---
title: CyberSelfPlay (Cyber POSG)
emoji: 🛡️
colorFrom: blue
colorTo: red
sdk: docker
app_port: 7870
pinned: true
---
# CyberSelfPlay: Autonomous Red-vs-Blue Cyber Defense Environment
**Training Script Link:** [League (PFSP + PSRO) — Colab (mixed)](https://colab.research.google.com/drive/192y6Xf6uYjW0Z0yffBaKjtfVJGCT4b4S?usp=sharing)
**An interactive Game based on Environment:** [Game](https://openenv-ui.vercel.app/)
CyberSelfPlay is an OpenEnv-compatible reinforcement learning environment for cyber defense. The setting is a partially observable, stochastic Red-vs-Blue contest where Blue must execute enterprise recovery playbooks while Red applies adversarial pressure.
## Environment on Hugging Face Space
- **Live Space (hub):** [CyberSelfPlay on Hugging Face](https://huggingface.co/spaces/HarshitShri026)
- **Running app / API base:** [https://harshitshri026-cyberselfplay-env.hf.space](https://harshitshri026-cyberselfplay-env.hf.space/)
- **Interactive API (Swagger):** [https://harshitshri026-cyberselfplay-env.hf.space/docs](https://harshitshri026-cyberselfplay-env.hf.space/docs)
- **ReDoc:** [https://harshitshri026-cyberselfplay-env.hf.space/redoc](https://harshitshri026-cyberselfplay-env.hf.space/redoc)
- **Narrative, Colab context, and results figures:** [Blogs](Blog.md)
---
## Problem and Capability Gap
Most agent benchmarks are short and single-agent. Cyber defense in practice is multi-step, partially observable, adversarial, and stochastic. CyberSelfPlay targets that gap by coupling multi-step mission execution with attacker-defender interaction and structured tool actions.
**Connection to long-horizon and self-play themes:** the setting stresses **(super) long-horizon planning and instruction following**—episodes with many steps, many playbook instructions, and security rewards that are often sparse or delayed, so the agent must track state, recover from mis-steps, and keep coherent plans across long runs. It also supports **self-improvement through interaction**: the non-league recipes use **SFT** followed by **GRPO**; **league** methods combine the same **SFT** initialization and per-round **mini-GRPO** steps with **PFSP / PSRO / mix** updates over Red archetypes or pools. Opponents and rounds change, so the LLM policy is not tuned on a static task set but on an evolving curriculum over the same family of tasks.
---
## Environment Design
Two **agents** interact in a shared hidden state: **Blue** (defender) is the trainable side in most recipes; **Red** (attacker) can be scripted, drawn from a pool, or used as a **league** opponent. Time advances in **discrete steps**: each `step` takes one `CyberAction` and returns a **player-specific** `CyberObservation` (then you alternate or follow your rollout script). The OpenEnv **server** exposes the same `CyberAction` / `CyberObservation` contract over HTTP for remote rollouts and demos.
### What the agent observes
`CyberObservation` is built in `cyber_selfplay_env/models.py` and returned by `CyberSelfPlayEnvironment.reset` and `step`. It includes:
- **`public_state`**: a **partial** dict from `CyberSimulator.visible_state(actor)`. For Blue, expect fields such as `time_step`, a window of `detections`, `business_impact`, a coarse `known_incident_count`, and `instruction_progress` with counts of **completed**, **violated**, and **total** mission instructions. Red’s public view is different (e.g., limited `known_targets`, `high_value_guess_count`, `detection_pressure`) so the game is a true two-sided **POSG** with distinct observation channels.
- **`telemetry`**: a short list of event-like records (e.g., recent detections for Blue; a compact risk string for Red).
- **`incident_summary`**: episode-level fields including `terminated`, `winner` when set, exfil and **time_step** (exact keys evolve with simulator state but stay consistent in the client).
- **`reward`**: scalar reward from the environment for the last transition.
- **`done`**: whether the episode has ended.
- **`metadata`**: on normal steps, includes **`reward_components`**, raw **`events`**, **`posg_metrics`** (aggregates like exfil and instruction completion rates), and **`curriculum`** block (scenario name, rolling Blue win rate, episode index). The initial reset also carries scenario/actor hints. Invalid tool calls return **`metadata["error"]`** without terminating the run.
### What the agent does
Policies act through **`CyberAction`**: `actor` (`"red"` | `"blue"`), `tool_name`, optional `target` (host/asset id), `params` (tool-specific `dict`, e.g. for `execute_instruction`), and optional `rationale`. The environment validates the tool name against the allowed set for that side, then the **CyberSimulator** applies the effect.
**Blue tools** (defense and playbook): e.g. `query_siem`, `triage_alerts`, `isolate_host`, `disable_account`, `rotate_secrets`, `deploy_patch`, `harden_policy`, `restore_backup`, `run_forensics`, `publish_ioc_blocklist`, `execute_instruction`, `checkpoint_plan`, `reconcile_state`.
**Red tools** (attack chain): e.g. `recon_network`, `enumerate_services`, `attempt_exploit`, `dump_credentials`, `pivot_host`, `establish_persistence`, `prepare_exfiltration`, `execute_exfiltration`, `cover_tracks`, `sabotage_recovery_plan`.
(Authoritative sets live in `cyber_selfplay_env/tools_blue.py` and `tools_red.py`.)
### What the agent is rewarded for
Rewards combine security outcomes (detection, containment, recovery, exfiltration pressure) and mission outcomes (instruction progress, checkpoints, violations).
### Formal game model
CyberSelfPlay is modeled as a two-player partially observable stochastic game (POSG):
$$
\mathcal{G}=\langle \mathcal{S},\mathcal{A}_R,\mathcal{A}_B,\mathcal{O}_R,\mathcal{O}_B,T,Z_R,Z_B,r_R,r_B,\gamma \rangle
$$
where:
$$
\begin{align*}
\mathcal{S} &: \text{hidden environment state space} \\
\mathcal{A}_R, \mathcal{A}_B &: \text{Red and Blue action spaces} \\
\mathcal{O}_R, \mathcal{O}_B &: \text{Red and Blue observation spaces} \\
T &: \text{state-transition kernel} \\
Z_R, Z_B &: \text{observation emission models for each player} \\
r_R, r_B &: \text{Red and Blue reward functions} \\
\gamma &: \text{discount factor}
\end{align*}
$$
with objective:
$$
J_i(\pi_i,\pi_{-i})=\mathbb{E}\left[\sum_{t=0}^{H}\gamma^t r_i\left(s_t,a_t^{R},a_t^{B}\right)\right],\quad i\in\{R,B\}
$$
with:
$$
\begin{aligned}
\pi_i &: \text{the policy of player } i \text{ and } \pi_{-i} \text{ the opponent policy} \\
H &: \text{the episode horizon (maximum time steps)} \\
s_t &: \text{the state at time } t \\
a_t^{R}, a_t^{B} &: \text{the Red and Blue actions at time } t \\
r_i(\cdot) &: \text{the reward received by player } i
\end{aligned}
$$
and near-zero-sum coupling:
$$
r_B=-r_R-\lambda C_{\mathrm{collateral}}.
$$
---
## Reward Structure
**Red reward**
$$
\begin{aligned}
r_R &= w_1 \mathbb{1}_{\mathrm{foothold}} + w_2 \mathbb{1}_{\mathrm{priv}} + w_3 \mathbb{1}_{\mathrm{lateral}} + w_4 \mathbb{1}_{\mathrm{exfil}} \\
&\quad - w_5 \mathbb{1}_{\mathrm{detect}} + w_6 \mathbb{1}_{\mathrm{plan\_sabotage}} - \eta_R
\end{aligned}
$$
**Blue reward**
$$
\begin{aligned}
r_B &= v_1 \mathbb{1}_{\mathrm{detect}} + v_2 \mathbb{1}_{\mathrm{contain}} + v_3 \mathbb{1}_{\mathrm{recover}} - v_4 \mathbb{1}_{\mathrm{exfil}} \\
&\quad + v_5 \mathbb{1}_{\mathrm{instr\_progress}} + v_6 \mathbb{1}_{\mathrm{checkpoint}} - v_7 \mathbb{1}_{\mathrm{instr\_violation}} \\
&\quad + v_8 \rho_{\mathrm{inst}} - \eta_B
\end{aligned}
$$
The reward rubric is implemented directly in the environment’s scoring logic.
---
## Environment Architecture
 ## Training Flow
## Training Flow
 ---
## 🚀 Training Approaches in This Project
This project explores multiple training strategies for learning robust Blue policies in the CyberSelfPlay environment.
We experiment across **SFT + GRPO baselines**, **reward smoothing**, **diversity shaping**, and **league-based RL** where each round still relies on **SFT**-style warm-start and **GRPO** (mini-GRPO per round) in addition to **PFSP / PSRO** opponent scheduling.
---
### 📊 Overview of Training Methods
| Method | Description | Colab | Metrics / Curves |
|--------|------------|-------|------------------|
| **🔹 GRPO (Single-Policy RL)** ||||
| **SFT → GRPO (Vanilla)** | Baseline using only environment reward | [Open](https://colab.research.google.com/drive/1K5771KT0-2lyU6eNghqQEStBS4OSF7D7?usp=sharing) |
---
## 🚀 Training Approaches in This Project
This project explores multiple training strategies for learning robust Blue policies in the CyberSelfPlay environment.
We experiment across **SFT + GRPO baselines**, **reward smoothing**, **diversity shaping**, and **league-based RL** where each round still relies on **SFT**-style warm-start and **GRPO** (mini-GRPO per round) in addition to **PFSP / PSRO** opponent scheduling.
---
### 📊 Overview of Training Methods
| Method | Description | Colab | Metrics / Curves |
|--------|------------|-------|------------------|
| **🔹 GRPO (Single-Policy RL)** ||||
| **SFT → GRPO (Vanilla)** | Baseline using only environment reward | [Open](https://colab.research.google.com/drive/1K5771KT0-2lyU6eNghqQEStBS4OSF7D7?usp=sharing) | 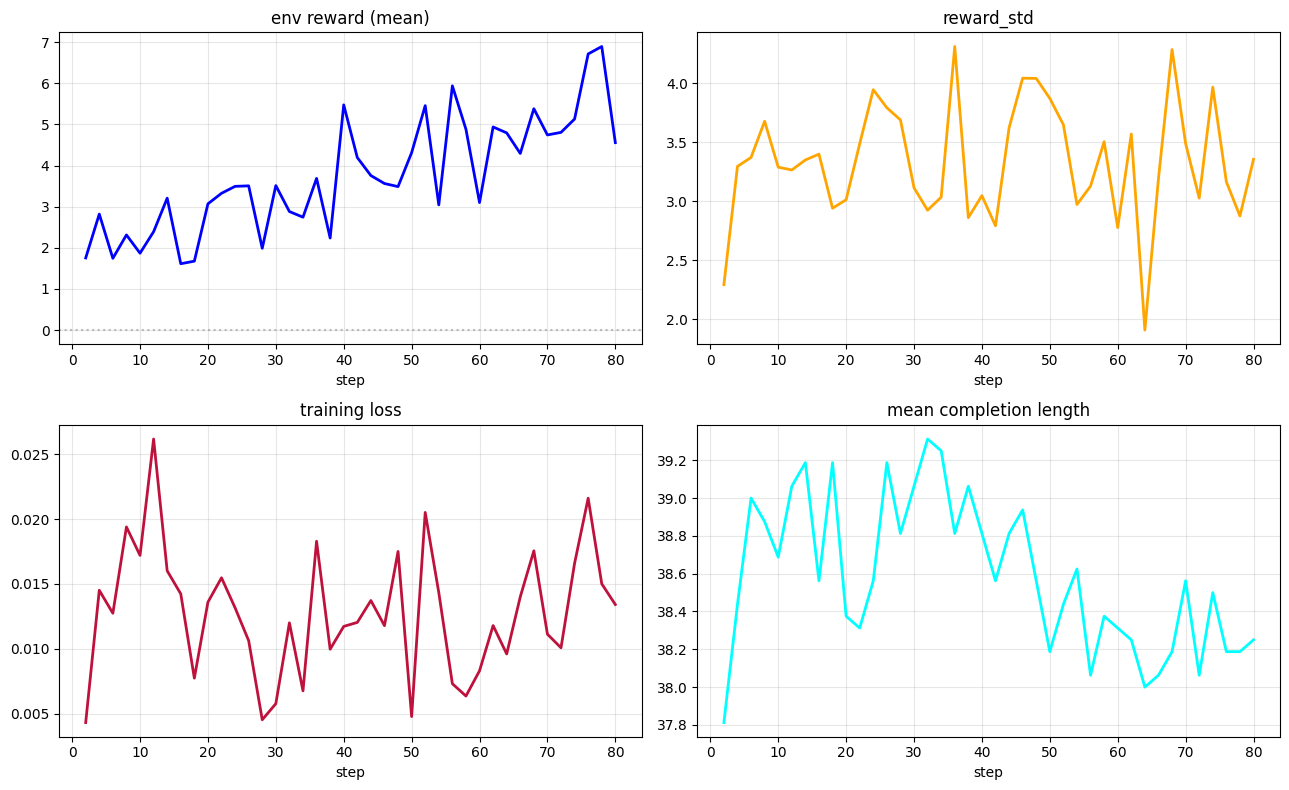 |
| **SFT → GRPO (Anti-Collapse)** | Adds diversity penalty to avoid mode collapse | [Open](https://colab.research.google.com/drive/1HivyWte1q-sugE04XsyMi1U_RY1oGkJ8?usp=sharing) |
|
| **SFT → GRPO (Anti-Collapse)** | Adds diversity penalty to avoid mode collapse | [Open](https://colab.research.google.com/drive/1HivyWte1q-sugE04XsyMi1U_RY1oGkJ8?usp=sharing) | 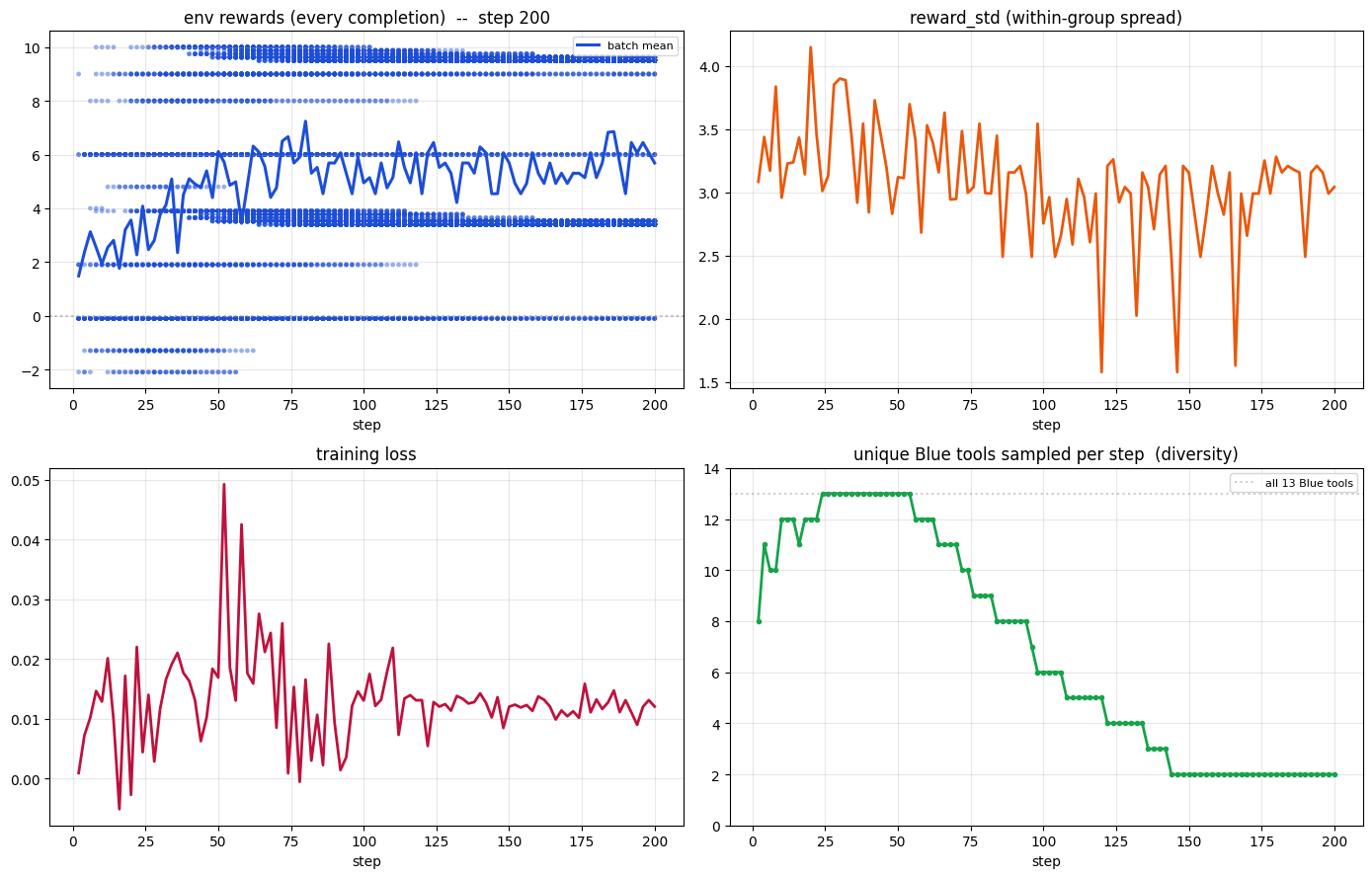 |
| **🔹 League (Multi-Policy RL)** ||||
| **League (PFSP)** | SFT, then per-round **mini-GRPO**; **PFSP** weights which Red-style opponent to sample | [Open](https://colab.research.google.com/drive/1g2QCBqdvo7QwRC7dJaV8QdO7RvTPGyY1?usp=sharing) |
|
| **🔹 League (Multi-Policy RL)** ||||
| **League (PFSP)** | SFT, then per-round **mini-GRPO**; **PFSP** weights which Red-style opponent to sample | [Open](https://colab.research.google.com/drive/1g2QCBqdvo7QwRC7dJaV8QdO7RvTPGyY1?usp=sharing) | 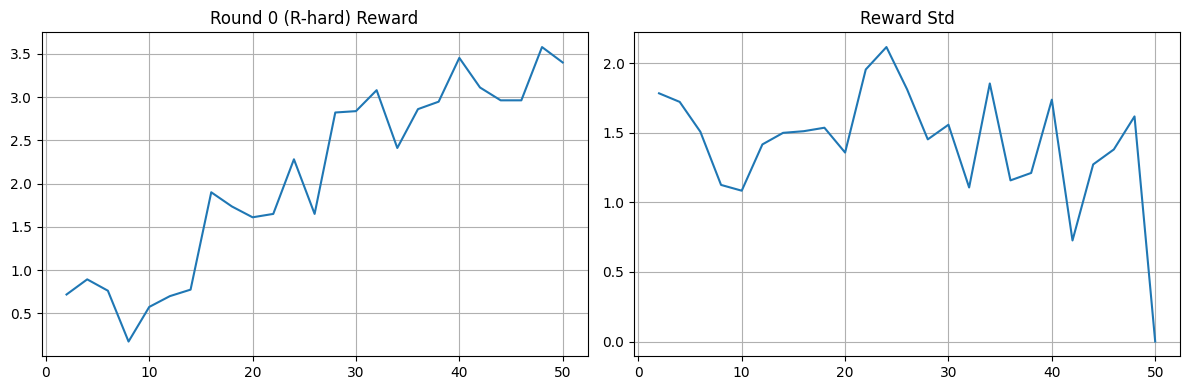 |
| **League (PSRO)** | SFT, then per-round **mini-GRPO**; **PSRO**-style meta-updates on the opponent population | [Open](https://colab.research.google.com/drive/1O6IoE-_UloAeDXKve2ZA1W4OajychglP?usp=sharing) |
|
| **League (PSRO)** | SFT, then per-round **mini-GRPO**; **PSRO**-style meta-updates on the opponent population | [Open](https://colab.research.google.com/drive/1O6IoE-_UloAeDXKve2ZA1W4OajychglP?usp=sharing) | 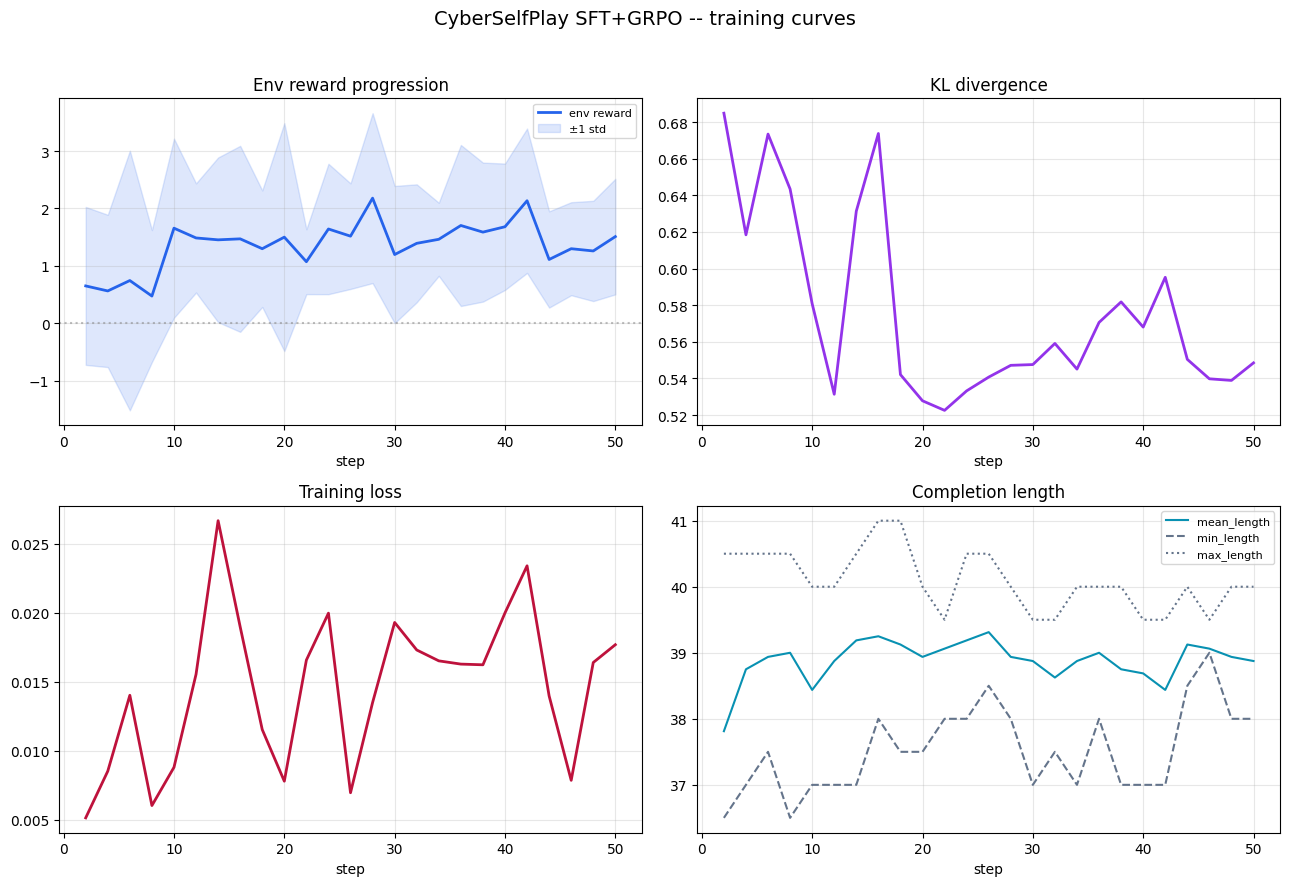 |
| **League (PFSP + PSRO)** | SFT, then per-round **mini-GRPO**; **PFSP** sampling and **PSRO** replicator updates used together | [Open](https://colab.research.google.com/drive/192y6Xf6uYjW0Z0yffBaKjtfVJGCT4b4S?usp=sharing) |
|
| **League (PFSP + PSRO)** | SFT, then per-round **mini-GRPO**; **PFSP** sampling and **PSRO** replicator updates used together | [Open](https://colab.research.google.com/drive/192y6Xf6uYjW0Z0yffBaKjtfVJGCT4b4S?usp=sharing) | 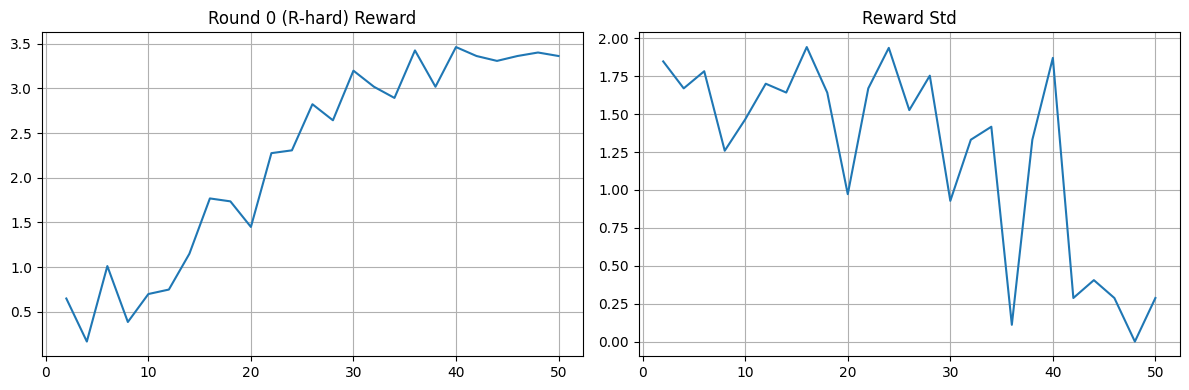 |
---
## 📐 Mathematical Formulation
### 1. GRPO (Vanilla)
$$
\mathcal{L}*{\text{GRPO}} = \mathbb{E}\left[\log \pi*\theta(a_i \mid s),(r_i - \bar{r})\right]
$$
$$
\bar{r} = \frac{1}{N}\sum_{i=1}^{N} r_i
$$
---
### 2. GRPO + Regularization (Anti-Collapse)
$$
r_i' = r_i - \lambda ,\max\big(0,; p(a_i) - \tau\big)
$$
where:
$$
\begin{aligned}
p(a_i) &= \text{frequency of action in batch} \
\tau &= \text{threshold}
\end{aligned}
$$
---
### 3. PFSP (Prioritized Fictitious Self-Play)
$$
p_j \propto f(w_j), \qquad f(w) = w(1 - w)
$$
where:
$$
\begin{aligned}
w_j &= \text{win-rate against opponent } j
\end{aligned}
$$
---
### 4. PSRO (Policy-Space Response Oracles)
$$
p_i' \propto p_i \left(1 + \eta (u_i - \bar{u}) \right)
$$
$$
\bar{u} = \sum_i p_i u_i
$$
where:
$$
\begin{aligned}
u_i &= \text{utility of policy } i \\
\eta &= \text{learning rate}
\end{aligned}
$$
---
### 5. PFSP + PSRO (Combined)
$$
p_j \propto f(w_j), \qquad f(w) = w(1 - w)
$$
$$
p_i' \propto p_i \left(1 + \eta (u_i - \bar{u}) \right)
$$
Combines opponent sampling (PFSP) with meta-policy updates (PSRO).
## Core Optimization Math
### SFT (Supervised Fine-Tuning)
Token-level cross-entropy (negative log-likelihood) on expert trajectories.
### GRPO (Group Relative Policy Optimization)
For prompt $x$, sample a group of completions:
$$
\{y^{(1)},\ldots,y^{(G)}\} \sim \pi_\theta(\cdot\mid x)
$$
Score each completion with reward $R^{(j)}$, compute group-relative advantages, and update policy parameters with optional KL regularization toward a reference policy $\pi_{\text{ref}}$.
---
## Scenario Scale
| scenario | turns | instructions | checkpoint stride |
| --- | ---: | ---: | ---: |
| small | 60 | 40 | 8 |
| medium | 100 | 120 | 12 |
| large | 180 | 300 | 20 |
Instruction progress and violation signals are tracked in environment metadata.
---
## Results Summary
Across training runs, Blue policies generally move from imitation-only behavior (SFT) to stronger environment-aligned behavior after GRPO. In league mode, the same **SFT** and **GRPO** steps appear inside each **round**, while **PFSP / PSRO / mix** reshapes *which* opponents or archetypes the learner faces; together this yields distinct multi-round learning dynamics and robustness to varied Red behavior.
Common result artifacts produced by training include:
- consolidated training curves,
- step-by-step optimization history,
- metrics logs,
- per-sample reward traces,
- per-step visualization snapshots,
- and, for league experiments, combined multi-round trend and meta-state reports.
---
## Why It Matters
- **Security operations relevance:** models multi-step defense decisions closer to real incident response.
- **Research relevance:** provides a reproducible adversarial benchmark for instruction-following under uncertainty.
- **Evaluation relevance:** combines environment dynamics, tool-structured actions, and measurable outcomes.
---
## Abbreviations
| Short form | Full form |
| --- | --- |
| SFT | Supervised Fine-Tuning |
| GRPO | Group Relative Policy Optimization |
| TRL | Transformers Reinforcement Learning |
| LoRA | Low-Rank Adaptation |
| PFSP | Prioritized Fictitious Self-Play |
| PSRO | Policy-Space Response Orbit |
| POSG | Partially Observable Stochastic Game |
| POMDP | Partially Observable Markov Decision Process |
| MTTD | Mean Time To Detect |
| MTTR | Mean Time To Repair |
---
## Project Structure (high level)
```text
cyber_selfplay/
├── cyber_selfplay_env/ # environment core, simulator, rubrics, metrics
├── server/ # OpenEnv API server
├── train/
│ ├── kaggle_grpo.py
│ ├── kaggle_grpo_league.py
│ ├── pfsp.py
│ └── psro_meta.py
└── openenv.yaml
```
---
## References
- Vinyals et al., *Nature* 2019 — AlphaStar / league training
- Lanctot et al., *NeurIPS* 2017 — PSRO
- Hu et al., *ACM Transactions on Privacy and Security* (TOPS), 2021 — cyber defense POMDP
- TTCP CAGE-2 — defender POMDP framing
- Hugging Face TRL documentation (`GRPOTrainer`)
|
---
## 📐 Mathematical Formulation
### 1. GRPO (Vanilla)
$$
\mathcal{L}*{\text{GRPO}} = \mathbb{E}\left[\log \pi*\theta(a_i \mid s),(r_i - \bar{r})\right]
$$
$$
\bar{r} = \frac{1}{N}\sum_{i=1}^{N} r_i
$$
---
### 2. GRPO + Regularization (Anti-Collapse)
$$
r_i' = r_i - \lambda ,\max\big(0,; p(a_i) - \tau\big)
$$
where:
$$
\begin{aligned}
p(a_i) &= \text{frequency of action in batch} \
\tau &= \text{threshold}
\end{aligned}
$$
---
### 3. PFSP (Prioritized Fictitious Self-Play)
$$
p_j \propto f(w_j), \qquad f(w) = w(1 - w)
$$
where:
$$
\begin{aligned}
w_j &= \text{win-rate against opponent } j
\end{aligned}
$$
---
### 4. PSRO (Policy-Space Response Oracles)
$$
p_i' \propto p_i \left(1 + \eta (u_i - \bar{u}) \right)
$$
$$
\bar{u} = \sum_i p_i u_i
$$
where:
$$
\begin{aligned}
u_i &= \text{utility of policy } i \\
\eta &= \text{learning rate}
\end{aligned}
$$
---
### 5. PFSP + PSRO (Combined)
$$
p_j \propto f(w_j), \qquad f(w) = w(1 - w)
$$
$$
p_i' \propto p_i \left(1 + \eta (u_i - \bar{u}) \right)
$$
Combines opponent sampling (PFSP) with meta-policy updates (PSRO).
## Core Optimization Math
### SFT (Supervised Fine-Tuning)
Token-level cross-entropy (negative log-likelihood) on expert trajectories.
### GRPO (Group Relative Policy Optimization)
For prompt $x$, sample a group of completions:
$$
\{y^{(1)},\ldots,y^{(G)}\} \sim \pi_\theta(\cdot\mid x)
$$
Score each completion with reward $R^{(j)}$, compute group-relative advantages, and update policy parameters with optional KL regularization toward a reference policy $\pi_{\text{ref}}$.
---
## Scenario Scale
| scenario | turns | instructions | checkpoint stride |
| --- | ---: | ---: | ---: |
| small | 60 | 40 | 8 |
| medium | 100 | 120 | 12 |
| large | 180 | 300 | 20 |
Instruction progress and violation signals are tracked in environment metadata.
---
## Results Summary
Across training runs, Blue policies generally move from imitation-only behavior (SFT) to stronger environment-aligned behavior after GRPO. In league mode, the same **SFT** and **GRPO** steps appear inside each **round**, while **PFSP / PSRO / mix** reshapes *which* opponents or archetypes the learner faces; together this yields distinct multi-round learning dynamics and robustness to varied Red behavior.
Common result artifacts produced by training include:
- consolidated training curves,
- step-by-step optimization history,
- metrics logs,
- per-sample reward traces,
- per-step visualization snapshots,
- and, for league experiments, combined multi-round trend and meta-state reports.
---
## Why It Matters
- **Security operations relevance:** models multi-step defense decisions closer to real incident response.
- **Research relevance:** provides a reproducible adversarial benchmark for instruction-following under uncertainty.
- **Evaluation relevance:** combines environment dynamics, tool-structured actions, and measurable outcomes.
---
## Abbreviations
| Short form | Full form |
| --- | --- |
| SFT | Supervised Fine-Tuning |
| GRPO | Group Relative Policy Optimization |
| TRL | Transformers Reinforcement Learning |
| LoRA | Low-Rank Adaptation |
| PFSP | Prioritized Fictitious Self-Play |
| PSRO | Policy-Space Response Orbit |
| POSG | Partially Observable Stochastic Game |
| POMDP | Partially Observable Markov Decision Process |
| MTTD | Mean Time To Detect |
| MTTR | Mean Time To Repair |
---
## Project Structure (high level)
```text
cyber_selfplay/
├── cyber_selfplay_env/ # environment core, simulator, rubrics, metrics
├── server/ # OpenEnv API server
├── train/
│ ├── kaggle_grpo.py
│ ├── kaggle_grpo_league.py
│ ├── pfsp.py
│ └── psro_meta.py
└── openenv.yaml
```
---
## References
- Vinyals et al., *Nature* 2019 — AlphaStar / league training
- Lanctot et al., *NeurIPS* 2017 — PSRO
- Hu et al., *ACM Transactions on Privacy and Security* (TOPS), 2021 — cyber defense POMDP
- TTCP CAGE-2 — defender POMDP framing
- Hugging Face TRL documentation (`GRPOTrainer`)