
PARD-2
Collection
3 items • Updated

PARD is a high-performance speculative decoding method that also enables low-cost adaptation of autoregressive draft models into parallel draft models. PARD-2 further advances PARD by introducing a Target-Aligned Parallel Draft Model for dual-mode speculative decoding. Instead of optimizing draft models only for token-level prediction accuracy, PARD-2 aligns draft-model training with the inference-time objective of maximizing consecutive token acceptance. PARD-2 offers the following advantages:
Target-Aligned Optimization: PARD-2 reformulates the draft-model objective from next-token prediction accuracy to acceptance-length optimization, better matching the draft-then-verify process used during speculative decoding.
Confidence-Adaptive Token Optimization: PARD-2 introduces Confidence-Adaptive Token (CAT) optimization, which adaptively reweights tokens according to their contribution to the verification process. This improves the alignment between draft generation and target-model acceptance.
Dual-Mode Speculative Decoding: A single PARD-2 draft model supports both target-independent and target-dependent modes, combining the deployment flexibility of PARD with the stronger alignment capability of target-aware methods.
State-of-the-Art Performance: Across diverse models and tasks, PARD-2 achieves up to 6.94× lossless acceleration. On LLaMA3.1-8B, PARD-2 surpasses EAGLE-3 by 1.9× and PARD by 1.3×, setting a new performance frontier for speculative decoding.
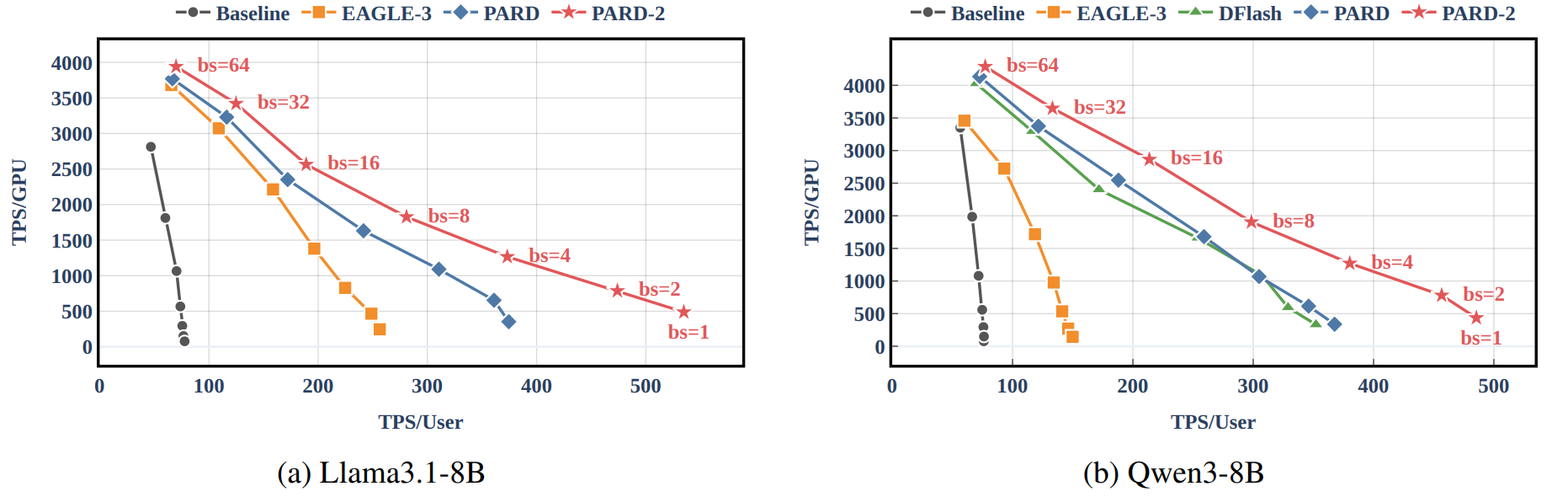
Throughput and Latency Trade-offs on vLLM. PARD-2 consistently achieves a superior Pareto frontier across various batch sizes from 1 to 64.
| Model Series | Model Name | Download |
|---|---|---|
| Llama3 | amd/PARD2-Llama-3.1-8B | 🤗 HuggingFace |
| Qwen3 | amd/PARD2-Qwen3-8B | 🤗 HuggingFace |
| Qwen3 | amd/PARD2-Qwen3-14B | 🤗 HuggingFace |
Please visit PARD2 repo for more information
@article{an2026pard,
title={PARD-2: Target-Aligned Parallel Draft Model for Dual-Mode Speculative Decoding},
author={An, Zihao and Liu, Taichi and Liu, Ziqiong and Li, Dong and Liu, Ruofeng and Barsoum, Emad},
journal={arXiv preprint arXiv:2605.08632},
year={2026}
}