_channels=3,
+ kernel_sizes=[3, 3, 5],
+ in_channels=[32, 16, 24],
+ out_channels=[16, 24, 20],
+ strides=[1, 1, 2],
+ num_block_repeats=[1, 1, 2],
+ expand_ratios=[1, 6, 6],
+ is_training=True,
+ use_labels=True,
+ intermediate_size=37,
+ hidden_act="gelu",
+ num_labels=10,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.num_channels = num_channels
+ self.kernel_sizes = kernel_sizes
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.strides = strides
+ self.num_block_repeats = num_block_repeats
+ self.expand_ratios = expand_ratios
+ self.is_training = is_training
+ self.hidden_act = hidden_act
+ self.num_labels = num_labels
+ self.use_labels = use_labels
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.num_labels)
+
+ config = self.get_config()
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return EfficientNetConfig(
+ image_size=self.image_size,
+ num_channels=self.num_channels,
+ kernel_sizes=self.kernel_sizes,
+ in_channels=self.in_channels,
+ out_channels=self.out_channels,
+ strides=self.strides,
+ num_block_repeats=self.num_block_repeats,
+ expand_ratios=self.expand_ratios,
+ hidden_act=self.hidden_act,
+ num_labels=self.num_labels,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = EfficientNetModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ # expected last hidden states: B, C, H // 4, W // 4
+ self.parent.assertEqual(
+ result.last_hidden_state.shape,
+ (self.batch_size, config.hidden_dim, self.image_size // 4, self.image_size // 4),
+ )
+
+ def create_and_check_for_image_classification(self, config, pixel_values, labels):
+ model = EfficientNetForImageClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values, labels=labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class EfficientNetModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as EfficientNet does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (EfficientNetModel, EfficientNetForImageClassification) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {"image-feature-extraction": EfficientNetModel, "image-classification": EfficientNetForImageClassification}
+ if is_torch_available()
+ else {}
+ )
+
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ has_attentions = False
+ test_torch_exportable = True
+
+ def setUp(self):
+ self.model_tester = EfficientNetModelTester(self)
+ self.config_tester = ConfigTester(
+ self,
+ config_class=EfficientNetConfig,
+ has_text_modality=False,
+ hidden_size=37,
+ common_properties=["num_channels", "image_size", "hidden_dim"],
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="EfficientNet does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="EfficientNet does not support input and output embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @unittest.skip(reason="EfficientNet does not use feedforward chunking")
+ def test_feed_forward_chunking(self):
+ pass
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.encoder_hidden_states if config.is_encoder_decoder else outputs.hidden_states
+ num_blocks = sum(config.num_block_repeats) * 4
+ self.assertEqual(len(hidden_states), num_blocks)
+
+ # EfficientNet's feature maps are of shape (batch_size, num_channels, height, width)
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [self.model_tester.image_size // 2, self.model_tester.image_size // 2],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ def test_for_image_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_image_classification(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "google/efficientnet-b7"
+ model = EfficientNetModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ @is_pipeline_test
+ @require_vision
+ @slow
+ def test_pipeline_image_feature_extraction(self):
+ super().test_pipeline_image_feature_extraction()
+
+ @is_pipeline_test
+ @require_vision
+ @slow
+ def test_pipeline_image_feature_extraction_fp16(self):
+ super().test_pipeline_image_feature_extraction_fp16()
+
+ @is_pipeline_test
+ @require_vision
+ @slow
+ def test_pipeline_image_classification(self):
+ super().test_pipeline_image_classification()
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+class EfficientNetModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_image_processor(self):
+ return AutoImageProcessor.from_pretrained("google/efficientnet-b7") if is_vision_available() else None
+
+ @slow
+ def test_inference_image_classification_head(self):
+ model = EfficientNetForImageClassification.from_pretrained("google/efficientnet-b7").to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 1000))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([-0.2962, 0.4487, 0.4499]).to(torch_device)
+ torch.testing.assert_close(outputs.logits[0, :3], expected_slice, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/emu3/__init__.py b/transformers/tests/models/emu3/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/emu3/test_modeling_emu3.py b/transformers/tests/models/emu3/test_modeling_emu3.py
new file mode 100644
index 0000000000000000000000000000000000000000..978febaa4977dfe0b35401223cb55fef0147fda7
--- /dev/null
+++ b/transformers/tests/models/emu3/test_modeling_emu3.py
@@ -0,0 +1,515 @@
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch emu3 model."""
+
+import unittest
+
+import numpy as np
+import pytest
+import requests
+from huggingface_hub import hf_hub_download
+from parameterized import parameterized
+
+from transformers import Emu3Config, Emu3TextConfig, is_torch_available, is_vision_available, set_seed
+from transformers.testing_utils import (
+ Expectations,
+ require_bitsandbytes,
+ require_torch,
+ require_torch_large_accelerator,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_vision_available():
+ from PIL import Image
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ Emu3ForCausalLM,
+ Emu3ForConditionalGeneration,
+ Emu3Model,
+ Emu3Processor,
+ Emu3TextModel,
+ )
+
+
+class Emu3Text2TextModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=False,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=2,
+ num_key_value_heads=2,
+ intermediate_size=37,
+ max_position_embeddings=512,
+ initializer_range=0.02,
+ pad_token_id=0,
+ bos_token_id=1,
+ eos_token_id=2,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.num_key_value_heads = num_key_value_heads
+ self.intermediate_size = intermediate_size
+ self.max_position_embeddings = max_position_embeddings
+ self.initializer_range = initializer_range
+ self.pad_token_id = pad_token_id
+ self.bos_token_id = bos_token_id
+ self.eos_token_id = eos_token_id
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+ attention_mask = input_ids.ne(1).to(torch_device)
+
+ config = self.get_config()
+
+ return config, input_ids, attention_mask
+
+ def get_config(self):
+ return Emu3TextConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ num_key_value_heads=self.num_key_value_heads,
+ intermediate_size=self.intermediate_size,
+ max_position_embeddings=self.max_position_embeddings,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ pad_token_id=self.pad_token_id,
+ bos_token_id=self.bos_token_id,
+ eos_token_id=self.eos_token_id,
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ attention_mask,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": attention_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class Emu3Text2TextModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (Emu3ForCausalLM,) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "text-generation": Emu3ForCausalLM,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_headmasking = False
+ test_pruning = False
+ fx_compatible = False
+
+ def setUp(self):
+ self.model_tester = Emu3Text2TextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=Emu3TextConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @parameterized.expand([("linear",), ("dynamic",)])
+ def test_model_rope_scaling(self, scaling_type):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ short_input = ids_tensor([1, 10], config.vocab_size)
+ long_input = ids_tensor([1, int(config.max_position_embeddings * 1.5)], config.vocab_size)
+
+ set_seed(42) # Fixed seed at init time so the two models get the same random weights
+ original_model = Emu3TextModel(config)
+ original_model.to(torch_device)
+ original_model.eval()
+ original_short_output = original_model(short_input).last_hidden_state
+ original_long_output = original_model(long_input).last_hidden_state
+
+ set_seed(42) # Fixed seed at init time so the two models get the same random weights
+ config.rope_scaling = {"type": scaling_type, "factor": 10.0}
+ scaled_model = Emu3TextModel(config)
+ scaled_model.to(torch_device)
+ scaled_model.eval()
+ scaled_short_output = scaled_model(short_input).last_hidden_state
+ scaled_long_output = scaled_model(long_input).last_hidden_state
+
+ # Dynamic scaling does not change the RoPE embeddings until it receives an input longer than the original
+ # maximum sequence length, so the outputs for the short input should match.
+ if scaling_type == "dynamic":
+ torch.testing.assert_close(original_short_output, scaled_short_output, rtol=1e-5, atol=1e-5)
+ else:
+ self.assertFalse(torch.allclose(original_short_output, scaled_short_output, atol=1e-5))
+
+ # The output should be different for long inputs
+ self.assertFalse(torch.allclose(original_long_output, scaled_long_output, atol=1e-5))
+
+ @unittest.skip("Doesn't work, tensors are not almost same") # TODO raushan fixme
+ def test_custom_4d_attention_mask(self):
+ pass
+
+
+class Emu3Vision2TextModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=False,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=2,
+ num_key_value_heads=2,
+ intermediate_size=37,
+ max_position_embeddings=512,
+ initializer_range=0.02,
+ pad_token_id=0,
+ bos_token_id=1,
+ eos_token_id=2,
+ image_token_id=3,
+ image_size=30,
+ codebook_size=20,
+ temporal_downsample_factor=1,
+ base_channels=32,
+ vq_channel_multiplier=[1, 1],
+ image_seq_length=100,
+ vq_img_token_start_id=3,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.is_training = is_training
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.num_key_value_heads = num_key_value_heads
+ self.intermediate_size = intermediate_size
+ self.max_position_embeddings = max_position_embeddings
+ self.initializer_range = initializer_range
+ self.pad_token_id = pad_token_id
+ self.bos_token_id = bos_token_id
+ self.eos_token_id = eos_token_id
+ self.image_token_id = image_token_id
+ self.image_size = image_size
+ self.codebook_size = codebook_size
+ self.temporal_downsample_factor = temporal_downsample_factor
+ self.vq_channel_multiplier = vq_channel_multiplier
+ self.vq_img_token_start_id = vq_img_token_start_id
+ self.base_channels = base_channels
+ self.seq_length = seq_length + image_seq_length
+ self.image_seq_length = image_seq_length
+
+ def prepare_config_and_inputs(self):
+ config = self.get_config()
+
+ input_ids = ids_tensor([self.batch_size, self.seq_length], config.text_config.vocab_size)
+ attention_mask = input_ids.ne(1).to(torch_device)
+ input_ids[input_ids == self.image_token_id] = self.pad_token_id
+ input_ids[:, : self.image_seq_length] = self.image_token_id
+
+ pixel_values = floats_tensor(
+ [
+ self.batch_size,
+ 3,
+ self.image_size,
+ self.image_size,
+ ]
+ )
+ image_sizes = [[self.image_size, self.image_size]] * self.batch_size
+ image_sizes = torch.tensor(image_sizes, device=torch_device, dtype=torch.int64)
+
+ return config, input_ids, attention_mask, pixel_values, image_sizes
+
+ def get_config(self):
+ # create dummy vocab map for image2bpe mapping if it needs remapping
+ # we assume that vocab size is big enough to account for `codebook_size` amount of
+ # image tokens somewhere at the beginning of total vocab size
+
+ vocab_map = {i: chr(i) for i in range(self.vocab_size)}
+ start = self.vq_img_token_start_id
+ end = self.vq_img_token_start_id + self.codebook_size
+ for i in range(start, end):
+ # dummy str for each token, anything that fits pattern "<|visual token XXXXXX|>"
+ vocab_map[i] = f"<|visual token{i:06d}|>"
+
+ # add tokens that have to be in the vocab, we'll retrieve their ids later in modeling code
+ vocab_map[self.image_token_id] = ""
+ vocab_map[self.image_token_id + 1] = "<|extra_200|>"
+ vocab_map = {v: k for k, v in vocab_map.items()}
+
+ text_config = Emu3TextConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ num_key_value_heads=self.num_key_value_heads,
+ intermediate_size=self.intermediate_size,
+ max_position_embeddings=self.max_position_embeddings,
+ initializer_range=self.initializer_range,
+ pad_token_id=self.pad_token_id,
+ bos_token_id=self.bos_token_id,
+ eos_token_id=self.eos_token_id,
+ )
+
+ vq_config = {
+ "codebook_size": self.codebook_size,
+ "temporal_downsample_factor": self.temporal_downsample_factor,
+ "base_channels": self.base_channels,
+ "channel_multiplier": self.vq_channel_multiplier,
+ "hidden_size": self.base_channels,
+ }
+ return Emu3Config(text_config=text_config, vq_config=vq_config, vocabulary_map=vocab_map)
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ attention_mask,
+ pixel_values,
+ image_sizes,
+ ) = config_and_inputs
+ inputs_dict = {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "pixel_values": pixel_values,
+ "image_sizes": image_sizes,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class Emu3Vision2TextModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ Emu3Model,
+ Emu3ForConditionalGeneration,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = {}
+ test_headmasking = False
+ test_pruning = False
+ fx_compatible = False
+
+ def setUp(self):
+ self.model_tester = Emu3Vision2TextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=Emu3Config, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(
+ "Emu3 has a VQ module that uses `weight.data` directly in forward which prevent offloding on that module"
+ )
+ def test_disk_offload_safetensors(self):
+ pass
+
+ @unittest.skip(
+ "Emu3 has a VQ module that uses `weight.data` directly in forward which prevent offloding on that module"
+ )
+ def test_disk_offload_bin(self):
+ pass
+
+ @unittest.skip(
+ "Emu3 has a VQ module that uses `weight.data` directly in forward which prevent offloding on that module"
+ )
+ def test_cpu_offload(self):
+ pass
+
+ @unittest.skip("VQ-VAE module doesn't initialize weights properly")
+ def test_initialization(self):
+ pass
+
+ @pytest.mark.generate
+ @unittest.skip("Emu3 has dynamic control flow in vision backbone")
+ def test_generate_with_static_cache(self):
+ pass
+
+
+@require_torch
+class Emu3IntegrationTest(unittest.TestCase):
+ @slow
+ @require_bitsandbytes
+ def test_model_generation(self):
+ model = Emu3ForConditionalGeneration.from_pretrained("BAAI/Emu3-Chat-hf", load_in_4bit=True)
+ processor = Emu3Processor.from_pretrained("BAAI/Emu3-Chat-hf")
+
+ image = Image.open(requests.get("https://picsum.photos/id/237/200/200", stream=True).raw)
+ prompt = "USER: Describe what do you see here and tell me about the history behind it? ASSISTANT:"
+
+ inputs = processor(images=image, text=prompt, return_tensors="pt").to(model.device, torch.float16)
+
+ # greedy generation outputs
+ EXPECTED_TEXT_COMPLETION = ['USER: 64*64Describe what do you see here and tell me about the history behind it? ASSISTANT: The image captures a moment of tranquility with a black Labrador Retriever resting on a wooden floor. The dog, with its glossy black coat, is lying down with its front legs stretched out in'] # fmt: skip
+ generated_ids = model.generate(**inputs, max_new_tokens=40, do_sample=False)
+ text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ @slow
+ @require_bitsandbytes
+ @require_torch_large_accelerator
+ def test_model_generation_batched(self):
+ model = Emu3ForConditionalGeneration.from_pretrained("BAAI/Emu3-Chat-hf", load_in_4bit=True)
+ processor = Emu3Processor.from_pretrained("BAAI/Emu3-Chat-hf")
+ processor.tokenizer.padding_side = "left"
+
+ image = Image.open(requests.get("https://picsum.photos/id/237/50/50", stream=True).raw)
+ image_2 = Image.open(requests.get("https://picsum.photos/id/247/50/50", stream=True).raw)
+ prompts = [
+ "USER: Describe what do you see here? ASSISTANT:",
+ "USER: What can you say about the image? ASSISTANT:",
+ ]
+
+ inputs = processor(images=[image, image_2], text=prompts, padding=True, return_tensors="pt").to(
+ model.device, torch.float16
+ )
+
+ # greedy generation outputs
+ EXPECTED_TEXT_COMPLETIONS = Expectations(
+ {
+ ("xpu", 3): [
+ "USER: 64*64Describe what do you see here? ASSISTANT: The image depicts a black panther in a crouched position. The panther's body is elongated and its head is lowered, suggesting a state of alertness or readiness. The animal's",
+ "USER: 64*64What can you say about the image? ASSISTANT: The image depicts a serene natural landscape. The foreground consists of a grassy area with some patches of bare earth. The middle ground shows a gently sloping hill with a reddish-brown hue,",
+ ],
+ (None, None): [
+ "USER: 64*64Describe what do you see here? ASSISTANT: The image depicts a black panther in a crouched position. The panther's body is elongated and curved, with its head lowered and ears pointed forward, suggesting alertness or focus.",
+ "USER: 64*64What can you say about the image? ASSISTANT: The image depicts a serene natural landscape. The foreground consists of a grassy area with some patches of bare earth. The middle ground shows a steep, reddish-brown cliff, which could be a",
+ ],
+ # We switch to A10 on 2025/06/29, and A10 gives strange values
+ ("cuda", 8): [
+ 'USER: 64*64Describe what do you see here? ASSISTANT: 1.Filed with 1.Computing theComputing.Computing.',
+ 'USER: 64*64What can you say about the image? ASSISTANT: 1.Filed with theComputing theComputing.Computing.',
+ ],
+ }
+ ) # fmt: skip
+ EXPECTED_TEXT_COMPLETION = EXPECTED_TEXT_COMPLETIONS.get_expectation()
+
+ generated_ids = model.generate(**inputs, max_new_tokens=40, do_sample=False)
+ text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ @slow
+ @require_bitsandbytes
+ @require_torch_large_accelerator
+ def test_model_generation_multi_image(self):
+ model = Emu3ForConditionalGeneration.from_pretrained("BAAI/Emu3-Chat-hf", load_in_4bit=True)
+ processor = Emu3Processor.from_pretrained("BAAI/Emu3-Chat-hf")
+
+ image = Image.open(requests.get("https://picsum.photos/id/237/50/50", stream=True).raw)
+ image_2 = Image.open(requests.get("https://picsum.photos/id/247/50/50", stream=True).raw)
+ prompt = "USER: What do these two images have in common? ASSISTANT:"
+
+ inputs = processor(images=[image, image_2], text=prompt, return_tensors="pt").to(model.device, torch.float16)
+
+ # greedy generation outputs
+ EXPECTED_TEXT_COMPLETIONS = Expectations(
+ {
+ ("xpu", 3): ['USER: 64*6464*64What do these two images have in common? ASSISTANT: The two images both depict a rhinoceros, yet they are significantly different in terms of focus and clarity. The rhinoceros in the upper image is in sharp focus, showing detailed textures'],
+ (None, None): ["USER: 64*6464*64What do these two images have in common? ASSISTANT: Both images feature a black animal, but they are not the same animal. The top image shows a close-up of a black cow's head, while the bottom image depicts a black cow in a natural"],
+ # We switch to A10 on 2025/06/29, and A10 gives strange values
+ ("cuda", 8): ['USER: 64*6464*64What do these two images have in common? ASSISTANT:Computing.Filed.Filed.11.Computing theComputing.Computing.'],
+ }
+ ) # fmt: skip
+ EXPECTED_TEXT_COMPLETION = EXPECTED_TEXT_COMPLETIONS.get_expectation()
+ generated_ids = model.generate(**inputs, max_new_tokens=40, do_sample=False)
+ text = processor.batch_decode(generated_ids, skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ @slow
+ @require_bitsandbytes
+ @require_torch_large_accelerator
+ def test_model_generate_images(self):
+ model = Emu3ForConditionalGeneration.from_pretrained("BAAI/Emu3-Gen-hf", load_in_4bit=True)
+ processor = Emu3Processor.from_pretrained("BAAI/Emu3-Gen-hf")
+
+ inputs = processor(
+ text=["a portrait of young girl. masterpiece, film grained, best quality."],
+ padding=True,
+ return_tensors="pt",
+ return_for_image_generation=True,
+ image_area=1600,
+ ).to(model.device)
+ self.assertTrue(inputs.input_ids.shape[1] == 21)
+
+ image_sizes = inputs.pop("image_sizes")
+ HEIGHT, WIDTH = image_sizes[0]
+ VISUAL_TOKENS = model.vocabulary_mapping.image_tokens
+
+ def prefix_allowed_tokens_fn(batch_id, input_ids):
+ height, width = HEIGHT, WIDTH
+ visual_tokens = VISUAL_TOKENS
+ image_wrapper_token_id = torch.tensor([processor.tokenizer.image_wrapper_token_id], device=model.device)
+ eoi_token_id = torch.tensor([processor.tokenizer.eoi_token_id], device=model.device)
+ eos_token_id = torch.tensor([processor.tokenizer.eos_token_id], device=model.device)
+ pad_token_id = torch.tensor([processor.tokenizer.pad_token_id], device=model.device)
+ eof_token_id = torch.tensor([processor.tokenizer.eof_token_id], device=model.device)
+ eol_token_id = processor.tokenizer.encode("<|extra_200|>", return_tensors="pt")[0]
+
+ position = torch.nonzero(input_ids == image_wrapper_token_id, as_tuple=True)[0][0]
+ offset = input_ids.shape[0] - position
+ if offset % (width + 1) == 0:
+ return (eol_token_id,)
+ elif offset == (width + 1) * height + 1:
+ return (eof_token_id,)
+ elif offset == (width + 1) * height + 2:
+ return (eoi_token_id,)
+ elif offset == (width + 1) * height + 3:
+ return (eos_token_id,)
+ elif offset > (width + 1) * height + 3:
+ return (pad_token_id,)
+ else:
+ return visual_tokens
+
+ out = model.generate(
+ **inputs,
+ max_new_tokens=200,
+ prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
+ do_sample=False,
+ )
+ self.assertTrue(out.shape[1] == 54)
+
+ image = model.decode_image_tokens(image_tokens=out[:, inputs.input_ids.shape[1] :], height=HEIGHT, width=WIDTH)
+ images = processor.postprocess(list(image.float()), return_tensors="np")
+ self.assertTrue(images["pixel_values"].shape == (3, 40, 40))
+ self.assertTrue(isinstance(images["pixel_values"], np.ndarray))
+
+ filepath = hf_hub_download(
+ repo_id="raushan-testing-hf/images_test",
+ filename="emu3_image.npy",
+ repo_type="dataset",
+ )
+ original_pixels = np.load(filepath)
+ self.assertTrue(np.allclose(original_pixels, images["pixel_values"], atol=1))
diff --git a/transformers/tests/models/emu3/test_processor_emu3.py b/transformers/tests/models/emu3/test_processor_emu3.py
new file mode 100644
index 0000000000000000000000000000000000000000..c595a91ee99ff802ba9ba4940e6e6d6875717b16
--- /dev/null
+++ b/transformers/tests/models/emu3/test_processor_emu3.py
@@ -0,0 +1,92 @@
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch emu3 model."""
+
+import tempfile
+import unittest
+
+import numpy as np
+
+from transformers import Emu3Processor, GPT2TokenizerFast
+from transformers.utils import is_vision_available
+
+from ...test_processing_common import ProcessorTesterMixin
+
+
+if is_vision_available():
+ from transformers import Emu3ImageProcessor
+
+
+class Emu3ProcessorTest(ProcessorTesterMixin, unittest.TestCase):
+ processor_class = Emu3Processor
+
+ @classmethod
+ def setUpClass(cls):
+ cls.tmpdirname = tempfile.mkdtemp()
+ image_processor = Emu3ImageProcessor(min_pixels=28 * 28, max_pixels=56 * 56)
+ extra_special_tokens = extra_special_tokens = {
+ "image_token": "",
+ "boi_token": "<|image start|>",
+ "eoi_token": "<|image end|>",
+ "image_wrapper_token": "<|image token|>",
+ "eof_token": "<|extra_201|>",
+ }
+ tokenizer = GPT2TokenizerFast.from_pretrained(
+ "openai-community/gpt2", extra_special_tokens=extra_special_tokens
+ )
+ tokenizer.pad_token_id = 0
+ tokenizer.sep_token_id = 1
+ processor = cls.processor_class(
+ image_processor=image_processor, tokenizer=tokenizer, chat_template="dummy_template"
+ )
+ processor.save_pretrained(cls.tmpdirname)
+ cls.image_token = processor.image_token
+
+ @staticmethod
+ def prepare_processor_dict():
+ return {
+ "chat_template": "{% for message in messages %}{% if message['role'] != 'system' %}{{ message['role'].upper() + ': '}}{% endif %}{# Render all images first #}{% for content in message['content'] | selectattr('type', 'equalto', 'image') %}{{ '' }}{% endfor %}{# Render all text next #}{% if message['role'] != 'assistant' %}{% for content in message['content'] | selectattr('type', 'equalto', 'text') %}{{ content['text'] + ' '}}{% endfor %}{% else %}{% for content in message['content'] | selectattr('type', 'equalto', 'text') %}{% generation %}{{ content['text'] + ' '}}{% endgeneration %}{% endfor %}{% endif %}{% endfor %}{% if add_generation_prompt %}{{ 'ASSISTANT:' }}{% endif %}",
+ } # fmt: skip
+
+ def test_processor_for_generation(self):
+ processor_components = self.prepare_components()
+ processor = self.processor_class(**processor_components)
+
+ # we don't need an image as input because the model will generate one
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+ inputs = processor(text=input_str, return_for_image_generation=True, return_tensors="pt")
+ self.assertListEqual(list(inputs.keys()), ["input_ids", "attention_mask", "image_sizes"])
+ self.assertEqual(inputs[self.text_input_name].shape[-1], 8)
+
+ # when `return_for_image_generation` is set, we raise an error that image should not be provided
+ with self.assertRaises(ValueError):
+ inputs = processor(
+ text=input_str, images=image_input, return_for_image_generation=True, return_tensors="pt"
+ )
+
+ def test_processor_postprocess(self):
+ processor_components = self.prepare_components()
+ processor = self.processor_class(**processor_components)
+
+ input_str = "lower newer"
+ orig_image_input = self.prepare_image_inputs()
+ orig_image = np.array(orig_image_input).transpose(2, 0, 1)
+
+ inputs = processor(text=input_str, images=orig_image, do_resize=False, return_tensors="np")
+ normalized_image_input = inputs.pixel_values
+ unnormalized_images = processor.postprocess(normalized_image_input, return_tensors="np")["pixel_values"]
+
+ # For an image where pixels go from 0 to 255 the diff can be 1 due to some numerical precision errors when scaling and unscaling
+ self.assertTrue(np.abs(orig_image - unnormalized_images).max() >= 1)
diff --git a/transformers/tests/models/ernie/__init__.py b/transformers/tests/models/ernie/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/ernie/test_modeling_ernie.py b/transformers/tests/models/ernie/test_modeling_ernie.py
new file mode 100644
index 0000000000000000000000000000000000000000..7e99ba8e81db2c0acfb8d27d622745c24cbac79a
--- /dev/null
+++ b/transformers/tests/models/ernie/test_modeling_ernie.py
@@ -0,0 +1,591 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+import tempfile
+import unittest
+
+from transformers import ErnieConfig, is_torch_available
+from transformers.models.auto import get_values
+from transformers.testing_utils import require_torch, require_torch_accelerator, slow, torch_device
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ MODEL_FOR_PRETRAINING_MAPPING,
+ ErnieForCausalLM,
+ ErnieForMaskedLM,
+ ErnieForMultipleChoice,
+ ErnieForNextSentencePrediction,
+ ErnieForPreTraining,
+ ErnieForQuestionAnswering,
+ ErnieForSequenceClassification,
+ ErnieForTokenClassification,
+ ErnieModel,
+ )
+
+
+class ErnieModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ """
+ Returns a tiny configuration by default.
+ """
+ return ErnieConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ )
+
+ def prepare_config_and_inputs_for_decoder(self):
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = self.prepare_config_and_inputs()
+
+ config.is_decoder = True
+ encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size])
+ encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
+
+ return (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ )
+
+ def create_and_check_model(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = ErnieModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
+ result = model(input_ids, token_type_ids=token_type_ids)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def create_and_check_model_as_decoder(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ config.add_cross_attention = True
+ model = ErnieModel(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ encoder_hidden_states=encoder_hidden_states,
+ )
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def create_and_check_for_causal_lm(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ model = ErnieForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_for_masked_lm(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = ErnieForMaskedLM(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_model_for_causal_lm_as_decoder(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ config.add_cross_attention = True
+ model = ErnieForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ labels=token_labels,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ )
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ labels=token_labels,
+ encoder_hidden_states=encoder_hidden_states,
+ )
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_decoder_model_past_large_inputs(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ):
+ config.is_decoder = True
+ config.add_cross_attention = True
+ model = ErnieForCausalLM(config=config).to(torch_device).eval()
+
+ # first forward pass
+ outputs = model(
+ input_ids,
+ attention_mask=input_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ use_cache=True,
+ )
+ past_key_values = outputs.past_key_values
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
+
+ output_from_no_past = model(
+ next_input_ids,
+ attention_mask=next_attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+ output_from_past = model(
+ next_tokens,
+ attention_mask=next_attention_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ past_key_values=past_key_values,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_for_next_sequence_prediction(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = ErnieForNextSentencePrediction(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ labels=sequence_labels,
+ )
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, 2))
+
+ def create_and_check_for_pretraining(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = ErnieForPreTraining(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ labels=token_labels,
+ next_sentence_label=sequence_labels,
+ )
+ self.parent.assertEqual(result.prediction_logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+ self.parent.assertEqual(result.seq_relationship_logits.shape, (self.batch_size, 2))
+
+ def create_and_check_for_question_answering(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = ErnieForQuestionAnswering(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ start_positions=sequence_labels,
+ end_positions=sequence_labels,
+ )
+ self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
+ self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
+
+ def create_and_check_for_sequence_classification(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_labels = self.num_labels
+ model = ErnieForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=sequence_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def create_and_check_for_token_classification(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_labels = self.num_labels
+ model = ErnieForTokenClassification(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+
+ def create_and_check_for_multiple_choice(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_choices = self.num_choices
+ model = ErnieForMultipleChoice(config=config)
+ model.to(torch_device)
+ model.eval()
+ multiple_choice_inputs_ids = input_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ multiple_choice_token_type_ids = token_type_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ multiple_choice_input_mask = input_mask.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ result = model(
+ multiple_choice_inputs_ids,
+ attention_mask=multiple_choice_input_mask,
+ token_type_ids=multiple_choice_token_type_ids,
+ labels=choice_labels,
+ )
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class ErnieModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ ErnieModel,
+ ErnieForCausalLM,
+ ErnieForMaskedLM,
+ ErnieForMultipleChoice,
+ ErnieForNextSentencePrediction,
+ ErnieForPreTraining,
+ ErnieForQuestionAnswering,
+ ErnieForSequenceClassification,
+ ErnieForTokenClassification,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": ErnieModel,
+ "fill-mask": ErnieForMaskedLM,
+ "question-answering": ErnieForQuestionAnswering,
+ "text-classification": ErnieForSequenceClassification,
+ "text-generation": ErnieForCausalLM,
+ "token-classification": ErnieForTokenClassification,
+ "zero-shot": ErnieForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ fx_compatible = False
+
+ # special case for ForPreTraining model
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class in get_values(MODEL_FOR_PRETRAINING_MAPPING):
+ inputs_dict["labels"] = torch.zeros(
+ (self.model_tester.batch_size, self.model_tester.seq_length), dtype=torch.long, device=torch_device
+ )
+ inputs_dict["next_sentence_label"] = torch.zeros(
+ self.model_tester.batch_size, dtype=torch.long, device=torch_device
+ )
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = ErnieModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=ErnieConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_various_embeddings(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["absolute", "relative_key", "relative_key_query"]:
+ config_and_inputs[0].position_embedding_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_as_decoder(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
+ self.model_tester.create_and_check_model_as_decoder(*config_and_inputs)
+
+ def test_model_as_decoder_with_default_input_mask(self):
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ ) = self.model_tester.prepare_config_and_inputs_for_decoder()
+
+ input_mask = None
+
+ self.model_tester.create_and_check_model_as_decoder(
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ )
+
+ def test_for_causal_lm(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
+ self.model_tester.create_and_check_for_causal_lm(*config_and_inputs)
+
+ def test_for_masked_lm(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
+
+ def test_for_causal_lm_decoder(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
+ self.model_tester.create_and_check_model_for_causal_lm_as_decoder(*config_and_inputs)
+
+ def test_decoder_model_past_with_large_inputs(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
+ self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
+
+ def test_decoder_model_past_with_large_inputs_relative_pos_emb(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
+ config_and_inputs[0].position_embedding_type = "relative_key"
+ self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
+
+ def test_for_multiple_choice(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs)
+
+ def test_for_next_sequence_prediction(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_next_sequence_prediction(*config_and_inputs)
+
+ def test_for_pretraining(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_pretraining(*config_and_inputs)
+
+ def test_for_question_answering(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
+
+ def test_for_sequence_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
+
+ def test_for_token_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "nghuyong/ernie-1.0-base-zh"
+ model = ErnieModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ @slow
+ @require_torch_accelerator
+ def test_torchscript_device_change(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ for model_class in self.all_model_classes:
+ if model_class == ErnieForMultipleChoice:
+ self.skipTest(reason="ErnieForMultipleChoice behaves incorrectly in JIT environments.")
+
+ config.torchscript = True
+ model = model_class(config=config)
+
+ inputs_dict = self._prepare_for_class(inputs_dict, model_class)
+ traced_model = torch.jit.trace(
+ model, (inputs_dict["input_ids"].to("cpu"), inputs_dict["attention_mask"].to("cpu"))
+ )
+
+ with tempfile.TemporaryDirectory() as tmp:
+ torch.jit.save(traced_model, os.path.join(tmp, "ernie.pt"))
+ loaded = torch.jit.load(os.path.join(tmp, "ernie.pt"), map_location=torch_device)
+ loaded(inputs_dict["input_ids"].to(torch_device), inputs_dict["attention_mask"].to(torch_device))
diff --git a/transformers/tests/models/esm/__init__.py b/transformers/tests/models/esm/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/esm/test_modeling_esm.py b/transformers/tests/models/esm/test_modeling_esm.py
new file mode 100644
index 0000000000000000000000000000000000000000..18887bb5927cd887b5c73a17175a2317120fb9c9
--- /dev/null
+++ b/transformers/tests/models/esm/test_modeling_esm.py
@@ -0,0 +1,394 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch ESM model."""
+
+import tempfile
+import unittest
+
+import pytest
+
+from transformers import EsmConfig, is_torch_available
+from transformers.testing_utils import (
+ TestCasePlus,
+ is_flaky,
+ require_bitsandbytes,
+ require_flash_attn,
+ require_torch,
+ require_torch_gpu,
+ slow,
+ torch_device,
+)
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import EsmForMaskedLM, EsmForSequenceClassification, EsmForTokenClassification, EsmModel
+ from transformers.models.esm.modeling_esm import (
+ EsmEmbeddings,
+ create_position_ids_from_input_ids,
+ )
+
+
+# copied from tests.test_modeling_roberta
+class EsmModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=False,
+ use_input_mask=True,
+ use_token_type_ids=False,
+ use_labels=True,
+ vocab_size=33,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ scope=None,
+ position_embedding_type="rotary",
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.scope = scope
+ self.position_embedding_type = position_embedding_type
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ return EsmConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ pad_token_id=1,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ initializer_range=self.initializer_range,
+ position_embedding_type=self.position_embedding_type,
+ )
+
+ def create_and_check_model(self, config, input_ids, input_mask, sequence_labels, token_labels, choice_labels):
+ model = EsmModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ result = model(input_ids)
+
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def create_and_check_for_masked_lm(
+ self, config, input_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = EsmForMaskedLM(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_for_token_classification(
+ self, config, input_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_labels = self.num_labels
+ model = EsmForTokenClassification(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+
+ def create_and_check_forward_and_backwards(
+ self,
+ config,
+ input_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ gradient_checkpointing=False,
+ ):
+ model = EsmForMaskedLM(config)
+ if gradient_checkpointing:
+ model.gradient_checkpointing_enable()
+ model.to(torch_device)
+ result = model(input_ids, attention_mask=input_mask, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+ result.loss.backward()
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class EsmModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ test_mismatched_shapes = False
+
+ all_model_classes = (
+ (
+ EsmForMaskedLM,
+ EsmModel,
+ EsmForSequenceClassification,
+ EsmForTokenClassification,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": EsmModel,
+ "fill-mask": EsmForMaskedLM,
+ "text-classification": EsmForSequenceClassification,
+ "token-classification": EsmForTokenClassification,
+ "zero-shot": EsmForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_sequence_classification_problem_types = True
+ model_split_percents = [0.5, 0.8, 0.9]
+
+ def setUp(self):
+ self.model_tester = EsmModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=EsmConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_various_embeddings(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["absolute", "relative_key", "relative_key_query"]:
+ config_and_inputs[0].position_embedding_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_masked_lm(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
+
+ def test_for_token_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
+
+ def test_esm_gradient_checkpointing(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_forward_and_backwards(*config_and_inputs, gradient_checkpointing=True)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "facebook/esm2_t6_8M_UR50D"
+ model = EsmModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ def test_create_position_ids_respects_padding_index(self):
+ """This is a regression test for https://github.com/huggingface/transformers/issues/1761
+
+ The position ids should be masked with the embedding object's padding index. Therefore, the
+ first available non-padding position index is EsmEmbeddings.padding_idx + 1
+ """
+ config = self.model_tester.prepare_config_and_inputs()[0]
+ model = EsmEmbeddings(config=config)
+
+ input_ids = torch.as_tensor([[12, 31, 13, model.padding_idx]])
+ expected_positions = torch.as_tensor(
+ [
+ [
+ 0 + model.padding_idx + 1,
+ 1 + model.padding_idx + 1,
+ 2 + model.padding_idx + 1,
+ model.padding_idx,
+ ]
+ ]
+ )
+ position_ids = create_position_ids_from_input_ids(input_ids, model.padding_idx)
+ self.assertEqual(position_ids.shape, expected_positions.shape)
+ self.assertTrue(torch.all(torch.eq(position_ids, expected_positions)))
+
+ def test_create_position_ids_from_inputs_embeds(self):
+ """This is a regression test for https://github.com/huggingface/transformers/issues/1761
+
+ The position ids should be masked with the embedding object's padding index. Therefore, the
+ first available non-padding position index is EsmEmbeddings.padding_idx + 1
+ """
+ config = self.model_tester.prepare_config_and_inputs()[0]
+ embeddings = EsmEmbeddings(config=config)
+
+ inputs_embeds = torch.empty(2, 4, 30)
+ expected_single_positions = [
+ 0 + embeddings.padding_idx + 1,
+ 1 + embeddings.padding_idx + 1,
+ 2 + embeddings.padding_idx + 1,
+ 3 + embeddings.padding_idx + 1,
+ ]
+ expected_positions = torch.as_tensor([expected_single_positions, expected_single_positions])
+ position_ids = embeddings.create_position_ids_from_inputs_embeds(inputs_embeds)
+ self.assertEqual(position_ids.shape, expected_positions.shape)
+ self.assertTrue(torch.all(torch.eq(position_ids, expected_positions)))
+
+ @unittest.skip(reason="Esm does not support embedding resizing")
+ def test_resize_embeddings_untied(self):
+ pass
+
+ @unittest.skip(reason="Esm does not support embedding resizing")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @is_flaky()
+ @slow
+ def test_flash_attn_2_equivalence(self):
+ for model_class in self.all_model_classes:
+ if not model_class._supports_flash_attn_2:
+ self.skipTest(reason="Model does not support Flash Attention 2")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_fa = model_class.from_pretrained(
+ tmpdirname, torch_dtype=torch.float16, attn_implementation="flash_attention_2"
+ )
+ model_fa.to(torch_device)
+
+ model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, attn_implementation="eager")
+ model.to(torch_device)
+
+ dummy_input = inputs_dict[model_class.main_input_name]
+ dummy_input = dummy_input.to(torch_device)
+ outputs = model(dummy_input, output_hidden_states=True)
+ outputs_fa = model_fa(dummy_input, output_hidden_states=True)
+
+ logits = outputs.hidden_states[-1]
+ logits_fa = outputs_fa.hidden_states[-1]
+
+ torch.testing.assert_close(logits_fa, logits, atol=1e-2, rtol=1e-3)
+
+
+@slow
+@require_torch
+class EsmModelIntegrationTest(TestCasePlus):
+ def test_inference_masked_lm(self):
+ with torch.no_grad():
+ model = EsmForMaskedLM.from_pretrained("facebook/esm2_t6_8M_UR50D")
+ model.eval()
+ input_ids = torch.tensor([[0, 1, 2, 3, 4, 5]])
+ output = model(input_ids)[0]
+
+ vocab_size = 33
+
+ expected_shape = torch.Size((1, 6, vocab_size))
+ self.assertEqual(output.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[[8.9215, -10.5898, -6.4671], [-6.3967, -13.9114, -1.1212], [-7.7812, -13.9516, -3.7406]]]
+ )
+ torch.testing.assert_close(output[:, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ def test_inference_no_head(self):
+ with torch.no_grad():
+ model = EsmModel.from_pretrained("facebook/esm2_t6_8M_UR50D")
+ model.eval()
+
+ input_ids = torch.tensor([[0, 6, 4, 13, 5, 4, 16, 12, 11, 7, 2]])
+ output = model(input_ids)[0]
+ # compare the actual values for a slice.
+ expected_slice = torch.tensor(
+ [[[0.1444, 0.5413, 0.3248], [0.3034, 0.0053, 0.3108], [0.3228, -0.2499, 0.3415]]]
+ )
+ torch.testing.assert_close(output[:, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ @require_bitsandbytes
+ def test_inference_bitsandbytes(self):
+ model = EsmForMaskedLM.from_pretrained("facebook/esm2_t36_3B_UR50D", load_in_8bit=True)
+
+ input_ids = torch.tensor([[0, 6, 4, 13, 5, 4, 16, 12, 11, 7, 2]]).to(model.device)
+ # Just test if inference works
+ with torch.no_grad():
+ _ = model(input_ids)[0]
+
+ model = EsmForMaskedLM.from_pretrained("facebook/esm2_t36_3B_UR50D", load_in_4bit=True)
+
+ input_ids = torch.tensor([[0, 6, 4, 13, 5, 4, 16, 12, 11, 7, 2]]).to(model.device)
+ # Just test if inference works
+ _ = model(input_ids)[0]
diff --git a/transformers/tests/models/esm/test_modeling_esmfold.py b/transformers/tests/models/esm/test_modeling_esmfold.py
new file mode 100644
index 0000000000000000000000000000000000000000..b13e7fe58b1d4d96f230ab6684bfb39de9e93a7d
--- /dev/null
+++ b/transformers/tests/models/esm/test_modeling_esmfold.py
@@ -0,0 +1,279 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch ESM model."""
+
+import unittest
+
+from transformers import EsmConfig, is_torch_available
+from transformers.testing_utils import TestCasePlus, is_flaky, require_torch, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers.models.esm.modeling_esmfold import EsmForProteinFolding
+
+
+class EsmFoldModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=False,
+ use_input_mask=True,
+ use_token_type_ids=False,
+ use_labels=False,
+ vocab_size=19,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ esmfold_config = {
+ "trunk": {
+ "num_blocks": 2,
+ "sequence_state_dim": 64,
+ "pairwise_state_dim": 16,
+ "sequence_head_width": 4,
+ "pairwise_head_width": 4,
+ "position_bins": 4,
+ "chunk_size": 16,
+ "structure_module": {
+ "ipa_dim": 16,
+ "num_angles": 7,
+ "num_blocks": 2,
+ "num_heads_ipa": 4,
+ "pairwise_dim": 16,
+ "resnet_dim": 16,
+ "sequence_dim": 48,
+ },
+ },
+ "fp16_esm": False,
+ "lddt_head_hid_dim": 16,
+ }
+ config = EsmConfig(
+ vocab_size=33,
+ hidden_size=self.hidden_size,
+ pad_token_id=1,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ initializer_range=self.initializer_range,
+ is_folding_model=True,
+ esmfold_config=esmfold_config,
+ )
+ return config
+
+ def create_and_check_model(self, config, input_ids, input_mask, sequence_labels, token_labels, choice_labels):
+ model = EsmForProteinFolding(config=config).float()
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ result = model(input_ids)
+
+ self.parent.assertEqual(result.positions.shape, (2, self.batch_size, self.seq_length, 14, 3))
+ self.parent.assertEqual(result.angles.shape, (2, self.batch_size, self.seq_length, 7, 2))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class EsmFoldModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ test_mismatched_shapes = False
+
+ all_model_classes = (EsmForProteinFolding,) if is_torch_available() else ()
+ pipeline_model_mapping = {} if is_torch_available() else {}
+ test_sequence_classification_problem_types = False
+
+ def setUp(self):
+ self.model_tester = EsmFoldModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=EsmConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @is_flaky(
+ description="The computed `s = s / norm_denom` in `EsmFoldAngleResnet` is numerically instable if `norm_denom` is very small."
+ )
+ def test_batching_equivalence(self):
+ super().test_batching_equivalence()
+
+ @unittest.skip(reason="Does not support attention outputs")
+ def test_attention_outputs(self):
+ pass
+
+ @unittest.skip
+ def test_correct_missing_keys(self):
+ pass
+
+ @unittest.skip(reason="Esm does not support embedding resizing")
+ def test_resize_embeddings_untied(self):
+ pass
+
+ @unittest.skip(reason="Esm does not support embedding resizing")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ @unittest.skip(reason="ESMFold does not support passing input embeds!")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="ESMFold does not support head pruning.")
+ def test_head_pruning(self):
+ pass
+
+ @unittest.skip(reason="ESMFold does not support head pruning.")
+ def test_head_pruning_integration(self):
+ pass
+
+ @unittest.skip(reason="ESMFold does not support head pruning.")
+ def test_head_pruning_save_load_from_config_init(self):
+ pass
+
+ @unittest.skip(reason="ESMFold does not support head pruning.")
+ def test_head_pruning_save_load_from_pretrained(self):
+ pass
+
+ @unittest.skip(reason="ESMFold does not support head pruning.")
+ def test_headmasking(self):
+ pass
+
+ @unittest.skip(reason="ESMFold does not output hidden states in the normal way.")
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip(reason="ESMfold does not output hidden states in the normal way.")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ @unittest.skip(reason="ESMFold only has one output format.")
+ def test_model_outputs_equivalence(self):
+ pass
+
+ @unittest.skip(reason="ESMFold does not support input chunking.")
+ def test_feed_forward_chunking(self):
+ pass
+
+ @unittest.skip(
+ reason="ESMFold doesn't respect you and it certainly doesn't respect your initialization arguments."
+ )
+ def test_initialization(self):
+ pass
+
+ @unittest.skip(reason="ESMFold doesn't support torchscript compilation.")
+ def test_torchscript_output_attentions(self):
+ pass
+
+ @unittest.skip(reason="ESMFold doesn't support torchscript compilation.")
+ def test_torchscript_output_hidden_state(self):
+ pass
+
+ @unittest.skip(reason="ESMFold doesn't support torchscript compilation.")
+ def test_torchscript_simple(self):
+ pass
+
+ @unittest.skip(reason="ESMFold doesn't support data parallel.")
+ def test_multi_gpu_data_parallel_forward(self):
+ pass
+
+
+@require_torch
+class EsmModelIntegrationTest(TestCasePlus):
+ @slow
+ def test_inference_protein_folding(self):
+ model = EsmForProteinFolding.from_pretrained("facebook/esmfold_v1").float()
+ model.eval()
+ input_ids = torch.tensor([[0, 6, 4, 13, 5, 4, 16, 12, 11, 7, 2]])
+ position_outputs = model(input_ids)["positions"]
+ expected_slice = torch.tensor([2.5828, 0.7993, -10.9334], dtype=torch.float32)
+ torch.testing.assert_close(position_outputs[0, 0, 0, 0], expected_slice, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/esm/test_tokenization_esm.py b/transformers/tests/models/esm/test_tokenization_esm.py
new file mode 100644
index 0000000000000000000000000000000000000000..57c66d53a8c41fe742e2d186ac909fe4bf20fa3d
--- /dev/null
+++ b/transformers/tests/models/esm/test_tokenization_esm.py
@@ -0,0 +1,118 @@
+# Copyright 2021 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import os
+import tempfile
+import unittest
+from functools import lru_cache
+
+from transformers.models.esm.tokenization_esm import VOCAB_FILES_NAMES, EsmTokenizer
+from transformers.testing_utils import require_tokenizers
+from transformers.tokenization_utils import PreTrainedTokenizer
+from transformers.tokenization_utils_base import PreTrainedTokenizerBase
+
+from ...test_tokenization_common import use_cache_if_possible
+
+
+@require_tokenizers
+class ESMTokenizationTest(unittest.TestCase):
+ tokenizer_class = EsmTokenizer
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ cls.tmpdirname = tempfile.mkdtemp()
+ vocab_tokens: list[str] = ["", "", "", "", "L", "A", "G", "V", "S", "E", "R", "T", "I", "D", "P", "K", "Q", "N", "F", "Y", "M", "H", "W", "C", "X", "B", "U", "Z", "O", ".", "-", "", ""] # fmt: skip
+ cls.vocab_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ with open(cls.vocab_file, "w", encoding="utf-8") as vocab_writer:
+ vocab_writer.write("".join([x + "\n" for x in vocab_tokens]))
+
+ def get_tokenizers(cls, **kwargs) -> list[PreTrainedTokenizerBase]:
+ return [cls.get_tokenizer(**kwargs)]
+
+ @classmethod
+ @use_cache_if_possible
+ @lru_cache(maxsize=64)
+ def get_tokenizer(cls, pretrained_name=None, **kwargs) -> PreTrainedTokenizer:
+ pretrained_name = pretrained_name or cls.tmpdirname
+ return cls.tokenizer_class.from_pretrained(pretrained_name, **kwargs)
+
+ def test_tokenizer_single_example(self):
+ tokenizer = self.tokenizer_class(self.vocab_file)
+
+ tokens = tokenizer.tokenize("LAGVS")
+ self.assertListEqual(tokens, ["L", "A", "G", "V", "S"])
+ self.assertListEqual(tokenizer.convert_tokens_to_ids(tokens), [4, 5, 6, 7, 8])
+
+ def test_tokenizer_encode_single(self):
+ tokenizer = self.tokenizer_class(self.vocab_file)
+
+ seq = "LAGVS"
+ self.assertListEqual(tokenizer.encode(seq), [0, 4, 5, 6, 7, 8, 2])
+
+ def test_tokenizer_call_no_pad(self):
+ tokenizer = self.tokenizer_class(self.vocab_file)
+
+ seq_batch = ["LAGVS", "WCB"]
+ tokens_batch = tokenizer(seq_batch, padding=False)["input_ids"]
+
+ self.assertListEqual(tokens_batch, [[0, 4, 5, 6, 7, 8, 2], [0, 22, 23, 25, 2]])
+
+ def test_tokenizer_call_pad(self):
+ tokenizer = self.tokenizer_class(self.vocab_file)
+
+ seq_batch = ["LAGVS", "WCB"]
+ tokens_batch = tokenizer(seq_batch, padding=True)["input_ids"]
+
+ self.assertListEqual(tokens_batch, [[0, 4, 5, 6, 7, 8, 2], [0, 22, 23, 25, 2, 1, 1]])
+
+ def test_tokenize_special_tokens(self):
+ """Test `tokenize` with special tokens."""
+ tokenizers = self.get_tokenizers(fast=True)
+ for tokenizer in tokenizers:
+ with self.subTest(f"{tokenizer.__class__.__name__}"):
+ SPECIAL_TOKEN_1 = ""
+ SPECIAL_TOKEN_2 = ""
+
+ token_1 = tokenizer.tokenize(SPECIAL_TOKEN_1)
+ token_2 = tokenizer.tokenize(SPECIAL_TOKEN_2)
+
+ self.assertEqual(len(token_1), 1)
+ self.assertEqual(len(token_2), 1)
+ self.assertEqual(token_1[0], SPECIAL_TOKEN_1)
+ self.assertEqual(token_2[0], SPECIAL_TOKEN_2)
+
+ def test_add_tokens(self):
+ tokenizer = self.tokenizer_class(self.vocab_file)
+
+ vocab_size = len(tokenizer)
+ self.assertEqual(tokenizer.add_tokens(""), 0)
+ self.assertEqual(tokenizer.add_tokens("testoken"), 1)
+ self.assertEqual(tokenizer.add_tokens(["testoken1", "testtoken2"]), 2)
+ self.assertEqual(len(tokenizer), vocab_size + 3)
+
+ self.assertEqual(tokenizer.add_special_tokens({}), 0)
+ self.assertEqual(tokenizer.add_special_tokens({"bos_token": "[BOS]", "eos_token": "[EOS]"}), 2)
+ self.assertRaises(AssertionError, tokenizer.add_special_tokens, {"additional_special_tokens": ""})
+ self.assertEqual(tokenizer.add_special_tokens({"additional_special_tokens": [""]}), 1)
+ self.assertEqual(
+ tokenizer.add_special_tokens({"additional_special_tokens": ["", ""]}), 2
+ )
+ self.assertIn("", tokenizer.special_tokens_map["additional_special_tokens"])
+ self.assertIsInstance(tokenizer.special_tokens_map["additional_special_tokens"], list)
+ self.assertGreaterEqual(len(tokenizer.special_tokens_map["additional_special_tokens"]), 2)
+
+ self.assertEqual(len(tokenizer), vocab_size + 8)
diff --git a/transformers/tests/models/falcon/__init__.py b/transformers/tests/models/falcon/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/falcon/test_modeling_falcon.py b/transformers/tests/models/falcon/test_modeling_falcon.py
new file mode 100644
index 0000000000000000000000000000000000000000..661ba98cf16913ce36e0bed59e5c57e57e932bf7
--- /dev/null
+++ b/transformers/tests/models/falcon/test_modeling_falcon.py
@@ -0,0 +1,227 @@
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Falcon model."""
+
+import unittest
+
+from transformers import (
+ AutoModelForCausalLM,
+ AutoTokenizer,
+ FalconConfig,
+ is_torch_available,
+)
+from transformers.testing_utils import (
+ require_bitsandbytes,
+ require_torch,
+ require_torch_sdpa,
+ slow,
+ torch_device,
+)
+
+from ...causal_lm_tester import CausalLMModelTest, CausalLMModelTester
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ FalconForCausalLM,
+ FalconForQuestionAnswering,
+ FalconForSequenceClassification,
+ FalconForTokenClassification,
+ FalconModel,
+ )
+
+
+class FalconModelTester(CausalLMModelTester):
+ if is_torch_available():
+ config_class = FalconConfig
+ base_model_class = FalconModel
+ causal_lm_class = FalconForCausalLM
+ sequence_class = FalconForSequenceClassification
+ token_class = FalconForTokenClassification
+
+ def __init__(self, parent, new_decoder_architecture=True):
+ super().__init__(parent)
+ self.new_decoder_architecture = new_decoder_architecture
+
+
+@require_torch
+class FalconModelTest(CausalLMModelTest, unittest.TestCase):
+ model_tester_class = FalconModelTester
+ all_model_classes = (
+ (
+ FalconModel,
+ FalconForCausalLM,
+ FalconForSequenceClassification,
+ FalconForTokenClassification,
+ FalconForQuestionAnswering,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": FalconModel,
+ "text-classification": FalconForSequenceClassification,
+ "token-classification": FalconForTokenClassification,
+ "text-generation": FalconForCausalLM,
+ "zero-shot": FalconForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_headmasking = False
+ test_pruning = False
+
+ # TODO (ydshieh): Check this. See https://app.circleci.com/pipelines/github/huggingface/transformers/79245/workflows/9490ef58-79c2-410d-8f51-e3495156cf9c/jobs/1012146
+ def is_pipeline_test_to_skip(
+ self,
+ pipeline_test_case_name,
+ config_class,
+ model_architecture,
+ tokenizer_name,
+ image_processor_name,
+ feature_extractor_name,
+ processor_name,
+ ):
+ return True
+
+
+@require_torch
+class FalconLanguageGenerationTest(unittest.TestCase):
+ @slow
+ def test_lm_generate_falcon(self):
+ tokenizer = AutoTokenizer.from_pretrained("Rocketknight1/falcon-rw-1b")
+ model = FalconForCausalLM.from_pretrained("Rocketknight1/falcon-rw-1b")
+ model.eval()
+ model.to(torch_device)
+ inputs = tokenizer("My favorite food is", return_tensors="pt").to(torch_device)
+
+ EXPECTED_OUTPUT = (
+ "My favorite food is pizza. I love it so much that I have a pizza party every year for my birthday."
+ )
+
+ output_ids = model.generate(**inputs, do_sample=False, max_new_tokens=19)
+ output_str = tokenizer.batch_decode(output_ids)[0]
+
+ self.assertEqual(output_str, EXPECTED_OUTPUT)
+
+ @slow
+ @require_bitsandbytes
+ def test_lm_generate_falcon_11b(self):
+ tokenizer = AutoTokenizer.from_pretrained("tiiuae/falcon-11B", padding_side="left")
+ model = FalconForCausalLM.from_pretrained(
+ "tiiuae/falcon-11B", device_map={"": torch_device}, load_in_8bit=True
+ )
+ model.eval()
+ inputs = tokenizer(
+ "Two roads diverged in a yellow wood,", return_tensors="pt", return_token_type_ids=False
+ ).to(torch_device)
+
+ EXPECTED_OUTPUT = "Two roads diverged in a yellow wood,\nAnd sorry I could not travel both\n"
+
+ output_ids = model.generate(**inputs, do_sample=False, max_new_tokens=9)
+ output_str = tokenizer.batch_decode(output_ids)[0]
+
+ self.assertEqual(output_str, EXPECTED_OUTPUT)
+
+ @slow
+ def test_lm_generation_big_models(self):
+ # The big models are way too big for the CI, so we use tiny random models that resemble their
+ # architectures but with much smaller and fewer layers
+ for repo in ["Rocketknight1/tiny-random-falcon-7b", "Rocketknight1/tiny-random-falcon-40b"]:
+ tokenizer = AutoTokenizer.from_pretrained(repo)
+ model = FalconForCausalLM.from_pretrained(repo)
+ model.eval()
+ model.to(torch_device)
+ inputs = tokenizer("My favorite food is", return_tensors="pt").to(torch_device)
+
+ # We just test that these run without errors - the models are randomly initialized
+ # and so the actual text outputs will be garbage
+ model.generate(**inputs, do_sample=False, max_new_tokens=4)
+ model.generate(**inputs, do_sample=True, max_new_tokens=4)
+ model.generate(**inputs, num_beams=2, max_new_tokens=4)
+
+ @slow
+ def test_lm_generation_use_cache(self):
+ # The big models are way too big for the CI, so we use tiny random models that resemble their
+ # architectures but with much smaller and fewer layers
+ with torch.no_grad():
+ for repo in [
+ "Rocketknight1/falcon-rw-1b",
+ "Rocketknight1/tiny-random-falcon-7b",
+ "Rocketknight1/tiny-random-falcon-40b",
+ ]:
+ tokenizer = AutoTokenizer.from_pretrained(repo)
+ model = FalconForCausalLM.from_pretrained(repo)
+ model.eval()
+ model.to(device=torch_device)
+ inputs = tokenizer("My favorite food is", return_tensors="pt").to(torch_device)
+
+ # Test results are the same with and without cache
+ outputs_no_cache = model.generate(**inputs, do_sample=False, max_new_tokens=20, use_cache=False)
+ outputs_cache = model.generate(**inputs, do_sample=False, max_new_tokens=20, use_cache=True)
+ self.assertTrue((outputs_cache - outputs_no_cache).sum().item() == 0)
+
+ @require_bitsandbytes
+ @slow
+ def test_batched_generation(self):
+ tokenizer = AutoTokenizer.from_pretrained("tiiuae/falcon-7b", padding_side="left")
+ tokenizer.pad_token = tokenizer.eos_token
+ model = AutoModelForCausalLM.from_pretrained(
+ "tiiuae/falcon-7b",
+ device_map={"": torch_device},
+ load_in_4bit=True,
+ )
+
+ test_text = "A sequence: 1, 2" # should generate the rest of the sequence
+
+ unpadded_inputs = tokenizer([test_text], return_tensors="pt").to(f"{torch_device}:0")
+ unpadded_gen_out = model.generate(**unpadded_inputs, max_new_tokens=20)
+ unpadded_gen_text = tokenizer.batch_decode(unpadded_gen_out, skip_special_tokens=True)
+
+ dummy_text = "This is a longer text " * 2 # forces left-padding on `test_text`
+ padded_inputs = tokenizer([test_text, dummy_text], return_tensors="pt", padding=True).to(f"{torch_device}:0")
+ padded_gen_out = model.generate(**padded_inputs, max_new_tokens=20)
+ padded_gen_text = tokenizer.batch_decode(padded_gen_out, skip_special_tokens=True)
+
+ expected_output = "A sequence: 1, 2, 3, 4, 5, 6, 7, 8, "
+ self.assertLess(unpadded_inputs.input_ids.shape[-1], padded_inputs.input_ids.shape[-1]) # left-padding exists
+ self.assertEqual(unpadded_gen_text[0], expected_output)
+ self.assertEqual(padded_gen_text[0], expected_output)
+
+ @slow
+ @require_torch_sdpa
+ def test_falcon_alibi_sdpa_matches_eager(self):
+ input_ids = torch.randint(0, 1000, (5, 20))
+
+ config = FalconConfig(
+ vocab_size=1000,
+ hidden_size=64,
+ num_hidden_layers=3,
+ num_attention_heads=4,
+ new_decoder_architecture=True,
+ alibi=True,
+ )
+
+ falcon = FalconForCausalLM(config)
+ falcon = falcon.eval()
+
+ with torch.no_grad():
+ # output_attentions=True dispatches to eager path
+ falcon_output_eager = falcon(input_ids, output_attentions=True)[0]
+ falcon_output_sdpa = falcon(input_ids)[0]
+
+ torch.testing.assert_close(falcon_output_eager, falcon_output_sdpa, rtol=1e-3, atol=1e-3)
diff --git a/transformers/tests/models/falcon_h1/__init__.py b/transformers/tests/models/falcon_h1/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/falcon_h1/test_modeling_falcon_h1.py b/transformers/tests/models/falcon_h1/test_modeling_falcon_h1.py
new file mode 100644
index 0000000000000000000000000000000000000000..31c9b72e28b529d91f17b43f77efca5de989afb1
--- /dev/null
+++ b/transformers/tests/models/falcon_h1/test_modeling_falcon_h1.py
@@ -0,0 +1,558 @@
+# coding=utf-8
+# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch FalconH1 model."""
+
+import inspect
+import unittest
+
+import pytest
+
+from transformers import FalconH1Config, is_torch_available
+from transformers.testing_utils import (
+ Expectations,
+ get_device_properties,
+ require_torch,
+ require_torch_gpu,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import AutoTokenizer, FalconH1ForCausalLM, FalconH1Model
+ from transformers.models.falcon_h1.modeling_falcon_h1 import (
+ FalconHybridMambaAttentionDynamicCache,
+ )
+
+
+class FalconH1ModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=4,
+ num_attention_heads=4,
+ num_key_value_heads=2,
+ intermediate_size=64,
+ hidden_act="silu",
+ attention_dropout=0.0,
+ attn_layer_indices=None,
+ attn_rotary_emb=8,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ initializer_range=0.02,
+ num_labels=3,
+ pad_token_id=0,
+ mamba_n_groups=1,
+ mamba_n_heads=16,
+ mamba_d_state=16,
+ mamba_d_conv=4,
+ mamba_expand=2,
+ mamba_chunk_size=16,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.num_key_value_heads = num_key_value_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.attention_dropout = attention_dropout
+ self.attn_layer_indices = attn_layer_indices
+ self.attn_rotary_emb = attn_rotary_emb
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.pad_token_id = pad_token_id
+ self.scope = scope
+ self.mamba_n_groups = mamba_n_groups
+ self.mamba_n_heads = mamba_n_heads
+ self.mamba_d_state = mamba_d_state
+ self.mamba_d_conv = mamba_d_conv
+ self.mamba_expand = mamba_expand
+ self.mamba_chunk_size = mamba_chunk_size
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = torch.tril(torch.ones_like(input_ids).to(torch_device))
+
+ token_labels = None
+ if self.use_labels:
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask, token_labels
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ input_mask,
+ token_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+ def get_config(self):
+ # Fix for SDPA tests, force at least 4 layers
+ if self.num_hidden_layers < 4:
+ self.num_hidden_layers = 4
+ if self.attn_layer_indices is None:
+ d = [x for x in range(2, self.num_hidden_layers) if self.num_hidden_layers % x == 0]
+ if len(d) == 0:
+ raise ValueError("num_hidden_layers is prime, cannot automatically set attn_layer_indices.")
+ d = d[-1] # get the largest divisor
+ self.attn_layer_indices = [x + 1 for x in range(0, self.num_hidden_layers, d)]
+
+ return FalconH1Config(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ num_key_value_heads=self.num_key_value_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ attention_dropout=self.attention_dropout,
+ attn_layer_indices=self.attn_layer_indices,
+ attn_rotary_emb=self.attn_rotary_emb,
+ max_position_embeddings=self.max_position_embeddings,
+ initializer_range=self.initializer_range,
+ pad_token_id=self.pad_token_id,
+ mamba_n_groups=self.mamba_n_groups,
+ mamba_n_heads=self.mamba_n_heads,
+ mamba_d_state=self.mamba_d_state,
+ mamba_d_conv=self.mamba_d_conv,
+ mamba_expand=self.mamba_expand,
+ mamba_chunk_size=self.mamba_chunk_size,
+ )
+
+ def create_and_check_model(
+ self,
+ config,
+ input_ids,
+ input_mask,
+ token_labels,
+ ):
+ model = FalconH1Model(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_for_causal_lm(
+ self,
+ config,
+ input_ids,
+ input_mask,
+ token_labels,
+ ):
+ model = FalconH1ForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, labels=token_labels)
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids, labels=token_labels)
+ result = model(input_ids)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_decoder_model_past_large_inputs(
+ self,
+ config,
+ input_ids,
+ input_mask,
+ token_labels,
+ ):
+ # config.is_decoder = True
+ # config.add_cross_attention = True
+ model = FalconH1ForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # first forward pass
+ # Attention: Jamba needs the cache to be initialized to return a cache!
+ past_key_values = FalconHybridMambaAttentionDynamicCache(
+ config,
+ input_ids.shape[0],
+ model.dtype,
+ devices=[model.device for _ in range(model.config.num_hidden_layers)],
+ )
+ outputs = model(
+ input_ids,
+ attention_mask=input_mask,
+ past_key_values=past_key_values,
+ use_cache=True,
+ )
+ past_key_values = outputs.past_key_values
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
+
+ output_from_no_past = model(
+ next_input_ids,
+ attention_mask=next_attention_mask,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+ output_from_past = model(
+ next_tokens,
+ attention_mask=next_attention_mask,
+ past_key_values=past_key_values,
+ output_hidden_states=True,
+ cache_position=torch.arange(
+ input_ids.shape[1], input_ids.shape[1] + next_tokens.shape[1], device=model.device
+ ),
+ )["hidden_states"][0]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+
+@require_torch
+class FalconH1ModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (FalconH1Model, FalconH1ForCausalLM) if is_torch_available() else ()
+ test_headmasking = False
+ test_pruning = False
+ fx_compatible = False
+
+ # Need to use `0.8` instead of `0.9` for `test_cpu_offload`
+ # This is because we are hitting edge cases with the causal_mask buffer
+ model_split_percents = [0.5, 0.7, 0.8]
+
+ pipeline_model_mapping = (
+ {"feature-extraction": FalconH1Model, "text-generation": FalconH1ForCausalLM} if is_torch_available() else {}
+ )
+
+ def setUp(self):
+ self.model_tester = FalconH1ModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=FalconH1Config, hidden_size=64)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_casual_lm(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_causal_lm(*config_and_inputs)
+
+ def test_decoder_model_past_with_large_inputs(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
+
+ # def test_initialization(self):
+ # r"""
+ # Overriding the test_initialization test as the A_log and D params of the FalconH1 mixer are initialized differently
+ # """
+ # config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # configs_no_init = _config_zero_init(config)
+ # for model_class in self.all_model_classes:
+ # model = model_class(config=configs_no_init)
+ # for name, param in model.named_parameters():
+ # if param.requires_grad:
+ # if "A_log" in name:
+ # A = torch.arange(1, config.mamba_n_heads + 1, dtype=torch.float32)
+ # torch.testing.assert_close(param.data, torch.log(A), rtol=1e-5, atol=1e-5)
+ # elif "D" in name:
+ # D = torch.ones(config.mamba_n_heads, dtype=torch.float32)
+ # torch.testing.assert_close(param.data, D, rtol=1e-5, atol=1e-5)
+ # else:
+ # self.assertIn(
+ # ((param.data.mean() * 1e9).round() / 1e9).item(),
+ # [0.0, 1.0],
+ # msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ # )
+
+ def test_mismatched_shapes_have_properly_initialized_weights(self):
+ r"""
+ Overriding the test_mismatched_shapes_have_properly_initialized_weights test because A_log and D params of the
+ FalconH1 mixer are initialized differently and we tested that in test_initialization
+ """
+ self.skipTest(reason="Cumbersome and redundant for FalconH1")
+
+ def test_attention_outputs(self):
+ r"""
+ Overriding the test_attention_outputs test as the FalconH1 model outputs attention only for its attention layers
+ """
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ seq_len = getattr(self.model_tester, "seq_length", None)
+ encoder_seq_length = getattr(self.model_tester, "encoder_seq_length", seq_len)
+ encoder_key_length = getattr(self.model_tester, "key_length", encoder_seq_length)
+
+ expected_num_attentions = self.model_tester.num_hidden_layers
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class._from_config(config, attn_implementation="eager")
+ config = model.config
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ self.assertEqual(len(attentions), expected_num_attentions)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ self.assertEqual(len(attentions), expected_num_attentions)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length],
+ )
+ out_len = len(outputs)
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ added_hidden_states = 1
+ self.assertEqual(out_len + added_hidden_states, len(outputs))
+
+ self_attentions = outputs.attentions
+
+ self.assertEqual(len(self_attentions), expected_num_attentions)
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length],
+ )
+
+ def test_batching_equivalence(self):
+ # need to disable the tril input mask
+ orig = self.model_tester.use_input_mask
+ self.model_tester.use_input_mask = False
+ super().test_batching_equivalence()
+ self.model_tester.use_input_mask = orig
+
+ # essentially the same test in test_utils, just adjustment for rtol for this model
+ @pytest.mark.generate
+ def test_left_padding_compatibility(self):
+ # NOTE: left-padding results in small numerical differences. This is expected.
+ # See https://github.com/huggingface/transformers/issues/25420#issuecomment-1775317535
+
+ # First, filter out models that don't support left padding
+ # - The model must have generative capabilities
+ if len(self.all_generative_model_classes) == 0:
+ self.skipTest(reason="No generative architecture available for this model.")
+
+ # - The model must support padding
+ if not self.has_attentions:
+ self.skipTest(reason="This model doesn't support padding.")
+
+ # - The model must be a decoder-only architecture (encoder-based architectures use right-padding)
+ decoder_only_classes = []
+ for model_class in self.all_generative_model_classes:
+ config, _ = self.prepare_config_and_inputs_for_generate()
+ if config.is_encoder_decoder:
+ continue
+ else:
+ decoder_only_classes.append(model_class)
+ if len(decoder_only_classes) == 0:
+ self.skipTest(reason="No decoder-only architecture available for this model.")
+
+ # - Decoder-only architectures derived from encoder-decoder models could support it in theory, but we haven't
+ # added support for it yet. We skip these models for now.
+ has_encoder_attributes = any(
+ attr_name
+ for attr_name in config.to_dict().keys()
+ if attr_name.startswith("encoder") and attr_name != "encoder_no_repeat_ngram_size"
+ )
+ if has_encoder_attributes:
+ self.skipTest(
+ reason="The decoder-only derived from encoder-decoder models are not expected to support left-padding."
+ )
+
+ # Then, test left-padding
+ def _prepare_model_kwargs(input_ids, attention_mask, signature):
+ model_kwargs = {"input_ids": input_ids, "attention_mask": attention_mask}
+ if "position_ids" in signature:
+ position_ids = torch.cumsum(attention_mask, dim=-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ model_kwargs["position_ids"] = position_ids
+ if "cache_position" in signature:
+ cache_position = torch.arange(input_ids.shape[-1], device=torch_device)
+ model_kwargs["cache_position"] = cache_position
+ return model_kwargs
+
+ for model_class in decoder_only_classes:
+ config, inputs_dict = self.prepare_config_and_inputs_for_generate()
+ input_ids = inputs_dict["input_ids"]
+
+ # - for left padding we absolutely need to use an all ones
+ # attention mask, so we do not use the one in inputs_dict
+ attention_mask = torch.ones_like(input_ids)
+
+ model = model_class(config).to(torch_device).eval()
+ signature = inspect.signature(model.forward).parameters.keys()
+
+ # no cache as some models require special cache classes to be init outside forward
+ model.generation_config.use_cache = False
+
+ # Without padding
+ model_kwargs = _prepare_model_kwargs(input_ids, attention_mask, signature)
+ next_logits_wo_padding = model(**model_kwargs).logits[:, -1, :]
+
+ # With left-padding (length 32)
+ # can hardcode pad_token to be 0 as we'll do attn masking anyway
+ pad_token_id = (
+ config.get_text_config().pad_token_id if config.get_text_config().pad_token_id is not None else 0
+ )
+ pad_size = (input_ids.shape[0], 32)
+ padding = torch.ones(pad_size, dtype=input_ids.dtype, device=torch_device) * pad_token_id
+ padded_input_ids = torch.cat((padding, input_ids), dim=1)
+ padded_attention_mask = torch.cat((torch.zeros_like(padding), attention_mask), dim=1)
+ model_kwargs = _prepare_model_kwargs(padded_input_ids, padded_attention_mask, signature)
+ next_logits_with_padding = model(**model_kwargs).logits[:, -1, :]
+
+ # They should result in very similar logits
+ torch.testing.assert_close(next_logits_wo_padding, next_logits_with_padding, rtol=1e-5, atol=1e-5)
+
+
+@slow
+@require_torch
+@require_torch_gpu
+class FalconH1ModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_falcon_h1_hard(self):
+ """
+ An integration test for Falcon-H1.
+ """
+ EXPECTED_TEXT_DEFAULT = """
+ user
+ Tell me about the french revolution.
+ assistant
+ The French Revolution (1789–1799) was a period of radical social and political upheaval in France that fundamentally transformed the nation and had profound effects on the rest of Europe and the world. Here are the key aspects of the revolution:
+
+ ### **Causes**
+ 1. **Economic Crisis**: France was in severe financial trouble due to costly wars (particularly the American Revolution), extravagant spending by the monarchy, and inefficient taxation.
+ 2. **Social Inequality**: The rigid class system (the Ancien Régime) divided society into the privileged nobility and clergy (First Estate) and the commoners (Third Estate), who bore the brunt of taxation and had few rights.
+ 3. **Enlightenment Ideas**: Philosophers like Voltaire, Rousseau, and Montesquieu inspired ideas of liberty, equality, and popular sovereignty.
+ 4. **Settlement of 1789**: The Estates-General convened to address the financial crisis, leading to the Third Estate's assertion of its rights and the eventual abolition of the feudal system.
+
+ ### **Key Events**
+ 1. **Storming of the Bastille (July 14, 1789)**: A symbol of royal tyranny, the Bastille fortress was stormed by revolutionaries, sparking widespread rebellion.
+ 2. **Declaration of the Rights of Man and of the Citizen (August 1789)**: A foundational document proclaiming liberty, equality, and fraternity.
+ 3. **National Assembly and King’s Trial (1791–1792)**: King Louis XVI and his ministers were tried and executed (King Louis was guillotined, Marie Antoinette was banished), marking the end of the monarchy.
+ 4. **Rise of the Jacobins and Reign of Terror (1793–1794)**: Radical leaders like Maximilien Robespierre sought to purge France of counter-revolutionaries, leading to mass executions and widespread fear.
+ 5. **Thermidorian Reaction
+ """
+
+ EXPECTED_TEXT_A10 = """
+ user
+ Tell me about the french revolution.
+ assistant
+ The French Revolution (1789–1799) was a period of profound social upheaval and radical political change in France that fundamentally transformed the nation and had far-reaching effects on the rest of Europe and the world. Here are the key aspects of the revolution:
+
+ ### **Causes**
+ 1. **Economic Crisis**: France was in severe financial trouble due to costly wars (particularly the American Revolution), extravagant spending by the monarchy, and an inefficient tax system.
+ 2. **Social Inequality**: The privileged classes (the nobility and clergy) enjoyed immense wealth and power, while the majority of the population (the Third Estate, comprising commoners) faced poverty and lack of representation.
+ 3. **Enlightenment Ideas**: Philosophers like Voltaire, Rousseau, and Montesquieu inspired ideas of liberty, equality, and popular sovereignty, which fueled revolutionary fervor.
+ 4. **Political Instability**: The absolute monarchy under King Louis XVI proved unable to address the nation's problems, leading to growing discontent.
+
+ ### **Key Events**
+ 1. **Estates-General (1789)**: The Third Estate broke away and formed the National Assembly, forcing King Louis XVI to convene the Estates-General, an old legislative body, to address the financial crisis.
+ 2. **Storming of the Bastille (July 14, 1789)**: A symbol of royal tyranny, the Bastille fortress was stormed by revolutionaries, sparking widespread rebellion.
+ 3. **Declaration of the Rights of Man and of the Citizen (August 1789)**: This foundational document proclaimed liberty, equality, and fraternity as fundamental rights.
+ 4. **Abolition of Feudalism (November 1789)**: The National Assembly abolished feudal privileges, redistributing church lands to the people.
+ 5. **Tennis Court Oath (May 5, 1789)**: The National Assembly members, meeting on a tennis court, pledged to continue their work until a new constitution was established.
+ 6.
+ """
+
+ expected_texts = Expectations(
+ {
+ (None, None): EXPECTED_TEXT_DEFAULT,
+ ("cuda", 8): EXPECTED_TEXT_A10,
+ }
+ )
+ EXPECTED_TEXT = expected_texts.get_expectation()
+ # Remove the first char (`\n`) and the consecutive whitespaces caused by the formatting.
+ EXPECTED_TEXT = EXPECTED_TEXT.strip().replace(" " * 12, "")
+
+ device_properties = get_device_properties()
+ # For A10, there is an ending " "
+ if device_properties[0] == "cuda" and device_properties[1] == 8:
+ EXPECTED_TEXT = EXPECTED_TEXT + " "
+
+ model_id = "tiiuae/Falcon-H1-1.5B-Deep-Instruct"
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = FalconH1ForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")
+ device = "cuda"
+ messages = [{"role": "user", "content": "Tell me about the french revolution."}]
+ input_text = tokenizer.apply_chat_template(messages, tokenize=False)
+ inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
+
+ with torch.no_grad():
+ outputs = model.generate(inputs, max_new_tokens=512, do_sample=False)
+
+ generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
+
+ self.assertEqual(generated_text, EXPECTED_TEXT)
diff --git a/transformers/tests/models/falcon_mamba/__init__.py b/transformers/tests/models/falcon_mamba/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/falcon_mamba/test_modeling_falcon_mamba.py b/transformers/tests/models/falcon_mamba/test_modeling_falcon_mamba.py
new file mode 100644
index 0000000000000000000000000000000000000000..cada419ea03add7b1469d474608782eb44bc2bc0
--- /dev/null
+++ b/transformers/tests/models/falcon_mamba/test_modeling_falcon_mamba.py
@@ -0,0 +1,601 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import math
+import unittest
+from unittest.util import safe_repr
+
+from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, FalconMambaConfig, is_torch_available
+from transformers.testing_utils import (
+ Expectations,
+ cleanup,
+ require_bitsandbytes,
+ require_torch,
+ require_torch_accelerator,
+ require_torch_large_accelerator,
+ require_torch_multi_accelerator,
+ require_torch_multi_gpu,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ FalconMambaForCausalLM,
+ FalconMambaModel,
+ )
+ from transformers.cache_utils import MambaCache
+
+
+# Copied from transformers.tests.models.mamba.MambaModelTester with Mamba->FalconMamba,mamba->falcon_mamba
+class FalconMambaModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=14,
+ seq_length=7,
+ is_training=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ intermediate_size=32,
+ hidden_act="silu",
+ hidden_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ num_labels=3,
+ num_choices=4,
+ scope=None,
+ tie_word_embeddings=True,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.scope = scope
+ self.bos_token_id = vocab_size - 1
+ self.eos_token_id = vocab_size - 1
+ self.pad_token_id = vocab_size - 1
+ self.tie_word_embeddings = tie_word_embeddings
+
+ # Ignore copy
+ def get_large_model_config(self):
+ return FalconMambaConfig.from_pretrained("tiiuae/falcon-mamba-7b")
+
+ def prepare_config_and_inputs(
+ self, gradient_checkpointing=False, scale_attn_by_inverse_layer_idx=False, reorder_and_upcast_attn=False
+ ):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+ attention_mask = ids_tensor([self.batch_size, self.seq_length], 1)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config(
+ gradient_checkpointing=gradient_checkpointing,
+ scale_attn_by_inverse_layer_idx=scale_attn_by_inverse_layer_idx,
+ reorder_and_upcast_attn=reorder_and_upcast_attn,
+ )
+
+ return (
+ config,
+ input_ids,
+ attention_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ )
+
+ def get_config(
+ self, gradient_checkpointing=False, scale_attn_by_inverse_layer_idx=False, reorder_and_upcast_attn=False
+ ):
+ return FalconMambaConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ intermediate_size=self.intermediate_size,
+ activation_function=self.hidden_act,
+ n_positions=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ use_cache=True,
+ bos_token_id=self.bos_token_id,
+ eos_token_id=self.eos_token_id,
+ pad_token_id=self.pad_token_id,
+ gradient_checkpointing=gradient_checkpointing,
+ tie_word_embeddings=self.tie_word_embeddings,
+ )
+
+ def get_pipeline_config(self):
+ config = self.get_config()
+ config.vocab_size = 300
+ return config
+
+ def prepare_config_and_inputs_for_decoder(self):
+ (
+ config,
+ input_ids,
+ attention_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = self.prepare_config_and_inputs()
+
+ return (
+ config,
+ input_ids,
+ attention_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ )
+
+ def create_and_check_falcon_mamba_model(self, config, input_ids, *args):
+ config.output_hidden_states = True
+ model = FalconMambaModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids)
+
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(len(result.hidden_states), config.num_hidden_layers + 1)
+
+ def create_and_check_causal_lm(self, config, input_ids, *args):
+ model = FalconMambaForCausalLM(config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids, labels=input_ids)
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_state_equivalency(self, config, input_ids, *args):
+ model = FalconMambaModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ outputs = model(input_ids)
+ output_whole = outputs.last_hidden_state
+
+ outputs = model(
+ input_ids[:, :-1],
+ use_cache=True,
+ cache_position=torch.arange(0, config.conv_kernel, device=input_ids.device),
+ )
+ output_one = outputs.last_hidden_state
+
+ # Using the state computed on the first inputs, we will get the same output
+ outputs = model(
+ input_ids[:, -1:],
+ use_cache=True,
+ cache_params=outputs.cache_params,
+ cache_position=torch.arange(config.conv_kernel, config.conv_kernel + 1, device=input_ids.device),
+ )
+ output_two = outputs.last_hidden_state
+
+ self.parent.assertTrue(torch.allclose(torch.cat([output_one, output_two], dim=1), output_whole, atol=1e-5))
+ # TODO the original mamba does not support decoding more than 1 token neither do we
+
+ def create_and_check_falcon_mamba_cached_slow_forward_and_backwards(
+ self, config, input_ids, *args, gradient_checkpointing=False
+ ):
+ model = FalconMambaModel(config)
+ model.to(torch_device)
+ if gradient_checkpointing:
+ model.gradient_checkpointing_enable()
+
+ # create cache
+ cache = model(input_ids, use_cache=True).cache_params
+ cache.reset()
+
+ # use cache
+ token_emb = model.embeddings(input_ids)
+ outputs = model.layers[0].mixer.slow_forward(
+ token_emb, cache, cache_position=torch.arange(0, config.conv_kernel, device=input_ids.device)
+ )
+
+ loss = torch.log1p(torch.abs(outputs.sum()))
+ self.parent.assertEqual(loss.shape, ())
+ self.parent.assertEqual(outputs.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ loss.backward()
+
+ def create_and_check_falcon_mamba_lm_head_forward_and_backwards(
+ self, config, input_ids, *args, gradient_checkpointing=False
+ ):
+ model = FalconMambaForCausalLM(config)
+ model.to(torch_device)
+ if gradient_checkpointing:
+ model.gradient_checkpointing_enable()
+
+ result = model(input_ids, labels=input_ids)
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+ result.loss.backward()
+
+ def prepare_config_and_inputs_for_common(self):
+ (
+ config,
+ input_ids,
+ attention_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = self.prepare_config_and_inputs()
+ inputs_dict = {"input_ids": input_ids, "attention_mask": attention_mask}
+ return config, inputs_dict
+
+
+@require_torch
+# Copied from transformers.tests.models.mamba.MambaModelTest with Mamba->Falcon,mamba->falcon_mamba,FalconMambaCache->MambaCache
+class FalconMambaModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (FalconMambaModel, FalconMambaForCausalLM) if is_torch_available() else ()
+ has_attentions = False # FalconMamba does not support attentions
+ fx_compatible = False # FIXME let's try to support this @ArthurZucker
+ test_torchscript = False # FIXME let's try to support this @ArthurZucker
+ test_missing_keys = False
+ test_model_parallel = False
+ test_pruning = False
+ test_head_masking = False # FalconMamba does not have attention heads
+ pipeline_model_mapping = (
+ {"feature-extraction": FalconMambaModel, "text-generation": FalconMambaForCausalLM}
+ if is_torch_available()
+ else {}
+ )
+
+ def setUp(self):
+ self.model_tester = FalconMambaModelTester(self)
+ self.config_tester = ConfigTester(
+ self, config_class=FalconMambaConfig, n_embd=37, common_properties=["hidden_size", "num_hidden_layers"]
+ )
+
+ def assertInterval(self, member, container, msg=None):
+ r"""
+ Simple utility function to check if a member is inside an interval.
+ """
+ if isinstance(member, torch.Tensor):
+ max_value, min_value = member.max().item(), member.min().item()
+ elif isinstance(member, list) or isinstance(member, tuple):
+ max_value, min_value = max(member), min(member)
+
+ if not isinstance(container, list):
+ raise TypeError("container should be a list or tuple")
+ elif len(container) != 2:
+ raise ValueError("container should have 2 elements")
+
+ expected_min, expected_max = container
+
+ is_inside_interval = (min_value >= expected_min) and (max_value <= expected_max)
+
+ if not is_inside_interval:
+ standardMsg = f"{safe_repr(member)} not found in {safe_repr(container)}"
+ self.fail(self._formatMessage(msg, standardMsg))
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @require_torch_multi_gpu
+ def test_multi_gpu_data_parallel_forward(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # some params shouldn't be scattered by nn.DataParallel
+ # so just remove them if they are present.
+ blacklist_non_batched_params = ["cache_params"]
+ for k in blacklist_non_batched_params:
+ inputs_dict.pop(k, None)
+
+ # move input tensors to cuda:O
+ for k, v in inputs_dict.items():
+ if torch.is_tensor(v):
+ inputs_dict[k] = v.to(0)
+
+ for model_class in self.all_model_classes:
+ model = model_class(config=config)
+ model.to(0)
+ model.eval()
+
+ # Wrap model in nn.DataParallel
+ model = torch.nn.DataParallel(model)
+ with torch.no_grad():
+ _ = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ def test_falcon_mamba_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_falcon_mamba_model(*config_and_inputs)
+
+ def test_falcon_mamba_lm_head_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_causal_lm(*config_and_inputs)
+
+ def test_state_equivalency(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_state_equivalency(*config_and_inputs)
+
+ def test_falcon_mamba_cached_slow_forward_and_backwards(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_falcon_mamba_cached_slow_forward_and_backwards(*config_and_inputs)
+
+ def test_falcon_mamba_lm_head_forward_and_backwards(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_falcon_mamba_lm_head_forward_and_backwards(*config_and_inputs)
+
+ def test_initialization(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ config.rescale_prenorm_residual = True
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if "dt_proj.bias" in name:
+ dt = torch.exp(
+ torch.tensor([0, 1]) * (math.log(config.time_step_max) - math.log(config.time_step_min))
+ + math.log(config.time_step_min)
+ ).clamp(min=config.time_step_floor)
+ inv_dt = dt + torch.log(-torch.expm1(-dt))
+ if param.requires_grad:
+ self.assertTrue(param.data.max().item() <= inv_dt[1])
+ self.assertTrue(param.data.min().item() >= inv_dt[0])
+ elif "A_log" in name:
+ A = torch.arange(1, config.state_size + 1, dtype=torch.float32)[None, :]
+ A = A.expand(config.intermediate_size, -1).contiguous()
+ torch.testing.assert_close(param.data, torch.log(A), rtol=1e-5, atol=1e-5)
+ elif "D" in name:
+ if param.requires_grad:
+ # check if it's a ones like
+ torch.testing.assert_close(param.data, torch.ones_like(param.data), rtol=1e-5, atol=1e-5)
+ else:
+ if param.requires_grad:
+ if (
+ "mixer.conv1d.weight" in name
+ or "mixer.dt_proj.weight" in name
+ or "mixer.out_proj.weight" in name
+ ):
+ continue
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ @slow
+ # Ignore copy
+ def test_model_from_pretrained(self):
+ model = FalconMambaModel.from_pretrained("tiiuae/falcon-mamba-7b", torch_dtype=torch.float16)
+ self.assertIsNotNone(model)
+
+ def test_model_outputs_equivalence(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ def check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs={}):
+ with torch.no_grad():
+ tuple_output = model(**tuple_inputs, return_dict=False, **additional_kwargs)
+ dict_output = model(**dict_inputs, return_dict=True, **additional_kwargs).to_tuple()
+
+ def recursive_check(tuple_object, dict_object):
+ if isinstance(tuple_object, MambaCache): # MODIFIED PART START
+ recursive_check(tuple_object.conv_states, dict_object.conv_states)
+ recursive_check(tuple_object.ssm_states, dict_object.ssm_states)
+ elif isinstance(tuple_object, (list, tuple)): # MODIFIED PART END
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object, dict_object):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif isinstance(tuple_object, dict):
+ for tuple_iterable_value, dict_iterable_value in zip(
+ tuple_object.values(), dict_object.values()
+ ):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif tuple_object is None:
+ return
+ else:
+ self.assertTrue(
+ torch.allclose(tuple_object, dict_object, atol=1e-5),
+ msg=(
+ "Tuple and dict output are not equal. Difference:"
+ f" {torch.max(torch.abs(tuple_object - dict_object))}. Tuple has `nan`:"
+ f" {torch.isnan(tuple_object).any()} and `inf`: {torch.isinf(tuple_object)}. Dict has"
+ f" `nan`: {torch.isnan(dict_object).any()} and `inf`: {torch.isinf(dict_object)}."
+ ),
+ )
+
+ recursive_check(tuple_output, dict_output)
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True})
+
+
+@require_torch
+@require_torch_accelerator
+@slow
+class FalconMambaIntegrationTests(unittest.TestCase):
+ def setUp(self):
+ self.model_id = "tiiuae/falcon-mamba-7b"
+ self.tokenizer = AutoTokenizer.from_pretrained(self.model_id)
+ self.text = "Hello today"
+
+ cleanup(torch_device, gc_collect=True)
+
+ def tearDown(self):
+ cleanup(torch_device, gc_collect=True)
+
+ # On T4, get `NotImplementedError: Cannot copy out of meta tensor; no data!`
+ @require_torch_large_accelerator
+ def test_generation_fp16(self):
+ model = AutoModelForCausalLM.from_pretrained(self.model_id, torch_dtype=torch.float16, device_map="auto")
+
+ inputs = self.tokenizer(self.text, return_tensors="pt").to(torch_device)
+ out = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+
+ EXPECTED_OUTPUTS = Expectations(
+ {
+ ("cuda", 7): "Hello today I am going to show you how to make a simple and easy to make paper plane.\nStep",
+ ("cuda", 8): 'Hello today Iava,\n\nI am writing to you today to discuss the importance of maintaining a healthy lifestyle',
+ }
+ ) # fmt: skip
+ EXPECTED_OUTPUT = EXPECTED_OUTPUTS.get_expectation()
+
+ self.assertEqual(
+ self.tokenizer.batch_decode(out, skip_special_tokens=False)[0],
+ EXPECTED_OUTPUT,
+ )
+
+ @require_bitsandbytes
+ def test_generation_4bit(self):
+ quantization_config = BitsAndBytesConfig(load_in_4bit=True)
+ model = AutoModelForCausalLM.from_pretrained(self.model_id, quantization_config=quantization_config)
+
+ inputs = self.tokenizer(self.text, return_tensors="pt").to(torch_device)
+ out = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+
+ self.assertEqual(
+ self.tokenizer.batch_decode(out, skip_special_tokens=False)[0],
+ "Hello today Iava,\n\nI'm sorry to hear that you're having trouble with the ",
+ )
+
+ def test_generation_torch_compile(self):
+ model = AutoModelForCausalLM.from_pretrained(self.model_id, torch_dtype=torch.float16).to(torch_device)
+ model = torch.compile(model)
+
+ inputs = self.tokenizer(self.text, return_tensors="pt").to(torch_device)
+ out = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+
+ self.assertEqual(
+ self.tokenizer.batch_decode(out, skip_special_tokens=False)[0],
+ "Hello today Iava,\n\nI am writing to you today to discuss the importance of maintaining a healthy lifestyle",
+ )
+
+ def test_batched_generation(self):
+ model_id = "tiiuae/falcon-mamba-7b"
+ tok = AutoTokenizer.from_pretrained(model_id)
+ tok.pad_token_id = tok.eos_token_id
+
+ texts = ["Hello today", "Hello my name is Younes and today"]
+
+ EXPECTED_OUTPUTS = Expectations(
+ {
+ ("cuda", 7): [
+ 'Hello today I will be talking about the “Theory of Relativity” by Albert Einstein.\nThe',
+ 'Hello my name is Younes and today I will be talking about the importance of the internet in our lives.\nThe internet is a global',
+ ],
+ ("cuda", 8): [
+ 'Hello today I am going to talk about the “Theory of Relativity” by Albert Einstein.\n',
+ 'Hello my name is Younes and today I will be talking about the importance of the internet in our lives.\nThe internet is a global',
+ ],
+ }
+ ) # fmt: skip
+ EXPECTED_OUTPUT = EXPECTED_OUTPUTS.get_expectation()
+
+ inputs = tok(texts, return_tensors="pt", padding=True, return_token_type_ids=False).to(torch_device)
+ model = AutoModelForCausalLM.from_pretrained(model_id, device_map=0, torch_dtype=torch.float16)
+
+ out = model.generate(**inputs, max_new_tokens=20)
+ out = tok.batch_decode(out, skip_special_tokens=True)
+
+ self.assertListEqual(out, EXPECTED_OUTPUT)
+
+ # We test the same generations with inputs_embeds
+ with torch.no_grad():
+ inputs_embeds = model.get_input_embeddings()(inputs.pop("input_ids"))
+
+ inputs["inputs_embeds"] = inputs_embeds
+ out = model.generate(**inputs, max_new_tokens=20)
+ out = tok.batch_decode(out, skip_special_tokens=True)
+
+ EXPECTED_OUTPUTS = Expectations(
+ {
+ ("cuda", 7): [
+ ' I will be talking about the “Theory of Relativity” by Albert Einstein.\nThe',
+ ' I will be talking about the importance of the internet in our lives.\nThe internet is a global',
+ ],
+ ("cuda", 8): [
+ ' I am going to talk about the “Theory of Relativity” by Albert Einstein.\n',
+ ' I will be talking about the importance of the internet in our lives.\nThe internet is a global'
+ ],
+ }
+ ) # fmt: skip
+ EXPECTED_OUTPUT = EXPECTED_OUTPUTS.get_expectation()
+ self.assertListEqual(out, EXPECTED_OUTPUT)
+
+ @require_torch_multi_accelerator
+ def test_training_kernel(self):
+ model_id = "tiiuae/falcon-mamba-7b"
+
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", torch_dtype=torch.float16)
+ tokenizer.pad_token_id = tokenizer.eos_token_id
+
+ text = "Hello today"
+
+ inputs = tokenizer(text, return_tensors="pt").to(torch_device)
+
+ with torch.no_grad():
+ logits = torch.argmax(model(**inputs).logits, dim=-1)
+
+ out_no_training = tokenizer.batch_decode(logits)
+
+ model.train()
+ lm_logits = model(**inputs).logits
+ next_token = torch.argmax(lm_logits, dim=-1)
+
+ out_training = tokenizer.batch_decode(next_token)
+
+ # Just verify backward works
+ loss = (1 - lm_logits).mean()
+ loss.backward()
+
+ self.assertEqual(out_training, out_no_training)
diff --git a/transformers/tests/models/flaubert/__init__.py b/transformers/tests/models/flaubert/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/flaubert/test_modeling_flaubert.py b/transformers/tests/models/flaubert/test_modeling_flaubert.py
new file mode 100644
index 0000000000000000000000000000000000000000..f98773a1199b7468cea38931f2a4924e47543637
--- /dev/null
+++ b/transformers/tests/models/flaubert/test_modeling_flaubert.py
@@ -0,0 +1,518 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import os
+import tempfile
+import unittest
+
+from transformers import FlaubertConfig, is_sacremoses_available, is_torch_available
+from transformers.testing_utils import require_torch, require_torch_accelerator, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ FlaubertForMultipleChoice,
+ FlaubertForQuestionAnswering,
+ FlaubertForQuestionAnsweringSimple,
+ FlaubertForSequenceClassification,
+ FlaubertForTokenClassification,
+ FlaubertModel,
+ FlaubertWithLMHeadModel,
+ )
+ from transformers.models.flaubert.modeling_flaubert import create_sinusoidal_embeddings
+
+
+class FlaubertModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_lengths=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ gelu_activation=True,
+ sinusoidal_embeddings=False,
+ causal=False,
+ asm=False,
+ n_langs=2,
+ vocab_size=99,
+ n_special=0,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=12,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ summary_type="last",
+ use_proj=None,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_lengths = use_input_lengths
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.gelu_activation = gelu_activation
+ self.sinusoidal_embeddings = sinusoidal_embeddings
+ self.causal = causal
+ self.asm = asm
+ self.n_langs = n_langs
+ self.vocab_size = vocab_size
+ self.n_special = n_special
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.summary_type = summary_type
+ self.use_proj = use_proj
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ input_lengths = None
+ if self.use_input_lengths:
+ input_lengths = (
+ ids_tensor([self.batch_size], vocab_size=2) + self.seq_length - 2
+ ) # small variation of seq_length
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.n_langs)
+
+ sequence_labels = None
+ token_labels = None
+ is_impossible_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ is_impossible_labels = ids_tensor([self.batch_size], 2).float()
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return (
+ config,
+ input_ids,
+ token_type_ids,
+ input_lengths,
+ sequence_labels,
+ token_labels,
+ is_impossible_labels,
+ choice_labels,
+ input_mask,
+ )
+
+ def get_config(self):
+ return FlaubertConfig(
+ vocab_size=self.vocab_size,
+ n_special=self.n_special,
+ emb_dim=self.hidden_size,
+ n_layers=self.num_hidden_layers,
+ n_heads=self.num_attention_heads,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ gelu_activation=self.gelu_activation,
+ sinusoidal_embeddings=self.sinusoidal_embeddings,
+ asm=self.asm,
+ causal=self.causal,
+ n_langs=self.n_langs,
+ max_position_embeddings=self.max_position_embeddings,
+ initializer_range=self.initializer_range,
+ summary_type=self.summary_type,
+ use_proj=self.use_proj,
+ )
+
+ def create_and_check_flaubert_model(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_lengths,
+ sequence_labels,
+ token_labels,
+ is_impossible_labels,
+ choice_labels,
+ input_mask,
+ ):
+ model = FlaubertModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, lengths=input_lengths, langs=token_type_ids)
+ result = model(input_ids, langs=token_type_ids)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_flaubert_lm_head(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_lengths,
+ sequence_labels,
+ token_labels,
+ is_impossible_labels,
+ choice_labels,
+ input_mask,
+ ):
+ model = FlaubertWithLMHeadModel(config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids, token_type_ids=token_type_ids, labels=token_labels)
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_flaubert_simple_qa(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_lengths,
+ sequence_labels,
+ token_labels,
+ is_impossible_labels,
+ choice_labels,
+ input_mask,
+ ):
+ model = FlaubertForQuestionAnsweringSimple(config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids)
+
+ result = model(input_ids, start_positions=sequence_labels, end_positions=sequence_labels)
+ self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
+ self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
+
+ def create_and_check_flaubert_qa(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_lengths,
+ sequence_labels,
+ token_labels,
+ is_impossible_labels,
+ choice_labels,
+ input_mask,
+ ):
+ model = FlaubertForQuestionAnswering(config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids)
+
+ result_with_labels = model(
+ input_ids,
+ start_positions=sequence_labels,
+ end_positions=sequence_labels,
+ cls_index=sequence_labels,
+ is_impossible=is_impossible_labels,
+ p_mask=input_mask,
+ )
+
+ result_with_labels = model(
+ input_ids,
+ start_positions=sequence_labels,
+ end_positions=sequence_labels,
+ cls_index=sequence_labels,
+ is_impossible=is_impossible_labels,
+ )
+
+ (total_loss,) = result_with_labels.to_tuple()
+
+ result_with_labels = model(input_ids, start_positions=sequence_labels, end_positions=sequence_labels)
+
+ (total_loss,) = result_with_labels.to_tuple()
+
+ self.parent.assertEqual(result_with_labels.loss.shape, ())
+ self.parent.assertEqual(result.start_top_log_probs.shape, (self.batch_size, model.config.start_n_top))
+ self.parent.assertEqual(result.start_top_index.shape, (self.batch_size, model.config.start_n_top))
+ self.parent.assertEqual(
+ result.end_top_log_probs.shape, (self.batch_size, model.config.start_n_top * model.config.end_n_top)
+ )
+ self.parent.assertEqual(
+ result.end_top_index.shape, (self.batch_size, model.config.start_n_top * model.config.end_n_top)
+ )
+ self.parent.assertEqual(result.cls_logits.shape, (self.batch_size,))
+
+ def create_and_check_flaubert_sequence_classif(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_lengths,
+ sequence_labels,
+ token_labels,
+ is_impossible_labels,
+ choice_labels,
+ input_mask,
+ ):
+ model = FlaubertForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids)
+ result = model(input_ids, labels=sequence_labels)
+
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
+
+ def create_and_check_flaubert_token_classif(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_lengths,
+ sequence_labels,
+ token_labels,
+ is_impossible_labels,
+ choice_labels,
+ input_mask,
+ ):
+ config.num_labels = self.num_labels
+ model = FlaubertForTokenClassification(config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids, attention_mask=input_mask, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+
+ def create_and_check_flaubert_multiple_choice(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_lengths,
+ sequence_labels,
+ token_labels,
+ is_impossible_labels,
+ choice_labels,
+ input_mask,
+ ):
+ config.num_choices = self.num_choices
+ model = FlaubertForMultipleChoice(config=config)
+ model.to(torch_device)
+ model.eval()
+ multiple_choice_inputs_ids = input_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ multiple_choice_token_type_ids = token_type_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ multiple_choice_input_mask = input_mask.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ result = model(
+ multiple_choice_inputs_ids,
+ attention_mask=multiple_choice_input_mask,
+ token_type_ids=multiple_choice_token_type_ids,
+ labels=choice_labels,
+ )
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_lengths,
+ sequence_labels,
+ token_labels,
+ is_impossible_labels,
+ choice_labels,
+ input_mask,
+ ) = config_and_inputs
+ inputs_dict = {
+ "input_ids": input_ids,
+ "token_type_ids": token_type_ids,
+ "lengths": input_lengths,
+ "attention_mask": input_mask,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class FlaubertModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ FlaubertModel,
+ FlaubertWithLMHeadModel,
+ FlaubertForQuestionAnswering,
+ FlaubertForQuestionAnsweringSimple,
+ FlaubertForSequenceClassification,
+ FlaubertForTokenClassification,
+ FlaubertForMultipleChoice,
+ )
+ if is_torch_available()
+ else ()
+ )
+ # Doesn't run generation tests. Outdated custom `prepare_inputs_for_generation` -- TODO @gante
+ all_generative_model_classes = ()
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": FlaubertModel,
+ "fill-mask": FlaubertWithLMHeadModel,
+ "question-answering": FlaubertForQuestionAnsweringSimple,
+ "text-classification": FlaubertForSequenceClassification,
+ "token-classification": FlaubertForTokenClassification,
+ "zero-shot": FlaubertForSequenceClassification,
+ }
+ if is_torch_available() and is_sacremoses_available()
+ else {}
+ )
+
+ # TODO: Fix the failed tests
+ def is_pipeline_test_to_skip(
+ self,
+ pipeline_test_case_name,
+ config_class,
+ model_architecture,
+ tokenizer_name,
+ image_processor_name,
+ feature_extractor_name,
+ processor_name,
+ ):
+ if (
+ pipeline_test_case_name == "QAPipelineTests"
+ and tokenizer_name is not None
+ and not tokenizer_name.endswith("Fast")
+ ):
+ # `QAPipelineTests` fails for a few models when the slower tokenizer are used.
+ # (The slower tokenizers were never used for pipeline tests before the pipeline testing rework)
+ # TODO: check (and possibly fix) the `QAPipelineTests` with slower tokenizer
+ return True
+
+ return False
+
+ # Flaubert has 2 QA models -> need to manually set the correct labels for one of them here
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class.__name__ == "FlaubertForQuestionAnswering":
+ inputs_dict["start_positions"] = torch.zeros(
+ self.model_tester.batch_size, dtype=torch.long, device=torch_device
+ )
+ inputs_dict["end_positions"] = torch.zeros(
+ self.model_tester.batch_size, dtype=torch.long, device=torch_device
+ )
+
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = FlaubertModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=FlaubertConfig, emb_dim=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_flaubert_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_flaubert_model(*config_and_inputs)
+
+ # Copied from tests/models/distilbert/test_modeling_distilbert.py with Distilbert->Flaubert
+ def test_flaubert_model_with_sinusoidal_encodings(self):
+ config = FlaubertConfig(sinusoidal_embeddings=True)
+ model = FlaubertModel(config=config)
+ sinusoidal_pos_embds = torch.empty((config.max_position_embeddings, config.emb_dim), dtype=torch.float32)
+ create_sinusoidal_embeddings(config.max_position_embeddings, config.emb_dim, sinusoidal_pos_embds)
+ self.model_tester.parent.assertTrue(torch.equal(model.position_embeddings.weight, sinusoidal_pos_embds))
+
+ def test_flaubert_lm_head(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_flaubert_lm_head(*config_and_inputs)
+
+ def test_flaubert_simple_qa(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_flaubert_simple_qa(*config_and_inputs)
+
+ def test_flaubert_qa(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_flaubert_qa(*config_and_inputs)
+
+ def test_flaubert_sequence_classif(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_flaubert_sequence_classif(*config_and_inputs)
+
+ def test_flaubert_token_classif(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_flaubert_token_classif(*config_and_inputs)
+
+ def test_flaubert_multiple_choice(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_flaubert_multiple_choice(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "flaubert/flaubert_small_cased"
+ model = FlaubertModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ @slow
+ @require_torch_accelerator
+ def test_torchscript_device_change(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ for model_class in self.all_model_classes:
+ # FlauBertForMultipleChoice behaves incorrectly in JIT environments.
+ if model_class == FlaubertForMultipleChoice:
+ self.skipTest(reason="FlauBertForMultipleChoice behaves incorrectly in JIT environments.")
+
+ config.torchscript = True
+ model = model_class(config=config)
+
+ inputs_dict = self._prepare_for_class(inputs_dict, model_class)
+ traced_model = torch.jit.trace(
+ model, (inputs_dict["input_ids"].to("cpu"), inputs_dict["attention_mask"].to("cpu"))
+ )
+
+ with tempfile.TemporaryDirectory() as tmp:
+ torch.jit.save(traced_model, os.path.join(tmp, "traced_model.pt"))
+ loaded = torch.jit.load(os.path.join(tmp, "traced_model.pt"), map_location=torch_device)
+ loaded(inputs_dict["input_ids"].to(torch_device), inputs_dict["attention_mask"].to(torch_device))
+
+
+@require_torch
+class FlaubertModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference_no_head_absolute_embedding(self):
+ model = FlaubertModel.from_pretrained("flaubert/flaubert_base_cased")
+ input_ids = torch.tensor([[0, 345, 232, 328, 740, 140, 1695, 69, 6078, 1588, 2]])
+ with torch.no_grad():
+ output = model(input_ids)[0]
+ expected_shape = torch.Size((1, 11, 768))
+ self.assertEqual(output.shape, expected_shape)
+ expected_slice = torch.tensor(
+ [[[-2.6251, -1.4298, -0.0227], [-2.8510, -1.6387, 0.2258], [-2.8114, -1.1832, -0.3066]]]
+ )
+
+ torch.testing.assert_close(output[:, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/flaubert/test_tokenization_flaubert.py b/transformers/tests/models/flaubert/test_tokenization_flaubert.py
new file mode 100644
index 0000000000000000000000000000000000000000..30c65349883bc1983d226bc329535e632ed8acf3
--- /dev/null
+++ b/transformers/tests/models/flaubert/test_tokenization_flaubert.py
@@ -0,0 +1,75 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the FlauBERT tokenizer."""
+
+import json
+import os
+import unittest
+
+from transformers import FlaubertTokenizer
+from transformers.models.flaubert.tokenization_flaubert import VOCAB_FILES_NAMES
+from transformers.testing_utils import slow
+
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+class FlaubertTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "flaubert/flaubert_base_cased"
+ tokenizer_class = FlaubertTokenizer
+ test_rust_tokenizer = False
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ # Adapted from Sennrich et al. 2015 and https://github.com/rsennrich/subword-nmt
+ vocab = ["l", "o", "w", "e", "r", "s", "t", "i", "d", "n", "w", "r", "t", "i", "lo", "low", "ne", "new", "er", "low", "lowest", "new", "newer", "wider", ""] # fmt: skip
+
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+ merges = ["n e 300", "ne w 301", "e r 302", ""]
+
+ cls.vocab_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ cls.merges_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["merges_file"])
+ with open(cls.vocab_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps(vocab_tokens) + "\n")
+ with open(cls.merges_file, "w", encoding="utf-8") as fp:
+ fp.write("\n".join(merges))
+
+ # Copied from transformers.tests.models.xlm.test_tokenization_xlm.XLMTokenizationTest.test_full_tokenizer
+ def test_full_tokenizer(self):
+ tokenizer = self.get_tokenizer()
+ text = "lower newer"
+ bpe_tokens = ["l", "o", "w", "er", "new", "er"]
+ tokens = tokenizer.tokenize(text)
+ self.assertListEqual(tokens, bpe_tokens)
+
+ input_tokens = tokens + [tokenizer.unk_token]
+ input_bpe_tokens = [0, 1, 2, 18, 17, 18, 24]
+ self.assertListEqual(tokenizer.convert_tokens_to_ids(input_tokens), input_bpe_tokens)
+
+ @slow
+ # Copied from transformers.tests.models.xlm.test_tokenization_xlm.XLMTokenizationTest.test_sequence_builders
+ def test_sequence_builders(self):
+ tokenizer = FlaubertTokenizer.from_pretrained("flaubert/flaubert_base_cased")
+
+ text = tokenizer.encode("sequence builders", add_special_tokens=False)
+ text_2 = tokenizer.encode("multi-sequence build", add_special_tokens=False)
+
+ encoded_sentence = tokenizer.build_inputs_with_special_tokens(text)
+ encoded_pair = tokenizer.build_inputs_with_special_tokens(text, text_2)
+ print(encoded_sentence)
+ print(encoded_sentence)
+
+ assert encoded_sentence == [0] + text + [1]
+ assert encoded_pair == [0] + text + [1] + text_2 + [1]
diff --git a/transformers/tests/models/fsmt/__init__.py b/transformers/tests/models/fsmt/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/fsmt/test_modeling_fsmt.py b/transformers/tests/models/fsmt/test_modeling_fsmt.py
new file mode 100644
index 0000000000000000000000000000000000000000..aaf3e0e91ac84f22aea6e290cb2deb0acee85438
--- /dev/null
+++ b/transformers/tests/models/fsmt/test_modeling_fsmt.py
@@ -0,0 +1,618 @@
+# Copyright 2020 Huggingface
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import tempfile
+import unittest
+
+import timeout_decorator # noqa
+from parameterized import parameterized
+
+from transformers import FSMTConfig, is_torch_available
+from transformers.testing_utils import (
+ require_sentencepiece,
+ require_tokenizers,
+ require_torch,
+ require_torch_fp16,
+ slow,
+ torch_device,
+)
+from transformers.utils import cached_property
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import FSMTForConditionalGeneration, FSMTModel, FSMTTokenizer
+ from transformers.models.fsmt.modeling_fsmt import (
+ SinusoidalPositionalEmbedding,
+ _prepare_fsmt_decoder_inputs,
+ invert_mask,
+ shift_tokens_right,
+ )
+ from transformers.pipelines import TranslationPipeline
+
+
+class FSMTModelTester:
+ def __init__(
+ self,
+ parent,
+ src_vocab_size=99,
+ tgt_vocab_size=99,
+ langs=["ru", "en"],
+ batch_size=13,
+ seq_length=7,
+ is_training=False,
+ use_labels=False,
+ hidden_size=16,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=4,
+ hidden_act="relu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=20,
+ bos_token_id=0,
+ pad_token_id=1,
+ eos_token_id=2,
+ ):
+ self.parent = parent
+ self.src_vocab_size = src_vocab_size
+ self.tgt_vocab_size = tgt_vocab_size
+ self.langs = langs
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.bos_token_id = bos_token_id
+ self.pad_token_id = pad_token_id
+ self.eos_token_id = eos_token_id
+ torch.manual_seed(0)
+
+ # hack needed for modeling_common tests - despite not really having this attribute in this model
+ self.vocab_size = self.src_vocab_size
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.src_vocab_size).clamp(
+ 3,
+ )
+ input_ids[:, -1] = 2 # Eos Token
+
+ config = self.get_config()
+ inputs_dict = prepare_fsmt_inputs_dict(config, input_ids)
+ return config, inputs_dict
+
+ def get_config(self):
+ return FSMTConfig(
+ vocab_size=self.src_vocab_size, # hack needed for common tests
+ src_vocab_size=self.src_vocab_size,
+ tgt_vocab_size=self.tgt_vocab_size,
+ langs=self.langs,
+ d_model=self.hidden_size,
+ encoder_layers=self.num_hidden_layers,
+ decoder_layers=self.num_hidden_layers,
+ encoder_attention_heads=self.num_attention_heads,
+ decoder_attention_heads=self.num_attention_heads,
+ encoder_ffn_dim=self.intermediate_size,
+ decoder_ffn_dim=self.intermediate_size,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ eos_token_id=self.eos_token_id,
+ bos_token_id=self.bos_token_id,
+ pad_token_id=self.pad_token_id,
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config, inputs_dict = self.prepare_config_and_inputs()
+ inputs_dict["decoder_input_ids"] = inputs_dict["input_ids"]
+ inputs_dict["decoder_attention_mask"] = inputs_dict["attention_mask"]
+ inputs_dict["use_cache"] = False
+ return config, inputs_dict
+
+
+def prepare_fsmt_inputs_dict(
+ config,
+ input_ids,
+ attention_mask=None,
+ head_mask=None,
+ decoder_head_mask=None,
+ cross_attn_head_mask=None,
+):
+ if attention_mask is None:
+ attention_mask = input_ids.ne(config.pad_token_id)
+ if head_mask is None:
+ head_mask = torch.ones(config.encoder_layers, config.encoder_attention_heads, device=torch_device)
+ if decoder_head_mask is None:
+ decoder_head_mask = torch.ones(config.decoder_layers, config.decoder_attention_heads, device=torch_device)
+ if cross_attn_head_mask is None:
+ cross_attn_head_mask = torch.ones(config.decoder_layers, config.decoder_attention_heads, device=torch_device)
+ return {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "head_mask": head_mask,
+ "decoder_head_mask": decoder_head_mask,
+ }
+
+
+@require_torch
+class FSMTModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (FSMTModel, FSMTForConditionalGeneration) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": FSMTModel,
+ "summarization": FSMTForConditionalGeneration,
+ "text2text-generation": FSMTForConditionalGeneration,
+ "translation": FSMTForConditionalGeneration,
+ }
+ if is_torch_available()
+ else {}
+ )
+ is_encoder_decoder = True
+ test_pruning = False
+ test_missing_keys = False
+
+ def setUp(self):
+ self.model_tester = FSMTModelTester(self)
+ self.langs = ["en", "ru"]
+ config = {
+ "langs": self.langs,
+ "src_vocab_size": 10,
+ "tgt_vocab_size": 20,
+ }
+ # XXX: hack to appease to all other models requiring `vocab_size`
+ config["vocab_size"] = 99 # no such thing in FSMT
+ self.config_tester = ConfigTester(self, config_class=FSMTConfig, **config)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ # XXX: override test_model_get_set_embeddings / different Embedding type
+ def test_model_get_set_embeddings(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Embedding))
+ model.set_input_embeddings(nn.Embedding(10, 10))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.modules.sparse.Embedding))
+
+ def test_initialization_more(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs()
+ model = FSMTModel(config)
+ model.to(torch_device)
+ model.eval()
+ # test init
+ # self.assertTrue((model.encoder.embed_tokens.weight == model.shared.weight).all().item())
+
+ def _check_var(module):
+ """Check that we initialized various parameters from N(0, config.init_std)."""
+ self.assertAlmostEqual(torch.std(module.weight).item(), config.init_std, 2)
+
+ _check_var(model.encoder.embed_tokens)
+ _check_var(model.encoder.layers[0].self_attn.k_proj)
+ _check_var(model.encoder.layers[0].fc1)
+ # XXX: different std for fairseq version of SinusoidalPositionalEmbedding
+ # self.assertAlmostEqual(torch.std(model.encoder.embed_positions.weights).item(), config.init_std, 2)
+
+ def test_advanced_inputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs()
+ config.use_cache = False
+ inputs_dict["input_ids"][:, -2:] = config.pad_token_id
+ decoder_input_ids, decoder_attn_mask, causal_mask = _prepare_fsmt_decoder_inputs(
+ config, inputs_dict["input_ids"]
+ )
+ model = FSMTModel(config).to(torch_device).eval()
+
+ decoder_features_with_created_mask = model(**inputs_dict)[0]
+ decoder_features_with_passed_mask = model(
+ decoder_attention_mask=invert_mask(decoder_attn_mask), decoder_input_ids=decoder_input_ids, **inputs_dict
+ )[0]
+ _assert_tensors_equal(decoder_features_with_passed_mask, decoder_features_with_created_mask)
+ useless_mask = torch.zeros_like(decoder_attn_mask)
+ decoder_features = model(decoder_attention_mask=useless_mask, **inputs_dict)[0]
+ self.assertTrue(isinstance(decoder_features, torch.Tensor)) # no hidden states or attentions
+ self.assertEqual(
+ decoder_features.size(),
+ (self.model_tester.batch_size, self.model_tester.seq_length, config.tgt_vocab_size),
+ )
+ if decoder_attn_mask.min().item() < -1e3: # some tokens were masked
+ self.assertFalse((decoder_features_with_created_mask == decoder_features).all().item())
+
+ # Test different encoder attention masks
+ decoder_features_with_long_encoder_mask = model(
+ inputs_dict["input_ids"], attention_mask=inputs_dict["attention_mask"].long()
+ )[0]
+ _assert_tensors_equal(decoder_features_with_long_encoder_mask, decoder_features_with_created_mask)
+
+ def test_save_load_missing_keys(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
+ self.assertEqual(info["missing_keys"], [])
+
+ def test_ensure_weights_are_shared(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs()
+
+ config.tie_word_embeddings = True
+ model = FSMTForConditionalGeneration(config)
+
+ # FSMT shares three weights.
+ # Not an issue to not have these correctly tied for torch.load, but it is an issue for safetensors.
+ self.assertEqual(
+ len(
+ {
+ model.get_output_embeddings().weight.data_ptr(),
+ model.get_input_embeddings().weight.data_ptr(),
+ model.base_model.decoder.output_projection.weight.data_ptr(),
+ }
+ ),
+ 1,
+ )
+
+ config.tie_word_embeddings = False
+ model = FSMTForConditionalGeneration(config)
+
+ # FSMT shares three weights.
+ # Not an issue to not have these correctly tied for torch.load, but it is an issue for safetensors.
+ self.assertEqual(
+ len(
+ {
+ model.get_output_embeddings().weight.data_ptr(),
+ model.get_input_embeddings().weight.data_ptr(),
+ model.base_model.decoder.output_projection.weight.data_ptr(),
+ }
+ ),
+ 2,
+ )
+
+ @unittest.skip(reason="can't be implemented for FSMT due to dual vocab.")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ @unittest.skip(reason="Passing inputs_embeds not implemented for FSMT.")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Input ids is required for FSMT.")
+ def test_inputs_embeds_matches_input_ids(self):
+ pass
+
+ @unittest.skip(reason="model weights aren't tied in FSMT.")
+ def test_tie_model_weights(self):
+ pass
+
+ @unittest.skip(reason="TODO: Decoder embeddings cannot be resized at the moment")
+ def test_resize_embeddings_untied(self):
+ pass
+
+
+@require_torch
+class FSMTHeadTests(unittest.TestCase):
+ src_vocab_size = 99
+ tgt_vocab_size = 99
+ langs = ["ru", "en"]
+
+ def _get_config(self):
+ return FSMTConfig(
+ src_vocab_size=self.src_vocab_size,
+ tgt_vocab_size=self.tgt_vocab_size,
+ langs=self.langs,
+ d_model=24,
+ encoder_layers=2,
+ decoder_layers=2,
+ encoder_attention_heads=2,
+ decoder_attention_heads=2,
+ encoder_ffn_dim=32,
+ decoder_ffn_dim=32,
+ max_position_embeddings=48,
+ eos_token_id=2,
+ pad_token_id=1,
+ bos_token_id=0,
+ )
+
+ def _get_config_and_data(self):
+ input_ids = torch.tensor(
+ [
+ [71, 82, 18, 33, 46, 91, 2],
+ [68, 34, 26, 58, 30, 82, 2],
+ [5, 97, 17, 39, 94, 40, 2],
+ [76, 83, 94, 25, 70, 78, 2],
+ [87, 59, 41, 35, 48, 66, 2],
+ [55, 13, 16, 58, 5, 2, 1], # note padding
+ [64, 27, 31, 51, 12, 75, 2],
+ [52, 64, 86, 17, 83, 39, 2],
+ [48, 61, 9, 24, 71, 82, 2],
+ [26, 1, 60, 48, 22, 13, 2],
+ [21, 5, 62, 28, 14, 76, 2],
+ [45, 98, 37, 86, 59, 48, 2],
+ [70, 70, 50, 9, 28, 0, 2],
+ ],
+ dtype=torch.long,
+ device=torch_device,
+ )
+
+ batch_size = input_ids.shape[0]
+ config = self._get_config()
+ return config, input_ids, batch_size
+
+ def test_generate_beam_search(self):
+ input_ids = torch.tensor([[71, 82, 2], [68, 34, 2]], dtype=torch.long, device=torch_device)
+ config = self._get_config()
+ lm_model = FSMTForConditionalGeneration(config).to(torch_device)
+ lm_model.eval()
+
+ max_length = 5
+ new_input_ids = lm_model.generate(
+ input_ids.clone(),
+ do_sample=True,
+ num_return_sequences=1,
+ num_beams=2,
+ no_repeat_ngram_size=3,
+ max_length=max_length,
+ )
+ self.assertEqual(new_input_ids.shape, (input_ids.shape[0], max_length))
+
+ def test_shift_tokens_right(self):
+ input_ids = torch.tensor([[71, 82, 18, 33, 2, 1, 1], [68, 34, 26, 58, 30, 82, 2]], dtype=torch.long)
+ shifted = shift_tokens_right(input_ids, 1)
+ n_pad_before = input_ids.eq(1).float().sum()
+ n_pad_after = shifted.eq(1).float().sum()
+ self.assertEqual(shifted.shape, input_ids.shape)
+ self.assertEqual(n_pad_after, n_pad_before - 1)
+ self.assertTrue(torch.eq(shifted[:, 0], 2).all())
+
+ @require_torch_fp16
+ def test_generate_fp16(self):
+ config, input_ids, batch_size = self._get_config_and_data()
+ attention_mask = input_ids.ne(1).to(torch_device)
+ model = FSMTForConditionalGeneration(config).eval().to(torch_device)
+ model.half()
+ model.generate(input_ids, attention_mask=attention_mask)
+ model.generate(num_beams=4, do_sample=True, early_stopping=False, num_return_sequences=3)
+
+ def test_dummy_inputs(self):
+ config, *_ = self._get_config_and_data()
+ model = FSMTForConditionalGeneration(config).eval().to(torch_device)
+ model(**model.dummy_inputs)
+
+ def test_prepare_fsmt_decoder_inputs(self):
+ config, *_ = self._get_config_and_data()
+ input_ids = _long_tensor([4, 4, 2])
+ decoder_input_ids = _long_tensor([[26388, 2, config.pad_token_id]])
+ causal_mask_dtype = torch.float32
+ ignore = torch.finfo(causal_mask_dtype).min
+ decoder_input_ids, decoder_attn_mask, causal_mask = _prepare_fsmt_decoder_inputs(
+ config, input_ids, decoder_input_ids, causal_mask_dtype=causal_mask_dtype
+ )
+ expected_causal_mask = torch.tensor(
+ [[0, ignore, ignore], [0, 0, ignore], [0, 0, 0]] # never attend to the final token, because its pad
+ ).to(input_ids.device)
+ self.assertEqual(decoder_attn_mask.size(), decoder_input_ids.size())
+ self.assertTrue(torch.eq(expected_causal_mask, causal_mask).all())
+
+
+def _assert_tensors_equal(a, b, atol=1e-12, prefix=""):
+ """If tensors not close, or a and b aren't both tensors, raise a nice Assertion error."""
+ if a is None and b is None:
+ return True
+ try:
+ if torch.allclose(a, b, atol=atol):
+ return True
+ raise
+ except Exception:
+ if len(prefix) > 0:
+ prefix = f"{prefix}: "
+ raise AssertionError(f"{prefix}{a} != {b}")
+
+
+def _long_tensor(tok_lst):
+ return torch.tensor(tok_lst, dtype=torch.long, device=torch_device)
+
+
+TOLERANCE = 1e-4
+
+
+pairs = [
+ ["en-ru"],
+ ["ru-en"],
+ ["en-de"],
+ ["de-en"],
+]
+
+
+@require_torch
+@require_sentencepiece
+@require_tokenizers
+class FSMTModelIntegrationTests(unittest.TestCase):
+ tokenizers_cache = {}
+ models_cache = {}
+ default_mname = "facebook/wmt19-en-ru"
+
+ @cached_property
+ def default_tokenizer(self):
+ return self.get_tokenizer(self.default_mname)
+
+ @cached_property
+ def default_model(self):
+ return self.get_model(self.default_mname)
+
+ def get_tokenizer(self, mname):
+ if mname not in self.tokenizers_cache:
+ self.tokenizers_cache[mname] = FSMTTokenizer.from_pretrained(mname)
+ return self.tokenizers_cache[mname]
+
+ def get_model(self, mname):
+ if mname not in self.models_cache:
+ # The safetensors checkpoint on `facebook/wmt19-de-en` (and other repositories) has issues.
+ # Hub PRs are opened, see https://huggingface.co/facebook/wmt19-de-en/discussions/6
+ # We have asked Meta to merge them but no response yet:
+ # https://huggingface.slack.com/archives/C01NE71C4F7/p1749565278015529?thread_ts=1749031628.757929&cid=C01NE71C4F7
+ # Below is what produced the Hub PRs that work (loading without safetensors, saving the reloading)
+ model = FSMTForConditionalGeneration.from_pretrained(mname, use_safetensors=False)
+ with tempfile.TemporaryDirectory() as tmpdir:
+ model.save_pretrained(tmpdir)
+ self.models_cache[mname] = FSMTForConditionalGeneration.from_pretrained(tmpdir).to(torch_device)
+
+ if torch_device == "cuda":
+ self.models_cache[mname].half()
+ return self.models_cache[mname]
+
+ @slow
+ def test_inference_no_head(self):
+ tokenizer = self.default_tokenizer
+ model = FSMTModel.from_pretrained(self.default_mname).to(torch_device)
+
+ src_text = "My friend computer will translate this for me"
+ input_ids = tokenizer([src_text], return_tensors="pt")["input_ids"]
+ input_ids = _long_tensor(input_ids).to(torch_device)
+ inputs_dict = prepare_fsmt_inputs_dict(model.config, input_ids)
+ with torch.no_grad():
+ output = model(**inputs_dict)[0]
+ expected_shape = torch.Size((1, 10, model.config.tgt_vocab_size))
+ self.assertEqual(output.shape, expected_shape)
+ # expected numbers were generated when en-ru model, using just fairseq's model4.pt
+ # may have to adjust if switched to a different checkpoint
+ expected_slice = torch.tensor(
+ [[-1.5753, -1.5753, 2.8975], [-0.9540, -0.9540, 1.0299], [-3.3131, -3.3131, 0.5219]]
+ ).to(torch_device)
+ torch.testing.assert_close(output[0, :3, :3], expected_slice, rtol=TOLERANCE, atol=TOLERANCE)
+
+ def translation_setup(self, pair):
+ text = {
+ "en": "Machine learning is great, isn't it?",
+ "ru": "Машинное обучение - это здорово, не так ли?",
+ "de": "Maschinelles Lernen ist großartig, oder?",
+ }
+
+ src, tgt = pair.split("-")
+ print(f"Testing {src} -> {tgt}")
+ mname = f"facebook/wmt19-{pair}"
+
+ src_text = text[src]
+ tgt_text = text[tgt]
+ # To make `test_translation_pipeline_0_en_ru` pass in #38904. When translating it back to `en`, we get
+ # `Machine learning is fine, isn't it?`.
+ if (src, tgt) == ("en", "ru"):
+ tgt_text = "Машинное обучение - это прекрасно, не так ли?"
+
+ tokenizer = self.get_tokenizer(mname)
+ model = self.get_model(mname)
+ return tokenizer, model, src_text, tgt_text
+
+ @parameterized.expand(pairs)
+ @slow
+ def test_translation_direct(self, pair):
+ tokenizer, model, src_text, tgt_text = self.translation_setup(pair)
+
+ input_ids = tokenizer.encode(src_text, return_tensors="pt").to(torch_device)
+
+ outputs = model.generate(input_ids)
+ decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
+ assert decoded == tgt_text, f"\n\ngot: {decoded}\nexp: {tgt_text}\n"
+
+ @parameterized.expand(pairs)
+ @slow
+ def test_translation_pipeline(self, pair):
+ tokenizer, model, src_text, tgt_text = self.translation_setup(pair)
+ pipeline = TranslationPipeline(model, tokenizer, framework="pt", device=torch_device)
+ output = pipeline([src_text])
+ self.assertEqual([tgt_text], [x["translation_text"] for x in output])
+
+
+@require_torch
+class TestSinusoidalPositionalEmbeddings(unittest.TestCase):
+ padding_idx = 1
+ tolerance = 1e-4
+
+ def test_basic(self):
+ input_ids = torch.tensor([[4, 10]], dtype=torch.long, device=torch_device)
+ emb1 = SinusoidalPositionalEmbedding(num_positions=6, embedding_dim=6, padding_idx=self.padding_idx).to(
+ torch_device
+ )
+ emb1.make_weight(*emb1.weight.shape, emb1.padding_idx)
+ emb = emb1(input_ids)
+ desired_weights = torch.tensor(
+ [
+ [9.0930e-01, 1.9999e-02, 2.0000e-04, -4.1615e-01, 9.9980e-01, 1.0000e00],
+ [1.4112e-01, 2.9995e-02, 3.0000e-04, -9.8999e-01, 9.9955e-01, 1.0000e00],
+ ]
+ ).to(torch_device)
+ self.assertTrue(
+ torch.allclose(emb[0], desired_weights, atol=self.tolerance),
+ msg=f"\nexp:\n{desired_weights}\ngot:\n{emb[0]}\n",
+ )
+
+ def test_odd_embed_dim(self):
+ # odd embedding_dim is allowed
+ test = SinusoidalPositionalEmbedding(num_positions=4, embedding_dim=5, padding_idx=self.padding_idx).to(
+ torch_device
+ )
+ test.make_weight(*test.weight.shape, test.padding_idx)
+
+ # odd num_embeddings is allowed
+ test = SinusoidalPositionalEmbedding(num_positions=5, embedding_dim=4, padding_idx=self.padding_idx).to(
+ torch_device
+ )
+ test.make_weight(*test.weight.shape, test.padding_idx)
+
+ @unittest.skip(reason="different from marian (needs more research)")
+ def test_positional_emb_weights_against_marian(self):
+ desired_weights = torch.tensor(
+ [
+ [0, 0, 0, 0, 0],
+ [0.84147096, 0.82177866, 0.80180490, 0.78165019, 0.76140374],
+ [0.90929741, 0.93651021, 0.95829457, 0.97505713, 0.98720258],
+ ]
+ )
+ emb1 = SinusoidalPositionalEmbedding(num_positions=512, embedding_dim=512, padding_idx=self.padding_idx).to(
+ torch_device
+ )
+ emb1.make_weight(*emb1.weight.shape, emb1.padding_idx)
+ weights = emb1.weights.data[:3, :5]
+ # XXX: only the 1st and 3rd lines match - this is testing against
+ # verbatim copy of SinusoidalPositionalEmbedding from fairseq
+ self.assertTrue(
+ torch.allclose(weights, desired_weights, atol=self.tolerance),
+ msg=f"\nexp:\n{desired_weights}\ngot:\n{weights}\n",
+ )
+
+ # test that forward pass is just a lookup, there is no ignore padding logic
+ input_ids = torch.tensor(
+ [[4, 10, self.padding_idx, self.padding_idx, self.padding_idx]], dtype=torch.long, device=torch_device
+ )
+ no_cache_pad_zero = emb1(input_ids)[0]
+ # XXX: only the 1st line matches the 3rd
+ torch.testing.assert_close(
+ torch.tensor(desired_weights, device=torch_device), no_cache_pad_zero[:3, :5], rtol=1e-3, atol=1e-3
+ )
diff --git a/transformers/tests/models/fsmt/test_tokenization_fsmt.py b/transformers/tests/models/fsmt/test_tokenization_fsmt.py
new file mode 100644
index 0000000000000000000000000000000000000000..bfaf3df195935dd94ea8714fee0032d8e981d6fc
--- /dev/null
+++ b/transformers/tests/models/fsmt/test_tokenization_fsmt.py
@@ -0,0 +1,169 @@
+# Copyright 2020 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import os
+import unittest
+
+from transformers.models.fsmt.tokenization_fsmt import VOCAB_FILES_NAMES, FSMTTokenizer
+from transformers.testing_utils import slow
+from transformers.utils import cached_property
+
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+# using a different tiny model than the one used for default params defined in init to ensure proper testing
+FSMT_TINY2 = "stas/tiny-wmt19-en-ru"
+
+
+class FSMTTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "stas/tiny-wmt19-en-de"
+ tokenizer_class = FSMTTokenizer
+ test_rust_tokenizer = False
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ # Adapted from Sennrich et al. 2015 and https://github.com/rsennrich/subword-nmt
+ vocab = [
+ "l",
+ "o",
+ "w",
+ "e",
+ "r",
+ "s",
+ "t",
+ "i",
+ "d",
+ "n",
+ "w",
+ "r",
+ "t",
+ "lo",
+ "low",
+ "er",
+ "low",
+ "lowest",
+ "newer",
+ "wider",
+ "",
+ ]
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+ merges = ["l o 123", "lo w 1456", "e r 1789", ""]
+
+ cls.langs = ["en", "ru"]
+ config = {
+ "langs": cls.langs,
+ "src_vocab_size": 10,
+ "tgt_vocab_size": 20,
+ }
+
+ cls.src_vocab_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["src_vocab_file"])
+ cls.tgt_vocab_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["tgt_vocab_file"])
+ config_file = os.path.join(cls.tmpdirname, "tokenizer_config.json")
+ cls.merges_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["merges_file"])
+ with open(cls.src_vocab_file, "w") as fp:
+ fp.write(json.dumps(vocab_tokens))
+ with open(cls.tgt_vocab_file, "w") as fp:
+ fp.write(json.dumps(vocab_tokens))
+ with open(cls.merges_file, "w") as fp:
+ fp.write("\n".join(merges))
+ with open(config_file, "w") as fp:
+ fp.write(json.dumps(config))
+
+ @cached_property
+ def tokenizer_ru_en(self):
+ return FSMTTokenizer.from_pretrained("facebook/wmt19-ru-en")
+
+ @cached_property
+ def tokenizer_en_ru(self):
+ return FSMTTokenizer.from_pretrained("facebook/wmt19-en-ru")
+
+ def test_online_tokenizer_config(self):
+ """this just tests that the online tokenizer files get correctly fetched and
+ loaded via its tokenizer_config.json and it's not slow so it's run by normal CI
+ """
+ tokenizer = FSMTTokenizer.from_pretrained(FSMT_TINY2)
+ self.assertListEqual([tokenizer.src_lang, tokenizer.tgt_lang], ["en", "ru"])
+ self.assertEqual(tokenizer.src_vocab_size, 21)
+ self.assertEqual(tokenizer.tgt_vocab_size, 21)
+
+ def test_full_tokenizer(self):
+ """Adapted from Sennrich et al. 2015 and https://github.com/rsennrich/subword-nmt"""
+ tokenizer = FSMTTokenizer(self.langs, self.src_vocab_file, self.tgt_vocab_file, self.merges_file)
+
+ text = "lower"
+ bpe_tokens = ["low", "er"]
+ tokens = tokenizer.tokenize(text)
+ self.assertListEqual(tokens, bpe_tokens)
+
+ input_tokens = tokens + [""]
+ input_bpe_tokens = [14, 15, 20]
+ self.assertListEqual(tokenizer.convert_tokens_to_ids(input_tokens), input_bpe_tokens)
+
+ @slow
+ def test_sequence_builders(self):
+ tokenizer = self.tokenizer_ru_en
+
+ text = tokenizer.encode("sequence builders", add_special_tokens=False)
+ text_2 = tokenizer.encode("multi-sequence build", add_special_tokens=False)
+
+ encoded_sentence = tokenizer.build_inputs_with_special_tokens(text)
+ encoded_pair = tokenizer.build_inputs_with_special_tokens(text, text_2)
+
+ assert encoded_sentence == text + [2]
+ assert encoded_pair == text + [2] + text_2 + [2]
+
+ @slow
+ def test_match_encode_decode(self):
+ tokenizer_enc = self.tokenizer_en_ru
+ tokenizer_dec = self.tokenizer_ru_en
+
+ targets = [
+ [
+ "Here's a little song I wrote. Don't worry, be happy.",
+ [2470, 39, 11, 2349, 7222, 70, 5979, 7, 8450, 1050, 13160, 5, 26, 6445, 7, 2],
+ ],
+ ["This is it. No more. I'm done!", [132, 21, 37, 7, 1434, 86, 7, 70, 6476, 1305, 427, 2]],
+ ]
+
+ # if data needs to be recreated or added, run:
+ # import torch
+ # model = torch.hub.load("pytorch/fairseq", "transformer.wmt19.en-ru", checkpoint_file="model4.pt", tokenizer="moses", bpe="fastbpe")
+ # for src_text, _ in targets: print(f"""[\n"{src_text}",\n {model.encode(src_text).tolist()}\n],""")
+
+ for src_text, tgt_input_ids in targets:
+ encoded_ids = tokenizer_enc.encode(src_text, return_tensors=None)
+ self.assertListEqual(encoded_ids, tgt_input_ids)
+
+ # and decode backward, using the reversed languages model
+ decoded_text = tokenizer_dec.decode(encoded_ids, skip_special_tokens=True)
+ self.assertEqual(decoded_text, src_text)
+
+ @slow
+ def test_tokenizer_lower(self):
+ tokenizer = FSMTTokenizer.from_pretrained("facebook/wmt19-ru-en", do_lower_case=True)
+ tokens = tokenizer.tokenize("USA is United States of America")
+ expected = ["us", "a", "is", "un", "i", "ted", "st", "ates", "of", "am", "er", "ica"]
+ self.assertListEqual(tokens, expected)
+
+ @unittest.skip(reason="FSMTConfig.__init__ requires non-optional args")
+ def test_torch_encode_plus_sent_to_model(self):
+ pass
+
+ @unittest.skip(reason="FSMTConfig.__init__ requires non-optional args")
+ def test_np_encode_plus_sent_to_model(self):
+ pass
diff --git a/transformers/tests/models/funnel/__init__.py b/transformers/tests/models/funnel/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/funnel/test_modeling_funnel.py b/transformers/tests/models/funnel/test_modeling_funnel.py
new file mode 100644
index 0000000000000000000000000000000000000000..3d28924bee1c2c32b2a2623d20a8e181e4475500
--- /dev/null
+++ b/transformers/tests/models/funnel/test_modeling_funnel.py
@@ -0,0 +1,524 @@
+# Copyright 2020 HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers import FunnelConfig, FunnelTokenizer, is_torch_available
+from transformers.models.auto import get_values
+from transformers.testing_utils import require_sentencepiece, require_tokenizers, require_torch, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ MODEL_FOR_PRETRAINING_MAPPING,
+ FunnelBaseModel,
+ FunnelForMaskedLM,
+ FunnelForMultipleChoice,
+ FunnelForPreTraining,
+ FunnelForQuestionAnswering,
+ FunnelForSequenceClassification,
+ FunnelForTokenClassification,
+ FunnelModel,
+ )
+
+
+class FunnelModelTester:
+ """You can also import this e.g, from .test_modeling_funnel import FunnelModelTester"""
+
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ vocab_size=99,
+ block_sizes=[1, 1, 2],
+ num_decoder_layers=1,
+ d_model=32,
+ n_head=4,
+ d_head=8,
+ d_inner=37,
+ hidden_act="gelu_new",
+ hidden_dropout=0.1,
+ attention_dropout=0.1,
+ activation_dropout=0.0,
+ max_position_embeddings=512,
+ type_vocab_size=3,
+ initializer_std=0.02, # Set to a smaller value, so we can keep the small error threshold (1e-5) in the test
+ num_labels=3,
+ num_choices=4,
+ scope=None,
+ base=False,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.block_sizes = block_sizes
+ self.num_decoder_layers = num_decoder_layers
+ self.d_model = d_model
+ self.n_head = n_head
+ self.d_head = d_head
+ self.d_inner = d_inner
+ self.hidden_act = hidden_act
+ self.hidden_dropout = hidden_dropout
+ self.attention_dropout = attention_dropout
+ self.activation_dropout = activation_dropout
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = 2
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.scope = scope
+ self.initializer_std = initializer_std
+
+ # Used in the tests to check the size of the first attention layer
+ self.num_attention_heads = n_head
+ # Used in the tests to check the size of the first hidden state
+ self.hidden_size = self.d_model
+ # Used in the tests to check the number of output hidden states/attentions
+ self.num_hidden_layers = sum(self.block_sizes) + (0 if base else self.num_decoder_layers)
+ # FunnelModel adds two hidden layers: input embeddings and the sum of the upsampled encoder hidden state with
+ # the last hidden state of the first block (which is the first hidden state of the decoder).
+ if not base:
+ self.expected_num_hidden_layers = self.num_hidden_layers + 2
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+ fake_token_labels = ids_tensor([self.batch_size, self.seq_length], 1)
+
+ config = self.get_config()
+
+ return (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ fake_token_labels,
+ )
+
+ def get_config(self):
+ return FunnelConfig(
+ vocab_size=self.vocab_size,
+ block_sizes=self.block_sizes,
+ num_decoder_layers=self.num_decoder_layers,
+ d_model=self.d_model,
+ n_head=self.n_head,
+ d_head=self.d_head,
+ d_inner=self.d_inner,
+ hidden_act=self.hidden_act,
+ hidden_dropout=self.hidden_dropout,
+ attention_dropout=self.attention_dropout,
+ activation_dropout=self.activation_dropout,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ initializer_std=self.initializer_std,
+ )
+
+ def create_and_check_model(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ fake_token_labels,
+ ):
+ model = FunnelModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
+ result = model(input_ids, token_type_ids=token_type_ids)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.d_model))
+
+ model.config.truncate_seq = False
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.d_model))
+
+ model.config.separate_cls = False
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.d_model))
+
+ def create_and_check_base_model(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ fake_token_labels,
+ ):
+ model = FunnelBaseModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
+ result = model(input_ids, token_type_ids=token_type_ids)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, 2, self.d_model))
+
+ model.config.truncate_seq = False
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, 3, self.d_model))
+
+ model.config.separate_cls = False
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, 2, self.d_model))
+
+ def create_and_check_for_pretraining(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ fake_token_labels,
+ ):
+ config.num_labels = self.num_labels
+ model = FunnelForPreTraining(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=fake_token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length))
+
+ def create_and_check_for_masked_lm(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ fake_token_labels,
+ ):
+ model = FunnelForMaskedLM(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_for_sequence_classification(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ fake_token_labels,
+ ):
+ config.num_labels = self.num_labels
+ model = FunnelForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=sequence_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def create_and_check_for_multiple_choice(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ fake_token_labels,
+ ):
+ config.num_choices = self.num_choices
+ model = FunnelForMultipleChoice(config=config)
+ model.to(torch_device)
+ model.eval()
+ multiple_choice_inputs_ids = input_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ multiple_choice_token_type_ids = token_type_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ multiple_choice_input_mask = input_mask.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
+ result = model(
+ multiple_choice_inputs_ids,
+ attention_mask=multiple_choice_input_mask,
+ token_type_ids=multiple_choice_token_type_ids,
+ labels=choice_labels,
+ )
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
+
+ def create_and_check_for_token_classification(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ fake_token_labels,
+ ):
+ config.num_labels = self.num_labels
+ model = FunnelForTokenClassification(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+
+ def create_and_check_for_question_answering(
+ self,
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ fake_token_labels,
+ ):
+ model = FunnelForQuestionAnswering(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ start_positions=sequence_labels,
+ end_positions=sequence_labels,
+ )
+ self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
+ self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ fake_token_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class FunnelModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ test_head_masking = False
+ test_pruning = False
+ all_model_classes = (
+ (
+ FunnelModel,
+ FunnelForMaskedLM,
+ FunnelForPreTraining,
+ FunnelForQuestionAnswering,
+ FunnelForTokenClassification,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": (FunnelBaseModel, FunnelModel),
+ "fill-mask": FunnelForMaskedLM,
+ "question-answering": FunnelForQuestionAnswering,
+ "text-classification": FunnelForSequenceClassification,
+ "token-classification": FunnelForTokenClassification,
+ "zero-shot": FunnelForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ # special case for ForPreTraining model
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class in get_values(MODEL_FOR_PRETRAINING_MAPPING):
+ inputs_dict["labels"] = torch.zeros(
+ (self.model_tester.batch_size, self.model_tester.seq_length), dtype=torch.long, device=torch_device
+ )
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = FunnelModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=FunnelConfig)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_pretraining(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_pretraining(*config_and_inputs)
+
+ def test_for_masked_lm(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
+
+ def test_for_token_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
+
+ def test_for_question_answering(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
+
+ # overwrite from test_modeling_common
+ def _mock_init_weights(self, module):
+ if hasattr(module, "weight") and module.weight is not None:
+ module.weight.data.fill_(3)
+ if hasattr(module, "bias") and module.bias is not None:
+ module.bias.data.fill_(3)
+
+ for param in ["r_w_bias", "r_r_bias", "r_kernel", "r_s_bias", "seg_embed"]:
+ if hasattr(module, param) and getattr(module, param) is not None:
+ weight = getattr(module, param)
+ weight.data.fill_(3)
+
+
+@require_torch
+class FunnelBaseModelTest(ModelTesterMixin, unittest.TestCase):
+ test_head_masking = False
+ test_pruning = False
+ all_model_classes = (
+ (FunnelBaseModel, FunnelForMultipleChoice, FunnelForSequenceClassification) if is_torch_available() else ()
+ )
+
+ def setUp(self):
+ self.model_tester = FunnelModelTester(self, base=True)
+ self.config_tester = ConfigTester(self, config_class=FunnelConfig)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_base_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_base_model(*config_and_inputs)
+
+ def test_for_sequence_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
+
+ def test_for_multiple_choice(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs)
+
+ # overwrite from test_modeling_common
+ def test_training(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ if model_class.__name__ == "FunnelBaseModel":
+ continue
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ # overwrite from test_modeling_common
+ def _mock_init_weights(self, module):
+ if hasattr(module, "weight") and module.weight is not None:
+ module.weight.data.fill_(3)
+ if hasattr(module, "bias") and module.bias is not None:
+ module.bias.data.fill_(3)
+
+ for param in ["r_w_bias", "r_r_bias", "r_kernel", "r_s_bias", "seg_embed"]:
+ if hasattr(module, param) and getattr(module, param) is not None:
+ weight = getattr(module, param)
+ weight.data.fill_(3)
+
+
+@require_torch
+@require_sentencepiece
+@require_tokenizers
+class FunnelModelIntegrationTest(unittest.TestCase):
+ def test_inference_tiny_model(self):
+ batch_size = 13
+ sequence_length = 7
+ input_ids = torch.arange(0, batch_size * sequence_length).long().reshape(batch_size, sequence_length)
+ lengths = [0, 1, 2, 3, 4, 5, 6, 4, 1, 3, 5, 0, 1]
+ token_type_ids = torch.tensor([[2] + [0] * a + [1] * (sequence_length - a - 1) for a in lengths])
+
+ model = FunnelModel.from_pretrained("sgugger/funnel-random-tiny")
+ output = model(input_ids, token_type_ids=token_type_ids)[0].abs()
+
+ expected_output_sum = torch.tensor(2344.8352)
+ expected_output_mean = torch.tensor(0.8052)
+ torch.testing.assert_close(output.sum(), expected_output_sum, rtol=1e-4, atol=1e-4)
+ torch.testing.assert_close(output.mean(), expected_output_mean, rtol=1e-4, atol=1e-4)
+
+ attention_mask = torch.tensor([[1] * 7, [1] * 4 + [0] * 3] * 6 + [[0, 1, 1, 0, 0, 1, 1]])
+ output = model(input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids)[0].abs()
+
+ expected_output_sum = torch.tensor(2343.8425)
+ expected_output_mean = torch.tensor(0.8049)
+ torch.testing.assert_close(output.sum(), expected_output_sum, rtol=1e-4, atol=1e-4)
+ torch.testing.assert_close(output.mean(), expected_output_mean, rtol=1e-4, atol=1e-4)
+
+ @slow
+ def test_inference_model(self):
+ tokenizer = FunnelTokenizer.from_pretrained("huggingface/funnel-small")
+ model = FunnelModel.from_pretrained("huggingface/funnel-small")
+ inputs = tokenizer("Hello! I am the Funnel Transformer model.", return_tensors="pt")
+ output = model(**inputs)[0]
+
+ expected_output_sum = torch.tensor(235.7246)
+ expected_output_mean = torch.tensor(0.0256)
+ torch.testing.assert_close(output.sum(), expected_output_sum, rtol=1e-4, atol=1e-4)
+ torch.testing.assert_close(output.mean(), expected_output_mean, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/funnel/test_tokenization_funnel.py b/transformers/tests/models/funnel/test_tokenization_funnel.py
new file mode 100644
index 0000000000000000000000000000000000000000..2d04fc0ac2d3cbb933b8b314c0019c2e0a07faa1
--- /dev/null
+++ b/transformers/tests/models/funnel/test_tokenization_funnel.py
@@ -0,0 +1,92 @@
+# Copyright 2020 HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import os
+import unittest
+from functools import lru_cache
+
+from transformers import FunnelTokenizer, FunnelTokenizerFast
+from transformers.models.funnel.tokenization_funnel import VOCAB_FILES_NAMES
+from transformers.testing_utils import require_tokenizers
+
+from ...test_tokenization_common import TokenizerTesterMixin, use_cache_if_possible
+
+
+@require_tokenizers
+class FunnelTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "funnel-transformer/small"
+ tokenizer_class = FunnelTokenizer
+ rust_tokenizer_class = FunnelTokenizerFast
+ test_rust_tokenizer = True
+ space_between_special_tokens = True
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ vocab_tokens = [
+ "",
+ "",
+ "",
+ "want",
+ "##want",
+ "##ed",
+ "wa",
+ "un",
+ "runn",
+ "##ing",
+ ",",
+ "low",
+ "lowest",
+ ]
+ cls.vocab_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ with open(cls.vocab_file, "w", encoding="utf-8") as vocab_writer:
+ vocab_writer.write("".join([x + "\n" for x in vocab_tokens]))
+
+ @classmethod
+ @use_cache_if_possible
+ @lru_cache(maxsize=64)
+ def get_tokenizer(cls, pretrained_name=None, **kwargs):
+ pretrained_name = pretrained_name or cls.tmpdirname
+ return FunnelTokenizer.from_pretrained(pretrained_name, **kwargs)
+
+ @classmethod
+ @use_cache_if_possible
+ @lru_cache(maxsize=64)
+ def get_rust_tokenizer(cls, pretrained_name=None, **kwargs):
+ pretrained_name = pretrained_name or cls.tmpdirname
+ return FunnelTokenizerFast.from_pretrained(pretrained_name, **kwargs)
+
+ def get_input_output_texts(self, tokenizer):
+ input_text = "UNwant\u00e9d,running"
+ output_text = "unwanted, running"
+ return input_text, output_text
+
+ def test_full_tokenizer(self):
+ tokenizer = self.tokenizer_class(self.vocab_file)
+
+ tokens = tokenizer.tokenize("UNwant\u00e9d,running")
+ self.assertListEqual(tokens, ["un", "##want", "##ed", ",", "runn", "##ing"])
+ self.assertListEqual(tokenizer.convert_tokens_to_ids(tokens), [7, 4, 5, 10, 8, 9])
+
+ def test_token_type_ids(self):
+ tokenizers = self.get_tokenizers(do_lower_case=False)
+ for tokenizer in tokenizers:
+ inputs = tokenizer("UNwant\u00e9d,running")
+ sentence_len = len(inputs["input_ids"]) - 1
+ self.assertListEqual(inputs["token_type_ids"], [2] + [0] * sentence_len)
+
+ inputs = tokenizer("UNwant\u00e9d,running", "UNwant\u00e9d,running")
+ self.assertListEqual(inputs["token_type_ids"], [2] + [0] * sentence_len + [1] * sentence_len)
diff --git a/transformers/tests/models/fuyu/__init__.py b/transformers/tests/models/fuyu/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/fuyu/test_image_processing_fuyu.py b/transformers/tests/models/fuyu/test_image_processing_fuyu.py
new file mode 100644
index 0000000000000000000000000000000000000000..fd9fea1f741a2d27f93fb1ea0e4fd63b1c10c599
--- /dev/null
+++ b/transformers/tests/models/fuyu/test_image_processing_fuyu.py
@@ -0,0 +1,63 @@
+import unittest
+
+import numpy as np
+
+from transformers import is_torch_available, is_vision_available
+from transformers.testing_utils import (
+ require_torch,
+ require_torchvision,
+ require_vision,
+)
+
+
+if is_torch_available() and is_vision_available():
+ import torch
+
+ from transformers import FuyuImageProcessor
+
+if is_vision_available():
+ from PIL import Image
+
+
+@require_torch
+@require_vision
+@require_torchvision
+class TestFuyuImageProcessor(unittest.TestCase):
+ def setUp(self):
+ self.size = {"height": 160, "width": 320}
+ self.processor = FuyuImageProcessor(size=self.size, padding_value=1.0)
+ self.batch_size = 3
+ self.channels = 3
+ self.height = 300
+ self.width = 300
+
+ self.image_input = torch.rand(self.batch_size, self.channels, self.height, self.width)
+
+ self.image_patch_dim_h = 30
+ self.image_patch_dim_w = 30
+ self.sample_image = np.zeros((450, 210, 3), dtype=np.uint8)
+ self.sample_image_pil = Image.fromarray(self.sample_image)
+
+ def test_patches(self):
+ expected_num_patches = self.processor.get_num_patches(image_height=self.height, image_width=self.width)
+
+ patches_final = self.processor.patchify_image(image=self.image_input)
+ assert patches_final.shape[1] == expected_num_patches, (
+ f"Expected {expected_num_patches} patches, got {patches_final.shape[1]}."
+ )
+
+ def test_scale_to_target_aspect_ratio(self):
+ # (h:450, w:210) fitting (160, 320) -> (160, 210*160/450)
+ scaled_image = self.processor.resize(self.sample_image, size=self.size)
+ self.assertEqual(scaled_image.shape[0], 160)
+ self.assertEqual(scaled_image.shape[1], 74)
+
+ def test_apply_transformation_numpy(self):
+ transformed_image = self.processor.preprocess(self.sample_image).images[0][0]
+ self.assertEqual(transformed_image.shape[1], 160)
+ self.assertEqual(transformed_image.shape[2], 320)
+
+ def test_apply_transformation_pil(self):
+ transformed_image = self.processor.preprocess(self.sample_image_pil).images[0][0]
+ self.assertEqual(transformed_image.shape[1], 160)
+ self.assertEqual(transformed_image.shape[2], 320)
diff --git a/transformers/tests/models/fuyu/test_modeling_fuyu.py b/transformers/tests/models/fuyu/test_modeling_fuyu.py
new file mode 100644
index 0000000000000000000000000000000000000000..1be8d9fcca8e06a8fb1a1ee5f41a4783c28ac4d6
--- /dev/null
+++ b/transformers/tests/models/fuyu/test_modeling_fuyu.py
@@ -0,0 +1,307 @@
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Fuyu model."""
+
+import io
+import unittest
+
+import pytest
+import requests
+from parameterized import parameterized
+
+from transformers import FuyuConfig, is_torch_available, is_vision_available
+from transformers.testing_utils import require_torch, require_torch_accelerator, slow
+from transformers.utils import cached_property
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_vision_available():
+ from PIL import Image
+
+
+if is_torch_available() and is_vision_available():
+ from transformers import FuyuProcessor
+
+
+if is_torch_available():
+ from transformers import FuyuForCausalLM, FuyuModel
+
+
+class FuyuModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ image_size=30,
+ patch_size=15,
+ num_channels=3,
+ is_training=True,
+ use_input_mask=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ pad_token_id=0,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.pad_token_id = pad_token_id
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ sequence_labels = None
+ token_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask, sequence_labels, token_labels
+
+ def get_config(self):
+ return FuyuConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ pad_token_id=self.pad_token_id,
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class FuyuModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ FuyuModel,
+ FuyuForCausalLM,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {"text-generation": FuyuForCausalLM, "image-text-to-text": FuyuForCausalLM} if is_torch_available() else {}
+ )
+
+ test_head_masking = False
+ test_pruning = False
+ test_cpu_offload = False
+ test_disk_offload = False
+ test_model_parallel = False
+
+ def setUp(self):
+ self.model_tester = FuyuModelTester(self)
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @parameterized.expand([("random",), ("same",)])
+ @pytest.mark.generate
+ @unittest.skip("Fuyu doesn't support assisted generation due to the need to crop/extend image patches indices")
+ def test_assisted_decoding_matches_greedy_search(self):
+ pass
+
+ @pytest.mark.generate
+ @unittest.skip("Fuyu doesn't support assisted generation due to the need to crop/extend image patches indices")
+ def test_assisted_decoding_sample(self):
+ pass
+
+ # TODO: Fix me (once this model gets more usage)
+ @unittest.skip(reason="Does not work on the tiny model.")
+ def test_disk_offload_bin(self):
+ super().test_disk_offload()
+
+ # TODO: Fix me (once this model gets more usage)
+ @unittest.skip(reason="Does not work on the tiny model.")
+ def test_disk_offload_safetensors(self):
+ super().test_disk_offload()
+
+ # TODO: Fix me (once this model gets more usage)
+ @unittest.skip(reason="Does not work on the tiny model.")
+ def test_model_parallelism(self):
+ super().test_model_parallelism()
+
+ @unittest.skip(reason="Fuyu `prepare_inputs_for_generation` function doesn't have cache position.")
+ def test_generate_continue_from_inputs_embeds():
+ pass
+
+
+@slow
+@require_torch_accelerator
+class FuyuModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_processor(self):
+ return FuyuProcessor.from_pretrained("adept/fuyu-8b")
+
+ @cached_property
+ def default_model(self):
+ return FuyuForCausalLM.from_pretrained("adept/fuyu-8b")
+
+ def test_greedy_generation(self):
+ processor = self.default_processor
+ model = self.default_model
+
+ url = "https://huggingface.co/datasets/hf-internal-testing/fixtures-captioning/resolve/main/bus.png"
+ image = Image.open(io.BytesIO(requests.get(url).content))
+
+ text_prompt_coco_captioning = "Generate a coco-style caption.\n"
+
+ inputs = processor(images=image, text=text_prompt_coco_captioning, return_tensors="pt")
+ generated_ids = model.generate(**inputs, max_new_tokens=10)
+
+ # take the last 8 tokens (in order to skip special \n\x04 characters) and decode them
+ generated_text = processor.batch_decode(generated_ids[:, -8:], skip_special_tokens=True)[0]
+ self.assertEqual(generated_text, "A blue bus parked on the side of a road.")
+
+
+"""
+ @slow
+ @require_torch_accelerator
+ def test_model_8b_chat_greedy_generation_bus_color(self):
+ EXPECTED_TEXT_COMPLETION = "The bus is blue.\n|ENDOFTEXT|"
+ text_prompt_bus_color = "What color is the bus?\n"
+ model_inputs_bus_color = self.processor(text=text_prompt_bus_color, images=self.bus_image_pil)
+
+ generated_tokens = self.model.generate(**model_inputs_bus_color, max_new_tokens=10)
+ text = self.processor.tokenizer.batch_decode(generated_tokens)
+ end_sequence = text[0].split("\x04")[1]
+ clean_sequence = (
+ end_sequence[: end_sequence.find("|ENDOFTEXT|") + len("|ENDOFTEXT|")]
+ if "|ENDOFTEXT|" in end_sequence
+ else end_sequence
+ )
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, clean_sequence)
+
+ @slow
+ @require_torch_accelerator
+ def test_model_8b_chat_greedy_generation_chart_vqa(self):
+ EXPECTED_TEXT_TOKENS = ["The","life expectancy","at","birth","of male","s in","","20","18","is","","80",".","7",".","\n","|ENDOFTEXT|",] # fmt: skip
+ expected_text_completion = " ".join(EXPECTED_TEXT_TOKENS) # TODO make sure the end string matches
+
+ text_prompt_chart_vqa = "What is the highest life expectancy at birth of male?\n"
+
+ chart_image_url = (
+ "https://huggingface.co/datasets/hf-internal-testing/fixtures-captioning/resolve/main/chart.png"
+ )
+ chart_image_pil = Image.open(io.BytesIO(requests.get(chart_image_url).content))
+
+ model_inputs_chart_vqa = self.processor(text=text_prompt_chart_vqa, images=chart_image_pil)
+ generated_tokens = self.model.generate(**model_inputs_chart_vqa, max_new_tokens=10)
+ text = self.processor.tokenizer.batch_decode(generated_tokens)
+ end_sequence = text[0].split("\x04")[1]
+ clean_sequence = (
+ end_sequence[: end_sequence.find("|ENDOFTEXT|") + len("|ENDOFTEXT|")]
+ if "|ENDOFTEXT|" in end_sequence
+ else end_sequence
+ )
+ self.assertEqual(expected_text_completion, clean_sequence)
+
+ @slow
+ @require_torch_accelerator
+ def test_model_8b_chat_greedy_generation_bounding_box(self):
+ EXPECTED_TEXT_COMPLETION = "\x00194213202244\x01|ENDOFTEXT|"
+ text_prompt_bbox = "When presented with a box, perform OCR to extract text contained within it. If provided with text, generate the corresponding bounding box.\\nWilliams" # noqa: E231
+
+ bbox_image_url = "https://huggingface.co/datasets/hf-internal-testing/fixtures-captioning/resolve/main/bbox_sample_image.png"
+ bbox_image_pil = Image.open(io.BytesIO(requests.get(bbox_image_url).content))
+
+ model_inputs_bbox = self.processor(text=text_prompt_bbox, images=bbox_image_pil)
+ generated_tokens = self.model.generate(**model_inputs_bbox, max_new_tokens=10)
+ text = self.processor.tokenizer.batch_decode(generated_tokens)
+ end_sequence = text[0].split("\x04")[1]
+ clean_sequence = (
+ end_sequence[: end_sequence.find("|ENDOFTEXT|") + len("|ENDOFTEXT|")]
+ if "|ENDOFTEXT|" in end_sequence
+ else end_sequence
+ )
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, clean_sequence)
+"""
diff --git a/transformers/tests/models/fuyu/test_processor_fuyu.py b/transformers/tests/models/fuyu/test_processor_fuyu.py
new file mode 100644
index 0000000000000000000000000000000000000000..1f2c754bd597a71b65633a1e8c052b492ffbba79
--- /dev/null
+++ b/transformers/tests/models/fuyu/test_processor_fuyu.py
@@ -0,0 +1,409 @@
+import io
+import tempfile
+import unittest
+from shutil import rmtree
+
+import requests
+
+from transformers import (
+ AutoProcessor,
+ AutoTokenizer,
+ FuyuImageProcessor,
+ FuyuProcessor,
+ is_torch_available,
+ is_vision_available,
+)
+from transformers.testing_utils import require_torch, require_vision
+
+from ...test_processing_common import ProcessorTesterMixin
+
+
+if is_vision_available():
+ from PIL import Image
+
+
+if is_torch_available():
+ import torch
+
+ from transformers.models.fuyu.processing_fuyu import construct_full_unpacked_stream, full_unpacked_stream_to_tensor
+
+
+@require_torch
+@require_vision
+class FuyuProcessingTest(ProcessorTesterMixin, unittest.TestCase):
+ processor_class = FuyuProcessor
+
+ @classmethod
+ def setUpClass(cls):
+ cls.tmpdirname = tempfile.mkdtemp()
+
+ image_processor = FuyuImageProcessor()
+ tokenizer = AutoTokenizer.from_pretrained("adept/fuyu-8b")
+
+ processor = FuyuProcessor(image_processor=image_processor, tokenizer=tokenizer)
+ processor.save_pretrained(cls.tmpdirname)
+
+ cls.text_prompt = "Generate a coco-style caption.\\n"
+ bus_image_url = "https://huggingface.co/datasets/hf-internal-testing/fixtures-captioning/resolve/main/bus.png"
+ cls.bus_image_pil = Image.open(io.BytesIO(requests.get(bus_image_url).content))
+
+ @classmethod
+ def tearDownClass(cls):
+ rmtree(cls.tmpdirname)
+
+ def get_processor(self):
+ image_processor = FuyuImageProcessor()
+ tokenizer = AutoTokenizer.from_pretrained("adept/fuyu-8b")
+ processor = FuyuProcessor(image_processor, tokenizer, **self.prepare_processor_dict())
+
+ return processor
+
+ def get_tokenizer(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).tokenizer
+
+ def get_image_processor(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).image_processor
+
+ def test_fuyu_processing(self):
+ """
+ Test to ensure that the standard processing on a gold example matches adept's code.
+ """
+ # fmt: off
+ EXPECTED_IMAGE_PATCH_INPUTS = torch.Tensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, -1, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, -1, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, -1, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, -1, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, -1, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, -1, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, -1, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, -1, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, -1, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, -1, 220, 221, 222, 223, 224, 225, 226, 227, 228, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239, 240, 241, -1, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255, 256, 257, 258, 259, 260, 261, 262, 263, -1, 264, 265, 266, 267, 268, 269, 270, 271, 272, 273, 274, 275, 276, 277, 278, 279, 280, 281, 282, 283, 284, 285, -1, 286, 287, 288, 289, 290, 291, 292, 293, 294, 295, 296, 297, 298, 299, 300, 301, 302, 303, 304, 305, 306, 307, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,]]).to(torch.int64)
+ EXPECTED_PADDED_UNPACKED_TOKEN_INPUTS = torch.Tensor([[71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 1, 128340, 71374, 71389, 120412, 71377, 71835, 71374, 73615, 71375, 71399, 71435, 71122,]]).to(torch.int64)
+
+ one_image_bus_model_inputs = self.get_processor()(text=self.text_prompt, images=self.bus_image_pil)
+
+ # fmt: on
+ torch.testing.assert_close(one_image_bus_model_inputs["image_patches_indices"], EXPECTED_IMAGE_PATCH_INPUTS)
+ torch.testing.assert_close(one_image_bus_model_inputs["input_ids"], EXPECTED_PADDED_UNPACKED_TOKEN_INPUTS)
+
+ def test_fuyu_processing_no_image(self):
+ """
+ Test to check processor works with just text input
+ """
+ processor_outputs = self.get_processor()(text=self.text_prompt)
+ tokenizer_outputs = self.get_tokenizer()(self.text_prompt)
+ self.assertEqual(processor_outputs["input_ids"], tokenizer_outputs["input_ids"])
+
+ def test_fuyu_processing_no_text(self):
+ """
+ Test to check processor works with just image input
+ """
+ # fmt: off
+ EXPECTED_IMAGE_PATCH_INPUTS = torch.Tensor([
+ [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13,
+ 14, 15, 16, 17, 18, 19, 20, 21, -1, 22, 23, 24, 25, 26,
+ 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
+ 41, 42, 43, -1, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53,
+ 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, -1, 66,
+ 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80,
+ 81, 82, 83, 84, 85, 86, 87, -1, 88, 89, 90, 91, 92, 93,
+ 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107,
+ 108, 109, -1, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120,
+ 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, -1, 132, 133,
+ 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147,
+ 148, 149, 150, 151, 152, 153, -1, 154, 155, 156, 157, 158, 159, 160,
+ 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174,
+ 175, -1, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187,
+ 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, -1, 198, 199, 200,
+ 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 214,
+ 215, 216, 217, 218, 219, -1, 220, 221, 222, 223, 224, 225, 226, 227,
+ 228, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239, 240, 241,
+ -1, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254,
+ 255, 256, 257, 258, 259, 260, 261, 262, 263, -1, 264, 265, 266, 267,
+ 268, 269, 270, 271, 272, 273, 274, 275, 276, 277, 278, 279, 280, 281,
+ 282, 283, 284, 285, -1, 286, 287, 288, 289, 290, 291, 292, 293, 294,
+ 295, 296, 297, 298, 299, 300, 301, 302, 303, 304, 305, 306, 307, -1,
+ -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1]
+ ]).to(torch.int64)
+ # fmt: on
+
+ processor_outputs = self.get_processor()(images=self.bus_image_pil)
+ self.assertTrue((processor_outputs["image_patches_indices"] == EXPECTED_IMAGE_PATCH_INPUTS).all())
+
+ def test_fuyu_processing_multiple_image_sample(self):
+ """
+ Test to check processor works with multiple image inputs for a single text input
+ """
+ # fmt: off
+ SINGLE_IMAGE_PATCH_INPUTS = torch.Tensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, -1, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, -1, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, -1, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, -1, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, -1, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, -1, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, -1, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, -1, 176, 177, 178, 179, 180, 181, 182, 183, 184, 185, 186, 187, 188, 189, 190, 191, 192, 193, 194, 195, 196, 197, -1, 198, 199, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 213, 214, 215, 216, 217, 218, 219, -1, 220, 221, 222, 223, 224, 225, 226, 227, 228, 229, 230, 231, 232, 233, 234, 235, 236, 237, 238, 239, 240, 241, -1, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255, 256, 257, 258, 259, 260, 261, 262, 263, -1, 264, 265, 266, 267, 268, 269, 270, 271, 272, 273, 274, 275, 276, 277, 278, 279, 280, 281, 282, 283, 284, 285, -1, 286, 287, 288, 289, 290, 291, 292, 293, 294, 295, 296, 297, 298, 299, 300, 301, 302, 303, 304, 305, 306, 307, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,]]).to(torch.int64)
+ SINGLE_PADDED_UNPACKED_TOKEN_INPUTS = torch.Tensor([[71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71011, 71019, 1, 128340, 71374, 71389, 120412, 71377, 71835, 71374, 73615, 71375, 71399, 71435, 71122,]]).to(torch.int64)
+
+ SINGLE_RESIZED_IMAGE_PATCH_INPUTS = torch.Tensor([[ 0, 1, 2, -1, 3, 4, 5, -1, 6, 7, 8, -1, 9, 10, 11, -1, 12, 13, 14, -1, 15, 16, 17, -1, 18, 19, 20, -1, 21, 22, 23, -1, 24, 25, 26, -1, 27, 28, 29, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1]])
+ SINGLE_RESIZED_PADDED_UNPACKED_TOKEN_INPUTS = torch.Tensor([[ 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71019, 71011, 71011, 71011, 71019, 1, 128340, 71374, 71389, 120412, 71377, 71835, 71374, 73615, 71375, 71399, 71435, 71122]])
+ # fmt: on
+
+ # Batch of two images - equally sized
+ images = [self.bus_image_pil, self.bus_image_pil]
+ processor_outputs = self.get_processor()(text=[self.text_prompt, self.text_prompt], images=images)
+
+ self.assertTrue(
+ (
+ processor_outputs["image_patches_indices"]
+ == torch.cat([SINGLE_IMAGE_PATCH_INPUTS, SINGLE_IMAGE_PATCH_INPUTS], dim=0)
+ ).all()
+ )
+ self.assertTrue(
+ (
+ processor_outputs["input_ids"]
+ == torch.cat([SINGLE_PADDED_UNPACKED_TOKEN_INPUTS, SINGLE_PADDED_UNPACKED_TOKEN_INPUTS], dim=0)
+ ).all()
+ )
+
+ # Processes single images with different sizes as expected
+ images = [self.bus_image_pil]
+ processor_outputs = self.get_processor()(text=self.text_prompt, images=images)
+ self.assertTrue((processor_outputs["image_patches_indices"] == SINGLE_IMAGE_PATCH_INPUTS).all())
+ self.assertTrue((processor_outputs["input_ids"] == SINGLE_PADDED_UNPACKED_TOKEN_INPUTS).all())
+
+ images = [self.bus_image_pil.resize((64, 300))]
+ processor_outputs = self.get_processor()(text=self.text_prompt, images=images)
+ self.assertTrue((processor_outputs["image_patches_indices"] == SINGLE_RESIZED_IMAGE_PATCH_INPUTS).all())
+ self.assertTrue((processor_outputs["input_ids"] == SINGLE_RESIZED_PADDED_UNPACKED_TOKEN_INPUTS).all())
+
+ # Batch of two images - different sizes. Left-pads the smaller image inputs
+ images = [self.bus_image_pil, self.bus_image_pil.resize((64, 300))]
+ processor_outputs = self.get_processor()(text=[self.text_prompt, self.text_prompt], images=images)
+
+ padding_len_patch = SINGLE_IMAGE_PATCH_INPUTS.shape[1] - SINGLE_RESIZED_IMAGE_PATCH_INPUTS.shape[1]
+ padded_single_resized_image_patch = torch.cat(
+ [torch.ones([1, padding_len_patch]) * -1, SINGLE_RESIZED_IMAGE_PATCH_INPUTS], dim=1
+ )
+ expected_image_patch_inputs = torch.cat([SINGLE_IMAGE_PATCH_INPUTS, padded_single_resized_image_patch], dim=0)
+
+ padding_len_token = (
+ SINGLE_PADDED_UNPACKED_TOKEN_INPUTS.shape[1] - SINGLE_RESIZED_PADDED_UNPACKED_TOKEN_INPUTS.shape[1]
+ )
+ padded_single_resized_padded_unpacked_token_inputs = torch.cat(
+ [torch.zeros([1, padding_len_token]), SINGLE_RESIZED_PADDED_UNPACKED_TOKEN_INPUTS], dim=1
+ )
+ expected_padded_unpacked_token_inputs = torch.cat(
+ [SINGLE_PADDED_UNPACKED_TOKEN_INPUTS, padded_single_resized_padded_unpacked_token_inputs], dim=0
+ )
+
+ self.assertTrue((processor_outputs["image_patches_indices"] == expected_image_patch_inputs).all())
+ self.assertTrue((processor_outputs["input_ids"] == expected_padded_unpacked_token_inputs).all())
+
+ # Rewrite as Fuyu supports tokenizer kwargs only when image is None.
+ @require_vision
+ @require_torch
+ def test_kwargs_overrides_default_tokenizer_kwargs(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ image_processor = self.get_component("image_processor")
+ tokenizer = self.get_component("tokenizer", max_length=117)
+
+ processor = self.processor_class(tokenizer=tokenizer, image_processor=image_processor)
+ self.skip_processor_without_typed_kwargs(processor)
+ input_str = self.prepare_text_inputs()
+ # Fuyu uses tokenizer kwargs only when image is None.
+ image_input = None
+
+ inputs = processor(
+ text=input_str, images=image_input, return_tensors="pt", max_length=112, padding="max_length"
+ )
+ self.assertEqual(len(inputs["input_ids"][0]), 112)
+
+ @unittest.skip("Fuyu processor does not support image_processor kwargs")
+ def test_image_processor_defaults_preserved_by_image_kwargs(self):
+ pass
+
+ @unittest.skip("Fuyu processor does not support image_processor kwargs")
+ def test_kwargs_overrides_default_image_processor_kwargs(self):
+ pass
+
+ # Rewrite as Fuyu supports tokenizer kwargs only when image is None.
+ @require_vision
+ @require_torch
+ def test_tokenizer_defaults_preserved_by_kwargs(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ image_processor = self.get_component("image_processor")
+ tokenizer = self.get_component("tokenizer", max_length=117, padding="max_length")
+
+ processor = self.processor_class(tokenizer=tokenizer, image_processor=image_processor)
+ self.skip_processor_without_typed_kwargs(processor)
+ input_str = self.prepare_text_inputs()
+ # Fuyu uses tokenizer kwargs only when image is None.
+ image_input = None
+
+ inputs = processor(text=input_str, images=image_input, return_tensors="pt")
+ self.assertEqual(len(inputs["input_ids"][0]), 117)
+
+ # Rewrite as Fuyu image processor does not return pixel values
+ @require_torch
+ @require_vision
+ def test_structured_kwargs_nested(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ image_processor = self.get_component("image_processor")
+ tokenizer = self.get_component("tokenizer")
+
+ processor = self.processor_class(tokenizer=tokenizer, image_processor=image_processor)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ input_str = self.prepare_text_inputs()
+ # Fuyu uses tokenizer kwargs only when image is None.
+ image_input = None
+
+ # Define the kwargs for each modality
+ all_kwargs = {
+ "common_kwargs": {"return_tensors": "pt"},
+ "text_kwargs": {"padding": "max_length", "max_length": 76},
+ }
+
+ inputs = processor(text=input_str, images=image_input, **all_kwargs)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ self.assertEqual(len(inputs["input_ids"][0]), 76)
+
+ # Rewrite as Fuyu image processor does not return pixel values
+ @require_torch
+ @require_vision
+ def test_structured_kwargs_nested_from_dict(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+
+ image_processor = self.get_component("image_processor")
+ tokenizer = self.get_component("tokenizer")
+
+ processor = self.processor_class(tokenizer=tokenizer, image_processor=image_processor)
+ self.skip_processor_without_typed_kwargs(processor)
+ input_str = self.prepare_text_inputs()
+ # Fuyu uses tokenizer kwargs only when image is None.
+ image_input = None
+
+ # Define the kwargs for each modality
+ all_kwargs = {
+ "common_kwargs": {"return_tensors": "pt"},
+ "text_kwargs": {"padding": "max_length", "max_length": 76},
+ }
+
+ inputs = processor(text=input_str, images=image_input, **all_kwargs)
+
+ self.assertEqual(len(inputs["input_ids"][0]), 76)
+
+ # Rewrite as Fuyu supports tokenizer kwargs only when image is None.
+ @require_torch
+ @require_vision
+ def test_unstructured_kwargs(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ image_processor = self.get_component("image_processor")
+ tokenizer = self.get_component("tokenizer")
+
+ processor = self.processor_class(tokenizer=tokenizer, image_processor=image_processor)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ input_str = self.prepare_text_inputs()
+ # Fuyu uses tokenizer kwargs only when image is None.
+ image_input = None
+ inputs = processor(
+ text=input_str,
+ images=image_input,
+ return_tensors="pt",
+ padding="max_length",
+ max_length=76,
+ )
+
+ self.assertEqual(len(inputs["input_ids"][0]), 76)
+
+ # Rewrite as Fuyu supports tokenizer kwargs only when image is None.
+ @require_torch
+ @require_vision
+ def test_unstructured_kwargs_batched(self):
+ if "image_processor" not in self.processor_class.attributes:
+ self.skipTest(f"image_processor attribute not present in {self.processor_class}")
+ image_processor = self.get_component("image_processor")
+ tokenizer = self.get_component("tokenizer")
+
+ processor = self.processor_class(tokenizer=tokenizer, image_processor=image_processor)
+ self.skip_processor_without_typed_kwargs(processor)
+
+ input_str = self.prepare_text_inputs(batch_size=2)
+ # Fuyu uses tokenizer kwargs only when image is None.
+ image_input = None
+ inputs = processor(
+ text=input_str,
+ images=image_input,
+ return_tensors="pt",
+ padding="longest",
+ max_length=76,
+ )
+
+ self.assertEqual(len(inputs["input_ids"][0]), 7)
+
+
+@require_torch
+class TestImageTextProcessingUtils(unittest.TestCase):
+ def setUp(self):
+ self.batch_size = 2
+ self.new_seq_len = 8
+ self.num_sub_sequences = 1
+
+ self.all_bi_tokens_to_place = [4, 6]
+ self.full_unpacked_stream = [torch.tensor([1, 2, 3, 4]), torch.tensor([5, 6, 7, 8, 9, 10])]
+ self.fill_value = 0
+
+ self.num_real_text_tokens = [[3, 2], [2, 4]]
+ # Here the input stream is padded to avoid inconsistencies (current model release matches)
+ self.input_stream = torch.tensor([[[1, 2, 3], [4, 5, 0]], [[6, 7, 0], [8, 9, 10]]])
+ self.image_tokens = [
+ [torch.tensor([1, 2]), torch.tensor([3])],
+ [torch.tensor([4, 5, 6]), torch.tensor([7, 8])],
+ ]
+
+ def test_full_unpacked_stream_to_tensor(self):
+ result = full_unpacked_stream_to_tensor(
+ self.all_bi_tokens_to_place,
+ self.full_unpacked_stream,
+ self.fill_value,
+ self.batch_size,
+ self.new_seq_len,
+ offset=0,
+ )
+ EXPECTED_TENSOR = torch.tensor([[1, 2, 3, 4, 0, 0, 0, 0], [5, 6, 7, 8, 9, 10, 0, 0]])
+ self.assertTrue(torch.equal(result, EXPECTED_TENSOR))
+
+ def test_construct_full_unpacked_stream(self):
+ result = construct_full_unpacked_stream(
+ self.num_real_text_tokens, self.input_stream, self.image_tokens, self.batch_size, self.num_sub_sequences
+ )
+ EXPECTED_UNPACKED_STREAM = [torch.tensor([1, 2, 1, 2, 3]), torch.tensor([4, 5, 6, 6, 7])]
+ for i in range(len(result)):
+ self.assertTrue(torch.equal(result[i], EXPECTED_UNPACKED_STREAM[i]))
+
+
+@require_torch
+class TestProcessImagesForModelInput(unittest.TestCase):
+ def setUp(self):
+ """
+ Adding a mix of present and absent images.
+ """
+
+ self.image_input = torch.randn([1, 1, 3, 64, 64])
+ self.image_present = torch.tensor([[1]])
+ self.image_unpadded_h = torch.tensor([[45]]) # Adjusted for subsequence of 1
+ self.image_unpadded_w = torch.tensor([[50]]) # Adjusted for subsequence of 1
+ self.image_patch_dim_h = 16
+ self.image_patch_dim_w = 16
+ self.image_placeholder_id = 999
+ self.image_newline_id = 888
+ self.variable_sized = True
+ self.image_processor = FuyuImageProcessor(
+ patch_size={"height": self.image_patch_dim_h, "width": self.image_patch_dim_w}
+ )
+
+ def test_process_images_for_model_input_fixed_sized(self):
+ self.variable_sized = False
+ result = self.image_processor.preprocess_with_tokenizer_info(
+ image_input=self.image_input,
+ image_present=self.image_present,
+ image_unpadded_h=self.image_unpadded_h,
+ image_unpadded_w=self.image_unpadded_w,
+ image_placeholder_id=self.image_placeholder_id,
+ image_newline_id=self.image_newline_id,
+ variable_sized=self.variable_sized,
+ )
+ self.assertEqual(result["images"][0][0].shape, torch.Size([3, 64, 64]))
diff --git a/transformers/tests/models/gemma2/__init__.py b/transformers/tests/models/gemma2/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/gemma2/test_modeling_gemma2.py b/transformers/tests/models/gemma2/test_modeling_gemma2.py
new file mode 100644
index 0000000000000000000000000000000000000000..0f06ed3cea5689d28097715e4784ebb1967bb191
--- /dev/null
+++ b/transformers/tests/models/gemma2/test_modeling_gemma2.py
@@ -0,0 +1,472 @@
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Gemma2 model."""
+
+import unittest
+
+import pytest
+from packaging import version
+from parameterized import parameterized
+from pytest import mark
+
+from transformers import AutoModelForCausalLM, AutoTokenizer, Gemma2Config, is_torch_available, pipeline
+from transformers.generation.configuration_utils import GenerationConfig
+from transformers.testing_utils import (
+ Expectations,
+ cleanup,
+ is_flash_attn_2_available,
+ require_flash_attn,
+ require_large_cpu_ram,
+ require_read_token,
+ require_torch,
+ require_torch_accelerator,
+ require_torch_large_accelerator,
+ require_torch_large_gpu,
+ slow,
+ torch_device,
+)
+
+from ...causal_lm_tester import CausalLMModelTest, CausalLMModelTester
+from ...test_configuration_common import ConfigTester
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ Gemma2ForCausalLM,
+ Gemma2ForSequenceClassification,
+ Gemma2ForTokenClassification,
+ Gemma2Model,
+ )
+
+
+class Gemma2ModelTester(CausalLMModelTester):
+ if is_torch_available():
+ config_class = Gemma2Config
+ base_model_class = Gemma2Model
+ causal_lm_class = Gemma2ForCausalLM
+ sequence_class = Gemma2ForSequenceClassification
+ token_class = Gemma2ForTokenClassification
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": Gemma2Model,
+ "text-classification": Gemma2ForSequenceClassification,
+ "token-classification": Gemma2ForTokenClassification,
+ "text-generation": Gemma2ForCausalLM,
+ "zero-shot": Gemma2ForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+
+@require_torch
+class Gemma2ModelTest(CausalLMModelTest, unittest.TestCase):
+ all_model_classes = (
+ (Gemma2Model, Gemma2ForCausalLM, Gemma2ForSequenceClassification, Gemma2ForTokenClassification)
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": Gemma2Model,
+ "text-classification": Gemma2ForSequenceClassification,
+ "token-classification": Gemma2ForTokenClassification,
+ "text-generation": Gemma2ForCausalLM,
+ "zero-shot": Gemma2ForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ test_headmasking = False
+ test_pruning = False
+ _is_stateful = True
+ model_split_percents = [0.5, 0.6]
+ model_tester_class = Gemma2ModelTester
+
+ def setUp(self):
+ self.model_tester = Gemma2ModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=Gemma2Config, hidden_size=37)
+
+ @unittest.skip("Failing because of unique cache (HybridCache)")
+ def test_model_outputs_equivalence(self, **kwargs):
+ pass
+
+ @unittest.skip("Gemma2's forcefully disables sdpa due to softcapping")
+ def test_sdpa_can_dispatch_non_composite_models(self):
+ pass
+
+ @unittest.skip("Gemma2's eager attn/sdpa attn outputs are expected to be different")
+ def test_eager_matches_sdpa_generate(self):
+ pass
+
+ @parameterized.expand([("random",), ("same",)])
+ @pytest.mark.generate
+ @unittest.skip("Gemma2 has HybridCache which is not compatible with assisted decoding")
+ def test_assisted_decoding_matches_greedy_search(self, assistant_type):
+ pass
+
+ @unittest.skip("Gemma2 has HybridCache which is not compatible with assisted decoding")
+ def test_prompt_lookup_decoding_matches_greedy_search(self, assistant_type):
+ pass
+
+ @pytest.mark.generate
+ @unittest.skip("Gemma2 has HybridCache which is not compatible with assisted decoding")
+ def test_assisted_decoding_sample(self):
+ pass
+
+ @unittest.skip("Gemma2 has HybridCache which is not compatible with dola decoding")
+ def test_dola_decoding_sample(self):
+ pass
+
+ @unittest.skip("Gemma2 has HybridCache and doesn't support continue from past kv")
+ def test_generate_continue_from_past_key_values(self):
+ pass
+
+ @unittest.skip("Gemma2 has HybridCache and doesn't support contrastive generation")
+ def test_contrastive_generate(self):
+ pass
+
+ @unittest.skip("Gemma2 has HybridCache and doesn't support contrastive generation")
+ def test_contrastive_generate_dict_outputs_use_cache(self):
+ pass
+
+ @unittest.skip("Gemma2 has HybridCache and doesn't support contrastive generation")
+ def test_contrastive_generate_low_memory(self):
+ pass
+
+ @unittest.skip("Gemma2 has HybridCache and doesn't support StaticCache. Though it could, it shouldn't support.")
+ def test_generate_with_static_cache(self):
+ pass
+
+ @unittest.skip("Gemma2 has HybridCache and doesn't support StaticCache. Though it could, it shouldn't support.")
+ def test_generate_from_inputs_embeds_with_static_cache(self):
+ pass
+
+ @unittest.skip("Gemma2 has HybridCache and doesn't support StaticCache. Though it could, it shouldn't support.")
+ def test_generate_continue_from_inputs_embeds(self):
+ pass
+
+ @unittest.skip(
+ reason="HybridCache can't be gathered because it is not iterable. Adding a simple iter and dumping `distributed_iterator`"
+ " as in Dynamic Cache doesn't work. NOTE: @gante all cache objects would need better compatibility with multi gpu setting"
+ )
+ def test_multi_gpu_data_parallel_forward(self):
+ pass
+
+ @unittest.skip("Gemma2 has HybridCache which auto-compiles. Compile and FA2 don't work together.")
+ def test_eager_matches_fa2_generate(self):
+ pass
+
+ @unittest.skip("Gemma2 eager/FA2 attention outputs are expected to be different")
+ def test_flash_attn_2_equivalence(self):
+ pass
+
+
+@slow
+@require_torch_accelerator
+class Gemma2IntegrationTest(unittest.TestCase):
+ input_text = ["Hello I am doing", "Hi today"]
+
+ def setUp(self):
+ cleanup(torch_device, gc_collect=True)
+
+ def tearDown(self):
+ cleanup(torch_device, gc_collect=True)
+
+ @require_torch_large_accelerator
+ @require_read_token
+ def test_model_9b_bf16(self):
+ model_id = "google/gemma-2-9b"
+ EXPECTED_TEXTS = [
+ "Hello I am doing a project on the 1918 flu pandemic and I am trying to find out how many",
+ "Hi today I'm going to be talking about the history of the United States. The United States of America",
+ ]
+
+ model = AutoModelForCausalLM.from_pretrained(
+ model_id, torch_dtype=torch.bfloat16, attn_implementation="eager"
+ ).to(torch_device)
+
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ inputs = tokenizer(self.input_text, return_tensors="pt", padding=True).to(torch_device)
+
+ output = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+ output_text = tokenizer.batch_decode(output, skip_special_tokens=False)
+
+ self.assertEqual(output_text, EXPECTED_TEXTS)
+
+ @require_torch_large_accelerator
+ @require_read_token
+ def test_model_9b_fp16(self):
+ model_id = "google/gemma-2-9b"
+ EXPECTED_TEXTS = [
+ "Hello I am doing a project on the 1918 flu pandemic and I am trying to find out how many",
+ "Hi today I'm going to be talking about the history of the United States. The United States of America",
+ ]
+
+ model = AutoModelForCausalLM.from_pretrained(
+ model_id, torch_dtype=torch.float16, attn_implementation="eager"
+ ).to(torch_device)
+
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ inputs = tokenizer(self.input_text, return_tensors="pt", padding=True).to(torch_device)
+
+ output = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+ output_text = tokenizer.batch_decode(output, skip_special_tokens=False)
+
+ self.assertEqual(output_text, EXPECTED_TEXTS)
+
+ @require_read_token
+ @require_torch_large_accelerator
+ def test_model_9b_pipeline_bf16(self):
+ # See https://github.com/huggingface/transformers/pull/31747 -- pipeline was broken for Gemma2 before this PR
+ model_id = "google/gemma-2-9b"
+ # EXPECTED_TEXTS should match the same non-pipeline test, minus the special tokens
+ EXPECTED_TEXTS = [
+ "Hello I am doing a project on the 1918 flu pandemic and I am trying to find out how many",
+ "Hi today I'm going to be talking about the history of the United States. The United States of America",
+ ]
+
+ model = AutoModelForCausalLM.from_pretrained(
+ model_id, torch_dtype=torch.bfloat16, attn_implementation="flex_attention"
+ ).to(torch_device)
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
+
+ output = pipe(self.input_text, max_new_tokens=20, do_sample=False, padding=True)
+
+ self.assertEqual(output[0][0]["generated_text"], EXPECTED_TEXTS[0])
+ self.assertEqual(output[1][0]["generated_text"], EXPECTED_TEXTS[1])
+
+ @require_read_token
+ def test_model_2b_pipeline_bf16_flex_attention(self):
+ # See https://github.com/huggingface/transformers/pull/31747 -- pipeline was broken for Gemma2 before this PR
+ model_id = "google/gemma-2-2b"
+ # EXPECTED_TEXTS should match the same non-pipeline test, minus the special tokens
+ EXPECTED_BATCH_TEXTS = Expectations(
+ {
+ ("xpu", 3): [
+ "Hello I am doing a project on the 1960s and I am trying to find out what the average",
+ "Hi today I'm going to be talking about the 10 most powerful characters in the Naruto series.",
+ ],
+ ("cuda", 8): [
+ "Hello I am doing a project on the 1960s and I am trying to find out what the average",
+ "Hi today I'm going to be talking about the 10 most powerful characters in the Naruto series.",
+ ],
+ }
+ )
+ EXPECTED_BATCH_TEXT = EXPECTED_BATCH_TEXTS.get_expectation()
+
+ model = AutoModelForCausalLM.from_pretrained(
+ model_id, torch_dtype=torch.bfloat16, attn_implementation="flex_attention"
+ ).to(torch_device)
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
+
+ output = pipe(self.input_text, max_new_tokens=20, do_sample=False, padding=True)
+
+ self.assertEqual(output[0][0]["generated_text"], EXPECTED_BATCH_TEXT[0])
+ self.assertEqual(output[1][0]["generated_text"], EXPECTED_BATCH_TEXT[1])
+
+ @require_read_token
+ @require_flash_attn
+ @require_torch_large_gpu
+ @mark.flash_attn_test
+ @slow
+ def test_model_9b_flash_attn(self):
+ # See https://github.com/huggingface/transformers/issues/31953 --- flash attn was generating garbage for gemma2, especially in long context
+ model_id = "google/gemma-2-9b"
+ EXPECTED_TEXTS = [
+ 'Hello I am doing a project on the 1918 flu pandemic and I am trying to find out how many people died in the United States. I have found a few sites that say 500,000 but I am not sure if that is correct. I have also found a site that says 675,000 but I am not sure if that is correct either. I am trying to find out how many people died in the United States. I have found a few',
+ "Hi today I'm going to be talking about the history of the United States. The United States of America is a country in North America. It is the third largest country in the world by total area and the third most populous country with over 320 million people. The United States is a federal republic composed of 50 states and a federal district. The 48 contiguous states and the district of Columbia are in central North America between Canada and Mexico. The state of Alaska is in the",
+ ] # fmt: skip
+
+ model = AutoModelForCausalLM.from_pretrained(
+ model_id, attn_implementation="flash_attention_2", torch_dtype="float16"
+ ).to(torch_device)
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ inputs = tokenizer(self.input_text, return_tensors="pt", padding=True).to(torch_device)
+
+ output = model.generate(**inputs, max_new_tokens=100, do_sample=False)
+ output_text = tokenizer.batch_decode(output, skip_special_tokens=False)
+
+ self.assertEqual(output_text, EXPECTED_TEXTS)
+
+ @slow
+ @require_read_token
+ def test_export_static_cache(self):
+ if version.parse(torch.__version__) < version.parse("2.5.0"):
+ self.skipTest(reason="This test requires torch >= 2.5 to run.")
+
+ from transformers.integrations.executorch import (
+ TorchExportableModuleWithStaticCache,
+ )
+
+ tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-2b", pad_token="", padding_side="right")
+ EXPECTED_TEXT_COMPLETIONS = Expectations(
+ {
+ ("xpu", 3): [
+ "Hello I am doing a project for my school and I need to know how to make a program that will take a number"
+ ],
+ ("cuda", 7): [
+ "Hello I am doing a project for my school and I need to know how to make a program that will take a number"
+ ],
+ ("cuda", 8): [
+ "Hello I am doing a project for my class and I am having trouble with the code. I am trying to make a"
+ ],
+ }
+ )
+ EXPECTED_TEXT_COMPLETION = EXPECTED_TEXT_COMPLETIONS.get_expectation()
+ max_generation_length = tokenizer(EXPECTED_TEXT_COMPLETION, return_tensors="pt", padding=True)[
+ "input_ids"
+ ].shape[-1]
+
+ # Load model
+ device = "cpu"
+ dtype = torch.bfloat16
+ cache_implementation = "static"
+ attn_implementation = "sdpa"
+ batch_size = 1
+ model = AutoModelForCausalLM.from_pretrained(
+ "google/gemma-2-2b",
+ device_map=device,
+ torch_dtype=dtype,
+ attn_implementation=attn_implementation,
+ generation_config=GenerationConfig(
+ use_cache=True,
+ cache_implementation=cache_implementation,
+ max_length=max_generation_length,
+ cache_config={
+ "batch_size": batch_size,
+ "max_cache_len": max_generation_length,
+ },
+ ),
+ )
+
+ prompts = ["Hello I am doing"]
+ prompt_tokens = tokenizer(prompts, return_tensors="pt", padding=True).to(model.device)
+ prompt_token_ids = prompt_tokens["input_ids"]
+ max_new_tokens = max_generation_length - prompt_token_ids.shape[-1]
+
+ # Static Cache + export
+ from transformers.integrations.executorch import TorchExportableModuleForDecoderOnlyLM
+
+ exportable_module = TorchExportableModuleForDecoderOnlyLM(model)
+ exported_program = exportable_module.export()
+ ep_generated_ids = TorchExportableModuleWithStaticCache.generate(
+ exported_program=exported_program, prompt_token_ids=prompt_token_ids, max_new_tokens=max_new_tokens
+ )
+ ep_generated_text = tokenizer.batch_decode(ep_generated_ids, skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, ep_generated_text)
+
+ @slow
+ @require_read_token
+ @require_large_cpu_ram
+ def test_export_hybrid_cache(self):
+ from transformers.integrations.executorch import TorchExportableModuleForDecoderOnlyLM
+ from transformers.pytorch_utils import is_torch_greater_or_equal
+
+ if not is_torch_greater_or_equal("2.6.0"):
+ self.skipTest(reason="This test requires torch >= 2.6 to run.")
+
+ model_id = "google/gemma-2-2b"
+ model = AutoModelForCausalLM.from_pretrained(model_id)
+ self.assertEqual(model.config.cache_implementation, "hybrid")
+
+ # Export + HybridCache
+ model.eval()
+ exportable_module = TorchExportableModuleForDecoderOnlyLM(model)
+ exported_program = exportable_module.export()
+
+ # Test generation with the exported model
+ prompt = "What is the capital of France?"
+ max_new_tokens_to_generate = 20
+ # Generate text with the exported model
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ export_generated_text = TorchExportableModuleForDecoderOnlyLM.generate(
+ exported_program, tokenizer, prompt, max_new_tokens=max_new_tokens_to_generate
+ )
+
+ input_text = tokenizer(prompt, return_tensors="pt")
+ with torch.no_grad():
+ eager_outputs = model.generate(
+ **input_text,
+ max_new_tokens=max_new_tokens_to_generate,
+ do_sample=False, # Use greedy decoding to match the exported model
+ )
+
+ eager_generated_text = tokenizer.decode(eager_outputs[0], skip_special_tokens=True)
+ self.assertEqual(export_generated_text, eager_generated_text)
+
+ @require_torch_large_accelerator
+ @require_read_token
+ def test_model_9b_bf16_flex_attention(self):
+ model_id = "google/gemma-2-9b"
+ EXPECTED_TEXTS = [
+ "Hello I am doing a project on the 1918 flu pandemic and I am trying to find out how many",
+ "Hi today I'm going to be talking about the history of the United States. The United States of America",
+ ]
+
+ model = AutoModelForCausalLM.from_pretrained(
+ model_id, torch_dtype=torch.bfloat16, attn_implementation="flex_attention"
+ ).to(torch_device)
+ assert model.config._attn_implementation == "flex_attention"
+ tokenizer = AutoTokenizer.from_pretrained(model_id)
+ inputs = tokenizer(self.input_text, return_tensors="pt", padding=True).to(torch_device)
+
+ output = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+ output_text = tokenizer.batch_decode(output, skip_special_tokens=False)
+
+ self.assertEqual(output_text, EXPECTED_TEXTS)
+
+ @parameterized.expand([("flash_attention_2",), ("sdpa",), ("flex_attention",), ("eager",)])
+ @require_read_token
+ def test_generation_beyond_sliding_window(self, attn_implementation: str):
+ """Test that we can correctly generate beyond the sliding window. This is non trivial as
+ we need to correctly slice the attention mask in all cases (because we use a HybridCache).
+ Outputs for every attention functions should be coherent and identical.
+ """
+ if attn_implementation == "flash_attention_2" and not is_flash_attn_2_available():
+ self.skipTest("FlashAttention2 is required for this test.")
+
+ if torch_device == "xpu" and attn_implementation == "flash_attention_2":
+ self.skipTest(reason="Intel XPU doesn't support falsh_attention_2 as of now.")
+
+ model_id = "google/gemma-2-2b"
+ EXPECTED_COMPLETIONS = [
+ " the people, the food, the culture, the history, the music, the art, the architecture",
+ ", green, yellow, orange, purple, pink, brown, black, white, gray, silver",
+ ]
+
+ input_text = [
+ "This is a nice place. " * 800 + "I really enjoy the scenery,", # This is larger than 4096 tokens
+ "A list of colors: red, blue", # This will almost all be padding tokens
+ ]
+ tokenizer = AutoTokenizer.from_pretrained(model_id, padding="left")
+ inputs = tokenizer(input_text, padding=True, return_tensors="pt").to(torch_device)
+
+ model = AutoModelForCausalLM.from_pretrained(
+ model_id, attn_implementation=attn_implementation, torch_dtype=torch.float16
+ ).to(torch_device)
+
+ # Make sure prefill is larger than sliding window
+ input_size = inputs.input_ids.shape[-1]
+ self.assertTrue(input_size > model.config.sliding_window)
+
+ out = model.generate(**inputs, max_new_tokens=20)[:, input_size:]
+ output_text = tokenizer.batch_decode(out)
+
+ self.assertEqual(output_text, EXPECTED_COMPLETIONS)
diff --git a/transformers/tests/models/gemma3n/__init__.py b/transformers/tests/models/gemma3n/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/gemma3n/test_feature_extraction_gemma3n.py b/transformers/tests/models/gemma3n/test_feature_extraction_gemma3n.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2b10315bd6e6de98ddcd114d3014bbdb669a5c6
--- /dev/null
+++ b/transformers/tests/models/gemma3n/test_feature_extraction_gemma3n.py
@@ -0,0 +1,277 @@
+# Copyright 2025 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import itertools
+import os
+import random
+import tempfile
+import unittest
+from typing import Optional, Sequence
+
+import numpy as np
+from parameterized import parameterized
+
+from transformers.models.gemma3n import Gemma3nAudioFeatureExtractor
+from transformers.testing_utils import (
+ check_json_file_has_correct_format,
+ require_torch,
+)
+from transformers.utils.import_utils import is_torch_available
+
+from ...test_sequence_feature_extraction_common import SequenceFeatureExtractionTestMixin
+
+
+if is_torch_available():
+ pass
+
+global_rng = random.Random()
+
+MAX_LENGTH_FOR_TESTING = 512
+
+
+def floats_list(shape, scale=1.0, rng=None):
+ """Creates a random float32 tensor"""
+ if rng is None:
+ rng = global_rng
+
+ values = []
+ for _ in range(shape[0]):
+ values.append([])
+ for _ in range(shape[1]):
+ values[-1].append(rng.random() * scale)
+
+ return values
+
+
+class Gemma3nAudioFeatureExtractionTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ min_seq_length=400,
+ max_seq_length=2000,
+ feature_size: int = 128,
+ sampling_rate: int = 16_000,
+ padding_value: float = 0.0,
+ return_attention_mask: bool = False,
+ # ignore hop_length / frame_length for now, as ms -> length conversion causes issues with serialization tests
+ # frame_length_ms: float = 32.0,
+ # hop_length: float = 10.0,
+ min_frequency: float = 125.0,
+ max_frequency: float = 7600.0,
+ preemphasis: float = 0.97,
+ preemphasis_htk_flavor: bool = True,
+ fft_overdrive: bool = True,
+ dither: float = 0.0,
+ input_scale_factor: float = 1.0,
+ mel_floor: float = 1e-5,
+ per_bin_mean: Optional[Sequence[float]] = None,
+ per_bin_stddev: Optional[Sequence[float]] = None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.min_seq_length = min_seq_length
+ self.max_seq_length = max_seq_length
+ self.seq_length_diff = (self.max_seq_length - self.min_seq_length) // (self.batch_size - 1)
+ self.feature_size = feature_size
+ self.sampling_rate = sampling_rate
+ self.padding_value = padding_value
+ self.return_attention_mask = return_attention_mask
+ # ignore hop_length / frame_length for now, as ms -> length conversion causes issues with serialization tests
+ # self.frame_length_ms = frame_length_ms
+ # self.hop_length = hop_length
+ self.min_frequency = min_frequency
+ self.max_frequency = max_frequency
+ self.preemphasis = preemphasis
+ self.preemphasis_htk_flavor = preemphasis_htk_flavor
+ self.fft_overdrive = fft_overdrive
+ self.dither = dither
+ self.input_scale_factor = input_scale_factor
+ self.mel_floor = mel_floor
+ self.per_bin_mean = per_bin_mean
+ self.per_bin_stddev = per_bin_stddev
+
+ def prepare_feat_extract_dict(self):
+ return {
+ "feature_size": self.feature_size,
+ "sampling_rate": self.sampling_rate,
+ "padding_value": self.padding_value,
+ "return_attention_mask": self.return_attention_mask,
+ "min_frequency": self.min_frequency,
+ "max_frequency": self.max_frequency,
+ "preemphasis": self.preemphasis,
+ "preemphasis_htk_flavor": self.preemphasis_htk_flavor,
+ "fft_overdrive": self.fft_overdrive,
+ "dither": self.dither,
+ "input_scale_factor": self.input_scale_factor,
+ "mel_floor": self.mel_floor,
+ "per_bin_mean": self.per_bin_mean,
+ "per_bin_stddev": self.per_bin_stddev,
+ }
+
+ def prepare_inputs_for_common(self, equal_length=False, numpify=False):
+ def _flatten(list_of_lists):
+ return list(itertools.chain(*list_of_lists))
+
+ if equal_length:
+ speech_inputs = [floats_list((self.max_seq_length, self.feature_size)) for _ in range(self.batch_size)]
+ else:
+ # make sure that inputs increase in size
+ speech_inputs = [
+ floats_list((x, self.feature_size))
+ for x in range(self.min_seq_length, self.max_seq_length, self.seq_length_diff)
+ ]
+ if numpify:
+ speech_inputs = [np.asarray(x) for x in speech_inputs]
+ return speech_inputs
+
+
+class Gemma3nAudioFeatureExtractionTest(SequenceFeatureExtractionTestMixin, unittest.TestCase):
+ feature_extraction_class = Gemma3nAudioFeatureExtractor
+
+ def setUp(self):
+ self.feat_extract_tester = Gemma3nAudioFeatureExtractionTester(self)
+
+ def test_feat_extract_from_and_save_pretrained(self):
+ feat_extract_first = self.feature_extraction_class(**self.feat_extract_dict)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ saved_file = feat_extract_first.save_pretrained(tmpdirname)[0]
+ check_json_file_has_correct_format(saved_file)
+ feat_extract_second = self.feature_extraction_class.from_pretrained(tmpdirname)
+
+ dict_first = feat_extract_first.to_dict()
+ dict_second = feat_extract_second.to_dict()
+ mel_1 = feat_extract_first.mel_filters
+ mel_2 = feat_extract_second.mel_filters
+ self.assertTrue(np.allclose(mel_1, mel_2))
+ self.assertEqual(dict_first, dict_second)
+
+ def test_feat_extract_to_json_file(self):
+ feat_extract_first = self.feature_extraction_class(**self.feat_extract_dict)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ json_file_path = os.path.join(tmpdirname, "feat_extract.json")
+ feat_extract_first.to_json_file(json_file_path)
+ feat_extract_second = self.feature_extraction_class.from_json_file(json_file_path)
+
+ dict_first = feat_extract_first.to_dict()
+ dict_second = feat_extract_second.to_dict()
+ mel_1 = feat_extract_first.mel_filters
+ mel_2 = feat_extract_second.mel_filters
+ self.assertTrue(np.allclose(mel_1, mel_2))
+ self.assertEqual(dict_first, dict_second)
+
+ def test_feat_extract_from_pretrained_kwargs(self):
+ feat_extract_first = self.feature_extraction_class(**self.feat_extract_dict)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ saved_file = feat_extract_first.save_pretrained(tmpdirname)[0]
+ check_json_file_has_correct_format(saved_file)
+ feat_extract_second = self.feature_extraction_class.from_pretrained(
+ tmpdirname, feature_size=2 * self.feat_extract_dict["feature_size"]
+ )
+
+ mel_1 = feat_extract_first.mel_filters
+ mel_2 = feat_extract_second.mel_filters
+ self.assertTrue(2 * mel_1.shape[1] == mel_2.shape[1])
+
+ @parameterized.expand(
+ [
+ ([floats_list((1, x))[0] for x in range(800, 1400, 200)],),
+ ([floats_list((1, x))[0] for x in (800, 800, 800)],),
+ ([floats_list((1, x))[0] for x in range(200, (MAX_LENGTH_FOR_TESTING + 500), 200)], True),
+ ]
+ )
+ def test_call(self, audio_inputs, test_truncation=False):
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
+ np_audio_inputs = [np.asarray(audio_input) for audio_input in audio_inputs]
+
+ input_features = feature_extractor(np_audio_inputs, padding="max_length", return_tensors="np").input_features
+ self.assertTrue(input_features.ndim == 3)
+ # input_features.shape should be (batch, num_frames, n_mels) ~= (batch, num_frames, feature_size)
+ # 480_000 is the max_length that inputs are padded to. we use that to calculate num_frames
+ expected_num_frames = (480_000 - feature_extractor.frame_length) // (feature_extractor.hop_length) + 1
+ self.assertTrue(
+ input_features.shape[-2] == expected_num_frames,
+ f"no match: {input_features.shape[-1]} vs {expected_num_frames}",
+ )
+ self.assertTrue(input_features.shape[-1] == feature_extractor.feature_size)
+
+ encoded_sequences_1 = feature_extractor(audio_inputs, return_tensors="np").input_features
+ encoded_sequences_2 = feature_extractor(np_audio_inputs, return_tensors="np").input_features
+ for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
+ self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
+
+ if test_truncation:
+ audio_inputs_truncated = [x[:MAX_LENGTH_FOR_TESTING] for x in audio_inputs]
+ np_audio_inputs_truncated = [np.asarray(audio_input) for audio_input in audio_inputs_truncated]
+
+ encoded_sequences_1 = feature_extractor(
+ audio_inputs_truncated, max_length=MAX_LENGTH_FOR_TESTING, return_tensors="np"
+ ).input_features
+ encoded_sequences_2 = feature_extractor(
+ np_audio_inputs_truncated, max_length=MAX_LENGTH_FOR_TESTING, return_tensors="np"
+ ).input_features
+ for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
+ self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
+
+ def test_dither(self):
+ np.random.seed(42) # seed the dithering randn()
+
+ # Tests that features with and without little dithering are similar, but not the same
+ dict_no_dither = self.feat_extract_tester.prepare_feat_extract_dict()
+ dict_no_dither["dither"] = 0.0
+
+ dict_dither = self.feat_extract_tester.prepare_feat_extract_dict()
+ dict_dither["dither"] = 0.00003 # approx. 1/32k
+
+ feature_extractor_no_dither = self.feature_extraction_class(**dict_no_dither)
+ feature_extractor_dither = self.feature_extraction_class(**dict_dither)
+
+ # create three inputs of length 800, 1000, and 1200
+ speech_inputs = [floats_list((1, x))[0] for x in range(800, 1400, 200)]
+ np_speech_inputs = [np.asarray(speech_input) for speech_input in speech_inputs]
+
+ # compute features
+ input_features_no_dither = feature_extractor_no_dither(
+ np_speech_inputs, padding=True, return_tensors="np", sampling_rate=dict_no_dither["sampling_rate"]
+ ).input_features
+ input_features_dither = feature_extractor_dither(
+ np_speech_inputs, padding=True, return_tensors="np", sampling_rate=dict_dither["sampling_rate"]
+ ).input_features
+
+ # test there is a difference between features (there's added noise to input signal)
+ diff = input_features_dither - input_features_no_dither
+
+ # features are not identical
+ self.assertTrue(np.abs(diff).mean() > 1e-6)
+ # features are not too different
+ self.assertTrue(np.abs(diff).mean() <= 1e-4)
+ self.assertTrue(np.abs(diff).max() <= 5e-3)
+
+ @require_torch
+ def test_double_precision_pad(self):
+ import torch
+
+ feature_extractor = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
+ np_speech_inputs = np.random.rand(100, 32).astype(np.float64)
+ py_speech_inputs = np_speech_inputs.tolist()
+
+ for inputs in [py_speech_inputs, np_speech_inputs]:
+ np_processed = feature_extractor.pad([{"input_features": inputs}], return_tensors="np")
+ self.assertTrue(np_processed.input_features.dtype == np.float32)
+ pt_processed = feature_extractor.pad([{"input_features": inputs}], return_tensors="pt")
+ self.assertTrue(pt_processed.input_features.dtype == torch.float32)
diff --git a/transformers/tests/models/gemma3n/test_modeling_gemma3n.py b/transformers/tests/models/gemma3n/test_modeling_gemma3n.py
new file mode 100644
index 0000000000000000000000000000000000000000..060bf15ea1e937f68c7ee13077a86ef1e74c18c2
--- /dev/null
+++ b/transformers/tests/models/gemma3n/test_modeling_gemma3n.py
@@ -0,0 +1,952 @@
+# coding=utf-8
+# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Gemma3n model."""
+
+import tempfile
+import unittest
+
+import numpy as np
+import pytest
+from datasets import load_dataset
+from parameterized import parameterized
+
+from transformers import (
+ AutoModelForCausalLM,
+ AutoProcessor,
+ AutoTokenizer,
+ Gemma3nAudioConfig,
+ Gemma3nAudioFeatureExtractor,
+ Gemma3nConfig,
+ Gemma3nTextConfig,
+ GenerationConfig,
+ is_torch_available,
+)
+from transformers.testing_utils import (
+ cleanup,
+ require_flash_attn,
+ require_read_token,
+ require_torch,
+ require_torch_gpu,
+ require_torch_sdpa,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ TEST_EAGER_MATCHES_SDPA_INFERENCE_PARAMETERIZATION,
+ ModelTesterMixin,
+ _test_eager_matches_sdpa_inference,
+ floats_tensor,
+ ids_tensor,
+)
+from ..gemma.test_modeling_gemma import GemmaModelTester
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ Gemma3nAudioEncoder,
+ Gemma3nForCausalLM,
+ Gemma3nForConditionalGeneration,
+ Gemma3nModel,
+ Gemma3nTextModel,
+ )
+
+
+class Gemma3nAudioModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=2,
+ num_channels=32, # feature_size / input_feat_size
+ sampling_rate=16_000,
+ raw_audio_length=8_000,
+ is_training=True,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.sampling_rate = sampling_rate
+ self.raw_audio_length = raw_audio_length
+ self.is_training = is_training
+
+ def get_feature_extractor_config(self):
+ return {
+ "feature_size": self.num_channels,
+ "sampling_rate": self.sampling_rate,
+ "padding_value": 0.0,
+ "return_attention_mask": True,
+ "frame_length_ms": 32.0,
+ "hop_length_ms": 10.0,
+ "dither": 0.0, # Important for determinism
+ }
+
+ def get_audio_encoder_config(self):
+ return Gemma3nAudioConfig(
+ input_feat_size=self.num_channels,
+ hidden_size=32,
+ conf_num_attention_heads=4,
+ conf_num_hidden_layers=2,
+ sscp_conv_channel_size=(16, 8),
+ conf_conv_kernel_size=3,
+ conf_attention_chunk_size=4,
+ conf_attention_context_left=5,
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ # Prepare inputs for the audio encoder
+ feature_extractor_config = self.get_feature_extractor_config()
+ audio_encoder_config = self.get_audio_encoder_config()
+
+ np.random.seed(0)
+ raw_speech_1 = np.sin(2 * np.pi * 440 * np.linspace(0, 1, self.raw_audio_length)).astype(np.float32)
+ raw_speech_2 = np.random.randn(self.raw_audio_length // 2).astype(np.float32)
+ raw_speech = [raw_speech_1, raw_speech_2]
+
+ feature_extractor = Gemma3nAudioFeatureExtractor(**feature_extractor_config)
+ audio_inputs = feature_extractor(raw_speech, return_tensors="pt")
+
+ input_features = audio_inputs["input_features"]
+ # The encoder expects a padding mask (True for padding), while the feature extractor
+ # returns an attention mask (True for valid tokens). We must invert it.
+ input_features_mask = ~audio_inputs["input_features_mask"].to(torch.bool)
+
+ inputs_dict = {
+ "audio_mel": input_features,
+ "audio_mel_mask": input_features_mask,
+ }
+ return audio_encoder_config, inputs_dict
+
+
+@unittest.skip("Skipped for now!")
+@require_torch
+class Gemma3nAudioModelTest(ModelTesterMixin, unittest.TestCase):
+ all_model_classes = (Gemma3nAudioEncoder,) if is_torch_available() else ()
+ test_pruning = False
+ test_head_masking = False
+ test_missing_keys = False
+ is_generative = False
+ _is_stateful = True
+ main_input_name = "audio_mel"
+ test_initialization = False
+ test_can_init_all_missing_weights = False
+
+ def setUp(self):
+ self.model_tester = Gemma3nAudioModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=Gemma3nAudioConfig, hidden_size=37)
+ torch.manual_seed(0)
+
+ # The following values are golden outputs from a deterministic run of the components.
+ # They are used to ensure that changes to the code do not alter the numerical output.
+ # Generated with seeds np.random.seed(0) and torch.manual_seed(0).
+ self.expected_input_features_shape = (2, 48, 32)
+ self.expected_input_features_slice = np.array([-5.733152, -5.337127, -4.916284, -4.378989, -3.7622747])
+ self.expected_input_features_mask_shape = (2, 48)
+ self.expected_input_features_mask_slice = np.array([True, True, True, True, False])
+
+ self.expected_encoder_output_shape = (2, 3, 32)
+ self.expected_encoder_output_slice = torch.tensor([-0.4159, 0.6459, 0.6305, 2.2902, 0.9683])
+ self.expected_encoder_mask_shape = (2, 3)
+ self.expected_encoder_mask_slice = torch.tensor([False, False, True])
+
+ # Prepare a shared feature extractor and raw audio for the tests
+ self.feature_extractor = Gemma3nAudioFeatureExtractor(**self.model_tester.get_feature_extractor_config())
+ np.random.seed(0)
+ raw_speech_1 = np.sin(2 * np.pi * 440 * np.linspace(0, 1, self.model_tester.raw_audio_length)).astype(
+ np.float32
+ )
+ raw_speech_2 = np.random.randn(self.model_tester.raw_audio_length // 2).astype(np.float32)
+ self.raw_speech = [raw_speech_1, raw_speech_2]
+
+ @unittest.skip("Audio encoder does not support attention output")
+ def test_attention_outputs(self):
+ pass
+
+ @unittest.skip("Audio encoder does not support hidden state output")
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip("Audio encoder returns a tuple, not a ModelOutput object, skipping equivalence test.")
+ def test_model_outputs_equivalence(self):
+ pass
+
+ @unittest.skip("Audio encoder does not support retaining gradients on hidden states/attentions.")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ @unittest.skip("Audio encoder does not have a concept of token embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @unittest.skip("Audio encoder does not have a concept of token embeddings")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ @unittest.skip("This model has a complex downsampling scheme that is hard to test with the generic batching test.")
+ def test_batching_equivalence(self):
+ pass
+
+ def test_feature_extractor(self):
+ """
+ Tests the feature extractor's output against pre-computed golden values.
+ This ensures the NumPy-based audio preprocessing is correct and consistent.
+ """
+ audio_inputs = self.feature_extractor(
+ self.raw_speech, padding="longest", pad_to_multiple_of=128, return_tensors="np"
+ )
+
+ input_features = audio_inputs["input_features"]
+ self.assertEqual(input_features.shape, self.expected_input_features_shape)
+ np.testing.assert_allclose(input_features[0, 0, :5], self.expected_input_features_slice, rtol=1e-5, atol=1e-5)
+
+ print(input_features[0, 0, :5])
+
+ input_features_mask = audio_inputs["input_features_mask"]
+ self.assertEqual(input_features_mask.shape, self.expected_input_features_mask_shape)
+ # The second audio sample is shorter (22 frames vs 48), so its mask should become False at index 22
+ np.testing.assert_array_equal(input_features_mask[1, 21:26], self.expected_input_features_mask_slice)
+
+ def test_audio_encoder(self):
+ """
+ Tests the audio encoder's forward pass against pre-computed golden values.
+ This ensures the PyTorch-based audio encoding model is correct and consistent.
+ """
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = Gemma3nAudioEncoder(config).to(torch_device).eval()
+
+ with torch.no_grad():
+ encoder_output, encoder_mask = model(**inputs_dict)
+
+ print(encoder_output[0, 0, :5])
+
+ # Check output encodings
+ self.assertEqual(encoder_output.shape, self.expected_encoder_output_shape)
+ torch.testing.assert_close(
+ encoder_output[0, 0, :5], self.expected_encoder_output_slice.to(torch_device), rtol=1e-4, atol=1e-4
+ )
+
+ # Check output mask (True means padded)
+ # Second sample has 22 feature frames. After downsampling by 4 (conv) -> 5 frames. After downsampling by 4 (reduction) -> 1 frame.
+ # So the mask should be [False, True, True]
+ self.assertEqual(encoder_mask.shape, self.expected_encoder_mask_shape)
+ torch.testing.assert_close(encoder_mask[1, :], self.expected_encoder_mask_slice.to(torch_device))
+
+
+class Gemma3nTextModelTester(GemmaModelTester):
+ activation_sparsity_pattern = None
+ forced_config_args = ["activation_sparsity_pattern"]
+
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=False,
+ use_labels=True,
+ vocab_size=99,
+ vocab_size_per_layer_input=99,
+ hidden_size=16,
+ hidden_size_per_layer_input=16,
+ num_hidden_layers=4, # override to correctly test sharing cache pattern
+ num_kv_shared_layers=2, # important to override
+ layer_types=[
+ "full_attention",
+ "sliding_attention",
+ "full_attention",
+ "sliding_attention",
+ ], # similarly we want to test sharing on both types
+ num_attention_heads=2,
+ num_key_value_heads=2,
+ altup_num_inputs=2,
+ intermediate_size=21,
+ hidden_activation="gelu_pytorch_tanh",
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ pad_token_id=0,
+ bos_token_id=1,
+ eos_token_id=2,
+ is_decoder=False,
+ ):
+ self._verify_model_attributes()
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.vocab_size_per_layer_input = vocab_size_per_layer_input
+ self.hidden_size = hidden_size
+ self.hidden_size_per_layer_input = hidden_size_per_layer_input
+ self.num_hidden_layers = num_hidden_layers
+ self.num_kv_shared_layers = num_kv_shared_layers
+ self.layer_types = layer_types
+ self.num_attention_heads = num_attention_heads
+ self.num_key_value_heads = num_key_value_heads
+ self.altup_num_inputs = altup_num_inputs
+ self.intermediate_size = intermediate_size
+ self.hidden_activation = hidden_activation
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.pad_token_id = pad_token_id
+ self.bos_token_id = bos_token_id
+ self.eos_token_id = eos_token_id
+ self.head_dim = self.hidden_size // self.num_attention_heads
+ self.is_decoder = is_decoder
+
+ if is_torch_available():
+ config_class = Gemma3nTextConfig
+ model_class = Gemma3nTextModel
+ for_causal_lm_class = Gemma3nForCausalLM
+
+
+@require_torch
+class Gemma3nTextModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
+ all_model_classes = (Gemma3nTextModel, Gemma3nForCausalLM) if is_torch_available() else ()
+ all_generative_model_classes = (Gemma3nForCausalLM,) if is_torch_available() else ()
+ test_headmasking = False
+ test_pruning = False
+ _is_stateful = True
+ model_split_percents = [0.5, 0.6]
+
+ def setUp(self):
+ self.model_tester = Gemma3nTextModelTester(self)
+ self.config_tester = ConfigTester(
+ self,
+ config_class=Gemma3nConfig,
+ hidden_size=37,
+ text_config={"activation_sparsity_pattern": None},
+ )
+
+ def _check_hidden_states_for_generate(
+ self, batch_size, hidden_states, prompt_length, output_length, config, use_cache=False
+ ):
+ "Gemma3n has special hidden states shape with 1 additional dim (which is then reduced with projections)"
+
+ self.assertIsInstance(hidden_states, tuple)
+ self.assertListEqual(
+ [isinstance(iter_hidden_states, tuple) for iter_hidden_states in hidden_states],
+ [True] * len(hidden_states),
+ )
+ self.assertEqual(len(hidden_states), (output_length - prompt_length))
+
+ # When `output_hidden_states=True`, each iteration of generate appends the hidden states corresponding to the
+ # new token(s)
+ # NOTE: `HybridCache` may have different lengths on different layers, if this test starts failing add more
+ # elaborate checks
+ for generated_length, iter_hidden_states in enumerate(hidden_states):
+ # regardless of using cache, the first forward pass will have the full prompt as input
+ if use_cache and generated_length > 0:
+ model_input_length = 1
+ else:
+ model_input_length = prompt_length + generated_length
+ expected_shape = (config.altup_num_inputs, batch_size, model_input_length, config.hidden_size)
+ # check hidden size
+ self.assertListEqual(
+ [layer_hidden_states.shape for layer_hidden_states in iter_hidden_states],
+ [expected_shape] * len(iter_hidden_states),
+ )
+
+ @parameterized.expand(TEST_EAGER_MATCHES_SDPA_INFERENCE_PARAMETERIZATION)
+ @require_torch_sdpa
+ def test_eager_matches_sdpa_inference(
+ self,
+ name,
+ torch_dtype,
+ padding_side,
+ use_attention_mask,
+ output_attentions,
+ enable_kernels,
+ ):
+ "We need to relax a bit the `atols` for fp32 here due to the altup projections"
+ atols = {
+ ("cpu", False, torch.float32): 1e-3, # this was relaxed
+ ("cpu", False, torch.float16): 5e-3,
+ ("cpu", False, torch.bfloat16): 1e-2,
+ ("cpu", True, torch.float32): 1e-3, # this was relaxed
+ ("cpu", True, torch.float16): 5e-3,
+ ("cpu", True, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float32): 1e-3, # this was relaxed
+ ("cuda", False, torch.bfloat16): 1e-2,
+ ("cuda", False, torch.float16): 5e-3,
+ ("cuda", True, torch.float32): 1e-3, # this was relaxed
+ ("cuda", True, torch.bfloat16): 1e-2,
+ ("cuda", True, torch.float16): 5e-3,
+ }
+ _test_eager_matches_sdpa_inference(
+ self, name, torch_dtype, padding_side, use_attention_mask, output_attentions, enable_kernels, atols=atols
+ )
+
+ @pytest.mark.generate
+ @unittest.skip(
+ "Gemma3n has a special shape for hidden states (due to per-layer projs) which is not compatible with contrastive decoding"
+ )
+ def test_contrastive_generate(self):
+ pass
+
+ @pytest.mark.generate
+ @unittest.skip(
+ "Gemma3n has a special shape for hidden states (due to per-layer projs) which is not compatible with contrastive decoding"
+ )
+ def test_contrastive_generate_dict_outputs_use_cache(self):
+ pass
+
+ @pytest.mark.generate
+ @unittest.skip(
+ "Gemma3n has a special shape for hidden states (due to per-layer projs) which is not compatible with contrastive decoding"
+ )
+ def test_contrastive_generate_low_memory(self):
+ pass
+
+ @pytest.mark.generate
+ @unittest.skip(
+ "Gemma3n has a special shape for hidden states (due to per-layer projs) which is not compatible with dola decoding"
+ )
+ def test_dola_decoding_sample(self):
+ pass
+
+
+class Gemma3nVision2TextModelTester:
+ text_config = {"activation_sparsity_pattern": None}
+ forced_config_args = ["text_config"]
+
+ def __init__(
+ self,
+ parent,
+ mm_tokens_per_image=2,
+ image_token_index=1,
+ boi_token_index=2,
+ eoi_token_index=3,
+ seq_length=25,
+ is_training=True,
+ vision_config={
+ "use_labels": True,
+ "image_size": 20,
+ "patch_size": 5,
+ "num_channels": 3,
+ "is_training": True,
+ "hidden_size": 32,
+ "num_key_value_heads": 1,
+ "num_hidden_layers": 2,
+ "num_attention_heads": 4,
+ "intermediate_size": 37,
+ "dropout": 0.1,
+ "attention_dropout": 0.1,
+ "initializer_range": 0.02,
+ },
+ use_cache=False,
+ ):
+ self.parent = parent
+ # `image_token_index` is set to 0 to pass "resize_embeddings" test, do not modify
+ self.mm_tokens_per_image = mm_tokens_per_image
+ self.image_token_index = image_token_index
+ self.boi_token_index = boi_token_index
+ self.eoi_token_index = eoi_token_index
+ self.llm_tester = Gemma3nTextModelTester(self.parent)
+ self.text_config = self.llm_tester.get_config()
+ self.vision_config = vision_config
+ self.seq_length = seq_length
+ self.pad_token_id = self.text_config.pad_token_id
+
+ self.num_hidden_layers = self.text_config.num_hidden_layers
+ self.vocab_size = self.text_config.vocab_size
+ self.hidden_size = self.text_config.hidden_size
+ self.num_attention_heads = self.text_config.num_attention_heads
+ self.is_training = is_training
+
+ self.batch_size = 3
+ self.num_channels = vision_config["num_channels"]
+ self.image_size = vision_config["image_size"]
+ self.encoder_seq_length = seq_length
+ self.use_cache = use_cache
+
+ def get_config(self):
+ return Gemma3nConfig(
+ text_config=self.text_config,
+ vision_config=self.vision_config,
+ image_token_index=self.image_token_index,
+ boi_token_index=self.boi_token_index,
+ eoi_token_index=self.eoi_token_index,
+ mm_tokens_per_image=self.mm_tokens_per_image,
+ )
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor(
+ [
+ self.batch_size,
+ self.vision_config["num_channels"],
+ self.vision_config["image_size"],
+ self.vision_config["image_size"],
+ ]
+ )
+ config = self.get_config()
+
+ return config, pixel_values
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ input_ids = ids_tensor([self.batch_size, self.seq_length], config.text_config.vocab_size - 1) + 1
+ attention_mask = input_ids.ne(self.pad_token_id).to(torch_device)
+
+ # set the 3 first tokens to be image, and ensure that no other tokens are image tokens
+ # do not change this unless you modified image size or patch size
+ input_ids[input_ids == config.image_token_index] = self.pad_token_id
+ input_ids[:, :1] = config.image_token_index
+
+ token_type_ids = torch.zeros_like(input_ids)
+ token_type_ids[input_ids == config.image_token_index] = 1
+
+ inputs_dict = {
+ "pixel_values": pixel_values,
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "token_type_ids": token_type_ids,
+ }
+ return config, inputs_dict
+
+
+@unittest.skip("Skipped for now!")
+@require_torch
+class Gemma3nVision2TextModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
+ all_model_classes = (Gemma3nModel, Gemma3nForConditionalGeneration) if is_torch_available() else ()
+ all_generative_model_classes = (Gemma3nForConditionalGeneration,) if is_torch_available() else ()
+ test_headmasking = False
+ test_pruning = False
+ test_missing_keys = False
+ _is_stateful = True
+ model_split_percents = [0.5, 0.6]
+
+ # MP works but offload doesn't work when the SigLIP MultiheadAttention is offloaded
+ # TODO: One potential solution would be to add to set preload_module_classes = ["SiglipMultiheadAttentionPoolingHead"]
+ # in the dispatch_model function
+ test_cpu_offload = False
+ test_disk_offload_safetensors = False
+ test_disk_offload_bin = False
+
+ def setUp(self):
+ self.model_tester = Gemma3nVision2TextModelTester(self)
+ self.config_tester = ConfigTester(
+ self,
+ config_class=Gemma3nConfig,
+ hidden_size=37,
+ text_config={"activation_sparsity_pattern": None},
+ )
+
+ @unittest.skip(reason="SiglipVisionModel (vision backbone) does not support standalone training")
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(reason="SiglipVisionModel (vision backbone) does not support standalone training")
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(reason="SiglipVisionModel (vision backbone) does not support standalone training")
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @unittest.skip(
+ reason="HybridCache can't be gathered because it is not iterable. Adding a simple iter and dumping `distributed_iterator`"
+ " as in Dynamic Cache doesnt work. NOTE: @gante all cache objects would need better compatibility with multi gpu setting"
+ )
+ def test_multi_gpu_data_parallel_forward(self):
+ pass
+
+ @unittest.skip("Failing because of unique cache (HybridCache)")
+ def test_model_outputs_equivalence(self, **kwargs):
+ pass
+
+ @parameterized.expand([("random",), ("same",)])
+ @pytest.mark.generate
+ @unittest.skip("Gemma3n has HybridCache which is not compatible with assisted decoding")
+ def test_assisted_decoding_matches_greedy_search(self, assistant_type):
+ pass
+
+ @unittest.skip("Gemma3n has HybridCache which is not compatible with assisted decoding")
+ def test_prompt_lookup_decoding_matches_greedy_search(self, assistant_type):
+ pass
+
+ @pytest.mark.generate
+ @unittest.skip("Gemma3n has HybridCache which is not compatible with assisted decoding")
+ def test_assisted_decoding_sample(self):
+ pass
+
+ @unittest.skip("Gemma3n has HybridCache which is not compatible with dola decoding")
+ def test_dola_decoding_sample(self):
+ pass
+
+ @unittest.skip("Gemma3n has HybridCache and doesn't support continue from past kv")
+ def test_generate_continue_from_past_key_values(self):
+ pass
+
+ @unittest.skip("Gemma3n has HybridCache and doesn't support low_memory generation")
+ def test_beam_search_low_memory(self):
+ pass
+
+ @unittest.skip("Gemma3n has HybridCache and doesn't support contrastive generation")
+ def test_contrastive_generate(self):
+ pass
+
+ @unittest.skip("Gemma3n has HybridCache and doesn't support contrastive generation")
+ def test_contrastive_generate_dict_outputs_use_cache(self):
+ pass
+
+ @unittest.skip("Gemma3n has HybridCache and doesn't support contrastive generation")
+ def test_contrastive_generate_low_memory(self):
+ pass
+
+ @unittest.skip("Gemma3n has HybridCache and doesn't support StaticCache. Though it could, it shouldn't support.")
+ def test_generate_with_static_cache(self):
+ pass
+
+ @unittest.skip("Gemma3n has HybridCache and doesn't support StaticCache. Though it could, it shouldn't support.")
+ def test_generate_from_inputs_embeds_with_static_cache(self):
+ pass
+
+ @unittest.skip(
+ reason="Siglip (vision backbone) uses the same initialization scheme as the Flax original implementation"
+ )
+ def test_initialization(self):
+ pass
+
+ @unittest.skip(
+ reason="Siglip has no FLEX attention, and we don't have a proper way to set/test attn in VLMs. TODO @raushan"
+ )
+ def test_flex_attention_with_grads(self):
+ pass
+
+ def test_automodelforcausallm(self):
+ """
+ Regression test for #36741 -- make sure `AutoModelForCausalLM` works with a Gemma3n config, i.e. that
+ `AutoModelForCausalLM.from_pretrained` pulls the text config before loading the model
+ """
+ config = self.model_tester.get_config()
+ model = Gemma3nForConditionalGeneration(config)
+ with tempfile.TemporaryDirectory() as tmp_dir:
+ model.save_pretrained(tmp_dir)
+ for_causal_lm = AutoModelForCausalLM.from_pretrained(tmp_dir)
+ self.assertIsInstance(for_causal_lm, Gemma3nForCausalLM)
+
+
+@unittest.skip("Skipped for now!")
+@slow
+@require_torch_gpu
+@require_read_token
+class Gemma3nIntegrationTest(unittest.TestCase):
+ def setUp(self):
+ self.processor = AutoProcessor.from_pretrained("Google/gemma-3n-E4B-it", padding_side="left")
+
+ url = "https://huggingface.co/datasets/hf-internal-testing/fixtures-captioning/resolve/main/cow_beach_1.png"
+ self.messages = [
+ {"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant."}]},
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": url},
+ {"type": "text", "text": "What is shown in this image?"},
+ ],
+ },
+ ]
+
+ audio_ds = load_dataset(
+ "etechgrid/28.5k_wavfiles_dataset", "default", data_files="wav_dataset/103-1240-0000.wav"
+ )
+ self.audio_file_path = audio_ds["train"][0]["audio"]["path"]
+
+ def tearDown(self):
+ cleanup(torch_device, gc_collect=True)
+
+ def test_model_4b_bf16(self):
+ model_id = "Google/gemma-3n-E4B-it"
+
+ model = Gemma3nForConditionalGeneration.from_pretrained(
+ model_id, low_cpu_mem_usage=True, torch_dtype=torch.bfloat16
+ ).to(torch_device)
+
+ inputs = self.processor.apply_chat_template(
+ self.messages,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+ add_generation_prompt=True,
+ ).to(torch_device)
+
+ output = model.generate(**inputs, max_new_tokens=30, do_sample=False)
+ output_text = self.processor.batch_decode(output, skip_special_tokens=True)
+
+ EXPECTED_TEXTS = ['user\nYou are a helpful assistant.\n\n\n\n\n\nWhat is shown in this image?\nmodel\nCertainly! \n\nThe image shows a brown cow standing on a sandy beach with clear blue water and a blue sky in the background. It looks like'] # fmt: skip
+ self.assertEqual(output_text, EXPECTED_TEXTS)
+
+ def test_model_with_audio(self):
+ """
+ Tests the full model pipeline with batched audio inputs provided as file paths.
+ This ensures the processor correctly loads and processes audio files.
+ """
+
+ model_id = "Google/gemma-3n-E4B-it"
+
+ model = Gemma3nForConditionalGeneration.from_pretrained(
+ model_id, low_cpu_mem_usage=True, torch_dtype=torch.bfloat16
+ ).to(torch_device)
+
+ messages = [
+ [
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "Transcribe the following speech segment in English:"},
+ {"type": "audio", "audio": str(self.audio_file_path)},
+ ],
+ }
+ ],
+ ]
+
+ inputs = self.processor.apply_chat_template(
+ messages,
+ add_generation_prompt=True,
+ tokenize=True,
+ return_dict=True,
+ padding=True,
+ return_tensors="pt",
+ ).to(torch_device, dtype=model.dtype)
+
+ input_len = inputs["input_ids"].shape[-1]
+
+ output = model.generate(**inputs, max_new_tokens=16, do_sample=False)
+ output = output[:, input_len:]
+ output_text = self.processor.batch_decode(output, skip_special_tokens=True)
+
+ EXPECTED_TEXTS = ["Chapter 1. Mrs. Rachel Lind is surprised.\n\nMrs. Rachel Lind"]
+ self.assertEqual(output_text, EXPECTED_TEXTS)
+
+ def test_model_4b_batch(self):
+ model_id = "Google/gemma-3n-E4B-it"
+
+ model = Gemma3nForConditionalGeneration.from_pretrained(
+ model_id, low_cpu_mem_usage=False, torch_dtype=torch.bfloat16
+ ).to(torch_device)
+
+ messages_2 = [
+ {"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant."}]},
+ {
+ "role": "user",
+ "content": [
+ {
+ "type": "image",
+ "url": "https://huggingface.co/datasets/hf-internal-testing/fixtures-captioning/resolve/main/cow_beach_1.png",
+ },
+ {"type": "image", "url": "https://www.ilankelman.org/stopsigns/australia.jpg"},
+ {"type": "text", "text": "Are these images identical?"},
+ ],
+ },
+ ]
+
+ inputs = self.processor.apply_chat_template(
+ [self.messages, messages_2],
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+ padding=True,
+ add_generation_prompt=True,
+ ).to(torch_device)
+
+ output = model.generate(**inputs, max_new_tokens=30, do_sample=False)
+ output_text = self.processor.batch_decode(output, skip_special_tokens=True)
+
+ EXPECTED_TEXTS = [
+ 'user\nYou are a helpful assistant.\n\n\n\n\n\nWhat is shown in this image?\nmodel\nCertainly! \n\nThe image shows a brown cow standing on a sandy beach with clear turquoise water and a blue sky in the background. It looks like',
+ "user\nYou are a helpful assistant.\n\n\n\n\n\n\n\n\n\nAre these images identical?\nmodel\nNo, these images are not identical. \n\nHere's a breakdown of the differences:\n\n* **Image 1:** Shows a cow"
+ ] # fmt: skip
+ self.assertEqual(output_text, EXPECTED_TEXTS)
+
+ def test_model_4b_crops(self):
+ model_id = "Google/gemma-3n-E4B-it"
+
+ model = Gemma3nForConditionalGeneration.from_pretrained(
+ model_id, low_cpu_mem_usage=True, torch_dtype=torch.bfloat16
+ ).to(torch_device)
+
+ crop_config = {
+ "images_kwargs": {
+ "do_pan_and_scan": True,
+ "pan_and_scan_max_num_crops": 448,
+ "pan_and_scan_min_crop_size": 32,
+ "pan_and_scan_min_ratio_to_activate": 0.3,
+ }
+ }
+
+ inputs = self.processor.apply_chat_template(
+ self.messages,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+ add_generation_prompt=True,
+ **crop_config,
+ ).to(torch_device)
+
+ output = model.generate(**inputs, max_new_tokens=30, do_sample=False)
+ output_text = self.processor.batch_decode(output, skip_special_tokens=True)
+
+ EXPECTED_NUM_IMAGES = 3 # one for the origin image and two crops of images
+ EXPECTED_TEXTS = ['user\nYou are a helpful assistant.\n\nHere is the original image \n\n\n\n and here are some crops to help you see better \n\n\n\n \n\n\n\nWhat is shown in this image?\nmodel\nThe image shows a brown cow standing on a beach with a turquoise ocean and blue sky in the background.'] # fmt: skip
+ self.assertEqual(len(inputs["pixel_values"]), EXPECTED_NUM_IMAGES)
+ self.assertEqual(output_text, EXPECTED_TEXTS)
+
+ def test_model_4b_multiimage(self):
+ model_id = "Google/gemma-3n-E4B-it"
+
+ model = Gemma3nForConditionalGeneration.from_pretrained(
+ model_id, low_cpu_mem_usage=True, torch_dtype=torch.bfloat16
+ ).to(torch_device)
+
+ messages = [
+ {"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant."}]},
+ {
+ "role": "user",
+ "content": [
+ {"type": "image", "url": "https://www.ilankelman.org/stopsigns/australia.jpg"},
+ {"type": "text", "text": "What do you see here?"},
+ ],
+ },
+ ]
+
+ inputs = self.processor.apply_chat_template(
+ messages,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+ padding=True,
+ add_generation_prompt=True,
+ ).to(torch_device)
+
+ output = model.generate(**inputs, max_new_tokens=30, do_sample=False)
+ output_text = self.processor.batch_decode(output, skip_special_tokens=True)
+
+ EXPECTED_TEXTS = ["user\nYou are a helpful assistant.\n\n\n\n\n\nWhat do you see here?\nmodel\nOkay, let's break down what I see in this image:\n\n**Overall Scene:**\n\nIt looks like a street scene in a vibrant,"] # fmt: skip
+ self.assertEqual(output_text, EXPECTED_TEXTS)
+
+ def test_model_1b_text_only(self):
+ model_id = "google/gemma-3-1b-it"
+
+ model = Gemma3nForCausalLM.from_pretrained(model_id, low_cpu_mem_usage=True, torch_dtype=torch.bfloat16).to(
+ torch_device
+ )
+ tokenizer = AutoTokenizer.from_pretrained(model_id, padding_side="left")
+ inputs = tokenizer("Write a poem about Machine Learning.", return_tensors="pt").to(torch_device)
+
+ output = model.generate(**inputs, max_new_tokens=30, do_sample=False)
+ output_text = tokenizer.batch_decode(output, skip_special_tokens=True)
+
+ EXPECTED_TEXTS = ['Write a poem about Machine Learning.\n\n---\n\nThe data flows, a river deep,\nWith patterns hidden, secrets sleep.\nA neural net, a watchful eye,\nLearning'] # fmt: skip
+ self.assertEqual(output_text, EXPECTED_TEXTS)
+
+ # TODO: raushan FA2 generates gibberish for no reason, check later
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ def test_model_4b_flash_attn(self):
+ model_id = "Google/gemma-3n-E4B-it"
+
+ model = Gemma3nForConditionalGeneration.from_pretrained(
+ model_id, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
+ ).to(torch_device)
+
+ inputs = self.processor.apply_chat_template(
+ self.messages,
+ tokenize=True,
+ return_dict=True,
+ return_tensors="pt",
+ add_generation_prompt=True,
+ ).to(torch_device)
+
+ output = model.generate(**inputs, max_new_tokens=30, do_sample=False)
+ output_text = self.processor.batch_decode(output, skip_special_tokens=True)
+
+ EXPECTED_TEXTS = ['user\nYou are a helpful assistant.\n\n\n\n\n\nWhat is shown in this image?\nmodel\nCertainly! \n\nThe image shows a brown and white cow standing on a sandy beach next to a turquoise ocean. It looks like a very sunny and'] # fmt: skip
+ self.assertEqual(output_text, EXPECTED_TEXTS)
+
+ @parameterized.expand([("flash_attention_2",), ("sdpa",), ("eager",)])
+ def test_generation_beyond_sliding_window(self, attn_implementation: str):
+ """Test that we can correctly generate beyond the sliding window. This is non trivial as
+ we need to correctly slice the attention mask in all cases (because we use a HybridCache).
+ Outputs for every attention functions should be coherent and identical.
+ """
+ model_id = "google/gemma-3-1b-it"
+
+ input_text = [
+ "This is a nice place. " * 800 + "I really enjoy the scenery,", # This is larger than 4096 tokens
+ "A list of colors: red, blue", # This will almost all be padding tokens
+ ]
+ tokenizer = AutoTokenizer.from_pretrained(model_id, padding="left")
+ inputs = tokenizer(input_text, padding=True, return_tensors="pt").to(torch_device)
+
+ model = AutoModelForCausalLM.from_pretrained(
+ model_id, attn_implementation=attn_implementation, torch_dtype=torch.float16
+ ).to(torch_device)
+
+ # Make sure prefill is larger than sliding window
+ input_size = inputs.input_ids.shape[-1]
+ self.assertTrue(input_size > model.config.sliding_window)
+
+ out = model.generate(**inputs, max_new_tokens=20)[:, input_size:]
+ output_text = tokenizer.batch_decode(out)
+
+ EXPECTED_COMPLETIONS = [" and I'm going to take a walk.\n\nI really enjoy the scenery, and I'", ", green, yellow, orange, purple, brown, black, white, gray.\n\nI'"] # fmt: skip
+ self.assertEqual(output_text, EXPECTED_COMPLETIONS)
+
+ def test_generation_beyond_sliding_window_with_generation_config(self):
+ """
+ Same as `test_generation_beyond_sliding_window`, but passing a GenerationConfig. Regression test for #36684 --
+ ensures `cache_implementation='hybrid'` is correctly inherited from the base `model.generation_config`.
+ """
+ model_id = "google/gemma-3-1b-it"
+ attn_implementation = "sdpa"
+
+ input_text = [
+ "This is a nice place. " * 800 + "I really enjoy the scenery,", # This is larger than 4096 tokens
+ "A list of colors: red, blue", # This will almost all be padding tokens
+ ]
+ tokenizer = AutoTokenizer.from_pretrained(model_id, padding="left")
+ inputs = tokenizer(input_text, padding=True, return_tensors="pt").to(torch_device)
+
+ model = AutoModelForCausalLM.from_pretrained(
+ model_id, attn_implementation=attn_implementation, torch_dtype=torch.float16
+ ).to(torch_device)
+
+ # Make sure prefill is larger than sliding window
+ input_size = inputs.input_ids.shape[-1]
+ self.assertTrue(input_size > model.config.sliding_window)
+
+ generation_config = GenerationConfig(max_new_tokens=20)
+
+ out = model.generate(**inputs, generation_config=generation_config)[:, input_size:]
+ output_text = tokenizer.batch_decode(out)
+
+ EXPECTED_COMPLETIONS = [" and I'm going to take a walk.\n\nI really enjoy the scenery, and I'", ", green, yellow, orange, purple, brown, black, white, gray.\n\nI'"] # fmt: skip
+ self.assertEqual(output_text, EXPECTED_COMPLETIONS)
diff --git a/transformers/tests/models/gemma3n/test_processing_gemma3n.py b/transformers/tests/models/gemma3n/test_processing_gemma3n.py
new file mode 100644
index 0000000000000000000000000000000000000000..ffedb2b98aaca87a2090523fea9b53b33435160e
--- /dev/null
+++ b/transformers/tests/models/gemma3n/test_processing_gemma3n.py
@@ -0,0 +1,191 @@
+# Copyright 2025 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import shutil
+import tempfile
+import unittest
+
+import numpy as np
+from parameterized import parameterized
+
+from transformers import GemmaTokenizerFast, SiglipImageProcessorFast, is_speech_available
+from transformers.testing_utils import require_sentencepiece, require_torch, require_torchaudio, require_vision
+
+from .test_feature_extraction_gemma3n import floats_list
+
+
+if is_speech_available():
+ from transformers.models.gemma3n import Gemma3nAudioFeatureExtractor, Gemma3nProcessor
+
+
+@require_torch
+@require_torchaudio
+@require_vision
+@require_sentencepiece
+class Gemma3nProcessorTest(unittest.TestCase):
+ def setUp(self):
+ # TODO: update to google?
+ self.model_id = "hf-internal-testing/namespace-google-repo_name-gemma-3n-E4B-it"
+ self.tmpdirname = tempfile.mkdtemp(suffix="gemma3n")
+ self.maxDiff = None
+
+ def get_tokenizer(self, **kwargs):
+ return GemmaTokenizerFast.from_pretrained(self.model_id, **kwargs)
+
+ def get_feature_extractor(self, **kwargs):
+ return Gemma3nAudioFeatureExtractor.from_pretrained(self.model_id, **kwargs)
+
+ def get_image_processor(self, **kwargs):
+ return SiglipImageProcessorFast.from_pretrained(self.model_id, **kwargs)
+
+ def tearDown(self):
+ shutil.rmtree(self.tmpdirname)
+
+ def test_save_load_pretrained_default(self):
+ # NOTE: feature_extractor and image_processor both use the same filename, preprocessor_config.json, when saved to
+ # disk, but the files are overwritten by processor.save_pretrained(). This test does not attempt to address
+ # this potential issue, and as such, does not guarantee content accuracy.
+
+ tokenizer = self.get_tokenizer()
+ feature_extractor = self.get_feature_extractor()
+ image_processor = self.get_image_processor()
+
+ processor = Gemma3nProcessor(
+ tokenizer=tokenizer, feature_extractor=feature_extractor, image_processor=image_processor
+ )
+
+ processor.save_pretrained(self.tmpdirname)
+ processor = Gemma3nProcessor.from_pretrained(self.tmpdirname)
+
+ self.assertIsInstance(processor.tokenizer, GemmaTokenizerFast)
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer.get_vocab())
+
+ # `disable_grouping` is a new attribute that got added on main while gemma3n was being released - so was
+ # not part of the saved processor
+ del processor.feature_extractor.disable_grouping
+ self.assertIsInstance(processor.feature_extractor, Gemma3nAudioFeatureExtractor)
+ self.assertEqual(processor.feature_extractor.to_json_string(), feature_extractor.to_json_string())
+
+ def test_save_load_pretrained_additional_features(self):
+ tokenizer = self.get_tokenizer()
+ feature_extractor = self.get_feature_extractor()
+ image_processor = self.get_image_processor()
+
+ processor = Gemma3nProcessor(
+ tokenizer=tokenizer, feature_extractor=feature_extractor, image_processor=image_processor
+ )
+ processor.save_pretrained(self.tmpdirname)
+
+ tokenizer_add_kwargs = self.get_tokenizer(bos_token="(BOS-BOS)", eos_token="(EOS-EOS)")
+ feature_extractor_add_kwargs = self.get_feature_extractor(dither=5.0, padding_value=1.0)
+
+ processor = Gemma3nProcessor.from_pretrained(
+ self.tmpdirname, bos_token="(BOS-BOS)", eos_token="(EOS-EOS)", dither=5.0, padding_value=1.0
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, GemmaTokenizerFast)
+
+ # `disable_grouping` is a new attribute that got added on main while gemma3n was being released - so was
+ # not part of the saved processor
+ del processor.feature_extractor.disable_grouping
+ self.assertEqual(processor.feature_extractor.to_json_string(), feature_extractor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.feature_extractor, Gemma3nAudioFeatureExtractor)
+
+ @parameterized.expand([256, 512, 768, 1024])
+ def test_image_processor(self, image_size: int):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+ image_processor = self.get_image_processor()
+ processor = Gemma3nProcessor(
+ tokenizer=tokenizer, feature_extractor=feature_extractor, image_processor=image_processor
+ )
+
+ raw_image = np.random.randint(0, 256, size=(image_size, image_size, 3), dtype=np.uint8)
+ input_image_processor = image_processor(raw_image, return_tensors="pt")
+ input_processor = processor(text="Describe:", images=raw_image, return_tensors="pt")
+
+ for key in input_image_processor.keys():
+ self.assertAlmostEqual(input_image_processor[key].sum(), input_processor[key].sum(), delta=1e-2)
+ if "pixel_values" in key:
+ # NOTE: all images should be re-scaled to 768x768
+ self.assertEqual(input_image_processor[key].shape, (1, 3, 768, 768))
+ self.assertEqual(input_processor[key].shape, (1, 3, 768, 768))
+
+ def test_audio_feature_extractor(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+ image_processor = self.get_image_processor()
+ processor = Gemma3nProcessor(
+ tokenizer=tokenizer, feature_extractor=feature_extractor, image_processor=image_processor
+ )
+
+ raw_speech = floats_list((3, 1000))
+ input_feat_extract = feature_extractor(raw_speech, return_tensors="pt")
+ input_processor = processor(text="Transcribe:", audio=raw_speech, return_tensors="pt")
+
+ for key in input_feat_extract.keys():
+ self.assertAlmostEqual(input_feat_extract[key].sum(), input_processor[key].sum(), delta=1e-2)
+
+ def test_tokenizer(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+ image_processor = self.get_image_processor()
+ processor = Gemma3nProcessor(
+ tokenizer=tokenizer, feature_extractor=feature_extractor, image_processor=image_processor
+ )
+
+ input_str = "This is a test string"
+
+ encoded_processor = processor(text=input_str)
+
+ encoded_tok = tokenizer(input_str)
+
+ for key in encoded_tok.keys():
+ self.assertListEqual(encoded_tok[key], encoded_processor[key][0])
+
+ def test_tokenizer_decode(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+ image_processor = self.get_image_processor()
+ processor = Gemma3nProcessor(
+ tokenizer=tokenizer, feature_extractor=feature_extractor, image_processor=image_processor
+ )
+
+ predicted_ids = [[1, 4, 5, 8, 1, 0, 8], [3, 4, 3, 1, 1, 8, 9]]
+
+ decoded_processor = processor.batch_decode(predicted_ids)
+ decoded_tok = tokenizer.batch_decode(predicted_ids)
+
+ self.assertListEqual(decoded_tok, decoded_processor)
+
+ def test_model_input_names(self):
+ feature_extractor = self.get_feature_extractor()
+ tokenizer = self.get_tokenizer()
+ image_processor = self.get_image_processor()
+ processor = Gemma3nProcessor(
+ tokenizer=tokenizer, feature_extractor=feature_extractor, image_processor=image_processor
+ )
+
+ for key in feature_extractor.model_input_names:
+ self.assertIn(
+ key,
+ processor.model_input_names,
+ )
+
+ for key in image_processor.model_input_names:
+ self.assertIn(
+ key,
+ processor.model_input_names,
+ )
diff --git a/transformers/tests/models/git/__init__.py b/transformers/tests/models/git/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/git/test_modeling_git.py b/transformers/tests/models/git/test_modeling_git.py
new file mode 100644
index 0000000000000000000000000000000000000000..38aa2b4e879c9a33e523a2f653f49df59fc1e3ed
--- /dev/null
+++ b/transformers/tests/models/git/test_modeling_git.py
@@ -0,0 +1,621 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import inspect
+import unittest
+
+from huggingface_hub import hf_hub_download
+
+from transformers import GitConfig, GitProcessor, GitVisionConfig, is_torch_available, is_vision_available
+from transformers.models.auto import get_values
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import MODEL_FOR_CAUSAL_LM_MAPPING, GitForCausalLM, GitModel, GitVisionModel
+
+
+if is_vision_available():
+ from PIL import Image
+
+
+class GitVisionModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ image_size=32,
+ patch_size=16,
+ num_channels=3,
+ is_training=True,
+ hidden_size=32,
+ projection_dim=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ initializer_range=0.02,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.hidden_size = hidden_size
+ self.projection_dim = projection_dim
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ # in ViT, the seq length equals the number of patches + 1 (we add 1 for the [CLS] token)
+ num_patches = (image_size // patch_size) ** 2
+ self.seq_length = num_patches + 1
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+ config = self.get_config()
+
+ return config, pixel_values
+
+ def get_config(self):
+ return GitVisionConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ projection_dim=self.projection_dim,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, pixel_values):
+ model = GitVisionModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(pixel_values)
+ # expected sequence length = num_patches + 1 (we add 1 for the [CLS] token)
+ image_size = (self.image_size, self.image_size)
+ patch_size = (self.patch_size, self.patch_size)
+ num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, num_patches + 1, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class GitVisionModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as GIT does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (GitVisionModel,) if is_torch_available() else ()
+ fx_compatible = True
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = GitVisionModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=GitVisionConfig, has_text_modality=False, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="GIT does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_get_set_embeddings(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip
+ def test_training(self):
+ pass
+
+ @unittest.skip
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "microsoft/git-base"
+ model = GitVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+class GitModelTester:
+ def __init__(
+ self,
+ parent,
+ num_channels=3,
+ image_size=32,
+ patch_size=16,
+ batch_size=13,
+ text_seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ initializer_range=0.02,
+ num_labels=3,
+ scope=None,
+ ):
+ self.parent = parent
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.batch_size = batch_size
+ self.text_seq_length = text_seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.scope = scope
+
+ # make sure the BOS, EOS and PAD tokens are within the vocab
+ self.bos_token_id = vocab_size - 1
+ self.eos_token_id = vocab_size - 1
+ self.pad_token_id = vocab_size - 1
+
+ # for GIT, the sequence length is the sum of the text and patch tokens, + 1 due to the CLS token
+ self.seq_length = self.text_seq_length + int((self.image_size / self.patch_size) ** 2) + 1
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.text_seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.text_seq_length])
+
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask, pixel_values
+
+ def get_config(self):
+ """
+ Returns a tiny configuration by default.
+ """
+ return GitConfig(
+ vision_config={
+ "num_channels": self.num_channels,
+ "image_size": self.image_size,
+ "patch_size": self.patch_size,
+ "hidden_size": self.hidden_size,
+ "projection_dim": 32,
+ "num_hidden_layers": self.num_hidden_layers,
+ "num_attention_heads": self.num_attention_heads,
+ },
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ initializer_range=self.initializer_range,
+ bos_token_id=self.bos_token_id,
+ eos_token_id=self.eos_token_id,
+ pad_token_id=self.pad_token_id,
+ )
+
+ def create_and_check_model(self, config, input_ids, input_mask, pixel_values):
+ model = GitModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # inference with pixel values
+ result = model(input_ids, attention_mask=input_mask, pixel_values=pixel_values)
+
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ # inference without pixel values
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.text_seq_length, self.hidden_size)
+ )
+
+ def create_and_check_for_causal_lm(self, config, input_ids, input_mask, pixel_values):
+ model = GitForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # inference with pixel values
+ result = model(input_ids, attention_mask=input_mask, pixel_values=pixel_values)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ # inference without pixel values
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.text_seq_length, self.vocab_size))
+
+ # training
+ result = model(input_ids, attention_mask=input_mask, pixel_values=pixel_values, labels=input_ids)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertTrue(result.loss.item() > 0)
+
+ def _test_beam_search_generate(self, config, input_ids, input_mask, pixel_values):
+ model = GitForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # generate
+ generated_ids = model.generate(
+ input_ids,
+ attention_mask=input_mask,
+ pixel_values=pixel_values,
+ do_sample=False,
+ max_length=20,
+ num_beams=2,
+ num_return_sequences=2,
+ )
+
+ self.parent.assertEqual(generated_ids.shape, (self.batch_size * 2, 20))
+
+ def _test_batched_generate_captioning(self, config, input_ids, input_mask, pixel_values):
+ model = GitForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # generate
+ generated_ids = model.generate(
+ input_ids=None, # captioning -> no input_ids
+ attention_mask=None,
+ pixel_values=pixel_values,
+ do_sample=False,
+ min_length=20,
+ max_length=20,
+ num_beams=2,
+ num_return_sequences=2,
+ )
+
+ self.parent.assertEqual(generated_ids.shape, (self.batch_size * 2, 20))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+
+ (
+ config,
+ input_ids,
+ input_mask,
+ pixel_values,
+ ) = config_and_inputs
+
+ inputs_dict = {
+ "input_ids": input_ids,
+ "attention_mask": input_mask,
+ "pixel_values": pixel_values,
+ }
+
+ return config, inputs_dict
+
+
+@require_torch
+class GitModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (GitModel, GitForCausalLM) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": GitModel,
+ "image-to-text": GitForCausalLM,
+ "text-generation": GitForCausalLM,
+ "image-text-to-text": GitForCausalLM,
+ }
+ if is_torch_available()
+ else {}
+ )
+ fx_compatible = False
+ test_torchscript = False
+
+ # special case for GitForCausalLM model
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class in get_values(MODEL_FOR_CAUSAL_LM_MAPPING):
+ inputs_dict["labels"] = torch.zeros(
+ (self.model_tester.batch_size, self.model_tester.text_seq_length),
+ dtype=torch.long,
+ device=torch_device,
+ )
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = GitModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=GitConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_causal_lm(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_causal_lm(*config_and_inputs)
+
+ def test_beam_search_generate(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester._test_beam_search_generate(*config_and_inputs)
+
+ def test_batched_generate_captioning(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester._test_batched_generate_captioning(*config_and_inputs)
+
+ def test_model_various_embeddings(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["absolute", "relative_key", "relative_key_query"]:
+ config_and_inputs[0].position_embedding_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def _check_attentions_for_generate(
+ self, batch_size, attentions, prompt_length, output_length, config, decoder_past_key_values
+ ):
+ # GIT attention shape depends on image inputs, overwrite
+ image_length = int((config.vision_config.image_size / config.vision_config.patch_size) ** 2 + 1)
+ prompt_length += image_length
+ output_length += image_length
+ super()._check_attentions_for_generate(
+ batch_size, attentions, prompt_length, output_length, config, decoder_past_key_values
+ )
+
+ def _check_hidden_states_for_generate(
+ self, batch_size, hidden_states, prompt_length, output_length, config, use_cache=False
+ ):
+ # GIT attention shape depends on image inputs, overwrite
+ image_length = int((config.vision_config.image_size / config.vision_config.patch_size) ** 2 + 1)
+ prompt_length += image_length
+ output_length += image_length
+ super()._check_hidden_states_for_generate(
+ batch_size, hidden_states, prompt_length, output_length, config, use_cache=use_cache
+ )
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "microsoft/git-base"
+ model = GitModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ @unittest.skip(reason="GIT has pixel values as additional input")
+ def test_beam_search_generate_dict_outputs_use_cache(self):
+ pass
+
+ @unittest.skip(reason="GIT has pixel values as additional input")
+ def test_contrastive_generate(self):
+ pass
+
+ @unittest.skip(reason="GIT has pixel values as additional input")
+ def test_contrastive_generate_dict_outputs_use_cache(self):
+ pass
+
+ @unittest.skip(reason="GIT has pixel values as additional input")
+ def test_contrastive_generate_low_memory(self):
+ pass
+
+ @unittest.skip(reason="GIT has pixel values as additional input")
+ def test_greedy_generate_dict_outputs_use_cache(self):
+ pass
+
+ @unittest.skip(reason="GIT has pixel values as additional input")
+ def test_dola_decoding_sample(self):
+ pass
+
+
+@require_torch
+@require_vision
+@slow
+class GitModelIntegrationTest(unittest.TestCase):
+ def test_forward_pass(self):
+ processor = GitProcessor.from_pretrained("microsoft/git-base")
+ model = GitForCausalLM.from_pretrained("microsoft/git-base")
+
+ model.to(torch_device)
+
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ inputs = processor(images=image, text="hello world", return_tensors="pt").to(torch_device)
+
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ expected_shape = torch.Size((1, 201, 30522))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+ expected_slice = torch.tensor(
+ [[-0.9514, -0.9512, -0.9507], [-0.5454, -0.5453, -0.5453], [-0.8862, -0.8857, -0.8848]],
+ device=torch_device,
+ )
+ torch.testing.assert_close(outputs.logits[0, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ def test_inference_image_captioning(self):
+ processor = GitProcessor.from_pretrained("microsoft/git-base")
+ model = GitForCausalLM.from_pretrained("microsoft/git-base")
+ model.to(torch_device)
+
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ inputs = processor(images=image, return_tensors="pt")
+ pixel_values = inputs.pixel_values.to(torch_device)
+
+ outputs = model.generate(
+ pixel_values=pixel_values, max_length=20, output_scores=True, return_dict_in_generate=True
+ )
+ generated_caption = processor.batch_decode(outputs.sequences, skip_special_tokens=True)[0]
+
+ expected_shape = torch.Size((1, 9))
+ self.assertEqual(outputs.sequences.shape, expected_shape)
+ self.assertEqual(generated_caption, "two cats laying on a pink blanket")
+ self.assertTrue(outputs.scores[-1].shape, expected_shape)
+ expected_slice = torch.tensor([-0.8805, -0.8803, -0.8799], device=torch_device)
+ torch.testing.assert_close(outputs.scores[-1][0, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ def test_visual_question_answering(self):
+ processor = GitProcessor.from_pretrained("microsoft/git-base-textvqa")
+ model = GitForCausalLM.from_pretrained("microsoft/git-base-textvqa")
+ model.to(torch_device)
+
+ # prepare image
+ file_path = hf_hub_download(repo_id="nielsr/textvqa-sample", filename="bus.png", repo_type="dataset")
+ image = Image.open(file_path).convert("RGB")
+ inputs = processor(images=image, return_tensors="pt")
+ pixel_values = inputs.pixel_values.to(torch_device)
+
+ # prepare question
+ question = "what does the front of the bus say at the top?"
+ input_ids = processor(text=question, add_special_tokens=False).input_ids
+ input_ids = [processor.tokenizer.cls_token_id] + input_ids
+ input_ids = torch.tensor(input_ids).unsqueeze(0).to(torch_device)
+
+ generated_ids = model.generate(pixel_values=pixel_values, input_ids=input_ids, max_length=20)
+ generated_caption = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
+
+ expected_shape = torch.Size((1, 15))
+ self.assertEqual(generated_ids.shape, expected_shape)
+ self.assertEqual(generated_caption, "what does the front of the bus say at the top? special")
+
+ def test_batched_generation(self):
+ processor = GitProcessor.from_pretrained("microsoft/git-base-coco")
+ model = GitForCausalLM.from_pretrained("microsoft/git-base-coco")
+ model.to(torch_device)
+
+ # create batch of size 2
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ inputs = processor(images=[image, image], return_tensors="pt")
+ pixel_values = inputs.pixel_values.to(torch_device)
+
+ # we have to prepare `input_ids` with the same batch size as `pixel_values`
+ start_token_id = model.config.bos_token_id
+ input_ids = torch.tensor([[start_token_id], [start_token_id]], device=torch_device)
+ generated_ids = model.generate(pixel_values=pixel_values, input_ids=input_ids, max_length=50)
+ generated_captions = processor.batch_decode(generated_ids, skip_special_tokens=True)
+
+ self.assertEqual(generated_captions, ["two cats sleeping on a pink blanket next to remotes."] * 2)
+
+ @slow
+ def test_inference_interpolate_pos_encoding(self):
+ # CLIP family models have an `interpolate_pos_encoding` argument in their forward method,
+ # allowing to interpolate the pre-trained position embeddings in order to use
+ # the model on higher resolutions. The DINO model by Facebook AI leverages this
+ # to visualize self-attention on higher resolution images.
+ model = GitModel.from_pretrained("microsoft/git-base").to(torch_device)
+
+ processor = GitProcessor.from_pretrained(
+ "microsoft/git-base", size={"height": 180, "width": 180}, crop_size={"height": 180, "width": 180}
+ )
+
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ inputs = processor(text="what's in the image", images=image, return_tensors="pt").to(torch_device)
+
+ # interpolate_pos_encodiung false should return value error
+ with self.assertRaises(ValueError, msg="doesn't match model"):
+ with torch.no_grad():
+ model(**inputs, interpolate_pos_encoding=False)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs, interpolate_pos_encoding=True)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 130, 768))
+
+ self.assertEqual(outputs.last_hidden_state.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[-1.0296, 2.5960, 0.8703], [1.7027, 1.3302, -0.4543], [-1.4932, -0.1084, 0.0502]]
+ ).to(torch_device)
+
+ torch.testing.assert_close(outputs.last_hidden_state[0, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/git/test_processor_git.py b/transformers/tests/models/git/test_processor_git.py
new file mode 100644
index 0000000000000000000000000000000000000000..c15301a5875ac3a2df226d86fece3f975b2802c0
--- /dev/null
+++ b/transformers/tests/models/git/test_processor_git.py
@@ -0,0 +1,146 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import shutil
+import tempfile
+import unittest
+
+import pytest
+
+from transformers.testing_utils import require_vision
+from transformers.utils import is_vision_available
+
+from ...test_processing_common import ProcessorTesterMixin
+
+
+if is_vision_available():
+ from transformers import AutoProcessor, BertTokenizer, CLIPImageProcessor, GitProcessor, PreTrainedTokenizerFast
+
+
+@require_vision
+class GitProcessorTest(ProcessorTesterMixin, unittest.TestCase):
+ processor_class = GitProcessor
+
+ @classmethod
+ def setUpClass(cls):
+ cls.tmpdirname = tempfile.mkdtemp()
+
+ image_processor = CLIPImageProcessor()
+ tokenizer = BertTokenizer.from_pretrained(
+ "hf-internal-testing/tiny-random-BertModel", model_input_names=["input_ids", "attention_mask"]
+ )
+
+ processor = GitProcessor(image_processor, tokenizer)
+
+ processor.save_pretrained(cls.tmpdirname)
+
+ def get_tokenizer(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).tokenizer
+
+ def get_image_processor(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).image_processor
+
+ @classmethod
+ def tearDownClass(cls):
+ shutil.rmtree(cls.tmpdirname, ignore_errors=True)
+
+ def test_save_load_pretrained_additional_features(self):
+ with tempfile.TemporaryDirectory() as tmpdir:
+ processor = GitProcessor(tokenizer=self.get_tokenizer(), image_processor=self.get_image_processor())
+ processor.save_pretrained(tmpdir)
+
+ tokenizer_add_kwargs = self.get_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
+ image_processor_add_kwargs = self.get_image_processor(do_normalize=False, padding_value=1.0)
+
+ processor = GitProcessor.from_pretrained(
+ tmpdir, bos_token="(BOS)", eos_token="(EOS)", do_normalize=False, padding_value=1.0
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, PreTrainedTokenizerFast)
+
+ self.assertEqual(processor.image_processor.to_json_string(), image_processor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.image_processor, CLIPImageProcessor)
+
+ def test_image_processor(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GitProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ image_input = self.prepare_image_inputs()
+
+ input_feat_extract = image_processor(image_input, return_tensors="np")
+ input_processor = processor(images=image_input, return_tensors="np")
+
+ for key in input_feat_extract.keys():
+ self.assertAlmostEqual(input_feat_extract[key].sum(), input_processor[key].sum(), delta=1e-2)
+
+ def test_tokenizer(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GitProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+
+ encoded_processor = processor(text=input_str)
+
+ encoded_tok = tokenizer(input_str, return_token_type_ids=False)
+
+ for key in encoded_tok.keys():
+ self.assertListEqual(encoded_tok[key], encoded_processor[key])
+
+ def test_processor(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GitProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ self.assertListEqual(list(inputs.keys()), ["input_ids", "attention_mask", "pixel_values"])
+
+ # test if it raises when no input is passed
+ with pytest.raises(ValueError):
+ processor()
+
+ def test_tokenizer_decode(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GitProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ predicted_ids = [[1, 4, 5, 8, 1, 0, 8], [3, 4, 3, 1, 1, 8, 9]]
+
+ decoded_processor = processor.batch_decode(predicted_ids)
+ decoded_tok = tokenizer.batch_decode(predicted_ids)
+
+ self.assertListEqual(decoded_tok, decoded_processor)
+
+ def test_model_input_names(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GitProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ # For now the processor supports only ['input_ids', 'attention_mask', 'pixel_values']
+ self.assertListEqual(list(inputs.keys()), ["input_ids", "attention_mask", "pixel_values"])
diff --git a/transformers/tests/models/glm/__init__.py b/transformers/tests/models/glm/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/glm/test_modeling_glm.py b/transformers/tests/models/glm/test_modeling_glm.py
new file mode 100644
index 0000000000000000000000000000000000000000..ed1a0d459098c5c59efa431ab08bdf27f0833093
--- /dev/null
+++ b/transformers/tests/models/glm/test_modeling_glm.py
@@ -0,0 +1,199 @@
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Glm model."""
+
+import unittest
+
+import pytest
+
+from transformers import AutoModelForCausalLM, AutoTokenizer, GlmConfig, is_torch_available
+from transformers.testing_utils import (
+ Expectations,
+ require_flash_attn,
+ require_torch,
+ require_torch_large_accelerator,
+ require_torch_sdpa,
+ slow,
+ torch_device,
+)
+
+from ...causal_lm_tester import CausalLMModelTest, CausalLMModelTester
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ GlmForCausalLM,
+ GlmForSequenceClassification,
+ GlmForTokenClassification,
+ GlmModel,
+ )
+
+
+@require_torch
+class GlmModelTester(CausalLMModelTester):
+ config_class = GlmConfig
+ if is_torch_available():
+ base_model_class = GlmModel
+ causal_lm_class = GlmForCausalLM
+ sequence_class = GlmForSequenceClassification
+ token_class = GlmForTokenClassification
+
+
+@require_torch
+class GlmModelTest(CausalLMModelTest, unittest.TestCase):
+ all_model_classes = (
+ (GlmModel, GlmForCausalLM, GlmForSequenceClassification, GlmForTokenClassification)
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": GlmModel,
+ "text-classification": GlmForSequenceClassification,
+ "token-classification": GlmForTokenClassification,
+ "text-generation": GlmForCausalLM,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ test_headmasking = False
+ test_pruning = False
+ model_tester_class = GlmModelTester
+
+
+@slow
+@require_torch_large_accelerator
+class GlmIntegrationTest(unittest.TestCase):
+ input_text = ["Hello I am doing", "Hi today"]
+ model_id = "THUDM/glm-4-9b"
+ revision = "refs/pr/15"
+
+ def test_model_9b_fp16(self):
+ EXPECTED_TEXTS = [
+ "Hello I am doing a project on the history of the internetSolution:\n\nStep 1: Introduction\nThe history of the",
+ "Hi today I am going to show you how to make a simple and easy to make a DIY paper flower.",
+ ]
+
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_id, torch_dtype=torch.float16, revision=self.revision
+ ).to(torch_device)
+
+ tokenizer = AutoTokenizer.from_pretrained(self.model_id, revision=self.revision)
+ inputs = tokenizer(self.input_text, return_tensors="pt", padding=True).to(torch_device)
+
+ output = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+ output_text = tokenizer.batch_decode(output, skip_special_tokens=True)
+
+ self.assertEqual(output_text, EXPECTED_TEXTS)
+
+ def test_model_9b_bf16(self):
+ EXPECTED_TEXTS = [
+ "Hello I am doing a project on the history of the internetSolution:\n\nStep 1: Introduction\nThe history of the",
+ "Hi today I am going to show you how to make a simple and easy to make a DIY paper flower.",
+ ]
+
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_id, torch_dtype=torch.bfloat16, revision=self.revision
+ ).to(torch_device)
+
+ tokenizer = AutoTokenizer.from_pretrained(self.model_id, revision=self.revision)
+ inputs = tokenizer(self.input_text, return_tensors="pt", padding=True).to(torch_device)
+
+ output = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+ output_text = tokenizer.batch_decode(output, skip_special_tokens=True)
+
+ self.assertEqual(output_text, EXPECTED_TEXTS)
+
+ def test_model_9b_eager(self):
+ expected_texts = Expectations({
+ (None, None): [
+ "Hello I am doing a project on the history of the internetSolution:\n\nStep 1: Introduction\nThe history of the",
+ "Hi today I am going to show you how to make a simple and easy to make a DIY paper flower.",
+ ],
+ ("cuda", 8): [
+ 'Hello I am doing a project on the history of the internetSolution:\n\nStep 1: Introduction\nThe history of the',
+ 'Hi today I am going to show you how to make a simple and easy to make a DIY paper lantern.',
+ ],
+ ("rocm", (9, 5)) : [
+ "Hello I am doing a project on the history of the internetSolution:\n\nStep 1: Introduction\nThe history of the",
+ "Hi today I am going to show you how to make a simple and easy to make a paper airplane. First",
+ ]
+ }) # fmt: skip
+ EXPECTED_TEXTS = expected_texts.get_expectation()
+
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_id,
+ torch_dtype=torch.bfloat16,
+ attn_implementation="eager",
+ revision=self.revision,
+ )
+ model.to(torch_device)
+
+ tokenizer = AutoTokenizer.from_pretrained(self.model_id, revision=self.revision)
+ inputs = tokenizer(self.input_text, return_tensors="pt", padding=True).to(torch_device)
+
+ output = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+ output_text = tokenizer.batch_decode(output, skip_special_tokens=True)
+
+ self.assertEqual(output_text, EXPECTED_TEXTS)
+
+ @require_torch_sdpa
+ def test_model_9b_sdpa(self):
+ EXPECTED_TEXTS = [
+ "Hello I am doing a project on the history of the internetSolution:\n\nStep 1: Introduction\nThe history of the",
+ "Hi today I am going to show you how to make a simple and easy to make a DIY paper flower.",
+ ]
+
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_id,
+ torch_dtype=torch.bfloat16,
+ attn_implementation="sdpa",
+ revision=self.revision,
+ )
+ model.to(torch_device)
+
+ tokenizer = AutoTokenizer.from_pretrained(self.model_id, revision=self.revision)
+ inputs = tokenizer(self.input_text, return_tensors="pt", padding=True).to(torch_device)
+
+ output = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+ output_text = tokenizer.batch_decode(output, skip_special_tokens=True)
+
+ self.assertEqual(output_text, EXPECTED_TEXTS)
+
+ @require_flash_attn
+ @pytest.mark.flash_attn_test
+ def test_model_9b_flash_attn(self):
+ EXPECTED_TEXTS = [
+ "Hello I am doing a project on the history of the internetSolution:\n\nStep 1: Introduction\nThe history of the",
+ "Hi today I am going to show you how to make a simple and easy to make a DIY paper flower.",
+ ]
+
+ model = AutoModelForCausalLM.from_pretrained(
+ self.model_id,
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+ revision=self.revision,
+ )
+ model.to(torch_device)
+
+ tokenizer = AutoTokenizer.from_pretrained(self.model_id, revision=self.revision)
+ inputs = tokenizer(self.input_text, return_tensors="pt", padding=True).to(torch_device)
+
+ output = model.generate(**inputs, max_new_tokens=20, do_sample=False)
+ output_text = tokenizer.batch_decode(output, skip_special_tokens=True)
+
+ self.assertEqual(output_text, EXPECTED_TEXTS)
diff --git a/transformers/tests/models/glm4v/__init__.py b/transformers/tests/models/glm4v/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/glm4v/test_modeling_glm4v.py b/transformers/tests/models/glm4v/test_modeling_glm4v.py
new file mode 100644
index 0000000000000000000000000000000000000000..1e962e4c334ea68b4109663c41dd8fc898403e36
--- /dev/null
+++ b/transformers/tests/models/glm4v/test_modeling_glm4v.py
@@ -0,0 +1,554 @@
+# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch GLM-4.1V model."""
+
+import copy
+import gc
+import unittest
+
+from transformers import (
+ AutoProcessor,
+ Glm4vConfig,
+ Glm4vForConditionalGeneration,
+ Glm4vModel,
+ is_torch_available,
+)
+from transformers.testing_utils import (
+ require_flash_attn,
+ require_torch,
+ require_torch_gpu,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ ModelTesterMixin,
+ floats_tensor,
+ ids_tensor,
+)
+
+
+if is_torch_available():
+ import torch
+
+
+class Glm4vVisionText2TextModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=3,
+ seq_length=7,
+ num_channels=3,
+ ignore_index=-100,
+ image_size=112,
+ video_start_token_id=3,
+ video_end_token_id=4,
+ image_start_token_id=5,
+ image_end_token_id=6,
+ image_token_id=7,
+ video_token_id=8,
+ is_training=True,
+ text_config={
+ "vocab_size": 99,
+ "hidden_size": 16,
+ "intermediate_size": 22,
+ "num_hidden_layers": 2,
+ "num_attention_heads": 2,
+ "num_key_value_heads": 1,
+ "output_channels": 64,
+ "hidden_act": "silu",
+ "max_position_embeddings": 512,
+ "rope_scaling": {"type": "default", "mrope_section": [2, 1, 1]},
+ "rope_theta": 10000,
+ "tie_word_embeddings": True,
+ "bos_token_id": 0,
+ "eos_token_id": 0,
+ "pad_token_id": 0,
+ },
+ vision_config={
+ "depth": 2,
+ "hidden_act": "silu",
+ "hidden_size": 48,
+ "out_hidden_size": 16,
+ "intermediate_size": 22,
+ "patch_size": 14,
+ "spatial_merge_size": 1,
+ "temporal_patch_size": 2,
+ },
+ ):
+ self.parent = parent
+ self.ignore_index = ignore_index
+ self.bos_token_id = text_config["bos_token_id"]
+ self.eos_token_id = text_config["eos_token_id"]
+ self.pad_token_id = text_config["pad_token_id"]
+ self.video_start_token_id = video_start_token_id
+ self.video_end_token_id = video_end_token_id
+ self.image_start_token_id = image_start_token_id
+ self.image_end_token_id = image_end_token_id
+ self.image_token_id = image_token_id
+ self.video_token_id = video_token_id
+ self.text_config = text_config
+ self.vision_config = vision_config
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.is_training = is_training
+ self.hidden_size = text_config["hidden_size"]
+ self.num_hidden_layers = text_config["num_hidden_layers"]
+ self.num_attention_heads = text_config["num_attention_heads"]
+ self.vocab_size = text_config["vocab_size"]
+ self.num_image_tokens = 64
+ self.seq_length = seq_length + self.num_image_tokens
+
+ def get_config(self):
+ return Glm4vConfig(
+ text_config=self.text_config,
+ vision_config=self.vision_config,
+ image_token_id=self.image_token_id,
+ video_token_id=self.video_token_id,
+ video_start_token_id=self.video_start_token_id,
+ video_end_token_id=self.video_end_token_id,
+ image_start_token_id=self.image_start_token_id,
+ image_end_token_id=self.image_end_token_id,
+ )
+
+ def prepare_config_and_inputs(self):
+ config = self.get_config()
+ patch_size = config.vision_config.patch_size
+ temporal_patch_size = config.vision_config.temporal_patch_size
+ pixel_values = floats_tensor(
+ [
+ self.batch_size * (self.image_size**2) // (patch_size**2),
+ self.num_channels * (patch_size**2) * temporal_patch_size,
+ ]
+ )
+
+ return config, pixel_values
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+ attention_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
+
+ input_ids[input_ids == self.video_token_id] = self.pad_token_id
+ input_ids[input_ids == self.image_token_id] = self.pad_token_id
+ input_ids[input_ids == self.video_start_token_id] = self.pad_token_id
+ input_ids[input_ids == self.image_start_token_id] = self.pad_token_id
+ input_ids[input_ids == self.video_end_token_id] = self.pad_token_id
+ input_ids[input_ids == self.image_end_token_id] = self.pad_token_id
+
+ input_ids[:, 0] = self.image_start_token_id
+ input_ids[:, 1 : 1 + self.num_image_tokens] = self.image_token_id
+ input_ids[:, 1 + self.num_image_tokens] = self.image_end_token_id
+ patch_size = config.vision_config.patch_size
+ patches_per_side = self.image_size // patch_size
+
+ inputs_dict = {
+ "pixel_values": pixel_values,
+ "image_grid_thw": torch.tensor([[1, patches_per_side, patches_per_side]] * self.batch_size),
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class Glm4vModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
+ all_model_classes = (Glm4vModel, Glm4vForConditionalGeneration) if is_torch_available() else ()
+ test_pruning = False
+ test_head_masking = False
+ test_torchscript = False
+ model_split_percents = [0.7, 0.9] # model too big to split at 0.5
+ _is_composite = True
+
+ def setUp(self):
+ self.model_tester = Glm4vVisionText2TextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=Glm4vConfig, has_text_modality=False)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ # GLM4V has images shaped as (bs*patch_len, dim) so we can't slice to batches in generate
+ def prepare_config_and_inputs_for_generate(self, batch_size=2):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # We don't want a few model inputs in our model input dictionary for generation tests
+ input_keys_to_ignore = [
+ # we don't want to mask attention heads
+ "head_mask",
+ "decoder_head_mask",
+ "cross_attn_head_mask",
+ # we don't want encoder-decoder models to start from filled decoder ids
+ "decoder_input_ids",
+ "decoder_attention_mask",
+ # we'll set cache use in each test differently
+ "use_cache",
+ # Ignore labels if it is in the input dict
+ "labels",
+ # model-specific exceptions should overload/overwrite this function
+ ]
+
+ # The diff from the general `prepare_config_and_inputs_for_generate` lies here
+ patch_size = config.vision_config.patch_size
+ filtered_image_length = batch_size * (self.model_tester.image_size**2) // (patch_size**2)
+ filtered_inputs_dict = {
+ k: v[:batch_size, ...] if isinstance(v, torch.Tensor) else v
+ for k, v in inputs_dict.items()
+ if k not in input_keys_to_ignore
+ }
+ filtered_inputs_dict["pixel_values"] = inputs_dict["pixel_values"][:filtered_image_length]
+
+ # It is important set `eos_token_id` to `None` to avoid early stopping (would break for length-based checks)
+ text_gen_config = config.get_text_config(decoder=True)
+ if text_gen_config.eos_token_id is not None and text_gen_config.pad_token_id is None:
+ text_gen_config.pad_token_id = (
+ text_gen_config.eos_token_id
+ if isinstance(text_gen_config.eos_token_id, int)
+ else text_gen_config.eos_token_id[0]
+ )
+ text_gen_config.eos_token_id = None
+ text_gen_config.forced_eos_token_id = None
+
+ return config, filtered_inputs_dict
+
+ @unittest.skip(reason="No available kernels - not supported")
+ def test_sdpa_can_dispatch_on_flash(self):
+ pass
+
+ @unittest.skip(reason="Size mismatch")
+ def test_multi_gpu_data_parallel_forward(self):
+ pass
+
+ @unittest.skip("Error with compilation")
+ def test_generate_from_inputs_embeds_with_static_cache(self):
+ pass
+
+ def test_inputs_embeds(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ inputs = copy.deepcopy(self._prepare_for_class(inputs_dict, model_class))
+
+ input_ids = inputs["input_ids"]
+ del inputs["input_ids"]
+ del inputs["pixel_values"]
+ del inputs["image_grid_thw"]
+
+ wte = model.get_input_embeddings()
+ inputs["inputs_embeds"] = wte(input_ids)
+ with torch.no_grad():
+ model(**inputs)[0]
+
+ def test_inputs_embeds_matches_input_ids(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ inputs = self._prepare_for_class(inputs_dict, model_class)
+ input_ids = inputs["input_ids"]
+ del inputs["input_ids"]
+ del inputs["pixel_values"]
+ del inputs["image_grid_thw"]
+
+ inputs_embeds = model.get_input_embeddings()(input_ids)
+
+ with torch.no_grad():
+ out_ids = model(input_ids=input_ids, **inputs)[0]
+ out_embeds = model(inputs_embeds=inputs_embeds, **inputs)[0]
+ torch.testing.assert_close(out_embeds, out_ids)
+
+
+@require_torch
+class Glm4vIntegrationTest(unittest.TestCase):
+ def setUp(self):
+ self.processor = AutoProcessor.from_pretrained("THUDM/GLM-4.1V-9B-Thinking")
+ self.message = [
+ {
+ "role": "user",
+ "content": [
+ {
+ "type": "image",
+ "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg",
+ },
+ {"type": "text", "text": "What kind of dog is this?"},
+ ],
+ }
+ ]
+ self.message2 = [
+ {
+ "role": "user",
+ "content": [
+ {
+ "type": "image",
+ "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png",
+ },
+ {"type": "text", "text": "What kind of dog is this?"},
+ ],
+ }
+ ]
+
+ def tearDown(self):
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ @slow
+ def test_small_model_integration_test(self):
+ model = Glm4vForConditionalGeneration.from_pretrained(
+ "THUDM/GLM-4.1V-9B-Thinking", torch_dtype="auto", device_map="auto"
+ )
+
+ inputs = self.processor.apply_chat_template(
+ self.message, tokenize=True, add_generation_prompt=True, return_dict=True, return_tensors="pt"
+ )
+ expected_input_ids = [151331, 151333, 151336, 198, 151339, 151343, 151343, 151343, 151343, 151343, 151343, 151343, 151343, 151343, 151343, 151343, 151343] # fmt: skip
+ assert expected_input_ids == inputs.input_ids[0].tolist()[:17]
+
+ expected_pixel_slice = torch.tensor(
+ [
+ [-0.0988, -0.0842, -0.0842],
+ [-0.5660, -0.5514, -0.4200],
+ [-0.0259, -0.0259, -0.0259],
+ [-0.1280, -0.0988, -0.2010],
+ [-0.4638, -0.5806, -0.6974],
+ [-1.2083, -1.2229, -1.2083],
+ ],
+ dtype=torch.float32,
+ device="cpu",
+ )
+ assert torch.allclose(expected_pixel_slice, inputs.pixel_values[:6, :3], atol=3e-3)
+
+ # verify generation
+ inputs = inputs.to(torch_device)
+
+ output = model.generate(**inputs, max_new_tokens=30)
+ EXPECTED_DECODED_TEXT = "\nWhat kind of dog is this?\nGot it, let's look at the image. The animal in the picture is not a dog; it's a cat. Specifically, it looks"
+ self.assertEqual(
+ self.processor.decode(output[0], skip_special_tokens=True),
+ EXPECTED_DECODED_TEXT,
+ )
+
+ @slow
+ def test_small_model_integration_test_batch(self):
+ model = Glm4vForConditionalGeneration.from_pretrained(
+ "THUDM/GLM-4.1V-9B-Thinking", torch_dtype="auto", device_map="auto"
+ )
+ batch_messages = [self.message] * 2
+ inputs = self.processor.apply_chat_template(
+ batch_messages, tokenize=True, add_generation_prompt=True, return_dict=True, return_tensors="pt"
+ ).to(torch_device)
+
+ # it should not matter whether two images are the same size or not
+ output = model.generate(**inputs, max_new_tokens=30)
+
+ EXPECTED_DECODED_TEXT = [
+ "\nWhat kind of dog is this?\nGot it, let's look at the image. The animal in the picture is not a dog; it's a cat. Specifically, it looks",
+ "\nWhat kind of dog is this?\nGot it, let's look at the image. The animal in the picture is not a dog; it's a cat. Specifically, it looks"
+ ] # fmt: skip
+ self.assertEqual(
+ self.processor.batch_decode(output, skip_special_tokens=True),
+ EXPECTED_DECODED_TEXT,
+ )
+
+ @slow
+ def test_small_model_integration_test_with_video(self):
+ processor = AutoProcessor.from_pretrained("THUDM/GLM-4.1V-9B-Thinking", max_image_size={"longest_edge": 50176})
+ model = Glm4vForConditionalGeneration.from_pretrained(
+ "THUDM/GLM-4.1V-9B-Thinking", torch_dtype=torch.float16, device_map="auto"
+ )
+ questions = ["Describe this video."] * 2
+ video_urls = [
+ "https://huggingface.co/datasets/hf-internal-testing/fixtures_videos/resolve/main/tennis.mp4"
+ ] * 2
+ messages = [
+ [
+ {
+ "role": "user",
+ "content": [
+ {
+ "type": "video",
+ "video": video_url,
+ },
+ {"type": "text", "text": question},
+ ],
+ }
+ ]
+ for question, video_url in zip(questions, video_urls)
+ ]
+ inputs = processor.apply_chat_template(
+ messages, tokenize=True, add_generation_prompt=True, return_dict=True, return_tensors="pt", padding=True
+ ).to(torch_device)
+ output = model.generate(**inputs, max_new_tokens=30)
+ EXPECTED_DECODED_TEXT = [
+ "\n012345Describe this video.\nGot it, let's analyze the video. First, the scene is a room with a wooden floor, maybe a traditional Japanese room with tatami",
+ "\n012345Describe this video.\nGot it, let's analyze the video. First, the scene is a room with a wooden floor, maybe a traditional Japanese room with tatami"
+ ] # fmt: skip
+ self.assertEqual(
+ processor.batch_decode(output, skip_special_tokens=True),
+ EXPECTED_DECODED_TEXT,
+ )
+
+ @slow
+ def test_small_model_integration_test_expand(self):
+ model = Glm4vForConditionalGeneration.from_pretrained(
+ "THUDM/GLM-4.1V-9B-Thinking", torch_dtype="auto", device_map="auto"
+ )
+ inputs = self.processor.apply_chat_template(
+ self.message, tokenize=True, add_generation_prompt=True, return_dict=True, return_tensors="pt"
+ ).to(torch_device)
+
+ output = model.generate(**inputs, max_new_tokens=30, do_sample=False, num_beams=2, num_return_sequences=2)
+
+ EXPECTED_DECODED_TEXT = [
+ "\nWhat kind of dog is this?\nGot it, let's look at the image. The animal in the picture doesn't look like a dog; it's actually a cat. Specifically",
+ "\nWhat kind of dog is this?\nGot it, let's look at the image. The animal in the picture doesn't look like a dog; it's actually a cat, specifically"
+ ] # fmt: skip
+ self.assertEqual(
+ self.processor.batch_decode(output, skip_special_tokens=True),
+ EXPECTED_DECODED_TEXT,
+ )
+
+ @slow
+ def test_small_model_integration_test_batch_wo_image(self):
+ model = Glm4vForConditionalGeneration.from_pretrained(
+ "THUDM/GLM-4.1V-9B-Thinking", torch_dtype="auto", device_map="auto"
+ )
+ message_wo_image = [
+ {"role": "user", "content": [{"type": "text", "text": "Who are you?"}]},
+ ]
+ batched_messages = [self.message, message_wo_image]
+ inputs = self.processor.apply_chat_template(
+ batched_messages,
+ tokenize=True,
+ add_generation_prompt=True,
+ return_dict=True,
+ return_tensors="pt",
+ padding=True,
+ ).to(torch_device)
+
+ # it should not matter whether two images are the same size or not
+ output = model.generate(**inputs, max_new_tokens=30)
+
+ EXPECTED_DECODED_TEXT = [
+ "\nWhat kind of dog is this?\nGot it, let's look at the image. The animal in the picture is not a dog; it's a cat. Specifically, it looks",
+ '\nWho are you?\nGot it, the user is asking "Who are you?" I need to respond appropriately. First, I should clarify that I\'m an AI assistant'
+ ] # fmt: skip
+ self.assertEqual(
+ self.processor.batch_decode(output, skip_special_tokens=True),
+ EXPECTED_DECODED_TEXT,
+ )
+
+ @slow
+ def test_small_model_integration_test_batch_different_resolutions(self):
+ model = Glm4vForConditionalGeneration.from_pretrained(
+ "THUDM/GLM-4.1V-9B-Thinking", torch_dtype="auto", device_map="auto"
+ )
+ batched_messages = [self.message, self.message2]
+ inputs = self.processor.apply_chat_template(
+ batched_messages,
+ tokenize=True,
+ add_generation_prompt=True,
+ return_dict=True,
+ return_tensors="pt",
+ padding=True,
+ ).to(torch_device)
+
+ # it should not matter whether two images are the same size or not
+ output = model.generate(**inputs, max_new_tokens=30)
+
+ EXPECTED_DECODED_TEXT = [
+ "\nWhat kind of dog is this?\nGot it, let's look at the image. The animal in the picture is not a dog; it's a cat. Specifically, it looks",
+ "\nWhat kind of dog is this?\nGot it, let's look at the image. Wait, the animals here are cats, not dogs. The question is about a dog, but"
+ ] # fmt: skip
+ self.assertEqual(
+ self.processor.batch_decode(output, skip_special_tokens=True),
+ EXPECTED_DECODED_TEXT,
+ )
+
+ @slow
+ @require_flash_attn
+ @require_torch_gpu
+ def test_small_model_integration_test_batch_flashatt2(self):
+ model = Glm4vForConditionalGeneration.from_pretrained(
+ "THUDM/GLM-4.1V-9B-Thinking",
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+ device_map="auto",
+ )
+ batched_messages = [self.message, self.message2]
+ inputs = self.processor.apply_chat_template(
+ batched_messages,
+ tokenize=True,
+ add_generation_prompt=True,
+ return_dict=True,
+ return_tensors="pt",
+ padding=True,
+ ).to(torch_device)
+
+ # it should not matter whether two images are the same size or not
+ output = model.generate(**inputs, max_new_tokens=30)
+
+ EXPECTED_DECODED_TEXT = [
+ "\nWhat kind of dog is this?\nGot it, let's look at the image. The animal in the picture has a stocky build, thick fur, and a face that's",
+ "\nWhat kind of dog is this?\nGot it, let's look at the image. Wait, the animals here are cats, not dogs. The question is about a dog, but"
+ ] # fmt: skip
+ self.assertEqual(
+ self.processor.batch_decode(output, skip_special_tokens=True),
+ EXPECTED_DECODED_TEXT,
+ )
+
+ @slow
+ @require_flash_attn
+ @require_torch_gpu
+ def test_small_model_integration_test_batch_wo_image_flashatt2(self):
+ model = Glm4vForConditionalGeneration.from_pretrained(
+ "THUDM/GLM-4.1V-9B-Thinking",
+ torch_dtype=torch.bfloat16,
+ attn_implementation="flash_attention_2",
+ device_map="auto",
+ )
+ message_wo_image = [
+ {"role": "user", "content": [{"type": "text", "text": "Who are you?"}]},
+ ]
+ batched_messages = [self.message, message_wo_image]
+ inputs = self.processor.apply_chat_template(
+ batched_messages,
+ tokenize=True,
+ add_generation_prompt=True,
+ return_dict=True,
+ return_tensors="pt",
+ padding=True,
+ ).to(torch_device)
+
+ # it should not matter whether two images are the same size or not
+ output = model.generate(**inputs, max_new_tokens=30)
+
+ EXPECTED_DECODED_TEXT = [
+ "\nWhat kind of dog is this?\nGot it, let's look at the image. The animal in the picture is not a dog; it's a cat. Specifically, it looks",
+ '\nWho are you?\nGot it, let\'s look at the question. The user is asking "Who are you?" which is a common question when someone meets an AI'
+ ] # fmt: skip
+
+ self.assertEqual(
+ self.processor.batch_decode(output, skip_special_tokens=True),
+ EXPECTED_DECODED_TEXT,
+ )
diff --git a/transformers/tests/models/glm4v/test_video_processing_glm4v.py b/transformers/tests/models/glm4v/test_video_processing_glm4v.py
new file mode 100644
index 0000000000000000000000000000000000000000..b629e61eb50c61b8d7ad5b78d16904fa9b66c20e
--- /dev/null
+++ b/transformers/tests/models/glm4v/test_video_processing_glm4v.py
@@ -0,0 +1,330 @@
+# coding=utf-8
+# Copyright 2025 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import numpy as np
+
+from transformers.image_utils import IMAGENET_STANDARD_MEAN, IMAGENET_STANDARD_STD
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torch_available, is_torchvision_available, is_vision_available
+
+from ...test_video_processing_common import VideoProcessingTestMixin, prepare_video_inputs
+
+
+if is_torch_available():
+ from PIL import Image
+
+if is_vision_available():
+ if is_torchvision_available():
+ from transformers import Glm4vVideoProcessor
+ from transformers.models.glm4v.video_processing_glm4v import smart_resize
+
+
+class Glm4vVideoProcessingTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=5,
+ num_frames=8,
+ num_channels=3,
+ min_resolution=30,
+ max_resolution=80,
+ temporal_patch_size=2,
+ patch_size=14,
+ merge_size=2,
+ do_resize=True,
+ size=None,
+ do_normalize=True,
+ image_mean=IMAGENET_STANDARD_MEAN,
+ image_std=IMAGENET_STANDARD_STD,
+ do_convert_rgb=True,
+ ):
+ size = size if size is not None else {"longest_edge": 20}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_frames = num_frames
+ self.num_channels = num_channels
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.do_convert_rgb = do_convert_rgb
+ self.temporal_patch_size = temporal_patch_size
+ self.patch_size = patch_size
+ self.merge_size = merge_size
+
+ def prepare_video_processor_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_convert_rgb": self.do_convert_rgb,
+ "do_sample_frames": True,
+ }
+
+ def prepare_video_metadata(self, videos):
+ video_metadata = []
+ for video in videos:
+ if isinstance(video, list):
+ num_frames = len(video)
+ elif hasattr(video, "shape"):
+ if len(video.shape) == 4: # (T, H, W, C)
+ num_frames = video.shape[0]
+ else:
+ num_frames = 1
+ else:
+ num_frames = self.num_frames
+
+ metadata = {
+ "fps": 2,
+ "duration": num_frames / 2,
+ "total_frames": num_frames,
+ }
+ video_metadata.append(metadata)
+ return video_metadata
+
+ def expected_output_video_shape(self, videos):
+ grid_t = self.num_frames // self.temporal_patch_size
+ hidden_dim = self.num_channels * self.temporal_patch_size * self.patch_size * self.patch_size
+ seq_len = 0
+ for video in videos:
+ if isinstance(video, list) and isinstance(video[0], Image.Image):
+ video = np.stack([np.array(frame) for frame in video])
+ elif hasattr(video, "shape"):
+ pass
+ else:
+ video = np.array(video)
+
+ if hasattr(video, "shape") and len(video.shape) >= 3:
+ if len(video.shape) == 4:
+ t, height, width = video.shape[:3]
+ elif len(video.shape) == 3:
+ height, width = video.shape[:2]
+ t = 1
+ else:
+ t, height, width = self.num_frames, self.min_resolution, self.min_resolution
+ else:
+ t, height, width = self.num_frames, self.min_resolution, self.min_resolution
+
+ resized_height, resized_width = smart_resize(
+ t,
+ height,
+ width,
+ factor=self.patch_size * self.merge_size,
+ )
+ grid_h, grid_w = resized_height // self.patch_size, resized_width // self.patch_size
+ seq_len += grid_t * grid_h * grid_w
+ return [seq_len, hidden_dim]
+
+ def prepare_video_inputs(self, equal_resolution=False, return_tensors="pil"):
+ videos = prepare_video_inputs(
+ batch_size=self.batch_size,
+ num_frames=self.num_frames,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ return_tensors=return_tensors,
+ )
+ return videos
+
+
+@require_torch
+@require_vision
+class Glm4vVideoProcessingTest(VideoProcessingTestMixin, unittest.TestCase):
+ fast_video_processing_class = Glm4vVideoProcessor if is_torchvision_available() else None
+ input_name = "pixel_values_videos"
+
+ def setUp(self):
+ super().setUp()
+ self.video_processor_tester = Glm4vVideoProcessingTester(self)
+
+ @property
+ def video_processor_dict(self):
+ return self.video_processor_tester.prepare_video_processor_dict()
+
+ def test_video_processor_from_dict_with_kwargs(self):
+ video_processor = self.fast_video_processing_class.from_dict(self.video_processor_dict)
+ self.assertEqual(video_processor.size, {"longest_edge": 20})
+
+ video_processor = self.fast_video_processing_class.from_dict(self.video_processor_dict, size=42)
+ self.assertEqual(video_processor.size, {"height": 42, "width": 42})
+
+ def test_call_pil(self):
+ for video_processing_class in self.video_processor_list:
+ video_processing = video_processing_class(**self.video_processor_dict)
+ video_inputs = self.video_processor_tester.prepare_video_inputs(
+ equal_resolution=False, return_tensors="pil"
+ )
+
+ for video in video_inputs:
+ self.assertIsInstance(video[0], Image.Image)
+
+ video_metadata = self.video_processor_tester.prepare_video_metadata(video_inputs)
+ encoded_videos = video_processing(
+ video_inputs[0], video_metadata=[video_metadata[0]], return_tensors="pt"
+ )[self.input_name]
+ expected_output_video_shape = self.video_processor_tester.expected_output_video_shape([video_inputs[0]])
+ self.assertEqual(list(encoded_videos.shape), expected_output_video_shape)
+ encoded_videos = video_processing(video_inputs, video_metadata=video_metadata, return_tensors="pt")[
+ self.input_name
+ ]
+ expected_output_video_shape = self.video_processor_tester.expected_output_video_shape(video_inputs)
+ self.assertEqual(list(encoded_videos.shape), expected_output_video_shape)
+
+ def test_call_numpy(self):
+ for video_processing_class in self.video_processor_list:
+ video_processing = video_processing_class(**self.video_processor_dict)
+ video_inputs = self.video_processor_tester.prepare_video_inputs(
+ equal_resolution=False, return_tensors="np"
+ )
+
+ video_metadata = self.video_processor_tester.prepare_video_metadata(video_inputs)
+ encoded_videos = video_processing(
+ video_inputs[0], video_metadata=[video_metadata[0]], return_tensors="pt"
+ )[self.input_name]
+ expected_output_video_shape = self.video_processor_tester.expected_output_video_shape([video_inputs[0]])
+ self.assertEqual(list(encoded_videos.shape), expected_output_video_shape)
+
+ encoded_videos = video_processing(video_inputs, video_metadata=video_metadata, return_tensors="pt")[
+ self.input_name
+ ]
+ expected_output_video_shape = self.video_processor_tester.expected_output_video_shape(video_inputs)
+ self.assertEqual(list(encoded_videos.shape), expected_output_video_shape)
+
+ def test_call_pytorch(self):
+ for video_processing_class in self.video_processor_list:
+ video_processing = video_processing_class(**self.video_processor_dict)
+ video_inputs = self.video_processor_tester.prepare_video_inputs(
+ equal_resolution=False, return_tensors="pt"
+ )
+ video_metadata = self.video_processor_tester.prepare_video_metadata(video_inputs)
+ encoded_videos = video_processing(
+ video_inputs[0], video_metadata=[video_metadata[0]], return_tensors="pt"
+ )[self.input_name]
+ expected_output_video_shape = self.video_processor_tester.expected_output_video_shape([video_inputs[0]])
+ self.assertEqual(list(encoded_videos.shape), expected_output_video_shape)
+ encoded_videos = video_processing(video_inputs, video_metadata=video_metadata, return_tensors="pt")[
+ self.input_name
+ ]
+ expected_output_video_shape = self.video_processor_tester.expected_output_video_shape(video_inputs)
+ self.assertEqual(list(encoded_videos.shape), expected_output_video_shape)
+
+ @unittest.skip("Skip for now, the test needs adjustment for GLM-4.1V")
+ def test_call_numpy_4_channels(self):
+ for video_processing_class in self.video_processor_list:
+ # Test that can process videos which have an arbitrary number of channels
+ # Initialize video_processing
+ video_processor = video_processing_class(**self.video_processor_dict)
+
+ # create random numpy tensors
+ self.video_processor_tester.num_channels = 4
+ video_inputs = self.video_processor_tester.prepare_video_inputs(
+ equal_resolution=False, return_tensors="np"
+ )
+
+ # Test not batched input
+ encoded_videos = video_processor(
+ video_inputs[0],
+ return_tensors="pt",
+ input_data_format="channels_last",
+ image_mean=0,
+ image_std=1,
+ )[self.input_name]
+ expected_output_video_shape = self.video_processor_tester.expected_output_video_shape([video_inputs[0]])
+ self.assertEqual(list(encoded_videos.shape), expected_output_video_shape)
+
+ # Test batched
+ encoded_videos = video_processor(
+ video_inputs,
+ return_tensors="pt",
+ input_data_format="channels_last",
+ image_mean=0,
+ image_std=1,
+ )[self.input_name]
+ expected_output_video_shape = self.video_processor_tester.expected_output_video_shape(video_inputs)
+ self.assertEqual(list(encoded_videos.shape), expected_output_video_shape)
+
+ def test_nested_input(self):
+ """Tests that the processor can work with nested list where each video is a list of arrays"""
+ for video_processing_class in self.video_processor_list:
+ video_processing = video_processing_class(**self.video_processor_dict)
+ video_inputs = self.video_processor_tester.prepare_video_inputs(
+ equal_resolution=False, return_tensors="np"
+ )
+
+ video_inputs_nested = [list(video) for video in video_inputs]
+ video_metadata = self.video_processor_tester.prepare_video_metadata(video_inputs)
+
+ # Test not batched input
+ encoded_videos = video_processing(
+ video_inputs_nested[0], video_metadata=[video_metadata[0]], return_tensors="pt"
+ )[self.input_name]
+ expected_output_video_shape = self.video_processor_tester.expected_output_video_shape([video_inputs[0]])
+ self.assertEqual(list(encoded_videos.shape), expected_output_video_shape)
+
+ # Test batched
+ encoded_videos = video_processing(video_inputs_nested, video_metadata=video_metadata, return_tensors="pt")[
+ self.input_name
+ ]
+ expected_output_video_shape = self.video_processor_tester.expected_output_video_shape(video_inputs)
+ self.assertEqual(list(encoded_videos.shape), expected_output_video_shape)
+
+ def test_call_sample_frames(self):
+ for video_processing_class in self.video_processor_list:
+ video_processor_dict = self.video_processor_dict.copy()
+ video_processing = video_processing_class(**video_processor_dict)
+
+ prev_num_frames = self.video_processor_tester.num_frames
+ self.video_processor_tester.num_frames = 8
+ prev_min_resolution = getattr(self.video_processor_tester, "min_resolution", None)
+ prev_max_resolution = getattr(self.video_processor_tester, "max_resolution", None)
+ self.video_processor_tester.min_resolution = 56
+ self.video_processor_tester.max_resolution = 112
+
+ video_inputs = self.video_processor_tester.prepare_video_inputs(
+ equal_resolution=False,
+ return_tensors="torch",
+ )
+
+ metadata = [[{"total_num_frames": 8, "fps": 4}]]
+ batched_metadata = metadata * len(video_inputs)
+
+ encoded_videos = video_processing(video_inputs[0], return_tensors="pt", video_metadata=metadata)[
+ self.input_name
+ ]
+ encoded_videos_batched = video_processing(
+ video_inputs, return_tensors="pt", video_metadata=batched_metadata
+ )[self.input_name]
+
+ self.assertIsNotNone(encoded_videos)
+ self.assertIsNotNone(encoded_videos_batched)
+ self.assertEqual(len(encoded_videos.shape), 2)
+ self.assertEqual(len(encoded_videos_batched.shape), 2)
+
+ with self.assertRaises(ValueError):
+ video_processing(video_inputs[0], return_tensors="pt")[self.input_name]
+
+ self.video_processor_tester.num_frames = prev_num_frames
+ if prev_min_resolution is not None:
+ self.video_processor_tester.min_resolution = prev_min_resolution
+ if prev_max_resolution is not None:
+ self.video_processor_tester.max_resolution = prev_max_resolution
diff --git a/transformers/tests/models/glpn/__init__.py b/transformers/tests/models/glpn/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/glpn/test_image_processing_glpn.py b/transformers/tests/models/glpn/test_image_processing_glpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..7f6a960755e724298d27a31e3cb768635d7ff0e4
--- /dev/null
+++ b/transformers/tests/models/glpn/test_image_processing_glpn.py
@@ -0,0 +1,163 @@
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+import numpy as np
+
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import GLPNImageProcessor
+
+
+class GLPNImageProcessingTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size_divisor=32,
+ do_rescale=True,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size_divisor = size_divisor
+ self.do_rescale = do_rescale
+
+ def prepare_image_processor_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size_divisor": self.size_divisor,
+ "do_rescale": self.do_rescale,
+ }
+
+ def expected_output_image_shape(self, images):
+ if isinstance(images[0], Image.Image):
+ width, height = images[0].size
+ elif isinstance(images[0], np.ndarray):
+ height, width = images[0].shape[0], images[0].shape[1]
+ else:
+ height, width = images[0].shape[1], images[0].shape[2]
+
+ height = height // self.size_divisor * self.size_divisor
+ width = width // self.size_divisor * self.size_divisor
+
+ return self.num_channels, height, width
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ size_divisor=self.size_divisor,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class GLPNImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = GLPNImageProcessor if is_vision_available() else None
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = GLPNImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size_divisor"))
+ self.assertTrue(hasattr(image_processing, "resample"))
+ self.assertTrue(hasattr(image_processing, "do_rescale"))
+
+ def test_call_pil(self):
+ # Initialize image_processing
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ # create random PIL images
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False)
+ for image in image_inputs:
+ self.assertIsInstance(image, Image.Image)
+
+ # Test not batched input (GLPNImageProcessor doesn't support batching)
+ encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape(image_inputs)
+ self.assertTrue(tuple(encoded_images.shape) == (1, *expected_output_image_shape))
+
+ def test_call_numpy(self):
+ # Initialize image_processing
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ # create random numpy tensors
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, numpify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, np.ndarray)
+
+ # Test not batched input (GLPNImageProcessor doesn't support batching)
+ encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape(image_inputs)
+ self.assertTrue(tuple(encoded_images.shape) == (1, *expected_output_image_shape))
+
+ def test_call_pytorch(self):
+ # Initialize image_processing
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ # create random PyTorch tensors
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, torchify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, torch.Tensor)
+
+ # Test not batched input (GLPNImageProcessor doesn't support batching)
+ encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape(image_inputs)
+ self.assertTrue(tuple(encoded_images.shape) == (1, *expected_output_image_shape))
+
+ def test_call_numpy_4_channels(self):
+ # Initialize image_processing
+ image_processing = self.image_processing_class(**self.image_processor_dict)
+ # create random numpy tensors
+ self.image_processing_class.num_channels = 4
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, numpify=True)
+ for image in image_inputs:
+ self.assertIsInstance(image, np.ndarray)
+
+ # Test not batched input (GLPNImageProcessor doesn't support batching)
+ encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape(image_inputs)
+ self.assertTrue(tuple(encoded_images.shape) == (1, *expected_output_image_shape))
+ self.image_processing_class.num_channels = 3
diff --git a/transformers/tests/models/glpn/test_modeling_glpn.py b/transformers/tests/models/glpn/test_modeling_glpn.py
new file mode 100644
index 0000000000000000000000000000000000000000..b98743de357291f746b924a0c35d813fbe7889a6
--- /dev/null
+++ b/transformers/tests/models/glpn/test_modeling_glpn.py
@@ -0,0 +1,349 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch GLPN model."""
+
+import unittest
+
+from transformers import is_torch_available, is_vision_available
+from transformers.testing_utils import require_torch, require_vision, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import GLPNConfig, GLPNForDepthEstimation, GLPNModel
+ from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import GLPNImageProcessor
+
+
+class GLPNConfigTester(ConfigTester):
+ def create_and_test_config_common_properties(self):
+ config = self.config_class(**self.inputs_dict)
+ self.parent.assertTrue(hasattr(config, "hidden_sizes"))
+ self.parent.assertTrue(hasattr(config, "num_attention_heads"))
+ self.parent.assertTrue(hasattr(config, "num_encoder_blocks"))
+
+
+class GLPNModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=64,
+ num_channels=3,
+ num_encoder_blocks=4,
+ depths=[2, 2, 2, 2],
+ sr_ratios=[8, 4, 2, 1],
+ hidden_sizes=[16, 32, 64, 128],
+ downsampling_rates=[1, 4, 8, 16],
+ num_attention_heads=[1, 2, 4, 8],
+ is_training=True,
+ use_labels=True,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ initializer_range=0.02,
+ decoder_hidden_size=16,
+ num_labels=3,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.num_channels = num_channels
+ self.num_encoder_blocks = num_encoder_blocks
+ self.sr_ratios = sr_ratios
+ self.depths = depths
+ self.hidden_sizes = hidden_sizes
+ self.downsampling_rates = downsampling_rates
+ self.num_attention_heads = num_attention_heads
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.initializer_range = initializer_range
+ self.decoder_hidden_size = decoder_hidden_size
+ self.num_labels = num_labels
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size, self.image_size, self.image_size], self.num_labels)
+
+ config = self.get_config()
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return GLPNConfig(
+ image_size=self.image_size,
+ num_channels=self.num_channels,
+ num_encoder_blocks=self.num_encoder_blocks,
+ depths=self.depths,
+ hidden_sizes=self.hidden_sizes,
+ num_attention_heads=self.num_attention_heads,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ initializer_range=self.initializer_range,
+ decoder_hidden_size=self.decoder_hidden_size,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = GLPNModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ expected_height = expected_width = self.image_size // (self.downsampling_rates[-1] * 2)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.hidden_sizes[-1], expected_height, expected_width)
+ )
+
+ def create_and_check_for_depth_estimation(self, config, pixel_values, labels):
+ config.num_labels = self.num_labels
+ model = GLPNForDepthEstimation(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ self.parent.assertEqual(result.predicted_depth.shape, (self.batch_size, self.image_size, self.image_size))
+ result = model(pixel_values, labels=labels)
+ self.parent.assertEqual(result.predicted_depth.shape, (self.batch_size, self.image_size, self.image_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class GLPNModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (GLPNModel, GLPNForDepthEstimation) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {"depth-estimation": GLPNForDepthEstimation, "image-feature-extraction": GLPNModel}
+ if is_torch_available()
+ else {}
+ )
+
+ test_head_masking = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_torch_exportable = True
+
+ def setUp(self):
+ self.model_tester = GLPNModelTester(self)
+ self.config_tester = GLPNConfigTester(self, config_class=GLPNConfig)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_batching_equivalence(self, atol=3e-4, rtol=3e-4):
+ super().test_batching_equivalence(atol=atol, rtol=rtol)
+
+ def test_for_depth_estimation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_depth_estimation(*config_and_inputs)
+
+ @unittest.skip(reason="GLPN does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="GLPN does not have get_input_embeddings method and get_output_embeddings methods")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class._from_config(config, attn_implementation="eager")
+ config = model.config
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+
+ expected_num_attentions = sum(self.model_tester.depths)
+ self.assertEqual(len(attentions), expected_num_attentions)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+
+ self.assertEqual(len(attentions), expected_num_attentions)
+
+ # verify the first attentions (first block, first layer)
+ expected_seq_len = (self.model_tester.image_size // 4) ** 2
+ expected_reduced_seq_len = (self.model_tester.image_size // (4 * self.model_tester.sr_ratios[0])) ** 2
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads[0], expected_seq_len, expected_reduced_seq_len],
+ )
+
+ # verify the last attentions (last block, last layer)
+ expected_seq_len = (self.model_tester.image_size // 32) ** 2
+ expected_reduced_seq_len = (self.model_tester.image_size // (32 * self.model_tester.sr_ratios[-1])) ** 2
+ self.assertListEqual(
+ list(attentions[-1].shape[-3:]),
+ [self.model_tester.num_attention_heads[-1], expected_seq_len, expected_reduced_seq_len],
+ )
+ out_len = len(outputs)
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ self.assertEqual(out_len + 1, len(outputs))
+
+ self_attentions = outputs.attentions
+
+ self.assertEqual(len(self_attentions), expected_num_attentions)
+ # verify the first attentions (first block, first layer)
+ expected_seq_len = (self.model_tester.image_size // 4) ** 2
+ expected_reduced_seq_len = (self.model_tester.image_size // (4 * self.model_tester.sr_ratios[0])) ** 2
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads[0], expected_seq_len, expected_reduced_seq_len],
+ )
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.hidden_states
+
+ expected_num_layers = self.model_tester.num_encoder_blocks
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ # verify the first hidden states (first block)
+ self.assertListEqual(
+ list(hidden_states[0].shape[-3:]),
+ [
+ self.model_tester.hidden_sizes[0],
+ self.model_tester.image_size // 4,
+ self.model_tester.image_size // 4,
+ ],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ def test_training(self):
+ if not self.model_tester.is_training:
+ self.skipTest(reason="model_tester.is_training is set to False")
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ if model_class.__name__ in MODEL_MAPPING_NAMES.values():
+ continue
+ # TODO: remove the following 3 lines once we have a MODEL_FOR_DEPTH_ESTIMATION_MAPPING
+ # this can then be incorporated into _prepare_for_class in test_modeling_common.py
+ if model_class.__name__ == "GLPNForDepthEstimation":
+ batch_size, num_channels, height, width = inputs_dict["pixel_values"].shape
+ inputs_dict["labels"] = torch.zeros(
+ [self.model_tester.batch_size, height, width], device=torch_device
+ ).long()
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "vinvino02/glpn-kitti"
+ model = GLPNModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+@slow
+class GLPNModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference_depth_estimation(self):
+ image_processor = GLPNImageProcessor.from_pretrained("vinvino02/glpn-kitti")
+ model = GLPNForDepthEstimation.from_pretrained("vinvino02/glpn-kitti").to(torch_device)
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the predicted depth
+ expected_shape = torch.Size([1, 480, 640])
+ self.assertEqual(outputs.predicted_depth.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[3.4291, 2.7865, 2.5151], [3.2841, 2.7021, 2.3502], [3.1147, 2.4625, 2.2481]]
+ ).to(torch_device)
+
+ torch.testing.assert_close(outputs.predicted_depth[0, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/got_ocr2/__init__.py b/transformers/tests/models/got_ocr2/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/got_ocr2/test_image_processing_got_ocr2.py b/transformers/tests/models/got_ocr2/test_image_processing_got_ocr2.py
new file mode 100644
index 0000000000000000000000000000000000000000..53b44eba61519964c66ab0f2b15c4d02532f4080
--- /dev/null
+++ b/transformers/tests/models/got_ocr2/test_image_processing_got_ocr2.py
@@ -0,0 +1,171 @@
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers.image_utils import SizeDict
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torch_available, is_torchvision_available, is_vision_available
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+if is_vision_available():
+ from transformers import GotOcr2ImageProcessor
+
+ if is_torchvision_available():
+ from transformers import GotOcr2ImageProcessorFast
+
+
+class GotOcr2ImageProcessingTester(unittest.TestCase):
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ do_normalize=True,
+ do_pad=False,
+ image_mean=[0.48145466, 0.4578275, 0.40821073],
+ image_std=[0.26862954, 0.26130258, 0.27577711],
+ do_convert_rgb=True,
+ ):
+ super().__init__()
+ size = size if size is not None else {"height": 20, "width": 20}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.do_pad = do_pad
+ self.do_convert_rgb = do_convert_rgb
+
+ def prepare_image_processor_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_convert_rgb": self.do_convert_rgb,
+ "do_pad": self.do_pad,
+ }
+
+ def expected_output_image_shape(self, images):
+ return self.num_channels, self.size["height"], self.size["width"]
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class GotOcr2ProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = GotOcr2ImageProcessor if is_vision_available() else None
+ fast_image_processing_class = GotOcr2ImageProcessorFast if is_torchvision_available() else None
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = GotOcr2ImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processor, "do_resize"))
+ self.assertTrue(hasattr(image_processor, "size"))
+ self.assertTrue(hasattr(image_processor, "do_normalize"))
+ self.assertTrue(hasattr(image_processor, "image_mean"))
+ self.assertTrue(hasattr(image_processor, "image_std"))
+ self.assertTrue(hasattr(image_processor, "do_convert_rgb"))
+
+ def test_slow_fast_equivalence_crop_to_patches(self):
+ dummy_image = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, torchify=True)[0]
+
+ image_processor_slow = self.image_processing_class(**self.image_processor_dict, crop_to_patches=True)
+ image_processor_fast = self.fast_image_processing_class(**self.image_processor_dict, crop_to_patches=True)
+
+ encoding_slow = image_processor_slow(dummy_image, return_tensors="pt")
+ encoding_fast = image_processor_fast(dummy_image, return_tensors="pt")
+
+ torch.testing.assert_close(encoding_slow.num_patches, encoding_fast.num_patches)
+ self._assert_slow_fast_tensors_equivalence(encoding_slow.pixel_values, encoding_fast.pixel_values)
+
+ def test_slow_fast_equivalence_batched_crop_to_patches(self):
+ # Prepare image inputs so that we have two groups of images with equal resolution with a group of images with
+ # different resolutions in between
+ dummy_images = self.image_processor_tester.prepare_image_inputs(equal_resolution=True, torchify=True)
+ dummy_images += self.image_processor_tester.prepare_image_inputs(equal_resolution=False, torchify=True)
+ dummy_images += self.image_processor_tester.prepare_image_inputs(equal_resolution=True, torchify=True)
+
+ image_processor_slow = self.image_processing_class(**self.image_processor_dict, crop_to_patches=True)
+ image_processor_fast = self.fast_image_processing_class(**self.image_processor_dict, crop_to_patches=True)
+
+ encoding_slow = image_processor_slow(dummy_images, return_tensors="pt")
+ encoding_fast = image_processor_fast(dummy_images, return_tensors="pt")
+
+ torch.testing.assert_close(encoding_slow.num_patches, encoding_fast.num_patches)
+ self._assert_slow_fast_tensors_equivalence(encoding_slow.pixel_values, encoding_fast.pixel_values)
+
+ def test_crop_to_patches(self):
+ # test slow image processor
+ image_processor = self.image_processor_list[0](**self.image_processor_dict)
+ image = self.image_processor_tester.prepare_image_inputs(equal_resolution=True, numpify=True)[0]
+ processed_images = image_processor.crop_image_to_patches(
+ image,
+ min_patches=1,
+ max_patches=6,
+ use_thumbnail=True,
+ patch_size={"height": 20, "width": 20},
+ )
+ self.assertEqual(len(processed_images), 5)
+ self.assertEqual(processed_images[0].shape[:2], (20, 20))
+
+ # test fast image processor (process batch)
+ image_processor = self.image_processor_list[1](**self.image_processor_dict)
+ image = self.image_processor_tester.prepare_image_inputs(equal_resolution=True, torchify=True)[0]
+ processed_images = image_processor.crop_image_to_patches(
+ image.unsqueeze(0),
+ min_patches=1,
+ max_patches=6,
+ use_thumbnail=True,
+ patch_size=SizeDict(height=20, width=20),
+ )
+ self.assertEqual(len(processed_images[0]), 5)
+ self.assertEqual(processed_images.shape[-2:], (20, 20))
diff --git a/transformers/tests/models/got_ocr2/test_modeling_got_ocr2.py b/transformers/tests/models/got_ocr2/test_modeling_got_ocr2.py
new file mode 100644
index 0000000000000000000000000000000000000000..87f182ac9cdb7e51e4f46b06be0de37ea2f0f832
--- /dev/null
+++ b/transformers/tests/models/got_ocr2/test_modeling_got_ocr2.py
@@ -0,0 +1,302 @@
+# Copyright 2024 The Qwen team, Alibaba Group and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch GotOcr2 model."""
+
+import unittest
+
+from transformers import (
+ AutoProcessor,
+ GotOcr2Config,
+ is_torch_available,
+ is_vision_available,
+)
+from transformers.testing_utils import cleanup, require_torch, slow, torch_device
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ GotOcr2ForConditionalGeneration,
+ GotOcr2Model,
+ )
+
+
+if is_vision_available():
+ from transformers.image_utils import load_image
+
+
+class GotOcr2VisionText2TextModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=3,
+ seq_length=7,
+ num_channels=3,
+ ignore_index=-100,
+ image_size=64,
+ image_token_index=1,
+ model_type="got_ocr2",
+ is_training=True,
+ text_config={
+ "model_type": "qwen2",
+ "vocab_size": 99,
+ "hidden_size": 128,
+ "intermediate_size": 37,
+ "num_hidden_layers": 4,
+ "num_attention_heads": 4,
+ "num_key_value_heads": 2,
+ "output_channels": 64,
+ "hidden_act": "silu",
+ "max_position_embeddings": 512,
+ "rope_theta": 10000,
+ "mlp_ratio": 4,
+ "tie_word_embeddings": True,
+ "bos_token_id": 2,
+ "eos_token_id": 3,
+ "pad_token_id": 4,
+ },
+ vision_config={
+ "num_hidden_layers": 2,
+ "output_channels": 64,
+ "hidden_act": "quick_gelu",
+ "hidden_size": 32,
+ "mlp_dim": 128,
+ "num_attention_heads": 4,
+ "patch_size": 2,
+ "image_size": 64,
+ },
+ ):
+ self.parent = parent
+ self.ignore_index = ignore_index
+ self.bos_token_id = text_config["bos_token_id"]
+ self.eos_token_id = text_config["eos_token_id"]
+ self.pad_token_id = text_config["pad_token_id"]
+ self.image_token_index = image_token_index
+ self.model_type = model_type
+ self.text_config = text_config
+ self.vision_config = vision_config
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.is_training = is_training
+ self.num_image_tokens = 64
+ self.seq_length = seq_length + self.num_image_tokens
+
+ self.num_hidden_layers = text_config["num_hidden_layers"]
+ self.vocab_size = text_config["vocab_size"]
+ self.hidden_size = text_config["hidden_size"]
+ self.num_attention_heads = text_config["num_attention_heads"]
+
+ def get_config(self):
+ return GotOcr2Config(
+ text_config=self.text_config,
+ vision_config=self.vision_config,
+ model_type=self.model_type,
+ image_token_index=self.image_token_index,
+ )
+
+ def prepare_config_and_inputs(self):
+ config = self.get_config()
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ return config, pixel_values
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+ attention_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
+
+ input_ids[input_ids == self.image_token_index] = self.pad_token_id
+ input_ids[:, : self.num_image_tokens] = self.image_token_index
+
+ inputs_dict = {
+ "pixel_values": pixel_values,
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class GotOcr2ModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ GotOcr2Model,
+ GotOcr2ForConditionalGeneration,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "image-to-text": GotOcr2ForConditionalGeneration,
+ "image-text-to-text": GotOcr2ForConditionalGeneration,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_headmasking = False
+ test_pruning = False
+
+ def setUp(self):
+ self.model_tester = GotOcr2VisionText2TextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=GotOcr2Config, has_text_modality=False)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ @unittest.skip(
+ reason="GotOcr2's language backbone is Qwen2 which uses GQA so the KV cache is a non standard format"
+ )
+ def test_past_key_values_format(self):
+ pass
+
+
+@require_torch
+class GotOcr2IntegrationTest(unittest.TestCase):
+ def setUp(self):
+ self.processor = AutoProcessor.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf")
+
+ def tearDown(self):
+ cleanup(torch_device, gc_collect=True)
+
+ @slow
+ def test_small_model_integration_test_got_ocr_stop_strings(self):
+ model_id = "stepfun-ai/GOT-OCR-2.0-hf"
+ model = GotOcr2ForConditionalGeneration.from_pretrained(model_id, device_map=torch_device)
+ image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/fixtures_ocr/resolve/main/iam_picture.jpeg"
+ )
+
+ inputs = self.processor(image, return_tensors="pt").to(torch_device)
+ generate_ids = model.generate(
+ **inputs,
+ do_sample=False,
+ num_beams=1,
+ tokenizer=self.processor.tokenizer,
+ stop_strings="<|im_end|>",
+ max_new_tokens=4096,
+ )
+ decoded_output = self.processor.decode(
+ generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True
+ )
+ expected_output = "industre"
+ self.assertEqual(decoded_output, expected_output)
+
+ @slow
+ def test_small_model_integration_test_got_ocr_format(self):
+ model_id = "stepfun-ai/GOT-OCR-2.0-hf"
+ model = GotOcr2ForConditionalGeneration.from_pretrained(model_id, device_map=torch_device)
+ image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/image_ocr.jpg"
+ )
+
+ inputs = self.processor(image, return_tensors="pt", format=True).to(torch_device)
+ generate_ids = model.generate(**inputs, do_sample=False, num_beams=1, max_new_tokens=4)
+ decoded_output = self.processor.decode(
+ generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True
+ )
+ expected_output = "\\title{\nR"
+ self.assertEqual(decoded_output, expected_output)
+
+ @slow
+ def test_small_model_integration_test_got_ocr_fine_grained(self):
+ model_id = "stepfun-ai/GOT-OCR-2.0-hf"
+ model = GotOcr2ForConditionalGeneration.from_pretrained(model_id, device_map=torch_device)
+ image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/multi_box.png"
+ )
+
+ inputs = self.processor(image, return_tensors="pt", color="green").to(torch_device)
+ generate_ids = model.generate(**inputs, do_sample=False, num_beams=1, max_new_tokens=4)
+ decoded_output = self.processor.decode(
+ generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True
+ )
+ expected_output = "You should keep in"
+ self.assertEqual(decoded_output, expected_output)
+
+ @slow
+ def test_small_model_integration_test_got_ocr_crop_to_patches(self):
+ model_id = "stepfun-ai/GOT-OCR-2.0-hf"
+ model = GotOcr2ForConditionalGeneration.from_pretrained(model_id, device_map=torch_device)
+ image = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/one_column.png"
+ )
+
+ inputs = self.processor(image, return_tensors="pt", crop_to_patches=True).to(torch_device)
+ generate_ids = model.generate(**inputs, do_sample=False, num_beams=1, max_new_tokens=4)
+ decoded_output = self.processor.decode(
+ generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True
+ )
+ expected_output = "on developing architectural improvements"
+ self.assertEqual(decoded_output, expected_output)
+
+ @slow
+ def test_small_model_integration_test_got_ocr_multi_pages(self):
+ model_id = "stepfun-ai/GOT-OCR-2.0-hf"
+ model = GotOcr2ForConditionalGeneration.from_pretrained(model_id, device_map=torch_device)
+ image1 = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/one_column.png"
+ )
+ image2 = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/multi_box.png"
+ )
+
+ inputs = self.processor([image1, image2], return_tensors="pt", multi_page=True).to(torch_device)
+ generate_ids = model.generate(**inputs, do_sample=False, num_beams=1, max_new_tokens=4)
+ decoded_output = self.processor.decode(
+ generate_ids[0, inputs["input_ids"].shape[1] :], skip_special_tokens=True
+ )
+ expected_output = "on developing architectural improvements"
+ self.assertEqual(decoded_output, expected_output)
+
+ @slow
+ def test_small_model_integration_test_got_ocr_batched(self):
+ model_id = "stepfun-ai/GOT-OCR-2.0-hf"
+ model = GotOcr2ForConditionalGeneration.from_pretrained(model_id, device_map=torch_device)
+ image1 = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/multi_box.png"
+ )
+ image2 = load_image(
+ "https://huggingface.co/datasets/hf-internal-testing/fixtures_got_ocr/resolve/main/image_ocr.jpg"
+ )
+
+ inputs = self.processor([image1, image2], return_tensors="pt").to(torch_device)
+ generate_ids = model.generate(**inputs, do_sample=False, num_beams=1, max_new_tokens=4)
+ decoded_output = self.processor.batch_decode(
+ generate_ids[:, inputs["input_ids"].shape[1] :], skip_special_tokens=True
+ )
+ expected_output = ["Reducing the number", "R&D QUALITY"]
+ self.assertEqual(decoded_output, expected_output)
diff --git a/transformers/tests/models/got_ocr2/test_processor_got_ocr2.py b/transformers/tests/models/got_ocr2/test_processor_got_ocr2.py
new file mode 100644
index 0000000000000000000000000000000000000000..0719d211ddad3e33b6304b75bbfa244794bd9e6f
--- /dev/null
+++ b/transformers/tests/models/got_ocr2/test_processor_got_ocr2.py
@@ -0,0 +1,80 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import shutil
+import tempfile
+import unittest
+
+from transformers import AutoProcessor, GotOcr2Processor, PreTrainedTokenizerFast
+from transformers.testing_utils import require_vision
+from transformers.utils import is_vision_available
+
+from ...test_processing_common import ProcessorTesterMixin
+
+
+if is_vision_available():
+ from transformers import GotOcr2ImageProcessor
+
+
+@require_vision
+class GotOcr2ProcessorTest(ProcessorTesterMixin, unittest.TestCase):
+ processor_class = GotOcr2Processor
+
+ @classmethod
+ def setUpClass(cls):
+ cls.tmpdirname = tempfile.mkdtemp()
+
+ image_processor = GotOcr2ImageProcessor()
+ tokenizer = PreTrainedTokenizerFast.from_pretrained("stepfun-ai/GOT-OCR-2.0-hf")
+ processor_kwargs = {}
+ processor = GotOcr2Processor(image_processor, tokenizer, **processor_kwargs)
+ processor.save_pretrained(cls.tmpdirname)
+ cls.image_token = processor.img_pad_token
+
+ def get_tokenizer(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).tokenizer
+
+ def get_image_processor(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).image_processor
+
+ @classmethod
+ def tearDownClass(cls):
+ shutil.rmtree(cls.tmpdirname, ignore_errors=True)
+
+ def test_ocr_queries(self):
+ processor = self.get_processor()
+ image_input = self.prepare_image_inputs()
+ inputs = processor(image_input, return_tensors="pt")
+ self.assertEqual(inputs["input_ids"].shape, (1, 286))
+ self.assertEqual(inputs["pixel_values"].shape, (1, 3, 384, 384))
+
+ inputs = processor(image_input, return_tensors="pt", format=True)
+ self.assertEqual(inputs["input_ids"].shape, (1, 288))
+ self.assertEqual(inputs["pixel_values"].shape, (1, 3, 384, 384))
+
+ inputs = processor(image_input, return_tensors="pt", color="red")
+ self.assertEqual(inputs["input_ids"].shape, (1, 290))
+ self.assertEqual(inputs["pixel_values"].shape, (1, 3, 384, 384))
+
+ inputs = processor(image_input, return_tensors="pt", box=[0, 0, 100, 100])
+ self.assertEqual(inputs["input_ids"].shape, (1, 303))
+ self.assertEqual(inputs["pixel_values"].shape, (1, 3, 384, 384))
+
+ inputs = processor([image_input, image_input], return_tensors="pt", multi_page=True, format=True)
+ self.assertEqual(inputs["input_ids"].shape, (1, 547))
+ self.assertEqual(inputs["pixel_values"].shape, (2, 3, 384, 384))
+
+ inputs = processor(image_input, return_tensors="pt", crop_to_patches=True, max_patches=6)
+ self.assertEqual(inputs["input_ids"].shape, (1, 1826))
+ self.assertEqual(inputs["pixel_values"].shape, (7, 3, 384, 384))
diff --git a/transformers/tests/models/gpt_neo/__init__.py b/transformers/tests/models/gpt_neo/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/gpt_neo/test_modeling_gpt_neo.py b/transformers/tests/models/gpt_neo/test_modeling_gpt_neo.py
new file mode 100644
index 0000000000000000000000000000000000000000..fc552ab4afeaab3d85516ed321c94ff1282b0df2
--- /dev/null
+++ b/transformers/tests/models/gpt_neo/test_modeling_gpt_neo.py
@@ -0,0 +1,573 @@
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch GPT Neo model."""
+
+import unittest
+
+from transformers import GPTNeoConfig, is_torch_available
+from transformers.testing_utils import require_torch, slow, torch_device
+from transformers.utils import cached_property
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ GPT2Tokenizer,
+ GPTNeoForCausalLM,
+ GPTNeoForQuestionAnswering,
+ GPTNeoForSequenceClassification,
+ GPTNeoForTokenClassification,
+ GPTNeoModel,
+ )
+
+
+class GPTNeoModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=14,
+ seq_length=7,
+ is_training=True,
+ use_token_type_ids=True,
+ use_input_mask=True,
+ use_labels=True,
+ use_mc_token_ids=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ attention_types=[[["global", "local"], 1]],
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ window_size=7,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_token_type_ids = use_token_type_ids
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.use_mc_token_ids = use_mc_token_ids
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.window_size = window_size
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.bos_token_id = vocab_size - 1
+ self.eos_token_id = vocab_size - 1
+ self.pad_token_id = vocab_size - 1
+ self.attention_types = attention_types
+
+ def get_large_model_config(self):
+ return GPTNeoConfig.from_pretrained("gpt-neo-125M")
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ mc_token_ids = None
+ if self.use_mc_token_ids:
+ mc_token_ids = ids_tensor([self.batch_size, self.num_choices], self.seq_length)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ head_mask = ids_tensor([self.num_hidden_layers, self.num_attention_heads], 2)
+
+ return (
+ config,
+ input_ids,
+ input_mask,
+ head_mask,
+ token_type_ids,
+ mc_token_ids,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ )
+
+ def get_config(self):
+ return GPTNeoConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_layers=self.num_hidden_layers,
+ num_heads=self.num_attention_heads,
+ max_position_embeddings=self.max_position_embeddings,
+ use_cache=True,
+ bos_token_id=self.bos_token_id,
+ eos_token_id=self.eos_token_id,
+ pad_token_id=self.pad_token_id,
+ window_size=self.window_size,
+ attention_types=self.attention_types,
+ )
+
+ def get_pipeline_config(self):
+ config = self.get_config()
+ config.vocab_size = 300
+ return config
+
+ def create_and_check_gpt_neo_model(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
+ model = GPTNeoModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids, token_type_ids=token_type_ids, head_mask=head_mask)
+ result = model(input_ids, token_type_ids=token_type_ids)
+ result = model(input_ids)
+
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ # past_key_values is not implemented
+ # self.parent.assertEqual(len(result.past_key_values), config.n_layer)
+
+ def create_and_check_gpt_neo_model_past(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
+ model = GPTNeoModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # first forward pass
+ outputs = model(input_ids, token_type_ids=token_type_ids, use_cache=True)
+ outputs_use_cache_conf = model(input_ids, token_type_ids=token_type_ids)
+ outputs_no_past = model(input_ids, token_type_ids=token_type_ids, use_cache=False)
+
+ self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf))
+ self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1)
+
+ output, past = outputs.to_tuple()
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
+ next_token_types = ids_tensor([self.batch_size, 1], self.type_vocab_size)
+
+ # append to next input_ids and token_type_ids
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_token_type_ids = torch.cat([token_type_ids, next_token_types], dim=-1)
+
+ output_from_no_past = model(next_input_ids, token_type_ids=next_token_type_ids)["last_hidden_state"]
+ output_from_past = model(next_tokens, token_type_ids=next_token_types, past_key_values=past)[
+ "last_hidden_state"
+ ]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_gpt_neo_model_attention_mask_past(
+ self, config, input_ids, input_mask, head_mask, token_type_ids, *args
+ ):
+ model = GPTNeoModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # create attention mask
+ attn_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
+ half_seq_length = self.seq_length // 2
+ attn_mask[:, half_seq_length:] = 0
+
+ # first forward pass
+ output, past = model(input_ids, attention_mask=attn_mask).to_tuple()
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
+
+ # change a random masked slice from input_ids
+ random_seq_idx_to_change = ids_tensor((1,), half_seq_length).item() + 1
+ random_other_next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size).squeeze(-1)
+ input_ids[:, -random_seq_idx_to_change] = random_other_next_tokens
+
+ # append to next input_ids and attn_mask
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ attn_mask = torch.cat(
+ [attn_mask, torch.ones((attn_mask.shape[0], 1), dtype=torch.long, device=torch_device)],
+ dim=1,
+ )
+
+ # get two different outputs
+ output_from_no_past = model(next_input_ids, attention_mask=attn_mask)["last_hidden_state"]
+ output_from_past = model(next_tokens, past_key_values=past, attention_mask=attn_mask)["last_hidden_state"]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_gpt_neo_model_past_large_inputs(
+ self, config, input_ids, input_mask, head_mask, token_type_ids, *args
+ ):
+ model = GPTNeoModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # first forward pass
+ outputs = model(input_ids, token_type_ids=token_type_ids, attention_mask=input_mask, use_cache=True)
+
+ output, past = outputs.to_tuple()
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_token_types = ids_tensor([self.batch_size, 3], self.type_vocab_size)
+ next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
+
+ # append to next input_ids and token_type_ids
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_token_type_ids = torch.cat([token_type_ids, next_token_types], dim=-1)
+ next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
+
+ output_from_no_past = model(
+ next_input_ids, token_type_ids=next_token_type_ids, attention_mask=next_attention_mask
+ )["last_hidden_state"]
+ output_from_past = model(
+ next_tokens, token_type_ids=next_token_types, attention_mask=next_attention_mask, past_key_values=past
+ )["last_hidden_state"]
+ self.parent.assertTrue(output_from_past.shape[1] == next_tokens.shape[1])
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_lm_head_model(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
+ model = GPTNeoForCausalLM(config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids, token_type_ids=token_type_ids, labels=input_ids)
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_gpt_neo_for_question_answering(
+ self, config, input_ids, input_mask, head_mask, token_type_ids, mc_token_ids, sequence_labels, *args
+ ):
+ config.num_labels = self.num_labels
+ model = GPTNeoForQuestionAnswering(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
+ self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
+ self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
+
+ def create_and_check_gpt_neo_for_sequence_classification(
+ self, config, input_ids, input_mask, head_mask, token_type_ids, mc_token_ids, sequence_labels, *args
+ ):
+ config.num_labels = self.num_labels
+ model = GPTNeoForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=sequence_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def create_and_check_gpt_neo_for_token_classification(
+ self, config, input_ids, input_mask, head_mask, token_type_ids, mc_token_ids, sequence_labels, *args
+ ):
+ config.num_labels = self.num_labels
+ model = GPTNeoForTokenClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+
+ def create_and_check_forward_and_backwards(
+ self, config, input_ids, input_mask, head_mask, token_type_ids, *args, gradient_checkpointing=False
+ ):
+ model = GPTNeoForCausalLM(config)
+ if gradient_checkpointing:
+ model.gradient_checkpointing_enable()
+ model.to(torch_device)
+
+ result = model(input_ids, token_type_ids=token_type_ids, labels=input_ids)
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+ result.loss.backward()
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+
+ (
+ config,
+ input_ids,
+ input_mask,
+ head_mask,
+ token_type_ids,
+ mc_token_ids,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+
+ inputs_dict = {
+ "input_ids": input_ids,
+ "token_type_ids": token_type_ids,
+ "head_mask": head_mask,
+ }
+
+ return config, inputs_dict
+
+
+@require_torch
+class GPTNeoModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ GPTNeoModel,
+ GPTNeoForCausalLM,
+ GPTNeoForQuestionAnswering,
+ GPTNeoForSequenceClassification,
+ GPTNeoForTokenClassification,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": GPTNeoModel,
+ "question-answering": GPTNeoForQuestionAnswering,
+ "text-classification": GPTNeoForSequenceClassification,
+ "text-generation": GPTNeoForCausalLM,
+ "token-classification": GPTNeoForTokenClassification,
+ "zero-shot": GPTNeoForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ fx_compatible = True
+ test_missing_keys = False
+ test_pruning = False
+ test_model_parallel = False
+
+ # special case for DoubleHeads model
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = GPTNeoModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=GPTNeoConfig, n_embd=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_gpt_neo_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_gpt_neo_model(*config_and_inputs)
+
+ def test_gpt_neo_model_past(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_gpt_neo_model_past(*config_and_inputs)
+
+ def test_gpt_neo_model_att_mask_past(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_gpt_neo_model_attention_mask_past(*config_and_inputs)
+
+ def test_gpt_neo_model_past_large_inputs(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_gpt_neo_model_past_large_inputs(*config_and_inputs)
+
+ def test_gpt_neo_lm_head_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_lm_head_model(*config_and_inputs)
+
+ def test_gpt_neo_question_answering_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_gpt_neo_for_question_answering(*config_and_inputs)
+
+ def test_gpt_neo_sequence_classification_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_gpt_neo_for_sequence_classification(*config_and_inputs)
+
+ def test_gpt_neo_token_classification_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_gpt_neo_for_token_classification(*config_and_inputs)
+
+ def test_gpt_neo_gradient_checkpointing(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_forward_and_backwards(*config_and_inputs, gradient_checkpointing=True)
+
+ def _get_hidden_states(self):
+ return torch.tensor(
+ [
+ [
+ [0.4983, -0.7584, -1.6944, 0.5440],
+ [2.6918, 0.4206, 0.4176, 0.2055],
+ [-0.0071, -0.0405, -1.4920, -0.3630],
+ [1.0492, 0.1599, -1.7648, 0.2419],
+ [-1.8348, 2.0514, -0.1946, 0.3203],
+ [0.7672, -1.1600, -1.7118, -0.9056],
+ [0.2986, 0.5372, 0.7729, -0.1927],
+ [0.0285, 0.2629, -1.1156, -1.1992],
+ ]
+ ],
+ dtype=torch.float32,
+ device=torch_device,
+ )
+
+ def test_local_attn_probs(self):
+ model = GPTNeoModel.from_pretrained("valhalla/gpt-neo-random-tiny").eval()
+ layer = model.h[1].attn.attention.to(torch_device)
+ hidden_states = self._get_hidden_states()
+ hidden_states = torch.cat([hidden_states, hidden_states - 0.5], dim=2)
+
+ batch_size, seq_length, _ = hidden_states.shape
+ mask_tokens = 2
+ attention_mask = torch.ones(batch_size, seq_length, device=torch_device, dtype=torch.long)
+ attention_mask[:, -mask_tokens:] = 0 # dont attend last mask_tokens
+
+ attention_mask = attention_mask.view(batch_size, -1)
+ attention_mask = attention_mask[:, None, None, :]
+ attention_mask = (1.0 - attention_mask) * -10000.0
+
+ attn_probs = layer(hidden_states, attention_mask=attention_mask, output_attentions=True)[-1]
+
+ # the last 2 tokens are masked, and should have 0 attn_probs
+ self.assertTrue(torch.all(attn_probs[:, :, -mask_tokens:, -mask_tokens:] == 0))
+
+ # in local attention each token can only attend to the previous window_size tokens (including itself)
+ # here window_size is 4, so a token at index 5 can only attend to indices [2, 3, 4, 5]
+ # and the attn_probs should be 0 for token [0, 1]
+ self.assertTrue(torch.all(attn_probs[:, :, 5, 2:6] != 0))
+ self.assertTrue(torch.all(attn_probs[:, :, 5, :2] == 0))
+
+
+@require_torch
+class GPTNeoModelLanguageGenerationTest(unittest.TestCase):
+ @cached_property
+ def model(self):
+ return GPTNeoForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B").to(torch_device)
+
+ @cached_property
+ def tokenizer(self):
+ return GPT2Tokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
+
+ @slow
+ def test_lm_generate_gpt_neo(self):
+ for checkpointing in [True, False]:
+ model = self.model
+ if checkpointing:
+ model.gradient_checkpointing_enable()
+ else:
+ model.gradient_checkpointing_disable()
+ input_ids = torch.tensor([[464, 3290]], dtype=torch.long, device=torch_device) # The dog
+ # The dog-eared copy of the book, which is a collection of essays by the late author,
+ expected_output_ids = [464, 3290, 12, 3380, 4866, 286, 262, 1492, 11, 543, 318, 257, 4947, 286, 27126, 416, 262, 2739, 1772, 11] # fmt: skip
+ output_ids = model.generate(input_ids, do_sample=False)
+ self.assertListEqual(output_ids[0].tolist(), expected_output_ids)
+
+ @slow
+ def test_gpt_neo_sample(self):
+ model = self.model
+ tokenizer = self.tokenizer
+
+ torch.manual_seed(0)
+ tokenized = tokenizer("Today is a nice day and", return_tensors="pt", return_token_type_ids=True)
+ input_ids = tokenized.input_ids.to(torch_device)
+ output_ids = model.generate(input_ids, do_sample=True)
+ output_str = tokenizer.decode(output_ids[0], skip_special_tokens=True)
+
+ EXPECTED_OUTPUT_STR = "Today is a nice day and if you don’t get the memo here is what you can"
+ self.assertEqual(output_str, EXPECTED_OUTPUT_STR)
+
+ @slow
+ def test_batch_generation(self):
+ model = self.model
+ tokenizer = self.tokenizer
+
+ tokenizer.padding_side = "left"
+
+ # Define PAD Token = EOS Token = 50256
+ tokenizer.pad_token = tokenizer.eos_token
+ model.config.pad_token_id = model.config.eos_token_id
+
+ # use different length sentences to test batching
+ sentences = [
+ "Hello, my dog is a little",
+ "Today, I am",
+ ]
+
+ inputs = tokenizer(sentences, return_tensors="pt", padding=True)
+ input_ids = inputs["input_ids"].to(torch_device)
+
+ outputs = model.generate(
+ input_ids=input_ids,
+ attention_mask=inputs["attention_mask"].to(torch_device),
+ )
+
+ inputs_non_padded = tokenizer(sentences[0], return_tensors="pt").input_ids.to(torch_device)
+ output_non_padded = model.generate(input_ids=inputs_non_padded)
+
+ num_paddings = inputs_non_padded.shape[-1] - inputs["attention_mask"][-1].long().sum().item()
+ inputs_padded = tokenizer(sentences[1], return_tensors="pt").input_ids.to(torch_device)
+ output_padded = model.generate(input_ids=inputs_padded, max_length=model.config.max_length - num_paddings)
+
+ batch_out_sentence = tokenizer.batch_decode(outputs, skip_special_tokens=True)
+ non_padded_sentence = tokenizer.decode(output_non_padded[0], skip_special_tokens=True)
+ padded_sentence = tokenizer.decode(output_padded[0], skip_special_tokens=True)
+
+ expected_output_sentence = [
+ "Hello, my dog is a little bit of a kitty. She is a very sweet and loving",
+ "Today, I am going to talk about the best way to get a job in the",
+ ]
+ self.assertListEqual(expected_output_sentence, batch_out_sentence)
+ self.assertListEqual(expected_output_sentence, [non_padded_sentence, padded_sentence])
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "EleutherAI/gpt-neo-1.3B"
+ model = GPTNeoModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
diff --git a/transformers/tests/models/gpt_neox/__init__.py b/transformers/tests/models/gpt_neox/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/gpt_neox/test_modeling_gpt_neox.py b/transformers/tests/models/gpt_neox/test_modeling_gpt_neox.py
new file mode 100644
index 0000000000000000000000000000000000000000..b0a0a6a3ccb487faab9a1b385d7f7732b17d8cbf
--- /dev/null
+++ b/transformers/tests/models/gpt_neox/test_modeling_gpt_neox.py
@@ -0,0 +1,482 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch GPTNeoX model."""
+
+import unittest
+
+from parameterized import parameterized
+
+from transformers import AutoTokenizer, DynamicCache, GPTNeoXConfig, is_torch_available, set_seed
+from transformers.testing_utils import require_torch, slow, torch_device
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ GPTNeoXForCausalLM,
+ GPTNeoXForQuestionAnswering,
+ GPTNeoXForSequenceClassification,
+ GPTNeoXForTokenClassification,
+ GPTNeoXModel,
+ )
+ from transformers.models.gpt_neox.modeling_gpt_neox import GPTNeoXRotaryEmbedding
+
+
+class GPTNeoXModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=64,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.scope = scope
+ self.pad_token_id = vocab_size - 1
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ token_labels = None
+ if self.use_labels:
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask, token_labels
+
+ def get_config(self):
+ return GPTNeoXConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ pad_token_id=self.pad_token_id,
+ )
+
+ def prepare_config_and_inputs_for_decoder(self):
+ config, input_ids, input_mask, token_labels = self.prepare_config_and_inputs()
+
+ config.is_decoder = True
+
+ return config, input_ids, input_mask, token_labels
+
+ def create_and_check_model(self, config, input_ids, input_mask):
+ model = GPTNeoXModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ _ = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_model_as_decoder(self, config, input_ids, input_mask):
+ config.add_cross_attention = True
+ model = GPTNeoXModel(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def create_and_check_for_causal_lm(self, config, input_ids, input_mask, token_labels):
+ model = GPTNeoXForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_for_question_answering(self, config, input_ids, input_mask, token_labels):
+ config.num_labels = self.num_labels
+ model = GPTNeoXForQuestionAnswering(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask)
+ self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
+ self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
+
+ def create_and_check_for_sequence_classification(self, config, input_ids, input_mask, token_labels):
+ config.num_labels = self.num_labels
+ model = GPTNeoXForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ result = model(input_ids, attention_mask=input_mask, labels=sequence_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def create_and_check_for_token_classification(self, config, input_ids, input_mask, token_labels):
+ config.num_labels = self.num_labels
+ model = GPTNeoXForTokenClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+
+ def create_and_check_decoder_model_past_large_inputs(self, config, input_ids, input_mask):
+ config.is_decoder = True
+ model = GPTNeoXForCausalLM(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # first forward pass
+ outputs = model(input_ids, attention_mask=input_mask, use_cache=True)
+ past_key_values = outputs.past_key_values
+
+ # create hypothetical multiple next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
+
+ # append to next input_ids and
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
+
+ output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask, output_hidden_states=True)
+ output_from_no_past = output_from_no_past["hidden_states"][0]
+ output_from_past = model(
+ next_tokens,
+ attention_mask=next_attention_mask,
+ past_key_values=past_key_values,
+ output_hidden_states=True,
+ )["hidden_states"][0]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_cached_forward_with_and_without_attention_mask(self, config, input_ids, *args):
+ # Relevant issue: https://github.com/huggingface/transformers/issues/31943
+ model = GPTNeoXModel(config)
+ model.to(torch_device)
+ model.eval()
+
+ # We want this for SDPA, eager works with a `None` attention mask
+ assert model.config._attn_implementation == "sdpa", (
+ "This test assumes the model to have the SDPA implementation for its attention calculations."
+ )
+
+ # Prepare cache and non_cache input, needs a full attention mask
+ cached_len = input_ids.shape[-1] // 2
+ input_mask = torch.ones(size=input_ids.size()).to(torch_device)
+ cache_inputs = {"input_ids": input_ids[:, :cached_len], "attention_mask": input_mask[:, :cached_len]}
+ non_cache_inputs = {"input_ids": input_ids[:, cached_len:], "attention_mask": input_mask}
+
+ def copy_cache(cache: DynamicCache):
+ """Deep copy a DynamicCache to reuse the same one multiple times."""
+ new_cache = cache
+ for i in range(len(cache)):
+ new_cache.key_cache[i] = cache.key_cache[i].clone()
+ new_cache.value_cache[i] = cache.value_cache[i].clone()
+
+ # Cached forward once with the attention mask provided and the other time without it (which should assume full attention)
+ # We need to run both on a copy of the cache, otherwise it is modified in-place
+ cache_outputs = model(**cache_inputs)
+ cache = cache_outputs.past_key_values
+ full_outputs_with_attention_mask = model(
+ **non_cache_inputs, past_key_values=copy_cache(cache)
+ ).last_hidden_state
+ full_outputs_without_attention_mask = model(
+ non_cache_inputs["input_ids"], past_key_values=copy_cache(cache)
+ ).last_hidden_state
+
+ self.parent.assertTrue(
+ torch.allclose(full_outputs_with_attention_mask, full_outputs_without_attention_mask, atol=1e-5)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, input_mask, token_labels = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class GPTNeoXModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ GPTNeoXModel,
+ GPTNeoXForCausalLM,
+ GPTNeoXForQuestionAnswering,
+ GPTNeoXForSequenceClassification,
+ GPTNeoXForTokenClassification,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": GPTNeoXModel,
+ "question-answering": GPTNeoXForQuestionAnswering,
+ "text-classification": GPTNeoXForSequenceClassification,
+ "text-generation": GPTNeoXForCausalLM,
+ "token-classification": GPTNeoXForTokenClassification,
+ "zero-shot": GPTNeoXForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_pruning = False
+ test_missing_keys = False
+ test_model_parallel = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = GPTNeoXModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=GPTNeoXConfig, hidden_size=64, num_attention_heads=8)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config, input_ids, input_mask, token_labels = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(config, input_ids, input_mask)
+
+ def test_model_as_decoder(self):
+ config, input_ids, input_mask, token_labels = self.model_tester.prepare_config_and_inputs_for_decoder()
+ self.model_tester.create_and_check_model_as_decoder(config, input_ids, input_mask)
+
+ def test_model_as_decoder_with_default_input_mask(self):
+ config, input_ids, input_mask, token_labels = self.model_tester.prepare_config_and_inputs_for_decoder()
+
+ input_mask = None
+
+ self.model_tester.create_and_check_model_as_decoder(config, input_ids, input_mask)
+
+ def test_decoder_model_past_large_inputs(self):
+ config, input_ids, input_mask, token_labels = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_decoder_model_past_large_inputs(config, input_ids, input_mask)
+
+ def test_model_for_causal_lm(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_causal_lm(*config_and_inputs)
+
+ def test_model_for_question_answering(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
+
+ def test_model_for_sequence_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
+
+ def test_model_for_token_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
+
+ def test_cached_forward_with_and_without_attention_mask(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_cached_forward_with_and_without_attention_mask(*config_and_inputs)
+
+ @unittest.skip(reason="Feed forward chunking is not implemented")
+ def test_feed_forward_chunking(self):
+ pass
+
+ @parameterized.expand([("linear",), ("dynamic",)])
+ def test_model_rope_scaling_from_config(self, scaling_type):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ short_input = ids_tensor([1, 10], config.vocab_size)
+ long_input = ids_tensor([1, int(config.max_position_embeddings * 1.5)], config.vocab_size)
+
+ set_seed(42) # Fixed seed at init time so the two models get the same random weights
+ original_model = GPTNeoXModel(config)
+ original_model.to(torch_device)
+ original_model.eval()
+ original_short_output = original_model(short_input).last_hidden_state
+ original_long_output = original_model(long_input).last_hidden_state
+
+ set_seed(42) # Fixed seed at init time so the two models get the same random weights
+ config.rope_scaling = {"type": scaling_type, "factor": 10.0}
+ scaled_model = GPTNeoXModel(config)
+ scaled_model.to(torch_device)
+ scaled_model.eval()
+ scaled_short_output = scaled_model(short_input).last_hidden_state
+ scaled_long_output = scaled_model(long_input).last_hidden_state
+
+ # Dynamic scaling does not change the RoPE embeddings until it receives an input longer than the original
+ # maximum sequence length, so the outputs for the short input should match.
+ if scaling_type == "dynamic":
+ torch.testing.assert_close(original_short_output, scaled_short_output, rtol=1e-5, atol=1e-5)
+ else:
+ self.assertFalse(torch.allclose(original_short_output, scaled_short_output, atol=1e-5))
+
+ # The output should be different for long inputs
+ self.assertFalse(torch.allclose(original_long_output, scaled_long_output, atol=1e-5))
+
+ def test_model_rope_scaling(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ scaling_factor = 10
+ short_input_length = 10
+ long_input_length = int(config.max_position_embeddings * 1.5)
+
+ # Inputs
+ x = torch.randn(
+ 1, dtype=torch.float32, device=torch_device
+ ) # used exclusively to get the dtype and the device
+ position_ids_short = torch.arange(short_input_length, dtype=torch.long, device=torch_device)
+ position_ids_short = position_ids_short.unsqueeze(0)
+ position_ids_long = torch.arange(long_input_length, dtype=torch.long, device=torch_device)
+ position_ids_long = position_ids_long.unsqueeze(0)
+
+ # Sanity check original RoPE
+ original_rope = GPTNeoXRotaryEmbedding(config).to(torch_device)
+ original_cos_short, original_sin_short = original_rope(x, position_ids_short)
+ original_cos_long, original_sin_long = original_rope(x, position_ids_long)
+ torch.testing.assert_close(original_cos_short, original_cos_long[:, :short_input_length, :])
+ torch.testing.assert_close(original_sin_short, original_sin_long[:, :short_input_length, :])
+
+ # Sanity check linear RoPE scaling
+ # New position "x" should match original position with index "x/scaling_factor"
+ config.rope_scaling = {"type": "linear", "factor": scaling_factor}
+ linear_scaling_rope = GPTNeoXRotaryEmbedding(config).to(torch_device)
+ linear_cos_short, linear_sin_short = linear_scaling_rope(x, position_ids_short)
+ linear_cos_long, linear_sin_long = linear_scaling_rope(x, position_ids_long)
+ torch.testing.assert_close(linear_cos_short, linear_cos_long[:, :short_input_length, :])
+ torch.testing.assert_close(linear_sin_short, linear_sin_long[:, :short_input_length, :])
+ for new_position in range(0, long_input_length, scaling_factor):
+ original_position = int(new_position // scaling_factor)
+ torch.testing.assert_close(linear_cos_long[:, new_position, :], original_cos_long[:, original_position, :])
+ torch.testing.assert_close(linear_sin_long[:, new_position, :], original_sin_long[:, original_position, :])
+
+ # Sanity check Dynamic NTK RoPE scaling
+ # Scaling should only be observed after a long input is fed. We can observe that the frequencies increase
+ # with scaling_factor (or that `inv_freq` decreases)
+ config.rope_scaling = {"type": "dynamic", "factor": scaling_factor}
+ ntk_scaling_rope = GPTNeoXRotaryEmbedding(config).to(torch_device)
+ ntk_cos_short, ntk_sin_short = ntk_scaling_rope(x, position_ids_short)
+ ntk_cos_long, ntk_sin_long = ntk_scaling_rope(x, position_ids_long)
+ torch.testing.assert_close(ntk_cos_short, original_cos_short)
+ torch.testing.assert_close(ntk_sin_short, original_sin_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_cos_long, original_cos_long)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_sin_long, original_sin_long)
+ self.assertTrue((ntk_scaling_rope.inv_freq <= original_rope.inv_freq).all())
+
+
+@require_torch
+class GPTNeoXLanguageGenerationTest(unittest.TestCase):
+ @slow
+ def test_lm_generate_gptneox(self):
+ tokenizer = AutoTokenizer.from_pretrained("EleutherAI/pythia-410m-deduped")
+ for checkpointing in [True, False]:
+ model = GPTNeoXForCausalLM.from_pretrained("EleutherAI/pythia-410m-deduped")
+
+ if checkpointing:
+ model.gradient_checkpointing_enable()
+ else:
+ model.gradient_checkpointing_disable()
+ model.to(torch_device)
+
+ inputs = tokenizer("My favorite food is", return_tensors="pt").to(torch_device)
+ # The hub repo. is updated on 2023-04-04, resulting in poor outputs.
+ # See: https://github.com/huggingface/transformers/pull/24193
+ expected_output = "My favorite food is a good old-fashioned, old-fashioned, old-fashioned.\n\nI'm not sure"
+
+ output_ids = model.generate(**inputs, do_sample=False, max_new_tokens=20)
+ output_str = tokenizer.batch_decode(output_ids)[0]
+
+ self.assertEqual(output_str, expected_output)
+
+ @slow
+ def test_lm_generate_flex_attn_gptneox(self):
+ tokenizer = AutoTokenizer.from_pretrained("EleutherAI/pythia-410m-deduped")
+ for checkpointing in [True, False]:
+ model = GPTNeoXForCausalLM.from_pretrained(
+ "EleutherAI/pythia-410m-deduped", attn_implementation="flex_attention"
+ )
+ self.assertTrue(model.config._attn_implementation == "flex_attention")
+
+ if checkpointing:
+ model.gradient_checkpointing_enable()
+ else:
+ model.gradient_checkpointing_disable()
+ model.to(torch_device)
+
+ inputs = tokenizer("My favorite food is", return_tensors="pt").to(torch_device)
+ # The hub repo. is updated on 2023-04-04, resulting in poor outputs.
+ # See: https://github.com/huggingface/transformers/pull/24193
+ expected_output = "My favorite food is a good old-fashioned, old-fashioned, old-fashioned.\n\nI'm not sure"
+
+ output_ids = model.generate(**inputs, do_sample=False, max_new_tokens=20)
+ output_str = tokenizer.batch_decode(output_ids)[0]
+
+ self.assertEqual(output_str, expected_output)
+
+ def pythia_integration_test(self):
+ model_name_or_path = "EleutherAI/pythia-70m"
+ model = GPTNeoXForCausalLM.from_pretrained(model_name_or_path, torch_dtype=torch.float16).to(torch_device)
+ EXPECTED_LOGITS = torch.tensor([1069.0000, 228.7500, 1072.0000, 1072.0000, 1069.0000, 1068.0000, 1068.0000, 1071.0000, 1071.0000, 1071.0000, 1073.0000, 1070.0000, 1071.0000, 1075.0000, 1073.0000, 1075.0000, 1074.0000, 1069.0000, 1072.0000, 1071.0000, 1071.0000, 1071.0000, 1070.0000, 1069.0000, 1069.0000, 1069.0000, 1070.0000, 1075.0000, 1073.0000, 1074.0000]) # fmt: skip
+ input_ids = [29, 93, 303, 64, 5478, 49651, 10394, 187, 34, 12939, 875]
+ # alternative: tokenizer('<|im_start|>system\nA chat between')
+ input_ids = torch.as_tensor(input_ids)[None].to(torch_device)
+ outputs = model(input_ids)["logits"][:, -1][0, :30]
+ torch.testing.assert_close(EXPECTED_LOGITS, outputs, rtol=1e-5, atol=1e-5)
diff --git a/transformers/tests/models/gptj/__init__.py b/transformers/tests/models/gptj/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/gptj/test_modeling_gptj.py b/transformers/tests/models/gptj/test_modeling_gptj.py
new file mode 100644
index 0000000000000000000000000000000000000000..9614c5de1acb3ba31a73c693f5a2ad15d4579a71
--- /dev/null
+++ b/transformers/tests/models/gptj/test_modeling_gptj.py
@@ -0,0 +1,579 @@
+# Copyright 2021 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers import GPTJConfig, is_torch_available
+from transformers.testing_utils import (
+ require_torch,
+ slow,
+ tooslow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ AutoTokenizer,
+ GPTJForCausalLM,
+ GPTJForQuestionAnswering,
+ GPTJForSequenceClassification,
+ GPTJModel,
+ )
+
+
+class GPTJModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=14,
+ seq_length=7,
+ is_training=True,
+ use_token_type_ids=True,
+ use_input_mask=True,
+ use_labels=True,
+ use_mc_token_ids=True,
+ vocab_size=99,
+ hidden_size=32,
+ rotary_dim=4,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.0,
+ attention_probs_dropout_prob=0.0,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_token_type_ids = use_token_type_ids
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.use_mc_token_ids = use_mc_token_ids
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.rotary_dim = rotary_dim
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.scope = None
+ self.bos_token_id = vocab_size - 1
+ self.eos_token_id = vocab_size - 1
+ self.pad_token_id = vocab_size - 1
+
+ def get_large_model_config(self):
+ return GPTJConfig.from_pretrained("EleutherAI/gpt-j-6B")
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ mc_token_ids = None
+ if self.use_mc_token_ids:
+ mc_token_ids = ids_tensor([self.batch_size, self.num_choices], self.seq_length)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ head_mask = ids_tensor([self.num_hidden_layers, self.num_attention_heads], 2)
+
+ return (
+ config,
+ input_ids,
+ input_mask,
+ head_mask,
+ token_type_ids,
+ mc_token_ids,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ )
+
+ def get_config(self):
+ return GPTJConfig(
+ vocab_size=self.vocab_size,
+ n_embd=self.hidden_size,
+ n_layer=self.num_hidden_layers,
+ n_head=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ n_positions=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ initializer_range=self.initializer_range,
+ use_cache=True,
+ bos_token_id=self.bos_token_id,
+ eos_token_id=self.eos_token_id,
+ pad_token_id=self.pad_token_id,
+ rotary_dim=self.rotary_dim,
+ )
+
+ def get_pipeline_config(self):
+ config = self.get_config()
+ config.vocab_size = 300
+ return config
+
+ def create_and_check_gptj_model(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
+ model = GPTJModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids, token_type_ids=token_type_ids, head_mask=head_mask)
+ result = model(input_ids, token_type_ids=token_type_ids)
+ result = model(input_ids)
+
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(len(result.past_key_values), config.n_layer)
+
+ def create_and_check_gptj_model_past(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
+ model = GPTJModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # first forward pass
+ outputs = model(input_ids, token_type_ids=token_type_ids, use_cache=True)
+ outputs_use_cache_conf = model(input_ids, token_type_ids=token_type_ids)
+ outputs_no_past = model(input_ids, token_type_ids=token_type_ids, use_cache=False)
+
+ self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf))
+ self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1)
+
+ output, past = outputs.to_tuple()
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
+ next_token_types = ids_tensor([self.batch_size, 1], self.type_vocab_size)
+
+ # append to next input_ids and token_type_ids
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_token_type_ids = torch.cat([token_type_ids, next_token_types], dim=-1)
+
+ output_from_no_past = model(next_input_ids, token_type_ids=next_token_type_ids)["last_hidden_state"]
+ output_from_past = model(next_tokens, token_type_ids=next_token_types, past_key_values=past)[
+ "last_hidden_state"
+ ]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_gptj_model_attention_mask_past(
+ self, config, input_ids, input_mask, head_mask, token_type_ids, *args
+ ):
+ model = GPTJModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # create attention mask
+ attn_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
+ half_seq_length = self.seq_length // 2
+ attn_mask[:, half_seq_length:] = 0
+
+ # first forward pass
+ output, past = model(input_ids, attention_mask=attn_mask).to_tuple()
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
+
+ # change a random masked slice from input_ids
+ random_seq_idx_to_change = ids_tensor((1,), half_seq_length).item() + 1
+ random_other_next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size).squeeze(-1)
+ input_ids[:, -random_seq_idx_to_change] = random_other_next_tokens
+
+ # append to next input_ids and attn_mask
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ attn_mask = torch.cat(
+ [attn_mask, torch.ones((attn_mask.shape[0], 1), dtype=torch.long, device=torch_device)],
+ dim=1,
+ )
+
+ # get two different outputs
+ output_from_no_past = model(next_input_ids, attention_mask=attn_mask)["last_hidden_state"]
+ output_from_past = model(next_tokens, past_key_values=past, attention_mask=attn_mask)["last_hidden_state"]
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_gptj_model_past_large_inputs(
+ self, config, input_ids, input_mask, head_mask, token_type_ids, *args
+ ):
+ model = GPTJModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # first forward pass
+ outputs = model(input_ids, token_type_ids=token_type_ids, attention_mask=input_mask, use_cache=True)
+
+ output, past = outputs.to_tuple()
+
+ # create hypothetical next token and extent to next_input_ids
+ next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
+ next_token_types = ids_tensor([self.batch_size, 3], self.type_vocab_size)
+ next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
+
+ # append to next input_ids and token_type_ids
+ next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
+ next_token_type_ids = torch.cat([token_type_ids, next_token_types], dim=-1)
+ next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
+
+ output_from_no_past = model(
+ next_input_ids, token_type_ids=next_token_type_ids, attention_mask=next_attention_mask
+ )["last_hidden_state"]
+ output_from_past = model(
+ next_tokens, token_type_ids=next_token_types, attention_mask=next_attention_mask, past_key_values=past
+ )["last_hidden_state"]
+ self.parent.assertTrue(output_from_past.shape[1] == next_tokens.shape[1])
+
+ # select random slice
+ random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
+ output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
+ output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
+
+ # test that outputs are equal for slice
+ self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
+
+ def create_and_check_lm_head_model(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
+ model = GPTJForCausalLM(config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(input_ids, token_type_ids=token_type_ids, labels=input_ids)
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_forward_and_backwards(
+ self, config, input_ids, input_mask, head_mask, token_type_ids, *args, gradient_checkpointing=False
+ ):
+ model = GPTJForCausalLM(config)
+ if gradient_checkpointing:
+ model.gradient_checkpointing_enable()
+ model.to(torch_device)
+
+ result = model(input_ids, token_type_ids=token_type_ids, labels=input_ids)
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+ result.loss.backward()
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+
+ (
+ config,
+ input_ids,
+ input_mask,
+ head_mask,
+ token_type_ids,
+ mc_token_ids,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+
+ inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "head_mask": head_mask}
+
+ return config, inputs_dict
+
+
+@require_torch
+class GPTJModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (GPTJModel, GPTJForCausalLM, GPTJForSequenceClassification, GPTJForQuestionAnswering)
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": GPTJModel,
+ "question-answering": GPTJForQuestionAnswering,
+ "text-classification": GPTJForSequenceClassification,
+ "text-generation": GPTJForCausalLM,
+ "zero-shot": GPTJForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ fx_compatible = True
+ test_pruning = False
+ test_missing_keys = False
+ test_model_parallel = False
+ test_head_masking = False
+
+ def test_torch_fx(self):
+ super().test_torch_fx()
+
+ def test_torch_fx_output_loss(self):
+ super().test_torch_fx_output_loss()
+
+ # TODO: Fix the failed tests
+ def is_pipeline_test_to_skip(
+ self,
+ pipeline_test_case_name,
+ config_class,
+ model_architecture,
+ tokenizer_name,
+ image_processor_name,
+ feature_extractor_name,
+ processor_name,
+ ):
+ if (
+ pipeline_test_case_name == "QAPipelineTests"
+ and tokenizer_name is not None
+ and not tokenizer_name.endswith("Fast")
+ ):
+ # `QAPipelineTests` fails for a few models when the slower tokenizer are used.
+ # (The slower tokenizers were never used for pipeline tests before the pipeline testing rework)
+ # TODO: check (and possibly fix) the `QAPipelineTests` with slower tokenizer
+ return True
+
+ return False
+
+ # special case for DoubleHeads model
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = GPTJModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=GPTJConfig, n_embd=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_gptj_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_gptj_model(*config_and_inputs)
+
+ def test_gptj_model_past(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_gptj_model_past(*config_and_inputs)
+
+ def test_gptj_model_att_mask_past(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_gptj_model_attention_mask_past(*config_and_inputs)
+
+ def test_gptj_model_past_large_inputs(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_gptj_model_past_large_inputs(*config_and_inputs)
+
+ def test_gptj_lm_head_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_lm_head_model(*config_and_inputs)
+
+ def test_gptj_gradient_checkpointing(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_forward_and_backwards(*config_and_inputs, gradient_checkpointing=True)
+
+ @tooslow
+ def test_batch_generation(self):
+ # Marked as @tooslow due to GPU OOM
+ model = GPTJForCausalLM.from_pretrained("EleutherAI/gpt-j-6B", revision="float16", torch_dtype=torch.float16)
+ model.to(torch_device)
+ tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B", revision="float16")
+
+ tokenizer.padding_side = "left"
+
+ # Define PAD Token = EOS Token = 50256
+ tokenizer.pad_token = tokenizer.eos_token
+ model.config.pad_token_id = model.config.eos_token_id
+
+ # use different length sentences to test batching
+ sentences = [
+ "Hello, my dog is a little",
+ "Today, I",
+ ]
+
+ inputs = tokenizer(sentences, return_tensors="pt", padding=True)
+ input_ids = inputs["input_ids"].to(torch_device)
+ token_type_ids = torch.cat(
+ [
+ input_ids.new_full((input_ids.shape[0], input_ids.shape[1] - 1), 0),
+ input_ids.new_full((input_ids.shape[0], 1), 500),
+ ],
+ dim=-1,
+ )
+
+ outputs = model.generate(
+ input_ids=input_ids,
+ attention_mask=inputs["attention_mask"].to(torch_device),
+ )
+
+ outputs_tt = model.generate(
+ input_ids=input_ids,
+ attention_mask=inputs["attention_mask"].to(torch_device),
+ token_type_ids=token_type_ids,
+ )
+
+ inputs_non_padded = tokenizer(sentences[0], return_tensors="pt").input_ids.to(torch_device)
+ output_non_padded = model.generate(input_ids=inputs_non_padded)
+
+ num_paddings = inputs_non_padded.shape[-1] - inputs["attention_mask"][-1].long().sum().item()
+ inputs_padded = tokenizer(sentences[1], return_tensors="pt").input_ids.to(torch_device)
+ output_padded = model.generate(input_ids=inputs_padded, max_length=model.config.max_length - num_paddings)
+
+ batch_out_sentence = tokenizer.batch_decode(outputs, skip_special_tokens=True)
+ batch_out_sentence_tt = tokenizer.batch_decode(outputs_tt, skip_special_tokens=True)
+ non_padded_sentence = tokenizer.decode(output_non_padded[0], skip_special_tokens=True)
+ padded_sentence = tokenizer.decode(output_padded[0], skip_special_tokens=True)
+
+ expected_output_sentence = [
+ "Hello, my dog is a little over a year old and has been diagnosed with a heart murmur",
+ "Today, I’m going to talk about the most important thing in the",
+ ]
+ self.assertListEqual(expected_output_sentence, batch_out_sentence)
+ self.assertTrue(batch_out_sentence_tt != batch_out_sentence) # token_type_ids should change output
+ self.assertListEqual(expected_output_sentence, [non_padded_sentence, padded_sentence])
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "EleutherAI/gpt-j-6B"
+ model = GPTJModel.from_pretrained(model_name, revision="float16", torch_dtype=torch.float16)
+ self.assertIsNotNone(model)
+
+
+@require_torch
+class GPTJModelLanguageGenerationTest(unittest.TestCase):
+ @tooslow
+ def test_lm_generate_gptj(self):
+ # Marked as @tooslow due to GPU OOM
+ for checkpointing in [True, False]:
+ model = GPTJForCausalLM.from_pretrained(
+ "EleutherAI/gpt-j-6B", revision="float16", torch_dtype=torch.float16
+ )
+ if checkpointing:
+ model.gradient_checkpointing_enable()
+ else:
+ model.gradient_checkpointing_disable()
+ model.to(torch_device)
+ input_ids = torch.tensor([[464, 3290]], dtype=torch.long, device=torch_device) # The dog
+ # The dog is a man's best friend. It is a loyal companion, and it is a friend
+ expected_output_ids = [464, 3290, 318, 257, 582, 338, 1266, 1545, 13, 632, 318, 257, 9112, 15185, 11, 290, 340, 318, 257, 1545] # fmt: skip
+ output_ids = model.generate(input_ids, do_sample=False)
+ self.assertListEqual(output_ids[0].tolist(), expected_output_ids)
+
+ @tooslow
+ def test_gptj_sample(self):
+ # Marked as @tooslow due to GPU OOM (issue #13676)
+ tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B", revision="float16")
+ model = GPTJForCausalLM.from_pretrained("EleutherAI/gpt-j-6B", revision="float16", torch_dtype=torch.float16)
+ model.to(torch_device)
+
+ torch.manual_seed(0)
+ tokenized = tokenizer("Today is a nice day and", return_tensors="pt", return_token_type_ids=True)
+ input_ids = tokenized.input_ids.to(torch_device)
+ output_ids = model.generate(input_ids, do_sample=True)
+ output_str = tokenizer.decode(output_ids[0], skip_special_tokens=True)
+
+ token_type_ids = tokenized.token_type_ids.to(torch_device)
+ output_seq = model.generate(input_ids=input_ids, do_sample=True, num_return_sequences=5)
+ output_seq_tt = model.generate(
+ input_ids=input_ids, token_type_ids=token_type_ids, do_sample=True, num_return_sequences=5
+ )
+ output_seq_strs = tokenizer.batch_decode(output_seq, skip_special_tokens=True)
+ output_seq_tt_strs = tokenizer.batch_decode(output_seq_tt, skip_special_tokens=True)
+
+ if torch_device != "cpu":
+ # currently this expect value is only for `cuda`
+ EXPECTED_OUTPUT_STR = (
+ "Today is a nice day and I've already been enjoying it. I walked to work with my wife"
+ )
+ else:
+ EXPECTED_OUTPUT_STR = "Today is a nice day and one of those days that feels a bit more alive. I am ready"
+
+ self.assertEqual(output_str, EXPECTED_OUTPUT_STR)
+ self.assertTrue(
+ all(output_seq_strs[idx] != output_seq_tt_strs[idx] for idx in range(len(output_seq_tt_strs)))
+ ) # token_type_ids should change output
+
+ @tooslow
+ def test_contrastive_search_gptj(self):
+ article = (
+ "DeepMind Technologies is a British artificial intelligence subsidiary of Alphabet Inc. and "
+ "research laboratory founded in 2010. DeepMind was acquired by Google in 2014. The company is based"
+ )
+
+ tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
+ model = GPTJForCausalLM.from_pretrained(
+ "EleutherAI/gpt-j-6B", revision="float16", torch_dtype=torch.float16
+ ).to(torch_device)
+ input_ids = tokenizer(article, return_tensors="pt").input_ids.to(torch_device)
+
+ outputs = model.generate(input_ids, penalty_alpha=0.6, top_k=4, max_length=256)
+ generated_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)
+
+ self.assertListEqual(
+ generated_text,
+ [
+ "DeepMind Technologies is a British artificial intelligence subsidiary of Alphabet Inc. and research "
+ "laboratory founded in 2010. DeepMind was acquired by Google in 2014. The company is based in London, "
+ "United Kingdom with offices in Mountain View, San Francisco, New York City, Paris, Tokyo, Seoul, "
+ "Beijing, Singapore, Tel Aviv, Dublin, Sydney, and Melbourne.[1]\n\nContents\n\nIn 2010, Google's "
+ "parent company, Alphabet, announced a $500 million investment in DeepMind, with the aim of creating "
+ "a company that would apply deep learning to problems in healthcare, energy, transportation, and "
+ "other areas.[2]\n\nOn April 23, 2014, Google announced that it had acquired DeepMind for $400 "
+ "million in cash and stock.[3] The acquisition was seen as a way for Google to enter the "
+ "fast-growing field of artificial intelligence (AI), which it had so far avoided due to concerns "
+ 'about ethical and social implications.[4] Google co-founder Sergey Brin said that he was "thrilled" '
+ 'to have acquired DeepMind, and that it would "help us push the boundaries of AI even further."'
+ "[5]\n\nDeepMind's founders, Demis Hassabis and Mustafa Suleyman, were joined by a number of Google "
+ "employees"
+ ],
+ )
diff --git a/transformers/tests/models/granitemoe/__init__.py b/transformers/tests/models/granitemoe/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/granitemoe/test_modeling_granitemoe.py b/transformers/tests/models/granitemoe/test_modeling_granitemoe.py
new file mode 100644
index 0000000000000000000000000000000000000000..ccc0dfd6a51238a783cb8d874eaeef5e4f486685
--- /dev/null
+++ b/transformers/tests/models/granitemoe/test_modeling_granitemoe.py
@@ -0,0 +1,384 @@
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch GraniteMoe model."""
+
+import unittest
+
+from parameterized import parameterized
+
+from transformers import AutoTokenizer, GraniteMoeConfig, is_torch_available, set_seed
+from transformers.testing_utils import (
+ Expectations,
+ require_read_token,
+ require_torch,
+ require_torch_accelerator,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ GraniteMoeForCausalLM,
+ GraniteMoeModel,
+ )
+ from transformers.models.granitemoe.modeling_granitemoe import (
+ GraniteMoeRotaryEmbedding,
+ )
+
+
+class GraniteMoeModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=False,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ pad_token_id=0,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.pad_token_id = pad_token_id
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = torch.tril(torch.ones_like(input_ids).to(torch_device))
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ return GraniteMoeConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ is_decoder=False,
+ initializer_range=self.initializer_range,
+ pad_token_id=self.pad_token_id,
+ )
+
+ def create_and_check_model(
+ self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = GraniteMoeModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class GraniteMoeModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ GraniteMoeModel,
+ GraniteMoeForCausalLM,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": GraniteMoeModel,
+ "text-generation": GraniteMoeForCausalLM,
+ }
+ if is_torch_available()
+ else {}
+ )
+ test_headmasking = False
+ test_pruning = False
+ fx_compatible = False
+
+ # Need to use `0.8` instead of `0.9` for `test_cpu_offload`
+ # This is because we are hitting edge cases with the causal_mask buffer
+ model_split_percents = [0.5, 0.7, 0.8]
+
+ def setUp(self):
+ self.model_tester = GraniteMoeModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=GraniteMoeConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_various_embeddings(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["absolute", "relative_key", "relative_key_query"]:
+ config_and_inputs[0].position_embedding_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @parameterized.expand([("linear",), ("dynamic",)])
+ def test_model_rope_scaling_from_config(self, scaling_type):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ short_input = ids_tensor([1, 10], config.vocab_size)
+ long_input = ids_tensor([1, int(config.max_position_embeddings * 1.5)], config.vocab_size)
+
+ set_seed(42) # Fixed seed at init time so the two models get the same random weights
+ original_model = GraniteMoeModel(config)
+ original_model.to(torch_device)
+ original_model.eval()
+ original_short_output = original_model(short_input).last_hidden_state
+ original_long_output = original_model(long_input).last_hidden_state
+
+ set_seed(42) # Fixed seed at init time so the two models get the same random weights
+ config.rope_scaling = {"type": scaling_type, "factor": 10.0}
+ scaled_model = GraniteMoeModel(config)
+ scaled_model.to(torch_device)
+ scaled_model.eval()
+ scaled_short_output = scaled_model(short_input).last_hidden_state
+ scaled_long_output = scaled_model(long_input).last_hidden_state
+
+ # Dynamic scaling does not change the RoPE embeddings until it receives an input longer than the original
+ # maximum sequence length, so the outputs for the short input should match.
+ if scaling_type == "dynamic":
+ torch.testing.assert_close(original_short_output, scaled_short_output, rtol=1e-5, atol=1e-5)
+ else:
+ self.assertFalse(torch.allclose(original_short_output, scaled_short_output, atol=1e-5))
+
+ # The output should be different for long inputs
+ self.assertFalse(torch.allclose(original_long_output, scaled_long_output, atol=1e-5))
+
+ def test_model_rope_scaling(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ scaling_factor = 10
+ short_input_length = 10
+ long_input_length = int(config.max_position_embeddings * 1.5)
+
+ # Inputs
+ x = torch.randn(
+ 1, dtype=torch.float32, device=torch_device
+ ) # used exclusively to get the dtype and the device
+ position_ids_short = torch.arange(short_input_length, dtype=torch.long, device=torch_device)
+ position_ids_short = position_ids_short.unsqueeze(0)
+ position_ids_long = torch.arange(long_input_length, dtype=torch.long, device=torch_device)
+ position_ids_long = position_ids_long.unsqueeze(0)
+
+ # Sanity check original RoPE
+ original_rope = GraniteMoeRotaryEmbedding(config=config).to(torch_device)
+ original_cos_short, original_sin_short = original_rope(x, position_ids_short)
+ original_cos_long, original_sin_long = original_rope(x, position_ids_long)
+ torch.testing.assert_close(original_cos_short, original_cos_long[:, :short_input_length, :])
+ torch.testing.assert_close(original_sin_short, original_sin_long[:, :short_input_length, :])
+
+ # Sanity check linear RoPE scaling
+ # New position "x" should match original position with index "x/scaling_factor"
+ config.rope_scaling = {"type": "linear", "factor": scaling_factor}
+ linear_scaling_rope = GraniteMoeRotaryEmbedding(config=config).to(torch_device)
+ linear_cos_short, linear_sin_short = linear_scaling_rope(x, position_ids_short)
+ linear_cos_long, linear_sin_long = linear_scaling_rope(x, position_ids_long)
+ torch.testing.assert_close(linear_cos_short, linear_cos_long[:, :short_input_length, :])
+ torch.testing.assert_close(linear_sin_short, linear_sin_long[:, :short_input_length, :])
+ for new_position in range(0, long_input_length, scaling_factor):
+ original_position = int(new_position // scaling_factor)
+ torch.testing.assert_close(linear_cos_long[:, new_position, :], original_cos_long[:, original_position, :])
+ torch.testing.assert_close(linear_sin_long[:, new_position, :], original_sin_long[:, original_position, :])
+
+ # Sanity check Dynamic NTK RoPE scaling
+ # Scaling should only be observed after a long input is fed. We can observe that the frequencies increase
+ # with scaling_factor (or that `inv_freq` decreases)
+ config.rope_scaling = {"type": "dynamic", "factor": scaling_factor}
+ ntk_scaling_rope = GraniteMoeRotaryEmbedding(config=config).to(torch_device)
+ ntk_cos_short, ntk_sin_short = ntk_scaling_rope(x, position_ids_short)
+ ntk_cos_long, ntk_sin_long = ntk_scaling_rope(x, position_ids_long)
+ torch.testing.assert_close(ntk_cos_short, original_cos_short)
+ torch.testing.assert_close(ntk_sin_short, original_sin_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_cos_long, original_cos_long)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(ntk_sin_long, original_sin_long)
+ self.assertTrue((ntk_scaling_rope.inv_freq <= original_rope.inv_freq).all())
+
+ # Sanity check Yarn RoPE scaling
+ # Scaling should be over the entire input
+ config.rope_scaling = {"type": "yarn", "factor": scaling_factor}
+ yarn_scaling_rope = GraniteMoeRotaryEmbedding(config=config).to(torch_device)
+ yarn_cos_short, yarn_sin_short = yarn_scaling_rope(x, position_ids_short)
+ yarn_cos_long, yarn_sin_long = yarn_scaling_rope(x, position_ids_long)
+ torch.testing.assert_close(yarn_cos_short, yarn_cos_long[:, :short_input_length, :])
+ torch.testing.assert_close(yarn_sin_short, yarn_sin_long[:, :short_input_length, :])
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(yarn_cos_short, original_cos_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(yarn_sin_short, original_sin_short)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(yarn_cos_long, original_cos_long)
+ with self.assertRaises(AssertionError):
+ torch.testing.assert_close(yarn_sin_long, original_sin_long)
+
+
+@require_torch_accelerator
+class GraniteMoeIntegrationTest(unittest.TestCase):
+ @slow
+ @require_read_token
+ def test_model_3b_logits(self):
+ input_ids = [1, 306, 4658, 278, 6593, 310, 2834, 338]
+
+ model = GraniteMoeForCausalLM.from_pretrained("ibm/PowerMoE-3b", device_map="auto")
+
+ with torch.no_grad():
+ out = model(torch.tensor([input_ids]).to(torch_device))
+
+ # fmt: off
+ # Expected mean on dim = -1
+ EXPECTED_MEANS = Expectations(
+ {
+ ("xpu", 3): torch.tensor([[-4.4005, -3.6689, -3.6187, -2.8308, -3.9871, -3.1001, -2.8738, -2.8063]]),
+ ("cuda", 7): torch.tensor([[-2.2122, -1.6632, -2.9269, -2.3344, -2.0143, -3.0146, -2.6839, -2.5610]]),
+ ("cuda", 8): torch.tensor([[-4.4005, -3.6689, -3.6187, -2.8308, -3.9871, -3.1001, -2.8738, -2.8063]]),
+ }
+ )
+ EXPECTED_MEAN = EXPECTED_MEANS.get_expectation()
+
+ torch.testing.assert_close(EXPECTED_MEAN.to(torch_device), out.logits.float().mean(-1), rtol=1e-2, atol=1e-2)
+
+ # slicing logits[0, 0, 0:15]
+ EXPECTED_SLICES = Expectations(
+ {
+ ("xpu", 3): torch.tensor([[2.5479, -9.2123, -9.2121, -9.2175, -9.2122, -1.5024, -9.2121, -9.2122, -9.2161, -9.2122, -6.3100, -3.6223, -3.6377, -5.2542, -5.2523]]),
+ ("cuda", 7): torch.tensor([[4.8785, -2.2890, -2.2892, -2.2885, -2.2890, -3.5007, -2.2897, -2.2892, -2.2895, -2.2891, -2.2887, -2.2882, -2.2889, -2.2898, -2.2892]]),
+ ("cuda", 8): torch.tensor([[2.5479, -9.2124, -9.2121, -9.2175, -9.2122, -1.5024, -9.2121, -9.2122, -9.2162, -9.2122, -6.3101, -3.6224, -3.6377, -5.2542, -5.2524]]),
+ }
+ )
+ EXPECTED_SLICE = EXPECTED_SLICES.get_expectation()
+ # fmt: on
+
+ self.assertTrue(
+ torch.allclose(
+ EXPECTED_SLICE.to(torch_device),
+ out.logits[0, 0, :15].float(),
+ atol=1e-3,
+ rtol=1e-3,
+ )
+ )
+
+ @slow
+ def test_model_3b_generation(self):
+ # ground truth text generated with dola_layers="low", repetition_penalty=1.2
+ # fmt: off
+ EXPECTED_TEXT_COMPLETIONS = Expectations(
+ {
+ ("xpu", 3): (
+ "Simply put, the theory of relativity states that 1) the speed of light is constant, and 2) the speed of light is the same for all observers.\n\n"
+ "The first part is easy to understand. The second part is a little more difficult.\n\n"
+ "The second part of the theory of relativity is a little more difficult to understand.\n"
+ ),
+ ("cuda", 7): (
+ "Simply put, the theory of relativity states that \n$$\n\\frac{d^2x^\\mu}{d\\tau^2} = "
+ "\\frac{1}{c^2}\\frac{d^2x^\\mu}{dt^2}\n$$\nwhere $x^\\mu$ is a four-vector, $\\tau$ is the proper time"
+ ),
+ ("cuda", 8): (
+ "Simply put, the theory of relativity states that 1) the speed of light is constant, and 2) the speed of light is the same for all observers.\n\n"
+ "The first part is easy to understand. The second part is a little more difficult.\n\n"
+ "The second part of the theory of relativity is a little more difficult to understand.\n"
+ ),
+ }
+ )
+ # fmt: on
+ EXPECTED_TEXT_COMPLETION = EXPECTED_TEXT_COMPLETIONS.get_expectation()
+
+ prompt = "Simply put, the theory of relativity states that "
+ tokenizer = AutoTokenizer.from_pretrained("ibm/PowerMoE-3b")
+ model = GraniteMoeForCausalLM.from_pretrained("ibm/PowerMoE-3b", device_map="auto")
+ model_inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
+
+ # greedy generation outputs
+ generated_ids = model.generate(**model_inputs, max_new_tokens=64, top_p=None, temperature=1, do_sample=False)
+ text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
+
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
diff --git a/transformers/tests/models/grounding_dino/__init__.py b/transformers/tests/models/grounding_dino/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/grounding_dino/test_image_processing_grounding_dino.py b/transformers/tests/models/grounding_dino/test_image_processing_grounding_dino.py
new file mode 100644
index 0000000000000000000000000000000000000000..2c4ecb297e62db69e5db3ead2cbda5bcf89757ca
--- /dev/null
+++ b/transformers/tests/models/grounding_dino/test_image_processing_grounding_dino.py
@@ -0,0 +1,646 @@
+# Copyright 2024 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import pathlib
+import unittest
+
+import numpy as np
+
+from transformers.testing_utils import require_torch, require_vision, slow
+from transformers.utils import is_torch_available, is_torchvision_available, is_vision_available
+
+from ...test_image_processing_common import AnnotationFormatTestMixin, ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_torch_available():
+ import torch
+
+ from transformers.models.grounding_dino.modeling_grounding_dino import GroundingDinoObjectDetectionOutput
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import GroundingDinoImageProcessor
+
+ if is_torchvision_available():
+ from transformers import GroundingDinoImageProcessorFast
+
+
+class GroundingDinoImageProcessingTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_pad=True,
+ ):
+ # by setting size["longest_edge"] > max_resolution we're effectively not testing this :p
+ size = size if size is not None else {"shortest_edge": 18, "longest_edge": 1333}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_pad = do_pad
+ self.num_queries = 5
+ self.embed_dim = 5
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTester.prepare_image_processor_dict with DeformableDetr->GroundingDino
+ def prepare_image_processor_dict(self):
+ return {
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
+ "do_pad": self.do_pad,
+ }
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTester.get_expected_values with DeformableDetr->GroundingDino
+ def get_expected_values(self, image_inputs, batched=False):
+ """
+ This function computes the expected height and width when providing images to GroundingDinoImageProcessor,
+ assuming do_resize is set to True with a scalar size.
+ """
+ if not batched:
+ image = image_inputs[0]
+ if isinstance(image, Image.Image):
+ w, h = image.size
+ elif isinstance(image, np.ndarray):
+ h, w = image.shape[0], image.shape[1]
+ else:
+ h, w = image.shape[1], image.shape[2]
+ if w < h:
+ expected_height = int(self.size["shortest_edge"] * h / w)
+ expected_width = self.size["shortest_edge"]
+ elif w > h:
+ expected_height = self.size["shortest_edge"]
+ expected_width = int(self.size["shortest_edge"] * w / h)
+ else:
+ expected_height = self.size["shortest_edge"]
+ expected_width = self.size["shortest_edge"]
+
+ else:
+ expected_values = []
+ for image in image_inputs:
+ expected_height, expected_width = self.get_expected_values([image])
+ expected_values.append((expected_height, expected_width))
+ expected_height = max(expected_values, key=lambda item: item[0])[0]
+ expected_width = max(expected_values, key=lambda item: item[1])[1]
+
+ return expected_height, expected_width
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTester.expected_output_image_shape with DeformableDetr->GroundingDino
+ def expected_output_image_shape(self, images):
+ height, width = self.get_expected_values(images, batched=True)
+ return self.num_channels, height, width
+
+ def get_fake_grounding_dino_output(self):
+ torch.manual_seed(42)
+ return GroundingDinoObjectDetectionOutput(
+ pred_boxes=torch.rand(self.batch_size, self.num_queries, 4),
+ logits=torch.rand(self.batch_size, self.num_queries, self.embed_dim),
+ )
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTester.prepare_image_inputs with DeformableDetr->GroundingDino
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_vision
+class GroundingDinoImageProcessingTest(AnnotationFormatTestMixin, ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = GroundingDinoImageProcessor if is_vision_available() else None
+ fast_image_processing_class = GroundingDinoImageProcessorFast if is_torchvision_available() else None
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = GroundingDinoImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTest.test_image_processor_properties with DeformableDetr->GroundingDino
+ def test_image_processor_properties(self):
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "do_rescale"))
+ self.assertTrue(hasattr(image_processing, "do_pad"))
+ self.assertTrue(hasattr(image_processing, "size"))
+
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTest.test_image_processor_from_dict_with_kwargs with DeformableDetr->GroundingDino
+ def test_image_processor_from_dict_with_kwargs(self):
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"shortest_edge": 18, "longest_edge": 1333})
+ self.assertEqual(image_processor.do_pad, True)
+
+ image_processor = image_processing_class.from_dict(
+ self.image_processor_dict, size=42, max_size=84, pad_and_return_pixel_mask=False
+ )
+ self.assertEqual(image_processor.size, {"shortest_edge": 42, "longest_edge": 84})
+ self.assertEqual(image_processor.do_pad, False)
+
+ def test_post_process_object_detection(self):
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class(**self.image_processor_dict)
+ outputs = self.image_processor_tester.get_fake_grounding_dino_output()
+ results = image_processor.post_process_object_detection(outputs, threshold=0.0)
+
+ self.assertEqual(len(results), self.image_processor_tester.batch_size)
+ self.assertEqual(list(results[0].keys()), ["scores", "labels", "boxes"])
+ self.assertEqual(results[0]["boxes"].shape, (self.image_processor_tester.num_queries, 4))
+ self.assertEqual(results[0]["scores"].shape, (self.image_processor_tester.num_queries,))
+
+ expected_scores = torch.tensor([0.7050, 0.7222, 0.7222, 0.6829, 0.7220])
+ torch.testing.assert_close(results[0]["scores"], expected_scores, rtol=1e-4, atol=1e-4)
+
+ expected_box_slice = torch.tensor([0.6908, 0.4354, 1.0737, 1.3947])
+ torch.testing.assert_close(results[0]["boxes"][0], expected_box_slice, rtol=1e-4, atol=1e-4)
+
+ @slow
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTest.test_call_pytorch_with_coco_detection_annotations with DeformableDetr->GroundingDino
+ def test_call_pytorch_with_coco_detection_annotations(self):
+ # prepare image and target
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ target = {"image_id": 39769, "annotations": target}
+
+ for image_processing_class in self.image_processor_list:
+ # encode them
+ image_processing = image_processing_class()
+ encoding = image_processing(images=image, annotations=target, return_tensors="pt")
+
+ # verify pixel values
+ expected_shape = torch.Size([1, 3, 800, 1066])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ expected_slice = torch.tensor([0.2796, 0.3138, 0.3481])
+ torch.testing.assert_close(encoding["pixel_values"][0, 0, 0, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ # verify area
+ expected_area = torch.tensor([5887.9600, 11250.2061, 489353.8438, 837122.7500, 147967.5156, 165732.3438])
+ torch.testing.assert_close(encoding["labels"][0]["area"], expected_area)
+ # verify boxes
+ expected_boxes_shape = torch.Size([6, 4])
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, expected_boxes_shape)
+ expected_boxes_slice = torch.tensor([0.5503, 0.2765, 0.0604, 0.2215])
+ torch.testing.assert_close(encoding["labels"][0]["boxes"][0], expected_boxes_slice, rtol=1e-3, atol=1e-3)
+ # verify image_id
+ expected_image_id = torch.tensor([39769])
+ torch.testing.assert_close(encoding["labels"][0]["image_id"], expected_image_id)
+ # verify is_crowd
+ expected_is_crowd = torch.tensor([0, 0, 0, 0, 0, 0])
+ torch.testing.assert_close(encoding["labels"][0]["iscrowd"], expected_is_crowd)
+ # verify class_labels
+ expected_class_labels = torch.tensor([75, 75, 63, 65, 17, 17])
+ torch.testing.assert_close(encoding["labels"][0]["class_labels"], expected_class_labels)
+ # verify orig_size
+ expected_orig_size = torch.tensor([480, 640])
+ torch.testing.assert_close(encoding["labels"][0]["orig_size"], expected_orig_size)
+ # verify size
+ expected_size = torch.tensor([800, 1066])
+ torch.testing.assert_close(encoding["labels"][0]["size"], expected_size)
+
+ @slow
+ # Copied from tests.models.detr.test_image_processing_detr.DetrImageProcessingTest.test_batched_coco_detection_annotations with Detr->GroundingDino
+ def test_batched_coco_detection_annotations(self):
+ image_0 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ image_1 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png").resize((800, 800))
+
+ with open("./tests/fixtures/tests_samples/COCO/coco_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ annotations_0 = {"image_id": 39769, "annotations": target}
+ annotations_1 = {"image_id": 39769, "annotations": target}
+
+ # Adjust the bounding boxes for the resized image
+ w_0, h_0 = image_0.size
+ w_1, h_1 = image_1.size
+ for i in range(len(annotations_1["annotations"])):
+ coords = annotations_1["annotations"][i]["bbox"]
+ new_bbox = [
+ coords[0] * w_1 / w_0,
+ coords[1] * h_1 / h_0,
+ coords[2] * w_1 / w_0,
+ coords[3] * h_1 / h_0,
+ ]
+ annotations_1["annotations"][i]["bbox"] = new_bbox
+
+ images = [image_0, image_1]
+ annotations = [annotations_0, annotations_1]
+
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class()
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ return_segmentation_masks=True,
+ return_tensors="pt", # do_convert_annotations=True
+ )
+
+ # Check the pixel values have been padded
+ postprocessed_height, postprocessed_width = 800, 1066
+ expected_shape = torch.Size([2, 3, postprocessed_height, postprocessed_width])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ # Check the bounding boxes have been adjusted for padded images
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ expected_boxes_0 = torch.tensor(
+ [
+ [0.6879, 0.4609, 0.0755, 0.3691],
+ [0.2118, 0.3359, 0.2601, 0.1566],
+ [0.5011, 0.5000, 0.9979, 1.0000],
+ [0.5010, 0.5020, 0.9979, 0.9959],
+ [0.3284, 0.5944, 0.5884, 0.8112],
+ [0.8394, 0.5445, 0.3213, 0.9110],
+ ]
+ )
+ expected_boxes_1 = torch.tensor(
+ [
+ [0.4130, 0.2765, 0.0453, 0.2215],
+ [0.1272, 0.2016, 0.1561, 0.0940],
+ [0.3757, 0.4933, 0.7488, 0.9865],
+ [0.3759, 0.5002, 0.7492, 0.9955],
+ [0.1971, 0.5456, 0.3532, 0.8646],
+ [0.5790, 0.4115, 0.3430, 0.7161],
+ ]
+ )
+ torch.testing.assert_close(encoding["labels"][0]["boxes"], expected_boxes_0, atol=1e-3, rtol=1e-3)
+ torch.testing.assert_close(encoding["labels"][1]["boxes"], expected_boxes_1, atol=1e-3, rtol=1e-3)
+
+ # Check the masks have also been padded
+ self.assertEqual(encoding["labels"][0]["masks"].shape, torch.Size([6, 800, 1066]))
+ self.assertEqual(encoding["labels"][1]["masks"].shape, torch.Size([6, 800, 1066]))
+
+ # Check if do_convert_annotations=False, then the annotations are not converted to centre_x, centre_y, width, height
+ # format and not in the range [0, 1]
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ return_segmentation_masks=True,
+ do_convert_annotations=False,
+ return_tensors="pt",
+ )
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ # Convert to absolute coordinates
+ unnormalized_boxes_0 = torch.vstack(
+ [
+ expected_boxes_0[:, 0] * postprocessed_width,
+ expected_boxes_0[:, 1] * postprocessed_height,
+ expected_boxes_0[:, 2] * postprocessed_width,
+ expected_boxes_0[:, 3] * postprocessed_height,
+ ]
+ ).T
+ unnormalized_boxes_1 = torch.vstack(
+ [
+ expected_boxes_1[:, 0] * postprocessed_width,
+ expected_boxes_1[:, 1] * postprocessed_height,
+ expected_boxes_1[:, 2] * postprocessed_width,
+ expected_boxes_1[:, 3] * postprocessed_height,
+ ]
+ ).T
+ # Convert from centre_x, centre_y, width, height to x_min, y_min, x_max, y_max
+ expected_boxes_0 = torch.vstack(
+ [
+ unnormalized_boxes_0[:, 0] - unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] - unnormalized_boxes_0[:, 3] / 2,
+ unnormalized_boxes_0[:, 0] + unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] + unnormalized_boxes_0[:, 3] / 2,
+ ]
+ ).T
+ expected_boxes_1 = torch.vstack(
+ [
+ unnormalized_boxes_1[:, 0] - unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] - unnormalized_boxes_1[:, 3] / 2,
+ unnormalized_boxes_1[:, 0] + unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] + unnormalized_boxes_1[:, 3] / 2,
+ ]
+ ).T
+ torch.testing.assert_close(encoding["labels"][0]["boxes"], expected_boxes_0, atol=1, rtol=1)
+ torch.testing.assert_close(encoding["labels"][1]["boxes"], expected_boxes_1, atol=1, rtol=1)
+
+ @slow
+ # Copied from tests.models.deformable_detr.test_image_processing_deformable_detr.DeformableDetrImageProcessingTest.test_call_pytorch_with_coco_panoptic_annotations with DeformableDetr->GroundingDino
+ def test_call_pytorch_with_coco_panoptic_annotations(self):
+ # prepare image, target and masks_path
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ with open("./tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ target = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+
+ masks_path = pathlib.Path("./tests/fixtures/tests_samples/COCO/coco_panoptic")
+
+ for image_processing_class in self.image_processor_list:
+ # encode them
+ image_processing = image_processing_class(format="coco_panoptic")
+ encoding = image_processing(images=image, annotations=target, masks_path=masks_path, return_tensors="pt")
+
+ # verify pixel values
+ expected_shape = torch.Size([1, 3, 800, 1066])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ expected_slice = torch.tensor([0.2796, 0.3138, 0.3481])
+ torch.testing.assert_close(encoding["pixel_values"][0, 0, 0, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ # verify area
+ expected_area = torch.tensor([147979.6875, 165527.0469, 484638.5938, 11292.9375, 5879.6562, 7634.1147])
+ torch.testing.assert_close(encoding["labels"][0]["area"], expected_area)
+ # verify boxes
+ expected_boxes_shape = torch.Size([6, 4])
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, expected_boxes_shape)
+ expected_boxes_slice = torch.tensor([0.2625, 0.5437, 0.4688, 0.8625])
+ torch.testing.assert_close(encoding["labels"][0]["boxes"][0], expected_boxes_slice, rtol=1e-3, atol=1e-3)
+ # verify image_id
+ expected_image_id = torch.tensor([39769])
+ torch.testing.assert_close(encoding["labels"][0]["image_id"], expected_image_id)
+ # verify is_crowd
+ expected_is_crowd = torch.tensor([0, 0, 0, 0, 0, 0])
+ torch.testing.assert_close(encoding["labels"][0]["iscrowd"], expected_is_crowd)
+ # verify class_labels
+ expected_class_labels = torch.tensor([17, 17, 63, 75, 75, 93])
+ torch.testing.assert_close(encoding["labels"][0]["class_labels"], expected_class_labels)
+ # verify masks
+ expected_masks_sum = 822873
+ relative_error = torch.abs(encoding["labels"][0]["masks"].sum() - expected_masks_sum) / expected_masks_sum
+ self.assertTrue(relative_error < 1e-3)
+ # verify orig_size
+ expected_orig_size = torch.tensor([480, 640])
+ torch.testing.assert_close(encoding["labels"][0]["orig_size"], expected_orig_size)
+ # verify size
+ expected_size = torch.tensor([800, 1066])
+ torch.testing.assert_close(encoding["labels"][0]["size"], expected_size)
+
+ @slow
+ # Copied from tests.models.detr.test_image_processing_detr.DetrImageProcessingTest.test_batched_coco_panoptic_annotations with Detr->GroundingDino
+ def test_batched_coco_panoptic_annotations(self):
+ # prepare image, target and masks_path
+ image_0 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ image_1 = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png").resize((800, 800))
+
+ with open("./tests/fixtures/tests_samples/COCO/coco_panoptic_annotations.txt") as f:
+ target = json.loads(f.read())
+
+ annotation_0 = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+ annotation_1 = {"file_name": "000000039769.png", "image_id": 39769, "segments_info": target}
+
+ w_0, h_0 = image_0.size
+ w_1, h_1 = image_1.size
+ for i in range(len(annotation_1["segments_info"])):
+ coords = annotation_1["segments_info"][i]["bbox"]
+ new_bbox = [
+ coords[0] * w_1 / w_0,
+ coords[1] * h_1 / h_0,
+ coords[2] * w_1 / w_0,
+ coords[3] * h_1 / h_0,
+ ]
+ annotation_1["segments_info"][i]["bbox"] = new_bbox
+
+ masks_path = pathlib.Path("./tests/fixtures/tests_samples/COCO/coco_panoptic")
+
+ images = [image_0, image_1]
+ annotations = [annotation_0, annotation_1]
+
+ for image_processing_class in self.image_processor_list:
+ # encode them
+ image_processing = image_processing_class(format="coco_panoptic")
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ masks_path=masks_path,
+ return_tensors="pt",
+ return_segmentation_masks=True,
+ )
+
+ # Check the pixel values have been padded
+ postprocessed_height, postprocessed_width = 800, 1066
+ expected_shape = torch.Size([2, 3, postprocessed_height, postprocessed_width])
+ self.assertEqual(encoding["pixel_values"].shape, expected_shape)
+
+ # Check the bounding boxes have been adjusted for padded images
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ expected_boxes_0 = torch.tensor(
+ [
+ [0.2625, 0.5437, 0.4688, 0.8625],
+ [0.7719, 0.4104, 0.4531, 0.7125],
+ [0.5000, 0.4927, 0.9969, 0.9854],
+ [0.1688, 0.2000, 0.2063, 0.0917],
+ [0.5492, 0.2760, 0.0578, 0.2187],
+ [0.4992, 0.4990, 0.9984, 0.9979],
+ ]
+ )
+ expected_boxes_1 = torch.tensor(
+ [
+ [0.1576, 0.3262, 0.2814, 0.5175],
+ [0.4634, 0.2463, 0.2720, 0.4275],
+ [0.3002, 0.2956, 0.5985, 0.5913],
+ [0.1013, 0.1200, 0.1238, 0.0550],
+ [0.3297, 0.1656, 0.0347, 0.1312],
+ [0.2997, 0.2994, 0.5994, 0.5987],
+ ]
+ )
+ torch.testing.assert_close(encoding["labels"][0]["boxes"], expected_boxes_0, atol=1e-3, rtol=1e-3)
+ torch.testing.assert_close(encoding["labels"][1]["boxes"], expected_boxes_1, atol=1e-3, rtol=1e-3)
+
+ # Check the masks have also been padded
+ self.assertEqual(encoding["labels"][0]["masks"].shape, torch.Size([6, 800, 1066]))
+ self.assertEqual(encoding["labels"][1]["masks"].shape, torch.Size([6, 800, 1066]))
+
+ # Check if do_convert_annotations=False, then the annotations are not converted to centre_x, centre_y, width, height
+ # format and not in the range [0, 1]
+ encoding = image_processing(
+ images=images,
+ annotations=annotations,
+ masks_path=masks_path,
+ return_segmentation_masks=True,
+ do_convert_annotations=False,
+ return_tensors="pt",
+ )
+ self.assertEqual(encoding["labels"][0]["boxes"].shape, torch.Size([6, 4]))
+ self.assertEqual(encoding["labels"][1]["boxes"].shape, torch.Size([6, 4]))
+ # Convert to absolute coordinates
+ unnormalized_boxes_0 = torch.vstack(
+ [
+ expected_boxes_0[:, 0] * postprocessed_width,
+ expected_boxes_0[:, 1] * postprocessed_height,
+ expected_boxes_0[:, 2] * postprocessed_width,
+ expected_boxes_0[:, 3] * postprocessed_height,
+ ]
+ ).T
+ unnormalized_boxes_1 = torch.vstack(
+ [
+ expected_boxes_1[:, 0] * postprocessed_width,
+ expected_boxes_1[:, 1] * postprocessed_height,
+ expected_boxes_1[:, 2] * postprocessed_width,
+ expected_boxes_1[:, 3] * postprocessed_height,
+ ]
+ ).T
+ # Convert from centre_x, centre_y, width, height to x_min, y_min, x_max, y_max
+ expected_boxes_0 = torch.vstack(
+ [
+ unnormalized_boxes_0[:, 0] - unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] - unnormalized_boxes_0[:, 3] / 2,
+ unnormalized_boxes_0[:, 0] + unnormalized_boxes_0[:, 2] / 2,
+ unnormalized_boxes_0[:, 1] + unnormalized_boxes_0[:, 3] / 2,
+ ]
+ ).T
+ expected_boxes_1 = torch.vstack(
+ [
+ unnormalized_boxes_1[:, 0] - unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] - unnormalized_boxes_1[:, 3] / 2,
+ unnormalized_boxes_1[:, 0] + unnormalized_boxes_1[:, 2] / 2,
+ unnormalized_boxes_1[:, 1] + unnormalized_boxes_1[:, 3] / 2,
+ ]
+ ).T
+ torch.testing.assert_close(encoding["labels"][0]["boxes"], expected_boxes_0, atol=1, rtol=1)
+ torch.testing.assert_close(encoding["labels"][1]["boxes"], expected_boxes_1, atol=1, rtol=1)
+
+ # Copied from tests.models.detr.test_image_processing_detr.DetrImageProcessingTest.test_max_width_max_height_resizing_and_pad_strategy with Detr->GroundingDino
+ def test_max_width_max_height_resizing_and_pad_strategy(self):
+ for image_processing_class in self.image_processor_list:
+ image_1 = torch.ones([200, 100, 3], dtype=torch.uint8)
+
+ # do_pad=False, max_height=100, max_width=100, image=200x100 -> 100x50
+ image_processor = image_processing_class(
+ size={"max_height": 100, "max_width": 100},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 100, 50]))
+
+ # do_pad=False, max_height=300, max_width=100, image=200x100 -> 200x100
+ image_processor = image_processing_class(
+ size={"max_height": 300, "max_width": 100},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+
+ # do_pad=True, max_height=100, max_width=100, image=200x100 -> 100x100
+ image_processor = image_processing_class(
+ size={"max_height": 100, "max_width": 100}, do_pad=True, pad_size={"height": 100, "width": 100}
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 100, 100]))
+
+ # do_pad=True, max_height=300, max_width=100, image=200x100 -> 300x100
+ image_processor = image_processing_class(
+ size={"max_height": 300, "max_width": 100},
+ do_pad=True,
+ pad_size={"height": 301, "width": 101},
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 301, 101]))
+
+ ### Check for batch
+ image_2 = torch.ones([100, 150, 3], dtype=torch.uint8)
+
+ # do_pad=True, max_height=150, max_width=100, images=[200x100, 100x150] -> 150x100
+ image_processor = image_processing_class(
+ size={"max_height": 150, "max_width": 100},
+ do_pad=True,
+ pad_size={"height": 150, "width": 100},
+ )
+ inputs = image_processor(images=[image_1, image_2], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([2, 3, 150, 100]))
+
+ def test_longest_edge_shortest_edge_resizing_strategy(self):
+ image_1 = torch.ones([958, 653, 3], dtype=torch.uint8)
+
+ # max size is set; width < height;
+ # do_pad=False, longest_edge=640, shortest_edge=640, image=958x653 -> 640x436
+ image_processor = GroundingDinoImageProcessor(
+ size={"longest_edge": 640, "shortest_edge": 640},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_1], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 640, 436]))
+
+ image_2 = torch.ones([653, 958, 3], dtype=torch.uint8)
+ # max size is set; height < width;
+ # do_pad=False, longest_edge=640, shortest_edge=640, image=653x958 -> 436x640
+ image_processor = GroundingDinoImageProcessor(
+ size={"longest_edge": 640, "shortest_edge": 640},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_2], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 436, 640]))
+
+ image_3 = torch.ones([100, 120, 3], dtype=torch.uint8)
+ # max size is set; width == size; height > max_size;
+ # do_pad=False, longest_edge=118, shortest_edge=100, image=120x100 -> 118x98
+ image_processor = GroundingDinoImageProcessor(
+ size={"longest_edge": 118, "shortest_edge": 100},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_3], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 98, 118]))
+
+ image_4 = torch.ones([128, 50, 3], dtype=torch.uint8)
+ # max size is set; height == size; width < max_size;
+ # do_pad=False, longest_edge=256, shortest_edge=50, image=50x128 -> 50x128
+ image_processor = GroundingDinoImageProcessor(
+ size={"longest_edge": 256, "shortest_edge": 50},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_4], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 128, 50]))
+
+ image_5 = torch.ones([50, 50, 3], dtype=torch.uint8)
+ # max size is set; height == width; width < max_size;
+ # do_pad=False, longest_edge=117, shortest_edge=50, image=50x50 -> 50x50
+ image_processor = GroundingDinoImageProcessor(
+ size={"longest_edge": 117, "shortest_edge": 50},
+ do_pad=False,
+ )
+ inputs = image_processor(images=[image_5], return_tensors="pt")
+ self.assertEqual(inputs["pixel_values"].shape, torch.Size([1, 3, 50, 50]))
diff --git a/transformers/tests/models/grounding_dino/test_modeling_grounding_dino.py b/transformers/tests/models/grounding_dino/test_modeling_grounding_dino.py
new file mode 100644
index 0000000000000000000000000000000000000000..953255797b51809fd20cab8d8430dc2c951d034f
--- /dev/null
+++ b/transformers/tests/models/grounding_dino/test_modeling_grounding_dino.py
@@ -0,0 +1,891 @@
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Grounding DINO model."""
+
+import collections
+import inspect
+import math
+import re
+import unittest
+
+from datasets import load_dataset
+
+from transformers import (
+ GroundingDinoConfig,
+ SwinConfig,
+ is_torch_available,
+ is_vision_available,
+)
+from transformers.file_utils import cached_property
+from transformers.testing_utils import (
+ Expectations,
+ is_flaky,
+ require_timm,
+ require_torch,
+ require_torch_accelerator,
+ require_vision,
+ slow,
+ torch_device,
+)
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import GroundingDinoConfig, GroundingDinoForObjectDetection, GroundingDinoModel
+ from transformers.pytorch_utils import id_tensor_storage
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import AutoProcessor
+
+
+def generate_fake_bounding_boxes(n_boxes):
+ """Generate bounding boxes in the format (center_x, center_y, width, height)"""
+ # Validate the input
+ if not isinstance(n_boxes, int):
+ raise ValueError("n_boxes must be an integer")
+ if n_boxes <= 0:
+ raise ValueError("n_boxes must be a positive integer")
+
+ # Generate random bounding boxes in the format (center_x, center_y, width, height)
+ bounding_boxes = torch.rand((n_boxes, 4))
+
+ # Extract the components
+ center_x = bounding_boxes[:, 0]
+ center_y = bounding_boxes[:, 1]
+ width = bounding_boxes[:, 2]
+ height = bounding_boxes[:, 3]
+
+ # Ensure width and height do not exceed bounds
+ width = torch.min(width, torch.tensor(1.0))
+ height = torch.min(height, torch.tensor(1.0))
+
+ # Ensure the bounding box stays within the normalized space
+ center_x = torch.where(center_x - width / 2 < 0, width / 2, center_x)
+ center_x = torch.where(center_x + width / 2 > 1, 1 - width / 2, center_x)
+ center_y = torch.where(center_y - height / 2 < 0, height / 2, center_y)
+ center_y = torch.where(center_y + height / 2 > 1, 1 - height / 2, center_y)
+
+ # Combine back into bounding boxes
+ bounding_boxes = torch.stack([center_x, center_y, width, height], dim=1)
+
+ return bounding_boxes
+
+
+class GroundingDinoModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=4,
+ is_training=True,
+ use_labels=True,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ num_queries=2,
+ num_channels=3,
+ image_size=98,
+ n_targets=8,
+ num_labels=2,
+ num_feature_levels=4,
+ encoder_n_points=2,
+ decoder_n_points=6,
+ max_text_len=7,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.num_queries = num_queries
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.n_targets = n_targets
+ self.num_labels = num_labels
+ self.num_feature_levels = num_feature_levels
+ self.encoder_n_points = encoder_n_points
+ self.decoder_n_points = decoder_n_points
+ self.max_text_len = max_text_len
+
+ # we also set the expected seq length for both encoder and decoder
+ self.encoder_seq_length_vision = (
+ math.ceil(self.image_size / 8) ** 2
+ + math.ceil(self.image_size / 16) ** 2
+ + math.ceil(self.image_size / 32) ** 2
+ + math.ceil(self.image_size / 64) ** 2
+ )
+
+ self.encoder_seq_length_text = self.max_text_len
+
+ self.decoder_seq_length = self.num_queries
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+ pixel_mask = torch.ones([self.batch_size, self.image_size, self.image_size], device=torch_device)
+
+ # When using `GroundingDino` the text input template is '{label1}. {label2}. {label3. ... {labelN}.'
+ # Therefore to avoid errors when running tests with `labels` `input_ids` have to follow this structure.
+ # Otherwise when running `build_label_maps` it will throw an error when trying to split the input_ids into segments.
+ input_ids = torch.tensor([101, 3869, 1012, 11420, 3869, 1012, 102], device=torch_device)
+ input_ids = input_ids.unsqueeze(0).expand(self.batch_size, -1)
+
+ labels = None
+ if self.use_labels:
+ # labels is a list of Dict (each Dict being the labels for a given example in the batch)
+ labels = []
+ for i in range(self.batch_size):
+ target = {}
+ target["class_labels"] = torch.randint(
+ high=self.num_labels, size=(self.n_targets,), device=torch_device
+ )
+ target["boxes"] = generate_fake_bounding_boxes(self.n_targets).to(torch_device)
+ target["masks"] = torch.rand(self.n_targets, self.image_size, self.image_size, device=torch_device)
+ labels.append(target)
+
+ config = self.get_config()
+ return config, pixel_values, pixel_mask, input_ids, labels
+
+ def get_config(self):
+ swin_config = SwinConfig(
+ window_size=7,
+ embed_dim=8,
+ depths=[1, 1, 1, 1],
+ num_heads=[1, 1, 1, 1],
+ image_size=self.image_size,
+ out_features=["stage2", "stage3", "stage4"],
+ out_indices=[2, 3, 4],
+ )
+ text_backbone = {
+ "hidden_size": 8,
+ "num_hidden_layers": 2,
+ "num_attention_heads": 2,
+ "intermediate_size": 8,
+ "max_position_embeddings": 8,
+ "model_type": "bert",
+ }
+ return GroundingDinoConfig(
+ d_model=self.hidden_size,
+ encoder_layers=self.num_hidden_layers,
+ decoder_layers=self.num_hidden_layers,
+ encoder_attention_heads=self.num_attention_heads,
+ decoder_attention_heads=self.num_attention_heads,
+ encoder_ffn_dim=self.intermediate_size,
+ decoder_ffn_dim=self.intermediate_size,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ num_queries=self.num_queries,
+ num_labels=self.num_labels,
+ num_feature_levels=self.num_feature_levels,
+ encoder_n_points=self.encoder_n_points,
+ decoder_n_points=self.decoder_n_points,
+ use_timm_backbone=False,
+ backbone_config=swin_config,
+ max_text_len=self.max_text_len,
+ text_config=text_backbone,
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config, pixel_values, pixel_mask, input_ids, labels = self.prepare_config_and_inputs()
+ inputs_dict = {"pixel_values": pixel_values, "pixel_mask": pixel_mask, "input_ids": input_ids}
+ return config, inputs_dict
+
+ def create_and_check_model(self, config, pixel_values, pixel_mask, input_ids, labels):
+ model = GroundingDinoModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask, input_ids=input_ids)
+
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.num_queries, self.hidden_size))
+
+ def create_and_check_object_detection_head_model(self, config, pixel_values, pixel_mask, input_ids, labels):
+ model = GroundingDinoForObjectDetection(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask, input_ids=input_ids)
+
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_queries, config.max_text_len))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_queries, 4))
+
+ result = model(pixel_values=pixel_values, pixel_mask=pixel_mask, input_ids=input_ids, labels=labels)
+
+ self.parent.assertEqual(result.loss.shape, ())
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_queries, config.max_text_len))
+ self.parent.assertEqual(result.pred_boxes.shape, (self.batch_size, self.num_queries, 4))
+
+
+@require_torch
+class GroundingDinoModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (GroundingDinoModel, GroundingDinoForObjectDetection) if is_torch_available() else ()
+ is_encoder_decoder = True
+ test_torchscript = False
+ test_pruning = False
+ test_head_masking = False
+ test_missing_keys = False
+ pipeline_model_mapping = (
+ {"image-feature-extraction": GroundingDinoModel, "zero-shot-object-detection": GroundingDinoForObjectDetection}
+ if is_torch_available()
+ else {}
+ )
+
+ # special case for head models
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
+
+ if return_labels:
+ if model_class.__name__ == "GroundingDinoForObjectDetection":
+ labels = []
+ for i in range(self.model_tester.batch_size):
+ target = {}
+ target["class_labels"] = torch.ones(
+ size=(self.model_tester.n_targets,), device=torch_device, dtype=torch.long
+ )
+ target["boxes"] = torch.ones(
+ self.model_tester.n_targets, 4, device=torch_device, dtype=torch.float
+ )
+ target["masks"] = torch.ones(
+ self.model_tester.n_targets,
+ self.model_tester.image_size,
+ self.model_tester.image_size,
+ device=torch_device,
+ dtype=torch.float,
+ )
+ labels.append(target)
+ inputs_dict["labels"] = labels
+
+ return inputs_dict
+
+ def setUp(self):
+ self.model_tester = GroundingDinoModelTester(self)
+ self.config_tester = ConfigTester(
+ self,
+ config_class=GroundingDinoConfig,
+ has_text_modality=False,
+ common_properties=["d_model", "encoder_attention_heads", "decoder_attention_heads"],
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_object_detection_head_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_object_detection_head_model(*config_and_inputs)
+
+ @unittest.skip(reason="Grounding DINO does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Grounding DINO does not have a get_input_embeddings method")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @unittest.skip(reason="Grounding DINO does not use token embeddings")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ @unittest.skip(reason="Feed forward chunking is not implemented")
+ def test_feed_forward_chunking(self):
+ pass
+
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class._from_config(config, attn_implementation="eager")
+ config = model.config
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions[-1]
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions[-1]
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ self.model_tester.num_feature_levels,
+ self.model_tester.encoder_n_points,
+ ],
+ )
+ out_len = len(outputs)
+
+ correct_outlen = 12
+
+ # loss is at first position
+ if "labels" in inputs_dict:
+ correct_outlen += 1 # loss is added to beginning
+ # Object Detection model returns pred_logits and pred_boxes and input_ids
+ if model_class.__name__ == "GroundingDinoForObjectDetection":
+ correct_outlen += 3
+
+ self.assertEqual(out_len, correct_outlen)
+
+ # decoder attentions
+ decoder_attentions = outputs.decoder_attentions[0]
+ self.assertIsInstance(decoder_attentions, (list, tuple))
+ self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(decoder_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, self.model_tester.num_queries, self.model_tester.num_queries],
+ )
+
+ # cross attentions
+ cross_attentions = outputs.decoder_attentions[-1]
+ self.assertIsInstance(cross_attentions, (list, tuple))
+ self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(cross_attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ self.model_tester.num_feature_levels,
+ self.model_tester.decoder_n_points,
+ ],
+ )
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ self.assertEqual(out_len + 3, len(outputs))
+
+ self_attentions = outputs.encoder_attentions[-1]
+
+ self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ self.model_tester.num_feature_levels,
+ self.model_tester.encoder_n_points,
+ ],
+ )
+
+ # overwrite since hidden_states are called encoder_text_hidden_states
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.encoder_vision_hidden_states
+
+ expected_num_layers = getattr(
+ self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers + 1
+ )
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ seq_len = self.model_tester.encoder_seq_length_vision
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [seq_len, self.model_tester.hidden_size],
+ )
+
+ hidden_states = outputs.encoder_text_hidden_states
+
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ seq_len = self.model_tester.encoder_seq_length_text
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [seq_len, self.model_tester.hidden_size],
+ )
+
+ hidden_states = outputs.decoder_hidden_states
+
+ self.assertIsInstance(hidden_states, (list, tuple))
+ self.assertEqual(len(hidden_states), expected_num_layers)
+ seq_len = getattr(self.model_tester, "seq_length", None)
+ decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len)
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [decoder_seq_length, self.model_tester.hidden_size],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # removed retain_grad and grad on decoder_hidden_states, as queries don't require grad
+ def test_retain_grad_hidden_states_attentions(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.output_hidden_states = True
+ config.output_attentions = True
+
+ # no need to test all models as different heads yield the same functionality
+ model_class = self.all_model_classes[0]
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ outputs = model(**inputs)
+
+ output = outputs[0]
+
+ encoder_hidden_states = outputs.encoder_vision_hidden_states[0]
+ encoder_attentions = outputs.encoder_attentions[0][0]
+ encoder_hidden_states.retain_grad()
+ encoder_attentions.retain_grad()
+
+ cross_attentions = outputs.decoder_attentions[-1][0]
+ cross_attentions.retain_grad()
+
+ output.flatten()[0].backward(retain_graph=True)
+
+ self.assertIsNotNone(encoder_hidden_states.grad)
+ self.assertIsNotNone(encoder_attentions.grad)
+ self.assertIsNotNone(cross_attentions.grad)
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values", "input_ids"]
+ self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
+
+ def test_different_timm_backbone(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # let's pick a random timm backbone
+ config.backbone = "tf_mobilenetv3_small_075"
+ config.use_timm_backbone = True
+ config.backbone_config = None
+ config.backbone_kwargs = {"in_chans": 3, "out_indices": (2, 3, 4)}
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if model_class.__name__ == "GroundingDinoForObjectDetection":
+ expected_shape = (
+ self.model_tester.batch_size,
+ self.model_tester.num_queries,
+ config.max_text_len,
+ )
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ self.assertTrue(outputs)
+
+ @require_timm
+ def test_hf_backbone(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # Load a pretrained HF checkpoint as backbone
+ config.backbone = "microsoft/resnet-18"
+ config.backbone_config = None
+ config.use_timm_backbone = False
+ config.use_pretrained_backbone = True
+ config.backbone_kwargs = {"out_indices": [2, 3, 4]}
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ if model_class.__name__ == "GroundingDinoForObjectDetection":
+ expected_shape = (
+ self.model_tester.batch_size,
+ self.model_tester.num_queries,
+ config.max_text_len,
+ )
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ self.assertTrue(outputs)
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ if (
+ "level_embed" in name
+ or "sampling_offsets.bias" in name
+ or "text_param" in name
+ or "vision_param" in name
+ or "value_proj" in name
+ or "output_proj" in name
+ or "reference_points" in name
+ or "vision_proj" in name
+ or "text_proj" in name
+ ):
+ continue
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ # Copied from tests.models.deformable_detr.test_modeling_deformable_detr.DeformableDetrModelTest.test_two_stage_training with DeformableDetr->GroundingDino
+ def test_two_stage_training(self):
+ model_class = GroundingDinoForObjectDetection
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+ config.two_stage = True
+ config.auxiliary_loss = True
+ config.with_box_refine = True
+
+ model = model_class(config)
+ model.to(torch_device)
+ model.train()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ loss = model(**inputs).loss
+ loss.backward()
+
+ def test_tied_weights_keys(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+ config.tie_word_embeddings = True
+ for model_class in self.all_model_classes:
+ model_tied = model_class(config)
+
+ ptrs = collections.defaultdict(list)
+ for name, tensor in model_tied.state_dict().items():
+ ptrs[id_tensor_storage(tensor)].append(name)
+
+ # These are all the pointers of shared tensors.
+ tied_params = [names for _, names in ptrs.items() if len(names) > 1]
+
+ tied_weight_keys = model_tied._tied_weights_keys if model_tied._tied_weights_keys is not None else []
+ # Detect we get a hit for each key
+ for key in tied_weight_keys:
+ if not any(re.search(key, p) for group in tied_params for p in group):
+ raise ValueError(f"{key} is not a tied weight key for {model_class}.")
+
+ # Removed tied weights found from tied params -> there should only be one left after
+ for key in tied_weight_keys:
+ for i in range(len(tied_params)):
+ tied_params[i] = [p for p in tied_params[i] if re.search(key, p) is None]
+
+ # GroundingDino when sharing weights also uses the shared ones in GroundingDinoDecoder
+ # Therefore, differently from DeformableDetr, we expect the group lens to be 2
+ # one for self.bbox_embed in GroundingDinoForObejectDetection and another one
+ # in the decoder
+ tied_params = [group for group in tied_params if len(group) > 2]
+ self.assertListEqual(
+ tied_params,
+ [],
+ f"Missing `_tied_weights_keys` for {model_class}: add all of {tied_params} except one.",
+ )
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+def prepare_text():
+ text = "a cat."
+ return text
+
+
+@require_timm
+@require_vision
+@slow
+class GroundingDinoModelIntegrationTests(unittest.TestCase):
+ @cached_property
+ def default_processor(self):
+ return AutoProcessor.from_pretrained("IDEA-Research/grounding-dino-tiny") if is_vision_available() else None
+
+ def test_inference_object_detection_head(self):
+ model = GroundingDinoForObjectDetection.from_pretrained("IDEA-Research/grounding-dino-tiny").to(torch_device)
+
+ processor = self.default_processor
+ image = prepare_img()
+ text = prepare_text()
+ encoding = processor(images=image, text=text, return_tensors="pt").to(torch_device)
+
+ with torch.no_grad():
+ outputs = model(**encoding)
+
+ expected_shape_logits = torch.Size((1, model.config.num_queries, model.config.d_model))
+ self.assertEqual(outputs.logits.shape, expected_shape_logits)
+
+ expectations = Expectations(
+ {
+ (None, None): [[0.7674, 0.4136, 0.4572], [0.2566, 0.5463, 0.4760], [0.2585, 0.5442, 0.4641]],
+ ("cuda", 8): [[0.7674, 0.4135, 0.4571], [0.2566, 0.5463, 0.4760], [0.2585, 0.5442, 0.4640]],
+ }
+ )
+ expected_boxes = torch.tensor(expectations.get_expectation()).to(torch_device)
+
+ expectations = Expectations(
+ {
+ (None, None): [[-4.8913, -0.1900, -0.2161], [-4.9653, -0.3719, -0.3950], [-5.9599, -3.3765, -3.3104]],
+ ("cuda", 8): [[-4.8927, -0.1910, -0.2169], [-4.9657, -0.3748, -0.3980], [-5.9579, -3.3812, -3.3153]],
+ }
+ )
+ expected_logits = torch.tensor(expectations.get_expectation()).to(torch_device)
+
+ torch.testing.assert_close(outputs.logits[0, :3, :3], expected_logits, rtol=1e-3, atol=1e-3)
+
+ expected_shape_boxes = torch.Size((1, model.config.num_queries, 4))
+ self.assertEqual(outputs.pred_boxes.shape, expected_shape_boxes)
+ torch.testing.assert_close(outputs.pred_boxes[0, :3, :3], expected_boxes, rtol=2e-4, atol=2e-4)
+
+ # verify postprocessing
+ results = processor.image_processor.post_process_object_detection(
+ outputs, threshold=0.35, target_sizes=[(image.height, image.width)]
+ )[0]
+
+ expectations = Expectations(
+ {
+ (None, None): [[0.4526, 0.4082]],
+ ("cuda", 8): [0.4524, 0.4074],
+ }
+ )
+ expected_scores = torch.tensor(expectations.get_expectation()).to(torch_device)
+
+ expectations = Expectations(
+ {
+ (None, None): [344.8143, 23.1796, 637.4004, 373.8295],
+ ("cuda", 8): [344.8210, 23.1831, 637.3943, 373.8227],
+ }
+ )
+ expected_slice_boxes = torch.tensor(expectations.get_expectation()).to(torch_device)
+
+ self.assertEqual(len(results["scores"]), 2)
+ torch.testing.assert_close(results["scores"], expected_scores, rtol=1e-3, atol=1e-3)
+ torch.testing.assert_close(results["boxes"][0, :], expected_slice_boxes, rtol=1e-2, atol=1e-2)
+
+ # verify grounded postprocessing
+ expected_labels = ["a cat", "a cat"]
+ results = processor.post_process_grounded_object_detection(
+ outputs=outputs,
+ input_ids=encoding.input_ids,
+ threshold=0.35,
+ text_threshold=0.3,
+ target_sizes=[(image.height, image.width)],
+ )[0]
+
+ torch.testing.assert_close(results["scores"], expected_scores, rtol=1e-3, atol=1e-3)
+ torch.testing.assert_close(results["boxes"][0, :], expected_slice_boxes, rtol=1e-2, atol=1e-2)
+ self.assertListEqual(results["text_labels"], expected_labels)
+
+ @require_torch_accelerator
+ @is_flaky()
+ def test_inference_object_detection_head_equivalence_cpu_accelerator(self):
+ processor = self.default_processor
+ image = prepare_img()
+ text = prepare_text()
+ encoding = processor(images=image, text=text, return_tensors="pt")
+
+ # 1. run model on CPU
+ model = GroundingDinoForObjectDetection.from_pretrained("IDEA-Research/grounding-dino-tiny")
+
+ with torch.no_grad():
+ cpu_outputs = model(**encoding)
+
+ # 2. run model on accelerator
+ model.to(torch_device)
+ encoding = encoding.to(torch_device)
+ with torch.no_grad():
+ gpu_outputs = model(**encoding)
+
+ # 3. assert equivalence
+ for key in cpu_outputs.keys():
+ torch.testing.assert_close(cpu_outputs[key], gpu_outputs[key].cpu(), rtol=1e-3, atol=1e-3)
+
+ expected_logits = torch.tensor(
+ [[-4.8915, -0.1900, -0.2161], [-4.9658, -0.3716, -0.3948], [-5.9596, -3.3763, -3.3103]]
+ )
+ torch.testing.assert_close(cpu_outputs.logits[0, :3, :3], expected_logits, rtol=1e-3, atol=1e-3)
+
+ # assert postprocessing
+ results_cpu = processor.image_processor.post_process_object_detection(
+ cpu_outputs, threshold=0.35, target_sizes=[(image.height, image.width)]
+ )[0]
+
+ result_gpu = processor.image_processor.post_process_object_detection(
+ gpu_outputs, threshold=0.35, target_sizes=[(image.height, image.width)]
+ )[0]
+
+ torch.testing.assert_close(results_cpu["scores"], result_gpu["scores"].cpu(), rtol=1e-3, atol=1e-3)
+ torch.testing.assert_close(results_cpu["boxes"], result_gpu["boxes"].cpu(), rtol=1e-3, atol=1e-3)
+
+ @is_flaky()
+ def test_cross_attention_mask(self):
+ model = GroundingDinoForObjectDetection.from_pretrained("IDEA-Research/grounding-dino-tiny").to(torch_device)
+
+ processor = self.default_processor
+ image = prepare_img()
+ text1 = "a cat."
+ text2 = "a remote control."
+ text_batched = [text1, text2]
+
+ encoding1 = processor(images=image, text=text1, return_tensors="pt").to(torch_device)
+ encoding2 = processor(images=image, text=text2, return_tensors="pt").to(torch_device)
+ # If we batch the text and cross attention masking is working the batched result should be equal to
+ # The single text result
+ encoding_batched = processor(
+ images=[image] * len(text_batched), text=text_batched, padding="longest", return_tensors="pt"
+ ).to(torch_device)
+
+ with torch.no_grad():
+ outputs1 = model(**encoding1)
+ outputs2 = model(**encoding2)
+ outputs_batched = model(**encoding_batched)
+
+ torch.testing.assert_close(outputs1.logits, outputs_batched.logits[:1], rtol=1e-3, atol=1e-3)
+ # For some reason 12 elements are > 1e-3, but the rest are fine
+ self.assertTrue(torch.allclose(outputs2.logits, outputs_batched.logits[1:], atol=1.8e-3))
+
+ def test_grounding_dino_loss(self):
+ ds = load_dataset("EduardoPacheco/aquarium-sample", split="train")
+ image_processor = self.default_processor.image_processor
+ tokenizer = self.default_processor.tokenizer
+ id2label = {0: "fish", 1: "jellyfish", 2: "penguins", 3: "sharks", 4: "puffins", 5: "stingrays", 6: "starfish"}
+ prompt = ". ".join(id2label.values()) + "."
+
+ text_inputs = tokenizer([prompt, prompt], return_tensors="pt")
+ image_inputs = image_processor(images=ds["image"], annotations=ds["annotations"], return_tensors="pt")
+
+ # Passing auxiliary_loss=True to compare with the expected loss
+ model = GroundingDinoForObjectDetection.from_pretrained(
+ "IDEA-Research/grounding-dino-tiny",
+ auxiliary_loss=True,
+ )
+ # Interested in the loss only
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**text_inputs, **image_inputs)
+
+ # Loss differs by CPU and accelerator, also this can be changed in future.
+ expected_loss_dicts = Expectations(
+ {
+ ("xpu", 3): {
+ "loss_ce": torch.tensor(1.1147),
+ "loss_bbox": torch.tensor(0.2031),
+ "loss_giou": torch.tensor(0.5819),
+ "loss_ce_0": torch.tensor(1.1941),
+ "loss_bbox_0": torch.tensor(0.1978),
+ "loss_giou_0": torch.tensor(0.5524),
+ "loss_ce_1": torch.tensor(1.1621),
+ "loss_bbox_1": torch.tensor(0.1909),
+ "loss_giou_1": torch.tensor(0.5892),
+ "loss_ce_2": torch.tensor(1.1641),
+ "loss_bbox_2": torch.tensor(0.1892),
+ "loss_giou_2": torch.tensor(0.5626),
+ "loss_ce_3": torch.tensor(1.1943),
+ "loss_bbox_3": torch.tensor(0.1941),
+ "loss_giou_3": torch.tensor(0.5592),
+ "loss_ce_4": torch.tensor(1.0956),
+ "loss_bbox_4": torch.tensor(0.2037),
+ "loss_giou_4": torch.tensor(0.5813),
+ "loss_ce_enc": torch.tensor(16226.3164),
+ "loss_bbox_enc": torch.tensor(0.3063),
+ "loss_giou_enc": torch.tensor(0.7380),
+ },
+ ("cuda", None): {
+ "loss_ce": torch.tensor(1.1147),
+ "loss_bbox": torch.tensor(0.2031),
+ "loss_giou": torch.tensor(0.5819),
+ "loss_ce_0": torch.tensor(1.1941),
+ "loss_bbox_0": torch.tensor(0.1978),
+ "loss_giou_0": torch.tensor(0.5524),
+ "loss_ce_1": torch.tensor(1.1621),
+ "loss_bbox_1": torch.tensor(0.1909),
+ "loss_giou_1": torch.tensor(0.5892),
+ "loss_ce_2": torch.tensor(1.1641),
+ "loss_bbox_2": torch.tensor(0.1892),
+ "loss_giou_2": torch.tensor(0.5626),
+ "loss_ce_3": torch.tensor(1.1943),
+ "loss_bbox_3": torch.tensor(0.1941),
+ "loss_giou_3": torch.tensor(0.5607),
+ "loss_ce_4": torch.tensor(1.0956),
+ "loss_bbox_4": torch.tensor(0.2008),
+ "loss_giou_4": torch.tensor(0.5836),
+ "loss_ce_enc": torch.tensor(16226.3164),
+ "loss_bbox_enc": torch.tensor(0.3063),
+ "loss_giou_enc": torch.tensor(0.7380),
+ },
+ }
+ ) # fmt: skip
+ expected_loss_dict = expected_loss_dicts.get_expectation()
+
+ expected_loss = torch.tensor(32482.2305)
+
+ for key in expected_loss_dict:
+ torch.testing.assert_close(outputs.loss_dict[key], expected_loss_dict[key], rtol=1e-5, atol=1e-3)
+
+ self.assertTrue(torch.allclose(outputs.loss, expected_loss, atol=1e-3))
diff --git a/transformers/tests/models/grounding_dino/test_processor_grounding_dino.py b/transformers/tests/models/grounding_dino/test_processor_grounding_dino.py
new file mode 100644
index 0000000000000000000000000000000000000000..35b77c39f2ba959ff25b2da96b39b5022dfce44a
--- /dev/null
+++ b/transformers/tests/models/grounding_dino/test_processor_grounding_dino.py
@@ -0,0 +1,296 @@
+# Copyright 2024 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import shutil
+import tempfile
+import unittest
+from typing import Optional
+
+import pytest
+
+from transformers import BertTokenizer, BertTokenizerFast, GroundingDinoProcessor
+from transformers.models.bert.tokenization_bert import VOCAB_FILES_NAMES
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import IMAGE_PROCESSOR_NAME, is_torch_available, is_vision_available
+
+from ...test_processing_common import ProcessorTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers.models.grounding_dino.modeling_grounding_dino import GroundingDinoObjectDetectionOutput
+
+if is_vision_available():
+ from transformers import GroundingDinoImageProcessor
+
+
+@require_torch
+@require_vision
+class GroundingDinoProcessorTest(ProcessorTesterMixin, unittest.TestCase):
+ from_pretrained_id = "IDEA-Research/grounding-dino-base"
+ processor_class = GroundingDinoProcessor
+
+ @classmethod
+ def setUpClass(cls):
+ cls.tmpdirname = tempfile.mkdtemp()
+
+ vocab_tokens = ["[UNK]","[CLS]","[SEP]","[PAD]","[MASK]","want","##want","##ed","wa","un","runn","##ing",",","low","lowest"] # fmt: skip
+ cls.vocab_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ with open(cls.vocab_file, "w", encoding="utf-8") as vocab_writer:
+ vocab_writer.write("".join([x + "\n" for x in vocab_tokens]))
+
+ image_processor_map = {
+ "do_resize": True,
+ "size": None,
+ "do_normalize": True,
+ "image_mean": [0.5, 0.5, 0.5],
+ "image_std": [0.5, 0.5, 0.5],
+ "do_rescale": True,
+ "rescale_factor": 1 / 255,
+ "do_pad": True,
+ }
+ cls.image_processor_file = os.path.join(cls.tmpdirname, IMAGE_PROCESSOR_NAME)
+ with open(cls.image_processor_file, "w", encoding="utf-8") as fp:
+ json.dump(image_processor_map, fp)
+
+ image_processor = GroundingDinoImageProcessor()
+ tokenizer = BertTokenizer.from_pretrained(cls.from_pretrained_id)
+
+ processor = GroundingDinoProcessor(image_processor, tokenizer)
+
+ processor.save_pretrained(cls.tmpdirname)
+
+ cls.batch_size = 7
+ cls.num_queries = 5
+ cls.embed_dim = 5
+ cls.seq_length = 5
+
+ def prepare_text_inputs(self, batch_size: Optional[int] = None, modality: Optional[str] = None):
+ labels = ["a cat", "remote control"]
+ labels_longer = ["a person", "a car", "a dog", "a cat"]
+
+ if batch_size is None:
+ return labels
+
+ if batch_size < 1:
+ raise ValueError("batch_size must be greater than 0")
+
+ if batch_size == 1:
+ return [labels]
+ return [labels, labels_longer] + [labels] * (batch_size - 2)
+
+ @classmethod
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.get_tokenizer with CLIP->Bert
+ def get_tokenizer(cls, **kwargs):
+ return BertTokenizer.from_pretrained(cls.tmpdirname, **kwargs)
+
+ @classmethod
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.get_rust_tokenizer with CLIP->Bert
+ def get_rust_tokenizer(cls, **kwargs):
+ return BertTokenizerFast.from_pretrained(cls.tmpdirname, **kwargs)
+
+ @classmethod
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.get_image_processor with CLIP->GroundingDino
+ def get_image_processor(cls, **kwargs):
+ return GroundingDinoImageProcessor.from_pretrained(cls.tmpdirname, **kwargs)
+
+ @classmethod
+ def tearDownClass(cls):
+ shutil.rmtree(cls.tmpdirname, ignore_errors=True)
+
+ def get_fake_grounding_dino_output(self):
+ torch.manual_seed(42)
+ return GroundingDinoObjectDetectionOutput(
+ pred_boxes=torch.rand(self.batch_size, self.num_queries, 4),
+ logits=torch.rand(self.batch_size, self.num_queries, self.embed_dim),
+ input_ids=self.get_fake_grounding_dino_input_ids(),
+ )
+
+ def get_fake_grounding_dino_input_ids(self):
+ input_ids = torch.tensor([101, 1037, 4937, 1012, 102])
+ return torch.stack([input_ids] * self.batch_size, dim=0)
+
+ def test_post_process_grounded_object_detection(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ grounding_dino_output = self.get_fake_grounding_dino_output()
+
+ post_processed = processor.post_process_grounded_object_detection(grounding_dino_output)
+
+ self.assertEqual(len(post_processed), self.batch_size)
+ self.assertEqual(list(post_processed[0].keys()), ["scores", "boxes", "text_labels", "labels"])
+ self.assertEqual(post_processed[0]["boxes"].shape, (self.num_queries, 4))
+ self.assertEqual(post_processed[0]["scores"].shape, (self.num_queries,))
+
+ expected_scores = torch.tensor([0.7050, 0.7222, 0.7222, 0.6829, 0.7220])
+ torch.testing.assert_close(post_processed[0]["scores"], expected_scores, rtol=1e-4, atol=1e-4)
+
+ expected_box_slice = torch.tensor([0.6908, 0.4354, 1.0737, 1.3947])
+ torch.testing.assert_close(post_processed[0]["boxes"][0], expected_box_slice, rtol=1e-4, atol=1e-4)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_save_load_pretrained_default with CLIP->GroundingDino,GroundingDinoTokenizer->BertTokenizer
+ def test_save_load_pretrained_default(self):
+ tokenizer_slow = self.get_tokenizer()
+ tokenizer_fast = self.get_rust_tokenizer()
+ image_processor = self.get_image_processor()
+
+ with tempfile.TemporaryDirectory() as tmpdir:
+ processor_slow = GroundingDinoProcessor(tokenizer=tokenizer_slow, image_processor=image_processor)
+ processor_slow.save_pretrained(tmpdir)
+ processor_slow = GroundingDinoProcessor.from_pretrained(tmpdir, use_fast=False)
+
+ processor_fast = GroundingDinoProcessor(tokenizer=tokenizer_fast, image_processor=image_processor)
+ processor_fast.save_pretrained(tmpdir)
+ processor_fast = GroundingDinoProcessor.from_pretrained(tmpdir)
+
+ self.assertEqual(processor_slow.tokenizer.get_vocab(), tokenizer_slow.get_vocab())
+ self.assertEqual(processor_fast.tokenizer.get_vocab(), tokenizer_fast.get_vocab())
+ self.assertEqual(tokenizer_slow.get_vocab(), tokenizer_fast.get_vocab())
+ self.assertIsInstance(processor_slow.tokenizer, BertTokenizer)
+ self.assertIsInstance(processor_fast.tokenizer, BertTokenizerFast)
+
+ self.assertEqual(processor_slow.image_processor.to_json_string(), image_processor.to_json_string())
+ self.assertEqual(processor_fast.image_processor.to_json_string(), image_processor.to_json_string())
+ self.assertIsInstance(processor_slow.image_processor, GroundingDinoImageProcessor)
+ self.assertIsInstance(processor_fast.image_processor, GroundingDinoImageProcessor)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_save_load_pretrained_additional_features with CLIP->GroundingDino,GroundingDinoTokenizer->BertTokenizer
+ def test_save_load_pretrained_additional_features(self):
+ with tempfile.TemporaryDirectory() as tmpdir:
+ processor = GroundingDinoProcessor(
+ tokenizer=self.get_tokenizer(), image_processor=self.get_image_processor()
+ )
+ processor.save_pretrained(tmpdir)
+
+ tokenizer_add_kwargs = BertTokenizer.from_pretrained(tmpdir, bos_token="(BOS)", eos_token="(EOS)")
+ image_processor_add_kwargs = GroundingDinoImageProcessor.from_pretrained(
+ tmpdir, do_normalize=False, padding_value=1.0
+ )
+
+ processor = GroundingDinoProcessor.from_pretrained(
+ tmpdir, bos_token="(BOS)", eos_token="(EOS)", do_normalize=False, padding_value=1.0
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, BertTokenizerFast)
+
+ self.assertEqual(processor.image_processor.to_json_string(), image_processor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.image_processor, GroundingDinoImageProcessor)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_image_processor with CLIP->GroundingDino
+ def test_image_processor(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ image_input = self.prepare_image_inputs()
+
+ input_image_proc = image_processor(image_input, return_tensors="np")
+ input_processor = processor(images=image_input, return_tensors="np")
+
+ for key in input_image_proc.keys():
+ self.assertAlmostEqual(input_image_proc[key].sum(), input_processor[key].sum(), delta=1e-2)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_tokenizer with CLIP->GroundingDino
+ def test_tokenizer(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+
+ encoded_processor = processor(text=input_str)
+
+ encoded_tok = tokenizer(input_str)
+
+ for key in encoded_tok.keys():
+ self.assertListEqual(encoded_tok[key], encoded_processor[key])
+
+ def test_processor(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ self.assertListEqual(
+ list(inputs.keys()), ["input_ids", "token_type_ids", "attention_mask", "pixel_values", "pixel_mask"]
+ )
+
+ # test if it raises when no input is passed
+ with pytest.raises(ValueError):
+ processor()
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_tokenizer_decode with CLIP->GroundingDino
+ def test_tokenizer_decode(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ predicted_ids = [[1, 4, 5, 8, 1, 0, 8], [3, 4, 3, 1, 1, 8, 9]]
+
+ decoded_processor = processor.batch_decode(predicted_ids)
+ decoded_tok = tokenizer.batch_decode(predicted_ids)
+
+ self.assertListEqual(decoded_tok, decoded_processor)
+
+ # Copied from tests.models.clip.test_processor_clip.CLIPProcessorTest.test_model_input_names with CLIP->GroundingDino
+ def test_model_input_names(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = GroundingDinoProcessor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ self.assertListEqual(list(inputs.keys()), processor.model_input_names)
+
+ def test_text_preprocessing_equivalence(self):
+ processor = GroundingDinoProcessor.from_pretrained(self.tmpdirname)
+
+ # check for single input
+ formatted_labels = "a cat. a remote control."
+ labels = ["a cat", "a remote control"]
+ inputs1 = processor(text=formatted_labels, return_tensors="pt")
+ inputs2 = processor(text=labels, return_tensors="pt")
+ self.assertTrue(
+ torch.allclose(inputs1["input_ids"], inputs2["input_ids"]),
+ f"Input ids are not equal for single input: {inputs1['input_ids']} != {inputs2['input_ids']}",
+ )
+
+ # check for batched input
+ formatted_labels = ["a cat. a remote control.", "a car. a person."]
+ labels = [["a cat", "a remote control"], ["a car", "a person"]]
+ inputs1 = processor(text=formatted_labels, return_tensors="pt", padding=True)
+ inputs2 = processor(text=labels, return_tensors="pt", padding=True)
+ self.assertTrue(
+ torch.allclose(inputs1["input_ids"], inputs2["input_ids"]),
+ f"Input ids are not equal for batched input: {inputs1['input_ids']} != {inputs2['input_ids']}",
+ )
diff --git a/transformers/tests/models/groupvit/__init__.py b/transformers/tests/models/groupvit/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/groupvit/test_modeling_groupvit.py b/transformers/tests/models/groupvit/test_modeling_groupvit.py
new file mode 100644
index 0000000000000000000000000000000000000000..24e4328ac7ed45ae4c371fb6ffd4300e03881290
--- /dev/null
+++ b/transformers/tests/models/groupvit/test_modeling_groupvit.py
@@ -0,0 +1,724 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch GroupViT model."""
+
+import inspect
+import os
+import random
+import tempfile
+import unittest
+
+import numpy as np
+import requests
+
+from transformers import GroupViTConfig, GroupViTTextConfig, GroupViTVisionConfig
+from transformers.testing_utils import is_flaky, require_torch, require_vision, slow, torch_device
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ ModelTesterMixin,
+ _config_zero_init,
+ floats_tensor,
+ ids_tensor,
+ random_attention_mask,
+)
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import GroupViTModel, GroupViTTextModel, GroupViTVisionModel
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import CLIPProcessor
+
+
+class GroupViTVisionModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ image_size=30,
+ patch_size=2,
+ num_channels=3,
+ is_training=True,
+ hidden_size=32,
+ depths=[6, 3, 3],
+ num_group_tokens=[64, 8, 0],
+ num_output_groups=[64, 8, 8],
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ initializer_range=0.02,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.hidden_size = hidden_size
+ self.depths = depths
+ self.num_hidden_layers = sum(depths)
+ self.expected_num_hidden_layers = len(depths) + 1
+ self.num_group_tokens = num_group_tokens
+ self.num_output_groups = num_output_groups
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ num_patches = (image_size // patch_size) ** 2
+ # no [CLS] token for GroupViT
+ self.seq_length = num_patches
+
+ def prepare_config_and_inputs(self):
+ rng = random.Random(0)
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size], rng=rng)
+ config = self.get_config()
+
+ return config, pixel_values
+
+ def get_config(self):
+ return GroupViTVisionConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ depths=self.depths,
+ num_group_tokens=self.num_group_tokens,
+ num_output_groups=self.num_output_groups,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, pixel_values):
+ model = GroupViTVisionModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(pixel_values)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.num_output_groups[-1], self.hidden_size)
+ )
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class GroupViTVisionModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as GROUPVIT does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (GroupViTVisionModel,) if is_torch_available() else ()
+
+ test_pruning = False
+ test_torchscript = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = GroupViTVisionModelTester(self)
+ self.config_tester = ConfigTester(
+ self, config_class=GroupViTVisionConfig, has_text_modality=False, hidden_size=37
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="GroupViT does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @is_flaky(description="The `index` computed with `max()` in `hard_softmax` is not stable.")
+ def test_batching_equivalence(self):
+ super().test_batching_equivalence()
+
+ def test_model_get_set_embeddings(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ seq_len = getattr(self.model_tester, "seq_length", None)
+
+ expected_num_attention_outputs = sum(g > 0 for g in self.model_tester.num_group_tokens)
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class._from_config(config, attn_implementation="eager")
+ config = model.config
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ # GroupViT returns attention grouping of each stage
+ self.assertEqual(len(attentions), sum(g > 0 for g in self.model_tester.num_group_tokens))
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ # GroupViT returns attention grouping of each stage
+ self.assertEqual(len(attentions), expected_num_attention_outputs)
+
+ out_len = len(outputs)
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ added_hidden_states = 1
+ self.assertEqual(out_len + added_hidden_states, len(outputs))
+
+ self_attentions = outputs.attentions
+
+ # GroupViT returns attention grouping of each stage
+ self.assertEqual(len(self_attentions), expected_num_attention_outputs)
+ for i, self_attn in enumerate(self_attentions):
+ if self_attn is None:
+ continue
+
+ self.assertListEqual(
+ list(self_attentions[i].shape[-2:]),
+ [
+ self.model_tester.num_output_groups[i],
+ self.model_tester.num_output_groups[i - 1] if i > 0 else seq_len,
+ ],
+ )
+
+ @unittest.skip
+ def test_training(self):
+ pass
+
+ @unittest.skip
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ # override since the attention mask from GroupViT is not used to compute loss, thus no grad
+ def test_retain_grad_hidden_states_attentions(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.output_hidden_states = True
+ config.output_attentions = self.has_attentions
+
+ # no need to test all models as different heads yield the same functionality
+ model_class = self.all_model_classes[0]
+ model = model_class(config)
+ model.to(torch_device)
+
+ inputs = self._prepare_for_class(inputs_dict, model_class)
+
+ outputs = model(**inputs)
+
+ output = outputs[0]
+
+ if config.is_encoder_decoder:
+ # Seq2Seq models
+ encoder_hidden_states = outputs.encoder_hidden_states[0]
+ encoder_hidden_states.retain_grad()
+
+ decoder_hidden_states = outputs.decoder_hidden_states[0]
+ decoder_hidden_states.retain_grad()
+
+ if self.has_attentions:
+ encoder_attentions = outputs.encoder_attentions[0]
+ encoder_attentions.retain_grad()
+
+ decoder_attentions = outputs.decoder_attentions[0]
+ decoder_attentions.retain_grad()
+
+ cross_attentions = outputs.cross_attentions[0]
+ cross_attentions.retain_grad()
+
+ output.flatten()[0].backward(retain_graph=True)
+
+ self.assertIsNotNone(encoder_hidden_states.grad)
+ self.assertIsNotNone(decoder_hidden_states.grad)
+
+ if self.has_attentions:
+ self.assertIsNotNone(encoder_attentions.grad)
+ self.assertIsNotNone(decoder_attentions.grad)
+ self.assertIsNotNone(cross_attentions.grad)
+ else:
+ # Encoder-/Decoder-only models
+ hidden_states = outputs.hidden_states[0]
+ hidden_states.retain_grad()
+
+ if self.has_attentions:
+ attentions = outputs.attentions[0]
+ attentions.retain_grad()
+
+ output.flatten()[0].backward(retain_graph=True)
+
+ self.assertIsNotNone(hidden_states.grad)
+
+ if self.has_attentions:
+ self.assertIsNone(attentions.grad)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "nvidia/groupvit-gcc-yfcc"
+ model = GroupViTVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+class GroupViTTextModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ max_position_embeddings=512,
+ initializer_range=0.02,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.max_position_embeddings = max_position_embeddings
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ def prepare_config_and_inputs(self):
+ rng = random.Random(0)
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size, rng=rng)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ if input_mask is not None:
+ batch_size, seq_length = input_mask.shape
+ rnd_start_indices = np.random.randint(1, seq_length - 1, size=(batch_size,))
+ for batch_idx, start_index in enumerate(rnd_start_indices):
+ input_mask[batch_idx, :start_index] = 1
+ input_mask[batch_idx, start_index:] = 0
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask
+
+ def get_config(self):
+ return GroupViTTextConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ max_position_embeddings=self.max_position_embeddings,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, input_ids, input_mask):
+ model = GroupViTTextModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(input_ids, attention_mask=input_mask)
+ result = model(input_ids)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, input_mask = config_and_inputs
+ inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class GroupViTTextModelTest(ModelTesterMixin, unittest.TestCase):
+ all_model_classes = (GroupViTTextModel,) if is_torch_available() else ()
+ test_pruning = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = GroupViTTextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=GroupViTTextConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip
+ def test_training(self):
+ pass
+
+ @unittest.skip
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @unittest.skip(reason="GroupViTTextModel does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "nvidia/groupvit-gcc-yfcc"
+ model = GroupViTTextModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+class GroupViTModelTester:
+ def __init__(self, parent, text_kwargs=None, vision_kwargs=None, is_training=True):
+ if text_kwargs is None:
+ text_kwargs = {}
+ if vision_kwargs is None:
+ vision_kwargs = {}
+
+ self.parent = parent
+ self.text_model_tester = GroupViTTextModelTester(parent, **text_kwargs)
+ self.vision_model_tester = GroupViTVisionModelTester(parent, **vision_kwargs)
+ self.batch_size = self.text_model_tester.batch_size # need bs for batching_equivalence test
+ self.is_training = is_training
+
+ def prepare_config_and_inputs(self):
+ text_config, input_ids, attention_mask = self.text_model_tester.prepare_config_and_inputs()
+ vision_config, pixel_values = self.vision_model_tester.prepare_config_and_inputs()
+
+ config = self.get_config()
+
+ return config, input_ids, attention_mask, pixel_values
+
+ def get_config(self):
+ return GroupViTConfig.from_text_vision_configs(
+ self.text_model_tester.get_config(), self.vision_model_tester.get_config(), projection_dim=64
+ )
+
+ def create_and_check_model(self, config, input_ids, attention_mask, pixel_values):
+ model = GroupViTModel(config).to(torch_device).eval()
+ with torch.no_grad():
+ result = model(input_ids, pixel_values, attention_mask)
+ self.parent.assertEqual(
+ result.logits_per_image.shape, (self.vision_model_tester.batch_size, self.text_model_tester.batch_size)
+ )
+ self.parent.assertEqual(
+ result.logits_per_text.shape, (self.text_model_tester.batch_size, self.vision_model_tester.batch_size)
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, attention_mask, pixel_values = config_and_inputs
+ inputs_dict = {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "pixel_values": pixel_values,
+ "return_loss": True,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class GroupViTModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (GroupViTModel,) if is_torch_available() else ()
+ pipeline_model_mapping = {"feature-extraction": GroupViTModel} if is_torch_available() else {}
+ test_head_masking = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_attention_outputs = False
+
+ def setUp(self):
+ self.model_tester = GroupViTModelTester(self)
+ common_properties = ["projection_dim", "projection_intermediate_dim", "logit_scale_init_value"]
+ self.config_tester = ConfigTester(
+ self, config_class=GroupViTConfig, has_text_modality=False, common_properties=common_properties
+ )
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @is_flaky(description="The `index` computed with `max()` in `hard_softmax` is not stable.")
+ def test_batching_equivalence(self):
+ super().test_batching_equivalence()
+
+ @unittest.skip(reason="hidden_states are tested in individual model tests")
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip(reason="input_embeds are tested in individual model tests")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="tested in individual model tests")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ @unittest.skip(reason="GroupViTModel does not have input/output embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ # override as the `logit_scale` parameter initialization is different for GROUPVIT
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ if param.requires_grad:
+ # check if `logit_scale` is initialized as per the original implementation
+ if name == "logit_scale":
+ self.assertAlmostEqual(
+ param.data.item(),
+ np.log(1 / 0.07),
+ delta=1e-3,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ else:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ def _create_and_check_torchscript(self, config, inputs_dict):
+ if not self.test_torchscript:
+ self.skipTest(reason="test_torchscript is set to False")
+
+ configs_no_init = _config_zero_init(config) # To be sure we have no Nan
+ configs_no_init.torchscript = True
+ configs_no_init.return_dict = False
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ model.to(torch_device)
+ model.eval()
+
+ try:
+ input_ids = inputs_dict["input_ids"]
+ pixel_values = inputs_dict["pixel_values"] # GROUPVIT needs pixel_values
+ traced_model = torch.jit.trace(model, (input_ids, pixel_values))
+ except RuntimeError:
+ self.fail("Couldn't trace module.")
+
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ pt_file_name = os.path.join(tmp_dir_name, "traced_model.pt")
+
+ try:
+ torch.jit.save(traced_model, pt_file_name)
+ except Exception:
+ self.fail("Couldn't save module.")
+
+ try:
+ loaded_model = torch.jit.load(pt_file_name)
+ except Exception:
+ self.fail("Couldn't load module.")
+
+ model.to(torch_device)
+ model.eval()
+
+ loaded_model.to(torch_device)
+ loaded_model.eval()
+
+ model_state_dict = model.state_dict()
+ loaded_model_state_dict = loaded_model.state_dict()
+
+ non_persistent_buffers = {}
+ for key in loaded_model_state_dict.keys():
+ if key not in model_state_dict.keys():
+ non_persistent_buffers[key] = loaded_model_state_dict[key]
+
+ loaded_model_state_dict = {
+ key: value for key, value in loaded_model_state_dict.items() if key not in non_persistent_buffers
+ }
+
+ self.assertEqual(set(model_state_dict.keys()), set(loaded_model_state_dict.keys()))
+
+ model_buffers = list(model.buffers())
+ for non_persistent_buffer in non_persistent_buffers.values():
+ found_buffer = False
+ for i, model_buffer in enumerate(model_buffers):
+ if torch.equal(non_persistent_buffer, model_buffer):
+ found_buffer = True
+ break
+
+ self.assertTrue(found_buffer)
+ model_buffers.pop(i)
+
+ models_equal = True
+ for layer_name, p1 in model_state_dict.items():
+ p2 = loaded_model_state_dict[layer_name]
+ if p1.data.ne(p2.data).sum() > 0:
+ models_equal = False
+
+ self.assertTrue(models_equal)
+
+ def test_load_vision_text_config(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # Save GroupViTConfig and check if we can load GroupViTVisionConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ vision_config = GroupViTVisionConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.vision_config.to_dict(), vision_config.to_dict())
+
+ # Save GroupViTConfig and check if we can load GroupViTTextConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ text_config = GroupViTTextConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.text_config.to_dict(), text_config.to_dict())
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "nvidia/groupvit-gcc-yfcc"
+ model = GroupViTModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "http://images.cocodataset.org/val2017/000000039769.jpg"
+ im = Image.open(requests.get(url, stream=True).raw)
+ return im
+
+
+@require_vision
+@require_torch
+class GroupViTModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_inference(self):
+ model_name = "nvidia/groupvit-gcc-yfcc"
+ model = GroupViTModel.from_pretrained(model_name)
+ processor = CLIPProcessor.from_pretrained(model_name)
+
+ image = prepare_img()
+ inputs = processor(
+ text=["a photo of a cat", "a photo of a dog"], images=image, padding=True, return_tensors="pt"
+ )
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ self.assertEqual(
+ outputs.logits_per_image.shape,
+ torch.Size((inputs.pixel_values.shape[0], inputs.input_ids.shape[0])),
+ )
+ self.assertEqual(
+ outputs.logits_per_text.shape,
+ torch.Size((inputs.input_ids.shape[0], inputs.pixel_values.shape[0])),
+ )
+
+ expected_logits = torch.tensor([[13.3523, 6.3629]])
+
+ torch.testing.assert_close(outputs.logits_per_image, expected_logits, rtol=1e-3, atol=1e-3)
diff --git a/transformers/tests/models/herbert/__init__.py b/transformers/tests/models/herbert/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/herbert/test_tokenization_herbert.py b/transformers/tests/models/herbert/test_tokenization_herbert.py
new file mode 100644
index 0000000000000000000000000000000000000000..6bd95000d6200f2d5172f14172d495a51ae4a44a
--- /dev/null
+++ b/transformers/tests/models/herbert/test_tokenization_herbert.py
@@ -0,0 +1,141 @@
+# Copyright 2018 The Google AI Language Team Authors, Allegro.pl and The HuggingFace Inc. team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import json
+import os
+import unittest
+
+from transformers import HerbertTokenizer, HerbertTokenizerFast
+from transformers.models.herbert.tokenization_herbert import VOCAB_FILES_NAMES
+from transformers.testing_utils import get_tests_dir, require_sacremoses, require_tokenizers, slow
+
+from ...test_tokenization_common import TokenizerTesterMixin
+
+
+@require_sacremoses
+@require_tokenizers
+class HerbertTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "allegro/herbert-base-cased"
+ tokenizer_class = HerbertTokenizer
+ rust_tokenizer_class = HerbertTokenizerFast
+ test_rust_tokenizer = True
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ # Use a simpler test file without japanese/chinese characters
+ with open(f"{get_tests_dir()}/fixtures/sample_text_no_unicode.txt", encoding="utf-8") as f_data:
+ cls._data = f_data.read().replace("\n\n", "\n").strip()
+
+ vocab = [
+ "",
+ "",
+ "l",
+ "o",
+ "w",
+ "e",
+ "r",
+ "s",
+ "t",
+ "i",
+ "d",
+ "n",
+ "w",
+ "r",
+ "t",
+ "lo",
+ "low",
+ "er",
+ "low",
+ "lowest",
+ "newer",
+ "wider",
+ ",",
+ "",
+ ]
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+ merges = ["l o 123", "lo w 1456", "e r 1789", ""]
+
+ cls.vocab_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ cls.merges_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["merges_file"])
+ with open(cls.vocab_file, "w") as fp:
+ fp.write(json.dumps(vocab_tokens))
+ with open(cls.merges_file, "w") as fp:
+ fp.write("\n".join(merges))
+
+ def get_input_output_texts(self, tokenizer):
+ input_text = "lower newer"
+ output_text = "lower newer"
+ return input_text, output_text
+
+ def test_full_tokenizer(self):
+ tokenizer = self.tokenizer_class(vocab_file=self.vocab_file, merges_file=self.merges_file)
+
+ text = "lower"
+ bpe_tokens = ["low", "er"]
+ tokens = tokenizer.tokenize(text)
+ self.assertListEqual(tokens, bpe_tokens)
+
+ input_tokens = tokens + [""]
+ input_bpe_tokens = [16, 17, 23]
+ self.assertListEqual(tokenizer.convert_tokens_to_ids(input_tokens), input_bpe_tokens)
+
+ def test_rust_and_python_full_tokenizers(self):
+ if not self.test_rust_tokenizer:
+ self.skipTest(reason="test_rust_tokenizer is set to False")
+
+ tokenizer = self.get_tokenizer()
+ rust_tokenizer = self.get_rust_tokenizer()
+
+ sequence = "lower,newer"
+
+ tokens = tokenizer.tokenize(sequence)
+ rust_tokens = rust_tokenizer.tokenize(sequence)
+ self.assertListEqual(tokens, rust_tokens)
+
+ ids = tokenizer.encode(sequence, add_special_tokens=False)
+ rust_ids = rust_tokenizer.encode(sequence, add_special_tokens=False)
+ self.assertListEqual(ids, rust_ids)
+
+ rust_tokenizer = self.get_rust_tokenizer()
+ ids = tokenizer.encode(sequence)
+ rust_ids = rust_tokenizer.encode(sequence)
+ self.assertListEqual(ids, rust_ids)
+
+ @slow
+ def test_sequence_builders(self):
+ tokenizer = self.tokenizer_class.from_pretrained("allegro/herbert-base-cased")
+
+ text = tokenizer.encode("konstruowanie sekwencji", add_special_tokens=False)
+ text_2 = tokenizer.encode("konstruowanie wielu sekwencji", add_special_tokens=False)
+
+ encoded_sentence = tokenizer.build_inputs_with_special_tokens(text)
+ encoded_pair = tokenizer.build_inputs_with_special_tokens(text, text_2)
+
+ assert encoded_sentence == [0] + text + [2]
+ assert encoded_pair == [0] + text + [2] + text_2 + [2]
+
+ @unittest.skip(
+ "Test passes if run individually but not with the full tests (internal state of the tokenizer is modified). Will fix later"
+ )
+ def test_training_new_tokenizer_with_special_tokens_change(self):
+ pass
+
+ @unittest.skip(
+ "Test passes if run individually but not with the full tests (internal state of the tokenizer is modified). Will fix later"
+ )
+ def test_training_new_tokenizer(self):
+ pass
diff --git a/transformers/tests/models/hgnet_v2/__init__.py b/transformers/tests/models/hgnet_v2/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/hgnet_v2/test_modeling_hgnet_v2.py b/transformers/tests/models/hgnet_v2/test_modeling_hgnet_v2.py
new file mode 100644
index 0000000000000000000000000000000000000000..2dad713308b47353f7da0a103b46116c43ec414d
--- /dev/null
+++ b/transformers/tests/models/hgnet_v2/test_modeling_hgnet_v2.py
@@ -0,0 +1,286 @@
+# coding=utf-8
+# Copyright 2025 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import unittest
+
+import torch
+from torch import nn
+
+from transformers import HGNetV2Config
+from transformers.testing_utils import require_torch, torch_device
+from transformers.utils.import_utils import is_torch_available
+
+from ...test_backbone_common import BackboneTesterMixin
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ from transformers import HGNetV2Backbone, HGNetV2ForImageClassification
+
+
+class HGNetV2ModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=3,
+ image_size=32,
+ num_channels=3,
+ embeddings_size=10,
+ hidden_sizes=[64, 128, 256, 512],
+ stage_in_channels=[16, 64, 128, 256],
+ stage_mid_channels=[16, 32, 64, 128],
+ stage_out_channels=[64, 128, 256, 512],
+ stage_num_blocks=[1, 1, 2, 1],
+ stage_downsample=[False, True, True, True],
+ stage_light_block=[False, False, True, True],
+ stage_kernel_size=[3, 3, 5, 5],
+ stage_numb_of_layers=[3, 3, 3, 3],
+ stem_channels=[3, 16, 16],
+ depths=[1, 1, 2, 1],
+ is_training=True,
+ use_labels=True,
+ hidden_act="relu",
+ num_labels=3,
+ scope=None,
+ out_features=["stage2", "stage3", "stage4"],
+ out_indices=[2, 3, 4],
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.num_channels = num_channels
+ self.embeddings_size = embeddings_size
+ self.hidden_sizes = hidden_sizes
+ self.stage_in_channels = stage_in_channels
+ self.stage_mid_channels = stage_mid_channels
+ self.stage_out_channels = stage_out_channels
+ self.stage_num_blocks = stage_num_blocks
+ self.stage_downsample = stage_downsample
+ self.stage_light_block = stage_light_block
+ self.stage_kernel_size = stage_kernel_size
+ self.stage_numb_of_layers = stage_numb_of_layers
+ self.stem_channels = stem_channels
+ self.depths = depths
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.hidden_act = hidden_act
+ self.num_labels = num_labels
+ self.scope = scope
+ self.num_stages = len(hidden_sizes)
+ self.out_features = out_features
+ self.out_indices = out_indices
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.num_labels)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return HGNetV2Config(
+ num_channels=self.num_channels,
+ embeddings_size=self.embeddings_size,
+ hidden_sizes=self.hidden_sizes,
+ stage_in_channels=self.stage_in_channels,
+ stage_mid_channels=self.stage_mid_channels,
+ stage_out_channels=self.stage_out_channels,
+ stage_num_blocks=self.stage_num_blocks,
+ stage_downsample=self.stage_downsample,
+ stage_light_block=self.stage_light_block,
+ stage_kernel_size=self.stage_kernel_size,
+ stage_numb_of_layers=self.stage_numb_of_layers,
+ stem_channels=self.stem_channels,
+ depths=self.depths,
+ hidden_act=self.hidden_act,
+ num_labels=self.num_labels,
+ out_features=self.out_features,
+ out_indices=self.out_indices,
+ )
+
+ def create_and_check_backbone(self, config, pixel_values, labels):
+ model = HGNetV2Backbone(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+
+ # verify feature maps
+ self.parent.assertEqual(len(result.feature_maps), len(config.out_features))
+ self.parent.assertListEqual(list(result.feature_maps[0].shape), [self.batch_size, self.hidden_sizes[1], 4, 4])
+
+ # verify channels
+ self.parent.assertEqual(len(model.channels), len(config.out_features))
+ self.parent.assertListEqual(model.channels, config.hidden_sizes[1:])
+
+ # verify backbone works with out_features=None
+ config.out_features = None
+ model = HGNetV2Backbone(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+
+ # verify feature maps
+ self.parent.assertEqual(len(result.feature_maps), 1)
+ self.parent.assertListEqual(list(result.feature_maps[0].shape), [self.batch_size, self.hidden_sizes[-1], 1, 1])
+
+ # verify channels
+ self.parent.assertEqual(len(model.channels), 1)
+ self.parent.assertListEqual(model.channels, [config.hidden_sizes[-1]])
+
+ def create_and_check_for_image_classification(self, config, pixel_values, labels):
+ config.num_labels = self.num_labels
+ model = HGNetV2ForImageClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values, labels=labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values, labels = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class RTDetrResNetBackboneTest(BackboneTesterMixin, unittest.TestCase):
+ all_model_classes = (HGNetV2Backbone,) if is_torch_available() else ()
+ has_attentions = False
+ config_class = HGNetV2Config
+
+ def setUp(self):
+ self.model_tester = HGNetV2ModelTester(self)
+
+
+@require_torch
+class HGNetV2ForImageClassificationTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some tests of test_modeling_common.py, as TextNet does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (HGNetV2ForImageClassification, HGNetV2Backbone) if is_torch_available() else ()
+ pipeline_model_mapping = {"image-classification": HGNetV2ForImageClassification} if is_torch_available() else {}
+
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ test_torch_exportable = True
+ has_attentions = False
+
+ def setUp(self):
+ self.model_tester = HGNetV2ModelTester(self)
+
+ @unittest.skip(reason="Does not work on the tiny model.")
+ def test_model_parallelism(self):
+ super().test_model_parallelism()
+
+ @unittest.skip(reason="HGNetV2 does not output attentions")
+ def test_attention_outputs(self):
+ pass
+
+ @unittest.skip(reason="HGNetV2 does not have input/output embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ @unittest.skip(reason="HGNetV2 does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="HGNetV2 does not support input and output embeddings")
+ def test_model_common_attributes(self):
+ pass
+
+ @unittest.skip(reason="HGNetV2 does not have a model")
+ def test_model(self):
+ pass
+
+ @unittest.skip(reason="Not relevant for the model")
+ def test_can_init_all_missing_weights(self):
+ pass
+
+ def test_backbone(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_backbone(*config_and_inputs)
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config=config)
+ for name, module in model.named_modules():
+ if isinstance(module, (nn.BatchNorm2d, nn.GroupNorm)):
+ self.assertTrue(
+ torch.all(module.weight == 1),
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ self.assertTrue(
+ torch.all(module.bias == 0),
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.encoder_hidden_states if config.is_encoder_decoder else outputs.hidden_states
+
+ self.assertEqual(len(hidden_states), self.model_tester.num_stages + 1)
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [self.model_tester.image_size // 4, self.model_tester.image_size // 4],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ layers_type = ["preactivation", "bottleneck"]
+ for model_class in self.all_model_classes:
+ for layer_type in layers_type:
+ config.layer_type = layer_type
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ @unittest.skip(reason="Retain_grad is not supposed to be tested")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ @unittest.skip(reason="TextNet does not use feedforward chunking")
+ def test_feed_forward_chunking(self):
+ pass
+
+ def test_for_image_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_image_classification(*config_and_inputs)
+
+ @unittest.skip(reason="HGNetV2 does not use model")
+ def test_model_from_pretrained(self):
+ pass
diff --git a/transformers/tests/models/hiera/__init__.py b/transformers/tests/models/hiera/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/hiera/test_modeling_hiera.py b/transformers/tests/models/hiera/test_modeling_hiera.py
new file mode 100644
index 0000000000000000000000000000000000000000..1e3ed8e7952273679f3ead14ca106b34408d8bb4
--- /dev/null
+++ b/transformers/tests/models/hiera/test_modeling_hiera.py
@@ -0,0 +1,634 @@
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Hiera model."""
+
+import math
+import unittest
+
+from transformers import HieraConfig
+from transformers.testing_utils import (
+ require_torch,
+ require_vision,
+ slow,
+ torch_device,
+)
+from transformers.utils import (
+ cached_property,
+ is_torch_available,
+ is_vision_available,
+)
+
+from ...test_backbone_common import BackboneTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import HieraBackbone, HieraForImageClassification, HieraForPreTraining, HieraModel
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import AutoImageProcessor
+
+
+class HieraModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ image_size=[64, 64],
+ mlp_ratio=1.0,
+ num_channels=3,
+ depths=[1, 1, 1, 1],
+ patch_stride=[4, 4],
+ patch_size=[7, 7],
+ patch_padding=[3, 3],
+ masked_unit_size=[8, 8],
+ num_heads=[1, 1, 1, 1],
+ embed_dim_multiplier=2.0,
+ is_training=True,
+ use_labels=True,
+ embed_dim=8,
+ hidden_act="gelu",
+ decoder_hidden_size=2,
+ decoder_depth=1,
+ decoder_num_heads=1,
+ initializer_range=0.02,
+ scope=None,
+ type_sequence_label_size=10,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.mlp_ratio = mlp_ratio
+ self.num_channels = num_channels
+ self.depths = depths
+ self.patch_stride = patch_stride
+ self.patch_size = patch_size
+ self.patch_padding = patch_padding
+ self.masked_unit_size = masked_unit_size
+ self.num_heads = num_heads
+ self.embed_dim_multiplier = embed_dim_multiplier
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.embed_dim = embed_dim
+ self.hidden_act = hidden_act
+ self.decoder_hidden_size = decoder_hidden_size
+ self.decoder_depth = decoder_depth
+ self.decoder_num_heads = decoder_num_heads
+ self.initializer_range = initializer_range
+ self.scope = scope
+ self.type_sequence_label_size = type_sequence_label_size
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size[0], self.image_size[1]])
+
+ labels = None
+ if self.use_labels:
+ labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+
+ config = self.get_config()
+
+ return config, pixel_values, labels
+
+ def get_config(self):
+ return HieraConfig(
+ embed_dim=self.embed_dim,
+ image_size=self.image_size,
+ patch_stride=self.patch_stride,
+ patch_size=self.patch_size,
+ patch_padding=self.patch_padding,
+ masked_unit_size=self.masked_unit_size,
+ mlp_ratio=self.mlp_ratio,
+ num_channels=self.num_channels,
+ depths=self.depths,
+ num_heads=self.num_heads,
+ embed_dim_multiplier=self.embed_dim_multiplier,
+ hidden_act=self.hidden_act,
+ decoder_hidden_size=self.decoder_hidden_size,
+ decoder_depth=self.decoder_depth,
+ decoder_num_heads=self.decoder_num_heads,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, pixel_values, labels):
+ model = HieraModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+
+ tokens_spatial_shape = [i // s for i, s in zip(self.image_size, config.patch_stride)]
+ expected_seq_len = math.prod(tokens_spatial_shape) // math.prod(config.query_stride) ** (config.num_query_pool)
+ expected_dim = int(config.embed_dim * config.embed_dim_multiplier ** (len(config.depths) - 1))
+
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, expected_seq_len, expected_dim))
+
+ def create_and_check_backbone(self, config, pixel_values, labels):
+ model = HieraBackbone(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+
+ # verify hidden states
+ self.parent.assertEqual(len(result.feature_maps), len(config.out_features))
+ num_patches = config.image_size[0] // config.patch_stride[0] // config.masked_unit_size[0]
+ self.parent.assertListEqual(
+ list(result.feature_maps[0].shape), [self.batch_size, model.channels[0], num_patches, num_patches]
+ )
+
+ # verify channels
+ self.parent.assertEqual(len(model.channels), len(config.out_features))
+
+ # verify backbone works with out_features=None
+ config.out_features = None
+ model = HieraBackbone(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+
+ # verify feature maps
+ self.parent.assertEqual(len(result.feature_maps), 1)
+ self.parent.assertListEqual(
+ list(result.feature_maps[0].shape), [self.batch_size, model.channels[-1], num_patches, num_patches]
+ )
+
+ # verify channels
+ self.parent.assertEqual(len(model.channels), 1)
+
+ def create_and_check_for_pretraining(self, config, pixel_values, labels):
+ model = HieraForPreTraining(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values)
+ pred_stride = config.patch_stride[-1] * (config.query_stride[-1] ** config.num_query_pool)
+ num_patches = self.image_size[0] // pred_stride
+ self.parent.assertEqual(
+ result.logits.shape, (self.batch_size, num_patches**2, self.num_channels * pred_stride**2)
+ )
+
+ # test greyscale images
+ config.num_channels = 1
+ model = HieraForPreTraining(config)
+ model.to(torch_device)
+ model.eval()
+
+ pixel_values = floats_tensor([self.batch_size, 1, self.image_size[0], self.image_size[0]])
+ result = model(pixel_values)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, num_patches**2, pred_stride**2))
+
+ def create_and_check_for_image_classification(self, config, pixel_values, labels):
+ config.num_labels = self.type_sequence_label_size
+ model = HieraForImageClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(pixel_values, labels=labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
+
+ # test greyscale images
+ config.num_channels = 1
+ model = HieraForImageClassification(config)
+ model.to(torch_device)
+ model.eval()
+
+ pixel_values = floats_tensor([self.batch_size, 1, self.image_size[0], self.image_size[0]])
+ result = model(pixel_values)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ pixel_values,
+ labels,
+ ) = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class HieraModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as Hiera does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (
+ (
+ HieraModel,
+ HieraBackbone,
+ HieraForImageClassification,
+ HieraForPreTraining,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {"image-feature-extraction": HieraModel, "image-classification": HieraForImageClassification}
+ if is_torch_available()
+ else {}
+ )
+ fx_compatible = True
+
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+ test_torch_exportable = True
+
+ def setUp(self):
+ self.model_tester = HieraModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=HieraConfig, has_text_modality=False)
+
+ def test_config(self):
+ self.config_tester.create_and_test_config_to_json_string()
+ self.config_tester.create_and_test_config_to_json_file()
+ self.config_tester.create_and_test_config_from_and_save_pretrained()
+ self.config_tester.create_and_test_config_with_num_labels()
+ self.config_tester.check_config_can_be_init_without_params()
+ self.config_tester.check_config_arguments_init()
+
+ def test_batching_equivalence(self, atol=3e-4, rtol=3e-4):
+ super().test_batching_equivalence(atol=atol, rtol=rtol)
+
+ # Overriding as Hiera `get_input_embeddings` returns HieraPatchEmbeddings
+ def test_model_get_set_embeddings(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ # Overriding as attention shape depends on patch_stride and mask_unit_size
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class._from_config(config, attn_implementation="eager")
+ config = model.config
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ expected_num_attentions = len(self.model_tester.depths)
+ self.assertEqual(len(attentions), expected_num_attentions)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ seq_len = math.prod([i // s for i, s in zip(config.image_size, config.patch_stride)])
+ mask_unit_area = math.prod(config.masked_unit_size)
+ num_windows = seq_len // mask_unit_area
+ if model_class.__name__ == "HieraForPreTraining":
+ num_windows = int(num_windows * (1 - config.mask_ratio))
+ seq_len = int(num_windows * mask_unit_area)
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.attentions
+ self.assertEqual(len(attentions), expected_num_attentions)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-4:]),
+ [self.model_tester.num_heads[0], num_windows, mask_unit_area, seq_len // num_windows],
+ )
+ out_len = len(outputs)
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ # also another +1 for reshaped_hidden_states
+ added_hidden_states = 1 if model_class.__name__ == "HieraBackbone" else 2
+ self.assertEqual(out_len + added_hidden_states, len(outputs))
+
+ self_attentions = outputs.attentions
+
+ self.assertEqual(len(self_attentions), expected_num_attentions)
+
+ self.assertListEqual(
+ list(self_attentions[0].shape[-4:]),
+ [self.model_tester.num_heads[0], num_windows, mask_unit_area, seq_len // num_windows],
+ )
+
+ # Overriding as attention shape depends on patch_stride and mask_unit_size
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class, image_size):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.hidden_states
+
+ expected_num_layers = getattr(
+ self.model_tester, "expected_num_hidden_layers", len(self.model_tester.depths) + 1
+ )
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ # Hiera has a different seq_length
+ patch_size = config.patch_stride
+
+ num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
+ if model_class.__name__ == "HieraForPreTraining":
+ mask_unit_area = math.prod(config.masked_unit_size)
+ num_windows = num_patches // mask_unit_area
+ num_windows = int(num_windows * (1 - config.mask_ratio))
+ num_patches = int(num_windows * mask_unit_area)
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [num_patches, self.model_tester.embed_dim],
+ )
+
+ if not model_class.__name__ == "HieraBackbone":
+ reshaped_hidden_states = outputs.reshaped_hidden_states
+ self.assertEqual(len(reshaped_hidden_states), expected_num_layers)
+
+ batch_size = reshaped_hidden_states[0].shape[0]
+ num_channels = reshaped_hidden_states[0].shape[-1]
+
+ reshaped_hidden_states = reshaped_hidden_states[0].view(batch_size, -1, num_channels)
+ self.assertListEqual(
+ list(reshaped_hidden_states.shape[-2:]),
+ [num_patches, self.model_tester.embed_dim],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ image_size = self.model_tester.image_size
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class, image_size)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class, image_size)
+
+ # Overriding since HieraForPreTraining outputs bool_masked_pos which has to be converted to float in the msg
+ def test_model_outputs_equivalence(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ def set_nan_tensor_to_zero(t):
+ t[t != t] = 0
+ return t
+
+ def check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs={}):
+ with torch.no_grad():
+ tuple_output = model(**tuple_inputs, return_dict=False, **additional_kwargs)
+ dict_output = model(**dict_inputs, return_dict=True, **additional_kwargs).to_tuple()
+
+ def recursive_check(tuple_object, dict_object):
+ if isinstance(tuple_object, (list, tuple)):
+ for tuple_iterable_value, dict_iterable_value in zip(tuple_object, dict_object):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif isinstance(tuple_object, dict):
+ for tuple_iterable_value, dict_iterable_value in zip(
+ tuple_object.values(), dict_object.values()
+ ):
+ recursive_check(tuple_iterable_value, dict_iterable_value)
+ elif tuple_object is None:
+ return
+ else:
+ self.assertTrue(
+ torch.allclose(
+ set_nan_tensor_to_zero(tuple_object), set_nan_tensor_to_zero(dict_object), atol=1e-5
+ ),
+ msg=(
+ "Tuple and dict output are not equal. Difference:"
+ f" {torch.max(torch.abs(tuple_object.float() - dict_object.float()))}. Tuple has `nan`:"
+ f" {torch.isnan(tuple_object).any()} and `inf`: {torch.isinf(tuple_object)}. Dict has"
+ f" `nan`: {torch.isnan(dict_object).any()} and `inf`: {torch.isinf(dict_object)}."
+ ),
+ )
+
+ recursive_check(tuple_output, dict_output)
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ additional_kwargs = {}
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ additional_kwargs["output_hidden_states"] = True
+ check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs)
+
+ if self.has_attentions:
+ # Removing "output_hidden_states"
+ del additional_kwargs["output_hidden_states"]
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class)
+ additional_kwargs["output_attentions"] = True
+ check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs)
+
+ tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
+ additional_kwargs["output_hidden_states"] = True
+ check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs)
+
+ @unittest.skip(reason="Hiera Transformer does not use feedforward chunking")
+ def test_feed_forward_chunking(self):
+ pass
+
+ @unittest.skip(reason="Hiera does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_common_attributes(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_backbone(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_backbone(*config_and_inputs)
+
+ def test_for_pretraining(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_pretraining(*config_and_inputs)
+
+ def test_for_image_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_image_classification(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ for model_name in ["facebook/hiera-tiny-224-hf"]:
+ model = HieraModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+@require_vision
+class HieraModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_image_processor(self):
+ return AutoImageProcessor.from_pretrained("facebook/hiera-tiny-224-in1k-hf") if is_vision_available() else None
+
+ @slow
+ def test_inference_image_classification_head(self):
+ model = HieraForImageClassification.from_pretrained("facebook/hiera-tiny-224-in1k-hf").to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ expected_pixel_values = torch.tensor(
+ [
+ [[0.2967, 0.4679, 0.4508], [0.3309, 0.4337, 0.3309], [0.3309, 0.3823, 0.3309]],
+ [[-1.5455, -1.4930, -1.5455], [-1.5280, -1.4755, -1.5980], [-1.5630, -1.5280, -1.4755]],
+ [[-0.6367, -0.4973, -0.5321], [-0.7936, -0.6715, -0.6715], [-0.8284, -0.7413, -0.5670]],
+ ]
+ ).to(torch_device)
+
+ torch.testing.assert_close(inputs.pixel_values[0, :3, :3, :3], expected_pixel_values, rtol=1e-4, atol=1e-4)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 1000))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor([[0.8028, 0.2409, -0.2254, -0.3712, -0.2848]]).to(torch_device)
+
+ torch.testing.assert_close(outputs.logits[0, :5], expected_slice, rtol=1e-4, atol=1e-4)
+
+ def test_inference_interpolate_pos_encoding(self):
+ model = HieraModel.from_pretrained("facebook/hiera-tiny-224-hf").to(torch_device)
+
+ image_processor = AutoImageProcessor.from_pretrained(
+ "facebook/hiera-tiny-224-hf", size={"shortest_edge": 448}, crop_size={"height": 448, "width": 448}
+ )
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt")
+ pixel_values = inputs.pixel_values.to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(pixel_values, interpolate_pos_encoding=True)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 196, 768))
+ self.assertEqual(outputs.last_hidden_state.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[1.7853, 0.0690, 0.3177], [2.6853, -0.2334, 0.0889], [1.5445, -0.1515, -0.0300]]
+ ).to(torch_device)
+
+ torch.testing.assert_close(outputs.last_hidden_state[0, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
+
+ @slow
+ def test_inference_for_pretraining(self):
+ # make random mask reproducible
+ torch.manual_seed(2)
+
+ model = HieraForPreTraining.from_pretrained("facebook/hiera-tiny-224-mae-hf").to(torch_device)
+ image_processor = self.default_image_processor
+
+ image = prepare_img()
+ inputs = image_processor(images=image, return_tensors="pt").to(torch_device)
+
+ config = model.config
+ mask_spatial_shape = [
+ i // s // ms for i, s, ms in zip(config.image_size, config.patch_stride, config.masked_unit_size)
+ ]
+ num_windows = math.prod(mask_spatial_shape)
+ noise = torch.rand(1, num_windows).to(torch_device)
+
+ # forward pass
+ with torch.no_grad():
+ outputs = model(**inputs, noise=noise)
+
+ # verify the logits
+ expected_shape = torch.Size((1, 196, 768))
+ self.assertEqual(outputs.logits.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [
+ [1.6407, 1.6506, 1.6541, 1.6617, 1.6703],
+ [1.9730, 1.9842, 1.9848, 1.9896, 1.9947],
+ [1.5949, 1.8262, 1.2602, 1.4801, 1.4448],
+ [1.2341, 1.7907, 0.8618, 1.5202, 1.4523],
+ [2.0140, 1.9846, 1.9434, 1.9019, 1.8648],
+ ]
+ )
+
+ torch.testing.assert_close(outputs.logits[0, :5, :5], expected_slice.to(torch_device), rtol=1e-4, atol=1e-4)
+
+
+@require_torch
+class HieraBackboneTest(unittest.TestCase, BackboneTesterMixin):
+ all_model_classes = (HieraBackbone,) if is_torch_available() else ()
+ config_class = HieraConfig
+
+ def setUp(self):
+ self.model_tester = HieraModelTester(self)
diff --git a/transformers/tests/models/hubert/__init__.py b/transformers/tests/models/hubert/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/hubert/test_modeling_hubert.py b/transformers/tests/models/hubert/test_modeling_hubert.py
new file mode 100644
index 0000000000000000000000000000000000000000..904a04e1f9a446464952787f00384474544c3c19
--- /dev/null
+++ b/transformers/tests/models/hubert/test_modeling_hubert.py
@@ -0,0 +1,985 @@
+# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Hubert model."""
+
+import math
+import os
+import pickle
+import tempfile
+import unittest
+
+import pytest
+
+from transformers import HubertConfig, is_torch_available
+from transformers.testing_utils import require_torch, require_torchcodec, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ ModelTesterMixin,
+ _config_zero_init,
+ floats_tensor,
+ ids_tensor,
+ random_attention_mask,
+)
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ HubertForCTC,
+ HubertForSequenceClassification,
+ HubertModel,
+ Wav2Vec2FeatureExtractor,
+ Wav2Vec2Processor,
+ )
+ from transformers.models.hubert.modeling_hubert import _compute_mask_indices
+
+from transformers.utils.fx import symbolic_trace
+
+
+class HubertModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=1024, # speech is longer
+ is_training=False,
+ hidden_size=16,
+ feat_extract_norm="group",
+ feat_extract_dropout=0.0,
+ feat_extract_activation="gelu",
+ conv_dim=(32, 32, 32),
+ conv_stride=(4, 4, 4),
+ conv_kernel=(8, 8, 8),
+ conv_bias=False,
+ num_conv_pos_embeddings=16,
+ num_conv_pos_embedding_groups=2,
+ num_hidden_layers=2,
+ num_attention_heads=2,
+ hidden_dropout_prob=0.1, # this is most likely not correctly set yet
+ intermediate_size=20,
+ layer_norm_eps=1e-5,
+ hidden_act="gelu",
+ initializer_range=0.02,
+ vocab_size=32,
+ do_stable_layer_norm=False,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.hidden_size = hidden_size
+ self.feat_extract_norm = feat_extract_norm
+ self.feat_extract_dropout = feat_extract_dropout
+ self.feat_extract_activation = feat_extract_activation
+ self.conv_dim = conv_dim
+ self.conv_stride = conv_stride
+ self.conv_kernel = conv_kernel
+ self.conv_bias = conv_bias
+ self.num_conv_pos_embeddings = num_conv_pos_embeddings
+ self.num_conv_pos_embedding_groups = num_conv_pos_embedding_groups
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.intermediate_size = intermediate_size
+ self.layer_norm_eps = layer_norm_eps
+ self.hidden_act = hidden_act
+ self.initializer_range = initializer_range
+ self.vocab_size = vocab_size
+ self.do_stable_layer_norm = do_stable_layer_norm
+ self.scope = scope
+
+ output_seq_length = self.seq_length
+ for kernel, stride in zip(self.conv_kernel, self.conv_stride):
+ output_seq_length = (output_seq_length - (kernel - 1)) / stride
+ self.output_seq_length = int(math.ceil(output_seq_length))
+ self.encoder_seq_length = self.output_seq_length
+
+ def prepare_config_and_inputs(self):
+ input_values = floats_tensor([self.batch_size, self.seq_length], scale=1.0)
+ attention_mask = random_attention_mask([self.batch_size, self.seq_length])
+
+ config = self.get_config()
+
+ return config, input_values, attention_mask
+
+ def get_config(self):
+ return HubertConfig(
+ hidden_size=self.hidden_size,
+ feat_extract_norm=self.feat_extract_norm,
+ feat_extract_dropout=self.feat_extract_dropout,
+ feat_extract_activation=self.feat_extract_activation,
+ conv_dim=self.conv_dim,
+ conv_stride=self.conv_stride,
+ conv_kernel=self.conv_kernel,
+ conv_bias=self.conv_bias,
+ num_conv_pos_embeddings=self.num_conv_pos_embeddings,
+ num_conv_pos_embedding_groups=self.num_conv_pos_embedding_groups,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ intermediate_size=self.intermediate_size,
+ layer_norm_eps=self.layer_norm_eps,
+ hidden_act=self.hidden_act,
+ initializer_range=self.initializer_range,
+ vocab_size=self.vocab_size,
+ do_stable_layer_norm=self.do_stable_layer_norm,
+ )
+
+ def create_and_check_model(self, config, input_values, attention_mask):
+ model = HubertModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_values, attention_mask=attention_mask)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.output_seq_length, self.hidden_size)
+ )
+
+ def create_and_check_batch_inference(self, config, input_values, *args):
+ # test does not pass for models making use of `group_norm`
+ # check: https://github.com/pytorch/fairseq/issues/3227
+ model = HubertModel(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ input_values = input_values[:3]
+ attention_mask = torch.ones(input_values.shape, device=torch_device, dtype=torch.bool)
+
+ input_lengths = [input_values.shape[-1] // i for i in [4, 2, 1]]
+
+ # pad input
+ for i in range(len(input_lengths)):
+ input_values[i, input_lengths[i] :] = 0.0
+ attention_mask[i, input_lengths[i] :] = 0.0
+
+ batch_outputs = model(input_values, attention_mask=attention_mask).last_hidden_state
+
+ for i in range(input_values.shape[0]):
+ input_slice = input_values[i : i + 1, : input_lengths[i]]
+ output = model(input_slice).last_hidden_state
+
+ batch_output = batch_outputs[i : i + 1, : output.shape[1]]
+ self.parent.assertTrue(torch.allclose(output, batch_output, atol=1e-3))
+
+ def check_ctc_loss(self, config, input_values, *args):
+ model = HubertForCTC(config=config)
+ model.to(torch_device)
+
+ # make sure that dropout is disabled
+ model.eval()
+
+ input_values = input_values[:3]
+ attention_mask = torch.ones(input_values.shape, device=torch_device, dtype=torch.long)
+
+ input_lengths = [input_values.shape[-1] // i for i in [4, 2, 1]]
+ max_length_labels = model._get_feat_extract_output_lengths(torch.tensor(input_lengths))
+ labels = ids_tensor((input_values.shape[0], min(max_length_labels) - 1), model.config.vocab_size)
+
+ # pad input
+ for i in range(len(input_lengths)):
+ input_values[i, input_lengths[i] :] = 0.0
+ attention_mask[i, input_lengths[i] :] = 0
+
+ model.config.ctc_loss_reduction = "sum"
+ sum_loss = model(input_values, attention_mask=attention_mask, labels=labels).loss.item()
+
+ model.config.ctc_loss_reduction = "mean"
+ mean_loss = model(input_values, attention_mask=attention_mask, labels=labels).loss.item()
+
+ self.parent.assertTrue(isinstance(sum_loss, float))
+ self.parent.assertTrue(isinstance(mean_loss, float))
+
+ def check_seq_classifier_loss(self, config, input_values, *args):
+ model = HubertForSequenceClassification(config=config)
+ model.to(torch_device)
+
+ # make sure that dropout is disabled
+ model.eval()
+
+ input_values = input_values[:3]
+ attention_mask = torch.ones(input_values.shape, device=torch_device, dtype=torch.long)
+
+ input_lengths = [input_values.shape[-1] // i for i in [4, 2, 1]]
+ labels = ids_tensor((input_values.shape[0], 1), len(model.config.id2label))
+
+ # pad input
+ for i in range(len(input_lengths)):
+ input_values[i, input_lengths[i] :] = 0.0
+ attention_mask[i, input_lengths[i] :] = 0
+
+ masked_loss = model(input_values, attention_mask=attention_mask, labels=labels).loss.item()
+ unmasked_loss = model(input_values, labels=labels).loss.item()
+
+ self.parent.assertTrue(isinstance(masked_loss, float))
+ self.parent.assertTrue(isinstance(unmasked_loss, float))
+ self.parent.assertTrue(masked_loss != unmasked_loss)
+
+ def check_ctc_training(self, config, input_values, *args):
+ config.ctc_zero_infinity = True
+ model = HubertForCTC(config=config)
+ model.to(torch_device)
+ model.train()
+
+ # freeze feature encoder
+ model.freeze_feature_encoder()
+
+ input_values = input_values[:3]
+
+ input_lengths = [input_values.shape[-1] // i for i in [4, 2, 1]]
+ max_length_labels = model._get_feat_extract_output_lengths(torch.tensor(input_lengths))
+ labels = ids_tensor((input_values.shape[0], max(max_length_labels) - 2), model.config.vocab_size)
+
+ # pad input
+ for i in range(len(input_lengths)):
+ input_values[i, input_lengths[i] :] = 0.0
+
+ if max_length_labels[i] < labels.shape[-1]:
+ # it's important that we make sure that target lengths are at least
+ # one shorter than logit lengths to prevent -inf
+ labels[i, max_length_labels[i] - 1 :] = -100
+
+ loss = model(input_values, labels=labels).loss
+ self.parent.assertFalse(torch.isinf(loss).item())
+
+ loss.backward()
+
+ def check_seq_classifier_training(self, config, input_values, *args):
+ config.ctc_zero_infinity = True
+ model = HubertForSequenceClassification(config=config)
+ model.to(torch_device)
+ model.train()
+
+ # freeze everything but the classification head
+ model.freeze_base_model()
+
+ input_values = input_values[:3]
+
+ input_lengths = [input_values.shape[-1] // i for i in [4, 2, 1]]
+ labels = ids_tensor((input_values.shape[0], 1), len(model.config.id2label))
+
+ # pad input
+ for i in range(len(input_lengths)):
+ input_values[i, input_lengths[i] :] = 0.0
+
+ loss = model(input_values, labels=labels).loss
+ self.parent.assertFalse(torch.isinf(loss).item())
+
+ loss.backward()
+
+ def check_labels_out_of_vocab(self, config, input_values, *args):
+ model = HubertForCTC(config)
+ model.to(torch_device)
+ model.train()
+
+ input_values = input_values[:3]
+
+ input_lengths = [input_values.shape[-1] // i for i in [4, 2, 1]]
+ max_length_labels = model._get_feat_extract_output_lengths(torch.tensor(input_lengths))
+ labels = ids_tensor((input_values.shape[0], max(max_length_labels) - 2), model.config.vocab_size + 100)
+
+ with pytest.raises(ValueError):
+ model(input_values, labels=labels)
+
+ def prepare_config_and_inputs_for_common(self):
+ config, input_values, attention_mask = self.prepare_config_and_inputs()
+ inputs_dict = {"input_values": input_values, "attention_mask": attention_mask}
+ return config, inputs_dict
+
+
+@require_torch
+class HubertModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (HubertForCTC, HubertForSequenceClassification, HubertModel) if is_torch_available() else ()
+ pipeline_model_mapping = (
+ {
+ "audio-classification": HubertForSequenceClassification,
+ "automatic-speech-recognition": HubertForCTC,
+ "feature-extraction": HubertModel,
+ }
+ if is_torch_available()
+ else {}
+ )
+ fx_compatible = True
+ test_pruning = False
+ test_headmasking = False
+
+ def setUp(self):
+ self.model_tester = HubertModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=HubertConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_ctc_loss_inference(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_ctc_loss(*config_and_inputs)
+
+ def test_seq_classifier_loss_inference(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_seq_classifier_loss(*config_and_inputs)
+
+ def test_ctc_train(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_ctc_training(*config_and_inputs)
+
+ def test_seq_classifier_train(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_seq_classifier_training(*config_and_inputs)
+
+ def test_labels_out_of_vocab(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_labels_out_of_vocab(*config_and_inputs)
+
+ @unittest.skip(reason="Hubert has no inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Hubert has no inputs_embeds")
+ def test_forward_signature(self):
+ pass
+
+ # Hubert cannot resize token embeddings
+ # since it has no tokens embeddings
+ @unittest.skip(reason="Hubert has no tokens embeddings")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ @unittest.skip(reason="Hubert has no inputs_embeds")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ def test_retain_grad_hidden_states_attentions(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.output_hidden_states = True
+ config.output_attentions = True
+
+ # force eager attention to support output attentions
+ config._attn_implementation = "eager"
+
+ # no need to test all models as different heads yield the same functionality
+ model_class = self.all_model_classes[0]
+ model = model_class(config)
+ model.to(torch_device)
+
+ # set layer drop to 0
+ model.config.layerdrop = 0.0
+
+ input_values = inputs_dict["input_values"]
+
+ input_lengths = torch.tensor(
+ [input_values.shape[1] for _ in range(input_values.shape[0])], dtype=torch.long, device=torch_device
+ )
+ output_lengths = model._get_feat_extract_output_lengths(input_lengths)
+
+ labels = ids_tensor((input_values.shape[0], output_lengths[0] - 2), self.model_tester.vocab_size)
+ inputs_dict["attention_mask"] = torch.ones_like(inputs_dict["attention_mask"])
+ inputs_dict["labels"] = labels
+
+ outputs = model(**inputs_dict)
+
+ output = outputs[0]
+
+ # Encoder-/Decoder-only models
+ hidden_states = outputs.hidden_states[0]
+ attentions = outputs.attentions[0]
+
+ hidden_states.retain_grad()
+ attentions.retain_grad()
+
+ output.flatten()[0].backward(retain_graph=True)
+
+ self.assertIsNotNone(hidden_states.grad)
+ self.assertIsNotNone(attentions.grad)
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ uniform_init_parms = [
+ "conv.weight",
+ "conv.parametrizations.weight",
+ "masked_spec_embed",
+ "quantizer.weight_proj.weight",
+ ]
+ if param.requires_grad:
+ if any(x in name for x in uniform_init_parms):
+ self.assertTrue(
+ -1.0 <= ((param.data.mean() * 1e9).round() / 1e9).item() <= 1.0,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ else:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ # Hubert cannot be TorchScripted because of torch.nn.utils.weight_norm
+ def _create_and_check_torch_fx_tracing(self, config, inputs_dict, output_loss=False):
+ # TODO: fix it
+ self.skipTest(reason="torch 2.1 breaks torch fx tests for wav2vec2/hubert.")
+
+ if not self.fx_compatible:
+ self.skipTest(reason="torch fx is not compatible with this model")
+
+ configs_no_init = _config_zero_init(config) # To be sure we have no Nan
+ configs_no_init.return_dict = False
+
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ model.to(torch_device)
+ model.eval()
+ inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=output_loss)
+
+ try:
+ if model.config.is_encoder_decoder:
+ model.config.use_cache = False # FSTM still requires this hack -> FSTM should probably be refactored similar to BART afterward
+ labels = inputs.get("labels", None)
+ input_names = [
+ "attention_mask",
+ "decoder_attention_mask",
+ "decoder_input_ids",
+ "input_features",
+ "input_ids",
+ "input_values",
+ ]
+ if labels is not None:
+ input_names.append("labels")
+
+ filtered_inputs = {k: v for (k, v) in inputs.items() if k in input_names}
+ input_names = list(filtered_inputs.keys())
+
+ model_output = model(**filtered_inputs)
+
+ traced_model = symbolic_trace(model, input_names)
+ traced_output = traced_model(**filtered_inputs)
+ else:
+ input_names = [
+ "attention_mask",
+ "bbox",
+ "input_features",
+ "input_ids",
+ "input_values",
+ "pixel_values",
+ "token_type_ids",
+ "visual_feats",
+ "visual_pos",
+ ]
+
+ labels = inputs.get("labels", None)
+ start_positions = inputs.get("start_positions", None)
+ end_positions = inputs.get("end_positions", None)
+ if labels is not None:
+ input_names.append("labels")
+ if start_positions is not None:
+ input_names.append("start_positions")
+ if end_positions is not None:
+ input_names.append("end_positions")
+
+ filtered_inputs = {k: v for (k, v) in inputs.items() if k in input_names}
+ input_names = list(filtered_inputs.keys())
+
+ model_output = model(**filtered_inputs)
+
+ traced_model = symbolic_trace(model, input_names)
+ traced_output = traced_model(**filtered_inputs)
+
+ except Exception as e:
+ self.fail(f"Couldn't trace module: {e}")
+
+ def flatten_output(output):
+ flatten = []
+ for x in output:
+ if isinstance(x, (tuple, list)):
+ flatten += flatten_output(x)
+ elif not isinstance(x, torch.Tensor):
+ continue
+ else:
+ flatten.append(x)
+ return flatten
+
+ model_output = flatten_output(model_output)
+ traced_output = flatten_output(traced_output)
+ num_outputs = len(model_output)
+
+ for i in range(num_outputs):
+ self.assertTrue(
+ torch.allclose(model_output[i], traced_output[i]),
+ f"traced {i}th output doesn't match model {i}th output for {model_class}",
+ )
+
+ # Test that the model can be serialized and restored properly
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ pkl_file_name = os.path.join(tmp_dir_name, "model.pkl")
+ try:
+ with open(pkl_file_name, "wb") as f:
+ pickle.dump(traced_model, f)
+ with open(pkl_file_name, "rb") as f:
+ loaded = pickle.load(f)
+ except Exception as e:
+ self.fail(f"Couldn't serialize / deserialize the traced model: {e}")
+
+ loaded_output = loaded(**filtered_inputs)
+ loaded_output = flatten_output(loaded_output)
+
+ for i in range(num_outputs):
+ self.assertTrue(
+ torch.allclose(model_output[i], loaded_output[i]),
+ f"serialized model {i}th output doesn't match model {i}th output for {model_class}",
+ )
+
+ # overwrite from test_modeling_common
+ def _mock_init_weights(self, module):
+ if hasattr(module, "weight") and module.weight is not None:
+ module.weight.data.fill_(3)
+ if hasattr(module, "weight_g") and module.weight_g is not None:
+ module.weight_g.data.fill_(3)
+ if hasattr(module, "weight_v") and module.weight_v is not None:
+ module.weight_v.data.fill_(3)
+ if hasattr(module, "bias") and module.bias is not None:
+ module.bias.data.fill_(3)
+ if hasattr(module, "masked_spec_embed") and module.masked_spec_embed is not None:
+ module.masked_spec_embed.data.fill_(3)
+
+ @unittest.skip(reason="Feed forward chunking is not implemented")
+ def test_feed_forward_chunking(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ model = HubertModel.from_pretrained("facebook/hubert-base-ls960")
+ self.assertIsNotNone(model)
+
+
+@require_torch
+class HubertRobustModelTest(ModelTesterMixin, unittest.TestCase):
+ all_model_classes = (HubertForCTC, HubertForSequenceClassification, HubertModel) if is_torch_available() else ()
+ test_pruning = False
+ test_headmasking = False
+
+ def setUp(self):
+ self.model_tester = HubertModelTester(
+ self, conv_stride=(3, 3, 3), feat_extract_norm="layer", do_stable_layer_norm=True
+ )
+ self.config_tester = ConfigTester(self, config_class=HubertConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_batched_inference(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_batch_inference(*config_and_inputs)
+
+ def test_ctc_loss_inference(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_ctc_loss(*config_and_inputs)
+
+ def test_seq_classifier_loss_inference(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_seq_classifier_loss(*config_and_inputs)
+
+ def test_ctc_train(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_ctc_training(*config_and_inputs)
+
+ def test_seq_classifier_train(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_seq_classifier_training(*config_and_inputs)
+
+ def test_labels_out_of_vocab(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.check_labels_out_of_vocab(*config_and_inputs)
+
+ @unittest.skip(reason="Hubert has no inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Hubert has input_values instead of input_ids")
+ def test_forward_signature(self):
+ pass
+
+ @unittest.skip(reason="Hubert has no tokens embeddings")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ @unittest.skip(reason="Hubert has no inputs_embeds")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ def test_retain_grad_hidden_states_attentions(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.output_hidden_states = True
+ config.output_attentions = True
+
+ # force eager attention to support output attentions
+ config._attn_implementation = "eager"
+
+ # no need to test all models as different heads yield the same functionality
+ model_class = self.all_model_classes[0]
+ model = model_class(config)
+ model.to(torch_device)
+
+ # set layer drop to 0
+ model.config.layerdrop = 0.0
+
+ input_values = inputs_dict["input_values"]
+
+ input_lengths = torch.tensor(
+ [input_values.shape[1] for _ in range(input_values.shape[0])], dtype=torch.long, device=torch_device
+ )
+ output_lengths = model._get_feat_extract_output_lengths(input_lengths)
+
+ labels = ids_tensor((input_values.shape[0], output_lengths[0] - 2), self.model_tester.vocab_size)
+ inputs_dict["attention_mask"] = torch.ones_like(inputs_dict["attention_mask"])
+ inputs_dict["labels"] = labels
+
+ outputs = model(**inputs_dict)
+
+ output = outputs[0]
+
+ # Encoder-/Decoder-only models
+ hidden_states = outputs.hidden_states[0]
+ attentions = outputs.attentions[0]
+
+ hidden_states.retain_grad()
+ attentions.retain_grad()
+
+ output.flatten()[0].backward(retain_graph=True)
+
+ self.assertIsNotNone(hidden_states.grad)
+ self.assertIsNotNone(attentions.grad)
+
+ def test_initialization(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ configs_no_init = _config_zero_init(config)
+ for model_class in self.all_model_classes:
+ model = model_class(config=configs_no_init)
+ for name, param in model.named_parameters():
+ uniform_init_parms = [
+ "conv.weight",
+ "conv.parametrizations.weight",
+ "masked_spec_embed",
+ "quantizer.weight_proj.weight",
+ ]
+ if param.requires_grad:
+ if any(x in name for x in uniform_init_parms):
+ self.assertTrue(
+ -1.0 <= ((param.data.mean() * 1e9).round() / 1e9).item() <= 1.0,
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+ else:
+ self.assertIn(
+ ((param.data.mean() * 1e9).round() / 1e9).item(),
+ [0.0, 1.0],
+ msg=f"Parameter {name} of model {model_class} seems not properly initialized",
+ )
+
+ # overwrite from test_modeling_common
+ def _mock_init_weights(self, module):
+ if hasattr(module, "weight") and module.weight is not None:
+ module.weight.data.fill_(3)
+ if hasattr(module, "weight_g") and module.weight_g is not None:
+ module.weight_g.data.fill_(3)
+ if hasattr(module, "weight_v") and module.weight_v is not None:
+ module.weight_v.data.fill_(3)
+ if hasattr(module, "bias") and module.bias is not None:
+ module.bias.data.fill_(3)
+ if hasattr(module, "masked_spec_embed") and module.masked_spec_embed is not None:
+ module.masked_spec_embed.data.fill_(3)
+
+ @unittest.skip(reason="Feed forward chunking is not implemented")
+ def test_feed_forward_chunking(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ model = HubertModel.from_pretrained("facebook/hubert-large-ls960-ft")
+ self.assertIsNotNone(model)
+
+
+@require_torch
+class HubertUtilsTest(unittest.TestCase):
+ def test_compute_mask_indices(self):
+ batch_size = 4
+ sequence_length = 60
+ mask_prob = 0.5
+ mask_length = 1
+
+ mask = _compute_mask_indices((batch_size, sequence_length), mask_prob, mask_length)
+ mask = torch.from_numpy(mask).to(torch_device)
+
+ self.assertListEqual(mask.sum(axis=-1).tolist(), [mask_prob * sequence_length for _ in range(batch_size)])
+
+ def test_compute_mask_indices_overlap(self):
+ batch_size = 4
+ sequence_length = 80
+ mask_prob = 0.5
+ mask_length = 4
+
+ mask = _compute_mask_indices((batch_size, sequence_length), mask_prob, mask_length)
+ mask = torch.from_numpy(mask).to(torch_device)
+
+ # because of overlap mask don't have to add up exactly to `mask_prob * sequence_length`, but have to be smaller or equal
+ for batch_sum in mask.sum(axis=-1):
+ self.assertTrue(int(batch_sum) <= mask_prob * sequence_length)
+
+
+@require_torch
+@require_torchcodec
+@slow
+class HubertModelIntegrationTest(unittest.TestCase):
+ def _load_datasamples(self, num_samples):
+ from datasets import load_dataset
+
+ ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
+ # automatic decoding with librispeech
+ speech_samples = ds.sort("id").filter(
+ lambda x: x["id"] in [f"1272-141231-000{i}" for i in range(num_samples)]
+ )[:num_samples]["audio"]
+
+ return [x["array"] for x in speech_samples]
+
+ def _load_superb(self, task, num_samples):
+ from datasets import load_dataset
+
+ ds = load_dataset("anton-l/superb_dummy", task, split="test")
+
+ return ds[:num_samples]
+
+ def test_inference_ctc_batched(self):
+ model = HubertForCTC.from_pretrained("facebook/hubert-large-ls960-ft", torch_dtype=torch.float16).to(
+ torch_device
+ )
+ processor = Wav2Vec2Processor.from_pretrained("facebook/hubert-large-ls960-ft", do_lower_case=True)
+
+ input_speech = self._load_datasamples(2)
+
+ inputs = processor(input_speech, return_tensors="pt", padding=True)
+
+ input_values = inputs.input_values.half().to(torch_device)
+ attention_mask = inputs.attention_mask.to(torch_device)
+
+ with torch.no_grad():
+ logits = model(input_values, attention_mask=attention_mask).logits
+
+ predicted_ids = torch.argmax(logits, dim=-1)
+ predicted_trans = processor.batch_decode(predicted_ids)
+
+ EXPECTED_TRANSCRIPTIONS = [
+ "a man said to the universe sir i exist",
+ "sweat covered brion's body trickling into the tight loin cloth that was the only garment he wore",
+ ]
+ self.assertListEqual(predicted_trans, EXPECTED_TRANSCRIPTIONS)
+
+ def test_inference_keyword_spotting(self):
+ model = HubertForSequenceClassification.from_pretrained(
+ "superb/hubert-base-superb-ks", torch_dtype=torch.float16
+ ).to(torch_device)
+ processor = Wav2Vec2FeatureExtractor.from_pretrained("superb/hubert-base-superb-ks")
+ input_data = self._load_superb("ks", 4)
+ inputs = processor(input_data["speech"], return_tensors="pt", padding=True)
+
+ input_values = inputs.input_values.half().to(torch_device)
+ attention_mask = inputs.attention_mask.to(torch_device)
+ with torch.no_grad():
+ outputs = model(input_values, attention_mask=attention_mask)
+ predicted_logits, predicted_ids = torch.max(outputs.logits, dim=-1)
+
+ expected_labels = [2, 6, 10, 9]
+ # s3prl logits for the same batch
+ expected_logits = torch.tensor([7.6692, 17.7795, 11.1562, 11.8232], dtype=torch.float16, device=torch_device)
+
+ self.assertListEqual(predicted_ids.tolist(), expected_labels)
+ torch.testing.assert_close(predicted_logits, expected_logits, rtol=3e-2, atol=3e-2)
+
+ def test_inference_intent_classification(self):
+ model = HubertForSequenceClassification.from_pretrained(
+ "superb/hubert-base-superb-ic", torch_dtype=torch.float16
+ ).to(torch_device)
+ processor = Wav2Vec2FeatureExtractor.from_pretrained("superb/hubert-base-superb-ic")
+ input_data = self._load_superb("ic", 4)
+ inputs = processor(input_data["speech"], return_tensors="pt", padding=True)
+
+ input_values = inputs.input_values.half().to(torch_device)
+ attention_mask = inputs.attention_mask.to(torch_device)
+ with torch.no_grad():
+ outputs = model(input_values, attention_mask=attention_mask)
+
+ predicted_logits_action, predicted_ids_action = torch.max(outputs.logits[:, :6], dim=-1)
+ predicted_logits_object, predicted_ids_object = torch.max(outputs.logits[:, 6:20], dim=-1)
+ predicted_logits_location, predicted_ids_location = torch.max(outputs.logits[:, 20:24], dim=-1)
+
+ expected_labels_action = [1, 0, 4, 3]
+ expected_logits_action = torch.tensor(
+ [5.9052, 12.5865, 4.4840, 10.0240], dtype=torch.float16, device=torch_device
+ )
+ expected_labels_object = [1, 10, 3, 4]
+ expected_logits_object = torch.tensor(
+ [5.5316, 11.7946, 8.1672, 23.2415], dtype=torch.float16, device=torch_device
+ )
+ expected_labels_location = [0, 0, 0, 1]
+ expected_logits_location = torch.tensor(
+ [5.2053, 8.9577, 10.0447, 8.1481], dtype=torch.float16, device=torch_device
+ )
+
+ self.assertListEqual(predicted_ids_action.tolist(), expected_labels_action)
+ self.assertListEqual(predicted_ids_object.tolist(), expected_labels_object)
+ self.assertListEqual(predicted_ids_location.tolist(), expected_labels_location)
+
+ # TODO: lower the tolerance after merging the padding fix https://github.com/pytorch/fairseq/pull/3572
+ torch.testing.assert_close(predicted_logits_action, expected_logits_action, rtol=3e-1, atol=3e-1)
+ torch.testing.assert_close(predicted_logits_object, expected_logits_object, rtol=3e-1, atol=3e-1)
+ torch.testing.assert_close(predicted_logits_location, expected_logits_location, rtol=3e-1, atol=3e-1)
+
+ def test_inference_speaker_identification(self):
+ model = HubertForSequenceClassification.from_pretrained(
+ "superb/hubert-base-superb-sid", torch_dtype=torch.float16
+ ).to(torch_device)
+ processor = Wav2Vec2FeatureExtractor.from_pretrained("superb/hubert-base-superb-sid")
+ input_data = self._load_superb("si", 4)
+
+ output_logits = []
+ with torch.no_grad():
+ for example in input_data["speech"]:
+ input = processor(example, return_tensors="pt", padding=True)
+ output = model(input.input_values.half().to(torch_device), attention_mask=None)
+ output_logits.append(output.logits[0])
+ output_logits = torch.stack(output_logits)
+ predicted_logits, predicted_ids = torch.max(output_logits, dim=-1)
+
+ expected_labels = [5, 1, 1, 3]
+ # s3prl logits for the same batch
+ expected_logits = torch.tensor(
+ [78231.5547, 123166.6094, 122785.4141, 84851.2969], dtype=torch.float16, device=torch_device
+ )
+
+ self.assertListEqual(predicted_ids.tolist(), expected_labels)
+ # TODO: lower the tolerance after merging the padding fix https://github.com/pytorch/fairseq/pull/3572
+ torch.testing.assert_close(predicted_logits, expected_logits, rtol=10, atol=10)
+
+ def test_inference_emotion_recognition(self):
+ model = HubertForSequenceClassification.from_pretrained(
+ "superb/hubert-base-superb-er", torch_dtype=torch.float16
+ ).to(torch_device)
+ processor = Wav2Vec2FeatureExtractor.from_pretrained("superb/hubert-base-superb-er")
+ input_data = self._load_superb("er", 4)
+ inputs = processor(input_data["speech"], return_tensors="pt", padding=True)
+
+ input_values = inputs.input_values.half().to(torch_device)
+ attention_mask = inputs.attention_mask.to(torch_device)
+ with torch.no_grad():
+ outputs = model(input_values, attention_mask=attention_mask)
+ predicted_logits, predicted_ids = torch.max(outputs.logits, dim=-1)
+
+ expected_labels = [1, 1, 2, 2]
+ # s3prl logits for the same batch
+ expected_logits = torch.tensor([2.8384, 2.3389, 3.8564, 4.5558], dtype=torch.float16, device=torch_device)
+
+ self.assertListEqual(predicted_ids.tolist(), expected_labels)
+ # TODO: lower the tolerance after merging the padding fix https://github.com/pytorch/fairseq/pull/3572
+ torch.testing.assert_close(predicted_logits, expected_logits, rtol=1e-1, atol=1e-1)
+
+ def test_inference_distilhubert(self):
+ model = HubertModel.from_pretrained("ntu-spml/distilhubert").to(torch_device)
+ processor = Wav2Vec2FeatureExtractor.from_pretrained("ntu-spml/distilhubert")
+
+ # TODO: can't test on batched inputs due to incompatible padding https://github.com/pytorch/fairseq/pull/3572
+ input_speech = self._load_datasamples(1)
+
+ inputs = processor(input_speech, return_tensors="pt", padding=True)
+
+ input_values = inputs.input_values.to(torch_device)
+
+ with torch.no_grad():
+ outputs = model(input_values).last_hidden_state
+
+ # expected outputs taken from the original SEW implementation
+ expected_outputs_first = torch.tensor(
+ [
+ [
+ [-0.3505, 0.1167, 0.0608, 0.1294],
+ [-0.3085, 0.0481, 0.1106, 0.0955],
+ [-0.3107, -0.0391, 0.0739, 0.1360],
+ [-0.2385, -0.1795, -0.0928, 0.2389],
+ ]
+ ],
+ device=torch_device,
+ )
+ expected_outputs_last = torch.tensor(
+ [
+ [
+ [-0.0732, 0.0255, 0.0529, -0.1372],
+ [-0.0812, 0.1259, 0.0564, -0.0438],
+ [-0.0054, 0.0758, -0.0002, -0.1617],
+ [0.0133, -0.0320, -0.0687, 0.0062],
+ ]
+ ],
+ device=torch_device,
+ )
+ expected_output_sum = -3776.0730
+
+ torch.testing.assert_close(outputs[:, :4, :4], expected_outputs_first, rtol=5e-3, atol=5e-3)
+ torch.testing.assert_close(outputs[:, -4:, -4:], expected_outputs_last, rtol=5e-3, atol=5e-3)
+ self.assertTrue(abs(outputs.sum() - expected_output_sum) < 0.1)
+
+ def test_inference_hubert_25hz(self):
+ model = HubertModel.from_pretrained("slprl/mhubert-base-25hz").to(torch_device)
+
+ sample = self._load_datasamples(1)
+ input_speech = torch.tensor(sample[0], dtype=torch.float, device=torch_device).unsqueeze(0)
+
+ with torch.no_grad():
+ outputs = model(input_speech, output_hidden_states=True).hidden_states[11]
+
+ # expected outputs taken from the original textlesslib implementation by:
+ # model = SpeechEncoder.by_name(dense_model_name='mhubert-base-25hz', quantizer_model_name='kmeans',
+ # vocab_size=500, deduplicate=False, need_f0=False)
+ # model(wav)['dense']
+ expected_outputs_first = torch.tensor(
+ [
+ [0.0267, 0.1776, -0.1706, -0.4559],
+ [-0.2430, -0.2943, -0.1864, -0.1187],
+ [-0.1812, -0.4239, -0.1916, -0.0858],
+ [-0.1495, -0.4758, -0.4036, 0.0302],
+ ],
+ device=torch_device,
+ )
+ expected_outputs_last = torch.tensor(
+ [
+ [0.3366, -0.2734, -0.1415, -0.3055],
+ [0.2329, -0.3580, -0.1421, -0.3197],
+ [0.1631, -0.4301, -0.1965, -0.2956],
+ [0.3342, -0.2185, -0.2253, -0.2363],
+ ],
+ device=torch_device,
+ )
+ expected_output_sum = 1681.7603
+
+ torch.testing.assert_close(outputs[:, :4, :4], expected_outputs_first, rtol=5e-3, atol=5e-3)
+ torch.testing.assert_close(outputs[:, -4:, -4:], expected_outputs_last, rtol=5e-3, atol=5e-3)
+ self.assertTrue(abs(outputs.sum() - expected_output_sum) < 0.1)
diff --git a/transformers/tests/models/idefics3/__init__.py b/transformers/tests/models/idefics3/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/idefics3/test_image_processing_idefics3.py b/transformers/tests/models/idefics3/test_image_processing_idefics3.py
new file mode 100644
index 0000000000000000000000000000000000000000..7a1eb4f44fc1cefea0afb5a0b70e65b0472b2a17
--- /dev/null
+++ b/transformers/tests/models/idefics3/test_image_processing_idefics3.py
@@ -0,0 +1,360 @@
+# coding=utf-8
+# Copyright 2024 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+import numpy as np
+import requests
+
+from transformers.image_utils import PILImageResampling
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_torch_available, is_torchvision_available, is_vision_available
+
+from ...test_image_processing_common import ImageProcessingTestMixin
+
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import Idefics3ImageProcessor
+
+ if is_torchvision_available():
+ from transformers import Idefics3ImageProcessorFast
+
+
+if is_torch_available():
+ import torch
+
+
+class Idefics3ImageProcessingTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ num_images=1,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=40,
+ do_resize=True,
+ size=None,
+ max_image_size=None,
+ do_rescale=True,
+ rescale_factor=1 / 255,
+ do_normalize=True,
+ image_mean=[0.5, 0.5, 0.5],
+ image_std=[0.5, 0.5, 0.5],
+ do_convert_rgb=True,
+ do_pad=True,
+ do_image_splitting=True,
+ resample=PILImageResampling.LANCZOS,
+ ):
+ self.size = size if size is not None else {"longest_edge": max_resolution}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.num_images = num_images
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.resample = resample
+ self.do_image_splitting = do_image_splitting
+ self.max_image_size = max_image_size if max_image_size is not None else {"longest_edge": 20}
+ self.do_rescale = do_rescale
+ self.rescale_factor = rescale_factor
+ self.do_normalize = do_normalize
+ self.image_mean = image_mean
+ self.image_std = image_std
+ self.do_convert_rgb = do_convert_rgb
+ self.do_pad = do_pad
+
+ def prepare_image_processor_dict(self):
+ return {
+ "do_convert_rgb": self.do_convert_rgb,
+ "do_resize": self.do_resize,
+ "size": self.size,
+ "max_image_size": self.max_image_size,
+ "do_rescale": self.do_rescale,
+ "rescale_factor": self.rescale_factor,
+ "do_normalize": self.do_normalize,
+ "image_mean": self.image_mean,
+ "image_std": self.image_std,
+ "do_pad": self.do_pad,
+ "do_image_splitting": self.do_image_splitting,
+ }
+
+ def get_expected_values(self, image_inputs, batched=False):
+ """
+ This function computes the expected height and width when providing images to Idefics3ImageProcessor,
+ assuming do_resize is set to True. The expected size in that case the max image size.
+ """
+ return self.max_image_size["longest_edge"], self.max_image_size["longest_edge"]
+
+ def expected_output_image_shape(self, images):
+ height, width = self.get_expected_values(images, batched=True)
+ effective_nb_images = (
+ self.num_images * 5 if self.do_image_splitting else 1
+ ) # 5 is a squared image divided into 4 + global image resized
+ return effective_nb_images, self.num_channels, height, width
+
+ def prepare_image_inputs(
+ self,
+ batch_size=None,
+ min_resolution=None,
+ max_resolution=None,
+ num_channels=None,
+ num_images=None,
+ size_divisor=None,
+ equal_resolution=False,
+ numpify=False,
+ torchify=False,
+ ):
+ """This function prepares a list of PIL images, or a list of numpy arrays if one specifies numpify=True,
+ or a list of PyTorch tensors if one specifies torchify=True.
+
+ One can specify whether the images are of the same resolution or not.
+ """
+ assert not (numpify and torchify), "You cannot specify both numpy and PyTorch tensors at the same time"
+
+ batch_size = batch_size if batch_size is not None else self.batch_size
+ min_resolution = min_resolution if min_resolution is not None else self.min_resolution
+ max_resolution = max_resolution if max_resolution is not None else self.max_resolution
+ num_channels = num_channels if num_channels is not None else self.num_channels
+ num_images = num_images if num_images is not None else self.num_images
+
+ images_list = []
+ for i in range(batch_size):
+ images = []
+ for j in range(num_images):
+ if equal_resolution:
+ width = height = max_resolution
+ else:
+ # To avoid getting image width/height 0
+ if size_divisor is not None:
+ # If `size_divisor` is defined, the image needs to have width/size >= `size_divisor`
+ min_resolution = max(size_divisor, min_resolution)
+ width, height = np.random.choice(np.arange(min_resolution, max_resolution), 2)
+ images.append(np.random.randint(255, size=(num_channels, width, height), dtype=np.uint8))
+ images_list.append(images)
+
+ if not numpify and not torchify:
+ # PIL expects the channel dimension as last dimension
+ images_list = [[Image.fromarray(np.moveaxis(image, 0, -1)) for image in images] for images in images_list]
+
+ if torchify:
+ images_list = [[torch.from_numpy(image) for image in images] for images in images_list]
+
+ if numpify:
+ # Numpy images are typically in channels last format
+ images_list = [[image.transpose(1, 2, 0) for image in images] for images in images_list]
+
+ return images_list
+
+
+@require_torch
+@require_vision
+class Idefics3ImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = Idefics3ImageProcessor if is_vision_available() else None
+ fast_image_processing_class = Idefics3ImageProcessorFast if is_torchvision_available() else None
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = Idefics3ImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "do_convert_rgb"))
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "resample"))
+ self.assertTrue(hasattr(image_processing, "do_image_splitting"))
+ self.assertTrue(hasattr(image_processing, "max_image_size"))
+ self.assertTrue(hasattr(image_processing, "do_rescale"))
+ self.assertTrue(hasattr(image_processing, "rescale_factor"))
+ self.assertTrue(hasattr(image_processing, "do_normalize"))
+ self.assertTrue(hasattr(image_processing, "image_mean"))
+ self.assertTrue(hasattr(image_processing, "image_std"))
+ self.assertTrue(hasattr(image_processing, "do_pad"))
+ self.assertTrue(hasattr(image_processing, "do_image_splitting"))
+
+ def test_call_numpy(self):
+ for image_processing_class in self.image_processor_list:
+ # Initialize image_processing
+ image_processing = image_processing_class(**self.image_processor_dict)
+ # create random numpy tensors
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, numpify=True)
+ for sample_images in image_inputs:
+ for image in sample_images:
+ self.assertIsInstance(image, np.ndarray)
+
+ # Test not batched input
+ encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape([image_inputs[0]])
+ self.assertEqual(tuple(encoded_images.shape), (1, *expected_output_image_shape))
+
+ # Test batched
+ encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape(image_inputs)
+ self.assertEqual(
+ tuple(encoded_images.shape), (self.image_processor_tester.batch_size, *expected_output_image_shape)
+ )
+
+ def test_call_numpy_4_channels(self):
+ # Idefics3 always processes images as RGB, so it always returns images with 3 channels
+ for image_processing_class in self.image_processor_list:
+ # Initialize image_processing
+ image_processor_dict = self.image_processor_dict
+ image_processing = image_processing_class(**image_processor_dict)
+ # create random numpy tensors
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, numpify=True)
+
+ for sample_images in image_inputs:
+ for image in sample_images:
+ self.assertIsInstance(image, np.ndarray)
+
+ # Test not batched input
+ encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape([image_inputs[0]])
+ self.assertEqual(tuple(encoded_images.shape), (1, *expected_output_image_shape))
+
+ # Test batched
+ encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape(image_inputs)
+ self.assertEqual(
+ tuple(encoded_images.shape), (self.image_processor_tester.batch_size, *expected_output_image_shape)
+ )
+
+ def test_call_pil(self):
+ for image_processing_class in self.image_processor_list:
+ # Initialize image_processing
+ image_processing = image_processing_class(**self.image_processor_dict)
+ # create random PIL images
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False)
+ for images in image_inputs:
+ for image in images:
+ self.assertIsInstance(image, Image.Image)
+
+ # Test not batched input
+ encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape([image_inputs[0]])
+ self.assertEqual(tuple(encoded_images.shape), (1, *expected_output_image_shape))
+
+ # Test batched
+ encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape(image_inputs)
+ self.assertEqual(
+ tuple(encoded_images.shape), (self.image_processor_tester.batch_size, *expected_output_image_shape)
+ )
+
+ def test_call_pytorch(self):
+ for image_processing_class in self.image_processor_list:
+ # Initialize image_processing
+ image_processing = image_processing_class(**self.image_processor_dict)
+ # create random PyTorch tensors
+ image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, torchify=True)
+
+ for images in image_inputs:
+ for image in images:
+ self.assertIsInstance(image, torch.Tensor)
+
+ # Test not batched input
+ encoded_images = image_processing(image_inputs[0], return_tensors="pt").pixel_values
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape([image_inputs[0]])
+ self.assertEqual(tuple(encoded_images.shape), (1, *expected_output_image_shape))
+
+ # Test batched
+ expected_output_image_shape = self.image_processor_tester.expected_output_image_shape(image_inputs)
+ encoded_images = image_processing(image_inputs, return_tensors="pt").pixel_values
+ self.assertEqual(
+ tuple(encoded_images.shape),
+ (self.image_processor_tester.batch_size, *expected_output_image_shape),
+ )
+
+ @require_vision
+ @require_torch
+ def test_slow_fast_equivalence(self):
+ if not self.test_slow_image_processor or not self.test_fast_image_processor:
+ self.skipTest(reason="Skipping slow/fast equivalence test")
+
+ if self.image_processing_class is None or self.fast_image_processing_class is None:
+ self.skipTest(reason="Skipping slow/fast equivalence test as one of the image processors is not defined")
+
+ dummy_image = Image.open(
+ requests.get("http://images.cocodataset.org/val2017/000000039769.jpg", stream=True).raw
+ )
+ dummy_image = dummy_image.resize((100, 150))
+ image_processor_slow = self.image_processing_class(
+ **self.image_processor_dict, resample=PILImageResampling.BICUBIC
+ )
+ image_processor_fast = self.fast_image_processing_class(
+ **self.image_processor_dict, resample=PILImageResampling.BICUBIC
+ )
+
+ encoding_slow = image_processor_slow(dummy_image, return_tensors="pt", return_row_col_info=True)
+ encoding_fast = image_processor_fast(dummy_image, return_tensors="pt", return_row_col_info=True)
+
+ self._assert_slow_fast_tensors_equivalence(encoding_slow.pixel_values, encoding_fast.pixel_values)
+ self._assert_slow_fast_tensors_equivalence(
+ encoding_slow.pixel_attention_mask.float(), encoding_fast.pixel_attention_mask.float()
+ )
+ self.assertEqual(encoding_slow.rows, encoding_fast.rows)
+ self.assertEqual(encoding_slow.cols, encoding_fast.cols)
+
+ @require_vision
+ @require_torch
+ def test_slow_fast_equivalence_batched(self):
+ if not self.test_slow_image_processor or not self.test_fast_image_processor:
+ self.skipTest(reason="Skipping slow/fast equivalence test")
+
+ if self.image_processing_class is None or self.fast_image_processing_class is None:
+ self.skipTest(reason="Skipping slow/fast equivalence test as one of the image processors is not defined")
+
+ if hasattr(self.image_processor_tester, "do_center_crop") and self.image_processor_tester.do_center_crop:
+ self.skipTest(
+ reason="Skipping as do_center_crop is True and center_crop functions are not equivalent for fast and slow processors"
+ )
+
+ dummy_images = self.image_processor_tester.prepare_image_inputs(
+ equal_resolution=False, num_images=5, torchify=True
+ )
+ # pop some images to have non homogenous batches:
+ indices_to_pop = [i if np.random.random() < 0.5 else None for i in range(len(dummy_images))]
+ for i in indices_to_pop:
+ if i is not None:
+ dummy_images[i].pop()
+
+ image_processor_slow = self.image_processing_class(
+ **self.image_processor_dict, resample=PILImageResampling.BICUBIC
+ )
+ image_processor_fast = self.fast_image_processing_class(
+ **self.image_processor_dict, resample=PILImageResampling.BICUBIC
+ )
+
+ encoding_slow = image_processor_slow(dummy_images, return_tensors="pt", return_row_col_info=True)
+ encoding_fast = image_processor_fast(dummy_images, return_tensors="pt", return_row_col_info=True)
+
+ self._assert_slow_fast_tensors_equivalence(encoding_slow.pixel_values, encoding_fast.pixel_values, atol=3e-1)
+ self._assert_slow_fast_tensors_equivalence(
+ encoding_slow.pixel_attention_mask.float(), encoding_fast.pixel_attention_mask.float()
+ )
+ self.assertEqual(encoding_slow.rows, encoding_fast.rows)
+ self.assertEqual(encoding_slow.cols, encoding_fast.cols)
diff --git a/transformers/tests/models/idefics3/test_modeling_idefics3.py b/transformers/tests/models/idefics3/test_modeling_idefics3.py
new file mode 100644
index 0000000000000000000000000000000000000000..5cf06a50be10e32735f4617ab2bbad07b5db98b1
--- /dev/null
+++ b/transformers/tests/models/idefics3/test_modeling_idefics3.py
@@ -0,0 +1,567 @@
+# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Idefics3 model."""
+
+import copy
+import unittest
+from io import BytesIO
+
+import pytest
+import requests
+
+from transformers import (
+ AutoProcessor,
+ is_torch_available,
+ is_vision_available,
+)
+from transformers.testing_utils import (
+ cleanup,
+ require_bitsandbytes,
+ require_torch,
+ require_torch_sdpa,
+ slow,
+ torch_device,
+)
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ Idefics3Config,
+ Idefics3ForConditionalGeneration,
+ Idefics3Model,
+ )
+
+if is_vision_available():
+ from PIL import Image
+
+
+class Idefics3VisionText2TextModelTester:
+ def __init__(
+ self,
+ parent,
+ is_training=True,
+ batch_size=2,
+ scale_factor=2,
+ num_images=2,
+ vision_config={
+ "image_size": 16,
+ "patch_size": 4,
+ "hidden_size": 32,
+ "num_hidden_layers": 2,
+ "num_attention_heads": 4,
+ "intermediate_size": 32,
+ "dropout": 0.1,
+ "attention_dropout": 0.1,
+ "initializer_range": 0.02,
+ },
+ text_config={
+ "vocab_size": 100,
+ "hidden_size": 64,
+ "intermediate_size": 56,
+ "num_hidden_layers": 3,
+ "num_attention_heads": 2,
+ "num_key_value_heads": 2,
+ "hidden_act": "silu",
+ "max_position_embeddings": 256,
+ "initializer_range": 0.02,
+ "rms_norm_eps": 1e-6,
+ "pad_token_id": 2,
+ "bos_token_id": 0,
+ "eos_token_id": 1,
+ "image_token_id": 57,
+ "tie_word_embeddings": False,
+ "rope_theta": 10000.0,
+ "sliding_window": 32,
+ "attention_dropout": 0.0,
+ },
+ use_cache=False,
+ tie_word_embeddings=False,
+ image_token_id=57,
+ ):
+ self.parent = parent
+ self.pad_token_id = text_config["pad_token_id"]
+ self.is_training = is_training
+ self.batch_size = batch_size
+ self.num_images = num_images
+ self.scale_factor = scale_factor
+ self.seq_length = (
+ int(((vision_config["image_size"] // vision_config["patch_size"]) ** 2) / (self.scale_factor**2))
+ * self.num_images
+ )
+ self.use_cache = use_cache
+ self.image_token_id = image_token_id
+ self.tie_word_embeddings = tie_word_embeddings
+ # Hack - add properties here so use common tests
+ self.vocab_size = text_config["vocab_size"]
+ self.num_hidden_layers = text_config["num_hidden_layers"]
+ self.num_attention_heads = text_config["num_attention_heads"]
+ self.hidden_size = text_config["hidden_size"]
+
+ self.vision_config = vision_config
+ self.text_config = text_config
+
+ def get_config(self):
+ return Idefics3Config(
+ use_cache=self.use_cache,
+ image_token_id=self.image_token_id,
+ tie_word_embeddings=self.tie_word_embeddings,
+ vision_config=self.vision_config,
+ text_config=self.text_config,
+ vocab_size=self.vocab_size,
+ scale_factor=self.scale_factor,
+ )
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor(
+ [
+ self.batch_size,
+ self.num_images,
+ 3, # Idefics3ImageProcessor always generates RGB pixel values
+ self.vision_config["image_size"],
+ self.vision_config["image_size"],
+ ]
+ )
+ config = self.get_config()
+
+ return config, pixel_values
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ input_ids = ids_tensor([self.batch_size, self.seq_length], config.text_config.vocab_size - 2) + 1
+
+ # For simplicity just set the last n tokens to the image token
+ n_image_tokens_per_batch = self.seq_length
+ input_ids[input_ids == self.image_token_id] = self.pad_token_id
+ input_ids[:, -n_image_tokens_per_batch:] = self.image_token_id
+ attention_mask = input_ids.ne(1).to(torch_device)
+ inputs_dict = {
+ "pixel_values": pixel_values,
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class Idefics3ModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Model tester for `Idefics3`.
+ """
+
+ all_model_classes = (Idefics3Model,) if is_torch_available() else ()
+ fx_compatible = False
+ test_torchscript = False
+ test_pruning = False
+ test_resize_embeddings = True
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = Idefics3VisionText2TextModelTester(self)
+ self.config_tester = ConfigTester(
+ self, config_class=Idefics3Config, has_text_modality=False, common_properties=["image_token_id"]
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="input_embeds cannot be passed in without input_ids")
+ def test_inputs_embeds():
+ pass
+
+ @unittest.skip(reason="input_embeds cannot be passed in without input_ids")
+ def test_inputs_embeds_matches_input_ids(self):
+ pass
+
+ @unittest.skip(reason="Model does not support padding right")
+ def test_flash_attn_2_inference_padding_right(self):
+ pass
+
+ @unittest.skip(reason="Compile not yet supported in idefics3 models")
+ def test_sdpa_can_compile_dynamic(self):
+ pass
+
+ # We need to override as we need to prepare such that the image token is the last token
+ def test_resize_tokens_embeddings(self):
+ (original_config, inputs_dict) = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ config = copy.deepcopy(original_config)
+ model = model_class(config)
+ model.to(torch_device)
+
+ if self.model_tester.is_training is False:
+ model.eval()
+
+ model_vocab_size = config.text_config.vocab_size
+ # Retrieve the embeddings and clone theme
+ model_embed = model.resize_token_embeddings(model_vocab_size)
+ cloned_embeddings = model_embed.weight.clone()
+
+ # Check that resizing the token embeddings with a larger vocab size increases the model's vocab size
+ model_embed = model.resize_token_embeddings(model_vocab_size + 10)
+ self.assertEqual(model.config.text_config.vocab_size, model_vocab_size + 10)
+ # Check that it actually resizes the embeddings matrix
+ self.assertEqual(model_embed.weight.shape[0], cloned_embeddings.shape[0] + 10)
+ # Check that the model can still do a forward pass successfully (every parameter should be resized)
+ model(**self._prepare_for_class(inputs_dict, model_class))
+
+ # Check that resizing the token embeddings with a smaller vocab size decreases the model's vocab size
+ model_embed = model.resize_token_embeddings(model_vocab_size - 15)
+ self.assertEqual(model.config.text_config.vocab_size, model_vocab_size - 15)
+ # Check that it actually resizes the embeddings matrix
+ self.assertEqual(model_embed.weight.shape[0], cloned_embeddings.shape[0] - 15)
+
+ # Ignore copy
+ # Check that the model can still do a forward pass successfully (every parameter should be resized)
+ # Input ids should be clamped to the maximum size of the vocabulary - 1 and the image token should be the last token
+ inputs_dict["input_ids"].clamp_(max=model_vocab_size - 15 - 2)
+ n_images = self.model_tester.num_images * self.model_tester.seq_length
+ model.image_token_id = model_vocab_size - 15 - 1
+ inputs_dict["input_ids"][:, -n_images:] = model.image_token_id
+
+ # make sure that decoder_input_ids are resized as well
+ if "decoder_input_ids" in inputs_dict:
+ inputs_dict["decoder_input_ids"].clamp_(max=model_vocab_size - 15 - 1)
+ model(**self._prepare_for_class(inputs_dict, model_class))
+
+ # Check that adding and removing tokens has not modified the first part of the embedding matrix.
+ models_equal = True
+ for p1, p2 in zip(cloned_embeddings, model_embed.weight):
+ if p1.data.ne(p2.data).sum() > 0:
+ models_equal = False
+
+ self.assertTrue(models_equal)
+
+ config = copy.deepcopy(original_config)
+ model = model_class(config)
+ model.to(torch_device)
+
+ model_vocab_size = config.text_config.vocab_size
+ model.resize_token_embeddings(model_vocab_size + 10, pad_to_multiple_of=1)
+ self.assertTrue(model.config.text_config.vocab_size + 10, model_vocab_size)
+
+ model_embed = model.resize_token_embeddings(model_vocab_size, pad_to_multiple_of=64)
+ self.assertTrue(model_embed.weight.shape[0] // 64, 0)
+
+ self.assertTrue(model_embed.weight.shape[0], model.config.text_config.vocab_size)
+ self.assertTrue(model.config.text_config.vocab_size, model.vocab_size)
+
+ model_embed = model.resize_token_embeddings(model_vocab_size + 13, pad_to_multiple_of=64)
+ self.assertTrue(model_embed.weight.shape[0] // 64, 0)
+
+ # Check that resizing a model to a multiple of pad_to_multiple leads to a model of exactly that size
+ target_dimension = 128
+ model_embed = model.resize_token_embeddings(target_dimension, pad_to_multiple_of=64)
+ self.assertTrue(model_embed.weight.shape[0], target_dimension)
+
+ with self.assertRaisesRegex(
+ ValueError,
+ "Asking to pad the embedding matrix to a multiple of `1.3`, which is not and integer. Please make sure to pass an integer",
+ ):
+ model.resize_token_embeddings(model_vocab_size, pad_to_multiple_of=1.3)
+
+ # We need to override as we need to prepare such that the image token is the last token
+ def test_resize_embeddings_untied(self):
+ (original_config, inputs_dict) = self.model_tester.prepare_config_and_inputs_for_common()
+
+ original_config.tie_word_embeddings = False
+
+ for model_class in self.all_model_classes:
+ config = copy.deepcopy(original_config)
+ model = model_class(config).to(torch_device)
+
+ # if no output embeddings -> leave test
+ if model.get_output_embeddings() is None:
+ continue
+
+ # Check that resizing the token embeddings with a larger vocab size increases the model's vocab size
+ model_vocab_size = config.text_config.vocab_size
+ model.resize_token_embeddings(model_vocab_size + 10)
+ self.assertEqual(model.config.text_config.vocab_size, model_vocab_size + 10)
+ output_embeds = model.get_output_embeddings()
+ self.assertEqual(output_embeds.weight.shape[0], model_vocab_size + 10)
+ # Check bias if present
+ if output_embeds.bias is not None:
+ self.assertEqual(output_embeds.bias.shape[0], model_vocab_size + 10)
+ # Check that the model can still do a forward pass successfully (every parameter should be resized)
+ model(**self._prepare_for_class(inputs_dict, model_class))
+
+ # Check that resizing the token embeddings with a smaller vocab size decreases the model's vocab size
+ model.resize_token_embeddings(model_vocab_size - 15)
+ self.assertEqual(model.config.text_config.vocab_size, model_vocab_size - 15)
+ # Check that it actually resizes the embeddings matrix
+ output_embeds = model.get_output_embeddings()
+ self.assertEqual(output_embeds.weight.shape[0], model_vocab_size - 15)
+ # Check bias if present
+ if output_embeds.bias is not None:
+ self.assertEqual(output_embeds.bias.shape[0], model_vocab_size - 15)
+
+ # Check that the model can still do a forward pass successfully (every parameter should be resized)
+ # Input ids should be clamped to the maximum size of the vocabulary - 1 and the image token should be the last token
+ inputs_dict["input_ids"].clamp_(max=model_vocab_size - 15 - 2)
+ n_images = self.model_tester.num_images * self.model_tester.seq_length
+ model.image_token_id = model_vocab_size - 15 - 1
+ inputs_dict["input_ids"][:, -n_images:] = model.image_token_id
+
+ # Check that the model can still do a forward pass successfully (every parameter should be resized)
+ model(**self._prepare_for_class(inputs_dict, model_class))
+
+
+@require_torch
+class Idefics3ForConditionalGenerationModelTest(GenerationTesterMixin, ModelTesterMixin, unittest.TestCase):
+ """
+ Model tester for `Idefics3ForConditionalGeneration`.
+ """
+
+ all_model_classes = (Idefics3ForConditionalGeneration,) if is_torch_available() else ()
+ pipeline_model_mapping = {"image-text-to-text": Idefics3ForConditionalGeneration} if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = True
+ test_head_masking = False
+ test_torchscript = False
+
+ def setUp(self):
+ self.model_tester = Idefics3VisionText2TextModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=Idefics3Config, has_text_modality=False)
+
+ @unittest.skip(reason="input_embeds cannot be passed in without input_ids")
+ def test_inputs_embeds():
+ pass
+
+ @unittest.skip(reason="Model does not support padding right")
+ def test_flash_attn_2_inference_padding_right(self):
+ pass
+
+ @unittest.skip(reason="Contrastive search is not implemented for VLMs that do cross-attn")
+ def test_contrastive_generate(self):
+ pass
+
+ @unittest.skip(reason="Contrastive search is not implemented for VLMs that do cross-attn")
+ def test_contrastive_generate_dict_outputs_use_cache(self):
+ pass
+
+ @unittest.skip(reason="Contrastive search is not implemented for VLMs that do cross-attn")
+ def test_contrastive_generate_low_memory(self):
+ pass
+
+ @unittest.skip(
+ reason="Prompt lookup decoding needs a way to indicate `bad_word_ids` that should not be suggested as candidates"
+ )
+ def test_prompt_lookup_decoding_matches_greedy_search(self):
+ pass
+
+ @pytest.mark.generate
+ @require_torch_sdpa
+ @slow
+ @unittest.skip(
+ reason="Idefics3 doesn't support SDPA for all backbones, vision backbones has only eager/FA2 attention"
+ )
+ def test_eager_matches_sdpa_generate(self):
+ pass
+
+ @unittest.skip(reason="Compile not yet supported in Idefics3 models end-to-end")
+ def test_sdpa_can_compile_dynamic(self):
+ pass
+
+ # We need to override as we need to prepare such that the image token is the last token
+ def test_resize_tokens_embeddings(self):
+ (original_config, inputs_dict) = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ config = copy.deepcopy(original_config)
+ model = model_class(config)
+ model.to(torch_device)
+
+ model_vocab_size = config.text_config.vocab_size
+ # Retrieve the embeddings and clone theme
+ model_embed = model.resize_token_embeddings(model_vocab_size)
+ cloned_embeddings = model_embed.weight.clone()
+
+ # Check that resizing the token embeddings with a larger vocab size increases the model's vocab size
+ model_embed = model.resize_token_embeddings(model_vocab_size + 10)
+ self.assertEqual(model.config.text_config.vocab_size, model_vocab_size + 10)
+ # Check that it actually resizes the embeddings matrix
+ self.assertEqual(model_embed.weight.shape[0], cloned_embeddings.shape[0] + 10)
+ # Check that the model can still do a forward pass successfully (every parameter should be resized)
+ model(**self._prepare_for_class(inputs_dict, model_class))
+
+ # Check that resizing the token embeddings with a smaller vocab size decreases the model's vocab size
+ model_embed = model.resize_token_embeddings(model_vocab_size - 15)
+ self.assertEqual(model.config.text_config.vocab_size, model_vocab_size - 15)
+ # Check that it actually resizes the embeddings matrix
+ self.assertEqual(model_embed.weight.shape[0], cloned_embeddings.shape[0] - 15)
+
+ # Check that the model can still do a forward pass successfully (every parameter should be resized)
+ # Input ids should be clamped to the maximum size of the vocabulary - 1 and the image token should be the last token
+ inputs_dict["input_ids"].clamp_(max=model_vocab_size - 15 - 2)
+ n_images = self.model_tester.num_images * self.model_tester.seq_length
+ model.model.image_token_id = model_vocab_size - 15 - 1
+ inputs_dict["input_ids"][:, -n_images:] = model.model.image_token_id
+
+ model(**self._prepare_for_class(inputs_dict, model_class))
+
+ # Check that adding and removing tokens has not modified the first part of the embedding matrix.
+ models_equal = True
+ for p1, p2 in zip(cloned_embeddings, model_embed.weight):
+ if p1.data.ne(p2.data).sum() > 0:
+ models_equal = False
+
+ self.assertTrue(models_equal)
+
+ config = copy.deepcopy(original_config)
+ model = model_class(config)
+ model.to(torch_device)
+
+ model_vocab_size = config.text_config.vocab_size
+ model.resize_token_embeddings(model_vocab_size + 10, pad_to_multiple_of=1)
+ self.assertTrue(model.config.text_config.vocab_size + 10, model_vocab_size)
+
+ model_embed = model.resize_token_embeddings(model_vocab_size, pad_to_multiple_of=64)
+ self.assertTrue(model_embed.weight.shape[0] // 64, 0)
+
+ self.assertTrue(model_embed.weight.shape[0], model.config.text_config.vocab_size)
+ self.assertTrue(model.config.text_config.vocab_size, model.vocab_size)
+
+ model_embed = model.resize_token_embeddings(model_vocab_size + 13, pad_to_multiple_of=64)
+ self.assertTrue(model_embed.weight.shape[0] // 64, 0)
+
+ # Check that resizing a model to a multiple of pad_to_multiple leads to a model of exactly that size
+ target_dimension = 128
+ model_embed = model.resize_token_embeddings(target_dimension, pad_to_multiple_of=64)
+ self.assertTrue(model_embed.weight.shape[0], target_dimension)
+
+ with self.assertRaisesRegex(
+ ValueError,
+ "Asking to pad the embedding matrix to a multiple of `1.3`, which is not and integer. Please make sure to pass an integer",
+ ):
+ model.resize_token_embeddings(model_vocab_size, pad_to_multiple_of=1.3)
+
+ # We need to override as we need to prepare such that the image token is the last token
+ def test_resize_embeddings_untied(self):
+ (original_config, inputs_dict) = self.model_tester.prepare_config_and_inputs_for_common()
+
+ original_config.tie_word_embeddings = False
+
+ for model_class in self.all_model_classes:
+ config = copy.deepcopy(original_config)
+ model = model_class(config).to(torch_device)
+
+ # Check that resizing the token embeddings with a larger vocab size increases the model's vocab size
+ model_vocab_size = config.text_config.vocab_size
+ model.resize_token_embeddings(model_vocab_size + 10)
+ self.assertEqual(model.config.text_config.vocab_size, model_vocab_size + 10)
+ output_embeds = model.get_output_embeddings()
+ self.assertEqual(output_embeds.weight.shape[0], model_vocab_size + 10)
+ # Check bias if present
+ if output_embeds.bias is not None:
+ self.assertEqual(output_embeds.bias.shape[0], model_vocab_size + 10)
+ # Check that the model can still do a forward pass successfully (every parameter should be resized)
+ model(**self._prepare_for_class(inputs_dict, model_class))
+
+ # Check that resizing the token embeddings with a smaller vocab size decreases the model's vocab size
+ model.resize_token_embeddings(model_vocab_size - 15)
+ self.assertEqual(model.config.text_config.vocab_size, model_vocab_size - 15)
+ # Check that it actually resizes the embeddings matrix
+ output_embeds = model.get_output_embeddings()
+ self.assertEqual(output_embeds.weight.shape[0], model_vocab_size - 15)
+ # Check bias if present
+ if output_embeds.bias is not None:
+ self.assertEqual(output_embeds.bias.shape[0], model_vocab_size - 15)
+
+ # Check that the model can still do a forward pass successfully (every parameter should be resized)
+ # Input ids should be clamped to the maximum size of the vocabulary - 1 and the image token should be the last token
+ inputs_dict["input_ids"].clamp_(max=model_vocab_size - 15 - 2)
+ n_images = self.model_tester.num_images * self.model_tester.seq_length
+ model.model.image_token_id = model_vocab_size - 15 - 1
+ inputs_dict["input_ids"][:, -n_images:] = model.model.image_token_id
+
+ # Check that the model can still do a forward pass successfully (every parameter should be resized)
+ model(**self._prepare_for_class(inputs_dict, model_class))
+
+
+@require_torch
+class Idefics3ForConditionalGenerationIntegrationTest(unittest.TestCase):
+ def setUp(self):
+ self.processor = AutoProcessor.from_pretrained("HuggingFaceM4/Idefics3-8B-Llama3")
+ self.image1 = Image.open(
+ BytesIO(
+ requests.get(
+ "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg"
+ ).content
+ )
+ )
+ self.image2 = Image.open(
+ BytesIO(requests.get("https://cdn.britannica.com/59/94459-050-DBA42467/Skyline-Chicago.jpg").content)
+ )
+ self.image3 = Image.open(
+ BytesIO(
+ requests.get(
+ "https://thumbs.dreamstime.com/b/golden-gate-bridge-san-francisco-purple-flowers-california-echium-candicans-36805947.jpg"
+ ).content
+ )
+ )
+
+ def tearDown(self):
+ cleanup(torch_device, gc_collect=True)
+
+ @slow
+ @unittest.skip("multi-gpu tests are disabled for now")
+ def test_integration_test(self):
+ model = Idefics3ForConditionalGeneration.from_pretrained(
+ "HuggingFaceM4/Idefics3-8B-Llama3",
+ torch_dtype=torch.bfloat16,
+ device_map="auto",
+ )
+
+ # Create inputs
+ text = "In this image, we see"
+ images = self.image1
+ inputs = self.processor(text=text, images=images, return_tensors="pt", padding=True)
+ inputs.to(torch_device)
+
+ generated_ids = model.generate(**inputs, max_new_tokens=10)
+ generated_texts = self.processor.batch_decode(generated_ids, skip_special_tokens=True)
+
+ expected_generated_text = "In this image, we see the Statue of Liberty, which is located on Liberty"
+ self.assertEqual(generated_texts[0], expected_generated_text)
+
+ @slow
+ @require_bitsandbytes
+ @unittest.skip("multi-gpu tests are disabled for now")
+ def test_integration_test_4bit(self):
+ # Let' s make sure we test the preprocessing to replace what is used
+ model = Idefics3ForConditionalGeneration.from_pretrained(
+ "HuggingFaceM4/Idefics3-8B-Llama3",
+ load_in_4bit=True,
+ device_map="auto",
+ )
+
+ # Create pixel inputs
+ text = ["In this image, we see", "bla, bla "]
+ images = [[self.image1], [self.image2, self.image3]]
+ inputs = self.processor(text=text, images=images, padding=True, return_tensors="pt")
+
+ generated_ids = model.generate(**inputs, max_new_tokens=10)
+ generated_texts = self.processor.batch_decode(generated_ids, skip_special_tokens=True)
+
+ expected_generated_text = "In this image, we see the Statue of Liberty, trees, buildings, water"
+ self.assertEqual(generated_texts[0], expected_generated_text)
diff --git a/transformers/tests/models/idefics3/test_processor_idefics3.py b/transformers/tests/models/idefics3/test_processor_idefics3.py
new file mode 100644
index 0000000000000000000000000000000000000000..99b931a12c280c4f7cbf474a4aeb988c008804dd
--- /dev/null
+++ b/transformers/tests/models/idefics3/test_processor_idefics3.py
@@ -0,0 +1,427 @@
+# Copyright 2024 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import shutil
+import tempfile
+import unittest
+from io import BytesIO
+
+import numpy as np
+import requests
+
+from transformers import Idefics3Processor
+from transformers.models.auto.processing_auto import AutoProcessor
+from transformers.testing_utils import require_torch, require_vision
+from transformers.utils import is_vision_available
+
+from ...test_processing_common import ProcessorTesterMixin
+
+
+if is_vision_available():
+ from PIL import Image
+
+
+@require_torch
+@require_vision
+class Idefics3ProcessorTest(ProcessorTesterMixin, unittest.TestCase):
+ processor_class = Idefics3Processor
+
+ @classmethod
+ def setUpClass(cls):
+ cls.tmpdirname = tempfile.mkdtemp()
+ processor = Idefics3Processor.from_pretrained("HuggingFaceM4/Idefics3-8B-Llama3", image_seq_len=2)
+ processor.save_pretrained(cls.tmpdirname)
+ cls.image1 = Image.open(
+ BytesIO(
+ requests.get(
+ "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg"
+ ).content
+ )
+ )
+ cls.image2 = Image.open(
+ BytesIO(requests.get("https://cdn.britannica.com/59/94459-050-DBA42467/Skyline-Chicago.jpg").content)
+ )
+ cls.image3 = Image.open(
+ BytesIO(
+ requests.get(
+ "https://thumbs.dreamstime.com/b/golden-gate-bridge-san-francisco-purple-flowers-california-echium-candicans-36805947.jpg"
+ ).content
+ )
+ )
+ cls.bos_token = processor.tokenizer.bos_token
+ cls.image_token = processor.image_token
+ cls.fake_image_token = processor.fake_image_token
+ cls.global_img_token = processor.global_image_tag
+
+ cls.bos_token_id = processor.tokenizer.convert_tokens_to_ids(cls.bos_token)
+ cls.image_token_id = processor.tokenizer.convert_tokens_to_ids(cls.image_token)
+ cls.fake_image_token_id = processor.tokenizer.convert_tokens_to_ids(cls.fake_image_token)
+ cls.global_img_tokens_id = processor.tokenizer(cls.global_img_token, add_special_tokens=False)["input_ids"]
+ cls.padding_token_id = processor.tokenizer.pad_token_id
+ cls.image_seq_len = processor.image_seq_len
+
+ def get_tokenizer(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).tokenizer
+
+ def get_image_processor(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).image_processor
+
+ def get_processor(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs)
+
+ @staticmethod
+ def prepare_processor_dict():
+ return {"image_seq_len": 2}
+
+ def get_split_image_expected_tokens(self, processor, image_rows, image_cols):
+ text_split_images = []
+ for n_h in range(image_rows):
+ for n_w in range(image_cols):
+ text_split_images += (
+ [self.fake_image_token_id]
+ + processor.tokenizer(f"", add_special_tokens=False)["input_ids"]
+ + [self.image_token_id] * self.image_seq_len
+ )
+ text_split_images += processor.tokenizer("\n", add_special_tokens=False)["input_ids"]
+ text_split_images = text_split_images[:-1] # remove last newline
+ # add double newline, as it gets its own token
+ text_split_images += processor.tokenizer("\n\n", add_special_tokens=False)["input_ids"]
+ text_split_images += (
+ [self.fake_image_token_id]
+ + self.global_img_tokens_id
+ + [self.image_token_id] * self.image_seq_len
+ + [self.fake_image_token_id]
+ )
+ return text_split_images
+
+ @classmethod
+ def tearDownClass(cls):
+ shutil.rmtree(cls.tmpdirname, ignore_errors=True)
+
+ def test_process_interleaved_images_prompts_no_image_splitting(self):
+ processor = self.get_processor()
+ processor.image_processor.do_image_splitting = False
+
+ # Test that a single image is processed correctly
+ inputs = processor(images=self.image1)
+ image1_expected_size = (364, 364)
+ self.assertEqual(np.array(inputs["pixel_values"]).shape, (1, 1, 3, *image1_expected_size))
+ self.assertEqual(np.array(inputs["pixel_attention_mask"]).shape, (1, 1, *image1_expected_size))
+ # fmt: on
+
+ # Test a single sample with image and text
+ image_str = ""
+ text_str = "In this image, we see"
+ text = image_str + text_str
+ inputs = processor(text=text, images=self.image1)
+
+ # fmt: off
+ tokenized_sentence = processor.tokenizer(text_str, add_special_tokens=False)
+ expected_input_ids = [[self.bos_token_id] + [self.fake_image_token_id] + self.global_img_tokens_id + [self.image_token_id] * self.image_seq_len + [self.fake_image_token_id] + tokenized_sentence["input_ids"]]
+ self.assertEqual(inputs["input_ids"], expected_input_ids)
+ self.assertEqual(inputs["attention_mask"], [[1] * len(expected_input_ids[0])])
+ self.assertEqual(np.array(inputs["pixel_values"]).shape, (1, 1, 3, *image1_expected_size))
+ self.assertEqual(np.array(inputs["pixel_attention_mask"]).shape, (1, 1, *image1_expected_size))
+ # fmt: on
+
+ # Test that batch is correctly processed
+ image_str = ""
+ text_str_1 = "In this image, we see"
+ text_str_2 = "In this image, we see"
+
+ text = [
+ image_str + text_str_1,
+ image_str + image_str + text_str_2,
+ ]
+ images = [[self.image1], [self.image2, self.image3]]
+
+ inputs = processor(text=text, images=images, padding=True)
+
+ # fmt: off
+ tokenized_sentence_1 = processor.tokenizer(text_str_1, add_special_tokens=False)
+ tokenized_sentence_2 = processor.tokenizer(text_str_2, add_special_tokens=False)
+ image_tokens = [self.fake_image_token_id] + self.global_img_tokens_id + [self.image_token_id] * self.image_seq_len + [self.fake_image_token_id]
+ expected_input_ids_1 = [self.bos_token_id] + image_tokens + tokenized_sentence_1["input_ids"]
+ expected_input_ids_2 = [self.bos_token_id] + 2 * image_tokens + tokenized_sentence_2["input_ids"]
+ # Pad the first input to match the second input
+ pad_len = len(expected_input_ids_2) - len(expected_input_ids_1)
+ padded_expected_input_ids_1 = [self.padding_token_id] * pad_len + expected_input_ids_1
+
+ self.assertEqual(
+ inputs["input_ids"], [padded_expected_input_ids_1, expected_input_ids_2]
+ )
+ self.assertEqual(
+ inputs["attention_mask"],
+ [[0] * pad_len + [1] * len(expected_input_ids_1), [1] * len(expected_input_ids_2)]
+ )
+ self.assertEqual(np.array(inputs['pixel_values']).shape, (2, 2, 3, 364, 364))
+ self.assertEqual(np.array(inputs['pixel_attention_mask']).shape, (2, 2, 364, 364))
+ # fmt: on
+
+ def test_process_interleaved_images_prompts_image_splitting(self):
+ processor = self.get_processor()
+ processor.image_processor.do_image_splitting = True
+
+ # Test that a single image is processed correctly
+ inputs = processor(images=self.image1)
+ self.assertEqual(np.array(inputs["pixel_values"]).shape, (1, 13, 3, 364, 364))
+ self.assertEqual(np.array(inputs["pixel_attention_mask"]).shape, (1, 13, 364, 364))
+ # fmt: on
+ self.maxDiff = None
+
+ # Test a single sample with image and text
+ image_str = ""
+ text_str = "In this image, we see"
+ text = image_str + text_str
+ inputs = processor(text=text, images=self.image1)
+
+ # fmt: off
+ tokenized_sentence = processor.tokenizer(text_str, add_special_tokens=False)
+ split_image1_tokens = self.get_split_image_expected_tokens(processor, 3, 4)
+ expected_input_ids_1 = [[self.bos_token_id] + split_image1_tokens + tokenized_sentence["input_ids"]]
+ self.assertEqual(inputs["input_ids"], expected_input_ids_1)
+ self.assertEqual(inputs["attention_mask"], [[1] * len(expected_input_ids_1[0])])
+ self.assertEqual(np.array(inputs["pixel_values"]).shape, (1, 13, 3, 364, 364))
+ self.assertEqual(np.array(inputs["pixel_attention_mask"]).shape, (1, 13, 364, 364))
+ # fmt: on
+
+ # Test that batch is correctly processed
+ image_str = ""
+ text_str_1 = "In this image, we see"
+ text_str_2 = "bla, bla"
+
+ text = [
+ image_str + text_str_1,
+ text_str_2 + image_str + image_str,
+ ]
+ images = [[self.image1], [self.image2, self.image3]]
+
+ inputs = processor(text=text, images=images, padding=True)
+
+ # fmt: off
+ tokenized_sentence_1 = processor.tokenizer(text_str_1, add_special_tokens=False)
+ tokenized_sentence_2 = processor.tokenizer(text_str_2, add_special_tokens=False)
+
+ split_image1_tokens = self.get_split_image_expected_tokens(processor, 3, 4)
+ split_image2_tokens = self.get_split_image_expected_tokens(processor, 4, 4)
+ split_image3_tokens = self.get_split_image_expected_tokens(processor, 3, 4)
+ expected_input_ids_1 = [self.bos_token_id] + split_image1_tokens + tokenized_sentence_1["input_ids"]
+ expected_input_ids_2 = [self.bos_token_id] + tokenized_sentence_2["input_ids"] + split_image2_tokens + split_image3_tokens
+ # Pad the first input to match the second input
+ pad_len = len(expected_input_ids_2) - len(expected_input_ids_1)
+ padded_expected_input_ids_1 = [self.padding_token_id] * pad_len + expected_input_ids_1
+
+ self.assertEqual(
+ inputs["input_ids"], [padded_expected_input_ids_1, expected_input_ids_2]
+ )
+ self.assertEqual(
+ inputs["attention_mask"],
+ [[0] * pad_len + [1] * len(expected_input_ids_1), [1] * len(expected_input_ids_2)]
+ )
+ self.assertEqual(np.array(inputs['pixel_values']).shape, (2, 30, 3, 364, 364))
+ self.assertEqual(np.array(inputs['pixel_attention_mask']).shape, (2, 30, 364, 364))
+ # fmt: on
+
+ def test_add_special_tokens_processor(self):
+ processor = self.get_processor()
+
+ image_str = ""
+ text_str = "In this image, we see"
+ text = text_str + image_str
+
+ # fmt: off
+ inputs = processor(text=text, images=self.image1, add_special_tokens=False)
+ tokenized_sentence = processor.tokenizer(text_str, add_special_tokens=False)
+ split_image1_tokens = self.get_split_image_expected_tokens(processor, 3, 4)
+ expected_input_ids = [tokenized_sentence["input_ids"] + split_image1_tokens]
+ self.assertEqual(inputs["input_ids"], expected_input_ids)
+
+ inputs = processor(text=text, images=self.image1)
+ expected_input_ids = [[self.bos_token_id] + tokenized_sentence["input_ids"] + split_image1_tokens]
+ self.assertEqual(inputs["input_ids"], expected_input_ids)
+ # fmt: on
+
+ def test_non_nested_images_with_batched_text(self):
+ processor = self.get_processor()
+ processor.image_processor.do_image_splitting = False
+
+ image_str = ""
+ text_str_1 = "In this image, we see"
+ text_str_2 = "In this image, we see"
+
+ text = [
+ image_str + text_str_1,
+ image_str + image_str + text_str_2,
+ ]
+ images = [self.image1, self.image2, self.image3]
+
+ inputs = processor(text=text, images=images, padding=True)
+
+ self.assertEqual(np.array(inputs["pixel_values"]).shape, (2, 2, 3, 364, 364))
+ self.assertEqual(np.array(inputs["pixel_attention_mask"]).shape, (2, 2, 364, 364))
+
+ # Copied from tests.models.idefics2.test_processor_idefics2.Idefics2ProcessorTest.test_process_interleaved_images_prompts_image_error
+ def test_process_interleaved_images_prompts_image_error(self):
+ processor = self.get_processor()
+
+ text = [
+ "This is a test sentence.",
+ "In this other sentence we try some good things",
+ ]
+ images = [[self.image1], [self.image2]]
+ with self.assertRaises(ValueError):
+ processor(text=text, images=images, padding=True)
+ images = [[self.image1], []]
+ with self.assertRaises(ValueError):
+ processor(text=text, images=images, padding=True)
+
+ text = [
+ "This is a test sentence.",
+ "In this other sentence we try some good things",
+ ]
+ images = [[self.image1], [self.image2, self.image3]]
+ with self.assertRaises(ValueError):
+ processor(text=text, images=images, padding=True)
+ images = [[], [self.image2]]
+ with self.assertRaises(ValueError):
+ processor(text=text, images=images, padding=True)
+ images = [self.image1, self.image2, self.image3]
+ with self.assertRaises(ValueError):
+ processor(text=text, images=images, padding=True)
+ images = [self.image1]
+ with self.assertRaises(ValueError):
+ processor(text=text, images=images, padding=True)
+
+ text = [
+ "This is a test sentence.",
+ "In this other sentence we try some good things",
+ ]
+ images = [[self.image1], []]
+ with self.assertRaises(ValueError):
+ processor(text=text, images=images, padding=True)
+ images = [[], [self.image2]]
+ with self.assertRaises(ValueError):
+ processor(text=text, images=images, padding=True)
+ images = [self.image1, self.image2]
+ with self.assertRaises(ValueError):
+ processor(text=text, images=images, padding=True)
+ images = [self.image1]
+ with self.assertRaises(ValueError):
+ processor(text=text, images=images, padding=True)
+
+ def test_apply_chat_template(self):
+ # Message contains content which a mix of lists with images and image urls and string
+ messages = [
+ {
+ "role": "user",
+ "content": [
+ {"type": "text", "text": "What do these images show?"},
+ {"type": "image"},
+ {"type": "image"},
+ "What do these images show?",
+ ],
+ },
+ {
+ "role": "assistant",
+ "content": [
+ {
+ "type": "text",
+ "text": "The first image shows the statue of Liberty in New York. The second image picture depicts Idefix, the dog of Obelix in Asterix and Obelix.",
+ }
+ ],
+ },
+ {"role": "user", "content": [{"type": "text", "text": "And who is that?"}]},
+ ]
+ processor = self.get_processor()
+ # Make short sequence length to test that the fake tokens are added correctly
+ rendered = processor.apply_chat_template(messages, add_generation_prompt=True)
+
+ expected_rendered = (
+ "<|begin_of_text|>User: What do these images show?\n"
+ "Assistant: The first image shows the statue of Liberty in New York. The second image picture depicts Idefix, the dog of Obelix in Asterix and Obelix.\n"
+ "User: And who is that?\n"
+ "Assistant:"
+ )
+ self.assertEqual(rendered, expected_rendered)
+
+ @require_torch
+ @require_vision
+ def test_text_only_inference(self):
+ """Test that the processor works correctly with text-only input."""
+ processor = self.get_processor()
+
+ text = "This is a simple text without images."
+ inputs = processor(text=text)
+
+ tokenized_sentence = processor.tokenizer(text, add_special_tokens=False)
+ expected_input_ids = [[self.bos_token_id] + tokenized_sentence["input_ids"]]
+
+ self.assertEqual(inputs["input_ids"], expected_input_ids)
+ self.assertEqual(inputs["attention_mask"], [[1] * len(expected_input_ids[0])])
+ self.assertTrue("pixel_values" not in inputs)
+ self.assertTrue("pixel_attention_mask" not in inputs)
+
+ # Test batch of texts without image tokens
+ texts = ["First text.", "Second piece of text."]
+ batch_inputs = processor(text=texts, padding=True)
+
+ tokenized_1 = processor.tokenizer(texts[0], add_special_tokens=False)
+ tokenized_2 = processor.tokenizer(texts[1], add_special_tokens=False)
+
+ expected_1 = [self.bos_token_id] + tokenized_1["input_ids"]
+ expected_2 = [self.bos_token_id] + tokenized_2["input_ids"]
+
+ # Pad the shorter sequence
+ pad_len = len(expected_2) - len(expected_1)
+ if pad_len > 0:
+ padded_expected_1 = [self.padding_token_id] * pad_len + expected_1
+ expected_attention_1 = [0] * pad_len + [1] * len(expected_1)
+ self.assertEqual(batch_inputs["input_ids"], [padded_expected_1, expected_2])
+ self.assertEqual(batch_inputs["attention_mask"], [expected_attention_1, [1] * len(expected_2)])
+ else:
+ pad_len = -pad_len
+ padded_expected_2 = [self.padding_token_id] * pad_len + expected_2
+ expected_attention_2 = [0] * pad_len + [1] * len(expected_2)
+ self.assertEqual(batch_inputs["input_ids"], [expected_1, padded_expected_2])
+ self.assertEqual(batch_inputs["attention_mask"], [[1] * len(expected_1), expected_attention_2])
+
+ @require_torch
+ @require_vision
+ def test_missing_images_error(self):
+ """Test that appropriate error is raised when images are referenced but not provided."""
+ processor = self.get_processor()
+
+ # Test single text with image token but no image
+ text = "Let me show you this image: What do you think?"
+ with self.assertRaises(ValueError) as context:
+ processor(text=text)
+ self.assertTrue("tokens in the text but no images were passed" in str(context.exception))
+
+ # Test batch with image tokens but no images
+ texts = [
+ "First text with token.",
+ "Second text with token.",
+ ]
+ with self.assertRaises(ValueError) as context:
+ processor(text=texts)
+ self.assertTrue("tokens in the text but no images were passed" in str(context.exception))
+
+ # Test with None as Images
+ with self.assertRaises(ValueError) as context:
+ processor(text=text, images=None)
+ self.assertTrue("tokens in the text but no images were passed" in str(context.exception))
+
+ with self.assertRaises(ValueError) as context:
+ processor(text=texts, images=None)
+ self.assertTrue("tokens in the text but no images were passed" in str(context.exception))
diff --git a/transformers/tests/models/informer/__init__.py b/transformers/tests/models/informer/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/informer/test_modeling_informer.py b/transformers/tests/models/informer/test_modeling_informer.py
new file mode 100644
index 0000000000000000000000000000000000000000..22e6217c72c1ec7e151e8438d6175090d19947dc
--- /dev/null
+++ b/transformers/tests/models/informer/test_modeling_informer.py
@@ -0,0 +1,553 @@
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch Informer model."""
+
+import inspect
+import tempfile
+import unittest
+
+import numpy as np
+from huggingface_hub import hf_hub_download
+
+from transformers import is_torch_available
+from transformers.testing_utils import is_flaky, require_torch, slow, torch_device
+from transformers.utils import check_torch_load_is_safe
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+TOLERANCE = 1e-4
+
+if is_torch_available():
+ import torch
+
+ from transformers import InformerConfig, InformerForPrediction, InformerModel
+ from transformers.models.informer.modeling_informer import (
+ InformerDecoder,
+ InformerEncoder,
+ InformerSinusoidalPositionalEmbedding,
+ )
+
+
+@require_torch
+class InformerModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ prediction_length=7,
+ context_length=14,
+ cardinality=19,
+ embedding_dimension=5,
+ num_time_features=4,
+ is_training=True,
+ hidden_size=16,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ lags_sequence=[1, 2, 3, 4, 5],
+ sampling_factor=10,
+ distil=False,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.prediction_length = prediction_length
+ self.context_length = context_length
+ self.cardinality = cardinality
+ self.num_time_features = num_time_features
+ self.lags_sequence = lags_sequence
+ self.embedding_dimension = embedding_dimension
+ self.is_training = is_training
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+
+ self.encoder_seq_length = min(
+ sampling_factor * np.ceil(np.log1p(context_length)).astype("int").item(), context_length
+ )
+ self.decoder_seq_length = min(
+ sampling_factor * np.ceil(np.log1p(prediction_length)).astype("int").item(), prediction_length
+ )
+ self.sampling_factor = sampling_factor
+ self.distil = distil
+
+ def get_config(self):
+ return InformerConfig(
+ prediction_length=self.prediction_length,
+ d_model=self.hidden_size,
+ encoder_layers=self.num_hidden_layers,
+ decoder_layers=self.num_hidden_layers,
+ encoder_attention_heads=self.num_attention_heads,
+ decoder_attention_heads=self.num_attention_heads,
+ encoder_ffn_dim=self.intermediate_size,
+ decoder_ffn_dim=self.intermediate_size,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ context_length=self.context_length,
+ lags_sequence=self.lags_sequence,
+ num_time_features=self.num_time_features,
+ num_static_categorical_features=1,
+ num_static_real_features=1,
+ cardinality=[self.cardinality],
+ embedding_dimension=[self.embedding_dimension],
+ sampling_factor=self.sampling_factor,
+ distil=self.distil,
+ )
+
+ def prepare_informer_inputs_dict(self, config):
+ _past_length = config.context_length + max(config.lags_sequence)
+
+ static_categorical_features = ids_tensor([self.batch_size, 1], config.cardinality[0])
+ static_real_features = floats_tensor([self.batch_size, 1])
+
+ past_time_features = floats_tensor([self.batch_size, _past_length, config.num_time_features])
+ past_values = floats_tensor([self.batch_size, _past_length])
+ past_observed_mask = floats_tensor([self.batch_size, _past_length]) > 0.5
+
+ # decoder inputs
+ future_time_features = floats_tensor([self.batch_size, config.prediction_length, config.num_time_features])
+ future_values = floats_tensor([self.batch_size, config.prediction_length])
+
+ inputs_dict = {
+ "past_values": past_values,
+ "static_categorical_features": static_categorical_features,
+ "static_real_features": static_real_features,
+ "past_time_features": past_time_features,
+ "past_observed_mask": past_observed_mask,
+ "future_time_features": future_time_features,
+ "future_values": future_values,
+ }
+ return inputs_dict
+
+ def prepare_config_and_inputs(self):
+ config = self.get_config()
+ inputs_dict = self.prepare_informer_inputs_dict(config)
+ return config, inputs_dict
+
+ def prepare_config_and_inputs_for_common(self):
+ config, inputs_dict = self.prepare_config_and_inputs()
+ return config, inputs_dict
+
+ def check_encoder_decoder_model_standalone(self, config, inputs_dict):
+ model = InformerModel(config=config).to(torch_device).eval()
+ outputs = model(**inputs_dict)
+
+ encoder_last_hidden_state = outputs.encoder_last_hidden_state
+ last_hidden_state = outputs.last_hidden_state
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ encoder = model.get_encoder()
+ encoder.save_pretrained(tmpdirname)
+ encoder = InformerEncoder.from_pretrained(tmpdirname).to(torch_device)
+
+ transformer_inputs, _, _, _ = model.create_network_inputs(**inputs_dict)
+ enc_input = transformer_inputs[:, : config.context_length, ...]
+ dec_input = transformer_inputs[:, config.context_length :, ...]
+
+ encoder_last_hidden_state_2 = encoder(inputs_embeds=enc_input)[0]
+
+ self.parent.assertTrue((encoder_last_hidden_state_2 - encoder_last_hidden_state).abs().max().item() < 1e-3)
+
+ embed_positions = InformerSinusoidalPositionalEmbedding(
+ config.context_length + config.prediction_length, config.d_model
+ )
+ embed_positions._init_weight()
+ embed_positions = embed_positions.to(torch_device)
+ self.parent.assertTrue(torch.equal(model.encoder.embed_positions.weight, embed_positions.weight))
+ self.parent.assertTrue(torch.equal(model.decoder.embed_positions.weight, embed_positions.weight))
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ decoder = model.get_decoder()
+ decoder.save_pretrained(tmpdirname)
+ decoder = InformerDecoder.from_pretrained(tmpdirname).to(torch_device)
+
+ last_hidden_state_2 = decoder(
+ inputs_embeds=dec_input,
+ encoder_hidden_states=encoder_last_hidden_state,
+ )[0]
+
+ self.parent.assertTrue((last_hidden_state_2 - last_hidden_state).abs().max().item() < 1e-3)
+
+
+@require_torch
+class InformerModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (InformerModel, InformerForPrediction) if is_torch_available() else ()
+ pipeline_model_mapping = {"feature-extraction": InformerModel} if is_torch_available() else {}
+ is_encoder_decoder = True
+ test_pruning = False
+ test_head_masking = False
+ test_missing_keys = False
+ test_torchscript = False
+ test_inputs_embeds = False
+
+ def setUp(self):
+ self.model_tester = InformerModelTester(self)
+ self.config_tester = ConfigTester(
+ self,
+ config_class=InformerConfig,
+ has_text_modality=False,
+ prediction_length=self.model_tester.prediction_length,
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_save_load_strict(self):
+ config, _ = self.model_tester.prepare_config_and_inputs()
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
+ self.assertEqual(info["missing_keys"], [])
+
+ def test_encoder_decoder_model_standalone(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
+ self.model_tester.check_encoder_decoder_model_standalone(*config_and_inputs)
+
+ def test_hidden_states_output(self):
+ def check_hidden_states_output(inputs_dict, config, model_class):
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ hidden_states = outputs.encoder_hidden_states if config.is_encoder_decoder else outputs.hidden_states
+
+ expected_num_layers = getattr(
+ self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers + 1
+ )
+ self.assertEqual(len(hidden_states), expected_num_layers)
+
+ if hasattr(self.model_tester, "encoder_seq_length"):
+ seq_length = self.model_tester.context_length
+ if hasattr(self.model_tester, "chunk_length") and self.model_tester.chunk_length > 1:
+ seq_length = seq_length * self.model_tester.chunk_length
+ else:
+ seq_length = self.model_tester.seq_length
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [seq_length, self.model_tester.hidden_size],
+ )
+
+ if config.is_encoder_decoder:
+ hidden_states = outputs.decoder_hidden_states
+
+ self.assertIsInstance(hidden_states, (list, tuple))
+ self.assertEqual(len(hidden_states), expected_num_layers)
+ seq_len = getattr(self.model_tester, "seq_length", None)
+ decoder_seq_length = getattr(self.model_tester, "prediction_length", seq_len)
+
+ self.assertListEqual(
+ list(hidden_states[0].shape[-2:]),
+ [decoder_seq_length, self.model_tester.hidden_size],
+ )
+
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_hidden_states"] = True
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ # check that output_hidden_states also work using config
+ del inputs_dict["output_hidden_states"]
+ config.output_hidden_states = True
+
+ check_hidden_states_output(inputs_dict, config, model_class)
+
+ @unittest.skip(reason="Informer does not have tokens embeddings")
+ def test_resize_tokens_embeddings(self):
+ pass
+
+ @unittest.skip
+ def test_model_outputs_equivalence(self):
+ pass
+
+ @unittest.skip
+ def test_determinism(self):
+ pass
+
+ @unittest.skip(reason="randomly selects U keys while calculating attentions")
+ def test_batching_equivalence(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ # # Input is 'static_categorical_features' not 'input_ids'
+ def test_model_main_input_name(self):
+ model_signature = inspect.signature(getattr(InformerModel, "forward"))
+ # The main input is the name of the argument after `self`
+ observed_main_input_name = list(model_signature.parameters.keys())[1]
+ self.assertEqual(InformerModel.main_input_name, observed_main_input_name)
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = [
+ "past_values",
+ "past_time_features",
+ "past_observed_mask",
+ "static_categorical_features",
+ "static_real_features",
+ "future_values",
+ "future_time_features",
+ ]
+
+ expected_arg_names.extend(
+ [
+ "future_observed_mask",
+ "decoder_attention_mask",
+ "head_mask",
+ "decoder_head_mask",
+ "cross_attn_head_mask",
+ "encoder_outputs",
+ "past_key_values",
+ "output_hidden_states",
+ "output_attentions",
+ "use_cache",
+ "return_dict",
+ ]
+ if "future_observed_mask" in arg_names
+ else [
+ "decoder_attention_mask",
+ "head_mask",
+ "decoder_head_mask",
+ "cross_attn_head_mask",
+ "encoder_outputs",
+ "past_key_values",
+ "output_hidden_states",
+ "output_attentions",
+ "use_cache",
+ "return_dict",
+ ]
+ )
+
+ self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
+
+ def test_attention_outputs(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ config.return_dict = True
+
+ seq_len = getattr(self.model_tester, "seq_length", None)
+ decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len)
+ encoder_seq_length = getattr(self.model_tester, "encoder_seq_length", seq_len)
+ context_length = getattr(self.model_tester, "context_length", seq_len)
+ prediction_length = getattr(self.model_tester, "prediction_length", seq_len)
+
+ for model_class in self.all_model_classes:
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = False
+ config.return_dict = True
+ model = model_class._from_config(config, attn_implementation="eager")
+ config = model.config
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ # check that output_attentions also work using config
+ del inputs_dict["output_attentions"]
+ config.output_attentions = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+ attentions = outputs.encoder_attentions
+ self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
+
+ self.assertListEqual(
+ list(attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, encoder_seq_length, context_length],
+ )
+ out_len = len(outputs)
+
+ correct_outlen = 7
+
+ if "last_hidden_state" in outputs:
+ correct_outlen += 1
+
+ if "past_key_values" in outputs:
+ correct_outlen += 1 # past_key_values have been returned
+
+ if "loss" in outputs:
+ correct_outlen += 1
+
+ if "params" in outputs:
+ correct_outlen += 1
+
+ self.assertEqual(out_len, correct_outlen)
+
+ # decoder attentions
+ decoder_attentions = outputs.decoder_attentions
+ self.assertIsInstance(decoder_attentions, (list, tuple))
+ self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(decoder_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, decoder_seq_length, prediction_length],
+ )
+
+ # cross attentions
+ cross_attentions = outputs.cross_attentions
+ self.assertIsInstance(cross_attentions, (list, tuple))
+ self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(cross_attentions[0].shape[-3:]),
+ [
+ self.model_tester.num_attention_heads,
+ decoder_seq_length,
+ encoder_seq_length,
+ ],
+ )
+
+ # Check attention is always last and order is fine
+ inputs_dict["output_attentions"] = True
+ inputs_dict["output_hidden_states"] = True
+ model = model_class(config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ outputs = model(**self._prepare_for_class(inputs_dict, model_class))
+
+ self.assertEqual(out_len + 2, len(outputs))
+
+ self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
+
+ self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
+ self.assertListEqual(
+ list(self_attentions[0].shape[-3:]),
+ [self.model_tester.num_attention_heads, encoder_seq_length, context_length],
+ )
+
+ @is_flaky()
+ def test_retain_grad_hidden_states_attentions(self):
+ super().test_retain_grad_hidden_states_attentions()
+
+ @unittest.skip(reason="Model does not have input embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+
+def prepare_batch(filename="train-batch.pt"):
+ file = hf_hub_download(repo_id="hf-internal-testing/tourism-monthly-batch", filename=filename, repo_type="dataset")
+ check_torch_load_is_safe()
+ batch = torch.load(file, map_location=torch_device, weights_only=True)
+ return batch
+
+
+@require_torch
+@slow
+class InformerModelIntegrationTests(unittest.TestCase):
+ def test_inference_no_head(self):
+ model = InformerModel.from_pretrained("huggingface/informer-tourism-monthly").to(torch_device)
+ batch = prepare_batch()
+
+ torch.manual_seed(0)
+ with torch.no_grad():
+ output = model(
+ past_values=batch["past_values"],
+ past_time_features=batch["past_time_features"],
+ past_observed_mask=batch["past_observed_mask"],
+ static_categorical_features=batch["static_categorical_features"],
+ future_values=batch["future_values"],
+ future_time_features=batch["future_time_features"],
+ ).last_hidden_state
+ expected_shape = torch.Size((64, model.config.context_length, model.config.d_model))
+ self.assertEqual(output.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[0.4699, 0.7295, 0.8967], [0.4858, 0.3810, 0.9641], [-0.0233, 0.3608, 1.0303]],
+ device=torch_device,
+ )
+ torch.testing.assert_close(output[0, :3, :3], expected_slice, rtol=TOLERANCE, atol=TOLERANCE)
+
+ def test_inference_head(self):
+ model = InformerForPrediction.from_pretrained("huggingface/informer-tourism-monthly").to(torch_device)
+ batch = prepare_batch("val-batch.pt")
+
+ torch.manual_seed(0)
+ with torch.no_grad():
+ output = model(
+ past_values=batch["past_values"],
+ past_time_features=batch["past_time_features"],
+ past_observed_mask=batch["past_observed_mask"],
+ static_categorical_features=batch["static_categorical_features"],
+ future_time_features=batch["future_time_features"],
+ ).encoder_last_hidden_state
+
+ # encoder distils the context length to 1/8th of the original length
+ expected_shape = torch.Size((64, model.config.context_length // 8, model.config.d_model))
+ self.assertEqual(output.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[0.4170, 0.9067, 0.8153], [0.3004, 0.7574, 0.7066], [0.6803, -0.6323, 1.2802]], device=torch_device
+ )
+ torch.testing.assert_close(output[0, :3, :3], expected_slice, rtol=TOLERANCE, atol=TOLERANCE)
+
+ def test_seq_to_seq_generation(self):
+ model = InformerForPrediction.from_pretrained("huggingface/informer-tourism-monthly").to(torch_device)
+ batch = prepare_batch("val-batch.pt")
+
+ torch.manual_seed(0)
+ with torch.no_grad():
+ outputs = model.generate(
+ static_categorical_features=batch["static_categorical_features"],
+ past_time_features=batch["past_time_features"],
+ past_values=batch["past_values"],
+ future_time_features=batch["future_time_features"],
+ past_observed_mask=batch["past_observed_mask"],
+ )
+ expected_shape = torch.Size((64, model.config.num_parallel_samples, model.config.prediction_length))
+ self.assertEqual(outputs.sequences.shape, expected_shape)
+
+ expected_slice = torch.tensor([3400.8005, 4289.2637, 7101.9209], device=torch_device)
+ mean_prediction = outputs.sequences.mean(dim=1)
+ torch.testing.assert_close(mean_prediction[0, -3:], expected_slice, rtol=1e-1, atol=1e-1)
diff --git a/transformers/tests/models/instructblip/__init__.py b/transformers/tests/models/instructblip/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/instructblip/test_modeling_instructblip.py b/transformers/tests/models/instructblip/test_modeling_instructblip.py
new file mode 100644
index 0000000000000000000000000000000000000000..341e57017292b22e641011900bd3798a6921d95c
--- /dev/null
+++ b/transformers/tests/models/instructblip/test_modeling_instructblip.py
@@ -0,0 +1,842 @@
+# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch InstructBLIP model."""
+
+import inspect
+import tempfile
+import unittest
+
+import numpy as np
+import pytest
+import requests
+
+from transformers import (
+ CONFIG_MAPPING,
+ InstructBlipConfig,
+ InstructBlipProcessor,
+ InstructBlipQFormerConfig,
+ InstructBlipVisionConfig,
+)
+from transformers.testing_utils import (
+ Expectations,
+ cleanup,
+ require_accelerate,
+ require_bitsandbytes,
+ require_torch,
+ require_torch_sdpa,
+ require_vision,
+ slow,
+ torch_device,
+)
+from transformers.utils import is_torch_available, is_vision_available
+
+from ...generation.test_utils import GenerationTesterMixin
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import (
+ ModelTesterMixin,
+ floats_tensor,
+ ids_tensor,
+ random_attention_mask,
+)
+
+
+if is_torch_available():
+ import torch
+ from torch import nn
+
+ from transformers import InstructBlipForConditionalGeneration, InstructBlipModel, InstructBlipVisionModel
+
+
+if is_vision_available():
+ from PIL import Image
+
+
+class InstructBlipVisionModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ image_size=30,
+ patch_size=2,
+ num_channels=3,
+ is_training=True,
+ hidden_size=32,
+ projection_dim=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ initializer_range=1e-10,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.num_channels = num_channels
+ self.is_training = is_training
+ self.hidden_size = hidden_size
+ self.projection_dim = projection_dim
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.initializer_range = initializer_range
+ self.scope = scope
+
+ # in case of a vision transformer, the seq length equals the number of patches + 1 (we add 1 for the [CLS] token)
+ num_patches = (image_size // patch_size) ** 2
+ self.seq_length = num_patches + 1
+
+ def prepare_config_and_inputs(self):
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+ config = self.get_config()
+
+ return config, pixel_values
+
+ def get_config(self):
+ return InstructBlipVisionConfig(
+ image_size=self.image_size,
+ patch_size=self.patch_size,
+ num_channels=self.num_channels,
+ hidden_size=self.hidden_size,
+ projection_dim=self.projection_dim,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(self, config, pixel_values):
+ model = InstructBlipVisionModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ with torch.no_grad():
+ result = model(pixel_values)
+ # expected sequence length = num_patches + 1 (we add 1 for the [CLS] token)
+ image_size = (self.image_size, self.image_size)
+ patch_size = (self.patch_size, self.patch_size)
+ num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, num_patches + 1, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, pixel_values = config_and_inputs
+ inputs_dict = {"pixel_values": pixel_values}
+ return config, inputs_dict
+
+
+@require_torch
+class InstructBlipVisionModelTest(ModelTesterMixin, unittest.TestCase):
+ """
+ Here we also overwrite some of the tests of test_modeling_common.py, as InstructBLIP's vision encoder does not use input_ids, inputs_embeds,
+ attention_mask and seq_length.
+ """
+
+ all_model_classes = (InstructBlipVisionModel,) if is_torch_available() else ()
+ fx_compatible = False
+ test_pruning = False
+ test_resize_embeddings = False
+ test_head_masking = False
+
+ def setUp(self):
+ self.model_tester = InstructBlipVisionModelTester(self)
+ self.config_tester = ConfigTester(
+ self,
+ config_class=InstructBlipConfig,
+ has_text_modality=False,
+ common_properties=["num_query_tokens", "image_token_index"],
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ @unittest.skip(reason="InstructBLIP's vision encoder does not use inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ def test_model_get_set_embeddings(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
+ x = model.get_output_embeddings()
+ self.assertTrue(x is None or isinstance(x, nn.Linear))
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ @unittest.skip(reason="InstructBlipVisionModel is an internal building block, doesn't support standalone training")
+ def test_training(self):
+ pass
+
+ @unittest.skip(reason="InstructBlipVisionModel is an internal building block, doesn't support standalone training")
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "Salesforce/instructblip-flan-t5-xl"
+ model = InstructBlipVisionModel.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+class InstructBlipQFormerModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ projection_dim=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ dropout=0.1,
+ attention_dropout=0.1,
+ max_position_embeddings=512,
+ initializer_range=0.02,
+ bos_token_id=0,
+ scope=None,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.projection_dim = projection_dim
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.dropout = dropout
+ self.attention_dropout = attention_dropout
+ self.max_position_embeddings = max_position_embeddings
+ self.initializer_range = initializer_range
+ self.scope = scope
+ self.bos_token_id = bos_token_id
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+ qformer_input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.seq_length])
+ qformer_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
+
+ if input_mask is not None:
+ batch_size, seq_length = input_mask.shape
+ rnd_start_indices = np.random.randint(1, seq_length - 1, size=(batch_size,))
+ for batch_idx, start_index in enumerate(rnd_start_indices):
+ input_mask[batch_idx, :start_index] = 1
+ input_mask[batch_idx, start_index:] = 0
+
+ config = self.get_config()
+
+ return config, input_ids, input_mask, qformer_input_ids, qformer_attention_mask
+
+ def get_config(self):
+ return InstructBlipQFormerConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ projection_dim=self.projection_dim,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ dropout=self.dropout,
+ attention_dropout=self.attention_dropout,
+ max_position_embeddings=self.max_position_embeddings,
+ initializer_range=self.initializer_range,
+ bos_token_id=self.bos_token_id,
+ )
+
+
+# this class is based on `OPTModelTester` found in tests/models/opt/test_modeling_opt.py
+class InstructBlipTextModelDecoderOnlyTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=12,
+ seq_length=7,
+ is_training=True,
+ use_labels=False,
+ vocab_size=99,
+ hidden_size=16,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=4,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=100,
+ eos_token_id=2,
+ pad_token_id=1,
+ bos_token_id=0,
+ embed_dim=16,
+ num_labels=3,
+ word_embed_proj_dim=16,
+ type_sequence_label_size=2,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.eos_token_id = eos_token_id
+ self.pad_token_id = pad_token_id
+ self.bos_token_id = bos_token_id
+ self.embed_dim = embed_dim
+ self.num_labels = num_labels
+ self.type_sequence_label_size = type_sequence_label_size
+ self.word_embed_proj_dim = word_embed_proj_dim
+ self.is_encoder_decoder = False
+
+ def prepare_config_and_inputs(self):
+ config = self.get_config()
+
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size).clamp(3)
+ input_ids[:, -1] = self.eos_token_id # Eos Token
+
+ attention_mask = input_ids.ne(self.pad_token_id)
+
+ return config, input_ids, attention_mask
+
+ def get_config(self):
+ return CONFIG_MAPPING["opt"](
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ ffn_dim=self.intermediate_size,
+ dropout=self.hidden_dropout_prob,
+ attention_dropout=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ eos_token_id=self.eos_token_id,
+ bos_token_id=self.bos_token_id,
+ pad_token_id=self.pad_token_id,
+ embed_dim=self.embed_dim,
+ is_encoder_decoder=False,
+ word_embed_proj_dim=self.word_embed_proj_dim,
+ )
+
+
+# this model tester uses a decoder-only language model (OPT)
+class InstructBlipForConditionalGenerationDecoderOnlyModelTester:
+ def __init__(
+ self,
+ parent,
+ vision_kwargs=None,
+ qformer_kwargs=None,
+ text_kwargs=None,
+ is_training=True,
+ num_query_tokens=10,
+ image_token_index=4,
+ ):
+ if vision_kwargs is None:
+ vision_kwargs = {}
+ if qformer_kwargs is None:
+ qformer_kwargs = {}
+ if text_kwargs is None:
+ text_kwargs = {}
+
+ self.parent = parent
+ self.vision_model_tester = InstructBlipVisionModelTester(parent, **vision_kwargs)
+ self.qformer_model_tester = InstructBlipQFormerModelTester(parent, **qformer_kwargs)
+ self.text_model_tester = InstructBlipTextModelDecoderOnlyTester(parent, **text_kwargs)
+ self.batch_size = self.text_model_tester.batch_size # need bs for batching_equivalence test
+ self.seq_length = self.text_model_tester.seq_length + num_query_tokens # need seq_length for common tests
+ self.is_training = is_training
+ self.num_query_tokens = num_query_tokens
+ self.image_token_index = image_token_index
+
+ def prepare_config_and_inputs(self):
+ _, pixel_values = self.vision_model_tester.prepare_config_and_inputs()
+ _, _, _, qformer_input_ids, qformer_attention_mask = self.qformer_model_tester.prepare_config_and_inputs()
+ _, input_ids, attention_mask = self.text_model_tester.prepare_config_and_inputs()
+
+ config = self.get_config()
+ vision_tokens = (
+ torch.ones((input_ids.shape[0], self.num_query_tokens), device=torch_device, dtype=input_ids.dtype)
+ * self.image_token_index
+ )
+ input_ids[input_ids == self.image_token_index] = self.text_model_tester.pad_token_id
+ input_ids = torch.cat([vision_tokens, input_ids], dim=-1)
+ vision_attention_mask = torch.ones_like(vision_tokens)
+ attention_mask = torch.cat([vision_attention_mask, attention_mask], dim=-1)
+
+ return config, input_ids, attention_mask, qformer_input_ids, qformer_attention_mask, pixel_values
+
+ def get_config(self):
+ return InstructBlipConfig.from_vision_qformer_text_configs(
+ vision_config=self.vision_model_tester.get_config(),
+ qformer_config=self.qformer_model_tester.get_config(),
+ text_config=self.text_model_tester.get_config(),
+ num_query_tokens=self.num_query_tokens,
+ image_token_index=self.image_token_index,
+ )
+
+ def create_and_check_for_conditional_generation(
+ self, config, input_ids, attention_mask, qformer_input_ids, qformer_attention_mask, pixel_values
+ ):
+ model = InstructBlipForConditionalGeneration(config).to(torch_device).eval()
+ with torch.no_grad():
+ result = model(
+ pixel_values,
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ qformer_input_ids=qformer_input_ids,
+ qformer_attention_mask=qformer_attention_mask,
+ )
+
+ expected_seq_length = self.num_query_tokens + self.text_model_tester.seq_length
+ self.parent.assertEqual(
+ result.logits.shape,
+ (self.vision_model_tester.batch_size, expected_seq_length, self.text_model_tester.vocab_size),
+ )
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ config, input_ids, attention_mask, qformer_input_ids, qformer_attention_mask, pixel_values = config_and_inputs
+ inputs_dict = {
+ "pixel_values": pixel_values,
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "qformer_input_ids": qformer_input_ids,
+ "qformer_attention_mask": qformer_attention_mask,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class InstructBlipForConditionalGenerationDecoderOnlyTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ InstructBlipModel,
+ InstructBlipForConditionalGeneration,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = {"image-text-to-text": InstructBlipForConditionalGeneration}
+ additional_model_inputs = ["qformer_input_ids", "input_ids"]
+ fx_compatible = False
+ test_head_masking = False
+ test_pruning = False
+ test_resize_embeddings = True
+ test_attention_outputs = False
+ test_torchscript = False
+ _is_composite = True
+
+ def setUp(self):
+ self.model_tester = InstructBlipForConditionalGenerationDecoderOnlyModelTester(self)
+ self.config_tester = ConfigTester(
+ self,
+ config_class=InstructBlipConfig,
+ has_text_modality=False,
+ common_properties=["num_query_tokens", "image_token_index"],
+ )
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_for_conditional_generation(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_conditional_generation(*config_and_inputs)
+
+ @unittest.skip(
+ reason=" InstructBlipQFormerModel does not support an attention implementation through torch.nn.functional.scaled_dot_product_attention yet."
+ )
+ def test_eager_matches_sdpa_generate(self):
+ pass
+
+ @unittest.skip(reason="Hidden_states is tested in individual model tests")
+ def test_hidden_states_output(self):
+ pass
+
+ @unittest.skip(reason="InstructBlipForConditionalGeneration doesn't support inputs_embeds")
+ def test_inputs_embeds(self):
+ pass
+
+ @unittest.skip(reason="Tied weights are tested in individual model tests")
+ def test_tied_weights_keys(self):
+ pass
+
+ @unittest.skip(reason="Retain_grad is tested in individual model tests")
+ def test_retain_grad_hidden_states_attentions(self):
+ pass
+
+ @unittest.skip(reason="InstructBlipModel does not have input/output embeddings")
+ def test_model_get_set_embeddings(self):
+ pass
+
+ def test_forward_signature(self):
+ config, _ = self.model_tester.prepare_config_and_inputs_for_common()
+
+ for model_class in self.all_model_classes:
+ model = model_class(config)
+ signature = inspect.signature(model.forward)
+ # signature.parameters is an OrderedDict => so arg_names order is deterministic
+ arg_names = [*signature.parameters.keys()]
+
+ expected_arg_names = ["pixel_values"]
+ self.assertListEqual(arg_names[:1], expected_arg_names)
+
+ def test_load_vision_qformer_text_config(self):
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+
+ # Save InstructBlipConfig and check if we can load InstructBlipVisionConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ vision_config = InstructBlipVisionConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.vision_config.to_dict(), vision_config.to_dict())
+
+ # Save InstructBlipConfig and check if we can load InstructBlipQFormerConfig from it
+ with tempfile.TemporaryDirectory() as tmp_dir_name:
+ config.save_pretrained(tmp_dir_name)
+ qformer_config = InstructBlipQFormerConfig.from_pretrained(tmp_dir_name)
+ self.assertDictEqual(config.qformer_config.to_dict(), qformer_config.to_dict())
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "Salesforce/instructblip-flan-t5-xl"
+ model = InstructBlipForConditionalGeneration.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+ # overwrite because InstructBLIP internally calls LM.generate() with embeds thus it cannot operate in no cache format
+ def _check_generate_outputs(self, output, config, use_cache=False, num_return_sequences=1, num_beams=1):
+ use_cache = True # force this to be True in case False is passed
+ super()._check_generate_outputs(
+ output, config, use_cache=use_cache, num_return_sequences=num_return_sequences, num_beams=num_beams
+ )
+
+ # overwrite because InstructBLIP cannot generate only from input ids, and requires `pixel` values and `qformer_input_ids` in all cases to be present
+ @pytest.mark.generate
+ def test_left_padding_compatibility(self):
+ # NOTE: left-padding results in small numerical differences. This is expected.
+ # See https://github.com/huggingface/transformers/issues/25420#issuecomment-1775317535
+
+ # First, filter out models that don't support left padding
+ # - The model must have generative capabilities
+ if len(self.all_generative_model_classes) == 0:
+ self.skipTest(reason="No generative architecture available for this model.")
+
+ # - The model must support padding
+ if not self.has_attentions:
+ self.skipTest(reason="This model doesn't support padding.")
+
+ # - The model must be a decoder-only architecture (encoder-based architectures use right-padding)
+ decoder_only_classes = []
+ for model_class in self.all_generative_model_classes:
+ config, _ = self.prepare_config_and_inputs_for_generate()
+ if config.is_encoder_decoder:
+ continue
+ else:
+ decoder_only_classes.append(model_class)
+ if len(decoder_only_classes) == 0:
+ self.skipTest(reason="No decoder-only architecture available for this model.")
+
+ # - Decoder-only architectures derived from encoder-decoder models could support it in theory, but we haven't
+ # added support for it yet. We skip these models for now.
+ has_encoder_attributes = any(
+ attr_name
+ for attr_name in config.to_dict().keys()
+ if attr_name.startswith("encoder") and attr_name != "encoder_no_repeat_ngram_size"
+ )
+ if has_encoder_attributes:
+ self.skipTest(
+ reason="The decoder-only derived from encoder-decoder models are not expected to support left-padding."
+ )
+
+ # Then, test left-padding
+ def _prepare_model_kwargs(input_ids, attention_mask, signature):
+ model_kwargs = {"input_ids": input_ids, "attention_mask": attention_mask}
+ if "position_ids" in signature:
+ position_ids = torch.cumsum(attention_mask, dim=-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ model_kwargs["position_ids"] = position_ids
+ if "cache_position" in signature:
+ cache_position = torch.arange(input_ids.shape[-1], device=torch_device)
+ model_kwargs["cache_position"] = cache_position
+ return model_kwargs
+
+ for model_class in decoder_only_classes:
+ config, inputs_dict = self.prepare_config_and_inputs_for_generate()
+ input_ids = inputs_dict["input_ids"]
+ attention_mask = inputs_dict.get("attention_mask")
+ pixel_values = inputs_dict["pixel_values"]
+ qformer_input_ids = inputs_dict["qformer_input_ids"]
+ if attention_mask is None:
+ attention_mask = torch.ones_like(input_ids)
+
+ model = model_class(config).to(torch_device).eval()
+ signature = inspect.signature(model.forward).parameters.keys()
+
+ # no cache as some models require special cache classes to be init outside forward
+ model.generation_config.use_cache = False
+
+ # Without padding
+ model_kwargs = _prepare_model_kwargs(input_ids, attention_mask, signature)
+ next_logits_wo_padding = model(
+ **model_kwargs, pixel_values=pixel_values, qformer_input_ids=qformer_input_ids
+ ).logits[:, -1, :]
+
+ # With left-padding (length 32)
+ # can hardcode pad_token to be 0 as we'll do attn masking anyway
+ pad_token_id = (
+ config.get_text_config().pad_token_id if config.get_text_config().pad_token_id is not None else 0
+ )
+ pad_size = (input_ids.shape[0], 32)
+ padding = torch.ones(pad_size, dtype=input_ids.dtype, device=torch_device) * pad_token_id
+ padded_input_ids = torch.cat((padding, input_ids), dim=1)
+ padded_attention_mask = torch.cat((torch.zeros_like(padding), attention_mask), dim=1)
+ model_kwargs = _prepare_model_kwargs(padded_input_ids, padded_attention_mask, signature)
+ next_logits_with_padding = model(
+ **model_kwargs, pixel_values=pixel_values, qformer_input_ids=qformer_input_ids
+ ).logits[:, -1, :]
+
+ # They should result in very similar logits
+ torch.testing.assert_close(next_logits_wo_padding, next_logits_with_padding, rtol=1e-5, atol=1e-5)
+
+ @require_torch_sdpa
+ def test_sdpa_can_dispatch_composite_models(self):
+ """
+ Tests if composite models dispatch correctly on SDPA/eager when requested so when loading the model.
+ This tests only by looking at layer names, as usually SDPA layers are called "SDPAAttention".
+ In contrast to the above test, this one checks if the "config._attn_implamentation" is a dict after the model
+ is loaded, because we manually replicate requested attn implementation on each sub-config when loading.
+ See https://github.com/huggingface/transformers/pull/32238 for more info
+
+ The test tries to cover most general cases of composite models, VLMs with vision and text configs. Any model
+ that has a different set of sub-configs has to overwrite this test.
+ """
+ if not self.has_attentions:
+ self.skipTest(reason="Model architecture does not support attentions")
+
+ if not self._is_composite:
+ self.skipTest(f"{self.all_model_classes[0].__name__} does not support SDPA")
+
+ for model_class in self.all_model_classes:
+ config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
+ model = model_class(config)
+
+ with tempfile.TemporaryDirectory() as tmpdirname:
+ model.save_pretrained(tmpdirname)
+ model_sdpa = model_class.from_pretrained(tmpdirname)
+ model_sdpa = model_sdpa.eval().to(torch_device)
+
+ # `None` as it is the requested one which will be assigned to each sub-config
+ # Sub-model will dispatch to SDPA if it can (checked below that `SDPA` layers are present)
+ self.assertTrue(model.language_model.config._attn_implementation == "sdpa")
+ self.assertTrue(model.vision_model.config._attn_implementation == "sdpa")
+ self.assertTrue(model.qformer.config._attn_implementation == "eager")
+
+ model_eager = model_class.from_pretrained(tmpdirname, attn_implementation="eager")
+ model_eager = model_eager.eval().to(torch_device)
+ self.assertTrue(model_eager.config._attn_implementation == "eager")
+ self.assertTrue(model_eager.language_model.config._attn_implementation == "eager")
+ self.assertTrue(model_eager.vision_model.config._attn_implementation == "eager")
+ self.assertTrue(model_eager.qformer.config._attn_implementation == "eager")
+
+ for name, submodule in model_eager.named_modules():
+ class_name = submodule.__class__.__name__
+ if (
+ class_name.endswith("Attention")
+ and getattr(submodule, "config", None)
+ and submodule.config._attn_implementation == "sdpa"
+ ):
+ raise ValueError("The eager model should not have SDPA attention layers")
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ url = "https://huggingface.co/hf-internal-testing/blip-test-image/resolve/main/demo.jpg"
+ image = Image.open(requests.get(url, stream=True).raw)
+ return image
+
+
+@require_vision
+@require_torch
+@slow
+class InstructBlipModelIntegrationTest(unittest.TestCase):
+ def tearDown(self):
+ cleanup(torch_device, gc_collect=False)
+
+ @require_bitsandbytes
+ @require_accelerate
+ def test_inference_vicuna_7b(self):
+ processor = InstructBlipProcessor.from_pretrained("Salesforce/instructblip-vicuna-7b")
+ model = InstructBlipForConditionalGeneration.from_pretrained(
+ "Salesforce/instructblip-vicuna-7b", load_in_8bit=True
+ )
+
+ url = "https://raw.githubusercontent.com/salesforce/LAVIS/main/docs/_static/Confusing-Pictures.jpg"
+ image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+ prompt = "What is unusual about this image?"
+ inputs = processor(images=image, text=prompt, return_tensors="pt").to(torch_device, torch.float16)
+
+ # verify generation
+ outputs = model.generate(**inputs, max_new_tokens=30)
+ generated_text = processor.batch_decode(outputs, skip_special_tokens=True)[0].strip()
+
+ expected_outputs = Expectations(
+ {
+ ("xpu", 3): [32001] * 32 + [2, 1724, 338, 22910, 1048, 445, 1967, 29973, 450, 22910, 9565, 310, 445, 1967, 338, 393, 263, 767, 338, 13977, 292, 22095, 373, 278, 1250, 310, 263, 13328, 20134, 29963, 1550, 19500, 1623, 263, 19587, 4272, 11952, 29889],
+ ("cuda", None): [32001] * 32 + [2, 1724, 338, 22910, 1048, 445, 1967, 29973, 450, 22910, 9565, 310, 445, 1967, 338, 393, 263, 767, 338, 13977, 292, 22095, 373, 278, 1250, 310, 263, 13328, 20134, 29963, 1550, 19500, 373, 263, 19587, 4272, 11952, 29889],
+ }
+ ) # fmt: off
+ expected_output = expected_outputs.get_expectation()
+
+ expected_texts = Expectations(
+ {
+ ("xpu", 3): "What is unusual about this image? The unusual aspect of this image is that a man is ironing clothes on the back of a yellow SUV while driving down a busy city street.",
+ ("cuda", None): "What is unusual about this image? The unusual aspect of this image is that a man is ironing clothes on the back of a yellow SUV while driving on a busy city street.",
+ }
+ ) # fmt: off
+ expected_text = expected_texts.get_expectation()
+
+ self.assertEqual(outputs[0].tolist(), expected_output)
+ self.assertEqual(generated_text, expected_text)
+
+ def test_inference_flant5_xl(self):
+ processor = InstructBlipProcessor.from_pretrained("Salesforce/instructblip-flan-t5-xl")
+ model = InstructBlipForConditionalGeneration.from_pretrained(
+ "Salesforce/instructblip-flan-t5-xl",
+ torch_dtype=torch.bfloat16,
+ ).to(torch_device)
+
+ url = "https://raw.githubusercontent.com/salesforce/LAVIS/main/docs/_static/Confusing-Pictures.jpg"
+ image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
+ prompt = "What is unusual about this image?"
+ inputs = processor(images=image, text=prompt, return_tensors="pt").to(torch_device)
+
+ for k, v in inputs.items():
+ if torch.is_floating_point(v):
+ inputs[k] = v.to(torch.bfloat16)
+
+ outputs = model.generate(
+ **inputs,
+ do_sample=False,
+ num_beams=5,
+ max_length=256,
+ min_length=1,
+ repetition_penalty=1.5,
+ length_penalty=1.0,
+ temperature=1,
+ )
+ generated_text = processor.batch_decode(outputs, skip_special_tokens=True)[0]
+ expected_outputs = [0, 37, 1023, 9850, 7, 3, 9, 388, 3575, 53, 4954, 30, 8, 223, 13, 3, 9, 4459, 4049, 16, 8, 2214, 13, 3, 9, 3164, 690, 2815, 5, 37, 388, 19, 5119, 3, 9, 4459, 8677, 28, 3, 9, 4459, 6177, 6, 11, 3, 88, 19, 338, 46, 3575, 53, 1476, 5223, 12, 8, 223, 13, 8, 4049, 5, 37, 1023, 19, 7225, 16, 24, 34, 1267, 3, 9, 388, 3575, 53, 4954, 30, 8, 223, 13, 3, 9, 4049, 16, 8, 2214, 13, 3, 9, 3164, 690, 2815, 5, 37, 388, 19, 338, 46, 3575, 53, 1476, 5223, 12, 8, 223, 13, 3, 9, 4049, 16, 8, 2214, 13, 3, 9, 3164, 690, 2815, 5, 37, 388, 19, 338, 46, 3575, 53, 1476, 5223, 12, 8, 223, 13, 3, 9, 4049, 16, 8, 2214, 13, 3, 9, 3164, 690, 2815, 5, 37, 1023, 19, 7225, 16, 24, 34, 1267, 3, 9, 388, 3575, 53, 4954, 30, 8, 223, 13, 3, 9, 4049, 16, 8, 2214, 13, 3, 9, 3164, 690, 2815, 5, 37, 388, 19, 338, 46, 3575, 53, 1476, 5223, 12, 8, 223, 13, 3, 9, 4049, 16, 8, 2214, 13, 3, 9, 3164, 690, 2815, 5, 1] # fmt: skip
+
+ self.assertEqual(outputs[0].tolist(), expected_outputs)
+ self.assertEqual(
+ generated_text,
+ "The image depicts a man ironing clothes on the back of a yellow van in the middle of a busy city street. The man is wearing a yellow shirt with a yellow tie, and he is using an ironing board attached to the back of the van. The image is unusual in that it shows a man ironing clothes on the back of a van in the middle of a busy city street. The man is using an ironing board attached to the back of a van in the middle of a busy city street. The man is using an ironing board attached to the back of a van in the middle of a busy city street. The image is unusual in that it shows a man ironing clothes on the back of a van in the middle of a busy city street. The man is using an ironing board attached to the back of a van in the middle of a busy city street.",
+ )
+
+ def test_inference_interpolate_pos_encoding(self):
+ processor = InstructBlipProcessor.from_pretrained("Salesforce/instructblip-flan-t5-xl")
+ model = InstructBlipForConditionalGeneration.from_pretrained(
+ "Salesforce/instructblip-flan-t5-xl",
+ torch_dtype=torch.bfloat16,
+ ).to(torch_device)
+ processor.image_processor.size = {"height": 500, "width": 500}
+
+ image = prepare_img()
+ prompt = "What's in the image?"
+ inputs = processor(images=image, text=prompt, return_tensors="pt").to(torch_device)
+
+ predictions = model.generate(**inputs, interpolate_pos_encoding=True)
+ generated_text = processor.batch_decode(predictions, skip_special_tokens=True)[0].strip()
+
+ self.assertEqual(
+ predictions[0].tolist(), [0, 37, 1023, 753, 3, 9, 2335, 3823, 30, 8, 2608, 28, 3, 9, 1782, 5, 1]
+ )
+ self.assertEqual(generated_text, "The image features a woman sitting on the beach with a dog.")
+
+ def test_expansion_in_processing(self):
+ processor = InstructBlipProcessor.from_pretrained("Salesforce/instructblip-flan-t5-xl")
+ model = InstructBlipForConditionalGeneration.from_pretrained(
+ "Salesforce/instructblip-flan-t5-xl",
+ torch_dtype=torch.bfloat16,
+ ).to(torch_device)
+
+ image = prepare_img()
+ prompt = "What's in the image?"
+
+ # Make sure we will go the legacy path by setting these args to None
+ processor.num_query_tokens = None
+ model.config.image_token_index = None
+ inputs = processor(images=image, text=prompt, return_tensors="pt").to(torch_device, dtype=torch.float16)
+
+ predictions = model.generate(**inputs, do_sample=False, max_new_tokens=15)
+ generated_text = processor.batch_decode(predictions, skip_special_tokens=True)[0].strip()
+
+ # Add args to the config to trigger new logic when inputs are expanded in processing file
+ processor.num_query_tokens = model.config.num_query_tokens
+ processor.tokenizer.add_special_tokens({"additional_special_tokens": [""]})
+ model.config.image_token_index = len(processor.tokenizer) - 2
+ model.resize_token_embeddings(processor.tokenizer.vocab_size, pad_to_multiple_of=64)
+
+ # Generate again with new inputs
+ inputs = processor(images=image, text=prompt, return_tensors="pt").to(torch_device, dtype=torch.float16)
+ predictions_expanded = model.generate(**inputs, do_sample=False, max_new_tokens=15)
+ generated_text_expanded = processor.batch_decode(predictions_expanded, skip_special_tokens=True)[0].strip()
+
+ self.assertTrue(generated_text_expanded == generated_text)
diff --git a/transformers/tests/models/instructblip/test_processor_instructblip.py b/transformers/tests/models/instructblip/test_processor_instructblip.py
new file mode 100644
index 0000000000000000000000000000000000000000..6675390e0b2f88237958b7f8817bbb0f93e5a85e
--- /dev/null
+++ b/transformers/tests/models/instructblip/test_processor_instructblip.py
@@ -0,0 +1,184 @@
+# Copyright 2023 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import shutil
+import tempfile
+import unittest
+
+import pytest
+
+from transformers.testing_utils import require_vision
+from transformers.utils import is_vision_available
+
+from ...test_processing_common import ProcessorTesterMixin
+
+
+if is_vision_available():
+ from transformers import (
+ AutoProcessor,
+ BertTokenizerFast,
+ BlipImageProcessor,
+ GPT2Tokenizer,
+ InstructBlipProcessor,
+ PreTrainedTokenizerFast,
+ )
+
+
+@require_vision
+class InstructBlipProcessorTest(ProcessorTesterMixin, unittest.TestCase):
+ processor_class = InstructBlipProcessor
+
+ @classmethod
+ def setUpClass(cls):
+ cls.tmpdirname = tempfile.mkdtemp()
+
+ image_processor = BlipImageProcessor()
+ tokenizer = GPT2Tokenizer.from_pretrained("hf-internal-testing/tiny-random-GPT2Model")
+ qformer_tokenizer = BertTokenizerFast.from_pretrained("hf-internal-testing/tiny-random-bert")
+
+ processor = InstructBlipProcessor(image_processor, tokenizer, qformer_tokenizer)
+
+ processor.save_pretrained(cls.tmpdirname)
+
+ def get_tokenizer(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).tokenizer
+
+ def get_image_processor(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).image_processor
+
+ def get_qformer_tokenizer(self, **kwargs):
+ return AutoProcessor.from_pretrained(self.tmpdirname, **kwargs).qformer_tokenizer
+
+ @classmethod
+ def tearDownClass(cls):
+ shutil.rmtree(cls.tmpdirname, ignore_errors=True)
+
+ def test_save_load_pretrained_additional_features(self):
+ processor = InstructBlipProcessor(
+ tokenizer=self.get_tokenizer(),
+ image_processor=self.get_image_processor(),
+ qformer_tokenizer=self.get_qformer_tokenizer(),
+ )
+ with tempfile.TemporaryDirectory() as tmpdir:
+ processor.save_pretrained(tmpdir)
+
+ tokenizer_add_kwargs = self.get_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
+ image_processor_add_kwargs = self.get_image_processor(do_normalize=False, padding_value=1.0)
+
+ processor = InstructBlipProcessor.from_pretrained(
+ tmpdir, bos_token="(BOS)", eos_token="(EOS)", do_normalize=False, padding_value=1.0
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, PreTrainedTokenizerFast)
+
+ self.assertEqual(processor.image_processor.to_json_string(), image_processor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.image_processor, BlipImageProcessor)
+ self.assertIsInstance(processor.qformer_tokenizer, BertTokenizerFast)
+
+ def test_image_processor(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+ qformer_tokenizer = self.get_qformer_tokenizer()
+
+ processor = InstructBlipProcessor(
+ tokenizer=tokenizer, image_processor=image_processor, qformer_tokenizer=qformer_tokenizer
+ )
+
+ image_input = self.prepare_image_inputs()
+
+ input_feat_extract = image_processor(image_input, return_tensors="np")
+ input_processor = processor(images=image_input, return_tensors="np")
+
+ for key in input_feat_extract.keys():
+ self.assertAlmostEqual(input_feat_extract[key].sum(), input_processor[key].sum(), delta=1e-2)
+
+ def test_tokenizer(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+ qformer_tokenizer = self.get_qformer_tokenizer()
+
+ processor = InstructBlipProcessor(
+ tokenizer=tokenizer, image_processor=image_processor, qformer_tokenizer=qformer_tokenizer
+ )
+
+ input_str = ["lower newer"]
+
+ encoded_processor = processor(text=input_str)
+
+ encoded_tokens = tokenizer(input_str, return_token_type_ids=False)
+ encoded_tokens_qformer = qformer_tokenizer(input_str, return_token_type_ids=False)
+
+ for key in encoded_tokens.keys():
+ self.assertListEqual(encoded_tokens[key], encoded_processor[key])
+
+ for key in encoded_tokens_qformer.keys():
+ self.assertListEqual(encoded_tokens_qformer[key], encoded_processor["qformer_" + key])
+
+ def test_processor(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+ qformer_tokenizer = self.get_qformer_tokenizer()
+
+ processor = InstructBlipProcessor(
+ tokenizer=tokenizer, image_processor=image_processor, qformer_tokenizer=qformer_tokenizer
+ )
+
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ self.assertListEqual(
+ list(inputs.keys()),
+ ["input_ids", "attention_mask", "qformer_input_ids", "qformer_attention_mask", "pixel_values"],
+ )
+
+ # test if it raises when no input is passed
+ with pytest.raises(ValueError):
+ processor()
+
+ def test_tokenizer_decode(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+ qformer_tokenizer = self.get_qformer_tokenizer()
+
+ processor = InstructBlipProcessor(
+ tokenizer=tokenizer, image_processor=image_processor, qformer_tokenizer=qformer_tokenizer
+ )
+
+ predicted_ids = [[1, 4, 5, 8, 1, 0, 8], [3, 4, 3, 1, 1, 8, 9]]
+
+ decoded_processor = processor.batch_decode(predicted_ids)
+ decoded_tok = tokenizer.batch_decode(predicted_ids)
+
+ self.assertListEqual(decoded_tok, decoded_processor)
+
+ def test_model_input_names(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+ qformer_tokenizer = self.get_qformer_tokenizer()
+
+ processor = InstructBlipProcessor(
+ tokenizer=tokenizer, image_processor=image_processor, qformer_tokenizer=qformer_tokenizer
+ )
+
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+
+ inputs = processor(text=input_str, images=image_input)
+
+ self.assertListEqual(
+ list(inputs.keys()),
+ ["input_ids", "attention_mask", "qformer_input_ids", "qformer_attention_mask", "pixel_values"],
+ )
diff --git a/transformers/tests/models/jetmoe/__init__.py b/transformers/tests/models/jetmoe/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/jetmoe/test_modeling_jetmoe.py b/transformers/tests/models/jetmoe/test_modeling_jetmoe.py
new file mode 100644
index 0000000000000000000000000000000000000000..7dd6ca728af0872adb64268c522668506d9b9835
--- /dev/null
+++ b/transformers/tests/models/jetmoe/test_modeling_jetmoe.py
@@ -0,0 +1,197 @@
+# Copyright 2024 JetMoe AI and The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch JetMoe model."""
+
+import gc
+import unittest
+
+import pytest
+
+from transformers import AutoTokenizer, JetMoeConfig, is_torch_available
+from transformers.testing_utils import (
+ backend_empty_cache,
+ require_flash_attn,
+ require_torch,
+ require_torch_gpu,
+ slow,
+ torch_device,
+)
+
+from ...causal_lm_tester import CausalLMModelTest, CausalLMModelTester
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ JetMoeForCausalLM,
+ JetMoeForSequenceClassification,
+ JetMoeModel,
+ )
+
+
+class JetMoeModelTester(CausalLMModelTester):
+ config_class = JetMoeConfig
+ forced_config_args = ["pad_token_id"]
+ if is_torch_available():
+ base_model_class = JetMoeModel
+ causal_lm_class = JetMoeForCausalLM
+ sequence_class = JetMoeForSequenceClassification
+
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=False,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_key_value_heads=2,
+ kv_channels=8,
+ intermediate_size=37,
+ hidden_act="silu",
+ num_local_experts=4,
+ num_experts_per_tok=2,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ pad_token_id=0,
+ scope=None,
+ ):
+ super().__init__(parent)
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.kv_channels = kv_channels
+ self.num_attention_heads = num_key_value_heads * num_experts_per_tok
+ self.num_key_value_heads = num_key_value_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.num_local_experts = num_local_experts
+ self.num_experts_per_tok = num_experts_per_tok
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.pad_token_id = pad_token_id
+ self.scope = scope
+
+
+@require_torch
+class JetMoeModelTest(CausalLMModelTest, unittest.TestCase):
+ all_model_classes = (
+ (JetMoeModel, JetMoeForCausalLM, JetMoeForSequenceClassification) if is_torch_available() else ()
+ )
+ test_headmasking = False
+ test_pruning = False
+ test_mismatched_shapes = False
+ test_cpu_offload = False
+ test_disk_offload_bin = False
+ test_disk_offload_safetensors = False
+ model_tester_class = JetMoeModelTester
+ pipeline_model_mapping = (
+ {
+ "feature-extraction": JetMoeModel,
+ "text-classification": JetMoeForSequenceClassification,
+ "text-generation": JetMoeForCausalLM,
+ }
+ if is_torch_available()
+ else {}
+ )
+
+ @require_flash_attn
+ @require_torch_gpu
+ @pytest.mark.flash_attn_test
+ @slow
+ def test_flash_attn_2_inference_equivalence_right_padding(self):
+ self.skipTest(reason="JetMoe flash attention does not support right padding")
+
+
+@require_torch
+class JetMoeIntegrationTest(unittest.TestCase):
+ @slow
+ def test_model_8b_logits(self):
+ input_ids = [1, 306, 4658, 278, 6593, 310, 2834, 338]
+ model = JetMoeForCausalLM.from_pretrained("jetmoe/jetmoe-8b")
+ input_ids = torch.tensor([input_ids]).to(model.model.embed_tokens.weight.device)
+ with torch.no_grad():
+ out = model(input_ids).logits.float().cpu()
+ # Expected mean on dim = -1
+ EXPECTED_MEAN = torch.tensor([[0.2507, -2.7073, -1.3445, -1.9363, -1.7216, -1.7370, -1.9054, -1.9792]])
+ torch.testing.assert_close(out.mean(-1), EXPECTED_MEAN, rtol=1e-2, atol=1e-2)
+ # slicing logits[0, 0, 0:30]
+ EXPECTED_SLICE = torch.tensor([-3.3689, 5.9006, 5.7450, -1.7012, -4.7072, -4.7071, -4.7071, -4.7071, -4.7072, -4.7072, -4.7072, -4.7071, 3.8321, 9.1746, -4.7071, -4.7072, -4.7071, -4.7072, -4.7071, -4.7072, -4.7071, -4.7071, -4.7071, -4.7071, -4.7071, -4.7071, -4.7071, -4.7071, -4.7071, -4.7071]) # fmt: skip
+ torch.testing.assert_close(out[0, 0, :30], EXPECTED_SLICE, rtol=1e-4, atol=1e-4)
+
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
+
+ @slow
+ def test_model_8b_generation(self):
+ EXPECTED_TEXT_COMPLETION = """My favourite condiment is ....\nI love ketchup. I love"""
+ prompt = "My favourite condiment is "
+ tokenizer = AutoTokenizer.from_pretrained("jetmoe/jetmoe-8b", use_fast=False)
+ model = JetMoeForCausalLM.from_pretrained("jetmoe/jetmoe-8b")
+ input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.model.embed_tokens.weight.device)
+
+ # greedy generation outputs
+ generated_ids = model.generate(input_ids, max_new_tokens=10, temperature=0)
+ text = tokenizer.decode(generated_ids[0], skip_special_tokens=True)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
+
+ @slow
+ def test_model_8b_batched_generation(self):
+ EXPECTED_TEXT_COMPLETION = [
+ """My favourite condiment is ....\nI love ketchup. I love""",
+ """My favourite 2018 Christmas present was a new pair""",
+ ]
+ prompt = [
+ "My favourite condiment is ",
+ "My favourite ",
+ ]
+ tokenizer = AutoTokenizer.from_pretrained("jetmoe/jetmoe-8b", use_fast=False)
+ model = JetMoeForCausalLM.from_pretrained("jetmoe/jetmoe-8b")
+ input_ids = tokenizer(prompt, return_tensors="pt", padding=True).to(model.model.embed_tokens.weight.device)
+ print(input_ids)
+
+ # greedy generation outputs
+ generated_ids = model.generate(**input_ids, max_new_tokens=10, temperature=0)
+ text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
+ print(text)
+ self.assertEqual(EXPECTED_TEXT_COMPLETION, text)
+
+ del model
+ backend_empty_cache(torch_device)
+ gc.collect()
diff --git a/transformers/tests/models/layoutlm/__init__.py b/transformers/tests/models/layoutlm/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/layoutlm/test_modeling_layoutlm.py b/transformers/tests/models/layoutlm/test_modeling_layoutlm.py
new file mode 100644
index 0000000000000000000000000000000000000000..a7cd87015609ada7a01b32abb02789c301e207df
--- /dev/null
+++ b/transformers/tests/models/layoutlm/test_modeling_layoutlm.py
@@ -0,0 +1,404 @@
+# Copyright 2018 The Microsoft Research Asia LayoutLM Team Authors, The Hugging Face Team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+import unittest
+
+from transformers import LayoutLMConfig, is_torch_available
+from transformers.testing_utils import require_torch, slow, torch_device
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, ids_tensor
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ LayoutLMForMaskedLM,
+ LayoutLMForQuestionAnswering,
+ LayoutLMForSequenceClassification,
+ LayoutLMForTokenClassification,
+ LayoutLMModel,
+ )
+
+
+class LayoutLMModelTester:
+ """You can also import this e.g from .test_modeling_layoutlm import LayoutLMModelTester"""
+
+ def __init__(
+ self,
+ parent,
+ batch_size=13,
+ seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=32,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ num_labels=3,
+ num_choices=4,
+ scope=None,
+ range_bbox=1000,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.seq_length = seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.scope = scope
+ self.range_bbox = range_bbox
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
+
+ bbox = ids_tensor([self.batch_size, self.seq_length, 4], self.range_bbox)
+ # Ensure that bbox is legal
+ for i in range(bbox.shape[0]):
+ for j in range(bbox.shape[1]):
+ if bbox[i, j, 3] < bbox[i, j, 1]:
+ t = bbox[i, j, 3]
+ bbox[i, j, 3] = bbox[i, j, 1]
+ bbox[i, j, 1] = t
+ if bbox[i, j, 2] < bbox[i, j, 0]:
+ t = bbox[i, j, 2]
+ bbox[i, j, 2] = bbox[i, j, 0]
+ bbox[i, j, 0] = t
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ choice_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
+ choice_labels = ids_tensor([self.batch_size], self.num_choices)
+
+ config = self.get_config()
+
+ return config, input_ids, bbox, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+
+ def get_config(self):
+ return LayoutLMConfig(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ initializer_range=self.initializer_range,
+ )
+
+ def create_and_check_model(
+ self, config, input_ids, bbox, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = LayoutLMModel(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, bbox, attention_mask=input_mask, token_type_ids=token_type_ids)
+ result = model(input_ids, bbox, token_type_ids=token_type_ids)
+ result = model(input_ids, bbox)
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+ self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
+
+ def create_and_check_for_masked_lm(
+ self, config, input_ids, bbox, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = LayoutLMForMaskedLM(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, bbox, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
+
+ def create_and_check_for_sequence_classification(
+ self, config, input_ids, bbox, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_labels = self.num_labels
+ model = LayoutLMForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids, bbox, attention_mask=input_mask, token_type_ids=token_type_ids, labels=sequence_labels
+ )
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def create_and_check_for_token_classification(
+ self, config, input_ids, bbox, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ config.num_labels = self.num_labels
+ model = LayoutLMForTokenClassification(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(input_ids, bbox, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
+
+ def create_and_check_for_question_answering(
+ self, config, input_ids, bbox, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
+ ):
+ model = LayoutLMForQuestionAnswering(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ bbox=bbox,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ start_positions=sequence_labels,
+ end_positions=sequence_labels,
+ )
+ self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
+ self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ bbox,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ choice_labels,
+ ) = config_and_inputs
+ inputs_dict = {
+ "input_ids": input_ids,
+ "bbox": bbox,
+ "token_type_ids": token_type_ids,
+ "attention_mask": input_mask,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class LayoutLMModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ all_model_classes = (
+ (
+ LayoutLMModel,
+ LayoutLMForMaskedLM,
+ LayoutLMForSequenceClassification,
+ LayoutLMForTokenClassification,
+ LayoutLMForQuestionAnswering,
+ )
+ if is_torch_available()
+ else None
+ )
+ pipeline_model_mapping = (
+ {
+ "document-question-answering": LayoutLMForQuestionAnswering,
+ "feature-extraction": LayoutLMModel,
+ "fill-mask": LayoutLMForMaskedLM,
+ "text-classification": LayoutLMForSequenceClassification,
+ "token-classification": LayoutLMForTokenClassification,
+ "zero-shot": LayoutLMForSequenceClassification,
+ }
+ if is_torch_available()
+ else {}
+ )
+ fx_compatible = False # Cannot support if `can_return_tuple`
+
+ def setUp(self):
+ self.model_tester = LayoutLMModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=LayoutLMConfig, hidden_size=37)
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_various_embeddings(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["absolute", "relative_key", "relative_key_query"]:
+ config_and_inputs[0].position_embedding_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_masked_lm(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
+
+ def test_for_sequence_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
+
+ def test_for_token_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
+
+ def test_for_question_answering(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant(self):
+ pass
+
+ @unittest.skip(
+ reason="This architecture seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
+ )
+ def test_training_gradient_checkpointing_use_reentrant_false(self):
+ pass
+
+
+def prepare_layoutlm_batch_inputs():
+ # Here we prepare a batch of 2 sequences to test a LayoutLM forward pass on:
+ # fmt: off
+ input_ids = torch.tensor([[101,1019,1014,1016,1037,12849,4747,1004,14246,2278,5439,4524,5002,2930,2193,2930,4341,3208,1005,1055,2171,2848,11300,3531,102],[101,4070,4034,7020,1024,3058,1015,1013,2861,1013,6070,19274,2772,6205,27814,16147,16147,4343,2047,10283,10969,14389,1012,2338,102]],device=torch_device) # noqa: E231
+ attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],],device=torch_device) # noqa: E231
+ bbox = torch.tensor([[[0,0,0,0],[423,237,440,251],[427,272,441,287],[419,115,437,129],[961,885,992,912],[256,38,330,58],[256,38,330,58],[336,42,353,57],[360,39,401,56],[360,39,401,56],[411,39,471,59],[479,41,528,59],[533,39,630,60],[67,113,134,131],[141,115,209,132],[68,149,133,166],[141,149,187,164],[195,148,287,165],[195,148,287,165],[195,148,287,165],[295,148,349,165],[441,149,492,166],[497,149,546,164],[64,201,125,218],[1000,1000,1000,1000]],[[0,0,0,0],[662,150,754,166],[665,199,742,211],[519,213,554,228],[519,213,554,228],[134,433,187,454],[130,467,204,480],[130,467,204,480],[130,467,204,480],[130,467,204,480],[130,467,204,480],[314,469,376,482],[504,684,582,706],[941,825,973,900],[941,825,973,900],[941,825,973,900],[941,825,973,900],[610,749,652,765],[130,659,168,672],[176,657,237,672],[238,657,312,672],[443,653,628,672],[443,653,628,672],[716,301,825,317],[1000,1000,1000,1000]]],device=torch_device) # noqa: E231
+ token_type_ids = torch.tensor([[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0]],device=torch_device) # noqa: E231
+ # these are sequence labels (i.e. at the token level)
+ labels = torch.tensor([[-100,10,10,10,9,1,-100,7,7,-100,7,7,4,2,5,2,8,8,-100,-100,5,0,3,2,-100],[-100,12,12,12,-100,12,10,-100,-100,-100,-100,10,12,9,-100,-100,-100,10,10,10,9,12,-100,10,-100]],device=torch_device) # noqa: E231
+ # fmt: on
+
+ return input_ids, attention_mask, bbox, token_type_ids, labels
+
+
+@require_torch
+class LayoutLMModelIntegrationTest(unittest.TestCase):
+ @slow
+ def test_forward_pass_no_head(self):
+ model = LayoutLMModel.from_pretrained("microsoft/layoutlm-base-uncased").to(torch_device)
+
+ input_ids, attention_mask, bbox, token_type_ids, labels = prepare_layoutlm_batch_inputs()
+
+ # forward pass
+ outputs = model(input_ids=input_ids, bbox=bbox, attention_mask=attention_mask, token_type_ids=token_type_ids)
+
+ # test the sequence output on [0, :3, :3]
+ expected_slice = torch.tensor(
+ [[0.1785, -0.1947, -0.0425], [-0.3254, -0.2807, 0.2553], [-0.5391, -0.3322, 0.3364]],
+ device=torch_device,
+ )
+
+ torch.testing.assert_close(outputs.last_hidden_state[0, :3, :3], expected_slice, rtol=1e-3, atol=1e-3)
+
+ # test the pooled output on [1, :3]
+ expected_slice = torch.tensor([-0.6580, -0.0214, 0.8552], device=torch_device)
+
+ torch.testing.assert_close(outputs.pooler_output[1, :3], expected_slice, rtol=1e-3, atol=1e-3)
+
+ @slow
+ def test_forward_pass_sequence_classification(self):
+ # initialize model with randomly initialized sequence classification head
+ model = LayoutLMForSequenceClassification.from_pretrained("microsoft/layoutlm-base-uncased", num_labels=2).to(
+ torch_device
+ )
+
+ input_ids, attention_mask, bbox, token_type_ids, _ = prepare_layoutlm_batch_inputs()
+
+ # forward pass
+ outputs = model(
+ input_ids=input_ids,
+ bbox=bbox,
+ attention_mask=attention_mask,
+ token_type_ids=token_type_ids,
+ labels=torch.tensor([1, 1], device=torch_device),
+ )
+
+ # test whether we get a loss as a scalar
+ loss = outputs.loss
+ expected_shape = torch.Size([])
+ self.assertEqual(loss.shape, expected_shape)
+
+ # test the shape of the logits
+ logits = outputs.logits
+ expected_shape = torch.Size((2, 2))
+ self.assertEqual(logits.shape, expected_shape)
+
+ @slow
+ def test_forward_pass_token_classification(self):
+ # initialize model with randomly initialized token classification head
+ model = LayoutLMForTokenClassification.from_pretrained("microsoft/layoutlm-base-uncased", num_labels=13).to(
+ torch_device
+ )
+
+ input_ids, attention_mask, bbox, token_type_ids, labels = prepare_layoutlm_batch_inputs()
+
+ # forward pass
+ outputs = model(
+ input_ids=input_ids, bbox=bbox, attention_mask=attention_mask, token_type_ids=token_type_ids, labels=labels
+ )
+
+ # test the loss calculation to be around 2.65
+ # expected_loss = torch.tensor(2.65, device=torch_device)
+
+ # The loss is currently somewhat random and can vary between 0.1-0.3 atol.
+ # self.assertTrue(torch.allclose(outputs.loss, expected_loss, atol=0.1))
+
+ # test the shape of the logits
+ logits = outputs.logits
+ expected_shape = torch.Size((2, 25, 13))
+ self.assertEqual(logits.shape, expected_shape)
+
+ @slow
+ def test_forward_pass_question_answering(self):
+ # initialize model with randomly initialized token classification head
+ model = LayoutLMForQuestionAnswering.from_pretrained("microsoft/layoutlm-base-uncased").to(torch_device)
+
+ input_ids, attention_mask, bbox, token_type_ids, labels = prepare_layoutlm_batch_inputs()
+
+ # forward pass
+ outputs = model(input_ids=input_ids, bbox=bbox, attention_mask=attention_mask, token_type_ids=token_type_ids)
+
+ # test the shape of the logits
+ expected_shape = torch.Size((2, 25))
+ self.assertEqual(outputs.start_logits.shape, expected_shape)
+ self.assertEqual(outputs.end_logits.shape, expected_shape)
diff --git a/transformers/tests/models/layoutlm/test_tokenization_layoutlm.py b/transformers/tests/models/layoutlm/test_tokenization_layoutlm.py
new file mode 100644
index 0000000000000000000000000000000000000000..305dbcaa2e5b034b3bba63ac7331323669b9e53e
--- /dev/null
+++ b/transformers/tests/models/layoutlm/test_tokenization_layoutlm.py
@@ -0,0 +1,80 @@
+# Copyright 2018 The Microsoft Research Asia LayoutLM Team Authors, The Hugging Face Team.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import os
+import unittest
+from functools import lru_cache
+
+from transformers import LayoutLMTokenizer, LayoutLMTokenizerFast
+from transformers.models.layoutlm.tokenization_layoutlm import VOCAB_FILES_NAMES
+from transformers.testing_utils import require_tokenizers
+
+from ...test_tokenization_common import TokenizerTesterMixin, use_cache_if_possible
+
+
+@require_tokenizers
+class LayoutLMTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
+ from_pretrained_id = "microsoft/layoutlm-base-uncased"
+ tokenizer_class = LayoutLMTokenizer
+ rust_tokenizer_class = LayoutLMTokenizerFast
+ test_rust_tokenizer = True
+ space_between_special_tokens = True
+
+ @classmethod
+ def setUpClass(cls):
+ super().setUpClass()
+
+ vocab_tokens = [
+ "[UNK]",
+ "[CLS]",
+ "[SEP]",
+ "want",
+ "##want",
+ "##ed",
+ "wa",
+ "un",
+ "runn",
+ "##ing",
+ ",",
+ "low",
+ "lowest",
+ ]
+ cls.vocab_file = os.path.join(cls.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ with open(cls.vocab_file, "w", encoding="utf-8") as vocab_writer:
+ vocab_writer.write("".join([x + "\n" for x in vocab_tokens]))
+
+ @classmethod
+ @use_cache_if_possible
+ @lru_cache(maxsize=64)
+ def get_tokenizer(cls, pretrained_name=None, **kwargs):
+ pretrained_name = pretrained_name or cls.tmpdirname
+ return LayoutLMTokenizer.from_pretrained(pretrained_name, **kwargs)
+
+ def get_input_output_texts(self, tokenizer):
+ input_text = "UNwant\u00e9d,running"
+ output_text = "unwanted, running"
+ return input_text, output_text
+
+ def test_full_tokenizer(self):
+ tokenizer = self.tokenizer_class(self.vocab_file)
+
+ tokens = tokenizer.tokenize("UNwant\u00e9d,running")
+ self.assertListEqual(tokens, ["un", "##want", "##ed", ",", "runn", "##ing"])
+ self.assertListEqual(tokenizer.convert_tokens_to_ids(tokens), [7, 4, 5, 10, 8, 9])
+
+ @unittest.skip
+ def test_special_tokens_as_you_expect(self):
+ """If you are training a seq2seq model that expects a decoder_prefix token make sure it is prepended to decoder_input_ids"""
+ pass
diff --git a/transformers/tests/models/layoutlmv3/__init__.py b/transformers/tests/models/layoutlmv3/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/transformers/tests/models/layoutlmv3/test_image_processing_layoutlmv3.py b/transformers/tests/models/layoutlmv3/test_image_processing_layoutlmv3.py
new file mode 100644
index 0000000000000000000000000000000000000000..8d3577e553717e3d78f42b3792a992652ad7339c
--- /dev/null
+++ b/transformers/tests/models/layoutlmv3/test_image_processing_layoutlmv3.py
@@ -0,0 +1,136 @@
+# Copyright 2022 HuggingFace Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import unittest
+
+from transformers.testing_utils import require_pytesseract, require_torch
+from transformers.utils import is_pytesseract_available, is_torchvision_available
+
+from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
+
+
+if is_pytesseract_available():
+ from transformers import LayoutLMv3ImageProcessor
+
+ if is_torchvision_available():
+ from transformers import LayoutLMv3ImageProcessorFast
+
+
+class LayoutLMv3ImageProcessingTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=7,
+ num_channels=3,
+ image_size=18,
+ min_resolution=30,
+ max_resolution=400,
+ do_resize=True,
+ size=None,
+ apply_ocr=True,
+ ):
+ size = size if size is not None else {"height": 18, "width": 18}
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.min_resolution = min_resolution
+ self.max_resolution = max_resolution
+ self.do_resize = do_resize
+ self.size = size
+ self.apply_ocr = apply_ocr
+
+ def prepare_image_processor_dict(self):
+ return {"do_resize": self.do_resize, "size": self.size, "apply_ocr": self.apply_ocr}
+
+ def expected_output_image_shape(self, images):
+ return self.num_channels, self.size["height"], self.size["width"]
+
+ def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
+ return prepare_image_inputs(
+ batch_size=self.batch_size,
+ num_channels=self.num_channels,
+ min_resolution=self.min_resolution,
+ max_resolution=self.max_resolution,
+ equal_resolution=equal_resolution,
+ numpify=numpify,
+ torchify=torchify,
+ )
+
+
+@require_torch
+@require_pytesseract
+class LayoutLMv3ImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
+ image_processing_class = LayoutLMv3ImageProcessor if is_pytesseract_available() else None
+ fast_image_processing_class = (
+ LayoutLMv3ImageProcessorFast if (is_torchvision_available() and is_pytesseract_available()) else None
+ )
+
+ def setUp(self):
+ super().setUp()
+ self.image_processor_tester = LayoutLMv3ImageProcessingTester(self)
+
+ @property
+ def image_processor_dict(self):
+ return self.image_processor_tester.prepare_image_processor_dict()
+
+ def test_image_processor_properties(self):
+ for image_processing_class in self.image_processor_list:
+ image_processing = image_processing_class(**self.image_processor_dict)
+ self.assertTrue(hasattr(image_processing, "do_resize"))
+ self.assertTrue(hasattr(image_processing, "size"))
+ self.assertTrue(hasattr(image_processing, "apply_ocr"))
+
+ def test_image_processor_from_dict_with_kwargs(self):
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class.from_dict(self.image_processor_dict)
+ self.assertEqual(image_processor.size, {"height": 18, "width": 18})
+
+ image_processor = image_processing_class.from_dict(self.image_processor_dict, size=42)
+ self.assertEqual(image_processor.size, {"height": 42, "width": 42})
+
+ def test_LayoutLMv3_integration_test(self):
+ from datasets import load_dataset
+
+ ds = load_dataset("hf-internal-testing/fixtures_docvqa", split="test")
+
+ # with apply_OCR = True
+ for image_processing_class in self.image_processor_list:
+ image_processor = image_processing_class()
+
+ image = ds[0]["image"].convert("RGB")
+
+ encoding = image_processor(image, return_tensors="pt")
+
+ self.assertEqual(encoding.pixel_values.shape, (1, 3, 224, 224))
+ self.assertEqual(len(encoding.words), len(encoding.boxes))
+
+ # fmt: off
+ # the words and boxes were obtained with Tesseract 5.3.0
+ expected_words = [['11:14', 'to', '11:39', 'a.m', '11:39', 'to', '11:44', 'a.m.', '11:44', 'a.m.', 'to', '12:25', 'p.m.', '12:25', 'to', '12:58', 'p.m.', '12:58', 'to', '4:00', 'p.m.', '2:00', 'to', '5:00', 'p.m.', 'Coffee', 'Break', 'Coffee', 'will', 'be', 'served', 'for', 'men', 'and', 'women', 'in', 'the', 'lobby', 'adjacent', 'to', 'exhibit', 'area.', 'Please', 'move', 'into', 'exhibit', 'area.', '(Exhibits', 'Open)', 'TRRF', 'GENERAL', 'SESSION', '(PART', '|)', 'Presiding:', 'Lee', 'A.', 'Waller', 'TRRF', 'Vice', 'President', '“Introductory', 'Remarks”', 'Lee', 'A.', 'Waller,', 'TRRF', 'Vice', 'Presi-', 'dent', 'Individual', 'Interviews', 'with', 'TRRF', 'Public', 'Board', 'Members', 'and', 'Sci-', 'entific', 'Advisory', 'Council', 'Mem-', 'bers', 'Conducted', 'by', 'TRRF', 'Treasurer', 'Philip', 'G.', 'Kuehn', 'to', 'get', 'answers', 'which', 'the', 'public', 'refrigerated', 'warehousing', 'industry', 'is', 'looking', 'for.', 'Plus', 'questions', 'from', 'the', 'floor.', 'Dr.', 'Emil', 'M.', 'Mrak,', 'University', 'of', 'Cal-', 'ifornia,', 'Chairman,', 'TRRF', 'Board;', 'Sam', 'R.', 'Cecil,', 'University', 'of', 'Georgia', 'College', 'of', 'Agriculture;', 'Dr.', 'Stanley', 'Charm,', 'Tufts', 'University', 'School', 'of', 'Medicine;', 'Dr.', 'Robert', 'H.', 'Cotton,', 'ITT', 'Continental', 'Baking', 'Company;', 'Dr.', 'Owen', 'Fennema,', 'University', 'of', 'Wis-', 'consin;', 'Dr.', 'Robert', 'E.', 'Hardenburg,', 'USDA.', 'Questions', 'and', 'Answers', 'Exhibits', 'Open', 'Capt.', 'Jack', 'Stoney', 'Room', 'TRRF', 'Scientific', 'Advisory', 'Council', 'Meeting', 'Ballroom', 'Foyer']] # noqa: E231
+ # We get different outputs on CircleCI and on Github runners since 2025/06/26. It might be different versions of some 3rd party libraries in these 2 environments.
+ expected_boxes_1 = [[[141, 57, 210, 69], [228, 58, 252, 69], [141, 75, 216, 88], [230, 79, 280, 88], [142, 260, 218, 273], [230, 261, 255, 273], [143, 279, 218, 290], [231, 282, 290, 291], [143, 342, 218, 354], [231, 345, 289, 355], [202, 362, 227, 373], [143, 379, 220, 392], [231, 382, 291, 394], [144, 714, 220, 726], [231, 715, 256, 726], [144, 732, 220, 745], [232, 736, 291, 747], [144, 769, 218, 782], [231, 770, 256, 782], [141, 788, 202, 801], [215, 791, 274, 804], [143, 826, 204, 838], [215, 826, 240, 838], [142, 844, 202, 857], [215, 847, 274, 859], [334, 57, 427, 69], [440, 57, 522, 69], [369, 75, 461, 88], [469, 75, 516, 88], [528, 76, 562, 88], [570, 76, 667, 88], [675, 75, 711, 87], [721, 79, 778, 88], [789, 75, 840, 88], [369, 97, 470, 107], [484, 94, 507, 106], [518, 94, 562, 107], [576, 94, 655, 110], [668, 94, 792, 109], [804, 95, 829, 107], [369, 113, 465, 125], [477, 116, 547, 125], [562, 113, 658, 125], [671, 116, 748, 125], [761, 113, 811, 125], [369, 131, 465, 143], [477, 133, 548, 143], [563, 130, 698, 145], [710, 130, 802, 146], [336, 171, 412, 183], [423, 171, 572, 183], [582, 170, 716, 184], [728, 171, 817, 187], [829, 171, 844, 186], [338, 197, 482, 212], [507, 196, 557, 209], [569, 196, 595, 208], [610, 196, 702, 209], [505, 214, 583, 226], [595, 214, 656, 227], [670, 215, 807, 227], [335, 259, 543, 274], [556, 259, 708, 272], [372, 279, 422, 291], [435, 279, 460, 291], [474, 279, 574, 292], [587, 278, 664, 291], [676, 278, 738, 291], [751, 279, 834, 291], [372, 298, 434, 310], [335, 341, 483, 354], [497, 341, 655, 354], [667, 341, 728, 354], [740, 341, 825, 354], [335, 360, 430, 372], [442, 360, 534, 372], [545, 359, 687, 372], [697, 360, 754, 372], [765, 360, 823, 373], [334, 378, 428, 391], [440, 378, 577, 394], [590, 378, 705, 391], [720, 378, 801, 391], [334, 397, 400, 409], [370, 416, 529, 429], [544, 416, 576, 432], [587, 416, 665, 428], [677, 416, 814, 429], [372, 435, 452, 450], [465, 434, 495, 447], [511, 434, 600, 447], [611, 436, 637, 447], [649, 436, 694, 451], [705, 438, 824, 447], [369, 453, 452, 466], [464, 454, 509, 466], [522, 453, 611, 469], [625, 453, 792, 469], [370, 472, 556, 488], [570, 472, 684, 487], [697, 472, 718, 485], [732, 472, 835, 488], [369, 490, 411, 503], [425, 490, 484, 503], [496, 490, 635, 506], [645, 490, 707, 503], [718, 491, 761, 503], [771, 490, 840, 503], [336, 510, 374, 521], [388, 510, 447, 522], [460, 510, 489, 521], [503, 510, 580, 522], [592, 509, 736, 525], [745, 509, 770, 522], [781, 509, 840, 522], [338, 528, 434, 541], [448, 528, 596, 541], [609, 527, 687, 540], [700, 528, 792, 541], [336, 546, 397, 559], [407, 546, 431, 559], [443, 546, 525, 560], [537, 546, 680, 562], [695, 546, 714, 559], [722, 546, 837, 562], [336, 565, 449, 581], [461, 565, 485, 577], [497, 565, 665, 581], [681, 565, 718, 577], [732, 565, 837, 580], [337, 584, 438, 597], [452, 583, 521, 596], [535, 584, 677, 599], [690, 583, 787, 596], [801, 583, 825, 596], [338, 602, 478, 615], [492, 602, 530, 614], [543, 602, 638, 615], [650, 602, 676, 614], [688, 602, 788, 615], [802, 602, 843, 614], [337, 621, 502, 633], [516, 621, 615, 637], [629, 621, 774, 636], [789, 621, 827, 633], [337, 639, 418, 652], [432, 640, 571, 653], [587, 639, 731, 655], [743, 639, 769, 652], [780, 639, 841, 652], [338, 658, 440, 673], [455, 658, 491, 670], [508, 658, 602, 671], [616, 658, 638, 670], [654, 658, 835, 674], [337, 677, 429, 689], [337, 714, 482, 726], [495, 714, 548, 726], [561, 714, 683, 726], [338, 770, 461, 782], [474, 769, 554, 785], [489, 788, 562, 803], [576, 788, 643, 801], [656, 787, 751, 804], [764, 788, 844, 801], [334, 825, 421, 838], [430, 824, 574, 838], [584, 824, 723, 841], [335, 844, 450, 857], [464, 843, 583, 860], [628, 862, 755, 875], [769, 861, 848, 878]]] # noqa: E231
+ expected_boxes_2 = [[[141, 57, 214, 69], [228, 58, 252, 69], [141, 75, 216, 88], [230, 79, 280, 88], [142, 260, 218, 273], [230, 261, 255, 273], [143, 279, 218, 290], [231, 282, 290, 291], [143, 342, 218, 354], [231, 345, 289, 355], [202, 362, 227, 373], [143, 379, 220, 392], [231, 382, 291, 394], [144, 714, 220, 726], [231, 715, 256, 726], [144, 732, 220, 745], [232, 736, 291, 747], [144, 769, 218, 782], [231, 770, 256, 782], [141, 788, 202, 801], [215, 791, 274, 804], [143, 826, 204, 838], [215, 826, 240, 838], [142, 844, 202, 857], [215, 847, 274, 859], [334, 57, 427, 69], [440, 57, 522, 69], [369, 75, 461, 88], [469, 75, 516, 88], [528, 76, 562, 88], [570, 76, 667, 88], [675, 75, 711, 87], [721, 79, 778, 88], [789, 75, 840, 88], [369, 97, 470, 107], [484, 94, 507, 106], [518, 94, 562, 107], [576, 94, 655, 110], [668, 94, 792, 109], [804, 95, 829, 107], [369, 113, 465, 125], [477, 116, 547, 125], [562, 113, 658, 125], [671, 116, 748, 125], [761, 113, 811, 125], [369, 131, 465, 143], [477, 133, 548, 143], [563, 130, 698, 145], [710, 130, 802, 146], [336, 171, 412, 183], [423, 171, 572, 183], [582, 170, 716, 184], [728, 171, 817, 187], [829, 171, 844, 186], [338, 197, 482, 212], [507, 196, 557, 209], [569, 196, 595, 208], [610, 196, 702, 209], [505, 214, 583, 226], [595, 214, 656, 227], [670, 215, 807, 227], [335, 259, 543, 274], [556, 259, 708, 272], [372, 279, 422, 291], [435, 279, 460, 291], [474, 279, 574, 292], [587, 278, 664, 291], [676, 278, 738, 291], [751, 279, 834, 291], [372, 298, 434, 310], [335, 341, 483, 354], [497, 341, 655, 354], [667, 341, 728, 354], [740, 341, 825, 354], [335, 360, 430, 372], [442, 360, 534, 372], [545, 359, 687, 372], [697, 360, 754, 372], [765, 360, 823, 373], [334, 378, 428, 391], [440, 378, 577, 394], [590, 378, 705, 391], [720, 378, 801, 391], [334, 397, 400, 409], [370, 416, 529, 429], [544, 416, 576, 432], [587, 416, 665, 428], [677, 416, 814, 429], [372, 435, 452, 450], [465, 434, 495, 447], [511, 434, 600, 447], [611, 436, 637, 447], [649, 436, 694, 451], [705, 438, 824, 447], [369, 453, 452, 466], [464, 454, 509, 466], [522, 453, 611, 469], [625, 453, 792, 469], [370, 472, 556, 488], [570, 472, 684, 487], [697, 472, 718, 485], [732, 472, 835, 488], [369, 490, 411, 503], [425, 490, 484, 503], [496, 490, 635, 506], [645, 490, 707, 503], [718, 491, 761, 503], [771, 490, 840, 503], [336, 510, 374, 521], [388, 510, 447, 522], [460, 510, 489, 521], [503, 510, 580, 522], [592, 509, 736, 525], [745, 509, 770, 522], [781, 509, 840, 522], [338, 528, 434, 541], [448, 528, 596, 541], [609, 527, 687, 540], [700, 528, 792, 541], [336, 546, 397, 559], [407, 546, 431, 559], [443, 546, 525, 560], [537, 546, 680, 562], [688, 546, 714, 559], [722, 546, 837, 562], [336, 565, 449, 581], [461, 565, 485, 577], [497, 565, 665, 581], [681, 565, 718, 577], [732, 565, 837, 580], [337, 584, 438, 597], [452, 583, 521, 596], [535, 584, 677, 599], [690, 583, 787, 596], [801, 583, 825, 596], [338, 602, 478, 615], [492, 602, 530, 614], [543, 602, 638, 615], [650, 602, 676, 614], [688, 602, 788, 615], [802, 602, 843, 614], [337, 621, 502, 633], [516, 621, 615, 637], [629, 621, 774, 636], [789, 621, 827, 633], [337, 639, 418, 652], [432, 640, 571, 653], [587, 639, 731, 655], [743, 639, 769, 652], [780, 639, 841, 652], [338, 658, 440, 673], [455, 658, 491, 670], [508, 658, 602, 671], [616, 658, 638, 670], [654, 658, 835, 674], [337, 677, 429, 689], [337, 714, 482, 726], [495, 714, 548, 726], [561, 714, 683, 726], [338, 770, 461, 782], [474, 769, 554, 785], [489, 788, 562, 803], [576, 788, 643, 801], [656, 787, 751, 804], [764, 788, 844, 801], [334, 825, 421, 838], [430, 824, 574, 838], [584, 824, 723, 841], [335, 844, 450, 857], [464, 843, 583, 860], [628, 862, 755, 875], [769, 861, 848, 878]]] # noqa: E231
+ # fmt: on
+
+ self.assertListEqual(encoding.words, expected_words)
+ self.assertIn(encoding.boxes, [expected_boxes_1, expected_boxes_2])
+
+ # with apply_OCR = False
+ image_processor = image_processing_class(apply_ocr=False)
+
+ encoding = image_processor(image, return_tensors="pt")
+
+ self.assertEqual(encoding.pixel_values.shape, (1, 3, 224, 224))
diff --git a/transformers/tests/models/layoutlmv3/test_modeling_layoutlmv3.py b/transformers/tests/models/layoutlmv3/test_modeling_layoutlmv3.py
new file mode 100644
index 0000000000000000000000000000000000000000..7fa143d0d321eb97d2c0c99e2f2df4924dbe751f
--- /dev/null
+++ b/transformers/tests/models/layoutlmv3/test_modeling_layoutlmv3.py
@@ -0,0 +1,419 @@
+# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""Testing suite for the PyTorch LayoutLMv3 model."""
+
+import copy
+import unittest
+
+from transformers.models.auto import get_values
+from transformers.testing_utils import require_torch, slow, torch_device
+from transformers.utils import cached_property, is_torch_available, is_vision_available
+
+from ...test_configuration_common import ConfigTester
+from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
+from ...test_pipeline_mixin import PipelineTesterMixin
+
+
+if is_torch_available():
+ import torch
+
+ from transformers import (
+ MODEL_FOR_MULTIPLE_CHOICE_MAPPING,
+ MODEL_FOR_QUESTION_ANSWERING_MAPPING,
+ MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING,
+ MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING,
+ LayoutLMv3Config,
+ LayoutLMv3ForQuestionAnswering,
+ LayoutLMv3ForSequenceClassification,
+ LayoutLMv3ForTokenClassification,
+ LayoutLMv3Model,
+ )
+
+if is_vision_available():
+ from PIL import Image
+
+ from transformers import LayoutLMv3ImageProcessor
+
+
+class LayoutLMv3ModelTester:
+ def __init__(
+ self,
+ parent,
+ batch_size=2,
+ num_channels=3,
+ image_size=4,
+ patch_size=2,
+ text_seq_length=7,
+ is_training=True,
+ use_input_mask=True,
+ use_token_type_ids=True,
+ use_labels=True,
+ vocab_size=99,
+ hidden_size=36,
+ num_hidden_layers=2,
+ num_attention_heads=4,
+ intermediate_size=37,
+ hidden_act="gelu",
+ hidden_dropout_prob=0.1,
+ attention_probs_dropout_prob=0.1,
+ max_position_embeddings=512,
+ type_vocab_size=16,
+ type_sequence_label_size=2,
+ initializer_range=0.02,
+ coordinate_size=6,
+ shape_size=6,
+ num_labels=3,
+ num_choices=4,
+ scope=None,
+ range_bbox=1000,
+ ):
+ self.parent = parent
+ self.batch_size = batch_size
+ self.num_channels = num_channels
+ self.image_size = image_size
+ self.patch_size = patch_size
+ self.text_seq_length = text_seq_length
+ self.is_training = is_training
+ self.use_input_mask = use_input_mask
+ self.use_token_type_ids = use_token_type_ids
+ self.use_labels = use_labels
+ self.vocab_size = vocab_size
+ self.hidden_size = hidden_size
+ self.num_hidden_layers = num_hidden_layers
+ self.num_attention_heads = num_attention_heads
+ self.intermediate_size = intermediate_size
+ self.hidden_act = hidden_act
+ self.hidden_dropout_prob = hidden_dropout_prob
+ self.attention_probs_dropout_prob = attention_probs_dropout_prob
+ self.max_position_embeddings = max_position_embeddings
+ self.type_vocab_size = type_vocab_size
+ self.type_sequence_label_size = type_sequence_label_size
+ self.initializer_range = initializer_range
+ self.coordinate_size = coordinate_size
+ self.shape_size = shape_size
+ self.num_labels = num_labels
+ self.num_choices = num_choices
+ self.scope = scope
+ self.range_bbox = range_bbox
+
+ # LayoutLMv3's sequence length equals the number of text tokens + number of patches + 1 (we add 1 for the CLS token)
+ self.text_seq_length = text_seq_length
+ self.image_seq_length = (image_size // patch_size) ** 2 + 1
+ self.seq_length = self.text_seq_length + self.image_seq_length
+
+ def prepare_config_and_inputs(self):
+ input_ids = ids_tensor([self.batch_size, self.text_seq_length], self.vocab_size)
+
+ bbox = ids_tensor([self.batch_size, self.text_seq_length, 4], self.range_bbox)
+ # Ensure that bbox is legal
+ for i in range(bbox.shape[0]):
+ for j in range(bbox.shape[1]):
+ if bbox[i, j, 3] < bbox[i, j, 1]:
+ t = bbox[i, j, 3]
+ bbox[i, j, 3] = bbox[i, j, 1]
+ bbox[i, j, 1] = t
+ if bbox[i, j, 2] < bbox[i, j, 0]:
+ t = bbox[i, j, 2]
+ bbox[i, j, 2] = bbox[i, j, 0]
+ bbox[i, j, 0] = t
+
+ pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
+
+ input_mask = None
+ if self.use_input_mask:
+ input_mask = random_attention_mask([self.batch_size, self.text_seq_length])
+
+ token_type_ids = None
+ if self.use_token_type_ids:
+ token_type_ids = ids_tensor([self.batch_size, self.text_seq_length], self.type_vocab_size)
+
+ sequence_labels = None
+ token_labels = None
+ if self.use_labels:
+ sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
+ token_labels = ids_tensor([self.batch_size, self.text_seq_length], self.num_labels)
+
+ config = LayoutLMv3Config(
+ vocab_size=self.vocab_size,
+ hidden_size=self.hidden_size,
+ num_hidden_layers=self.num_hidden_layers,
+ num_attention_heads=self.num_attention_heads,
+ intermediate_size=self.intermediate_size,
+ hidden_act=self.hidden_act,
+ hidden_dropout_prob=self.hidden_dropout_prob,
+ attention_probs_dropout_prob=self.attention_probs_dropout_prob,
+ max_position_embeddings=self.max_position_embeddings,
+ type_vocab_size=self.type_vocab_size,
+ initializer_range=self.initializer_range,
+ coordinate_size=self.coordinate_size,
+ shape_size=self.shape_size,
+ input_size=self.image_size,
+ patch_size=self.patch_size,
+ )
+
+ return config, input_ids, bbox, pixel_values, token_type_ids, input_mask, sequence_labels, token_labels
+
+ def create_and_check_model(
+ self, config, input_ids, bbox, pixel_values, token_type_ids, input_mask, sequence_labels, token_labels
+ ):
+ model = LayoutLMv3Model(config=config)
+ model.to(torch_device)
+ model.eval()
+
+ # text + image
+ result = model(input_ids, pixel_values=pixel_values)
+ result = model(
+ input_ids, bbox=bbox, pixel_values=pixel_values, attention_mask=input_mask, token_type_ids=token_type_ids
+ )
+ result = model(input_ids, bbox=bbox, pixel_values=pixel_values, token_type_ids=token_type_ids)
+ result = model(input_ids, bbox=bbox, pixel_values=pixel_values)
+
+ self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
+
+ # text only
+ result = model(input_ids)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.text_seq_length, self.hidden_size)
+ )
+
+ # image only
+ result = model(pixel_values=pixel_values)
+ self.parent.assertEqual(
+ result.last_hidden_state.shape, (self.batch_size, self.image_seq_length, self.hidden_size)
+ )
+
+ def create_and_check_for_sequence_classification(
+ self, config, input_ids, bbox, pixel_values, token_type_ids, input_mask, sequence_labels, token_labels
+ ):
+ config.num_labels = self.num_labels
+ model = LayoutLMv3ForSequenceClassification(config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ bbox=bbox,
+ pixel_values=pixel_values,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ labels=sequence_labels,
+ )
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
+
+ def create_and_check_for_token_classification(
+ self, config, input_ids, bbox, pixel_values, token_type_ids, input_mask, sequence_labels, token_labels
+ ):
+ config.num_labels = self.num_labels
+ model = LayoutLMv3ForTokenClassification(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ bbox=bbox,
+ pixel_values=pixel_values,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ labels=token_labels,
+ )
+ self.parent.assertEqual(result.logits.shape, (self.batch_size, self.text_seq_length, self.num_labels))
+
+ def create_and_check_for_question_answering(
+ self, config, input_ids, bbox, pixel_values, token_type_ids, input_mask, sequence_labels, token_labels
+ ):
+ model = LayoutLMv3ForQuestionAnswering(config=config)
+ model.to(torch_device)
+ model.eval()
+ result = model(
+ input_ids,
+ bbox=bbox,
+ pixel_values=pixel_values,
+ attention_mask=input_mask,
+ token_type_ids=token_type_ids,
+ start_positions=sequence_labels,
+ end_positions=sequence_labels,
+ )
+ self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
+ self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
+
+ def prepare_config_and_inputs_for_common(self):
+ config_and_inputs = self.prepare_config_and_inputs()
+ (
+ config,
+ input_ids,
+ bbox,
+ pixel_values,
+ token_type_ids,
+ input_mask,
+ sequence_labels,
+ token_labels,
+ ) = config_and_inputs
+ inputs_dict = {
+ "input_ids": input_ids,
+ "bbox": bbox,
+ "pixel_values": pixel_values,
+ "token_type_ids": token_type_ids,
+ "attention_mask": input_mask,
+ }
+ return config, inputs_dict
+
+
+@require_torch
+class LayoutLMv3ModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
+ test_pruning = False
+ test_torchscript = False
+ test_mismatched_shapes = False
+
+ all_model_classes = (
+ (
+ LayoutLMv3Model,
+ LayoutLMv3ForSequenceClassification,
+ LayoutLMv3ForTokenClassification,
+ LayoutLMv3ForQuestionAnswering,
+ )
+ if is_torch_available()
+ else ()
+ )
+ pipeline_model_mapping = (
+ {"document-question-answering": LayoutLMv3ForQuestionAnswering, "feature-extraction": LayoutLMv3Model}
+ if is_torch_available()
+ else {}
+ )
+
+ # TODO: Fix the failed tests
+ def is_pipeline_test_to_skip(
+ self,
+ pipeline_test_case_name,
+ config_class,
+ model_architecture,
+ tokenizer_name,
+ image_processor_name,
+ feature_extractor_name,
+ processor_name,
+ ):
+ # `DocumentQuestionAnsweringPipeline` is expected to work with this model, but it combines the text and visual
+ # embedding along the sequence dimension (dim 1), which causes an error during post-processing as `p_mask` has
+ # the sequence dimension of the text embedding only.
+ # (see the line `embedding_output = torch.cat([embedding_output, visual_embeddings], dim=1)`)
+ return True
+
+ def setUp(self):
+ self.model_tester = LayoutLMv3ModelTester(self)
+ self.config_tester = ConfigTester(self, config_class=LayoutLMv3Config, hidden_size=37)
+
+ def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
+ inputs_dict = copy.deepcopy(inputs_dict)
+ if model_class in get_values(MODEL_FOR_MULTIPLE_CHOICE_MAPPING):
+ inputs_dict = {
+ k: v.unsqueeze(1).expand(-1, self.model_tester.num_choices, -1).contiguous()
+ if isinstance(v, torch.Tensor) and v.ndim > 1
+ else v
+ for k, v in inputs_dict.items()
+ }
+ if return_labels:
+ if model_class in get_values(MODEL_FOR_MULTIPLE_CHOICE_MAPPING):
+ inputs_dict["labels"] = torch.ones(self.model_tester.batch_size, dtype=torch.long, device=torch_device)
+ elif model_class in get_values(MODEL_FOR_QUESTION_ANSWERING_MAPPING):
+ inputs_dict["start_positions"] = torch.zeros(
+ self.model_tester.batch_size, dtype=torch.long, device=torch_device
+ )
+ inputs_dict["end_positions"] = torch.zeros(
+ self.model_tester.batch_size, dtype=torch.long, device=torch_device
+ )
+ elif model_class in [
+ *get_values(MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING),
+ ]:
+ inputs_dict["labels"] = torch.zeros(
+ self.model_tester.batch_size, dtype=torch.long, device=torch_device
+ )
+ elif model_class in [
+ *get_values(MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING),
+ ]:
+ inputs_dict["labels"] = torch.zeros(
+ (self.model_tester.batch_size, self.model_tester.text_seq_length),
+ dtype=torch.long,
+ device=torch_device,
+ )
+
+ return inputs_dict
+
+ def test_config(self):
+ self.config_tester.run_common_tests()
+
+ def test_model(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_model_various_embeddings(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ for type in ["absolute", "relative_key", "relative_key_query"]:
+ config_and_inputs[0].position_embedding_type = type
+ self.model_tester.create_and_check_model(*config_and_inputs)
+
+ def test_for_sequence_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
+
+ def test_for_token_classification(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
+
+ def test_for_question_answering(self):
+ config_and_inputs = self.model_tester.prepare_config_and_inputs()
+ self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
+
+ @slow
+ def test_model_from_pretrained(self):
+ model_name = "microsoft/layoutlmv3-base"
+ model = LayoutLMv3Model.from_pretrained(model_name)
+ self.assertIsNotNone(model)
+
+
+# We will verify our results on an image of cute cats
+def prepare_img():
+ image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
+ return image
+
+
+@require_torch
+class LayoutLMv3ModelIntegrationTest(unittest.TestCase):
+ @cached_property
+ def default_image_processor(self):
+ return LayoutLMv3ImageProcessor(apply_ocr=False) if is_vision_available() else None
+
+ @slow
+ def test_inference_no_head(self):
+ model = LayoutLMv3Model.from_pretrained("microsoft/layoutlmv3-base").to(torch_device)
+
+ image_processor = self.default_image_processor
+ image = prepare_img()
+ pixel_values = image_processor(images=image, return_tensors="pt").pixel_values.to(torch_device)
+
+ input_ids = torch.tensor([[1, 2]])
+ bbox = torch.tensor([[1, 2, 3, 4], [5, 6, 7, 8]]).unsqueeze(0)
+
+ # forward pass
+ outputs = model(
+ input_ids=input_ids.to(torch_device),
+ bbox=bbox.to(torch_device),
+ pixel_values=pixel_values.to(torch_device),
+ )
+
+ # verify the logits
+ expected_shape = torch.Size((1, 199, 768))
+ self.assertEqual(outputs.last_hidden_state.shape, expected_shape)
+
+ expected_slice = torch.tensor(
+ [[-0.0529, 0.3618, 0.1632], [-0.1587, -0.1667, -0.0400], [-0.1557, -0.1671, -0.0505]]
+ ).to(torch_device)
+
+ torch.testing.assert_close(outputs.last_hidden_state[0, :3, :3], expected_slice, rtol=1e-4, atol=1e-4)
diff --git a/transformers/tests/models/layoutlmv3/test_processor_layoutlmv3.py b/transformers/tests/models/layoutlmv3/test_processor_layoutlmv3.py
new file mode 100644
index 0000000000000000000000000000000000000000..cf367c615ea0a88d818ee5aad64c4e6b38b839d5
--- /dev/null
+++ b/transformers/tests/models/layoutlmv3/test_processor_layoutlmv3.py
@@ -0,0 +1,448 @@
+# Copyright 2022 The HuggingFace Team. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import json
+import os
+import shutil
+import tempfile
+import unittest
+
+from transformers import PreTrainedTokenizer, PreTrainedTokenizerBase, PreTrainedTokenizerFast
+from transformers.models.layoutlmv3 import LayoutLMv3Processor, LayoutLMv3Tokenizer, LayoutLMv3TokenizerFast
+from transformers.models.layoutlmv3.tokenization_layoutlmv3 import VOCAB_FILES_NAMES
+from transformers.testing_utils import require_pytesseract, require_tokenizers, require_torch, slow
+from transformers.utils import FEATURE_EXTRACTOR_NAME, cached_property, is_pytesseract_available
+
+from ...test_processing_common import ProcessorTesterMixin
+
+
+if is_pytesseract_available():
+ from transformers import LayoutLMv3ImageProcessor
+
+
+@require_pytesseract
+@require_tokenizers
+class LayoutLMv3ProcessorTest(ProcessorTesterMixin, unittest.TestCase):
+ tokenizer_class = LayoutLMv3Tokenizer
+ rust_tokenizer_class = LayoutLMv3TokenizerFast
+ processor_class = LayoutLMv3Processor
+
+ def setUp(self):
+ # Adapted from Sennrich et al. 2015 and https://github.com/rsennrich/subword-nmt
+ vocab = [
+ "l",
+ "o",
+ "w",
+ "e",
+ "r",
+ "s",
+ "t",
+ "i",
+ "d",
+ "n",
+ "\u0120",
+ "\u0120l",
+ "\u0120n",
+ "\u0120lo",
+ "\u0120low",
+ "er",
+ "\u0120lowest",
+ "\u0120newer",
+ "\u0120wider",
+ "",
+ ]
+ self.tmpdirname = tempfile.mkdtemp()
+ vocab_tokens = dict(zip(vocab, range(len(vocab))))
+ merges = ["#version: 0.2", "\u0120 l", "\u0120l o", "\u0120lo w", "e r", ""]
+ self.special_tokens_map = {"unk_token": ""}
+
+ self.vocab_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["vocab_file"])
+ self.merges_file = os.path.join(self.tmpdirname, VOCAB_FILES_NAMES["merges_file"])
+ with open(self.vocab_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps(vocab_tokens) + "\n")
+ with open(self.merges_file, "w", encoding="utf-8") as fp:
+ fp.write("\n".join(merges))
+
+ image_processor_map = {
+ "do_resize": True,
+ "size": 224,
+ "apply_ocr": True,
+ }
+
+ self.feature_extraction_file = os.path.join(self.tmpdirname, FEATURE_EXTRACTOR_NAME)
+ with open(self.feature_extraction_file, "w", encoding="utf-8") as fp:
+ fp.write(json.dumps(image_processor_map) + "\n")
+
+ def get_tokenizer(self, **kwargs) -> PreTrainedTokenizer:
+ return self.tokenizer_class.from_pretrained(self.tmpdirname, **kwargs)
+
+ def get_rust_tokenizer(self, **kwargs) -> PreTrainedTokenizerFast:
+ return self.rust_tokenizer_class.from_pretrained(self.tmpdirname, **kwargs)
+
+ def get_tokenizers(self, **kwargs) -> list[PreTrainedTokenizerBase]:
+ return [self.get_tokenizer(**kwargs), self.get_rust_tokenizer(**kwargs)]
+
+ def get_image_processor(self, **kwargs):
+ return LayoutLMv3ImageProcessor.from_pretrained(self.tmpdirname, **kwargs)
+
+ def tearDown(self):
+ shutil.rmtree(self.tmpdirname)
+
+ def test_save_load_pretrained_default(self):
+ image_processor = self.get_image_processor()
+ tokenizers = self.get_tokenizers()
+ for tokenizer in tokenizers:
+ processor = LayoutLMv3Processor(image_processor=image_processor, tokenizer=tokenizer)
+
+ processor.save_pretrained(self.tmpdirname)
+ processor = LayoutLMv3Processor.from_pretrained(self.tmpdirname)
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer.get_vocab())
+ self.assertIsInstance(processor.tokenizer, (LayoutLMv3Tokenizer, LayoutLMv3TokenizerFast))
+
+ self.assertEqual(processor.image_processor.to_json_string(), image_processor.to_json_string())
+ self.assertIsInstance(processor.image_processor, LayoutLMv3ImageProcessor)
+
+ def test_save_load_pretrained_additional_features(self):
+ processor = LayoutLMv3Processor(image_processor=self.get_image_processor(), tokenizer=self.get_tokenizer())
+ processor.save_pretrained(self.tmpdirname)
+
+ # slow tokenizer
+ tokenizer_add_kwargs = self.get_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
+ image_processor_add_kwargs = self.get_image_processor(do_resize=False, size=30)
+
+ processor = LayoutLMv3Processor.from_pretrained(
+ self.tmpdirname, use_fast=False, bos_token="(BOS)", eos_token="(EOS)", do_resize=False, size=30
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, LayoutLMv3Tokenizer)
+
+ self.assertEqual(processor.image_processor.to_json_string(), image_processor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.image_processor, LayoutLMv3ImageProcessor)
+
+ # fast tokenizer
+ tokenizer_add_kwargs = self.get_rust_tokenizer(bos_token="(BOS)", eos_token="(EOS)")
+ image_processor_add_kwargs = self.get_image_processor(do_resize=False, size=30)
+
+ processor = LayoutLMv3Processor.from_pretrained(
+ self.tmpdirname, bos_token="(BOS)", eos_token="(EOS)", do_resize=False, size=30
+ )
+
+ self.assertEqual(processor.tokenizer.get_vocab(), tokenizer_add_kwargs.get_vocab())
+ self.assertIsInstance(processor.tokenizer, LayoutLMv3TokenizerFast)
+
+ self.assertEqual(processor.image_processor.to_json_string(), image_processor_add_kwargs.to_json_string())
+ self.assertIsInstance(processor.image_processor, LayoutLMv3ImageProcessor)
+
+ def test_model_input_names(self):
+ image_processor = self.get_image_processor()
+ tokenizer = self.get_tokenizer()
+
+ processor = LayoutLMv3Processor(tokenizer=tokenizer, image_processor=image_processor)
+
+ input_str = "lower newer"
+ image_input = self.prepare_image_inputs()
+
+ # add extra args
+ inputs = processor(text=input_str, images=image_input, return_codebook_pixels=False, return_image_mask=False)
+
+ self.assertListEqual(list(inputs.keys()), processor.model_input_names)
+
+
+# different use cases tests
+@require_torch
+@require_pytesseract
+class LayoutLMv3ProcessorIntegrationTests(unittest.TestCase):
+ @cached_property
+ def get_images(self):
+ # we verify our implementation on 2 document images from the DocVQA dataset
+ from datasets import load_dataset
+
+ ds = load_dataset("hf-internal-testing/fixtures_docvqa", split="test")
+ return ds[0]["image"].convert("RGB"), ds[1]["image"].convert("RGB")
+
+ @cached_property
+ def get_tokenizers(self):
+ slow_tokenizer = LayoutLMv3Tokenizer.from_pretrained("microsoft/layoutlmv3-base", add_visual_labels=False)
+ fast_tokenizer = LayoutLMv3TokenizerFast.from_pretrained("microsoft/layoutlmv3-base", add_visual_labels=False)
+ return [slow_tokenizer, fast_tokenizer]
+
+ @slow
+ def test_processor_case_1(self):
+ # case 1: document image classification (training, inference) + token classification (inference), apply_ocr = True
+
+ image_processor = LayoutLMv3ImageProcessor()
+ tokenizers = self.get_tokenizers
+ images = self.get_images
+
+ for tokenizer in tokenizers:
+ processor = LayoutLMv3Processor(image_processor=image_processor, tokenizer=tokenizer)
+
+ # not batched
+ input_image_proc = image_processor(images[0], return_tensors="pt")
+ input_processor = processor(images[0], return_tensors="pt")
+
+ # verify keys
+ expected_keys = ["attention_mask", "bbox", "input_ids", "pixel_values"]
+ actual_keys = sorted(input_processor.keys())
+ self.assertListEqual(actual_keys, expected_keys)
+
+ # verify image
+ self.assertAlmostEqual(
+ input_image_proc["pixel_values"].sum(), input_processor["pixel_values"].sum(), delta=1e-2
+ )
+
+ # verify input_ids
+ # this was obtained with Tesseract 4.1.1
+ expected_decoding = " 11:14 to 11:39 a.m 11:39 to 11:44 a.m. 11:44 a.m. to 12:25 p.m. 12:25 to 12:58 p.m. 12:58 to 4:00 p.m. 2:00 to 5:00 p.m. Coffee Break Coffee will be served for men and women in the lobby adjacent to exhibit area. Please move into exhibit area. (Exhibits Open) TRRF GENERAL SESSION (PART |) Presiding: Lee A. Waller TRRF Vice President “Introductory Remarks” Lee A. Waller, TRRF Vice Presi- dent Individual Interviews with TRRF Public Board Members and Sci- entific Advisory Council Mem- bers Conducted by TRRF Treasurer Philip G. Kuehn to get answers which the public refrigerated warehousing industry is looking for. Plus questions from the floor. Dr. Emil M. Mrak, University of Cal- ifornia, Chairman, TRRF Board; Sam R. Cecil, University of Georgia College of Agriculture; Dr. Stanley Charm, Tufts University School of Medicine; Dr. Robert H. Cotton, ITT Continental Baking Company; Dr. Owen Fennema, University of Wis- consin; Dr. Robert E. Hardenburg, USDA. Questions and Answers Exhibits Open Capt. Jack Stoney Room TRRF Scientific Advisory Council Meeting Ballroom Foyer" # fmt: skip
+ decoding = processor.decode(input_processor.input_ids.squeeze().tolist())
+ self.assertSequenceEqual(decoding, expected_decoding)
+
+ # batched
+ input_image_proc = image_processor(images, return_tensors="pt")
+ input_processor = processor(images, padding=True, return_tensors="pt")
+
+ # verify keys
+ expected_keys = ["attention_mask", "bbox", "input_ids", "pixel_values"]
+ actual_keys = sorted(input_processor.keys())
+ self.assertListEqual(actual_keys, expected_keys)
+
+ # verify images
+ self.assertAlmostEqual(
+ input_image_proc["pixel_values"].sum(), input_processor["pixel_values"].sum(), delta=1e-2
+ )
+
+ # verify input_ids
+ # this was obtained with Tesseract 4.1.1
+ expected_decoding = " 7 ITC Limited REPORT AND ACCOUNTS 2013 ITC’s Brands: An Asset for the Nation The consumer needs and aspirations they fulfil, the benefit they generate for millions across ITC’s value chains, the future-ready capabilities that support them, and the value that they create for the country, have made ITC’s brands national assets, adding to India’s competitiveness. It is ITC’s aspiration to be the No 1 FMCG player in the country, driven by its new FMCG businesses. A recent Nielsen report has highlighted that ITC's new FMCG businesses are the fastest growing among the top consumer goods companies operating in India. ITC takes justifiable pride that, along with generating economic value, these celebrated Indian brands also drive the creation of larger societal capital through the virtuous cycle of sustainable and inclusive growth. DI WILLS * ; LOVE DELIGHTFULLY SOFT SKIN? aia Ans Source: https://www.industrydocuments.ucsf.edu/docs/snbx0223