
OpenAI GPT-2 Samsum
Model description
This model has been trained with the SAMSum dataset. The SAMSum dataset contains approximately 16,000 conversational dialogues accompanied by summaries. These conversations were created and written by linguists proficient in fluent English. Linguists were instructed to create conversations that reflect the ratio of topics found in real-life journalistic conversations similar to their daily written conversations. The style and tone vary; conversations can be informal, semi-formal, or formal, and may include slang terms, expressions, and spelling errors. Subsequently, the conversations were annotated with summaries. The summaries are expected to be concise summaries of what people were talking about during the conversation, written in the third person. The SAMSum dataset was prepared by the Samsung Research Institute Poland and is distributed for research purposes.
Training
This GPT-2 model is rated for an average of 1 hour with an L4 GPU.
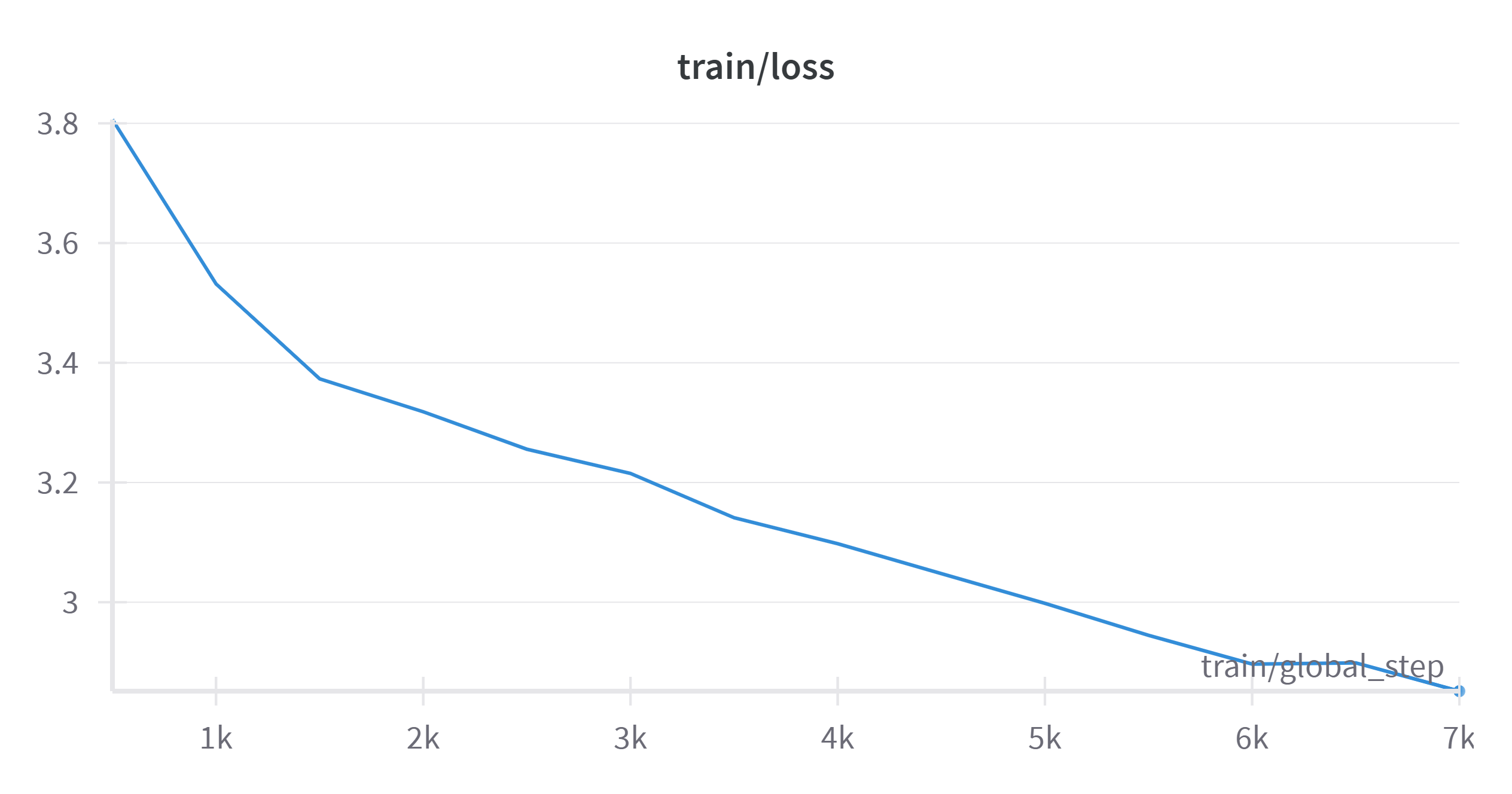
Training Results
 Authors
Authors
- Developed by: Anezatra
- Model type: GPT2
- Contacts: https://github.com/anezatra
- Downloads last month
- 3